\n\nWe believe that only an **open-source** solution to data movement can cover the **long tail of data sources** while empowering data engineers to **customize existing connectors**. Our ultimate vision is to help you move data from any source to any destination. Airbyte already provides [300+ connectors](https://docs.airbyte.com/integrations/) for popular APIs, databases, data warehouses, and data lakes.\n\nYou can implement Airbyte connectors in any language and take the form of a Docker image that follows the [Airbyte specification](https://docs.airbyte.com/understanding-airbyte/airbyte-protocol/). You can create new connectors very fast with:\n\n- The [low-code Connector Development Kit](https://docs.airbyte.com/connector-development/config-based/low-code-cdk-overview) (CDK) for API connectors ([demo](https://www.youtube.com/watch?v=i7VSL2bDvmw))\n- The [Python CDK](https://docs.airbyte.com/connector-development/cdk-python/) ([tutorial](https://docs.airbyte.com/connector-development/tutorials/cdk-speedrun))\n\nAirbyte has a built-in scheduler and uses [Temporal](https://airbyte.com/blog/scale-workflow-orchestration-with-temporal) to orchestrate jobs and ensure reliability at scale. Airbyte leverages [dbt](https://www.youtube.com/watch?v=saXwh6SpeHA) to normalize extracted data and can trigger custom transformations in SQL and dbt. You can also orchestrate Airbyte syncs with [Airflow](https://docs.airbyte.com/operator-guides/using-the-airflow-airbyte-operator), [Prefect](https://docs.airbyte.com/operator-guides/using-prefect-task), or [Dagster](https://docs.airbyte.com/operator-guides/using-dagster-integration).\n\n\n\nExplore our [demo app](https://demo.airbyte.io/).\n\n## Quick start\n\n### Run Airbyte locally\n\nYou can run Airbyte locally with Docker. The shell script below will retrieve the requisite docker files from the [platform repository](https://github.com/airbytehq/airbyte-platform) and run docker compose for you.\n\n```bash\ngit clone --depth 1 https://github.com/airbytehq/airbyte.git\ncd airbyte\n./run-ab-platform.sh\n```\n\nLogin to the web app at [http://localhost:8000](http://localhost:8000) by entering the default credentials found in your .env file.\n\n```\nBASIC_AUTH_USERNAME=airbyte\nBASIC_AUTH_PASSWORD=password\n```\n\nFollow web app UI instructions to set up a source, destination, and connection to replicate data. Connections support the most popular sync modes: full refresh, incremental and change data capture for databases.\n\nRead the [Airbyte docs](https://docs.airbyte.com).\n\n### Manage Airbyte configurations with code\n\nYou can also programmatically manage sources, destinations, and connections with YAML files, [Octavia CLI](https://github.com/airbytehq/airbyte/tree/master/octavia-cli), and API.\n\n### Deploy Airbyte to production\n\nDeployment options: [Docker](https://docs.airbyte.com/deploying-airbyte/local-deployment), [AWS EC2](https://docs.airbyte.com/deploying-airbyte/on-aws-ec2), [Azure](https://docs.airbyte.com/deploying-airbyte/on-azure-vm-cloud-shell), [GCP](https://docs.airbyte.com/deploying-airbyte/on-gcp-compute-engine), [Kubernetes](https://docs.airbyte.com/deploying-airbyte/on-kubernetes), [Restack](https://docs.airbyte.com/deploying-airbyte/on-restack), [Plural](https://docs.airbyte.com/deploying-airbyte/on-plural), [Oracle Cloud](https://docs.airbyte.com/deploying-airbyte/on-oci-vm), [Digital Ocean](https://docs.airbyte.com/deploying-airbyte/on-digitalocean-droplet)...\n\n### Use Airbyte Cloud\n\nAirbyte Cloud is the fastest and most reliable way to run Airbyte. It is a cloud-based data integration platform that allows you to collect and consolidate data from various sources into a single, unified system. It provides a user-friendly interface for data integration, transformation, and migration.\n\nWith Airbyte Cloud, you can easily connect to various data sources such as databases, APIs, and SaaS applications. It also supports a wide range of popular data sources like Salesforce, Stripe, Hubspot, PostgreSQL, and MySQL, among others.\n\nAirbyte Cloud provides a scalable and secure platform for data integration, making it easier for users to move, transform, and replicate data across different applications and systems. It also offers features like monitoring, alerting, and scheduling to ensure data quality and reliability.\n\nSign up for [Airbyte Cloud](https://cloud.airbyte.io/signup) and get free credits in minutes.\n\n## Contributing\n\nGet started by checking Github issues and creating a Pull Request. An easy way to start contributing is to update an existing connector or create a new connector using the low-code and Python CDKs. You can find the code for existing connectors in the [connectors](https://github.com/airbytehq/airbyte/tree/master/airbyte-integrations/connectors) directory. The Airbyte platform is written in Java, and the frontend in React. You can also contribute to our docs and tutorials. Advanced Airbyte users can apply to the [Maintainer program](https://airbyte.com/maintainer-program) and [Writer Program](https://airbyte.com/write-for-the-community).\n\nIf you would like to make a contribution to the platform itself, please refer to guides in [the platform repository](https://github.com/airbytehq/airbyte-platform).\n\nRead the [Contributing guide](https://docs.airbyte.com/contributing-to-airbyte/).\n\n## Reporting vulnerabilities\n\n\u26a0\ufe0f Please do not file GitHub issues or post on our public forum for security vulnerabilities, as they are public! \u26a0\ufe0f\n\nAirbyte takes security issues very seriously. If you have any concerns about Airbyte or believe you have uncovered a vulnerability, please get in touch via the e-mail address security@airbyte.io. In the message, try to provide a description of the issue and ideally a way of reproducing it. The security team will get back to you as soon as possible.\n\nNote that this security address should be used only for undisclosed vulnerabilities. Dealing with fixed issues or general questions on how to use the security features should be handled regularly via the user and the dev lists. Please report any security problems to us before disclosing it publicly.\n\n## License\n\nSee the [LICENSE](docs/project-overview/licenses/) file for licensing information, and our [FAQ](docs/project-overview/licenses/license-faq.md) for any questions you may have on that topic.\n\n## Resources\n\n- [Connectors Registry Report](https://connectors.airbyte.com/files/generated_reports/connector_registry_report.html) for a list of connectors available in Airbyte and Airbyte Cloud\n- [Weekly office hours](https://airbyte.io/weekly-office-hours/) for live informal sessions with the Airbyte team\n- [Slack](https://slack.airbyte.io) for quick discussion with the Community and Airbyte team\n- [Discourse](https://discuss.airbyte.io/) for deeper conversations about features, connectors, and problems\n- [GitHub](https://github.com/airbytehq/airbyte) for code, issues and pull requests\n- [Youtube](https://www.youtube.com/c/AirbyteHQ) for videos on data engineering\n- [Newsletter](https://airbyte.com/newsletter) for product updates and data news\n- [Blog](https://airbyte.com/blog) for data insights articles, tutorials and updates\n- [Docs](https://docs.airbyte.com/) for Airbyte features\n- [Roadmap](https://app.harvestr.io/roadmap/view/pQU6gdCyc/launch-week-roadmap) for planned features\n\n## Thank You\n\nAirbyte would not be possible without the support and assistance of other open-source tools and companies. Visit our [thank you page](THANK-YOU.md) to lear more about how we build Airbyte.\n\n",
- "source_links": [],
- "id": 0
- },
- {
- "page_link": "basic-auth.md",
- "title": "basic-auth",
- "text": "## Configuring Basic Auth\n\nAirbyte's api and web interface is not authenticated by default. We provide an oauth proxy by default to grant some security to your airbyte install, but in order to integrate with tools like airflow, you'll likely want a means to authenticate with static creds. That's where basic auth can be very useful. The process is very simple.\n\n### modify context.yaml\n\nin the `context.yaml` file at the root of your repo, simply add:\n\n```yaml\nconfiguration:\n airbyte:\n users:\n : \n : \n```\nyou can use `plural crypto random` to generate a high-entropy password if that is helpful as well.\n\n### redeploy\n\nSimply run `plural build --only airbyte && plural deploy --commit \"enabling basic auth\"` to wire in the credentials to our oauth proxy. Occasionally you need to restart the web pods to get it to take, you can find them with:\n\n```sh\nkubectl get pods -n airbyte | grep airbyte-web\n```\n\nthen delete them (allowing k8s to restart) with:\n\n```sh\nkubectl delete pod -n airbyte\n```",
- "source_links": [],
- "id": 1
- },
- {
- "page_link": "bring-your-own-db.md",
- "title": "bring-your-own-db",
- "text": "## Connecting to a managed SQL\u00a0instance\n\nWe ship airbyte with the zalando postgres operator's db for persistence by default. This provides a lot of the benefits of a managed postgres instance at a lower cost, but if you'd rather use a familiar service like RDS this is still possible. You'll need to do a few things:\n\n### edit context.yaml\n\nAt the root of the repo, edit the `context.yaml` field and set `configuration.airbyte.postgresDisabled: true`, this will allow us to reconfigure airbyte for bring-your-own-db.\n\n### save the database password to a secret\n\nyou can use a number of methods for this, but simply adding a secret file as `airbyte/helm/airbyte/templates/db-password.yaml` like:\n\n```yaml\napiVersion: v1\nkind: Secret\nmetadata:\n name: airbyte-db-password\nstringData:\n password: {{ .Values.externalDb.password }}\n```\n\nNote: this password needs to be in the `airbyte` namespace. If you put it in our wrapper helm chart, that will be done by default for you.\n\n### modify airbyte's helm values.yaml \n\nIf you go to `airbyte/helm/airbyte/values.yaml` you'll need to provide credentials for postgres. They should look something like:\n\n```yaml\nexternalDb:\n password: \nglobal:\n database:\n secretName: airbyte-db-password\n secretValue: password\nairbyte:\n airbyte:\n externalDatabase:\n database: \n host: \n user: \n port: 5432\n```\n\n(we're ultimately beholden to the structure defined in airbyte's upstream helm chart here)\n\n### redeploy\n\nFrom there, you should be able to run `plural build --only airbyte && plural deploy --commit \"using existing postgres instance\"` to use the managed sql instance",
- "source_links": [],
- "id": 2
- },
- {
- "page_link": "troubleshooting.md",
- "title": "troubleshooting",
- "text": "# Troubleshooting Guide\n\nThis is a running doc of things that could potentially surface in your airbyte instance that can be easily addressed. You'll find most of these errors in the logs for airbyte but they can surface elsewhere as well\n\n### Failure executing: POST at: https://172.20.0.1/api/v1/namespaces/airbyte/pods. Message: Unauthorized! Configured service account doesn't have access. Service account may have been revoked. Unauthorized.\n\nIt's unclear exactly what causes this, but it's likely a bug in airbyte's kubernetes client implementation. There's a spot-fix for this, simply delete the airbyte-worker pods in your instance and allow k8s to respawn them. That will regenerate the service account token and allow airbyte to continue as normal.",
- "source_links": [],
- "id": 3
- },
- {
- "page_link": "https://github.com/apache/airflow",
- "title": "airflow readme",
- "text": "\n\n# Apache Airflow\n\n[](https://badge.fury.io/py/apache-airflow)\n[](https://github.com/apache/airflow/actions)\n[](https://app.codecov.io/gh/apache/airflow/branch/main)\n[](https://www.apache.org/licenses/LICENSE-2.0.txt)\n[](https://pypi.org/project/apache-airflow/)\n[](https://hub.docker.com/r/apache/airflow)\n[](https://hub.docker.com/r/apache/airflow)\n[](https://pypi.org/project/apache-airflow/)\n[](https://artifacthub.io/packages/search?repo=apache-airflow)\n[](https://github.com/psf/black)\n[](https://twitter.com/ApacheAirflow)\n[](https://s.apache.org/airflow-slack)\n[](https://github.com/apache/airflow/graphs/contributors)\n[](https://ossrank.com/p/6)\n\n[Apache Airflow](https://airflow.apache.org/docs/apache-airflow/stable/) (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows.\n\nWhen workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.\n\nUse Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.\n\n\n\n**Table of contents**\n\n- [Project Focus](#project-focus)\n- [Principles](#principles)\n- [Requirements](#requirements)\n- [Getting started](#getting-started)\n- [Installing from PyPI](#installing-from-pypi)\n- [Official source code](#official-source-code)\n- [Convenience packages](#convenience-packages)\n- [User Interface](#user-interface)\n- [Semantic versioning](#semantic-versioning)\n- [Version Life Cycle](#version-life-cycle)\n- [Support for Python and Kubernetes versions](#support-for-python-and-kubernetes-versions)\n- [Base OS support for reference Airflow images](#base-os-support-for-reference-airflow-images)\n- [Approach to dependencies of Airflow](#approach-to-dependencies-of-airflow)\n- [Contributing](#contributing)\n- [Who uses Apache Airflow?](#who-uses-apache-airflow)\n- [Who Maintains Apache Airflow?](#who-maintains-apache-airflow)\n- [Can I use the Apache Airflow logo in my presentation?](#can-i-use-the-apache-airflow-logo-in-my-presentation)\n- [Airflow merchandise](#airflow-merchandise)\n- [Links](#links)\n- [Sponsors](#sponsors)\n\n\n\n## Project Focus\n\nAirflow works best with workflows that are mostly static and slowly changing. When the DAG structure is similar from one run to the next, it clarifies the unit of work and continuity. Other similar projects include [Luigi](https://github.com/spotify/luigi), [Oozie](https://oozie.apache.org/) and [Azkaban](https://azkaban.github.io/).\n\nAirflow is commonly used to process data, but has the opinion that tasks should ideally be idempotent (i.e., results of the task will be the same, and will not create duplicated data in a destination system), and should not pass large quantities of data from one task to the next (though tasks can pass metadata using Airflow's [XCom feature](https://airflow.apache.org/docs/apache-airflow/stable/concepts/xcoms.html)). For high-volume, data-intensive tasks, a best practice is to delegate to external services specializing in that type of work.\n\nAirflow is not a streaming solution, but it is often used to process real-time data, pulling data off streams in batches.\n\n## Principles\n\n- **Dynamic**: Airflow pipelines are configuration as code (Python), allowing for dynamic pipeline generation. This allows for writing code that instantiates pipelines dynamically.\n- **Extensible**: Easily define your own operators, executors and extend the library so that it fits the level of abstraction that suits your environment.\n- **Elegant**: Airflow pipelines are lean and explicit. Parameterizing your scripts is built into the core of Airflow using the powerful **Jinja** templating engine.\n- **Scalable**: Airflow has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers.\n\n## Requirements\n\nApache Airflow is tested with:\n\n| | Main version (dev) | Stable version (2.6.0) |\n|---------------------|------------------------------|------------------------------|\n| Python | 3.7, 3.8, 3.9, 3.10 | 3.7, 3.8, 3.9, 3.10 |\n| Platform | AMD64/ARM64(\\*) | AMD64/ARM64(\\*) |\n| Kubernetes | 1.23, 1.24, 1.25, 1.26 | 1.21, 1.22, 1.23, 1.24, 1.25 |\n| PostgreSQL | 11, 12, 13, 14, 15 | 11, 12, 13, 14, 15 |\n| MySQL | 5.7, 8 | 5.7, 8 |\n| SQLite | 3.15.0+ | 3.15.0+ |\n| MSSQL | 2017(\\*), 2019(\\*) | 2017(\\*), 2019(\\*) |\n\n\\* Experimental\n\n**Note**: MySQL 5.x versions are unable to or have limitations with\nrunning multiple schedulers -- please see the [Scheduler docs](https://airflow.apache.org/docs/apache-airflow/stable/scheduler.html).\nMariaDB is not tested/recommended.\n\n**Note**: SQLite is used in Airflow tests. Do not use it in production. We recommend\nusing the latest stable version of SQLite for local development.\n\n**Note**: Airflow currently can be run on POSIX-compliant Operating Systems. For development it is regularly\ntested on fairly modern Linux Distros and recent versions of MacOS.\nOn Windows you can run it via WSL2 (Windows Subsystem for Linux 2) or via Linux Containers.\nThe work to add Windows support is tracked via [#10388](https://github.com/apache/airflow/issues/10388) but\nit is not a high priority. You should only use Linux-based distros as \"Production\" execution environment\nas this is the only environment that is supported. The only distro that is used in our CI tests and that\nis used in the [Community managed DockerHub image](https://hub.docker.com/p/apache/airflow) is\n`Debian Bullseye`.\n\n## Getting started\n\nVisit the official Airflow website documentation (latest **stable** release) for help with\n[installing Airflow](https://airflow.apache.org/docs/apache-airflow/stable/installation.html),\n[getting started](https://airflow.apache.org/docs/apache-airflow/stable/start.html), or walking\nthrough a more complete [tutorial](https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html).\n\n> Note: If you're looking for documentation for the main branch (latest development branch): you can find it on [s.apache.org/airflow-docs](https://s.apache.org/airflow-docs/).\n\nFor more information on Airflow Improvement Proposals (AIPs), visit\nthe [Airflow Wiki](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvement+Proposals).\n\nDocumentation for dependent projects like provider packages, Docker image, Helm Chart, you'll find it in [the documentation index](https://airflow.apache.org/docs/).\n\n## Installing from PyPI\n\nWe publish Apache Airflow as `apache-airflow` package in PyPI. Installing it however might be sometimes tricky\nbecause Airflow is a bit of both a library and application. Libraries usually keep their dependencies open, and\napplications usually pin them, but we should do neither and both simultaneously. We decided to keep\nour dependencies as open as possible (in `setup.py`) so users can install different versions of libraries\nif needed. This means that `pip install apache-airflow` will not work from time to time or will\nproduce unusable Airflow installation.\n\nTo have repeatable installation, however, we keep a set of \"known-to-be-working\" constraint\nfiles in the orphan `constraints-main` and `constraints-2-0` branches. We keep those \"known-to-be-working\"\nconstraints files separately per major/minor Python version.\nYou can use them as constraint files when installing Airflow from PyPI. Note that you have to specify\ncorrect Airflow tag/version/branch and Python versions in the URL.\n\n\n1. Installing just Airflow:\n\n> Note: Only `pip` installation is currently officially supported.\n\nWhile it is possible to install Airflow with tools like [Poetry](https://python-poetry.org) or\n[pip-tools](https://pypi.org/project/pip-tools), they do not share the same workflow as\n`pip` - especially when it comes to constraint vs. requirements management.\nInstalling via `Poetry` or `pip-tools` is not currently supported.\n\nIf you wish to install Airflow using those tools, you should use the constraint files and convert\nthem to the appropriate format and workflow that your tool requires.\n\n\n```bash\npip install 'apache-airflow==2.6.0' \\\n --constraint \"https://raw.githubusercontent.com/apache/airflow/constraints-2.6.0/constraints-3.7.txt\"\n```\n\n2. Installing with extras (i.e., postgres, google)\n\n```bash\npip install 'apache-airflow[postgres,google]==2.6.0' \\\n --constraint \"https://raw.githubusercontent.com/apache/airflow/constraints-2.6.0/constraints-3.7.txt\"\n```\n\nFor information on installing provider packages, check\n[providers](http://airflow.apache.org/docs/apache-airflow-providers/index.html).\n\n## Official source code\n\nApache Airflow is an [Apache Software Foundation](https://www.apache.org) (ASF) project,\nand our official source code releases:\n\n- Follow the [ASF Release Policy](https://www.apache.org/legal/release-policy.html)\n- Can be downloaded from [the ASF Distribution Directory](https://downloads.apache.org/airflow)\n- Are cryptographically signed by the release manager\n- Are officially voted on by the PMC members during the\n [Release Approval Process](https://www.apache.org/legal/release-policy.html#release-approval)\n\nFollowing the ASF rules, the source packages released must be sufficient for a user to build and test the\nrelease provided they have access to the appropriate platform and tools.\n\n## Convenience packages\n\nThere are other ways of installing and using Airflow. Those are \"convenience\" methods - they are\nnot \"official releases\" as stated by the `ASF Release Policy`, but they can be used by the users\nwho do not want to build the software themselves.\n\nThose are - in the order of most common ways people install Airflow:\n\n- [PyPI releases](https://pypi.org/project/apache-airflow/) to install Airflow using standard `pip` tool\n- [Docker Images](https://hub.docker.com/r/apache/airflow) to install airflow via\n `docker` tool, use them in Kubernetes, Helm Charts, `docker-compose`, `docker swarm`, etc. You can\n read more about using, customising, and extending the images in the\n [Latest docs](https://airflow.apache.org/docs/docker-stack/index.html), and\n learn details on the internals in the [IMAGES.rst](https://github.com/apache/airflow/blob/main/IMAGES.rst) document.\n- [Tags in GitHub](https://github.com/apache/airflow/tags) to retrieve the git project sources that\n were used to generate official source packages via git\n\nAll those artifacts are not official releases, but they are prepared using officially released sources.\nSome of those artifacts are \"development\" or \"pre-release\" ones, and they are clearly marked as such\nfollowing the ASF Policy.\n\n## User Interface\n\n- **DAGs**: Overview of all DAGs in your environment.\n\n \n\n- **Grid**: Grid representation of a DAG that spans across time.\n\n \n\n- **Graph**: Visualization of a DAG's dependencies and their current status for a specific run.\n\n \n\n- **Task Duration**: Total time spent on different tasks over time.\n\n \n\n- **Gantt**: Duration and overlap of a DAG.\n\n \n\n- **Code**: Quick way to view source code of a DAG.\n\n \n\n## Semantic versioning\n\nAs of Airflow 2.0.0, we support a strict [SemVer](https://semver.org/) approach for all packages released.\n\nThere are few specific rules that we agreed to that define details of versioning of the different\npackages:\n\n* **Airflow**: SemVer rules apply to core airflow only (excludes any changes to providers).\n Changing limits for versions of Airflow dependencies is not a breaking change on its own.\n* **Airflow Providers**: SemVer rules apply to changes in the particular provider's code only.\n SemVer MAJOR and MINOR versions for the packages are independent of the Airflow version.\n For example, `google 4.1.0` and `amazon 3.0.3` providers can happily be installed\n with `Airflow 2.1.2`. If there are limits of cross-dependencies between providers and Airflow packages,\n they are present in providers as `install_requires` limitations. We aim to keep backwards\n compatibility of providers with all previously released Airflow 2 versions but\n there will sometimes be breaking changes that might make some, or all\n providers, have minimum Airflow version specified. Change of that minimum supported Airflow version\n is a breaking change for provider because installing the new provider might automatically\n upgrade Airflow (which might be an undesired side effect of upgrading provider).\n* **Airflow Helm Chart**: SemVer rules apply to changes in the chart only. SemVer MAJOR and MINOR\n versions for the chart are independent from the Airflow version. We aim to keep backwards\n compatibility of the Helm Chart with all released Airflow 2 versions, but some new features might\n only work starting from specific Airflow releases. We might however limit the Helm\n Chart to depend on minimal Airflow version.\n* **Airflow API clients**: SemVer MAJOR and MINOR versions follow MAJOR and MINOR versions of Airflow.\n The first MAJOR or MINOR X.Y.0 release of Airflow should always be followed by X.Y.0 release of\n all clients. An airflow PATCH X.Y.Z release can be followed by a PATCH release of API clients, only\n if this PATCH is relevant to the clients.\n The clients then can release their own PATCH releases with bugfixes, independently of Airflow PATCH releases.\n As a consequence, each API client will have its own PATCH version that may or may not be in sync with the Airflow\n PATCH version. For a specific MAJOR/MINOR Airflow version, users should favor the latest PATCH version of clients\n independently of their Airflow PATCH version.\n\n## Version Life Cycle\n\nApache Airflow version life cycle:\n\n\n\n\n| Version | Current Patch/Minor | State | First Release | Limited Support | EOL/Terminated |\n|-----------|-----------------------|-----------|-----------------|-------------------|------------------|\n| 2 | 2.6.0 | Supported | Dec 17, 2020 | TBD | TBD |\n| 1.10 | 1.10.15 | EOL | Aug 27, 2018 | Dec 17, 2020 | June 17, 2021 |\n| 1.9 | 1.9.0 | EOL | Jan 03, 2018 | Aug 27, 2018 | Aug 27, 2018 |\n| 1.8 | 1.8.2 | EOL | Mar 19, 2017 | Jan 03, 2018 | Jan 03, 2018 |\n| 1.7 | 1.7.1.2 | EOL | Mar 28, 2016 | Mar 19, 2017 | Mar 19, 2017 |\n\n\n\nLimited support versions will be supported with security and critical bug fix only.\nEOL versions will not get any fixes nor support.\nWe always recommend that all users run the latest available minor release for whatever major version is in use.\nWe **highly** recommend upgrading to the latest Airflow major release at the earliest convenient time and before the EOL date.\n\n## Support for Python and Kubernetes versions\n\nAs of Airflow 2.0, we agreed to certain rules we follow for Python and Kubernetes support.\nThey are based on the official release schedule of Python and Kubernetes, nicely summarized in the\n[Python Developer's Guide](https://devguide.python.org/#status-of-python-branches) and\n[Kubernetes version skew policy](https://kubernetes.io/docs/setup/release/version-skew-policy/).\n\n1. We drop support for Python and Kubernetes versions when they reach EOL. Except for Kubernetes, a\n version stays supported by Airflow if two major cloud providers still provide support for it. We drop\n support for those EOL versions in main right after EOL date, and it is effectively removed when we release\n the first new MINOR (Or MAJOR if there is no new MINOR version) of Airflow. For example, for Python 3.7 it\n means that we will drop support in main right after 27.06.2023, and the first MAJOR or MINOR version of\n Airflow released after will not have it.\n\n2. The \"oldest\" supported version of Python/Kubernetes is the default one until we decide to switch to\n later version. \"Default\" is only meaningful in terms of \"smoke tests\" in CI PRs, which are run using this\n default version and the default reference image available. Currently `apache/airflow:latest`\n and `apache/airflow:2.6.0` images are Python 3.7 images. This means that default reference image will\n become the default at the time when we start preparing for dropping 3.7 support which is few months\n before the end of life for Python 3.7.\n\n3. We support a new version of Python/Kubernetes in main after they are officially released, as soon as we\n make them work in our CI pipeline (which might not be immediate due to dependencies catching up with\n new versions of Python mostly) we release new images/support in Airflow based on the working CI setup.\n\n## Base OS support for reference Airflow images\n\nThe Airflow Community provides conveniently packaged container images that are published whenever\nwe publish an Apache Airflow release. Those images contain:\n\n* Base OS with necessary packages to install Airflow (stable Debian OS)\n* Base Python installation in versions supported at the time of release for the MINOR version of\n Airflow released (so there could be different versions for 2.3 and 2.2 line for example)\n* Libraries required to connect to supported Databases (again the set of databases supported depends\n on the MINOR version of Airflow.\n* Predefined set of popular providers (for details see the [Dockerfile](https://raw.githubusercontent.com/apache/airflow/main/Dockerfile)).\n* Possibility of building your own, custom image where the user can choose their own set of providers\n and libraries (see [Building the image](https://airflow.apache.org/docs/docker-stack/build.html))\n* In the future Airflow might also support a \"slim\" version without providers nor database clients installed\n\nThe version of the base OS image is the stable version of Debian. Airflow supports using all currently active\nstable versions - as soon as all Airflow dependencies support building, and we set up the CI pipeline for\nbuilding and testing the OS version. Approximately 6 months before the end-of-life of a previous stable\nversion of the OS, Airflow switches the images released to use the latest supported version of the OS.\nFor example since ``Debian Buster`` end-of-life was August 2022, Airflow switched the images in `main` branch\nto use ``Debian Bullseye`` in February/March 2022. The version was used in the next MINOR release after\nthe switch happened. In case of the Bullseye switch - 2.3.0 version used ``Debian Bullseye``.\nThe images released in the previous MINOR version continue to use the version that all other releases\nfor the MINOR version used.\n\nSupport for ``Debian Buster`` image was dropped in August 2022 completely and everyone is expected to\nstop building their images using ``Debian Buster``.\n\nUsers will continue to be able to build their images using stable Debian releases until the end of life and\nbuilding and verifying of the images happens in our CI but no unit tests were executed using this image in\nthe `main` branch.\n\n## Approach to dependencies of Airflow\n\nAirflow has a lot of dependencies - direct and transitive, also Airflow is both - library and application,\ntherefore our policies to dependencies has to include both - stability of installation of application,\nbut also ability to install newer version of dependencies for those users who develop DAGs. We developed\nthe approach where `constraints` are used to make sure airflow can be installed in a repeatable way, while\nwe do not limit our users to upgrade most of the dependencies. As a result we decided not to upper-bound\nversion of Airflow dependencies by default, unless we have good reasons to believe upper-bounding them is\nneeded because of importance of the dependency as well as risk it involves to upgrade specific dependency.\nWe also upper-bound the dependencies that we know cause problems.\n\nThe constraint mechanism of ours takes care about finding and upgrading all the non-upper bound dependencies\nautomatically (providing that all the tests pass). Our `main` build failures will indicate in case there\nare versions of dependencies that break our tests - indicating that we should either upper-bind them or\nthat we should fix our code/tests to account for the upstream changes from those dependencies.\n\nWhenever we upper-bound such a dependency, we should always comment why we are doing it - i.e. we should have\na good reason why dependency is upper-bound. And we should also mention what is the condition to remove the\nbinding.\n\n### Approach for dependencies for Airflow Core\n\nThose `extras` and `providers` dependencies are maintained in `setup.cfg`.\n\nThere are few dependencies that we decided are important enough to upper-bound them by default, as they are\nknown to follow predictable versioning scheme, and we know that new versions of those are very likely to\nbring breaking changes. We commit to regularly review and attempt to upgrade to the newer versions of\nthe dependencies as they are released, but this is manual process.\n\nThe important dependencies are:\n\n* `SQLAlchemy`: upper-bound to specific MINOR version (SQLAlchemy is known to remove deprecations and\n introduce breaking changes especially that support for different Databases varies and changes at\n various speed (example: SQLAlchemy 1.4 broke MSSQL integration for Airflow)\n* `Alembic`: it is important to handle our migrations in predictable and performant way. It is developed\n together with SQLAlchemy. Our experience with Alembic is that it very stable in MINOR version\n* `Flask`: We are using Flask as the back-bone of our web UI and API. We know major version of Flask\n are very likely to introduce breaking changes across those so limiting it to MAJOR version makes sense\n* `werkzeug`: the library is known to cause problems in new versions. It is tightly coupled with Flask\n libraries, and we should update them together\n* `celery`: Celery is crucial component of Airflow as it used for CeleryExecutor (and similar). Celery\n [follows SemVer](https://docs.celeryq.dev/en/stable/contributing.html?highlight=semver#versions), so\n we should upper-bound it to the next MAJOR version. Also when we bump the upper version of the library,\n we should make sure Celery Provider minimum Airflow version is updated).\n* `kubernetes`: Kubernetes is a crucial component of Airflow as it is used for the KubernetesExecutor\n (and similar). Kubernetes Python library [follows SemVer](https://github.com/kubernetes-client/python#compatibility),\n so we should upper-bound it to the next MAJOR version. Also when we bump the upper version of the library,\n we should make sure Kubernetes Provider minimum Airflow version is updated.\n\n### Approach for dependencies in Airflow Providers and extras\n\nThe main part of the Airflow is the Airflow Core, but the power of Airflow also comes from a number of\nproviders that extend the core functionality and are released separately, even if we keep them (for now)\nin the same monorepo for convenience. You can read more about the providers in the\n[Providers documentation](https://airflow.apache.org/docs/apache-airflow-providers/index.html). We also\nhave set of policies implemented for maintaining and releasing community-managed providers as well\nas the approach for community vs. 3rd party providers in the [providers](PROVIDERS.rst) document.\n\nThose `extras` and `providers` dependencies are maintained in `provider.yaml` of each provider.\n\nBy default, we should not upper-bound dependencies for providers, however each provider's maintainer\nmight decide to add additional limits (and justify them with comment).\n\n## Contributing\n\nWant to help build Apache Airflow? Check out our [contributing documentation](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst).\n\nOfficial Docker (container) images for Apache Airflow are described in [IMAGES.rst](https://github.com/apache/airflow/blob/main/IMAGES.rst).\n\n## Who uses Apache Airflow?\n\nMore than 400 organizations are using Apache Airflow\n[in the wild](https://github.com/apache/airflow/blob/main/INTHEWILD.md).\n\n## Who Maintains Apache Airflow?\n\nAirflow is the work of the [community](https://github.com/apache/airflow/graphs/contributors),\nbut the [core committers/maintainers](https://people.apache.org/committers-by-project.html#airflow)\nare responsible for reviewing and merging PRs as well as steering conversations around new feature requests.\nIf you would like to become a maintainer, please review the Apache Airflow\n[committer requirements](https://github.com/apache/airflow/blob/main/COMMITTERS.rst#guidelines-to-become-an-airflow-committer).\n\n## Can I use the Apache Airflow logo in my presentation?\n\nYes! Be sure to abide by the Apache Foundation [trademark policies](https://www.apache.org/foundation/marks/#books) and the Apache Airflow [Brandbook](https://cwiki.apache.org/confluence/display/AIRFLOW/Brandbook). The most up to date logos are found in [this repo](/docs/apache-airflow/img/logos) and on the Apache Software Foundation [website](https://www.apache.org/logos/about.html).\n\n## Airflow merchandise\n\nIf you would love to have Apache Airflow stickers, t-shirt, etc. then check out\n[Redbubble Shop](https://www.redbubble.com/i/sticker/Apache-Airflow-by-comdev/40497530.EJUG5).\n\n## Links\n\n- [Documentation](https://airflow.apache.org/docs/apache-airflow/stable/)\n- [Chat](https://s.apache.org/airflow-slack)\n\n## Sponsors\n\nThe CI infrastructure for Apache Airflow has been sponsored by:\n\n\n\n\n\n",
- "source_links": [],
- "id": 4
- },
- {
- "page_link": "bring-your-db.md",
- "title": "bring-your-db",
- "text": "## Connecting to a managed SQL\u00a0instance\n\nWe ship airbyte with the zalando postgres operator's db for persistence by default. This provides a lot of the benefits of a managed postgres instance at a lower cost, but if you'd rather use a familiar service like RDS this is still possible. You'll need to do a few things:\n\n### edit context.yaml\n\nAt the root of the repo, edit the `context.yaml` field and set `configuration.airflow.postgresDisabled: true`, this will allow us to reconfigure airflow for bring-your-own-db.\n\n### save the database password to a secret\n\nyou can use a number of methods for this, but simply adding a secret file as `airflow/helm/airflow/templates/db-password.yaml` like:\n\n```yaml\napiVersion: v1\nkind: Secret\nmetadata:\n name: airflow-db-password\nstringData:\n password: {{ .Values.externalDb.password }}\n```\n\nNote: this password needs to be in the `airflow` namespace. If you put it in our wrapper helm chart, that will be done by default for you.\n\n### modify airflow's helm values.yaml \n\nIf you go to `airflow/helm/airflow/values.yaml` you'll need to provide credentials for postgres. They should look something like:\n\n```yaml\nexternalDb:\n password: \nairflow:\n airflow:\n externalDatabase:\n database: \n host: \n passwordSecret: airflow-db-password\n passwordSecretKey: password\n user: \n port: 5432\n\n # use this for any extra connection-string settings, e.g. ?sslmode=disable\n properties: \"?sslmode=allow\"\n```\n\n### redeploy\n\nFrom there, you should be able to run `plural build --only airflow && plural deploy --commit \"using existing postgres instance\"` to use the managed sql instance",
- "source_links": [],
- "id": 5
- },
- {
- "page_link": "pip-packages.md",
- "title": "pip-packages",
- "text": "## Installing pip packages\n\nFrequently an airflow project needs more than our default pip setup installed to work fully. Airflow's codebase is brittle, and we recommend you handle pip installs by baking a new docker image against ours and then wiring it into your installation. It's not actually too hard, and we can walk you through it.\n\n### Custom Dockerfile\n\nThe dockerfile for our image is found at https://github.com/pluralsh/containers/tree/main/airflow. You'll also want to keep the `requirements.txt` file adjacent to it. Simply move these two wherever you manage docker, add whatever pip packages to `requirements.txt` and push it to your container registry.\n\n### wire airflow to point to new dockerfile\n\nYou'll then want to edit `airflow/helm/airflow/values.yaml` in your installation repo with something like:\n\n```yaml\nairflow:\n airflow:\n airflow:\n image:\n repository: your.docker.repository\n tag: your-tag\n```\n\nAlternatively, you should be able to do this in the configuration section for airflow in your plural console as well.\n\n### redeploy\n\nfrom there you can simply run `plural build --only airflow && plural deploy --commit \"using custom docker image\"` to set this up",
- "source_links": [],
- "id": 6
- },
- {
- "page_link": "https://github.com/argoproj/argo-cd",
- "title": "argo-cd readme",
- "text": "[](https://github.com/argoproj/argo-cd/actions?query=workflow%3A%22Integration+tests%22) [](https://argoproj.github.io/community/join-slack) [](https://codecov.io/gh/argoproj/argo-cd) [](https://github.com/argoproj/argo-cd/releases/latest) [](https://bestpractices.coreinfrastructure.org/projects/4486) [](https://twitter.com/argoproj)\n[](https://artifacthub.io/packages/helm/argo/argo-cd)\n\n# Argo CD - Declarative Continuous Delivery for Kubernetes\n\n## What is Argo CD?\n\nArgo CD is a declarative, GitOps continuous delivery tool for Kubernetes.\n\n\n\n[](https://youtu.be/0WAm0y2vLIo)\n\n## Why Argo CD?\n\n1. Application definitions, configurations, and environments should be declarative and version controlled.\n1. Application deployment and lifecycle management should be automated, auditable, and easy to understand.\n\n## Who uses Argo CD?\n\n[Official Argo CD user list](USERS.md)\n\n## Documentation\n\nTo learn more about Argo CD [go to the complete documentation](https://argo-cd.readthedocs.io/).\nCheck live demo at https://cd.apps.argoproj.io/.\n\n## Community\n\n### Contribution, Discussion and Support\n\n You can reach the Argo CD community and developers via the following channels:\n\n* Q & A : [Github Discussions](https://github.com/argoproj/argo-cd/discussions)\n* Chat : [The #argo-cd Slack channel](https://argoproj.github.io/community/join-slack)\n* Contributors Office Hours: [Every Thursday](https://calendar.google.com/calendar/u/0/embed?src=argoproj@gmail.com) | [Agenda](https://docs.google.com/document/d/1xkoFkVviB70YBzSEa4bDnu-rUZ1sIFtwKKG1Uw8XsY8)\n* User Community meeting: [First Wednesday of the month](https://calendar.google.com/calendar/u/0/embed?src=argoproj@gmail.com) | [Agenda](https://docs.google.com/document/d/1ttgw98MO45Dq7ZUHpIiOIEfbyeitKHNfMjbY5dLLMKQ)\n\n\nParticipation in the Argo CD project is governed by the [CNCF Code of Conduct](https://github.com/cncf/foundation/blob/master/code-of-conduct.md)\n\n\n### Blogs and Presentations\n\n1. [Awesome-Argo: A Curated List of Awesome Projects and Resources Related to Argo](https://github.com/terrytangyuan/awesome-argo)\n1. [Unveil the Secret Ingredients of Continuous Delivery at Enterprise Scale with Argo CD](https://blog.akuity.io/unveil-the-secret-ingredients-of-continuous-delivery-at-enterprise-scale-with-argo-cd-7c5b4057ee49)\n1. [GitOps Without Pipelines With ArgoCD Image Updater](https://youtu.be/avPUQin9kzU)\n1. [Combining Argo CD (GitOps), Crossplane (Control Plane), And KubeVela (OAM)](https://youtu.be/eEcgn_gU3SM)\n1. [How to Apply GitOps to Everything - Combining Argo CD and Crossplane](https://youtu.be/yrj4lmScKHQ)\n1. [Couchbase - How To Run a Database Cluster in Kubernetes Using Argo CD](https://youtu.be/nkPoPaVzExY)\n1. [Automation of Everything - How To Combine Argo Events, Workflows & Pipelines, CD, and Rollouts](https://youtu.be/XNXJtxkUKeY)\n1. [Environments Based On Pull Requests (PRs): Using Argo CD To Apply GitOps Principles On Previews](https://youtu.be/cpAaI8p4R60)\n1. [Argo CD: Applying GitOps Principles To Manage Production Environment In Kubernetes](https://youtu.be/vpWQeoaiRM4)\n1. [Creating Temporary Preview Environments Based On Pull Requests With Argo CD And Codefresh](https://codefresh.io/continuous-deployment/creating-temporary-preview-environments-based-pull-requests-argo-cd-codefresh/)\n1. [Tutorial: Everything You Need To Become A GitOps Ninja](https://www.youtube.com/watch?v=r50tRQjisxw) 90m tutorial on GitOps and Argo CD.\n1. [Comparison of Argo CD, Spinnaker, Jenkins X, and Tekton](https://www.inovex.de/blog/spinnaker-vs-argo-cd-vs-tekton-vs-jenkins-x/)\n1. [Simplify and Automate Deployments Using GitOps with IBM Multicloud Manager 3.1.2](https://www.ibm.com/cloud/blog/simplify-and-automate-deployments-using-gitops-with-ibm-multicloud-manager-3-1-2)\n1. [GitOps for Kubeflow using Argo CD](https://v0-6.kubeflow.org/docs/use-cases/gitops-for-kubeflow/)\n1. [GitOps Toolsets on Kubernetes with CircleCI and Argo CD](https://www.digitalocean.com/community/tutorials/webinar-series-gitops-tool-sets-on-kubernetes-with-circleci-and-argo-cd)\n1. [CI/CD in Light Speed with K8s and Argo CD](https://www.youtube.com/watch?v=OdzH82VpMwI&feature=youtu.be)\n1. [Machine Learning as Code](https://www.youtube.com/watch?v=VXrGp5er1ZE&t=0s&index=135&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU). Among other things, describes how Kubeflow uses Argo CD to implement GitOPs for ML\n1. [Argo CD - GitOps Continuous Delivery for Kubernetes](https://www.youtube.com/watch?v=aWDIQMbp1cc&feature=youtu.be&t=1m4s)\n1. [Introduction to Argo CD : Kubernetes DevOps CI/CD](https://www.youtube.com/watch?v=2WSJF7d8dUg&feature=youtu.be)\n1. [GitOps Deployment and Kubernetes - using Argo CD](https://medium.com/riskified-technology/gitops-deployment-and-kubernetes-f1ab289efa4b)\n1. [Deploy Argo CD with Ingress and TLS in Three Steps: No YAML Yak Shaving Required](https://itnext.io/deploy-argo-cd-with-ingress-and-tls-in-three-steps-no-yaml-yak-shaving-required-bc536d401491)\n1. [GitOps Continuous Delivery with Argo and Codefresh](https://codefresh.io/events/cncf-member-webinar-gitops-continuous-delivery-argo-codefresh/)\n1. [Stay up to date with Argo CD and Renovate](https://mjpitz.com/blog/2020/12/03/renovate-your-gitops/)\n1. [Setting up Argo CD with Helm](https://www.arthurkoziel.com/setting-up-argocd-with-helm/)\n1. [Applied GitOps with Argo CD](https://thenewstack.io/applied-gitops-with-argocd/)\n1. [Solving configuration drift using GitOps with Argo CD](https://www.cncf.io/blog/2020/12/17/solving-configuration-drift-using-gitops-with-argo-cd/)\n1. [Decentralized GitOps over environments](https://blogs.sap.com/2021/05/06/decentralized-gitops-over-environments/)\n1. [How GitOps and Operators mark the rise of Infrastructure-As-Software](https://paytmlabs.com/blog/2021/10/how-to-improve-operational-work-with-operators-and-gitops/)\n1. [Getting Started with ArgoCD for GitOps Deployments](https://youtu.be/AvLuplh1skA)\n1. [Using Argo CD & Datree for Stable Kubernetes CI/CD Deployments](https://youtu.be/17894DTru2Y)\n\n",
- "source_links": [],
- "id": 7
- },
- {
- "page_link": "https://github.com/argoproj/argo-workflows",
- "title": "argo-workflows readme",
- "text": "[](https://argoproj.github.io/community/join-slack)\n[](https://github.com/argoproj/argo-workflows/actions?query=event%3Apush+branch%3Amaster)\n[](https://bestpractices.coreinfrastructure.org/projects/3830)\n[](https://artifacthub.io/packages/helm/argo/argo-workflows)\n[](https://twitter.com/argoproj)\n\n## What is Argo Workflows?\n\nArgo Workflows is an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo\nWorkflows is implemented as a Kubernetes CRD (Custom Resource Definition).\n\n* Define workflows where each step in the workflow is a container.\n* Model multi-step workflows as a sequence of tasks or capture the dependencies between tasks using a directed acyclic\n graph (DAG).\n* Easily run compute intensive jobs for machine learning or data processing in a fraction of the time using Argo\n Workflows on Kubernetes.\n\nArgo is a [Cloud Native Computing Foundation (CNCF)](https://cncf.io/) hosted project.\n\n[](https://www.youtube.com/watch?v=TZgLkCFQ2tk)\n\n## Use Cases\n\n* Machine Learning pipelines\n* Data and batch processing\n* ETL\n* Infrastructure automation\n* CI/CD\n\n## Why Argo Workflows?\n\n* Argo Workflows is the most popular workflow execution engine for Kubernetes.\n* It can run 1000s of workflows a day, each with 1000s of concurrent tasks.\n* Our users say it is lighter-weight, faster, more powerful, and easier to use\n* Designed from the ground up for containers without the overhead and limitations of legacy VM and server-based\n environments.\n* Cloud agnostic and can run on any Kubernetes cluster.\n\n[Read what people said in our latest survey](https://blog.argoproj.io/argo-workflows-2021-survey-results-d6fa890030ee)\n\n## Try Argo Workflows\n\n[Access the demo environment](https://workflows.apps.argoproj.io/workflows/argo) (login using Github)\n\n\n\n## Documentation\n\n[View the docs](https://argoproj.github.io/argo-workflows/)\n\n## Ecosystem\n\nJust some of the projects that use or rely on Argo Workflows:\n\n* [Argo Events](https://github.com/argoproj/argo-events)\n* [Couler](https://github.com/couler-proj/couler)\n* [Katib](https://github.com/kubeflow/katib)\n* [Kedro](https://kedro.readthedocs.io/en/stable/)\n* [Kubeflow Pipelines](https://github.com/kubeflow/pipelines)\n* [Netflix Metaflow](https://metaflow.org)\n* [Onepanel](https://www.onepanel.ai/)\n* [Ploomber](https://github.com/ploomber/ploomber)\n* [Seldon](https://github.com/SeldonIO/seldon-core)\n* [SQLFlow](https://github.com/sql-machine-learning/sqlflow)\n* [Orchest](https://github.com/orchest/orchest/)\n\n## Client Libraries\n\nCheck out our [Java, Golang and Python clients](docs/client-libraries.md).\n\n## Quickstart\n\nThe following commands install Argo Workflows as well as some commmonly used components:\n\n```bash\nkubectl create ns argo\nkubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo-workflows/master/manifests/quick-start-postgres.yaml\n```\n\n> **These manifests are intended to help you get started quickly. They contain hard-coded passwords that are publicly available and are not suitable in production.**\n\n## Who uses Argo Workflows?\n\n[Official Argo Workflows user list](USERS.md)\n\n## Documentation\n\n* [Get started here](docs/quick-start.md)\n* [How to write Argo Workflow specs](https://github.com/argoproj/argo-workflows/blob/master/examples/README.md)\n* [How to configure your artifact repository](docs/configure-artifact-repository.md)\n\n## Features\n\n* UI to visualize and manage Workflows\n* Artifact support (S3, Artifactory, Alibaba Cloud OSS, Azure Blob Storage, HTTP, Git, GCS, raw)\n* Workflow templating to store commonly used Workflows in the cluster\n* Archiving Workflows after executing for later access\n* Scheduled workflows using cron\n* Server interface with REST API (HTTP and GRPC)\n* DAG or Steps based declaration of workflows\n* Step level input & outputs (artifacts/parameters)\n* Loops\n* Parameterization\n* Conditionals\n* Timeouts (step & workflow level)\n* Retry (step & workflow level)\n* Resubmit (memoized)\n* Suspend & Resume\n* Cancellation\n* K8s resource orchestration\n* Exit Hooks (notifications, cleanup)\n* Garbage collection of completed workflow\n* Scheduling (affinity/tolerations/node selectors)\n* Volumes (ephemeral/existing)\n* Parallelism limits\n* Daemoned steps\n* DinD (docker-in-docker)\n* Script steps\n* Event emission\n* Prometheus metrics\n* Multiple executors\n* Multiple pod and workflow garbage collection strategies\n* Automatically calculated resource usage per step\n* Java/Golang/Python SDKs\n* Pod Disruption Budget support\n* Single-sign on (OAuth2/OIDC)\n* Webhook triggering\n* CLI\n* Out-of-the box and custom Prometheus metrics\n* Windows container support\n* Embedded widgets\n* Multiplex log viewer\n\n## Community Meetings\n\nWe host monthly community meetings where we and the community showcase demos and discuss the current and future state of\nthe project. Feel free to join us! For Community Meeting information, minutes and recordings\nplease [see here](https://bit.ly/argo-wf-cmty-mtng).\n\nParticipation in the Argo Workflows project is governed by\nthe [CNCF Code of Conduct](https://github.com/cncf/foundation/blob/master/code-of-conduct.md)\n\n## Community Blogs and Presentations\n\n* [Awesome-Argo: A Curated List of Awesome Projects and Resources Related to Argo](https://github.com/terrytangyuan/awesome-argo)\n* [Automation of Everything - How To Combine Argo Events, Workflows & Pipelines, CD, and Rollouts](https://youtu.be/XNXJtxkUKeY)\n* [Argo Workflows and Pipelines - CI/CD, Machine Learning, and Other Kubernetes Workflows](https://youtu.be/UMaivwrAyTA)\n* [Argo Ansible role: Provisioning Argo Workflows on OpenShift](https://medium.com/@marekermk/provisioning-argo-on-openshift-with-ansible-and-kustomize-340a1fda8b50)\n* [Argo Workflows vs Apache Airflow](http://bit.ly/30YNIvT)\n* [CI/CD with Argo on Kubernetes](https://medium.com/@bouwe.ceunen/ci-cd-with-argo-on-kubernetes-28c1a99616a9)\n* [Running Argo Workflows Across Multiple Kubernetes Clusters](https://admiralty.io/blog/running-argo-workflows-across-multiple-kubernetes-clusters/)\n* [Open Source Model Management Roundup: Polyaxon, Argo, and Seldon](https://www.anaconda.com/blog/developer-blog/open-source-model-management-roundup-polyaxon-argo-and-seldon/)\n* [Producing 200 OpenStreetMap extracts in 35 minutes using a scalable data workflow](https://www.interline.io/blog/scaling-openstreetmap-data-workflows/)\n* [Argo integration review](http://dev.matt.hillsdon.net/2018/03/24/argo-integration-review.html)\n* TGI Kubernetes with Joe Beda: [Argo workflow system](https://www.youtube.com/watch?v=M_rxPPLG8pU&start=859)\n\n## Project Resources\n\n* Argo GitHub: https://github.com/argoproj\n* Argo Website: https://argoproj.github.io/\n* Argo Slack: [click here to join](https://argoproj.github.io/community/join-slack)\n\n## Security\n\nSee [SECURITY.md](SECURITY.md).\n",
- "source_links": [],
- "id": 8
- },
- {
- "page_link": "https://github.com/bram2w/baserow",
- "title": "baserow readme",
- "text": "## Baserow is an open source no-code database tool and Airtable alternative.\n\nCreate your own online database without technical experience. Our user-friendly no-code\ntool gives you the powers of a developer without leaving your browser.\n\n* A spreadsheet database hybrid combining ease of use and powerful data organization.\n* Easily self-hosted with no storage restrictions or sign-up on https://baserow.io to\n get started immediately.\n* Alternative to Airtable.\n* Open-core with all non-premium and non-enterprise features under\n the [MIT License](https://choosealicense.com/licenses/mit/) allowing commercial and\n private use.\n* Headless and API first.\n* Uses popular frameworks and tools like [Django](https://www.djangoproject.com/),\n [Vue.js](https://vuejs.org/) and [PostgreSQL](https://www.postgresql.org/).\n\n[](https://heroku.com/deploy?template=https://github.com/bram2w/baserow/tree/master)\n\n```bash\ndocker run -v baserow_data:/baserow/data -p 80:80 -p 443:443 baserow/baserow:1.16.0\n```\n\n\n\n## Get Involved\n\n**We're hiring remotely**! More information at https://baserow.io/jobs.\n\nJoin our forum on https://community.baserow.io/ or on Gitter via\nhttps://gitter.im/bramw-baserow/community. See [CONTRIBUTING.md](./CONTRIBUTING.md) on\nhow to become a contributor.\n\n## Installation\n\n* [**Docker**](docs/installation/install-with-docker.md)\n* [**Ubuntu**](docs/installation/install-on-ubuntu.md)\n* [**Docker Compose** ](docs/installation/install-with-docker-compose.md)\n* [**\n Heroku**: Easily install and scale up Baserow on Heroku.](docs/installation/install-on-heroku.md)\n* [**\n Render**: Easily install and scale up Baserow on Render.](docs/installation/install-on-render.md)\n* [**\n Cloudron**: Install and update Baserow on your own Cloudron server.](docs/installation/install-on-cloudron.md)\n\n## Official documentation\n\nThe official documentation can be found on the website at https://baserow.io/docs/index\nor [here](./docs/index.md) inside the repository. The API docs can be found here at\nhttps://api.baserow.io/api/redoc/ or if you are looking for the OpenAPI schema here\nhttps://api.baserow.io/api/schema.json.\n\n## Become a sponsor\n\nIf you would like to get new features faster, then you might want to consider becoming a\nsponsor. By becoming a sponsor we can spend more time on Baserow which means faster\ndevelopment.\n\n[Become a GitHub Sponsor](https://github.com/sponsors/bram2w)\n\n## Development environment\n\nIf you want to contribute to Baserow you can setup a development environment like so:\n\n```\n$ git clone https://gitlab.com/bramw/baserow.git\n$ cd baserow\n$ ./dev.sh --build\n```\n\nThe Baserow development environment is now running.\nVisit [http://localhost:3000](http://localhost:3000) in your browser to see a working\nversion in development mode with hot code reloading and other dev features enabled.\n\nMore detailed instructions and more information about the development environment can be\nfound\nat [https://baserow.io/docs/development/development-environment](./docs/development/development-environment.md)\n.\n\n## Plugin development\n\nBecause of the modular architecture of Baserow it is possible to create plugins. Make\nyour own fields, views, applications, pages or endpoints. We also have a plugin\nboilerplate to get you started right away. More information can be found in the\n[plugin introduction](./docs/plugins/introduction.md) and in the\n[plugin boilerplate docs](./docs/plugins/boilerplate.md).\n\n## Meta\n\nCreated by Baserow B.V. - bram@baserow.io.\n\nDistributes under the MIT license. See `LICENSE` for more information.\n\nVersion: 1.16.0\n\nThe official repository can be found at https://gitlab.com/bramw/baserow.\n\nThe changelog can be found [here](./changelog.md).\n\nBecome a GitHub Sponsor [here](https://github.com/sponsors/bram2w).\n\nCommunity chat via https://gitter.im/bramw-baserow/community.\n",
- "source_links": [],
- "id": 9
- },
- {
- "page_link": null,
- "title": "bootstrap readme",
- "text": null,
- "source_links": [],
- "id": 10
- },
- {
- "page_link": "overview.md",
- "title": "overview",
- "text": "hello world",
- "source_links": [],
- "id": 11
- },
- {
- "page_link": null,
- "title": "bootstrap-cluster-api readme",
- "text": null,
- "source_links": [],
- "id": 12
- },
- {
- "page_link": null,
- "title": "bytebase readme",
- "text": null,
- "source_links": [],
- "id": 13
- },
- {
- "page_link": "https://github.com/calcom/cal.com",
- "title": "calendso readme",
- "text": "\n
\n\n\n\n## About The Project\n\n\n\n# Scheduling infrastructure for absolutely everyone\n\nThe open source Calendly alternative. You are in charge\nof your own data, workflow and appearance.\n\nCalendly and other scheduling tools are awesome. It made our lives massively easier. We're using it for business meetings, seminars, yoga classes and even calls with our families. However, most tools are very limited in terms of control and customisations.\n\nThat's where Cal.com comes in. Self-hosted or hosted by us. White-label by design. API-driven and ready to be deployed on your own domain. Full control of your events and data.\n\n## Product of the Month: April\n\n#### Support us on [Product Hunt](https://www.producthunt.com/posts/calendso?utm_source=badge-top-post-badge&utm_medium=badge&utm_souce=badge-calendso)\n\n\n\n \n\n\n### Built With\n\n- [Next.js](https://nextjs.org/)\n- [React](https://reactjs.org/)\n- [Tailwind](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n## Stay Up-to-Date\n\nCal officially launched as v.1.0 on 15th of September, however a lot of new features are coming. Watch **releases** of this repository to be notified for future updates:\n\n\n\n\n\n## Getting Started\n\nTo get a local copy up and running, please follow these simple steps.\n\n### Prerequisites\n\nHere is what you need to be able to run Cal.\n\n- Node.js (Version: >=15.x <17)\n- PostgreSQL\n- Yarn _(recommended)_\n\n> If you want to enable any of the available integrations, you may want to obtain additional credentials for each one. More details on this can be found below under the [integrations section](#integrations).\n\n## Development\n\n### Setup\n\n1. Clone the repo into a public GitHub repository (or fork https://github.com/calcom/cal.com/fork). If you plan to distribute the code, keep the source code public to comply with [AGPLv3](https://github.com/calcom/cal.com/blob/main/LICENSE). To clone in a private repository, [acquire a commercial license](https://cal.com/sales))\n\n ```sh\n git clone https://github.com/calcom/cal.com.git\n ```\n\n1. Go to the project folder\n\n ```sh\n cd cal.com\n ```\n\n1. Install packages with yarn\n\n ```sh\n yarn\n ```\n\n1. Use `openssl rand -base64 32` to generate a key and add it under `NEXTAUTH_SECRET` in the .env file.\n\n#### Quick start with `yarn dx`\n\n> - **Requires Docker and Docker Compose to be installed**\n> - Will start a local Postgres instance with a few test users - the credentials will be logged in the console\n\n```sh\nyarn dx\n```\n\n#### Development tip\n\n> Add `NEXT_PUBLIC_DEBUG=1` anywhere in your `.env` to get logging information for all the queries and mutations driven by **trpc**.\n\n```sh\necho 'NEXT_PUBLIC_DEBUG=1' >> .env\n```\n\n#### Manual setup\n\n1. Configure environment variables in the `packages/prisma/.env` file. Replace ``, ``, ``, `` with their applicable values\n\n ```\n DATABASE_URL='postgresql://:@:'\n ```\n\n \n If you don't know how to configure the DATABASE_URL, then follow the steps here to create a quick DB using Heroku\n\n 1. Create a free account with [Heroku](https://www.heroku.com/).\n\n 2. Create a new app.\n \n\n 3. In your new app, go to `Overview` and next to `Installed add-ons`, click `Configure Add-ons`. We need this to set up our database.\n 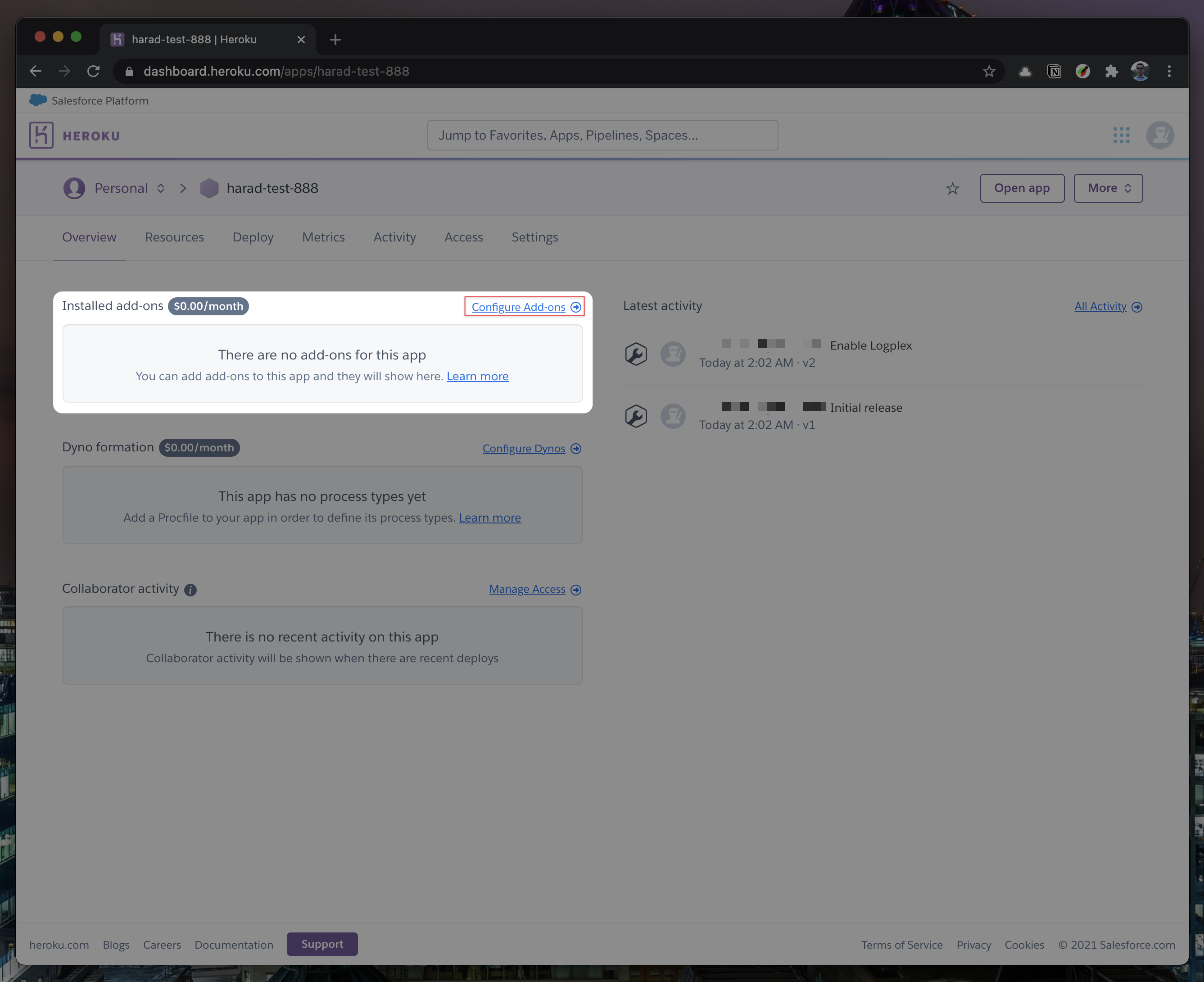\n\n 4. Once you clicked on `Configure Add-ons`, click on `Find more add-ons` and search for `postgres`. One of the options will be `Heroku Postgres` - click on that option.\n 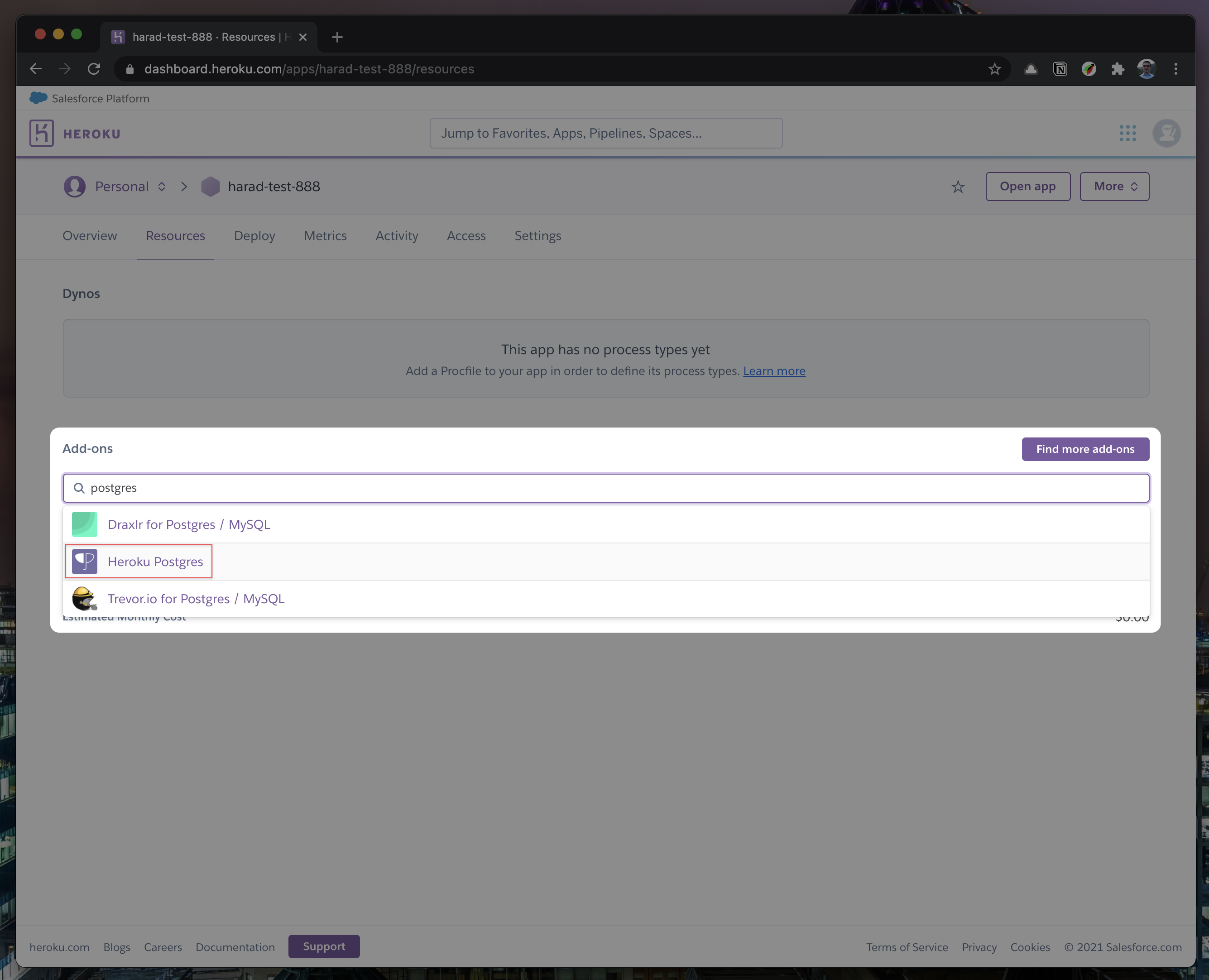\n\n 5. Once the pop-up appears, click `Submit Order Form` - plan name should be `Hobby Dev - Free`.\n \n\n 6. Once you completed the above steps, click on your newly created `Heroku Postgres` and go to its `Settings`.\n 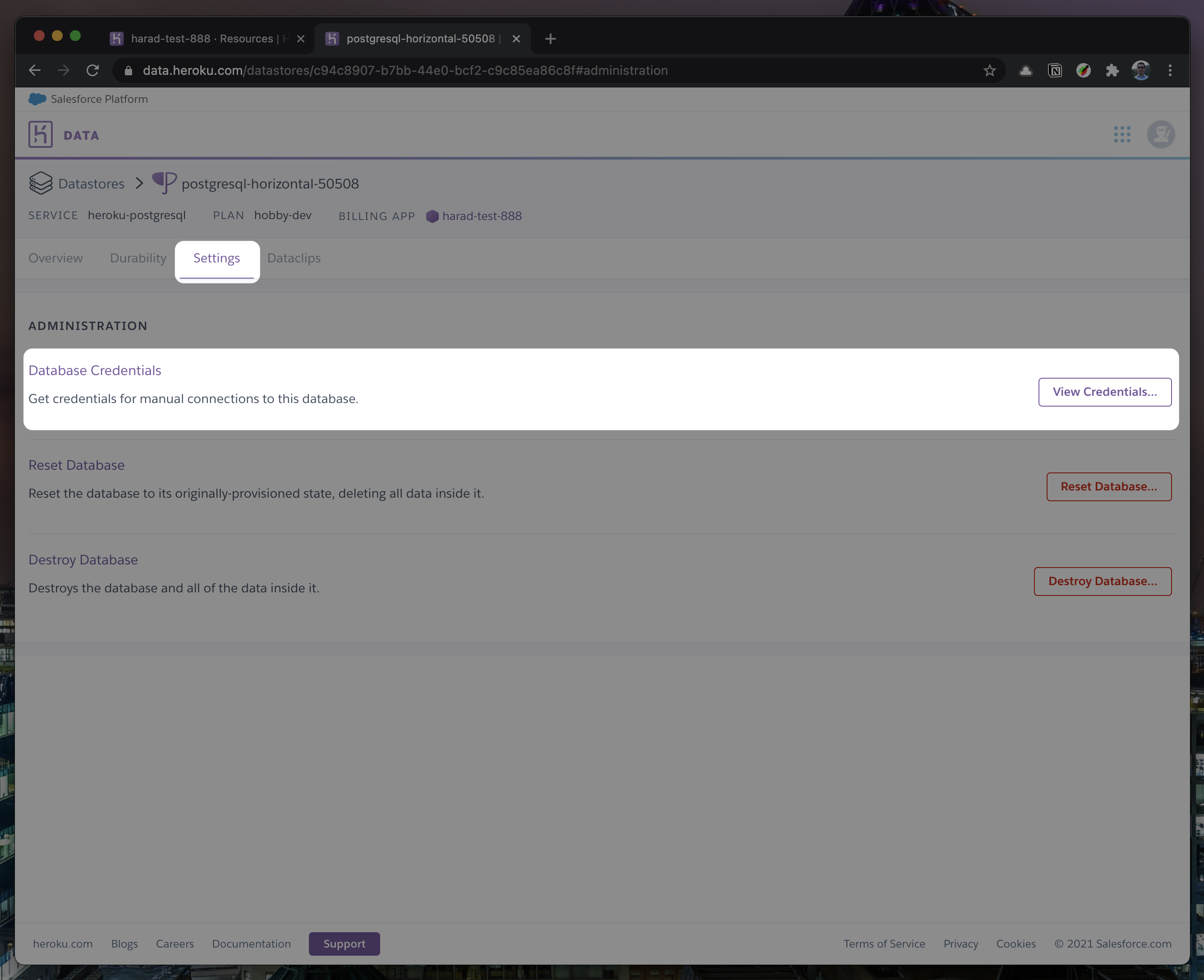\n\n 7. In `Settings`, copy your URI to your Cal.com .env file and replace the `postgresql://:@:` with it.\n 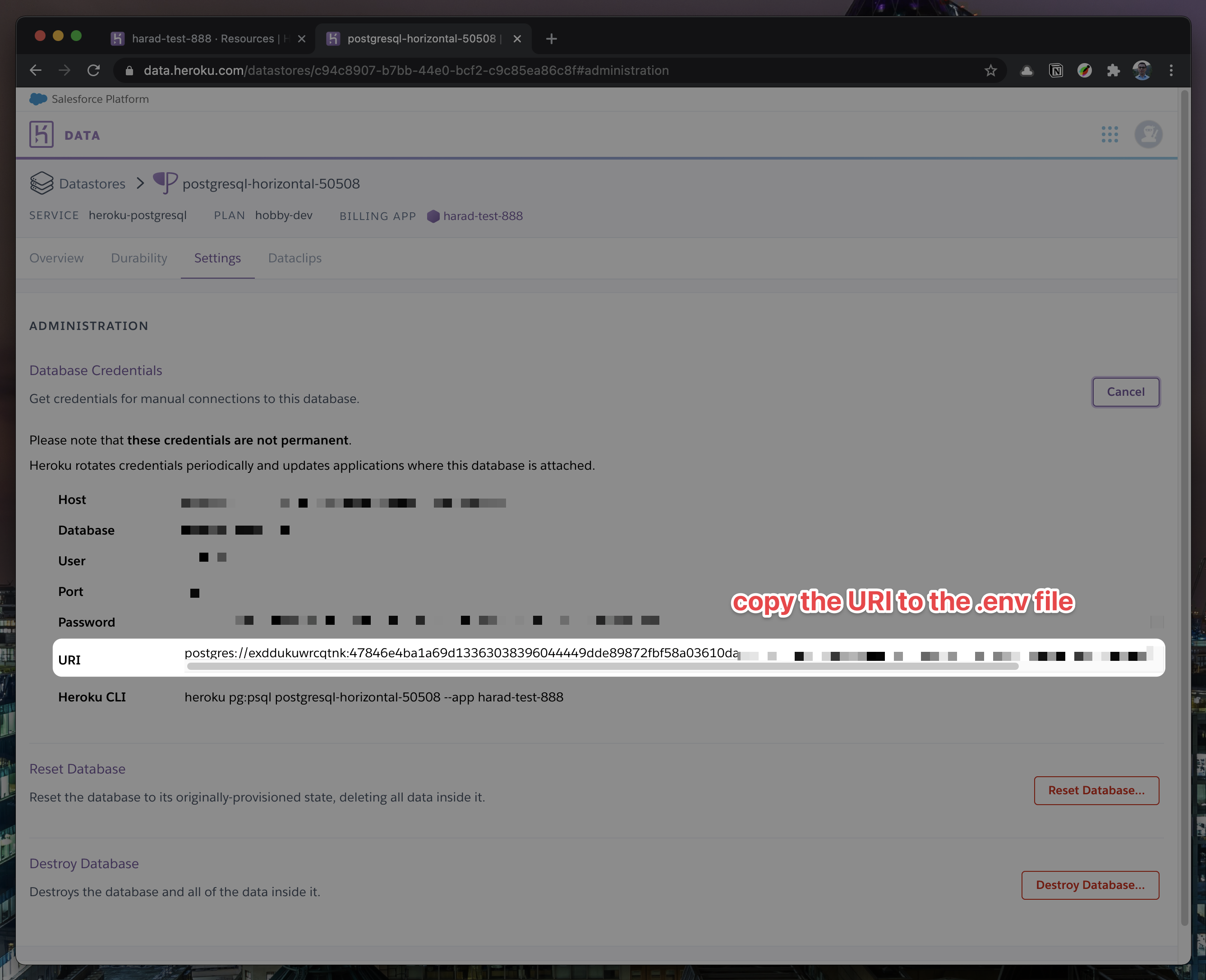\n \n\n 8. To view your DB, once you add new data in Prisma, you can use [Heroku Data Explorer](https://heroku-data-explorer.herokuapp.com/).\n \n\n1. Set a 32 character random string in your .env file for the `CALENDSO_ENCRYPTION_KEY` (You can use a command like `openssl rand -base64 24` to generate one).\n1. Set up the database using the Prisma schema (found in `packages/prisma/schema.prisma`)\n\n ```sh\n yarn workspace @calcom/prisma db-deploy\n ```\n\n1. Run (in development mode)\n\n ```sh\n yarn dev\n ```\n\n#### Setting up your first user\n\n1. Open [Prisma Studio](https://www.prisma.io/studio) to look at or modify the database content:\n\n ```sh\n yarn db-studio\n ```\n\n1. Click on the `User` model to add a new user record.\n1. Fill out the fields `email`, `username`, `password`, and set `metadata` to empty `{}` (remembering to encrypt your password with [BCrypt](https://bcrypt-generator.com/)) and click `Save 1 Record` to create your first user.\n > New users are set on a `TRIAL` plan by default. You might want to adjust this behavior to your needs in the `packages/prisma/schema.prisma` file.\n1. Open a browser to [http://localhost:3000](http://localhost:3000) and login with your just created, first user.\n\n### E2E-Testing\n\nBe sure to set the environment variable `NEXTAUTH_URL` to the correct value. If you are running locally, as the documentation within `.env.example` mentions, the value should be `http://localhost:3000`.\n\n```sh\n# In a terminal just run:\nyarn test-e2e\n\n# To open last HTML report run:\nyarn workspace @calcom/web playwright-report\n```\n\n### Upgrading from earlier versions\n\n1. Pull the current version:\n\n ```sh\n git pull\n ```\n\n1. Check if dependencies got added/updated/removed\n\n ```sh\n yarn\n ```\n\n1. Apply database migrations by running one of the following commands:\n\n In a development environment, run:\n\n ```sh\n yarn workspace @calcom/prisma db-migrate\n ```\n\n (this can clear your development database in some cases)\n\n In a production environment, run:\n\n ```sh\n yarn workspace @calcom/prisma db-deploy\n ```\n\n1. Check for `.env` variables changes\n\n ```sh\n yarn predev\n ```\n\n1. Start the server. In a development environment, just do:\n\n ```sh\n yarn dev\n ```\n\n For a production build, run for example:\n\n ```sh\n yarn build\n yarn start\n ```\n\n1. Enjoy the new version.\n\n\n## Deployment\n\n### Docker\n\nThe Docker configuration for Cal is an effort powered by people within the community. Cal.com, Inc. does not provide official support for Docker, but we will accept fixes and documentation. Use at your own risk.\n\nIf you want to contribute to the Docker repository, [reply here](https://github.com/calcom/docker/discussions/32).\n\nThe Docker configuration can be found [in our docker repository](https://github.com/calcom/docker).\n\n### Heroku\n\n\n \n\n\n### Railway\n\n[](https://railway.app/new/template?template=https%3A%2F%2Fgithub.com%2Fcalendso%2Fcalendso&plugins=postgresql&envs=GOOGLE_API_CREDENTIALS%2CBASE_URL%2CNEXTAUTH_URL%2CPORT&BASE_URLDefault=http%3A%2F%2Flocalhost%3A3000&NEXTAUTH_URLDefault=http%3A%2F%2Flocalhost%3A3000&PORTDefault=3000)\n\nYou can deploy Cal on [Railway](https://railway.app/) using the button above. The team at Railway also have a [detailed blog post](https://blog.railway.app/p/calendso) on deploying Cal on their platform.\n\n### Vercel\n\nCurrently Vercel Pro Plan is required to be able to Deploy this application with Vercel, due to limitations on the number of serverless functions on the free plan.\n\n[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com&env=DATABASE_URL,NEXT_PUBLIC_WEBAPP_URL,NEXTAUTH_URL,NEXTAUTH_SECRET,CRON_API_KEY,CALENDSO_ENCRYPTION_KEY,NEXT_PUBLIC_LICENSE_CONSENT&envDescription=See%20all%20available%20env%20vars&envLink=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com%2Fblob%2Fmain%2F.env.example&project-name=cal&repo-name=cal.com&build-command=cd%20../..%20%26%26%20yarn%20build&root-directory=apps%2Fweb%2F)\n\n\n\n## Roadmap\n\n\n\nSee the [roadmap project](https://cal.com/roadmap) for a list of proposed features (and known issues). You can change the view to see planned tagged releases.\n\n\n\n## Contributing\n\nPlease see our [contributing guide](/CONTRIBUTING.md).\n\n### Good First Issues\n\nWe have a list of [help wanted](https://github.com/orgs/calcom/projects/1/views/25) that contain small features and bugs which have a relatively limited scope. This is a great place to get started, gain experience, and get familiar with our contribution process.\n\n## Integrations\n\n### Obtaining the Google API Credentials\n\n1. Open [Google API Console](https://console.cloud.google.com/apis/dashboard). If you don't have a project in your Google Cloud subscription, you'll need to create one before proceeding further. Under Dashboard pane, select Enable APIS and Services.\n2. In the search box, type calendar and select the Google Calendar API search result.\n3. Enable the selected API.\n4. Next, go to the [OAuth consent screen](https://console.cloud.google.com/apis/credentials/consent) from the side pane. Select the app type (Internal or External) and enter the basic app details on the first page.\n5. In the second page on Scopes, select Add or Remove Scopes. Search for Calendar.event and select the scope with scope value `.../auth/calendar.events`, `.../auth/calendar.readonly` and select Update.\n6. In the third page (Test Users), add the Google account(s) you'll using. Make sure the details are correct on the last page of the wizard and your consent screen will be configured.\n7. Now select [Credentials](https://console.cloud.google.com/apis/credentials) from the side pane and then select Create Credentials. Select the OAuth Client ID option.\n8. Select Web Application as the Application Type.\n9. Under Authorized redirect URI's, select Add URI and then add the URI `/api/integrations/googlecalendar/callback` replacing Cal.com URL with the URI at which your application runs.\n10. The key will be created and you will be redirected back to the Credentials page. Select the newly generated client ID under OAuth 2.0 Client IDs.\n11. Select Download JSON. Copy the contents of this file and paste the entire JSON string in the .env file as the value for GOOGLE_API_CREDENTIALS key.\n\n#### *Adding google calendar to Cal.com App Store*\n\nAfter adding Google credentials, you can now Google Calendar App to the app store.\nYou can repopulate the App store by running\n\n```\ncd packages/prisma\nyarn seed-app-store\n```\n\nYou will need to complete a few more steps to activate Google Calendar App.\nMake sure to complete section \"Obtaining the Google API Credentials\". After the do the\nfollowing\n\n1. Add extra redirect URL `/api/auth/callback/google`\n1. Under 'OAuth concent screen', click \"PUBLISH APP\"\n### Obtaining Microsoft Graph Client ID and Secret\n\n1. Open [Azure App Registration](https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/RegisteredApps) and select New registration\n2. Name your application\n3. Set **Who can use this application or access this API?** to **Accounts in any organizational directory (Any Azure AD directory - Multitenant)**\n4. Set the **Web** redirect URI to `/api/integrations/office365calendar/callback` replacing Cal.com URL with the URI at which your application runs.\n5. Use **Application (client) ID** as the **MS_GRAPH_CLIENT_ID** attribute value in .env\n6. Click **Certificates & secrets** create a new client secret and use the value as the **MS_GRAPH_CLIENT_SECRET** attribute\n\n### Obtaining Slack Client ID and Secret and Signing Secret\n\nTo test this you will need to create a Slack app for yourself on [their apps website](https://api.slack.com/apps).\n\nCopy and paste the app manifest below into the setting on your slack app. Be sure to replace `YOUR_DOMAIN` with your own domain or your proxy host if you're testing locally.\n\n\n App Manifest\n \n ```yaml\n display_information:\n name: Cal.com Slack\nfeatures:\n bot_user:\n display_name: Cal.com Slack\n always_online: false\n slash_commands:\n - command: /create-event\n url: https://YOUR_DOMAIN/api/integrations/slackmessaging/commandHandler\n description: Create an event within Cal!\n should_escape: false\n - command: /today\n url: https://YOUR_DOMAIN/api/integrations/slackmessaging/commandHandler\n description: View all your bookings for today\n should_escape: false\noauth_config:\n redirect_urls:\n - https://YOUR_DOMAIN/api/integrations/slackmessaging/callback\n scopes:\n bot:\n - chat:write\n - commands\n - chat:write.public \nsettings:\n interactivity:\n is_enabled: true\n request_url: https://YOUR_DOMAIN/api/integrations/slackmessaging/interactiveHandler\n message_menu_options_url: https://YOUR_DOMAIN/api/integrations/slackmessaging/interactiveHandler\n org_deploy_enabled: false\n socket_mode_enabled: false\n token_rotation_enabled: false\n```\n\n\n\nAdd the integration as normal - slack app - add. Follow the oauth flow to add it to a server.\n\nNext make sure you have your app running `yarn dx`. Then in the slack chat type one of these commands: `/create-event` or `/today`\n\n> NOTE: Next you will need to setup a proxy server like [ngrok](https://ngrok.com/) to allow your local host machine to be hosted on a public https server.\n\n### Obtaining Zoom Client ID and Secret\n\n1. Open [Zoom Marketplace](https://marketplace.zoom.us/) and sign in with your Zoom account.\n2. On the upper right, click \"Develop\" => \"Build App\".\n3. On \"OAuth\", select \"Create\".\n4. Name your App.\n5. Choose \"User-managed app\" as the app type.\n6. De-select the option to publish the app on the Zoom App Marketplace.\n7. Click \"Create\".\n8. Now copy the Client ID and Client Secret to your .env file into the `ZOOM_CLIENT_ID` and `ZOOM_CLIENT_SECRET` fields.\n9. Set the Redirect URL for OAuth `/api/integrations/zoomvideo/callback` replacing Cal.com URL with the URI at which your application runs.\n10. Also add the redirect URL given above as a allow list URL and enable \"Subdomain check\". Make sure, it says \"saved\" below the form.\n11. You don't need to provide basic information about your app. Instead click at \"Scopes\" and then at \"+ Add Scopes\". On the left, click the category \"Meeting\" and check the scope `meeting:write`.\n12. Click \"Done\".\n13. You're good to go. Now you can easily add your Zoom integration in the Cal.com settings.\n\n### Obtaining Daily API Credentials\n\n1. Open [Daily](https://www.daily.co/) and sign into your account.\n2. From within your dashboard, go to the [developers](https://dashboard.daily.co/developers) tab.\n3. Copy your API key.\n4. Now paste the API key to your .env file into the `DAILY_API_KEY` field in your .env file.\n5. If you have the [Daily Scale Plan](https://www.daily.co/pricing) set the `DAILY_SCALE_PLAN` variable to `true` in order to use features like video recording.\n\n### Obtaining HubSpot Client ID and Secret\n\n1. Open [HubSpot Developer](https://developer.hubspot.com/) and sign into your account, or create a new one.\n2. From within the home of the Developer account page, go to \"Manage apps\".\n3. Click \"Create app\" button top right.\n4. Fill in any information you want in the \"App info\" tab\n5. Go to tab \"Auth\"\n6. Now copy the Client ID and Client Secret to your .env file into the `HUBSPOT_CLIENT_ID` and `HUBSPOT_CLIENT_SECRET` fields.\n7. Set the Redirect URL for OAuth `/api/integrations/hubspotothercalendar/callback` replacing Cal.com URL with the URI at which your application runs.\n8. In the \"Scopes\" section at the bottom of the page, make sure you select \"Read\" and \"Write\" for scope called `crm.objects.contacts`\n9. Click the \"Save\" button at the bottom footer.\n10. You're good to go. Now you can see any booking in Cal.com created as a meeting in HubSpot for your contacts.\n\n### Obtaining Vital API Keys\n\n1. Open [Vital](https://tryvital.io/) and click Get API Keys.\n1. Create a team with the team name you desire\n1. Head to the configuration section on the sidebar of the dashboard\n1. Click on API keys and you'll find your sandbox `api_key`.\n1. Copy your `api_key` to `VITAL_API_KEY` in the .env.appStore file.\n1. Open [Vital Webhooks](https://app.tryvital.io/team/{team_id}/webhooks) and add `/api/integrations/vital/webhook` as webhook for connected applications.\n1. Select all events for the webhook you interested, e.g. `sleep_created`\n1. Copy the webhook secret (`sec...`) to `VITAL_WEBHOOK_SECRET` in the .env.appStore file.\n\n## Workflows\n\n### Setting up SendGrid for Email reminders\n\n1. Create a SendGrid account (https://signup.sendgrid.com/)\n2. Go to Settings -> API keys and create an API key\n3. Copy API key to your .env file into the SENDGRID_API_KEY field\n4. Go to Settings -> Sender Authentication and verify a single sender\n5. Copy the verified E-Mail to your .env file into the SENDGRID_EMAIL field\n\n### Setting up Twilio for SMS reminders\n\n1. Create a Twilio account (https://www.twilio.com/try-twilio)\n2. Click \u2018Get a Twilio phone number\u2019\n3. Copy Account SID to your .env file into the TWILIO_SID field\n4. Copy Auth Token to your .env file into the TWILIO_TOKEN field\n5. Create a messaging service (Develop -> Messaging -> Services)\n6. Choose any name for the messaging service\n7. Click 'Add Senders'\n8. Choose phone number as sender type\n9. Add the listed phone number\n10. Leave all other fields as they are\n11. Complete setup and click \u2018View my new Messaging Service\u2019\n12. Copy Messaging Service SID to your .env file into the TWILIO_MESSAGING_SID field\n\n\n\n## License\n\nDistributed under the AGPLv3 License. See `LICENSE` for more information.\n\n\n\n## Acknowledgements\n\nSpecial thanks to these amazing projects which help power Cal.com:\n\n[](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n\n- [Vercel](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n- [Next.js](https://nextjs.org/)\n- [Day.js](https://day.js.org/)\n- [Tailwind CSS](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n\n\nCal.com is an [open startup](https://cal.com/open) and [Jitsu](https://github.com/jitsucom/jitsu) (an open-source Segment alternative) helps us to track most of the usage metrics.\n",
- "source_links": [],
- "id": 14
- },
- {
- "page_link": "https://github.com/chatwoot/chatwoot",
- "title": "chatwoot readme",
- "text": "
\n \n\n
Customer engagement suite, an open-source alternative to Intercom, Zendesk, Salesforce Service Cloud etc.
\n\n[Website](https://cube.dev?ref=github-readme) \u2022 [Getting Started](https://cube.dev/docs/getting-started?ref=github-readme) \u2022 [Docs](https://cube.dev/docs?ref=github-readme) \u2022 [Examples](https://cube.dev/docs/examples?ref=github-readme) \u2022 [Blog](https://cube.dev/blog?ref=github-readme) \u2022 [Slack](https://slack.cube.dev?ref=github-readme) \u2022 [Twitter](https://twitter.com/the_cube_dev)\n\n[](https://badge.fury.io/js/%40cubejs-backend%2Fserver)\n[](https://github.com/cube-js/cube/actions?query=workflow%3ABuild+branch%3Amaster)\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fcube-js%2Fcube.js?ref=badge_shield)\n\n__Cube is the semantic layer for building data applications.__ It helps data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application.\n\n\n\n
\n\nCube was designed to work with all SQL-enabled data sources, including cloud data warehouses like Snowflake or Google BigQuery, query engines like Presto or Amazon Athena, and application databases like Postgres. Cube has a built-in relational caching engine to provide sub-second latency and high concurrency for API requests.\n\nFor more details, see the [introduction](https://cube.dev/docs/cubejs-introduction?ref=github-readme) page in our documentation. \n\n## Why Cube?\n\nIf you are building a data application\u2014such as a business intelligence tool or a customer-facing analytics feature\u2014you\u2019ll probably face the following problems:\n\n1. __SQL code organization.__ Sooner or later, modeling even a dozen metrics with a dozen dimensions using pure SQL queries becomes a maintenance nightmare, which leads to building a modeling framework.\n2. __Performance.__ Most of the time and effort in modern analytics software development is spent providing adequate time to insight. In a world where every company\u2019s data is big data, writing just SQL queries to get insight isn\u2019t enough anymore.\n3. __Access Control.__ It is important to secure and govern access to data for all downstream data consuming applications.\n\nCube has the necessary infrastructure and features to implement efficient data modeling, access control, and performance optimizations so that every application\u2014like embedded analytics, dashboarding and reporting tools, data notebooks, and other tools\u2014can access consistent data via REST, SQL, and GraphQL APIs.\n\n\n\n## Getting Started \ud83d\ude80\n\n### Cube Cloud\n\n[Cube Cloud](https://cube.dev/cloud?ref=github-readme) is the fastest way to get started with Cube. It provides managed infrastructure as well as an instant and free access for development projects and proofs of concept.\n\n\n\nFor a step-by-step guide on Cube Cloud, [see the docs](https://cube.dev/docs/getting-started/cloud/overview?ref=github-readme).\n\n### Docker\n\nAlternatively, you can get started with Cube locally or self-host it with [Docker](https://www.docker.com/).\n\nOnce Docker is installed, in a new folder for your project, run the following command:\n\n```bash\ndocker run -p 4000:4000 \\\n -p 15432:15432 \\\n -v ${PWD}:/cube/conf \\\n -e CUBEJS_DEV_MODE=true \\\n cubejs/cube\n```\n\nThen, open http://localhost:4000 in your browser to continue setup.\n\nFor a step-by-step guide on Docker, [see the docs](https://cube.dev/docs/getting-started-docker?ref=github-readme).\n\n## Resources\n\n- [Documentation](https://cube.dev/docs?ref=github-readme)\n- [Getting Started](https://cube.dev/docs/getting-started?ref=github-readme)\n- [Examples & Tutorials](https://cube.dev/docs/examples?ref=github-readme)\n- [Architecture](https://cube.dev/docs/cubejs-introduction?ref=github-readme#architecture)\n\n## Community\n\nIf you have any questions or need help - [please join our Slack community](https://slack.cube.dev?ref=github-readme) of amazing developers and data engineers.\n\nYou are also welcome to join our **monthly community calls** where we discuss community news, Cube Dev team's plans, backlogs, use cases, etc. If you miss the call, the recordings will also be available after the meeting. \n* When: Second Wednesday of each month at [9am Pacific Time](https://www.thetimezoneconverter.com/?t=09:00&tz=PT%20%28Pacific%20Time%29). \n* Meeting link: https://us02web.zoom.us/j/86717042169?pwd=VlBEd2VVK01DNDVVbU1EUXd5ajhsdz09\n* [Meeting page](https://cube.dev/community-call/). \n* Recordings will be posted on the [Community Call Playlist](https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9). \n\n### Our quarterly roadmap\n\nWe publish our open source roadmap every quarter and discuss them during our [monthly community calls](https://cube.dev/community-call/). You can find our roadmap under [projects in our Cube.js repository](https://github.com/cube-js/cube/projects?query=is%3Aopen+sort%3Aupdated-desc). \n\n### Contributing\n\nThere are many ways you can contribute to Cube! Here are a few possibilities:\n\n* Star this repo and follow us on [Twitter](https://twitter.com/the_cube_dev).\n* Add Cube to your stack on [Stackshare](https://stackshare.io/cube-js).\n* Upvote issues with \ud83d\udc4d reaction so we know what's the demand for particular issue to prioritize it within road map.\n* Create issues every time you feel something is missing or goes wrong.\n* Ask questions on [Stack Overflow with cube.js tag](https://stackoverflow.com/questions/tagged/cube.js) if others can have these questions as well.\n* Provide pull requests for all open issues and especially for those with [help wanted](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"help+wanted\") and [good first issue](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"good+first+issue\") labels.\n\nAll sort of contributions are **welcome and extremely helpful** \ud83d\ude4c Please refer to [the contribution guide](https://github.com/cube-js/cube/blob/master/CONTRIBUTING.md) for more information.\n\n## License\n\nCube Client is [MIT licensed](./packages/cubejs-client-core/LICENSE).\n\nCube Backend is [Apache 2.0 licensed](./packages/cubejs-server/LICENSE).\n\n\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fcube-js%2Fcube.js?ref=badge_large)\n",
- "source_links": [],
- "id": 25
- },
- {
- "page_link": "add-your-datasources.md",
- "title": "add-your-datasources",
- "text": "# Add Your Cube Datasources\n\nCube allows you to connect to multiple datasources. To configure them with Plural, you'll need to update the `cube/helm/cube/values.yaml` file.\nAll supported datasources could be found [here](https://cube.dev/docs/config/databases).\n\n\nExample of a postgres datasource\n```yaml\ncube:\n cube:\n datasources:\n default: # one default datasource is required\n type: postgres\n host: \n port: \"5432\"\n name: postgres\n user: postgres\n pass: \n postgres_2: # you can define the name you want\n type: postgres\n host: \n port: \"5432\"\n name: postgres\n user: postgres\n pass: \n```\n\nLooking at a specific datasource? Check next parts.\n\n### Datasources configuration\n\n| Name | Description | Value |\n| ------------- | ------------------------------------------------------------------------ | -------------- |\n| `datasources` | map of named datasources. The first datasource has to be named \"default\" | { default: {}} |\n\n### Common datasource parameters\n\n| Name | Description | Value |\n| ---------------------------------------------------------- | --------------------------------------------------------------------------------------------- | ------- |\n| `datasources..type` | A database type supported by Cube.js | |\n| `datasources..url` | The URL for a database | |\n| `datasources..host` | The host URL for a database | |\n| `datasources..port` | The port for the database connection | |\n| `datasources..schema` | The schema within the database to connect to | |\n| `datasources..name` | The name of the database to connect to | |\n| `datasources..user` | The username used to connect to the database | |\n| `datasources..pass` | The password used to connect to the database | |\n| `datasources..passFromSecret.name` | The password used to connect to the database (using secret) | |\n| `datasources..passFromSecret.key` | The password used to connect to the database (using secret) | |\n| `datasources..domain` | A domain name within the database to connect to | |\n| `datasources..socketPath` | The path to a Unix socket for a MySQL database | |\n| `datasources..catalog` | The catalog within the database to connect to | |\n| `datasources..maxPool` | The maximum number of connections to keep active in the database connection pool | |\n| `datasources..queryTimeout` | The timeout value for any queries made to the database by Cube | |\n| `datasources..export.name` | The name of a bucket in cloud storage | |\n| `datasources..export.type` | The cloud provider where the bucket is hosted (gcs, s3) | |\n| `datasources..export.gcs.credentials` | Base64 encoded JSON key file for connecting to Google Cloud | |\n| `datasources..export.gcs.credentialsFromSecret.name` | Base64 encoded JSON key file for connecting to Google Cloud (using secret) | |\n| `datasources..export.gcs.credentialsFromSecret.key` | Base64 encoded JSON key file for connecting to Google Cloud (using secret) | |\n| `datasources..export.aws.key` | The AWS Access Key ID to use for the export bucket | |\n| `datasources..export.aws.secret` | The AWS Secret Access Key to use for the export bucket | |\n| `datasources..export.aws.secretFromSecret.name` | The AWS Secret Access Key to use for the export bucket (using secret) | |\n| `datasources..export.aws.secretFromSecret.key` | The AWS Secret Access Key to use for the export bucket (using secret) | |\n| `datasources..export.aws.region` | The AWS region of the export bucket | |\n| `datasources..export.redshift.arn` | An ARN of an AWS IAM role with permission to write to the configured bucket (see export.name) | |\n| `datasources..ssl.enabled` | If true, enables SSL encryption for database connections from Cube.js | `false` |\n| `datasources..ssl.rejectUnAuthorized` | If true, verifies the CA chain with the system's built-in CA chain | |\n| `datasources..ssl.ca` | The contents of a CA bundle in PEM format, or a path to one | |\n| `datasources..ssl.cert` | The contents of an SSL certificate in PEM format, or a path to one | |\n| `datasources..ssl.key` | The contents of a private key in PEM format, or a path to one | |\n| `datasources..ssl.ciphers` | The ciphers used by the SSL certificate | |\n| `datasources..ssl.serverName` | The server name for the SNI TLS extension | |\n| `datasources..ssl.passPhrase` | he passphrase used to encrypt the SSL private key | |\n\n### Athena datasource parameters\n\n| Name | Description | Value |\n| ------------------------------------------------- | ------------------------------------------------------------------------ | ----- |\n| `datasources..athena.key` | The AWS Access Key ID to use for database connections | |\n| `datasources..athena.keyFromSecret.name` | The AWS Access Key ID to use for database connections (using secret) | |\n| `datasources..athena.keyFromSecret.key` | The AWS Access Key ID to use for database connections (using secret) | |\n| `datasources..athena.region` | The AWS region of the Cube.js deployment | |\n| `datasources..athena.s3OutputLocation` | The S3 path to store query results made by the Cube.js deployment | |\n| `datasources..athena.secret` | The AWS Secret Access Key to use for database connections | |\n| `datasources..athena.secretFromSecret.name` | The AWS Secret Access Key to use for database connections (using secret) | |\n| `datasources..athena.secretFromSecret.key` | The AWS Secret Access Key to use for database connections (using secret) | |\n| `datasources..athena.workgroup` | The name of the workgroup in which the query is being started | |\n| `datasources..athena.catalog` | The name of the catalog to use by default | |\n\n### Bigquery datasource parameters\n\n| Name | Description | Value |\n| -------------------------------------------------------- | ------------------------------------------------------------------------------- | ----- |\n| `datasources..bigquery.projectId` | The Google BigQuery project ID to connect to | |\n| `datasources..bigquery.location` | The Google BigQuery dataset location to connect to | |\n| `datasources..bigquery.credentials` | A Base64 encoded JSON key file for connecting to Google BigQuery | |\n| `datasources..bigquery.credentialsFromSecret.name` | A Base64 encoded JSON key file for connecting to Google BigQuery (using secret) | |\n| `datasources..bigquery.credentialsFromSecret.key` | A Base64 encoded JSON key file for connecting to Google BigQuery (using secret) | |\n| `datasources..bigquery.keyFile` | The path to a JSON key file for connecting to Google BigQuery | |\n\n### Databricks datasource parameters\n\n| Name | Description | Value |\n| -------------------------------------------- | ------------------------------------------------------------------------- | ----- |\n| `datasources..databricks.url` | The URL for a JDBC connection | |\n| `datasources..databricks.acceptPolicy` | Whether or not to accept the license terms for the Databricks JDBC driver | |\n| `datasources..databricks.token` | The personal access token used to authenticate the Databricks connection | |\n| `datasources..databricks.catalog` | Databricks catalog name | |\n\n### Clickhouse datasource parameters\n\n| Name | Description | Value |\n| ---------------------------------------- | ------------------------------------------------------- | ----- |\n| `datasources..clickhouse.readonly` | Whether the ClickHouse user has read-only access or not | |\n\n### Firebolt datasource parameters\n\n| Name | Description | Value |\n| ----------------------------------------- | ---------------------------------------------- | ----- |\n| `datasources..firebolt.account` | Account name | |\n| `datasources..firebolt.engineName` | Engine name to connect to | |\n| `datasources..firebolt.apiEndpoint` | Firebolt API endpoint. Used for authentication | |\n\n### Hive datasource parameters\n\n| Name | Description | Value |\n| --------------------------------------- | ----------------------------------------------- | ----- |\n| `datasources..hive.cdhVersion` | The version of the CDH instance for Apache Hive | |\n| `datasources..hive.thriftVersion` | The version of Thrift Server for Apache Hive | |\n| `datasources..hive.type` | The type of Apache Hive server | |\n| `datasources..hive.version` | The version of Apache Hive | |\n\n### Presto datasource parameters\n\n| Name | Description | Value |\n| ----------------------------------- | --------------------------------------- | ----- |\n| `datasources..presto.catalog` | The catalog within Presto to connect to | |\n\n### Snowflake datasource parameters\n\n| Name | Description | Value |\n| ----------------------------------------------------- | ---------------------------------------------------------------------- | ----- |\n| `datasources..snowFlake.account` | The Snowflake account ID to use when connecting to the database | |\n| `datasources..snowFlake.region` | The Snowflake region to use when connecting to the database | |\n| `datasources..snowFlake.role` | The Snowflake role to use when connecting to the database | |\n| `datasources..snowFlake.warehouse` | The Snowflake warehouse to use when connecting to the database | |\n| `datasources..snowFlake.clientSessionKeepAlive` | If true, keep the Snowflake connection alive indefinitely | |\n| `datasources..snowFlake.authenticator` | The type of authenticator to use with Snowflake. Defaults to SNOWFLAKE | |\n| `datasources..snowFlake.privateKeyPath` | The path to the private RSA key folder | |\n| `datasources..snowFlake.privateKeyPass` | The password for the private RSA key. Only required for encrypted keys | |\n\n### Trino datasource parameters\n\n| Name | Description | Value |\n| ---------------------------------- | -------------------------------------- | ----- |\n| `datasources..trino.catalog` | The catalog within Trino to connect to | |",
- "source_links": [],
- "id": 26
- },
- {
- "page_link": "add-your-models.md",
- "title": "add-your-models",
- "text": "# Add Your Cube Models\n\nTo overwrite default schema, create a new folder `schemas` inside `cube/helm/cube` folder.\n\nThen you can add your `yaml` or `js` files.\n\nExample of a yaml model file looks like (More info [here](https://cube.dev/docs/schema/getting-started))\n```yaml\ncubes:\n - name: my_table\n sql_table: my_table\n data_source: default\n dimensions:\n - name: id\n sql: id\n type: string\n primary_key: true\n - name: product_id\n sql: product_id\n type: string\n measures:\n - name: count\n type: count\n```\n\nYou can add as many model as you want inside `schemas` folder.\n\nThen, you'll to create a `configmap.yaml` inside `cube/helm/cube/templates` with the following value:\n\n```yaml\napiVersion: v1\nkind: ConfigMap\nmetadata:\n name: cube-model\ndata:\n{{ (.Files.Glob \"schemas/**.yaml\").AsConfig | indent 2 }} # Note the **.yaml, adjust it if you want to use js models\n```\n\nFinally, you need to edit `cube/helm/cube/values.yaml`\n```yaml\ncube:\n cube:\n config:\n volumes:\n - name: cube-model\n configMap:\n name: cube-model\n volumeMounts:\n - name: cube-model\n readOnly: true\n mountPath: /cube/conf/schema/example.yaml\n subPath: example.yaml\n <...>\n```\n\nOnce that reconfiguration has been made, simply run: `plural build --only cube && plural deploy --commit \"feat(cube): add cube models\"` to apply the changes on your cluster.",
- "source_links": [],
- "id": 27
- },
- {
- "page_link": "https://github.com/dagster-io/dagster",
- "title": "dagster readme",
- "text": "python_modules/dagster/README.md",
- "source_links": [],
- "id": 28
- },
- {
- "page_link": "private-ingress.md",
- "title": "private-ingress",
- "text": "# Deploying on a private network\n\nTo deploy your dagster instance on a private network, the simplest solution is to use our provided private ingress class, which can be done easily by adding the following to `dagster/helm/dagster/values.yaml`:\n\n```yaml\ndagster:\n dagster:\n ingress:\n ingressClassName: internal-nginx\n```\n\n(this can also be done in the configuration tab of the plural console for your dagster app)",
- "source_links": [],
- "id": 29
- },
- {
- "page_link": "user-code.md",
- "title": "user-code",
- "text": "# Add Your Own User Code Deployment\n\nDagster has a concept of user code deployments which allow you to specify multiple independent repositories of dags to register with the same dagster orchestrator. This is a great way to separate dependency trees between codebases or manage a complex data org. An example user code deployment configuration can be seen here, which can be added to `dagster/helm/dagster/values.yaml` or updated directly in the configuration tab of the console's dagster app page:\n\n```yaml\ndagster:\n dagster:\n dagster-user-deployments:\n deployments:\n - dagsterApiGrpcArgs:\n - -m\n - dags\n envSecrets:\n - name: dagster-user-secrets # if you want to add env vars from a k8s secret\n image:\n pullPolicy: Always\n repository: ghcr.io/your/dagster-code\n tag: v0.0.4\n name: dags\n port: 4000\n resources:\n requests:\n cpu: 20m\n memory: 100Mi\n imagePullSecrets:\n - name: gh-creds # additional pull credentials if you would like to use then\n```\n\nIt can be a bit tedious to manually maintain this configuration as your codebase, so we've provided the `plural upgrade` command to automate this out of CI. Here's an example github action doing just that: https://github.com/pluralsh/dagster-example/blob/main/.github/workflows/publish.yml#L49. The `upgrade.yaml` file it references can be seen here: https://github.com/pluralsh/dagster-example/blob/main/upgrade.yaml\n\n",
- "source_links": [],
- "id": 30
- },
- {
- "page_link": "https://github.com/dagster-io/dagster",
- "title": "dagster-agent readme",
- "text": "python_modules/dagster/README.md",
- "source_links": [],
- "id": 31
- },
- {
- "page_link": "https://github.com/pluralsh/dash-controller",
- "title": "dash-controller readme",
- "text": "# Dash controller\n\nDash controller is responsible to manage lifecycle of DashApplication objects.\n\n## Local Kubernets\n\nYou can spin up kubernetes cluster using kind.\nThe following script deploy also load balancer and ingress controller.\n\n```bash\n$ example/kind/run-kind.sh\n```\n\n## Installation\n\nInstall CRD: \n```bash\nkubectl create -f config/crd/bases\n```\n\nNow you can deploy the controller:\n\n```bash\nkubectl create -f resources/\n```\n\nGo to `example` directory to deploy your first dash application\n```bash\nkubectl create -f example/dash_picsum.yaml\n```\n\n\n```yaml\napiVersion: dash.plural.sh/v1alpha1\nkind: DashApplication\nmetadata:\n name: picsum\n namespace: default\nspec:\n replicas: 1\n container:\n image: \"zreigz/dash-picsum:0.1.0\"\n containerPort: 8050\n ingress:\n ingressClassName: \"nginx\"\n path: \"/picsum\"\n```\n\nThe controller will create Deployment, Service and Ingress with the DashApplication name: `picsum`\nWhen you deployed kind cluster the application will be available on this address: `http://localhost/picsum`\n",
- "source_links": [],
- "id": 32
- },
- {
- "page_link": "https://github.com/DataDog/helm-charts",
- "title": "datadog readme",
- "text": "# Datadog Helm Charts\n\n[](https://artifacthub.io/packages/search?repo=datadog) \n\nOfficial Helm charts for Datadog products. Currently supported:\n- [Datadog Agents](charts/datadog/README.md) (datadog/datadog)\n\n## How to use Datadog Helm repository\n\nYou need to add this repository to your Helm repositories:\n\n```\nhelm repo add datadog https://helm.datadoghq.com\nhelm repo update\n```\n",
- "source_links": [],
- "id": 33
- },
- {
- "page_link": "https://github.com/datahub-project/datahub",
- "title": "datahub readme",
- "text": "\n
\n\n
\n\n\n# DataHub: The Metadata Platform for the Modern Data Stack\n## Built with \u2764\ufe0f by [Acryl Data](https://acryldata.io) and [LinkedIn](https://engineering.linkedin.com)\n[](https://github.com/datahub-project/datahub/releases/latest)\n[](https://badge.fury.io/py/acryl-datahub)\n[](https://github.com/datahub-project/datahub/actions?query=workflow%3A%22build+%26+test%22+branch%3Amaster+event%3Apush)\n[](https://hub.docker.com/r/linkedin/datahub-gms)\n[](https://slack.datahubproject.io)\n[](https://github.com/datahub-project/datahub/blob/master/docs/CONTRIBUTING.md)\n[](https://github.com/datahub-project/datahub/pulls?q=is%3Apr)\n[](https://github.com/datahub-project/datahub/blob/master/LICENSE)\n[](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n[](https://medium.com/datahub-project)\n[](https://twitter.com/datahubproject)\n### \ud83c\udfe0 Hosted DataHub Docs (Courtesy of Acryl Data): [datahubproject.io](https://datahubproject.io/docs)\n\n---\n\n[Quickstart](https://datahubproject.io/docs/quickstart) |\n[Features](https://datahubproject.io/docs/features) |\n[Roadmap](https://feature-requests.datahubproject.io/roadmap) |\n[Adoption](#adoption) |\n[Demo](https://datahubproject.io/docs/demo) |\n[Town Hall](https://datahubproject.io/docs/townhalls)\n\n---\n> \ud83d\udce3\u2002DataHub Town Hall is the 4th Thursday at 9am US PT of every month - [add it to your calendar!](https://rsvp.datahubproject.io/)\n>\n> - Town-hall Zoom link: [zoom.datahubproject.io](https://zoom.datahubproject.io)\n> - [Meeting details](docs/townhalls.md) & [past recordings](docs/townhall-history.md)\n\n> \u2728\u2002DataHub Community Highlights:\n>\n> - Read our Monthly Project Updates [here](https://blog.datahubproject.io/tagged/project-updates).\n> - Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data: [Data Engineering Podcast](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n> - Check out our most-read blog post, [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained) @ LinkedIn Engineering Blog.\n> - Join us on [Slack](docs/slack.md)! Ask questions and keep up with the latest announcements.\n\n## Introduction\n\nDataHub is an open-source metadata platform for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels [here](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained). Also read our\n[LinkedIn Engineering blog post](https://engineering.linkedin.com/blog/2019/data-hub), check out our [Strata presentation](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) and watch our [Crunch Conference Talk](https://www.youtube.com/watch?v=OB-O0Y6OYDE). You should also visit [DataHub Architecture](docs/architecture/architecture.md) to get a better understanding of how DataHub is implemented.\n\n## Features & Roadmap\n\nCheck out DataHub's [Features](docs/features.md) & [Roadmap](https://feature-requests.datahubproject.io/roadmap).\n\n## Demo and Screenshots\n\nThere's a [hosted demo environment](https://datahubproject.io/docs/demo) courtesy of [Acryl Data](https://acryldata.io) where you can explore DataHub without installing it locally\n\n## Quickstart\n\nPlease follow the [DataHub Quickstart Guide](https://datahubproject.io/docs/quickstart) to get a copy of DataHub up & running locally using [Docker](https://docker.com). As the guide assumes some basic knowledge of Docker, we'd recommend you to go through the \"Hello World\" example of [A Docker Tutorial for Beginners](https://docker-curriculum.com) if Docker is completely foreign to you.\n\n## Development\n\nIf you're looking to build & modify datahub please take a look at our [Development Guide](https://datahubproject.io/docs/developers).\n\n[](https://datahubproject.io/docs/demo)\n\n## Source Code and Repositories\n\n- [datahub-project/datahub](https://github.com/datahub-project/datahub): This repository contains the complete source code for DataHub's metadata model, metadata services, integration connectors and the web application.\n- [acryldata/datahub-actions](https://github.com/acryldata/datahub-actions): DataHub Actions is a framework for responding to changes to your DataHub Metadata Graph in real time.\n- [acryldata/datahub-helm](https://github.com/acryldata/datahub-helm): Repository of helm charts for deploying DataHub on a Kubernetes cluster\n- [acryldata/meta-world](https://github.com/acryldata/meta-world): A repository to store recipes, custom sources, transformations and other things to make your DataHub experience magical\n\n## Releases\n\nSee [Releases](https://github.com/datahub-project/datahub/releases) page for more details. We follow the [SemVer Specification](https://semver.org) when versioning the releases and adopt the [Keep a Changelog convention](https://keepachangelog.com/) for the changelog format.\n\n## Contributing\n\nWe welcome contributions from the community. Please refer to our [Contributing Guidelines](docs/CONTRIBUTING.md) for more details. We also have a [contrib](contrib) directory for incubating experimental features.\n\n## Community\n\nJoin our [Slack workspace](https://slack.datahubproject.io) for discussions and important announcements. You can also find out more about our upcoming [town hall meetings](docs/townhalls.md) and view past recordings.\n\n## Adoption\n\nHere are the companies that have officially adopted DataHub. Please feel free to add yours to the list if we missed it.\n\n- [ABLY](https://ably.team/)\n- [Adevinta](https://www.adevinta.com/)\n- [Banksalad](https://www.banksalad.com)\n- [Cabify](https://cabify.tech/)\n- [DefinedCrowd](http://www.definedcrowd.com)\n- [DFDS](https://www.dfds.com/)\n- [Expedia Group](http://expedia.com)\n- [Experius](https://www.experius.nl)\n- [Geotab](https://www.geotab.com)\n- [Grofers](https://grofers.com)\n- [Haibo Technology](https://www.botech.com.cn)\n- [hipages](https://hipages.com.au/)\n- [IOMED](https://iomed.health)\n- [Klarna](https://www.klarna.com)\n- [LinkedIn](http://linkedin.com)\n- [Moloco](https://www.moloco.com/en)\n- [Peloton](https://www.onepeloton.com)\n- [Saxo Bank](https://www.home.saxo)\n- [Stash](https://www.stash.com)\n- [Shanghai HuaRui Bank](https://www.shrbank.com)\n- [ThoughtWorks](https://www.thoughtworks.com)\n- [TypeForm](http://typeform.com)\n- [Uphold](https://uphold.com)\n- [Viasat](https://viasat.com)\n- [Wolt](https://wolt.com)\n- [Zynga](https://www.zynga.com)\n\n\n## Select Articles & Talks\n\n- [DataHub Blog](https://blog.datahubproject.io/)\n- [DataHub YouTube Channel](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n- [Optum: Data Mesh via DataHub](https://optum.github.io/blog/2022/03/23/data-mesh-via-datahub/)\n- [Saxo Bank: Enabling Data Discovery in Data Mesh](https://medium.com/datahub-project/enabling-data-discovery-in-a-data-mesh-the-saxo-journey-451b06969c8f)\n- [Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n- [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained)\n- [Driving DataOps Culture with LinkedIn DataHub](https://www.youtube.com/watch?v=ccsIKK9nVxk) @ [DataOps Unleashed 2021](https://dataopsunleashed.com/#shirshanka-session)\n- [The evolution of metadata: LinkedIn\u2019s story](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) @ [Strata Data Conference 2019](https://conferences.oreilly.com/strata/strata-ny-2019.html)\n- [Journey of metadata at LinkedIn](https://www.youtube.com/watch?v=OB-O0Y6OYDE) @ [Crunch Data Conference 2019](https://crunchconf.com/2019)\n- [DataHub Journey with Expedia Group](https://www.youtube.com/watch?v=ajcRdB22s5o)\n- [Data Discoverability at SpotHero](https://www.slideshare.net/MaggieHays/data-discoverability-at-spothero)\n- [Data Catalogue \u2014 Knowing your data](https://medium.com/albert-franzi/data-catalogue-knowing-your-data-15f7d0724900)\n- [DataHub: A Generalized Metadata Search & Discovery Tool](https://engineering.linkedin.com/blog/2019/data-hub)\n- [Open sourcing DataHub: LinkedIn\u2019s metadata search and discovery platform](https://engineering.linkedin.com/blog/2020/open-sourcing-datahub--linkedins-metadata-search-and-discovery-p)\n- [Emerging Architectures for Modern Data Infrastructure](https://future.com/emerging-architectures-for-modern-data-infrastructure-2020/)\n\nSee the full list [here](docs/links.md).\n\n## License\n\n[Apache License 2.0](./LICENSE).\n",
- "source_links": [],
- "id": 34
- },
- {
- "page_link": null,
- "title": "dex readme",
- "text": null,
- "source_links": [],
- "id": 35
- },
- {
- "page_link": "https://github.com/directus/directus",
- "title": "directus readme",
- "text": null,
- "source_links": [],
- "id": 36
- },
- {
- "page_link": "bring-your-own-postgres.md",
- "title": "bring-your-own-postgres",
- "text": "# Bring Your Own Postgres DB\n\nSome users might prefer to use and external or managed postgres instance rather than an on-cluster one. In that case, only a small reconfiguration is required, in `directus/helm/directus/values.yaml` overlay the following:\n\n```yaml\ndirectus:\n postgres:\n enabled: false # if you'd like to remove the existing db\n dsn: 'postgresql://:@:/'\n```\n\nYou can use any valid postgres connection string, and might need to tweak sslmode and so forth to get the exact correct value. This file will be encrypted, so no worries about secret exposure as well.\n\nOnce that reconfiguration has been made, simply run: `plural build --only directus && plural deploy --commit \"redeploy directus\"` to apply the changes on your cluster.",
- "source_links": [],
- "id": 37
- },
- {
- "page_link": "https://github.com/elastic/cloud-on-k8s",
- "title": "elasticsearch readme",
- "text": "\n[](https://buildkite.com/elastic/cloud-on-k8s-operator)\n[](https://github.com/elastic/cloud-on-k8s/releases/latest)\n\n# Elastic Cloud on Kubernetes (ECK)\n\nElastic Cloud on Kubernetes automates the deployment, provisioning, management, and orchestration of Elasticsearch, Kibana, APM Server, Enterprise Search, Beats, Elastic Agent, Elastic Maps Server, and Logstash on Kubernetes based on the operator pattern.\n\nCurrent features:\n\n* Elasticsearch, Kibana, APM Server, Enterprise Search, and Beats deployments\n* TLS Certificates management\n* Safe Elasticsearch cluster configuration & topology changes\n* Persistent volumes usage\n* Custom node configuration and attributes\n* Secure settings keystore updates\n\nSupported versions:\n\n* Kubernetes 1.24-1.27\n* OpenShift 4.9-4.13\n* Elasticsearch, Kibana, APM Server: 6.8+, 7.1+, 8+\n* Enterprise Search: 7.7+, 8+\n* Beats: 7.0+, 8+\n* Elastic Agent: 7.10+ (standalone), 7.14+, 8+ (Fleet)\n* Elastic Maps Server: 7.11+, 8+\n* Logstash 8.7+\n\nCheck the [Quickstart](https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html) to deploy your first cluster with ECK.\n\nIf you want to contribute to the project, check our [contributing guide](CONTRIBUTING.md) and see [how to setup a local development environment](dev-setup.md).\n\nFor general questions, please see the Elastic [forums](https://discuss.elastic.co/c/eck).\n",
- "source_links": [],
- "id": 38
- },
- {
- "page_link": "external-ingress.md",
- "title": "external-ingress",
- "text": "# Set Up External Ingress\n\nIf you'd like to access your elasticsearch cluster externally, you can do that with a relatively simply helm reconfiguration. At `elasticsearch/helm/elasticsearch/values.yaml` add:\n\n```yaml\nelasticsearch:\n ingressElastic:\n enabled: true\n hostname: elasticsearch.CLUSTER_SUBDOMAIN\n```\n\n`CLUSTER_SUBDOMAIN` should be the same subdomain you use for all other apps in the cluster, if it were given something differently, externaldns and cert isssuance will fail and your install will not be accessible.",
- "source_links": [],
- "id": 39
- },
- {
- "page_link": "https://github.com/etcd-io/etcd",
- "title": "etcd readme",
- "text": "# etcd\n\n[](https://goreportcard.com/report/github.com/etcd-io/etcd)\n[](https://codecov.io/gh/etcd-io/etcd)\n[](https://github.com/etcd-io/etcd/actions/workflows/tests.yaml)\n[](https://github.com/etcd-io/etcd/actions/workflows/codeql-analysis.yml)\n[](https://etcd.io/docs)\n[](https://godoc.org/github.com/etcd-io/etcd)\n[](https://github.com/etcd-io/etcd/releases)\n[](https://github.com/etcd-io/etcd/blob/main/LICENSE)\n[](https://api.securityscorecards.dev/projects/github.com/etcd-io/etcd)\n\n**Note**: The `main` branch may be in an *unstable or even broken state* during development. For stable versions, see [releases][github-release].\n\n\n\netcd is a distributed reliable key-value store for the most critical data of a distributed system, with a focus on being:\n\n* *Simple*: well-defined, user-facing API (gRPC)\n* *Secure*: automatic TLS with optional client cert authentication\n* *Fast*: benchmarked 10,000 writes/sec\n* *Reliable*: properly distributed using Raft\n\netcd is written in Go and uses the [Raft][] consensus algorithm to manage a highly-available replicated log.\n\netcd is used [in production by many companies](./ADOPTERS.md), and the development team stands behind it in critical deployment scenarios, where etcd is frequently teamed with applications such as [Kubernetes][k8s], [locksmith][], [vulcand][], [Doorman][], and many others. Reliability is further ensured by [**rigorous testing**](https://github.com/etcd-io/etcd/tree/main/tests/functional).\n\nSee [etcdctl][etcdctl] for a simple command line client.\n\n[raft]: https://raft.github.io/\n[k8s]: http://kubernetes.io/\n[doorman]: https://github.com/youtube/doorman\n[locksmith]: https://github.com/coreos/locksmith\n[vulcand]: https://github.com/vulcand/vulcand\n[etcdctl]: https://github.com/etcd-io/etcd/tree/main/etcdctl\n\n## Maintainers\n\n[MAINTAINERS](MAINTAINERS) strive to shape an inclusive open source project culture where users are heard and contributors feel respected and empowered. MAINTAINERS maintain productive relationships across different companies and disciplines. Read more about [MAINTAINERS role and responsibilities](GOVERNANCE.md#maintainers).\n\n## Getting started\n\n### Getting etcd\n\nThe easiest way to get etcd is to use one of the pre-built release binaries which are available for OSX, Linux, Windows, and Docker on the [release page][github-release].\n\nFor more installation guides, please check out [play.etcd.io](http://play.etcd.io) and [operating etcd](https://etcd.io/docs/latest/op-guide).\n\n[github-release]: https://github.com/etcd-io/etcd/releases\n[branch-management]: https://etcd.io/docs/latest/branch_management\n\n### Running etcd\n\nFirst start a single-member cluster of etcd.\n\nIf etcd is installed using the [pre-built release binaries][github-release], run it from the installation location as below:\n\n```bash\n/tmp/etcd-download-test/etcd\n```\n\nThe etcd command can be simply run as such if it is moved to the system path as below:\n\n```bash\nmv /tmp/etcd-download-test/etcd /usr/local/bin/\netcd\n```\n\nThis will bring up etcd listening on port 2379 for client communication and on port 2380 for server-to-server communication.\n\nNext, let's set a single key, and then retrieve it:\n\n```\netcdctl put mykey \"this is awesome\"\netcdctl get mykey\n```\n\netcd is now running and serving client requests. For more, please check out:\n\n- [Interactive etcd playground](http://play.etcd.io)\n- [Animated quick demo](https://etcd.io/docs/latest/demo)\n\n### etcd TCP ports\n\nThe [official etcd ports][iana-ports] are 2379 for client requests, and 2380 for peer communication.\n\n[iana-ports]: http://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.txt\n\n### Running a local etcd cluster\n\nFirst install [goreman](https://github.com/mattn/goreman), which manages Procfile-based applications.\n\nOur [Procfile script](./Procfile) will set up a local example cluster. Start it with:\n\n```bash\ngoreman start\n```\n\nThis will bring up 3 etcd members `infra1`, `infra2` and `infra3` and optionally etcd `grpc-proxy`, which runs locally and composes a cluster.\n\nEvery cluster member and proxy accepts key value reads and key value writes.\n\nFollow the steps in [Procfile.learner](./Procfile.learner) to add a learner node to the cluster. Start the learner node with:\n\n```bash\ngoreman -f ./Procfile.learner start\n```\n\n### Install etcd client v3\n\n```bash\ngo get go.etcd.io/etcd/client/v3\n```\n\n### Next steps\n\nNow it's time to dig into the full etcd API and other guides.\n\n- Read the full [documentation][].\n- Explore the full gRPC [API][].\n- Set up a [multi-machine cluster][clustering].\n- Learn the [config format, env variables and flags][configuration].\n- Find [language bindings and tools][integrations].\n- Use TLS to [secure an etcd cluster][security].\n- [Tune etcd][tuning].\n\n[documentation]: https://etcd.io/docs/latest\n[api]: https://etcd.io/docs/latest/learning/api\n[clustering]: https://etcd.io/docs/latest/op-guide/clustering\n[configuration]: https://etcd.io/docs/latest/op-guide/configuration\n[integrations]: https://etcd.io/docs/latest/integrations\n[security]: https://etcd.io/docs/latest/op-guide/security\n[tuning]: https://etcd.io/docs/latest/tuning\n\n## Contact\n\n- Email: [etcd-dev](https://groups.google.com/forum/?hl=en#!forum/etcd-dev)\n- Slack: [#etcd](https://kubernetes.slack.com/messages/C3HD8ARJ5/details/) channel on Kubernetes ([get an invite](http://slack.kubernetes.io/))\n- [Community meetings](#Community-meetings)\n\n### Community meetings\n\netcd contributors and maintainers have monthly (every four weeks) meetings at 11:00 AM (USA Pacific) on Thursday.\n\nAn initial agenda will be posted to the [shared Google docs][shared-meeting-notes] a day before each meeting, and everyone is welcome to suggest additional topics or other agendas.\n\nMeeting recordings are uploaded to official etcd [YouTube channel].\n\nGet calendar invitation by joining [etcd-dev](https://groups.google.com/forum/?hl=en#!forum/etcd-dev) mailing group.\n\nJoin Hangouts Meet: [meet.google.com/umg-nrxn-qvs](https://meet.google.com/umg-nrxn-qvs)\n\nJoin by phone: +1 405-792-0633\u202c PIN: \u202a299 906\u202c#\n\n[shared-meeting-notes]: https://docs.google.com/document/d/16XEGyPBisZvmmoIHSZzv__LoyOeluC5a4x353CX0SIM/edit\n[YouTube channel]: https://www.youtube.com/channel/UC7tUWR24I5AR9NMsG-NYBlg\n\n## Contributing\n\nSee [CONTRIBUTING](CONTRIBUTING.md) for details on submitting patches and the contribution workflow.\n\n## Reporting bugs\n\nSee [reporting bugs](https://github.com/etcd-io/etcd/blob/main/Documentation/contributor-guide/reporting_bugs.md) for details about reporting any issues.\n\n## Reporting a security vulnerability\n\nSee [security disclosure and release process](security/README.md) for details on how to report a security vulnerability and how the etcd team manages it.\n\n## Issue and PR management\n\nSee [issue triage guidelines](https://github.com/etcd-io/etcd/blob/main/Documentation/contributor-guide/triage_issues.md) for details on how issues are managed.\n\nSee [PR management](https://github.com/etcd-io/etcd/blob/main/Documentation/contributor-guide/triage_prs.md) for guidelines on how pull requests are managed.\n\n## etcd Emeritus Maintainers\n\nThese emeritus maintainers dedicated a part of their career to etcd and reviewed code, triaged bugs and pushed the project forward over a substantial period of time. Their contribution is greatly appreciated.\n\n* Fanmin Shi\n* Anthony Romano\n* Brandon Philips\n* Joe Betz\n* Gyuho Lee\n* Jingyi Hu\n* Wenjia Zhang\n* Xiang Li\n* Ben Darnell\n* Tobias Grieger\n\n### License\n\netcd is under the Apache 2.0 license. See the [LICENSE](LICENSE) file for details.\n",
- "source_links": [],
- "id": 40
- },
- {
- "page_link": null,
- "title": "external-secrets readme",
- "text": null,
- "source_links": [],
- "id": 41
- },
- {
- "page_link": null,
- "title": "filecoin readme",
- "text": null,
- "source_links": [],
- "id": 42
- },
- {
- "page_link": null,
- "title": "gcp-config-connector readme",
- "text": null,
- "source_links": [],
- "id": 43
- },
- {
- "page_link": "https://github.com/TryGhost/Ghost",
- "title": "ghost readme",
- "text": " \n
\n Love open source? We're hiring JavaScript engineers to work on Ghost full-time.\n
\n\n \n\n\n\n \n\n\n\n\nThe easiest way to get a production instance deployed is with our official **[Ghost(Pro)](https://ghost.org/pricing/)** managed service. It takes about 2 minutes to launch a new site with worldwide CDN, backups, security and maintenance all done for you.\n\nFor most people this ends up being the best value option cause of [how much time it saves](https://ghost.org/docs/hosting/) \u2014 and 100% of revenue goes to the Ghost Foundation; funding the maintenance and further development of the project itself. So you\u2019ll be supporting open source software *and* getting a great service!\n\nIf you prefer to run on your own infrastructure, we also offer official 1-off installs and managed support and maintenance plans via **[Ghost(Valet)](https://valet.ghost.org)** - which can save a substantial amount of developer time and resources.\n\n \n\n# Quickstart install\n\nIf you want to run your own instance of Ghost, in most cases the best way is to use our **CLI tool**\n\n```\nnpm install ghost-cli -g\n```\n\n \n\nThen, if installing locally add the `local` flag to get up and running in under a minute - [Local install docs](https://ghost.org/docs/install/local/)\n\n```\nghost install local\n```\n\n \n\nor on a server run the full install, including automatic SSL setup using LetsEncrypt - [Production install docs](https://ghost.org/docs/install/ubuntu/)\n\n```\nghost install\n```\n\n \n\nCheck out our [official documentation](https://ghost.org/docs/) for more information about our [recommended hosting stack](https://ghost.org/docs/hosting/) & properly [upgrading Ghost](https://ghost.org/docs/update/), plus everything you need to develop your own Ghost [themes](https://ghost.org/docs/themes/) or work with [our API](https://ghost.org/docs/content-api/).\n\n### Contributors & advanced developers\n\nFor anyone wishing to contribute to Ghost or to hack/customize core files we recommend following our full development setup guides: [Contributor guide](https://ghost.org/docs/contributing/) \u2022 [Developer setup](https://ghost.org/docs/install/source/)\n\n \n\n# Ghost sponsors\n\nWe'd like to extend big thanks to our sponsors and partners who make Ghost possible. If you're interested in sponsoring Ghost and supporting the project, please check out our profile on [GitHub sponsors](https://github.com/sponsors/TryGhost) :heart:\n\n**[DigitalOcean](https://m.do.co/c/9ff29836d717)** \u2022 **[Fastly](https://www.fastly.com/)**\n\n \n\n# Getting help\n\nYou can find answers to a huge variety of questions, along with a large community of helpful developers over on the [Ghost forum](https://forum.ghost.org/) - replies are generally very quick. **Ghost(Pro)** customers also have access to 24/7 email support.\n\nTo stay up to date with all the latest news and product updates, make sure you [subscribe to our blog](https://ghost.org/blog/) \u2014 or you can always follow us [on Twitter](https://twitter.com/Ghost), if you prefer your updates bite-sized and facetious. :saxophone::turtle:\n\n \n\n# Copyright & license\n\nCopyright (c) 2013-2022 Ghost Foundation - Released under the [MIT license](LICENSE). Ghost and the Ghost Logo are trademarks of Ghost Foundation Ltd. Please see our [trademark policy](https://ghost.org/trademark/) for info on acceptable usage.\n",
- "source_links": [],
- "id": 44
- },
- {
- "page_link": "https://gitlab.com/gitlab-org/gitlab",
- "title": "gitlab readme",
- "text": "# GitLab\n\n## Canonical source\n\nThe canonical source of GitLab where all development takes place is [hosted on GitLab.com](https://gitlab.com/gitlab-org/gitlab).\n\nIf you wish to clone a copy of GitLab without proprietary code, you can use the read-only mirror of GitLab located at https://gitlab.com/gitlab-org/gitlab-foss/. However, please do not submit any issues and/or merge requests to that project.\n\n## Free trial\n\nYou can request a free trial of GitLab Ultimate [on our website](https://about.gitlab.com/free-trial/).\n\n## Open source software to collaborate on code\n\nTo see how GitLab looks please see the [features page on our website](https://about.gitlab.com/features/).\n\n- Manage Git repositories with fine grained access controls that keep your code secure\n- Perform code reviews and enhance collaboration with merge requests\n- Complete continuous integration (CI) and continuous deployment/delivery (CD) pipelines to build, test, and deploy your applications\n- Each project can also have an issue tracker, issue board, and a wiki\n- Used by more than 100,000 organizations, GitLab is the most popular solution to manage Git repositories on-premises\n- Completely free and open source (MIT Expat license)\n\n## Editions\n\nThere are three editions of GitLab:\n\n- GitLab Community Edition (CE) is available freely under the MIT Expat license.\n- GitLab Enterprise Edition (EE) includes [extra features](https://about.gitlab.com/pricing/#compare-options) that are more useful for organizations with more than 100 users. To use EE and get official support please [become a subscriber](https://about.gitlab.com/pricing/).\n- JiHu Edition (JH) tailored specifically for the [Chinese market](https://about.gitlab.cn/).\n\n## Licensing\n\nSee the [LICENSE](LICENSE) file for licensing information as it pertains to\nfiles in this repository.\n\n## Hiring\n\nWe are hiring developers, support people, and production engineers all the time, please see our [jobs page](https://about.gitlab.com/jobs/).\n\n## Website\n\nOn [about.gitlab.com](https://about.gitlab.com/) you can find more information about:\n\n- [Subscriptions](https://about.gitlab.com/pricing/)\n- [Consultancy](https://about.gitlab.com/consultancy/)\n- [Community](https://about.gitlab.com/community/)\n- [Hosted GitLab.com](https://about.gitlab.com/gitlab-com/) use GitLab as a free service\n- [GitLab Enterprise Edition](https://about.gitlab.com/features/#enterprise) with additional features aimed at larger organizations.\n- [GitLab CI](https://about.gitlab.com/gitlab-ci/) a continuous integration (CI) server that is easy to integrate with GitLab.\n\n## Requirements\n\nPlease see the [requirements documentation](doc/install/requirements.md) for system requirements and more information about the supported operating systems.\n\n## Installation\n\nThe recommended way to install GitLab is with the [Omnibus packages](https://about.gitlab.com/downloads/) on our package server.\nCompared to an installation from source, this is faster and less error prone.\nJust select your operating system, download the respective package (Debian or RPM) and install it using the system's package manager.\n\nThere are various other options to install GitLab, please refer to the [installation page on the GitLab website](https://about.gitlab.com/installation/) for more information.\n\n## Contributing\n\nGitLab is an open source project and we are very happy to accept community contributions. Please refer to [Contributing to GitLab page](https://about.gitlab.com/contributing/) for more details.\n\n## Install a development environment\n\nTo work on GitLab itself, we recommend setting up your development environment with [the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit).\nIf you do not use the GitLab Development Kit you need to install and configure all the dependencies yourself, this is a lot of work and error prone.\nOne small thing you also have to do when installing it yourself is to copy the example development Puma configuration file:\n\n```shell\ncp config/puma.example.development.rb config/puma.rb\n```\n\nInstructions on how to start GitLab and how to run the tests can be found in the [getting started section of the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit#getting-started).\n\n## Software stack\n\nGitLab is a Ruby on Rails application that runs on the following software:\n\n- Ubuntu/Debian/CentOS/RHEL/OpenSUSE\n- Ruby (MRI) 3.0.5\n- Git 2.33+\n- Redis 5.0+\n- PostgreSQL 12+\n\nFor more information please see the [architecture](https://docs.gitlab.com/ee/development/architecture.html) and [requirements](https://docs.gitlab.com/ee/install/requirements.html) documentation.\n\n## UX design\n\nPlease adhere to the [UX Guide](https://design.gitlab.com/) when creating designs and implementing code.\n\n## Third-party applications\n\nThere are a lot of [third-party applications integrating with GitLab](https://about.gitlab.com/applications/). These include GUI Git clients, mobile applications and API wrappers for various languages.\n\n## GitLab release cycle\n\nFor more information about the release process see the [release documentation](https://gitlab.com/gitlab-org/release-tools/blob/master/README.md).\n\n## Upgrading\n\nFor upgrading information please see our [update page](https://about.gitlab.com/update/).\n\n## Documentation\n\nAll documentation can be found on .\n\n## Getting help\n\nPlease see [Getting help for GitLab](https://about.gitlab.com/getting-help/) on our website for the many options to get help.\n\n## Why?\n\n[Read here](https://about.gitlab.com/why/)\n\n## Is it any good?\n\n[Yes](https://about.gitlab.com/is-it-any-good/)\n\n## Is it awesome?\n\n[These people](https://twitter.com/gitlab/followers) seem to like it.\n",
- "source_links": [],
- "id": 45
- },
- {
- "page_link": null,
- "title": "goldilocks readme",
- "text": null,
- "source_links": [],
- "id": 46
- },
- {
- "page_link": "https://github.com/grafana/grafana",
- "title": "grafana readme",
- "text": "\n\nThe open-source platform for monitoring and observability\n\n[](LICENSE)\n[](https://drone.grafana.net/grafana/grafana)\n[](https://goreportcard.com/report/github.com/grafana/grafana)\n\nGrafana allows you to query, visualize, alert on and understand your metrics no matter where they are stored. Create, explore, and share dashboards with your team and foster a data-driven culture:\n\n- **Visualizations:** Fast and flexible client side graphs with a multitude of options. Panel plugins offer many different ways to visualize metrics and logs.\n- **Dynamic Dashboards:** Create dynamic & reusable dashboards with template variables that appear as dropdowns at the top of the dashboard.\n- **Explore Metrics:** Explore your data through ad-hoc queries and dynamic drilldown. Split view and compare different time ranges, queries and data sources side by side.\n- **Explore Logs:** Experience the magic of switching from metrics to logs with preserved label filters. Quickly search through all your logs or streaming them live.\n- **Alerting:** Visually define alert rules for your most important metrics. Grafana will continuously evaluate and send notifications to systems like Slack, PagerDuty, VictorOps, OpsGenie.\n- **Mixed Data Sources:** Mix different data sources in the same graph! You can specify a data source on a per-query basis. This works for even custom datasources.\n\n## Get started\n\n- [Get Grafana](https://grafana.com/get)\n- [Installation guides](https://grafana.com/docs/grafana/latest/setup-grafana/installation/)\n\nUnsure if Grafana is for you? Watch Grafana in action on [play.grafana.org](https://play.grafana.org/)!\n\n## Documentation\n\nThe Grafana documentation is available at [grafana.com/docs](https://grafana.com/docs/).\n\n## Contributing\n\nIf you're interested in contributing to the Grafana project:\n\n- Start by reading the [Contributing guide](https://github.com/grafana/grafana/blob/HEAD/CONTRIBUTING.md).\n- Learn how to set up your local environment, in our [Developer guide](https://github.com/grafana/grafana/blob/HEAD/contribute/developer-guide.md).\n- Explore our [beginner-friendly issues](https://github.com/grafana/grafana/issues?q=is%3Aopen+is%3Aissue+label%3A%22beginner+friendly%22).\n- Look through our [style guide and Storybook](https://developers.grafana.com/ui/latest/index.html).\n\n## Get involved\n\n- Follow [@grafana on Twitter](https://twitter.com/grafana/).\n- Read and subscribe to the [Grafana blog](https://grafana.com/blog/).\n- If you have a specific question, check out our [discussion forums](https://community.grafana.com/).\n- For general discussions, join us on the [official Slack](https://slack.grafana.com) team.\n\n## License\n\nGrafana is distributed under [AGPL-3.0-only](LICENSE). For Apache-2.0 exceptions, see [LICENSING.md](https://github.com/grafana/grafana/blob/HEAD/LICENSING.md).\n",
- "source_links": [],
- "id": 47
- },
- {
- "page_link": "plugins.md",
- "title": "plugins",
- "text": "## Adding grafana plugins to your install\n\nyou can simply add to `grafana/helm/grafana/values.yaml` or in grafana's configuration page in your plural console:\n\n```yaml\ngrafana:\n grafana:\n plugins:\n - your-plugin-name\n```",
- "source_links": [],
- "id": 48
- },
- {
- "page_link": "https://github.com/grafana/agent",
- "title": "grafana-agent readme",
- "text": "
\n\nGrafana Agent is a vendor-neutral, batteries-included telemetry collector with\nconfiguration inspired by [Terraform][]. It is designed to be flexible,\nperformant, and compatible with multiple ecosystems such as Prometheus and\nOpenTelemetry.\n\nGrafana Agent is based around **components**. Components are wired together to\nform programmable observability **pipelines** for telemetry collection,\nprocessing, and delivery.\n\n> **NOTE**: This page focuses mainly on \"[Flow mode][Grafana Agent Flow],\" the\n> Terraform-inspired revision of Grafana Agent.\n\nGrafana Agent can collect, transform, and send data to:\n\n* The [Prometheus][] ecosystem\n* The [OpenTelemetry][] ecosystem\n* The Grafana open source ecosystem ([Loki][], [Grafana][], [Tempo][], [Mimir][], [Phlare][])\n\n[Terraform]: https://terraform.io\n[Grafana Agent Flow]: https://grafana.com/docs/agent/latest/flow/\n[Prometheus]: https://prometheus.io\n[OpenTelemetry]: https://opentelemetry.io\n[Loki]: https://github.com/grafana/loki\n[Grafana]: https://github.com/grafana/grafana\n[Tempo]: https://github.com/grafana/tempo\n[Mimir]: https://github.com/grafana/mimir\n[Phlare]: https://github.com/grafana/phlare\n\n## Why use Grafana Agent?\n\n* **Vendor-neutral**: Fully compatible with the Prometheus, OpenTelemetry, and\n Grafana open source ecosystems.\n* **Every signal**: Collect telemetry data for metrics, logs, traces, and\n continuous profiles.\n* **Scalable**: Deploy on any number of machines to collect millions of active\n series and terabytes of logs.\n* **Battle-tested**: Grafana Agent extends the existing battle-tested code from\n the Prometheus and OpenTelemetry Collector projects.\n* **Powerful**: Write programmable pipelines with ease, and debug them using a\n [built-in UI][UI].\n* **Batteries included**: Integrate with systems like MySQL, Kubernetes, and\n Apache to get telemetry that's immediately useful.\n\n[UI]: https://grafana.com/docs/agent/latest/flow/monitoring/debugging/#grafana-agent-flow-ui\n\n## Getting started\n\nCheck out our [documentation][] to see:\n\n* [Installation instructions][] for Grafana Agent\n* Details about [Grafana Agent Flow][]\n* Steps for [Getting started][] with Grafana Agent Flow\n* The list of Grafana Agent Flow [Components][]\n\n[documentation]: https://grafana.com/docs/agent/latest/\n[Installation instructions]: https://grafana.com/docs/agent/latest/set-up/\n[Grafana Agent Flow]: https://grafana.com/docs/agent/latest/flow/\n[Getting started]: https://grafana.com/docs/agent/latest/flow/getting_started/\n[Components]: https://grafana.com/docs/agent/latest/flow/reference/components/\n\n## Example\n\n```river\n// Discover Kubernetes pods to collect metrics from.\ndiscovery.kubernetes \"pods\" {\n role = \"pod\"\n}\n\n// Collect metrics from Kubernetes pods.\nprometheus.scrape \"default\" {\n targets = discovery.kubernetes.pods.targets\n forward_to = [prometheus.remote_write.default.receiver]\n}\n\n// Get an API key from disk.\nlocal.file \"apikey\" {\n filename = \"/var/data/my-api-key.txt\"\n is_secret = true\n}\n\n// Send metrics to a Prometheus remote_write endpoint.\nprometheus.remote_write \"default\" {\n endpoint {\n url = \"http://localhost:9009/api/prom/push\"\n\n basic_auth {\n username = \"MY_USERNAME\"\n password = local.file.apikey.content\n }\n }\n}\n```\n\nWe maintain an example [Docker Compose environment][] that can be used to\nlaunch dependencies to play with Grafana Agent locally.\n\n[Docker Compose environment]: ./example/docker-compose/\n\n## Release cadence\n\nA new minor release is planned every six weeks. You can use the list of\n[Milestones][] to see what maintainers are planning on working on for a given\nrelease cycle.\n\nBoth the release cadence and the items assigned to a milestone are best-effort:\nreleases may be moved forwards or backwards if needed, and items may be moved\nto a different milestone or removed entirely. The planned release dates for\nfuture minor releases do not change if one minor release is moved.\n\nPatch and security releases may be created at any time.\n\n[Milestones]: https://github.com/grafana/agent/milestones\n\n## Community\n\nTo engage with the Grafana Agent community:\n\n* Chat with us on our community Slack channel. To invite yourself to the\n Grafana Slack, visit and join the `#agent`\n channel.\n* Ask questions on the [Discussions page][].\n* [File an issue][] for bugs, issues, and feature suggestions.\n* Attend the monthly [community call][].\n\n[Discussions page]: https://github.com/grafana/agent/discussions\n[File an issue]: https://github.com/grafana/agent/issues/new\n[community call]: https://docs.google.com/document/d/1TqaZD1JPfNadZ4V81OCBPCG_TksDYGlNlGdMnTWUSpo\n\n## Contribute\n\nRefer to our [contributors guide][] to learn how to contribute.\n\n[contributors guide]: ./docs/developer/contributing.md\n",
- "source_links": [],
- "id": 49
- },
- {
- "page_link": "https://github.com/grafana/tempo",
- "title": "grafana-tempo readme",
- "text": "
\n
\n \n \n \n \n \n \n \n
\n\n\nGrafana Tempo is an open source, easy-to-use and high-scale distributed tracing backend. Tempo is cost-efficient, requiring only object storage to operate, and is deeply integrated with Grafana, Prometheus, and Loki. Tempo can be used with any of the open source tracing protocols, including Jaeger, Zipkin, OpenCensus, Kafka, and OpenTelemetry. It supports key/value lookup only and is designed to work in concert with logs and metrics (exemplars) for discovery.\n\nTempo is Jaeger, Zipkin, Kafka, OpenCensus and OpenTelemetry compatible. It ingests batches in any of the mentioned formats, buffers them and then writes them to Azure, GCS, S3 or local disk. As such it is robust, cheap and easy to operate!\n\n
\n\n\n## Getting Started\n\n- [Documentation](https://grafana.com/docs/tempo/latest/)\n- [Deployment Examples](./example)\n - Deployment and log discovery Examples\n- [What is Distributed Tracing?](https://opentracing.io/docs/overview/what-is-tracing/)\n\n## Further Reading\n\nTo learn more about Tempo, consult the following documents & talks:\n\n- October 2020 Launch blog post: \"[Announcing Grafana Tempo, a massively scalable distributed tracing system][tempo-launch-post]\"\n- October 2020 Motivations and tradeoffs blog post: \"[Tempo: A game of trade-offs][tempo-tradeoffs-post]\"\n- October 2020 Grafana ObservabilityCON Keynote Tempo announcement: \"[Keynote: What is observability?][tempo-o11ycon-keynote]\"\n- October 2020 Grafana ObservabilityCON Tempo Deep Dive: \"[Tracing made simple with Grafana][tempo-o11ycon-deep-dive]\"\n\n[tempo-launch-post]: https://grafana.com/blog/2020/10/27/announcing-grafana-tempo-a-massively-scalable-distributed-tracing-system/\n[tempo-tradeoffs-post]: https://gouthamve.dev/tempo-a-game-of-trade-offs/\n[tempo-o11ycon-keynote]: https://grafana.com/go/observabilitycon/keynote-what-is-observability/\n[tempo-o11ycon-deep-dive]: https://grafana.com/go/observabilitycon/tracing-made-simple-with-grafana/\n\n## Getting Help\n\nIf you have any questions or feedback regarding Tempo:\n\n- Search existing thread in the Grafana Labs community forum for Tempo: [https://community.grafana.com](https://community.grafana.com/c/grafana-tempo/40)\n- Ask a question on the Tempo Slack channel. To invite yourself to the Grafana Slack, visit [https://slack.grafana.com/](https://slack.grafana.com/) and join the #tempo channel.\n- [File an issue](https://github.com/grafana/tempo/issues/new/choose) for bugs, issues and feature suggestions.\n- UI issues should be filed with [Grafana](https://github.com/grafana/grafana/issues/new/choose).\n\n## OpenTelemetry\n\nTempo's receiver layer, wire format and storage format are all based directly on [standards](https://github.com/open-telemetry/opentelemetry-proto) and [code](https://github.com/open-telemetry/opentelemetry-collector) established by [OpenTelemetry](https://opentelemetry.io/). We support open standards at Grafana!\n\nCheck out the [Integration Guides](https://grafana.com/docs/tempo/latest/guides/instrumentation/) to see examples of OpenTelemetry instrumentation with Tempo.\n\n## Other Components\n\n### tempo-vulture\ntempo-vulture is tempo's bird themed consistency checking tool. It pushes traces and queries Tempo. It metrics 404s and traces with missing spans.\n\n### tempo-cli\ntempo-cli is the place to put any utility functionality related to tempo. See [Documentation](https://grafana.com/docs/tempo/latest/operations/tempo_cli/) for more info.\n\n\n## TempoDB\n\n[TempoDB](https://github.com/grafana/tempo/tree/main/tempodb) is included in the this repository but is meant to be a stand alone key value database built on top of cloud object storage (azure/gcs/s3). It is a natively multitenant, supports a WAL and is the storage engine for Tempo.\n\n## License\n\nGrafana Tempo is distributed under [AGPL-3.0-only](LICENSE). For Apache-2.0 exceptions, see [LICENSING.md](LICENSING.md).\n",
- "source_links": [],
- "id": 50
- },
- {
- "page_link": "https://github.com/growthbook/growthbook",
- "title": "growthbook readme",
- "text": "
\n
Open Source Feature Flagging and A/B Testing
\n
\n \n \n \n \n
\n\nGet up and running in 1 minute with:\n\n```sh\ngit clone https://github.com/growthbook/growthbook.git\ncd growthbook\ndocker-compose up -d\n```\n\nThen visit http://localhost:3000\n\n[](https://www.growthbook.io)\n\n## Our Philosophy\n\nThe top 1% of companies spend thousands of hours building their own feature flagging and A/B testing platforms in-house.\nThe other 99% are left paying for expensive 3rd party SaaS tools or hacking together unmaintained open source libraries.\n\nWe want to give all companies the flexibility and power of a fully-featured in-house platform without needing to build it themselves.\n\n## Major Features\n\n- \ud83c\udfc1 Feature flags with advanced targeting, gradual rollouts, and experiments\n- \ud83d\udcbb SDKs for [React](https://docs.growthbook.io/lib/react), [Javascript](https://docs.growthbook.io/lib/js), [PHP](https://docs.growthbook.io/lib/php), [Ruby](https://docs.growthbook.io/lib/ruby), [Python](https://docs.growthbook.io/lib/python), [Go](https://docs.growthbook.io/lib/go), and [Kotlin (Android)](https://docs.growthbook.io/lib/kotlin) with more coming soon\n- \ud83c\udd8e Powerful A/B test analysis with support for binomial, count, duration, and revenue metrics\n- \u2744\ufe0f Use your existing data stack - BigQuery, Mixpanel, Redshift, Google Analytics, [and more](https://docs.growthbook.io/app/datasources)\n- \u2b07\ufe0f Drill down into A/B test results by browser, country, or any other custom attribute\n- \ud83e\ude90 Export reports as a Jupyter Notebook!\n- \ud83d\udcdd Document everything with screenshots and GitHub Flavored Markdown throughout\n- \ud83d\udd14 Automated email alerts when A/B tests become significant\n\n## Try GrowthBook\n\n### Managed Cloud Hosting\n\nCreate a free [GrowthBook Cloud](https://app.growthbook.io) account to get started.\n\n### Open Source\n\nThe included [docker-compose.yml](https://github.com/growthbook/growthbook/blob/main/docker-compose.yml) file contains the GrowthBook App and a MongoDB instance (for storing cached experiment results and metadata):\n\n```sh\ngit clone https://github.com/growthbook/growthbook.git\ncd growthbook\ndocker-compose up -d\n```\n\nThen visit http://localhost:3000 to view the app.\n\nCheck out the full [Self-Hosting Instructions](https://docs.growthbook.io/self-host) for more details.\n\n## Documentation and Support\n\nView the [GrowthBook Docs](https://docs.growthbook.io) for info on how to configure and use the platform.\n\nJoin [our Slack community](https://slack.growthbook.io?ref=readme-support) if you get stuck, want to chat, or are thinking of a new feature.\n\nOr email us at [hello@growthbook.io](mailto:hello@growthbook.io) if Slack isn't your thing.\n\nWe're here to help - and to make GrowthBook even better!\n\n## Contributors\n\nWe \u2764\ufe0f all contributions, big and small!\n\nRead [CONTRIBUTING.md](/CONTRIBUTING.md) for how to setup your local development environment.\n\nIf you want to, you can reach out via [Slack](https://slack.growthbook.io?ref=readme-contributing) or [email](mailto:hello@growthbook.io) and we'll set up a pair programming session to get you started.\n\n## License\n\nThis project uses the MIT license. The core GrowthBook app will always remain open and free, although we may add some commercial enterprise add-ons in the future.\n",
- "source_links": [],
- "id": 51
- },
- {
- "page_link": "https://github.com/goharbor/harbor",
- "title": "harbor readme",
- "text": "# Harbor\n\n[](https://github.com/goharbor/harbor/actions?query=event%3Apush+branch%3Amain+workflow%3ACI+)\n[](https://codecov.io/gh/goharbor/harbor)\n[](https://goreportcard.com/report/github.com/goharbor/harbor)\n[](https://bestpractices.coreinfrastructure.org/projects/2095)\n[](https://www.codacy.com/gh/goharbor/harbor/dashboard?utm_source=github.com&utm_medium=referral&utm_content=goharbor/harbor&utm_campaign=Badge_Grade)\n\n[](https://www.googleapis.com/storage/v1/b/harbor-nightly/o)\n\n[](https://app.fossa.com/projects/git%2Bgithub.com%2Fgoharbor%2Fharbor?ref=badge_shield)\n\n\n|Community Meeting|\n|------------------|\n|The Harbor Project holds bi-weekly community calls in two different timezones. To join the community calls or to watch previous meeting notes and recordings, please visit the [meeting schedule](https://github.com/goharbor/community/blob/master/MEETING_SCHEDULE.md).|\n\n \n\n**Note**: The `main` branch may be in an *unstable or even broken state* during development.\nPlease use [releases](https://github.com/vmware/harbor/releases) instead of the `main` branch in order to get a stable set of binaries.\n\n\n\nHarbor is an open source trusted cloud native registry project that stores, signs, and scans content. Harbor extends the open source Docker Distribution by adding the functionalities usually required by users such as security, identity and management. Having a registry closer to the build and run environment can improve the image transfer efficiency. Harbor supports replication of images between registries, and also offers advanced security features such as user management, access control and activity auditing.\n\nHarbor is hosted by the [Cloud Native Computing Foundation](https://cncf.io) (CNCF). If you are an organization that wants to help shape the evolution of cloud native technologies, consider joining the CNCF. For details about whose involved and how Harbor plays a role, read the CNCF\n[announcement](https://www.cncf.io/blog/2018/07/31/cncf-to-host-harbor-in-the-sandbox/).\n\n## Features\n\n* **Cloud native registry**: With support for both container images and [Helm](https://helm.sh) charts, Harbor serves as registry for cloud native environments like container runtimes and orchestration platforms.\n* **Role based access control**: Users access different repositories through 'projects' and a user can have different permission for images or Helm charts under a project.\n* **Policy based replication**: Images and charts can be replicated (synchronized) between multiple registry instances based on policies with using filters (repository, tag and label). Harbor automatically retries a replication if it encounters any errors. This can be used to assist loadbalancing, achieve high availability, and facilitate multi-datacenter deployments in hybrid and multi-cloud scenarios.\n* **Vulnerability Scanning**: Harbor scans images regularly for vulnerabilities and has policy checks to prevent vulnerable images from being deployed.\n* **LDAP/AD support**: Harbor integrates with existing enterprise LDAP/AD for user authentication and management, and supports importing LDAP groups into Harbor that can then be given permissions to specific projects. \n* **OIDC support**: Harbor leverages OpenID Connect (OIDC) to verify the identity of users authenticated by an external authorization server or identity provider. Single sign-on can be enabled to log into the Harbor portal. \n* **Image deletion & garbage collection**: System admin can run garbage collection jobs so that images(dangling manifests and unreferenced blobs) can be deleted and their space can be freed up periodically.\n* **Notary**: Support signing container images using Docker Content Trust (leveraging Notary) for guaranteeing authenticity and provenance. In addition, policies that prevent unsigned images from being deployed can also be activated.\n* **Graphical user portal**: User can easily browse, search repositories and manage projects.\n* **Auditing**: All the operations to the repositories are tracked through logs.\n* **RESTful API**: RESTful APIs are provided to facilitate administrative operations, and are easy to use for integration with external systems. An embedded Swagger UI is available for exploring and testing the API.\n* **Easy deployment**: Harbor can be deployed via Docker compose as well Helm Chart, and a Harbor Operator was added recently as well.\n\n## Architecture\n\nFor learning the architecture design of Harbor, check the document [Architecture Overview of Harbor](https://github.com/goharbor/harbor/wiki/Architecture-Overview-of-Harbor).\n\n## API\n\n* Harbor RESTful API: The APIs for most administrative operations of Harbor and can be used to perform integrations with Harbor programmatically.\n * Part 1: [New or changed APIs](https://editor.swagger.io/?url=https://raw.githubusercontent.com/goharbor/harbor/main/api/v2.0/swagger.yaml)\n\n## Install & Run\n\n**System requirements:**\n\n**On a Linux host:** docker 17.06.0-ce+ and docker-compose 1.18.0+ .\n\nDownload binaries of **[Harbor release ](https://github.com/vmware/harbor/releases)** and follow **[Installation & Configuration Guide](https://goharbor.io/docs/latest/install-config/)** to install Harbor.\n\nIf you want to deploy Harbor on Kubernetes, please use the **[Harbor chart](https://github.com/goharbor/harbor-helm)**.\n\nRefer to the **[documentation](https://goharbor.io/docs/)** for more details on how to use Harbor.\n\n## OCI Distribution Conformance Tests\n\nCheck the OCI distribution conformance tests [report](https://storage.googleapis.com/harbor-conformance-test/report.html) of Harbor.\n\n## Compatibility\n\nThe [compatibility list](https://goharbor.io/docs/edge/install-config/harbor-compatibility-list/) document provides compatibility information for the Harbor components.\n\n* [Replication adapters](https://goharbor.io/docs/edge/install-config/harbor-compatibility-list/#replication-adapters)\n* [OIDC adapters](https://goharbor.io/docs/edge/install-config/harbor-compatibility-list/#oidc-adapters)\n* [Scanner adapters](https://goharbor.io/docs/edge/install-config/harbor-compatibility-list/#scanner-adapters)\n\n## Community\n\n* **Twitter:** [@project_harbor](https://twitter.com/project_harbor) \n* **User Group:** Join Harbor user email group: [harbor-users@lists.cncf.io](https://lists.cncf.io/g/harbor-users) to get update of Harbor's news, features, releases, or to provide suggestion and feedback. \n* **Developer Group:** Join Harbor developer group: [harbor-dev@lists.cncf.io](https://lists.cncf.io/g/harbor-dev) for discussion on Harbor development and contribution.\n* **Slack:** Join Harbor's community for discussion and ask questions: [Cloud Native Computing Foundation](https://slack.cncf.io/), channel: [#harbor](https://cloud-native.slack.com/messages/harbor/) and [#harbor-dev](https://cloud-native.slack.com/messages/harbor-dev/)\n\n## Demos\n\n* **[Live Demo](https://demo.goharbor.io)** - A demo environment with the latest Harbor stable build installed. For additional information please refer to [this page](https://goharbor.io/docs/latest/install-config/demo-server/).\n* **[Video Demos](https://github.com/goharbor/harbor/wiki/Video-demos-for-Harbor)** - Demos for Harbor features and continuously updated.\n\n## Partners and Users\n\nFor a list of users, please refer to [ADOPTERS.md](ADOPTERS.md).\n\n## Security\n\n### Security Audit\n\nA third party security audit was performed by Cure53 in October 2019. You can see the full report [here](https://goharbor.io/docs/2.0.0/security/Harbor_Security_Audit_Oct2019.pdf).\n\n### Reporting security vulnerabilities\n\nIf you've found a security related issue, a vulnerability, or a potential vulnerability in Harbor please let the [Harbor Security Team](mailto:cncf-harbor-security@lists.cncf.io) know with the details of the vulnerability. We'll send a confirmation\nemail to acknowledge your report, and we'll send an additional email when we've identified the issue\npositively or negatively.\n\nFor further details please see our complete [security release process](SECURITY.md).\n\n## License\n\nHarbor is available under the [Apache 2 license](LICENSE).\n\nThis project uses open source components which have additional licensing terms. The official docker images and licensing terms for these open source components can be found at the following locations:\n\n* Photon OS 1.0: [docker image](https://hub.docker.com/_/photon/), [license](https://github.com/vmware/photon/blob/master/COPYING)\n\n\n## Fossa Status\n\n[](https://app.fossa.com/projects/git%2Bgithub.com%2Fgoharbor%2Fharbor?ref=badge_large)",
- "source_links": [],
- "id": 52
- },
- {
- "page_link": "https://github.com/hasura/graphql-engine",
- "title": "hasura readme",
- "text": "# Hasura GraphQL Engine\n\n[](https://github.com/hasura/graphql-engine/releases/latest)\n[](https://hasura.io/docs)\n[](https://circleci.com/gh/hasura/graphql-engine)\n\n\n\n\n\n\nHasura GraphQL Engine is a blazing-fast GraphQL server that gives you **instant, realtime GraphQL APIs over Postgres**, with [**webhook triggers**](event-triggers.md) on database events, and [**remote schemas**](remote-schemas.md) for business logic.\n\nHasura helps you build [GraphQL](https://hasura.io/graphql/) apps backed by Postgres or incrementally move to GraphQL for existing applications using Postgres.\n\nRead more at [hasura.io](https://hasura.io) and the [docs](https://hasura.io/docs/).\n\n------------------\n\n\n\n------------------\n\n\n\n-------------------\n\n## Features\n\n* **Make powerful queries**: Built-in filtering, pagination, pattern search, bulk insert, update, delete mutations\n* **Realtime**: Convert any GraphQL query to a live query by using subscriptions\n* **Merge remote schemas**: Access custom GraphQL schemas for business logic via a single GraphQL Engine endpoint. [**Read more**](remote-schemas.md).\n* **Trigger webhooks or serverless functions**: On Postgres insert/update/delete events ([read more](event-triggers.md))\n* **Works with existing, live databases**: Point it to an existing Postgres database to instantly get a ready-to-use GraphQL API\n* **Fine-grained access control**: Dynamic access control that integrates with your auth system (eg: auth0, firebase-auth)\n* **High-performance & low-footprint**: ~15MB docker image; ~50MB RAM @ 1000 req/s; multi-core aware\n* **Admin UI & Migrations**: Admin UI & Rails-inspired schema migrations\n* **Postgres** \u2764\ufe0f: Supports Postgres types (PostGIS/geo-location, etc.), turns views to *graphs*, trigger stored functions or procedures with mutations\n\nRead more at [hasura.io](https://hasura.io) and the [docs](https://hasura.io/docs/).\n\n## Table of contents\n\n**Table of Contents**\n\n- [Quickstart:](#quickstart)\n - [One-click deployment on Hasura Cloud](#one-click-deployment-on-hasura-cloud)\n - [Other one-click deployment options](#other-one-click-deployment-options)\n - [Other deployment methods](#other-deployment-methods)\n- [Architecture](#architecture)\n- [Client-side tooling](#client-side-tooling)\n- [Add business logic](#add-business-logic)\n - [Remote schemas](#remote-schemas)\n - [Trigger webhooks on database events](#trigger-webhooks-on-database-events)\n- [Demos](#demos)\n - [Realtime applications](#realtime-applications)\n - [Videos](#videos)\n- [Support & Troubleshooting](#support--troubleshooting)\n- [Contributing](#contributing)\n- [Brand assets](#brand-assets)\n- [License](#license)\n- [Translations](#translations)\n\n\n\n## Quickstart:\n\n### One-click deployment on Hasura Cloud\n\nThe fastest and easiest way to try Hasura out is via [Hasura Cloud](https://hasura.io/docs/cloud/1.0/manual/getting-started/index.html).\n\n1. Click on the following button to deploy GraphQL engine on Hasura Cloud including Postgres add-on or using an existing Postgres database:\n\n [](https://cloud.hasura.io/)\n\n2. Open the Hasura console\n\n Click on the button \"Launch console\" to open the Hasura console.\n\n3. Make your first GraphQL query\n\n Create a table and instantly run your first query. Follow this [simple guide](https://hasura.io/docs/latest/graphql/core/getting-started/first-graphql-query.html).\n\n### Other one-click deployment options\n\nCheck out the instructions for the following one-click deployment options:\n\n| **Infra provider** | **One-click link** | **Additional information** |\n|:------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------:|\n| Heroku | [](https://heroku.com/deploy?template=https://github.com/hasura/graphql-engine-heroku) | [docs](https://hasura.io/docs/latest/graphql/core/guides/deployment/heroku-one-click.html) |\n| DigitalOcean | [](https://marketplace.digitalocean.com/apps/hasura?action=deploy&refcode=c4d9092d2c48&utm_source=hasura&utm_campaign=readme) | [docs](https://hasura.io/docs/latest/graphql/core/guides/deployment/digital-ocean-one-click.html#hasura-graphql-engine-digitalocean-one-click-app) |\n| Azure | [](https://portal.azure.com/#create/Microsoft.Template/uri/https%3a%2f%2fraw.githubusercontent.com%2fhasura%2fgraphql-engine%2fmaster%2finstall-manifests%2fazure-container-with-pg%2fazuredeploy.json) | [docs](https://hasura.io/docs/latest/graphql/core/guides/deployment/azure-container-instances-postgres.html) |\n| Render | [](https://render.com/deploy?repo=https://github.com/render-examples/hasura-graphql) | [docs](https://hasura.io/docs/latest/graphql/core/guides/deployment/render-one-click.html) |\n\n### Other deployment methods\n\nFor Docker-based deployment and advanced configuration options, see [deployment\nguides](https://hasura.io/docs/latest/graphql/core/getting-started/index.html) or\n[install manifests](install-manifests).\n\n## Architecture\n\nThe Hasura GraphQL Engine fronts a Postgres database instance and can accept GraphQL requests from your client apps. It can be configured to work with your existing auth system and can handle access control using field-level rules with dynamic variables from your auth system.\n\nYou can also merge remote GraphQL schemas and provide a unified GraphQL API.\n\n\n\n## Client-side tooling\n\nHasura works with any GraphQL client. We recommend using [Apollo Client](https://github.com/apollographql/apollo-client). See [awesome-graphql](https://github.com/chentsulin/awesome-graphql) for a list of clients.\n\n## Add business logic\n\nGraphQL Engine provides easy-to-reason, scalable and performant methods for adding custom business logic to your backend:\n\n### Remote schemas\n\nAdd custom resolvers in a remote schema in addition to Hasura's Postgres-based GraphQL schema. Ideal for use-cases like implementing a payment API, or querying data that is not in your database - [read more](remote-schemas.md).\n\n### Trigger webhooks on database events\n\nAdd asynchronous business logic that is triggered based on database events.\nIdeal for notifications, data-pipelines from Postgres or asynchronous\nprocessing - [read more](event-triggers.md).\n\n### Derived data or data transformations\n\nTransform data in Postgres or run business logic on it to derive another dataset that can be queried using GraphQL Engine - [read more](https://hasura.io/docs/latest/graphql/core/queries/derived-data.html).\n\n## Demos\n\nCheck out all the example applications in the [community/sample-apps](community/sample-apps) directory.\n\n### Realtime applications\n\n- Group Chat application built with React, includes a typing indicator, online users & new\n message notifications.\n - [Try it out](https://realtime-chat.demo.hasura.app/)\n - [Tutorial](community/sample-apps/realtime-chat)\n - [Browse APIs](https://realtime-chat.demo.hasura.app/console)\n\n- Live location tracking app that shows a running vehicle changing current GPS\n coordinates moving on a map.\n - [Try it out](https://realtime-location-tracking.demo.hasura.app/)\n - [Tutorial](community/sample-apps/realtime-location-tracking)\n - [Browse APIs](https://realtime-location-tracking.demo.hasura.app/console)\n\n- A realtime dashboard for data aggregations on continuously changing data.\n - [Try it out](https://realtime-poll.demo.hasura.app/)\n - [Tutorial](community/sample-apps/realtime-poll)\n - [Browse APIs](https://realtime-poll.demo.hasura.app/console)\n\n### Videos\n\n* [Add GraphQL to a self-hosted GitLab instance](https://www.youtube.com/watch?v=a2AhxKqd82Q) (*3:44 mins*)\n* [Todo app with Auth0 and GraphQL backend](https://www.youtube.com/watch?v=15ITBYnccgc) (*4:00 mins*)\n* [GraphQL on GitLab integrated with GitLab auth](https://www.youtube.com/watch?v=m1ChRhRLq7o) (*4:05 mins*)\n* [Dashboard for 10million rides with geo-location (PostGIS, Timescale)](https://www.youtube.com/watch?v=tsY573yyGWA) (*3:06 mins*)\n\n\n## Support & Troubleshooting\n\nThe documentation and community will help you troubleshoot most issues. If you have encountered a bug or need to get in touch with us, you can contact us using one of the following channels:\n\n* Support & feedback: [Discord](https://discord.gg/hasura)\n* Issue & bug tracking: [GitHub issues](https://github.com/hasura/graphql-engine/issues)\n* Follow product updates: [@HasuraHQ](https://twitter.com/hasurahq)\n* Talk to us on our [website chat](https://hasura.io)\n\nWe are committed to fostering an open and welcoming environment in the community. Please see the [Code of Conduct](code-of-conduct.md).\n\nIf you want to report a security issue, please [read this](SECURITY.md).\n\n## Contributing\n\nCheck out our [contributing guide](CONTRIBUTING.md) for more details.\n\n## Brand assets\n\nHasura brand assets (logos, the Hasura mascot, powered by badges etc.) can be\nfound in the [assets/brand](assets/brand) folder. Feel free to use them in your\napplication/website etc. We'd be thrilled if you add the \"Powered by Hasura\"\nbadge to your applications built using Hasura. \u2764\ufe0f\n\n
\n \n \n
\n\n```html\n\n\n \n\n\n\n\n \n\n```\n\n## License\n\nThe core GraphQL Engine is available under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0) (Apache-2.0).\n\nAll **other contents** (except those in [`server`](server), [`cli`](cli) and\n[`console`](console) directories) are available under the [MIT License](LICENSE-community).\nThis includes everything in the [`docs`](docs) and [`community`](community)\ndirectories.\n\n## Translations\n\nThis readme is available in the following translations:\n\n- [Japanese :jp:](translations/README.japanese.md) (:pray: [@moksahero](https://github.com/moksahero))\n- [French :fr:](translations/README.french.md) (:pray: [@l0ck3](https://github.com/l0ck3))\n- [Bosnian :bosnia_herzegovina:](translations/README.bosnian.md) (:pray: [@hajro92](https://github.com/hajro92))\n- [Russian :ru:](translations/README.russian.md) (:pray: [@highflyer910](https://github.com/highflyer910))\n- [Greek \ud83c\uddec\ud83c\uddf7](translations/README.greek.md) (:pray: [@MIP2000](https://github.com/MIP2000))\n- [Spanish \ud83c\uddf2\ud83c\uddfd](/translations/README.mx_spanish.md)(:pray: [@ferdox2](https://github.com/ferdox2))\n- [Indonesian :indonesia:](translations/README.indonesian.md) (:pray: [@anwari666](https://github.com/anwari666))\n- [Brazilian Portuguese :brazil:](translations/README.portuguese_br.md) (:pray: [@rubensmp](https://github.com/rubensmp))\n- [German \ud83c\udde9\ud83c\uddea](translations/README.german.md) (:pray: [@FynnGrandke](https://github.com/FynnGrandke))\n- [Chinese :cn:](translations/README.chinese.md) (:pray: [@jagreetdg](https://github.com/jagreetdg) & [@johnbanq](https://github.com/johnbanq))\n- [Turkish :tr:](translations/README.turkish.md) (:pray: [@berat](https://github.com/berat))\n- [Korean :kr:](translations/README.korean.md) (:pray: [@\ub77c\uc2a4\ud06c](https://github.com/laskdjlaskdj12))\n\nTranslations for other files can be found [here](translations).\n",
- "source_links": [],
- "id": 53
- },
- {
- "page_link": "https://github.com/segmentio/ory-hydra",
- "title": "hydra readme",
- "text": "# \n\n[](https://gitter.im/ory-am/hydra?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)\n[](http://eepurl.com/bKT3N9)\n[](https://twitter.com/_aeneasr)\n[](https://github.com/arekkas)\n[](https://patreon.com/user?u=4298803)\n\n[](https://travis-ci.org/ory/hydra)\n[](https://coveralls.io/github/ory/hydra?branch=master)\n[](https://codeclimate.com/github/ory/hydra)\n[](https://goreportcard.com/report/github.com/ory/hydra)\n[](https://bestpractices.coreinfrastructure.org/projects/364)\n\n[](https://ory.gitbooks.io/hydra/content/)\n[](http://docs.hydra13.apiary.io/)\n[](https://godoc.org/github.com/ory/hydra)\n\nORY Hydra offers OAuth 2.0 and OpenID Connect Core 1.0 capabilities as a service and is built on top of the security-first\nOAuth2 and OpenID Connect SDK [ORY Fosite](https://github.com/ory/fosite) and the access control\nSDK [ORY Ladon](https://github.com/ory/ladon). ORY Hydra is different, because it works with\nany existing authentication infrastructure, not just LDAP or SAML. By implementing a consent app (works with any programming language)\nyou build a bridge between ORY Hydra and your authentication infrastructure.\n\nORY Hydra is able to securely manage JSON Web Keys, and has a sophisticated policy-based access control you can use if you want to.\n\nORY Hydra is suitable for green- (new) and brownfield (existing) projects. If you are not familiar with OAuth 2.0 and are working\non a greenfield project, we recommend evaluating if OAuth 2.0 really serves your purpose.\n**Knowledge of OAuth 2.0 is imperative in understanding what ORY Hydra does and how it works.**\n\nJoin the [ORY Hydra Newsletter](http://eepurl.com/bKT3N9) to stay on top of new developments. ORY Hydra has a lovely, active\ncommunity on [Gitter](https://gitter.im/ory-am/hydra). For advanced use cases, check out the\n[Enterprise Edition](#enterprise-edition) section.\n\n---\n\n\n\n**Table of Contents**\n\n- [What is ORY Hydra?](#what-is-ory-hydra)\n - [ORY Hydra implements open standards](#ory-hydra-implements-open-standards)\n- [Sponsors & Adopters](#sponsors-&-adopters)\n - [Sponsors](#sponsors)\n - [Adopters](#adopters)\n- [ORY Hydra for Enterprise](#ory-hydra-for-enterprise)\n- [Quickstart](#quickstart)\n - [5 minutes tutorial: Run your very own OAuth2 environment](#5-minutes-tutorial-run-your-very-own-oauth2-environment)\n - [Installation](#installation)\n - [Download binaries](#download-binaries)\n - [Using Docker](#using-docker)\n - [Building from source](#building-from-source)\n- [Security](#security)\n- [Telemetry](#telemetry)\n- [Documentation](#documentation)\n - [Guide](#guide)\n - [HTTP API documentation](#http-api-documentation)\n - [Command line documentation](#command-line-documentation)\n - [Develop](#develop)\n- [Reception](#reception)\n- [Libraries and third-party projects](#libraries-and-third-party-projects)\n- [Blog posts & articles](#blog-posts-&-articles)\n\n\n\n## What is ORY Hydra?\n\nORY Hydra is a server implementation of the OAuth 2.0 authorization framework and the OpenID Connect Core 1.0. Existing OAuth2\nimplementations usually ship as libraries or SDKs such as [node-oauth2-server](https://github.com/oauthjs/node-oauth2-server)\nor [fosite](https://github.com/ory/fosite/issues), or as fully featured identity solutions with user\nmanagement and user interfaces, such as [Dex](https://github.com/coreos/dex).\n\nImplementing and using OAuth2 without understanding the whole specification is challenging and prone to errors, even when\nSDKs are being used. The primary goal of ORY Hydra is to make OAuth 2.0 and OpenID Connect 1.0 better accessible.\n\nORY Hydra implements the flows described in OAuth2 and OpenID Connect 1.0 without forcing you to use a \"Hydra User Management\"\nor some template engine or a predefined front-end. Instead it relies on HTTP redirection and cryptographic methods\nto verify user consent allowing you to use ORY Hydra with any authentication endpoint, be it [authboss](https://github.com/go-authboss/authboss),\n[auth0.com](https://auth0.com/) or your proprietary PHP authentication.\n\n### ORY Hydra implements open standards\n\nORY Hydra implements Open Standards set by the IETF:\n\n* [The OAuth 2.0 Authorization Framework](https://tools.ietf.org/html/rfc6749)\n* [OAuth 2.0 Threat Model and Security Considerations](https://tools.ietf.org/html/rfc6819)\n* [OAuth 2.0 Token Revocation](https://tools.ietf.org/html/rfc7009)\n* [OAuth 2.0 Token Introspection](https://tools.ietf.org/html/rfc7662)\n* [OAuth 2.0 Dynamic Client Registration Protocol](https://tools.ietf.org/html/rfc7591)\n* [OAuth 2.0 Dynamic Client Registration Management Protocol](https://tools.ietf.org/html/rfc7592)\n* [OAuth 2.0 for Native Apps](https://tools.ietf.org/html/draft-ietf-oauth-native-apps-10)\n\nand the OpenID Foundation:\n\n* [OpenID Connect Core 1.0](http://openid.net/specs/openid-connect-core-1_0.html)\n* [OpenID Connect Discovery 1.0](https://openid.net/specs/openid-connect-discovery-1_0.html)\n\n## Sponsors & Adopters\n\nThis is a cureated list of Hydra sponsors and adopters. If you want to be on this list, [contact us](mailto:hi@ory.am).\n\n### Sponsors\n\n\n\nWe are proud to have [Auth0](https://auth0.com) as a **gold sponsor** for ORY Hydra. [Auth0](https://auth0.com) solves\nthe most complex identity use cases with an extensible and easy to integrate platform that secures billions of logins\nevery year. At ORY, we use [Auth0](https://auth0.com) in conjunction with ORY Hydra for various internal projects.\n\n \n\n### Adopters\n\nORY Hydra is battle-tested in production systems. This is a curated list of ORY Hydra adopters.\n\n \n\n
Arduino is an open-source electronics platform based on easy-to-use hardware and software. It's intended\nfor anyone making interactive projects. ORY Hydra secures Arduino's developer platform.
\n\n \n\n## ORY Hydra for Enterprise\n\nORY Hydra is available as an Apache 2.0-licensed Open Source technology. In enterprise environments however,\nthere are numerous demands, such as\n\n* OAuth 2.0 and OpenID Connect consulting.\n* security auditing and certification.\n* auditable log trails.\n* guaranteed performance metrics, such as throughput per second.\n* management user interfaces.\n* ... and a wide range of narrow use cases specific to each business demands.\n\nGain access to more features and our security experts with ORY Hydra for Enterprise! [Request details now!](https://docs.google.com/forms/d/e/1FAIpQLSf53GJwQxzIatTSEM7sXhpkWRh6kddKxzNfNAQ9GsLNEfuFRA/viewform)\n\n## Quickstart\n\nThis section is a quickstart guide to working with ORY Hydra. In-depth docs are available as well:\n\n* The documentation is available on [GitBook](https://ory.gitbooks.io/hydra/content/).\n* The REST API documentation is available at [Apiary](http://docs.hydra13.apiary.io/).\n\n### 5 minutes tutorial: Run your very own OAuth2 environment\n\nThe **[tutorial](https://ory.gitbooks.io/hydra/content/tutorial.html)** teaches you to set up ORY Hydra,\na Postgres instance and an exemplary identity provider written in React using docker compose.\nIt will take you about 5 minutes to complete the **[tutorial](https://ory.gitbooks.io/hydra/content/tutorial.html)**.\n\n\n\n \n\n### Installation\n\nThere are various ways of installing ORY Hydra on your system.\n\n#### Download binaries\n\nThe client and server **binaries are downloadable at [releases](https://github.com/ory/hydra/releases)**.\nThere is currently no installer available. You have to add the ORY Hydra binary to the PATH environment variable yourself or put\nthe binary in a location that is already in your path (`/usr/bin`, ...). \nIf you do not understand what that all of this means, ask in our [chat channel](https://gitter.im/ory-am/hydra). We are happy to help.\n\n#### Using Docker\n\n**Starting the host** is easiest with docker. The host process handles HTTP requests and is backed by a database.\nRead how to install docker on [Linux](https://docs.docker.com/linux/), [OSX](https://docs.docker.com/mac/) or\n[Windows](https://docs.docker.com/windows/). ORY Hydra is available on [Docker Hub](https://hub.docker.com/r/oryd/hydra/).\n\nYou can use ORY Hydra without a database, but be aware that restarting, scaling\nor stopping the container will **lose all data**:\n\n```\n$ docker run -e \"DATABASE_URL=memory\" -d --name my-hydra -p 4444:4444 oryd/hydra\nec91228cb105db315553499c81918258f52cee9636ea2a4821bdb8226872f54b\n```\n\n*Note: We had to create a new docker hub repository. Tags prior to 0.7.5 are available [here](https://hub.docker.com/r/ory-am/hydra/).*\n\n**Using the client command line interface:** You can ssh into the ORY Hydra container\nand execute the ORY Hydra command from there:\n\n```\n$ docker exec -i -t /bin/bash\n# e.g. docker exec -i -t ec91228 /bin/bash\n\nroot@ec91228cb105:/go/src/github.com/ory/hydra# hydra\nHydra is a twelve factor OAuth2 and OpenID Connect provider\n\n[...]\n```\n\n#### Building from source\n\nIf you wish to compile ORY Hydra yourself, you need to install and set up [Go 1.8+](https://golang.org/) and add `$GOPATH/bin`\nto your `$PATH`. To do so, run the following commands in a shell (bash, sh, cmd.exe, ...):\n\n```\ngo get -d -u github.com/ory/hydra\ngo get github.com/Masterminds/glide\ncd $GOPATH/src/github.com/ory/hydra\nglide install\ngo install github.com/ory/hydra\nhydra\n```\n\n**Notes**\n\n* We changed organization name from `ory-am` to `ory`. In order to keep backwards compatibility, we did not rename Go packages.\n* You can ignore warnings similar to `package github.com/ory/hydra/cmd/server: case-insensitive import collision: \"github.com/Sirupsen/logrus\" and \"github.com/sirupsen/logrus\"`.\n\n## Security\n\n*Why should I use ORY Hydra? It's not that hard to implement two OAuth2 endpoints and there are numerous SDKs out there!*\n\nOAuth2 and OAuth2 related specifications are over 400 written pages. Implementing OAuth2 is easy, getting it right is hard.\nORY Hydra is trusted by companies all around the world, has a vibrant community and faces millions of requests in production\neach day. Of course, we also compiled a security guide with more details on cryptography and security concepts.\nRead [the security guide now](https://ory.gitbooks.io/hydra/content/security.html).\n\n## Telemetry\n\nORY Hydra collects summarized, anonymized telemetry which can optionally be turned off. Click [here](https://ory.gitbooks.io/hydra/content/telemetry.html)\nto learn more.\n\n## Documentation\n\n### Guide\n\nThe Guide is available on [GitBook](https://ory.gitbooks.io/hydra/content/).\n\n### HTTP API documentation\n\nThe HTTP API is documented at [Apiary](http://docs.hydra13.apiary.io/).\n\n### Command line documentation\n\nRun `hydra -h` or `hydra help`.\n\n### Develop\n\nDeveloping with ORY Hydra is as easy as:\n\n```\ngo get -d -u github.com/ory/hydra\ngo get github.com/Masterminds/glide\ncd $GOPATH/src/github.com/ory/hydra\nglide install\ngo test $(glide novendor)\n```\n\nThen run it with in-memory database:\n\n```\nDATABASE_URL=memory go run main.go host\n```\n\n**Notes**\n\n* We changed organization name from `ory-am` to `ory`. In order to keep backwards compatibility, we did not rename Go packages.\n* You can ignore warnings similar to `package github.com/ory/hydra/cmd/server: case-insensitive import collision: \"github.com/Sirupsen/logrus\" and \"github.com/sirupsen/logrus\"`.\n\n## Reception\n\nHydra has received a lot of positive feedback. Let's see what the community is saying:\n\n> Nice! Lowering barriers to the use of technologies like these is important.\n\n[Pyxl101](https://news.ycombinator.com/item?id=11798641)\n\n> OAuth is a framework not a protocol. The security it provides can vary greatly between implementations.\nFosite (which is what this is based on) is a very good implementation from a security perspective: https://github.com/ory/fosite#a-word-on-security\n\n[abritishguy](https://news.ycombinator.com/item?id=11800515)\n\n> [...] Thanks for releasing this by the way, looks really well engineered. [...]\n\n## Libraries and third-party projects\n\nOfficial:\n* [Consent App SDK For NodeJS](https://github.com/ory/hydra-js)\n* [Consent App Example written in Go](https://github.com/ory/hydra-consent-app-go)\n* [Exemplary Consent App with Express and NodeJS](https://github.com/ory/hydra-consent-app-express)\n\nCommunity:\n* [Consent App SDK for Go](https://github.com/janekolszak/idp)\n* [ORY Hydra middleware for Gin](https://github.com/janekolszak/gin-hydra)\n* [Kubernetes helm chart](https://github.com/kubernetes/charts/pull/1022)\n\n## Blog posts & articles\n\n* [Creating an oauth2 custom lamda authorizer for use with Amazons (AWS) API Gateway using Hydra](https://blogs.edwardwilde.com/2017/01/12/creating-an-oauth2-custom-lamda-authorizer-for-use-with-amazons-aws-api-gateway-using-hydra/)\n* Warning, ORY Hydra has changed almost everything since writing this\narticle: [Hydra: Run your own Identity and Access Management service in <5 Minutes](https://blog.gopheracademy.com/advent-2015/hydra-auth/)\n",
- "source_links": [],
- "id": 54
- },
- {
- "page_link": "https://github.com/imgproxy/imgproxy",
- "title": "imgproxy readme",
- "text": "
\n\n---\n\n[imgproxy](https://imgproxy.net) is a fast and secure standalone server for resizing and converting remote images. The guiding principles behind imgproxy are security, speed, and simplicity.\n\nimgproxy is able to quickly and easily resize images on the fly, and it's well-equipped to handle a large amount of image resizing. imgproxy is a fast, secure replacement for all the image resizing code inside your web application (such as resizing libraries, or code that calls ImageMagick or GraphicsMagic). It's also an indispensable tool for processing images from a remote source. With imgproxy, you don\u2019t need to repeatedly prepare images to fit your design every time it changes.\n\nTo get an even better introduction, and to dive deeper into the nitty gritty details, check out this article: [imgproxy: Resize your images instantly and securely](https://evilmartians.com/chronicles/introducing-imgproxy)\n\n\n \n \n \n \n\n\n#### Simplicity\n\n> \"No code is better than no code.\"\n\nimgproxy only includes the must-have features for image processing, fine-tuning and security. Specifically,\n\n* It would be great to be able to rotate, flip and apply masks to images, but in most of the cases, it is possible \u2014 and is much easier \u2014 to do that using CSS3.\n* It may be great to have built-in HTTP caching of some kind, but it is way better to use a Content-Delivery Network or a caching proxy server for this, as you will have to do this sooner or later in the production environment.\n* It might be useful to have everything built in \u2014 such as HTTPS support \u2014 but an easy way to solve that would be just to use a proxying HTTP server such as nginx.\n\n#### Speed\n\nimgproxy takes advantage of probably the most efficient image processing library out there \u2013 `libvips`. It\u2019s scary fast and comes with a very low memory footprint. Thanks to libvips, we can readily and extemporaneously process a massive amount of images.\n\nimgproxy uses Go\u2019s raw (no wrappers) native `net/http` package to omit any overhead while processing requests and provides the best possible HTTP support.\n\nYou can take a look at some benchmarking results and compare imgproxy with some well-known alternatives in our [benchmark report](https://github.com/imgproxy/imgproxy/blob/master/BENCHMARK.md).\n\n#### Security\n\nIn terms of security, the massive processing of remote images is a potentially dangerous endeavor. There are a number of possible attack vectors, so it\u2019s a good idea to take an approach that considers attack prevention measures as a priority. Here\u2019s how imgproxy does this:\n\n* imgproxy checks the image type and its \u201creal\u201d dimensions when downloading. The image will not be fully downloaded if it has an unknown format or if the dimensions are too big (you can set the max allowed dimensions). This is how imgproxy protects from so called \"image bombs\u201d, like those described in [this doc](https://www.bamsoftware.com/hacks/deflate.html).\n\n* imgproxy protects image URLs with a signature, so an attacker cannot enact a denial-of-service attack by requesting multiple image resizes.\n\n* imgproxy supports authorization by HTTP header. This prevents imgproxy from being used directly by an attacker, but allows it to be used via a CDN or a caching server \u2014 simply by adding a header to a proxy or CDN config.\n\n## Usage\n\nCheck out our \ud83d\udcd1 [Documentation](https://docs.imgproxy.net).\n\n## Author\n\nSergey \"[DarthSim](https://github.com/DarthSim)\" Alexandrovich\n\n## Special thanks\n\nMany thanks to:\n\n* [Roman Shamin](https://github.com/romashamin) for the awesome logo.\n* [Alena Kirdina](https://github.com/egodyston) and [Alexander Madyankin](https://github.com/madyankin) for the great website.\n* [John Cupitt](https://github.com/jcupitt) for developing [libvips](https://github.com/libvips/libvips) and for helping me optimize its usage with imgproxy.\n* [Kirill Kuznetsov](https://github.com/dragonsmith) for the [Helm chart](https://github.com/imgproxy/imgproxy-helm).\n* [Travis Turner](https://github.com/Travis-Turner) for keeping the documentation in good shape.\n\n## License\n\nimgproxy is licensed under the MIT license.\n\nSee [LICENSE](https://github.com/imgproxy/imgproxy/blob/master/LICENSE) for the full license text.\n\n## Security Contact\n\nTo report a security vulnerability, please contact us at security@imgproxy.net. We will coordinate the fix and disclosure.\n",
- "source_links": [],
- "id": 55
- },
- {
- "page_link": "https://github.com/influxdata/influxdb",
- "title": "influx readme",
- "text": "# InfluxDB\n
\n\n---\n\nInfluxDB is an open source time series platform. This includes APIs for storing and querying data, processing it in the background for ETL or monitoring and alerting purposes, user dashboards, and visualizing and exploring the data and more. The master branch on this repo now represents the latest InfluxDB, which now includes functionality for Kapacitor (background processing) and Chronograf (the UI) all in a single binary.\n\nThe list of InfluxDB Client Libraries that are compatible with the latest version can be found in [our documentation](https://docs.influxdata.com/influxdb/latest/tools/client-libraries/).\n\nIf you are looking for the 1.x line of releases, there are branches for each minor version as well as a `master-1.x` branch that will contain the code for the next 1.x release. The master-1.x [working branch is here](https://github.com/influxdata/influxdb/tree/master-1.x). The [InfluxDB 1.x Go Client can be found here](https://github.com/influxdata/influxdb1-client).\n\n| Try **InfluxDB Cloud** for free and get started fast with no local setup required. Click [**here**](https://cloud2.influxdata.com/signup) to start building your application on InfluxDB Cloud. |\n|:------|\n\n## Install\n\nWe have nightly and versioned Docker images, Debian packages, RPM packages, and tarballs of InfluxDB available at the [InfluxData downloads page](https://portal.influxdata.com/downloads/). We also provide the `influx` command line interface (CLI) client as a separate binary available at the same location.\n\nIf you are interested in building from source, see the [building from source](CONTRIBUTING.md#building-from-source) guide for contributors.\n\n\n \n\n\n## Get Started\n\nFor a complete getting started guide, please see our full [online documentation site](https://docs.influxdata.com/influxdb/latest/).\n\nTo write and query data or use the API in any way, you'll need to first create a user, credentials, organization and bucket.\nEverything in InfluxDB is organized under a concept of an organization. The API is designed to be multi-tenant.\nBuckets represent where you store time series data.\nThey're synonymous with what was previously in InfluxDB 1.x a database and retention policy.\n\nThe simplest way to get set up is to point your browser to [http://localhost:8086](http://localhost:8086) and go through the prompts.\n\nYou can also get set up from the CLI using the command `influx setup`:\n\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup\nWelcome to InfluxDB 2.0!\nPlease type your primary username: marty\n\nPlease type your password:\n\nPlease type your password again:\n\nPlease type your primary organization name.: InfluxData\n\nPlease type your primary bucket name.: telegraf\n\nPlease type your retention period in hours.\nOr press ENTER for infinite.: 72\n\n\nYou have entered:\n Username: marty\n Organization: InfluxData\n Bucket: telegraf\n Retention Period: 72 hrs\nConfirm? (y/n): y\n\nUserID Username Organization Bucket\n033a3f2c5ccaa000 marty InfluxData Telegraf\nYour token has been stored in /Users/marty/.influxdbv2/credentials\n```\n\nYou can run this command non-interactively using the `-f, --force` flag if you are automating the setup.\nSome added flags can help:\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup \\\n--username marty \\\n--password F1uxKapacit0r85 \\\n--org InfluxData \\\n--bucket telegraf \\\n--retention 168 \\\n--token where-were-going-we-dont-need-roads \\\n--force\n```\n\nOnce setup is complete, a configuration profile is created to allow you to interact with your local InfluxDB without passing in credentials each time. You can list and manage those profiles using the `influx config` command.\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx config\nActive\tName\tURL\t\t\t Org\n*\t default\thttp://localhost:8086\tInfluxData\n```\n\n## Write Data\nWrite to measurement `m`, with tag `v=2`, in bucket `telegraf`, which belongs to organization `InfluxData`:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket telegraf --precision s \"m v=2 $(date +%s)\"\n```\n\nSince you have a default profile set up, you can omit the Organization and Token from the command.\n\nWrite the same point using `curl`:\n\n```bash\ncurl --header \"Authorization: Token $(bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx auth list --json | jq -r '.[0].token')\" \\\n--data-raw \"m v=2 $(date +%s)\" \\\n\"http://localhost:8086/api/v2/write?org=InfluxData&bucket=telegraf&precision=s\"\n```\n\nRead that back with a simple Flux query:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx query 'from(bucket:\"telegraf\") |> range(start:-1h)'\nResult: _result\nTable: keys: [_start, _stop, _field, _measurement]\n _start:time _stop:time _field:string _measurement:string _time:time _value:float\n------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------\n2019-12-30T22:19:39.043918000Z 2019-12-30T23:19:39.043918000Z v m 2019-12-30T23:17:02.000000000Z 2\n```\n\nUse the `-r, --raw` option to return the raw flux response from the query. This is useful for moving data from one instance to another as the `influx write` command can accept the Flux response using the `--format csv` option.\n\n## Script with Flux\n\nFlux (previously named IFQL) is an open source functional data scripting language designed for querying, analyzing, and acting on data. Flux supports multiple data source types, including:\n\n- Time series databases (such as InfluxDB)\n- Relational SQL databases (such as MySQL and PostgreSQL)\n- CSV\n\nThe source for Flux is [available on GitHub](https://github.com/influxdata/flux).\nTo learn more about Flux, see the latest [InfluxData Flux documentation](https://docs.influxdata.com/flux/) and [CTO Paul Dix's presentation](https://speakerdeck.com/pauldix/flux-number-fluxlang-a-new-time-series-data-scripting-language).\n\n## Contribute to the Project\n\nInfluxDB is an [MIT licensed](LICENSE) open source project and we love our community. The fastest way to get something fixed is to open a PR. Check out our [contributing](CONTRIBUTING.md) guide if you're interested in helping out. Also, join us on our [Community Slack Workspace](https://influxdata.com/slack) if you have questions or comments for our engineering teams.\n\n## CI and Static Analysis\n\n### CI\n\nAll pull requests will run through CI, which is currently hosted by Circle.\nCommunity contributors should be able to see the outcome of this process by looking at the checks on their PR.\nPlease fix any issues to ensure a prompt review from members of the team.\n\nThe InfluxDB project is used internally in a number of proprietary InfluxData products, and as such, PRs and changes need to be tested internally.\nThis can take some time, and is not really visible to community contributors.\n\n### Static Analysis\n\nThis project uses the following static analysis tools.\nFailure during the running of any of these tools results in a failed build.\nGenerally, code must be adjusted to satisfy these tools, though there are exceptions.\n\n- [go vet](https://golang.org/cmd/vet/) checks for Go code that should be considered incorrect.\n- [go fmt](https://golang.org/cmd/gofmt/) checks that Go code is correctly formatted.\n- [go mod tidy](https://tip.golang.org/cmd/go/#hdr-Add_missing_and_remove_unused_modules) ensures that the source code and go.mod agree.\n- [staticcheck](https://staticcheck.io/docs/) checks for things like: unused code, code that can be simplified, code that is incorrect and code that will have performance issues.\n\n### staticcheck\n\nIf your PR fails `staticcheck` it is easy to dig into why it failed, and also to fix the problem.\nFirst, take a look at the error message in Circle under the `staticcheck` build section, e.g.,\n\n```\ntsdb/tsm1/encoding.gen.go:1445:24: func BooleanValues.assertOrdered is unused (U1000)\ntsdb/tsm1/encoding.go:172:7: receiver name should not be an underscore, omit the name if it is unused (ST1006)\n```\n\nNext, go and take a [look here](http://next.staticcheck.io/docs/checks) for some clarification on the error code that you have received, e.g., `U1000`.\nThe docs will tell you what's wrong, and often what you need to do to fix the issue.\n\n#### Generated Code\n\nSometimes generated code will contain unused code or occasionally that will fail a different check.\n`staticcheck` allows for [entire files](http://next.staticcheck.io/docs/#ignoring-problems) to be ignored, though it's not ideal.\nA linter directive, in the form of a comment, must be placed within the generated file.\nThis is problematic because it will be erased if the file is re-generated.\nUntil a better solution comes about, below is the list of generated files that need an ignores comment.\nIf you re-generate a file and find that `staticcheck` has failed, please see this list below for what you need to put back:\n\n| File | Comment |\n| :--------------------: | :--------------------------------------------------------------: |\n| query/promql/promql.go | //lint:file-ignore SA6001 Ignore all unused code, it's generated |\n\n#### End-to-End Tests\n\nCI also runs end-to-end tests. These test the integration between the `influxd` server the UI.\nSince the UI is used by interal repositories as well as the `influxdb` repository, the\nend-to-end tests cannot be run on forked pull requests or run locally. The extent of end-to-end\ntesting required for forked pull requests will be determined as part of the review process.\n\n## Additional Resources\n- [InfluxDB Tips and Tutorials](https://www.influxdata.com/blog/category/tech/influxdb/)\n- [InfluxDB Essentials Course](https://university.influxdata.com/courses/influxdb-essentials-tutorial/)\n- [Exploring InfluxDB Cloud Course](https://university.influxdata.com/courses/exploring-influxdb-cloud-tutorial/)",
- "source_links": [],
- "id": 56
- },
- {
- "page_link": "https://github.com/kubernetes/ingress-nginx",
- "title": "ingress-nginx readme",
- "text": "# Ingress NGINX Controller\n\n[](https://bestpractices.coreinfrastructure.org/projects/5691)\n[](https://goreportcard.com/report/github.com/kubernetes/ingress-nginx)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n[](https://github.com/kubernetes/ingress-nginx/stargazers)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md)\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fkubernetes%2Fingress-nginx?ref=badge_shield)\n\nPlease fill out our 2022 Ingress-Nginx User Survey and let us know what you want to see in future releases.\n\nhttps://www.surveymonkey.com/r/ingressngx2022\n\n## Overview\n\ningress-nginx is an Ingress controller for Kubernetes using [NGINX](https://www.nginx.org/) as a reverse proxy and load balancer.\n\n[Learn more about Ingress on the main Kubernetes documentation site](https://kubernetes.io/docs/concepts/services-networking/ingress/).\n\n## Get started\n\nSee the [Getting Started](https://kubernetes.github.io/ingress-nginx/deploy/) document.\n\n## Troubleshooting\n\nIf you encounter issues, review the [troubleshooting docs](docs/troubleshooting.md), [file an issue](https://github.com/kubernetes/ingress-nginx/issues), or talk to us on the [#ingress-nginx channel](https://kubernetes.slack.com/messages/ingress-nginx) on the Kubernetes Slack server.\n\n## Changelog\n\nSee [the list of releases](https://github.com/kubernetes/ingress-nginx/releases) to find out about feature changes.\nFor detailed changes for each release; please check the [Changelog.md](Changelog.md) file.\nFor detailed changes on the `ingress-nginx` helm chart, please check the following [CHANGELOG.md](charts/ingress-nginx/CHANGELOG.md) file.\n\n### Support Versions table \n\n| Ingress-NGINX version | k8s supported version | Alpine Version | Nginx Version |\n|-----------------------|------------------------------|----------------|---------------|\n| v1.3.1 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.2 | 1.19.10\u2020 |\n| v1.3.0 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.0 | 1.19.10\u2020 |\n| v1.2.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.6 | 1.19.10\u2020 |\n| v1.1.3 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.4 | 1.19.10\u2020 |\n| v1.1.2 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.0 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.5 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.4 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.3 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.2 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.1 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.0 | 1.22, 1.21, 1.20, 1.19 | 3.13.5 | 1.20.1 |\n\n\n\u2020 _This build is [patched against CVE-2021-23017](https://github.com/openresty/openresty/commit/4b5ec7edd78616f544abc194308e0cf4b788725b#diff-42ef841dc27fe0b5aa2d06bd31308bb63a59cdcddcbcddd917248349d22020a3)._\n\nSee [this article](https://kubernetes.io/blog/2021/07/26/update-with-ingress-nginx/) if you want upgrade to the stable Ingress API. \n\n## Get Involved\n\nThanks for taking the time to join our community and start contributing!\n\n- This project adheres to the [Kubernetes Community Code of Conduct](https://git.k8s.io/community/code-of-conduct.md). By participating in this project, you agree to abide by its terms.\n\n- **Contributing**: Contributions of all kind are welcome!\n \n - Read [`CONTRIBUTING.md`](CONTRIBUTING.md) for information about setting up your environment, the workflow that we expect, and instructions on the developer certificate of origin that we require.\n\n - Join our Kubernetes Slack channel for developer discussion : [#ingress-nginx-dev](https://kubernetes.slack.com/archives/C021E147ZA4).\n \n - Submit github issues for any feature enhancements, bugs or documentation problems. Please make sure to read the [Issue Reporting Checklist](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md#issue-reporting-guidelines) before opening an issue. Issues not conforming to the guidelines **may be closed immediately**.\n\n- **Support**: Join the [#ingress-nginx-users](https://kubernetes.slack.com/messages/CANQGM8BA/) channel inside the [Kubernetes Slack](http://slack.kubernetes.io/) to ask questions or get support from the maintainers and other users.\n \n - The [GitHub issues](https://github.com/kubernetes/ingress-nginx/issues) in the repository are **exclusively** for bug reports and feature requests.\n\n- **Discuss**: Tweet using the `#IngressNginx` hashtag.\n\n## License\n\n[Apache License 2.0](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n",
- "source_links": [],
- "id": 57
- },
- {
- "page_link": "https://github.com/istio/istio",
- "title": "istio readme",
- "text": "# Istio\n\n[](https://bestpractices.coreinfrastructure.org/projects/1395)\n[](https://goreportcard.com/report/github.com/istio/istio)\n[](https://godoc.org/istio.io/istio)\n\n\n \n\n\n---\n\nAn open platform to connect, manage, and secure microservices.\n\n- For in-depth information about how to use Istio, visit [istio.io](https://istio.io)\n- To ask questions and get assistance from our community, visit [discuss.istio.io](https://discuss.istio.io)\n- To learn how to participate in our overall community, visit [our community page](https://istio.io/about/community)\n\nIn this README:\n\n- [Introduction](#introduction)\n- [Repositories](#repositories)\n- [Issue management](#issue-management)\n\nIn addition, here are some other documents you may wish to read:\n\n- [Istio Community](https://github.com/istio/community#istio-community) - describes how to get involved and contribute to the Istio project\n- [Istio Developer's Guide](https://github.com/istio/istio/wiki/Preparing-for-Development) - explains how to set up and use an Istio development environment\n- [Project Conventions](https://github.com/istio/istio/wiki/Development-Conventions) - describes the conventions we use within the code base\n- [Creating Fast and Lean Code](https://github.com/istio/istio/wiki/Writing-Fast-and-Lean-Code) - performance-oriented advice and guidelines for the code base\n\nYou'll find many other useful documents on our [Wiki](https://github.com/istio/istio/wiki).\n\n## Introduction\n\n[Istio](https://istio.io/latest/docs/concepts/what-is-istio/) is an open platform for providing a uniform way to [integrate\nmicroservices](https://istio.io/latest/docs/examples/microservices-istio/), manage [traffic flow](https://istio.io/latest/docs/concepts/traffic-management/) across microservices, enforce policies\nand aggregate telemetry data. Istio's control plane provides an abstraction\nlayer over the underlying cluster management platform, such as Kubernetes.\n\nIstio is composed of these components:\n\n- **Envoy** - Sidecar proxies per microservice to handle ingress/egress traffic\n between services in the cluster and from a service to external\n services. The proxies form a _secure microservice mesh_ providing a rich\n set of functions like discovery, rich layer-7 routing, circuit breakers,\n policy enforcement and telemetry recording/reporting\n functions.\n\n > Note: The service mesh is not an overlay network. It\n > simplifies and enhances how microservices in an application talk to each\n > other over the network provided by the underlying platform.\n\n- **Istiod** - The Istio control plane. It provides service discovery, configuration and certificate management. It consists of the following sub-components:\n\n - **Pilot** - Responsible for configuring the proxies at runtime.\n\n - **Citadel** - Responsible for certificate issuance and rotation.\n\n - **Galley** - Responsible for validating, ingesting, aggregating, transforming and distributing config within Istio.\n\n- **Operator** - The component provides user friendly options to operate the Istio service mesh.\n\n## Repositories\n\nThe Istio project is divided across a few GitHub repositories:\n\n- [istio/api](https://github.com/istio/api). This repository defines\ncomponent-level APIs and common configuration formats for the Istio platform.\n\n- [istio/community](https://github.com/istio/community). This repository contains\ninformation on the Istio community, including the various documents that govern\nthe Istio open source project.\n\n- [istio/istio](README.md). This is the main code repository. It hosts Istio's\ncore components, install artifacts, and sample programs. It includes:\n\n - [istioctl](istioctl/). This directory contains code for the\n[_istioctl_](https://istio.io/latest/docs/reference/commands/istioctl/) command line utility.\n\n - [operator](operator/). This directory contains code for the\n[Istio Operator](https://istio.io/latest/docs/setup/install/operator/).\n\n - [pilot](pilot/). This directory\ncontains platform-specific code to populate the\n[abstract service model](https://istio.io/docs/concepts/traffic-management/#pilot), dynamically reconfigure the proxies\nwhen the application topology changes, as well as translate\n[routing rules](https://istio.io/latest/docs/reference/config/networking/) into proxy specific configuration.\n\n - [security](security/). This directory contains [security](https://istio.io/latest/docs/concepts/security/) related code,\nincluding Citadel (acting as Certificate Authority), citadel agent, etc.\n\n- [istio/proxy](https://github.com/istio/proxy). The Istio proxy contains\nextensions to the [Envoy proxy](https://github.com/envoyproxy/envoy) (in the form of\nEnvoy filters) that support authentication, authorization, and telemetry collection.\n\n## Issue management\n\nWe use GitHub to track all of our bugs and feature requests. Each issue we track has a variety of metadata:\n\n- **Epic**. An epic represents a feature area for Istio as a whole. Epics are fairly broad in scope and are basically product-level things.\nEach issue is ultimately part of an epic.\n\n- **Milestone**. Each issue is assigned a milestone. This is 0.1, 0.2, ..., or 'Nebulous Future'. The milestone indicates when we\nthink the issue should get addressed.\n\n- **Priority**. Each issue has a priority which is represented by the column in the [Prioritization](https://github.com/orgs/istio/projects/6) project. Priority can be one of\nP0, P1, P2, or >P2. The priority indicates how important it is to address the issue within the milestone. P0 says that the\nmilestone cannot be considered achieved if the issue isn't resolved.\n",
- "source_links": [],
- "id": 58
- },
- {
- "page_link": "https://github.com/jenkinsci/jenkins",
- "title": "jenkins readme",
- "text": "\n \n \n \n \n\n\n# About\n\n[](https://www.jenkins.io/changelog)\n[](https://www.jenkins.io/changelog-stable)\n[](https://hub.docker.com/r/jenkins/jenkins/)\n[](https://bestpractices.coreinfrastructure.org/projects/3538)\n\nIn a nutshell, Jenkins is the leading open-source automation server.\nBuilt with Java, it provides over 1,800 [plugins](https://plugins.jenkins.io/) to support automating virtually anything,\nso that humans can spend their time doing things machines cannot.\n\n# What to Use Jenkins for and When to Use It\n\nUse Jenkins to automate your development workflow, so you can focus on work that matters most. Jenkins is commonly used for:\n\n- Building projects\n- Running tests to detect bugs and other issues as soon as they are introduced\n- Static code analysis\n- Deployment\n\nExecute repetitive tasks, save time, and optimize your development process with Jenkins.\n\n# Downloads\n\nThe Jenkins project provides official distributions as WAR files, Docker images, native packages and installers for platforms including several Linux distributions and Windows.\nSee the [Downloads](https://www.jenkins.io/download) page for references.\n\nFor all distributions Jenkins offers two release lines:\n\n- [Weekly](https://www.jenkins.io/download/weekly/) -\n Frequent releases which include all new features, improvements, and bug fixes.\n- [Long-Term Support (LTS)](https://www.jenkins.io/download/lts/) -\n Older release line which gets periodically updated via bug fix backports.\n\nLatest releases:\n[](https://www.jenkins.io/changelog)\n[](https://www.jenkins.io/changelog-stable)\n\n# Source\n\nOur latest and greatest source of Jenkins can be found on [GitHub](https://github.com/jenkinsci/jenkins). Fork us!\n\n# Contributing to Jenkins\n\nFollow the [contributing guidelines](CONTRIBUTING.md) if you want to propose a change in the Jenkins core.\nFor more information about participating in the community and contributing to the Jenkins project,\nsee [this page](https://www.jenkins.io/participate/).\n\nDocumentation for Jenkins core maintainers is in the [maintainers guidelines](docs/MAINTAINERS.adoc).\n\n# News and Website\n\nAll information about Jenkins can be found on our [website](https://www.jenkins.io/).\nFollow us on [Twitter](https://twitter.com/jenkinsci) or [LinkedIn](https://www.linkedin.com/company/jenkins-project/).\n\n# Governance\n\nSee the [Jenkins Governance Document](https://www.jenkins.io/project/governance/) for information about the project's open governance, our philosophy and values, and development practices.\nJenkins Code of Conduct can be found [here](https://www.jenkins.io/project/conduct/).\n\n# Adopters\n\nJenkins is used by millions of users and thousands of companies.\nSee [adopters](https://www.jenkins.io/project/adopters/) for the list of Jenkins adopters and their success stories.\n\n# License\n\nJenkins is **licensed** under the **[MIT License](https://github.com/jenkinsci/jenkins/blob/master/LICENSE.txt)**.\n",
- "source_links": [],
- "id": 59
- },
- {
- "page_link": "https://github.com/jitsucom/jitsu",
- "title": "jitsu readme",
- "text": "
\n\n**[Jitsu](https://jitsu.com/?utm_source=gh)** is an open source high-performance data collection service. It can:\n\n* Capture events your application generates and stream to Data Warehouse;\n* Pull data from APIs and save it to Data Warehouse\n\nRead more about [our features](https://jitsu.com/#features) and check out the [platform overview](https://jitsu.com/overview)!\n\n\n## Quick Start\n\nTwo easiest ways to start Jitsu are Heroku deployment and local docker-compose. \n\n### 1-click Heroku deploy\nIt may take up to 5 minutes for Heroku to install environment. \nAfter that you can visit `.herokuapp.com`\n\n\n\n### Docker Compose\nStart Jitsu using docker-compose:\n\n```bash\ngit clone https://github.com/jitsucom/jitsu.git\ncd jitsu\n```\n\nAdd permission for writing log files:\n\n```bash\n#Ubuntu/Mac OS\nchmod -R 777 compose-data/\n```\n\nFor running `latest` version use:\n\n```bash\ndocker-compose up\n```\n\nNote: `latest` image will be downloaded and started.\n\nVisit `http://localhost:8000/configurator` after the build is complete.\n\nTo learn more check out [Jitsu deployment documentation](https://jitsu.com/docs/deployment/):\n\n- [Docker deployment](https://jitsu.com/docs/deployment/deploy-with-docker)\n- [Heroku Deployment](https://jitsu.com/docs/deployment/deploy-on-heroku)\n- [Plural Deployment (On Kubernetes)](https://jitsu.com/docs/deployment/deploy-on-plural) \n- [Building from sources](https://jitsu.com/docs/deployment/build-from-sources)\n\nAlso, we maintain a [Jitsu.Cloud](https://cloud.jitsu.com) \u2014 a hosted version of Jitsu. Jitsu.Cloud [is free](https://jitsu.com/pricing) for up to 250,000 events per month. Each\nproject comes with demo PostgresSQL Database (up 10,000 records).\n\n\n\n## Documentation\n\nPlease see our extensive documentation [here](https://jitsu.com/docs). Key sections include:\n\n* [Deployment](https://jitsu.com/docs/deployment) - Getting Jitsu running on Heroku, Docker, and building from source.\n* [Configuration](https://jitsu.com/docs/configuration) - How to modify Jitsu Server's `yaml` file.\n* [Geo Data](https://jitsu.com/docs/geo-data-resolution) - Configuring data enrichment with [MaxMind](https://www.maxmind.com/en/home).\n* [Scaling](https://jitsu.com/docs/other-features/scaling-eventnative) - How to setup a distributed deployment of Jitsu.\n\n\n\n## Reporting Bugs and Contributing Code\n\n* Want to report a bug or request a feature? Please open [an issue](https://github.com/jitsucom/jitsu/issues/new).\n* Want to help us build **Jitsu**? Fork the project, and check our an issues [that are good for first pull request](https://github.com/jitsucom/jitsu/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+first+issue%22)!\n* Questions? Join our [Slack](https://jitsu.com/slack)!\n* [hello@jitsu.com](mailto:hello@jitsu.com) - send us an email if you have any questions!\n",
- "source_links": [],
- "id": 60
- },
- {
- "page_link": "https://github.com/jupyterhub/jupyterhub",
- "title": "jupyterhub readme",
- "text": "**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n\n---\n\n# [JupyterHub](https://github.com/jupyterhub/jupyterhub)\n\n[](https://pypi.python.org/pypi/jupyterhub)\n[](https://anaconda.org/conda-forge/jupyterhub)\n[](https://jupyterhub.readthedocs.org/en/latest/)\n[](https://github.com/jupyterhub/jupyterhub/actions)\n[](https://hub.docker.com/r/jupyterhub/jupyterhub/tags)\n[](https://codecov.io/gh/jupyterhub/jupyterhub)\n[](https://github.com/jupyterhub/jupyterhub/issues)\n[](https://discourse.jupyter.org/c/jupyterhub)\n[](https://gitter.im/jupyterhub/jupyterhub)\n\nWith [JupyterHub](https://jupyterhub.readthedocs.io) you can create a\n**multi-user Hub** that spawns, manages, and proxies multiple instances of the\nsingle-user [Jupyter notebook](https://jupyter-notebook.readthedocs.io)\nserver.\n\n[Project Jupyter](https://jupyter.org) created JupyterHub to support many\nusers. The Hub can offer notebook servers to a class of students, a corporate\ndata science workgroup, a scientific research project, or a high-performance\ncomputing group.\n\n## Technical overview\n\nThree main actors make up JupyterHub:\n\n- multi-user **Hub** (tornado process)\n- configurable http **proxy** (node-http-proxy)\n- multiple **single-user Jupyter notebook servers** (Python/Jupyter/tornado)\n\nBasic principles for operation are:\n\n- Hub launches a proxy.\n- The Proxy forwards all requests to Hub by default.\n- Hub handles login and spawns single-user servers on demand.\n- Hub configures proxy to forward URL prefixes to the single-user notebook\n servers.\n\nJupyterHub also provides a\n[REST API][]\nfor administration of the Hub and its users.\n\n[rest api]: https://jupyterhub.readthedocs.io/en/latest/reference/rest-api.html\n\n## Installation\n\n### Check prerequisites\n\n- A Linux/Unix based system\n- [Python](https://www.python.org/downloads/) 3.6 or greater\n- [nodejs/npm](https://www.npmjs.com/)\n\n - If you are using **`conda`**, the nodejs and npm dependencies will be installed for\n you by conda.\n\n - If you are using **`pip`**, install a recent version (at least 12.0) of\n [nodejs/npm](https://docs.npmjs.com/getting-started/installing-node).\n\n- If using the default PAM Authenticator, a [pluggable authentication module (PAM)](https://en.wikipedia.org/wiki/Pluggable_authentication_module).\n- TLS certificate and key for HTTPS communication\n- Domain name\n\n### Install packages\n\n#### Using `conda`\n\nTo install JupyterHub along with its dependencies including nodejs/npm:\n\n```bash\nconda install -c conda-forge jupyterhub\n```\n\nIf you plan to run notebook servers locally, install JupyterLab or Jupyter notebook:\n\n```bash\nconda install jupyterlab\nconda install notebook\n```\n\n#### Using `pip`\n\nJupyterHub can be installed with `pip`, and the proxy with `npm`:\n\n```bash\nnpm install -g configurable-http-proxy\npython3 -m pip install jupyterhub\n```\n\nIf you plan to run notebook servers locally, you will need to install\n[JupyterLab or Jupyter notebook](https://jupyter.readthedocs.io/en/latest/install.html):\n\n python3 -m pip install --upgrade jupyterlab\n python3 -m pip install --upgrade notebook\n\n### Run the Hub server\n\nTo start the Hub server, run the command:\n\n jupyterhub\n\nVisit `http://localhost:8000` in your browser, and sign in with your system username and password.\n\n_Note_: To allow multiple users to sign in to the server, you will need to\nrun the `jupyterhub` command as a _privileged user_, such as root.\nThe [wiki](https://github.com/jupyterhub/jupyterhub/wiki/Using-sudo-to-run-JupyterHub-without-root-privileges)\ndescribes how to run the server as a _less privileged user_, which requires\nmore configuration of the system.\n\n## Configuration\n\nThe [Getting Started](https://jupyterhub.readthedocs.io/en/latest/tutorial/index.html#getting-started) section of the\ndocumentation explains the common steps in setting up JupyterHub.\n\nThe [**JupyterHub tutorial**](https://github.com/jupyterhub/jupyterhub-tutorial)\nprovides an in-depth video and sample configurations of JupyterHub.\n\n### Create a configuration file\n\nTo generate a default config file with settings and descriptions:\n\n jupyterhub --generate-config\n\n### Start the Hub\n\nTo start the Hub on a specific url and port `10.0.1.2:443` with **https**:\n\n jupyterhub --ip 10.0.1.2 --port 443 --ssl-key my_ssl.key --ssl-cert my_ssl.cert\n\n### Authenticators\n\n| Authenticator | Description |\n| ---------------------------------------------------------------------------- | ------------------------------------------------- |\n| PAMAuthenticator | Default, built-in authenticator |\n| [OAuthenticator](https://github.com/jupyterhub/oauthenticator) | OAuth + JupyterHub Authenticator = OAuthenticator |\n| [ldapauthenticator](https://github.com/jupyterhub/ldapauthenticator) | Simple LDAP Authenticator Plugin for JupyterHub |\n| [kerberosauthenticator](https://github.com/jupyterhub/kerberosauthenticator) | Kerberos Authenticator Plugin for JupyterHub |\n\n### Spawners\n\n| Spawner | Description |\n| -------------------------------------------------------------- | -------------------------------------------------------------------------- |\n| LocalProcessSpawner | Default, built-in spawner starts single-user servers as local processes |\n| [dockerspawner](https://github.com/jupyterhub/dockerspawner) | Spawn single-user servers in Docker containers |\n| [kubespawner](https://github.com/jupyterhub/kubespawner) | Kubernetes spawner for JupyterHub |\n| [sudospawner](https://github.com/jupyterhub/sudospawner) | Spawn single-user servers without being root |\n| [systemdspawner](https://github.com/jupyterhub/systemdspawner) | Spawn single-user notebook servers using systemd |\n| [batchspawner](https://github.com/jupyterhub/batchspawner) | Designed for clusters using batch scheduling software |\n| [yarnspawner](https://github.com/jupyterhub/yarnspawner) | Spawn single-user notebook servers distributed on a Hadoop cluster |\n| [wrapspawner](https://github.com/jupyterhub/wrapspawner) | WrapSpawner and ProfilesSpawner enabling runtime configuration of spawners |\n\n## Docker\n\nA starter [**docker image for JupyterHub**](https://hub.docker.com/r/jupyterhub/jupyterhub/)\ngives a baseline deployment of JupyterHub using Docker.\n\n**Important:** This `jupyterhub/jupyterhub` image contains only the Hub itself,\nwith no configuration. In general, one needs to make a derivative image, with\nat least a `jupyterhub_config.py` setting up an Authenticator and/or a Spawner.\nTo run the single-user servers, which may be on the same system as the Hub or\nnot, Jupyter Notebook version 4 or greater must be installed.\n\nThe JupyterHub docker image can be started with the following command:\n\n docker run -p 8000:8000 -d --name jupyterhub jupyterhub/jupyterhub jupyterhub\n\nThis command will create a container named `jupyterhub` that you can\n**stop and resume** with `docker stop/start`.\n\nThe Hub service will be listening on all interfaces at port 8000, which makes\nthis a good choice for **testing JupyterHub on your desktop or laptop**.\n\nIf you want to run docker on a computer that has a public IP then you should\n(as in MUST) **secure it with ssl** by adding ssl options to your docker\nconfiguration or by using an ssl enabled proxy.\n\n[Mounting volumes](https://docs.docker.com/engine/admin/volumes/volumes/) will\nallow you to **store data outside the docker image (host system) so it will be persistent**, even when you start\na new image.\n\nThe command `docker exec -it jupyterhub bash` will spawn a root shell in your docker\ncontainer. You can **use the root shell to create system users in the container**.\nThese accounts will be used for authentication in JupyterHub's default configuration.\n\n## Contributing\n\nIf you would like to contribute to the project, please read our\n[contributor documentation](https://jupyter.readthedocs.io/en/latest/contributing/content-contributor.html)\nand the [`CONTRIBUTING.md`](CONTRIBUTING.md). The `CONTRIBUTING.md` file\nexplains how to set up a development installation, how to run the test suite,\nand how to contribute to documentation.\n\nFor a high-level view of the vision and next directions of the project, see the\n[JupyterHub community roadmap](docs/source/contributing/roadmap.md).\n\n### A note about platform support\n\nJupyterHub is supported on Linux/Unix based systems.\n\nJupyterHub officially **does not** support Windows. You may be able to use\nJupyterHub on Windows if you use a Spawner and Authenticator that work on\nWindows, but the JupyterHub defaults will not. Bugs reported on Windows will not\nbe accepted, and the test suite will not run on Windows. Small patches that fix\nminor Windows compatibility issues (such as basic installation) **may** be accepted,\nhowever. For Windows-based systems, we would recommend running JupyterHub in a\ndocker container or Linux VM.\n\n[Additional Reference:](http://www.tornadoweb.org/en/stable/#installation) Tornado's documentation on Windows platform support\n\n## License\n\nWe use a shared copyright model that enables all contributors to maintain the\ncopyright on their contributions.\n\nAll code is licensed under the terms of the [revised BSD license](./COPYING.md).\n\n## Help and resources\n\nWe encourage you to ask questions and share ideas on the [Jupyter community forum](https://discourse.jupyter.org/).\nYou can also talk with us on our JupyterHub [Gitter](https://gitter.im/jupyterhub/jupyterhub) channel.\n\n- [Reporting Issues](https://github.com/jupyterhub/jupyterhub/issues)\n- [JupyterHub tutorial](https://github.com/jupyterhub/jupyterhub-tutorial)\n- [Documentation for JupyterHub](https://jupyterhub.readthedocs.io/en/latest/)\n- [Documentation for JupyterHub's REST API][rest api]\n- [Documentation for Project Jupyter](http://jupyter.readthedocs.io/en/latest/index.html)\n- [Project Jupyter website](https://jupyter.org)\n- [Project Jupyter community](https://jupyter.org/community)\n\nJupyterHub follows the Jupyter [Community Guides](https://jupyter.readthedocs.io/en/latest/community/content-community.html).\n\n---\n\n**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n",
- "source_links": [],
- "id": 61
- },
- {
- "page_link": "network-policies.md",
- "title": "network-policies",
- "text": "# Network Policy\n\nJupyterhub makes extensive use of kubernetes network policies. This allows you to finely scope a jupyter notebook's access to resources available on the network, which can be very important in a multi-tenant kubernetes cluster. That said, you might want to expose some services to your network either on-cluster or in an adjacent network, and here are some recipes to do that.\n\nIn all cases, the following yaml will be added to `jupyterhub/helm/jupyterhub/values.yaml` or you can modify directly in the console at `/apps/jupyterhub/config`\n\n## Get access to an adjacent namespace\n\n```yaml\njupyterhub:\n jupyterhub:\n singleuser:\n networkPolicy:\n egress:\n - to:\n - namespaceSelector:\n matchLabels:\n kubernetes.io/metadata.name: \n```\n\n## Get access to a CIDR range\n\n\n```yaml\njupyterhub:\n jupyterhub:\n singleuser:\n networkPolicy:\n egress:\n - to:\n - ipBlock:\n cidr: 10.0.0.0/16 # access resources on an internal subnetwork for example\n```\n\n## Combine multiple policies\n\n\n```yaml\njupyterhub:\n jupyterhub:\n singleuser:\n networkPolicy:\n egress:\n - to:\n - namespaceSelector:\n matchLabels:\n kubernetes.io/metadata.name: \n - to:\n - ipBlock:\n cidr: 10.0.0.0/16\n```",
- "source_links": [],
- "id": 62
- },
- {
- "page_link": "https://github.com/apache/kafka",
- "title": "kafka readme",
- "text": null,
- "source_links": [],
- "id": 63
- },
- {
- "page_link": "https://github.com/knative/serving",
- "title": "knative readme",
- "text": "# Knative Serving\n\n[](https://pkg.go.dev/github.com/knative/serving)\n[](https://goreportcard.com/report/knative/serving)\n[](https://github.com/knative/serving/releases)\n[](https://github.com/knative/serving/blob/main/LICENSE)\n[](https://knative.slack.com)\n[](https://codecov.io/gh/knative/serving)\n[](https://bestpractices.coreinfrastructure.org/projects/5913)\n\nKnative Serving builds on Kubernetes to support deploying and serving of\napplications and functions as serverless containers. Serving is easy to get\nstarted with and scales to support advanced scenarios.\n\nThe Knative Serving project provides middleware primitives that enable:\n\n- Rapid deployment of serverless containers\n- Automatic scaling up and down to zero\n- Routing and network programming\n- Point-in-time snapshots of deployed code and configurations\n\nFor documentation on using Knative Serving, see the\n[serving section](https://www.knative.dev/docs/serving/) of the\n[Knative documentation site](https://www.knative.dev/docs).\n\nFor documentation on the Knative Serving specification, see the\n[docs](https://github.com/knative/serving/tree/main/docs) folder of this\nrepository.\n\nIf you are interested in contributing, see [CONTRIBUTING.md](./CONTRIBUTING.md)\nand [DEVELOPMENT.md](./DEVELOPMENT.md).\n",
- "source_links": [],
- "id": 64
- },
- {
- "page_link": "https://github.com/ory/kratos",
- "title": "kratos readme",
- "text": "
\n \n \n \n \n \n \n\n\nOry Kratos is the first cloud native Identity and User Management System in the\nworld. Finally, it is no longer necessary to implement a User Login process for\nthe umpteenth time!\n\n## Ory Kratos in Ory Cloud\n\nThe easiest way to get started with Ory Software is in Ory Cloud! Ory Cloud is\n[**free forever for developers**](https://console.ory.sh/registration?utm_source=github&utm_medium=banner&utm_campaign=kratos-readme),\nno credit card required.\n\nInstall the [Ory CLI](https://www.ory.sh/docs/guides/cli/installation) and\ncreate a new project to get started with Ory Kratos right away:\n\n```\n# If you don't have Ory CLI installed yet:\nbash <(curl https://raw.githubusercontent.com/ory/meta/master/install.sh) -b . ory\nsudo mv ./ory /usr/local/bin/\n\n# Sign up\nory auth\n\n# Create project\nory create project\n```\n\nOry Cloud ships administrative user interfaces, hosted pages (e.g. for login or\nregistration), support for custom domains, collaborative features for your\ncolleagues, integration services, and much more!\n\n\n\n\n**Table of Contents**\n\n- [What is Ory Kratos?](#what-is-ory-kratos)\n - [Who is using it?](#who-is-using-it)\n- [Getting Started](#getting-started)\n - [Installation](#installation)\n- [Ecosystem](#ecosystem)\n - [Ory Kratos: Identity and User Infrastructure and Management](#ory-kratos-identity-and-user-infrastructure-and-management)\n - [Ory Hydra: OAuth2 & OpenID Connect Server](#ory-hydra-oauth2--openid-connect-server)\n - [Ory Oathkeeper: Identity & Access Proxy](#ory-oathkeeper-identity--access-proxy)\n - [Ory Keto: Access Control Policies as a Server](#ory-keto-access-control-policies-as-a-server)\n- [Security](#security)\n - [Disclosing vulnerabilities](#disclosing-vulnerabilities)\n- [Telemetry](#telemetry)\n- [Documentation](#documentation)\n - [Guide](#guide)\n - [HTTP API documentation](#http-api-documentation)\n - [Upgrading and Changelog](#upgrading-and-changelog)\n - [Command line documentation](#command-line-documentation)\n - [Develop](#develop)\n - [Dependencies](#dependencies)\n - [Install from source](#install-from-source)\n - [Formatting Code](#formatting-code)\n - [Running Tests](#running-tests)\n - [Short Tests](#short-tests)\n - [Regular Tests](#regular-tests)\n - [Updating Test Fixtures](#updating-test-fixtures)\n - [End-to-End Tests](#end-to-end-tests)\n - [Build Docker](#build-docker)\n - [Documentation Tests](#documentation-tests)\n - [Preview API documentation](#preview-api-documentation)\n\n\n\n## What is Ory Kratos?\n\nOry Kratos is an API-first Identity and User Management system that is built\naccording to\n[cloud architecture best practices](https://www.ory.sh/docs/ecosystem/software-architecture-philosophy).\nIt implements core use cases that almost every software application needs to\ndeal with:\n\n- **Self-service Login and Registration**: Allow end-users to create and sign\n into accounts (we call them **identities**) using Username / Email and\n password combinations, Social Sign In (\"Sign in with Google, GitHub\"),\n Passwordless flows, and others.\n- **Multi-Factor Authentication (MFA/2FA)**: Support protocols such as TOTP\n ([RFC 6238](https://tools.ietf.org/html/rfc6238) and\n [IETF RFC 4226](https://tools.ietf.org/html/rfc4226) - better known as\n [Google Authenticator](https://en.wikipedia.org/wiki/Google_Authenticator))\n- **Account Verification**: Verify that an E-Mail address, phone number, or\n physical address actually belong to that identity.\n- **Account Recovery**: Recover access using \"Forgot Password\" flows, Security\n Codes (in case of MFA device loss), and others.\n- **Profile and Account Management**: Update passwords, personal details, email\n addresses, linked social profiles using secure flows.\n- **Admin APIs**: Import, update, delete identities.\n\nWe highly recommend reading the\n[Ory Kratos introduction docs](https://www.ory.sh/kratos/docs/) to learn more\nabout Ory Krato's background, feature set, and differentiation from other\nproducts.\n\n### Who is using it?\n\n\n\nThe Ory community stands on the shoulders of individuals, companies, and\nmaintainers. We thank everyone involved - from submitting bug reports and\nfeature requests, to contributing patches, to sponsoring our work. Our community\nis 1000+ strong and growing rapidly. The Ory stack protects 16.000.000.000+ API\nrequests every month with over 250.000+ active service nodes. We would have\nnever been able to achieve this without each and everyone of you!\n\nThe following list represents companies that have accompanied us along the way\nand that have made outstanding contributions to our ecosystem. _If you think\nthat your company deserves a spot here, reach out to\noffice-muc@ory.sh now_!\n\n**Please consider giving back by becoming a sponsor of our open source work on\nPatreon or\nOpen Collective.**\n\n
\n\nWe also want to thank all individual contributors\n\n\n\nas well as all of our backers\n\n\n\nand past & current supporters (in alphabetical order) on\n[Patreon](https://www.patreon.com/_ory): Alexander Alimovs, Billy, Chancy\nKennedy, Drozzy, Edwin Trejos, Howard Edidin, Ken Adler Oz Haven, Stefan Hans,\nTheCrealm.\n\n\\* Uses one of Ory's major projects in production.\n\n\n\n## Getting Started\n\nTo get started with some easy examples, head over to the\n[Get Started Documentation](https://www.ory.sh/docs/guides/protect-page-login/).\n\n### Installation\n\nHead over to the\n[Ory Developer Documentation](https://www.ory.sh/kratos/docs/install) to learn\nhow to install Ory Kratos on Linux, macOS, Windows, and Docker and how to build\nOry Kratos from source.\n\n## Ecosystem\n\n\n\nWe build Ory on several guiding principles when it comes to our architecture\ndesign:\n\n- Minimal dependencies\n- Runs everywhere\n- Scales without effort\n- Minimize room for human and network errors\n\nOry's architecture is designed to run best on a Container Orchestration system\nsuch as Kubernetes, CloudFoundry, OpenShift, and similar projects. Binaries are\nsmall (5-15MB) and available for all popular processor types (ARM, AMD64, i386)\nand operating systems (FreeBSD, Linux, macOS, Windows) without system\ndependencies (Java, Node, Ruby, libxml, ...).\n\n### Ory Kratos: Identity and User Infrastructure and Management\n\n[Ory Kratos](https://github.com/ory/kratos) is an API-first Identity and User\nManagement system that is built according to\n[cloud architecture best practices](https://www.ory.sh/docs/next/ecosystem/software-architecture-philosophy).\nIt implements core use cases that almost every software application needs to\ndeal with: Self-service Login and Registration, Multi-Factor Authentication\n(MFA/2FA), Account Recovery and Verification, Profile, and Account Management.\n\n### Ory Hydra: OAuth2 & OpenID Connect Server\n\n[Ory Hydra](https://github.com/ory/hydra) is an OpenID Certified\u2122 OAuth2 and\nOpenID Connect Provider which easily connects to any existing identity system by\nwriting a tiny \"bridge\" application. Gives absolute control over user interface\nand user experience flows.\n\n### Ory Oathkeeper: Identity & Access Proxy\n\n[Ory Oathkeeper](https://github.com/ory/oathkeeper) is a BeyondCorp/Zero Trust\nIdentity & Access Proxy (IAP) with configurable authentication, authorization,\nand request mutation rules for your web services: Authenticate JWT, Access\nTokens, API Keys, mTLS; Check if the contained subject is allowed to perform the\nrequest; Encode resulting content into custom headers (`X-User-ID`), JSON Web\nTokens and more!\n\n### Ory Keto: Access Control Policies as a Server\n\n[Ory Keto](https://github.com/ory/keto) is a policy decision point. It uses a\nset of access control policies, similar to AWS IAM Policies, in order to\ndetermine whether a subject (user, application, service, car, ...) is authorized\nto perform a certain action on a resource.\n\n\n\n## Security\n\nRunning identity infrastructure requires\n[attention and knowledge of threat models](https://www.ory.sh/kratos/docs/concepts/security).\n\n### Disclosing vulnerabilities\n\nIf you think you found a security vulnerability, please refrain from posting it\npublicly on the forums, the chat, or GitHub and send us an email to\n[hi@ory.am](mailto:hi@ory.sh) instead.\n\n## Telemetry\n\nOry's services collect summarized, anonymized data that can optionally be turned\noff. Click [here](https://www.ory.sh/docs/ecosystem/sqa) to learn more.\n\n## Documentation\n\n### Guide\n\nThe Guide is available [here](https://www.ory.sh/kratos/docs).\n\n### HTTP API documentation\n\nThe HTTP API is documented [here](https://www.ory.sh/kratos/docs/sdk/api).\n\n### Upgrading and Changelog\n\nNew releases might introduce breaking changes. To help you identify and\nincorporate those changes, we document these changes in the\n[CHANGELOG.md](./CHANGELOG.md). For upgrading, please visit the\n[upgrade guide](https://www.ory.sh/kratos/docs/guides/upgrade).\n\n### Command line documentation\n\nRun kratos -h or\nkratos help.\n\n### Develop\n\nWe encourage all contributions and encourage you to read our\n[contribution guidelines](./CONTRIBUTING.md)\n\n#### Dependencies\n\nYou need Go 1.16+ and (for the test suites):\n\n- Docker and Docker Compose\n- Makefile\n- NodeJS / npm\n\nIt is possible to develop Ory Kratos on Windows, but please be aware that all\nguides assume a Unix shell like bash or zsh.\n\n#### Install from source\n\n
\nmake install\n
\n\n#### Formatting Code\n\nYou can format all code using make format. Our\nCI checks if your code is properly formatted.\n\n#### Running Tests\n\nThere are three types of tests you can run:\n\n- Short tests (do not require a SQL database like PostgreSQL)\n- Regular tests (do require PostgreSQL, MySQL, CockroachDB)\n- End to end tests (do require databases and will use a test browser)\n\n##### Short Tests\n\nShort tests run fairly quickly. You can either test all of the code at once\n\n```shell script\ngo test -short -tags sqlite ./...\n```\n\nor test just a specific module:\n\n```shell script\ncd client; go test -tags sqlite -short .\n```\n\n##### Regular Tests\n\nRegular tests require a database set up. Our test suite is able to work with\ndocker directly (using [ory/dockertest](https://github.com/ory/dockertest)) but\nwe encourage to use the Makefile instead. Using dockertest can bloat the number\nof Docker Images on your system and are quite slow. Instead we recommend doing:\n\n
\n\nYou can run all tests (with databases) using:\n\n
\nmake test-e2e\n
\n\nFor more details, run:\n\n
\n./test/e2e/run.sh\n
\n\n**Run only a singular test**\n\nAdd `.only` to the test you would like to run.\n\nFor example:\n\n```ts\nit.only('invalid remote recovery email template', () => {\n ...\n})\n```\n\n**Run a subset of tests**\n\nThis will require editing the `cypress.json` file located in the `test/e2e/`\nfolder.\n\nAdd the `testFiles` option and specify the test to run inside the\n`cypress/integration` folder. As an example we will add only the `network`\ntests.\n\n```json\n\"testFiles\": [\"profiles/network/*\"],\n```\n\nNow start the tests again using the run script or makefile.\n\n#### Build Docker\n\nYou can build a development Docker Image using:\n\n
\nmake docker\n
\n\n#### Documentation Tests\n\nTo prepare documentation tests, run `npm i` to install\n[Text-Runner](https://github.com/kevgo/text-runner).\n\n- test all documentation: make test-docs\n- test an individual file: text-run\n\n#### Preview API documentation\n\n- update the SDK including the OpenAPI specification:\n make sdk\n- run preview server for API documentation: make\n docs/api\n- run preview server for swagger documentation: make\n docs/swagger\n",
- "source_links": [],
- "id": 65
- },
- {
- "page_link": null,
- "title": "kserve readme",
- "text": null,
- "source_links": [],
- "id": 66
- },
- {
- "page_link": "https://github.com/kubecost/cost-model",
- "title": "kubecost readme",
- "text": "## Kubecost\n\nKubecost models give teams visibility into current and historical Kubernetes spend and resource allocation. These models provide cost transparency in Kubernetes environments that support multiple applications, teams, departments, etc.\n\n\n\nTo see more on the functionality of the full Kubecost product, please visit the [features page](https://kubecost.com/#features) on our website. \nHere is a summary of features enabled by this cost model:\n\n- Real-time cost allocation by Kubernetes service, deployment, namespace, label, statefulset, daemonset, pod, and container\n- Dynamic asset pricing enabled by integrations with AWS, Azure, and GCP billing APIs \n- Supports on-prem k8s clusters with custom pricing sheets\n- Allocation for in-cluster resources like CPU, GPU, memory, and persistent volumes.\n- Allocation for AWS & GCP out-of-cluster resources like RDS instances and S3 buckets with key (optional)\n- Easily export pricing data to Prometheus with /metrics endpoint ([learn more](PROMETHEUS.md))\n- Free and open source distribution (Apache2 license)\n\n## Requirements\n\n- Kubernetes version 1.8 or higher\n- Prometheus\n- kube-state-metrics (optional) \n\n## Getting Started\n\nYou can deploy Kubecost on any Kubernetes 1.8+ cluster in a matter of minutes, if not seconds. \nVisit the Kubecost docs for [recommended install options](https://docs.kubecost.com/install). Compared to building from source, installing from Helm is faster and includes all necessary dependencies. \n\n## Usage\n\n* User interface\n* [Cost APIs](https://github.com/kubecost/docs/blob/master/apis.md)\n* [CLI / kubectl cost](https://github.com/kubecost/kubectl-cost)\n* [Prometheus metric exporter](kubecost-exporter.md)\n\n## Contributing\n\nWe :heart: pull requests! See [`CONTRIBUTING.md`](CONTRIBUTING.md) for information on buiding the project from source\nand contributing changes. \n\n## Licensing\n\nLicensed under the Apache License, Version 2.0 (the \"License\")\n\n ## Software stack\n\nGolang application. \nPrometheus. \nKubernetes. \n\n## Frequently Asked Questions\n\n#### How do you measure the cost of CPU/RAM/GPU/storage for a container, pod, deployment, etc.\n\nThe Kubecost model collects pricing data from major cloud providers, e.g. GCP, Azure and AWS, to provide the real-time cost of running workloads. Based on data from these APIs, each container/pod inherits a cost per CPU-hour, GPU-hour, Storage Gb-hour and cost per RAM Gb-hour based on the node where it was running or the class of storage provisioned. This means containers of the same size, as measured by the max of requests or usage, could be charged different resource rates if they are scheduled in seperate regions, on nodes with different usage types (on-demand vs preemptible), etc. \n\nFor on-prem clusters, these resource prices can be configured directly with custom pricing sheets (more below).\n\nMeasuring the CPU/RAM/GPU cost of a deployment, service, namespace, etc is the aggregation of its individual container costs.\n\n#### How do you determine RAM/CPU costs for a node when this data isn\u2019t provided by a cloud provider?\n\nWhen explicit RAM or CPU prices are not provided by your cloud provider, the Kubecost model falls back to the ratio of base CPU and RAM price inputs supplied. The default values for these parameters are based on the marginal resource rates of the cloud provider, but they can be customized within Kubecost.\n\nThese base RAM/CPU prices are normalized to ensure the sum of each component is equal to the total price of the node provisioned, based on billing rates from your provider. When the sum of RAM/CPU costs is greater (or less) than the price of the node, then the ratio between the two input prices are held constant. \n\nAs an example, let's imagine a node with 1 CPU and 1 Gb of RAM that costs $20/mo. If your base CPU price is $30 and your RAM Gb price is $10, then these inputs will be normlized to $15 for CPU and $5 for RAM so that the sum equals the cost of the node. Note that the price of a CPU remains 3x the price of a Gb of RAM. \n\n NodeHourlyCost = NORMALIZED_CPU_PRICE * # of CPUS + NORMALIZED_RAM_PRICE * # of RAM Gb\n\n#### How do you allocate a specific amount of RAM/CPU to an individual pod or container?\n\nResources are allocated based on the time-weighted maximum of resource Requests and Usage over the measured period. For example, a pod with no usage and 1 CPU requested for 12 hours out of a 24 hour window would be allocated 12 CPU hours. For pods with BestEffort quality of service (i.e. no requests) allocation is done solely on resource usage. \n\n#### How do I set my AWS Spot estimates for cost allocation?\n\nModify [spotCPU](https://github.com/kubecost/cost-model/blob/master/configs/default.json#L5) and [spotRAM](https://github.com/kubecost/cost-model/blob/master/configs/default.json#L7) in default.json to the level of recent market prices. Allocation will use these prices, but it does not take into account what you are actually charged by AWS. Alternatively, you can provide an AWS key to allow access to the Spot data feed. This will provide accurate Spot price reconciliation. \n\n#### Do I need a GCP billing API key?\n\nWe supply a global key with a low limit for evaluation, but you will want to supply your own before moving to production. \n \nPlease reach out with any additional questions on [Slack](https://join.slack.com/t/kubecost/shared_invite/enQtNTA2MjQ1NDUyODE5LWFjYzIzNWE4MDkzMmUyZGU4NjkwMzMyMjIyM2E0NGNmYjExZjBiNjk1YzY5ZDI0ZTNhZDg4NjlkMGRkYzFlZTU) or via email at [team@kubecost.com](team@kubecost.com). \n",
- "source_links": [],
- "id": 67
- },
- {
- "page_link": "https://github.com/kubeflow/kubeflow",
- "title": "kubeflow readme",
- "text": "\nKubeflow the cloud-native platform for machine learning operations - pipelines, training and deployment.\n\n---\n\n## Documentation\nPlease refer to the official docs at [kubeflow.org](http://kubeflow.org).\n\n## Working Groups\nThe Kubeflow community is organized into working groups (WGs) with associated repositories, that focus on specific pieces of the ML platform. \n\n* [AutoML](https://github.com/kubeflow/community/tree/master/wg-automl)\n* [Deployment](https://github.com/kubeflow/community/tree/master/wg-deployment)\n* [Manifests](https://github.com/kubeflow/community/tree/master/wg-manifests)\n* [Notebooks](https://github.com/kubeflow/community/tree/master/wg-notebooks)\n* [Pipelines](https://github.com/kubeflow/community/tree/master/wg-pipelines)\n* [Serving](https://github.com/kubeflow/community/tree/master/wg-serving)\n* [Training](https://github.com/kubeflow/community/tree/master/wg-training)\n\n## Quick Links\n* [Prow jobs dashboard](http://prow.kubeflow-testing.com)\n* [PR Dashboard](https://k8s-gubernator.appspot.com/pr)\n* [Argo UI for E2E tests](https://argo.kubeflow-testing.com)\n\n## Get Involved\nPlease refer to the [Community](https://www.kubeflow.org/docs/about/community/) page.\n\n",
- "source_links": [],
- "id": 68
- },
- {
- "page_link": "https://github.com/armosec/kubescape",
- "title": "kubescape readme",
- "text": "
\n \n
\n\n---\n\n[](https://github.com/kubescape/kubescape/actions/workflows/build.yaml)\n[](https://goreportcard.com/report/github.com/kubescape/kubescape)\n[](https://gitpod.io/#https://github.com/kubescape/kubescape)\n\n:sunglasses: [Want to contribute?](#being-a-part-of-the-team) :innocent: \n\n\nKubescape is a K8s open-source tool providing a Kubernetes single pane of glass, including risk analysis, security compliance, RBAC visualizer, and image vulnerability scanning. \nKubescape scans K8s clusters, YAML files, and HELM charts, detecting misconfigurations according to multiple frameworks (such as the [NSA-CISA](https://www.armosec.io/blog/kubernetes-hardening-guidance-summary-by-armo/?utm_source=github&utm_medium=repository), [MITRE ATT&CK\u00ae](https://www.microsoft.com/security/blog/2021/03/23/secure-containerized-environments-with-updated-threat-matrix-for-kubernetes/)), software vulnerabilities, and RBAC (role-based-access-control) violations at early stages of the CI/CD pipeline, calculates risk score instantly and shows risk trends over time.\n\nIt has become one of the fastest-growing Kubernetes tools among developers due to its easy-to-use CLI interface, flexible output formats, and automated scanning capabilities, saving Kubernetes users and admins precious time, effort, and resources.\nKubescape integrates natively with other DevOps tools, including Jenkins, CircleCI, Github workflows, Prometheus, and Slack, and supports multi-cloud K8s deployments like EKS, GKE, and AKS.\n\n\n\n# Kubescape CLI:\n\n\n\n\n# TL;DR\n## Install:\n```sh\ncurl -s https://raw.githubusercontent.com/kubescape/kubescape/master/install.sh | /bin/bash\n```\n\n*OR:*\n\n[Install on windows](#install-on-windows)\n\n[Install on macOS](#install-on-macos)\n\n[Install on NixOS or Linux/macOS via nix](#install-on-nixos-or-with-nix-community)\n\n## Run:\n```sh\nkubescape scan --submit --enable-host-scan --verbose\n```\n\n\n\n\n\n> Kubescape is an open source project. We welcome your feedback and ideas for improvement. We\u2019re also aiming to collaborate with the Kubernetes community to help make the tests more robust and complete as Kubernetes develops.\n\n\n\n## Architecture in short\n### CLI\n\n\n### Operator\n\n\n### Please [star \u2b50](https://github.com/kubescape/kubescape/stargazers) the repo if you want us to continue developing and improving Kubescape \ud83d\ude00\n\n\n\n# Being a part of the team\n\n## Community\nWe invite you to our community! We are excited about this project and want to return the love we get.\n\nWe hold community meetings in [Zoom](https://us02web.zoom.us/j/84020231442) on the first Tuesday of every month at 14:00 GMT! :sunglasses:\n\n## Contributions \n[Want to contribute?](https://github.com/kubescape/kubescape/blob/master/CONTRIBUTING.md) Want to discuss something? Have an issue? Please make sure that you follow our [Code Of Conduct](https://github.com/kubescape/kubescape/blob/master/CODE_OF_CONDUCT.md) . \n\n* Feel free to pick a task from the [issues](https://github.com/kubescape/kubescape/issues?q=is%3Aissue+is%3Aopen+label%3A%22open+for+contribution%22), [roadmap](docs/roadmap.md) or suggest a feature of your own. [Contact us](MAINTAINERS.md) directly for more information :) \n* [Open an issue](https://github.com/kubescape/kubescape/issues/new/choose) , we are trying to respond within 48 hours\n* [Join us](https://discord.com/invite/WKZRaCtBxN) in the discussion on our discord server!\n\n[](https://discord.com/invite/WKZRaCtBxN)\n\n\n\n# Options and examples\n\n[Kubescape docs](https://hub.armosec.io/docs?utm_source=github&utm_medium=repository)\n\n## Playground\n* [Kubescape playground](https://killercoda.com/saiyampathak/scenario/kubescape)\n\n## Tutorials\n\n* [Overview](https://youtu.be/wdBkt_0Qhbg)\n* [How To Secure Kubernetes Clusters With Kubescape And Armo](https://youtu.be/ZATGiDIDBQk)\n* [Scan Kubernetes YAML files](https://youtu.be/Ox6DaR7_4ZI)\n* [Scan Kubescape on an air-gapped environment (offline support)](https://youtu.be/IGXL9s37smM)\n* [Managing exceptions in the Kubescape SaaS version](https://youtu.be/OzpvxGmCR80)\n* [Configure and run customized frameworks](https://youtu.be/12Sanq_rEhs)\n* Customize control configurations: \n - [Kubescape CLI](https://youtu.be/955psg6TVu4) \n - [Kubescape SaaS](https://youtu.be/lIMVSVhH33o)\n\n## Install on Windows\n\nWindows\n\n**Requires powershell v5.0+**\n\n``` powershell\niwr -useb https://raw.githubusercontent.com/kubescape/kubescape/master/install.ps1 | iex\n```\n\nNote: if you get an error you might need to change the execution policy (i.e. enable Powershell) with\n\n``` powershell\nSet-ExecutionPolicy RemoteSigned -scope CurrentUser\n```\n\n\n\n## Install on macOS\n\nMacOS\n\n1. ```sh\n brew tap kubescape/tap\n ```\n2. ```sh\n brew install kubescape-cli\n ```\n\n\n## Install on NixOS or with nix (Community)\n\nNix/NixOS\n\nDirect issues installing `kubescape` via `nix` through the channels mentioned [here](https://nixos.wiki/wiki/Support)\n\nYou can use `nix` on Linux or macOS and on other platforms unofficially.\n\nTry it out in an ephemeral shell: `nix-shell -p kubescape`\n\nInstall declarative as usual\n\nNixOS:\n\n```nix\n # your other config ...\n environment.systemPackages = with pkgs; [\n # your other packages ...\n kubescape\n ];\n```\n\nhome-manager:\n\n```nix\n # your other config ...\n home.packages = with pkgs; [\n # your other packages ...\n kubescape\n ];\n```\n\nOr to your profile (not preferred): `nix-env --install -A nixpkgs.kubescape`\n\n\n\n## Usage & Examples\n\n### Examples\n\n\n#### Scan a running Kubernetes cluster and submit results to the [Kubescape SaaS version](https://cloud.armosec.io?utm_source=github&utm_medium=repository)\n```\nkubescape scan --submit --enable-host-scan --verbose\n```\n\n> Read [here](https://hub.armosec.io/docs/host-sensor?utm_source=github&utm_medium=repository) more about the `enable-host-scan` flag\n\n#### Scan a running Kubernetes cluster with [`nsa`](https://www.nsa.gov/Press-Room/News-Highlights/Article/Article/2716980/nsa-cisa-release-kubernetes-hardening-guidance/) framework and submit results to the [Kubescape SaaS version](https://cloud.armosec.io?utm_source=github&utm_medium=repository)\n```\nkubescape scan framework nsa --submit\n```\n\n\n#### Scan a running Kubernetes cluster with [`MITRE ATT&CK\u00ae`](https://www.microsoft.com/security/blog/2021/03/23/secure-containerized-environments-with-updated-threat-matrix-for-kubernetes/) framework and submit results to the [Kubescape SaaS version](https://cloud.armosec.io?utm_source=github&utm_medium=repository)\n```\nkubescape scan framework mitre --submit\n```\n\n\n#### Scan a running Kubernetes cluster with a specific control using the control name or control ID. [List of controls](https://hub.armosec.io/docs/controls?utm_source=github&utm_medium=repository) \n```\nkubescape scan control \"Privileged container\"\n```\n\n#### Scan using an alternative kubeconfig file\n```\nkubescape scan --kubeconfig cluster.conf\n```\n\n#### Scan specific namespaces\n```\nkubescape scan --include-namespaces development,staging,production\n```\n\n#### Scan cluster and exclude some namespaces\n```\nkubescape scan --exclude-namespaces kube-system,kube-public\n```\n\n#### Scan local `yaml`/`json` files before deploying. [Take a look at the demonstration](https://youtu.be/Ox6DaR7_4ZI). Submit the results in case the directory is a git repo. [docs](https://hub.armosec.io/docs/repository-scanning?utm_source=github&utm_medium=repository)\n```\nkubescape scan *.yaml --submit\n```\n\n#### Scan Kubernetes manifest files from a git repository [and submit the results](https://hub.armosec.io/docs/repository-scanning?utm_source=github&utm_medium=repository)\n```\nkubescape scan https://github.com/kubescape/kubescape --submit\n```\n\n#### Display all scanned resources (including the resources which passed) \n```\nkubescape scan --verbose\n```\n\n#### Output in `json` format\n\n> Add the `--format-version v2` flag \n\n```\nkubescape scan --format json --format-version v2 --output results.json\n```\n\n#### Output in `junit xml` format\n```\nkubescape scan --format junit --output results.xml\n```\n\n#### Output in `pdf` format - Contributed by [@alegrey91](https://github.com/alegrey91)\n\n```\nkubescape scan --format pdf --output results.pdf\n```\n\n#### Output in `prometheus` metrics format - Contributed by [@Joibel](https://github.com/Joibel)\n\n```\nkubescape scan --format prometheus\n```\n\n#### Output in `html` format\n\n```\nkubescape scan --format html --output results.html\n```\n\n#### Scan with exceptions, objects with exceptions will be presented as `exclude` and not `fail`\n[Full documentation](examples/exceptions/README.md)\n```\nkubescape scan --exceptions examples/exceptions/exclude-kube-namespaces.json\n```\n\n#### Scan Helm charts \n```\nkubescape scan --submit\n```\n> Kubescape will load the default value file\n\n#### Scan Kustomize Directory \n```\nkubescape scan --submit\n```\n> Kubescape will generate Kubernetes Yaml Objects using 'Kustomize' file and scans them for security.\n\n### Offline/Air-gaped Environment Support\n\n[Video tutorial](https://youtu.be/IGXL9s37smM)\n\nIt is possible to run Kubescape offline!\n#### Download all artifacts\n\n1. Download and save in local directory, if path not specified, will save all in `~/.kubescape`\n```\nkubescape download artifacts --output path/to/local/dir\n```\n2. Copy the downloaded artifacts to the air-gaped/offline environment\n\n3. Scan using the downloaded artifacts\n```\nkubescape scan --use-artifacts-from path/to/local/dir\n```\n\n#### Download a single artifact\n\nYou can also download a single artifact and scan with the `--use-from` flag\n\n1. Download and save in a file, if the file name is not specified, will save in `~/.kubescape/.json`\n```\nkubescape download framework nsa --output /path/nsa.json\n```\n2. Copy the downloaded artifacts to the air-gaped/offline environment\n\n3. Scan using the downloaded framework\n```\nkubescape scan framework nsa --use-from /path/nsa.json\n```\n\n\n## Scan Periodically using Helm \n[Please follow the instructions here](https://hub.armosec.io/docs/installation-of-armo-in-cluster?utm_source=github&utm_medium=repository)\n[helm chart repo](https://github.com/armosec/armo-helm)\n\n# Integrations\n\n## VS Code Extension \n\n \n\nScan the YAML files while writing them using the [vs code extension](https://github.com/armosec/vscode-kubescape/blob/master/README.md) \n\n## Lens Extension\n\nView Kubescape scan results directly in [Lens IDE](https://k8slens.dev/) using kubescape [Lens extension](https://github.com/armosec/lens-kubescape/blob/master/README.md)\n\n\n# Building Kubescape\n\n## Build on Windows\n\nWindows\n\n1. Install MSYS2 & build libgit _(needed only for the first time)_\n\n ```\n build.bat all\n ```\n\n> You can install MSYS2 separately by running `build.bat install` and build libgit2 separately by running `build.bat build`\n\n2. Build kubescape\n\n ```\n make build\n ```\n\n OR \n\n ```\n go build -tags=static .\n ```\n\n\n## Build on Linux/MacOS\n\nLinux / MacOS\n\n1. Install libgit2 dependency _(needed only for the first time)_\n \n ```\n make libgit2\n ```\n\n> `cmake` is required to build libgit2. You can install it by running `sudo apt-get install cmake` (Linux) or `brew install cmake` (macOS)\n\n2. Build kubescape\n\n ```\n make build\n ```\n\n OR \n\n ```\n go build -tags=static .\n ```\n\n3. Test\n\n ```\n make test\n ```\n\n\n\n## Build on pre-configured killercoda's ubuntu playground\n\n* [Pre-configured Killercoda's Ubuntu Playground](https://killercoda.com/suhas-gumma/scenario/kubescape-build-for-development)\n\n Pre-programmed actions executed by the playground \n\n\n* Clone the official GitHub repository of `Kubescape`.\n* [Automate the build process on Linux](https://github.com/kubescape/kubescape#build-on-linuxmacos)\n* The entire process involves executing multiple commands in order and it takes around 5-6 minutes to execute them all.\n\n\n\n\nInstructions to use the playground\n\n* Apply changes you wish to make to the kubescape directory using text editors like `Vim`.\n* [Build on Linux](https://github.com/kubescape/kubescape#build-on-linuxmacos)\n* Now, you can use Kubescape just like a normal user. Instead of using `kubescape`, use `./kubescape`. (Make sure you are inside kubescape directory because the command will execute the binary named `kubescape` in `kubescape directory`)\n\n\n\n## VS code configuration samples\n\nYou can use the sample files below to setup your VS code environment for building and debugging purposes.\n\n\n.vscode/settings.json\n\n```json5\n// .vscode/settings.json\n{\n \"go.testTags\": \"static\",\n \"go.buildTags\": \"static\",\n \"go.toolsEnvVars\": {\n \"CGO_ENABLED\": \"1\"\n }\n}\n```\n\n\n.vscode/launch.json\n\n```json5\n// .vscode/launch.json\n{\n \"version\": \"0.2.0\",\n \"configurations\": [\n {\n \"name\": \"Launch Package\",\n \"type\": \"go\",\n \"request\": \"launch\",\n \"mode\": \"auto\",\n \"program\": \"${workspaceFolder}/main.go\",\n \"args\": [\n \"scan\",\n \"--logger\",\n \"debug\"\n ],\n \"buildFlags\": \"-tags=static\"\n }\n ]\n}\n```\n\n\n# Under the hood\n\n## Technology\nKubescape is based on the [OPA engine](https://github.com/open-policy-agent/opa) and ARMO's posture controls.\n\nThe tools retrieve Kubernetes objects from the API server and run a set of [rego's snippets](https://www.openpolicyagent.org/docs/latest/policy-language/) developed by [ARMO](https://www.armosec.io?utm_source=github&utm_medium=repository).\n\nThe results by default are printed in a pretty \"console friendly\" manner, but they can be retrieved in JSON format for further processing.\n\nKubescape is an open source project, we welcome your feedback and ideas for improvement. We\u2019re also aiming to collaborate with the Kubernetes community to help make the tests more robust and complete as Kubernetes develops.\n\n## Thanks to all the contributors \u2764\ufe0f\n\n \n\n\n",
- "source_links": [],
- "id": 69
- },
- {
- "page_link": null,
- "title": "kubricks readme",
- "text": null,
- "source_links": [],
- "id": 70
- },
- {
- "page_link": null,
- "title": "kyverno readme",
- "text": null,
- "source_links": [],
- "id": 71
- },
- {
- "page_link": null,
- "title": "lakefs readme",
- "text": null,
- "source_links": [],
- "id": 72
- },
- {
- "page_link": "https://github.com/lightdash/lightdash",
- "title": "lightdash readme",
- "text": "
\n\n### Enable everybody in your company to answer their own questions using data\n\nconnect your dbt project --> add metrics into dbt --> share insights with your team\n\nIf you're a fan, star the repo \u2b50\ufe0f (we [plant a tree](#the-lightdash-forest) for every GitHub star we get \ud83c\udf31).\n\nCome join the team, [we're hiring](https://lightdash.notion.site/Lightdash-Job-Board-a2c7d872794b45deb7b76ad68701d750).\n\n
\n\n## Features:\n\n- [x] \ud83d\ude4f Familiar interface for your users to self-serve using pre-defined metrics\n- [x] \ud83d\udc69\u200d\ud83d\udcbb Declare dimensions and metrics in yaml alongside your dbt project\n- [x] \ud83e\udd16 Automatically creates dimensions from your dbt models\n- [x] \ud83d\udcd6 All dbt descriptions synced for your users\n- [x] \ud83e\uddee Table calculations make it easy to dig into your data, on the fly\n- [x] \ud83d\udd75\ufe0f\u200d\u2640\ufe0f Lineage lets you see the upstream and downstream dependencies of a model\n- [x] \ud83d\udcca Simple data visualisations for your metrics\n- [x] \ud83d\udc77\u200d\u2642\ufe0f Save charts & build dashboards to share your insights with your team\n- [x] \ud83d\ude80 Share your work as a URL or export results to use in any other tool\n\nSomething missing? Check out our [open issues](https://github.com/lightdash/lightdash/issues)\nto see if what you're looking for already exists (and give it a \ud83d\udc4d). Otherwise, we'd love it if\nyou'd [open a new issue with your request](https://github.com/lightdash/lightdash/issues/new/choose) \ud83d\ude0a\n\n## Demo\n\nPlay with our [demo app](https://demo.lightdash.com)!\n\n## Quick start\n\n### 1-click deploy\n\nDeploy Lightdash with 1-click (free options available\n\n
\n\nDeploy your own hosted Lightdash instance with Heroku (free account available). Check\nthe [documentation page](https://docs.lightdash.com/get-started/setup-lightdash/install-lightdash#deploy-to-heroku) for\nmore details.\n\n### Run locally\n\nTake advantage of our installation script to easily run Lightdash locally. Check\nthe [documentation page](https://docs.lightdash.com/get-started/setup-lightdash/install-lightdash#deploy-locally-with-our-installation-script)\nfor more details.\n\n```bash\ngit clone https://github.com/lightdash/lightdash\ncd lightdash\n./scripts/install.sh\n```\n\n### Deploy to production\n\nFollow our [kubernetes guide](https://docs.lightdash.com/guides/how-to-deploy-to-kubernetes) to deploy Lightdash to\nproduction using our [community helm charts](https://github.com/lightdash/helm-charts).\n\n### Sign up to Lightdash Cloud\n\nYou can avoid the hassle of hosting and configuring Lightdash yourself by\u00a0[signing up for Lightdash Cloud Public Beta](https://lightdash.typeform.com/public-beta#source=github) . We'll let you know once we're ready to bring you on board \ud83d\ude42\n\n## Getting started\n\nStep 1 - \u26a1\ufe0f [Install Lightdash](https://docs.lightdash.com/get-started/setup-lightdash/install-lightdash)\n\nStep 2 - \ud83d\udd0c [Connect a project](https://docs.lightdash.com/get-started/setup-lightdash/connect-project)\n\nStep 3 - \ud83d\udc69\u200d\ud83d\udcbb [Create your first metric](https://docs.lightdash.com/get-started/setup-lightdash/intro-metrics-dimensions)\n\n## Community Support\n\n\ud83d\udce3 If you want something a bit more, then [head on over to our Slack Community](https://join.slack.com/t/lightdash-community/shared_invite/zt-1bfmfnyfq-nSeTVj0cT7i2ekAHYbBVdQ) where you\u2019ll be able to chat directly with all of us at Lightdash and all the other amazing members of our community. We\u2019re happy to talk about anything from feature requests, implementation details or dbt quirks to memes and SQL jokes!\n\nYou can also keep up to date with Lightdash by following us elsewhere:\n\n- [Twitter](https://twitter.com/lightdash_devs)\n- [LinkedIn](https://www.linkedin.com/company/lightdash)\n\n## About Lightdash\n\n### \ud83d\uddc2 **Keep all of your business logic in one place.**\n\nWe let you define your metrics and dimensions directly in your dbt project, keeping all of your business logic in one place and increasing the context around your analytics.\n\nNo more deciding which of the four different values for total revenue is the **_right_** one (you can thank us later \ud83d\ude09).\n\n### \ud83e\udd1d **Build trust in your data.**\n\nWe want everyone at your company to feel like they can trust the data. So, why not **_show_** them that they can?\n\nWe bring the context you want around data quality _into_ your BI tool so people know that they can trust the data.\n\n### \ud83e\uddf1 **Give users meaningful building blocks to answer their own data questions.**\n\nWith Lightdash, you can leave the SQL to the experts. We give your data team the tools they need to build metrics and dimensions that everyone else can use.\n\nSo, anybody in the business can combine, segment, and filter these metrics and dimensions to answer their own questions.\n\n### \ud83d\udcd6 **Open source, now and forever**\n\n**Lightdash is built with our community, for our community.**\n\nWe think that a BI tool should be affordable, configurable, and secure - and being open source lets us be all three \ud83d\ude42\n\n### \ud83e\udd11 **Affordable analytics**\n\nLove Looker, but don't love Looker's price tag?\n\nWith Lightdash, we offer a free self-hosted service (it's all just open source!), or an affordable cloud-service option if you're looking for an easy analytics set up.\n\n## Docs\n\nHave a question about a feature? Or maybe fancy some light reading? Head on over to\nour [Lightdash documentation](https://docs.lightdash.com/) to check out some tutorials, reference docs, FAQs and more.\n\n## Reporting bugs and feature requests\n\nWant to report a bug or request a feature? Open an [issue](https://github.com/lightdash/lightdash/issues/new/choose).\n\n## The Lightdash Forest\n\nWe're planting trees with the help of the Lightdash community.\n\nTree planting is one of the simplest and most cost-effective means of mitigating climate change, by absorbing CO2 from the atmosphere. So we thought it would be pretty neat to grow a forest while we grow Lightdash.\n\nWant to help us grow our forest?\n\nJust star this repo! We plant a tree for every star we get on Github. \u2b50\ufe0f \u27a1\ufe0f \ud83c\udf31\n\nWe plant trees with TIST, you can read all about them here: https://program.tist.org/.\n\n## Developing locally & Contributing\n\nWe love contributions big or small, check out [our guide](https://github.com/lightdash/lightdash/blob/main/.github/CONTRIBUTING.md#contributing-to-lightdash) on how to get started.\n\nSee our [instructions](https://github.com/lightdash/lightdash/blob/main/.github/CONTRIBUTING.md#setup-development-environment) on developing Lightdash locally.\n\n## Contributors \u2728\n\nThanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):\n\n\n\n\n
\n\n\n\n\n\n\nThis project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification.\nContributions of any kind welcome!\n\n+\n",
- "source_links": [],
- "id": 73
- },
- {
- "page_link": "https://github.com/grafana/loki",
- "title": "loki readme",
- "text": "
\n\n\n\n\n[](https://bugs.chromium.org/p/oss-fuzz/issues/list?sort=-opened&can=1&q=proj:loki)\n\n# Loki: like Prometheus, but for logs.\n\nLoki is a horizontally-scalable, highly-available, multi-tenant log aggregation system inspired by [Prometheus](https://prometheus.io/).\nIt is designed to be very cost effective and easy to operate.\nIt does not index the contents of the logs, but rather a set of labels for each log stream.\n\nCompared to other log aggregation systems, Loki:\n\n- does not do full text indexing on logs. By storing compressed, unstructured logs and only indexing metadata, Loki is simpler to operate and cheaper to run.\n- indexes and groups log streams using the same labels you\u2019re already using with Prometheus, enabling you to seamlessly switch between metrics and logs using the same labels that you\u2019re already using with Prometheus.\n- is an especially good fit for storing [Kubernetes](https://kubernetes.io/) Pod logs. Metadata such as Pod labels is automatically scraped and indexed.\n- has native support in Grafana (needs Grafana v6.0).\n\nA Loki-based logging stack consists of 3 components:\n\n- `promtail` is the agent, responsible for gathering logs and sending them to Loki.\n- `loki` is the main server, responsible for storing logs and processing queries.\n- [Grafana](https://github.com/grafana/grafana) for querying and displaying the logs.\n\nLoki is like Prometheus, but for logs: we prefer a multidimensional label-based approach to indexing, and want a single-binary, easy to operate system with no dependencies.\nLoki differs from Prometheus by focusing on logs instead of metrics, and delivering logs via push, instead of pull.\n\n## Getting started\n\n* [Installing Loki](https://grafana.com/docs/loki/latest/installation/)\n* [Installing Promtail](https://grafana.com/docs/loki/latest/clients/promtail/installation/)\n* [Getting Started](https://grafana.com/docs/loki/latest/getting-started/)\n\n## Upgrading\n\n* [Upgrading Loki](https://grafana.com/docs/loki/latest/upgrading/)\n\n## Documentation\n\n* [Latest release](https://grafana.com/docs/loki/latest/)\n* [Upcoming release](https://grafana.com/docs/loki/next/), at the tip of the main branch\n\nCommonly used sections:\n\n- [API documentation](https://grafana.com/docs/loki/latest/api/) for getting logs into Loki.\n- [Labels](https://grafana.com/docs/loki/latest/getting-started/labels/)\n- [Operations](https://grafana.com/docs/loki/latest/operations/)\n- [Promtail](https://grafana.com/docs/loki/latest/clients/promtail/) is an agent which tails log files and pushes them to Loki.\n- [Pipelines](https://grafana.com/docs/loki/latest/clients/promtail/pipelines/) details the log processing pipeline.\n- [Docker Driver Client](https://grafana.com/docs/loki/latest/clients/docker-driver/) is a Docker plugin to send logs directly to Loki from Docker containers.\n- [LogCLI](https://grafana.com/docs/loki/latest/getting-started/logcli/) provides a command-line interface for querying logs.\n- [Loki Canary](https://grafana.com/docs/loki/latest/operations/loki-canary/) monitors your Loki installation for missing logs.\n- [Troubleshooting](https://grafana.com/docs/loki/latest/getting-started/troubleshooting/) presents help dealing with error messages.\n- [Loki in Grafana](https://grafana.com/docs/loki/latest/getting-started/grafana/) describes how to set up a Loki datasource in Grafana.\n\n## Getting Help\n\nIf you have any questions or feedback regarding Loki:\n\n- Search existing thread in the Grafana Labs community forum for Loki: [https://community.grafana.com](https://community.grafana.com/c/grafana-loki/)\n- Ask a question on the Loki Slack channel. To invite yourself to the Grafana Slack, visit [https://slack.grafana.com/](https://slack.grafana.com/) and join the #loki channel.\n- [File an issue](https://github.com/grafana/loki/issues/new) for bugs, issues and feature suggestions.\n- Send an email to [lokiproject@googlegroups.com](mailto:lokiproject@googlegroups.com), or use the [web interface](https://groups.google.com/forum/#!forum/lokiproject).\n- UI issues should be filed directly in [Grafana](https://github.com/grafana/grafana/issues/new).\n\nYour feedback is always welcome.\n\n## Further Reading\n\n- The original [design doc](https://docs.google.com/document/d/11tjK_lvp1-SVsFZjgOTr1vV3-q6vBAsZYIQ5ZeYBkyM/view) for Loki is a good source for discussion of the motivation and design decisions.\n- Callum Styan's March 2019 DevOpsDays Vancouver talk \"[Grafana Loki: Log Aggregation for Incident Investigations][devopsdays19-talk]\".\n- Grafana Labs blog post \"[How We Designed Loki to Work Easily Both as Microservices and as Monoliths][architecture-blog]\".\n- Tom Wilkie's early-2019 CNCF Paris/FOSDEM talk \"[Grafana Loki: like Prometheus, but for logs][fosdem19-talk]\" ([slides][fosdem19-slides], [video][fosdem19-video]).\n- David Kaltschmidt's KubeCon 2018 talk \"[On the OSS Path to Full Observability with Grafana][kccna18-event]\" ([slides][kccna18-slides], [video][kccna18-video]) on how Loki fits into a cloud-native environment.\n- Goutham Veeramachaneni's blog post \"[Loki: Prometheus-inspired, open source logging for cloud natives](https://grafana.com/blog/2018/12/12/loki-prometheus-inspired-open-source-logging-for-cloud-natives/)\" on details of the Loki architecture.\n- David Kaltschmidt's blog post \"[Closer look at Grafana's user interface for Loki](https://grafana.com/blog/2019/01/02/closer-look-at-grafanas-user-interface-for-loki/)\" on the ideas that went into the logging user interface.\n\n[devopsdays19-talk]: https://grafana.com/blog/2019/05/06/how-loki-correlates-metrics-and-logs-and-saves-you-money/\n[architecture-blog]: https://grafana.com/blog/2019/04/15/how-we-designed-loki-to-work-easily-both-as-microservices-and-as-monoliths/\n[fosdem19-talk]: https://fosdem.org/2019/schedule/event/loki_prometheus_for_logs/\n[fosdem19-slides]: https://speakerdeck.com/grafana/grafana-loki-like-prometheus-but-for-logs\n[fosdem19-video]: https://mirror.as35701.net/video.fosdem.org/2019/UB2.252A/loki_prometheus_for_logs.mp4\n[kccna18-event]: https://kccna18.sched.com/event/GrXC/on-the-oss-path-to-full-observability-with-grafana-david-kaltschmidt-grafana-labs\n[kccna18-slides]: https://speakerdeck.com/davkal/on-the-path-to-full-observability-with-oss-and-launch-of-loki\n[kccna18-video]: https://www.youtube.com/watch?v=U7C5SpRtK74&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU&index=346\n\n## Contributing\n\nRefer to [CONTRIBUTING.md](CONTRIBUTING.md)\n\n### Building from source\n\nLoki can be run in a single host, no-dependencies mode using the following commands.\n\nYou need `go`, we recommend using the version found in [our build Dockerfile](https://github.com/grafana/loki/blob/main/loki-build-image/Dockerfile)\n\n```bash\n\n$ go get github.com/grafana/loki\n$ cd $GOPATH/src/github.com/grafana/loki # GOPATH is $HOME/go by default.\n\n$ go build ./cmd/loki\n$ ./loki -config.file=./cmd/loki/loki-local-config.yaml\n...\n```\n\nTo build Promtail on non-Linux platforms, use the following command:\n\n```bash\n$ go build ./clients/cmd/promtail\n```\n\nOn Linux, Promtail requires the systemd headers to be installed if\nJournal support is enabled.\nTo enable Journal support the go build tag flag `promtail_journal_enabled` should be passed\n\nWith Journal support on Ubuntu, run with the following commands:\n\n```bash\n$ sudo apt install -y libsystemd-dev\n$ go build --tags=promtail_journal_enabled ./clients/cmd/promtail\n```\n\nWith Journal support on CentOS, run with the following commands:\n\n```bash\n$ sudo yum install -y systemd-devel\n$ go build --tags=promtail_journal_enabled ./clients/cmd/promtail\n```\n\nOtherwise, to build Promtail without Journal support, run `go build`\nwith CGO disabled:\n\n```bash\n$ CGO_ENABLED=0 go build ./clients/cmd/promtail\n```\n## Adopters\nPlease see [ADOPTERS.md](ADOPTERS.md) for some of the organizations using Loki today.\nIf you would like to add your organization to the list, please open a PR to add it to the list.\n\n## License\n\nGrafana Loki is distributed under [AGPL-3.0-only](LICENSE). For Apache-2.0 exceptions, see [LICENSING.md](LICENSING.md).\n",
- "source_links": [],
- "id": 74
- },
- {
- "page_link": "external-access.md",
- "title": "external-access",
- "text": "# Ship Logs to Loki from beyond this cluster\n\nLoki by default is deployed in a cluster local way. The simplest way to enable external ingress is to set your install to use basic auth, which can be done via editing your `context.yaml` file with:\n\n\n```yaml\nconfiguration:\n loki:\n hostname: loki. # you can find the configured domain in `workspace.yaml`\n basicAuth:\n user: \n password: \n```\nyou can use `plural crypto random` to generate a high-entropy password if that is helpful as well.\n\n\nOnce that file has been edited, you can run `plural build --only loki && plural deploy --commit \"configure loki ingress\"` to update your loki install.",
- "source_links": [],
- "id": 75
- },
- {
- "page_link": "https://github.com/mage-ai/mage-ai",
- "title": "mage readme",
- "text": "
\n \n \n \n
\n
\n \ud83e\uddd9 A modern replacement for Airflow.\n
\n\n
\n Documentation \ud83c\udf2a\ufe0f \n Watch 2 min demo \ud83c\udf0a \n Play with live tool \ud83d\udd25 \n \n Get instant help\n \n
\n Integrate and synchronize data from 3rd party sources\n
\n\n
\n Build real-time and batch pipelines to transform data using Python, SQL, and R\n
\n\n
\n Run, monitor, and orchestrate thousands of pipelines without losing sleep\n
\n\n \n\n
1\ufe0f\u20e3 \ud83c\udfd7\ufe0f
\n
Build
\n
\n Have you met anyone who said they loved developing in Airflow?\n \n That\u2019s why we designed an easy developer experience that you\u2019ll enjoy.\n
\n\n| | |\n| --- | --- |\n| Easy developer experience Start developing locally with a single command or launch a dev environment in your cloud using Terraform.
Language of choice Write code in Python, SQL, or R in the same data pipeline for ultimate flexibility.
Engineering best practices built-in Each step in your pipeline is a standalone file containing modular code that\u2019s reusable and testable with data validations. No more DAGs with spaghetti code. | |\n\n
\n \u2193\n
\n\n
2\ufe0f\u20e3 \ud83d\udd2e
\n
Preview
\n
\n Stop wasting time waiting around for your DAGs to finish testing.\n \n Get instant feedback from your code each time you run it.\n
\n\n| | |\n| --- | --- |\n| Interactive code Immediately see results from your code\u2019s output with an interactive notebook UI.
Data is a first-class citizen Each block of code in your pipeline produces data that can be versioned, partitioned, and cataloged for future use.
Collaborate on cloud Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment. | |\n\n
\n \u2193\n
\n\n
3\ufe0f\u20e3 \ud83d\ude80
\n
Launch
\n
\n Don\u2019t have a large team dedicated to Airflow?\n \n Mage makes it easy for a single developer or small team to scale up and manage thousands of pipelines.\n
\n\n| | |\n| --- | --- |\n| Fast deploy Deploy Mage to AWS, GCP, or Azure with only 2 commands using maintained Terraform templates.
Scaling made simple Transform very large datasets directly in your data warehouse or through a native integration with Spark.
Observability Operationalize your pipelines with built-in monitoring, alerting, and observability through an intuitive UI. | |\n\n \n\n# \ud83e\uddd9 Intro\n\nMage is an open-source data pipeline tool for transforming and integrating data.\n\n1. [Quick start](#%EF%B8%8F-quick-start)\n1. [Demo](#-demo)\n1. [Tutorials](#-tutorials)\n1. [Documentation](https://docs.mage.ai)\n1. [Features](#-features)\n1. [Core design principles](https://docs.mage.ai/design/core-design-principles)\n1. [Core abstractions](https://docs.mage.ai/design/core-abstractions)\n1. [Contributing](https://docs.mage.ai/community/contributing)\n\n \n\n# \ud83c\udfc3\u200d\u2640\ufe0f Quick start\n\nYou can install and run Mage using Docker (recommended), `pip`, or `conda`.\n\n### Install using Docker\n\n1. Create a new project and launch tool (change `demo_project` to any other name if you want):\n ```bash\n docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai \\\n /app/run_app.sh mage start demo_project\n ```\n\n - If you want to run Mage locally on a different port, change the first port after `-p`\n in the command above. For example, to change the port to `6790`, run:\n\n ```bash\n docker run -it -p 6790:6789 -v $(pwd):/home/src mageai/mageai \\\n /app/run_app.sh mage start demo_project\n ```\n\n Want to use Spark or other integrations? Read more about [integrations](https://docs.mage.ai/data-integrations/overview).\n\n1. Open [http://localhost:6789](http://localhost:6789) in your browser and build a pipeline.\n\n - If you changed the Docker port for running Mage locally, go to the url\n `http://127.0.0.1:[port]` (e.g. http://127.0.0.1:6790) in your browser to\n view the pipelines dashboard.\n\n\n### Using `pip` or `conda`\n\n1. Install Mage\n\n #### (a) To the current virtual environment:\n ```bash\n pip install mage-ai\n ```\n or\n ```bash\n conda install -c conda-forge mage-ai\n ```\n\n #### (b) To a new virtual environment (e.g., `myenv`):\n ```bash\n python3 -m venv myenv\n source myenv/bin/activate\n pip install mage-ai\n ```\n or\n ```bash\n conda create -n myenv -c conda-forge mage-ai\n conda activate myenv\n ```\n\n For additional packages (e.g. `spark`, `postgres`, etc), please see [Installing extra packages](https://docs.mage.ai/getting-started/setup#installing-extra-packages).\n\n If you run into errors, please see [Install errors](https://docs.mage.ai/getting-started/setup#errors).\n\n1. Create new project and launch tool (change `demo_project` to any other name if you want):\n ```bash\n mage start demo_project\n ```\n1. Open [http://localhost:6789](http://localhost:6789) in your browser and build a pipeline.\n\n \n\n# \ud83c\udfae Demo\n\n### Live demo\n\nBuild and run a data pipeline with our [demo app](https://demo.mage.ai/).\n\n> WARNING\n>\n> The live demo is public to everyone, please don\u2019t save anything sensitive (e.g. passwords, secrets, etc).\n### Demo video (2 min)\n\n[](https://www.youtube.com/watch?v=hrsErfPDits \"Mage quick start demo\")\n\nClick the image to play video\n\n \n\n# \ud83d\udc69\u200d\ud83c\udfeb Tutorials\n\n- [Load data from API, transform it, and export it to PostgreSQL](https://docs.mage.ai/tutorials/load-api-data)\n- [Integrate Mage into an existing Airflow project](https://docs.mage.ai/integrations/airflow)\n- [Train model on Titanic dataset](https://docs.mage.ai/tutorials/train-model)\n- [Set up DBT models and orchestrate DBT runs](https://docs.mage.ai/integrations/dbt-models)\n\n\n\n \n\n# \ud83d\udd2e [Features](https://docs.mage.ai/about/features)\n\n| | | |\n| --- | --- | --- |\n| \ud83c\udfb6 | [Orchestration](https://docs.mage.ai/design/data-pipeline-management) | Schedule and manage data pipelines with observability. |\n| \ud83d\udcd3 | [Notebook](https://docs.mage.ai/about/features#notebook-for-building-data-pipelines) | Interactive Python, SQL, & R editor for coding data pipelines. |\n| \ud83c\udfd7\ufe0f | [Data integrations](https://docs.mage.ai/data-integrations/overview) | Synchronize data from 3rd party sources to your internal destinations. |\n| \ud83d\udeb0 | [Streaming pipelines](https://docs.mage.ai/guides/streaming-pipeline) | Ingest and transform real-time data. |\n| \u274e | [DBT](https://docs.mage.ai/dbt/overview) | Build, run, and manage your DBT models with Mage. |\n\nA sample data pipeline defined across 3 files \u279d\n\n1. Load data \u279d\n ```python\n @data_loader\n def load_csv_from_file():\n return pd.read_csv('default_repo/titanic.csv')\n ```\n1. Transform data \u279d\n ```python\n @transformer\n def select_columns_from_df(df, *args):\n return df[['Age', 'Fare', 'Survived']]\n ```\n1. Export data \u279d\n ```python\n @data_exporter\n def export_titanic_data_to_disk(df) -> None:\n df.to_csv('default_repo/titanic_transformed.csv')\n ```\n\nWhat the data pipeline looks like in the UI \u279d\n\n\n\nNew? We recommend reading about [blocks](https://docs.mage.ai/design/blocks) and\nlearning from a [hands-on tutorial](https://docs.mage.ai/tutorials/load-api-data).\n\n[](https://www.mage.ai/chat)\n\n \n\n# \ud83c\udfd4\ufe0f [Core design principles](https://docs.mage.ai/design/core-design-principles)\n\nEvery user experience and technical design decision adheres to these principles.\n\n| | | |\n| --- | --- | --- |\n| \ud83d\udcbb | [Easy developer experience](https://docs.mage.ai/design/core-design-principles#easy-developer-experience) | Open-source engine that comes with a custom notebook UI for building data pipelines. |\n| \ud83d\udea2 | [Engineering best practices built-in](https://docs.mage.ai/design/core-design-principles#engineering-best-practices-built-in) | Build and deploy data pipelines using modular code. No more writing throwaway code or trying to turn notebooks into scripts. |\n| \ud83d\udcb3 | [Data is a first-class citizen](https://docs.mage.ai/design/core-design-principles#data-is-a-first-class-citizen) | Designed from the ground up specifically for running data-intensive workflows. |\n| \ud83e\ude90 | [Scaling is made simple](https://docs.mage.ai/design/core-design-principles#scaling-is-made-simple) | Analyze and process large data quickly for rapid iteration. |\n\n \n\n# \ud83d\udef8 [Core abstractions](https://docs.mage.ai/design/core-abstractions)\n\nThese are the fundamental concepts that Mage uses to operate.\n\n| | |\n| --- | --- |\n| [Project](https://docs.mage.ai/design/core-abstractions#project) | Like a repository on GitHub; this is where you write all your code. |\n| [Pipeline](https://docs.mage.ai/design/core-abstractions#pipeline) | Contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. |\n| [Block](https://docs.mage.ai/design/core-abstractions#block) | A file with code that can be executed independently or within a pipeline. |\n| [Data product](https://docs.mage.ai/design/core-abstractions#data-product) | Every block produces data after it's been executed. These are called data products in Mage. |\n| [Trigger](https://docs.mage.ai/design/core-abstractions#trigger) | A set of instructions that determine when or how a pipeline should run. |\n| [Run](https://docs.mage.ai/design/core-abstractions#run) | Stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. |\n\n \n\n# \ud83d\ude4b\u200d\u2640\ufe0f Contributing and developing\n\nAdd features and instantly improve the experience for everyone.\n\nCheck out the [contributing guide](https://docs.mage.ai/community/contributing)\nto setup your development environment and start building.\n\n \n\n# \ud83d\udc68\u200d\ud83d\udc69\u200d\ud83d\udc67\u200d\ud83d\udc66 Community\nIndividually, we\u2019re a mage.\n\n> \ud83e\uddd9 Mage\n>\n> Magic is indistinguishable from advanced technology.\n> A mage is someone who uses magic (aka advanced technology).\nTogether, we\u2019re Magers!\n\n> \ud83e\uddd9\u200d\u2642\ufe0f\ud83e\uddd9 Magers (`/\u02c8m\u0101j\u0259r/`)\n>\n> A group of mages who help each other realize their full potential!\nLet\u2019s hang out and chat together \u279d\n\n[](https://www.mage.ai/chat)\n\nFor real-time news, fun memes, data engineering topics, and more, join us on \u279d\n\n| | |\n| --- | --- |\n| | [Twitter](https://twitter.com/mage_ai) |\n| | [LinkedIn](https://www.linkedin.com/company/magetech/mycompany) |\n| | [GitHub](https://github.com/mage-ai/mage-ai) |\n| | [Slack](https://www.mage.ai/chat) |\n\n \n\n# \ud83e\udd14 Frequently Asked Questions (FAQs)\n\nCheck out our [FAQ page](https://www.notion.so/mageai/Mage-FAQs-33d93ee65f934ed39568f8a4bc823b39) to find answers to some of our most asked questions.\n\n \n\n# \ud83e\udeaa License\nSee the [LICENSE](LICENSE) file for licensing information.\n\n[](https://www.mage.ai/)\n\n \n",
- "source_links": [],
- "id": 76
- },
- {
- "page_link": "https://github.com/meilisearch/meilisearch",
- "title": "meilisearch readme",
- "text": "
\n\n\ud83d\udd25 [**Try it!**](https://where2watch.meilisearch.com/) \ud83d\udd25\n\n## \u2728 Features\n\n- **Search-as-you-type:** find search results in less than 50 milliseconds\n- **[Typo tolerance](https://www.meilisearch.com/docs/learn/getting_started/customizing_relevancy#typo-tolerance):** get relevant matches even when queries contain typos and misspellings\n- **[Filtering](https://www.meilisearch.com/docs/learn/fine_tuning_results/filtering) and [faceted search](https://www.meilisearch.com/docs/learn/fine_tuning_results/faceted_search):** enhance your user's search experience with custom filters and build a faceted search interface in a few lines of code\n- **[Sorting](https://www.meilisearch.com/docs/learn/fine_tuning_results/sorting):** sort results based on price, date, or pretty much anything else your users need\n- **[Synonym support](https://www.meilisearch.com/docs/learn/getting_started/customizing_relevancy#synonyms):** configure synonyms to include more relevant content in your search results\n- **[Geosearch](https://www.meilisearch.com/docs/learn/fine_tuning_results/geosearch):** filter and sort documents based on geographic data\n- **[Extensive language support](https://www.meilisearch.com/docs/learn/what_is_meilisearch/language):** search datasets in any language, with optimized support for Chinese, Japanese, Hebrew, and languages using the Latin alphabet\n- **[Security management](https://www.meilisearch.com/docs/learn/security/master_api_keys):** control which users can access what data with API keys that allow fine-grained permissions handling\n- **[Multi-Tenancy](https://www.meilisearch.com/docs/learn/security/tenant_tokens):** personalize search results for any number of application tenants\n- **Highly Customizable:** customize Meilisearch to your specific needs or use our out-of-the-box and hassle-free presets\n- **[RESTful API](https://www.meilisearch.com/docs/reference/api/overview):** integrate Meilisearch in your technical stack with our plugins and SDKs\n- **Easy to install, deploy, and maintain**\n\n## \ud83d\udcd6 Documentation\n\nYou can consult Meilisearch's documentation at [https://www.meilisearch.com/docs](https://www.meilisearch.com/docs/).\n\n## \ud83d\ude80 Getting started\n\nFor basic instructions on how to set up Meilisearch, add documents to an index, and search for documents, take a look at our [Quick Start](https://www.meilisearch.com/docs/learn/getting_started/quick_start) guide.\n\nYou may also want to check out [Meilisearch 101](https://www.meilisearch.com/docs/learn/getting_started/filtering_and_sorting) for an introduction to some of Meilisearch's most popular features.\n\n## \u26a1 Supercharge your Meilisearch experience\n\nSay goodbye to server deployment and manual updates with [Meilisearch Cloud](https://www.meilisearch.com/pricing?utm_campaign=oss&utm_source=engine&utm_medium=meilisearch). Get started with a 14-day free trial! No credit card required.\n\n## \ud83e\uddf0 SDKs & integration tools\n\nInstall one of our SDKs in your project for seamless integration between Meilisearch and your favorite language or framework!\n\nTake a look at the complete [Meilisearch integration list](https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks).\n\n[](https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks)\n\n## \u2699\ufe0f Advanced usage\n\nExperienced users will want to keep our [API Reference](https://www.meilisearch.com/docs/reference/api/overview) close at hand.\n\nWe also offer a wide range of dedicated guides to all Meilisearch features, such as [filtering](https://www.meilisearch.com/docs/learn/fine_tuning_results/filtering), [sorting](https://www.meilisearch.com/docs/learn/fine_tuning_results/sorting), [geosearch](https://www.meilisearch.com/docs/learn/fine_tuning_results/geosearch), [API keys](https://www.meilisearch.com/docs/learn/security/master_api_keys), and [tenant tokens](https://www.meilisearch.com/docs/learn/security/tenant_tokens).\n\nFinally, for more in-depth information, refer to our articles explaining fundamental Meilisearch concepts such as [documents](https://www.meilisearch.com/docs/learn/core_concepts/documents) and [indexes](https://www.meilisearch.com/docs/learn/core_concepts/indexes).\n\n## \ud83d\udcca Telemetry\n\nMeilisearch collects **anonymized** data from users to help us improve our product. You can [deactivate this](https://www.meilisearch.com/docs/learn/what_is_meilisearch/telemetry#how-to-disable-data-collection) whenever you want.\n\nTo request deletion of collected data, please write to us at\u00a0[privacy@meilisearch.com](mailto:privacy@meilisearch.com). Don't forget to include your `Instance UID` in the message, as this helps us quickly find and delete your data.\n\nIf you want to know more about the kind of data we collect and what we use it for, check the [telemetry section](https://www.meilisearch.com/docs/learn/what_is_meilisearch/telemetry) of our documentation.\n\n## \ud83d\udceb Get in touch!\n\nMeilisearch is a search engine created by [Meili](https://www.welcometothejungle.com/en/companies/meilisearch), a software development company based in France and with team members all over the world. Want to know more about us? [Check out our blog!](https://blog.meilisearch.com/)\n\n\ud83d\uddde [Subscribe to our newsletter](https://meilisearch.us2.list-manage.com/subscribe?u=27870f7b71c908a8b359599fb&id=79582d828e) if you don't want to miss any updates! We promise we won't clutter your mailbox: we only send one edition every two months.\n\n\ud83d\udc8c Want to make a suggestion or give feedback? Here are some of the channels where you can reach us:\n\n- For feature requests, please visit our [product repository](https://github.com/meilisearch/product/discussions)\n- Found a bug? Open an [issue](https://github.com/meilisearch/meilisearch/issues)!\n- Want to be part of our Discord community? [Join us!](https://discord.gg/meilisearch)\n\nThank you for your support!\n\n## \ud83d\udc69\u200d\ud83d\udcbb Contributing\n\nMeilisearch is, and will always be, open-source! If you want to contribute to the project, please take a look at [our contribution guidelines](CONTRIBUTING.md).\n\n## \ud83d\udce6 Versioning\n\nMeilisearch releases and their associated binaries are available [in this GitHub page](https://github.com/meilisearch/meilisearch/releases).\n\nThe binaries are versioned following [SemVer conventions](https://semver.org/). To know more, read our [versioning policy](https://github.com/meilisearch/engine-team/blob/main/resources/versioning-policy.md).\n\nDifferently from the binaries, crates in this repository are not currently available on [crates.io](https://crates.io/) and do not follow [SemVer conventions](https://semver.org).\n",
- "source_links": [],
- "id": 77
- },
- {
- "page_link": "https://github.com/metabase/metabase",
- "title": "metabase readme",
- "text": "# Metabase\n\n[Metabase](https://www.metabase.com) is the easy, open-source way for everyone in your company to ask questions and learn from data.\n\n\n\n[](https://github.com/metabase/metabase/releases)\n[](https://circleci.com/gh/metabase/metabase)\n[](https://codecov.io/gh/metabase/metabase)\n\n\n## Features\n\n- [Set up in five minutes](https://www.metabase.com/docs/latest/setting-up-metabase.html) (we're not kidding).\n- Let anyone on your team [ask questions](https://www.metabase.com/docs/latest/users-guide/04-asking-questions.html) without knowing SQL.\n- Use the [SQL editor](https://www.metabase.com/docs/latest/users-guide/writing-sql.html) for more complex queries.\n- Build handsome, interactive [dashboards](https://www.metabase.com/docs/latest/users-guide/07-dashboards.html) with filters, auto-refresh, fullscreen, and custom click behavior.\n- Create [models](https://www.metabase.com/learn/getting-started/models) that clean up, annotate, and/or combine raw tables.\n- Define canonical [segments and metrics](https://www.metabase.com/docs/latest/administration-guide/07-segments-and-metrics.html) for your team to use.\n- Send data to Slack or email on a schedule with [dashboard subscriptions](https://www.metabase.com/docs/latest/users-guide/dashboard-subscriptions).\n- Set up [alerts](https://www.metabase.com/docs/latest/users-guide/15-alerts.html) to have Metabase notify you when your data changes.\n- [Embed charts and dashboards](https://www.metabase.com/docs/latest/administration-guide/13-embedding.html) in your app, or even [your entire Metabase](https://www.metabase.com/docs/latest/enterprise-guide/full-app-embedding.html).\n\nTake a [tour of Metabase](https://www.metabase.com/learn/getting-started/tour-of-metabase).\n\n## Supported databases\n\n- [Officially supported databases](../../databases/connecting.md#connecting-to-supported-databases)\n- [Community-supported drivers](../partner-and-community-drivers.md#community-drivers)\n\n## Installation\n\nMetabase can be run just about anywhere. Check out our [Installation Guides](https://www.metabase.com/docs/latest/operations-guide/installing-metabase.html).\n\n## Contributing\n\nTo get started with a development installation of the Metabase, check out our [Developers Guide](https://www.metabase.com/docs/latest/developers-guide/start).\n\n## Internationalization\n\nWe want Metabase to be available in as many languages as possible. See which translations are available and help contribute to internationalization using our project over at [POEditor](https://poeditor.com/join/project/ynjQmwSsGh). You can also check out our [policies on translations](https://www.metabase.com/docs/latest/administration-guide/localization.html).\n\n## Extending Metabase\n\nMetabase also allows you to hit our Query API directly from Javascript to integrate the simple analytics we provide with your own application or third party services to do things like:\n\n- Build moderation interfaces.\n- Export subsets of your users to third party marketing automation software.\n- Provide a specialized customer lookup application for the people in your company.\n\nCheck out our guide, [Working with the Metabase API](https://www.metabase.com/learn/administration/metabase-api).\n\n## Security Disclosure\n\nSee [SECURITY.md](./SECURITY.md) for details.\n\n## License\n\nThis repository contains the source code for both the Open Source edition of Metabase, released under the AGPL, as well as the [commercial editions of Metabase](https://www.metabase.com/pricing), which are released under the Metabase Commercial Software License.\n\nSee [LICENSE.txt](./LICENSE.txt) for details.\n\nUnless otherwise noted, all files \u00a9 2022 Metabase, Inc.\n\n## [Metabase Experts](https://www.metabase.com/partners/)\n\nIf you\u2019d like more technical resources to set up your data stack with Metabase, connect with a [Metabase Expert](https://www.metabase.com/partners/?utm_source=readme&utm_medium=metabase-expetrs&utm_campaign=readme).\n",
- "source_links": [],
- "id": 78
- },
- {
- "page_link": "https://github.com/grafana/mimir",
- "title": "mimir readme",
- "text": "# Grafana Mimir\n\n
\n\nGrafana Mimir is an open source software project that provides a scalable long-term storage for [Prometheus](https://prometheus.io). Some of the core strengths of Grafana Mimir include:\n\n- **Easy to install and maintain:** Grafana Mimir\u2019s extensive documentation, tutorials, and deployment tooling make it quick to get started. Using its monolithic mode, you can get Grafana Mimir up and running with just one binary and no additional dependencies. Once deployed, the best-practice dashboards, alerts, and runbooks packaged with Grafana Mimir make it easy to monitor the health of the system.\n- **Massive scalability:** You can run Grafana Mimir's horizontally-scalable architecture across multiple machines, resulting in the ability to process orders of magnitude more time series than a single Prometheus instance. Internal testing shows that Grafana Mimir handles up to 1 billion active time series.\n- **Global view of metrics:** Grafana Mimir enables you to run queries that aggregate series from multiple Prometheus instances, giving you a global view of your systems. Its query engine extensively parallelizes query execution, so that even the highest-cardinality queries complete with blazing speed.\n- **Cheap, durable metric storage:** Grafana Mimir uses object storage for long-term data storage, allowing it to take advantage of this ubiquitous, cost-effective, high-durability technology. It is compatible with multiple object store implementations, including AWS S3, Google Cloud Storage, Azure Blob Storage, OpenStack Swift, as well as any S3-compatible object storage.\n- **High availability:** Grafana Mimir replicates incoming metrics, ensuring that no data is lost in the event of machine failure. Its horizontally scalable architecture also means that it can be restarted, upgraded, or downgraded with zero downtime, which means no interruptions to metrics ingestion or querying.\n- **Natively multi-tenant:** Grafana Mimir\u2019s multi-tenant architecture enables you to isolate data and queries from independent teams or business units, making it possible for these groups to share the same cluster. Advanced limits and quality-of-service controls ensure that capacity is shared fairly among tenants.\n\n## Migrating to Grafana Mimir\n\nIf you're migrating to Grafana Mimir, refer to the following documents:\n\n- [Migrating from Thanos or Prometheus to Grafana Mimir](https://grafana.com/docs/mimir/latest/migrate/migrating-from-thanos-or-prometheus/).\n- [Migrating from Cortex to Grafana Mimir](https://grafana.com/docs/mimir/latest/migrate/migrate-from-cortex/)\n\n## Deploying Grafana Mimir\n\nFor information about how to deploy Grafana Mimir, refer to [Deploy Grafana Mimir](https://grafana.com/docs/mimir/latest/operators-guide/deploy-grafana-mimir/).\n\n## Getting started\n\nIf you\u2019re new to Grafana Mimir, read the [Getting started guide](https://grafana.com/docs/mimir/latest/operators-guide/get-started/).\n\nBefore deploying Grafana Mimir in a production environment, read:\n\n1. [An overview of Grafana Mimir\u2019s architecture](https://grafana.com/docs/mimir/latest/operators-guide/architecture/)\n1. [Configure Grafana Mimir](https://grafana.com/docs/mimir/latest/operators-guide/configure/)\n1. [Run Grafana Mimir in production](https://grafana.com/docs/mimir/latest/operators-guide/run-production-environment/)\n\n## Documentation\n\nRefer to the following links to access Grafana Mimir documentation:\n\n- [Latest release](https://grafana.com/docs/mimir/latest/)\n- [Upcoming release](https://grafana.com/docs/mimir/next/), at the tip of the main branch\n\n## Contributing\n\nTo contribute to Grafana Mimir, refer to [Contributing to Grafana Mimir](https://github.com/grafana/mimir/tree/main/docs/internal/contributing).\n\n## Join the Grafana Mimir discussion\n\nIf you have any questions or feedback regarding Grafana Mimir, join the [Grafana Mimir Discussion](https://github.com/grafana/mimir/discussions). Alternatively, consider joining the monthly [Grafana Mimir Community Call](https://docs.google.com/document/d/1E4jJcGicvLTyMEY6cUFFZUg_I8ytrBuW8r5yt1LyMv4).\n\nYour feedback is always welcome, and you can also share it via the [`#mimir` Slack channel](https://slack.grafana.com/).\n\n## License\n\nGrafana Mimir is distributed under [AGPL-3.0-only](LICENSE).\n",
- "source_links": [],
- "id": 79
- },
- {
- "page_link": "external-access.md",
- "title": "external-access",
- "text": "# Ship Metrics to Mimir from beyond this cluster\n\nMimir by default is deployed in a cluster local way. The simplest way to enable external ingress is to set your install to use basic auth, which can be done via editing your `context.yaml` file with:\n\n\n```yaml\nconfiguration:\n mimir:\n hostname: mimir. # you can find the configured domain in `workspace.yaml`\n basicAuth:\n user: \n password: \n```\nyou can use `plural crypto random` to generate a high-entropy password if that is helpful as well.\n\n\nOnce that file has been edited, you can run `plural build --only mimir && plural deploy --commit \"configure loki ingress\"` to update your loki install.\n\nWe have often seen people use remote prometheus writes to ship metrics from a prometheus scraper to this centralized mimir instance.\n\n## Connection Setup\n\nTo authenticate to your mimir instance from a remote metric shipper, you'll need to add two headers:\n\n```\nAuthentication: Basic b64(:)\nX-Scope-OrgID: \n```\n\nYou'll need to base64 encode the username:password pair, which can be done with `echo $user:$password | base64`. Since we set up mimir with multi-tenancy, you'll need to add an `X-Scope-OrgID` with a tenant header, which the default global tenant is just the name of your plural cluster found in `workspace.yaml`\n",
- "source_links": [],
- "id": 80
- },
- {
- "page_link": null,
- "title": "minecraft readme",
- "text": null,
- "source_links": [],
- "id": 81
- },
- {
- "page_link": "https://github.com/minio/minio",
- "title": "minio readme",
- "text": "# MinIO Quickstart Guide\n\n[](https://slack.min.io) [](https://hub.docker.com/r/minio/minio/) [](https://github.com/minio/minio/blob/master/LICENSE)\n\n[](https://min.io)\n\nMinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.\n\nThis README provides quickstart instructions on running MinIO on bare metal hardware, including container-based installations. For Kubernetes environments, use the [MinIO Kubernetes Operator](https://github.com/minio/operator/blob/master/README.md).\n\n## Container Installation\n\nUse the following commands to run a standalone MinIO server as a container.\n\nStandalone MinIO servers are best suited for early development and evaluation. Certain features such as versioning, object locking, and bucket replication\nrequire distributed deploying MinIO with Erasure Coding. For extended development and production, deploy MinIO with Erasure Coding enabled - specifically,\nwith a *minimum* of 4 drives per MinIO server. See [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html)\nfor more complete documentation.\n\n### Stable\n\nRun the following command to run the latest stable image of MinIO as a container using an ephemeral data volume:\n\n```sh\npodman run -p 9000:9000 -p 9001:9001 \\\n quay.io/minio/minio server /data --console-address \":9001\"\n```\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded\nobject browser built into MinIO Server. Point a web browser running on the host machine to and log in with the\nroot credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See\n[Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers,\nsee to view MinIO SDKs for supported languages.\n\n> NOTE: To deploy MinIO on with persistent storage, you must map local persistent directories from the host OS to the container using the `podman -v` option. For example, `-v /mnt/data:/data` maps the host OS drive at `/mnt/data` to `/data` on the container.\n\n## macOS\n\nUse the following commands to run a standalone MinIO server on macOS.\n\nStandalone MinIO servers are best suited for early development and evaluation. Certain features such as versioning, object locking, and bucket replication require distributed deploying MinIO with Erasure Coding. For extended development and production, deploy MinIO with Erasure Coding enabled - specifically, with a *minimum* of 4 drives per MinIO server. See [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html) for more complete documentation.\n\n### Homebrew (recommended)\n\nRun the following command to install the latest stable MinIO package using [Homebrew](https://brew.sh/). Replace ``/data`` with the path to the drive or directory in which you want MinIO to store data.\n\n```sh\nbrew install minio/stable/minio\nminio server /data\n```\n\n> NOTE: If you previously installed minio using `brew install minio` then it is recommended that you reinstall minio from `minio/stable/minio` official repo instead.\n\n```sh\nbrew uninstall minio\nbrew install minio/stable/minio\n```\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded web-based object browser built into MinIO Server. Point a web browser running on the host machine to and log in with the root credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See [Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers, see to view MinIO SDKs for supported languages.\n\n### Binary Download\n\nUse the following command to download and run a standalone MinIO server on macOS. Replace ``/data`` with the path to the drive or directory in which you want MinIO to store data.\n\n```sh\nwget https://dl.min.io/server/minio/release/darwin-amd64/minio\nchmod +x minio\n./minio server /data\n```\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded web-based object browser built into MinIO Server. Point a web browser running on the host machine to and log in with the root credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See [Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers, see to view MinIO SDKs for supported languages.\n\n## GNU/Linux\n\nUse the following command to run a standalone MinIO server on Linux hosts running 64-bit Intel/AMD architectures. Replace ``/data`` with the path to the drive or directory in which you want MinIO to store data.\n\n```sh\nwget https://dl.min.io/server/minio/release/linux-amd64/minio\nchmod +x minio\n./minio server /data\n```\n\nReplace ``/data`` with the path to the drive or directory in which you want MinIO to store data.\n\nThe following table lists supported architectures. Replace the `wget` URL with the architecture for your Linux host.\n\n| Architecture | URL |\n| -------- | ------ |\n| 64-bit Intel/AMD | |\n| 64-bit ARM | |\n| 64-bit PowerPC LE (ppc64le) | |\n| IBM Z-Series (S390X) | |\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded web-based object browser built into MinIO Server. Point a web browser running on the host machine to and log in with the root credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See [Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers, see to view MinIO SDKs for supported languages.\n\n> NOTE: Standalone MinIO servers are best suited for early development and evaluation. Certain features such as versioning, object locking, and bucket replication require distributed deploying MinIO with Erasure Coding. For extended development and production, deploy MinIO with Erasure Coding enabled - specifically, with a *minimum* of 4 drives per MinIO server. See [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html#) for more complete documentation.\n\n## Microsoft Windows\n\nTo run MinIO on 64-bit Windows hosts, download the MinIO executable from the following URL:\n\n```sh\nhttps://dl.min.io/server/minio/release/windows-amd64/minio.exe\n```\n\nUse the following command to run a standalone MinIO server on the Windows host. Replace ``D:\\`` with the path to the drive or directory in which you want MinIO to store data. You must change the terminal or powershell directory to the location of the ``minio.exe`` executable, *or* add the path to that directory to the system ``$PATH``:\n\n```sh\nminio.exe server D:\\\n```\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded web-based object browser built into MinIO Server. Point a web browser running on the host machine to and log in with the root credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See [Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers, see to view MinIO SDKs for supported languages.\n\n> NOTE: Standalone MinIO servers are best suited for early development and evaluation. Certain features such as versioning, object locking, and bucket replication require distributed deploying MinIO with Erasure Coding. For extended development and production, deploy MinIO with Erasure Coding enabled - specifically, with a *minimum* of 4 drives per MinIO server. See [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html#) for more complete documentation.\n\n## Install from Source\n\nUse the following commands to compile and run a standalone MinIO server from source. Source installation is only intended for developers and advanced users. If you do not have a working Golang environment, please follow [How to install Golang](https://golang.org/doc/install). Minimum version required is [go1.18](https://golang.org/dl/#stable)\n\n```sh\ngo install github.com/minio/minio@latest\n```\n\nThe MinIO deployment starts using default root credentials `minioadmin:minioadmin`. You can test the deployment using the MinIO Console, an embedded web-based object browser built into MinIO Server. Point a web browser running on the host machine to and log in with the root credentials. You can use the Browser to create buckets, upload objects, and browse the contents of the MinIO server.\n\nYou can also connect using any S3-compatible tool, such as the MinIO Client `mc` commandline tool. See [Test using MinIO Client `mc`](#test-using-minio-client-mc) for more information on using the `mc` commandline tool. For application developers, see to view MinIO SDKs for supported languages.\n\n> NOTE: Standalone MinIO servers are best suited for early development and evaluation. Certain features such as versioning, object locking, and bucket replication require distributed deploying MinIO with Erasure Coding. For extended development and production, deploy MinIO with Erasure Coding enabled - specifically, with a *minimum* of 4 drives per MinIO server. See [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html) for more complete documentation.\n\nMinIO strongly recommends *against* using compiled-from-source MinIO servers for production environments.\n\n## Deployment Recommendations\n\n### Allow port access for Firewalls\n\nBy default MinIO uses the port 9000 to listen for incoming connections. If your platform blocks the port by default, you may need to enable access to the port.\n\n### ufw\n\nFor hosts with ufw enabled (Debian based distros), you can use `ufw` command to allow traffic to specific ports. Use below command to allow access to port 9000\n\n```sh\nufw allow 9000\n```\n\nBelow command enables all incoming traffic to ports ranging from 9000 to 9010.\n\n```sh\nufw allow 9000:9010/tcp\n```\n\n### firewall-cmd\n\nFor hosts with firewall-cmd enabled (CentOS), you can use `firewall-cmd` command to allow traffic to specific ports. Use below commands to allow access to port 9000\n\n```sh\nfirewall-cmd --get-active-zones\n```\n\nThis command gets the active zone(s). Now, apply port rules to the relevant zones returned above. For example if the zone is `public`, use\n\n```sh\nfirewall-cmd --zone=public --add-port=9000/tcp --permanent\n```\n\nNote that `permanent` makes sure the rules are persistent across firewall start, restart or reload. Finally reload the firewall for changes to take effect.\n\n```sh\nfirewall-cmd --reload\n```\n\n### iptables\n\nFor hosts with iptables enabled (RHEL, CentOS, etc), you can use `iptables` command to enable all traffic coming to specific ports. Use below command to allow\naccess to port 9000\n\n```sh\niptables -A INPUT -p tcp --dport 9000 -j ACCEPT\nservice iptables restart\n```\n\nBelow command enables all incoming traffic to ports ranging from 9000 to 9010.\n\n```sh\niptables -A INPUT -p tcp --dport 9000:9010 -j ACCEPT\nservice iptables restart\n```\n\n## Test MinIO Connectivity\n\n### Test using MinIO Console\n\nMinIO Server comes with an embedded web based object browser. Point your web browser to to ensure your server has started successfully.\n\n> NOTE: MinIO runs console on random port by default if you wish choose a specific port use `--console-address` to pick a specific interface and port.\n\n### Things to consider\n\nMinIO redirects browser access requests to the configured server port (i.e. `127.0.0.1:9000`) to the configured Console port. MinIO uses the hostname or IP address specified in the request when building the redirect URL. The URL and port *must* be accessible by the client for the redirection to work.\n\nFor deployments behind a load balancer, proxy, or ingress rule where the MinIO host IP address or port is not public, use the `MINIO_BROWSER_REDIRECT_URL` environment variable to specify the external hostname for the redirect. The LB/Proxy must have rules for directing traffic to the Console port specifically.\n\nFor example, consider a MinIO deployment behind a proxy `https://minio.example.net`, `https://console.minio.example.net` with rules for forwarding traffic on port :9000 and :9001 to MinIO and the MinIO Console respectively on the internal network. Set `MINIO_BROWSER_REDIRECT_URL` to `https://console.minio.example.net` to ensure the browser receives a valid reachable URL.\n\nSimilarly, if your TLS certificates do not have the IP SAN for the MinIO server host, the MinIO Console may fail to validate the connection to the server. Use the `MINIO_SERVER_URL` environment variable and specify the proxy-accessible hostname of the MinIO server to allow the Console to use the MinIO server API using the TLS certificate.\n\nFor example: `export MINIO_SERVER_URL=\"https://minio.example.net\"`\n\n| Dashboard | Creating a bucket |\n| ------------- | ------------- |\n|  |  |\n\n## Test using MinIO Client `mc`\n\n`mc` provides a modern alternative to UNIX commands like ls, cat, cp, mirror, diff etc. It supports filesystems and Amazon S3 compatible cloud storage services. Follow the MinIO Client [Quickstart Guide](https://min.io/docs/minio/linux/reference/minio-mc.html#quickstart) for further instructions.\n\n## Upgrading MinIO\n\nUpgrades require zero downtime in MinIO, all upgrades are non-disruptive, all transactions on MinIO are atomic. So upgrading all the servers simultaneously is the recommended way to upgrade MinIO.\n\n> NOTE: requires internet access to update directly from , optionally you can host any mirrors at \n\n- For deployments that installed the MinIO server binary by hand, use [`mc admin update`](https://min.io/docs/minio/linux/reference/minio-mc-admin/mc-admin-update.html)\n\n```sh\nmc admin update \n```\n\n- For deployments without external internet access (e.g. airgapped environments), download the binary from and replace the existing MinIO binary let's say for example `/opt/bin/minio`, apply executable permissions `chmod +x /opt/bin/minio` and proceed to perform `mc admin service restart alias/`.\n\n- For installations using Systemd MinIO service, upgrade via RPM/DEB packages **parallelly** on all servers or replace the binary lets say `/opt/bin/minio` on all nodes, apply executable permissions `chmod +x /opt/bin/minio` and process to perform `mc admin service restart alias/`.\n\n### Upgrade Checklist\n\n- Test all upgrades in a lower environment (DEV, QA, UAT) before applying to production. Performing blind upgrades in production environments carries significant risk.\n- Read the release notes for MinIO *before* performing any upgrade, there is no forced requirement to upgrade to latest releases upon every releases. Some releases may not be relevant to your setup, avoid upgrading production environments unnecessarily.\n- If you plan to use `mc admin update`, MinIO process must have write access to the parent directory where the binary is present on the host system.\n- `mc admin update` is not supported and should be avoided in kubernetes/container environments, please upgrade containers by upgrading relevant container images.\n- **We do not recommend upgrading one MinIO server at a time, the product is designed to support parallel upgrades please follow our recommended guidelines.**\n\n## Explore Further\n\n- [MinIO Erasure Code Overview](https://min.io/docs/minio/linux/operations/concepts/erasure-coding.html)\n- [Use `mc` with MinIO Server](https://min.io/docs/minio/linux/reference/minio-mc.html)\n- [Use `minio-go` SDK with MinIO Server](https://min.io/docs/minio/linux/developers/go/minio-go.html)\n- [The MinIO documentation website](https://min.io/docs/minio/linux/index.html)\n\n## Contribute to MinIO Project\n\nPlease follow MinIO [Contributor's Guide](https://github.com/minio/minio/blob/master/CONTRIBUTING.md)\n\n## License\n\n- MinIO source is licensed under the GNU AGPLv3 license that can be found in the [LICENSE](https://github.com/minio/minio/blob/master/LICENSE) file.\n- MinIO [Documentation](https://github.com/minio/minio/tree/master/docs) \u00a9 2021 by MinIO, Inc is licensed under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/).\n- [License Compliance](https://github.com/minio/minio/blob/master/COMPLIANCE.md)\n",
- "source_links": [],
- "id": 82
- },
- {
- "page_link": "https://github.com/mlflow/mlflow",
- "title": "mlflow readme",
- "text": null,
- "source_links": [],
- "id": 83
- },
- {
- "page_link": "https://github.com/mongodb/mongo",
- "title": "mongodb readme",
- "text": "#  MongoDB README\n\nWelcome to MongoDB!\n\n## Components\n\n - `mongod` - The database server.\n - `mongos` - Sharding router.\n - `mongo` - The database shell (uses interactive javascript).\n\n## Utilities\n\n `install_compass` - Installs MongoDB Compass for your platform.\n\n## Building\n\n See [Building MongoDB](docs/building.md).\n\n## Running\n\n For command line options invoke:\n\n ```bash\n $ ./mongod --help\n ```\n\n To run a single server database:\n\n ```bash\n $ sudo mkdir -p /data/db\n $ ./mongod\n $\n $ # The mongo javascript shell connects to localhost and test database by default:\n $ ./mongo\n > help\n ```\n\n## Installing Compass\n\n You can install compass using the `install_compass` script packaged with MongoDB:\n\n ```bash\n $ ./install_compass\n ```\n\n This will download the appropriate MongoDB Compass package for your platform\n and install it.\n\n## Drivers\n\n Client drivers for most programming languages are available at\n https://docs.mongodb.com/manual/applications/drivers/. Use the shell\n (`mongo`) for administrative tasks.\n\n## Bug Reports\n\n See https://github.com/mongodb/mongo/wiki/Submit-Bug-Reports.\n\n## Packaging\n\n Packages are created dynamically by the [buildscripts/packager.py](buildscripts/packager.py) script.\n This will generate RPM and Debian packages.\n\n## Documentation\n\n https://docs.mongodb.com/manual/\n\n## Cloud Hosted MongoDB\n\n https://www.mongodb.com/cloud/atlas\n\n## Forums\n\n - https://community.mongodb.com\n\n Technical questions about using MongoDB.\n\n - https://community.mongodb.com/c/server-dev\n\n Technical questions about building and developing MongoDB.\n\n## Learn MongoDB\n\n https://university.mongodb.com/\n\n## LICENSE\n\n MongoDB is free and the source is available. Versions released prior to\n October 16, 2018 are published under the AGPL. All versions released after\n October 16, 2018, including patch fixes for prior versions, are published\n under the [Server Side Public License (SSPL) v1](LICENSE-Community.txt).\n See individual files for details.\n",
- "source_links": [],
- "id": 84
- },
- {
- "page_link": "https://github.com/prometheus/prometheus",
- "title": "monitoring readme",
- "text": "# Prometheus\n\n[][circleci]\n[][quay]\n[][hub]\n[](https://goreportcard.com/report/github.com/prometheus/prometheus)\n[](https://bestpractices.coreinfrastructure.org/projects/486)\n[](https://gitpod.io/#https://github.com/prometheus/prometheus)\n[](https://bugs.chromium.org/p/oss-fuzz/issues/list?sort=-opened&can=1&q=proj:prometheus)\n\nVisit [prometheus.io](https://prometheus.io) for the full documentation,\nexamples and guides.\n\nPrometheus, a [Cloud Native Computing Foundation](https://cncf.io/) project, is a systems and service monitoring system. It collects metrics\nfrom configured targets at given intervals, evaluates rule expressions,\ndisplays the results, and can trigger alerts when specified conditions are observed.\n\nThe features that distinguish Prometheus from other metrics and monitoring systems are:\n\n* A **multi-dimensional** data model (time series defined by metric name and set of key/value dimensions)\n* PromQL, a **powerful and flexible query language** to leverage this dimensionality\n* No dependency on distributed storage; **single server nodes are autonomous**\n* An HTTP **pull model** for time series collection\n* **Pushing time series** is supported via an intermediary gateway for batch jobs\n* Targets are discovered via **service discovery** or **static configuration**\n* Multiple modes of **graphing and dashboarding support**\n* Support for hierarchical and horizontal **federation**\n\n## Architecture overview\n\n\n\n## Install\n\nThere are various ways of installing Prometheus.\n\n### Precompiled binaries\n\nPrecompiled binaries for released versions are available in the\n[*download* section](https://prometheus.io/download/)\non [prometheus.io](https://prometheus.io). Using the latest production release binary\nis the recommended way of installing Prometheus.\nSee the [Installing](https://prometheus.io/docs/introduction/install/)\nchapter in the documentation for all the details.\n\n### Docker images\n\nDocker images are available on [Quay.io](https://quay.io/repository/prometheus/prometheus) or [Docker Hub](https://hub.docker.com/r/prom/prometheus/).\n\nYou can launch a Prometheus container for trying it out with\n\n```bash\ndocker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus\n```\n\nPrometheus will now be reachable at .\n\n### Building from source\n\nTo build Prometheus from source code, You need:\n\n* Go [version 1.17 or greater](https://golang.org/doc/install).\n* NodeJS [version 16 or greater](https://nodejs.org/).\n* npm [version 7 or greater](https://www.npmjs.com/).\n\nStart by cloning the repository:\n\n```bash\ngit clone https://github.com/prometheus/prometheus.git\ncd prometheus\n```\n\nYou can use the `go` tool to build and install the `prometheus`\nand `promtool` binaries into your `GOPATH`:\n\n```bash\nGO111MODULE=on go install github.com/prometheus/prometheus/cmd/...\nprometheus --config.file=your_config.yml\n```\n\n*However*, when using `go install` to build Prometheus, Prometheus will expect to be able to\nread its web assets from local filesystem directories under `web/ui/static` and\n`web/ui/templates`. In order for these assets to be found, you will have to run Prometheus\nfrom the root of the cloned repository. Note also that these directories do not include the\nReact UI unless it has been built explicitly using `make assets` or `make build`.\n\nAn example of the above configuration file can be found [here.](https://github.com/prometheus/prometheus/blob/main/documentation/examples/prometheus.yml)\n\nYou can also build using `make build`, which will compile in the web assets so that\nPrometheus can be run from anywhere:\n\n```bash\nmake build\n./prometheus --config.file=your_config.yml\n```\n\nThe Makefile provides several targets:\n\n* *build*: build the `prometheus` and `promtool` binaries (includes building and compiling in web assets)\n* *test*: run the tests\n* *test-short*: run the short tests\n* *format*: format the source code\n* *vet*: check the source code for common errors\n* *assets*: build the React UI\n\n### Service discovery plugins\n\nPrometheus is bundled with many service discovery plugins.\nWhen building Prometheus from source, you can edit the [plugins.yml](./plugins.yml)\nfile to disable some service discoveries. The file is a yaml-formated list of go\nimport path that will be built into the Prometheus binary.\n\nAfter you have changed the file, you\nneed to run `make build` again.\n\nIf you are using another method to compile Prometheus, `make plugins` will\ngenerate the plugins file accordingly.\n\nIf you add out-of-tree plugins, which we do not endorse at the moment,\nadditional steps might be needed to adjust the `go.mod` and `go.sum` files. As\nalways, be extra careful when loading third party code.\n\n### Building the Docker image\n\nThe `make docker` target is designed for use in our CI system.\nYou can build a docker image locally with the following commands:\n\n```bash\nmake promu\npromu crossbuild -p linux/amd64\nmake npm_licenses\nmake common-docker-amd64\n```\n\n*NB* if you are on a Mac, you will need [gnu-tar](https://formulae.brew.sh/formula/gnu-tar).\n\n## Using Prometheus as a Go Library\n\n### Remote Write\n\nWe are publishing our Remote Write protobuf independently at\n[buf.build](https://buf.build/prometheus/prometheus/assets).\n\nYou can use that as a library:\n\n```shell\ngo get go.buf.build/protocolbuffers/go/prometheus/prometheus\n```\n\nThis is experimental.\n\n### Prometheus code base\n\nIn order to comply with [go mod](https://go.dev/ref/mod#versions) rules,\nPrometheus release number do not exactly match Go module releases. For the\nPrometheus v2.y.z releases, we are publishing equivalent v0.y.z tags.\n\nTherefore, a user that would want to use Prometheus v2.35.0 as a library could do:\n\n```shell\ngo get github.com/prometheus/prometheus@v0.35.0\n```\n\nThis solution makes it clear that we might break our internal Go APIs between\nminor user-facing releases, as [breaking changes are allowed in major version\nzero](https://semver.org/#spec-item-4).\n\n## React UI Development\n\nFor more information on building, running, and developing on the React-based UI, see the React app's [README.md](web/ui/README.md).\n\n## More information\n\n* Godoc documentation is available via [pkg.go.dev](https://pkg.go.dev/github.com/prometheus/prometheus). Due to peculiarities of Go Modules, v2.x.y will be displayed as v0.x.y.\n* You will find a CircleCI configuration in [`.circleci/config.yml`](.circleci/config.yml).\n* See the [Community page](https://prometheus.io/community) for how to reach the Prometheus developers and users on various communication channels.\n\n## Contributing\n\nRefer to [CONTRIBUTING.md](https://github.com/prometheus/prometheus/blob/main/CONTRIBUTING.md)\n\n## License\n\nApache License 2.0, see [LICENSE](https://github.com/prometheus/prometheus/blob/main/LICENSE).\n\n[hub]: https://hub.docker.com/r/prom/prometheus/\n[circleci]: https://circleci.com/gh/prometheus/prometheus\n[quay]: https://quay.io/repository/prometheus/prometheus\n",
- "source_links": [],
- "id": 85
- },
- {
- "page_link": "https://github.com/mysql/mysql-server",
- "title": "mysql readme",
- "text": null,
- "source_links": [],
- "id": 86
- },
- {
- "page_link": "https://github.com/n8n-io/n8n",
- "title": "n8n readme",
- "text": "\n\n# n8n - Workflow automation tool\n\nn8n is an extendable workflow automation tool. With a [fair-code](http://faircode.io) distribution model, n8n\nwill always have visible source code, be available to self-host, and allow you to add your own custom\nfunctions, logic and apps. n8n's node-based approach makes it highly versatile, enabling you to connect\nanything to everything.\n\n\n\n## Demo\n\n[:tv: A short video (< 4 min)](https://www.youtube.com/watch?v=RpjQTGKm-ok) that goes over key concepts of\ncreating workflows in n8n.\n\n## Available integrations\n\nn8n has 200+ different nodes to automate workflows. The list can be found on:\n[https://n8n.io/integrations](https://n8n.io/integrations)\n\n## Documentation\n\nThe official n8n documentation can be found under: [https://docs.n8n.io](https://docs.n8n.io)\n\nAdditional information and example workflows on the n8n.io website: [https://n8n.io](https://n8n.io)\n\nThe changelog can be found [here](https://docs.n8n.io/reference/changelog.html) and the list of breaking\nchanges [here](https://github.com/n8n-io/n8n/blob/master/packages/cli/BREAKING-CHANGES.md).\n\n## Usage\n\n- :books: Learn\n [how to **install** and **use** it from the command line](https://github.com/n8n-io/n8n/tree/master/packages/cli/README.md)\n- :whale: Learn\n [how to run n8n in **Docker**](https://github.com/n8n-io/n8n/tree/master/docker/images/n8n/README.md)\n\n## Start\n\nExecute: `npx n8n`\n\n## n8n cloud\n\nSign-up for an [n8n cloud](https://www.n8n.io/cloud/) account.\n\nWhile n8n cloud and n8n are the same in terms of features, n8 cloud provides certain conveniences such as:\n\n- Not having to set up and maintain your n8n instance\n- Managed OAuth for authentication\n- Easily upgrading to the newer n8n versions\n\n## Support\n\nIf you have problems or questions go to our forum, we will then try to help you asap:\n\n[https://community.n8n.io](https://community.n8n.io)\n\n## Jobs\n\nIf you are interested in working for n8n and so shape the future of the project check out our\n[job posts](https://apply.workable.com/n8n/)\n\n## What does n8n mean and how do you pronounce it?\n\n**Short answer:** It means \"nodemation\" and it is pronounced as n-eight-n.\n\n**Long answer:** \"I get that question quite often (more often than I expected) so I decided it is probably\nbest to answer it here. While looking for a good name for the project with a free domain I realized very\nquickly that all the good ones I could think of were already taken. So, in the end, I chose nodemation.\n'node-' in the sense that it uses a Node-View and that it uses Node.js and '-mation' for 'automation' which is\nwhat the project is supposed to help with. However, I did not like how long the name was and I could not\nimagine writing something that long every time in the CLI. That is when I then ended up on 'n8n'.\" - **Jan\nOberhauser, Founder and CEO, n8n.io**\n\n## Development setup\n\nHave you found a bug :bug: ? Or maybe you have a nice feature :sparkles: to contribute ? The\n[CONTRIBUTING guide](https://github.com/n8n-io/n8n/blob/master/CONTRIBUTING.md) will help you get your\ndevelopment environment ready in minutes.\n\n## License\n\nn8n is [fair-code](http://faircode.io) distributed under the\n[**Sustainable Use License**](https://github.com/n8n-io/n8n/blob/master/packages/cli/LICENSE.md) and the\n[**n8n Enterprise License**](https://github.com/n8n-io/n8n/blob/master/packages/cli/LICENSE_EE.md).\n\nAdditional information about the license model can be found in the\n[docs](https://docs.n8n.io/reference/license/).\n",
- "source_links": [],
- "id": 87
- },
- {
- "page_link": "https://github.com/neo4j/neo4j",
- "title": "neo4j readme",
- "text": null,
- "source_links": [],
- "id": 88
- },
- {
- "page_link": "https://github.com/nextcloud/server",
- "title": "nextcloud readme",
- "text": "# Nextcloud Server \u2601\n[](https://scrutinizer-ci.com/g/nextcloud/server/?branch=master)\n[](https://codecov.io/gh/nextcloud/server)\n[](https://bestpractices.coreinfrastructure.org/projects/209)\n\n**A safe home for all your data.**\n\n\n\n## Why is this so awesome? \ud83e\udd29\n\n* \ud83d\udcc1 **Access your Data** You can store your files, contacts, calendars, and more on a server of your choosing.\n* \ud83d\udd04 **Sync your Data** You keep your files, contacts, calendars, and more synchronized amongst your devices.\n* \ud83d\ude4c **Share your Data** \u2026by giving others access to the stuff you want them to see or to collaborate with.\n* \ud83d\ude80 **Expandable with hundreds of Apps** ...like [Calendar](https://github.com/nextcloud/calendar), [Contacts](https://github.com/nextcloud/contacts), [Mail](https://github.com/nextcloud/mail), [Video Chat](https://github.com/nextcloud/spreed) and all those you can discover in our [App Store](https://apps.nextcloud.com)\n* \ud83d\udd12 **Security** with our encryption mechanisms, [HackerOne bounty program](https://hackerone.com/nextcloud) and two-factor authentication.\n\nDo you want to learn more about how you can use Nextcloud to access, share and protect your files, calendars, contacts, communication & more at home and in your organization? [**Learn about all our Features**](https://nextcloud.com/athome/).\n\n## Get your Nextcloud \ud83d\ude9a\n\n- \u2611\ufe0f [**Simply sign up**](https://nextcloud.com/signup/) at one of our providers either through our website or through the apps directly.\n- \ud83d\udda5 [**Install** a server by yourself](https://nextcloud.com/install/#instructions-server) on your hardware or by using one of our ready to use **appliances**\n- \ud83d\udce6 Buy one of the [awesome **devices** coming with a preinstalled Nextcloud](https://nextcloud.com/devices/)\n- \ud83c\udfe2 Find a [service **provider**](https://nextcloud.com/providers/) who hosts Nextcloud for you or your company\n\nEnterprise? Public Sector or Education user? You may want to have a look into [**Nextcloud Enterprise**](https://nextcloud.com/enterprise/) provided by Nextcloud GmbH.\n\n## Get in touch \ud83d\udcac\n\n* [\ud83d\udccb Forum](https://help.nextcloud.com)\n* [\ud83d\udc65 Facebook](https://www.facebook.com/nextclouders)\n* [\ud83d\udc23 Twitter](https://twitter.com/Nextclouders)\n* [\ud83d\udc18 Mastodon](https://mastodon.xyz/@nextcloud)\n\nYou can also [get support for Nextcloud](https://nextcloud.com/support)!\n\n\n## Join the team \ud83d\udc6a\n\nThere are many ways to contribute, of which development is only one! Find out [how to get involved](https://nextcloud.com/contribute/), including as a translator, designer, tester, helping others, and much more! \ud83d\ude0d\n\n\n### Development setup \ud83d\udc69\u200d\ud83d\udcbb\n\n1. \ud83d\ude80 [Set up your local development environment](https://docs.nextcloud.com/server/latest/developer_manual/getting_started/devenv.html)\n2. \ud83d\udc1b [Pick a good first issue](https://github.com/nextcloud/server/labels/good%20first%20issue)\n3. \ud83d\udc69\u200d\ud83d\udd27 Create a branch and make your changes. Remember to sign off your commits using `git commit -sm \"Your commit message\"`\n4. \u2b06 Create a [pull request](https://opensource.guide/how-to-contribute/#opening-a-pull-request) and `@mention` the people from the issue to review\n5. \ud83d\udc4d Fix things that come up during a review\n6. \ud83c\udf89 Wait for it to get merged!\n\nThird-party components are handled as git submodules which have to be initialized first. So aside from the regular git checkout invoking `git submodule update --init` or a similar command is needed, for details see Git documentation.\n\nSeveral apps that are included by default in regular releases such as [First run wizard](https://github.com/nextcloud/firstrunwizard) or [Activity](https://github.com/nextcloud/activity) are missing in `master` and have to be installed manually by cloning them into the `apps` subfolder.\n\nOtherwise, git checkouts can be handled the same as release archives, by using the `stable*` branches. Note they should never be used on production systems.\n\n### Working with front-end code \ud83c\udfd7\n\n#### Building\n\nWe are moving more and more toward using Vue.js in the front-end, starting with Settings. For building the code on changes, use these terminal commands in the root folder:\n\n```bash\n# install dependencies\nmake dev-setup\n\n# build for development\nmake build-js\n\n# build for development and watch edits\nmake watch-js\n\n# build for production with minification\nmake build-js-production\n```\n\n#### Committing changes\n\n**When making changes, also commit the compiled files!**\n\nWe still use Handlebars templates in some places in Files and Settings. We will replace these step-by-step with Vue.js, but in the meantime, you need to compile them separately.\n\nIf you don\u2019t have Handlebars installed yet, you can do it with this terminal command:\n```bash\nsudo npm install -g handlebars\n```\n\nThen inside the root folder of your local Nextcloud development installation, run this command in the terminal every time you changed a `.handlebars` file to compile it:\n```bash\n./build/compile-handlebars-templates.sh\n```\n\nBefore checking in JS changes, make sure to also build for production:\n```bash\nmake build-js-production\n```\nThen add the compiled files for committing.\n\nTo save some time, to only rebuild for a specific app, use the following and replace the module with the app name:\n```bash\nMODULE=user_status make build-js-production\n```\n\nPlease note that if you used `make build-js` or `make watch-js` before, you'll notice that a lot of files were marked as changed, so might need to clear the workspace first.\n\n### Working with back-end code \ud83c\udfd7\n\nWhen changing back-end PHP code, in general, no additional steps are needed before checking in.\n\nHowever, if new files were created, you will need to run the following command to update the autoloader files:\n```bash\nbuild/autoloaderchecker.sh\n```\n\nAfter that, please also include the autoloader file changes in your commits.\n\n### Tools we use \ud83d\udee0\n\n- [\ud83d\udc40 BrowserStack](https://browserstack.com) for cross-browser testing\n- [\ud83c\udf0a WAVE](https://wave.webaim.org/extension/) for accessibility testing\n- [\ud83d\udea8 Lighthouse](https://developers.google.com/web/tools/lighthouse/) for testing performance, accessibility, and more\n\n\n## Contribution guidelines \ud83d\udcdc\n\nAll contributions to this repository from June 16, 2016, and onward are considered to be\nlicensed under the AGPLv3 or any later version.\n\nNextcloud doesn't require a CLA (Contributor License Agreement).\nThe copyright belongs to all the individual contributors. Therefore we recommend\nthat every contributor adds the following line to the header of a file if they\nchanged it substantially:\n\n```\n@copyright Copyright (c) , ()\n```\n\nPlease read the [Code of Conduct](https://nextcloud.com/community/code-of-conduct/). This document offers some guidance to ensure Nextcloud participants can cooperate effectively in a positive and inspiring atmosphere, and to explain how together we can strengthen and support each other.\n\nPlease review the [guidelines for contributing](.github/CONTRIBUTING.md) to this repository.\n\nMore information how to contribute: [https://nextcloud.com/contribute/](https://nextcloud.com/contribute/)\n",
- "source_links": [],
- "id": 89
- },
- {
- "page_link": "https://github.com/nocodb/nocodb",
- "title": "nocodb readme",
- "text": "
\n\n# Join Our Community\n\n\n\n\n\n\n[](https://github.com/nocodb/nocodb/stargazers)\n\n\n# Quick try\n\n## 1-Click Deploy to Heroku\n\nBefore doing so, make sure you have a Heroku account. By default, an add-on Heroku Postgres will be used as meta database. You can see the connection string defined in `DATABASE_URL` by navigating to Heroku App Settings and selecting Config Vars.\n\n\n \n\n\n \n\n## NPX\n\nYou can run below command if you need an interactive configuration.\n\n```\nnpx create-nocodb-app\n```\n\n\n\n## Node Application\n\nWe provide a simple NodeJS Application for getting started.\n\n```bash\ngit clone https://github.com/nocodb/nocodb-seed\ncd nocodb-seed\nnpm install\nnpm start\n```\n\n## Docker \n\n```bash\n# for SQLite\ndocker run -d --name nocodb \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\nnocodb/nocodb:latest\n\n# for MySQL\ndocker run -d --name nocodb-mysql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mysql2://host.docker.internal:3306?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for PostgreSQL\ndocker run -d --name nocodb-postgres \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"pg://host.docker.internal:5432?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for MSSQL\ndocker run -d --name nocodb-mssql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mssql://host.docker.internal:1433?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n```\n\n> To persist data in docker you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker](https://github.com/nocodb/nocodb/issues/1340#issuecomment-1049481043).\n\n## Binaries\n##### MacOS (x64)\n```bash\ncurl http://get.nocodb.com/macos-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### MacOS (arm64)\n```bash\ncurl http://get.nocodb.com/macos-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Linux (x64)\n```bash\ncurl http://get.nocodb.com/linux-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n##### Linux (arm64)\n```bash\ncurl http://get.nocodb.com/linux-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Windows (x64)\n```bash\niwr http://get.nocodb.com/win-x64.exe\n.\\Noco-win-x64.exe\n```\n\n##### Windows (arm64)\n```bash\niwr http://get.nocodb.com/win-arm64.exe\n.\\Noco-win-arm64.exe\n```\n\n## Docker Compose\n\nWe provide different docker-compose.yml files under [this directory](https://github.com/nocodb/nocodb/tree/master/docker-compose). Here are some examples.\n\n```bash\ngit clone https://github.com/nocodb/nocodb\n# for MySQL\ncd nocodb/docker-compose/mysql\n# for PostgreSQL\ncd nocodb/docker-compose/pg\n# for MSSQL\ncd nocodb/docker-compose/mssql\ndocker-compose up -d\n```\n\n> To persist data in docker, you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker Compose](https://github.com/nocodb/nocodb/issues/1313#issuecomment-1046625974).\n\n# GUI\n\nAccess Dashboard using : [http://localhost:8080/dashboard](http://localhost:8080/dashboard)\n\n# Screenshots\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# Table of Contents\n\n- [Quick try](#quick-try)\n * [1-Click Deploy to Heroku](#1-click-deploy-to-heroku)\n * [NPX](#npx)\n * [Node Application](#node-application)\n * [Docker](#docker)\n * [Docker Compose](#docker-compose)\n- [GUI](#gui)\n- [Join Our Community](#join-our-community)\n- [Screenshots](#screenshots)\n- [Table of Contents](#table-of-contents)\n- [Features](#features)\n + [Rich Spreadsheet Interface](#rich-spreadsheet-interface)\n + [App Store for Workflow Automations](#app-store-for-workflow-automations)\n + [Programmatic Access](#programmatic-access)\n + [Sync Schema](#sync-schema)\n + [Audit](#audit)\n- [Production Setup](#production-setup)\n * [Environment variables](#environment-variables)\n- [Development Setup](#development-setup)\n- [Contributing](#contributing)\n- [Why are we building this?](#why-are-we-building-this)\n- [Our Mission](#our-mission)\n- [License](#license)\n- [Contributors](#contributors)\n\n# Features\n\n### Rich Spreadsheet Interface\n\n- \u26a1 Basic Operations: Create, Read, Update and Delete on Tables, Columns, and Rows\n- \u26a1 Fields Operations: Sort, Filter, Hide / Unhide Columns\n- \u26a1 Multiple Views Types: Grid (By default), Gallery, Form View and Kanban View\n- \u26a1 View Permissions Types: Collaborative Views, & Locked Views \n- \u26a1 Share Bases / Views: either Public or Private (with Password Protected)\n- \u26a1 Variant Cell Types: ID, LinkToAnotherRecord, Lookup, Rollup, SingleLineText, Attachement, Currency, Formula and etc\n- \u26a1 Access Control with Roles : Fine-grained Access Control at different levels\n- \u26a1 and more ...\n\n### App Store for Workflow Automations\n\nWe provide different integrations in three main categories. See App Store for details.\n\n- \u26a1 Chat : Slack, Discord, Mattermost, and etc\n- \u26a1 Email : AWS SES, SMTP, MailerSend, and etc\n- \u26a1 Storage : AWS S3, Google Cloud Storage, Minio, and etc\n\n### Programmatic Access\n\nWe provide the following ways to let users to invoke actions in a programmatic way. You can use a token (either JWT or Social Auth) to sign your requests for authorization to NocoDB. \n\n- \u26a1 REST APIs\n- \u26a1 NocoDB SDK\n\n### Sync Schema\n\nWe allow you to sync schema changes if you have made changes outside NocoDB GUI. However, it has to be noted then you will have to bring your own schema migrations for moving from environment to others. See Sync Schema for details.\n\n### Audit \n\nWe are keeping all the user operation logs under one place. See Audit for details.\n\n# Production Setup \n\nBy default, SQLite is used for storing meta data. However, you can specify your own database. The connection params for this database can be specified in `NC_DB` environment variable. Moreover, we also provide the below environment variables for configuration.\n\n## Environment variables \n\nPlease refer to [Environment variables](https://docs.nocodb.com/getting-started/installation#environment-variables)\n\n# Development Setup \n\nPlease refer to [Development Setup](https://docs.nocodb.com/engineering/development-setup)\n\n# Contributing\n\nPlease refer to [Contribution Guide](https://github.com/nocodb/nocodb/blob/master/.github/CONTRIBUTING.md).\n\n# Why are we building this?\nMost internet businesses equip themselves with either spreadsheet or a database to solve their business needs. Spreadsheets are used by a Billion+ humans collaboratively every single day. However, we are way off working at similar speeds on databases which are way more powerful tools when it comes to computing. Attempts to solve this with SaaS offerings has meant horrible access controls, vendor lockin, data lockin, abrupt price changes & most importantly a glass ceiling on what's possible in future.\n\n# Our Mission\nOur mission is to provide the most powerful no-code interface for databases which is open source to every single internet business in the world. This would not only democratise access to a powerful computing tool but also bring forth a billion+ people who will have radical tinkering-and-building abilities on internet. \n\n# License \n
\n\n# Contributors\n\nThank you for your contributions! We appreciate all the contributions from the community.\n\n\n \n",
- "source_links": [],
- "id": 90
- },
- {
- "page_link": "https://github.com/NVIDIA/gpu-operator",
- "title": "nvidia-operator readme",
- "text": "[](https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/LICENSE)\n[](https://gitlab.com/nvidia/kubernetes/gpu-operator/-/pipelines)\n[](https://gitlab.com/nvidia/kubernetes/gpu-operator/-/pipelines)\n\n# NVIDIA GPU Operator\n\n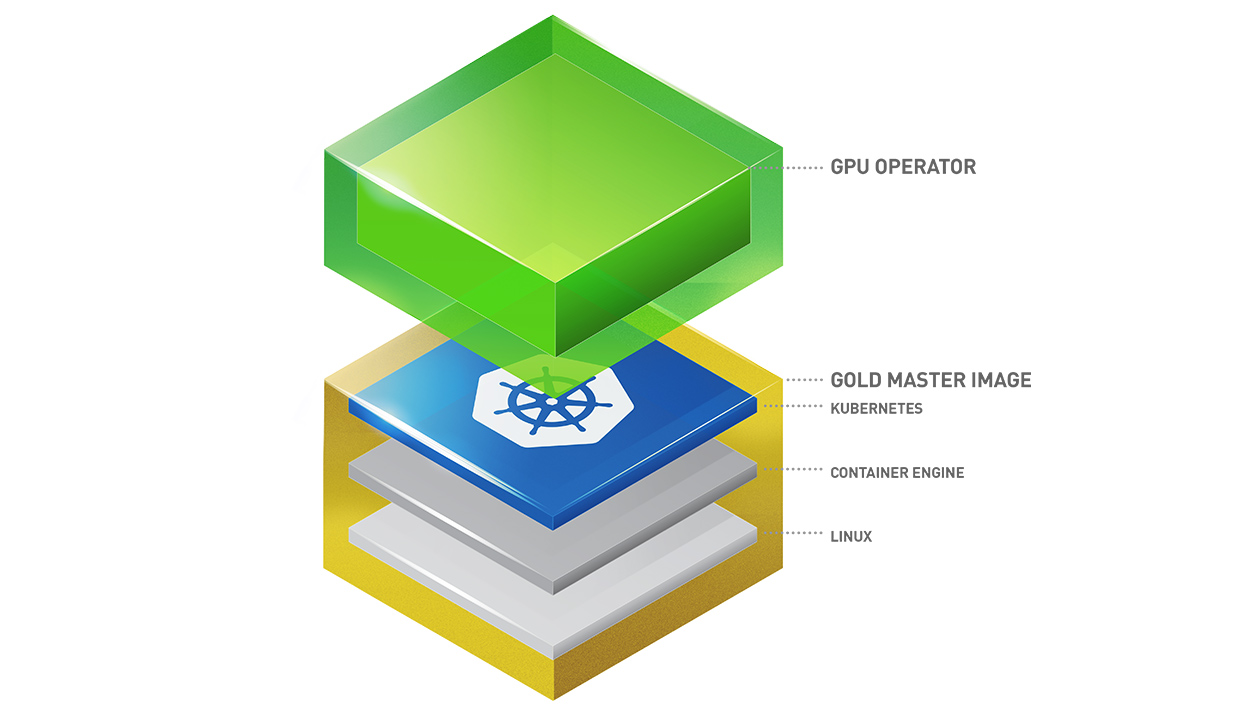\n\nKubernetes provides access to special hardware resources such as NVIDIA GPUs, NICs, Infiniband adapters and other devices through the [device plugin framework](https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/). However, configuring and managing nodes with these hardware resources requires configuration of multiple software components such as drivers, container runtimes or other libraries which are difficult and prone to errors.\nThe NVIDIA GPU Operator uses the [operator framework](https://cloud.redhat.com/blog/introducing-the-operator-framework) within Kubernetes to automate the management of all NVIDIA software components needed to provision GPU. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin for GPUs, the NVIDIA Container Runtime, automatic node labelling, [DCGM](https://developer.nvidia.com/dcgm) based monitoring and others.\n\n## Audience and Use-Cases\nThe GPU Operator allows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. Instead of provisioning a special OS image for GPU nodes, administrators can rely on a standard OS image for both CPU and GPU nodes and then rely on the GPU Operator to provision the required software components for GPUs.\n\nNote that the GPU Operator is specifically useful for scenarios where the Kubernetes cluster needs to scale quickly - for example provisioning additional GPU nodes on the cloud or on-prem and managing the lifecycle of the underlying software components. Since the GPU Operator runs everything as containers including NVIDIA drivers, the administrators can easily swap various components - simply by starting or stopping containers.\n\n## Product Documentation\nFor information on platform support and getting started, visit the official documentation [repository](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/overview.html).\n\n## Webinar\n[How to easily use GPUs on Kubernetes](https://info.nvidia.com/how-to-use-gpus-on-kubernetes-webinar.html)\n\n## Contributions\n[Read the document on contributions](https://github.com/NVIDIA/gpu-operator/blob/master/CONTRIBUTING.md). You can contribute by opening a [pull request](https://help.github.com/en/articles/about-pull-requests).\n\n## Support and Getting Help\nPlease open [an issue on the GitHub project](https://github.com/NVIDIA/gpu-operator/issues/new) for any questions. Your feedback is appreciated.\n",
- "source_links": [],
- "id": 91
- },
- {
- "page_link": "https://github.com/oauth2-proxy/oauth2-proxy",
- "title": "oauth2-proxy readme",
- "text": "\n\n[](http://travis-ci.org/oauth2-proxy/oauth2-proxy)\n[](https://goreportcard.com/report/github.com/oauth2-proxy/oauth2-proxy)\n[](https://godoc.org/github.com/oauth2-proxy/oauth2-proxy)\n[](./LICENSE)\n[](https://codeclimate.com/github/oauth2-proxy/oauth2-proxy/maintainability)\n[](https://codeclimate.com/github/oauth2-proxy/oauth2-proxy/test_coverage)\n\nA reverse proxy and static file server that provides authentication using Providers (Google, GitHub, and others)\nto validate accounts by email, domain or group.\n\n**Note:** This repository was forked from [bitly/OAuth2_Proxy](https://github.com/bitly/oauth2_proxy) on 27/11/2018.\nVersions v3.0.0 and up are from this fork and will have diverged from any changes in the original fork.\nA list of changes can be seen in the [CHANGELOG](CHANGELOG.md).\n\n**Note:** This project was formerly hosted as `pusher/oauth2_proxy` but has been renamed as of 29/03/2020 to `oauth2-proxy/oauth2-proxy`.\nGoing forward, all images shall be available at `quay.io/oauth2-proxy/oauth2-proxy` and binaries will be named `oauth2-proxy`.\n\n\n\n## Installation\n\n1. Choose how to deploy:\n\n a. Download [Prebuilt Binary](https://github.com/oauth2-proxy/oauth2-proxy/releases) (current release is `v7.3.0`)\n\n b. Build with `$ go get github.com/oauth2-proxy/oauth2-proxy/v7` which will put the binary in `$GOROOT/bin`\n\n c. Using the prebuilt docker image [quay.io/oauth2-proxy/oauth2-proxy](https://quay.io/oauth2-proxy/oauth2-proxy) (AMD64, PPC64LE, ARMv6, ARMv8 and ARM64 available)\n\n Prebuilt binaries can be validated by extracting the file and verifying it against the `sha256sum.txt` checksum file provided for each release starting with version `v3.0.0`.\n\n ```\n sha256sum -c sha256sum.txt 2>&1 | grep OK\n oauth2-proxy-x.y.z.linux-amd64: OK\n ```\n\n2. [Select a Provider and Register an OAuth Application with a Provider](https://oauth2-proxy.github.io/oauth2-proxy/docs/configuration/oauth_provider)\n3. [Configure OAuth2 Proxy using config file, command line options, or environment variables](https://oauth2-proxy.github.io/oauth2-proxy/docs/configuration/overview)\n4. [Configure SSL or Deploy behind a SSL endpoint](https://oauth2-proxy.github.io/oauth2-proxy/docs/configuration/tls) (example provided for Nginx)\n\n\n## Security\n\nIf you are running a version older than v6.0.0 we **strongly recommend you please update** to a current version.\nSee [open redirect vulnerability](https://github.com/oauth2-proxy/oauth2-proxy/security/advisories/GHSA-5m6c-jp6f-2vcv) for details.\n\n## Docs\n\nRead the docs on our [Docs site](https://oauth2-proxy.github.io/oauth2-proxy/docs/).\n\n\n\n## Getting Involved\n\nIf you would like to reach out to the maintainers, come talk to us in the `#oauth2-proxy` channel in the [Gophers slack](http://gophers.slack.com/).\n\n## Contributing\n\nPlease see our [Contributing](CONTRIBUTING.md) guidelines. For releasing see our [release creation guide](RELEASE.md).\n",
- "source_links": [],
- "id": 92
- },
- {
- "page_link": "https://github.com/grafana/oncall",
- "title": "oncall readme",
- "text": "\n\n[](https://github.com/grafana/oncall/releases)\n[](https://github.com/grafana/oncall/blob/dev/LICENSE)\n[](https://hub.docker.com/r/grafana/oncall/tags)\n[](https://slack.grafana.com/)\n[](https://github.com/grafana/oncall/discussions)\n[](https://drone.grafana.net/grafana/oncall)\n\nDeveloper-friendly incident response with brilliant Slack integration.\n\n\n\n- Collect and analyze alerts from multiple monitoring systems\n- On-call rotations based on schedules\n- Automatic escalations\n- Phone calls, SMS, Slack, Telegram notifications\n\n## Getting Started\n\nWe prepared multiple environments: [production](https://grafana.com/docs/grafana-cloud/oncall/open-source/#production-environment), [developer](DEVELOPER.md) and hobby:\n\n1. Download docker-compose.yaml:\n\n```bash\ncurl -fsSL https://raw.githubusercontent.com/grafana/oncall/dev/docker-compose.yml -o docker-compose.yml\n```\n\n2. Set variables:\n\n```bash\necho \"DOMAIN=http://localhost:8080\nCOMPOSE_PROFILES=with_grafana # Remove this line if you want to use existing grafana\nSECRET_KEY=my_random_secret_must_be_more_than_32_characters_long\nRABBITMQ_PASSWORD=rabbitmq_secret_pw\nMYSQL_PASSWORD=mysql_secret_pw\" > .env\n```\n\n3. Launch services:\n\n```bash\ndocker-compose up -d\n```\n\n4. Issue one-time invite token:\n\n```bash\ndocker-compose run engine python manage.py issue_invite_for_the_frontend --override\n```\n\n**Note**: if you remove the plugin configuration and reconfigure it, you will need to generate a new one-time invite token for your new configuration.\n\n5. Go to [OnCall Plugin Configuration](http://localhost:3000/plugins/grafana-oncall-app), using log in credentials as defined above: `admin`/`admin` (or find OnCall plugin in configuration->plugins) and connect OnCall _plugin_ with OnCall _backend_:\n\n```\nInvite token: ^^^ from the previous step.\nOnCall backend URL: http://engine:8080\nGrafana Url: http://grafana:3000\n```\n\n6. Enjoy! Check our [OSS docs](https://grafana.com/docs/grafana-cloud/oncall/open-source/) if you want to set up Slack, Telegram, Twilio or SMS/calls through Grafana Cloud.\n\n## Update version\n\nTo update your Grafana OnCall hobby environment:\n\n```shell\n# Update Docker image\ndocker-compose pull engine\n\n# Re-deploy\ndocker-compose up -d\n```\n\nAfter updating the engine, you'll also need to click the \"Update\" button on the [plugin version page](http://localhost:3000/plugins/grafana-oncall-app?page=version-history).\nSee [Grafana docs](https://grafana.com/docs/grafana/latest/administration/plugin-management/#update-a-plugin) for more info on updating Grafana plugins.\n\n## Join community\n\n\n\n\n\n## Stargazers over time\n\n[](https://starchart.cc/grafana/oncall)\n\n## Further Reading\n\n- _Migration from the PagerDuty_ - [Migrator](https://github.com/grafana/oncall/tree/dev/tools/pagerduty-migrator)\n- _Documentation_ - [Grafana OnCall](https://grafana.com/docs/grafana-cloud/oncall/)\n- _Blog Post_ - [Announcing Grafana OnCall, the easiest way to do on-call management](https://grafana.com/blog/2021/11/09/announcing-grafana-oncall/)\n- _Presentation_ - [Deep dive into the Grafana, Prometheus, and Alertmanager stack for alerting and on-call management](https://grafana.com/go/observabilitycon/2021/alerting/?pg=blog)\n",
- "source_links": [],
- "id": 93
- },
- {
- "page_link": null,
- "title": "openmetadata readme",
- "text": null,
- "source_links": [],
- "id": 94
- },
- {
- "page_link": "https://github.com/pluralsh/plural",
- "title": "plural readme",
- "text": "
\n \n
\n\n\n
\n The fastest way to build great infrastructure\n
\n\n
\n Plural empowers you to build and maintain cloud-native and production-ready open source infrastructure on Kubernetes.\n
\n\n\n## \u2728 Features\n\nPlural will deploy open source applications on Kubernetes in your cloud using common standards like Helm and Terraform.\n\nThe Plural platform provides the following:\n\n* Dependency management between Terraform/Helm modules, with dependency-aware deployment and upgrades.\n* Authenticated docker registry and chartmuseum proxy per repository.\n* Secret encryption using AES-256 (so you can keep the entire workflow in git).\n\nIn addition, Plural also handles:\n* Issuing the certificates.\n* Configuring a DNS service to register fully-qualified domains under onplural.sh to eliminate the hassle of DNS registration for users.\n* Being an OIDC provider to enable zero touch login security for all Plural applications.\n\nWe think it's pretty cool! \ud83d\ude0e Some other nice things:\n\n### \u2601\ufe0f Build and manage open cloud-native architectures\n\n
\n \n \n
\n
\n\nThe plural platform ingests all deployment artifacts needed to deploy cloud-native applications and tracks their dependencies, allowing for easy installs and no-touch upgrades post-install.\n\n### \ud83e\udd16 Day-2 Operational Toolkit\n\n
\n \n \n
\n\nScale deploys with operational run-books for key cluster operations. Every dependency is automatically upgraded in the correct order, in a rolling manner. Plural provides a timestamped audit trail for all cluster applications along with searchable, downloadable logs. In addition, there are also pre-packaged dashboards for the highest importance metrics.\n\n### \ud83d\udd13 Secure by default\nPlural performs regular security scans for application images, helm charts, and terraform modules and comes equipped with OpenID connect for user auth to applications deployed by Plural.\n\n### \ud83e\udd73 Open source and extensible\nAll Plural applications are fully customizable and able to be ejected at any time. New applications can be wrapped and packaged onto Plural easily, giving you total freedom about how, when and where to use Plural.\n
\n\n\n## \ud83d\udcfd Check out a video Demo\n\nhttps://user-images.githubusercontent.com/28541758/164427949-3f14cfbb-cf5e-40dc-8996-385691ec2f01.mp4\n\n
\n\n\n## \ud83c\udfc1 Getting Started\n\n1. Go to https://app.plural.sh to create an account. \n*Note: This is simply to track your installations and allow for the delivery of automated upgrades, you will not be asked to provide any infrastructure credentials or sensitive information.*\n2. [Install the Plural CLI](https://docs.plural.sh/getting-started/getting-started#install-plural-cli)\n3. [Create and initialize a new git repo](https://docs.plural.sh/getting-started/getting-started#create-your-plural-repo) to store your Plural installation.\n4. [Install, build and deploy applications](https://docs.plural.sh/getting-started/getting-started#install-plural-applications) from the Plural marketplace\n5. [Install the Plural Management Console](https://docs.plural.sh/basic-setup-and-deployment/admin-console).\n\nYou should now have a fully functioning Plural environment with apps and the management console running. For more details or further information check out the rest of the docs below.\n\n### The Plural Workflow\n\nThe workflow is literally two commands:\n\n```bash\nplural build\nplural deploy\n```\n\nOur tooling will take care of the rest.\n
\n\n\n\n## \ud83d\udcda Documentation\n\nThe full documentation is available on our [Documentation site](https://docs.plural.sh/).\n
\n\n\n\n## \ud83d\udcac Community\n\nFor general help, please refer to the Plural documentation. For additional help you can use the following channels:\n\n* [Discord](https://discord.gg/pluralsh) (For live discussions with the Plural team).\n* [GitHub](https://github.com/pluralsh/plural/) (Bug reports, feature requests, contributions).\n* [Twitter](https://twitter.com/plural_sh) (For our latest news).\n\nPlural is dedicated to providing a welcoming, diverse, and harassment-free experience for everyone. We expect everyone in the community to abide by our [Code of Conduct](CODE_OF_CONDUCT.md). *Please read it.*\n
\n\n\n## \ud83d\ude97 Roadmap\nSee what we're working on in these GitHub projects. Help us prioritize issues by reacting with an emoji on the issue!\n* Application Onboarding Roadmap: https://github.com/orgs/pluralsh/projects/2/views/2\n* Plural Core Issues: https://github.com/pluralsh/plural/issues\n* Plural CLI Issues: https://github.com/pluralsh/plural-cli/issues\n
\n\n\n\n## \ud83d\ude4c Contributing to Plural\n\nWe love contributions to Plural, big or small! To learn more about the repo and the architecture, see our [Contribution Guide](CONTRIBUTING.md). \n\nIf you're not sure where to start, or if you have any questions, please open a draft PR or visit our [Discord](https://discord.gg/pluralsh) server where the core team can help answer your questions.\n
\n\n\n\n## \ud83d\udcdd License\n\nSee [LICENSE](LICENSE) for licensing information. If there are any questions on the license please visit our [Discord](https://discord.gg/pluralsh).\n\n## Thanks to all the contributors \u2764\n \n \n \n",
- "source_links": [],
- "id": 95
- },
- {
- "page_link": "https://github.com/zalando/postgres-operator",
- "title": "postgres readme",
- "text": "# Postgres Operator\n\n\n\n[](https://coveralls.io/github/zalando/postgres-operator?branch=master)\n\n\n\nThe Postgres Operator delivers an easy to run highly-available [PostgreSQL](https://www.postgresql.org/)\nclusters on Kubernetes (K8s) powered by [Patroni](https://github.com/zalando/patroni).\nIt is configured only through Postgres manifests (CRDs) to ease integration into automated CI/CD\npipelines with no access to Kubernetes API directly, promoting infrastructure as code vs manual operations.\n\n### Operator features\n\n* Rolling updates on Postgres cluster changes, incl. quick minor version updates\n* Live volume resize without pod restarts (AWS EBS, PVC)\n* Database connection pooling with PGBouncer\n* Support fast in place major version upgrade. Supports global upgrade of all clusters.\n* Restore and cloning Postgres clusters on AWS, GCS and Azure\n* Additionally logical backups to S3 or GCS bucket can be configured\n* Standby cluster from S3 or GCS WAL archive\n* Configurable for non-cloud environments\n* Basic credential and user management on K8s, eases application deployments\n* Support for custom TLS certificates\n* UI to create and edit Postgres cluster manifests\n* Support for AWS EBS gp2 to gp3 migration, supporting iops and throughput configuration\n* Compatible with OpenShift\n\n### PostgreSQL features\n\n* Supports PostgreSQL 15, starting from 10+\n* Streaming replication cluster via Patroni\n* Point-In-Time-Recovery with\n[pg_basebackup](https://www.postgresql.org/docs/11/app-pgbasebackup.html) /\n[WAL-E](https://github.com/wal-e/wal-e) via [Spilo](https://github.com/zalando/spilo)\n* Preload libraries: [bg_mon](https://github.com/CyberDem0n/bg_mon),\n[pg_stat_statements](https://www.postgresql.org/docs/15/pgstatstatements.html),\n[pgextwlist](https://github.com/dimitri/pgextwlist),\n[pg_auth_mon](https://github.com/RafiaSabih/pg_auth_mon)\n* Incl. popular Postgres extensions such as\n[decoderbufs](https://github.com/debezium/postgres-decoderbufs),\n[hypopg](https://github.com/HypoPG/hypopg),\n[pg_cron](https://github.com/citusdata/pg_cron),\n[pg_partman](https://github.com/pgpartman/pg_partman),\n[pg_stat_kcache](https://github.com/powa-team/pg_stat_kcache),\n[pgq](https://github.com/pgq/pgq),\n[plpgsql_check](https://github.com/okbob/plpgsql_check),\n[postgis](https://postgis.net/),\n[set_user](https://github.com/pgaudit/set_user) and\n[timescaledb](https://github.com/timescale/timescaledb)\n\nThe Postgres Operator has been developed at Zalando and is being used in\nproduction for over three years.\n\n## Using Spilo 12 images or lower\n\nIf you are already using the Postgres operator in older version with a Spilo 12 Docker image you need to be aware of the changes for the backup path.\nWe introduce the major version into the backup path to smoothen the [major version upgrade](docs/administrator.md#minor-and-major-version-upgrade) that is now supported.\n\nThe new operator configuration can set a compatibility flag *enable_spilo_wal_path_compat* to make Spilo look for wal segments in the current path but also old format paths.\nThis comes at potential performance costs and should be disabled after a few days.\n\nThe newest Spilo image is: `ghcr.io/zalando/spilo-15:2.1-p9`\n\nThe last Spilo 12 image is: `registry.opensource.zalan.do/acid/spilo-12:1.6-p5`\n\n\n## Getting started\n\nFor a quick first impression follow the instructions of this\n[tutorial](docs/quickstart.md).\n\n## Supported setups of Postgres and Applications\n\n\n\n## Documentation\n\nThere is a browser-friendly version of this documentation at\n[postgres-operator.readthedocs.io](https://postgres-operator.readthedocs.io)\n\n* [How it works](docs/index.md)\n* [Installation](docs/quickstart.md#deployment-options)\n* [The Postgres experience on K8s](docs/user.md)\n* [The Postgres Operator UI](docs/operator-ui.md)\n* [DBA options - from RBAC to backup](docs/administrator.md)\n* [Build, debug and extend the operator](docs/developer.md)\n* [Configuration options](docs/reference/operator_parameters.md)\n* [Postgres manifest reference](docs/reference/cluster_manifest.md)\n* [Command-line options and environment variables](docs/reference/command_line_and_environment.md)\n\n## Community\n\nThere are two places to get in touch with the community:\n1. The [GitHub issue tracker](https://github.com/zalando/postgres-operator/issues)\n2. The **#postgres-operator** [slack channel](https://postgres-slack.herokuapp.com)\n",
- "source_links": [],
- "id": 96
- },
- {
- "page_link": "backup-restore.md",
- "title": "backup-restore",
- "text": "## Postgres Backup and Restore\n\nZalando's postgres operator has a number of useful backup/restore features that can be useful if you want to leverage them.\nThe two main one's we've used is:\n\n* clone from object storage - backs up snapshots and WAL logs to S3 or an equivalent object store where you can then pull it back down\n* clone from another instance - nice for creating hot backups\n\n### Finding your postgres database\n\nThe process will involve usage of kubectl so it's useful to get familiar with how to manage postgres with zalando's custom resource and kubectl:\n\n```sh\nkubectl get postgresql -n $namespace # get postgres isntances in a namespace\nkubectl get postgresql $name -n $namespace -o yaml > db.yaml # dump the yaml for a postgres instance to a file\nkubectl delete postgresql $name -n $namespace # deletes an instance\n```\n\nThese are some basic commands you'll likely want to use\n\n### Clone from object storage\n\nThe procedure from this is relatively simple:\n\n* run `kubectl get postgresql -n -o yaml > db.yaml` to get the current yaml\n* copy the `uid` in the metadata section of the yam, you'll need it later. This can be found in a block like:\n\n```yaml\napiVersion: acid.zalan.do/v1\nkind: postgresql\nmetadata:\n annotations:\n meta.helm.sh/release-name: airbyte\n meta.helm.sh/release-namespace: airbyte\n creationTimestamp: \"2022-10-31T23:53:27Z\"\n generation: 6\n labels:\n app.kubernetes.io/instance: airbyte\n app.kubernetes.io/managed-by: Helm\n app.kubernetes.io/name: postgres\n app.kubernetes.io/version: 1.16.0\n helm.sh/chart: postgres-0.1.16\n name: plural-airbyte\n namespace: airbyte\n resourceVersion: \"966219670\"\n uid: 40c1d314-f667-421e-a059-f4521e8eb811\nspec:\n databases:\n airbyte: airbyte\n numberOfInstances: 2\n postgresql:\n parameters:\n max_connections: \"101\"\n version: \"13\"\n resources:\n limits:\n cpu: \"2\"\n memory: 1Gi\n requests:\n cpu: 50m\n memory: 100Mi\n teamId: plural\n users:\n airbyte:\n - superuser\n - createdb\n volume:\n size: 27Gi\n```\n* delete your existing cluster (you can also create a hot standby if you want using the subsequent station just in case)\n * `kubectl delete postgresql -n ` is the command here\n* add a `clone` block within the spec field of your postgres db, that will look something like. You'll also want to strip out extraneous fields from the metadata, `creationTimestamp`, `generation`, `resourceVersion`, `uid`. K8s will probably understand this but still good practice.\n\n```yaml\napiVersion: acid.zalan.do/v1\nkind: postgresql\nmetadata:\n annotations:\n meta.helm.sh/release-name: airbyte\n meta.helm.sh/release-namespace: airbyte\n creationTimestamp: \"2022-10-31T23:53:27Z\"\n generation: 6\n labels:\n app.kubernetes.io/instance: airbyte\n app.kubernetes.io/managed-by: Helm\n app.kubernetes.io/name: postgres\n app.kubernetes.io/version: 1.16.0\n helm.sh/chart: postgres-0.1.16\n name: plural-airbyte\n namespace: airbyte\n resourceVersion: \"966219670\"\n uid: 40c1d314-f667-421e-a059-f4521e8eb811\nspec:\n clone:\n cluster: plural-airbyte # notice this is the same as `metadata.name`\n s3_access_key_id: AWS_ACCESS_KEY_ID\n s3_secret_access_key: AWS_SECRET_ACCESS_KEY\n timestamp: \"2022-10-31T19:00:00+04:00\"\n uid: SOME-UUID\n databases:\n airbyte: airbyte\n numberOfInstances: 2\n postgresql:\n parameters:\n max_connections: \"101\"\n version: \"13\"\n resources:\n limits:\n cpu: \"2\"\n memory: 1Gi\n requests:\n cpu: 50m\n memory: 100Mi\n teamId: plural\n users:\n airbyte:\n - superuser\n - createdb\n volume:\n size: 27Gi\n```\n* `kubectl apply -f db.yaml` - reapply the database to k8s using the file you were working on\n\nPostgres will perform the backup w/in the postgres pod itself, so if you want to track its status, you can look at the pods with:\n\n```sh\nkubectl logs DB-NAME-0 -n NAMESPACE # inject whatever the name of the postgres db you created and the namespace it was applied to\n```\n\n### Clone from another cluster\n\nThis is really useful for creating hot standbys or recreating a cluster entirely if you say want to change the underlying storage class of the db. The preparation is similar to above:\n\n* dump the db to a file with `kubectl get postgresql -n -o yaml > db.yaml`\n* edit the file and add a clone block like:\n\n```yaml\napiVersion: acid.zalan.do/v1\nkind: postgresql\nmetadata:\n annotations:\n meta.helm.sh/release-name: airbyte\n meta.helm.sh/release-namespace: airbyte\n creationTimestamp: \"2022-10-31T23:53:27Z\"\n generation: 6\n labels:\n app.kubernetes.io/instance: airbyte\n app.kubernetes.io/managed-by: Helm\n app.kubernetes.io/name: postgres\n app.kubernetes.io/version: 1.16.0\n helm.sh/chart: postgres-0.1.16\n name: plural-airbyte\n namespace: airbyte\n resourceVersion: \"966219670\"\n uid: 40c1d314-f667-421e-a059-f4521e8eb811\nspec:\n clone:\n cluster: plural-airbyte-old # notice no timestamp or uid triggers a pg_basebackup from a running cluster\n databases:\n airbyte: airbyte\n numberOfInstances: 2\n postgresql:\n parameters:\n max_connections: \"101\"\n version: \"13\"\n resources:\n limits:\n cpu: \"2\"\n memory: 1Gi\n requests:\n cpu: 50m\n memory: 100Mi\n teamId: plural\n users:\n airbyte:\n - superuser\n - createdb\n volume:\n size: 27Gi\n```\n* `kubectl apply -f db.yaml`\n* same as above, you can track the clone via `kubectl logs ...`\n\n",
- "source_links": [],
- "id": 97
- },
- {
- "page_link": "https://github.com/PostHog/posthog",
- "title": "posthog readme",
- "text": "
\n\n## PostHog is an open-source suite of product and data tools, built for engineers\n\n- Specify events manually, or use autocapture to get started quickly\n- Analyze your data with visualizations and session recordings\n- Improve your product with A/B testing and feature flags\n- Keep control over your data by deploying PostHog on your infrastructure\n- Use apps to connect to external services and manage data flows\n\n## Table of Contents\n\n- [Get started for free](#get-started-for-free)\n- [Features](#features)\n- [Docs and support](#docs-and-support)\n- [Contributing](#contributing)\n- [Philosophy](#philosophy)\n- [Open-source vs paid](#open-source-vs-paid)\n\n## Get started for free\n\n### PostHog Cloud\n\nThe fastest and most reliable way to get started with PostHog is signing up for free to\u00a0[PostHog Cloud](https://app.posthog.com/signup) or [PostHog Cloud EU](https://eu.posthog.com/signup)\n\n### Open-source hobby deploy\n\nDeploy a hobby instance in one line on Linux with Docker (recommended 4GB memory):\n\n\n ```bash \n /bin/bash -c \"$(curl -fsSL https://raw.githubusercontent.com/posthog/posthog/HEAD/bin/deploy-hobby)\" \n ``` \n\nGood for <100K events ingested monthly. See our [docs for more info and limitations](https://posthog.com/docs/self-host/open-source/deployment).\n\n### Enterprise self-hosted\n\nSee our [enterprise self-hosted docs](https://posthog.com/docs/self-host/enterprise/overview) to deploy a scalable, production-ready instance with support from our team.\n\n## Features\n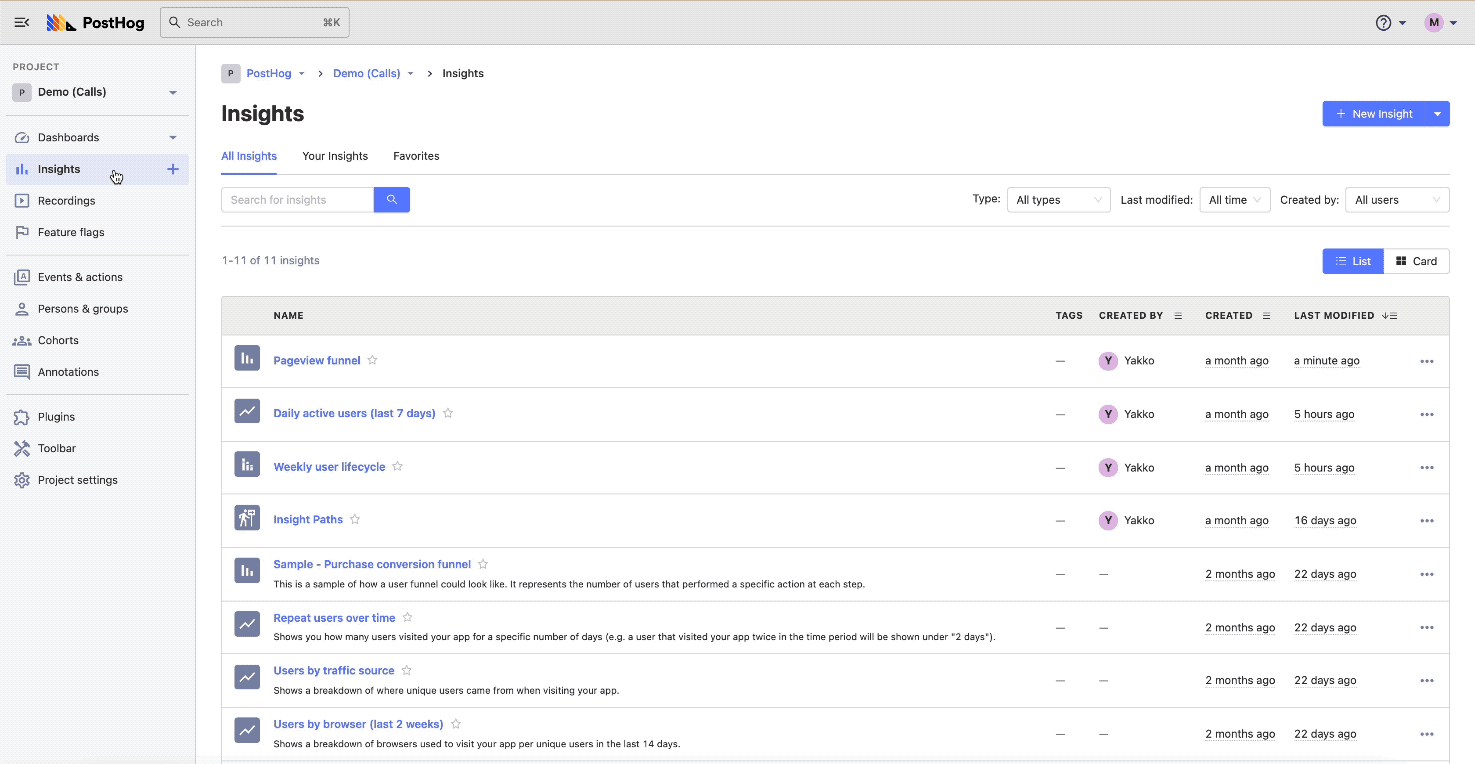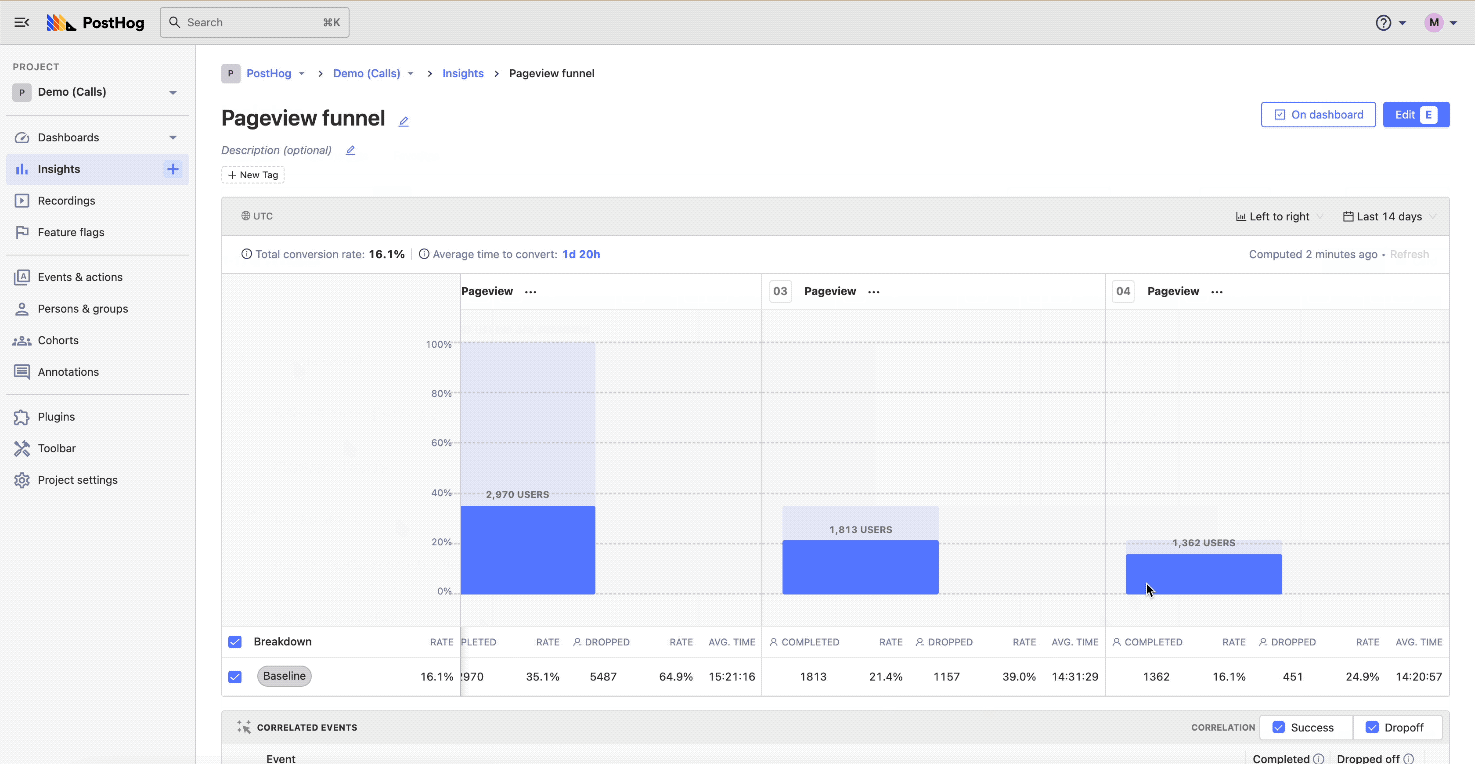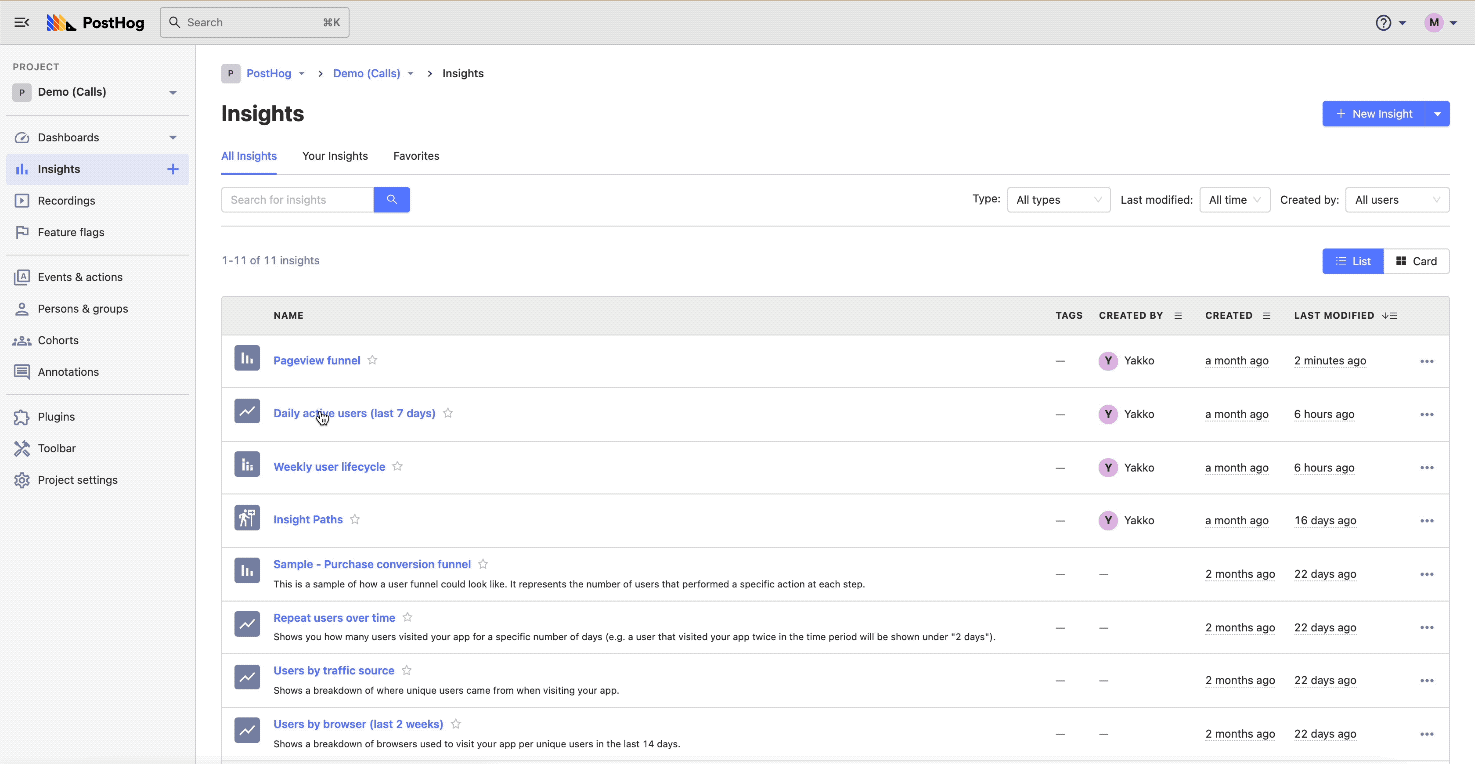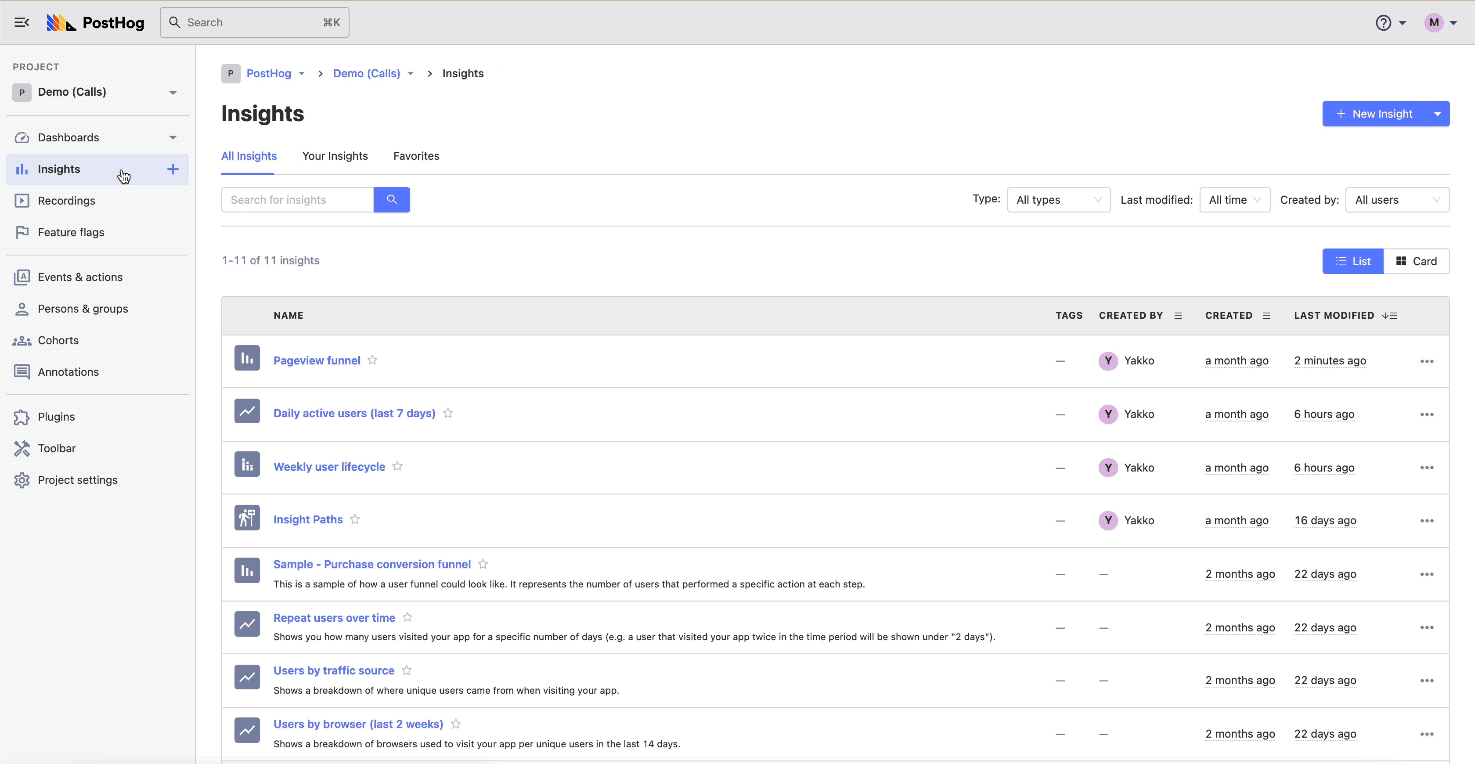\n\nWe bring together all the tools and data in one place to help you build better products\n\n### Product analytics and optimization\n\n- **Event-based analytics:** capture your product's usage [automatically](https://posthog.com/docs/integrate/client/js#autocapture), or [customize](https://posthog.com/docs/integrate) it to your needs\n- **User and group tracking:** understand the [people](https://posthog.com/manual/persons) and [groups](https://posthog.com/manual/group-analytics) behind the events and track properties about them\n- **Data visualizations:** create and share [graphs](https://posthog.com/docs/features/trends), [funnels](https://posthog.com/docs/features/funnels), [paths](https://posthog.com/docs/features/paths), [retention](https://posthog.com/docs/features/retention), and [dashboards](https://posthog.com/docs/features/dashboards)\n- **Session recording:** [watch videos](https://posthog.com/docs/features/session-recording) of your users' behavior, with fine-grained filters and privacy controls\n- **Heatmaps:** see where users are using your product with the [PostHog Toolbar](https://posthog.com/docs/features/toolbar)\n- **Feature flags:** test and manage the rollout of new features, target specific users and groups\n- **A/B and multi-variate testing:** run simple or complex changes as [experiments](https://posthog.com/manual/experimentation) and get automatic significance calculations\n- **Correlation analysis:** discover what events and properties [correlate](https://posthog.com/manual/correlation) with success and failure\n\n### Data and infrastructure tools\n\n- **Complete control over your data:** [host it yourself](https://posthog.com/docs/self-host/overview#deploy) on any infrastructure\n- **Import and export your data:** import from and export to the services that matter to you with [apps](https://posthog.com/apps)\n- **Ready-made libraries:** we\u2019ve built libraries for [JavaScript](https://posthog.com/docs/integrations/js-integration), [Python](https://posthog.com/docs/integrations/python-integration), [Ruby](https://posthog.com/docs/integrations/ruby-integration), [Node](https://posthog.com/docs/integrations/node-integration), [Go](https://posthog.com/docs/integrations/go-integration), [Android](https://posthog.com/docs/integrations/android-integration), [iOS](https://posthog.com/docs/integrations/ios-integration), [PHP](https://posthog.com/docs/integrations/php-integration), [Flutter](https://posthog.com/docs/integrations/flutter-integration), [React Native](https://posthog.com/docs/integrations/react-native-integration), [Elixir](https://posthog.com/docs/integrations/elixir-integration), [Nim](https://github.com/Yardanico/posthog-nim), and an [API](https://posthog.com/docs/integrations/api) for anything else\n- **Plays nicely with data warehouses:** import events or user data from your warehouse by writing a simple transformation plugin, and export data with pre-built apps - such as [BigQuery](https://posthog.com/apps/bigquery-export), [Redshift](https://posthog.com/apps/redshift-export), [Snowflake](https://posthog.com/apps/snowflake-export), and [S3](https://posthog.com/apps/s3-expo)\n\n[Read a full list of PostHog features](https://posthog.com/product).\n\n## Docs and support\n\nRead how to [deploy](https://posthog.com/docs/self-host), [integrate](https://posthog.com/docs/integrate), and [extend](https://posthog.com/docs/apps) PostHog in our [documentation](https://posthog.com/docs).\n\nCheck out our [tutorials](https://posthog.com/docs/apps) for step-by-step guides, how-to's, and best practices.\n\nLearn more about getting the most out of PostHog's features in [our product manual](https://posthog.com/using-posthog).\n\n[Ask a question](https://posthog.com/questions) or join our [Slack community](https://posthog.com/slack) to get support.\n\n## Contributing\n\nWe <3 contributions big and small. In priority order (although everything is appreciated) with the most helpful first:\n\n- Give us feedback in our [Slack community](https://posthog.com/slack)\n- Vote on features or get early access to beta functionality in our [roadmap](https://posthog.com/roadmap)\n- Open a PR (see our instructions on [developing PostHog locally](https://posthog.com/handbook/engineering/developing-locally))\n- Submit a [feature request](https://github.com/PostHog/posthog/issues/new?assignees=&labels=enhancement%2C+feature&template=feature_request.md) or [bug report](https://github.com/PostHog/posthog/issues/new?assignees=&labels=bug&template=bug_report.md)\n\n## Philosophy\n\nOur mission is to\u00a0increase the number of successful products\u00a0in the world. To do that, we build product and data tools that help you understand user behavior without losing control of your data.\n\nIn our view, third-party analytics tools do not work in a world of cookie deprecation, GDPR, HIPAA, CCPA, and many other four-letter acronyms. PostHog is the alternative to sending all of your customers' personal information and usage data to third-parties.\n\nPostHog gives you every tool you need to understand user behavior, develop and test improvements, and release changes to make your product more successful.\n\nPostHog operates in public as much as possible. We detail how we work and our learning on building and running a fast-growing, product-focused startup in our [handbook](https://posthog.com/handbook/getting-started/start-here).\n\n## Open-source vs. paid\n\nThis repo is available under the [MIT expat license](https://github.com/PostHog/posthog/blob/master/LICENSE), except for the `ee` directory (which has it's [license here](https://github.com/PostHog/posthog/blob/master/ee/LICENSE)) if applicable. \n\nNeed *absolutely \ud83d\udcaf% FOSS*? Check out our [posthog-foss](https://github.com/PostHog/posthog-foss) repository, which is purged of all proprietary code and features.\n\nUsing premium features (contained in the `ee` directory) with a self-hosted instance require a PostHog license. To learn more, [book a demo](https://posthog.com/book-a-demo) or see our [pricing page](https://posthog.com/pricing).\n\n### We\u2019re hiring!\n\nCome help us make PostHog even better. We're growing fast [and would love for you to join us](https://posthog.com/careers).\n\n## Contributors \ud83e\uddb8\n\n[//]: contributor-faces\n\n\n\n\n \n\n\n\n\n",
- "source_links": [],
- "id": 98
- },
- {
- "page_link": "https://github.com/PrefectHQ/prefect",
- "title": "prefect readme",
- "text": "
\n\n# Prefect\n\nPrefect is an orchestrator for data-intensive workflows. It's the simplest way to transform any Python function into a unit of work that can be observed and orchestrated. With Prefect, you can build resilient, dynamic workflows that react to the world around them and recover from unexpected changes. With just a few decorators, Prefect supercharges your code with features like automatic retries, distributed execution, scheduling, caching, and much more. Every activity is tracked and can be monitored with the Prefect server or Prefect Cloud dashboard.\n\n```python\nfrom prefect import flow, task\nfrom typing import List\nimport httpx\n\n\n@task(retries=3)\ndef get_stars(repo: str):\n url = f\"https://api.github.com/repos/{repo}\"\n count = httpx.get(url).json()[\"stargazers_count\"]\n print(f\"{repo} has {count} stars!\")\n\n\n@flow(name=\"GitHub Stars\")\ndef github_stars(repos: List[str]):\n for repo in repos:\n get_stars(repo)\n\n\n# run the flow!\ngithub_stars([\"PrefectHQ/Prefect\"])\n```\n\nAfter running some flows, fire up the Prefect UI to see what happened:\n\n```bash\nprefect server start\n```\n\n\n\nFrom here, you can continue to use Prefect interactively or [deploy your flows](https://docs.prefect.io/concepts/deployments) to remote environments, running on a scheduled or event-driven basis.\n\n## Getting Started\n\nPrefect requires Python 3.7 or later. To [install Prefect](https://docs.prefect.io/getting-started/installation/), run the following command in a shell or terminal session:\n\n```bash\npip install prefect\n```\n\nStart by then exploring the [core concepts of Prefect workflows](https://docs.prefect.io/concepts/), then follow one of our [friendly tutorials](https://docs.prefect.io/tutorials/first-steps) to learn by example.\n\n## Join the community\n\nPrefect is made possible by the fastest growing community of thousands of friendly data engineers. Join us in building a new kind of workflow system. The [Prefect Slack community](https://prefect.io/slack) is a fantastic place to learn more about Prefect, ask questions, or get help with workflow design. The [Prefect Discourse](https://discourse.prefect.io/) is a community-driven knowledge base to find answers to your Prefect-related questions. All community forums, including code contributions, issue discussions, and slack messages are subject to our [Code of Conduct](https://discourse.prefect.io/faq).\n\n## Contribute\n\nSee our [documentation on contributing to Prefect](https://docs.prefect.io/contributing/overview/).\n\nThanks for being part of the mission to build a new kind of workflow system and, of course, **happy engineering!**\n",
- "source_links": [],
- "id": 99
- },
- {
- "page_link": "https://github.com/PrefectHQ/prefect",
- "title": "prefect-agent readme",
- "text": "
\n\n# Prefect\n\nPrefect is an orchestrator for data-intensive workflows. It's the simplest way to transform any Python function into a unit of work that can be observed and orchestrated. With Prefect, you can build resilient, dynamic workflows that react to the world around them and recover from unexpected changes. With just a few decorators, Prefect supercharges your code with features like automatic retries, distributed execution, scheduling, caching, and much more. Every activity is tracked and can be monitored with the Prefect server or Prefect Cloud dashboard.\n\n```python\nfrom prefect import flow, task\nfrom typing import List\nimport httpx\n\n\n@task(retries=3)\ndef get_stars(repo: str):\n url = f\"https://api.github.com/repos/{repo}\"\n count = httpx.get(url).json()[\"stargazers_count\"]\n print(f\"{repo} has {count} stars!\")\n\n\n@flow(name=\"GitHub Stars\")\ndef github_stars(repos: List[str]):\n for repo in repos:\n get_stars(repo)\n\n\n# run the flow!\ngithub_stars([\"PrefectHQ/Prefect\"])\n```\n\nAfter running some flows, fire up the Prefect UI to see what happened:\n\n```bash\nprefect server start\n```\n\n\n\nFrom here, you can continue to use Prefect interactively or [deploy your flows](https://docs.prefect.io/concepts/deployments) to remote environments, running on a scheduled or event-driven basis.\n\n## Getting Started\n\nPrefect requires Python 3.7 or later. To [install Prefect](https://docs.prefect.io/getting-started/installation/), run the following command in a shell or terminal session:\n\n```bash\npip install prefect\n```\n\nStart by then exploring the [core concepts of Prefect workflows](https://docs.prefect.io/concepts/), then follow one of our [friendly tutorials](https://docs.prefect.io/tutorials/first-steps) to learn by example.\n\n## Join the community\n\nPrefect is made possible by the fastest growing community of thousands of friendly data engineers. Join us in building a new kind of workflow system. The [Prefect Slack community](https://prefect.io/slack) is a fantastic place to learn more about Prefect, ask questions, or get help with workflow design. The [Prefect Discourse](https://discourse.prefect.io/) is a community-driven knowledge base to find answers to your Prefect-related questions. All community forums, including code contributions, issue discussions, and slack messages are subject to our [Code of Conduct](https://discourse.prefect.io/faq).\n\n## Contribute\n\nSee our [documentation on contributing to Prefect](https://docs.prefect.io/contributing/overview/).\n\nThanks for being part of the mission to build a new kind of workflow system and, of course, **happy engineering!**\n",
- "source_links": [],
- "id": 100
- },
- {
- "page_link": "https://github.com/PrefectHQ/prefect",
- "title": "prefect-worker readme",
- "text": "
\n\n# Prefect\n\nPrefect is an orchestrator for data-intensive workflows. It's the simplest way to transform any Python function into a unit of work that can be observed and orchestrated. With Prefect, you can build resilient, dynamic workflows that react to the world around them and recover from unexpected changes. With just a few decorators, Prefect supercharges your code with features like automatic retries, distributed execution, scheduling, caching, and much more. Every activity is tracked and can be monitored with the Prefect server or Prefect Cloud dashboard.\n\n```python\nfrom prefect import flow, task\nfrom typing import List\nimport httpx\n\n\n@task(retries=3)\ndef get_stars(repo: str):\n url = f\"https://api.github.com/repos/{repo}\"\n count = httpx.get(url).json()[\"stargazers_count\"]\n print(f\"{repo} has {count} stars!\")\n\n\n@flow(name=\"GitHub Stars\")\ndef github_stars(repos: List[str]):\n for repo in repos:\n get_stars(repo)\n\n\n# run the flow!\ngithub_stars([\"PrefectHQ/Prefect\"])\n```\n\nAfter running some flows, fire up the Prefect UI to see what happened:\n\n```bash\nprefect server start\n```\n\n\n\nFrom here, you can continue to use Prefect interactively or [deploy your flows](https://docs.prefect.io/concepts/deployments) to remote environments, running on a scheduled or event-driven basis.\n\n## Getting Started\n\nPrefect requires Python 3.7 or later. To [install Prefect](https://docs.prefect.io/getting-started/installation/), run the following command in a shell or terminal session:\n\n```bash\npip install prefect\n```\n\nStart by then exploring the [core concepts of Prefect workflows](https://docs.prefect.io/concepts/), then follow one of our [friendly tutorials](https://docs.prefect.io/tutorials/first-steps) to learn by example.\n\n## Join the community\n\nPrefect is made possible by the fastest growing community of thousands of friendly data engineers. Join us in building a new kind of workflow system. The [Prefect Slack community](https://prefect.io/slack) is a fantastic place to learn more about Prefect, ask questions, or get help with workflow design. The [Prefect Discourse](https://discourse.prefect.io/) is a community-driven knowledge base to find answers to your Prefect-related questions. All community forums, including code contributions, issue discussions, and slack messages are subject to our [Code of Conduct](https://discourse.prefect.io/faq).\n\n## Contribute\n\nSee our [documentation on contributing to Prefect](https://docs.prefect.io/contributing/overview/).\n\nThanks for being part of the mission to build a new kind of workflow system and, of course, **happy engineering!**\n",
- "source_links": [],
- "id": 101
- },
- {
- "page_link": "https://github.com/rabbitmq/rabbitmq-server",
- "title": "rabbitmq readme",
- "text": "[](https://github.com/rabbitmq/rabbitmq-server/actions/workflows/test.yaml)\n\n# RabbitMQ Server\n\n[RabbitMQ](https://rabbitmq.com) is a [feature rich](https://rabbitmq.com/documentation.html),\nmulti-protocol messaging and streaming broker. It supports:\n\n * AMQP 0-9-1\n * AMQP 1.0\n * [RabbitMQ Stream Protocol](https://rabbitmq.com/streams.html)\n * MQTT 3.1.1\n * STOMP 1.0 through 1.2\n\n\n## Installation\n\n * [Installation guides](https://rabbitmq.com/download.html) for various platforms\n * [Kubernetes Cluster Operator](https://rabbitmq.com/kubernetes/operator/operator-overview.html)\n * [Changelog](https://www.rabbitmq.com/changelog.html)\n * [Releases](https://github.com/rabbitmq/rabbitmq-server/releases) on GitHub\n * [Currently supported released series](https://www.rabbitmq.com/versions.html)\n * [Supported Erlang versions](https://www.rabbitmq.com/which-erlang.html)\n\n\n## Tutorials and Documentation\n\n * [RabbitMQ tutorials](https://rabbitmq.com/getstarted.html)\n * [All documentation guides](https://rabbitmq.com/documentation.html)\n * [RabbitMQ blog](https://blog.rabbitmq.com/)\n\nSome key doc guides include\n\n * [CLI tools guide](https://rabbitmq.com/cli.html) \n * [Clustering](https://www.rabbitmq.com/clustering.html) and [Cluster Formation](https://www.rabbitmq.com/cluster-formation.html) guides\n * [Configuration guide](https://rabbitmq.com/configure.html) \n * [Client libraries and tools](https://rabbitmq.com/devtools.html)\n * [Monitoring](https://rabbitmq.com/monitoring.html) and [Prometheus/Grafana](https://www.rabbitmq.com/prometheus.html) guides\n * [Kubernetes Cluster Operator](https://rabbitmq.com/kubernetes/operator/operator-overview.html)\n * [Production checklist](https://rabbitmq.com/production-checklist.html)\n * [Quorum queues](https://rabbitmq.com/quorum-queues.html): a replicated, data safety- and consistency-oriented queue type\n * [Streams](https://rabbitmq.com/streams.html): a persistent and replicated append-only log with non-destructive consumer semantics\n * [Runnable tutorials](https://github.com/rabbitmq/rabbitmq-tutorials/)\n\nRabbitMQ documentation is also [developed on GitHub](https://github.com/rabbitmq/rabbitmq-website/).\n\n## Commercial Features and Support\n\n * [Commercial edition of RabbitMQ](https://www.vmware.com/products/rabbitmq.html)\n * [Commercial edition for Kubernetes](https://rabbitmq.com/kubernetes/tanzu/installation.html)\n * [Commercial support](https://rabbitmq.com/services.html) from [VMware](https://vmware.com) for open source RabbitMQ\n\n## Getting Help from the Community\n\n * [Community Discord server](https://rabbitmq.com/discord/)\n * [Community Slack](https://rabbitmq.com/slack/)\n * [GitHub Discussions](https://github.com/rabbitmq/rabbitmq-server/discussions/)\n * [RabbitMQ mailing list](https://groups.google.com/forum/#!forum/rabbitmq-users)\n * `#rabbitmq` on [Libera Chat](https://libera.chat/)\n\n\n## Contributing\n\nSee [CONTRIBUTING.md](./CONTRIBUTING.md) and our [development process overview](https://rabbitmq.com/github.html).\n\nQuestions about contributing, internals and so on are very welcome on the [mailing list](https://groups.google.com/forum/#!forum/rabbitmq-users).\n\n\n## Licensing\n\nRabbitMQ server is [licensed under the MPL 2.0](LICENSE-MPL-RabbitMQ).\n\n\n## Building From Source and Packaging\n\n * [Contributor resources](https://github.com/rabbitmq/contribute)\n * [Building RabbitMQ from Source](https://rabbitmq.com/build-server.html)\n * [Building RabbitMQ Distribution Packages](https://rabbitmq.com/build-server.html)\n\n\n## Copyright\n\n(c) 2007-2023 VMware, Inc. or its affiliates.\n",
- "source_links": [],
- "id": 102
- },
- {
- "page_link": "https://github.com/ray-project/ray",
- "title": "ray readme",
- "text": null,
- "source_links": [],
- "id": 103
- },
- {
- "page_link": null,
- "title": "redash readme",
- "text": null,
- "source_links": [],
- "id": 104
- },
- {
- "page_link": "https://github.com/redis/redis",
- "title": "redis readme",
- "text": null,
- "source_links": [],
- "id": 105
- },
- {
- "page_link": "external-hostname.md",
- "title": "external-hostname",
- "text": "# Expose Redis Outside Cluster\n\nWe ship redis with only internal cluster networking by default for security reasons, but you can still expose either the redis master or replicas externally from the cluster. The process simply involves editing the `context.yaml` file at the root of your repo with:\n\n```\nconfiguration:\n ...\n redis:\n masterHostname: redis-master.CLUSTER-SUBDOMAIN\n replicaHostname: redis-replica.CLUSTER-SUBDOMAIN # if you want to expose the replica as well\n```\n\nyou can then simply run: `plural build --only redis && plural deploy --commit \"expose redis\"`",
- "source_links": [],
- "id": 106
- },
- {
- "page_link": "https://github.com/redpanda-data/redpanda",
- "title": "redpanda readme",
- "text": null,
- "source_links": [],
- "id": 107
- },
- {
- "page_link": "https://github.com/stakater/Reloader",
- "title": "reloader readme",
- "text": "#  RELOADER\n\n[](https://goreportcard.com/report/github.com/stakater/reloader)\n[](http://godoc.org/github.com/stakater/reloader)\n[](https://github.com/stakater/reloader/releases/latest)\n[](https://github.com/stakater/reloader/releases/latest)\n[](https://hub.docker.com/r/stakater/reloader/)\n[](https://hub.docker.com/r/stakater/reloader/)\n[](LICENSE)\n[](http://stakater.com/?utm_source=Reloader&utm_medium=github)\n\n## Problem\n\nWe would like to watch if some change happens in `ConfigMap` and/or `Secret`; then perform a rolling upgrade on relevant `DeploymentConfig`, `Deployment`, `Daemonset`, `Statefulset` and `Rollout`\n\n## Solution\n\nReloader can watch changes in `ConfigMap` and `Secret` and do rolling upgrades on Pods with their associated `DeploymentConfigs`, `Deployments`, `Daemonsets` `Statefulsets` and `Rollouts`.\n\n## Compatibility\n\nReloader is compatible with kubernetes >= 1.9\n\n## How to use Reloader\n\nFor a `Deployment` called `foo` have a `ConfigMap` called `foo-configmap` or `Secret` called `foo-secret` or both. Then add your annotation (by default `reloader.stakater.com/auto`) to main metadata of your `Deployment`\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n reloader.stakater.com/auto: \"true\"\nspec:\n template:\n metadata:\n```\n\nThis will discover deploymentconfigs/deployments/daemonsets/statefulset/rollouts automatically where `foo-configmap` or `foo-secret` is being used either via environment variable or from volume mount. And it will perform rolling upgrade on related pods when `foo-configmap` or `foo-secret`are updated.\n\nYou can restrict this discovery to only `ConfigMap` or `Secret` objects that\nare tagged with a special annotation. To take advantage of that, annotate\nyour deploymentconfigs/deployments/daemonsets/statefulset/rollouts like this:\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n reloader.stakater.com/search: \"true\"\nspec:\n template:\n```\n\nand Reloader will trigger the rolling upgrade upon modification of any\n`ConfigMap` or `Secret` annotated like this:\n\n```yaml\nkind: ConfigMap\nmetadata:\n annotations:\n reloader.stakater.com/match: \"true\"\ndata:\n key: value\n```\n\nprovided the secret/configmap is being used in an environment variable, or a\nvolume mount.\n\nPlease note that `reloader.stakater.com/search` and\n`reloader.stakater.com/auto` do not work together. If you have the\n`reloader.stakater.com/auto: \"true\"` annotation on your deployment, then it\nwill always restart upon a change in configmaps or secrets it uses, regardless\nof whether they have the `reloader.stakater.com/match: \"true\"` annotation or\nnot.\n\nWe can also specify a specific configmap or secret which would trigger rolling upgrade only upon change in our specified configmap or secret, this way, it will not trigger rolling upgrade upon changes in all configmaps or secrets used in a deploymentconfig, deployment, daemonset, statefulset or rollout.\nTo do this either set the auto annotation to `\"false\"` (`reloader.stakater.com/auto: \"false\"`) or remove it altogether, and use annotations mentioned [here](#Configmap) or [here](#Secret)\n\n### Configmap\n\nTo perform rolling upgrade when change happens only on specific configmaps use below annotation.\n\nFor a `Deployment` called `foo` have a `ConfigMap` called `foo-configmap`. Then add this annotation to main metadata of your `Deployment`\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n configmap.reloader.stakater.com/reload: \"foo-configmap\"\nspec:\n template:\n metadata:\n```\n\nUse comma separated list to define multiple configmaps.\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n configmap.reloader.stakater.com/reload: \"foo-configmap,bar-configmap,baz-configmap\"\nspec:\n template: \n metadata:\n```\n\n### Secret\n\nTo perform rolling upgrade when change happens only on specific secrets use below annotation.\n\nFor a `Deployment` called `foo` have a `Secret` called `foo-secret`. Then add this annotation to main metadata of your `Deployment`\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n secret.reloader.stakater.com/reload: \"foo-secret\"\nspec:\n template: \n metadata:\n```\n\nUse comma separated list to define multiple secrets.\n\n```yaml\nkind: Deployment\nmetadata:\n annotations:\n secret.reloader.stakater.com/reload: \"foo-secret,bar-secret,baz-secret\"\nspec:\n template: \n metadata:\n```\n\n### NOTES\n\n- Reloader also supports [sealed-secrets](https://github.com/bitnami-labs/sealed-secrets). [Here](docs/Reloader-with-Sealed-Secrets.md) are the steps to use sealed-secrets with reloader.\n- For [rollouts](https://github.com/argoproj/argo-rollouts/) reloader simply triggers a change is up to you how you configure the rollout strategy.\n- `reloader.stakater.com/auto: \"true\"` will only reload the pod, if the configmap or secret is used (as a volume mount or as an env) in `DeploymentConfigs/Deployment/Daemonsets/Statefulsets`\n- `secret.reloader.stakater.com/reload` or `configmap.reloader.stakater.com/reload` annotation will reload the pod upon changes in specified configmap or secret, irrespective of the usage of configmap or secret.\n- you may override the auto annotation with the `--auto-annotation` flag\n- you may override the search annotation with the `--auto-search-annotation` flag\n and the match annotation with the `--search-match-annotation` flag\n- you may override the configmap annotation with the `--configmap-annotation` flag\n- you may override the secret annotation with the `--secret-annotation` flag\n- you may want to prevent watching certain namespaces with the `--namespaces-to-ignore` flag\n- you may want to prevent watching certain resources with the `--resources-to-ignore` flag\n- you can configure logging in JSON format with the `--log-format=json` option\n- you can configure the \"reload strategy\" with the `--reload-strategy=` option (details below)\n\n## Reload Strategies\nReloader supports multiple \"reload\" strategies for performing rolling upgrades to resources. The following list describes them:\n- **env-vars**: When a tracked `configMap`/`secret` is updated, this strategy attaches a Reloader specific environment variable to any containers \n referencing the changed `configMap` or `secret` on the owning resource (e.g., `Deployment`, `StatefulSet`, etc.).\n This strategy can be specified with the `--reload-strategy=env-vars` argument. Note: This is the default reload strategy.\n- **annotations**: When a tracked `configMap`/`secret` is updated, this strategy attaches a `reloader.stakater.com/last-reloaded-from` pod template annotation\n on the owning resource (e.g., `Deployment`, `StatefulSet`, etc.). This strategy is useful when using resource syncing tools like ArgoCD, since it will not cause these tools\n to detect configuration drift after a resource is reloaded. Note: Since the attached pod template annotation only tracks the last reload source, this strategy will reload any tracked resource should its \n `configMap` or `secret` be deleted and recreated.\n This strategy can be specified with the `--reload-strategy=annotations` argument.\n \n\n## Deploying to Kubernetes\n\nYou can deploy Reloader by following methods:\n\n### Vanilla Manifests\n\nYou can apply vanilla manifests by changing `RELEASE-NAME` placeholder provided in manifest with a proper value and apply it by running the command given below:\n\n```bash\nkubectl apply -f https://raw.githubusercontent.com/stakater/Reloader/master/deployments/kubernetes/reloader.yaml\n```\n\nBy default, Reloader gets deployed in `default` namespace and watches changes `secrets` and `configmaps` in all namespaces.\n\nReloader can be configured to ignore the resources `secrets` and `configmaps` by passing the following args (`spec.template.spec.containers.args`) to its container :\n\n| Args | Description |\n| -------------------------------- | -------------------- |\n| --resources-to-ignore=configMaps | To ignore configMaps |\n| --resources-to-ignore=secrets | To ignore secrets |\n\n`Note`: At one time only one of these resource can be ignored, trying to do it will cause error in Reloader. Workaround for ignoring both resources is by scaling down the reloader pods to `0`.\n\n### Vanilla kustomize\n\nYou can also apply the vanilla manifests by running the following command\n\n```bash\nkubectl apply -k https://github.com/stakater/Reloader/deployments/kubernetes\n```\n\nSimilarly to vanilla manifests get deployed in `default` namespace and watches changes `secrets` and `configmaps` in all namespaces.\n\n### Kustomize\n\nYou can write your own `kustomization.yaml` using ours as a 'base' and write patches to tweak the configuration.\n\n```yaml\napiVersion: kustomize.config.k8s.io/v1beta1\nkind: Kustomization\n\nbases:\n - https://github.com/stakater/Reloader/deployments/kubernetes\n\nnamespace: reloader\n```\n\n### Helm Charts\n\nAlternatively if you have configured helm on your cluster, you can add reloader to helm from our public chart repository and deploy it via helm using below mentioned commands. Follow [this](docs/Helm2-to-Helm3.md) guide, in case you have trouble migrating reloader from Helm2 to Helm3\n\n```bash\nhelm repo add stakater https://stakater.github.io/stakater-charts\n\nhelm repo update\n\nhelm install stakater/reloader # For helm3 add --generate-name flag or set the release name\n```\n\n**Note:** By default reloader watches in all namespaces. To watch in single namespace, please run following command. It will install reloader in `test` namespace which will only watch `Deployments`, `Daemonsets` `Statefulsets` and `Rollouts` in `test` namespace.\n\n```bash\nhelm install stakater/reloader --set reloader.watchGlobally=false --namespace test # For helm3 add --generate-name flag or set the release name\n```\n\nReloader can be configured to ignore the resources `secrets` and `configmaps` by using the following parameters of `values.yaml` file:\n\n| Parameter | Description | Type |\n| ---------------- | -------------------------------------------------------------- | ------- |\n| ignoreSecrets | To ignore secrets. Valid value are either `true` or `false` | boolean |\n| ignoreConfigMaps | To ignore configMaps. Valid value are either `true` or `false` | boolean |\n\n`Note`: At one time only one of these resource can be ignored, trying to do it will cause error in helm template compilation.\n\nYou can also set the log format of Reloader to json by setting `logFormat` to `json` in values.yaml and apply the chart\n\nYou can enable to scrape Reloader's Prometheus metrics by setting `serviceMonitor.enabled` or `podMonitor.enabled` to `true` in values.yaml file. Service monitor will be removed in future releases of reloader in favour of Pod monitor.\n\n**Note:** Reloading of OpenShift (DeploymentConfig) and/or Argo Rollouts has to be enabled explicitly because it might not be always possible to use it on a cluster with restricted permissions. This can be done by changing the following parameters:\n\n| Parameter | Description | Type |\n| ---------------- |------------------------------------------------------------------------------| ------- |\n| isOpenshift | Enable OpenShift DeploymentConfigs. Valid value are either `true` or `false` | boolean |\n| isArgoRollouts | Enable Argo Rollouts. Valid value are either `true` or `false` | boolean |\n| reloadOnCreate | Enable reload on create events. Valid value are either `true` or `false` | boolean |\n\n## Help\n\n### Documentation\n\nYou can find more documentation [here](docs)\n\n### Have a question?\n\nFile a GitHub [issue](https://github.com/stakater/Reloader/issues), or send us an [email](mailto:stakater@gmail.com).\n\n### Talk to us on Slack\n\nJoin and talk to us on Slack for discussing Reloader\n\n[](https://slack.stakater.com/)\n[](https://stakater-community.slack.com/messages/CC5S05S12)\n\n## Contributing\n\n### Bug Reports & Feature Requests\n\nPlease use the [issue tracker](https://github.com/stakater/Reloader/issues) to report any bugs or file feature requests.\n\n### Developing\n\n1. Deploy Reloader.\n2. Run `okteto up` to activate your development container.\n3. `make build`.\n4. `./Reloader`\n\nPRs are welcome. In general, we follow the \"fork-and-pull\" Git workflow.\n\n1. **Fork** the repo on GitHub\n2. **Clone** the project to your own machine\n3. **Commit** changes to your own branch\n4. **Push** your work back up to your fork\n5. Submit a **Pull request** so that we can review your changes\n\nNOTE: Be sure to merge the latest from \"upstream\" before making a pull request!\n\n## Changelog\n\nView our closed [Pull Requests](https://github.com/stakater/Reloader/pulls?q=is%3Apr+is%3Aclosed).\n\n## License\n\nApache2 \u00a9 [Stakater](http://stakater.com)\n\n## About\n\n`Reloader` is maintained by [Stakater][website]. Like it? Please let us know at \n\nSee [our other projects][community]\nor contact us in case of professional services and queries on \n\n[website]: http://stakater.com/\n[community]: https://github.com/stakater/\n\n## Acknowledgements\n\n- [ConfigmapController](https://github.com/fabric8io/configmapcontroller); We documented here why we re-created [Reloader](docs/Reloader-vs-ConfigmapController.md)\n",
- "source_links": [],
- "id": 108
- },
- {
- "page_link": null,
- "title": "renovate readme",
- "text": null,
- "source_links": [],
- "id": 109
- },
- {
- "page_link": "https://github.com/mend/renovate-on-prem",
- "title": "renovate-on-prem readme",
- "text": "\n\n# WhiteSource Renovate On-Premises\n\nThis repository contains Documentation, Release Notes and an Issue Tracker for WhiteSource Renovate On-Premises, which was originally known as \"Renovate Pro\".\n\n## Documentation\n\nPlease view [the markdown docs in this repository](https://github.com/whitesource/renovate-on-prem/tree/main/docs).\n\n## Download\n\nWhiteSource Renovate is distributed via Docker Hub using the namespace [whitesource/renovate](https://hub.docker.com/r/whitesource/renovate).\n\n## License\n\nUse of WhiteSource Renovate On-Premises is bound by [WhiteSource's Terms of Service](https://renovate.whitesourcesoftware.com/terms-of-service/). You can request a license key by submitting the form at [https://renovate.whitesourcesoftware.com/on-premises/](https://renovate.whitesourcesoftware.com/on-premises/). License requests are processed semi-manually so please allow up to 3 working days to receive your license key by email.\n\nThe documentation and examples in this repository are MIT-licensed.\n\n## Usage\n\nPlease see the `docs/` and `examples/` directories within this repository.\n",
- "source_links": [],
- "id": 110
- },
- {
- "page_link": "https://github.com/tryretool/retool-onpremise",
- "title": "retool readme",
- "text": "
\n \n Build internal tools, remarkably fast.\n
\n\n# Deploying Retool on-premise\n\n[Deploying Retool on-premise](https://docs.retool.com/docs/self-hosted) ensures that all access to internal data is managed within your own cloud environment. It also provides the flexibility to control how Retool is setup within your infrastructure, the ability to configure logging, and access to enable custom SAML SSO using providers like Okta and Active Directory.\n\n## Table of contents\n\n- [Select a Retool version number](#select-a-retool-version-number)\n- [One-Click Deploy](#one-click-deploy)\n - [AWS](#one-click-deployment-to-aws)\n - [Render](#one-click-deployment-to-render)\n- [Single deployments](#single-deployments)\n - [General Machine Specifications](#general-machine-specifications)\n - [AWS w/ EC2](#aws-deploy-with-ec2)\n - [GCP w/ Compute Engine VM](#gcp-deploy-with-compute-engine-virtual-machine)\n - [Azure w/ Azure VM](#azure-deploy-with-azure-virtual-machine)\n - [Heroku](#deploying-retool-on-heroku)\n - [Aptible](#deploying-retool-using-aptible)\n- [Managed deployments](#managed-deployments)\n - [General](#general-managed-deployments)\n - [Kubernetes](#deploying-on-kubernetes)\n - [Kubernetes + Helm](#deploying-on-kubernetes-with-helm)\n - [AWS](#amazon-web-services---managed-deployments)\n - [ECS](#deploying-on-ecs)\n - [ECS + Fargate](#deploying-on-ecs-with-fargate)\n\n- [Additional Resources](#additional-resources)\n - [Health check endpoint](#health-check-endpoint)\n - [Troubleshooting](#troubleshooting)\n - [Updating Retool](#updating-retool)\n - [Environment variables](#environment-variables)\n - [Deployment Health Checklist](#deployment-health-checklist)\n - [Docker cheatsheet](#docker-cheatsheet)\n\n## Select a Retool version number\n\nWe recommend you set your Retool deployment to a specific version of Retool (that is, a specific semver version number in the format `X.Y.Z`, instead of a tag name). This will help prevent unexpected behavior in your Retool instances. When you are ready to upgrade Retool, you can bump the version number to the specific new version you want.\n\nTo help you select a version, see our guide on [Retool Release Versions](https://docs.retool.com/docs/self-hosted-release-notes).\n\n## One-Click Deploy\n\n### One-click Deployment to AWS\n\nRegion name | Region code | Launch\n--- | --- | ---\nUS East (N. Virginia) | us-east-1 | [](https://us-east-1.console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \nUS West (N. California) |\tus-west-1 | [](https://us-west-1.console.aws.amazon.com/cloudformation/home?region=us-west-1#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \nEU (Ireland) |\teu-west-1 | [](https://eu-west-1.console.aws.amazon.com/cloudformation/home?region=eu-west-1#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \nAsia Pacific (Mumbai) |\tap-south-1 | [](https://ap-south-1.console.aws.amazon.com/cloudformation/home?region=ap-south-1#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool)\nUS East (Ohio) | us-east-2 | [](https://us-east-2.console.aws.amazon.com/cloudformation/home?region=us-east-2#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \nUS West (Oregon) |\tus-west-2 | [](https://us-west-2.console.aws.amazon.com/cloudformation/home?region=us-west-2#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \nEU (Frankfurt) |\teu-central-1 | [](https://eu-central-1.console.aws.amazon.com/cloudformation/home?region=eu-central-1#/stacks/quickcreate?templateURL=https://s3-external-1.amazonaws.com/cf-templates-x1ljyg3aygh-us-east-1/2021157Dqr-SSOPLaunchJuneo3g1bsca3hh&stackName=retool) \n\n### One-click Deployment to Render\n\nJust use the Deploy to Render button below! Here are [some docs](https://render.com/docs/deploy-retool) on deploying Retool with Render.\n\n[](https://render.com/deploy?repo=https://github.com/render-examples/retool)\n\n## Single Deployments\n\n### General Machine Specifications\n- Linux Virtual Machine\n - Ubuntu `16.04` or higher\n- `2` vCPUs\n- `8` GiB + of Memory\n- `60` GiB + of Storage \n- Networking Requirements for Initial Setup:\n - `80` (http): for connecting to the server from the browser\n - `443` (https): for connecting to the server from the browser\n - `22` (SSH): To allow you to SSH into your instance and configure it\n - `3000` (Retool): This is the default port Retool runs on\n\n#### With Workflows\nIf your deployment contains [Retool Workflows](http://retool.com/products/workflows), you may need additional resourcing.\n\nWe recommend bumping up the cluster memory to at least `12` GiB of memory and `4` vCPUs.\n\n### AWS Deploy With EC2\n\nSpin up a new EC2 instance. If using AWS, use the following steps:\n\n1. Click **Launch Instance** from the EC2 dashboard.\n1. Click **Select** for an instance of Ubuntu `16.04` or higher.\n1. Select an instance type of at least `t3.medium` and click **Next**.\n1. Ensure you select the VPC that also includes the databases / API\u2019s you will want to connect to and click **Next**.\n1. Increase the storage size to `60` GB or higher and click **Next**.\n1. Optionally add some Tags (e.g. `app = retool`) and click **Next**. This makes it easier to find if you have a lot of instances.\n1. Set the network security groups for ports `80`, `443`, `22` and `3000`, with sources set to `0.0.0.0/0` and `::/0`, and click **Review and Launch**. We need to open ports `80` (http) and `443` (https) so you can connect to the server from a browser, as well as port `22` (ssh) so that you can ssh into the instance to configure it and run Retool. By default on a vanilla EC2, Retool will run on port `3000`.\n1. On the **Review Instance Launch** screen, click **Launch** to start your instance.\n1. If you're connecting to internal databases, whitelist the VPS's IP address in your database.\n1. From your command line tool, SSH into your EC2 instance.\n1. Run the command `git clone https://github.com/tryretool/retool-onpremise.git`.\n1. Run the command `cd retool-onpremise` to enter the cloned repository's directory.\n1. Edit the `Dockerfile` to set the version of Retool you want to install. To do this, replace `X.Y.Z` in `FROM tryretool/backend:X.Y.Z` with your desired version. See [Select a Retool version number](#select-a-retool-version-number) to help you choose a version.\n1. Run `./install.sh` to install Docker and Docker Compose.\n1. In your `docker.env` (this file is only created after running `./install.sh`) add the following:\n\n ```docker\n # License key granted to you by Retool\n LICENSE_KEY=YOUR_LICENSE_KEY\n\n # This is necessary if you plan on logging in before setting up https\n COOKIE_INSECURE=true\n ```\n\n1. Run `sudo docker-compose up -d` to start the Retool server.\n1. Run `sudo docker-compose ps` to make sure all the containers are up and running.\n1. Navigate to your server's IP address in a web browser. Retool should now be running on port `3000`.\n1. Click Sign Up, since we're starting from a clean slate. The first user to create an account on an instance becomes the administrator.\n\n### GCP Deploy With Compute Engine Virtual Machine\n\n1. Click the Compute Engine Resource from the GCP Dashboard and select VM Instances\n1. In the top menu, select \u2018Create Instance\u2019\n1. Create a new VM to these Specs\n - Ubuntu Operating System Version 16.04 LTS or higher\n - Storage Size 60 GB or higher\n - Ram 4 GB or Higher (e2-medium)\n - Optionally add Labels (eg app = retool)\n1. Create Instance\n1. Navigate via search to the VPC Network Firewall settings and be sure to add the following ports set to`0.0.0.0/0` and `::/0`\n - `80` (HTTP)\n - `443` (HTTPS)\n - `22` (SSH)\n - `3000` (Retool access in browser)\n1. If you're connecting to an internal database, be sure to whitelist the VPC\u2019s ip address in your DB\n1. SSH into your instance, or use the Google SSH Button to open a VM Terminal in a browser window.\n1. Run Command `git clone https://github.com/tryretool/retool-onpremise.git`\n1. Run Command `cd retool-onpremise`\n1. Edit the Dockerfile using VIM (or other text editor) to specify your desired version number of Retool. To do this, replace `X.Y.Z` in `FROM tryretool/backend:X.Y.Z` with your desired version. See\u00a0[Select a Retool version number](#select-a-retool-version-number)\u00a0to help you choose a version.\n1. Run Command `./install.sh` to install docker containers, docker, and docker-compose\n1. In your docker.env file (this file will only exist after step 11)\n - Add the license key from `my.retool.com` to replace `YOUR_LICENSE_KEY`\n - If you will need to access your instance before configuring HTTPS, you will need to uncomment the line `COOKIE_INSECURE=true`\n1. Run `sudo docker-compose up -d` to start the Retool docker containers\n1. Run `sudo docker-compose ps` to see container status and ensure all are running\n1. Navigate to your servers IP address or domain in a web browser. Retool will be running on `port 3000`\n1. Click Sign Up, since this is a brand new instance. The first user created will become the administrator\n\n### Azure Deploy with Azure Virtual Machine\n\n1. In the main Azure Portal select Virtual Machine under Azure Services\n1. Click the Create button and select Virtual Machine \n1. Select an image of Ubuntu 16.04 or higher\n1. For instance size, select `Standard_D2s_v3 - 2 vcpus, 8 GiB memory`\n1. Under the Networking tab, Ensure you select the same Virtual Network that also includes the databases / API\u2019s you will want to connect to and click\u00a0**Next**.\n1. Under the Networking tab, configure your network security group to contain the following ports. You may need to create a new Security group that contains these 4 ports (`80`,\u00a0`443`,\u00a0`22`\u00a0and\u00a0`3000`): \n - `80` (http) and `443` (https) for connecting to the server from a browser \n - `22` (ssh) to allow you to ssh into the instance and configure it\n - `3000` is the port that Retool runs on by default\n1. From your command line tool, SSH into your Azure instance.\n1. Run the command\u00a0`git clone https://github.com/tryretool/retool-onpremise.git`.\n1. Run the command\u00a0`cd retool-onpremise`\u00a0to enter the cloned repository's directory.\n1. Edit the\u00a0`Dockerfile`\u00a0to set the version of Retool you want to install. To do this, replace\u00a0`X.Y.Z`\u00a0in\u00a0`FROM tryretool/backend:X.Y.Z`\u00a0with your desired version. See\u00a0[Select a Retool version number](https://github.com/tryretool/retool-onpremise#select-a-retool-version-number)\u00a0to help you choose a version.\n1. Run\u00a0`./install.sh`\u00a0to install Docker and Docker Compose.\n1. In your\u00a0`docker.env`\u00a0(this file is only created after running\u00a0`./install.sh`) add the following:\n \n `# License key granted to you by Retool\n LICENSE_KEY=YOUR_LICENSE_KEY`\n \n `# This is necessary if you plan on logging in before setting up https\n COOKIE_INSECURE=true`\n \n1. Run\u00a0`sudo docker-compose up -d`\u00a0to start the Retool server.\n1. Run\u00a0`sudo docker-compose ps`\u00a0to make sure all the containers are up and running.\n1. Navigate to your server's IP address in a web browser. Retool should now be running on port\u00a0`3000`.\n1. Click Sign Up, since we're starting from a clean slate. The first user to create an account on an instance becomes the administrator.\n\n\n### General Single-Instance Deploy\n\n### Deploying Retool on Heroku\n\nYou can manually deploy to Heroku using the following steps:\n\n1. Install the Heroku CLI, and login. Documentation for this can be found here: \n1. Clone this repo `git clone https://github.com/tryretool/retool-onpremise`\n1. Change the working directory to the newly cloned repository `cd ./retool-onpremise`\n1. Create a new Heroku app with the stack set to `container` with `heroku create your-app-name --stack=container`\n1. Add a free database: `heroku addons:create heroku-postgresql:hobby-dev`\n1. In the `Settings` page of your Heroku app, add the following environment variables:\n 1. `NODE_ENV` - set to `production`\n 1. `HEROKU_HOSTED` set to `true`\n 1. `JWT_SECRET` - set to a long secure random string used to sign JSON Web Tokens\n 1. `ENCRYPTION_KEY` - a long secure random string used to encrypt database credentials\n 1. `USE_GCM_ENCRYPTION` set to `true` for authenticated encryption of secrets; if true, `ENCRYPTION_KEY` must be 24 bytes\n 1. `LICENSE_KEY` - your Retool license key\n 1. `PGSSLMODE` - set to `require`\n1. Push the code: `git push heroku master`\n\nTo lockdown the version of Retool used, just edit the first line under `./heroku/Dockerfile` to:\n\n```docker\nFROM tryretool/backend:X.Y.Z\n```\n\n### Deploying Retool using Aptible\n\n1. Add your public SSH key to your Aptible account through the Aptible dashboard\n1. Install the Aptible CLI, and login. Documentation for this can be found here: \n1. Clone this repo `git clone https://github.com/tryretool/retool-onpremise`\n1. Change the working directory to the newly cloned repository `cd ./retool-onpremise`\n1. Edit the `Dockerfile` to set the version of Retool you want to install. To do this, replace `X.Y.Z` in `FROM tryretool/backend:X.Y.Z` with your desired version. See [Select a Retool version number](#select-a-retool-version-number) to help you choose a version.\n1. Create a new Aptible app with `aptible apps:create your-app-name`\n1. Add a database: `aptible db:create your-database-name --type postgresql`\n1. Set your config variables (your database connection string will be in your Aptible Dashboard and you can parse out the individual values by following [these instructions](https://www.aptible.com/documentation/deploy/reference/databases/credentials.html#using-database-credentials)). Be sure to rename `EXPIRED-LICENSE-KEY-TRIAL` to the license key provided to you.\n1. If secrets need an authenticated encryption method, add `USE_GCM_ENCRYTPION=true` to the command below and change `ENCRYPTION_KEY=$(cat /dev/urandom | base64 | head -c 24)`\n\n ```yml\n aptible config:set --app your-app-name \\\n POSTGRES_DB=your-db \\\n POSTGRES_HOST=your-db-host \\\n POSTGRES_USER=your-user \\\n POSTGRES_PASSWORD=your-db-password \\\n POSTGRES_PORT=your-db-port \\\n POSTGRES_SSL_ENABLED=true \\\n FORCE_SSL=true \\\n NODE_ENV=production \\\n JWT_SECRET=$(cat /dev/urandom | base64 | head -c 256) \\\n ENCRYPTION_KEY=$(cat /dev/urandom | base64 | head -c 64) \\\n LICENSE_KEY=EXPIRED-LICENSE-KEY-TRIAL\n ```\n\n1. Set your git remote which you can find in the Aptible dashboard: `git remote add aptible your-git-url`\n1. Push the code: `git push aptible master`\n1. Create a default Aptible endpoint\n1. Navigate to your endpoint and sign up as a new user in your Retool instance\n\n## Managed deployments\n\nDeploy Retool on a managed service. We've provided some starter template files for Cloudformation setups (ECS + Fargate), Kubernetes, and Helm.\n\n### General Managed Deployments\n\n### Deploying on Kubernetes\n\n1. Navigate into the `kubernetes` directory\n1. Edit the `retool-container.yaml` and `retool-jobs-runner.yaml` files to set the version of Retool you want to install. To do this, replace `X.Y.Z` in `image: tryretool/backend:X.Y.Z` with your desired version. See [Select a Retool version number](#select-a-retool-version-number) to help you choose a version.\n1. Copy the `retool-secrets.template.yaml` file to `retool-secrets.yaml` and inside the `{{ ... }}` sections, replace with a suitable base64 encoded string.\n 1. To base64 encode your license key, run `echo -n | base64` in the command line. Be sure to add the `-n` character, as it removes the trailing newline character from the encoding.\n 1. If you do not wish to add google authentication, replace the templates with an empty string.\n 1. You will need a license key in order to proceed.\n1. Run `kubectl apply -f ./retool-secrets.yaml`\n1. Run `kubectl apply -f ./retool-postgres.yaml`\n1. Run `kubectl apply -f ./retool-container.yaml`\n1. Run `kubectl apply -f ./retool-jobs-runner.yaml`\n\nFor ease of use, this will create a postgres container with a persistent volume for the storage of Retool data. We recommend that you use a managed database service like RDS as a long-term solution. The application will be exposed on a public ip address on port 3000 - we leave it to the user to handle DNS and SSL.\n\nPlease note that by default Retool is configured to use Secure Cookies - that means that you will be unable to login unless https has been correctly setup.\n\nTo force Retool to send the auth cookies over HTTP, please set the `COOKIE_INSECURE` environment variable to `'true'` in `./retool-container.yaml`. Do this by adding the following two lines to the `env` section.\n\n```yaml\n - name: COOKIE_INSECURE\n value: 'true'\n```\n\nThen, to update the running deployment, run `$ kubectl apply -f ./retool-container.yaml`\n\n### Deploying on Kubernetes with Helm\n\nSee for full Helm chart documentation\nand instructions.\n\n### Amazon Web Services - Managed Deployments\n\n### Deploying on ECS\n\nWe provide a [template file](/cloudformation/retool.yaml) for you to get started deploying on ECS.\n\n1. In the ECS Dashboard, click **Create Cluster**\n1. Select `EC2 Linux + Networking` as the cluster template.\n1. In your instance configuration, enter the following:\n - Select **On-demand instance**\n - Select **t2.medium** as the instance type (or your desired instance size)\n - Choose how many instances you want to spin up\n - (Optional) Add key pair\n - Choose your existing VPC (or create a new one)\n - (Optional) Add tags\n - Enable CloudWatch container insights\n1. Select the VPC in which you\u2019d like to launch the ECS cluster; make sure that you select a [public subnet](https://stackoverflow.com/questions/48830793/aws-vpc-identify-private-and-public-subnet).\n1. Download the [retool.yaml](/cloudformation/retool.yaml) file, and add your license key and other relevant variables.\n1. Go to the AWS Cloudformation dashboard, and click **Create Stack with new resources \u2192 Upload a template file**. Upload your edited `retool.yaml` file.\n1. Then, enter the following parameters:\n - Cluster: the name of the ECS cluster you created earlier\n - DesiredCount: 2\n - Environment: staging\n - Force: false\n - Image: `tryretool/backend:X.Y.Z` (But replace `X.Y.Z` with your desired version. See [Select a Retool version number](#select-a-retool-version-number) to help you choose a version.)\n - MaximumPercent: 250\n - MinimumPercent: 50\n - SubnetId: Select 2 subnets in your VPC - make sure these subnets are public (have an internet gateway in their route table)\n - VPC ID: select the VPC you want to use\n1. Click through to create the stack; this could take up to 15 minutes; you can monitor the progress of the stack being created in the `Events` tab in Cloudformation\n1. After everything is complete, you should see all the resources with a `CREATE_COMPLETE` status.\n1. In the **Outputs** section within the CloudFormation dashboard, you should be able to find the ALB DNS URL. This is where Retool should be running.\n1. The backend tries to guess your domain to create invite links, but with a load balancer in front of Retool you'll need to set the `BASE_DOMAIN` environment variable to your fully qualified domain (i.e. `https://retool.company.com`). Docs [here](https://docs.retool.com/docs/environment-variables).\n\n#### OOM issues\n\nIf running into OOM issues (especially on larger instance sizes with >4 vCPUs)\n\n- Verify the issue by going into the ECS console and checking the Service Metrics. Ideally\n - Memory utilization should fall around 40% (20% - 60%)\n - CPU utilization should be close to zero (0% - 5%)\n- If the values fall outside these ranges, increase the CPU and memory allocation in `retool.yml`\n\n### Deploying on ECS with Fargate\n\nWe provide Fargate template files supporting [public](/cloudformation/fargate.yaml) and [private](/cloudformation/fargate.private.yaml) subnets.\n\n1. In the ECS Dashboard, click **Create Cluster**\n1. In **Step 1: Select a cluster template**, select `Networking Only (Powered by AWS Fargate)` as the cluster template.\n1. In **Step 2: Configure cluster**, be sure to enable CloudWatch Container Insights. This will help us monitor logs and the health of our deployment through CloudWatch.\n1. Download the [public](/cloudformation/fargate.yaml) or [private](/cloudformation/fargate.private.yaml) template file.\n1. Edit the template file to provide your license key and any required [environment variables](https://docs.retool.com/docs/environment-variables) (under the Environment key within the retool ContainerDefinitions). Do not modify the Parameters object on line 2 of the template file. CloudFormation will prompt for these values after you upload the template file.\n1. Go to the AWS CloudFormation dashboard, and click **Create Stack with new resources \u2192 Upload a template file**. Upload your edited `.yaml` file.\n1. Enter the following parameters:\n - Cluster: the name of the ECS cluster you created earlier\n - DesiredCount: 2\n - Environment: staging\n - Force: false\n - Image: `tryretool/backend:X.Y.Z` (But replace `X.Y.Z` with your desired version. See [Select a Retool version number](#select-a-retool-version-number) to help you choose a version.)\n - MaximumPercent: 250\n - MinimumPercent: 50\n - SubnetId: Select 2 subnets in your VPC - make sure these subnets are public (have an internet gateway in their route table)\n - VPC ID: select the VPC you want to use\n1. Click through to create the stack; this could take up to 15 minutes; you can monitor the progress of the stack being created in the `Events` tab in Cloudformation\n1. In the **Outputs** section, you should be able to find the ALB DNS URL.\n1. Currently the load balancer is listening on port 3000; to make it available on port 80 we have to go to the **EC2 dashboard \u2192 Load Balancers \u2192 Listeners** and click Edit to to change the port to 80.\n - If you get an error that your security group does not allow traffic on this listener port, you must add an inbound rule allowing HTTP on port 80.\n1. In the **Outputs** section within the CloudFormation dashboard, you should be able to find the ALB DNS URL. This is where Retool should be running.\n1. The backend tries to guess your domain to create invite links, but with a load balancer in front of Retool you'll need to set the `BASE_DOMAIN` environment variable to your fully qualified domain (i.e. `https://retool.company.com`). Docs [here](https://docs.retool.com/docs/environment-variables).\n\n### Google Cloud Platform - Managed Deployments\n\n\n## Additional Resources\n\n**For details on additional features like SAML SSO, gRPC, custom certs, and more, visit our [docs](https://docs.retool.com/docs).**\n\n### Environment Variables\n\nYou can set environment variables to enable custom functionality like [managing secrets](https://docs.retool.com/docs/secret-management-using-environment-variables), customizing logs, and much more. For a list of all environment variables visit our [docs](https://docs.retool.com/docs/environment-variables).\n\n### Health check endpoint\n\nRetool also has a health check endpoint that you can set up to monitor liveliness of Retool. You can configure your probe to make a `GET` request to `/api/checkHealth`.\n\n### Troubleshooting\n\n- On Kubernetes, I get the error `SequelizeConnectionError: password authentication failed for user \"...\"`\n - Make sure that the secrets that you encoded in base64 don't have trailing whitespace! You can use `kubectl exec printenv` to help debug this issue.\n - Run `echo -n | base64` in the command line. The `-n` character removes the trailing newline character from the encoding.\n- I can't seem to login? I keep getting redirected to the login page after signing in.\n - If you have not enabled SSL yet, you will need to add the line `COOKIE_INSECURE=true` to your `docker.env` file / environment configuration so that the authentication cookies can be sent over http. Make sure to run `sudo docker-compose up -d` after modifying the `docker.env` file.\n- `TypeError: Cannot read property 'licenseVerification' of null` or `TypeError: Cannot read property 'name' of null`\n - There is an issue with your license key. Double check that the license key is correct and that it has no trailing whitespaces.\n- I want to use a private IP of the machine, not the default public one\n - When you run\u00a0`./install.sh`, instead of just clicking enter, type in your private IP. If you want to change this after it has already been set, modify the\u00a0DOMAINS\u00a0variable in the\u00a0docker.env\u00a0file.\n\n\n### Updating Retool\n\nThe latest Retool releases can be pulled from Docker Hub. When you run an on-premise instance of Retool, you\u2019ll need to pull an updated image in order to get new features and fixes.\n\nSee more information on our different release channels and recommended update strategies in [our documentation](https://docs.retool.com/docs/updating-retool-on-premise#retool-release-versions).\n\n### Docker Compose deployments\n\nUpdate the version number in the first line of your `Dockerfile`.\n\n```docker\nFROM tryretool/backend:X.Y.Z\n```\n\nThen run the included update script `./update_retool.sh` from this directory.\n\n### Kubernetes deployments\n\nTo update Retool on Kubernetes, you can use the following command, replacing `X.Y.Z` with the version number or named tag that you\u2019d like to update to.\n\n```zsh\nkubectl set image deploy/api api=tryretool/backend:X.Y.Z\n```\n\n### Heroku deployments\n\nTo update a Heroku deployment that was created with the button above, you may first set up a `git` repo to push to Heroku\n\n```zsh\nheroku login\ngit clone https://github.com/tryretool/retool-onpremise\ncd retool-onpremise\nheroku git:remote -a YOUR_HEROKU_APP_NAME\n```\n\nTo update Retool (this will automatically fetch the latest version of Retool)\n\n```zsh\ngit commit --allow-empty -m 'Redeploying'\ngit push heroku master\n```\n\n### Deployment Health Checklist\n\n###### Overview\nWe recommend completing our Deployment Health Checklist to help you improve the stability and reliability of your Retool deployment.\n\nPlease fill out the checklist and share it with our team. This information will help us better understand your infrastructure so that we can support you through product changes, proactive outreach, and more informed support.\n\n###### Instructions\nMake a copy of the [Deployment Health Checklist](https://docs.google.com/spreadsheets/d/19XYpWTnYrvsllTuM2VQGFWLiXzMHmTNAzZKyWY-sfSU) for your Retool deployment. Add your company name to the document title for reference.\nFill out the requested information on the first and second tabs.\nShare your filled out with your Retool contact or support@retool.com. We will reference this in the event of any support conversations.\n\n\n\n### Docker cheatsheet\n\nBelow is a cheatsheet for useful Docker commands. Note that you may need to prefix them with `sudo`.\n\n| Command | Description |\n| ----------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------- |\n| `docker-compose up -d` | Builds, (re)creates, starts, and attaches to containers for a service. `-d`allows containers to run in background (detached). |\n| `docker-compose down` | Stops and remove containers and networks |\n| `docker-compose stop` | Stops containers, but does not remove them and their networks |\n| `docker ps -a` | Display all Docker containers |\n| `docker-compose ps -a` | Display all containers related to images declared in the `docker-compose` file. |\n| `docker logs -f ` | Stream container logs to stdout |\n| `docker exec -it psql -U -W ` | Runs `psql` inside a container |\n| `docker kill $(docker ps -q)` | Kills all running containers |\n| `docker rm $(docker ps -a -q)` | Removes all containers and networks |\n| `docker rmi -f $(docker images -q)` | Removes (and un-tags) all images from the host |\n| `docker volume rm $(docker volume ls -q)` | Removes all volumes and completely wipes any persisted data |\n",
- "source_links": [],
- "id": 111
- },
- {
- "page_link": "https://github.com/rook/rook",
- "title": "rook readme",
- "text": "\n\n[](https://www.cncf.io/projects)\n[](https://github.com/rook/rook/releases)\n[](https://hub.docker.com/u/rook)\n[](https://goreportcard.com/report/github.com/rook/rook)\n[](https://bestpractices.coreinfrastructure.org/projects/1599)\n[](https://github.com/rook/rook/actions/workflows/synk.yaml)\n[](https://slack.rook.io)\n[](https://twitter.com/intent/follow?screen_name=rook_io&user_id=788180534543339520)\n\n# What is Rook?\n\nRook is an open source **cloud-native storage orchestrator** for Kubernetes, providing the platform, framework, and support for a diverse set of storage solutions to natively integrate with cloud-native environments.\n\nRook turns storage software into self-managing, self-scaling, and self-healing storage services. It does this by automating deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management. Rook uses the facilities provided by the underlying cloud-native container management, scheduling and orchestration platform to perform its duties.\n\nRook integrates deeply into cloud native environments leveraging extension points and providing a seamless experience for scheduling, lifecycle management, resource management, security, monitoring, and user experience.\n\nFor more details about the storage solutions currently supported by Rook, please refer to the [project status section](#project-status) below.\nWe plan to continue adding support for other storage systems and environments based on community demand and engagement in future releases. See our [roadmap](ROADMAP.md) for more details.\n\nRook is hosted by the [Cloud Native Computing Foundation](https://cncf.io) (CNCF) as a [graduated](https://www.cncf.io/announcements/2020/10/07/cloud-native-computing-foundation-announces-rook-graduation/) level project. If you are a company that wants to help shape the evolution of technologies that are container-packaged, dynamically-scheduled and microservices-oriented, consider joining the CNCF. For details about who's involved and how Rook plays a role, read the CNCF [announcement](https://www.cncf.io/blog/2018/01/29/cncf-host-rook-project-cloud-native-storage-capabilities).\n\n## Getting Started and Documentation\n\nFor installation, deployment, and administration, see our [Documentation](https://rook.github.io/docs/rook/latest).\n\n## Contributing\n\nWe welcome contributions. See [Contributing](CONTRIBUTING.md) to get started.\n\n## Report a Bug\n\nFor filing bugs, suggesting improvements, or requesting new features, please open an [issue](https://github.com/rook/rook/issues).\n\n### Reporting Security Vulnerabilities\n\nIf you find a vulnerability or a potential vulnerability in Rook please let us know immediately at\n[cncf-rook-security@lists.cncf.io](mailto:cncf-rook-security@lists.cncf.io). We'll send a confirmation email to acknowledge your\nreport, and we'll send an additional email when we've identified the issues positively or\nnegatively.\n\nFor further details, please see the complete [security release process](SECURITY.md).\n\n## Contact\n\nPlease use the following to reach members of the community:\n\n- Slack: Join our [slack channel](https://slack.rook.io)\n- GitHub: Start a [discussion](https://github.com/rook/rook/discussions) or open an [issue](https://github.com/rook/rook/issues)\n- Twitter: [@rook_io](https://twitter.com/rook_io)\n- Security topics: [cncf-rook-security@lists.cncf.io](#reporting-security-vulnerabilities)\n\n### Community Meeting\n\nA regular community meeting takes place every other [Tuesday at 9:00 AM PT (Pacific Time)](https://zoom.us/j/392602367?pwd=NU1laFZhTWF4MFd6cnRoYzVwbUlSUT09).\nConvert to your [local timezone](http://www.thetimezoneconverter.com/?t=9:00&tz=PT%20%28Pacific%20Time%29).\n\nAny changes to the meeting schedule will be added to the [agenda doc](https://docs.google.com/document/d/1exd8_IG6DkdvyA0eiTtL2z5K2Ra-y68VByUUgwP7I9A/edit?usp=sharing) and posted to [Slack #announcements](https://rook-io.slack.com/messages/C76LLCEE7/).\n\nAnyone who wants to discuss the direction of the project, design and implementation reviews, or general questions with the broader community is welcome and encouraged to join.\n\n- Meeting link: \n- [Current agenda and past meeting notes](https://docs.google.com/document/d/1exd8_IG6DkdvyA0eiTtL2z5K2Ra-y68VByUUgwP7I9A/edit?usp=sharing)\n- [Past meeting recordings](https://www.youtube.com/playlist?list=PLP0uDo-ZFnQP6NAgJWAtR9jaRcgqyQKVy)\n\n## Project Status\n\nThe status of each storage provider supported by Rook can be found in the table below.\nEach API group is assigned its own individual status to reflect their varying maturity and stability.\nMore details about API versioning and status in Kubernetes can be found on the Kubernetes [API versioning page](https://kubernetes.io/docs/concepts/overview/kubernetes-api/#api-versioning), but the key difference between the statuses are summarized below:\n\n- **Alpha:** The API may change in incompatible ways in a later software release without notice, recommended for use only in short-lived testing clusters, due to increased risk of bugs and lack of long-term support.\n- **Beta:** Support for the overall features will not be dropped, though details may change. Support for upgrading or migrating between versions will be provided, either through automation or manual steps.\n- **Stable:** Features will appear in released software for many subsequent versions and support for upgrading between versions will be provided with software automation in the vast majority of scenarios.\n\n| Name | Details | API Group | Status |\n| ---- | ---------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------- | ------ |\n| Ceph | [Ceph](https://ceph.com/) is a distributed storage system that provides file, block and object storage and is deployed in large scale production clusters. | ceph.rook.io/v1 | Stable |\n\nThis repo is for the Ceph storage provider. The [Cassandra](https://github.com/rook/cassandra) and [NFS](https://github.com/rook/nfs) storage providers moved to a separate repo to allow for each [storage provider](https://rook.github.io/docs/rook/latest/storage-providers.html) to have an independent development and release schedule.\n\n### Official Releases\n\nOfficial releases of Rook can be found on the [releases page](https://github.com/rook/rook/releases).\nPlease note that it is **strongly recommended** that you use [official releases](https://github.com/rook/rook/releases) of Rook, as unreleased versions from the master branch are subject to changes and incompatibilities that will not be supported in the official releases.\nBuilds from the master branch can have functionality changed and even removed at any time without compatibility support and without prior notice.\n\n## Licensing\n\nRook is under the Apache 2.0 license.\n\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Frook%2Frook?ref=badge_large)\n",
- "source_links": [],
- "id": 112
- },
- {
- "page_link": "https://github.com/getsentry/sentry",
- "title": "sentry readme",
- "text": "
\n Users and logs provide clues. Sentry provides answers.\n
\n\n\n# What's Sentry?\n\nSentry is a developer-first error tracking and performance monitoring platform that helps developers see what actually matters, solve quicker, and learn continuously about their applications.\n\n\n\n
\n \n \n \n \n
\n\n## Official Sentry SDKs\n\n - [JavaScript](https://github.com/getsentry/sentry-javascript)\n - [Electron](https://github.com/getsentry/sentry-electron/)\n - [React-Native](https://github.com/getsentry/sentry-react-native)\n - [Python](https://github.com/getsentry/sentry-python)\n - [Ruby](https://github.com/getsentry/sentry-ruby)\n - [PHP](https://github.com/getsentry/sentry-php)\n - [Laravel](https://github.com/getsentry/sentry-laravel)\n - [Go](https://github.com/getsentry/sentry-go)\n - [Rust](https://github.com/getsentry/sentry-rust)\n - [Java/Kotlin](https://github.com/getsentry/sentry-java)\n - [Objective-C/Swift](https://github.com/getsentry/sentry-cocoa)\n - [C\\#/F\\#](https://github.com/getsentry/sentry-dotnet)\n - [C/C++](https://github.com/getsentry/sentry-native)\n - [Dart](https://github.com/getsentry/sentry-dart)\n - [Perl](https://github.com/getsentry/perl-raven)\n - [Clojure](https://github.com/getsentry/sentry-clj/)\n - [Elixir](https://github.com/getsentry/sentry-elixir)\n - [Unity](https://github.com/getsentry/sentry-unity)\n - [Unreal Engine](https://github.com/getsentry/sentry-unreal)\n\n# Resources\n\n - [Documentation](https://docs.sentry.io/)\n - [Community](https://forum.sentry.io/) (Bugs, feature requests,\n general questions)\n - [Discord](https://discord.gg/PXa5Apfe7K)\n - [Contributing](https://docs.sentry.io/internal/contributing/)\n - [Bug Tracker](https://github.com/getsentry/sentry/issues)\n - [Code](https://github.com/getsentry/sentry)\n - [Transifex](https://www.transifex.com/getsentry/sentry/) (Translate\n Sentry\\!)\n",
- "source_links": [],
- "id": 113
- },
- {
- "page_link": "https://github.com/drakkan/sftpgo/",
- "title": "sftpgo readme",
- "text": "# SFTPGo\n\n[](https://github.com/drakkan/sftpgo/workflows/CI/badge.svg?branch=main&event=push)\n[](https://codecov.io/gh/drakkan/sftpgo/branch/main)\n[](https://www.gnu.org/licenses/agpl-3.0)\n[](https://hub.docker.com/r/drakkan/sftpgo)\n[](https://github.com/avelino/awesome-go)\n\n[English](./README.md) | [\u7b80\u4f53\u4e2d\u6587](./README.zh_CN.md)\n\nFully featured and highly configurable SFTP server with optional HTTP/S, FTP/S and WebDAV support.\nSeveral storage backends are supported: local filesystem, encrypted local filesystem, S3 (compatible) Object Storage, Google Cloud Storage, Azure Blob Storage, SFTP.\n\n## Sponsors\n\nIf you find SFTPGo useful please consider supporting this Open Source project.\n\nMaintaining and evolving SFTPGo is a lot of work - easily the equivalent of a full time job - for me.\n\nI'd like to make SFTPGo into a sustainable long term project and would not like to introduce a dual licensing option and limit some features to the proprietary version only.\n\nIf you use SFTPGo, it is in your best interest to ensure that the project you rely on stays healthy and well maintained.\nThis can only happen with your donations and [sponsorships](https://github.com/sponsors/drakkan) :heart:\n\nWith sponsorships/donations we establish a channel for reciprocal access, ensuring better outcomes for both you and the project.\n\nIf you just take and don't return anything back, the project will die in the long run and you will be forced to pay for a similar proprietary solution.\n\nMore [info](https://github.com/drakkan/sftpgo/issues/452).\n\n### Thank you to our sponsors\n\n#### Platinum sponsors\n\n[](https://www.aledade.com/)\n\n#### Silver sponsors\n\n[](https://dendisoftware.com/)\n\n#### Bronze sponsors\n\n[](https://www.7digital.com/)\n\n## Support policy\n\nSFTPGo is an Open Source project and you can of course use it for free but please don't ask for free support as well.\n\nWe will check the reported issues to see if you are experiencing a bug and if so we'll will fix it, but will only provide support to project [sponsors/donors](#sponsors).\n\nIf you report an invalid issue or ask for step-by-step support, your issue will remain open with no answer or will be closed as invalid without further explanation. Thanks for understanding.\n\n## Features\n\n- Support for serving local filesystem, encrypted local filesystem, S3 Compatible Object Storage, Google Cloud Storage, Azure Blob Storage or other SFTP accounts over SFTP/SCP/FTP/WebDAV.\n- Virtual folders are supported: a virtual folder can use any of the supported storage backends. So you can have, for example, a user with the S3 backend mapping a GCS bucket (or part of it) on a specified path and an encrypted local filesystem on another one. Virtual folders can be private or shared among multiple users, for shared virtual folders you can define different quota limits for each user.\n- Configurable [custom commands and/or HTTP hooks](./docs/custom-actions.md) on upload, pre-upload, download, pre-download, delete, pre-delete, rename, mkdir, rmdir on SSH commands and on user add, update and delete.\n- Virtual accounts stored within a \"data provider\".\n- SQLite, MySQL, PostgreSQL, CockroachDB, Bolt (key/value store in pure Go) and in-memory data providers are supported.\n- Chroot isolation for local accounts. Cloud-based accounts can be restricted to a certain base path.\n- Per-user and per-directory virtual permissions, for each path you can allow or deny: directory listing, upload, overwrite, download, delete, rename, create directories, create symlinks, change owner/group/file mode and modification time.\n- [REST API](./docs/rest-api.md) for users and folders management, data retention, backup, restore and real time reports of the active connections with possibility of forcibly closing a connection.\n- The [Event Manager](./docs/eventmanager.md) allows to define custom workflows based on server events or schedules.\n- [Web based administration interface](./docs/web-admin.md) to easily manage users, folders and connections.\n- [Web client interface](./docs/web-client.md) so that end users can change their credentials, manage and share their files in the browser.\n- Public key and password authentication. Multiple public keys per-user are supported.\n- SSH user [certificate authentication](https://cvsweb.openbsd.org/src/usr.bin/ssh/PROTOCOL.certkeys?rev=1.8).\n- Keyboard interactive authentication. You can easily setup a customizable multi-factor authentication.\n- Partial authentication. You can configure multi-step authentication requiring, for example, the user password after successful public key authentication.\n- Per-user authentication methods.\n- [Two-factor authentication](./docs/howto/two-factor-authentication.md) based on time-based one time passwords (RFC 6238) which works with Authy, Google Authenticator and other compatible apps.\n- Simplified user administrations using [groups](./docs/groups.md).\n- [Roles](./docs/roles.md) allow you to create limited administrators who can only create and manage users with their role.\n- Custom authentication via [external programs/HTTP API](./docs/external-auth.md).\n- Web Client and Web Admin user interfaces support [OpenID Connect](https://openid.net/connect/) authentication and so they can be integrated with identity providers such as [Keycloak](https://www.keycloak.org/). You can find more details [here](./docs/oidc.md).\n- [Data At Rest Encryption](./docs/dare.md).\n- Dynamic user modification before login via [external programs/HTTP API](./docs/dynamic-user-mod.md).\n- Quota support: accounts can have individual disk quota expressed as max total size and/or max number of files.\n- Bandwidth throttling, with separate settings for upload and download and overrides based on the client's IP address.\n- Data transfer bandwidth limits, with total limit or separate settings for uploads and downloads and overrides based on the client's IP address. Limits can be reset using the REST API.\n- Per-protocol [rate limiting](./docs/rate-limiting.md) is supported and can be optionally connected to the built-in defender to automatically block hosts that repeatedly exceed the configured limit.\n- Per-user maximum concurrent sessions.\n- Per-user and global IP filters: login can be restricted to specific ranges of IP addresses or to a specific IP address.\n- Per-user and per-directory shell like patterns filters: files can be allowed, denied and optionally hidden based on shell like patterns.\n- Automatically terminating idle connections.\n- Automatic blocklist management using the built-in [defender](./docs/defender.md).\n- Geo-IP filtering using a [plugin](https://github.com/sftpgo/sftpgo-plugin-geoipfilter).\n- Atomic uploads are configurable.\n- Per-user files/folders ownership mapping: you can map all the users to the system account that runs SFTPGo (all platforms are supported) or you can run SFTPGo as root user and map each user or group of users to a different system account (\\*NIX only).\n- Support for Git repositories over SSH.\n- SCP and rsync are supported.\n- FTP/S is supported. You can configure the FTP service to require TLS for both control and data connections.\n- [WebDAV](./docs/webdav.md) is supported.\n- ACME protocol is supported. SFTPGo can obtain and automatically renew TLS certificates for HTTPS, WebDAV and FTPS from `Let's Encrypt` or other ACME compliant certificate authorities, using the the `HTTP-01` or `TLS-ALPN-01` [challenge types](https://letsencrypt.org/docs/challenge-types/).\n- Two-Way TLS authentication, aka TLS with client certificate authentication, is supported for REST API/Web Admin, FTPS and WebDAV over HTTPS.\n- Per-user protocols restrictions. You can configure the allowed protocols (SSH/HTTP/FTP/WebDAV) for each user.\n- [Prometheus metrics](./docs/metrics.md) are supported.\n- Support for HAProxy PROXY protocol: you can proxy and/or load balance the SFTP/SCP/FTP service without losing the information about the client's address.\n- Easy [migration](./examples/convertusers) from Linux system user accounts.\n- [Portable mode](./docs/portable-mode.md): a convenient way to share a single directory on demand.\n- [SFTP subsystem mode](./docs/sftp-subsystem.md): you can use SFTPGo as OpenSSH's SFTP subsystem.\n- Performance analysis using built-in [profiler](./docs/profiling.md).\n- Configuration format is at your choice: JSON, TOML, YAML, HCL, envfile are supported.\n- Log files are accurate and they are saved in the easily parsable JSON format ([more information](./docs/logs.md)).\n- SFTPGo supports a [plugin system](./docs/plugins.md) and therefore can be extended using external plugins.\n- Infrastructure as Code (IaC) support using the [Terraform provider](https://registry.terraform.io/providers/drakkan/sftpgo/latest).\n\n## Platforms\n\nSFTPGo is developed and tested on Linux. After each commit, the code is automatically built and tested on Linux, macOS, Windows and FreeBSD. Other *BSD variants should work too.\n\n## Requirements\n\n- Go as build only dependency. We support the Go version(s) used in [continuous integration workflows](./.github/workflows).\n- A suitable SQL server to use as data provider:\n - upstream supported versions of PostgreSQL, MySQL and MariaDB.\n - CockroachDB stable.\n- The SQL server is optional: you can choose to use an embedded SQLite, bolt or in memory data provider.\n\n## Installation\n\nBinary releases for Linux, macOS, and Windows are available. Please visit the [releases](https://github.com/drakkan/sftpgo/releases \"releases\") page.\n\nAn official Docker image is available. Documentation is [here](./docker/README.md).\n\n\n\nSome Linux distro packages are available\n\n- For Arch Linux via AUR:\n - [sftpgo](https://aur.archlinux.org/packages/sftpgo/). This package follows stable releases. It requires `git`, `gcc` and `go` to build.\n - [sftpgo-bin](https://aur.archlinux.org/packages/sftpgo-bin/). This package follows stable releases downloading the prebuilt linux binary from GitHub. It does not require `git`, `gcc` and `go` to build.\n - [sftpgo-git](https://aur.archlinux.org/packages/sftpgo-git/). This package builds and installs the latest git `main` branch. It requires `git`, `gcc` and `go` to build.\n- Deb and RPM packages are built after each commit and for each release.\n- For Ubuntu a PPA is available [here](https://launchpad.net/~sftpgo/+archive/ubuntu/sftpgo).\n- Void Linux provides an [official package](https://github.com/void-linux/void-packages/tree/master/srcpkgs/sftpgo).\n\n\n\nAPT and YUM repositories are [available](./docs/repo.md).\n\nSFTPGo is also available on some marketplaces:\n\n- [AWS Marketplace](https://aws.amazon.com/marketplace/seller-profile?id=6e849ab8-70a6-47de-9a43-13c3fa849335)\n- [Azure Marketplace](https://azuremarketplace.microsoft.com/en-us/marketplace/apps/eliamarzia1667381463185.sftpgo_linux)\n- [Elest.io](https://elest.io/open-source/sftpgo)\n\nPurchasing from there will help keep SFTPGo a long-term sustainable project.\n\nWindows packages\n\n- The Windows installer to install and run SFTPGo as a Windows service.\n- The portable package to start SFTPGo on demand.\n- The [winget](https://docs.microsoft.com/en-us/windows/package-manager/winget/install) package to install and run SFTPGo as a Windows service: `winget install SFTPGo`.\n- The [Chocolatey package](https://community.chocolatey.org/packages/sftpgo) to install and run SFTPGo as a Windows service.\n\n\n\nOn macOS you can install from the Homebrew [Formula](https://formulae.brew.sh/formula/sftpgo).\nOn FreeBSD you can install from the [SFTPGo port](https://www.freshports.org/ftp/sftpgo).\nOn DragonFlyBSD you can install SFTPGo from [DPorts](https://github.com/DragonFlyBSD/DPorts/tree/master/ftp/sftpgo).\n\nYou can easily test new features selecting a commit from the [Actions](https://github.com/drakkan/sftpgo/actions) page and downloading the matching build artifacts for Linux, macOS or Windows. GitHub stores artifacts for 90 days.\n\nAlternately, you can [build from source](./docs/build-from-source.md).\n\n[Getting Started Guide for the Impatient](./docs/howto/getting-started.md).\n\n## Configuration\n\nA full explanation of all configuration methods can be found [here](./docs/full-configuration.md).\n\nPlease make sure to [initialize the data provider](#data-provider-initialization-and-management) before running the daemon.\n\nTo start SFTPGo with the default settings, simply run:\n\n```bash\nsftpgo serve\n```\n\nCheck out [this documentation](./docs/service.md) if you want to run SFTPGo as a service.\n\n### Data provider initialization and management\n\nBefore starting the SFTPGo server please ensure that the configured data provider is properly initialized/updated.\n\nFor PostgreSQL, MySQL and CockroachDB providers, you need to create the configured database. For SQLite, the configured database will be automatically created at startup. Memory and bolt data providers do not require an initialization but they could require an update to the existing data after upgrading SFTPGo.\n\nSFTPGo will attempt to automatically detect if the data provider is initialized/updated and if not, will attempt to initialize/ update it on startup as needed.\n\nAlternately, you can create/update the required data provider structures yourself using the `initprovider` command.\n\nFor example, you can simply execute the following command from the configuration directory:\n\n```bash\nsftpgo initprovider\n```\n\nTake a look at the CLI usage to learn how to specify a different configuration file:\n\n```bash\nsftpgo initprovider --help\n```\n\nYou can disable automatic data provider checks/updates at startup by setting the `update_mode` configuration key to `1`.\n\nYou can also reset your provider by using the `resetprovider` sub-command. Take a look at the CLI usage for more details:\n\n```bash\nsftpgo resetprovider --help\n```\n\n:warning: Please note that some data providers (e.g. MySQL and CockroachDB) do not support schema changes within a transaction, this means that you may end up with an inconsistent schema if migrations are forcibly aborted. CockroachDB doesn't support database-level locks, so make sure you don't execute migrations concurrently.\n\n## Create the first admin\n\nTo start using SFTPGo you need to create an admin user, you can do it in several ways:\n\n- by using the web admin interface. The default URL is [http://127.0.0.1:8080/web/admin](http://127.0.0.1:8080/web/admin)\n- by loading initial data\n- by enabling `create_default_admin` in your configuration file and setting the environment variables `SFTPGO_DEFAULT_ADMIN_USERNAME` and `SFTPGO_DEFAULT_ADMIN_PASSWORD`\n\n## Upgrading\n\nSFTPGo supports upgrading from the previous release branch to the current one.\nSome examples for supported upgrade paths are:\n\n- from 2.1.x to 2.2.x\n- from 2.2.x to 2.3.x and so on.\n\nFor supported upgrade paths, the data and schema are migrated automatically when SFTPGo starts, alternatively you can use the `initprovider` command before starting SFTPGo.\n\nSo if, for example, you want to upgrade from 2.0.x to 2.2.x, you must first install version 2.1.x, update the data provider (automatically, by starting SFTPGo or manually using the `initprovider` command) and finally install the version 2.2.x. It is recommended to always install the latest available minor version, ie do not install 2.1.0 if 2.1.2 is available.\n\nLoading data from a provider independent JSON dump is supported from the previous release branch to the current one too. After upgrading SFTPGo it is advisable to regenerate the JSON dump from the new version.\n\n## Downgrading\n\nIf for some reason you want to downgrade SFTPGo, you may need to downgrade your data provider schema and data as well. You can use the `revertprovider` command for this task.\n\nAs for upgrading, SFTPGo supports downgrading from the previous release branch to the current one.\n\nSo, if you plan to downgrade from 2.3.x to 2.2.x, before uninstalling 2.3.x version, you can prepare your data provider executing the following command from the configuration directory:\n\n```shell\nsftpgo revertprovider\n```\n\nTake a look at the CLI usage to learn how to specify a configuration file:\n\n```shell\nsftpgo revertprovider --help\n```\n\nThe `revertprovider` command is not supported for the memory provider.\n\nPlease note that we only support the current release branch and the current main branch, if you find a bug it is better to report it rather than downgrading to an older unsupported version.\n\n## Users, groups, folders and other resource management\n\nAfter starting SFTPGo you can manage users, groups, folders and other resources using:\n\n- the [WebAdmin UI](./docs/web-admin.md)\n- the [REST API](./docs/rest-api.md)\n\nTo support embedded data providers like `bolt` and `SQLite`, which do not support concurrent connections, we can't have a CLI that directly write users and other resources to the data provider, we always have to use the REST API.\n\nFull details for users, groups, folders, admins and other resources are documented in the [OpenAPI](./openapi/openapi.yaml) schema. If you want to render the schema without importing it manually, you can explore it on [Stoplight](https://sftpgo.stoplight.io/docs/sftpgo/openapi.yaml).\n\n:warning: SFTPGo users, groups and folders are virtual and therefore unrelated to the system ones. There is no need to create system-wide users and groups.\n\n## Tutorials\n\nSome step-to-step tutorials can be found inside the source tree [howto](./docs/howto \"How-to\") directory.\n\n## Authentication options\n\n External Authentication\n\nCustom authentication methods can easily be added. SFTPGo supports external authentication modules, and writing a new backend can be as simple as a few lines of shell script. More information can be found [here](./docs/external-auth.md).\n\n\n\n Keyboard Interactive Authentication\n\nKeyboard interactive authentication is, in general, a series of questions asked by the server with responses provided by the client.\nThis authentication method is typically used for multi-factor authentication.\n\nMore information can be found [here](./docs/keyboard-interactive.md).\n\n\n\n## Dynamic user creation or modification\n\nA user can be created or modified by an external program just before the login. More information about this can be found [here](./docs/dynamic-user-mod.md).\n\n## Custom Actions\n\nSFTPGo allows you to configure custom commands and/or HTTP hooks to receive notifications about file uploads, deletions and several other events.\n\nMore information about custom actions can be found [here](./docs/custom-actions.md).\n\n## Virtual folders\n\nDirectories outside the user home directory or based on a different storage provider can be mapped as virtual folders, more information [here](./docs/virtual-folders.md).\n\n## Other hooks\n\nYou can get notified as soon as a new connection is established using the [Post-connect hook](./docs/post-connect-hook.md) and after each login using the [Post-login hook](./docs/post-login-hook.md).\nYou can use your own hook to [check passwords](./docs/check-password-hook.md).\n\n## Storage backends\n\n### S3/GCP/Azure\n\nEach user can be mapped with a [S3 Compatible Object Storage](./docs/s3.md) /[Google Cloud Storage](./docs/google-cloud-storage.md)/[Azure Blob Storage](./docs/azure-blob-storage.md) bucket or a bucket virtual folder.\n\n### SFTP backend\n\nEach user can be mapped to another SFTP server account or a subfolder of it. More information can be found [here](./docs/sftpfs.md).\n\n### Encrypted backend\n\nData at-rest encryption is supported via the [cryptfs backend](./docs/dare.md).\n\n### HTTP/S backend\n\nHTTP/S backend allows you to write your own custom storage backend by implementing a REST API. More information can be found [here](./docs/httpfs.md).\n\n### Other Storage backends\n\nAdding new storage backends is quite easy:\n\n- implement the [Fs interface](./internal/vfs/vfs.go#L86 \"interface for filesystem backends\").\n- update the user method `GetFilesystem` to return the new backend\n- update the web interface and the REST API CLI\n- add the flags for the new storage backed to the `portable` mode\n\nAnyway, some backends require a pay per-use account (or they offer free account for a limited time period only). To be able to add support for such backends or to review pull requests, please provide a test account. The test account must be available for enough time to be able to maintain the backend and do basic tests before each new release.\n\n## Brute force protection\n\nSFTPGo supports a built-in [defender](./docs/defender.md).\n\nAlternately you can use the [connection failed logs](./docs/logs.md) for integration in tools such as [Fail2ban](http://www.fail2ban.org/). Example of [jails](./fail2ban/jails) and [filters](./fail2ban/filters) working with `systemd`/`journald` are available in fail2ban directory.\n\n## Account's configuration properties\n\nDetails information about account configuration properties can be found [here](./docs/account.md).\n\n## Performance\n\nSFTPGo can easily saturate a Gigabit connection on low end hardware with no special configuration, this is generally enough for most use cases.\n\nMore in-depth analysis of performance can be found [here](./docs/performance.md).\n\n## Release Cadence\n\nSFTPGo releases are feature-driven, we don't have a fixed time based schedule. As a rough estimate, you can expect 1 or 2 new releases per year.\n\n## Acknowledgements\n\nSFTPGo makes use of the third party libraries listed inside [go.mod](./go.mod).\n\nWe are very grateful to all the people who contributed with ideas and/or pull requests.\n\nThank you [ysura](https://www.ysura.com/) for granting me stable access to a test AWS S3 account.\n\n## License\n\nGNU AGPL-3.0-only\n",
- "source_links": [],
- "id": 114
- },
- {
- "page_link": "https://github.com/SonarSource/sonarqube",
- "title": "sonarqube readme",
- "text": "# SonarQube [](https://app.travis-ci.com/SonarSource/sonarqube) [](https://next.sonarqube.com/sonarqube/dashboard?id=sonarqube)\n\n## Continuous Inspection\n\nSonarQube provides the capability to not only show health of an application but also to highlight issues newly introduced. With a Quality Gate in place, you can [Clean as You Code](https://www.sonarsource.com/blog/clean-as-you-code/) and therefore improve code quality systematically.\n\n## Links\n\n- [Website](https://www.sonarqube.org)\n- [Download](https://www.sonarqube.org/downloads/)\n- [Documentation](https://docs.sonarqube.org)\n- [Twitter](https://twitter.com/SonarQube)\n- [SonarSource](https://www.sonarsource.com), author of SonarQube\n- [Issue tracking](https://jira.sonarsource.com/browse/SONAR/), read-only. Only SonarSourcers can create tickets.\n- [Responsible Disclosure](https://community.sonarsource.com/t/responsible-vulnerability-disclosure/9317)\n- [Next](https://next.sonarqube.com/sonarqube) instance of the next SonarQube version\n\n## Have Question or Feedback?\n\nFor support questions (\"How do I?\", \"I got this error, why?\", ...), please first read the [documentation](https://docs.sonarqube.org) and then head to the [SonarSource Community](https://community.sonarsource.com/c/help/sq/10). The answer to your question has likely already been answered! \ud83e\udd13\n\nBe aware that this forum is a community, so the standard pleasantries (\"Hi\", \"Thanks\", ...) are expected. And if you don't get an answer to your thread, you should sit on your hands for at least three days before bumping it. Operators are not standing by. \ud83d\ude04\n\n## Contributing\n\nIf you would like to see a new feature, please create a new Community thread: [\"Suggest new features\"](https://community.sonarsource.com/c/suggestions/features).\n\nPlease be aware that we are not actively looking for feature contributions. The truth is that it's extremely difficult for someone outside SonarSource to comply with our roadmap and expectations. Therefore, we typically only accept minor cosmetic changes and typo fixes.\n\nWith that in mind, if you would like to submit a code contribution, please create a pull request for this repository. Please explain your motives to contribute this change: what problem you are trying to fix, what improvement you are trying to make.\n\nMake sure that you follow our [code style](https://github.com/SonarSource/sonar-developer-toolset#code-style) and all tests are passing (Travis build is executed for each pull request).\n\nWilling to contribute to SonarSource products? We are looking for smart, passionate, and skilled people to help us build world-class code quality solutions. Have a look at our current [job offers here](https://www.sonarsource.com/company/jobs/)!\n\n## Building\n\nTo build sources locally follow these instructions.\n\n### Build and Run Unit Tests\n\nExecute from project base directory:\n\n ./gradlew build\n\nThe zip distribution file is generated in `sonar-application/build/distributions/`. Unzip it and start server by executing:\n\n # on linux\n bin/linux-x86-64/sonar.sh start\n # or on MacOS\n bin/macosx-universal-64/sonar.sh start\n # or on Windows\n bin\\windows-x86-64\\StartSonar.bat\n\n### Open in IDE\n\nIf the project has never been built, then build it as usual (see previous section) or use the quicker command:\n\n ./gradlew ide\n\nThen open the root file `build.gradle` as a project in Intellij or Eclipse.\n\n### Gradle Hints\n\n| ./gradlew command | Description |\n| -------------------------------- | ----------------------------------------- |\n| `dependencies` | list dependencies |\n| `licenseFormat --rerun-tasks` | fix source headers by applying HEADER.txt |\n| `wrapper --gradle-version 5.2.1` | upgrade wrapper |\n\n## License\n\nCopyright 2008-2023 SonarSource.\n\nLicensed under the [GNU Lesser General Public License, Version 3.0](https://www.gnu.org/licenses/lgpl.txt)\n",
- "source_links": [],
- "id": 115
- },
- {
- "page_link": "https://github.com/apache/spark",
- "title": "spark readme",
- "text": "# Apache Spark\n\nSpark is a unified analytics engine for large-scale data processing. It provides\nhigh-level APIs in Scala, Java, Python, and R, and an optimized engine that\nsupports general computation graphs for data analysis. It also supports a\nrich set of higher-level tools including Spark SQL for SQL and DataFrames,\npandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing,\nand Structured Streaming for stream processing.\n\n\n\n[](https://github.com/apache/spark/actions/workflows/build_main.yml)\n[](https://ci.appveyor.com/project/ApacheSoftwareFoundation/spark)\n[](https://codecov.io/gh/apache/spark)\n[](https://pypi.org/project/pyspark/)\n\n\n## Online Documentation\n\nYou can find the latest Spark documentation, including a programming\nguide, on the [project web page](https://spark.apache.org/documentation.html).\nThis README file only contains basic setup instructions.\n\n## Building Spark\n\nSpark is built using [Apache Maven](https://maven.apache.org/).\nTo build Spark and its example programs, run:\n\n```bash\n./build/mvn -DskipTests clean package\n```\n\n(You do not need to do this if you downloaded a pre-built package.)\n\nMore detailed documentation is available from the project site, at\n[\"Building Spark\"](https://spark.apache.org/docs/latest/building-spark.html).\n\nFor general development tips, including info on developing Spark using an IDE, see [\"Useful Developer Tools\"](https://spark.apache.org/developer-tools.html).\n\n## Interactive Scala Shell\n\nThe easiest way to start using Spark is through the Scala shell:\n\n```bash\n./bin/spark-shell\n```\n\nTry the following command, which should return 1,000,000,000:\n\n```scala\nscala> spark.range(1000 * 1000 * 1000).count()\n```\n\n## Interactive Python Shell\n\nAlternatively, if you prefer Python, you can use the Python shell:\n\n```bash\n./bin/pyspark\n```\n\nAnd run the following command, which should also return 1,000,000,000:\n\n```python\n>>> spark.range(1000 * 1000 * 1000).count()\n```\n\n## Example Programs\n\nSpark also comes with several sample programs in the `examples` directory.\nTo run one of them, use `./bin/run-example [params]`. For example:\n\n```bash\n./bin/run-example SparkPi\n```\n\nwill run the Pi example locally.\n\nYou can set the MASTER environment variable when running examples to submit\nexamples to a cluster. This can be a mesos:// or spark:// URL,\n\"yarn\" to run on YARN, and \"local\" to run\nlocally with one thread, or \"local[N]\" to run locally with N threads. You\ncan also use an abbreviated class name if the class is in the `examples`\npackage. For instance:\n\n```bash\nMASTER=spark://host:7077 ./bin/run-example SparkPi\n```\n\nMany of the example programs print usage help if no params are given.\n\n## Running Tests\n\nTesting first requires [building Spark](#building-spark). Once Spark is built, tests\ncan be run using:\n\n```bash\n./dev/run-tests\n```\n\nPlease see the guidance on how to\n[run tests for a module, or individual tests](https://spark.apache.org/developer-tools.html#individual-tests).\n\nThere is also a Kubernetes integration test, see resource-managers/kubernetes/integration-tests/README.md\n\n## A Note About Hadoop Versions\n\nSpark uses the Hadoop core library to talk to HDFS and other Hadoop-supported\nstorage systems. Because the protocols have changed in different versions of\nHadoop, you must build Spark against the same version that your cluster runs.\n\nPlease refer to the build documentation at\n[\"Specifying the Hadoop Version and Enabling YARN\"](https://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version-and-enabling-yarn)\nfor detailed guidance on building for a particular distribution of Hadoop, including\nbuilding for particular Hive and Hive Thriftserver distributions.\n\n## Configuration\n\nPlease refer to the [Configuration Guide](https://spark.apache.org/docs/latest/configuration.html)\nin the online documentation for an overview on how to configure Spark.\n\n## Contributing\n\nPlease review the [Contribution to Spark guide](https://spark.apache.org/contributing.html)\nfor information on how to get started contributing to the project.\n",
- "source_links": [],
- "id": 116
- },
- {
- "page_link": null,
- "title": "strapi readme",
- "text": null,
- "source_links": [],
- "id": 117
- },
- {
- "page_link": "https://github.com/apache/superset",
- "title": "superset readme",
- "text": "\n\n# Superset\n\n[](https://opensource.org/licenses/Apache-2.0)\n[](https://github.com/apache/superset/tree/latest)\n[](https://github.com/apache/superset/actions)\n[](https://badge.fury.io/py/apache-superset)\n[](https://codecov.io/github/apache/superset)\n[](https://pypi.python.org/pypi/apache-superset)\n[](http://bit.ly/join-superset-slack)\n[](https://superset.apache.org)\n\n\n\nA modern, enterprise-ready business intelligence web application.\n\n[**Why Superset?**](#why-superset) |\n[**Supported Databases**](#supported-databases) |\n[**Installation and Configuration**](#installation-and-configuration) |\n[**Release Notes**](RELEASING/README.md#release-notes-for-recent-releases) |\n[**Get Involved**](#get-involved) |\n[**Contributor Guide**](#contributor-guide) |\n[**Resources**](#resources) |\n[**Organizations Using Superset**](RESOURCES/INTHEWILD.md)\n\n## Why Superset?\n\nSuperset is a modern data exploration and data visualization platform. Superset can replace or augment proprietary business intelligence tools for many teams. Superset integrates well with a variety of data sources.\n\nSuperset provides:\n\n- A **no-code interface** for building charts quickly\n- A powerful, web-based **SQL Editor** for advanced querying\n- A **lightweight semantic layer** for quickly defining custom dimensions and metrics\n- Out of the box support for **nearly any SQL** database or data engine\n- A wide array of **beautiful visualizations** to showcase your data, ranging from simple bar charts to geospatial visualizations\n- Lightweight, configurable **caching layer** to help ease database load\n- Highly extensible **security roles and authentication** options\n- An **API** for programmatic customization\n- A **cloud-native architecture** designed from the ground up for scale\n\n## Screenshots & Gifs\n\n**Large Gallery of Visualizations**\n\n \n\n**Craft Beautiful, Dynamic Dashboards**\n\n \n\n**No-Code Chart Builder**\n\n \n\n**Powerful SQL Editor**\n\n \n\n## Supported Databases\n\nSuperset can query data from any SQL-speaking datastore or data engine (Presto, Trino, Athena, [and more](https://superset.apache.org/docs/databases/installing-database-drivers/)) that has a Python DB-API driver and a SQLAlchemy dialect.\n\nHere are some of the major database solutions that are supported:\n\n
\n\n**A more comprehensive list of supported databases** along with the configuration instructions can be found [here](https://superset.apache.org/docs/databases/installing-database-drivers).\n\nWant to add support for your datastore or data engine? Read more [here](https://superset.apache.org/docs/frequently-asked-questions#does-superset-work-with-insert-database-engine-here) about the technical requirements.\n\n## Installation and Configuration\n\n[Extended documentation for Superset](https://superset.apache.org/docs/installation/installing-superset-using-docker-compose)\n\n## Get Involved\n\n- Ask and answer questions on [StackOverflow](https://stackoverflow.com/questions/tagged/apache-superset) using the **apache-superset** tag\n- [Join our community's Slack](http://bit.ly/join-superset-slack)\n and please read our [Slack Community Guidelines](https://github.com/apache/superset/blob/master/CODE_OF_CONDUCT.md#slack-community-guidelines)\n- [Join our dev@superset.apache.org Mailing list](https://lists.apache.org/list.html?dev@superset.apache.org)\n\n## Contributor Guide\n\nInterested in contributing? Check out our\n[CONTRIBUTING.md](https://github.com/apache/superset/blob/master/CONTRIBUTING.md)\nto find resources around contributing along with a detailed guide on\nhow to set up a development environment.\n\n## Resources\n\nSuperset 2.0!\n- [Superset 2.0 Meetup](https://preset.io/events/superset-2-0-meetup/)\n- [Superset 2.0 Release Notes](https://github.com/apache/superset/tree/master/RELEASING/release-notes-2-0)\n\nUnderstanding the Superset Points of View\n- [The Case for Dataset-Centric Visualization](https://preset.io/blog/dataset-centric-visualization/)\n- [Understanding the Superset Semantic Layer](https://preset.io/blog/understanding-superset-semantic-layer/)\n\n\n- Getting Started with Superset\n - [Superset in 2 Minutes using Docker Compose](https://superset.apache.org/docs/installation/installing-superset-using-docker-compose#installing-superset-locally-using-docker-compose)\n - [Installing Database Drivers](https://superset.apache.org/docs/databases/docker-add-drivers/)\n - [Building New Database Connectors](https://preset.io/blog/building-database-connector/)\n - [Create Your First Dashboard](https://superset.apache.org/docs/creating-charts-dashboards/first-dashboard)\n - [Comprehensive Tutorial for Contributing Code to Apache Superset\n ](https://preset.io/blog/tutorial-contributing-code-to-apache-superset/)\n- [Resources to master Superset by Preset](https://preset.io/resources/)\n\n- Deploying Superset\n - [Official Docker image](https://hub.docker.com/r/apache/superset)\n - [Helm Chart](https://github.com/apache/superset/tree/master/helm/superset)\n\n- Recordings of Past [Superset Community Events](https://preset.io/events)\n - [Mixed Time Series Charts](https://preset.io/events/mixed-time-series-visualization-in-superset-workshop/) \n - [How the Bing Team Customized Superset for the Internal Self-Serve Data & Analytics Platform](https://preset.io/events/how-the-bing-team-heavily-customized-superset-for-their-internal-data/)\n - [Live Demo: Visualizing MongoDB and Pinot Data using Trino](https://preset.io/events/2021-04-13-visualizing-mongodb-and-pinot-data-using-trino/)\n\t- [Introduction to the Superset API](https://preset.io/events/introduction-to-the-superset-api/)\n\t- [Building a Database Connector for Superset](https://preset.io/events/2021-02-16-building-a-database-connector-for-superset/)\n\n- Visualizations\n - [Creating Viz Plugins](https://superset.apache.org/docs/contributing/creating-viz-plugins/)\n - [Managing and Deploying Custom Viz Plugins](https://medium.com/nmc-techblog/apache-superset-manage-custom-viz-plugins-in-production-9fde1a708e55)\n - [Why Apache Superset is Betting on Apache ECharts](https://preset.io/blog/2021-4-1-why-echarts/)\n\n- [Superset API](https://superset.apache.org/docs/rest-api)\n",
- "source_links": [],
- "id": 118
- },
- {
- "page_link": "pip-packages.md",
- "title": "pip-packages",
- "text": "## Adding additional pip packages\n\nSuperset doesn't come pre-installed with all drivers you might need for your visualizations. To add additional db drivers, the most stable solution is to extend our docker image, which is relatively easy to do.\n\n### Build your extended image\n\nFirst copy the dockerfile here https://github.com/pluralsh/plural-artifacts/blob/main/superset/Dockerfile to wherever you want to manage your image. You'll also want to copy the requirements.txt in the same subfolder, and add whatever additional packages you want to it. Build the image then push it to your registry of choice to use it in the next step.\n\n### Wire Superset with this image\n\n\nYou'll then want to edit `superset/helm/superset/values.yaml` in your installation repo with something like:\n\n```yaml\nsuperset:\n superset:\n image:\n repository: your.docker.repository\n tag: your-tag\n```\n\nAlternatively, you should be able to do this in the configuration section for superset in your plural console as well.\n\n### redeploy\n\nfrom there you can simply run `plural build --only airflow && plural deploy --commit \"using custom docker image\"` to set this up",
- "source_links": [],
- "id": 119
- },
- {
- "page_link": "https://github.com/grafana/tempo",
- "title": "tempo readme",
- "text": "
\n
\n \n \n \n \n \n \n
\n\nGrafana Tempo is an open source, easy-to-use and high-scale distributed tracing backend. Tempo is cost-efficient, requiring only object storage to operate, and is deeply integrated with Grafana, Prometheus, and Loki.\n\nTempo is Jaeger, Zipkin, Kafka, OpenCensus and OpenTelemetry compatible. It ingests batches in any of the mentioned formats, buffers them and then writes them to Azure, GCS, S3 or local disk. As such it is robust, cheap and easy to operate!\n\nTempo implements [TraceQL](https://grafana.com/docs/tempo/latest/traceql/), a traces-first query language inspired by LogQL and PromQL. This query language allows users to very precisely and easily select spans and jump directly to the spans fulfilling the specified conditions:\n\n
\n\n## Getting Started\n\n- [Get started documentation](https://grafana.com/docs/tempo/latest/getting-started/)\n- [Deployment Examples](./example)\n - [Docker Compose](./example/docker-compose)\n - [Helm](./example/helm)\n - [Jsonnet](./example/tk)\n\n## Further Reading\n\nTo learn more about Tempo, consult the following documents & talks:\n\n- [New in Grafana Tempo 2.0: Apache Parquet as the default storage format, support for TraceQL][tempo_20_announce]\n- [Get to know TraceQL: A powerful new query language for distributed tracing][traceql-post]\n\n[tempo_20_announce]: https://grafana.com/blog/2023/02/01/new-in-grafana-tempo-2.0-apache-parquet-as-the-default-storage-format-support-for-traceql/\n[traceql-post]: https://grafana.com/blog/2023/02/07/get-to-know-traceql-a-powerful-new-query-language-for-distributed-tracing/\n\n## Getting Help\n\nIf you have any questions or feedback regarding Tempo:\n\n- Grafana Labs hosts a [forum](https://community.grafana.com/c/grafana-tempo/40) for Tempo. This is a great place to post questions and search for answers.\n- Ask a question on the [Tempo Slack channel](https://grafana.slack.com/archives/C01D981PEE5).\n- [File an issue](https://github.com/grafana/tempo/issues/new/choose) for bugs, issues and feature suggestions.\n- UI issues should be filed with [Grafana](https://github.com/grafana/grafana/issues/new/choose).\n\n## OpenTelemetry\n\nTempo's receiver layer, wire format and storage format are all based directly on [standards](https://github.com/open-telemetry/opentelemetry-proto) and [code](https://github.com/open-telemetry/opentelemetry-collector) established by [OpenTelemetry](https://opentelemetry.io/). We support open standards at Grafana!\n\nCheck out the [Integration Guides](https://grafana.com/docs/tempo/latest/guides/instrumentation/) to see examples of OpenTelemetry instrumentation with Tempo.\n\n## Other Components\n\n### tempo-vulture\n[tempo-vulture](https://github.com/grafana/tempo/tree/main/cmd/tempo-vulture) is Tempo's bird themed consistency checking tool. It writes traces to Tempo and then queries them back in a variety of ways.\n\n### tempo-cli\n[tempo-cli](https://github.com/grafana/tempo/tree/main/cmd/tempo-cli) is the place to put any utility functionality related to Tempo. See [Documentation](https://grafana.com/docs/tempo/latest/operations/tempo_cli/) for more info.\n\n## License\n\nGrafana Tempo is distributed under [AGPL-3.0-only](LICENSE). For Apache-2.0 exceptions, see [LICENSING.md](LICENSING.md).\n",
- "source_links": [],
- "id": 120
- },
- {
- "page_link": null,
- "title": "terraria readme",
- "text": null,
- "source_links": [],
- "id": 121
- },
- {
- "page_link": null,
- "title": "test-harness readme",
- "text": null,
- "source_links": [],
- "id": 122
- },
- {
- "page_link": null,
- "title": "test repo readme",
- "text": null,
- "source_links": [],
- "id": 123
- },
- {
- "page_link": null,
- "title": "test-repo-3 readme",
- "text": null,
- "source_links": [],
- "id": 124
- },
- {
- "page_link": "https://github.com/tierrun/tier",
- "title": "tier readme",
- "text": "
\n \n
\n\n\n# Pricing as Code\n\n`tier` is a tool that lets you define and manage your SaaS application's pricing model in one place (pricing.json). \n\nTier will handle setting up and managing Stripe in a way that is much more friendly for SaaS and consumption based billing models. Tier's SDK can then be implemented for access checking, metering/reporting, and more.\n\n [](https://opensource.org/licenses/)\n []()\n [](https://github.com/tierrun/tier/discussions)\n []()\n\n\n## Docs and Community\n- [Documentation is available here](https://docs.tier.run/)\n- Join our Slack here: [](https://join.slack.com/t/tier-community/shared_invite/zt-1blotqjb9-wvkYMo8QkhaEWziprdjnIA)\n\n# Key Features and Capabilities\n- Manage your features, plans and their pricing in one place\n- On demand test environments and preview deployments allow you to work with confidence\n- Create custom plans and variants as needed for specific customers or tests\n- Stripe is kept in sync and fully managed by Tier\n- Access Checking and Entitlements are handled by the Tier SDKs \n\n## How to use Tier\n\n1. [Install Tier CLI](#install)\n2. [Create your first pricing.json](https://model.tier.run) and `tier push` to your dev or live environment\n3. [Get a Tier SDK and add it](https://www.tier.run/docs/sdk/) to enable Access Checks and Metering\n\nYou can see and example here: [Tier Hello World!](https://blog.tier.run/tier-hello-world-demo)\n\n
\n \n
\n\n## Install\n\n### Homebrew (macOS)\n\n```\nbrew install tierrun/tap/tier\n```\n### Binary (macOS, linux, Windows)\n\nBinaries for major architectures can be found at [here](https://tier.run/releases).\n\n### Go (most operating systems and architectures)\n\nIf go1.19 or later is installed, running or installing tier like:\n\n```\ngo run tier.run/cmd/tier@latest\n```\n\nor\n\n```\ngo install tier.run/cmd/tier@latest\n```\n\n\n## Authors\n\n- [@bmizerany](https://www.github.com/bmizerany)\n- [@isaacs](https://www.github.com/isaacs)\n- [@jevon](https://www.github.com/jevon)\n\n",
- "source_links": [],
- "id": 125
- },
- {
- "page_link": "https://github.com/trytouca/trytouca",
- "title": "touca readme",
- "text": "
\n\n
\n
\n\n\n\n
\n\n## Continuous Regression Testing for Engineering Teams\n\nTouca provides feedback when you write code that could break your software. It\nremotely compares the behavior and performance of your software against a\nprevious trusted version and visualizes differences in near real-time.\n\n[](https://vimeo.com/703039452 \"Touca Quick Product Demo\")\n\n## Start for free\n\n[](https://hub.docker.com/r/touca/touca)\n\n### Option 1: Self-host locally\n\nYou can self-host Touca by running the following command on a UNIX machine with\nat least 2GB of RAM, with Docker and Docker Compose installed.\n\n```bash\n/bin/bash -c \"$(curl -fsSL https://touca.io/install.sh)\"\n```\n\n### Option 2: Use Touca Cloud\n\nOr you can use https://app.touca.io that we manage and maintain. We have a free\nplan and offer additional features suitable for larger teams.\n\n## Sneak Peek\n\n> Touca has SDKs in Python, C++, Java, and JavaScript.\n\n[](https://github.com/trytouca/trytouca/tree/main/sdk/cpp)\n[](https://pypi.org/project/touca/)\n[](https://www.npmjs.com/package/@touca/node)\n[](https://search.maven.org/artifact/io.touca/touca)\n\nLet us imagine that we want to test a software workflow that takes the username\nof a student and provides basic information about them.\n\n```python\n@dataclass\nclass Student:\n username: str\n fullname: str\n dob: datetime.date\n gpa: float\n\ndef find_student(username: str) -> Student:\n # ...\n```\n\nWe can use unit testing in which we hard-code a set of usernames and list our\nexpected return value for each input. In this example, the input and output of\nour code under test are `username` and `Student`. If we were testing a video\ncompression algorithm, they may have been video files. In that case:\n\n- Describing the expected output for a given video file would be difficult.\n- When we make changes to our compression algorithm, accurately reflecting those\n changes in our expected values would be time-consuming.\n- We would need a large number of input video files to gain confidence that our\n algorithm works correctly.\n\nTouca makes it easier to continuously test workflows of any complexity and with\nany number of test cases.\n\n```python\nimport touca\nfrom students import find_student\n\n@touca.workflow\ndef students_test(username: str):\n student = find_student(username)\n touca.check(\"username\", student.username)\n touca.check(\"fullname\", student.fullname)\n touca.check(\"birth_date\", student.dob)\n touca.check(\"gpa\", student.gpa)\n```\n\nThis is slightly different from a typical unit test:\n\n- Touca tests do not use expected values.\n- Touca tests do not hard-code input values.\n\nWith Touca, we describe how we run our code under test for any given test case.\nWe can capture values of interesting variables and runtime of important\nfunctions to describe the behavior and performance of our workflow for that test\ncase.\n\nWe can run Touca tests with any number of inputs from the command line:\n\n```bash\ntouca config set api-key=\"\"\ntouca config set api-url=\"https://api.touca.io/@/tutorial\"\ntouca test --revision=1.0 --testcase alice bob charlie\n```\n\nThis command produces the following output:\n\n```text\n\nTouca Test Framework\n\nSuite: students_test/1.0\n\n 1. SENT alice (0 ms)\n 2. SENT bob (0 ms)\n 3. SENT charlie (0 ms)\n\nTests: 3 submitted, 3 total\nTime: 0.39 s\n\n\u2728 Ran all test suites.\n\n```\n\nNow if we make changes to our workflow under test, we can rerun this test and\nrely on Touca to check if our changes affect the behavior or performance of our\nsoftware.\n\nUnlike integration tests, we are not bound to the output of our workflow. We can\ncapture any number of data points and from anywhere within our code. This is\nspecially useful if our workflow has multiple stages. We can capture the output\nof each stage without publicly exposing its API. When any stage changes behavior\nin a future version of our software, our captured data points will help find the\nroot cause more easily.\n\n## Value Proposition\n\nTouca is very effective in addressing common problems in the following\nsituations:\n\n- When we need to test our workflow with a large number of inputs.\n- When the output of our workflow is too complex, or too difficult to describe\n in our unit tests.\n- When interesting information to check for regression is not exposed through\n the interface of our workflow.\n\nThe highlighted design features of Touca can help us test these workflows at any\nscale.\n\n- Decoupling our test input from our test logic helps us manage our long list of\n inputs without modifying the test logic. Managing that list on a remote server\n accessible to all members of our team helps us add notes to each test case,\n explain why they are needed and track their stability and performance changes\n over time.\n- Submitting our test results to a remote server, instead of storing them in\n files, helps us avoid the mundane tasks of managing and processing of test\n results. Touca server retains all test results and makes them accessible to\n all members of the team. It compares test results using their original data\n types and reports discovered differences in real-time to all interested\n members of our team. It helps us audit how our software evolves over time and\n provides high-level information about our tests.\n\n## Documentation\n\nIf you are new to Touca, the best place to start is our\n[documentation website](https://touca.io/docs).\n\n## Community\n\nWe hang on [Discord](https://touca.io/discord). Come say hi! We love making new\nfriends. If you need help, have any questions, or like to contribute or provide\nfeedback, that's the best place to be.\n\n## Contributors\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n## Sponsors\n\n\n\n\n## License\n\nThis repository is released under the Apache-2.0 License. See\n[`LICENSE`](https://github.com/trytouca/trytouca/blob/main/LICENSE).\n",
- "source_links": [],
- "id": 126
- },
- {
- "page_link": null,
- "title": "trace-shield readme",
- "text": null,
- "source_links": [],
- "id": 127
- },
- {
- "page_link": "https://github.com/trinodb/trino",
- "title": "trino readme",
- "text": "
\n \n
\n
\n Trino is a fast distributed SQL query engine for big data analytics.\n
\n
\n See the User Manual for deployment instructions and end user documentation.\n
\n\n## Development\n\nSee [DEVELOPMENT](.github/DEVELOPMENT.md) for information about code style,\ndevelopment process, and guidelines.\n\nSee [CONTRIBUTING](.github/CONTRIBUTING.md) for contribution requirements.\n\n## Security\n\nSee the project [security policy](.github/SECURITY.md) for\ninformation about reporting vulnerabilities.\n\n## Build requirements\n\n* Mac OS X or Linux\n* Java 17.0.4+, 64-bit\n* Docker\n\n## Building Trino\n\nTrino is a standard Maven project. Simply run the following command from the\nproject root directory:\n\n ./mvnw clean install -DskipTests\n\nOn the first build, Maven downloads all the dependencies from the internet\nand caches them in the local repository (`~/.m2/repository`), which can take a\nwhile, depending on your connection speed. Subsequent builds are faster.\n\nTrino has a comprehensive set of tests that take a considerable amount of time\nto run, and are thus disabled by the above command. These tests are run by the\nCI system when you submit a pull request. We recommend only running tests\nlocally for the areas of code that you change.\n\n## Running Trino in your IDE\n\n### Overview\n\nAfter building Trino for the first time, you can load the project into your IDE\nand run the server. We recommend using\n[IntelliJ IDEA](http://www.jetbrains.com/idea/). Because Trino is a standard\nMaven project, you easily can import it into your IDE. In IntelliJ, choose\n*Open Project* from the *Quick Start* box or choose *Open*\nfrom the *File* menu and select the root `pom.xml` file.\n\nAfter opening the project in IntelliJ, double check that the Java SDK is\nproperly configured for the project:\n\n* Open the File menu and select Project Structure\n* In the SDKs section, ensure that JDK 17 is selected (create one if none exist)\n* In the Project section, ensure the Project language level is set to 17\n\n### Running a testing server\n\nThe simplest way to run Trino for development is to run the `TpchQueryRunner`\nclass. It will start a development version of the server that is configured with\nthe TPCH connector. You can then use the CLI to execute queries against this\nserver. Many other connectors have their own `*QueryRunner` class that you can\nuse when working on a specific connector.\n\n### Running the full server\n\nTrino comes with sample configuration that should work out-of-the-box for\ndevelopment. Use the following options to create a run configuration:\n\n* Main Class: `io.trino.server.DevelopmentServer`\n* VM Options: `-ea -Dconfig=etc/config.properties -Dlog.levels-file=etc/log.properties -Djdk.attach.allowAttachSelf=true`\n* Working directory: `$MODULE_DIR$`\n* Use classpath of module: `trino-server-dev`\n\nThe working directory should be the `trino-server-dev` subdirectory. In\nIntelliJ, using `$MODULE_DIR$` accomplishes this automatically.\n\nIf `VM options` doesn't exist in the dialog, you need to select `Modify options`\nand enable `Add VM options`.\n\n### Running the CLI\n\nStart the CLI to connect to the server and run SQL queries:\n\n client/trino-cli/target/trino-cli-*-executable.jar\n\nRun a query to see the nodes in the cluster:\n\n SELECT * FROM system.runtime.nodes;\n\nRun a query against the TPCH connector:\n\n SELECT * FROM tpch.tiny.region;\n",
- "source_links": [],
- "id": 128
- },
- {
- "page_link": "adding-catalogs.md",
- "title": "adding-catalogs",
- "text": "# Adding Data Catalogs\n\nTrino doesn't come with a natural way to preconfigure datasources, but it's relatively easy to do through helm. You simply need to edit `trino/helm/trino/values.yaml` and add something like:\n\n```yaml\ntrino:\n additionalCatalogs:\n lakehouse.properties: |-\n connector.name=iceberg\n hive.metastore.uri=thrift://example.net:9083\n rdbms.properties: |-\n connector.name=postgresql\n connection-url=jdbc:postgresql://example.net:5432/database\n connection-user=root\n connection-password=secret\n```\n\n(note this is an encrypted file in your repo so safe to edit however you want).\n\nIn the console, you can simply use trino's configuration tab at Configuration -> Helm\n",
- "source_links": [],
- "id": 129
- },
- {
- "page_link": "https://github.com/aquasecurity/trivy-operator",
- "title": "trivy readme",
- "text": "\n\n> Kubernetes-native security toolkit. ([Documentation](https://aquasecurity.github.io/trivy-operator/latest))\n\n[![GitHub Release][release-img]][release]\n[![Build Action][action-build-img]][action-build]\n[![Release snapshot Action][action-release-snapshot-img]][action-release-snapshot]\n[![Go Report Card][report-card-img]][report-card]\n[![License][license-img]][license]\n[![GitHub All Releases][github-all-releases-img]][release]\n![Docker Pulls Trivy-operator][docker-pulls-trivy-operator]\n\n\n\n[](https://artifacthub.io/packages/search?repo=trivy-operator)\n\n# Introduction\n\nThere are lots of security tools in the cloud native world, created by Aqua and by others, for identifying and informing\nusers about security issues in Kubernetes workloads and infrastructure components. However powerful and useful they\nmight be, they tend to sit alongside Kubernetes, with each new product requiring users to learn a separate set of\ncommands and installation steps in order to operate them and find critical security information.\n\nThe Trivy-Operator leverages trivy security tools by incorporating their outputs into Kubernetes CRDs\n(Custom Resource Definitions) and from there, making security reports accessible through the Kubernetes API. This way\nusers can find and view the risks that relate to different resources in what we call a Kubernetes-native way.\n\nThe Trivy operator automatically updates security reports in response to workload and other changes on a Kubernetes cluster, generating the following reports:\n\n- Vulnerability Scans: Automated vulnerability scanning for Kubernetes workloads.\n- ConfigAudit Scans: Automated configuration audits for Kubernetes resources with predefined rules or custom Open Policy Agent (OPA) policies.\n- Exposed Secret Scans: Automated secret scans which find and detail the location of exposed Secrets within your cluster.\n- RBAC scans: Role Based Access Control scans provide detailed information on the access rights of the different resources installed.\n\n
\n\n
\n\n# Status\n\nAlthough we are trying to keep new releases backward compatible with previous versions, this project is still incubating,\nand some APIs and [Custom Resource Definitions] may change.\n\n# Usage\n\nThe official [Documentation] provides detailed installation, configuration, troubleshooting, and quick start guides.\n\nYou can install the Trivy-operator Operator with [Static YAML Manifests] and follow the [Getting Started][getting-started-operator]\nguide to see how vulnerability and configuration audit reports are generated automatically.\n\n# Contributing\n\nAt this early stage we would love your feedback on the overall concept of Trivy-Operator. Over time, we'd love to see\ncontributions integrating different security tools so that users can access security information in standard,\nKubernetes-native ways.\n\n* See [Contributing] for information about setting up your development environment, and the contribution workflow that\n we expect.\n* Please ensure that you are following our [Code Of Conduct](https://github.com/aquasecurity/community/blob/main/CODE_OF_CONDUCT.md) during any interaction with the Aqua projects and their community.\n\n---\nTrivy-Operator is an [Aqua Security](https://aquasec.com) open source project. \nLearn about our [Open Source Work and Portfolio]. \nJoin the community, and talk to us about any matter in [GitHub Discussions] or [Slack].\n\n[release-img]: https://img.shields.io/github/release/aquasecurity/trivy-operator.svg?logo=github\n[release]: https://github.com/aquasecurity/trivy-operator/releases\n[action-build-img]: https://github.com/aquasecurity/trivy-operator/actions/workflows/build.yaml/badge.svg\n[action-build]: https://github.com/aquasecurity/trivy-operator/actions/workflows/build.yaml\n[action-release-snapshot-img]: https://github.com/aquasecurity/trivy-operator/actions/workflows/release-snapshot.yaml/badge.svg\n[action-release-snapshot]: https://github.com/aquasecurity/trivy-operator/actions/workflows/release-snapshot.yaml\n[cov-img]: https://codecov.io/github/aquasecurity/trivy-operator/branch/main/graph/badge.svg\n[cov]: https://codecov.io/github/aquasecurity/trivy-operator\n[report-card-img]: https://goreportcard.com/badge/github.com/aquasecurity/trivy-operator\n[report-card]: https://goreportcard.com/report/github.com/aquasecurity/trivy-operator\n[license-img]: https://img.shields.io/github/license/aquasecurity/trivy-operator.svg\n[license]: https://github.com/aquasecurity/trivy-operator/blob/main/LICENSE\n[github-all-releases-img]: https://img.shields.io/github/downloads/aquasecurity/trivy-operator/total?logo=github\n[docker-pulls-trivy-operator]: https://img.shields.io/docker/pulls/aquasec/trivy-operator?logo=docker&label=docker%20pulls%20%2F%20trivy%20operator\n[Contributing]: CONTRIBUTING.md\n[GitHub Discussions]: https://github.com/aquasecurity/trivy-operator/discussions\n[Slack]: https://slack.aquasec.com/\n[Open Source Work and Portfolio]: https://www.aquasec.com/products/open-source-projects/\n\n[Custom Resource Definitions]: https://aquasecurity.github.io/trivy-operator/latest/crds\n[Go module]: https://pkg.go.dev/github.com/aquasecurity/trivy-operator/pkg\n[Documentation]: https://aquasecurity.github.io/trivy-operator/latest\n[Static YAML Manifests]: https://aquasecurity.github.io/trivy-operator/latest/operator/installation/kubectl\n[getting-started-operator]: https://aquasecurity.github.io/trivy-operator/latest/operator\n[Kubernetes operator]: https://aquasecurity.github.io/trivy-operator/latest\n\n[Lens Extension]: https://github.com/aquasecurity/trivy-operator-lens-extension\n[kubectl]: https://kubernetes.io/docs/reference/kubectl\n",
- "source_links": [],
- "id": 130
- },
- {
- "page_link": "https://github.com/typesense/typesense",
- "title": "typesense readme",
- "text": "
\n \n
\n
\n Typesense is a fast, typo-tolerant search engine for building delightful search experiences.\n
\n\n
\n An Open Source Algolia Alternative & \n An Easier-to-Use ElasticSearch Alternative\n
\n\n\n \n\n\n \n \n\n[](https://github.com/Unleash/unleash/actions/workflows/build.yaml) [](https://coveralls.io/github/Unleash/unleash?branch=main) [](https://hub.docker.com/r/unleashorg/unleash-server) [](https://github.com/Unleash/unleash/blob/main/LICENSE) [](https://slack.unleash.run)\n\n[Open Live Demo \u2192](https://www.getunleash.io/interactive-demo)\n\n
\n\n## About Unleash\n\nUnleash is an open source feature management solution. It improves the workflow of your development team and leads to quicker software delivery. Unleash increases efficiency and gives teams _full control_ of how and when they enable new functionality for end users. Unleash lets teams ship code to production in _smaller_ releases _whenever_ they want.\n\nFeature toggles make it easy to test how your code works with real production data without the fear that you'll accidentally break your users' experience. It also helps your team work on multiple features in parallel without each maintaining an separate feature branch.\n\nUnleash is the largest open source solution for feature flagging on GitHub. There's 12 official client and server SDKs and 10+ community SDKs available; you can even make your own if you want to. You can use Unleash with any language and any framework.\n\n \n\n## Get started in 2 steps\n\n### 1. Start Unleash\n\nWith [`git`](https://git-scm.com/) and [`docker`](https://www.docker.com/) installed, it's easy to get started:\n\nRun this script:\n\n```bash\ngit clone git@github.com:Unleash/unleash.git\ncd unleash\ndocker compose up -d\n```\n\nThen point your browser to `localhost:4242` and log in using:\n\n- username: `admin`\n- password: `unleash4all`\n\nIf you'd rather run the source code in this repo directly via Node.js, see the [step-by-step instructions to get up and running in the contributing guide](./CONTRIBUTING.md#how-to-run-the-project).\n\n### 2. Connect your SDK\n\nFind your preferred SDK in [our list of official SDKs](#unleash-sdks) and import it into your project. Follow the setup guides for your specific SDK.\n\nIf you use the docker compose file from the previous step, here's the configuration details you'll need to get going:\n\n- For front-end SDKs, use:\n - URL: `http://localhost:4242/api/frontend/`\n - `clientKey`: `default:development.unleash-insecure-frontend-api-token`\n- For server-side SDKs, use:\n - Unleash API URL: `http://localhost:4242/api/`\n - API token: `default:development.unleash-insecure-api-token`\n\nIf you use a different setup, your configuration details will most likely also be different.\n\n### Check a feature toggle\n\nChecking the state of a feature toggle in your code is easy! The syntax will vary depending on your language, but all you need is a simple function call to check whether a toggle is available. Here's how it might look in Java:\n\n```java\nif (unleash.isEnabled(\"AwesomeFeature\")) {\n // do new, flashy thing\n} else {\n // do old, boring stuff\n}\n```\n\n### Run Unleash on a service?\n\nIf you don't want to run Unleash locally, we also provide easy deployment setups for Heroku and Digital Ocean:\n\n[](https://www.heroku.com/deploy/?template=https://github.com/Unleash/unleash) [](https://cloud.digitalocean.com/apps/new?repo=https://github.com/Unleash/unleash/tree/main&refcode=0e1d75187044)\n\n### Configure and run Unleash anywhere\n\nThe above sections show you how to get up and running quickly and easily. When you're ready to start configuring and customizing Unleash for your own environment, check out the documentation for [getting started with self-managed deployments](https://docs.getunleash.io/reference/deploy/getting-started), [Unleash configuration options](https://docs.getunleash.io/reference/deploy/configuring-unleash), or [running Unleash locally via docker](https://docs.getunleash.io/tutorials/quickstart#i-want-to-run-unleash-locally).\n\n \n\n## Online demo\n\nTry out [the Unleash online demo](https://www.getunleash.io/interactive-demo).\n\n[](https://www.getunleash.io/interactive-demo)\n\n \n\n## Community and help \u2014 sharing is caring\n\nWe know that learning a new tool can be hard and time-consuming. We have a growing community that loves to help out. Please don't hesitate to reach out for help.\n\n[](https://slack.unleash.run)\n\n\ud83d\udcac [Join Unleash on Slack](https://slack.unleash.run) if you want ask open questions about Unleash, feature toggling or discuss these topics in general.\n\n\ud83d\udcbb [Create a GitHub issue](https://github.com/Unleash/unleash/issues/new) if you have found a bug or have ideas on how to improve Unleash.\n\n\ud83d\udcda [Visit the documentation](https://docs.getunleash.io/) for more in-depth descriptions, how-to guides, and more.\n\n \n\n## Contribute to Unleash\n\nBuilding Unleash is a collaborative effort, and we owe a lot of gratitude to many smart and talented individuals. Building it together with community ensures that we build a product that solves real problems for real people. We'd love to have your help too: Please feel free to open issues or provide pull requests.\n\nCheck out [the CONTRIBUTING.md file](./CONTRIBUTING.md) for contribution guidelines and the [Unleash developer guide](./website/docs/contributing/developer-guide.md) for tips on environment setup, running the tests, and running Unleash from source.\n\n### Contributors\n\n
\n\n \n\n## Features our users love\n\n### Flexibility and adaptability\n\n- Get an easy overview of all feature toggles across all your environments, applications and services\n- Use included [activation strategies](https://docs.getunleash.io/reference/activation-strategies) for most common use cases, or use a [custom activation strategy](https://docs.getunleash.io/reference/custom-activation-strategies) to support any need you might have\n- Organise feature toggles by [feature toggle tags](https://docs.getunleash.io/reference/tags)\n- [Canary releases / gradual rollouts](https://docs.getunleash.io/reference/activation-strategies#gradual-rollout)\n- Targeted releases: release features to specific [users](https://docs.getunleash.io/reference/activation-strategies#userids), [IPs](https://docs.getunleash.io/reference/activation-strategies#ips), or [hostnames](https://docs.getunleash.io/reference/activation-strategies#hostnames)\n- [Kill switches](https://docs.getunleash.io/reference/feature-toggle-types#feature-toggle-types)\n- [A/B testing](https://docs.getunleash.io/topics/a-b-testing)\n- 2 [environments](https://docs.getunleash.io/reference/environments)\n- Out-of-the-box integrations with popular tools ([Slack](https://docs.getunleash.io/addons/slack), [Microsoft Teams](https://docs.getunleash.io/addons/teams), [Datadog](https://docs.getunleash.io/addons/datadog)) + integrate with anything with [webhooks](https://docs.getunleash.io/addons/webhook)\n- [Dashboard for managing technical debt](https://docs.getunleash.io/reference/technical-debt) and [stale toggles](https://docs.getunleash.io/reference/technical-debt#stale-and-potentially-stale-toggles)\n- API-first: _everything_ can be automated. No exceptions.\n- [12 official client SDKs](https://docs.getunleash.io/reference/sdks#official-sdks), and ten [community-contributed client SDKs](https://docs.getunleash.io/reference/sdks#community-sdks)\n- Run it via Docker with the [official Docker image](https://hub.docker.com/r/unleashorg/unleash-server) or as a pure Node.js application\n\n### Security and performance\n\n- Privacy by design (GDPR and Schrems II). End-user data never leaves your application.\n- [Audit logs](https://docs.getunleash.io/advanced/audit_log)\n- Enforce [OWASP's secure headers](https://owasp.org/www-project-secure-headers/) via the strict HTTPS-only mode\n- Flexible hosting options: host it on premise or in the cloud (_any_ cloud)\n- Scale [the Unleash Proxy](https://docs.getunleash.io/reference/unleash-proxy) independently of the Unleash server to support any number of front-end clients without overloading your Unleash instance\n\n### Looking for more features?\n\nIf you're looking for one of the following features, please take a look at our [Pro and Enterprise plans](https://www.getunleash.io/plans):\n\n- [role-based access control (RBAC)](https://docs.getunleash.io/reference/rbac)\n- [single sign-on (SSO)](https://docs.getunleash.io/reference/sso)\n- more environments\n- [feature toggles project support](https://docs.getunleash.io/reference/projects)\n- [advanced segmentation](https://docs.getunleash.io/reference/segments)\n- [additional strategy constraints](https://docs.getunleash.io/reference/strategy-constraints)\n- tighter security\n- more hosting options (we can even host it for you!)\n\n \n\n## Architecture\n\n\n\nRead more in the [_system overview_ section of the Unleash documentation](https://docs.getunleash.io/tutorials/unleash_overview#system-overview).\n\n \n\n## Unleash SDKs\n\nTo connect your application to Unleash you'll need to use a client SDK for your programming language.\n\n**Official server-side SDKs:**\n\n- [Go SDK](https://docs.getunleash.io/reference/sdks/go)\n- [Java SDK](https://docs.getunleash.io/reference/sdks/java)\n- [Node.js SDK](https://docs.getunleash.io/reference/sdks/node)\n- [PHP SDK](https://docs.getunleash.io/reference/sdks/php)\n- [Python SDK](https://docs.getunleash.io/reference/sdks/python)\n- [Ruby SDK](https://docs.getunleash.io/reference/sdks/ruby)\n- [Rust SDK](https://github.com/unleash/unleash-client-rust)\n- [.NET SDK](https://docs.getunleash.io/reference/sdks/dotnet)\n\n**Official front-end SDKs:**\n\nThe front-end SDKs connects via the [Unleash Proxy](https://docs.getunleash.io/reference/unleash-proxy) in order to ensure privacy, scalability and security.\n\n- [Android Proxy SDK](https://docs.getunleash.io/reference/sdks/android-proxy)\n- [Flutter Proxy SDK](https://docs.getunleash.io/reference/sdks/flutter)\n- [iOS Proxy SDK](https://docs.getunleash.io/reference/sdks/ios-proxy)\n- [JavaScript Proxy SDK](https://docs.getunleash.io/reference/sdks/javascript-browser)\n- [React Proxy SDK](https://docs.getunleash.io/reference/sdks/react)\n- [Svelte Proxy SDK](https://docs.getunleash.io/reference/sdks/svelte)\n- [Vue Proxy SDK](https://docs.getunleash.io/reference/sdks/vue)\n\n**Community SDKs:**\n\nIf none of the official SDKs fit your need, there's also a number of [community-developed SDKs](https://docs.getunleash.io/reference/sdks#community-sdks) where you might find an implementation for your preferred language (such as [Elixir](https://gitlab.com/afontaine/unleash_ex), [Dart](https://pub.dev/packages/unleash), [Clojure](https://github.com/AppsFlyer/unleash-client-clojure), and more).\n\n \n\n## Users of Unleash\n\n**Unleash is trusted by thousands of companies all over the world**.\n\n**Proud Open-Source users:** (send us a message if you want to add your logo here)\n\n\n\n \n\n## Migration guides\n\nUnleash has evolved significantly over the past few years, and we know how hard it can be to keep software up to date. If you're using the current major version, upgrading shouldn't be an issue. If you're on a previous major version, check out the [Unleash migration guide](https://docs.getunleash.io/deploy/migration_guide)!\n\n \n\n## Want to know more about Unleash?\n\n### Videos and podcasts\n\n- [The Unleash YouTube channel](https://www.youtube.com/channel/UCJjGVOc5QBbEje-r7nZEa4A)\n- [_Feature toggles \u2014 Why and how to add to your software_ \u2014 freeCodeCamp (YouTube)](https://www.youtube.com/watch?v=-yHZ9uLVSp4&t=0s)\n- [_Feature flags with Unleash_ \u2014 The Code Kitchen (podcast)](https://share.fireside.fm/episode/zD-4e4KI+Pr379KBv)\n- [_Feature Flags og Unleash med Fredrik Oseberg_ \u2014 Utviklerpodden (podcast; Norwegian)](https://pod.space/utviklerpodden/feature-flags-og-unleash-med-fredrik-oseberg)\n\n### Articles and more\n\n- [The Unleash Blog](https://www.getunleash.io/blog)\n- [_Designing the Rust Unleash API client_ \u2014 Medium](https://medium.com/cognite/designing-the-rust-unleash-api-client-6809c95aa568)\n- [_FeatureToggle_ by Martin Fowler](http://martinfowler.com/bliki/FeatureToggle.html)\n- [_Feature toggling transient errors in load tests_ \u2014 nrkbeta](https://nrkbeta.no/2021/08/23/feature-toggling-transient-errors-in-load-tests/)\n- [_An Interview with Ivar of Unleash_ \u2014 Console](https://console.substack.com/p/console-42)\n- [_Unleash your features gradually_](http://ivarconr.github.io/feature-toggles-presentation/sch-dev-lunch-2017/#1 ' '), slideshow/presentation by Ivar, the creator of Unleash\n",
- "source_links": [],
- "id": 132
- },
- {
- "page_link": null,
- "title": "valheim readme",
- "text": null,
- "source_links": [],
- "id": 133
- },
- {
- "page_link": null,
- "title": "vault readme",
- "text": null,
- "source_links": [],
- "id": 134
- },
- {
- "page_link": "https://github.com/dani-garcia/vaultwarden",
- "title": "vaultwarden readme",
- "text": "### Alternative implementation of the Bitwarden server API written in Rust and compatible with [upstream Bitwarden clients](https://bitwarden.com/download/)*, perfect for self-hosted deployment where running the official resource-heavy service might not be ideal.\n\n\ud83d\udce2 Note: This project was known as Bitwarden_RS and has been renamed to separate itself from the official Bitwarden server in the hopes of avoiding confusion and trademark/branding issues. Please see [#1642](https://github.com/dani-garcia/vaultwarden/discussions/1642) for more explanation.\n\n---\n\n[](https://hub.docker.com/r/vaultwarden/server)\n[](https://deps.rs/repo/github/dani-garcia/vaultwarden)\n[](https://github.com/dani-garcia/vaultwarden/releases/latest)\n[](https://github.com/dani-garcia/vaultwarden/blob/main/LICENSE.txt)\n[](https://matrix.to/#/#vaultwarden:matrix.org)\n\nImage is based on [Rust implementation of Bitwarden API](https://github.com/dani-garcia/vaultwarden).\n\n**This project is not associated with the [Bitwarden](https://bitwarden.com/) project nor Bitwarden, Inc.**\n\n#### \u26a0\ufe0f**IMPORTANT**\u26a0\ufe0f: When using this server, please report any bugs or suggestions to us directly (look at the bottom of this page for ways to get in touch), regardless of whatever clients you are using (mobile, desktop, browser...). DO NOT use the official support channels.\n\n---\n\n## Features\n\nBasically full implementation of Bitwarden API is provided including:\n\n * Organizations support\n * Attachments\n * Vault API support\n * Serving the static files for Vault interface\n * Website icons API\n * Authenticator and U2F support\n * YubiKey and Duo support\n\n## Installation\nPull the docker image and mount a volume from the host for persistent storage:\n\n```sh\ndocker pull vaultwarden/server:latest\ndocker run -d --name vaultwarden -v /vw-data/:/data/ -p 80:80 vaultwarden/server:latest\n```\nThis will preserve any persistent data under /vw-data/, you can adapt the path to whatever suits you.\n\n**IMPORTANT**: Some web browsers, like Chrome, disallow the use of Web Crypto APIs in insecure contexts. In this case, you might get an error like `Cannot read property 'importKey'`. To solve this problem, you need to access the web vault from HTTPS. \n\nThis can be configured in [vaultwarden directly](https://github.com/dani-garcia/vaultwarden/wiki/Enabling-HTTPS) or using a third-party reverse proxy ([some examples](https://github.com/dani-garcia/vaultwarden/wiki/Proxy-examples)).\n\nIf you have an available domain name, you can get HTTPS certificates with [Let's Encrypt](https://letsencrypt.org/), or you can generate self-signed certificates with utilities like [mkcert](https://github.com/FiloSottile/mkcert). Some proxies automatically do this step, like Caddy (see examples linked above).\n\n## Usage\nSee the [vaultwarden wiki](https://github.com/dani-garcia/vaultwarden/wiki) for more information on how to configure and run the vaultwarden server.\n\n## Get in touch\nTo ask a question, offer suggestions or new features or to get help configuring or installing the software, please [use the forum](https://vaultwarden.discourse.group/).\n\nIf you spot any bugs or crashes with vaultwarden itself, please [create an issue](https://github.com/dani-garcia/vaultwarden/issues/). Make sure there aren't any similar issues open, though!\n\nIf you prefer to chat, we're usually hanging around at [#vaultwarden:matrix.org](https://matrix.to/#/#vaultwarden:matrix.org) room on Matrix. Feel free to join us!\n\n### Sponsors\nThanks for your contribution to the project!\n\n\n\n
\n\n[](https://github.com/weaviate/weaviate/actions/workflows/.github/workflows/pull_requests.yaml)\n[](https://goreportcard.com/report/github.com/weaviate/weaviate)\n[](https://codecov.io/gh/weaviate/weaviate)\n[](https://weaviate.io/slack)\n\n## Overview\n\nWeaviate is an **open source \u200bvector database** that is robust, scalable, cloud-native, and fast.\n\nIf you just want to get started, great! Try:\n- the [quickstart tutorial](https://weaviate.io/developers/weaviate/quickstart) if you are looking to use Weaviate, or\n- the [contributor guide](https://weaviate.io/developers/contributor-guide) if you are looking to contribute to the project.\n\nAnd you can find our [documentation here](https://weaviate.io/developers/weaviate/).\n\nIf you have a bit more time, stick around and check out our summary below \ud83d\ude09\n\n-----\n\n## Why Weaviate?\n\nWith Weaviate, you can turn your text, images and more into a searchable vector database using state-of-the-art ML models.\n\nSome of its highlights are:\n\n### Speed\n\nWeaviate typically performs a 10-NN neighbor search out of millions of objects in single-digit milliseconds. See [benchmarks](https://weaviate.io/developers/weaviate/benchmarks).\n\n### Flexibility\n\nYou can use Weaviate to conveniently **vectorize your data at import time**, or alternatively you can **upload your own vectors**.\n\nThese vectorization options are enabled by Weaviate modules. Modules enable use of popular services and model hubs such as [OpenAI](https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/text2vec-openai), [Cohere](https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/text2vec-cohere) or [HuggingFace](https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/text2vec-huggingface) and much more, including use of local and custom models.\n\n### Production-readiness\n\nWeaviate is designed to take you from **rapid prototyping** all the way to **production at scale**.\n\nTo this end, Weaviate is built with [scaling](https://weaviate.io/developers/weaviate/concepts/cluster), [replication](https://weaviate.io/developers/weaviate/concepts/replication-architecture), and [security](https://weaviate.io/developers/weaviate/configuration/authentication) in mind, among others.\n\n### Beyond search\n\nWeaviate powers lightning-fast vector searches, but it is capable of much more. Some of its other superpowers include **recommendation**, **summarization**, and **integrations with neural search frameworks**.\n\n## What can you build with Weaviate?\n\nFor starters, you can build vector databases with text, images, or a combination of both.\n\nYou can also build question and answer extraction, summarization and classification systems.\n\nYou can find [code examples here](https://github.com/weaviate/weaviate-examples), and you might blog posts like these useful:\n\n- [How to build an Image Search Application with Weaviate](https://weaviate.io/blog/how-to-build-an-image-search-application-with-weaviate)\n- [Cohere Multilingual ML Models with Weaviate](https://weaviate.io/blog/cohere-multilingual-with-weaviate)\n- [The Sphere Dataset in Weaviate](https://weaviate.io/blog/sphere-dataset-in-weaviate)\n\n## Weaviate content\n\nSpeaking of content - we love connecting with our community through these. We love helping amazing people build cool things with Weaviate, and we love getting to know them as well as talking to them about their passions.\n\nTo this end, our team does an amazing job with our [blog](https://weaviate.io/blog) and [podcast](https://weaviate.io/podcast).\n\nSome of our past favorites include:\n\n### \ud83d\udcdd Blogs\n\n- [Why is vector search so fast?](https://weaviate.io/blog/Why-is-Vector-Search-so-fast)\n- [Cohere Multilingual ML Models with Weaviate](https://weaviate.io/blog/Cohere-multilingual-with-weaviate)\n- [Vamana vs. HNSW - Exploring ANN algorithms Part 1](https://weaviate.io/blog/ann-algorithms-vamana-vs-hnsw)\n\n### \ud83c\udf99\ufe0f Podcasts\n\n- [Neural Magic in Weaviate](https://www.youtube.com/watch?v=leGgjIQkVYo)\n- [BERTopic](https://www.youtube.com/watch?v=IwXOaHanfUU)\n- [Jina AI's Neural Search Framework](https://www.youtube.com/watch?v=o6MD0tWl0SM)\n\nBoth our [\ud83d\udcdd blogs](https://weaviate.io/blog) and [\ud83c\udf99\ufe0f podcasts](https://weaviate.io/podcast) are updated regularly. To keep up to date with all things Weaviate including new software releases, meetup news and of course all of the content, you can subscribe to our [\ud83d\uddde\ufe0f newsletter](https://newsletter.weaviate.io/).\n\n## Join our community!\n\nAlso, we invite you to join our [Slack](https://weaviate.io/slack) community. There, you can meet other Weaviate users and members of the Weaviate team to talk all things Weaviate and AI (and other topics!).\n\nYou can also say hi to us below:\n- [Twitter](https://twitter.com/weaviate_io)\n- [LinkedIn](https://www.linkedin.com/company/weaviate-io)\n\nOr connect to us via:\n- [Stack Overflow for questions](https://stackoverflow.com/questions/tagged/weaviate)\n- [GitHub for issues](https://github.com/weaviate/weaviate/issues)\n\n-----\n\n## Weaviate helps ...\n\n1. **Software Engineers** ([docs](https://weaviate.io/developers/weaviate/current/)) - Who use Weaviate as an ML-first database for your applications.\n * Out-of-the-box modules for: NLP/semantic search, automatic classification and image similarity search.\n * Easy to integrate into your current architecture, with full CRUD support like you're used to from other OSS databases.\n * Cloud-native, distributed, runs well on Kubernetes and scales with your workloads.\n\n2. **Data Engineers** ([docs](https://weaviate.io/developers/weaviate/current/)) - Who use Weaviate as a vector database that is built up from the ground with ANN at its core, and with the same UX they love from Lucene-based search engines.\n * Weaviate has a modular setup that allows you to use your ML models inside Weaviate, but you can also use out-of-the-box ML models (e.g., SBERT, ResNet, fasttext, etc).\n * Weaviate takes care of the scalability, so that you don't have to.\n * Deploy and maintain ML models in production reliably and efficiently.\n\n3. **Data Scientists** ([docs](https://weaviate.io/developers/weaviate/current/)) - Who use Weaviate for a seamless handover of their Machine Learning models to MLOps.\n * Deploy and maintain your ML models in production reliably and efficiently.\n * Weaviate's modular design allows you to easily package any custom trained model you want.\n * Smooth and accelerated handover of your Machine Learning models to engineers.\n\n## Interfaces\n\nYou can use Weaviate with any of these clients:\n\n- [Python](https://weaviate.io/developers/weaviate/client-libraries/python)\n- [Javascript](https://weaviate.io/developers/weaviate/client-libraries/javascript)\n- [Go](https://weaviate.io/developers/weaviate/client-libraries/go)\n- [Java](https://weaviate.io/developers/weaviate/client-libraries/java)\n\nYou can also use its GraphQL API to retrieve objects and properties.\n\n### GraphQL interface demo\n\n\n\n\n## Additional material\n\n### Reading\n\n- [Weaviate is an open-source search engine powered by ML, vectors, graphs, and GraphQL (ZDNet)](https://www.zdnet.com/article/weaviate-an-open-source-search-engine-powered-by-machine-learning-vectors-graphs-and-graphql/)\n- [Weaviate, an ANN Database with CRUD support (DB-Engines.com)](https://db-engines.com/en/blog_post/87)\n- [A sub-50ms neural search with DistilBERT and Weaviate (Towards Datascience)](https://towardsdatascience.com/a-sub-50ms-neural-search-with-distilbert-and-weaviate-4857ae390154)\n- [Getting Started with Weaviate Python Library (Towards Datascience)](https://towardsdatascience.com/getting-started-with-weaviate-python-client-e85d14f19e4f)\n",
- "source_links": [],
- "id": 136
- },
- {
- "page_link": "https://github.com/WireGuard/wireguard-go",
- "title": "wireguard readme",
- "text": "# Go Implementation of [WireGuard](https://www.wireguard.com/)\n\nThis is an implementation of WireGuard in Go.\n\n## Usage\n\nMost Linux kernel WireGuard users are used to adding an interface with `ip link add wg0 type wireguard`. With wireguard-go, instead simply run:\n\n```\n$ wireguard-go wg0\n```\n\nThis will create an interface and fork into the background. To remove the interface, use the usual `ip link del wg0`, or if your system does not support removing interfaces directly, you may instead remove the control socket via `rm -f /var/run/wireguard/wg0.sock`, which will result in wireguard-go shutting down.\n\nTo run wireguard-go without forking to the background, pass `-f` or `--foreground`:\n\n```\n$ wireguard-go -f wg0\n```\n\nWhen an interface is running, you may use [`wg(8)`](https://git.zx2c4.com/wireguard-tools/about/src/man/wg.8) to configure it, as well as the usual `ip(8)` and `ifconfig(8)` commands.\n\nTo run with more logging you may set the environment variable `LOG_LEVEL=debug`.\n\n## Platforms\n\n### Linux\n\nThis will run on Linux; however you should instead use the kernel module, which is faster and better integrated into the OS. See the [installation page](https://www.wireguard.com/install/) for instructions.\n\n### macOS\n\nThis runs on macOS using the utun driver. It does not yet support sticky sockets, and won't support fwmarks because of Darwin limitations. Since the utun driver cannot have arbitrary interface names, you must either use `utun[0-9]+` for an explicit interface name or `utun` to have the kernel select one for you. If you choose `utun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n### Windows\n\nThis runs on Windows, but you should instead use it from the more [fully featured Windows app](https://git.zx2c4.com/wireguard-windows/about/), which uses this as a module.\n\n### FreeBSD\n\nThis will run on FreeBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_USER_COOKIE`.\n\n### OpenBSD\n\nThis will run on OpenBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_RTABLE`. Since the tun driver cannot have arbitrary interface names, you must either use `tun[0-9]+` for an explicit interface name or `tun` to have the program select one for you. If you choose `tun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n## Building\n\nThis requires an installation of [go](https://golang.org) \u2265 1.18.\n\n```\n$ git clone https://git.zx2c4.com/wireguard-go\n$ cd wireguard-go\n$ make\n```\n\n## License\n\n Copyright (C) 2017-2022 WireGuard LLC. All Rights Reserved.\n \n Permission is hereby granted, free of charge, to any person obtaining a copy of\n this software and associated documentation files (the \"Software\"), to deal in\n the Software without restriction, including without limitation the rights to\n use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies\n of the Software, and to permit persons to whom the Software is furnished to do\n so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.\n",
- "source_links": [],
- "id": 137
- },
- {
- "page_link": "https://github.com/bentoml/Yatai",
- "title": "yatai readme",
- "text": "# \ud83e\udd84\ufe0f Yatai: Model Deployment at Scale on Kubernetes\n\n[](https://github.com/bentoml/yatai/actions)\n[](https://docs.bentoml.org/projects/yatai)\n[](https://join.slack.bentoml.org)\n\nYatai (\u5c4b\u53f0, food cart) lets you deploy, operate and scale Machine Learning services on Kubernetes. \n\nIt supports deploying any ML models via [BentoML: the unified model serving framework](https://github.com/bentoml/bentoml).\n\n\n\n\n\ud83d\udc49 [Join our Slack community today!](https://l.bentoml.com/join-slack)\n\n\u2728 Looking for the fastest way to give Yatai a try? Check out [BentoML Cloud](https://l.bentoml.com/bento-cloud) to get started today.\n\n\n---\n\n## Why Yatai?\n\n\ud83c\udf71 Made for BentoML, deploy at scale\n\n- Scale [BentoML](https://github.com/bentoml) to its full potential on a distributed system, optimized for cost saving and performance.\n- Manage deployment lifecycle to deploy, update, or rollback via API or Web UI.\n- Centralized registry providing the **foundation for CI/CD** via artifact management APIs, labeling, and WebHooks for custom integration.\n\n\ud83d\ude85 Cloud native & DevOps friendly\n\n- Kubernetes-native workflow via [BentoDeployment CRD](https://docs.bentoml.org/projects/yatai/en/latest/concepts/bentodeployment_crd.html) (Custom Resource Definition), which can easily fit into an existing GitOps workflow.\n- Native [integration with Grafana](https://docs.bentoml.org/projects/yatai/en/latest/observability/metrics.html) stack for observability.\n- Support for traffic control with Istio.\n- Compatible with all major cloud platforms (AWS, Azure, and GCP).\n\n\n## Getting Started\n\n- \ud83d\udcd6 [Documentation](https://docs.bentoml.org/projects/yatai/) - Overview of the Yatai docs and related resources\n- \u2699\ufe0f [Installation](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html) - Hands-on instruction on how to install Yatai for production use\n- \ud83d\udc49 [Join Community Slack](https://l.linklyhq.com/l/ktPW) - Get help from our community and maintainers\n\n\n## Quick Tour\n\nLet's try out Yatai locally in a minikube cluster!\n\n### \u2699\ufe0f Prerequisites:\n * Install latest minikube: https://minikube.sigs.k8s.io/docs/start/\n * Install latest Helm: https://helm.sh/docs/intro/install/\n * Start a minikube Kubernetes cluster: `minikube start --cpus 4 --memory 4096`, if you are using macOS, you should use [hyperkit](https://minikube.sigs.k8s.io/docs/drivers/hyperkit/) driver to prevent the macOS docker desktop [network limitation](https://docs.docker.com/desktop/networking/#i-cannot-ping-my-containers)\n * Check that minikube cluster status is \"running\": `minikube status`\n * Make sure your `kubectl` is configured with `minikube` context: `kubectl config current-context`\n * Enable ingress controller: `minikube addons enable ingress`\n\n### \ud83d\udea7 Install Yatai\n\nInstall Yatai with the following script:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai/main/scripts/quick-install-yatai.sh\")\n```\n\nThis script will install Yatai along with its dependencies (PostgreSQL and MinIO) on\nyour minikube cluster. \n\nNote that this installation script is made for development and testing use only.\nFor production deployment, check out the [Installation Guide](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html).\n\nTo access Yatai web UI, run the following command and keep the terminal open:\n\n```bash\nkubectl --namespace yatai-system port-forward svc/yatai 8080:80\n```\n\nIn a separate terminal, run:\n\n```bash\nYATAI_INITIALIZATION_TOKEN=$(kubectl get secret yatai-env --namespace yatai-system -o jsonpath=\"{.data.YATAI_INITIALIZATION_TOKEN}\" | base64 --decode)\necho \"Open in browser: http://127.0.0.1:8080/setup?token=$YATAI_INITIALIZATION_TOKEN\"\n``` \n\nOpen the URL printed above from your browser to finish admin account setup.\n\n\n### \ud83c\udf71 Push Bento to Yatai\n\nFirst, get an API token and login to the BentoML CLI:\n\n* Keep the `kubectl port-forward` command in the step above running\n* Go to Yatai's API tokens page: http://127.0.0.1:8080/api_tokens\n* Create a new API token from the UI, making sure to assign \"API\" access under \"Scopes\"\n* Copy the login command upon token creation and run as a shell command, e.g.:\n\n ```bash\n bentoml yatai login --api-token {YOUR_TOKEN} --endpoint http://127.0.0.1:8080\n ```\n\nIf you don't already have a Bento built, run the following commands from the [BentoML Quickstart Project](https://github.com/bentoml/BentoML/tree/main/examples/quickstart) to build a sample Bento:\n\n```bash\ngit clone https://github.com/bentoml/bentoml.git && cd ./examples/quickstart\npip install -r ./requirements.txt\npython train.py\nbentoml build\n```\n\nPush your newly built Bento to Yatai:\n\n```bash\nbentoml push iris_classifier:latest\n```\n\nNow you can view and manage models and bentos from the web UI:\n\n\n\n\n### \ud83d\udd27 Install yatai-image-builder component\n\nYatai's image builder feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-image-builder/main/scripts/quick-install-yatai-image-builder.sh\")\n```\n\nThis will install the `BentoRequest` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/)) and `Bento` CRD\nin your cluster. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udd27 Install yatai-deployment component\n\nYatai's Deployment feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-deployment/main/scripts/quick-install-yatai-deployment.sh\")\n```\n\nThis will install the `BentoDeployment` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/))\nin your cluster and enable the deployment UI on Yatai. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udea2 Deploy Bento!\n\nOnce the `yatai-deployment` component was installed, Bentos pushed to Yatai can be deployed to your \nKubernetes cluster and exposed via a Service endpoint. \n\nA Bento Deployment can be created either via Web UI or via a Kubernetes CRD config:\n\n#### Option 1. Simple Deployment via Web UI\n\n* Go to the deployments page: http://127.0.0.1:8080/deployments\n* Click `Create` button and follow the instructions on the UI\n\n\n\n#### Option 2. Deploy with kubectl & CRD\n\nDefine your Bento deployment in a `my_deployment.yaml` file:\n\n```yaml\napiVersion: resources.yatai.ai/v1alpha1\nkind: BentoRequest\nmetadata:\n name: iris-classifier\n namespace: yatai\nspec:\n bentoTag: iris_classifier:3oevmqfvnkvwvuqj\n---\napiVersion: serving.yatai.ai/v2alpha1\nkind: BentoDeployment\nmetadata:\n name: my-bento-deployment\n namespace: yatai\nspec:\n bento: iris-classifier\n ingress:\n enabled: true\n resources:\n limits:\n cpu: \"500m\"\n memory: \"512m\"\n requests:\n cpu: \"250m\"\n memory: \"128m\"\n autoscaling:\n maxReplicas: 10\n minReplicas: 2\n runners:\n - name: iris_clf\n resources:\n limits:\n cpu: \"1000m\"\n memory: \"1Gi\"\n requests:\n cpu: \"500m\"\n memory: \"512m\"\n autoscaling:\n maxReplicas: 4\n minReplicas: 1\n```\n\nApply the deployment to your minikube cluster:\n```bash\nkubectl apply -f my_deployment.yaml\n```\n\nNow you can see the deployment process from the Yatai Web UI and find the endpoint URL for accessing\nthe deployed Bento.\n\n\n\n\n\n\n## Community\n\n- To report a bug or suggest a feature request, use [GitHub Issues](https://github.com/bentoml/yatai/issues/new/choose).\n- For other discussions, use [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/)\n- To receive release announcements and get support, join us on [Slack](https://join.slack.bentoml.org).\n\n## Contributing\n\nThere are many ways to contribute to the project:\n\n- If you have any feedback on the project, share it with the community in [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/).\n- Report issues you're facing and \"Thumbs up\" on issues and feature requests that are relevant to you.\n- Investigate bugs and review other developers' pull requests.\n- Contributing code or documentation to the project by submitting a GitHub pull request. See the [development guide](https://github.com/bentoml/yatai/blob/main/DEVELOPMENT.md).\n\n### Usage Reporting\n\nYatai collects usage data that helps our team to improve the product.\nOnly Yatai's internal API calls are being reported. We strip out as much potentially\nsensitive information as possible, and we will never collect user code, model data, model names, or stack traces.\nHere's the [code](./api-server/services/tracking/) for usage tracking.\nYou can opt-out of usage by configuring the helm chart option `doNotTrack` to\n`true`.\n\n```yaml\ndoNotTrack: false\n```\n\nOr by setting the `YATAI_DONOT_TRACK` env var in yatai deployment.\n```yaml\nspec:\n template:\n spec:\n containers:\n env:\n - name: YATAI_DONOT_TRACK\n value: \"true\"\n```\n\n\n## Licence\n\n[Elastic License 2.0 (ELv2)](https://github.com/bentoml/yatai/blob/main/LICENSE.md)\n",
- "source_links": [],
- "id": 138
- },
- {
- "page_link": "https://github.com/yugabyte/yugabyte-db",
- "title": "yugabyte readme",
- "text": "\n\n---------------------------------------\n\n[](https://opensource.org/licenses/Apache-2.0)\n[](https://docs.yugabyte.com/)\n[](https://forum.yugabyte.com/)\n[](https://communityinviter.com/apps/yugabyte-db/register)\n[](https://github.com/yugabyte/ga-beacon)\n\n# What is YugabyteDB? \n\n**YugabyteDB** is a **high-performance, cloud-native, distributed SQL database** that aims to support **all PostgreSQL features**. It is best suited for **cloud-native OLTP (i.e., real-time, business-critical) applications** that need absolute **data correctness** and require at least one of the following: **scalability, high tolerance to failures, or globally-distributed deployments.**\n\n* [Core Features](#core-features)\n* [Get Started](#get-started)\n* [Build Apps](#build-apps)\n* [What's being worked on?](#whats-being-worked-on)\n* [Architecture](#architecture)\n* [Need Help?](#need-help)\n* [Contribute](#contribute)\n* [License](#license)\n* [Read More](#read-more)\n\n# Core Features\n\n* **Powerful RDBMS capabilities** Yugabyte SQL (*YSQL* for short) reuses the query layer of PostgreSQL (similar to Amazon Aurora PostgreSQL), thereby supporting most of its features (datatypes, queries, expressions, operators and functions, stored procedures, triggers, extensions, etc). Here is a detailed [list of features currently supported by YSQL](https://docs.yugabyte.com/preview/explore/ysql-language-features/postgresql-compatibility/).\n\n* **Distributed transactions** The transaction design is based on the Google Spanner architecture. Strong consistency of writes is achieved by using Raft consensus for replication and cluster-wide distributed ACID transactions using *hybrid logical clocks*. *Snapshot*, *serializable* and *read committed* isolation levels are supported. Reads (queries) have strong consistency by default, but can be tuned dynamically to read from followers and read-replicas.\n\n* **Continuous availability** YugabyteDB is extremely resilient to common outages with native failover and repair. YugabyteDB can be configured to tolerate disk, node, zone, region, and cloud failures automatically. For a typical deployment where a YugabyteDB cluster is deployed in one region across multiple zones on a public cloud, the RPO is 0 (meaning no data is lost on failure) and the RTO is 3 seconds (meaning the data being served by the failed node is available in 3 seconds).\n\n* **Horizontal scalability** Scaling a YugabyteDB cluster to achieve more IOPS or data storage is as simple as adding nodes to the cluster.\n\n* **Geo-distributed, multi-cloud** YugabyteDB can be deployed in public clouds and natively inside Kubernetes. It supports deployments that span three or more fault domains, such as multi-zone, multi-region, and multi-cloud deployments. It also supports xCluster asynchronous replication with unidirectional master-slave and bidirectional multi-master configurations that can be leveraged in two-region deployments. To serve (stale) data with low latencies, read replicas are also a supported feature.\n\n* **Multi API design** The query layer of YugabyteDB is built to be extensible. Currently, YugabyteDB supports two distributed SQL APIs: **[Yugabyte SQL (YSQL)](https://docs.yugabyte.com/preview/api/ysql/)**, a fully relational API that re-uses query layer of PostgreSQL, and **[Yugabyte Cloud QL (YCQL)](https://docs.yugabyte.com/preview/api/ycql/)**, a semi-relational SQL-like API with documents/indexing support with Apache Cassandra QL roots.\n\n* **100% open source** YugabyteDB is fully open-source under the [Apache 2.0 license](https://github.com/yugabyte/yugabyte-db/blob/master/LICENSE.md). The open-source version has powerful enterprise features such as distributed backups, encryption of data-at-rest, in-flight TLS encryption, change data capture, read replicas, and more.\n\nRead more about YugabyteDB in our [FAQ](https://docs.yugabyte.com/preview/faq/general/).\n\n# Get Started\n\n* [Quick Start](https://docs.yugabyte.com/preview/quick-start/)\n* Try running a real-world demo application:\n * [Microservices-oriented e-commerce app](https://github.com/yugabyte/yugastore-java)\n * [Streaming IoT app with Kafka and Spark Streaming](https://docs.yugabyte.com/preview/develop/realworld-apps/iot-spark-kafka-ksql/)\n\nCannot find what you are looking for? Have a question? Please post your questions or comments on our Community [Slack](https://communityinviter.com/apps/yugabyte-db/register) or [Forum](https://forum.yugabyte.com).\n\n# Build Apps\n\nYugabyteDB supports many languages and client drivers, including Java, Go, NodeJS, Python, and more. For a complete list, including examples, see [Drivers and ORMs](https://docs.yugabyte.com/preview/drivers-orms/).\n\n# What's being worked on?\n\n> This section was last updated in **March, 2022**.\n\n## Current roadmap\n\nHere is a list of some of the key features being worked on for the upcoming releases (the YugabyteDB [**v2.13 preview release**](https://docs.yugabyte.com/preview/releases/release-notes/v2.13/) has been released in **March, 2022**, and the [**v2.12 stable release**](https://blog.yugabyte.com/announcing-yugabytedb-2-12/) was released in **Feb 2022**).\n\n| Feature | Status | Release Target | Progress | Comments |\n| ----------------------------------------------- | --------- | -------------- | --------------- | ------------- |\n|[Faster Bulk-Data Loading in YugabyteDB](https://github.com/yugabyte/yugabyte-db/issues/11765)| PROGRESS| v2.15 |[Track](https://github.com/yugabyte/yugabyte-db/issues/11765)| Master issue to track improvements to make it easier and faster to get large amounts of data into YugabyteDB.\n|[Database-level multi-tenancy with tablegroups](https://github.com/yugabyte/yugabyte-db/issues/11665)| PROGRESS| v2.15 |[Track](https://github.com/yugabyte/yugabyte-db/issues/11665)| Master issue to track Database-level multi-tenancy using tablegroups.\n|[Upgrade to PostgreSQL v13](https://github.com/yugabyte/yugabyte-db/issues/9797)| PROGRESS| v2.15 |[Track](https://github.com/yugabyte/yugabyte-db/issues/9797)| For latest features, new PostgreSQL extensions, performance, and community fixes\n|Support for [in-cluster PITR](https://github.com/yugabyte/yugabyte-db/issues/7120) | PROGRESS| v2.15 |[Track](https://github.com/yugabyte/yugabyte-db/issues/7120)|Point in time recovery of YSQL databases, to a fixed point in time, across DDL and DML changes|\n| [Automatic tablet splitting enabled by default](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/docdb-automatic-tablet-splitting.md) | PROGRESS | v2.15 | [Track](https://github.com/yugabyte/yugabyte-db/issues/1004) |Enables changing the number of tablets (which are splits of data) at runtime.|\n| YSQL-table statistics and cost based optimizer(CBO) | PROGRESS | v2.15 | [Track](https://github.com/yugabyte/yugabyte-db/issues/5242) | Improve YSQL query performance |\n| [YSQL-Feature support - ALTER TABLE](https://github.com/yugabyte/yugabyte-db/issues/1124) | PROGRESS | v2.15 | [Track](https://github.com/yugabyte/yugabyte-db/issues/1124) | Support for various `ALTER TABLE` variants |\n| [YSQL-Online schema migration](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/online-schema-migrations.md) | PROGRESS | v2.15 | [Track](https://github.com/yugabyte/yugabyte-db/issues/4192) | Schema migrations(includes DDL operations) to be safely run concurrently with foreground operations |\n| Pessimistic locking Design | PROGRESS | v2.15 | [Track](https://github.com/yugabyte/yugabyte-db/issues/5680) | |\n| Make [`COLOCATED` tables](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/ysql-colocated-tables.md) default for YSQL | PLANNING | | [Track](https://github.com/yugabyte/yugabyte-db/issues/5239) | |\n| Support for transactions in async [xCluster replication](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/multi-region-xcluster-async-replication.md) | PLANNING | | [Track](https://github.com/yugabyte/yugabyte-db/issues/1808) | Apply transactions atomically on consumer cluster. |\n| Support for GiST indexes | PLANNING | | [Track](https://github.com/yugabyte/yugabyte-db/issues/1337) |Suppor for GiST (Generalized Search Tree) based index|\n\n## Recently released features\n\n| Feature | Status | Release Target | Docs / Enhancements | Comments |\n| ----------------------------------------------- | --------- | -------------- | ------------------- | ------------- |\n|[Change Data Capture](https://github.com/yugabyte/yugabyte-db/issues/9019)| \u2705 *DONE*| v2.13 ||Change data capture (CDC) allows multiple downstream apps and services to consume the continuous and never-ending stream(s) of changes to Yugabyte databases|\n|[Support for materalized views](https://github.com/yugabyte/yugabyte-db/issues/10102) | \u2705 *DONE*| v2.13 |[Docs](https://docs.yugabyte.com/preview/explore/ysql-language-features/advanced-features/views/#materialized-views)|A materialized view is a pre-computed data set derived from a query specification and stored for later use|\n|[Geo-partitioning support](https://github.com/yugabyte/yugabyte-db/issues/9980) for the transaction status table | \u2705 *DONE*| v2.13 |[Docs](https://docs.yugabyte.com/preview/explore/multi-region-deployments/row-level-geo-partitioning/)|Instead of central remote transaction execution metatda, it is now optimized for access from different regions. Since the transaction metadata is also geo partitioned, it eliminates the need for round-trip to remote regions to update transaction statuses.|\n| Transparently restart transactions | \u2705 *DONE*| v2.13 | |Decrease the incidence of transaction restart errors seen in various scenarios |\n| [Row-level geo-partitioning](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/ysql-row-level-partitioning.md) | \u2705 *DONE*| v2.13 |[Docs](https://docs.yugabyte.com/preview/explore/multi-region-deployments/row-level-geo-partitioning/)|Row-level geo-partitioning allows fine-grained control over pinning data in a user table (at a per-row level) to geographic locations, thereby allowing the data residency to be managed at the table-row level.|\n| [YSQL-Support `GIN` indexes](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/ysql-gin-indexes.md) | \u2705 *DONE* | v2.11 | [Docs](https://docs.yugabyte.com/preview/explore/ysql-language-features/gin/) | Support for generalized inverted indexes for container data types like jsonb, tsvector, and array |\n| [YSQL-Collation Support](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/ysql-collation-support.md) | \u2705 *DONE* | v2.11 |[Docs](https://docs.yugabyte.com/preview/explore/ysql-language-features/collations/) |Allows specifying the sort order and character classification behavior of data per-column, or even per-operation according to language and country-specific rules |\n[YSQL-Savepoint Support](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/savepoints.md) | \u2705 *DONE* | v2.11 |[Docs](https://docs.yugabyte.com/preview/explore/ysql-language-features/savepoints/) | Useful for implementing complex error recovery in multi-statement transaction|\n| [xCluster replication management through Platform](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/platform-xcluster-replication-management.md) | \u2705 *DONE* | v2.11 | [Docs](https://docs.yugabyte.com/preview/yugabyte-platform/create-deployments/async-replication-platform/) | \n| [Spring Data YugabyteDB module](https://github.com/yugabyte/yugabyte-db/blob/master/architecture/design/spring-data-yugabytedb.md) | \u2705 *DONE* | v2.9 | [Track](https://github.com/yugabyte/yugabyte-db/issues/7956) | Bridges the gap for learning the distributed SQL concepts with familiarity and ease of Spring Data APIs |\n| Support Liquibase, Flyway, ORM schema migrations | \u2705 *DONE* | v2.9 | [Docs](https://blog.yugabyte.com/schema-versioning-in-yugabytedb-using-flyway/) | \n| [Support `ALTER TABLE` add primary key](https://github.com/yugabyte/yugabyte-db/issues/1124) | \u2705 *DONE* | v2.9 | [Track](https://github.com/yugabyte/yugabyte-db/issues/1124) | |\n| [YCQL-LDAP Support](https://github.com/yugabyte/yugabyte-db/issues/4421) | \u2705 *DONE* | v2.8 |[Docs](https://docs.yugabyte.com/preview/secure/authentication/ldap-authentication-ycql/#root) | support LDAP authentication in YCQL API | \n| [Platform Alerting and Notification](https://blog.yugabyte.com/yugabytedb-2-8-alerts-and-notifications/) | \u2705 *DONE* | v2.8 | [Docs](https://docs.yugabyte.com/preview/yugabyte-platform/alerts-monitoring/alert/) | To get notified in real time about database alerts, user defined alert policies notify you when a performance metric rises above or falls below a threshold you set.| \n| [Platform API](https://blog.yugabyte.com/yugabytedb-2-8-api-automated-operations/) | \u2705 *DONE* | v2.8 | [Docs](https://api-docs.yugabyte.com/docs/yugabyte-platform/ZG9jOjIwMDY0MTA4-platform-api-overview) | Securely Deploy YugabyteDB Clusters Using Infrastructure-as-Code| \n\n# Architecture\n\n\n\nReview detailed architecture in our [Docs](https://docs.yugabyte.com/preview/architecture/).\n\n# Need Help?\n\n* You can ask questions, find answers, and help others on our Community [Slack](https://communityinviter.com/apps/yugabyte-db/register), [Forum](https://forum.yugabyte.com), [Stack Overflow](https://stackoverflow.com/questions/tagged/yugabyte-db), as well as Twitter [@Yugabyte](https://twitter.com/yugabyte)\n\n* Please use [GitHub issues](https://github.com/yugabyte/yugabyte-db/issues) to report issues or request new features.\n\n* To Troubleshoot YugabyteDB, cluser/node level isssues, Please refer to [Troubleshooting documentation](https://docs.yugabyte.com/preview/troubleshoot/)\n\n# Contribute\n\nAs an an open-source project with a strong focus on the user community, we welcome contributions as GitHub pull requests. See our [Contributor Guides](https://docs.yugabyte.com/preview/contribute/) to get going. Discussions and RFCs for features happen on the design discussions section of our [Forum](https://forum.yugabyte.com).\n\n# License\n\nSource code in this repository is variously licensed under the Apache License 2.0 and the Polyform Free Trial License 1.0.0. A copy of each license can be found in the [licenses](licenses) directory.\n\nThe build produces two sets of binaries:\n\n* The entire database with all its features (including the enterprise ones) are licensed under the Apache License 2.0\n* The binaries that contain `-managed` in the artifact and help run a managed service are licensed under the Polyform Free Trial License 1.0.0.\n\n> By default, the build options generate only the Apache License 2.0 binaries.\n\n# Read More\n\n* To see our updates, go to [The Distributed SQL Blog](https://blog.yugabyte.com/).\n* For an in-depth design and the YugabyteDB architecture, see our [design specs](https://github.com/yugabyte/yugabyte-db/tree/master/architecture/design).\n* Tech Talks and [Videos](https://www.youtube.com/c/YugaByte).\n* See how YugabyteDB [compares with other databases](https://docs.yugabyte.com/preview/faq/comparisons/).\n",
- "source_links": [],
- "id": 139
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks",
- "title": " Getting Started With Runbooks",
- "text": "# Getting Started With Runbooks\n\nWhat are Plural runbooks? How do I use and create them?\n\n## Articles in this section:\n\nXML Runbooks YAML Runbooks\n\n[XML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\n[YAML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\nPlural Runbooks are meant to be installed alongside your open source applications and serve as interactive tutorials for how to perform common maintenance tasks.\n\nPlural comes with a library of runbooks for each application; you are also free to create your own.\n\nYou can create a runbook just for your own use in your Plural installation, or you can choose to publish the runbook and make it available for other Plural users.\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\nYou can access the runbooks through the Plural admin console; i.e. you must first install the Plural admin console in order to use the runbooks.\n\n[install the Plural admin console](/getting-started/admin-console)\n\n#### \n\n[](/adding-new-application/getting-started-with-runbooks#_)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/getting-started-with-runbooks/index.md)",
- "source_links": [],
- "id": 140
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks/runbook-xml",
- "title": " XML Runbooks",
- "text": "# XML Runbooks\n\nCreating a Plural runbook from XML.\n\n#### XML Tag Definitions\n\n[](/adding-new-application/getting-started-with-runbooks/runbook-xml#xml-tag-definitions)\n\nPlural runbooks are written in XML. XML doesn\u2019t have a predefined markup language, like HTML does. Instead, XML allows users to create their own markup symbols to describe content, making an unlimited and self-defining symbol set.\n\nWe have defined the following xml attributes in an Elixir file that may be used in the creation of your own runbooks and help standardize their layout.\n\n```\ndefmodule Console.Runbooks.Display do\n use Console.Runbooks.Display.Base\n alias Console.Runbooks.Display.{Xml}\n\n schema do\n component \"box\" do\n attributes ~w(direction width height pad margin align justify gap fill color border borderSide borderSize)\n parents ~w(root box)\n end\n\n component \"text\" do\n attributes ~w(size weight value color)\n parents ~w(box text root link)\n end\n\n component \"markdown\" do\n attributes ~w(size weight value)\n parents ~w(box text root)\n end\n\n component \"button\" do\n attributes ~w(primary label href target action headline)\n parents ~w(box)\n end\n\n component \"input\" do\n attributes ~w(placeholder name label datatype)\n parents ~w(box)\n end\n\n component \"timeseries\" do\n attributes ~w(label datasource)\n parents ~w(box)\n end\n\n component \"valueFrom\" do\n attributes ~w(datasource path doc)\n parents ~w(input text)\n end\n\n component \"image\" do\n attributes ~w(width height url)\n parents ~w(box link)\n end\n\n component \"video\" do\n attributes ~w(width height url autoPlay loop)\n parents ~w(box link)\n end\n\n component \"link\" do\n attributes ~w(href target value color weight)\n parents ~w(text box)\n end\n\n component \"table\" do\n attributes ~w(name width height datasource path)\n parents ~w(box)\n end\n\n component \"tableColumn\" do\n attributes ~w(path header width)\n parents ~w(table)\n end\n end\n\n def parse_doc(xml) do\n with {:ok, parsed} <- Xml.from_xml(xml) do\n case validate(parsed) do\n :pass -> {:ok, parsed}\n {:fail, error} -> {:error, error}\n end\n end\n end\nend\n```\n\nMost of these attributes, like box and input are basically grommet React components. However, we would like to call out a few custom attributes that interact with other data from the runbook. They each refer to a datasource and then maybe also a way to access a value at that datasource.\n\ntimeseriesdatasourcevalueFromdatasourcedocpath\n\ndatasource\n\ndatasourcedocpath\n\nHere is an example Runbook XML template composed of these attributes.\n\n```\n\n \n \n \n \n \n You should set a reservation to\n roughly correspond to 30% utilization\n \n \n \n You should set a reservation to\n roughly correspond to 60% utilization\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n You can also add more replicas to provide failover in case of outages, or optionally remove them to save cost\n \n \n \n \n \n \n \n \n Be sure to scale your rabbitmq nodes within your nodes capacities, listed here:\n
\n \n \n \n
\n \n\n```\n\nThis XML file is referred to in the runbooks.yaml file, where you will also pass along the datasources that will hydrate this template.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/getting-started-with-runbooks/runbook-xml.md)",
- "source_links": [],
- "id": 141
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks/runbook-yaml",
- "title": " YAML Runbooks",
- "text": "# YAML Runbooks\n\nCreating a Plural runbook from YAML.\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: Runbook\nmetadata:\n name: scaling-manual\n labels:\n platform.plural.sh/pinned: 'true'\n{{ include \"ghost.labels\" . | indent 4 }}\nspec:\n name: Ghost Scaling\n description: overview of how to accurately scale ghost deployment\n display: |-\n{{ .Files.Get \"runbooks/scaling.xml\" | indent 4 }}\n datasources:\n - name: cpu\n type: prometheus\n prometheus:\n format: cpu\n legend: $pod\n query: sum(rate(container_cpu_usage_seconds_total{namespace=\"{{ .Release.Namespace }}\",pod=~\"ghost-[0-9]+\"}[5m])) by (pod)\n - name: memory\n type: prometheus\n prometheus:\n format: memory\n legend: $pod\n query: sum(container_memory_working_set_bytes{namespace=\"{{ .Release.Namespace }}\",pod=~\"ghost-[0-9]+\"}) by (pod)\n - name: statefulset\n type: kubernetes\n kubernetes:\n resource: statefulset\n name: ghost\n - name: nodes\n type: nodes\n actions:\n - name: scale\n action: config\n redirectTo: '/'\n configuration:\n updates:\n - path:\n - ghost\n - resources\n - requests\n - cpu\n valueFrom: cpu\n - path:\n - ghost\n - resources\n - requests\n - memory\n valueFrom: memory\n```\n\nEach datasource has a type. At the moment, the only types Plural supports are prometheus, kubernetes, and nodes. Each type has a spec that's specific to the type.\n\nprometheus spec:\n\n```\nprometheus:\n format:\n legend:\n query:\n```\n\nkubernetes spec:\n\n```\nkubernetes:\n resource: # the kind of Kubernetes resource, i.e. statefulset\n name: # the name of the Kubernetes resource, i.e. ghost\n```\n\nnodes spec:\n\n```\n# No spec needed, this just fetches all the nodes in the Kubernetes cluster.\n```\n\nAdditionally, in runbooks.yaml, you can define a specific action that the runbook can take based off of context from what the user input has given it.\n\nFor example, in the file above, we've defined an action that allows the runbook to update the home values file for that installation. It's done by yaml path, which means it will recursively update ghost.resources.request.cpu.\n\n[home values file](https://github.com/pluralsh/plural-artifacts/blob/760ad90c55d42a8f3081d6e5082c8a8e508ef1b4/ghost/helm/ghost/values.yaml)\n\nThis will update the yaml file, save it back, issue a commit, and create a build in the console to actually apply the change.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/getting-started-with-runbooks/runbook-yaml.md)",
- "source_links": [],
- "id": 142
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/guide",
- "title": " Guide",
- "text": "# Guide\n\nThis guide is for anyone who wants to make an open-source application available on the Plural marketplace.\n\nTo add your own application, you'll need the Helm chart for your application and corresponding Terraform.\n\n## 1. Create a new directory in plural-artifacts\n\n[](/adding-new-application/guide#_1-create-a-new-directory-in-plural-artifacts)\n\nClone the plural-artifacts repository\n\n[plural-artifacts](https://github.com/pluralsh/plural-artifacts)\n\n```\ngit clone https://github.com/pluralsh/plural-artifacts.git\n```\n\nFor this getting started guide, let's pretend that we are onboarding Hasura. We have a useful make target to scaffold some of the necessary stubs for integrating with Plural.\n\n```\nplural create\n```\n\nThe repository structure after running the make command should look something like this:\n\n```\nhasura/\n Pluralfile\n helm\n plural\n repository.yaml\n terraform\n```\n\nIn the steps below we will go through and fill out the stubs.\n\n## 2. Add your Helm chart\n\n[](/adding-new-application/guide#_2-add-your-helm-chart)\n\nThis section assumes familiarity with helm, the Kubernetes package manager. If you have not worked with helm before, it's strongly recommended that you read through the helm docs to understand core helm concepts, particularly helm templates and helm template values.\n\n[helm templates](https://helm.sh/docs/chart_template_guide/getting_started/)\n\n### Getting Started with Helm\n\n[](/adding-new-application/guide#getting-started-with-helm)\n\nFrom the root of your newly created hasura directory, navigate to the helm chart.\n\n```\ncd helm/hasura\n```\n\nA helm chart is organized as a collection of files inside of a directory:\n\n```\nhasura/\n Chart.yaml # A YAML file containing information about the chart\n values.yaml # The default configuration values for this chart\n values.schema.json # OPTIONAL: A JSON Schema for imposing a structure on the values.yaml file\n charts/ # A directory containing any charts upon which this chart depends.\n templates/ # A directory of templates that, when combined with values,\n # will generate valid Kubernetes manifest files.\n```\n\nThe Chart.yaml file contains a description of the chart. You can access it from within a template.\n\nThe templates directory is for template files. When Helm evaluates a chart, it will send all of the files in the templates directory through the template rendering engine. It then collects the results of those templates and sends them on to Kubernetes.\n\nThe values.yaml file is also important to templates. This file contains the default values for a chart. These values may be overridden by users during helm install or helm upgrade.\n\nYou should also see a deps.yaml file. This is a Plural file used to track dependencies and sequence order of installations and upgrades.\n\n### Fill out Chart.yaml\n\n[](/adding-new-application/guide#fill-out-chart-yaml)\n\nOpen up the Chart.yaml file.\n\nChart.yaml is a yaml file containing information about the chart. You can refer to the helm documentation for a comprehensive list of fields in the chart.\n\n[a comprehensive list of fields](https://helm.sh/docs/topics/charts/#the-chartyaml-file)\n\nThe yaml is largely self-documenting. The field to pay attention to is the field at the end, dependencies. If your open source project has an existing helm chart (for example on ArtifactHub), this is where you'll want to link it.\n\n```\ndependencies:\n - name: hasura\n version: 1.1.6\n repository: https://charts.platy.plus\n```\n\n### Fill out the templates directory\n\n[](/adding-new-application/guide#fill-out-the-templates-directory)\n\nNext, let's fill out the templates directory. Recall that the templates directory is for template files. When Helm evaluates a chart, it will send all of the files in the templates directory through the template rendering engine. It then collects the results of those templates and sends them on to Kubernetes.\n\nThe Plural platform includes a number of custom resources that you might find useful to fully productionize your application and can copy and paste over for your own use:\n\ndashboard.yaml -- creates dashboards in the console that reference Prometheus metricsrunbook.yaml -- creates interactive tutorials in the console that show how to perform common maintenance tasks. For more documentation on runbooks refer here.proxies.yaml -- wrappers around kubectl port-forward and kubectl proxy which allow you to get shells into running pods, databases or access private web uisconfigurationOverlay.yaml -- creates form fields to modify helm configuration within the console\n\n[dashboard.yaml](/adding-new-application/plural-custom-resources#dashboards.yaml)\n\n[runbook.yaml](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\n[here](/adding-new-application/getting-started-with-runbooks)\n\n[proxies.yaml](/adding-new-application/plural-custom-resources#proxies-yaml)\n\n[configurationOverlay.yaml](/adding-new-application/plural-custom-resources#configurationoverlay-yaml)\n\n.png)\n\nlogfilter.yaml\n\n### Fill out deps.yaml\n\n[](/adding-new-application/guide#fill-out-deps-yaml)\n\nThe deps.yaml file is a Plural file that is used for determining the sequence of installations and updates. It should look something like this:\n\n```\napiVersion: plural.sh/v1alpha1\nkind: Dependencies\nmetadata:\n application: true\n description: Deploys hasura crafted for the target cloud\nspec:\n dependencies:\n - type: helm\n name: bootstrap\n repo: bootstrap\n version: '>= 0.5.1'\n - type: helm\n name: ingress-nginx\n repo: ingress-nginx\n version: '>= 0.1.2'\n - type: helm\n name: postgres\n repo: postgres\n version: '>= 0.1.6'\n - type: terraform\n name: aws\n repo: hasura\n version: '>= 0.1.0'\n optional: true\n - type: terraform\n name: azure\n repo: hasura\n version: '>= 0.1.0'\n optional: true\n - type: terraform\n name: gcp\n repo: hasura\n version: '>= 0.1.0'\n optional: true\n```\n\n## 3. Add your cloud config\n\n[](/adding-new-application/guide#_3-add-your-cloud-config)\n\nFrom the root of the hasura/ directory (not the one on helm/ directory but its parent directory), navigate to the terraform/ directory. Terraform is a tool for creating, updating, and destroying cloud infrastructure via configuration rather than a graphical user interface. If you are not familiar with it, we suggest reading through the Terraform docs. The files that are located inside this directory are responsible for creating various cloud objects -- i.e. Kubernetes namespaces, AWS IAM roles, and service accounts.\n\n[Terraform docs](https://www.terraform.io/language)\n\n```\ncd terraform\n```\n\nYou should see three folders:\n\n```\nterraform\n aws\n azure\n gcp\n```\n\nThey each have the same structure:\n\n```\nterraform/aws\n deps.yaml\n main.tf\n terraform.tfvars\n variables.tf\n```\n\nmain.tf will contain the main set of configuration for your Terraform module. You can also create other configuration files and organize them however it makes sense for your project. It will look something like this:\n\n[main.tf](https://learn.hashicorp.com/tutorials/terraform/module-create?in=terraform/modules#main-tf)\n\n```\nresource \"kubernetes_namespace\" \"hasura\" {\n metadata {\n name = var.namespace\n labels = {\n \"app.kubernetes.io/managed-by\" = \"plural\"\n \"app.plural.sh/name\" = \"hasura\"\n }\n }\n}\n\ndata \"aws_iam_role\" \"postgres\" {\n name = \"${var.cluster_name}-postgres\"\n}\n\nresource \"kubernetes_service_account\" \"postgres\" {\n metadata {\n name = \"postgres-pod\"\n namespace = var.namespace\n\n annotations = {\n \"eks.amazonaws.com/role-arn\" = data.aws_iam_role.postgres.arn\n }\n }\n\n depends_on = [\n kubernetes_namespace.superset\n ]\n}\n```\n\nvariables.tf will contain the variable definitions for your terraform module (the variables are used in main.tf\n\n[variables.tf](https://learn.hashicorp.com/tutorials/terraform/module-create?in=terraform/modules#variables-tf)\n\n## 4. Add your Plural config\n\n[](/adding-new-application/guide#_4-add-your-plural-config)\n\nFinally, let's look at how to set up the config that will go to Plural.\n\nFrom the root of hasura/, navigate to plural/recipes.\n\n```\nplural/recipes\n hasura-aws.yaml\n hasura-azure.yaml\n hasura-gcp.yaml\n```\n\nHere, you will specify the other Plural packages that must be installed alongside this package, as well as configuration and documentation for parameters that you will be asking users to input.\n\n```\nname: hasura-aws\ndescription: Installs hasura on an EKS cluster\nprovider: AWS\ndependencies: # Other Plural packages that must be installed alongside this bundle\n - repo: bootstrap\n name: aws-k8s\n - repo: ingress-nginx\n name: ingress-nginx-aws\n - repo: postgres\n name: aws-postgres\nsections:\n - name: hasura\n items:\n - type: TERRAFORM\n name: aws\n - type: HELM\n name: hasura\n configuration: # Users will be asked to input values for these parameters\n - name: hostname\n documentation: Fully Qualified Domain Name to use for your hasura installation, eg hasura.topleveldomain.com if topleveldomain.com is the domain you inputed for dns_domain above.\n type: DOMAIN\n```\n\n## 5. Testing Locally\n\n[](/adding-new-application/guide#_5-testing-locally)\n\nYou can validate your changes locally using the plural link command. You'll need to have your packages pushed to plural first, then installed in an installation repo. Once done, you can link your local version of a helm or terraform package using:\n\n```\nplural link helm --path ../path/to/helm --name \n```\n\n## 6. Push your local changes and open a PR\n\n[](/adding-new-application/guide#_6-push-your-local-changes-and-open-a-pr)\n\nAssuming that you have been working on a branch add-hasura you should now commit your changes and open up a PR on Github against the pluralsh/plural-artifacts repository.\n\n[pluralsh/plural-artifacts](https://github.com/pluralsh/plural-artifacts/)\n\n```\ngit add .\ngit commit -m \"Integrate hasura changes\"\ngit push\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/guide.md)",
- "source_links": [],
- "id": 143
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application",
- "title": " Add an Application",
- "text": "# Add an Application\n\nIs something missing from the Plural marketplace? Are you a vendor who wants to add your solution? We'd love for you to onboard your application! This guide outlines the process.\n\n## Articles in this section:\n\nGuidePlural Custom ResourcesModule Library\n\n[Guide](/adding-new-application/guide)\n\n[Plural Custom Resources](/adding-new-application/plural-custom-resources)\n\n[Module Library](/adding-new-application/module-library)\n\nThe two main functionalities that make Plural work are dependency tracking between DevOps tools (Helm and Terraform) and templating.\n\nWhen a user sets up a new Plural workspace in a git repository a workspace.yaml file is created that stores global values for that cluster such as the cloud account and region, the cluster and VPC name and what subdomain all the applications will be hosted under. Next, the user can install an application using the plural bundle CLI command. The CLI will then prompt the user for for inputs needed to setup that application, along with any dependencies of the application. These inputs are saved in the context.yaml file.\n\nNext, the user runs plural build which will create a wrapper Helm chart and Terraform module. The wrapper Helm chart and Terraform module depend on the application Helm chart(s) and Terraform module(s) it gets from the Plural API, which the CLI downloads. The CLI will then generate the values.yaml for the wrapper helm chart and main.tf for the wrapper Terraform module using the values saved in the context.yaml using its templating engine.\n\n## Plural application artifacts\n\n[](/adding-new-application#plural-application-artifacts)\n\nAs mentioned above, the Plural CLI creates a wrapper Helm chart and Terraform module for each installed application and inputs the user defined values for that installation. Some extra files are necessary in Helm charts and Terraform modules for Plural to be able to understand their dependencies and run them through its templating engine. Namely, a deps.yaml file which lists the dependencies of the Helm chart or Terraform module, and the values.yaml.tpl and terraform.tfvars file for Helm and Terraform respectively.\n\nThe values.yaml.tpl and terraform.tfvars files are run through the Plural templating engine, which is similar to that of Helm, and are used to generate the values.yaml for the wrapper helm chart and main.tf for the wrapper Terraform module.\n\nThe next example is a snippet of the values.yaml.tpl file for Grafana:\n\n```\ngrafana:\n admin:\n password:\n { { dedupe . \"grafana.grafana.admin.password\" (randAlphaNum 14) } }\n user: admin\n ingress:\n tls:\n - hosts:\n - { { .Values.hostname } }\n secretName: grafana-tls\n hosts:\n - { { .Values.hostname } }\n```\n\nIn the above example, the hostname a for Grafana that is saved in the context.yaml will be set in the ingress for Grafana by {{ .Values.hostname }}. It also showcases dedupe, which is one of the templating functions available in the Plural CLI.\n\nWe are using the dedupe function so that a new random password for the Grafana admin is not generated if it has already been set. The reason grafana.grafana.admin.password is specified for the path, is because the CLI will create a wrapper Helm chart named grafana in a user's installation workspace. Please see this section of the Helm docs for an explanation on how to pass values to a subchart.\n\n[this section](https://helm.sh/docs/chart_template_guide/subcharts_and_globals/#overriding-values-from-a-parent-chart)\n\nThe next snippet shows a part of the terraform.tfvars for the AWS bootstrap terraform module:\n\n```\nvpc_name = {{ .Values.vpc_name | quote }}\ncluster_name = {{ .Cluster | quote }}\n```\n\nExcept for the user's application inputs from the context.yaml and the aforementioned dedupe function, Plural includes a lot of other values and functions that make it possible to simplify otherwise complex application configurations.\n\n### Templating reference\n\n[](/adding-new-application#templating-reference)\n\nAlong with the standard functions available in the Go templating language, the following Plural specific functions can be used.\n\n##### Functions:\n\n[](/adding-new-application#functions)\n\n##### Template values:\n\n[](/adding-new-application#template-values)\n\n##### .Config values:\n\n[](/adding-new-application#config-values)\n\n##### .OIDC values:\n\n[](/adding-new-application#oidc-values)\n\n##### .OIDC.Bindings values:\n\n[](/adding-new-application#oidc-bindings-values)\n\n##### .SMTP values:\n\n[](/adding-new-application#smtp-values)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/index.md)",
- "source_links": [],
- "id": 144
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/module-library",
- "title": " Module Library",
- "text": "# Module Library\n\nWe have a number of helper Terraform modules and Helm charts to encapsulate some of the common tasks in applications available at pluralsh/module-library. Some of the more common use cases here are:\n\n[pluralsh/module-library](https://github.com/pluralsh/module-library)\n\nCreating object storage buckets and generating credentials for them. This covers S3, GCS, and Minio for cases where applications don't support Azure Blob Store. Creating a Postgres database with all the supporting Plural artifactsRunbook for scalingDashboardsPrometheus rules\n\nRunbook for scalingDashboardsPrometheus rules\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/module-library.md)",
- "source_links": [],
- "id": 145
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/plural-custom-resources",
- "title": " Plural Custom Resources",
- "text": "# Plural Custom Resources\n\n## dashboards.yaml\n\n[](/adding-new-application/plural-custom-resources#dashboards-yaml)\n\nDashboards are the source of truth for the Dashboards section in plural. They're very similar in structure to grafana dashboards, and you can actually scaffold them from existing grafana dashboards using the plural from-grafana command.\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: Dashboard\nmetadata:\n name: dashboard-name\nspec:\n name: postgres # name of the dashboard in the console UI\n description: Monitoring for hasura's postgres db # short description\n timeslices: [30m, 1h, 2h, 1d] # durations options to allow display for\n defaultTime: 30m\n labels: # global values to slice the dashboard further\n - name: instance\n query:\n query: pg_stat_database_tup_fetched{namespace=\"{{ .Release.Namespace }}\"}\n label: instance\n graphs:\n - queries: # list of grouped prometheus queries per graph\n - query: SUM(pg_stat_database_tup_fetched{instance=~\"$instance\"})\n legend: tuples fetched\n - query: SUM(pg_stat_database_tup_inserted{instance=~\"$instance\"})\n legend: tuples inserted\n - query: SUM(pg_stat_database_tup_updated{instance=~\"$instance\"})\n legend: tuples updated\n name: Storage Performance\n - queries:\n - query: pg_settings_max_connections{instance=\"$instance\"}\n legend: connections\n name: Max Connections\n - queries:\n - query: avg(rate(process_cpu_seconds_total{instance=\"$instance\"}[5m]) * 1000)\n legend: seconds\n name: CPU time\n - queries:\n - query: avg(rate(process_resident_memory_bytes{instance=\"$instance\"}[5m]))\n legend: resident mem\n - query: avg(rate(process_virtual_memory_bytes{instance=\"$instance\"}[5m]))\n legend: process mem\n format: bytes\n name: Memory utilization\n - queries:\n - query: process_open_fds{instance=\"$instance\"}\n legend: fds\n name: Open file descriptors\n - queries:\n - query: pg_settings_max_wal_size_bytes{instance=\"$instance\"}\n legend: WAL size\n name: Max WAL size\n - queries:\n - query: irate(pg_stat_database_xact_commit{instance=\"$instance\"}[5m])\n legend: commits\n - query: irate(pg_stat_database_xact_rollback{instance=\"$instance\"}[5m])\n legend: rollbacks\n name: Transactions\n - queries:\n - query: pg_stat_database_blks_hit{instance=\"$instance\"} / (pg_stat_database_blks_read{instance=\"$instance\"} + pg_stat_database_blks_hit{instance=\"$instance\"})\n legend: hit rate\n name: Cache hit rate\n```\n\n## runbook.yaml\n\n[](/adding-new-application/plural-custom-resources#runbook-yaml)\n\nRunbooks are dynamically generated web interfaces to provide guided experiences for operational interactions within Plural. A common one that's needed is managing the database for an application, shown here, but they're meant to be adaptable to a wide array of operational use-cases. The api is also naturally extensible if other datasources are needed.\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: Runbook\nmetadata:\n name: db-scaling\n labels:\n platform.plural.sh/pinned: 'true' # whether this runbook should be on the homepage\nspec:\n name: Postgres Scaling\n description: overview of how to accurately scale hasura's postgres instance\n alerts: # Alertmanager alerts to bind to this runbook\n - name: HasuraPostgresCPU\n - name: HasuraPostgresMEM\n display: |- # xml template for the layout of the runbook\n{{ .Files.Get \"runbooks/db-scaling.xml\" | indent 4 }}\n datasources: # list of datasources to hydrate the runbook\n - name: cpu\n type: prometheus # prometheus query datasource\n prometheus:\n format: cpu\n legend: $pod\n query: sum(rate(container_cpu_usage_seconds_total{namespace=\"{{ .Release.Namespace }}\",pod=~\"plural-hasura-[0-9]+\"}[5m])) by (pod)\n - name: memory\n type: prometheus\n prometheus:\n format: memory\n legend: $pod\n query: sum(container_memory_working_set_bytes{namespace=\"{{ .Release.Namespace }}\",pod=~\"plural-hasura-[0-9]+\"}) by (pod)\n - name: statefulset\n type: kubernetes # kubernetes api call\n kubernetes:\n resource: statefulset\n name: plural-hasura\n - name: volume\n type: prometheus\n prometheus:\n format: none\n legend: $persistentvolumeclaim\n query: (kubelet_volume_stats_capacity_bytes{namespace=\"{{ .Release.Namespace }}\", persistentvolumeclaim=~\"pgdata-plural-hasura-.*\"} - kubelet_volume_stats_available_bytes{namespace=\"{{ .Release.Namespace }}\", persistentvolumeclaim=~\"pgdata-plural-hasura-.*\"}) / kubelet_volume_stats_capacity_bytes{namespace=\"{{ .Release.Namespace }}\", persistentvolumeclaim=~\"pgdata-plural-hasura-.*\"}\n - name: nodes\n type: nodes # nodes api call\n actions: # actions to perform on form submits\n - name: scale\n action: config\n redirectTo: '/'\n configuration:\n updates: # path update into helm values\n - path:\n - hasura\n - postgres\n - resources\n - requests\n - cpu\n valueFrom: cpu\n - path:\n - hasura\n - postgres\n - resources\n - requests\n - memory\n valueFrom: memory\n - path:\n - hasura\n - postgres\n - replicas\n valueFrom: replicas\n - path:\n - hasura\n - postgres\n - storage\n - size\n valueFrom: volume\n```\n\n## proxies.yaml\n\n[](/adding-new-application/plural-custom-resources#proxies-yaml)\n\nThese drive the plural proxy connect command, and can be used to establish local connections to databases or private web interfaces running in your cluster.\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: Proxy\nmetadata:\n name: db\nspec:\n type: db # establishes a db shell\n target: service/hasura-master\n credentials:\n secret: hasura.plural-hasura.credentials.postgresql.acid.zalan.do\n key: password\n user: hasura\n dbConfig:\n name: hasura\n engine: postgres\n port: 5432\n```\n\n## configurationOverlay.yaml\n\n[](/adding-new-application/plural-custom-resources#configurationoverlay-yaml)\n\nThese drive form fields which can customize applications in the console's Configuration section. At the moment they resolve to a helm values update according to a yaml path.\n\n```\n{{- define \"nocodb.config-overlay\" -}}\napiVersion: platform.plural.sh/v1alpha1\nkind: ConfigurationOverlay\nmetadata:\n name: my-overlay\nspec:\n name: Airflow Registry\n documentation: docker repository to use for airflow (default is dkr.plural.sh/airflow/apache/airflow)\n updates: # a helm path update fo\n - path: ['airflow', 'airflow', 'airflow', 'image', 'repository']\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/plural-custom-resources.md)",
- "source_links": [],
- "id": 146
- },
- {
- "page_link": "https://docs.plural.sh/applications",
- "title": " Catalog Overview",
- "text": "# Catalog Overview\n\nApplications you can install with Plural.\n\nHere is where all the documentation for configuring the installation of your Plural apps live.\n\n## Application Updates\n\n[](/applications#application-updates)\n\nWe use a tool called Renovate to automate creation of PRs to update Application version images to newer versions. Here is an example of one of these PRs.\n\n[Renovate](https://github.com/renovatebot/renovate)\n\n[Here](https://github.com/pluralsh/plural-artifacts/pull/288)\n\nOnce we have tried out the changes and have confirmed that the new version works, we will merge the PR and the change will be available for all Plural installations to pull down when they wish to.\n\n## Our Catalog\n\n[Airbyte](/applications/airbyte)\n\n\n\nAirbyte\n\n[Airflow](/applications/airflow)\n\n\n\nAirflow\n\n[Argo CD](/applications/argo-cd)\n\n\n\nArgo CD\n\n[Argo Workflows](/applications/argo-workflows)\n\n\n\nArgo Workflows\n\n[Chatwoot](/applications/chatwoot)\n\n\n\nChatwoot\n\n[Clickhouse](/applications/clickhouse)\n\n\n\nClickhouse\n\n[Plural Console](/applications/console)\n\n\n\nPlural Console\n\n[Crossplane](/applications/crossplane)\n\n\n\nCrossplane\n\n[Dagster](/applications/dagster)\n\n\n\nDagster\n\n[Dagster Agent](/applications/dagster-agent)\n\n\n\nDagster Agent\n\n[Datadog](/applications/datadog)\n\n\n\nDatadog\n\n[Datahub](/applications/datahub)\n\n\n\nDatahub\n\n[Directus](/applications/directus)\n\n\n\nDirectus\n\n[Elasticsearch](/applications/elasticsearch)\n\n\n\nElasticsearch\n\n[Etcd](/applications/etcd)\n\n\n\nEtcd\n\n[External Secrets](/applications/external-secrets)\n\n\n\nExternal Secrets\n\n[Filecoin](/applications/filecoin)\n\n\n\nFilecoin\n\n[Ghost](/applications/ghost)\n\n\n\nGhost\n\n[Gitlab](/applications/gitlab)\n\n\n\nGitlab\n\n[Goldilocks](/applications/goldilocks)\n\n\n\nGoldilocks\n\n[Grafana](/applications/grafana)\n\n\n\nGrafana\n\n[Grafana Agent](/applications/grafana-agent)\n\n\n\nGrafana Agent\n\n[Grafana Tempo](/applications/grafana-tempo)\n\n\n\nGrafana Tempo\n\n[Growthbook](/applications/growthbook)\n\n\n\nGrowthbook\n\n[Harbor](/applications/harbor)\n\n\n\nHarbor\n\n[Hasura](/applications/hasura)\n\n\n\nHasura\n\n[Hydra](/applications/hydra)\n\n\n\nHydra\n\n[Influx](/applications/influx)\n\n\n\nInflux\n\n[Ingress Nginx](/applications/ingress-nginx)\n\n\n\nIngress Nginx\n\n[Istio](/applications/istio)\n\n\n\nIstio\n\n[Jitsu](/applications/jitsu)\n\n\n\nJitsu\n\n[Jupyterhub](/applications/jupyterhub)\n\n\n\nJupyterhub\n\n[Kafka](/applications/kafka)\n\n\n\nKafka\n\n[Knative](/applications/knative)\n\n\n\nKnative\n\n[Kserve](/applications/kserve)\n\n\n\nKserve\n\n[Kubecost](/applications/kubecost)\n\n\n\nKubecost\n\n[Kubeflow](/applications/kubeflow)\n\n\n\nKubeflow\n\n[Kubescape](/applications/kubescape)\n\n\n\nKubescape\n\n[Kubricks](/applications/kubricks)\n\n\n\nKubricks\n\n[Kyverno](/applications/kyverno)\n\n\n\nKyverno\n\n[Lightdash](/applications/lightdash)\n\n\n\nLightdash\n\n[Loki](/applications/loki)\n\n\n\nLoki\n\n[Mage](/applications/mage)\n\n\n\nMage\n\n[Meilisearch](/applications/meilisearch)\n\n\n\nMeilisearch\n\n[Metabase](/applications/metabase)\n\n\n\nMetabase\n\n[Mimir](/applications/mimir)\n\n\n\nMimir\n\n[Minecraft](/applications/minecraft)\n\n\n\nMinecraft\n\n[Minio](/applications/minio)\n\n\n\nMinio\n\n[MLflow](/applications/mlflow)\n\n\n\nMLflow\n\n[MongoDB](/applications/mongodb)\n\n\n\nMongoDB\n\n[Monitoring](/applications/monitoring)\n\n\n\nMonitoring\n\n[MySQL](/applications/mysql)\n\n\n\nMySQL\n\n[n8n](/applications/n8n)\n\n\n\nn8n\n\n[Nextcloud](/applications/nextcloud)\n\n\n\nNextcloud\n\n[NocoDB](/applications/nocodb)\n\n\n\nNocoDB\n\n[NVIDIA Operator](/applications/nvidia-operator)\n\n\n\nNVIDIA Operator\n\n[OAuth2 Proxy](/applications/oauth2-proxy)\n\n\n\nOAuth2 Proxy\n\n[Plural](/applications/plural)\n\n\n\nPlural\n\n[PostgreSQL](/applications/postgres)\n\n\n\nPostgreSQL\n\n[Posthog](/applications/posthog)\n\n\n\nPosthog\n\n[Prefect](/applications/prefect)\n\n\n\nPrefect\n\n[Prefect Agent](/applications/prefect-agent)\n\n\n\nPrefect Agent\n\n[Prefect Worker](/applications/prefect-worker)\n\n\n\nPrefect Worker\n\n[RabbitMQ](/applications/rabbitmq)\n\n\n\nRabbitMQ\n\n[Ray](/applications/ray)\n\n\n\nRay\n\n[Redis](/applications/redis)\n\n\n\nRedis\n\n[Redpanda](/applications/redpanda)\n\n\n\nRedpanda\n\n[Reloader](/applications/reloader)\n\n\n\nReloader\n\n[Renovate on Prem](/applications/renovate-on-prem)\n\n\n\nRenovate on Prem\n\n[Retool](/applications/retool)\n\n\n\nRetool\n\n[Rook](/applications/rook)\n\n\n\nRook\n\n[Sentry](/applications/sentry)\n\n\n\nSentry\n\n[Sftpgo](/applications/sftpgo)\n\n\n\nSftpgo\n\n[Sonarqube](/applications/sonarqube)\n\n\n\nSonarqube\n\n[Spark](/applications/spark)\n\n\n\nSpark\n\n[Superset](/applications/superset)\n\n\n\nSuperset\n\n[Tempo](/applications/tempo)\n\n\n\nTempo\n\n[Terraria](/applications/terraria)\n\n\n\nTerraria\n\n[Tier](/applications/tier)\n\n\n\nTier\n\n[Touca](/applications/touca)\n\n\n\nTouca\n\n[Trace Shield](/applications/trace-shield)\n\n\n\nTrace Shield\n\n[Trino](/applications/trino)\n\n\n\nTrino\n\n[Trivy](/applications/trivy)\n\n\n\nTrivy\n\n[Typesense](/applications/typesense)\n\n\n\nTypesense\n\n[Unleash](/applications/unleash)\n\n\n\nUnleash\n\n[Valheim](/applications/valheim)\n\n\n\nValheim\n\n[Vault](/applications/vault)\n\n\n\nVault\n\n[Vaultwarden](/applications/vaultwarden)\n\n\n\nVaultwarden\n\n[Wireguard](/applications/wireguard)\n\n\n\nWireguard\n\n[Yatai](/applications/yatai)\n\n\n\nYatai\n\n[Yugabyte](/applications/yugabyte)\n\n\n\nYugabyte\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/index.md)",
- "source_links": [],
- "id": 147
- },
- {
- "page_link": "https://docs.plural.sh/archive/architecture",
- "title": " Architecture",
- "text": "# Architecture\n\nThe Plural architecture has three main components:\n\nPlural API and Catalog site (available at https://app.plural.sh)Plural CLI and Git SCM to maintain the state of a user's applicationsPlural console for management of all plural applications on your infrastructure\n\n[https://app.plural.sh](https://app.plural.sh)\n\nAt a high level, the interactions between all three components look something like this:\n\n\n\n## Plural API\n\n[](/archive/architecture#plural-api)\n\nThe primary responsibility of the Plural API is to store the packages needed for application installation - terraform, helm - and ingesting high-level dependency information about them. This allows us to properly sequence installations. It also serves as a publish-subscribe layer to communicate updates to clusters that have installed those applications, and can leverage the dependency information ingested to delay updates until a cluster has caught up with all the necessary dependencies.\n\nIt also can serve as an identity provider for any Plural application, delegating authentication via OIDC and also maintaining user group info and communicating it down to applications.\n\nFinally it handles billing and licensing, supporting all the common constructs seen in modern SaaS billing\n\n## Plural CLI\n\n[](/archive/architecture#plural-cli)\n\nThe Plural CLI effectively uses the Plural API as a package manager, and works as a higher level build tool on top of the DevOps packages it supports. It will handle things like running installations in dependency order, detecting changes between runs, and templating out a workspace from scratch.\n\nIt also is responsible for managing secret encryption of all application state in plural installation repos and provides a few useful tools for troubleshooting an application our admin console might not be well-suited to solve.\n\nFinally it also provides the toolchain for publishing applications to the plural API.\n\n## Plural Console\n\n[](/archive/architecture#plural-console)\n\nThe Plural Console is the operational hub for all applications managed by Plural. It is deployed in-cluster alongside applications and provides a few key features:\n\nAutomated upgrades - by subscribing to the API's upgrade websocketObservability - leveraging the dashboard and logging Kubernetes CRDs deployed alongside Plural applicationsSupport - in-person support can be handled in our chat interface available directly in the admin console, with a lot of nice features like direct zoom integration\n\nIt's deployed as a highly available, scalable web service, with postgres as its datastore. It also directly integrates with Plural's OIDC for login and user management.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/architecture.md)",
- "source_links": [],
- "id": 148
- },
- {
- "page_link": "https://docs.plural.sh/archive/basics/AdminConsole",
- "title": " Plural Admin Console",
- "text": "# Plural Admin Console\n\nThe plural admin console serves a number of different roles\n\nmanaging automated upgrades delivered from the kubernetes apiserving as a thin grafana to visualize application metrics and logsserving as a built-in k8s dashboard for all plural apps in the cluster, along with providing app-level health checkingbeing the touchpoint at which incidents can be filed with the owner of an application\n\n# Installation\n\n[](/archive/basics/AdminConsole#installation)\n\nThe plural console is installable like any other plural app, to find the available bundles, just run:\n\n```\nplural bundle list console\n```\n\nThen once you've found an eligible bundle to install, do (for the aws bundle as an example):\n\n```\nplural bundle install console console-aws\nplural build --only console\nplural deploy\n```\n\n# Dependencies\n\n[](/archive/basics/AdminConsole#dependencies)\n\nThe console takes over the gitops flow for managing plural apps for you, but that also means it needs your git repo set up appropriately. Currently we require these details (although we'll support other git operating modes in the future):\n\nthe remote url should be ssh not httpsyou have a passphraseless ssh key with access to that repo you can offer to the consolethe ssh key should have write perms to the repo\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/basics/AdminConsole.md)",
- "source_links": [],
- "id": 149
- },
- {
- "page_link": "https://docs.plural.sh/archive/basics/GettingStarted",
- "title": " Getting Started using Plural",
- "text": "# Getting Started using Plural\n\nBefore getting started with plural, you'll need to install a few dependencies:\n\nhelmterraformcloud provider cli (awscli, gcloud, az)\n\nIn addition, we require a few helm plugins to add additional features (like authenticated chartmuseum and diffing):\n\n```\nhelm plugin install https://github.com/chartmuseum/helm-push\nhelm plugin install https://github.com/databus23/helm-diff\n```\n\nFinally, you'll want to install the plural cli. This can actually be found using plural's artifact registry here:\n\n```\ncurl -L https://app.plural.sh/artifacts/plural/plural?platform=${plat}&arch=${arch} > /on/your/path/plural\nchmod +x /on/your/path/plural\n```\n\nCurrent values of (plat, arch) are:\n\nYou can see them listed here: https://app.plural.sh/repositories/b4ea03b9-d51f-4934-b030-ff864b720df6/artifacts along with download links\n\n## DNS\n\n[](/archive/basics/GettingStarted#dns)\n\nPlural uses externaldns for dns management in k8s. Programmatic registration of domains is not a solved problem at the moment, so we assume you've already set one up and have it available. It is best practice to consolidate your plural resources into a single subdomain to ensure we don't trample existing entries, but it should be safe if you don't as well.\n\n[externaldns](https://github.com/kubernetes-sigs/external-dns)\n\nThe dns providers we currently support are:\n\nRoute53Google Cloud DNSAzure DNS\n\nIn all cases externaldns is configured to use pod assigned, temporary credentials.\n\n## Git setup\n\n[](/archive/basics/GettingStarted#git-setup)\n\nThe state of your installation is stored in a fresh git repo. Currently we're limited to a one cluster to one repo mapping, but eventually that will be relaxed. Additionally, the best supported method of authenticating to git using plural is via passphraseless ssh keys. Both GitLab and GitHub support this mode of operation, and you can always choose to use https://gitlab.plural.sh if your organization has no existing git-based SCM.\n\nOnce your repo has been cloned, run:\n\n```\nplural init\n```\n\nto log into plural, set the git attributes to configure encryption, and configure your cloud provider for this installation.\n\n## Installation\n\n[](/archive/basics/GettingStarted#installation)\n\nTo install applications on plural, the preferred method is to use our installation bundles, which provide a wizard-like installation process across an apps entire dependency tree. You can view the available bundles by navigating to the app on https://app.plural.sh or listing them via the cli using:\n\n```\nplural bundle list \n```\n\nIf the app is paid, you should click on the bundle in the interface to ensure you set up all the subscriptions needed to install the application properly.\n\nOnce you've found the bundle you want and are ready to go, run this in the root of your repo:\n\n```\nplural bundle install \n```\n\nYou should be asked a lot of questions about how your app will be configured, which will ultimately spool your configuration to a file called context.yaml at the root of your repo.\n\n## Deployment\n\n[](/archive/basics/GettingStarted#deployment)\n\nWith all bundles installed, simply run:\n\n```\nplural build\nplural deploy\n```\n\nThis will generate all deployment artifacts in the repo, then deploy them in dependency order.\n\nOnce you're finished, commit your changes and push them upstream. This will be needed in case you use our admin console, which also uses git for state management:\n\n```\ngit add . && git commit -m \"Initial plural setup\"\ngit push\n```\n\n## Log In\n\n[](/archive/basics/GettingStarted#log-in)\n\nOnce plural deploy has completed, you should be ready to log in. The login credentials are usually available in the values.yaml for the applciation's helm chart. The key name should be pretty self-descriptive, for instance the initial admin password for the plural console is in a key named: secrets.adminPassword.\n\n## Upgrading and deploying new apps to an existing cluster\n\n[](/archive/basics/GettingStarted#upgrading-and-deploying-new-apps-to-an-existing-cluster)\n\nThe full plural build && plural deploy commands are only necessary if you have a queue of multiple apps to be deployed that you need assistance with sequencing the installations. If there's just a single targeted application to deploy, simply do:\n\n```\nplural build --only ${app}\nplural deploy\ngit add . && git commit -m \"updated ${app}\" # don't forget to commit and push your changes!\ngit push\n```\n\nFor the most part, plural console will do all of this for you if you chose to install it.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/basics/GettingStarted.md)",
- "source_links": [],
- "id": 150
- },
- {
- "page_link": "https://docs.plural.sh/archive/basics/SecretManagement",
- "title": " Secret Management",
- "text": "# Secret Management\n\nPlural reimplements git-crypt in its management of secret data within git. This provides transparent file access to users with the repo's AES key, along with full support for tooling like diffing locally, but obfuscation of secret data when pushed to remote, or if the repo is checked out by a user without proper access.\n\n[git-crypt](https://github.com/AGWA/git-crypt)\n\nThe encryption key is automatically generated by plural and stored in plural's config directory ~/.plural. We provide commands for importing/exporting the key, in addition we have a mechanism for sharing the repo with multiple users using the successor to PGP, age.\n\n[age](https://github.com/FiloSottile/age)\n\n## Sharing a repo\n\n[](/archive/basics/SecretManagement#sharing-a-repo)\n\nTo share an encrypted plural repo, there are two steps:\n\nRegister an age public key with pluralShare the repo with a list of emails for plural users with registered keys\n\n### Registering a public key\n\n[](/archive/basics/SecretManagement#registering-a-public-key)\n\nTo register a key for your current machine, run:\n\n```\nplural crypto setup-keys\n```\n\nThis will generate a new age keypair, and automatically register the public key with the plural api. You should be able to see it listed here: https://app.plural.sh/me/edit/keys and the keypair will be stored in ~/.plural/identity\n\n### Share a repo\n\n[](/archive/basics/SecretManagement#share-a-repo)\n\nTo share a repo, simply run:\n\n```\nplural crypto share --email --email \n```\n\nThis will do a few things:\n\ncreate a base age identity to encrypt the repo's current aes key and store it in a gitignored place under ${REPO_ROOT}/.plural-crypt.register all the users who have access in a yaml file under ${REPO_ROOT}/.plural-cryptage encrypt the file using all this information and store it under ${REPO_ROOT}/.plural-crypt\n\nIf you have the plural console deployed, it's also recommended you run:\n\n```\nplural build --only console\nplural deploy\ngit add . && git commit -m \"set up age\"\ngit push\n```\n\nto ensure it now uses age to manage its encryption key.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/basics/SecretManagement.md)",
- "source_links": [],
- "id": 151
- },
- {
- "page_link": "https://docs.plural.sh/archive/basics/WorkspaceLayout",
- "title": " Plural Workspace Layout",
- "text": "# Plural Workspace Layout\n\nPlural ensures the state of all installed applications are stored in a git repository, under a common format. Broadly, a working workspace should look like\n\n```\napp-one/\n-> helm/app-one # helm chart for k8s manifests\n-> terraform/* # terraform modules\n-> terraform/main.tf # main terraform entrypoint\n-> build.hcl # configuration for build commands for that application\n-> deploy.hcl # configuration for deployments\n-> output.yaml # outputs from various tools (terraform, helm, etc) that can be imported into inputs for others\n-> manifest.yaml # metadata about the plural app itself\n\napp-two/\n-> helm/app-two\n-> terraform/*\n-> build.hcl\n-> deploy.hcl\n-> output.yaml\n-> manifest.yaml\n\ncontext.yaml\nworkspace.yaml\n```\n\n## {build | deploy}.hcl\n\n[](/archive/basics/WorkspaceLayout#build-deploy-hcl)\n\nThe build/deploy files manage two things:\n\nthe steps needed to build or apply a specific repository in pluralchange detection between runs\n\nWe'll automatically sha whatever subtree is needed to run any stage in the file, and if there's no detectable change, ignore the command. This is especially useful for avoiding slow, unneeded terraform commands\n\n## context.yaml\n\n[](/archive/basics/WorkspaceLayout#context-yaml)\n\nThis is where the results to all bundle installs are stored. It can also be manually extended if there's some customization that a user wants to apply beyond what the bundle provided.\n\n## workspace.yaml\n\n[](/archive/basics/WorkspaceLayout#workspace-yaml)\n\nStores base cloud provider setup for this repository. It uses a general format modelled after GCP, but the mapping to the resources in other clouds is pretty straightforward.\n\nOn each app installation, you have the option of inheriting this setup, or reconfiguring for the specific app.\n\n## .gitattributes\n\n[](/archive/basics/WorkspaceLayout#gitattributes)\n\nThe git attributes file specifies the filters that drive secret encryption. This file should not be tampered with, unless the user is confident they know what they're doing.\n\nWe'll also add additional .gitattributes as different modules add or create secrets that might be stored in the repo (eg ssh keys).\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/basics/WorkspaceLayout.md)",
- "source_links": [],
- "id": 152
- },
- {
- "page_link": "https://docs.plural.sh/archive/cloud-shell",
- "title": " Cloud Shell",
- "text": "# Cloud Shell\n\nThis page gives an overview of what the Cloud Shell is.\n\n## Quickstart\n\n[](/archive/cloud-shell#quickstart)\n\nFor a guide on how to get up and running with the Cloud Shell, click here.\n\n[here](/getting-started/cloud-shell-quickstart)\n\n## Overview\n\n[](/archive/cloud-shell#overview)\n\nWe provide a fully managed cloud shell environment with plural cli and all dependencies installed for you to get started on. To create a shell, navigate to https://app.plural.sh/shell and fill out the setup wizard. Note that this will ask for cloud credentials which will be stored in our database to facilitate provisioning, but you can purge your shell at any time to remove access. Once done, this will create a GitHub repository, deploy keys for pushing to it, and create a shell environment with all configuration set up for you to get running quickly. Your fully working shell should look something like this:\n\n[https://app.plural.sh/shell](https://app.plural.sh/shell)\n\n###### Warning:\n\nNote that you must to manually push any uncommitted changes as your shell might not be persisted through restarts\n\n\n\nIf you'd like to sync your shell locally once you've gotten up and running, all you'll need to do is follow the instructions to install the plural cli and run these commands:\n\n```\nplural shell sync\nplural shell purge # if you want to remove the shell from our servers\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/cloud-shell.md)",
- "source_links": [],
- "id": 153
- },
- {
- "page_link": "https://docs.plural.sh/archive/introduction",
- "title": " Introduction",
- "text": "# Introduction\n\nPlural comes pre-built with a lot of the core concepts needed for IAM at any organizational scale. These include:\n\nUsers and Groups - maintain a full directory to manage identity within PluralRoles - which can be bound to any set of users or groups of users to allocate permissionsService Accounts - dedicated identities with a fixed policy as far as what other entities can impersonate them and act on their behalf.\n\n### Account Basics\n\n[](/archive/introduction#account-basics)\n\nWhen you sign up to plural, you'll immediately be allocated an account. You can then invite users by using the form at https://app.plural.sh/accounts/edit/users. Users who sign up organically will get their own accounts, and will have to be linked afterwards, so we recommend onboarding additional users via invite.\n\n[https://app.plural.sh/accounts/edit/users](https://app.plural.sh/accounts/edit/users)\n\n###### Info:\n\nThe only users eligible for sharing repo encryption keys are also those users in your account .\n\n### RBAC Basics\n\n[](/archive/introduction#rbac-basics)\n\nEach Plural role is configurable using the role creation form at https://app.plural.sh/accounts/edit/roles:\n\n[https://app.plural.sh/accounts/edit/roles](https://app.plural.sh/accounts/edit/roles)\n\n\n\nThe permissions are fairly self explanatory, but you do have the ability to map a role to whatever identity grouping you'd want to use, and filter the roles application to a list of repositories (or a regex on repository name). The latter mode is helpful if you'd like a certain role to only be able to install, say, airflow and sentry.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/introduction.md)",
- "source_links": [],
- "id": 154
- },
- {
- "page_link": "https://docs.plural.sh/archive/secret-management",
- "title": " Secret Management",
- "text": "# Secret Management\n\nPlural reimplements git-crypt in its management of secret data within git. This provides transparent file access to users with the repo's AES key, along with full support for tooling like diffs locally, while still providing full obfuscation of secret data when pushed to remote.\n\n[git-crypt](https://github.com/AGWA/git-crypt)\n\nThe encryption key is automatically generated by plural and stored in plural's config directory ~/.plural. We provide commands for importing/exporting the key, in addition we have a mechanism for sharing the repo with multiple users using the successor to PGP, age.\n\n[age](https://github.com/FiloSottile/age)\n\n## Sharing a repo\n\n[](/archive/secret-management#sharing-a-repo)\n\nTo share an encrypted plural repo, there are two steps:\n\nRegister an age public key with pluralShare the repo with a list of emails for plural users with registered keys\n\n### Registering a public key\n\n[](/archive/secret-management#registering-a-public-key)\n\nTo register a key for your current machine, run:\n\n```\nplural crypto setup-keys --name \n```\n\nThis will generate a new age keypair, and automatically register the public key with the plural api. You should be able to see it listed here and the keypair will be stored in ~/.plural/identity\n\n[here](https://app.plural.sh/me/edit/keys)\n\n### Share a repo\n\n[](/archive/secret-management#share-a-repo)\n\nTo share a repo, use the following command:\n\n```\nplural crypto share --email --email \n```\n\nNote: --email refers to a user's email associated with their Plural account\n\nThis will do a few things:\n\ncreate a base age identity to encrypt the repo's current aes key and store it in a gitignored place under ${REPO_ROOT}/.plural-crypt.register all the users who have access in a yaml file under ${REPO_ROOT}/.plural-cryptage encrypt the file using all this information and store it under ${REPO_ROOT}/.plural-crypt\n\nIf you have the plural console deployed, it's also recommended you run:\n\n```\nplural build --only console\nplural deploy\ngit add . && git commit -m \"set up age\"\ngit push\n```\n\nto ensure it now uses age to manage its encryption key.\n\n### Cloning a shared repo\n\n[](/archive/secret-management#cloning-a-shared-repo)\n\nIf you're cloning a repo that's just been shared, you'll need to initialize plural cryptography locally. Fortunately, this is all done via:\n\n```\nplural crypto init\nplural crypto unlock\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/secret-management.md)",
- "source_links": [],
- "id": 155
- },
- {
- "page_link": "https://docs.plural.sh/archive/sharing-existing-repos",
- "title": " Sharing Existing Plural Installation Repos",
- "text": "# Sharing Existing Plural Installation Repos\n\nLet's say that you have an existing Plural installation repo and you would like to share it with other users. A common scenario might be an individual developer playing around with Plural who would then like to expand Plural adoption across their team or company. Below, we show how to do this.\n\nLet's say that Alice is the original user and already has a few applications installed in their own Plural installation repo. Alice would now like to share the repo with Bob and Cory, their teammates on the machine learning infrastructure team.\n\n### 1. Bob and Cory Create Plural Accounts at plural.sh\n\n[plural.sh](https://app.plural.sh)\n\n[](/archive/sharing-existing-repos#_1-bob-and-cory-create-plural-accounts-at-plural-sh)\n\n### 2. Bob and Cory Install Plural CLI\n\n[](/archive/sharing-existing-repos#_2-bob-and-cory-install-plural-cli)\n\nThe Plural CLI and dependencies are available using a package manager for your system. For Mac, we recommend using Homebrew, although our Docker image should be usable on virtually any platform.\n\n```\nbrew install pluralsh/plural/plural\n```\n\nThe brew tap will install plural, alongside terraform, helm and kubectl for you. If you've already installed any of those dependencies, you can add --without-helm, --without-terraform, or --without-kubectl\n\nYou can also download any of our vendored binaries via curl:\n\n```\ncurl -L -o plural.o 'https://app.plural.sh/artifacts/plural/plural?platform={{plat}}&arch={{arch}}'\nchmod +x plural.o\nmv plural.o /usr/local/bin/plural\n```\n\nreplace plat and arch with any of:\n\nAll binaries can also be viewed in the artifacts tab of the plural repo on app.plural.sh. You can also find sha256 checksums for each there to guarantee file integrity\n\n[artifacts tab](https://app.plural.sh/repositories/b4ea03b9-d51f-4934-b030-ff864b720df6/artifacts)\n\nYou will still need to ensure helm, terraform and kubectl are properly installed, you can find installers for each here.\n\n[https://helm.sh/docs/intro/install/](https://helm.sh/docs/intro/install/)\n\n[https://learn.hashicorp.com/tutorials/terraform/install-cli](https://learn.hashicorp.com/tutorials/terraform/install-cli)\n\n[https://kubernetes.io/docs/tasks/tools/#kubectl](https://kubernetes.io/docs/tasks/tools/#kubectl)\n\nOnce these are installed, you'll also need to add the helm push plugin like so:\n\n```\nhelm plugin install https://github.com/pluralsh/helm-push\n```\n\nWe offer a docker image with the plural cli installed along with all cli dependencies: Terraform, Helm, kubectl, and all the major cloud CLIs: gcr.io/pluralsh/plural-cli:0.1.1-cloud. We also provide a decent configuration of zsh in it, so you can drive the entire plural workflow in an interactive session. The best strategy is probably to mount the config dir of the cloud provider you're using, like \\~/.aws, in the docker run command:\n\n```\ndocker run -it --volume $HOME/.aws:/root/aws \\\n --volume $HOME/.plural:/root/.plural \\\n --volume $HOME/.ssh:/root/.ssh \\\n gcr.io/pluralsh/plural-cli:0.1.1-cloud zsh\n```\n\nWe have EC2 AMI's with Plural CLI installed, along with all cloud provider CLIs, Terraform, Helm and kubectl for those interested in creating a remote environment. A registry of the AMIs can be viewed here:\n\n[here](https://github.com/pluralsh/plural-cli/blob/master/packer/manifest.json)\n\nIf there's interest in images for GCP and Azure, please to give us a shout in our discord or feel free to open a GitHub issue.\n\nThis doc gives more details on launching AMIs if you are unfamiliar. You'll want to select \"Public images\" within the AMI search bar and you can use the AMI id embedded in the artifact_id in our manifests, eg ami-0249247d5fc865089. Be sure to choose the one for the appropriate region.\n\n[This doc](https://aws.amazon.com/premiumsupport/knowledge-center/launch-instance-custom-ami/)\n\nThe brew tap will install Plural, alongside Terraform, Helm and kubectl for you. If you've already installed any of those dependencies, you can add --without-helm, --without-terraform, or --without-kubectl\n\n### 3. Alice creates a Plural service account\n\n[Plural service account](/operations/auth-access-control/identity-and-installations/service-accounts)\n\n[](/archive/sharing-existing-repos#_3-alice-creates-a-plural-service-account)\n\nAlice follows the instructions here to create a Plural service account under the ml-infra@plural.sh email.\n\n[here](/operations/auth-access-control/identity-and-installations/service-accounts)\n\n### 4. Alice copies down which bundles they have installed for later reference\n\n[](/archive/sharing-existing-repos#_4-alice-copies-down-which-bundles-they-have-installed-for-later-reference)\n\nAlice can find which bundles they have installed at https://app.plural.sh/explore/installed\n\n[https://app.plural.sh/explore/installed](https://app.plural.sh/explore/installed)\n\n\n\n### 5. Alice changes the owner of the Plural installation repo\n\n[](/archive/sharing-existing-repos#_5-alice-changes-the-owner-of-the-plural-installation-repo)\n\nAlice goes to workspace.yaml in the root of their installation repo, and changes the owner to ml-infra@plural.sh. In the example below, owner is set to nick@plural.sh on line 12.\n\n\n\n### 6. Alice initializes Plural as service account\n\n[](/archive/sharing-existing-repos#_6-alice-initializes-plural-as-service-account)\n\nAlice runs the following command from inside their Plural installation repo:\n\n```\nplural init --service-account ml-infra@plural.sh\n```\n\nThis switches to the ml-infra service account user.\n\n### 7. Alice registers all the bundles as the service account user\n\n[](/archive/sharing-existing-repos#_7-alice-registers-all-the-bundles-as-the-service-account-user)\n\nNow that Alice is using a different user, they need to re-register each installed application with the Plural API under the service account user. For each application, Alice should run:\n\n```\nplural bundle install \n```\n\nTo recall which applications they have installed, Alice should refer to the information they copied in step 4.\n\n###### Info:\n\nService accounts need to be explicitly granted install permissions in your account before you can successfully run the bundle install command. Be sure to create a role here with install permissions and add the service account to it to grant them access.\n\n[here](https://app.plural.sh/account/roles)\n\n### 8. Alice builds and deploys the Plural installation repo under the new user\n\n[](/archive/sharing-existing-repos#_8-alice-builds-and-deploys-the-plural-installation-repo-under-the-new-user)\n\nAlice should run:\n\n```\nplural build\nplural deploy\n```\n\nFinally, Alice can push up these changes up to the installation repo on Github\n\n```\ngit commit -m \"Change owner of repo\"\ngit push\n```\n\n###### Info:\n\nIf a user has oidc configured for an app, occasionally you'll need to manually delete the pods associated with their webservers as our oidc proxy does not respect config changes. This is just a matter of finding the relevant pods in the console and clicking the trash icon. For airbyte as an example, you'd want to delete all the pods in deployment/airbyte-webapp.\n\nIf you'd like help with this process feel free to reach out to us on discord as well!\n\n### 9. Alice, Bob, and Cory set up cryptographic keys for sharing\n\n[](/archive/sharing-existing-repos#_9-alice-bob-and-cory-set-up-cryptographic-keys-for-sharing)\n\nThe next step is sharing the repository's cryptography layer with any users you expect to need to use the repo locally. If you want to learn more about how Plural encrypts your repository's state, we'd definitely recommend you read our docs here\n\n[here](/operations/security/secret-management)\n\nAlice, Bob, and Cory should each run:\n\n```\nplural crypto setup-keys --name \n```\n\nThis causes each user to register a public key with Plural for sharing.\n\n### 10. Alice encrypts encryption key for every user's keypair\n\n[](/archive/sharing-existing-repos#_10-alice-encrypts-encryption-key-for-every-user-s-keypair)\n\nAlice should now run:\n\n```\nplural crypto share --email bob@plural.sh cory@plural.sh\n```\n\nThis will share the encryption key Alice has with Bob and Cory.\n\n### 11. Bob and Cory download Plural installation repo from Github\n\n[](/archive/sharing-existing-repos#_11-bob-and-cory-download-plural-installation-repo-from-github)\n\nBob and Cory should now go to Github and download the Plural installation repos.\n\n```\ngit clone \n```\n\n### 12. Bob and Cory initialize Plural in their own workspaces as service account\n\n[](/archive/sharing-existing-repos#_12-bob-and-cory-initialize-plural-in-their-own-workspaces-as-service-account)\n\nBob and Cory should initialize Plural as the service account\n\n```\nplural init --service-account ml-infra@plural.sh\n```\n\n### 13. Profit!\n\n[](/archive/sharing-existing-repos#_13-profit)\n\nFrom this point on, any of Alice, Bob, or Cory can install, build, and deploy new applications and have it be reflected under the ml-infra@plural.sh service account. They should always remember to push up their changes in Git, and to pull down any new changes that their teammates may have made prior to making new installations.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/archive/sharing-existing-repos.md)",
- "source_links": [],
- "id": 156
- },
- {
- "page_link": "https://docs.plural.sh/debugging/application-issues",
- "title": " Application Issues",
- "text": "# Application Issues\n\nFiguring out what is going wrong with your deployed applications.\n\nIssues with applications are often due to issues with the underlying Pods. You can use kubectl commands to get, find logs for, and delete pods as necessary. Note that Plural automatically configures kubectl for use with your Plural cluster.\n\n## With Plural CLI\n\n[](/debugging/application-issues#with-plural-cli)\n\nTo find Pods related to an application with the CLI, you can run:\n\n```\nkubectl get pods -n \n```\n\nIf you see failed Pods, you can get the logs for the Pods by running:\n\n```\nkubectl logs -n \n```\n\nWe also curate a list of helpful logging shortcuts for each application, which you can use the plural logs subcommand for, eg with\n\n```\nplural logs list # shows all log tails available\nplural logs tail # tails that specific log\n```\n\nTo delete problematic Pods, run:\n\n```\nkubectl delete pod \n```\n\nIn most cases, kubernetes will restart the pod for you. You can always also run plural bounce to regenerate your deleted Pods.\n\n## With Plural Console\n\n[](/debugging/application-issues#with-plural-console)\n\nIf you have the Plural Console installed, you can debug your Kubernetes Pods with the following steps:\n\nNavigate to the Application Overview tab, select the relevant application and click on the Components option in the menu on the left. Click on the failing component.\n\nThe Pods section at the top of the screen should have the failing pod; hit the red trash can button located on the right of the screen to delete it.\n\nHead back to the Builds tab in the sidebar and create a Bounce build to redeploy your deleted Pods.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/debugging/application-issues.md)",
- "source_links": [],
- "id": 157
- },
- {
- "page_link": "https://docs.plural.sh/debugging/health-checks",
- "title": " Health Checks",
- "text": "# Health Checks\n\nEvery application has a general application-level health check, which aggregates the statuses of all core kubernetes components and generates a digestable summary for human consumption. These are viewable in the application switcher in the admin console, or by running:\n\n```\nplural watch \n```\n\nThis will generate output like:\n\n```\nApplication: console (0.5.35) READY\nplural admin console\n\nComponents Ready: 15/15\n\nReady Components:\n- service/console :: Ready\n- service/console-headless :: Ready\n- service/console-master :: Ready\n- service/console-replica :: Ready\n- service/plural-console :: Ready\n- service/plural-console-repl :: Ready\n...\n```\n\nIf a component is not ready, it will also generate hints to kubectl commands which might help debug further.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/debugging/health-checks.md)",
- "source_links": [],
- "id": 158
- },
- {
- "page_link": "https://docs.plural.sh/debugging",
- "title": " Debugging",
- "text": "# Debugging\n\nSome tips to help debug your Plural installation.\n\n## Articles in this section:\n\nHealth ChecksProxiesLogs\n\n[Health Checks](/debugging/health-checks)\n\n[Proxies](/debugging/proxies)\n\n[Logs](/debugging/logs)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/debugging/index.md)",
- "source_links": [],
- "id": 159
- },
- {
- "page_link": "https://docs.plural.sh/debugging/logs",
- "title": " Logs",
- "text": "# Logs\n\nApplication aware log tails can be baked into any Plural application to prevent a user from having to dig through the Kubernetes API to find the specific Pod they should tail. They can be discovered and watched using:\n\n```\nplural logs list \nplural logs tail \n```\n\nNow the relevant logs will be streamed to stdout.\n\nThe specification for these is baked into the LogTail crd, for example:\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: LogTail\nmetadata:\n name: aws-load-balancer\n labels:\nspec:\n limit: 50\n target: deployment/bootstrap-aws-load-balancer-controller\n follow: true\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/debugging/logs.md)",
- "source_links": [],
- "id": 160
- },
- {
- "page_link": "https://docs.plural.sh/debugging/proxies",
- "title": " Proxies",
- "text": "# Proxies\n\nPlural also helps with discovering useful proxy commands for inspecting core resources. This is done via the Proxy crd. A decent example is the proxy to the admin consoles underlying Postgres database:\n\n```\napiVersion: platform.plural.sh/v1alpha1\nkind: Proxy\nmetadata:\n name: db\n labels:\nspec:\n type: db\n target: statefulset/console-postgresql\n credentials:\n secret: console-postgresql\n key: postgresql-password\n user: console\n dbConfig:\n name: console\n engine: postgres\n port: 5432\n```\n\nThe interface is quite powerful, and supports things like fetching db credentials and initiating a sql shell, or spawning a web ui via kubectl port-forward and printing the credentials to stdout to allow a user easily log in.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/debugging/proxies.md)",
- "source_links": [],
- "id": 161
- },
- {
- "page_link": "https://docs.plural.sh/faq/certifications",
- "title": " Certifications",
- "text": "# Certifications\n\nWhat certifications does Plural have?\n\nPlural is currently a part of the Cloud Native Computing Foundation and Cloud Native Landscape, and is certified to be GDPR-compliant.\n\nWe are currently working toward SOC 2 compliance.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/faq/certifications.md)",
- "source_links": [],
- "id": 162
- },
- {
- "page_link": "https://docs.plural.sh/faq/local-development",
- "title": " Local Development",
- "text": "# Local Development\n\nDeveloping locally with Plural\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/faq/local-development.md)",
- "source_links": [],
- "id": 163
- },
- {
- "page_link": "https://docs.plural.sh/faq/plural-paid-tiers",
- "title": " Plural Paid Tiers",
- "text": "# Plural Paid Tiers\n\nWhat is included with Plural's paid offerings?\n\nIn addition to Plural's open-source offering, there are two paid tiers that provide additional features and support over our baseline.\n\nSee below for a comparison of different tiers, and you can find more information on our pricing page.\n\n[on our pricing page](https://www.plural.sh/pricing)\n\n## Plural Open-source\n\n[](/faq/plural-paid-tiers#plural-open-source)\n\nFreeUnlimited applicationsUp to 5 usersOAuth integrationCommunity support (Discord)\n\n## Plural Professional\n\n[](/faq/plural-paid-tiers#plural-professional)\n\n$399/Cluster/Month + $49/User/MonthEverything in open-source, plus:24 hour SLAsAdvanced user management (use of Roles, Groups, and Service Accounts)Multi-cluster managementAudit logsVPN interfacePrioritized emergency hotfixes\n\n## Plural Custom\n\n[](/faq/plural-paid-tiers#plural-custom)\n\nTailored pricingEverything in Plural Professional, plus:4 hour SLAsDedicated SRE supportSSO integrationCommercial licensing options\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/faq/plural-paid-tiers.md)",
- "source_links": [],
- "id": 164
- },
- {
- "page_link": "https://docs.plural.sh/first-party/manage-your-microservices",
- "title": " Manage your own microservices with Plural",
- "text": "# Manage your own microservices with Plural\n\nHow to manage your organization's internal applications with Plural\n\nThe Plural team is currently exploring a solution to allow our customers to deploy their in-house services using Plural.\n\nWe believe that combining the ability to quickly spin up new clusters, author simple Kubernetes manifests, and control the deployment of code changes from development to production would the process of developing on Kubernetes significantly easier.\n\nIf you're interested, you can find more information on our website at https://www.plural.sh/plural-deployments-early-access.\n\n[https://www.plural.sh/plural-deployments-early-access](https://www.plural.sh/plural-deployments-early-access)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/first-party/manage-your-microservices.md)",
- "source_links": [],
- "id": 165
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/admin-console",
- "title": " Installing Plural Console",
- "text": "# Installing Plural Console\n\nSupercharge your day two operations.\n\n## Introduction\n\n[](/getting-started/admin-console#introduction)\n\nThe Plural Admin Console is a web application that serves as a control panel for all your Plural applications. It:\n\nmanages automated upgrades delivered from the Kubernetes apiserves as a thin Grafana to visualize application metrics and logsserves as a built-in K8s dashboard for all plural apps in the cluster, along with providing app-level health checkingis the touchpoint at which incidents can be filed with the owner of an application\n\nPlural Console is installed by default in the Cloud Shell, and we also highly recommend installing it if using the Plural CLI. It can be deployed and managed like any other application on Plural.\n\n###### Info:\n\nThe admin console is separate from app.plural.sh which is primarily a package registry.\n\n[app.plural.sh](https://app.plural.sh)\n\n## Installation\n\n[](/getting-started/admin-console#installation)\n\n#### 1. Check your Git authentication method.\n\n[](/getting-started/admin-console#_1-check-your-git-authentication-method)\n\n```\n# show repo remote with details\ngit remote -v\n```\n\nIf the remote urls start with git@github.com then you're using SSH.\n\nIf the remote urls start with https then you're using HTTPS.\n\n#### 2. Setup for Git authentication\n\n[](/getting-started/admin-console#_2-setup-for-git-authentication)\n\nFollow the instructions here to generate a revokable personal access token (PAT). The access token needs to have write permissions. Keep track of this access token, you will need it later in the console install process. The PAT should have both push and pull permissions to the repository.\n\n[here](https://docs.github.com/en/github/authenticating-to-github/keeping-your-account-and-data-secure/creating-a-personal-access-token)\n\nIf you need to update your PAT you can go to the context.yaml file at the root of your repo and modify the access_token variable within the console block.\n\nFollow the instructions here if you are using GitHub to generate an SSH key and add it to your ssh-agent and GitHub account. The bundle install command below will then ask you to provide an SSH key and a valid path to the key you created.\n\n[here](https://docs.github.com/en/github/authenticating-to-github/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)\n\nIf you need to update your SSH key for any reason (e.g. creating a new scoped deploy key) then update the private_key key in the console block of the context.yaml file at the root of your repo.\n\nIf you modified context.yaml to reconfigure your git auth, be sure to run:\n\n```\nplural build --only console ## wires the creds into the console helm chart from context.yaml\nplural deploy\n```\n\n#### 3. Install and build the Console\n\n[](/getting-started/admin-console#_3-install-and-build-the-console)\n\nThe plural console is installable like any other plural app. To find the available bundles, just run:\n\n```\nplural bundle list console\n```\n\nThen once you've found an eligible bundle to install, do:\n\n```\nplural bundle install console \n```\n\nYou will now be guided through a configuration wizard. If you have any questions about a specific parameter, refer to this document.\n\n[this document](/applications/console)\n\nOnce the bundle has installed, run:\n\n```\nplural build\n```\n\nThe console takes over the gitops flow of managing plural apps for you. You will be asked for the git authentication credentials you created at Step 1.\n\n#### 4. Deploy Console\n\n[](/getting-started/admin-console#_4-deploy-console)\n\nOnce the build has completed, run:\n\n```\nplural deploy --commit \"installed console\"\n```\n\n#### 5. Login to Console\n\n[](/getting-started/admin-console#_5-login-to-console)\n\nOnce the deploy finishes, it will output the url that the console has been deployed to. Navigate to that url and it will show a login screen that looks like this:\n\n\n\nIf you selected (y) to OIDC, one-login has already been configured, and you'll be able to sign in with the same credentials you use for app.plural.sh.\n\nIf you didn't select (y) to OIDC, your login credentials for this console are different from your login credentials for app.plural.sh. You can find them inconsole/helm/console/values.yaml under the console.secrets.admin_username and console.secrets.admin_password keys.\n\n## Console Highlights\n\n[](/getting-started/admin-console#console-highlights)\n\nThe Console is the command center for your Plural applications, and it comes with built-in goodies. Some highlights include:\n\n#### Application Overview\n\n[](/getting-started/admin-console#application-overview)\n\nThe first place you'll land in the Plural Console is the Application Overview. Here you can see all installed applications, along with their version and status. Clicking into an application shows all available dashboards, runbooks, an overview of components related to that application, cost analysis, user management, and configuration options.\n\nThe features in this section can be used to manage applications. As an example, select applications have interactive runbooks that serve as guided tutorials for advanced operations on Plural applications.\n\n\n\n#### Builds Overview\n\n[](/getting-started/admin-console#builds-overview)\n\nThe Builds Overview shows all scheduled, running, and completed builds. Completed builds will display the status of that build, and clicking into an individual build shows the build output and available actions to take.\n\n#### Nodes Overview\n\n[](/getting-started/admin-console#nodes-overview)\n\nThe Nodes Overview gives you an overview of your Kubernetes cluster, including total memory and CPU reservation, as well as the detail on each individual node.\n\nClicking on a node shows the pods assigned to that node, along with metadata and events associated with that node.\n\n#### Pods Overview\n\n[](/getting-started/admin-console#pods-overview)\n\nThe Pods Overview gives a filterable list of pods, their status, and running containers. Pod details give more information on containers, conditions, available metadata, and access to logs.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/admin-console.md)",
- "source_links": [],
- "id": 166
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/cloud-shell-quickstart",
- "title": " In-Browser Quickstart",
- "text": "# In-Browser Quickstart\n\nSetting up your first cluster in your browser using the Plural Cloud Shell.\n\n## Overview\n\n[](/getting-started/cloud-shell-quickstart#overview)\n\nThis guide goes over how to get started with Plural using our in-browser Cloud Shell. At the end of this tutorial, you will have:\n\nProvisioned a virtual shell loaded with the dependencies to run Plural.Created a Plural GitHub repository to store your configuration in.Provisioned a fully-configured Kubernetes cluster.Installed an application and all its dependencies on your Kubernetes cluster.\n\nin under 30 minutes, all within your browser. You can see the process in the video here or follow the instructions step-by-step, esp for unique cloud providers:\n\n## Login and Create the Plural Repository\n\n[](/getting-started/cloud-shell-quickstart#login-and-create-the-plural-repository)\n\nOnce you're logged in, you'll land on the Clusters Overview page. You can click on the \"Start onboarding\" button to kick off your onboarding process in your shell app.plural.sh/shell.\n\n[app.plural.sh/shell](https://app.plural.sh/shell)\n\n### Set up a Cloud Provider\n\n[](/getting-started/cloud-shell-quickstart#set-up-a-cloud-provider)\n\nChoose either the option to set up Plural using your own cloud credentials, or try our free 6-hour GCP sandbox demo. If you use your own cloud credentials, choose our Cloud Shell setup option. If you'd prefer to use the CLI, choose \"Local terminal\" and switch to the CLI quickstart.\n\n\n\nYou'll then be prompted to OAuth with either GitHub or GitLab. We're just getting your permission to create a repository for Plural configuration on your behalf. Give your repository a name, being sure to select the right organization or individual account in the first box. Your repository name must be unique within your account, which will be checked before you can advance to the next step.\n\n\n\nPlural can be set up on AWS, GCP, or Azure. You can provide your credentials in the following screen:\n\n\n\nEach cloud provider requires a slightly different set of credentials. Follow the steps below to generate the credentials for your provider.\n\nFor AWS, you'll need to create or use a user with AdministratorAccess and create an access key for Plural to use.\n\nTo create a new user, navigate to the IAM section of your AWS Console.\n\n\n\nSelect the Users tab and click Add users. You should see the following screen:\n\n\n\nFill in the details for your user. On the \"Set permissions\" screen, you can either choose to add your user to a group with AdministratorAccess, or attach the AdministratorAccess policy directly.\n\n\n\nReview your user and hit the \"Create user\" button. Navigate to your newly created user and click the \"Security credentials\" tab. Find the section for Access keys and click \"Create access key\". You should see the following:\n\n\n\nChoose \"Command Line Interface\", optionally add a tag, and create your access key. Make sure to download and save your new credentials; you can then enter the Access Key ID and Secret Access Key in your Plural onboarding.\n\n\n\nFor GCP, you'll want to create a service account with the Owner role and generate an access key for Plural to use.\n\nTo create a new service account, navigate to the \"Service Accounts\" section of your GCP Console.\n\n\n\nSelect the \"Create Service Account\" from the top banner. You should see the following input fields:\n\n\n\nFill in the details for your user. On the second step, add the Owner role for your service account.\n\n\n\nFinish creating your service account, and you should see your new service account in the Service Accounts home page. Click the three dots at the end of the row and select \"Manage keys\" like in the screenshot below:\n\n\n\nSelect \"Add Key\" and save the generated file. This will be used to configure your GCP credentials in your Plural onboarding.\n\n\n\nYou can either follow along with the text instructions here or use the following video to set up your Azure installation on Plural.\n\nFor Azure, you'll need various fields including your Client ID, Client Secret, Subscription ID, Tenant ID, Resource Group, and Storage Account.\n\nTo find your Subscription ID, navigate to the home page of your Azure console and search for \"Subscriptions\". You should see a page like the following:\n\n\n\nYour Subscription ID should be visible next to the Subscription name.\n\nNext, navigate to the Azure Active Directory section. Your Tenant ID should be displayed under \"Basic information\".\n\nFinally, navigate to the App registrations tab within your Directory. You should see an option to add a new registration:\n\n\n\nClick to add a new registration. Fill in the details for your registration as indicated below and click the \"Register\" button.\n\n\n\nYour new App Registration should then be displayed. The displayed \"Application (client) ID\" will be the Client ID in your Plural configuration. Click on the option \"Add a certificate or secret\" of Client credentials. Select \"New client secret\" from the screen:\n\n\n\nSet your preferred timeframe and generate your new secret. The \"Value\" field will be the Client Secret in your Plural configuration.\n\nYou can optionally navigate to the Resource groups section of your Azure console to retrieve a Resource Group and Storage Account, or you can enter new values in the Plural configuration which can create them for you.\n\nFrom here, you have two options. You either need to give your app a role on either your overall Subscription or scoped to a Resource Group. As an example, navigate to the Access Control (IAM) tab of your Subscription. Click the \"Role Assignments\" tab and Select \"Add\" at the top.\n\n\n\nSelect the Owner role, and click on \"Select members\" to search for your app name. Select the app and continue until your new Role assignment is complete. You should now see your app listed as an owner for the Subscription. The process is the same if choosing to scope to a Resource Group.\n\n\n\nReturn to your Plural onboarding. Enter the values noted above into your Cloud Credential configuration, and proceed to the next step.\n\n\n\n### Set up a Workspace\n\n[](/getting-started/cloud-shell-quickstart#set-up-a-workspace)\n\nWe'll now start setting up your Kubernetes cluster configuration. Here's a guide to the config:\n\ncluster: The name of your Kubernetes cluster. Name this based on what you're planning to run.\n\nbucket prefix: We provision S3 buckets for storing logs and state. Enter any string to help us uniquely name your buckets.\n\nsubdomain: We'll provision a subdomain for you to host your cluster and applications under. For example, if you choose nintendo as your subdomain and spin up an instance of Airflow, it will be available at airflow.nintendo.onplural.sh.\n\nYou should hit the following verification screen afterward. Hit Create once you're ready to go!\n\n\n\nWhile your Cloud Shell is provisioning, double check that your repository was initialized by checking your GitHub repos. There should be a repository with an initial commit with the name that you configured.\n\n## Install Wizard and Cloud Shell\n\n[](/getting-started/cloud-shell-quickstart#install-wizard-and-cloud-shell)\n\nYou'll be redirected into your Cloud Shell environment after confirmation. Your Cloud Shell is where you can install applications, inspect your workspace, and run terminal commands.\n\nThe left-hand side of the screen is the Install Wizard, where you can configure applications for installation. Applications can be configured and installed in a fully point-and-click manner by following the available prompts. When Plural is installing your applications, you can follow progress on the right-hand side of the screen in the terminal window.\n\nThe terminal window is an interactive shell where you can follow along with installation progress and optionally run any additional commands you need to set up your Plural instance.\n\n\n\n### Select Applications\n\n[](/getting-started/cloud-shell-quickstart#select-applications)\n\nOnce you have successfully booted into your Cloud Shell, you can configure and install applications.\n\nIn the Install Wizard on the left-hand side of the screen, choose the applications you want to install on your cluster. This will add these applications and their dependencies to the configuration flow, shown at the top of the Install Wizard.\n\n\n\nYou'll now be guided through a setup wizard for the applications you chose. For help with Plural Console configuration, refer to this guide for explanations on each step. For help with configuring Airflow, refer to this guide. Required fields are indicated with a star and will appear in red until they've been populated. Many fields have default values populated; you can use those defaults or provide your own inputs. Any steps without required configuration will be auto-skipped.\n\n[this guide](/applications/console)\n\n[this guide](/applications/airflow)\n\n\n\nAfter configuration, you'll be provided with an overview screen of exactly which applications will be installed. When you're happy with the configuration, click Install to proceed.\n\n\n\n## Provision the Kubernetes Cluster and Install Applications\n\n[](/getting-started/cloud-shell-quickstart#provision-the-kubernetes-cluster-and-install-applications)\n\nNow it's time for Plural to write all the Helm and Terraform required to bring up your Kubernetes cluster based on the config that you've entered. When you click install, Plural will be running the commands to build and deploy your cluster. Your terminal window will display the output from these ongoing operations.\n\n\n\nNow grab a coffee or your favorite hot beverage while we wait for your cloud provider to provision your infrastructure.\n\nWhen your applications are finished installing, you'll be able to see the domains for each application in the terminal window, and you can launch them once all components are ready.\n\n\n\n### Troubleshooting\n\n[](/getting-started/cloud-shell-quickstart#troubleshooting)\n\nOccasionally errors can crop up during the build and deploy process. If your build or deploy fails, you can try re-running the commands to see if it resolves an intermittent issue. To do this, click into the terminal window and either tap the up arrow key to see the last command or type in plural build && plural deploy --commit \"deploying a few apps with plural\" to relaunch the process from where it left off and commit your changes when finished.\n\nIf errors persist, check out our Troubleshooting documentation or reach out to us on our community Discord for help.\n\n[Troubleshooting documentation](/debugging/common-errors)\n\n[reach out to us on our community Discord](https://discord.gg/pluralsh)\n\n## Check out your Deployments\n\n[](/getting-started/cloud-shell-quickstart#check-out-your-deployments)\n\n### Plural Console\n\n[](/getting-started/cloud-shell-quickstart#plural-console)\n\nOnce your cluster has completed deployment, click the Launch Console button to head over to console.YOUR_WORKSPACE.onplural.sh (or the hostname you picked) and view the console that you have provisioned. If you enabled Plural OIDC, you'll be able to quickly login using your Plural account.\n\nHere, you'll be able to check node health, Pod health, logs, pre-built dashboards tailored for Airflow, and more.\n\n\n\n### Airflow / Other Applications\n\n[](/getting-started/cloud-shell-quickstart#airflow-other-applications)\n\nTo access your Airflow installation, access it similarly to the console at airflow.YOUR_WORKSPACE.onplural.sh\n\n\n\nYou can now access your DAGs from the GitHub repo that you set up earlier. Just add any DAGs you want to use the repo and a sync will run every 5 minutes or so to pull them in.\n\nAccessing other applications deployed on Plural will work exactly the same way.\n\n## Wrapping Up\n\n[](/getting-started/cloud-shell-quickstart#wrapping-up)\n\nNow that we've set up a running cluster with Plural, we can add and remove applications to our existing cluster as we so choose.\n\n### Uninstalling Applications\n\n[](/getting-started/cloud-shell-quickstart#uninstalling-applications)\n\nTo uninstall an application from your cluster, run the following in your Cloud Shell:\n\n```\nplural destroy \n```\n\n### Deleting your Cluster and Resetting the Cloud Shell\n\n[](/getting-started/cloud-shell-quickstart#deleting-your-cluster-and-resetting-the-cloud-shell)\n\nTo fully delete your Plural Cluster, run the following in your Cloud Shell:\n\n```\nplural destroy\n```\n\nThis will tear down your Plural Cluster and all attached installations.\n\nTo also delete the Cloud Shell itself (e.g., to change Cloud Providers or restart onboarding), click the three dots on the upper-right side of the Cloud Shell and select Delete cloud shell. This will bring up a confirmation prompt; enter \"delete\" to wipe your shell and restart onboarding from the beginning.\n\n### Leaving the Shell Experience\n\n[](/getting-started/cloud-shell-quickstart#leaving-the-shell-experience)\n\nIf you want to start using the CLI locally, just install the Plural CLI and run:\n\n[install the Plural CLI](/getting-started/quickstart#install-plural-cli)\n\n```\nplural shell sync\n```\n\nThis will sync your local installation with the Cloud Shell. You can then proceed to purge the shell if you wish to spin it down:\n\n```\nplural shell purge\n```\n\n### Feedback\n\n[](/getting-started/cloud-shell-quickstart#feedback)\n\nIf you have any feedback or questions about the experience, head over to our community Discord and drop us some feedback. The Cloud Shell is still in development and we are dedicated to perfecting the user experience, so any feedback would be immensely helpful to us.\n\n[head over to our community Discord](https://discord.gg/pluralsh)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/cloud-shell-quickstart.md)",
- "source_links": [],
- "id": 167
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/concepts",
- "title": " Concepts",
- "text": "# Concepts\n\nA brief overview of concepts used throughout our docs.\n\n## Components\n\n[](/getting-started/concepts#components)\n\nPlural deploys open-source third party applications into a net new cluster in your cloud environment. You can browse a list of all available applications in the Plural Marketplace. Plural uses Terraform to create and manage the cluster, and uses an application\u2019s Helm charts to deploy and update that application.\n\n[Marketplace](https://www.plural.sh/marketplace)\n\n[Terraform](https://www.terraform.io/)\n\n[Helm charts](https://helm.sh/docs/topics/charts/)\n\nAll the necessary configuration for an individual cluster and its applications is stored in an installation repository in your Github or Gitlab account that\u2019s created at the time of deployment.\n\nEach application has a set of packages that encompasses the application\u2019s Helm charts, Terraform, and Docker images necessary to install and manage that application. These packages are stored in a repository, and a user can install that repository and the set of packages within.\n\nA bundle is a collection of packages that we automate the installation and configuration of that\u2019s specific to a cloud provider. Stacks are collections of bundles (i.e., a one-shot installation of a set of applications with a guided configuration experience).\n\nAn installation is a specific deployment of an application onto a cluster. As an example, an organization can have multiple installations of the same application on different clusters.\n\nPlural OIDC (OpenID Connect) is a form of\u00a0SSO\u00a0that enables Plural users to add an authentication layer on top of any apps they deploy with Plural. Instead of using the application's normal login screen,\u00a0you are instead prompted to login with Plural. This login is connected to your login at\u00a0app.plural.sh.\n\n[SSO](https://www.onelogin.com/learn/how-single-sign-on-works)\n\n[app.plural.sh](https://app.plural.sh/?__hstc=156969850.241daab91cb4e8e8e57fdd6f2b1266f5.1675451782881.1680120796944.1680203822803.30&__hssc=156969850.1.1680203822803&__hsfp=646352474)\n\n## Environment\n\n[](/getting-started/concepts#environment)\n\nThe Plural Cloud Shell is an in-browser alternative to running the Plural CLI that provides a hosted interactive terminal for you to deploy and manage clusters. All CLI commands will work in the Cloud Shell, and currently each Cloud Shell instance is tied to a single cluster and account.\n\nThe Plural CLI is a command line interface that can be used to run all Plural commands locally.\n\nThe Console is a web application created by Plural that runs within a cluster deployed by Plural. The Console serves as a control panel for all your Plural applications by managing automated upgrades delivered from the Kubernetes API, showing application metrics and logs, serving as a built-in K8s dashboard, and being the touchpoint for incidents which can be filed with the owner of an application.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/concepts.md)",
- "source_links": [],
- "id": 168
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/manage-git-repositories",
- "title": " Manage Plural Git Repositories",
- "text": "# Manage Plural Git Repositories\n\nLearn Git setup, the anatomy of a Plural workspace, and how to share repositories with colleagues.\n\n## Articles in this section:\n\nSetting Up GitOpsWorkspace Encryption Guide\n\n[Setting Up GitOps](/getting-started/manage-git-repositories/setting-up-gitops)\n\n[Workspace Encryption Guide](/getting-started/manage-git-repositories/workspace-encryption)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/manage-git-repositories/index.md)",
- "source_links": [],
- "id": 169
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/manage-git-repositories/setting-up-gitops",
- "title": " Setting up GitOps",
- "text": "# Setting up GitOps\n\nConfiguring your version control management to work with Plural.\n\n## Overview\n\n[](/getting-started/manage-git-repositories/setting-up-gitops#overview)\n\nPlural defines all of your infrastructure as code, using Helm, Terraform, and YAML files to denote what is being deployed into your cloud provider or on-prem environment. To manage versioning safely, we use a GitOps practice that requires you to store these files in their own Git repository.\n\nIf you are using the Plural Cloud Shell, we handle setting this up for you.\n\n[Plural Cloud Shell](https://app.plural.sh/shell)\n\n###### Info:\n\nCurrently we're limited to a one cluster to one repo mapping, but eventually that will be relaxed. We also strongly urge users to store installations in a fresh, separate repository to avoid our automation trampling existing files.\n\nPlural currently supports the following version control providers:\n\nGitHubGitLabBitbucket (Follow Manual Git Setup below to use Bitbucket)\n\n[GitHub](https://github.com/)\n\n[GitLab](https://about.gitlab.com/)\n\n[Bitbucket](https://bitbucket.org/product/)\n\nSupport for the following providers is on our roadmap:\n\nMercurial\n\n[Mercurial](https://www.mercurial-scm.org/)\n\nYou have two options when setting up a Git repository for use with a Plural workspace:\n\nUsing Plural OAuth by running plural init anywhere. (Recommended)Manual Git Setup with an empty, configured Git repository beforehand.\n\n## Using Plural OAuth\n\n[](/getting-started/manage-git-repositories/setting-up-gitops#using-plural-oauth)\n\nSupported for: (GitHub, GitLab)\n\nTo have Plural set up your Git repository, you'll need to have SSH set up with your version control provider. Then, run:\n\n```\nplural init\n```\n\nThis will kick off the process of setting up your Plural workspace. Once you've gone through a few setup steps, you'll get the following prompt:? you're attempting to setup plural outside a git repository. would you like us to set one up for you here?\n\nEnter Y, pick your version control provider of choice, and you will receive an OAuth screen to let Plural create and manage repositories on your behalf. Note, Plural can only manage repositories that it has created.\n\nIf everything goes well, it should look like this:\n\n\n\n## Manual Git Setup\n\n[](/getting-started/manage-git-repositories/setting-up-gitops#manual-git-setup)\n\nSupported for: (GitHub, GitLab, Bitbucket)\n\nTo set up a Git repository yourself, you'll need a fresh repository with the following requirements:\n\nCloned with SSHMust have an initial commitMust be in sync with the upstream/origin repository\n\nIf the requirements aren't fulfilled, you'll hit an error in the plural init setup process. To get started, follow these steps:\n\nAnd you should be good to go!\n\n## GitOps Best Practices\n\n[](/getting-started/manage-git-repositories/setting-up-gitops#gitops-best-practices)\n\nPlural has three basic steps to the deploy process:\n\nWhen plural build is completed, you'll notice all of your new configuration has been created in your local repository. In this state, the files are not yet committed or pushed up to your origin repository.\n\nYou can manually commit and push the files yourself, but we recommend using the --commit CLI argument when running plural deploy\n\n```\nplural deploy --commit \"deploying console and dagster\"\n```\n\nThis will commit and push up your configuration changes for you to your origin repository, using the commit message you've specified.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/manage-git-repositories/setting-up-gitops.md)",
- "source_links": [],
- "id": 170
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/manage-git-repositories/sharing-git-repositories",
- "title": " Sharing Your Git Repositories",
- "text": "# Sharing Your Git Repositories\n\nHow to securely share a Plural workspace and Git repository with a collaborator.\n\nPlural reimplements git-crypt in its management of secret data within git. This provides transparent file access to users with the repo's AES key, along with full support for tooling like local diffs, while still providing full obfuscation of secret data when pushed to remote.\n\n[git-crypt](https://github.com/AGWA/git-crypt)\n\nThe encryption key is automatically generated by Plural and stored in Plural's config directory ~/.plural. We provide commands for importing/exporting the key, as well as a mechanism for sharing the repo with multiple users using the successor to PGP, age.\n\n[age](https://github.com/FiloSottile/age)\n\n## Sharing a Plural Git Repository\n\n[](/getting-started/manage-git-repositories/sharing-git-repositories#sharing-a-plural-git-repository)\n\n### Register a public key\n\n[](/getting-started/manage-git-repositories/sharing-git-repositories#register-a-public-key)\n\nTo register a key for your current machine, run:\n\n```\nplural crypto setup-keys --name \n```\n\nThis will generate a new keypair and automatically register the public key with the Plural API. You should be able to see it listed here in our web app and the keypair will be stored in ~/.plural/identity.\n\n[here](https://app.plural.sh/profile/keys)\n\n### Share the repository\n\n[](/getting-started/manage-git-repositories/sharing-git-repositories#share-the-repository)\n\nTo share a repo, use the following command:\n\n```\nplural crypto share --email --email \n```\n\n###### Info:\n\n--email refers to a user's email associated with their Plural account\n\nThis will do a few things:\n\ncreate a base identity to encrypt the repo's current AES key and store it in a git-ignored place under ${REPO_ROOT}/.plural-crypt.register all the users who have access in a yaml file under ${REPO_ROOT}/.plural-cryptencrypt the file using all this information and store it under ${REPO_ROOT}/.plural-crypt\n\nIf you have the Plural Console deployed, run:\n\n```\nplural build --only console\nplural deploy\ngit add . && git commit -m \"set up encryption\"\ngit push\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/manage-git-repositories/sharing-git-repositories.md)",
- "source_links": [],
- "id": 171
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/manage-git-repositories/workspace-encryption",
- "title": " Workspace Encryption Guide",
- "text": "# Workspace Encryption Guide\n\nHow to use `plural crypto backups` to create, list, and restore workspace backups.\n\nOut of the box, Plural encrypts all configuration in your Plural workspace and stores an encryption key on your local machine. This means that if anyone gets a copy of your Plural Git repository/workspace, all sensitive information will appear encrypted to them.\n\nIf you are changing machines or collaborating with colleagues, you'll need to know how to create and restore from the workspace encryption backups.\n\n## Your encryption key\n\n[](/getting-started/manage-git-repositories/workspace-encryption#your-encryption-key)\n\nWhen you initialize your Plural repository, Plural creates a directory in your home directory called .plural. Within this directory is a file called key, which is your local encryption key. This key is required to decrypt any sensitive configuration within your Plural workspace.\n\nTo import a preexisting key, you can run the following command:\n\n```\ncat /path/to/key | plural crypto import\n```\n\n## Encryption backup operations\n\n[](/getting-started/manage-git-repositories/workspace-encryption#encryption-backup-operations)\n\n### Create workspace backup\n\n[](/getting-started/manage-git-repositories/workspace-encryption#create-workspace-backup)\n\nTo create a backup for your local key, run:\n\n```\nplural crypto backups create\n```\n\nIn the case that you lose your local encryption key, this will allow you to decrypt your repo.\n\n### List backups\n\n[](/getting-started/manage-git-repositories/workspace-encryption#list-backups)\n\nTo list your workspace backups that you have created, run:\n\n```\nplural crypto backups list\n```\n\n### Restore from backup\n\n[](/getting-started/manage-git-repositories/workspace-encryption#restore-from-backup)\n\nIn the event that you lose your key file or are on a new machine, you can restore from a backup that you have created with this command:\n\n```\nplural crypto backups restore\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/manage-git-repositories/workspace-encryption.md)",
- "source_links": [],
- "id": 172
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/manage-git-repositories/your-plural-workspace",
- "title": " Your Plural Workspace",
- "text": "# Your Plural Workspace\n\nLearn about your Plural Git workspaces and how to manage them.\n\nPlural ensures the state of all installed applications are stored in a git repository, under a common format. A typical workspace should have a similar layout to the following example:\n\n```\n\ud83d\udce6installation-repository\n\u2523 \ud83d\udcdc.gitattributes\n\u2523 \ud83d\udcdc.gitignore\n\u2523 \ud83d\udcdccontext.yaml\n\u2517 \ud83d\udcdcworkspace.yaml\n```\n\n## Top level files\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#top-level-files)\n\n### context.yaml\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#context-yaml)\n\nWhen you run plural bundle install and go through the configuration for an application, that information is stored here. In advanced use cases, it can also be manually edited if you want to apply configuration beyond what the bundle provided.\n\n### workspace.yaml\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#workspace-yaml)\n\nBase cloud provider setup for this repository is stored here. On each app installation, you have the option of inheriting this setup, or reconfiguring for the specific app.\n\n### .gitattributes\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#gitattributes)\n\nThis file specifies the filters that drive secret encryption. In general, do not manually edit this file.\n\n## Application folders\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#application-folders)\n\nThese files exist in every application directory that you install with plural bundle install . To see these files for a specific application, cd .\n\n### Helm\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#helm)\n\nhelm/\n\nWhen installing an application with Plural, the Kubernetes resources are deployed using Helm. The Plural CLI creates a second Helm chart that wraps the chart(s) downloaded from the Plural API for every application.\n\n[Helm](https://helm.sh/)\n\nThe values.yaml file contains all the configurations specific for this deployment.\n\nThe values.yaml file is created during the plural build command using the user inputs from the plural bundle install command.\n\n### Terraform\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#terraform)\n\nterraform/*\n\nThe cloud resources required for an application installed through Plural are created using Terraform.\n\nThe main entrypoint for the Terraform configuration is terraform/main.tf. Similar to the values.yaml file for Helm, the terraform/main.tf is created during the plural build command for every application you have installed.\n\n### Build and Deploy files\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#build-and-deploy-files)\n\nOur build and deploy files are written in HCL, HashiCorp's proprietary configuration language that interacts with Terraform.\n\n{build | deploy}.hcl\n\nThe build/deploy/diff files manage two things:\n\nthe steps needed to build or apply a specific application in Pluralchange detection between runs\n\nWe automatically detect if changes have been made to your Terraform files, which enables us to ignore unneeded Terraform commands that take a long time to execute.\n\n### Miscellaneous Directories and Files\n\n[](/getting-started/manage-git-repositories/your-plural-workspace#miscellaneous-directories-and-files)\n\n.pluralignore\n\nThis file tells the Plural CLI to ignore certain paths during change detection, is similar to a .gitignore file for Git.\n\nmanifest.yaml\n\nMetadata about the plural application.\n\noutput.yaml\n\nOutputs from various tools (Terraform, Helm, etc) that can be imported and used in other applications.\n\ncrds/\n\nThe crds directory contains all the CRDs for the Helm chart. We manage these through the Plural CLI rather than Helm so we can do more advanced change detection.\n\n.plural/\n\nThe .plural folder within each application folder container two files: ONCE and NONCE. These files are used as targets for change detection by the Plural CLI.\n\nThe NONCE file is used for commands that should be executed a single time after a plural build command. The ONCE file is used for commands that should only be executed the first time an application is deployed.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/manage-git-repositories/your-plural-workspace.md)",
- "source_links": [],
- "id": 173
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/openid-connect",
- "title": " OpenID Connect",
- "text": "# OpenID Connect\n\nWhat is OIDC and how do you set it up?\n\nWhen you run plural bundle install to install an application, you may be asked about whether or not you want to enable Plural OIDC for that application.\n\n## What is OpenID Connect?\n\n[](/getting-started/openid-connect#what-is-openid-connect)\n\nOpenID Connect is a form of SSO that enables Plural users to add an authentication layer on top of any apps they deploy with Plural. Instead of using the application's normal login screen, you are instead prompted to login with Plural. This login is connected to your login at app.plural.sh. For example, if you have enabled OIDC, if you are logged in and try to access airbyte.$YOUR_WORKSPACE.onplural.sh, this pops up:\n\n[SSO](https://www.onelogin.com/learn/how-single-sign-on-works)\n\n[app.plural.sh](https://app.plural.sh)\n\n\n\nIf you aren't logged in, you'll see this screen when you navigate to your application:\n\n\n\nAll Plural applications have the capability to create a custom OIDC provider for a user's installation. This allows Plural to become a unified identity management solution for your entire open source portfolio. We have even automated upgrades for OIDC configuration changes, so the setup process is entirely turnkey.\n\n## Login Policies\n\n[](/getting-started/openid-connect#login-policies)\n\nThe provider is mapped to a set of users+groups, just like a Plural role, and if that login policy does not pass, you cannot complete the OIDC login and consent flow. Plural ID tokens will include core user information along with the plural groups they belong to, allowing for seamless identity mapping onto the applications governed by Plural.\n\n## Supported Applications\n\n[](/getting-started/openid-connect#supported-applications)\n\nApplications that currently support Plural OIDC are:\n\nPlural Console - includes group provisioning as wellAirflowAirbyteSentryGitLabGrafanaArgo CD\n\n[Plural Console](https://www.plural.sh/applications/console)\n\n[Airflow](https://www.plural.sh/applications/airflow)\n\n[Airbyte](https://www.plural.sh/applications/airbyte)\n\n[Sentry](https://www.plural.sh/applications/sentry)\n\n[GitLab](https://www.plural.sh/applications/gitlab)\n\n[Grafana](https://www.plural.sh/applications/grafana)\n\n[Argo CD](https://www.plural.sh/applications/argo-cd)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/openid-connect.md)",
- "source_links": [],
- "id": 174
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/plural-difference",
- "title": " What makes Plural different?",
- "text": "# What makes Plural different?\n\nA brief overview of Plural's differentiation.\n\n## Plural Differentiators\n\n[](/getting-started/plural-difference#plural-differentiators)\n\nPlural was built to make deploying and managing applications on Kubernetes as easy as possible. A few things set us apart:\n\nPlural is self-hosted. You retain full control over your deployments in your cloud.We're open-source. We were built as an open-source solution from day 1, and allow for full transparency of what our software is doing.Bring your own cloud. We support deploying on all major cloud providers, including AWS, Azure, and GCP.We perform automated testing and upgrades of supported applications, including all dependency management. Set your preferred upgrade channels and we'll do the hard work for you.We're entirely portable. Plural is built on common open-source tools, so if you don't like us, you can always eject your application from Plural and use it as you please.We provide out-of-the-box Day 2 operational workflows. Monitor, manage, and scale your configuration with ease to meet changing demands of your business.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/plural-difference.md)",
- "source_links": [],
- "id": 175
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/quickstart",
- "title": " CLI Quickstart",
- "text": "# CLI Quickstart\n\nA guide to getting up and running with Plural using our CLI in under 30 minutes.\n\n## Overview\n\n[](/getting-started/quickstart#overview)\n\nThis is a guide on how to get Plural running using our CLI. If you prefer an in-browser Cloud Shell experience with all the dependencies loaded, check out our Quickstart Guide for Cloud Shell here. You can see the process in the video here or follow the instructions step-by-step, especially for unique cloud providers:\n\n[here](/getting-started/cloud-shell-quickstart)\n\n## Prerequisites\n\n[](/getting-started/quickstart#prerequisites)\n\nYou will need the following things to successfully get up and running with Plural:\n\nA cloud account: Plural will deploy directly into your cloud provider of choice. We currently support AWS, GCP and Azure. Follow this guide to make sure it's set up correctly.Your cloud provider CLI installed and configured: Plural will leverage your cloud provider's CLI tooling in places. If need to install the cloud provider CLI, or aren't sure if it's properly configured you can follow this guide.A GitHub/GitLab account: Plural manages the state of your infrastructure using a git-ops workflow, so you'll need an account with a version control management system. Follow the instructions in our GitOps resources for more information.\n\n[this guide](/reference/configuring-cloud-provider)\n\n[this guide](/reference/configuring-cloud-provider)\n\n[in our GitOps resources](/getting-started/manage-git-repositories/setting-up-gitops)\n\n## Install Plural CLI\n\n[](/getting-started/quickstart#install-plural-cli)\n\nThe Plural CLI and its dependencies are available using a package manager for your system. For Mac, we recommend using Homebrew. For other operating systems, curl and our Docker image should work universally.\n\n[Homebrew](https://brew.sh/)\n\nThe brew tap will install Plural, alongside Terraform, Helm and kubectl for you. If you've already installed any of those dependencies, you can add --without-helm, --without-terraform, or --without-kubectl\n\n```\nbrew install pluralsh/plural/plural\n```\n\n###### Warning:\n\nBefore you proceed, make sure that your cloud provider CLI is properly configured and updated to the latest version. If you aren't sure about how to do that, refer to this guide. If it is not configured correctly, Plural will fail and won't be able to create resources on your behalf.\n\n[this guide](/reference/configuring-cloud-provider)\n\nYou can download the binaries attached to our GitHub releases here. There will be binaries for linux, windows, and mac and all compatible platforms.\n\n[here](https://github.com/pluralsh/plural-cli/releases)\n\nFor example, you can download v0.6.2 for Darwin arm64 via:\n\n```\nVSN=$(curl --silent -qI https://github.com/pluralsh/plural-cli/releases/latest | awk -F '/' '/^location/ {print substr($NF, 1, length($NF)-1)}')\ncurl -L -o plural.tgz 'https://github.com/pluralsh/plural-cli/releases/download/${VSN}/plural-cli_${VSN#v}_Darwin_arm64.tar.gz'\ntar -xvf plural.tgz\nchmod +x plural\nmv plural /usr/local/bin/plural\n```\n\n###### Info:\n\nBe sure to download the CLI version for your target OS/architecture, the above example is only valid for ARM Mac's\n\nYou will still need to ensure helm, terraform and kubectl are properly installed, you can find installers for each here\n\n[https://helm.sh/docs/intro/install/](https://helm.sh/docs/intro/install/)\n\n[https://learn.hashicorp.com/tutorials/terraform/install-cli](https://learn.hashicorp.com/tutorials/terraform/install-cli)\n\n[https://kubernetes.io/docs/tasks/tools/#kubectl](https://kubernetes.io/docs/tasks/tools/#kubectl)\n\n###### Warning:\n\nBefore you proceed, make sure that your cloud provider CLI is properly configured and updated to the latest version. If you aren't sure about how to do that, refer to this guide. If it is not configured correctly, Plural will fail and won't be able to create resources on your behalf.\n\n[this guide](/reference/configuring-cloud-provider)\n\n## Create your Plural Repo\n\n[](/getting-started/quickstart#create-your-plural-repo)\n\nPlural stores all configuration artifacts within a Git repository that we will create on your behalf. Run this command within the directory that you want to store your configuration in:\n\n```\nplural init\n```\n\nThe Plural CLI will then guide you through a workflow using GitHub/GitLab OAuth to create a repository on your behalf.\n\n###### Info:\n\nIf you'd prefer to set up Git manually vs. using OAuth, refer to our guide on setting up Gitops.\n\n[setting up Gitops](/getting-started/manage-git-repositories/setting-up-gitops)\n\nAlong the plural init workflow, we will set the Git attributes to configure encryption and configure your cloud provider for this installation.\n\nYou will also be asked whether you want to use Plural's domain service and if so, what you want the subdomain to be. We recommend that you use our DNS service if you don't have any security reasons that prevent you from doing so. The hostname that you configure with us will determine where your applications are hosted. For example, if you enter singular.onplural.sh, your applications will be available at $APP_NAME.singular.onplural.sh.\n\nThis process will generate a workspace.yaml file at the root of your repo that stores your cloud provider configuration information.\n\n###### Info:\n\nCurrently we're limited to a one cluster to one repo mapping, but eventually that will be relaxed. We also strongly urge users to store installations in a fresh, separate repository to avoid our automation trampling existing files.\n\n## Install Plural Applications\n\n[](/getting-started/quickstart#install-plural-applications)\n\nTo view the applications you can install on Plural, head to this link.\n\n[this link](https://app.plural.sh/explore/public)\n\nOnce you've selected your applications, you can install Plural bundles using our interactive GUI. To start the GUI, run:\n\n```\nplural install\n```\n\nYou should see a window pop up like the below:\n\n\n\nYou can then follow a guided flow to select and configure your applications.\n\nAlternatively, you can run plural repos list on the CLI or Cloud Shell and find the bundle name specific to your cloud provider.\n\nRun plural bundle list to find installation commands and information about each application available for install. For example, to list the bundle information for the Plural console, a powerful Kubernetes control plane:\n\nHere's what we get from running plural bundle list console:\n\n```\n+-------------+--------------------------------+----------+--------------------------------+\n| NAME | DESCRIPTION | PROVIDER | INSTALL COMMAND |\n+-------------+--------------------------------+----------+--------------------------------+\n| console-aws | Deploys console on an EKS | AWS | plural bundle install console |\n| | cluster | | console-aws |\n+-------------+--------------------------------+----------+--------------------------------+\n```\n\nTo install applications on Plural, run:\n\n```\nplural bundle install \n```\n\nWe can try this out by installing the Plural Console:\n\n```\nplural bundle install console console-aws\n```\n\n```\nplural bundle install console console-gcp\n```\n\n```\nplural bundle install console console-azure\n```\n\nAs of CLI version 0.6.19, the bundle name can be inferred from primary bundles, optionally shortening the command to:\n\n```\nplural bundle install console\n```\n\nAfter running the install command, you will be asked a few questions about how your app will be configured, including whether you want to enable Plural OIDC (single sign-on). Unless you don't wish to use Plural as an identity provider due to internal company security requirements, you should enter (Y). This will enable you to use your existing app.plural.sh login information to access Plural-deployed applications. This will add an extra layer of security for applications without built-in authentication.\n\nUltimately all the values you input at this step will be stored in a file called context.yaml at the root of your repo.\n\n## Build and Deploy your Kubernetes Cluster and Applications\n\n[](/getting-started/quickstart#build-and-deploy-your-kubernetes-cluster-and-applications)\n\nWith all bundles installed, run:\n\n```\nplural build\nplural deploy --commit \"initial deploy\"\n```\n\nThis will generate all deployment artifacts in the repo, then deploy them in dependency order.\n\nIt is common for plural deploy to take a fair amount of time, as is the case with most Terraform and cloud infrastructure deployments. Network disconnects can cause potential issues as a result. If you're running on a spotty network, or would like to step out while it's running we recommend running it in tmux.\n\n[tmux](https://github.com/tmux/tmux/wiki)\n\nOnce plural deploy has completed, you should be ready to log in to your application at {app-name}.{domain-name}.\n\n###### Warning:\n\nYou may experience a delayed creation of your SSL certs for your applications. ZeroSSL currently may take up to 24 hours to provide you your certs.\n\nAnd you are done! You now have a fully-configured Kubernetes cluster and are free to install applications on it to your heart's content. If you want to take down any of your individual applications, run plural destroy . If you're just testing us out and want to take down the entire thing, run plural destroy.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/quickstart.md)",
- "source_links": [],
- "id": 176
- },
- {
- "page_link": "https://docs.plural.sh/getting-started/video-cli-quickstart",
- "title": " Video: Installing with CLI",
- "text": "# Video: Installing with CLI\n\nA short video on installing applications on Plural with the CLI\n\nIn under 10 minutes, you will learn how to:\n\nCreate a repository to store your infrastructure configurationProvision a fully configured Kubernetes cluster with no prior knowledgeInstall an instance of the Plural consoleInstall an instance of Airbyte on your cluster\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/getting-started/video-cli-quickstart.md)",
- "source_links": [],
- "id": 177
- },
- {
- "page_link": "https://docs.plural.sh/",
- "title": "Docs | Plural",
- "text": "# Documentation\n\nGet started, master your operations, and troubleshoot your problems.\n\n\n\n## Explore Topics\n\n[](/#explore-topics)\n\nFind what\u2019s most relevant to you\n\n[QuickstartA guide to getting up and running.](/getting-started/quickstart)\n\n### Quickstart\n\nA guide to getting up and running.\n\n[SecurityWhat does Plural have access to?](/operations/security)\n\n### Security\n\nWhat does Plural have access to?\n\n[Cloud ShellSetting up your first cluster in browser.](/getting-started/cloud-shell-quickstart)\n\n### Cloud Shell\n\nSetting up your first cluster in browser.\n\n[Application catalogApplications you can install with Plural.](/applications)\n\n### Application catalog\n\nApplications you can install with Plural.\n\n[TroubleshootingCommon issues or errors.](/reference/troubleshooting)\n\n### Troubleshooting\n\nCommon issues or errors.\n\n[GitOpsShare and manage your Git repositories.](/getting-started/manage-git-repositories/setting-up-gitops)\n\n### GitOps\n\nShare and manage your Git repositories.\n\n## Join the community\n\n[](/#join-the-community)\n\nJoin the group of Plural users and contributors that are helping shape the future of DevOps.\n\n[DiscordJoin the discussion and get help.](https://discord.gg/pluralsh)\n\n### Discord\n\nJoin the discussion and get help.\n\n[Become an open-sourcererStart your contribution journey.](https://github.com/pluralsh/plural)\n\n### Become an open-sourcerer\n\nStart your contribution journey.",
- "source_links": [],
- "id": 178
- },
- {
- "page_link": "https://docs.plural.sh/introduction",
- "title": " Introduction",
- "text": "# Introduction\n\nPlural empowers you to build and maintain production-ready applications on Kubernetes in minutes with no management overhead.\n\n## What is Plural?\n\n[](/introduction#what-is-plural)\n\nPlural is an open-source, unified, application deployment platform that stands up a Kubernetes cluster and selected applications in the cloud provider of your choice. Plural stores your infrastructure code and configuration in a fresh Git repository of your choosing, which we refer to as a Plural workspace.\n\n[workspace](/getting-started/manage-git-repositories/your-plural-workspace)\n\nPlural writes all the Helm, Terraform, and YAML needed for your desired infrastructure with plural build, and deploys it all into production with plural deploy. All configuration within your Plural Git repository is fully ejectable from the platform and ecosystem.\n\n\n\nSome key features of the platform include:\n\nAutomated UpgradesCross-tool dependency managementGitOps workflow with batteries-included transparent secret encryptionBuilt on common open-source tools, so if you don't like us, you can always eject your application from Plural and use it as you please.\n\nNotably, we do not support bringing your own Kubernetes cluster yet, but it's on our roadmap.\n\n## Deployment Options\n\n[](/introduction#deployment-options)\n\n### Plural CLI\n\n[](/introduction#plural-cli)\n\nThis is the current standard deployment method. Click below for a quickstart to managing configuration locally.\n\nQuickstart: Using the Plural CLI on your Machine\n\n[Quickstart: Using the Plural CLI on your Machine](/getting-started/quickstart)\n\n### Plural Cloud Shell\n\n[](/introduction#plural-cloud-shell)\n\nWe have created a Cloud Shell with all of the tools and dependencies needed to run Plural. This is available here to try out. If you want to try out Plural without entering cloud credentials, we offer a demo environment of our Plural Console that you can access here.\n\n[here](https://app.plural.sh/shell)\n\n[here](https://www.plural.sh/demo-login)\n\nUsing our in-browser Cloud Shell\n\n[Using our in-browser Cloud Shell](/getting-started/cloud-shell-quickstart)\n\nIf you need support getting your Plural deployment up and running, join the Plural Discord here!\n\n[Plural Discord here!](https://discord.gg/pluralsh)\n\n## Architecture\n\n[](/introduction#architecture)\n\nThe Plural architecture has three main components:\n\nPlural API and Catalog site (available at https://app.plural.sh)Plural CLI and Git SCM to maintain the state of a user's applicationsPlural Console for management of all plural applications on your infrastructure\n\n[https://app.plural.sh](https://app.plural.sh)\n\nAt a high level, the interactions between all three components look something like this:\n\n\n\n### Plural API\n\n[](/introduction#plural-api)\n\nThe primary responsibility of the Plural API is to store the packages needed for application installation - terraform, helm - and ingesting high-level dependency information about them. This allows us to properly sequence installations. It also serves as a publish-subscribe layer to communicate updates to clusters that have installed those applications, and can leverage the dependency information ingested to delay updates until a cluster has caught up with all the necessary dependencies.\n\nIt also can serve as an identity provider for any Plural application, delegating authentication via OIDC and also maintaining user group info and communicating it down to applications.\n\n### Plural CLI\n\n[](/introduction#plural-cli)\n\nThe Plural CLI effectively uses the Plural API as a package manager, and works as a higher level build tool on top of the DevOps packages it supports. It will handle things like running installations in dependency order, detecting changes between runs, and templating out a workspace from scratch.\n\nIt also is responsible for managing secret encryption of all application state in plural installation repos and provides a few useful tools for troubleshooting an application our admin console might not be well-suited to solve.\n\nFinally it also provides the toolchain for publishing applications to the plural API.\n\n### Plural Console\n\n[](/introduction#plural-console)\n\nThe Plural Console is the operational hub for all applications managed by Plural. It is deployed in-cluster alongside applications and provides a few key features:\n\nAutomated upgrades - by subscribing to the API's upgrade websocketObservability - leveraging the dashboard and logging Kubernetes CRDs deployed alongside Plural applicationsSupport - in-person support can be handled in our chat interface available directly in the admin console, with a lot of nice features like direct zoom integration\n\nIt's deployed as a highly available, scalable web service, with postgres as its datastore. It also directly integrates with Plural's OIDC for login and user management.\n\n## Docs Translations\n\n[](/introduction#docs-translations)\n\n### Japanese\n\n[](/introduction#japanese)\n\nThe wonderful team at St-Hakky has translated most of our docs to Japanese on their website. To view the translated docs, click here.\n\n[St-Hakky](https://www.about.st-hakky.com/)\n\n[translated docs, click here](https://book.st-hakky.com/docs/plural-overview)\n\nSt-Hakky \u306e\u3059\u3070\u3089\u3057\u3044\u30c1\u30fc\u30e0\u304c\u3001\u30a6\u30a7\u30d6\u30b5\u30a4\u30c8\u3067\u307b\u3068\u3093\u3069\u306e\u30c9\u30ad\u30e5\u30e1\u30f3\u30c8\u3092\u65e5\u672c\u8a9e\u306b\u7ffb\u8a33\u3057\u3066\u304f\u308c\u307e\u3057\u305f\u3002 \u7ffb\u8a33\u3055\u308c\u305f\u30c9\u30ad\u30e5\u30e1\u30f3\u30c8\u3092\u8868\u793a\u3059\u308b\u306b\u306f\u3001\u3053\u3053\u3092\u30af\u30ea\u30c3\u30af\u3057\u3066\u304f\u3060\u3055\u3044\u3002\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/introduction.md)",
- "source_links": [],
- "id": 179
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control/api-tokens",
- "title": " API Tokens",
- "text": "# API Tokens\n\nIn addition to the temporary JWTs the API issues on login, it's possible to create persistent access tokens to access the API. This is also the common way credentials are managed when using the plural CLI, with the plural login command either creating or fetching a recent access token to use for all API calls.\n\n### Creating a Token\n\n[](/operations/auth-access-control/api-tokens#creating-a-token)\n\nYou can create a token manually using the web interface here: https://app.plural.sh/me/edit/tokens or you can simply run:\n\n[https://app.plural.sh/me/edit/tokens](https://app.plural.sh/me/edit/tokens)\n\n```\nplural login\nplural config read\n```\n\nto grab the token configured at login.\n\n### Token Security\n\n[](/operations/auth-access-control/api-tokens#token-security)\n\nPlural captures access logs for all token usage, including IP information, available by inspecting the token in the access tokens page. You are also free to revoke a token at any time, although this might require you to rotate the keys used by your plural installations manually, so it's recommended to check the logs for that token before doing so to understand your exposure\n\n[access tokens page](https://app.plural.sh/me/edit/tokens)\n\n###### Info:\n\nRevoking a token while an instance of the plural console is using it will prevent it from receiving upgrades, but once the token is rotated, it will pick back up and apply the upgrades as normal.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/api-tokens.md)",
- "source_links": [],
- "id": 180
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control/identity-and-installations/audit-logging",
- "title": " Audit Logging",
- "text": "# Audit Logging\n\nAll mutations in both Plural and the Plural Console have full audit logging, which can be attributed back to the actor and IP address responsible. You can view the Plural audit logs here: https://app.plural.sh/audits and should be able to see a table of actions, the resources acted upon and the actor looking somewhat like\n\n[https://app.plural.sh/audits](https://app.plural.sh/audits)\n\n\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/identity-and-installations/audit-logging.md)",
- "source_links": [],
- "id": 181
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control/identity-and-installations",
- "title": " Advanced Topics",
- "text": "# Advanced Topics\n\n### Installation\n\n[](/operations/auth-access-control/identity-and-installations#installation)\n\nAny Plural identity can install applications, which will then be tied back to the installing user to track their history and validate whether upgrades are still eligible. This has a few implications:\n\nUsers should fix the cloud provider that identity is installing to, as a workspace for that users installation likely can't span multiple providersFor production-grade workloads where you'd like to have a full team managing an installation, it's typically better to use a Service Account to manage an installation.\n\nAny activity the Plural Console does against the Plural API is also authenticated as the installer's identity. So support tickets will usually be created using that user, and the upgrade websocket is created on behalf of that user. This makes a lot of things a lot simpler in a disconnected architecture like Plural's.\n\n### Publishing\n\n[](/operations/auth-access-control/identity-and-installations#publishing)\n\nMembers on a Plural account can become publishers if given the appropriate role, or if they are the account owner. Publishers have the ability to create application repositories, publish terraform or helm packages to repositories, and determine payment plans for applications.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/identity-and-installations/index.md)",
- "source_links": [],
- "id": 182
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control/identity-and-installations/service-accounts",
- "title": " Creating Multiple Plural Clusters",
- "text": "# Creating Multiple Plural Clusters\n\n## Setting up a new cluster\n\n[](/operations/auth-access-control/identity-and-installations/service-accounts#setting-up-a-new-cluster)\n\nThere are many scenarios where it's useful to have multiple Kubernetes clusters running (e.g., a development and product cluster). For those users on paid tiers, Plural allows you to manage multiple clusters from a single UI.\n\n\n\nAdditional clusters are spun up using a unique Service Account for each new cluster. Service Accounts are assumable identities, specifically meant to facilitate group management of a set of installations. To spin up a new cluster, first create a new Service Account.\n\nTo create a service account, from https://app.plural.sh/, navigate to account, then service accounts.\n\n[https://app.plural.sh/](https://app.plural.sh/accounts/edit/service-accounts)\n\n\n\nFrom here, you can create a new service account, and attach users or groups.\n\n\n\nOnce created, you can impersonate the service account by clicking the impersonate button in the dashboard, or via the CLI:\n\n```\nplural login --service-account \n```\n\nIn all other respects, service accounts behave just like normal Plural users, and will be present in audit logs, can be used in support chats, and, of course, can install and deploy applications just like users.\n\nYou can then create a new cluster on the Service Account via the Cloud Shell or CLI.\n\nThe Clusters tab on your main Plural account will show all clusters that you have access to. From here, you can manage user access, navigate to a cluster's Cloud Shell, set Upgrade Channels for applications, and more.\n\n## Setting up Promotions\n\n[](/operations/auth-access-control/identity-and-installations/service-accounts#setting-up-promotions)\n\nOne major benefit of setting up multiple clusters is the ability to promote versions of different applications between clusters. Assuming both clusters are on the same provider, you can try out new versions of applications in a development cluster, and promote to production when you're ready.\n\nYou can set up promotions either in the browser or via the Plural CLI.\n\n### CLI Setup\n\n[](/operations/auth-access-control/identity-and-installations/service-accounts#cli-setup)\n\nTo set up promotions via the CLI, you can first run plural clusters list to see all available clusters and associated IDs. From there, you can run:\n\n```\nplural clusters depend \n```\n\nwhere source is your development cluster and destination is your production cluster.\n\nTo run a promotion, use:\n\n```\nplural clusters promote\n```\n\nThis will propagate versions for all apps from your source cluster to your destination cluster.\n\n### UI Setup\n\n[](/operations/auth-access-control/identity-and-installations/service-accounts#ui-setup)\n\nFor a full demonstration of in-browser cluster promotion, check out our demo video or read on below.\n\nTo do this from the Plural UI, navigate to the Clusters Overview tab. Choose the cluster you want as your destination cluster, and click into the Cluster details page.\n\nClick the \"Set up promotions\" button, select your source cluster, and click the Save button.\n\nYou can then click the \"Promote\" button to see pending upgrades and execute a promotion.\n\nAlternatively, you can promote from the Clusters Overview page by clicking the green checkmark in the clusters table.\n\n\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/identity-and-installations/service-accounts.md)",
- "source_links": [],
- "id": 183
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control",
- "title": " Auth & Access Control",
- "text": "# Auth & Access Control\n\nLearn about configuring access control within Plural.\n\nPlural comes pre-built with a lot of the core concepts needed for IAM at any organizational scale. These include:\n\nUsers and Groups - maintain a full directory to manage identity within PluralRoles - which can be bound to any set of users or groups of users to allocate permissionsService Accounts - dedicated identities with a fixed policy as far as what other entities can impersonate them and act on their behalf.\n\n### Account Basics\n\n[](/operations/auth-access-control#account-basics)\n\nWhen you sign up to plural, you'll immediately be allocated an account. You can then invite users by using the form at https://app.plural.sh/accounts/edit/users. Users who sign up organically will get their own accounts, and will have to be linked afterwards, so we recommend onboarding additional users via invite.\n\n[https://app.plural.sh/accounts/edit/users](https://app.plural.sh/accounts/edit/users)\n\n###### Info:\n\nThe only users eligible for sharing repo encryption keys are also those users in your account .\n\n### RBAC Basics\n\n[](/operations/auth-access-control#rbac-basics)\n\nEach Plural role is configurable using the role creation form at https://app.plural.sh/accounts/edit/roles:\n\n[https://app.plural.sh/accounts/edit/roles](https://app.plural.sh/accounts/edit/roles)\n\n\n\nThe permissions are fairly self explanatory, but you do have the ability to map a role to whatever identity grouping you'd want to use, and filter the roles application to a list of repositories (or a regex on repository name). The latter mode is helpful if you'd like a certain role to only be able to install, say, airflow and sentry.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/index.md)",
- "source_links": [],
- "id": 184
- },
- {
- "page_link": "https://docs.plural.sh/operations/auth-access-control/openid-connect",
- "title": " OpenID Connect",
- "text": "# OpenID Connect\n\nAll Plural applications have the capability to create a custom OIDC provider for a user's installation. This allows Plural to become a unified identity management solution for your entire open source portfolio. We have even automated upgrades for OIDC configuration changes, so the setup process is entirely turnkey.\n\nFor more information about adding users to applications using OpenID Connect, see the page on Adding Users to Applications\n\n[Adding Users to Applications](/operations/managing-applications/add-users-to-application)\n\n### Login Policies\n\n[](/operations/auth-access-control/openid-connect#login-policies)\n\nThe provider is mapped to a set of users+groups, just like a Plural role, and if that login policy does not pass, you cannot complete the OIDC login and consent flow. Plural ID tokens will include core user information along with the plural groups they belong to, allowing for seamless identity mapping onto the applications governed by Plural.\n\n### Supported Applications\n\n[](/operations/auth-access-control/openid-connect#supported-applications)\n\nApplications that currently support Plural OIDC are:\n\nPlural Console - includes group provisioning as wellAirflowAirbyteSentryGitLabGrafanaArgo CD\n\n[Plural Console](https://www.plural.sh/applications/console)\n\n[Airflow](https://www.plural.sh/applications/airflow)\n\n[Airbyte](https://www.plural.sh/applications/airbyte)\n\n[Sentry](https://www.plural.sh/applications/sentry)\n\n[GitLab](https://www.plural.sh/applications/gitlab)\n\n[Grafana](https://www.plural.sh/applications/grafana)\n\n[Argo CD](https://www.plural.sh/applications/argo-cd)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/auth-access-control/openid-connect.md)",
- "source_links": [],
- "id": 185
- },
- {
- "page_link": "https://docs.plural.sh/operations/cluster-configuration",
- "title": " Cluster Configuration",
- "text": "# Cluster Configuration\n\nDevOps workflows that involve editing your cluster's Terraform files.\n\nPlural offers a set of sane defaults to spin up a one-size-fits-all Kubernetes cluster, but there will be cases where you'll want to edit the default cluster configuration to better fit your organization's needs. This will involve editing the Terraform that we generate for you, which carries risks if administered incorrectly.\n\nIn general, all core cluster configuration is set up in a Terraform stack in the bootstrap app directory. You can find the Terraform code under bootstrap/terraform if you want to dive in yourself, but we can help guide you here as well.\n\n## Operations on node groups\n\n[](/operations/cluster-configuration#operations-on-node-groups)\n\n### Modifying node types\n\n[](/operations/cluster-configuration#modifying-node-types)\n\nModifying node types allows you to optimize the infrastructure backing your applications for cost and/or performance reasons.\n\nOn AWS, EKS has some interesting limitations around node groups. Since EBS doesn't support multi-AZ disks, to make node autoscaling work properly for stateful workloads, you need to split node groups across all availability zones deployed in a region. Some non-stateful workloads don't need this complexity, so we also have a set of multi-AZ groups as well. To modify either, simply update the aws-bootstrap module's single_az_node_groups or multi_az_node_groups configuration (in bootstrap/terraform/main.tf) with:\n\n```\nsingle_az_node_groups = {\n my_node_group = {\n name = \"my-node-group\"\n capacity_type = \"ON_DEMAND\" # or SPOT\n min_capacity = 3\n desired_capacity = 3\n instance_types = [\"t3.large\", \"t3a.large\"] # or whatever other types you'd like\n k8s_labels = {\n \"plural.sh/capacityType\" = \"ON_DEMAND\"\n \"plural.sh/performanceType\" = \"BURST\"\n \"plural.sh/scalingGroup\" = \"small-burst-on-demand\"\n } # kubernetes labels are good for targeting workloads\n}\n```\n\nfor multi-AZ groups you can do the following:\n\n```\nmulti_az_node_groups = {\n my_node_group = {\n name = \"my-node-group\"\n capacity_type = \"SPOT\"\n instance_types = [\"t3.large\", \"t3a.large\"]\n k8s_labels = {\n \"plural.sh/capacityType\" = \"SPOT\"\n \"plural.sh/performanceType\" = \"BURST\"\n \"plural.sh/scalingGroup\" = \"small-burst-spot\"\n }\n k8s_taints = [{\n key = \"plural.sh/capacityType\"\n value = \"SPOT\"\n effect = \"NO_SCHEDULE\"\n }] # taints prevent a node from being schedulable unless a pod explicitly accepts it, good for preventing spot instances from being accidentally used\n }\n}\n```\n\nOn GCP, update the gcp-bootstrap modules configuration (in bootstrap/terraform/main.tf) with:\n\n```\nnode_pools = [\n {\n name = \"small-burst-on-demand\"\n machine_type = \"e2-standard-2\" # or whatever you'd like\n min_count = 1\n max_count = 9\n disk_size_gb = 50\n disk_type = \"pd-standard\"\n image_type = \"COS_CONTAINERD\"\n spot = false\n auto_repair = true\n auto_upgrade = true\n preemptible = false\n initial_node_count = 1\n autoscaling = true\n }\n]\n# if you'd like to add lables\nnode_pools_labels = {\n \"small-burst-on-demand\" = {\n \"plural.sh/capacityType\" = \"ON_DEMAND\"\n \"plural.sh/performanceType\" = \"BURST\"\n \"plural.sh/scalingGroup\" = \"small-burst-on-demand\"\n }\n}\n# if you'd also like to add taints\nnode_pools_taints = {\n small-burst-spot = [\n {\n key = \"plural.sh/capacityType\"\n value = \"SPOT\"\n effect = \"NO_SCHEDULE\"\n },\n ],\n}\n```\n\nCurrently Azure has an annoying chicken-egg issue with the requirement that at least one node pool must be created. Terraform manages this poorly by forcing cluster recreation if the default node pool changes. To ensure no instability, we strongly recommend you confirm any node topology changes do not interfere with the default node pool on the AKS cluster.\n\nWith Azure, update the azure-bootstrap modules configuration in bootstrap/terraform/main.tf with:\n\n```\nnode_groups = [\n {\n name = \"ssod1\"\n priority = \"Regular\"\n enable_auto_scaling = true\n availability_zones = [\"1\"]\n mode = \"System\"\n node_count = null\n min_count = 1\n max_count = 9\n spot_max_price = null\n eviction_policy = null\n vm_size = \"Standard_D2as_v5\"\n os_disk_type = \"Managed\"\n os_disk_size_gb = 50\n max_pods = 110\n\n node_labels = {\n \"plural.sh/capacityType\" = \"ON_DEMAND\"\n \"plural.sh/performanceType\" = \"SUSTAINED\"\n \"plural.sh/scalingGroup\" = \"small-sustained-on-demand\"\n } # or whatever labels you'd prefer\n node_taints = [\n # \"someTaintName\"\n ]\n tags = {\n \"ScalingGroup\": \"small-sustained-on-demand\"\n }\n }\n]\n```\n\n## Adding users/roles [AWS]\n\n[](/operations/cluster-configuration#adding-users-roles-aws)\n\nBecause of the limitations set by AWS' IAM authenticator, you'll need to follow this process to add new users or roles to a cluster running in AWS.\n\nAdd these input to aws-bootstrap in bootstrap/terraform/main.tf\n\n```\nmap_users = [\n {\n userarn = \"arn:aws:iam:::user/yourusername\"\n username = \"yourusername\"\n groups = [\"system:masters\"] # or whatever k8s group you'd prefer\n }\n ]\n\n# if you'd rather authenticate with an IAM role (a recommended approach), add this block\nmanual_roles = [\n {\n rolearn = \"arn:aws:iam:::role/yourrolename\"\n username = \"yourrolename\"\n groups = [\"system:masters\"]\n }\n]\n```\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/cluster-configuration.md)",
- "source_links": [],
- "id": 186
- },
- {
- "page_link": "https://docs.plural.sh/operations/cost-management",
- "title": " Cost Optimization",
- "text": "# Cost Optimization\n\nControlling the cost of your cluster and applications.\n\nOut of the box, Plural performs a lot of optimizations behind the scenes with our built-in autoscaler that schedules workloads efficiently across your infrastructure. However, there are some efforts you can make to monitor and optimize this cost.\n\n## Console Scaling Recommendations\n\n[](/operations/cost-management#console-scaling-recommendations)\n\nThe Plural Console offers scaling recommendations for certain apps, some of which can be immediately applied from the Console.\n\nTo do this, select your desired application from the Application Overview tab and then click on the Components tab in the sidebar on the left. Then click on the specific component you want to get recommendations for and you will see a Scaling button in the top right.\n\nWhen you click on the Scaling button, if you see Apply in the bottom right, you can immediately enforce the recommendations given by Plural.\n\n## Node Optimization\n\n[](/operations/cost-management#node-optimization)\n\n### Helping the Autoscaler\n\n[](/operations/cost-management#helping-the-autoscaler)\n\nThe Plural autoscaler does a good job of scheduling new Pods and resources onto nodes that can handle the extra workload, but cannot delete Pods, as it could lead to potentially destructive scenarios. Because of this, you may end up with imbalanced nodes that are overworked or underworked.\n\nTo address this, you'll need the Plural Console installed. Head to the Nodes tab in the sidebar on the left of the Console. Here, you'll see the utilization of resources for all of your nodes. You are looking for nodes that are overworked or underworked, which can be observed by seeing if cpu and/or memory is in the red (overworked) or close to zero and green (underworked).\n\nTo delete these nodes, hit the red trash can symbol to the right of the problematic node and it will deprovision, letting the autoscaler schedule the Pods it was running on a different node.\n\n###### Info:\n\nAs with any operations that involve taking down resources, you will likely encounter a small amount of downtime as your resources get rescheduled.\n\n### Node Sizing at Scale\n\n[](/operations/cost-management#node-sizing-at-scale)\n\nIf you deploy a lot of applications and resources, you may start seeing cost go up faster than expected due to the fixed cost of installing Kubernetes and its services on every node. This fixed Kubernetes tax per node varies based on your cloud provider. Essentially, if a small node is used, it will be a higher percentage of your usage than a large node, making the cost differences more evident at large scale with small node sizes.\n\nTo control this, it is recommended that you increase your node sizes to accommodate more resources and applications per node, reducing the amount of times you're paying the fixed cost for running Kubernetes. Learn how to modify your node types here.\n\n[here](/operations/cluster-configuration#modifying-node-types)\n\n## Kubecost\n\n[](/operations/cost-management#kubecost)\n\nTo monitor your cost and keep an eye out for spend, you can install Kubecost on Plural just how you would install any other application. Check out their documentation here.\n\n[Kubecost](/applications/kubecost)\n\n[here](https://docs.kubecost.com/)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/cost-management.md)",
- "source_links": [],
- "id": 187
- },
- {
- "page_link": "https://docs.plural.sh/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console",
- "title": " Creating a DNS Zone in Console",
- "text": "# Creating a DNS Zone in Console\n\nSign in to the AWS Management Console and open the Route 53 console at https://console.aws.amazon.com/route53/.\n\n[https://console.aws.amazon.com/route53/](https://console.aws.amazon.com/route53/)\n\nIf you're new to Route 53, choose Get started under DNS management, and then choose Create hosted zones.\n\nIf you're already using Route 53, choose Hosted zones in the navigation pane, and then choose Create hosted zones.\n\nIn the Create hosted zone pane, enter a newly registered domain (eg pluraldemo.com), or a subdomain (eg, plural.pinterest.com ).\n\nFor Type, accept the default value of Public hosted zone.\n\nChoose Create hosted zone.\n\nNow in the navigation pane, click Hosted zones. On the Hosted zones page, choose the radio button (not the name) for the hosted zone, then choose View details.\n\nOn the details page for the hosted zone, choose Hosted zone details. Make note of the four servers listed for Name servers. You will need these records to proceed with Step 3.\n\nIn your Google Cloud Console, go to your Plural project and enable the Cloud DNS API.\n\n[enable the Cloud DNS API](https://console.cloud.google.com/flows/enableapi?apiid=dns&_ga=2.143906805.1313565175.1629139974-335821397.1624570886)\n\nIn your Google Cloud Console, go to the Create a DNS zone page.\n\nGo to Create a DNS zone\n\n[Go to Create a DNS zone](https://console.cloud.google.com/networking/dns/zones/~new)\n\nFor the Zone type, select Public.\n\nFor the Zone name, enter an appropriate string.\n\nFor the DNS name, enter a DNS name for the zone , enter a newly registered domain (eg pluraldemo.com), or a subdomain (eg, plural.pinterest.com ).\n\nUnder DNSSEC, ensure that the Off setting is selected.\n\nClick Create to create a zone populated with the NS and SOA records.\n\nOn the Zone details page, retrieve the Name server (NS) records. You need these records to proceed with Step 3.\n\n\n\n#### \n\n[](/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console#_)\n\nName: The DNS zone name can be any value that is not already configured on the Azure DNS servers. A real-world value would be a newly registered domain (eg pluraldemo.com), or a subdomain (eg, plural.pinterest.com ).Resource group: Select Create new, enter MyResourceGroup, and select OK. The resource group name must be unique within the Azure subscription.\n\n\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console.md)",
- "source_links": [],
- "id": 188
- },
- {
- "page_link": "https://docs.plural.sh/operations/dns-setup",
- "title": " Configuring DNS",
- "text": "# Configuring DNS\n\nRegistering and setting up a domain\n\n## Articles in this section:\n\nCreating a DNS Zone in Console\n\n[Creating a DNS Zone in Console](/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console)\n\n#### 1. Register a Domain Name\n\n[](/operations/dns-setup#_1-register-a-domain-name)\n\nThis domain name, eg pluraldemo.com can be registered with any registrar, for example Google Domains, GoDaddy, or Namecheap.\n\n#### 2. Create a DNS Zone in Your Cloud Provider Console Corresponding to the registered Domain Name\n\n[](/operations/dns-setup#_2-create-a-dns-zone-in-your-cloud-provider-console-corresponding-to-the-registered-domain-name)\n\nFollow the instructions for creating a DNS Zone named pluraldemo.com within the DNS service of your cloud provider.\n\n[the instructions](/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console)\n\nRecord the nameservers corresponding to this zone.\n\n#### 3. Update name servers\n\n[](/operations/dns-setup#_3-update-name-servers)\n\nGo back to where you registered pluraldemo.comand add the nameservers from Step 2 as \"custom nameservers\" under its DNS configuration.\n\n###### Info:\n\nThe domain name registrars will typically provide default name servers and also the ability to set up custom name servers. For example, in Google Domains, you can set custom name servers under the DNS tab once you click into a specific domain name.\n\n\n\nThe more likely scenario is that you will have an existing company domain, i.e. pinterest.com and you will want to create a subdomain under which you can consolidate all your plural applications, eg plural.pinterest.com\n\n#### 1. Create DNS Zone in Your Cloud Provider Console\n\n[](/operations/dns-setup#_1-create-dns-zone-in-your-cloud-provider-console)\n\nFollow the instructions for creating a DNS Zone named plural.pinterest.com within the DNS service of your cloud provider.\n\n[the instructions](/operations/dns-setup/creating-dns-zone-in-your-cloud-provider-console)\n\nRecord the nameservers corresponding to this zone.\n\n#### 2. Create NS Record\n\n[](/operations/dns-setup#_2-create-ns-record)\n\nGo back to where you registered pinterest.com and add a NS record that corresponds to the plural.pinterest.com subdomain -- for the data field of the record, input the nameservers from step 1.\n\n\n\nThese are the terraform snippets for reference:\n\n```\nresource \"aws_route53_zone\" \"test\" {\n name = \"plural.pinterest.com\"\n\n tags = {\n Environment = \"test\"\n }\n}\n\nresource \"aws_route53_record\" \"test-ns\" {\n zone_id = data.aws_route53_zone.main.zone_id\n name = \"plural.pinterest.com\"\n type = \"NS\"\n ttl = \"30\"\n records = aws_route53_zone.test.name_servers\n}\n```\n\n# Configuring Externaldns for your cluster\n\n[](/operations/dns-setup#configuring-externaldns-for-your-cluster)\n\nThere are two ways this can be done:\n\nfor a new clusterfor an existing cluster using plural's dns service you want to switch over\n\n## Fresh Cluster\n\n[](/operations/dns-setup#fresh-cluster)\n\nFor a fresh cluster, you'll be prompted in plural init whether you want to enable plural dns. Simply answer no, provide the subdomain you created above, and we'll configure externaldns correctly for you from the start.\n\n## Existing Plural Cluster\n\n[](/operations/dns-setup#existing-plural-cluster)\n\nFor existing clusters, there's a bit of cleanup you'll need to do to reconfigure from plural dns. You'll want to edit the workspace.yaml file at the root of your repo to set false to the pluralDns entry. You'll also want to rewire the subdomain to point to your new subdomain so domain validation works in the future.\n\nAdditionally, in the context.yaml file, there will likely be a number of dns entries in the configuration for your apps, you'll want to move those to the new subdomain as well (the old plural dns records will still work during this transition).\n\nOnce all this is done, you can reconfigure all the helm charts with plural build then run plural deploy to apply them.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/dns-setup/index.md)",
- "source_links": [],
- "id": 189
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/add-application-to-cluster",
- "title": " Add Applications to your Cluster",
- "text": "# Add Applications to your Cluster\n\nHow to install additional applications to a running Plural cluster\n\nTo add a new application to your Plural cluster, you can use either the Cloud Shell or CLI (depending on your setup) or install directly from the Plural Console.\n\n## Install from the Cloud Shell\n\n[](/operations/managing-applications/add-application-to-cluster#install-from-the-cloud-shell)\n\nIf you originally set up your Plural cluster with the in-browser Cloud Shell option, you can easily add new installations from within the Cloud Shell. Navigate to the Cloud Shell tab and click the \"Install\" button in the left-hand pane.\n\n\n\nThis will re-launch your Install Wizard, where you can configure and deploy new applications. For more detailed information on the Install Wizard, refer to the In-Browser setup guide.\n\n[In-Browser setup guide](/getting-started/cloud-shell-quickstart)\n\nIf for any reason your deployment fails, try rebuilding and redeploying the application by clicking \"Rebuild\" from the installed apps dropdown.\n\n\n\n## Install from the CLI\n\n[](/operations/managing-applications/add-application-to-cluster#install-from-the-cli)\n\nIf you originally set up your Plural cluster with the local CLI, you can add new installations with a CLI command.\n\nRun plural bundle list to find installation commands and information about each application available for install.\n\nTo install applications on Plural, run:\n\n```\nplural bundle install \n```\n\nAs of CLI version 0.6.19, the bundle name can be inferred from primary bundles, optionally shortening the command to:\n\n```\nplural bundle install console\n```\n\nAfter running the install command, you will be asked a few questions about how your app will be configured, including whether you want to enable Plural OIDC (single sign-on).\n\nWith all new bundles installed, run:\n\n```\nplural build\nplural deploy --commit \"added new applications\"\n```\n\nOnce plural deploy has completed, you should be ready to log in to your application at {app-name}.{domain-name}.\n\n## Install from the Plural Console\n\n[](/operations/managing-applications/add-application-to-cluster#install-from-the-plural-console)\n\nYou can also easily install new applications from the Plural Console associated with a given cluster. Navigate to your Console and click the \"Install\" button in the top right corner.\n\n\n\nThis will bring up the in-Console Install Wizard, where you can configure and deploy new applications. Once you're done configuring, you can track the deployment of your new apps from the Builds page.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/add-application-to-cluster.md)",
- "source_links": [],
- "id": 190
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/add-users-to-application",
- "title": " Add Users to an Application",
- "text": "# Add Users to an Application\n\nHow to give end users access to an application installed using Plural.\n\nIf you've enabled OIDC for a set of applications, you can easily give users or groups access to that application. To enable access to a particular application, you can add permissions via the App Settings for a specific cluster or from the Plural Console. Any changes made in either location will be synced.\n\n## Through Plural App Settings\n\n[](/operations/managing-applications/add-users-to-application#through-plural-app-settings)\n\nAdmin users who have installed an application have the ability to add users to that application. To add users, navigate to the installed application from your Clusters Overview page. Click the three dots on the application and select \"App settings\" in the menu. Select OpenID Connect from the sidebar on the left, and add any new users or groups and click \"Save\" in the bottom right.\n\n\n\n## Through Plural Console\n\n[](/operations/managing-applications/add-users-to-application#through-plural-console)\n\nAny Plural Console user with permissions to manage users and groups can add users to any installed application. Navigate to the Plural Console and select your application from the Application Overview tab. Click the \"User management\" option from the menu on the left. This allows you to search for additional user or group bindings to add for access. Add any new users or groups and click \"Update\" in the bottom right.\n\n\n\nFor applications not using OIDC, permissions are managed through the individual applications.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/add-users-to-application.md)",
- "source_links": [],
- "id": 191
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/bounce-application",
- "title": " Bounce an Application",
- "text": "# Bounce an Application\n\nHow to restart an application to pull in new changes or troubleshoot.\n\nTo bounce an application, you can either:\n\nRun plural bounce in the CLI or Cloud ShellGo to the Plural Console, select your application in the top right, then click the Bounce button on the Console home page (Builds).\n\n## When to bounce an application\n\n[](/operations/managing-applications/bounce-application#when-to-bounce-an-application)\n\nBouncing an application restarts the appropriate running software in your cloud provider. You may need to bounce an installed application for reasons including:\n\nApplying changes to an application that require a redeployResolving transient errors in deploymentResolving transient errors with your cloud providerRefreshing the Plural Console to get an updated view of your repository\n\nEspecially perceptive users may notice that behind the scenes, plural bounce runs helm upgrade with some special arguments.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/bounce-application.md)",
- "source_links": [],
- "id": 192
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/connect-application-db",
- "title": " Connect to an Application DB",
- "text": "# Connect to an Application DB\n\nHow to connect to the underlying database for a deployed application.\n\nFor various reasons, you may want to connect to the underlying database for an application. This could be for routine operations, verifying state, or for surgical procedures.\n\n## Connecting with the Plural CLI\n\n[](/operations/managing-applications/connect-application-db#connecting-with-the-plural-cli)\n\nYou can list all possible proxies for an application by running:\n\n```\nplural proxy list \n```\n\nYou can connect directly to the database with the following command:\n\n```\nplural proxy connect db\n```\n\n## Connecting with the Plural Console\n\n[](/operations/managing-applications/connect-application-db#connecting-with-the-plural-console)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/connect-application-db.md)",
- "source_links": [],
- "id": 193
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/credentials-non-oidc",
- "title": " Find Credentials for non-OIDC Applications",
- "text": "# Find Credentials for non-OIDC Applications\n\nSurface creds for applications without OIDC enabled\n\nIf you need to find credentials for an application that does not have OIDC enabled, run the following command in either the Cloud Shell or CLI:\n\n```\nplural info \n```\n\nThis will surface credentials and any other useful information about the application.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/credentials-non-oidc.md)",
- "source_links": [],
- "id": 194
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/customize-application",
- "title": " Customize an Application",
- "text": "# Customize an Application\n\nHow to tailor application configuration\n\nIf you need to modify the Helm or Terraform for a given application, you can do so directly from the Plural Console. Navigate to the application you want to update, and click the Configuration sub-tab.\n\n\n\nAdd or update your configuration, and click \"Commit\" in the bottom right corner to save your changes.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/customize-application.md)",
- "source_links": [],
- "id": 195
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/delete-application",
- "title": " Delete an Application",
- "text": "# Delete an Application\n\nHow to uninstall your Plural applications.\n\nTo uninstall applications run the following command in the CLI or Cloud Shell:\n\n```\nplural destroy \n```\n\nThis will:\n\nDestroy all Terraform resourcesBring down application in your cloudEmpty the Kubernetes namespace associated with your application\n\nThis will not:\n\nRemove application builds from your local Plural Git repositoryRemove application configuration values from context.yaml (you are prompted on whether to do this during the destroy process)\n\nWe don't remove certain information as it contains required configuration for spinning up the same instance again. If we removed that information, you would be unable to restore an application after destroying it.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/delete-application.md)",
- "source_links": [],
- "id": 196
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications",
- "title": " Managing Applications",
- "text": "# Managing Applications\n\nGuides to accomplishing day-to-day management of your installed Plural applications.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/index.md)",
- "source_links": [],
- "id": 197
- },
- {
- "page_link": "https://docs.plural.sh/operations/managing-applications/update-application",
- "title": " Update an Application",
- "text": "# Update an Application\n\nHow to change an application's version.\n\nUpdates to Plural applications are applied automatically based on a per-application setting. This setting supports telling Plural to only upgrade for Stable or Warm releases, as well as disabling automatic upgrades altogether. Here's what each of the settings mean:\n\nLatest: Everytime the Plural team tests and publishes a new release, you receive it.Stable: You only receive versions that have passed a set of Plural determined tests.None: You never receive automatic updates and have to manually update your application versions or change this setting.\n\nYou can change this setting in the App settings menu, accessible from each cluster's details page. You can dive into each cluster from the Clusters Overview page https://app.plural.sh/overview/clusters.\n\n[https://app.plural.sh/overview/clusters](https://app.plural.sh/overview/clusters)\n\n\n\n## Rollback to a previous version\n\n[](/operations/managing-applications/update-application#rollback-to-a-previous-version)\n\nThis requires having the Plural Console installed. We'll need this to create an upgrade policy that tells Plural to not deploy an upgrade to your application, which is normally performed automatically unless disabled using the setting in our app. You could just disable upgrades altogether in the application as stated above, but then you'd lose out on easy upgrade delivery later.\n\n[Plural Console installed](/getting-started/admin-console)\n\nFirst, navigate to the Plural Console and select the Builds tab.\n\nClick on the gear icon in the top right to enter the Upgrade Policy section and then click Create More.\n\nHere is an example for a policy that will require approval before runninng plural deploy for Airflow.\n\n\n\nThen head back to our marketplace, go to the repository page for your installed application, and click the Packages section in the sidebar. This will allow you to pick Helm charts and Terraform modules that correspond to previously deployed versions of your application.\n\n[marketplace](https://app.plural.sh/marketplace)\n\nOnce you click on the Helm chart, the associated application version for the Helm chart is displayed in the CHART.YAML section on the right. On the left will be a drop-down menu showing which version you are currently on. Scroll through the chart versions to find the application version that you want to rollback to. Then click Install in the top right.\n\nWe'll be honest. This process isn't ideal, so we're working on a simple rollback command in our CLI.\n\n## How Plural updates app versions\n\n[](/operations/managing-applications/update-application#how-plural-updates-app-versions)\n\nWe use a tool called Renovate to automate the updating of application version images. Renovate creates pull requests against our plural-artifacts GitHub repository to perform these updates on a regular basis. Here is an example of one of those PRs.\n\n[Renovate](https://github.com/renovatebot/renovate)\n\n[Here](https://github.com/pluralsh/plural-artifacts/pull/236)\n\nOnce we have tried out the changes and have confirmed that the new version is stable, we will merge the PR and the change will be available for all Plural installations to pull down when they wish to.\n\nOccasionally, we do manually update these versions to pull in application changes more quickly. If a current version is breaking user workflows or if a new version of an application is heavily requested, we will manually perform this operation.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/managing-applications/update-application.md)",
- "source_links": [],
- "id": 198
- },
- {
- "page_link": "https://docs.plural.sh/operations/network-configuration",
- "title": " Network Configuration",
- "text": "# Network Configuration\n\nIn your infrastructure, Plural will create a VPC, a public ingress controller, and a private ingress controller. Sometimes your organization or project will want to change our networking defaults to better suit your deployment.\n\n## VPC Subnet configuration\n\n[](/operations/network-configuration#vpc-subnet-configuration)\n\nYou\u2019ll want to overwrite our default subnet configuration if you need to add the VPC that Plural creates to any adjacent VPCs/networks in your infrastructure.\n\nFrequently, VPC peering APIs require all subnets to be non-overlapping, which isn't guaranteed from our defaults. This can always be updated in bootstrap/terrraform/main.tf (As a reference, CIDR blocks follow this format: 10.xx.xx.xx/yy, the examples below are placeholders.)\n\nOn AWS, update the aws-bootstrap modules configuration with:\n\n```\npublic_subnets = [\"your.cidr.pub.1\", \"your.cidr.pub.2\", \"your.cidr.pub.3\"]\nprivate_subnets = [\"your.cidr.priv.1\", \"your.cidr.priv.2\", \"your.cidr.priv.3\"]\nworker_private_subnets = [\"your.cidr.worker.1\", \"your.cidr.worker.2\", \"your.cidr.worker.3\"]\n```\n\nOn GCP, update the gcp-bootstrap modules configuration with:\n\n```\nvpc_subnetwork_cidr_range = \"your.cidr\"\n\n# you might also want to update cluster_secondary_range_cidr\n# and services_secondary_range_cidr\n```\n\nWith Azure, update the azure-bootstrap modules configuration with:\n\n```\naddress_space = \"your.cidr\"\nsubnet_prefixes = [\"your.cidr.pref\"]\n```\n\n###### Warning:\n\nNote that updating these will likely cause the VPC to be replaced, which will recreate your cluster. We recommend that you destroy your cluster before applying network config modifications to it.\n\n[destroy your cluster](/operations/uninstall)\n\n## Configuring VPC Peering\n\n[](/operations/network-configuration#configuring-vpc-peering)\n\nPlural creates a fresh VPC and Kubernetes cluster for deploying applications. This ensures that we have a clean environment to deploy into and minimizes disruption to existing systems. It does come with the tradeoff of slightly increased network complexity, but most cloud providers can bridge this using VPC peering. This is a technology that effectively allows you to combine the address spaces of two VPCs in the cloud you operate in.\n\nThere is a caveat: the VPCs should have no overlapping subnets in addition to some other complexities per cloud provider. Refer to the guide above on subnet configuration before proceeding.\n\nPlural makes it easy to add additional Terraform to the stacks we generate. Effectively, as long as you don\u2019t modify the [main.tf](http://main.tf) file at the root of a Terraform folder, or any of the module folders, we\u2019ll preserve your Terraform between builds and apply it for you appropriately as changes arise. For configuring a VPC peer, let\u2019s create a new Terraform file called [network.tf](http://network.tf) and drop the configuration in there for your respective cloud:\n\n```\nresource \"aws_vpc_peering_connection\" \"foo\" {\n peer_owner_id = \"my-owner-id\" # Use appropriate values here.\n peer_vpc_id = \"peer-vpc-id\"\n vpc_id = module.aws-bootstrap.vpc.id\n}\n```\n\n```\ndata \"google_compute_network\" \"peer\" {\n name = \"peer-network\"\n}\n\nresource \"google_compute_network_peering\" \"peering1\" {\n name = \"plrl-peer\"\n network = module.gcp-bootstrap.vpc_network.self_link\n peer_network = data.google_compute_network.peer.self_link\n}\n```\n\n```\ndata \"azure_rm_virtual_network\" \"peer\" {\n resource_group_name = \"your-azure-resource-group\" # Use appropriate values here.\n name = \"peer-network-name\"\n}\n\nresource \"azurerm_virtual_network_peering\" \"example-1\" {\n name = \"plrl-peer\"\n resource_group_name = \"your-azure-resource-group\"\n virtual_network_name = module.azure-bootstrap.network.name\n remote_virtual_network_id = data.azurerm_virtual_network.peer.id\n}\n```\n\n###### Warning:\n\nAs mentioned earlier, consult the section on customizing subnets to ensure your vpc subnets don\u2019t overlap when attempting to peer to existing networks.\n\n## Adding an IP Allowlist to the Public Ingress Controller\n\n[](/operations/network-configuration#adding-an-ip-allowlist-to-the-public-ingress-controller)\n\nPlural ships with two ingress controllers, both using the open-source ingress-nginx project. Some users might want to restrict what IPs the public ingress is available on. For example, this is required for locking it down to an office VPN. We can implement this by updating Kubernetes' loadBalancerSourceRanges attribute on LoadBalancer services. To configure this, head to your Plural repository and modify ingress-nginx/helm/ingress-nginx/values.yaml by overlaying:\n\n[ingress-nginx](https://github.com/kubernetes/ingress-nginx)\n\n```\ningress-nginx:\n ingress-nginx:\n controller:\n service:\n loadBalancerSourceRanges:\n - cidr.1\n - cidr.2\n annotations:\n # this is only needed for aws\n service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: preserve_client_ip.enabled=true\n```\n\nOnce that\u2019s updated, run plural deploy --commit \"adding ip allowlist\" and it will update the service for you and push the changes upstream to your git repository.\n\nFor many users this will be sufficient, but some may prefer the application not have a public network address at all. In this case, check out the next section on using our private ingress controller.\n\n## Using our Private Ingress Controller\n\n[](/operations/network-configuration#using-our-private-ingress-controller)\n\nIf you only want your application directly addressable on a private network via ingress, e.g. if simply allowlisting source IPs is not secure enough for you, you can rewire an application to use our internal ingress controller. In general, you need to do a little diving to find exactly how the application\u2019s Helm chart configures its ingresses, and modify it to wire in the internal-nginx ingress class. Then run plural deploy --commit \"update app to use private ingress\" and it\u2019ll apply for you.\n\nLet's use Dagster as an example. To make Dagster only use the private ingress, apply this yaml on dagster/helm/dagster/values.yaml:\n\n```\ndagster:\n dagster:\n ingress:\n annotations:\n kubernetes.io/ingress.class: 'internal-nginx'\n```\n\nSometimes an application will require you to update an attribute called ingressClass. This will depend on whether the Helm chart is still using the legacy annotation-based ingress class flag or if it has migrated to the new first-class spec field.\n\nWe\u2019ll also build out configuration overlays in our console in the \u201cConfiguration\u201d tab to edit these, so you don\u2019t have to scavenge for the exact yaml update to do this, although that\u2019s still WIP.\n\n###### Warning:\n\nWe\u2019ve occasionally seen it take some time for the ingress controllers to swap classes. If you want to accelerate that, you can run kubectl delete ingress -n then plural bounce to speed things along. You can usually find the ingresses in the components tab in our console.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/network-configuration.md)",
- "source_links": [],
- "id": 199
- },
- {
- "page_link": "https://docs.plural.sh/operations/pricing-calculator",
- "title": " Pricing Calculator",
- "text": "# Pricing Calculator\n\nEstimate the costs of using Plural to running the applications and configuration you need for your business with our Pricing Calculator.\n\n###### Info: How do we calculate cloud costs?\n\nBy default, Plural deploys the following on a given provider:\n\nThe Kubernetes control plane3 nodes, each with 2 cores / 8GB\n\nEach initial deployment has a certain amount of headroom for installing applications and will scale accordingly as more are added. Costs to Plural are calculated based on which plan is chosen; Plural Professional is priced by the number of users and clusters.\n\n###### Info: What is a cluster?\n\nA cluster is a set of worker machines (called nodes) that run containerized applications. A single cluster can contain many different applications that work together to perform various workflows. A single cluster is often sufficient for getting started, but it can be beneficial in some circumstances to have multiple clusters running (e.g., a development and production cluster).\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/pricing-calculator.md)",
- "source_links": [],
- "id": 200
- },
- {
- "page_link": "https://docs.plural.sh/operations/security",
- "title": " Security Concepts",
- "text": "# Security Concepts\n\nLearn about what Plural has access to at various steps of deployment.\n\n## Cloud Access\n\n[](/operations/security#cloud-access)\n\n### Plural CLI\n\n[](/operations/security#plural-cli)\n\nPlural does not have access to any cloud environments when deployed through the CLI. We generate deployment manifests in the Plural Git repository and then use your configured cloud provider's CLI on your behalf. We cannot perform anything outside of deploying and managing the manifests that are created in your Plural Git repository.\n\n### Plural Cloud Shell\n\n[](/operations/security#plural-cloud-shell)\n\nPlural does have access to your cloud credentials when deployed through the Cloud Shell. In order to streamline the Cloud Shell experience, we securely store cloud credentials to create resources on your behalf. You can eject from the Cloud Shell to the CLI at any time to save your configuration and revoke our access. This is done with the following steps:\n\n[Install the Plural CLI](/getting-started/quickstart)\n\n## Plural Console\n\n[](/operations/security#plural-console)\n\nOur console has elevated permissions when running in your Plural Kubernetes cluster, but it runs in its own environment to alleviate security concerns. Its permissions are required in order to listen for new versions of packages to apply automated updates to your applications.\n\n## GitHub\n\n[](/operations/security#github)\n\nWhen using the CLI or Cloud Shell, Plural will receive the following permissions:\n\nCreate GitHub repositories on your behalfCommit changes to repositories that Plural has created\n\nPlural does not have access to repositories that have not been created by Plural.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/security/index.md)",
- "source_links": [],
- "id": 201
- },
- {
- "page_link": "https://docs.plural.sh/operations/uninstall",
- "title": " Destroying the Cluster and Installations",
- "text": "# Destroying the Cluster and Installations\n\nHow do I bring things down safely?\n\n## Overview\n\n[](/operations/uninstall#overview)\n\nPlural provides options to uninstall specific applications, tear down your clusters, and wipe any references to installations to start from zero. Uninstalling any Plural application or an entire Plural installation is a one-liner in your terminal or Cloud Shell. If you want to delete your Plural installation, make sure to run plural destroy before deleting your Git repository. If you delete your Git repository first, you will have to manually clean up all the resources that Plural has provisioned for you.\n\n## Purging the Cloud Shell\n\n[](/operations/uninstall#purging-the-cloud-shell)\n\nIf you created a Plural installation in our Cloud Shell and want to move it to your local dev environment, you can sync your shell and delete the Cloud Shell instance from our servers. To sync your shell and delete your current Cloud Shell instance, use:\n\n```\nplural shell sync\nplural shell purge\n```\n\nThe purge command will destroy your current Cloud Shell instance, but preserve your existing cluster and installations. Your account will still be pinned to the same cloud provider chosen at the beginning of your onboarding.\n\n## Uninstalling Individual Applications\n\n[](/operations/uninstall#uninstalling-individual-applications)\n\nTo uninstall specific applications, use:\n\n```\nplural destroy \n```\n\nThis will do things like destroying terraform resources and emptying k8s namespaces, but it won't remove the application builds from your local repo, or the application configuration values from context.yaml.\n\n## Uninstalling your Entire Installation\n\n[](/operations/uninstall#uninstalling-your-entire-installation)\n\nTo uninstall your entire Plural installation and Kubernetes cluster, run:\n\n```\nplural destroy\n```\n\n###### Danger:\n\nOnly do this if you're absolutely sure you want to bring down all associated resources with this repository.\n\nBy default, previously installed applications will still appear in your installed applications page on app.plural.sh after running plural destroy. To remove all installation history, run plural repos reset as documented below.\n\n[installed applications](https://app.plural.sh/installed)\n\n## Terraform Destroy\n\n[](/operations/uninstall#terraform-destroy)\n\nTo tear down the current cluster but leave installation references as pointers to the Helm/Terraform, cd into bootstrap/terraform and run:\n\n```\nterraform destroy\n```\n\n## Remove Installation References\n\n[](/operations/uninstall#remove-installation-references)\n\nBy default, app.plural.sh will retain your list of \u201cinstalled apps\u201d. After running plural destroy, if you also want to remove your installation history on app.plural.sh you can run:\n\n```\nplural repos reset\n```\n\nThis command does not interact with any infrastructure, but removes references to all installations. This will also reset any association with a specific cloud provider.\n\n## Fully Start Over\n\n[](/operations/uninstall#fully-start-over)\n\nTo tear down a cluster and fully start over, run plural destroy and then plural repos reset.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/operations/uninstall.md)",
- "source_links": [],
- "id": 202
- },
- {
- "page_link": "https://docs.plural.sh/reference/api/console-api",
- "title": " Console API",
- "text": "# Console API\n\nWhile the console API is not public facing, it's still available for you to explore and use if you wish. It has a built-in graphql interface like Plural itself, accessible at https://console.domain.com/graphiql, with the actual graphql api available at https://console.domain.com/gql.\n\n[https://console.domain.com/graphiql](https://console.domain.com/graphiql)\n\n[https://console.domain.com/gql](https://console.domain.com/gql)\n\nThe console does not have an API key system like Plural does, so you'll need to pull out a bearer token from the web app to interact with it directly. You can find this by just looking at the Authorization headers for gql requests in chrome inspector.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/api/console-api.md)",
- "source_links": [],
- "id": 203
- },
- {
- "page_link": "https://docs.plural.sh/reference/api",
- "title": " API / Developer Tools",
- "text": "# API / Developer Tools\n\n## Articles in this section:\n\nPlural APIConsole API\n\n[Plural API](/reference/api/plural-api)\n\n[Console API](/reference/api/console-api)\n\nPlural has two main components, each with their own graphql API:\n\nPlural - available at https://app.plural.sh/gqlPlural Console - deployable in any plural kubernetes cluster, and accessible at https://console.domain.com/gql\n\n[Plural](https://app.plural.sh/graphiql)\n\n[Plural Console](https://app.plural.sh/repository/a051a0bf-61b5-4ab5-813d-2c541c83a979)\n\nEach have a graphiql dashboard which can be used to play around at will with the APIs. You can also use the schema explorer to view all the data types and query/mutation fields available for whatever automation you'd like to build.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/api/index.md)",
- "source_links": [],
- "id": 204
- },
- {
- "page_link": "https://docs.plural.sh/reference/api/plural-api",
- "title": " Plural API",
- "text": "# Plural API\n\nYou can explore the plural API in more depth using our graphiql console, viewable at https://app.plural.sh/graphiql.\n\n[https://app.plural.sh/graphiql](https://app.plural.sh/graphiql)\n\nYou'll need to do two things to allow the graphiql interface to be functional:\n\nConfigure the endpoint to point to https://app.plural.sh/gqlAdd your access token as an authorization header with Bearer as the format.\n\n###### Info:\n\nYou can use the docs here to learn how to create API tokens\n\n[here](/operations/auth-access-control/api-tokens)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/api/plural-api.md)",
- "source_links": [],
- "id": 205
- },
- {
- "page_link": "https://docs.plural.sh/reference/cli-reference",
- "title": " CLI Command Reference",
- "text": "# CLI Command Reference\n\nOverview of all Plural CLI commands.\n\nTo install the Plural CLI, use:\n\n```\nbrew install pluralsh/plural/plural\n```\n\nRefer to the CLI quickstart for more information.\n\n###### Info:\n\nMake sure to update your CLI to the latest version to pick up any new features.\n\n## Synopsis\n\n[](/reference/cli-reference#synopsis)\n\n```\nplural [options] [parameters]\n```\n\nUse plural command help for information on a specific command. The synopsis for each command shows its parameters and their usage. Optional parameters are shown in square brackets.\n\n## Global Options\n\n[](/reference/cli-reference#global-options)\n\n--profile-file [FILE] configure your config.yml profile FILE [$PLURAL_PROFILE_FILE]\n\n--encryption-key-file [FILE] configure your encryption key FILE [$PLURAL_ENCRYPTION_KEY_FILE]\n\n--help, -h show help\n\n## Commands\n\n[](/reference/cli-reference#commands)\n\nGeneral\n\nversion, v, vsn Gets cli version info\n\nbuild, b Builds your workspace\n\ndeploy, d Deploys the current workspace. This command will first sniff out git diffs in workspaces, topsort them, then apply all changes.\n\ndiff, df Diffs the state of the current workspace with the deployed version and dumps results to diffs/\n\nbounce Redeploys the charts in a workspace\n\ndestroy Iterates through all installations in reverse topological order, deleting helm installations and terraform\n\ninit Initializes plural within a git repo\n\npreflights Runs provider preflight checks\n\nbundle Commands for installing and discovering installation bundles\n\nstack Commands for installing and discovering plural stacks\n\npackages Commands for managing your installed packages\n\nlink links a local package into an installation repo\n\nunlink Unlinks a linked package\n\nhelp, h Shows a list of commands or help for one command\n\nAPI\n\nrepos View and manage plural repositories\n\napi Inspect the plural api\n\nDebugging\n\nwatch Watches applications until they become ready\n\nwait Waits on applications until they become ready\n\ninfo Generates a console dashboard for the namespace of this repo\n\nproxy Proxies into running processes in your cluster\n\nlogs Commands for tailing logs for specific apps\n\nops Commands for simplifying cluster operations\n\nai Utilize openai to get help with your setup\n\nMiscellaneous\n\nutils Useful plural utilities\n\nvpn Interacting with the plural vpn\n\nPublishing\n\napply Applies the current pluralfile\n\ntest Validate a values templace\n\npush Utilities for pushing tf or helm packages\n\ntemplate, tpl Templates a helm chart to be uploaded to plural\n\nfrom-grafana Imports a grafana dashboard to a plural crd\n\nUser Profile\n\nlogin Logs into plural and saves credentials to the current config profile\n\nimport Imports plural config from another file\n\ncrypto Plural encryption utilities\n\nconfig, conf Reads/modifies cli configuration\n\nprofile Commands for managing config profiles for plural\n\nWorkspace\n\ncreate Scaffolds the resources needed to create a new plural repository\n\nrepair Commits any new encrypted changes in your local workspace automatically\n\nvalidate, v Validates your workspace\n\ntopsort Renders a dependency-inferred topological sort of the installations in a workspace\n\ndependencies, deps Prints ordered dependencies for a repo in your workspace\n\nserve Launch the server\n\nshell Manages your cloud shell\n\nworkspace, wkspace Commands for managing installations in your workspace\n\noutput Commands for generating outputs from supported tools\n\nbuild-context Creates a fresh context.yaml for legacy repos\n\nchanged Shows repos with pending changes\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/cli-reference.md)",
- "source_links": [],
- "id": 206
- },
- {
- "page_link": "https://docs.plural.sh/reference/configuring-cloud-provider",
- "title": " Cloud Provider CLI Setup",
- "text": "# Cloud Provider CLI Setup\n\nMake sure that your cloud provider CLI is properly set up before installing Plural.\n\nBefore you can start installing your Kubernetes cluster and applications with the Plural CLI, you will need to make sure that your cloud provider CLI is set up correctly.\n\n###### Info:\n\nIf you have already configured and installed your cloud provider CLI and are still seeing errors, make sure that you are on the latest version of the CLI.\n\n## Installation\n\n[](/reference/configuring-cloud-provider#installation)\n\nFollow the provider-specific instructions below.\n\nFollow the instructions here to install your AWS cli.Verify that the cli has been added to your $PATHFollow the instructions here to configure your cli and connect it to your aws consoleVerify that your cli has been properly configured by running\n\n[here](https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html)\n\n[here](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-quickstart.html)\n\n```\naws configure list\n```\n\nYou should see a set of values that looks like this:\n\n```\nName Value Type Location\n ---- ----- ---- --------\n profile None None\naccess_key ****************RUG2 shared-credentials-file\nsecret_key ****************hJUU shared-credentials-file\n region us-east-2 config-file ~/.aws/config\n```\n\nIf you are deploying to an AWS account with SSO enabled, you'll need to pass that specific AWS profile to the Plural CLI, or it won't be able to create resources on your behalf. You can do this with the following two steps:\n\nIf you need to update your AWS CLI for any reason, make sure to run plural wkspace kube-init to regenerate your kubeconfig to be compatible with the changes. This will be required if you're on a new machine, were using a different Kubernetes cluster, or if the kubeconfig has stale credentials.\n\nFollow the instructions here to install the gcloud CLI.Verify that the CLI has been added to your $PATHCreate a new project in gcp via the CLI:\n\n[here](https://cloud.google.com/sdk/docs/install)\n\n```\ngcloud projects create example-project-name\n```\n\nEnable the Kubernetes Engine API for the project you just created.Enable the Google DNS API for the project you just created.Run gcloud init and follow the prompts to configure the gcloud CLI and connect it to the project you just created.Verify that your CLI has been properly configured. It should look something like this. Make sure that your active configuration is set to the project you just created.\n\n[Enable the Kubernetes Engine API](https://cloud.google.com/kubernetes-engine/docs/quickstart)\n\n[Enable the Google DNS API](https://excelnotes.com/enable-cloud-dns-api/)\n\n```\n> gcloud config list\n[compute]\nregion = us-east1\nzone = us-east1-b\n[core]\naccount = yirenlu92@gmail.com\ndisable_usage_reporting = True\nproject = example-project-name\n\nYour active configuration is: [example-project-name]\n```\n\nIt can be the case that you have multiple accounts or projects in GCP and previously have configured your gcloud CLI to point to a different project. Verify your active configuration with\n\n```\n> gcloud config configurations list\nNAME IS_ACTIVE ACCOUNT PROJECT COMPUTE_DEFAULT_ZONE COMPUTE_DEFAULT_REGION\npersonalprj False yirenlu92@gmail.com personalprj us-east1-b us-east1\nexample-project-name True yirenlu92@gmail.com example-project-name us-east1-b us-east1\n```\n\nTo change the active configuration run\n\n```\n> gcloud config configurations activate example-project-name\nActivated [example-project-name].\n```\n\nTo refresh the login for this gcloud configuration run\n\n```\n> gcloud auth login\n```\n\nIn addition to the gcloud CLI, the Plural CLI, as well as the employed GCP Terraform providers, also use the gcloud SDK. So you will also need to setup Application Default Credentials. Make sure to use the same account as you used to authenticate your active gcloud CLI configuration!\n\n[Application Default Credentials](https://cloud.google.com/sdk/gcloud/reference/auth/application-default/login)\n\n```\n> gcloud auth application-default login\n```\n\nFailure to do this could result in project requested not found or permission related errors further along.\n\nFollow the instructions here to install your Azure CLI.Follow the instructions here to sign into your Azure CLI.\n\n[here](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli)\n\n[here](https://docs.microsoft.com/en-us/cli/azure/get-started-with-azure-cli)\n\n###### Warning:\n\nKeep in mind that your Azure subscription type can limit the availability of your VMs, so make sure to tailor your subscription to the availability requirements of your infrastructure.\n\n## Permissions\n\n[](/reference/configuring-cloud-provider#permissions)\n\nSince Plural is responsible for creating over 50 different applications, what permissions are required will vary based on what you're deploying. In most cases, Admin access is the simplest to use. For example, when provisioning Airbyte, we'll need to create an IAM role and IRSA binding to the EKS control plane, which is an Admin only action.\n\n#### Service Account Permissions\n\n[](/reference/configuring-cloud-provider#service-account-permissions)\n\nWhen deploying via GCP, you may run into a Terraform error around permissions. Plural will need to create a various set of resources in order to make sure that your Kubernetes cluster is configured correctly. We recommend attaching the following permission roles to the service account associated with your CLI or Cloud Shell:\n\nownerstorage.admin\n\nFollow these steps to authorize your GCloud CLI with a new or existing Service Account.\n\n[these steps](https://cloud.google.com/sdk/docs/authorizing#authorize_with_a_service_account)\n\nNo special permissions necessary, but as mentioned above, providing Plural Administrator access will prevent issues around application specific requirements.\n\nNo special permissions necessary, but as mentioned above, providing Plural Administrator access will prevent issues around application specific requirements. Make sure you're specifically providing Administrator access for the resource group you're deploying Plural into.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/configuring-cloud-provider.md)",
- "source_links": [],
- "id": 207
- },
- {
- "page_link": "https://docs.plural.sh/reference",
- "title": " Reference",
- "text": "# Reference\n\nNon-Operational Reference\n\nPlural's reference is split up into a few sections. Here are short descriptions for what they are:\n\nWorkspacesLearn about how Plural workspaces are organized and how you can share your repositories with others securely.Identity and Access ManagementLearn about setting up RBAC in Plural and how we manage Auth for access to your applications.DebuggingThe tools you need to figure out what's going on with your Plural installation.APIFor those that want to integrate Plural into their applications or run commands programmatically.\n\n[Workspaces](/reference/workspace/index)\n\nLearn about how Plural workspaces are organized and how you can share your repositories with others securely.\n\n[Identity and Access Management](/reference/identity-and-access-management/index)\n\nLearn about setting up RBAC in Plural and how we manage Auth for access to your applications.\n\n[Debugging](/reference/debugging/index)\n\nThe tools you need to figure out what's going on with your Plural installation.\n\n[API](/reference/api/introduction/index)\n\nFor those that want to integrate Plural into their applications or run commands programmatically.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/index.md)",
- "source_links": [],
- "id": 208
- },
- {
- "page_link": "https://docs.plural.sh/reference/operator-guides/adding-kubecost-for-cost-analysis",
- "title": "Docs | Plural",
- "text": "# Page not found\n\nSorry, this page doesn't appear to exist. Would you like to vist the home page?\n\n[home page](/)",
- "source_links": [],
- "id": 209
- },
- {
- "page_link": "https://docs.plural.sh/reference/operator-guides",
- "title": " Catalog Overview",
- "text": "# Catalog Overview\n\nApplications you can install with Plural.\n\nHere is where all the documentation for configuring the installation of your Plural apps live.\n\n## Application Updates\n\n[](/applications#application-updates)\n\nWe use a tool called Renovate to automate creation of PRs to update Application version images to newer versions. Here is an example of one of these PRs.\n\n[Renovate](https://github.com/renovatebot/renovate)\n\n[Here](https://github.com/pluralsh/plural-artifacts/pull/288)\n\nOnce we have tried out the changes and have confirmed that the new version works, we will merge the PR and the change will be available for all Plural installations to pull down when they wish to.\n\n## Our Catalog\n\n[Airbyte](/applications/airbyte)\n\n\n\nAirbyte\n\n[Airflow](/applications/airflow)\n\n\n\nAirflow\n\n[Argo CD](/applications/argo-cd)\n\n\n\nArgo CD\n\n[Argo Workflows](/applications/argo-workflows)\n\n\n\nArgo Workflows\n\n[Chatwoot](/applications/chatwoot)\n\n\n\nChatwoot\n\n[Clickhouse](/applications/clickhouse)\n\n\n\nClickhouse\n\n[Plural Console](/applications/console)\n\n\n\nPlural Console\n\n[Crossplane](/applications/crossplane)\n\n\n\nCrossplane\n\n[Dagster](/applications/dagster)\n\n\n\nDagster\n\n[Dagster Agent](/applications/dagster-agent)\n\n\n\nDagster Agent\n\n[Datadog](/applications/datadog)\n\n\n\nDatadog\n\n[Datahub](/applications/datahub)\n\n\n\nDatahub\n\n[Directus](/applications/directus)\n\n\n\nDirectus\n\n[Elasticsearch](/applications/elasticsearch)\n\n\n\nElasticsearch\n\n[Etcd](/applications/etcd)\n\n\n\nEtcd\n\n[External Secrets](/applications/external-secrets)\n\n\n\nExternal Secrets\n\n[Filecoin](/applications/filecoin)\n\n\n\nFilecoin\n\n[Ghost](/applications/ghost)\n\n\n\nGhost\n\n[Gitlab](/applications/gitlab)\n\n\n\nGitlab\n\n[Goldilocks](/applications/goldilocks)\n\n\n\nGoldilocks\n\n[Grafana](/applications/grafana)\n\n\n\nGrafana\n\n[Grafana Agent](/applications/grafana-agent)\n\n\n\nGrafana Agent\n\n[Grafana Tempo](/applications/grafana-tempo)\n\n\n\nGrafana Tempo\n\n[Growthbook](/applications/growthbook)\n\n\n\nGrowthbook\n\n[Harbor](/applications/harbor)\n\n\n\nHarbor\n\n[Hasura](/applications/hasura)\n\n\n\nHasura\n\n[Hydra](/applications/hydra)\n\n\n\nHydra\n\n[Influx](/applications/influx)\n\n\n\nInflux\n\n[Ingress Nginx](/applications/ingress-nginx)\n\n\n\nIngress Nginx\n\n[Istio](/applications/istio)\n\n\n\nIstio\n\n[Jitsu](/applications/jitsu)\n\n\n\nJitsu\n\n[Jupyterhub](/applications/jupyterhub)\n\n\n\nJupyterhub\n\n[Kafka](/applications/kafka)\n\n\n\nKafka\n\n[Knative](/applications/knative)\n\n\n\nKnative\n\n[Kserve](/applications/kserve)\n\n\n\nKserve\n\n[Kubecost](/applications/kubecost)\n\n\n\nKubecost\n\n[Kubeflow](/applications/kubeflow)\n\n\n\nKubeflow\n\n[Kubescape](/applications/kubescape)\n\n\n\nKubescape\n\n[Kubricks](/applications/kubricks)\n\n\n\nKubricks\n\n[Kyverno](/applications/kyverno)\n\n\n\nKyverno\n\n[Lightdash](/applications/lightdash)\n\n\n\nLightdash\n\n[Loki](/applications/loki)\n\n\n\nLoki\n\n[Mage](/applications/mage)\n\n\n\nMage\n\n[Meilisearch](/applications/meilisearch)\n\n\n\nMeilisearch\n\n[Metabase](/applications/metabase)\n\n\n\nMetabase\n\n[Mimir](/applications/mimir)\n\n\n\nMimir\n\n[Minecraft](/applications/minecraft)\n\n\n\nMinecraft\n\n[Minio](/applications/minio)\n\n\n\nMinio\n\n[MLflow](/applications/mlflow)\n\n\n\nMLflow\n\n[MongoDB](/applications/mongodb)\n\n\n\nMongoDB\n\n[Monitoring](/applications/monitoring)\n\n\n\nMonitoring\n\n[MySQL](/applications/mysql)\n\n\n\nMySQL\n\n[n8n](/applications/n8n)\n\n\n\nn8n\n\n[Nextcloud](/applications/nextcloud)\n\n\n\nNextcloud\n\n[NocoDB](/applications/nocodb)\n\n\n\nNocoDB\n\n[NVIDIA Operator](/applications/nvidia-operator)\n\n\n\nNVIDIA Operator\n\n[OAuth2 Proxy](/applications/oauth2-proxy)\n\n\n\nOAuth2 Proxy\n\n[Plural](/applications/plural)\n\n\n\nPlural\n\n[PostgreSQL](/applications/postgres)\n\n\n\nPostgreSQL\n\n[Posthog](/applications/posthog)\n\n\n\nPosthog\n\n[Prefect](/applications/prefect)\n\n\n\nPrefect\n\n[Prefect Agent](/applications/prefect-agent)\n\n\n\nPrefect Agent\n\n[Prefect Worker](/applications/prefect-worker)\n\n\n\nPrefect Worker\n\n[RabbitMQ](/applications/rabbitmq)\n\n\n\nRabbitMQ\n\n[Ray](/applications/ray)\n\n\n\nRay\n\n[Redis](/applications/redis)\n\n\n\nRedis\n\n[Redpanda](/applications/redpanda)\n\n\n\nRedpanda\n\n[Reloader](/applications/reloader)\n\n\n\nReloader\n\n[Renovate on Prem](/applications/renovate-on-prem)\n\n\n\nRenovate on Prem\n\n[Retool](/applications/retool)\n\n\n\nRetool\n\n[Rook](/applications/rook)\n\n\n\nRook\n\n[Sentry](/applications/sentry)\n\n\n\nSentry\n\n[Sftpgo](/applications/sftpgo)\n\n\n\nSftpgo\n\n[Sonarqube](/applications/sonarqube)\n\n\n\nSonarqube\n\n[Spark](/applications/spark)\n\n\n\nSpark\n\n[Superset](/applications/superset)\n\n\n\nSuperset\n\n[Tempo](/applications/tempo)\n\n\n\nTempo\n\n[Terraria](/applications/terraria)\n\n\n\nTerraria\n\n[Tier](/applications/tier)\n\n\n\nTier\n\n[Touca](/applications/touca)\n\n\n\nTouca\n\n[Trace Shield](/applications/trace-shield)\n\n\n\nTrace Shield\n\n[Trino](/applications/trino)\n\n\n\nTrino\n\n[Trivy](/applications/trivy)\n\n\n\nTrivy\n\n[Typesense](/applications/typesense)\n\n\n\nTypesense\n\n[Unleash](/applications/unleash)\n\n\n\nUnleash\n\n[Valheim](/applications/valheim)\n\n\n\nValheim\n\n[Vault](/applications/vault)\n\n\n\nVault\n\n[Vaultwarden](/applications/vaultwarden)\n\n\n\nVaultwarden\n\n[Wireguard](/applications/wireguard)\n\n\n\nWireguard\n\n[Yatai](/applications/yatai)\n\n\n\nYatai\n\n[Yugabyte](/applications/yugabyte)\n\n\n\nYugabyte\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/index.md)",
- "source_links": [],
- "id": 210
- },
- {
- "page_link": "https://docs.plural.sh/reference/partial-installation",
- "title": " Continue a Partial Deployment",
- "text": "# Continue a Partial Deployment\n\nHow to fix a failure in a partially deployed cluster\n\nOccasionally things will happen which will prevent Plural from fully deploying your cluster. Some common causes are:\n\nnot extending cloud quotas sufficientlyusing underprivileged cloud creds to apply all the needed terraformslight misconfiguration (eg using an existing resource name)\n\nIn general there are two paths, resolve the issue or start from scratch. This will show you how to handle either one and some pitfalls that might happen.\n\n## Restart From Scratch\n\n[](/reference/partial-installation#restart-from-scratch)\n\nGenerally we'd recommend this approach as its by far the cleanest. The first thing you'd want to do is wipe all resources from the old cluster. A simple shortcut for this would be to run:\n\n```\nplural destroy bootstrap\n```\n\nThis will destroy the cluster and its vpc directly. You should also run plural repos reset to wipe all installations in our api and you might also need to go to https://app.plural.sh/account/domains to delete any stale dns entries associated with your cluster. DNS records are owned by a cluster and cannot be created if an old cluster references them.\n\nIf you were using the cloud shell to create your cluster, we also recommend you delete the cloud shell using the Delete cloud shell button in the three dots menu in the top right of the shell.\n\nOnce all the cleanup has been done, you should be able to start fresh. I recommend renaming the cluster and vpc to a new name to avoid any possible conflicts with the old one, and potentially chose a new bucket prefix as well. This will minimize any risk of naming conflict. From there you should be able to restart the deployment from scratch.\n\n## Fix existing deployment\n\n[](/reference/partial-installation#fix-existing-deployment)\n\nSometimes the issue is pretty clear and you can resolve it quickly, eg giving a few more permissions to an IAM role or extending a cloud quota. In that case, here are a few pointers to help guide you in unjamming your deployment.\n\nyou can safely retry plural deploy at any time. The command is meant to bypass already-run steps and detect local changes. The terraform and helm also have internal mechanisms to guarantee idempotency and so it is generally safe to runyou might need to reconfigure settings in context.yaml then rerun a plural build if you have a misconfiguration. All bundle inputs are persisted there.avoid reusing the same dns name multiple times, as it can cause thrashing in registering dns records.\n\nTo better understand the workspace structure in general, I recommend reading the README.md file we persist in the repo for you as well.\n\nAnother pointer, if for whatever reason you committed changes early, you might find this output:\n\n```\n\u279c plural deploy\nDeploying applications [] in topological order\n\n\n==> Commit and push your changes to record your deployment\n```\n\nThe plural deploy command by default filters apps by whatever has a local uncommitted change in the git repository. If nothing is there to commit it will think there's nothing to deploy. You can bypass that by running plural deploy --all. This will happen pretty often, especially if the cloud shell was turned off in the background due to being idled for a while.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/partial-installation.md)",
- "source_links": [],
- "id": 211
- },
- {
- "page_link": "https://docs.plural.sh/reference/release-notes",
- "title": " Release Notes",
- "text": "# Release Notes\n\nLinks to Plural Release Notes\n\nTo see what's new with Plural, check out the following resources:\n\nMain repository release notesPlural artifacts release notesPlural CLI release notesPlural Console release notesPlural In-App Roadmap\n\n[Main repository release notes](https://github.com/pluralsh/plural/releases)\n\n[Plural artifacts release notes](https://github.com/pluralsh/plural-artifacts/releases)\n\n[Plural CLI release notes](https://github.com/pluralsh/plural-cli/releases)\n\n[Plural Console release notes](https://github.com/pluralsh/console/releases)\n\n[Plural In-App Roadmap](https://app.plural.sh/roadmap)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/release-notes.md)",
- "source_links": [],
- "id": 212
- },
- {
- "page_link": "https://docs.plural.sh/reference/troubleshooting",
- "title": " Troubleshooting",
- "text": "# Troubleshooting\n\nHere is a non-exhaustive list of common issues or errors during the install or operation of Plural. If you see an error not listed here or get stuck in general, just hop into our Discord for help.\n\n## Helm Errors\n\n[](/reference/troubleshooting#helm-errors)\n\nHelm can be tempermental at times, here are some errors that will ocassionally pop up\n\n### another operation (install/upgrade/rollback) is in progress\n\n[](/reference/troubleshooting#another-operation-install-upgrade-rollback-is-in-progress)\n\nhelm upgrade --install --skip-crds --namespace APP APP /path/to/chart 2023/03/23 02:02:15 another operation (install/upgrade/rollback) is in progress\n\nIn this case you need to roll back your helm release to the last successful version. You can do this by running:\n\nhelm history APP --namespace APP to find the latest safe version, then run: helm rollback APP VSN --namespace APP to get helm back in a safe state.\n\nYou should then be able to run either plural deploy or plural bounce without issue.\n\n## Git Errors\n\n[](/reference/troubleshooting#git-errors)\n\n### Could not compare workspace to origin\n\n[](/reference/troubleshooting#could-not-compare-workspace-to-origin)\n\nFailed to get git information: Could not compare current workspace to origin, do you have an 'origin' remote configured, or does your repo not have an inital commit?\n\nThis error either means you cannot push information to Git, or you do not have a remote branch set up to track your local one. Make sure you've added your SSH keys to Github and verify that your origin is set by running git remote -v.\n\n### Out of date\n\n[](/reference/troubleshooting#out-of-date)\n\nYour local workspace is not in sync with remote, either 'git pull' recent changes or 'git push' any missed changes.\n\nThis error can happen if you're ahead of or behind your remote by a few commits, so try git push if git pull does not resolve the issue.\n\n## Cloud Errors\n\n[](/reference/troubleshooting#cloud-errors)\n\n### Google Credentials\n\n[](/reference/troubleshooting#google-credentials)\n\nYou don't have necessary services enabled. Please run: 'gcloud services enable serviceusage.googleapis.com cloudresourcemanager.googleapis.com container.googleapis.com' with an owner of the project to enable or enable them in the GCP console.\n\nEnsure that you've run the gcloud command in the correct project, and make sure you have owner rights.\n\n### AWS Credentials\n\n[](/reference/troubleshooting#aws-credentials)\n\nFailed to get aws account (is your aws cli configured?)\n\nEnsure your AWS CLI is set up, that you have the correct profile chosen, and that you're authenticated in to AWS. If necessary, run export AWS_PROFILE= in the terminal you are running Plural in and auth in with aws sso login.\n\napi error AuthorizationHeaderMalformed: The authorization header is malformed; a non-empty Access Key (AKID) must be provided in the credential.\n\nMake sure you're authenticated in to AWS with aws sso login.\n\n### IAM policy update 403 permission denied\n\n[](/reference/troubleshooting#iam-policy-update-403-permission-denied)\n\nYou will see permission errors if your Cloud account does not have permissions to create the IAM roles needed by Plural. Apply the correct permissions to the user account that Plural is deploying as.\n\n### Requested project not found\n\n[](/reference/troubleshooting#requested-project-not-found)\n\nError 404: The requested project was not found., notFound\n\nIf you are running plural build and encounter a project requested not found error it's possible that your application default credential is set to the wrong gcp project. Run:\n\n```\ngcloud auth application-default login\n```\n\nto reset the credential and reauthorize the browser for the correct project.\n\n###### Info:\n\nIf you're experiencing persistent issues with a Cloud Provider CLI, try updating the CLI and/or SDK.\n\n## Initialization Errors\n\n[](/reference/troubleshooting#initialization-errors)\n\n### Workspace Initialization\n\n[](/reference/troubleshooting#workspace-initialization)\n\nYour workspace hasn't been configured, try running 'plural init' Could not find workspace.yaml file, you might need to run 'plural init'\n\nBase cloud provider setup for a Plural repository is stored in your workspace.yaml file. This should be created when running plural init.\n\n### Kubconfig missing\n\n[](/reference/troubleshooting#kubconfig-missing)\n\n2022/12/19 16:56:24 stat /home/plural/.kube/config: no such file or directory\n\nThis will happen because for whatever reason your kubeconfig is not available locally. This will occasionally happen if your cloud shell pod was recently recreated, if you're using a new laptop, or if the file was deleted/expired accidentally. To fix, run:\n\n```\nplural wkspace kube-init\n```\n\nin your repo and we'll generate a new one for you.\n\n## Deployment Errors\n\n[](/reference/troubleshooting#deployment-errors)\n\n### Invalid apiVersion for K8s\n\n[](/reference/troubleshooting#invalid-apiversion-for-k8s)\n\nerror: exec plugin: invalid apiVersion \"client.authentication.k8s.io/v1alpha1\" error: exec plugin: invalid apiVersion \"client.authentication.k8s.io/v1alpha1\" exit status 1\n\nYou might see this when attempting to sync crds or run helm commands in a run of plural deploy. It's due to legacy versions of the aws cli generating deprecated kubeconfigs, if you upgrade your cli and rerun plural deploy it should be able to proceed successfully.\n\n### Failed deploy model\n\n[](/reference/troubleshooting#failed-deploy-model)\n\nFailed deploy model due to Internal error occurred: failed calling webhook \"mtargetgroupbinding.elbv2.k8s.aws\": Post \"https://aws-load-balancer-webhook-service.bootstrap.svc:443/mutate-elbv2-k8s-aws-v1beta1-targetgroupbinding?timeout=10s\"\n\nThe aws load balancer controller webhook is not fully reliable; if you see this error it's just a matter of recreating the webhook which you can do with:\n\n```\nkubectl delete validatingwebhookconfiguration aws-load-balancer-webhook -n bootstrap\nplural bounce bootstrap\n```\n\n### Error acquiring state lock\n\n[](/reference/troubleshooting#error-acquiring-state-lock)\n\nTerraform acquires a state lock to protect the state from being written by multiple users at the same time. Please resolve the issue above and try again.\n\nIf your deploy is interrupted, it's possible terraform state gets confused. To fix this, you'll need to:\n\n```\ncd /terraform\nterraform force-unlock \n```\n\nYou should be able to find the state lock id from the error message. Terraform stacks for each app are located in a standard terraform folder each time.\n\n### May not specify more than one provider type\n\n[](/reference/troubleshooting#may-not-specify-more-than-one-provider-type)\n\nIf you are running plural deploy and encounter the error below there may be stale state from the previous install.\n\n```\nError: UPGRADE FAILED: cannot patch \"letsencrypt-prod\" with kind ClusterIssuer: admission webhook \"webhook.cert-manager.io\" denied the request: spec.acme.solvers[0].dns01.route53: Forbidden: may not specify more than one provider type\n```\n\nRun:\n\n```\nhelm del bootstrap -n bootstrap\nplural deploy\n```\n\n### Error reading route table association\n\n[](/reference/troubleshooting#error-reading-route-table-association)\n\nerror reading Route Table Association () : Empty result\n\nThis is a possible terraform race condition where the route tables think they're being read before they've been created, but in fact, they have already been created. As a temporary fix, just wait some time and rerun the deploy:\n\n```\nplural deploy\n```\n\n### Cloud resource limits exceeded\n\n[](/reference/troubleshooting#cloud-resource-limits-exceeded)\n\nIt's possible plural will deploy resources that exceed your cloud limits. In general the most pessimistic of these are load balancer limits and VPC limits. Be sure you have headroom in both those dimensions. This can lead to terraform state corruption, in which case you'll need to do something along the lines of for all resources missing from your terraform state:\n\n```\ncd application-name/terraform\nterraform import path_to_terraform_resource resource_id\n```\n\nIf you devise a better way to recover crashed terraform state, please give us a shout in our Discord. We'd love to automate this better.\n\n[Discord](https://discord.gg/pluralsh)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/reference/troubleshooting.md)",
- "source_links": [],
- "id": 213
- },
- {
- "page_link": "https://docs.plural.sh/test/blockquotes",
- "title": " Blockquotes",
- "text": "# Blockquotes\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/blockquotes#)\n\n[linked code highlights](/test/blockquotes#)\n\nList itemAnother list itemAnother list itemAnother list item\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported.\n\n[inline links](/test/blockquotes#)\n\n[linked code highlights](/test/blockquotes#)\n\nShould support things like inline links.\n\n[inline links](/test/blockquotes#)\n\nShould support things like code highlights.\n\nShould support things like linked code highlights.\n\n[linked code highlights](/test/blockquotes#)\n\nShould support things like italic text, bold text or bold italic text.\n\nSupports\n\nMultiple\n\nParagraphs\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/blockquotes.md)",
- "source_links": [],
- "id": 214
- },
- {
- "page_link": "https://docs.plural.sh/test/buttons",
- "title": " Buttons",
- "text": "# Buttons\n\n# Standalone buttons\n\n[](/test/buttons#standalone-buttons)\n\n```\n{% button type=\"floating\" href=\"/\" %}A string with **formatted** text and a _local_ link{% /button %}\n\n{% button type=\"floating\" href=\"http://google.com\" %}\nA string with **formatted** text and an _external_ link\n{% /button %}\n```\n\nA string with formatted text and a local link\n\n[A string with formatted text and a local link](/)\n\n[A string with formatted text and an external link](http://google.com)\n\n# Icons\n\n[](/test/buttons#icons)\n\nSee full icon list here\n\n[here](https://pluralsh-design.web.app/?path=/story/icons--default)\n\n```\n{% button href=\"#\" icon=\"WarningOutline\" %}Icon Button{% /button %}\n```\n\n[Warning\u00adOutline](/test/buttons#)\n\n[Video](/test/buttons#)\n\n[MagicWand](/test/buttons#)\n\n[Tool](/test/buttons#)\n\n[Book](/test/buttons#)\n\n[Workspace](/test/buttons#)\n\n[PushPin](/test/buttons#)\n\n# Button groups\n\n[](/test/buttons#button-groups)\n\n```\n{% buttonGroup %}\n{% button href=\"#\" %}Three{% /button %}\n{% button href=\"#\" %}buttons{% /button %}\n{% button href=\"#\" %}in a row{% /button %}\nNon-button content will be ignored\n{% /buttonGroup %}\n```\n\n[Three](/test/buttons#)\n\n[buttons](/test/buttons#)\n\n[in a row](/test/buttons#)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/buttons.md)",
- "source_links": [],
- "id": 215
- },
- {
- "page_link": "https://docs.plural.sh/test/callouts",
- "title": " Callouts",
- "text": "# Callouts\n\n## Full size kitchen sink\n\n[](/test/callouts#full-size-kitchen-sink)\n\n###### Info: This is an info callout\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Warning: This is a warning callout\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Danger: This is a danger callout\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Success: This is a success callout\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n## Full size\n\n[](/test/callouts#full-size)\n\n###### Info:\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Warning:\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Danger:\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n###### Success:\n\nThings like inline links, code highlights, linked code highlights and other text styles should be supported. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n\n[inline links](/test/callouts#)\n\n[linked code highlights](/test/callouts#)\n\nList item 1List item 2\n\n## Compact size\n\n[](/test/callouts#compact-size)\n\n###### Info:\n\nShould support things like inline links.\n\n[inline links](/test/callouts#)\n\n###### Warning:\n\nShould support things like code highlights.\n\n###### Danger:\n\nShould support things like linked code highlights.\n\n[linked code highlights](/test/callouts#)\n\n###### Success:\n\nShould support things like italic text, bold text or bold italic text.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/callouts.md)",
- "source_links": [],
- "id": 216
- },
- {
- "page_link": "https://docs.plural.sh/test/global-variables",
- "title": " Global Variables",
- "text": "# Global Variables\n\n# From design system default\n\n[](/test/global-variables#from-design-system-default)\n\nGlobal test content\n\n# Added locally\n\n[](/test/global-variables#added-locally)\n\nDocs global test content\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/global-variables.md)",
- "source_links": [],
- "id": 217
- },
- {
- "page_link": "https://docs.plural.sh/test/images",
- "title": " Images",
- "text": "# Images\n\n# Basic caption\n\n[](/test/images#basic-caption)\n\n```\n')\n```\n\n\n\n# Formatted caption\n\n[](/test/images#formatted-caption)\n\n```\n{% figure %}\n\n{% caption %}\nA more **complex** caption with `formatted` text and [links](#)\n{% /caption %}\n{% /figure %}\n```\n\n\n\n[links](/test/images#)\n\n# No caption\n\n[](/test/images#no-caption)\n\n```\n{% figure %}\n\n{% /figure %}\n```\n\n\n\n# Multiple images in a row mixed with other content\n\n[](/test/images#multiple-images-in-a-row-mixed-with-other-content)\n\n\n\nOther text\n\n\n\n\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/images.md)",
- "source_links": [],
- "id": 218
- },
- {
- "page_link": "https://docs.plural.sh/test/tabs",
- "title": " Tabs",
- "text": "# Tabs\n\n## Basic\n\n[](/test/tabs#basic)\n\n```\n{% tabs %}\n\n{% tab title=\"Personal Runbooks\" %}\nEu qui laborum fugiat ipsum labore proident consequat id dolor exercitation irure ad et qui. Eiusmod anim magna est et eiusmod sit. Esse cillum id pariatur velit laborum. Ex irure amet magna voluptate excepteur exercitation in sit Lorem irure mollit. Incididunt non pariatur velit pariatur fugiat duis velit consequat labore quis dolore.\n\n1. After you have deployed your application with Plural, go to `my-plural-repo//helm//templates` and create a file called `runbooks.yaml`. For more information about how to write a `runbooks.yaml` please refer to the guide [here](/adding-new-application/getting-started-with-runbooks/runbook-yaml).\n2. Go to `my-plural-repo//helm//runbooks` and create an `xml` file for the runbook display. For more information on how to write `xml` for the runbook, please refer to the guide [here](/adding-new-application/getting-started-with-runbooks/runbook-xml).\n\n{% /tab %}\n\n{% tab title=\"Publishing a Runbook on Plural\" %}\n\n1. `git clone git@github.com:pluralsh/plural-artifacts.git`\n2. `cd plural-artifacts`\n3. Add your configuration to `/helm//templates/runbooks.yaml`\n4. Add your custom xml template to `/helm//runbooks`\n5. Open up a PR; once the new runbook has been code reviewed, it will be merged into the repo and available for others to download.\n\n{% /tab %}\n\n{% /tabs %}\n```\n\nEu qui laborum fugiat ipsum labore proident consequat id dolor exercitation irure ad et qui. Eiusmod anim magna est et eiusmod sit. Esse cillum id pariatur velit laborum. Ex irure amet magna voluptate excepteur exercitation in sit Lorem irure mollit. Incididunt non pariatur velit pariatur fugiat duis velit consequat labore quis dolore.\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/test/tabs.md)",
- "source_links": [],
- "id": 219
- },
- {
- "page_link": "https://docs.plural.sh/applications/airbyte",
- "title": " Installing Airbyte",
- "text": "# Installing Airbyte\n\nOpen-source ELT platform.\n\n## Description\n\nPlural will install Airbyte in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Airbyte for the following providers:\n\n```\nplural bundle install airbyte airbyte-aws\n```\n\n```\nplural bundle install airbyte airbyte-azure\n```\n\n```\nplural bundle install airbyte airbyte-gcp\n```\n\n```\nplural bundle install airbyte airbyte-kind\n```\n\n## Setup Configuration\n\n[](/applications/airbyte#setup-configuration)\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again.wal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.airbyteBucket: We want to store your Airbyte logs in a S3-like bucket for easy access. Use the default by pressing [Enter] unless it's been used before. This configuration step is not idempotent, if you have to redo configuration for any reason, you'll need to create a new bucket. Alternatively you can directly edit the context.yaml file to use the existing bucket that you create in this step.hostname: This will be where your Airbyte instance is hosted. Generally, use airbyte.$YOUR_ORG_NAME.onplural.sh.privateHostname: This will be the hostname under which the Airbyte API will be accessible. As a suggestion, use airbytedev.$YOUR_ORG_NAME.onplural.sh.Enable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again.\n\nwal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.\n\nairbyteBucket: We want to store your Airbyte logs in a S3-like bucket for easy access. Use the default by pressing [Enter] unless it's been used before. This configuration step is not idempotent, if you have to redo configuration for any reason, you'll need to create a new bucket. Alternatively you can directly edit the context.yaml file to use the existing bucket that you create in this step.\n\nhostname: This will be where your Airbyte instance is hosted. Generally, use airbyte.$YOUR_ORG_NAME.onplural.sh.\n\nprivateHostname: This will be the hostname under which the Airbyte API will be accessible. As a suggestion, use airbytedev.$YOUR_ORG_NAME.onplural.sh.\n\nEnable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/airbyte.mdpart)",
- "source_links": [],
- "id": 220
- },
- {
- "page_link": "https://docs.plural.sh/applications/airflow",
- "title": " Installing Airflow",
- "text": "# Installing Airflow\n\nA DAG-based, dependency-aware job scheduler.\n\n## Description\n\nPlural will install Airflow in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Airflow for the following providers:\n\n```\nplural bundle install airflow airflow-aws\n```\n\n```\nplural bundle install airflow airflow-azure\n```\n\n```\nplural bundle install airflow airflow-gcp\n```\n\n```\nplural bundle install airflow kind-airflow\n```\n\n## Setup Configuration\n\n[](/applications/airflow#setup-configuration)\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you have set this up, you won't need to do it again.wal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.airflowBucket: We want to store your Airflow logs in a S3-like bucket for easy access. Use the default by pressing [Enter] unless it's been used before. This configuration step is not idempotent, if you have to redo configuration for any reason, you'll need to create a new bucket. Alternatively you can directly edit the context.yaml file to use the existing bucket that you create in this step.hostname: This will be where your Airflow instance is hosted. Generally, use airflow.$YOUR_ORG_NAME.onplural.sh.dagRepo: We'll need a preexisting GitHub repository to store the DAGs that you create and use in Airflow. Either create one now or use an existing DAG repository. Then grab the SSH URL from the Code tab on the repo to use here.branchName: If you have an existing DAG repository, you may want to sync your existing dags into and from a specific branch. This will be the branch that Plural stays up to date with, so use main unless you want to prevent direct changes to the repository.adminUsername: Use your naming preference for admin accounts. No need to reinvent the wheel, admin is fine too.adminFirst: Use your relevant operator's first name or just use admin.adminLast: Use your relevant operator's last name or just use admin.adminEmail: Use your relevant admin operator's email address. This will the email used to manage the Airflow instance.private_key: This makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.public_key: Similar to private_key, this makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.Enable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you have set this up, you won't need to do it again.\n\nwal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.\n\nairflowBucket: We want to store your Airflow logs in a S3-like bucket for easy access. Use the default by pressing [Enter] unless it's been used before. This configuration step is not idempotent, if you have to redo configuration for any reason, you'll need to create a new bucket. Alternatively you can directly edit the context.yaml file to use the existing bucket that you create in this step.\n\nhostname: This will be where your Airflow instance is hosted. Generally, use airflow.$YOUR_ORG_NAME.onplural.sh.\n\ndagRepo: We'll need a preexisting GitHub repository to store the DAGs that you create and use in Airflow. Either create one now or use an existing DAG repository. Then grab the SSH URL from the Code tab on the repo to use here.\n\nbranchName: If you have an existing DAG repository, you may want to sync your existing dags into and from a specific branch. This will be the branch that Plural stays up to date with, so use main unless you want to prevent direct changes to the repository.\n\nadminUsername: Use your naming preference for admin accounts. No need to reinvent the wheel, admin is fine too.\n\nadminFirst: Use your relevant operator's first name or just use admin.\n\nadminLast: Use your relevant operator's last name or just use admin.\n\nadminEmail: Use your relevant admin operator's email address. This will the email used to manage the Airflow instance.\n\nprivate_key: This makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.\n\npublic_key: Similar to private_key, this makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.\n\nEnable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\n## Auth Configuration\n\n[](/applications/airflow#auth-configuration)\n\ngit_user: Plural will perform Git operations on your behalf to manage your config repository. Just use your GitHub username here, unless you have a dedicated user for Ops.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/airflow.mdpart)",
- "source_links": [],
- "id": 221
- },
- {
- "page_link": "https://docs.plural.sh/applications/argo-cd",
- "title": " Installing Argo CD",
- "text": "# Installing Argo CD\n\nDeclarative, GitOps continuous delivery tool for Kubernetes.\n\n## Description\n\nPlural will install Argo CD in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Argo CD for the following providers:\n\n```\nplural bundle install argo-cd argo-cd-aws\n```\n\n```\nplural bundle install argo-cd argo-cd-azure\n```\n\n```\nplural bundle install argo-cd argo-cd-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your Argo CD installationadminGroup: OIDC group that should receive admin permissionsconfigPrivateRepo: Configure access too private repositoriescredentialTemplateURL: Domain for which to configure private repository credentialscredentialUsername: Username to access private repositoriescredentialPassword: Password or Personal Access Token to access private repositoriesprivateRepoName: Name for the private repository to addprivateRepoURL: URL of the private repositoryenableImageUpdater: Enable the Argo CD Image Updater",
- "source_links": [],
- "id": 222
- },
- {
- "page_link": "https://docs.plural.sh/applications/argo-workflows",
- "title": " Installing Argo Workflows",
- "text": "# Installing Argo Workflows\n\nContainer-native workflow engine for orchestrating parallel jobs on Kubernetes.\n\n## Description\n\nPlural will install Argo Workflows in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Argo Workflows for the following providers:\n\n```\nplural bundle install argo-workflows argo-workflows-aws\n```\n\n```\nplural bundle install argo-workflows argo-workflows-azure\n```\n\n```\nplural bundle install argo-workflows argo-workflows-gcp\n```\n\n## Setup Configuration\n\nworkflowBucket: bucket to workflow artifacts inhostname: FQDN to use for your Argo Workflows installationadminEmail: email address for the admin useradminGroup: specify a user group to grant admin rights to",
- "source_links": [],
- "id": 223
- },
- {
- "page_link": "https://docs.plural.sh/applications/chatwoot",
- "title": " Installing Chatwoot",
- "text": "# Installing Chatwoot\n\nOpen-source and self-hosted customer engagement suite.\n\n## Description\n\nPlural will install Chatwoot in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Chatwoot for the following providers:\n\n```\nplural bundle install chatwoot chatwoot-aws\n```\n\n```\nplural bundle install chatwoot chatwoot-azure\n```\n\n```\nplural bundle install chatwoot chatwoot-gcp\n```\n\n## Setup Configuration\n\nchatwootBucket: bucket to store chatwoot files inhostname: FQDN to use for your chatwoot installation",
- "source_links": [],
- "id": 224
- },
- {
- "page_link": "https://docs.plural.sh/applications/clickhouse",
- "title": " Installing Clickhouse",
- "text": "# Installing Clickhouse\n\nclickhouse deployed on plural\n\n## Description\n\nPlural will install Clickhouse in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Clickhouse for the following providers:\n\n```\nplural bundle install clickhouse clickhouse-aws\n```\n\n```\nplural bundle install clickhouse clickhouse-azure\n```\n\n```\nplural bundle install clickhouse clickhouse-gcp\n```",
- "source_links": [],
- "id": 225
- },
- {
- "page_link": "https://docs.plural.sh/applications/console",
- "title": " Installing Plural Console",
- "text": "# Installing Plural Console\n\nA Plural admin console for monitoring and ops.\n\n## Description\n\nPlural will install Plural Console in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Plural Console for the following providers:\n\n```\nplural bundle install console console-aws\n```\n\n```\nplural bundle install console console-azure\n```\n\n```\nplural bundle install console console-equinix\n```\n\n```\nplural bundle install console console-gcp\n```\n\n```\nplural bundle install console console-generic\n```\n\n```\nplural bundle install console console-kind\n```\n\n## Setup Configuration\n\n[](/applications/console#setup-configuration)\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again.wal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.console_dns: This will be where your console is hosted. Generally, use console.$YOUR_ORG_NAME.onplural.sh.Enable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\nvpc_name: We need an isolated VPC to launch your resources in, so we create one for you. Stick with plural for most cases. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again.\n\nwal_bucket: Plural uses Postgres as the backing database for cluster information. We need to store the WAL logs somewhere to backup and restore from. This is a cluster-level setting that we only ask for once. Once you've set this up, you won't need to do it again unless you destroy all existing applications.\n\nconsole_dns: This will be where your console is hosted. Generally, use console.$YOUR_ORG_NAME.onplural.sh.\n\nEnable plural OIDC: Enabling Plural OIDC means that you won't need to worry about authenticating into this app if you're logged into Plural. We highly recommend this as long as you don't have any specific security requirements.\n\n## Auth Configuration\n\n[](/applications/console#auth-configuration)\n\ngit_user: Plural will perform Git operations on your behalf to manage your config repository. Just use your GitHub username here, unless you have a dedicated user for Ops.git_email: Use the email tied to the account associated with git_useradmin_name: Use your naming preference for admin accounts. No need to reinvent the wheel, admin is fine too.private_key: This makes sure that your admin account has Read/Write access to the config repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.public_key: Similar to private_key, this makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.passphrase: If you have encrypted your SSH key with a passphrase for extra security, you'll need to enter it here in order for Plural to use it for Git operations.\n\ngit_user: Plural will perform Git operations on your behalf to manage your config repository. Just use your GitHub username here, unless you have a dedicated user for Ops.\n\ngit_email: Use the email tied to the account associated with git_user\n\nadmin_name: Use your naming preference for admin accounts. No need to reinvent the wheel, admin is fine too.\n\nprivate_key: This makes sure that your admin account has Read/Write access to the config repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.\n\npublic_key: Similar to private_key, this makes sure that your admin account has Read/Write access to the DAG repo. We recommend you stick with the default, unless you have compliance reasons for this file not existing here.\n\npassphrase: If you have encrypted your SSH key with a passphrase for extra security, you'll need to enter it here in order for Plural to use it for Git operations.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/console.mdpart)",
- "source_links": [],
- "id": 226
- },
- {
- "page_link": "https://docs.plural.sh/applications/crossplane",
- "title": " Installing Crossplane",
- "text": "# Installing Crossplane\n\nAn open-source Kubernetes add-on that transforms your cluster into a universal control plane.\n\n## Description\n\nPlural will install Crossplane in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Crossplane for the following providers:\n\n```\nplural bundle install crossplane crossplane-aws\n```",
- "source_links": [],
- "id": 227
- },
- {
- "page_link": "https://docs.plural.sh/applications/dagster",
- "title": " Installing Dagster",
- "text": "# Installing Dagster\n\nGuide to self-hosting Dagster with Plural\n\n## Description\n\nPlural will install Dagster in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Dagster for the following providers:\n\n```\nplural bundle install dagster dagster-aws\n```\n\n```\nplural bundle install dagster dagster-azure\n```\n\n```\nplural bundle install dagster dagster-gcp\n```\n\n## Setup Configuration\n\ndagsterBucket: s3 bucket for storing dagster logshostname: fqdn on which to deploy your dagster instance\n\n## Getting Started\n\n[](/applications/dagster#getting-started)\n\nFirst, create an account on https://app.plural.sh. This is to sync your installations and allow for the delivery of automated upgrades. You will not be asked to provide any infrastructure credentials or sensitive information.\n\n[https://app.plural.sh](https://app.plural.sh)\n\nNext, install the Plural CLI. If you're on Mac, the brew tap is the easiest way to do this, as it installs Helm, Terraform, and kubectl for you. For alternate installation methods such as curl and Docker, click here.\n\n[click here](https://docs.plural.sh/getting-started/quickstart#install-plural-cli)\n\n```\nbrew install pluralsh/plural/plural\n```\n\n###### Warning:\n\nBefore you proceed, make sure that your cloud provider CLI is properly configured and updated to the latest version. If it is not configured correctly, Plural will fail and won't be able to create resources on your behalf.\n\nPlural uses a GitOps workflow to manage configuration files and deployment state, so you'll need a Git repository to store your Plural configuration. Plural supports GitHub, GitLab, and Bitbucket currently. If you're planning on using Bitbucket, follow this guide. This repository will contain the Helm charts, Terraform config, and Kubernetes manifests that Plural will autogenerate for you.\n\n[this guide](https://docs.plural.sh/getting-started/manage-git-repositories/setting-up-gitops#manual-git-setup)\n\nNavigate to a directory that you would like to create this Git repository in and run plural init. This will start a configuration wizard to configure your Git repo and cloud provider for use with Plural.\n\n## Installing Dagster\n\n[](/applications/dagster#installing-dagster)\n\nRun this command to find the bundle name associated with your cloud provider:\n\n```\nplural bundle list dagster\n```\n\nNow, to add it to your workspace, run the install command with the bundle name that you received in the previous step. This will guide you through some minor configuration of your Dagster installation, such as choosing the subdomain that your Dagster installation will be hosted at. If you are on AWS, it would look like this:\n\n```\nplural bundle install dagster dagster-aws\n```\n\nTo generate the Helm charts, Terraform, and deployment YAML, run:\n\n```\nplural build\n```\n\nTo deploy your infrastructure and commit the changes to your origin Git repository, run:\n\n```\nplural deploy --commit \"deploying dagster\"\n```\n\n## Installing the Plural Console\n\n[](/applications/dagster#installing-the-plural-console)\n\nPlural comes with a console that provides DevOps workflows, customized dashboards, and an interactive UI for managing your Kubernetes cluster. It's not required, but highly recommended. You can install the console the same way that you installed Dagster:\n\n```\nplural bundle install console console-aws\nplural build\nplural deploy --commit \"deploying the console too\"\n```\n\n## Accessing your Dagster installation\n\n[](/applications/dagster#accessing-your-dagster-installation)\n\nNavigate to dagster.YOUR_SUBDOMAIN.onplural.sh to access the Dagster UI. If you set up a different subdomain for Dagster during the plural bundle install phase, use that instead.\n\n## Uninstalling Dagster\n\n[](/applications/dagster#uninstalling-dagster)\n\nTo bring down your Plural installation of Dagster, run:\n\n```\nplural destroy dagster\n```\n\nTo bring down your entire Plural deployment, run:\n\n```\nplural destroy\n```\n\n###### Warning:\n\nOnly do this if you're absolutely sure you want to bring down all associated resources with this repository.\n\n## Troubleshooting\n\n[](/applications/dagster#troubleshooting)\n\nIf you run into any issues with installing Dagster on Plural, feel free to join our Discord Community so that we can help you out.\n\n[Discord Community](https://discord.gg/pluralsh)\n\nIf you'd like to request any updates or new features for our Dagster installation, feel free to open an issue here.\n\n[here](https://github.com/pluralsh/plural-artifacts)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/dagster.mdpart)",
- "source_links": [],
- "id": 228
- },
- {
- "page_link": "https://docs.plural.sh/applications/dagster-agent",
- "title": " Installing Dagster Agent",
- "text": "# Installing Dagster Agent\n\ndagster-agent deployed on plural\n\n## Description\n\nPlural will install Dagster Agent in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Dagster Agent for the following providers:\n\n```\nplural bundle install dagster-agent dagster-agent-aws\n```\n\n```\nplural bundle install dagster-agent dagster-agent-azure\n```\n\n```\nplural bundle install dagster-agent dagster-agent-gcp\n```\n\n## Setup Configuration\n\nagentToken: the dagster agent token to communicate with dagster cloud",
- "source_links": [],
- "id": 229
- },
- {
- "page_link": "https://docs.plural.sh/applications/datadog",
- "title": " Installing Datadog",
- "text": "# Installing Datadog\n\nObservability service for cloud-scale applications.\n\n## Description\n\nPlural will install Datadog in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Datadog for the following providers:\n\n```\nplural bundle install datadog datadog-aws\n```\n\n```\nplural bundle install datadog datadog-azure\n```\n\n```\nplural bundle install datadog datadog-gcp\n```\n\n## Setup Configuration\n\napiKey: the api key for your datadog account",
- "source_links": [],
- "id": 230
- },
- {
- "page_link": "https://docs.plural.sh/applications/datahub",
- "title": " Installing Datahub",
- "text": "# Installing Datahub\n\nAn open-source metadata platform for the modern data stack.\n\n## Description\n\nPlural will install Datahub in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Datahub for the following providers:\n\n```\nplural bundle install datahub datahub-aws\n```\n\n```\nplural bundle install datahub datahub-azure\n```\n\n```\nplural bundle install datahub datahub-gcp\n```\n\n## Setup Configuration\n\nhostname: domain on which you'd like to host datahub's page",
- "source_links": [],
- "id": 231
- },
- {
- "page_link": "https://docs.plural.sh/applications/directus",
- "title": " Installing Directus",
- "text": "# Installing Directus\n\nThe Modern Data Stack \ud83d\udc30 \u2014 Directus is an instant REST+GraphQL API and intuitive no-code data collaboration app for any SQL database.\n\n## Description\n\nPlural will install Directus in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Directus for the following providers:\n\n```\nplural bundle install directus directus-aws\n```\n\n```\nplural bundle install directus directus-azure\n```\n\n```\nplural bundle install directus directus-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your directus installationdirectusBucket: the bucket for blob assets stored in directus, like imagesadminEmail: email for the initial admin user",
- "source_links": [],
- "id": 232
- },
- {
- "page_link": "https://docs.plural.sh/applications/elasticsearch",
- "title": " Installing Elasticsearch",
- "text": "# Installing Elasticsearch\n\nde facto open source search databse\n\n## Description\n\nPlural will install Elasticsearch in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Elasticsearch for the following providers:\n\n```\nplural bundle install elasticsearch elasticsearch-aws\n```\n\n```\nplural bundle install elasticsearch elasticsearch-azure\n```\n\n```\nplural bundle install elasticsearch elasticsearch-gcp\n```\n\n## Setup Configuration\n\nhostname: hostname for your kibana instance",
- "source_links": [],
- "id": 233
- },
- {
- "page_link": "https://docs.plural.sh/applications/etcd",
- "title": " Installing Etcd",
- "text": "# Installing Etcd\n\nA distributed reliable key-value store for the most critical data of a distributed system.\n\n## Description\n\nPlural will install Etcd in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Etcd for the following providers:\n\n```\nplural bundle install etcd etcd-aws\n```\n\n```\nplural bundle install etcd etcd-azure\n```\n\n```\nplural bundle install etcd etcd-equinix\n```\n\n```\nplural bundle install etcd etcd-gcp\n```\n\n```\nplural bundle install etcd etcd-kind\n```",
- "source_links": [],
- "id": 234
- },
- {
- "page_link": "https://docs.plural.sh/applications/external-secrets",
- "title": " Installing External Secrets",
- "text": "# Installing External Secrets\n\nexternal-secrets deployed on plural\n\n## Description\n\nPlural will install External Secrets in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support External Secrets for the following providers:\n\n```\nplural bundle install external-secrets external-secrets-aws\n```",
- "source_links": [],
- "id": 235
- },
- {
- "page_link": "https://docs.plural.sh/applications/filecoin",
- "title": " Installing Filecoin",
- "text": "# Installing Filecoin\n\nDecentralized storage network for renting unused hard disk space.\n\n## Description\n\nPlural will install Filecoin in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Filecoin for the following providers:\n\n```\nplural bundle install filecoin filecoin-aws\n```",
- "source_links": [],
- "id": 236
- },
- {
- "page_link": "https://docs.plural.sh/applications/ghost",
- "title": " Installing Ghost",
- "text": "# Installing Ghost\n\nOpen-source blog to publish, share, and grow a business around your content.\n\n## Description\n\nPlural will install Ghost in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Ghost for the following providers:\n\n```\nplural bundle install ghost ghost-aws\n```\n\n```\nplural bundle install ghost ghost-gcp\n```\n\n## Setup Configuration\n\nghostUser: username for your initial ghost user accountghostEmail: email address for the initial ghost userghostDomain: fully qualified domain name for the ghost blog instanceblogTitle: title for your ghost-powered blog",
- "source_links": [],
- "id": 237
- },
- {
- "page_link": "https://docs.plural.sh/applications/gitlab",
- "title": " Installing Gitlab",
- "text": "# Installing Gitlab\n\nSource control management tool with built-in CI/CD and DevOps solutions.\n\n## Description\n\nPlural will install Gitlab in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Gitlab for the following providers:\n\n```\nplural bundle install gitlab aws-gitlab\n```\n\n```\nplural bundle install gitlab gcp-gitlab\n```\n\n## Setup Configuration\n\nregistryBucket: bucket name for gitlab registryartifactsBucket: bucket name for gitlab artifactsuploadsBucket: bucket name for gitlab uploadspackagesBucket: bucket name for gitlab packagesbackupsBucket: bucket name for gitlab backupsbackupsTmpBucket: bucket name for gitlab tmp backupslfsBucket: bucket name for git large file storagerunnerCacheBucket: bucket name for gitlab runner cacheterraformBucket: bucket name for gitlab managed terraform state",
- "source_links": [],
- "id": 238
- },
- {
- "page_link": "https://docs.plural.sh/applications/goldilocks",
- "title": " Installing Goldilocks",
- "text": "# Installing Goldilocks\n\nK8s controller that provides a dashboard with guidance for setting up your resource requests.\n\n## Description\n\nPlural will install Goldilocks in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Goldilocks for the following providers:\n\n```\nplural bundle install goldilocks goldilocks-aws\n```\n\n```\nplural bundle install goldilocks goldilocks-azure\n```\n\n```\nplural bundle install goldilocks goldilocks-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your accessing the goldilocks dashboard",
- "source_links": [],
- "id": 239
- },
- {
- "page_link": "https://docs.plural.sh/applications/grafana",
- "title": " Installing Grafana",
- "text": "# Installing Grafana\n\nAn open-source platform for monitoring and observability with interactive visualizations.\n\n## Description\n\nPlural will install Grafana in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Grafana for the following providers:\n\n```\nplural bundle install grafana aws-grafana\n```\n\n```\nplural bundle install grafana azure-grafana\n```\n\n```\nplural bundle install grafana equinix-grafana\n```\n\n```\nplural bundle install grafana gcp-grafana\n```\n\n```\nplural bundle install grafana kind-grafana\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your grafana installation",
- "source_links": [],
- "id": 240
- },
- {
- "page_link": "https://docs.plural.sh/applications/grafana-agent",
- "title": " Installing Grafana Agent",
- "text": "# Installing Grafana Agent\n\ngrafana-agent deployed on plural\n\n## Description\n\nPlural will install Grafana Agent in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Grafana Agent for the following providers:\n\n```\nplural bundle install grafana-agent grafana-agent-aws\n```\n\n```\nplural bundle install grafana-agent grafana-agent-azure\n```",
- "source_links": [],
- "id": 241
- },
- {
- "page_link": "https://docs.plural.sh/applications/grafana-tempo",
- "title": " Installing Grafana Tempo",
- "text": "# Installing Grafana Tempo\n\nAn open-source high-scale distributed tracing backend.\n\n## Description\n\nPlural will install Grafana Tempo in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Grafana Tempo for the following providers:",
- "source_links": [],
- "id": 242
- },
- {
- "page_link": "https://docs.plural.sh/applications/growthbook",
- "title": " Installing Growthbook",
- "text": "# Installing Growthbook\n\nFeature flagging and experimentation platform.\n\n## Description\n\nPlural will install Growthbook in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Growthbook for the following providers:\n\n```\nplural bundle install growthbook growthbook-aws\n```\n\n```\nplural bundle install growthbook growthbook-azure\n```\n\n```\nplural bundle install growthbook growthbook-gcp\n```\n\n## Setup Configuration\n\nhostname: the domain name for your growthbook instanceapiHostname: the domain name for the growthbook api (should be different from hostname)growthbookBucket: bucket for your growthbook instance",
- "source_links": [],
- "id": 243
- },
- {
- "page_link": "https://docs.plural.sh/applications/harbor",
- "title": " Installing Harbor",
- "text": "# Installing Harbor\n\nAn open source trusted cloud native registry project that stores, signs, and scans content.\n\n## Description\n\nPlural will install Harbor in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Harbor for the following providers:\n\n```\nplural bundle install harbor harbor-aws\n```\n\n```\nplural bundle install harbor harbor-azure\n```\n\n```\nplural bundle install harbor harbor-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your harbor installationnotaryHostname: FQDN to use for your harbor notary servicebucket: S3 Bucket to store harbor images",
- "source_links": [],
- "id": 244
- },
- {
- "page_link": "https://docs.plural.sh/applications/hasura",
- "title": " Installing Hasura",
- "text": "# Installing Hasura\n\nAn open-source product that gives you GraphQL or REST APIs with built-in authorization on your data.\n\n## Description\n\nPlural will install Hasura in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Hasura for the following providers:\n\n```\nplural bundle install hasura hasura-aws\n```\n\n```\nplural bundle install hasura hasura-azure\n```\n\n```\nplural bundle install hasura hasura-gcp\n```\n\n## Setup Configuration\n\nhostname: Fully Qualified Domain Name to use for your hasura installation, eg hasura.topleveldomain.com if topleveldomain.com is the domain you inputed for dns_domain above.",
- "source_links": [],
- "id": 245
- },
- {
- "page_link": "https://docs.plural.sh/applications/hydra",
- "title": " Installing Hydra",
- "text": "# Installing Hydra\n\nLow latency, high-throughput OAuth 2.0 and OpenID Connect provider.\n\n## Description\n\nPlural will install Hydra in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Hydra for the following providers:\n\n```\nplural bundle install hydra hydra-aws\n```\n\n```\nplural bundle install hydra hydra-azure\n```\n\n```\nplural bundle install hydra hydra-gcp\n```\n\n## Setup Configuration\n\nhostname: domain on which you'd like to host hydraadminHostname: dns name for the internal endpoint for hydra admin (leave empty to not enable ingress)loginUrl: url on which oauth logins will occurconsentUrl: url for oauth consent requests",
- "source_links": [],
- "id": 246
- },
- {
- "page_link": "https://docs.plural.sh/applications/influx",
- "title": " Installing Influx",
- "text": "# Installing Influx\n\nAn open-source time-series database.\n\n## Description\n\nPlural will install Influx in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Influx for the following providers:\n\n```\nplural bundle install influx influx-aws\n```\n\n```\nplural bundle install influx influx-azure\n```\n\n```\nplural bundle install influx influx-gcp\n```\n\n## Setup Configuration\n\nenableChronograf: whether to deploy the chronograf web uichronografHostname: Fully Qualified Domain Name for the chronograf web uienableKapacitor: whether to deploy kapacitor alertingenableTelegraf: whether to deploy telegraf metrics collectiondatabaseName: name for the initial bootstrapped databaseinfluxdbHostname: external dns name for your influxdb instance (leave empty if you don't want ingress)",
- "source_links": [],
- "id": 247
- },
- {
- "page_link": "https://docs.plural.sh/applications/ingress-nginx",
- "title": " Installing Ingress Nginx",
- "text": "# Installing Ingress Nginx\n\nAn Ingress controller for Kubernetes that uses NGINX as a reverse proxy and load balancer.\n\n## Description\n\nPlural will install Ingress Nginx in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Ingress Nginx for the following providers:\n\n```\nplural bundle install ingress-nginx ingress-nginx-aws\n```\n\n```\nplural bundle install ingress-nginx ingress-nginx-azure\n```\n\n```\nplural bundle install ingress-nginx ingress-nginx-equinix\n```\n\n```\nplural bundle install ingress-nginx ingress-nginx-gcp\n```\n\n```\nplural bundle install ingress-nginx ingress-nginx-generic\n```\n\n```\nplural bundle install ingress-nginx ingress-nginx-kind\n```",
- "source_links": [],
- "id": 248
- },
- {
- "page_link": "https://docs.plural.sh/applications/istio",
- "title": " Installing Istio",
- "text": "# Installing Istio\n\nOpen-source service mesh platform that controls data sharing across microservices.\n\n## Description\n\nPlural will install Istio in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Istio for the following providers:\n\n```\nplural bundle install istio istio-aws\n```\n\n```\nplural bundle install istio istio-azure\n```\n\n```\nplural bundle install istio istio-gcp\n```\n\n## Setup Configuration\n\nkialiHostname: FQDN to use for the Kiali installation",
- "source_links": [],
- "id": 249
- },
- {
- "page_link": "https://docs.plural.sh/applications/jitsu",
- "title": " Installing Jitsu",
- "text": "# Installing Jitsu\n\nOpen-source Segment alternative; high-performance data collection service.\n\n## Description\n\nPlural will install Jitsu in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Jitsu for the following providers:\n\n```\nplural bundle install jitsu jitsu-aws\n```\n\n```\nplural bundle install jitsu jitsu-azure\n```\n\n```\nplural bundle install jitsu jitsu-gcp\n```\n\n## Setup Configuration\n\nhostname: domain on which you'd like to host jitsu's configuration pageapiHostname: domain on which you'd like to host jitsu's apiairbyteEnabled: enable docker-in-docker airbyte support",
- "source_links": [],
- "id": 250
- },
- {
- "page_link": "https://docs.plural.sh/applications/jupyterhub",
- "title": " Installing Jupyterhub",
- "text": "# Installing Jupyterhub\n\nAn application that you can use to create documents that contain live code, equations, visualizations, and text.\n\n## Description\n\nPlural will install Jupyterhub in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Jupyterhub for the following providers:\n\n```\nplural bundle install jupyterhub jupyterhub-aws\n```\n\n```\nplural bundle install jupyterhub jupyterhub-azure\n```\n\n```\nplural bundle install jupyterhub jupyterhub-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your jupyterhub installation",
- "source_links": [],
- "id": 251
- },
- {
- "page_link": "https://docs.plural.sh/applications/kafka",
- "title": " Installing Kafka",
- "text": "# Installing Kafka\n\nAn open-source distributed event streaming platform.\n\n## Description\n\nPlural will install Kafka in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kafka for the following providers:\n\n```\nplural bundle install kafka aws-kafka\n```\n\n```\nplural bundle install kafka azure-kafka\n```\n\n```\nplural bundle install kafka gcp-kafka\n```",
- "source_links": [],
- "id": 252
- },
- {
- "page_link": "https://docs.plural.sh/applications/knative",
- "title": " Installing Knative",
- "text": "# Installing Knative\n\nAn open-source enterprise-level solution to build serverless and event-driven applications.\n\n## Description\n\nPlural will install Knative in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Knative for the following providers:\n\n```\nplural bundle install knative knative-aws\n```\n\n```\nplural bundle install knative knative-gcp\n```\n\n```\nplural bundle install knative knative-operator-aws\n```",
- "source_links": [],
- "id": 253
- },
- {
- "page_link": "https://docs.plural.sh/applications/kserve",
- "title": " Installing Kserve",
- "text": "# Installing Kserve\n\nKServe provides a K8s CRD for serving ML models on arbitrary frameworks.\n\n## Description\n\nPlural will install Kserve in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kserve for the following providers:\n\n```\nplural bundle install kserve kserve-aws\n```\n\n```\nplural bundle install kserve kserve-azure\n```\n\n```\nplural bundle install kserve kserve-gcp\n```",
- "source_links": [],
- "id": 254
- },
- {
- "page_link": "https://docs.plural.sh/applications/kubecost",
- "title": " Kubecost",
- "text": "# Kubecost\n\nGet visibility into your Kubernetes spend and resource allocation.\n\n## Description\n\nPlural will install Kubecost in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kubecost for the following providers:\n\n```\nplural bundle install kubecost kubecost-aws\n```\n\n```\nplural bundle install kubecost kubecost-azure\n```\n\n```\nplural bundle install kubecost kubecost-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your KubeCost installation\n\n## Examples\n\n[](/applications/kubecost#examples)\n\nPlural integrates directly with kubecost to provide cost analysis for any application deployed on your plural kubernetes clusters. Kubecost can be installed just like any other application, although perhaps the easiest is to just go to your console and click the install button in the top right:\n\n\n\n\n\nOnce Kubecost is installed, the plural console will query its api to surface granular cost information for all your apps, which you can see by clicking the app information icon also in the top right, giving a modal looking something like this:\n\n\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/kubecost.mdpart)",
- "source_links": [],
- "id": 255
- },
- {
- "page_link": "https://docs.plural.sh/applications/kubeflow",
- "title": " Installing Kubeflow",
- "text": "# Installing Kubeflow\n\nCloud-native platform for machine learning operations - pipelines, training, and deployment.\n\n## Description\n\nPlural will install Kubeflow in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kubeflow for the following providers:\n\n```\nplural bundle install kubeflow kubeflow-aws\n```\n\n```\nplural bundle install kubeflow kubeflow-gcp\n```\n\n## Setup Configuration\n\npipelines_bucket: bucket to store the pipeline artifacts and logs inhostname: FQDN to use for your Kubeflow installation",
- "source_links": [],
- "id": 256
- },
- {
- "page_link": "https://docs.plural.sh/applications/kubescape",
- "title": " Installing Kubescape",
- "text": "# Installing Kubescape\n\nMulti-cloud K8s single pane of glass for security.\n\n## Description\n\nPlural will install Kubescape in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kubescape for the following providers:\n\n```\nplural bundle install kubescape kubescape-aws\n```\n\n```\nplural bundle install kubescape kubescape-azure\n```\n\n```\nplural bundle install kubescape kubescape-gcp\n```\n\n## Setup Configuration\n\naccountGuid: Unique identifier connecting results to the Kubescape Cloud account. To learn more go here https://hub.armosec.io/docs/kubescape-cloud-account#account-id",
- "source_links": [],
- "id": 257
- },
- {
- "page_link": "https://docs.plural.sh/applications/kubricks",
- "title": " Installing Kubricks",
- "text": "# Installing Kubricks\n\nkubricks deployed on plural\n\n## Description\n\nPlural will install Kubricks in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kubricks for the following providers:\n\n```\nplural bundle install kubricks kubricks-aws\n```\n\n```\nplural bundle install kubricks kubricks-azure\n```\n\n```\nplural bundle install kubricks kubricks-gcp\n```\n\n## Setup Configuration\n\nhostname: domain on which you'd like to host n8n's page",
- "source_links": [],
- "id": 258
- },
- {
- "page_link": "https://docs.plural.sh/applications/kyverno",
- "title": " Installing Kyverno",
- "text": "# Installing Kyverno\n\nA policy engine designed for Kubernetes that can validate, mutate, and generate configurations.\n\n## Description\n\nPlural will install Kyverno in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Kyverno for the following providers:\n\n```\nplural bundle install kyverno kyverno-aws\n```\n\n```\nplural bundle install kyverno kyverno-azure\n```\n\n```\nplural bundle install kyverno kyverno-gcp\n```\n\n## Setup Configuration\n\nenablePolicies: Deploy Kyverno policies",
- "source_links": [],
- "id": 259
- },
- {
- "page_link": "https://docs.plural.sh/applications/lightdash",
- "title": " Installing Lightdash",
- "text": "# Installing Lightdash\n\nAn open source alternative to looker built on dbt\n\n## Description\n\nPlural will install Lightdash in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Lightdash for the following providers:\n\n```\nplural bundle install lightdash lightdash-aws\n```\n\n```\nplural bundle install lightdash lightdash-azure\n```\n\n```\nplural bundle install lightdash lightdash-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your Lightdash installation",
- "source_links": [],
- "id": 260
- },
- {
- "page_link": "https://docs.plural.sh/applications/loki",
- "title": " Installing Loki",
- "text": "# Installing Loki\n\nA horizontally scalable, highly available, multi-tenant log aggregation system inspired by Prometheus.\n\n## Description\n\nPlural will install Loki in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Loki for the following providers:\n\n```\nplural bundle install loki loki-aws\n```\n\n```\nplural bundle install loki loki-azure\n```\n\n```\nplural bundle install loki loki-gcp\n```\n\n## Setup Configuration\n\nlokiBucket: bucket to store the logs inhostname: the hostname you'll deploy loki with (will only be available on a private network)multiTenant: if loki should be deployed in multi-tenant mode",
- "source_links": [],
- "id": 261
- },
- {
- "page_link": "https://docs.plural.sh/applications/mage",
- "title": " Installing Mage",
- "text": "# Installing Mage\n\n\ud83e\uddd9 The modern replacement for Airflow. Build, run, and manage data pipelines for integrating and transforming data.\n\n## Description\n\nPlural will install Mage in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Mage for the following providers:\n\n```\nplural bundle install mage mage-aws\n```\n\n```\nplural bundle install mage mage-azure\n```\n\n```\nplural bundle install mage mage-gcp\n```\n\n## Setup Configuration\n\nhostname: the fully qualified domain name your Mage instance will be available at",
- "source_links": [],
- "id": 262
- },
- {
- "page_link": "https://docs.plural.sh/applications/meilisearch",
- "title": " Installing Meilisearch",
- "text": "# Installing Meilisearch\n\nA lightning-fast search engine that fits effortlessly into your apps, websites, and workflow.\n\n## Description\n\nPlural will install Meilisearch in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Meilisearch for the following providers:\n\n```\nplural bundle install meilisearch meilisearch-aws\n```\n\n```\nplural bundle install meilisearch meilisearch-azure\n```\n\n```\nplural bundle install meilisearch meilisearch-gcp\n```\n\n## Setup Configuration\n\nhostname: the fully qualified domain name your meilisearch instance will be available at",
- "source_links": [],
- "id": 263
- },
- {
- "page_link": "https://docs.plural.sh/applications/metabase",
- "title": " Installing Metabase",
- "text": "# Installing Metabase\n\nAn easy, open-source way for everyone to ask questions and learn from data.\n\n## Description\n\nPlural will install Metabase in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Metabase for the following providers:\n\n```\nplural bundle install metabase metabase-aws\n```\n\n```\nplural bundle install metabase metabase-azure\n```\n\n```\nplural bundle install metabase metabase-gcp\n```\n\n## Setup Configuration\n\nhostname: fqdn for your metabase instance",
- "source_links": [],
- "id": 264
- },
- {
- "page_link": "https://docs.plural.sh/applications/mimir",
- "title": " Installing Mimir",
- "text": "# Installing Mimir\n\nmimir deployed on plural\n\n## Description\n\nPlural will install Mimir in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Mimir for the following providers:\n\n```\nplural bundle install mimir mimir-aws\n```\n\n```\nplural bundle install mimir mimir-azure\n```\n\n## Setup Configuration\n\nmimirBlocksBucket: bucket to store the mimir blocks inmimirAlertBucket: bucket for mimir alertmanagermimirRulerBucket: bucket for mimir ruler storagehostname: the hostname you'll deploy mimir with (only used if trace-shield is deployed)",
- "source_links": [],
- "id": 265
- },
- {
- "page_link": "https://docs.plural.sh/applications/minecraft",
- "title": " Installing Minecraft",
- "text": "# Installing Minecraft\n\nDeploy your very own Minecraft server on Kubernetes.\n\n## Description\n\nPlural will install Minecraft in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Minecraft for the following providers:\n\n```\nplural bundle install minecraft minecraft-aws\n```\n\n```\nplural bundle install minecraft minecraft-azure\n```\n\n```\nplural bundle install minecraft minecraft-gcp\n```\n\n## Setup Configuration\n\nhostname: fqdn for your metabase instance",
- "source_links": [],
- "id": 266
- },
- {
- "page_link": "https://docs.plural.sh/applications/minio",
- "title": " Installing Minio",
- "text": "# Installing Minio\n\nHigh-performance Kubernetes-native object storage compatible with the S3 API.\n\n## Description\n\nPlural will install Minio in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Minio for the following providers:\n\n```\nplural bundle install minio minio-aws\n```\n\n```\nplural bundle install minio minio-azure\n```\n\n```\nplural bundle install minio minio-equinix\n```\n\n```\nplural bundle install minio minio-gcp\n```\n\n```\nplural bundle install minio minio-kind\n```\n\n## Setup Configuration\n\nminio_bucket: bucket to store minio datahostname: Fully Qualified Domain Name to use for your minio gateway installation, eg minio.topleveldomain.com if topleveldomain.com is the domain you inputed for dns_domain above.consoleHostname: Fully Qualified Domain Name to use for your minio console installation, eg minio.topleveldomain.com if topleveldomain.com is the domain you inputed for dns_domain above.",
- "source_links": [],
- "id": 267
- },
- {
- "page_link": "https://docs.plural.sh/applications/mlflow",
- "title": " Installing MLflow",
- "text": "# Installing MLflow\n\nAn open-source platform that streamlines machine learning development.\n\n## Description\n\nPlural will install MLflow in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support MLflow for the following providers:\n\n```\nplural bundle install mlflow mlflow-aws\n```\n\n## Setup Configuration\n\nmlflow_bucket: bucket to store the mlflow artifacts inhostname: FQDN to use for your MLFlow installation",
- "source_links": [],
- "id": 268
- },
- {
- "page_link": "https://docs.plural.sh/applications/mongodb",
- "title": " Installing MongoDB",
- "text": "# Installing MongoDB\n\nA scalable NoSQL document-oriented database.\n\n## Description\n\nPlural will install MongoDB in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support MongoDB for the following providers:\n\n```\nplural bundle install mongodb mongodb-aws\n```\n\n```\nplural bundle install mongodb mongodb-azure\n```\n\n```\nplural bundle install mongodb mongodb-gcp\n```",
- "source_links": [],
- "id": 269
- },
- {
- "page_link": "https://docs.plural.sh/applications/monitoring",
- "title": " Installing Monitoring",
- "text": "# Installing Monitoring\n\nAn OpenMetrics suite for Plural.\n\n## Description\n\nPlural will install Monitoring in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Monitoring for the following providers:\n\n```\nplural bundle install monitoring monitoring-aws\n```\n\n```\nplural bundle install monitoring monitoring-azure\n```\n\n```\nplural bundle install monitoring monitoring-equinix\n```\n\n```\nplural bundle install monitoring monitoring-gcp\n```\n\n```\nplural bundle install monitoring monitoring-generic\n```\n\n```\nplural bundle install monitoring monitoring-kind\n```",
- "source_links": [],
- "id": 270
- },
- {
- "page_link": "https://docs.plural.sh/applications/mysql",
- "title": " Installing MySQL",
- "text": "# Installing MySQL\n\nAn open-source relational database management system.\n\n## Description\n\nPlural will install MySQL in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support MySQL for the following providers:\n\n```\nplural bundle install mysql aws-mysql\n```\n\n```\nplural bundle install mysql aws-mysql-percona\n```\n\n```\nplural bundle install mysql gcp-mysql\n```\n\n## Setup Configuration\n\nbackup_bucket: bucket to store mysql backups inhostname: FQDN to use for your accessing the mysql orchestrator",
- "source_links": [],
- "id": 271
- },
- {
- "page_link": "https://docs.plural.sh/applications/n8n",
- "title": " Installing n8n",
- "text": "# Installing n8n\n\nAn extendable workflow automation tool.\n\n## Description\n\nPlural will install n8n in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support n8n for the following providers:\n\n```\nplural bundle install n8n n8n-aws\n```\n\n```\nplural bundle install n8n n8n-azure\n```\n\n```\nplural bundle install n8n n8n-gcp\n```\n\n## Setup Configuration\n\nhostname: domain on which you'd like to host n8n's page",
- "source_links": [],
- "id": 272
- },
- {
- "page_link": "https://docs.plural.sh/applications/nextcloud",
- "title": " Installing Nextcloud",
- "text": "# Installing Nextcloud\n\nA completely integrated on-premises content collaboration platform.\n\n## Description\n\nPlural will install Nextcloud in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Nextcloud for the following providers:\n\n```\nplural bundle install nextcloud nextcloud-aws\n```\n\n```\nplural bundle install nextcloud nextcloud-azure\n```\n\n## Setup Configuration\n\nnextcloud_bucket: bucket to store nextcloud datahostname: FQDN to use for your nextcloud installation",
- "source_links": [],
- "id": 273
- },
- {
- "page_link": "https://docs.plural.sh/applications/nocodb",
- "title": " Installing NocoDB",
- "text": "# Installing NocoDB\n\nOpen-source alternative to Airtable that turns any database into a smart spreadsheet.\n\n## Description\n\nPlural will install NocoDB in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support NocoDB for the following providers:\n\n```\nplural bundle install nocodb nocodb-aws\n```\n\n```\nplural bundle install nocodb nocodb-azure\n```\n\n```\nplural bundle install nocodb nocodb-gcp\n```\n\n## Setup Configuration\n\nhostname: Fully Qualified Domain Name to use for your nocodb installation",
- "source_links": [],
- "id": 274
- },
- {
- "page_link": "https://docs.plural.sh/applications/nvidia-operator",
- "title": " Installing NVIDIA Operator",
- "text": "# Installing NVIDIA Operator\n\nAllows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster.\n\n## Description\n\nPlural will install NVIDIA Operator in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support NVIDIA Operator for the following providers:\n\n```\nplural bundle install nvidia-operator nvidia-operator-aws\n```\n\n```\nplural bundle install nvidia-operator nvidia-operator-azure\n```\n\n```\nplural bundle install nvidia-operator nvidia-operator-gcp\n```",
- "source_links": [],
- "id": 275
- },
- {
- "page_link": "https://docs.plural.sh/applications/oauth2-proxy",
- "title": " Installing OAuth2 Proxy",
- "text": "# Installing OAuth2 Proxy\n\nA reverse proxy & static file server that issues auth to validate accounts by email or domain.\n\n## Description\n\nPlural will install OAuth2 Proxy in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support OAuth2 Proxy for the following providers:\n\n```\nplural bundle install oauth2-proxy oauth2-proxy-aws\n```\n\n## Setup Configuration\n\nauth_cookie_domain: domain to use for the auth cookieauth_whitelist_domain: whitelist domain for authoidc_issuer_url: uri of your oidc issueruser_id_claim: claim used for the user id",
- "source_links": [],
- "id": 276
- },
- {
- "page_link": "https://docs.plural.sh/applications/plural",
- "title": " Installing Plural",
- "text": "# Installing Plural\n\nEmpowers devs to build & maintain cloud-native & production-ready OSS infrastructure on Kubernetes.\n\n## Description\n\nPlural will install Plural in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Plural for the following providers:\n\n```\nplural bundle install plural plural-aws\n```\n\n```\nplural bundle install plural plural-gcp\n```\n\n## Setup Configuration\n\nchartmuseum_bucket: Bucket for helm chartsassets_bucket: bucket for misc assets (docker imgs/terraform modules)images_bucket: bucket for images and iconsplural_dns: FQDN to use for your plural clusterplural_dkr_dns: FQDN for your plural docker registryadmin_name: name for initial admin useradmin_email: email for initial admin userpublisher: name for initial publisherpublisher_description: description for initial publisherhydra_host: the fqdn to use for hydra, for managing plural oauth",
- "source_links": [],
- "id": 277
- },
- {
- "page_link": "https://docs.plural.sh/applications/postgres",
- "title": " Installing PostgreSQL",
- "text": "# Installing PostgreSQL\n\nGeneral-use OLTP database for stateful use cases.\n\n## Description\n\nPlural will install PostgreSQL in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support PostgreSQL for the following providers:\n\n```\nplural bundle install postgres aws-postgres\n```\n\n```\nplural bundle install postgres azure-postgres\n```\n\n```\nplural bundle install postgres equinix-postgres\n```\n\n```\nplural bundle install postgres gcp-postgres\n```\n\n```\nplural bundle install postgres generic-postgres\n```\n\n```\nplural bundle install postgres kind-postgres\n```\n\n## Setup Configuration\n\nwal_bucket: Arbitary name for s3 bucket to store wal archives in, eg plural-wal-archives\n\n## Introduction\n\n[](/applications/postgres#introduction)\n\nYou may have noticed that Plural sometimes deploys with the Postgres application pre-installed. This is because it is a dependency for the Plural Console, which requires a Postgres database to store state about your Plural installation.\n\nSome applications may also have a Postgres database as a dependency, in which case a separate database would be deployed for that application. These databases can be accessed directly using the plural proxy CLI command which you can learn about here.\n\n[here](/operations/managing-applications/connect-application-db)\n\nTo fulfill these requests for a database, Plural uses the Zalando Postgres Operator. This allows us to create Postgres databases on-demand when required by an application.\n\n[Zalando Postgres Operator](https://github.com/zalando/postgres-operator)\n\n## Using the Postgres Operator\n\n[](/applications/postgres#using-the-postgres-operator)\n\nWhile we use the operator automatically to create databases for applications, you can invoke the operator yourself to manually spin up a database for your own use cases.\n\nTo do this, place the following YAML into any application directory (we recommend /postgres/helm/postgres/templates):\n\n```\napiVersion: acid.zalan.do/v1\nkind: postgresql\nmetadata:\n annotations:\n meta.helm.sh/release-name: plural\n meta.helm.sh/release-namespace: plural\n labels:\n app: postgres\n app.kubernetes.io/instance: plural\n app.kubernetes.io/managed-by: Helm\n app.kubernetes.io/name: plural\n app.kubernetes.io/version: 0.9.16-rc5\n db: plural\n helm.sh/chart: plural-0.9.37\n name: plural-plural\n namespace: plural\nspec:\n clone:\n cluster: plural-clone\n databases:\n plural: plural\n numberOfInstances: 2\n postgresql:\n parameters:\n max_connections: \"101\"\n version: \"13\"\n resources:\n limits:\n cpu: \"2\"\n memory: 1Gi\n requests:\n cpu: 400m\n memory: 1Gi\n sidecars:\n - env:\n - name: DATA_SOURCE_URI\n value: 127.0.0.1:5432/plural?sslmode=disable\n - name: DATA_SOURCE_USER\n valueFrom:\n secretKeyRef:\n key: username\n name: postgres.plural-plural.credentials.postgresql.acid.zalan.do\n - name: DATA_SOURCE_PASS\n valueFrom:\n secretKeyRef:\n key: password\n name: postgres.plural-plural.credentials.postgresql.acid.zalan.do\n image: gcr.io/pluralsh/postgres-exporter:0.8.0\n livenessProbe:\n failureThreshold: 6\n httpGet:\n path: /\n port: http-metrics\n scheme: HTTP\n initialDelaySeconds: 5\n periodSeconds: 10\n successThreshold: 1\n timeoutSeconds: 5\n name: exporter\n ports:\n - containerPort: 9187\n name: http-metrics\n protocol: TCP\n readinessProbe:\n failureThreshold: 6\n httpGet:\n path: /\n port: http-metrics\n scheme: HTTP\n initialDelaySeconds: 5\n periodSeconds: 10\n successThreshold: 1\n timeoutSeconds: 5\n teamId: plural\n tolerations:\n - effect: NoSchedule\n key: plural.sh/pluralReserved\n operator: Exists\n users:\n plural:\n - superuser\n - createdb\n volume:\n size: 75Gi\n```\n\nNow run plural deploy --commit \"deploy postgres\" and the Postgres Operator will pick up your request and create the database for you.\n\n## Accessing the Database manually\n\n[](/applications/postgres#accessing-the-database-manually)\n\nIn order to access your database directly, you'll need to get the generated password. This is located in a Kubernetes secret within the Postgres namespace.\n\nTo find the password secret, make sure that you have kubectl configured to point at the relevant cluster and run the following command:\n\n```\nkubectl get secrets -n postgres\n```\n\nThe relevant secret should follow the naming convention dbuser.dbname.acid.zalando. To decrypt the secret, run the following command:\n\n```\nkubectl get secrets/{SECRET_NAME} --template={{.data.password}} | base64 -d\n```\n\nNow with the username in the name of this secret and the decrypted password, you can now access your database.\n\n## Using the Database with other Plural Applications\n\n[](/applications/postgres#using-the-database-with-other-plural-applications)\n\nA common use case for spinning up a new Postgres database is using it with another Plural application, for example, Superset. To connect any application to the Postgres database on the same Kubernetes cluster, use the following address:\n\n{POSTGRES_POD_NAME}.postgres:5432\n\nTo get the Pod name for your Postgres database, run kubectl get pods -n postgres in the relevant Kubernetes cluster.\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/applications/postgres.mdpart)",
- "source_links": [],
- "id": 278
- },
- {
- "page_link": "https://docs.plural.sh/applications/posthog",
- "title": " Installing Posthog",
- "text": "# Installing Posthog\n\nThe all-in-one platform for building better products.\n\n## Description\n\nPlural will install Posthog in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Posthog for the following providers:\n\n```\nplural bundle install posthog posthog-aws\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your posthog installationposthogBucket: S3 bucket to use for posthognotificationEmail: email for notifications to be sent to from the PostHog stack",
- "source_links": [],
- "id": 279
- },
- {
- "page_link": "https://docs.plural.sh/applications/prefect",
- "title": " Installing Prefect",
- "text": "# Installing Prefect\n\nModern orchestration tool and Airflow alternative.\n\n## Description\n\nPlural will install Prefect in a dependency-aware manner onto a Plural-managed Kubernetes cluster with one CLI command.\n\n## Installation\n\nWe currently support Prefect for the following providers:\n\n```\nplural bundle install prefect prefect-aws\n```\n\n```\nplural bundle install prefect prefect-azure\n```\n\n```\nplural bundle install prefect prefect-gcp\n```\n\n## Setup Configuration\n\nhostname: FQDN to use for your prefect installation\n\n## Setting up Prefect with Plural\n\n[](/applications/prefect#setting-up-prefect-with-plural)\n\nThis guide goes over the basics to getting started with running Prefect flows on Plural.\n\n### Step 1: Configure Access to Plural\n\n[](/applications/prefect#step-1-configure-access-to-plural)\n\nThe Prefect CLI needs API access to Prefect on the Plural cluster. A simple solution is to create a basic auth user in Plural.\n\nprefect: users: { : }\n\nPlural has a utility to create a password. `plural crypto random will create a random string that can be used as a password.\n\n### Step 2: Install Prefect CLI\n\n[](/applications/prefect#step-2-install-prefect-cli)\n\nTo install the Prefect CLI locally, you will need to have Python and pip installed on your machine.\n\nOpen a terminal window and run the following command to install the Prefect CLI:\n\n```\npip install prefect\n```\n\nOnce the installation is complete, you can verify that the CLI is installed by running the following command:\n\n```\nprefect --version\n``\n\n### Step 3: Create a profile to connect to Plural\n\nPrefect allows you to have multiple profiles to connect to different Orion instances. I.e local, cloud or self-hosted. Plural is a self-hosted solution.\n\n1) Create a new profile prefect profile create set the profile name to plural\n2) On the new profile, set the PREFECT_API_URL with prefect config set PREFECT_API_URL=\"https://:@.onplural.sh/api\"\n3) and






 \n
\n \n",
- "source_links": [],
- "id": 4
- },
- {
- "page_link": "bring-your-db.md",
- "title": "bring-your-db",
- "text": "## Connecting to a managed SQL\u00a0instance\n\nWe ship airbyte with the zalando postgres operator's db for persistence by default. This provides a lot of the benefits of a managed postgres instance at a lower cost, but if you'd rather use a familiar service like RDS this is still possible. You'll need to do a few things:\n\n### edit context.yaml\n\nAt the root of the repo, edit the `context.yaml` field and set `configuration.airflow.postgresDisabled: true`, this will allow us to reconfigure airflow for bring-your-own-db.\n\n### save the database password to a secret\n\nyou can use a number of methods for this, but simply adding a secret file as `airflow/helm/airflow/templates/db-password.yaml` like:\n\n```yaml\napiVersion: v1\nkind: Secret\nmetadata:\n name: airflow-db-password\nstringData:\n password: {{ .Values.externalDb.password }}\n```\n\nNote: this password needs to be in the `airflow` namespace. If you put it in our wrapper helm chart, that will be done by default for you.\n\n### modify airflow's helm values.yaml \n\nIf you go to `airflow/helm/airflow/values.yaml` you'll need to provide credentials for postgres. They should look something like:\n\n```yaml\nexternalDb:\n password:
\n",
- "source_links": [],
- "id": 4
- },
- {
- "page_link": "bring-your-db.md",
- "title": "bring-your-db",
- "text": "## Connecting to a managed SQL\u00a0instance\n\nWe ship airbyte with the zalando postgres operator's db for persistence by default. This provides a lot of the benefits of a managed postgres instance at a lower cost, but if you'd rather use a familiar service like RDS this is still possible. You'll need to do a few things:\n\n### edit context.yaml\n\nAt the root of the repo, edit the `context.yaml` field and set `configuration.airflow.postgresDisabled: true`, this will allow us to reconfigure airflow for bring-your-own-db.\n\n### save the database password to a secret\n\nyou can use a number of methods for this, but simply adding a secret file as `airflow/helm/airflow/templates/db-password.yaml` like:\n\n```yaml\napiVersion: v1\nkind: Secret\nmetadata:\n name: airflow-db-password\nstringData:\n password: {{ .Values.externalDb.password }}\n```\n\nNote: this password needs to be in the `airflow` namespace. If you put it in our wrapper helm chart, that will be done by default for you.\n\n### modify airflow's helm values.yaml \n\nIf you go to `airflow/helm/airflow/values.yaml` you'll need to provide credentials for postgres. They should look something like:\n\n```yaml\nexternalDb:\n password:  \n\n \n\n
\n\n \n\n  \n
\n 




 \n\n# Scheduling infrastructure for absolutely everyone\n\nThe open source Calendly alternative. You are in charge\nof your own data, workflow and appearance.\n\nCalendly and other scheduling tools are awesome. It made our lives massively easier. We're using it for business meetings, seminars, yoga classes and even calls with our families. However, most tools are very limited in terms of control and customisations.\n\nThat's where Cal.com comes in. Self-hosted or hosted by us. White-label by design. API-driven and ready to be deployed on your own domain. Full control of your events and data.\n\n## Product of the Month: April\n\n#### Support us on [Product Hunt](https://www.producthunt.com/posts/calendso?utm_source=badge-top-post-badge&utm_medium=badge&utm_souce=badge-calendso)\n\n
\n\n# Scheduling infrastructure for absolutely everyone\n\nThe open source Calendly alternative. You are in charge\nof your own data, workflow and appearance.\n\nCalendly and other scheduling tools are awesome. It made our lives massively easier. We're using it for business meetings, seminars, yoga classes and even calls with our families. However, most tools are very limited in terms of control and customisations.\n\nThat's where Cal.com comes in. Self-hosted or hosted by us. White-label by design. API-driven and ready to be deployed on your own domain. Full control of your events and data.\n\n## Product of the Month: April\n\n#### Support us on [Product Hunt](https://www.producthunt.com/posts/calendso?utm_source=badge-top-post-badge&utm_medium=badge&utm_souce=badge-calendso)\n\n
 \n\n \n\n\n### Built With\n\n- [Next.js](https://nextjs.org/)\n- [React](https://reactjs.org/)\n- [Tailwind](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n## Stay Up-to-Date\n\nCal officially launched as v.1.0 on 15th of September, however a lot of new features are coming. Watch **releases** of this repository to be notified for future updates:\n\n\n\n\n\n## Getting Started\n\nTo get a local copy up and running, please follow these simple steps.\n\n### Prerequisites\n\nHere is what you need to be able to run Cal.\n\n- Node.js (Version: >=15.x <17)\n- PostgreSQL\n- Yarn _(recommended)_\n\n> If you want to enable any of the available integrations, you may want to obtain additional credentials for each one. More details on this can be found below under the [integrations section](#integrations).\n\n## Development\n\n### Setup\n\n1. Clone the repo into a public GitHub repository (or fork https://github.com/calcom/cal.com/fork). If you plan to distribute the code, keep the source code public to comply with [AGPLv3](https://github.com/calcom/cal.com/blob/main/LICENSE). To clone in a private repository, [acquire a commercial license](https://cal.com/sales))\n\n ```sh\n git clone https://github.com/calcom/cal.com.git\n ```\n\n1. Go to the project folder\n\n ```sh\n cd cal.com\n ```\n\n1. Install packages with yarn\n\n ```sh\n yarn\n ```\n\n1. Use `openssl rand -base64 32` to generate a key and add it under `NEXTAUTH_SECRET` in the .env file.\n\n#### Quick start with `yarn dx`\n\n> - **Requires Docker and Docker Compose to be installed**\n> - Will start a local Postgres instance with a few test users - the credentials will be logged in the console\n\n```sh\nyarn dx\n```\n\n#### Development tip\n\n> Add `NEXT_PUBLIC_DEBUG=1` anywhere in your `.env` to get logging information for all the queries and mutations driven by **trpc**.\n\n```sh\necho 'NEXT_PUBLIC_DEBUG=1' >> .env\n```\n\n#### Manual setup\n\n1. Configure environment variables in the `packages/prisma/.env` file. Replace `
\n\n \n\n\n### Built With\n\n- [Next.js](https://nextjs.org/)\n- [React](https://reactjs.org/)\n- [Tailwind](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n## Stay Up-to-Date\n\nCal officially launched as v.1.0 on 15th of September, however a lot of new features are coming. Watch **releases** of this repository to be notified for future updates:\n\n\n\n\n\n## Getting Started\n\nTo get a local copy up and running, please follow these simple steps.\n\n### Prerequisites\n\nHere is what you need to be able to run Cal.\n\n- Node.js (Version: >=15.x <17)\n- PostgreSQL\n- Yarn _(recommended)_\n\n> If you want to enable any of the available integrations, you may want to obtain additional credentials for each one. More details on this can be found below under the [integrations section](#integrations).\n\n## Development\n\n### Setup\n\n1. Clone the repo into a public GitHub repository (or fork https://github.com/calcom/cal.com/fork). If you plan to distribute the code, keep the source code public to comply with [AGPLv3](https://github.com/calcom/cal.com/blob/main/LICENSE). To clone in a private repository, [acquire a commercial license](https://cal.com/sales))\n\n ```sh\n git clone https://github.com/calcom/cal.com.git\n ```\n\n1. Go to the project folder\n\n ```sh\n cd cal.com\n ```\n\n1. Install packages with yarn\n\n ```sh\n yarn\n ```\n\n1. Use `openssl rand -base64 32` to generate a key and add it under `NEXTAUTH_SECRET` in the .env file.\n\n#### Quick start with `yarn dx`\n\n> - **Requires Docker and Docker Compose to be installed**\n> - Will start a local Postgres instance with a few test users - the credentials will be logged in the console\n\n```sh\nyarn dx\n```\n\n#### Development tip\n\n> Add `NEXT_PUBLIC_DEBUG=1` anywhere in your `.env` to get logging information for all the queries and mutations driven by **trpc**.\n\n```sh\necho 'NEXT_PUBLIC_DEBUG=1' >> .env\n```\n\n#### Manual setup\n\n1. Configure environment variables in the `packages/prisma/.env` file. Replace ` \n\n 3. In your new app, go to `Overview` and next to `Installed add-ons`, click `Configure Add-ons`. We need this to set up our database.\n \n\n 4. Once you clicked on `Configure Add-ons`, click on `Find more add-ons` and search for `postgres`. One of the options will be `Heroku Postgres` - click on that option.\n \n\n 5. Once the pop-up appears, click `Submit Order Form` - plan name should be `Hobby Dev - Free`.\n
\n\n 3. In your new app, go to `Overview` and next to `Installed add-ons`, click `Configure Add-ons`. We need this to set up our database.\n \n\n 4. Once you clicked on `Configure Add-ons`, click on `Find more add-ons` and search for `postgres`. One of the options will be `Heroku Postgres` - click on that option.\n \n\n 5. Once the pop-up appears, click `Submit Order Form` - plan name should be `Hobby Dev - Free`.\n  \n\n 6. Once you completed the above steps, click on your newly created `Heroku Postgres` and go to its `Settings`.\n \n\n 7. In `Settings`, copy your URI to your Cal.com .env file and replace the `postgresql://
\n\n 6. Once you completed the above steps, click on your newly created `Heroku Postgres` and go to its `Settings`.\n \n\n 7. In `Settings`, copy your URI to your Cal.com .env file and replace the `postgresql:// \n\n\n### Railway\n\n[](https://railway.app/new/template?template=https%3A%2F%2Fgithub.com%2Fcalendso%2Fcalendso&plugins=postgresql&envs=GOOGLE_API_CREDENTIALS%2CBASE_URL%2CNEXTAUTH_URL%2CPORT&BASE_URLDefault=http%3A%2F%2Flocalhost%3A3000&NEXTAUTH_URLDefault=http%3A%2F%2Flocalhost%3A3000&PORTDefault=3000)\n\nYou can deploy Cal on [Railway](https://railway.app/) using the button above. The team at Railway also have a [detailed blog post](https://blog.railway.app/p/calendso) on deploying Cal on their platform.\n\n### Vercel\n\nCurrently Vercel Pro Plan is required to be able to Deploy this application with Vercel, due to limitations on the number of serverless functions on the free plan.\n\n[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com&env=DATABASE_URL,NEXT_PUBLIC_WEBAPP_URL,NEXTAUTH_URL,NEXTAUTH_SECRET,CRON_API_KEY,CALENDSO_ENCRYPTION_KEY,NEXT_PUBLIC_LICENSE_CONSENT&envDescription=See%20all%20available%20env%20vars&envLink=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com%2Fblob%2Fmain%2F.env.example&project-name=cal&repo-name=cal.com&build-command=cd%20../..%20%26%26%20yarn%20build&root-directory=apps%2Fweb%2F)\n\n\n\n## Roadmap\n\n
\n\n\n### Railway\n\n[](https://railway.app/new/template?template=https%3A%2F%2Fgithub.com%2Fcalendso%2Fcalendso&plugins=postgresql&envs=GOOGLE_API_CREDENTIALS%2CBASE_URL%2CNEXTAUTH_URL%2CPORT&BASE_URLDefault=http%3A%2F%2Flocalhost%3A3000&NEXTAUTH_URLDefault=http%3A%2F%2Flocalhost%3A3000&PORTDefault=3000)\n\nYou can deploy Cal on [Railway](https://railway.app/) using the button above. The team at Railway also have a [detailed blog post](https://blog.railway.app/p/calendso) on deploying Cal on their platform.\n\n### Vercel\n\nCurrently Vercel Pro Plan is required to be able to Deploy this application with Vercel, due to limitations on the number of serverless functions on the free plan.\n\n[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com&env=DATABASE_URL,NEXT_PUBLIC_WEBAPP_URL,NEXTAUTH_URL,NEXTAUTH_SECRET,CRON_API_KEY,CALENDSO_ENCRYPTION_KEY,NEXT_PUBLIC_LICENSE_CONSENT&envDescription=See%20all%20available%20env%20vars&envLink=https%3A%2F%2Fgithub.com%2Fcalcom%2Fcal.com%2Fblob%2Fmain%2F.env.example&project-name=cal&repo-name=cal.com&build-command=cd%20../..%20%26%26%20yarn%20build&root-directory=apps%2Fweb%2F)\n\n\n\n## Roadmap\n\n \n\nSee the [roadmap project](https://cal.com/roadmap) for a list of proposed features (and known issues). You can change the view to see planned tagged releases.\n\n\n\n## Contributing\n\nPlease see our [contributing guide](/CONTRIBUTING.md).\n\n### Good First Issues\n\nWe have a list of [help wanted](https://github.com/orgs/calcom/projects/1/views/25) that contain small features and bugs which have a relatively limited scope. This is a great place to get started, gain experience, and get familiar with our contribution process.\n\n## Integrations\n\n### Obtaining the Google API Credentials\n\n1. Open [Google API Console](https://console.cloud.google.com/apis/dashboard). If you don't have a project in your Google Cloud subscription, you'll need to create one before proceeding further. Under Dashboard pane, select Enable APIS and Services.\n2. In the search box, type calendar and select the Google Calendar API search result.\n3. Enable the selected API.\n4. Next, go to the [OAuth consent screen](https://console.cloud.google.com/apis/credentials/consent) from the side pane. Select the app type (Internal or External) and enter the basic app details on the first page.\n5. In the second page on Scopes, select Add or Remove Scopes. Search for Calendar.event and select the scope with scope value `.../auth/calendar.events`, `.../auth/calendar.readonly` and select Update.\n6. In the third page (Test Users), add the Google account(s) you'll using. Make sure the details are correct on the last page of the wizard and your consent screen will be configured.\n7. Now select [Credentials](https://console.cloud.google.com/apis/credentials) from the side pane and then select Create Credentials. Select the OAuth Client ID option.\n8. Select Web Application as the Application Type.\n9. Under Authorized redirect URI's, select Add URI and then add the URI `
\n\nSee the [roadmap project](https://cal.com/roadmap) for a list of proposed features (and known issues). You can change the view to see planned tagged releases.\n\n\n\n## Contributing\n\nPlease see our [contributing guide](/CONTRIBUTING.md).\n\n### Good First Issues\n\nWe have a list of [help wanted](https://github.com/orgs/calcom/projects/1/views/25) that contain small features and bugs which have a relatively limited scope. This is a great place to get started, gain experience, and get familiar with our contribution process.\n\n## Integrations\n\n### Obtaining the Google API Credentials\n\n1. Open [Google API Console](https://console.cloud.google.com/apis/dashboard). If you don't have a project in your Google Cloud subscription, you'll need to create one before proceeding further. Under Dashboard pane, select Enable APIS and Services.\n2. In the search box, type calendar and select the Google Calendar API search result.\n3. Enable the selected API.\n4. Next, go to the [OAuth consent screen](https://console.cloud.google.com/apis/credentials/consent) from the side pane. Select the app type (Internal or External) and enter the basic app details on the first page.\n5. In the second page on Scopes, select Add or Remove Scopes. Search for Calendar.event and select the scope with scope value `.../auth/calendar.events`, `.../auth/calendar.readonly` and select Update.\n6. In the third page (Test Users), add the Google account(s) you'll using. Make sure the details are correct on the last page of the wizard and your consent screen will be configured.\n7. Now select [Credentials](https://console.cloud.google.com/apis/credentials) from the side pane and then select Create Credentials. Select the OAuth Client ID option.\n8. Select Web Application as the Application Type.\n9. Under Authorized redirect URI's, select Add URI and then add the URI ` ](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n\n- [Vercel](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n- [Next.js](https://nextjs.org/)\n- [Day.js](https://day.js.org/)\n- [Tailwind CSS](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n
](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n\n- [Vercel](https://vercel.com/?utm_source=calend-so&utm_campaign=oss)\n- [Next.js](https://nextjs.org/)\n- [Day.js](https://day.js.org/)\n- [Tailwind CSS](https://tailwindcss.com/)\n- [Prisma](https://prisma.io/)\n\n \n\nCal.com is an [open startup](https://cal.com/open) and [Jitsu](https://github.com/jitsucom/jitsu) (an open-source Segment alternative) helps us to track most of the usage metrics.\n",
- "source_links": [],
- "id": 14
- },
- {
- "page_link": "https://github.com/chatwoot/chatwoot",
- "title": "chatwoot readme",
- "text": "
\n\nCal.com is an [open startup](https://cal.com/open) and [Jitsu](https://github.com/jitsucom/jitsu) (an open-source Segment alternative) helps us to track most of the usage metrics.\n",
- "source_links": [],
- "id": 14
- },
- {
- "page_link": "https://github.com/chatwoot/chatwoot",
- "title": "chatwoot readme",
- "text": " \n\n
\n\n 



 \n
\n 


 \n\n\n\nChatwoot is an open-source, self-hosted customer engagement suite. Chatwoot lets you view and manage your customer data, communicate with them irrespective of which medium they use, and re-engage them based on their profile.\n\n## Features\n\nChatwoot supports the following conversation channels:\n\n - **Website**: Talk to your customers using our live chat widget and make use of our SDK to identify a user and provide contextual support.\n - **Facebook**: Connect your Facebook pages and start replying to the direct messages to your page.\n - **Instagram**: Connect your Instagram profile and start replying to the direct messages.\n - **Twitter**: Connect your Twitter profiles and reply to direct messages or the tweets where you are mentioned.\n - **Telegram**: Connect your Telegram bot and reply to your customers right from a single dashboard.\n - **WhatsApp**: Connect your WhatsApp business account and manage the conversation in Chatwoot.\n - **Line**: Connect your Line account and manage the conversations in Chatwoot.\n - **SMS**: Connect your Twilio SMS account and reply to the SMS queries in Chatwoot.\n - **API Channel**: Build custom communication channels using our API channel.\n - **Email**: Forward all your email queries to Chatwoot and view it in our integrated dashboard.\n\nAnd more.\n\nOther features include:\n\n- **CRM**: Save all your customer information right inside Chatwoot, use contact notes to log emails, phone calls, or meeting notes.\n- **Custom Attributes**: Define custom attribute attributes to store information about a contact or a conversation and extend the product to match your workflow.\n- **Shared multi-brand inboxes**: Manage multiple brands or pages using a shared inbox.\n- **Private notes**: Use @mentions and private notes to communicate internally about a conversation.\n- **Canned responses (Saved replies)**: Improve the response rate by adding saved replies for frequently asked questions.\n- **Conversation Labels**: Use conversation labels to create custom workflows.\n- **Auto assignment**: Chatwoot intelligently assigns a ticket to the agents who have access to the inbox depending on their availability and load.\n- **Conversation continuity**: If the user has provided an email address through the chat widget, Chatwoot will send an email to the customer under the agent name so that the user can continue the conversation over the email.\n- **Multi-lingual support**: Chatwoot supports 10+ languages.\n- **Powerful API & Webhooks**: Extend the capability of the software using Chatwoot\u2019s webhooks and APIs.\n- **Integrations**: Chatwoot natively integrates with Slack right now. Manage your conversations in Slack without logging into the dashboard.\n\n## Documentation\n\nDetailed documentation is available at [chatwoot.com/help-center](https://www.chatwoot.com/help-center).\n\n## Translation process\n\nThe translation process for Chatwoot web and mobile app is managed at [https://translate.chatwoot.com](https://translate.chatwoot.com) using Crowdin. Please read the [translation guide](https://www.chatwoot.com/docs/contributing/translating-chatwoot-to-your-language) for contributing to Chatwoot.\n\n## Branching model\n\nWe use the [git-flow](https://nvie.com/posts/a-successful-git-branching-model/) branching model. The base branch is `develop`.\nIf you are looking for a stable version, please use the `master` or tags labelled as `v1.x.x`.\n\n## Deployment\n\n### Heroku one-click deploy\n\nDeploying Chatwoot to Heroku is a breeze. It's as simple as clicking this button:\n\n[](https://heroku.com/deploy?template=https://github.com/chatwoot/chatwoot/tree/master)\n\nFollow this [link](https://www.chatwoot.com/docs/environment-variables) to understand setting the correct environment variables for the app to work with all the features. There might be breakages if you do not set the relevant environment variables.\n\n\n### DigitalOcean 1-Click Kubernetes deployment\n\nChatwoot now supports 1-Click deployment to DigitalOcean as a kubernetes app.\n\n\n
\n\n\n\nChatwoot is an open-source, self-hosted customer engagement suite. Chatwoot lets you view and manage your customer data, communicate with them irrespective of which medium they use, and re-engage them based on their profile.\n\n## Features\n\nChatwoot supports the following conversation channels:\n\n - **Website**: Talk to your customers using our live chat widget and make use of our SDK to identify a user and provide contextual support.\n - **Facebook**: Connect your Facebook pages and start replying to the direct messages to your page.\n - **Instagram**: Connect your Instagram profile and start replying to the direct messages.\n - **Twitter**: Connect your Twitter profiles and reply to direct messages or the tweets where you are mentioned.\n - **Telegram**: Connect your Telegram bot and reply to your customers right from a single dashboard.\n - **WhatsApp**: Connect your WhatsApp business account and manage the conversation in Chatwoot.\n - **Line**: Connect your Line account and manage the conversations in Chatwoot.\n - **SMS**: Connect your Twilio SMS account and reply to the SMS queries in Chatwoot.\n - **API Channel**: Build custom communication channels using our API channel.\n - **Email**: Forward all your email queries to Chatwoot and view it in our integrated dashboard.\n\nAnd more.\n\nOther features include:\n\n- **CRM**: Save all your customer information right inside Chatwoot, use contact notes to log emails, phone calls, or meeting notes.\n- **Custom Attributes**: Define custom attribute attributes to store information about a contact or a conversation and extend the product to match your workflow.\n- **Shared multi-brand inboxes**: Manage multiple brands or pages using a shared inbox.\n- **Private notes**: Use @mentions and private notes to communicate internally about a conversation.\n- **Canned responses (Saved replies)**: Improve the response rate by adding saved replies for frequently asked questions.\n- **Conversation Labels**: Use conversation labels to create custom workflows.\n- **Auto assignment**: Chatwoot intelligently assigns a ticket to the agents who have access to the inbox depending on their availability and load.\n- **Conversation continuity**: If the user has provided an email address through the chat widget, Chatwoot will send an email to the customer under the agent name so that the user can continue the conversation over the email.\n- **Multi-lingual support**: Chatwoot supports 10+ languages.\n- **Powerful API & Webhooks**: Extend the capability of the software using Chatwoot\u2019s webhooks and APIs.\n- **Integrations**: Chatwoot natively integrates with Slack right now. Manage your conversations in Slack without logging into the dashboard.\n\n## Documentation\n\nDetailed documentation is available at [chatwoot.com/help-center](https://www.chatwoot.com/help-center).\n\n## Translation process\n\nThe translation process for Chatwoot web and mobile app is managed at [https://translate.chatwoot.com](https://translate.chatwoot.com) using Crowdin. Please read the [translation guide](https://www.chatwoot.com/docs/contributing/translating-chatwoot-to-your-language) for contributing to Chatwoot.\n\n## Branching model\n\nWe use the [git-flow](https://nvie.com/posts/a-successful-git-branching-model/) branching model. The base branch is `develop`.\nIf you are looking for a stable version, please use the `master` or tags labelled as `v1.x.x`.\n\n## Deployment\n\n### Heroku one-click deploy\n\nDeploying Chatwoot to Heroku is a breeze. It's as simple as clicking this button:\n\n[](https://heroku.com/deploy?template=https://github.com/chatwoot/chatwoot/tree/master)\n\nFollow this [link](https://www.chatwoot.com/docs/environment-variables) to understand setting the correct environment variables for the app to work with all the features. There might be breakages if you do not set the relevant environment variables.\n\n\n### DigitalOcean 1-Click Kubernetes deployment\n\nChatwoot now supports 1-Click deployment to DigitalOcean as a kubernetes app.\n\n\n  \n\n\n### Other deployment options\n\nFor other supported options, checkout our [deployment page](https://chatwoot.com/deploy). \n\n## Security\n\nLooking to report a vulnerability? Please refer our [SECURITY.md](./SECURITY.md) file.\n\n\n## Community? Questions? Support ?\n\nIf you need help or just want to hang out, come, say hi on our [Discord](https://discord.gg/cJXdrwS) server.\n\n\n## Contributors \u2728\n\nThanks goes to all these [wonderful people](https://www.chatwoot.com/docs/contributors):\n\n
\n\n\n### Other deployment options\n\nFor other supported options, checkout our [deployment page](https://chatwoot.com/deploy). \n\n## Security\n\nLooking to report a vulnerability? Please refer our [SECURITY.md](./SECURITY.md) file.\n\n\n## Community? Questions? Support ?\n\nIf you need help or just want to hang out, come, say hi on our [Discord](https://discord.gg/cJXdrwS) server.\n\n\n## Contributors \u2728\n\nThanks goes to all these [wonderful people](https://www.chatwoot.com/docs/contributors):\n\n \n\n\n*Chatwoot* © 2017-2022, Chatwoot Inc - Released under the MIT License.\n",
- "source_links": [],
- "id": 15
- },
- {
- "page_link": "https://github.com/Altinity/clickhouse-operator",
- "title": "clickhouse readme",
- "text": "# Altinity Operator for ClickHouse\n\nOperator creates, configures and manages ClickHouse clusters running on Kubernetes.\n\n[](https://github.com/Altinity/clickhouse-operator/actions/workflows/build_master.yaml)\n[](https://img.shields.io/github/v/release/altinity/clickhouse-operator?include_prereleases)\n[](https://github.com/altinity/clickhouse-operator/tags)\n[](https://hub.docker.com/r/altinity/clickhouse-operator)\n[](https://img.shields.io/github/go-mod/go-version/altinity/clickhouse-operator)\n[](https://goreportcard.com/report/github.com/altinity/clickhouse-operator)\n[](https://github.com/altinity/clickhouse-operator/issues)\n\n## Features\n\n- Creates ClickHouse clusters defined as custom resources\n- Customized storage provisioning (VolumeClaim templates)\n- Customized pod templates\n- Customized service templates for endpoints\n- ClickHouse configuration management\n- ClickHouse users management\n- ClickHouse cluster scaling including automatic schema propagation\n- ClickHouse version upgrades\n- Exporting ClickHouse metrics to Prometheus\n\n## Requirements\n\n * Kubernetes 1.15.11+\n \n## Documentation\n\n[Quick Start Guide][quick_start_guide]\n\n**Advanced configuration**\n * [Detailed Operator Installation Instructions][detailed_installation_instructions]\n * [Operator Configuration][operator_configuration]\n * [Setup ClickHouse cluster with replication][replication_setup]\n * [Setting up Zookeeper][zookeeper_setup]\n * [Persistent Storage Configuration][storage_configuration]\n * [Security Hardening][security_hardening]\n * [ClickHouse Installation Custom Resource specification][crd_explained]\n \n**Maintenance tasks**\n * [Add replication to an existing ClickHouse cluster][update_cluster_add_replication]\n * [Schema maintenance][schema_migration]\n * [Update ClickHouse version][update_clickhouse_version]\n * [Update Operator version][update_operator]\n\n**Monitoring**\n * [Setup Monitoring][monitoring_setup]\n * [Prometheus & clickhouse-operator integration][prometheus_setup]\n * [Grafana & Prometheus integration][grafana_setup]\n\n**How to contribute**\n * [How to contribute/submit a patch][contributing_manual]\n * [How to easy development process with devspace.sh][devspace_manual]\n \n---\n * [Documentation index][all_docs_list]\n---\n \n## License\n\nCopyright (c) 2019-2023, Altinity Inc and/or its affiliates. All rights reserved.\n\nAltinity Operator for ClickHouse is licensed under the Apache License 2.0.\n\nSee [LICENSE](./LICENSE) for more details.\n \n[chi_max_yaml]: ./docs/chi-examples/99-clickhouseinstallation-max.yaml\n[intro]: ./docs/introduction.md\n[quick_start_guide]: ./docs/quick_start.md\n[detailed_installation_instructions]: ./docs/operator_installation_details.md\n[replication_setup]: ./docs/replication_setup.md\n[crd_explained]: ./docs/custom_resource_explained.md\n[zookeeper_setup]: ./docs/zookeeper_setup.md\n[monitoring_setup]: ./docs/monitoring_setup.md\n[prometheus_setup]: ./docs/prometheus_setup.md\n[grafana_setup]: ./docs/grafana_setup.md\n[storage_configuration]: ./docs/storage.md\n[update_cluster_add_replication]: ./docs/chi_update_add_replication.md\n[update_clickhouse_version]: ./docs/chi_update_clickhouse_version.md\n[update_operator]: ./docs/operator_upgrade.md\n[schema_migration]: ./docs/schema_migration.md\n[operator_configuration]: ./docs/operator_configuration.md\n[contributing_manual]: ./CONTRIBUTING.md\n[devspace_manual]: ./docs/devspace.md\n[all_docs_list]: ./docs/README.md\n[security_hardening]: ./docs/security_hardening.md\n",
- "source_links": [],
- "id": 16
- },
- {
- "page_link": "exposing-via-loadbalancer.md",
- "title": "exposing-via-loadbalancer",
- "text": "# Expose your clickhouse installation via a load balancer\n\nYou can opt into using a load balancer service to expose your clickhouse installation. This can be especially useful if you'd like services outside your k8s cluster to access it. It requires a minor change to your ClickhouseInstallation crd, like so:\n\n```yaml\napiVersion: \"clickhouse.altinity.com/v1\"\nkind: \"ClickHouseInstallation\"\nmetadata:\n \n # your clickhouse metadata\n\nspec:\n \n # additional clickhouse spec\n\n templates:\n serviceTemplates:\n - name: chi-service-template\n generateName: \"service-{chi}\"\n # type ObjectMeta struct from k8s.io/meta/v1\n metadata:\n labels:\n custom.label: \"custom.value\"\n annotations:\n # For more details on Internal Load Balancer check\n # https://kubernetes.io/docs/concepts/services-networking/service/#internal-load-balancer\n external-dns.alpha.kubernetes.io/hostname: \"your.dns.name\" # NOTE: this should be under the domain specified in `workspace.yaml`\n\n service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing # can also be \"internal\" if you'd rather it be only accessible w/in your vpc\n service.beta.kubernetes.io/aws-load-balancer-backend-protocol: tcp\n service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: 'true'\n service.beta.kubernetes.io/aws-load-balancer-type: external\n service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip\n service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: \"*\"\n\n ## aws and gcp annotations to opt into private network load balancing\n networking.gke.io/load-balancer-type: \"Internal\"\n service.beta.kubernetes.io/azure-load-balancer-internal: \"true\"\n\n # NLB Load Balancer\n service.beta.kubernetes.io/aws-load-balancer-type: \"nlb\"\n # type ServiceSpec struct from k8s.io/core/v1\n spec:\n ports:\n - name: http\n port: 8123\n - name: tcp\n port: 9000\n type: LoadBalancer\n```\n\n",
- "source_links": [],
- "id": 17
- },
- {
- "page_link": "setup.md",
- "title": "setup",
- "text": "# Setting Up Your first clickhouse instance\n\nThis deploys a kubernetes operator which allows you to proivision as many clickhouse instances as you see fit. You'll need to create your instance of its crd, which you can add to `clickhouse/helm/clickhouse/templates`. Here's an example yaml file to get you started:\n\n```yaml\napiVersion: \"clickhouse.altinity.com/v1\"\nkind: \"ClickHouseInstallation\"\nmetadata:\n name: \"clickhouse\"\nspec:\n configuration:\n clusters:\n - name: \"cluster\"\n layout:\n shardsCount: 3\n replicasCount: 2\n```\n\nThe operator is actually quite well documented, and you can dive deeper by checking out some of the examples here: https://github.com/Altinity/clickhouse-operator/tree/master/docs/chi-examples if you want a more sophisticated setup",
- "source_links": [],
- "id": 18
- },
- {
- "page_link": null,
- "title": "cluster-api-operator readme",
- "text": null,
- "source_links": [],
- "id": 19
- },
- {
- "page_link": null,
- "title": "cluster-api-operator-installer readme",
- "text": null,
- "source_links": [],
- "id": 20
- },
- {
- "page_link": "https://github.com/pluralsh/console",
- "title": "console readme",
- "text": "# Plural Console\n\n\n\nThe Plural Console is the administrative hub of the plural platform. It has a number of key features:\n\n* Reception of over-the-air application updates\n* Configurable, application-targeted observability\n - dashboards\n - logging\n* Common incident management, including zoom integration and slash commands\n* Interactive Runbooks\n\nWe strive to make it powerful enough to make you feel like any application you deploy using Plural has an operational profile comparable to a managed service, even without being one.\n\n## Development\n\nConsole's server side is written in elixir, and exposes a graphql api. The frontend is in react, all code lives in this single repo and common development tasks can be done using the Makefile at the root of the repo.\n\n\n### Developing Web\nTo begin developing the web app, install npm & yarn, then run:\n\n```sh\ncd assets && yarn install && cd -\nmake web\n```\n\n### Developing Server\nTo make changes to the server codebase, you'll want to install elixir on your machine. For mac desktops, we do this via asdf, which can be done simply at the root of the repo like so:\n\n```sh\nasdf install\n```\n\nOnce elixir is available, all server dependencies are managed via docker-compose, and tests can be run via `mix`, like so:\n\n```sh\nmake testup\nmix local.hex\nmix deps.get\nmix test\n```\n\n### Troubleshooting\n#### Installing Erlang \nIf `asdf install` fails with `cannot find required auxiliary files: install-sh config.guess config.sub` then run:\n\n```sh\nbrew install autoconf@2.69 && \\\nbrew link --overwrite autoconf@2.69 && \\\nautoconf -V\n```\n\nFor Mac Machines, if unable to download Erlang via `asdf` then run:\n\n```sh\nbrew install erlang@23\ncp -r /opt/homebrew/opt/erlang@23/lib/erlang ~/.asdf/installs/erlang/23.1.5\nasdf reshim erlang 23.1.5\n```",
- "source_links": [],
- "id": 21
- },
- {
- "page_link": null,
- "title": "counterstrike readme",
- "text": null,
- "source_links": [],
- "id": 22
- },
- {
- "page_link": "https://github.com/crossplane/crossplane",
- "title": "crossplane readme",
- "text": " [](https://github.com/crossplane/crossplane/releases) [](https://hub.docker.com/r/crossplane/crossplane) [](https://goreportcard.com/report/github.com/crossplane/crossplane) [](https://slack.crossplane.io) [](https://twitter.com/intent/follow?screen_name=crossplane_io&user_id=788180534543339520)\n\n\n\n\nCrossplane is a framework for building cloud native control planes without\nneeding to write code. It has a highly extensible backend that enables you to\nbuild a control plane that can orchestrate applications and infrastructure no\nmatter where they run, and a highly configurable frontend that puts you in\ncontrol of the schema of the declarative API it offers.\n\nCrossplane is a [Cloud Native Compute Foundation][cncf] project.\n\n## Releases\n\nCurrently maintained releases, as well as the next upcoming release are listed\nbelow. For more information take a look at the Crossplane [release cycle\ndocumentation].\n\n| Release | Release Date | EOL |\n|:-------:|:------------:|:-------------:|\n| v1.7 | Mar 22, 2022 | Sept 2022 |\n| v1.8 | May 17, 2022 | Nov 2022 |\n| v1.9 | Jul 14, 2022 | Jan 2023 |\n\nYou can subscribe to the [community calendar] to track all release dates, and\nfind the most recent releases on the [releases] page.\n\n## Get Involved\n\nCrossplane is a community driven project; we welcome your contribution. To file\na bug, suggest an improvement, or request a new feature please open an [issue\nagainst Crossplane] or the relevant provider. Refer to our [contributing guide]\nfor more information on how you can help.\n\n* Discuss Crossplane on [Slack] or our [developer mailing list].\n* Follow us on [Twitter], or contact us via [Email].\n* Join our regular community meetings.\n* Provide feedback on our [roadmap].\n\nThe Crossplane community meeting takes place every other [Thursday at 10:00am\nPacific Time][community meeting time]. Anyone who wants to discuss the direction\nof the project, design and implementation reviews, or raise general questions\nwith the broader community is encouraged to join.\n\n* Meeting link:
\n\n\n*Chatwoot* © 2017-2022, Chatwoot Inc - Released under the MIT License.\n",
- "source_links": [],
- "id": 15
- },
- {
- "page_link": "https://github.com/Altinity/clickhouse-operator",
- "title": "clickhouse readme",
- "text": "# Altinity Operator for ClickHouse\n\nOperator creates, configures and manages ClickHouse clusters running on Kubernetes.\n\n[](https://github.com/Altinity/clickhouse-operator/actions/workflows/build_master.yaml)\n[](https://img.shields.io/github/v/release/altinity/clickhouse-operator?include_prereleases)\n[](https://github.com/altinity/clickhouse-operator/tags)\n[](https://hub.docker.com/r/altinity/clickhouse-operator)\n[](https://img.shields.io/github/go-mod/go-version/altinity/clickhouse-operator)\n[](https://goreportcard.com/report/github.com/altinity/clickhouse-operator)\n[](https://github.com/altinity/clickhouse-operator/issues)\n\n## Features\n\n- Creates ClickHouse clusters defined as custom resources\n- Customized storage provisioning (VolumeClaim templates)\n- Customized pod templates\n- Customized service templates for endpoints\n- ClickHouse configuration management\n- ClickHouse users management\n- ClickHouse cluster scaling including automatic schema propagation\n- ClickHouse version upgrades\n- Exporting ClickHouse metrics to Prometheus\n\n## Requirements\n\n * Kubernetes 1.15.11+\n \n## Documentation\n\n[Quick Start Guide][quick_start_guide]\n\n**Advanced configuration**\n * [Detailed Operator Installation Instructions][detailed_installation_instructions]\n * [Operator Configuration][operator_configuration]\n * [Setup ClickHouse cluster with replication][replication_setup]\n * [Setting up Zookeeper][zookeeper_setup]\n * [Persistent Storage Configuration][storage_configuration]\n * [Security Hardening][security_hardening]\n * [ClickHouse Installation Custom Resource specification][crd_explained]\n \n**Maintenance tasks**\n * [Add replication to an existing ClickHouse cluster][update_cluster_add_replication]\n * [Schema maintenance][schema_migration]\n * [Update ClickHouse version][update_clickhouse_version]\n * [Update Operator version][update_operator]\n\n**Monitoring**\n * [Setup Monitoring][monitoring_setup]\n * [Prometheus & clickhouse-operator integration][prometheus_setup]\n * [Grafana & Prometheus integration][grafana_setup]\n\n**How to contribute**\n * [How to contribute/submit a patch][contributing_manual]\n * [How to easy development process with devspace.sh][devspace_manual]\n \n---\n * [Documentation index][all_docs_list]\n---\n \n## License\n\nCopyright (c) 2019-2023, Altinity Inc and/or its affiliates. All rights reserved.\n\nAltinity Operator for ClickHouse is licensed under the Apache License 2.0.\n\nSee [LICENSE](./LICENSE) for more details.\n \n[chi_max_yaml]: ./docs/chi-examples/99-clickhouseinstallation-max.yaml\n[intro]: ./docs/introduction.md\n[quick_start_guide]: ./docs/quick_start.md\n[detailed_installation_instructions]: ./docs/operator_installation_details.md\n[replication_setup]: ./docs/replication_setup.md\n[crd_explained]: ./docs/custom_resource_explained.md\n[zookeeper_setup]: ./docs/zookeeper_setup.md\n[monitoring_setup]: ./docs/monitoring_setup.md\n[prometheus_setup]: ./docs/prometheus_setup.md\n[grafana_setup]: ./docs/grafana_setup.md\n[storage_configuration]: ./docs/storage.md\n[update_cluster_add_replication]: ./docs/chi_update_add_replication.md\n[update_clickhouse_version]: ./docs/chi_update_clickhouse_version.md\n[update_operator]: ./docs/operator_upgrade.md\n[schema_migration]: ./docs/schema_migration.md\n[operator_configuration]: ./docs/operator_configuration.md\n[contributing_manual]: ./CONTRIBUTING.md\n[devspace_manual]: ./docs/devspace.md\n[all_docs_list]: ./docs/README.md\n[security_hardening]: ./docs/security_hardening.md\n",
- "source_links": [],
- "id": 16
- },
- {
- "page_link": "exposing-via-loadbalancer.md",
- "title": "exposing-via-loadbalancer",
- "text": "# Expose your clickhouse installation via a load balancer\n\nYou can opt into using a load balancer service to expose your clickhouse installation. This can be especially useful if you'd like services outside your k8s cluster to access it. It requires a minor change to your ClickhouseInstallation crd, like so:\n\n```yaml\napiVersion: \"clickhouse.altinity.com/v1\"\nkind: \"ClickHouseInstallation\"\nmetadata:\n \n # your clickhouse metadata\n\nspec:\n \n # additional clickhouse spec\n\n templates:\n serviceTemplates:\n - name: chi-service-template\n generateName: \"service-{chi}\"\n # type ObjectMeta struct from k8s.io/meta/v1\n metadata:\n labels:\n custom.label: \"custom.value\"\n annotations:\n # For more details on Internal Load Balancer check\n # https://kubernetes.io/docs/concepts/services-networking/service/#internal-load-balancer\n external-dns.alpha.kubernetes.io/hostname: \"your.dns.name\" # NOTE: this should be under the domain specified in `workspace.yaml`\n\n service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing # can also be \"internal\" if you'd rather it be only accessible w/in your vpc\n service.beta.kubernetes.io/aws-load-balancer-backend-protocol: tcp\n service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: 'true'\n service.beta.kubernetes.io/aws-load-balancer-type: external\n service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip\n service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: \"*\"\n\n ## aws and gcp annotations to opt into private network load balancing\n networking.gke.io/load-balancer-type: \"Internal\"\n service.beta.kubernetes.io/azure-load-balancer-internal: \"true\"\n\n # NLB Load Balancer\n service.beta.kubernetes.io/aws-load-balancer-type: \"nlb\"\n # type ServiceSpec struct from k8s.io/core/v1\n spec:\n ports:\n - name: http\n port: 8123\n - name: tcp\n port: 9000\n type: LoadBalancer\n```\n\n",
- "source_links": [],
- "id": 17
- },
- {
- "page_link": "setup.md",
- "title": "setup",
- "text": "# Setting Up Your first clickhouse instance\n\nThis deploys a kubernetes operator which allows you to proivision as many clickhouse instances as you see fit. You'll need to create your instance of its crd, which you can add to `clickhouse/helm/clickhouse/templates`. Here's an example yaml file to get you started:\n\n```yaml\napiVersion: \"clickhouse.altinity.com/v1\"\nkind: \"ClickHouseInstallation\"\nmetadata:\n name: \"clickhouse\"\nspec:\n configuration:\n clusters:\n - name: \"cluster\"\n layout:\n shardsCount: 3\n replicasCount: 2\n```\n\nThe operator is actually quite well documented, and you can dive deeper by checking out some of the examples here: https://github.com/Altinity/clickhouse-operator/tree/master/docs/chi-examples if you want a more sophisticated setup",
- "source_links": [],
- "id": 18
- },
- {
- "page_link": null,
- "title": "cluster-api-operator readme",
- "text": null,
- "source_links": [],
- "id": 19
- },
- {
- "page_link": null,
- "title": "cluster-api-operator-installer readme",
- "text": null,
- "source_links": [],
- "id": 20
- },
- {
- "page_link": "https://github.com/pluralsh/console",
- "title": "console readme",
- "text": "# Plural Console\n\n\n\nThe Plural Console is the administrative hub of the plural platform. It has a number of key features:\n\n* Reception of over-the-air application updates\n* Configurable, application-targeted observability\n - dashboards\n - logging\n* Common incident management, including zoom integration and slash commands\n* Interactive Runbooks\n\nWe strive to make it powerful enough to make you feel like any application you deploy using Plural has an operational profile comparable to a managed service, even without being one.\n\n## Development\n\nConsole's server side is written in elixir, and exposes a graphql api. The frontend is in react, all code lives in this single repo and common development tasks can be done using the Makefile at the root of the repo.\n\n\n### Developing Web\nTo begin developing the web app, install npm & yarn, then run:\n\n```sh\ncd assets && yarn install && cd -\nmake web\n```\n\n### Developing Server\nTo make changes to the server codebase, you'll want to install elixir on your machine. For mac desktops, we do this via asdf, which can be done simply at the root of the repo like so:\n\n```sh\nasdf install\n```\n\nOnce elixir is available, all server dependencies are managed via docker-compose, and tests can be run via `mix`, like so:\n\n```sh\nmake testup\nmix local.hex\nmix deps.get\nmix test\n```\n\n### Troubleshooting\n#### Installing Erlang \nIf `asdf install` fails with `cannot find required auxiliary files: install-sh config.guess config.sub` then run:\n\n```sh\nbrew install autoconf@2.69 && \\\nbrew link --overwrite autoconf@2.69 && \\\nautoconf -V\n```\n\nFor Mac Machines, if unable to download Erlang via `asdf` then run:\n\n```sh\nbrew install erlang@23\ncp -r /opt/homebrew/opt/erlang@23/lib/erlang ~/.asdf/installs/erlang/23.1.5\nasdf reshim erlang 23.1.5\n```",
- "source_links": [],
- "id": 21
- },
- {
- "page_link": null,
- "title": "counterstrike readme",
- "text": null,
- "source_links": [],
- "id": 22
- },
- {
- "page_link": "https://github.com/crossplane/crossplane",
- "title": "crossplane readme",
- "text": " [](https://github.com/crossplane/crossplane/releases) [](https://hub.docker.com/r/crossplane/crossplane) [](https://goreportcard.com/report/github.com/crossplane/crossplane) [](https://slack.crossplane.io) [](https://twitter.com/intent/follow?screen_name=crossplane_io&user_id=788180534543339520)\n\n\n\n\nCrossplane is a framework for building cloud native control planes without\nneeding to write code. It has a highly extensible backend that enables you to\nbuild a control plane that can orchestrate applications and infrastructure no\nmatter where they run, and a highly configurable frontend that puts you in\ncontrol of the schema of the declarative API it offers.\n\nCrossplane is a [Cloud Native Compute Foundation][cncf] project.\n\n## Releases\n\nCurrently maintained releases, as well as the next upcoming release are listed\nbelow. For more information take a look at the Crossplane [release cycle\ndocumentation].\n\n| Release | Release Date | EOL |\n|:-------:|:------------:|:-------------:|\n| v1.7 | Mar 22, 2022 | Sept 2022 |\n| v1.8 | May 17, 2022 | Nov 2022 |\n| v1.9 | Jul 14, 2022 | Jan 2023 |\n\nYou can subscribe to the [community calendar] to track all release dates, and\nfind the most recent releases on the [releases] page.\n\n## Get Involved\n\nCrossplane is a community driven project; we welcome your contribution. To file\na bug, suggest an improvement, or request a new feature please open an [issue\nagainst Crossplane] or the relevant provider. Refer to our [contributing guide]\nfor more information on how you can help.\n\n* Discuss Crossplane on [Slack] or our [developer mailing list].\n* Follow us on [Twitter], or contact us via [Email].\n* Join our regular community meetings.\n* Provide feedback on our [roadmap].\n\nThe Crossplane community meeting takes place every other [Thursday at 10:00am\nPacific Time][community meeting time]. Anyone who wants to discuss the direction\nof the project, design and implementation reviews, or raise general questions\nwith the broader community is encouraged to join.\n\n* Meeting link:  \n\nFor a step-by-step guide on Cube Cloud, [see the docs](https://cube.dev/docs/getting-started/cloud/overview?ref=github-readme).\n\n### Docker\n\nAlternatively, you can get started with Cube locally or self-host it with [Docker](https://www.docker.com/).\n\nOnce Docker is installed, in a new folder for your project, run the following command:\n\n```bash\ndocker run -p 4000:4000 \\\n -p 15432:15432 \\\n -v ${PWD}:/cube/conf \\\n -e CUBEJS_DEV_MODE=true \\\n cubejs/cube\n```\n\nThen, open http://localhost:4000 in your browser to continue setup.\n\nFor a step-by-step guide on Docker, [see the docs](https://cube.dev/docs/getting-started-docker?ref=github-readme).\n\n## Resources\n\n- [Documentation](https://cube.dev/docs?ref=github-readme)\n- [Getting Started](https://cube.dev/docs/getting-started?ref=github-readme)\n- [Examples & Tutorials](https://cube.dev/docs/examples?ref=github-readme)\n- [Architecture](https://cube.dev/docs/cubejs-introduction?ref=github-readme#architecture)\n\n## Community\n\nIf you have any questions or need help - [please join our Slack community](https://slack.cube.dev?ref=github-readme) of amazing developers and data engineers.\n\nYou are also welcome to join our **monthly community calls** where we discuss community news, Cube Dev team's plans, backlogs, use cases, etc. If you miss the call, the recordings will also be available after the meeting. \n* When: Second Wednesday of each month at [9am Pacific Time](https://www.thetimezoneconverter.com/?t=09:00&tz=PT%20%28Pacific%20Time%29). \n* Meeting link: https://us02web.zoom.us/j/86717042169?pwd=VlBEd2VVK01DNDVVbU1EUXd5ajhsdz09\n* [Meeting page](https://cube.dev/community-call/). \n* Recordings will be posted on the [Community Call Playlist](https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9). \n\n### Our quarterly roadmap\n\nWe publish our open source roadmap every quarter and discuss them during our [monthly community calls](https://cube.dev/community-call/). You can find our roadmap under [projects in our Cube.js repository](https://github.com/cube-js/cube/projects?query=is%3Aopen+sort%3Aupdated-desc). \n\n### Contributing\n\nThere are many ways you can contribute to Cube! Here are a few possibilities:\n\n* Star this repo and follow us on [Twitter](https://twitter.com/the_cube_dev).\n* Add Cube to your stack on [Stackshare](https://stackshare.io/cube-js).\n* Upvote issues with \ud83d\udc4d reaction so we know what's the demand for particular issue to prioritize it within road map.\n* Create issues every time you feel something is missing or goes wrong.\n* Ask questions on [Stack Overflow with cube.js tag](https://stackoverflow.com/questions/tagged/cube.js) if others can have these questions as well.\n* Provide pull requests for all open issues and especially for those with [help wanted](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"help+wanted\") and [good first issue](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"good+first+issue\") labels.\n\nAll sort of contributions are **welcome and extremely helpful** \ud83d\ude4c Please refer to [the contribution guide](https://github.com/cube-js/cube/blob/master/CONTRIBUTING.md) for more information.\n\n## License\n\nCube Client is [MIT licensed](./packages/cubejs-client-core/LICENSE).\n\nCube Backend is [Apache 2.0 licensed](./packages/cubejs-server/LICENSE).\n\n\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fcube-js%2Fcube.js?ref=badge_large)\n",
- "source_links": [],
- "id": 25
- },
- {
- "page_link": "add-your-datasources.md",
- "title": "add-your-datasources",
- "text": "# Add Your Cube Datasources\n\nCube allows you to connect to multiple datasources. To configure them with Plural, you'll need to update the `cube/helm/cube/values.yaml` file.\nAll supported datasources could be found [here](https://cube.dev/docs/config/databases).\n\n\nExample of a postgres datasource\n```yaml\ncube:\n cube:\n datasources:\n default: # one default datasource is required\n type: postgres\n host:
\n\nFor a step-by-step guide on Cube Cloud, [see the docs](https://cube.dev/docs/getting-started/cloud/overview?ref=github-readme).\n\n### Docker\n\nAlternatively, you can get started with Cube locally or self-host it with [Docker](https://www.docker.com/).\n\nOnce Docker is installed, in a new folder for your project, run the following command:\n\n```bash\ndocker run -p 4000:4000 \\\n -p 15432:15432 \\\n -v ${PWD}:/cube/conf \\\n -e CUBEJS_DEV_MODE=true \\\n cubejs/cube\n```\n\nThen, open http://localhost:4000 in your browser to continue setup.\n\nFor a step-by-step guide on Docker, [see the docs](https://cube.dev/docs/getting-started-docker?ref=github-readme).\n\n## Resources\n\n- [Documentation](https://cube.dev/docs?ref=github-readme)\n- [Getting Started](https://cube.dev/docs/getting-started?ref=github-readme)\n- [Examples & Tutorials](https://cube.dev/docs/examples?ref=github-readme)\n- [Architecture](https://cube.dev/docs/cubejs-introduction?ref=github-readme#architecture)\n\n## Community\n\nIf you have any questions or need help - [please join our Slack community](https://slack.cube.dev?ref=github-readme) of amazing developers and data engineers.\n\nYou are also welcome to join our **monthly community calls** where we discuss community news, Cube Dev team's plans, backlogs, use cases, etc. If you miss the call, the recordings will also be available after the meeting. \n* When: Second Wednesday of each month at [9am Pacific Time](https://www.thetimezoneconverter.com/?t=09:00&tz=PT%20%28Pacific%20Time%29). \n* Meeting link: https://us02web.zoom.us/j/86717042169?pwd=VlBEd2VVK01DNDVVbU1EUXd5ajhsdz09\n* [Meeting page](https://cube.dev/community-call/). \n* Recordings will be posted on the [Community Call Playlist](https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9). \n\n### Our quarterly roadmap\n\nWe publish our open source roadmap every quarter and discuss them during our [monthly community calls](https://cube.dev/community-call/). You can find our roadmap under [projects in our Cube.js repository](https://github.com/cube-js/cube/projects?query=is%3Aopen+sort%3Aupdated-desc). \n\n### Contributing\n\nThere are many ways you can contribute to Cube! Here are a few possibilities:\n\n* Star this repo and follow us on [Twitter](https://twitter.com/the_cube_dev).\n* Add Cube to your stack on [Stackshare](https://stackshare.io/cube-js).\n* Upvote issues with \ud83d\udc4d reaction so we know what's the demand for particular issue to prioritize it within road map.\n* Create issues every time you feel something is missing or goes wrong.\n* Ask questions on [Stack Overflow with cube.js tag](https://stackoverflow.com/questions/tagged/cube.js) if others can have these questions as well.\n* Provide pull requests for all open issues and especially for those with [help wanted](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"help+wanted\") and [good first issue](https://github.com/cube-js/cube/issues?q=is%3Aissue+is%3Aopen+label%3A\"good+first+issue\") labels.\n\nAll sort of contributions are **welcome and extremely helpful** \ud83d\ude4c Please refer to [the contribution guide](https://github.com/cube-js/cube/blob/master/CONTRIBUTING.md) for more information.\n\n## License\n\nCube Client is [MIT licensed](./packages/cubejs-client-core/LICENSE).\n\nCube Backend is [Apache 2.0 licensed](./packages/cubejs-server/LICENSE).\n\n\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fcube-js%2Fcube.js?ref=badge_large)\n",
- "source_links": [],
- "id": 25
- },
- {
- "page_link": "add-your-datasources.md",
- "title": "add-your-datasources",
- "text": "# Add Your Cube Datasources\n\nCube allows you to connect to multiple datasources. To configure them with Plural, you'll need to update the `cube/helm/cube/values.yaml` file.\nAll supported datasources could be found [here](https://cube.dev/docs/config/databases).\n\n\nExample of a postgres datasource\n```yaml\ncube:\n cube:\n datasources:\n default: # one default datasource is required\n type: postgres\n host:  [LinkedIn](https://engineering.linkedin.com)\n[](https://github.com/datahub-project/datahub/releases/latest)\n[](https://badge.fury.io/py/acryl-datahub)\n[](https://github.com/datahub-project/datahub/actions?query=workflow%3A%22build+%26+test%22+branch%3Amaster+event%3Apush)\n[](https://hub.docker.com/r/linkedin/datahub-gms)\n[](https://slack.datahubproject.io)\n[](https://github.com/datahub-project/datahub/blob/master/docs/CONTRIBUTING.md)\n[](https://github.com/datahub-project/datahub/pulls?q=is%3Apr)\n[](https://github.com/datahub-project/datahub/blob/master/LICENSE)\n[](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n[](https://medium.com/datahub-project)\n[](https://twitter.com/datahubproject)\n### \ud83c\udfe0 Hosted DataHub Docs (Courtesy of Acryl Data): [datahubproject.io](https://datahubproject.io/docs)\n\n---\n\n[Quickstart](https://datahubproject.io/docs/quickstart) |\n[Features](https://datahubproject.io/docs/features) |\n[Roadmap](https://feature-requests.datahubproject.io/roadmap) |\n[Adoption](#adoption) |\n[Demo](https://datahubproject.io/docs/demo) |\n[Town Hall](https://datahubproject.io/docs/townhalls)\n\n---\n> \ud83d\udce3\u2002DataHub Town Hall is the 4th Thursday at 9am US PT of every month - [add it to your calendar!](https://rsvp.datahubproject.io/)\n>\n> - Town-hall Zoom link: [zoom.datahubproject.io](https://zoom.datahubproject.io)\n> - [Meeting details](docs/townhalls.md) & [past recordings](docs/townhall-history.md)\n\n> \u2728\u2002DataHub Community Highlights:\n>\n> - Read our Monthly Project Updates [here](https://blog.datahubproject.io/tagged/project-updates).\n> - Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data: [Data Engineering Podcast](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n> - Check out our most-read blog post, [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained) @ LinkedIn Engineering Blog.\n> - Join us on [Slack](docs/slack.md)! Ask questions and keep up with the latest announcements.\n\n## Introduction\n\nDataHub is an open-source metadata platform for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels [here](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained). Also read our\n[LinkedIn Engineering blog post](https://engineering.linkedin.com/blog/2019/data-hub), check out our [Strata presentation](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) and watch our [Crunch Conference Talk](https://www.youtube.com/watch?v=OB-O0Y6OYDE). You should also visit [DataHub Architecture](docs/architecture/architecture.md) to get a better understanding of how DataHub is implemented.\n\n## Features & Roadmap\n\nCheck out DataHub's [Features](docs/features.md) & [Roadmap](https://feature-requests.datahubproject.io/roadmap).\n\n## Demo and Screenshots\n\nThere's a [hosted demo environment](https://datahubproject.io/docs/demo) courtesy of [Acryl Data](https://acryldata.io) where you can explore DataHub without installing it locally\n\n## Quickstart\n\nPlease follow the [DataHub Quickstart Guide](https://datahubproject.io/docs/quickstart) to get a copy of DataHub up & running locally using [Docker](https://docker.com). As the guide assumes some basic knowledge of Docker, we'd recommend you to go through the \"Hello World\" example of [A Docker Tutorial for Beginners](https://docker-curriculum.com) if Docker is completely foreign to you.\n\n## Development\n\nIf you're looking to build & modify datahub please take a look at our [Development Guide](https://datahubproject.io/docs/developers).\n\n[](https://datahubproject.io/docs/demo)\n\n## Source Code and Repositories\n\n- [datahub-project/datahub](https://github.com/datahub-project/datahub): This repository contains the complete source code for DataHub's metadata model, metadata services, integration connectors and the web application.\n- [acryldata/datahub-actions](https://github.com/acryldata/datahub-actions): DataHub Actions is a framework for responding to changes to your DataHub Metadata Graph in real time.\n- [acryldata/datahub-helm](https://github.com/acryldata/datahub-helm): Repository of helm charts for deploying DataHub on a Kubernetes cluster\n- [acryldata/meta-world](https://github.com/acryldata/meta-world): A repository to store recipes, custom sources, transformations and other things to make your DataHub experience magical\n\n## Releases\n\nSee [Releases](https://github.com/datahub-project/datahub/releases) page for more details. We follow the [SemVer Specification](https://semver.org) when versioning the releases and adopt the [Keep a Changelog convention](https://keepachangelog.com/) for the changelog format.\n\n## Contributing\n\nWe welcome contributions from the community. Please refer to our [Contributing Guidelines](docs/CONTRIBUTING.md) for more details. We also have a [contrib](contrib) directory for incubating experimental features.\n\n## Community\n\nJoin our [Slack workspace](https://slack.datahubproject.io) for discussions and important announcements. You can also find out more about our upcoming [town hall meetings](docs/townhalls.md) and view past recordings.\n\n## Adoption\n\nHere are the companies that have officially adopted DataHub. Please feel free to add yours to the list if we missed it.\n\n- [ABLY](https://ably.team/)\n- [Adevinta](https://www.adevinta.com/)\n- [Banksalad](https://www.banksalad.com)\n- [Cabify](https://cabify.tech/)\n- [DefinedCrowd](http://www.definedcrowd.com)\n- [DFDS](https://www.dfds.com/)\n- [Expedia Group](http://expedia.com)\n- [Experius](https://www.experius.nl)\n- [Geotab](https://www.geotab.com)\n- [Grofers](https://grofers.com)\n- [Haibo Technology](https://www.botech.com.cn)\n- [hipages](https://hipages.com.au/)\n- [IOMED](https://iomed.health)\n- [Klarna](https://www.klarna.com)\n- [LinkedIn](http://linkedin.com)\n- [Moloco](https://www.moloco.com/en)\n- [Peloton](https://www.onepeloton.com)\n- [Saxo Bank](https://www.home.saxo)\n- [Stash](https://www.stash.com)\n- [Shanghai HuaRui Bank](https://www.shrbank.com)\n- [ThoughtWorks](https://www.thoughtworks.com)\n- [TypeForm](http://typeform.com)\n- [Uphold](https://uphold.com)\n- [Viasat](https://viasat.com)\n- [Wolt](https://wolt.com)\n- [Zynga](https://www.zynga.com)\n\n\n## Select Articles & Talks\n\n- [DataHub Blog](https://blog.datahubproject.io/)\n- [DataHub YouTube Channel](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n- [Optum: Data Mesh via DataHub](https://optum.github.io/blog/2022/03/23/data-mesh-via-datahub/)\n- [Saxo Bank: Enabling Data Discovery in Data Mesh](https://medium.com/datahub-project/enabling-data-discovery-in-a-data-mesh-the-saxo-journey-451b06969c8f)\n- [Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n- [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained)\n- [Driving DataOps Culture with LinkedIn DataHub](https://www.youtube.com/watch?v=ccsIKK9nVxk) @ [DataOps Unleashed 2021](https://dataopsunleashed.com/#shirshanka-session)\n- [The evolution of metadata: LinkedIn\u2019s story](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) @ [Strata Data Conference 2019](https://conferences.oreilly.com/strata/strata-ny-2019.html)\n- [Journey of metadata at LinkedIn](https://www.youtube.com/watch?v=OB-O0Y6OYDE) @ [Crunch Data Conference 2019](https://crunchconf.com/2019)\n- [DataHub Journey with Expedia Group](https://www.youtube.com/watch?v=ajcRdB22s5o)\n- [Data Discoverability at SpotHero](https://www.slideshare.net/MaggieHays/data-discoverability-at-spothero)\n- [Data Catalogue \u2014 Knowing your data](https://medium.com/albert-franzi/data-catalogue-knowing-your-data-15f7d0724900)\n- [DataHub: A Generalized Metadata Search & Discovery Tool](https://engineering.linkedin.com/blog/2019/data-hub)\n- [Open sourcing DataHub: LinkedIn\u2019s metadata search and discovery platform](https://engineering.linkedin.com/blog/2020/open-sourcing-datahub--linkedins-metadata-search-and-discovery-p)\n- [Emerging Architectures for Modern Data Infrastructure](https://future.com/emerging-architectures-for-modern-data-infrastructure-2020/)\n\nSee the full list [here](docs/links.md).\n\n## License\n\n[Apache License 2.0](./LICENSE).\n",
- "source_links": [],
- "id": 34
- },
- {
- "page_link": null,
- "title": "dex readme",
- "text": null,
- "source_links": [],
- "id": 35
- },
- {
- "page_link": "https://github.com/directus/directus",
- "title": "directus readme",
- "text": null,
- "source_links": [],
- "id": 36
- },
- {
- "page_link": "bring-your-own-postgres.md",
- "title": "bring-your-own-postgres",
- "text": "# Bring Your Own Postgres DB\n\nSome users might prefer to use and external or managed postgres instance rather than an on-cluster one. In that case, only a small reconfiguration is required, in `directus/helm/directus/values.yaml` overlay the following:\n\n```yaml\ndirectus:\n postgres:\n enabled: false # if you'd like to remove the existing db\n dsn: 'postgresql://
[LinkedIn](https://engineering.linkedin.com)\n[](https://github.com/datahub-project/datahub/releases/latest)\n[](https://badge.fury.io/py/acryl-datahub)\n[](https://github.com/datahub-project/datahub/actions?query=workflow%3A%22build+%26+test%22+branch%3Amaster+event%3Apush)\n[](https://hub.docker.com/r/linkedin/datahub-gms)\n[](https://slack.datahubproject.io)\n[](https://github.com/datahub-project/datahub/blob/master/docs/CONTRIBUTING.md)\n[](https://github.com/datahub-project/datahub/pulls?q=is%3Apr)\n[](https://github.com/datahub-project/datahub/blob/master/LICENSE)\n[](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n[](https://medium.com/datahub-project)\n[](https://twitter.com/datahubproject)\n### \ud83c\udfe0 Hosted DataHub Docs (Courtesy of Acryl Data): [datahubproject.io](https://datahubproject.io/docs)\n\n---\n\n[Quickstart](https://datahubproject.io/docs/quickstart) |\n[Features](https://datahubproject.io/docs/features) |\n[Roadmap](https://feature-requests.datahubproject.io/roadmap) |\n[Adoption](#adoption) |\n[Demo](https://datahubproject.io/docs/demo) |\n[Town Hall](https://datahubproject.io/docs/townhalls)\n\n---\n> \ud83d\udce3\u2002DataHub Town Hall is the 4th Thursday at 9am US PT of every month - [add it to your calendar!](https://rsvp.datahubproject.io/)\n>\n> - Town-hall Zoom link: [zoom.datahubproject.io](https://zoom.datahubproject.io)\n> - [Meeting details](docs/townhalls.md) & [past recordings](docs/townhall-history.md)\n\n> \u2728\u2002DataHub Community Highlights:\n>\n> - Read our Monthly Project Updates [here](https://blog.datahubproject.io/tagged/project-updates).\n> - Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data: [Data Engineering Podcast](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n> - Check out our most-read blog post, [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained) @ LinkedIn Engineering Blog.\n> - Join us on [Slack](docs/slack.md)! Ask questions and keep up with the latest announcements.\n\n## Introduction\n\nDataHub is an open-source metadata platform for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels [here](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained). Also read our\n[LinkedIn Engineering blog post](https://engineering.linkedin.com/blog/2019/data-hub), check out our [Strata presentation](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) and watch our [Crunch Conference Talk](https://www.youtube.com/watch?v=OB-O0Y6OYDE). You should also visit [DataHub Architecture](docs/architecture/architecture.md) to get a better understanding of how DataHub is implemented.\n\n## Features & Roadmap\n\nCheck out DataHub's [Features](docs/features.md) & [Roadmap](https://feature-requests.datahubproject.io/roadmap).\n\n## Demo and Screenshots\n\nThere's a [hosted demo environment](https://datahubproject.io/docs/demo) courtesy of [Acryl Data](https://acryldata.io) where you can explore DataHub without installing it locally\n\n## Quickstart\n\nPlease follow the [DataHub Quickstart Guide](https://datahubproject.io/docs/quickstart) to get a copy of DataHub up & running locally using [Docker](https://docker.com). As the guide assumes some basic knowledge of Docker, we'd recommend you to go through the \"Hello World\" example of [A Docker Tutorial for Beginners](https://docker-curriculum.com) if Docker is completely foreign to you.\n\n## Development\n\nIf you're looking to build & modify datahub please take a look at our [Development Guide](https://datahubproject.io/docs/developers).\n\n[](https://datahubproject.io/docs/demo)\n\n## Source Code and Repositories\n\n- [datahub-project/datahub](https://github.com/datahub-project/datahub): This repository contains the complete source code for DataHub's metadata model, metadata services, integration connectors and the web application.\n- [acryldata/datahub-actions](https://github.com/acryldata/datahub-actions): DataHub Actions is a framework for responding to changes to your DataHub Metadata Graph in real time.\n- [acryldata/datahub-helm](https://github.com/acryldata/datahub-helm): Repository of helm charts for deploying DataHub on a Kubernetes cluster\n- [acryldata/meta-world](https://github.com/acryldata/meta-world): A repository to store recipes, custom sources, transformations and other things to make your DataHub experience magical\n\n## Releases\n\nSee [Releases](https://github.com/datahub-project/datahub/releases) page for more details. We follow the [SemVer Specification](https://semver.org) when versioning the releases and adopt the [Keep a Changelog convention](https://keepachangelog.com/) for the changelog format.\n\n## Contributing\n\nWe welcome contributions from the community. Please refer to our [Contributing Guidelines](docs/CONTRIBUTING.md) for more details. We also have a [contrib](contrib) directory for incubating experimental features.\n\n## Community\n\nJoin our [Slack workspace](https://slack.datahubproject.io) for discussions and important announcements. You can also find out more about our upcoming [town hall meetings](docs/townhalls.md) and view past recordings.\n\n## Adoption\n\nHere are the companies that have officially adopted DataHub. Please feel free to add yours to the list if we missed it.\n\n- [ABLY](https://ably.team/)\n- [Adevinta](https://www.adevinta.com/)\n- [Banksalad](https://www.banksalad.com)\n- [Cabify](https://cabify.tech/)\n- [DefinedCrowd](http://www.definedcrowd.com)\n- [DFDS](https://www.dfds.com/)\n- [Expedia Group](http://expedia.com)\n- [Experius](https://www.experius.nl)\n- [Geotab](https://www.geotab.com)\n- [Grofers](https://grofers.com)\n- [Haibo Technology](https://www.botech.com.cn)\n- [hipages](https://hipages.com.au/)\n- [IOMED](https://iomed.health)\n- [Klarna](https://www.klarna.com)\n- [LinkedIn](http://linkedin.com)\n- [Moloco](https://www.moloco.com/en)\n- [Peloton](https://www.onepeloton.com)\n- [Saxo Bank](https://www.home.saxo)\n- [Stash](https://www.stash.com)\n- [Shanghai HuaRui Bank](https://www.shrbank.com)\n- [ThoughtWorks](https://www.thoughtworks.com)\n- [TypeForm](http://typeform.com)\n- [Uphold](https://uphold.com)\n- [Viasat](https://viasat.com)\n- [Wolt](https://wolt.com)\n- [Zynga](https://www.zynga.com)\n\n\n## Select Articles & Talks\n\n- [DataHub Blog](https://blog.datahubproject.io/)\n- [DataHub YouTube Channel](https://www.youtube.com/channel/UC3qFQC5IiwR5fvWEqi_tJ5w)\n- [Optum: Data Mesh via DataHub](https://optum.github.io/blog/2022/03/23/data-mesh-via-datahub/)\n- [Saxo Bank: Enabling Data Discovery in Data Mesh](https://medium.com/datahub-project/enabling-data-discovery-in-a-data-mesh-the-saxo-journey-451b06969c8f)\n- [Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At Acryl Data](https://www.dataengineeringpodcast.com/acryl-data-datahub-metadata-graph-episode-230/)\n- [DataHub: Popular Metadata Architectures Explained](https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained)\n- [Driving DataOps Culture with LinkedIn DataHub](https://www.youtube.com/watch?v=ccsIKK9nVxk) @ [DataOps Unleashed 2021](https://dataopsunleashed.com/#shirshanka-session)\n- [The evolution of metadata: LinkedIn\u2019s story](https://speakerdeck.com/shirshanka/the-evolution-of-metadata-linkedins-journey-strata-nyc-2019) @ [Strata Data Conference 2019](https://conferences.oreilly.com/strata/strata-ny-2019.html)\n- [Journey of metadata at LinkedIn](https://www.youtube.com/watch?v=OB-O0Y6OYDE) @ [Crunch Data Conference 2019](https://crunchconf.com/2019)\n- [DataHub Journey with Expedia Group](https://www.youtube.com/watch?v=ajcRdB22s5o)\n- [Data Discoverability at SpotHero](https://www.slideshare.net/MaggieHays/data-discoverability-at-spothero)\n- [Data Catalogue \u2014 Knowing your data](https://medium.com/albert-franzi/data-catalogue-knowing-your-data-15f7d0724900)\n- [DataHub: A Generalized Metadata Search & Discovery Tool](https://engineering.linkedin.com/blog/2019/data-hub)\n- [Open sourcing DataHub: LinkedIn\u2019s metadata search and discovery platform](https://engineering.linkedin.com/blog/2020/open-sourcing-datahub--linkedins-metadata-search-and-discovery-p)\n- [Emerging Architectures for Modern Data Infrastructure](https://future.com/emerging-architectures-for-modern-data-infrastructure-2020/)\n\nSee the full list [here](docs/links.md).\n\n## License\n\n[Apache License 2.0](./LICENSE).\n",
- "source_links": [],
- "id": 34
- },
- {
- "page_link": null,
- "title": "dex readme",
- "text": null,
- "source_links": [],
- "id": 35
- },
- {
- "page_link": "https://github.com/directus/directus",
- "title": "directus readme",
- "text": null,
- "source_links": [],
- "id": 36
- },
- {
- "page_link": "bring-your-own-postgres.md",
- "title": "bring-your-own-postgres",
- "text": "# Bring Your Own Postgres DB\n\nSome users might prefer to use and external or managed postgres instance rather than an on-cluster one. In that case, only a small reconfiguration is required, in `directus/helm/directus/values.yaml` overlay the following:\n\n```yaml\ndirectus:\n postgres:\n enabled: false # if you'd like to remove the existing db\n dsn: 'postgresql:// \n \n \n
\n \n \n  \n \n
\n \n \n\n \n\n
\n\n \n\n \n
\n \n\nThe easiest way to get a production instance deployed is with our official **[Ghost(Pro)](https://ghost.org/pricing/)** managed service. It takes about 2 minutes to launch a new site with worldwide CDN, backups, security and maintenance all done for you.\n\nFor most people this ends up being the best value option cause of [how much time it saves](https://ghost.org/docs/hosting/) \u2014 and 100% of revenue goes to the Ghost Foundation; funding the maintenance and further development of the project itself. So you\u2019ll be supporting open source software *and* getting a great service!\n\nIf you prefer to run on your own infrastructure, we also offer official 1-off installs and managed support and maintenance plans via **[Ghost(Valet)](https://valet.ghost.org)** - which can save a substantial amount of developer time and resources.\n\n \n\n# Quickstart install\n\nIf you want to run your own instance of Ghost, in most cases the best way is to use our **CLI tool**\n\n```\nnpm install ghost-cli -g\n```\n\n \n\nThen, if installing locally add the `local` flag to get up and running in under a minute - [Local install docs](https://ghost.org/docs/install/local/)\n\n```\nghost install local\n```\n\n \n\nor on a server run the full install, including automatic SSL setup using LetsEncrypt - [Production install docs](https://ghost.org/docs/install/ubuntu/)\n\n```\nghost install\n```\n\n \n\nCheck out our [official documentation](https://ghost.org/docs/) for more information about our [recommended hosting stack](https://ghost.org/docs/hosting/) & properly [upgrading Ghost](https://ghost.org/docs/update/), plus everything you need to develop your own Ghost [themes](https://ghost.org/docs/themes/) or work with [our API](https://ghost.org/docs/content-api/).\n\n### Contributors & advanced developers\n\nFor anyone wishing to contribute to Ghost or to hack/customize core files we recommend following our full development setup guides: [Contributor guide](https://ghost.org/docs/contributing/) \u2022 [Developer setup](https://ghost.org/docs/install/source/)\n\n \n\n# Ghost sponsors\n\nWe'd like to extend big thanks to our sponsors and partners who make Ghost possible. If you're interested in sponsoring Ghost and supporting the project, please check out our profile on [GitHub sponsors](https://github.com/sponsors/TryGhost) :heart:\n\n**[DigitalOcean](https://m.do.co/c/9ff29836d717)** \u2022 **[Fastly](https://www.fastly.com/)**\n\n \n\n# Getting help\n\nYou can find answers to a huge variety of questions, along with a large community of helpful developers over on the [Ghost forum](https://forum.ghost.org/) - replies are generally very quick. **Ghost(Pro)** customers also have access to 24/7 email support.\n\nTo stay up to date with all the latest news and product updates, make sure you [subscribe to our blog](https://ghost.org/blog/) \u2014 or you can always follow us [on Twitter](https://twitter.com/Ghost), if you prefer your updates bite-sized and facetious. :saxophone::turtle:\n\n \n\n# Copyright & license\n\nCopyright (c) 2013-2022 Ghost Foundation - Released under the [MIT license](LICENSE). Ghost and the Ghost Logo are trademarks of Ghost Foundation Ltd. Please see our [trademark policy](https://ghost.org/trademark/) for info on acceptable usage.\n",
- "source_links": [],
- "id": 44
- },
- {
- "page_link": "https://gitlab.com/gitlab-org/gitlab",
- "title": "gitlab readme",
- "text": "# GitLab\n\n## Canonical source\n\nThe canonical source of GitLab where all development takes place is [hosted on GitLab.com](https://gitlab.com/gitlab-org/gitlab).\n\nIf you wish to clone a copy of GitLab without proprietary code, you can use the read-only mirror of GitLab located at https://gitlab.com/gitlab-org/gitlab-foss/. However, please do not submit any issues and/or merge requests to that project.\n\n## Free trial\n\nYou can request a free trial of GitLab Ultimate [on our website](https://about.gitlab.com/free-trial/).\n\n## Open source software to collaborate on code\n\nTo see how GitLab looks please see the [features page on our website](https://about.gitlab.com/features/).\n\n- Manage Git repositories with fine grained access controls that keep your code secure\n- Perform code reviews and enhance collaboration with merge requests\n- Complete continuous integration (CI) and continuous deployment/delivery (CD) pipelines to build, test, and deploy your applications\n- Each project can also have an issue tracker, issue board, and a wiki\n- Used by more than 100,000 organizations, GitLab is the most popular solution to manage Git repositories on-premises\n- Completely free and open source (MIT Expat license)\n\n## Editions\n\nThere are three editions of GitLab:\n\n- GitLab Community Edition (CE) is available freely under the MIT Expat license.\n- GitLab Enterprise Edition (EE) includes [extra features](https://about.gitlab.com/pricing/#compare-options) that are more useful for organizations with more than 100 users. To use EE and get official support please [become a subscriber](https://about.gitlab.com/pricing/).\n- JiHu Edition (JH) tailored specifically for the [Chinese market](https://about.gitlab.cn/).\n\n## Licensing\n\nSee the [LICENSE](LICENSE) file for licensing information as it pertains to\nfiles in this repository.\n\n## Hiring\n\nWe are hiring developers, support people, and production engineers all the time, please see our [jobs page](https://about.gitlab.com/jobs/).\n\n## Website\n\nOn [about.gitlab.com](https://about.gitlab.com/) you can find more information about:\n\n- [Subscriptions](https://about.gitlab.com/pricing/)\n- [Consultancy](https://about.gitlab.com/consultancy/)\n- [Community](https://about.gitlab.com/community/)\n- [Hosted GitLab.com](https://about.gitlab.com/gitlab-com/) use GitLab as a free service\n- [GitLab Enterprise Edition](https://about.gitlab.com/features/#enterprise) with additional features aimed at larger organizations.\n- [GitLab CI](https://about.gitlab.com/gitlab-ci/) a continuous integration (CI) server that is easy to integrate with GitLab.\n\n## Requirements\n\nPlease see the [requirements documentation](doc/install/requirements.md) for system requirements and more information about the supported operating systems.\n\n## Installation\n\nThe recommended way to install GitLab is with the [Omnibus packages](https://about.gitlab.com/downloads/) on our package server.\nCompared to an installation from source, this is faster and less error prone.\nJust select your operating system, download the respective package (Debian or RPM) and install it using the system's package manager.\n\nThere are various other options to install GitLab, please refer to the [installation page on the GitLab website](https://about.gitlab.com/installation/) for more information.\n\n## Contributing\n\nGitLab is an open source project and we are very happy to accept community contributions. Please refer to [Contributing to GitLab page](https://about.gitlab.com/contributing/) for more details.\n\n## Install a development environment\n\nTo work on GitLab itself, we recommend setting up your development environment with [the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit).\nIf you do not use the GitLab Development Kit you need to install and configure all the dependencies yourself, this is a lot of work and error prone.\nOne small thing you also have to do when installing it yourself is to copy the example development Puma configuration file:\n\n```shell\ncp config/puma.example.development.rb config/puma.rb\n```\n\nInstructions on how to start GitLab and how to run the tests can be found in the [getting started section of the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit#getting-started).\n\n## Software stack\n\nGitLab is a Ruby on Rails application that runs on the following software:\n\n- Ubuntu/Debian/CentOS/RHEL/OpenSUSE\n- Ruby (MRI) 3.0.5\n- Git 2.33+\n- Redis 5.0+\n- PostgreSQL 12+\n\nFor more information please see the [architecture](https://docs.gitlab.com/ee/development/architecture.html) and [requirements](https://docs.gitlab.com/ee/install/requirements.html) documentation.\n\n## UX design\n\nPlease adhere to the [UX Guide](https://design.gitlab.com/) when creating designs and implementing code.\n\n## Third-party applications\n\nThere are a lot of [third-party applications integrating with GitLab](https://about.gitlab.com/applications/). These include GUI Git clients, mobile applications and API wrappers for various languages.\n\n## GitLab release cycle\n\nFor more information about the release process see the [release documentation](https://gitlab.com/gitlab-org/release-tools/blob/master/README.md).\n\n## Upgrading\n\nFor upgrading information please see our [update page](https://about.gitlab.com/update/).\n\n## Documentation\n\nAll documentation can be found on
\n\nThe easiest way to get a production instance deployed is with our official **[Ghost(Pro)](https://ghost.org/pricing/)** managed service. It takes about 2 minutes to launch a new site with worldwide CDN, backups, security and maintenance all done for you.\n\nFor most people this ends up being the best value option cause of [how much time it saves](https://ghost.org/docs/hosting/) \u2014 and 100% of revenue goes to the Ghost Foundation; funding the maintenance and further development of the project itself. So you\u2019ll be supporting open source software *and* getting a great service!\n\nIf you prefer to run on your own infrastructure, we also offer official 1-off installs and managed support and maintenance plans via **[Ghost(Valet)](https://valet.ghost.org)** - which can save a substantial amount of developer time and resources.\n\n \n\n# Quickstart install\n\nIf you want to run your own instance of Ghost, in most cases the best way is to use our **CLI tool**\n\n```\nnpm install ghost-cli -g\n```\n\n \n\nThen, if installing locally add the `local` flag to get up and running in under a minute - [Local install docs](https://ghost.org/docs/install/local/)\n\n```\nghost install local\n```\n\n \n\nor on a server run the full install, including automatic SSL setup using LetsEncrypt - [Production install docs](https://ghost.org/docs/install/ubuntu/)\n\n```\nghost install\n```\n\n \n\nCheck out our [official documentation](https://ghost.org/docs/) for more information about our [recommended hosting stack](https://ghost.org/docs/hosting/) & properly [upgrading Ghost](https://ghost.org/docs/update/), plus everything you need to develop your own Ghost [themes](https://ghost.org/docs/themes/) or work with [our API](https://ghost.org/docs/content-api/).\n\n### Contributors & advanced developers\n\nFor anyone wishing to contribute to Ghost or to hack/customize core files we recommend following our full development setup guides: [Contributor guide](https://ghost.org/docs/contributing/) \u2022 [Developer setup](https://ghost.org/docs/install/source/)\n\n \n\n# Ghost sponsors\n\nWe'd like to extend big thanks to our sponsors and partners who make Ghost possible. If you're interested in sponsoring Ghost and supporting the project, please check out our profile on [GitHub sponsors](https://github.com/sponsors/TryGhost) :heart:\n\n**[DigitalOcean](https://m.do.co/c/9ff29836d717)** \u2022 **[Fastly](https://www.fastly.com/)**\n\n \n\n# Getting help\n\nYou can find answers to a huge variety of questions, along with a large community of helpful developers over on the [Ghost forum](https://forum.ghost.org/) - replies are generally very quick. **Ghost(Pro)** customers also have access to 24/7 email support.\n\nTo stay up to date with all the latest news and product updates, make sure you [subscribe to our blog](https://ghost.org/blog/) \u2014 or you can always follow us [on Twitter](https://twitter.com/Ghost), if you prefer your updates bite-sized and facetious. :saxophone::turtle:\n\n \n\n# Copyright & license\n\nCopyright (c) 2013-2022 Ghost Foundation - Released under the [MIT license](LICENSE). Ghost and the Ghost Logo are trademarks of Ghost Foundation Ltd. Please see our [trademark policy](https://ghost.org/trademark/) for info on acceptable usage.\n",
- "source_links": [],
- "id": 44
- },
- {
- "page_link": "https://gitlab.com/gitlab-org/gitlab",
- "title": "gitlab readme",
- "text": "# GitLab\n\n## Canonical source\n\nThe canonical source of GitLab where all development takes place is [hosted on GitLab.com](https://gitlab.com/gitlab-org/gitlab).\n\nIf you wish to clone a copy of GitLab without proprietary code, you can use the read-only mirror of GitLab located at https://gitlab.com/gitlab-org/gitlab-foss/. However, please do not submit any issues and/or merge requests to that project.\n\n## Free trial\n\nYou can request a free trial of GitLab Ultimate [on our website](https://about.gitlab.com/free-trial/).\n\n## Open source software to collaborate on code\n\nTo see how GitLab looks please see the [features page on our website](https://about.gitlab.com/features/).\n\n- Manage Git repositories with fine grained access controls that keep your code secure\n- Perform code reviews and enhance collaboration with merge requests\n- Complete continuous integration (CI) and continuous deployment/delivery (CD) pipelines to build, test, and deploy your applications\n- Each project can also have an issue tracker, issue board, and a wiki\n- Used by more than 100,000 organizations, GitLab is the most popular solution to manage Git repositories on-premises\n- Completely free and open source (MIT Expat license)\n\n## Editions\n\nThere are three editions of GitLab:\n\n- GitLab Community Edition (CE) is available freely under the MIT Expat license.\n- GitLab Enterprise Edition (EE) includes [extra features](https://about.gitlab.com/pricing/#compare-options) that are more useful for organizations with more than 100 users. To use EE and get official support please [become a subscriber](https://about.gitlab.com/pricing/).\n- JiHu Edition (JH) tailored specifically for the [Chinese market](https://about.gitlab.cn/).\n\n## Licensing\n\nSee the [LICENSE](LICENSE) file for licensing information as it pertains to\nfiles in this repository.\n\n## Hiring\n\nWe are hiring developers, support people, and production engineers all the time, please see our [jobs page](https://about.gitlab.com/jobs/).\n\n## Website\n\nOn [about.gitlab.com](https://about.gitlab.com/) you can find more information about:\n\n- [Subscriptions](https://about.gitlab.com/pricing/)\n- [Consultancy](https://about.gitlab.com/consultancy/)\n- [Community](https://about.gitlab.com/community/)\n- [Hosted GitLab.com](https://about.gitlab.com/gitlab-com/) use GitLab as a free service\n- [GitLab Enterprise Edition](https://about.gitlab.com/features/#enterprise) with additional features aimed at larger organizations.\n- [GitLab CI](https://about.gitlab.com/gitlab-ci/) a continuous integration (CI) server that is easy to integrate with GitLab.\n\n## Requirements\n\nPlease see the [requirements documentation](doc/install/requirements.md) for system requirements and more information about the supported operating systems.\n\n## Installation\n\nThe recommended way to install GitLab is with the [Omnibus packages](https://about.gitlab.com/downloads/) on our package server.\nCompared to an installation from source, this is faster and less error prone.\nJust select your operating system, download the respective package (Debian or RPM) and install it using the system's package manager.\n\nThere are various other options to install GitLab, please refer to the [installation page on the GitLab website](https://about.gitlab.com/installation/) for more information.\n\n## Contributing\n\nGitLab is an open source project and we are very happy to accept community contributions. Please refer to [Contributing to GitLab page](https://about.gitlab.com/contributing/) for more details.\n\n## Install a development environment\n\nTo work on GitLab itself, we recommend setting up your development environment with [the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit).\nIf you do not use the GitLab Development Kit you need to install and configure all the dependencies yourself, this is a lot of work and error prone.\nOne small thing you also have to do when installing it yourself is to copy the example development Puma configuration file:\n\n```shell\ncp config/puma.example.development.rb config/puma.rb\n```\n\nInstructions on how to start GitLab and how to run the tests can be found in the [getting started section of the GitLab Development Kit](https://gitlab.com/gitlab-org/gitlab-development-kit#getting-started).\n\n## Software stack\n\nGitLab is a Ruby on Rails application that runs on the following software:\n\n- Ubuntu/Debian/CentOS/RHEL/OpenSUSE\n- Ruby (MRI) 3.0.5\n- Git 2.33+\n- Redis 5.0+\n- PostgreSQL 12+\n\nFor more information please see the [architecture](https://docs.gitlab.com/ee/development/architecture.html) and [requirements](https://docs.gitlab.com/ee/install/requirements.html) documentation.\n\n## UX design\n\nPlease adhere to the [UX Guide](https://design.gitlab.com/) when creating designs and implementing code.\n\n## Third-party applications\n\nThere are a lot of [third-party applications integrating with GitLab](https://about.gitlab.com/applications/). These include GUI Git clients, mobile applications and API wrappers for various languages.\n\n## GitLab release cycle\n\nFor more information about the release process see the [release documentation](https://gitlab.com/gitlab-org/release-tools/blob/master/README.md).\n\n## Upgrading\n\nFor upgrading information please see our [update page](https://about.gitlab.com/update/).\n\n## Documentation\n\nAll documentation can be found on 



 \n
\n  \n
\n \n\n\n\n\n
\n\n\n\n\n  \n\n```\n\n## License\n\nThe core GraphQL Engine is available under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0) (Apache-2.0).\n\nAll **other contents** (except those in [`server`](server), [`cli`](cli) and\n[`console`](console) directories) are available under the [MIT License](LICENSE-community).\nThis includes everything in the [`docs`](docs) and [`community`](community)\ndirectories.\n\n## Translations\n\nThis readme is available in the following translations:\n\n- [Japanese :jp:](translations/README.japanese.md) (:pray: [@moksahero](https://github.com/moksahero))\n- [French :fr:](translations/README.french.md) (:pray: [@l0ck3](https://github.com/l0ck3))\n- [Bosnian :bosnia_herzegovina:](translations/README.bosnian.md) (:pray: [@hajro92](https://github.com/hajro92))\n- [Russian :ru:](translations/README.russian.md) (:pray: [@highflyer910](https://github.com/highflyer910))\n- [Greek \ud83c\uddec\ud83c\uddf7](translations/README.greek.md) (:pray: [@MIP2000](https://github.com/MIP2000))\n- [Spanish \ud83c\uddf2\ud83c\uddfd](/translations/README.mx_spanish.md)(:pray: [@ferdox2](https://github.com/ferdox2))\n- [Indonesian :indonesia:](translations/README.indonesian.md) (:pray: [@anwari666](https://github.com/anwari666))\n- [Brazilian Portuguese :brazil:](translations/README.portuguese_br.md) (:pray: [@rubensmp](https://github.com/rubensmp))\n- [German \ud83c\udde9\ud83c\uddea](translations/README.german.md) (:pray: [@FynnGrandke](https://github.com/FynnGrandke))\n- [Chinese :cn:](translations/README.chinese.md) (:pray: [@jagreetdg](https://github.com/jagreetdg) & [@johnbanq](https://github.com/johnbanq))\n- [Turkish :tr:](translations/README.turkish.md) (:pray: [@berat](https://github.com/berat))\n- [Korean :kr:](translations/README.korean.md) (:pray: [@\ub77c\uc2a4\ud06c](https://github.com/laskdjlaskdj12))\n\nTranslations for other files can be found [here](translations).\n",
- "source_links": [],
- "id": 53
- },
- {
- "page_link": "https://github.com/segmentio/ory-hydra",
- "title": "hydra readme",
- "text": "# \n\n[](https://gitter.im/ory-am/hydra?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)\n[](http://eepurl.com/bKT3N9)\n[](https://twitter.com/_aeneasr)\n[](https://github.com/arekkas)\n[](https://patreon.com/user?u=4298803)\n\n[](https://travis-ci.org/ory/hydra)\n[](https://coveralls.io/github/ory/hydra?branch=master)\n[](https://codeclimate.com/github/ory/hydra)\n[](https://goreportcard.com/report/github.com/ory/hydra)\n[](https://bestpractices.coreinfrastructure.org/projects/364)\n\n[](https://ory.gitbooks.io/hydra/content/)\n[](http://docs.hydra13.apiary.io/)\n[](https://godoc.org/github.com/ory/hydra)\n\nORY Hydra offers OAuth 2.0 and OpenID Connect Core 1.0 capabilities as a service and is built on top of the security-first\nOAuth2 and OpenID Connect SDK [ORY Fosite](https://github.com/ory/fosite) and the access control\nSDK [ORY Ladon](https://github.com/ory/ladon). ORY Hydra is different, because it works with\nany existing authentication infrastructure, not just LDAP or SAML. By implementing a consent app (works with any programming language)\nyou build a bridge between ORY Hydra and your authentication infrastructure.\n\nORY Hydra is able to securely manage JSON Web Keys, and has a sophisticated policy-based access control you can use if you want to.\n\nORY Hydra is suitable for green- (new) and brownfield (existing) projects. If you are not familiar with OAuth 2.0 and are working\non a greenfield project, we recommend evaluating if OAuth 2.0 really serves your purpose.\n**Knowledge of OAuth 2.0 is imperative in understanding what ORY Hydra does and how it works.**\n\nJoin the [ORY Hydra Newsletter](http://eepurl.com/bKT3N9) to stay on top of new developments. ORY Hydra has a lovely, active\ncommunity on [Gitter](https://gitter.im/ory-am/hydra). For advanced use cases, check out the\n[Enterprise Edition](#enterprise-edition) section.\n\n---\n\n\n\n**Table of Contents**\n\n- [What is ORY Hydra?](#what-is-ory-hydra)\n - [ORY Hydra implements open standards](#ory-hydra-implements-open-standards)\n- [Sponsors & Adopters](#sponsors-&-adopters)\n - [Sponsors](#sponsors)\n - [Adopters](#adopters)\n- [ORY Hydra for Enterprise](#ory-hydra-for-enterprise)\n- [Quickstart](#quickstart)\n - [5 minutes tutorial: Run your very own OAuth2 environment](#5-minutes-tutorial-run-your-very-own-oauth2-environment)\n - [Installation](#installation)\n - [Download binaries](#download-binaries)\n - [Using Docker](#using-docker)\n - [Building from source](#building-from-source)\n- [Security](#security)\n- [Telemetry](#telemetry)\n- [Documentation](#documentation)\n - [Guide](#guide)\n - [HTTP API documentation](#http-api-documentation)\n - [Command line documentation](#command-line-documentation)\n - [Develop](#develop)\n- [Reception](#reception)\n- [Libraries and third-party projects](#libraries-and-third-party-projects)\n- [Blog posts & articles](#blog-posts-&-articles)\n\n\n\n## What is ORY Hydra?\n\nORY Hydra is a server implementation of the OAuth 2.0 authorization framework and the OpenID Connect Core 1.0. Existing OAuth2\nimplementations usually ship as libraries or SDKs such as [node-oauth2-server](https://github.com/oauthjs/node-oauth2-server)\nor [fosite](https://github.com/ory/fosite/issues), or as fully featured identity solutions with user\nmanagement and user interfaces, such as [Dex](https://github.com/coreos/dex).\n\nImplementing and using OAuth2 without understanding the whole specification is challenging and prone to errors, even when\nSDKs are being used. The primary goal of ORY Hydra is to make OAuth 2.0 and OpenID Connect 1.0 better accessible.\n\nORY Hydra implements the flows described in OAuth2 and OpenID Connect 1.0 without forcing you to use a \"Hydra User Management\"\nor some template engine or a predefined front-end. Instead it relies on HTTP redirection and cryptographic methods\nto verify user consent allowing you to use ORY Hydra with any authentication endpoint, be it [authboss](https://github.com/go-authboss/authboss),\n[auth0.com](https://auth0.com/) or your proprietary PHP authentication.\n\n### ORY Hydra implements open standards\n\nORY Hydra implements Open Standards set by the IETF:\n\n* [The OAuth 2.0 Authorization Framework](https://tools.ietf.org/html/rfc6749)\n* [OAuth 2.0 Threat Model and Security Considerations](https://tools.ietf.org/html/rfc6819)\n* [OAuth 2.0 Token Revocation](https://tools.ietf.org/html/rfc7009)\n* [OAuth 2.0 Token Introspection](https://tools.ietf.org/html/rfc7662)\n* [OAuth 2.0 Dynamic Client Registration Protocol](https://tools.ietf.org/html/rfc7591)\n* [OAuth 2.0 Dynamic Client Registration Management Protocol](https://tools.ietf.org/html/rfc7592)\n* [OAuth 2.0 for Native Apps](https://tools.ietf.org/html/draft-ietf-oauth-native-apps-10)\n\nand the OpenID Foundation:\n\n* [OpenID Connect Core 1.0](http://openid.net/specs/openid-connect-core-1_0.html)\n* [OpenID Connect Discovery 1.0](https://openid.net/specs/openid-connect-discovery-1_0.html)\n\n## Sponsors & Adopters\n\nThis is a cureated list of Hydra sponsors and adopters. If you want to be on this list, [contact us](mailto:hi@ory.am).\n\n### Sponsors\n\n
\n\n```\n\n## License\n\nThe core GraphQL Engine is available under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0) (Apache-2.0).\n\nAll **other contents** (except those in [`server`](server), [`cli`](cli) and\n[`console`](console) directories) are available under the [MIT License](LICENSE-community).\nThis includes everything in the [`docs`](docs) and [`community`](community)\ndirectories.\n\n## Translations\n\nThis readme is available in the following translations:\n\n- [Japanese :jp:](translations/README.japanese.md) (:pray: [@moksahero](https://github.com/moksahero))\n- [French :fr:](translations/README.french.md) (:pray: [@l0ck3](https://github.com/l0ck3))\n- [Bosnian :bosnia_herzegovina:](translations/README.bosnian.md) (:pray: [@hajro92](https://github.com/hajro92))\n- [Russian :ru:](translations/README.russian.md) (:pray: [@highflyer910](https://github.com/highflyer910))\n- [Greek \ud83c\uddec\ud83c\uddf7](translations/README.greek.md) (:pray: [@MIP2000](https://github.com/MIP2000))\n- [Spanish \ud83c\uddf2\ud83c\uddfd](/translations/README.mx_spanish.md)(:pray: [@ferdox2](https://github.com/ferdox2))\n- [Indonesian :indonesia:](translations/README.indonesian.md) (:pray: [@anwari666](https://github.com/anwari666))\n- [Brazilian Portuguese :brazil:](translations/README.portuguese_br.md) (:pray: [@rubensmp](https://github.com/rubensmp))\n- [German \ud83c\udde9\ud83c\uddea](translations/README.german.md) (:pray: [@FynnGrandke](https://github.com/FynnGrandke))\n- [Chinese :cn:](translations/README.chinese.md) (:pray: [@jagreetdg](https://github.com/jagreetdg) & [@johnbanq](https://github.com/johnbanq))\n- [Turkish :tr:](translations/README.turkish.md) (:pray: [@berat](https://github.com/berat))\n- [Korean :kr:](translations/README.korean.md) (:pray: [@\ub77c\uc2a4\ud06c](https://github.com/laskdjlaskdj12))\n\nTranslations for other files can be found [here](translations).\n",
- "source_links": [],
- "id": 53
- },
- {
- "page_link": "https://github.com/segmentio/ory-hydra",
- "title": "hydra readme",
- "text": "# \n\n[](https://gitter.im/ory-am/hydra?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)\n[](http://eepurl.com/bKT3N9)\n[](https://twitter.com/_aeneasr)\n[](https://github.com/arekkas)\n[](https://patreon.com/user?u=4298803)\n\n[](https://travis-ci.org/ory/hydra)\n[](https://coveralls.io/github/ory/hydra?branch=master)\n[](https://codeclimate.com/github/ory/hydra)\n[](https://goreportcard.com/report/github.com/ory/hydra)\n[](https://bestpractices.coreinfrastructure.org/projects/364)\n\n[](https://ory.gitbooks.io/hydra/content/)\n[](http://docs.hydra13.apiary.io/)\n[](https://godoc.org/github.com/ory/hydra)\n\nORY Hydra offers OAuth 2.0 and OpenID Connect Core 1.0 capabilities as a service and is built on top of the security-first\nOAuth2 and OpenID Connect SDK [ORY Fosite](https://github.com/ory/fosite) and the access control\nSDK [ORY Ladon](https://github.com/ory/ladon). ORY Hydra is different, because it works with\nany existing authentication infrastructure, not just LDAP or SAML. By implementing a consent app (works with any programming language)\nyou build a bridge between ORY Hydra and your authentication infrastructure.\n\nORY Hydra is able to securely manage JSON Web Keys, and has a sophisticated policy-based access control you can use if you want to.\n\nORY Hydra is suitable for green- (new) and brownfield (existing) projects. If you are not familiar with OAuth 2.0 and are working\non a greenfield project, we recommend evaluating if OAuth 2.0 really serves your purpose.\n**Knowledge of OAuth 2.0 is imperative in understanding what ORY Hydra does and how it works.**\n\nJoin the [ORY Hydra Newsletter](http://eepurl.com/bKT3N9) to stay on top of new developments. ORY Hydra has a lovely, active\ncommunity on [Gitter](https://gitter.im/ory-am/hydra). For advanced use cases, check out the\n[Enterprise Edition](#enterprise-edition) section.\n\n---\n\n\n\n**Table of Contents**\n\n- [What is ORY Hydra?](#what-is-ory-hydra)\n - [ORY Hydra implements open standards](#ory-hydra-implements-open-standards)\n- [Sponsors & Adopters](#sponsors-&-adopters)\n - [Sponsors](#sponsors)\n - [Adopters](#adopters)\n- [ORY Hydra for Enterprise](#ory-hydra-for-enterprise)\n- [Quickstart](#quickstart)\n - [5 minutes tutorial: Run your very own OAuth2 environment](#5-minutes-tutorial-run-your-very-own-oauth2-environment)\n - [Installation](#installation)\n - [Download binaries](#download-binaries)\n - [Using Docker](#using-docker)\n - [Building from source](#building-from-source)\n- [Security](#security)\n- [Telemetry](#telemetry)\n- [Documentation](#documentation)\n - [Guide](#guide)\n - [HTTP API documentation](#http-api-documentation)\n - [Command line documentation](#command-line-documentation)\n - [Develop](#develop)\n- [Reception](#reception)\n- [Libraries and third-party projects](#libraries-and-third-party-projects)\n- [Blog posts & articles](#blog-posts-&-articles)\n\n\n\n## What is ORY Hydra?\n\nORY Hydra is a server implementation of the OAuth 2.0 authorization framework and the OpenID Connect Core 1.0. Existing OAuth2\nimplementations usually ship as libraries or SDKs such as [node-oauth2-server](https://github.com/oauthjs/node-oauth2-server)\nor [fosite](https://github.com/ory/fosite/issues), or as fully featured identity solutions with user\nmanagement and user interfaces, such as [Dex](https://github.com/coreos/dex).\n\nImplementing and using OAuth2 without understanding the whole specification is challenging and prone to errors, even when\nSDKs are being used. The primary goal of ORY Hydra is to make OAuth 2.0 and OpenID Connect 1.0 better accessible.\n\nORY Hydra implements the flows described in OAuth2 and OpenID Connect 1.0 without forcing you to use a \"Hydra User Management\"\nor some template engine or a predefined front-end. Instead it relies on HTTP redirection and cryptographic methods\nto verify user consent allowing you to use ORY Hydra with any authentication endpoint, be it [authboss](https://github.com/go-authboss/authboss),\n[auth0.com](https://auth0.com/) or your proprietary PHP authentication.\n\n### ORY Hydra implements open standards\n\nORY Hydra implements Open Standards set by the IETF:\n\n* [The OAuth 2.0 Authorization Framework](https://tools.ietf.org/html/rfc6749)\n* [OAuth 2.0 Threat Model and Security Considerations](https://tools.ietf.org/html/rfc6819)\n* [OAuth 2.0 Token Revocation](https://tools.ietf.org/html/rfc7009)\n* [OAuth 2.0 Token Introspection](https://tools.ietf.org/html/rfc7662)\n* [OAuth 2.0 Dynamic Client Registration Protocol](https://tools.ietf.org/html/rfc7591)\n* [OAuth 2.0 Dynamic Client Registration Management Protocol](https://tools.ietf.org/html/rfc7592)\n* [OAuth 2.0 for Native Apps](https://tools.ietf.org/html/draft-ietf-oauth-native-apps-10)\n\nand the OpenID Foundation:\n\n* [OpenID Connect Core 1.0](http://openid.net/specs/openid-connect-core-1_0.html)\n* [OpenID Connect Discovery 1.0](https://openid.net/specs/openid-connect-discovery-1_0.html)\n\n## Sponsors & Adopters\n\nThis is a cureated list of Hydra sponsors and adopters. If you want to be on this list, [contact us](mailto:hi@ory.am).\n\n### Sponsors\n\n \n\nWe are proud to have [Auth0](https://auth0.com) as a **gold sponsor** for ORY Hydra. [Auth0](https://auth0.com) solves\nthe most complex identity use cases with an extensible and easy to integrate platform that secures billions of logins\nevery year. At ORY, we use [Auth0](https://auth0.com) in conjunction with ORY Hydra for various internal projects.\n\n
\n\nWe are proud to have [Auth0](https://auth0.com) as a **gold sponsor** for ORY Hydra. [Auth0](https://auth0.com) solves\nthe most complex identity use cases with an extensible and easy to integrate platform that secures billions of logins\nevery year. At ORY, we use [Auth0](https://auth0.com) in conjunction with ORY Hydra for various internal projects.\n\n \n\n
\n\n \n\n
\n\n

 \n
\n \n \n \n \n
\n \n \n \n 

 \n\n\n## Get Started\n\nFor a complete getting started guide, please see our full [online documentation site](https://docs.influxdata.com/influxdb/latest/).\n\nTo write and query data or use the API in any way, you'll need to first create a user, credentials, organization and bucket.\nEverything in InfluxDB is organized under a concept of an organization. The API is designed to be multi-tenant.\nBuckets represent where you store time series data.\nThey're synonymous with what was previously in InfluxDB 1.x a database and retention policy.\n\nThe simplest way to get set up is to point your browser to [http://localhost:8086](http://localhost:8086) and go through the prompts.\n\nYou can also get set up from the CLI using the command `influx setup`:\n\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup\nWelcome to InfluxDB 2.0!\nPlease type your primary username: marty\n\nPlease type your password:\n\nPlease type your password again:\n\nPlease type your primary organization name.: InfluxData\n\nPlease type your primary bucket name.: telegraf\n\nPlease type your retention period in hours.\nOr press ENTER for infinite.: 72\n\n\nYou have entered:\n Username: marty\n Organization: InfluxData\n Bucket: telegraf\n Retention Period: 72 hrs\nConfirm? (y/n): y\n\nUserID Username Organization Bucket\n033a3f2c5ccaa000 marty InfluxData Telegraf\nYour token has been stored in /Users/marty/.influxdbv2/credentials\n```\n\nYou can run this command non-interactively using the `-f, --force` flag if you are automating the setup.\nSome added flags can help:\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup \\\n--username marty \\\n--password F1uxKapacit0r85 \\\n--org InfluxData \\\n--bucket telegraf \\\n--retention 168 \\\n--token where-were-going-we-dont-need-roads \\\n--force\n```\n\nOnce setup is complete, a configuration profile is created to allow you to interact with your local InfluxDB without passing in credentials each time. You can list and manage those profiles using the `influx config` command.\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx config\nActive\tName\tURL\t\t\t Org\n*\t default\thttp://localhost:8086\tInfluxData\n```\n\n## Write Data\nWrite to measurement `m`, with tag `v=2`, in bucket `telegraf`, which belongs to organization `InfluxData`:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket telegraf --precision s \"m v=2 $(date +%s)\"\n```\n\nSince you have a default profile set up, you can omit the Organization and Token from the command.\n\nWrite the same point using `curl`:\n\n```bash\ncurl --header \"Authorization: Token $(bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx auth list --json | jq -r '.[0].token')\" \\\n--data-raw \"m v=2 $(date +%s)\" \\\n\"http://localhost:8086/api/v2/write?org=InfluxData&bucket=telegraf&precision=s\"\n```\n\nRead that back with a simple Flux query:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx query 'from(bucket:\"telegraf\") |> range(start:-1h)'\nResult: _result\nTable: keys: [_start, _stop, _field, _measurement]\n _start:time _stop:time _field:string _measurement:string _time:time _value:float\n------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------\n2019-12-30T22:19:39.043918000Z 2019-12-30T23:19:39.043918000Z v m 2019-12-30T23:17:02.000000000Z 2\n```\n\nUse the `-r, --raw` option to return the raw flux response from the query. This is useful for moving data from one instance to another as the `influx write` command can accept the Flux response using the `--format csv` option.\n\n## Script with Flux\n\nFlux (previously named IFQL) is an open source functional data scripting language designed for querying, analyzing, and acting on data. Flux supports multiple data source types, including:\n\n- Time series databases (such as InfluxDB)\n- Relational SQL databases (such as MySQL and PostgreSQL)\n- CSV\n\nThe source for Flux is [available on GitHub](https://github.com/influxdata/flux).\nTo learn more about Flux, see the latest [InfluxData Flux documentation](https://docs.influxdata.com/flux/) and [CTO Paul Dix's presentation](https://speakerdeck.com/pauldix/flux-number-fluxlang-a-new-time-series-data-scripting-language).\n\n## Contribute to the Project\n\nInfluxDB is an [MIT licensed](LICENSE) open source project and we love our community. The fastest way to get something fixed is to open a PR. Check out our [contributing](CONTRIBUTING.md) guide if you're interested in helping out. Also, join us on our [Community Slack Workspace](https://influxdata.com/slack) if you have questions or comments for our engineering teams.\n\n## CI and Static Analysis\n\n### CI\n\nAll pull requests will run through CI, which is currently hosted by Circle.\nCommunity contributors should be able to see the outcome of this process by looking at the checks on their PR.\nPlease fix any issues to ensure a prompt review from members of the team.\n\nThe InfluxDB project is used internally in a number of proprietary InfluxData products, and as such, PRs and changes need to be tested internally.\nThis can take some time, and is not really visible to community contributors.\n\n### Static Analysis\n\nThis project uses the following static analysis tools.\nFailure during the running of any of these tools results in a failed build.\nGenerally, code must be adjusted to satisfy these tools, though there are exceptions.\n\n- [go vet](https://golang.org/cmd/vet/) checks for Go code that should be considered incorrect.\n- [go fmt](https://golang.org/cmd/gofmt/) checks that Go code is correctly formatted.\n- [go mod tidy](https://tip.golang.org/cmd/go/#hdr-Add_missing_and_remove_unused_modules) ensures that the source code and go.mod agree.\n- [staticcheck](https://staticcheck.io/docs/) checks for things like: unused code, code that can be simplified, code that is incorrect and code that will have performance issues.\n\n### staticcheck\n\nIf your PR fails `staticcheck` it is easy to dig into why it failed, and also to fix the problem.\nFirst, take a look at the error message in Circle under the `staticcheck` build section, e.g.,\n\n```\ntsdb/tsm1/encoding.gen.go:1445:24: func BooleanValues.assertOrdered is unused (U1000)\ntsdb/tsm1/encoding.go:172:7: receiver name should not be an underscore, omit the name if it is unused (ST1006)\n```\n\nNext, go and take a [look here](http://next.staticcheck.io/docs/checks) for some clarification on the error code that you have received, e.g., `U1000`.\nThe docs will tell you what's wrong, and often what you need to do to fix the issue.\n\n#### Generated Code\n\nSometimes generated code will contain unused code or occasionally that will fail a different check.\n`staticcheck` allows for [entire files](http://next.staticcheck.io/docs/#ignoring-problems) to be ignored, though it's not ideal.\nA linter directive, in the form of a comment, must be placed within the generated file.\nThis is problematic because it will be erased if the file is re-generated.\nUntil a better solution comes about, below is the list of generated files that need an ignores comment.\nIf you re-generate a file and find that `staticcheck` has failed, please see this list below for what you need to put back:\n\n| File | Comment |\n| :--------------------: | :--------------------------------------------------------------: |\n| query/promql/promql.go | //lint:file-ignore SA6001 Ignore all unused code, it's generated |\n\n#### End-to-End Tests\n\nCI also runs end-to-end tests. These test the integration between the `influxd` server the UI.\nSince the UI is used by interal repositories as well as the `influxdb` repository, the\nend-to-end tests cannot be run on forked pull requests or run locally. The extent of end-to-end\ntesting required for forked pull requests will be determined as part of the review process.\n\n## Additional Resources\n- [InfluxDB Tips and Tutorials](https://www.influxdata.com/blog/category/tech/influxdb/)\n- [InfluxDB Essentials Course](https://university.influxdata.com/courses/influxdb-essentials-tutorial/)\n- [Exploring InfluxDB Cloud Course](https://university.influxdata.com/courses/exploring-influxdb-cloud-tutorial/)",
- "source_links": [],
- "id": 56
- },
- {
- "page_link": "https://github.com/kubernetes/ingress-nginx",
- "title": "ingress-nginx readme",
- "text": "# Ingress NGINX Controller\n\n[](https://bestpractices.coreinfrastructure.org/projects/5691)\n[](https://goreportcard.com/report/github.com/kubernetes/ingress-nginx)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n[](https://github.com/kubernetes/ingress-nginx/stargazers)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md)\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fkubernetes%2Fingress-nginx?ref=badge_shield)\n\nPlease fill out our 2022 Ingress-Nginx User Survey and let us know what you want to see in future releases.\n\nhttps://www.surveymonkey.com/r/ingressngx2022\n\n## Overview\n\ningress-nginx is an Ingress controller for Kubernetes using [NGINX](https://www.nginx.org/) as a reverse proxy and load balancer.\n\n[Learn more about Ingress on the main Kubernetes documentation site](https://kubernetes.io/docs/concepts/services-networking/ingress/).\n\n## Get started\n\nSee the [Getting Started](https://kubernetes.github.io/ingress-nginx/deploy/) document.\n\n## Troubleshooting\n\nIf you encounter issues, review the [troubleshooting docs](docs/troubleshooting.md), [file an issue](https://github.com/kubernetes/ingress-nginx/issues), or talk to us on the [#ingress-nginx channel](https://kubernetes.slack.com/messages/ingress-nginx) on the Kubernetes Slack server.\n\n## Changelog\n\nSee [the list of releases](https://github.com/kubernetes/ingress-nginx/releases) to find out about feature changes.\nFor detailed changes for each release; please check the [Changelog.md](Changelog.md) file.\nFor detailed changes on the `ingress-nginx` helm chart, please check the following [CHANGELOG.md](charts/ingress-nginx/CHANGELOG.md) file.\n\n### Support Versions table \n\n| Ingress-NGINX version | k8s supported version | Alpine Version | Nginx Version |\n|-----------------------|------------------------------|----------------|---------------|\n| v1.3.1 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.2 | 1.19.10\u2020 |\n| v1.3.0 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.0 | 1.19.10\u2020 |\n| v1.2.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.6 | 1.19.10\u2020 |\n| v1.1.3 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.4 | 1.19.10\u2020 |\n| v1.1.2 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.0 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.5 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.4 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.3 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.2 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.1 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.0 | 1.22, 1.21, 1.20, 1.19 | 3.13.5 | 1.20.1 |\n\n\n\u2020 _This build is [patched against CVE-2021-23017](https://github.com/openresty/openresty/commit/4b5ec7edd78616f544abc194308e0cf4b788725b#diff-42ef841dc27fe0b5aa2d06bd31308bb63a59cdcddcbcddd917248349d22020a3)._\n\nSee [this article](https://kubernetes.io/blog/2021/07/26/update-with-ingress-nginx/) if you want upgrade to the stable Ingress API. \n\n## Get Involved\n\nThanks for taking the time to join our community and start contributing!\n\n- This project adheres to the [Kubernetes Community Code of Conduct](https://git.k8s.io/community/code-of-conduct.md). By participating in this project, you agree to abide by its terms.\n\n- **Contributing**: Contributions of all kind are welcome!\n \n - Read [`CONTRIBUTING.md`](CONTRIBUTING.md) for information about setting up your environment, the workflow that we expect, and instructions on the developer certificate of origin that we require.\n\n - Join our Kubernetes Slack channel for developer discussion : [#ingress-nginx-dev](https://kubernetes.slack.com/archives/C021E147ZA4).\n \n - Submit github issues for any feature enhancements, bugs or documentation problems. Please make sure to read the [Issue Reporting Checklist](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md#issue-reporting-guidelines) before opening an issue. Issues not conforming to the guidelines **may be closed immediately**.\n\n- **Support**: Join the [#ingress-nginx-users](https://kubernetes.slack.com/messages/CANQGM8BA/) channel inside the [Kubernetes Slack](http://slack.kubernetes.io/) to ask questions or get support from the maintainers and other users.\n \n - The [GitHub issues](https://github.com/kubernetes/ingress-nginx/issues) in the repository are **exclusively** for bug reports and feature requests.\n\n- **Discuss**: Tweet using the `#IngressNginx` hashtag.\n\n## License\n\n[Apache License 2.0](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n",
- "source_links": [],
- "id": 57
- },
- {
- "page_link": "https://github.com/istio/istio",
- "title": "istio readme",
- "text": "# Istio\n\n[](https://bestpractices.coreinfrastructure.org/projects/1395)\n[](https://goreportcard.com/report/github.com/istio/istio)\n[](https://godoc.org/istio.io/istio)\n\n\n
\n\n\n## Get Started\n\nFor a complete getting started guide, please see our full [online documentation site](https://docs.influxdata.com/influxdb/latest/).\n\nTo write and query data or use the API in any way, you'll need to first create a user, credentials, organization and bucket.\nEverything in InfluxDB is organized under a concept of an organization. The API is designed to be multi-tenant.\nBuckets represent where you store time series data.\nThey're synonymous with what was previously in InfluxDB 1.x a database and retention policy.\n\nThe simplest way to get set up is to point your browser to [http://localhost:8086](http://localhost:8086) and go through the prompts.\n\nYou can also get set up from the CLI using the command `influx setup`:\n\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup\nWelcome to InfluxDB 2.0!\nPlease type your primary username: marty\n\nPlease type your password:\n\nPlease type your password again:\n\nPlease type your primary organization name.: InfluxData\n\nPlease type your primary bucket name.: telegraf\n\nPlease type your retention period in hours.\nOr press ENTER for infinite.: 72\n\n\nYou have entered:\n Username: marty\n Organization: InfluxData\n Bucket: telegraf\n Retention Period: 72 hrs\nConfirm? (y/n): y\n\nUserID Username Organization Bucket\n033a3f2c5ccaa000 marty InfluxData Telegraf\nYour token has been stored in /Users/marty/.influxdbv2/credentials\n```\n\nYou can run this command non-interactively using the `-f, --force` flag if you are automating the setup.\nSome added flags can help:\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx setup \\\n--username marty \\\n--password F1uxKapacit0r85 \\\n--org InfluxData \\\n--bucket telegraf \\\n--retention 168 \\\n--token where-were-going-we-dont-need-roads \\\n--force\n```\n\nOnce setup is complete, a configuration profile is created to allow you to interact with your local InfluxDB without passing in credentials each time. You can list and manage those profiles using the `influx config` command.\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx config\nActive\tName\tURL\t\t\t Org\n*\t default\thttp://localhost:8086\tInfluxData\n```\n\n## Write Data\nWrite to measurement `m`, with tag `v=2`, in bucket `telegraf`, which belongs to organization `InfluxData`:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket telegraf --precision s \"m v=2 $(date +%s)\"\n```\n\nSince you have a default profile set up, you can omit the Organization and Token from the command.\n\nWrite the same point using `curl`:\n\n```bash\ncurl --header \"Authorization: Token $(bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx auth list --json | jq -r '.[0].token')\" \\\n--data-raw \"m v=2 $(date +%s)\" \\\n\"http://localhost:8086/api/v2/write?org=InfluxData&bucket=telegraf&precision=s\"\n```\n\nRead that back with a simple Flux query:\n\n```bash\n$ bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx query 'from(bucket:\"telegraf\") |> range(start:-1h)'\nResult: _result\nTable: keys: [_start, _stop, _field, _measurement]\n _start:time _stop:time _field:string _measurement:string _time:time _value:float\n------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------\n2019-12-30T22:19:39.043918000Z 2019-12-30T23:19:39.043918000Z v m 2019-12-30T23:17:02.000000000Z 2\n```\n\nUse the `-r, --raw` option to return the raw flux response from the query. This is useful for moving data from one instance to another as the `influx write` command can accept the Flux response using the `--format csv` option.\n\n## Script with Flux\n\nFlux (previously named IFQL) is an open source functional data scripting language designed for querying, analyzing, and acting on data. Flux supports multiple data source types, including:\n\n- Time series databases (such as InfluxDB)\n- Relational SQL databases (such as MySQL and PostgreSQL)\n- CSV\n\nThe source for Flux is [available on GitHub](https://github.com/influxdata/flux).\nTo learn more about Flux, see the latest [InfluxData Flux documentation](https://docs.influxdata.com/flux/) and [CTO Paul Dix's presentation](https://speakerdeck.com/pauldix/flux-number-fluxlang-a-new-time-series-data-scripting-language).\n\n## Contribute to the Project\n\nInfluxDB is an [MIT licensed](LICENSE) open source project and we love our community. The fastest way to get something fixed is to open a PR. Check out our [contributing](CONTRIBUTING.md) guide if you're interested in helping out. Also, join us on our [Community Slack Workspace](https://influxdata.com/slack) if you have questions or comments for our engineering teams.\n\n## CI and Static Analysis\n\n### CI\n\nAll pull requests will run through CI, which is currently hosted by Circle.\nCommunity contributors should be able to see the outcome of this process by looking at the checks on their PR.\nPlease fix any issues to ensure a prompt review from members of the team.\n\nThe InfluxDB project is used internally in a number of proprietary InfluxData products, and as such, PRs and changes need to be tested internally.\nThis can take some time, and is not really visible to community contributors.\n\n### Static Analysis\n\nThis project uses the following static analysis tools.\nFailure during the running of any of these tools results in a failed build.\nGenerally, code must be adjusted to satisfy these tools, though there are exceptions.\n\n- [go vet](https://golang.org/cmd/vet/) checks for Go code that should be considered incorrect.\n- [go fmt](https://golang.org/cmd/gofmt/) checks that Go code is correctly formatted.\n- [go mod tidy](https://tip.golang.org/cmd/go/#hdr-Add_missing_and_remove_unused_modules) ensures that the source code and go.mod agree.\n- [staticcheck](https://staticcheck.io/docs/) checks for things like: unused code, code that can be simplified, code that is incorrect and code that will have performance issues.\n\n### staticcheck\n\nIf your PR fails `staticcheck` it is easy to dig into why it failed, and also to fix the problem.\nFirst, take a look at the error message in Circle under the `staticcheck` build section, e.g.,\n\n```\ntsdb/tsm1/encoding.gen.go:1445:24: func BooleanValues.assertOrdered is unused (U1000)\ntsdb/tsm1/encoding.go:172:7: receiver name should not be an underscore, omit the name if it is unused (ST1006)\n```\n\nNext, go and take a [look here](http://next.staticcheck.io/docs/checks) for some clarification on the error code that you have received, e.g., `U1000`.\nThe docs will tell you what's wrong, and often what you need to do to fix the issue.\n\n#### Generated Code\n\nSometimes generated code will contain unused code or occasionally that will fail a different check.\n`staticcheck` allows for [entire files](http://next.staticcheck.io/docs/#ignoring-problems) to be ignored, though it's not ideal.\nA linter directive, in the form of a comment, must be placed within the generated file.\nThis is problematic because it will be erased if the file is re-generated.\nUntil a better solution comes about, below is the list of generated files that need an ignores comment.\nIf you re-generate a file and find that `staticcheck` has failed, please see this list below for what you need to put back:\n\n| File | Comment |\n| :--------------------: | :--------------------------------------------------------------: |\n| query/promql/promql.go | //lint:file-ignore SA6001 Ignore all unused code, it's generated |\n\n#### End-to-End Tests\n\nCI also runs end-to-end tests. These test the integration between the `influxd` server the UI.\nSince the UI is used by interal repositories as well as the `influxdb` repository, the\nend-to-end tests cannot be run on forked pull requests or run locally. The extent of end-to-end\ntesting required for forked pull requests will be determined as part of the review process.\n\n## Additional Resources\n- [InfluxDB Tips and Tutorials](https://www.influxdata.com/blog/category/tech/influxdb/)\n- [InfluxDB Essentials Course](https://university.influxdata.com/courses/influxdb-essentials-tutorial/)\n- [Exploring InfluxDB Cloud Course](https://university.influxdata.com/courses/exploring-influxdb-cloud-tutorial/)",
- "source_links": [],
- "id": 56
- },
- {
- "page_link": "https://github.com/kubernetes/ingress-nginx",
- "title": "ingress-nginx readme",
- "text": "# Ingress NGINX Controller\n\n[](https://bestpractices.coreinfrastructure.org/projects/5691)\n[](https://goreportcard.com/report/github.com/kubernetes/ingress-nginx)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n[](https://github.com/kubernetes/ingress-nginx/stargazers)\n[](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md)\n[](https://app.fossa.io/projects/git%2Bgithub.com%2Fkubernetes%2Fingress-nginx?ref=badge_shield)\n\nPlease fill out our 2022 Ingress-Nginx User Survey and let us know what you want to see in future releases.\n\nhttps://www.surveymonkey.com/r/ingressngx2022\n\n## Overview\n\ningress-nginx is an Ingress controller for Kubernetes using [NGINX](https://www.nginx.org/) as a reverse proxy and load balancer.\n\n[Learn more about Ingress on the main Kubernetes documentation site](https://kubernetes.io/docs/concepts/services-networking/ingress/).\n\n## Get started\n\nSee the [Getting Started](https://kubernetes.github.io/ingress-nginx/deploy/) document.\n\n## Troubleshooting\n\nIf you encounter issues, review the [troubleshooting docs](docs/troubleshooting.md), [file an issue](https://github.com/kubernetes/ingress-nginx/issues), or talk to us on the [#ingress-nginx channel](https://kubernetes.slack.com/messages/ingress-nginx) on the Kubernetes Slack server.\n\n## Changelog\n\nSee [the list of releases](https://github.com/kubernetes/ingress-nginx/releases) to find out about feature changes.\nFor detailed changes for each release; please check the [Changelog.md](Changelog.md) file.\nFor detailed changes on the `ingress-nginx` helm chart, please check the following [CHANGELOG.md](charts/ingress-nginx/CHANGELOG.md) file.\n\n### Support Versions table \n\n| Ingress-NGINX version | k8s supported version | Alpine Version | Nginx Version |\n|-----------------------|------------------------------|----------------|---------------|\n| v1.3.1 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.2 | 1.19.10\u2020 |\n| v1.3.0 | 1.24, 1.23, 1.22, 1.21, 1.20 | 3.16.0 | 1.19.10\u2020 |\n| v1.2.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.6 | 1.19.10\u2020 |\n| v1.1.3 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.4 | 1.19.10\u2020 |\n| v1.1.2 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.1 | 1.23, 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.1.0 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.5 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.4 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.3 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.2 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.1 | 1.22, 1.21, 1.20, 1.19 | 3.14.2 | 1.19.9\u2020 |\n| v1.0.0 | 1.22, 1.21, 1.20, 1.19 | 3.13.5 | 1.20.1 |\n\n\n\u2020 _This build is [patched against CVE-2021-23017](https://github.com/openresty/openresty/commit/4b5ec7edd78616f544abc194308e0cf4b788725b#diff-42ef841dc27fe0b5aa2d06bd31308bb63a59cdcddcbcddd917248349d22020a3)._\n\nSee [this article](https://kubernetes.io/blog/2021/07/26/update-with-ingress-nginx/) if you want upgrade to the stable Ingress API. \n\n## Get Involved\n\nThanks for taking the time to join our community and start contributing!\n\n- This project adheres to the [Kubernetes Community Code of Conduct](https://git.k8s.io/community/code-of-conduct.md). By participating in this project, you agree to abide by its terms.\n\n- **Contributing**: Contributions of all kind are welcome!\n \n - Read [`CONTRIBUTING.md`](CONTRIBUTING.md) for information about setting up your environment, the workflow that we expect, and instructions on the developer certificate of origin that we require.\n\n - Join our Kubernetes Slack channel for developer discussion : [#ingress-nginx-dev](https://kubernetes.slack.com/archives/C021E147ZA4).\n \n - Submit github issues for any feature enhancements, bugs or documentation problems. Please make sure to read the [Issue Reporting Checklist](https://github.com/kubernetes/ingress-nginx/blob/main/CONTRIBUTING.md#issue-reporting-guidelines) before opening an issue. Issues not conforming to the guidelines **may be closed immediately**.\n\n- **Support**: Join the [#ingress-nginx-users](https://kubernetes.slack.com/messages/CANQGM8BA/) channel inside the [Kubernetes Slack](http://slack.kubernetes.io/) to ask questions or get support from the maintainers and other users.\n \n - The [GitHub issues](https://github.com/kubernetes/ingress-nginx/issues) in the repository are **exclusively** for bug reports and feature requests.\n\n- **Discuss**: Tweet using the `#IngressNginx` hashtag.\n\n## License\n\n[Apache License 2.0](https://github.com/kubernetes/ingress-nginx/blob/main/LICENSE)\n",
- "source_links": [],
- "id": 57
- },
- {
- "page_link": "https://github.com/istio/istio",
- "title": "istio readme",
- "text": "# Istio\n\n[](https://bestpractices.coreinfrastructure.org/projects/1395)\n[](https://goreportcard.com/report/github.com/istio/istio)\n[](https://godoc.org/istio.io/istio)\n\n\n  \n \n
\n \n
 \n
\n
 \n
\n  \n
\n  \n## Quick Start\n\nTwo easiest ways to start Jitsu are Heroku deployment and local docker-compose. \n\n### 1-click Heroku deploy\nIt may take up to 5 minutes for Heroku to install environment. \nAfter that you can visit `
\n## Quick Start\n\nTwo easiest ways to start Jitsu are Heroku deployment and local docker-compose. \n\n### 1-click Heroku deploy\nIt may take up to 5 minutes for Heroku to install environment. \nAfter that you can visit ` \n## Documentation\n\nPlease see our extensive documentation [here](https://jitsu.com/docs). Key sections include:\n\n* [Deployment](https://jitsu.com/docs/deployment) - Getting Jitsu running on Heroku, Docker, and building from source.\n* [Configuration](https://jitsu.com/docs/configuration) - How to modify Jitsu Server's `yaml` file.\n* [Geo Data](https://jitsu.com/docs/geo-data-resolution) - Configuring data enrichment with [MaxMind](https://www.maxmind.com/en/home).\n* [Scaling](https://jitsu.com/docs/other-features/scaling-eventnative) - How to setup a distributed deployment of Jitsu.\n\n\n
\n## Documentation\n\nPlease see our extensive documentation [here](https://jitsu.com/docs). Key sections include:\n\n* [Deployment](https://jitsu.com/docs/deployment) - Getting Jitsu running on Heroku, Docker, and building from source.\n* [Configuration](https://jitsu.com/docs/configuration) - How to modify Jitsu Server's `yaml` file.\n* [Geo Data](https://jitsu.com/docs/geo-data-resolution) - Configuring data enrichment with [MaxMind](https://www.maxmind.com/en/home).\n* [Scaling](https://jitsu.com/docs/other-features/scaling-eventnative) - How to setup a distributed deployment of Jitsu.\n\n\n \n## Reporting Bugs and Contributing Code\n\n* Want to report a bug or request a feature? Please open [an issue](https://github.com/jitsucom/jitsu/issues/new).\n* Want to help us build **Jitsu**? Fork the project, and check our an issues [that are good for first pull request](https://github.com/jitsucom/jitsu/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+first+issue%22)!\n* Questions? Join our [Slack](https://jitsu.com/slack)!\n* [hello@jitsu.com](mailto:hello@jitsu.com) - send us an email if you have any questions!\n",
- "source_links": [],
- "id": 60
- },
- {
- "page_link": "https://github.com/jupyterhub/jupyterhub",
- "title": "jupyterhub readme",
- "text": "**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n\n---\n\n# [JupyterHub](https://github.com/jupyterhub/jupyterhub)\n\n[](https://pypi.python.org/pypi/jupyterhub)\n[](https://anaconda.org/conda-forge/jupyterhub)\n[](https://jupyterhub.readthedocs.org/en/latest/)\n[](https://github.com/jupyterhub/jupyterhub/actions)\n[](https://hub.docker.com/r/jupyterhub/jupyterhub/tags)\n[](https://codecov.io/gh/jupyterhub/jupyterhub)\n[](https://github.com/jupyterhub/jupyterhub/issues)\n[](https://discourse.jupyter.org/c/jupyterhub)\n[](https://gitter.im/jupyterhub/jupyterhub)\n\nWith [JupyterHub](https://jupyterhub.readthedocs.io) you can create a\n**multi-user Hub** that spawns, manages, and proxies multiple instances of the\nsingle-user [Jupyter notebook](https://jupyter-notebook.readthedocs.io)\nserver.\n\n[Project Jupyter](https://jupyter.org) created JupyterHub to support many\nusers. The Hub can offer notebook servers to a class of students, a corporate\ndata science workgroup, a scientific research project, or a high-performance\ncomputing group.\n\n## Technical overview\n\nThree main actors make up JupyterHub:\n\n- multi-user **Hub** (tornado process)\n- configurable http **proxy** (node-http-proxy)\n- multiple **single-user Jupyter notebook servers** (Python/Jupyter/tornado)\n\nBasic principles for operation are:\n\n- Hub launches a proxy.\n- The Proxy forwards all requests to Hub by default.\n- Hub handles login and spawns single-user servers on demand.\n- Hub configures proxy to forward URL prefixes to the single-user notebook\n servers.\n\nJupyterHub also provides a\n[REST API][]\nfor administration of the Hub and its users.\n\n[rest api]: https://jupyterhub.readthedocs.io/en/latest/reference/rest-api.html\n\n## Installation\n\n### Check prerequisites\n\n- A Linux/Unix based system\n- [Python](https://www.python.org/downloads/) 3.6 or greater\n- [nodejs/npm](https://www.npmjs.com/)\n\n - If you are using **`conda`**, the nodejs and npm dependencies will be installed for\n you by conda.\n\n - If you are using **`pip`**, install a recent version (at least 12.0) of\n [nodejs/npm](https://docs.npmjs.com/getting-started/installing-node).\n\n- If using the default PAM Authenticator, a [pluggable authentication module (PAM)](https://en.wikipedia.org/wiki/Pluggable_authentication_module).\n- TLS certificate and key for HTTPS communication\n- Domain name\n\n### Install packages\n\n#### Using `conda`\n\nTo install JupyterHub along with its dependencies including nodejs/npm:\n\n```bash\nconda install -c conda-forge jupyterhub\n```\n\nIf you plan to run notebook servers locally, install JupyterLab or Jupyter notebook:\n\n```bash\nconda install jupyterlab\nconda install notebook\n```\n\n#### Using `pip`\n\nJupyterHub can be installed with `pip`, and the proxy with `npm`:\n\n```bash\nnpm install -g configurable-http-proxy\npython3 -m pip install jupyterhub\n```\n\nIf you plan to run notebook servers locally, you will need to install\n[JupyterLab or Jupyter notebook](https://jupyter.readthedocs.io/en/latest/install.html):\n\n python3 -m pip install --upgrade jupyterlab\n python3 -m pip install --upgrade notebook\n\n### Run the Hub server\n\nTo start the Hub server, run the command:\n\n jupyterhub\n\nVisit `http://localhost:8000` in your browser, and sign in with your system username and password.\n\n_Note_: To allow multiple users to sign in to the server, you will need to\nrun the `jupyterhub` command as a _privileged user_, such as root.\nThe [wiki](https://github.com/jupyterhub/jupyterhub/wiki/Using-sudo-to-run-JupyterHub-without-root-privileges)\ndescribes how to run the server as a _less privileged user_, which requires\nmore configuration of the system.\n\n## Configuration\n\nThe [Getting Started](https://jupyterhub.readthedocs.io/en/latest/tutorial/index.html#getting-started) section of the\ndocumentation explains the common steps in setting up JupyterHub.\n\nThe [**JupyterHub tutorial**](https://github.com/jupyterhub/jupyterhub-tutorial)\nprovides an in-depth video and sample configurations of JupyterHub.\n\n### Create a configuration file\n\nTo generate a default config file with settings and descriptions:\n\n jupyterhub --generate-config\n\n### Start the Hub\n\nTo start the Hub on a specific url and port `10.0.1.2:443` with **https**:\n\n jupyterhub --ip 10.0.1.2 --port 443 --ssl-key my_ssl.key --ssl-cert my_ssl.cert\n\n### Authenticators\n\n| Authenticator | Description |\n| ---------------------------------------------------------------------------- | ------------------------------------------------- |\n| PAMAuthenticator | Default, built-in authenticator |\n| [OAuthenticator](https://github.com/jupyterhub/oauthenticator) | OAuth + JupyterHub Authenticator = OAuthenticator |\n| [ldapauthenticator](https://github.com/jupyterhub/ldapauthenticator) | Simple LDAP Authenticator Plugin for JupyterHub |\n| [kerberosauthenticator](https://github.com/jupyterhub/kerberosauthenticator) | Kerberos Authenticator Plugin for JupyterHub |\n\n### Spawners\n\n| Spawner | Description |\n| -------------------------------------------------------------- | -------------------------------------------------------------------------- |\n| LocalProcessSpawner | Default, built-in spawner starts single-user servers as local processes |\n| [dockerspawner](https://github.com/jupyterhub/dockerspawner) | Spawn single-user servers in Docker containers |\n| [kubespawner](https://github.com/jupyterhub/kubespawner) | Kubernetes spawner for JupyterHub |\n| [sudospawner](https://github.com/jupyterhub/sudospawner) | Spawn single-user servers without being root |\n| [systemdspawner](https://github.com/jupyterhub/systemdspawner) | Spawn single-user notebook servers using systemd |\n| [batchspawner](https://github.com/jupyterhub/batchspawner) | Designed for clusters using batch scheduling software |\n| [yarnspawner](https://github.com/jupyterhub/yarnspawner) | Spawn single-user notebook servers distributed on a Hadoop cluster |\n| [wrapspawner](https://github.com/jupyterhub/wrapspawner) | WrapSpawner and ProfilesSpawner enabling runtime configuration of spawners |\n\n## Docker\n\nA starter [**docker image for JupyterHub**](https://hub.docker.com/r/jupyterhub/jupyterhub/)\ngives a baseline deployment of JupyterHub using Docker.\n\n**Important:** This `jupyterhub/jupyterhub` image contains only the Hub itself,\nwith no configuration. In general, one needs to make a derivative image, with\nat least a `jupyterhub_config.py` setting up an Authenticator and/or a Spawner.\nTo run the single-user servers, which may be on the same system as the Hub or\nnot, Jupyter Notebook version 4 or greater must be installed.\n\nThe JupyterHub docker image can be started with the following command:\n\n docker run -p 8000:8000 -d --name jupyterhub jupyterhub/jupyterhub jupyterhub\n\nThis command will create a container named `jupyterhub` that you can\n**stop and resume** with `docker stop/start`.\n\nThe Hub service will be listening on all interfaces at port 8000, which makes\nthis a good choice for **testing JupyterHub on your desktop or laptop**.\n\nIf you want to run docker on a computer that has a public IP then you should\n(as in MUST) **secure it with ssl** by adding ssl options to your docker\nconfiguration or by using an ssl enabled proxy.\n\n[Mounting volumes](https://docs.docker.com/engine/admin/volumes/volumes/) will\nallow you to **store data outside the docker image (host system) so it will be persistent**, even when you start\na new image.\n\nThe command `docker exec -it jupyterhub bash` will spawn a root shell in your docker\ncontainer. You can **use the root shell to create system users in the container**.\nThese accounts will be used for authentication in JupyterHub's default configuration.\n\n## Contributing\n\nIf you would like to contribute to the project, please read our\n[contributor documentation](https://jupyter.readthedocs.io/en/latest/contributing/content-contributor.html)\nand the [`CONTRIBUTING.md`](CONTRIBUTING.md). The `CONTRIBUTING.md` file\nexplains how to set up a development installation, how to run the test suite,\nand how to contribute to documentation.\n\nFor a high-level view of the vision and next directions of the project, see the\n[JupyterHub community roadmap](docs/source/contributing/roadmap.md).\n\n### A note about platform support\n\nJupyterHub is supported on Linux/Unix based systems.\n\nJupyterHub officially **does not** support Windows. You may be able to use\nJupyterHub on Windows if you use a Spawner and Authenticator that work on\nWindows, but the JupyterHub defaults will not. Bugs reported on Windows will not\nbe accepted, and the test suite will not run on Windows. Small patches that fix\nminor Windows compatibility issues (such as basic installation) **may** be accepted,\nhowever. For Windows-based systems, we would recommend running JupyterHub in a\ndocker container or Linux VM.\n\n[Additional Reference:](http://www.tornadoweb.org/en/stable/#installation) Tornado's documentation on Windows platform support\n\n## License\n\nWe use a shared copyright model that enables all contributors to maintain the\ncopyright on their contributions.\n\nAll code is licensed under the terms of the [revised BSD license](./COPYING.md).\n\n## Help and resources\n\nWe encourage you to ask questions and share ideas on the [Jupyter community forum](https://discourse.jupyter.org/).\nYou can also talk with us on our JupyterHub [Gitter](https://gitter.im/jupyterhub/jupyterhub) channel.\n\n- [Reporting Issues](https://github.com/jupyterhub/jupyterhub/issues)\n- [JupyterHub tutorial](https://github.com/jupyterhub/jupyterhub-tutorial)\n- [Documentation for JupyterHub](https://jupyterhub.readthedocs.io/en/latest/)\n- [Documentation for JupyterHub's REST API][rest api]\n- [Documentation for Project Jupyter](http://jupyter.readthedocs.io/en/latest/index.html)\n- [Project Jupyter website](https://jupyter.org)\n- [Project Jupyter community](https://jupyter.org/community)\n\nJupyterHub follows the Jupyter [Community Guides](https://jupyter.readthedocs.io/en/latest/community/content-community.html).\n\n---\n\n**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n",
- "source_links": [],
- "id": 61
- },
- {
- "page_link": "network-policies.md",
- "title": "network-policies",
- "text": "# Network Policy\n\nJupyterhub makes extensive use of kubernetes network policies. This allows you to finely scope a jupyter notebook's access to resources available on the network, which can be very important in a multi-tenant kubernetes cluster. That said, you might want to expose some services to your network either on-cluster or in an adjacent network, and here are some recipes to do that.\n\nIn all cases, the following yaml will be added to `jupyterhub/helm/jupyterhub/values.yaml` or you can modify directly in the console at `/apps/jupyterhub/config`\n\n## Get access to an adjacent namespace\n\n```yaml\njupyterhub:\n jupyterhub:\n singleuser:\n networkPolicy:\n egress:\n - to:\n - namespaceSelector:\n matchLabels:\n kubernetes.io/metadata.name:
\n## Reporting Bugs and Contributing Code\n\n* Want to report a bug or request a feature? Please open [an issue](https://github.com/jitsucom/jitsu/issues/new).\n* Want to help us build **Jitsu**? Fork the project, and check our an issues [that are good for first pull request](https://github.com/jitsucom/jitsu/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+first+issue%22)!\n* Questions? Join our [Slack](https://jitsu.com/slack)!\n* [hello@jitsu.com](mailto:hello@jitsu.com) - send us an email if you have any questions!\n",
- "source_links": [],
- "id": 60
- },
- {
- "page_link": "https://github.com/jupyterhub/jupyterhub",
- "title": "jupyterhub readme",
- "text": "**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n\n---\n\n# [JupyterHub](https://github.com/jupyterhub/jupyterhub)\n\n[](https://pypi.python.org/pypi/jupyterhub)\n[](https://anaconda.org/conda-forge/jupyterhub)\n[](https://jupyterhub.readthedocs.org/en/latest/)\n[](https://github.com/jupyterhub/jupyterhub/actions)\n[](https://hub.docker.com/r/jupyterhub/jupyterhub/tags)\n[](https://codecov.io/gh/jupyterhub/jupyterhub)\n[](https://github.com/jupyterhub/jupyterhub/issues)\n[](https://discourse.jupyter.org/c/jupyterhub)\n[](https://gitter.im/jupyterhub/jupyterhub)\n\nWith [JupyterHub](https://jupyterhub.readthedocs.io) you can create a\n**multi-user Hub** that spawns, manages, and proxies multiple instances of the\nsingle-user [Jupyter notebook](https://jupyter-notebook.readthedocs.io)\nserver.\n\n[Project Jupyter](https://jupyter.org) created JupyterHub to support many\nusers. The Hub can offer notebook servers to a class of students, a corporate\ndata science workgroup, a scientific research project, or a high-performance\ncomputing group.\n\n## Technical overview\n\nThree main actors make up JupyterHub:\n\n- multi-user **Hub** (tornado process)\n- configurable http **proxy** (node-http-proxy)\n- multiple **single-user Jupyter notebook servers** (Python/Jupyter/tornado)\n\nBasic principles for operation are:\n\n- Hub launches a proxy.\n- The Proxy forwards all requests to Hub by default.\n- Hub handles login and spawns single-user servers on demand.\n- Hub configures proxy to forward URL prefixes to the single-user notebook\n servers.\n\nJupyterHub also provides a\n[REST API][]\nfor administration of the Hub and its users.\n\n[rest api]: https://jupyterhub.readthedocs.io/en/latest/reference/rest-api.html\n\n## Installation\n\n### Check prerequisites\n\n- A Linux/Unix based system\n- [Python](https://www.python.org/downloads/) 3.6 or greater\n- [nodejs/npm](https://www.npmjs.com/)\n\n - If you are using **`conda`**, the nodejs and npm dependencies will be installed for\n you by conda.\n\n - If you are using **`pip`**, install a recent version (at least 12.0) of\n [nodejs/npm](https://docs.npmjs.com/getting-started/installing-node).\n\n- If using the default PAM Authenticator, a [pluggable authentication module (PAM)](https://en.wikipedia.org/wiki/Pluggable_authentication_module).\n- TLS certificate and key for HTTPS communication\n- Domain name\n\n### Install packages\n\n#### Using `conda`\n\nTo install JupyterHub along with its dependencies including nodejs/npm:\n\n```bash\nconda install -c conda-forge jupyterhub\n```\n\nIf you plan to run notebook servers locally, install JupyterLab or Jupyter notebook:\n\n```bash\nconda install jupyterlab\nconda install notebook\n```\n\n#### Using `pip`\n\nJupyterHub can be installed with `pip`, and the proxy with `npm`:\n\n```bash\nnpm install -g configurable-http-proxy\npython3 -m pip install jupyterhub\n```\n\nIf you plan to run notebook servers locally, you will need to install\n[JupyterLab or Jupyter notebook](https://jupyter.readthedocs.io/en/latest/install.html):\n\n python3 -m pip install --upgrade jupyterlab\n python3 -m pip install --upgrade notebook\n\n### Run the Hub server\n\nTo start the Hub server, run the command:\n\n jupyterhub\n\nVisit `http://localhost:8000` in your browser, and sign in with your system username and password.\n\n_Note_: To allow multiple users to sign in to the server, you will need to\nrun the `jupyterhub` command as a _privileged user_, such as root.\nThe [wiki](https://github.com/jupyterhub/jupyterhub/wiki/Using-sudo-to-run-JupyterHub-without-root-privileges)\ndescribes how to run the server as a _less privileged user_, which requires\nmore configuration of the system.\n\n## Configuration\n\nThe [Getting Started](https://jupyterhub.readthedocs.io/en/latest/tutorial/index.html#getting-started) section of the\ndocumentation explains the common steps in setting up JupyterHub.\n\nThe [**JupyterHub tutorial**](https://github.com/jupyterhub/jupyterhub-tutorial)\nprovides an in-depth video and sample configurations of JupyterHub.\n\n### Create a configuration file\n\nTo generate a default config file with settings and descriptions:\n\n jupyterhub --generate-config\n\n### Start the Hub\n\nTo start the Hub on a specific url and port `10.0.1.2:443` with **https**:\n\n jupyterhub --ip 10.0.1.2 --port 443 --ssl-key my_ssl.key --ssl-cert my_ssl.cert\n\n### Authenticators\n\n| Authenticator | Description |\n| ---------------------------------------------------------------------------- | ------------------------------------------------- |\n| PAMAuthenticator | Default, built-in authenticator |\n| [OAuthenticator](https://github.com/jupyterhub/oauthenticator) | OAuth + JupyterHub Authenticator = OAuthenticator |\n| [ldapauthenticator](https://github.com/jupyterhub/ldapauthenticator) | Simple LDAP Authenticator Plugin for JupyterHub |\n| [kerberosauthenticator](https://github.com/jupyterhub/kerberosauthenticator) | Kerberos Authenticator Plugin for JupyterHub |\n\n### Spawners\n\n| Spawner | Description |\n| -------------------------------------------------------------- | -------------------------------------------------------------------------- |\n| LocalProcessSpawner | Default, built-in spawner starts single-user servers as local processes |\n| [dockerspawner](https://github.com/jupyterhub/dockerspawner) | Spawn single-user servers in Docker containers |\n| [kubespawner](https://github.com/jupyterhub/kubespawner) | Kubernetes spawner for JupyterHub |\n| [sudospawner](https://github.com/jupyterhub/sudospawner) | Spawn single-user servers without being root |\n| [systemdspawner](https://github.com/jupyterhub/systemdspawner) | Spawn single-user notebook servers using systemd |\n| [batchspawner](https://github.com/jupyterhub/batchspawner) | Designed for clusters using batch scheduling software |\n| [yarnspawner](https://github.com/jupyterhub/yarnspawner) | Spawn single-user notebook servers distributed on a Hadoop cluster |\n| [wrapspawner](https://github.com/jupyterhub/wrapspawner) | WrapSpawner and ProfilesSpawner enabling runtime configuration of spawners |\n\n## Docker\n\nA starter [**docker image for JupyterHub**](https://hub.docker.com/r/jupyterhub/jupyterhub/)\ngives a baseline deployment of JupyterHub using Docker.\n\n**Important:** This `jupyterhub/jupyterhub` image contains only the Hub itself,\nwith no configuration. In general, one needs to make a derivative image, with\nat least a `jupyterhub_config.py` setting up an Authenticator and/or a Spawner.\nTo run the single-user servers, which may be on the same system as the Hub or\nnot, Jupyter Notebook version 4 or greater must be installed.\n\nThe JupyterHub docker image can be started with the following command:\n\n docker run -p 8000:8000 -d --name jupyterhub jupyterhub/jupyterhub jupyterhub\n\nThis command will create a container named `jupyterhub` that you can\n**stop and resume** with `docker stop/start`.\n\nThe Hub service will be listening on all interfaces at port 8000, which makes\nthis a good choice for **testing JupyterHub on your desktop or laptop**.\n\nIf you want to run docker on a computer that has a public IP then you should\n(as in MUST) **secure it with ssl** by adding ssl options to your docker\nconfiguration or by using an ssl enabled proxy.\n\n[Mounting volumes](https://docs.docker.com/engine/admin/volumes/volumes/) will\nallow you to **store data outside the docker image (host system) so it will be persistent**, even when you start\na new image.\n\nThe command `docker exec -it jupyterhub bash` will spawn a root shell in your docker\ncontainer. You can **use the root shell to create system users in the container**.\nThese accounts will be used for authentication in JupyterHub's default configuration.\n\n## Contributing\n\nIf you would like to contribute to the project, please read our\n[contributor documentation](https://jupyter.readthedocs.io/en/latest/contributing/content-contributor.html)\nand the [`CONTRIBUTING.md`](CONTRIBUTING.md). The `CONTRIBUTING.md` file\nexplains how to set up a development installation, how to run the test suite,\nand how to contribute to documentation.\n\nFor a high-level view of the vision and next directions of the project, see the\n[JupyterHub community roadmap](docs/source/contributing/roadmap.md).\n\n### A note about platform support\n\nJupyterHub is supported on Linux/Unix based systems.\n\nJupyterHub officially **does not** support Windows. You may be able to use\nJupyterHub on Windows if you use a Spawner and Authenticator that work on\nWindows, but the JupyterHub defaults will not. Bugs reported on Windows will not\nbe accepted, and the test suite will not run on Windows. Small patches that fix\nminor Windows compatibility issues (such as basic installation) **may** be accepted,\nhowever. For Windows-based systems, we would recommend running JupyterHub in a\ndocker container or Linux VM.\n\n[Additional Reference:](http://www.tornadoweb.org/en/stable/#installation) Tornado's documentation on Windows platform support\n\n## License\n\nWe use a shared copyright model that enables all contributors to maintain the\ncopyright on their contributions.\n\nAll code is licensed under the terms of the [revised BSD license](./COPYING.md).\n\n## Help and resources\n\nWe encourage you to ask questions and share ideas on the [Jupyter community forum](https://discourse.jupyter.org/).\nYou can also talk with us on our JupyterHub [Gitter](https://gitter.im/jupyterhub/jupyterhub) channel.\n\n- [Reporting Issues](https://github.com/jupyterhub/jupyterhub/issues)\n- [JupyterHub tutorial](https://github.com/jupyterhub/jupyterhub-tutorial)\n- [Documentation for JupyterHub](https://jupyterhub.readthedocs.io/en/latest/)\n- [Documentation for JupyterHub's REST API][rest api]\n- [Documentation for Project Jupyter](http://jupyter.readthedocs.io/en/latest/index.html)\n- [Project Jupyter website](https://jupyter.org)\n- [Project Jupyter community](https://jupyter.org/community)\n\nJupyterHub follows the Jupyter [Community Guides](https://jupyter.readthedocs.io/en/latest/community/content-community.html).\n\n---\n\n**[Technical Overview](#technical-overview)** |\n**[Installation](#installation)** |\n**[Configuration](#configuration)** |\n**[Docker](#docker)** |\n**[Contributing](#contributing)** |\n**[License](#license)** |\n**[Help and Resources](#help-and-resources)**\n",
- "source_links": [],
- "id": 61
- },
- {
- "page_link": "network-policies.md",
- "title": "network-policies",
- "text": "# Network Policy\n\nJupyterhub makes extensive use of kubernetes network policies. This allows you to finely scope a jupyter notebook's access to resources available on the network, which can be very important in a multi-tenant kubernetes cluster. That said, you might want to expose some services to your network either on-cluster or in an adjacent network, and here are some recipes to do that.\n\nIn all cases, the following yaml will be added to `jupyterhub/helm/jupyterhub/values.yaml` or you can modify directly in the console at `/apps/jupyterhub/config`\n\n## Get access to an adjacent namespace\n\n```yaml\njupyterhub:\n jupyterhub:\n singleuser:\n networkPolicy:\n egress:\n - to:\n - namespaceSelector:\n matchLabels:\n kubernetes.io/metadata.name: 
 \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n\nas well as all of our backers\n\n
\n\nas well as all of our backers\n\n \n\nand past & current supporters (in alphabetical order) on\n[Patreon](https://www.patreon.com/_ory): Alexander Alimovs, Billy, Chancy\nKennedy, Drozzy, Edwin Trejos, Howard Edidin, Ken Adler Oz Haven, Stefan Hans,\nTheCrealm.\n\n\\* Uses one of Ory's major projects in production.\n\n\n\n## Getting Started\n\nTo get started with some easy examples, head over to the\n[Get Started Documentation](https://www.ory.sh/docs/guides/protect-page-login/).\n\n### Installation\n\nHead over to the\n[Ory Developer Documentation](https://www.ory.sh/kratos/docs/install) to learn\nhow to install Ory Kratos on Linux, macOS, Windows, and Docker and how to build\nOry Kratos from source.\n\n## Ecosystem\n\n\n\nWe build Ory on several guiding principles when it comes to our architecture\ndesign:\n\n- Minimal dependencies\n- Runs everywhere\n- Scales without effort\n- Minimize room for human and network errors\n\nOry's architecture is designed to run best on a Container Orchestration system\nsuch as Kubernetes, CloudFoundry, OpenShift, and similar projects. Binaries are\nsmall (5-15MB) and available for all popular processor types (ARM, AMD64, i386)\nand operating systems (FreeBSD, Linux, macOS, Windows) without system\ndependencies (Java, Node, Ruby, libxml, ...).\n\n### Ory Kratos: Identity and User Infrastructure and Management\n\n[Ory Kratos](https://github.com/ory/kratos) is an API-first Identity and User\nManagement system that is built according to\n[cloud architecture best practices](https://www.ory.sh/docs/next/ecosystem/software-architecture-philosophy).\nIt implements core use cases that almost every software application needs to\ndeal with: Self-service Login and Registration, Multi-Factor Authentication\n(MFA/2FA), Account Recovery and Verification, Profile, and Account Management.\n\n### Ory Hydra: OAuth2 & OpenID Connect Server\n\n[Ory Hydra](https://github.com/ory/hydra) is an OpenID Certified\u2122 OAuth2 and\nOpenID Connect Provider which easily connects to any existing identity system by\nwriting a tiny \"bridge\" application. Gives absolute control over user interface\nand user experience flows.\n\n### Ory Oathkeeper: Identity & Access Proxy\n\n[Ory Oathkeeper](https://github.com/ory/oathkeeper) is a BeyondCorp/Zero Trust\nIdentity & Access Proxy (IAP) with configurable authentication, authorization,\nand request mutation rules for your web services: Authenticate JWT, Access\nTokens, API Keys, mTLS; Check if the contained subject is allowed to perform the\nrequest; Encode resulting content into custom headers (`X-User-ID`), JSON Web\nTokens and more!\n\n### Ory Keto: Access Control Policies as a Server\n\n[Ory Keto](https://github.com/ory/keto) is a policy decision point. It uses a\nset of access control policies, similar to AWS IAM Policies, in order to\ndetermine whether a subject (user, application, service, car, ...) is authorized\nto perform a certain action on a resource.\n\n\n\n## Security\n\nRunning identity infrastructure requires\n[attention and knowledge of threat models](https://www.ory.sh/kratos/docs/concepts/security).\n\n### Disclosing vulnerabilities\n\nIf you think you found a security vulnerability, please refrain from posting it\npublicly on the forums, the chat, or GitHub and send us an email to\n[hi@ory.am](mailto:hi@ory.sh) instead.\n\n## Telemetry\n\nOry's services collect summarized, anonymized data that can optionally be turned\noff. Click [here](https://www.ory.sh/docs/ecosystem/sqa) to learn more.\n\n## Documentation\n\n### Guide\n\nThe Guide is available [here](https://www.ory.sh/kratos/docs).\n\n### HTTP API documentation\n\nThe HTTP API is documented [here](https://www.ory.sh/kratos/docs/sdk/api).\n\n### Upgrading and Changelog\n\nNew releases might introduce breaking changes. To help you identify and\nincorporate those changes, we document these changes in the\n[CHANGELOG.md](./CHANGELOG.md). For upgrading, please visit the\n[upgrade guide](https://www.ory.sh/kratos/docs/guides/upgrade).\n\n### Command line documentation\n\nRun
\n\nand past & current supporters (in alphabetical order) on\n[Patreon](https://www.patreon.com/_ory): Alexander Alimovs, Billy, Chancy\nKennedy, Drozzy, Edwin Trejos, Howard Edidin, Ken Adler Oz Haven, Stefan Hans,\nTheCrealm.\n\n\\* Uses one of Ory's major projects in production.\n\n\n\n## Getting Started\n\nTo get started with some easy examples, head over to the\n[Get Started Documentation](https://www.ory.sh/docs/guides/protect-page-login/).\n\n### Installation\n\nHead over to the\n[Ory Developer Documentation](https://www.ory.sh/kratos/docs/install) to learn\nhow to install Ory Kratos on Linux, macOS, Windows, and Docker and how to build\nOry Kratos from source.\n\n## Ecosystem\n\n\n\nWe build Ory on several guiding principles when it comes to our architecture\ndesign:\n\n- Minimal dependencies\n- Runs everywhere\n- Scales without effort\n- Minimize room for human and network errors\n\nOry's architecture is designed to run best on a Container Orchestration system\nsuch as Kubernetes, CloudFoundry, OpenShift, and similar projects. Binaries are\nsmall (5-15MB) and available for all popular processor types (ARM, AMD64, i386)\nand operating systems (FreeBSD, Linux, macOS, Windows) without system\ndependencies (Java, Node, Ruby, libxml, ...).\n\n### Ory Kratos: Identity and User Infrastructure and Management\n\n[Ory Kratos](https://github.com/ory/kratos) is an API-first Identity and User\nManagement system that is built according to\n[cloud architecture best practices](https://www.ory.sh/docs/next/ecosystem/software-architecture-philosophy).\nIt implements core use cases that almost every software application needs to\ndeal with: Self-service Login and Registration, Multi-Factor Authentication\n(MFA/2FA), Account Recovery and Verification, Profile, and Account Management.\n\n### Ory Hydra: OAuth2 & OpenID Connect Server\n\n[Ory Hydra](https://github.com/ory/hydra) is an OpenID Certified\u2122 OAuth2 and\nOpenID Connect Provider which easily connects to any existing identity system by\nwriting a tiny \"bridge\" application. Gives absolute control over user interface\nand user experience flows.\n\n### Ory Oathkeeper: Identity & Access Proxy\n\n[Ory Oathkeeper](https://github.com/ory/oathkeeper) is a BeyondCorp/Zero Trust\nIdentity & Access Proxy (IAP) with configurable authentication, authorization,\nand request mutation rules for your web services: Authenticate JWT, Access\nTokens, API Keys, mTLS; Check if the contained subject is allowed to perform the\nrequest; Encode resulting content into custom headers (`X-User-ID`), JSON Web\nTokens and more!\n\n### Ory Keto: Access Control Policies as a Server\n\n[Ory Keto](https://github.com/ory/keto) is a policy decision point. It uses a\nset of access control policies, similar to AWS IAM Policies, in order to\ndetermine whether a subject (user, application, service, car, ...) is authorized\nto perform a certain action on a resource.\n\n\n\n## Security\n\nRunning identity infrastructure requires\n[attention and knowledge of threat models](https://www.ory.sh/kratos/docs/concepts/security).\n\n### Disclosing vulnerabilities\n\nIf you think you found a security vulnerability, please refrain from posting it\npublicly on the forums, the chat, or GitHub and send us an email to\n[hi@ory.am](mailto:hi@ory.sh) instead.\n\n## Telemetry\n\nOry's services collect summarized, anonymized data that can optionally be turned\noff. Click [here](https://www.ory.sh/docs/ecosystem/sqa) to learn more.\n\n## Documentation\n\n### Guide\n\nThe Guide is available [here](https://www.ory.sh/kratos/docs).\n\n### HTTP API documentation\n\nThe HTTP API is documented [here](https://www.ory.sh/kratos/docs/sdk/api).\n\n### Upgrading and Changelog\n\nNew releases might introduce breaking changes. To help you identify and\nincorporate those changes, we document these changes in the\n[CHANGELOG.md](./CHANGELOG.md). For upgrading, please visit the\n[upgrade guide](https://www.ory.sh/kratos/docs/guides/upgrade).\n\n### Command line documentation\n\nRun  \n
\n \n\n\n\n# TL;DR\n## Install:\n```sh\ncurl -s https://raw.githubusercontent.com/kubescape/kubescape/master/install.sh | /bin/bash\n```\n\n*OR:*\n\n[Install on windows](#install-on-windows)\n\n[Install on macOS](#install-on-macos)\n\n[Install on NixOS or Linux/macOS via nix](#install-on-nixos-or-with-nix-community)\n\n## Run:\n```sh\nkubescape scan --submit --enable-host-scan --verbose\n```\n\n
\n\n\n\n# TL;DR\n## Install:\n```sh\ncurl -s https://raw.githubusercontent.com/kubescape/kubescape/master/install.sh | /bin/bash\n```\n\n*OR:*\n\n[Install on windows](#install-on-windows)\n\n[Install on macOS](#install-on-macos)\n\n[Install on NixOS or Linux/macOS via nix](#install-on-nixos-or-with-nix-community)\n\n## Run:\n```sh\nkubescape scan --submit --enable-host-scan --verbose\n```\n\n \n\n\n\n> Kubescape is an open source project. We welcome your feedback and ideas for improvement. We\u2019re also aiming to collaborate with the Kubernetes community to help make the tests more robust and complete as Kubernetes develops.\n\n\n\n## Architecture in short\n### CLI\n
\n\n\n\n> Kubescape is an open source project. We welcome your feedback and ideas for improvement. We\u2019re also aiming to collaborate with the Kubernetes community to help make the tests more robust and complete as Kubernetes develops.\n\n\n\n## Architecture in short\n### CLI\n \n\n### Operator\n
\n\n### Operator\n \n\n### Please [star \u2b50](https://github.com/kubescape/kubescape/stargazers) the repo if you want us to continue developing and improving Kubescape \ud83d\ude00\n\n\n\n# Being a part of the team\n\n## Community\nWe invite you to our community! We are excited about this project and want to return the love we get.\n\nWe hold community meetings in [Zoom](https://us02web.zoom.us/j/84020231442) on the first Tuesday of every month at 14:00 GMT! :sunglasses:\n\n## Contributions \n[Want to contribute?](https://github.com/kubescape/kubescape/blob/master/CONTRIBUTING.md) Want to discuss something? Have an issue? Please make sure that you follow our [Code Of Conduct](https://github.com/kubescape/kubescape/blob/master/CODE_OF_CONDUCT.md) . \n\n* Feel free to pick a task from the [issues](https://github.com/kubescape/kubescape/issues?q=is%3Aissue+is%3Aopen+label%3A%22open+for+contribution%22), [roadmap](docs/roadmap.md) or suggest a feature of your own. [Contact us](MAINTAINERS.md) directly for more information :) \n* [Open an issue](https://github.com/kubescape/kubescape/issues/new/choose) , we are trying to respond within 48 hours\n* [Join us](https://discord.com/invite/WKZRaCtBxN) in the discussion on our discord server!\n\n[
\n\n### Please [star \u2b50](https://github.com/kubescape/kubescape/stargazers) the repo if you want us to continue developing and improving Kubescape \ud83d\ude00\n\n\n\n# Being a part of the team\n\n## Community\nWe invite you to our community! We are excited about this project and want to return the love we get.\n\nWe hold community meetings in [Zoom](https://us02web.zoom.us/j/84020231442) on the first Tuesday of every month at 14:00 GMT! :sunglasses:\n\n## Contributions \n[Want to contribute?](https://github.com/kubescape/kubescape/blob/master/CONTRIBUTING.md) Want to discuss something? Have an issue? Please make sure that you follow our [Code Of Conduct](https://github.com/kubescape/kubescape/blob/master/CODE_OF_CONDUCT.md) . \n\n* Feel free to pick a task from the [issues](https://github.com/kubescape/kubescape/issues?q=is%3Aissue+is%3Aopen+label%3A%22open+for+contribution%22), [roadmap](docs/roadmap.md) or suggest a feature of your own. [Contact us](MAINTAINERS.md) directly for more information :) \n* [Open an issue](https://github.com/kubescape/kubescape/issues/new/choose) , we are trying to respond within 48 hours\n* [Join us](https://discord.com/invite/WKZRaCtBxN) in the discussion on our discord server!\n\n[ ](https://discord.com/invite/WKZRaCtBxN)\n\n\n\n# Options and examples\n\n[Kubescape docs](https://hub.armosec.io/docs?utm_source=github&utm_medium=repository)\n\n## Playground\n* [Kubescape playground](https://killercoda.com/saiyampathak/scenario/kubescape)\n\n## Tutorials\n\n* [Overview](https://youtu.be/wdBkt_0Qhbg)\n* [How To Secure Kubernetes Clusters With Kubescape And Armo](https://youtu.be/ZATGiDIDBQk)\n* [Scan Kubernetes YAML files](https://youtu.be/Ox6DaR7_4ZI)\n* [Scan Kubescape on an air-gapped environment (offline support)](https://youtu.be/IGXL9s37smM)\n* [Managing exceptions in the Kubescape SaaS version](https://youtu.be/OzpvxGmCR80)\n* [Configure and run customized frameworks](https://youtu.be/12Sanq_rEhs)\n* Customize control configurations: \n - [Kubescape CLI](https://youtu.be/955psg6TVu4) \n - [Kubescape SaaS](https://youtu.be/lIMVSVhH33o)\n\n## Install on Windows\n\n
](https://discord.com/invite/WKZRaCtBxN)\n\n\n\n# Options and examples\n\n[Kubescape docs](https://hub.armosec.io/docs?utm_source=github&utm_medium=repository)\n\n## Playground\n* [Kubescape playground](https://killercoda.com/saiyampathak/scenario/kubescape)\n\n## Tutorials\n\n* [Overview](https://youtu.be/wdBkt_0Qhbg)\n* [How To Secure Kubernetes Clusters With Kubescape And Armo](https://youtu.be/ZATGiDIDBQk)\n* [Scan Kubernetes YAML files](https://youtu.be/Ox6DaR7_4ZI)\n* [Scan Kubescape on an air-gapped environment (offline support)](https://youtu.be/IGXL9s37smM)\n* [Managing exceptions in the Kubescape SaaS version](https://youtu.be/OzpvxGmCR80)\n* [Configure and run customized frameworks](https://youtu.be/12Sanq_rEhs)\n* Customize control configurations: \n - [Kubescape CLI](https://youtu.be/955psg6TVu4) \n - [Kubescape SaaS](https://youtu.be/lIMVSVhH33o)\n\n## Install on Windows\n\n.png\") \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n \n
\n \n  \n \n
\n \n  \n \n
\n \n  \n \n
\n \n  \n \n
\n \n  |\n\n
|\n\n |\n\n
|\n\n |\n\n
|\n\n \n\n
\n\n | [Twitter](https://twitter.com/mage_ai) |\n|
| [Twitter](https://twitter.com/mage_ai) |\n|  | [LinkedIn](https://www.linkedin.com/company/magetech/mycompany) |\n|
| [LinkedIn](https://www.linkedin.com/company/magetech/mycompany) |\n|  | [GitHub](https://github.com/mage-ai/mage-ai) |\n|
| [GitHub](https://github.com/mage-ai/mage-ai) |\n|  | [Slack](https://www.mage.ai/chat) |\n\n
| [Slack](https://www.mage.ai/chat) |\n\n ](https://www.mage.ai/)\n\n
](https://www.mage.ai/)\n\n \n
\n  ](scripts/markdown/readme/languages/chinese.md)\n[
](scripts/markdown/readme/languages/chinese.md)\n[ ](scripts/markdown/readme/languages/french.md)\n[
](scripts/markdown/readme/languages/french.md)\n[ ](scripts/markdown/readme/languages/german.md)\n[
](scripts/markdown/readme/languages/german.md)\n[ ](scripts/markdown/readme/languages/spanish.md)\n[
](scripts/markdown/readme/languages/spanish.md)\n[ ](scripts/markdown/readme/languages/portuguese.md)\n[
](scripts/markdown/readme/languages/portuguese.md)\n[ ](scripts/markdown/readme/languages/italian.md)\n[
](scripts/markdown/readme/languages/italian.md)\n[ ](scripts/markdown/readme/languages/japanese.md)\n[
](scripts/markdown/readme/languages/japanese.md)\n[ ](scripts/markdown/readme/languages/korean.md)\n[
](scripts/markdown/readme/languages/korean.md)\n[ ](scripts/markdown/readme/languages/russian.md)\n\n
](scripts/markdown/readme/languages/russian.md)\n\n \n\n# Join Our Team\n
\n\n# Join Our Team\n
 \n\n\n\n[](https://github.com/nocodb/nocodb/stargazers)\n\n\n# Quick try\n\n## 1-Click Deploy to Heroku\n\nBefore doing so, make sure you have a Heroku account. By default, an add-on Heroku Postgres will be used as meta database. You can see the connection string defined in `DATABASE_URL` by navigating to Heroku App Settings and selecting Config Vars.\n\n\n
\n\n\n\n[](https://github.com/nocodb/nocodb/stargazers)\n\n\n# Quick try\n\n## 1-Click Deploy to Heroku\n\nBefore doing so, make sure you have a Heroku account. By default, an add-on Heroku Postgres will be used as meta database. You can see the connection string defined in `DATABASE_URL` by navigating to Heroku App Settings and selecting Config Vars.\n\n\n  \n\n## Node Application\n\nWe provide a simple NodeJS Application for getting started.\n\n```bash\ngit clone https://github.com/nocodb/nocodb-seed\ncd nocodb-seed\nnpm install\nnpm start\n```\n\n## Docker \n\n```bash\n# for SQLite\ndocker run -d --name nocodb \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\nnocodb/nocodb:latest\n\n# for MySQL\ndocker run -d --name nocodb-mysql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mysql2://host.docker.internal:3306?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for PostgreSQL\ndocker run -d --name nocodb-postgres \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"pg://host.docker.internal:5432?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for MSSQL\ndocker run -d --name nocodb-mssql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mssql://host.docker.internal:1433?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n```\n\n> To persist data in docker you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker](https://github.com/nocodb/nocodb/issues/1340#issuecomment-1049481043).\n\n## Binaries\n##### MacOS (x64)\n```bash\ncurl http://get.nocodb.com/macos-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### MacOS (arm64)\n```bash\ncurl http://get.nocodb.com/macos-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Linux (x64)\n```bash\ncurl http://get.nocodb.com/linux-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n##### Linux (arm64)\n```bash\ncurl http://get.nocodb.com/linux-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Windows (x64)\n```bash\niwr http://get.nocodb.com/win-x64.exe\n.\\Noco-win-x64.exe\n```\n\n##### Windows (arm64)\n```bash\niwr http://get.nocodb.com/win-arm64.exe\n.\\Noco-win-arm64.exe\n```\n\n## Docker Compose\n\nWe provide different docker-compose.yml files under [this directory](https://github.com/nocodb/nocodb/tree/master/docker-compose). Here are some examples.\n\n```bash\ngit clone https://github.com/nocodb/nocodb\n# for MySQL\ncd nocodb/docker-compose/mysql\n# for PostgreSQL\ncd nocodb/docker-compose/pg\n# for MSSQL\ncd nocodb/docker-compose/mssql\ndocker-compose up -d\n```\n\n> To persist data in docker, you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker Compose](https://github.com/nocodb/nocodb/issues/1313#issuecomment-1046625974).\n\n# GUI\n\nAccess Dashboard using : [http://localhost:8080/dashboard](http://localhost:8080/dashboard)\n\n# Screenshots\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# Table of Contents\n\n- [Quick try](#quick-try)\n * [1-Click Deploy to Heroku](#1-click-deploy-to-heroku)\n * [NPX](#npx)\n * [Node Application](#node-application)\n * [Docker](#docker)\n * [Docker Compose](#docker-compose)\n- [GUI](#gui)\n- [Join Our Community](#join-our-community)\n- [Screenshots](#screenshots)\n- [Table of Contents](#table-of-contents)\n- [Features](#features)\n + [Rich Spreadsheet Interface](#rich-spreadsheet-interface)\n + [App Store for Workflow Automations](#app-store-for-workflow-automations)\n + [Programmatic Access](#programmatic-access)\n + [Sync Schema](#sync-schema)\n + [Audit](#audit)\n- [Production Setup](#production-setup)\n * [Environment variables](#environment-variables)\n- [Development Setup](#development-setup)\n- [Contributing](#contributing)\n- [Why are we building this?](#why-are-we-building-this)\n- [Our Mission](#our-mission)\n- [License](#license)\n- [Contributors](#contributors)\n\n# Features\n\n### Rich Spreadsheet Interface\n\n- \u26a1 Basic Operations: Create, Read, Update and Delete on Tables, Columns, and Rows\n- \u26a1 Fields Operations: Sort, Filter, Hide / Unhide Columns\n- \u26a1 Multiple Views Types: Grid (By default), Gallery, Form View and Kanban View\n- \u26a1 View Permissions Types: Collaborative Views, & Locked Views \n- \u26a1 Share Bases / Views: either Public or Private (with Password Protected)\n- \u26a1 Variant Cell Types: ID, LinkToAnotherRecord, Lookup, Rollup, SingleLineText, Attachement, Currency, Formula and etc\n- \u26a1 Access Control with Roles : Fine-grained Access Control at different levels\n- \u26a1 and more ...\n\n### App Store for Workflow Automations\n\nWe provide different integrations in three main categories. See App Store for details.\n\n- \u26a1 Chat : Slack, Discord, Mattermost, and etc\n- \u26a1 Email : AWS SES, SMTP, MailerSend, and etc\n- \u26a1 Storage : AWS S3, Google Cloud Storage, Minio, and etc\n\n### Programmatic Access\n\nWe provide the following ways to let users to invoke actions in a programmatic way. You can use a token (either JWT or Social Auth) to sign your requests for authorization to NocoDB. \n\n- \u26a1 REST APIs\n- \u26a1 NocoDB SDK\n\n### Sync Schema\n\nWe allow you to sync schema changes if you have made changes outside NocoDB GUI. However, it has to be noted then you will have to bring your own schema migrations for moving from environment to others. See Sync Schema for details.\n\n### Audit \n\nWe are keeping all the user operation logs under one place. See Audit for details.\n\n# Production Setup \n\nBy default, SQLite is used for storing meta data. However, you can specify your own database. The connection params for this database can be specified in `NC_DB` environment variable. Moreover, we also provide the below environment variables for configuration.\n\n## Environment variables \n\nPlease refer to [Environment variables](https://docs.nocodb.com/getting-started/installation#environment-variables)\n\n# Development Setup \n\nPlease refer to [Development Setup](https://docs.nocodb.com/engineering/development-setup)\n\n# Contributing\n\nPlease refer to [Contribution Guide](https://github.com/nocodb/nocodb/blob/master/.github/CONTRIBUTING.md).\n\n# Why are we building this?\nMost internet businesses equip themselves with either spreadsheet or a database to solve their business needs. Spreadsheets are used by a Billion+ humans collaboratively every single day. However, we are way off working at similar speeds on databases which are way more powerful tools when it comes to computing. Attempts to solve this with SaaS offerings has meant horrible access controls, vendor lockin, data lockin, abrupt price changes & most importantly a glass ceiling on what's possible in future.\n\n# Our Mission\nOur mission is to provide the most powerful no-code interface for databases which is open source to every single internet business in the world. This would not only democratise access to a powerful computing tool but also bring forth a billion+ people who will have radical tinkering-and-building abilities on internet. \n\n# License \n
\n\n## Node Application\n\nWe provide a simple NodeJS Application for getting started.\n\n```bash\ngit clone https://github.com/nocodb/nocodb-seed\ncd nocodb-seed\nnpm install\nnpm start\n```\n\n## Docker \n\n```bash\n# for SQLite\ndocker run -d --name nocodb \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\nnocodb/nocodb:latest\n\n# for MySQL\ndocker run -d --name nocodb-mysql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mysql2://host.docker.internal:3306?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for PostgreSQL\ndocker run -d --name nocodb-postgres \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"pg://host.docker.internal:5432?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n\n# for MSSQL\ndocker run -d --name nocodb-mssql \\\n-v \"$(pwd)\"/nocodb:/usr/app/data/ \\\n-p 8080:8080 \\\n-e NC_DB=\"mssql://host.docker.internal:1433?u=root&p=password&d=d1\" \\\n-e NC_AUTH_JWT_SECRET=\"569a1821-0a93-45e8-87ab-eb857f20a010\" \\\nnocodb/nocodb:latest\n```\n\n> To persist data in docker you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker](https://github.com/nocodb/nocodb/issues/1340#issuecomment-1049481043).\n\n## Binaries\n##### MacOS (x64)\n```bash\ncurl http://get.nocodb.com/macos-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### MacOS (arm64)\n```bash\ncurl http://get.nocodb.com/macos-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Linux (x64)\n```bash\ncurl http://get.nocodb.com/linux-x64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n##### Linux (arm64)\n```bash\ncurl http://get.nocodb.com/linux-arm64 -o nocodb -L && chmod +x nocodb && ./nocodb\n```\n\n##### Windows (x64)\n```bash\niwr http://get.nocodb.com/win-x64.exe\n.\\Noco-win-x64.exe\n```\n\n##### Windows (arm64)\n```bash\niwr http://get.nocodb.com/win-arm64.exe\n.\\Noco-win-arm64.exe\n```\n\n## Docker Compose\n\nWe provide different docker-compose.yml files under [this directory](https://github.com/nocodb/nocodb/tree/master/docker-compose). Here are some examples.\n\n```bash\ngit clone https://github.com/nocodb/nocodb\n# for MySQL\ncd nocodb/docker-compose/mysql\n# for PostgreSQL\ncd nocodb/docker-compose/pg\n# for MSSQL\ncd nocodb/docker-compose/mssql\ndocker-compose up -d\n```\n\n> To persist data in docker, you can mount volume at `/usr/app/data/` since 0.10.6. Otherwise your data will be lost after recreating the container.\n\n> If you plan to input some special characters, you may need to change the character set and collation yourself when creating the database. Please check out the examples for [MySQL Docker Compose](https://github.com/nocodb/nocodb/issues/1313#issuecomment-1046625974).\n\n# GUI\n\nAccess Dashboard using : [http://localhost:8080/dashboard](http://localhost:8080/dashboard)\n\n# Screenshots\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# Table of Contents\n\n- [Quick try](#quick-try)\n * [1-Click Deploy to Heroku](#1-click-deploy-to-heroku)\n * [NPX](#npx)\n * [Node Application](#node-application)\n * [Docker](#docker)\n * [Docker Compose](#docker-compose)\n- [GUI](#gui)\n- [Join Our Community](#join-our-community)\n- [Screenshots](#screenshots)\n- [Table of Contents](#table-of-contents)\n- [Features](#features)\n + [Rich Spreadsheet Interface](#rich-spreadsheet-interface)\n + [App Store for Workflow Automations](#app-store-for-workflow-automations)\n + [Programmatic Access](#programmatic-access)\n + [Sync Schema](#sync-schema)\n + [Audit](#audit)\n- [Production Setup](#production-setup)\n * [Environment variables](#environment-variables)\n- [Development Setup](#development-setup)\n- [Contributing](#contributing)\n- [Why are we building this?](#why-are-we-building-this)\n- [Our Mission](#our-mission)\n- [License](#license)\n- [Contributors](#contributors)\n\n# Features\n\n### Rich Spreadsheet Interface\n\n- \u26a1 Basic Operations: Create, Read, Update and Delete on Tables, Columns, and Rows\n- \u26a1 Fields Operations: Sort, Filter, Hide / Unhide Columns\n- \u26a1 Multiple Views Types: Grid (By default), Gallery, Form View and Kanban View\n- \u26a1 View Permissions Types: Collaborative Views, & Locked Views \n- \u26a1 Share Bases / Views: either Public or Private (with Password Protected)\n- \u26a1 Variant Cell Types: ID, LinkToAnotherRecord, Lookup, Rollup, SingleLineText, Attachement, Currency, Formula and etc\n- \u26a1 Access Control with Roles : Fine-grained Access Control at different levels\n- \u26a1 and more ...\n\n### App Store for Workflow Automations\n\nWe provide different integrations in three main categories. See App Store for details.\n\n- \u26a1 Chat : Slack, Discord, Mattermost, and etc\n- \u26a1 Email : AWS SES, SMTP, MailerSend, and etc\n- \u26a1 Storage : AWS S3, Google Cloud Storage, Minio, and etc\n\n### Programmatic Access\n\nWe provide the following ways to let users to invoke actions in a programmatic way. You can use a token (either JWT or Social Auth) to sign your requests for authorization to NocoDB. \n\n- \u26a1 REST APIs\n- \u26a1 NocoDB SDK\n\n### Sync Schema\n\nWe allow you to sync schema changes if you have made changes outside NocoDB GUI. However, it has to be noted then you will have to bring your own schema migrations for moving from environment to others. See Sync Schema for details.\n\n### Audit \n\nWe are keeping all the user operation logs under one place. See Audit for details.\n\n# Production Setup \n\nBy default, SQLite is used for storing meta data. However, you can specify your own database. The connection params for this database can be specified in `NC_DB` environment variable. Moreover, we also provide the below environment variables for configuration.\n\n## Environment variables \n\nPlease refer to [Environment variables](https://docs.nocodb.com/getting-started/installation#environment-variables)\n\n# Development Setup \n\nPlease refer to [Development Setup](https://docs.nocodb.com/engineering/development-setup)\n\n# Contributing\n\nPlease refer to [Contribution Guide](https://github.com/nocodb/nocodb/blob/master/.github/CONTRIBUTING.md).\n\n# Why are we building this?\nMost internet businesses equip themselves with either spreadsheet or a database to solve their business needs. Spreadsheets are used by a Billion+ humans collaboratively every single day. However, we are way off working at similar speeds on databases which are way more powerful tools when it comes to computing. Attempts to solve this with SaaS offerings has meant horrible access controls, vendor lockin, data lockin, abrupt price changes & most importantly a glass ceiling on what's possible in future.\n\n# Our Mission\nOur mission is to provide the most powerful no-code interface for databases which is open source to every single internet business in the world. This would not only democratise access to a powerful computing tool but also bring forth a billion+ people who will have radical tinkering-and-building abilities on internet. \n\n# License \n \n\n- Collect and analyze alerts from multiple monitoring systems\n- On-call rotations based on schedules\n- Automatic escalations\n- Phone calls, SMS, Slack, Telegram notifications\n\n## Getting Started\n\nWe prepared multiple environments: [production](https://grafana.com/docs/grafana-cloud/oncall/open-source/#production-environment), [developer](DEVELOPER.md) and hobby:\n\n1. Download docker-compose.yaml:\n\n```bash\ncurl -fsSL https://raw.githubusercontent.com/grafana/oncall/dev/docker-compose.yml -o docker-compose.yml\n```\n\n2. Set variables:\n\n```bash\necho \"DOMAIN=http://localhost:8080\nCOMPOSE_PROFILES=with_grafana # Remove this line if you want to use existing grafana\nSECRET_KEY=my_random_secret_must_be_more_than_32_characters_long\nRABBITMQ_PASSWORD=rabbitmq_secret_pw\nMYSQL_PASSWORD=mysql_secret_pw\" > .env\n```\n\n3. Launch services:\n\n```bash\ndocker-compose up -d\n```\n\n4. Issue one-time invite token:\n\n```bash\ndocker-compose run engine python manage.py issue_invite_for_the_frontend --override\n```\n\n**Note**: if you remove the plugin configuration and reconfigure it, you will need to generate a new one-time invite token for your new configuration.\n\n5. Go to [OnCall Plugin Configuration](http://localhost:3000/plugins/grafana-oncall-app), using log in credentials as defined above: `admin`/`admin` (or find OnCall plugin in configuration->plugins) and connect OnCall _plugin_ with OnCall _backend_:\n\n```\nInvite token: ^^^ from the previous step.\nOnCall backend URL: http://engine:8080\nGrafana Url: http://grafana:3000\n```\n\n6. Enjoy! Check our [OSS docs](https://grafana.com/docs/grafana-cloud/oncall/open-source/) if you want to set up Slack, Telegram, Twilio or SMS/calls through Grafana Cloud.\n\n## Update version\n\nTo update your Grafana OnCall hobby environment:\n\n```shell\n# Update Docker image\ndocker-compose pull engine\n\n# Re-deploy\ndocker-compose up -d\n```\n\nAfter updating the engine, you'll also need to click the \"Update\" button on the [plugin version page](http://localhost:3000/plugins/grafana-oncall-app?page=version-history).\nSee [Grafana docs](https://grafana.com/docs/grafana/latest/administration/plugin-management/#update-a-plugin) for more info on updating Grafana plugins.\n\n## Join community\n\n
\n\n- Collect and analyze alerts from multiple monitoring systems\n- On-call rotations based on schedules\n- Automatic escalations\n- Phone calls, SMS, Slack, Telegram notifications\n\n## Getting Started\n\nWe prepared multiple environments: [production](https://grafana.com/docs/grafana-cloud/oncall/open-source/#production-environment), [developer](DEVELOPER.md) and hobby:\n\n1. Download docker-compose.yaml:\n\n```bash\ncurl -fsSL https://raw.githubusercontent.com/grafana/oncall/dev/docker-compose.yml -o docker-compose.yml\n```\n\n2. Set variables:\n\n```bash\necho \"DOMAIN=http://localhost:8080\nCOMPOSE_PROFILES=with_grafana # Remove this line if you want to use existing grafana\nSECRET_KEY=my_random_secret_must_be_more_than_32_characters_long\nRABBITMQ_PASSWORD=rabbitmq_secret_pw\nMYSQL_PASSWORD=mysql_secret_pw\" > .env\n```\n\n3. Launch services:\n\n```bash\ndocker-compose up -d\n```\n\n4. Issue one-time invite token:\n\n```bash\ndocker-compose run engine python manage.py issue_invite_for_the_frontend --override\n```\n\n**Note**: if you remove the plugin configuration and reconfigure it, you will need to generate a new one-time invite token for your new configuration.\n\n5. Go to [OnCall Plugin Configuration](http://localhost:3000/plugins/grafana-oncall-app), using log in credentials as defined above: `admin`/`admin` (or find OnCall plugin in configuration->plugins) and connect OnCall _plugin_ with OnCall _backend_:\n\n```\nInvite token: ^^^ from the previous step.\nOnCall backend URL: http://engine:8080\nGrafana Url: http://grafana:3000\n```\n\n6. Enjoy! Check our [OSS docs](https://grafana.com/docs/grafana-cloud/oncall/open-source/) if you want to set up Slack, Telegram, Twilio or SMS/calls through Grafana Cloud.\n\n## Update version\n\nTo update your Grafana OnCall hobby environment:\n\n```shell\n# Update Docker image\ndocker-compose pull engine\n\n# Re-deploy\ndocker-compose up -d\n```\n\nAfter updating the engine, you'll also need to click the \"Update\" button on the [plugin version page](http://localhost:3000/plugins/grafana-oncall-app?page=version-history).\nSee [Grafana docs](https://grafana.com/docs/grafana/latest/administration/plugin-management/#update-a-plugin) for more info on updating Grafana plugins.\n\n## Join community\n\n \n
\n \n
\n \n\n## Stargazers over time\n\n[](https://starchart.cc/grafana/oncall)\n\n## Further Reading\n\n- _Migration from the PagerDuty_ - [Migrator](https://github.com/grafana/oncall/tree/dev/tools/pagerduty-migrator)\n- _Documentation_ - [Grafana OnCall](https://grafana.com/docs/grafana-cloud/oncall/)\n- _Blog Post_ - [Announcing Grafana OnCall, the easiest way to do on-call management](https://grafana.com/blog/2021/11/09/announcing-grafana-oncall/)\n- _Presentation_ - [Deep dive into the Grafana, Prometheus, and Alertmanager stack for alerting and on-call management](https://grafana.com/go/observabilitycon/2021/alerting/?pg=blog)\n",
- "source_links": [],
- "id": 93
- },
- {
- "page_link": null,
- "title": "openmetadata readme",
- "text": null,
- "source_links": [],
- "id": 94
- },
- {
- "page_link": "https://github.com/pluralsh/plural",
- "title": "plural readme",
- "text": "
\n\n## Stargazers over time\n\n[](https://starchart.cc/grafana/oncall)\n\n## Further Reading\n\n- _Migration from the PagerDuty_ - [Migrator](https://github.com/grafana/oncall/tree/dev/tools/pagerduty-migrator)\n- _Documentation_ - [Grafana OnCall](https://grafana.com/docs/grafana-cloud/oncall/)\n- _Blog Post_ - [Announcing Grafana OnCall, the easiest way to do on-call management](https://grafana.com/blog/2021/11/09/announcing-grafana-oncall/)\n- _Presentation_ - [Deep dive into the Grafana, Prometheus, and Alertmanager stack for alerting and on-call management](https://grafana.com/go/observabilitycon/2021/alerting/?pg=blog)\n",
- "source_links": [],
- "id": 93
- },
- {
- "page_link": null,
- "title": "openmetadata readme",
- "text": null,
- "source_links": [],
- "id": 94
- },
- {
- "page_link": "https://github.com/pluralsh/plural",
- "title": "plural readme",
- "text": " \n
\n 






 \n
\n  \n
\n  \n
\n




























































































































































































































































 \n\n\n\n\n",
- "source_links": [],
- "id": 98
- },
- {
- "page_link": "https://github.com/PrefectHQ/prefect",
- "title": "prefect readme",
- "text": "
\n\n\n\n\n",
- "source_links": [],
- "id": 98
- },
- {
- "page_link": "https://github.com/PrefectHQ/prefect",
- "title": "prefect readme",
- "text": "



 \n \n
\n \n  \n
\n  \n
\n  \n
\n



 \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n
 \n
\n  \n
\n


 \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n
\n \n\n## Sponsors\n\n
\n\n## Sponsors\n\n \n
\n \n\n## License\n\nThis repository is released under the Apache-2.0 License. See\n[`LICENSE`](https://github.com/trytouca/trytouca/blob/main/LICENSE).\n",
- "source_links": [],
- "id": 126
- },
- {
- "page_link": null,
- "title": "trace-shield readme",
- "text": null,
- "source_links": [],
- "id": 127
- },
- {
- "page_link": "https://github.com/trinodb/trino",
- "title": "trino readme",
- "text": "
\n\n## License\n\nThis repository is released under the Apache-2.0 License. See\n[`LICENSE`](https://github.com/trytouca/trytouca/blob/main/LICENSE).\n",
- "source_links": [],
- "id": 126
- },
- {
- "page_link": null,
- "title": "trace-shield readme",
- "text": null,
- "source_links": [],
- "id": 127
- },
- {
- "page_link": "https://github.com/trinodb/trino",
- "title": "trino readme",
- "text": " \n
\n \n\n[](https://artifacthub.io/packages/search?repo=trivy-operator)\n\n# Introduction\n\nThere are lots of security tools in the cloud native world, created by Aqua and by others, for identifying and informing\nusers about security issues in Kubernetes workloads and infrastructure components. However powerful and useful they\nmight be, they tend to sit alongside Kubernetes, with each new product requiring users to learn a separate set of\ncommands and installation steps in order to operate them and find critical security information.\n\nThe Trivy-Operator leverages trivy security tools by incorporating their outputs into Kubernetes CRDs\n(Custom Resource Definitions) and from there, making security reports accessible through the Kubernetes API. This way\nusers can find and view the risks that relate to different resources in what we call a Kubernetes-native way.\n\nThe Trivy operator automatically updates security reports in response to workload and other changes on a Kubernetes cluster, generating the following reports:\n\n- Vulnerability Scans: Automated vulnerability scanning for Kubernetes workloads.\n- ConfigAudit Scans: Automated configuration audits for Kubernetes resources with predefined rules or custom Open Policy Agent (OPA) policies.\n- Exposed Secret Scans: Automated secret scans which find and detail the location of exposed Secrets within your cluster.\n- RBAC scans: Role Based Access Control scans provide detailed information on the access rights of the different resources installed.\n\n
\n\n[](https://artifacthub.io/packages/search?repo=trivy-operator)\n\n# Introduction\n\nThere are lots of security tools in the cloud native world, created by Aqua and by others, for identifying and informing\nusers about security issues in Kubernetes workloads and infrastructure components. However powerful and useful they\nmight be, they tend to sit alongside Kubernetes, with each new product requiring users to learn a separate set of\ncommands and installation steps in order to operate them and find critical security information.\n\nThe Trivy-Operator leverages trivy security tools by incorporating their outputs into Kubernetes CRDs\n(Custom Resource Definitions) and from there, making security reports accessible through the Kubernetes API. This way\nusers can find and view the risks that relate to different resources in what we call a Kubernetes-native way.\n\nThe Trivy operator automatically updates security reports in response to workload and other changes on a Kubernetes cluster, generating the following reports:\n\n- Vulnerability Scans: Automated vulnerability scanning for Kubernetes workloads.\n- ConfigAudit Scans: Automated configuration audits for Kubernetes resources with predefined rules or custom Open Policy Agent (OPA) policies.\n- Exposed Secret Scans: Automated secret scans which find and detail the location of exposed Secrets within your cluster.\n- RBAC scans: Role Based Access Control scans provide detailed information on the access rights of the different resources installed.\n\n \n
\n

 \n
\n \n\n## Quick Start\n\nHere's a quick example showcasing how you can create a collection, index a document and search it on Typesense.\n \nLet's begin by starting the Typesense server via Docker:\n\n```\ndocker run -p 8108:8108 -v/tmp/data:/data typesense/typesense:0.24.1 --data-dir /data --api-key=Hu52dwsas2AdxdE\n```\n\nWe have [API Clients](#api-clients) in a couple of languages, but let's use the Python client for this example.\n\nInstall the Python client for Typesense:\n \n```\npip install typesense\n```\n\nWe can now initialize the client and create a `companies` collection:\n\n```python\nimport typesense\n\nclient = typesense.Client({\n 'api_key': 'Hu52dwsas2AdxdE',\n 'nodes': [{\n 'host': 'localhost',\n 'port': '8108',\n 'protocol': 'http'\n }],\n 'connection_timeout_seconds': 2\n})\n\ncreate_response = client.collections.create({\n \"name\": \"companies\",\n \"fields\": [\n {\"name\": \"company_name\", \"type\": \"string\" },\n {\"name\": \"num_employees\", \"type\": \"int32\" },\n {\"name\": \"country\", \"type\": \"string\", \"facet\": True }\n ],\n \"default_sorting_field\": \"num_employees\"\n})\n```\n\nNow, let's add a document to the collection we just created:\n\n```python\ndocument = {\n \"id\": \"124\",\n \"company_name\": \"Stark Industries\",\n \"num_employees\": 5215,\n \"country\": \"USA\"\n}\n\nclient.collections['companies'].documents.create(document)\n```\n\nFinally, let's search for the document we just indexed:\n\n```python\nsearch_parameters = {\n 'q' : 'stork',\n 'query_by' : 'company_name',\n 'filter_by' : 'num_employees:>100',\n 'sort_by' : 'num_employees:desc'\n}\n\nclient.collections['companies'].documents.search(search_parameters)\n```\n\n**Did you notice the typo in the query text?** No big deal. Typesense handles typographic errors out-of-the-box!\n\n## Step-by-step Walk-through\n\nA step-by-step walk-through is available on our website [here](https://typesense.org/guide). \n\nThis will guide you through the process of starting up a Typesense server, indexing data in it and querying the data set. \n\n## API Documentation\n\nHere's our official API documentation, available on our website: [https://typesense.org/api](https://typesense.org/api).\n\nIf you notice any issues with the documentation or walk-through, please let us know or send us a PR here: [https://github.com/typesense/typesense-website](https://github.com/typesense/typesense-website).\n\n## API Clients\n\nWhile you can definitely use CURL to interact with Typesense Server directly, we offer official API clients to simplify using Typesense from your language of choice. The API Clients come built-in with a smart retry strategy to ensure that API calls made via them are resilient, especially in an HA setup.\n\n- [typesense-js](https://github.com/typesense/typesense-js)\n- [typesense-php](https://github.com/typesense/typesense-php)\n- [typesense-python](https://github.com/typesense/typesense-python)\n- [typesense-ruby](https://github.com/typesense/typesense-ruby)\n\nIf we don't offer an API client in your language, you can still use any popular HTTP client library to access Typesense's APIs directly. \n\nHere are some community-contributed clients and integrations:\n\n- [API client for Go](https://github.com/typesense/typesense-go)\n- [API client for Dart](https://github.com/typesense/typesense-dart)\n- [API client for C#](https://github.com/DAXGRID/typesense-dotnet)\n- [Laravel Scout driver](https://github.com/devloopsnet/laravel-scout-typesense-engine)\n- [Symfony integration](https://github.com/acseo/TypesenseBundle)\n\nWe welcome community contributions to add more official client libraries and integrations. Please reach out to us at contact@typsense.org or open an issue on Github to collaborate with us on the architecture. \ud83d\ude4f\n\n## Search UI Components\n\nYou can use our [InstantSearch.js adapter](https://github.com/typesense/typesense-instantsearch-adapter) \nto quickly build powerful search experiences, complete with filtering, sorting, pagination and more.\n\nHere's how: [https://typesense.org/docs/0.24.1/guide/#search-ui](https://typesense.org/docs/0.24.1/guide/#search-ui) \n\n## FAQ\n\n### How does this differ from Elasticsearch?\n\nElasticsearch is a large piece of software, that takes non-trivial amount of effort to setup, administer, scale and fine-tune. \nIt offers you a few thousand configuration parameters to get to your ideal configuration. So it's better suited for large teams \nwho have the bandwidth to get it production-ready, regularly monitor it and scale it, especially when they have a need to store \nbillions of documents and petabytes of data (eg: logs).\n\nTypesense is built specifically for decreasing the \"time to market\" for a delightful search experience. It's a light-weight\nyet powerful & scaleable alternative that focuses on Developer Happiness and Experience with a clean well-documented API, clear semantics \nand smart defaults so it just works well out-of-the-box, without you having to turn many knobs.\n\nElasticsearch also runs on the JVM, which by itself can be quite an effort to tune to run optimally. Typesense, on the other hand, \nis a single light-weight self-contained native binary, so it's simple to setup and operate.\n\nSee a side-by-side feature comparison [here](https://typesense.org/typesense-vs-algolia-vs-elasticsearch-vs-meilisearch/).\n\n### How does this differ from Algolia?\n\nAlgolia is a proprietary, hosted, search-as-a-service product that works well, when cost is not an issue. From our experience,\nfast growing sites and apps quickly run into search & indexing limits, accompanied by expensive plan upgrades as they scale.\n\nTypesense on the other hand is an open-source product that you can run on your own infrastructure or\nuse our managed SaaS offering - [Typesense Cloud](https://cloud.typesense.org). \nThe open source version is free to use (besides of course your own infra costs). \nWith Typesense Cloud we don't charge by records or search operations. Instead, you get a dedicated cluster\nand you can throw as much data and traffic at it as it can handle. You only pay a fixed hourly cost & bandwidth charges \nfor it, depending on the configuration your choose, similar to most modern cloud platforms. \n\nFrom a product perspective, Typesense is closer in spirit to Algolia than Elasticsearch. \nHowever, we've addressed some important limitations with Algolia: \n\nAlgolia requires separate indices for each sort order, which counts towards your plan limits. Most of the index settings like \nfields to search, fields to facet, fields to group by, ranking settings, etc \nare defined upfront when the index is created vs being able to set them on the fly at query time.\n\nWith Typesense, these settings can be configured at search time via query parameters which makes it very flexible\nand unlocks new use cases. Typesense is also able to give you sorted results with a single index, vs having to create multiple.\nThis helps reduce memory consumption.\n\nAlgolia offers the following features that Typesense does not have currently: personalization & server-based search analytics. For analytics, you can still instrument your search on the client-side and send search metrics to your web analytics tool of choice. \n\nWe intend to bridge this gap in Typesense, but in the meantime, please let us know\nif any of these are a show stopper for your use case by creating a feature request in our issue tracker. \n\nSee a side-by-side feature comparison [here](https://typesense.org/typesense-vs-algolia-vs-elasticsearch-vs-meilisearch/).\n\n### Speed is great, but what about the memory footprint?\n\nA fresh Typesense server will consume about 30 MB of memory. As you start indexing documents, the memory use will \nincrease correspondingly. How much it increases depends on the number and type of fields you index. \n\nWe've strived to keep the in-memory data structures lean. To give you a rough idea: when 1 million \nHacker News titles are indexed along with their points, Typesense consumes 165 MB of memory. The same size of that data \non disk in JSON format is 88 MB. If you have any numbers from your own datasets that we can add to this section, please send us a PR!\n\n### Why the GPL license?\n\nFrom our experience companies are generally concerned when **libraries** they use are GPL licensed, since library code is directly integrated into their code and will lead to derivative work and trigger GPL compliance. However, Typesense Server is **server software** and we expect users to typically run it as a separate daemon, and not integrate it with their own code. GPL covers and allows for this use case generously **(eg: Linux is GPL licensed)**. Now, AGPL is what makes server software accessed over a network result in derivative work and not GPL. And for that reason we\u2019ve opted to not use AGPL for Typesense. \n\nNow, if someone makes modifications to Typesense server, GPL actually allows you to still keep the modifications to yourself as long as you don't distribute the modified code. So a company can for example modify Typesense server and run the modified code internally and still not have to open source their modifications, as long as they make the modified code available to everyone who has access to the modified software.\n\nNow, if someone makes modifications to Typesense server and distributes the modifications, that's where GPL kicks in. Given that we\u2019ve published our work to the community, we'd like for others' modifications to also be made open to the community in the spirit of open source. **We use GPL for this purpose.** Other licenses would allow our open source work to be modified, made closed source and distributed, which we want to avoid with Typesense for the project\u2019s long term sustainability.\n\nHere's more background on why GPL, as described by Discourse: https://meta.discourse.org/t/why-gnu-license/2531. Many of the points mentioned there resonate with us.\n\nNow, all of the above only apply to Typesense Server. Our client libraries are indeed meant to be integrated into our users\u2019 code and so they use Apache license.\n\nSo in summary, AGPL is what is usually problematic for server software and we\u2019ve opted not to use it. We believe GPL for Typesense Server captures the essence of what we want for this open source project. GPL has a long history of successfully being used by popular open source projects. Our libraries are still Apache licensed.\n\nIf you have specifics that prevent you from using Typesense due to a licensing issue, we're happy to explore this topic further with you. Please reach out to us.\n\n## Support\n\n\ud83d\udc4b \ud83c\udf10 New: If you have general questions about Typesense, want to say hello or just follow along, we'd like to invite you to join our [Slack Community](https://join.slack.com/t/typesense-community/shared_invite/zt-mx4nbsbn-AuOL89O7iBtvkz136egSJg). \n\nWe also do virtual office hours every Friday. Reserve a time slot [here](https://calendly.com/jason-typesense/typesense-office-hours).\n\nIf you run into any problems or issues, please create a Github issue and we'll try our best to help.\n\nWe strive to provide good support through our issue trackers on Github. However, if you'd like to receive private & prioritized support with:\n\n- Guaranteed SLAs\n- Phone / video calls to discuss your specific use case and get recommendations on best practices\n- Private discussions over Slack\n- Guidance around deployment, ops and scaling best practices\n- Prioritized feature requests\n\nWe do offer Paid Support options. Please reach out to us at contact@typesense.org to sign up.\n\n## Contributing\n\nWe are a lean team on a mission to democratize search and we'll take all the help we can get! If you'd like to get involved, here's information on where we could use your help: [Contributing.md](https://github.com/typesense/typesense/blob/master/CONTRIBUTING.md)\n\n## Getting Latest Updates\n\nIf you'd like to get updates when we release new versions, click on the \"Watch\" button on the top and select \"Releases only\". Github will then send you notifications along with a changelog with each new release.\n\nWe also post updates to our Twitter account about releases and additional topics related to Typesense. Follow us here: [@typesense](https://twitter.com/typesense).\n\n\ud83d\udc4b \ud83c\udf10 New: We'll also post updates on our [Slack Community](https://join.slack.com/t/typesense-community/shared_invite/zt-mx4nbsbn-AuOL89O7iBtvkz136egSJg). \n\n## Build from source\n\n**Building with Docker**\n\nThe docker build script takes care of all required dependencies, so it's the easiest way to build Typesense:\n\n```\nTYPESENSE_VERSION=nightly ./docker-build.sh --build-deploy-image --create-binary [--clean] [--depclean]\n```\n\n**Building on your machine**\n\nTypesense requires the following dependencies: \n\n* C++11 compatible compiler (GCC >= 4.9.0, Apple Clang >= 8.0, Clang >= 3.9.0)\n* Snappy\n* zlib\n* OpenSSL (>=1.0.2)\n* curl\n* ICU\n* brpc\n* braft\n\n```\n./build.sh --create-binary [--clean] [--depclean]\n```\n\nThe first build will take some time since other third-party libraries are pulled and built as part of the build process.\n\n---\n© 2016-present Typesense Inc.\n",
- "source_links": [],
- "id": 131
- },
- {
- "page_link": "https://github.com/Unleash/unleash",
- "title": "unleash readme",
- "text": "
\n\n## Quick Start\n\nHere's a quick example showcasing how you can create a collection, index a document and search it on Typesense.\n \nLet's begin by starting the Typesense server via Docker:\n\n```\ndocker run -p 8108:8108 -v/tmp/data:/data typesense/typesense:0.24.1 --data-dir /data --api-key=Hu52dwsas2AdxdE\n```\n\nWe have [API Clients](#api-clients) in a couple of languages, but let's use the Python client for this example.\n\nInstall the Python client for Typesense:\n \n```\npip install typesense\n```\n\nWe can now initialize the client and create a `companies` collection:\n\n```python\nimport typesense\n\nclient = typesense.Client({\n 'api_key': 'Hu52dwsas2AdxdE',\n 'nodes': [{\n 'host': 'localhost',\n 'port': '8108',\n 'protocol': 'http'\n }],\n 'connection_timeout_seconds': 2\n})\n\ncreate_response = client.collections.create({\n \"name\": \"companies\",\n \"fields\": [\n {\"name\": \"company_name\", \"type\": \"string\" },\n {\"name\": \"num_employees\", \"type\": \"int32\" },\n {\"name\": \"country\", \"type\": \"string\", \"facet\": True }\n ],\n \"default_sorting_field\": \"num_employees\"\n})\n```\n\nNow, let's add a document to the collection we just created:\n\n```python\ndocument = {\n \"id\": \"124\",\n \"company_name\": \"Stark Industries\",\n \"num_employees\": 5215,\n \"country\": \"USA\"\n}\n\nclient.collections['companies'].documents.create(document)\n```\n\nFinally, let's search for the document we just indexed:\n\n```python\nsearch_parameters = {\n 'q' : 'stork',\n 'query_by' : 'company_name',\n 'filter_by' : 'num_employees:>100',\n 'sort_by' : 'num_employees:desc'\n}\n\nclient.collections['companies'].documents.search(search_parameters)\n```\n\n**Did you notice the typo in the query text?** No big deal. Typesense handles typographic errors out-of-the-box!\n\n## Step-by-step Walk-through\n\nA step-by-step walk-through is available on our website [here](https://typesense.org/guide). \n\nThis will guide you through the process of starting up a Typesense server, indexing data in it and querying the data set. \n\n## API Documentation\n\nHere's our official API documentation, available on our website: [https://typesense.org/api](https://typesense.org/api).\n\nIf you notice any issues with the documentation or walk-through, please let us know or send us a PR here: [https://github.com/typesense/typesense-website](https://github.com/typesense/typesense-website).\n\n## API Clients\n\nWhile you can definitely use CURL to interact with Typesense Server directly, we offer official API clients to simplify using Typesense from your language of choice. The API Clients come built-in with a smart retry strategy to ensure that API calls made via them are resilient, especially in an HA setup.\n\n- [typesense-js](https://github.com/typesense/typesense-js)\n- [typesense-php](https://github.com/typesense/typesense-php)\n- [typesense-python](https://github.com/typesense/typesense-python)\n- [typesense-ruby](https://github.com/typesense/typesense-ruby)\n\nIf we don't offer an API client in your language, you can still use any popular HTTP client library to access Typesense's APIs directly. \n\nHere are some community-contributed clients and integrations:\n\n- [API client for Go](https://github.com/typesense/typesense-go)\n- [API client for Dart](https://github.com/typesense/typesense-dart)\n- [API client for C#](https://github.com/DAXGRID/typesense-dotnet)\n- [Laravel Scout driver](https://github.com/devloopsnet/laravel-scout-typesense-engine)\n- [Symfony integration](https://github.com/acseo/TypesenseBundle)\n\nWe welcome community contributions to add more official client libraries and integrations. Please reach out to us at contact@typsense.org or open an issue on Github to collaborate with us on the architecture. \ud83d\ude4f\n\n## Search UI Components\n\nYou can use our [InstantSearch.js adapter](https://github.com/typesense/typesense-instantsearch-adapter) \nto quickly build powerful search experiences, complete with filtering, sorting, pagination and more.\n\nHere's how: [https://typesense.org/docs/0.24.1/guide/#search-ui](https://typesense.org/docs/0.24.1/guide/#search-ui) \n\n## FAQ\n\n### How does this differ from Elasticsearch?\n\nElasticsearch is a large piece of software, that takes non-trivial amount of effort to setup, administer, scale and fine-tune. \nIt offers you a few thousand configuration parameters to get to your ideal configuration. So it's better suited for large teams \nwho have the bandwidth to get it production-ready, regularly monitor it and scale it, especially when they have a need to store \nbillions of documents and petabytes of data (eg: logs).\n\nTypesense is built specifically for decreasing the \"time to market\" for a delightful search experience. It's a light-weight\nyet powerful & scaleable alternative that focuses on Developer Happiness and Experience with a clean well-documented API, clear semantics \nand smart defaults so it just works well out-of-the-box, without you having to turn many knobs.\n\nElasticsearch also runs on the JVM, which by itself can be quite an effort to tune to run optimally. Typesense, on the other hand, \nis a single light-weight self-contained native binary, so it's simple to setup and operate.\n\nSee a side-by-side feature comparison [here](https://typesense.org/typesense-vs-algolia-vs-elasticsearch-vs-meilisearch/).\n\n### How does this differ from Algolia?\n\nAlgolia is a proprietary, hosted, search-as-a-service product that works well, when cost is not an issue. From our experience,\nfast growing sites and apps quickly run into search & indexing limits, accompanied by expensive plan upgrades as they scale.\n\nTypesense on the other hand is an open-source product that you can run on your own infrastructure or\nuse our managed SaaS offering - [Typesense Cloud](https://cloud.typesense.org). \nThe open source version is free to use (besides of course your own infra costs). \nWith Typesense Cloud we don't charge by records or search operations. Instead, you get a dedicated cluster\nand you can throw as much data and traffic at it as it can handle. You only pay a fixed hourly cost & bandwidth charges \nfor it, depending on the configuration your choose, similar to most modern cloud platforms. \n\nFrom a product perspective, Typesense is closer in spirit to Algolia than Elasticsearch. \nHowever, we've addressed some important limitations with Algolia: \n\nAlgolia requires separate indices for each sort order, which counts towards your plan limits. Most of the index settings like \nfields to search, fields to facet, fields to group by, ranking settings, etc \nare defined upfront when the index is created vs being able to set them on the fly at query time.\n\nWith Typesense, these settings can be configured at search time via query parameters which makes it very flexible\nand unlocks new use cases. Typesense is also able to give you sorted results with a single index, vs having to create multiple.\nThis helps reduce memory consumption.\n\nAlgolia offers the following features that Typesense does not have currently: personalization & server-based search analytics. For analytics, you can still instrument your search on the client-side and send search metrics to your web analytics tool of choice. \n\nWe intend to bridge this gap in Typesense, but in the meantime, please let us know\nif any of these are a show stopper for your use case by creating a feature request in our issue tracker. \n\nSee a side-by-side feature comparison [here](https://typesense.org/typesense-vs-algolia-vs-elasticsearch-vs-meilisearch/).\n\n### Speed is great, but what about the memory footprint?\n\nA fresh Typesense server will consume about 30 MB of memory. As you start indexing documents, the memory use will \nincrease correspondingly. How much it increases depends on the number and type of fields you index. \n\nWe've strived to keep the in-memory data structures lean. To give you a rough idea: when 1 million \nHacker News titles are indexed along with their points, Typesense consumes 165 MB of memory. The same size of that data \non disk in JSON format is 88 MB. If you have any numbers from your own datasets that we can add to this section, please send us a PR!\n\n### Why the GPL license?\n\nFrom our experience companies are generally concerned when **libraries** they use are GPL licensed, since library code is directly integrated into their code and will lead to derivative work and trigger GPL compliance. However, Typesense Server is **server software** and we expect users to typically run it as a separate daemon, and not integrate it with their own code. GPL covers and allows for this use case generously **(eg: Linux is GPL licensed)**. Now, AGPL is what makes server software accessed over a network result in derivative work and not GPL. And for that reason we\u2019ve opted to not use AGPL for Typesense. \n\nNow, if someone makes modifications to Typesense server, GPL actually allows you to still keep the modifications to yourself as long as you don't distribute the modified code. So a company can for example modify Typesense server and run the modified code internally and still not have to open source their modifications, as long as they make the modified code available to everyone who has access to the modified software.\n\nNow, if someone makes modifications to Typesense server and distributes the modifications, that's where GPL kicks in. Given that we\u2019ve published our work to the community, we'd like for others' modifications to also be made open to the community in the spirit of open source. **We use GPL for this purpose.** Other licenses would allow our open source work to be modified, made closed source and distributed, which we want to avoid with Typesense for the project\u2019s long term sustainability.\n\nHere's more background on why GPL, as described by Discourse: https://meta.discourse.org/t/why-gnu-license/2531. Many of the points mentioned there resonate with us.\n\nNow, all of the above only apply to Typesense Server. Our client libraries are indeed meant to be integrated into our users\u2019 code and so they use Apache license.\n\nSo in summary, AGPL is what is usually problematic for server software and we\u2019ve opted not to use it. We believe GPL for Typesense Server captures the essence of what we want for this open source project. GPL has a long history of successfully being used by popular open source projects. Our libraries are still Apache licensed.\n\nIf you have specifics that prevent you from using Typesense due to a licensing issue, we're happy to explore this topic further with you. Please reach out to us.\n\n## Support\n\n\ud83d\udc4b \ud83c\udf10 New: If you have general questions about Typesense, want to say hello or just follow along, we'd like to invite you to join our [Slack Community](https://join.slack.com/t/typesense-community/shared_invite/zt-mx4nbsbn-AuOL89O7iBtvkz136egSJg). \n\nWe also do virtual office hours every Friday. Reserve a time slot [here](https://calendly.com/jason-typesense/typesense-office-hours).\n\nIf you run into any problems or issues, please create a Github issue and we'll try our best to help.\n\nWe strive to provide good support through our issue trackers on Github. However, if you'd like to receive private & prioritized support with:\n\n- Guaranteed SLAs\n- Phone / video calls to discuss your specific use case and get recommendations on best practices\n- Private discussions over Slack\n- Guidance around deployment, ops and scaling best practices\n- Prioritized feature requests\n\nWe do offer Paid Support options. Please reach out to us at contact@typesense.org to sign up.\n\n## Contributing\n\nWe are a lean team on a mission to democratize search and we'll take all the help we can get! If you'd like to get involved, here's information on where we could use your help: [Contributing.md](https://github.com/typesense/typesense/blob/master/CONTRIBUTING.md)\n\n## Getting Latest Updates\n\nIf you'd like to get updates when we release new versions, click on the \"Watch\" button on the top and select \"Releases only\". Github will then send you notifications along with a changelog with each new release.\n\nWe also post updates to our Twitter account about releases and additional topics related to Typesense. Follow us here: [@typesense](https://twitter.com/typesense).\n\n\ud83d\udc4b \ud83c\udf10 New: We'll also post updates on our [Slack Community](https://join.slack.com/t/typesense-community/shared_invite/zt-mx4nbsbn-AuOL89O7iBtvkz136egSJg). \n\n## Build from source\n\n**Building with Docker**\n\nThe docker build script takes care of all required dependencies, so it's the easiest way to build Typesense:\n\n```\nTYPESENSE_VERSION=nightly ./docker-build.sh --build-deploy-image --create-binary [--clean] [--depclean]\n```\n\n**Building on your machine**\n\nTypesense requires the following dependencies: \n\n* C++11 compatible compiler (GCC >= 4.9.0, Apple Clang >= 8.0, Clang >= 3.9.0)\n* Snappy\n* zlib\n* OpenSSL (>=1.0.2)\n* curl\n* ICU\n* brpc\n* braft\n\n```\n./build.sh --create-binary [--clean] [--depclean]\n```\n\nThe first build will take some time since other third-party libraries are pulled and built as part of the build process.\n\n---\n© 2016-present Typesense Inc.\n",
- "source_links": [],
- "id": 131
- },
- {
- "page_link": "https://github.com/Unleash/unleash",
- "title": "unleash readme",
- "text": " \n\n\n
\n\n\n \n\nRead more in the [_system overview_ section of the Unleash documentation](https://docs.getunleash.io/tutorials/unleash_overview#system-overview).\n\n
\n\nRead more in the [_system overview_ section of the Unleash documentation](https://docs.getunleash.io/tutorials/unleash_overview#system-overview).\n\n \n\n\n## Additional material\n\n### Reading\n\n- [Weaviate is an open-source search engine powered by ML, vectors, graphs, and GraphQL (ZDNet)](https://www.zdnet.com/article/weaviate-an-open-source-search-engine-powered-by-machine-learning-vectors-graphs-and-graphql/)\n- [Weaviate, an ANN Database with CRUD support (DB-Engines.com)](https://db-engines.com/en/blog_post/87)\n- [A sub-50ms neural search with DistilBERT and Weaviate (Towards Datascience)](https://towardsdatascience.com/a-sub-50ms-neural-search-with-distilbert-and-weaviate-4857ae390154)\n- [Getting Started with Weaviate Python Library (Towards Datascience)](https://towardsdatascience.com/getting-started-with-weaviate-python-client-e85d14f19e4f)\n",
- "source_links": [],
- "id": 136
- },
- {
- "page_link": "https://github.com/WireGuard/wireguard-go",
- "title": "wireguard readme",
- "text": "# Go Implementation of [WireGuard](https://www.wireguard.com/)\n\nThis is an implementation of WireGuard in Go.\n\n## Usage\n\nMost Linux kernel WireGuard users are used to adding an interface with `ip link add wg0 type wireguard`. With wireguard-go, instead simply run:\n\n```\n$ wireguard-go wg0\n```\n\nThis will create an interface and fork into the background. To remove the interface, use the usual `ip link del wg0`, or if your system does not support removing interfaces directly, you may instead remove the control socket via `rm -f /var/run/wireguard/wg0.sock`, which will result in wireguard-go shutting down.\n\nTo run wireguard-go without forking to the background, pass `-f` or `--foreground`:\n\n```\n$ wireguard-go -f wg0\n```\n\nWhen an interface is running, you may use [`wg(8)`](https://git.zx2c4.com/wireguard-tools/about/src/man/wg.8) to configure it, as well as the usual `ip(8)` and `ifconfig(8)` commands.\n\nTo run with more logging you may set the environment variable `LOG_LEVEL=debug`.\n\n## Platforms\n\n### Linux\n\nThis will run on Linux; however you should instead use the kernel module, which is faster and better integrated into the OS. See the [installation page](https://www.wireguard.com/install/) for instructions.\n\n### macOS\n\nThis runs on macOS using the utun driver. It does not yet support sticky sockets, and won't support fwmarks because of Darwin limitations. Since the utun driver cannot have arbitrary interface names, you must either use `utun[0-9]+` for an explicit interface name or `utun` to have the kernel select one for you. If you choose `utun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n### Windows\n\nThis runs on Windows, but you should instead use it from the more [fully featured Windows app](https://git.zx2c4.com/wireguard-windows/about/), which uses this as a module.\n\n### FreeBSD\n\nThis will run on FreeBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_USER_COOKIE`.\n\n### OpenBSD\n\nThis will run on OpenBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_RTABLE`. Since the tun driver cannot have arbitrary interface names, you must either use `tun[0-9]+` for an explicit interface name or `tun` to have the program select one for you. If you choose `tun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n## Building\n\nThis requires an installation of [go](https://golang.org) \u2265 1.18.\n\n```\n$ git clone https://git.zx2c4.com/wireguard-go\n$ cd wireguard-go\n$ make\n```\n\n## License\n\n Copyright (C) 2017-2022 WireGuard LLC. All Rights Reserved.\n \n Permission is hereby granted, free of charge, to any person obtaining a copy of\n this software and associated documentation files (the \"Software\"), to deal in\n the Software without restriction, including without limitation the rights to\n use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies\n of the Software, and to permit persons to whom the Software is furnished to do\n so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.\n",
- "source_links": [],
- "id": 137
- },
- {
- "page_link": "https://github.com/bentoml/Yatai",
- "title": "yatai readme",
- "text": "# \ud83e\udd84\ufe0f Yatai: Model Deployment at Scale on Kubernetes\n\n[](https://github.com/bentoml/yatai/actions)\n[](https://docs.bentoml.org/projects/yatai)\n[](https://join.slack.bentoml.org)\n\nYatai (\u5c4b\u53f0, food cart) lets you deploy, operate and scale Machine Learning services on Kubernetes. \n\nIt supports deploying any ML models via [BentoML: the unified model serving framework](https://github.com/bentoml/bentoml).\n\n
\n\n\n## Additional material\n\n### Reading\n\n- [Weaviate is an open-source search engine powered by ML, vectors, graphs, and GraphQL (ZDNet)](https://www.zdnet.com/article/weaviate-an-open-source-search-engine-powered-by-machine-learning-vectors-graphs-and-graphql/)\n- [Weaviate, an ANN Database with CRUD support (DB-Engines.com)](https://db-engines.com/en/blog_post/87)\n- [A sub-50ms neural search with DistilBERT and Weaviate (Towards Datascience)](https://towardsdatascience.com/a-sub-50ms-neural-search-with-distilbert-and-weaviate-4857ae390154)\n- [Getting Started with Weaviate Python Library (Towards Datascience)](https://towardsdatascience.com/getting-started-with-weaviate-python-client-e85d14f19e4f)\n",
- "source_links": [],
- "id": 136
- },
- {
- "page_link": "https://github.com/WireGuard/wireguard-go",
- "title": "wireguard readme",
- "text": "# Go Implementation of [WireGuard](https://www.wireguard.com/)\n\nThis is an implementation of WireGuard in Go.\n\n## Usage\n\nMost Linux kernel WireGuard users are used to adding an interface with `ip link add wg0 type wireguard`. With wireguard-go, instead simply run:\n\n```\n$ wireguard-go wg0\n```\n\nThis will create an interface and fork into the background. To remove the interface, use the usual `ip link del wg0`, or if your system does not support removing interfaces directly, you may instead remove the control socket via `rm -f /var/run/wireguard/wg0.sock`, which will result in wireguard-go shutting down.\n\nTo run wireguard-go without forking to the background, pass `-f` or `--foreground`:\n\n```\n$ wireguard-go -f wg0\n```\n\nWhen an interface is running, you may use [`wg(8)`](https://git.zx2c4.com/wireguard-tools/about/src/man/wg.8) to configure it, as well as the usual `ip(8)` and `ifconfig(8)` commands.\n\nTo run with more logging you may set the environment variable `LOG_LEVEL=debug`.\n\n## Platforms\n\n### Linux\n\nThis will run on Linux; however you should instead use the kernel module, which is faster and better integrated into the OS. See the [installation page](https://www.wireguard.com/install/) for instructions.\n\n### macOS\n\nThis runs on macOS using the utun driver. It does not yet support sticky sockets, and won't support fwmarks because of Darwin limitations. Since the utun driver cannot have arbitrary interface names, you must either use `utun[0-9]+` for an explicit interface name or `utun` to have the kernel select one for you. If you choose `utun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n### Windows\n\nThis runs on Windows, but you should instead use it from the more [fully featured Windows app](https://git.zx2c4.com/wireguard-windows/about/), which uses this as a module.\n\n### FreeBSD\n\nThis will run on FreeBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_USER_COOKIE`.\n\n### OpenBSD\n\nThis will run on OpenBSD. It does not yet support sticky sockets. Fwmark is mapped to `SO_RTABLE`. Since the tun driver cannot have arbitrary interface names, you must either use `tun[0-9]+` for an explicit interface name or `tun` to have the program select one for you. If you choose `tun` as the interface name, and the environment variable `WG_TUN_NAME_FILE` is defined, then the actual name of the interface chosen by the kernel is written to the file specified by that variable.\n\n## Building\n\nThis requires an installation of [go](https://golang.org) \u2265 1.18.\n\n```\n$ git clone https://git.zx2c4.com/wireguard-go\n$ cd wireguard-go\n$ make\n```\n\n## License\n\n Copyright (C) 2017-2022 WireGuard LLC. All Rights Reserved.\n \n Permission is hereby granted, free of charge, to any person obtaining a copy of\n this software and associated documentation files (the \"Software\"), to deal in\n the Software without restriction, including without limitation the rights to\n use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies\n of the Software, and to permit persons to whom the Software is furnished to do\n so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.\n",
- "source_links": [],
- "id": 137
- },
- {
- "page_link": "https://github.com/bentoml/Yatai",
- "title": "yatai readme",
- "text": "# \ud83e\udd84\ufe0f Yatai: Model Deployment at Scale on Kubernetes\n\n[](https://github.com/bentoml/yatai/actions)\n[](https://docs.bentoml.org/projects/yatai)\n[](https://join.slack.bentoml.org)\n\nYatai (\u5c4b\u53f0, food cart) lets you deploy, operate and scale Machine Learning services on Kubernetes. \n\nIt supports deploying any ML models via [BentoML: the unified model serving framework](https://github.com/bentoml/bentoml).\n\n \n\n\n\ud83d\udc49 [Join our Slack community today!](https://l.bentoml.com/join-slack)\n\n\u2728 Looking for the fastest way to give Yatai a try? Check out [BentoML Cloud](https://l.bentoml.com/bento-cloud) to get started today.\n\n\n---\n\n## Why Yatai?\n\n\ud83c\udf71 Made for BentoML, deploy at scale\n\n- Scale [BentoML](https://github.com/bentoml) to its full potential on a distributed system, optimized for cost saving and performance.\n- Manage deployment lifecycle to deploy, update, or rollback via API or Web UI.\n- Centralized registry providing the **foundation for CI/CD** via artifact management APIs, labeling, and WebHooks for custom integration.\n\n\ud83d\ude85 Cloud native & DevOps friendly\n\n- Kubernetes-native workflow via [BentoDeployment CRD](https://docs.bentoml.org/projects/yatai/en/latest/concepts/bentodeployment_crd.html) (Custom Resource Definition), which can easily fit into an existing GitOps workflow.\n- Native [integration with Grafana](https://docs.bentoml.org/projects/yatai/en/latest/observability/metrics.html) stack for observability.\n- Support for traffic control with Istio.\n- Compatible with all major cloud platforms (AWS, Azure, and GCP).\n\n\n## Getting Started\n\n- \ud83d\udcd6 [Documentation](https://docs.bentoml.org/projects/yatai/) - Overview of the Yatai docs and related resources\n- \u2699\ufe0f [Installation](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html) - Hands-on instruction on how to install Yatai for production use\n- \ud83d\udc49 [Join Community Slack](https://l.linklyhq.com/l/ktPW) - Get help from our community and maintainers\n\n\n## Quick Tour\n\nLet's try out Yatai locally in a minikube cluster!\n\n### \u2699\ufe0f Prerequisites:\n * Install latest minikube: https://minikube.sigs.k8s.io/docs/start/\n * Install latest Helm: https://helm.sh/docs/intro/install/\n * Start a minikube Kubernetes cluster: `minikube start --cpus 4 --memory 4096`, if you are using macOS, you should use [hyperkit](https://minikube.sigs.k8s.io/docs/drivers/hyperkit/) driver to prevent the macOS docker desktop [network limitation](https://docs.docker.com/desktop/networking/#i-cannot-ping-my-containers)\n * Check that minikube cluster status is \"running\": `minikube status`\n * Make sure your `kubectl` is configured with `minikube` context: `kubectl config current-context`\n * Enable ingress controller: `minikube addons enable ingress`\n\n### \ud83d\udea7 Install Yatai\n\nInstall Yatai with the following script:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai/main/scripts/quick-install-yatai.sh\")\n```\n\nThis script will install Yatai along with its dependencies (PostgreSQL and MinIO) on\nyour minikube cluster. \n\nNote that this installation script is made for development and testing use only.\nFor production deployment, check out the [Installation Guide](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html).\n\nTo access Yatai web UI, run the following command and keep the terminal open:\n\n```bash\nkubectl --namespace yatai-system port-forward svc/yatai 8080:80\n```\n\nIn a separate terminal, run:\n\n```bash\nYATAI_INITIALIZATION_TOKEN=$(kubectl get secret yatai-env --namespace yatai-system -o jsonpath=\"{.data.YATAI_INITIALIZATION_TOKEN}\" | base64 --decode)\necho \"Open in browser: http://127.0.0.1:8080/setup?token=$YATAI_INITIALIZATION_TOKEN\"\n``` \n\nOpen the URL printed above from your browser to finish admin account setup.\n\n\n### \ud83c\udf71 Push Bento to Yatai\n\nFirst, get an API token and login to the BentoML CLI:\n\n* Keep the `kubectl port-forward` command in the step above running\n* Go to Yatai's API tokens page: http://127.0.0.1:8080/api_tokens\n* Create a new API token from the UI, making sure to assign \"API\" access under \"Scopes\"\n* Copy the login command upon token creation and run as a shell command, e.g.:\n\n ```bash\n bentoml yatai login --api-token {YOUR_TOKEN} --endpoint http://127.0.0.1:8080\n ```\n\nIf you don't already have a Bento built, run the following commands from the [BentoML Quickstart Project](https://github.com/bentoml/BentoML/tree/main/examples/quickstart) to build a sample Bento:\n\n```bash\ngit clone https://github.com/bentoml/bentoml.git && cd ./examples/quickstart\npip install -r ./requirements.txt\npython train.py\nbentoml build\n```\n\nPush your newly built Bento to Yatai:\n\n```bash\nbentoml push iris_classifier:latest\n```\n\nNow you can view and manage models and bentos from the web UI:\n\n
\n\n\n\ud83d\udc49 [Join our Slack community today!](https://l.bentoml.com/join-slack)\n\n\u2728 Looking for the fastest way to give Yatai a try? Check out [BentoML Cloud](https://l.bentoml.com/bento-cloud) to get started today.\n\n\n---\n\n## Why Yatai?\n\n\ud83c\udf71 Made for BentoML, deploy at scale\n\n- Scale [BentoML](https://github.com/bentoml) to its full potential on a distributed system, optimized for cost saving and performance.\n- Manage deployment lifecycle to deploy, update, or rollback via API or Web UI.\n- Centralized registry providing the **foundation for CI/CD** via artifact management APIs, labeling, and WebHooks for custom integration.\n\n\ud83d\ude85 Cloud native & DevOps friendly\n\n- Kubernetes-native workflow via [BentoDeployment CRD](https://docs.bentoml.org/projects/yatai/en/latest/concepts/bentodeployment_crd.html) (Custom Resource Definition), which can easily fit into an existing GitOps workflow.\n- Native [integration with Grafana](https://docs.bentoml.org/projects/yatai/en/latest/observability/metrics.html) stack for observability.\n- Support for traffic control with Istio.\n- Compatible with all major cloud platforms (AWS, Azure, and GCP).\n\n\n## Getting Started\n\n- \ud83d\udcd6 [Documentation](https://docs.bentoml.org/projects/yatai/) - Overview of the Yatai docs and related resources\n- \u2699\ufe0f [Installation](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html) - Hands-on instruction on how to install Yatai for production use\n- \ud83d\udc49 [Join Community Slack](https://l.linklyhq.com/l/ktPW) - Get help from our community and maintainers\n\n\n## Quick Tour\n\nLet's try out Yatai locally in a minikube cluster!\n\n### \u2699\ufe0f Prerequisites:\n * Install latest minikube: https://minikube.sigs.k8s.io/docs/start/\n * Install latest Helm: https://helm.sh/docs/intro/install/\n * Start a minikube Kubernetes cluster: `minikube start --cpus 4 --memory 4096`, if you are using macOS, you should use [hyperkit](https://minikube.sigs.k8s.io/docs/drivers/hyperkit/) driver to prevent the macOS docker desktop [network limitation](https://docs.docker.com/desktop/networking/#i-cannot-ping-my-containers)\n * Check that minikube cluster status is \"running\": `minikube status`\n * Make sure your `kubectl` is configured with `minikube` context: `kubectl config current-context`\n * Enable ingress controller: `minikube addons enable ingress`\n\n### \ud83d\udea7 Install Yatai\n\nInstall Yatai with the following script:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai/main/scripts/quick-install-yatai.sh\")\n```\n\nThis script will install Yatai along with its dependencies (PostgreSQL and MinIO) on\nyour minikube cluster. \n\nNote that this installation script is made for development and testing use only.\nFor production deployment, check out the [Installation Guide](https://docs.bentoml.org/projects/yatai/en/latest/installation/index.html).\n\nTo access Yatai web UI, run the following command and keep the terminal open:\n\n```bash\nkubectl --namespace yatai-system port-forward svc/yatai 8080:80\n```\n\nIn a separate terminal, run:\n\n```bash\nYATAI_INITIALIZATION_TOKEN=$(kubectl get secret yatai-env --namespace yatai-system -o jsonpath=\"{.data.YATAI_INITIALIZATION_TOKEN}\" | base64 --decode)\necho \"Open in browser: http://127.0.0.1:8080/setup?token=$YATAI_INITIALIZATION_TOKEN\"\n``` \n\nOpen the URL printed above from your browser to finish admin account setup.\n\n\n### \ud83c\udf71 Push Bento to Yatai\n\nFirst, get an API token and login to the BentoML CLI:\n\n* Keep the `kubectl port-forward` command in the step above running\n* Go to Yatai's API tokens page: http://127.0.0.1:8080/api_tokens\n* Create a new API token from the UI, making sure to assign \"API\" access under \"Scopes\"\n* Copy the login command upon token creation and run as a shell command, e.g.:\n\n ```bash\n bentoml yatai login --api-token {YOUR_TOKEN} --endpoint http://127.0.0.1:8080\n ```\n\nIf you don't already have a Bento built, run the following commands from the [BentoML Quickstart Project](https://github.com/bentoml/BentoML/tree/main/examples/quickstart) to build a sample Bento:\n\n```bash\ngit clone https://github.com/bentoml/bentoml.git && cd ./examples/quickstart\npip install -r ./requirements.txt\npython train.py\nbentoml build\n```\n\nPush your newly built Bento to Yatai:\n\n```bash\nbentoml push iris_classifier:latest\n```\n\nNow you can view and manage models and bentos from the web UI:\n\n \n
\n \n\n### \ud83d\udd27 Install yatai-image-builder component\n\nYatai's image builder feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-image-builder/main/scripts/quick-install-yatai-image-builder.sh\")\n```\n\nThis will install the `BentoRequest` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/)) and `Bento` CRD\nin your cluster. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udd27 Install yatai-deployment component\n\nYatai's Deployment feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-deployment/main/scripts/quick-install-yatai-deployment.sh\")\n```\n\nThis will install the `BentoDeployment` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/))\nin your cluster and enable the deployment UI on Yatai. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udea2 Deploy Bento!\n\nOnce the `yatai-deployment` component was installed, Bentos pushed to Yatai can be deployed to your \nKubernetes cluster and exposed via a Service endpoint. \n\nA Bento Deployment can be created either via Web UI or via a Kubernetes CRD config:\n\n#### Option 1. Simple Deployment via Web UI\n\n* Go to the deployments page: http://127.0.0.1:8080/deployments\n* Click `Create` button and follow the instructions on the UI\n\n
\n\n### \ud83d\udd27 Install yatai-image-builder component\n\nYatai's image builder feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-image-builder/main/scripts/quick-install-yatai-image-builder.sh\")\n```\n\nThis will install the `BentoRequest` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/)) and `Bento` CRD\nin your cluster. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udd27 Install yatai-deployment component\n\nYatai's Deployment feature comes as a separate component, you can install it via the following\nscript:\n\n```bash\nbash <(curl -s \"https://raw.githubusercontent.com/bentoml/yatai-deployment/main/scripts/quick-install-yatai-deployment.sh\")\n```\n\nThis will install the `BentoDeployment` CRD([Custom Resource Definition](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/))\nin your cluster and enable the deployment UI on Yatai. Similarly, this script is made for development and testing purposes only.\n\n### \ud83d\udea2 Deploy Bento!\n\nOnce the `yatai-deployment` component was installed, Bentos pushed to Yatai can be deployed to your \nKubernetes cluster and exposed via a Service endpoint. \n\nA Bento Deployment can be created either via Web UI or via a Kubernetes CRD config:\n\n#### Option 1. Simple Deployment via Web UI\n\n* Go to the deployments page: http://127.0.0.1:8080/deployments\n* Click `Create` button and follow the instructions on the UI\n\n \n\n#### Option 2. Deploy with kubectl & CRD\n\nDefine your Bento deployment in a `my_deployment.yaml` file:\n\n```yaml\napiVersion: resources.yatai.ai/v1alpha1\nkind: BentoRequest\nmetadata:\n name: iris-classifier\n namespace: yatai\nspec:\n bentoTag: iris_classifier:3oevmqfvnkvwvuqj\n---\napiVersion: serving.yatai.ai/v2alpha1\nkind: BentoDeployment\nmetadata:\n name: my-bento-deployment\n namespace: yatai\nspec:\n bento: iris-classifier\n ingress:\n enabled: true\n resources:\n limits:\n cpu: \"500m\"\n memory: \"512m\"\n requests:\n cpu: \"250m\"\n memory: \"128m\"\n autoscaling:\n maxReplicas: 10\n minReplicas: 2\n runners:\n - name: iris_clf\n resources:\n limits:\n cpu: \"1000m\"\n memory: \"1Gi\"\n requests:\n cpu: \"500m\"\n memory: \"512m\"\n autoscaling:\n maxReplicas: 4\n minReplicas: 1\n```\n\nApply the deployment to your minikube cluster:\n```bash\nkubectl apply -f my_deployment.yaml\n```\n\nNow you can see the deployment process from the Yatai Web UI and find the endpoint URL for accessing\nthe deployed Bento.\n\n
\n\n#### Option 2. Deploy with kubectl & CRD\n\nDefine your Bento deployment in a `my_deployment.yaml` file:\n\n```yaml\napiVersion: resources.yatai.ai/v1alpha1\nkind: BentoRequest\nmetadata:\n name: iris-classifier\n namespace: yatai\nspec:\n bentoTag: iris_classifier:3oevmqfvnkvwvuqj\n---\napiVersion: serving.yatai.ai/v2alpha1\nkind: BentoDeployment\nmetadata:\n name: my-bento-deployment\n namespace: yatai\nspec:\n bento: iris-classifier\n ingress:\n enabled: true\n resources:\n limits:\n cpu: \"500m\"\n memory: \"512m\"\n requests:\n cpu: \"250m\"\n memory: \"128m\"\n autoscaling:\n maxReplicas: 10\n minReplicas: 2\n runners:\n - name: iris_clf\n resources:\n limits:\n cpu: \"1000m\"\n memory: \"1Gi\"\n requests:\n cpu: \"500m\"\n memory: \"512m\"\n autoscaling:\n maxReplicas: 4\n minReplicas: 1\n```\n\nApply the deployment to your minikube cluster:\n```bash\nkubectl apply -f my_deployment.yaml\n```\n\nNow you can see the deployment process from the Yatai Web UI and find the endpoint URL for accessing\nthe deployed Bento.\n\n \n\n\n\n\n## Community\n\n- To report a bug or suggest a feature request, use [GitHub Issues](https://github.com/bentoml/yatai/issues/new/choose).\n- For other discussions, use [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/)\n- To receive release announcements and get support, join us on [Slack](https://join.slack.bentoml.org).\n\n## Contributing\n\nThere are many ways to contribute to the project:\n\n- If you have any feedback on the project, share it with the community in [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/).\n- Report issues you're facing and \"Thumbs up\" on issues and feature requests that are relevant to you.\n- Investigate bugs and review other developers' pull requests.\n- Contributing code or documentation to the project by submitting a GitHub pull request. See the [development guide](https://github.com/bentoml/yatai/blob/main/DEVELOPMENT.md).\n\n### Usage Reporting\n\nYatai collects usage data that helps our team to improve the product.\nOnly Yatai's internal API calls are being reported. We strip out as much potentially\nsensitive information as possible, and we will never collect user code, model data, model names, or stack traces.\nHere's the [code](./api-server/services/tracking/) for usage tracking.\nYou can opt-out of usage by configuring the helm chart option `doNotTrack` to\n`true`.\n\n```yaml\ndoNotTrack: false\n```\n\nOr by setting the `YATAI_DONOT_TRACK` env var in yatai deployment.\n```yaml\nspec:\n template:\n spec:\n containers:\n env:\n - name: YATAI_DONOT_TRACK\n value: \"true\"\n```\n\n\n## Licence\n\n[Elastic License 2.0 (ELv2)](https://github.com/bentoml/yatai/blob/main/LICENSE.md)\n",
- "source_links": [],
- "id": 138
- },
- {
- "page_link": "https://github.com/yugabyte/yugabyte-db",
- "title": "yugabyte readme",
- "text": "
\n\n\n\n\n## Community\n\n- To report a bug or suggest a feature request, use [GitHub Issues](https://github.com/bentoml/yatai/issues/new/choose).\n- For other discussions, use [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/)\n- To receive release announcements and get support, join us on [Slack](https://join.slack.bentoml.org).\n\n## Contributing\n\nThere are many ways to contribute to the project:\n\n- If you have any feedback on the project, share it with the community in [GitHub Discussions](https://github.com/bentoml/BentoML/discussions) under the [BentoML repo](https://github.com/bentoml/BentoML/).\n- Report issues you're facing and \"Thumbs up\" on issues and feature requests that are relevant to you.\n- Investigate bugs and review other developers' pull requests.\n- Contributing code or documentation to the project by submitting a GitHub pull request. See the [development guide](https://github.com/bentoml/yatai/blob/main/DEVELOPMENT.md).\n\n### Usage Reporting\n\nYatai collects usage data that helps our team to improve the product.\nOnly Yatai's internal API calls are being reported. We strip out as much potentially\nsensitive information as possible, and we will never collect user code, model data, model names, or stack traces.\nHere's the [code](./api-server/services/tracking/) for usage tracking.\nYou can opt-out of usage by configuring the helm chart option `doNotTrack` to\n`true`.\n\n```yaml\ndoNotTrack: false\n```\n\nOr by setting the `YATAI_DONOT_TRACK` env var in yatai deployment.\n```yaml\nspec:\n template:\n spec:\n containers:\n env:\n - name: YATAI_DONOT_TRACK\n value: \"true\"\n```\n\n\n## Licence\n\n[Elastic License 2.0 (ELv2)](https://github.com/bentoml/yatai/blob/main/LICENSE.md)\n",
- "source_links": [],
- "id": 138
- },
- {
- "page_link": "https://github.com/yugabyte/yugabyte-db",
- "title": "yugabyte readme",
- "text": " \n\nReview detailed architecture in our [Docs](https://docs.yugabyte.com/preview/architecture/).\n\n# Need Help?\n\n* You can ask questions, find answers, and help others on our Community [Slack](https://communityinviter.com/apps/yugabyte-db/register), [Forum](https://forum.yugabyte.com), [Stack Overflow](https://stackoverflow.com/questions/tagged/yugabyte-db), as well as Twitter [@Yugabyte](https://twitter.com/yugabyte)\n\n* Please use [GitHub issues](https://github.com/yugabyte/yugabyte-db/issues) to report issues or request new features.\n\n* To Troubleshoot YugabyteDB, cluser/node level isssues, Please refer to [Troubleshooting documentation](https://docs.yugabyte.com/preview/troubleshoot/)\n\n# Contribute\n\nAs an an open-source project with a strong focus on the user community, we welcome contributions as GitHub pull requests. See our [Contributor Guides](https://docs.yugabyte.com/preview/contribute/) to get going. Discussions and RFCs for features happen on the design discussions section of our [Forum](https://forum.yugabyte.com).\n\n# License\n\nSource code in this repository is variously licensed under the Apache License 2.0 and the Polyform Free Trial License 1.0.0. A copy of each license can be found in the [licenses](licenses) directory.\n\nThe build produces two sets of binaries:\n\n* The entire database with all its features (including the enterprise ones) are licensed under the Apache License 2.0\n* The binaries that contain `-managed` in the artifact and help run a managed service are licensed under the Polyform Free Trial License 1.0.0.\n\n> By default, the build options generate only the Apache License 2.0 binaries.\n\n# Read More\n\n* To see our updates, go to [The Distributed SQL Blog](https://blog.yugabyte.com/).\n* For an in-depth design and the YugabyteDB architecture, see our [design specs](https://github.com/yugabyte/yugabyte-db/tree/master/architecture/design).\n* Tech Talks and [Videos](https://www.youtube.com/c/YugaByte).\n* See how YugabyteDB [compares with other databases](https://docs.yugabyte.com/preview/faq/comparisons/).\n",
- "source_links": [],
- "id": 139
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks",
- "title": " Getting Started With Runbooks",
- "text": "# Getting Started With Runbooks\n\nWhat are Plural runbooks? How do I use and create them?\n\n## Articles in this section:\n\nXML Runbooks YAML Runbooks\n\n[XML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\n[YAML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\nPlural Runbooks are meant to be installed alongside your open source applications and serve as interactive tutorials for how to perform common maintenance tasks.\n\nPlural comes with a library of runbooks for each application; you are also free to create your own.\n\nYou can create a runbook just for your own use in your Plural installation, or you can choose to publish the runbook and make it available for other Plural users.\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\nYou can access the runbooks through the Plural admin console; i.e. you must first install the Plural admin console in order to use the runbooks.\n\n[install the Plural admin console](/getting-started/admin-console)\n\n#### \n\n[](/adding-new-application/getting-started-with-runbooks#_)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/getting-started-with-runbooks/index.md)",
- "source_links": [],
- "id": 140
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks/runbook-xml",
- "title": " XML Runbooks",
- "text": "# XML Runbooks\n\nCreating a Plural runbook from XML.\n\n#### XML Tag Definitions\n\n[](/adding-new-application/getting-started-with-runbooks/runbook-xml#xml-tag-definitions)\n\nPlural runbooks are written in XML. XML doesn\u2019t have a predefined markup language, like HTML does. Instead, XML allows users to create their own markup symbols to describe content, making an unlimited and self-defining symbol set.\n\nWe have defined the following xml attributes in an Elixir file that may be used in the creation of your own runbooks and help standardize their layout.\n\n```\ndefmodule Console.Runbooks.Display do\n use Console.Runbooks.Display.Base\n alias Console.Runbooks.Display.{Xml}\n\n schema do\n component \"box\" do\n attributes ~w(direction width height pad margin align justify gap fill color border borderSide borderSize)\n parents ~w(root box)\n end\n\n component \"text\" do\n attributes ~w(size weight value color)\n parents ~w(box text root link)\n end\n\n component \"markdown\" do\n attributes ~w(size weight value)\n parents ~w(box text root)\n end\n\n component \"button\" do\n attributes ~w(primary label href target action headline)\n parents ~w(box)\n end\n\n component \"input\" do\n attributes ~w(placeholder name label datatype)\n parents ~w(box)\n end\n\n component \"timeseries\" do\n attributes ~w(label datasource)\n parents ~w(box)\n end\n\n component \"valueFrom\" do\n attributes ~w(datasource path doc)\n parents ~w(input text)\n end\n\n component \"image\" do\n attributes ~w(width height url)\n parents ~w(box link)\n end\n\n component \"video\" do\n attributes ~w(width height url autoPlay loop)\n parents ~w(box link)\n end\n\n component \"link\" do\n attributes ~w(href target value color weight)\n parents ~w(text box)\n end\n\n component \"table\" do\n attributes ~w(name width height datasource path)\n parents ~w(box)\n end\n\n component \"tableColumn\" do\n attributes ~w(path header width)\n parents ~w(table)\n end\n end\n\n def parse_doc(xml) do\n with {:ok, parsed} <- Xml.from_xml(xml) do\n case validate(parsed) do\n :pass -> {:ok, parsed}\n {:fail, error} -> {:error, error}\n end\n end\n end\nend\n```\n\nMost of these attributes, like box and input are basically grommet React components. However, we would like to call out a few custom attributes that interact with other data from the runbook. They each refer to a datasource and then maybe also a way to access a value at that datasource.\n\ntimeseriesdatasourcevalueFromdatasourcedocpath\n\ndatasource\n\ndatasourcedocpath\n\nHere is an example Runbook XML template composed of these attributes.\n\n```\n
\n\nReview detailed architecture in our [Docs](https://docs.yugabyte.com/preview/architecture/).\n\n# Need Help?\n\n* You can ask questions, find answers, and help others on our Community [Slack](https://communityinviter.com/apps/yugabyte-db/register), [Forum](https://forum.yugabyte.com), [Stack Overflow](https://stackoverflow.com/questions/tagged/yugabyte-db), as well as Twitter [@Yugabyte](https://twitter.com/yugabyte)\n\n* Please use [GitHub issues](https://github.com/yugabyte/yugabyte-db/issues) to report issues or request new features.\n\n* To Troubleshoot YugabyteDB, cluser/node level isssues, Please refer to [Troubleshooting documentation](https://docs.yugabyte.com/preview/troubleshoot/)\n\n# Contribute\n\nAs an an open-source project with a strong focus on the user community, we welcome contributions as GitHub pull requests. See our [Contributor Guides](https://docs.yugabyte.com/preview/contribute/) to get going. Discussions and RFCs for features happen on the design discussions section of our [Forum](https://forum.yugabyte.com).\n\n# License\n\nSource code in this repository is variously licensed under the Apache License 2.0 and the Polyform Free Trial License 1.0.0. A copy of each license can be found in the [licenses](licenses) directory.\n\nThe build produces two sets of binaries:\n\n* The entire database with all its features (including the enterprise ones) are licensed under the Apache License 2.0\n* The binaries that contain `-managed` in the artifact and help run a managed service are licensed under the Polyform Free Trial License 1.0.0.\n\n> By default, the build options generate only the Apache License 2.0 binaries.\n\n# Read More\n\n* To see our updates, go to [The Distributed SQL Blog](https://blog.yugabyte.com/).\n* For an in-depth design and the YugabyteDB architecture, see our [design specs](https://github.com/yugabyte/yugabyte-db/tree/master/architecture/design).\n* Tech Talks and [Videos](https://www.youtube.com/c/YugaByte).\n* See how YugabyteDB [compares with other databases](https://docs.yugabyte.com/preview/faq/comparisons/).\n",
- "source_links": [],
- "id": 139
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks",
- "title": " Getting Started With Runbooks",
- "text": "# Getting Started With Runbooks\n\nWhat are Plural runbooks? How do I use and create them?\n\n## Articles in this section:\n\nXML Runbooks YAML Runbooks\n\n[XML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\n[YAML Runbooks](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\nPlural Runbooks are meant to be installed alongside your open source applications and serve as interactive tutorials for how to perform common maintenance tasks.\n\nPlural comes with a library of runbooks for each application; you are also free to create your own.\n\nYou can create a runbook just for your own use in your Plural installation, or you can choose to publish the runbook and make it available for other Plural users.\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-yaml)\n\n[here](/adding-new-application/getting-started-with-runbooks/runbook-xml)\n\nYou can access the runbooks through the Plural admin console; i.e. you must first install the Plural admin console in order to use the runbooks.\n\n[install the Plural admin console](/getting-started/admin-console)\n\n#### \n\n[](/adding-new-application/getting-started-with-runbooks#_)\n\n[Edit on Github](https://github.com/pluralsh/documentation/blob/main/pages/adding-new-application/getting-started-with-runbooks/index.md)",
- "source_links": [],
- "id": 140
- },
- {
- "page_link": "https://docs.plural.sh/adding-new-application/getting-started-with-runbooks/runbook-xml",
- "title": " XML Runbooks",
- "text": "# XML Runbooks\n\nCreating a Plural runbook from XML.\n\n#### XML Tag Definitions\n\n[](/adding-new-application/getting-started-with-runbooks/runbook-xml#xml-tag-definitions)\n\nPlural runbooks are written in XML. XML doesn\u2019t have a predefined markup language, like HTML does. Instead, XML allows users to create their own markup symbols to describe content, making an unlimited and self-defining symbol set.\n\nWe have defined the following xml attributes in an Elixir file that may be used in the creation of your own runbooks and help standardize their layout.\n\n```\ndefmodule Console.Runbooks.Display do\n use Console.Runbooks.Display.Base\n alias Console.Runbooks.Display.{Xml}\n\n schema do\n component \"box\" do\n attributes ~w(direction width height pad margin align justify gap fill color border borderSide borderSize)\n parents ~w(root box)\n end\n\n component \"text\" do\n attributes ~w(size weight value color)\n parents ~w(box text root link)\n end\n\n component \"markdown\" do\n attributes ~w(size weight value)\n parents ~w(box text root)\n end\n\n component \"button\" do\n attributes ~w(primary label href target action headline)\n parents ~w(box)\n end\n\n component \"input\" do\n attributes ~w(placeholder name label datatype)\n parents ~w(box)\n end\n\n component \"timeseries\" do\n attributes ~w(label datasource)\n parents ~w(box)\n end\n\n component \"valueFrom\" do\n attributes ~w(datasource path doc)\n parents ~w(input text)\n end\n\n component \"image\" do\n attributes ~w(width height url)\n parents ~w(box link)\n end\n\n component \"video\" do\n attributes ~w(width height url autoPlay loop)\n parents ~w(box link)\n end\n\n component \"link\" do\n attributes ~w(href target value color weight)\n parents ~w(text box)\n end\n\n component \"table\" do\n attributes ~w(name width height datasource path)\n parents ~w(box)\n end\n\n component \"tableColumn\" do\n attributes ~w(path header width)\n parents ~w(table)\n end\n end\n\n def parse_doc(xml) do\n with {:ok, parsed} <- Xml.from_xml(xml) do\n case validate(parsed) do\n :pass -> {:ok, parsed}\n {:fail, error} -> {:error, error}\n end\n end\n end\nend\n```\n\nMost of these attributes, like box and input are basically grommet React components. However, we would like to call out a few custom attributes that interact with other data from the runbook. They each refer to a datasource and then maybe also a way to access a value at that datasource.\n\ntimeseriesdatasourcevalueFromdatasourcedocpath\n\ndatasource\n\ndatasourcedocpath\n\nHere is an example Runbook XML template composed of these attributes.\n\n```\n \n
\n  \n
\n  \n
\n 
 \n
\n 
 \n
\n




























































































 \n
\n  \n
\n  \n
\n  \n
\n