Lava is an emerging open-source software framework for neuromorphic computing. Many parts of Lava are still under development. Therefore the following sections describe Lava's key attributes and fundamental architectural concepts that are partly implemented and partly envisioned today. A deeper dive into these architectural concepts can be found in the 'Getting started with Lava' section. We hope to inspire and invite developers to contribute to this open-source effort to solve some of the key challenges of neuromorphic hardware, software and application development.
- Asynchronous parallelism: Lava is a software framework for asynchronous event-based processing for distributed, neuromorphic, heterogeneous, and massively parallel hardware platforms supporting edge to cloud based systems.
- Refinement: Lava facilitates iterative software development through refinement of abstract computational processes into architecture-specific implementations. This allows application development to start from high-level behavioral models that can be broken down successively into lower-level models optimized for different platforms.
- Cross-platform: Lava supports flexible cross-platform execution of computational processes on novel neuromorphic architectures such as Intel Loihi as well as conventional CPU/GPU architectures. It is flexible in the dual sense of allowing the same computational processes to execute on different platforms while also allowing different processes to execute and interact across architectures through message passing.
- Modular and composable: Lava's computational processes follow a consistent architecture, to make them interoperable which allows to compose modular systems from other computational processes.
- Extensible: Lava is open and extensible to support use cases of increasing breadth over time and to interact with other third party frameworks such as TensorFlow, ROS, Brian and more.
- Trainable: Lava comes with powerful training algorithms to train models offline and continually online in real-time in the future.
- Accessible: Lava provides an intuitive Python API to quickly build and execute models on distributed parallel systems.
At a micro-scale, neuromorphic systems are brain-inspired. Brains consist of a large number of neurons and synapses that operate in parallel and communicate with each other with sparse asynchronous messages (spikes), which lead to large gains in computational efficiency.
At a macro-scale, neuromorphic hardware systems often involve multiple physical computing elements, ranging from special purpose neural accelerators to conventional CPU/GPUs, sensors, or actuator devices. Neuromorphic hardware systems and Lava mirror this general, massively parallel, heterogenous architecture from the ground up. All algorithms built in Lava are built from independent, modular computational processes that may execute on different hardware platforms and communicate through generalized message types.
So far, there is no single open software framework today that combines all of these architectural aspects in a coherent, easy to use, and performant fashion to pave the way for broader adoption of neuromorphic technologies.
Processes are the fundamental building block in the Lava architecture from which all algorithms and applications are built. Processes are stateful objects with internal variables, input and output ports for message-based communication via channels. Processes come in different forms. A Process can be as simple as a single neuron or as complex an entire neural network like a ResNet architecture, or an excitatory/inhibitory network. A Process could also represent regular program code like a search algorithm, a system management process or be used for data pre and post processing. In addition, peripheral devices such as sensors or actuators can also be wrapped into the Process abstraction to integrate them seamlessly into a Lava application alongside other computational processes. In short, everything in Lava is a Process, which has its own private memory and communicates with its environment solely via messages. This makes Lava Processes a recursive programming abstraction from which modular, large-scale parallel applications can be built.
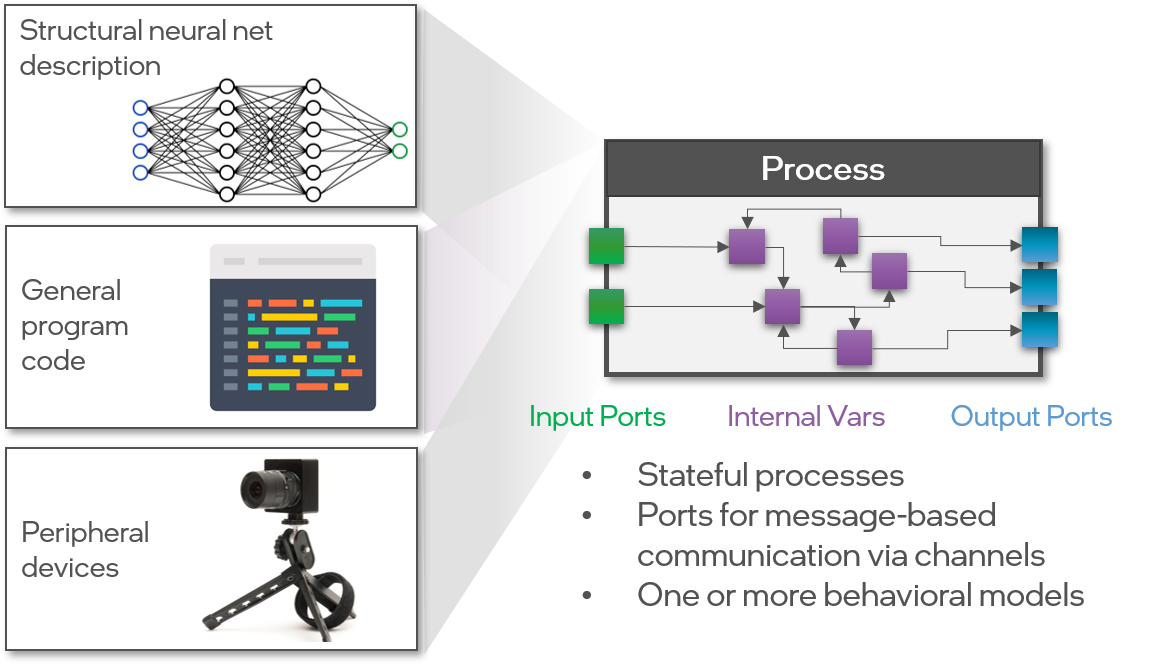
Process classes themselves only define the interface of a Process in terms of state variables, ports, and other class methods for other Processes to use or interact with any given Process. However, Processes do not provide a behavioral implementation to make a Process executable on a particular hardware architecture.
The behavioral implementation - i.e. a concrete implementation of variables, ports, channels and internal business logic - is provided via separate ProcessModel classes. Processes can have one or more ProcessModels of the same or different types. We distinguish between two categories of ProcessModel types:
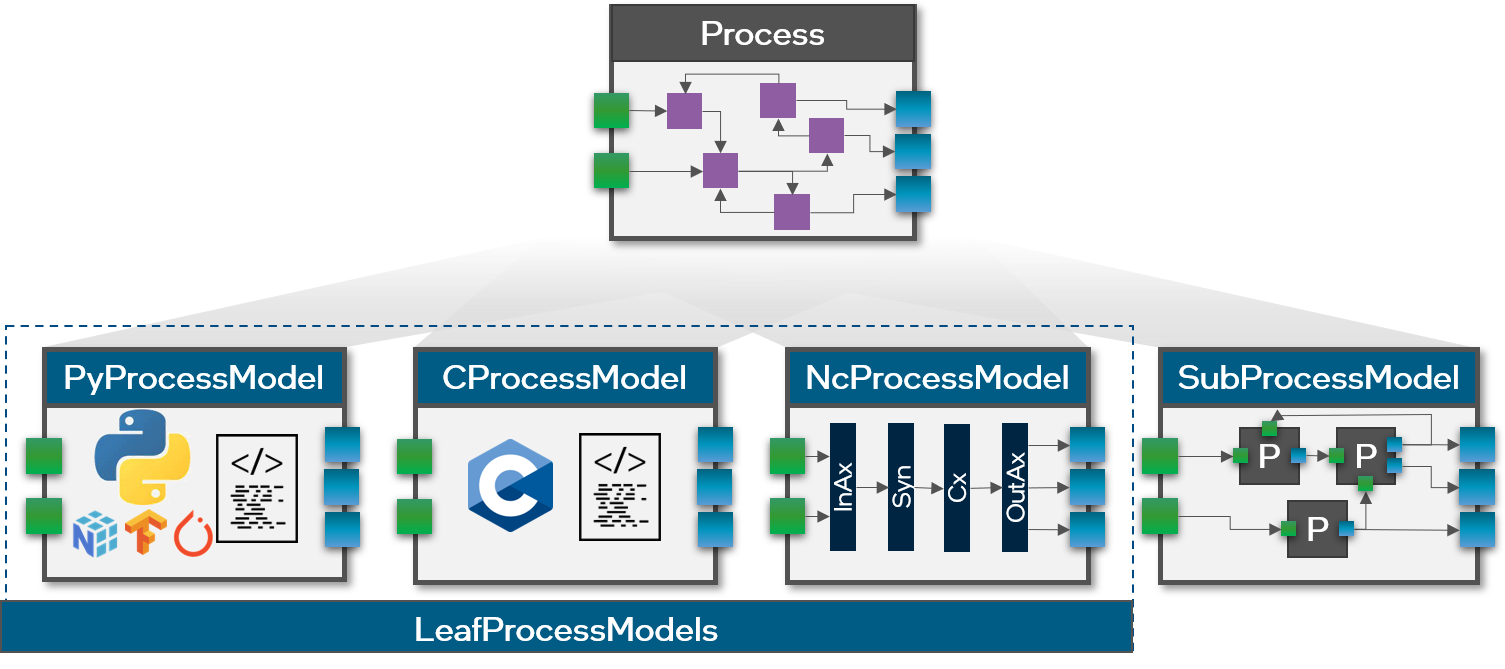
- SubProcessModels: The first way ProcessModels can be implemented is in terms of other Processes. With a SubProcessModel, other sub-Processes can be instantiated, configured, and connected to define the behavior of the parent-Process. The ports of a SubProcessModel can be connected to the ports of its sub-Processes and variables of sub-Processes can be exposed as variables of the parent-Process as needed to make them accessible in its environment. This type of refinement of a parent-Process by means of sub-Processes can be applied recursively and will result in a tree-structured Process/ProcessModel hierarchy which allows to build sophisticated and reusable application modules.
- LeafProcessModels: ProcessModels can also be implemented directly as opposed to the composition of other sub-Processes. In this case, we refer to them as LeafProcessModels because they form the leaves of the tree-structured Process hierarchy. Such LeafProcesses can be implemented in a programming language such as Python or C. For different hardware architectures, the LeafProcessModel code either describes computations directly in terms of executable instructions for a von-Neumann processor, possibly using external libraries such as Numpy, TensorFlow or PyTorch. In contrast, compute resources like neuromorphic cores do not execute arbitrary sequences of instructions but gain computational advantages by executing through collective dynamics specified by structural descriptions. In this case, the code of corresponding NcProcessModels for such cores is responsible for the structural allocation and configuration of neural network resources such as axons, synapses, and neurons in a neuro core. In the future, Lava Processes may also model and specify the operation of analog neuromorphic chips with behavioral models that will only approximately match their real-time execution.
In general, in neuromorphic architectures computation emerges from collective dynamical processes that are often approximate, nondeterministic, and may vary in detailed execution from platform to platform. Therefore Lava views behavior as modeled rather than programmed or specified, and this perspective motivates the name ProcessModel.
Fundamentally, all Processes within a system or network operate in parallel and communicate asynchronously with each other through the exchange of message tokens. But many use cases require synchronization among Processes, for instance to implement a discrete-time dynamical system representing a particular neuron model progressing from one algorithmic time step to the next. Lava allows developers to define synchronization protocols that describe how Processes in the same synchronization domain synchronize with each other. This SyncProtocol is orchestrated by a Synchronizer within a SyncDomain which exchanges synchronization message tokens with all Processes in a SyncDomain. The compiler either assigns Processes automatically to a SyncDomain based on the SyncProtocol it implements but also allows users to assign Processes manually to SyncDomains to customize synchronization among Processes in more detail.
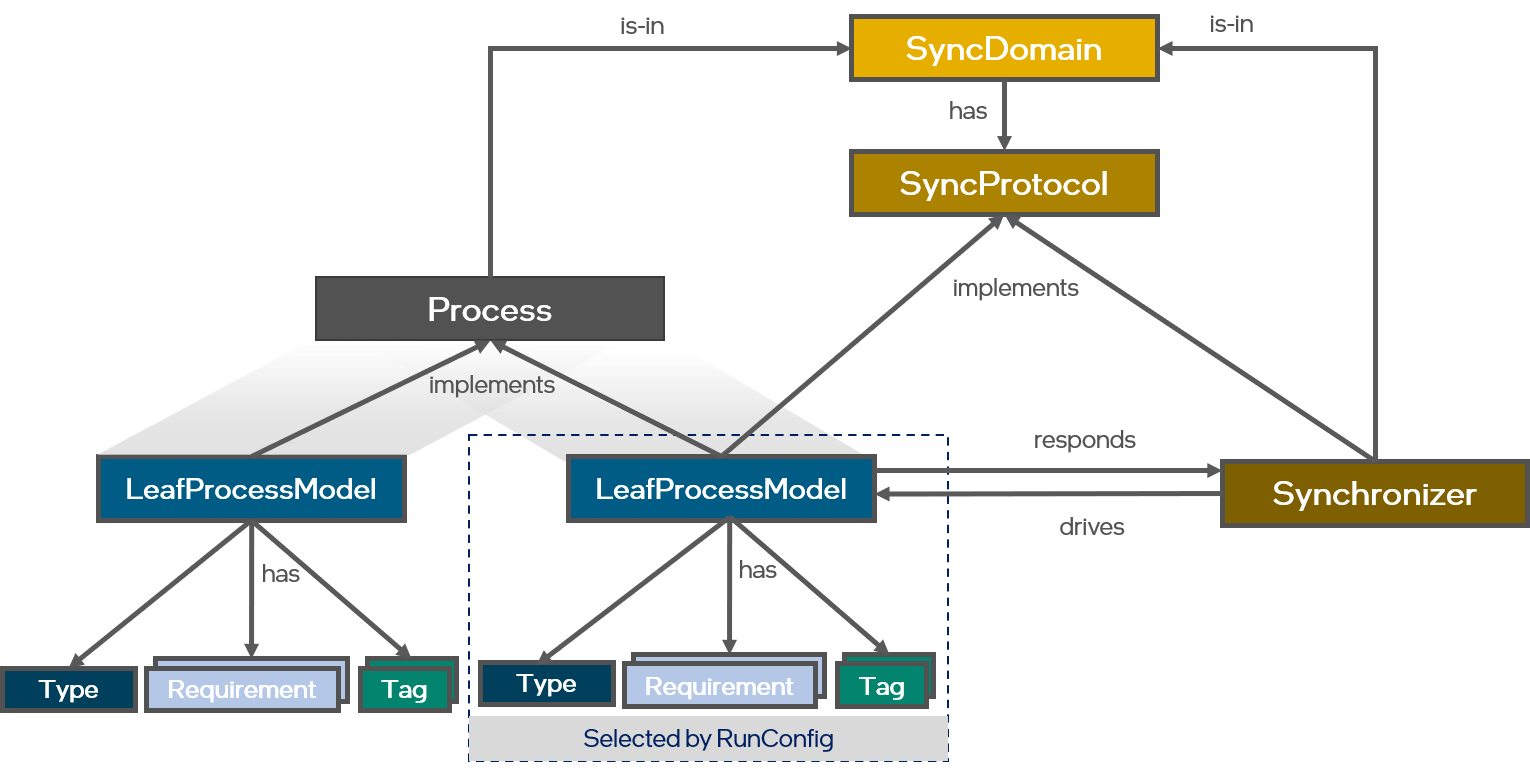
Besides implementing a specific Process and SyncProtocol, a ProcessModel has a specific type (such as PyProcessModel, CProcessModel, SubProcessModel, etc.), has one or more resource requirements, and has one or more tags. Resource requirements specify what compute or peripheral resources a ProcessModel may require in order to execute, such as CPU, neuromorphic core, hard disk, or access to a camera. Furthermore, tags specify additional behavioral attributes of a ProcessModel.
In order to execute a specific instance of a Process, the compiler will select one of the ProcessModels that implement a given Process class. In order to allow for different selection strategies, the compiler delegates this ProcessModel selection to instances of a separate RunConfig class. Such RunConfigs correspond to a set of rules that determine which ProcessModel to select for a Process given user preferences and the resource requirements and tags of a ProcessModel. For instance, a particular RunConfig may always select the highest-level Python-based implementation of a Process for quick application prototyping on a conventional CPU or GPU architecture without physical access to neuromorphic systems like Intel's Kapoho Bay or Pohohiki Springs. Another RunConfig might prefer to map Processes to neuro cores or embedded CPUs whenever such neuromorphic systems are available. Lava will provide several pre-configured RunConfigs but allows users to customize them or create their own.
In summary, while Processes only provide a universal interface to interact with their environment via message passing, one or more ProcessModels are what implement the behavioral model of a Process in different languages and ways tailored to different hardware architectures. This implementation can either be provided directly or by refining a given Process iteratively by implementing its behavior via sub-Processes which allows for code reuse and greater modularity.
Overall, this programming model enables quick application prototyping at a high level, agnostic of the intricate constraints and complexities that are often associated with neuromorphic architectures, in the language of choice of a user, while deferring specifics about the hardware architecture for later. Once ready, high-level behavioral models can be replaced or refined by more efficient lower-level implementations (often provided by the Lava process library). At the same time, the availability of different behavioral implementations allows users to run the same application on different hardware platforms such as a CPU or a neuromorphic system when only one of them is available.
Processes are connected via ports with each other for message-based communication over channels. For hierarchical Processes, ports of a parent process can also be internally connected to ports of a child Process and vice versa within a SubProcessModel. In general, connections between Processes can be feed-forward or recurrent and support branching and joining of connections. While ports at the Process-level are only responsible for establishing connectivity between Processes before compilation, the port implementation at ProcessModel-level is responsible for actual message-passing at runtime.
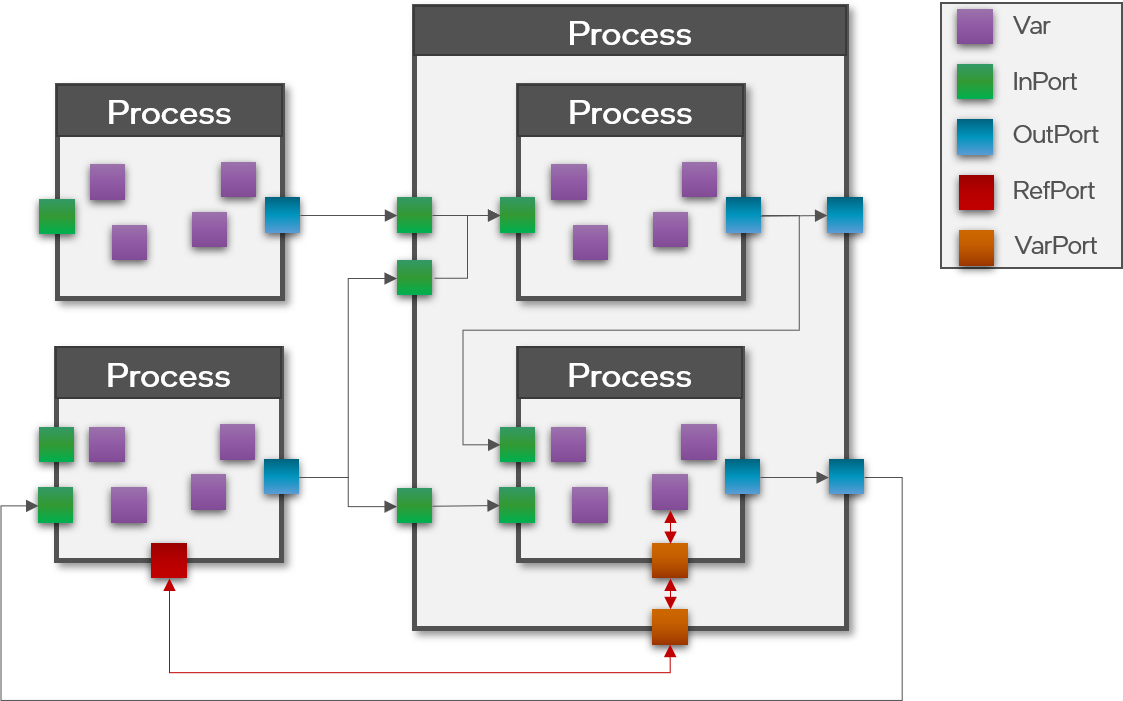
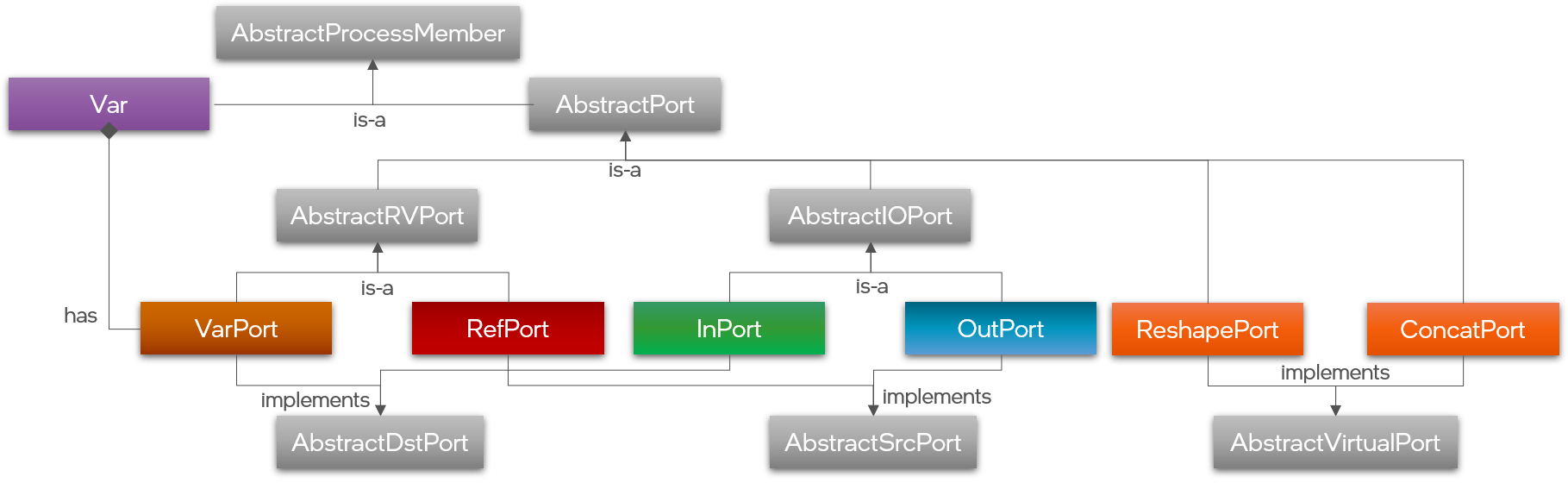
The different kinds of ports and variables are part of the same formal class hierarchy. Both ports and variables are members of a Process. As such, both ports and variables communicate or represent numeric data, characterized by a data type that must be specified when allocating them in a Process. Additionally, port and variable implementations have an associated type and support a configurable precision of the numeric data they communicate or represent. There are four main types of ports that can be grouped in two different ways:
- OutPorts connect to and send messages to InPorts by value; meaning that the InPort receives a copy of the data sent via the OutPort. Thus changes to that data on the sender or receiver side will not affect the other side, enabling safe parallel processing without side-effects.
- On the other hand, RefPorts connect to VarPorts which act as a proxy to internal state variables of a Process. RefPorts enable one Process to directly access a variable or internal memory of another Process by reference as if it was its own. Such direct-memory access is generally very powerful, but also more dangerous as it can lead to unforeseen side effect in parallel programming and should therefore only be used with caution. Yet, sometimes it is necessary to achieve certain behaviors.
Aside from these main port types, there are additional virtual ports that effectively act as directives to the compiler to transform the shape of ports or how to combine multiple ports. Currently, Lava supports ReshapePorts and ConcatPorts to change the shape of a port or to concatenate multiple ports into one. Finally, system-level communication between Processes such as for synchronization is also implemented via ports and channels, but those are not managed directly by -- and therefore are hidden from -- the user.
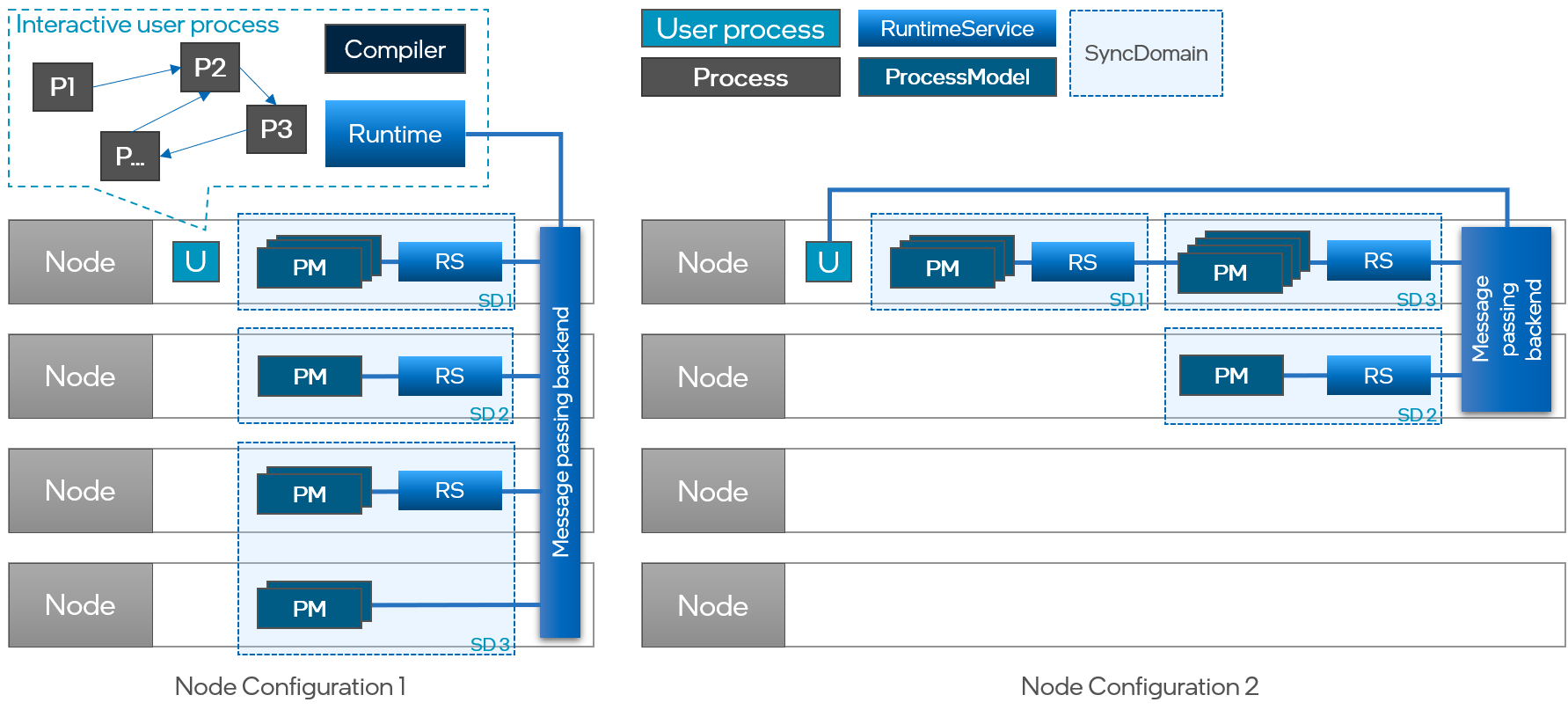
Lava supports cross-platform execution of processes on a distributed set of compute nodes. Nodes in Lava have compute resources associated with them such as CPUs or neuro cores, and peripheral resources such as sensors, actuators or hard-disks. Given a graph of Processes, their ProcessModels and a RunConfig, this allows the compiler to map the Processes defined in the user system process to one or more NodeConfigurations. Depending on which type of node a Process is mapped to, a different ProcessModel with a node-specific implementation of its variables, ports, channels and behavior is chosen. In the end, each node in a NodeConfiguration can host one or more SyncDomains with one or more ProcModels in it. Each such SyncDomain also contains a local RuntimeService process. The RuntimeService is responsible for system management and includes the Synchronizer for orchestrating the SyncProtocol of the SyncDomain. Irrespective of the presence of multiple SyncDomains on multiple nodes, all user-defined and system processes communicate seamlessly via one asynchronous message-passing backend with each other and the global Runtime within the user system process.
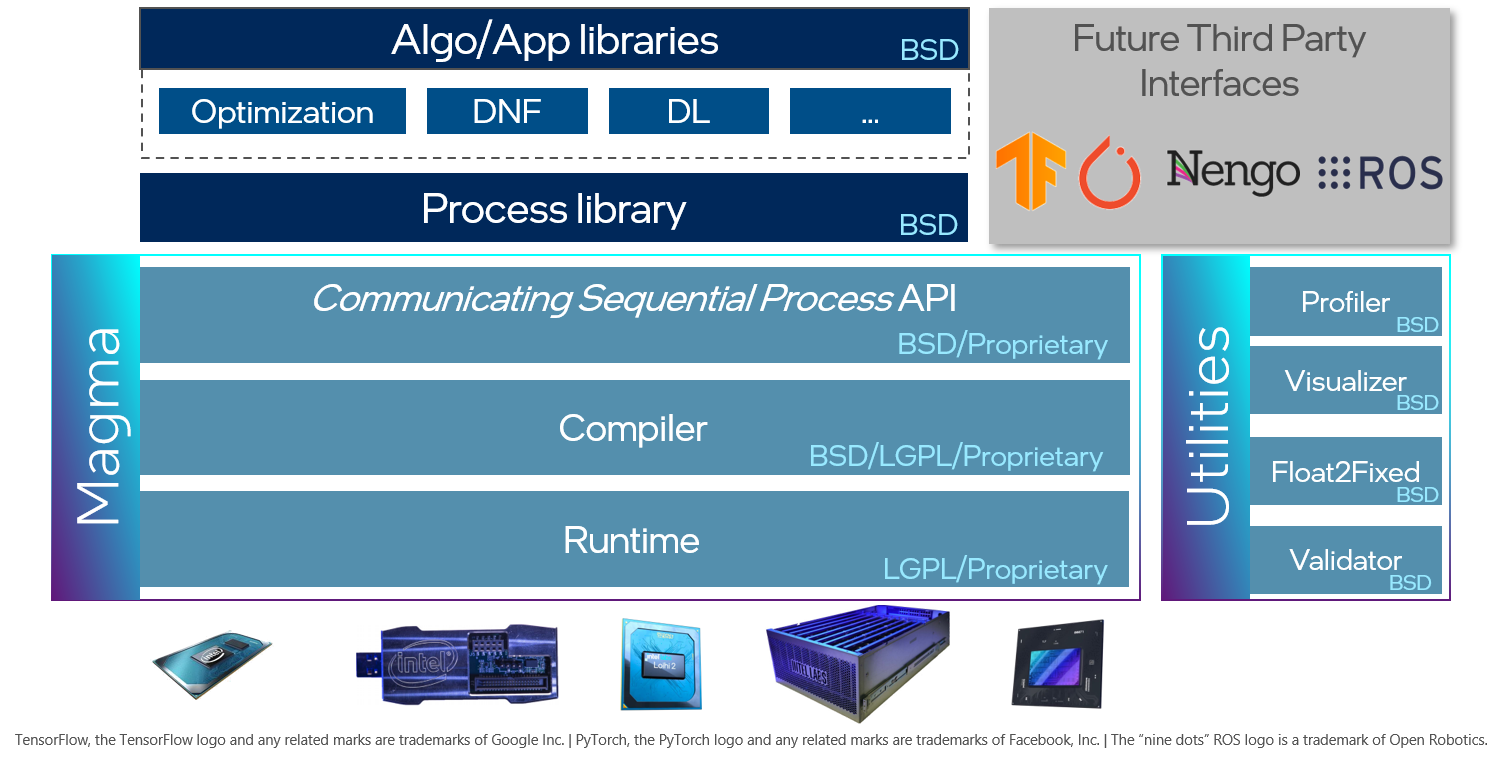
The core components of the Lava software stack are comprised of the Communicating Sequential Process API, a powerful compiler, and a runtime. In combination, these components form the Magma layer of Lava, which is the foundation on which new Processes and ProcessModels are built. The Lava process library provides a growing collection of generic, low-level, reusable, and widely applicable Processes from which higher-level algorithm and application libraries are built.
The first libraries, to be released as part of the Lava software framework, are libraries for deep learning (lava-dl), optimization (lava-optim), and dynamic neural fields (lava-dnf). Future libraries will add support for vector symbolic architectures (lava-vsa) and evolutionary optimization (lava-evo).
Besides these components, future releases of Lava will offer several utilities for application profiling, automatic float to fixed-point model conversion, network visualization, and more. Finally, Lava is open for extension to other third-party frameworks such as TensorFlow, ROS or Nengo. We welcome open-source contributions to any of these future libraries and utilities.