原文:Building powerful image classification models using very little data
在本教程中,我们将介绍一个有点简单但是有效的方法,仅需非常少的训练样本 —— 只要你想要识别的那些类中几百或几千张图片,你就可以用它来构建一个强大的图像分类器。
我们将经历下面过程:
- 从无到有训练一个小型网络(作为基线)
- 使用预先训练的网络的瓶颈特征
- 微调预先训练的网络的顶层
这将让我们涵盖以下的Keras特征:
- 用于使用Python数据生成器训练Keras模型的
fit_generator - 用于实时数据增强的
ImageDataGenerator - 冻结层和模型微调
- ...等等。
我们将从以下步骤开始:
- 一台安装了Keras, SciPy, PIL的机器。如果你能使用NVIDIA GPU(并安装了cuDNN),也是棒棒哒,但由于我们只需要使用少量的图片,因此这不是绝对必要的。注意,由于本教程使用在1.0.4版本引入的Keras特性,因此在开始之前,你应该升级Keras。
- 一个训练数据目录和验证数据目录,其中每类图像有一个子目录,里面是.png或者.jpg图像:
data/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
validation/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
要获得几百或几千张属于你所感兴趣的类别的训练图像,一个可能的方法是使用Flickr API,在一个友好许可下,下载匹配给定标签的图片。
在我们的例子中,将使用两种图片集合,它们来自于Kaggle:1000张猫咪和1000张狗狗 (虽然原始的数据集有12,500张猫咪和12,500张狗狗的图片,但是我们仅需为每个类选取前1000张图片即可)。我们还使用每个类别中的400个额外的样本作为验证数据,以评估我们的模型。
对于一个远非如此简单的分类问题来说,这是要学习的极少数样例。因此这是一个极具挑战的机器学习问题,但也是一个实际的问题:在很多实际使用的情况下,即使是小规模的数据集合也可能是非常昂贵的,有时近乎无法获得(例如,在医学图像领域)。能够最大限度利用非常少的数据是一个称职的数据科学家的关键技能。

这个问题有多难?当两年多前Kaggle开始了cat与dog的对决(总共用了25,000张训练图像),出现了以下声明:
"在许多年前进行的一项非正式调查中,计算机视觉专家假定,在现有技术状态没有出现大进步的情况下,超过60%准确性的分类器将是一个难题。作为参考,一个60%的分类器将一个12张图像的HIP的猜测概率从1/4096提高到1/459。当前文献表明,在这项任务上,机器分类器可以取得高于80%的准确性 [参考]."
在结果竞争中,通过使用现代深度学习技术,排名靠前的竞争者能够获得超过98%的准确率。在我们的例子中,由于我们自我限制了只用数据集的8%,因此问题会更难。
我常听到的一个消息是,“只有当你有一个庞大的数据量时,深度学习才有意义。” 虽然这不是完全不正确,它有点误导。当然,深度学习需要自动从数据学习特性的能力,这通常只有当大量的训练数据可用时才有可能 —— 特别是对于那些输入样本非常高维度的问题,例如图像。然而,卷积神经网络 —— 深度学习的一个柱算法(pillar algorithm) —— 在设计上是可用于大多数“感性”问题(如图像分类)的最好的模型之一,甚至用很少的数据来学习。在一个小的图像数据集从头开始训练卷积神经网络仍然会产生合理的结果,而无需任何自定义功能的工程。卷积神经网络只是刚刚好。它们是关于这个工作的一个合适的工具。
但更重要的是,深度学习模型本质上是高度多用途的:你可以采取,比如说,在大型数据集上训练的图像分类或语音到文本模型,然后在只有轻微的变化的问题上重用它,我们将在这篇文章中看到的。特别是对于计算机视觉,很多预先训练模型(通常在ImageNet数据集上训练),现在可以公开下载,并且可以用用很少的数据来引导强大的视觉模型。
为了充分利用我们的一些训练例子,我们将通过一系列的随机变换“增强”它们,从而让我们的模型绝不会两次看到完全相同的图像。这有助于防止过度拟合,并帮助该模型更好的一般化。
在Keras中,这可以通过keras.preprocessing.image.ImageDataGenerator类来完成。这个类允许你:
- 在训练期间,在你的图像数据上配置随机转换和一般化操作
- 通过
.flow(data, labels)或者.flow_from_directory(directory),实例化增强的图像(及其标签)。然后,这些生成器可以用在将数据生成器作为输入的Keras模型上,fit_generator,evaluate_generator和predict_generator.
让我们马上看看一个例子:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
这仅仅是一些可用的选项,(详细信息,见文档)。让我们赶紧看看我们刚刚写了什么:
rotation_range是在(0-180)度之间的值,这个范围指的是随机选择图片的范围width_shift和height_shift指的是随机垂直或水平平移图片的范围(作为总宽度或总高度的一部分)rescale是我们在进行任何处理之前用来乘以数据的一个值。我们到原始图像由在0~255之间的RGB系数组成,但这样的值对于我们的模型而言太高而无法处理(给定一个典型的学习率),所以我们规定值在0和1之前,以取代用1/255缩放。因子。shear_range用来随机应用剪切变换zoom_range用来随机缩放图片horizontal_flip用来随机水平翻转一半的图像 —— 当没有水平对称性假设的时候相关 (例如,真实世界的图像)。fill_mode是用来填充新建像素的策略,它可以在旋转或者宽度/高度变换后出现。
现在,让我们开始使用这个工具来生成一些图片,并将它们保存到一个临时目录下,因此我们可以感受到我们的增强策略在做什么 —— 在这种情况下,我们禁用了重新调整,以保持图像可显示:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('data/train/cats/cat.0.jpg') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='cat', save_format='jpeg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefinitely
下面是我们得到的图像 —— 这就是我们的数据增强策略的结果。

用于图像分类工作的一个正确的工具是卷积神经网络(convnet),所以试着在我们的数据上训练一个,以作为初始的基准。由于我们仅有几个例子,我们的头号关注点应该是过拟合。当一个模型拥有过少的样例学习模式,无法生成新数据时,过拟合就发生了,例如,当该模型开始使用不相关特性进行预测时。打个比方,如果作为人类的你,只看到三张伐木工人的图像和三张水手的图像,其中,只有一个伐木工人带了帽子,那么你可能会开始任务,戴帽子是伐木工人相对于水手的一个标志。这样,你将会进行一个非常糟糕的伐木工人/水手分类。
数据增强是一种对抗过拟合的方式,但并不够,因为我们增强的样本仍然是高度相关的。你针对过拟合的主要关注点应该是模型的熵容量,即允许你的模型存储多少信息。能够存储大量信息的模型有潜力通过利用更多的特性变得更准确,但它也会更冒着开始存储不相干特性的风险。同时,一个只能存储一些特性的模型将必须关注于在数据中找到的最显著的特性,而这些更可能真正相关且概况良好。
有不同的方式来调节熵容量。主要的一个是在模型中参数数量的选择,即层的数量和每一层的大小。另一种方式是使用权重正则化,例如如L1或L2正则化,它们在于迫使模型权重接受较小的值。
在我们的例子中,我们将使用一个非常小的卷积神经网络,它具有一些层,每一层拥有一些过滤器,并伴有数据增强和丢弃。丢弃也有助于减少过度拟合,它防止每一层看到两次完全相同的模式,因此与数据增强殊途同归(你可以认为,丢弃和数据增强倾向于打乱你的数据中存在的随机相关)。
下面的代码片段是我们的第一个模型,带有ReLU激活的3层卷积的一个简单的堆栈,其次是MAX-汇聚层。这非常类似于Yann LeCun在20世纪90年代主张图像分类(除了ReLU以外)的架构。
该实验的完整代码可以在这里找到。
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# the model so far outputs 3D feature maps (height, width, features)
在此之上,我们坚持两个全连接层。我们用一个单一的单元和一个sigmoid激活结束模型,这对于二分模型是完美的。与之相匹配,我们也将使用binary_crossentropy损耗来训练我们的模型。
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
让我们准备数据。我们将使用.flow_from_directory(),直接从jpg图像中,在其各自的文件夹中生成批量的图像数据(及其标签)。
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in
# subfolers of 'data/train', and indefinitely generate
# batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'data/train', # this is the target directory
target_size=(150, 150), # all images will be resized to 150x150
batch_size=32,
class_mode='binary') # since we use binary_crossentropy loss, we need binary labels
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
现在,我们可以使用这些生成器来训练我们的模型了。每个阶段在花费GPU上20-30秒,在CPU上300-400秒。因此,如果你不赶时间,在CPU上运行这个模型是绝对可行的。
model.fit_generator(
train_generator,
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800)
model.save_weights('first_try.h5') # always save your weights after training or during training
在50次(这是随意选择的数字 —— 由于模型很小,并使用了积极丢弃,到那以后,它似乎并没有太多的过度拟合)后,该方法得到了0.79-0.81的验证准确率。所以在Kaggle比赛开始后,我们将已经位于“技术发展最新水平” —— 使用8%的数据,并且没有努力优化我们的架构或者超参数。事实上,在Kaggle比赛中,这个模型得分将排名前100(在215个参赛者中)。我猜至少有115个参赛者没有使用深度学习 ;)
注意,验证精度的方差是相当高的,一方面是因为精度是一种高方差度量。另一方面是因为我们只使用800个验证样例。在这种情况下,一个很好的验证策略是进行k-fold交叉验证,但这需要为每一轮的评估培训K模型。
更精确的方法是在一个大型数据集上利用网络预训练。这样网络将已经学习到对于大多数计算机视觉问题有用的特性,而利用这些特性将使我们能够达到比只能依靠现有数据的任何方法更好的精度。
我们将使用VGG16架构,在ImageNet数据集,这一个在本博客中前面指出的模型上进行预训练。由于在ImageNet数据集中总数为1000的类中包含几个“猫”类(波斯猫,暹罗猫...)和许多“狗”类,这种模式将已经了解到与我们的分类问题相关的特性。事实上,可能仅记录我们的数据上该模型的softmax预测,而不是瓶颈特征,就足以非常好地解决我们的狗与猫分类问题。但是,我们在这里提出的方法更容易推广到更广泛的问题,包括在ImageNet缺席的特性类问题。
下面是VGG16架构:
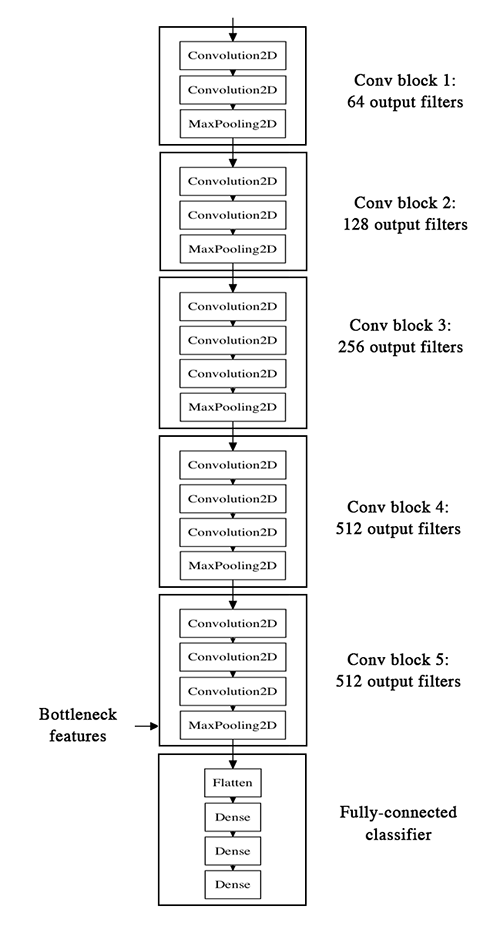
我们的战略将如下:我们将只实例化模型的卷积部分,一切都交给了全连接层。然后,我们将在我们的训练集上运行该模型,并验证数据一次,在两个numpy数组中记录输出(VGG16模型的“瓶颈特征”:在全连接层前的最后激活图)。然后,我们将在存储特性之上训练一个小型全连接模型。
我们之所以离线存储特性,而不是直接在冻结的卷积基础上增加了全连接模型并运行整个东东,是因为计算效率。运行VGG16是昂贵的,特别是当你在CPU上运行,而我们只想做一次。请注意,这阻止我们使用数据增强。
你可以在这里找到这个实验的完整代码。你可以从Github上获得权重文件。我们不会回头审视该模型是如何构建和加载的 —— 在多个Keras例子中已经有了。但是,让我们看看我们如何使用图像数据生成器记录瓶颈特性:
generator = datagen.flow_from_directory(
'data/train',
target_size=(150, 150),
batch_size=32,
class_mode=None, # this means our generator will only yield batches of data, no labels
shuffle=False) # our data will be in order, so all first 1000 images will be cats, then 1000 dogs
# the predict_generator method returns the output of a model, given
# a generator that yields batches of numpy data
bottleneck_features_train = model.predict_generator(generator, 2000)
# save the output as a Numpy array
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
generator = datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(generator, 800)
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
然后,我们可以加载保存的数据,并训练一个小型全连接模型:
train_data = np.load(open('bottleneck_features_train.npy'))
# the features were saved in order, so recreating the labels is easy
train_labels = np.array([0] * 1000 + [1] * 1000)
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * 400 + [1] * 400)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(train_data, train_labels,
nb_epoch=50, batch_size=32,
validation_data=(validation_data, validation_labels))
model.save_weights('bottleneck_fc_model.h5')
多亏了它比较小,即使在CPU(每个时钟1秒)上,该模型也能快速训练:
Train on 2000 samples, validate on 800 samples
Epoch 1/50
2000/2000 [==============================] - 1s - loss: 0.8932 - acc: 0.7345 - val_loss: 0.2664 - val_acc: 0.8862
Epoch 2/50
2000/2000 [==============================] - 1s - loss: 0.3556 - acc: 0.8460 - val_loss: 0.4704 - val_acc: 0.7725
...
Epoch 47/50
2000/2000 [==============================] - 1s - loss: 0.0063 - acc: 0.9990 - val_loss: 0.8230 - val_acc: 0.9125
Epoch 48/50
2000/2000 [==============================] - 1s - loss: 0.0144 - acc: 0.9960 - val_loss: 0.8204 - val_acc: 0.9075
Epoch 49/50
2000/2000 [==============================] - 1s - loss: 0.0102 - acc: 0.9960 - val_loss: 0.8334 - val_acc: 0.9038
Epoch 50/50
2000/2000 [==============================] - 1s - loss: 0.0040 - acc: 0.9985 - val_loss: 0.8556 - val_acc: 0.9075
我们达到了0.90-0.91的验证准确性:不差。这肯定部分是因为这个事实:基础模型是在一个已经精选了狗和猫(在数百个其他类之间)的数据集上训练的。
要进一步改善我们之前的结果,可以试着“微调”带有顶级分类器的VGG16模型的最后的卷积块。微调包括从训练网络开始,然后在一个新的数据集上使用非常小的权重更新来重新训练。在我们的例子中,可以用3个步骤完成:
- 实例化VGG16的卷积基础,然后加载其权重
- 在上面添加我们先前定义的全连接模型,然后加载其权重
- 冻结VGG16模型的层到最后的卷积块
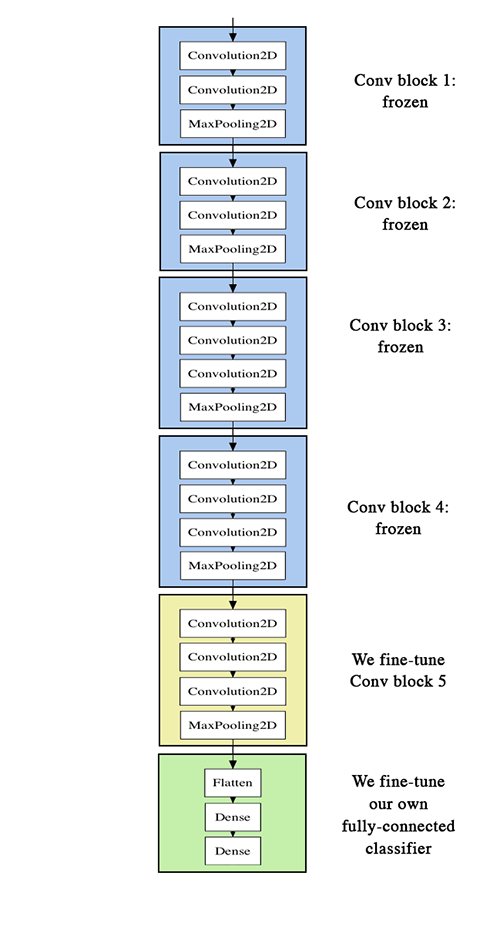
注意:
- 为了进行微调,所有层应使用适当的训练权重开始:比如,你不应该在一个预先训练的卷积基顶部使用一个随机初始化的全连接网络。这是因为随机初始权值引发的大坡度更新会破坏在卷积基学到的权重。在我们的例子,这就是为什么我们首先训练顶级分类器,然后才开始微调卷积权重。
- 我们选择仅微调最后的卷积块,而不是整个网络,是为了防止过度拟合,因为整个网络将有非常大的熵容量,因此有强烈的过度拟合倾向。由低层次卷积块学到的特性是更普遍的,比那些更高层次发现的更不抽象,因此保持前几个块固定(更一般的功能),并且仅微调最后一个(更专门的特性),是明智的。
- 微调应该以非常缓慢的学习率来完成,而通常使用SGD优化器,而不是一个诸如RMSProp的适应性学习率优化器。这是为了确保更新的幅度保持很小,以免破坏以前学过的特性。
你可以在这里找到该实验完整的代码。
实例化VGG基和加载其权重之后,我们在上面添加我们以前训练的全连通分类器:
# build a classifier model to put on top of the convolutional model
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
# note that it is necessary to start with a fully-trained
# classifier, including the top classifier,
# in order to successfully do fine-tuning
top_model.load_weights(top_model_weights_path)
# add the model on top of the convolutional base
model.add(top_model)
然后,我们继续冻结所有卷积层到最后卷积块:
# set the first 25 layers (up to the last conv block)
# to non-trainable (weights will not be updated)
for layer in model.layers[:25]:
layer.trainable = False
# compile the model with a SGD/momentum optimizer
# and a very slow learning rate.
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
最后,我们开始使用一个非常慢的学习率,来训练整个东西:
# prepare data augmentation configuration
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=32,
class_mode='binary')
# fine-tune the model
model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
该方法在50个阶段后提供了0.94的验证准确度。巨大的成功!
这里有一些方法,你可以尝试以获得超过0.95的准确度:
- 更积极的数据增强
- 更积极的丢弃
- 使用L1和L2正则化(也被称为“重衰变”)
- 微调多一个卷积块(伴随更大的正规化)
该文到这里就结束了!总结来说,这里你可以找到我们三个实验的代码:
如果你有任何关于该文的评论,或者关于未来要涵盖什么样的主题的建议,可以在Twitter上联系我。