2021年末,学校升级相关接口,旧脚本会出现死循环的问题。
借此机会,本项目将移交至一个小组维护。请移步 libthu/reserves-lib-tsinghua-downloader,本仓库今后将不再更新。在新仓库中,应已完成对接口的升级。
谢谢大家的支持!



Download pages from http://reserves.lib.tsinghua.edu.cn/
自动下载书籍每一页的原图,生成PDF,免登录。
从Releases或项目网站,下载Assets中对应系统的可执行文件。
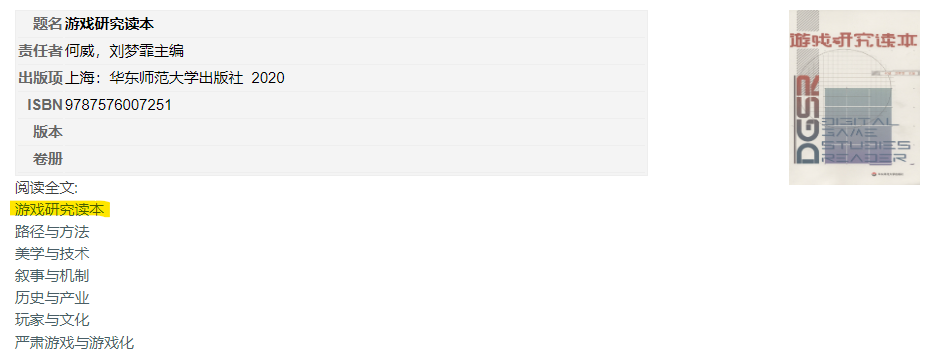
运行downloader,输入网站“阅读全文”之下的链接地址(如图中标黄的位置)。程序会自动爬取当前章节以下的所有章节。
程序会将图片保存在./clawed下,并自动生成PDF。
此程序无需登录即可使用。
MacOS用户可能无法直接运行下载的downloader,是因为它没有被标记为“可执行的”。
解决方法:在终端中进入downloader文件所在的文件夹,执行chmod +x downloader命令。有关此命令的更多帮助请参阅Apple。
MacOS上的第一次启动可能会有点慢。
Q: 图片压缩的quality ratio怎样设置?
A: 范围[1, 96]:其中96为不压缩,[1, 95]从最差到最佳。
Q: 运行报错Cookie Required,怎么办?
A: 经测试,绝大部分教参无需cookie即可访问。少数教参需要cookie进行身份验证,请将网站cookie中,.ASPXAUTH和ASP.NET_SessionId的值依次写入cookie.txt中,每行一个。(我将会完善获取网站cookie的相关教程。若急需,请与我发邮件)
Q: 下载的章节不全?
A: 这是因为此图书的目录编号不连续。请再次运行程序并输入下一位置的章节链接。通常不会出现此情况。
Q: 分享一点高级玩法?
A: 使用学校提供的正版福昕编辑器可以进行OCR文字识别。
Run downloader --help in terminal.
usage: downloader.exe [-h] [--url URL] [--no-pdf] [--no-img] [--quality QUALITY] [--con CON] [--resume]
See README.md for help. Repo: https://github.com/i207M/reserves-lib-tsinghua-downloader
optional arguments:
-h, --help show this help message and exit
--url URL input target URL
--no-pdf disable generating PDF
--no-img disable saving images
--quality QUALITY reduce file size, [1, 96] (75 by recommendation, 96 by default)
--con CON the number of concurrent downloads (6 by default)
--resume skip downloading images (for testing)
希望尝鲜?从GitHub Actions中下载预览版的可执行文件!
- PDF Bookmark
- You tell me
请查看contribution.md。
欢迎Star/Issue/PR~
仅供Python语言的学习参考,请勿用于非法用途!
更多清华常用信息/服务汇总请看这里。