During the last few decades, with the rise of YouTube, Amazon, Netflix, and many other such web services, recommender systems have taken more and more place in our lives. From e-commerce (suggest to buyers articles that could interest them) to online advertisement (suggest to users the right contents, matching their preferences), recommender systems are today unavoidable in our daily online journeys. By analyzing the problems with ‘Book Recommendation System’ feature, how we can predict the best recommendation for users according to their items approach. A recommendation system helps an organization to create loyal customers and build trust by them desired products and services for which they came on your site. The recommendation system today is so powerful that they can handle the new customer too who has visited the site for the first time. They recommend the products which are currently trending or highly rated and they can also recommend the products which bring maximum profit to the company. Providing specific data analysis and prediction to done with this data. The main objective of our project is to built a predictive book recommender model, which could help users to choose a suitable book based on their reading habits.
We've three dataset - • Book data – (ISBN, Book-Title, Book-Author, Year-Of-Publication, Publisher, Image-URL-S, Image-URL-M, Image-URL-L) • Users data - (User-ID, Location, Age) • Ratings data - (User-ID, ISBN, Book-Rating) The users interaction is very vital role for recommendation. To successful build collaborative filtering model in recommender system, data preparation is important. We will not use the Users dataset as it has no significance for the recommendation system.
There are 4 types of recommendation system:
1.Popularity based
The popularity based recommendations system is based on recommending the most popular book to the users based on overall ratings of the platform
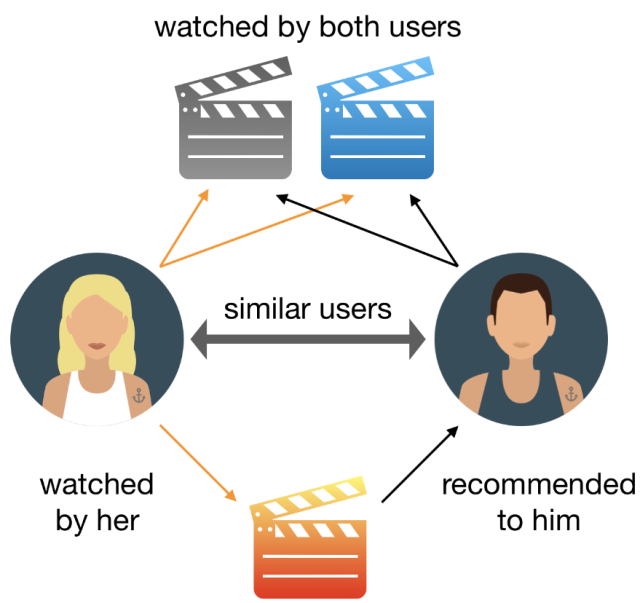
2.Collaborative Filtering
The collaborative filtering method is based on gathering and analyzing data on user’s behavior. This includes the user’s online activities and predicting what they will like based on the similarity with other users.
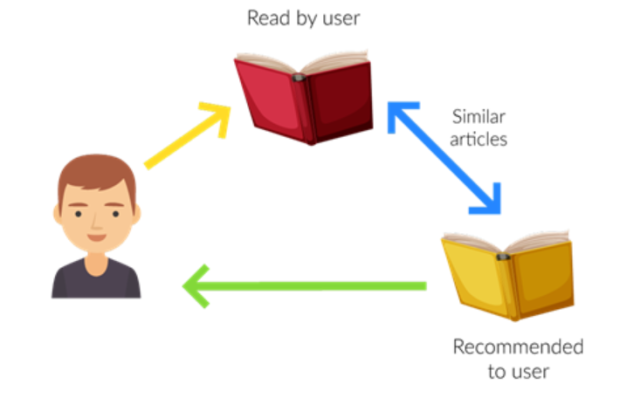
3.Content-Based Filtering
Content-based filtering methods are based on the description of a product and a profile of the user’s preferred choices. In this recommendation system, products are described using keywords, and a user profile is built to express the kind of item this user likes.
4.Hybrid Recommendation Systems
In hybrid recommendation systems, products are recommended using both content-based and collaborative filtering simultaneously to suggest a broader range of products to customers. This recommendation system is up-and-coming and is said to provide more accurate than other recommender systems.
A book recommendation system is a type of recommendation system where we have to recommend similar books to the reader based on his interest. We’ve all recorded data with three different datasets – Book dataset (ISBN, Book-Title, Book-Author, Year-Of-Publication, Publisher, Image-URL-S, Image-URL-M, Image-URL-L); Users dataset (User-ID, Location, Age); Rating dataset (User-ID, ISBN, Book-Rating).
As the first step, we performed data preparation (i.e data cleaning and feature engineering) and EDA part. After data preparation, build a recommendation system based on popularity (i.e ratings). These recommendations are usually given to every user irrespective of personal characterization. Merged book_data dataset and ratings, considering ISBNs that were explicitly rated for this recommendation system. We have listed all the top 50 books with the highest average rating but we have only selected those books whose no ratings are more than 250
The third step is to do Collaborative Filtering - Memory based approach was our first trial on train and test dataset which uses the memory of previous user's interactions to compute user's similarities based on items they’ve interacted with (i.e user-based approach) or compute items similarities based on the users that have interacted with them (i.e item-based approach). Our approach here is that we will only select users who have rated more than 200 books and we will only select books that are rated by more than 50 users to get more accurate results for the model and avoid outliners. Then we apply cosine similarity to make item similarity need to take the transpose of a matrix. This matrix would help in managing the train-test matrix. After all views predictions based on similarity, we find recommendation on it based on score.
The last step is to create a function recommend which will take the book name as input from the user and it will return 4 similar books with the author.