为了充分利用本工具的单词学习和查阅功能,你可能需要添加具有详细单词释义的词典库。由于词典数据库文件可能会很大,请按照以下步骤添加:
- 下载词典数据库:
- 访问提供的非永久下载链接
http://vitogo.tpddns.cn:19081/_download/dict-ox10-v3.zip,请复制该链接到浏览器中下载词典数据文件。
- 联系和支持:
- 如果你在使用本工具或添加词典时遇到了问题,或者想要与我们分享你的学习经验和进度,请通过以下方式联系我们:
- WeChat:
vitogo-chat - Email:
[email protected]
- WeChat:
- 你还可以加入我们的微信学习分享交流群,与其他学员一起分享英语学习心得,共同学习进步。扫描下面的二维码即可加入微信群:
-

- 词典库格式说明:
-
词典库应当是一个zip压缩文件,该文件包含以下内容:
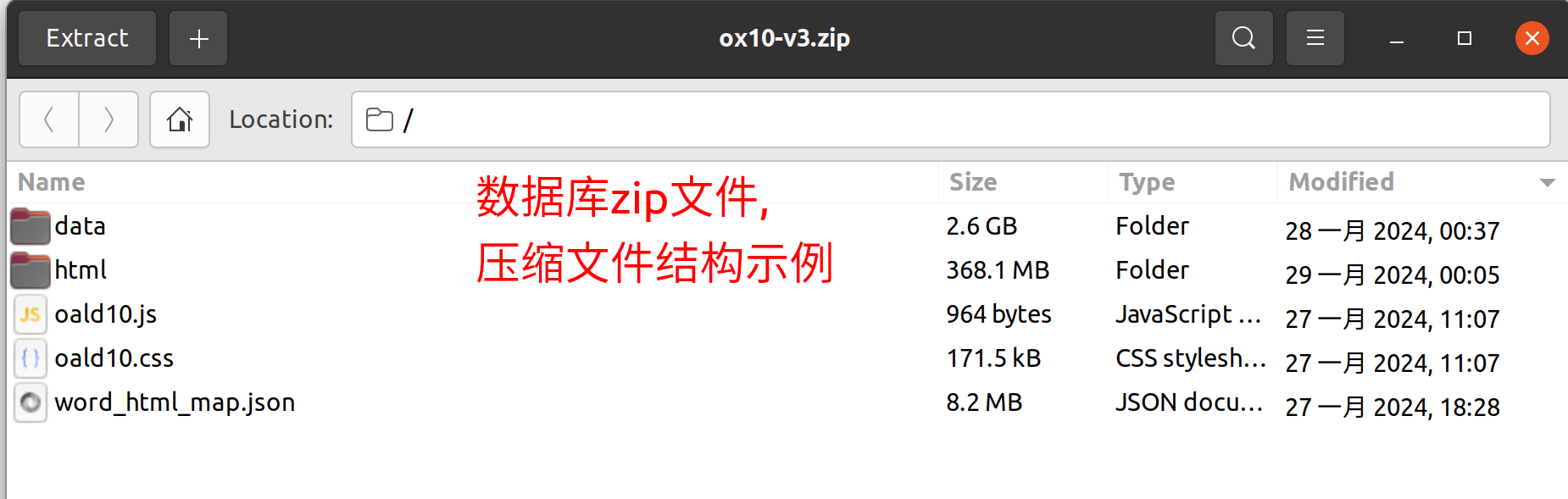
-
结构说明:
data/: 文件夹,存放字典资源文件,如图片、声音等。html/: 文件夹,存放单词释义的html页面文件,文件名应包含.html后缀。*.css,*.js: 静态资源文件,可以在压缩包根目录,也可以放在data文件夹下word_html_map.json: json文件,存放单词和html文件名的映射关系,格式为键值对json(key为单词,value为html文件名,不含.html后缀)。
- 自制词典数据:
- 你可以下载mdx/mdd格式的词典文件,例如牛津高阶英汉双解词典(第10版)V3
- 获取并使用相关的Python代码进行mdx/mdd资源的提取和转换:
在下载mdx/mdd格式词典文件以及提取词典资源代码文件后,你需要按照以下步骤制作词典数据库文件:
- 提取制作html文件及
word_html_map.json:# coding: utf-8 import json import os from readmdict import MDX import os import sys def makeHtml(mdxPath): mdx = MDX(mdxPath) base_dir=os.path.dirname(mdxPath) all_words_path=os.path.join(base_dir,"word_html_map.json") html_dir=os.path.join(base_dir,"html") print("html directory is: "+html_dir) print("all words json file path: "+all_words_path) os.makedirs(html_dir,exist_ok=True) i=1 allWordsMap={} items=mdx.items() for key,value in items: word=key.decode(encoding='utf-8') # ### 修复部分字典html文件中图片标签错误,图片放在span标签内. 如果没有此类问题可以注释掉下面的替换逻辑 htmlContent=value.decode().strip() if htmlContent.startswith("<span id=")and htmlContent.endswith("</span>") and 'src="data:image/' in htmlContent: htmlContent=htmlContent.replace("<span id=","<img id=") htmlContent=htmlContent.replace("</span>","</img>") htmlContent=htmlContent.replace('style="display:none"','style="max-width: 100%"') value=htmlContent.encode() # ############## work_html_name = str(i) allWordsMap[word]=work_html_name html_path=os.path.join(html_dir,work_html_name+".html") df = open(html_path, 'wb') df.write(value) df.close() i+=1 b = json.dumps(allWordsMap,sort_keys=True,separators=None,indent=" ",ensure_ascii=False,) f2 = open(all_words_path, 'w') f2.write(b) f2.close() print(i,"exit with 0") if __name__ == '__main__': # python extract_html.py <mdx_path> mdx_path=sys.argv[1] makeHtml(mdx_path)
-
- 提取图片、声音资源文件(data 文件夹):
python readmdict.py -x <.mdd文件>-
- 制作zip词典数据库压缩文件:
zip -q -r -9 mydict.zip data/ html/ *.css *.js word_html_map.json- 如果压缩文件中包含其他文件,如.ini文件等,可以在zip命令中添加相应的文件名。
-
- 将以上词典数据库文件添加设置为词典数据库文件
-
加载本地词典数据库文件--开始解析
-

请按照上述步骤确保词典数据正确添加至你的学习工具中,以便在学习过程中查阅单词和词组的详细释义,从而更有效地提升你的语言能力。