\n",
- "
\n",
+ "

\n",
"
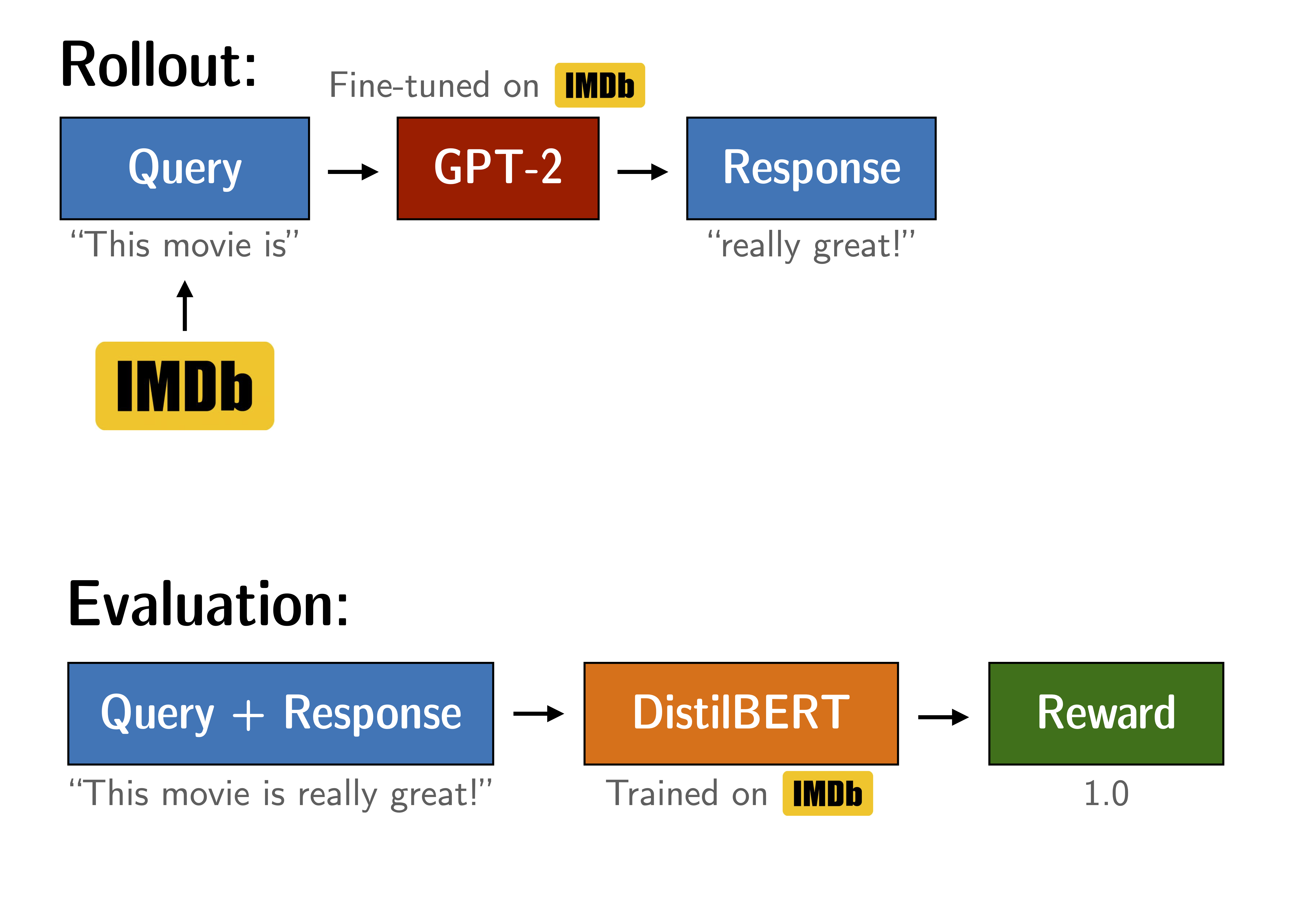
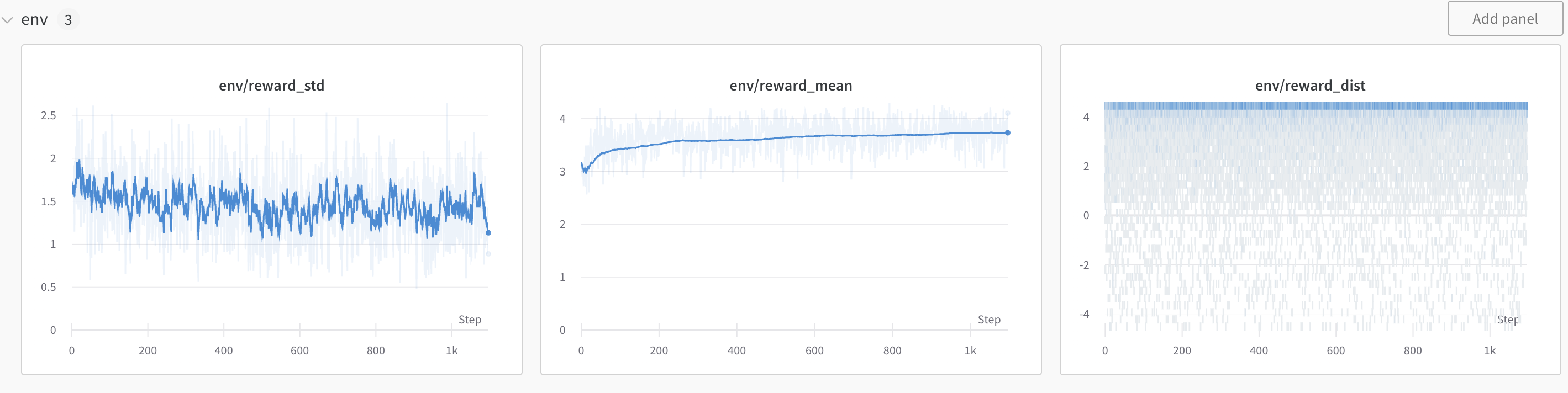
Figure: Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face.
\n",
"
 +
+













 +
+
 +
+
 +
+
 +
+
 +
+
 +
+ 
 +
+
 +
+
 +
+ ## Minimal example
diff --git a/docs/source/reducing_memory_usage.md b/docs/source/reducing_memory_usage.md
new file mode 100644
index 0000000000..dfe6dc5a7a
--- /dev/null
+++ b/docs/source/reducing_memory_usage.md
@@ -0,0 +1,54 @@
+# Reducing Memory Usage
+
+
## Minimal example
diff --git a/docs/source/reducing_memory_usage.md b/docs/source/reducing_memory_usage.md
new file mode 100644
index 0000000000..dfe6dc5a7a
--- /dev/null
+++ b/docs/source/reducing_memory_usage.md
@@ -0,0 +1,54 @@
+# Reducing Memory Usage
+
+ +
+ +
+ +
+ +
+
 +
+
 +
+
 +
+
 +
+
 +
+