diff --git a/_posts/2023-12-12-LLM.md b/_posts/2023-12-12-LLM.md
new file mode 100644
index 00000000..a6f96968
--- /dev/null
+++ b/_posts/2023-12-12-LLM.md
@@ -0,0 +1,253 @@
+---
+layout: post
+title: Large Language Models
+author: [Richard Kuo]
+category: [Lecture]
+tags: [jekyll, ai]
+---
+
+Introduction to Large Language Models (LLMs), LLM in Vision, etc.
+
+---
+## History of LLM
+[A Survey of Large Language Models](https://arxiv.org/abs/2303.18223)
+*Since the introduction of Transformer model in 2017, large language models (LLMs) have evolved significantly.*
+*ChatGPT saw 1.6B visits in May 2023.*
+*Meta also released three versions of LLaMA-2 (7B, 13B, 70B) free for commercial use in July.*
+
+---
+### 從解題能力來看四代語言模型的演進
+An evolution process of the four generations of language models (LM) from the perspective of task solving capacity.
+
+
+---
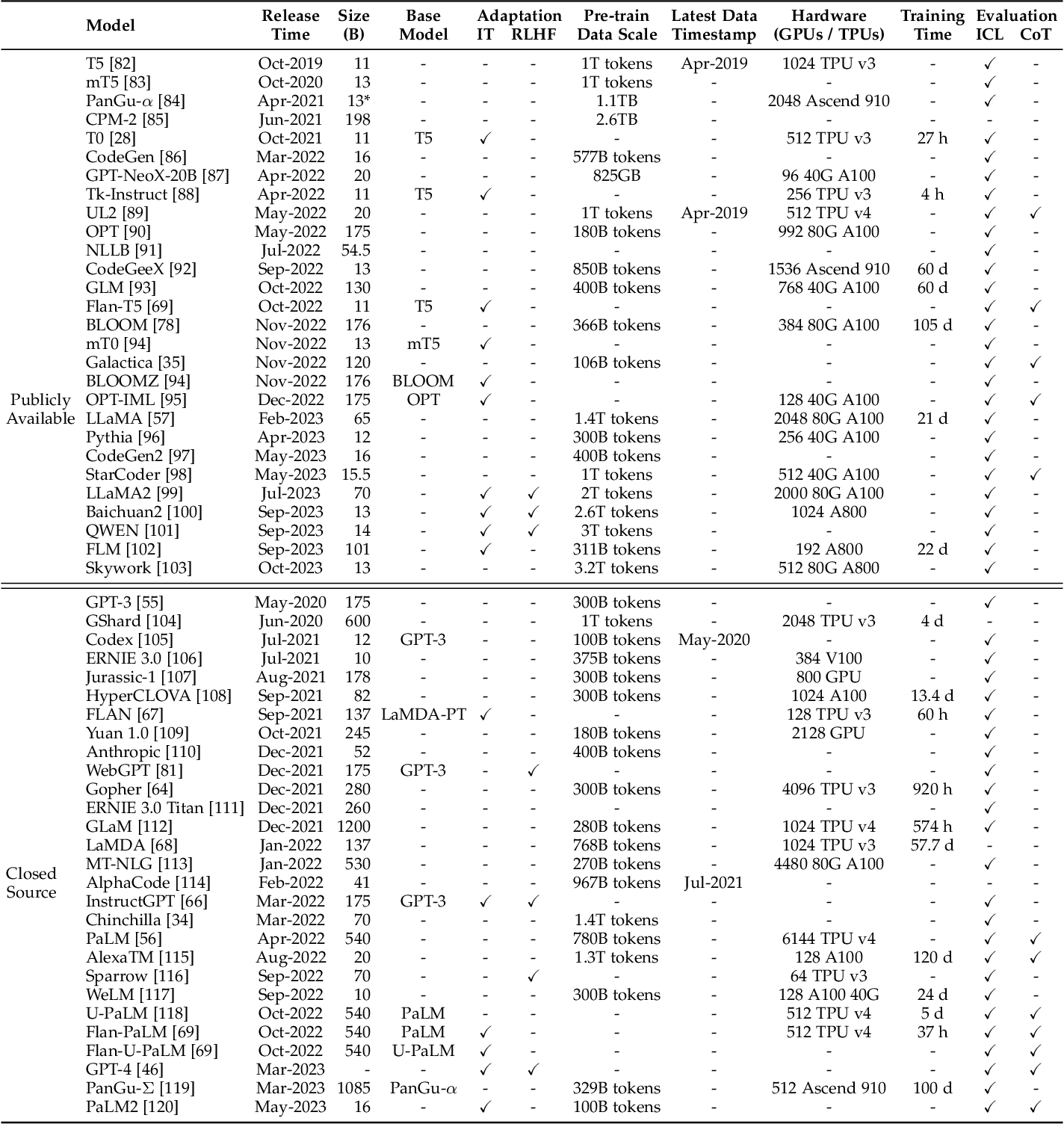
+### 大型語言模型統計表
+
+
+---
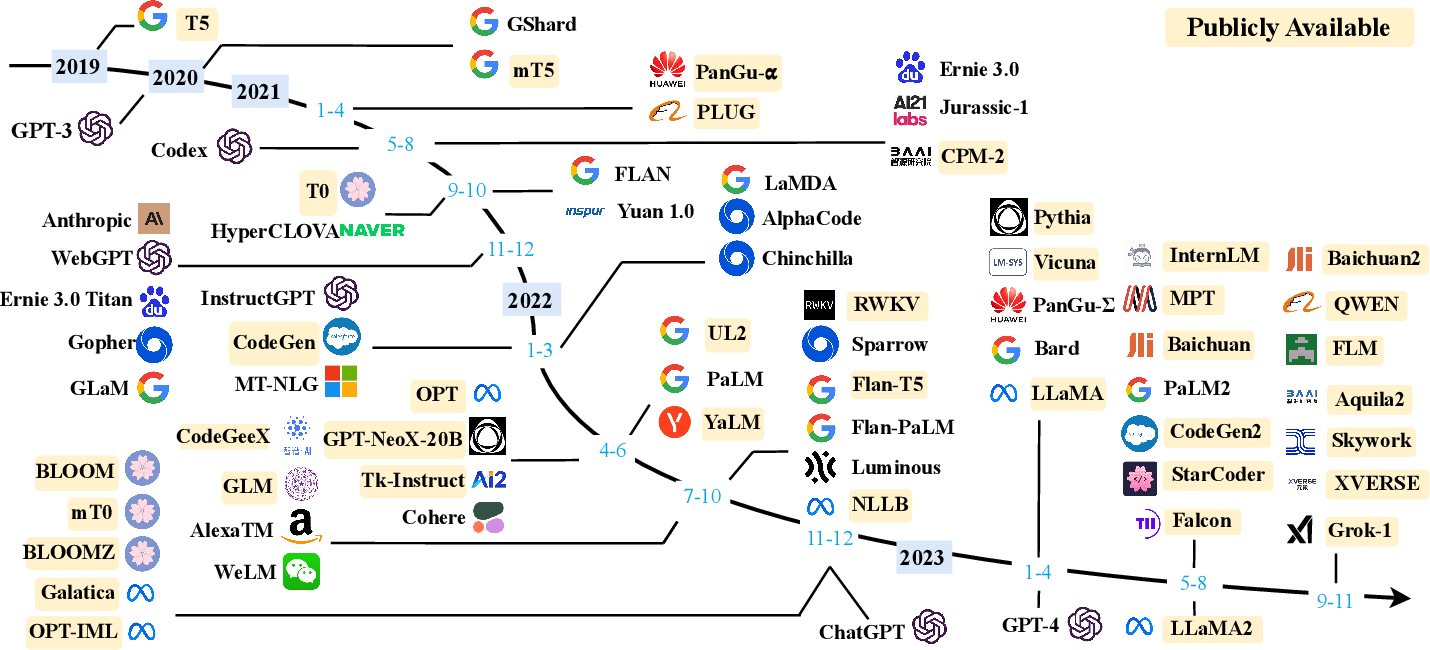
+### 近年大型語言模型(>10B)的時間軸
+
+
+---
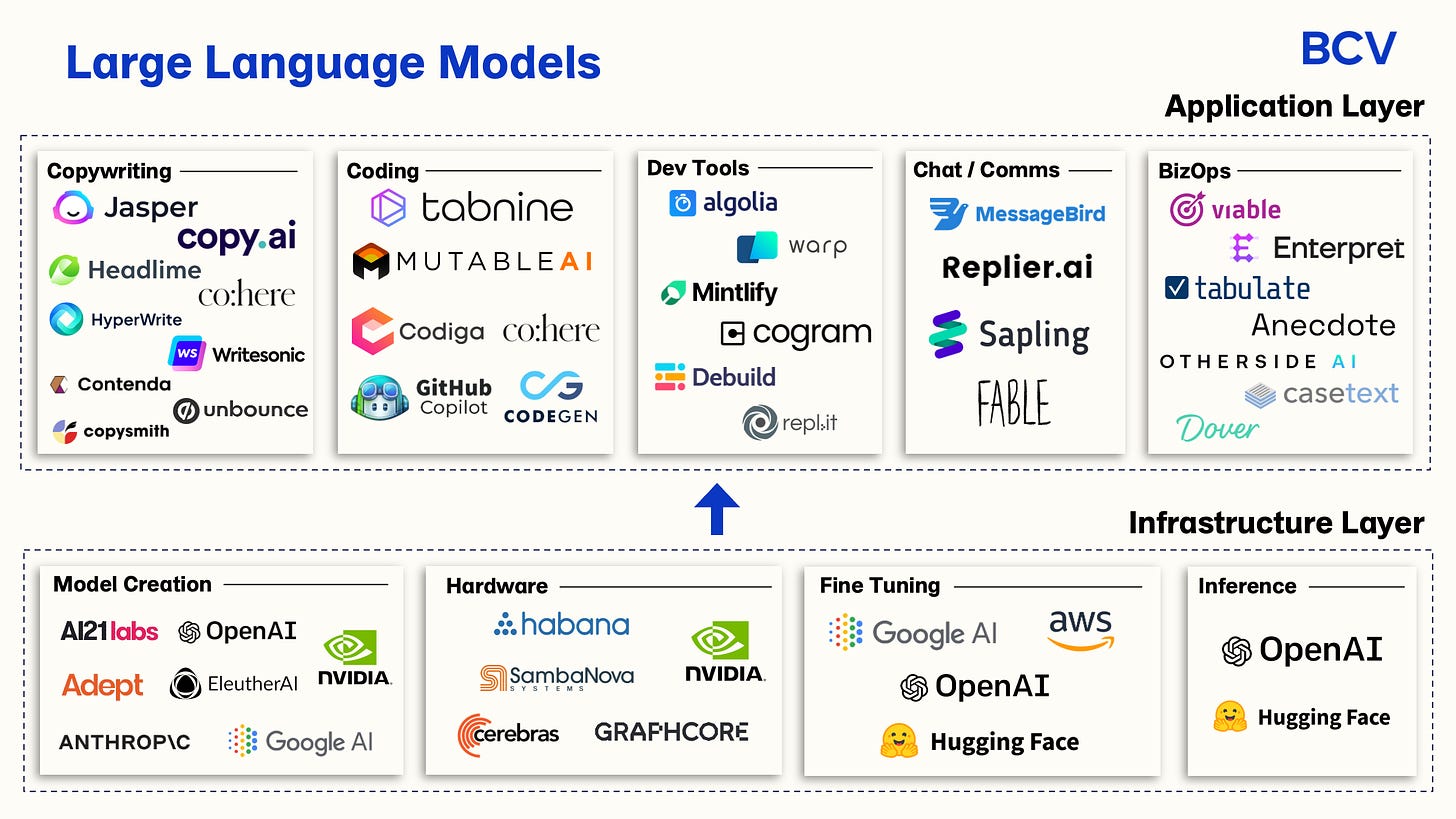
+### 大型語言模型之產業分類
+
+
+---
+### 大型語言模型之技術分類
+
+
+---
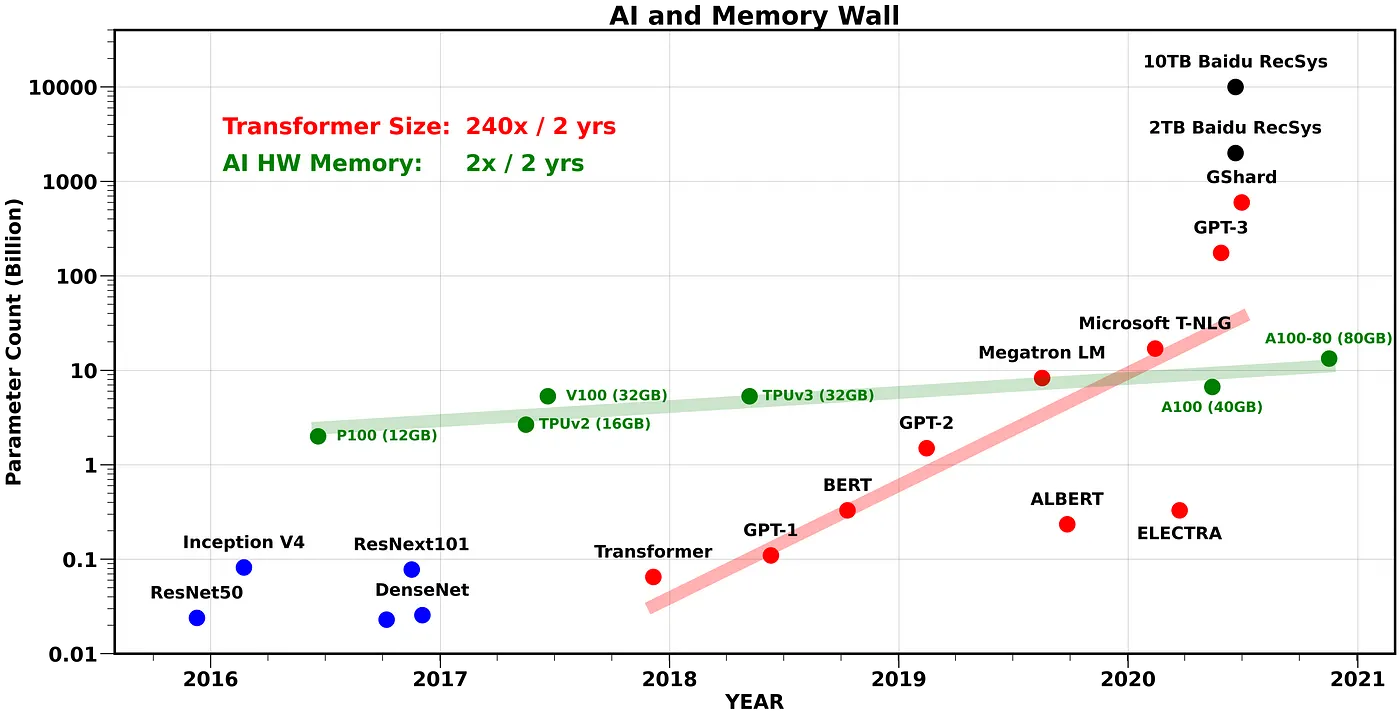
+### 計算記憶體的成長與Transformer大小的關係
+[AI and Memory Wall](https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8)
+
+
+---
+### LLMops 針對生成式 AI 用例調整了 MLops 技術堆疊
+
+
+---
+## Large Language Models
+
+### ChatGPT
+[ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/)
+ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
+
+
+
+
+
+---
+### GPT4
+**Paper:** [GPT-4 Technical Report](https://arxiv.org/abs/2303.08774)
+
+**Paper:** [From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting](https://arxiv.org/abs/2309.04269)
+**Blog:** [GPT-4 Code Interpreter: The Next Big Thing in AI](https://medium.com/@aaabulkhair/gpt-4-code-interpreter-the-next-big-thing-in-ai-56bbf72d746)
+
+---
+### Open LLMs
+**[Open LLM leardboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)**
+
+---
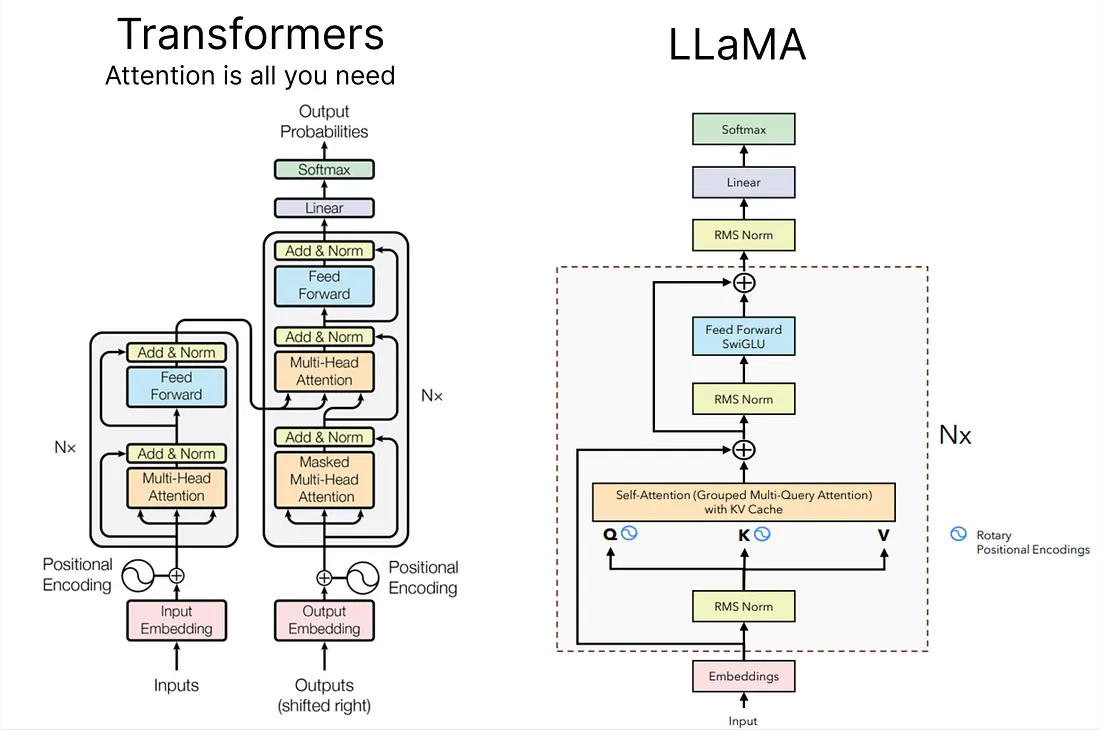
+### [LLaMA](https://huggingface.co/docs/transformers/main/model_doc/llama)
+*It is a collection of foundation language models ranging from 7B to 65B parameters.*
+**Paper:** [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
+
+
+---
+### [OpenLLaMA](https://github.com/openlm-research/open_llama)
+**model:** [https://huggingface.co/openlm-research/open_llama_3b_v2](https://huggingface.co/openlm-research/open_llama_3b_v2)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-openllama](https://www.kaggle.com/code/rkuo2000/llm-openllama)
+
+---
+**Blog:** [Building a Million-Parameter LLM from Scratch Using Python](https://levelup.gitconnected.com/building-a-million-parameter-llm-from-scratch-using-python-f612398f06c2)
+**Kaggle:** [LLM LLaMA from scratch](https://www.kaggle.com/rkuo2000/llm-llama-from-scratch/)
+
+---
+### Pythia
+**Paper:** [Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling](https://arxiv.org/abs/2304.01373)
+**Dataset:**
+[The Pile: An 800GB Dataset of Diverse Text for Language Modeling](https://arxiv.org/abs/2101.00027)
+[Datasheet for the Pile](https://arxiv.org/abs/2201.07311)
+**Code:** [Pythia: Interpreting Transformers Across Time and Scale](https://github.com/EleutherAI/pythia)
+
+---
+### Falcon-40B
+**Paper:** [The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only](https://arxiv.org/abs/2306.01116)
+**Dataset:** [https://huggingface.co/datasets/tiiuae/falcon-refinedweb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb)
+**Code:** [https://huggingface.co/tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b)
+
+---
+### LLaMA-2
+**Paper:** [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://arxiv.org/abs/2307.09288)
+**Code:** [https://github.com/facebookresearch/llama](https://github.com/facebookresearch/llama)
+**models:** [https://huggingface.co/meta-llama](https://huggingface.co/meta-llama)
+
+---
+### Orca
+**Paper:** [Orca: Progressive Learning from Complex Explanation Traces of GPT-4](https://arxiv.org/abs/2306.02707)
+
+---
+### Vicuna
+**Paper:** [Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena](https://arxiv.org/abs/2306.05685)
+**model:** [https://huggingface.co/lmsys/vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5)
+**Code:** [https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)
+
+---
+### [Platypus](https://platypus-llm.github.io/)
+**Paper:** [Platypus: Quick, Cheap, and Powerful Refinement of LLMs](https://arxiv.org/abs/2308.07317)
+**Code:** [https://github.com/arielnlee/Platypus/](https://github.com/arielnlee/Platypus/)
+
+---
+### Mistral
+**Paper:** [Mistral 7B](https://arxiv.org/abs/2310.06825)
+**Code:** [https://github.com/mistralai/mistral-src](https://github.com/mistralai/mistral-src)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct](https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct)
+
+
+---
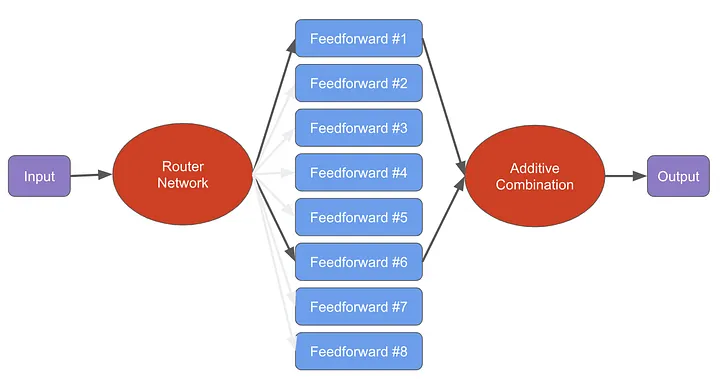
+### Mistral 8X7B
+
+
+---
+### Zephyr
+**Paper:** [Zephyr: Direct Distillation of LM Alignment](https://arxiv.org/abs/2310.16944)
+**Code:** [https://huggingface.co/HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b](https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b)
+
+
+---
+**Blog:** [Zephyr-7B : HuggingFace’s Hyper-Optimized LLM Built on Top of Mistral 7B](https://www.unite.ai/zephyr-7b-huggingfaces-hyper-optimized-llm-built-on-top-of-mistral-7b/)
+
+
+
+
+---
+### SOLAR-10.7B ~ Depth Upscaling
+**Code:** [https://huggingface.co/upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0)
+Depth-Upscaled SOLAR-10.7B has remarkable performance. It outperforms models with up to 30B parameters, even surpassing the recent Mixtral 8X7B model.
+Leveraging state-of-the-art instruction fine-tuning methods, including supervised fine-tuning (SFT) and direct preference optimization (DPO),
+researchers utilized a diverse set of datasets for training. This fine-tuned model, SOLAR-10.7B-Instruct-v1.0, achieves a remarkable Model H6 score of 74.20,
+boasting its effectiveness in single-turn dialogue scenarios.
+
+---
+### Phi-2 (Transformer with 2.7B parameters)
+**Blog:** [Phi-2: The surprising power of small language models](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)
+**Code:** [https://huggingface.co/microsoft/phi-2](https://huggingface.co/microsoft/phi-2)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-phi-2](https://www.kaggle.com/code/rkuo2000/llm-phi-2)
+
+---
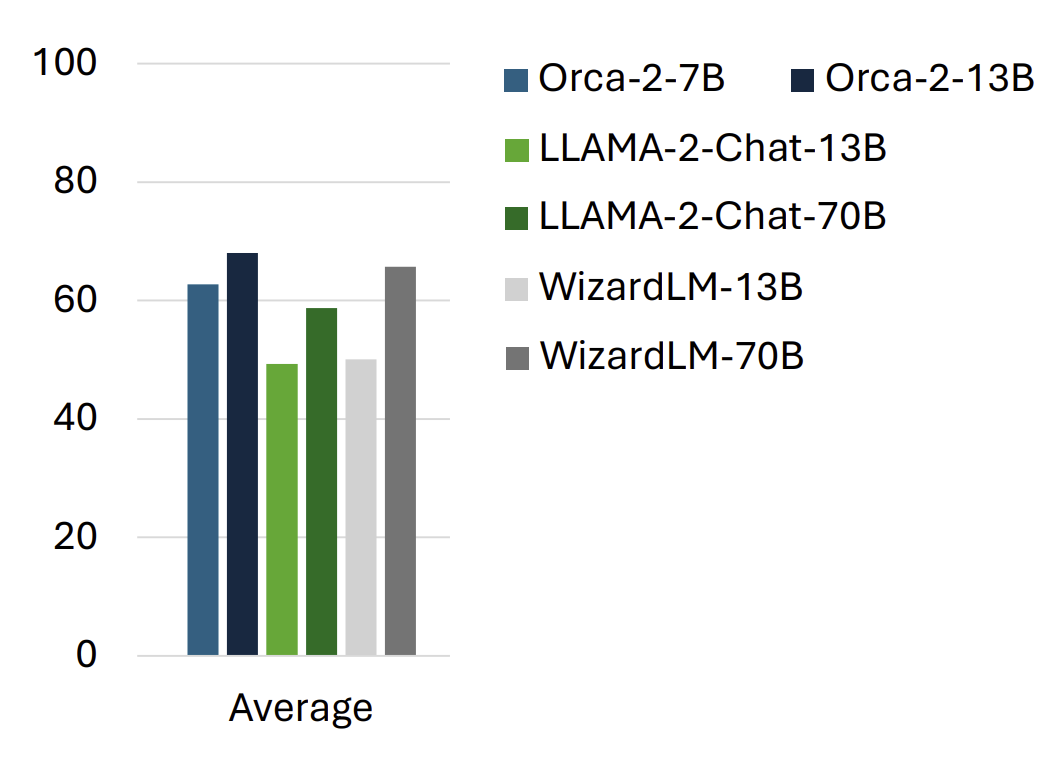
+### Orca 2
+**Paper:** [https://arxiv.org/abs/2311.11045](https://arxiv.org/abs/2311.11045)
+**model:** [Orca 2: Teaching Small Language Models How to Reason](https://huggingface.co/microsoft/Orca-2-13b)
+**Blog:** [Microsoft's Orca 2 LLM Outperforms Models That Are 10x Larger](https://www.infoq.com/news/2023/12/microsoft-orca-2-llm/)
+
+
+---
+**Paper:** [Variety and Quality over Quantity: Towards Versatile Instruction Curation](https://arxiv.org/abs/2312.11508)
+
+---
+### [Next-GPT](https://next-gpt.github.io/)
+**Paper:** [Any-to-Any Multimodal Large Language Model](https://arxiv.org/abs/2309.05519)
+
+
+---
+### MLLM FineTuning
+**Paper:** [Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning](https://arxiv.org/abs/2312.11420)
+
+---
+## LLM in Vision
+**Papers:** [https://github.com/DirtyHarryLYL/LLM-in-Vision](https://github.com/DirtyHarryLYL/LLM-in-Vision)
+
+---
+### VisionLLM
+**Paper:** [VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks](https://arxiv.org/abs/2305.11175)
+
+
+---
+### MiniGPT-v2
+**Paper:** [MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning](https://arxiv.org/abs/2310.09478)
+**Code:** [https://github.com/Vision-CAIR/MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)
+
+
+---
+### GPT4-V
+**Paper:** [Assessing GPT4-V on Structured Reasoning Tasks](https://arxiv.org/abs/2312.11524)
+
+---
+### Gemini
+**Paper:** [Gemini: A Family of Highly Capable Multimodal Models](https://arxiv.org/abs/2312.11805)
+
+
+---
+### [LLaVA](https://llava-vl.github.io/)
+**Paper:** [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)
+**Paper:** [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744)
+**Code:** [https://github.com/haotian-liu/LLaVA](https://github.com/haotian-liu/LLaVA)
+**Demo:** [https://llava.hliu.cc/](https://llava.hliu.cc/)
+
+---
+### [VLFeedback and Silkie](https://vlf-silkie.github.io/)
+A GPT-4V annotated preference dataset for large vision language models.
+**Paper:** [Silkie: Preference Distillation for Large Visual Language Models](https://arxiv.org/abs/2312.10665)
+**Code:** [https://github.com/vlf-silkie/VLFeedback](https://github.com/vlf-silkie/VLFeedback)
+
+
+---
+## LLM in Robotics
+**Paper:** [Language-conditioned Learning for Robotic Manipulation: A Survey](https://arxiv.org/abs/2312.10807)
+
+---
+**Paper:** [Human Demonstrations are Generalizable Knowledge for Robots](https://arxiv.org/abs/2312.02419)
+
+---
+## Advanced Topics
+
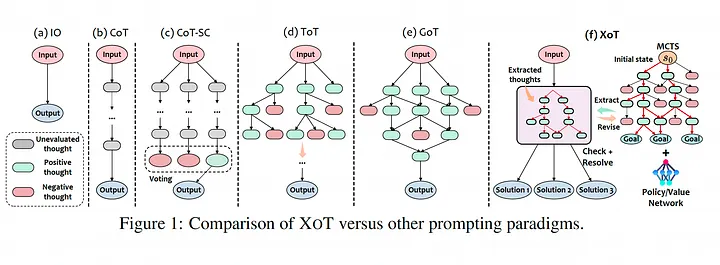
+### XoT
+**Paper:** [Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation](https://arxiv.org/abs/2311.04254)
+
+
+---
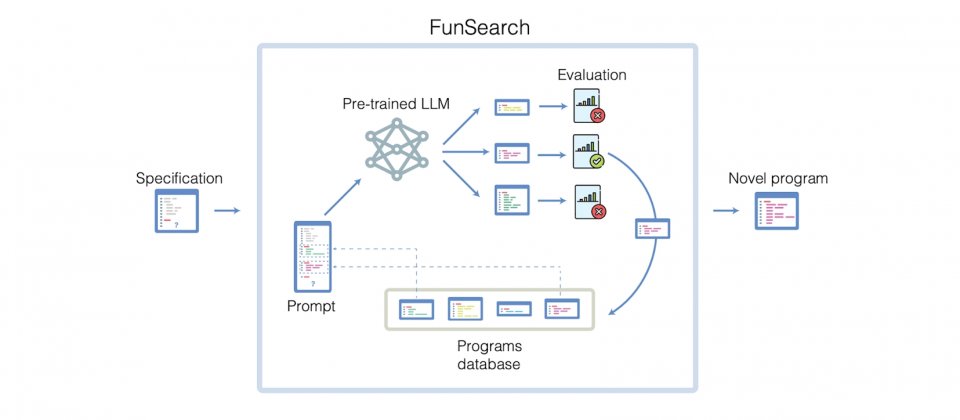
+### FunSearch
+[DeepMind發展用LLM解困難數學問題的方法](https://www.ithome.com.tw/news/160354)
+
+
+---
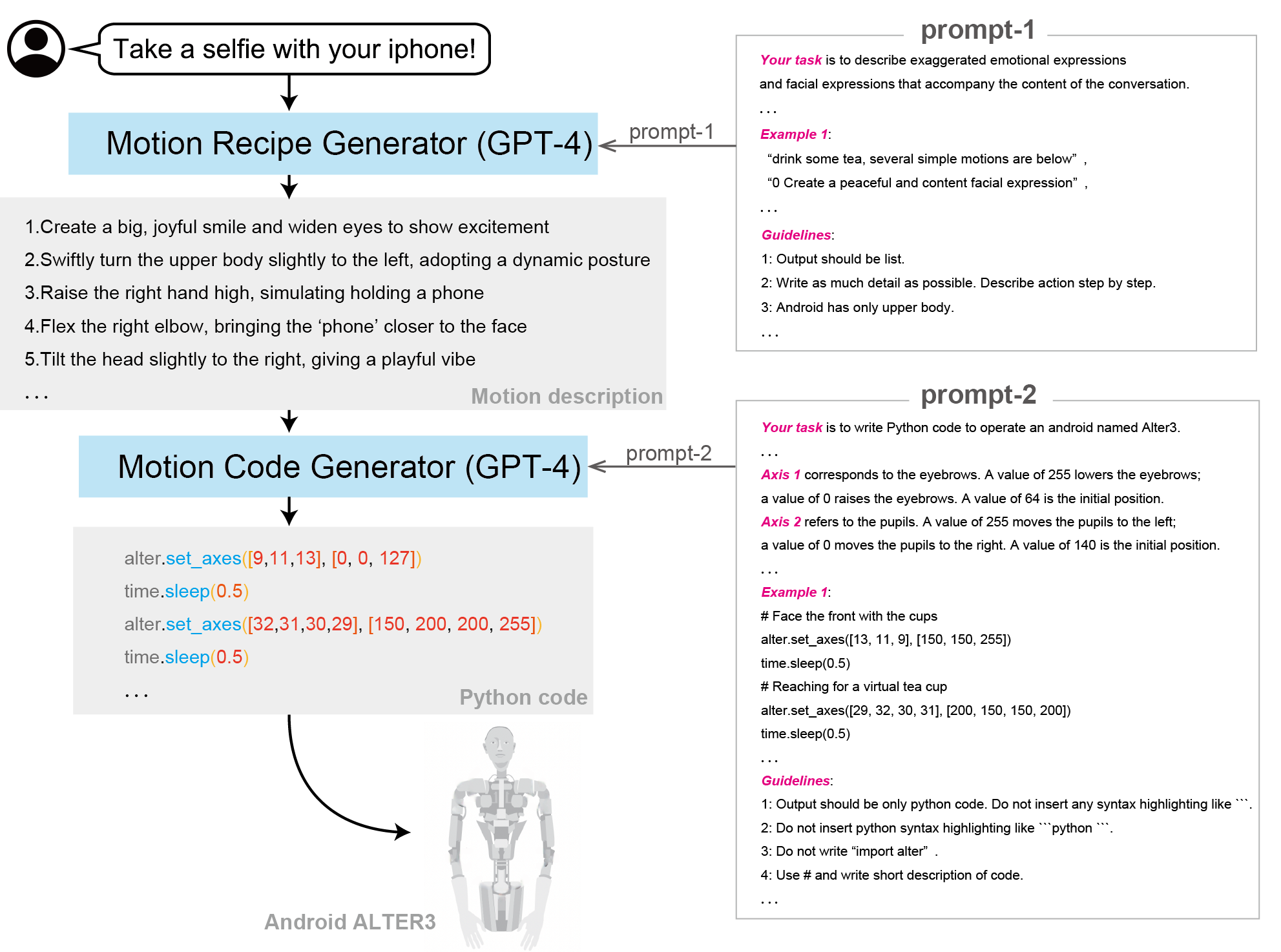
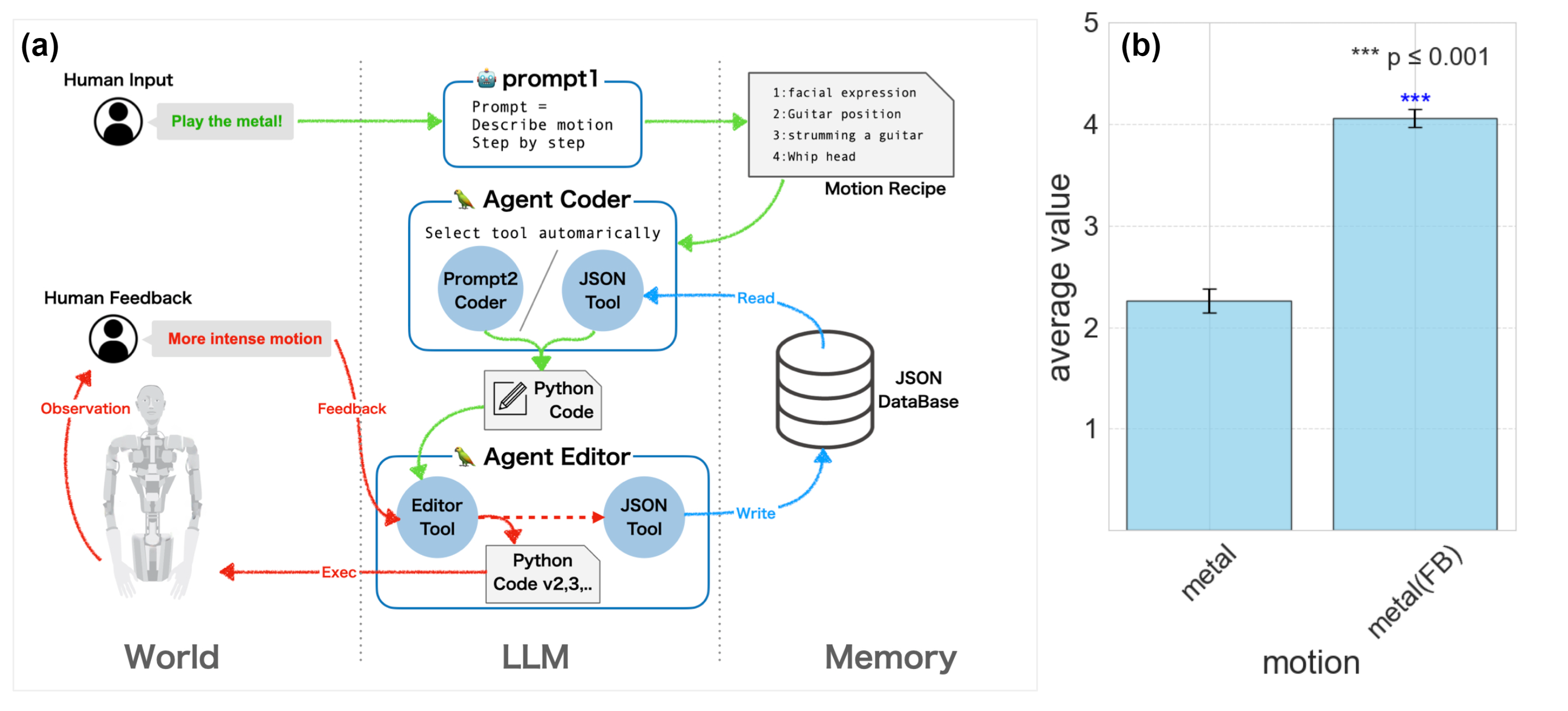
+### [ALTER-LLM](https://tnoinkwms.github.io/ALTER-LLM/)
+**Paper:** [From Text to Motion: Grounding GPT-4 in a Humanoid Robot "Alter3"](https://arxiv.org/abs/2312.06571)
+
+
+
+
+---
+### BrainGPT
+**Paper:** [DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation](https://arxiv.org/abs/2309.14030)
+**Blog:** [New Mind-Reading "BrainGPT" Turns Thoughts Into Text On Screen](https://www.iflscience.com/new-mind-reading-braingpt-turns-thoughts-into-text-on-screen-72054)
+
+
+
+
+
+
+
+*This site was last updated {{ site.time | date: "%B %d, %Y" }}.*
+
diff --git a/_posts/2023-12-13-RAG.md b/_posts/2023-12-13-RAG.md
new file mode 100644
index 00000000..c4ed2600
--- /dev/null
+++ b/_posts/2023-12-13-RAG.md
@@ -0,0 +1,245 @@
+---
+layout: post
+title: Retrieval Augmented Generation
+author: [Richard Kuo]
+category: [Lecture]
+tags: [jekyll, ai]
+---
+
+Introduction to Retrieval Augmented Generation (RAG)
+
+---
+## RAG
+
+### [Contemporary LLMs](https://www.kaggle.com/code/rkuo2000/contemporary-large-language-models-llms)
+
+---
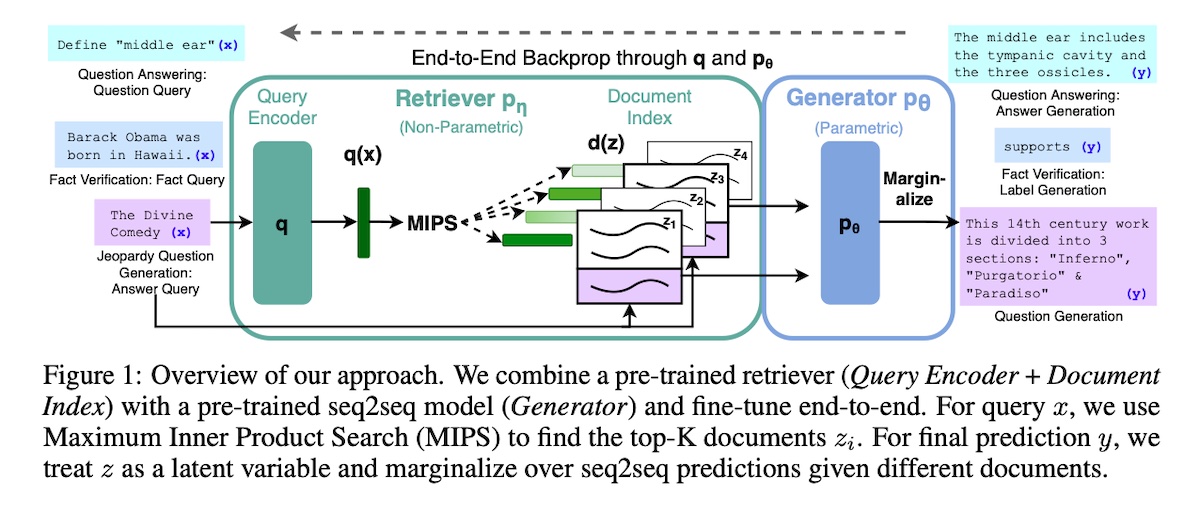
+### [Retrieval Augmented Generation (RAG)](https://arxiv.org/abs/2005.11401)
+
+
+---
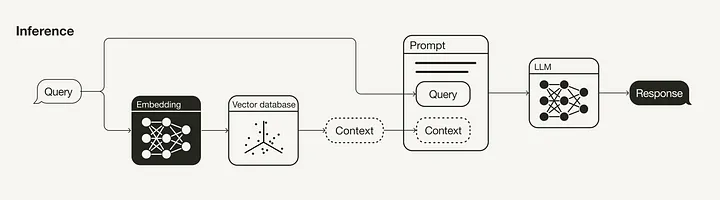
+#### [A Guide on 12 Tuning Strategies for Production-Ready RAG Applications](https://towardsdatascience.com/a-guide-on-12-tuning-strategies-for-production-ready-rag-applications-7ca646833439#156e)
+
+
+---
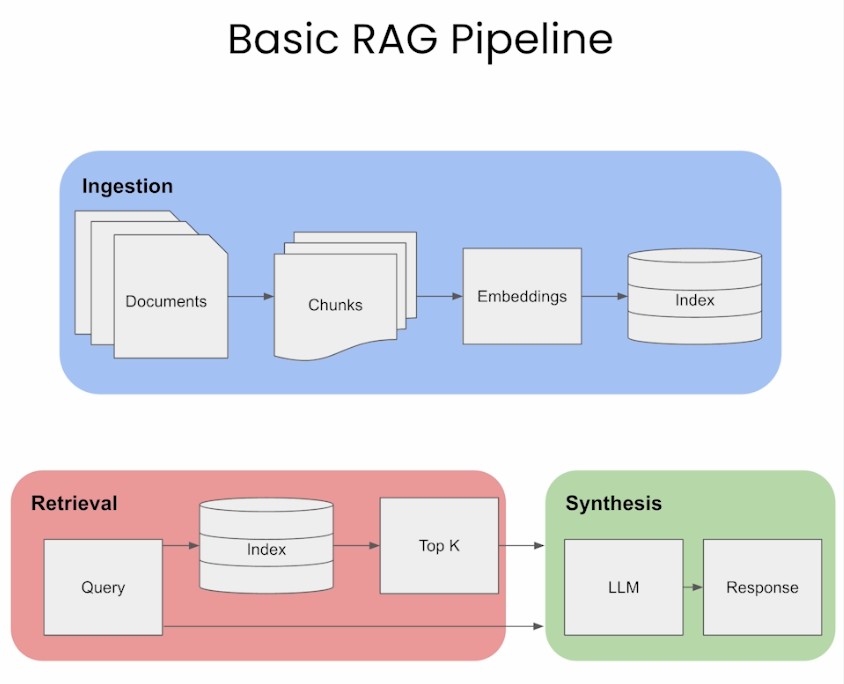
+#### [NLP • Retrieval Augmented Generation](https://aman.ai/primers/ai/RAG/)
+
+
+---
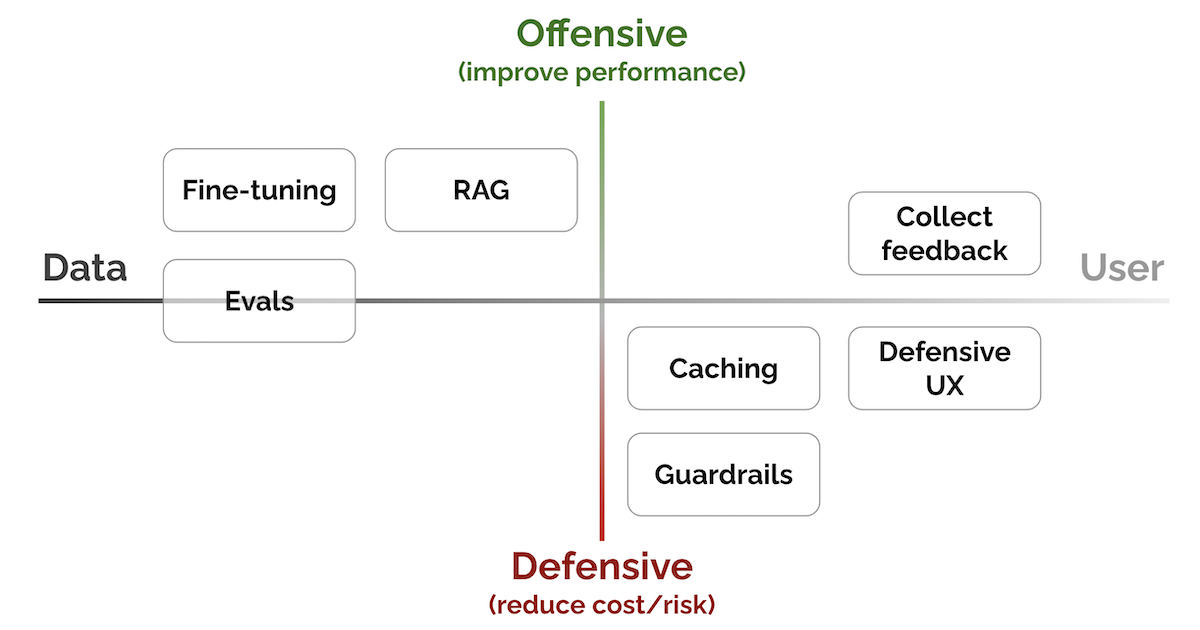
+### [Patterns for Building LLM-based Systems & Products](https://eugeneyan.com/writing/llm-patterns/)
+
+
+---
+### [Building RAG-based LLM Applications for Production](https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1)
+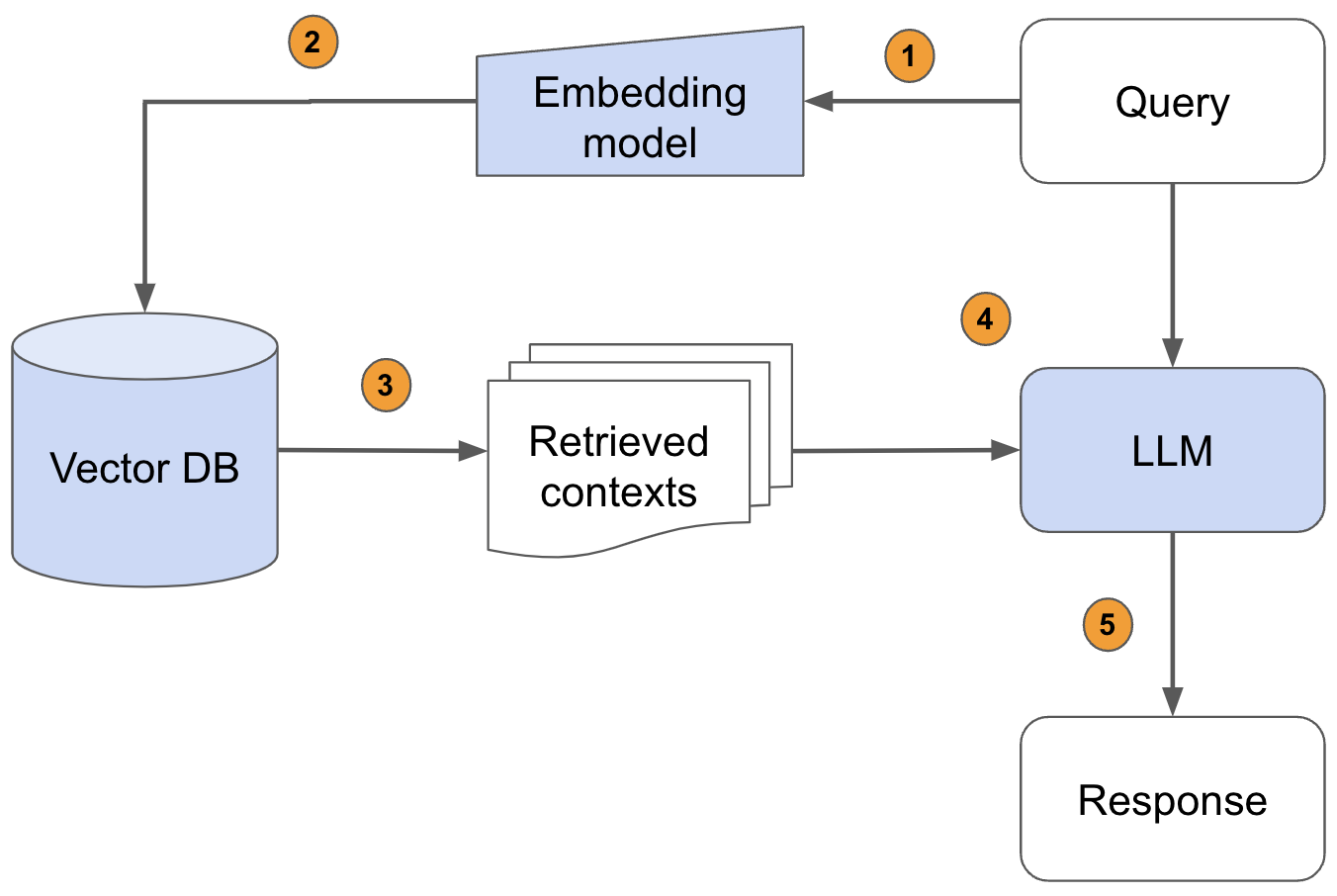
+(1)將外部文件做分塊(chunking)再分詞(tokenize)轉成token
+(2)利用嵌入模型,將token做嵌入(embeds)運算,轉成向量,儲存至向量資料庫(Vector Database)並索引(Indexes)
+(3)用戶提出問題,向量資料庫將問題字串轉成向量(利用前一個步驟的嵌入模型),再透過餘弦(Cosine)相似度或歐氏距離演算法來搜尋資料庫裡的近似資料
+(4)將用戶的問題、資料庫查詢結果一起放進Prompt(提示),交由LLM推理出最終答案
+以上是基本的RAG流程,利用Langchain或LlamaIndex或Haystack之類的應用程式開發框架,大概用不到一百行的程式碼就能做掉(含LLM的裝載)。
+
+Anyscale剛剛發布的一篇精彩好文,裡頭介紹了很多提升RAG成效的高段技巧,內容包括:
+🚀從頭開始建構基於RAG的LLM應用程式。
+🚀 在具有不同運算資源的多個工作人員之間擴展主要工作負載(載入、分塊、嵌入、索引、服務等)。
+🚀評估應用程式的不同配置,以最佳化每個元件(例如retrieval_score)和整體效能(quality_score)。
+🚀 透過開源和閉源LLM實作混合代理路由方法,以建立效能最佳且最具成本效益的應用程式。
+🚀以高擴展性與高可用性的方式為應用程式提供服務。
+🚀了解微調、提示工程、詞彙搜尋(lexical search)、重新排名、資料飛輪(data flywheel)等方法如何影響應用程式的效能。
+
+---
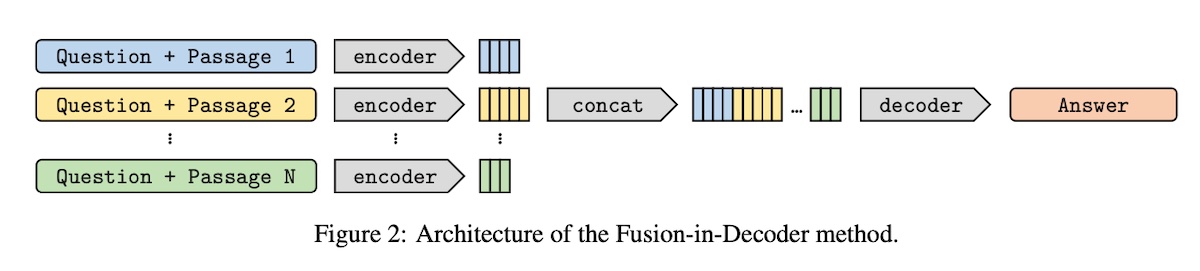
+#### [Fusion-in-Decoder (FiD)](https://arxiv.org/abs/2007.01282)
+
+
+---
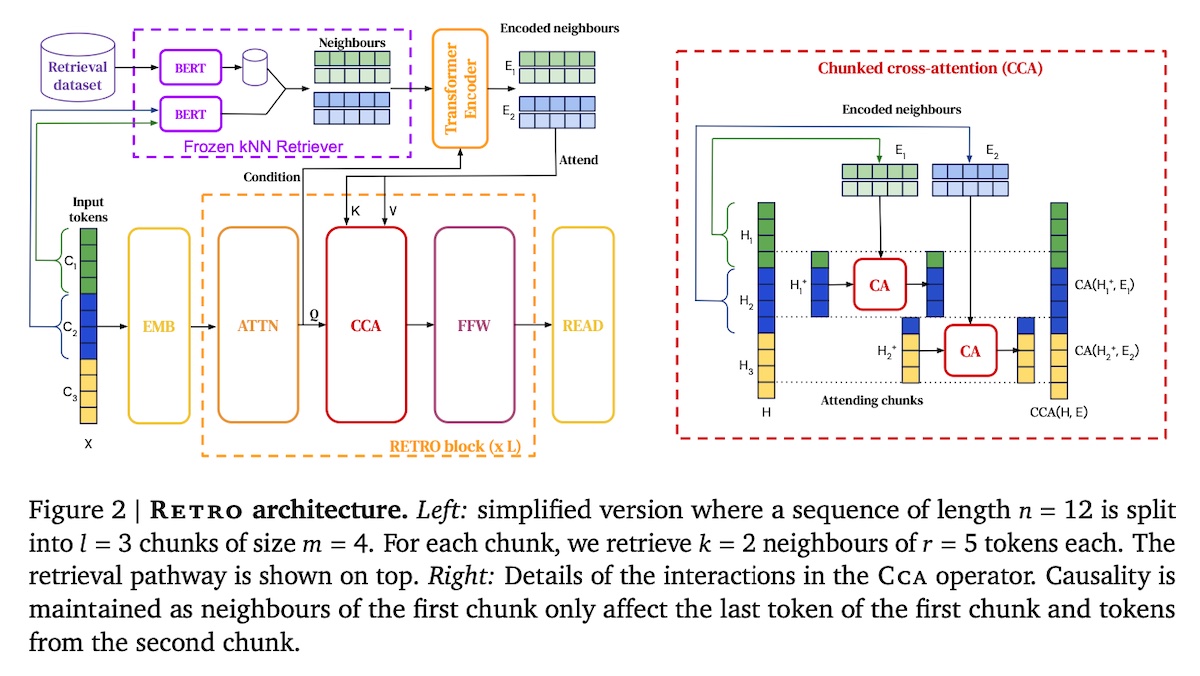
+#### [Retrieval-Enhanced Transformer (RETRO)](https://arxiv.org/abs/2112.04426)
+
+
+---
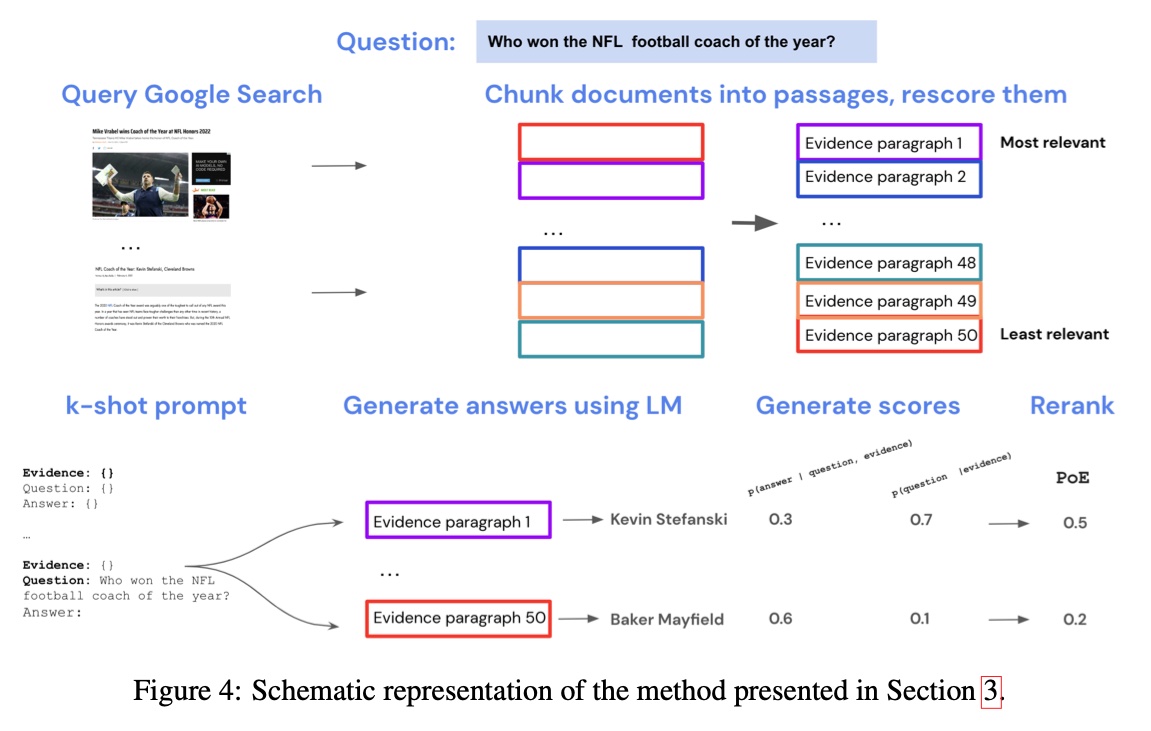
+#### [Internet-augmented LMs](https://arxiv.org/abs/2203.05115)
+
+
+---
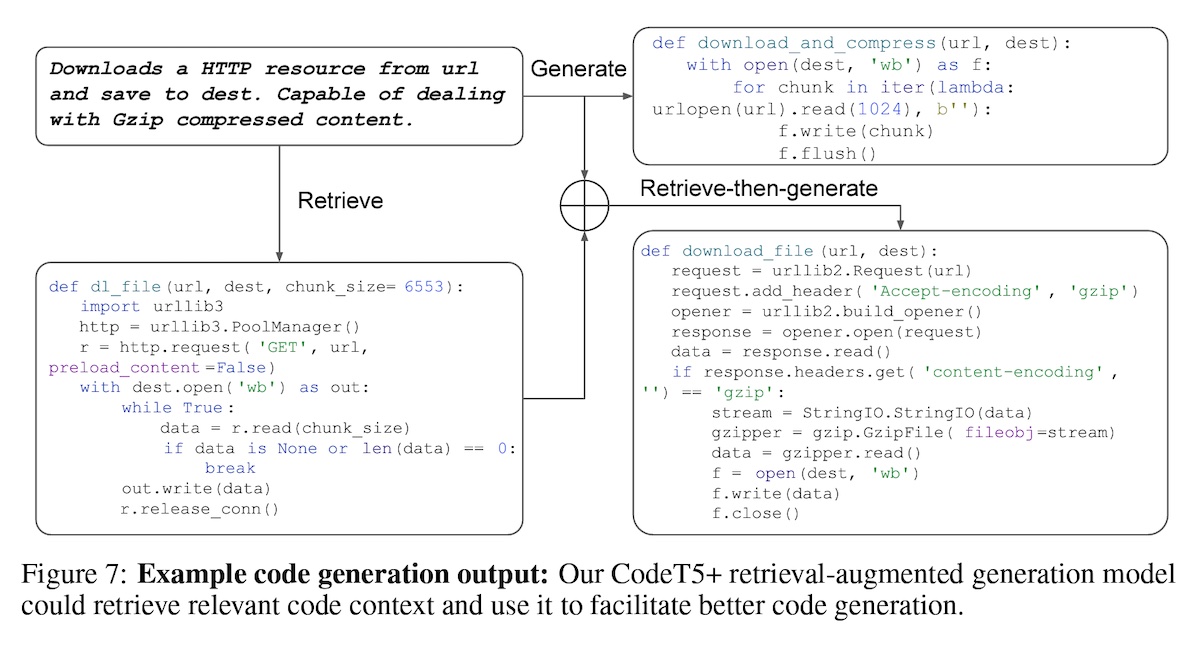
+#### [Overview of RAG for CodeT5+](https://arxiv.org/abs/2305.07922)
+
+
+---
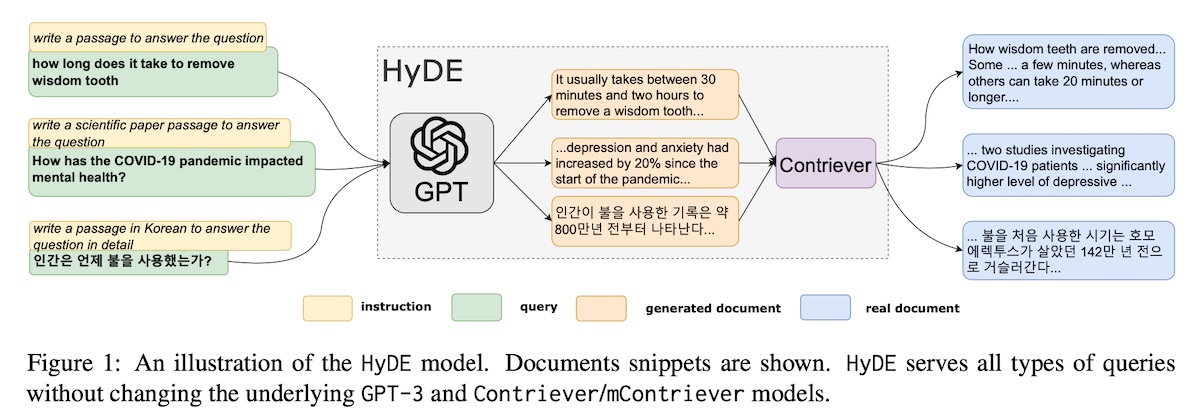
+#### [Hypothetical document embeddings (HyDE)](https://arxiv.org/abs/2212.10496)
+
+
+### LlamaIndex
+**Code:** [https://github.com/run-llama/llama_index](https://github.com/run-llama/llama_index)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-llamaindex](https://www.kaggle.com/code/rkuo2000/llm-llamaindex)
+LlamaIndex (GPT Index) is a data framework for your LLM application.
+* Offers data connectors to ingest your existing data sources and data formats (APIs, PDFs, docs, SQL, etc.)
+* Provides ways to structure your data (indices, graphs) so that this data can be easily used with LLMs.
+* Provides an advanced retrieval/query interface over your data: Feed in any LLM input prompt, get back retrieved context and knowledge-augmented output.
+* Allows easy integrations with your outer application framework (e.g. with LangChain, Flask, Docker, ChatGPT, anything else).
+
+---
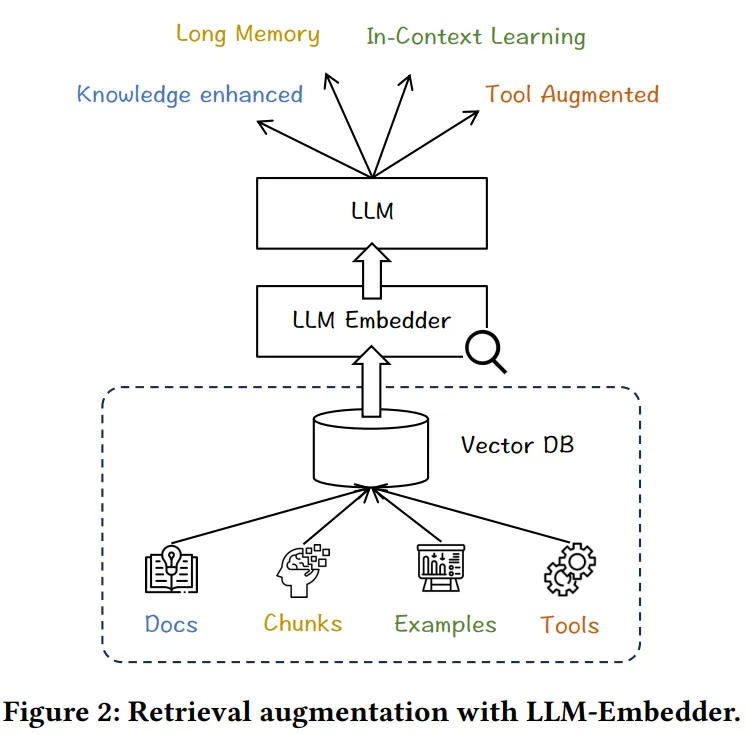
+### LLM Embedder
+**Paper:** [Retrieve Anything To Augment Large Language Models](https://arxiv.org/abs/2310.07554)
+**Code:** [https://github.com/FlagOpen/FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-flagembedding](https://www.kaggle.com/code/rkuo2000/llm-flagembedding)
+
+
+
+---
+### LM-Cocktail
+**Paper:** [LM-Cocktail: Resilient Tuning of Language Models via Model Merging](https://arxiv.org/abs/2311.13534)
+**Code:** [https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
+
+---
+### EAGLE-LLM
+3X faster for LLM
+**Blog:** [EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation](https://sites.google.com/view/eagle-llm)
+**Code:** [https://github.com/SafeAILab/EAGLE](https://github.com/SafeAILab/EAGLE)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/eagle-llm](https://www.kaggle.com/code/rkuo2000/eagle-llm)
+
+---
+### Purple Llama CyberSecEval
+**Paper:** [Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models](https://arxiv.org/abs/2312.04724)
+**Code:** [CybersecurityBenchmarks](https://github.com/facebookresearch/PurpleLlama/tree/main/CybersecurityBenchmarks)
+[meta-llama/LlamaGuard-7b](https://huggingface.co/meta-llama/LlamaGuard-7b)
+
+
Our Test Set (Prompt)
OpenAI Mod
ToxicChat
Our Test Set (Response)
+
Llama-Guard
0.945
0.847
0.626
0.953
+
OpenAI API
0.764
0.856
0.588
0.769
+
Perspective API
0.728
0.787
0.532
0.699
+
+
+---
+### Fine-tuning : To get better at specific tasks
+
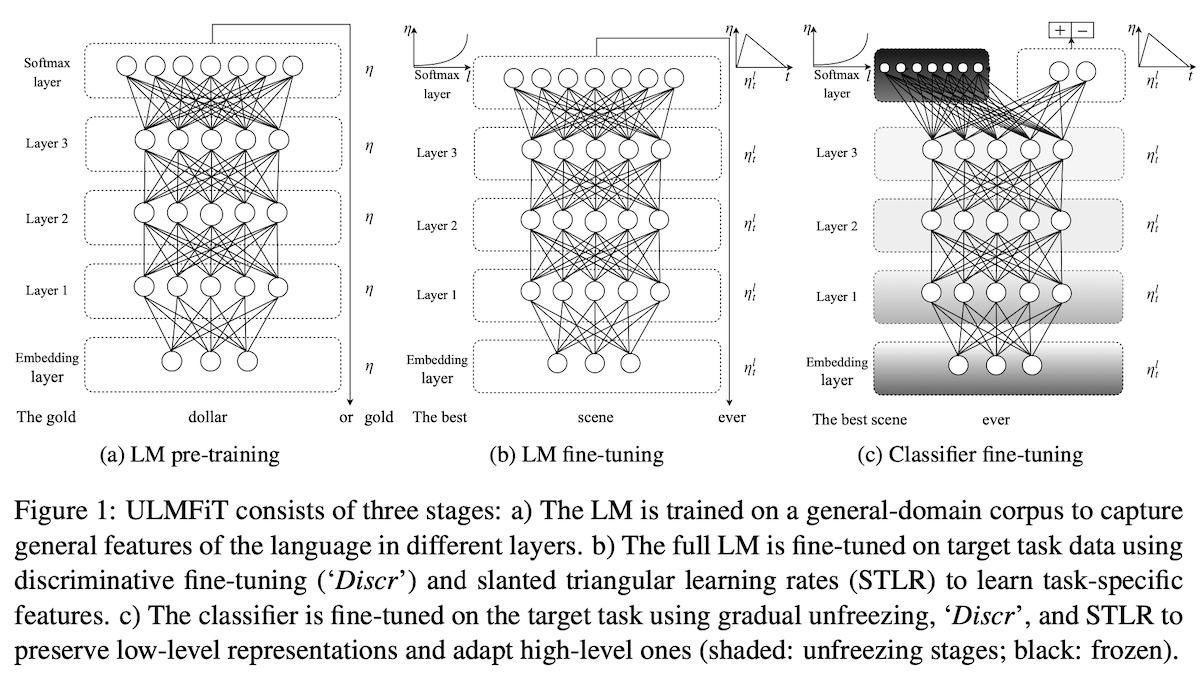
+#### [ULMFit](https://arxiv.org/abs/1801.06146)
+
+
+---
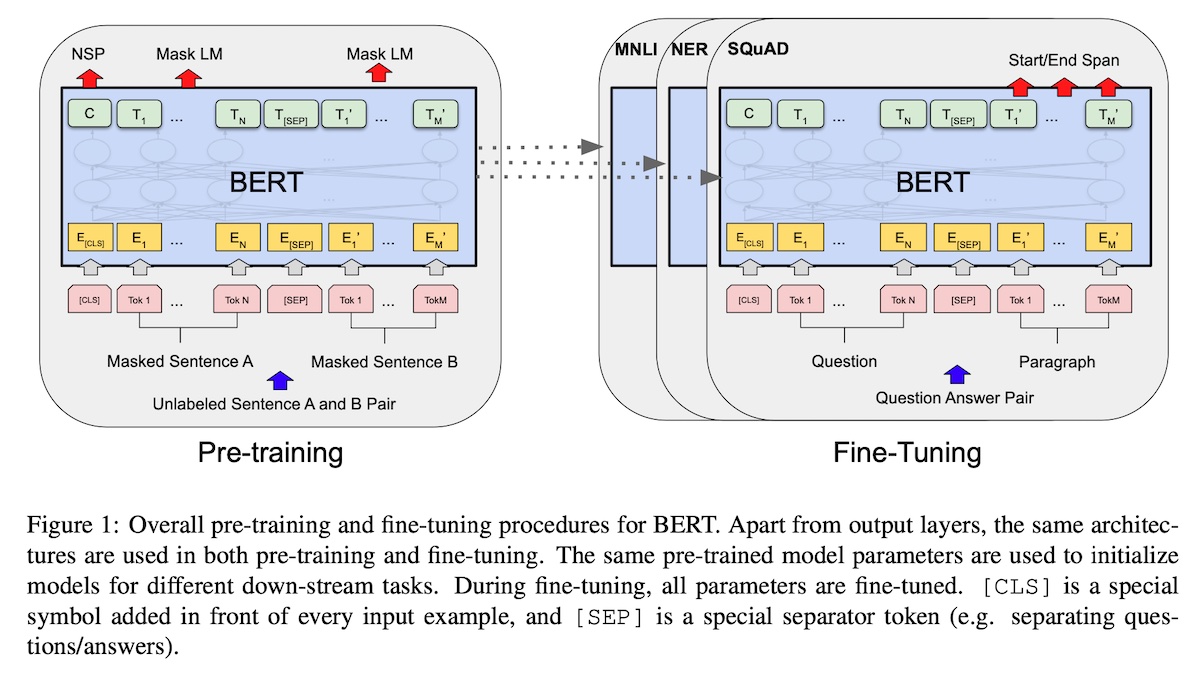
+#### [Bidirectional Encoder Representations from Transformers (BERT; encoder only)](https://arxiv.org/abs/1810.04805)
+
+
+---
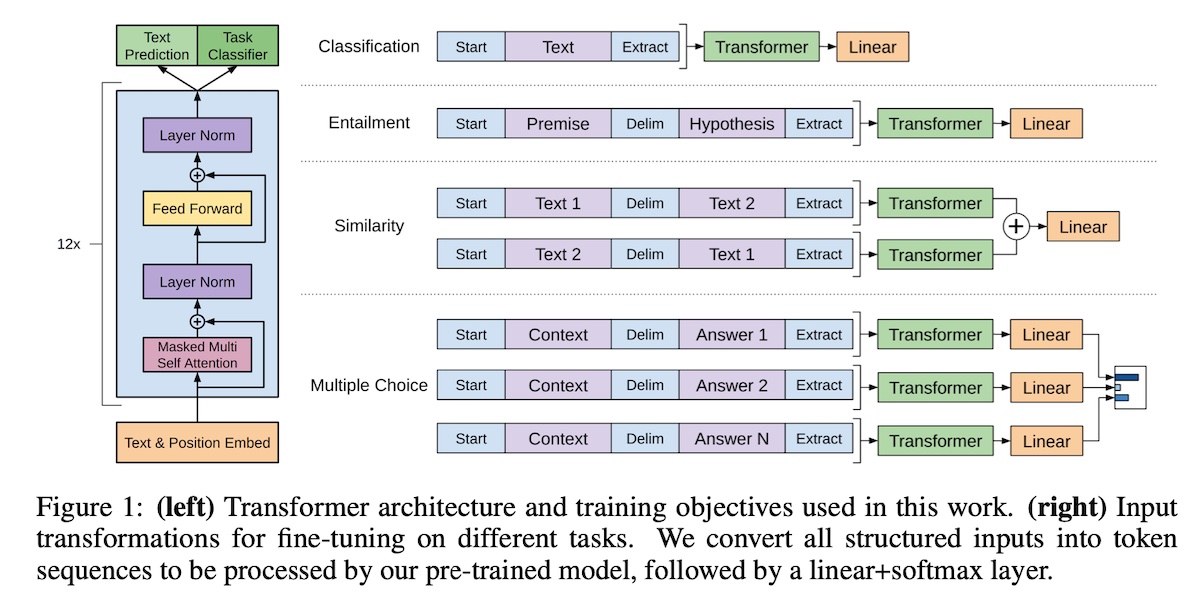
+#### [Generative Pre-trained Transformers (GPT; decoder only)](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
+
+
+---
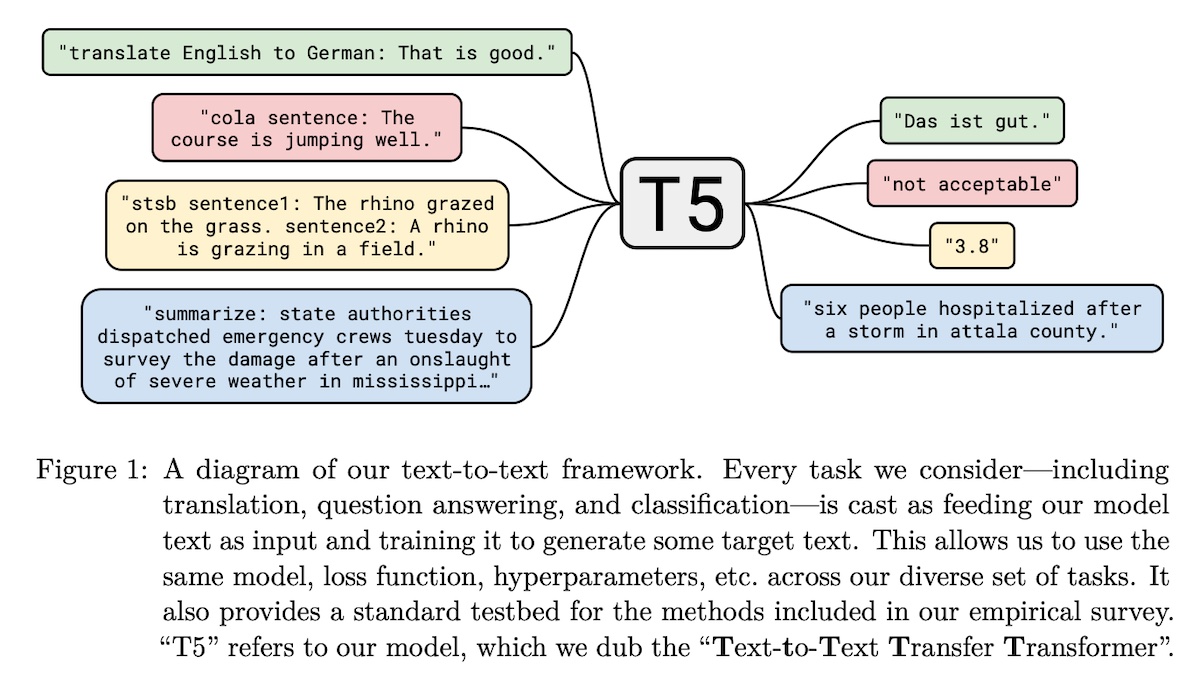
+#### [Text-to-text Transfer Transformer (T5; encoder-decoder)](https://arxiv.org/abs/1910.10683)
+
+
+---
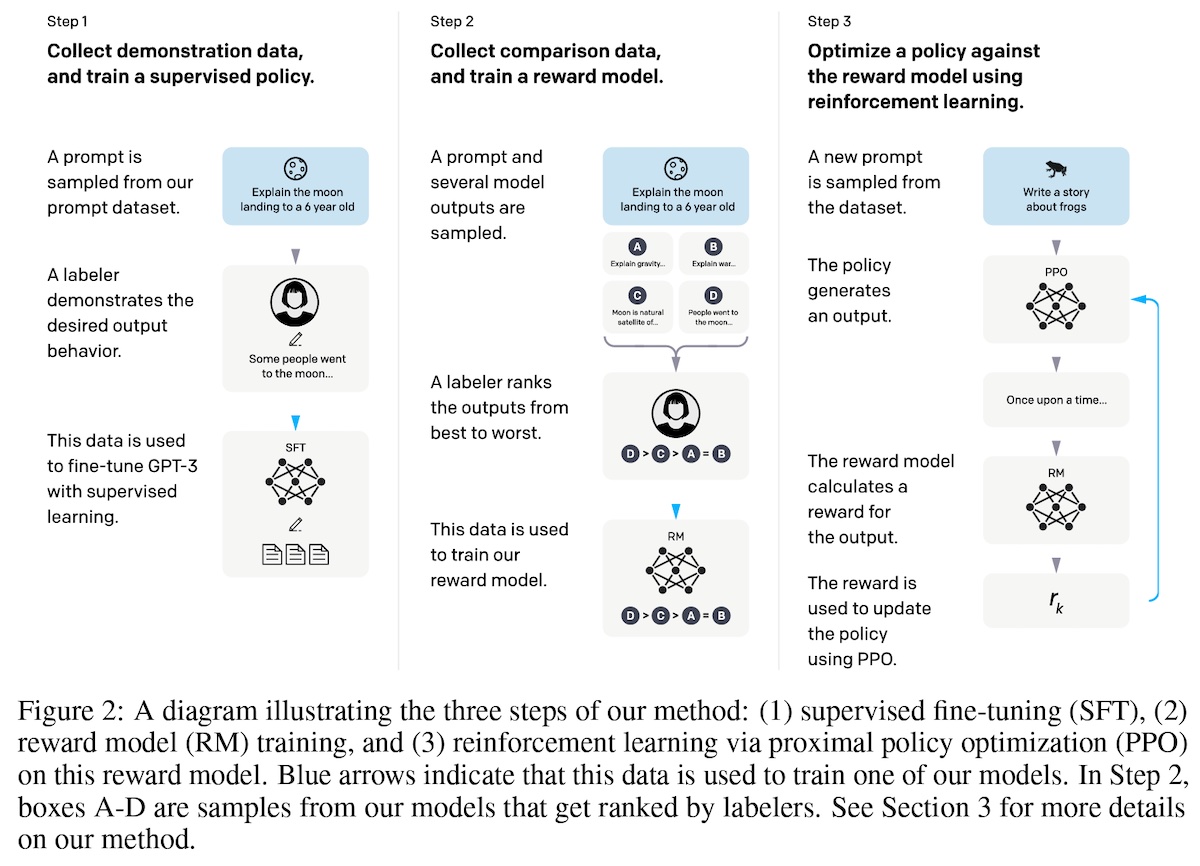
+#### [InstructGPT](https://arxiv.org/abs/2203.02155)
+
+
+---
+#### [Soft prompt tuning](https://arxiv.org/abs/2104.08691)
+**Blog:** [Guiding Frozen Language Models with Learned Soft Prompts](https://blog.research.google/2022/02/guiding-frozen-language-models-with.html)
+
+
+
+---
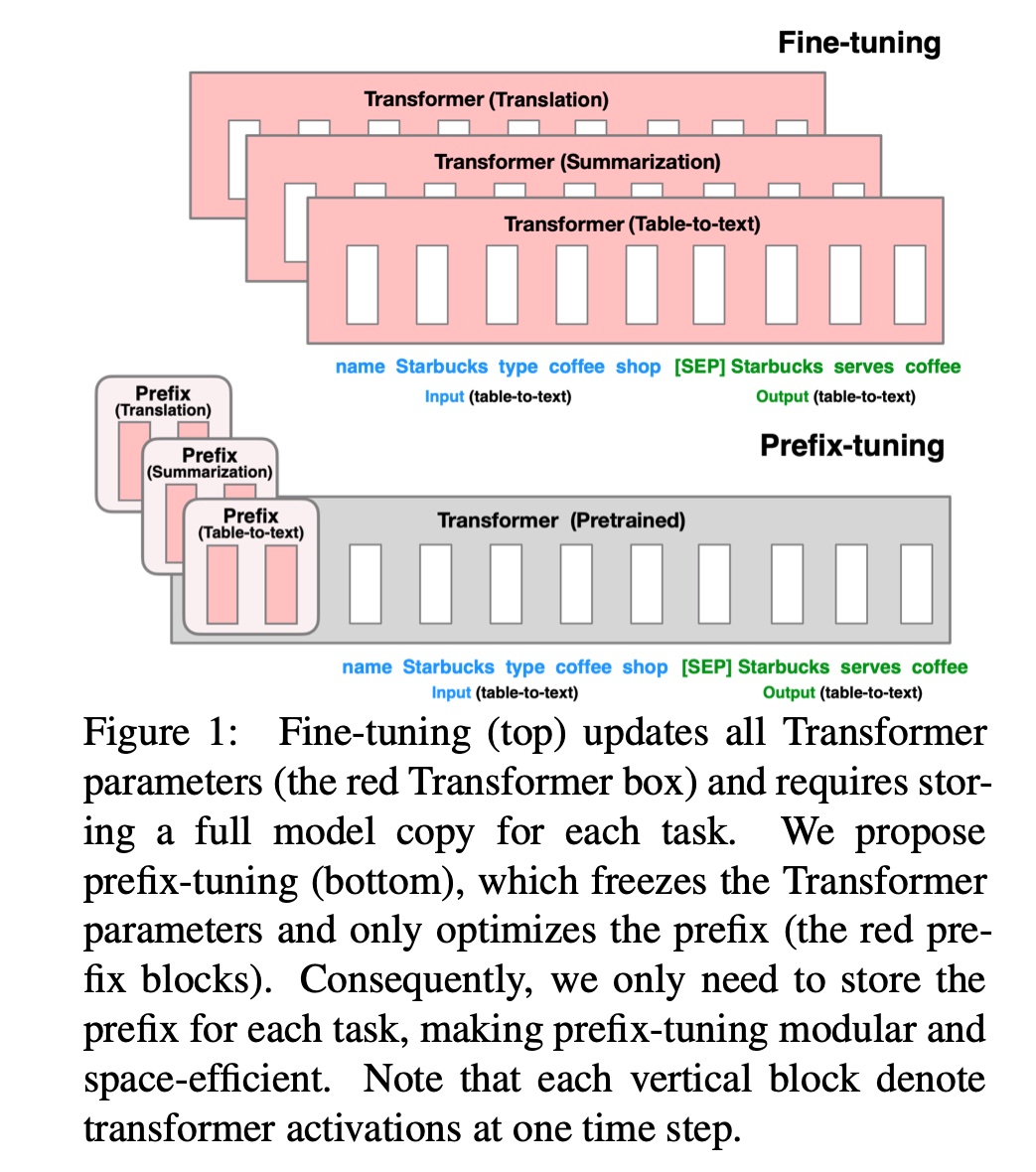
+#### [prefix tuning](https://arxiv.org/abs/2101.00190)
+
+
+---
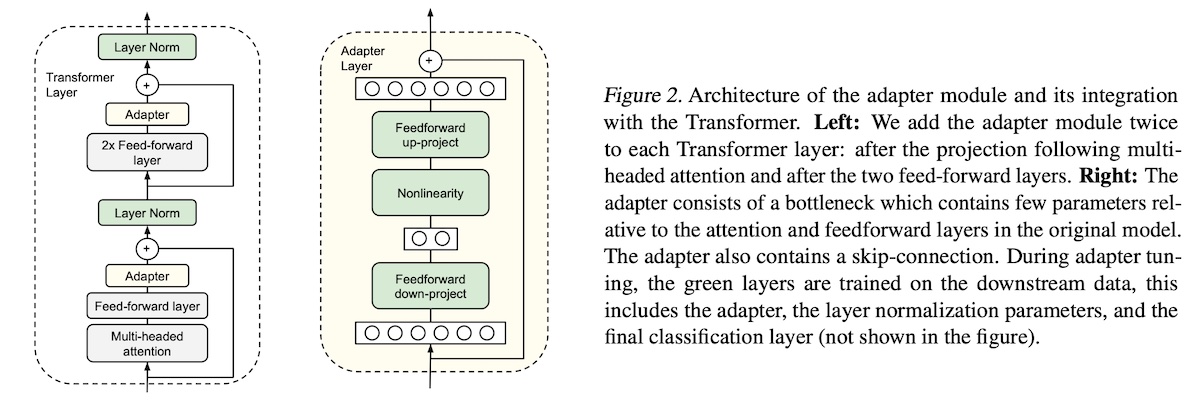
+#### [adapter](https://arxiv.org/abs/1902.00751)
+
+
+---
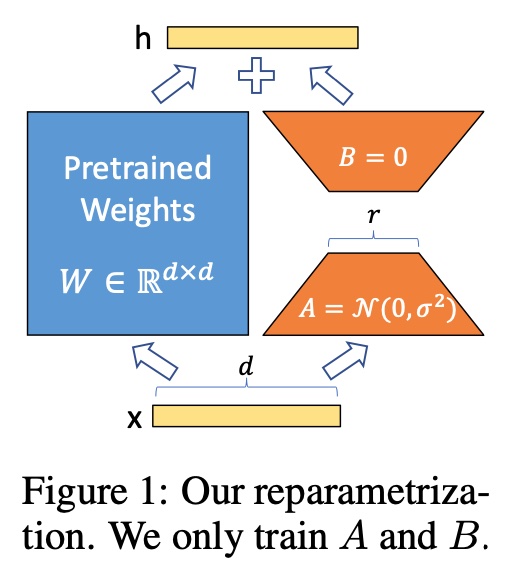
+#### [Low-Rank Adaptation (LoRA)](https://arxiv.org/abs/2106.09685)
+
+
+---
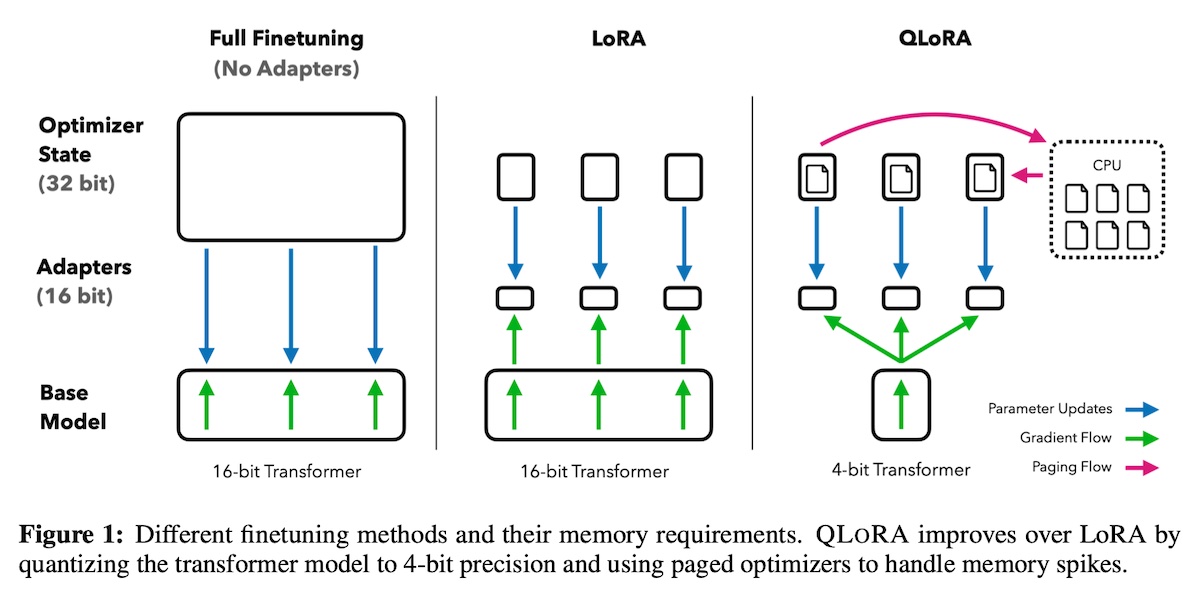
+#### [QLoRA](https://arxiv.org/abs/2305.14314)
+
+
+---
+### LongLoRA
+**Code:** [https://github.com/dvlab-research/LongLoRA](https://github.com/dvlab-research/LongLoRA)
+[2023.11.19] We release a new version of LongAlpaca models, LongAlpaca-7B-16k, LongAlpaca-7B-16k, and LongAlpaca-7B-16k.
+
+
+---
+## Prompt Engineering
+[Prompt Engineering Guide](https://www.promptingguide.ai/)
+
+---
+### Chain of Density (CoD)
+**Paper:** [From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting](https://arxiv.org/abs/2309.04269)
+
+---
+### Chain of Thougths (CoT)
+**Paper:** [Chain-of-Thought Prompting Elicits Reasoning in Large Language Models](https://arxiv.org/abs/2201.11903)
+**Paper:** [Automatic Chain of Thought Prompting in Large Language Models](https://arxiv.org/abs/2210.03493)
+**Blog:** [Chain-of-Thought Prompting](https://www.promptingguide.ai/techniques/cot)
+
+
+
+---
+### Tree of Thoughts (ToT)
+**Paper:** [Tree of Thoughts: Deliberate Problem Solving with Large Language Models](https://arxiv.org/abs/2305.10601)
+**Code:** [https://github.com/princeton-nlp/tree-of-thought-llm](https://github.com/princeton-nlp/tree-of-thought-llm)
+
+
+---
+### Soft-prompt Tuning
+**Paper:** [Soft-prompt Tuning for Large Language Models to Evaluate Bias](https://arxiv.org/abs/2306.04735)
+
+---
+### LLM Lingua
+**Paper: [LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models](https://arxiv.org/abs/2310.05736)
+**Code: [https://github.com/microsoft/LLMLingua](https://github.com/microsoft/LLMLingua)
+**Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-lingua](https://www.kaggle.com/code/rkuo2000/llm-lingua)
+
+
+---
+### Caching: To reduce latency and cost
+
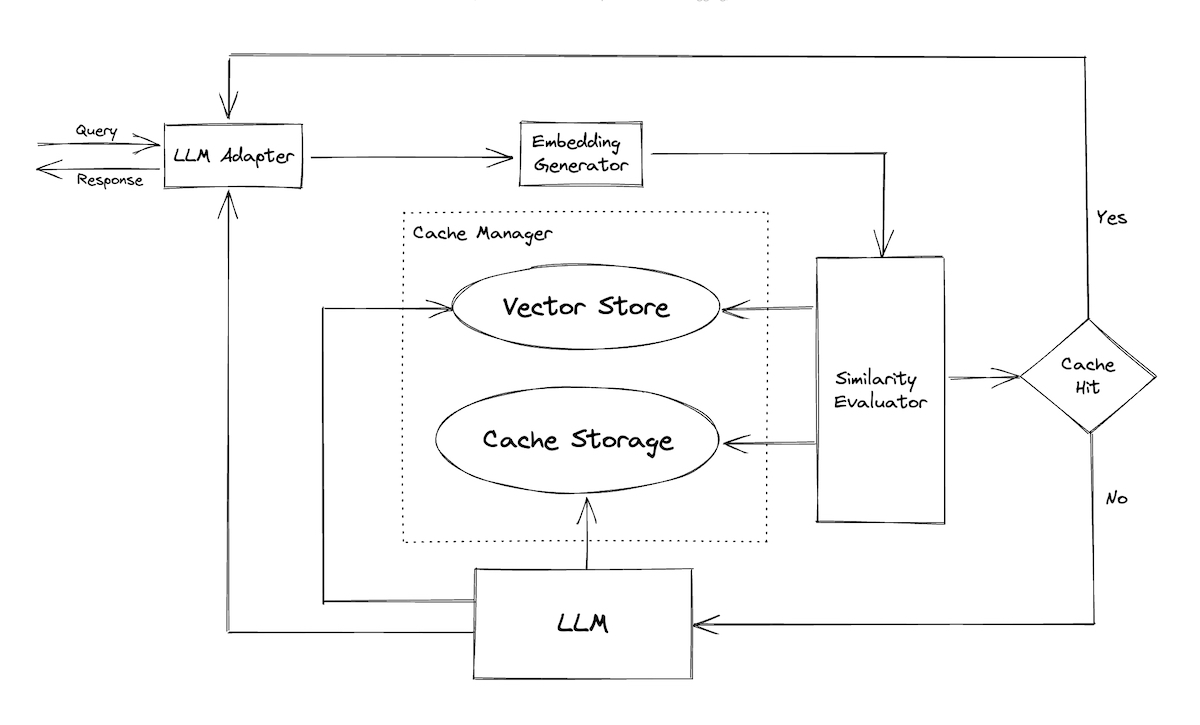
+#### [GPTCache](https://github.com/zilliztech/GPTCache)
+
+
+---
+### [Open-LLMs](https://github.com/eugeneyan/open-llms)
+Open LLMs
+Open LLM for Coder
+
+---
+## Deployment
+
+### [LLaMA-2-7B Benchmark](https://github.com/liltom-eth/llama2-webui/blob/main/docs/performance.md)
+
+---
+### [Run Llama 2 Locally in 7 Lines! (Apple Silicon Mac)](https://blog.lastmileai.dev/run-llama-2-locally-in-7-lines-apple-silicon-mac-c3f46143f327)
+
+On an `M2 Max MacBook Pro`, I was able to get 35–40 tokens per second using the LLAMA_METAL build flag.
+
+---
+### [Lamini LLM Finetuning on AMD ROCm™: A Technical Recipe](https://www.lamini.ai/blog/lamini-llm-finetuning-on-amd-rocm-a-technical-recipe)
+
+---
+### localLLM
+**Code:** [https://github.com/ykhli/local-ai-stack](https://github.com/ykhli/local-ai-stack)
+🦙 Inference: Ollama
+💻 VectorDB: Supabase pgvector
+🧠 LLM Orchestration: Langchain.js
+🖼️ App logic: Next.js
+🧮 Embeddings generation: Transformer.js and all-MiniLM-L6-v2
+
+---
+### AirLLM
+**Blog:** [Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW Technique](https://ai.gopubby.com/unbelievable-run-70b-llm-inference-on-a-single-4gb-gpu-with-this-new-technique-93e2057c7eeb)
+**Code:** [https://github.com/lyogavin/Anima/tree/main/air_llm](https://github.com/lyogavin/Anima/tree/main/air_llm)
+
+---
+### PowerInfer
+**Paper:** [PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU](https://arxiv.org/abs/2312.12456)
+**Code:** [https://github.com/SJTU-IPADS/PowerInfer](https://github.com/SJTU-IPADS/PowerInfer)
+**Blog:** [2080 Ti就能跑70B大模型,上交大新框架让LLM推理增速11倍](https://mp.weixin.qq.com/s/GnEK3xE5EhR5N9Mzs3tOtA)
+
+https://github.com/SJTU-IPADS/PowerInfer/assets/34213478/fe441a42-5fce-448b-a3e5-ea4abb43ba23
+PowerInfer v.s. llama.cpp on a single RTX 4090(24G) running Falcon(ReLU)-40B-FP16 with a 11x speedup!
+Both PowerInfer and llama.cpp were running on the same hardware and fully utilized VRAM on RTX 4090.
+
+
+
+
+*This site was last updated {{ site.time | date: "%B %d, %Y" }}.*
+