Troubleshooting jobs on Elastic MapReduce
EmrEtlRunner has three different ways of failing:
- The ETL job on Elastic MapReduce fails to start
- The ETL job starts on Elastic MapReduce but errors part way through
- One or more S3 file copy operations fail
This page helps you to diagnose what is going wrong, and gives suggestions for fixing the issue.
A problem running the ETL job on Elastic MapReduce looks like this:
------------------
Waiting a minute to allow S3 to settle (eventual consistency)
Initializing EMR jobflow
EMR jobflow j-397K2WS5ZTOOT failed, check Amazon logs for details. Data files not archived.
---------------
This tells you that you have a problem with your ETL job - continue to the next section, Diagnosing an ETL job failure.
On the other hand, when S3 file copy operations fail repeatedly, you will see errors (e.g. "500 InternalServerErrors") reported by Sluice sluice, which is the library we use to handle S3 file operations. In this case, jump to the final section, Fixing S3 file copy failures.
### Diagnosing an ETL job failureIf you haven't successfully run EmrEtlRunner before, it's 95% likely that the problem is a misconfiguration in your config.yml file. Please double-check this before proceeding.
To investigate a problem with the ETL job, first follow these steps:
- Login to the Amazon Elastic MapReduce interface
- Browse to your failed job flow
- Click on it and look at the lower pane
- Check for an error message explaining why your job failed to start
Here is an example where Elastic MapReduce simply failed to bootstrap the cluster (which happens occasionally):
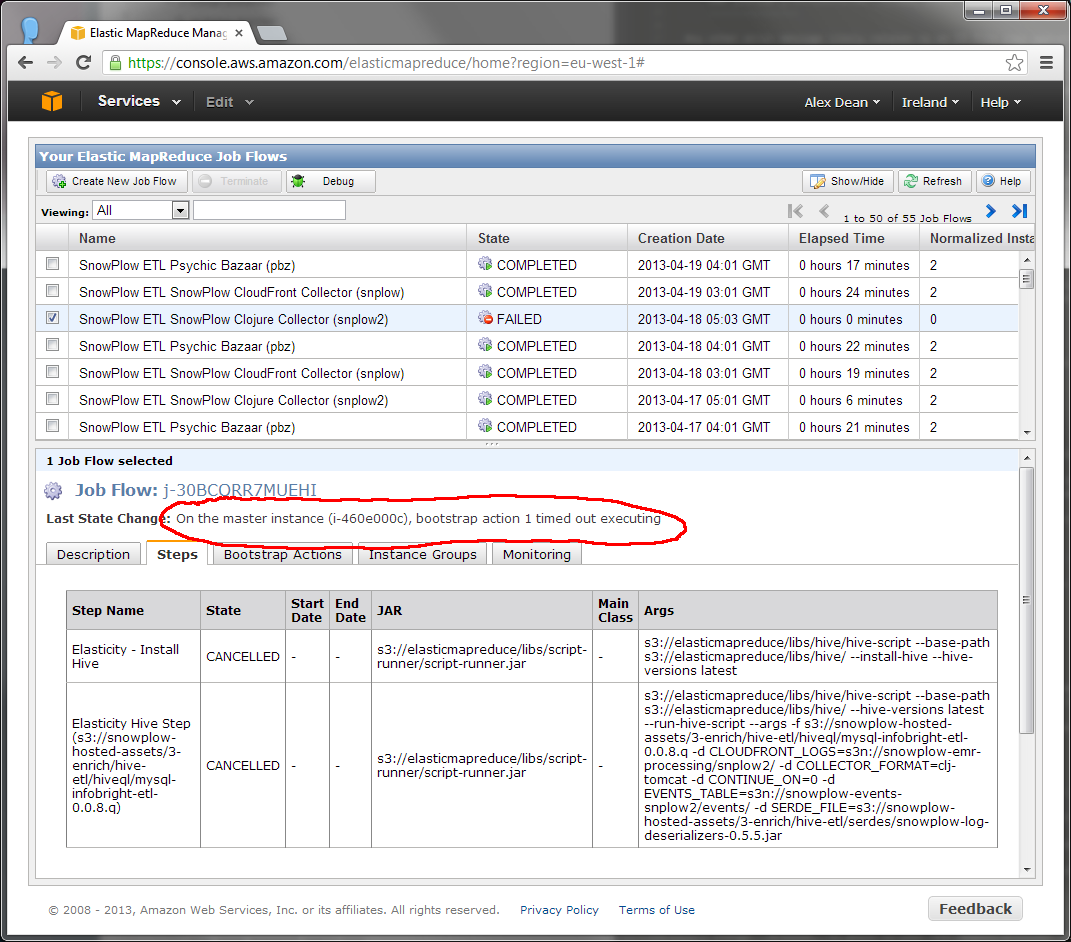
In this case, we would simply rerun EmrEtlRunner with the command-line option of --skip staging.
On the other hand, if your job started but encountered errors part way through, then you should see something like this:
To find out what happened, we will need to dig into the Hadoop logs for the step - please continue to the next section, Checking the Hadoop logs for errors.
### Checking the Hadoop logs for errorsElastic MapReduce saves all Hadoop logs into your Log Bucket. To check them for errors, follow these steps:
- Browse to your Log Bucket (as defined in your
config.ymlfile) in the Amazon S3 interface (or in CloudBerry, BucketExplorer or similar) - Open the sub-folder named after the jobflow which just failed (in the example above,
j-397K2WS5ZTOOT) - Open the
task_attemptssub-folder - Open the
job_*sub-folder - You should now see something like this:

Note the sub-folders where there have been multiple attempts to process the same file. Check in each of these sub-folders to find the most complete set of log files. In this example, the _0 and _1 sub-folders contained no logs but the _2 and _3 folders both contained the below:
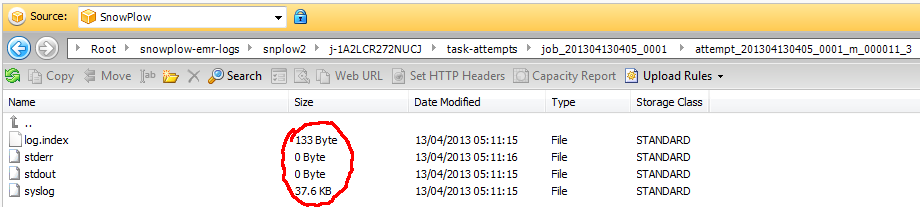
Now download these files locally and open the files in your editor, and search for "ERROR" or similar. In my case, I found the following error in syslog:
2013-04-13 04:10:25,336 WARN com.snowplowanalytics.snowplow.hadoop.hive.SnowPlowEventStruct (main): Unexpected params { ?: null }
2013-04-13 04:10:25,338 FATAL ExecMapper (main): org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing writable 2013-04-12 03:22:57 - 37 50.63.184.196 GET 50.63.184.196 /i 200 Googlebot-Image%2F1.0 ?e=pv&page=Root+README&aid=snowplowgithub&p=web&tv=no-js-0.1.0&nuid=9d0d1b67-4dd9-40d2-acb9-da3b207492a8 - - -
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:524)
at org.apache.hadoop.hive.ql.exec.ExecMapper.map(ExecMapper.java:143)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:50)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:441)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:377)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1132)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
Caused by: org.apache.hadoop.hive.serde2.SerDeException: org.apache.hadoop.hive.serde2.SerDeException: Row does not match expected CloudFront regexp pattern
at com.snowplowanalytics.snowplow.hadoop.hive.SnowPlowEventDeserializer.deserialize(SnowPlowEventDeserializer.java:185)
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:508)
... 9 more
Caused by: org.apache.hadoop.hive.serde2.SerDeException: Row does not match expected CloudFront regexp pattern
at com.snowplowanalytics.snowplow.hadoop.hive.SnowPlowEventStruct.updateByParsing(SnowPlowEventStruct.java:282)
at com.snowplowanalytics.snowplow.hadoop.hive.SnowPlowEventDeserializer.deserialize(SnowPlowEventDeserializer.java:173)
... 10 more
In fact this error was caused by this bug in the Clojure Collector - to fix it, I added the missing "-" into the failing line in the Snowplow log file and re-ran the job.
If you go through the above process and discover a log row which our ETL process cannot handle, please raise a ticket in our GitHub repository, making sure to include the full log row in your description.
### S3 file copy operation errorsOccasionally Amazon S3 fails repeatedly to perform a file operation, causing EmrEtlRunner to die. If this happens, you need to rerun your EmrEtlRunner - hopefully the file copy error will not recur.
To rerun your job correctly, use the following guidance:
If the job died during the move-to-processing step, either:
- Rerun EmrEtlRunner with the command-line option of
--skip staging, or: - Move any files from the Processing Bucket back to the In Bucket and rerun EmrEtlRunner without any
--skipoption*
* We recommend option 2 if only a handful of files were transferred to your Processing Bucket before the S3 error.
If the job died during the archiving step, rerun EmrEtlRunner with the command-line option of --skip staging,emr