diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 58c9b317bc754b..da7ad1fd70c651 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -73,6 +73,8 @@
title: Depth estimation
- local: tasks/image_to_image
title: Image-to-Image
+ - local: tasks/mask_generation
+ title: Mask Generation
- local: tasks/knowledge_distillation_for_image_classification
title: Knowledge Distillation for Computer Vision
title: Computer Vision
diff --git a/docs/source/en/tasks/mask_generation.md b/docs/source/en/tasks/mask_generation.md
new file mode 100644
index 00000000000000..e16b014f3757ab
--- /dev/null
+++ b/docs/source/en/tasks/mask_generation.md
@@ -0,0 +1,238 @@
+
+
+# Mask Generation
+
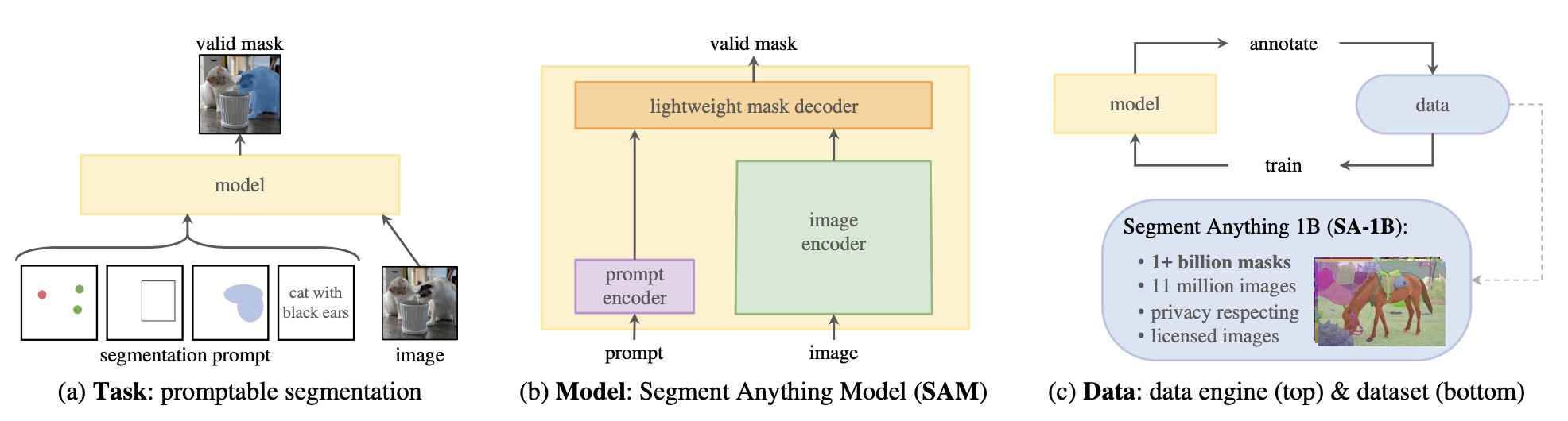
+Mask generation is the task of generating semantically meaningful masks for an image.
+This task is very similar to [image segmentation](semantic_segmentation), but many differences exist. Image segmentation models are trained on labeled datasets and are limited to the classes they have seen during training; they return a set of masks and corresponding classes, given an image.
+
+Mask generation models are trained on large amounts of data and operate in two modes.
+- Prompting mode: In this mode, the model takes in an image and a prompt, where a prompt can be a 2D point location (XY coordinates) in the image within an object or a bounding box surrounding an object. In prompting mode, the model only returns the mask over the object
+that the prompt is pointing out.
+- Segment Everything mode: In segment everything, given an image, the model generates every mask in the image. To do so, a grid of points is generated and overlaid on the image for inference.
+
+Mask generation task is supported by [Segment Anything Model (SAM)](model_doc/sam). It's a powerful model that consists of a Vision Transformer-based image encoder, a prompt encoder, and a two-way transformer mask decoder. Images and prompts are encoded, and the decoder takes these embeddings and generates valid masks.
+
+
+
+
+

+
+

+
+

+
+

+
+

+