From 64174fb150428e547f61724b06c361ba42652762 Mon Sep 17 00:00:00 2001
From: HenryCheval <875542931@qq.com>
Date: Thu, 7 Sep 2023 14:27:24 +0800
Subject: [PATCH 1/3] 1427
---
.../the-azure-ml-sdk-way.md | 15 +--------------
1 file changed, 1 insertion(+), 14 deletions(-)
diff --git a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.md b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.md
index edba1b8518..3121e298c1 100644
--- a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.md
+++ b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.md
@@ -1,17 +1,4 @@
----
-jupytext:
- cell_metadata_filter: -all
- formats: md:myst
- text_representation:
- extension: .md
- format_name: myst
- format_version: 0.13
- jupytext_version: 1.11.5
-kernelspec:
- display_name: Python 3
- language: python
- name: python3
----
+
# Data Science in the cloud: The "Azure ML SDK" way
From 6b4f6b4751827088f82e218365f21d1144ca4092 Mon Sep 17 00:00:00 2001
From: HenryCheval <875542931@qq.com>
Date: Thu, 7 Sep 2023 17:36:10 +0800
Subject: [PATCH 2/3] 1736
---
.../the-low-code-no-code-way.md | 14 --------------
1 file changed, 14 deletions(-)
diff --git a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-low-code-no-code-way.md b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-low-code-no-code-way.md
index ae8b659dfd..6b197dabb7 100644
--- a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-low-code-no-code-way.md
+++ b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-low-code-no-code-way.md
@@ -1,17 +1,3 @@
----
-jupytext:
- cell_metadata_filter: -all
- formats: md:myst
- text_representation:
- extension: .md
- format_name: myst
- format_version: 0.13
- jupytext_version: 1.11.5
-kernelspec:
- display_name: Python 3
- language: Python
- name: Python3
----
# The "low code/no code" way
From d2cdf1aa473163e246a929e38a1f6393d61294bf Mon Sep 17 00:00:00 2001
From: HenryCheval <875542931@qq.com>
Date: Tue, 12 Sep 2023 14:28:39 +0800
Subject: [PATCH 3/3] data_science_int_the_cloud_and_loss-functions
---
.../data-science-in-the-cloud.ipynb | 98 +++
.../introduction.ipynb | 177 +++++
.../the-azure-ml-sdk-way.ipynb | 653 ++++++++++++++++++
.../regression/loss-function.md | 314 +++++++++
.../regression/loss-function_en.ipynb | 264 +++++++
.../regression/loss-function_en.md | 250 +++++++
6 files changed, 1756 insertions(+)
create mode 100644 open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/data-science-in-the-cloud.ipynb
create mode 100644 open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/introduction.ipynb
create mode 100644 open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.ipynb
create mode 100644 open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function.md
create mode 100644 open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb
create mode 100644 open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md
diff --git a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/data-science-in-the-cloud.ipynb b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/data-science-in-the-cloud.ipynb
new file mode 100644
index 0000000000..c26969d578
--- /dev/null
+++ b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/data-science-in-the-cloud.ipynb
@@ -0,0 +1,98 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1d836c62-8f2c-4865-9fac-ed5b564eb5cb",
+ "metadata": {
+ "tags": [
+ "hide-cell"
+ ]
+ },
+ "source": [
+ "---\n",
+ "jupytext:\n",
+ " cell_metadata_filter: -all\n",
+ " formats: md:myst\n",
+ " text_representation:\n",
+ " extension: .md\n",
+ " format_name: myst\n",
+ " format_version: 0.13\n",
+ " jupytext_version: 1.11.5\n",
+ "kernelspec:\n",
+ " display_name: Python 3\n",
+ " language: python\n",
+ " name: python3\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "974e7f14-2559-4c4a-90ac-17dba0c00cdc",
+ "metadata": {
+ "tags": [
+ "hide-input"
+ ]
+ },
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "此时不应有 pip。\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Install the necessary dependencies\n",
+ "import os\n",
+ "import sys\n",
+ "!(sys.executable) -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0bf72540",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Data Science in the cloud\n",
+ "\n",
+ "\n",
+ "\n",
+ "> Photo by [Jelleke Vanooteghem](https://unsplash.com/@ilumire) from [Unsplash](https://unsplash.com/s/photos/cloud?orientation=landscape)\n",
+ "\n",
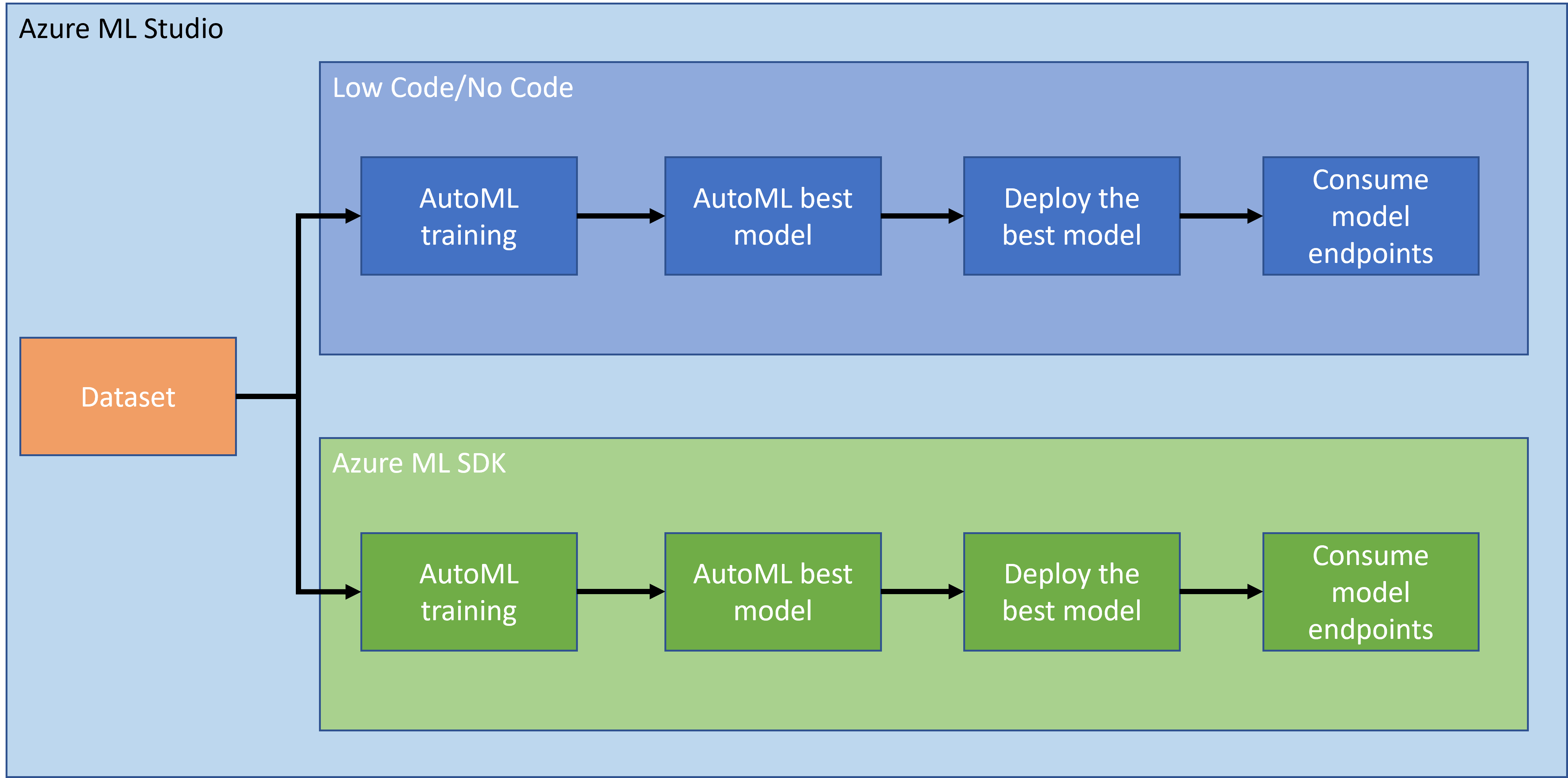
+ "When it comes to doing data science with big data, the cloud can be a game changer. In the next three sections, we are going to see what the cloud is and why it can be very helpful. We are also going to explore a heart failure dataset and build a model to help assess the probability of someone having heart failure. We will use the power of the cloud to train, deploy and consume a model in two different ways. One way uses only the user interface in a Low code/No code fashion, and the other way uses the Azure Machine Learning Software Developer Kit (Azure ML SDK).\n",
+ "\n",
+ "\n",
+ "\n",
+ "---\n",
+ "\n",
+ ":::{tableofcontents}\n",
+ ":::"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/introduction.ipynb b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/introduction.ipynb
new file mode 100644
index 0000000000..d065fd3f5b
--- /dev/null
+++ b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/introduction.ipynb
@@ -0,0 +1,177 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "3a4fd454-064e-4abe-a85a-e4fa3fc480d2",
+ "metadata": {
+ "tags": [
+ "hide-cell"
+ ]
+ },
+ "source": [
+ "---\n",
+ "jupytext:\n",
+ " cell_metadata_filter: -all\n",
+ " formats: md:myst\n",
+ " text_representation:\n",
+ " extension: .md\n",
+ " format_name: myst\n",
+ " format_version: 0.13\n",
+ " jupytext_version: 1.11.5\n",
+ "kernelspec:\n",
+ " display_name: Python 3\n",
+ " language: python\n",
+ " name: python3\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "115df6f4-970c-40fe-b8cb-d8d6399d3b5f",
+ "metadata": {
+ "tags": [
+ "hide-input"
+ ]
+ },
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "此时不应有 -m。\n"
+ ]
+ }
+ ],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "!(sys.executable) -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8937ab8d",
+ "metadata": {},
+ "source": [
+ "# Introduction\n",
+ "\n",
+ "In this section, you will learn the fundamental principles of the cloud, then you will see why it can be interesting for you to use cloud services to run your data science projects and we'll look at some examples of data science projects run in the cloud.\n",
+ "\n",
+ "## What is the cloud?\n",
+ "\n",
+ "The Cloud, or Cloud Computing, is the delivery of a wide range of pay-as-you-go computing services hosted on infrastructure over the internet. Services include solutions such as storage, databases, networking, software, analytics, and intelligent services.\n",
+ "\n",
+ "We usually differentiate the Public, Private and Hybrid clouds as follows:\n",
+ "\n",
+ "* Public cloud: a public cloud is owned and operated by a third-party cloud service provider which delivers its computing resources over the Internet to the public.\n",
+ "* Private cloud: refers to cloud computing resources used exclusively by a single business or organization, with services and infrastructure maintained on a private network.\n",
+ "* Hybrid cloud: the hybrid cloud is a system that combines public and private clouds. Users opt for an on-premises data center while allowing data and applications to be run on one or more public clouds.\n",
+ "\n",
+ "Most cloud computing services fall into three categories: Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS).\n",
+ "\n",
+ "* Infrastructure as a Service (IaaS): users rent an IT infrastructure such as servers and virtual machines (VMs), storage, networks, operating systems\n",
+ "* Platform as a Service (PaaS): users rent an environment for developing, testing, delivering, and managing software applications. Users don鈥檛 need to worry about setting up or managing the underlying infrastructure of servers, storage, network, and databases needed for development.\n",
+ "* Software as a Service (SaaS): users get access to software applications over the Internet, on-demand and typically on a subscription basis. Users don't need to worry about hosting and managing the software application, the underlying infrastructure or the maintenance, like software upgrades and security patching.\n",
+ "\n",
+ "Some of the largest Cloud providers are Amazon Web Services, Google Cloud Platform and Microsoft Azure.\n",
+ "\n",
+ "## Why choose the cloud for Data Science?\n",
+ "\n",
+ "Developers and IT professionals chose to work with the Cloud for many reasons, including the following:\n",
+ "\n",
+ "* Innovation: you can power your applications by integrating innovative services created by Cloud providers directly into your apps.\n",
+ "* Flexibility: you only pay for the services that you need and can choose from a wide range of services. You typically pay as you go and adapt your services according to your evolving needs.\n",
+ "* Budget: you don't need to make initial investments to purchase hardware and software, set up and run on-site data centers and you can just pay for what you use.\n",
+ "* Scalability: your resources can scale according to the needs of your project, which means that your apps can use more or less computing power, storage and bandwidth, by adapting to external factors at any given time.\n",
+ "* Productivity: you can focus on your business rather than spending time on tasks that can be managed by someone else, such as managing data centers.\n",
+ "* Reliability: Cloud Computing offers several ways to continuously back up your data and you can set up disaster recovery plans to keep your business and services going, even in times of crisis.\n",
+ "* Security: you can benefit from policies, technologies and controls that strengthen the security of your project.\n",
+ "\n",
+ "These are some of the most common reasons why people choose to use Cloud services. Now that we have a better understanding of what the Cloud is and what its main benefits are, let's look more specifically into the jobs of Data scientists and developers working with data, and how the Cloud can help them with several challenges they might face:\n",
+ "\n",
+ "* Storing large amounts of data: instead of buying, managing and protecting big servers, you can store your data directly in the cloud, with solutions such as Azure Cosmos DB, Azure SQL Database and Azure Data Lake Storage.\n",
+ "* Performing Data Integration: data integration is an essential part of Data Science, that lets you make a transition from data collection to taking action. With data integration services offered in the cloud, you can collect, transform and integrate data from various sources into a single data warehouse, with Data Factory.\n",
+ "* Processing data: processing vast amounts of data requires a lot of computing power, and not everyone has access to machines powerful enough for that, which is why many people choose to directly harness the cloud's huge computing power to run and deploy their solutions.\n",
+ "* Using data analytics services: cloud services like Azure Synapse Analytics, Azure Stream Analytics and Azure Databricks to help you turn your data into actionable insights.\n",
+ "* Using Machine Learning and data intelligence services: Instead of starting from scratch, you can use machine learning algorithms offered by the cloud provider, with services such as AzureML. You can also use cognitive services such as speech-to-text, text-to-speech, computer vision and more.\n",
+ "\n",
+ "## Examples of Data Science in the cloud\n",
+ "\n",
+ "Let's make this more tangible by looking at a couple of scenarios.\n",
+ "\n",
+ "### Real-time social media sentiment analysis\n",
+ "\n",
+ "We'll start with a scenario commonly studied by people who start with machine learning: social media sentiment analysis in real time.\n",
+ "\n",
+ "Let's say you run a news media website and you want to leverage live data to understand what content your readers could be interested in. To know more about that, you can build a program that performs real-time sentiment analysis of data from Twitter publications, on topics that are relevant to your readers.\n",
+ "\n",
+ "The key indicators you will look at are the volume of tweets on specific topics (hashtags) and sentiment, which is established using analytics tools that perform sentiment analysis around the specified topics.\n",
+ "\n",
+ "The steps necessary to create this project are as follows:\n",
+ "\n",
+ "* Create an event hub for streaming input, which will collect data from Twitter.\n",
+ "* Configure and start a Twitter client application, which will call the Twitter Streaming APIs.\n",
+ "* Create a Stream Analytics job.\n",
+ "* Specify the job input and query.\n",
+ "* Create an output sink and specify the job output.\n",
+ "* Start the job.\n",
+ "\n",
+ "To view the full process, check out the [documentation](https://docs.microsoft.com/azure/stream-analytics/stream-analytics-twitter-sentiment-analysis-trends?WT.mc_id=academic-77958-bethanycheum&ocid=AID30411099).\n",
+ "\n",
+ "### Scientific papers analysis\n",
+ "\n",
+ "Let's take another example of a project created by [Dmitry Soshnikov](http://soshnikov.com), one of the authors of this curriculum.\n",
+ "\n",
+ "Dmitry created a tool that analyses COVID papers. By reviewing this project, you will see how you can create a tool that extracts knowledge from scientific papers, gains insights and helps researchers navigate through large collections of papers in an efficient way.\n",
+ "\n",
+ "Lets see the different steps used for this:\n",
+ "\n",
+ "* Extracting and pre-processing information with [Text Analytics for Health](https://docs.microsoft.com/azure/cognitive-services/text-analytics/how-tos/text-analytics-for-health?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109).\n",
+ "* Using [Azure ML](https://azure.microsoft.com/services/machine-learning?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) to parallelize the processing.\n",
+ "* Storing and querying information with [Cosmos DB](https://azure.microsoft.com/services/cosmos-db?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109).\n",
+ "* Create an interactive dashboard for data exploration and visualization using Power BI.\n",
+ "\n",
+ "To see the full process, visit [Dmitry's blog](https://soshnikov.com/science/analyzing-medical-papers-with-azure-and-text-analytics-for-health/).\n",
+ "\n",
+ "As you can see, we can leverage Cloud services in many ways to perform Data Science.\n",
+ "\n",
+ "## Self study\n",
+ "\n",
+ "* [What Is Cloud Computing? A Beginner's Guide | Microsoft Azure](https://azure.microsoft.com/overview/what-is-cloud-computing?ocid=AID3041109)\n",
+ "* [Social media analysis with Azure Stream Analytics | Microsoft Learn](https://docs.microsoft.com/azure/stream-analytics/stream-analytics-twitter-sentiment-analysis-trends?ocid=AID3041109)\n",
+ "* [Analyzing COVID Medical Papers with Azure and Text Analytics for Health](https://soshnikov.com/science/analyzing-medical-papers-with-azure-and-text-analytics-for-health/)\n",
+ "\n",
+ "## Your turn! 馃殌\n",
+ "\n",
+ "[Market research](https://static-1300131294.cos.ap-shanghai.myqcloud.com\n",
+ "/assignments/data-science/market-research.md)\n",
+ "\n",
+ "## Acknowledgments\n",
+ "\n",
+ "Thanks to Microsoft for creating the open-source course [Data Science for Beginners](https://github.com/microsoft/Data-Science-For-Beginners). It inspires the majority of the content in this chapter."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.ipynb b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.ipynb
new file mode 100644
index 0000000000..1b88e173c9
--- /dev/null
+++ b/open-machine-learning-jupyter-book/data-science/data-science-in-the-cloud/the-azure-ml-sdk-way.ipynb
@@ -0,0 +1,653 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "29b93d70-961b-4303-9e72-c4234d2732ab",
+ "metadata": {
+ "tags": [
+ "hide-cell"
+ ]
+ },
+ "source": [
+ "---\n",
+ "jupytext:\n",
+ " cell_metadata_filter: -all\n",
+ " formats: md:myst\n",
+ " text_representation:\n",
+ " extension: .md\n",
+ " format_name: myst\n",
+ " format_version: 0.13\n",
+ " jupytext_version: 1.11.5\n",
+ "kernelspec:\n",
+ " display_name: Python 3\n",
+ " language: python\n",
+ " name: python3\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "03ad9f8f-77a4-43ed-8f1f-844e41283a77",
+ "metadata": {
+ "tags": [
+ "hide-input"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "# Install the necessary dependencies\n",
+ "import os\n",
+ "import sys\n",
+ "!(sys.executable) -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59d64a78",
+ "metadata": {},
+ "source": [
+ "# Data Science in the cloud: The \"Azure ML SDK\" way\n",
+ "\n",
+ "## Introduction\n",
+ "\n",
+ "### What is Azure ML SDK?\n",
+ "\n",
+ "Data scientists and AI developers use the Azure Machine Learning SDK to build and run Machine Learning workflows with the Azure Machine Learning service. You can interact with the service in any Python environment, including Jupyter Notebooks, Visual Studio Code, or your favorite Python IDE.\n",
+ "\n",
+ "Key areas of the SDK include:\n",
+ "\n",
+ "- Explore, prepare and manage the lifecycle of your datasets used in Machine Learning experiments.\n",
+ "- Manage cloud resources for monitoring, logging, and organizing your Machine Learning experiments.\n",
+ "- Train models either locally or by using cloud resources, including GPU-accelerated model training.\n",
+ "- Use automated Machine Learning, which accepts configuration parameters and training data. It automatically iterates through algorithms and hyperparameter settings to find the best model for running predictions.\n",
+ "- Deploy web services to convert your trained models into RESTful services that can be consumed in any application.\n",
+ "\n",
+ "[Learn more about the Azure Machine Learning SDK](https://docs.microsoft.com/python/api/overview/azure/ml?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109)\n",
+ "\n",
+ "In the [previous section](./the-low-code-no-code-way.md), we saw how to train, deploy and consume a model in a Low code/No code fashion. We used the Heart Failure dataset to generate and Heart failure prediction model. In this section, we are going to do the exact same thing but using the Azure Machine Learning SDK.\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Heart failure prediction project and dataset introduction\n",
+ "\n",
+ "Check [here](./the-low-code-no-code-way.md) the Heart failure prediction project and dataset introduction.\n",
+ "\n",
+ "## Training a model with the Azure ML SDK\n",
+ "\n",
+ "### Create an Azure ML workspace\n",
+ "\n",
+ "For simplicity, we are going to work on a Jupyter Notebook. This implies that you already have a Workspace and a compute instance. If you already have a Workspace, you can directly jump to section 2.3 Notebook creation.\n",
+ "\n",
+ "If not, please follow the instructions in section **2.1 Create an Azure ML workspace** in the [previous section](./the-low-code-no-code-way.md) to create a workspace.\n",
+ "\n",
+ "### Create a compute instance\n",
+ "\n",
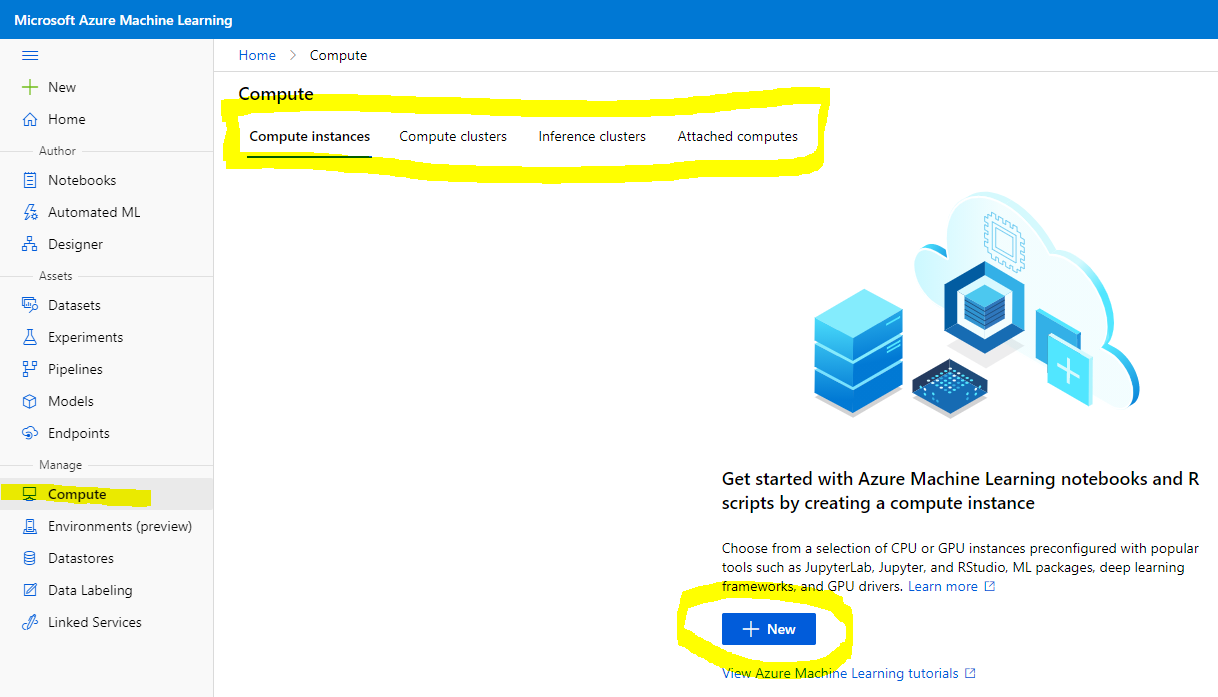
+ "In the [Azure ML workspace](https://ml.azure.com/) that we created earlier, go to the compute menu and you will see the different compute resources available\n",
+ "\n",
+ "\n",
+ "\n",
+ "Let's create a compute instance to provision a Jupyter Notebook.\n",
+ "\n",
+ "1. Click on the + New button. \n",
+ "2. Give a name to your compute instance.\n",
+ "3. Choose your options: CPU or GPU, VM size and core number.\n",
+ "4. Click in the Create button.\n",
+ "\n",
+ "Congratulations, you have just created a compute instance! We will use this compute instance to create a Notebook in the [Creating Notebooks section](#23-creating-notebooks).\n",
+ "\n",
+ "### Loading the dataset\n",
+ "\n",
+ "Refer to the [previous section](./the-low-code-no-code-way.md) in the section [Loading the dataset](#loading-the-dataset) if you have not uploaded the dataset yet.\n",
+ "\n",
+ "### Creating Notebooks\n",
+ ":::{note}\n",
+ "For the next step you can either create a new notebook from scratch, or you can upload the [notebook we created](https://static-1300131294.cos.ap-shanghai.myqcloud.com/assignments/data-science/data-science-in-the-cloud-the-azure-ml-sdk-way.ipynb) in you Azure ML Studio. To upload it, simply click on the \"Notebook\" menu and upload the notebook.\n",
+ ":::\n",
+ "\n",
+ "Notebooks are a really important part of the data science process. They can be used to Conduct Exploratory Data Analysis (EDA), call out to a computer cluster to train a model, and call out to an inference cluster to deploy an endpoint.\n",
+ "\n",
+ "To create a Notebook, we need a compute node that is serving out the Jupyter Notebook instance. Go back to the [Azure ML workspace](https://ml.azure.com/) and click on Compute instances. In the list of compute instances, you should see the [compute instance we created earlier](#create-a-compute-instance).\n",
+ "\n",
+ "1. In the Applications section, click on the Jupyter option.\n",
+ "2. Tick the \"Yes, I understand\" box and click on the Continue button.\n",
+ "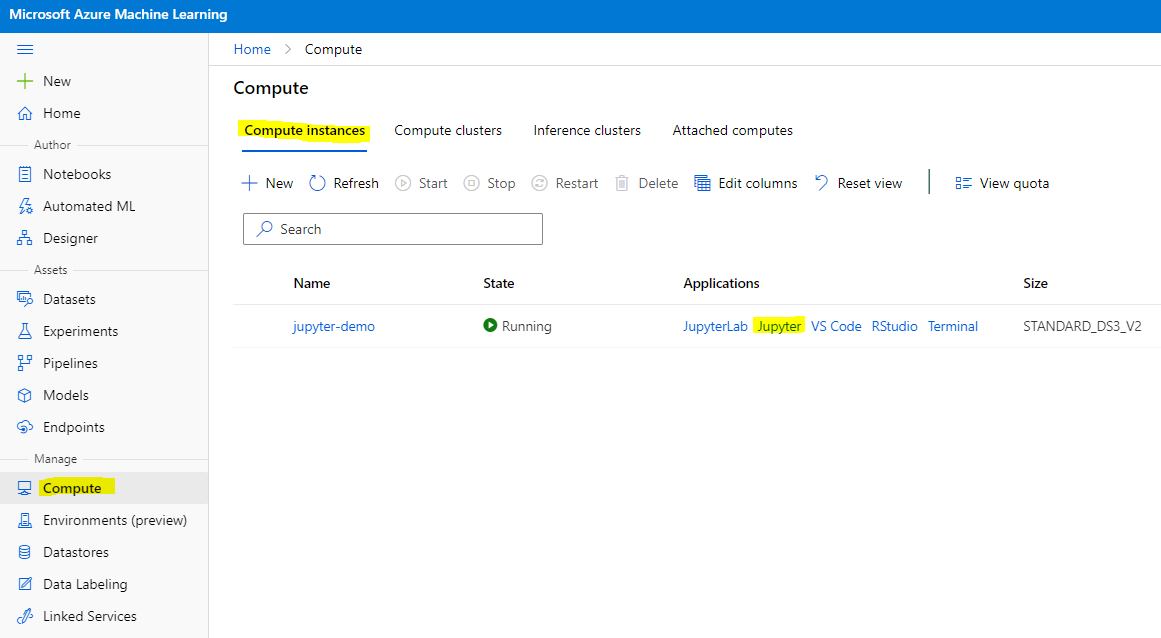\n",
+ "3. This should open a new browser tab with your Jupyter Notebook instance as follow. Click on the \"New\" button to create a notebook.\n",
+ "\n",
+ "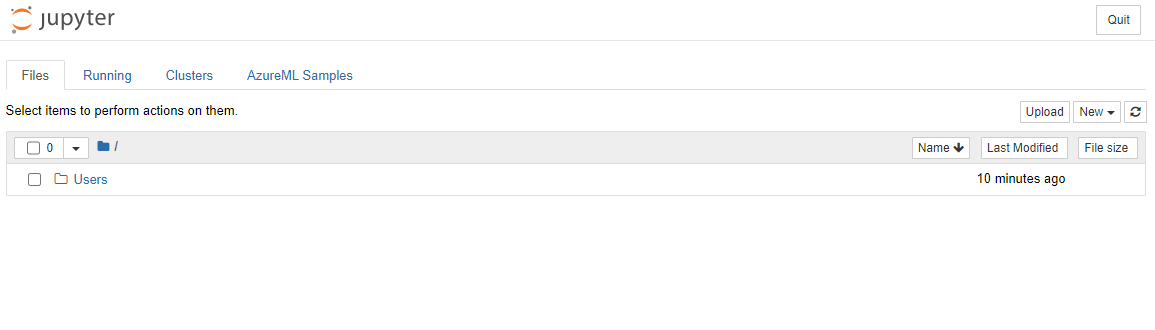\n",
+ "\n",
+ "Now that we have a Notebook, we can start training the model with Azure ML SDK.\n",
+ "\n",
+ "### Training a model\n",
+ "\n",
+ "First of all, if you ever have a doubt, refer to the [Azure ML SDK documentation](https://docs.microsoft.com/python/api/overview/azure/ml?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109). It contains all the necessary information to understand the modules we are going to see in this section.\n",
+ "\n",
+ "#### Setup Workspace, experiment, compute cluster and dataset\n",
+ "\n",
+ "You need to load the `workspace` from the configuration file using the following code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b627f214",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.core import Workspace\n",
+ "ws = Workspace.from_config()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "feb816c2",
+ "metadata": {},
+ "source": [
+ "This returns an object of type `Workspace` that represents the workspace. You need to create an `experiment` using the following code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "580f0059",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.core import Experiment\n",
+ "experiment_name = 'aml-experiment'\n",
+ "experiment = Experiment(ws, experiment_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a0a8d6a0",
+ "metadata": {},
+ "source": [
+ "To get or create an experiment from a workspace, you request the experiment using the experiment name. Experiment name must be 3-36 characters, start with a letter or a number, and can only contain letters, numbers, underscores, and dashes. If the experiment is not found in the workspace, a new experiment is created.\n",
+ "\n",
+ "Now you need to create a compute cluster for the training using the following code. Note that this step can take a few minutes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ee657af3",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.core.compute import AmlCompute\n",
+ "\n",
+ "aml_name = \"heart-f-cluster\"\n",
+ "try:\n",
+ " aml_compute = AmlCompute(ws, aml_name)\n",
+ " print('Found existing AML compute context.')\n",
+ "except:\n",
+ " print('Creating new AML compute context.')\n",
+ " aml_config = AmlCompute.provisioning_configuration(vm_size=\"Standard_D2_v2\", min_nodes=1, max_nodes=3)\n",
+ " aml_compute = AmlCompute.create(ws, name=aml_name, provisioning_configuration=aml_config)\n",
+ " aml_compute.wait_for_completion(show_output=True)\n",
+ "\n",
+ "cts = ws.compute_targets\n",
+ "compute_target = cts[aml_name]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fe24fcbf",
+ "metadata": {},
+ "source": [
+ "You can get the dataset from the workspace using the dataset name in the following way:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27146c4f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "dataset = ws.datasets['heart-failure-records']\n",
+ "df = dataset.to_pandas_dataframe()\n",
+ "df.describe()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6e5ff9df",
+ "metadata": {},
+ "source": [
+ "#### AutoML configuration and training\n",
+ "\n",
+ "To set the AutoML configuration, use the [AutoMLConfig class](https://docs.microsoft.com/python/api/azureml-train-automl-client/azureml.train.automl.automlconfig(class)?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109).\n",
+ "\n",
+ "As described in the doc, there are a lot of parameters with which you can play with. For this project, we will use the following parameters:\n",
+ "\n",
+ "- `experiment_timeout_minutes`: The maximum amount of time (in minutes) that the experiment is allowed to run before it is automatically stopped and results are automatically made available\n",
+ "- `max_concurrent_iterations`: The maximum number of concurrent training iterations allowed for the experiment.\n",
+ "- `primary_metric`: The primary metric used to determine the experiment's status.\n",
+ "- `compute_target`: The Azure Machine Learning compute target to run the Automated Machine Learning experiment on.\n",
+ "- `task`: The type of task to run. Values can be 'classification', 'regression', or 'forecasting' depending on the type of automated ML problem to solve.\n",
+ "- `training_data`: The training data to be used within the experiment. It should contain both training features and a label column (optionally a sample weights column).\n",
+ "- `label_column_name`: The name of the label column.\n",
+ "- `path`: The full path to the Azure Machine Learning project folder.\n",
+ "- `enable_early_stopping`: Whether to enable early termination if the score is not improving in the short term.\n",
+ "- `featurization`: Indicator for whether the featurization step should be done automatically or not, or whether customized featurization should be used.\n",
+ "- `debug_log`: The log file to write debug information to."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "803d5333",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.train.automl import AutoMLConfig\n",
+ "\n",
+ "project_folder = './aml-project'\n",
+ "\n",
+ "automl_settings = {\n",
+ " \"experiment_timeout_minutes\": 20,\n",
+ " \"max_concurrent_iterations\": 3,\n",
+ " \"primary_metric\" : 'AUC_weighted'\n",
+ "}\n",
+ "\n",
+ "automl_config = AutoMLConfig(compute_target=compute_target,\n",
+ " task = \"classification\",\n",
+ " training_data=dataset,\n",
+ " label_column_name=\"DEATH_EVENT\",\n",
+ " path = project_folder, \n",
+ " enable_early_stopping= True,\n",
+ " featurization= 'auto',\n",
+ " debug_log = \"automl_errors.log\",\n",
+ " **automl_settings\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "329e6b63",
+ "metadata": {},
+ "source": [
+ "Now that you have your configuration set, you can train the model using the following code. This step can take up to an hour depending on your cluster size."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "faac0a89",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "remote_run = experiment.submit(automl_config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6505578a",
+ "metadata": {},
+ "source": [
+ "You can run the RunDetails widget to show the different experiments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e2cb2729",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.widgets import RunDetails\n",
+ "RunDetails(remote_run).show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "95a6b0e4",
+ "metadata": {},
+ "source": [
+ "## Model deployment and endpoint consumption with the Azure ML SDK\n",
+ "\n",
+ "### Saving the best model\n",
+ "\n",
+ "The `remote_run` is an object of type [AutoMLRun](https://docs.microsoft.com/python/api/azureml-train-automl-client/azureml.train.automl.run.automlrun?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109). This object contains the method `get_output()` which returns the best run and the corresponding fitted model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7f9b1cda",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "best_run, fitted_model = remote_run.get_output()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "30d9a6b5",
+ "metadata": {},
+ "source": [
+ "You can see the parameters used for the best model by just printing the fitted_model and see the properties of the best model by using the [get_properties()](https://docs.microsoft.com/python/api/azureml-core/azureml.core.run(class)?view=azure-ml-py#azureml_core_Run_get_properties?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98f6aedd",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "best_run.get_properties()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19886101",
+ "metadata": {},
+ "source": [
+ "Now register the model with the [register_model](https://docs.microsoft.com/python/api/azureml-train-automl-client/azureml.train.automl.run.automlrun?view=azure-ml-py#register-model-model-name-none--description-none--tags-none--iteration-none--metric-none-?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58bfb854",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "model_name = best_run.properties['model_name']\n",
+ "script_file_name = 'inference/score.py'\n",
+ "best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')\n",
+ "description = \"aml heart failure project sdk\"\n",
+ "model = best_run.register_model(\n",
+ " model_name = model_name,\n",
+ " model_path = './outputs/',\n",
+ " description = description,\n",
+ " tags = None\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "60f1f2ed",
+ "metadata": {},
+ "source": [
+ "### Model deployment\n",
+ "\n",
+ "Once the best model is saved, we can deploy it with the [InferenceConfig](https://docs.microsoft.com/python/api/azureml-core/azureml.core.model.inferenceconfig?view=azure-ml-py?ocid=AID3041109) class. InferenceConfig represents the configuration settings for a custom environment used for deployment. The [AciWebservice](https://docs.microsoft.com/python/api/azureml-core/azureml.core.webservice.aciwebservice?view=azure-ml-py) class represents a Machine Learning model deployed as a web service endpoint on Azure Container Instances. A deployed service is created from a model, script, and associated files. The resulting web service is a load-balanced, HTTP endpoint with a REST API. You can send data to this API and receive the prediction returned by the model.\n",
+ "\n",
+ "The model is deployed using the [deploy](https://docs.microsoft.com/python/api/azureml-core/azureml.core.model(class)?view=azure-ml-py#deploy-workspace--name--models--inference-config-none--deployment-config-none--deployment-target-none--overwrite-false--show-output-false-?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff017022",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "from azureml.core.model import InferenceConfig, Model\n",
+ "from azureml.core.webservice import AciWebservice\n",
+ "\n",
+ "inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())\n",
+ "\n",
+ "aciconfig = AciWebservice.deploy_configuration(\n",
+ " cpu_cores = 1,\n",
+ " memory_gb = 1,\n",
+ " tags = {'type': \"automl-heart-failure-prediction\"},\n",
+ " description = 'Sample service for AutoML Heart Failure Prediction'\n",
+ ")\n",
+ "\n",
+ "aci_service_name = 'automl-hf-sdk'\n",
+ "aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)\n",
+ "aci_service.wait_for_deployment(True)\n",
+ "print(aci_service.state)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fa4f3650",
+ "metadata": {},
+ "source": [
+ "This step should take a few minutes.\n",
+ "\n",
+ "### Endpoint consumption\n",
+ "\n",
+ "You consume your endpoint by creating a sample input:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "150970ae",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "data = {\n",
+ " \"data\":\n",
+ " [\n",
+ " {\n",
+ " 'age': \"60\",\n",
+ " 'anaemia': \"false\",\n",
+ " 'creatinine_phosphokinase': \"500\",\n",
+ " 'diabetes': \"false\",\n",
+ " 'ejection_fraction': \"38\",\n",
+ " 'high_blood_pressure': \"false\",\n",
+ " 'platelets': \"260000\",\n",
+ " 'serum_creatinine': \"1.40\",\n",
+ " 'serum_sodium': \"137\",\n",
+ " 'sex': \"false\",\n",
+ " 'smoking': \"false\",\n",
+ " 'time': \"130\",\n",
+ " },\n",
+ " ],\n",
+ "}\n",
+ "\n",
+ "test_sample = str.encode(json.dumps(data))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "126e712f",
+ "metadata": {},
+ "source": [
+ "And then you can send this input to your model for prediction :"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f0c75509",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "code-cell"
+ ],
+ "id": ""
+ },
+ "tags": [
+ "output-scoll"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "response = aci_service.run(input_data=test_sample)\n",
+ "response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "14c00460",
+ "metadata": {},
+ "source": [
+ "This should output `'{\"result\": [false]}'`. This means that the patient input we sent to the endpoint generated the prediction `false` which means this person is not likely to have a heart attack.\n",
+ "\n",
+ "Congratulations! You just consumed the model deployed and trained on Azure ML with the Azure ML SDK!\n",
+ "\n",
+ ":::{note}\n",
+ "Once you are done with the project, don't forget to delete all the resources.\n",
+ ":::\n",
+ "\n",
+ "## Your turn! 馃殌\n",
+ "\n",
+ " There are many other things you can do through the SDK, unfortunately, we can not view them all in this section. But good news, learning how to skim through the SDK documentation can take you a long way on your own. Have a look at the Azure ML SDK documentation and find the `Pipeline` class that allows you to create pipelines. A Pipeline is a collection of steps which can be executed as a workflow.\n",
+ "\n",
+ ":::{note}\n",
+ "**HINT:** Go to the [SDK documentation](https://docs.microsoft.com/python/api/overview/azure/ml/?view=azure-ml-py?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) and type keywords in the search bar like \"Pipeline\". You should have the `azureml.pipeline.core.Pipeline` class in the search results.\n",
+ ":::\n",
+ "\n",
+ "Assignment - [Data Science project using Azure ML SDK](https://static-1300131294.cos.ap-shanghai.myqcloud.com/assignments/data-science/data-science-project-using-azure-ml-sdk.md)\n",
+ "\n",
+ "## Self study\n",
+ "\n",
+ "In this section, you learned how to train, deploy and consume a model to predict heart failure risk with the Azure ML SDK in the cloud. Check this [documentation](https://docs.microsoft.com/python/api/overview/azure/ml/?view=azure-ml-py?WT.mc_id=academic-77958-bethanycheum&ocid=AID3041109) for further information about the Azure ML SDK. Try to create your own model with the Azure ML SDK.\n",
+ "\n",
+ "## Acknowledgments\n",
+ "\n",
+ "Thanks to Microsoft for creating the open-source course [Data Science for Beginners](https://github.com/microsoft/Data-Science-For-Beginners). It inspires the majority of the content in this chapter."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function.md b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function.md
new file mode 100644
index 0000000000..5c26ad26ee
--- /dev/null
+++ b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function.md
@@ -0,0 +1,314 @@
+# 股市预测实操训练线性回归模型(1/6)
+
+机器学习中的线性回归就能预测股市?这个真实数据集包含了2005-2020年间美国几个巨头公司的股市数据,包括每天的开盘价、收盘价、最高价、最低价、成交量、换手率等信息。今天我们就用它来练练手,看看我们会亏还是会赚。
+
+
+
+ +
+
+
+加载数据集,我们先来看一看这些年表现一直非常稳健的苹果公司。
+
+
+
+
+
+
+加载数据集,我们先来看一看这些年表现一直非常稳健的苹果公司。
+
+
+ +
+
+这里一共有3732天的股市数据,每一行数据有63列。这里有一列数据很特别,叫做Close_forecast,
+它是股票的次日收盘价。在爬取的原始数据中这一列并不存在,是Kaggle
+为了将其改为更适合机器学习练习数据集而加入的。
+
+
+
+
+
+这里一共有3732天的股市数据,每一行数据有63列。这里有一列数据很特别,叫做Close_forecast,
+它是股票的次日收盘价。在爬取的原始数据中这一列并不存在,是Kaggle
+为了将其改为更适合机器学习练习数据集而加入的。
+
+
+ +
+
+我们选取Close_forecast这一列作为机器学习模型的预测目标
+target、也就是标签
+label,其余的62列作为特征feature。然后用75%的数据作为训练集,25%的数据作为测试集。
+
+
+
+
+
+我们选取Close_forecast这一列作为机器学习模型的预测目标
+target、也就是标签
+label,其余的62列作为特征feature。然后用75%的数据作为训练集,25%的数据作为测试集。
+
+
+ +
+
+最后调用 sklearn 的 LinearRegression.fit
+方法,还是简单的两行代码,我们就把线性回归模型训练出来了。
+
+
+
+
+
+最后调用 sklearn 的 LinearRegression.fit
+方法,还是简单的两行代码,我们就把线性回归模型训练出来了。
+
+
+ +
+
+有了模型,就该我们的测试集上场了,我们将模型在测试集上进行预测做个测试来看一看。
+
+
+
+
+
+有了模型,就该我们的测试集上场了,我们将模型在测试集上进行预测做个测试来看一看。
+
+
+ +
+
+这结果乍一看可能会吓你一跳,预测出来的股价波动的也太厉害了。不过我可以先给大家吃一颗定心丸,我们的线性回归模型没有问题,而且事实上它的效果很好。上面的代码,大家只管放心去用。至于为什么会有这么杂乱变动的预测结果,我们将在下起内容中再详细分析。
+
+
+
+
+
+这结果乍一看可能会吓你一跳,预测出来的股价波动的也太厉害了。不过我可以先给大家吃一颗定心丸,我们的线性回归模型没有问题,而且事实上它的效果很好。上面的代码,大家只管放心去用。至于为什么会有这么杂乱变动的预测结果,我们将在下起内容中再详细分析。
+
+
+ +
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操模型性能评估(2/6)
+
+在上期内容中我们在一个真实股市数据集上,用线性回归进行了股价预测,得到的结果看上去杂乱无章、大涨大跌。线性回归真的能预测股价吗?如果股市是这个样子,相信你和我的内心OS会是一样的:跑!跑的越远越好!
+
+
+
+
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操模型性能评估(2/6)
+
+在上期内容中我们在一个真实股市数据集上,用线性回归进行了股价预测,得到的结果看上去杂乱无章、大涨大跌。线性回归真的能预测股价吗?如果股市是这个样子,相信你和我的内心OS会是一样的:跑!跑的越远越好!
+
+
+ +
+
+
+
+
+
+
+ +
+
+事出反常必有妖,我们来仔细看看测试集里面的y_test 长什么样。原来,y_test
+在创建的时候,顺序是打乱的。事实上,sklearn里面的train_test_split方面里面有个参数叫做shuffle,它默认是
+True ,也就是在训练测试集分离时默认是顺序打乱的。
+
+打乱顺序本身其实并没有什么问题,但在日常生活里股价是随着时间比较平滑变动的一条曲线,所以我们测试的结果乍看上去会很怪,因为它不符合常识。如果我们把shuffle设置为False就能避免这种情况,大家感兴趣可以自己动手试试。
+
+
+
+
+
+事出反常必有妖,我们来仔细看看测试集里面的y_test 长什么样。原来,y_test
+在创建的时候,顺序是打乱的。事实上,sklearn里面的train_test_split方面里面有个参数叫做shuffle,它默认是
+True ,也就是在训练测试集分离时默认是顺序打乱的。
+
+打乱顺序本身其实并没有什么问题,但在日常生活里股价是随着时间比较平滑变动的一条曲线,所以我们测试的结果乍看上去会很怪,因为它不符合常识。如果我们把shuffle设置为False就能避免这种情况,大家感兴趣可以自己动手试试。
+
+
+ +
+
+我们这里把训练集中真实的 y标签值和预测出来的
+y标签值放在一起,然后排序,将两者对比一下,能看到每天的差别都很小。
+
+
+
+
+
+我们这里把训练集中真实的 y标签值和预测出来的
+y标签值放在一起,然后排序,将两者对比一下,能看到每天的差别都很小。
+
+
+ +
+
+我们把上面的数据用 matplotlib
+作图来看一下,更加一目了然,结果非常的好,蓝色的真实值和绿色的标签值几乎完全重合。
+
+
+
+
+
+我们把上面的数据用 matplotlib
+作图来看一下,更加一目了然,结果非常的好,蓝色的真实值和绿色的标签值几乎完全重合。
+
+
+ +
+
+我们计算一下R平方、MAPE这些评估指标,结果也很好,和上面的分析一致。这都表明线性回归在这个真实的股市数据上用起来效果很好。
+
+
+
+
+
+我们计算一下R平方、MAPE这些评估指标,结果也很好,和上面的分析一致。这都表明线性回归在这个真实的股市数据上用起来效果很好。
+
+
+ +
+
+需要提醒大家注意,评估指标往往是在测试数据集上使用,但也可以同时在训练集和测试集上计算再进行对比评估。为什么跟大家强调这一点呢?因为在下一期的内容中我们会学习到损失函数,它的计算是只针对训练集的。
+
+
+
+
+
+需要提醒大家注意,评估指标往往是在测试数据集上使用,但也可以同时在训练集和测试集上计算再进行对比评估。为什么跟大家强调这一点呢?因为在下一期的内容中我们会学习到损失函数,它的计算是只针对训练集的。
+
+
+ +
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操引入损失函数(3/6)
+
+在往期内容中我们使用线性回归对股价进行了预测,在测试集上测试,并计算评估指标,模型的效果非常的好。股市中赚钱是不是有点太容易了?没错,这完全是在做梦。
+
+
+
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操引入损失函数(3/6)
+
+在往期内容中我们使用线性回归对股价进行了预测,在测试集上测试,并计算评估指标,模型的效果非常的好。股市中赚钱是不是有点太容易了?没错,这完全是在做梦。
+
+ +
+
+
+我们把苹果公司2005年到2022年每天的收盘价作图来看,如果你在图中的第一天买入,一直持有到最后一天,大概会有几十倍的投资回报。但实际中想要做到这一点其实非常的难。
+
+作为普通投资者,我们没有时间机器,即使我们非常看好苹果公司的股票,也无法预测出15年后的事情。所以一般来说我们也不会特别长期的持有股票,往往是进行短期或者中期的投资。如果股价在一定时间内有较好的增长,我们会在某个时间点卖出,选择见好就收;或者,股价持续低迷,我们也会在某个时间点选择卖出,及时止损。
+
+
+
+
+
+我们把苹果公司2005年到2022年每天的收盘价作图来看,如果你在图中的第一天买入,一直持有到最后一天,大概会有几十倍的投资回报。但实际中想要做到这一点其实非常的难。
+
+作为普通投资者,我们没有时间机器,即使我们非常看好苹果公司的股票,也无法预测出15年后的事情。所以一般来说我们也不会特别长期的持有股票,往往是进行短期或者中期的投资。如果股价在一定时间内有较好的增长,我们会在某个时间点卖出,选择见好就收;或者,股价持续低迷,我们也会在某个时间点选择卖出,及时止损。
+
+ +
+
+
+
+
+
+
+ +
+
+当然,我们在这里没法教给大家股票投资的策略,但如果机器学习能够比较好的预测股价,那么对于我们制定投资策略则会有很大的帮助。通过模型预测我们知道,苹果的股票在15年中持续上涨,那么我们在2005年买入,在2020年卖出,是一定可以盈利的。
+
+而如果上面得到的模型在更细的粒度上也足够准确,那么我们甚至可以在这15年中多次交易,每逢股价要降时就在局部高点抛出手里的全部股票,而每逢股价要升时就在局部低点将资金全部买入股票,这样的收益肯定要比简单的长期持有要更加的优化。当然这里的前提是我们的预测结果要与真实情况完全吻合,事实上它是不可能的。
+
+
+
+
+
+当然,我们在这里没法教给大家股票投资的策略,但如果机器学习能够比较好的预测股价,那么对于我们制定投资策略则会有很大的帮助。通过模型预测我们知道,苹果的股票在15年中持续上涨,那么我们在2005年买入,在2020年卖出,是一定可以盈利的。
+
+而如果上面得到的模型在更细的粒度上也足够准确,那么我们甚至可以在这15年中多次交易,每逢股价要降时就在局部高点抛出手里的全部股票,而每逢股价要升时就在局部低点将资金全部买入股票,这样的收益肯定要比简单的长期持有要更加的优化。当然这里的前提是我们的预测结果要与真实情况完全吻合,事实上它是不可能的。
+
+
+ +
+
+虽然评估指标显示我们模型的性能是不错的,但它是否好到能够支撑前面提到的第二种投资策略呢?或者说,是否可以对它进一步优化,让我们就能够从第二种投资策略中赚到更多的钱呢?
+
+答案是肯定的,而且这里我们就需要引出一个新的概念了,它就是损失函数Loss
+Function,也叫作代价函数cost
+function,用来在训练集上度量模型预测与真实值之间的差异或错误程度。那么下节内容,我们就来看一看如何计算损失函数。
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操计算损失函数(4/6)
+
+往期内容我们使用线性回归成功进行了股市的预测,在它的指导下我们高买低卖,赚的盆满钵满。但我们还不满足,因为模型的预测和真实情况还是会出现偏差,导致我们有几次买在了高点而卖在了低点。本着钱多了不烫手的原则,我们希望通过损失函数来对模型进一步优化,今天就先来看一看如何计算损失函数。
+
+针对回归任务,常见的损失函数有三种。第一种, 均方误差(Mean Squared
+Error,MSE),用来衡量**训练集上**预测值与真实值之间的**平方差**的平均值;第二种,
+均绝对误差(Mean Absolute
+Error,MAE),用来衡量**训练集上**预测值与真实值之间的**绝对差**的平均值。
+
+
+
+
+
+虽然评估指标显示我们模型的性能是不错的,但它是否好到能够支撑前面提到的第二种投资策略呢?或者说,是否可以对它进一步优化,让我们就能够从第二种投资策略中赚到更多的钱呢?
+
+答案是肯定的,而且这里我们就需要引出一个新的概念了,它就是损失函数Loss
+Function,也叫作代价函数cost
+function,用来在训练集上度量模型预测与真实值之间的差异或错误程度。那么下节内容,我们就来看一看如何计算损失函数。
+
+跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操计算损失函数(4/6)
+
+往期内容我们使用线性回归成功进行了股市的预测,在它的指导下我们高买低卖,赚的盆满钵满。但我们还不满足,因为模型的预测和真实情况还是会出现偏差,导致我们有几次买在了高点而卖在了低点。本着钱多了不烫手的原则,我们希望通过损失函数来对模型进一步优化,今天就先来看一看如何计算损失函数。
+
+针对回归任务,常见的损失函数有三种。第一种, 均方误差(Mean Squared
+Error,MSE),用来衡量**训练集上**预测值与真实值之间的**平方差**的平均值;第二种,
+均绝对误差(Mean Absolute
+Error,MAE),用来衡量**训练集上**预测值与真实值之间的**绝对差**的平均值。
+
+
+ +
+
+那么我们就来计算一下训练集上每个数据点的平方误差和绝对误差,代码非常的简单,取出训练集的标签与预测结果两列,借助NumPy进行一些简单的数学运算即可。得到的结果我们将它们命名为AE与SE两列,就是图中紫色线框中的数据。大家能看到它的取值不论大小总不为0,也就是说我们的预测值与实际值总是多多少少存在一些差异。
+
+
+
+
+
+那么我们就来计算一下训练集上每个数据点的平方误差和绝对误差,代码非常的简单,取出训练集的标签与预测结果两列,借助NumPy进行一些简单的数学运算即可。得到的结果我们将它们命名为AE与SE两列,就是图中紫色线框中的数据。大家能看到它的取值不论大小总不为0,也就是说我们的预测值与实际值总是多多少少存在一些差异。
+
+
+ +
+
+更进一步,我们可以作图看看AE和SE的结果随时间变化的情况。能够发现,随着时间的推移它们的结果呈现出不断变大的趋势,这也就是说,在训练集上测试出的结果越靠近2005年越准确。
+
+
+
+
+
+更进一步,我们可以作图看看AE和SE的结果随时间变化的情况。能够发现,随着时间的推移它们的结果呈现出不断变大的趋势,这也就是说,在训练集上测试出的结果越靠近2005年越准确。
+
+
+ +
+
+最后,我们在AE和SE这两列数据上取均值,就可以得到损失函数的结果MAE和MSE了。到这里,我们就计算出了线性回归的两种最常见的损失函数的值。
+
+
+
+
+
+最后,我们在AE和SE这两列数据上取均值,就可以得到损失函数的结果MAE和MSE了。到这里,我们就计算出了线性回归的两种最常见的损失函数的值。
+
+
+ +
+
+用心的同学可能已经发现了,这两个损失函数跟之前学过的评估指标中的MAE和MSE好像很相似啊。没错,损失函数和评估指标这两个概念确实有很多重叠之处,但也有关键区别。下期内容我们来一起好好分析一下。
+
+
+
+
+
+用心的同学可能已经发现了,这两个损失函数跟之前学过的评估指标中的MAE和MSE好像很相似啊。没错,损失函数和评估指标这两个概念确实有很多重叠之处,但也有关键区别。下期内容我们来一起好好分析一下。
+
+
+ +
+
+跟我一起,一天一点机器学习。
+
+# 股市预测实操理解损失函数(5/6)
+
+损失函数,评估指标,傻傻分不清楚,首先我们来看看它们两者之间的相同之处。损失函数和评估指标都是用来衡量模型预测能力的。其实我们说的
+MAE或MSE
+本身只是一些统计学概念,它们可以被用作评估指标、也可以被用作损失函数,两者的数学计算完全一样。
+
+这里上方的代码块计算的是MAE和MSE两个损失函数,下方的代码块计算的是MAE和MSE两个评估指标,如果输入数据一样,得到的结果也会完全一样。
+
+
+
+
+
+跟我一起,一天一点机器学习。
+
+# 股市预测实操理解损失函数(5/6)
+
+损失函数,评估指标,傻傻分不清楚,首先我们来看看它们两者之间的相同之处。损失函数和评估指标都是用来衡量模型预测能力的。其实我们说的
+MAE或MSE
+本身只是一些统计学概念,它们可以被用作评估指标、也可以被用作损失函数,两者的数学计算完全一样。
+
+这里上方的代码块计算的是MAE和MSE两个损失函数,下方的代码块计算的是MAE和MSE两个评估指标,如果输入数据一样,得到的结果也会完全一样。
+
+
+ +
+
+那么损失函数和评估指标又有哪些关键不同呢?第一,评估指标除了 MAE、MSE
+等外,还有 R squared、explained
+variance等,这些是损失函数里没有的概念。第二,两者的目的不同,损失函数主要用于模型训练,帮助模型逐步调整参数以减小预测误差;而评估指标用于对训练好的模型的性能进行总结和比较,以了解模型的整体效果,或者比较不同模型之间的性能差异,指导模型选择。第三,两者的优化方向不同,对于损失函数,我们往往追求最小化它的结果,因为更小的损失值意味着预测值与真实值更为接近;而在评估指标中,我们往往追求最大化其值,比如
+R
+squared,因为更大的评估指标值意味着模型性能更好。这个差异反映了损失函数和评估指标在机器学习任务中的不同角色。第四,在上期的内容中我强调过损失函数往往是在训练集上计算,在测试集上计算的情况很少;相反,评估指标往往是在测试集上计算,在训练集上计算的情况少一些。
+
+
+
+
+
+那么损失函数和评估指标又有哪些关键不同呢?第一,评估指标除了 MAE、MSE
+等外,还有 R squared、explained
+variance等,这些是损失函数里没有的概念。第二,两者的目的不同,损失函数主要用于模型训练,帮助模型逐步调整参数以减小预测误差;而评估指标用于对训练好的模型的性能进行总结和比较,以了解模型的整体效果,或者比较不同模型之间的性能差异,指导模型选择。第三,两者的优化方向不同,对于损失函数,我们往往追求最小化它的结果,因为更小的损失值意味着预测值与真实值更为接近;而在评估指标中,我们往往追求最大化其值,比如
+R
+squared,因为更大的评估指标值意味着模型性能更好。这个差异反映了损失函数和评估指标在机器学习任务中的不同角色。第四,在上期的内容中我强调过损失函数往往是在训练集上计算,在测试集上计算的情况很少;相反,评估指标往往是在测试集上计算,在训练集上计算的情况少一些。
+
+
+ +
+
+
+
+
+
+
+ +
+
+
+
+
+
+
+ +
+
+
+
+
+
+
+ +
+
+
+
+
+ +
+
+这四点差异是不是有些太多了,一时难以消化吸收?没有关系,在回归任务中这两者的区别没有在分类任务中明显。这里只是打一个伏笔,在分类任务中,我们会再次学习评估指标和损失函数的概念。在对机器学习的全貌有了更多的了解之后,这些知识就会逐渐融会贯通,变得简单起来。
+
+大家循序渐进,跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操梯度下降优化模型(6/6)
+
+往期内容我们使用sklearn的LinearRegression,在真实的美国股市数据集上训练,用线性回归模型进行了股价的预测,并且计算了模型的损失函数。我们还可以使用SGDRegressor进行线性回归模型的求解。这里的
+SGD 是随机梯度下降Stochastic Gradient
+Descent的缩写,大家暂时不用管它的细节,我们很快将学习到。
+
+
+
+
+
+这四点差异是不是有些太多了,一时难以消化吸收?没有关系,在回归任务中这两者的区别没有在分类任务中明显。这里只是打一个伏笔,在分类任务中,我们会再次学习评估指标和损失函数的概念。在对机器学习的全貌有了更多的了解之后,这些知识就会逐渐融会贯通,变得简单起来。
+
+大家循序渐进,跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# 股市预测实操梯度下降优化模型(6/6)
+
+往期内容我们使用sklearn的LinearRegression,在真实的美国股市数据集上训练,用线性回归模型进行了股价的预测,并且计算了模型的损失函数。我们还可以使用SGDRegressor进行线性回归模型的求解。这里的
+SGD 是随机梯度下降Stochastic Gradient
+Descent的缩写,大家暂时不用管它的细节,我们很快将学习到。
+
+
+ +
+
+SGDRegressor的训练过程是迭代式的,我们可以记录下训练过程中损失函数的变化,这样就可以利用损失函数对模型进行优化。
+
+我们从模型的初始状态开始,训练100个Epoch,也就是100个轮次,并且把每轮训练后的损失函数记录在一个数组里面。大家再次注意,我们的损失函数是在训练数据集上计算的。
+
+
+
+
+
+SGDRegressor的训练过程是迭代式的,我们可以记录下训练过程中损失函数的变化,这样就可以利用损失函数对模型进行优化。
+
+我们从模型的初始状态开始,训练100个Epoch,也就是100个轮次,并且把每轮训练后的损失函数记录在一个数组里面。大家再次注意,我们的损失函数是在训练数据集上计算的。
+
+
+ +
+
+我们把前30个损失函数的结果用Matplotlib作图,可以看出随着轮次的增加,损失函数逐渐下降,而且前期下降较快、后期下降较慢。
+
+
+
+
+
+我们把前30个损失函数的结果用Matplotlib作图,可以看出随着轮次的增加,损失函数逐渐下降,而且前期下降较快、后期下降较慢。
+
+
+ +
+
+进一步,我们把100个训练轮次的损失函数结果都作图展示,可以看出,它的值在前期一直下降,直到大概60个轮次后才趋于稳定。
+
+
+
+
+
+进一步,我们把100个训练轮次的损失函数结果都作图展示,可以看出,它的值在前期一直下降,直到大概60个轮次后才趋于稳定。
+
+
+ +
+
+你肯定会好奇,SDGRegressor模型的损失函数在训练的过程中逐渐变小,这背后究竟发生了什么?我们打印一下模型的
+coef_属性来看看,它也就是线性模型的各项系数。首先从1个训练轮次得到的模型开始,我们得到了这样的结果。
+
+
+
+
+
+你肯定会好奇,SDGRegressor模型的损失函数在训练的过程中逐渐变小,这背后究竟发生了什么?我们打印一下模型的
+coef_属性来看看,它也就是线性模型的各项系数。首先从1个训练轮次得到的模型开始,我们得到了这样的结果。
+
+
+ +
+
+然后是10个训练轮次时的模型参数,我们得到了这样的结果。
+
+
+
+
+
+然后是10个训练轮次时的模型参数,我们得到了这样的结果。
+
+
+ +
+
+最后再看100个训练轮次时的模型参数,可以发现,随着训练轮次的增加,线性模型的参数也一直在变动。
+
+
+
+
+
+最后再看100个训练轮次时的模型参数,可以发现,随着训练轮次的增加,线性模型的参数也一直在变动。
+
+
+ +
+
+其实大家可以这么理解,在SDGRegressor模型的训练过程中,算法在一直尝试降低损失函数,换句话说这就是模型优化的方向。SDGRegressor的每一轮训练都会得到一个模型,这个模型在训练集上就可以得到一个新的损失函数值。如果算法每一次都能寻找到一个比上一次更小的损失函数结果,那么模型也就会比上一个轮次更优化一些。这样,随着训练轮次的增加,损失函数会越变越小直至趋于稳定,而模型的参数也与其共同变化,最终达到最优结果。
+
+
+
+
+
+其实大家可以这么理解,在SDGRegressor模型的训练过程中,算法在一直尝试降低损失函数,换句话说这就是模型优化的方向。SDGRegressor的每一轮训练都会得到一个模型,这个模型在训练集上就可以得到一个新的损失函数值。如果算法每一次都能寻找到一个比上一次更小的损失函数结果,那么模型也就会比上一个轮次更优化一些。这样,随着训练轮次的增加,损失函数会越变越小直至趋于稳定,而模型的参数也与其共同变化,最终达到最优结果。
+
+
+ +
+
+当然这里的表述有一些不严谨的地方,我们将在接下来的梯度下降系列内容中为大家带来更加细致的解答。跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
diff --git a/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb
new file mode 100644
index 0000000000..274bdddf4b
--- /dev/null
+++ b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb
@@ -0,0 +1,264 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "867b1fe7",
+ "metadata": {},
+ "source": [
+ "# Stock Market Prediction Hands-On: Training a Linear Regression Model (1/6)\n",
+ "\n",
+ "Can linear regression in machine learning predict the stock market? This real dataset includes stock market data from several major U.S. companies between 2005 and 2020, including daily opening and closing prices, highest and lowest prices, trading volume, turnover rate, and other information. Today, we are going to use it to practice and see if we will make a profit or incur losses.\n",
+ "\n",
+ "
+
+
+当然这里的表述有一些不严谨的地方,我们将在接下来的梯度下降系列内容中为大家带来更加细致的解答。跟我一起,一天一点机器学习。
+
+对应 kaggle数据集:
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+对应代码:
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
diff --git a/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb
new file mode 100644
index 0000000000..274bdddf4b
--- /dev/null
+++ b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.ipynb
@@ -0,0 +1,264 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "867b1fe7",
+ "metadata": {},
+ "source": [
+ "# Stock Market Prediction Hands-On: Training a Linear Regression Model (1/6)\n",
+ "\n",
+ "Can linear regression in machine learning predict the stock market? This real dataset includes stock market data from several major U.S. companies between 2005 and 2020, including daily opening and closing prices, highest and lowest prices, trading volume, turnover rate, and other information. Today, we are going to use it to practice and see if we will make a profit or incur losses.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Let's begin by taking a look at Apple Inc., a company that has shown consistently robust performance over the years.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Let's begin by taking a look at Apple Inc., a company that has shown consistently robust performance over the years.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Here, we have a total of 3,732 days' worth of stock market data, with each row containing 63 columns. There's one particular column that stands out, known as 'Close_forecast,' which represents the stock's closing price for the next day. It's important to note that this column doesn't exist in the original scraped data; it was added by Kaggle to make the dataset more suitable for machine learning exercises.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Here, we have a total of 3,732 days' worth of stock market data, with each row containing 63 columns. There's one particular column that stands out, known as 'Close_forecast,' which represents the stock's closing price for the next day. It's important to note that this column doesn't exist in the original scraped data; it was added by Kaggle to make the dataset more suitable for machine learning exercises.\n",
+ "\n",
+ " \n",
+ "\n",
+ "We will select the 'Close_forecast' column as the target for our machine learning model, which serves as the label. The remaining 62 columns will be used as features. We will split the data, using 75% for training and 25% for testing.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We will select the 'Close_forecast' column as the target for our machine learning model, which serves as the label. The remaining 62 columns will be used as features. We will split the data, using 75% for training and 25% for testing.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Finally, with just two simple lines of code, we will call the `LinearRegression.fit` method from sklearn to train our linear regression model.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Finally, with just two simple lines of code, we will call the `LinearRegression.fit` method from sklearn to train our linear regression model.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Now that we have our model, it's time to put it to the test on our testing dataset. We'll use the model to make predictions on the test set and evaluate its performance.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Now that we have our model, it's time to put it to the test on our testing dataset. We'll use the model to make predictions on the test set and evaluate its performance.\n",
+ "\n",
+ " \n",
+ "\n",
+ "At first glance, the results might seem a bit surprising, given the significant fluctuations in the predicted stock prices. However, I can offer some reassurance that our linear regression model is functioning correctly, and in fact, it performs quite well. You can confidently use the code provided above. As for the reason behind the seemingly chaotic predictions, we will delve into a more detailed analysis in the upcoming sections.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "At first glance, the results might seem a bit surprising, given the significant fluctuations in the predicted stock prices. However, I can offer some reassurance that our linear regression model is functioning correctly, and in fact, it performs quite well. You can confidently use the code provided above. As for the reason behind the seemingly chaotic predictions, we will delve into a more detailed analysis in the upcoming sections.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Model Performance Evaluation (2/6)\n",
+ "\n",
+ "In the previous segment, we attempted stock price prediction using linear regression on a real stock market dataset. The results seemed chaotic, with significant fluctuations and sharp ups and downs in stock prices. Can linear regression truly predict stock prices? If the stock market behaves in this manner, I believe both you and me would share the sentiment: Run! The farther, the better!\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Model Performance Evaluation (2/6)\n",
+ "\n",
+ "In the previous segment, we attempted stock price prediction using linear regression on a real stock market dataset. The results seemed chaotic, with significant fluctuations and sharp ups and downs in stock prices. Can linear regression truly predict stock prices? If the stock market behaves in this manner, I believe both you and me would share the sentiment: Run! The farther, the better!\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "Strange occurrences often have underlying reasons. Let's take a closer look at what y_test in the test set actually looks like. As it turns out, when y_test was created, the order was shuffled. In fact, there's a parameter in sklearn's train_test_split function called 'shuffle,' which is set to 'True' by default. This means that by default, the order is shuffled when splitting the training and test sets.\n",
+ "\n",
+ "Shuffling the order itself isn't necessarily a problem, but in our daily lives, stock prices generally follow a relatively smooth curve over time. Therefore, the test results may initially appear odd because they don't align with common sense. If we set 'shuffle' to 'False,' we can avoid this situation. You might find it interesting to try this out for yourselves.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "Strange occurrences often have underlying reasons. Let's take a closer look at what y_test in the test set actually looks like. As it turns out, when y_test was created, the order was shuffled. In fact, there's a parameter in sklearn's train_test_split function called 'shuffle,' which is set to 'True' by default. This means that by default, the order is shuffled when splitting the training and test sets.\n",
+ "\n",
+ "Shuffling the order itself isn't necessarily a problem, but in our daily lives, stock prices generally follow a relatively smooth curve over time. Therefore, the test results may initially appear odd because they don't align with common sense. If we set 'shuffle' to 'False,' we can avoid this situation. You might find it interesting to try this out for yourselves.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Here, we're taking the real y-label values from the training set and the predicted y-label values, placing them together, and then sorting them. By doing this, we can compare the two and observe that the differences between them are quite small on a daily basis.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Here, we're taking the real y-label values from the training set and the predicted y-label values, placing them together, and then sorting them. By doing this, we can compare the two and observe that the differences between them are quite small on a daily basis.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Let's visualize the data using matplotlib to gain a clearer understanding. The results are highly promising, as the blue real values and the green predicted values almost perfectly overlap.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Let's visualize the data using matplotlib to gain a clearer understanding. The results are highly promising, as the blue real values and the green predicted values almost perfectly overlap.\n",
+ "\n",
+ " \n",
+ "\n",
+ "We calculate the R-squared, MAPE, and other evaluation metrics, and the results are excellent, consistent with the previous analysis. All of this indicates that linear regression performs well when applied to this real stock market dataset.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We calculate the R-squared, MAPE, and other evaluation metrics, and the results are excellent, consistent with the previous analysis. All of this indicates that linear regression performs well when applied to this real stock market dataset.\n",
+ "\n",
+ " \n",
+ "\n",
+ "It's important to note that evaluation metrics are often calculated on the test dataset, but they can also be computed on both the training and test datasets for comparison. Why do I emphasize this? Because in the next segment, we'll delve into loss functions, and their computation is exclusively for the training dataset.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "It's important to note that evaluation metrics are often calculated on the test dataset, but they can also be computed on both the training and test datasets for comparison. Why do I emphasize this? Because in the next segment, we'll delve into loss functions, and their computation is exclusively for the training dataset.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Introduction to Loss Functions (3/6)\n",
+ "\n",
+ "In past segments, we used linear regression to predict stock prices, tested it on the test set, and calculated evaluation metrics, with the model performing exceptionally well. Does it seem like making money in the stock market is a bit too easy? Well, you're absolutely right, it's just a dream.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Introduction to Loss Functions (3/6)\n",
+ "\n",
+ "In past segments, we used linear regression to predict stock prices, tested it on the test set, and calculated evaluation metrics, with the model performing exceptionally well. Does it seem like making money in the stock market is a bit too easy? Well, you're absolutely right, it's just a dream.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "We plot the daily closing prices of Apple Inc. from 2005 to 2022. If you bought Apple stock on the first day shown in the graph and held it until the last day, you would have roughly multiplied your investment many times over. However, achieving this in reality is exceedingly challenging.\n",
+ "\n",
+ "As ordinary investors, we don't possess a time machine, and even if we have a strong belief in Apple's stock, we cannot predict what will happen 15 years into the future. Typically, we do not hold stocks for extended periods. Instead, we engage in short-term or medium-term investments. If the stock price shows substantial growth within a certain timeframe, we may choose to sell at a certain point, seizing the opportunity. Conversely, if the stock price remains stagnant or declines, we may also decide to sell at a specific point, implementing a timely stop-loss strategy.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "We plot the daily closing prices of Apple Inc. from 2005 to 2022. If you bought Apple stock on the first day shown in the graph and held it until the last day, you would have roughly multiplied your investment many times over. However, achieving this in reality is exceedingly challenging.\n",
+ "\n",
+ "As ordinary investors, we don't possess a time machine, and even if we have a strong belief in Apple's stock, we cannot predict what will happen 15 years into the future. Typically, we do not hold stocks for extended periods. Instead, we engage in short-term or medium-term investments. If the stock price shows substantial growth within a certain timeframe, we may choose to sell at a certain point, seizing the opportunity. Conversely, if the stock price remains stagnant or declines, we may also decide to sell at a specific point, implementing a timely stop-loss strategy.\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "Of course, we can't provide stock investment strategies here, but if machine learning can effectively predict stock prices, it can certainly assist in shaping our investment strategies. With model predictions, we can observe that Apple's stock steadily increased over 15 years, indicating that buying in 2005 and selling in 2020 would have been profitable.\n",
+ "\n",
+ "Furthermore, if the model we've developed provides accurate predictions at finer granularities, we could potentially engage in multiple trades within those 15 years. Selling all stocks at local highs whenever the price is about to drop and buying in at local lows when the price is about to rise can optimize returns even further. However, this scenario assumes that our predictions align perfectly with reality, which, in practice, is unlikely to be the case.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "Of course, we can't provide stock investment strategies here, but if machine learning can effectively predict stock prices, it can certainly assist in shaping our investment strategies. With model predictions, we can observe that Apple's stock steadily increased over 15 years, indicating that buying in 2005 and selling in 2020 would have been profitable.\n",
+ "\n",
+ "Furthermore, if the model we've developed provides accurate predictions at finer granularities, we could potentially engage in multiple trades within those 15 years. Selling all stocks at local highs whenever the price is about to drop and buying in at local lows when the price is about to rise can optimize returns even further. However, this scenario assumes that our predictions align perfectly with reality, which, in practice, is unlikely to be the case.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "While the evaluation metrics indicate that our model's performance is good, is it good enough to support the second investment strategy mentioned earlier? Or can it be further optimized to help us earn more from that strategy?\n",
+ "\n",
+ "The answer is affirmative, and here we introduce a new concept: the Loss Function, also known as the Cost Function. It is used to measure the difference or error between model predictions and real values on the training dataset. In the next segment, we will delve into how to calculate the loss function.\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Calculating Loss Functions (4/6)\n",
+ "\n",
+ "\n",
+ "In previous segments, we successfully used linear regression for stock market prediction, guiding us to buy low and sell high, resulting in substantial profits. However, we are not content because there are still deviations between the model's predictions and the actual situation. This has caused us to buy at high points and sell at low points on several occasions. Following the principle that there's no harm in having more money, we aim to further optimize the model using a loss function. Today, let's first learn how to calculate the loss function.\n",
+ "\n",
+ "For regression tasks, there are three common types of loss functions. The first one is the Mean Squared Error (MSE), which measures the average of the squared differences between **predicted values** and **actual values** on the **training dataset** . The second one is the Mean Absolute Error (MAE), which measures the average of the absolute differences between **predicted values** and **actual values** on the **training dataset** .\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "While the evaluation metrics indicate that our model's performance is good, is it good enough to support the second investment strategy mentioned earlier? Or can it be further optimized to help us earn more from that strategy?\n",
+ "\n",
+ "The answer is affirmative, and here we introduce a new concept: the Loss Function, also known as the Cost Function. It is used to measure the difference or error between model predictions and real values on the training dataset. In the next segment, we will delve into how to calculate the loss function.\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Calculating Loss Functions (4/6)\n",
+ "\n",
+ "\n",
+ "In previous segments, we successfully used linear regression for stock market prediction, guiding us to buy low and sell high, resulting in substantial profits. However, we are not content because there are still deviations between the model's predictions and the actual situation. This has caused us to buy at high points and sell at low points on several occasions. Following the principle that there's no harm in having more money, we aim to further optimize the model using a loss function. Today, let's first learn how to calculate the loss function.\n",
+ "\n",
+ "For regression tasks, there are three common types of loss functions. The first one is the Mean Squared Error (MSE), which measures the average of the squared differences between **predicted values** and **actual values** on the **training dataset** . The second one is the Mean Absolute Error (MAE), which measures the average of the absolute differences between **predicted values** and **actual values** on the **training dataset** .\n",
+ "\n",
+ " \n",
+ "\n",
+ "So, let's go ahead and calculate the squared error and absolute error for each data point in the training set. The code is quite simple: we extract the labels and predicted results columns from the training set and use NumPy for some basic mathematical operations. The results are labeled as 'AE' and 'SE,' as shown in the purple-bordered section of the graph. As you can see, regardless of their magnitude, their values are never zero, meaning that there is always some difference between our predicted values and the actual values.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "So, let's go ahead and calculate the squared error and absolute error for each data point in the training set. The code is quite simple: we extract the labels and predicted results columns from the training set and use NumPy for some basic mathematical operations. The results are labeled as 'AE' and 'SE,' as shown in the purple-bordered section of the graph. As you can see, regardless of their magnitude, their values are never zero, meaning that there is always some difference between our predicted values and the actual values.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Furthermore, we can visualize how AE and SE change over time. It's evident that as time progresses, their values tend to increase, indicating that the results tested on the training set become more accurate as they approach 2005.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Furthermore, we can visualize how AE and SE change over time. It's evident that as time progresses, their values tend to increase, indicating that the results tested on the training set become more accurate as they approach 2005.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Finally, by taking the mean of the AE and SE columns, we obtain the results for the loss functions, MAE and MSE. With this, we have computed the values of the two most common loss functions for linear regression.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Finally, by taking the mean of the AE and SE columns, we obtain the results for the loss functions, MAE and MSE. With this, we have computed the values of the two most common loss functions for linear regression.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Attentive students might have already noticed that these two loss functions seem quite similar to the MAE and MSE metrics we learned earlier. You're absolutely right, there is indeed significant overlap between the concepts of loss functions and evaluation metrics, but there are also key differences. In the next segment, we will thoroughly analyze these distinctions.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Attentive students might have already noticed that these two loss functions seem quite similar to the MAE and MSE metrics we learned earlier. You're absolutely right, there is indeed significant overlap between the concepts of loss functions and evaluation metrics, but there are also key differences. In the next segment, we will thoroughly analyze these distinctions.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Understanding Loss Functions (5/6)\n",
+ "\n",
+ "\n",
+ "Loss functions and evaluation metrics share common ground in that they are both used to assess a model's predictive capabilities. In fact, terms like MAE or MSE are statistical concepts that can serve both as evaluation metrics and as loss functions, with identical mathematical calculations.\n",
+ "\n",
+ "The code blocks above compute MAE and MSE as loss functions, while the code blocks below calculate MAE and MSE as evaluation metrics. If the input data is the same, the results will be entirely identical.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Understanding Loss Functions (5/6)\n",
+ "\n",
+ "\n",
+ "Loss functions and evaluation metrics share common ground in that they are both used to assess a model's predictive capabilities. In fact, terms like MAE or MSE are statistical concepts that can serve both as evaluation metrics and as loss functions, with identical mathematical calculations.\n",
+ "\n",
+ "The code blocks above compute MAE and MSE as loss functions, while the code blocks below calculate MAE and MSE as evaluation metrics. If the input data is the same, the results will be entirely identical.\n",
+ "\n",
+ " \n",
+ "\n",
+ "So, what are the key differences between loss functions and evaluation metrics? \n",
+ "\n",
+ "Firstly, evaluation metrics include concepts like R-squared and explained variance, which are not present in loss functions. \n",
+ "\n",
+ "Secondly, their purposes differ; loss functions are primarily used during model training to help the model gradually adjust its parameters to minimize prediction errors. In contrast, evaluation metrics are used to summarize and compare the performance of a trained model, to understand the overall effectiveness of the model, or to compare the performance differences between different models, guiding model selection.\n",
+ "\n",
+ "Thirdly, their optimization directions are different. With loss functions, the goal is typically to minimize them because smaller loss values imply that the predicted values are closer to the actual values. In contrast, for evaluation metrics, the goal is often to maximize their values; for example, in the case of R-squared, higher values indicate better model performance. This difference reflects the distinct roles of loss functions and evaluation metrics in machine learning tasks. \n",
+ "\n",
+ "Finally, as mentioned in the previous segment, loss functions are often calculated on the training set, while evaluation metrics are typically computed on the test set, with fewer instances of calculating them on the training set.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "So, what are the key differences between loss functions and evaluation metrics? \n",
+ "\n",
+ "Firstly, evaluation metrics include concepts like R-squared and explained variance, which are not present in loss functions. \n",
+ "\n",
+ "Secondly, their purposes differ; loss functions are primarily used during model training to help the model gradually adjust its parameters to minimize prediction errors. In contrast, evaluation metrics are used to summarize and compare the performance of a trained model, to understand the overall effectiveness of the model, or to compare the performance differences between different models, guiding model selection.\n",
+ "\n",
+ "Thirdly, their optimization directions are different. With loss functions, the goal is typically to minimize them because smaller loss values imply that the predicted values are closer to the actual values. In contrast, for evaluation metrics, the goal is often to maximize their values; for example, in the case of R-squared, higher values indicate better model performance. This difference reflects the distinct roles of loss functions and evaluation metrics in machine learning tasks. \n",
+ "\n",
+ "Finally, as mentioned in the previous segment, loss functions are often calculated on the training set, while evaluation metrics are typically computed on the test set, with fewer instances of calculating them on the training set.\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "You're absolutely right, these differences might seem a bit overwhelming at first, but don't worry! In regression tasks, the distinctions between loss functions and evaluation metrics might not be as pronounced as in classification tasks. This was just a setup to introduce the concepts of evaluation metrics and loss functions.\n",
+ "\n",
+ "In classification tasks, we'll revisit the concepts of evaluation metrics and loss functions, and their differences will become clearer. As you gain a more comprehensive understanding of machine learning, these pieces of knowledge will gradually come together and become more straightforward.\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Optimizing Models with Gradient Descent (6/6)\n",
+ "\n",
+ "In previous segments, we used sklearn's LinearRegression to train on real U.S. stock market data, employed a linear regression model for stock price prediction, and calculated the model's loss functions. Another option for solving linear regression models is to use SGDRegressor. Here, SGD stands for Stochastic Gradient Descent, and you don't need to worry about its details for now; we'll be learning about it soon.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "You're absolutely right, these differences might seem a bit overwhelming at first, but don't worry! In regression tasks, the distinctions between loss functions and evaluation metrics might not be as pronounced as in classification tasks. This was just a setup to introduce the concepts of evaluation metrics and loss functions.\n",
+ "\n",
+ "In classification tasks, we'll revisit the concepts of evaluation metrics and loss functions, and their differences will become clearer. As you gain a more comprehensive understanding of machine learning, these pieces of knowledge will gradually come together and become more straightforward.\n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)\n",
+ "\n",
+ "# Stock Market Prediction Hands-On: Optimizing Models with Gradient Descent (6/6)\n",
+ "\n",
+ "In previous segments, we used sklearn's LinearRegression to train on real U.S. stock market data, employed a linear regression model for stock price prediction, and calculated the model's loss functions. Another option for solving linear regression models is to use SGDRegressor. Here, SGD stands for Stochastic Gradient Descent, and you don't need to worry about its details for now; we'll be learning about it soon.\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "The training process of SGDRegressor is iterative, and we can keep track of the changes in the loss function during training. This allows us to utilize the loss function to optimize the model.\n",
+ "\n",
+ "We start from the model's initial state and train for 100 epochs, which means 100 rounds of training, recording the loss function after each round in an array. Please note that our loss function is calculated on the training dataset.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "The training process of SGDRegressor is iterative, and we can keep track of the changes in the loss function during training. This allows us to utilize the loss function to optimize the model.\n",
+ "\n",
+ "We start from the model's initial state and train for 100 epochs, which means 100 rounds of training, recording the loss function after each round in an array. Please note that our loss function is calculated on the training dataset.\n",
+ "\n",
+ " \n",
+ "\n",
+ "We use Matplotlib to plot the results of the first 30 loss functions. As we can see, with an increase in epochs, the loss function gradually decreases. Moreover, the early epochs show a relatively rapid decline, while the later epochs exhibit a slower decrease.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We use Matplotlib to plot the results of the first 30 loss functions. As we can see, with an increase in epochs, the loss function gradually decreases. Moreover, the early epochs show a relatively rapid decline, while the later epochs exhibit a slower decrease.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Furthermore, we plot the results of the loss function for all 100 training epochs. It's evident that the loss value keeps decreasing in the early epochs and only starts stabilizing after around 60 epochs.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Furthermore, we plot the results of the loss function for all 100 training epochs. It's evident that the loss value keeps decreasing in the early epochs and only starts stabilizing after around 60 epochs.\n",
+ "\n",
+ " \n",
+ "\n",
+ "You might be curious about what's happening behind the scenes when the loss function of the SGDRegressor model decreases during training. Let's print the model's `coef_` attribute, which represents the coefficients of the linear model. Starting with the model obtained after one training epoch, we get the following results.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "You might be curious about what's happening behind the scenes when the loss function of the SGDRegressor model decreases during training. Let's print the model's `coef_` attribute, which represents the coefficients of the linear model. Starting with the model obtained after one training epoch, we get the following results.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Next, here are the model parameters after 10 training epochs, and we obtain the following results.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Next, here are the model parameters after 10 training epochs, and we obtain the following results.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Finally, when we examine the model parameters after 100 training epochs, we observe that the linear model's parameters continue to change with an increase in training epochs.\n",
+ "\n",
+ "\n",
+ "\n",
+ "In essence, you can think of it this way: during the training process of the SGDRegressor model, the algorithm is continually trying to reduce the loss function. In other words, this is the direction of model optimization. Each training round of SGDRegressor results in a new model, which can yield a new loss function value on the training dataset. If the algorithm consistently finds a smaller loss function value in each iteration compared to the previous one, the model becomes incrementally more optimized with each round. Consequently, as the number of training epochs increases, the loss function tends to decrease until it stabilizes, and the model's parameters change along with it, ultimately achieving the optimal result.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Of course, the explanation here might be a bit simplified, and we will provide more detailed answers in the upcoming gradient descent series. \n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md
new file mode 100644
index 0000000000..55e4321658
--- /dev/null
+++ b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md
@@ -0,0 +1,250 @@
+# Stock Market Prediction Hands-On: Training a Linear Regression Model (1/6)
+
+Can linear regression in machine learning predict the stock market? This real dataset includes stock market data from several major U.S. companies between 2005 and 2020, including daily opening and closing prices, highest and lowest prices, trading volume, turnover rate, and other information. Today, we are going to use it to practice and see if we will make a profit or incur losses.
+
+
+
+Let's begin by taking a look at Apple Inc., a company that has shown consistently robust performance over the years.
+
+
+
+Here, we have a total of 3,732 days' worth of stock market data, with each row containing 63 columns. There's one particular column that stands out, known as 'Close_forecast,' which represents the stock's closing price for the next day. It's important to note that this column doesn't exist in the original scraped data; it was added by Kaggle to make the dataset more suitable for machine learning exercises.
+
+
+
+We will select the 'Close_forecast' column as the target for our machine learning model, which serves as the label. The remaining 62 columns will be used as features. We will split the data, using 75% for training and 25% for testing.
+
+
+
+Finally, with just two simple lines of code, we will call the `LinearRegression.fit` method from sklearn to train our linear regression model.
+
+
+
+Now that we have our model, it's time to put it to the test on our testing dataset. We'll use the model to make predictions on the test set and evaluate its performance.
+
+
+
+At first glance, the results might seem a bit surprising, given the significant fluctuations in the predicted stock prices. However, I can offer some reassurance that our linear regression model is functioning correctly, and in fact, it performs quite well. You can confidently use the code provided above. As for the reason behind the seemingly chaotic predictions, we will delve into a more detailed analysis in the upcoming sections.
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Model Performance Evaluation (2/6)
+
+In the previous segment, we attempted stock price prediction using linear regression on a real stock market dataset. The results seemed chaotic, with significant fluctuations and sharp ups and downs in stock prices. Can linear regression truly predict stock prices? If the stock market behaves in this manner, I believe both you and me would share the sentiment: Run! The farther, the better!
+
+
+
+
+
+
+Strange occurrences often have underlying reasons. Let's take a closer look at what y_test in the test set actually looks like. As it turns out, when y_test was created, the order was shuffled. In fact, there's a parameter in sklearn's train_test_split function called 'shuffle,' which is set to 'True' by default. This means that by default, the order is shuffled when splitting the training and test sets.
+
+Shuffling the order itself isn't necessarily a problem, but in our daily lives, stock prices generally follow a relatively smooth curve over time. Therefore, the test results may initially appear odd because they don't align with common sense. If we set 'shuffle' to 'False,' we can avoid this situation. You might find it interesting to try this out for yourselves.
+
+
+
+Here, we're taking the real y-label values from the training set and the predicted y-label values, placing them together, and then sorting them. By doing this, we can compare the two and observe that the differences between them are quite small on a daily basis.
+
+
+
+Let's visualize the data using matplotlib to gain a clearer understanding. The results are highly promising, as the blue real values and the green predicted values almost perfectly overlap.
+
+
+
+We calculate the R-squared, MAPE, and other evaluation metrics, and the results are excellent, consistent with the previous analysis. All of this indicates that linear regression performs well when applied to this real stock market dataset.
+
+
+
+It's important to note that evaluation metrics are often calculated on the test dataset, but they can also be computed on both the training and test datasets for comparison. Why do I emphasize this? Because in the next segment, we'll delve into loss functions, and their computation is exclusively for the training dataset.
+
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Introduction to Loss Functions (3/6)
+
+In past segments, we used linear regression to predict stock prices, tested it on the test set, and calculated evaluation metrics, with the model performing exceptionally well. Does it seem like making money in the stock market is a bit too easy? Well, you're absolutely right, it's just a dream.
+
+
+
+
+We plot the daily closing prices of Apple Inc. from 2005 to 2022. If you bought Apple stock on the first day shown in the graph and held it until the last day, you would have roughly multiplied your investment many times over. However, achieving this in reality is exceedingly challenging.
+
+As ordinary investors, we don't possess a time machine, and even if we have a strong belief in Apple's stock, we cannot predict what will happen 15 years into the future. Typically, we do not hold stocks for extended periods. Instead, we engage in short-term or medium-term investments. If the stock price shows substantial growth within a certain timeframe, we may choose to sell at a certain point, seizing the opportunity. Conversely, if the stock price remains stagnant or declines, we may also decide to sell at a specific point, implementing a timely stop-loss strategy.
+
+
+
+
+
+
+Of course, we can't provide stock investment strategies here, but if machine learning can effectively predict stock prices, it can certainly assist in shaping our investment strategies. With model predictions, we can observe that Apple's stock steadily increased over 15 years, indicating that buying in 2005 and selling in 2020 would have been profitable.
+
+Furthermore, if the model we've developed provides accurate predictions at finer granularities, we could potentially engage in multiple trades within those 15 years. Selling all stocks at local highs whenever the price is about to drop and buying in at local lows when the price is about to rise can optimize returns even further. However, this scenario assumes that our predictions align perfectly with reality, which, in practice, is unlikely to be the case.
+
+
+
+
+While the evaluation metrics indicate that our model's performance is good, is it good enough to support the second investment strategy mentioned earlier? Or can it be further optimized to help us earn more from that strategy?
+
+The answer is affirmative, and here we introduce a new concept: the Loss Function, also known as the Cost Function. It is used to measure the difference or error between model predictions and real values on the training dataset. In the next segment, we will delve into how to calculate the loss function.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Calculating Loss Functions (4/6)
+
+
+In previous segments, we successfully used linear regression for stock market prediction, guiding us to buy low and sell high, resulting in substantial profits. However, we are not content because there are still deviations between the model's predictions and the actual situation. This has caused us to buy at high points and sell at low points on several occasions. Following the principle that there's no harm in having more money, we aim to further optimize the model using a loss function. Today, let's first learn how to calculate the loss function.
+
+For regression tasks, there are three common types of loss functions. The first one is the Mean Squared Error (MSE), which measures the average of the squared differences between **predicted values** and **actual values** on the **training dataset** . The second one is the Mean Absolute Error (MAE), which measures the average of the absolute differences between **predicted values** and **actual values** on the **training dataset** .
+
+
+
+So, let's go ahead and calculate the squared error and absolute error for each data point in the training set. The code is quite simple: we extract the labels and predicted results columns from the training set and use NumPy for some basic mathematical operations. The results are labeled as 'AE' and 'SE,' as shown in the purple-bordered section of the graph. As you can see, regardless of their magnitude, their values are never zero, meaning that there is always some difference between our predicted values and the actual values.
+
+
+
+Furthermore, we can visualize how AE and SE change over time. It's evident that as time progresses, their values tend to increase, indicating that the results tested on the training set become more accurate as they approach 2005.
+
+
+
+Finally, by taking the mean of the AE and SE columns, we obtain the results for the loss functions, MAE and MSE. With this, we have computed the values of the two most common loss functions for linear regression.
+
+
+
+Attentive students might have already noticed that these two loss functions seem quite similar to the MAE and MSE metrics we learned earlier. You're absolutely right, there is indeed significant overlap between the concepts of loss functions and evaluation metrics, but there are also key differences. In the next segment, we will thoroughly analyze these distinctions.
+
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Understanding Loss Functions (5/6)
+
+
+Loss functions and evaluation metrics share common ground in that they are both used to assess a model's predictive capabilities. In fact, terms like MAE or MSE are statistical concepts that can serve both as evaluation metrics and as loss functions, with identical mathematical calculations.
+
+The code blocks above compute MAE and MSE as loss functions, while the code blocks below calculate MAE and MSE as evaluation metrics. If the input data is the same, the results will be entirely identical.
+
+
+
+So, what are the key differences between loss functions and evaluation metrics?
+
+Firstly, evaluation metrics include concepts like R-squared and explained variance, which are not present in loss functions.
+
+Secondly, their purposes differ; loss functions are primarily used during model training to help the model gradually adjust its parameters to minimize prediction errors. In contrast, evaluation metrics are used to summarize and compare the performance of a trained model, to understand the overall effectiveness of the model, or to compare the performance differences between different models, guiding model selection.
+
+Thirdly, their optimization directions are different. With loss functions, the goal is typically to minimize them because smaller loss values imply that the predicted values are closer to the actual values. In contrast, for evaluation metrics, the goal is often to maximize their values; for example, in the case of R-squared, higher values indicate better model performance. This difference reflects the distinct roles of loss functions and evaluation metrics in machine learning tasks.
+
+Finally, as mentioned in the previous segment, loss functions are often calculated on the training set, while evaluation metrics are typically computed on the test set, with fewer instances of calculating them on the training set.
+
+
+
+
+
+
+
+
+
+
+
+
+You're absolutely right, these differences might seem a bit overwhelming at first, but don't worry! In regression tasks, the distinctions between loss functions and evaluation metrics might not be as pronounced as in classification tasks. This was just a setup to introduce the concepts of evaluation metrics and loss functions.
+
+In classification tasks, we'll revisit the concepts of evaluation metrics and loss functions, and their differences will become clearer. As you gain a more comprehensive understanding of machine learning, these pieces of knowledge will gradually come together and become more straightforward.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Optimizing Models with Gradient Descent (6/6)
+
+In previous segments, we used sklearn's LinearRegression to train on real U.S. stock market data, employed a linear regression model for stock price prediction, and calculated the model's loss functions. Another option for solving linear regression models is to use SGDRegressor. Here, SGD stands for Stochastic Gradient Descent, and you don't need to worry about its details for now; we'll be learning about it soon.
+
+
+
+
+The training process of SGDRegressor is iterative, and we can keep track of the changes in the loss function during training. This allows us to utilize the loss function to optimize the model.
+
+We start from the model's initial state and train for 100 epochs, which means 100 rounds of training, recording the loss function after each round in an array. Please note that our loss function is calculated on the training dataset.
+
+
+
+We use Matplotlib to plot the results of the first 30 loss functions. As we can see, with an increase in epochs, the loss function gradually decreases. Moreover, the early epochs show a relatively rapid decline, while the later epochs exhibit a slower decrease.
+
+
+
+Furthermore, we plot the results of the loss function for all 100 training epochs. It's evident that the loss value keeps decreasing in the early epochs and only starts stabilizing after around 60 epochs.
+
+
+
+You might be curious about what's happening behind the scenes when the loss function of the SGDRegressor model decreases during training. Let's print the model's `coef_` attribute, which represents the coefficients of the linear model. Starting with the model obtained after one training epoch, we get the following results.
+
+
+
+Next, here are the model parameters after 10 training epochs, and we obtain the following results.
+
+
+
+Finally, when we examine the model parameters after 100 training epochs, we observe that the linear model's parameters continue to change with an increase in training epochs.
+
+
+
+In essence, you can think of it this way: during the training process of the SGDRegressor model, the algorithm is continually trying to reduce the loss function. In other words, this is the direction of model optimization. Each training round of SGDRegressor results in a new model, which can yield a new loss function value on the training dataset. If the algorithm consistently finds a smaller loss function value in each iteration compared to the previous one, the model becomes incrementally more optimized with each round. Consequently, as the number of training epochs increases, the loss function tends to decrease until it stabilizes, and the model's parameters change along with it, ultimately achieving the optimal result.
+
+
+
+Of course, the explanation here might be a bit simplified, and we will provide more detailed answers in the upcoming gradient descent series.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
\n",
+ "\n",
+ "Finally, when we examine the model parameters after 100 training epochs, we observe that the linear model's parameters continue to change with an increase in training epochs.\n",
+ "\n",
+ "\n",
+ "\n",
+ "In essence, you can think of it this way: during the training process of the SGDRegressor model, the algorithm is continually trying to reduce the loss function. In other words, this is the direction of model optimization. Each training round of SGDRegressor results in a new model, which can yield a new loss function value on the training dataset. If the algorithm consistently finds a smaller loss function value in each iteration compared to the previous one, the model becomes incrementally more optimized with each round. Consequently, as the number of training epochs increases, the loss function tends to decrease until it stabilizes, and the model's parameters change along with it, ultimately achieving the optimal result.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Of course, the explanation here might be a bit simplified, and we will provide more detailed answers in the upcoming gradient descent series. \n",
+ "\n",
+ "\n",
+ "Let's embark on this machine learning journey together, one day at a time.\n",
+ "\n",
+ "You can find the Kaggle dataset at\n",
+ "\n",
+ "[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)\n",
+ "\n",
+ "The corresponding code is available at\n",
+ "\n",
+ "[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md
new file mode 100644
index 0000000000..55e4321658
--- /dev/null
+++ b/open-machine-learning-jupyter-book/ml-fundamentals/regression/loss-function_en.md
@@ -0,0 +1,250 @@
+# Stock Market Prediction Hands-On: Training a Linear Regression Model (1/6)
+
+Can linear regression in machine learning predict the stock market? This real dataset includes stock market data from several major U.S. companies between 2005 and 2020, including daily opening and closing prices, highest and lowest prices, trading volume, turnover rate, and other information. Today, we are going to use it to practice and see if we will make a profit or incur losses.
+
+
+
+Let's begin by taking a look at Apple Inc., a company that has shown consistently robust performance over the years.
+
+
+
+Here, we have a total of 3,732 days' worth of stock market data, with each row containing 63 columns. There's one particular column that stands out, known as 'Close_forecast,' which represents the stock's closing price for the next day. It's important to note that this column doesn't exist in the original scraped data; it was added by Kaggle to make the dataset more suitable for machine learning exercises.
+
+
+
+We will select the 'Close_forecast' column as the target for our machine learning model, which serves as the label. The remaining 62 columns will be used as features. We will split the data, using 75% for training and 25% for testing.
+
+
+
+Finally, with just two simple lines of code, we will call the `LinearRegression.fit` method from sklearn to train our linear regression model.
+
+
+
+Now that we have our model, it's time to put it to the test on our testing dataset. We'll use the model to make predictions on the test set and evaluate its performance.
+
+
+
+At first glance, the results might seem a bit surprising, given the significant fluctuations in the predicted stock prices. However, I can offer some reassurance that our linear regression model is functioning correctly, and in fact, it performs quite well. You can confidently use the code provided above. As for the reason behind the seemingly chaotic predictions, we will delve into a more detailed analysis in the upcoming sections.
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Model Performance Evaluation (2/6)
+
+In the previous segment, we attempted stock price prediction using linear regression on a real stock market dataset. The results seemed chaotic, with significant fluctuations and sharp ups and downs in stock prices. Can linear regression truly predict stock prices? If the stock market behaves in this manner, I believe both you and me would share the sentiment: Run! The farther, the better!
+
+
+
+
+
+
+Strange occurrences often have underlying reasons. Let's take a closer look at what y_test in the test set actually looks like. As it turns out, when y_test was created, the order was shuffled. In fact, there's a parameter in sklearn's train_test_split function called 'shuffle,' which is set to 'True' by default. This means that by default, the order is shuffled when splitting the training and test sets.
+
+Shuffling the order itself isn't necessarily a problem, but in our daily lives, stock prices generally follow a relatively smooth curve over time. Therefore, the test results may initially appear odd because they don't align with common sense. If we set 'shuffle' to 'False,' we can avoid this situation. You might find it interesting to try this out for yourselves.
+
+
+
+Here, we're taking the real y-label values from the training set and the predicted y-label values, placing them together, and then sorting them. By doing this, we can compare the two and observe that the differences between them are quite small on a daily basis.
+
+
+
+Let's visualize the data using matplotlib to gain a clearer understanding. The results are highly promising, as the blue real values and the green predicted values almost perfectly overlap.
+
+
+
+We calculate the R-squared, MAPE, and other evaluation metrics, and the results are excellent, consistent with the previous analysis. All of this indicates that linear regression performs well when applied to this real stock market dataset.
+
+
+
+It's important to note that evaluation metrics are often calculated on the test dataset, but they can also be computed on both the training and test datasets for comparison. Why do I emphasize this? Because in the next segment, we'll delve into loss functions, and their computation is exclusively for the training dataset.
+
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Introduction to Loss Functions (3/6)
+
+In past segments, we used linear regression to predict stock prices, tested it on the test set, and calculated evaluation metrics, with the model performing exceptionally well. Does it seem like making money in the stock market is a bit too easy? Well, you're absolutely right, it's just a dream.
+
+
+
+
+We plot the daily closing prices of Apple Inc. from 2005 to 2022. If you bought Apple stock on the first day shown in the graph and held it until the last day, you would have roughly multiplied your investment many times over. However, achieving this in reality is exceedingly challenging.
+
+As ordinary investors, we don't possess a time machine, and even if we have a strong belief in Apple's stock, we cannot predict what will happen 15 years into the future. Typically, we do not hold stocks for extended periods. Instead, we engage in short-term or medium-term investments. If the stock price shows substantial growth within a certain timeframe, we may choose to sell at a certain point, seizing the opportunity. Conversely, if the stock price remains stagnant or declines, we may also decide to sell at a specific point, implementing a timely stop-loss strategy.
+
+
+
+
+
+
+Of course, we can't provide stock investment strategies here, but if machine learning can effectively predict stock prices, it can certainly assist in shaping our investment strategies. With model predictions, we can observe that Apple's stock steadily increased over 15 years, indicating that buying in 2005 and selling in 2020 would have been profitable.
+
+Furthermore, if the model we've developed provides accurate predictions at finer granularities, we could potentially engage in multiple trades within those 15 years. Selling all stocks at local highs whenever the price is about to drop and buying in at local lows when the price is about to rise can optimize returns even further. However, this scenario assumes that our predictions align perfectly with reality, which, in practice, is unlikely to be the case.
+
+
+
+
+While the evaluation metrics indicate that our model's performance is good, is it good enough to support the second investment strategy mentioned earlier? Or can it be further optimized to help us earn more from that strategy?
+
+The answer is affirmative, and here we introduce a new concept: the Loss Function, also known as the Cost Function. It is used to measure the difference or error between model predictions and real values on the training dataset. In the next segment, we will delve into how to calculate the loss function.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Calculating Loss Functions (4/6)
+
+
+In previous segments, we successfully used linear regression for stock market prediction, guiding us to buy low and sell high, resulting in substantial profits. However, we are not content because there are still deviations between the model's predictions and the actual situation. This has caused us to buy at high points and sell at low points on several occasions. Following the principle that there's no harm in having more money, we aim to further optimize the model using a loss function. Today, let's first learn how to calculate the loss function.
+
+For regression tasks, there are three common types of loss functions. The first one is the Mean Squared Error (MSE), which measures the average of the squared differences between **predicted values** and **actual values** on the **training dataset** . The second one is the Mean Absolute Error (MAE), which measures the average of the absolute differences between **predicted values** and **actual values** on the **training dataset** .
+
+
+
+So, let's go ahead and calculate the squared error and absolute error for each data point in the training set. The code is quite simple: we extract the labels and predicted results columns from the training set and use NumPy for some basic mathematical operations. The results are labeled as 'AE' and 'SE,' as shown in the purple-bordered section of the graph. As you can see, regardless of their magnitude, their values are never zero, meaning that there is always some difference between our predicted values and the actual values.
+
+
+
+Furthermore, we can visualize how AE and SE change over time. It's evident that as time progresses, their values tend to increase, indicating that the results tested on the training set become more accurate as they approach 2005.
+
+
+
+Finally, by taking the mean of the AE and SE columns, we obtain the results for the loss functions, MAE and MSE. With this, we have computed the values of the two most common loss functions for linear regression.
+
+
+
+Attentive students might have already noticed that these two loss functions seem quite similar to the MAE and MSE metrics we learned earlier. You're absolutely right, there is indeed significant overlap between the concepts of loss functions and evaluation metrics, but there are also key differences. In the next segment, we will thoroughly analyze these distinctions.
+
+
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Understanding Loss Functions (5/6)
+
+
+Loss functions and evaluation metrics share common ground in that they are both used to assess a model's predictive capabilities. In fact, terms like MAE or MSE are statistical concepts that can serve both as evaluation metrics and as loss functions, with identical mathematical calculations.
+
+The code blocks above compute MAE and MSE as loss functions, while the code blocks below calculate MAE and MSE as evaluation metrics. If the input data is the same, the results will be entirely identical.
+
+
+
+So, what are the key differences between loss functions and evaluation metrics?
+
+Firstly, evaluation metrics include concepts like R-squared and explained variance, which are not present in loss functions.
+
+Secondly, their purposes differ; loss functions are primarily used during model training to help the model gradually adjust its parameters to minimize prediction errors. In contrast, evaluation metrics are used to summarize and compare the performance of a trained model, to understand the overall effectiveness of the model, or to compare the performance differences between different models, guiding model selection.
+
+Thirdly, their optimization directions are different. With loss functions, the goal is typically to minimize them because smaller loss values imply that the predicted values are closer to the actual values. In contrast, for evaluation metrics, the goal is often to maximize their values; for example, in the case of R-squared, higher values indicate better model performance. This difference reflects the distinct roles of loss functions and evaluation metrics in machine learning tasks.
+
+Finally, as mentioned in the previous segment, loss functions are often calculated on the training set, while evaluation metrics are typically computed on the test set, with fewer instances of calculating them on the training set.
+
+
+
+
+
+
+
+
+
+
+
+
+You're absolutely right, these differences might seem a bit overwhelming at first, but don't worry! In regression tasks, the distinctions between loss functions and evaluation metrics might not be as pronounced as in classification tasks. This was just a setup to introduce the concepts of evaluation metrics and loss functions.
+
+In classification tasks, we'll revisit the concepts of evaluation metrics and loss functions, and their differences will become clearer. As you gain a more comprehensive understanding of machine learning, these pieces of knowledge will gradually come together and become more straightforward.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)
+
+# Stock Market Prediction Hands-On: Optimizing Models with Gradient Descent (6/6)
+
+In previous segments, we used sklearn's LinearRegression to train on real U.S. stock market data, employed a linear regression model for stock price prediction, and calculated the model's loss functions. Another option for solving linear regression models is to use SGDRegressor. Here, SGD stands for Stochastic Gradient Descent, and you don't need to worry about its details for now; we'll be learning about it soon.
+
+
+
+
+The training process of SGDRegressor is iterative, and we can keep track of the changes in the loss function during training. This allows us to utilize the loss function to optimize the model.
+
+We start from the model's initial state and train for 100 epochs, which means 100 rounds of training, recording the loss function after each round in an array. Please note that our loss function is calculated on the training dataset.
+
+
+
+We use Matplotlib to plot the results of the first 30 loss functions. As we can see, with an increase in epochs, the loss function gradually decreases. Moreover, the early epochs show a relatively rapid decline, while the later epochs exhibit a slower decrease.
+
+
+
+Furthermore, we plot the results of the loss function for all 100 training epochs. It's evident that the loss value keeps decreasing in the early epochs and only starts stabilizing after around 60 epochs.
+
+
+
+You might be curious about what's happening behind the scenes when the loss function of the SGDRegressor model decreases during training. Let's print the model's `coef_` attribute, which represents the coefficients of the linear model. Starting with the model obtained after one training epoch, we get the following results.
+
+
+
+Next, here are the model parameters after 10 training epochs, and we obtain the following results.
+
+
+
+Finally, when we examine the model parameters after 100 training epochs, we observe that the linear model's parameters continue to change with an increase in training epochs.
+
+
+
+In essence, you can think of it this way: during the training process of the SGDRegressor model, the algorithm is continually trying to reduce the loss function. In other words, this is the direction of model optimization. Each training round of SGDRegressor results in a new model, which can yield a new loss function value on the training dataset. If the algorithm consistently finds a smaller loss function value in each iteration compared to the previous one, the model becomes incrementally more optimized with each round. Consequently, as the number of training epochs increases, the loss function tends to decrease until it stabilizes, and the model's parameters change along with it, ultimately achieving the optimal result.
+
+
+
+Of course, the explanation here might be a bit simplified, and we will provide more detailed answers in the upcoming gradient descent series.
+
+
+Let's embark on this machine learning journey together, one day at a time.
+
+You can find the Kaggle dataset at
+
+[https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features](https://www.kaggle.com/datasets/nikhilkohli/us-stock-market-data-60-extracted-features)
+
+The corresponding code is available at
+
+[https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb](https://github.com/ocademy-ai/python-code-for-videos/blob/main/linear-regression-loss-function.ipynb)