diff --git a/.nojekyll b/.nojekyll
index a43b028..eda675b 100644
--- a/.nojekyll
+++ b/.nojekyll
@@ -1 +1 @@
-be6cdd8c
\ No newline at end of file
+916b612a
\ No newline at end of file
diff --git a/decision_checklist.html b/decision_checklist.html
index 18e2d62..35c8b37 100644
--- a/decision_checklist.html
+++ b/decision_checklist.html
@@ -229,6 +229,12 @@
10. Accessibility and literacy
+
+
diff --git a/search.json b/search.json
index 97d76c5..fede8bf 100644
--- a/search.json
+++ b/search.json
@@ -22,365 +22,311 @@
]
},
{
- "objectID": "weeks/05_good_code.html",
- "href": "weeks/05_good_code.html",
- "title": "5. Writing good code",
+ "objectID": "weeks/11_merging.html",
+ "href": "weeks/11_merging.html",
+ "title": "11. Merging data",
"section": "",
- "text": "Think about what you need in order to leave the house for work or school. What things do you need to get out the door—some variation on “phone, wallet, keys”? Think about what influences your list, e.g. maybe you switch modes of transportation, which will decide whether you need car keys, a bike helmet and lights, or a bus card.\nWrite down:\n\nthe things you always need\nthe things you sometimes need",
+ "text": "library(dplyr)\nlibrary(justviz)\nlibrary(ggplot2)\nHere are some notes on merging data from different data frames. A lot of the functions here come from dplyr, including all the *_join ones.",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "11. Merging data"
]
},
{
- "objectID": "weeks/05_good_code.html#warm-up",
- "href": "weeks/05_good_code.html#warm-up",
- "title": "5. Writing good code",
- "section": "",
- "text": "Think about what you need in order to leave the house for work or school. What things do you need to get out the door—some variation on “phone, wallet, keys”? Think about what influences your list, e.g. maybe you switch modes of transportation, which will decide whether you need car keys, a bike helmet and lights, or a bus card.\nWrite down:\n\nthe things you always need\nthe things you sometimes need",
+ "objectID": "weeks/11_merging.html#types-of-joins",
+ "href": "weeks/11_merging.html#types-of-joins",
+ "title": "11. Merging data",
+ "section": "Types of joins",
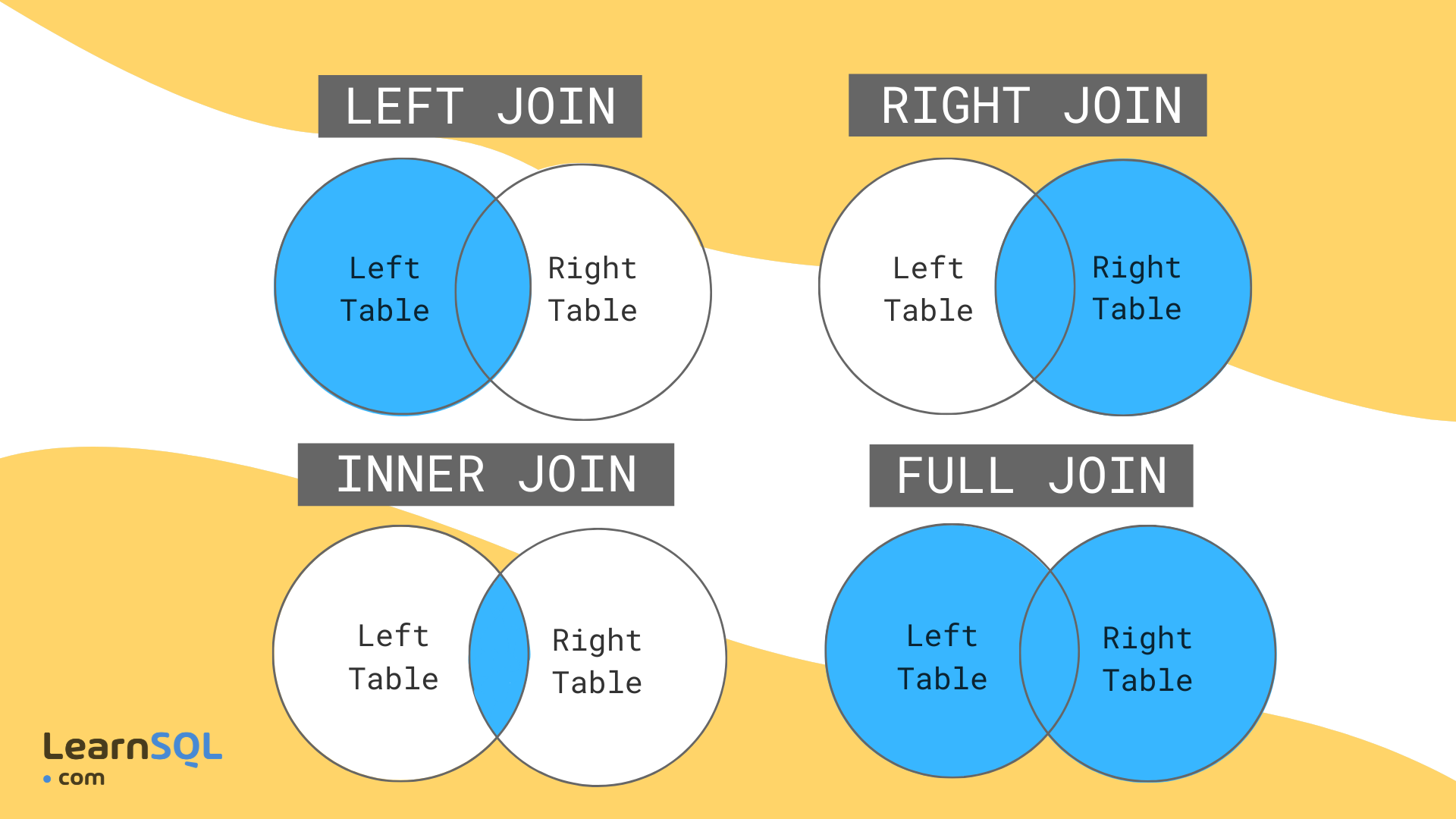
+ "text": "Types of joins\nThere are different types of joins that are defined by what data you want to keep and under what circumstances. These are consistent across many different languages (e.g. same terminology in R should apply in most/all SQL variants). The ones you’ll use most often are left joins and inner joins; when in doubt, a left join is safer than an inner join.\nThere’s an overly complicated chapter in R for Data Science on joins. There are some less complicated examples in the dplyr docs.\n\n\n\nAn illustration of joins\n\n\nImagine we’re joining two tables of data for counties A, B, C, D, and E, one row per county. The left table, housing, has housing information for each county but is missing County B. The right table, income, has income information for counties A, B, and E. That means there are a total of 5 counties, but only 2 of them are in both tables.\n\nLeft join will include every county that’s in housing, regardless of whether it’s also in income. There will be a row for income variables, but their values will be NA.\nInner join will include every county that’s in both housing and income.\nRight join is like left join: it will include every county that’s in income, regardless of whether it’s also in housing.\nFull join will include every county in either table.\n\n\nset.seed(1)\nhousing <- data.frame(county = c(\"A\", \"C\", \"D\", \"E\"), \n homeownership = runif(4),\n vacancy = runif(4, min = 0, max = 0.1))\nincome <- data.frame(county = c(\"A\", \"B\", \"E\"), \n poverty = runif(3))\n\nleft_join(housing, income, by = \"county\")\n\n\n\n\n\ncounty\nhomeownership\nvacancy\npoverty\n\n\n\n\nA\n0.2655087\n0.0201682\n0.6291140\n\n\nC\n0.3721239\n0.0898390\nNA\n\n\nD\n0.5728534\n0.0944675\nNA\n\n\nE\n0.9082078\n0.0660798\n0.2059746\n\n\n\n\n\ninner_join(housing, income, by = \"county\")\n\n\n\n\n\ncounty\nhomeownership\nvacancy\npoverty\n\n\n\n\nA\n0.2655087\n0.0201682\n0.6291140\n\n\nE\n0.9082078\n0.0660798\n0.2059746\n\n\n\n\n\nright_join(housing, income, by = \"county\")\n\n\n\n\n\ncounty\nhomeownership\nvacancy\npoverty\n\n\n\n\nA\n0.2655087\n0.0201682\n0.6291140\n\n\nE\n0.9082078\n0.0660798\n0.2059746\n\n\nB\nNA\nNA\n0.0617863\n\n\n\n\n\nfull_join(housing, income, by = \"county\")\n\n\n\n\n\ncounty\nhomeownership\nvacancy\npoverty\n\n\n\n\nA\n0.2655087\n0.0201682\n0.6291140\n\n\nC\n0.3721239\n0.0898390\nNA\n\n\nD\n0.5728534\n0.0944675\nNA\n\n\nE\n0.9082078\n0.0660798\n0.2059746\n\n\nB\nNA\nNA\n0.0617863\n\n\n\n\n\n\nThere are other joins that might be useful for filtering, but that don’t add any new columns. Semi joins return the rows of the left table that have a match in the right table, and anti joins return the rows of the left table that do not have a match in the right table. If you were making separate charts on housing and income, but wanted your housing chart to only include counties that are also in your income data, semi join would help.\n\nsemi_join(housing, income, by = \"county\")\n\n\n\n\n\ncounty\nhomeownership\nvacancy\n\n\n\n\nA\n0.2655087\n0.0201682\n\n\nE\n0.9082078\n0.0660798",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "11. Merging data"
]
},
{
- "objectID": "weeks/05_good_code.html#documenting-code",
- "href": "weeks/05_good_code.html#documenting-code",
- "title": "5. Writing good code",
- "section": "Documenting code",
- "text": "Documenting code\nOne of the most important things you can do as a programmer is to document your code. This can be hard to do well, but it’s essential to making sure your code is clear and accountable and that your work can be reproduced or repurposed. (If you’ve followed the “replicability crisis” in the sciences over the past decade or so, you’ve seen what can go very wrong when your work isn’t documented accurately for yourself and others!)\nA common suggestion is to write your code assuming you’ll come back to it in 6 months and need to be able to pick up where you left off. I usually also assume a coworker or colleague will need to rerun or reuse my code, so even if I’m doing something that I’ll remember 6 months from now, they might not know what things mean. It also gets me out of spending unnecessary amounts of time walking interns through an analysis if I can say, “I tried to document everything really well, so read through it, run all the code, and let me know if you need help after that.” Documenting code also helps ease the transition into package development, which requires a lot of documentation.\nI don’t document everything—plenty of my work is routine and straightforward enough—but some of the things I try to always take note of:\n\nAny sort of analysis or process that’s out of the ordinary or complex. Don’t assume you’ll remember later why you used a new approach.\nAnything I know someone else will need to be able to reference. Sometimes I do EDA on something that a coworker will then finish up or need to write about. I need to make sure they can do that accurately.\nOutside sources that don’t come from that specific project. If your project is contained within a set of folders, and you’ve copied data in from some other project, make a note of where it comes from so if you need to update it you know where to get it from.\nDecision-making that you might need to keep track of or argue for later. e.g. a comparison of categories between datasets with a note that says “these categories changed significantly since the previous data collection” will be helpful when someone asks why you didn’t include trends in an analysis.\nReferences. If I came up with some code based on a Stack Overflow post or a blog post somewhere, or I’m building off of someone else’s methodology, I’ll usually include a link in my comments.\n\nThis also applies to simple things like organizing your projects. If you have a bunch of folders called things like “data analysis 1” and they all contain a jumble of different notebooks and scripts for different purposes, and the scripts are all called “analysis_of_stuff.R”, you’re going to lose things easily and not know how different pieces build on each other. Similarly, don’t spend time doing an analysis only to write your data out to a file called “data.csv” and a plot called “map.png”. This might seem obvious, but I’ve seen people do all of these things.\n\nExercises\nGoing back to your list for leaving the house, add notes for how you decide whether you’ll need something. For example, if your laptop is on your “sometimes” list, write down what decides that.\n\n\n\n\n\n\nBrainstorm\n\n\n\n\nCash – if you’re going somewhere that doesn’t take cards / mobile\nSweater – weather / environment\nTea – sleepiness\nEarbuds – length of time out of house / time of day\nWork badge – going to office\nLaptop charger – if not already charged",
+ "objectID": "weeks/11_merging.html#joining-justviz-datasets",
+ "href": "weeks/11_merging.html#joining-justviz-datasets",
+ "title": "11. Merging data",
+ "section": "Joining justviz datasets",
+ "text": "Joining justviz datasets\n\nacs_tract <- acs |> filter(level == \"tract\")\n\nhead(acs_tract)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nlevel\ncounty\nname\ntotal_pop\nwhite\nblack\nlatino\nasian\nother_race\ndiversity_idx\nforeign_born\ntotal_hh\nhomeownership\ntotal_cost_burden\ntotal_severe_cost_burden\nowner_cost_burden\nowner_severe_cost_burden\nrenter_cost_burden\nrenter_severe_cost_burden\nno_vehicle_hh\nmedian_hh_income\nages25plus\nless_than_high_school\nhigh_school_grad\nsome_college_or_aa\nbachelors\ngrad_degree\npov_status_determined\npoverty\nlow_income\narea_sqmi\npop_density\n\n\n\n\ntract\nAllegany County\n24001000100\n3474\n0.98\n0.00\n0.01\n0.00\n0.01\n0.1019\n0.01\n1577\n0.78\n0.18\n0.08\n0.12\n0.07\n0.39\n0.14\n0.06\n56232\n2671\n0.09\n0.47\n0.28\n0.07\n0.08\n3461\n0.12\n0.35\n187.932766\n18.48533\n\n\ntract\nAllegany County\n24001000200\n4052\n0.75\n0.19\n0.02\n0.00\n0.03\n0.5135\n0.03\n1390\n0.86\n0.20\n0.12\n0.18\n0.11\n0.33\n0.18\n0.04\n66596\n3255\n0.15\n0.49\n0.24\n0.08\n0.05\n2949\n0.11\n0.30\n48.072019\n84.29020\n\n\ntract\nAllegany County\n24001000500\n2304\n0.66\n0.19\n0.05\n0.01\n0.07\n0.6036\n0.04\n683\n0.60\n0.20\n0.04\n0.09\n0.02\n0.36\n0.07\n0.13\n47781\n1283\n0.09\n0.37\n0.38\n0.11\n0.06\n1777\n0.27\n0.51\n4.422954\n520.91879\n\n\ntract\nAllegany County\n24001000600\n3005\n0.91\n0.02\n0.01\n0.00\n0.07\n0.2902\n0.00\n1374\n0.70\n0.20\n0.09\n0.14\n0.04\n0.36\n0.23\n0.10\n48607\n2141\n0.07\n0.35\n0.35\n0.13\n0.09\n2910\n0.14\n0.37\n1.582466\n1898.93501\n\n\ntract\nAllegany County\n24001000700\n3233\n0.93\n0.02\n0.01\n0.00\n0.04\n0.2312\n0.02\n1462\n0.49\n0.37\n0.16\n0.25\n0.07\n0.48\n0.24\n0.25\n36090\n2045\n0.13\n0.38\n0.33\n0.08\n0.08\n3217\n0.28\n0.58\n0.712350\n4538.49941\n\n\ntract\nAllegany County\n24001000800\n1932\n0.89\n0.01\n0.06\n0.01\n0.03\n0.2919\n0.02\n786\n0.48\n0.52\n0.25\n0.35\n0.19\n0.68\n0.30\n0.17\n27130\n1253\n0.14\n0.48\n0.28\n0.06\n0.04\n1926\n0.35\n0.61\n1.263143\n1529.51773\n\n\n\n\n\nhead(ejscreen)\n\n\n\n\n\ntract\nindicator\nvalue_ptile\nd2_ptile\nd5_ptile\n\n\n\n\n24001000100\npm25\n6\n7\n9\n\n\n24001000100\nozone\n0\n0\n0\n\n\n24001000100\ndiesel\n3\n5\n5\n\n\n24001000100\nair_cancer\n0\n0\n0\n\n\n24001000100\nresp\n0\n0\n0\n\n\n24001000100\nreleases_to_air\n65\n44\n73\n\n\n\n\n\n\nACS data has several geographies, including census tracts (I’ve subset for just tract data). Their ID (GEOID, or FIPS codes) are in the column name. The EPA data is only by tract, and its column of IDs is labeled tract. So we’ll be joining name from acs_tract with tract from ejscreen.\n\nn_distinct(acs_tract$name)\n\n[1] 1460\n\nn_distinct(ejscreen$tract)\n\n[1] 1475\n\n\nThere are 15 tracts that are included in the EPA data but not the ACS data. That’s because those are tracts with no population that I dropped from the ACS table when I made it. I can check up on that with an anti-join (not running this here but it confirms that these are all zero-population tracts).\n\npop <- tidycensus::get_acs(\"tract\", table = \"B01003\", state = \"MD\", year = 2022)\n\nanti_join(ejscreen, acs_tract, by = c(\"tract\" = \"name\")) |>\n distinct(tract) |>\n inner_join(pop, by = c(\"tract\" = \"GEOID\"))\n\nThere’s another hiccup for merging data here: the ACS data is in a wide format (each variable has its own column), while the EPA data is in a long format (one column gives the indicator, then different types of values have their own columns). Those formatting differences could be awkward because you’d end up with some values repeated. The easiest thing to do is select just the data you’re interested in, either by selecting certain columns or filtering rows, then reshape, then join.\nLet’s say I’m interested in the relationship, if any, between demographics and a few waste-related risk factors (proximity to wastewater, hazardous waste, and superfund sites). I’ll filter ejscreen for just those 2 indicators and reshape it so the columns have the value percentiles for each of those two risk factors (not the adjusted percentiles). Then I’ll select the columns I want from acs, then join them.\nThe tidyr::pivot_wider and tidyr::pivot_longer functions can be confusing, but there are some good examples in the docs and a lot of Stack Overflow posts on them. Basically here I’m reshaping from a long shape to a wide shape, so I’ll use pivot_wider.\n\n# in practice I would do this all at once, but want to keep the steps separate\n# so they're more visible\nwaste_long <- ejscreen |>\n filter(indicator %in% c(\"haz_waste\", \"superfund\", \"wastewater\"))\n\nhead(waste_long)\n\n\n\n\n\ntract\nindicator\nvalue_ptile\nd2_ptile\nd5_ptile\n\n\n\n\n24001000100\nsuperfund\n38\n31\n52\n\n\n24001000100\nhaz_waste\n2\n2\n3\n\n\n24001000100\nwastewater\n69\n46\n81\n\n\n24001000200\nsuperfund\n88\n67\n85\n\n\n24001000200\nhaz_waste\n21\n27\n33\n\n\n24001000200\nwastewater\n80\n73\n89\n\n\n\n\n\n# id_cols are the anchor of the pivoting\n# only using value_ptile as a value column, not scaled ones\nwaste_wide <- waste_long |> \n tidyr::pivot_wider(id_cols = tract, \n names_from = indicator, \n values_from = value_ptile)\n\nhead(waste_wide)\n\n\n\n\n\ntract\nsuperfund\nhaz_waste\nwastewater\n\n\n\n\n24001000100\n38\n2\n69\n\n\n24001000200\n88\n21\n80\n\n\n24001000500\n90\n28\n24\n\n\n24001000600\n93\n36\n78\n\n\n24001000700\n92\n49\n83\n\n\n24001000800\n89\n70\n87\n\n\n\n\n\n\nThen the columns I’m interested in from the ACS data:\n\nacs_demo <- acs_tract |>\n select(name, county, white, poverty, foreign_born)\n\nhead(acs_demo)\n\n\n\n\n\nname\ncounty\nwhite\npoverty\nforeign_born\n\n\n\n\n24001000100\nAllegany County\n0.98\n0.12\n0.01\n\n\n24001000200\nAllegany County\n0.75\n0.11\n0.03\n\n\n24001000500\nAllegany County\n0.66\n0.27\n0.04\n\n\n24001000600\nAllegany County\n0.91\n0.14\n0.00\n\n\n24001000700\nAllegany County\n0.93\n0.28\n0.02\n\n\n24001000800\nAllegany County\n0.89\n0.35\n0.02\n\n\n\n\n\n\nSo each of these two data frames has a column of tract IDs, and several columns of relevant values. I only want tracts that are in both datasets, so I’ll use an inner join.\n\nwaste_x_demo <- inner_join(acs_demo, waste_wide, by = c(\"name\" = \"tract\"))\n\nhead(waste_x_demo)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nname\ncounty\nwhite\npoverty\nforeign_born\nsuperfund\nhaz_waste\nwastewater\n\n\n\n\n24001000100\nAllegany County\n0.98\n0.12\n0.01\n38\n2\n69\n\n\n24001000200\nAllegany County\n0.75\n0.11\n0.03\n88\n21\n80\n\n\n24001000500\nAllegany County\n0.66\n0.27\n0.04\n90\n28\n24\n\n\n24001000600\nAllegany County\n0.91\n0.14\n0.00\n93\n36\n78\n\n\n24001000700\nAllegany County\n0.93\n0.28\n0.02\n92\n49\n83\n\n\n24001000800\nAllegany County\n0.89\n0.35\n0.02\n89\n70\n87\n\n\n\n\n\n\n\nggplot(waste_x_demo, aes(x = poverty, y = haz_waste, color = county == \"Baltimore city\")) +\n geom_point(alpha = 0.5, size = 1) +\n scale_color_manual(values = c(\"TRUE\" = \"firebrick\", \"FALSE\" = \"gray60\"))\n\n\n\n\n\n\n\n\nIs there a pattern? Maybe not, but now we know how to investigate it. There’s definitely something up with Baltimore though.",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "11. Merging data"
]
},
{
- "objectID": "weeks/05_good_code.html#reusable-code",
- "href": "weeks/05_good_code.html#reusable-code",
- "title": "5. Writing good code",
- "section": "Reusable code",
- "text": "Reusable code\nOne rule of thumb I’ve heard is that it’s fine to repeat your code to do the same thing twice, but if you need to do it a third time, you should write a function. It might mean taking a step back from what you’re working on at the moment, but it’s pretty much always worth the time. Alongside documenting your code in general, it’s important to document your functions—what they do, what the arguments mean, what types of values arguments can take. Try to your functions and their arguments in ways that make it clear what they mean as well.",
+ "objectID": "weeks/04_understanding_data.html",
+ "href": "weeks/04_understanding_data.html",
+ "title": "4. Learning about your data",
+ "section": "",
+ "text": "From Wickham et al. (2023), Exploratory Data Analysis chapter:\nWe’ll follow the steps of the EDA chapter using the acs dataset in the {justviz} package. For simplicity, we’ll focus on Maryland census tracts and just a few variables dealing with housing and income.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nacs_tr <- acs |>\n filter(level == \"tract\") |>\n select(county, name, total_pop, total_hh,\n homeownership, total_cost_burden, renter_cost_burden,\n owner_cost_burden, no_vehicle_hh, median_hh_income, pop_density)\nknitr::kable(head(acs_tr))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncounty\nname\ntotal_pop\ntotal_hh\nhomeownership\ntotal_cost_burden\nrenter_cost_burden\nowner_cost_burden\nno_vehicle_hh\nmedian_hh_income\npop_density\n\n\n\n\nAllegany County\n24001000100\n3474\n1577\n0.78\n0.18\n0.39\n0.12\n0.06\n56232\n18.48533\n\n\nAllegany County\n24001000200\n4052\n1390\n0.86\n0.20\n0.33\n0.18\n0.04\n66596\n84.29020\n\n\nAllegany County\n24001000500\n2304\n683\n0.60\n0.20\n0.36\n0.09\n0.13\n47781\n520.91879\n\n\nAllegany County\n24001000600\n3005\n1374\n0.70\n0.20\n0.36\n0.14\n0.10\n48607\n1898.93501\n\n\nAllegany County\n24001000700\n3233\n1462\n0.49\n0.37\n0.48\n0.25\n0.25\n36090\n4538.49941\n\n\nAllegany County\n24001000800\n1932\n786\n0.48\n0.52\n0.68\n0.35\n0.17\n27130\n1529.51773\n\n\n\n\nsummary(acs_tr)\n\n county name total_pop total_hh \n Length:1460 Length:1460 Min. : 5 Min. : 0 \n Class :character Class :character 1st Qu.: 2960 1st Qu.:1120 \n Mode :character Mode :character Median : 4026 Median :1528 \n Mean : 4220 Mean :1588 \n 3rd Qu.: 5358 3rd Qu.:1999 \n Max. :14109 Max. :4644 \n \n homeownership total_cost_burden renter_cost_burden owner_cost_burden\n Min. :0.0000 Min. :0.0400 Min. :0.00 Min. :0.0000 \n 1st Qu.:0.5000 1st Qu.:0.2100 1st Qu.:0.31 1st Qu.:0.1600 \n Median :0.7400 Median :0.2800 Median :0.44 Median :0.2100 \n Mean :0.6752 Mean :0.2932 Mean :0.43 Mean :0.2181 \n 3rd Qu.:0.8800 3rd Qu.:0.3700 3rd Qu.:0.55 3rd Qu.:0.2700 \n Max. :1.0000 Max. :0.7400 Max. :1.00 Max. :1.0000 \n NA's :4 NA's :4 NA's :7 NA's :12 \n no_vehicle_hh median_hh_income pop_density \n Min. :0.00000 Min. : 10000 Min. : 1.05 \n 1st Qu.:0.02000 1st Qu.: 70525 1st Qu.: 984.33 \n Median :0.05000 Median : 98164 Median : 3413.10 \n Mean :0.09468 Mean :104585 Mean : 4968.47 \n 3rd Qu.:0.12000 3rd Qu.:132052 3rd Qu.: 6822.62 \n Max. :0.85000 Max. :250001 Max. :57424.37 \n NA's :4 NA's :6\nWhat types of values do each of these variables represent? Why are their scales so different?",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "4. Learning about your data"
]
},
{
- "objectID": "weeks/05_good_code.html#exercises-1",
- "href": "weeks/05_good_code.html#exercises-1",
- "title": "5. Writing good code",
- "section": "Exercises",
- "text": "Exercises\nBuild out your morning routine into a pseudocode function, complete with arguments. Aim to make it flexible enough that you could use it any day of the week.\n\nExample\nPseudocode\nalways need: keys, wallet, phone, meds, mask\nif I'm biking:\n bring a helmet\notherwise:\n bring a bus card\nif I'm working:\n bring my laptop\nif it's Wednesday:\n take a covid test\nWorking R example\n\n# PARAMETERS:\n# date: Date object, today's date\n# biking: Logical, whether or not I'll be biking\n# working: Logical, whether or not I'm going to work\n# RETURNS:\n# prints a string\nleave_the_house <- function(date = lubridate::today(), biking = TRUE, working = TRUE) {\n day_of_week <- lubridate::wday(date, label = TRUE, abbr = FALSE)\n always_need <- c(\"keys\", \"phone\", \"wallet\", \"meds\")\n sometimes_need <- c()\n if (biking) {\n sometimes_need <- c(sometimes_need, \"helmet\")\n } else {\n sometimes_need <- c(sometimes_need, \"bus card\")\n }\n if (working) {\n sometimes_need <- c(sometimes_need, \"laptop\")\n }\n \n need <- c(always_need, sometimes_need)\n cat(\n sprintf(\"Happy %s! Today you need:\", day_of_week), \"\\n\",\n paste(need, collapse = \", \")\n )\n if (day_of_week == \"Wednesday\") {\n cat(\"\\n\\nBut take a COVID test first!\")\n }\n}\n\nleave_the_house(biking = FALSE)\n\nHappy Sunday! Today you need: \n keys, phone, wallet, meds, bus card, laptop",
+ "objectID": "weeks/04_understanding_data.html#variation",
+ "href": "weeks/04_understanding_data.html#variation",
+ "title": "4. Learning about your data",
+ "section": "Variation",
+ "text": "Variation\nFirst a histogram of median household income values:\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(color = \"white\")\n\n`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.\n\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\nThere’s a message and a warning: the message suggests being intentional about the number of bins, and the warning calls our attention to missing values in this column.\nUse the next few chunks of code to experiment with bin specifications. Does your understanding of the data’s distribution change?\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(bins = 50) # bins can be determined by setting the number of bins\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(binwidth = 10000) # or by the width of bins, with a scale corresponding to the x-axis\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\n\nWhat are some values of bins or binwidth that seem reasonable? At what point do either of them start to obscure data?\nAs for the missing values:\n\nacs_tr |>\n filter(is.na(median_hh_income))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncounty\nname\ntotal_pop\ntotal_hh\nhomeownership\ntotal_cost_burden\nrenter_cost_burden\nowner_cost_burden\nno_vehicle_hh\nmedian_hh_income\npop_density\n\n\n\n\nAnne Arundel County\n24003740400\n4241\n0\nNA\nNA\nNA\nNA\nNA\nNA\n6000.504539\n\n\nAnne Arundel County\n24003980000\n5\n0\nNA\nNA\nNA\nNA\nNA\nNA\n1.048504\n\n\nWashington County\n24043011000\n5212\n0\nNA\nNA\nNA\nNA\nNA\nNA\n3049.954209\n\n\nBaltimore city\n24510100300\n1999\n0\nNA\nNA\nNA\nNA\nNA\nNA\n33122.764732\n\n\nBaltimore city\n24510190300\n2122\n839\n0.20\n0.48\n0.52\n0.34\n0.68\nNA\n15572.409097\n\n\nBaltimore city\n24510250600\n11\n11\n0.55\n0.55\n0.00\n1.00\n0.00\nNA\n5.033091\n\n\n\n\n\n\nEven though we’re probably not going to use the total population and total household variables for any analysis here, I kept them because those sorts of variables that define what your observational unit is are important for checking what’s going on in your data. By which I mean a census tract is made up of a bunch of people (usually about 4,000) in a contiguous area who mostly live in households. But if you work with census data enough, you’ll know that some places have population but few households, or only very small populations altogether—a tract might actually be a jail or a set of college dorms, or maybe the majority of a tract is those sorts of group quarters, and the remainder is too small to reliably calculate some of the data. What we want to do with those tracts can depend on context, but I’ll drop them here.\n\nacs_tr2 <- filter(acs_tr, !is.na(median_hh_income))\n\n\nTypical values\nDoes anything seem weird about the median household income values? Look back at Figure 1 where it may be more apparent. (We’ll talk about this anomaly in the data.)\nSwitching to cost burden rates:\n\nggplot(acs_tr2, aes(x = total_cost_burden)) +\n geom_histogram(binwidth = 0.03)\n\n\n\n\n\n\n\n\nThis approaches a normal curve, but is skewed. From the histogram, the mean looks to be around 0.3 (looking back at the summary, this is correct), but with quite a few tracts with higher rates. Because this is a proportion, we don’t expect there to be any values below 0 or above 1.\nA boxplot can make it a little easier to figure out what’s typical in your distribution.\n\n# use a dummy value for x because ggplot expects boxplots to be done by a discrete variable\nggplot(acs_tr2, aes(x = 1, y = total_cost_burden)) +\n geom_boxplot() +\n coord_flip()\n\n\n\n\n\n\n\n\n\n\nUnusual values\n\nggplot(acs_tr2, aes(x = pop_density)) +\n geom_histogram(binwidth = 1000)\n\n\n\n\n\n\n\n\nThere are a few tracts that are extremely dense. If we wanted to get a sense of more typical tracts, we could filter those, either from the data or within the limits of the chart:\n\nacs_tr2 |>\n filter(pop_density < 30000) |>\n ggplot(aes(x = pop_density)) +\n geom_histogram(binwidth = 1000)\n\n\n\n\n\n\n\n# if you want bars to be between tick marks instead of centered over them, set boundary = TRUE\nacs_tr2 |>\n ggplot(aes(x = pop_density)) +\n geom_histogram(binwidth = 1000, boundary = TRUE, color = \"white\") +\n scale_x_continuous(limits = c(NA, 30000))\n\nWarning: Removed 8 rows containing non-finite values (`stat_bin()`).\n\n\nWarning: Removed 1 rows containing missing values (`geom_bar()`).\n\n\n\n\n\n\n\n\n\nWe could decide to investigate those high-density tracts. For example, if we’re interested in housing costs, we might drop tracts that seem to mostly be dorms. However, at least these tracts in Montgomery County are actually high-rise condos bordering DC, so we should keep them in.",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "4. Learning about your data"
]
},
{
- "objectID": "weeks/05_good_code.html#organization",
- "href": "weeks/05_good_code.html#organization",
- "title": "5. Writing good code",
- "section": "Organization",
- "text": "Organization\nCome up with a structure of directories you like for a project, and stick with it. The notes template repo I setup for this class has a pared down version of what I usually use, but a full version of what I might have, even for a small project, looks like this:\ncool_project \n ¦--analysis # EDA, notebooks, and scripts that create output\n |--design # scripts *only* for creating publishable charts\n ¦--fetch_data # raw data, often downloaded in a script\n ¦ ¦--fr_comments # folders for each raw data source\n ¦ °--pums \n ¦--input_data # cleaned data that is sourced for the project, maybe cleaned in prep scripts\n ¦--output_data # data that's a product of analysis in this project\n ¦--plots # plots that can be distributed or published\n ¦--prep_scripts # scripts that download, clean, reshape data\n °--utils # misc scripts & bits of data to use throughout the project\n\n\n\n\n\n\nAn aside: build tools\n\n\n\nBuild tools are outside the scope of this class, but for larger projects especially or projects that will need to be updated over time, they’ll save you a lot of headaches. I have some projects that I rebuild once a year when new ACS data comes out, and I’ve got things down to where I can make one or two calls on the command line flagging the year as a variable, and all the data wrangling and analyses are ready to go. In fact, this site rebuilds from a frozen list of packages every time I push to GitHub, and if that build is successful, it publishes automatically.\nSome tools I use:\n\nGNU Make, the OG build tool\nSnakemake, like GNU Make but written in Python and designed for data analysis\nGitHub actions, including ones specifically for R\nDocker, build a small isolated environment for your projects, some designed for R\nPackage & environment managers: mamba or conda for Python, renv for R",
+ "objectID": "weeks/04_understanding_data.html#covariation",
+ "href": "weeks/04_understanding_data.html#covariation",
+ "title": "4. Learning about your data",
+ "section": "Covariation",
+ "text": "Covariation\nEspecially when we talk about housing and socio-economic data, we expect things to be correlated—probably even more so than with naturally occurring phenomena, since so much of where we live and what resources we have are determined by history and policy decisions. So it shouldn’t surprise you to find correlations in data like this. In fact, the CDC PLACES dataset uses demographic data to model health measures where they don’t have direct measurements available, so in cases like that you actually want to lean away from digging into correlations too much, or you might end up just confirming the makeup of the model, not finding anything new.\n\nA categorical and a numerical variable\nI’ll reshape the data to get housing tenure into one categorical variable. (If this code doesn’t make sense it’s okay.)\n\ncost_burden <- acs_tr2 |>\n tidyr::pivot_longer(cols = matches(\"cost_burden\"), \n names_to = c(\"tenure\", \".value\"), # split column names into tenure and the name of the measure (cost_burden)\n names_pattern = \"(^[a-z]+)_(\\\\w+$)\", # use regex to match a set of lowercase letters at the start of the string, followed by an underscore, then match word characters until the end\n names_ptypes = list(tenure = factor())) |>\n filter(!is.na(cost_burden))\n\n\nggplot(cost_burden, aes(x = cost_burden, color = tenure)) +\n geom_freqpoly(binwidth = 0.02)\n\n\n\n\n\n\n\n\nThe bit about calling after_stat in the book chapter doesn’t apply here, since we have the same number of observations for each tenure.\n\nggplot(cost_burden, aes(x = tenure, y = cost_burden)) +\n geom_boxplot()\n\n\n\n\n\n\n\n\n\nggplot(cost_burden, aes(x = forcats::fct_reorder(tenure, cost_burden), \n y = cost_burden)) +\n geom_boxplot()\n\n\n\n\n\n\n\n\n\n\nTwo categorical variables\nThis is a pretty contrived example to match section 10.5.2, but I’ll bin homeownership and housing cost burden into categorical variables, and look at these by county.\n\nacs_tr2 |>\n mutate(ownership_brk = cut(homeownership, \n breaks = c(0, 0.25, 0.5, 0.75, 1), \n include.lowest = TRUE, right = FALSE)) |>\n mutate(income_brk = cut(median_hh_income, \n breaks = c(0, 5e4, 1e5, 1.5e5, Inf),\n include.lowest = TRUE, right = FALSE)) |>\n count(income_brk, ownership_brk) |>\n ggplot(aes(x = income_brk, y = ownership_brk)) +\n geom_point(aes(size = n)) +\n scale_size_area()\n\n\n\n\n\n\n\n\nSee if you can adjust the code to use tiles and a color (fill) scale.\n\n\nTwo numerical variables\nSame variables, without the binning\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point()\n\n\n\n\n\n\n\n\nUse the methods in the book (changing alpha or using a 2D density) to deal with overplotting here.\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point(alpha = 0.4)\n\n\n\n\n\n\n\n\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point(shape = \"circle open\")\n\n\n\n\n\n\n\n\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_bin2d()",
"crumbs": [
"Weekly notes",
- "5. Writing good code"
+ "4. Learning about your data"
]
},
{
- "objectID": "weeks/06_color.html",
- "href": "weeks/06_color.html",
- "title": "6. Color",
+ "objectID": "weeks/07_annotations.html",
+ "href": "weeks/07_annotations.html",
+ "title": "7. Text and annotations",
"section": "",
- "text": "Code\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n\nsource(here::here(\"utils/plotting_utils.R\"))",
+ "text": "“Until the systems of power recognise different categories, the data I’m reporting on is also flawed,” she added.\nIn a bid to account for these biases, and any biases of her own, Chalabi is transparent about her sources and often includes disclaimers about her own decision-making process and about any gaps or uncertainties in the data.\n“I try to produce journalism where I’m explaining my methods to you,” she said. “If I can do this, you can do this, too. And it’s a very democratising experience, it’s very egalitarian.”\nIn an ideal scenario, she is able to integrate this background information into the illustrations themselves, as evidenced by her graphics on anti-Asian hate crimes and the ethnic cleansing of Uygurs in China.\nBut at other times, context is relegated to the caption to ensure the graphic is as grabby as possible.\n“What I have found is literally every single word that you add to an image reduces engagement, reduces people’s willingness or ability to absorb the information,” Chalabi said.\n“So there is a tension there. How can you be accurate and get it right without alienating people by putting up too much information? That’s a really, really hard balance.”\nMona Chalabi in Hahn (2023)\n\nHahn, J. (2023). \"Data replicates the existing systems of power\" says Pulitzer Prize-winner Mona Chalabi. Dezeen. https://www.dezeen.com/2023/11/16/mona-chalabi-pulitzer-prize-winner/",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "7. Text and annotations"
]
},
{
- "objectID": "weeks/06_color.html#warm-up",
- "href": "weeks/06_color.html#warm-up",
- "title": "6. Color",
- "section": "Warm-up",
- "text": "Warm-up\n\nColor perception\nWhich row uses a darker color?\n\n\n\n\n\n\n\n\n\nWhich line uses a darker color?\n\n\n\n\n\n\n\n\n\nWhich line uses a darker color?\n\n\n\n\n\n\n\n\n\nHow many purple dots are in each row?\n\n\n\n\n\n\n\n\n\n\n\nColors in R\nIf you don’t already have a color selection tool on your computer 1 you can install the colourpicker package that has a color picker addin for RStudio.\n1 Maybe the thing I miss most since switching from Mac to Linux is the color picker app Sip, definitely recommend it",
+ "objectID": "weeks/07_annotations.html#big-picture-providing-context-and-making-meaning",
+ "href": "weeks/07_annotations.html#big-picture-providing-context-and-making-meaning",
+ "title": "7. Text and annotations",
+ "section": "",
+ "text": "“Until the systems of power recognise different categories, the data I’m reporting on is also flawed,” she added.\nIn a bid to account for these biases, and any biases of her own, Chalabi is transparent about her sources and often includes disclaimers about her own decision-making process and about any gaps or uncertainties in the data.\n“I try to produce journalism where I’m explaining my methods to you,” she said. “If I can do this, you can do this, too. And it’s a very democratising experience, it’s very egalitarian.”\nIn an ideal scenario, she is able to integrate this background information into the illustrations themselves, as evidenced by her graphics on anti-Asian hate crimes and the ethnic cleansing of Uygurs in China.\nBut at other times, context is relegated to the caption to ensure the graphic is as grabby as possible.\n“What I have found is literally every single word that you add to an image reduces engagement, reduces people’s willingness or ability to absorb the information,” Chalabi said.\n“So there is a tension there. How can you be accurate and get it right without alienating people by putting up too much information? That’s a really, really hard balance.”\nMona Chalabi in Hahn (2023)\n\nHahn, J. (2023). \"Data replicates the existing systems of power\" says Pulitzer Prize-winner Mona Chalabi. Dezeen. https://www.dezeen.com/2023/11/16/mona-chalabi-pulitzer-prize-winner/",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "7. Text and annotations"
]
},
{
- "objectID": "weeks/06_color.html#chapters",
- "href": "weeks/06_color.html#chapters",
- "title": "6. Color",
- "section": "Chapters",
- "text": "Chapters\nWe’ll walk through Wilke chapters 4 and 19–I don’t have a ton to add until we get to mapping.\n\nWilke chapter 4\nWilke chapter 19\nDatawrapper (2021)\n\n\nDatawrapper. (2021). What to consider when choosing colors for data visualization. https://academy.datawrapper.de/article/140-what-to-consider-when-choosing-colors-for-data-visualization",
+ "objectID": "weeks/07_annotations.html#text",
+ "href": "weeks/07_annotations.html#text",
+ "title": "7. Text and annotations",
+ "section": "Text",
+ "text": "Text\n\nA data visualization is not a piece of art meant to be looked at only for its aesthetically pleasing features. Instead, its purpose is to convey information and make a point. To reliably achieve this goal when preparing visualizations, we have to place the data into context and provide accompanying titles, captions, and other annotations. – Wilke (2019) ch. 22\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\nThe type of text you use, phrasing, and placement all depend on where your visualizations will go, who will read them, and how they might be distributed. For example, I might put less detail in the titles and labels of a chart that will be part of a larger publication than a chart that might get distributed on its own (I’ll also tend towards more straightforward chart types and simpler analyses for something standalone).\n\nUses of text\nHere’s a good rundown on how to use text\n\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nsource(here::here(\"utils/plotting_utils.R\"))\n# source(here::here(\"utils/misc.R\"))\nbalt_metro <- readRDS(here::here(\"utils/balt_metro.rds\"))\n\n# set a default theme from the one I defined in plotting_utils.R\ntheme_set(theme_nice())\n\nIdentify all the text in this chart, what purpose it serves, and whether that could be done better through other means.\n\nacs |>\n filter(level %in% c(\"us\", \"state\") | name %in% balt_metro) |>\n mutate(name = forcats::fct_reorder(name, total_cost_burden)) |>\n mutate(level2 = forcats::fct_other(name, keep = c(\"United States\", \"Maryland\", \"Baltimore city\"))) |>\n stylehaven::offset_lbls(value = total_cost_burden, frac = 0.025, fun = scales::label_percent()) |>\n ggplot(aes(x = name, y = total_cost_burden, fill = level2)) +\n geom_col(width = 0.8) +\n geom_text(aes(label = lbl, hjust = just, y = y), color = \"white\", fontface = \"bold\") +\n scale_y_barcontinuous() +\n coord_flip() +\n labs(title = \"Baltimore city has a higher rate of cost burden than the state or nation\",\n subtitle = \"Share of households that are cost burdened, Maryland, 2022\",\n caption = \"Source: US Census Bureau American Community Survey, 2022 5-year estimates\",\n fill = \"fill\") +\n theme(panel.grid.major.y = element_blank(),\n panel.grid.major.x = element_line()) \n\n\n\n\n\n\n\n\n\n\n\n\n\n\nBrainstorm\n\n\n\n\n\n\n\n\n\n\n\nText\nPurpose\nCould be better?\n\n\n\n\nTitle\nTakeaway, what you’re looking at in context\n\n\n\nSubtitle\nSpecifics of what’s being measured\nDepending on context, maybe put cost burden definition here\n\n\nIndependent axis\nLocations\n\n\n\nIndependent axis title\nWhat’s on the axis\nNot necessary; we know what these names are\n\n\nLegend title\nWhat colors mean\n\n\n\nLegend labels\nLocation types\nDrop the legend, put any additional info in subtitle\n\n\nDependent axis title\nMeaning of variable being measured\nCan remove since it’s in the subtitle, but some styleguides may say keep it\n\n\nCaption\nSource\nCould put definition of cost burden here\n\n\nDependent axis labels\nSpecify meaning of breaks along axis\nCan drop because redundant\n\n\nDirect data labels on bars\nValues of each data point",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "7. Text and annotations"
]
},
{
- "objectID": "weeks/06_color.html#tools",
- "href": "weeks/06_color.html#tools",
- "title": "6. Color",
- "section": "Tools",
- "text": "Tools\n\nColorBrewer (access to these palettes comes with ggplot)\nCarto Colors (access comes with the rcartocolor package)\nViz Palette generator & preview\nGregor Aisch’s chroma palettes generator\nColorgorical categorical color generator 2\n\n2 I just read a post making fun of Colorgorical for leaning toward puke green colors; haven’t used it in a while but heads up I guess?",
+ "objectID": "weeks/07_annotations.html#other-annotations",
+ "href": "weeks/07_annotations.html#other-annotations",
+ "title": "7. Text and annotations",
+ "section": "Other annotations",
+ "text": "Other annotations\nThere are other annotations that are useful too. You might mark off a region to show a cluster of points, or a period in time. There are 2 approaches to this with ggplot: using geoms (geom_text, geom_hline, etc) or annotation layers (annotate, annotation_custom). The main difference is that annotations aren’t mapped to data the way geoms are. Because of that, I almost only use geoms for annotations, and usually make a small data frame just for the data that goes into the annotations to avoid hard-coding too much.\nAn example from DataHaven’s most recent books: we wanted to explicitly put evictions into a policy context, so we marked off the end of the federal eviction moratorium and the prepandemic average count as a threshhold. Without those labeled lines, you could tell that there was an abrupt drop in evictions, then a steep rise in them about a year and a half later, then counts that are higher than at the beginning of 2020. But unless you had followed eviction trends and COVID relief policies, you might not know why any of those things occurred.\n\n\n\nFrom Abraham et al. (2023)\n\nAbraham, M., Seaberry, C., Davila, K., & Carr, A. (2023). Greater New Haven Community Wellbeing Index 2023. https://ctdatahaven.org/reports/greater-new-haven-community-wellbeing-index",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "7. Text and annotations"
]
},
{
- "objectID": "weeks/06_color.html#types-of-color-palettes",
- "href": "weeks/06_color.html#types-of-color-palettes",
- "title": "6. Color",
- "section": "Types of color palettes",
- "text": "Types of color palettes\nThe main types of color palettes are:\n\nsequential / quantitative: values are numeric and continuous; values and colors (saturation, lightness, hue) increase in some way in tandem\ndiverging: values are likely numeric, but colors trend in opposite directions\nqualitative / categorical: values are not numeric / continuous, and colors should not imply continuity\n\nColorBrewer and Carto Colors are great because they have options for all three of these.\nThese are rough examples using ColorBrewer palettes; in practice you might want to make some adjustments to these.",
+ "objectID": "weeks/07_annotations.html#exercises",
+ "href": "weeks/07_annotations.html#exercises",
+ "title": "7. Text and annotations",
+ "section": "Exercises",
+ "text": "Exercises\nThis chart doesn’t have labels for its axes, but you know it’s unemployment rates in Baltimore and Maryland. How accurately can we guess what the labels would be?\n\n\n\n\n\n\n\n\n\nNext, what annotations would be helpful for contextualizing this trend?\n\n\n\n\n\n\nBrainstorm: contextualizing information\n\n\n\n\nTimespan–years on axis\nSource\nUnits of measurement\nHistorical events",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "7. Text and annotations"
]
},
{
- "objectID": "weeks/06_color.html#exercises",
- "href": "weeks/06_color.html#exercises",
- "title": "6. Color",
- "section": "Exercises",
- "text": "Exercises\n\nlocal_counties <- c(\"Baltimore city\", \"Baltimore County\", \"Harford County\", \"Howard County\", \"Anne Arundel County\")\nacs_county <- acs |>\n filter(level %in% c(\"us\", \"state\", \"county\")) |>\n mutate(local1 = forcats::as_factor(name) |>\n forcats::fct_other(keep = c(local_counties, \"United States\", \"Maryland\"), other_level = \"Other counties\"),\n local2 = forcats::fct_collapse(local1, \"Outside Baltimore\" = c(\"Baltimore County\", \"Harford County\", \"Howard County\", \"Anne Arundel County\")) |>\n forcats::fct_relevel(\"Outside Baltimore\", \"Other counties\", after = Inf))\n\ntheme_set(theme_nice())\nknitr::kable(head(acs_county))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nlevel\ncounty\nname\ntotal_pop\nwhite\nblack\nlatino\nasian\nother_race\ndiversity_idx\nforeign_born\ntotal_hh\nhomeownership\ntotal_cost_burden\ntotal_severe_cost_burden\nowner_cost_burden\nowner_severe_cost_burden\nrenter_cost_burden\nrenter_severe_cost_burden\nno_vehicle_hh\nmedian_hh_income\nages25plus\nless_than_high_school\nhigh_school_grad\nsome_college_or_aa\nbachelors\ngrad_degree\npov_status_determined\npoverty\nlow_income\narea_sqmi\npop_density\nlocal1\nlocal2\n\n\n\n\nus\nNA\nUnited States\n331097593\n0.59\n0.12\n0.19\n0.06\n0.05\n0.7443\n0.14\n125736353\n0.65\n0.29\n0.14\n0.21\n0.09\n0.45\n0.23\n0.08\n75149\n226600992\n0.11\n0.26\n0.28\n0.21\n0.13\n323275448\n0.13\n0.29\nNA\nNA\nUnited States\nUnited States\n\n\nstate\nNA\nMaryland\n6161707\n0.49\n0.29\n0.11\n0.06\n0.05\n0.7890\n0.16\n2318124\n0.67\n0.29\n0.13\n0.21\n0.09\n0.46\n0.23\n0.09\n98461\n4260095\n0.09\n0.24\n0.25\n0.22\n0.20\n6034320\n0.09\n0.21\nNA\nNA\nMaryland\nMaryland\n\n\ncounty\nNA\nAllegany County\n68161\n0.87\n0.07\n0.02\n0.01\n0.03\n0.3335\n0.02\n27462\n0.70\n0.23\n0.10\n0.16\n0.07\n0.39\n0.17\n0.10\n55248\n47914\n0.09\n0.41\n0.29\n0.12\n0.09\n61098\n0.16\n0.36\n422.19881\n161.4429\nOther counties\nOther counties\n\n\ncounty\nNA\nAnne Arundel County\n588109\n0.65\n0.17\n0.09\n0.04\n0.05\n0.6689\n0.09\n221704\n0.75\n0.26\n0.11\n0.20\n0.08\n0.44\n0.19\n0.04\n116009\n409052\n0.06\n0.22\n0.27\n0.25\n0.19\n577547\n0.06\n0.14\n414.80643\n1417.7914\nAnne Arundel County\nOutside Baltimore\n\n\ncounty\nNA\nBaltimore County\n850737\n0.54\n0.30\n0.06\n0.06\n0.04\n0.7209\n0.12\n328611\n0.67\n0.29\n0.14\n0.20\n0.09\n0.48\n0.24\n0.08\n88157\n589611\n0.08\n0.24\n0.26\n0.23\n0.18\n830921\n0.10\n0.23\n598.35821\n1421.7855\nBaltimore County\nOutside Baltimore\n\n\ncounty\nNA\nBaltimore city\n584548\n0.27\n0.61\n0.06\n0.03\n0.04\n0.6569\n0.08\n247232\n0.48\n0.37\n0.19\n0.26\n0.13\n0.47\n0.26\n0.26\n58349\n410221\n0.13\n0.28\n0.24\n0.18\n0.17\n564634\n0.20\n0.38\n80.94606\n7221.4510\nBaltimore city\nBaltimore city\n\n\n\n\n\nFind some ways to improve the use of color in these charts, including whether color even should be used. Before writing any code, write down:\n\nHow color is used / what color signifies\nWhat’s wrong with that use of color\nHow you want to change it\n\nHere are some charts that are bad because they use color inappropriately.\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = name)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")\n\n\n\n\n\n\n\n\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = local2)) +\n geom_col(width = 0.7, color = \"gray20\", linewidth = 0.2) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\") +\n scale_fill_brewer(palette = \"GnBu\")\n\n\n\n\n\n\n\n\nHere’s a chart that’s okay but not great; it uses color in a way that’s not wrong but not effective either.\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = local2)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")\n\n\n\n\n\n\n\n\nHere’s one that uses color when it should actually use something else to convey its pattern. What type of chart would be more appropriate?\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = median_hh_income)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate vs median household income by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")",
+ "objectID": "weeks/00_definitions.html",
+ "href": "weeks/00_definitions.html",
+ "title": "0. Definitions",
+ "section": "",
+ "text": "A few definitions of data visualization:\n\nThe rendering of information in a visual format to help communicate data while also generating new patterns and knowledge through the act of visualization itself (Du Bois et al., 2018, p. 8)\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nThe representation and presentation of data to facilitate understanding (Kirk, 2016, p. 19)\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\nIt’s pretty common to find a book with hundreds of pages of details on data visualization, but no definition.\nWhat else could we add here?",
"crumbs": [
"Weekly notes",
- "6. Color"
+ "0. Definitions"
]
},
{
- "objectID": "weeks/02_components.html",
- "href": "weeks/02_components.html",
- "title": "2. Components of a chart",
+ "objectID": "weeks/00_definitions.html#what-is-data-visualization",
+ "href": "weeks/00_definitions.html#what-is-data-visualization",
+ "title": "0. Definitions",
"section": "",
- "text": "Revisiting the wage gaps to break down a chart into its pieces and what they mean. This will be a subset of the wages data with just full-time workers by sex and education in Maryland.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nlibrary(ggtext)\n\nsource(here::here(\"utils/plotting_utils.R\"))\ngender_pal <- setNames(qual_pal[c(3, 6)], c(\"Men\", \"Women\"))\nsex_x_edu <- wages |>\n filter(dimension == \"sex_x_edu\",\n name == \"Maryland\") |>\n select(sex, edu, earn_q25, earn_q50, earn_q75) |>\n mutate(across(where(is.factor), forcats::fct_drop))\n\nknitr::kable(sex_x_edu)\n\n\n\n\nsex\nedu\nearn_q25\nearn_q50\nearn_q75\n\n\n\n\nMen\nHigh school or less\n33158\n49737\n70000\n\n\nMen\nSome college or AA\n43105\n63586\n93000\n\n\nMen\nBachelors\n60000\n91712\n135000\n\n\nMen\nGraduate degree\n82661\n121873\n171555\n\n\nWomen\nHigh school or less\n26974\n38000\n55475\n\n\nWomen\nSome college or AA\n35000\n50241\n75000\n\n\nWomen\nBachelors\n49737\n71842\n101684\n\n\nWomen\nGraduate degree\n65817\n92842\n129475\n\n\n\n\nsummary(sex_x_edu)\n\n sex edu earn_q25 earn_q50 \n Men :4 High school or less:2 Min. :26974 Min. : 38000 \n Women:4 Some college or AA :2 1st Qu.:34540 1st Qu.: 50115 \n Bachelors :2 Median :46421 Median : 67714 \n Graduate degree :2 Mean :49556 Mean : 72479 \n 3rd Qu.:61454 3rd Qu.: 91994 \n Max. :82661 Max. :121873 \n earn_q75 \n Min. : 55475 \n 1st Qu.: 73750 \n Median : 97342 \n Mean :103899 \n 3rd Qu.:130856 \n Max. :171555",
+ "text": "A few definitions of data visualization:\n\nThe rendering of information in a visual format to help communicate data while also generating new patterns and knowledge through the act of visualization itself (Du Bois et al., 2018, p. 8)\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nThe representation and presentation of data to facilitate understanding (Kirk, 2016, p. 19)\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\nIt’s pretty common to find a book with hundreds of pages of details on data visualization, but no definition.\nWhat else could we add here?",
"crumbs": [
"Weekly notes",
- "2. Components of a chart"
+ "0. Definitions"
]
},
{
- "objectID": "weeks/02_components.html#starting-point",
- "href": "weeks/02_components.html#starting-point",
- "title": "2. Components of a chart",
- "section": "Starting point",
- "text": "Starting point\nThis is the decent but not great chart from last week. We’re going to take a step back to break it into its components.\n\nwages |>\n filter(dimension == \"sex_x_edu\",\n name == \"Maryland\") |>\n ggplot(aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(width = 0.8, alpha = 0.9, position = position_dodge2()) +\n scale_y_barcontinuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n labs(x = NULL, y = NULL, fill = NULL,\n title = \"Median individual earnings\",\n subtitle = \"Adults ages 25+ with positive earnings by sex and educational attainment, Maryland full-time workers, 2021\") +\n theme(plot.subtitle = element_textbox_simple(margin = margin(0.2, 0, 0.2, 0, \"lines\")),\n legend.position = \"bottom\")\n\n\n\n\n\n\n\nFigure 1",
+ "objectID": "weeks/00_definitions.html#what-should-visualization-do",
+ "href": "weeks/00_definitions.html#what-should-visualization-do",
+ "title": "0. Definitions",
+ "section": "What should visualization do?",
+ "text": "What should visualization do?\n\nData visualization is part art and part science. The challenge is to get the art right without getting the science wrong and vice versa. A data visualization first and foremost has to accurately convey the data. It must not mislead or distort…. At the same time, a data visualization should be aesthetically pleasing (Wilke, 2019, ch 1)\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/",
"crumbs": [
"Weekly notes",
- "2. Components of a chart"
+ "0. Definitions"
]
},
{
- "objectID": "weeks/02_components.html#basics",
- "href": "weeks/02_components.html#basics",
- "title": "2. Components of a chart",
- "section": "Basics",
- "text": "Basics\nFocusing first on median wages (earn_q50), values here range from 38,000 to 121,873, so we should expect our dependent axis (usually y, but we might change it) to range from somewhere below that to somewhere above that. If we make a chart and it goes down to e.g. 10,000 that’s a sign that something weird might be happening. On the dependent axis, we have 2 categories of sex :-/ and 4 of education; if we end up with only 3 bars, or with 15 bars, something’s wrong.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50))\n\n\n\n\n\n\n\nFigure 2\n\n\n\n\n\nThese scales make sense so far—I haven’t signaled that sex will be included here, or that we’re making a bar chart which is why the dependent axis doesn’t have to go down to 0.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50)) +\n geom_col()\n\n\n\n\n\n\n\nFigure 3\n\n\n\n\n\nThe dependent scale has changed: it goes down to 0, which makes sense because now we have bars, but it goes up to 200,000, which is weird.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50)) +\n geom_col(color = \"white\")\n\n\n\n\n\n\n\nFigure 4\n\n\n\n\n\nThis still includes both men and women, but sex isn’t assigned to any aesthetic, so bars just get stacked. Setting the fill makes that clear.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col()\n\n\n\n\n\n\n\nFigure 5\n\n\n\n\n\nThese bars shouldn’t be stacked, though. Why not?\nThey represent median wages of distinct groups, not something that is cumulative. If men have a median income of $60,000 and women have a median income of $50,000, does that mean that men and women overall have a median income of $110,000? No! But that’s what these stacked bars imply.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(position = position_dodge2()) +\n labs(title = \"Median earnings by sex & education, Maryland, 2021\")\n\n\n\n\n\n\n\nFigure 6\n\n\n\n\n\nSo now we have a chart that represents the data appropriately. We can make it look nicer, but for now we have all the basic components set.\nWhat are all the components here?\n\n\n\n\n\n\nBrainstorming components\n\n\n\n\naxes (x & y)\ntick values (dollar amounts, education levels)–horizontal\nlegend (placement, title, labels, keys)\naxis titles\nbackground\ngridlines (x & y gridlines, x-axis major, y-axis major & minor)\ntitle\nbars with color\ntick marks\nunits (not included)\ntext choices (font, size, boldness)",
+ "objectID": "weeks/00_definitions.html#why-visualize-data",
+ "href": "weeks/00_definitions.html#why-visualize-data",
+ "title": "0. Definitions",
+ "section": "Why visualize data?",
+ "text": "Why visualize data?\n\nExplore\nExplain\nBoth\n\nWhat’s the difference, and what happens in the overlaps?",
"crumbs": [
"Weekly notes",
- "2. Components of a chart"
+ "0. Definitions"
]
},
{
- "objectID": "weeks/02_components.html#a-nicer-chart",
- "href": "weeks/02_components.html#a-nicer-chart",
- "title": "2. Components of a chart",
- "section": "A nicer chart",
- "text": "A nicer chart\nThat chart is fine but not great. Next we could clean up the axes, their labels, ticks, and gridlines. For each of these components, you should ask yourself if they’re necessary, or what they add to the chart that isn’t already provided through some other means. This helps you maximize your data-to-ink ratio, Wilke (2019)\n\nLive code: clean up this chart\n\ngg <- ggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(position = position_dodge2())\n\ngg +\n scale_y_continuous(labels = dollar_k) +\n theme(panel.grid.major.x = element_blank()) +\n theme(panel.grid.minor.y = element_blank()) +\n theme(axis.ticks = element_blank()) +\n labs(title = \"Median individual earnings\",\n subtitle = \"Adults ages 25+ working full time by sex and educational attainment, Maryland, 2021\",\n y = \"Median earnings\", x = NULL, fill = NULL) +\n scale_fill_manual(values = gender_pal)\n\n\n\n\n\n\n\n\n\n\nGoal: one option\nThis is one more complicated option of how I might do this. It uses a function from the package stylehaven which I wrote for work, and which you all are free to use. It also uses showtext to set the fonts, which can be very finicky.\n\n# can't get fonts to not be totally weird\nlibrary(showtext)\nshowtext_auto()\nshowtext_opts(dpi = 300)\nsysfonts::font_add_google(\"Barlow Semi Condensed\")\n\n# use both true/false and gender palettes\ncomb_pal <- c(purrr::map_chr(gender_pal, colorspace::darken, amount = 0.2, space = \"HCL\"), tf_pal)\n\nsex_x_edu |>\n mutate(edu = forcats::fct_recode(edu, \"Some college / Associate's\" = \"Some college or AA\", \"Bachelor's\" = \"Bachelors\")) |>\n stylehaven::offset_lbls(value = earn_q50, fun = dollar_k, frac = 0.03) |>\n ggplot(aes(x = edu, y = earn_q50, fill = sex, group = sex)) +\n geom_col(width = 0.8, position = position_dodge2()) +\n geom_text(aes(y = y, label = lbl, vjust = just, color = is_small),\n family = \"Barlow Semi Condensed\", fontface = \"bold\", size = 9.5,\n position = position_dodge2(width = 0.8)) +\n geom_text(aes(label = sex, color = sex, x = as.numeric(edu) - 0.18, y = earn_q50 - off/2),\n data = ~filter(., edu == first(edu)), vjust = 0, hjust = 0,\n family = \"Barlow Semi Condensed\", fontface = \"bold\", size = 8,\n position = position_dodge2(width = 0.8)) +\n scale_fill_manual(values = gender_pal) +\n scale_color_manual(values = comb_pal) +\n scale_x_discrete(labels = scales::label_wrap(15)) +\n scale_y_barcontinuous(breaks = NULL) +\n theme_minimal(base_family = \"Barlow Semi Condensed\", base_size = 28) +\n theme(text = element_text(lineheight = 0.5)) +\n theme(panel.grid = element_blank()) +\n theme(legend.position = \"none\") +\n theme(axis.text = element_text(color = \"black\", size = rel(0.9))) +\n theme(plot.title = element_text(family = \"Barlow Semi Condensed\", face = \"bold\")) +\n theme(plot.subtitle = ggtext::element_textbox_simple(family = \"Barlow Semi Condensed\", lineheight = 0.7)) +\n theme(plot.caption = element_text(color = \"gray30\")) +\n labs(x = NULL, y = NULL,\n title = \"The male-female wage gap persists across education levels\",\n subtitle = \"Median individual earnings, Maryland adults ages 25+ working full time by sex and educational attainment, 2021\",\n caption = \"Source: Analysis of US Census Bureau American Community Survey, 2021 5-year estimates\")",
+ "objectID": "weeks/00_definitions.html#how-is-data-visualization-used",
+ "href": "weeks/00_definitions.html#how-is-data-visualization-used",
+ "title": "0. Definitions",
+ "section": "How is data visualization used?",
+ "text": "How is data visualization used?\n\n\n\n\n\n\nBrainstorming\n\n\n\n\nPositive / constructive\n\nfacilitates & documents change\nhighlights social justice concerns\njustifying decisions\ntelling a story\nconnecting dots\ninform\nefficiency & safety\nelicit emotion\nconvey lots of information\nmake data more understandable\n\n\n\nNegative / destructive\n\nfacilitates & documents change in ways that are harmful\ntelling a story (misinformation)\nelicit emotion (sensationalize)",
"crumbs": [
"Weekly notes",
- "2. Components of a chart"
+ "0. Definitions"
]
},
{
- "objectID": "weeks/09_decisions.html",
- "href": "weeks/09_decisions.html",
- "title": "9. Making responsible decisions",
+ "objectID": "weeks/10_accessibility.html",
+ "href": "weeks/10_accessibility.html",
+ "title": "10. Accessibility and literacy",
"section": "",
- "text": "library(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n\nsource(here::here(\"utils/plotting_utils.R\"))\nupdate_geom_defaults(\"col\", list(fill = qual_pal[3]))\ntheme_set(theme_nice())",
+ "text": "For each of these two charts:\n\nDraft a possible headline-style title for this chart that would be appropriate for a general audience\nRevise that headline to what you estimate would be a US 6th grade reading level.\nWrite a very short (2-4 concise sentences) description of the chart that says what type of chart it is, what’s being measured, what types of groups are included (don’t name them all individually), and some important data points.\n\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\n\n\n\n\n\n\n\n\nFigure 2",
"crumbs": [
"Weekly notes",
- "9. Making responsible decisions"
+ "10. Accessibility and literacy"
]
},
{
- "objectID": "weeks/09_decisions.html#warm-up",
- "href": "weeks/09_decisions.html#warm-up",
- "title": "9. Making responsible decisions",
- "section": "Warm up",
- "text": "Warm up\n\nYou want to know how UMBC graduate students feel about their job prospects, and how this might differ between students in STEM programs and students in social science programs (you’re not interested in other degrees), so you’re tabling on campus with a survey. The only actual survey question is “Do you feel good about your job prospects after graduation?” Draw a flowchart of the questions you might ask people before you get to the one survey question.\nThere’s a virus circulating that has killed many people, but a vaccine is available and you trust reports that it greatly decreases the chances of dying from the disease. After about a year of a massive vaccination campaign, you find out that the majority of people dying from the disease at the hospital near you were already vaccinated. Does this change your beliefs about the vaccine’s effectiveness? What other information might help explain this?\n\n\n\n\n\n\n\nBrainstorm\n\n\n\n\nhealth of people who are dying before getting sick (comorbidities, etc)\nhow many people already vaccinated",
+ "objectID": "weeks/10_accessibility.html#warm-up",
+ "href": "weeks/10_accessibility.html#warm-up",
+ "title": "10. Accessibility and literacy",
+ "section": "",
+ "text": "For each of these two charts:\n\nDraft a possible headline-style title for this chart that would be appropriate for a general audience\nRevise that headline to what you estimate would be a US 6th grade reading level.\nWrite a very short (2-4 concise sentences) description of the chart that says what type of chart it is, what’s being measured, what types of groups are included (don’t name them all individually), and some important data points.\n\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\n\n\n\n\n\n\n\n\nFigure 2",
"crumbs": [
"Weekly notes",
- "9. Making responsible decisions"
+ "10. Accessibility and literacy"
]
},
{
- "objectID": "weeks/09_decisions.html#representing-data",
- "href": "weeks/09_decisions.html#representing-data",
- "title": "9. Making responsible decisions",
- "section": "Representing data",
- "text": "Representing data\nSome of the ways we’ve talked about data visualization being misleading are intentional and malicious. That definitely happens, and how often you run into it might depend on your sources of information (Fox News, boardroom presentations, Congress, social media influencers…) but more often it’s just lack of skill and fluency.\n\n\n\n\n\nDeceptive coffee creamer\n\n\n\nWho’s in the data\nOne of the easiest things to mess up is the universe of your data. This is basically your denominator—who or what is included and used as the unit of analysis. I’ve most often found (and made, and corrected) this type of mistake with survey data, because it can be hard to know exactly who’s being asked every question.\nAn easy way to catch this is to read the fine print on your data sources, and to do it routinely because it might change. Some examples:\n\nBirth outcomes: for some measures, unit might be babies; for others, parent giving birth\nACS tables: several tables seem like they match, but one is by household and another is by person. Be especially mindful with tables related to children and family composition—these get messy. 1\nProxies: when I analyzed data on police stops, I tried to figure out a population to compare to. I didn’t have data on how many people in each census tract had a driver’s license, decennial data wasn’t out yet so I didn’t have reliable local counts of population 16 and up by race, so I just used population. It wasn’t ideal.\nRelationships: is a question being asked of parents, or of adults with a child in their household? These aren’t necessarily the same.\n\n1 This one is especially brain-melting: Ratio of Income to Poverty Level in the Past 12 Months by Nativity of Children Under 18 Years in Families and Subfamilies by Living Arrangements and Nativity of Parents. The universe is own children under 18 years in families and subfamilies for whom poverty status is determined.Another example: how would you make sense of this?\n\n\n\nShare of adults reporting having been unfairly stopped by police, Connecticut, 2021\n\n\n\n\n\n\n\n\n\nname\ncategory\ngroup\never_unfairly_stopped\nmultiple_times_3yr\n\n\n\n\nConnecticut\nTotal\nTotal\n15%\n29%\n\n\nConnecticut\nRace/Ethnicity\nWhite\n12%\n16%\n\n\nConnecticut\nRace/Ethnicity\nBlack\n25%\n40%\n\n\nConnecticut\nRace/Ethnicity\nLatino\n20%\n50%\n\n\n\n\n\n\n\nObscuring data\nWe’ve talked some about dealing with missing data, and often the solution to data-related problems is to get more of it. But sometimes it’s important to not be counted, or to not show everything. There are even times when it might be good to intentionally mess up the data (maybe this isn’t the role of the visualizer, however). 2 I would argue that hiding data when necessary should also be part of doing data analysis and viz responsibly. Some examples:\n2 The Census Bureau made the controversial decision to basically do this, via differential privacy. Wang (2021)\nWang, H. L. (2021). For The U.S. Census, Keeping Your Data Anonymous And Useful Is A Tricky Balance. NPR. https://www.npr.org/2021/05/19/993247101/for-the-u-s-census-keeping-your-data-anonymous-and-useful-is-a-tricky-balance\n\nFilling period tracking apps with fake data after Roe v Wade was overturned\nNot adding citizenship to the census or other surveys; not asking about sexual orientation and gender identity. In theory these should both be fine, but in practice they may not be safe for people to disclose, or they could get misused.\nLeaving out parts of your data that could be stigmatizing or lead to misinformation\n\nAn example of this last point:\n\nMy organization’s survey asked a similar set of questions, but we chose not to release the question about getting COVID from the vaccine. The others are valid concerns; that one is misinformation that we didn’t want to repeat even with qualifiers.\n\n\nLack of a pattern\nSometimes the pattern you expect to find in a dataset isn’t there, and that’s okay. You want to go into your work with an open mind, rather than force the data into the story you want it to tell. I’m really into situations where the pattern you think you’re going to find isn’t there, and that’s the story—it might point to a disruption in the usual pattern.\n\n\nSay what you mean\n\nDon’t say “people of color” when you actually mean “Black people” or “Black and Latino people” or something else. This drives me crazy, and I’m sure I’ve done it as well. Sometimes because of small sample sizes or other limitations, you can’t break your data down further than white vs people of color. But if you can disaggregate further, do so, at least in the EDA process. This especially goes for data that deals with something that historically targeted e.g. Black people or indigenous people or some other group.\nAlong those same lines, don’t say BIPOC (Black, Indigenous, and people of color) if you don’t actually have any data to show on indigenous people, or LGBT if you have no data on trans people.",
+ "objectID": "weeks/10_accessibility.html#accessibility",
+ "href": "weeks/10_accessibility.html#accessibility",
+ "title": "10. Accessibility and literacy",
+ "section": "Accessibility",
+ "text": "Accessibility\nAfter talking about making responsible decisions in data visualization, it’s embarrassing to admit that accessibility has been a major oversight of mine, but it’s true, and it’s for no other reason than privilege. On a day-to-day basis I don’t have to think about whether learning or interacting with something will depend on my ability to see well, read complicated text, speak a certain language, navigate stimuli, process information, or access technology and resources. In fact, until last week I hadn’t even bothered writing alt texts for the charts in these notes; I’m going back and doing that now, but my hope for you all is that you start out your data viz careers being more mindful than I’ve been.\nFor the most part when we talk about accessibility, we mean this with respect to disabilities; in static data visualization, this mostly means visual impairments such as blindness, low vision, and colorblindness. If you go on to do interactive or web-based visualization, you’ll also need to think about things like navigation (access for keyboards and assistive devices vs clicking menus only) and animation (can be overstimulating or hard to process). 1\n1 Circa 2017, scrollytelling was very cool and people were very intense with it. I’ve noticed in recent years people have eased up. It can be disorienting for some readers. Webb (2018) convinced me to scrap my scrollytelling plans for some projects during that era.\nWebb, E. (2018). Your Interactive Makes Me Sick. https://source.opennews.org/articles/motion-sick/\nSome of the simplest tasks we can do for static data visualization are using colorblind-friendly palettes, writing alt-text descriptions, and maintaining high contrast ratios between backgrounds and text.\n\nColorblindness\nYou should generally assume your work will be read by at least a few colorblind readers (or people with color-vision deficiency, CVD) and plan your color palettes accordingly. Wilke mentions this as a reason for redundant coding as well, so you’re not relying on color alone to differentiate values. 2\n2 Something that blew my mind is in Frank Elavsky’s interview on PolicyViz. He acknowledges that awareness of CVD has become the norm in data viz, but that it actually predominantly affects white men, and that it shouldn’t be too surprising that that is often the only accommodation made in a field where white men are overrepresented.The most common form of CVD is what’s called red-green colorblindness. Many common R color palettes are colorblind-friendly, and some tools will help you tell whether a palette is or not, or for which color deficiencies they are legible.\nSome code examples:\n\n# Not all Color Brewer palettes are CVD-friendly, but you can filter in the R package\n# or on the website for ones that are\nRColorBrewer::display.brewer.all(colorblindFriendly = TRUE)\n\n\n\n\n\n\n\n# Same goes for Carto Colors\nrcartocolor::display_carto_all(colorblind_friendly = TRUE)\n\n\n\n\n\n\n\n# All Viridis palettes are designed to be CVD-friendly\n# use them with e.g. ggplot2::scale_fill_viridis_c()\ncolorspace::swatchplot(viridisLite::viridis(n = 9))\n\n\n\n\n\n\n\n# Okabe-Ito is built into R and based on lots of research into CVD\ncolorspace::swatchplot(palette.colors(n = 9, palette = \"Okabe-Ito\"))\n\n\n\n\n\n\n\n\nThere are also a lot of tools to help you simulate different types of CVD. This is particularly useful for diverging palettes, which can be hard to make accessible.\n\nset.seed(1)\ncvd_data <- data.frame(group = sample(letters[1:7], size = 200, replace = TRUE),\n value = rnorm(200))\ndiv_pal <- RColorBrewer::brewer.pal(n = 7, name = \"RdYlGn\")\n\np <- ggplot(cvd_data, aes(x = value, fill = group)) +\n geom_dotplot(method = \"histodot\", binpositions = \"all\", binwidth = 0.2)\n\np + \n scale_fill_manual(values = div_pal) +\n labs(title = \"Brewer palette RdYlGn\")\n\np + \n scale_fill_manual(values = colorspace::deutan(div_pal)) +\n labs(title = \"Deuteranomaly\")\n\np + \n scale_fill_manual(values = colorspace::protan(div_pal)) +\n labs(title = \"Protanomaly\")\n\np + \n scale_fill_manual(values = colorspace::tritan(div_pal)) +\n labs(title = \"Tritanomaly\")\n\n\n\n\n\n\n\nFigure 3\n\n\n\n\n\n\n\n\n\n\n\nFigure 4\n\n\n\n\n\n\n\n\n\n\n\nFigure 5\n\n\n\n\n\n\n\n\n\n\n\nFigure 6\n\n\n\n\n\nThere are lots of tools to do similar simulations, although many of them require you to have a graphic already saved to a file. An online one that’s good for developing and adjusting palettes is Viz Palette by Susie Lu; this one also accounts for the size of your geometries.\n\n\nViz Palette takes a set of space- or comma-separated colors as hex values. If you have a vector of colors, call\ncat(div_pal, sep = \" \")\nto get it all in one line that you only have to copy & paste once.\n\n\nAlt text\nAlt text is the text that’s displayed in place of, or alongside, and image online and in some types of documents (certain PDF versions, Microsoft Word, etc). If someone is using a screen reader, it will read this text aloud. This can be embedded in posts on most social media platforms as well, and is autogenerated on some (if you ever look at Facebook with a bad internet connection, you might see alt text until the images load.) As the designer of your visualizations, you’re in a unique position to write alt text, since you will have close knowledge of the data and what’s important about it.\nIncluding alt text in R:\n\nFor exporting ggplot charts, you can include alt text in labs(alt = \"\").\nIn Rmarkdown documents, you can include it as the fig.alt chunk option\nSimilar for Quarto documents: fig-alt\nWhen directly including images in Markdown, use {fig-alt=\"Alt text goes here\"}\n\n\n\nContrast\nDifferent pieces of your visualization need to have enough contrast to be legible at different sizes, especially between text and its background. This comes up with labels like titles, but especially with direct labels. Generally your labels will be all white or all black (or slightly darker or lighter, respectively), so if you’re putting direct labels on several bars with different colors, make sure you have enough contrast across all of them.\nFor example, this palette starts out very dark and ends very light, so neither white nor black will be legible across all bars. Switching between label colors (light on the dark bars, dark on the light bars) can be distracting or imply something about the data that isn’t there, so it’s better to use a palette where all labels can be the same color.\n\n\n\n\n\n\n\n\nFigure 7\n\n\n\n\n\nThe W3C recommends a minimum contrast ratio of 4.5 for regular-sized text, and 3 for large text. You can use colorspace::contrast_ratio to get calculations of these ratios.\n\ncolorspace::contrast_ratio(inferno, col2 = \"black\", plot = TRUE)\n\n\n\n\n\n\n\nFigure 8\n\n\n\n\n\n\n\nExercise\nGo back to the image descriptions you wrote in the warm-up. Using Cesal (2020) and W3C Web Accessibility Initiative (2024), revise your descriptions so they could work as alt text.\n\nCesal, A. (2020). Writing Alt Text for Data Visualization, Nightingale. In Nightingale. https://medium.com/nightingale/writing-alt-text-for-data-visualization-2a218ef43f81?source=friends_link&sk=32db60d651933b5ac2c5b6507f3763b5\n\nW3C Web Accessibility Initiative. (2024). Images Tutorial: Complex Images. In Web Accessibility Initiative (WAI). https://www.w3.org/WAI/tutorials/images/complex/",
"crumbs": [
"Weekly notes",
- "9. Making responsible decisions"
+ "10. Accessibility and literacy"
]
},
{
- "objectID": "weeks/09_decisions.html#exercise",
- "href": "weeks/09_decisions.html#exercise",
- "title": "9. Making responsible decisions",
- "section": "Exercise",
- "text": "Exercise\nThe youth_risks dataset in the justviz package has a set of questions from the DataHaven Community Wellbeing Survey, where survey respondents are asked to rate the likelihood of young people in their area experiencing different events (DataHaven (n.d.)). The allowed responses are “almost certain,” “very likely,” “a toss up,” “not very likely,” and “not at all likely”; this type of question is called a Likert scale. The universe of this dataset is adults in Connecticut, and the survey was conducted in 2021.\n\nDataHaven. (n.d.). DataHaven Community Wellbeing Survey. https://ctdatahaven.org/reports/datahaven-community-wellbeing-survey\n\nPirrone, A. (2020). Visualizing Likert Scale Data: Same Data, Displayed Seven Different Ways, Nightingale. In Nightingale. https://medium.com/nightingale/seven-different-ways-to-display-likert-scale-data-d0c1c9a9ad59?source=friends_link&sk=60cb93604b71ecc8820cc785ed1afd1a\nStarting with just stacked bars for a single question at a time (see example), explore the data visually and see if you can find an anomaly. (Hint: one of these questions is not like the other.) Browse through Pirrone (2020) to get some ideas of more ways to visualize Likert data, especially ways that will illustrate the pattern well.\n\ndiv_pal <- c('#00748a', '#479886', '#adadad', '#d06b56', '#b83654') # based on carto-color Temps\n\nrisks <- youth_risks |>\n filter(category %in% c(\"Total\", \"Race/Ethnicity\", \"Income\", \"With children\")) |>\n mutate(question = forcats::as_factor(question))\n\nrisks |>\n filter(question == \"Graduate from high school\") |>\n mutate(value = scales::label_percent(accuracy = 1)(value)) |>\n tidyr::pivot_wider(id_cols = c(category, group), names_from = response) |>\n knitr::kable(align = \"llrrrrr\")\n\n\n\nTable 1: Ratings of likelihood that young people will graduate from high school, share of Connecticut adults, 2021\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncategory\ngroup\nAlmost certain\nVery likely\nA toss up\nNot very likely\nNot at all likely\n\n\n\n\nTotal\nConnecticut\n39%\n55%\n4%\n0%\n1%\n\n\nRace/Ethnicity\nWhite\n39%\n56%\n4%\n0%\n1%\n\n\nRace/Ethnicity\nBlack\n36%\n55%\n3%\n1%\n4%\n\n\nRace/Ethnicity\nLatino\n44%\n44%\n11%\n0%\n0%\n\n\nIncome\n<$30K\n28%\n61%\n7%\n1%\n2%\n\n\nIncome\n$30K-$100K\n38%\n55%\n6%\n1%\n1%\n\n\nIncome\n$100K+\n44%\n55%\n1%\n0%\n0%\n\n\nWith children\nNo kids\n36%\n57%\n5%\n1%\n1%\n\n\nWith children\nKids in home\n45%\n51%\n4%\n0%\n0%",
+ "objectID": "weeks/10_accessibility.html#literacy",
+ "href": "weeks/10_accessibility.html#literacy",
+ "title": "10. Accessibility and literacy",
+ "section": "Literacy",
+ "text": "Literacy\nWe easily take for granted the ability to read English fluently, but it’s important to remember that, depending on our audience, many of our readers may not be able to. Twenty-two percent of US adults ages 16 to 74 are rated as having low literacy; in Maryland, this is 20% (National Center for Education Statistics, 2020). 3 So if you’re creating a visualization that needs to work for a general audience, you’ll want to keep your sentences short, language simple, and chart types pretty standard. Or, you can get more complex with the use of annotations or other guidance.\n\nNational Center for Education Statistics. (2020). Program for the International Assessment of Adult Competencies (PIAAC). National Center for Education Statistics. https://nces.ed.gov/surveys/piaac/state-county-estimates.asp\n3 This program outlines definitions of “low literacy,” but in news stories and Wikipedia it’s being referred to as corresponding to a sixth grade reading level. I haven’t found anything directly connected to the program that corroborates that.\nExercise\nTest the reading level of the headlines you wrote using each of these tools:\n\nWordcalc: https://www.wordcalc.com/readability/\nHemingway: https://hemingwayapp.com/\n\nFor the versions of the headlines that you thought were at sixth grade level, what level were they actually? Try to get them to sixth grade or below. What revisions did you have to make to get there?\n\nIf you have access to decent AI tools, they might help with this also. I tried with Chat GPT (GPT-3.5) with mixed results. It came out to 5th grade in the end, but loses some of the memorability of “one in four.”\n\nUser Rewrite the following sentence to be at a US 6th grade reading level: “One in four Black adults, and one in five Latinos, have been unfairly stopped or harassed by police.”\nChatGPT “Police have unfairly stopped or harassed one out of every four Black adults, and one out of every five Latinos.”\nUser Based on the Flesch-Kincaid scale, that’s a 9.9 reading level\nChatGPT Here’s a revised sentence with a lower reading level:\n“Police have unfairly stopped or harassed one out of every four Black adults, and one out of every five Latinos.”\nThis should be around a 6th grade reading level according to the Flesch-Kincaid scale.\nUser That’s the same sentence\nChatGPT I apologize for the confusion. Here’s another attempt:\n“Police have unfairly stopped or harassed 25% of Black adults and 20% of Latinos.”\nThis should be around a 6th grade reading level according to the Flesch-Kincaid scale.",
"crumbs": [
"Weekly notes",
- "9. Making responsible decisions"
+ "10. Accessibility and literacy"
]
},
{
- "objectID": "weeks/08_uncertainty.html",
- "href": "weeks/08_uncertainty.html",
- "title": "8. Uncertainty and distributions",
+ "objectID": "weeks/03_encoding.html",
+ "href": "weeks/03_encoding.html",
+ "title": "3. Visual encoding",
"section": "",
- "text": "Fill in this quick survey about probability:",
+ "text": "This is a walkthrough of Wickham et al. (2023) chapter 9 on chart layers, using the ACS data in the justviz package. For simplicity, we’ll focus on Maryland census tracts. I’m throwing in a few additional variables just to match the examples from the book.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n# create a variable that flags tracts being in the city or surrounding counties. \n# other values get lumped into \"other counties\" group\nlocal_counties <- c(\"Baltimore city\", \"Baltimore County\", \"Anne Arundel County\", \"Howard County\")\nacs_tr <- acs |>\n filter(level == \"tract\") |>\n mutate(county2 = ifelse(county %in% local_counties, county, \"Other counties\")) |>\n na.omit() |> # we'll talk about missing data in the next notebook\n mutate(income_brk = cut(median_hh_income, \n breaks = c(0, 1e5, Inf), \n labels = c(\"under_100k\", \"above_100k\"),\n include.lowest = TRUE, right = FALSE))\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1)",
"crumbs": [
"Weekly notes",
- "8. Uncertainty and distributions"
+ "3. Visual encoding"
]
},
{
- "objectID": "weeks/08_uncertainty.html#warm-up",
- "href": "weeks/08_uncertainty.html#warm-up",
- "title": "8. Uncertainty and distributions",
- "section": "",
- "text": "Fill in this quick survey about probability:",
+ "objectID": "weeks/03_encoding.html#aesthetic-mappings",
+ "href": "weeks/03_encoding.html#aesthetic-mappings",
+ "title": "3. Visual encoding",
+ "section": "Aesthetic mappings",
+ "text": "Aesthetic mappings\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county2), size = 1)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(shape = county2), size = 1)\n\n\n\n\n\n\n\n\nAs noted in the book, these are bad ideas:\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(size = county2), alpha = 0.5)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(alpha = county2), size = 1)\n\n\n\n\n\n\n\n\nCan you think of any exceptions to this?\n\nWhat’s going on with the next two charts?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(color = \"slateblue\")\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = \"slateblue\"))\n\n\n\n\n\n\n\n\nWhy does this one throw an error?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(color = county2)",
"crumbs": [
"Weekly notes",
- "8. Uncertainty and distributions"
+ "3. Visual encoding"
]
},
{
- "objectID": "weeks/08_uncertainty.html#distributions",
- "href": "weeks/08_uncertainty.html#distributions",
- "title": "8. Uncertainty and distributions",
- "section": "Distributions",
- "text": "Distributions\nWhen we visualize data, one of the most important decisions we make is what values exactly we’ll display. That’s because you usually can’t include every data point, so you’ll have to do some amount of summarizing. However, that means you’re losing a lot of information in the process. That’s a fine line you need to figure out how to walk, and like most things we’ve done so far, how you do that will depend on context, audience, and purpose. In my own work, I know I fall on the side of oversimplifying more often than I should.\nThe problem is that unless people have a background in statistics or other quantitative research-heavy fields, they probably aren’t used to hearing about ranges of data—let alone ways to describe distributions, like skew and kurtosis. So the chart types that are best for showing distributions or uncertainty are generally pretty technical.\nFor example, look at the range of median household incomes by county:\n\n\n\n\n\n\n\n\n\nThere’s already a wide range, but compare that to all their tracts:\n\n\n\n\n\n\n\n\n\nOf the counties in the Baltimore metro area, Howard County has a much higher overall median income than Baltimore city, yet there’s also a lot of overlapping values. Baltimore city has several tracts with pretty high incomes, but that fact gets washed out when we only look at summary values. Even just look at how different the income scales are!\nThink back to the wage gap data. When we just look at wages for men vs women, 1 we lose differences within and between those groups. Before we saw how median earnings increase with educational attainment, but women’s pay lags about one education level behind men’s pay. We’ll see other gaps when we look at earnings by sex and race/ethnicity.\n1 Speaking of distributions within data, there are gray areas in gender that aren’t captured by the Census.\n\n\n\n\n\n\n\n\nSide-by-side bars of race versus sex show much more of the range. When we talk about the wage gap as just men vs women, we miss the fact that white women have higher median earnings than Black or Latino men! 2\n2 We also miss gaps within those groups, such as disparities by ethnicity, origin, and immigration status. An intern I worked with a few years ago made this video looking at the wage gaps within Asian American groups.\n\n\n\n\n\n\n\n\nUnlike bars, dots don’t have to start at a 0 baseline, so we can zoom in on the actual range of the values. This view makes it easier to see that the gaps within white and Asian/Pacific Islander communities span about $20,000 each, but is nearly nonexistent for Black adults. (For charts like this, you’ll more often see the axes flipped and the groups ordered largest to smallest, or largest gap to smallest gap, but I’ll let you figure that out—take a look at forcats::fct_reorder.)\n\n\n\n\n\n\n\n\n\n\nExercise\nJust like we can disaggregate the data into race vs sex, we can also tease apart the distributions within those groups. The wage gap data has not just medians, but also 20th, 25th, 75th, and 80th percentile values for every group.\nHere’s a bad chart of this data that just dumps all the data into a bunch of points. Looking at the examples from Yau (2013) (on Blackboard), brainstorm some better ways to show this data, including what you would want to filter out.\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\n\n# reshape to long in order to make dot plot\nwages_quants <- wages_sex_race |>\n select(dimension, sex, race_eth, matches(\"earn_q\\\\d+\")) |>\n tidyr::pivot_longer(cols = earn_q20:earn_q80, names_to = c(\".value\", \"quantile\"), \n names_pattern = \"(^[a-z]+)_(.+$)\",\n names_ptypes = list(quantile = factor()))\n\n# diverging-ish palette is appropriate here, so I'll pull it to modify\n# diverging pals usually have a light color in the middle, which won't work well for points\n# div_pal <- RColorBrewer::brewer.pal(n = 5, name = \"Spectral\")\ndiv_pal <- viridisLite::turbo(n = 5, direction = -1, begin = 0.1, end = 0.9)\ndiv_pal[3] <- \"gray20\"\n\nwages_quants |>\n ggplot(aes(x = sex, y = earn, color = quantile, shape = sex, group = sex)) +\n geom_path(color = \"gray80\", linewidth = 2, alpha = 0.8) +\n geom_point(size = 3, alpha = 0.9) +\n scale_color_manual(values = div_pal) +\n facet_wrap(vars(race_eth), scales = \"free_x\")\n\n\n\n\n\n\n\n\nHere’s one option, although I’m not super satisfied with it:",
+ "objectID": "weeks/03_encoding.html#geometric-objects",
+ "href": "weeks/03_encoding.html#geometric-objects",
+ "title": "3. Visual encoding",
+ "section": "Geometric objects",
+ "text": "Geometric objects\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth()\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden, color = county2)) +\n geom_point(size = 1) +\n geom_smooth()\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth()\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth(aes(group = county2))\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth(aes(color = county2), show.legend = FALSE)\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county2), size = 1) +\n geom_smooth()\n\n\n\n\n\n\n\n\nI don’t like how they did this highlighting example in the book. Here’s a better one.\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county == \"Baltimore city\")) +\n scale_color_manual(values = c(\"TRUE\" = \"firebrick\", \"FALSE\" = \"gray60\"))\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = county2, fill = county2, color = county2)) +\n ggridges::geom_density_ridges(alpha = 0.5, show.legend = FALSE)",
"crumbs": [
"Weekly notes",
- "8. Uncertainty and distributions"
+ "3. Visual encoding"
]
},
{
- "objectID": "weeks/08_uncertainty.html#uncertainty",
- "href": "weeks/08_uncertainty.html#uncertainty",
- "title": "8. Uncertainty and distributions",
- "section": "Uncertainty",
- "text": "Uncertainty\nIt can be really hard to imagine or estimate uncertainty. We expect data to be exact, and it pretty much never is. Visualization can help explain this to people, but that can conflict with our usual desire to make our visualizations simple and quick to read. In fact, I dropped all the margins of error from the datasets in the justviz package when I made it, so I’m part of the problem.\nWilke’s chapter on uncertainty has some good examples of how to show uncertainty in terms of margin of error in a few different types of charts. At the same time, there are some arguments against using error bars like he’s done in some of the examples. One of the case study readings (Correll & Gleicher (2014)) finds that these can actually harm people’s ability to understand uncertainty.\n\nCorrell, M., & Gleicher, M. (2014). Error Bars Considered Harmful: Exploring Alternate Encodings for Mean and Error. IEEE Transactions on Visualization and Computer Graphics, 20(12), 2142–2151. https://doi.org/10.1109/TVCG.2014.2346298\nProbably the most famous and famously controversial attempt at visualizing uncertainty was the gauge chart the New York Times used on election night 2016. It was meant to show that the vote margins were in flux as counts came in, but the jittering effect was actually hard-coded into the visualization rather than based directly on tallies updating. People got extremely stressed and mad.\nFor working in ggplot, the ggdist package (Kay (2024)) has some good options for showing distributions and uncertainty. 3\n\nKay, M. (2024). Mjskay/ggdist. https://github.com/mjskay/ggdist\n3 ggdist::geom_dots or ggdist::geom_interval and its arguments could make a good replacement for the boxplot of median income above.4 I can never define margin of error properly, but here’s a good overview.To make up for dropping margins of error before, I made a new dataset that we’ll use here. It’s the same wages data by sex, education, and occupation group, and it includes margins of error at both the 90% and 95% confidence levels. 4 When I analyzed the wage data, it came from a subset of the ACS, so a sample of a sample. With survey data like this, you have to worry about having large enough sample sizes to get reliable estimates. So far we’ve used fairly large groups (women in Maryland with bachelor’s degrees, etc), but when we slice the data more, we start to get less reliable estimates.\nFor example, calculating median income of women in military occupations by education leaves us with some very small sample sizes, and some very large MOEs. Rule of thumb is usually that you need at least 30 observations in your sample for estimates to be useful; you might also want to set a minimum number of estimated counts.\n\nwages_moe <- readRDS(here::here(\"inputs/wages_sex_edu_occ.rds\")) |>\n mutate(occ_group = forcats::as_factor(occ_group) |>\n forcats::fct_relabel(stringr::str_replace, \",? \\\\band\\\\b\", \" &\")) |>\n mutate(lower_95 = earn_q50 - moe_95,\n lower_90 = earn_q50 - moe_90,\n upper_90 = earn_q50 + moe_90,\n upper_95 = earn_q50 + moe_95)\n\nwages_moe |>\n filter(sex == \"Women\",\n occ_group == \"Military Specific\") |>\n select(6:12)\n\n\n\n\n\nedu\ncount\nsample_n\nearn_q50\nse\nmoe_90\nmoe_95\n\n\n\n\nTotal\n2002\n92\n64738\n5916\n9731\n11595\n\n\nHigh school or less\n182\n14\n34600\n17175\n28250\n33662\n\n\nSome college or AA\n732\n28\n63586\n11043\n18164\n21644\n\n\nBachelors\n558\n27\n62580\n4182\n6879\n8197\n\n\nGraduate degree\n530\n23\n85000\n15611\n25678\n30597\n\n\n\n\n\n\nReporting that estimate for women in military occupations with a graduate degree would be silly: $85k ± $30k means that at a 95% confidence level, you’ve estimated the median to be between $55k and $115k, which tells you virtually nothing.\nError bars are one simple way to show the MOE. When we don’t split things up by education, and we look statewide, the MOEs aren’t so bad for most occupational groups (note which ones are pretty big, and for which genders).\n\n\n\n\n\n\n\n\n\nOnce we split by education, however, we get wider margins. Note also that we still have pretty wide distributions within occupation: what’s the difference between a healthcare job someone with a graduate degree has and one someone with at most a high school degree?\n\n\n\n\n\n\n\n\n\nAnother thing to know about margins of error is that they can be used as a kind of crude approximation of statistical testing (t-tests, etc). For example, the margins of error for people with graduate degrees in production occupations overlap, so we shouldn’t say they differ by sex until we do formal testing. For service jobs, however, the MOEs don’t overlap, so that’s a safer bet (but not a replacement for tests of statistical significance).",
- "crumbs": [
- "Weekly notes",
- "8. Uncertainty and distributions"
- ]
- },
- {
- "objectID": "weeks/08_uncertainty.html#missing-data",
- "href": "weeks/08_uncertainty.html#missing-data",
- "title": "8. Uncertainty and distributions",
- "section": "Missing data",
- "text": "Missing data\nThere’s a lot of different reasons data might be missing, and different ways to handle it. Here’s just one tidbit to handle those small samples from the wage data that you’re likely to encounter.\n\n# I'll use a few metrics to decide which observations to keep:\n# coefficient of variance (MOE / estimate) needs to be less than 0.3, based on 95% CI\n# sample size needs to be at least 50\nwages_sample_size <- wages_moe |>\n mutate(cov = moe_95 / earn_q50) |>\n filter(sex != \"Total\",\n edu == \"Graduate degree\") |>\n mutate(too_small = sample_n < 50 | cov > 0.3) |>\n select(sex, occ_group, earn_q50, too_small)\n\nwages_sample_size |>\n filter(too_small)\n\n\n\n\n\n\n\n\n\n\n\nsex\nocc_group\nearn_q50\ntoo_small\n\n\n\n\nWomen\nMilitary Specific\n85000\nTRUE\n\n\nWomen\nNatural Resources, Construction & Maintenance\n95378\nTRUE\n\n\n\n\n\n\nIf we drop those unreliable values, or have a similar dataset with missing values, we’ll get something like this:\n\nwages_sample_size |>\n filter(!too_small) |>\n ggplot(aes(x = occ_group, y = earn_q50, fill = sex)) +\n geom_col(width = 0.8, position = position_dodge2()) +\n coord_flip() +\n scale_x_discrete(labels = scales::label_wrap(30)) +\n scale_y_continuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n theme(panel.grid.major.x = element_line())\n\n\n\n\n\n\n\n\nDodged bars will fill up the available space by default. Instead, use preserve = \"single\" inside position_dodge.\n\nwages_sample_size |>\n filter(!too_small) |>\n ggplot(aes(x = occ_group, y = earn_q50, fill = sex, group = sex)) +\n geom_col(width = 0.8, position = position_dodge2(preserve = \"single\")) +\n coord_flip() +\n scale_x_discrete(labels = scales::label_wrap(30)) +\n scale_y_continuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n theme(panel.grid.major.x = element_line())\n\n\n\n\n\n\n\n\nWith time series data, you can usually assume the intervals are even (every month, every week, etc.). If it’s not for whatever reason, you might want to add some visual cues for transparency. This is a forced example where I drop some observations from the unemployment data.\n\n\n\n\n\n\n\n\n\nThere are 2 months missing here, but you can’t tell because the lines get connected regardless of discontinuities. Adding points makes it clearer when observations were made, although this might not work when you have a lot of points (that’s why I’m only using one year for this example).\n\n\n\n\n\n\n\n\n\nIn a lot of cases, that will be enough. If you need more accuracy, you might convert the data into a time series (I like the tsibble package because it works well with dplyr) and fill in missing observations. This also gives you options of imputing the missing values, but it’s outside the scope of this class.\n\n# install the tsibble library if you need to\nlibrary(tsibble)\n\n# fill_gaps adds explicitly missing observations in place of missing values, \n# in this case monthly\n# this isn't the best way to hack this chart together but it's the easiest\nunemp_ts <- unemp_missing |>\n mutate(month = yearmonth(date)) |>\n as_tsibble(key = name, index = month) |>\n fill_gaps() |>\n as_tibble() |>\n mutate(month = lubridate::ym(month))\n\nunemp_ts |>\n ggplot(aes(x = month, y = adjusted_rate)) +\n geom_line(aes(x = date), linetype = \"dashed\") +\n geom_line() +\n geom_point() +\n scale_x_date(date_breaks = \"2 months\", date_labels = \"%b %Y\") +\n theme(panel.grid.major.x = element_line())",
+ "objectID": "weeks/03_encoding.html#facets",
+ "href": "weeks/03_encoding.html#facets",
+ "title": "3. Visual encoding",
+ "section": "Facets",
+ "text": "Facets\n\nacs_tr |>\n ggplot(aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1) +\n facet_grid(cols = vars(county2), rows = vars(income_brk))",
"crumbs": [
"Weekly notes",
- "8. Uncertainty and distributions"
- ]
- },
- {
- "objectID": "syllabus.html",
- "href": "syllabus.html",
- "title": "Syllabus",
- "section": "",
- "text": "At its essence, the aim of data visualization is to move data and its meaning(s) and context(s) from some origin (spreadsheets, observed phenomena, etc.) to a larger audience. It’s a spectrum of incredibly powerful tools for not just understanding and explaining facts, but also for shaping what those facts are and creating the narrative around them. By the end of this course, you will have thought through your role and responsibility in an evolving field, developed a set of best practices that is likely to continue to change, engaged with larger social currents toward your own goals, and strengthened your skills in R.\nBecause this is part of a professional studies program based on open source software and the ethos behind it, the course will be very hands-on and require everyone’s willingness to contribute and participate. Instead of tests and graded homework assignments, we’ll focus on practice, critique, and revision, building continuously on individual projects and shared tools. To some extent, the class structure will mimic a workplace, where you have projects with checkpoints and meetings to brainstorm and workshop your ideas, with time to work both in class and on your own at home.\nBecause data science and data visualization—and the software we use for both—change so quickly, a lot of the community’s discourse happens in less formal settings, such as blogs, social media, podcasts, and workshops, rather than just traditional academic journals and books. Our readings (defined loosely enough to include videos of talks, podcasts, and simply browsing through data visualization projects) will likewise fall along this spectrum, and you’ll have some flexibility in what you read and share.\nAbove all, I want this to be a course that is useful to you as you build a career of critical engagement with data. The schedule is intentionally loose so we can adjust based on skills we may want or need to build upon, and each student’s goals and interests. Please be willing to share what you want to learn, contribute resources, and ask for what you need of me and each other.",
- "crumbs": [
- "Overview",
- "Syllabus"
- ]
- },
- {
- "objectID": "syllabus.html#objectives",
- "href": "syllabus.html#objectives",
- "title": "Syllabus",
- "section": "Objectives",
- "text": "Objectives\nThe first half of the course will be focused on non-spatial data visualization; the second half will be focused on spatial data and how to integrate the two. Some of the principles we go over for non-spatial and spatial will differ, but objectives remain the same.\nBy the end of the course, students will:\n\nHave an understanding of the basics of visual perception, and how to use that knowledge to design data visualizations well\nBe familiar with the grammar of graphics framework to think about components and purposes of visual elements\nBe skilled in programming in R and using the ggplot2 data visualization ecosystem\nKnow how to give and receive constructive feedback on visualizations, both their own and others’, and to revise and improve upon their work\nBe able to identify potential harms done by inappropriate or misleading visualizations, and make corrections\nBe able to make, articulate, and argue for good decisions in designing charts and maps\nHave made many, many unpolished visualizations and several polished, presentation-ready ones\n\nSuccessful students will finish the course with finished products for their portfolios of high enough quality to include with applications to jobs or other academic programs:\n\n1–2 completed, presentation-ready data visualization projects\nreproducible, documented code that can be repurposed at another organization\ncontributions to an open source codebase",
- "crumbs": [
- "Overview",
- "Syllabus"
- ]
- },
- {
- "objectID": "syllabus.html#materials",
- "href": "syllabus.html#materials",
- "title": "Syllabus",
- "section": "Materials",
- "text": "Materials\n\nReadings\nAll readings will be available to students for free. Many will be open source texts and have code available. Readings will be a mix of theory and practice.\nThe schedule of the course will roughly follow the structure of the book Fundamentals of Data Visualization (Wilke, 2019). Both the book and the source code used to write it are available for free online.\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\nCairo, A. (2019). How charts lie: Getting smarter about visual information (First edition). W. W. Norton & Company.\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\nWe’ll also read portions of R for Data Science (Wickham et al., 2023) (also open source), How Charts Lie (Cairo, 2019), and Data Points (Yau, 2013), as well as a variety of other sources of different media. I’ll keep a running list of resources in the online class notes with other tutorials and references.\n\n\nSoftware\nThis is a rough set of the software and tools we will use, with open source software in italics:\n\nR programming language\nggplot2 and related packages\nRStudio or another integrated development environment\nQuarto, a markdown-based publishing system from the same team as RStudio\ngit for version control, GitHub for storage of version-controlled materials, and GitHub Classroom for discussions and submitting code\nBlackboard for assignments and announcements\n\nI’m open to suggestions on any other tools you all think would be useful.\n\n\nOther tools\nIf at all possible, you should have a laptop of your own for this class. All the software we’re using is free and open source, so you should be able to install everything on your computer. If you do not have a laptop, you can borrow one from the library, or, because we will be using git for version tracking and GitHub for storage, you can use a lab computer and make sure to upload your work regularly.\nWe’ll be doing a lot of sketching by hand (you don’t have to be good at drawing), so you’ll need a notebook and pens or pencils that are nice to doodle with. I highly, highly recommend finding a graph paper or dotted notebook.",
- "crumbs": [
- "Overview",
- "Syllabus"
+ "3. Visual encoding"
]
},
{
- "objectID": "syllabus.html#schedule",
- "href": "syllabus.html#schedule",
- "title": "Syllabus",
- "section": "Schedule",
- "text": "Schedule\nThe schedule has some flexibility built into it, but tentatively goes as follows:\n\n\n\n\n\n\n\n\nWeek\nSection\nTopic\n\n\n\n\n1\nNon-spatial data viz\nWhat is a chart, and do you need one?\n\n\n2\n\nEncoding data to visuals; making meaning of your data\n\n\n3\n\nWriting good code; working with color\n\n\n4\n\nText and annotation; uncertainty and distribution\n\n\n5\n\nMaking good decisions pt. 1\n\n\n6\n\nAccessibility, literacy, and audience\n\n\n7\n\nStorytelling pt. 1 (empathy & equity); experimentation\n\n\n8\nSpatial data viz\nWhat is a map, and do you need one?\n\n\n\n\nProject 1 due\n\n\n9\n\nEncoding data to space; harmful practices\n\n\n10\n\nColor, text, and annotations pt. 2\n\n\n11\n\nMaking good decisions pt. 2\n\n\n12\n\nStorytelling pt. 2 (history & cohesion); experimentation\n\n\n13\n\nFinal critique; tying up loose ends\n\n\n14\n\nFinishing touches on projects\n\n\n\n\nProject 2 due\n\n\n\n\nClass structure\nA typical class session will be roughly:\n\n\n\nActivity\nTime\n\n\n\n\nWarm-up\n5-10 minutes\n\n\nReport-backs\n10-15 minutes, if any\n\n\nLecture\n1 hour max + questions\n\n\nWorkshop, critique, or lab\nRemaining time",
+ "objectID": "weeks/03_encoding.html#statistical-transformations",
+ "href": "weeks/03_encoding.html#statistical-transformations",
+ "title": "3. Visual encoding",
+ "section": "Statistical transformations",
+ "text": "Statistical transformations\nI am of the opinion that if you want to visualize summary statistics or other aggregations, you should calculate them explicitly, not let ggplot do them ad hoc, so I think the examples in section 9.5 are not great. Comparable charts with calculations:\n\nacs_tr |>\n group_by(county2) |>\n summarise(n = n()) |> # these 2 steps can be done with `count`\n ggplot(aes(x = county2, y = n)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nacs_tr |>\n group_by(county2) |>\n summarise(n = n()) |> # keeping data grouped by county2 lets you calc proportions\n mutate(prop = n / sum(n)) |>\n ggplot(aes(x = county2, y = prop)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nacs_tr |>\n group_by(county2) |>\n summarise(across(total_cost_burden, list(min = min, max = max, median = median))) |>\n ggplot(aes(x = county2)) +\n geom_pointrange(aes(y = total_cost_burden_median, \n ymin = total_cost_burden_min, \n ymax = total_cost_burden_max))",
"crumbs": [
- "Overview",
- "Syllabus"
+ "Weekly notes",
+ "3. Visual encoding"
]
},
{
- "objectID": "syllabus.html#grading",
- "href": "syllabus.html#grading",
- "title": "Syllabus",
- "section": "Grading",
- "text": "Grading\nIn data visualization there aren’t any perfectly right answers, and there aren’t too many perfectly wrong ones either. As a result, rather than tedious quizzes and problem sets, your grade will reflect the effort you put into developing your process and your critical eye, and how successfully you create compelling stories with data.\n\nParticipation\nThere will be opportunities for participation points every week, including:\n\nBringing in visualizations you’ve found for us to discuss\nOpening your work up for workshopping\nContributing code (there’s an R package in development for this class), with more points given for students with less experience in R—this includes the less glamorous but crucial tasks of testing, debugging, and documenting\nDoing an optional reading or attending a talk and reporting back to the class on some interesting things you learned\nAdding a resource to the class notes\n\nThere will be two opportunities to lose points as well:\n\nBeing mean or unnecessarily harsh in critique\nUnexcused absences (see below)\n\nThere’s no set number of participation points you need—just rack them up when you can, forgo them when you have to, and I’ll scale them at the end of the semester. Notice that most of these involve contributing to your classmates’ growth as well as your own.\n\n\nProjects\nThere will be 2 projects, one midterm and one final, that you’ll be working on throughout the semester. Both will build upon the exercises, and you’ll have lots of time to work on them in class and receive feedback from myself and your peers. The first will be non-spatial data, and the second will be both spatial and non-spatial. You’ll be responsible for moving from a dataset through to a polished visualization that tells a story and has real-world impact. You will also document your process along the way and have check-ins regularly. Each project will also have a semi-formal write-up to explain what you did and why, and to situate your work into the theory and principles we study.\n\n\nOther assignments\nWe’ll have a few more small assignments, including short case studies and peer reviews.\n\n\nGrading scale\nGrades will be rounded to the nearest whole percent.\n\n\n\nGrade\nPercentage\n\n\n\n\nA+\n97% +\n\n\nA\n93-96%\n\n\nA-\n90-92%\n\n\nB+\n87-89%\n\n\nB\n83-86%\n\n\nB-\n80-82%\n\n\nC+\n77-79%\n\n\nC\n73-76%\n\n\nC-\n70-72%\n\n\nD+\n67-69%\n\n\nD\n63-66%\n\n\nD-\n60-62%\n\n\nF\n< 60%\n\n\n\n\n\nGrade distribution\n\n\n\nCategory\nShare of grade\n\n\n\n\nCase studies\n15%\n\n\nPeer review & reflections\n5%\n\n\nParticipation\n20%\n\n\nProject 1 visualization\n20%\n\n\nProject 1 write-up\n5%\n\n\nProject 2 visualization\n25%\n\n\nProject 2 write-up\n10%",
+ "objectID": "weeks/03_encoding.html#position-aesthetics",
+ "href": "weeks/03_encoding.html#position-aesthetics",
+ "title": "3. Visual encoding",
+ "section": "Position aesthetics",
+ "text": "Position aesthetics\n\ninc_by_county <- acs_tr |>\n group_by(county2, income_brk) |>\n summarise(n = n())\n\nggplot(inc_by_county, aes(x = county2, y = n, color = income_brk)) +\n geom_col()\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(alpha = 1/5, position = position_identity())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_fill())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_dodge())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_dodge2())\n\n\n\n\n\n\n\n\nOther than the first chart with the weird opacity, which kinda sucks, these give you different views of the same data. What can you pick up from each?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1, position = position_jitter(seed = 1))",
"crumbs": [
- "Overview",
- "Syllabus"
+ "Weekly notes",
+ "3. Visual encoding"
]
},
{
- "objectID": "syllabus.html#attendance",
- "href": "syllabus.html#attendance",
- "title": "Syllabus",
- "section": "Attendance",
- "text": "Attendance\nAs grad students, your course load is one of many responsibilities you juggle, so I know things will come up from time to time that prevent you from getting to class. If you need to miss class or will be late, just let me know in advance (email or DM), and as long as absences don’t become excessive, it should be fine. If there is some reason you’ll need to miss class several times, such as chronic illness (after all, COVID’s still here), just let me know and we can figure something out. If you can’t attend class but are able to participate remotely, I can stream on Zoom or WebEx.\nUnexcused absences, except for a serious emergency (e.g. you got into a car accident on the way to campus), will cost you participation points. Excused absences will not.",
+ "objectID": "decision_checklist.html",
+ "href": "decision_checklist.html",
+ "title": "Decisionmaking checklist",
+ "section": "",
+ "text": "When you’re planning out your own work, it’s important to make conscious decisions about what you’re doing and why. I keep saying this, but one of the things I dislike the most about no-code visualization products like Excel or Tableau is that they encourage you to not make these decisions, but to just rely on defaults or automated suggestions.\nIn contrast to just going with defaults, you as a thoughtful visualization practitioner should go through the decisions you could make in order to determine what decisions you should make. This is something you do in your EDA process, as well as in sketching charts on paper.\nIt’s also useful for understanding a chart someone else made, whether just to read it, or to revise or critique it.",
"crumbs": [
"Overview",
- "Syllabus"
+ "Decisionmaking checklist"
]
},
{
- "objectID": "syllabus.html#umbc-policies-and-resources",
- "href": "syllabus.html#umbc-policies-and-resources",
- "title": "Syllabus",
- "section": "UMBC policies and resources",
- "text": "UMBC policies and resources\n\nAccessibility and Disability Accommodations, Guidance and Resources\nAccommodations for students with disabilities are provided for all students with a qualified disability under the Americans with Disabilities Act (ADA & ADAAA) and Section 504 of the Rehabilitation Act who request and are eligible for accommodations. The Office of Student Disability Services (SDS) is the UMBC department designated to coordinate accommodations that creates equal access for students when barriers to participation exist in University courses, programs, or activities.\nIf you have a documented disability and need to request academic accommodations in your courses, please refer to the SDS website at sds.umbc.edu for registration information and office procedures.\nSDS email: disAbility@umbc.edu (disability at umbc dot edu)\nSDS phone: 410-455-2459\nIf you will be using SDS approved accommodations in this class, please contact the instructor to discuss implementation of the accommodations. During remote instruction requirements due to COVID, communication and flexibility will be essential for success.\n\n\nSexual Assault, Sexual Harassment, and Gender Based Violence and Discrimination\nUMBC Policy in addition to federal and state law (to include Title IX) prohibits discrimination and harassment on the basis of sex, sexual orientation, and gender identity in University programs and activities. Any student who is impacted by sexual harassment, sexual assault, domestic violence, dating violence, stalking, sexual exploitation, gender discrimination, pregnancy discrimination, gender-based harassment, or related retaliation should contact the University’s Title IX Coordinator to make a report and/or access support and resources. The Title IX Coordinator can be reached at titleixcoordinator at umbc dot edu or 410-455-1717.\nYou can access support and resources even if you do not want to take any further action. You will not be forced to file a formal complaint or police report. Please be aware that the University may take action on its own if essential to protect the safety of the community.\nIf you are interested in making a report, please use the Online Reporting/Referral Form. Please note that, if you report anonymously, the University’s ability to respond will be limited.\n\nNotice that Faculty and Teaching Assistants are Responsible Employees with Mandatory Reporting Obligations\nAll faculty members and teaching assistants are considered Responsible Employees, per UMBC’s Policy on Sexual Misconduct, Sexual Harassment, and Gender Discrimination. Faculty and teaching assistants therefore required to report all known information regarding alleged conduct that may be a violation of the Policy to the Title IX Coordinator, even if a student discloses an experience that occurred before attending UMBC and/or an incident that only involves people not affiliated with UMBC. Reports are required regardless of the amount of detail provided and even in instances where support has already been offered or received.\nWhile faculty members want to encourage you to share information related to your life experiences through discussion and written work, students should understand that faculty are required to report past and present sexual harassment, sexual assault, domestic and dating violence, stalking, and gender discrimination that is shared with them to the Title IX Coordinator so that the University can inform students of their rights, resources, and support. While you are encouraged to do so, you are not obligated to respond to outreach conducted as a result of a report to the Title IX Coordinator.\nIf you need to speak with someone in confidence, who does not have an obligation to report to the Title IX Coordinator, UMBC has a number of Confidential Resources available to support you: \nRetriever Integrated Health (Main Campus): 410-455-2472; Monday – Friday 8:30 a.m. – 5 p.m.; For After-Hours Support, Call 988.\nCenter for Counseling and Well-Being (Shady Grove Campus): 301-738-6273; Monday-Thursday 10:00a.m. – 7:00 p.m. and Friday 10:00 a.m. – 2:00 p.m. (virtual) Online Appointment Request Form\nPastoral Counseling via The Gathering Space for Spiritual Well-Being: 410-455-6795; i3b at umbc dot edu; Monday – Friday 8:00 a.m. – 10:00 p.m.\n\n\nOther Resources\nWomen’s Center (open to students of all genders): 410-455-2714; womenscenter at umbc dot edu; Monday – Thursday 9:30 a.m. – 5:00 p.m. and Friday 10:00 a.m. – 4 p.m.\nShady Grove Student Resources, Maryland Resources, National Resources.\n\n\nChild Abuse and Neglect\nPlease note that Maryland law and UMBC policy require that faculty report all disclosures or suspicions of child abuse or neglect to the Department of Social Services and_/_or the police even if the person who experienced the abuse or neglect is now over 18.\n\n\n\nPregnant and Parenting Students\nUMBC’s Policy on Sexual Misconduct, Sexual Harassment and Gender Discrimination expressly prohibits all forms of discrimination and harassment on the basis of sex, including pregnancy. Resources for pregnant, parenting and breastfeeding students are available through the University’s Office of Equity and Civil Rights. Pregnant and parenting students are encouraged to contact the Title IX Coordinator to discuss plans and ensure ongoing access to their academic program with respect to a leave of absence – returning following leave, or any other accommodation that may be needed related to pregnancy, childbirth, adoption, breastfeeding, and/or the early months of parenting.\nIn addition, students who are pregnant and have an impairment related to their pregnancy that qualifies as disability under the ADA may be entitled to accommodations through the Office of Student Disability Services.\n\n\nReligious Observances & Accommodations\nUMBC Policy provides that students should not be penalized because of observances of their religious beliefs, and that students shall be given an opportunity, whenever feasible, to make up within a reasonable time any academic assignment that is missed due to individual participation in religious observances. It is the responsibility of the student to inform the instructor of any intended absences or requested modifications for religious observances in advance, and as early as possible. For questions or guidance regarding religious observances and accommodations, please contact the Office of Equity and Civil Rights at ecr at umbc dot edu.\n\n\nHate, Bias, Discrimination and Harassment\nUMBC values safety, cultural and ethnic diversity, social responsibility, lifelong learning, equity, and civic engagement.\nConsistent with these principles, UMBC Policy prohibits discrimination and harassment in its educational programs and activities or with respect to employment terms and conditions based on race, creed, color, religion, sex, gender, pregnancy, ancestry, age, gender identity or expression, national origin, veterans status, marital status, sexual orientation, physical or mental disability, or genetic information.\nStudents (and faculty and staff) who experience discrimination, harassment, hate, or bias based upon a protected status or who have such matters reported to them should use the online reporting/referral form to report discrimination, hate, or bias incidents. You may report incidents that happen to you anonymously. Please note that, if you report anonymously, the University’s ability to respond may be limited.\n\n\nUMBC Writing Center\nThe Academic Success Center offers free writing assistance through our Writing Center, which is located on the first floor of the Library. We also offer online and asynchronous tutoring. Writing tutors are students like you who receive ongoing training to stay up-to-date on the best tutoring techniques. To make an appointment, please visit http://academicsuccess.umbc.edu/writing-center",
+ "objectID": "decision_checklist.html#checklist",
+ "href": "decision_checklist.html#checklist",
+ "title": "Decisionmaking checklist",
+ "section": "Checklist",
+ "text": "Checklist\nWhat decisions could be / should be / were made about…\n\nwhat data to include\nwhat data to exclude\nwhat visual encodings to use\nwhat types of scales to use (sequential, qualitative, diverging)\nwhat to put on the x- and y-axes\nhow to scale the x- and y-axes\nhow to use color\nhow to use text\nhow to use annotations\nwhere to draw attention\nwhat conclusion to suggest\n\nWhat have I forgotten from this list?",
"crumbs": [
"Overview",
- "Syllabus"
- ]
- },
- {
- "objectID": "references.html",
- "href": "references.html",
- "title": "References by topic",
- "section": "",
- "text": "This is most of what’s in my Zotero bibliography for this class arranged by topic.\n\nMain texts\nFoundational books and chapters\n\n\nCairo (2019)\nWickham et al. (2023)\nWilke (2019)\nYau (2013)\n\n\n\n\n\nCairo, A. (2019). How charts lie: Getting smarter about visual information (First edition). W. W. Norton & Company.\n\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\n\n\n\n\nGeneral references\nReferences, frameworks, and grammar of graphics\n\n\nBBC (2010)\nCogley & Setlur (2022)\nChang (2018)\nDu Bois et al. (2018)\nD’Ignazio & Klein (2020)\nD’Ignazio (2015)\nGilmore (2023)\nKirk (2016)\nKosara (2019)\nMunzner (2014)\nRibecca (2024)\nSchwabish (n.d.-a)\nSchwabish (n.d.-b)\nSchwabish (2021)\nWickham et al. (2023)\nWickham (2010)\nWilke (2019)\n\n\n\n\n\nBBC. (2010). Hans Rosling’s 200 Countries, 200 Years, 4 Minutes - The Joy of Stats - BBC Four. https://www.youtube.com/watch?v=jbkSRLYSojo\n\n\nChang, W. (2018). R graphics cookbook: Practical recipes for visualizing data (Second edition). O’Reilly. https://r-graphics.org/\n\n\nCogley, B., & Setlur, V. (2022). Functional Aesthetics for Data Visualization. John Wiley and Sons.\n\n\nD’Ignazio, C. (2015). What would feminist data visualization look like? https://civic.mit.edu/feminist-data-visualization.html\n\n\nD’Ignazio, C., & Klein, L. F. (2020). Data feminism. The MIT Press. https://data-feminism.mitpress.mit.edu/\n\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nGilmore, R. W. (2023). Abolition Geography.\n\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\n\nKosara, R. (2019). The DataSaurus, Anscombe’s Quartet, and why summary statistics need to be taken with a grain of salt. https://www.youtube.com/watch?v=RbHCeANCbW0\n\n\nMunzner, T. (2014). Visualization Analysis and Design. A K Peters/CRC Press. https://doi.org/10.1201/b17511\n\n\nRibecca, S. (2024). The Data Visualisation Catalogue. https://datavizcatalogue.com/\n\n\nSchwabish, J. (n.d.-a). Catherine D’Ignazio and Lauren Klein (142). Retrieved January 30, 2024, from https://policyviz.com/podcast/episode-142-catherine-dignazio-and-lauren-klein/\n\n\nSchwabish, J. (n.d.-b). Sarah Williams (191). Retrieved January 18, 2024, from https://policyviz.com/podcast/episode-191-sarah-williams/\n\n\nSchwabish, J. (2021). Better Data Visualizations : A Guide for Scholars, Researchers, and Wonks. Columbia University Press.\n\n\nWickham, H. (2010). A Layered Grammar of Graphics. Journal of Computational and Graphical Statistics, 19(1), 3–28. https://doi.org/10.1198/jcgs.2009.07098\n\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\n\n\n\nAesthetics & styling\nColor, visual perception, annotations, text, and styleguides\n\n\nViz Palette (2019)\nAisch (2019)\nBertini & Stefaner (n.d.)\nBrewer (2006)\nGramazio et al. (2017)\nDatawrapper (2021)\nFrance (2020)\nHeer & Bostock (2010)\nKebonye et al. (2023)\nKim et al. (2021)\nKirk (2015)\nLiu & Heer (2018)\nMuth (2022)\nSkau & Kosara (2016)\nSetlur & Stone (2016)\nUrban Institute (2023)\nWorld Health Organization (2023)\n\n\n\n\n\nAisch, G. (2019). Chroma.js palette helper. https://gka.github.io/palettes\n\n\nBertini, E., & Stefaner, M. (n.d.). Color with Karen Schloss (119). Retrieved February 7, 2024, from https://datastori.es/119-color-with-karen-schloss/\n\n\nBrewer, C. A. (2006). Basic Mapping Principles for Visualizing Cancer Data Using Geographic Information Systems (GIS). American Journal of Preventive Medicine, 30(2), S25–S36. https://doi.org/10.1016/j.amepre.2005.09.007\n\n\nDatawrapper. (2021). What to consider when choosing colors for data visualization. https://academy.datawrapper.de/article/140-what-to-consider-when-choosing-colors-for-data-visualization\n\n\nFrance, T. (2020). Choosing Fonts for Your Data Visualization, Nightingale. In Nightingale. https://nightingaledvs.com/choosing-fonts-for-your-data-visualization/\n\n\nGramazio, C. C., Laidlaw, D. H., & Schloss, K. B. (2017). Colorgorical: Creating discriminable and preferable color palettes for information visualization. IEEE Transactions on Visualization and Computer Graphics. https://doi.org/10.1109/TVCG.2016.2598918\n\n\nHeer, J., & Bostock, M. (2010). Crowdsourcing graphical perception: Using mechanical turk to assess visualization design. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 203–212. https://doi.org/10.1145/1753326.1753357\n\n\nKebonye, N. M., Agyeman, P. C., Seletlo, Z., & Eze, P. N. (2023). On exploring bivariate and trivariate maps as visualization tools for spatial associations in digital soil mapping: A focus on soil properties. Precision Agriculture, 24(2), 511–532. https://doi.org/10.1007/s11119-022-09955-7\n\n\nKim, D. H., Setlur, V., & Agrawala, M. (2021). Towards Understanding How Readers Integrate Charts and Captions: A Case Study with Line Charts. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 1–11. https://doi.org/10.1145/3411764.3445443\n\n\nKirk, A. (2015). Make grey your best friend. In Visualising Data. https://visualisingdata.com/2015/01/make-grey-best-friend/\n\n\nLiu, Y., & Heer, J. (2018). Somewhere Over the Rainbow: An Empirical Assessment of Quantitative Colormaps. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. https://doi.org/10.1145/3173574.3174172\n\n\nMuth, L. C. (2022). What to consider when using text in data visualizations. In Datawrapper. https://blog.datawrapper.de/text-in-data-visualizations/\n\n\nSetlur, V., & Stone, M. C. (2016). A Linguistic Approach to Categorical Color Assignment for Data Visualization. IEEE Transactions on Visualization and Computer Graphics, 22(1), 698–707. https://doi.org/10.1109/TVCG.2015.2467471\n\n\nSkau, D., & Kosara, R. (2016). Arcs, Angles, or Areas: Individual Data Encodings in Pie and Donut Charts. Computer Graphics Forum, 35(3), 121–130. https://doi.org/10.1111/cgf.12888\n\n\nUrban Institute. (2023). Urban Institute Data Visualization style guide. http://urbaninstitute.github.io/graphics-styleguide/\n\n\nViz Palette. (2019). https://projects.susielu.com/viz-palette\n\n\nWorld Health Organization. (2023). WHO Data Design Language v.0.9.2. https://apps.who.int/gho/data/design-language/\n\n\n\n\nUnderstanding data\nDecision-making, uncertainty, missing data, and logical fallacies\n\n\nAisch (2016)\nBertini & Stefaner (n.d.-a)\nBertini & Stefaner (n.d.-b)\nCox et al. (2022)\nCorrell & Gleicher (2014)\nCorrell et al. (2018)\nEtter (2023)\nHamel et al. (2020)\nHamel et al. (2021)\nKay et al. (2016)\nKrackov et al. (2021)\nKay (2024)\nKirk (2016)\nKirk (n.d.)\nLee et al. (2021)\nmimimimimi (2024)\nNation (2024)\nNyame-Mensah (2022)\nPillai et al. (2024)\nSadler (2016)\nSchwabish (n.d.)\nSilver (2015)\nSimeoni (2023)\nSmith (2023)\n\n\n\n\n\nAisch, G. (2016). Why we used jittery gauges in our live election forecast. In vis4.net. https://vis4.net/blog/jittery-gauges-election-forecast\n\n\nBertini, E., & Stefaner, M. (n.d.-a). Cognitive Bias and Visualization with Evanthia Dimara (116). Retrieved February 14, 2024, from https://datastori.es/116-cognitive-bias-and-visualization-with-evanthia-dimara/\n\n\nBertini, E., & Stefaner, M. (n.d.-b). Visualizing Uncertainty with Jessica Hullman and Matthew Kay (134). Retrieved January 30, 2024, from https://datastori.es/134-visualizing-uncertainty-with-jessica-hullman-and-matthew-kay/\n\n\nCorrell, M., & Gleicher, M. (2014). Error Bars Considered Harmful: Exploring Alternate Encodings for Mean and Error. IEEE Transactions on Visualization and Computer Graphics, 20(12), 2142–2151. https://doi.org/10.1109/TVCG.2014.2346298\n\n\nCorrell, M., Moritz, D., & Heer, J. (2018). Value-Suppressing Uncertainty Palettes. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–11. https://doi.org/10.1145/3173574.3174216\n\n\nCox, C., Amin, K., Kates, J., & Published, J. M. (2022). Why Do Vaccinated People Represent Most COVID-19 Deaths Right Now? In KFF. https://www.kff.org/policy-watch/why-do-vaccinated-people-represent-most-covid-19-deaths-right-now/\n\n\nEtter, E. (2023). Data Visualization: A Subjective Lens on Reality. In Nightingale. https://nightingaledvs.com/data-visualization-a-subjective-lens-on-reality/\n\n\nHamel, L., Kirzinger, A., Muñana, C., & Published, M. B. (2020). KFF COVID-19 Vaccine Monitor: December 2020. In KFF. https://www.kff.org/coronavirus-covid-19/report/kff-covid-19-vaccine-monitor-december-2020/\n\n\nHamel, L., Lopes, L., & Published, M. B. (2021). KFF COVID-19 Vaccine Monitor: What Do We Know About Those Who Want to “Wait and See” Before Getting a COVID-19 Vaccine? In KFF. https://www.kff.org/coronavirus-covid-19/poll-finding/kff-covid-19-vaccine-monitor-wait-and-see/\n\n\nKay, M. (2024). Mjskay/ggdist. https://github.com/mjskay/ggdist\n\n\nKay, M., Kola, T., Hullman, J. R., & Munson, S. A. (2016). When (ish) is My Bus?: User-centered Visualizations of Uncertainty in Everyday, Mobile Predictive Systems. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, 5092–5103. https://doi.org/10.1145/2858036.2858558\n\n\nKirk, A. (n.d.). Alvin Chang (S2 E6). Retrieved February 2, 2024, from https://visualisingdata.com/2020/12/explore-explain-s2-e6-alvin-chang/\n\n\nKirk, A. (2016). Gauging election reaction. In Visualising Data. https://visualisingdata.com/2016/11/gauging-election-reaction/\n\n\nKrackov, A., Marikos, S., & Marikos, A. K. &. S. (2021). Asterisk Nation: One Tribe’s Challenge to Find Data About its Population, Nightingale. In Nightingale. https://nightingaledvs.com/asterisk-nation-one-tribes-challenge-to-find-data-about-its-population/\n\n\nLee, C., Yang, T., Inchoco, G. D., Jones, G. M., & Satyanarayan, A. (2021). Viral Visualizations: How Coronavirus Skeptics Use Orthodox Data Practices to Promote Unorthodox Science Online. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 1–18. https://doi.org/10.1145/3411764.3445211\n\n\nmimimimimi. (2024). MimiOnuoha/missing-datasets. https://github.com/MimiOnuoha/missing-datasets\n\n\nNation, Z. (2024). Zonination/perceptions. https://github.com/zonination/perceptions\n\n\nNyame-Mensah, A. (2022). When Oversimplification Obscures. In Nightingale. https://nightingaledvs.com/when-oversimplification-obscures/\n\n\nPillai, D., Artiga, S., Hamel, L., Schumacher, S., Kirzinger, A., Rao, A., & Published, A. K. (2024). Understanding the Diversity in the Asian Immigrant Experience in the U.S.: The 2023 KFF/LA Times Survey of Immigrants. In KFF. https://www.kff.org/racial-equity-and-health-policy/poll-finding/understanding-the-diversity-in-the-asian-immigrant-experience/\n\n\nSadler, R. C. (2016). How ZIP codes nearly masked the lead problem in Flint. In The Conversation. http://theconversation.com/how-zip-codes-nearly-masked-the-lead-problem-in-flint-65626\n\n\nSchwabish, J. (n.d.). Joe Sharpe and Mike Orwell (242). Retrieved February 13, 2024, from https://policyviz.com/podcast/episode-242-joe-sharpe-and-mike-orwell/\n\n\nSilver, N. (2015). The Most Diverse Cities Are Often The Most Segregated. In FiveThirtyEight. https://fivethirtyeight.com/features/the-most-diverse-cities-are-often-the-most-segregated/\n\n\nSimeoni, F. (2023). Querying the Quantification of Queer. In Nightingale. https://nightingaledvs.com/querying-the-quantification-of-the-queer/\n\n\nSmith, N. (2023). How not to be fooled by viral charts. https://www.noahpinion.blog/p/how-not-to-be-fooled-by-viral-charts\n\n\n\n\nStorytelling\nTelling a story and making a point\n\n\nFratczak (2023)\nHullman & Diakopoulos (2011)\nSeaberry (2018)\n\n\n\n\n\nFratczak, M. (2023). Can Datavis Make Unpalatable Data More Enjoyable? In Nightingale. https://nightingaledvs.com/can-datavis-make-unpalatable-data-more-enjoyable/\n\n\nHullman, J., & Diakopoulos, N. (2011). Visualization Rhetoric: Framing Effects in Narrative Visualization. IEEE Transactions on Visualization and Computer Graphics, 17(12), 2231–2240. https://doi.org/10.1109/TVCG.2011.255\n\n\nSeaberry, C. (2018). CT Data Story: Housing Segregation in Greater New Haven. DataHaven. https://ctdatahaven.org/reports/ct-data-story-housing-segregation-greater-new-haven\n\n\n\n\nSocial justice & ethics\nData viz for action in the real world\n\n\n“Dispersion & Disparity” Research Project Results (2023)\nAlderman & Inwood (2024)\nBocoupLLC (2017)\nElghany (2023)\nHolder (2022)\nLevy-Rubinett (2020)\nMakulec (2020)\nNey (2023)\nJustice Policy Institute & Prison Policy Initiative (2022)\nUniversity of Richmond Digital Scholarship Lab (n.d.)\nThomas et al. (2020)\n\n\n\n\n\nAlderman, D. H., & Inwood, J. F. J. (2024). Black communities are using mapping to document and restore a sense of place. In The Conversation. http://theconversation.com/black-communities-are-using-mapping-to-document-and-restore-a-sense-of-place-221299\n\n\nBocoupLLC. (2017). A Data Point Walks Into a Bar: Designing Data For Empathy - Lisa Charlotte Rost. https://www.youtube.com/watch?v=8XgF-RmNwUc\n\n\n“Dispersion & Disparity” Research Project Results. (2023). https://3iap.com/dispersion-disparity-equity-centered-data-visualization-research-project-Wi-58RCVQNSz6ypjoIoqOQ/\n\n\nElghany, S. (2023). How Ethical Data Visualization Tells the Human Story. In Nightingale. https://nightingaledvs.com/ethical-data-visualization-tells-the-human-story/\n\n\nHolder, E. (2022). Unfair Comparisons: How Visualizing Social Inequality Can Make It Worse, Nightingale. In Nightingale. https://nightingaledvs.com/unfair-comparisons-how-visualizing-social-inequality-can-make-it-worse/\n\n\nJustice Policy Institute, & Prison Policy Initiative. (2022). Where people in prison come from: The geography of mass incarceration in Maryland. https://www.prisonpolicy.org/origin/md/2020/report.html\n\n\nLevy-Rubinett, I. (2020). With Great Visualization Comes Great Responsibility. In Nightingale. https://nightingaledvs.com/with-great-visualization-comes-great-responsibility/\n\n\nMakulec, A. (2020). Ten Considerations Before you Create another Chart about COVID-19. In Nightingale. https://medium.com/nightingale/ten-considerations-before-you-create-another-chart-about-covid-19-27d3bd691be8\n\n\nNey, J. (2023). Mapping Inequality Can Drive Social Impact. In Nightingale. https://nightingaledvs.com/mapping-inequality-can-drive-social-impact/\n\n\nThomas, T., Drewery, M., Greif, M., Kennedy, I., Ramiller, A., Toomet, O., & Hernandez, J. (2020). Baltimore Eviction Map. Eviction Research Network, UC Berkeley. https://evictionresearch.net/maryland/report/baltimore.html\n\n\nUniversity of Richmond Digital Scholarship Lab. (n.d.). Mapping Inequality: Redlining in New Deal America. In American Panorama: An Atlas of United States History. Retrieved November 10, 2022, from https://dsl.richmond.edu/panorama/redlining/\n\n\n\n\nSpatial data\nSpatial is special\n\n\nUS Census Bureau (2021)\nWong (2024)\n\n\n\n\n\n\n\n\n\n\nUS Census Bureau. (2021). Appendix B: Measures of Residential Segregation. In Guidance for Housing Patterns Data Users. https://www.census.gov/topics/housing/housing-patterns/guidance/appendix-b.html\n\n\nWong, D. (2024). The SAGE Handbook of Spatial Analysis. SAGE Publications, Ltd. https://doi.org/10.4135/9780857020130\n\n\n\n\n Back to top",
- "crumbs": [
- "References by topic"
+ "Decisionmaking checklist"
]
},
{
@@ -461,278 +407,365 @@
]
},
{
- "objectID": "decision_checklist.html",
- "href": "decision_checklist.html",
- "title": "Decisionmaking checklist",
+ "objectID": "references.html",
+ "href": "references.html",
+ "title": "References by topic",
"section": "",
- "text": "When you’re planning out your own work, it’s important to make conscious decisions about what you’re doing and why. I keep saying this, but one of the things I dislike the most about no-code visualization products like Excel or Tableau is that they encourage you to not make these decisions, but to just rely on defaults or automated suggestions.\nIn contrast to just going with defaults, you as a thoughtful visualization practitioner should go through the decisions you could make in order to determine what decisions you should make. This is something you do in your EDA process, as well as in sketching charts on paper.\nIt’s also useful for understanding a chart someone else made, whether just to read it, or to revise or critique it.",
+ "text": "This is most of what’s in my Zotero bibliography for this class arranged by topic.\n\nMain texts\nFoundational books and chapters\n\n\nCairo (2019)\nWickham et al. (2023)\nWilke (2019)\nYau (2013)\n\n\n\n\n\nCairo, A. (2019). How charts lie: Getting smarter about visual information (First edition). W. W. Norton & Company.\n\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\n\n\n\n\nGeneral references\nReferences, frameworks, and grammar of graphics\n\n\nBBC (2010)\nCogley & Setlur (2022)\nChang (2018)\nDu Bois et al. (2018)\nD’Ignazio & Klein (2020)\nD’Ignazio (2015)\nGilmore (2023)\nKirk (2016)\nKosara (2019)\nMunzner (2014)\nRibecca (2024)\nSchwabish (n.d.-a)\nSchwabish (n.d.-b)\nSchwabish (2021)\nWickham et al. (2023)\nWickham (2010)\nWilke (2019)\n\n\n\n\n\nBBC. (2010). Hans Rosling’s 200 Countries, 200 Years, 4 Minutes - The Joy of Stats - BBC Four. https://www.youtube.com/watch?v=jbkSRLYSojo\n\n\nChang, W. (2018). R graphics cookbook: Practical recipes for visualizing data (Second edition). O’Reilly. https://r-graphics.org/\n\n\nCogley, B., & Setlur, V. (2022). Functional Aesthetics for Data Visualization. John Wiley and Sons.\n\n\nD’Ignazio, C. (2015). What would feminist data visualization look like? https://civic.mit.edu/feminist-data-visualization.html\n\n\nD’Ignazio, C., & Klein, L. F. (2020). Data feminism. The MIT Press. https://data-feminism.mitpress.mit.edu/\n\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nGilmore, R. W. (2023). Abolition Geography.\n\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\n\nKosara, R. (2019). The DataSaurus, Anscombe’s Quartet, and why summary statistics need to be taken with a grain of salt. https://www.youtube.com/watch?v=RbHCeANCbW0\n\n\nMunzner, T. (2014). Visualization Analysis and Design. A K Peters/CRC Press. https://doi.org/10.1201/b17511\n\n\nRibecca, S. (2024). The Data Visualisation Catalogue. https://datavizcatalogue.com/\n\n\nSchwabish, J. (n.d.-a). Catherine D’Ignazio and Lauren Klein (142). Retrieved January 30, 2024, from https://policyviz.com/podcast/episode-142-catherine-dignazio-and-lauren-klein/\n\n\nSchwabish, J. (n.d.-b). Sarah Williams (191). Retrieved January 18, 2024, from https://policyviz.com/podcast/episode-191-sarah-williams/\n\n\nSchwabish, J. (2021). Better Data Visualizations : A Guide for Scholars, Researchers, and Wonks. Columbia University Press.\n\n\nWickham, H. (2010). A Layered Grammar of Graphics. Journal of Computational and Graphical Statistics, 19(1), 3–28. https://doi.org/10.1198/jcgs.2009.07098\n\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\n\n\n\nAesthetics & styling\nColor, visual perception, annotations, text, and styleguides\n\n\nViz Palette (2019)\nAisch (2019)\nBertini & Stefaner (n.d.)\nBrewer (2006)\nGramazio et al. (2017)\nDatawrapper (2021)\nFrance (2020)\nHeer & Bostock (2010)\nKebonye et al. (2023)\nKim et al. (2021)\nKirk (2015)\nLiu & Heer (2018)\nMuth (2022)\nSkau & Kosara (2016)\nSetlur & Stone (2016)\nUrban Institute (2023)\nWorld Health Organization (2023)\n\n\n\n\n\nAisch, G. (2019). Chroma.js palette helper. https://gka.github.io/palettes\n\n\nBertini, E., & Stefaner, M. (n.d.). Color with Karen Schloss (119). Retrieved February 7, 2024, from https://datastori.es/119-color-with-karen-schloss/\n\n\nBrewer, C. A. (2006). Basic Mapping Principles for Visualizing Cancer Data Using Geographic Information Systems (GIS). American Journal of Preventive Medicine, 30(2), S25–S36. https://doi.org/10.1016/j.amepre.2005.09.007\n\n\nDatawrapper. (2021). What to consider when choosing colors for data visualization. https://academy.datawrapper.de/article/140-what-to-consider-when-choosing-colors-for-data-visualization\n\n\nFrance, T. (2020). Choosing Fonts for Your Data Visualization, Nightingale. In Nightingale. https://nightingaledvs.com/choosing-fonts-for-your-data-visualization/\n\n\nGramazio, C. C., Laidlaw, D. H., & Schloss, K. B. (2017). Colorgorical: Creating discriminable and preferable color palettes for information visualization. IEEE Transactions on Visualization and Computer Graphics. https://doi.org/10.1109/TVCG.2016.2598918\n\n\nHeer, J., & Bostock, M. (2010). Crowdsourcing graphical perception: Using mechanical turk to assess visualization design. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 203–212. https://doi.org/10.1145/1753326.1753357\n\n\nKebonye, N. M., Agyeman, P. C., Seletlo, Z., & Eze, P. N. (2023). On exploring bivariate and trivariate maps as visualization tools for spatial associations in digital soil mapping: A focus on soil properties. Precision Agriculture, 24(2), 511–532. https://doi.org/10.1007/s11119-022-09955-7\n\n\nKim, D. H., Setlur, V., & Agrawala, M. (2021). Towards Understanding How Readers Integrate Charts and Captions: A Case Study with Line Charts. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 1–11. https://doi.org/10.1145/3411764.3445443\n\n\nKirk, A. (2015). Make grey your best friend. In Visualising Data. https://visualisingdata.com/2015/01/make-grey-best-friend/\n\n\nLiu, Y., & Heer, J. (2018). Somewhere Over the Rainbow: An Empirical Assessment of Quantitative Colormaps. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. https://doi.org/10.1145/3173574.3174172\n\n\nMuth, L. C. (2022). What to consider when using text in data visualizations. In Datawrapper. https://blog.datawrapper.de/text-in-data-visualizations/\n\n\nSetlur, V., & Stone, M. C. (2016). A Linguistic Approach to Categorical Color Assignment for Data Visualization. IEEE Transactions on Visualization and Computer Graphics, 22(1), 698–707. https://doi.org/10.1109/TVCG.2015.2467471\n\n\nSkau, D., & Kosara, R. (2016). Arcs, Angles, or Areas: Individual Data Encodings in Pie and Donut Charts. Computer Graphics Forum, 35(3), 121–130. https://doi.org/10.1111/cgf.12888\n\n\nUrban Institute. (2023). Urban Institute Data Visualization style guide. http://urbaninstitute.github.io/graphics-styleguide/\n\n\nViz Palette. (2019). https://projects.susielu.com/viz-palette\n\n\nWorld Health Organization. (2023). WHO Data Design Language v.0.9.2. https://apps.who.int/gho/data/design-language/\n\n\n\n\nUnderstanding data\nDecision-making, uncertainty, missing data, and logical fallacies\n\n\nAisch (2016)\nBertini & Stefaner (n.d.-a)\nBertini & Stefaner (n.d.-b)\nCox et al. (2022)\nCorrell & Gleicher (2014)\nCorrell et al. (2018)\nEtter (2023)\nHamel et al. (2020)\nHamel et al. (2021)\nKay et al. (2016)\nKrackov et al. (2021)\nKay (2024)\nKirk (2016)\nKirk (n.d.)\nLee et al. (2021)\nmimimimimi (2024)\nNation (2024)\nNyame-Mensah (2022)\nPillai et al. (2024)\nSadler (2016)\nSchwabish (n.d.)\nSilver (2015)\nSimeoni (2023)\nSmith (2023)\n\n\n\n\n\nAisch, G. (2016). Why we used jittery gauges in our live election forecast. In vis4.net. https://vis4.net/blog/jittery-gauges-election-forecast\n\n\nBertini, E., & Stefaner, M. (n.d.-a). Cognitive Bias and Visualization with Evanthia Dimara (116). Retrieved February 14, 2024, from https://datastori.es/116-cognitive-bias-and-visualization-with-evanthia-dimara/\n\n\nBertini, E., & Stefaner, M. (n.d.-b). Visualizing Uncertainty with Jessica Hullman and Matthew Kay (134). Retrieved January 30, 2024, from https://datastori.es/134-visualizing-uncertainty-with-jessica-hullman-and-matthew-kay/\n\n\nCorrell, M., & Gleicher, M. (2014). Error Bars Considered Harmful: Exploring Alternate Encodings for Mean and Error. IEEE Transactions on Visualization and Computer Graphics, 20(12), 2142–2151. https://doi.org/10.1109/TVCG.2014.2346298\n\n\nCorrell, M., Moritz, D., & Heer, J. (2018). Value-Suppressing Uncertainty Palettes. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–11. https://doi.org/10.1145/3173574.3174216\n\n\nCox, C., Amin, K., Kates, J., & Published, J. M. (2022). Why Do Vaccinated People Represent Most COVID-19 Deaths Right Now? In KFF. https://www.kff.org/policy-watch/why-do-vaccinated-people-represent-most-covid-19-deaths-right-now/\n\n\nEtter, E. (2023). Data Visualization: A Subjective Lens on Reality. In Nightingale. https://nightingaledvs.com/data-visualization-a-subjective-lens-on-reality/\n\n\nHamel, L., Kirzinger, A., Muñana, C., & Published, M. B. (2020). KFF COVID-19 Vaccine Monitor: December 2020. In KFF. https://www.kff.org/coronavirus-covid-19/report/kff-covid-19-vaccine-monitor-december-2020/\n\n\nHamel, L., Lopes, L., & Published, M. B. (2021). KFF COVID-19 Vaccine Monitor: What Do We Know About Those Who Want to “Wait and See” Before Getting a COVID-19 Vaccine? In KFF. https://www.kff.org/coronavirus-covid-19/poll-finding/kff-covid-19-vaccine-monitor-wait-and-see/\n\n\nKay, M. (2024). Mjskay/ggdist. https://github.com/mjskay/ggdist\n\n\nKay, M., Kola, T., Hullman, J. R., & Munson, S. A. (2016). When (ish) is My Bus?: User-centered Visualizations of Uncertainty in Everyday, Mobile Predictive Systems. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, 5092–5103. https://doi.org/10.1145/2858036.2858558\n\n\nKirk, A. (n.d.). Alvin Chang (S2 E6). Retrieved February 2, 2024, from https://visualisingdata.com/2020/12/explore-explain-s2-e6-alvin-chang/\n\n\nKirk, A. (2016). Gauging election reaction. In Visualising Data. https://visualisingdata.com/2016/11/gauging-election-reaction/\n\n\nKrackov, A., Marikos, S., & Marikos, A. K. &. S. (2021). Asterisk Nation: One Tribe’s Challenge to Find Data About its Population, Nightingale. In Nightingale. https://nightingaledvs.com/asterisk-nation-one-tribes-challenge-to-find-data-about-its-population/\n\n\nLee, C., Yang, T., Inchoco, G. D., Jones, G. M., & Satyanarayan, A. (2021). Viral Visualizations: How Coronavirus Skeptics Use Orthodox Data Practices to Promote Unorthodox Science Online. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 1–18. https://doi.org/10.1145/3411764.3445211\n\n\nmimimimimi. (2024). MimiOnuoha/missing-datasets. https://github.com/MimiOnuoha/missing-datasets\n\n\nNation, Z. (2024). Zonination/perceptions. https://github.com/zonination/perceptions\n\n\nNyame-Mensah, A. (2022). When Oversimplification Obscures. In Nightingale. https://nightingaledvs.com/when-oversimplification-obscures/\n\n\nPillai, D., Artiga, S., Hamel, L., Schumacher, S., Kirzinger, A., Rao, A., & Published, A. K. (2024). Understanding the Diversity in the Asian Immigrant Experience in the U.S.: The 2023 KFF/LA Times Survey of Immigrants. In KFF. https://www.kff.org/racial-equity-and-health-policy/poll-finding/understanding-the-diversity-in-the-asian-immigrant-experience/\n\n\nSadler, R. C. (2016). How ZIP codes nearly masked the lead problem in Flint. In The Conversation. http://theconversation.com/how-zip-codes-nearly-masked-the-lead-problem-in-flint-65626\n\n\nSchwabish, J. (n.d.). Joe Sharpe and Mike Orwell (242). Retrieved February 13, 2024, from https://policyviz.com/podcast/episode-242-joe-sharpe-and-mike-orwell/\n\n\nSilver, N. (2015). The Most Diverse Cities Are Often The Most Segregated. In FiveThirtyEight. https://fivethirtyeight.com/features/the-most-diverse-cities-are-often-the-most-segregated/\n\n\nSimeoni, F. (2023). Querying the Quantification of Queer. In Nightingale. https://nightingaledvs.com/querying-the-quantification-of-the-queer/\n\n\nSmith, N. (2023). How not to be fooled by viral charts. https://www.noahpinion.blog/p/how-not-to-be-fooled-by-viral-charts\n\n\n\n\nStorytelling\nTelling a story and making a point\n\n\nFratczak (2023)\nHullman & Diakopoulos (2011)\nSeaberry (2018)\n\n\n\n\n\nFratczak, M. (2023). Can Datavis Make Unpalatable Data More Enjoyable? In Nightingale. https://nightingaledvs.com/can-datavis-make-unpalatable-data-more-enjoyable/\n\n\nHullman, J., & Diakopoulos, N. (2011). Visualization Rhetoric: Framing Effects in Narrative Visualization. IEEE Transactions on Visualization and Computer Graphics, 17(12), 2231–2240. https://doi.org/10.1109/TVCG.2011.255\n\n\nSeaberry, C. (2018). CT Data Story: Housing Segregation in Greater New Haven. DataHaven. https://ctdatahaven.org/reports/ct-data-story-housing-segregation-greater-new-haven\n\n\n\n\nSocial justice & ethics\nData viz for action in the real world\n\n\n“Dispersion & Disparity” Research Project Results (2023)\nAlderman & Inwood (2024)\nBocoupLLC (2017)\nElghany (2023)\nHolder (2022)\nLevy-Rubinett (2020)\nMakulec (2020)\nNey (2023)\nJustice Policy Institute & Prison Policy Initiative (2022)\nUniversity of Richmond Digital Scholarship Lab (n.d.)\nThomas et al. (2020)\n\n\n\n\n\nAlderman, D. H., & Inwood, J. F. J. (2024). Black communities are using mapping to document and restore a sense of place. In The Conversation. http://theconversation.com/black-communities-are-using-mapping-to-document-and-restore-a-sense-of-place-221299\n\n\nBocoupLLC. (2017). A Data Point Walks Into a Bar: Designing Data For Empathy - Lisa Charlotte Rost. https://www.youtube.com/watch?v=8XgF-RmNwUc\n\n\n“Dispersion & Disparity” Research Project Results. (2023). https://3iap.com/dispersion-disparity-equity-centered-data-visualization-research-project-Wi-58RCVQNSz6ypjoIoqOQ/\n\n\nElghany, S. (2023). How Ethical Data Visualization Tells the Human Story. In Nightingale. https://nightingaledvs.com/ethical-data-visualization-tells-the-human-story/\n\n\nHolder, E. (2022). Unfair Comparisons: How Visualizing Social Inequality Can Make It Worse, Nightingale. In Nightingale. https://nightingaledvs.com/unfair-comparisons-how-visualizing-social-inequality-can-make-it-worse/\n\n\nJustice Policy Institute, & Prison Policy Initiative. (2022). Where people in prison come from: The geography of mass incarceration in Maryland. https://www.prisonpolicy.org/origin/md/2020/report.html\n\n\nLevy-Rubinett, I. (2020). With Great Visualization Comes Great Responsibility. In Nightingale. https://nightingaledvs.com/with-great-visualization-comes-great-responsibility/\n\n\nMakulec, A. (2020). Ten Considerations Before you Create another Chart about COVID-19. In Nightingale. https://medium.com/nightingale/ten-considerations-before-you-create-another-chart-about-covid-19-27d3bd691be8\n\n\nNey, J. (2023). Mapping Inequality Can Drive Social Impact. In Nightingale. https://nightingaledvs.com/mapping-inequality-can-drive-social-impact/\n\n\nThomas, T., Drewery, M., Greif, M., Kennedy, I., Ramiller, A., Toomet, O., & Hernandez, J. (2020). Baltimore Eviction Map. Eviction Research Network, UC Berkeley. https://evictionresearch.net/maryland/report/baltimore.html\n\n\nUniversity of Richmond Digital Scholarship Lab. (n.d.). Mapping Inequality: Redlining in New Deal America. In American Panorama: An Atlas of United States History. Retrieved November 10, 2022, from https://dsl.richmond.edu/panorama/redlining/\n\n\n\n\nSpatial data\nSpatial is special\n\n\nUS Census Bureau (2021)\nWong (2024)\n\n\n\n\n\n\n\n\n\n\nUS Census Bureau. (2021). Appendix B: Measures of Residential Segregation. In Guidance for Housing Patterns Data Users. https://www.census.gov/topics/housing/housing-patterns/guidance/appendix-b.html\n\n\nWong, D. (2024). The SAGE Handbook of Spatial Analysis. SAGE Publications, Ltd. https://doi.org/10.4135/9780857020130\n\n\n\n\n Back to top",
+ "crumbs": [
+ "References by topic"
+ ]
+ },
+ {
+ "objectID": "syllabus.html",
+ "href": "syllabus.html",
+ "title": "Syllabus",
+ "section": "",
+ "text": "At its essence, the aim of data visualization is to move data and its meaning(s) and context(s) from some origin (spreadsheets, observed phenomena, etc.) to a larger audience. It’s a spectrum of incredibly powerful tools for not just understanding and explaining facts, but also for shaping what those facts are and creating the narrative around them. By the end of this course, you will have thought through your role and responsibility in an evolving field, developed a set of best practices that is likely to continue to change, engaged with larger social currents toward your own goals, and strengthened your skills in R.\nBecause this is part of a professional studies program based on open source software and the ethos behind it, the course will be very hands-on and require everyone’s willingness to contribute and participate. Instead of tests and graded homework assignments, we’ll focus on practice, critique, and revision, building continuously on individual projects and shared tools. To some extent, the class structure will mimic a workplace, where you have projects with checkpoints and meetings to brainstorm and workshop your ideas, with time to work both in class and on your own at home.\nBecause data science and data visualization—and the software we use for both—change so quickly, a lot of the community’s discourse happens in less formal settings, such as blogs, social media, podcasts, and workshops, rather than just traditional academic journals and books. Our readings (defined loosely enough to include videos of talks, podcasts, and simply browsing through data visualization projects) will likewise fall along this spectrum, and you’ll have some flexibility in what you read and share.\nAbove all, I want this to be a course that is useful to you as you build a career of critical engagement with data. The schedule is intentionally loose so we can adjust based on skills we may want or need to build upon, and each student’s goals and interests. Please be willing to share what you want to learn, contribute resources, and ask for what you need of me and each other.",
"crumbs": [
"Overview",
- "Decisionmaking checklist"
+ "Syllabus"
]
},
{
- "objectID": "decision_checklist.html#checklist",
- "href": "decision_checklist.html#checklist",
- "title": "Decisionmaking checklist",
- "section": "Checklist",
- "text": "Checklist\nWhat decisions could be / should be / were made about…\n\nwhat data to include\nwhat data to exclude\nwhat visual encodings to use\nwhat types of scales to use (sequential, qualitative, diverging)\nwhat to put on the x- and y-axes\nhow to scale the x- and y-axes\nhow to use color\nhow to use text\nhow to use annotations\nwhere to draw attention\nwhat conclusion to suggest\n\nWhat have I forgotten from this list?",
+ "objectID": "syllabus.html#objectives",
+ "href": "syllabus.html#objectives",
+ "title": "Syllabus",
+ "section": "Objectives",
+ "text": "Objectives\nThe first half of the course will be focused on non-spatial data visualization; the second half will be focused on spatial data and how to integrate the two. Some of the principles we go over for non-spatial and spatial will differ, but objectives remain the same.\nBy the end of the course, students will:\n\nHave an understanding of the basics of visual perception, and how to use that knowledge to design data visualizations well\nBe familiar with the grammar of graphics framework to think about components and purposes of visual elements\nBe skilled in programming in R and using the ggplot2 data visualization ecosystem\nKnow how to give and receive constructive feedback on visualizations, both their own and others’, and to revise and improve upon their work\nBe able to identify potential harms done by inappropriate or misleading visualizations, and make corrections\nBe able to make, articulate, and argue for good decisions in designing charts and maps\nHave made many, many unpolished visualizations and several polished, presentation-ready ones\n\nSuccessful students will finish the course with finished products for their portfolios of high enough quality to include with applications to jobs or other academic programs:\n\n1–2 completed, presentation-ready data visualization projects\nreproducible, documented code that can be repurposed at another organization\ncontributions to an open source codebase",
"crumbs": [
"Overview",
- "Decisionmaking checklist"
+ "Syllabus"
]
},
{
- "objectID": "weeks/03_encoding.html",
- "href": "weeks/03_encoding.html",
- "title": "3. Visual encoding",
- "section": "",
- "text": "This is a walkthrough of Wickham et al. (2023) chapter 9 on chart layers, using the ACS data in the justviz package. For simplicity, we’ll focus on Maryland census tracts. I’m throwing in a few additional variables just to match the examples from the book.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n# create a variable that flags tracts being in the city or surrounding counties. \n# other values get lumped into \"other counties\" group\nlocal_counties <- c(\"Baltimore city\", \"Baltimore County\", \"Anne Arundel County\", \"Howard County\")\nacs_tr <- acs |>\n filter(level == \"tract\") |>\n mutate(county2 = ifelse(county %in% local_counties, county, \"Other counties\")) |>\n na.omit() |> # we'll talk about missing data in the next notebook\n mutate(income_brk = cut(median_hh_income, \n breaks = c(0, 1e5, Inf), \n labels = c(\"under_100k\", \"above_100k\"),\n include.lowest = TRUE, right = FALSE))\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1)",
+ "objectID": "syllabus.html#materials",
+ "href": "syllabus.html#materials",
+ "title": "Syllabus",
+ "section": "Materials",
+ "text": "Materials\n\nReadings\nAll readings will be available to students for free. Many will be open source texts and have code available. Readings will be a mix of theory and practice.\nThe schedule of the course will roughly follow the structure of the book Fundamentals of Data Visualization (Wilke, 2019). Both the book and the source code used to write it are available for free online.\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\nWickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd edition). O’Reilly. https://r4ds.hadley.nz/\n\nCairo, A. (2019). How charts lie: Getting smarter about visual information (First edition). W. W. Norton & Company.\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\nWe’ll also read portions of R for Data Science (Wickham et al., 2023) (also open source), How Charts Lie (Cairo, 2019), and Data Points (Yau, 2013), as well as a variety of other sources of different media. I’ll keep a running list of resources in the online class notes with other tutorials and references.\n\n\nSoftware\nThis is a rough set of the software and tools we will use, with open source software in italics:\n\nR programming language\nggplot2 and related packages\nRStudio or another integrated development environment\nQuarto, a markdown-based publishing system from the same team as RStudio\ngit for version control, GitHub for storage of version-controlled materials, and GitHub Classroom for discussions and submitting code\nBlackboard for assignments and announcements\n\nI’m open to suggestions on any other tools you all think would be useful.\n\n\nOther tools\nIf at all possible, you should have a laptop of your own for this class. All the software we’re using is free and open source, so you should be able to install everything on your computer. If you do not have a laptop, you can borrow one from the library, or, because we will be using git for version tracking and GitHub for storage, you can use a lab computer and make sure to upload your work regularly.\nWe’ll be doing a lot of sketching by hand (you don’t have to be good at drawing), so you’ll need a notebook and pens or pencils that are nice to doodle with. I highly, highly recommend finding a graph paper or dotted notebook.",
"crumbs": [
- "Weekly notes",
- "3. Visual encoding"
+ "Overview",
+ "Syllabus"
]
},
{
- "objectID": "weeks/03_encoding.html#aesthetic-mappings",
- "href": "weeks/03_encoding.html#aesthetic-mappings",
- "title": "3. Visual encoding",
- "section": "Aesthetic mappings",
- "text": "Aesthetic mappings\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county2), size = 1)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(shape = county2), size = 1)\n\n\n\n\n\n\n\n\nAs noted in the book, these are bad ideas:\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(size = county2), alpha = 0.5)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(alpha = county2), size = 1)\n\n\n\n\n\n\n\n\nCan you think of any exceptions to this?\n\nWhat’s going on with the next two charts?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(color = \"slateblue\")\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = \"slateblue\"))\n\n\n\n\n\n\n\n\nWhy does this one throw an error?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(color = county2)",
+ "objectID": "syllabus.html#schedule",
+ "href": "syllabus.html#schedule",
+ "title": "Syllabus",
+ "section": "Schedule",
+ "text": "Schedule\nThe schedule has some flexibility built into it, but tentatively goes as follows:\n\n\n\n\n\n\n\n\nWeek\nSection\nTopic\n\n\n\n\n1\nNon-spatial data viz\nWhat is a chart, and do you need one?\n\n\n2\n\nEncoding data to visuals; making meaning of your data\n\n\n3\n\nWriting good code; working with color\n\n\n4\n\nText and annotation; uncertainty and distribution\n\n\n5\n\nMaking good decisions pt. 1\n\n\n6\n\nAccessibility, literacy, and audience\n\n\n7\n\nStorytelling pt. 1 (empathy & equity); experimentation\n\n\n8\nSpatial data viz\nWhat is a map, and do you need one?\n\n\n\n\nProject 1 due\n\n\n9\n\nEncoding data to space; harmful practices\n\n\n10\n\nColor, text, and annotations pt. 2\n\n\n11\n\nMaking good decisions pt. 2\n\n\n12\n\nStorytelling pt. 2 (history & cohesion); experimentation\n\n\n13\n\nFinal critique; tying up loose ends\n\n\n14\n\nFinishing touches on projects\n\n\n\n\nProject 2 due\n\n\n\n\nClass structure\nA typical class session will be roughly:\n\n\n\nActivity\nTime\n\n\n\n\nWarm-up\n5-10 minutes\n\n\nReport-backs\n10-15 minutes, if any\n\n\nLecture\n1 hour max + questions\n\n\nWorkshop, critique, or lab\nRemaining time",
"crumbs": [
- "Weekly notes",
- "3. Visual encoding"
+ "Overview",
+ "Syllabus"
]
},
{
- "objectID": "weeks/03_encoding.html#geometric-objects",
- "href": "weeks/03_encoding.html#geometric-objects",
- "title": "3. Visual encoding",
- "section": "Geometric objects",
- "text": "Geometric objects\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1)\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth()\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden, color = county2)) +\n geom_point(size = 1) +\n geom_smooth()\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth()\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth(aes(group = county2))\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_smooth(aes(color = county2), show.legend = FALSE)\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county2), size = 1) +\n geom_smooth()\n\n\n\n\n\n\n\n\nI don’t like how they did this highlighting example in the book. Here’s a better one.\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(aes(color = county == \"Baltimore city\")) +\n scale_color_manual(values = c(\"TRUE\" = \"firebrick\", \"FALSE\" = \"gray60\"))\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = homeownership, y = county2, fill = county2, color = county2)) +\n ggridges::geom_density_ridges(alpha = 0.5, show.legend = FALSE)",
+ "objectID": "syllabus.html#grading",
+ "href": "syllabus.html#grading",
+ "title": "Syllabus",
+ "section": "Grading",
+ "text": "Grading\nIn data visualization there aren’t any perfectly right answers, and there aren’t too many perfectly wrong ones either. As a result, rather than tedious quizzes and problem sets, your grade will reflect the effort you put into developing your process and your critical eye, and how successfully you create compelling stories with data.\n\nParticipation\nThere will be opportunities for participation points every week, including:\n\nBringing in visualizations you’ve found for us to discuss\nOpening your work up for workshopping\nContributing code (there’s an R package in development for this class), with more points given for students with less experience in R—this includes the less glamorous but crucial tasks of testing, debugging, and documenting\nDoing an optional reading or attending a talk and reporting back to the class on some interesting things you learned\nAdding a resource to the class notes\n\nThere will be two opportunities to lose points as well:\n\nBeing mean or unnecessarily harsh in critique\nUnexcused absences (see below)\n\nThere’s no set number of participation points you need—just rack them up when you can, forgo them when you have to, and I’ll scale them at the end of the semester. Notice that most of these involve contributing to your classmates’ growth as well as your own.\n\n\nProjects\nThere will be 2 projects, one midterm and one final, that you’ll be working on throughout the semester. Both will build upon the exercises, and you’ll have lots of time to work on them in class and receive feedback from myself and your peers. The first will be non-spatial data, and the second will be both spatial and non-spatial. You’ll be responsible for moving from a dataset through to a polished visualization that tells a story and has real-world impact. You will also document your process along the way and have check-ins regularly. Each project will also have a semi-formal write-up to explain what you did and why, and to situate your work into the theory and principles we study.\n\n\nOther assignments\nWe’ll have a few more small assignments, including short case studies and peer reviews.\n\n\nGrading scale\nGrades will be rounded to the nearest whole percent.\n\n\n\nGrade\nPercentage\n\n\n\n\nA+\n97% +\n\n\nA\n93-96%\n\n\nA-\n90-92%\n\n\nB+\n87-89%\n\n\nB\n83-86%\n\n\nB-\n80-82%\n\n\nC+\n77-79%\n\n\nC\n73-76%\n\n\nC-\n70-72%\n\n\nD+\n67-69%\n\n\nD\n63-66%\n\n\nD-\n60-62%\n\n\nF\n< 60%\n\n\n\n\n\nGrade distribution\n\n\n\nCategory\nShare of grade\n\n\n\n\nCase studies\n15%\n\n\nPeer review & reflections\n5%\n\n\nParticipation\n20%\n\n\nProject 1 visualization\n20%\n\n\nProject 1 write-up\n5%\n\n\nProject 2 visualization\n25%\n\n\nProject 2 write-up\n10%",
+ "crumbs": [
+ "Overview",
+ "Syllabus"
+ ]
+ },
+ {
+ "objectID": "syllabus.html#attendance",
+ "href": "syllabus.html#attendance",
+ "title": "Syllabus",
+ "section": "Attendance",
+ "text": "Attendance\nAs grad students, your course load is one of many responsibilities you juggle, so I know things will come up from time to time that prevent you from getting to class. If you need to miss class or will be late, just let me know in advance (email or DM), and as long as absences don’t become excessive, it should be fine. If there is some reason you’ll need to miss class several times, such as chronic illness (after all, COVID’s still here), just let me know and we can figure something out. If you can’t attend class but are able to participate remotely, I can stream on Zoom or WebEx.\nUnexcused absences, except for a serious emergency (e.g. you got into a car accident on the way to campus), will cost you participation points. Excused absences will not.",
+ "crumbs": [
+ "Overview",
+ "Syllabus"
+ ]
+ },
+ {
+ "objectID": "syllabus.html#umbc-policies-and-resources",
+ "href": "syllabus.html#umbc-policies-and-resources",
+ "title": "Syllabus",
+ "section": "UMBC policies and resources",
+ "text": "UMBC policies and resources\n\nAccessibility and Disability Accommodations, Guidance and Resources\nAccommodations for students with disabilities are provided for all students with a qualified disability under the Americans with Disabilities Act (ADA & ADAAA) and Section 504 of the Rehabilitation Act who request and are eligible for accommodations. The Office of Student Disability Services (SDS) is the UMBC department designated to coordinate accommodations that creates equal access for students when barriers to participation exist in University courses, programs, or activities.\nIf you have a documented disability and need to request academic accommodations in your courses, please refer to the SDS website at sds.umbc.edu for registration information and office procedures.\nSDS email: disAbility@umbc.edu (disability at umbc dot edu)\nSDS phone: 410-455-2459\nIf you will be using SDS approved accommodations in this class, please contact the instructor to discuss implementation of the accommodations. During remote instruction requirements due to COVID, communication and flexibility will be essential for success.\n\n\nSexual Assault, Sexual Harassment, and Gender Based Violence and Discrimination\nUMBC Policy in addition to federal and state law (to include Title IX) prohibits discrimination and harassment on the basis of sex, sexual orientation, and gender identity in University programs and activities. Any student who is impacted by sexual harassment, sexual assault, domestic violence, dating violence, stalking, sexual exploitation, gender discrimination, pregnancy discrimination, gender-based harassment, or related retaliation should contact the University’s Title IX Coordinator to make a report and/or access support and resources. The Title IX Coordinator can be reached at titleixcoordinator at umbc dot edu or 410-455-1717.\nYou can access support and resources even if you do not want to take any further action. You will not be forced to file a formal complaint or police report. Please be aware that the University may take action on its own if essential to protect the safety of the community.\nIf you are interested in making a report, please use the Online Reporting/Referral Form. Please note that, if you report anonymously, the University’s ability to respond will be limited.\n\nNotice that Faculty and Teaching Assistants are Responsible Employees with Mandatory Reporting Obligations\nAll faculty members and teaching assistants are considered Responsible Employees, per UMBC’s Policy on Sexual Misconduct, Sexual Harassment, and Gender Discrimination. Faculty and teaching assistants therefore required to report all known information regarding alleged conduct that may be a violation of the Policy to the Title IX Coordinator, even if a student discloses an experience that occurred before attending UMBC and/or an incident that only involves people not affiliated with UMBC. Reports are required regardless of the amount of detail provided and even in instances where support has already been offered or received.\nWhile faculty members want to encourage you to share information related to your life experiences through discussion and written work, students should understand that faculty are required to report past and present sexual harassment, sexual assault, domestic and dating violence, stalking, and gender discrimination that is shared with them to the Title IX Coordinator so that the University can inform students of their rights, resources, and support. While you are encouraged to do so, you are not obligated to respond to outreach conducted as a result of a report to the Title IX Coordinator.\nIf you need to speak with someone in confidence, who does not have an obligation to report to the Title IX Coordinator, UMBC has a number of Confidential Resources available to support you: \nRetriever Integrated Health (Main Campus): 410-455-2472; Monday – Friday 8:30 a.m. – 5 p.m.; For After-Hours Support, Call 988.\nCenter for Counseling and Well-Being (Shady Grove Campus): 301-738-6273; Monday-Thursday 10:00a.m. – 7:00 p.m. and Friday 10:00 a.m. – 2:00 p.m. (virtual) Online Appointment Request Form\nPastoral Counseling via The Gathering Space for Spiritual Well-Being: 410-455-6795; i3b at umbc dot edu; Monday – Friday 8:00 a.m. – 10:00 p.m.\n\n\nOther Resources\nWomen’s Center (open to students of all genders): 410-455-2714; womenscenter at umbc dot edu; Monday – Thursday 9:30 a.m. – 5:00 p.m. and Friday 10:00 a.m. – 4 p.m.\nShady Grove Student Resources, Maryland Resources, National Resources.\n\n\nChild Abuse and Neglect\nPlease note that Maryland law and UMBC policy require that faculty report all disclosures or suspicions of child abuse or neglect to the Department of Social Services and_/_or the police even if the person who experienced the abuse or neglect is now over 18.\n\n\n\nPregnant and Parenting Students\nUMBC’s Policy on Sexual Misconduct, Sexual Harassment and Gender Discrimination expressly prohibits all forms of discrimination and harassment on the basis of sex, including pregnancy. Resources for pregnant, parenting and breastfeeding students are available through the University’s Office of Equity and Civil Rights. Pregnant and parenting students are encouraged to contact the Title IX Coordinator to discuss plans and ensure ongoing access to their academic program with respect to a leave of absence – returning following leave, or any other accommodation that may be needed related to pregnancy, childbirth, adoption, breastfeeding, and/or the early months of parenting.\nIn addition, students who are pregnant and have an impairment related to their pregnancy that qualifies as disability under the ADA may be entitled to accommodations through the Office of Student Disability Services.\n\n\nReligious Observances & Accommodations\nUMBC Policy provides that students should not be penalized because of observances of their religious beliefs, and that students shall be given an opportunity, whenever feasible, to make up within a reasonable time any academic assignment that is missed due to individual participation in religious observances. It is the responsibility of the student to inform the instructor of any intended absences or requested modifications for religious observances in advance, and as early as possible. For questions or guidance regarding religious observances and accommodations, please contact the Office of Equity and Civil Rights at ecr at umbc dot edu.\n\n\nHate, Bias, Discrimination and Harassment\nUMBC values safety, cultural and ethnic diversity, social responsibility, lifelong learning, equity, and civic engagement.\nConsistent with these principles, UMBC Policy prohibits discrimination and harassment in its educational programs and activities or with respect to employment terms and conditions based on race, creed, color, religion, sex, gender, pregnancy, ancestry, age, gender identity or expression, national origin, veterans status, marital status, sexual orientation, physical or mental disability, or genetic information.\nStudents (and faculty and staff) who experience discrimination, harassment, hate, or bias based upon a protected status or who have such matters reported to them should use the online reporting/referral form to report discrimination, hate, or bias incidents. You may report incidents that happen to you anonymously. Please note that, if you report anonymously, the University’s ability to respond may be limited.\n\n\nUMBC Writing Center\nThe Academic Success Center offers free writing assistance through our Writing Center, which is located on the first floor of the Library. We also offer online and asynchronous tutoring. Writing tutors are students like you who receive ongoing training to stay up-to-date on the best tutoring techniques. To make an appointment, please visit http://academicsuccess.umbc.edu/writing-center",
+ "crumbs": [
+ "Overview",
+ "Syllabus"
+ ]
+ },
+ {
+ "objectID": "weeks/08_uncertainty.html",
+ "href": "weeks/08_uncertainty.html",
+ "title": "8. Uncertainty and distributions",
+ "section": "",
+ "text": "Fill in this quick survey about probability:",
"crumbs": [
"Weekly notes",
- "3. Visual encoding"
+ "8. Uncertainty and distributions"
]
},
{
- "objectID": "weeks/03_encoding.html#facets",
- "href": "weeks/03_encoding.html#facets",
- "title": "3. Visual encoding",
- "section": "Facets",
- "text": "Facets\n\nacs_tr |>\n ggplot(aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1) +\n facet_grid(cols = vars(county2), rows = vars(income_brk))",
+ "objectID": "weeks/08_uncertainty.html#warm-up",
+ "href": "weeks/08_uncertainty.html#warm-up",
+ "title": "8. Uncertainty and distributions",
+ "section": "",
+ "text": "Fill in this quick survey about probability:",
"crumbs": [
"Weekly notes",
- "3. Visual encoding"
+ "8. Uncertainty and distributions"
]
},
{
- "objectID": "weeks/03_encoding.html#statistical-transformations",
- "href": "weeks/03_encoding.html#statistical-transformations",
- "title": "3. Visual encoding",
- "section": "Statistical transformations",
- "text": "Statistical transformations\nI am of the opinion that if you want to visualize summary statistics or other aggregations, you should calculate them explicitly, not let ggplot do them ad hoc, so I think the examples in section 9.5 are not great. Comparable charts with calculations:\n\nacs_tr |>\n group_by(county2) |>\n summarise(n = n()) |> # these 2 steps can be done with `count`\n ggplot(aes(x = county2, y = n)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nacs_tr |>\n group_by(county2) |>\n summarise(n = n()) |> # keeping data grouped by county2 lets you calc proportions\n mutate(prop = n / sum(n)) |>\n ggplot(aes(x = county2, y = prop)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nacs_tr |>\n group_by(county2) |>\n summarise(across(total_cost_burden, list(min = min, max = max, median = median))) |>\n ggplot(aes(x = county2)) +\n geom_pointrange(aes(y = total_cost_burden_median, \n ymin = total_cost_burden_min, \n ymax = total_cost_burden_max))",
+ "objectID": "weeks/08_uncertainty.html#distributions",
+ "href": "weeks/08_uncertainty.html#distributions",
+ "title": "8. Uncertainty and distributions",
+ "section": "Distributions",
+ "text": "Distributions\nWhen we visualize data, one of the most important decisions we make is what values exactly we’ll display. That’s because you usually can’t include every data point, so you’ll have to do some amount of summarizing. However, that means you’re losing a lot of information in the process. That’s a fine line you need to figure out how to walk, and like most things we’ve done so far, how you do that will depend on context, audience, and purpose. In my own work, I know I fall on the side of oversimplifying more often than I should.\nThe problem is that unless people have a background in statistics or other quantitative research-heavy fields, they probably aren’t used to hearing about ranges of data—let alone ways to describe distributions, like skew and kurtosis. So the chart types that are best for showing distributions or uncertainty are generally pretty technical.\nFor example, look at the range of median household incomes by county:\n\n\n\n\n\n\n\n\n\nThere’s already a wide range, but compare that to all their tracts:\n\n\n\n\n\n\n\n\n\nOf the counties in the Baltimore metro area, Howard County has a much higher overall median income than Baltimore city, yet there’s also a lot of overlapping values. Baltimore city has several tracts with pretty high incomes, but that fact gets washed out when we only look at summary values. Even just look at how different the income scales are!\nThink back to the wage gap data. When we just look at wages for men vs women, 1 we lose differences within and between those groups. Before we saw how median earnings increase with educational attainment, but women’s pay lags about one education level behind men’s pay. We’ll see other gaps when we look at earnings by sex and race/ethnicity.\n1 Speaking of distributions within data, there are gray areas in gender that aren’t captured by the Census.\n\n\n\n\n\n\n\n\nSide-by-side bars of race versus sex show much more of the range. When we talk about the wage gap as just men vs women, we miss the fact that white women have higher median earnings than Black or Latino men! 2\n2 We also miss gaps within those groups, such as disparities by ethnicity, origin, and immigration status. An intern I worked with a few years ago made this video looking at the wage gaps within Asian American groups.\n\n\n\n\n\n\n\n\nUnlike bars, dots don’t have to start at a 0 baseline, so we can zoom in on the actual range of the values. This view makes it easier to see that the gaps within white and Asian/Pacific Islander communities span about $20,000 each, but is nearly nonexistent for Black adults. (For charts like this, you’ll more often see the axes flipped and the groups ordered largest to smallest, or largest gap to smallest gap, but I’ll let you figure that out—take a look at forcats::fct_reorder.)\n\n\n\n\n\n\n\n\n\n\nExercise\nJust like we can disaggregate the data into race vs sex, we can also tease apart the distributions within those groups. The wage gap data has not just medians, but also 20th, 25th, 75th, and 80th percentile values for every group.\nHere’s a bad chart of this data that just dumps all the data into a bunch of points. Looking at the examples from Yau (2013) (on Blackboard), brainstorm some better ways to show this data, including what you would want to filter out.\n\nYau, N. (2013). Data points: Visualization that means something. John Wiley & Sons, Inc.\n\n# reshape to long in order to make dot plot\nwages_quants <- wages_sex_race |>\n select(dimension, sex, race_eth, matches(\"earn_q\\\\d+\")) |>\n tidyr::pivot_longer(cols = earn_q20:earn_q80, names_to = c(\".value\", \"quantile\"), \n names_pattern = \"(^[a-z]+)_(.+$)\",\n names_ptypes = list(quantile = factor()))\n\n# diverging-ish palette is appropriate here, so I'll pull it to modify\n# diverging pals usually have a light color in the middle, which won't work well for points\n# div_pal <- RColorBrewer::brewer.pal(n = 5, name = \"Spectral\")\ndiv_pal <- viridisLite::turbo(n = 5, direction = -1, begin = 0.1, end = 0.9)\ndiv_pal[3] <- \"gray20\"\n\nwages_quants |>\n ggplot(aes(x = sex, y = earn, color = quantile, shape = sex, group = sex)) +\n geom_path(color = \"gray80\", linewidth = 2, alpha = 0.8) +\n geom_point(size = 3, alpha = 0.9) +\n scale_color_manual(values = div_pal) +\n facet_wrap(vars(race_eth), scales = \"free_x\")\n\n\n\n\n\n\n\n\nHere’s one option, although I’m not super satisfied with it:",
"crumbs": [
"Weekly notes",
- "3. Visual encoding"
+ "8. Uncertainty and distributions"
]
},
{
- "objectID": "weeks/03_encoding.html#position-aesthetics",
- "href": "weeks/03_encoding.html#position-aesthetics",
- "title": "3. Visual encoding",
- "section": "Position aesthetics",
- "text": "Position aesthetics\n\ninc_by_county <- acs_tr |>\n group_by(county2, income_brk) |>\n summarise(n = n())\n\nggplot(inc_by_county, aes(x = county2, y = n, color = income_brk)) +\n geom_col()\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col()\n\n\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(alpha = 1/5, position = position_identity())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_fill())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_dodge())\n\n\n\n\n\n\n\nggplot(inc_by_county, aes(x = county2, y = n, fill = income_brk)) +\n geom_col(position = position_dodge2())\n\n\n\n\n\n\n\n\nOther than the first chart with the weird opacity, which kinda sucks, these give you different views of the same data. What can you pick up from each?\n\nggplot(acs_tr, aes(x = homeownership, y = total_cost_burden)) +\n geom_point(size = 1, position = position_jitter(seed = 1))",
+ "objectID": "weeks/08_uncertainty.html#uncertainty",
+ "href": "weeks/08_uncertainty.html#uncertainty",
+ "title": "8. Uncertainty and distributions",
+ "section": "Uncertainty",
+ "text": "Uncertainty\nIt can be really hard to imagine or estimate uncertainty. We expect data to be exact, and it pretty much never is. Visualization can help explain this to people, but that can conflict with our usual desire to make our visualizations simple and quick to read. In fact, I dropped all the margins of error from the datasets in the justviz package when I made it, so I’m part of the problem.\nWilke’s chapter on uncertainty has some good examples of how to show uncertainty in terms of margin of error in a few different types of charts. At the same time, there are some arguments against using error bars like he’s done in some of the examples. One of the case study readings (Correll & Gleicher (2014)) finds that these can actually harm people’s ability to understand uncertainty.\n\nCorrell, M., & Gleicher, M. (2014). Error Bars Considered Harmful: Exploring Alternate Encodings for Mean and Error. IEEE Transactions on Visualization and Computer Graphics, 20(12), 2142–2151. https://doi.org/10.1109/TVCG.2014.2346298\nProbably the most famous and famously controversial attempt at visualizing uncertainty was the gauge chart the New York Times used on election night 2016. It was meant to show that the vote margins were in flux as counts came in, but the jittering effect was actually hard-coded into the visualization rather than based directly on tallies updating. People got extremely stressed and mad.\nFor working in ggplot, the ggdist package (Kay (2024)) has some good options for showing distributions and uncertainty. 3\n\nKay, M. (2024). Mjskay/ggdist. https://github.com/mjskay/ggdist\n3 ggdist::geom_dots or ggdist::geom_interval and its arguments could make a good replacement for the boxplot of median income above.4 I can never define margin of error properly, but here’s a good overview.To make up for dropping margins of error before, I made a new dataset that we’ll use here. It’s the same wages data by sex, education, and occupation group, and it includes margins of error at both the 90% and 95% confidence levels. 4 When I analyzed the wage data, it came from a subset of the ACS, so a sample of a sample. With survey data like this, you have to worry about having large enough sample sizes to get reliable estimates. So far we’ve used fairly large groups (women in Maryland with bachelor’s degrees, etc), but when we slice the data more, we start to get less reliable estimates.\nFor example, calculating median income of women in military occupations by education leaves us with some very small sample sizes, and some very large MOEs. Rule of thumb is usually that you need at least 30 observations in your sample for estimates to be useful; you might also want to set a minimum number of estimated counts.\n\nwages_moe <- readRDS(here::here(\"inputs/wages_sex_edu_occ.rds\")) |>\n mutate(occ_group = forcats::as_factor(occ_group) |>\n forcats::fct_relabel(stringr::str_replace, \",? \\\\band\\\\b\", \" &\")) |>\n mutate(lower_95 = earn_q50 - moe_95,\n lower_90 = earn_q50 - moe_90,\n upper_90 = earn_q50 + moe_90,\n upper_95 = earn_q50 + moe_95)\n\nwages_moe |>\n filter(sex == \"Women\",\n occ_group == \"Military Specific\") |>\n select(6:12)\n\n\n\n\n\nedu\ncount\nsample_n\nearn_q50\nse\nmoe_90\nmoe_95\n\n\n\n\nTotal\n2002\n92\n64738\n5916\n9731\n11595\n\n\nHigh school or less\n182\n14\n34600\n17175\n28250\n33662\n\n\nSome college or AA\n732\n28\n63586\n11043\n18164\n21644\n\n\nBachelors\n558\n27\n62580\n4182\n6879\n8197\n\n\nGraduate degree\n530\n23\n85000\n15611\n25678\n30597\n\n\n\n\n\n\nReporting that estimate for women in military occupations with a graduate degree would be silly: $85k ± $30k means that at a 95% confidence level, you’ve estimated the median to be between $55k and $115k, which tells you virtually nothing.\nError bars are one simple way to show the MOE. When we don’t split things up by education, and we look statewide, the MOEs aren’t so bad for most occupational groups (note which ones are pretty big, and for which genders).\n\n\n\n\n\n\n\n\n\nOnce we split by education, however, we get wider margins. Note also that we still have pretty wide distributions within occupation: what’s the difference between a healthcare job someone with a graduate degree has and one someone with at most a high school degree?\n\n\n\n\n\n\n\n\n\nAnother thing to know about margins of error is that they can be used as a kind of crude approximation of statistical testing (t-tests, etc). For example, the margins of error for people with graduate degrees in production occupations overlap, so we shouldn’t say they differ by sex until we do formal testing. For service jobs, however, the MOEs don’t overlap, so that’s a safer bet (but not a replacement for tests of statistical significance).",
"crumbs": [
"Weekly notes",
- "3. Visual encoding"
+ "8. Uncertainty and distributions"
]
},
{
- "objectID": "weeks/10_accessibility.html",
- "href": "weeks/10_accessibility.html",
- "title": "10. Accessibility and literacy",
- "section": "",
- "text": "For each of these two charts:\n\nDraft a possible headline-style title for this chart that would be appropriate for a general audience\nRevise that headline to what you estimate would be a US 6th grade reading level.\nWrite a very short (2-4 concise sentences) description of the chart that says what type of chart it is, what’s being measured, what types of groups are included (don’t name them all individually), and some important data points.\n\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\n\n\n\n\n\n\n\n\nFigure 2",
+ "objectID": "weeks/08_uncertainty.html#missing-data",
+ "href": "weeks/08_uncertainty.html#missing-data",
+ "title": "8. Uncertainty and distributions",
+ "section": "Missing data",
+ "text": "Missing data\nThere’s a lot of different reasons data might be missing, and different ways to handle it. Here’s just one tidbit to handle those small samples from the wage data that you’re likely to encounter.\n\n# I'll use a few metrics to decide which observations to keep:\n# coefficient of variance (MOE / estimate) needs to be less than 0.3, based on 95% CI\n# sample size needs to be at least 50\nwages_sample_size <- wages_moe |>\n mutate(cov = moe_95 / earn_q50) |>\n filter(sex != \"Total\",\n edu == \"Graduate degree\") |>\n mutate(too_small = sample_n < 50 | cov > 0.3) |>\n select(sex, occ_group, earn_q50, too_small)\n\nwages_sample_size |>\n filter(too_small)\n\n\n\n\n\n\n\n\n\n\n\nsex\nocc_group\nearn_q50\ntoo_small\n\n\n\n\nWomen\nMilitary Specific\n85000\nTRUE\n\n\nWomen\nNatural Resources, Construction & Maintenance\n95378\nTRUE\n\n\n\n\n\n\nIf we drop those unreliable values, or have a similar dataset with missing values, we’ll get something like this:\n\nwages_sample_size |>\n filter(!too_small) |>\n ggplot(aes(x = occ_group, y = earn_q50, fill = sex)) +\n geom_col(width = 0.8, position = position_dodge2()) +\n coord_flip() +\n scale_x_discrete(labels = scales::label_wrap(30)) +\n scale_y_continuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n theme(panel.grid.major.x = element_line())\n\n\n\n\n\n\n\n\nDodged bars will fill up the available space by default. Instead, use preserve = \"single\" inside position_dodge.\n\nwages_sample_size |>\n filter(!too_small) |>\n ggplot(aes(x = occ_group, y = earn_q50, fill = sex, group = sex)) +\n geom_col(width = 0.8, position = position_dodge2(preserve = \"single\")) +\n coord_flip() +\n scale_x_discrete(labels = scales::label_wrap(30)) +\n scale_y_continuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n theme(panel.grid.major.x = element_line())\n\n\n\n\n\n\n\n\nWith time series data, you can usually assume the intervals are even (every month, every week, etc.). If it’s not for whatever reason, you might want to add some visual cues for transparency. This is a forced example where I drop some observations from the unemployment data.\n\n\n\n\n\n\n\n\n\nThere are 2 months missing here, but you can’t tell because the lines get connected regardless of discontinuities. Adding points makes it clearer when observations were made, although this might not work when you have a lot of points (that’s why I’m only using one year for this example).\n\n\n\n\n\n\n\n\n\nIn a lot of cases, that will be enough. If you need more accuracy, you might convert the data into a time series (I like the tsibble package because it works well with dplyr) and fill in missing observations. This also gives you options of imputing the missing values, but it’s outside the scope of this class.\n\n# install the tsibble library if you need to\nlibrary(tsibble)\n\n# fill_gaps adds explicitly missing observations in place of missing values, \n# in this case monthly\n# this isn't the best way to hack this chart together but it's the easiest\nunemp_ts <- unemp_missing |>\n mutate(month = yearmonth(date)) |>\n as_tsibble(key = name, index = month) |>\n fill_gaps() |>\n as_tibble() |>\n mutate(month = lubridate::ym(month))\n\nunemp_ts |>\n ggplot(aes(x = month, y = adjusted_rate)) +\n geom_line(aes(x = date), linetype = \"dashed\") +\n geom_line() +\n geom_point() +\n scale_x_date(date_breaks = \"2 months\", date_labels = \"%b %Y\") +\n theme(panel.grid.major.x = element_line())",
"crumbs": [
"Weekly notes",
- "10. Accessibility and literacy"
+ "8. Uncertainty and distributions"
]
},
{
- "objectID": "weeks/10_accessibility.html#warm-up",
- "href": "weeks/10_accessibility.html#warm-up",
- "title": "10. Accessibility and literacy",
+ "objectID": "weeks/09_decisions.html",
+ "href": "weeks/09_decisions.html",
+ "title": "9. Making responsible decisions",
"section": "",
- "text": "For each of these two charts:\n\nDraft a possible headline-style title for this chart that would be appropriate for a general audience\nRevise that headline to what you estimate would be a US 6th grade reading level.\nWrite a very short (2-4 concise sentences) description of the chart that says what type of chart it is, what’s being measured, what types of groups are included (don’t name them all individually), and some important data points.\n\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\n\n\n\n\n\n\n\n\nFigure 2",
+ "text": "library(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n\nsource(here::here(\"utils/plotting_utils.R\"))\nupdate_geom_defaults(\"col\", list(fill = qual_pal[3]))\ntheme_set(theme_nice())",
"crumbs": [
"Weekly notes",
- "10. Accessibility and literacy"
+ "9. Making responsible decisions"
]
},
{
- "objectID": "weeks/10_accessibility.html#accessibility",
- "href": "weeks/10_accessibility.html#accessibility",
- "title": "10. Accessibility and literacy",
- "section": "Accessibility",
- "text": "Accessibility\nAfter talking about making responsible decisions in data visualization, it’s embarrassing to admit that accessibility has been a major oversight of mine, but it’s true, and it’s for no other reason than privilege. On a day-to-day basis I don’t have to think about whether learning or interacting with something will depend on my ability to see well, read complicated text, speak a certain language, navigate stimuli, process information, or access technology and resources. In fact, until last week I hadn’t even bothered writing alt texts for the charts in these notes; I’m going back and doing that now, but my hope for you all is that you start out your data viz careers being more mindful than I’ve been.\nFor the most part when we talk about accessibility, we mean this with respect to disabilities; in static data visualization, this mostly means visual impairments such as blindness, low vision, and colorblindness. If you go on to do interactive or web-based visualization, you’ll also need to think about things like navigation (access for keyboards and assistive devices vs clicking menus only) and animation (can be overstimulating or hard to process). 1\n1 Circa 2017, scrollytelling was very cool and people were very intense with it. I’ve noticed in recent years people have eased up. It can be disorienting for some readers. Webb (2018) convinced me to scrap my scrollytelling plans for some projects during that era.\nWebb, E. (2018). Your Interactive Makes Me Sick. https://source.opennews.org/articles/motion-sick/\nSome of the simplest tasks we can do for static data visualization are using colorblind-friendly palettes, writing alt-text descriptions, and maintaining high contrast ratios between backgrounds and text.\n\nColorblindness\nYou should generally assume your work will be read by at least a few colorblind readers (or people with color-vision deficiency, CVD) and plan your color palettes accordingly. Wilke mentions this as a reason for redundant coding as well, so you’re not relying on color alone to differentiate values. 2\n2 Something that blew my mind is in Frank Elavsky’s interview on PolicyViz. He acknowledges that awareness of CVD has become the norm in data viz, but that it actually predominantly affects white men, and that it shouldn’t be too surprising that that is often the only accommodation made in a field where white men are overrepresented.The most common form of CVD is what’s called red-green colorblindness. Many common R color palettes are colorblind-friendly, and some tools will help you tell whether a palette is or not, or for which color deficiencies they are legible.\nSome code examples:\n\n# Not all Color Brewer palettes are CVD-friendly, but you can filter in the R package\n# or on the website for ones that are\nRColorBrewer::display.brewer.all(colorblindFriendly = TRUE)\n\n\n\n\n\n\n\n# Same goes for Carto Colors\nrcartocolor::display_carto_all(colorblind_friendly = TRUE)\n\n\n\n\n\n\n\n# All Viridis palettes are designed to be CVD-friendly\n# use them with e.g. ggplot2::scale_fill_viridis_c()\ncolorspace::swatchplot(viridisLite::viridis(n = 9))\n\n\n\n\n\n\n\n# Okabe-Ito is built into R and based on lots of research into CVD\ncolorspace::swatchplot(palette.colors(n = 9, palette = \"Okabe-Ito\"))\n\n\n\n\n\n\n\n\nThere are also a lot of tools to help you simulate different types of CVD. This is particularly useful for diverging palettes, which can be hard to make accessible.\n\nset.seed(1)\ncvd_data <- data.frame(group = sample(letters[1:7], size = 200, replace = TRUE),\n value = rnorm(200))\ndiv_pal <- RColorBrewer::brewer.pal(n = 7, name = \"RdYlGn\")\n\np <- ggplot(cvd_data, aes(x = value, fill = group)) +\n geom_dotplot(method = \"histodot\", binpositions = \"all\", binwidth = 0.2)\n\np + \n scale_fill_manual(values = div_pal) +\n labs(title = \"Brewer palette RdYlGn\")\n\np + \n scale_fill_manual(values = colorspace::deutan(div_pal)) +\n labs(title = \"Deuteranomaly\")\n\np + \n scale_fill_manual(values = colorspace::protan(div_pal)) +\n labs(title = \"Protanomaly\")\n\np + \n scale_fill_manual(values = colorspace::tritan(div_pal)) +\n labs(title = \"Tritanomaly\")\n\n\n\n\n\n\n\nFigure 3\n\n\n\n\n\n\n\n\n\n\n\nFigure 4\n\n\n\n\n\n\n\n\n\n\n\nFigure 5\n\n\n\n\n\n\n\n\n\n\n\nFigure 6\n\n\n\n\n\nThere are lots of tools to do similar simulations, although many of them require you to have a graphic already saved to a file. An online one that’s good for developing and adjusting palettes is Viz Palette by Susie Lu; this one also accounts for the size of your geometries.\n\n\nViz Palette takes a set of space- or comma-separated colors as hex values. If you have a vector of colors, call\ncat(div_pal, sep = \" \")\nto get it all in one line that you only have to copy & paste once.\n\n\nAlt text\nAlt text is the text that’s displayed in place of, or alongside, and image online and in some types of documents (certain PDF versions, Microsoft Word, etc). If someone is using a screen reader, it will read this text aloud. This can be embedded in posts on most social media platforms as well, and is autogenerated on some (if you ever look at Facebook with a bad internet connection, you might see alt text until the images load.) As the designer of your visualizations, you’re in a unique position to write alt text, since you will have close knowledge of the data and what’s important about it.\nIncluding alt text in R:\n\nFor exporting ggplot charts, you can include alt text in labs(alt = \"\").\nIn Rmarkdown documents, you can include it as the fig.alt chunk option\nSimilar for Quarto documents: fig-alt\nWhen directly including images in Markdown, use {fig-alt=\"Alt text goes here\"}\n\n\n\nContrast\nDifferent pieces of your visualization need to have enough contrast to be legible at different sizes, especially between text and its background. This comes up with labels like titles, but especially with direct labels. Generally your labels will be all white or all black (or slightly darker or lighter, respectively), so if you’re putting direct labels on several bars with different colors, make sure you have enough contrast across all of them.\nFor example, this palette starts out very dark and ends very light, so neither white nor black will be legible across all bars. Switching between label colors (light on the dark bars, dark on the light bars) can be distracting or imply something about the data that isn’t there, so it’s better to use a palette where all labels can be the same color.\n\n\n\n\n\n\n\n\nFigure 7\n\n\n\n\n\nThe W3C recommends a minimum contrast ratio of 4.5 for regular-sized text, and 3 for large text. You can use colorspace::contrast_ratio to get calculations of these ratios.\n\ncolorspace::contrast_ratio(inferno, col2 = \"black\", plot = TRUE)\n\n\n\n\n\n\n\nFigure 8\n\n\n\n\n\n\n\nExercise\nGo back to the image descriptions you wrote in the warm-up. Using Cesal (2020) and W3C Web Accessibility Initiative (2024), revise your descriptions so they could work as alt text.\n\nCesal, A. (2020). Writing Alt Text for Data Visualization, Nightingale. In Nightingale. https://medium.com/nightingale/writing-alt-text-for-data-visualization-2a218ef43f81?source=friends_link&sk=32db60d651933b5ac2c5b6507f3763b5\n\nW3C Web Accessibility Initiative. (2024). Images Tutorial: Complex Images. In Web Accessibility Initiative (WAI). https://www.w3.org/WAI/tutorials/images/complex/",
+ "objectID": "weeks/09_decisions.html#warm-up",
+ "href": "weeks/09_decisions.html#warm-up",
+ "title": "9. Making responsible decisions",
+ "section": "Warm up",
+ "text": "Warm up\n\nYou want to know how UMBC graduate students feel about their job prospects, and how this might differ between students in STEM programs and students in social science programs (you’re not interested in other degrees), so you’re tabling on campus with a survey. The only actual survey question is “Do you feel good about your job prospects after graduation?” Draw a flowchart of the questions you might ask people before you get to the one survey question.\nThere’s a virus circulating that has killed many people, but a vaccine is available and you trust reports that it greatly decreases the chances of dying from the disease. After about a year of a massive vaccination campaign, you find out that the majority of people dying from the disease at the hospital near you were already vaccinated. Does this change your beliefs about the vaccine’s effectiveness? What other information might help explain this?\n\n\n\n\n\n\n\nBrainstorm\n\n\n\n\nhealth of people who are dying before getting sick (comorbidities, etc)\nhow many people already vaccinated",
"crumbs": [
"Weekly notes",
- "10. Accessibility and literacy"
+ "9. Making responsible decisions"
]
},
{
- "objectID": "weeks/10_accessibility.html#literacy",
- "href": "weeks/10_accessibility.html#literacy",
- "title": "10. Accessibility and literacy",
- "section": "Literacy",
- "text": "Literacy\nWe easily take for granted the ability to read English fluently, but it’s important to remember that, depending on our audience, many of our readers may not be able to. Twenty-two percent of US adults ages 16 to 74 are rated as having low literacy; in Maryland, this is 20% (National Center for Education Statistics, 2020). 3 So if you’re creating a visualization that needs to work for a general audience, you’ll want to keep your sentences short, language simple, and chart types pretty standard. Or, you can get more complex with the use of annotations or other guidance.\n\nNational Center for Education Statistics. (2020). Program for the International Assessment of Adult Competencies (PIAAC). National Center for Education Statistics. https://nces.ed.gov/surveys/piaac/state-county-estimates.asp\n3 This program outlines definitions of “low literacy,” but in news stories and Wikipedia it’s being referred to as corresponding to a sixth grade reading level. I haven’t found anything directly connected to the program that corroborates that.\nExercise\nTest the reading level of the headlines you wrote using each of these tools:\n\nWordcalc: https://www.wordcalc.com/readability/\nHemingway: https://hemingwayapp.com/\n\nFor the versions of the headlines that you thought were at sixth grade level, what level were they actually? Try to get them to sixth grade or below. What revisions did you have to make to get there?\n\nIf you have access to decent AI tools, they might help with this also. I tried with Chat GPT (GPT-3.5) with mixed results. It came out to 5th grade in the end, but loses some of the memorability of “one in four.”\n\nUser Rewrite the following sentence to be at a US 6th grade reading level: “One in four Black adults, and one in five Latinos, have been unfairly stopped or harassed by police.”\nChatGPT “Police have unfairly stopped or harassed one out of every four Black adults, and one out of every five Latinos.”\nUser Based on the Flesch-Kincaid scale, that’s a 9.9 reading level\nChatGPT Here’s a revised sentence with a lower reading level:\n“Police have unfairly stopped or harassed one out of every four Black adults, and one out of every five Latinos.”\nThis should be around a 6th grade reading level according to the Flesch-Kincaid scale.\nUser That’s the same sentence\nChatGPT I apologize for the confusion. Here’s another attempt:\n“Police have unfairly stopped or harassed 25% of Black adults and 20% of Latinos.”\nThis should be around a 6th grade reading level according to the Flesch-Kincaid scale.",
+ "objectID": "weeks/09_decisions.html#representing-data",
+ "href": "weeks/09_decisions.html#representing-data",
+ "title": "9. Making responsible decisions",
+ "section": "Representing data",
+ "text": "Representing data\nSome of the ways we’ve talked about data visualization being misleading are intentional and malicious. That definitely happens, and how often you run into it might depend on your sources of information (Fox News, boardroom presentations, Congress, social media influencers…) but more often it’s just lack of skill and fluency.\n\n\n\n\n\nDeceptive coffee creamer\n\n\n\nWho’s in the data\nOne of the easiest things to mess up is the universe of your data. This is basically your denominator—who or what is included and used as the unit of analysis. I’ve most often found (and made, and corrected) this type of mistake with survey data, because it can be hard to know exactly who’s being asked every question.\nAn easy way to catch this is to read the fine print on your data sources, and to do it routinely because it might change. Some examples:\n\nBirth outcomes: for some measures, unit might be babies; for others, parent giving birth\nACS tables: several tables seem like they match, but one is by household and another is by person. Be especially mindful with tables related to children and family composition—these get messy. 1\nProxies: when I analyzed data on police stops, I tried to figure out a population to compare to. I didn’t have data on how many people in each census tract had a driver’s license, decennial data wasn’t out yet so I didn’t have reliable local counts of population 16 and up by race, so I just used population. It wasn’t ideal.\nRelationships: is a question being asked of parents, or of adults with a child in their household? These aren’t necessarily the same.\n\n1 This one is especially brain-melting: Ratio of Income to Poverty Level in the Past 12 Months by Nativity of Children Under 18 Years in Families and Subfamilies by Living Arrangements and Nativity of Parents. The universe is own children under 18 years in families and subfamilies for whom poverty status is determined.Another example: how would you make sense of this?\n\n\n\nShare of adults reporting having been unfairly stopped by police, Connecticut, 2021\n\n\n\n\n\n\n\n\n\nname\ncategory\ngroup\never_unfairly_stopped\nmultiple_times_3yr\n\n\n\n\nConnecticut\nTotal\nTotal\n15%\n29%\n\n\nConnecticut\nRace/Ethnicity\nWhite\n12%\n16%\n\n\nConnecticut\nRace/Ethnicity\nBlack\n25%\n40%\n\n\nConnecticut\nRace/Ethnicity\nLatino\n20%\n50%\n\n\n\n\n\n\n\nObscuring data\nWe’ve talked some about dealing with missing data, and often the solution to data-related problems is to get more of it. But sometimes it’s important to not be counted, or to not show everything. There are even times when it might be good to intentionally mess up the data (maybe this isn’t the role of the visualizer, however). 2 I would argue that hiding data when necessary should also be part of doing data analysis and viz responsibly. Some examples:\n2 The Census Bureau made the controversial decision to basically do this, via differential privacy. Wang (2021)\nWang, H. L. (2021). For The U.S. Census, Keeping Your Data Anonymous And Useful Is A Tricky Balance. NPR. https://www.npr.org/2021/05/19/993247101/for-the-u-s-census-keeping-your-data-anonymous-and-useful-is-a-tricky-balance\n\nFilling period tracking apps with fake data after Roe v Wade was overturned\nNot adding citizenship to the census or other surveys; not asking about sexual orientation and gender identity. In theory these should both be fine, but in practice they may not be safe for people to disclose, or they could get misused.\nLeaving out parts of your data that could be stigmatizing or lead to misinformation\n\nAn example of this last point:\n\nMy organization’s survey asked a similar set of questions, but we chose not to release the question about getting COVID from the vaccine. The others are valid concerns; that one is misinformation that we didn’t want to repeat even with qualifiers.\n\n\nLack of a pattern\nSometimes the pattern you expect to find in a dataset isn’t there, and that’s okay. You want to go into your work with an open mind, rather than force the data into the story you want it to tell. I’m really into situations where the pattern you think you’re going to find isn’t there, and that’s the story—it might point to a disruption in the usual pattern.\n\n\nSay what you mean\n\nDon’t say “people of color” when you actually mean “Black people” or “Black and Latino people” or something else. This drives me crazy, and I’m sure I’ve done it as well. Sometimes because of small sample sizes or other limitations, you can’t break your data down further than white vs people of color. But if you can disaggregate further, do so, at least in the EDA process. This especially goes for data that deals with something that historically targeted e.g. Black people or indigenous people or some other group.\nAlong those same lines, don’t say BIPOC (Black, Indigenous, and people of color) if you don’t actually have any data to show on indigenous people, or LGBT if you have no data on trans people.",
"crumbs": [
"Weekly notes",
- "10. Accessibility and literacy"
+ "9. Making responsible decisions"
]
},
{
- "objectID": "weeks/00_definitions.html",
- "href": "weeks/00_definitions.html",
- "title": "0. Definitions",
- "section": "",
- "text": "A few definitions of data visualization:\n\nThe rendering of information in a visual format to help communicate data while also generating new patterns and knowledge through the act of visualization itself (Du Bois et al., 2018, p. 8)\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nThe representation and presentation of data to facilitate understanding (Kirk, 2016, p. 19)\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\nIt’s pretty common to find a book with hundreds of pages of details on data visualization, but no definition.\nWhat else could we add here?",
+ "objectID": "weeks/09_decisions.html#exercise",
+ "href": "weeks/09_decisions.html#exercise",
+ "title": "9. Making responsible decisions",
+ "section": "Exercise",
+ "text": "Exercise\nThe youth_risks dataset in the justviz package has a set of questions from the DataHaven Community Wellbeing Survey, where survey respondents are asked to rate the likelihood of young people in their area experiencing different events (DataHaven (n.d.)). The allowed responses are “almost certain,” “very likely,” “a toss up,” “not very likely,” and “not at all likely”; this type of question is called a Likert scale. The universe of this dataset is adults in Connecticut, and the survey was conducted in 2021.\n\nDataHaven. (n.d.). DataHaven Community Wellbeing Survey. https://ctdatahaven.org/reports/datahaven-community-wellbeing-survey\n\nPirrone, A. (2020). Visualizing Likert Scale Data: Same Data, Displayed Seven Different Ways, Nightingale. In Nightingale. https://medium.com/nightingale/seven-different-ways-to-display-likert-scale-data-d0c1c9a9ad59?source=friends_link&sk=60cb93604b71ecc8820cc785ed1afd1a\nStarting with just stacked bars for a single question at a time (see example), explore the data visually and see if you can find an anomaly. (Hint: one of these questions is not like the other.) Browse through Pirrone (2020) to get some ideas of more ways to visualize Likert data, especially ways that will illustrate the pattern well.\n\ndiv_pal <- c('#00748a', '#479886', '#adadad', '#d06b56', '#b83654') # based on carto-color Temps\n\nrisks <- youth_risks |>\n filter(category %in% c(\"Total\", \"Race/Ethnicity\", \"Income\", \"With children\")) |>\n mutate(question = forcats::as_factor(question))\n\nrisks |>\n filter(question == \"Graduate from high school\") |>\n mutate(value = scales::label_percent(accuracy = 1)(value)) |>\n tidyr::pivot_wider(id_cols = c(category, group), names_from = response) |>\n knitr::kable(align = \"llrrrrr\")\n\n\n\nTable 1: Ratings of likelihood that young people will graduate from high school, share of Connecticut adults, 2021\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncategory\ngroup\nAlmost certain\nVery likely\nA toss up\nNot very likely\nNot at all likely\n\n\n\n\nTotal\nConnecticut\n39%\n55%\n4%\n0%\n1%\n\n\nRace/Ethnicity\nWhite\n39%\n56%\n4%\n0%\n1%\n\n\nRace/Ethnicity\nBlack\n36%\n55%\n3%\n1%\n4%\n\n\nRace/Ethnicity\nLatino\n44%\n44%\n11%\n0%\n0%\n\n\nIncome\n<$30K\n28%\n61%\n7%\n1%\n2%\n\n\nIncome\n$30K-$100K\n38%\n55%\n6%\n1%\n1%\n\n\nIncome\n$100K+\n44%\n55%\n1%\n0%\n0%\n\n\nWith children\nNo kids\n36%\n57%\n5%\n1%\n1%\n\n\nWith children\nKids in home\n45%\n51%\n4%\n0%\n0%",
"crumbs": [
"Weekly notes",
- "0. Definitions"
+ "9. Making responsible decisions"
]
},
{
- "objectID": "weeks/00_definitions.html#what-is-data-visualization",
- "href": "weeks/00_definitions.html#what-is-data-visualization",
- "title": "0. Definitions",
+ "objectID": "weeks/02_components.html",
+ "href": "weeks/02_components.html",
+ "title": "2. Components of a chart",
"section": "",
- "text": "A few definitions of data visualization:\n\nThe rendering of information in a visual format to help communicate data while also generating new patterns and knowledge through the act of visualization itself (Du Bois et al., 2018, p. 8)\n\nDu Bois, W. E. B., Battle-Baptiste, W., & Rusert, B. (2018). W.E.B Du Bois’s data portraits: Visualizing Black America (First edition). The W.E.B. Du Bois Center At the University of Massachusetts Amherst ; Princeton Architectural Press.\n\n\nThe representation and presentation of data to facilitate understanding (Kirk, 2016, p. 19)\n\nKirk, A. (2016). Data visualisation: A handbook for data driven design. SAGE.\n\nIt’s pretty common to find a book with hundreds of pages of details on data visualization, but no definition.\nWhat else could we add here?",
+ "text": "Revisiting the wage gaps to break down a chart into its pieces and what they mean. This will be a subset of the wages data with just full-time workers by sex and education in Maryland.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nlibrary(ggtext)\n\nsource(here::here(\"utils/plotting_utils.R\"))\ngender_pal <- setNames(qual_pal[c(3, 6)], c(\"Men\", \"Women\"))\nsex_x_edu <- wages |>\n filter(dimension == \"sex_x_edu\",\n name == \"Maryland\") |>\n select(sex, edu, earn_q25, earn_q50, earn_q75) |>\n mutate(across(where(is.factor), forcats::fct_drop))\n\nknitr::kable(sex_x_edu)\n\n\n\n\nsex\nedu\nearn_q25\nearn_q50\nearn_q75\n\n\n\n\nMen\nHigh school or less\n33158\n49737\n70000\n\n\nMen\nSome college or AA\n43105\n63586\n93000\n\n\nMen\nBachelors\n60000\n91712\n135000\n\n\nMen\nGraduate degree\n82661\n121873\n171555\n\n\nWomen\nHigh school or less\n26974\n38000\n55475\n\n\nWomen\nSome college or AA\n35000\n50241\n75000\n\n\nWomen\nBachelors\n49737\n71842\n101684\n\n\nWomen\nGraduate degree\n65817\n92842\n129475\n\n\n\n\nsummary(sex_x_edu)\n\n sex edu earn_q25 earn_q50 \n Men :4 High school or less:2 Min. :26974 Min. : 38000 \n Women:4 Some college or AA :2 1st Qu.:34540 1st Qu.: 50115 \n Bachelors :2 Median :46421 Median : 67714 \n Graduate degree :2 Mean :49556 Mean : 72479 \n 3rd Qu.:61454 3rd Qu.: 91994 \n Max. :82661 Max. :121873 \n earn_q75 \n Min. : 55475 \n 1st Qu.: 73750 \n Median : 97342 \n Mean :103899 \n 3rd Qu.:130856 \n Max. :171555",
"crumbs": [
"Weekly notes",
- "0. Definitions"
+ "2. Components of a chart"
]
},
{
- "objectID": "weeks/00_definitions.html#what-should-visualization-do",
- "href": "weeks/00_definitions.html#what-should-visualization-do",
- "title": "0. Definitions",
- "section": "What should visualization do?",
- "text": "What should visualization do?\n\nData visualization is part art and part science. The challenge is to get the art right without getting the science wrong and vice versa. A data visualization first and foremost has to accurately convey the data. It must not mislead or distort…. At the same time, a data visualization should be aesthetically pleasing (Wilke, 2019, ch 1)\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/",
+ "objectID": "weeks/02_components.html#starting-point",
+ "href": "weeks/02_components.html#starting-point",
+ "title": "2. Components of a chart",
+ "section": "Starting point",
+ "text": "Starting point\nThis is the decent but not great chart from last week. We’re going to take a step back to break it into its components.\n\nwages |>\n filter(dimension == \"sex_x_edu\",\n name == \"Maryland\") |>\n ggplot(aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(width = 0.8, alpha = 0.9, position = position_dodge2()) +\n scale_y_barcontinuous(labels = dollar_k) +\n scale_fill_manual(values = gender_pal) +\n labs(x = NULL, y = NULL, fill = NULL,\n title = \"Median individual earnings\",\n subtitle = \"Adults ages 25+ with positive earnings by sex and educational attainment, Maryland full-time workers, 2021\") +\n theme(plot.subtitle = element_textbox_simple(margin = margin(0.2, 0, 0.2, 0, \"lines\")),\n legend.position = \"bottom\")\n\n\n\n\n\n\n\nFigure 1",
"crumbs": [
"Weekly notes",
- "0. Definitions"
+ "2. Components of a chart"
]
},
{
- "objectID": "weeks/00_definitions.html#why-visualize-data",
- "href": "weeks/00_definitions.html#why-visualize-data",
- "title": "0. Definitions",
- "section": "Why visualize data?",
- "text": "Why visualize data?\n\nExplore\nExplain\nBoth\n\nWhat’s the difference, and what happens in the overlaps?",
+ "objectID": "weeks/02_components.html#basics",
+ "href": "weeks/02_components.html#basics",
+ "title": "2. Components of a chart",
+ "section": "Basics",
+ "text": "Basics\nFocusing first on median wages (earn_q50), values here range from 38,000 to 121,873, so we should expect our dependent axis (usually y, but we might change it) to range from somewhere below that to somewhere above that. If we make a chart and it goes down to e.g. 10,000 that’s a sign that something weird might be happening. On the dependent axis, we have 2 categories of sex :-/ and 4 of education; if we end up with only 3 bars, or with 15 bars, something’s wrong.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50))\n\n\n\n\n\n\n\nFigure 2\n\n\n\n\n\nThese scales make sense so far—I haven’t signaled that sex will be included here, or that we’re making a bar chart which is why the dependent axis doesn’t have to go down to 0.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50)) +\n geom_col()\n\n\n\n\n\n\n\nFigure 3\n\n\n\n\n\nThe dependent scale has changed: it goes down to 0, which makes sense because now we have bars, but it goes up to 200,000, which is weird.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50)) +\n geom_col(color = \"white\")\n\n\n\n\n\n\n\nFigure 4\n\n\n\n\n\nThis still includes both men and women, but sex isn’t assigned to any aesthetic, so bars just get stacked. Setting the fill makes that clear.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col()\n\n\n\n\n\n\n\nFigure 5\n\n\n\n\n\nThese bars shouldn’t be stacked, though. Why not?\nThey represent median wages of distinct groups, not something that is cumulative. If men have a median income of $60,000 and women have a median income of $50,000, does that mean that men and women overall have a median income of $110,000? No! But that’s what these stacked bars imply.\n\nggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(position = position_dodge2()) +\n labs(title = \"Median earnings by sex & education, Maryland, 2021\")\n\n\n\n\n\n\n\nFigure 6\n\n\n\n\n\nSo now we have a chart that represents the data appropriately. We can make it look nicer, but for now we have all the basic components set.\nWhat are all the components here?\n\n\n\n\n\n\nBrainstorming components\n\n\n\n\naxes (x & y)\ntick values (dollar amounts, education levels)–horizontal\nlegend (placement, title, labels, keys)\naxis titles\nbackground\ngridlines (x & y gridlines, x-axis major, y-axis major & minor)\ntitle\nbars with color\ntick marks\nunits (not included)\ntext choices (font, size, boldness)",
"crumbs": [
"Weekly notes",
- "0. Definitions"
+ "2. Components of a chart"
]
},
{
- "objectID": "weeks/00_definitions.html#how-is-data-visualization-used",
- "href": "weeks/00_definitions.html#how-is-data-visualization-used",
- "title": "0. Definitions",
- "section": "How is data visualization used?",
- "text": "How is data visualization used?\n\n\n\n\n\n\nBrainstorming\n\n\n\n\nPositive / constructive\n\nfacilitates & documents change\nhighlights social justice concerns\njustifying decisions\ntelling a story\nconnecting dots\ninform\nefficiency & safety\nelicit emotion\nconvey lots of information\nmake data more understandable\n\n\n\nNegative / destructive\n\nfacilitates & documents change in ways that are harmful\ntelling a story (misinformation)\nelicit emotion (sensationalize)",
+ "objectID": "weeks/02_components.html#a-nicer-chart",
+ "href": "weeks/02_components.html#a-nicer-chart",
+ "title": "2. Components of a chart",
+ "section": "A nicer chart",
+ "text": "A nicer chart\nThat chart is fine but not great. Next we could clean up the axes, their labels, ticks, and gridlines. For each of these components, you should ask yourself if they’re necessary, or what they add to the chart that isn’t already provided through some other means. This helps you maximize your data-to-ink ratio, Wilke (2019)\n\nLive code: clean up this chart\n\ngg <- ggplot(sex_x_edu, aes(x = edu, y = earn_q50, fill = sex)) +\n geom_col(position = position_dodge2())\n\ngg +\n scale_y_continuous(labels = dollar_k) +\n theme(panel.grid.major.x = element_blank()) +\n theme(panel.grid.minor.y = element_blank()) +\n theme(axis.ticks = element_blank()) +\n labs(title = \"Median individual earnings\",\n subtitle = \"Adults ages 25+ working full time by sex and educational attainment, Maryland, 2021\",\n y = \"Median earnings\", x = NULL, fill = NULL) +\n scale_fill_manual(values = gender_pal)\n\n\n\n\n\n\n\n\n\n\nGoal: one option\nThis is one more complicated option of how I might do this. It uses a function from the package stylehaven which I wrote for work, and which you all are free to use. It also uses showtext to set the fonts, which can be very finicky.\n\n# can't get fonts to not be totally weird\nlibrary(showtext)\nshowtext_auto()\nshowtext_opts(dpi = 300)\nsysfonts::font_add_google(\"Barlow Semi Condensed\")\n\n# use both true/false and gender palettes\ncomb_pal <- c(purrr::map_chr(gender_pal, colorspace::darken, amount = 0.2, space = \"HCL\"), tf_pal)\n\nsex_x_edu |>\n mutate(edu = forcats::fct_recode(edu, \"Some college / Associate's\" = \"Some college or AA\", \"Bachelor's\" = \"Bachelors\")) |>\n stylehaven::offset_lbls(value = earn_q50, fun = dollar_k, frac = 0.03) |>\n ggplot(aes(x = edu, y = earn_q50, fill = sex, group = sex)) +\n geom_col(width = 0.8, position = position_dodge2()) +\n geom_text(aes(y = y, label = lbl, vjust = just, color = is_small),\n family = \"Barlow Semi Condensed\", fontface = \"bold\", size = 9.5,\n position = position_dodge2(width = 0.8)) +\n geom_text(aes(label = sex, color = sex, x = as.numeric(edu) - 0.18, y = earn_q50 - off/2),\n data = ~filter(., edu == first(edu)), vjust = 0, hjust = 0,\n family = \"Barlow Semi Condensed\", fontface = \"bold\", size = 8,\n position = position_dodge2(width = 0.8)) +\n scale_fill_manual(values = gender_pal) +\n scale_color_manual(values = comb_pal) +\n scale_x_discrete(labels = scales::label_wrap(15)) +\n scale_y_barcontinuous(breaks = NULL) +\n theme_minimal(base_family = \"Barlow Semi Condensed\", base_size = 28) +\n theme(text = element_text(lineheight = 0.5)) +\n theme(panel.grid = element_blank()) +\n theme(legend.position = \"none\") +\n theme(axis.text = element_text(color = \"black\", size = rel(0.9))) +\n theme(plot.title = element_text(family = \"Barlow Semi Condensed\", face = \"bold\")) +\n theme(plot.subtitle = ggtext::element_textbox_simple(family = \"Barlow Semi Condensed\", lineheight = 0.7)) +\n theme(plot.caption = element_text(color = \"gray30\")) +\n labs(x = NULL, y = NULL,\n title = \"The male-female wage gap persists across education levels\",\n subtitle = \"Median individual earnings, Maryland adults ages 25+ working full time by sex and educational attainment, 2021\",\n caption = \"Source: Analysis of US Census Bureau American Community Survey, 2021 5-year estimates\")",
"crumbs": [
"Weekly notes",
- "0. Definitions"
+ "2. Components of a chart"
]
},
{
- "objectID": "weeks/07_annotations.html",
- "href": "weeks/07_annotations.html",
- "title": "7. Text and annotations",
+ "objectID": "weeks/06_color.html",
+ "href": "weeks/06_color.html",
+ "title": "6. Color",
"section": "",
- "text": "“Until the systems of power recognise different categories, the data I’m reporting on is also flawed,” she added.\nIn a bid to account for these biases, and any biases of her own, Chalabi is transparent about her sources and often includes disclaimers about her own decision-making process and about any gaps or uncertainties in the data.\n“I try to produce journalism where I’m explaining my methods to you,” she said. “If I can do this, you can do this, too. And it’s a very democratising experience, it’s very egalitarian.”\nIn an ideal scenario, she is able to integrate this background information into the illustrations themselves, as evidenced by her graphics on anti-Asian hate crimes and the ethnic cleansing of Uygurs in China.\nBut at other times, context is relegated to the caption to ensure the graphic is as grabby as possible.\n“What I have found is literally every single word that you add to an image reduces engagement, reduces people’s willingness or ability to absorb the information,” Chalabi said.\n“So there is a tension there. How can you be accurate and get it right without alienating people by putting up too much information? That’s a really, really hard balance.”\nMona Chalabi in Hahn (2023)\n\nHahn, J. (2023). \"Data replicates the existing systems of power\" says Pulitzer Prize-winner Mona Chalabi. Dezeen. https://www.dezeen.com/2023/11/16/mona-chalabi-pulitzer-prize-winner/",
+ "text": "Code\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\n\nsource(here::here(\"utils/plotting_utils.R\"))",
"crumbs": [
"Weekly notes",
- "7. Text and annotations"
+ "6. Color"
]
},
{
- "objectID": "weeks/07_annotations.html#big-picture-providing-context-and-making-meaning",
- "href": "weeks/07_annotations.html#big-picture-providing-context-and-making-meaning",
- "title": "7. Text and annotations",
- "section": "",
- "text": "“Until the systems of power recognise different categories, the data I’m reporting on is also flawed,” she added.\nIn a bid to account for these biases, and any biases of her own, Chalabi is transparent about her sources and often includes disclaimers about her own decision-making process and about any gaps or uncertainties in the data.\n“I try to produce journalism where I’m explaining my methods to you,” she said. “If I can do this, you can do this, too. And it’s a very democratising experience, it’s very egalitarian.”\nIn an ideal scenario, she is able to integrate this background information into the illustrations themselves, as evidenced by her graphics on anti-Asian hate crimes and the ethnic cleansing of Uygurs in China.\nBut at other times, context is relegated to the caption to ensure the graphic is as grabby as possible.\n“What I have found is literally every single word that you add to an image reduces engagement, reduces people’s willingness or ability to absorb the information,” Chalabi said.\n“So there is a tension there. How can you be accurate and get it right without alienating people by putting up too much information? That’s a really, really hard balance.”\nMona Chalabi in Hahn (2023)\n\nHahn, J. (2023). \"Data replicates the existing systems of power\" says Pulitzer Prize-winner Mona Chalabi. Dezeen. https://www.dezeen.com/2023/11/16/mona-chalabi-pulitzer-prize-winner/",
+ "objectID": "weeks/06_color.html#warm-up",
+ "href": "weeks/06_color.html#warm-up",
+ "title": "6. Color",
+ "section": "Warm-up",
+ "text": "Warm-up\n\nColor perception\nWhich row uses a darker color?\n\n\n\n\n\n\n\n\n\nWhich line uses a darker color?\n\n\n\n\n\n\n\n\n\nWhich line uses a darker color?\n\n\n\n\n\n\n\n\n\nHow many purple dots are in each row?\n\n\n\n\n\n\n\n\n\n\n\nColors in R\nIf you don’t already have a color selection tool on your computer 1 you can install the colourpicker package that has a color picker addin for RStudio.\n1 Maybe the thing I miss most since switching from Mac to Linux is the color picker app Sip, definitely recommend it",
"crumbs": [
"Weekly notes",
- "7. Text and annotations"
+ "6. Color"
]
},
{
- "objectID": "weeks/07_annotations.html#text",
- "href": "weeks/07_annotations.html#text",
- "title": "7. Text and annotations",
- "section": "Text",
- "text": "Text\n\nA data visualization is not a piece of art meant to be looked at only for its aesthetically pleasing features. Instead, its purpose is to convey information and make a point. To reliably achieve this goal when preparing visualizations, we have to place the data into context and provide accompanying titles, captions, and other annotations. – Wilke (2019) ch. 22\n\nWilke, C. (2019). Fundamentals of data visualization: A primer on making informative and compelling figures (First edition). O’Reilly. https://clauswilke.com/dataviz/\n\nThe type of text you use, phrasing, and placement all depend on where your visualizations will go, who will read them, and how they might be distributed. For example, I might put less detail in the titles and labels of a chart that will be part of a larger publication than a chart that might get distributed on its own (I’ll also tend towards more straightforward chart types and simpler analyses for something standalone).\n\nUses of text\nHere’s a good rundown on how to use text\n\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nsource(here::here(\"utils/plotting_utils.R\"))\n# source(here::here(\"utils/misc.R\"))\nbalt_metro <- readRDS(here::here(\"utils/balt_metro.rds\"))\n\n# set a default theme from the one I defined in plotting_utils.R\ntheme_set(theme_nice())\n\nIdentify all the text in this chart, what purpose it serves, and whether that could be done better through other means.\n\nacs |>\n filter(level %in% c(\"us\", \"state\") | name %in% balt_metro) |>\n mutate(name = forcats::fct_reorder(name, total_cost_burden)) |>\n mutate(level2 = forcats::fct_other(name, keep = c(\"United States\", \"Maryland\", \"Baltimore city\"))) |>\n stylehaven::offset_lbls(value = total_cost_burden, frac = 0.025, fun = scales::label_percent()) |>\n ggplot(aes(x = name, y = total_cost_burden, fill = level2)) +\n geom_col(width = 0.8) +\n geom_text(aes(label = lbl, hjust = just, y = y), color = \"white\", fontface = \"bold\") +\n scale_y_barcontinuous() +\n coord_flip() +\n labs(title = \"Baltimore city has a higher rate of cost burden than the state or nation\",\n subtitle = \"Share of households that are cost burdened, Maryland, 2022\",\n caption = \"Source: US Census Bureau American Community Survey, 2022 5-year estimates\",\n fill = \"fill\") +\n theme(panel.grid.major.y = element_blank(),\n panel.grid.major.x = element_line()) \n\n\n\n\n\n\n\n\n\n\n\n\n\n\nBrainstorm\n\n\n\n\n\n\n\n\n\n\n\nText\nPurpose\nCould be better?\n\n\n\n\nTitle\nTakeaway, what you’re looking at in context\n\n\n\nSubtitle\nSpecifics of what’s being measured\nDepending on context, maybe put cost burden definition here\n\n\nIndependent axis\nLocations\n\n\n\nIndependent axis title\nWhat’s on the axis\nNot necessary; we know what these names are\n\n\nLegend title\nWhat colors mean\n\n\n\nLegend labels\nLocation types\nDrop the legend, put any additional info in subtitle\n\n\nDependent axis title\nMeaning of variable being measured\nCan remove since it’s in the subtitle, but some styleguides may say keep it\n\n\nCaption\nSource\nCould put definition of cost burden here\n\n\nDependent axis labels\nSpecify meaning of breaks along axis\nCan drop because redundant\n\n\nDirect data labels on bars\nValues of each data point",
+ "objectID": "weeks/06_color.html#chapters",
+ "href": "weeks/06_color.html#chapters",
+ "title": "6. Color",
+ "section": "Chapters",
+ "text": "Chapters\nWe’ll walk through Wilke chapters 4 and 19–I don’t have a ton to add until we get to mapping.\n\nWilke chapter 4\nWilke chapter 19\nDatawrapper (2021)\n\n\nDatawrapper. (2021). What to consider when choosing colors for data visualization. https://academy.datawrapper.de/article/140-what-to-consider-when-choosing-colors-for-data-visualization",
"crumbs": [
"Weekly notes",
- "7. Text and annotations"
+ "6. Color"
]
},
{
- "objectID": "weeks/07_annotations.html#other-annotations",
- "href": "weeks/07_annotations.html#other-annotations",
- "title": "7. Text and annotations",
- "section": "Other annotations",
- "text": "Other annotations\nThere are other annotations that are useful too. You might mark off a region to show a cluster of points, or a period in time. There are 2 approaches to this with ggplot: using geoms (geom_text, geom_hline, etc) or annotation layers (annotate, annotation_custom). The main difference is that annotations aren’t mapped to data the way geoms are. Because of that, I almost only use geoms for annotations, and usually make a small data frame just for the data that goes into the annotations to avoid hard-coding too much.\nAn example from DataHaven’s most recent books: we wanted to explicitly put evictions into a policy context, so we marked off the end of the federal eviction moratorium and the prepandemic average count as a threshhold. Without those labeled lines, you could tell that there was an abrupt drop in evictions, then a steep rise in them about a year and a half later, then counts that are higher than at the beginning of 2020. But unless you had followed eviction trends and COVID relief policies, you might not know why any of those things occurred.\n\n\n\nFrom Abraham et al. (2023)\n\nAbraham, M., Seaberry, C., Davila, K., & Carr, A. (2023). Greater New Haven Community Wellbeing Index 2023. https://ctdatahaven.org/reports/greater-new-haven-community-wellbeing-index",
+ "objectID": "weeks/06_color.html#tools",
+ "href": "weeks/06_color.html#tools",
+ "title": "6. Color",
+ "section": "Tools",
+ "text": "Tools\n\nColorBrewer (access to these palettes comes with ggplot)\nCarto Colors (access comes with the rcartocolor package)\nViz Palette generator & preview\nGregor Aisch’s chroma palettes generator\nColorgorical categorical color generator 2\n\n2 I just read a post making fun of Colorgorical for leaning toward puke green colors; haven’t used it in a while but heads up I guess?",
"crumbs": [
"Weekly notes",
- "7. Text and annotations"
+ "6. Color"
]
},
{
- "objectID": "weeks/07_annotations.html#exercises",
- "href": "weeks/07_annotations.html#exercises",
- "title": "7. Text and annotations",
+ "objectID": "weeks/06_color.html#types-of-color-palettes",
+ "href": "weeks/06_color.html#types-of-color-palettes",
+ "title": "6. Color",
+ "section": "Types of color palettes",
+ "text": "Types of color palettes\nThe main types of color palettes are:\n\nsequential / quantitative: values are numeric and continuous; values and colors (saturation, lightness, hue) increase in some way in tandem\ndiverging: values are likely numeric, but colors trend in opposite directions\nqualitative / categorical: values are not numeric / continuous, and colors should not imply continuity\n\nColorBrewer and Carto Colors are great because they have options for all three of these.\nThese are rough examples using ColorBrewer palettes; in practice you might want to make some adjustments to these.",
+ "crumbs": [
+ "Weekly notes",
+ "6. Color"
+ ]
+ },
+ {
+ "objectID": "weeks/06_color.html#exercises",
+ "href": "weeks/06_color.html#exercises",
+ "title": "6. Color",
"section": "Exercises",
- "text": "Exercises\nThis chart doesn’t have labels for its axes, but you know it’s unemployment rates in Baltimore and Maryland. How accurately can we guess what the labels would be?\n\n\n\n\n\n\n\n\n\nNext, what annotations would be helpful for contextualizing this trend?\n\n\n\n\n\n\nBrainstorm: contextualizing information\n\n\n\n\nTimespan–years on axis\nSource\nUnits of measurement\nHistorical events",
+ "text": "Exercises\n\nlocal_counties <- c(\"Baltimore city\", \"Baltimore County\", \"Harford County\", \"Howard County\", \"Anne Arundel County\")\nacs_county <- acs |>\n filter(level %in% c(\"us\", \"state\", \"county\")) |>\n mutate(local1 = forcats::as_factor(name) |>\n forcats::fct_other(keep = c(local_counties, \"United States\", \"Maryland\"), other_level = \"Other counties\"),\n local2 = forcats::fct_collapse(local1, \"Outside Baltimore\" = c(\"Baltimore County\", \"Harford County\", \"Howard County\", \"Anne Arundel County\")) |>\n forcats::fct_relevel(\"Outside Baltimore\", \"Other counties\", after = Inf))\n\ntheme_set(theme_nice())\nknitr::kable(head(acs_county))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nlevel\ncounty\nname\ntotal_pop\nwhite\nblack\nlatino\nasian\nother_race\ndiversity_idx\nforeign_born\ntotal_hh\nhomeownership\ntotal_cost_burden\ntotal_severe_cost_burden\nowner_cost_burden\nowner_severe_cost_burden\nrenter_cost_burden\nrenter_severe_cost_burden\nno_vehicle_hh\nmedian_hh_income\nages25plus\nless_than_high_school\nhigh_school_grad\nsome_college_or_aa\nbachelors\ngrad_degree\npov_status_determined\npoverty\nlow_income\narea_sqmi\npop_density\nlocal1\nlocal2\n\n\n\n\nus\nNA\nUnited States\n331097593\n0.59\n0.12\n0.19\n0.06\n0.05\n0.7443\n0.14\n125736353\n0.65\n0.29\n0.14\n0.21\n0.09\n0.45\n0.23\n0.08\n75149\n226600992\n0.11\n0.26\n0.28\n0.21\n0.13\n323275448\n0.13\n0.29\nNA\nNA\nUnited States\nUnited States\n\n\nstate\nNA\nMaryland\n6161707\n0.49\n0.29\n0.11\n0.06\n0.05\n0.7890\n0.16\n2318124\n0.67\n0.29\n0.13\n0.21\n0.09\n0.46\n0.23\n0.09\n98461\n4260095\n0.09\n0.24\n0.25\n0.22\n0.20\n6034320\n0.09\n0.21\nNA\nNA\nMaryland\nMaryland\n\n\ncounty\nNA\nAllegany County\n68161\n0.87\n0.07\n0.02\n0.01\n0.03\n0.3335\n0.02\n27462\n0.70\n0.23\n0.10\n0.16\n0.07\n0.39\n0.17\n0.10\n55248\n47914\n0.09\n0.41\n0.29\n0.12\n0.09\n61098\n0.16\n0.36\n422.19881\n161.4429\nOther counties\nOther counties\n\n\ncounty\nNA\nAnne Arundel County\n588109\n0.65\n0.17\n0.09\n0.04\n0.05\n0.6689\n0.09\n221704\n0.75\n0.26\n0.11\n0.20\n0.08\n0.44\n0.19\n0.04\n116009\n409052\n0.06\n0.22\n0.27\n0.25\n0.19\n577547\n0.06\n0.14\n414.80643\n1417.7914\nAnne Arundel County\nOutside Baltimore\n\n\ncounty\nNA\nBaltimore County\n850737\n0.54\n0.30\n0.06\n0.06\n0.04\n0.7209\n0.12\n328611\n0.67\n0.29\n0.14\n0.20\n0.09\n0.48\n0.24\n0.08\n88157\n589611\n0.08\n0.24\n0.26\n0.23\n0.18\n830921\n0.10\n0.23\n598.35821\n1421.7855\nBaltimore County\nOutside Baltimore\n\n\ncounty\nNA\nBaltimore city\n584548\n0.27\n0.61\n0.06\n0.03\n0.04\n0.6569\n0.08\n247232\n0.48\n0.37\n0.19\n0.26\n0.13\n0.47\n0.26\n0.26\n58349\n410221\n0.13\n0.28\n0.24\n0.18\n0.17\n564634\n0.20\n0.38\n80.94606\n7221.4510\nBaltimore city\nBaltimore city\n\n\n\n\n\nFind some ways to improve the use of color in these charts, including whether color even should be used. Before writing any code, write down:\n\nHow color is used / what color signifies\nWhat’s wrong with that use of color\nHow you want to change it\n\nHere are some charts that are bad because they use color inappropriately.\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = name)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")\n\n\n\n\n\n\n\n\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = local2)) +\n geom_col(width = 0.7, color = \"gray20\", linewidth = 0.2) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\") +\n scale_fill_brewer(palette = \"GnBu\")\n\n\n\n\n\n\n\n\nHere’s a chart that’s okay but not great; it uses color in a way that’s not wrong but not effective either.\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = local2)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")\n\n\n\n\n\n\n\n\nHere’s one that uses color when it should actually use something else to convey its pattern. What type of chart would be more appropriate?\n\nacs_county |>\n mutate(name = forcats::as_factor(name) |> forcats::fct_reorder(homeownership)) |>\n ggplot(aes(x = name, y = homeownership, fill = median_hh_income)) +\n geom_col(width = 0.8) +\n coord_flip() +\n labs(x = NULL, y = NULL, \n title = \"Homeownership rate vs median household income by location\", \n subtitle = \"US, Maryland, and Maryland counties, 2022\")",
"crumbs": [
"Weekly notes",
- "7. Text and annotations"
+ "6. Color"
]
},
{
- "objectID": "weeks/04_understanding_data.html",
- "href": "weeks/04_understanding_data.html",
- "title": "4. Learning about your data",
+ "objectID": "weeks/05_good_code.html",
+ "href": "weeks/05_good_code.html",
+ "title": "5. Writing good code",
"section": "",
- "text": "From Wickham et al. (2023), Exploratory Data Analysis chapter:\nWe’ll follow the steps of the EDA chapter using the acs dataset in the {justviz} package. For simplicity, we’ll focus on Maryland census tracts and just a few variables dealing with housing and income.\nlibrary(dplyr)\nlibrary(ggplot2)\nlibrary(justviz)\nacs_tr <- acs |>\n filter(level == \"tract\") |>\n select(county, name, total_pop, total_hh,\n homeownership, total_cost_burden, renter_cost_burden,\n owner_cost_burden, no_vehicle_hh, median_hh_income, pop_density)\nknitr::kable(head(acs_tr))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncounty\nname\ntotal_pop\ntotal_hh\nhomeownership\ntotal_cost_burden\nrenter_cost_burden\nowner_cost_burden\nno_vehicle_hh\nmedian_hh_income\npop_density\n\n\n\n\nAllegany County\n24001000100\n3474\n1577\n0.78\n0.18\n0.39\n0.12\n0.06\n56232\n18.48533\n\n\nAllegany County\n24001000200\n4052\n1390\n0.86\n0.20\n0.33\n0.18\n0.04\n66596\n84.29020\n\n\nAllegany County\n24001000500\n2304\n683\n0.60\n0.20\n0.36\n0.09\n0.13\n47781\n520.91879\n\n\nAllegany County\n24001000600\n3005\n1374\n0.70\n0.20\n0.36\n0.14\n0.10\n48607\n1898.93501\n\n\nAllegany County\n24001000700\n3233\n1462\n0.49\n0.37\n0.48\n0.25\n0.25\n36090\n4538.49941\n\n\nAllegany County\n24001000800\n1932\n786\n0.48\n0.52\n0.68\n0.35\n0.17\n27130\n1529.51773\n\n\n\n\nsummary(acs_tr)\n\n county name total_pop total_hh \n Length:1460 Length:1460 Min. : 5 Min. : 0 \n Class :character Class :character 1st Qu.: 2960 1st Qu.:1120 \n Mode :character Mode :character Median : 4026 Median :1528 \n Mean : 4220 Mean :1588 \n 3rd Qu.: 5358 3rd Qu.:1999 \n Max. :14109 Max. :4644 \n \n homeownership total_cost_burden renter_cost_burden owner_cost_burden\n Min. :0.0000 Min. :0.0400 Min. :0.00 Min. :0.0000 \n 1st Qu.:0.5000 1st Qu.:0.2100 1st Qu.:0.31 1st Qu.:0.1600 \n Median :0.7400 Median :0.2800 Median :0.44 Median :0.2100 \n Mean :0.6752 Mean :0.2932 Mean :0.43 Mean :0.2181 \n 3rd Qu.:0.8800 3rd Qu.:0.3700 3rd Qu.:0.55 3rd Qu.:0.2700 \n Max. :1.0000 Max. :0.7400 Max. :1.00 Max. :1.0000 \n NA's :4 NA's :4 NA's :7 NA's :12 \n no_vehicle_hh median_hh_income pop_density \n Min. :0.00000 Min. : 10000 Min. : 1.05 \n 1st Qu.:0.02000 1st Qu.: 70525 1st Qu.: 984.33 \n Median :0.05000 Median : 98164 Median : 3413.10 \n Mean :0.09468 Mean :104585 Mean : 4968.47 \n 3rd Qu.:0.12000 3rd Qu.:132052 3rd Qu.: 6822.62 \n Max. :0.85000 Max. :250001 Max. :57424.37 \n NA's :4 NA's :6\nWhat types of values do each of these variables represent? Why are their scales so different?",
+ "text": "Think about what you need in order to leave the house for work or school. What things do you need to get out the door—some variation on “phone, wallet, keys”? Think about what influences your list, e.g. maybe you switch modes of transportation, which will decide whether you need car keys, a bike helmet and lights, or a bus card.\nWrite down:\n\nthe things you always need\nthe things you sometimes need",
"crumbs": [
"Weekly notes",
- "4. Learning about your data"
+ "5. Writing good code"
]
},
{
- "objectID": "weeks/04_understanding_data.html#variation",
- "href": "weeks/04_understanding_data.html#variation",
- "title": "4. Learning about your data",
- "section": "Variation",
- "text": "Variation\nFirst a histogram of median household income values:\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(color = \"white\")\n\n`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.\n\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\nFigure 1\n\n\n\n\n\nThere’s a message and a warning: the message suggests being intentional about the number of bins, and the warning calls our attention to missing values in this column.\nUse the next few chunks of code to experiment with bin specifications. Does your understanding of the data’s distribution change?\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(bins = 50) # bins can be determined by setting the number of bins\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\n\n\nggplot(acs_tr, aes(x = median_hh_income)) +\n geom_histogram(binwidth = 10000) # or by the width of bins, with a scale corresponding to the x-axis\n\nWarning: Removed 6 rows containing non-finite values (`stat_bin()`).\n\n\n\n\n\n\n\n\n\nWhat are some values of bins or binwidth that seem reasonable? At what point do either of them start to obscure data?\nAs for the missing values:\n\nacs_tr |>\n filter(is.na(median_hh_income))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\ncounty\nname\ntotal_pop\ntotal_hh\nhomeownership\ntotal_cost_burden\nrenter_cost_burden\nowner_cost_burden\nno_vehicle_hh\nmedian_hh_income\npop_density\n\n\n\n\nAnne Arundel County\n24003740400\n4241\n0\nNA\nNA\nNA\nNA\nNA\nNA\n6000.504539\n\n\nAnne Arundel County\n24003980000\n5\n0\nNA\nNA\nNA\nNA\nNA\nNA\n1.048504\n\n\nWashington County\n24043011000\n5212\n0\nNA\nNA\nNA\nNA\nNA\nNA\n3049.954209\n\n\nBaltimore city\n24510100300\n1999\n0\nNA\nNA\nNA\nNA\nNA\nNA\n33122.764732\n\n\nBaltimore city\n24510190300\n2122\n839\n0.20\n0.48\n0.52\n0.34\n0.68\nNA\n15572.409097\n\n\nBaltimore city\n24510250600\n11\n11\n0.55\n0.55\n0.00\n1.00\n0.00\nNA\n5.033091\n\n\n\n\n\n\nEven though we’re probably not going to use the total population and total household variables for any analysis here, I kept them because those sorts of variables that define what your observational unit is are important for checking what’s going on in your data. By which I mean a census tract is made up of a bunch of people (usually about 4,000) in a contiguous area who mostly live in households. But if you work with census data enough, you’ll know that some places have population but few households, or only very small populations altogether—a tract might actually be a jail or a set of college dorms, or maybe the majority of a tract is those sorts of group quarters, and the remainder is too small to reliably calculate some of the data. What we want to do with those tracts can depend on context, but I’ll drop them here.\n\nacs_tr2 <- filter(acs_tr, !is.na(median_hh_income))\n\n\nTypical values\nDoes anything seem weird about the median household income values? Look back at Figure 1 where it may be more apparent. (We’ll talk about this anomaly in the data.)\nSwitching to cost burden rates:\n\nggplot(acs_tr2, aes(x = total_cost_burden)) +\n geom_histogram(binwidth = 0.03)\n\n\n\n\n\n\n\n\nThis approaches a normal curve, but is skewed. From the histogram, the mean looks to be around 0.3 (looking back at the summary, this is correct), but with quite a few tracts with higher rates. Because this is a proportion, we don’t expect there to be any values below 0 or above 1.\nA boxplot can make it a little easier to figure out what’s typical in your distribution.\n\n# use a dummy value for x because ggplot expects boxplots to be done by a discrete variable\nggplot(acs_tr2, aes(x = 1, y = total_cost_burden)) +\n geom_boxplot() +\n coord_flip()\n\n\n\n\n\n\n\n\n\n\nUnusual values\n\nggplot(acs_tr2, aes(x = pop_density)) +\n geom_histogram(binwidth = 1000)\n\n\n\n\n\n\n\n\nThere are a few tracts that are extremely dense. If we wanted to get a sense of more typical tracts, we could filter those, either from the data or within the limits of the chart:\n\nacs_tr2 |>\n filter(pop_density < 30000) |>\n ggplot(aes(x = pop_density)) +\n geom_histogram(binwidth = 1000)\n\n\n\n\n\n\n\n# if you want bars to be between tick marks instead of centered over them, set boundary = TRUE\nacs_tr2 |>\n ggplot(aes(x = pop_density)) +\n geom_histogram(binwidth = 1000, boundary = TRUE, color = \"white\") +\n scale_x_continuous(limits = c(NA, 30000))\n\nWarning: Removed 8 rows containing non-finite values (`stat_bin()`).\n\n\nWarning: Removed 1 rows containing missing values (`geom_bar()`).\n\n\n\n\n\n\n\n\n\nWe could decide to investigate those high-density tracts. For example, if we’re interested in housing costs, we might drop tracts that seem to mostly be dorms. However, at least these tracts in Montgomery County are actually high-rise condos bordering DC, so we should keep them in.",
+ "objectID": "weeks/05_good_code.html#warm-up",
+ "href": "weeks/05_good_code.html#warm-up",
+ "title": "5. Writing good code",
+ "section": "",
+ "text": "Think about what you need in order to leave the house for work or school. What things do you need to get out the door—some variation on “phone, wallet, keys”? Think about what influences your list, e.g. maybe you switch modes of transportation, which will decide whether you need car keys, a bike helmet and lights, or a bus card.\nWrite down:\n\nthe things you always need\nthe things you sometimes need",
"crumbs": [
"Weekly notes",
- "4. Learning about your data"
+ "5. Writing good code"
]
},
{
- "objectID": "weeks/04_understanding_data.html#covariation",
- "href": "weeks/04_understanding_data.html#covariation",
- "title": "4. Learning about your data",
- "section": "Covariation",
- "text": "Covariation\nEspecially when we talk about housing and socio-economic data, we expect things to be correlated—probably even more so than with naturally occurring phenomena, since so much of where we live and what resources we have are determined by history and policy decisions. So it shouldn’t surprise you to find correlations in data like this. In fact, the CDC PLACES dataset uses demographic data to model health measures where they don’t have direct measurements available, so in cases like that you actually want to lean away from digging into correlations too much, or you might end up just confirming the makeup of the model, not finding anything new.\n\nA categorical and a numerical variable\nI’ll reshape the data to get housing tenure into one categorical variable. (If this code doesn’t make sense it’s okay.)\n\ncost_burden <- acs_tr2 |>\n tidyr::pivot_longer(cols = matches(\"cost_burden\"), \n names_to = c(\"tenure\", \".value\"), # split column names into tenure and the name of the measure (cost_burden)\n names_pattern = \"(^[a-z]+)_(\\\\w+$)\", # use regex to match a set of lowercase letters at the start of the string, followed by an underscore, then match word characters until the end\n names_ptypes = list(tenure = factor())) |>\n filter(!is.na(cost_burden))\n\n\nggplot(cost_burden, aes(x = cost_burden, color = tenure)) +\n geom_freqpoly(binwidth = 0.02)\n\n\n\n\n\n\n\n\nThe bit about calling after_stat in the book chapter doesn’t apply here, since we have the same number of observations for each tenure.\n\nggplot(cost_burden, aes(x = tenure, y = cost_burden)) +\n geom_boxplot()\n\n\n\n\n\n\n\n\n\nggplot(cost_burden, aes(x = forcats::fct_reorder(tenure, cost_burden), \n y = cost_burden)) +\n geom_boxplot()\n\n\n\n\n\n\n\n\n\n\nTwo categorical variables\nThis is a pretty contrived example to match section 10.5.2, but I’ll bin homeownership and housing cost burden into categorical variables, and look at these by county.\n\nacs_tr2 |>\n mutate(ownership_brk = cut(homeownership, \n breaks = c(0, 0.25, 0.5, 0.75, 1), \n include.lowest = TRUE, right = FALSE)) |>\n mutate(income_brk = cut(median_hh_income, \n breaks = c(0, 5e4, 1e5, 1.5e5, Inf),\n include.lowest = TRUE, right = FALSE)) |>\n count(income_brk, ownership_brk) |>\n ggplot(aes(x = income_brk, y = ownership_brk)) +\n geom_point(aes(size = n)) +\n scale_size_area()\n\n\n\n\n\n\n\n\nSee if you can adjust the code to use tiles and a color (fill) scale.\n\n\nTwo numerical variables\nSame variables, without the binning\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point()\n\n\n\n\n\n\n\n\nUse the methods in the book (changing alpha or using a 2D density) to deal with overplotting here.\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point(alpha = 0.4)\n\n\n\n\n\n\n\n\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_point(shape = \"circle open\")\n\n\n\n\n\n\n\n\n\nggplot(acs_tr2, aes(x = median_hh_income, y = homeownership)) +\n geom_bin2d()",
+ "objectID": "weeks/05_good_code.html#documenting-code",
+ "href": "weeks/05_good_code.html#documenting-code",
+ "title": "5. Writing good code",
+ "section": "Documenting code",
+ "text": "Documenting code\nOne of the most important things you can do as a programmer is to document your code. This can be hard to do well, but it’s essential to making sure your code is clear and accountable and that your work can be reproduced or repurposed. (If you’ve followed the “replicability crisis” in the sciences over the past decade or so, you’ve seen what can go very wrong when your work isn’t documented accurately for yourself and others!)\nA common suggestion is to write your code assuming you’ll come back to it in 6 months and need to be able to pick up where you left off. I usually also assume a coworker or colleague will need to rerun or reuse my code, so even if I’m doing something that I’ll remember 6 months from now, they might not know what things mean. It also gets me out of spending unnecessary amounts of time walking interns through an analysis if I can say, “I tried to document everything really well, so read through it, run all the code, and let me know if you need help after that.” Documenting code also helps ease the transition into package development, which requires a lot of documentation.\nI don’t document everything—plenty of my work is routine and straightforward enough—but some of the things I try to always take note of:\n\nAny sort of analysis or process that’s out of the ordinary or complex. Don’t assume you’ll remember later why you used a new approach.\nAnything I know someone else will need to be able to reference. Sometimes I do EDA on something that a coworker will then finish up or need to write about. I need to make sure they can do that accurately.\nOutside sources that don’t come from that specific project. If your project is contained within a set of folders, and you’ve copied data in from some other project, make a note of where it comes from so if you need to update it you know where to get it from.\nDecision-making that you might need to keep track of or argue for later. e.g. a comparison of categories between datasets with a note that says “these categories changed significantly since the previous data collection” will be helpful when someone asks why you didn’t include trends in an analysis.\nReferences. If I came up with some code based on a Stack Overflow post or a blog post somewhere, or I’m building off of someone else’s methodology, I’ll usually include a link in my comments.\n\nThis also applies to simple things like organizing your projects. If you have a bunch of folders called things like “data analysis 1” and they all contain a jumble of different notebooks and scripts for different purposes, and the scripts are all called “analysis_of_stuff.R”, you’re going to lose things easily and not know how different pieces build on each other. Similarly, don’t spend time doing an analysis only to write your data out to a file called “data.csv” and a plot called “map.png”. This might seem obvious, but I’ve seen people do all of these things.\n\nExercises\nGoing back to your list for leaving the house, add notes for how you decide whether you’ll need something. For example, if your laptop is on your “sometimes” list, write down what decides that.\n\n\n\n\n\n\nBrainstorm\n\n\n\n\nCash – if you’re going somewhere that doesn’t take cards / mobile\nSweater – weather / environment\nTea – sleepiness\nEarbuds – length of time out of house / time of day\nWork badge – going to office\nLaptop charger – if not already charged",
"crumbs": [
"Weekly notes",
- "4. Learning about your data"
+ "5. Writing good code"
+ ]
+ },
+ {
+ "objectID": "weeks/05_good_code.html#reusable-code",
+ "href": "weeks/05_good_code.html#reusable-code",
+ "title": "5. Writing good code",
+ "section": "Reusable code",
+ "text": "Reusable code\nOne rule of thumb I’ve heard is that it’s fine to repeat your code to do the same thing twice, but if you need to do it a third time, you should write a function. It might mean taking a step back from what you’re working on at the moment, but it’s pretty much always worth the time. Alongside documenting your code in general, it’s important to document your functions—what they do, what the arguments mean, what types of values arguments can take. Try to your functions and their arguments in ways that make it clear what they mean as well.",
+ "crumbs": [
+ "Weekly notes",
+ "5. Writing good code"
+ ]
+ },
+ {
+ "objectID": "weeks/05_good_code.html#exercises-1",
+ "href": "weeks/05_good_code.html#exercises-1",
+ "title": "5. Writing good code",
+ "section": "Exercises",
+ "text": "Exercises\nBuild out your morning routine into a pseudocode function, complete with arguments. Aim to make it flexible enough that you could use it any day of the week.\n\nExample\nPseudocode\nalways need: keys, wallet, phone, meds, mask\nif I'm biking:\n bring a helmet\notherwise:\n bring a bus card\nif I'm working:\n bring my laptop\nif it's Wednesday:\n take a covid test\nWorking R example\n\n# PARAMETERS:\n# date: Date object, today's date\n# biking: Logical, whether or not I'll be biking\n# working: Logical, whether or not I'm going to work\n# RETURNS:\n# prints a string\nleave_the_house <- function(date = lubridate::today(), biking = TRUE, working = TRUE) {\n day_of_week <- lubridate::wday(date, label = TRUE, abbr = FALSE)\n always_need <- c(\"keys\", \"phone\", \"wallet\", \"meds\")\n sometimes_need <- c()\n if (biking) {\n sometimes_need <- c(sometimes_need, \"helmet\")\n } else {\n sometimes_need <- c(sometimes_need, \"bus card\")\n }\n if (working) {\n sometimes_need <- c(sometimes_need, \"laptop\")\n }\n \n need <- c(always_need, sometimes_need)\n cat(\n sprintf(\"Happy %s! Today you need:\", day_of_week), \"\\n\",\n paste(need, collapse = \", \")\n )\n if (day_of_week == \"Wednesday\") {\n cat(\"\\n\\nBut take a COVID test first!\")\n }\n}\n\nleave_the_house(biking = FALSE)\n\nHappy Tuesday! Today you need: \n keys, phone, wallet, meds, bus card, laptop",
+ "crumbs": [
+ "Weekly notes",
+ "5. Writing good code"
+ ]
+ },
+ {
+ "objectID": "weeks/05_good_code.html#organization",
+ "href": "weeks/05_good_code.html#organization",
+ "title": "5. Writing good code",
+ "section": "Organization",
+ "text": "Organization\nCome up with a structure of directories you like for a project, and stick with it. The notes template repo I setup for this class has a pared down version of what I usually use, but a full version of what I might have, even for a small project, looks like this:\ncool_project \n ¦--analysis # EDA, notebooks, and scripts that create output\n |--design # scripts *only* for creating publishable charts\n ¦--fetch_data # raw data, often downloaded in a script\n ¦ ¦--fr_comments # folders for each raw data source\n ¦ °--pums \n ¦--input_data # cleaned data that is sourced for the project, maybe cleaned in prep scripts\n ¦--output_data # data that's a product of analysis in this project\n ¦--plots # plots that can be distributed or published\n ¦--prep_scripts # scripts that download, clean, reshape data\n °--utils # misc scripts & bits of data to use throughout the project\n\n\n\n\n\n\nAn aside: build tools\n\n\n\nBuild tools are outside the scope of this class, but for larger projects especially or projects that will need to be updated over time, they’ll save you a lot of headaches. I have some projects that I rebuild once a year when new ACS data comes out, and I’ve got things down to where I can make one or two calls on the command line flagging the year as a variable, and all the data wrangling and analyses are ready to go. In fact, this site rebuilds from a frozen list of packages every time I push to GitHub, and if that build is successful, it publishes automatically.\nSome tools I use:\n\nGNU Make, the OG build tool\nSnakemake, like GNU Make but written in Python and designed for data analysis\nGitHub actions, including ones specifically for R\nDocker, build a small isolated environment for your projects, some designed for R\nPackage & environment managers: mamba or conda for Python, renv for R",
+ "crumbs": [
+ "Weekly notes",
+ "5. Writing good code"
]
},
{
@@ -740,7 +773,7 @@
"href": "weeks/index.html",
"title": "Weekly notes",
"section": "",
- "text": "Order By\n Default\n \n Title\n \n \n \n \n \n \n \n\n\n\n\n\nTitle\n\n\nModified\n\n\n\n\n\n\n0. Definitions\n\n\nMarch 17, 2024\n\n\n\n\n1. Walkthrough\n\n\nMarch 17, 2024\n\n\n\n\n10. Accessibility and literacy\n\n\nMarch 17, 2024\n\n\n\n\n2. Components of a chart\n\n\nMarch 17, 2024\n\n\n\n\n3. Visual encoding\n\n\nMarch 17, 2024\n\n\n\n\n3b. Encoding cheatsheets\n\n\nMarch 17, 2024\n\n\n\n\n4. Learning about your data\n\n\nMarch 17, 2024\n\n\n\n\n5. Writing good code\n\n\nMarch 17, 2024\n\n\n\n\n6. Color\n\n\nMarch 17, 2024\n\n\n\n\n7. Text and annotations\n\n\nMarch 17, 2024\n\n\n\n\n8. Uncertainty and distributions\n\n\nMarch 17, 2024\n\n\n\n\n9. Making responsible decisions\n\n\nMarch 17, 2024\n\n\n\n\n\nNo matching items\n\n Back to top",
+ "text": "Order By\n Default\n \n Title\n \n \n \n \n \n \n \n\n\n\n\n\nTitle\n\n\nModified\n\n\n\n\n\n\n0. Definitions\n\n\nMarch 19, 2024\n\n\n\n\n1. Walkthrough\n\n\nMarch 19, 2024\n\n\n\n\n10. Accessibility and literacy\n\n\nMarch 19, 2024\n\n\n\n\n11. Merging data\n\n\nMarch 19, 2024\n\n\n\n\n2. Components of a chart\n\n\nMarch 19, 2024\n\n\n\n\n3. Visual encoding\n\n\nMarch 19, 2024\n\n\n\n\n3b. Encoding cheatsheets\n\n\nMarch 19, 2024\n\n\n\n\n4. Learning about your data\n\n\nMarch 19, 2024\n\n\n\n\n5. Writing good code\n\n\nMarch 19, 2024\n\n\n\n\n6. Color\n\n\nMarch 19, 2024\n\n\n\n\n7. Text and annotations\n\n\nMarch 19, 2024\n\n\n\n\n8. Uncertainty and distributions\n\n\nMarch 19, 2024\n\n\n\n\n9. Making responsible decisions\n\n\nMarch 19, 2024\n\n\n\n\n\nNo matching items\n\n Back to top",
"crumbs": [
"Weekly notes"
]
diff --git a/sitemap.xml b/sitemap.xml
index 069971a..7eebec9 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -2,74 +2,78 @@
https://umbc-viz.github.io/ges778/index.html
- 2024-03-17T18:45:37.734Z
+ 2024-03-19T17:37:33.854Zhttps://umbc-viz.github.io/ges778/weeks/03b_encoding_refs.html
- 2024-03-17T18:45:37.738Z
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/05_good_code.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/11_merging.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/06_color.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/04_understanding_data.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/02_components.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/07_annotations.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/09_decisions.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/00_definitions.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/08_uncertainty.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/10_accessibility.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/syllabus.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/03_encoding.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/references.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/decision_checklist.html
+ 2024-03-19T17:37:33.854Zhttps://umbc-viz.github.io/ges778/readings.html
- 2024-03-17T18:45:37.734Z
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/decision_checklist.html
- 2024-03-17T18:45:37.734Z
+ https://umbc-viz.github.io/ges778/references.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/03_encoding.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/syllabus.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/10_accessibility.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/08_uncertainty.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/00_definitions.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/09_decisions.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/07_annotations.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/02_components.html
+ 2024-03-19T17:37:33.858Z
- https://umbc-viz.github.io/ges778/weeks/04_understanding_data.html
- 2024-03-17T18:45:37.738Z
+ https://umbc-viz.github.io/ges778/weeks/06_color.html
+ 2024-03-19T17:37:33.858Z
+
+
+ https://umbc-viz.github.io/ges778/weeks/05_good_code.html
+ 2024-03-19T17:37:33.858Zhttps://umbc-viz.github.io/ges778/weeks/index.html
- 2024-03-17T18:45:37.738Z
+ 2024-03-19T17:37:33.858Zhttps://umbc-viz.github.io/ges778/weeks/01_walkthrough.html
- 2024-03-17T18:45:37.738Z
+ 2024-03-19T17:37:33.858Z
diff --git a/syllabus.html b/syllabus.html
index 0c00908..696ad90 100644
--- a/syllabus.html
+++ b/syllabus.html
@@ -250,6 +250,12 @@
10. Accessibility and literacy
+
+
Here are some notes on merging data from different data frames. A lot of the functions here come from dplyr, including all the *_join ones.
+
+
Types of joins
+
There are different types of joins that are defined by what data you want to keep and under what circumstances. These are consistent across many different languages (e.g. same terminology in R should apply in most/all SQL variants). The ones you’ll use most often are left joins and inner joins; when in doubt, a left join is safer than an inner join.
+
There’s an overly complicated chapter in R for Data Science on joins. There are some less complicated examples in the dplyr docs.
+
+
+
+An illustration of joins
+
+
+
Imagine we’re joining two tables of data for counties A, B, C, D, and E, one row per county. The left table, housing, has housing information for each county but is missing County B. The right table, income, has income information for counties A, B, and E. That means there are a total of 5 counties, but only 2 of them are in both tables.
+
+
Left join will include every county that’s in housing, regardless of whether it’s also in income. There will be a row for income variables, but their values will be NA.
+
Inner join will include every county that’s in bothhousingandincome.
+
Right join is like left join: it will include every county that’s in income, regardless of whether it’s also in housing.
+
Full join will include every county in either table.
+
+
+
set.seed(1)
+housing <-data.frame(county =c("A", "C", "D", "E"),
+homeownership =runif(4),
+vacancy =runif(4, min =0, max =0.1))
+income <-data.frame(county =c("A", "B", "E"),
+poverty =runif(3))
+
+left_join(housing, income, by ="county")
+
+
+
+
+
+
county
+
homeownership
+
vacancy
+
poverty
+
+
+
+
+
A
+
0.2655087
+
0.0201682
+
0.6291140
+
+
+
C
+
0.3721239
+
0.0898390
+
NA
+
+
+
D
+
0.5728534
+
0.0944675
+
NA
+
+
+
E
+
0.9082078
+
0.0660798
+
0.2059746
+
+
+
+
+
+
inner_join(housing, income, by ="county")
+
+
+
+
+
+
county
+
homeownership
+
vacancy
+
poverty
+
+
+
+
+
A
+
0.2655087
+
0.0201682
+
0.6291140
+
+
+
E
+
0.9082078
+
0.0660798
+
0.2059746
+
+
+
+
+
+
right_join(housing, income, by ="county")
+
+
+
+
+
+
county
+
homeownership
+
vacancy
+
poverty
+
+
+
+
+
A
+
0.2655087
+
0.0201682
+
0.6291140
+
+
+
E
+
0.9082078
+
0.0660798
+
0.2059746
+
+
+
B
+
NA
+
NA
+
0.0617863
+
+
+
+
+
+
full_join(housing, income, by ="county")
+
+
+
+
+
+
county
+
homeownership
+
vacancy
+
poverty
+
+
+
+
+
A
+
0.2655087
+
0.0201682
+
0.6291140
+
+
+
C
+
0.3721239
+
0.0898390
+
NA
+
+
+
D
+
0.5728534
+
0.0944675
+
NA
+
+
+
E
+
0.9082078
+
0.0660798
+
0.2059746
+
+
+
B
+
NA
+
NA
+
0.0617863
+
+
+
+
+
+
+
There are other joins that might be useful for filtering, but that don’t add any new columns. Semi joins return the rows of the left table that have a match in the right table, and anti joins return the rows of the left table that do not have a match in the right table. If you were making separate charts on housing and income, but wanted your housing chart to only include counties that are also in your income data, semi join would help.
ACS data has several geographies, including census tracts (I’ve subset for just tract data). Their ID (GEOID, or FIPS codes) are in the column name. The EPA data is only by tract, and its column of IDs is labeled tract. So we’ll be joining name from acs_tract with tract from ejscreen.
+
+
n_distinct(acs_tract$name)
+
+
[1] 1460
+
+
n_distinct(ejscreen$tract)
+
+
[1] 1475
+
+
+
There are 15 tracts that are included in the EPA data but not the ACS data. That’s because those are tracts with no population that I dropped from the ACS table when I made it. I can check up on that with an anti-join (not running this here but it confirms that these are all zero-population tracts).
+
+
pop <- tidycensus::get_acs("tract", table ="B01003", state ="MD", year =2022)
+
+anti_join(ejscreen, acs_tract, by =c("tract"="name")) |>
+distinct(tract) |>
+inner_join(pop, by =c("tract"="GEOID"))
+
+
There’s another hiccup for merging data here: the ACS data is in a wide format (each variable has its own column), while the EPA data is in a long format (one column gives the indicator, then different types of values have their own columns). Those formatting differences could be awkward because you’d end up with some values repeated. The easiest thing to do is select just the data you’re interested in, either by selecting certain columns or filtering rows, then reshape, then join.
+
Let’s say I’m interested in the relationship, if any, between demographics and a few waste-related risk factors (proximity to wastewater, hazardous waste, and superfund sites). I’ll filter ejscreen for just those 2 indicators and reshape it so the columns have the value percentiles for each of those two risk factors (not the adjusted percentiles). Then I’ll select the columns I want from acs, then join them.
+
The tidyr::pivot_wider and tidyr::pivot_longer functions can be confusing, but there are some good examples in the docs and a lot of Stack Overflow posts on them. Basically here I’m reshaping from a long shape to a wide shape, so I’ll use pivot_wider.
+
+
# in practice I would do this all at once, but want to keep the steps separate
+# so they're more visible
+waste_long <- ejscreen |>
+filter(indicator %in%c("haz_waste", "superfund", "wastewater"))
+
+head(waste_long)
+
+
+
+
+
+
tract
+
indicator
+
value_ptile
+
d2_ptile
+
d5_ptile
+
+
+
+
+
24001000100
+
superfund
+
38
+
31
+
52
+
+
+
24001000100
+
haz_waste
+
2
+
2
+
3
+
+
+
24001000100
+
wastewater
+
69
+
46
+
81
+
+
+
24001000200
+
superfund
+
88
+
67
+
85
+
+
+
24001000200
+
haz_waste
+
21
+
27
+
33
+
+
+
24001000200
+
wastewater
+
80
+
73
+
89
+
+
+
+
+
+
# id_cols are the anchor of the pivoting
+# only using value_ptile as a value column, not scaled ones
+waste_wide <- waste_long |>
+ tidyr::pivot_wider(id_cols = tract,
+names_from = indicator,
+values_from = value_ptile)
+
+head(waste_wide)
+
+
+
+
+
+
tract
+
superfund
+
haz_waste
+
wastewater
+
+
+
+
+
24001000100
+
38
+
2
+
69
+
+
+
24001000200
+
88
+
21
+
80
+
+
+
24001000500
+
90
+
28
+
24
+
+
+
24001000600
+
93
+
36
+
78
+
+
+
24001000700
+
92
+
49
+
83
+
+
+
24001000800
+
89
+
70
+
87
+
+
+
+
+
+
+
Then the columns I’m interested in from the ACS data:
So each of these two data frames has a column of tract IDs, and several columns of relevant values. I only want tracts that are in both datasets, so I’ll use an inner join.
+
+
waste_x_demo <-inner_join(acs_demo, waste_wide, by =c("name"="tract"))
+
+head(waste_x_demo)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
name
+
county
+
white
+
poverty
+
foreign_born
+
superfund
+
haz_waste
+
wastewater
+
+
+
+
+
24001000100
+
Allegany County
+
0.98
+
0.12
+
0.01
+
38
+
2
+
69
+
+
+
24001000200
+
Allegany County
+
0.75
+
0.11
+
0.03
+
88
+
21
+
80
+
+
+
24001000500
+
Allegany County
+
0.66
+
0.27
+
0.04
+
90
+
28
+
24
+
+
+
24001000600
+
Allegany County
+
0.91
+
0.14
+
0.00
+
93
+
36
+
78
+
+
+
24001000700
+
Allegany County
+
0.93
+
0.28
+
0.02
+
92
+
49
+
83
+
+
+
24001000800
+
Allegany County
+
0.89
+
0.35
+
0.02
+
89
+
70
+
87
+
+
+
+
+
+
+
+
ggplot(waste_x_demo, aes(x = poverty, y = haz_waste, color = county =="Baltimore city")) +
+geom_point(alpha =0.5, size =1) +
+scale_color_manual(values =c("TRUE"="firebrick", "FALSE"="gray60"))
+
+
+
+
+
+
+
+
+
Is there a pattern? Maybe not, but now we know how to investigate it. There’s definitely something up with Baltimore though.