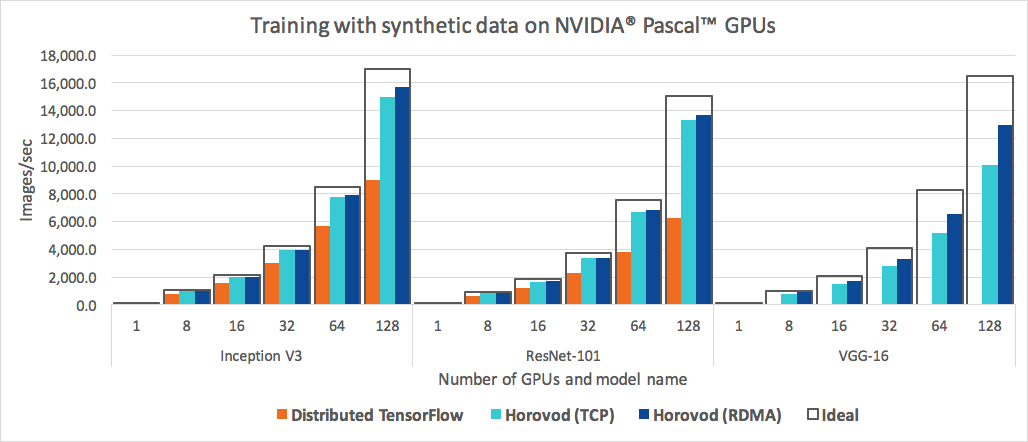
The above benchmark was done on 32 servers with 4 Pascal GPUs each connected by RoCE-capable 25 Gbit/s network. Horovod achieves 90% scaling efficiency for both Inception V3 and ResNet-101, and 79% scaling efficiency for VGG-16.
To reproduce the benchmarks:
-
Install Horovod using the instructions provided on the Horovod on GPU page.
$ git clone https://github.com/tensorflow/benchmarks
$ cd benchmarks-
Run the benchmark. Examples below are for Open MPI.
$ mpirun -np 16 \ -H server1:4,server2:4,server3:4,server4:4 \ -bind-to none -map-by slot \ -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH \ -mca pml ob1 -mca btl ^openib \ \ python scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \ --model resnet101 \ --batch_size 64 \ --variable_update horovod -
At the end of the run, you will see the number of images processed per second:
total images/sec: 1656.82
The benchmark instructions above are for the synthetic data benchmark.
To run the benchmark on a real data, you need to download the ImageNet dataset and convert it using the TFRecord preprocessing script.
Now, simply add --data_dir /path/to/imagenet/tfrecords --data_name imagenet --num_batches=2000 to your training command:
$ mpirun -np 16 \
-H server1:4,server2:4,server3:4,server4:4 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH \
-mca pml ob1 -mca btl ^openib \
\
python scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet101 \
--batch_size 64 \
--variable_update horovod \
--data_dir /path/to/imagenet/tfrecords \
--data_name imagenet \
--num_batches=2000