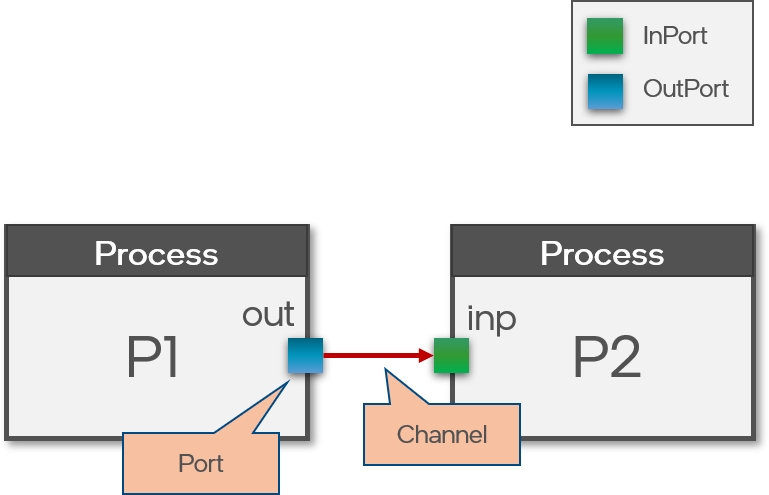
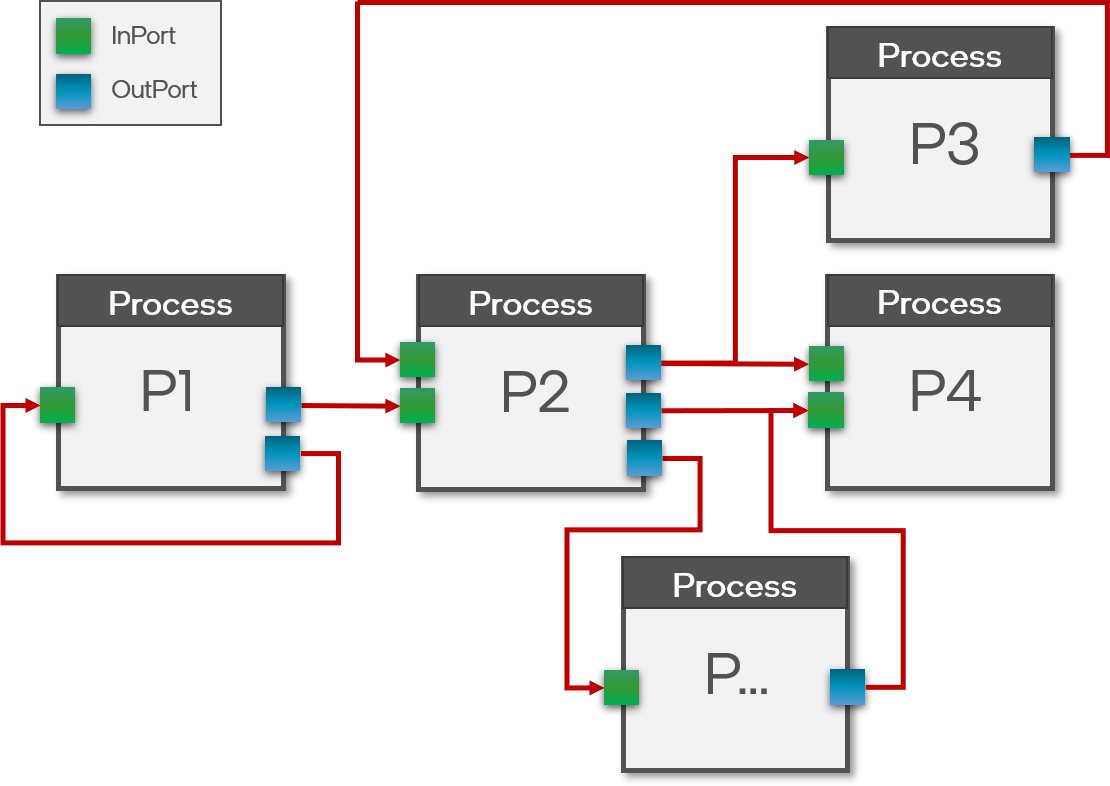
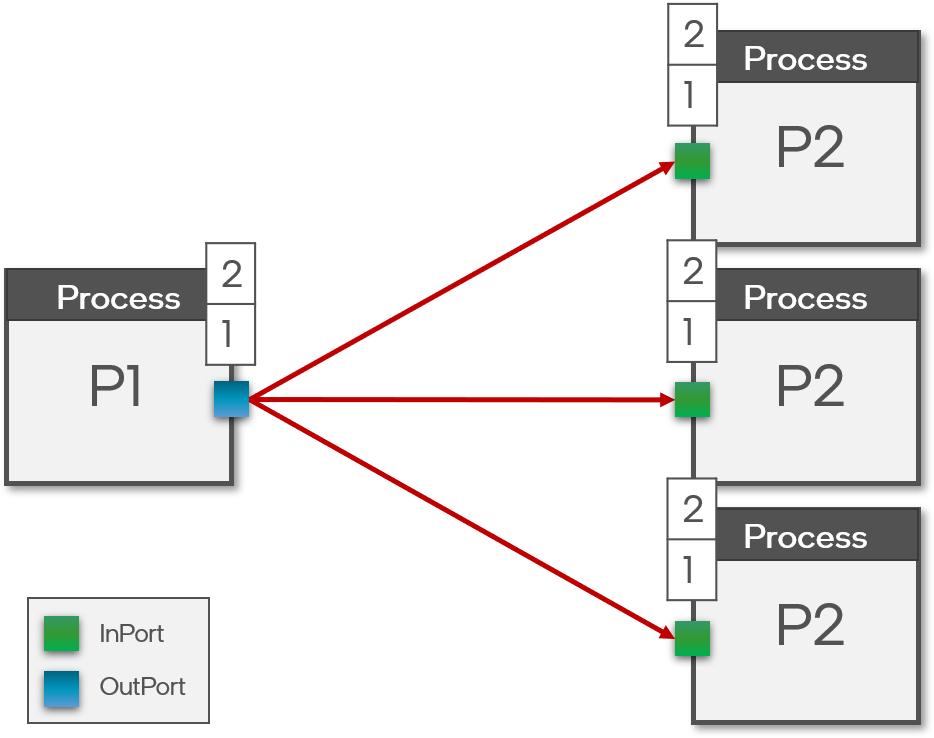
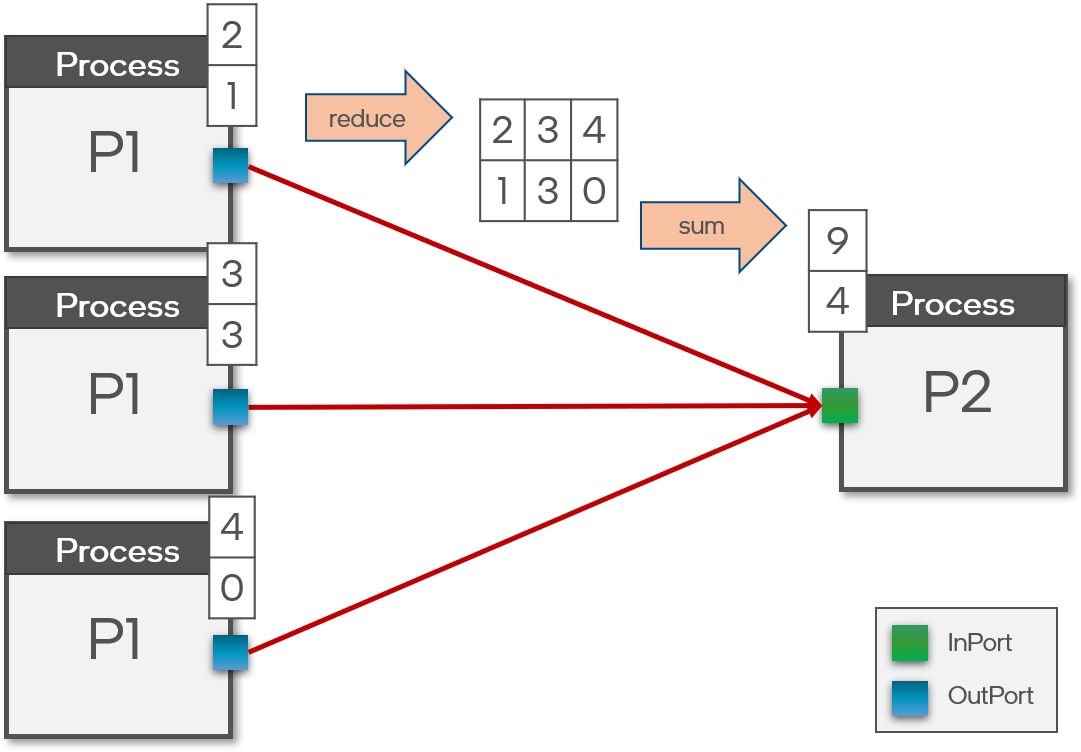
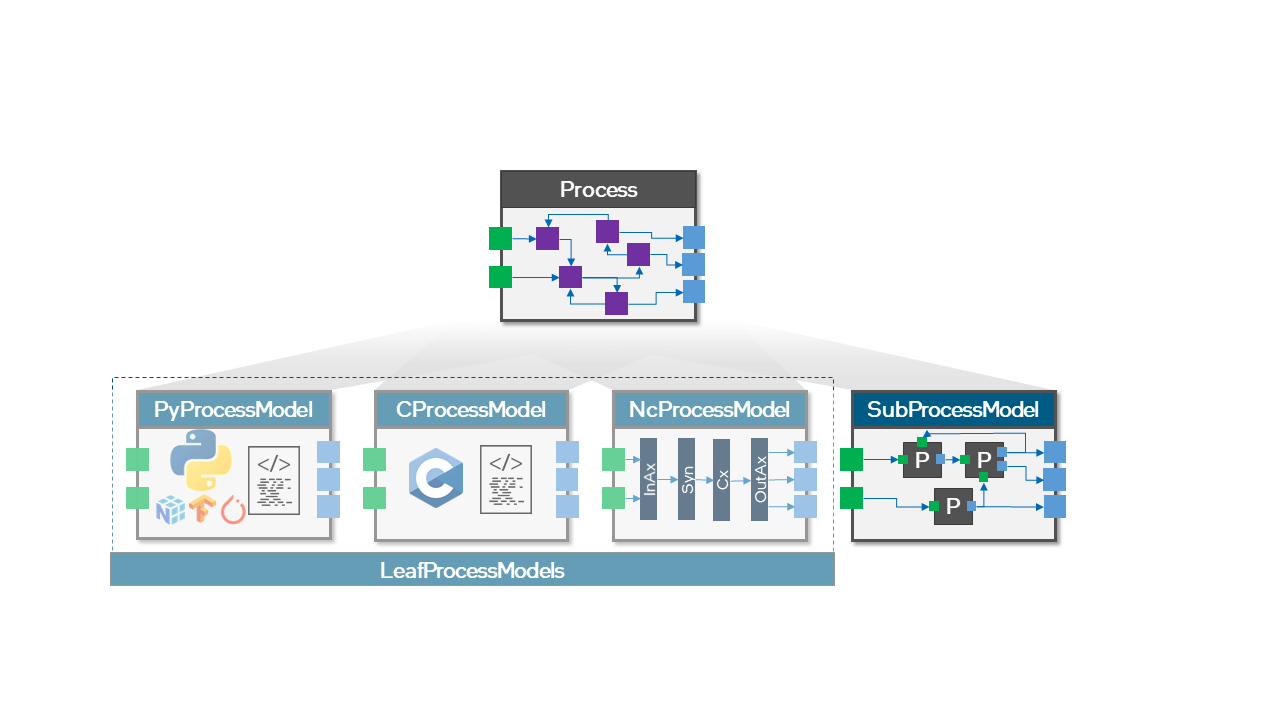
+A sigma-delta neuron is simply a regular activation wrapped around by a sigma unit at it’s input and a delta unit at its output.
When the input to the network is a temporal sequence, the activations do not change much. Therefore, the message between the layers are reduced which in turn reduces the synaptic computation in the next layer. In addition, the graded event values can encode the change in magnitude in one time-step. Therefore there is no increase in latency at the cost of time-steps unlike the rate coded Spiking Neural Networks.

diff --git a/lava/notebooks/in_depth/clp/tutorial01_one-shot_learning_with_novelty_detection.html b/lava/notebooks/in_depth/clp/tutorial01_one-shot_learning_with_novelty_detection.html
index fc2ed0f..7bed4e7 100644
--- a/lava/notebooks/in_depth/clp/tutorial01_one-shot_learning_with_novelty_detection.html
+++ b/lava/notebooks/in_depth/clp/tutorial01_one-shot_learning_with_novelty_detection.html
@@ -841,11 +841,11 @@ Online Continual Learning with Open-set Recognition |
|

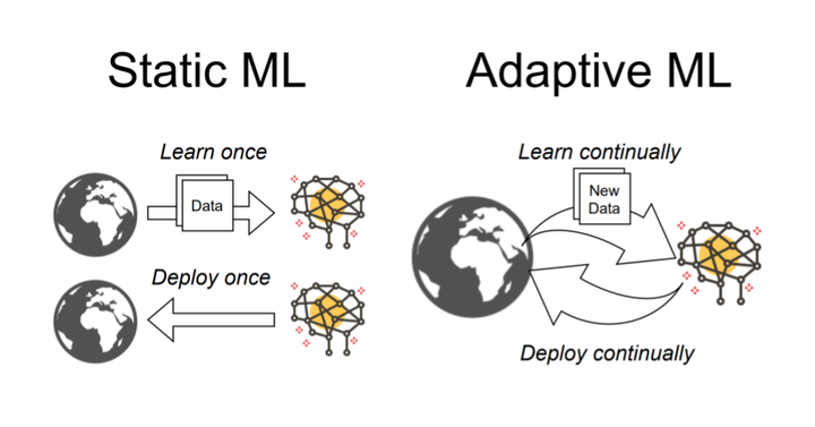
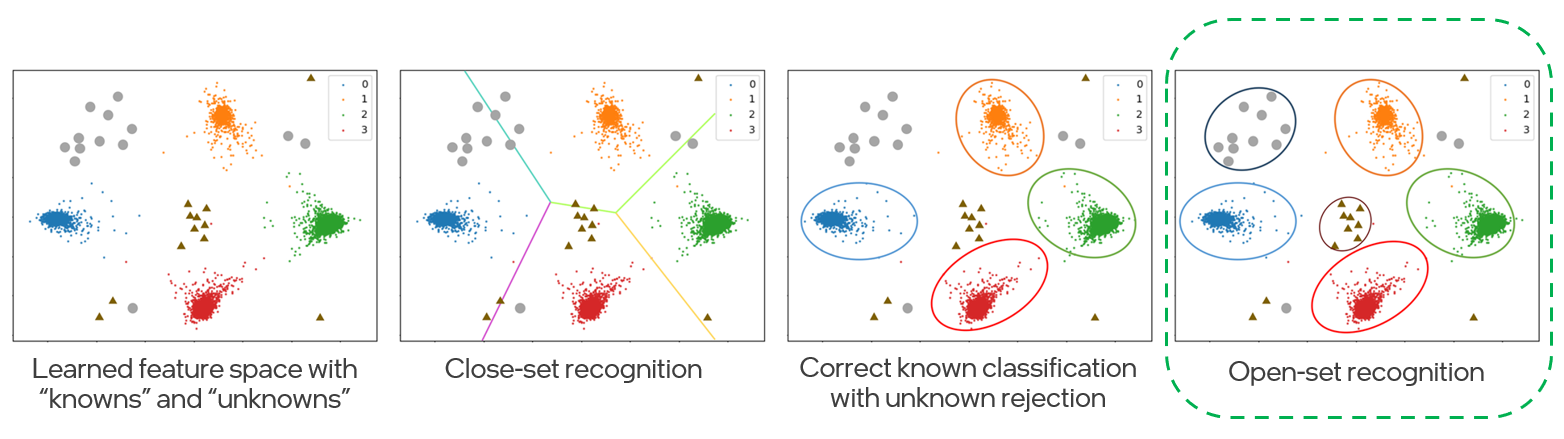
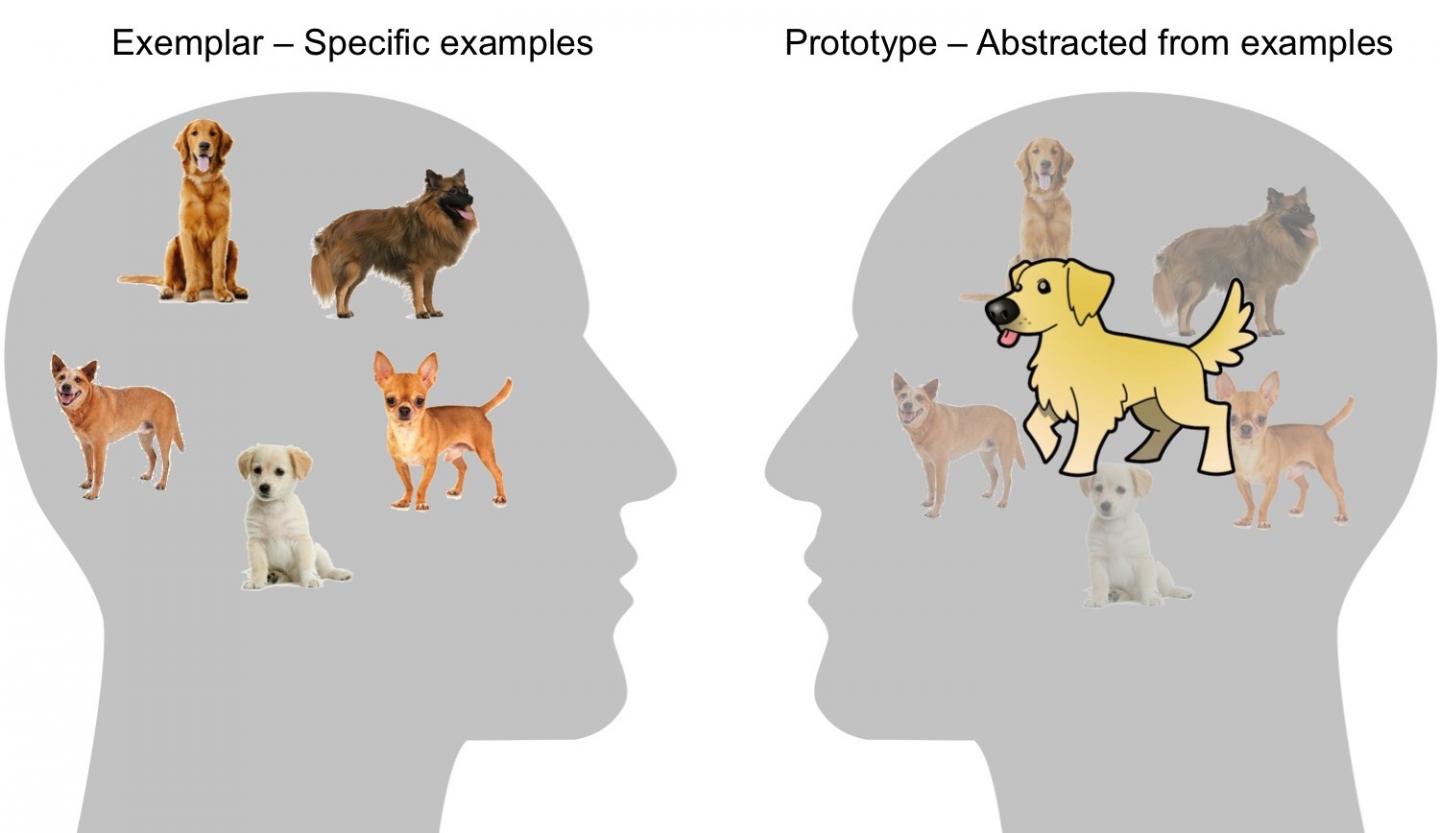

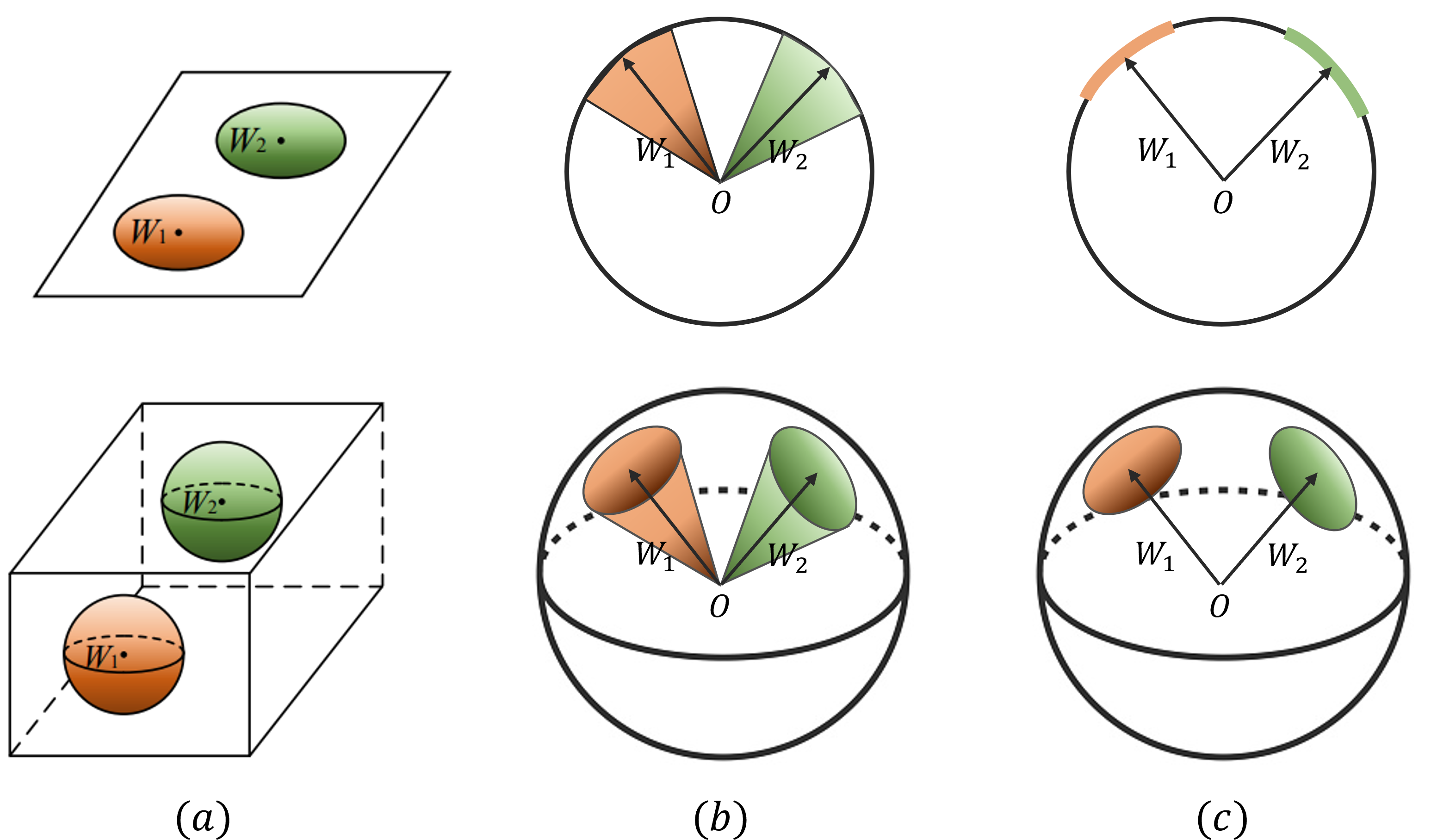
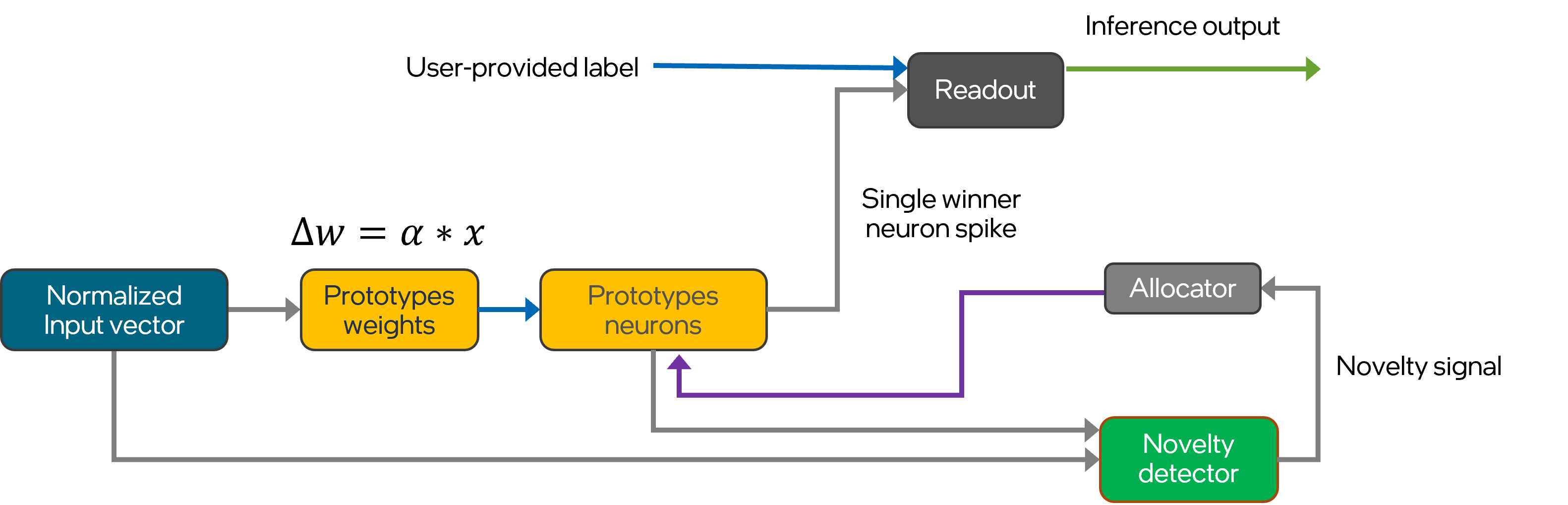
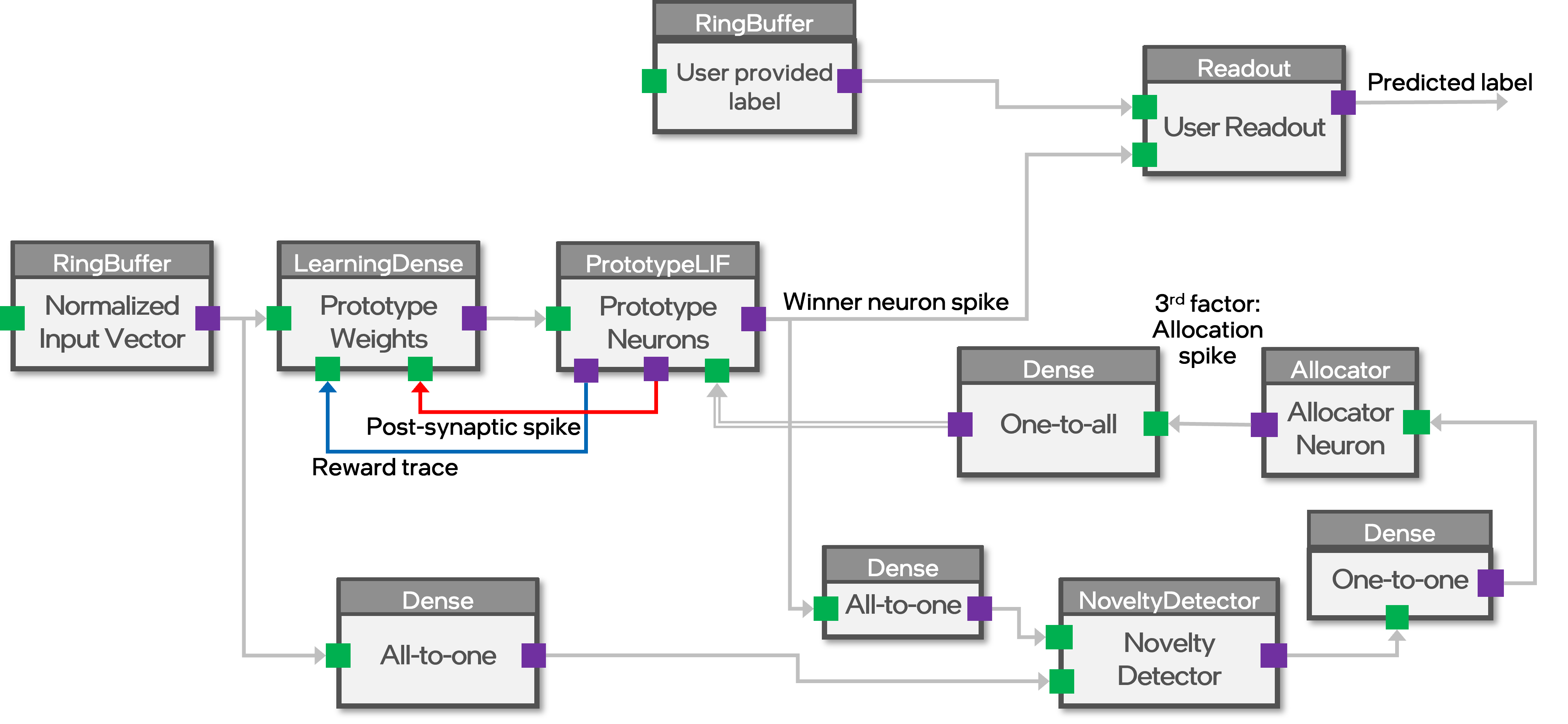
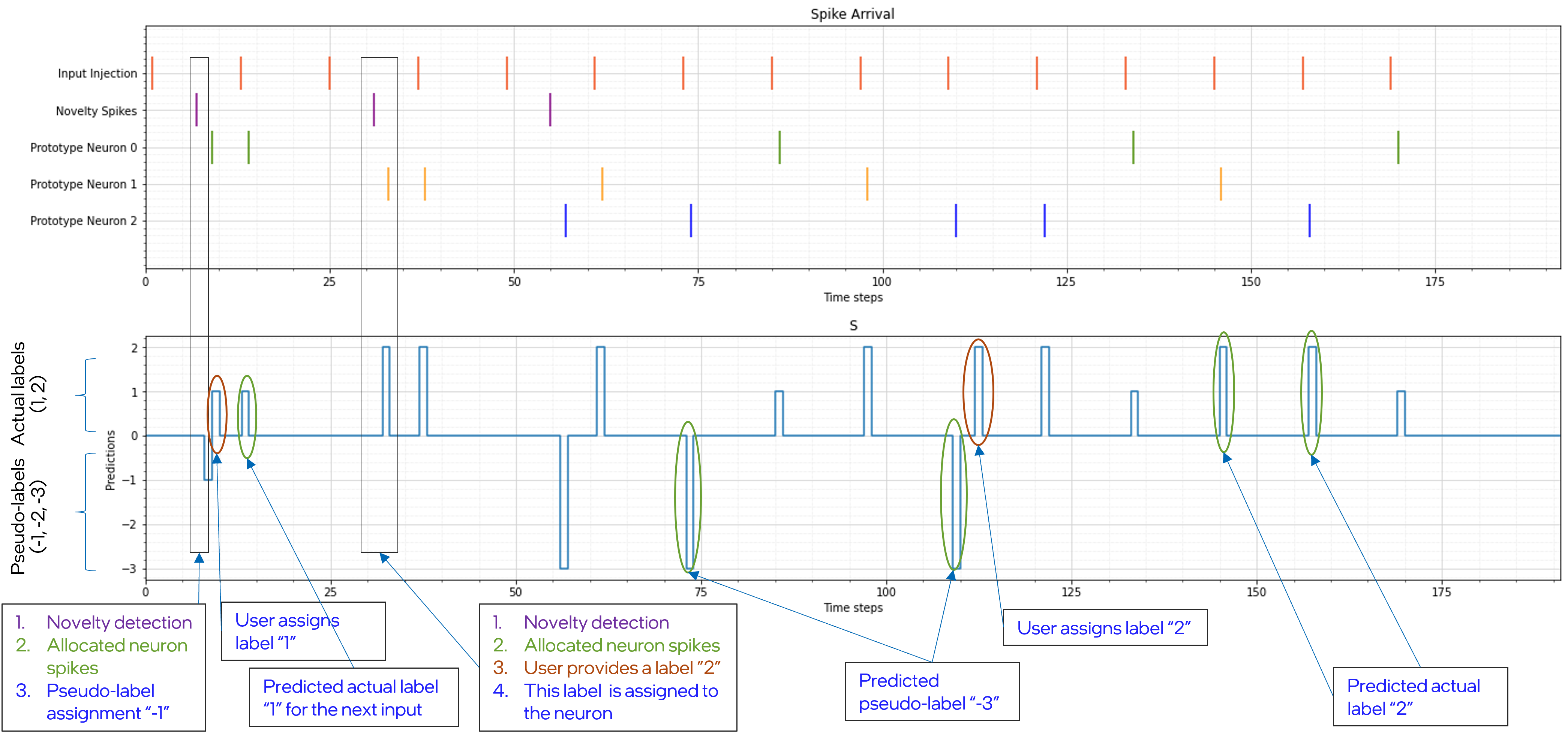

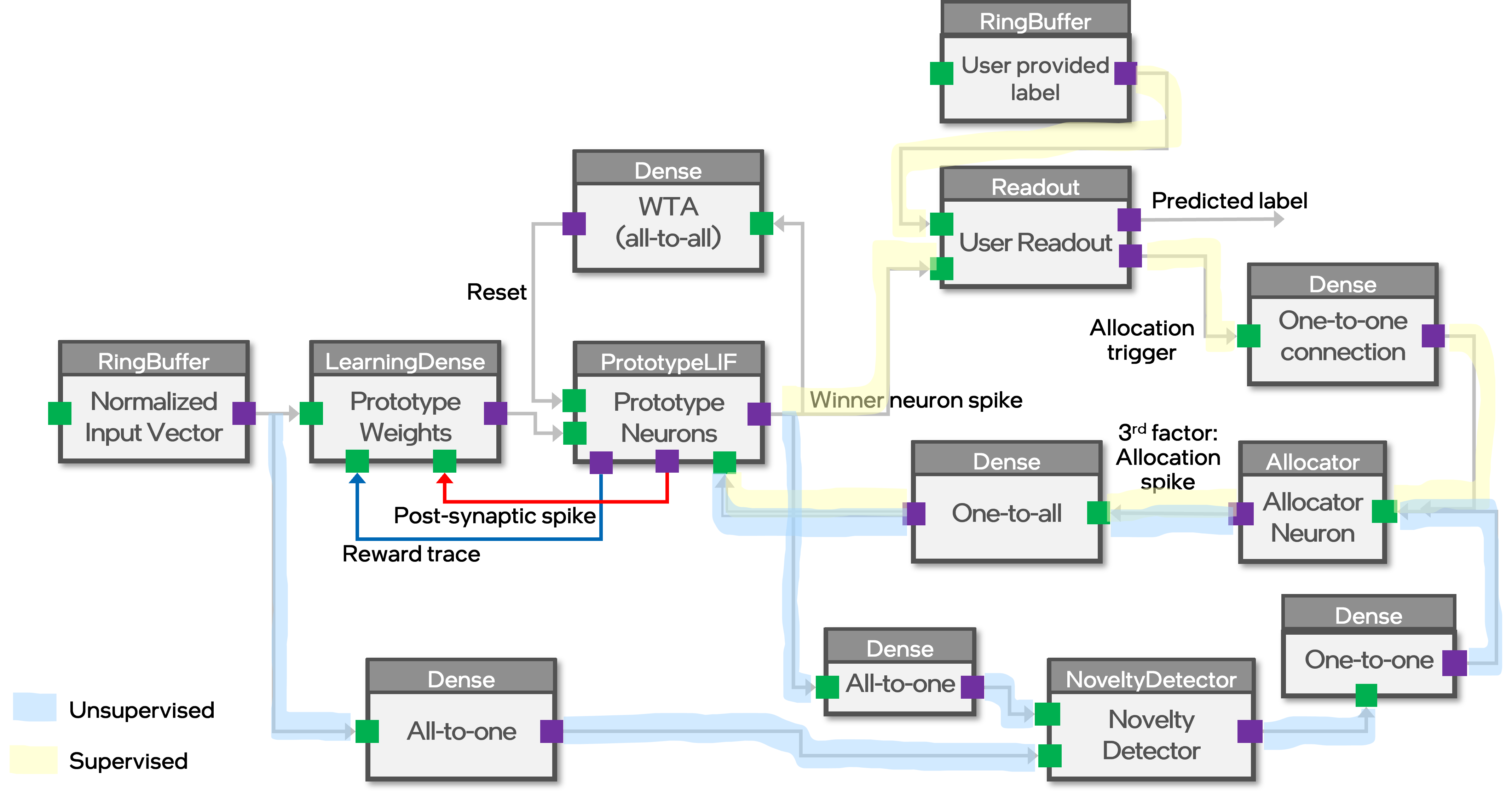


 "
@@ -28,7 +28,7 @@
},
{
"cell_type": "markdown",
- "id": "e5a09365",
+ "id": "3e6fc6bb",
"metadata": {},
"source": [
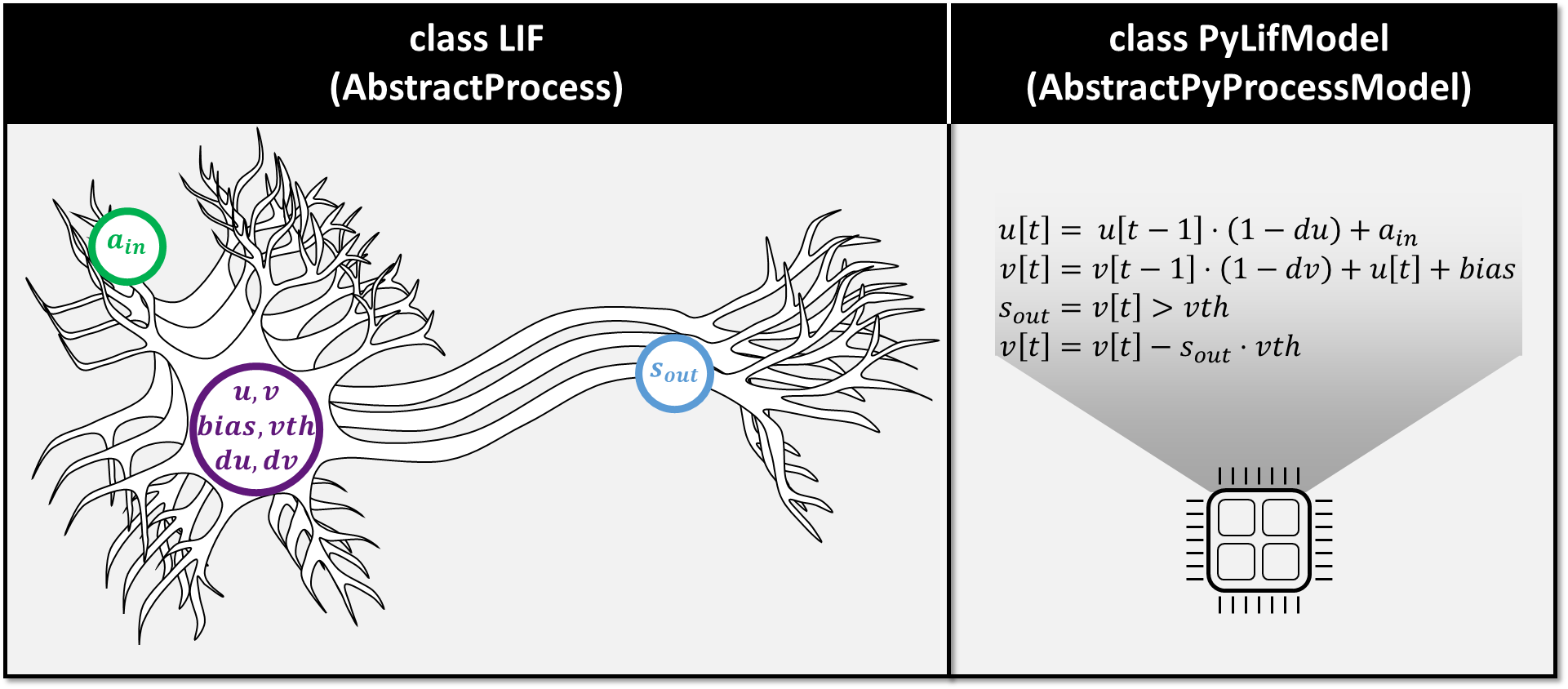
"In this tutorial, we walk through the creation of multiple _LeafProcessModels_ that could be used to implement the behavior of a Leaky Integrate-and-Fire (LIF) neuron _Process_."
@@ -36,7 +36,7 @@
},
{
"cell_type": "markdown",
- "id": "8ddbf3d8",
+ "id": "fb2871b8",
"metadata": {},
"source": [
"## Recommended tutorials before starting: \n",
@@ -46,7 +46,7 @@
},
{
"cell_type": "markdown",
- "id": "e05ac0b8",
+ "id": "67114ad6",
"metadata": {},
"source": [
"## Create a LIF _Process_"
@@ -54,7 +54,7 @@
},
{
"cell_type": "markdown",
- "id": "b1a380aa",
+ "id": "36293038",
"metadata": {},
"source": [
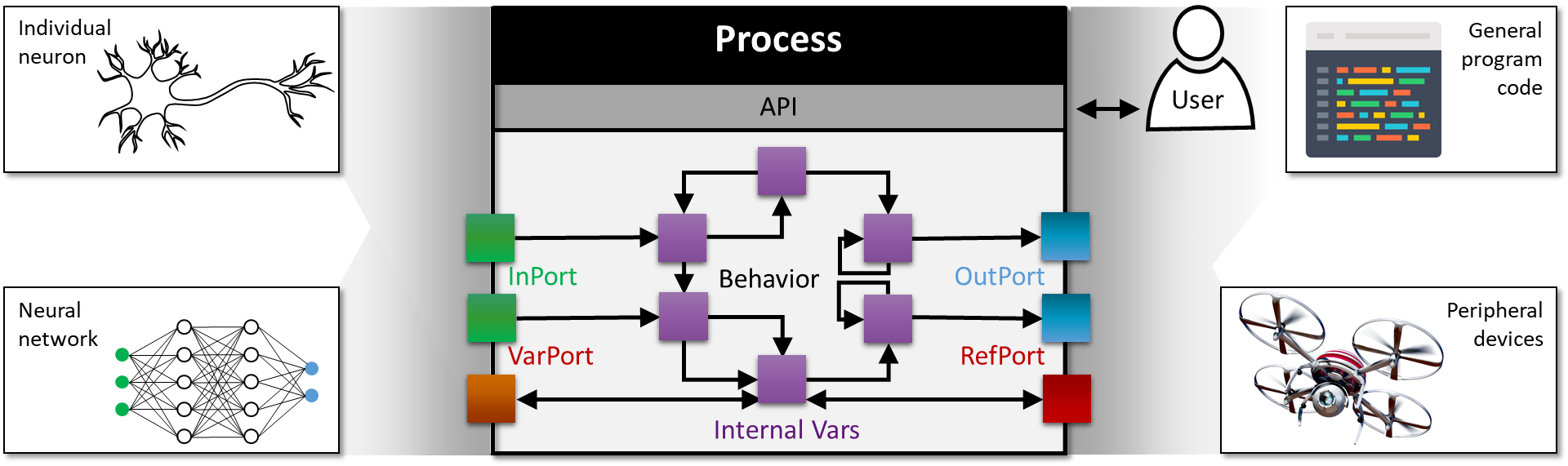
"First, we will define our LIF _Process_ exactly as it is defined in the `Magma` core library of Lava. (For more information on defining Lava Processes, see the [previous tutorial](./tutorial02_processes.ipynb).) Here the LIF neural _Process_ accepts activity from synaptic inputs via _InPort_ `a_in` and outputs spiking activity via _OutPort_ `s_out`."
@@ -63,7 +63,7 @@
{
"cell_type": "code",
"execution_count": 1,
- "id": "e06732ce",
+ "id": "b794b94d",
"metadata": {},
"outputs": [],
"source": [
@@ -113,7 +113,7 @@
},
{
"cell_type": "markdown",
- "id": "b3bd92c3",
+ "id": "99ef92c7",
"metadata": {},
"source": [
"## Create a Python _LeafProcessModel_ that implements the LIF _Process_"
@@ -121,7 +121,7 @@
},
{
"cell_type": "markdown",
- "id": "96e440ac",
+ "id": "4bb2d3e3",
"metadata": {},
"source": [
"Now, we will create a Python _ProcessModel_, or _PyProcessModel_, that runs on a CPU compute resource and implements the LIF _Process_ behavior."
@@ -129,7 +129,7 @@
},
{
"cell_type": "markdown",
- "id": "c0aef587",
+ "id": "12644ba3",
"metadata": {},
"source": [
"#### Setup"
@@ -137,7 +137,7 @@
},
{
"cell_type": "markdown",
- "id": "4b3130d3",
+ "id": "ba22172d",
"metadata": {},
"source": [
"We begin by importing the required Lava classes.\n",
@@ -147,7 +147,7 @@
{
"cell_type": "code",
"execution_count": 2,
- "id": "3d8fa081",
+ "id": "a46f5f3e",
"metadata": {},
"outputs": [],
"source": [
@@ -159,7 +159,7 @@
},
{
"cell_type": "markdown",
- "id": "0dc6ba51",
+ "id": "0ad7d044",
"metadata": {
"tags": []
},
@@ -170,7 +170,7 @@
{
"cell_type": "code",
"execution_count": 3,
- "id": "b36b9db8",
+ "id": "122cad39",
"metadata": {},
"outputs": [],
"source": [
@@ -181,7 +181,7 @@
},
{
"cell_type": "markdown",
- "id": "9e5ca66f",
+ "id": "e5f0ef77",
"metadata": {},
"source": [
"#### Defining a _PyLifModel_ for LIF"
@@ -189,7 +189,7 @@
},
{
"cell_type": "markdown",
- "id": "483ebd85",
+ "id": "e99c5a21",
"metadata": {
"tags": []
},
@@ -206,7 +206,7 @@
{
"cell_type": "code",
"execution_count": 4,
- "id": "21009606",
+ "id": "db0455f5",
"metadata": {},
"outputs": [],
"source": [
@@ -245,7 +245,7 @@
},
{
"cell_type": "markdown",
- "id": "d8b6b52a",
+ "id": "95f3eb36",
"metadata": {},
"source": [
"#### Compile and run _PyLifModel_"
@@ -254,7 +254,7 @@
{
"cell_type": "code",
"execution_count": 5,
- "id": "b03e263b",
+ "id": "ae4b5474",
"metadata": {},
"outputs": [
{
@@ -278,7 +278,7 @@
},
{
"cell_type": "markdown",
- "id": "2dffe4e3",
+ "id": "161ff13c",
"metadata": {},
"source": [
"## Selecting 1 _ProcessModel_: More on _LeafProcessModel_ attributes and relations"
@@ -286,7 +286,7 @@
},
{
"cell_type": "markdown",
- "id": "feb4f57a",
+ "id": "0c1ccff7",
"metadata": {},
"source": [
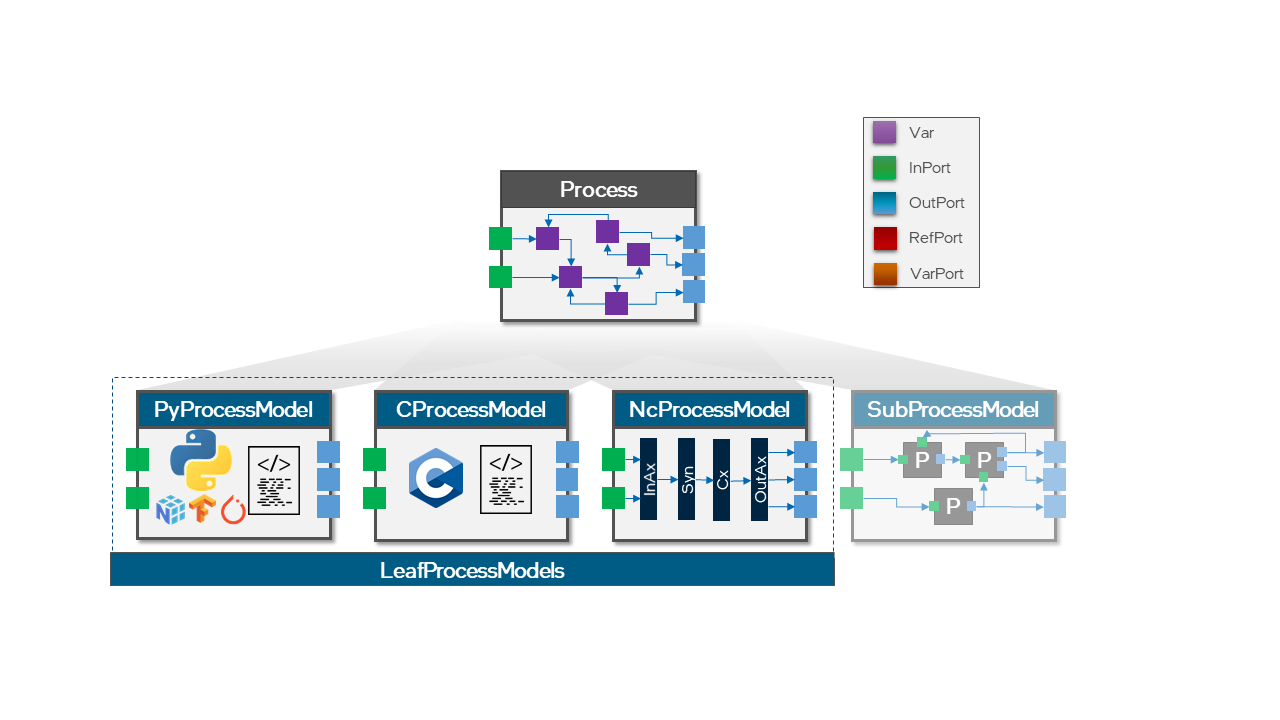
"We have demonstrated multiple _ProcessModel_ implementations of a single LIF _Process_. How is one of several _ProcessModels_ then selected as the implementation of a _Process_ during runtime? To answer that question, we take a deeper dive into the attributes of a _LeafProcessModel_ and the relationship between a _LeafProcessModel_, a _Process_, and a _SyncProtocol_. \n",
@@ -298,7 +298,7 @@
},
{
"cell_type": "markdown",
- "id": "7fc54a14",
+ "id": "2dee4f40",
"metadata": {
"tags": []
},
diff --git a/lava/notebooks/in_depth/tutorial05_connect_processes.html b/lava/notebooks/in_depth/tutorial05_connect_processes.html
index 98829de..adb374c 100644
--- a/lava/notebooks/in_depth/tutorial05_connect_processes.html
+++ b/lava/notebooks/in_depth/tutorial05_connect_processes.html
@@ -837,7 +837,7 @@
"
@@ -28,7 +28,7 @@
},
{
"cell_type": "markdown",
- "id": "e5a09365",
+ "id": "3e6fc6bb",
"metadata": {},
"source": [
"In this tutorial, we walk through the creation of multiple _LeafProcessModels_ that could be used to implement the behavior of a Leaky Integrate-and-Fire (LIF) neuron _Process_."
@@ -36,7 +36,7 @@
},
{
"cell_type": "markdown",
- "id": "8ddbf3d8",
+ "id": "fb2871b8",
"metadata": {},
"source": [
"## Recommended tutorials before starting: \n",
@@ -46,7 +46,7 @@
},
{
"cell_type": "markdown",
- "id": "e05ac0b8",
+ "id": "67114ad6",
"metadata": {},
"source": [
"## Create a LIF _Process_"
@@ -54,7 +54,7 @@
},
{
"cell_type": "markdown",
- "id": "b1a380aa",
+ "id": "36293038",
"metadata": {},
"source": [
"First, we will define our LIF _Process_ exactly as it is defined in the `Magma` core library of Lava. (For more information on defining Lava Processes, see the [previous tutorial](./tutorial02_processes.ipynb).) Here the LIF neural _Process_ accepts activity from synaptic inputs via _InPort_ `a_in` and outputs spiking activity via _OutPort_ `s_out`."
@@ -63,7 +63,7 @@
{
"cell_type": "code",
"execution_count": 1,
- "id": "e06732ce",
+ "id": "b794b94d",
"metadata": {},
"outputs": [],
"source": [
@@ -113,7 +113,7 @@
},
{
"cell_type": "markdown",
- "id": "b3bd92c3",
+ "id": "99ef92c7",
"metadata": {},
"source": [
"## Create a Python _LeafProcessModel_ that implements the LIF _Process_"
@@ -121,7 +121,7 @@
},
{
"cell_type": "markdown",
- "id": "96e440ac",
+ "id": "4bb2d3e3",
"metadata": {},
"source": [
"Now, we will create a Python _ProcessModel_, or _PyProcessModel_, that runs on a CPU compute resource and implements the LIF _Process_ behavior."
@@ -129,7 +129,7 @@
},
{
"cell_type": "markdown",
- "id": "c0aef587",
+ "id": "12644ba3",
"metadata": {},
"source": [
"#### Setup"
@@ -137,7 +137,7 @@
},
{
"cell_type": "markdown",
- "id": "4b3130d3",
+ "id": "ba22172d",
"metadata": {},
"source": [
"We begin by importing the required Lava classes.\n",
@@ -147,7 +147,7 @@
{
"cell_type": "code",
"execution_count": 2,
- "id": "3d8fa081",
+ "id": "a46f5f3e",
"metadata": {},
"outputs": [],
"source": [
@@ -159,7 +159,7 @@
},
{
"cell_type": "markdown",
- "id": "0dc6ba51",
+ "id": "0ad7d044",
"metadata": {
"tags": []
},
@@ -170,7 +170,7 @@
{
"cell_type": "code",
"execution_count": 3,
- "id": "b36b9db8",
+ "id": "122cad39",
"metadata": {},
"outputs": [],
"source": [
@@ -181,7 +181,7 @@
},
{
"cell_type": "markdown",
- "id": "9e5ca66f",
+ "id": "e5f0ef77",
"metadata": {},
"source": [
"#### Defining a _PyLifModel_ for LIF"
@@ -189,7 +189,7 @@
},
{
"cell_type": "markdown",
- "id": "483ebd85",
+ "id": "e99c5a21",
"metadata": {
"tags": []
},
@@ -206,7 +206,7 @@
{
"cell_type": "code",
"execution_count": 4,
- "id": "21009606",
+ "id": "db0455f5",
"metadata": {},
"outputs": [],
"source": [
@@ -245,7 +245,7 @@
},
{
"cell_type": "markdown",
- "id": "d8b6b52a",
+ "id": "95f3eb36",
"metadata": {},
"source": [
"#### Compile and run _PyLifModel_"
@@ -254,7 +254,7 @@
{
"cell_type": "code",
"execution_count": 5,
- "id": "b03e263b",
+ "id": "ae4b5474",
"metadata": {},
"outputs": [
{
@@ -278,7 +278,7 @@
},
{
"cell_type": "markdown",
- "id": "2dffe4e3",
+ "id": "161ff13c",
"metadata": {},
"source": [
"## Selecting 1 _ProcessModel_: More on _LeafProcessModel_ attributes and relations"
@@ -286,7 +286,7 @@
},
{
"cell_type": "markdown",
- "id": "feb4f57a",
+ "id": "0c1ccff7",
"metadata": {},
"source": [
"We have demonstrated multiple _ProcessModel_ implementations of a single LIF _Process_. How is one of several _ProcessModels_ then selected as the implementation of a _Process_ during runtime? To answer that question, we take a deeper dive into the attributes of a _LeafProcessModel_ and the relationship between a _LeafProcessModel_, a _Process_, and a _SyncProtocol_. \n",
@@ -298,7 +298,7 @@
},
{
"cell_type": "markdown",
- "id": "7fc54a14",
+ "id": "2dee4f40",
"metadata": {
"tags": []
},
diff --git a/lava/notebooks/in_depth/tutorial05_connect_processes.html b/lava/notebooks/in_depth/tutorial05_connect_processes.html
index 98829de..adb374c 100644
--- a/lava/notebooks/in_depth/tutorial05_connect_processes.html
+++ b/lava/notebooks/in_depth/tutorial05_connect_processes.html
@@ -837,7 +837,7 @@