!kaggle datasets download -d abhinavwalia95/entity-annotated-corpus
import zipfile
with zipfile.ZipFile("/entity-annotated-corpus.zip", 'r') as zip_ref:
zip_ref.extractall("/entity-annotated-corpus")$ python3 train.py NOTE: On Notebook use-
! git clone link-to-repo
%run train.pyusage: train.py [-h] [--train_path TRAIN_PATH] [--output_dir OUTPUT_DIR]
[--max_len MAX_LEN] [--batch_size BATCH_SIZE]
[--hidden_num HIDDEN_NUM] [--embedding_size EMBEDDING_SIZE]
[--embedding_file EMBEDDING_FILE] [--epoch EPOCH] [--lr LR]
[--require_improvement REQUIRE_IMPROVEMENT]
train
optional arguments:
-h, --help show this help message and exit
--train_path TRAIN_PATH
train file
--output_dir OUTPUT_DIR
output_dir
--max_len MAX_LEN max_len
--batch_size BATCH_SIZE
batch_size
--hidden_num HIDDEN_NUM
hidden_num
--embedding_size EMBEDDING_SIZE
embedding_size
--embedding_file EMBEDDING_FILE
embedding_file
--epoch EPOCH epoch
--lr LR lr
--require_improvement REQUIRE_IMPROVEMENT
require_improvement
- Title : Bidirectional LSTM-CRF Models for Sequence Tagging
- Link : https://arxiv.org/abs/1508.01991
- Author : Zhiheng Huang,Wei Xu,Kai Yu
- Tags : Recurrent Neral Network, Name Entity Recoginition
- Published : 9 Aug, 2015
The paper deals with sequence tagging task of NLP. This paper proposed a variety of Long-Short_Term Memory based models for sequence tagging including LSTM,BI-LSTM,LSTM-CRF anf BI-LSTM-CRF with focus on LSTM+CRF models . It compares performance of proposed model with other models like Conv-CRF etc also showing BI-LSTM-CRF is more robust as compared to others.
1. LSTM Networks
A RNN maintains a memory baseed on history information, which enables the model to predict the current output conditioned on long distances fetures. An input layer represents features at time t. An input layer has the same dimensionality as feature size. An output layer represents a probability distribution over labels at time t. It has the same dimensionality as size of labels. Compared to feedforward network, a RNN introduces the connection between the previous hidden state and current hidden state. This recurrent layer is designed to store history information. The values in the hidden and output layers are computed as follows:
h(t) = f(Ux(t) + Wh(t − 1)), (1)
y(t) = g(Vh(t)), (2)
where U, W, and V are the connection weights to be computed in training time, and f(z) is sigmoid and g(z) is softmax function


where σ is the logistic sigmoid function, and i, f, o and c are the input gate, forget gate, output gate and cell vectors, all of which are the same size as the hidden vector h
2. BI-LSTM Networks
In sequence tagging task, we have access to both past and future input features for a given time, we can thus utilize a bidirectional LSTM network In doing so, we can efficiently make use of past features (via forward states) and future features (viab ackward states) for a specific time frame. The forward and backward passes over the unfolded network over time are carried out in a similar way to regular network forward and backward passes, except unfolding the hidden states for all time steps,also need a special treatment at the beginning and the end of the data points. In paper,authors do forward and backward for whole sentences and reset the hidden states to 0 at the begning of each sentence and batch implementation enables multiple sentences to be processed at the same time.

3. CRF Networks
There are two different ways to make use of neighbor tag information in predicting current tags. The first is to predict a distribution of tags for each time step and then use beam-like decoding to find optimal tag sequences. The second one is to focus on sentence level instead of individual positions, thus leading to Conditional Random Fields (CRF) models. It has been shown that CRFs can produce higher tagging accuracy in general.

4. LSTM-CRF Networks
Combinig a CRF and LSTM model can efficiently use past input features via a LSTM layer and sentence level tag information via a CRF layer. A CRF layer has a state transition matrix as parameters. With such a layer, we can efficiently use past and future tags to predict the current tag. The element [f0]i,t of the matrix is the score output by the network with parameters θ, for the sentence [x]^T1 and for the i-th tag,at the t-th word and introduce a a transition score [A]i,j to model the transition from i-th state to jth for a pair of consecutive time steps.

Note that this transition matrix is position independent. We now denote the new parameters for our network as ˜θ = θ∪ {[A]i,j∀i, j}. The score of a sentence [x]^T1 along with a path of tags [i]^T1 is then given by the sum of transition scores and network scores:

5. BI-LSTM-CRF-Networks
Similar to a LSTM-CRF network, we combine a bidirectional LSTM network and a CRF network to form a BI-LSTM-CRF network. In addition to the past input features and sentence level tag information used in a LSTM-CRF model, a BILSTM-CRF model can use the future input features. The extra features can boost tagging accuracy as we will show in experiments.

All models used in this paper share a generic SGD forward and backward training procedure. authors choose the most complicated model, BI-LSTM-CRF, to illustrate the training algorithm as shown in Algorithm 1.

In each epoch,the whole training data is divided into batches and process one batch at a time. Each batch contains a list of sentences which is determined by the parameter of batch size. For each batch,first run bidirectional LSTM-CRF model forward pass which includes the forward pass for both forward state and backward state of LSTM. As a result, we get the the output score fθ([x]T1) for all tags at all positions, then run CRF layer forward and backward pass to compute gradients for network output and state transition edges. After that,back propagate the errors from the output to the input, which includes the backward pass for both forward and backward states of LSTM. Finally update the network parameters which include the state transition matrix [A]i,j∀i, j, and the original bidirectional LSTM
Default Parameters
- Learning Rate - 0.001
- Maximum length of Sentence - 50
- Epoch - 15
- Batch Size - 64
- Hidden Unit size 512
- Embedding size - 300
- Optimizer - Adam
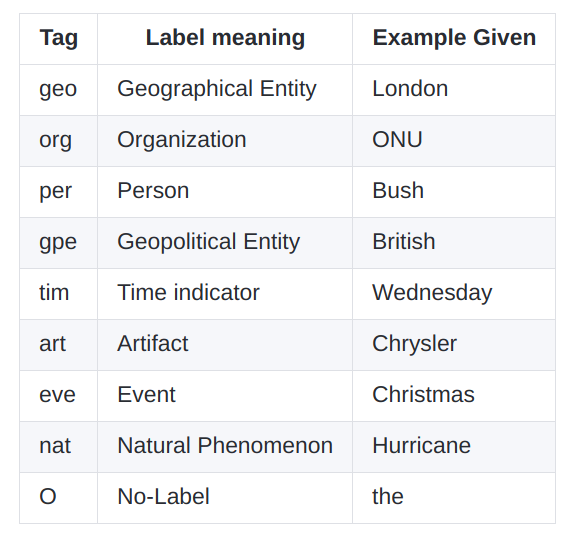
Dataset- Entity tags are encoded using a BIO annotation scheme, where each entity label is prefixed with either B or I letter. B- denotes the beginning and I- inside of an entity. The prefixes are used to detect multi-word entities All other words, which don’t refer to entities of interest, are labeled with the O tag.
- Loss vs Steps Graph

- Accuracy vs Steps Graph

To estimate the robustness of models with respect to engineered features,authors train LSTM, BI-LSTM, CRF, LSTMCRF, and BI-LSTM-CRF models with word features only. CRF models’ performance is significantly degraded with the removal of spelling and context features. This reveals the fact that CRF models heavily rely on engineered featuresto obtain good performance. On the other hand, LSTM based models, especially BI-LSTM and BI-LSTM-CRF models are more robust and they are less affected by the removal of engineering features. For all three tasks, BI-LSTM-CRF models result in the highest tagging accuracy