diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 20aee769939ad8..4a0e3e458c4b00 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -135,6 +135,8 @@
title: Overview
- local: quantization
title: Quantization
+ - local: trainer
+ title: Trainer
- sections:
- local: perf_train_gpu_one
title: Methods and tools for efficient training on a single GPU
diff --git a/docs/source/en/main_classes/trainer.md b/docs/source/en/main_classes/trainer.md
index cf1dd672d3d472..beb3241e6232a3 100644
--- a/docs/source/en/main_classes/trainer.md
+++ b/docs/source/en/main_classes/trainer.md
@@ -16,70 +16,23 @@ rendered properly in your Markdown viewer.
# Trainer
-The [`Trainer`] class provides an API for feature-complete training in PyTorch for most standard use cases. It's used in most of the [example scripts](https://github.com/huggingface/transformers/tree/main/examples).
+The [`Trainer`] class provides an API for feature-complete training in PyTorch, and it supports distributed training on multiple GPUs/TPUs, mixed precision for [NVIDIA GPUs](https://nvidia.github.io/apex/), [AMD GPUs](https://rocm.docs.amd.com/en/latest/rocm.html), and [`torch.amp`](https://pytorch.org/docs/stable/amp.html) for PyTorch. [`Trainer`] goes hand-in-hand with the [`TrainingArguments`] class, which offers a wide range of options to customize how a model is trained. Together, these two classes provide a complete training API.
-
-
-If you're looking to fine-tune a language model like Llama-2 or Mistral on a text dataset using autoregressive techniques, consider using [`trl`](https://github.com/huggingface/trl)'s [`~trl.SFTTrainer`]. The [`~trl.SFTTrainer`] wraps the [`Trainer`] and is specially optimized for this particular task and supports sequence packing, LoRA, quantization, and DeepSpeed for efficient scaling to any model size. On the other hand, the [`Trainer`] is a more versatile option, suitable for a broader spectrum of tasks.
-
-
-
-Before instantiating your [`Trainer`], create a [`TrainingArguments`] to access all the points of customization during training.
-
-The API supports distributed training on multiple GPUs/TPUs, mixed precision through [NVIDIA Apex] for NVIDIA GPUs, [ROCm APEX](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, and Native AMP for PyTorch.
-
-The [`Trainer`] contains the basic training loop which supports the above features. To inject custom behavior you can subclass them and override the following methods:
-
-- **get_train_dataloader** -- Creates the training DataLoader.
-- **get_eval_dataloader** -- Creates the evaluation DataLoader.
-- **get_test_dataloader** -- Creates the test DataLoader.
-- **log** -- Logs information on the various objects watching training.
-- **create_optimizer_and_scheduler** -- Sets up the optimizer and learning rate scheduler if they were not passed at
- init. Note, that you can also subclass or override the `create_optimizer` and `create_scheduler` methods
- separately.
-- **create_optimizer** -- Sets up the optimizer if it wasn't passed at init.
-- **create_scheduler** -- Sets up the learning rate scheduler if it wasn't passed at init.
-- **compute_loss** - Computes the loss on a batch of training inputs.
-- **training_step** -- Performs a training step.
-- **prediction_step** -- Performs an evaluation/test step.
-- **evaluate** -- Runs an evaluation loop and returns metrics.
-- **predict** -- Returns predictions (with metrics if labels are available) on a test set.
+[`Seq2SeqTrainer`] and [`Seq2SeqTrainingArguments`] inherit from the [`Trainer`] and [`TrainingArgument`] classes and they're adapted for training models for sequence-to-sequence tasks such as summarization or translation.
The [`Trainer`] class is optimized for 🤗 Transformers models and can have surprising behaviors
-when you use it on other models. When using it on your own model, make sure:
+when used with other models. When using it with your own model, make sure:
-- your model always return tuples or subclasses of [`~utils.ModelOutput`].
+- your model always return tuples or subclasses of [`~utils.ModelOutput`]
- your model can compute the loss if a `labels` argument is provided and that loss is returned as the first
element of the tuple (if your model returns tuples)
-- your model can accept multiple label arguments (use the `label_names` in your [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`.
+- your model can accept multiple label arguments (use `label_names` in [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`
-Here is an example of how to customize [`Trainer`] to use a weighted loss (useful when you have an unbalanced training set):
-
-```python
-from torch import nn
-from transformers import Trainer
-
-
-class CustomTrainer(Trainer):
- def compute_loss(self, model, inputs, return_outputs=False):
- labels = inputs.pop("labels")
- # forward pass
- outputs = model(**inputs)
- logits = outputs.get("logits")
- # compute custom loss (suppose one has 3 labels with different weights)
- loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
- loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
- return (loss, outputs) if return_outputs else loss
-```
-
-Another way to customize the training loop behavior for the PyTorch [`Trainer`] is to use [callbacks](callback) that can inspect the training loop state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early stopping).
-
-
-## Trainer
+## Trainer[[api-reference]]
[[autodoc]] Trainer
- all
@@ -100,105 +53,6 @@ Another way to customize the training loop behavior for the PyTorch [`Trainer`]
[[autodoc]] Seq2SeqTrainingArguments
- all
-## Checkpoints
-
-By default, [`Trainer`] will save all checkpoints in the `output_dir` you set in the
-[`TrainingArguments`] you are using. Those will go in subfolder named `checkpoint-xxx` with xxx
-being the step at which the training was at.
-
-Resuming training from a checkpoint can be done when calling [`Trainer.train`] with either:
-
-- `resume_from_checkpoint=True` which will resume training from the latest checkpoint
-- `resume_from_checkpoint=checkpoint_dir` which will resume training from the specific checkpoint in the directory
- passed.
-
-In addition, you can easily save your checkpoints on the Model Hub when using `push_to_hub=True`. By default, all
-the models saved in intermediate checkpoints are saved in different commits, but not the optimizer state. You can adapt
-the `hub-strategy` value of your [`TrainingArguments`] to either:
-
-- `"checkpoint"`: the latest checkpoint is also pushed in a subfolder named last-checkpoint, allowing you to
- resume training easily with `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")`.
-- `"all_checkpoints"`: all checkpoints are pushed like they appear in the output folder (so you will get one
- checkpoint folder per folder in your final repository)
-
-
-## Logging
-
-By default [`Trainer`] will use `logging.INFO` for the main process and `logging.WARNING` for the replicas if any.
-
-These defaults can be overridden to use any of the 5 `logging` levels with [`TrainingArguments`]'s
-arguments:
-
-- `log_level` - for the main process
-- `log_level_replica` - for the replicas
-
-Further, if [`TrainingArguments`]'s `log_on_each_node` is set to `False` only the main node will
-use the log level settings for its main process, all other nodes will use the log level settings for replicas.
-
-Note that [`Trainer`] is going to set `transformers`'s log level separately for each node in its
-[`Trainer.__init__`]. So you may want to set this sooner (see the next example) if you tap into other
-`transformers` functionality before creating the [`Trainer`] object.
-
-Here is an example of how this can be used in an application:
-
-```python
-[...]
-logger = logging.getLogger(__name__)
-
-# Setup logging
-logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
-)
-
-# set the main code and the modules it uses to the same log-level according to the node
-log_level = training_args.get_process_log_level()
-logger.setLevel(log_level)
-datasets.utils.logging.set_verbosity(log_level)
-transformers.utils.logging.set_verbosity(log_level)
-
-trainer = Trainer(...)
-```
-
-And then if you only want to see warnings on the main node and all other nodes to not print any most likely duplicated
-warnings you could run it as:
-
-```bash
-my_app.py ... --log_level warning --log_level_replica error
-```
-
-In the multi-node environment if you also don't want the logs to repeat for each node's main process, you will want to
-change the above to:
-
-```bash
-my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
-```
-
-and then only the main process of the first node will log at the "warning" level, and all other processes on the main
-node and all processes on other nodes will log at the "error" level.
-
-If you need your application to be as quiet as possible you could do:
-
-```bash
-my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
-```
-
-(add `--log_on_each_node 0` if on multi-node environment)
-
-
-## Randomness
-
-When resuming from a checkpoint generated by [`Trainer`] all efforts are made to restore the
-_python_, _numpy_ and _pytorch_ RNG states to the same states as they were at the moment of saving that checkpoint,
-which should make the "stop and resume" style of training as close as possible to non-stop training.
-
-However, due to various default non-deterministic pytorch settings this might not fully work. If you want full
-determinism please refer to [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness). As explained in the document, that some of those settings
-that make things deterministic (.e.g., `torch.backends.cudnn.deterministic`) may slow things down, therefore this
-can't be done by default, but you can enable those yourself if needed.
-
-
## Specific GPUs Selection
Let's discuss how you can tell your program which GPUs are to be used and in what order.
@@ -295,9 +149,6 @@ In this example we are working with just 2 GPUs, but of course the same would ap
Also if you do set this environment variable it's the best to set it in your `~/.bashrc` file or some other startup config file and forget about it.
-
-
-
## Trainer Integrations
The [`Trainer`] has been extended to support libraries that may dramatically improve your training
@@ -579,156 +430,6 @@ Finally, please, remember that, 🤗 `Trainer` only integrates MPS backend, ther
have any problems or questions with regards to MPS backend usage, please,
file an issue with [PyTorch GitHub](https://github.com/pytorch/pytorch/issues).
-
-## Using Accelerate Launcher with Trainer
-
-Accelerate now powers Trainer. In terms of what users should expect:
-- They can keep using the Trainer ingterations such as FSDP, DeepSpeed vis trainer arguments without any changes on their part.
-- They can now use Accelerate Launcher with Trainer (recommended).
-
-Steps to use Accelerate Launcher with Trainer:
-1. Make sure 🤗 Accelerate is installed, you can't use the `Trainer` without it anyway. If not `pip install accelerate`. You may also need to update your version of Accelerate: `pip install accelerate --upgrade`
-2. Run `accelerate config` and fill the questionnaire. Below are example accelerate configs:
- a. DDP Multi-node Multi-GPU config:
- ```yaml
- compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- downcast_bf16: 'no'
- gpu_ids: all
- machine_rank: 0 #change rank as per the node
- main_process_ip: 192.168.20.1
- main_process_port: 9898
- main_training_function: main
- mixed_precision: fp16
- num_machines: 2
- num_processes: 8
- rdzv_backend: static
- same_network: true
- tpu_env: []
- tpu_use_cluster: false
- tpu_use_sudo: false
- use_cpu: false
- ```
-
- b. FSDP config:
- ```yaml
- compute_environment: LOCAL_MACHINE
- distributed_type: FSDP
- downcast_bf16: 'no'
- fsdp_config:
- fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
- fsdp_backward_prefetch_policy: BACKWARD_PRE
- fsdp_forward_prefetch: true
- fsdp_offload_params: false
- fsdp_sharding_strategy: 1
- fsdp_state_dict_type: FULL_STATE_DICT
- fsdp_sync_module_states: true
- fsdp_transformer_layer_cls_to_wrap: BertLayer
- fsdp_use_orig_params: true
- machine_rank: 0
- main_training_function: main
- mixed_precision: bf16
- num_machines: 1
- num_processes: 2
- rdzv_backend: static
- same_network: true
- tpu_env: []
- tpu_use_cluster: false
- tpu_use_sudo: false
- use_cpu: false
- ```
- c. DeepSpeed config pointing to a file:
- ```yaml
- compute_environment: LOCAL_MACHINE
- deepspeed_config:
- deepspeed_config_file: /home/user/configs/ds_zero3_config.json
- zero3_init_flag: true
- distributed_type: DEEPSPEED
- downcast_bf16: 'no'
- machine_rank: 0
- main_training_function: main
- num_machines: 1
- num_processes: 4
- rdzv_backend: static
- same_network: true
- tpu_env: []
- tpu_use_cluster: false
- tpu_use_sudo: false
- use_cpu: false
- ```
-
- d. DeepSpeed config using accelerate plugin:
- ```yaml
- compute_environment: LOCAL_MACHINE
- deepspeed_config:
- gradient_accumulation_steps: 1
- gradient_clipping: 0.7
- offload_optimizer_device: cpu
- offload_param_device: cpu
- zero3_init_flag: true
- zero_stage: 2
- distributed_type: DEEPSPEED
- downcast_bf16: 'no'
- machine_rank: 0
- main_training_function: main
- mixed_precision: bf16
- num_machines: 1
- num_processes: 4
- rdzv_backend: static
- same_network: true
- tpu_env: []
- tpu_use_cluster: false
- tpu_use_sudo: false
- use_cpu: false
- ```
-
-3. Run the Trainer script with args other than the ones handled above by accelerate config or launcher args.
-Below is an example to run `run_glue.py` using `accelerate launcher` with FSDP config from above.
-
-```bash
-cd transformers
-
-accelerate launch \
-./examples/pytorch/text-classification/run_glue.py \
---model_name_or_path bert-base-cased \
---task_name $TASK_NAME \
---do_train \
---do_eval \
---max_seq_length 128 \
---per_device_train_batch_size 16 \
---learning_rate 5e-5 \
---num_train_epochs 3 \
---output_dir /tmp/$TASK_NAME/ \
---overwrite_output_dir
-```
-
-4. You can also directly use the cmd args for `accelerate launch`. Above example would map to:
-
-```bash
-cd transformers
-
-accelerate launch --num_processes=2 \
---use_fsdp \
---mixed_precision=bf16 \
---fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
---fsdp_transformer_layer_cls_to_wrap="BertLayer" \
---fsdp_sharding_strategy=1 \
---fsdp_state_dict_type=FULL_STATE_DICT \
-./examples/pytorch/text-classification/run_glue.py
---model_name_or_path bert-base-cased \
---task_name $TASK_NAME \
---do_train \
---do_eval \
---max_seq_length 128 \
---per_device_train_batch_size 16 \
---learning_rate 5e-5 \
---num_train_epochs 3 \
---output_dir /tmp/$TASK_NAME/ \
---overwrite_output_dir
-```
-
-For more information, please refer the 🤗 Accelerate CLI guide: [Launching your 🤗 Accelerate scripts](https://huggingface.co/docs/accelerate/basic_tutorials/launch).
-
Sections that were moved:
[ DeepSpeed
@@ -755,27 +456,3 @@ Sections that were moved:
| Gradient Clipping
| Getting The Model Weights Out
]
-
-## Boost your fine-tuning performances using NEFTune
-
-
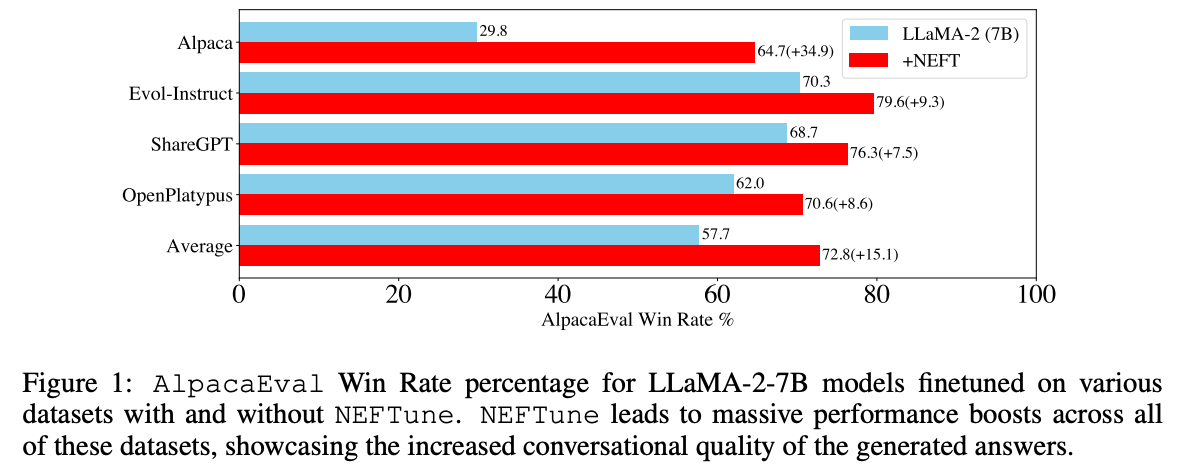
-NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
-
-> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
-
-
-
-
+
+Feel free to check out the [API reference](./main_classes/trainer) for these other [`Trainer`]-type classes to learn more about when to use which one. In general, [`Trainer`] is the most versatile option and is appropriate for a broad spectrum of tasks. [`Seq2SeqTrainer`] is designed for sequence-to-sequence tasks and [`~trl.SFTTrainer`] is designed for training language models.
+
+
+
+Before you start, make sure [Accelerate](https://hf.co/docs/accelerate) - a library for enabling and running PyTorch training across distributed environments - is installed.
+
+```bash
+pip install accelerate
+
+# upgrade
+pip install accelerate --upgrade
+```
+
+This guide provides an overview of the [`Trainer`] class.
+
+## Basic usage
+
+[`Trainer`] includes all the code you'll find in a basic training loop:
+
+1. perform a training step to calculate the loss
+2. calculate the gradients with the [`~accelerate.Accelerator.backward`] method
+3. update the weights based on the gradients
+4. repeat this process until you've reached a predetermined number of epochs
+
+The [`Trainer`] class abstracts all of this code away so you don't have to worry about manually writing a training loop every time or if you're just getting started with PyTorch and training. You only need to provide the essential components required for training, such as a model and a dataset, and the [`Trainer`] class handles everything else.
+
+If you want to specify any training options or hyperparameters, you can find them in the [`TrainingArguments`] class. For example, let's define where to save the model in `output_dir` and push the model to the Hub after training with `push_to_hub=True`.
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments(
+ output_dir="your-model",
+ learning_rate=2e-5,
+ per_device_train_batch_size=16,
+ per_device_eval_batch_size=16,
+ num_train_epochs=2,
+ weight_decay=0.01,
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ load_best_model_at_end=True,
+ push_to_hub=True,
+)
+```
+
+Pass `training_args` to the [`Trainer`] along with a model, dataset, something to preprocess the dataset with (depending on your data type it could be a tokenizer, feature extractor or image processor), a data collator, and a function to compute the metrics you want to track during training.
+
+Finally, call [`~Trainer.train`] to start training!
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ tokenizer=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+)
+
+trainer.train()
+```
+
+### Checkpoints
+
+The [`Trainer`] class saves your model checkpoints to the directory specified in the `output_dir` parameter of [`TrainingArguments`]. You'll find the checkpoints saved in a `checkpoint-000` subfolder where the numbers at the end correspond to the training step. Saving checkpoints are useful for resuming training later.
+
+```py
+# resume from latest checkpoint
+trainer.train(resume_from_checkpoint=True)
+
+# resume from specific checkpoint saved in output directory
+trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
+```
+
+You can save your checkpoints (the optimizer state is not saved by default) to the Hub by setting `push_to_hub=True` in [`TrainingArguments`] to commit and push them. Other options for deciding how your checkpoints are saved are set up in the [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy) parameter:
+
+* `hub_strategy="checkpoint"` pushes the latest checkpoint to a subfolder named "last-checkpoint" from which you can resume training
+* `hug_strategy="all_checkpoints"` pushes all checkpoints to the directory defined in `output_dir` (you'll see one checkpoint per folder in your model repository)
+
+When you resume training from a checkpoint, the [`Trainer`] tries to keep the Python, NumPy, and PyTorch RNG states the same as they were when the checkpoint was saved. But because PyTorch has various non-deterministic default settings, the RNG states aren't guaranteed to be the same. If you want to enable full determinism, take a look at the [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) guide to learn what you can enable to make your training fully deterministic. Keep in mind though that by making certain settings deterministic, training may be slower.
+
+## Customize the Trainer
+
+While the [`Trainer`] class is designed to be accessible and easy-to-use, it also offers a lot of customizability for more adventurous users. Many of the [`Trainer`]'s method can be subclassed and overridden to support the functionality you want, without having to rewrite the entire training loop from scratch to accommodate it. These methods include:
+
+* [`~Trainer.get_train_dataloader`] creates a training DataLoader
+* [`~Trainer.get_eval_dataloader`] creates an evaluation DataLoader
+* [`~Trainer.get_test_dataloader`] creates a test DataLoader
+* [`~Trainer.log`] logs information on the various objects that watch training
+* [`~Trainer.create_optimizer_and_scheduler`] creates an optimizer and learning rate scheduler if they weren't passed in the `__init__`; these can also be separately customized with [`~Trainer.create_optimizer`] and [`~Trainer.create_scheduler`] respectively
+* [`~Trainer.compute_loss`] computes the loss on a batch of training inputs
+* [`~Trainer.training_step`] performs the training step
+* [`~Trainer.prediction_step`] performs the prediction and test step
+* [`~Trainer.evaluate`] evaluates the model and returns the evaluation metrics
+* [`~Trainer.predict`] makes predictions (with metrics if labels are available) on the test set
+
+For example, if you want to customize the [`~Trainer.compute_loss`] method to use a weighted loss instead.
+
+```py
+from torch import nn
+from transformers import Trainer
+
+class CustomTrainer(Trainer):
+ def compute_loss(self, model, inputs, return_outputs=False):
+ labels = inputs.pop("labels")
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.get("logits")
+ # compute custom loss for 3 labels with different weights
+ loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
+ loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
+ return (loss, outputs) if return_outputs else loss
+```
+
+### Callbacks
+
+Another option for customizing the [`Trainer`] is to use [callbacks](callbacks). Callbacks *don't change* anything in the training loop. They inspect the training loop state and then execute some action (early stopping, logging results, etc.) depending on the state. In other words, a callback can't be used to implement something like a custom loss function and you'll need to subclass and override the [`~Trainer.compute_loss`] method for that.
+
+For example, if you want to add an early stopping callback to the training loop after 10 steps.
+
+```py
+from transformers import TrainerCallback
+
+class EarlyStoppingCallback(TrainerCallback):
+ def __init__(self, num_steps=10):
+ self.num_steps = num_steps
+
+ def on_step_end(self, args, state, control, **kwargs):
+ if state.global_step >= self.num_steps:
+ return {"should_training_stop": True}
+ else:
+ return {}
+```
+
+Then pass it to the [`Trainer`]'s `callback` parameter.
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ tokenizer=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ callback=[EarlyStoppingCallback()],
+)
+```
+
+## Logging
+
+
+
+Check out the [logging](./main_classes/logging) API reference for more information about the different logging levels.
+
+
+
+The [`Trainer`] is set to `logging.INFO` by default which reports errors, warnings, and other basic information. A [`Trainer`] replica - in distributed environments - is set to `logging.WARNING` which only reports errors and warnings. You can change the logging level with the [`log_level`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level) and [`log_level_replica`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level_replica) parameters in [`TrainingArguments`].
+
+To configure the log level setting for each node, use the [`log_on_each_node`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.log_on_each_node) parameter to determine whether to use the log level on each node or only on the main node.
+
+
+
+[`Trainer`] sets the log level separately for each node in the [`Trainer.__init__`] method, so you may want to consider setting this sooner if you're using other Transformers functionalities before creating the [`Trainer`] object.
+
+
+
+For example, to set your main code and modules to use the same log level according to each node:
+
+```py
+logger = logging.getLogger(__name__)
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+)
+
+log_level = training_args.get_process_log_level()
+logger.setLevel(log_level)
+datasets.utils.logging.set_verbosity(log_level)
+transformers.utils.logging.set_verbosity(log_level)
+
+trainer = Trainer(...)
+```
+
+Use different combinations of `log_level` and `log_level_replica` to configure what gets logged on each of the nodes.
+
+
+
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error
+```
+
+
+
+
+Add the `log_on_each_node 0` parameter for multi-node environments.
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
+
+# set to only report errors
+my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
+```
+
+
+
+
+## NEFTune
+
+[NEFTune](https://hf.co/papers/2310.05914) is a technique that can improve performance by adding noise to the embedding vectors during training. To enable it in [`Trainer`], set the `neftune_noise_alpha` parameter in [`TrainingArguments`] to control how much noise is added.
+
+```py
+from transformers import TrainingArguments, Trainer
+
+training_args = TrainingArguments(..., neftune_noise_alpha=0.1)
+trainer = Trainer(..., args=training_args)
+```
+
+NEFTune is disabled after training to restore the original embedding layer to avoid any unexpected behavior.
+
+## Accelerate and Trainer
+
+The [`Trainer`] class is powered by [Accelerate](https://hf.co/docs/accelerate), a library for easily training PyTorch models in distributed environments with support for integrations such as [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) and [DeepSpeed](https://www.deepspeed.ai/).
+
+To use Accelerate with [`Trainer`], run the [`accelerate.config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to set up training for your training environment. This command creates a `config_file.yaml` that'll be used when you launch your training script. For example, some example configurations you can setup are:
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
+downcast_bf16: 'no'
+gpu_ids: all
+machine_rank: 0 #change rank as per the node
+main_process_ip: 192.168.20.1
+main_process_port: 9898
+main_training_function: main
+mixed_precision: fp16
+num_machines: 2
+num_processes: 8
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+distributed_type: FSDP
+downcast_bf16: 'no'
+fsdp_config:
+ fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
+ fsdp_backward_prefetch_policy: BACKWARD_PRE
+ fsdp_forward_prefetch: true
+ fsdp_offload_params: false
+ fsdp_sharding_strategy: 1
+ fsdp_state_dict_type: FULL_STATE_DICT
+ fsdp_sync_module_states: true
+ fsdp_transformer_layer_cls_to_wrap: BertLayer
+ fsdp_use_orig_params: true
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 2
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ deepspeed_config_file: /home/user/configs/ds_zero3_config.json
+ zero3_init_flag: true
+distributed_type: DEEPSPEED
+downcast_bf16: 'no'
+machine_rank: 0
+main_training_function: main
+num_machines: 1
+num_processes: 4
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ gradient_accumulation_steps: 1
+ gradient_clipping: 0.7
+ offload_optimizer_device: cpu
+ offload_param_device: cpu
+ zero3_init_flag: true
+ zero_stage: 2
+distributed_type: DEEPSPEED
+downcast_bf16: 'no'
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 4
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+The [`accelerate_launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) command is the recommended way to launch your training script on a distributed system with Accelerate and [`Trainer`] with the parameters specified in `config_file.yaml`. This file is saved to the Accelerate cache folder and automatically loaded when you run `accelerate_launch`.
+
+For example, to run the [run_glue.py](https://github.com/huggingface/transformers/blob/f4db565b695582891e43a5e042e5d318e28f20b8/examples/pytorch/text-classification/run_glue.py#L4) training script with the FSDP configuration:
+
+```bash
+accelerate launch \
+ ./examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 16 \
+ --learning_rate 5e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+You could also specify the parameters from the `config_file.yaml` file directly in the command line:
+
+```bash
+accelerate launch --num_processes=2 \
+ --use_fsdp \
+ --mixed_precision=bf16 \
+ --fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
+ --fsdp_transformer_layer_cls_to_wrap="BertLayer" \
+ --fsdp_sharding_strategy=1 \
+ --fsdp_state_dict_type=FULL_STATE_DICT \
+ ./examples/pytorch/text-classification/run_glue.py
+ --model_name_or_path bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 16 \
+ --learning_rate 5e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+Check out the [Launching your Accelerate scripts](https://huggingface.co/docs/accelerate/basic_tutorials/launch) tutorial to learn more about `accelerate_launch` and custom configurations.