v1_1_cpp_unpacker
msgpack::unpacker unpacks msgpack::object from a buffer contains msgpack format data. msgpack provides the two unpack functionalities. One is used when a client controls a buffer, the other is used when a client don't want to control a buffer. Any approach uses msgpack::unpacked to access unpacked data.
When you call unpacking functions, you need to pass the msgpack::unpacked object as the argument. Here is msgpack::unpacked interface for clients:
class unpacked {
public:
unpacked();
const object& get() const;
msgpack::unique_ptr<msgpack::zone>& zone();
};For example:
void some_function(const char* data, std::size_t len) {
// Default construct msgpack::unpacked
msgpack::unpacked result;
// Pass the msgpack::unpacked object
unpack(result, data, len);
// Get msgpack::object from msgpack::unpacked (shallow copy)
msgpack::object obj(result.get());
// Get msgpack::zone from msgpack::unpacked (move)
msgpack::unique_ptr<msgpack::zone> z(result.zone());
...msgpack::object has a reference semantics. So copy construction and copy assignment of msgpack::object is shallow copy. msgpack::unpacked manages a lifetime of msgpack::object. msgpack::object is constructed on msgpack::zone's internal buffer. When msgpack::unpacked is destroyed, msgpack::object from the destroyed msgpack::unpacked would become a dangling reference. If you want to keep the msgpack::object's lifetime, you need to keep msgpack::unpacked's lifetime as follows:
msgpack::unpacked some_function(const char* data, std::size_t len) {
// Default construct msgpack::unpacked
msgpack::unpacked result;
// Pass the msgpack::unpacked object
unpack(result, data, len);
return result;
}
void foo() {
...
msgpack::unpacked handle = some_function(data, len);
// Use object
msgpack::object obj = handle.get();
You can also get msgpack::zone from msgpack::unpacked using zone(). That is for advanced use cases. In typical use cases, using msgpack::unpacked and get msgpack::object from that is good enough.
When you want to control a buffer memory precisely, parameter referenced is useful. After unpacking, referenced returns true if unpacked msgpack::object references to a buffer, otherwise referenced is false. When you call unpack(), the buffer is the argument that you pass. When you call unpacker::next(), the buffer is unpacker's internal buffer.
If msgpack user, client, has prepared a buffer that contains msgpack format data, use the following functions:
// simple (since C++11)
unpacked unpack(
const char* data,
std::size_t len,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// get referenced information (since C++11)
unpacked unpack(
const char* data,
std::size_t len,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// set and get offset information (since C++11)
unpacked unpack(
const char* data,
std::size_t len,
std::size_t& off,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// get referenced information
// set and get offset information
// (since C++11)
unpacked unpack(
const char* data,
std::size_t len,
std::size_t& off,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// simple
void unpack(
unpacked& result,
const char* data,
std::size_t len,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// get referenced information
void unpack(
unpacked& result,
const char* data,
std::size_t len,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// set and get offset information
void unpack(
unpacked& result,
const char* data,
std::size_t len,
std::size_t& off,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// get referenced information
// set and get offset information
void unpack(
unpacked& result,
const char* data,
std::size_t len,
std::size_t& off,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());If the buffer cointains one msgpack data, just pass the buffer address and length:
unpacked result;
const char* data = ...
std::size_t len = ...
unpack(result, data, len);
result = unpack(data, len); // since C++11
If the buffer countains multiple msgpack data, use the following function:
unpacked result;
const char* data = ...
std::size_t len = ...
std::size_t off = ...
unpack(result, data, len, off);
result = unpack(data, len, off); // since C++11If you know the number of msgpack data, you can write as follows:
// Caller knows there are three msgpack data in the buffer.
void some_function(const char* buffer, std::size_t len) {
msgpack::unpacked result1;
msgpack::unpacked result2;
msgpack::unpacked result3;
std::size_t off = 0;
// Unpack the first msgpack data.
// off is updated when function is retuened.
unpack(result1, buffer, len, off);
// Unpack the second msgpack data.
// off is updated when function is retuened.
unpack(result2, buffer, len, off);
// Unpack the third msgpack data.
// off is updated when function is retuened.
unpack(result3, buffer, len, off);
assert(len == off);
...If you don't know the number of msgpack data but data is complete, you can write as follows:
void some_function(const char* buffer, std::size_t len) {
std::size_t off = 0;
while (off != len) {
msgpack::unpacked result;
unpack(result, buffer, len, off);
msgpack::object obj(result.get());
// Use obj
}
}Those msgpack::unpack functions may throw msgpack::unpack_error.
- You get msgpack::unpack_error with "parse error" message if the buffer's msgpack data is invalid format.
- You get msgpack::unpack_error with "insufficient bytes" message if the buffer from off(offset) position contains incomplete msgpack data.
In order to use these unpack functions, the client need to prepare sevral number of complete msgpack data. If the client may get incomplete msgpack data, then use msgpack::unpacker.
You can pass unpack_limit to unpack().
Here is the definition of unpack_limit:
class unpack_limit {
public:
unpack_limit(
std::size_t array = 0xffffffff,
std::size_t map = 0xffffffff,
std::size_t str = 0xffffffff,
std::size_t bin = 0xffffffff,
std::size_t ext = 0xffffffff,
std::size_t depth = 0xffffffff);
std::size_t array() const;
std::size_t map() const;
std::size_t str() const;
std::size_t bin() const;
std::size_t ext() const;
std::size_t depth() const;
};The default limits are 0xffffffff. They are the maximum value of the msgpack format. Strigtly speaking, the limit of the depth is not defined by msgpack format.
If the number of elements is over unpack_limit, unpack functions throw the following exceptions:
struct size_overflow : public unpack_error {
};
struct array_size_overflow : public size_overflow {
};
struct map_size_overflow : public size_overflow {
};
struct str_size_overflow : public size_overflow {
};
struct bin_size_overflow : public size_overflow {
};
struct ext_size_overflow : public size_overflow {
};
struct depth_size_overflow : public size_overflow {
};You can protect your application from malformed msgpack format data.
See https://github.com/msgpack/msgpack-c/blob/master/test/limit.cpp
All msgpack data in a client buffer will be copied to msgpack::zone by default. You can free a buffer that contains msgpack format data after unpacking.
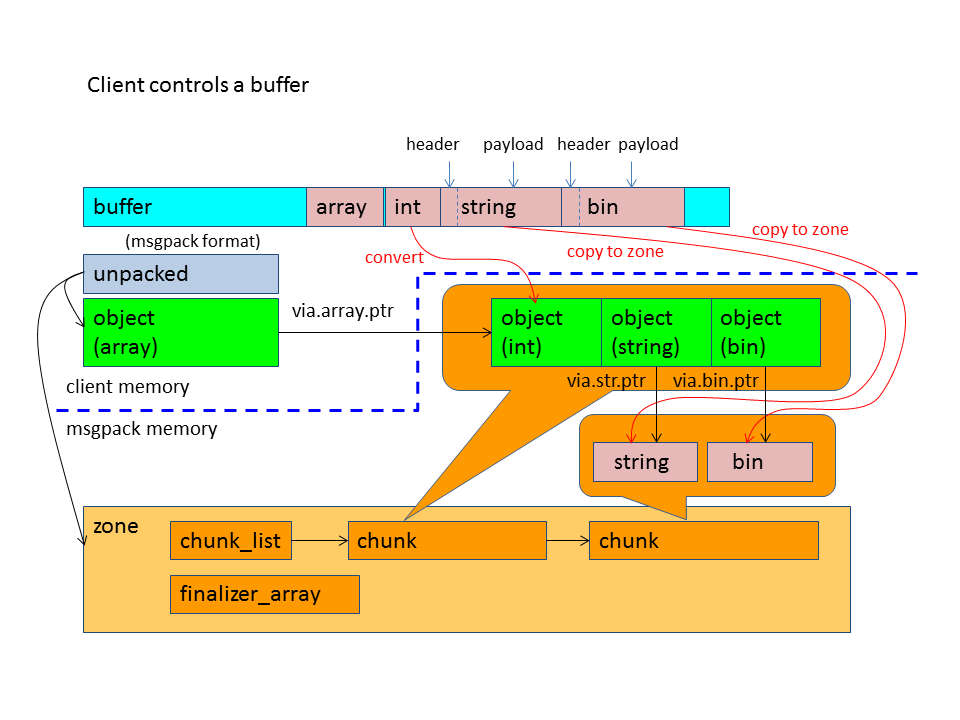
You can customize the behavior using unpack_reference_func. That function is called when STR, BIN, and EXT are unpacking. If the function returns true, the msgpack::object corresponding to STR, BIN, and EXT point to client buffer. So the client needs to keep the buffer's lifetime at least until msgpack::object is destroyed. If the function returns false, the msgpack::object point to STR, BIN, and EXT payloads on msgpack::zone that are copied from the client buffer.
unpack_reference_func is defined as follows:
typedef bool (*unpack_reference_func)(type::object_type type, std::size_t length, void* user_data);type::object_type is defined as follows:
namespace type {
enum object_type {
NIL = MSGPACK_OBJECT_NIL,
BOOLEAN = MSGPACK_OBJECT_BOOLEAN,
POSITIVE_INTEGER = MSGPACK_OBJECT_POSITIVE_INTEGER,
NEGATIVE_INTEGER = MSGPACK_OBJECT_NEGATIVE_INTEGER,
DOUBLE = MSGPACK_OBJECT_DOUBLE,
STR = MSGPACK_OBJECT_STR,
BIN = MSGPACK_OBJECT_BIN,
ARRAY = MSGPACK_OBJECT_ARRAY,
MAP = MSGPACK_OBJECT_MAP,
EXT = MSGPACK_OBJECT_EXT
};
}When msgpack unpacking object from a buffer, unpack_reference_func is called with 'type' as the unpacking type, 'length' as the payload size, and 'user_data' as the argument user_data when you pass to msgpack::unpack(). You may get STR, BIN, and EXT as a type parameter. Other types are never appeared becaulse the msgpack::object that have other types are created by conversion. On the contrary, STR, BIN, and EXT's payloads can be used directly from msgpack::object.
'size' means a payload size. The payload size for STR and BIN, it is actual data size. For EXT, it is EXT's type and data size.
Here is an example implementation of unpack_reference_func.
bool my_reference_func(type::object_type type, std::size_t length, void* user_data) {
switch (type) {
case: type::STR:
// Small strings are copied.
if (length < 32) return false;
break;
case: type::BIN:
// BIN is always copied.
return false;
case: type::EXT:
// fixext's are copied.
switch (length) {
case 1+1:
case 2+1:
case 4+1:
case 8+1:
case 16+1:
return false;
}
break;
default:
assert(false);
}
// otherwise referenced.
return true;
}When the size of string is equal or greater than 32bytes, then the memory layout as follows:
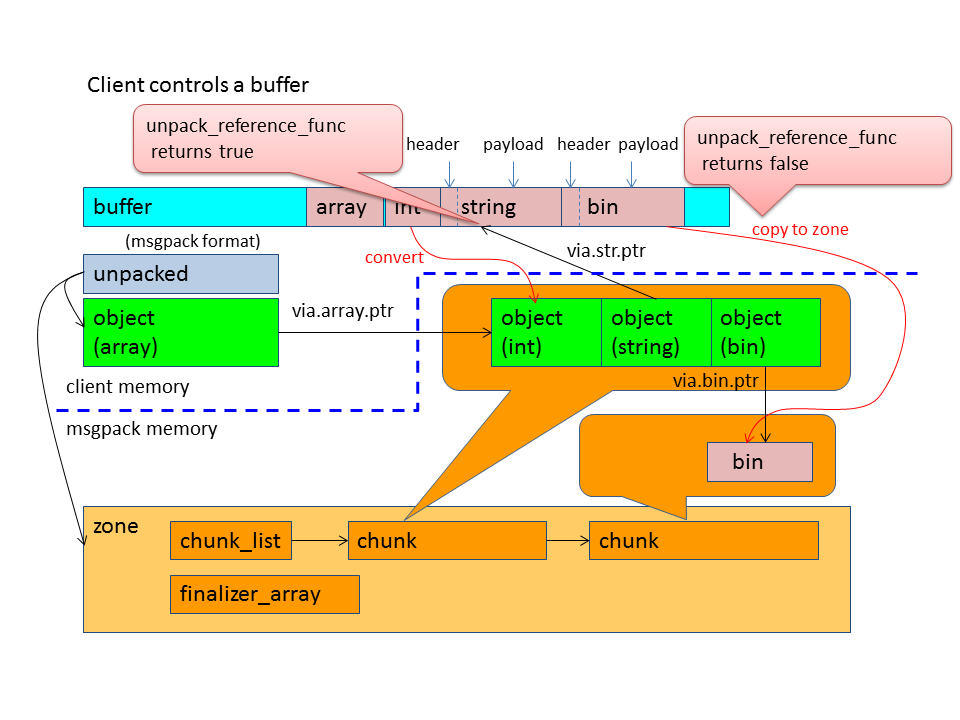
You can get whether the unpacked msgpack::object refer to the buffer or not using the following functions:
// get referenced information
void unpack(
unpacked& result,
const char* data,
std::size_t len,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());
// get referenced information
// set and get offset information
void unpack(
unpacked& result,
const char* data,
std::size_t len,
std::size_t& off,
bool& referenced,
unpack_reference_func f = nullptr,
void* user_data = nullptr,
unpack_limit const& limit = unpack_limit());If referenced is true, msgpack::object refer to the buffer that is passed as the parameter 'data', otherwise msgpack::object doesn't refer to the buffer.
msgpack provides a buffer management functionality named msgpack::unpacker. msgpack::unpacker is sutable for the following motivations:
- msgpack data is chopped, and the client doesn't know when it will complete. This is a typical situation when you develop streaming applications.
- You want to minimize copy opperations without careful memory management.
Here is the basic (not all) interface of msgpack::unpacker:
#ifndef MSGPACK_UNPACKER_INIT_BUFFER_SIZE
#define MSGPACK_UNPACKER_INIT_BUFFER_SIZE (64*1024)
#endif
#ifndef MSGPACK_UNPACKER_RESERVE_SIZE
#define MSGPACK_UNPACKER_RESERVE_SIZE (32*1024)
#endif
class unpacker {
public:
unpacker(unpack_reference_func f = &unpacker::default_reference_func,
void* user_data = nullptr,
std::size_t init_buffer_size = MSGPACK_UNPACKER_INIT_BUFFER_SIZE,
unpack_limit const& limit = unpack_limit());
void reserve_buffer(std::size_t size = MSGPACK_UNPACKER_RESERVE_SIZE);
char* buffer();
void buffer_consumed(std::size_t size);
bool next(unpacked& result);
};Here is a basic pattern using msgpack::unpacker:
// The size may decided by receive performance, transmit layer's protocol and so on.
std::size_t const try_read_size = 100;
msgpack::unpacker unp;
// Message receive loop
while (/* block until input becomes readable */) {
unp.reserve_buffer(try_read_size);
// unp has at least try_read_size buffer on this point.
// input is a kind of I/O library object.
// read message to msgpack::unpacker's internal buffer directly.
std::size_t actual_read_size = input.readsome(unp.buffer(), try_read_size);
// tell msgpack::unpacker actual consumed size.
unp.buffer_consumed(actual_read_size);
msgpack::unpacked result;
// Message pack data loop
while(unp.next(result)) {
msgpack::object obj(result.get());
// Use obj
}
// All complete msgpack message is proccessed at this point,
// then continue to read addtional message.
}msgpack::unpacker::next() returns true if one complete msgpack messege is proccessed. If msgpack message is correct but insufficient, it returns false. However, parsing proccess is proceeded and the context information is preserved in the msgpack::unpacker. It helps leveling the load of parse.
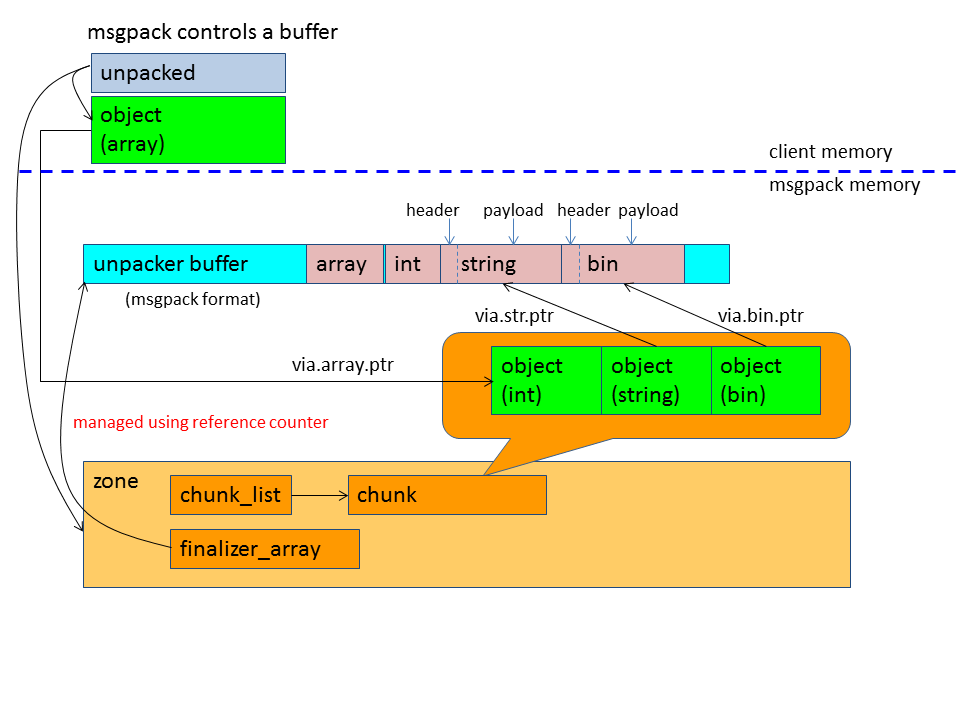
When msgpack message contains binary data, string data, or ext data, they are not copied but referenced from msgpack::object by default. See the following implementation:
inline bool unpacker::default_reference_func(type::object_type type, uint64_t len, void*)
{
return true;
}You can also customize unpack_reference_func. Even if you use references, you don't need to control buffer's lifetime. The buffers' lifetime is controled by msgpack using msgpack::zone's finalizer_array and msgpack::unpacker's reference counting mechanism.
So, in most cases, the default behavior is enough. If you want to control the peak of memory consumption when receiving msgpack data patterns are predictable, customizing unpack_reference_func might be useful.
You can get a reference information from msgpack::unpacker::next() using the following function:
bool next(unpacked& result, bool& referenced);However, mostly you don't need to use that version of next() because referenced memories are managed by unpacker.
If you want to know in detail about an internal mechanism, see internal mechanism, the slides were wrintten when ext support and unpack_reference_func was not implemented.