diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index 967049d89cbe12..130775f6420f9e 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -122,6 +122,7 @@ Flax), PyTorch, and/or TensorFlow.
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
+| [DepthPro](model_doc/depth_pro) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
diff --git a/docs/source/en/model_doc/depth_pro.md b/docs/source/en/model_doc/depth_pro.md
new file mode 100644
index 00000000000000..9019547434af84
--- /dev/null
+++ b/docs/source/en/model_doc/depth_pro.md
@@ -0,0 +1,123 @@
+
+
+# DepthPro
+
+## Overview
+
+The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
+
+It leverages a multi-scale [Vision Transformer (ViT)](vit) optimized for dense predictions. It downsamples an image at several scales. At each scale, it is split into patches, which are processed by a ViT-based [Dinov2](dinov2) patch encoder, with weights shared across scales. Patches are merged into feature maps, upsampled, and fused via a [DPT](dpt) like decoder.
+
+The abstract from the paper is the following:
+
+*We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions.*
+
+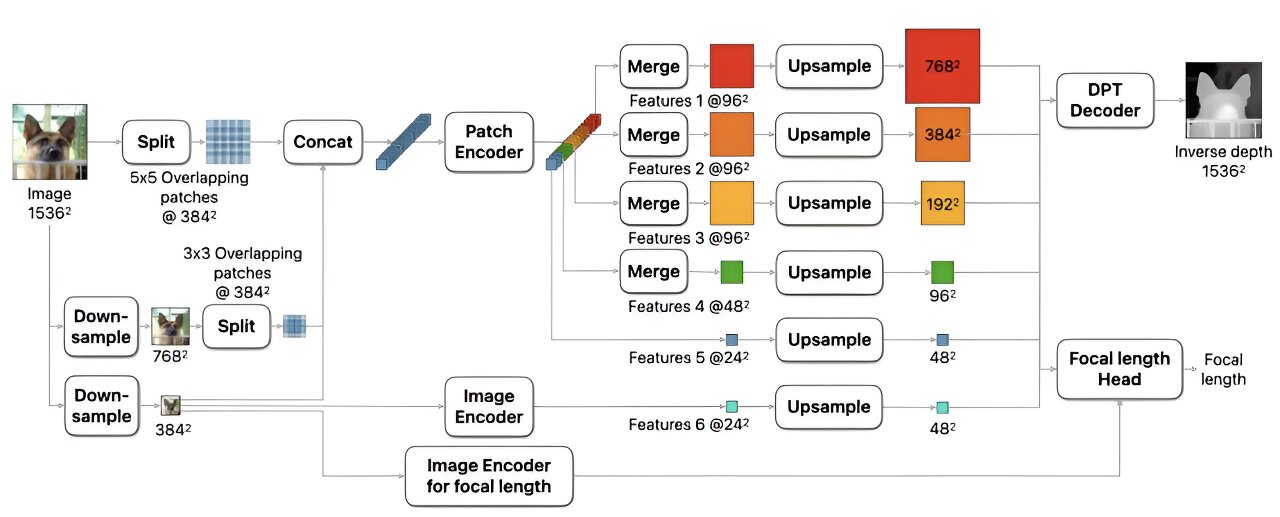 +
+ DepthPro architecture. Taken from the original paper.
+
+This model was contributed by [geetu040](https://github.com/geetu040). The original code can be found [here](https://github.com/apple/ml-depth-pro).
+
+
+
+## Usage tips
+
+```python
+from transformers import DepthProConfig, DepthProForDepthEstimation
+
+config = DepthProConfig()
+model = DPTForDepthEstimation(config=config)
+```
+
+- By default model takes an input image of size `1536`, this can be changed via config, however the model is compatible with images of different width and height.
+- Input image is scaled with different ratios, as specified in `scaled_images_ratios`, then each of the scaled image is patched to `patch_size` with an overlap ratio of `scaled_images_overlap_ratios`.
+- These patches go through `DinoV2 (ViT)` based encoders and are reassembled via a `DPT` based decoder.
+- `DepthProForDepthEstimation` can also predict the `FOV (Field of View)` if `use_fov_model` is set to `True` in the config.
+- `DepthProImageProcessor` can be used for preprocessing the inputs and postprocessing the outputs. `DepthProImageProcessor.post_process_depth_estimation` interpolates the `predicted_depth` back to match the input image size.
+- To generate `predicted_depth` of the same size as input image, make sure the config is created such that
+```
+image_size / 2**(n_fusion_blocks+1) == patch_size / patch_embeddings_size
+
+where
+n_fusion_blocks = len(intermediate_hook_ids) + len(scaled_images_ratios)
+```
+
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```py
+from transformers import DepthProForDepthEstimation
+model = DepthProForDepthEstimation.from_pretrained("geetu040/DepthPro", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `google/vit-base-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+
+- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
+
+
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthProConfig
+
+[[autodoc]] DepthProConfig
+
+## DepthProImageProcessor
+
+[[autodoc]] DepthProImageProcessor
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProImageProcessorFast
+
+[[autodoc]] DepthProImageProcessorFast
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProModel
+
+[[autodoc]] DepthProModel
+ - forward
+
+## DepthProForDepthEstimation
+
+[[autodoc]] DepthProForDepthEstimation
+ - forward
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 930f41b6fefba7..9ead5ac276693f 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -237,6 +237,7 @@ For now, Transformers supports SDPA inference and training for the following arc
* [data2vec_vision](https://huggingface.co/docs/transformers/main/en/model_doc/data2vec#transformers.Data2VecVisionModel)
* [Dbrx](https://huggingface.co/docs/transformers/model_doc/dbrx#transformers.DbrxModel)
* [DeiT](https://huggingface.co/docs/transformers/model_doc/deit#transformers.DeiTModel)
+* [DepthPro](https://huggingface.co/docs/transformers/model_doc/depth_pro#transformers.DepthProModel)
* [Dinov2](https://huggingface.co/docs/transformers/en/model_doc/dinov2)
* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
* [Dpr](https://huggingface.co/docs/transformers/model_doc/dpr#transformers.DprReader)
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index ef140cc6d3a843..ebcfe53848502e 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -400,6 +400,7 @@
"models.deprecated.vit_hybrid": ["ViTHybridConfig"],
"models.deprecated.xlm_prophetnet": ["XLMProphetNetConfig"],
"models.depth_anything": ["DepthAnythingConfig"],
+ "models.depth_pro": ["DepthProConfig"],
"models.detr": ["DetrConfig"],
"models.dialogpt": [],
"models.dinat": ["DinatConfig"],
@@ -1212,6 +1213,7 @@
_import_structure["models.deprecated.efficientformer"].append("EfficientFormerImageProcessor")
_import_structure["models.deprecated.tvlt"].append("TvltImageProcessor")
_import_structure["models.deprecated.vit_hybrid"].extend(["ViTHybridImageProcessor"])
+ _import_structure["models.depth_pro"].extend(["DepthProImageProcessor", "DepthProImageProcessorFast"])
_import_structure["models.detr"].extend(["DetrFeatureExtractor", "DetrImageProcessor"])
_import_structure["models.donut"].extend(["DonutFeatureExtractor", "DonutImageProcessor"])
_import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
@@ -2136,6 +2138,13 @@
"DepthAnythingPreTrainedModel",
]
)
+ _import_structure["models.depth_pro"].extend(
+ [
+ "DepthProForDepthEstimation",
+ "DepthProModel",
+ "DepthProPreTrainedModel",
+ ]
+ )
_import_structure["models.detr"].extend(
[
"DetrForObjectDetection",
@@ -5359,6 +5368,7 @@
XLMProphetNetConfig,
)
from .models.depth_anything import DepthAnythingConfig
+ from .models.depth_pro import DepthProConfig
from .models.detr import DetrConfig
from .models.dinat import DinatConfig
from .models.dinov2 import Dinov2Config
@@ -6207,6 +6217,7 @@
from .models.deprecated.efficientformer import EfficientFormerImageProcessor
from .models.deprecated.tvlt import TvltImageProcessor
from .models.deprecated.vit_hybrid import ViTHybridImageProcessor
+ from .models.depth_pro import DepthProImageProcessor, DepthProImageProcessorFast
from .models.detr import DetrFeatureExtractor, DetrImageProcessor
from .models.donut import DonutFeatureExtractor, DonutImageProcessor
from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
@@ -7001,6 +7012,11 @@
DepthAnythingForDepthEstimation,
DepthAnythingPreTrainedModel,
)
+ from .models.depth_pro import (
+ DepthProForDepthEstimation,
+ DepthProModel,
+ DepthProPreTrainedModel,
+ )
from .models.detr import (
DetrForObjectDetection,
DetrForSegmentation,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 7fcaddde704cf7..9030f178ab0cfa 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -73,6 +73,7 @@
deit,
deprecated,
depth_anything,
+ depth_pro,
detr,
dialogpt,
dinat,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 69ce8efa10c76c..b4b920b6d5886f 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -90,6 +90,7 @@
("deformable_detr", "DeformableDetrConfig"),
("deit", "DeiTConfig"),
("depth_anything", "DepthAnythingConfig"),
+ ("depth_pro", "DepthProConfig"),
("deta", "DetaConfig"),
("detr", "DetrConfig"),
("dinat", "DinatConfig"),
@@ -399,6 +400,7 @@
("deplot", "DePlot"),
("depth_anything", "Depth Anything"),
("depth_anything_v2", "Depth Anything V2"),
+ ("depth_pro", "DepthPro"),
("deta", "DETA"),
("detr", "DETR"),
("dialogpt", "DialoGPT"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index db25591eaa3544..41dbb4ab9e5be5 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -74,6 +74,7 @@
("deformable_detr", ("DeformableDetrImageProcessor", "DeformableDetrImageProcessorFast")),
("deit", ("DeiTImageProcessor",)),
("depth_anything", ("DPTImageProcessor",)),
+ ("depth_pro", ("DepthProImageProcessor", "DepthProImageProcessorFast")),
("deta", ("DetaImageProcessor",)),
("detr", ("DetrImageProcessor", "DetrImageProcessorFast")),
("dinat", ("ViTImageProcessor", "ViTImageProcessorFast")),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index e8a2dece432476..dcf3ee974d2bf1 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -88,6 +88,7 @@
("decision_transformer", "DecisionTransformerModel"),
("deformable_detr", "DeformableDetrModel"),
("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
("deta", "DetaModel"),
("detr", "DetrModel"),
("dinat", "DinatModel"),
@@ -580,6 +581,7 @@
("data2vec-vision", "Data2VecVisionModel"),
("deformable_detr", "DeformableDetrModel"),
("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
("deta", "DetaModel"),
("detr", "DetrModel"),
("dinat", "DinatModel"),
@@ -891,6 +893,7 @@
[
# Model for depth estimation mapping
("depth_anything", "DepthAnythingForDepthEstimation"),
+ ("depth_pro", "DepthProForDepthEstimation"),
("dpt", "DPTForDepthEstimation"),
("glpn", "GLPNForDepthEstimation"),
("zoedepth", "ZoeDepthForDepthEstimation"),
diff --git a/src/transformers/models/depth_pro/__init__.py b/src/transformers/models/depth_pro/__init__.py
new file mode 100644
index 00000000000000..6fa380d6420834
--- /dev/null
+++ b/src/transformers/models/depth_pro/__init__.py
@@ -0,0 +1,72 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+from ...utils import OptionalDependencyNotAvailable
+
+
+_import_structure = {"configuration_depth_pro": ["DepthProConfig"]}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_depth_pro"] = ["DepthProImageProcessor"]
+ _import_structure["image_processing_depth_pro_fast"] = ["DepthProImageProcessorFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_depth_pro"] = [
+ "DepthProForDepthEstimation",
+ "DepthProModel",
+ "DepthProPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_depth_pro import DepthProConfig
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_depth_pro import DepthProImageProcessor
+ from .image_processing_depth_pro_fast import DepthProImageProcessorFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_depth_pro import (
+ DepthProForDepthEstimation,
+ DepthProModel,
+ DepthProPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/depth_pro/configuration_depth_pro.py b/src/transformers/models/depth_pro/configuration_depth_pro.py
new file mode 100644
index 00000000000000..206c01eff191bd
--- /dev/null
+++ b/src/transformers/models/depth_pro/configuration_depth_pro.py
@@ -0,0 +1,203 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""DepthPro model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class DepthProConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`DepthProModel`]. It is used to instantiate a
+ DepthPro model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the DepthPro
+ [apple/DepthPro](https://huggingface.co/apple/DepthPro) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the encoder layers and the pooler layer.
+ fusion_hidden_size (`int`, *optional*, defaults to 256):
+ The number of channels before fusion.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ mlp_ratio (`int`, *optional*, defaults to 4):
+ Ratio of the hidden size of the MLPs relative to the `hidden_size`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ patch_size (`int`, *optional*, defaults to 384):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ patch_embeddings_size (`int`, *optional*, defaults to 16):
+ kernel_size and stride for convolution in PatchEmbeddings.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ layerscale_value (`float`, *optional*, defaults to 1.0):
+ Initial value to use for layer scale.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ Stochastic depth rate per sample (when applied in the main path of residual layers).
+ use_swiglu_ffn (`bool`, *optional*, defaults to `False`):
+ Whether to use the SwiGLU feedforward neural network.
+ intermediate_hook_ids (`List[int]`, *optional*, defaults to `[11, 5]`):
+ Indices of the intermediate hidden states from the patch encoder to use for fusion.
+ intermediate_feature_dims (`List[int]`, *optional*, defaults to `[256, 256]`):
+ Hidden state dimensions during upsampling for each intermediate hidden state in `intermediate_hook_ids`.
+ scaled_images_ratios (`List[float]`, *optional*, defaults to `[0.25, 0.5, 1]`):
+ Ratios of scaled images to be used by the patch encoder.
+ scaled_images_overlap_ratios (`List[float]`, *optional*, defaults to `[0.0, 0.5, 0.25]`):
+ Overlap ratios between patches for each scaled image in `scaled_images_ratios`.
+ scaled_images_feature_dims (`List[int]`, *optional*, defaults to `[1024, 1024, 512]`):
+ Hidden state dimensions during upsampling for each scaled image in `scaled_images_ratios`.
+ use_batch_norm_in_fusion_residual (`bool`, *optional*, defaults to `False`):
+ Whether to use batch normalization in the pre-activate residual units of the fusion blocks.
+ use_bias_in_fusion_residual (`bool`, *optional*, defaults to `True`):
+ Whether to use bias in the pre-activate residual units of the fusion blocks.
+ use_fov_model (`bool`, *optional*, defaults to `True`):
+ Whether to use `DepthProFOVModel` to generate the field of view.
+ num_fov_head_layers (`int`, *optional*, defaults to 2):
+ Number of convolution layers in the head of `DepthProFOVModel`.
+
+ Example:
+
+ ```python
+ >>> from transformers import DepthProConfig, DepthProModel
+
+ >>> # Initializing a DepthPro apple/DepthPro style configuration
+ >>> configuration = DepthProConfig()
+
+ >>> # Initializing a model (with random weights) from the apple/DepthPro style configuration
+ >>> model = DepthProModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "depth_pro"
+
+ def __init__(
+ self,
+ hidden_size=1024,
+ fusion_hidden_size=256,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ mlp_ratio=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-6,
+ patch_size=384,
+ num_channels=3,
+ patch_embeddings_size=16,
+ qkv_bias=True,
+ layerscale_value=1.0,
+ drop_path_rate=0.0,
+ use_swiglu_ffn=False,
+ intermediate_hook_ids=[11, 5],
+ intermediate_feature_dims=[256, 256],
+ scaled_images_ratios=[0.25, 0.5, 1],
+ scaled_images_overlap_ratios=[0.0, 0.5, 0.25],
+ scaled_images_feature_dims=[1024, 1024, 512],
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=True,
+ use_fov_model=True,
+ num_fov_head_layers=2,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ # scaled_images_ratios is sorted
+ if scaled_images_ratios != sorted(scaled_images_ratios):
+ raise ValueError(
+ f"Values in scaled_images_ratios={scaled_images_ratios} " "should be sorted from low to high"
+ )
+
+ # patch_size should be a divisible by patch_embeddings_size
+ # else it raises an exception in DepthProViTPatchEmbeddings
+ if patch_size % patch_embeddings_size != 0:
+ raise ValueError(
+ f"patch_size={patch_size} should be divisible " f"by patch_embeddings_size={patch_embeddings_size}."
+ )
+
+ # scaled_images_ratios, scaled_images_overlap_ratios, scaled_images_feature_dims should be consistent
+ if not (len(scaled_images_ratios) == len(scaled_images_overlap_ratios) == len(scaled_images_feature_dims)):
+ raise ValueError(
+ f"len(scaled_images_ratios)={len(scaled_images_ratios)} and "
+ f"len(scaled_images_overlap_ratios)={len(scaled_images_overlap_ratios)} and "
+ f"len(scaled_images_feature_dims)={len(scaled_images_feature_dims)}, "
+ f"should match in config."
+ )
+
+ # intermediate_hook_ids, intermediate_feature_dims should be consistent
+ if not (len(intermediate_hook_ids) == len(intermediate_feature_dims)):
+ raise ValueError(
+ f"len(intermediate_hook_ids)={len(intermediate_hook_ids)} and "
+ f"len(intermediate_feature_dims)={len(intermediate_feature_dims)}, "
+ f"should match in config."
+ )
+
+ # fusion_hidden_size should be consistent with num_fov_head_layers
+ if fusion_hidden_size // 2**num_fov_head_layers == 0:
+ raise ValueError(
+ f"fusion_hidden_size={fusion_hidden_size} should be consistent with num_fov_head_layers={num_fov_head_layers} "
+ "i.e fusion_hidden_size // 2**num_fov_head_layers > 0"
+ )
+
+ self.hidden_size = hidden_size
+ self.fusion_hidden_size = fusion_hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.mlp_ratio = mlp_ratio
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.patch_embeddings_size = patch_embeddings_size
+ self.qkv_bias = qkv_bias
+ self.layerscale_value = layerscale_value
+ self.drop_path_rate = drop_path_rate
+ self.use_swiglu_ffn = use_swiglu_ffn
+ self.use_batch_norm_in_fusion_residual = use_batch_norm_in_fusion_residual
+ self.use_bias_in_fusion_residual = use_bias_in_fusion_residual
+ self.use_fov_model = use_fov_model
+ self.num_fov_head_layers = num_fov_head_layers
+ self.intermediate_hook_ids = intermediate_hook_ids
+ self.intermediate_feature_dims = intermediate_feature_dims
+ self.scaled_images_ratios = scaled_images_ratios
+ self.scaled_images_overlap_ratios = scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = scaled_images_feature_dims
+
+
+__all__ = ["DepthProConfig"]
diff --git a/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py b/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py
new file mode 100644
index 00000000000000..cca89f6a8b8cac
--- /dev/null
+++ b/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py
@@ -0,0 +1,281 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import gc
+import os
+
+import regex as re
+import torch
+from huggingface_hub import hf_hub_download
+
+from transformers import (
+ DepthProConfig,
+ DepthProForDepthEstimation,
+ DepthProImageProcessorFast,
+)
+from transformers.image_utils import PILImageResampling
+
+
+# fmt: off
+ORIGINAL_TO_CONVERTED_KEY_MAPPING = {
+
+ # encoder and head
+ r"encoder.(patch|image)_encoder.cls_token": r"depth_pro.encoder.\1_encoder.embeddings.cls_token",
+ r"encoder.(patch|image)_encoder.pos_embed": r"depth_pro.encoder.\1_encoder.embeddings.position_embeddings",
+ r"encoder.(patch|image)_encoder.patch_embed.proj.(weight|bias)": r"depth_pro.encoder.\1_encoder.embeddings.patch_embeddings.projection.\2",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).norm(\d+).(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.norm\3.\4",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).attn.qkv.(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.attention.attention.(query|key|value).\3",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).attn.proj.(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.attention.output.dense.\3",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).ls(\d+).gamma": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.layer_scale\3.lambda1",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).mlp.fc(\d+).(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.mlp.fc\3.\4",
+ r"encoder.(patch|image)_encoder.norm.(weight|bias)": r"depth_pro.encoder.\1_encoder.layernorm.\2",
+ r"encoder.fuse_lowres.(weight|bias)": r"depth_pro.encoder.fuse_image_with_low_res.\1",
+ r"head.(\d+).(weight|bias)": r"head.head.\1.\2",
+
+ # fov
+ r"fov.encoder.0.cls_token": r"fov_model.encoder.embeddings.cls_token",
+ r"fov.encoder.0.pos_embed": r"fov_model.encoder.embeddings.position_embeddings",
+ r"fov.encoder.0.patch_embed.proj.(weight|bias)": r"fov_model.encoder.embeddings.patch_embeddings.projection.\1",
+ r"fov.encoder.0.blocks.(\d+).norm(\d+).(weight|bias)": r"fov_model.encoder.encoder.layer.\1.norm\2.\3",
+ r"fov.encoder.0.blocks.(\d+).attn.qkv.(weight|bias)": r"fov_model.encoder.encoder.layer.\1.attention.attention.(query|key|value).\2",
+ r"fov.encoder.0.blocks.(\d+).attn.proj.(weight|bias)": r"fov_model.encoder.encoder.layer.\1.attention.output.dense.\2",
+ r"fov.encoder.0.blocks.(\d+).ls(\d+).gamma": r"fov_model.encoder.encoder.layer.\1.layer_scale\2.lambda1",
+ r"fov.encoder.0.blocks.(\d+).mlp.fc(\d+).(weight|bias)": r"fov_model.encoder.encoder.layer.\1.mlp.fc\2.\3",
+ r"fov.encoder.0.norm.(weight|bias)": r"fov_model.encoder.layernorm.\1",
+ r"fov.downsample.(\d+).(weight|bias)": r"fov_model.global_neck.\1.\2",
+ r"fov.encoder.1.(weight|bias)": r"fov_model.encoder_neck.\1",
+ r"fov.head.head.(\d+).(weight|bias)": r"fov_model.head.\1.\2",
+
+ # upsamples (hard coded; regex is not very feasible here)
+ "encoder.upsample_latent0.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.0.weight",
+ "encoder.upsample_latent0.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.1.weight",
+ "encoder.upsample_latent0.2.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.2.weight",
+ "encoder.upsample_latent0.3.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.3.weight",
+ "encoder.upsample_latent1.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.0.weight",
+ "encoder.upsample_latent1.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.1.weight",
+ "encoder.upsample_latent1.2.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.2.weight",
+ "encoder.upsample0.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.3.0.weight",
+ "encoder.upsample0.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.3.1.weight",
+ "encoder.upsample1.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.2.0.weight",
+ "encoder.upsample1.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.2.1.weight",
+ "encoder.upsample2.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.1.0.weight",
+ "encoder.upsample2.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.1.1.weight",
+ "encoder.upsample_lowres.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.0.0.weight",
+ "encoder.upsample_lowres.bias": "depth_pro.encoder.feature_upsample.upsample_blocks.0.0.bias",
+
+ # projections between encoder and fusion
+ r"decoder.convs.(\d+).weight": lambda match: (
+ f"depth_pro.encoder.feature_projection.projections.{4-int(match.group(1))}.weight"
+ ),
+
+ # fusion stage
+ r"decoder.fusions.(\d+).resnet(\d+).residual.(\d+).(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.residual_layer{match.group(2)}.convolution{(int(match.group(3))+1)//2}.{match.group(4)}"
+ ),
+ r"decoder.fusions.(\d+).out_conv.(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.projection.{match.group(2)}"
+ ),
+ r"decoder.fusions.(\d+).deconv.(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.deconv.{match.group(2)}"
+ ),
+}
+# fmt: on
+
+
+def convert_old_keys_to_new_keys(state_dict_keys: dict = None):
+ output_dict = {}
+ if state_dict_keys is not None:
+ old_text = "\n".join(state_dict_keys)
+ new_text = old_text
+ for pattern, replacement in ORIGINAL_TO_CONVERTED_KEY_MAPPING.items():
+ if replacement is None:
+ new_text = re.sub(pattern, "", new_text) # an empty line
+ continue
+ new_text = re.sub(pattern, replacement, new_text)
+ output_dict = dict(zip(old_text.split("\n"), new_text.split("\n")))
+ return output_dict
+
+
+def get_qkv_state_dict(key, parameter):
+ """
+ new key which looks like this
+ xxxx.(q|k|v).xxx (m, n)
+
+ is converted to
+ xxxx.q.xxxx (m//3, n)
+ xxxx.k.xxxx (m//3, n)
+ xxxx.v.xxxx (m//3, n)
+ """
+ qkv_state_dict = {}
+ placeholder = re.search(r"(\(.*?\))", key).group(1) # finds "(query|key|value)"
+ replacements_keys = placeholder[1:-1].split("|") # creates ['query', 'key', 'value']
+ replacements_vals = torch.split(
+ parameter, split_size_or_sections=parameter.size(0) // len(replacements_keys), dim=0
+ )
+ for replacement_key, replacement_val in zip(replacements_keys, replacements_vals):
+ qkv_state_dict[key.replace(placeholder, replacement_key)] = replacement_val
+ return qkv_state_dict
+
+
+def write_model(
+ hf_repo_id: str,
+ output_dir: str,
+ safe_serialization: bool = True,
+):
+ os.makedirs(output_dir, exist_ok=True)
+
+ # ------------------------------------------------------------
+ # Create and save config
+ # ------------------------------------------------------------
+
+ # create config
+ config = DepthProConfig(
+ # this config is same as the default config and used for pre-trained weights
+ hidden_size=1024,
+ fusion_hidden_size=256,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ mlp_ratio=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-6,
+ patch_size=384,
+ num_channels=3,
+ patch_embeddings_size=16,
+ qkv_bias=True,
+ layerscale_value=1.0,
+ drop_path_rate=0.0,
+ use_swiglu_ffn=False,
+ apply_layernorm=True,
+ reshape_hidden_states=True,
+ intermediate_hook_ids=[11, 5],
+ intermediate_feature_dims=[256, 256],
+ scaled_images_ratios=[0.25, 0.5, 1],
+ scaled_images_overlap_ratios=[0.0, 0.5, 0.25],
+ scaled_images_feature_dims=[1024, 1024, 512],
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=True,
+ use_fov_model=True,
+ num_fov_head_layers=2,
+ )
+
+ # save config
+ config.save_pretrained(output_dir)
+ print("Model config saved successfully...")
+
+ # ------------------------------------------------------------
+ # Convert weights
+ # ------------------------------------------------------------
+
+ # download and load state_dict from hf repo
+ file_path = hf_hub_download(hf_repo_id, "depth_pro.pt")
+ # file_path = "/home/geetu/work/hf/depth_pro/depth_pro.pt" # when you already have the files locally
+ loaded = torch.load(file_path, weights_only=True)
+
+ print("Converting model...")
+ all_keys = list(loaded.keys())
+ new_keys = convert_old_keys_to_new_keys(all_keys)
+
+ state_dict = {}
+ for key in all_keys:
+ new_key = new_keys[key]
+ current_parameter = loaded.pop(key)
+
+ if "qkv" in key:
+ qkv_state_dict = get_qkv_state_dict(new_key, current_parameter)
+ state_dict.update(qkv_state_dict)
+ else:
+ state_dict[new_key] = current_parameter
+
+ print("Loading the checkpoint in a DepthPro model.")
+ model = DepthProForDepthEstimation(config)
+ model.load_state_dict(state_dict, strict=True, assign=True)
+ print("Checkpoint loaded successfully.")
+
+ print("Saving the model.")
+ model.save_pretrained(output_dir, safe_serialization=safe_serialization)
+ del state_dict, model
+
+ # Safety check: reload the converted model
+ gc.collect()
+ print("Reloading the model to check if it's saved correctly.")
+ model = DepthProForDepthEstimation.from_pretrained(output_dir, device_map="auto")
+ print("Model reloaded successfully.")
+ return model
+
+
+def write_image_processor(output_dir: str):
+ image_processor = DepthProImageProcessorFast(
+ do_resize=True,
+ size={"height": 1536, "width": 1536},
+ resample=PILImageResampling.BILINEAR,
+ antialias=False,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=0.5,
+ image_std=0.5,
+ )
+ image_processor.save_pretrained(output_dir)
+ return image_processor
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--hf_repo_id",
+ default="apple/DepthPro",
+ help="Location of official weights from apple on HF",
+ )
+ parser.add_argument(
+ "--output_dir",
+ default="apple_DepthPro",
+ help="Location to write the converted model and processor",
+ )
+ parser.add_argument(
+ "--safe_serialization", default=True, type=bool, help="Whether or not to save using `safetensors`."
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ action=argparse.BooleanOptionalAction,
+ help="Whether or not to push the converted model to the huggingface hub.",
+ )
+ parser.add_argument(
+ "--hub_repo_id",
+ default="geetu040/DepthPro",
+ help="Huggingface hub repo to write the converted model and processor",
+ )
+ args = parser.parse_args()
+
+ model = write_model(
+ hf_repo_id=args.hf_repo_id,
+ output_dir=args.output_dir,
+ safe_serialization=args.safe_serialization,
+ )
+
+ image_processor = write_image_processor(
+ output_dir=args.output_dir,
+ )
+
+ if args.push_to_hub:
+ print("Pushing to hub...")
+ model.push_to_hub(args.hub_repo_id)
+ image_processor.push_to_hub(args.hub_repo_id)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/models/depth_pro/image_processing_depth_pro.py b/src/transformers/models/depth_pro/image_processing_depth_pro.py
new file mode 100644
index 00000000000000..76a12577dd6330
--- /dev/null
+++ b/src/transformers/models/depth_pro/image_processing_depth_pro.py
@@ -0,0 +1,406 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for DepthPro."""
+
+from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+
+
+if TYPE_CHECKING:
+ from ...modeling_outputs import DepthProDepthEstimatorOutput
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import to_channel_dimension_format
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ is_torch_available,
+ make_list_of_images,
+ pil_torch_interpolation_mapping,
+ to_numpy_array,
+ valid_images,
+)
+from ...utils import (
+ TensorType,
+ filter_out_non_signature_kwargs,
+ logging,
+ requires_backends,
+)
+
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.get_logger(__name__)
+
+
+class DepthProImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a DepthPro image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `(size["height"],
+ size["width"])`. Can be overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`dict`, *optional*, defaults to `{"height": 1536, "width": 1536}`):
+ Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
+ method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
+ `preprocess` method.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 1536, "width": 1536}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.do_rescale = do_rescale
+ self.do_normalize = do_normalize
+ self.size = size
+ self.resample = resample
+ self.antialias = antialias
+ self.rescale_factor = rescale_factor
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> np.ndarray:
+ """
+ Resize an image to `(size["height"], size["width"])`.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Dictionary in the format `{"height": int, "width": int}` specifying the size of the output image.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ `PILImageResampling` filter to use when resizing the image e.g. `PILImageResampling.BILINEAR`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+
+ Returns:
+ `np.ndarray`: The resized images.
+ """
+ requires_backends(self, "torch")
+
+ size = get_size_dict(size)
+ if "height" not in size or "width" not in size:
+ raise ValueError(f"The `size` dictionary must contain the keys `height` and `width`. Got {size.keys()}")
+ output_size = (size["height"], size["width"])
+
+ # we use torch interpolation instead of image.resize because DepthProImageProcessor
+ # rescales, then normalizes, which may cause some values to become negative, before resizing the image.
+ # image.resize expects all values to be in range [0, 1] or [0, 255] and throws an exception otherwise,
+ # however pytorch interpolation works with negative values.
+ # relevant issue here: https://github.com/huggingface/transformers/issues/34920
+ return (
+ torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=torch.from_numpy(image).unsqueeze(0),
+ size=output_size,
+ mode=pil_torch_interpolation_mapping[resample].value,
+ antialias=antialias,
+ )
+ .squeeze(0)
+ .numpy()
+ )
+
+ def _validate_input_arguments(
+ self,
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ data_format: Union[str, ChannelDimension],
+ ):
+ if do_resize and None in (size, resample, antialias):
+ raise ValueError("Size, resample and antialias must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize and None in (image_mean, image_std):
+ raise ValueError("Image mean and standard deviation must be specified if do_normalize is True.")
+
+ @filter_out_non_signature_kwargs()
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: Optional[PILImageResampling] = None,
+ antialias: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Dictionary in the format `{"height": h, "width": w}` specifying the size of the output image after
+ resizing.
+ resample (`PILImageResampling` filter, *optional*, defaults to `self.resample`):
+ `PILImageResampling` filter to use if resizing the image e.g. `PILImageResampling.BILINEAR`. Only has
+ an effect if `do_resize` is set to `True`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use if `do_normalize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+ antialias = antialias if antialias is not None else self.antialias
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ size = size if size is not None else self.size
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ self._validate_input_arguments(
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ data_format=data_format,
+ )
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ all_images = []
+ for image in images:
+ if do_rescale:
+ image = self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+
+ if do_normalize:
+ image = self.normalize(
+ image=image, mean=image_mean, std=image_std, input_data_format=input_data_format
+ )
+
+ # depth-pro rescales and normalizes the image before resizing it
+ # uses torch interpolation which requires ChannelDimension.FIRST
+ if do_resize:
+ image = to_channel_dimension_format(image, ChannelDimension.FIRST, input_channel_dim=input_data_format)
+ image = self.resize(image=image, size=size, resample=resample, antialias=antialias)
+ image = to_channel_dimension_format(image, data_format, input_channel_dim=ChannelDimension.FIRST)
+ else:
+ image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
+
+ all_images.append(image)
+
+ data = {"pixel_values": all_images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def post_process_depth_estimation(
+ self,
+ outputs: "DepthProDepthEstimatorOutput",
+ target_sizes: Optional[Union[TensorType, List[Tuple[int, int]], None]] = None,
+ ) -> Dict[str, List[TensorType]]:
+ """
+ Post-processes the raw depth predictions from the model to generate final depth predictions and optionally
+ resizes them to specified target sizes. This function supports scaling based on the field of view (FoV)
+ and adjusts depth values accordingly.
+
+ Args:
+ outputs ([`DepthProDepthEstimatorOutput`]):
+ Raw outputs of the model.
+ target_sizes (`Optional[Union[TensorType, List[Tuple[int, int]], None]]`, *optional*, defaults to `None`):
+ Target sizes to resize the depth predictions. Can be a tensor of shape `(batch_size, 2)`
+ or a list of tuples `(height, width)` for each image in the batch. If `None`, no resizing
+ is performed.
+
+ Returns:
+ `List[Dict[str, TensorType]]`: A list of dictionaries of tensors representing the processed depth
+ predictions.
+
+ Raises:
+ `ValueError`:
+ If the lengths of `predicted_depths`, `fovs`, or `target_sizes` are mismatched.
+ """
+ requires_backends(self, "torch")
+
+ predicted_depth = outputs.predicted_depth
+ fov = outputs.fov
+
+ batch_size = len(predicted_depth)
+
+ if target_sizes is not None and batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many fov values as the batch dimension of the predicted depth"
+ )
+
+ results = []
+ fov = [None] * batch_size if fov is None else fov
+ target_sizes = [None] * batch_size if target_sizes is None else target_sizes
+ for depth, fov_value, target_size in zip(predicted_depth, fov, target_sizes):
+ if target_size is not None:
+ # scale image w.r.t fov
+ if fov_value is not None:
+ width = target_size[1]
+ fov_value = 0.5 * width / torch.tan(0.5 * torch.deg2rad(fov_value))
+ depth = depth * width / fov_value
+
+ # interpolate
+ depth = torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=depth.unsqueeze(0).unsqueeze(1),
+ size=target_size,
+ mode=pil_torch_interpolation_mapping[self.resample].value,
+ antialias=self.antialias,
+ ).squeeze()
+
+ # inverse the depth
+ depth = 1.0 / torch.clamp(depth, min=1e-4, max=1e4)
+
+ results.append(
+ {
+ "predicted_depth": depth,
+ "fov": fov_value,
+ }
+ )
+
+ return results
+
+
+__all__ = ["DepthProImageProcessor"]
diff --git a/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py b/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py
new file mode 100644
index 00000000000000..521e5b8a06282e
--- /dev/null
+++ b/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py
@@ -0,0 +1,386 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fast Image processor class for DepthPro."""
+
+import functools
+from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
+
+
+if TYPE_CHECKING:
+ from ...modeling_outputs import DepthProDepthEstimatorOutput
+
+from ...image_processing_base import BatchFeature
+from ...image_processing_utils import get_size_dict
+from ...image_processing_utils_fast import BaseImageProcessorFast, SizeDict
+from ...image_transforms import FusedRescaleNormalize, NumpyToTensor, Rescale
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ ImageType,
+ PILImageResampling,
+ get_image_type,
+ make_list_of_images,
+ pil_torch_interpolation_mapping,
+)
+from ...utils import TensorType, logging, requires_backends
+from ...utils.import_utils import is_torch_available, is_torchvision_available
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_available():
+ import torch
+
+
+if is_torchvision_available():
+ from torchvision.transforms import Compose, Normalize, PILToTensor, Resize
+
+
+class DepthProImageProcessorFast(BaseImageProcessorFast):
+ r"""
+ Constructs a DepthPro image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `(size["height"],
+ size["width"])`. Can be overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`dict`, *optional*, defaults to `{"height": 1536, "width": 1536}`):
+ Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
+ method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
+ `preprocess` method.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+ _transform_params = [
+ "do_resize",
+ "do_rescale",
+ "do_normalize",
+ "size",
+ "resample",
+ "antialias",
+ "rescale_factor",
+ "image_mean",
+ "image_std",
+ "image_type",
+ ]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 1536, "width": 1536}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.do_rescale = do_rescale
+ self.do_normalize = do_normalize
+ self.size = size
+ self.resample = resample
+ self.antialias = antialias
+ self.rescale_factor = rescale_factor
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ def _build_transforms(
+ self,
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ image_type: ImageType,
+ ) -> "Compose":
+ """
+ Given the input settings build the image transforms using `torchvision.transforms.Compose`.
+ """
+ transforms = []
+
+ # All PIL and numpy values need to be converted to a torch tensor
+ # to keep cross compatibility with slow image processors
+ if image_type == ImageType.PIL:
+ transforms.append(PILToTensor())
+
+ elif image_type == ImageType.NUMPY:
+ transforms.append(NumpyToTensor())
+
+ # We can combine rescale and normalize into a single operation for speed
+ if do_rescale and do_normalize:
+ transforms.append(FusedRescaleNormalize(image_mean, image_std, rescale_factor=rescale_factor))
+ elif do_rescale:
+ transforms.append(Rescale(rescale_factor=rescale_factor))
+ elif do_normalize:
+ transforms.append(Normalize(image_mean, image_std))
+
+ # depth-pro scales the image before resizing it
+ if do_resize:
+ transforms.append(
+ Resize(
+ (size["height"], size["width"]),
+ interpolation=pil_torch_interpolation_mapping[resample],
+ antialias=antialias,
+ )
+ )
+
+ return Compose(transforms)
+
+ @functools.lru_cache(maxsize=1)
+ def _validate_input_arguments(
+ self,
+ return_tensors: Union[str, TensorType],
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ data_format: Union[str, ChannelDimension],
+ image_type: ImageType,
+ ):
+ if return_tensors != "pt":
+ raise ValueError("Only returning PyTorch tensors is currently supported.")
+
+ if data_format != ChannelDimension.FIRST:
+ raise ValueError("Only channel first data format is currently supported.")
+
+ if do_resize and None in (size, resample, antialias):
+ raise ValueError("Size, resample and antialias must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize and None in (image_mean, image_std):
+ raise ValueError("Image mean and standard deviation must be specified if do_normalize is True.")
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: Optional[PILImageResampling] = None,
+ antialias: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = "pt",
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Dictionary in the format `{"height": h, "width": w}` specifying the size of the output image after
+ resizing.
+ resample (`PILImageResampling` filter, *optional*, defaults to `self.resample`):
+ `PILImageResampling` filter to use if resizing the image e.g. `PILImageResampling.BILINEAR`. Only has
+ an effect if `do_resize` is set to `True`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use if `do_normalize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Only "pt" is supported
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. The following formats are currently supported:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+ antialias = antialias if antialias is not None else self.antialias
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ size = size if size is not None else self.size
+ # Make hashable for cache
+ size = SizeDict(**size)
+ image_mean = tuple(image_mean) if isinstance(image_mean, list) else image_mean
+ image_std = tuple(image_std) if isinstance(image_std, list) else image_std
+
+ images = make_list_of_images(images)
+ image_type = get_image_type(images[0])
+
+ if image_type not in [ImageType.PIL, ImageType.TORCH, ImageType.NUMPY]:
+ raise ValueError(f"Unsupported input image type {image_type}")
+
+ self._validate_input_arguments(
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ image_type=image_type,
+ )
+
+ transforms = self.get_transforms(
+ do_resize=do_resize,
+ do_rescale=do_rescale,
+ do_normalize=do_normalize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ rescale_factor=rescale_factor,
+ image_mean=image_mean,
+ image_std=image_std,
+ image_type=image_type,
+ )
+ transformed_images = [transforms(image) for image in images]
+
+ data = {"pixel_values": torch.stack(transformed_images, dim=0)}
+ return BatchFeature(data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.depth_pro.image_processing_depth_pro.DepthProImageProcessor.post_process_depth_estimation
+ def post_process_depth_estimation(
+ self,
+ outputs: "DepthProDepthEstimatorOutput",
+ target_sizes: Optional[Union[TensorType, List[Tuple[int, int]], None]] = None,
+ ) -> Dict[str, List[TensorType]]:
+ """
+ Post-processes the raw depth predictions from the model to generate final depth predictions and optionally
+ resizes them to specified target sizes. This function supports scaling based on the field of view (FoV)
+ and adjusts depth values accordingly.
+
+ Args:
+ outputs ([`DepthProDepthEstimatorOutput`]):
+ Raw outputs of the model.
+ target_sizes (`Optional[Union[TensorType, List[Tuple[int, int]], None]]`, *optional*, defaults to `None`):
+ Target sizes to resize the depth predictions. Can be a tensor of shape `(batch_size, 2)`
+ or a list of tuples `(height, width)` for each image in the batch. If `None`, no resizing
+ is performed.
+
+ Returns:
+ `List[Dict[str, TensorType]]`: A list of dictionaries of tensors representing the processed depth
+ predictions.
+
+ Raises:
+ `ValueError`:
+ If the lengths of `predicted_depths`, `fovs`, or `target_sizes` are mismatched.
+ """
+ requires_backends(self, "torch")
+
+ predicted_depth = outputs.predicted_depth
+ fov = outputs.fov
+
+ batch_size = len(predicted_depth)
+
+ if target_sizes is not None and batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many fov values as the batch dimension of the predicted depth"
+ )
+
+ results = []
+ fov = [None] * batch_size if fov is None else fov
+ target_sizes = [None] * batch_size if target_sizes is None else target_sizes
+ for depth, fov_value, target_size in zip(predicted_depth, fov, target_sizes):
+ if target_size is not None:
+ # scale image w.r.t fov
+ if fov_value is not None:
+ width = target_size[1]
+ fov_value = 0.5 * width / torch.tan(0.5 * torch.deg2rad(fov_value))
+ depth = depth * width / fov_value
+
+ # interpolate
+ depth = torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=depth.unsqueeze(0).unsqueeze(1),
+ size=target_size,
+ mode=pil_torch_interpolation_mapping[self.resample].value,
+ antialias=self.antialias,
+ ).squeeze()
+
+ # inverse the depth
+ depth = 1.0 / torch.clamp(depth, min=1e-4, max=1e4)
+
+ results.append(
+ {
+ "predicted_depth": depth,
+ "fov": fov_value,
+ }
+ )
+
+ return results
+
+
+__all__ = ["DepthProImageProcessorFast"]
diff --git a/src/transformers/models/depth_pro/modeling_depth_pro.py b/src/transformers/models/depth_pro/modeling_depth_pro.py
new file mode 100644
index 00000000000000..633d765b49f3f0
--- /dev/null
+++ b/src/transformers/models/depth_pro/modeling_depth_pro.py
@@ -0,0 +1,1686 @@
+# coding=utf-8
+# Copyright 2024 The Apple Research Team Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch DepthPro model."""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Set, Tuple, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+ torch_int,
+)
+from .configuration_depth_pro import DepthProConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "DepthProConfig"
+
+
+DEPTH_PRO_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`DepthProConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+DEPTH_PRO_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`DPTImageProcessor.__call__`]
+ for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+DEPTH_PRO_FOR_DEPTH_ESTIMATION_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`DepthProConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+ use_fov_model (`bool`, *optional*, defaults to `True`):
+ Whether to use `DepthProFOVModel` to generate the field of view.
+"""
+
+
+@dataclass
+class DepthProOutput(ModelOutput):
+ """
+ Base class for DepthPro's outputs.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ features (`List[torch.FloatTensor]`, *optional*:
+ Features from scaled images and hidden_states.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer and the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, n_patches_per_batch, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ features: Optional[List[torch.FloatTensor]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class DepthProDepthEstimatorOutput(ModelOutput):
+ """
+ Base class for DepthProForDepthEstimation's output.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ predicted_depth (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Predicted depth for each pixel.
+ fov (`torch.FloatTensor` of shape `(batch_size,)`, *optional*, returned when `use_fov_model` is provided):
+ Field of View Scaler.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer and the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, n_patches_per_batch, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ predicted_depth: torch.FloatTensor = None
+ fov: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+def patch_to_batch(data: torch.Tensor, batch_size: int) -> torch.Tensor:
+ """
+ Converts tensor from shape:
+ (num_patches, seq_len, hidden_size) -> (batch_size, n_patches_per_batch, seq_len, hidden_size)
+ """
+ data = data.reshape(-1, batch_size, *data.shape[1:])
+ data = data.transpose(0, 1)
+ return data
+
+
+def batch_to_patch(data: torch.Tensor) -> torch.Tensor:
+ """
+ Converts tensor from shape:
+ (batch_size, n_patches_per_batch, seq_len, hidden_size) -> (num_patches, seq_len, hidden_size)
+ """
+ data = data.transpose(0, 1)
+ data = data.reshape(-1, *data.shape[2:])
+ return data
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2PatchEmbeddings with Dinov2->DepthProViT
+class DepthProViTPatchEmbeddings(nn.Module):
+ """
+ This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
+ `hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
+ Transformer.
+ """
+
+ # Ignore copy
+ # addition of config parameter patch_embeddings_size
+ def __init__(self, config):
+ super().__init__()
+
+ self.config = config
+ self.in_channels = config.num_channels
+ self.out_channels = config.hidden_size
+ self.patch_embeddings_size = config.patch_embeddings_size
+ self.num_channels = config.num_channels
+
+ self.projection = nn.Conv2d(
+ self.in_channels,
+ self.out_channels,
+ kernel_size=(self.patch_embeddings_size, self.patch_embeddings_size),
+ stride=(self.patch_embeddings_size, self.patch_embeddings_size),
+ )
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ num_channels = pixel_values.shape[1]
+ if num_channels != self.num_channels:
+ raise ValueError(
+ "Make sure that the channel dimension of the pixel values match with the one set in the configuration."
+ f" Expected {self.num_channels} but got {num_channels}."
+ )
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class DepthProViTEmbeddings(nn.Module):
+ """
+ Copied from transformers.models.dinov2.modeling_dinov2.Dinov2Embeddings
+ except antialias=True in interpolation and removal of mask_token
+ and enabling dynamic embeddings.
+ """
+
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+
+ self.config = config
+ self.seq_len = (config.patch_size // config.patch_embeddings_size) ** 2
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.patch_embeddings = DepthProViTPatchEmbeddings(config)
+ self.position_embeddings = nn.Parameter(torch.zeros(1, self.seq_len + 1, config.hidden_size))
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
+ """
+ This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
+ images. This method is also adapted to support torch.jit tracing and interpolation at torch.float32 precision.
+
+ Adapted from:
+ - https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
+ - https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
+ """
+
+ num_positions = embeddings.shape[1] - 1
+
+ # always interpolate when tracing to ensure the exported model works for dynamic input shapes
+ if not torch.jit.is_tracing() and self.seq_len == num_positions and height == width:
+ return self.position_embeddings
+
+ class_pos_embed = self.position_embeddings[:, :1]
+ patch_pos_embed = self.position_embeddings[:, 1:]
+
+ dim = embeddings.shape[-1]
+
+ new_height = height // self.config.patch_embeddings_size
+ new_width = width // self.config.patch_embeddings_size
+
+ patch_pos_embed_size = torch_int(patch_pos_embed.shape[1] ** 0.5)
+ patch_pos_embed = patch_pos_embed.reshape(1, patch_pos_embed_size, patch_pos_embed_size, dim)
+ patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+ target_dtype = patch_pos_embed.dtype
+
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed.to(torch.float32),
+ size=(new_height, new_width),
+ mode="bicubic",
+ align_corners=False,
+ antialias=True, # except for this, the class is same as transformers.models.dinov2.modeling_dinov2.DepthProViTPatchEmbeddings
+ ).to(dtype=target_dtype)
+
+ patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
+
+ return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ batch_size: Optional[int] = None,
+ ) -> torch.Tensor:
+ n, _, height, width = pixel_values.shape
+ target_dtype = self.patch_embeddings.projection.weight.dtype
+ embeddings = self.patch_embeddings(pixel_values.to(dtype=target_dtype))
+
+ # add the [CLS] token to the embedded patch tokens
+ cls_tokens = self.cls_token.expand(n, -1, -1)
+ embeddings = torch.cat((cls_tokens, embeddings), dim=1)
+
+ # add positional encoding to each token
+ embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
+
+ embeddings = self.dropout(embeddings)
+
+ if batch_size is not None:
+ embeddings = patch_to_batch(embeddings, batch_size)
+
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSelfAttention(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ # Ignore copy
+ # addition of parameter batch_size
+ def forward(
+ self,
+ hidden_states,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ if batch_size is not None:
+ attention_probs_batched = patch_to_batch(attention_probs, batch_size)
+ attention_probs_patched = batch_to_patch(attention_probs_batched)
+ else:
+ attention_probs_patched = attention_probs_batched = attention_probs
+
+ context_layer = torch.matmul(attention_probs_patched, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs_batched) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2SdpaSelfAttention with Dinov2Config->DepthProConfig, Dinov2->DepthProViT
+class DepthProViTSdpaSelfAttention(DepthProViTSelfAttention):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__(config)
+ self.attention_probs_dropout_prob = config.attention_probs_dropout_prob
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "DepthProViTModel is using DepthProViTSdpaSelfAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ batch_size=batch_size,
+ )
+
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ context_layer = torch.nn.functional.scaled_dot_product_attention(
+ query_layer,
+ key_layer,
+ value_layer,
+ head_mask,
+ self.attention_probs_dropout_prob if self.training else 0.0,
+ is_causal=False,
+ scale=None,
+ )
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ return context_layer, None
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSelfOutput(nn.Module):
+ """
+ The residual connection is defined in DepthProViTLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTAttention(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.attention = DepthProViTSelfAttention(config)
+ self.output = DepthProViTSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions, batch_size)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSdpaAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSdpaAttention(DepthProViTAttention):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__(config)
+ self.attention = DepthProViTSdpaSelfAttention(config)
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2LayerScale with Dinov2Config->DepthProConfig, Dinov2->DepthProViT
+class DepthProViTLayerScale(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.lambda1 = nn.Parameter(config.layerscale_value * torch.ones(config.hidden_size))
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ return hidden_state * self.lambda1
+
+
+# Copied from transformers.models.beit.modeling_beit.drop_path
+def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.beit.modeling_beit.BeitDropPath
+class DepthProViTDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2MLP with Dinov2->DepthPro
+class DepthProViTMLP(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ in_features = out_features = config.hidden_size
+ hidden_features = int(config.hidden_size * config.mlp_ratio)
+ self.fc1 = nn.Linear(in_features, hidden_features, bias=True)
+ if isinstance(config.hidden_act, str):
+ self.activation = ACT2FN[config.hidden_act]
+ else:
+ self.activation = config.hidden_act
+ self.fc2 = nn.Linear(hidden_features, out_features, bias=True)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.fc1(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ hidden_state = self.fc2(hidden_state)
+ return hidden_state
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2SwiGLUFFN with Dinov2->DepthPro
+class DepthProViTSwiGLUFFN(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ in_features = out_features = config.hidden_size
+ hidden_features = int(config.hidden_size * config.mlp_ratio)
+ hidden_features = (int(hidden_features * 2 / 3) + 7) // 8 * 8
+
+ self.weights_in = nn.Linear(in_features, 2 * hidden_features, bias=True)
+ self.weights_out = nn.Linear(hidden_features, out_features, bias=True)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.weights_in(hidden_state)
+ x1, x2 = hidden_state.chunk(2, dim=-1)
+ hidden = nn.functional.silu(x1) * x2
+ return self.weights_out(hidden)
+
+
+DEPTHPROVIT_ATTENTION_CLASSES = {
+ "eager": DepthProViTAttention,
+ "sdpa": DepthProViTSdpaAttention,
+}
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2Layer with Dinov2Config->DepthProConfig, Dinov2->DepthProViT all-casing
+class DepthProViTLayer(nn.Module):
+ """This corresponds to the Block class in the original implementation."""
+
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.attention = DEPTHPROVIT_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.layer_scale1 = DepthProViTLayerScale(config)
+ self.drop_path = DepthProViTDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
+
+ self.norm2 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ if config.use_swiglu_ffn:
+ self.mlp = DepthProViTSwiGLUFFN(config)
+ else:
+ self.mlp = DepthProViTMLP(config)
+ self.layer_scale2 = DepthProViTLayerScale(config)
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ if batch_size is not None:
+ hidden_states = batch_to_patch(hidden_states)
+
+ self_attention_outputs = self.attention(
+ self.norm1(hidden_states), # in DepthProViT, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ batch_size=batch_size,
+ )
+ attention_output = self_attention_outputs[0]
+
+ attention_output = self.layer_scale1(attention_output)
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = self.drop_path(attention_output) + hidden_states
+
+ # in DepthProViT, layernorm is also applied after self-attention
+ layer_output = self.norm2(hidden_states)
+ layer_output = self.mlp(layer_output)
+ layer_output = self.layer_scale2(layer_output)
+
+ # second residual connection
+ layer_output = self.drop_path(layer_output) + hidden_states
+
+ if batch_size is not None:
+ layer_output = patch_to_batch(layer_output, batch_size)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTEncoder(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([DepthProViTLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ batch_size: Optional[int] = None,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ batch_size,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions, batch_size)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class DepthProViT(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ self.embeddings = DepthProViTEmbeddings(config)
+ self.encoder = DepthProViTEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embedding_output = self.embeddings(pixel_values, batch_size=batch_size)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ batch_size=batch_size,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ if not return_dict:
+ head_outputs = (sequence_output,)
+ return head_outputs + encoder_outputs[1:]
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class DepthProFeatureUpsample(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ self.upsample_blocks = nn.ModuleList()
+
+ # for image_features
+ self.upsample_blocks.append(
+ self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=config.hidden_size,
+ output_dims=config.scaled_images_feature_dims[0],
+ n_upsample_layers=1,
+ use_proj=False,
+ bias=True,
+ )
+ )
+
+ # for scaled_images_features
+ for i, feature_dims in enumerate(config.scaled_images_feature_dims):
+ upsample_block = self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=feature_dims,
+ output_dims=feature_dims,
+ n_upsample_layers=1,
+ )
+ self.upsample_blocks.append(upsample_block)
+
+ # for intermediate_features
+ for i, feature_dims in enumerate(config.intermediate_feature_dims):
+ intermediate_dims = config.fusion_hidden_size if i == 0 else feature_dims
+ upsample_block = self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=intermediate_dims,
+ output_dims=feature_dims,
+ n_upsample_layers=2 + i,
+ )
+ self.upsample_blocks.append(upsample_block)
+
+ def _create_upsample_block(
+ self,
+ input_dims: int,
+ intermediate_dims: int,
+ output_dims: int,
+ n_upsample_layers: int,
+ use_proj: bool = True,
+ bias: bool = False,
+ ) -> nn.Module:
+ upsample_block = nn.Sequential()
+
+ # create first projection layer
+ if use_proj:
+ proj = nn.Conv2d(
+ in_channels=input_dims,
+ out_channels=intermediate_dims,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=bias,
+ )
+ upsample_block.append(proj)
+
+ # create following upsample layers
+ for i in range(n_upsample_layers):
+ in_channels = intermediate_dims if i == 0 else output_dims
+ layer = nn.ConvTranspose2d(
+ in_channels=in_channels,
+ out_channels=output_dims,
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=bias,
+ )
+ upsample_block.append(layer)
+
+ return upsample_block
+
+ def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
+ upsampled_features = []
+ for i, upsample_block in enumerate(self.upsample_blocks):
+ upsampled_feature = upsample_block(features[i])
+ upsampled_features.append(upsampled_feature)
+ return upsampled_features
+
+
+class DepthProFeatureProjection(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ combined_feature_dims = config.scaled_images_feature_dims + config.intermediate_feature_dims
+ self.projections = nn.ModuleList()
+ for i, in_channels in enumerate(combined_feature_dims):
+ if i == len(combined_feature_dims) - 1 and in_channels == config.fusion_hidden_size:
+ # projection for last layer can be ignored if input and output channels already match
+ self.projections.append(nn.Identity())
+ else:
+ self.projections.append(
+ nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ )
+ )
+
+ def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
+ projected_features = []
+ for i, projection in enumerate(self.projections):
+ upsampled_feature = projection(features[i])
+ projected_features.append(upsampled_feature)
+ return projected_features
+
+
+def interpolate(
+ pixel_values: torch.Tensor, size: Optional[int] = None, scale_factor: Optional[List[float]] = None
+) -> torch.Tensor:
+ return nn.functional.interpolate(
+ pixel_values,
+ size=size,
+ scale_factor=scale_factor,
+ mode="bilinear",
+ align_corners=False,
+ )
+
+
+def patch(pixel_values: torch.Tensor, patch_size: int, overlap_ratio: float) -> torch.Tensor:
+ """Creates Patches from Batch."""
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ if height == width == patch_size:
+ # create patches only if scaled image is not already equal to patch size
+ return pixel_values
+
+ stride = int(patch_size * (1 - overlap_ratio))
+
+ # (batch_size, num_channels, height, width)
+ patches = torch.nn.functional.unfold(pixel_values, kernel_size=(patch_size, patch_size), stride=(stride, stride))
+ # patches.shape (batch_size, patch_size**2 * num_channels, n_patches_per_batch)
+ patches = patches.permute(2, 0, 1)
+ # patches.shape (n_patches_per_batch, batch_size, patch_size**2 * C)
+ patches = patches.reshape(-1, num_channels, patch_size, patch_size)
+ # patches.shape (n_patches, num_channels, patch_size, patch_size)
+
+ return patches
+
+
+def reshape_feature(hidden_states: torch.Tensor) -> torch.Tensor:
+ """Discard class token and reshape 1D feature map to a 2D grid."""
+ n_samples, seq_len, hidden_size = hidden_states.shape
+ size = int(math.sqrt(seq_len))
+
+ # (n_samples, seq_len, hidden_size)
+ hidden_states = hidden_states[:, 1:, :] # remove class token
+ # (n_samples, seq_len, hidden_size)
+ hidden_states = hidden_states.reshape(n_samples, size, size, hidden_size)
+ # (n_samples, size, size, hideden_size)
+ hidden_states = hidden_states.permute(0, 3, 1, 2)
+ # (n_samples, hideden_size, size, size)
+ return hidden_states
+
+
+def merge(patches: torch.Tensor, batch_size: int, merge_out_size: int) -> torch.Tensor:
+ n_patches, hidden_size, out_size, out_size = patches.shape
+ n_patches_per_batch = n_patches // batch_size
+ sqrt_n_patches_per_batch = int(math.sqrt(n_patches_per_batch))
+ new_out_size = sqrt_n_patches_per_batch * out_size
+
+ if n_patches == batch_size:
+ # merge only if the patches were created from scaled image
+ # patches are not created when scaled image size is equal to patch size
+ return patches
+
+ # calculate padding using the formula
+ # merge_out_size = (box_size - 2) * (out_size - 2 * padding) + (2) * (out_size - padding)
+ padding = (sqrt_n_patches_per_batch * out_size - merge_out_size) // (2 * sqrt_n_patches_per_batch - 2)
+
+ # patches.shape (n_patches, hidden_size, out_size, out_size)
+
+ merged = patches.reshape(n_patches_per_batch, batch_size, hidden_size, out_size, out_size)
+ # (n_patches_per_batch, batch_size, hidden_size, out_size, out_size)
+ merged = merged.permute(1, 2, 0, 3, 4)
+ # (batch_size, hidden_size, n_patches_per_batch, out_size, out_size)
+
+ merged = merged[:, :, : sqrt_n_patches_per_batch**2, :, :]
+ # (batch_size, hidden_size, n_patches_per_batch, out_size, out_size)
+
+ merged = merged.reshape(
+ batch_size, hidden_size, sqrt_n_patches_per_batch, sqrt_n_patches_per_batch, out_size, out_size
+ )
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch, sqrt_n_patches_per_batch, out_size, out_size)
+ merged = merged.permute(0, 1, 2, 4, 3, 5)
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch, out_size, sqrt_n_patches_per_batch, out_size)
+ merged = merged.reshape(batch_size, hidden_size, new_out_size, new_out_size)
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch * out_size, sqrt_n_patches_per_batch * out_size)
+
+ if padding != 0:
+ padding_mask = torch.ones((new_out_size, new_out_size), dtype=torch.bool)
+ starting_index = torch.arange(start=out_size - padding, end=new_out_size - padding, step=out_size)
+ for index in starting_index:
+ padding_mask[index : index + padding * 2, :] = False
+ padding_mask[:, index : index + padding * 2] = False
+
+ merged = merged[:, :, padding_mask]
+ final_out_size = int(math.sqrt(merged.shape[-1]))
+ merged = merged.reshape(*merged.shape[:2], final_out_size, final_out_size)
+
+ return merged
+
+
+class DepthProEncoder(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.fusion_hidden_size = config.fusion_hidden_size
+
+ self.intermediate_hook_ids = config.intermediate_hook_ids
+ self.intermediate_feature_dims = config.intermediate_feature_dims
+ self.scaled_images_ratios = config.scaled_images_ratios
+ self.scaled_images_overlap_ratios = config.scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = config.scaled_images_feature_dims
+
+ self.n_scaled_images = len(self.scaled_images_ratios)
+ self.n_intermediate_hooks = len(self.intermediate_hook_ids)
+ self.out_size = config.patch_size // config.patch_embeddings_size
+ self.seq_len = self.out_size**2 # each patch is flattened
+
+ # patch encoder
+ self.patch_encoder = DepthProViT(config)
+
+ # image encoder
+ self.image_encoder = DepthProViT(config)
+
+ # upsample features
+ self.feature_upsample = DepthProFeatureUpsample(config)
+
+ # for STEP 7: fuse low_res and image features
+ self.fuse_image_with_low_res = nn.Conv2d(
+ in_channels=config.scaled_images_feature_dims[0] * 2,
+ out_channels=config.scaled_images_feature_dims[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=True,
+ )
+
+ # project features
+ self.feature_projection = DepthProFeatureProjection(config)
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, DepthProOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values.dim() != 4:
+ raise ValueError("Input tensor must have shape (batch_size, num_channels, height, width).")
+
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ if not (num_channels == self.config.num_channels):
+ raise ValueError(
+ f"Found {num_channels} channels in image, expected number of channels is {self.config.num_channels} from config."
+ )
+
+ if min(self.scaled_images_ratios) * min(height, width) < self.config.patch_size:
+ raise ValueError(
+ f"Image size {height}x{width} is too small to be scaled "
+ f"with scaled_images_ratios={self.scaled_images_ratios} "
+ f"when patch_size={self.config.patch_size}."
+ )
+
+ # pixel_values.shape (batch_size, num_channels, height, width)
+
+ # STEP 1: create 3-level image
+
+ scaled_images = []
+ for ratio in self.scaled_images_ratios:
+ scaled_images.append(interpolate(pixel_values, scale_factor=ratio))
+ # (batch_size, num_channels, height*ratio, width*ratio)
+
+ # STEP 2: create patches
+
+ for i in range(self.n_scaled_images):
+ scaled_images[i] = patch(
+ scaled_images[i],
+ patch_size=self.config.patch_size,
+ overlap_ratio=self.scaled_images_overlap_ratios[i],
+ )
+ # (n_patches_per_scaled_image[i], num_channels, patch_size, patch_size)
+ n_patches_per_scaled_image = [len(i) for i in scaled_images]
+ patches = torch.cat(scaled_images[::-1], dim=0) # -1 as patch encoder expects high res patches first
+ # (n_patches, num_channels, patch_size, patch_size)
+
+ # STEP 3: apply patch and image encoder
+
+ patch_encodings = self.patch_encoder(
+ patches,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ # required for intermediate features
+ output_hidden_states=self.n_intermediate_hooks or output_hidden_states,
+ return_dict=True,
+ batch_size=batch_size,
+ )
+ # patch_encodings.last_hidden_state (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ # patch_encodings.hidden_states[i] (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ # patch_encodings.attentions[i] (batch_size, n_patches/batch_size, num_heads, seq_len, seq_len)
+
+ last_hidden_state = patch_encodings.last_hidden_state
+ # (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ last_hidden_state = batch_to_patch(last_hidden_state)
+ # (n_patches, seq_len, hidden_size)
+ scaled_images_last_hidden_state = torch.split_with_sizes(last_hidden_state, n_patches_per_scaled_image[::-1])
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+ scaled_images_last_hidden_state = scaled_images_last_hidden_state[::-1]
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+ # -1 (reverse list) as patch encoder expects high res patches first
+
+ # scale the image to patch size for image_encoder
+ image_scaled_to_patch_size = interpolate(
+ pixel_values,
+ size=(self.config.patch_size, self.config.patch_size),
+ )
+ image_encodings = self.image_encoder(
+ pixel_values=image_scaled_to_patch_size,
+ head_mask=head_mask,
+ )
+ # image_encodings.last_hidden_state (batch_size, seq_len, hidden_size)
+ # image_encodings.hidden_states[i] (batch_size, seq_len, hidden_size)
+ # image_encodings.attentions[i] (batch_size, num_heads, seq_len, seq_len)
+
+ # STEP 4: get patch features (high_res, med_res, low_res) - (3-5) in diagram
+
+ exponent_value = int(math.log2(width / self.out_size))
+ base_height = height // 2**exponent_value
+ base_width = width // 2**exponent_value
+
+ scaled_images_features = []
+ for i in range(self.n_scaled_images):
+ # a. extract hidden_state
+ hidden_state = scaled_images_last_hidden_state[i]
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+
+ # b. reshape back to image like
+ features = reshape_feature(hidden_state)
+ # (n_patches_per_scaled_image[i], hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ features = merge(
+ features, batch_size=batch_size, merge_out_size=self.out_size * 2**i
+ ) # (batch_size, hidden_size, out_size*2**i, out_size*2**i)
+
+ # d. interpolate patches to base size
+ features = interpolate(features, size=(base_height * 2**i, base_width * 2**i))
+ # (batch_size, hidden_size, base_height*2**i, base_width*2**i)
+
+ scaled_images_features.append(features)
+
+ # STEP 5: get intermediate features - (1-2) in diagram
+
+ intermediate_features = []
+ for i in range(self.n_intermediate_hooks):
+ # a. extract hidden_state
+ layer_id = (
+ self.intermediate_hook_ids[i] + 1
+ ) # +1 to correct index position as hidden_states contain embedding output as well
+ hidden_state = patch_encodings.hidden_states[layer_id]
+ hidden_state = batch_to_patch(hidden_state)
+ hidden_state = hidden_state[
+ : n_patches_per_scaled_image[-1]
+ ] # number of patches to be of same length as highest resolution
+ # (n_patches_per_scaled_image[-1], seq_len, hidden_size)
+
+ # b. reshape back to image like
+ features = reshape_feature(hidden_state)
+ # (n_patches_per_scaled_image[-1], hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ features = merge(
+ features,
+ batch_size=batch_size,
+ merge_out_size=self.out_size * 2 ** (self.n_scaled_images - 1),
+ ) # (batch_size, hidden_size, out_size*2**(n_scaled_images-1), out_size*2**(n_scaled_images-1))
+
+ # d. interpolate patches to base size
+ features = interpolate(
+ features,
+ size=(base_height * 2 ** (self.n_scaled_images - 1), base_width * 2 ** (self.n_scaled_images - 1)),
+ )
+ # (batch_size, hidden_size, base_height*2**(n_scaled_images - 1), base_width*2**(n_scaled_images - 1))
+
+ intermediate_features.append(features)
+
+ # STEP 6: get image features - (6) in diagram
+
+ # a. extract hidden_state
+ hidden_state = image_encodings.last_hidden_state # (batch_size, seq_len, hidden_size)
+
+ # b. reshape back to image like
+ image_features = reshape_feature(hidden_state)
+ # (batch_size, hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ # no merge required for image_features as they are already in batches instead of patches
+
+ # d. interpolate patches to base size
+ image_features = interpolate(image_features, size=(base_height, base_width))
+ # (batch_size, hidden_size, base_height, base_width)
+
+ # STEP 7: combine all features
+ features = [
+ image_features,
+ # (batch_size, scaled_images_feature_dims[0], base_height*2, base_width*2)
+ *scaled_images_features,
+ # (batch_size, scaled_images_feature_dims[i], base_height*2**(i+1), base_width*2**(i+1))
+ *intermediate_features,
+ # (batch_size, intermediate_feature_dims[i], base_height*2**(n_scaled_images+i+1), base_width*2**(n_scaled_images+i+1))
+ ]
+
+ # STEP 8: upsample features
+ features = self.feature_upsample(features)
+
+ # STEP 9: apply fusion
+ # (global features = low res features + image features)
+ # fuses image_features with lowest resolution features as they are of same size
+ global_features = torch.cat((features[1], features[0]), dim=1)
+ global_features = self.fuse_image_with_low_res(global_features)
+ features = [global_features, *features[2:]]
+
+ # STEP 10: project features
+ features = self.feature_projection(features)
+
+ # STEP 11: return output
+
+ last_hidden_state = patch_encodings.last_hidden_state
+ hidden_states = patch_encodings.hidden_states if output_hidden_states else None
+ attentions = patch_encodings.attentions if output_attentions else None
+
+ if not return_dict:
+ return tuple(v for v in [last_hidden_state, features, hidden_states, attentions] if v is not None)
+
+ return DepthProOutput(
+ last_hidden_state=last_hidden_state,
+ features=features,
+ hidden_states=hidden_states,
+ attentions=attentions,
+ )
+
+
+class DepthProPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = DepthProConfig
+ base_model_prefix = "depth_pro"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["DepthProViTSwiGLUFFN"]
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d, nn.ConvTranspose2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+@add_start_docstrings(
+ "The bare DepthPro Model transformer outputting raw hidden-states without any specific head on top.",
+ DEPTH_PRO_START_DOCSTRING,
+)
+class DepthProModel(DepthProPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.encoder = DepthProEncoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.encoder.patch_encoder.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.patch_encoder.encoder.layer[layer].attention.prune_heads(heads)
+ self.encoder.image_encoder.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(DEPTH_PRO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, DepthProOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> import torch
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, DepthProModel
+
+ >>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> checkpoint = "geetu040/DepthPro"
+ >>> processor = AutoProcessor.from_pretrained(checkpoint)
+ >>> model = DepthProModel.from_pretrained(checkpoint)
+
+ >>> # prepare image for the model
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... output = model(**inputs)
+
+ >>> output.last_hidden_state.shape
+ torch.Size([1, 35, 577, 1024])
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ encodings = self.encoder(
+ pixel_values,
+ head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ return encodings
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreActResidualLayer DPT->DepthPro
+class DepthProPreActResidualLayer(nn.Module):
+ """
+ ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ config (`[DepthProConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.use_batch_norm = config.use_batch_norm_in_fusion_residual
+ use_bias_in_fusion_residual = (
+ config.use_bias_in_fusion_residual
+ if config.use_bias_in_fusion_residual is not None
+ else not self.use_batch_norm
+ )
+
+ self.activation1 = nn.ReLU()
+ self.convolution1 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ self.activation2 = nn.ReLU()
+ self.convolution2 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ if self.use_batch_norm:
+ self.batch_norm1 = nn.BatchNorm2d(config.fusion_hidden_size)
+ self.batch_norm2 = nn.BatchNorm2d(config.fusion_hidden_size)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ residual = hidden_state
+ hidden_state = self.activation1(hidden_state)
+
+ hidden_state = self.convolution1(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm1(hidden_state)
+
+ hidden_state = self.activation2(hidden_state)
+ hidden_state = self.convolution2(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm2(hidden_state)
+
+ return hidden_state + residual
+
+
+# Taken from transformers.models.dpt.modeling_dpt.DPTFeatureFusionLayer
+# except it uses deconv and skip_add and needs no interpolation
+class DepthProFeatureFusionLayer(nn.Module):
+ def __init__(self, config: DepthProConfig, use_deconv: bool = True):
+ super().__init__()
+ self.config = config
+ self.use_deconv = use_deconv
+
+ self.residual_layer1 = DepthProPreActResidualLayer(config)
+ self.residual_layer2 = DepthProPreActResidualLayer(config)
+
+ if self.use_deconv:
+ self.deconv = nn.ConvTranspose2d(
+ in_channels=config.fusion_hidden_size,
+ out_channels=config.fusion_hidden_size,
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=False,
+ )
+
+ self.projection = nn.Conv2d(config.fusion_hidden_size, config.fusion_hidden_size, kernel_size=1, bias=True)
+ self.skip_add = nn.quantized.FloatFunctional()
+
+ def forward(self, hidden_state: torch.Tensor, residual: Optional[torch.Tensor] = None) -> torch.Tensor:
+ if residual is not None:
+ hidden_state = self.skip_add.add(hidden_state, self.residual_layer1(residual))
+
+ hidden_state = self.residual_layer2(hidden_state)
+ if self.use_deconv:
+ hidden_state = self.deconv(hidden_state)
+ hidden_state = self.projection(hidden_state)
+
+ return hidden_state
+
+
+# Take from transformers.models.dpt.modeling_dpt.DPTFeatureFusionStage with DPT->DepthPro
+# with deconv and reversed layers
+class DepthProFeatureFusionStage(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ self.num_layers = len(config.intermediate_hook_ids) + len(config.scaled_images_ratios)
+ self.layers = nn.ModuleList()
+ for _ in range(self.num_layers - 1):
+ self.layers.append(DepthProFeatureFusionLayer(config))
+ # final layer doesnot require deconvolution
+ self.layers.append(DepthProFeatureFusionLayer(config, use_deconv=False))
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> List[torch.Tensor]:
+ if self.num_layers != len(hidden_states):
+ raise ValueError(
+ f"num_layers={self.num_layers} in DepthProFeatureFusionStage"
+ f"doesnot match len(hidden_states)={len(hidden_states)}"
+ )
+
+ fused_hidden_states = []
+ fused_hidden_state = None
+ for hidden_state, layer in zip(hidden_states, self.layers):
+ if fused_hidden_state is None:
+ # first layer only uses the last hidden_state
+ fused_hidden_state = layer(hidden_state)
+ else:
+ fused_hidden_state = layer(fused_hidden_state, hidden_state)
+ fused_hidden_states.append(fused_hidden_state)
+
+ return fused_hidden_states
+
+
+class DepthProFOVModel(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.fusion_hidden_size = config.fusion_hidden_size
+
+ self.out_size = config.patch_size // config.patch_embeddings_size
+
+ self.encoder = DepthProViT(config)
+ self.encoder_neck = nn.Linear(self.hidden_size, self.fusion_hidden_size // 2)
+ self.global_neck = nn.Sequential(
+ nn.Conv2d(self.fusion_hidden_size, self.fusion_hidden_size // 2, kernel_size=3, stride=2, padding=1),
+ nn.ReLU(True),
+ )
+
+ # create initial head layers
+ self.head = nn.Sequential()
+ for i in range(config.num_fov_head_layers):
+ self.head.append(
+ nn.Conv2d(
+ math.ceil(self.fusion_hidden_size / 2 ** (i + 1)),
+ math.ceil(self.fusion_hidden_size / 2 ** (i + 2)),
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ )
+ )
+ self.head.append(nn.ReLU(True))
+ # calculate expected shapes to finally generate a scalar output from final head layer
+ final_in_channels = math.ceil(self.fusion_hidden_size / 2 ** (config.num_fov_head_layers + 1))
+ final_kernal_size = int((self.out_size - 1) / 2**config.num_fov_head_layers + 1)
+ self.head.append(
+ nn.Conv2d(
+ in_channels=final_in_channels, out_channels=1, kernel_size=final_kernal_size, stride=1, padding=0
+ )
+ )
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ global_features: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ # follow the steps same as with image features in DepthProEncoder
+ # except for the extra encoder_neck layer applied
+
+ image_scaled_to_patch_size = interpolate(
+ pixel_values,
+ size=(self.config.patch_size, self.config.patch_size),
+ )
+ encodings = self.encoder(
+ image_scaled_to_patch_size,
+ head_mask=head_mask,
+ )
+
+ # a. extract hidden_state
+ hidden_state = encodings.last_hidden_state # (batch_size, seq_len, hidden_size)
+ # extra step
+ hidden_state = self.encoder_neck(hidden_state)
+ # (batch_size, seq_len, fusion_hidden_size//2)
+
+ # b. reshape back to image like
+ fov_features = reshape_feature(hidden_state)
+ # (batch_size, fusion_hidden_size//2, out_size, out_size)
+
+ # c. merge patches back together
+ # no merge required for fov_features as they are already in batches instead of patches
+
+ # d. interpolate patches to base size
+ # skip; instead interpolate the global features
+
+ global_features = self.global_neck(global_features)
+ global_features = interpolate(global_features, size=(self.out_size, self.out_size))
+
+ fov_features = fov_features + global_features
+ fov_output = self.head(fov_features)
+ fov_output = fov_output.reshape(batch_size)
+
+ return fov_output
+
+
+class DepthProDepthEstimationHead(nn.Module):
+ """
+ The DepthProDepthEstimationHead module serves as the output head for depth estimation tasks.
+ This module comprises a sequence of convolutional and transposed convolutional layers
+ that process the feature map from the fusion to produce a single-channel depth map.
+ Key operations include dimensionality reduction and upsampling to match the input resolution.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ features = config.fusion_hidden_size
+ self.head = nn.Sequential(
+ nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
+ nn.ConvTranspose2d(
+ in_channels=features // 2, out_channels=features // 2, kernel_size=2, stride=2, padding=0, bias=True
+ ),
+ nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
+ nn.ReLU(),
+ )
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> torch.Tensor:
+ predicted_depth = self.head(hidden_states)
+ predicted_depth = predicted_depth.squeeze(dim=1)
+ return predicted_depth
+
+
+@add_start_docstrings(
+ """
+ DepthPro Model with a depth estimation head on top (consisting of 3 convolutional layers).
+ """,
+ DEPTH_PRO_FOR_DEPTH_ESTIMATION_START_DOCSTRING,
+)
+class DepthProForDepthEstimation(DepthProPreTrainedModel):
+ def __init__(self, config, use_fov_model=None):
+ super().__init__(config)
+ self.config = config
+ self.use_fov_model = use_fov_model if use_fov_model is not None else self.config.use_fov_model
+
+ # dinov2 (vit) like encoders
+ self.depth_pro = DepthProModel(config)
+
+ # dpt (vit) like fusion stage
+ self.fusion_stage = DepthProFeatureFusionStage(config)
+
+ # depth estimation head
+ self.head = DepthProDepthEstimationHead(config)
+
+ # dinov2 (vit) like encoder
+ self.fov_model = DepthProFOVModel(config) if self.use_fov_model else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(DEPTH_PRO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=DepthProDepthEstimatorOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ head_mask: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor]]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Ground truth depth estimation maps for computing the loss.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoImageProcessor, DepthProForDepthEstimation
+ >>> import torch
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> checkpoint = "geetu040/DepthPro"
+ >>> processor = AutoImageProcessor.from_pretrained(checkpoint)
+ >>> model = DepthProForDepthEstimation.from_pretrained(checkpoint)
+
+ >>> # prepare image for the model
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+
+ >>> # interpolate to original size
+ >>> post_processed_output = processor.post_process_depth_estimation(
+ ... outputs, target_sizes=[(image.height, image.width)],
+ ... )
+
+ >>> # visualize the prediction
+ >>> predicted_depth = post_processed_output[0]["predicted_depth"]
+ >>> depth = predicted_depth * 255 / predicted_depth.max()
+ >>> depth = depth.detach().cpu().numpy()
+ >>> depth = Image.fromarray(depth.astype("uint8"))
+ ```"""
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not implemented yet")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+
+ depth_pro_outputs = self.depth_pro(
+ pixel_values=pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=True,
+ )
+ features = depth_pro_outputs.features
+ fused_hidden_states = self.fusion_stage(features)
+ predicted_depth = self.head(fused_hidden_states[-1])
+
+ fov = (
+ self.fov_model(
+ pixel_values=pixel_values,
+ # frozon features from encoder are used
+ global_features=features[0].detach(),
+ head_mask=head_mask,
+ )
+ if self.use_fov_model
+ else None
+ )
+
+ if not return_dict:
+ outputs = [loss, predicted_depth, fov, depth_pro_outputs.hidden_states, depth_pro_outputs.attentions]
+ return tuple(v for v in outputs if v is not None)
+
+ return DepthProDepthEstimatorOutput(
+ loss=loss,
+ predicted_depth=predicted_depth,
+ fov=fov,
+ hidden_states=depth_pro_outputs.hidden_states,
+ attentions=depth_pro_outputs.attentions,
+ )
+
+
+__all__ = ["DepthProPreTrainedModel", "DepthProModel", "DepthProForDepthEstimation"]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e3463461ea07e5..419bb07665e858 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -3551,6 +3551,27 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class DepthProForDepthEstimation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class DepthProModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class DepthProPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class DetrForObjectDetection(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 3ebda4404aae9c..2b3e46e63cc55b 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -184,6 +184,20 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class DepthProImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
+class DepthProImageProcessorFast(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/depth_pro/__init__.py b/tests/models/depth_pro/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/depth_pro/test_image_processing_depth_pro.py b/tests/models/depth_pro/test_image_processing_depth_pro.py
new file mode 100644
index 00000000000000..e9d94151e145ec
--- /dev/null
+++ b/tests/models/depth_pro/test_image_processing_depth_pro.py
@@ -0,0 +1,113 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.file_utils import is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import DepthProImageProcessor, DepthProImageProcessorFast
+
+
+class DepthProImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ super().__init__()
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DepthProImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DepthProImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DepthProImageProcessorFast if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DepthProImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "antialias"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
diff --git a/tests/models/depth_pro/test_modeling_depth_pro.py b/tests/models/depth_pro/test_modeling_depth_pro.py
new file mode 100644
index 00000000000000..ad17476c664dcf
--- /dev/null
+++ b/tests/models/depth_pro/test_modeling_depth_pro.py
@@ -0,0 +1,375 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DepthPro model."""
+
+import unittest
+
+from transformers import DepthProConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DepthProForDepthEstimation, DepthProModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DepthProImageProcessor
+
+
+class DepthProModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ image_size=64,
+ patch_size=8,
+ patch_embeddings_size=4,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ fusion_hidden_size=16,
+ intermediate_hook_ids=[0],
+ intermediate_feature_dims=[8],
+ scaled_images_ratios=[0.5, 1.0],
+ scaled_images_overlap_ratios=[0.0, 0.2],
+ scaled_images_feature_dims=[12, 12],
+ num_hidden_layers=1,
+ num_attention_heads=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ use_fov_model=False,
+ num_labels=3,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.patch_embeddings_size = patch_embeddings_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.fusion_hidden_size = fusion_hidden_size
+ self.intermediate_hook_ids = intermediate_hook_ids
+ self.intermediate_feature_dims = intermediate_feature_dims
+ self.scaled_images_ratios = scaled_images_ratios
+ self.scaled_images_overlap_ratios = scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = scaled_images_feature_dims
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.use_fov_model = use_fov_model
+ self.num_labels = num_labels
+
+ self.num_patches = (patch_size // patch_embeddings_size) ** 2
+ self.seq_length = (patch_size // patch_embeddings_size) ** 2 + 1 # we add 1 for the [CLS] token
+
+ n_fusion_blocks = len(intermediate_hook_ids) + len(scaled_images_ratios)
+ self.expected_depth_size = 2 ** (n_fusion_blocks + 1) * patch_size // patch_embeddings_size
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DepthProConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ patch_embeddings_size=self.patch_embeddings_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ fusion_hidden_size=self.fusion_hidden_size,
+ intermediate_hook_ids=self.intermediate_hook_ids,
+ intermediate_feature_dims=self.intermediate_feature_dims,
+ scaled_images_ratios=self.scaled_images_ratios,
+ scaled_images_overlap_ratios=self.scaled_images_overlap_ratios,
+ scaled_images_feature_dims=self.scaled_images_feature_dims,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ initializer_range=self.initializer_range,
+ use_fov_model=self.use_fov_model,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DepthProModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ num_patches = result.last_hidden_state.shape[1] # num_patches are created dynamically
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, num_patches, self.seq_length, self.hidden_size)
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DepthProForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.predicted_depth.shape, (self.batch_size, self.expected_depth_size, self.expected_depth_size)
+ )
+
+ def create_and_check_for_fov(self, config, pixel_values, labels):
+ model = DepthProForDepthEstimation(config, use_fov_model=True)
+ model.to(torch_device)
+ model.eval()
+
+ # check if the fov_model (DinoV2-based encoder) is created
+ self.parent.assertIsNotNone(model.fov_model)
+
+ batched_pixel_values = pixel_values
+ row_pixel_values = pixel_values[:1]
+
+ with torch.no_grad():
+ model_batched_output_fov = model(batched_pixel_values).fov
+ model_row_output_fov = model(row_pixel_values).fov
+
+ # check if fov is returned
+ self.parent.assertIsNotNone(model_batched_output_fov)
+ self.parent.assertIsNotNone(model_row_output_fov)
+
+ # check output shape consistency for fov
+ self.parent.assertEqual(model_batched_output_fov.shape, (self.batch_size,))
+
+ # check equivalence between batched and single row outputs for fov
+ diff = torch.max(torch.abs(model_row_output_fov - model_batched_output_fov[:1]))
+ model_name = model.__class__.__name__
+ self.parent.assertTrue(
+ diff <= 1e-03,
+ msg=(f"Batched and Single row outputs are not equal in {model_name} for fov. " f"Difference={diff}."),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DepthProModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DepthPro does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DepthProModel, DepthProForDepthEstimation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "depth-estimation": DepthProForDepthEstimation,
+ "image-feature-extraction": DepthProModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = DepthProModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DepthProConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="DepthPro does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_for_fov(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_fov(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ # Skip the check for the backbone
+ backbone_params = []
+ for name, module in model.named_modules():
+ if module.__class__.__name__ == "DepthProViTHybridEmbeddings":
+ backbone_params = [f"{name}.{key}" for key in module.state_dict().keys()]
+ break
+
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if name in backbone_params:
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_path = "geetu040/DepthPro"
+ model = DepthProModel.from_pretrained(model_path)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DepthProModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ model_path = "geetu040/DepthPro"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path).to(torch_device)
+ config = model.config
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ n_fusion_blocks = len(config.intermediate_hook_ids) + len(config.scaled_images_ratios)
+ expected_depth_size = 2 ** (n_fusion_blocks + 1) * config.patch_size // config.patch_embeddings_size
+ expected_shape = torch.Size((1, expected_depth_size, expected_depth_size))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.0582, 1.1225, 1.1335], [1.1154, 1.1398, 1.1486], [1.1434, 1.1500, 1.1643]]
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))
+
+ def test_post_processing_depth_estimation(self):
+ model_path = "geetu040/DepthPro"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ outputs = image_processor.post_process_depth_estimation(
+ outputs,
+ target_sizes=[[image.height, image.width]],
+ )
+ predicted_depth = outputs[0]["predicted_depth"]
+ expected_shape = torch.Size((image.height, image.width))
+ self.assertTrue(predicted_depth.shape == expected_shape)
+
+ DepthPro architecture. Taken from the original paper.
+
+This model was contributed by [geetu040](https://github.com/geetu040). The original code can be found [here](https://github.com/apple/ml-depth-pro).
+
+
+
+## Usage tips
+
+```python
+from transformers import DepthProConfig, DepthProForDepthEstimation
+
+config = DepthProConfig()
+model = DPTForDepthEstimation(config=config)
+```
+
+- By default model takes an input image of size `1536`, this can be changed via config, however the model is compatible with images of different width and height.
+- Input image is scaled with different ratios, as specified in `scaled_images_ratios`, then each of the scaled image is patched to `patch_size` with an overlap ratio of `scaled_images_overlap_ratios`.
+- These patches go through `DinoV2 (ViT)` based encoders and are reassembled via a `DPT` based decoder.
+- `DepthProForDepthEstimation` can also predict the `FOV (Field of View)` if `use_fov_model` is set to `True` in the config.
+- `DepthProImageProcessor` can be used for preprocessing the inputs and postprocessing the outputs. `DepthProImageProcessor.post_process_depth_estimation` interpolates the `predicted_depth` back to match the input image size.
+- To generate `predicted_depth` of the same size as input image, make sure the config is created such that
+```
+image_size / 2**(n_fusion_blocks+1) == patch_size / patch_embeddings_size
+
+where
+n_fusion_blocks = len(intermediate_hook_ids) + len(scaled_images_ratios)
+```
+
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```py
+from transformers import DepthProForDepthEstimation
+model = DepthProForDepthEstimation.from_pretrained("geetu040/DepthPro", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `google/vit-base-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+
+- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
+
+
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthProConfig
+
+[[autodoc]] DepthProConfig
+
+## DepthProImageProcessor
+
+[[autodoc]] DepthProImageProcessor
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProImageProcessorFast
+
+[[autodoc]] DepthProImageProcessorFast
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProModel
+
+[[autodoc]] DepthProModel
+ - forward
+
+## DepthProForDepthEstimation
+
+[[autodoc]] DepthProForDepthEstimation
+ - forward
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 930f41b6fefba7..9ead5ac276693f 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -237,6 +237,7 @@ For now, Transformers supports SDPA inference and training for the following arc
* [data2vec_vision](https://huggingface.co/docs/transformers/main/en/model_doc/data2vec#transformers.Data2VecVisionModel)
* [Dbrx](https://huggingface.co/docs/transformers/model_doc/dbrx#transformers.DbrxModel)
* [DeiT](https://huggingface.co/docs/transformers/model_doc/deit#transformers.DeiTModel)
+* [DepthPro](https://huggingface.co/docs/transformers/model_doc/depth_pro#transformers.DepthProModel)
* [Dinov2](https://huggingface.co/docs/transformers/en/model_doc/dinov2)
* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
* [Dpr](https://huggingface.co/docs/transformers/model_doc/dpr#transformers.DprReader)
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index ef140cc6d3a843..ebcfe53848502e 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -400,6 +400,7 @@
"models.deprecated.vit_hybrid": ["ViTHybridConfig"],
"models.deprecated.xlm_prophetnet": ["XLMProphetNetConfig"],
"models.depth_anything": ["DepthAnythingConfig"],
+ "models.depth_pro": ["DepthProConfig"],
"models.detr": ["DetrConfig"],
"models.dialogpt": [],
"models.dinat": ["DinatConfig"],
@@ -1212,6 +1213,7 @@
_import_structure["models.deprecated.efficientformer"].append("EfficientFormerImageProcessor")
_import_structure["models.deprecated.tvlt"].append("TvltImageProcessor")
_import_structure["models.deprecated.vit_hybrid"].extend(["ViTHybridImageProcessor"])
+ _import_structure["models.depth_pro"].extend(["DepthProImageProcessor", "DepthProImageProcessorFast"])
_import_structure["models.detr"].extend(["DetrFeatureExtractor", "DetrImageProcessor"])
_import_structure["models.donut"].extend(["DonutFeatureExtractor", "DonutImageProcessor"])
_import_structure["models.dpt"].extend(["DPTFeatureExtractor", "DPTImageProcessor"])
@@ -2136,6 +2138,13 @@
"DepthAnythingPreTrainedModel",
]
)
+ _import_structure["models.depth_pro"].extend(
+ [
+ "DepthProForDepthEstimation",
+ "DepthProModel",
+ "DepthProPreTrainedModel",
+ ]
+ )
_import_structure["models.detr"].extend(
[
"DetrForObjectDetection",
@@ -5359,6 +5368,7 @@
XLMProphetNetConfig,
)
from .models.depth_anything import DepthAnythingConfig
+ from .models.depth_pro import DepthProConfig
from .models.detr import DetrConfig
from .models.dinat import DinatConfig
from .models.dinov2 import Dinov2Config
@@ -6207,6 +6217,7 @@
from .models.deprecated.efficientformer import EfficientFormerImageProcessor
from .models.deprecated.tvlt import TvltImageProcessor
from .models.deprecated.vit_hybrid import ViTHybridImageProcessor
+ from .models.depth_pro import DepthProImageProcessor, DepthProImageProcessorFast
from .models.detr import DetrFeatureExtractor, DetrImageProcessor
from .models.donut import DonutFeatureExtractor, DonutImageProcessor
from .models.dpt import DPTFeatureExtractor, DPTImageProcessor
@@ -7001,6 +7012,11 @@
DepthAnythingForDepthEstimation,
DepthAnythingPreTrainedModel,
)
+ from .models.depth_pro import (
+ DepthProForDepthEstimation,
+ DepthProModel,
+ DepthProPreTrainedModel,
+ )
from .models.detr import (
DetrForObjectDetection,
DetrForSegmentation,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 7fcaddde704cf7..9030f178ab0cfa 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -73,6 +73,7 @@
deit,
deprecated,
depth_anything,
+ depth_pro,
detr,
dialogpt,
dinat,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 69ce8efa10c76c..b4b920b6d5886f 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -90,6 +90,7 @@
("deformable_detr", "DeformableDetrConfig"),
("deit", "DeiTConfig"),
("depth_anything", "DepthAnythingConfig"),
+ ("depth_pro", "DepthProConfig"),
("deta", "DetaConfig"),
("detr", "DetrConfig"),
("dinat", "DinatConfig"),
@@ -399,6 +400,7 @@
("deplot", "DePlot"),
("depth_anything", "Depth Anything"),
("depth_anything_v2", "Depth Anything V2"),
+ ("depth_pro", "DepthPro"),
("deta", "DETA"),
("detr", "DETR"),
("dialogpt", "DialoGPT"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index db25591eaa3544..41dbb4ab9e5be5 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -74,6 +74,7 @@
("deformable_detr", ("DeformableDetrImageProcessor", "DeformableDetrImageProcessorFast")),
("deit", ("DeiTImageProcessor",)),
("depth_anything", ("DPTImageProcessor",)),
+ ("depth_pro", ("DepthProImageProcessor", "DepthProImageProcessorFast")),
("deta", ("DetaImageProcessor",)),
("detr", ("DetrImageProcessor", "DetrImageProcessorFast")),
("dinat", ("ViTImageProcessor", "ViTImageProcessorFast")),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index e8a2dece432476..dcf3ee974d2bf1 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -88,6 +88,7 @@
("decision_transformer", "DecisionTransformerModel"),
("deformable_detr", "DeformableDetrModel"),
("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
("deta", "DetaModel"),
("detr", "DetrModel"),
("dinat", "DinatModel"),
@@ -580,6 +581,7 @@
("data2vec-vision", "Data2VecVisionModel"),
("deformable_detr", "DeformableDetrModel"),
("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
("deta", "DetaModel"),
("detr", "DetrModel"),
("dinat", "DinatModel"),
@@ -891,6 +893,7 @@
[
# Model for depth estimation mapping
("depth_anything", "DepthAnythingForDepthEstimation"),
+ ("depth_pro", "DepthProForDepthEstimation"),
("dpt", "DPTForDepthEstimation"),
("glpn", "GLPNForDepthEstimation"),
("zoedepth", "ZoeDepthForDepthEstimation"),
diff --git a/src/transformers/models/depth_pro/__init__.py b/src/transformers/models/depth_pro/__init__.py
new file mode 100644
index 00000000000000..6fa380d6420834
--- /dev/null
+++ b/src/transformers/models/depth_pro/__init__.py
@@ -0,0 +1,72 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+from ...utils import OptionalDependencyNotAvailable
+
+
+_import_structure = {"configuration_depth_pro": ["DepthProConfig"]}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_depth_pro"] = ["DepthProImageProcessor"]
+ _import_structure["image_processing_depth_pro_fast"] = ["DepthProImageProcessorFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_depth_pro"] = [
+ "DepthProForDepthEstimation",
+ "DepthProModel",
+ "DepthProPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_depth_pro import DepthProConfig
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_depth_pro import DepthProImageProcessor
+ from .image_processing_depth_pro_fast import DepthProImageProcessorFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_depth_pro import (
+ DepthProForDepthEstimation,
+ DepthProModel,
+ DepthProPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/depth_pro/configuration_depth_pro.py b/src/transformers/models/depth_pro/configuration_depth_pro.py
new file mode 100644
index 00000000000000..206c01eff191bd
--- /dev/null
+++ b/src/transformers/models/depth_pro/configuration_depth_pro.py
@@ -0,0 +1,203 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""DepthPro model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class DepthProConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`DepthProModel`]. It is used to instantiate a
+ DepthPro model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the DepthPro
+ [apple/DepthPro](https://huggingface.co/apple/DepthPro) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the encoder layers and the pooler layer.
+ fusion_hidden_size (`int`, *optional*, defaults to 256):
+ The number of channels before fusion.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ mlp_ratio (`int`, *optional*, defaults to 4):
+ Ratio of the hidden size of the MLPs relative to the `hidden_size`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ patch_size (`int`, *optional*, defaults to 384):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ patch_embeddings_size (`int`, *optional*, defaults to 16):
+ kernel_size and stride for convolution in PatchEmbeddings.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ layerscale_value (`float`, *optional*, defaults to 1.0):
+ Initial value to use for layer scale.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ Stochastic depth rate per sample (when applied in the main path of residual layers).
+ use_swiglu_ffn (`bool`, *optional*, defaults to `False`):
+ Whether to use the SwiGLU feedforward neural network.
+ intermediate_hook_ids (`List[int]`, *optional*, defaults to `[11, 5]`):
+ Indices of the intermediate hidden states from the patch encoder to use for fusion.
+ intermediate_feature_dims (`List[int]`, *optional*, defaults to `[256, 256]`):
+ Hidden state dimensions during upsampling for each intermediate hidden state in `intermediate_hook_ids`.
+ scaled_images_ratios (`List[float]`, *optional*, defaults to `[0.25, 0.5, 1]`):
+ Ratios of scaled images to be used by the patch encoder.
+ scaled_images_overlap_ratios (`List[float]`, *optional*, defaults to `[0.0, 0.5, 0.25]`):
+ Overlap ratios between patches for each scaled image in `scaled_images_ratios`.
+ scaled_images_feature_dims (`List[int]`, *optional*, defaults to `[1024, 1024, 512]`):
+ Hidden state dimensions during upsampling for each scaled image in `scaled_images_ratios`.
+ use_batch_norm_in_fusion_residual (`bool`, *optional*, defaults to `False`):
+ Whether to use batch normalization in the pre-activate residual units of the fusion blocks.
+ use_bias_in_fusion_residual (`bool`, *optional*, defaults to `True`):
+ Whether to use bias in the pre-activate residual units of the fusion blocks.
+ use_fov_model (`bool`, *optional*, defaults to `True`):
+ Whether to use `DepthProFOVModel` to generate the field of view.
+ num_fov_head_layers (`int`, *optional*, defaults to 2):
+ Number of convolution layers in the head of `DepthProFOVModel`.
+
+ Example:
+
+ ```python
+ >>> from transformers import DepthProConfig, DepthProModel
+
+ >>> # Initializing a DepthPro apple/DepthPro style configuration
+ >>> configuration = DepthProConfig()
+
+ >>> # Initializing a model (with random weights) from the apple/DepthPro style configuration
+ >>> model = DepthProModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "depth_pro"
+
+ def __init__(
+ self,
+ hidden_size=1024,
+ fusion_hidden_size=256,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ mlp_ratio=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-6,
+ patch_size=384,
+ num_channels=3,
+ patch_embeddings_size=16,
+ qkv_bias=True,
+ layerscale_value=1.0,
+ drop_path_rate=0.0,
+ use_swiglu_ffn=False,
+ intermediate_hook_ids=[11, 5],
+ intermediate_feature_dims=[256, 256],
+ scaled_images_ratios=[0.25, 0.5, 1],
+ scaled_images_overlap_ratios=[0.0, 0.5, 0.25],
+ scaled_images_feature_dims=[1024, 1024, 512],
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=True,
+ use_fov_model=True,
+ num_fov_head_layers=2,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ # scaled_images_ratios is sorted
+ if scaled_images_ratios != sorted(scaled_images_ratios):
+ raise ValueError(
+ f"Values in scaled_images_ratios={scaled_images_ratios} " "should be sorted from low to high"
+ )
+
+ # patch_size should be a divisible by patch_embeddings_size
+ # else it raises an exception in DepthProViTPatchEmbeddings
+ if patch_size % patch_embeddings_size != 0:
+ raise ValueError(
+ f"patch_size={patch_size} should be divisible " f"by patch_embeddings_size={patch_embeddings_size}."
+ )
+
+ # scaled_images_ratios, scaled_images_overlap_ratios, scaled_images_feature_dims should be consistent
+ if not (len(scaled_images_ratios) == len(scaled_images_overlap_ratios) == len(scaled_images_feature_dims)):
+ raise ValueError(
+ f"len(scaled_images_ratios)={len(scaled_images_ratios)} and "
+ f"len(scaled_images_overlap_ratios)={len(scaled_images_overlap_ratios)} and "
+ f"len(scaled_images_feature_dims)={len(scaled_images_feature_dims)}, "
+ f"should match in config."
+ )
+
+ # intermediate_hook_ids, intermediate_feature_dims should be consistent
+ if not (len(intermediate_hook_ids) == len(intermediate_feature_dims)):
+ raise ValueError(
+ f"len(intermediate_hook_ids)={len(intermediate_hook_ids)} and "
+ f"len(intermediate_feature_dims)={len(intermediate_feature_dims)}, "
+ f"should match in config."
+ )
+
+ # fusion_hidden_size should be consistent with num_fov_head_layers
+ if fusion_hidden_size // 2**num_fov_head_layers == 0:
+ raise ValueError(
+ f"fusion_hidden_size={fusion_hidden_size} should be consistent with num_fov_head_layers={num_fov_head_layers} "
+ "i.e fusion_hidden_size // 2**num_fov_head_layers > 0"
+ )
+
+ self.hidden_size = hidden_size
+ self.fusion_hidden_size = fusion_hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.mlp_ratio = mlp_ratio
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.patch_embeddings_size = patch_embeddings_size
+ self.qkv_bias = qkv_bias
+ self.layerscale_value = layerscale_value
+ self.drop_path_rate = drop_path_rate
+ self.use_swiglu_ffn = use_swiglu_ffn
+ self.use_batch_norm_in_fusion_residual = use_batch_norm_in_fusion_residual
+ self.use_bias_in_fusion_residual = use_bias_in_fusion_residual
+ self.use_fov_model = use_fov_model
+ self.num_fov_head_layers = num_fov_head_layers
+ self.intermediate_hook_ids = intermediate_hook_ids
+ self.intermediate_feature_dims = intermediate_feature_dims
+ self.scaled_images_ratios = scaled_images_ratios
+ self.scaled_images_overlap_ratios = scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = scaled_images_feature_dims
+
+
+__all__ = ["DepthProConfig"]
diff --git a/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py b/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py
new file mode 100644
index 00000000000000..cca89f6a8b8cac
--- /dev/null
+++ b/src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py
@@ -0,0 +1,281 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import gc
+import os
+
+import regex as re
+import torch
+from huggingface_hub import hf_hub_download
+
+from transformers import (
+ DepthProConfig,
+ DepthProForDepthEstimation,
+ DepthProImageProcessorFast,
+)
+from transformers.image_utils import PILImageResampling
+
+
+# fmt: off
+ORIGINAL_TO_CONVERTED_KEY_MAPPING = {
+
+ # encoder and head
+ r"encoder.(patch|image)_encoder.cls_token": r"depth_pro.encoder.\1_encoder.embeddings.cls_token",
+ r"encoder.(patch|image)_encoder.pos_embed": r"depth_pro.encoder.\1_encoder.embeddings.position_embeddings",
+ r"encoder.(patch|image)_encoder.patch_embed.proj.(weight|bias)": r"depth_pro.encoder.\1_encoder.embeddings.patch_embeddings.projection.\2",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).norm(\d+).(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.norm\3.\4",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).attn.qkv.(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.attention.attention.(query|key|value).\3",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).attn.proj.(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.attention.output.dense.\3",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).ls(\d+).gamma": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.layer_scale\3.lambda1",
+ r"encoder.(patch|image)_encoder.blocks.(\d+).mlp.fc(\d+).(weight|bias)": r"depth_pro.encoder.\1_encoder.encoder.layer.\2.mlp.fc\3.\4",
+ r"encoder.(patch|image)_encoder.norm.(weight|bias)": r"depth_pro.encoder.\1_encoder.layernorm.\2",
+ r"encoder.fuse_lowres.(weight|bias)": r"depth_pro.encoder.fuse_image_with_low_res.\1",
+ r"head.(\d+).(weight|bias)": r"head.head.\1.\2",
+
+ # fov
+ r"fov.encoder.0.cls_token": r"fov_model.encoder.embeddings.cls_token",
+ r"fov.encoder.0.pos_embed": r"fov_model.encoder.embeddings.position_embeddings",
+ r"fov.encoder.0.patch_embed.proj.(weight|bias)": r"fov_model.encoder.embeddings.patch_embeddings.projection.\1",
+ r"fov.encoder.0.blocks.(\d+).norm(\d+).(weight|bias)": r"fov_model.encoder.encoder.layer.\1.norm\2.\3",
+ r"fov.encoder.0.blocks.(\d+).attn.qkv.(weight|bias)": r"fov_model.encoder.encoder.layer.\1.attention.attention.(query|key|value).\2",
+ r"fov.encoder.0.blocks.(\d+).attn.proj.(weight|bias)": r"fov_model.encoder.encoder.layer.\1.attention.output.dense.\2",
+ r"fov.encoder.0.blocks.(\d+).ls(\d+).gamma": r"fov_model.encoder.encoder.layer.\1.layer_scale\2.lambda1",
+ r"fov.encoder.0.blocks.(\d+).mlp.fc(\d+).(weight|bias)": r"fov_model.encoder.encoder.layer.\1.mlp.fc\2.\3",
+ r"fov.encoder.0.norm.(weight|bias)": r"fov_model.encoder.layernorm.\1",
+ r"fov.downsample.(\d+).(weight|bias)": r"fov_model.global_neck.\1.\2",
+ r"fov.encoder.1.(weight|bias)": r"fov_model.encoder_neck.\1",
+ r"fov.head.head.(\d+).(weight|bias)": r"fov_model.head.\1.\2",
+
+ # upsamples (hard coded; regex is not very feasible here)
+ "encoder.upsample_latent0.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.0.weight",
+ "encoder.upsample_latent0.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.1.weight",
+ "encoder.upsample_latent0.2.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.2.weight",
+ "encoder.upsample_latent0.3.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.5.3.weight",
+ "encoder.upsample_latent1.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.0.weight",
+ "encoder.upsample_latent1.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.1.weight",
+ "encoder.upsample_latent1.2.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.4.2.weight",
+ "encoder.upsample0.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.3.0.weight",
+ "encoder.upsample0.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.3.1.weight",
+ "encoder.upsample1.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.2.0.weight",
+ "encoder.upsample1.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.2.1.weight",
+ "encoder.upsample2.0.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.1.0.weight",
+ "encoder.upsample2.1.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.1.1.weight",
+ "encoder.upsample_lowres.weight": "depth_pro.encoder.feature_upsample.upsample_blocks.0.0.weight",
+ "encoder.upsample_lowres.bias": "depth_pro.encoder.feature_upsample.upsample_blocks.0.0.bias",
+
+ # projections between encoder and fusion
+ r"decoder.convs.(\d+).weight": lambda match: (
+ f"depth_pro.encoder.feature_projection.projections.{4-int(match.group(1))}.weight"
+ ),
+
+ # fusion stage
+ r"decoder.fusions.(\d+).resnet(\d+).residual.(\d+).(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.residual_layer{match.group(2)}.convolution{(int(match.group(3))+1)//2}.{match.group(4)}"
+ ),
+ r"decoder.fusions.(\d+).out_conv.(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.projection.{match.group(2)}"
+ ),
+ r"decoder.fusions.(\d+).deconv.(weight|bias)": lambda match: (
+ f"fusion_stage.layers.{4-int(match.group(1))}.deconv.{match.group(2)}"
+ ),
+}
+# fmt: on
+
+
+def convert_old_keys_to_new_keys(state_dict_keys: dict = None):
+ output_dict = {}
+ if state_dict_keys is not None:
+ old_text = "\n".join(state_dict_keys)
+ new_text = old_text
+ for pattern, replacement in ORIGINAL_TO_CONVERTED_KEY_MAPPING.items():
+ if replacement is None:
+ new_text = re.sub(pattern, "", new_text) # an empty line
+ continue
+ new_text = re.sub(pattern, replacement, new_text)
+ output_dict = dict(zip(old_text.split("\n"), new_text.split("\n")))
+ return output_dict
+
+
+def get_qkv_state_dict(key, parameter):
+ """
+ new key which looks like this
+ xxxx.(q|k|v).xxx (m, n)
+
+ is converted to
+ xxxx.q.xxxx (m//3, n)
+ xxxx.k.xxxx (m//3, n)
+ xxxx.v.xxxx (m//3, n)
+ """
+ qkv_state_dict = {}
+ placeholder = re.search(r"(\(.*?\))", key).group(1) # finds "(query|key|value)"
+ replacements_keys = placeholder[1:-1].split("|") # creates ['query', 'key', 'value']
+ replacements_vals = torch.split(
+ parameter, split_size_or_sections=parameter.size(0) // len(replacements_keys), dim=0
+ )
+ for replacement_key, replacement_val in zip(replacements_keys, replacements_vals):
+ qkv_state_dict[key.replace(placeholder, replacement_key)] = replacement_val
+ return qkv_state_dict
+
+
+def write_model(
+ hf_repo_id: str,
+ output_dir: str,
+ safe_serialization: bool = True,
+):
+ os.makedirs(output_dir, exist_ok=True)
+
+ # ------------------------------------------------------------
+ # Create and save config
+ # ------------------------------------------------------------
+
+ # create config
+ config = DepthProConfig(
+ # this config is same as the default config and used for pre-trained weights
+ hidden_size=1024,
+ fusion_hidden_size=256,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ mlp_ratio=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-6,
+ patch_size=384,
+ num_channels=3,
+ patch_embeddings_size=16,
+ qkv_bias=True,
+ layerscale_value=1.0,
+ drop_path_rate=0.0,
+ use_swiglu_ffn=False,
+ apply_layernorm=True,
+ reshape_hidden_states=True,
+ intermediate_hook_ids=[11, 5],
+ intermediate_feature_dims=[256, 256],
+ scaled_images_ratios=[0.25, 0.5, 1],
+ scaled_images_overlap_ratios=[0.0, 0.5, 0.25],
+ scaled_images_feature_dims=[1024, 1024, 512],
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=True,
+ use_fov_model=True,
+ num_fov_head_layers=2,
+ )
+
+ # save config
+ config.save_pretrained(output_dir)
+ print("Model config saved successfully...")
+
+ # ------------------------------------------------------------
+ # Convert weights
+ # ------------------------------------------------------------
+
+ # download and load state_dict from hf repo
+ file_path = hf_hub_download(hf_repo_id, "depth_pro.pt")
+ # file_path = "/home/geetu/work/hf/depth_pro/depth_pro.pt" # when you already have the files locally
+ loaded = torch.load(file_path, weights_only=True)
+
+ print("Converting model...")
+ all_keys = list(loaded.keys())
+ new_keys = convert_old_keys_to_new_keys(all_keys)
+
+ state_dict = {}
+ for key in all_keys:
+ new_key = new_keys[key]
+ current_parameter = loaded.pop(key)
+
+ if "qkv" in key:
+ qkv_state_dict = get_qkv_state_dict(new_key, current_parameter)
+ state_dict.update(qkv_state_dict)
+ else:
+ state_dict[new_key] = current_parameter
+
+ print("Loading the checkpoint in a DepthPro model.")
+ model = DepthProForDepthEstimation(config)
+ model.load_state_dict(state_dict, strict=True, assign=True)
+ print("Checkpoint loaded successfully.")
+
+ print("Saving the model.")
+ model.save_pretrained(output_dir, safe_serialization=safe_serialization)
+ del state_dict, model
+
+ # Safety check: reload the converted model
+ gc.collect()
+ print("Reloading the model to check if it's saved correctly.")
+ model = DepthProForDepthEstimation.from_pretrained(output_dir, device_map="auto")
+ print("Model reloaded successfully.")
+ return model
+
+
+def write_image_processor(output_dir: str):
+ image_processor = DepthProImageProcessorFast(
+ do_resize=True,
+ size={"height": 1536, "width": 1536},
+ resample=PILImageResampling.BILINEAR,
+ antialias=False,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=0.5,
+ image_std=0.5,
+ )
+ image_processor.save_pretrained(output_dir)
+ return image_processor
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--hf_repo_id",
+ default="apple/DepthPro",
+ help="Location of official weights from apple on HF",
+ )
+ parser.add_argument(
+ "--output_dir",
+ default="apple_DepthPro",
+ help="Location to write the converted model and processor",
+ )
+ parser.add_argument(
+ "--safe_serialization", default=True, type=bool, help="Whether or not to save using `safetensors`."
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ action=argparse.BooleanOptionalAction,
+ help="Whether or not to push the converted model to the huggingface hub.",
+ )
+ parser.add_argument(
+ "--hub_repo_id",
+ default="geetu040/DepthPro",
+ help="Huggingface hub repo to write the converted model and processor",
+ )
+ args = parser.parse_args()
+
+ model = write_model(
+ hf_repo_id=args.hf_repo_id,
+ output_dir=args.output_dir,
+ safe_serialization=args.safe_serialization,
+ )
+
+ image_processor = write_image_processor(
+ output_dir=args.output_dir,
+ )
+
+ if args.push_to_hub:
+ print("Pushing to hub...")
+ model.push_to_hub(args.hub_repo_id)
+ image_processor.push_to_hub(args.hub_repo_id)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/models/depth_pro/image_processing_depth_pro.py b/src/transformers/models/depth_pro/image_processing_depth_pro.py
new file mode 100644
index 00000000000000..76a12577dd6330
--- /dev/null
+++ b/src/transformers/models/depth_pro/image_processing_depth_pro.py
@@ -0,0 +1,406 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for DepthPro."""
+
+from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+
+
+if TYPE_CHECKING:
+ from ...modeling_outputs import DepthProDepthEstimatorOutput
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import to_channel_dimension_format
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ is_torch_available,
+ make_list_of_images,
+ pil_torch_interpolation_mapping,
+ to_numpy_array,
+ valid_images,
+)
+from ...utils import (
+ TensorType,
+ filter_out_non_signature_kwargs,
+ logging,
+ requires_backends,
+)
+
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.get_logger(__name__)
+
+
+class DepthProImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a DepthPro image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `(size["height"],
+ size["width"])`. Can be overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`dict`, *optional*, defaults to `{"height": 1536, "width": 1536}`):
+ Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
+ method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
+ `preprocess` method.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 1536, "width": 1536}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.do_rescale = do_rescale
+ self.do_normalize = do_normalize
+ self.size = size
+ self.resample = resample
+ self.antialias = antialias
+ self.rescale_factor = rescale_factor
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> np.ndarray:
+ """
+ Resize an image to `(size["height"], size["width"])`.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Dictionary in the format `{"height": int, "width": int}` specifying the size of the output image.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ `PILImageResampling` filter to use when resizing the image e.g. `PILImageResampling.BILINEAR`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+
+ Returns:
+ `np.ndarray`: The resized images.
+ """
+ requires_backends(self, "torch")
+
+ size = get_size_dict(size)
+ if "height" not in size or "width" not in size:
+ raise ValueError(f"The `size` dictionary must contain the keys `height` and `width`. Got {size.keys()}")
+ output_size = (size["height"], size["width"])
+
+ # we use torch interpolation instead of image.resize because DepthProImageProcessor
+ # rescales, then normalizes, which may cause some values to become negative, before resizing the image.
+ # image.resize expects all values to be in range [0, 1] or [0, 255] and throws an exception otherwise,
+ # however pytorch interpolation works with negative values.
+ # relevant issue here: https://github.com/huggingface/transformers/issues/34920
+ return (
+ torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=torch.from_numpy(image).unsqueeze(0),
+ size=output_size,
+ mode=pil_torch_interpolation_mapping[resample].value,
+ antialias=antialias,
+ )
+ .squeeze(0)
+ .numpy()
+ )
+
+ def _validate_input_arguments(
+ self,
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ data_format: Union[str, ChannelDimension],
+ ):
+ if do_resize and None in (size, resample, antialias):
+ raise ValueError("Size, resample and antialias must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize and None in (image_mean, image_std):
+ raise ValueError("Image mean and standard deviation must be specified if do_normalize is True.")
+
+ @filter_out_non_signature_kwargs()
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: Optional[PILImageResampling] = None,
+ antialias: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Dictionary in the format `{"height": h, "width": w}` specifying the size of the output image after
+ resizing.
+ resample (`PILImageResampling` filter, *optional*, defaults to `self.resample`):
+ `PILImageResampling` filter to use if resizing the image e.g. `PILImageResampling.BILINEAR`. Only has
+ an effect if `do_resize` is set to `True`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use if `do_normalize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+ antialias = antialias if antialias is not None else self.antialias
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ size = size if size is not None else self.size
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ self._validate_input_arguments(
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ data_format=data_format,
+ )
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ all_images = []
+ for image in images:
+ if do_rescale:
+ image = self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+
+ if do_normalize:
+ image = self.normalize(
+ image=image, mean=image_mean, std=image_std, input_data_format=input_data_format
+ )
+
+ # depth-pro rescales and normalizes the image before resizing it
+ # uses torch interpolation which requires ChannelDimension.FIRST
+ if do_resize:
+ image = to_channel_dimension_format(image, ChannelDimension.FIRST, input_channel_dim=input_data_format)
+ image = self.resize(image=image, size=size, resample=resample, antialias=antialias)
+ image = to_channel_dimension_format(image, data_format, input_channel_dim=ChannelDimension.FIRST)
+ else:
+ image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
+
+ all_images.append(image)
+
+ data = {"pixel_values": all_images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
+
+ def post_process_depth_estimation(
+ self,
+ outputs: "DepthProDepthEstimatorOutput",
+ target_sizes: Optional[Union[TensorType, List[Tuple[int, int]], None]] = None,
+ ) -> Dict[str, List[TensorType]]:
+ """
+ Post-processes the raw depth predictions from the model to generate final depth predictions and optionally
+ resizes them to specified target sizes. This function supports scaling based on the field of view (FoV)
+ and adjusts depth values accordingly.
+
+ Args:
+ outputs ([`DepthProDepthEstimatorOutput`]):
+ Raw outputs of the model.
+ target_sizes (`Optional[Union[TensorType, List[Tuple[int, int]], None]]`, *optional*, defaults to `None`):
+ Target sizes to resize the depth predictions. Can be a tensor of shape `(batch_size, 2)`
+ or a list of tuples `(height, width)` for each image in the batch. If `None`, no resizing
+ is performed.
+
+ Returns:
+ `List[Dict[str, TensorType]]`: A list of dictionaries of tensors representing the processed depth
+ predictions.
+
+ Raises:
+ `ValueError`:
+ If the lengths of `predicted_depths`, `fovs`, or `target_sizes` are mismatched.
+ """
+ requires_backends(self, "torch")
+
+ predicted_depth = outputs.predicted_depth
+ fov = outputs.fov
+
+ batch_size = len(predicted_depth)
+
+ if target_sizes is not None and batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many fov values as the batch dimension of the predicted depth"
+ )
+
+ results = []
+ fov = [None] * batch_size if fov is None else fov
+ target_sizes = [None] * batch_size if target_sizes is None else target_sizes
+ for depth, fov_value, target_size in zip(predicted_depth, fov, target_sizes):
+ if target_size is not None:
+ # scale image w.r.t fov
+ if fov_value is not None:
+ width = target_size[1]
+ fov_value = 0.5 * width / torch.tan(0.5 * torch.deg2rad(fov_value))
+ depth = depth * width / fov_value
+
+ # interpolate
+ depth = torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=depth.unsqueeze(0).unsqueeze(1),
+ size=target_size,
+ mode=pil_torch_interpolation_mapping[self.resample].value,
+ antialias=self.antialias,
+ ).squeeze()
+
+ # inverse the depth
+ depth = 1.0 / torch.clamp(depth, min=1e-4, max=1e4)
+
+ results.append(
+ {
+ "predicted_depth": depth,
+ "fov": fov_value,
+ }
+ )
+
+ return results
+
+
+__all__ = ["DepthProImageProcessor"]
diff --git a/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py b/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py
new file mode 100644
index 00000000000000..521e5b8a06282e
--- /dev/null
+++ b/src/transformers/models/depth_pro/image_processing_depth_pro_fast.py
@@ -0,0 +1,386 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fast Image processor class for DepthPro."""
+
+import functools
+from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
+
+
+if TYPE_CHECKING:
+ from ...modeling_outputs import DepthProDepthEstimatorOutput
+
+from ...image_processing_base import BatchFeature
+from ...image_processing_utils import get_size_dict
+from ...image_processing_utils_fast import BaseImageProcessorFast, SizeDict
+from ...image_transforms import FusedRescaleNormalize, NumpyToTensor, Rescale
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ ImageType,
+ PILImageResampling,
+ get_image_type,
+ make_list_of_images,
+ pil_torch_interpolation_mapping,
+)
+from ...utils import TensorType, logging, requires_backends
+from ...utils.import_utils import is_torch_available, is_torchvision_available
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_available():
+ import torch
+
+
+if is_torchvision_available():
+ from torchvision.transforms import Compose, Normalize, PILToTensor, Resize
+
+
+class DepthProImageProcessorFast(BaseImageProcessorFast):
+ r"""
+ Constructs a DepthPro image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `(size["height"],
+ size["width"])`. Can be overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`dict`, *optional*, defaults to `{"height": 1536, "width": 1536}`):
+ Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
+ method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
+ `preprocess` method.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
+ parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+ _transform_params = [
+ "do_resize",
+ "do_rescale",
+ "do_normalize",
+ "size",
+ "resample",
+ "antialias",
+ "rescale_factor",
+ "image_mean",
+ "image_std",
+ "image_type",
+ ]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Optional[Dict[str, int]] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ antialias: bool = False,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 1536, "width": 1536}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.do_rescale = do_rescale
+ self.do_normalize = do_normalize
+ self.size = size
+ self.resample = resample
+ self.antialias = antialias
+ self.rescale_factor = rescale_factor
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ def _build_transforms(
+ self,
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ image_type: ImageType,
+ ) -> "Compose":
+ """
+ Given the input settings build the image transforms using `torchvision.transforms.Compose`.
+ """
+ transforms = []
+
+ # All PIL and numpy values need to be converted to a torch tensor
+ # to keep cross compatibility with slow image processors
+ if image_type == ImageType.PIL:
+ transforms.append(PILToTensor())
+
+ elif image_type == ImageType.NUMPY:
+ transforms.append(NumpyToTensor())
+
+ # We can combine rescale and normalize into a single operation for speed
+ if do_rescale and do_normalize:
+ transforms.append(FusedRescaleNormalize(image_mean, image_std, rescale_factor=rescale_factor))
+ elif do_rescale:
+ transforms.append(Rescale(rescale_factor=rescale_factor))
+ elif do_normalize:
+ transforms.append(Normalize(image_mean, image_std))
+
+ # depth-pro scales the image before resizing it
+ if do_resize:
+ transforms.append(
+ Resize(
+ (size["height"], size["width"]),
+ interpolation=pil_torch_interpolation_mapping[resample],
+ antialias=antialias,
+ )
+ )
+
+ return Compose(transforms)
+
+ @functools.lru_cache(maxsize=1)
+ def _validate_input_arguments(
+ self,
+ return_tensors: Union[str, TensorType],
+ do_resize: bool,
+ size: Dict[str, int],
+ resample: PILImageResampling,
+ antialias: bool,
+ do_rescale: bool,
+ rescale_factor: float,
+ do_normalize: bool,
+ image_mean: Union[float, List[float]],
+ image_std: Union[float, List[float]],
+ data_format: Union[str, ChannelDimension],
+ image_type: ImageType,
+ ):
+ if return_tensors != "pt":
+ raise ValueError("Only returning PyTorch tensors is currently supported.")
+
+ if data_format != ChannelDimension.FIRST:
+ raise ValueError("Only channel first data format is currently supported.")
+
+ if do_resize and None in (size, resample, antialias):
+ raise ValueError("Size, resample and antialias must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ if do_normalize and None in (image_mean, image_std):
+ raise ValueError("Image mean and standard deviation must be specified if do_normalize is True.")
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample: Optional[PILImageResampling] = None,
+ antialias: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = "pt",
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ):
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Dictionary in the format `{"height": h, "width": w}` specifying the size of the output image after
+ resizing.
+ resample (`PILImageResampling` filter, *optional*, defaults to `self.resample`):
+ `PILImageResampling` filter to use if resizing the image e.g. `PILImageResampling.BILINEAR`. Only has
+ an effect if `do_resize` is set to `True`.
+ antialias (`bool`, *optional*, defaults to `False`):
+ Whether to apply an anti-aliasing filter when resizing the image. It only affects tensors with
+ bilinear or bicubic modes and it is ignored otherwise.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use if `do_normalize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Only "pt" is supported
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. The following formats are currently supported:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+ antialias = antialias if antialias is not None else self.antialias
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ size = size if size is not None else self.size
+ # Make hashable for cache
+ size = SizeDict(**size)
+ image_mean = tuple(image_mean) if isinstance(image_mean, list) else image_mean
+ image_std = tuple(image_std) if isinstance(image_std, list) else image_std
+
+ images = make_list_of_images(images)
+ image_type = get_image_type(images[0])
+
+ if image_type not in [ImageType.PIL, ImageType.TORCH, ImageType.NUMPY]:
+ raise ValueError(f"Unsupported input image type {image_type}")
+
+ self._validate_input_arguments(
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ return_tensors=return_tensors,
+ data_format=data_format,
+ image_type=image_type,
+ )
+
+ transforms = self.get_transforms(
+ do_resize=do_resize,
+ do_rescale=do_rescale,
+ do_normalize=do_normalize,
+ size=size,
+ resample=resample,
+ antialias=antialias,
+ rescale_factor=rescale_factor,
+ image_mean=image_mean,
+ image_std=image_std,
+ image_type=image_type,
+ )
+ transformed_images = [transforms(image) for image in images]
+
+ data = {"pixel_values": torch.stack(transformed_images, dim=0)}
+ return BatchFeature(data, tensor_type=return_tensors)
+
+ # Copied from transformers.models.depth_pro.image_processing_depth_pro.DepthProImageProcessor.post_process_depth_estimation
+ def post_process_depth_estimation(
+ self,
+ outputs: "DepthProDepthEstimatorOutput",
+ target_sizes: Optional[Union[TensorType, List[Tuple[int, int]], None]] = None,
+ ) -> Dict[str, List[TensorType]]:
+ """
+ Post-processes the raw depth predictions from the model to generate final depth predictions and optionally
+ resizes them to specified target sizes. This function supports scaling based on the field of view (FoV)
+ and adjusts depth values accordingly.
+
+ Args:
+ outputs ([`DepthProDepthEstimatorOutput`]):
+ Raw outputs of the model.
+ target_sizes (`Optional[Union[TensorType, List[Tuple[int, int]], None]]`, *optional*, defaults to `None`):
+ Target sizes to resize the depth predictions. Can be a tensor of shape `(batch_size, 2)`
+ or a list of tuples `(height, width)` for each image in the batch. If `None`, no resizing
+ is performed.
+
+ Returns:
+ `List[Dict[str, TensorType]]`: A list of dictionaries of tensors representing the processed depth
+ predictions.
+
+ Raises:
+ `ValueError`:
+ If the lengths of `predicted_depths`, `fovs`, or `target_sizes` are mismatched.
+ """
+ requires_backends(self, "torch")
+
+ predicted_depth = outputs.predicted_depth
+ fov = outputs.fov
+
+ batch_size = len(predicted_depth)
+
+ if target_sizes is not None and batch_size != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many fov values as the batch dimension of the predicted depth"
+ )
+
+ results = []
+ fov = [None] * batch_size if fov is None else fov
+ target_sizes = [None] * batch_size if target_sizes is None else target_sizes
+ for depth, fov_value, target_size in zip(predicted_depth, fov, target_sizes):
+ if target_size is not None:
+ # scale image w.r.t fov
+ if fov_value is not None:
+ width = target_size[1]
+ fov_value = 0.5 * width / torch.tan(0.5 * torch.deg2rad(fov_value))
+ depth = depth * width / fov_value
+
+ # interpolate
+ depth = torch.nn.functional.interpolate(
+ # input should be (B, C, H, W)
+ input=depth.unsqueeze(0).unsqueeze(1),
+ size=target_size,
+ mode=pil_torch_interpolation_mapping[self.resample].value,
+ antialias=self.antialias,
+ ).squeeze()
+
+ # inverse the depth
+ depth = 1.0 / torch.clamp(depth, min=1e-4, max=1e4)
+
+ results.append(
+ {
+ "predicted_depth": depth,
+ "fov": fov_value,
+ }
+ )
+
+ return results
+
+
+__all__ = ["DepthProImageProcessorFast"]
diff --git a/src/transformers/models/depth_pro/modeling_depth_pro.py b/src/transformers/models/depth_pro/modeling_depth_pro.py
new file mode 100644
index 00000000000000..633d765b49f3f0
--- /dev/null
+++ b/src/transformers/models/depth_pro/modeling_depth_pro.py
@@ -0,0 +1,1686 @@
+# coding=utf-8
+# Copyright 2024 The Apple Research Team Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch DepthPro model."""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Set, Tuple, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+ torch_int,
+)
+from .configuration_depth_pro import DepthProConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "DepthProConfig"
+
+
+DEPTH_PRO_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`DepthProConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+DEPTH_PRO_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`DPTImageProcessor.__call__`]
+ for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+DEPTH_PRO_FOR_DEPTH_ESTIMATION_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`DepthProConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+ use_fov_model (`bool`, *optional*, defaults to `True`):
+ Whether to use `DepthProFOVModel` to generate the field of view.
+"""
+
+
+@dataclass
+class DepthProOutput(ModelOutput):
+ """
+ Base class for DepthPro's outputs.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ features (`List[torch.FloatTensor]`, *optional*:
+ Features from scaled images and hidden_states.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer and the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, n_patches_per_batch, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ features: Optional[List[torch.FloatTensor]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class DepthProDepthEstimatorOutput(ModelOutput):
+ """
+ Base class for DepthProForDepthEstimation's output.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ predicted_depth (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Predicted depth for each pixel.
+ fov (`torch.FloatTensor` of shape `(batch_size,)`, *optional*, returned when `use_fov_model` is provided):
+ Field of View Scaler.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, n_patches_per_batch, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer and the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, n_patches_per_batch, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ predicted_depth: torch.FloatTensor = None
+ fov: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+def patch_to_batch(data: torch.Tensor, batch_size: int) -> torch.Tensor:
+ """
+ Converts tensor from shape:
+ (num_patches, seq_len, hidden_size) -> (batch_size, n_patches_per_batch, seq_len, hidden_size)
+ """
+ data = data.reshape(-1, batch_size, *data.shape[1:])
+ data = data.transpose(0, 1)
+ return data
+
+
+def batch_to_patch(data: torch.Tensor) -> torch.Tensor:
+ """
+ Converts tensor from shape:
+ (batch_size, n_patches_per_batch, seq_len, hidden_size) -> (num_patches, seq_len, hidden_size)
+ """
+ data = data.transpose(0, 1)
+ data = data.reshape(-1, *data.shape[2:])
+ return data
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2PatchEmbeddings with Dinov2->DepthProViT
+class DepthProViTPatchEmbeddings(nn.Module):
+ """
+ This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
+ `hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
+ Transformer.
+ """
+
+ # Ignore copy
+ # addition of config parameter patch_embeddings_size
+ def __init__(self, config):
+ super().__init__()
+
+ self.config = config
+ self.in_channels = config.num_channels
+ self.out_channels = config.hidden_size
+ self.patch_embeddings_size = config.patch_embeddings_size
+ self.num_channels = config.num_channels
+
+ self.projection = nn.Conv2d(
+ self.in_channels,
+ self.out_channels,
+ kernel_size=(self.patch_embeddings_size, self.patch_embeddings_size),
+ stride=(self.patch_embeddings_size, self.patch_embeddings_size),
+ )
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ num_channels = pixel_values.shape[1]
+ if num_channels != self.num_channels:
+ raise ValueError(
+ "Make sure that the channel dimension of the pixel values match with the one set in the configuration."
+ f" Expected {self.num_channels} but got {num_channels}."
+ )
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class DepthProViTEmbeddings(nn.Module):
+ """
+ Copied from transformers.models.dinov2.modeling_dinov2.Dinov2Embeddings
+ except antialias=True in interpolation and removal of mask_token
+ and enabling dynamic embeddings.
+ """
+
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+
+ self.config = config
+ self.seq_len = (config.patch_size // config.patch_embeddings_size) ** 2
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.patch_embeddings = DepthProViTPatchEmbeddings(config)
+ self.position_embeddings = nn.Parameter(torch.zeros(1, self.seq_len + 1, config.hidden_size))
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
+ """
+ This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
+ images. This method is also adapted to support torch.jit tracing and interpolation at torch.float32 precision.
+
+ Adapted from:
+ - https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
+ - https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
+ """
+
+ num_positions = embeddings.shape[1] - 1
+
+ # always interpolate when tracing to ensure the exported model works for dynamic input shapes
+ if not torch.jit.is_tracing() and self.seq_len == num_positions and height == width:
+ return self.position_embeddings
+
+ class_pos_embed = self.position_embeddings[:, :1]
+ patch_pos_embed = self.position_embeddings[:, 1:]
+
+ dim = embeddings.shape[-1]
+
+ new_height = height // self.config.patch_embeddings_size
+ new_width = width // self.config.patch_embeddings_size
+
+ patch_pos_embed_size = torch_int(patch_pos_embed.shape[1] ** 0.5)
+ patch_pos_embed = patch_pos_embed.reshape(1, patch_pos_embed_size, patch_pos_embed_size, dim)
+ patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+ target_dtype = patch_pos_embed.dtype
+
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed.to(torch.float32),
+ size=(new_height, new_width),
+ mode="bicubic",
+ align_corners=False,
+ antialias=True, # except for this, the class is same as transformers.models.dinov2.modeling_dinov2.DepthProViTPatchEmbeddings
+ ).to(dtype=target_dtype)
+
+ patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
+
+ return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ batch_size: Optional[int] = None,
+ ) -> torch.Tensor:
+ n, _, height, width = pixel_values.shape
+ target_dtype = self.patch_embeddings.projection.weight.dtype
+ embeddings = self.patch_embeddings(pixel_values.to(dtype=target_dtype))
+
+ # add the [CLS] token to the embedded patch tokens
+ cls_tokens = self.cls_token.expand(n, -1, -1)
+ embeddings = torch.cat((cls_tokens, embeddings), dim=1)
+
+ # add positional encoding to each token
+ embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
+
+ embeddings = self.dropout(embeddings)
+
+ if batch_size is not None:
+ embeddings = patch_to_batch(embeddings, batch_size)
+
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSelfAttention(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ # Ignore copy
+ # addition of parameter batch_size
+ def forward(
+ self,
+ hidden_states,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ if batch_size is not None:
+ attention_probs_batched = patch_to_batch(attention_probs, batch_size)
+ attention_probs_patched = batch_to_patch(attention_probs_batched)
+ else:
+ attention_probs_patched = attention_probs_batched = attention_probs
+
+ context_layer = torch.matmul(attention_probs_patched, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs_batched) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2SdpaSelfAttention with Dinov2Config->DepthProConfig, Dinov2->DepthProViT
+class DepthProViTSdpaSelfAttention(DepthProViTSelfAttention):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__(config)
+ self.attention_probs_dropout_prob = config.attention_probs_dropout_prob
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "DepthProViTModel is using DepthProViTSdpaSelfAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ batch_size=batch_size,
+ )
+
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ context_layer = torch.nn.functional.scaled_dot_product_attention(
+ query_layer,
+ key_layer,
+ value_layer,
+ head_mask,
+ self.attention_probs_dropout_prob if self.training else 0.0,
+ is_causal=False,
+ scale=None,
+ )
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ return context_layer, None
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSelfOutput(nn.Module):
+ """
+ The residual connection is defined in DepthProViTLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTAttention(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.attention = DepthProViTSelfAttention(config)
+ self.output = DepthProViTSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions, batch_size)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSdpaAttention with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTSdpaAttention(DepthProViTAttention):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__(config)
+ self.attention = DepthProViTSdpaSelfAttention(config)
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2LayerScale with Dinov2Config->DepthProConfig, Dinov2->DepthProViT
+class DepthProViTLayerScale(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ self.lambda1 = nn.Parameter(config.layerscale_value * torch.ones(config.hidden_size))
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ return hidden_state * self.lambda1
+
+
+# Copied from transformers.models.beit.modeling_beit.drop_path
+def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.beit.modeling_beit.BeitDropPath
+class DepthProViTDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2MLP with Dinov2->DepthPro
+class DepthProViTMLP(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ in_features = out_features = config.hidden_size
+ hidden_features = int(config.hidden_size * config.mlp_ratio)
+ self.fc1 = nn.Linear(in_features, hidden_features, bias=True)
+ if isinstance(config.hidden_act, str):
+ self.activation = ACT2FN[config.hidden_act]
+ else:
+ self.activation = config.hidden_act
+ self.fc2 = nn.Linear(hidden_features, out_features, bias=True)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.fc1(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ hidden_state = self.fc2(hidden_state)
+ return hidden_state
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2SwiGLUFFN with Dinov2->DepthPro
+class DepthProViTSwiGLUFFN(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+ in_features = out_features = config.hidden_size
+ hidden_features = int(config.hidden_size * config.mlp_ratio)
+ hidden_features = (int(hidden_features * 2 / 3) + 7) // 8 * 8
+
+ self.weights_in = nn.Linear(in_features, 2 * hidden_features, bias=True)
+ self.weights_out = nn.Linear(hidden_features, out_features, bias=True)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.weights_in(hidden_state)
+ x1, x2 = hidden_state.chunk(2, dim=-1)
+ hidden = nn.functional.silu(x1) * x2
+ return self.weights_out(hidden)
+
+
+DEPTHPROVIT_ATTENTION_CLASSES = {
+ "eager": DepthProViTAttention,
+ "sdpa": DepthProViTSdpaAttention,
+}
+
+
+# Copied from transformers.models.dinov2.modeling_dinov2.Dinov2Layer with Dinov2Config->DepthProConfig, Dinov2->DepthProViT all-casing
+class DepthProViTLayer(nn.Module):
+ """This corresponds to the Block class in the original implementation."""
+
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.attention = DEPTHPROVIT_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.layer_scale1 = DepthProViTLayerScale(config)
+ self.drop_path = DepthProViTDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
+
+ self.norm2 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ if config.use_swiglu_ffn:
+ self.mlp = DepthProViTSwiGLUFFN(config)
+ else:
+ self.mlp = DepthProViTMLP(config)
+ self.layer_scale2 = DepthProViTLayerScale(config)
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ if batch_size is not None:
+ hidden_states = batch_to_patch(hidden_states)
+
+ self_attention_outputs = self.attention(
+ self.norm1(hidden_states), # in DepthProViT, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ batch_size=batch_size,
+ )
+ attention_output = self_attention_outputs[0]
+
+ attention_output = self.layer_scale1(attention_output)
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = self.drop_path(attention_output) + hidden_states
+
+ # in DepthProViT, layernorm is also applied after self-attention
+ layer_output = self.norm2(hidden_states)
+ layer_output = self.mlp(layer_output)
+ layer_output = self.layer_scale2(layer_output)
+
+ # second residual connection
+ layer_output = self.drop_path(layer_output) + hidden_states
+
+ if batch_size is not None:
+ layer_output = patch_to_batch(layer_output, batch_size)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViTConfig->DepthProConfig, ViT->DepthProViT
+class DepthProViTEncoder(nn.Module):
+ def __init__(self, config: DepthProConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([DepthProViTLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ # Ignore copy
+ # addition of `batch_size`
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ batch_size: Optional[int] = None,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ batch_size,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions, batch_size)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class DepthProViT(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ self.embeddings = DepthProViTEmbeddings(config)
+ self.encoder = DepthProViTEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ batch_size: Optional[int] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embedding_output = self.embeddings(pixel_values, batch_size=batch_size)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ batch_size=batch_size,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ if not return_dict:
+ head_outputs = (sequence_output,)
+ return head_outputs + encoder_outputs[1:]
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class DepthProFeatureUpsample(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ self.upsample_blocks = nn.ModuleList()
+
+ # for image_features
+ self.upsample_blocks.append(
+ self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=config.hidden_size,
+ output_dims=config.scaled_images_feature_dims[0],
+ n_upsample_layers=1,
+ use_proj=False,
+ bias=True,
+ )
+ )
+
+ # for scaled_images_features
+ for i, feature_dims in enumerate(config.scaled_images_feature_dims):
+ upsample_block = self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=feature_dims,
+ output_dims=feature_dims,
+ n_upsample_layers=1,
+ )
+ self.upsample_blocks.append(upsample_block)
+
+ # for intermediate_features
+ for i, feature_dims in enumerate(config.intermediate_feature_dims):
+ intermediate_dims = config.fusion_hidden_size if i == 0 else feature_dims
+ upsample_block = self._create_upsample_block(
+ input_dims=config.hidden_size,
+ intermediate_dims=intermediate_dims,
+ output_dims=feature_dims,
+ n_upsample_layers=2 + i,
+ )
+ self.upsample_blocks.append(upsample_block)
+
+ def _create_upsample_block(
+ self,
+ input_dims: int,
+ intermediate_dims: int,
+ output_dims: int,
+ n_upsample_layers: int,
+ use_proj: bool = True,
+ bias: bool = False,
+ ) -> nn.Module:
+ upsample_block = nn.Sequential()
+
+ # create first projection layer
+ if use_proj:
+ proj = nn.Conv2d(
+ in_channels=input_dims,
+ out_channels=intermediate_dims,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=bias,
+ )
+ upsample_block.append(proj)
+
+ # create following upsample layers
+ for i in range(n_upsample_layers):
+ in_channels = intermediate_dims if i == 0 else output_dims
+ layer = nn.ConvTranspose2d(
+ in_channels=in_channels,
+ out_channels=output_dims,
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=bias,
+ )
+ upsample_block.append(layer)
+
+ return upsample_block
+
+ def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
+ upsampled_features = []
+ for i, upsample_block in enumerate(self.upsample_blocks):
+ upsampled_feature = upsample_block(features[i])
+ upsampled_features.append(upsampled_feature)
+ return upsampled_features
+
+
+class DepthProFeatureProjection(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+
+ combined_feature_dims = config.scaled_images_feature_dims + config.intermediate_feature_dims
+ self.projections = nn.ModuleList()
+ for i, in_channels in enumerate(combined_feature_dims):
+ if i == len(combined_feature_dims) - 1 and in_channels == config.fusion_hidden_size:
+ # projection for last layer can be ignored if input and output channels already match
+ self.projections.append(nn.Identity())
+ else:
+ self.projections.append(
+ nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ )
+ )
+
+ def forward(self, features: List[torch.Tensor]) -> List[torch.Tensor]:
+ projected_features = []
+ for i, projection in enumerate(self.projections):
+ upsampled_feature = projection(features[i])
+ projected_features.append(upsampled_feature)
+ return projected_features
+
+
+def interpolate(
+ pixel_values: torch.Tensor, size: Optional[int] = None, scale_factor: Optional[List[float]] = None
+) -> torch.Tensor:
+ return nn.functional.interpolate(
+ pixel_values,
+ size=size,
+ scale_factor=scale_factor,
+ mode="bilinear",
+ align_corners=False,
+ )
+
+
+def patch(pixel_values: torch.Tensor, patch_size: int, overlap_ratio: float) -> torch.Tensor:
+ """Creates Patches from Batch."""
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ if height == width == patch_size:
+ # create patches only if scaled image is not already equal to patch size
+ return pixel_values
+
+ stride = int(patch_size * (1 - overlap_ratio))
+
+ # (batch_size, num_channels, height, width)
+ patches = torch.nn.functional.unfold(pixel_values, kernel_size=(patch_size, patch_size), stride=(stride, stride))
+ # patches.shape (batch_size, patch_size**2 * num_channels, n_patches_per_batch)
+ patches = patches.permute(2, 0, 1)
+ # patches.shape (n_patches_per_batch, batch_size, patch_size**2 * C)
+ patches = patches.reshape(-1, num_channels, patch_size, patch_size)
+ # patches.shape (n_patches, num_channels, patch_size, patch_size)
+
+ return patches
+
+
+def reshape_feature(hidden_states: torch.Tensor) -> torch.Tensor:
+ """Discard class token and reshape 1D feature map to a 2D grid."""
+ n_samples, seq_len, hidden_size = hidden_states.shape
+ size = int(math.sqrt(seq_len))
+
+ # (n_samples, seq_len, hidden_size)
+ hidden_states = hidden_states[:, 1:, :] # remove class token
+ # (n_samples, seq_len, hidden_size)
+ hidden_states = hidden_states.reshape(n_samples, size, size, hidden_size)
+ # (n_samples, size, size, hideden_size)
+ hidden_states = hidden_states.permute(0, 3, 1, 2)
+ # (n_samples, hideden_size, size, size)
+ return hidden_states
+
+
+def merge(patches: torch.Tensor, batch_size: int, merge_out_size: int) -> torch.Tensor:
+ n_patches, hidden_size, out_size, out_size = patches.shape
+ n_patches_per_batch = n_patches // batch_size
+ sqrt_n_patches_per_batch = int(math.sqrt(n_patches_per_batch))
+ new_out_size = sqrt_n_patches_per_batch * out_size
+
+ if n_patches == batch_size:
+ # merge only if the patches were created from scaled image
+ # patches are not created when scaled image size is equal to patch size
+ return patches
+
+ # calculate padding using the formula
+ # merge_out_size = (box_size - 2) * (out_size - 2 * padding) + (2) * (out_size - padding)
+ padding = (sqrt_n_patches_per_batch * out_size - merge_out_size) // (2 * sqrt_n_patches_per_batch - 2)
+
+ # patches.shape (n_patches, hidden_size, out_size, out_size)
+
+ merged = patches.reshape(n_patches_per_batch, batch_size, hidden_size, out_size, out_size)
+ # (n_patches_per_batch, batch_size, hidden_size, out_size, out_size)
+ merged = merged.permute(1, 2, 0, 3, 4)
+ # (batch_size, hidden_size, n_patches_per_batch, out_size, out_size)
+
+ merged = merged[:, :, : sqrt_n_patches_per_batch**2, :, :]
+ # (batch_size, hidden_size, n_patches_per_batch, out_size, out_size)
+
+ merged = merged.reshape(
+ batch_size, hidden_size, sqrt_n_patches_per_batch, sqrt_n_patches_per_batch, out_size, out_size
+ )
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch, sqrt_n_patches_per_batch, out_size, out_size)
+ merged = merged.permute(0, 1, 2, 4, 3, 5)
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch, out_size, sqrt_n_patches_per_batch, out_size)
+ merged = merged.reshape(batch_size, hidden_size, new_out_size, new_out_size)
+ # (batch_size, hidden_size, sqrt_n_patches_per_batch * out_size, sqrt_n_patches_per_batch * out_size)
+
+ if padding != 0:
+ padding_mask = torch.ones((new_out_size, new_out_size), dtype=torch.bool)
+ starting_index = torch.arange(start=out_size - padding, end=new_out_size - padding, step=out_size)
+ for index in starting_index:
+ padding_mask[index : index + padding * 2, :] = False
+ padding_mask[:, index : index + padding * 2] = False
+
+ merged = merged[:, :, padding_mask]
+ final_out_size = int(math.sqrt(merged.shape[-1]))
+ merged = merged.reshape(*merged.shape[:2], final_out_size, final_out_size)
+
+ return merged
+
+
+class DepthProEncoder(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.fusion_hidden_size = config.fusion_hidden_size
+
+ self.intermediate_hook_ids = config.intermediate_hook_ids
+ self.intermediate_feature_dims = config.intermediate_feature_dims
+ self.scaled_images_ratios = config.scaled_images_ratios
+ self.scaled_images_overlap_ratios = config.scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = config.scaled_images_feature_dims
+
+ self.n_scaled_images = len(self.scaled_images_ratios)
+ self.n_intermediate_hooks = len(self.intermediate_hook_ids)
+ self.out_size = config.patch_size // config.patch_embeddings_size
+ self.seq_len = self.out_size**2 # each patch is flattened
+
+ # patch encoder
+ self.patch_encoder = DepthProViT(config)
+
+ # image encoder
+ self.image_encoder = DepthProViT(config)
+
+ # upsample features
+ self.feature_upsample = DepthProFeatureUpsample(config)
+
+ # for STEP 7: fuse low_res and image features
+ self.fuse_image_with_low_res = nn.Conv2d(
+ in_channels=config.scaled_images_feature_dims[0] * 2,
+ out_channels=config.scaled_images_feature_dims[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=True,
+ )
+
+ # project features
+ self.feature_projection = DepthProFeatureProjection(config)
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, DepthProOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values.dim() != 4:
+ raise ValueError("Input tensor must have shape (batch_size, num_channels, height, width).")
+
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ if not (num_channels == self.config.num_channels):
+ raise ValueError(
+ f"Found {num_channels} channels in image, expected number of channels is {self.config.num_channels} from config."
+ )
+
+ if min(self.scaled_images_ratios) * min(height, width) < self.config.patch_size:
+ raise ValueError(
+ f"Image size {height}x{width} is too small to be scaled "
+ f"with scaled_images_ratios={self.scaled_images_ratios} "
+ f"when patch_size={self.config.patch_size}."
+ )
+
+ # pixel_values.shape (batch_size, num_channels, height, width)
+
+ # STEP 1: create 3-level image
+
+ scaled_images = []
+ for ratio in self.scaled_images_ratios:
+ scaled_images.append(interpolate(pixel_values, scale_factor=ratio))
+ # (batch_size, num_channels, height*ratio, width*ratio)
+
+ # STEP 2: create patches
+
+ for i in range(self.n_scaled_images):
+ scaled_images[i] = patch(
+ scaled_images[i],
+ patch_size=self.config.patch_size,
+ overlap_ratio=self.scaled_images_overlap_ratios[i],
+ )
+ # (n_patches_per_scaled_image[i], num_channels, patch_size, patch_size)
+ n_patches_per_scaled_image = [len(i) for i in scaled_images]
+ patches = torch.cat(scaled_images[::-1], dim=0) # -1 as patch encoder expects high res patches first
+ # (n_patches, num_channels, patch_size, patch_size)
+
+ # STEP 3: apply patch and image encoder
+
+ patch_encodings = self.patch_encoder(
+ patches,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ # required for intermediate features
+ output_hidden_states=self.n_intermediate_hooks or output_hidden_states,
+ return_dict=True,
+ batch_size=batch_size,
+ )
+ # patch_encodings.last_hidden_state (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ # patch_encodings.hidden_states[i] (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ # patch_encodings.attentions[i] (batch_size, n_patches/batch_size, num_heads, seq_len, seq_len)
+
+ last_hidden_state = patch_encodings.last_hidden_state
+ # (batch_size, n_patches/batch_size, seq_len, hidden_size)
+ last_hidden_state = batch_to_patch(last_hidden_state)
+ # (n_patches, seq_len, hidden_size)
+ scaled_images_last_hidden_state = torch.split_with_sizes(last_hidden_state, n_patches_per_scaled_image[::-1])
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+ scaled_images_last_hidden_state = scaled_images_last_hidden_state[::-1]
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+ # -1 (reverse list) as patch encoder expects high res patches first
+
+ # scale the image to patch size for image_encoder
+ image_scaled_to_patch_size = interpolate(
+ pixel_values,
+ size=(self.config.patch_size, self.config.patch_size),
+ )
+ image_encodings = self.image_encoder(
+ pixel_values=image_scaled_to_patch_size,
+ head_mask=head_mask,
+ )
+ # image_encodings.last_hidden_state (batch_size, seq_len, hidden_size)
+ # image_encodings.hidden_states[i] (batch_size, seq_len, hidden_size)
+ # image_encodings.attentions[i] (batch_size, num_heads, seq_len, seq_len)
+
+ # STEP 4: get patch features (high_res, med_res, low_res) - (3-5) in diagram
+
+ exponent_value = int(math.log2(width / self.out_size))
+ base_height = height // 2**exponent_value
+ base_width = width // 2**exponent_value
+
+ scaled_images_features = []
+ for i in range(self.n_scaled_images):
+ # a. extract hidden_state
+ hidden_state = scaled_images_last_hidden_state[i]
+ # (n_patches_per_scaled_image[i], seq_len, hidden_size)
+
+ # b. reshape back to image like
+ features = reshape_feature(hidden_state)
+ # (n_patches_per_scaled_image[i], hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ features = merge(
+ features, batch_size=batch_size, merge_out_size=self.out_size * 2**i
+ ) # (batch_size, hidden_size, out_size*2**i, out_size*2**i)
+
+ # d. interpolate patches to base size
+ features = interpolate(features, size=(base_height * 2**i, base_width * 2**i))
+ # (batch_size, hidden_size, base_height*2**i, base_width*2**i)
+
+ scaled_images_features.append(features)
+
+ # STEP 5: get intermediate features - (1-2) in diagram
+
+ intermediate_features = []
+ for i in range(self.n_intermediate_hooks):
+ # a. extract hidden_state
+ layer_id = (
+ self.intermediate_hook_ids[i] + 1
+ ) # +1 to correct index position as hidden_states contain embedding output as well
+ hidden_state = patch_encodings.hidden_states[layer_id]
+ hidden_state = batch_to_patch(hidden_state)
+ hidden_state = hidden_state[
+ : n_patches_per_scaled_image[-1]
+ ] # number of patches to be of same length as highest resolution
+ # (n_patches_per_scaled_image[-1], seq_len, hidden_size)
+
+ # b. reshape back to image like
+ features = reshape_feature(hidden_state)
+ # (n_patches_per_scaled_image[-1], hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ features = merge(
+ features,
+ batch_size=batch_size,
+ merge_out_size=self.out_size * 2 ** (self.n_scaled_images - 1),
+ ) # (batch_size, hidden_size, out_size*2**(n_scaled_images-1), out_size*2**(n_scaled_images-1))
+
+ # d. interpolate patches to base size
+ features = interpolate(
+ features,
+ size=(base_height * 2 ** (self.n_scaled_images - 1), base_width * 2 ** (self.n_scaled_images - 1)),
+ )
+ # (batch_size, hidden_size, base_height*2**(n_scaled_images - 1), base_width*2**(n_scaled_images - 1))
+
+ intermediate_features.append(features)
+
+ # STEP 6: get image features - (6) in diagram
+
+ # a. extract hidden_state
+ hidden_state = image_encodings.last_hidden_state # (batch_size, seq_len, hidden_size)
+
+ # b. reshape back to image like
+ image_features = reshape_feature(hidden_state)
+ # (batch_size, hidden_size, out_size, out_size)
+
+ # c. merge patches back together
+ # no merge required for image_features as they are already in batches instead of patches
+
+ # d. interpolate patches to base size
+ image_features = interpolate(image_features, size=(base_height, base_width))
+ # (batch_size, hidden_size, base_height, base_width)
+
+ # STEP 7: combine all features
+ features = [
+ image_features,
+ # (batch_size, scaled_images_feature_dims[0], base_height*2, base_width*2)
+ *scaled_images_features,
+ # (batch_size, scaled_images_feature_dims[i], base_height*2**(i+1), base_width*2**(i+1))
+ *intermediate_features,
+ # (batch_size, intermediate_feature_dims[i], base_height*2**(n_scaled_images+i+1), base_width*2**(n_scaled_images+i+1))
+ ]
+
+ # STEP 8: upsample features
+ features = self.feature_upsample(features)
+
+ # STEP 9: apply fusion
+ # (global features = low res features + image features)
+ # fuses image_features with lowest resolution features as they are of same size
+ global_features = torch.cat((features[1], features[0]), dim=1)
+ global_features = self.fuse_image_with_low_res(global_features)
+ features = [global_features, *features[2:]]
+
+ # STEP 10: project features
+ features = self.feature_projection(features)
+
+ # STEP 11: return output
+
+ last_hidden_state = patch_encodings.last_hidden_state
+ hidden_states = patch_encodings.hidden_states if output_hidden_states else None
+ attentions = patch_encodings.attentions if output_attentions else None
+
+ if not return_dict:
+ return tuple(v for v in [last_hidden_state, features, hidden_states, attentions] if v is not None)
+
+ return DepthProOutput(
+ last_hidden_state=last_hidden_state,
+ features=features,
+ hidden_states=hidden_states,
+ attentions=attentions,
+ )
+
+
+class DepthProPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = DepthProConfig
+ base_model_prefix = "depth_pro"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["DepthProViTSwiGLUFFN"]
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d, nn.ConvTranspose2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+@add_start_docstrings(
+ "The bare DepthPro Model transformer outputting raw hidden-states without any specific head on top.",
+ DEPTH_PRO_START_DOCSTRING,
+)
+class DepthProModel(DepthProPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+ self.encoder = DepthProEncoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.encoder.patch_encoder.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.patch_encoder.encoder.layer[layer].attention.prune_heads(heads)
+ self.encoder.image_encoder.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(DEPTH_PRO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, DepthProOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> import torch
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, DepthProModel
+
+ >>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> checkpoint = "geetu040/DepthPro"
+ >>> processor = AutoProcessor.from_pretrained(checkpoint)
+ >>> model = DepthProModel.from_pretrained(checkpoint)
+
+ >>> # prepare image for the model
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... output = model(**inputs)
+
+ >>> output.last_hidden_state.shape
+ torch.Size([1, 35, 577, 1024])
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ encodings = self.encoder(
+ pixel_values,
+ head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ return encodings
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreActResidualLayer DPT->DepthPro
+class DepthProPreActResidualLayer(nn.Module):
+ """
+ ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ config (`[DepthProConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.use_batch_norm = config.use_batch_norm_in_fusion_residual
+ use_bias_in_fusion_residual = (
+ config.use_bias_in_fusion_residual
+ if config.use_bias_in_fusion_residual is not None
+ else not self.use_batch_norm
+ )
+
+ self.activation1 = nn.ReLU()
+ self.convolution1 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ self.activation2 = nn.ReLU()
+ self.convolution2 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ if self.use_batch_norm:
+ self.batch_norm1 = nn.BatchNorm2d(config.fusion_hidden_size)
+ self.batch_norm2 = nn.BatchNorm2d(config.fusion_hidden_size)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ residual = hidden_state
+ hidden_state = self.activation1(hidden_state)
+
+ hidden_state = self.convolution1(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm1(hidden_state)
+
+ hidden_state = self.activation2(hidden_state)
+ hidden_state = self.convolution2(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm2(hidden_state)
+
+ return hidden_state + residual
+
+
+# Taken from transformers.models.dpt.modeling_dpt.DPTFeatureFusionLayer
+# except it uses deconv and skip_add and needs no interpolation
+class DepthProFeatureFusionLayer(nn.Module):
+ def __init__(self, config: DepthProConfig, use_deconv: bool = True):
+ super().__init__()
+ self.config = config
+ self.use_deconv = use_deconv
+
+ self.residual_layer1 = DepthProPreActResidualLayer(config)
+ self.residual_layer2 = DepthProPreActResidualLayer(config)
+
+ if self.use_deconv:
+ self.deconv = nn.ConvTranspose2d(
+ in_channels=config.fusion_hidden_size,
+ out_channels=config.fusion_hidden_size,
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=False,
+ )
+
+ self.projection = nn.Conv2d(config.fusion_hidden_size, config.fusion_hidden_size, kernel_size=1, bias=True)
+ self.skip_add = nn.quantized.FloatFunctional()
+
+ def forward(self, hidden_state: torch.Tensor, residual: Optional[torch.Tensor] = None) -> torch.Tensor:
+ if residual is not None:
+ hidden_state = self.skip_add.add(hidden_state, self.residual_layer1(residual))
+
+ hidden_state = self.residual_layer2(hidden_state)
+ if self.use_deconv:
+ hidden_state = self.deconv(hidden_state)
+ hidden_state = self.projection(hidden_state)
+
+ return hidden_state
+
+
+# Take from transformers.models.dpt.modeling_dpt.DPTFeatureFusionStage with DPT->DepthPro
+# with deconv and reversed layers
+class DepthProFeatureFusionStage(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ self.num_layers = len(config.intermediate_hook_ids) + len(config.scaled_images_ratios)
+ self.layers = nn.ModuleList()
+ for _ in range(self.num_layers - 1):
+ self.layers.append(DepthProFeatureFusionLayer(config))
+ # final layer doesnot require deconvolution
+ self.layers.append(DepthProFeatureFusionLayer(config, use_deconv=False))
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> List[torch.Tensor]:
+ if self.num_layers != len(hidden_states):
+ raise ValueError(
+ f"num_layers={self.num_layers} in DepthProFeatureFusionStage"
+ f"doesnot match len(hidden_states)={len(hidden_states)}"
+ )
+
+ fused_hidden_states = []
+ fused_hidden_state = None
+ for hidden_state, layer in zip(hidden_states, self.layers):
+ if fused_hidden_state is None:
+ # first layer only uses the last hidden_state
+ fused_hidden_state = layer(hidden_state)
+ else:
+ fused_hidden_state = layer(fused_hidden_state, hidden_state)
+ fused_hidden_states.append(fused_hidden_state)
+
+ return fused_hidden_states
+
+
+class DepthProFOVModel(nn.Module):
+ def __init__(self, config: DepthProConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.fusion_hidden_size = config.fusion_hidden_size
+
+ self.out_size = config.patch_size // config.patch_embeddings_size
+
+ self.encoder = DepthProViT(config)
+ self.encoder_neck = nn.Linear(self.hidden_size, self.fusion_hidden_size // 2)
+ self.global_neck = nn.Sequential(
+ nn.Conv2d(self.fusion_hidden_size, self.fusion_hidden_size // 2, kernel_size=3, stride=2, padding=1),
+ nn.ReLU(True),
+ )
+
+ # create initial head layers
+ self.head = nn.Sequential()
+ for i in range(config.num_fov_head_layers):
+ self.head.append(
+ nn.Conv2d(
+ math.ceil(self.fusion_hidden_size / 2 ** (i + 1)),
+ math.ceil(self.fusion_hidden_size / 2 ** (i + 2)),
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ )
+ )
+ self.head.append(nn.ReLU(True))
+ # calculate expected shapes to finally generate a scalar output from final head layer
+ final_in_channels = math.ceil(self.fusion_hidden_size / 2 ** (config.num_fov_head_layers + 1))
+ final_kernal_size = int((self.out_size - 1) / 2**config.num_fov_head_layers + 1)
+ self.head.append(
+ nn.Conv2d(
+ in_channels=final_in_channels, out_channels=1, kernel_size=final_kernal_size, stride=1, padding=0
+ )
+ )
+
+ def forward(
+ self,
+ pixel_values: torch.Tensor,
+ global_features: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ batch_size, num_channels, height, width = pixel_values.shape
+
+ # follow the steps same as with image features in DepthProEncoder
+ # except for the extra encoder_neck layer applied
+
+ image_scaled_to_patch_size = interpolate(
+ pixel_values,
+ size=(self.config.patch_size, self.config.patch_size),
+ )
+ encodings = self.encoder(
+ image_scaled_to_patch_size,
+ head_mask=head_mask,
+ )
+
+ # a. extract hidden_state
+ hidden_state = encodings.last_hidden_state # (batch_size, seq_len, hidden_size)
+ # extra step
+ hidden_state = self.encoder_neck(hidden_state)
+ # (batch_size, seq_len, fusion_hidden_size//2)
+
+ # b. reshape back to image like
+ fov_features = reshape_feature(hidden_state)
+ # (batch_size, fusion_hidden_size//2, out_size, out_size)
+
+ # c. merge patches back together
+ # no merge required for fov_features as they are already in batches instead of patches
+
+ # d. interpolate patches to base size
+ # skip; instead interpolate the global features
+
+ global_features = self.global_neck(global_features)
+ global_features = interpolate(global_features, size=(self.out_size, self.out_size))
+
+ fov_features = fov_features + global_features
+ fov_output = self.head(fov_features)
+ fov_output = fov_output.reshape(batch_size)
+
+ return fov_output
+
+
+class DepthProDepthEstimationHead(nn.Module):
+ """
+ The DepthProDepthEstimationHead module serves as the output head for depth estimation tasks.
+ This module comprises a sequence of convolutional and transposed convolutional layers
+ that process the feature map from the fusion to produce a single-channel depth map.
+ Key operations include dimensionality reduction and upsampling to match the input resolution.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ features = config.fusion_hidden_size
+ self.head = nn.Sequential(
+ nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
+ nn.ConvTranspose2d(
+ in_channels=features // 2, out_channels=features // 2, kernel_size=2, stride=2, padding=0, bias=True
+ ),
+ nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
+ nn.ReLU(),
+ )
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> torch.Tensor:
+ predicted_depth = self.head(hidden_states)
+ predicted_depth = predicted_depth.squeeze(dim=1)
+ return predicted_depth
+
+
+@add_start_docstrings(
+ """
+ DepthPro Model with a depth estimation head on top (consisting of 3 convolutional layers).
+ """,
+ DEPTH_PRO_FOR_DEPTH_ESTIMATION_START_DOCSTRING,
+)
+class DepthProForDepthEstimation(DepthProPreTrainedModel):
+ def __init__(self, config, use_fov_model=None):
+ super().__init__(config)
+ self.config = config
+ self.use_fov_model = use_fov_model if use_fov_model is not None else self.config.use_fov_model
+
+ # dinov2 (vit) like encoders
+ self.depth_pro = DepthProModel(config)
+
+ # dpt (vit) like fusion stage
+ self.fusion_stage = DepthProFeatureFusionStage(config)
+
+ # depth estimation head
+ self.head = DepthProDepthEstimationHead(config)
+
+ # dinov2 (vit) like encoder
+ self.fov_model = DepthProFOVModel(config) if self.use_fov_model else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(DEPTH_PRO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=DepthProDepthEstimatorOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ head_mask: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor]]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Ground truth depth estimation maps for computing the loss.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoImageProcessor, DepthProForDepthEstimation
+ >>> import torch
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> checkpoint = "geetu040/DepthPro"
+ >>> processor = AutoImageProcessor.from_pretrained(checkpoint)
+ >>> model = DepthProForDepthEstimation.from_pretrained(checkpoint)
+
+ >>> # prepare image for the model
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+
+ >>> # interpolate to original size
+ >>> post_processed_output = processor.post_process_depth_estimation(
+ ... outputs, target_sizes=[(image.height, image.width)],
+ ... )
+
+ >>> # visualize the prediction
+ >>> predicted_depth = post_processed_output[0]["predicted_depth"]
+ >>> depth = predicted_depth * 255 / predicted_depth.max()
+ >>> depth = depth.detach().cpu().numpy()
+ >>> depth = Image.fromarray(depth.astype("uint8"))
+ ```"""
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not implemented yet")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+
+ depth_pro_outputs = self.depth_pro(
+ pixel_values=pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=True,
+ )
+ features = depth_pro_outputs.features
+ fused_hidden_states = self.fusion_stage(features)
+ predicted_depth = self.head(fused_hidden_states[-1])
+
+ fov = (
+ self.fov_model(
+ pixel_values=pixel_values,
+ # frozon features from encoder are used
+ global_features=features[0].detach(),
+ head_mask=head_mask,
+ )
+ if self.use_fov_model
+ else None
+ )
+
+ if not return_dict:
+ outputs = [loss, predicted_depth, fov, depth_pro_outputs.hidden_states, depth_pro_outputs.attentions]
+ return tuple(v for v in outputs if v is not None)
+
+ return DepthProDepthEstimatorOutput(
+ loss=loss,
+ predicted_depth=predicted_depth,
+ fov=fov,
+ hidden_states=depth_pro_outputs.hidden_states,
+ attentions=depth_pro_outputs.attentions,
+ )
+
+
+__all__ = ["DepthProPreTrainedModel", "DepthProModel", "DepthProForDepthEstimation"]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index e3463461ea07e5..419bb07665e858 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -3551,6 +3551,27 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class DepthProForDepthEstimation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class DepthProModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class DepthProPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class DetrForObjectDetection(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 3ebda4404aae9c..2b3e46e63cc55b 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -184,6 +184,20 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class DepthProImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
+class DepthProImageProcessorFast(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DetrFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/depth_pro/__init__.py b/tests/models/depth_pro/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/depth_pro/test_image_processing_depth_pro.py b/tests/models/depth_pro/test_image_processing_depth_pro.py
new file mode 100644
index 00000000000000..e9d94151e145ec
--- /dev/null
+++ b/tests/models/depth_pro/test_image_processing_depth_pro.py
@@ -0,0 +1,113 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.file_utils import is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import DepthProImageProcessor, DepthProImageProcessorFast
+
+
+class DepthProImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ super().__init__()
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DepthProImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DepthProImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DepthProImageProcessorFast if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DepthProImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "antialias"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
diff --git a/tests/models/depth_pro/test_modeling_depth_pro.py b/tests/models/depth_pro/test_modeling_depth_pro.py
new file mode 100644
index 00000000000000..ad17476c664dcf
--- /dev/null
+++ b/tests/models/depth_pro/test_modeling_depth_pro.py
@@ -0,0 +1,375 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DepthPro model."""
+
+import unittest
+
+from transformers import DepthProConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DepthProForDepthEstimation, DepthProModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DepthProImageProcessor
+
+
+class DepthProModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ image_size=64,
+ patch_size=8,
+ patch_embeddings_size=4,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ fusion_hidden_size=16,
+ intermediate_hook_ids=[0],
+ intermediate_feature_dims=[8],
+ scaled_images_ratios=[0.5, 1.0],
+ scaled_images_overlap_ratios=[0.0, 0.2],
+ scaled_images_feature_dims=[12, 12],
+ num_hidden_layers=1,
+ num_attention_heads=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ use_fov_model=False,
+ num_labels=3,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.patch_embeddings_size = patch_embeddings_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.fusion_hidden_size = fusion_hidden_size
+ self.intermediate_hook_ids = intermediate_hook_ids
+ self.intermediate_feature_dims = intermediate_feature_dims
+ self.scaled_images_ratios = scaled_images_ratios
+ self.scaled_images_overlap_ratios = scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = scaled_images_feature_dims
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.use_fov_model = use_fov_model
+ self.num_labels = num_labels
+
+ self.num_patches = (patch_size // patch_embeddings_size) ** 2
+ self.seq_length = (patch_size // patch_embeddings_size) ** 2 + 1 # we add 1 for the [CLS] token
+
+ n_fusion_blocks = len(intermediate_hook_ids) + len(scaled_images_ratios)
+ self.expected_depth_size = 2 ** (n_fusion_blocks + 1) * patch_size // patch_embeddings_size
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DepthProConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ patch_embeddings_size=self.patch_embeddings_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ fusion_hidden_size=self.fusion_hidden_size,
+ intermediate_hook_ids=self.intermediate_hook_ids,
+ intermediate_feature_dims=self.intermediate_feature_dims,
+ scaled_images_ratios=self.scaled_images_ratios,
+ scaled_images_overlap_ratios=self.scaled_images_overlap_ratios,
+ scaled_images_feature_dims=self.scaled_images_feature_dims,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ initializer_range=self.initializer_range,
+ use_fov_model=self.use_fov_model,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DepthProModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ num_patches = result.last_hidden_state.shape[1] # num_patches are created dynamically
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, num_patches, self.seq_length, self.hidden_size)
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DepthProForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.predicted_depth.shape, (self.batch_size, self.expected_depth_size, self.expected_depth_size)
+ )
+
+ def create_and_check_for_fov(self, config, pixel_values, labels):
+ model = DepthProForDepthEstimation(config, use_fov_model=True)
+ model.to(torch_device)
+ model.eval()
+
+ # check if the fov_model (DinoV2-based encoder) is created
+ self.parent.assertIsNotNone(model.fov_model)
+
+ batched_pixel_values = pixel_values
+ row_pixel_values = pixel_values[:1]
+
+ with torch.no_grad():
+ model_batched_output_fov = model(batched_pixel_values).fov
+ model_row_output_fov = model(row_pixel_values).fov
+
+ # check if fov is returned
+ self.parent.assertIsNotNone(model_batched_output_fov)
+ self.parent.assertIsNotNone(model_row_output_fov)
+
+ # check output shape consistency for fov
+ self.parent.assertEqual(model_batched_output_fov.shape, (self.batch_size,))
+
+ # check equivalence between batched and single row outputs for fov
+ diff = torch.max(torch.abs(model_row_output_fov - model_batched_output_fov[:1]))
+ model_name = model.__class__.__name__
+ self.parent.assertTrue(
+ diff <= 1e-03,
+ msg=(f"Batched and Single row outputs are not equal in {model_name} for fov. " f"Difference={diff}."),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DepthProModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DepthPro does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DepthProModel, DepthProForDepthEstimation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "depth-estimation": DepthProForDepthEstimation,
+ "image-feature-extraction": DepthProModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = DepthProModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DepthProConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="DepthPro does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_for_fov(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_fov(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ # Skip the check for the backbone
+ backbone_params = []
+ for name, module in model.named_modules():
+ if module.__class__.__name__ == "DepthProViTHybridEmbeddings":
+ backbone_params = [f"{name}.{key}" for key in module.state_dict().keys()]
+ break
+
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if name in backbone_params:
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_path = "geetu040/DepthPro"
+ model = DepthProModel.from_pretrained(model_path)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DepthProModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ model_path = "geetu040/DepthPro"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path).to(torch_device)
+ config = model.config
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ n_fusion_blocks = len(config.intermediate_hook_ids) + len(config.scaled_images_ratios)
+ expected_depth_size = 2 ** (n_fusion_blocks + 1) * config.patch_size // config.patch_embeddings_size
+ expected_shape = torch.Size((1, expected_depth_size, expected_depth_size))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.0582, 1.1225, 1.1335], [1.1154, 1.1398, 1.1486], [1.1434, 1.1500, 1.1643]]
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))
+
+ def test_post_processing_depth_estimation(self):
+ model_path = "geetu040/DepthPro"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ outputs = image_processor.post_process_depth_estimation(
+ outputs,
+ target_sizes=[[image.height, image.width]],
+ )
+ predicted_depth = outputs[0]["predicted_depth"]
+ expected_shape = torch.Size((image.height, image.width))
+ self.assertTrue(predicted_depth.shape == expected_shape)