This notebook demonstrates how to deploy a model server and request predictions from a client application.
OpenVINO Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
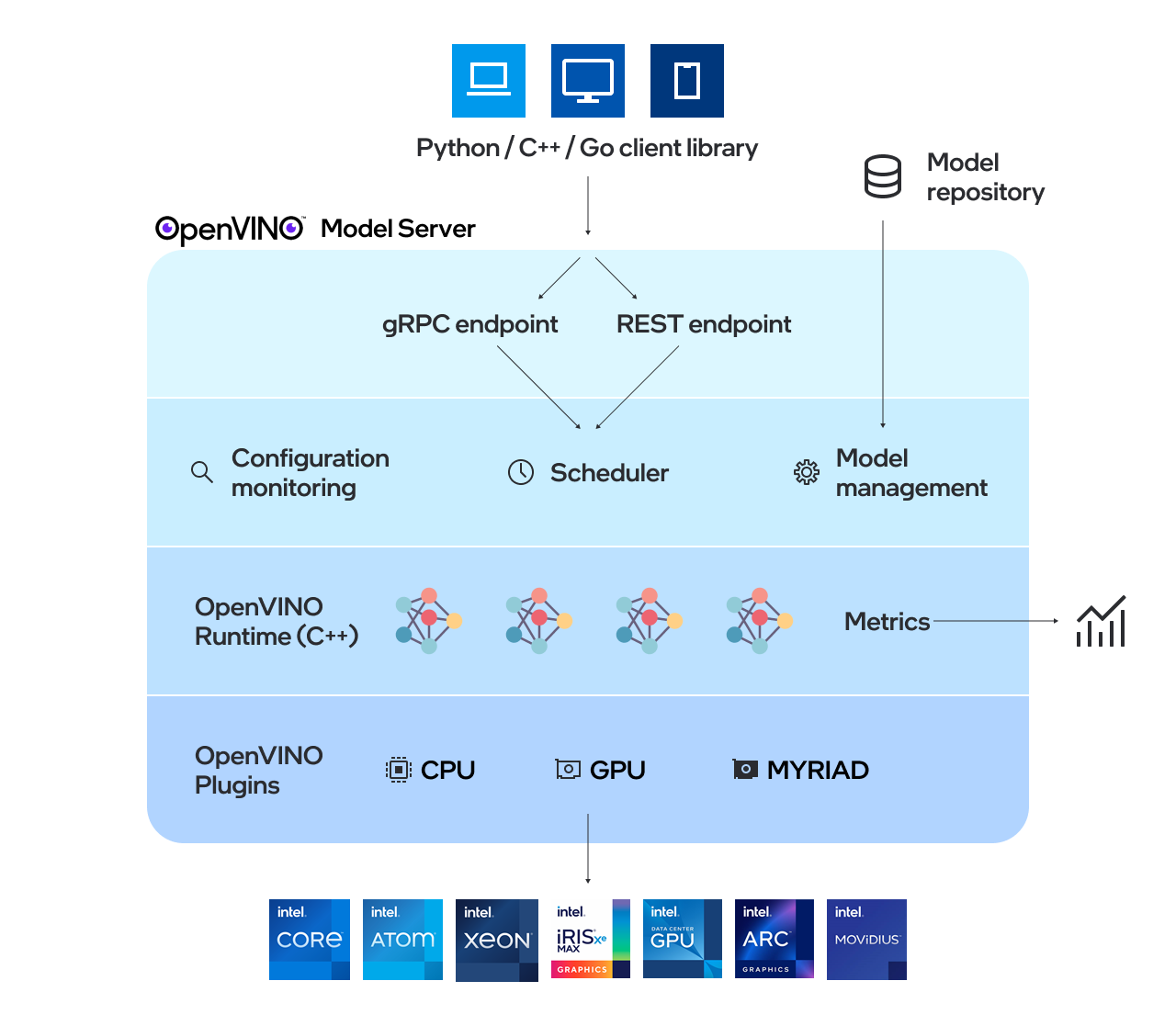
The notebook covers following steps:
- Prepare Docker
- Preparing a Model Repository
- Start the Model Server Container
- Prepare the Example Client Components
If you have not installed all required dependencies, follow the Installation Guide.