This is a Object Detection Model, that predicts the object location as well as classifies it.
Any object detection model comprises of three parts :
- Image Classification
- Locating the object ( Bounding Box prediction )
- Classifying each Bounding Box ( combining 1 and 2 )
- SSD Paper given by Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
- Object Detection using Keras- blog
- Blogs on implementating SSD model in keras
- Existing implementation of SSD on various datasets
Akhil Agrawal
We assign a number of default bounding boxes each of different aspect ratios and scale, accross various feature maps of different sizes. Then we match these default bounding boxes to actual ground truth boxes. This matching is done by Jaccard Overlap ( more on this later ). For each matching default box then model predicts a classification score for each class ( Image Classification ) and then provide adjustments to default boxes for a better overlap.
SSD works as a single model, eliminating the regional proposals, thus works very fast despite having a large number of parameters to train ( SSD300_VGG16 has 26284974 parameters to train before reaching predictions ). The main role in getting a good accuracy through this model, is of having default boxes of multiple scales / aspect ratios, that too, accross feature maps of multiple sizes. This takes account almost all possibilites for an object to lie in a bounding box. As written in the paper :
SSD is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stages and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component
The SSD network contains a deep CNN network to extract various features of the image. It is required manily because the image quality is not high, and various features extracted over diffferent convulational layers help the model to objects.
In the paper VGG_16 is used as base network. VGG_16 is CNN with 16 layers out of which 3 are Dense connected layers and remaining are Convolutional layers. We don't want the dense connected layers as it will loose the information about various features extracted through the CNN.
The output of the base network is then passed through various convulations to obtain feature maps of different sizes so that predictions accross different feature maps can be made. As written in paper :
We add convolutional feature layers to the end of the truncated base network. These layers decrease in size progressively and allow predictions of detections at multiple scales.
The detections from a particular feature map are made by (3, 3) kernel Convolutional filters. For example, say the feature map has dimensions ( 19, 19, _ ). So the image is thought to be divided into a 19 x 19 grid. We associate each grid_box with a number of default boxes ( In the paper, it is either 4 or 6 ). Now for each deafult box in the grid_box:
- We need to predict
num_classes + 1( +1 for background class ) class scores, which is achieved by convolution layer with num_default_boxes * (num_classes + 1) fiters. - We also need to predict the adjustments for bounding boxes, which is achieved by convolution layer with num_default_boxes * 4 filters.
So we have a total of num_default_boxes * (num_classes + 1 + 4) * m * m output values corresponding to a feature map of shape m * m. As written in paper:
Specifically, for each box out of k at a given location, we compute c class scores and the 4 offsets relative to the original default box shape. This results in a total of (c + 4)k filters that are applied around each location in the feature map, yielding (c + 4)kmn outputs for a m × n feature map

Each feature map is associated with a scale by which the size of default boxes are decided. For each feature map, depending on number of boxes required, we have that many aspect_ratios. For example if 4 default boxes are required, then aspect ratios are {1.0, 2.0, 0.5, 1.0 (with scale corresponding to next map)} (in case of 6 boxes, aspect ratios {3.0, 0.33} are added). Each deafult box is also associated with variance values, used in adjusting bounding_box_location. Therefore every grid_box in the feature map will be associated with 4 default boxes, each box has 8 values ( 4 for bounding box, 4 for variance ).
Hence the there will be output of num_default_boxes * 8 * m * m for a feature map of size m * m.
Finally the class_score predictions, bounding_box_location, default_boxes are concatenated, with the output shape being ( feature_map_size, feature_map_size, num_default_boxes * (num_classes + 1 + 4 + 8) ) give us the predictions corresponding to that particular feature map. SSD model obtain predicitons from 6 different feature maps, concatenating the predictions of each will give us the model output. In all there are 8732 predictions/boxes at the end of the model. The shape of model_output/ model_prediction is (8732, num_classes + 1 + 4 + 8).
Any deep learning model, during training evaluates a loss, that is a measure of how good or bad its predictions are. In SSD model, we need to detect the object location ( or find the bounding box parameters) as well as predict the class of the object ( Image classification ).
Hence, to calculate overall loss of the model, we first compute two losses,
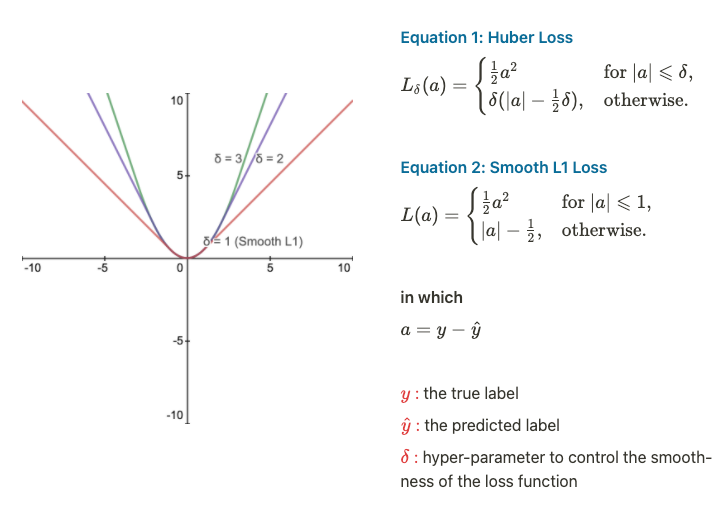
This is a loss function for regression output of parameters of bounding boxes.

This is loss function for classification output of scores for each class.
Now, to improve the model stability, Hard Negative Mining is done.
Since we associated a background class, most of the default boxes will predict to be negative ( By negative we mean that it predicts there is no object, or it is background ). Therefore, we sort the negative boxes and pick the top boxes keeping the number of negative_boxes to number of positive_boxes at most 3 : 1. As written in paper :
Instead of using all the negative examples, we sort them using the highest confidence loss for each default box and pick the top ones so that the ratio between the negatives and positives is at most 3:1.
Finally combining these concepts, the total model loss is calculated, which model will use in learning its parameters in further training.
One of the task to be done before model training is to match a set of default boxes with actual ground truth boxes. This matching is done by a method called Intersection over Union, in which we divide the area of intersection of the two boxes by the area of union of the two boxes to yield a iou value(floating point number). Now if this value is greater than a threshold ( mostly 0.5 ) then we say it is matched, otherwise it is not matched.