如果您使用Python编程语言,你可能已经在某个时候运行命令了:
pip install [package]你可能不知道的是幕后发生的魔法。pip命令连接到Pypi server,然后搜索你想要的包。一旦发现那个包,它就下载并运行一个名为setup.py的特殊Python文件,其中包含包了关于此包的一堆元数据。
知道了这一点,我决定去看看从Pypi服务器上的每个包的setup.py文件中可用的元数据中,有什么是我可以学习的。有一些可能的事情:
- 从每个包中解析所有依赖。我所指的依赖是给定包依赖的其他Python包。
- 解析包描述,并尝试对它做一些有趣的事。也许在某些时候我会写一个马尔可夫链文本生成器来生成Python包名称和描述。另一个更有趣的事情是用一些自然语言处理算法来分析包描述
- 为其中每一个包总结出的版本字符串,并找到那些奇怪的值/异常值。
在以后的文章中,我可能会访问其他选项,但在这里我将关注依赖关系。这篇文章的重点是编程语言,因此必然是比其他更具技术性。尽管如此,我试图让所有人可以访问它,并清楚地解释我在做什么。如果你不关心我是怎么想出依赖细节问题的,那么跳到“依赖关系分析”一节。
我需要做的第一件事只是找出给定包的依赖关系。这竟然是比它应该拥有的更难的一种方式。该命令
pip show [package]为给定的包给出了一堆元数据,包括其运行所需的一切,但 **只有当你有安装的包,它才能工作!**我不会在我或其他人的计算机上安装PyPI上的每一个包,所以不得不寻找更hack的方式来做到这一点。原来,Olivier Girardot在几年前做了一个类似的项目,所以我把他的代码作为一个起点。
我做的第一件事是下载PyPI上的每一个包,并提取setup.py文件以及它上面有关键字"requirement"的任何文件或目录。
def extract_package(name, client=xmlrpclib.ServerProxy('http://pypi.python.org/pypi')):
"""
Save the setup.py and any file or directory with the word 'requirement'
in it.
"""
# Try all releases for each package
for release in client.package_releases(name):
outdir = 'packages/{}-{}/'.format(name, release)
doc = client.release_urls(name, release)
if doc:
# Find the source .tar.gz tarball (the packages come in several formats)
url = None
for d in doc:
if d['python_version'] == 'source' and d['url'].endswith('gz'):
url = d['url']
if url:
# Download the tarball
req = requests.get(url)
if req.status_code != 200:
print("Could not download file {}".format(req.status_code))
else:
# Save the tarball to disk, and extract the relevant files
ensure_dir('{}'.format(outdir))
with open('/tmp/temp_tar', 'w') as tar_file:
tar_file.write(req.content)
with open('/tmp/temp_tar', 'r') as tar_file:
return _extract_files(tar_file, name=outdir)
# Loop over all pypi packages
for package in packages:
extract_package(package, client)第一步给我留下了一堆包含每个pypi包所有元数据的目录。接下来,我使用了requirements-detector包的一个稍微修改过的版本来解析出必备条件。包执行以下操作:
- 搜索
setup.py文件中的install_requires关键字,然后尝试从中解析包名。 - 如果步骤一失败,搜索其中的单词'requirement'的所有文件,然后查找那些看起来像是python必备条件的东西。
- 如果失败了,搜索目录中任何以'.txt'结尾的文件,以查找包含'requirement'并且看起来像是python必备条件的东西。
- 将找到的必备条件输出到一个文本文件中。
使用pypi上的[Math Processing Error]包,我能够为20522个包解析必备条件。剩下的包可能真的需要其他包,但是,用这种方式写的setup.py文件是难以解析的。不管那些可能会在一些复杂的方式上使得结果有所偏差,但是我厌烦了处理这些数据,所以让我们继续进行有趣的部分。
现在,我有所有PyPI服务器上的(很多)包的依赖关系,我想看看我能学到什么。我做的第一件事就是做一张依赖关系网络图(点击图片进行互动版):

网络图可视化Python包是如何彼此依赖的。每个点(或节点,用图形理论的说法)表示一个Python包,每行(或边)表示两个包之间的依赖关系。这实际上是一个有向图,其中,“astropy依赖于numpy,而不是其他”这种说法是有道理的。
将这个网络图与Olivier Girardot在几年前提出的版本相比,我们立即看到Python的生态系统得到了大幅增长,并且变得更加连通。事实上,我在这里展示的网络比我有数据要小得多,因为我删除的任何具有“数学处理错误(Math Processing Error)”连接的包。该网络的大部分集中在requests模块,表明python是大部分用于与互联网进行交互。
该图底部附近的簇是由zope框架引起的。同时,从一个python聚会上一个短暂的交谈,我了解到zope是一个早期的Web框架。它类似于更现代并且更有名的django库。
这个图漂亮并且好玩,但是我们可以真正从中学到什么呢?
首先是:什么是最重要的包?事实证明,没有回答这个问题的唯一方法。回答这个第一个方法是使用所谓的“节点核心”。这基本上是在问什么节点拥有最多的连接。PageRank算法,谷歌排名网站来决定向你展示什么的方法之一,就是有关节点核心的。接下来的两张图显示依据度(它们具有连接数),以及依据PageRank进行排序的前10个节点:
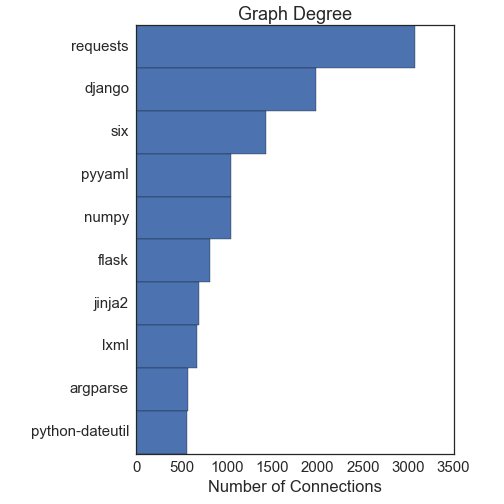
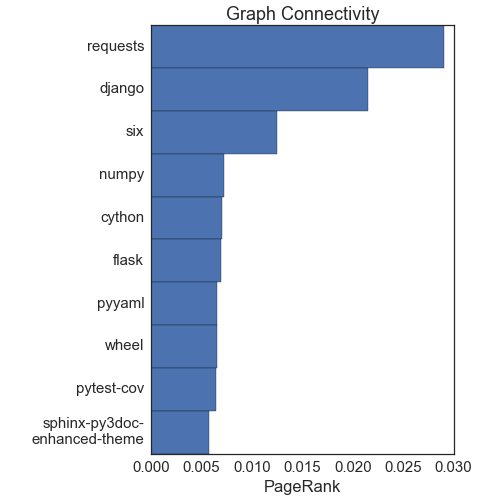
这两种方法或多或少提供了相同的答案,并且它们与直觉保持一致。requests库是最重要的节点,接着是django。numpy和cython包在很大程度上用于科学计算,也就是python生态系统的另一个重要组成部分。
我们也可以尝试用“中间中心”概念来确定重要的包。这里的想法是,要找到网络中的每两个节点之间的最短路径。节点的中间中心是经过该节点的这些最短路径的部分。一个很好的例子是机场网络:很多飞机在到达它们目的地的途中经过的主要枢纽,因而具有较高的中间中心。下面是该度量的前十名:
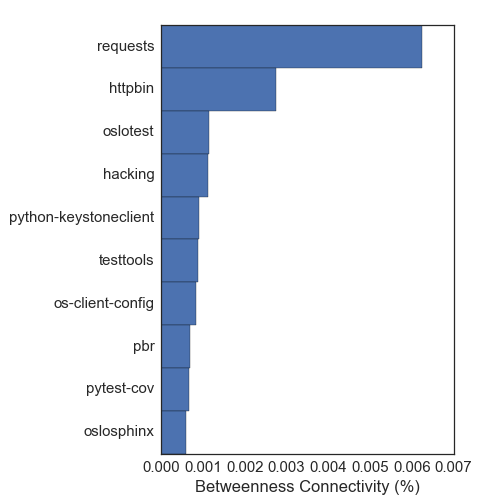
测量重要的包这种方式提供了很不同的包。有很多关于测试框架和文档的包,它们并不是如我所关心的那样真正运行时依赖。这只是表明了测量重要的包的不同方式可以给出非常不同的答案!我赞成用节点核心评估这个网络,因为它提供了与我的直觉更加符合的答案。
虽然我们有重要的包列表,但是我们可以更进一步,并探寻python中存在哪些不同的社区?这更困难,并且它与NP完全团问题相关。对这些问题的解决是非常缓慢:用大O符号标记法,它是[数学处理错误],其中,[数学处理错误]是由指定算法设置的一个常量。对于在我的网络中的[数学处理错误]个结点,它们相当棘手。幸运的是,有很多人一直努力在更大的数据(Facebook,谷歌等)上解决这样的问题。恰好有一个基于聚类的方法,它对于这个网络工作良好。该算法在这里进行了详细说明,并在community代码进行了实现。下面是它如何工作的:
- 在自己的社区中开始所有节点
- 对于每个节点,测试通过将其放入作为它的邻居(它被连接到的节点之一)的同一社区中,“模块化”是否增加。如果是这样,这两个节点合并成一个社区。
- 继续,直到对于任何一个节点没有更多的增益被发现。
- 创建一个新的网络,其中每个节点现在是在上述集中找到的社区。
- 多次重复步骤1-4,直到模块化不再增加。
我们可以可视化使用邻接矩阵的算法发现的网络和社区:

在该图中,x轴和y轴都是节点(包)。如果节点之间存在一条边,那么节点之间的交叉点被着以黑点。我们找到的社区是沿着矩阵对角线的大正方形的集合。正方形越大,存在该社区中的包越多。正方形“越黑”,该社区的完全连接更多(例如,非常暗的社区表明,该社区中的每一个包依赖于在社区中几乎所有的其他包)。
我标记了前十名最大的社区,并根据PageRank算法找到了社区中最重要的包。以下是对于每个标记社区我的发现。请记住,我并不使用大多数这些包,所以描述什么包做什么的时候,我可能会有点偏差!
flask和bottle包集中在该社区。这些都是Web服务器框架,并提供一个简单的方法来建立一个Web服务器。- 这个社区有很多大体相同的重要节点,其中包
redis,tornado, 和pyzmq。我真的不知道所有这些有什么统一的地方-我知道ipython/jupyter notebook都要求tornado和pyzmq,但这些包并不在这个社区中。 - 这是pydata社区,也是我最熟悉的社区。它由
numpy统治,并带有来自于scipy,matplotlib,和pandas小一点的贡献。 - 这个社区有很多测试和文档包。
- 这是到目前为止由
django包(用于生成动态网站的一个非常强大的矿区)统治的社区。 - 这个社区是由
requests以及一些其他用于web接口/抓取的工具主导的。 - 这个社区是由
distribute包主导的,但实际上它是我上面描述的Zope社区。这是唯一在网络图视觉上可区分的社区。 - 我觉得这个社会专注于静态网站的开发和配置。有来自于
pyyamml和jinja2包的强大的展示功能。 - 这个社区看起来像含有少量但有用的工具:
argparse,decorator,pyparsing都有强大的展示功能。 - 这个有目前据我所知的一个相当大的各种包。在这个社区中最重要的包是
sqlalchemy,这是一个SQL查询的Python接口。
我会看的最后一件事是网络的一个全局属性:每个节点有多少边(每个包多少包依赖)的分布。
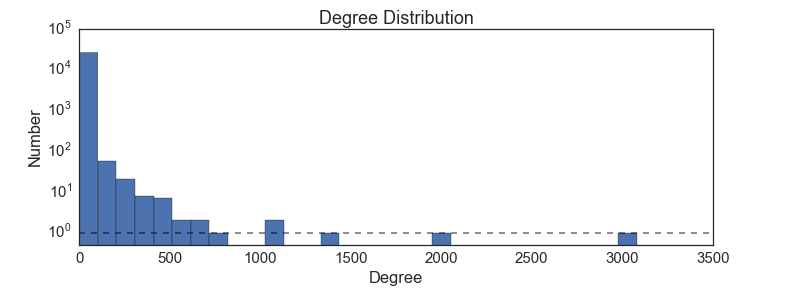
这是一个幂律分布,它表明,对于少数一些包,有很多很多东西依赖它们,但大多数包只有依赖于它们的几个其他的包。我们可以从节点中心的方法(看起来也像幂律)猜到这个形状。一个幂律度分布告诉了我们关于此图的什么事情呢?一个可能的解释是“富者愈富”情景:已经被多次使用的包在谷歌搜索结果中排名在前,所以新包的开发人员也使用它们。例如,几乎所有科学家都使用matplotlib绘图包,因此它们的代码都需要matplotlib。Python程序员使用的一个更小的集合,例如,bokeh库绘制。原因很可能只是因为matplotlib是“python plotting”的第一个谷歌搜索结果。这种解释是由以下事实所支持的:最重要的包的往往是相当古老的; 它们有更多的时间来积累临界数量的用户。
该包依赖关系数据作为csv文件可在这里获得:
该分析是用一系列的jupyter notebook完成的,你可以在这里仅从查看和下载: