You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
public int hashCode()
{
int hash = 0;
int skip = Math.max(1, length()/8);
// this is bad,increase possibility of hash collision
for (int i = 0; i < length(); i += skip)
hash = (hash * 37) + charAt(i);
return hash;
}
背景
做一个程序:
当然小说字数变多时,如何改进数据结构与算法,才能让程序性能令人满意?
分析
这里用到了符号表(symbol table):ST<word, count>
主要是用到了两个API:
也及涉及到了查找及修改,换句话说,需要一种支持快速查找与修改的数据结构,才能较好地解决问题。
实现
线性结构
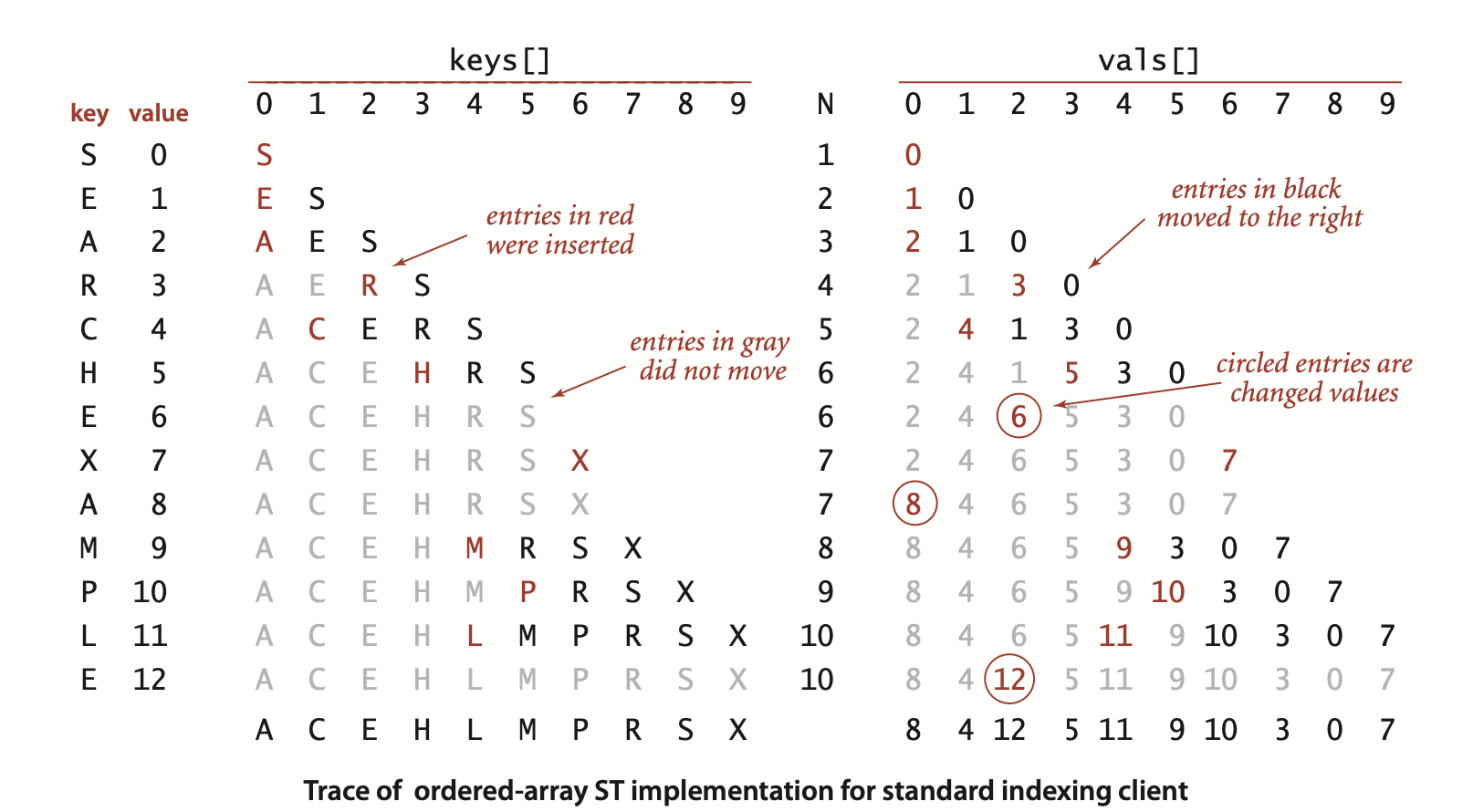
链表可以快速插入(添加一个尾指针),但查找的效率是O(N),不能令人满意。
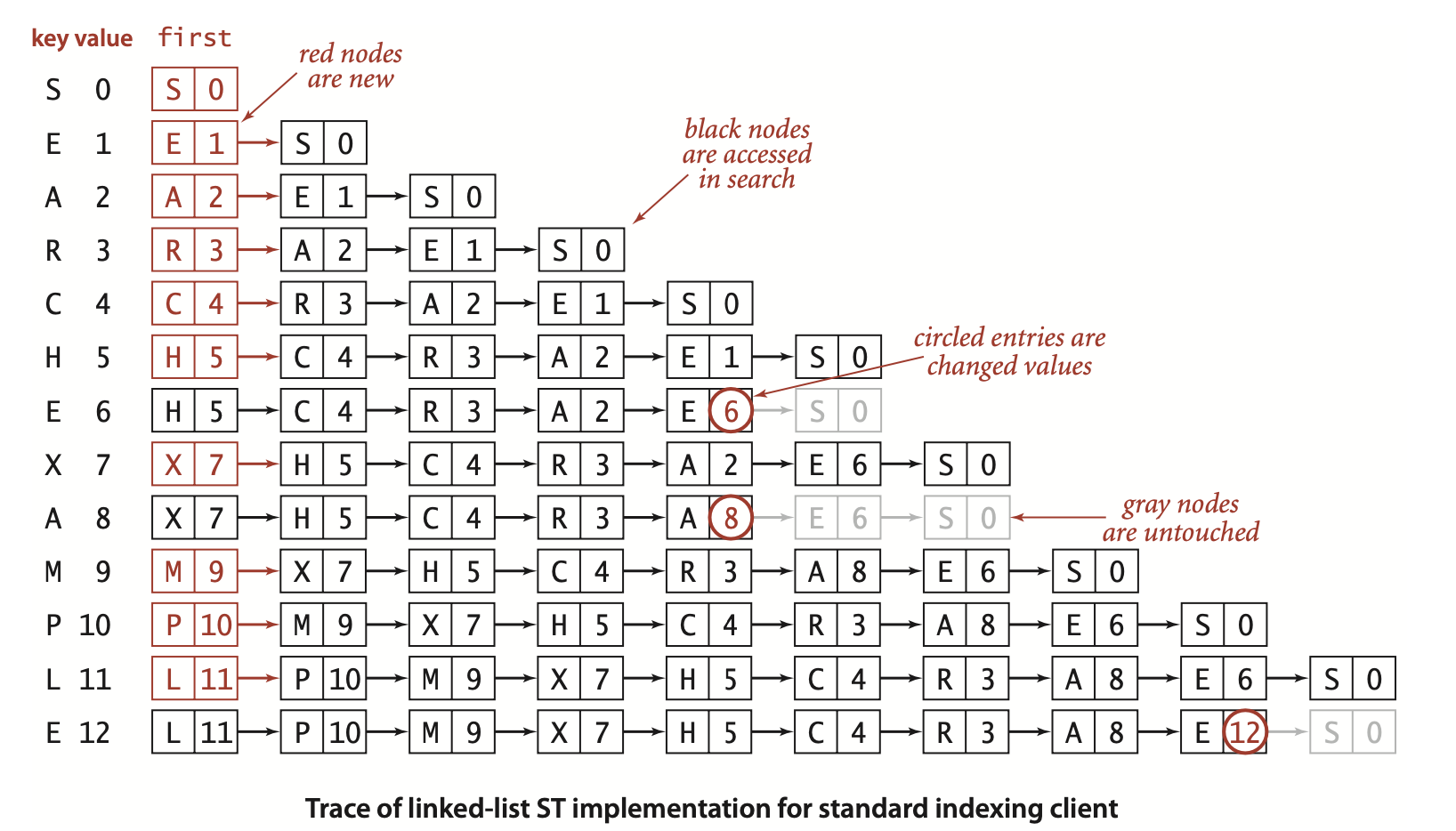
数组(平行数组,一个keys[],另一个vals[]),有序地插入时,可以利用二分查找,让查找效率为O(lgN)。但其插入效率为O(2N),不能令人满意。
二叉查找树(BST)
BST较好地结合了链表与数组的优点:有序,且支持二分查找,插入与查找的效率都是对数级别。
此外,还较好地支持了:rank、select、delete、range query的操作。
BST的效率取决于树的高度,在极端情况下,会退化成链表,而正是这一潜在的问题,促使进一步的研究。
2-3 树
同时包含2叉节点与3叉节点(中间子节点的值介于父节点两个值之间),自底向上构建,能够自我平衡。
插入后的变化操作如下:(右边的部分省略了对4叉节点的再次分裂操作)
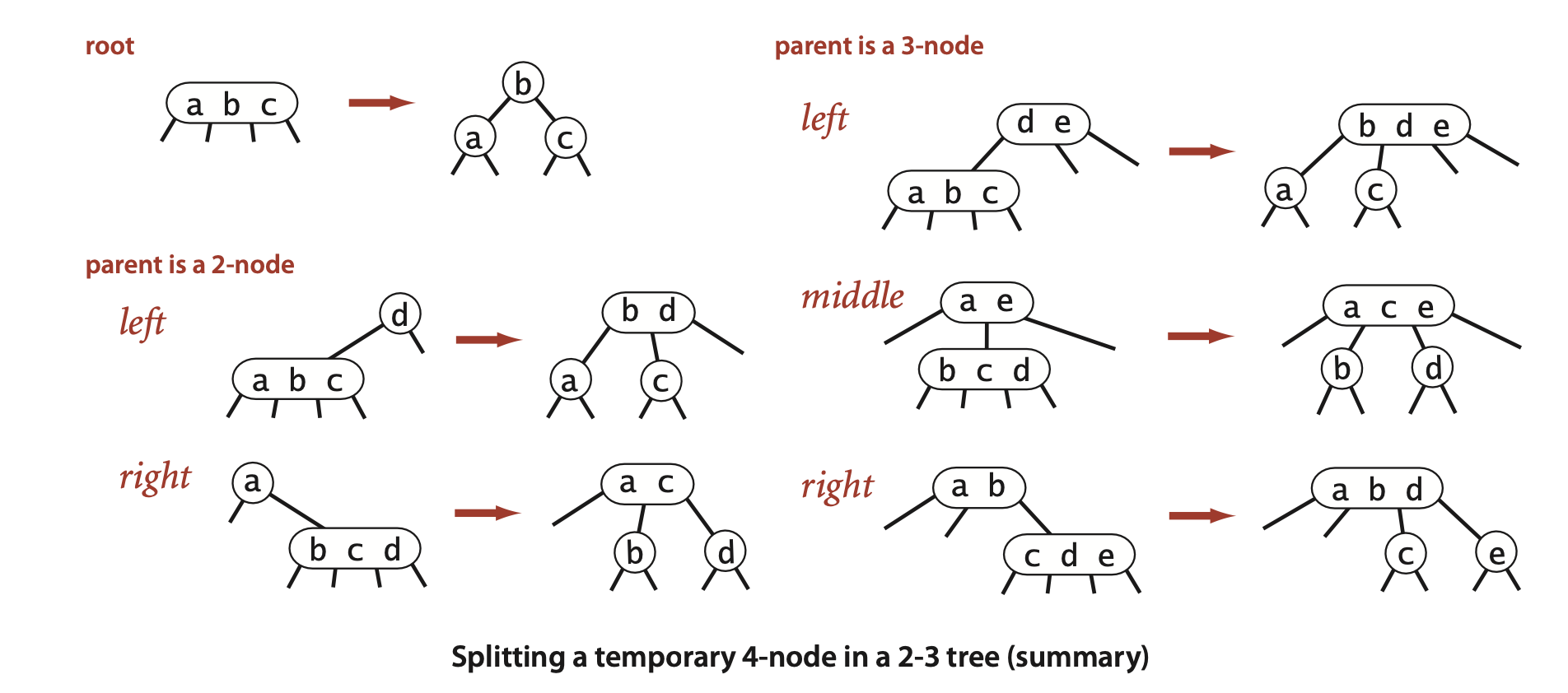
2-3树的难点在于,实现起来比较费力(与红黑树相比),出于工程实践考虑,促使了进一步的研究。
红黑树(Red-Black BST)
基于BST对2-3树的巧妙实现(只需要修改BST的put与delete的代码),如果把红线水平放置,视觉上就更容易看出就是2-3树。
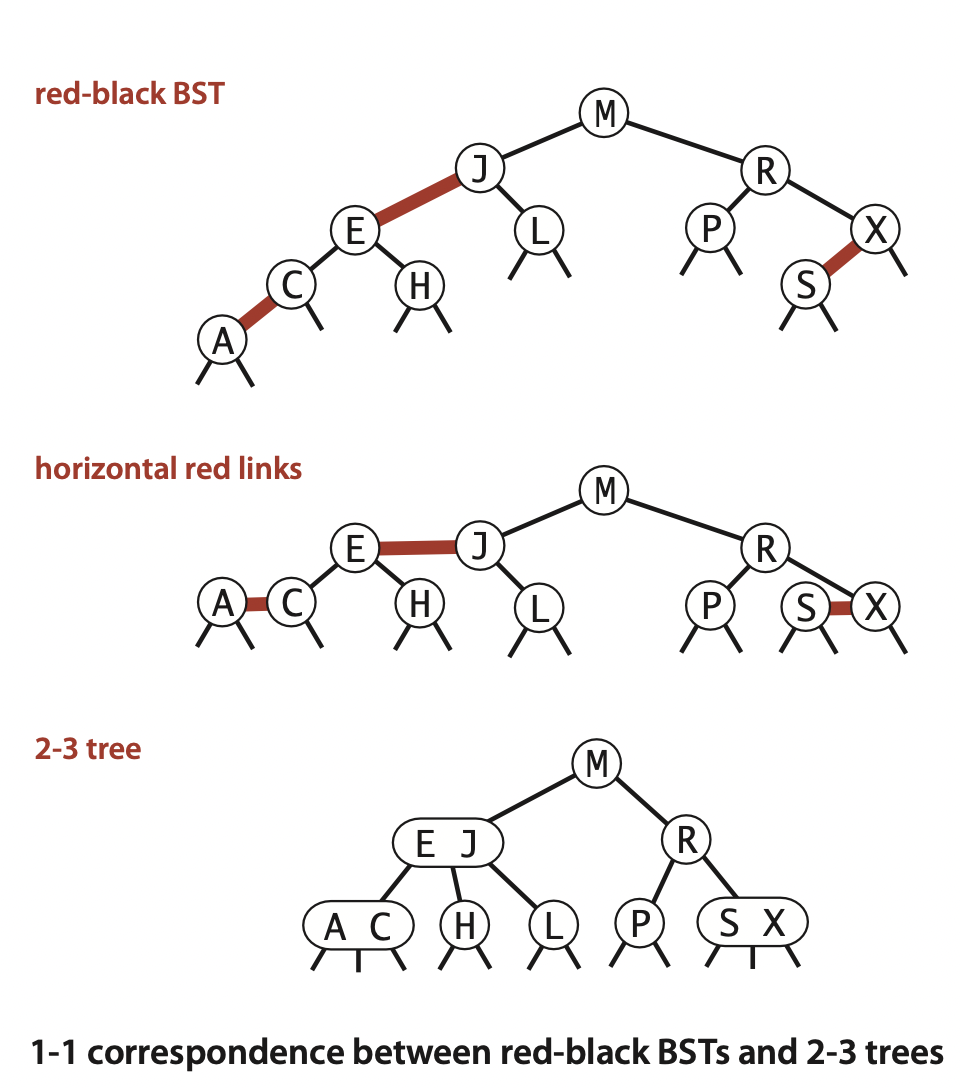
特点有:
小测试:答案是3、4(1不平衡,2无序)
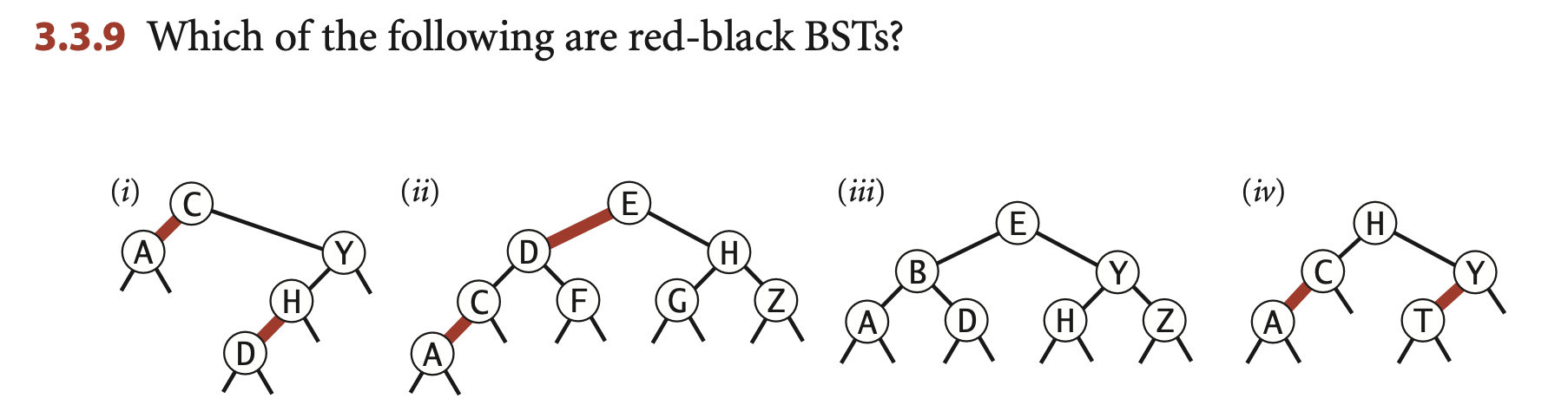
每次插入新节点,都要为新节点染上红色;此时如果违背了上述规则,则需要进行操作
记录一些细节,可点击查看视频:
散列表
基于数组可以随机访问的特点,提出设想:如果可以把ST<key, value>的 key 转换成整数,则可以用数组的下标作为 key,从而实现能快速查找与修改的符号表。这样实现的符号表就是散列表。
设散列表数组大小为M,则
核心步骤有两个:
当然,工程实践上,还要考虑数组的容量扩缩容,以及 load factor 的大小。
练习
public int hashCode() { return 17; }这样的散列函数是合法的(整数)The text was updated successfully, but these errors were encountered: