diff --git a/npyx.egg-info/PKG-INFO b/npyx.egg-info/PKG-INFO
index 380de029..85e087fe 100644
--- a/npyx.egg-info/PKG-INFO
+++ b/npyx.egg-info/PKG-INFO
@@ -14,24 +14,39 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
This package results from the needs of an experimentalist who could not stand MATLAB, hence wrote himself a suite of functions to emotionally bear with doing neuroscience. There isn't any dedicated preprint available yet, so if you enjoy this package and use it for your research, please star [the github repo](https://github.com/m-beau/NeuroPyxels) (click on the top-right star button!) and cite [this paper](https://www.nature.com/articles/s41593-019-0381-8). Cheers!
+ There isn't any better doc atm - post an issue if you have any question, or email [Maxime Beau](maximebeaujeanroch047@gmail.com) (PhD Hausser lab, UCL). You can also use the [Neuropixels slack workgroup](neuropixelsgroup.slack.com), channel #NeuroPyxels.
+
+ - **[Documentation](https://github.com/m-beau/NeuroPyxels#documentation)**
+ - [Load synchronyzation channel](https://github.com/m-beau/NeuroPyxels#load-synchronization-channel)
+ - [Get good units from dataset](https://github.com/m-beau/NeuroPyxels#get-good-units-from-dataset)
+ - [Load spike times from unit u](https://github.com/m-beau/NeuroPyxels#load-spike-times-from-unit-u)
+ - [Load waveforms from unit u](https://github.com/m-beau/NeuroPyxels#load-waveforms-from-unit-u)
+ - [Compute auto/crosscorrelogram between 2 units](https://github.com/m-beau/NeuroPyxels#compute-autocrosscorrelogram-between-2-units)
+ - [Plot waveforms and crosscorrelograms of unit u](https://github.com/m-beau/NeuroPyxels#plot-correlograms-and-waveforms-from-unit-u)
+ - [Plot chunk of raw data with overlaid units](https://github.com/m-beau/NeuroPyxels#plot-chunk-of-raw-data-with-overlaid-units)
+ - [Plot peri-stimulus time histograms across neurons and conditions](https://github.com/m-beau/NeuroPyxels/tree/m-beau#plot-peri-stimulus-time-histograms-across-neurons-and-conditions)
+ - [Merge datasets acquired on two probes simultaneously](https://github.com/m-beau/NeuroPyxels#merge-datasets-acquired-on-two-probes-simultaneously)
+ - **[Installation](https://github.com/m-beau/NeuroPyxels#installation)**
+ - **[Developer cheatsheet](https://github.com/m-beau/NeuroPyxels#developer-cheatsheet)**
+
## Documentation:
Npyx works in harmony with the data formatting employed by [SpikeGLX](https://billkarsh.github.io/SpikeGLX/) used in combination with [Kilosort](https://github.com/MouseLand/Kilosort) and [Phy](https://phy.readthedocs.io/en/latest/).
- Npyx is fast because it never computes the same thing twice - in the background, it saves most relevant outputs (spike trains, waveforms, correlograms...) at **./npyxMemory**, from where they are simply reloaded if called again. An important parameter controlling this behaviour is **`again`** (boolean), by default set to False: if True, the function will recompute the output rather than loading it from npyxMemory. This is important to be aware of this behaviour, as it can lead to mind boggling bugs. For instance, if you load the train of unit then re-spikesort your dataset, e.g. you split unit 56 in 504 and 505, the train of the old unit 56 will still exist at ./npyxMemory and you will be able to load it even though the unit is gone!
+ Npyx is fast because it never computes the same thing twice - in the background, it saves most relevant outputs (spike trains, waveforms, correlograms...) at **kilosort_dataset/npyxMemory**, from where they are simply reloaded if called again. An important parameter controlling this behaviour is **`again`** (boolean), by default set to False: if True, the function will recompute the output rather than loading it from npyxMemory. This is important to be aware of this behaviour, as it can lead to mind boggling bugs. For instance, if you load the train of unit then re-spikesort your dataset, e.g. you split unit 56 in 504 and 505, the train of the old unit 56 will still exist at kilosort_dataset/npyxMemory and you will be able to load it even though the unit is gone!
- Most npyx functions take at least one input: **`dp`**, which is the path to your Kilosort/phy dataset. You can find a [full description of the structure of such datasets](https://phy.readthedocs.io/en/latest/sorting_user_guide/#installation) on phy documentation.
+ Most npyx functions take at least one input: **`dp`**, which is the path to your Kilosort-phy dataset. You can find a [full description of the structure of such datasets](https://phy.readthedocs.io/en/latest/sorting_user_guide/#installation) on phy documentation.
- Other typical parameters are: **`verbose`** (whether to print a bunch of informative messages, useful when debugging), **`saveFig`** (boolean) and **`saveDir`** (whether to save the figure in saveDir for plotting functions)
+ Other typical parameters are: **`verbose`** (whether to print a bunch of informative messages, useful when debugging), **`saveFig`** (boolean) and **`saveDir`** (whether to save the figure in saveDir for plotting functions).
- Importantly, dp can also be the path to a merged dataset, generated with npyx.merge_datasets() - every function will (normally) run as smoothly on folders as any regular kilosort dataset folder. See below for more details.
+ Importantly, **`dp`** can also be the path to a merged dataset, generated with `npyx.merge_datasets()` - every function will run as smoothly on merged datasets as on any regular dataset. See below for more details.
- More precisely, every function requires the files `myrecording.ap.meta`, `spike_times.npy` and `spike_clusters.npy`. Then particular functions will require particular files: loading waveforms with `npyx.spk_wvf.wvf` or extracting your sync channel with `npyx.io.get_npix_sync` require the raw data `myrecording.ap.bin`, extracting the spike sorted group of your units `cluster_groups.tsv` and so on.
+ More precisely, every function requires the files `myrecording.ap.meta`, `spike_times.npy` and `spike_clusters.npy`. If you have started spike sorting, `cluter_groups.tsv` will also be required obviously (will be created filled with 'unsorted' groups if none is found). Then particular functions will require particular files: loading waveforms with `npyx.spk_wvf.wvf` or extracting your sync channel with `npyx.io.get_npix_sync` require the raw data `myrecording.ap.bin`, `npyx.spk_wvf.templates` the files `templates.npy` and `spike_templates.npy`, and so on. This allows you to only transfer the strictly necassary files for your use case from a machine to the next: for instance, if you only want to make behavioural analysis of spike trains but do not care about the waveforms, you can run `get_npix_sync` on a first machine (which will generate a `sync_chan` folder containing extracted onsets/offsets from the sync channel(s)), then excklusively transfer the `sync_chan` folder along with `spike_times.npy` and `spike_clusters.npy` (all very light files) on another computer and analyze your data there seemlessly.
Example use cases are:
### Load synchronization channel
```python
from npyx.io import get_npix_sync
- dp = 'path/to/dataset'
+ dp = 'datapath/to/kilosort_dataset'
onsets, offsets = get_npix_sync(dp)
# onsets/offsets are dictionnaries
# whose keys are ids of sync channel where signal was detected,
@@ -40,13 +55,11 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
### Get good units from dataset
```python
from npyx.gl import get_units
- dp = 'path/to/dataset'
units = get_units(dp, quality='good')
```
### Load spike times from unit u
```python
from npyx.spk_t import trn
- dp = 'path/to/dataset'
u=234
t = trn(dp, u) # gets all spikes from unit 234, in samples
```
@@ -56,25 +69,32 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
from npyx.io import read_spikeglx_meta
from npyx.spk_t import ids, trn
from npyx.spk_wvf import get_peak_chan, wvf, templates
- dp = 'path/to/dataset'
- u=234
+
# returns a random sample of 100 waveforms from unit 234, in uV, across 384 channels
- waveforms = wvf(dp, u, n_waveforms=100, t_waveforms=82) # return array of shape (100, 82, 384) by default
- waveforms = wvf(dp, u, periods='regular')
- waveforms = wvf(dp, u, spike_ids=None)
+ waveforms = wvf(dp, u) # return array of shape (n_waves, n_samples, n_channels)=(100, 82, 384) by default
+ waveforms = wvf(dp, u, n_waveforms=1000, t_waveforms=90) # now 1000 random waveforms, 90 samples=3ms long
+
# Get the unit peak channel (channel with the biggest amplitude)
peak_chan = get_peak_chan(dp,u)
# extract the waveforms located on peak channel
w=waves[:,:,peak_chan]
# Extract waveforms of spikes occurring between
- # 900 and 1000s in the recording, because that's when your mouse scratched its butt
+ # 0-100s and 300-400s in the recording,
+ # because that's when your mouse sneezed
+ waveforms = wvf(dp, u, periods=[(0,100),(300,400)])
+
+ # alternatively, longer but more flexible:
fs=read_spikeglx_meta['sRateHz']
t=trn(dp,u)/fs # convert in s
+ # get ids of unit u: all spikes have a unique index in the dataset,
+ # which is their rank sorted by time (as in spike_times.npy)
+ u_ids = ids(dp,u)
ids=ids(dp,u)[(t>900)&(t<1000)]
- waves = wvf(dp, u, spike_ids=ids)
+ mask = (t<100)|((t>300)&(t<400))
+ waves = wvf(dp, u, spike_ids=u_ids[mask])
- # If you want to load the templates instead (lighter)
+ # If you want to load the templates instead (faster and does not require binary file):
temp = templates(dp,u) # return array of shape (n_templates, 82, n_channels)
```
@@ -86,7 +106,7 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
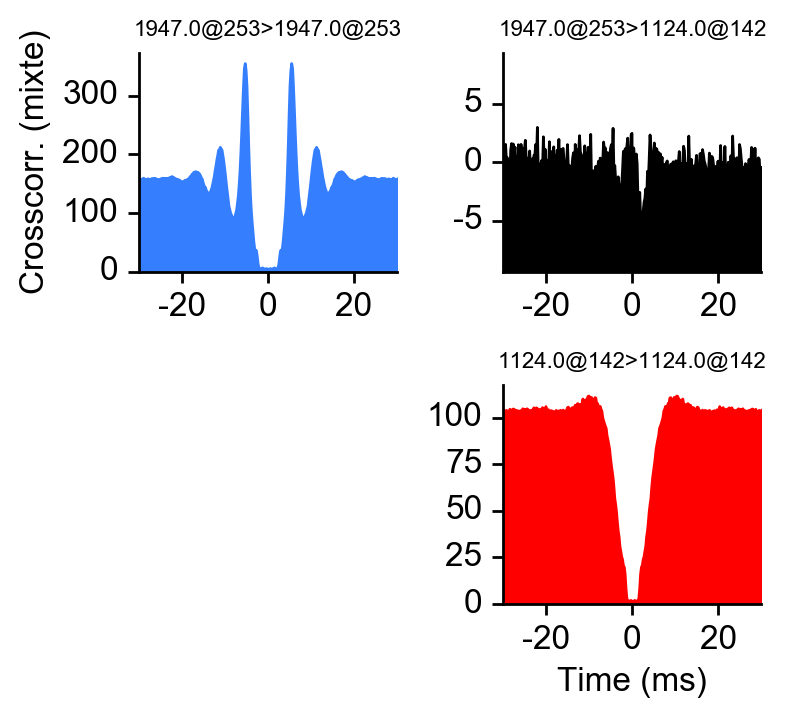
c = ccg(dp, [234,92], cbin=0.2, cwin=80)
```
- ### Plot correlograms and waveforms from unit u
+ ### Plot waveform and croccorrelogram of unit u
```python
# all plotting functions return matplotlib figures
from npyx.plot import plot_wvf, get_peak_chan
@@ -99,13 +119,46 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
# But if you wished to get it, simply run
peakchannel = get_peak_chan(dp, u)
```
- 
+  ```python
# plot ccg between 234 and 92
fig = plot_ccg(dp, [u,92], cbin=0.2, cwin=80, as_grid=True)
```
- 
+
```python
# plot ccg between 234 and 92
fig = plot_ccg(dp, [u,92], cbin=0.2, cwin=80, as_grid=True)
```
- 
+  +
+
+ ### Plot chunk of raw data with overlaid units
+ ```python
+ units = [1,2,3,4,5,6]
+ channels = np.arange(70,250)
+ # raw data are whitened, high-pass filtered and median-subtracted by default - parameters are explicit below
+ plot_raw_units(dp, times=[0,0.130], units = units, channels = channels,
+ colors=['orange', 'red', 'limegreen', 'darkgreen', 'cyan', 'navy'],
+ lw=1.5, offset=450, figsize=(6,16), Nchan_plot=10,
+ med_sub=1, whiten=1, hpfilt=1)
+ ```
+
+
+
+ ### Plot chunk of raw data with overlaid units
+ ```python
+ units = [1,2,3,4,5,6]
+ channels = np.arange(70,250)
+ # raw data are whitened, high-pass filtered and median-subtracted by default - parameters are explicit below
+ plot_raw_units(dp, times=[0,0.130], units = units, channels = channels,
+ colors=['orange', 'red', 'limegreen', 'darkgreen', 'cyan', 'navy'],
+ lw=1.5, offset=450, figsize=(6,16), Nchan_plot=10,
+ med_sub=1, whiten=1, hpfilt=1)
+ ```
+ 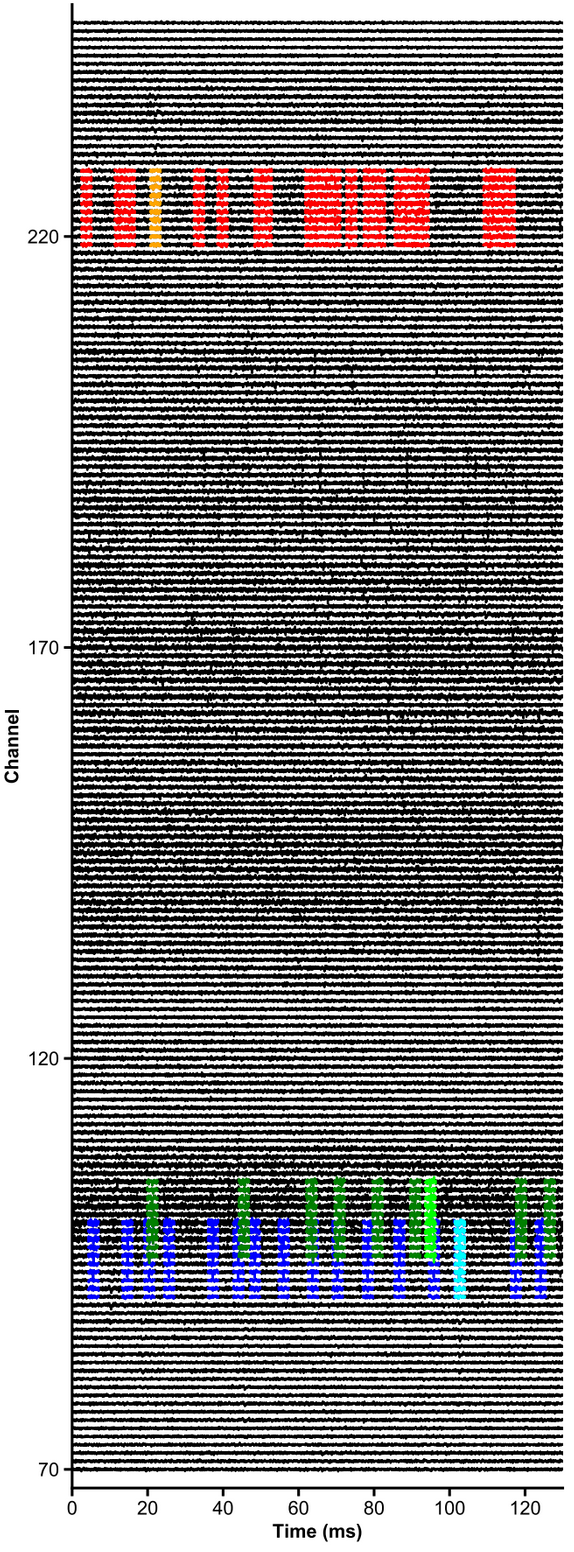 +
+ ### Plot peri-stimulus time histograms across neurons and conditions
+
+ ```python
+ # Explore responses of 3 neurons to 4 categories of events:
+ fs=30000 # Hz
+ units=[1,2,3]
+ trains=[trn(dp,u)/fs for u in units] # make list of trains of 3 units
+ trains_str=units # can give specific names to units here, show on the left of each row
+ events=[licks, sneezes, visual_stimuli, auditory_stimuli] # get events corresponding to 4 conditions
+ trains_str=['licking', 'sneezing', 'visual_stim', 'auditory_stim'] # can give specific names to events here, show above each column
+ events_col='batlow' # colormap from which the event colors will be drawn
+ fig=summary_psth(trains, trains_str, events, events_str, psthb=10, psthw=[-750,750],
+ zscore=0, bsl_subtract=False, bsl_window=[-3000,-750], convolve=True, gsd=2,
+ events_toplot=[0], events_col=events_col, trains_col_groups=trains_col_groups,
+ title=None, saveFig=0, saveDir='~/Downloads', _format='pdf',
+ figh=None, figratio=None, transpose=1,
+ as_heatmap=False, vmin=None, center=None, vmax=None, cmap_str=None)
+ ```
+
+
+ ### Plot peri-stimulus time histograms across neurons and conditions
+
+ ```python
+ # Explore responses of 3 neurons to 4 categories of events:
+ fs=30000 # Hz
+ units=[1,2,3]
+ trains=[trn(dp,u)/fs for u in units] # make list of trains of 3 units
+ trains_str=units # can give specific names to units here, show on the left of each row
+ events=[licks, sneezes, visual_stimuli, auditory_stimuli] # get events corresponding to 4 conditions
+ trains_str=['licking', 'sneezing', 'visual_stim', 'auditory_stim'] # can give specific names to events here, show above each column
+ events_col='batlow' # colormap from which the event colors will be drawn
+ fig=summary_psth(trains, trains_str, events, events_str, psthb=10, psthw=[-750,750],
+ zscore=0, bsl_subtract=False, bsl_window=[-3000,-750], convolve=True, gsd=2,
+ events_toplot=[0], events_col=events_col, trains_col_groups=trains_col_groups,
+ title=None, saveFig=0, saveDir='~/Downloads', _format='pdf',
+ figh=None, figratio=None, transpose=1,
+ as_heatmap=False, vmin=None, center=None, vmax=None, cmap_str=None)
+ ```
+ 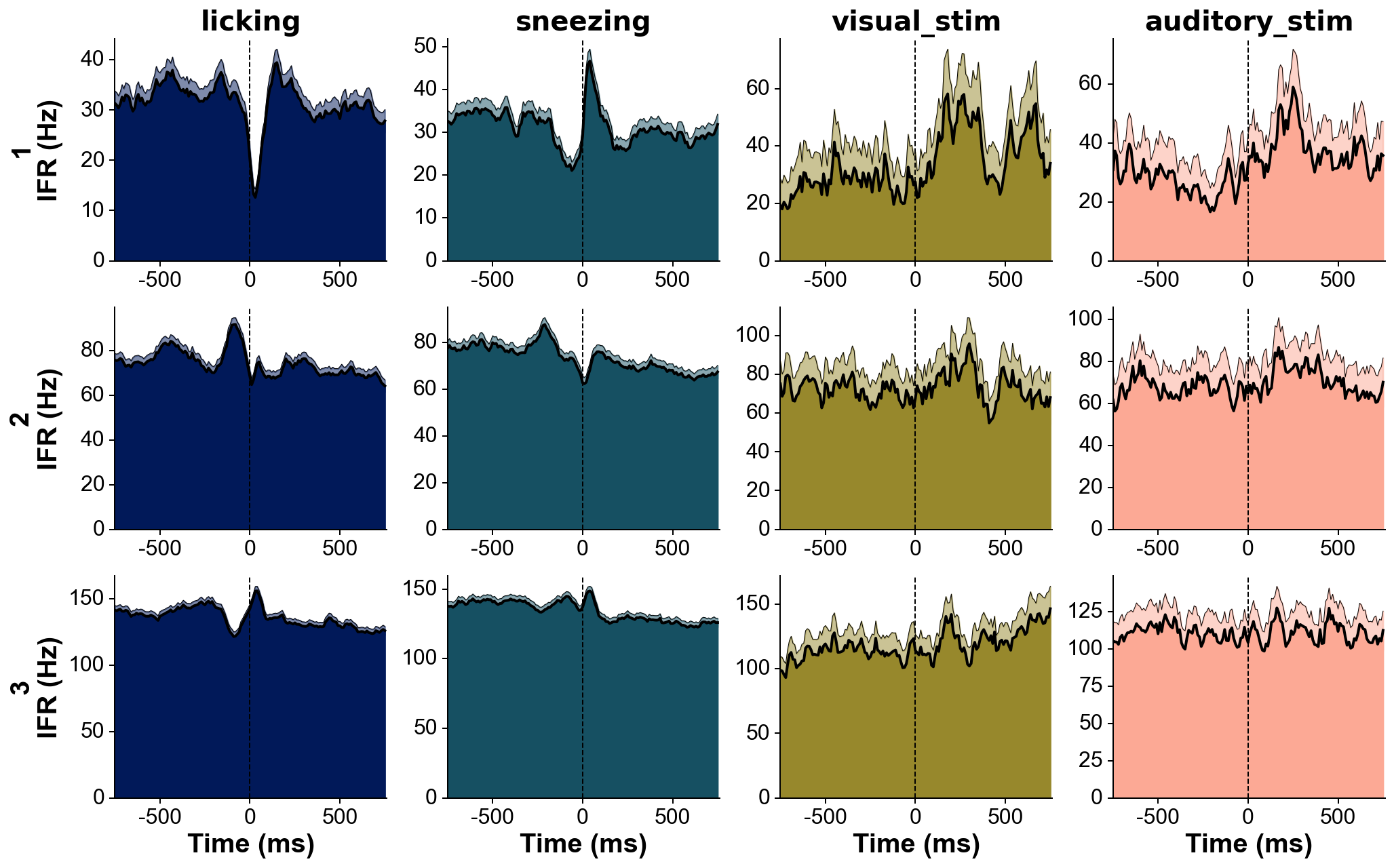 ### Merge datasets acquired on two probes simultaneously
```python
@@ -124,10 +177,11 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
# of format u.x (u=unit id, x=dataset id [0-2]).
# lateralprobe, medial probe and anteriorprobe x will be respectively 0,1 and 2.
dp_merged, datasets_table = merge_datasets(dp_dic)
- ```
- --- Merged data (from 2 dataset(s)) will be saved here: /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
- --- Loading spike trains of 2 datasets...
+
+ --- Merged data (from 2 dataset(s)) will be saved here: /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
+
+ --- Loading spike trains of 2 datasets...
sync channel extraction directory found: /same_folder/lateralprobe_dataset/sync_chan
Data found on sync channels:
@@ -156,23 +210,27 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
chan 7 (93609 events).
Which channel shall be used to synchronize probes? >>> 7
- --- Aligning spike trains of 2 datasets...
+ --- Aligning spike trains of 2 datasets...
More than 50 sync signals found - for performance reasons, sub-sampling to 50 homogenoeously spaced sync signals to align data.
50 sync events used for alignement - start-end drift of -3080.633ms
- --- Merged spike_times and spike_clusters saved at /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
+ --- Merged spike_times and spike_clusters saved at /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
- --> Merge successful! Use a float u.x in any npyx function to call unit u from dataset x:
+ --> Merge successful! Use a float u.x in any npyx function to call unit u from dataset x:
- u.0 for dataset lateralprobe_dataset,
- u.1 for dataset medialprobe_dataset,
- u.2 for dataset anteriorprobe_dataset.
+ ```
+ Now any npyx function runs on the merged dataset!
+ Under the hood, it will create a `merged_dataset_dataset1_dataset2/npyxMemory` folder to save any data computed across dataframes, but will use the original `dataset1/npyxMemory` folder to save data related to this dataset exclusively (e.g. waveforms). Hence, there is no redundancy: space and time are saved.
+ This is also why it is primordial that you do not move your datatasets from their original paths after merging them - else, functions ran on merged_dataset1_dataset2 will not know where to go fetch the data! They refer to the paths in `merged_dataset_dataset1_dataset2/datasets_table.csv`. If you really need to, you can move your datasets but do not forget to edit this file accordingly.
```python
+ # These will work!
t = trn(dp_merged, 92.1) # get spikes of unit 92 in dataset 1 i.e. medialprobe
fig=plot_ccg(dp_merged,[10.0, 92.1, cbin=0.2, cwin=80]) # compute CCG between 2 units across datasets
```
- There isn't any better doc atm - email [Maxime Beau](mailto:maximebeaujeanroch047@gmail.com) (PhD Hausser lab, UCL at time of writing) if you have any questions!
### Merge datasets acquired on two probes simultaneously
```python
@@ -124,10 +177,11 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
# of format u.x (u=unit id, x=dataset id [0-2]).
# lateralprobe, medial probe and anteriorprobe x will be respectively 0,1 and 2.
dp_merged, datasets_table = merge_datasets(dp_dic)
- ```
- --- Merged data (from 2 dataset(s)) will be saved here: /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
- --- Loading spike trains of 2 datasets...
+
+ --- Merged data (from 2 dataset(s)) will be saved here: /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
+
+ --- Loading spike trains of 2 datasets...
sync channel extraction directory found: /same_folder/lateralprobe_dataset/sync_chan
Data found on sync channels:
@@ -156,23 +210,27 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
chan 7 (93609 events).
Which channel shall be used to synchronize probes? >>> 7
- --- Aligning spike trains of 2 datasets...
+ --- Aligning spike trains of 2 datasets...
More than 50 sync signals found - for performance reasons, sub-sampling to 50 homogenoeously spaced sync signals to align data.
50 sync events used for alignement - start-end drift of -3080.633ms
- --- Merged spike_times and spike_clusters saved at /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
+ --- Merged spike_times and spike_clusters saved at /same_folder/merged_lateralprobe_dataset_medialprobe_dataset_anteriorprobe_dataset.
- --> Merge successful! Use a float u.x in any npyx function to call unit u from dataset x:
+ --> Merge successful! Use a float u.x in any npyx function to call unit u from dataset x:
- u.0 for dataset lateralprobe_dataset,
- u.1 for dataset medialprobe_dataset,
- u.2 for dataset anteriorprobe_dataset.
+ ```
+ Now any npyx function runs on the merged dataset!
+ Under the hood, it will create a `merged_dataset_dataset1_dataset2/npyxMemory` folder to save any data computed across dataframes, but will use the original `dataset1/npyxMemory` folder to save data related to this dataset exclusively (e.g. waveforms). Hence, there is no redundancy: space and time are saved.
+ This is also why it is primordial that you do not move your datatasets from their original paths after merging them - else, functions ran on merged_dataset1_dataset2 will not know where to go fetch the data! They refer to the paths in `merged_dataset_dataset1_dataset2/datasets_table.csv`. If you really need to, you can move your datasets but do not forget to edit this file accordingly.
```python
+ # These will work!
t = trn(dp_merged, 92.1) # get spikes of unit 92 in dataset 1 i.e. medialprobe
fig=plot_ccg(dp_merged,[10.0, 92.1, cbin=0.2, cwin=80]) # compute CCG between 2 units across datasets
```
- There isn't any better doc atm - email [Maxime Beau](mailto:maximebeaujeanroch047@gmail.com) (PhD Hausser lab, UCL at time of writing) if you have any questions!
@@ -191,7 +249,7 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
python -c 'import npyx' # should not return any error
# If it does, install any missing dependencies with pip (hopefully none!)
```
- - from the remote repository (always up to date - still private at time of writing, pip is a prerelease)
+ - from the remote repository (always up to date)
```bash
conda activate env_name
pip install git+https://github.com/Npix-routines/NeuroPyxels@master
@@ -211,6 +269,10 @@ Description: # NeuroPyxels: loading, processing and plotting Neuropixels data in
cd path/to/save_dir/NeuroPyxels
git pull
# And that's it, thanks to the egg link no need to reinstall the package!
+ # be careful though: this will break if you edited the package. If you wish to contribute, I advise you
+ # to either post issues and wait for me to fix your problem, or to get in touch with me and potentially
+ # create your own branch from where you will be able to gracefully merge your edits with the master branch
+ # after revision.
```
diff --git a/npyx/__init__.py b/npyx/__init__.py
index c7785bbc..23d099a6 100644
--- a/npyx/__init__.py
+++ b/npyx/__init__.py
@@ -38,4 +38,4 @@
npyx.stats
"""
-__version__ = '2.0.1'
+__version__ = '2.0.2'
\ No newline at end of file