diff --git a/_posts/2023-12-11-LLM.md b/_posts/2023-12-11-LLM.md
new file mode 100644
index 00000000..8c3e5c77
--- /dev/null
+++ b/_posts/2023-12-11-LLM.md
@@ -0,0 +1,377 @@
+---
+layout: post
+title: Large Language Models
+author: [Richard Kuo]
+category: [Lecture]
+tags: [jekyll, ai]
+---
+
+Introduction to Language Models, LLMs, Algorithms for building LLMs, etc.
+
+---
+## History of LLM
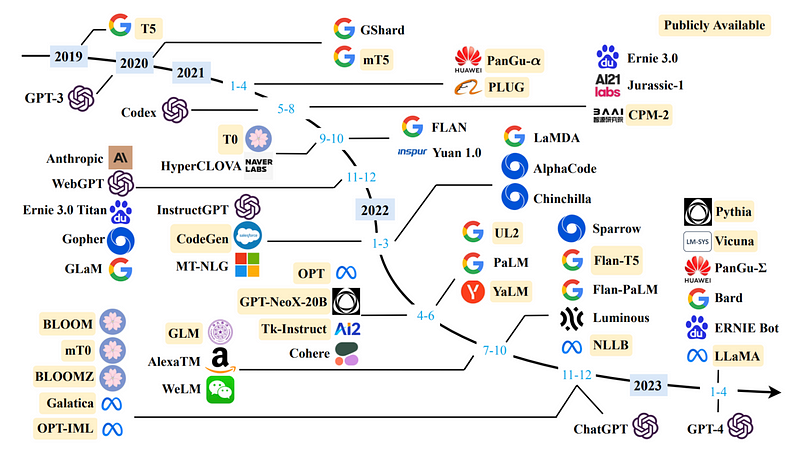
+Since the introduction of Transformer model in 2017, large language models (LLMs) have evolved significantly. ChatGPT saw 1.6B visits in May 2023. Meta also released three versions of LLaMA-2 (7B, 13B, 70B) free for commercial use in July.
+
+### LLM Landscape
+
+
+
+---
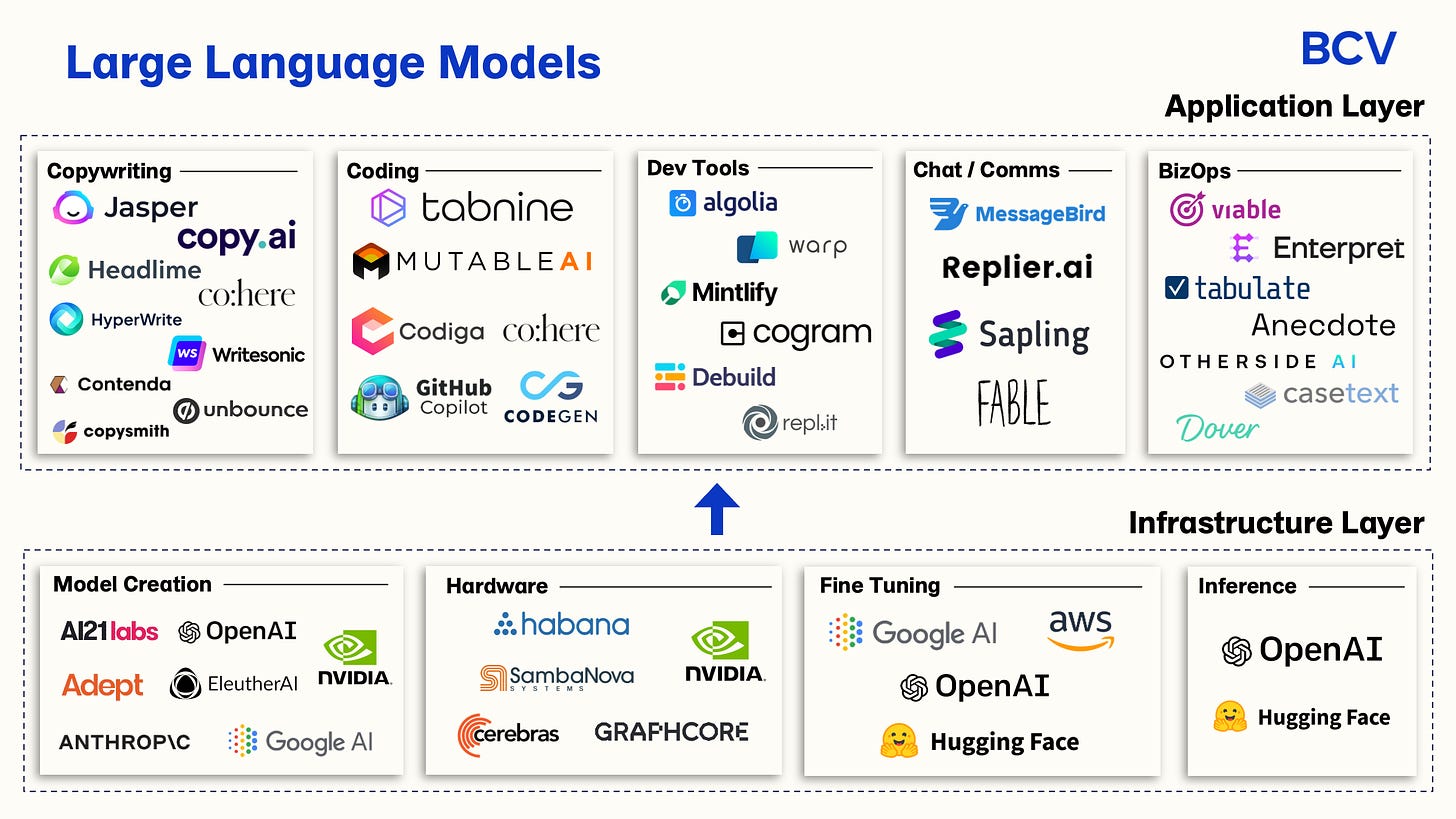
+### Companies Landscape
+
+
+---
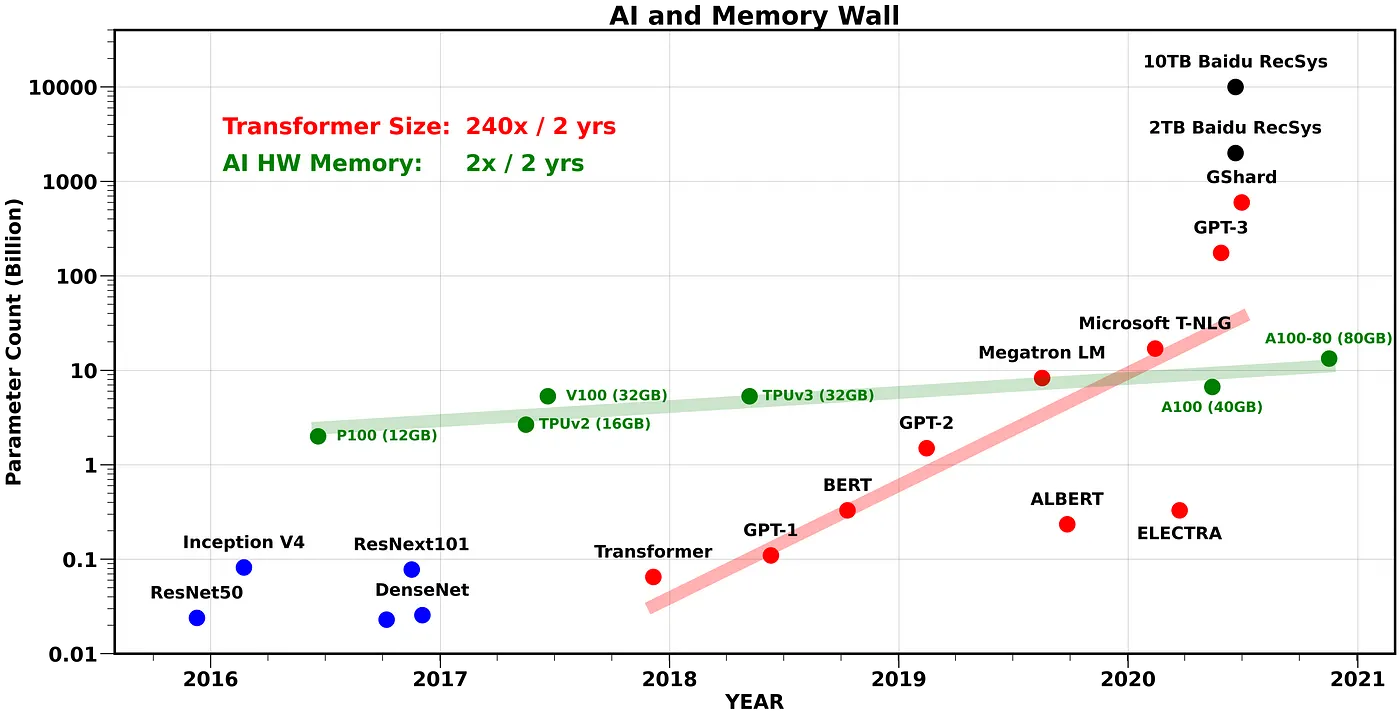
+### Growth of Compute Memory vs. Transformer Size
+Ref. [AI and Memory Wall](https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8)
+
+
+---
+
+
+---
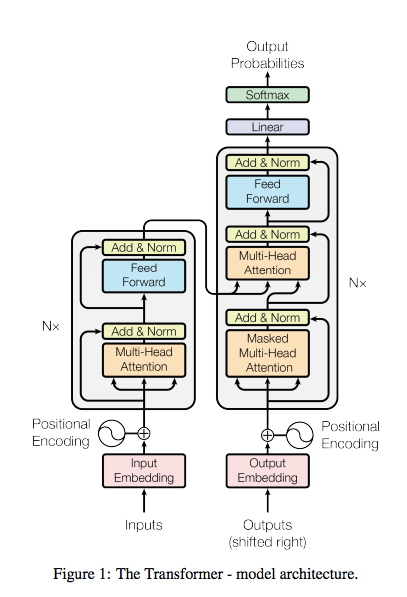
+## Transformer
+**Paper:** [Attention Is All You Need](https://arxiv.org/abs/1706.03762)
+**Code:** [huggingface/transformers](https://github.com/huggingface/transformers)
+
+
+
+
+
+
+
+
+---
+### New Understanding about Transformer
+**Blog:**
+* [Researchers Gain New Understanding From Simple AI](https://www.quantamagazine.org/researchers-glimpse-how-ai-gets-so-good-at-language-processing-20220414/)
+* [Transformer稱霸的原因找到了?OpenAI前核心員工揭開注意力頭協同工作機理](https://bangqu.com/A76oX7.html)
+
+**Papers:**
+* [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html)
+* [In-context Learning and Induction Heads](https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html)
+
+---
+### BERT
+**Paper:** [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
+**Blog:** [進擊的BERT:NLP 界的巨人之力與遷移學習](https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html)
+
+---
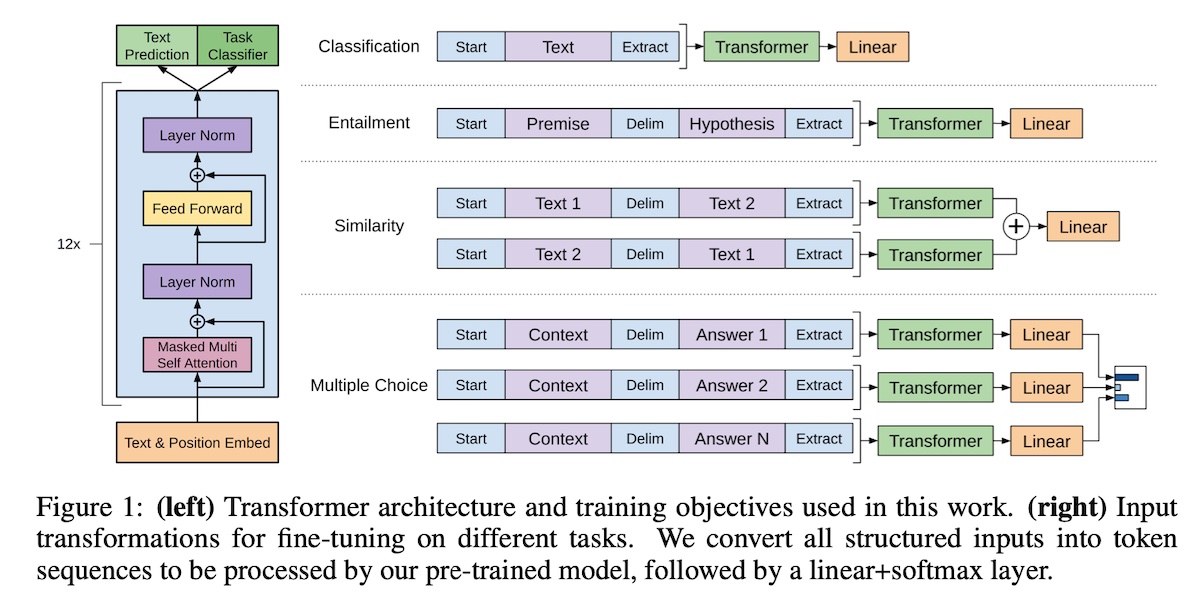
+### GPT (Generative Pre-Training Transformer)
+**Paper:** [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
+**Paper:** [Language Models are Few-Shot Learners](https://arxiv.org/abs/2005.14165)
+
+**Code:** [https://github.com/huggingface/transformers](https://github.com/huggingface/transformers)
+
+### GPT-2
+**Paper:** [Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf)
+**Code:** [openai/gpt-2](https://github.com/openai/gpt-2)
+**GPT2 Demo:** [Transformer Demo](https://app.inferkit.com/demo), [GPT-2 small](https://minimaxir.com/apps/gpt2-small/)
+**Blog:** [直觀理解GPT2語言模型並生成金庸武俠小說](https://leemeng.tw/gpt2-language-model-generate-chinese-jing-yong-novels.html)
+
+---
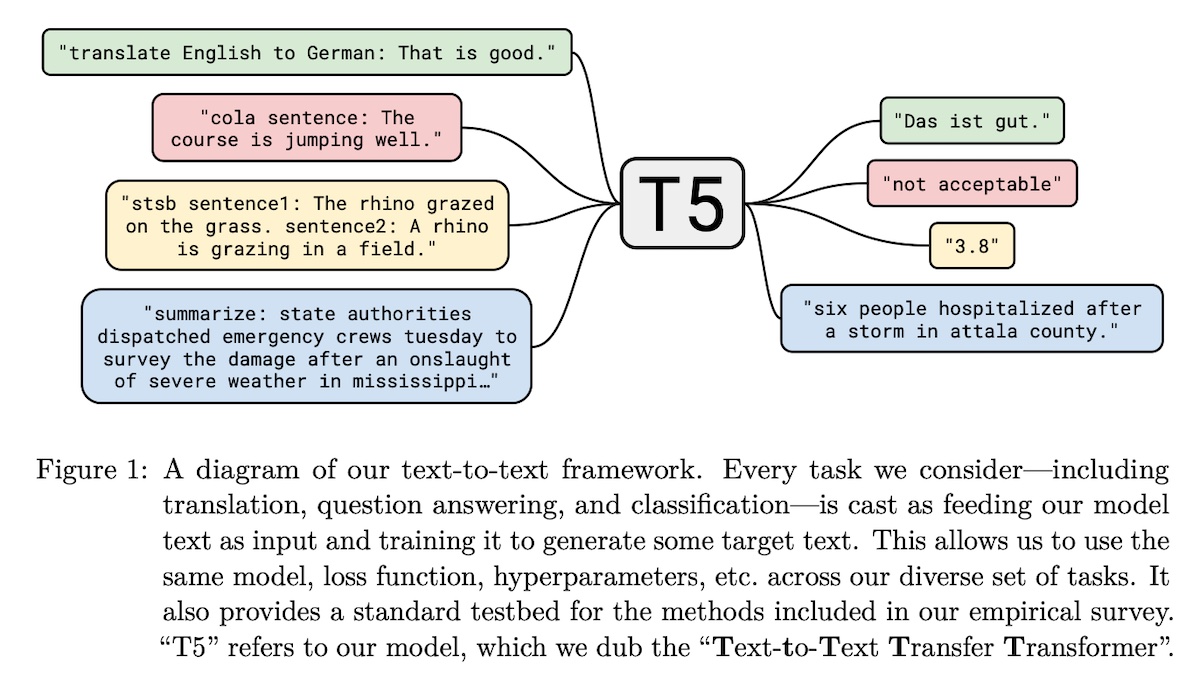
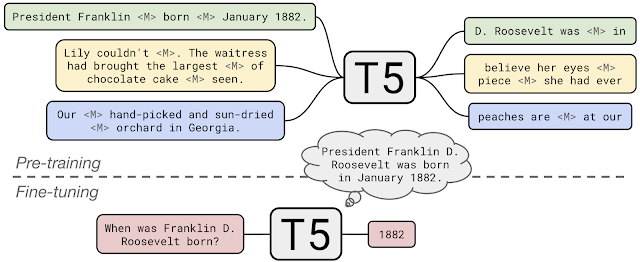
+### T5: Text-To-Text Transfer Transformer (by Google)
+**Paper:** [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)
+**Code:** [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer)
+
+
+---
+### GPT-3
+**Code:** [openai/gpt-3](https://github.com/openai/gpt-3)
+**[GPT-3 Demo](https://gpt3demo.com/)**
+
+
+---
+### [CKIP Lab 繁體中文詞庫小組](https://ckip.iis.sinica.edu.tw/)
+CKIP (CHINESE KNOWLEDGE AND INFORMATION PROCESSING): 繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具。
+[CKIP Lab 下載軟體與資源](https://ckip.iis.sinica.edu.tw/resource)
+* [CKIP Transformers](https://github.com/ckiplab/ckip-transformers)
+* [CKIP Tagger](https://github.com/ckiplab/ckiptagger)
+
+---
+## Question Answering
+### [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) - The Stanford Question Answering Dataset
+**Paper:** [Know What You Don't Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822)
+
+
+---
+### Instruct GPT
+**Paper:** [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155)
+**Blog:** [Aligning Language Models to Follow Instructions](https://openai.com/blog/instruction-following/)
+
+---
+### ChatGPT
+[ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/)
+ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
+
+
+
+
+
+---
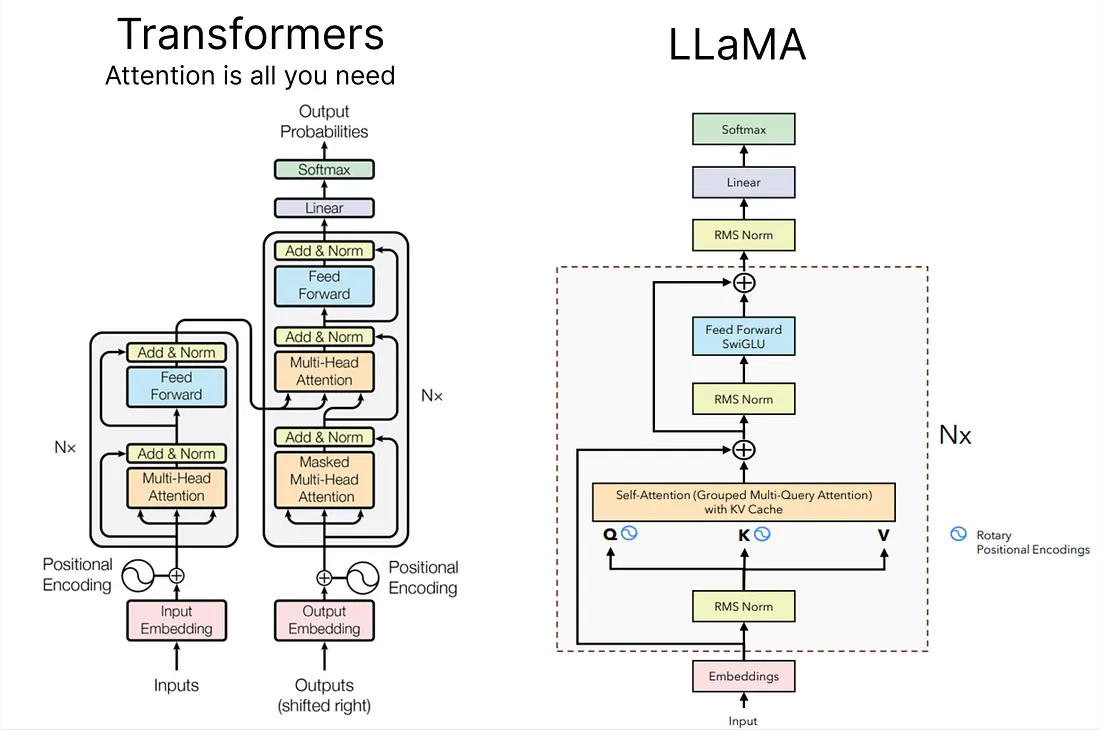
+### [LLaMA](https://huggingface.co/docs/transformers/main/model_doc/llama)
+*It is a collection of foundation language models ranging from 7B to 65B parameters.*
+**Paper:** [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
+
+
+---
+### [OpenLLaMA](https://github.com/openlm-research/open_llama)
+**model:** [https://huggingface.co/openlm-research/open_llama_3b_v2](https://huggingface.co/openlm-research/open_llama_3b_v2)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-openllama](https://www.kaggle.com/code/rkuo2000/llm-openllama)
+
+---
+**Blog:** [Building a Million-Parameter LLM from Scratch Using Python](https://levelup.gitconnected.com/building-a-million-parameter-llm-from-scratch-using-python-f612398f06c2)
+**Kaggle:** [LLM LLaMA from scratch](https://www.kaggle.com/rkuo2000/llm-llama-from-scratch/)
+
+---
+### Falcon-40B
+**Paper:** [The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only](https://arxiv.org/abs/2306.01116)
+**Code:** [https://huggingface.co/tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b)
+
+---
+### LLaMA-2
+**Paper:** [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://arxiv.org/abs/2307.09288)
+**Code:** [https://github.com/facebookresearch/llama](https://github.com/facebookresearch/llama)
+**models:** [https://huggingface.co/meta-llama](https://huggingface.co/meta-llama)
+
+---
+### GPT4
+**Paper:** [GPT-4 Technical Report](https://arxiv.org/abs/2303.08774)
+
+
+---
+### MiniGPT-4
+**Paper:** [MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models](https://arxiv.org/abs/2304.10592)
+**Paper:** [MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning](https://arxiv.org/abs/2310.09478)
+**Code:** [https://github.com/Vision-CAIR/MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)
+
+
+
+
+---
+### LLM Lingua
+**Paper: [LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models](https://arxiv.org/abs/2310.05736)
+**Code: [https://github.com/microsoft/LLMLingua](https://github.com/microsoft/LLMLingua)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-lingua](https://www.kaggle.com/code/rkuo2000/llm-lingua)
+
+
+---
+### Mistral Transformer
+**Paper:** [Mistral 7B](https://arxiv.org/abs/2310.06825)
+**Code:** [https://github.com/mistralai/mistral-src](https://github.com/mistralai/mistral-src)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct](https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct)
+
+---
+### Zephyr
+**Paper:** [Zephyr: Direct Distillation of LM Alignment](https://arxiv.org/abs/2310.16944)
+**Code:** [https://huggingface.co/HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b](https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b)
+
+
+---
+### SOLAR-10.7B ~ Depth Upscaling
+**Code:** [https://huggingface.co/upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0)
+Depth-Upscaled SOLAR-10.7B has remarkable performance. It outperforms models with up to 30B parameters, even surpassing the recent Mixtral 8X7B model.
+Leveraging state-of-the-art instruction fine-tuning methods, including supervised fine-tuning (SFT) and direct preference optimization (DPO),
+researchers utilized a diverse set of datasets for training. This fine-tuned model, SOLAR-10.7B-Instruct-v1.0, achieves a remarkable Model H6 score of 74.20,
+boasting its effectiveness in single-turn dialogue scenarios.
+
+---
+### Phi-2 (Transformer with 2.7B parameters)
+**Blog:** [Phi-2: The surprising power of small language models](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)
+**Code:** [https://huggingface.co/microsoft/phi-2](https://huggingface.co/microsoft/phi-2)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-phi-2](https://www.kaggle.com/code/rkuo2000/llm-phi-2)
+
+---
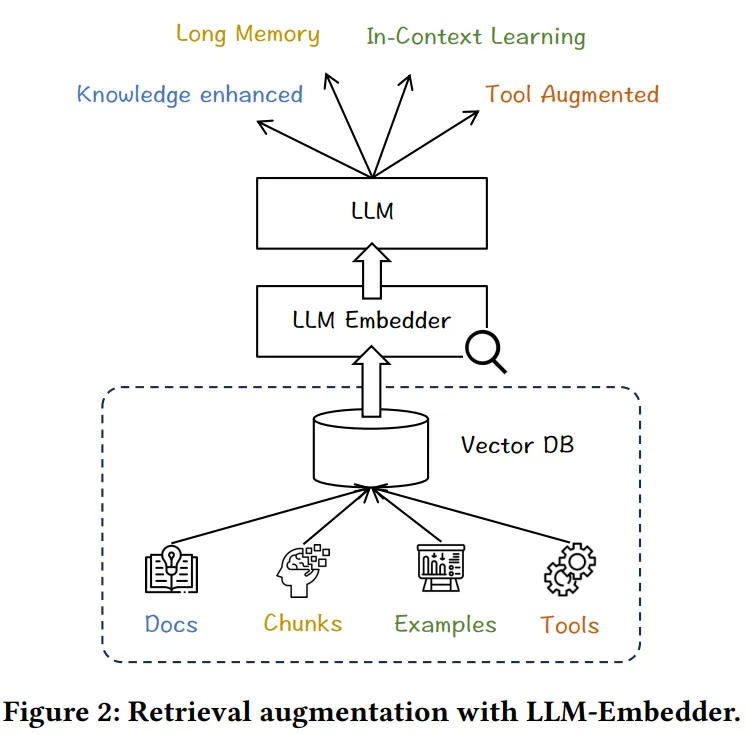
+### FlagEmbedding
+**Paper:** [Retrieve Anything To Augment Large Language Models](https://arxiv.org/abs/2310.07554)
+**Code:** [https://github.com/FlagOpen/FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-flagembedding](https://www.kaggle.com/code/rkuo2000/llm-flagembedding)
+
+
+---
+### LM-Cocktail
+**Paper:** [LM-Cocktail: Resilient Tuning of Language Models via Model Merging](https://arxiv.org/abs/2311.13534)
+**Code:** [https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
+
+---
+### LongLoRA
+**Code:** [https://github.com/dvlab-research/LongLoRA](https://github.com/dvlab-research/LongLoRA)
+[2023.11.19] We release a new version of LongAlpaca models, LongAlpaca-7B-16k, LongAlpaca-7B-16k, and LongAlpaca-7B-16k.
+
+
+---
+### Magicoder
+**Paper:** [Magicoder: Source Code Is All You Need](https://arxiv.org/abs/2312.02120)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-magicoder](https://www.kaggle.com/code/rkuo2000/llm-magicoder)
+
+
+---
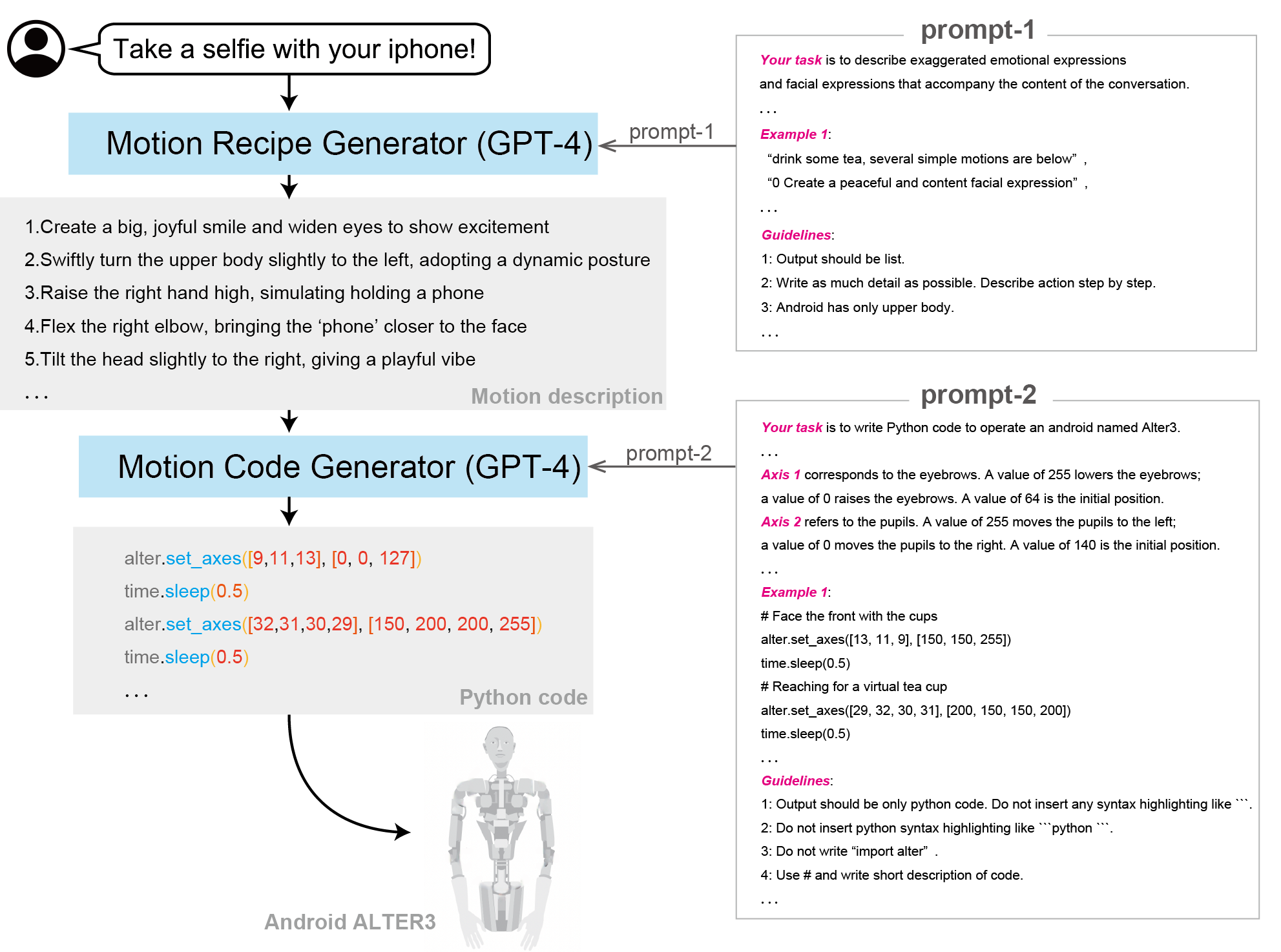
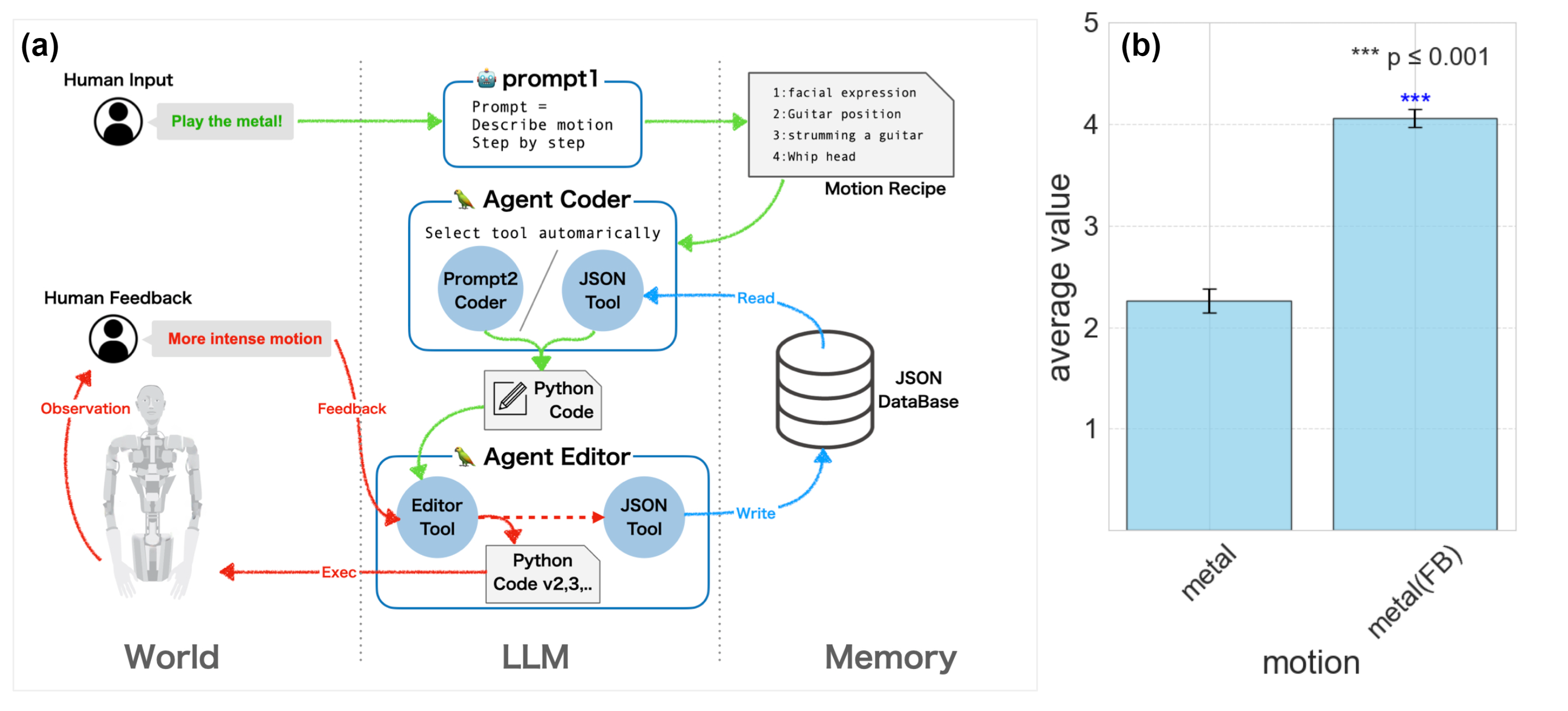
+### [ALTER-LLM](https://tnoinkwms.github.io/ALTER-LLM/)
+**Paper:** [From Text to Motion: Grounding GPT-4 in a Humanoid Robot "Alter3"](https://arxiv.org/abs/2312.06571)
+
+
+
+
+---
+### EAGLE-LLM
+**Blog:** [EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation](https://sites.google.com/view/eagle-llm)
+**Code:** [https://github.com/SafeAILab/EAGLE](https://github.com/SafeAILab/EAGLE)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/eagle-llm](https://www.kaggle.com/code/rkuo2000/eagle-llm)
+
+---
+### Purple Llama CyberSecEval
+**Paper:** [Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models](https://arxiv.org/abs/2312.04724)
+**Code:** [CybersecurityBenchmarks](https://github.com/facebookresearch/PurpleLlama/tree/main/CybersecurityBenchmarks)
+[meta-llama/LlamaGuard-7b](https://huggingface.co/meta-llama/LlamaGuard-7b)
+
+
Our Test Set (Prompt)
OpenAI Mod
ToxicChat
Our Test Set (Response)
+
Llama-Guard
0.945
0.847
0.626
0.953
+
OpenAI API
0.764
0.856
0.588
0.769
+
Perspective API
0.728
0.787
0.532
0.699
+
+
+---
+## Building LLM
+[Patterns for Building LLM-based Systems & Products](https://eugeneyan.com/writing/llm-patterns/)
+
+
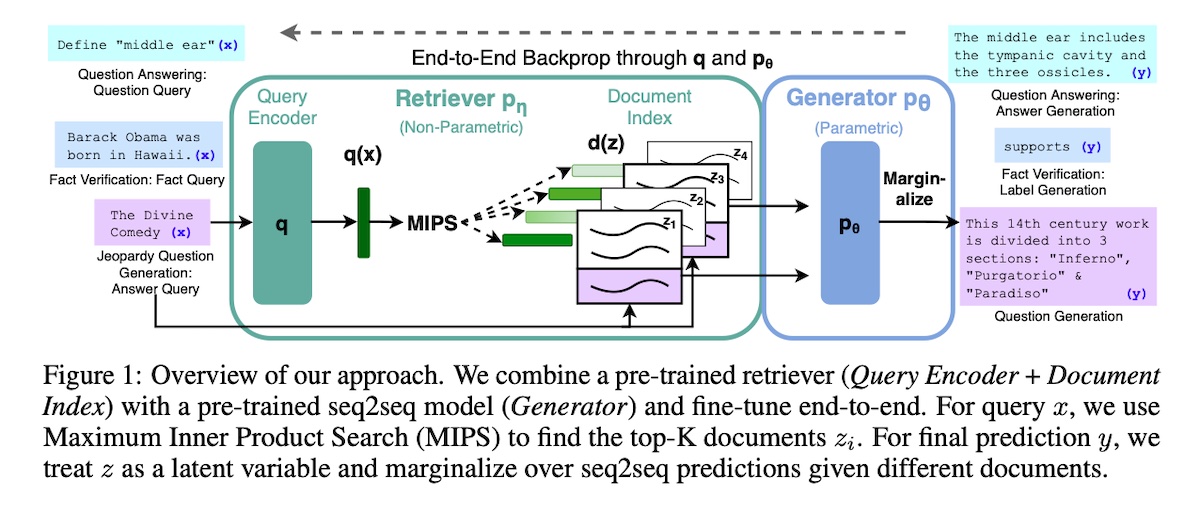
+### [Retrieval Augmented Generation (RAG)](https://arxiv.org/abs/2005.11401) to Add Knowledge
+
+
+---
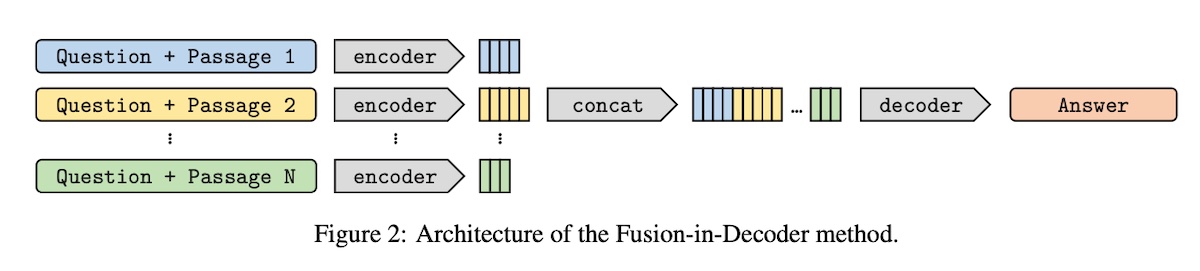
+#### [Fusion-in-Decoder (FiD)](https://arxiv.org/abs/2007.01282)
+
+
+---
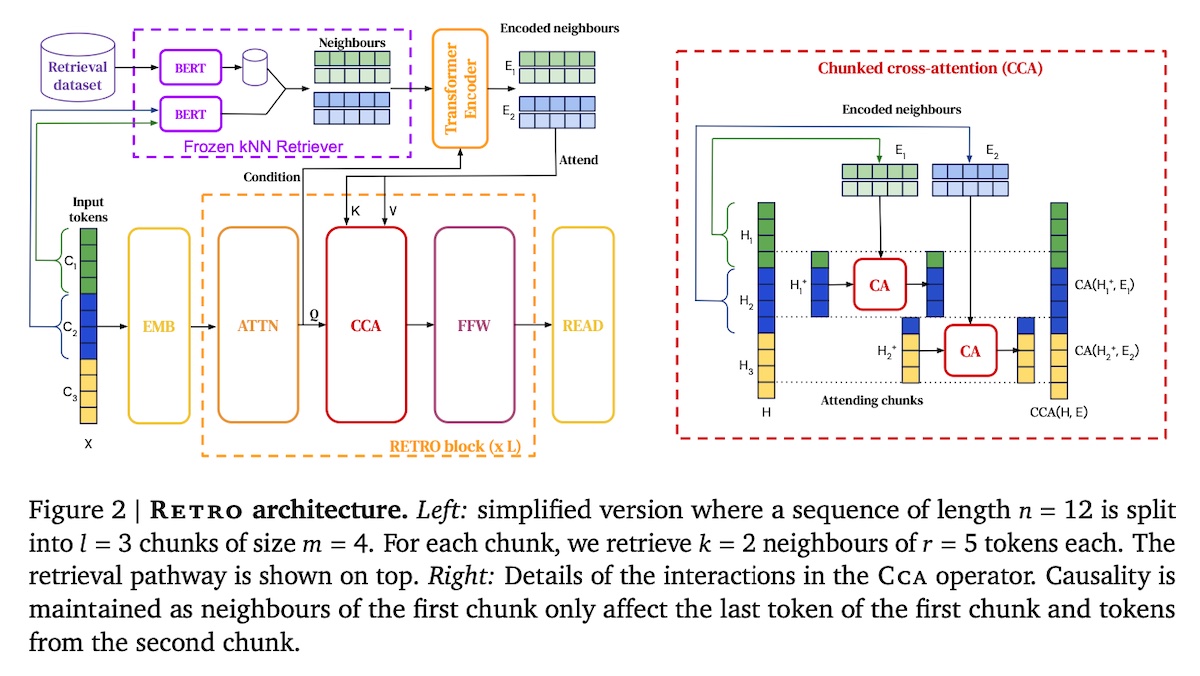
+#### [Retrieval-Enhanced Transformer (RETRO)](https://arxiv.org/abs/2112.04426)
+
+
+---
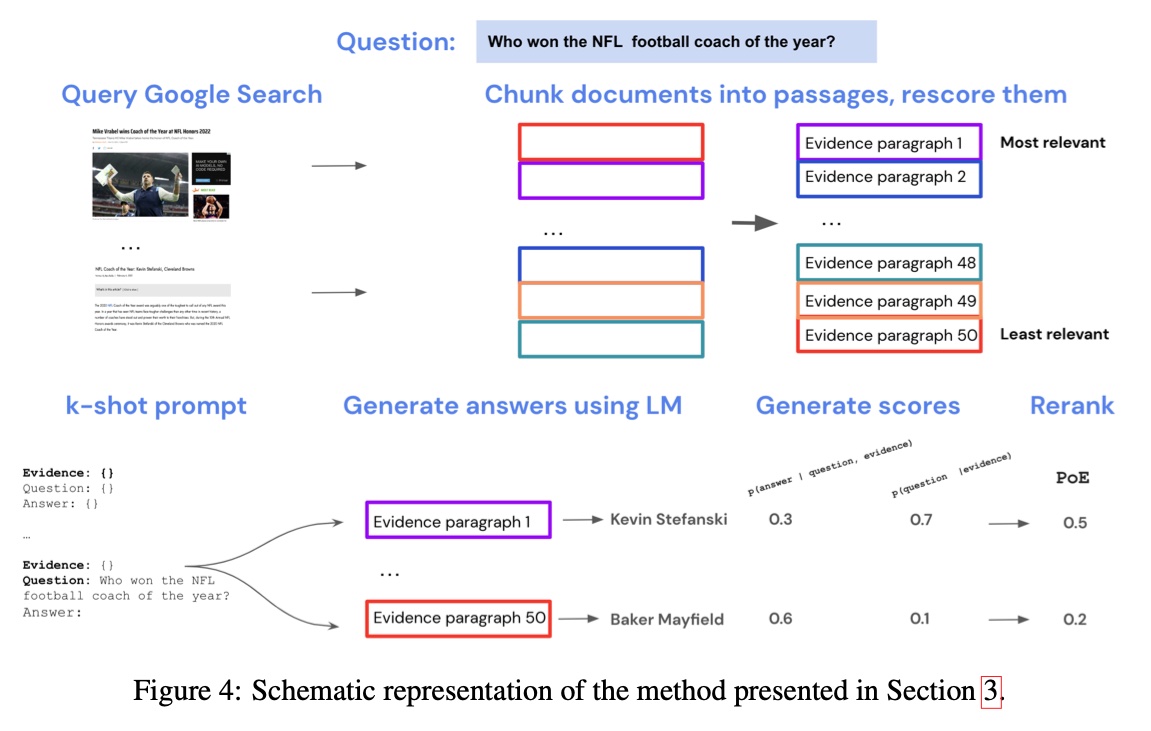
+#### [Internet-augmented LMs](https://arxiv.org/abs/2203.05115)
+
+
+---
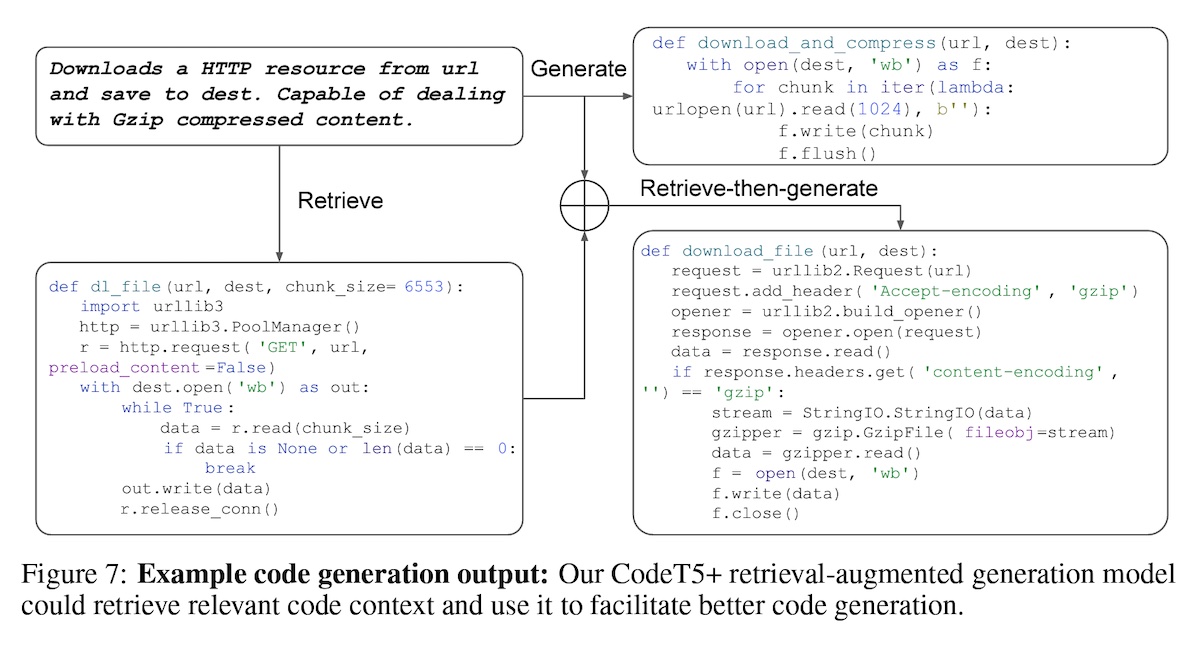
+#### [Overview of RAG for CodeT5+](https://arxiv.org/abs/2305.07922)
+
+
+---
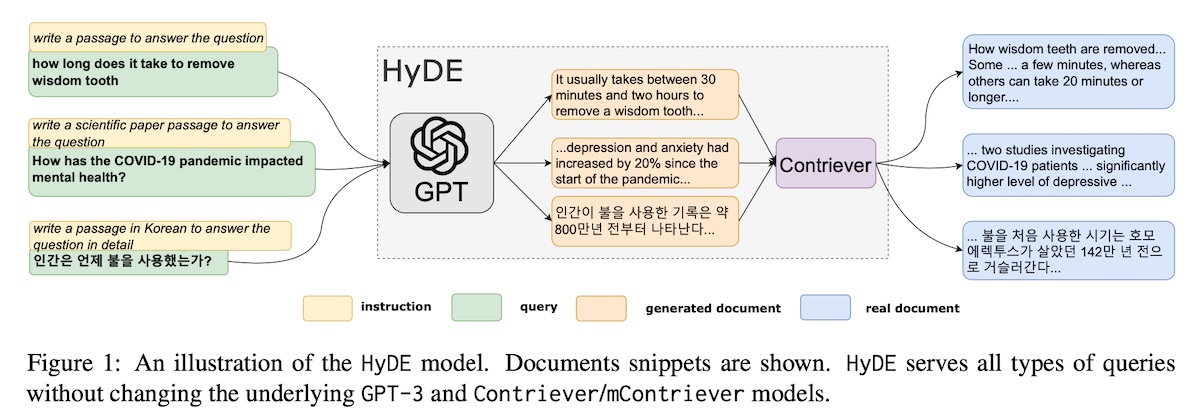
+#### [Hypothetical document embeddings (HyDE)](https://arxiv.org/abs/2212.10496)
+
+
+---
+### Fine-tuning : To get better at specific tasks
+
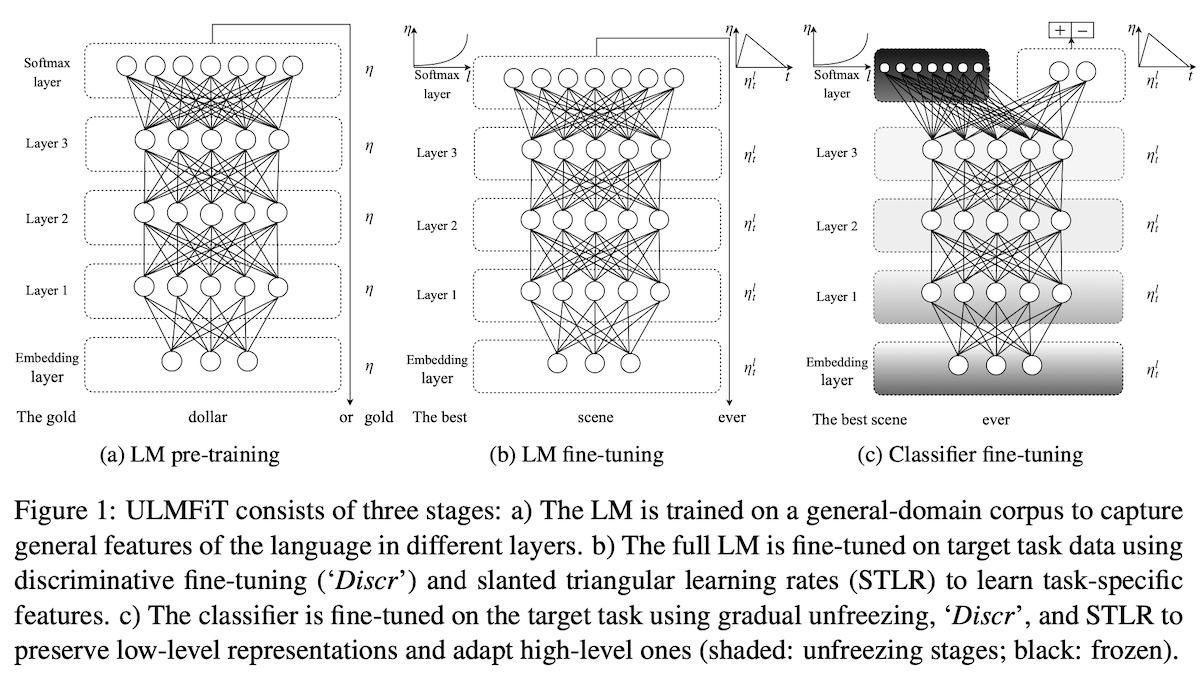
+#### [ULMFit](https://arxiv.org/abs/1801.06146)
+
+
+---
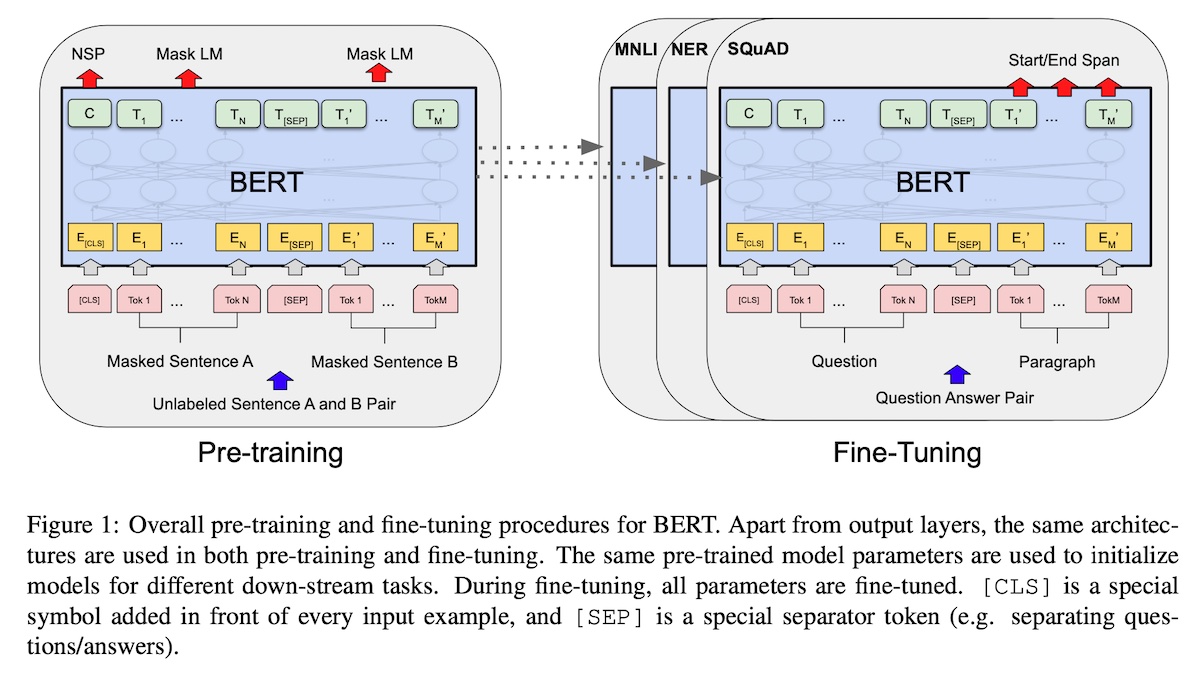
+#### [Bidirectional Encoder Representations from Transformers (BERT; encoder only)](https://arxiv.org/abs/1810.04805)
+
+
+---
+#### [Generative Pre-trained Transformers (GPT; decoder only)](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
+
+
+---
+#### [Text-to-text Transfer Transformer (T5; encoder-decoder)](https://arxiv.org/abs/1910.10683)
+
+
+---
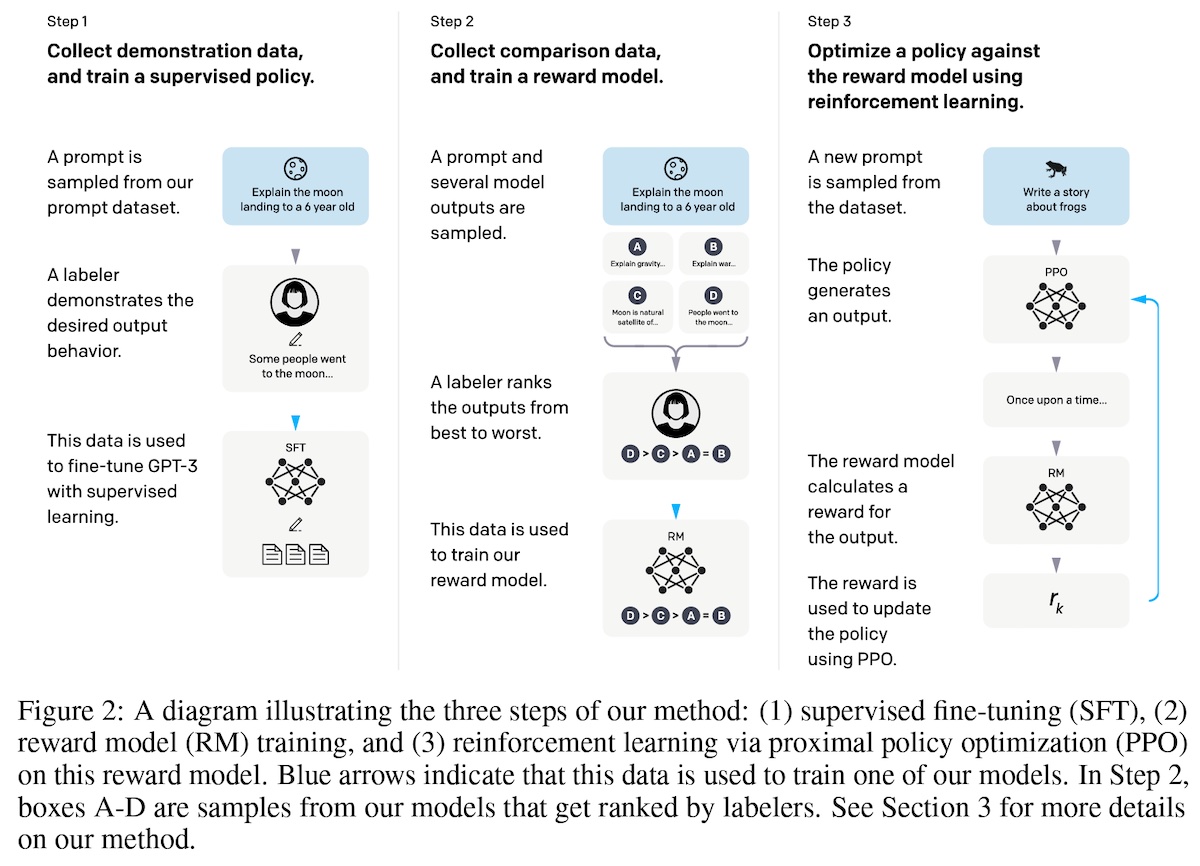
+#### [InstructGPT](https://arxiv.org/abs/2203.02155)
+
+
+---
+#### [Soft prompt tuning](https://arxiv.org/abs/2104.08691)
+**Paper:** [Soft-prompt Tuning for Large Language Models to Evaluate Bias](https://arxiv.org/abs/2306.04735)
+**Blog:** [Guiding Frozen Language Models with Learned Soft Prompts](https://blog.research.google/2022/02/guiding-frozen-language-models-with.html)
+
+
+
+---
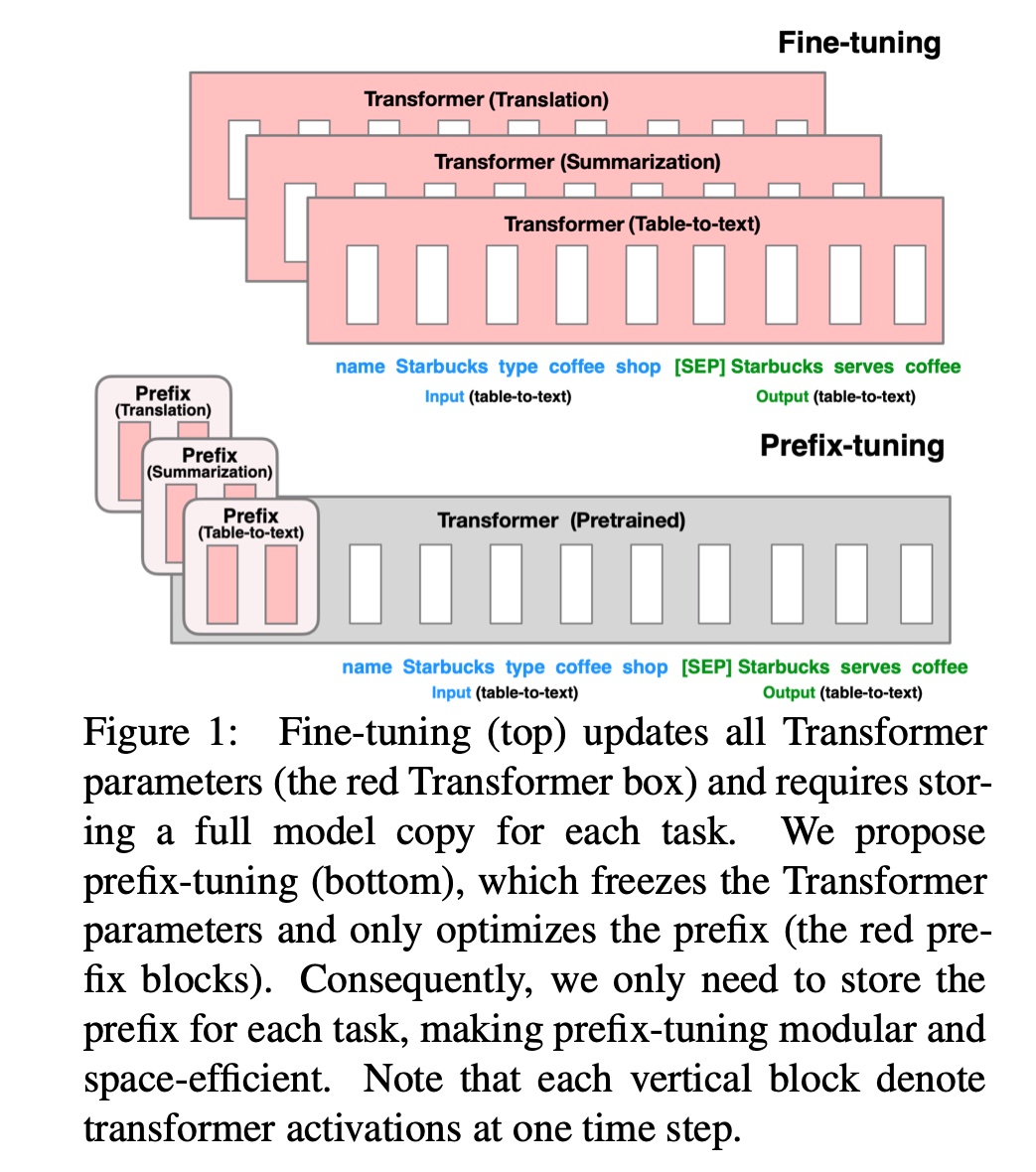
+#### [prefix tuning](https://arxiv.org/abs/2101.00190)
+
+
+---
+### Caching: To reduce latency and cost
+
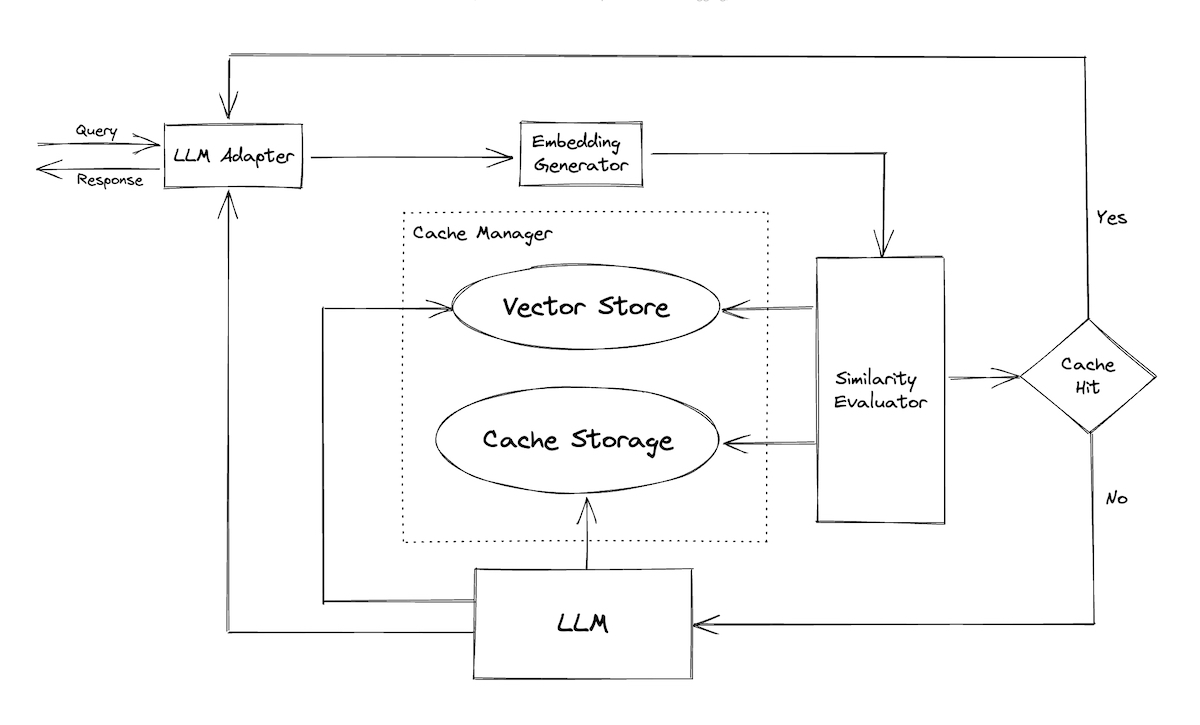
+#### [GPTCache](https://github.com/zilliztech/GPTCache)
+
+
+---
+### LLM Kaggle-examples:
+[https://www.kaggle.com/code/rkuo2000/llm-chromadb-langchain](https://www.kaggle.com/code/rkuo2000/llm-chromadb-langchain)
+[https://www.kaggle.com/code/rkuo2000/llm-finetuning](https://www.kaggle.com/code/rkuo2000/llm-finetuning/)
+[https://www.kaggle.com/code/rkuo2000/llama2-7b-hf-finetune](https://www.kaggle.com/code/rkuo2000/llama2-7b-hf-finetune)
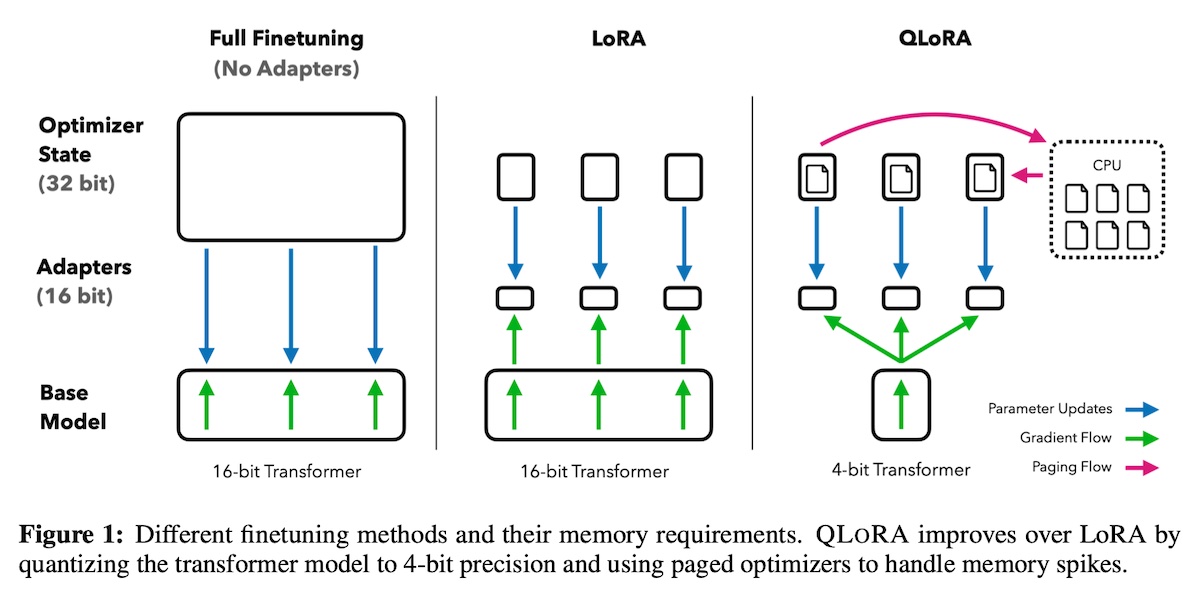
+[https://www.kaggle.com/code/rkuo2000/llama2-qlora](https://www.kaggle.com/code/rkuo2000/llama2-qlora)
+
+---
+### [Open-LLMs](https://github.com/eugeneyan/open-llms)
+Open LLMs
+Open LLM for Coder
+
+---
+## LLM Coders
+
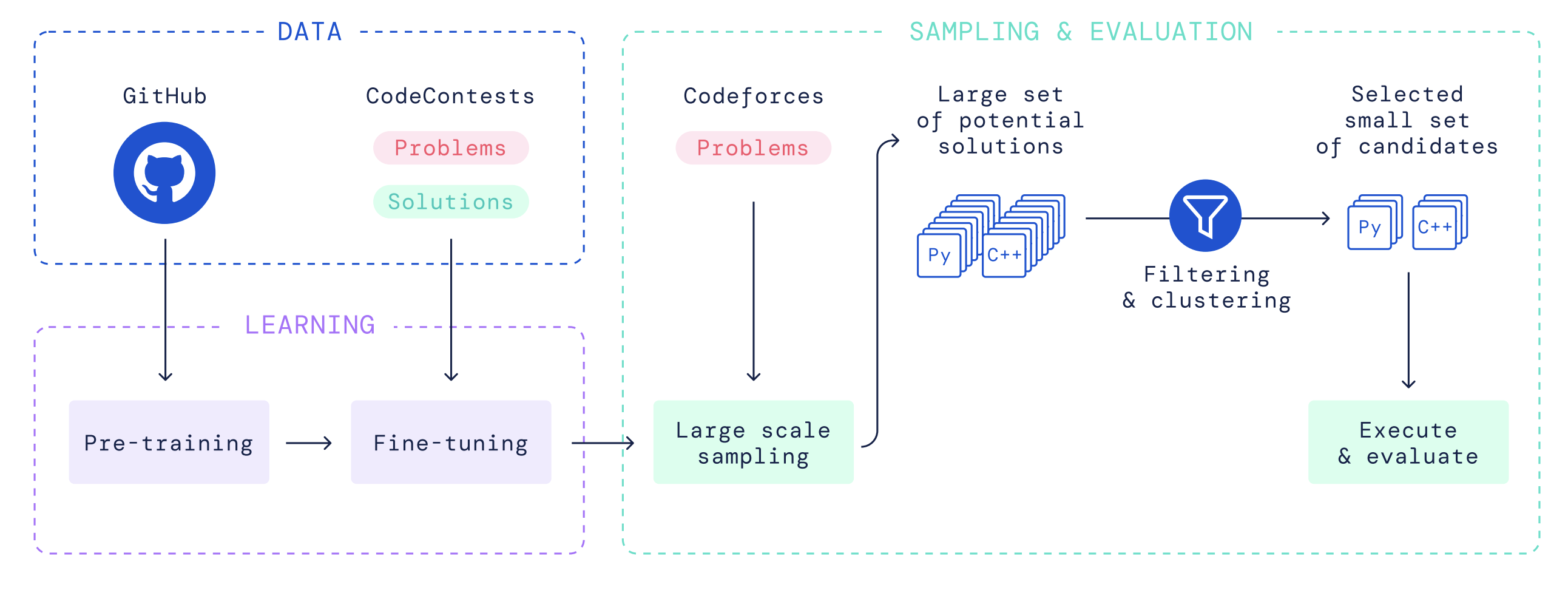
+### AlphaCode
+**Paper:** [Competition-Level Code Generation with AlphaCode](https://arxiv.org/pdf/2203.07814.pdf)
+
+
+---
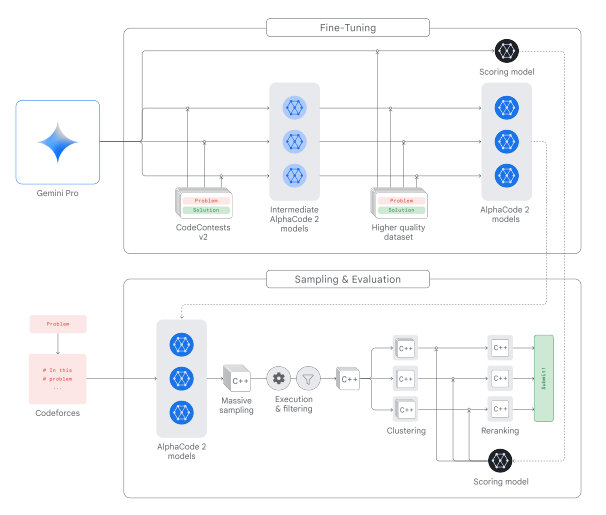
+### AlphaCode 2
+**Report:** [AlphaCode 2 Technical Report](https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf)
+
+
+---
+### StarCoder
+**Paper:** [StarCoder: may the source be with you!](https://arxiv.org/abs/2305.06161)
+The StarCoder models are 15.5B parameter models trained on **80+** programming languages from The Stack (v1.2), with opt-out requests excluded. The model uses Multi Query Attention, a context window of 8192 tokens, and was trained using the Fill-in-the-Middle objective on 1 trillion tokens.
+
+---
+### StarChat-Alpha
+**Blog:** [Creating a Coding Assistant with StarCoder](https://huggingface.co/blog/starchat-alpha)
+
+---
+### DeciCoder
+**Blog:** [Introducing DeciCoder: The New Gold Standard in Efficient and Accurate Code Generation](https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/)
+
+---
+### CodeGen2.5
+**Blog:** [CodeGen2.5: Small, but mighty](https://blog.salesforceairesearch.com/codegen25/)
+**Paper:** [CodeGen2: Lessons for Training LLMs on Programming and Natural Languages](https://arxiv.org/abs/2305.02309)
+**Code:** [https://github.com/salesforce/CodeGen/tree/main/codegen25](https://github.com/salesforce/CodeGen/tree/main/codegen25)
+
+---
+### Code Llama
+**Paper:** [Code Llama: Open Foundation Models for Code](https://arxiv.org/abs/2308.12950)
+
+**Kaggle:** [https://www.kaggle.com/rkuo2000/llm-code-llama](https://www.kaggle.com/rkuo2000/llm-code-llama)
+
+---
+## Thoughts
+
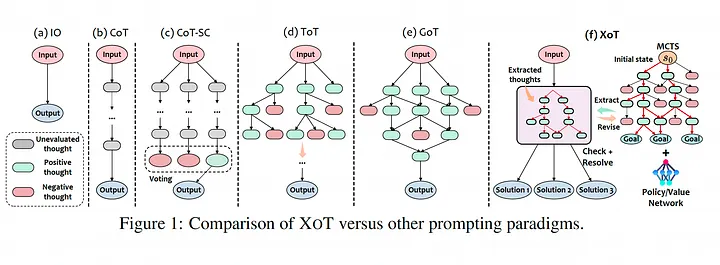
+### XoT
+**Paper:** [Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation](https://arxiv.org/abs/2311.04254)
+
+
+---
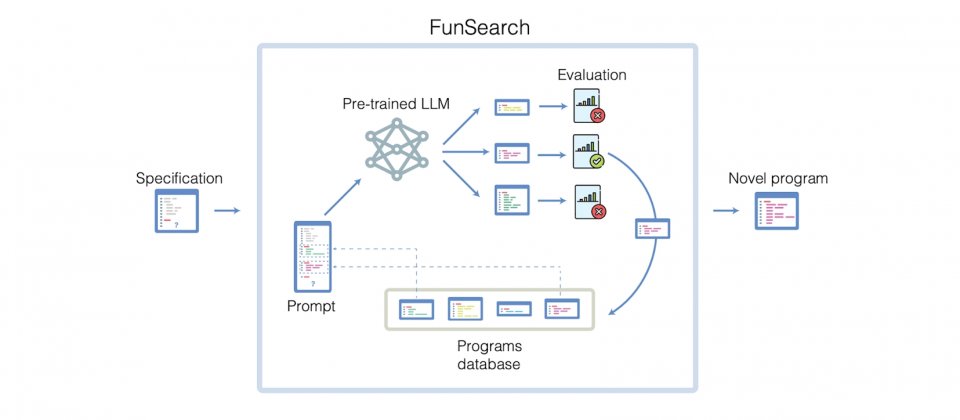
+### FunSearch
+[DeepMind發展用LLM解困難數學問題的方法](https://www.ithome.com.tw/news/160354)
+
+
+
+
+
+*This site was last updated {{ site.time | date: "%B %d, %Y" }}.*
+