
Modelscope Hub | Paper | Demo
中文 | 英文
The application of LLM (Large Language Models) agents has become widespread. However, single-agent systems often fall in complex interactive scenarios, such as Stanfordville, software companies, multi-party debates, etc. Thus, Multi-agent architectures have been proposed to address these limitations and are now widely used. In order to allow modelscope-agent run on multi-agent mode, we have proposed the following architecture.
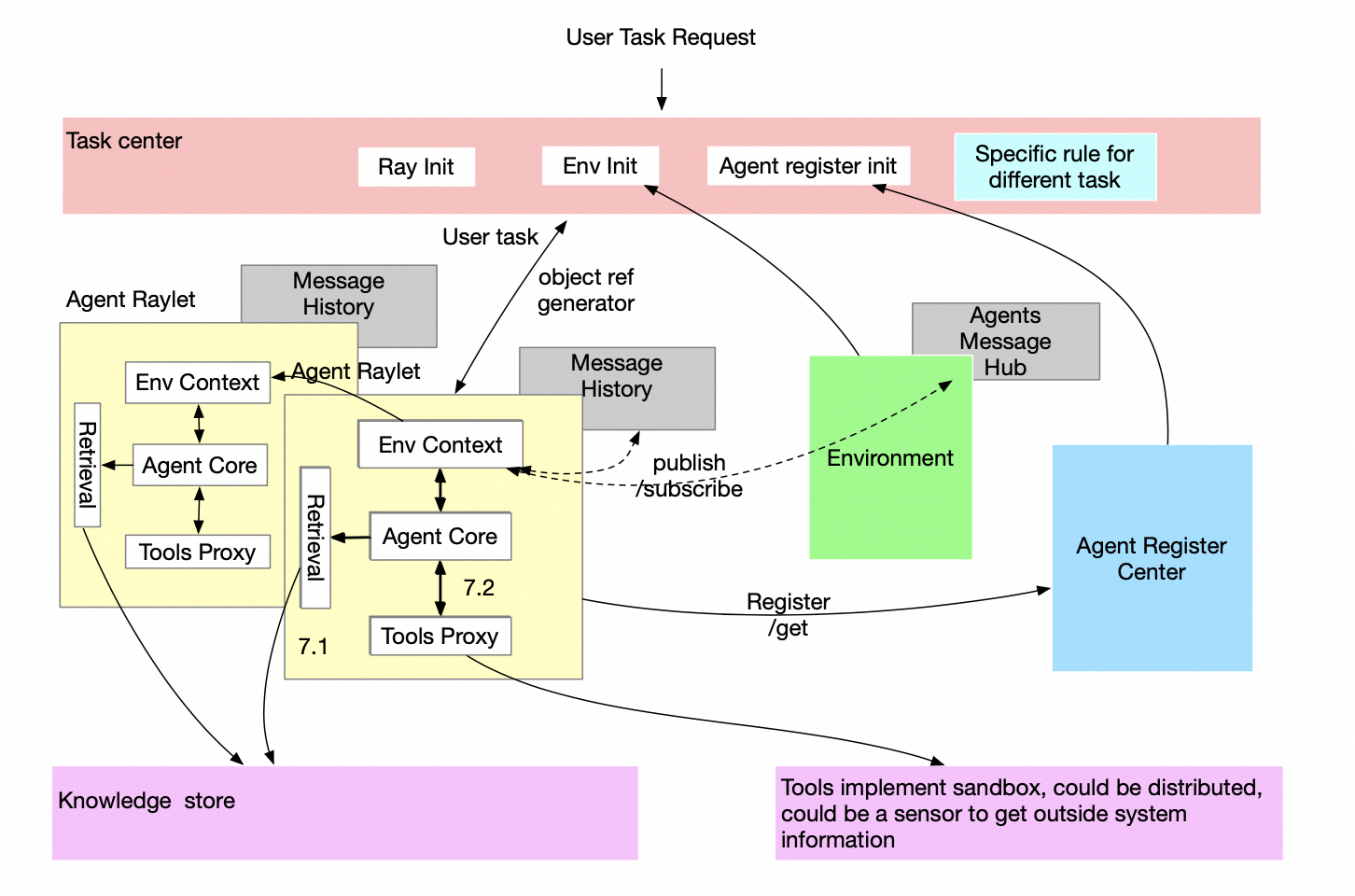
In our design, Ray is running an important role in multi-agent mode. With Ray we could easily scale modelscope-agent into a distribution system by only updating couples of lines code in current project, and make our application ready for parallel processing without taking care about Service Communication, Fault Recovery, Service Discovery and Resource Scheduling.
Why a multi-agent need such complicated abilities?
Current multi-agent is focusing on using different agents working on a task to get a better result, many papers have demonstrated that the multi-agent get a better result than single agent. However, in reality, many tasks should be accomplished by a swarm of agents with efficiency, such as hundreds of spider agents with dozens of data process agents for a data spider task. No open-source multi-agent has design for this scenario with supporting chatbot mode.
On the other hand, modelscope-agent has been demonstrated that can work on a production environment modelscope studio, and we believe that scaling up single-agent into distributed multi-agent could be a trending for multi-agent working on production environment
Considering the current status of ModelScope-Agent, the following design solutions are proposed:
-
Decouple multi-agent interactive logic from single-agent Logic:
- Use AgentEnvMixin class to handle all of multi-agent communication logic based on Ray, without changing any origin logic in single agent modules.
- Extract environment information in Environment module, using a publishing/subscribe mechanism to advance interactions without execution-level blocking between agents.
- Message hub is maintained in Environment module, meanwhile each multi-agent actor manage their own history
-
Introduce an Agent Registry Center Concept:
- Maintain system agents' information for capability expansion.
- Update agent status
-
Introduce a Task Center Concept:
- Design the Task Center to be open-ended, allowing messages to be subscribed or published to all agents, sent to random agents, or delivered in a round-robin fashion by user defined logic.
- Allow rapid development by using direct interaction methods like
send_toandsent_from. - Support both of Chatbot Mode and Terminal Mode, such that user could run multi-agent in a streaming chat gradio apps or on a terminal
A simple multi-roles chat room gradio app demonstrated the logic of multi-agent design.

Another demo shows it could work on multi-modality video generation task.
The multi-agent is running on Ray in a Process Oriented Design(POD) manner. Such that, user don't need to take care any additional distribution or multi-processes stuff, modelscope-agent with ray have covered this part. User only need to write the procedure based on the task type to drive the communication between agents.
There are two stages to run a multi-agent task, initialization and Process as shown below.

During initialization stage, Ray will covert all classes into actor by a sync operation,
such as: task_center, environment, agent_registry and agent.
Task center will use environment and agent_registry to step forward the task, and manage the task process.
The remote is used to allow Ray to run a core role in this process.
The user don't need to care about the distribution or multi-processes stuff.
Before running the task in multi processes mode, we have to initialize the Ray, and convert the task_center into a ray actor
inside the task_center, the environment and agent_registry will be converted into actor on ray automatically.
The following code is the initialization of the task center.
import ray
from modelscope_agent import create_component
from modelscope_agent.task_center import TaskCenter
from modelscope_agent.multi_agents_utils.executors.ray import RayTaskExecutor
REMOTE_MODE = True
if REMOTE_MODE:
RayTaskExecutor.init_ray()
task_center = create_component(
TaskCenter,
name='task_center',
remote=REMOTE_MODE)Agents will be initialized by the function create_component.
The remote=True will convert the agent into a ray actor and will run on an independent process,
if remote=False then it is a simple agent.
name is used to define the agent actor's name in Ray, on the other hand,
role is used to define the role name in ModelScope-Agent.
The rest definition of the inputs are the same as single agent.
import os
from modelscope_agent import create_component
from modelscope_agent.agents import RolePlay
llm_config = {
'model': 'qwen-max',
'api_key': os.getenv('DASHSCOPE_API_KEY'),
'model_server': 'dashscope'
}
function_list = []
role_play1 = create_component(
RolePlay,
name='role_play1',
remote=True,
llm=llm_config,
function_list=function_list)
role_play2 = create_component(
RolePlay,
name='role_play2',
remote=True,
llm=llm_config,
function_list=function_list)Those agents will then be registered to task_center by add_agents method.
Notice that when turning a class into a ray actor in the initialization method create_component(),
to be able to access information from a specific method within that actor in the ray cluster, we need to append .remote()
to the method call, as follows:
# register agents in remote = True mode
ray.get(task_center.add_agents.remote([role_play1, role_play2]))When ray.get() is used to retrieve the result of a remote method, this indicates a synchronous process.
This is to ensure that the value from this step has completed its operation before proceeding with subsequent actions.
If you want to run the multi-agent in a single process without Ray, you could set remote=False in the agent initialization.
We have to slightly modify the add_agents method to support the single process mode.
# register agents in remote = False mode
task_center.add_agents([role_play1, role_play2])All the operations so far are in a sync manner, in order to make sure all the actors are correctly initialized. No Matter in Ray mode or not.
We could start a new task by calling send_task_request, and send the task to the environment.
task = 'what is the best solution to land on moon?'
ray.get(task_center.send_task_request.remote(task))also we could send task request only to specific agents by passing the input send_to with role name of agent.
ray.get(task_center.send_task_request.remote(task, send_to=['role_play1']))The remote=False mode would be like this:
task_center.send_task_request(task)and
task_center.send_task_request(task, send_to=['role_play1'])Then, we could code our multi-agent procedure logic with task_center's static method step
import ray
n_round = 10
while n_round > 0:
for frame in task_center.step.remote():
print(ray.get(frame))
n_round -= 1The step method should be converted to a task function in ray as step.remote, so we have to make it static,
and pass in the task_center as input, in order to let this step function have the information about this task.
Inside the step task method, it will call each agent's step method parallely, for those agents who should response in this step.
The response will be a distributed generator so-called object reference generator in ray, which is a memory shared object among the ray cluster.
So we have to call ray.get(frame) to extract this object as normal generator.
For detail understanding of ray, please refer the Ray introduction document
The remote=False mode will be much easier:
n_round = 10
while n_round > 0:
for frame in task_center.step():
print(frame)
n_round -= 1So far, we have built a multi-agent system with two agents, and let then discuss a topic about 'what is the best solution to land on moon?'.
With the increasing number of agents, the efficiency of this multi-agent on ray will be revealed.
This is a very simple task, and we hope developers could explore more tasks with more complicated conditions, so as we will do.
And for the local mode without ray, only should we remove all of the ray.get(), .remote() and ray in the code.
The original ModelScope-Agent is designed for a single agent to work on a task, and allow user to instantiate multi-agents and let them communicate with each other as well.
In such case, user could also let multi-agents work on a task by using the original ModelScope-Agent, but the user has to take care of the communication between agents, and the task step forward, moreover, the agents have to run on a single process.
The following code show how to run two agents work on a topic discuss scenario with original ModelScope-Agent.
from modelscope_agent.agents import RolePlay
from modelscope_agent.memory import Memory
from modelscope_agent.schemas import Message
role_template_joe = 'you are the president of the United States Joe Biden, and you are debating with former president Donald Trump with couple of topics'
role_template_trump = 'you are the former president of the United States Donald Trump, and you are debating with current president Joe Biden with couple of topics'
llm_config = {
'model': 'qwen-max',
'model_server': 'dashscope',
}
# initialize the memory for each agent
joe_memory = Memory(path="/root/you_data/you_config/joe_biden.json")
trump_memory = Memory(path="/root/you_data/you_config/joe_biden.json")
# initialize the agents
joe_biden = RolePlay(llm=llm_config, instruction=role_template_joe)
trump = RolePlay(llm=llm_config, instruction=role_template_joe)
# start the task
task = 'what is the best solution to land on moon?'
round = 3
trump_response = ''
joe_response = ''
# assume joe always the first to response
for i in range(round):
# joe round
joe_history = joe_memory.get_history()
trump_history = trump_memory.get_history()
cur_joe_prompt = f'with topic {task}, in last round trump said, {trump_response}'
joe_response_stream = joe_biden.run(cur_joe_prompt, history=joe_history)
joe_response = ''
for chunk in joe_response_stream:
joe_response += chunk
print(joe_response)
joe_memory.update_history([
Message(role='user', content=cur_joe_prompt),
Message(role='assistant', content=joe_response),
])
# trump round
cur_trump_prompt = f'with topic {task}, in this round joe said, {joe_response}'
trump_response_stream = trump.run(cur_trump_prompt, history=trump_history)
trump_response = ''
for chunk in trump_response_stream:
trump_response += chunk
print(trump_response)
trump_memory.update_history([
Message(role='user', content=cur_trump_prompt),
Message(role='assistant', content=trump_response),
])As we can see, the user has to take care of the communication between agents, and the task step forward, and this is the only two agents scenario, if we have more agents, the code will be more complicated.
With the multi-agent mode, the user only need to take care of the task step forward, and the communication between agents
will be handled by the agent_registry, environment and task_center automatically.
A code will be like this to repeat the above case in multi-agents mode.
import os
from modelscope_agent import create_component
from modelscope_agent.agents import RolePlay
from modelscope_agent.task_center import TaskCenter
REMOTE_MODE = False
llm_config = {
'model': 'qwen-max',
'api_key': os.getenv('DASHSCOPE_API_KEY'),
'model_server': 'dashscope'
}
function_list = []
task_center = create_component(
TaskCenter, name='task_center', remote=REMOTE_MODE)
role_template_joe = 'you are the president of the United States Joe Biden, and you are debating with former president Donald Trump with couple of topics'
role_template_trump = 'you are the former president of the United States Donald Trump, and you are debating with current president Joe Biden with couple of topics'
joe_biden = create_component(
RolePlay,
name='joe_biden',
remote=REMOTE_MODE,
llm=llm_config,
function_list=function_list,
instruction=role_template_joe)
donald_trump = create_component(
RolePlay,
name='donald_trump',
remote=REMOTE_MODE,
llm=llm_config,
function_list=function_list,
instruction=role_template_trump)
task_center.add_agents([joe_biden, donald_trump])
n_round = 6 # 3 round for each agent
task = 'what is the best solution to land on moon?'
task_center.send_task_request(task, send_to='joe_biden')
while n_round > 0:
for frame in task_center.step():
print(frame)
n_round -= 1In the next sector, we will discuss how does task_center.step() work.
From the above code, the multi-agent mode is more efficient and easier to use than the original ModelScope-Agent single agent mode.
The task_center is the core of the multi-agent system, it will manage the task process, and the communication between agents.
Two API are provided in the task_center:
send_task_request: send a task to theenvironmentto start a new task, or continue the task with additional information from outside system (user input)step: step forward the task, and let each agent response in this step
The send_task_request will send a task to the environment, with the input send_to to specify which agent should respond in this step.
The input in the send_task_request include:
task: the task or input or informationsend_tocould be a list of agent role name, or a single agent role name, orallto let all agents response in this step.send_fromcould be used to specify the agent who send this task request, default asuser_requirement
In the above case,
task_center.send_task_request(task, send_to='joe_biden')meaning that a message with task as content is only sent to the agent with role name joe_biden, and the agent joe_biden will response in this step.
we could also speicify the send_from to let the agent know who send this task request
task_center.send_task_request('I dont agree with you about the landing project', send_to='joe_biden', send_from='donald_trump')The step method will let each agent response in this step, and the response will be a generator, which is a distributed generator in ray.
The inputs in the step method include:
task: additional task or input or information in current stepround: in some case the task is a round based task, and the round number is needed to be passed in, most of the time, the round number is 1send_to: specify who should the message generated in this step be sent to (default to all)allowed_roles: specify which agent should respond in this step, if not specified, only those who recieved message from last step will respond in this stepuser_response: the user response in this step, if the task is a chatbot mode, the user response will be passed in this step to replace the llm output, if user_agent is in this step
With the above inputs, the step could be used in different scenarios of multi-agent task.
For example, in a three-man debate scenario, the step method could be used like this:
# add new role
role_template_hillary = 'you are the former secretary of state Hillary Clinton, and you are debating with former president Donald Trump and current president Joe Biden with couple of topics'
hillary_clinton = create_component(
RolePlay,
name='hillary_clinton',
remote=REMOTE_MODE,
llm=llm_config,
function_list=function_list,
instruction=role_template_hillary)
# initialize the agents
task_center.add_agents([joe_biden, donald_trump, hillary_clinton])
# let joe_biden start the topic
task_center.send_task_request('what is the best solution to land on moon?', send_to='joe_biden')
# in 1st step, let joe_biden only send his opinion to hillary_clinton(considering as whisper), the message will print out
for frame in task_center.step(send_to='hillary_clinton'):
print(frame)
# in 2nd step, allow only donald_trump to response the topic
for frame in task_center.step(allowed_roles='donald_trump'):
print(frame)Notice that the frame will only show the message from different agents with format <[role_name]>: [message stream]
user should take care of the message format in the step method.
The above case show how to use send_to and allowed_roles in the step method to control the communication between agents in a multi-agent task.
There is another case, in a chatbot mode, the user_response could be used to let the user response in this step to replace the llm output, if user_agent is in this step.
# initialize a new user
user = create_component(
RolePlay,
name='user',
remote=REMOTE_MODE,
llm=llm_config,
function_list=function_list,
instruction=role_template_joe,
human_input_mode='ON'
)
# initialize the agents
task_center.add_agents([joe_biden, donald_trump, hillary_clinton, user])
# let joe_biden start the topic
task_center.send_task_request('what is the best solution to land on moon, in one sentence?', send_to='joe_biden')
# in 1st step, let joe_biden send his opinion to all agents.
for frame in task_center.step():
print(frame)
# in 2nd step, allow only user to response the topic, with user_response
result = ''
for frame in task_center.step(allowed_roles='user', user_response='I dont agree with you about the landing project'):
result += frame
print(frame)
# the input from outside will not print out here as the user_response is set
assert result == ''The user response will be used in this step to replace the llm output, because user is a human agent.
When send_task_request() is called, a Message containing send_to and send_from is recorded into the Environment.
Specifically, each role in the environment maintains an independent message queue, and when send_to includes a certain role,
that Message will be stored in the corresponding role's message queue.
When the step() method is called, it first determines which roles need to deal with information in the current step based on allowed_roles.
If not specified, it retrieves roles from the message queue that have messages pending processing for this round's step.
These roles with pending messages then enter the specific message execution phase, where each role follows the below process:
- First, the
pullmethod is called to take out the pending messages for environment message queue. - These messages are then processed into prompts, ready to be inputs for the llm.
- The original single agent's
runmethod is invoked to generate feedback for these messages. - Depending on whether there’s a specified
send_tofor the current round, the generated results are published into the environment's corresponding role. By default, all roles can receive it. This process is similar to what was done in the previous stepsend_task_request().
The agent_env_mixin is a mixin class to handle the communication between agents, and get the information from the environment.
The main method in the agent_env_mixin is step, which consist of the following steps:
- pull the message send to the role from the
environment - convert the message into a prompt
- send the prompt to the original agent's
runmethod - publish the response message to the
environment, the message includes the info that which roles should receive the message.
The environment is a class to manage the message hub, it maintains following information:
- store the message that send to each agent in queue, and the message will be popped from queue and pulled by each agent in the next step.
- store the entire history of the message from all roles in a list,
watcherrole will allow to read the entire history of the message - store the user_requirement in a list, the user requirement are the tasks or inputs from outside system, this message will allow all user to read, but only the
task_centercould write.
The agent_registry is a class to manage the agent information, it maintains following information:
- register the agent in the system, and update the agent status
- allow task_center to get the agent information, and get the agent by role name
Even though, we have designed such multi-agent system, it still has many challenges to get into production environment. The following problem are known issues:
- In a single-machine-multi-processes task, Ray is out-powered in such scenario, and has some overhead on initialization and multi-processes communication.
- Ray still have many issues on fork process, which might cause problems running with Gradio.
- User has to write code for different tasks, even for the rule based task, there is no silver bullet task template to avoid coding for task step forward.
- Hard to debugging for those who only code on single process, it should be better to track issues by logs.
Other than above issues, following features still need to be added, in order to make multi-agent fit in more complex task
- Support more complicated distributed task, such as the data spider system on multi-machine cluster
- Actually, we never try to run the multi-agents on a single process(
remote=True) with python native async function, might be tested and added for some simple case. - Better instruction & prompt for different task
- Distributed memory
- Distributed tool service
- TBD