Processes
- Processes
Who needs process isolation? - Intel Marketing on Meltdown and Spectre
To understand what a process is, you need to understand the concept of a boot order. In the beginning, there is a kernel. The operating system kernel is a special piece of software. This is the piece of software that is loaded up before all other programs. The following is an brief overview on the tasks performed by the kernel.
-
The operating system executes code from read-only memory, called firmware.
-
The operating system then executes a bootloader, which often conforms to the Extensible Firmware Interface (
EFI), which is an interface between the system firmware and the operating system. -
The bootloader’s boot manager loads the operating system kernels, based on the boot settings.
-
Your kernel executes
initto https://en.wikipedia.org/wiki/Bootstrapping itself from nothing. -
The kernel executes startup scripts.
-
The kernel executes userland scripts, and you get to use your computer!
You don’t need to know the specifics of the booting process, but there it is. When you are executing in user space, the kernel provides some important services to programs.
-
Scheduling processes and threads
-
Handling synchronization primitives (futexes, mutexes, semaphores etc.)
-
Providing system calls such as
writeorread -
Managing virtual memory and low level binary devices such as
USBdrivers -
Managing filesystems
-
Handling communication over networks
-
Handling communication between processes
-
Dynamically linking libraries
The kernel handles all of these tasks in kernel mode. Kernel mode gets you greater power, such as the ability to execute extra CPU instructions. However, a single failure can crash your entire computer – ouch. These services are what you will be interacting with in this class.
The kernel creates the first process init.d (an alternative is
system.d). init.d boots up programs such as graphical user interfaces,
terminals etc – by default, this is the only process explicitly created
by the system. All other processes are instantiated by using the system
calls fork and exec from that single process.
Although these were mentioned in the last chapter, we are going to give you a quick reminder about file descriptors. Here is a zine from Julia Evans that gives some details: (Evans #ref-evans_2018).
The kernel keeps track of the file descriptors and what they point to. Later we will learn two things: that file descriptors need not point to actual files and that the operating system keeps track of them for you.
Notice that file descriptors may be reused between processes, but inside of a process, they are unique. File descriptors may have a notion of position. These are known as seekable streams.
You can read a file on disk completely because the OS keeps track of the position in the file, an attribute that belongs to your process as well.
Other file descriptors point to network sockets and various other pieces of information, that are not seekable streams.
A process an instance of a computer program that may be running. Processes have many resources at their disposal. At the start of each program you get one process, but each program can make more processes. A program consists of the following:
-
A binary format: This tells the operating system about the various sections of bits in the binary – which parts are executable, which parts are constants, which libraries to include etc.
-
A set of machine instructions
-
A number denoting which instruction to start from
-
Constants
-
Libraries to link and where to fill in the address of those libraries
Processes are very powerful but they are isolated!
That means that by default, no process can communicate with another process.
This is very important because if you have a large system (let’s say the University of Illinois Engineering Workstations (EWS)) then it is likely that you want some processes to have higher privileges than your average user. One certainly doesn’t want the average user to be able to bring down the entire system, either on purpose or accidentally by modifying a process. As most of you have realized by now, if you stuck the following code snippet into a program, the variables would not be shared between two parallel invocations of the program.
int secrets;
secrets++;
printf("%d\n", secrets);On two different terminals, they would both print out 1 not 2. Even if we changed the code to attempt to affect other process instances, there would be no way to change another process’ state unintentionally. However, there are other intentional ways to change the program states of other processes.
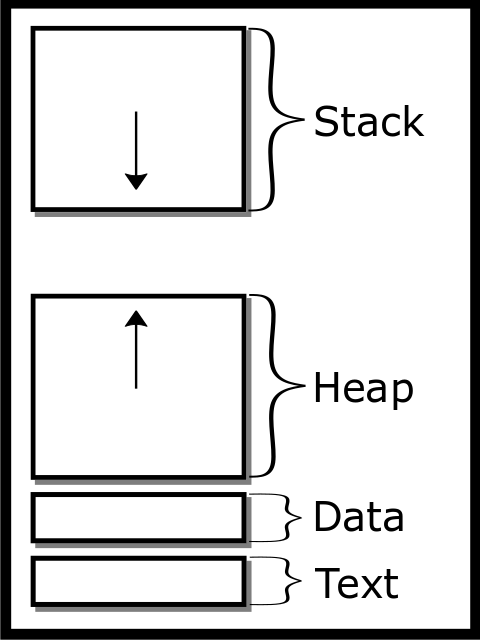
When a process starts, it gets its own address space. Each process gets the following.
-
A Stack. The stack is the place where automatically allocated variables and function call return addresses are stored. Every time a new variable is declared, the program moves the stack pointer down to reserve space for the variable. This segment of the stack is writable but not executable. This behavior is controlled by the no-execute (NX) bit, sometimes called the WX̂ (write XOR execute) bit, which helps prevent malicious code, such as
shellcodefrom being run on the stack.If the stack grows too far – meaning that it either grows beyond a preset boundary or intersects the heap – you will get a stack overflow error, most likely resulting in a SEGFAULT. The stack is statically allocated by default; there is only a certain amount of space to which one can write.
-
A Heap. The heap is a contiguous, expanding region of memory (“Overview of Malloc” #ref-mallocinternals). If you want to allocate a object whose memory you want to manually control, or whose size cannot be determined at compile time, you would want to create a heap variable.
The heap starts at the top of the text segment and grows upward, meaning sometimes when you call
mallocthat it asks the operating system to push the heap boundary (called the program break) upward.We will explore this in more depth in our chapter on memory allocation. This area is also writable but not executable. One can run out of heap memory if the system is constrained or if you run out of addresses, a phenomenon that is more common on a 32-bit system.
-
A Data Segment
This segment contains two parts, an initialized data segment, and an uninitialized segment. Furthermore, the initialized data segment is divided into a readable and writable section.
-
Initialized Data Segment This contains all of a program’s globals and any other static variables.
This section starts at the end of the text segment and starts at a constant size because the number of globals is known at compile time. The end of the data segment is called the
program break, and can be extended via the use of brk / sbrk.This section is be writable (Van der Linden #ref-van1994expert P. 124). Most notably, this section contains variables that were initialized with a static initializer, as follows:
int global = 1;
-
Uninitialized Data Segment / BSS BSS stands for an old assembler operator known as Block Started by Symbol.
This contains all of your globals and any other static duration variables that are implicitly zeroed out.
Example:
int assumed_to_be_zero;
It is not an error to assume that this will be zero because otherwise we would have a security risk involving isolation from other processes.
They just get put in a different section to speed up process start up time.
This section starts at the end of the data segment and is also static in size because the amount of globals is known at compile time.
Currently, both the initialized and BSS data segments are combined and referred to as the data segment (Van der Linden #ref-van1994expert P. 124), despite being somewhat different in purpose.
-
A Text Segment. This is where all executable instructions are stored, and is readable (function pointers) but not writable.
The program counter moves through this segment executing instructions one after the other.
It is important to note that this is the only executable section of the program, by default.
If you try to change the code while it’s running, most likely you will SEGFAULT.
There are ways around it, but we will not be exploring these in this course.
Why doesn’t it always start at zero? This is because of a security feature called https://en.wikipedia.org/wiki/Address_space_layout_randomization.
The reasons for and explanation about this is outside the scope of this class, but it is good to know about its existence.
Having said that, this address can be made constant, if a program is compiled with the DEBUG flag.
-
To keep track of all these processes, your operating system gives each
process a number called the process ID (PID). Processes are also given
the PID of their parent process, called parent process ID (PPID).
Every process has a parent, that parent could be init.d.
Processes could also contain the following information:
-
Running State - Whether a process is getting ready, running, stopped, terminated etc. (more on this is covered in the chapter on Scheduling).
-
File Descriptors - A list of mappings from integers to real devices (files, USB flash drives, sockets)
-
Permissions - What
userthe file is running on and whatgroupthe process belongs to. The process can then only perform operations based on the permissions given to theuserorgroup, such as accessing files. There are tricks to make a program not be the user who started the program i.e.sudotakes a program that auserstarts and executes it asroot. More specifically, a process has a real user ID (identifies the owner of the process), an effective user ID (used for non-privileged users trying to access files only accessible by superusers), and a saved user ID (used when privileged users perform non-privileged actions). -
Arguments - a list of strings that tell your program what parameters to run under.
-
Environment Variables - a list of key-value pair strings in the form
NAME=VALUEthat one can modify. These are often used to specify paths to libraries and binaries, program configuration settings etc.
According to the POSIX specification, a process only needs a thread and address space, but most kernel developers and users know that only these aren’t enough (“Definitions” #ref-process_def).
Process forking is a powerful and dangerous tool. If you make a mistake
resulting in a fork bomb, you can bring down an entire system. To
reduce the chances of this, limit your maximum number of processes to a
small number e.g. 40 by typing ulimit -u 40 into a command line. Note,
this limit is only for the user, which means if you fork bomb, then you
won’t be able to kill all of the processes you just created since
calling killall requires your shell to fork() … isn’t this ironic?
One solution is to spawn another shell instance as another user (for
example root) beforehand, and kill processes from there.
Another is to use the built in exec command to kill all the user
processes (you only have one attempt at this).
Finally, you could reboot the system, but you only have one shot at this with the exec function.
When testing fork() code, ensure that you have either root and/or physical access to the machine involved.
If you must work on fork() code remotely, remember that kill -9 -1 will save you in the event of an emergency.
n.b. Fork can be extremely dangerous if you aren’t prepared for it. You have been warned.
The fork system call clones the current process to create a new
process, called a child process. This occurs by duplicating the state of
the existing process with a few minor differences.
-
The child process does not start from main. Instead it executes the next line after the
fork()just as the parent process does. -
Just as a side remark, in older UNIX systems, the entire address space of the parent process was directly copied regardless of whether the resource was modified or not. Current behavior is for the kernel to perform a https://en.wikipedia.org/wiki/Copy-on-write, which saves a lot of resources, whilst being very time efficient (Bovet and Cesati #ref-Bovet:2005:ULK:1077084 Copy-on-write section).
Here is a very simple example:
printf("I'm printed once!\n");
fork();
// Now there are two processes running if fork succeeded
// and each process will print out the next line.
printf("You see this line twice!\n");Here is a simple example of this address space cloning. The following
program may print out 42 twice - but the fork() is after the
printf!? Why?
#include <unistd.h> /*fork declared here*/
#include <stdio.h> /* printf declared here*/
int main() {
int answer = 84 >> 1;
printf("Answer: %d", answer);
fork();
return 0;
}The printf line is executed only once however notice that the
printed contents is not flushed to standard out. There’s no newline
printed, we didn’t call fflush, or change the buffering mode. The
output text is therefore still in process memory waiting to be sent.
When fork() is executed the entire process memory is duplicated
including the buffer. Thus, the child process starts with a non-empty
output buffer which may be flushed when the program exits. We say may
because the contents may be unwritten given a bad program exit as well.
To write code that is different for the parent and child process, check
the return value of fork(). If fork() returns -1, that implies
something went wrong in the process of creating a new child. One should
check the value stored in errno to determine what kind of error
occurred. Common errors include EAGAIN and ENOENT Which are
essentially "try again – resource temporarily unavailable", and "no such
file or directory".
Similarly, a return value of 0 indicates that we are operating in the context of the child process, whereas a positive integer shows that we are in the context of the parent process.
The positive value returned by fork() is the process id (pid) of the
child.
A way to remember what is represented by the return value of fork is,
that the child process can find its parent - the original process that
was duplicated - by calling getppid() - so does not need any
additional return information from fork(). However, the parent process
may have many parents, and therefore needs to be explicitly informed of
its child PIDs.
According to the POSIX standard, every process only has a single parent process.
The parent process can only know the PID of the new child process from
the return value of fork:
pid_t id = fork();
if (id == -1) exit(1); // fork failed
if (id > 0) {
// I'm the original parent and
// I just created a child process with id 'id'
// Use waitpid to wait for the child to finish
} else { // returned zero
// I must be the newly made child process
}A slightly silly example is shown below. What will it print? Try running this program with multiple arguments.
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv) {
pid_t id;
int status;
while (--argc && (id=fork())) {
waitpid(id,&status,0); /* Wait for child*/
}
printf("%d:%s\n", argc, argv[argc]);
return 0;
}Another example is below. This is the amazing parallel apparent-O(N) sleepsort is today’s silly winner. First published on https://dis.4chan.org/read/prog/1295544154. A version of this awful but amusing sorting algorithm is shown below. This sorting algorithm is not guaranteed to produce the correct output.
int main(int c, char **v) {
while (--c > 1 && !fork());
int val = atoi(v[c]);
sleep(val);
printf("%d\n", val);
return 0;
}Imagine that we ran this program like so
$ ./ssort 1 3 2 4
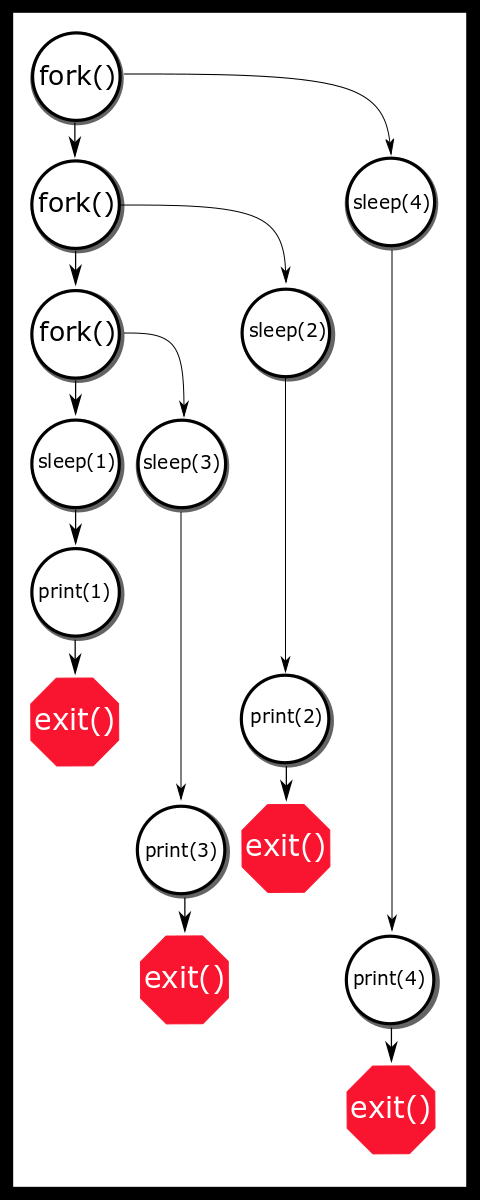
The algorithm isn’t actually O(N) because of how the system scheduler works. In essence, this program outsources the actual sorting to the operating system.
A ‘fork bomb’ is what we warned you about earlier. This occurs when
there is an attempt to create an infinite number of processes. This will
often bring a system to a near-standstill, as it attempts to allocate
CPU time and memory to a very large number of processes that are ready
to run. System administrators don’t like them, and may set upper limits
on the number of processes each user can have, or revoke login rights
because they create disturbances in the Force for other users’ programs.
You can limit the number of child processes created by using
setrlimit().
Fork bombs are not necessarily malicious - they occasionally occur due to programming errors. Below is a simple example that is malicious.
while (1) fork();It is easy to cause one, if you are careless while calling fork, especially in a loop. Can you spot the fork bomb here?
#include <unistd.h>
#define HELLO_NUMBER 10
int main(){
pid_t children[HELLO_NUMBER];
int i;
for(i = 0; i < HELLO_NUMBER; i++){
pid_t child = fork();
if(child == -1){
break;
}
if(child == 0){ //I am the child
execlp("ehco", "echo", "hello", NULL);
}
else{
children[i] = child;
}
}
int j;
for(j = 0; j < i; j++){
waitpid(children[j], NULL, 0);
}
return 0;
}We misspelled ehco, so the exec call fails. What does this mean?
Instead of creating 10 processes, we just created 1024 processes, fork
bombing our machine. How could we prevent this? Add an exit right
after exec, so that if exec fails, we won’t end up calling fork an
unbounded number of times. There are various other ways. What if we
removed the echo binary? What if the binary itself creates a fork
bomb?
We won’t fully explore signals until the very end of the course, but it is relevant to broach the subject now because various semantics related to fork and other function calls detail what a signal is.
A signal can be thought of as a software interrupt. This means that a process that receives a signal stops execution of the current program and makes the program respond to the signal.
There are various signals defined by the operating system, two of which you may already know: SIGSEGV and SIGINT. The first is caused by an illegal memory access, and the second is sent by a user wanting to terminate a program. In each case, the program jumps from the current line being executed, to the signal handler. If no signal handler is supplied by the program, a default handler is executed – such as terminating the program, or ignoring the signal.
Here is an example of a simple user defined signal handler:
void handler(int signum) {
write(1, "signaled!", 9);
// we don't need the signum because we are only catching SIGINT
// if you want to use the same piece of code for multiple
// signals, check the signum
}
int main() {
signal(SIGINT, handler);
while(1) ;
return 0;
}A signal has four states in its life cycle: generated, sent, pending, and received state. These refer to when a process generates a signal, the kernel sends a signal, the kernel is about to deliver a signal, and when the kernel delivers a signal, each of which take some time to do.
The terminology is important because fork and exec require different operations based on the state a signal is in.
To note, it is generally poor programming practice to use signals in program logic, that is to send a signal to perform a certain operation. The reason: signals have no time frame of delivery and no assurance that they will be delivered. There are better ways to communicate between two processes.
If you want to read more, feel free to skip ahead to the chapter on POSIX signals and read it over. It isn’t very long, and gives you the long and short about how to deal with signals in processes.
POSIX determines the standards of fork (“Fork” #ref-fork_2018). You can read the previous citation, but do note that it can be quite verbose. Here is a summary of what is relevant:
-
Fork will return a non-negative integer on success.
-
A child will inherit any open file descriptors of the parent. That means if a parent reads a half way of the file and forks, the child will start at that offset. Any other flags are also carried over.
-
Pending signals are not inherited. This means that if a parent has a pending signal and creates a child, the child will not receive that signal unless another process signals the child.
-
The process will be created with one thread (more on that later. The general consensus is to not fork and pthread at the same time).
-
Since we have copy on write (COW), read-only memory addresses are shared between processes.
-
If you set up certain regions of memory, they can be shared between processes.
-
Signal handlers are inherited but can be changed.
-
The process’ current working directory (often abbreviated to CWD) is inherited but can be changed.
-
Environment variables are inherited but can be changed.
Key differences between the parent and the child include:
-
The process id returned by
getpid(). The parent process id returned bygetppid(). -
The parent is notified via a signal, SIGCHLD, when the child process finishes but not vice versa.
-
The child does not inherit pending signals or timer alarms. For a complete list see the http://man7.org/linux/man-pages/man2/fork.2.html
-
The child has its own set of environment variables.
If the parent process wants to wait for the child to finish, it must use
waitpid (or wait), both of which wait for a child to change process
states, which can be one of the following:
-
The child terminated
-
The child was stopped by a signal
-
The child was resumed by a signal
Note that waitpid can be set to be non-blocking, which means they will return immediately, letting you know if the child has exited.
pid_t child_id = fork();
if (child_id == -1) { perror("fork"); exit(EXIT_FAILURE);}
if (child_id > 0) {
// We have a child! Get their exit code
int status;
waitpid( child_id, &status, 0 );
// code not shown to get exit status from child
} else { // In child ...
// start calculation
exit(123);
}wait is a simpler version of waitpid. wait accepts a pointer to an
integer and waits on any child process. After the first one changes
state, wait returns. Here is the behavior of waitpid:
You can wait on a specific process, or you can pass in special values
for the pid to do different things (check the man pages).
The last parameter to waitpid is an option parameter. The options are listed below:
WNOHANG - Return whether or not the searched process has exited
WNOWAIT - Wait, but leave the child wait-able by another wait call
WEXITED - Wait for exited children
WSTOPPED - Wait for stopped children
WCONTINUED - Wait for continued children
Exit statuses or the value stored in the integer pointer for both of the calls above are explained below.
To find the return value of main() or value included in exit()), Use
the Wait macros - typically you will use WIFEXITED and WEXITSTATUS
. See wait/waitpid man page for more information.
int status;
pid_t child = fork();
if (child == -1) {
return 1; //Failed
}
if (child > 0) { /* I am the parent - wait for the child to finish */
pid_t pid = waitpid(child, &status, 0);
if (pid != -1 && WIFEXITED(status)) {
int exit_status = WEXITSTATUS(status);
printf("Process %d returned %d" , pid, exit_status);
}
} else { /* I am the child */
// do something interesting
execl("/bin/ls", "/bin/ls", ".", (char *) NULL); // "ls ."
}A process can only have 256 return values, the rest of the bits are
informational, and the information is extracted with bit shifting.
However, the kernel has an internal way of keeping track of signaled,
exited, or stopped processes. This API is abstracted so that that the
kernel developers are free to change it at will. Remember: these macros
only make sense if the precondition is met. For example, a process’ exit
status won’t be defined if the process isn’t signaled. The macros will
not do the checking for you, so it’s up to the programmer to make sure
the logic is correct. As an example above, you should use the
WIFSTOPPED to check if a process was stopped and then the WSTOPSIG
to find the signal that stopped it. As such there is no need to memorize
the following. This is just a high level overview of how information is
stored inside the status variables. From the sys/wait.h of an old
Berkeley Standard Distribution(BSD) kernel (“Source to Sys/Wait.h,”
#ref-sys/wait.h):
/* If WIFEXITED(STATUS), the low-order 8 bits of the status. */
#define _WSTATUS(x) (_W_INT(x) & 0177)
#define _WSTOPPED 0177 /* _WSTATUS if process is stopped */
#define WIFSTOPPED(x) (_WSTATUS(x) == _WSTOPPED)
#define WSTOPSIG(x) (_W_INT(x) >> 8)
#define WIFSIGNALED(x) (_WSTATUS(x) != _WSTOPPED && _WSTATUS(x) != 0)
#define WTERMSIG(x) (_WSTATUS(x))
#define WIFEXITED(x) (_WSTATUS(x) == 0)There is a convention about exit codes. If the process exited normally
and everything was successful, then a zero should be returned. Beyond
that, there aren’t too many conventions except the ones that you place
on yourself. If you know how the program you spawn is going to interact,
you may be able to make more sense of the 256 error codes. You could for
example, write your program to return 1 if the program went to stage 1
(like writing to a file) 2 if it did something else etc... Usually,
UNIX programs are not designed to follow this policy, for the sake of
simplicity.
It is good practice to wait on your process’ children. If you don’t wait on your children they become, what are called zombies. Zombies are created when a child terminates and then takes up a spot in the kernel process table for your process. The process table keeps track of the following information about a process: PID, status, and how it was killed. The only way to get rid of a zombie is to wait on your children. If you never wait on your children, and the program is long running, you may lose the ability to fork.
Having said that, it is worth mentioning that you don’t always need to
wait for your children! Your parent process can continue to execute
code without having to wait for the child process. If a parent dies
without waiting on its children, a process can orphan its children. Once
a parent process completes, any of its children will be assigned to
init - the first process, whose PID is 1. Therefore, these children
would see getppid() return a value of 1. These orphans will eventually
finish and for a brief moment become a zombie. The init process
automatically waits for all of its children, thus removing these zombies
from the system.
Warning: This section uses signals which we have not yet fully introduced. The parent gets the signal SIGCHLD when a child completes, so the signal handler can wait on the process. A slightly simplified version is shown below.
pid_t child;
void cleanup(int signal) {
int status;
waitpid(child, &status, 0);
write(1,"cleanup!\n",9);
}
int main() {
// Register signal handler BEFORE the child can finish
signal(SIGCHLD, cleanup); // or better - sigaction
child = fork();
if (child == -1) { exit(EXIT_FAILURE);}
if (child == 0) { /* I am the child!*/
// Do background stuff e.g. call exec
} else { /* I'm the parent! */
sleep(4); // so we can see the cleanup
puts("Parent is done");
}
return 0;
}The above example however misses a couple of subtle points.
-
More than one child may have finished but the parent will only get one SIGCHLD signal (signals are not queued)
-
SIGCHLD signals can be sent for other reasons (e.g. a child process has temporarily stopped)
-
It uses the deprecated
signalcode, instead of the more portable sigaction.
A more robust code to reap zombies is shown below.
void cleanup(int signal) {
int status;
while (waitpid((pid_t) (-1), 0, WNOHANG) > 0) {
}
}To make the child process execute another program, use one of the
http://man7.org/linux/man-pages/man3/exec.3.html
functions after forking. The exec set of functions replaces the
process image with that of the specified program. This means that any
lines of code after the exec call are replaced with those of the
exec’d program. Any other work you want the child process to do should
be done before the exec call. The naming schemes can be shortened
mnemonically.
-
e – An array of pointers to environment variables is explicitly passed to the new process image.
-
l – Command-line arguments are passed individually (a list) to the function.
-
p – Uses the PATH environment variable to find the file named in the file argument to be executed.
-
v – Command-line arguments are passed to the function as an array (vector) of pointers.
Note that if you pass information via an array, the last element must be followed by a NULL element to terminate the array.
An example of this code is below. This code executes ls
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char**argv) {
pid_t child = fork();
if (child == -1) return EXIT_FAILURE;
if (child) { /* I have a child! */
int status;
waitpid(child , &status ,0);
return EXIT_SUCCESS;
} else { /* I am the child */
// Other versions of exec pass in arguments as arrays
// Remember first arg is the program name
// Last arg must be a char pointer to NULL
execl("/bin/ls", "/bin/ls", "-alh", (char *) NULL);
// If we get to this line, something went wrong!
perror("exec failed!");
}
}Try to decode the following example
#include <unistd.h>
#include <fcntl.h> // O_CREAT, O_APPEND etc. defined here
int main() {
close(1); // close standard out
open("log.txt", O_RDWR | O_CREAT | O_APPEND, S_IRUSR | S_IWUSR);
puts("Captain's log");
chdir("/usr/include");
// execl( executable, arguments for executable including program name and NULL at the end)
execl("/bin/ls", /* Remaining items sent to ls*/ "/bin/ls", ".", (char *) NULL); // "ls ."
perror("exec failed");
return 0;
}The example writes "Captain’s Log" to a file then prints everything in /usr/include to the same file. There’s no error checking in the above code (we assume close, open, chdir etc. work as expected).
-
open– will use the lowest available file descriptor (i.e. 1) ; so standard out(stdout) is now redirected to the log file. -
chdir– Change the current directory to /usr/include -
execl– Replace the program image with /bin/ls and call its main() method -
perror– We don’t expect to get here - if we did thenexecfailed. -
We need the "return 0;" because compilers complain if we don’t have it.
POSIX details all of the semantics that exec needs to cover (“Exec” #ref-exec_2018). What you need to know is the following bullet points.
-
File descriptors are preserved after an exec. That means if you open a file, and you forget to close it, it remains open in the child. This is a problem because usually the child doesn’t know about those file descriptors. Nevertheless, they take up a slot in the file descriptor table and could possible prevent other processes from accessing the file. The one exception to this is if the file descriptor has the Close-On-Exec flag set (O_CLOEXEC) – we will go over setting flags later.
-
Various signal semantics. The exec’d processes preserve the signal mask and the pending signal set, but does not preserve the signal handlers because it is a different program.
-
Environment variables are preserved unless using an environ version of exec
-
The operating system may open up 0, 1, 2 – stdin, stdout, stderr, if they are closed after exec, most of the time they leave them closed.
-
The exec’ed process runs as the same PID and has the same parent and process group as the previous process.
-
The exec’ed process is run on the same user and group with the same working directory
system pre-packs the above code (Jones
#ref-jones2010wg14 P. 371). The
following is a snippet of how to use system..
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char**argv) {
system("ls"); // execl("/bin/sh", "/bin/sh", "-c", "\\"ls\\"")
return 0;
}The system call will fork, execute the command passed by parameter and
the original parent process will wait for this to finish. This also
means that system is a blocking call. The parent process can’t
continue until the process started by system exits. Also, system
actually creates a shell which is then given the string, which is more
overhead than just using exec directly. The standard shell will use
the PATH environment variable to search for a filename that matches
the command. Using system will usually be sufficient for many simple
run-this-command problems but can quickly become limiting for more
complex or subtle problems, and it hides the mechanics of the
fork-exec-wait pattern so we encourage you to learn and use fork
exec and waitpid instead. It also tends to be a huge security risk.
By allowing someone to access a shell version of the environment, you
can run into all sorts of problems:
int main(int argc, char**argv) {
char *to_exec = asprintf("ls %s", argv[1]);
system(to_exec);
}Passing something along the lines of argv[1] = "; sudo su" is a huge security risk called https://en.wikipedia.org/wiki/Privilege_escalation.
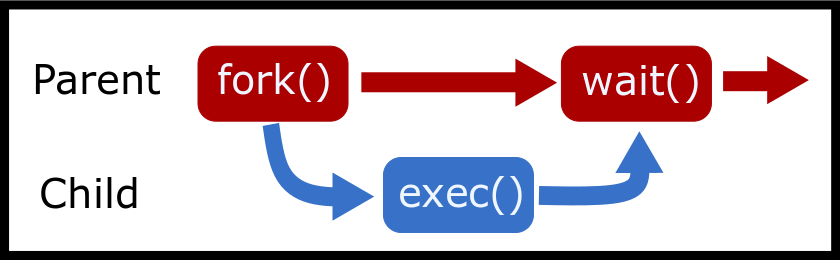
A common programming pattern is to call fork followed by exec and
wait. The original process calls fork, which creates a child process.
The child process then uses exec to start execution of a new program.
Meanwhile the parent uses wait (or waitpid) to wait for the child
process to finish.
[language=C]
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid < 0) { // fork failure
exit(1);
} else if (pid > 0) { // I am the parent
int status;
waitpid(pid, &status, 0);
} else { // I am the child
execl("/bin/ls", "/bin/ls", NULL);
exit(1); // For safety.
}
}You may ask why we didn’t just execute ls directly. The reason is that now we have a monitor program – our parent that can do other things. It can proceed afterwards and execute another function, or it can also modify the state of the system or read the output of the function call.
Environment variables are variables that the system keeps for all processes to use. Your system has these set up right now! In Bash, you can check some of these
$ echo $HOME
/home/bhuvy
$ echo $PATH
/usr/local/sbin:/usr/bin:...
How would you get and set these in C/C++? You can use the getenv and
setenv function respectively.
char* home = getenv("HOME"); // Will return /home/bhuvy
setenv("HOME", "/home/bhuvan", 1 /*set overwrite to true*/ );Environment variables are important because they are inherited between processes and can be used the specify a standard set of behaviors (“Environment Variables” #ref-env_std_2018), although you don’t need to memorize the options. Another security related concern is that environment variables cannot be read by an outside process, whereas argv can be.
Read the man pages and the POSIX groups above!
-
Correct use of fork, exec and waitpid
-
Using exec with a path
-
Understanding what fork and exec and waitpid do. E.g. how to use their return values.
-
SIGKILL vs SIGSTOP vs SIGINT.
-
What signal is sent when you press CTRL-C
-
Using kill from the shell or the kill POSIX call.
-
Process memory isolation.
-
Process memory layout (where is the heap, stack etc; invalid memory addresses).
-
What is a fork bomb, zombie and orphan? How to create/remove them.
-
getpid vs getppid
-
How to use the WAIT exit status macros WIFEXITED etc.
-
What is the difference between execs with a p and without a p? What does the operating system
-
How do you pass in command line arguments to
execl*? How aboutexecv*? What should be the first command line argument by convention? -
How do you know if
execorforkfailed? -
What is the
int statuspointer passed into wait? When does wait fail? -
What are some differences between
SIGKILL,SIGSTOP,SIGCONT,SIGINT? What are the default behaviors? Which ones can you set up a signal handler for? -
What signal is sent when you press
CTRL-C? -
My terminal is anchored to PID = 1337 and has just become unresponsive. Write me the terminal command and the C code to send
SIGQUITto it. -
Can one process alter another processes memory through normal means? Why?
-
Where is the heap, stack, data, and text segment? Which segments can you write to? What are invalid memory addresses?
-
Code me up a fork bomb in C (please don’t run it).
-
What is an orphan? How does it become a zombie? How do I be a good parent?
-
Don’t you hate it when your parents tell you that you can’t do something? Write me a program that sends
SIGSTOPto your parent. -
Write a function that fork exec waits an executable, and using the wait macros tells me if the process exited normally or if it was signaled. If the process exited normally, then print that with the return value. If not, then print the signal number that caused the process to terminate.
Bovet, Daniel, and Marco Cesati. 2005. Understanding the Linux Kernel. Oreilly & Associates Inc.
“Definitions.” 2018. The Open Group Base Specifications Issue 7, 2018 Edition. The Open Group/IEEE. http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap03.html#tag_03_210.
“Environment Variables.” 2018. Environment Variables. The Open Group/IEEE. https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap08.html.
Evans, Julia. 2018. “File Descriptors.” Julia’s Drawings. Julia Evans. https://drawings.jvns.ca/file-descriptors/.
“Exec.” 2018. Exec. The Open Group/IEEE. https://pubs.opengroup.org/onlinepubs/9699919799/functions/exec.html.
“Fork.” 2018. Fork. The Open Group/IEEE. https://pubs.opengroup.org/onlinepubs/9699919799/functions/fork.html.
Jones, Larry. 2010. “WG14 N1539 Committee Draft Iso/Iec 9899: 201x.” International Standards Organization.
“Overview of Malloc.” 2018. MallocInternals - Glibc Wiki. Free Software Foundation. https://sourceware.org/glibc/wiki/MallocInternals.
“Source to Sys/Wait.h.” n.d. Sys/Wait.h Source. superglobalmegacorp. http://unix.superglobalmegacorp.com/Net2/newsrc/sys/wait.h.html.
Van der Linden, Peter. 1994. Expert c Programming: Deep c Secrets. Prentice Hall Professional.