diff --git a/README.md b/README.md
index 8518fc09dce800..8356aaa3e27eba 100644
--- a/README.md
+++ b/README.md
@@ -389,6 +389,7 @@ Current number of checkpoints: ** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_de.md b/README_de.md
index 66fae9870653df..f0c712674f04e2 100644
--- a/README_de.md
+++ b/README_de.md
@@ -385,6 +385,7 @@ Aktuelle Anzahl der Checkpoints: ** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_es.md b/README_es.md
index e4f4dedc3ea0cf..f9fcb97ff35d6d 100644
--- a/README_es.md
+++ b/README_es.md
@@ -362,6 +362,7 @@ Número actual de puntos de control: ** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_fr.md b/README_fr.md
index c2da27829ecbb5..cb26e6631d507b 100644
--- a/README_fr.md
+++ b/README_fr.md
@@ -383,6 +383,7 @@ Nombre actuel de points de contrôle : ** (de BigCode) a été publié dans l'article [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) par Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** a été publié dans le dépôt [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) par Toshiyuki Sakamoto (tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (de Microsoft) a été publié dans l'article [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) par Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (de Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) publié dans l'article [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) parShilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (de l'UCSD, NVIDIA) a été publié dans l'article [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) par Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (d'Allegro.pl, AGH University of Science and Technology) a été publié dans l'article [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) par Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (de Facebook) a été publié dans l'article [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) par Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_hd.md b/README_hd.md
index a5bd56ee1c1dce..108e14b4225f97 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -336,6 +336,7 @@ conda install conda-forge::transformers
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (BigCode से) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra. द्वाराअनुसंधान पत्र [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) के साथ जारी किया गया
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others से) Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. द्वाराअनुसंधान पत्र [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) के साथ जारी किया गया
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA से) साथ में कागज [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) जियारुई जू, शालिनी डी मेलो, सिफ़ी लियू, वोनमिन बायन, थॉमस ब्रेउएल, जान कौट्ज़, ज़ियाओलोंग वांग द्वारा।
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (Allegro.pl, AGH University of Science and Technology से) Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik. द्वाराअनुसंधान पत्र [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) के साथ जारी किया गया
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (फेसबुक से) साथ में पेपर [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) वेई-निंग सू, बेंजामिन बोल्टे, याओ-हंग ह्यूबर्ट त्साई, कुशाल लखोटिया, रुस्लान सालाखुतदीनोव, अब्देलरहमान मोहम्मद द्वारा।
diff --git a/README_ja.md b/README_ja.md
index e42a5680a79d7f..0b251cb21200ac 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -396,6 +396,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (BigCode から) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra. から公開された研究論文 [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988)
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) 坂本俊之(tanreinama)からリリースされました.
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (Microsoft から) Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu から公開された研究論文: [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234).
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others から) Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. から公開された研究論文 [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499)
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094)
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (Allegro.pl, AGH University of Science and Technology から) Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik. から公開された研究論文 [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf)
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447)
diff --git a/README_ko.md b/README_ko.md
index 95cb1b0b79d5b0..03f2ff386ed3f4 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -311,6 +311,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (BigCode 에서 제공)은 Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.의 [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988)논문과 함께 발표했습니다.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu 의 [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) 논문과 함께 발표했습니다.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others 에서 제공)은 Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.의 [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499)논문과 함께 발표했습니다.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA 에서) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang 의 [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) 논문과 함께 발표했습니다.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (Allegro.pl, AGH University of Science and Technology 에서 제공)은 Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.의 [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf)논문과 함께 발표했습니다.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook 에서) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 의 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 논문과 함께 발표했습니다.
diff --git a/README_pt-br.md b/README_pt-br.md
index 7d10ce5e8c986c..94260ac34dd3c2 100644
--- a/README_pt-br.md
+++ b/README_pt-br.md
@@ -394,6 +394,7 @@ Número atual de pontos de verificação: ** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_ru.md b/README_ru.md
index 03cc1b919e889f..f70118b57d83f5 100644
--- a/README_ru.md
+++ b/README_ru.md
@@ -384,6 +384,7 @@ conda install conda-forge::transformers
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_te.md b/README_te.md
index fa762d5659b5da..ea3f5b28e3a745 100644
--- a/README_te.md
+++ b/README_te.md
@@ -386,6 +386,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_vi.md b/README_vi.md
index e7cad3b3649cc4..73ca0ecbf36946 100644
--- a/README_vi.md
+++ b/README_vi.md
@@ -385,6 +385,7 @@ Số lượng điểm kiểm tra hiện tại: ** (từ BigCode) được phát hành với bài báo [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (từ Microsoft) được phát hành với bài báo [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (từ Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) được phát hành với bài báo [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (từ UCSD, NVIDIA) được phát hành với bài báo [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (từ Allegro.pl, AGH University of Science and Technology) được phát hành với bài báo [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (từ Facebook) được phát hành với bài báo [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 8ac4d5c388ee15..33507ea4127d0a 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -335,6 +335,7 @@ conda install conda-forge::transformers
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (来自 BigCode) 伴随论文 [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) 由 Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra 发布。
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by 坂本俊之(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (来自 Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) 伴随论文 [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) 由 Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang 发布。
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (来自 UCSD, NVIDIA) 伴随论文 [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) 由 Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang 发布。
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (来自 Allegro.pl, AGH University of Science and Technology) 伴随论文 [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) 由 Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik 发布。
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (来自 Facebook) 伴随论文 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 0e31d8e6b52f4a..24ce3519d69285 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -347,6 +347,7 @@ conda install conda-forge::transformers
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by 坂本俊之(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[Grounding DINO](https://huggingface.co/docs/transformers/main/model_doc/grounding-dino)** (from Institute for AI, Tsinghua-Bosch Joint Center for ML, Tsinghua University, IDEA Research and others) released with the paper [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index af44de4d1067b1..07b5e760544e66 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -730,6 +730,8 @@
title: FLAVA
- local: model_doc/git
title: GIT
+ - local: model_doc/grounding-dino
+ title: Grounding DINO
- local: model_doc/groupvit
title: GroupViT
- local: model_doc/idefics
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index ffa9ae3f4b0b41..dac172f66a2866 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -154,6 +154,7 @@ Flax), PyTorch, and/or TensorFlow.
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
diff --git a/docs/source/en/model_doc/grounding-dino.md b/docs/source/en/model_doc/grounding-dino.md
new file mode 100644
index 00000000000000..3c6bd6fce06920
--- /dev/null
+++ b/docs/source/en/model_doc/grounding-dino.md
@@ -0,0 +1,97 @@
+
+
+# Grounding DINO
+
+## Overview
+
+The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
+
+The abstract from the paper is the following:
+
+*In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a 52.5 AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean 26.1 AP.*
+
+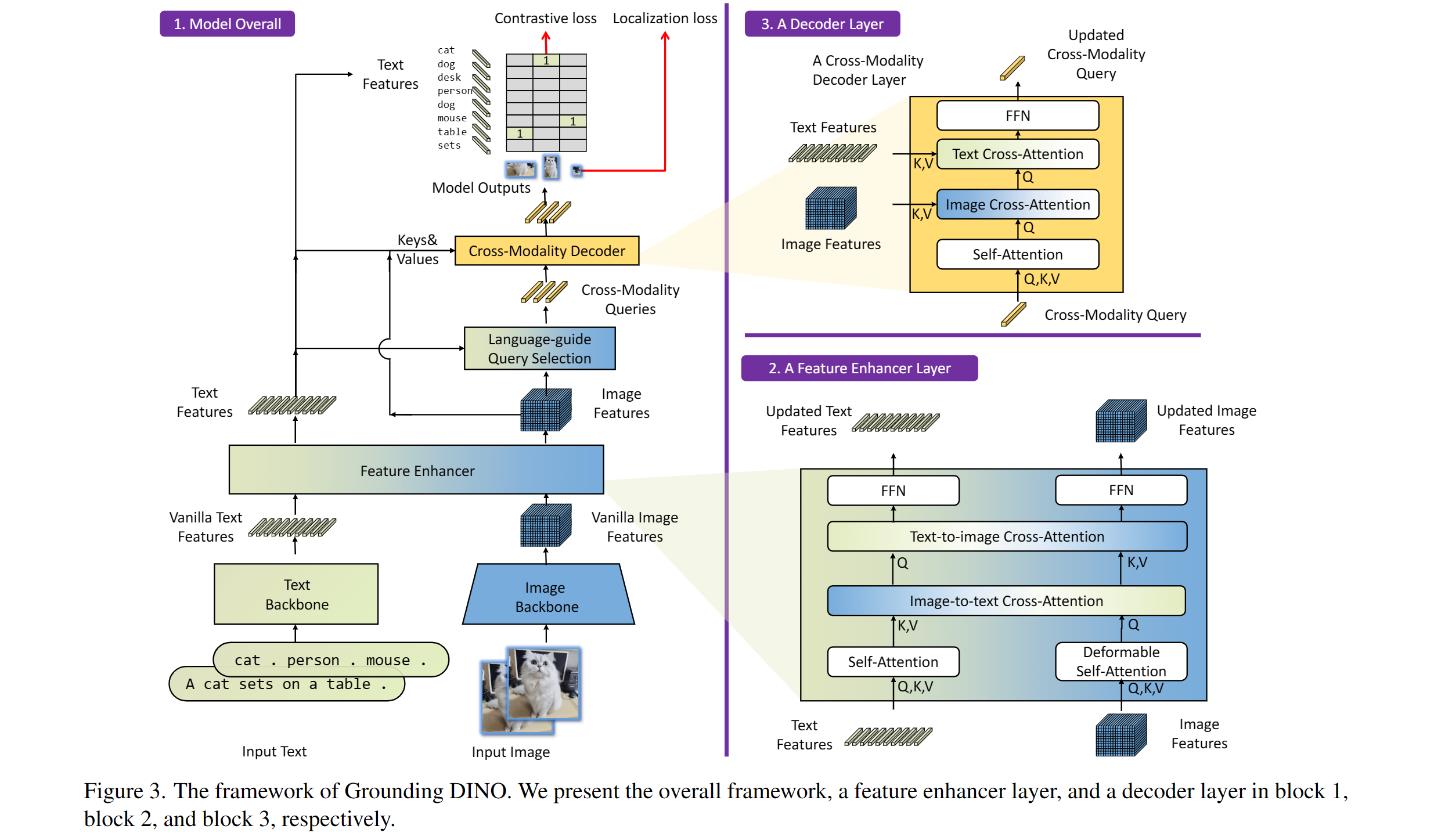 +
+ Grounding DINO overview. Taken from the original paper.
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
+
+## Usage tips
+
+- One can use [`GroundingDinoProcessor`] to prepare image-text pairs for the model.
+- To separate classes in the text use a period e.g. "a cat. a dog."
+- When using multiple classes (e.g. `"a cat. a dog."`), use `post_process_grounded_object_detection` from [`GroundingDinoProcessor`] to post process outputs. Since, the labels returned from `post_process_object_detection` represent the indices from the model dimension where prob > threshold.
+
+Here's how to use the model for zero-shot object detection:
+
+```python
+import requests
+
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection,
+
+model_id = "IDEA-Research/grounding-dino-tiny"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(image_url, stream=True).raw)
+# Check for cats and remote controls
+text = "a cat. a remote control."
+
+inputs = processor(images=image, text=text, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = processor.post_process_grounded_object_detection(
+ outputs,
+ inputs.input_ids,
+ box_threshold=0.4,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]]
+)
+```
+
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+ - post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+ - forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index da29d77972f425..ff6c04155f5a5f 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -488,9 +488,11 @@
"GPTSanJapaneseConfig",
"GPTSanJapaneseTokenizer",
],
- "models.graphormer": [
- "GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
- "GraphormerConfig",
+ "models.graphormer": ["GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "GraphormerConfig"],
+ "models.grounding_dino": [
+ "GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "GroundingDinoConfig",
+ "GroundingDinoProcessor",
],
"models.groupvit": [
"GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1330,6 +1332,7 @@
_import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaImageProcessor", "FlavaProcessor"])
_import_structure["models.fuyu"].extend(["FuyuImageProcessor", "FuyuProcessor"])
_import_structure["models.glpn"].extend(["GLPNFeatureExtractor", "GLPNImageProcessor"])
+ _import_structure["models.grounding_dino"].extend(["GroundingDinoImageProcessor"])
_import_structure["models.idefics"].extend(["IdeficsImageProcessor"])
_import_structure["models.imagegpt"].extend(["ImageGPTFeatureExtractor", "ImageGPTImageProcessor"])
_import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
@@ -2390,6 +2393,14 @@
"GraphormerPreTrainedModel",
]
)
+ _import_structure["models.grounding_dino"].extend(
+ [
+ "GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "GroundingDinoForObjectDetection",
+ "GroundingDinoModel",
+ "GroundingDinoPreTrainedModel",
+ ]
+ )
_import_structure["models.groupvit"].extend(
[
"GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -5372,9 +5383,11 @@
GPTSanJapaneseConfig,
GPTSanJapaneseTokenizer,
)
- from .models.graphormer import (
- GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
- GraphormerConfig,
+ from .models.graphormer import GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, GraphormerConfig
+ from .models.grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ GroundingDinoConfig,
+ GroundingDinoProcessor,
)
from .models.groupvit import (
GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -6186,6 +6199,7 @@
)
from .models.fuyu import FuyuImageProcessor, FuyuProcessor
from .models.glpn import GLPNFeatureExtractor, GLPNImageProcessor
+ from .models.grounding_dino import GroundingDinoImageProcessor
from .models.idefics import IdeficsImageProcessor
from .models.imagegpt import ImageGPTFeatureExtractor, ImageGPTImageProcessor
from .models.layoutlmv2 import (
@@ -7103,6 +7117,12 @@
GraphormerModel,
GraphormerPreTrainedModel,
)
+ from .models.grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST,
+ GroundingDinoForObjectDetection,
+ GroundingDinoModel,
+ GroundingDinoPreTrainedModel,
+ )
from .models.groupvit import (
GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
GroupViTModel,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 0599d3b876e6af..89baf93f6886f8 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -105,6 +105,7 @@
gptj,
gptsan_japanese,
graphormer,
+ grounding_dino,
groupvit,
herbert,
hubert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index bf46066002feb9..ce8298d8c5cfc8 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -120,6 +120,7 @@
("gptj", "GPTJConfig"),
("gptsan-japanese", "GPTSanJapaneseConfig"),
("graphormer", "GraphormerConfig"),
+ ("grounding-dino", "GroundingDinoConfig"),
("groupvit", "GroupViTConfig"),
("hubert", "HubertConfig"),
("ibert", "IBertConfig"),
@@ -382,6 +383,7 @@
("gptj", "GPT-J"),
("gptsan-japanese", "GPTSAN-japanese"),
("graphormer", "Graphormer"),
+ ("grounding-dino", "Grounding DINO"),
("groupvit", "GroupViT"),
("herbert", "HerBERT"),
("hubert", "Hubert"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index 3debf97fea2081..6ae28bfa32cb63 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -68,6 +68,7 @@
("fuyu", "FuyuImageProcessor"),
("git", "CLIPImageProcessor"),
("glpn", "GLPNImageProcessor"),
+ ("grounding-dino", "GroundingDinoImageProcessor"),
("groupvit", "CLIPImageProcessor"),
("idefics", "IdeficsImageProcessor"),
("imagegpt", "ImageGPTImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 150dea04f3745a..d422fe8c19b799 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -115,6 +115,7 @@
("gptj", "GPTJModel"),
("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
("graphormer", "GraphormerModel"),
+ ("grounding-dino", "GroundingDinoModel"),
("groupvit", "GroupViTModel"),
("hubert", "HubertModel"),
("ibert", "IBertModel"),
@@ -751,6 +752,7 @@
MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
[
# Model for Zero Shot Object Detection mapping
+ ("grounding-dino", "GroundingDinoForObjectDetection"),
("owlv2", "Owlv2ForObjectDetection"),
("owlvit", "OwlViTForObjectDetection"),
]
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 4bc5d8105316bf..c9143fd8be5200 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -195,6 +195,7 @@
("gpt_neox_japanese", ("GPTNeoXJapaneseTokenizer", None)),
("gptj", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
("gptsan-japanese", ("GPTSanJapaneseTokenizer", None)),
+ ("grounding-dino", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
("groupvit", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
("herbert", ("HerbertTokenizer", "HerbertTokenizerFast" if is_tokenizers_available() else None)),
("hubert", ("Wav2Vec2CTCTokenizer", None)),
diff --git a/src/transformers/models/deformable_detr/modeling_deformable_detr.py b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
index 1e2296d177c4de..c0ac7cffc7ab44 100755
--- a/src/transformers/models/deformable_detr/modeling_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
@@ -710,13 +710,14 @@ def forward(
batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
)
# batch_size, num_queries, n_heads, n_levels, n_points, 2
- if reference_points.shape[-1] == 2:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = (
reference_points[:, :, None, :, None, :]
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
)
- elif reference_points.shape[-1] == 4:
+ elif num_coordinates == 4:
sampling_locations = (
reference_points[:, :, None, :, None, :2]
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
@@ -1401,14 +1402,15 @@ def forward(
intermediate_reference_points = ()
for idx, decoder_layer in enumerate(self.layers):
- if reference_points.shape[-1] == 4:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
reference_points_input = (
reference_points[:, :, None] * torch.cat([valid_ratios, valid_ratios], -1)[:, None]
)
- else:
- if reference_points.shape[-1] != 2:
- raise ValueError("Reference points' last dimension must be of size 2")
+ elif reference_points.shape[-1] == 2:
reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
+ else:
+ raise ValueError("Reference points' last dimension must be of size 2")
if output_hidden_states:
all_hidden_states += (hidden_states,)
@@ -1442,17 +1444,18 @@ def forward(
# hack implementation for iterative bounding box refinement
if self.bbox_embed is not None:
tmp = self.bbox_embed[idx](hidden_states)
- if reference_points.shape[-1] == 4:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
new_reference_points = tmp + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
- else:
- if reference_points.shape[-1] != 2:
- raise ValueError(
- f"Reference points' last dimension must be of size 2, but is {reference_points.shape[-1]}"
- )
+ elif num_coordinates == 2:
new_reference_points = tmp
new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
+ else:
+ raise ValueError(
+ f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}"
+ )
reference_points = new_reference_points.detach()
intermediate += (hidden_states,)
diff --git a/src/transformers/models/deta/modeling_deta.py b/src/transformers/models/deta/modeling_deta.py
index 35d9b67d2f9923..e8491355591ab8 100644
--- a/src/transformers/models/deta/modeling_deta.py
+++ b/src/transformers/models/deta/modeling_deta.py
@@ -682,13 +682,14 @@ def forward(
batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
)
# batch_size, num_queries, n_heads, n_levels, n_points, 2
- if reference_points.shape[-1] == 2:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = (
reference_points[:, :, None, :, None, :]
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
)
- elif reference_points.shape[-1] == 4:
+ elif num_coordinates == 4:
sampling_locations = (
reference_points[:, :, None, :, None, :2]
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
diff --git a/src/transformers/models/grounding_dino/__init__.py b/src/transformers/models/grounding_dino/__init__.py
new file mode 100644
index 00000000000000..3b0f792068c5f0
--- /dev/null
+++ b/src/transformers/models/grounding_dino/__init__.py
@@ -0,0 +1,81 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_grounding_dino": [
+ "GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "GroundingDinoConfig",
+ ],
+ "processing_grounding_dino": ["GroundingDinoProcessor"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_grounding_dino"] = [
+ "GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "GroundingDinoForObjectDetection",
+ "GroundingDinoModel",
+ "GroundingDinoPreTrainedModel",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_grounding_dino"] = ["GroundingDinoImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ GroundingDinoConfig,
+ )
+ from .processing_grounding_dino import GroundingDinoProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST,
+ GroundingDinoForObjectDetection,
+ GroundingDinoModel,
+ GroundingDinoPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_grounding_dino import GroundingDinoImageProcessor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/grounding_dino/configuration_grounding_dino.py b/src/transformers/models/grounding_dino/configuration_grounding_dino.py
new file mode 100644
index 00000000000000..fe683035039600
--- /dev/null
+++ b/src/transformers/models/grounding_dino/configuration_grounding_dino.py
@@ -0,0 +1,301 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Grounding DINO model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+from ..auto import CONFIG_MAPPING
+
+
+logger = logging.get_logger(__name__)
+
+GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "IDEA-Research/grounding-dino-tiny": "https://huggingface.co/IDEA-Research/grounding-dino-tiny/resolve/main/config.json",
+}
+
+
+class GroundingDinoConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`GroundingDinoModel`]. It is used to instantiate a
+ Grounding DINO model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the Grounding DINO
+ [IDEA-Research/grounding-dino-tiny](https://huggingface.co/IDEA-Research/grounding-dino-tiny) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ backbone_config (`PretrainedConfig` or `dict`, *optional*, defaults to `ResNetConfig()`):
+ The configuration of the backbone model.
+ backbone (`str`, *optional*):
+ Name of backbone to use when `backbone_config` is `None`. If `use_pretrained_backbone` is `True`, this
+ will load the corresponding pretrained weights from the timm or transformers library. If `use_pretrained_backbone`
+ is `False`, this loads the backbone's config and uses that to initialize the backbone with random weights.
+ use_pretrained_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to use pretrained weights for the backbone.
+ use_timm_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to load `backbone` from the timm library. If `False`, the backbone is loaded from the transformers
+ library.
+ backbone_kwargs (`dict`, *optional*):
+ Keyword arguments to be passed to AutoBackbone when loading from a checkpoint
+ e.g. `{'out_indices': (0, 1, 2, 3)}`. Cannot be specified if `backbone_config` is set.
+ text_config (`Union[AutoConfig, dict]`, *optional*, defaults to `BertConfig`):
+ The config object or dictionary of the text backbone.
+ num_queries (`int`, *optional*, defaults to 900):
+ Number of object queries, i.e. detection slots. This is the maximal number of objects
+ [`GroundingDinoModel`] can detect in a single image.
+ encoder_layers (`int`, *optional*, defaults to 6):
+ Number of encoder layers.
+ encoder_ffn_dim (`int`, *optional*, defaults to 2048):
+ Dimension of the "intermediate" (often named feed-forward) layer in decoder.
+ encoder_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ decoder_layers (`int`, *optional*, defaults to 6):
+ Number of decoder layers.
+ decoder_ffn_dim (`int`, *optional*, defaults to 2048):
+ Dimension of the "intermediate" (often named feed-forward) layer in decoder.
+ decoder_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ is_encoder_decoder (`bool`, *optional*, defaults to `True`):
+ Whether the model is used as an encoder/decoder or not.
+ activation_function (`str` or `function`, *optional*, defaults to `"relu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ d_model (`int`, *optional*, defaults to 256):
+ Dimension of the layers.
+ dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ activation_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for activations inside the fully connected layer.
+ auxiliary_loss (`bool`, *optional*, defaults to `False`):
+ Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
+ position_embedding_type (`str`, *optional*, defaults to `"sine"`):
+ Type of position embeddings to be used on top of the image features. One of `"sine"` or `"learned"`.
+ num_feature_levels (`int`, *optional*, defaults to 4):
+ The number of input feature levels.
+ encoder_n_points (`int`, *optional*, defaults to 4):
+ The number of sampled keys in each feature level for each attention head in the encoder.
+ decoder_n_points (`int`, *optional*, defaults to 4):
+ The number of sampled keys in each feature level for each attention head in the decoder.
+ two_stage (`bool`, *optional*, defaults to `True`):
+ Whether to apply a two-stage deformable DETR, where the region proposals are also generated by a variant of
+ Grounding DINO, which are further fed into the decoder for iterative bounding box refinement.
+ class_cost (`float`, *optional*, defaults to 1.0):
+ Relative weight of the classification error in the Hungarian matching cost.
+ bbox_cost (`float`, *optional*, defaults to 5.0):
+ Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost.
+ giou_cost (`float`, *optional*, defaults to 2.0):
+ Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost.
+ bbox_loss_coefficient (`float`, *optional*, defaults to 5.0):
+ Relative weight of the L1 bounding box loss in the object detection loss.
+ giou_loss_coefficient (`float`, *optional*, defaults to 2.0):
+ Relative weight of the generalized IoU loss in the object detection loss.
+ focal_alpha (`float`, *optional*, defaults to 0.25):
+ Alpha parameter in the focal loss.
+ disable_custom_kernels (`bool`, *optional*, defaults to `False`):
+ Disable the use of custom CUDA and CPU kernels. This option is necessary for the ONNX export, as custom
+ kernels are not supported by PyTorch ONNX export.
+ max_text_len (`int`, *optional*, defaults to 256):
+ The maximum length of the text input.
+ text_enhancer_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the text enhancer.
+ fusion_droppath (`float`, *optional*, defaults to 0.1):
+ The droppath ratio for the fusion module.
+ fusion_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the fusion module.
+ embedding_init_target (`bool`, *optional*, defaults to `True`):
+ Whether to initialize the target with Embedding weights.
+ query_dim (`int`, *optional*, defaults to 4):
+ The dimension of the query vector.
+ decoder_bbox_embed_share (`bool`, *optional*, defaults to `True`):
+ Whether to share the bbox regression head for all decoder layers.
+ two_stage_bbox_embed_share (`bool`, *optional*, defaults to `False`):
+ Whether to share the bbox embedding between the two-stage bbox generator and the region proposal
+ generation.
+ positional_embedding_temperature (`float`, *optional*, defaults to 20):
+ The temperature for Sine Positional Embedding that is used together with vision backbone.
+ init_std (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+
+ Examples:
+
+ ```python
+ >>> from transformers import GroundingDinoConfig, GroundingDinoModel
+
+ >>> # Initializing a Grounding DINO IDEA-Research/grounding-dino-tiny style configuration
+ >>> configuration = GroundingDinoConfig()
+
+ >>> # Initializing a model (with random weights) from the IDEA-Research/grounding-dino-tiny style configuration
+ >>> model = GroundingDinoModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "grounding-dino"
+ attribute_map = {
+ "hidden_size": "d_model",
+ "num_attention_heads": "encoder_attention_heads",
+ }
+
+ def __init__(
+ self,
+ backbone_config=None,
+ backbone=None,
+ use_pretrained_backbone=False,
+ use_timm_backbone=False,
+ backbone_kwargs=None,
+ text_config=None,
+ num_queries=900,
+ encoder_layers=6,
+ encoder_ffn_dim=2048,
+ encoder_attention_heads=8,
+ decoder_layers=6,
+ decoder_ffn_dim=2048,
+ decoder_attention_heads=8,
+ is_encoder_decoder=True,
+ activation_function="relu",
+ d_model=256,
+ dropout=0.1,
+ attention_dropout=0.0,
+ activation_dropout=0.0,
+ auxiliary_loss=False,
+ position_embedding_type="sine",
+ num_feature_levels=4,
+ encoder_n_points=4,
+ decoder_n_points=4,
+ two_stage=True,
+ class_cost=1.0,
+ bbox_cost=5.0,
+ giou_cost=2.0,
+ bbox_loss_coefficient=5.0,
+ giou_loss_coefficient=2.0,
+ focal_alpha=0.25,
+ disable_custom_kernels=False,
+ # other parameters
+ max_text_len=256,
+ text_enhancer_dropout=0.0,
+ fusion_droppath=0.1,
+ fusion_dropout=0.0,
+ embedding_init_target=True,
+ query_dim=4,
+ decoder_bbox_embed_share=True,
+ two_stage_bbox_embed_share=False,
+ positional_embedding_temperature=20,
+ init_std=0.02,
+ layer_norm_eps=1e-5,
+ **kwargs,
+ ):
+ if not use_timm_backbone and use_pretrained_backbone:
+ raise ValueError(
+ "Loading pretrained backbone weights from the transformers library is not supported yet. `use_timm_backbone` must be set to `True` when `use_pretrained_backbone=True`"
+ )
+
+ if backbone_config is not None and backbone is not None:
+ raise ValueError("You can't specify both `backbone` and `backbone_config`.")
+
+ if backbone_config is None and backbone is None:
+ logger.info("`backbone_config` is `None`. Initializing the config with the default `Swin` backbone.")
+ backbone_config = CONFIG_MAPPING["swin"](
+ window_size=7,
+ image_size=224,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ out_indices=[2, 3, 4],
+ )
+ elif isinstance(backbone_config, dict):
+ backbone_model_type = backbone_config.pop("model_type")
+ config_class = CONFIG_MAPPING[backbone_model_type]
+ backbone_config = config_class.from_dict(backbone_config)
+
+ if backbone_kwargs is not None and backbone_kwargs and backbone_config is not None:
+ raise ValueError("You can't specify both `backbone_kwargs` and `backbone_config`.")
+
+ if text_config is None:
+ text_config = {}
+ logger.info("text_config is None. Initializing the text config with default values (`BertConfig`).")
+
+ self.backbone_config = backbone_config
+ self.backbone = backbone
+ self.use_pretrained_backbone = use_pretrained_backbone
+ self.use_timm_backbone = use_timm_backbone
+ self.backbone_kwargs = backbone_kwargs
+ self.num_queries = num_queries
+ self.d_model = d_model
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.encoder_layers = encoder_layers
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.decoder_layers = decoder_layers
+ self.decoder_attention_heads = decoder_attention_heads
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.activation_function = activation_function
+ self.auxiliary_loss = auxiliary_loss
+ self.position_embedding_type = position_embedding_type
+ # deformable attributes
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+ self.two_stage = two_stage
+ # Hungarian matcher
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ # Loss coefficients
+ self.bbox_loss_coefficient = bbox_loss_coefficient
+ self.giou_loss_coefficient = giou_loss_coefficient
+ self.focal_alpha = focal_alpha
+ self.disable_custom_kernels = disable_custom_kernels
+ # Text backbone
+ if isinstance(text_config, dict):
+ text_config["model_type"] = text_config["model_type"] if "model_type" in text_config else "bert"
+ text_config = CONFIG_MAPPING[text_config["model_type"]](**text_config)
+ elif text_config is None:
+ text_config = CONFIG_MAPPING["bert"]()
+
+ self.text_config = text_config
+ self.max_text_len = max_text_len
+
+ # Text Enhancer
+ self.text_enhancer_dropout = text_enhancer_dropout
+ # Fusion
+ self.fusion_droppath = fusion_droppath
+ self.fusion_dropout = fusion_dropout
+ # Others
+ self.embedding_init_target = embedding_init_target
+ self.query_dim = query_dim
+ self.decoder_bbox_embed_share = decoder_bbox_embed_share
+ self.two_stage_bbox_embed_share = two_stage_bbox_embed_share
+ if two_stage_bbox_embed_share and not decoder_bbox_embed_share:
+ raise ValueError("If two_stage_bbox_embed_share is True, decoder_bbox_embed_share must be True.")
+ self.positional_embedding_temperature = positional_embedding_temperature
+ self.init_std = init_std
+ self.layer_norm_eps = layer_norm_eps
+ super().__init__(is_encoder_decoder=is_encoder_decoder, **kwargs)
+
+ @property
+ def num_attention_heads(self) -> int:
+ return self.encoder_attention_heads
+
+ @property
+ def hidden_size(self) -> int:
+ return self.d_model
diff --git a/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py b/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py
new file mode 100644
index 00000000000000..ac8e82bfd825d6
--- /dev/null
+++ b/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py
@@ -0,0 +1,491 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Grounding DINO checkpoints from the original repository.
+
+URL: https://github.com/IDEA-Research/GroundingDINO"""
+
+import argparse
+
+import requests
+import torch
+from PIL import Image
+from torchvision import transforms as T
+
+from transformers import (
+ AutoTokenizer,
+ GroundingDinoConfig,
+ GroundingDinoForObjectDetection,
+ GroundingDinoImageProcessor,
+ GroundingDinoProcessor,
+ SwinConfig,
+)
+
+
+IMAGENET_MEAN = [0.485, 0.456, 0.406]
+IMAGENET_STD = [0.229, 0.224, 0.225]
+
+
+def get_grounding_dino_config(model_name):
+ if "tiny" in model_name:
+ window_size = 7
+ embed_dim = 96
+ depths = (2, 2, 6, 2)
+ num_heads = (3, 6, 12, 24)
+ image_size = 224
+ elif "base" in model_name:
+ window_size = 12
+ embed_dim = 128
+ depths = (2, 2, 18, 2)
+ num_heads = (4, 8, 16, 32)
+ image_size = 384
+ else:
+ raise ValueError("Model not supported, only supports base and large variants")
+
+ backbone_config = SwinConfig(
+ window_size=window_size,
+ image_size=image_size,
+ embed_dim=embed_dim,
+ depths=depths,
+ num_heads=num_heads,
+ out_indices=[2, 3, 4],
+ )
+
+ config = GroundingDinoConfig(backbone_config=backbone_config)
+
+ return config
+
+
+def create_rename_keys(state_dict, config):
+ rename_keys = []
+ # fmt: off
+ ########################################## VISION BACKBONE - START
+ # patch embedding layer
+ rename_keys.append(("backbone.0.patch_embed.proj.weight",
+ "model.backbone.conv_encoder.model.embeddings.patch_embeddings.projection.weight"))
+ rename_keys.append(("backbone.0.patch_embed.proj.bias",
+ "model.backbone.conv_encoder.model.embeddings.patch_embeddings.projection.bias"))
+ rename_keys.append(("backbone.0.patch_embed.norm.weight",
+ "model.backbone.conv_encoder.model.embeddings.norm.weight"))
+ rename_keys.append(("backbone.0.patch_embed.norm.bias",
+ "model.backbone.conv_encoder.model.embeddings.norm.bias"))
+
+ for layer, depth in enumerate(config.backbone_config.depths):
+ for block in range(depth):
+ # layernorms
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm1.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_before.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm1.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_before.bias"))
+
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm2.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_after.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm2.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_after.bias"))
+ # attention
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.relative_position_bias_table",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.relative_position_bias_table"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.proj.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.output.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.proj.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.output.dense.bias"))
+ # intermediate
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc1.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.intermediate.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc1.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.intermediate.dense.bias"))
+
+ # output
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc2.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.output.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc2.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.output.dense.bias"))
+
+ # downsample
+ if layer!=len(config.backbone_config.depths)-1:
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.reduction.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.reduction.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.norm.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.norm.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.norm.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.norm.bias"))
+
+ for out_indice in config.backbone_config.out_indices:
+ # Grounding DINO implementation of out_indices isn't aligned with transformers
+ rename_keys.append((f"backbone.0.norm{out_indice-1}.weight",
+ f"model.backbone.conv_encoder.model.hidden_states_norms.stage{out_indice}.weight"))
+ rename_keys.append((f"backbone.0.norm{out_indice-1}.bias",
+ f"model.backbone.conv_encoder.model.hidden_states_norms.stage{out_indice}.bias"))
+
+ ########################################## VISION BACKBONE - END
+
+ ########################################## ENCODER - START
+ deformable_key_mappings = {
+ 'self_attn.sampling_offsets.weight': 'deformable_layer.self_attn.sampling_offsets.weight',
+ 'self_attn.sampling_offsets.bias': 'deformable_layer.self_attn.sampling_offsets.bias',
+ 'self_attn.attention_weights.weight': 'deformable_layer.self_attn.attention_weights.weight',
+ 'self_attn.attention_weights.bias': 'deformable_layer.self_attn.attention_weights.bias',
+ 'self_attn.value_proj.weight': 'deformable_layer.self_attn.value_proj.weight',
+ 'self_attn.value_proj.bias': 'deformable_layer.self_attn.value_proj.bias',
+ 'self_attn.output_proj.weight': 'deformable_layer.self_attn.output_proj.weight',
+ 'self_attn.output_proj.bias': 'deformable_layer.self_attn.output_proj.bias',
+ 'norm1.weight': 'deformable_layer.self_attn_layer_norm.weight',
+ 'norm1.bias': 'deformable_layer.self_attn_layer_norm.bias',
+ 'linear1.weight': 'deformable_layer.fc1.weight',
+ 'linear1.bias': 'deformable_layer.fc1.bias',
+ 'linear2.weight': 'deformable_layer.fc2.weight',
+ 'linear2.bias': 'deformable_layer.fc2.bias',
+ 'norm2.weight': 'deformable_layer.final_layer_norm.weight',
+ 'norm2.bias': 'deformable_layer.final_layer_norm.bias',
+ }
+ text_enhancer_key_mappings = {
+ 'self_attn.in_proj_weight': 'text_enhancer_layer.self_attn.in_proj_weight',
+ 'self_attn.in_proj_bias': 'text_enhancer_layer.self_attn.in_proj_bias',
+ 'self_attn.out_proj.weight': 'text_enhancer_layer.self_attn.out_proj.weight',
+ 'self_attn.out_proj.bias': 'text_enhancer_layer.self_attn.out_proj.bias',
+ 'linear1.weight': 'text_enhancer_layer.fc1.weight',
+ 'linear1.bias': 'text_enhancer_layer.fc1.bias',
+ 'linear2.weight': 'text_enhancer_layer.fc2.weight',
+ 'linear2.bias': 'text_enhancer_layer.fc2.bias',
+ 'norm1.weight': 'text_enhancer_layer.layer_norm_before.weight',
+ 'norm1.bias': 'text_enhancer_layer.layer_norm_before.bias',
+ 'norm2.weight': 'text_enhancer_layer.layer_norm_after.weight',
+ 'norm2.bias': 'text_enhancer_layer.layer_norm_after.bias',
+ }
+ fusion_key_mappings = {
+ 'gamma_v': 'fusion_layer.vision_param',
+ 'gamma_l': 'fusion_layer.text_param',
+ 'layer_norm_v.weight': 'fusion_layer.layer_norm_vision.weight',
+ 'layer_norm_v.bias': 'fusion_layer.layer_norm_vision.bias',
+ 'layer_norm_l.weight': 'fusion_layer.layer_norm_text.weight',
+ 'layer_norm_l.bias': 'fusion_layer.layer_norm_text.bias',
+ 'attn.v_proj.weight': 'fusion_layer.attn.vision_proj.weight',
+ 'attn.v_proj.bias': 'fusion_layer.attn.vision_proj.bias',
+ 'attn.l_proj.weight': 'fusion_layer.attn.text_proj.weight',
+ 'attn.l_proj.bias': 'fusion_layer.attn.text_proj.bias',
+ 'attn.values_v_proj.weight': 'fusion_layer.attn.values_vision_proj.weight',
+ 'attn.values_v_proj.bias': 'fusion_layer.attn.values_vision_proj.bias',
+ 'attn.values_l_proj.weight': 'fusion_layer.attn.values_text_proj.weight',
+ 'attn.values_l_proj.bias': 'fusion_layer.attn.values_text_proj.bias',
+ 'attn.out_v_proj.weight': 'fusion_layer.attn.out_vision_proj.weight',
+ 'attn.out_v_proj.bias': 'fusion_layer.attn.out_vision_proj.bias',
+ 'attn.out_l_proj.weight': 'fusion_layer.attn.out_text_proj.weight',
+ 'attn.out_l_proj.bias': 'fusion_layer.attn.out_text_proj.bias',
+ }
+ for layer in range(config.encoder_layers):
+ # deformable
+ for src, dest in deformable_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ # text enhance
+ for src, dest in text_enhancer_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.text_layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ # fusion layers
+ for src, dest in fusion_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.fusion_layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ ########################################## ENCODER - END
+
+ ########################################## DECODER - START
+ key_mappings_decoder = {
+ 'cross_attn.sampling_offsets.weight': 'encoder_attn.sampling_offsets.weight',
+ 'cross_attn.sampling_offsets.bias': 'encoder_attn.sampling_offsets.bias',
+ 'cross_attn.attention_weights.weight': 'encoder_attn.attention_weights.weight',
+ 'cross_attn.attention_weights.bias': 'encoder_attn.attention_weights.bias',
+ 'cross_attn.value_proj.weight': 'encoder_attn.value_proj.weight',
+ 'cross_attn.value_proj.bias': 'encoder_attn.value_proj.bias',
+ 'cross_attn.output_proj.weight': 'encoder_attn.output_proj.weight',
+ 'cross_attn.output_proj.bias': 'encoder_attn.output_proj.bias',
+ 'norm1.weight': 'encoder_attn_layer_norm.weight',
+ 'norm1.bias': 'encoder_attn_layer_norm.bias',
+ 'ca_text.in_proj_weight': 'encoder_attn_text.in_proj_weight',
+ 'ca_text.in_proj_bias': 'encoder_attn_text.in_proj_bias',
+ 'ca_text.out_proj.weight': 'encoder_attn_text.out_proj.weight',
+ 'ca_text.out_proj.bias': 'encoder_attn_text.out_proj.bias',
+ 'catext_norm.weight': 'encoder_attn_text_layer_norm.weight',
+ 'catext_norm.bias': 'encoder_attn_text_layer_norm.bias',
+ 'self_attn.in_proj_weight': 'self_attn.in_proj_weight',
+ 'self_attn.in_proj_bias': 'self_attn.in_proj_bias',
+ 'self_attn.out_proj.weight': 'self_attn.out_proj.weight',
+ 'self_attn.out_proj.bias': 'self_attn.out_proj.bias',
+ 'norm2.weight': 'self_attn_layer_norm.weight',
+ 'norm2.bias': 'self_attn_layer_norm.bias',
+ 'linear1.weight': 'fc1.weight',
+ 'linear1.bias': 'fc1.bias',
+ 'linear2.weight': 'fc2.weight',
+ 'linear2.bias': 'fc2.bias',
+ 'norm3.weight': 'final_layer_norm.weight',
+ 'norm3.bias': 'final_layer_norm.bias',
+ }
+ for layer_num in range(config.decoder_layers):
+ source_prefix_decoder = f'transformer.decoder.layers.{layer_num}.'
+ target_prefix_decoder = f'model.decoder.layers.{layer_num}.'
+
+ for source_name, target_name in key_mappings_decoder.items():
+ rename_keys.append((source_prefix_decoder + source_name,
+ target_prefix_decoder + target_name))
+ ########################################## DECODER - END
+
+ ########################################## Additional - START
+ for layer_name, params in state_dict.items():
+ #### TEXT BACKBONE
+ if "bert" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("bert", "model.text_backbone")))
+ #### INPUT PROJ - PROJECT OUTPUT FEATURES FROM VISION BACKBONE
+ if "input_proj" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("input_proj", "model.input_proj_vision")))
+ #### INPUT PROJ - PROJECT OUTPUT FEATURES FROM TEXT BACKBONE
+ if "feat_map" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("feat_map", "model.text_projection")))
+ #### DECODER REFERENCE POINT HEAD
+ if "transformer.decoder.ref_point_head" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.decoder.ref_point_head",
+ "model.decoder.reference_points_head")))
+ #### DECODER BBOX EMBED
+ if "transformer.decoder.bbox_embed" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.decoder.bbox_embed",
+ "model.decoder.bbox_embed")))
+ if "transformer.enc_output" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer", "model")))
+
+ if "transformer.enc_out_bbox_embed" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.enc_out_bbox_embed",
+ "model.encoder_output_bbox_embed")))
+
+ rename_keys.append(("transformer.level_embed", "model.level_embed"))
+ rename_keys.append(("transformer.decoder.norm.weight", "model.decoder.layer_norm.weight"))
+ rename_keys.append(("transformer.decoder.norm.bias", "model.decoder.layer_norm.bias"))
+ rename_keys.append(("transformer.tgt_embed.weight", "model.query_position_embeddings.weight"))
+ ########################################## Additional - END
+
+ # fmt: on
+ return rename_keys
+
+
+def rename_key(dct, old, new):
+ val = dct.pop(old)
+ dct[new] = val
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v_encoder(state_dict, config):
+ ########################################## VISION BACKBONE - START
+ embed_dim = config.backbone_config.embed_dim
+ for layer, depth in enumerate(config.backbone_config.depths):
+ hidden_size = embed_dim * 2**layer
+ for block in range(depth):
+ # read in weights + bias of input projection layer (in timm, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"backbone.0.layers.{layer}.blocks.{block}.attn.qkv.weight")
+ in_proj_bias = state_dict.pop(f"backbone.0.layers.{layer}.blocks.{block}.attn.qkv.bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.query.weight"
+ ] = in_proj_weight[:hidden_size, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.query.bias"
+ ] = in_proj_bias[:hidden_size]
+
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.key.weight"
+ ] = in_proj_weight[hidden_size : hidden_size * 2, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.key.bias"
+ ] = in_proj_bias[hidden_size : hidden_size * 2]
+
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.value.weight"
+ ] = in_proj_weight[-hidden_size:, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.value.bias"
+ ] = in_proj_bias[-hidden_size:]
+ ########################################## VISION BACKBONE - END
+
+
+def read_in_q_k_v_text_enhancer(state_dict, config):
+ hidden_size = config.hidden_size
+ for idx in range(config.encoder_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.query.weight"] = in_proj_weight[
+ :hidden_size, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.value.weight"] = in_proj_weight[
+ -hidden_size:, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.value.bias"] = in_proj_bias[
+ -hidden_size:
+ ]
+
+
+def read_in_q_k_v_decoder(state_dict, config):
+ hidden_size = config.hidden_size
+ for idx in range(config.decoder_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"model.decoder.layers.{idx}.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.decoder.layers.{idx}.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.decoder.layers.{idx}.self_attn.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.decoder.layers.{idx}.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.key.bias"] = in_proj_bias[hidden_size : hidden_size * 2]
+
+ state_dict[f"model.decoder.layers.{idx}.self_attn.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.value.bias"] = in_proj_bias[-hidden_size:]
+
+ # read in weights + bias of cross-attention
+ in_proj_weight = state_dict.pop(f"model.decoder.layers.{idx}.encoder_attn_text.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.decoder.layers.{idx}.encoder_attn_text.in_proj_bias")
+
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.value.bias"] = in_proj_bias[-hidden_size:]
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ return image
+
+
+def preprocess_caption(caption: str) -> str:
+ result = caption.lower().strip()
+ if result.endswith("."):
+ return result
+ return result + "."
+
+
+@torch.no_grad()
+def convert_grounding_dino_checkpoint(args):
+ model_name = args.model_name
+ pytorch_dump_folder_path = args.pytorch_dump_folder_path
+ push_to_hub = args.push_to_hub
+ verify_logits = args.verify_logits
+
+ checkpoint_mapping = {
+ "grounding-dino-tiny": "https://huggingface.co/ShilongLiu/GroundingDino/resolve/main/groundingdino_swint_ogc.pth",
+ "grounding-dino-base": "https://huggingface.co/ShilongLiu/GroundingDino/resolve/main/groundingdino_swinb_cogcoor.pth",
+ }
+ # Define default GroundingDino configuation
+ config = get_grounding_dino_config(model_name)
+
+ # Load original checkpoint
+ checkpoint_url = checkpoint_mapping[model_name]
+ original_state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")["model"]
+ original_state_dict = {k.replace("module.", ""): v for k, v in original_state_dict.items()}
+
+ for name, param in original_state_dict.items():
+ print(name, param.shape)
+
+ # Rename keys
+ new_state_dict = original_state_dict.copy()
+ rename_keys = create_rename_keys(original_state_dict, config)
+
+ for src, dest in rename_keys:
+ rename_key(new_state_dict, src, dest)
+ read_in_q_k_v_encoder(new_state_dict, config)
+ read_in_q_k_v_text_enhancer(new_state_dict, config)
+ read_in_q_k_v_decoder(new_state_dict, config)
+
+ # Load HF model
+ model = GroundingDinoForObjectDetection(config)
+ model.eval()
+ missing_keys, unexpected_keys = model.load_state_dict(new_state_dict, strict=False)
+ print("Missing keys:", missing_keys)
+ print("Unexpected keys:", unexpected_keys)
+
+ # Load and process test image
+ image = prepare_img()
+ transforms = T.Compose([T.Resize(size=800, max_size=1333), T.ToTensor(), T.Normalize(IMAGENET_MEAN, IMAGENET_STD)])
+ original_pixel_values = transforms(image).unsqueeze(0)
+
+ image_processor = GroundingDinoImageProcessor()
+ tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+ processor = GroundingDinoProcessor(image_processor=image_processor, tokenizer=tokenizer)
+
+ text = "a cat"
+ inputs = processor(images=image, text=preprocess_caption(text), return_tensors="pt")
+
+ assert torch.allclose(original_pixel_values, inputs.pixel_values, atol=1e-4)
+
+ if verify_logits:
+ # Running forward
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ print(outputs.logits[0, :3, :3])
+
+ expected_slice = torch.tensor(
+ [[-4.8913, -0.1900, -0.2161], [-4.9653, -0.3719, -0.3950], [-5.9599, -3.3765, -3.3104]]
+ )
+
+ assert torch.allclose(outputs.logits[0, :3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ model.save_pretrained(pytorch_dump_folder_path)
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"EduardoPacheco/{model_name}")
+ processor.push_to_hub(f"EduardoPacheco/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="grounding-dino-tiny",
+ type=str,
+ choices=["grounding-dino-tiny", "grounding-dino-base"],
+ help="Name of the GroundingDino model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+ parser.add_argument(
+ "--verify_logits", action="store_false", help="Whether or not to verify logits after conversion."
+ )
+
+ args = parser.parse_args()
+ convert_grounding_dino_checkpoint(args)
diff --git a/src/transformers/models/grounding_dino/image_processing_grounding_dino.py b/src/transformers/models/grounding_dino/image_processing_grounding_dino.py
new file mode 100644
index 00000000000000..8b39d6801ca000
--- /dev/null
+++ b/src/transformers/models/grounding_dino/image_processing_grounding_dino.py
@@ -0,0 +1,1511 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Deformable DETR."""
+
+import io
+import pathlib
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from ...feature_extraction_utils import BatchFeature
+from ...image_processing_utils import BaseImageProcessor, get_size_dict
+from ...image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_annotations,
+ validate_kwargs,
+ validate_preprocess_arguments,
+)
+from ...utils import (
+ ExplicitEnum,
+ TensorType,
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+ logging,
+)
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+AnnotationType = Dict[str, Union[int, str, List[Dict]]]
+
+
+class AnnotationFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotationFormat.COCO_DETECTION, AnnotationFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray,
+ size: Union[int, Tuple[int, int], List[int]],
+ max_size: Optional[int] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ input_image (`np.ndarray`):
+ The image to resize.
+ size (`int` or `Tuple[int, int]` or `List[int]`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred from the input image.
+ """
+ image_size = get_image_size(input_image, input_data_format)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(
+ images: List[np.ndarray], input_data_format: Optional[Union[str, ChannelDimension]] = None
+) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if input_data_format == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_data_format == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_data_format}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(
+ image: np.ndarray, output_size: Tuple[int, int], input_data_format: Optional[Union[str, ChannelDimension]] = None
+) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image, channel_dim=input_data_format)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->GroundingDino
+def prepare_coco_detection_annotation(
+ image,
+ target,
+ return_segmentation_masks: bool = False,
+ input_data_format: Optional[Union[ChannelDimension, str]] = None,
+):
+ """
+ Convert the target in COCO format into the format expected by GroundingDino.
+ """
+ image_height, image_width = get_image_size(image, channel_dim=input_data_format)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ # Converting the filtered keypoints list to a numpy array
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ # Apply the keep mask here to filter the relevant annotations
+ keypoints = keypoints[keep]
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->GroundingDino
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray,
+ target: Dict,
+ masks_path: Union[str, pathlib.Path],
+ return_masks: bool = True,
+ input_data_format: Union[ChannelDimension, str] = None,
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for GroundingDino.
+ """
+ image_height, image_width = get_image_size(image, channel_dim=input_data_format)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return list(runs)
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class GroundingDinoImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Grounding DINO image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `AnnotationFormat.COCO_DETECTION`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method. Controls whether to normalize the image. Can be overridden by the `do_normalize`
+ parameter in the `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_convert_annotations (`bool`, *optional*, defaults to `True`):
+ Controls whether to convert the annotations to the format expected by the DETR model. Converts the
+ bounding boxes to the format `(center_x, center_y, width, height)` and in the range `[0, 1]`.
+ Can be overridden by the `do_convert_annotations` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotationFormat] = AnnotationFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_convert_annotations: Optional[bool] = None,
+ do_pad: bool = True,
+ **kwargs,
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ # Backwards compatibility
+ if do_convert_annotations is None:
+ do_convert_annotations = do_normalize
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.do_convert_annotations = do_convert_annotations
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+ self._valid_processor_keys = [
+ "images",
+ "annotations",
+ "return_segmentation_masks",
+ "masks_path",
+ "do_resize",
+ "size",
+ "resample",
+ "do_rescale",
+ "rescale_factor",
+ "do_normalize",
+ "do_convert_annotations",
+ "image_mean",
+ "image_std",
+ "do_pad",
+ "format",
+ "return_tensors",
+ "data_format",
+ "input_data_format",
+ ]
+
+ @classmethod
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.from_dict with Detr->GroundingDino
+ def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
+ """
+ Overrides the `from_dict` method from the base class to make sure parameters are updated if image processor is
+ created using from_dict and kwargs e.g. `GroundingDinoImageProcessor.from_pretrained(checkpoint, size=600,
+ max_size=800)`
+ """
+ image_processor_dict = image_processor_dict.copy()
+ if "max_size" in kwargs:
+ image_processor_dict["max_size"] = kwargs.pop("max_size")
+ if "pad_and_return_pixel_mask" in kwargs:
+ image_processor_dict["pad_and_return_pixel_mask"] = kwargs.pop("pad_and_return_pixel_mask")
+ return super().from_dict(image_processor_dict, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->GroundingDino
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotationFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into GroundingDino model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotationFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(
+ image, target, return_segmentation_masks, input_data_format=input_data_format
+ )
+ elif format == AnnotationFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image,
+ target,
+ masks_path=masks_path,
+ return_masks=return_segmentation_masks,
+ input_data_format=input_data_format,
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ logger.warning_once(
+ "The `prepare` method is deprecated and will be removed in a v4.33. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ logger.warning_once("The `convert_coco_poly_to_mask` method is deprecated and will be removed in v4.33. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection
+ def prepare_coco_detection(self, *args, **kwargs):
+ logger.warning_once("The `prepare_coco_detection` method is deprecated and will be removed in v4.33. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ logger.warning_once("The `prepare_coco_panoptic` method is deprecated and will be removed in v4.33. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Dictionary containing the size to resize to. Can contain the keys `shortest_edge` and `longest_edge` or
+ `height` and `width`.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ """
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(
+ image, size["shortest_edge"], size["longest_edge"], input_data_format=input_data_format
+ )
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(
+ image, size=size, resample=resample, data_format=data_format, input_data_format=input_data_format, **kwargs
+ )
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self,
+ image: np.ndarray,
+ rescale_factor: float,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor. image = image * rescale_factor.
+
+ Args:
+ image (`np.ndarray`):
+ Image to rescale.
+ rescale_factor (`float`):
+ The value to use for rescaling.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. If unset, is inferred from the input image. Can be
+ one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ """
+ return rescale(image, rescale_factor, data_format=data_format, input_data_format=input_data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format and from absolute to relative pixel values.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._update_annotation_for_padded_image
+ def _update_annotation_for_padded_image(
+ self,
+ annotation: Dict,
+ input_image_size: Tuple[int, int],
+ output_image_size: Tuple[int, int],
+ padding,
+ update_bboxes,
+ ) -> Dict:
+ """
+ Update the annotation for a padded image.
+ """
+ new_annotation = {}
+ new_annotation["size"] = output_image_size
+
+ for key, value in annotation.items():
+ if key == "masks":
+ masks = value
+ masks = pad(
+ masks,
+ padding,
+ mode=PaddingMode.CONSTANT,
+ constant_values=0,
+ input_data_format=ChannelDimension.FIRST,
+ )
+ masks = safe_squeeze(masks, 1)
+ new_annotation["masks"] = masks
+ elif key == "boxes" and update_bboxes:
+ boxes = value
+ boxes *= np.asarray(
+ [
+ input_image_size[1] / output_image_size[1],
+ input_image_size[0] / output_image_size[0],
+ input_image_size[1] / output_image_size[1],
+ input_image_size[0] / output_image_size[0],
+ ]
+ )
+ new_annotation["boxes"] = boxes
+ elif key == "size":
+ new_annotation["size"] = output_image_size
+ else:
+ new_annotation[key] = value
+ return new_annotation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ annotation: Optional[Dict[str, Any]] = None,
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ update_bboxes: bool = True,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image, channel_dim=input_data_format)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image,
+ padding,
+ mode=PaddingMode.CONSTANT,
+ constant_values=constant_values,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ )
+ if annotation is not None:
+ annotation = self._update_annotation_for_padded_image(
+ annotation, (input_height, input_width), (output_height, output_width), padding, update_bboxes
+ )
+ return padded_image, annotation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ annotations: Optional[Union[AnnotationType, List[AnnotationType]]] = None,
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ update_bboxes: bool = True,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ images (List[`np.ndarray`]):
+ Images to pad.
+ annotations (`AnnotationType` or `List[AnnotationType]`, *optional*):
+ Annotations to transform according to the padding that is applied to the images.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ update_bboxes (`bool`, *optional*, defaults to `True`):
+ Whether to update the bounding boxes in the annotations to match the padded images. If the
+ bounding boxes have not been converted to relative coordinates and `(centre_x, centre_y, width, height)`
+ format, the bounding boxes will not be updated.
+ """
+ pad_size = get_max_height_width(images, input_data_format=input_data_format)
+
+ annotation_list = annotations if annotations is not None else [None] * len(images)
+ padded_images = []
+ padded_annotations = []
+ for image, annotation in zip(images, annotation_list):
+ padded_image, padded_annotation = self._pad_image(
+ image,
+ pad_size,
+ annotation,
+ constant_values=constant_values,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ update_bboxes=update_bboxes,
+ )
+ padded_images.append(padded_image)
+ padded_annotations.append(padded_annotation)
+
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [
+ make_pixel_mask(image=image, output_size=pad_size, input_data_format=input_data_format)
+ for image in images
+ ]
+ data["pixel_mask"] = masks
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in padded_annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[AnnotationType, List[AnnotationType]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ do_convert_annotations: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotationFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess. Expects a single or batch of images with pixel values ranging
+ from 0 to 255. If passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ annotations (`AnnotationType` or `List[AnnotationType]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ do_convert_annotations (`bool`, *optional*, defaults to self.do_convert_annotations):
+ Whether to convert the annotations to the format expected by the model. Converts the bounding
+ boxes from the format `(top_left_x, top_left_y, width, height)` to `(center_x, center_y, width, height)`
+ and in relative coordinates.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image. If `True` will pad the images in the batch to the largest image in the batch
+ and create a pixel mask. Padding will be applied to the bottom and right of the image with zeros.
+ format (`str` or `AnnotationFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ logger.warning_once(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead."
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead."
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_convert_annotations = (
+ self.do_convert_annotations if do_convert_annotations is None else do_convert_annotations
+ )
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ validate_kwargs(captured_kwargs=kwargs.keys(), valid_processor_keys=self._valid_processor_keys)
+
+ # Here, the pad() method pads to the maximum of (width, height). It does not need to be validated.
+ validate_preprocess_arguments(
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ )
+
+ if annotations is not None and isinstance(annotations, dict):
+ annotations = [annotations]
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ format = AnnotationFormat(format)
+ if annotations is not None:
+ validate_annotations(format, SUPPORTED_ANNOTATION_FORMATS, annotations)
+
+ if (
+ masks_path is not None
+ and format == AnnotationFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image,
+ target,
+ format,
+ return_segmentation_masks=return_segmentation_masks,
+ masks_path=masks_path,
+ input_data_format=input_data_format,
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image, input_data_format)
+ resized_image = self.resize(
+ image, size=size, max_size=max_size, resample=resample, input_data_format=input_data_format
+ )
+ resized_annotation = self.resize_annotation(
+ target, orig_size, get_image_size(resized_image, input_data_format)
+ )
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [
+ self.resize(image, size=size, resample=resample, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor, input_data_format=input_data_format) for image in images]
+
+ if do_normalize:
+ images = [
+ self.normalize(image, image_mean, image_std, input_data_format=input_data_format) for image in images
+ ]
+
+ if do_convert_annotations and annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image, input_data_format))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ encoded_inputs = self.pad(
+ images,
+ annotations=annotations,
+ return_pixel_mask=True,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ update_bboxes=do_convert_annotations,
+ return_tensors=return_tensors,
+ )
+ else:
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
+ for image in images
+ ]
+ encoded_inputs = BatchFeature(data={"pixel_values": images}, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.owlvit.image_processing_owlvit.OwlViTImageProcessor.post_process_object_detection with OwlViT->GroundingDino
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.1, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the raw output of [`GroundingDinoForObjectDetection`] into final bounding boxes in (top_left_x, top_left_y,
+ bottom_right_x, bottom_right_y) format.
+
+ Args:
+ outputs ([`GroundingDinoObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ # TODO: (amy) add support for other frameworks
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+ labels = probs.indices
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/models/grounding_dino/modeling_grounding_dino.py b/src/transformers/models/grounding_dino/modeling_grounding_dino.py
new file mode 100644
index 00000000000000..7f9149de9155e4
--- /dev/null
+++ b/src/transformers/models/grounding_dino/modeling_grounding_dino.py
@@ -0,0 +1,3132 @@
+# coding=utf-8
+# Copyright 2024 IDEA Research and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Grounding DINO model."""
+
+import copy
+import math
+import os
+import warnings
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor, nn
+from torch.autograd import Function
+from torch.autograd.function import once_differentiable
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_scipy_available,
+ is_timm_available,
+ is_torch_cuda_available,
+ is_vision_available,
+ replace_return_docstrings,
+ requires_backends,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import meshgrid
+from ...utils import is_accelerate_available, is_ninja_available, logging
+from ...utils.backbone_utils import load_backbone
+from ..auto import AutoModel
+from .configuration_grounding_dino import GroundingDinoConfig
+
+
+if is_vision_available():
+ from transformers.image_transforms import center_to_corners_format
+
+if is_accelerate_available():
+ from accelerate import PartialState
+ from accelerate.utils import reduce
+
+if is_scipy_available():
+ from scipy.optimize import linear_sum_assignment
+
+if is_timm_available():
+ from timm import create_model
+
+
+logger = logging.get_logger(__name__)
+
+MultiScaleDeformableAttention = None
+
+
+# Copied from models.deformable_detr.load_cuda_kernels
+def load_cuda_kernels():
+ from torch.utils.cpp_extension import load
+
+ global MultiScaleDeformableAttention
+
+ root = Path(__file__).resolve().parent.parent.parent / "kernels" / "grounding_dino"
+ src_files = [
+ root / filename
+ for filename in [
+ "vision.cpp",
+ os.path.join("cpu", "ms_deform_attn_cpu.cpp"),
+ os.path.join("cuda", "ms_deform_attn_cuda.cu"),
+ ]
+ ]
+
+ MultiScaleDeformableAttention = load(
+ "MultiScaleDeformableAttention",
+ src_files,
+ with_cuda=True,
+ extra_include_paths=[str(root)],
+ extra_cflags=["-DWITH_CUDA=1"],
+ extra_cuda_cflags=[
+ "-DCUDA_HAS_FP16=1",
+ "-D__CUDA_NO_HALF_OPERATORS__",
+ "-D__CUDA_NO_HALF_CONVERSIONS__",
+ "-D__CUDA_NO_HALF2_OPERATORS__",
+ ],
+ )
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.MultiScaleDeformableAttentionFunction
+class MultiScaleDeformableAttentionFunction(Function):
+ @staticmethod
+ def forward(
+ context,
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ im2col_step,
+ ):
+ context.im2col_step = im2col_step
+ output = MultiScaleDeformableAttention.ms_deform_attn_forward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ context.im2col_step,
+ )
+ context.save_for_backward(
+ value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights
+ )
+ return output
+
+ @staticmethod
+ @once_differentiable
+ def backward(context, grad_output):
+ (
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ ) = context.saved_tensors
+ grad_value, grad_sampling_loc, grad_attn_weight = MultiScaleDeformableAttention.ms_deform_attn_backward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ grad_output,
+ context.im2col_step,
+ )
+
+ return grad_value, None, None, grad_sampling_loc, grad_attn_weight, None
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "GroundingDinoConfig"
+_CHECKPOINT_FOR_DOC = "IDEA-Research/grounding-dino-tiny"
+
+GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "IDEA-Research/grounding-dino-tiny",
+ # See all Grounding DINO models at https://huggingface.co/models?filter=grounding-dino
+]
+
+
+@dataclass
+class GroundingDinoDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of the GroundingDinoDecoder. This class adds two attributes to
+ BaseModelOutputWithCrossAttentions, namely:
+ - a stacked tensor of intermediate decoder hidden states (i.e. the output of each decoder layer)
+ - a stacked tensor of intermediate reference points.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, sequence_length, hidden_size)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ intermediate_hidden_states: torch.FloatTensor = None
+ intermediate_reference_points: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class GroundingDinoEncoderOutput(ModelOutput):
+ """
+ Base class for outputs of the GroundingDinoEncoder. This class extends BaseModelOutput, due to:
+ - vision and text last hidden states
+ - vision and text intermediate hidden states
+
+ Args:
+ last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the vision encoder.
+ last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the text encoder.
+ vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads.
+ """
+
+ last_hidden_state_vision: torch.FloatTensor = None
+ last_hidden_state_text: torch.FloatTensor = None
+ vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class GroundingDinoModelOutput(ModelOutput):
+ """
+ Base class for outputs of the Grounding DINO encoder-decoder model.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ init_reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Initial reference points sent through the Transformer decoder.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, 4)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_queries, hidden_size)`. Hidden-states of the decoder at the output of each layer
+ plus the initial embedding outputs.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ encoder_last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ encoder_text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads. attention softmax, used to compute the weighted average in the
+ bi-attention heads.
+ enc_outputs_class (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`, *optional*, returned when `config.two_stage=True`):
+ Predicted bounding boxes scores where the top `config.num_queries` scoring bounding boxes are picked as
+ region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and
+ background).
+ enc_outputs_coord_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, 4)`, *optional*, returned when `config.two_stage=True`):
+ Logits of predicted bounding boxes coordinates in the first stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ init_reference_points: torch.FloatTensor = None
+ intermediate_hidden_states: torch.FloatTensor = None
+ intermediate_reference_points: torch.FloatTensor = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ encoder_last_hidden_state_vision: Optional[torch.FloatTensor] = None
+ encoder_last_hidden_state_text: Optional[torch.FloatTensor] = None
+ encoder_vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ enc_outputs_class: Optional[torch.FloatTensor] = None
+ enc_outputs_coord_logits: Optional[torch.FloatTensor] = None
+
+
+@dataclass
+class GroundingDinoObjectDetectionOutput(ModelOutput):
+ """
+ Output type of [`GroundingDinoForObjectDetection`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` are provided)):
+ Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a
+ bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized
+ scale-invariant IoU loss.
+ loss_dict (`Dict`, *optional*):
+ A dictionary containing the individual losses. Useful for logging.
+ logits (`torch.FloatTensor` of shape `(batch_size, num_queries, num_classes + 1)`):
+ Classification logits (including no-object) for all queries.
+ pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
+ values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
+ possible padding). You can use [`~GroundingDinoProcessor.post_process_object_detection`] to retrieve the
+ unnormalized bounding boxes.
+ auxiliary_outputs (`List[Dict]`, *optional*):
+ Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
+ and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
+ `pred_boxes`) for each decoder layer.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_queries, hidden_size)`. Hidden-states of the decoder at the output of each layer
+ plus the initial embedding outputs.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ encoder_last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ encoder_text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, 4)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ init_reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Initial reference points sent through the Transformer decoder.
+ enc_outputs_class (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`, *optional*, returned when `config.two_stage=True`):
+ Predicted bounding boxes scores where the top `config.num_queries` scoring bounding boxes are picked as
+ region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and
+ background).
+ enc_outputs_coord_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, 4)`, *optional*, returned when `config.two_stage=True`):
+ Logits of predicted bounding boxes coordinates in the first stage.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ loss_dict: Optional[Dict] = None
+ logits: torch.FloatTensor = None
+ pred_boxes: torch.FloatTensor = None
+ auxiliary_outputs: Optional[List[Dict]] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ init_reference_points: Optional[torch.FloatTensor] = None
+ intermediate_hidden_states: Optional[torch.FloatTensor] = None
+ intermediate_reference_points: Optional[torch.FloatTensor] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ encoder_last_hidden_state_vision: Optional[torch.FloatTensor] = None
+ encoder_last_hidden_state_text: Optional[torch.FloatTensor] = None
+ encoder_vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ enc_outputs_class: Optional[torch.FloatTensor] = None
+ enc_outputs_coord_logits: Optional[torch.FloatTensor] = None
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrFrozenBatchNorm2d with Detr->GroundingDino
+class GroundingDinoFrozenBatchNorm2d(nn.Module):
+ """
+ BatchNorm2d where the batch statistics and the affine parameters are fixed.
+
+ Copy-paste from torchvision.misc.ops with added eps before rqsrt, without which any other models than
+ torchvision.models.resnet[18,34,50,101] produce nans.
+ """
+
+ def __init__(self, n):
+ super().__init__()
+ self.register_buffer("weight", torch.ones(n))
+ self.register_buffer("bias", torch.zeros(n))
+ self.register_buffer("running_mean", torch.zeros(n))
+ self.register_buffer("running_var", torch.ones(n))
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ num_batches_tracked_key = prefix + "num_batches_tracked"
+ if num_batches_tracked_key in state_dict:
+ del state_dict[num_batches_tracked_key]
+
+ super()._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def forward(self, x):
+ # move reshapes to the beginning
+ # to make it user-friendly
+ weight = self.weight.reshape(1, -1, 1, 1)
+ bias = self.bias.reshape(1, -1, 1, 1)
+ running_var = self.running_var.reshape(1, -1, 1, 1)
+ running_mean = self.running_mean.reshape(1, -1, 1, 1)
+ epsilon = 1e-5
+ scale = weight * (running_var + epsilon).rsqrt()
+ bias = bias - running_mean * scale
+ return x * scale + bias
+
+
+# Copied from transformers.models.detr.modeling_detr.replace_batch_norm with Detr->GroundingDino
+def replace_batch_norm(model):
+ r"""
+ Recursively replace all `torch.nn.BatchNorm2d` with `GroundingDinoFrozenBatchNorm2d`.
+
+ Args:
+ model (torch.nn.Module):
+ input model
+ """
+ for name, module in model.named_children():
+ if isinstance(module, nn.BatchNorm2d):
+ new_module = GroundingDinoFrozenBatchNorm2d(module.num_features)
+
+ if not module.weight.device == torch.device("meta"):
+ new_module.weight.data.copy_(module.weight)
+ new_module.bias.data.copy_(module.bias)
+ new_module.running_mean.data.copy_(module.running_mean)
+ new_module.running_var.data.copy_(module.running_var)
+
+ model._modules[name] = new_module
+
+ if len(list(module.children())) > 0:
+ replace_batch_norm(module)
+
+
+class GroundingDinoConvEncoder(nn.Module):
+ """
+ Convolutional backbone, using either the AutoBackbone API or one from the timm library.
+
+ nn.BatchNorm2d layers are replaced by GroundingDinoFrozenBatchNorm2d as defined above.
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.config = config
+
+ if config.use_timm_backbone:
+ requires_backends(self, ["timm"])
+ backbone = create_model(
+ config.backbone,
+ pretrained=config.use_pretrained_backbone,
+ features_only=True,
+ **config.backbone_kwargs,
+ )
+ else:
+ backbone = load_backbone(config)
+
+ # replace batch norm by frozen batch norm
+ with torch.no_grad():
+ replace_batch_norm(backbone)
+ self.model = backbone
+ self.intermediate_channel_sizes = (
+ self.model.feature_info.channels() if config.use_timm_backbone else self.model.channels
+ )
+
+ backbone_model_type = config.backbone if config.use_timm_backbone else config.backbone_config.model_type
+ if "resnet" in backbone_model_type:
+ for name, parameter in self.model.named_parameters():
+ if config.use_timm_backbone:
+ if "layer2" not in name and "layer3" not in name and "layer4" not in name:
+ parameter.requires_grad_(False)
+ else:
+ if "stage.1" not in name and "stage.2" not in name and "stage.3" not in name:
+ parameter.requires_grad_(False)
+
+ # Copied from transformers.models.detr.modeling_detr.DetrConvEncoder.forward with Detr->GroundingDino
+ def forward(self, pixel_values: torch.Tensor, pixel_mask: torch.Tensor):
+ # send pixel_values through the model to get list of feature maps
+ features = self.model(pixel_values) if self.config.use_timm_backbone else self.model(pixel_values).feature_maps
+
+ out = []
+ for feature_map in features:
+ # downsample pixel_mask to match shape of corresponding feature_map
+ mask = nn.functional.interpolate(pixel_mask[None].float(), size=feature_map.shape[-2:]).to(torch.bool)[0]
+ out.append((feature_map, mask))
+ return out
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrConvModel with Detr->GroundingDino
+class GroundingDinoConvModel(nn.Module):
+ """
+ This module adds 2D position embeddings to all intermediate feature maps of the convolutional encoder.
+ """
+
+ def __init__(self, conv_encoder, position_embedding):
+ super().__init__()
+ self.conv_encoder = conv_encoder
+ self.position_embedding = position_embedding
+
+ def forward(self, pixel_values, pixel_mask):
+ # send pixel_values and pixel_mask through backbone to get list of (feature_map, pixel_mask) tuples
+ out = self.conv_encoder(pixel_values, pixel_mask)
+ pos = []
+ for feature_map, mask in out:
+ # position encoding
+ pos.append(self.position_embedding(feature_map, mask).to(feature_map.dtype))
+
+ return out, pos
+
+
+class GroundingDinoSinePositionEmbedding(nn.Module):
+ """
+ This is a more standard version of the position embedding, very similar to the one used by the Attention is all you
+ need paper, generalized to work on images.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.embedding_dim = config.d_model // 2
+ self.temperature = config.positional_embedding_temperature
+ self.scale = 2 * math.pi
+
+ def forward(self, pixel_values, pixel_mask):
+ y_embed = pixel_mask.cumsum(1, dtype=torch.float32)
+ x_embed = pixel_mask.cumsum(2, dtype=torch.float32)
+ eps = 1e-6
+ y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
+ x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
+
+ dim_t = torch.arange(self.embedding_dim, dtype=torch.float32, device=pixel_values.device)
+ dim_t = self.temperature ** (2 * torch.div(dim_t, 2, rounding_mode="floor") / self.embedding_dim)
+
+ pos_x = x_embed[:, :, :, None] / dim_t
+ pos_y = y_embed[:, :, :, None] / dim_t
+ pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+ return pos
+
+
+class GroundingDinoLearnedPositionEmbedding(nn.Module):
+ """
+ This module learns positional embeddings up to a fixed maximum size.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ embedding_dim = config.d_model // 2
+ self.row_embeddings = nn.Embedding(50, embedding_dim)
+ self.column_embeddings = nn.Embedding(50, embedding_dim)
+
+ def forward(self, pixel_values, pixel_mask=None):
+ height, width = pixel_values.shape[-2:]
+ width_values = torch.arange(width, device=pixel_values.device)
+ height_values = torch.arange(height, device=pixel_values.device)
+ x_emb = self.column_embeddings(width_values)
+ y_emb = self.row_embeddings(height_values)
+ pos = torch.cat([x_emb.unsqueeze(0).repeat(height, 1, 1), y_emb.unsqueeze(1).repeat(1, width, 1)], dim=-1)
+ pos = pos.permute(2, 0, 1)
+ pos = pos.unsqueeze(0)
+ pos = pos.repeat(pixel_values.shape[0], 1, 1, 1)
+ return pos
+
+
+def build_position_encoding(config):
+ if config.position_embedding_type == "sine":
+ position_embedding = GroundingDinoSinePositionEmbedding(config)
+ elif config.position_embedding_type == "learned":
+ position_embedding = GroundingDinoLearnedPositionEmbedding(config)
+ else:
+ raise ValueError(f"Not supported {config.position_embedding_type}")
+
+ return position_embedding
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.multi_scale_deformable_attention
+def multi_scale_deformable_attention(
+ value: Tensor, value_spatial_shapes: Tensor, sampling_locations: Tensor, attention_weights: Tensor
+) -> Tensor:
+ batch_size, _, num_heads, hidden_dim = value.shape
+ _, num_queries, num_heads, num_levels, num_points, _ = sampling_locations.shape
+ value_list = value.split([height.item() * width.item() for height, width in value_spatial_shapes], dim=1)
+ sampling_grids = 2 * sampling_locations - 1
+ sampling_value_list = []
+ for level_id, (height, width) in enumerate(value_spatial_shapes):
+ # batch_size, height*width, num_heads, hidden_dim
+ # -> batch_size, height*width, num_heads*hidden_dim
+ # -> batch_size, num_heads*hidden_dim, height*width
+ # -> batch_size*num_heads, hidden_dim, height, width
+ value_l_ = (
+ value_list[level_id].flatten(2).transpose(1, 2).reshape(batch_size * num_heads, hidden_dim, height, width)
+ )
+ # batch_size, num_queries, num_heads, num_points, 2
+ # -> batch_size, num_heads, num_queries, num_points, 2
+ # -> batch_size*num_heads, num_queries, num_points, 2
+ sampling_grid_l_ = sampling_grids[:, :, :, level_id].transpose(1, 2).flatten(0, 1)
+ # batch_size*num_heads, hidden_dim, num_queries, num_points
+ sampling_value_l_ = nn.functional.grid_sample(
+ value_l_, sampling_grid_l_, mode="bilinear", padding_mode="zeros", align_corners=False
+ )
+ sampling_value_list.append(sampling_value_l_)
+ # (batch_size, num_queries, num_heads, num_levels, num_points)
+ # -> (batch_size, num_heads, num_queries, num_levels, num_points)
+ # -> (batch_size, num_heads, 1, num_queries, num_levels*num_points)
+ attention_weights = attention_weights.transpose(1, 2).reshape(
+ batch_size * num_heads, 1, num_queries, num_levels * num_points
+ )
+ output = (
+ (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights)
+ .sum(-1)
+ .view(batch_size, num_heads * hidden_dim, num_queries)
+ )
+ return output.transpose(1, 2).contiguous()
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrMultiscaleDeformableAttention with DeformableDetr->GroundingDino, Deformable DETR->Grounding DINO
+class GroundingDinoMultiscaleDeformableAttention(nn.Module):
+ """
+ Multiscale deformable attention as proposed in Deformable DETR.
+ """
+
+ def __init__(self, config: GroundingDinoConfig, num_heads: int, n_points: int):
+ super().__init__()
+
+ kernel_loaded = MultiScaleDeformableAttention is not None
+ if is_torch_cuda_available() and is_ninja_available() and not kernel_loaded:
+ try:
+ load_cuda_kernels()
+ except Exception as e:
+ logger.warning(f"Could not load the custom kernel for multi-scale deformable attention: {e}")
+
+ if config.d_model % num_heads != 0:
+ raise ValueError(
+ f"embed_dim (d_model) must be divisible by num_heads, but got {config.d_model} and {num_heads}"
+ )
+ dim_per_head = config.d_model // num_heads
+ # check if dim_per_head is power of 2
+ if not ((dim_per_head & (dim_per_head - 1) == 0) and dim_per_head != 0):
+ warnings.warn(
+ "You'd better set embed_dim (d_model) in GroundingDinoMultiscaleDeformableAttention to make the"
+ " dimension of each attention head a power of 2 which is more efficient in the authors' CUDA"
+ " implementation."
+ )
+
+ self.im2col_step = 64
+
+ self.d_model = config.d_model
+ self.n_levels = config.num_feature_levels
+ self.n_heads = num_heads
+ self.n_points = n_points
+
+ self.sampling_offsets = nn.Linear(config.d_model, num_heads * self.n_levels * n_points * 2)
+ self.attention_weights = nn.Linear(config.d_model, num_heads * self.n_levels * n_points)
+ self.value_proj = nn.Linear(config.d_model, config.d_model)
+ self.output_proj = nn.Linear(config.d_model, config.d_model)
+
+ self.disable_custom_kernels = config.disable_custom_kernels
+
+ self._reset_parameters()
+
+ def _reset_parameters(self):
+ nn.init.constant_(self.sampling_offsets.weight.data, 0.0)
+ default_dtype = torch.get_default_dtype()
+ thetas = torch.arange(self.n_heads, dtype=torch.int64).to(default_dtype) * (2.0 * math.pi / self.n_heads)
+ grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
+ grid_init = (
+ (grid_init / grid_init.abs().max(-1, keepdim=True)[0])
+ .view(self.n_heads, 1, 1, 2)
+ .repeat(1, self.n_levels, self.n_points, 1)
+ )
+ for i in range(self.n_points):
+ grid_init[:, :, i, :] *= i + 1
+ with torch.no_grad():
+ self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
+ nn.init.constant_(self.attention_weights.weight.data, 0.0)
+ nn.init.constant_(self.attention_weights.bias.data, 0.0)
+ nn.init.xavier_uniform_(self.value_proj.weight.data)
+ nn.init.constant_(self.value_proj.bias.data, 0.0)
+ nn.init.xavier_uniform_(self.output_proj.weight.data)
+ nn.init.constant_(self.output_proj.bias.data, 0.0)
+
+ def with_pos_embed(self, tensor: torch.Tensor, position_embeddings: Optional[Tensor]):
+ return tensor if position_embeddings is None else tensor + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ position_embeddings: Optional[torch.Tensor] = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ output_attentions: bool = False,
+ ):
+ # add position embeddings to the hidden states before projecting to queries and keys
+ if position_embeddings is not None:
+ hidden_states = self.with_pos_embed(hidden_states, position_embeddings)
+
+ batch_size, num_queries, _ = hidden_states.shape
+ batch_size, sequence_length, _ = encoder_hidden_states.shape
+ if (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() != sequence_length:
+ raise ValueError(
+ "Make sure to align the spatial shapes with the sequence length of the encoder hidden states"
+ )
+
+ value = self.value_proj(encoder_hidden_states)
+ if attention_mask is not None:
+ # we invert the attention_mask
+ value = value.masked_fill(~attention_mask[..., None], float(0))
+ value = value.view(batch_size, sequence_length, self.n_heads, self.d_model // self.n_heads)
+ sampling_offsets = self.sampling_offsets(hidden_states).view(
+ batch_size, num_queries, self.n_heads, self.n_levels, self.n_points, 2
+ )
+ attention_weights = self.attention_weights(hidden_states).view(
+ batch_size, num_queries, self.n_heads, self.n_levels * self.n_points
+ )
+ attention_weights = F.softmax(attention_weights, -1).view(
+ batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
+ )
+ # batch_size, num_queries, n_heads, n_levels, n_points, 2
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
+ offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
+ sampling_locations = (
+ reference_points[:, :, None, :, None, :]
+ + sampling_offsets / offset_normalizer[None, None, None, :, None, :]
+ )
+ elif num_coordinates == 4:
+ sampling_locations = (
+ reference_points[:, :, None, :, None, :2]
+ + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
+ )
+ else:
+ raise ValueError(f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}")
+
+ if self.disable_custom_kernels:
+ # PyTorch implementation
+ output = multi_scale_deformable_attention(value, spatial_shapes, sampling_locations, attention_weights)
+ else:
+ try:
+ # custom kernel
+ output = MultiScaleDeformableAttentionFunction.apply(
+ value,
+ spatial_shapes,
+ level_start_index,
+ sampling_locations,
+ attention_weights,
+ self.im2col_step,
+ )
+ except Exception:
+ # PyTorch implementation
+ output = multi_scale_deformable_attention(value, spatial_shapes, sampling_locations, attention_weights)
+ output = self.output_proj(output)
+
+ return output, attention_weights
+
+
+class GroundingDinoTextEnhancerLayer(nn.Module):
+ """Vanilla Transformer with text embeddings as input"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.self_attn = GroundingDinoMultiheadAttention(
+ config, num_attention_heads=config.encoder_attention_heads // 2
+ )
+
+ # Implementation of Feedforward model
+ self.fc1 = nn.Linear(config.d_model, config.encoder_ffn_dim // 2)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim // 2, config.d_model)
+
+ self.layer_norm_before = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layer_norm_after = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+
+ self.activation = ACT2FN[config.activation_function]
+ self.num_heads = config.encoder_attention_heads // 2
+ self.dropout = config.text_enhancer_dropout
+
+ def with_pos_embed(self, hidden_state: Tensor, position_embeddings: Optional[Tensor]):
+ return hidden_state if position_embeddings is None else hidden_state + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_masks: Optional[torch.BoolTensor] = None,
+ position_embeddings: Optional[torch.FloatTensor] = None,
+ ) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
+ """Text self-attention to enhance projection of text features generated by
+ the text encoder (AutoModel based on text_config) within GroundingDinoEncoderLayer
+
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_dim)`):
+ Text features generated by the text encoder.
+ attention_masks (`torch.BoolTensor`, *optional*):
+ Attention mask for text self-attention. False for real tokens and True for padding tokens.
+ position_embeddings (`torch.FloatTensor`, *optional*):
+ Position embeddings to be added to the hidden states.
+
+ Returns:
+ `tuple(torch.FloatTensor)` comprising two elements:
+ - **hidden_states** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`) --
+ Output of the text self-attention layer.
+ - **attention_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`) --
+ Attention weights of the text self-attention layer.
+ """
+
+ # repeat attn mask
+ if attention_masks.dim() == 3 and attention_masks.shape[0] == hidden_states.shape[0]:
+ # batch_size, num_queries, num_keys
+ attention_masks = attention_masks[:, None, :, :]
+ attention_masks = attention_masks.repeat(1, self.num_heads, 1, 1)
+
+ dtype = torch.float16
+ attention_masks = attention_masks.to(dtype=dtype) # fp16 compatibility
+ attention_masks = (1.0 - attention_masks) * torch.finfo(dtype).min
+
+ queries = keys = self.with_pos_embed(hidden_states, position_embeddings)
+ attention_output, attention_weights = self.self_attn(
+ queries=queries,
+ keys=keys,
+ values=hidden_states,
+ attention_mask=attention_masks,
+ output_attentions=True,
+ )
+ attention_output = nn.functional.dropout(attention_output, p=self.dropout, training=self.training)
+ hidden_states = hidden_states + attention_output
+ hidden_states = self.layer_norm_before(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = hidden_states + residual
+ hidden_states = self.layer_norm_after(hidden_states)
+
+ return hidden_states, attention_weights
+
+
+class GroundingDinoBiMultiHeadAttention(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+
+ vision_dim = text_dim = config.d_model
+ embed_dim = config.encoder_ffn_dim // 2
+ num_heads = config.encoder_attention_heads // 2
+ dropout = config.fusion_dropout
+
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.head_dim = embed_dim // num_heads
+ self.vision_dim = vision_dim
+ self.text_dim = text_dim
+
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"`embed_dim` must be divisible by `num_heads` (got `embed_dim`: {self.embed_dim} and `num_heads`: {self.num_heads})."
+ )
+ self.scale = self.head_dim ** (-0.5)
+ self.dropout = dropout
+
+ self.vision_proj = nn.Linear(self.vision_dim, self.embed_dim)
+ self.text_proj = nn.Linear(self.text_dim, self.embed_dim)
+ self.values_vision_proj = nn.Linear(self.vision_dim, self.embed_dim)
+ self.values_text_proj = nn.Linear(self.text_dim, self.embed_dim)
+
+ self.out_vision_proj = nn.Linear(self.embed_dim, self.vision_dim)
+ self.out_text_proj = nn.Linear(self.embed_dim, self.text_dim)
+
+ def _reshape(self, tensor: torch.Tensor, seq_len: int, batch_size: int):
+ return tensor.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ vision_features: torch.FloatTensor,
+ text_features: torch.FloatTensor,
+ vision_attention_mask: Optional[torch.BoolTensor] = None,
+ text_attention_mask: Optional[torch.BoolTensor] = None,
+ ) -> Tuple[Tuple[torch.FloatTensor, torch.FloatTensor], Tuple[torch.FloatTensor, torch.FloatTensor]]:
+ """Image-to-text and text-to-image cross-attention
+
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_dim)`):
+ Projected flattened image features generated by the vision backbone.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`):
+ Projected text features generated by the text encoder.
+ vision_attention_mask (`torch.BoolTensor`, **optional**):
+ Attention mask for image-to-text cross-attention. False for real tokens and True for padding tokens.
+ text_attention_mask (`torch.BoolTensor`, **optional**):
+ Attention mask for text-to-image cross-attention. False for real tokens and True for padding tokens.
+
+ Returns:
+ `tuple(tuple(torch.FloatTensor), tuple(torch.FloatTensor))` where each inner tuple comprises an attention
+ output and weights:
+ - **vision_attn_output** (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_din)`)
+ --
+ Output of the image-to-text cross-attention layer.
+ - **vision_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, vision_sequence_length,
+ vision_sequence_length)`) --
+ Attention weights of the image-to-text cross-attention layer.
+ - **text_attn_output** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`) --
+ Output of the text-to-image cross-attention layer.
+ - **text_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, text_sequence_length,
+ text_sequence_length)`) --
+ Attention weights of the text-to-image cross-attention layer.
+ """
+ batch_size, tgt_len, _ = vision_features.size()
+
+ vision_query_states = self.vision_proj(vision_features) * self.scale
+ vision_query_states = self._reshape(vision_query_states, tgt_len, batch_size)
+
+ text_key_states = self.text_proj(text_features)
+ text_key_states = self._reshape(text_key_states, -1, batch_size)
+
+ vision_value_states = self.values_vision_proj(vision_features)
+ vision_value_states = self._reshape(vision_value_states, -1, batch_size)
+
+ text_value_states = self.values_text_proj(text_features)
+ text_value_states = self._reshape(text_value_states, -1, batch_size)
+
+ proj_shape = (batch_size * self.num_heads, -1, self.head_dim)
+
+ vision_query_states = vision_query_states.view(*proj_shape)
+ text_key_states = text_key_states.view(*proj_shape)
+ vision_value_states = vision_value_states.view(*proj_shape)
+ text_value_states = text_value_states.view(*proj_shape)
+
+ src_len = text_key_states.size(1)
+ attn_weights = torch.bmm(vision_query_states, text_key_states.transpose(1, 2)) # bs*nhead, nimg, ntxt
+
+ if attn_weights.size() != (batch_size * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(batch_size * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
+ )
+
+ attn_weights = attn_weights - attn_weights.max()
+ # Do not increase -50000/50000, data type half has quite limited range
+ attn_weights = torch.clamp(attn_weights, min=-50000, max=50000)
+
+ attn_weights_transposed = attn_weights.transpose(1, 2)
+ text_attn_weights = attn_weights_transposed - torch.max(attn_weights_transposed, dim=-1, keepdim=True)[0]
+
+ # Do not increase -50000/50000, data type half has quite limited range
+ text_attn_weights = torch.clamp(text_attn_weights, min=-50000, max=50000)
+
+ # mask vision for language
+ if vision_attention_mask is not None:
+ vision_attention_mask = (
+ vision_attention_mask[:, None, None, :].repeat(1, self.num_heads, 1, 1).flatten(0, 1)
+ )
+ text_attn_weights.masked_fill_(vision_attention_mask, float("-inf"))
+
+ text_attn_weights = text_attn_weights.softmax(dim=-1)
+
+ # mask language for vision
+ if text_attention_mask is not None:
+ text_attention_mask = text_attention_mask[:, None, None, :].repeat(1, self.num_heads, 1, 1).flatten(0, 1)
+ attn_weights.masked_fill_(text_attention_mask, float("-inf"))
+ vision_attn_weights = attn_weights.softmax(dim=-1)
+
+ vision_attn_probs = F.dropout(vision_attn_weights, p=self.dropout, training=self.training)
+ text_attn_probs = F.dropout(text_attn_weights, p=self.dropout, training=self.training)
+
+ vision_attn_output = torch.bmm(vision_attn_probs, text_value_states)
+ text_attn_output = torch.bmm(text_attn_probs, vision_value_states)
+
+ if vision_attn_output.size() != (batch_size * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`vision_attn_output` should be of size {(batch_size, self.num_heads, tgt_len, self.head_dim)}, but is {vision_attn_output.size()}"
+ )
+
+ if text_attn_output.size() != (batch_size * self.num_heads, src_len, self.head_dim):
+ raise ValueError(
+ f"`text_attn_output` should be of size {(batch_size, self.num_heads, src_len, self.head_dim)}, but is {text_attn_output.size()}"
+ )
+
+ vision_attn_output = vision_attn_output.view(batch_size, self.num_heads, tgt_len, self.head_dim)
+ vision_attn_output = vision_attn_output.transpose(1, 2)
+ vision_attn_output = vision_attn_output.reshape(batch_size, tgt_len, self.embed_dim)
+
+ text_attn_output = text_attn_output.view(batch_size, self.num_heads, src_len, self.head_dim)
+ text_attn_output = text_attn_output.transpose(1, 2)
+ text_attn_output = text_attn_output.reshape(batch_size, src_len, self.embed_dim)
+
+ vision_attn_output = self.out_vision_proj(vision_attn_output)
+ text_attn_output = self.out_text_proj(text_attn_output)
+
+ return (vision_attn_output, vision_attn_weights), (text_attn_output, text_attn_weights)
+
+
+# Copied from transformers.models.beit.modeling_beit.drop_path
+def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.beit.modeling_beit.BeitDropPath with Beit->GroundingDino
+class GroundingDinoDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+class GroundingDinoFusionLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ drop_path = config.fusion_droppath
+
+ # pre layer norm
+ self.layer_norm_vision = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layer_norm_text = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.attn = GroundingDinoBiMultiHeadAttention(config)
+
+ # add layer scale for training stability
+ self.drop_path = GroundingDinoDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+ init_values = 1e-4
+ self.vision_param = nn.Parameter(init_values * torch.ones((config.d_model)), requires_grad=True)
+ self.text_param = nn.Parameter(init_values * torch.ones((config.d_model)), requires_grad=True)
+
+ def forward(
+ self,
+ vision_features: torch.FloatTensor,
+ text_features: torch.FloatTensor,
+ attention_mask_vision: Optional[torch.BoolTensor] = None,
+ attention_mask_text: Optional[torch.BoolTensor] = None,
+ ) -> Tuple[Tuple[torch.FloatTensor, torch.FloatTensor], Tuple[torch.FloatTensor, torch.FloatTensor]]:
+ """Image and text features fusion
+
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_dim)`):
+ Projected flattened image features generated by the vision backbone.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`):
+ Projected text features generated by the text encoder.
+ attention_mask_vision (`torch.BoolTensor`, **optional**):
+ Attention mask for image-to-text cross-attention. False for real tokens and True for padding tokens.
+ attention_mask_text (`torch.BoolTensor`, **optional**):
+ Attention mask for text-to-image cross-attention. False for real tokens and True for padding tokens.
+
+ Returns:
+ `tuple(tuple(torch.FloatTensor), tuple(torch.FloatTensor))` where each inner tuple comprises an enhanced
+ feature and attention output and weights:
+ - **vision_features** (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, vision_dim)`) --
+ Updated vision features with attention output from image-to-text cross-attention layer.
+ - **vision_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, vision_sequence_length,
+ vision_sequence_length)`) --
+ Attention weights of the image-to-text cross-attention layer.
+ - **text_features** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, text_dim)`) --
+ Updated text features with attention output from text-to-image cross-attention layer.
+ - **text_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, text_sequence_length,
+ text_sequence_length)`) --
+ Attention weights of the text-to-image cross-attention layer.
+ """
+ vision_features = self.layer_norm_vision(vision_features)
+ text_features = self.layer_norm_text(text_features)
+ (delta_v, vision_attn), (delta_t, text_attn) = self.attn(
+ vision_features,
+ text_features,
+ vision_attention_mask=attention_mask_vision,
+ text_attention_mask=attention_mask_text,
+ )
+ vision_features = vision_features + self.drop_path(self.vision_param * delta_v)
+ text_features = text_features + self.drop_path(self.text_param * delta_t)
+
+ return (vision_features, vision_attn), (text_features, text_attn)
+
+
+class GroundingDinoDeformableLayer(nn.Module):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+ self.self_attn = GroundingDinoMultiscaleDeformableAttention(
+ config, num_heads=config.encoder_attention_heads, n_points=config.encoder_n_points
+ )
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+ self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ position_embeddings: torch.Tensor = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ output_attentions: bool = False,
+ ):
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Input to the layer.
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Attention mask.
+ position_embeddings (`torch.FloatTensor`, *optional*):
+ Position embeddings, to be added to `hidden_states`.
+ reference_points (`torch.FloatTensor`, *optional*):
+ Reference points.
+ spatial_shapes (`torch.LongTensor`, *optional*):
+ Spatial shapes of the backbone feature maps.
+ level_start_index (`torch.LongTensor`, *optional*):
+ Level start index.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ # Apply Multi-scale Deformable Attention Module on the multi-scale feature maps.
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=attention_mask,
+ position_embeddings=position_embeddings,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if self.training:
+ if torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any():
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ return hidden_states, attn_weights
+
+
+# Based on https://github.com/IDEA-Research/GroundingDINO/blob/2b62f419c292ca9c518daae55512fabc3fead4a4/groundingdino/models/GroundingDINO/utils.py#L24
+def get_sine_pos_embed(
+ pos_tensor: torch.Tensor, num_pos_feats: int = 128, temperature: int = 10000, exchange_xy: bool = True
+) -> Tensor:
+ """
+ Generate sine position embeddings from a position tensor.
+
+ Args:
+ pos_tensor (torch.Tensor):
+ Tensor containing positions. Shape: [..., n].
+ num_pos_feats (`int`, *optional*, defaults to 128):
+ Projected shape for each float in the tensor.
+ temperature (`int`, *optional*, defaults to 10000):
+ Temperature in the sine/cosine function.
+ exchange_xy (`bool`, *optional*, defaults to `True`):
+ Exchange pos x and pos y. For example, input tensor is [x,y], the results will be [pos(y), pos(x)].
+
+ Returns:
+ position_embeddings (torch.Tensor): shape: [..., n * hidden_size].
+ """
+ scale = 2 * math.pi
+ dim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos_tensor.device)
+ dim_t = temperature ** (2 * torch.div(dim_t, 2, rounding_mode="floor") / num_pos_feats)
+
+ def sine_func(x: torch.Tensor):
+ sin_x = x * scale / dim_t
+ sin_x = torch.stack((sin_x[..., 0::2].sin(), sin_x[..., 1::2].cos()), dim=3).flatten(2)
+ return sin_x
+
+ pos_tensor = pos_tensor.split([1] * pos_tensor.shape[-1], dim=-1)
+ position_embeddings = [sine_func(x) for x in pos_tensor]
+ if exchange_xy:
+ position_embeddings[0], position_embeddings[1] = position_embeddings[1], position_embeddings[0]
+ position_embeddings = torch.cat(position_embeddings, dim=-1)
+ return position_embeddings
+
+
+class GroundingDinoEncoderLayer(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+
+ self.d_model = config.d_model
+
+ self.text_enhancer_layer = GroundingDinoTextEnhancerLayer(config)
+ self.fusion_layer = GroundingDinoFusionLayer(config)
+ self.deformable_layer = GroundingDinoDeformableLayer(config)
+
+ def get_text_position_embeddings(
+ self,
+ text_features: Tensor,
+ text_position_embedding: Optional[torch.Tensor],
+ text_position_ids: Optional[torch.Tensor],
+ ) -> Tensor:
+ batch_size, seq_length, _ = text_features.shape
+ if text_position_embedding is None and text_position_ids is None:
+ text_position_embedding = torch.arange(seq_length, device=text_features.device)
+ text_position_embedding = text_position_embedding.float()
+ text_position_embedding = text_position_embedding.unsqueeze(0).unsqueeze(-1)
+ text_position_embedding = text_position_embedding.repeat(batch_size, 1, 1)
+ text_position_embedding = get_sine_pos_embed(
+ text_position_embedding, num_pos_feats=self.d_model, exchange_xy=False
+ )
+ if text_position_ids is not None:
+ text_position_embedding = get_sine_pos_embed(
+ text_position_ids[..., None], num_pos_feats=self.d_model, exchange_xy=False
+ )
+
+ return text_position_embedding
+
+ def forward(
+ self,
+ vision_features: Tensor,
+ vision_position_embedding: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ key_padding_mask: Tensor,
+ reference_points: Tensor,
+ text_features: Optional[Tensor] = None,
+ text_attention_mask: Optional[Tensor] = None,
+ text_position_embedding: Optional[Tensor] = None,
+ text_self_attention_masks: Optional[Tensor] = None,
+ text_position_ids: Optional[Tensor] = None,
+ ):
+ text_position_embedding = self.get_text_position_embeddings(
+ text_features, text_position_embedding, text_position_ids
+ )
+
+ (vision_features, vision_fused_attn), (text_features, text_fused_attn) = self.fusion_layer(
+ vision_features=vision_features,
+ text_features=text_features,
+ attention_mask_vision=key_padding_mask,
+ attention_mask_text=text_attention_mask,
+ )
+
+ (text_features, text_enhanced_attn) = self.text_enhancer_layer(
+ hidden_states=text_features,
+ attention_masks=~text_self_attention_masks, # note we use ~ for mask here
+ position_embeddings=(text_position_embedding if text_position_embedding is not None else None),
+ )
+
+ (vision_features, vision_deformable_attn) = self.deformable_layer(
+ hidden_states=vision_features,
+ attention_mask=~key_padding_mask,
+ position_embeddings=vision_position_embedding,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ )
+
+ return (
+ (vision_features, text_features),
+ (vision_fused_attn, text_fused_attn, text_enhanced_attn, vision_deformable_attn),
+ )
+
+
+class GroundingDinoMultiheadAttention(nn.Module):
+ """Equivalent implementation of nn.MultiheadAttention with `batch_first=True`."""
+
+ def __init__(self, config, num_attention_heads=None):
+ super().__init__()
+ if config.hidden_size % num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({num_attention_heads})"
+ )
+
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_size = int(config.hidden_size / num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.out_proj = nn.Linear(config.hidden_size, config.hidden_size)
+
+ self.dropout = nn.Dropout(config.attention_dropout)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ queries: torch.Tensor,
+ keys: torch.Tensor,
+ values: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ query_layer = self.transpose_for_scores(self.query(queries))
+ key_layer = self.transpose_for_scores(self.key(keys))
+ value_layer = self.transpose_for_scores(self.value(values))
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in GroundingDinoModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ context_layer = self.out_proj(context_layer)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+class GroundingDinoDecoderLayer(nn.Module):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+
+ # self-attention
+ self.self_attn = GroundingDinoMultiheadAttention(config, num_attention_heads=config.decoder_attention_heads)
+
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # cross-attention text
+ self.encoder_attn_text = GroundingDinoMultiheadAttention(
+ config, num_attention_heads=config.decoder_attention_heads
+ )
+ self.encoder_attn_text_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # cross-attention
+ self.encoder_attn = GroundingDinoMultiscaleDeformableAttention(
+ config,
+ num_heads=config.decoder_attention_heads,
+ n_points=config.decoder_n_points,
+ )
+ self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # feedforward neural networks
+ self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
+ self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+
+ def with_pos_embed(self, tensor: torch.Tensor, position_embeddings: Optional[Tensor]):
+ return tensor if position_embeddings is None else tensor + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: Optional[torch.Tensor] = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ vision_encoder_hidden_states: Optional[torch.Tensor] = None,
+ vision_encoder_attention_mask: Optional[torch.Tensor] = None,
+ text_encoder_hidden_states: Optional[torch.Tensor] = None,
+ text_encoder_attention_mask: Optional[torch.Tensor] = None,
+ self_attn_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ):
+ residual = hidden_states
+
+ # Self Attention
+ queries = keys = self.with_pos_embed(hidden_states, position_embeddings)
+ hidden_states, self_attn_weights = self.self_attn(
+ queries=queries,
+ keys=keys,
+ values=hidden_states,
+ attention_mask=self_attn_mask,
+ output_attentions=True,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ second_residual = hidden_states
+
+ # Cross-Attention Text
+ queries = self.with_pos_embed(hidden_states, position_embeddings)
+
+ hidden_states, text_cross_attn_weights = self.encoder_attn_text(
+ queries=queries,
+ keys=text_encoder_hidden_states,
+ values=text_encoder_hidden_states,
+ # attention_mask=text_encoder_attention_mask, # TODO fix cross-attention mask here
+ output_attentions=True,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = second_residual + hidden_states
+ hidden_states = self.encoder_attn_text_layer_norm(hidden_states)
+
+ third_residual = hidden_states
+
+ # Cross-Attention
+ cross_attn_weights = None
+ hidden_states, cross_attn_weights = self.encoder_attn(
+ hidden_states=hidden_states,
+ attention_mask=vision_encoder_attention_mask,
+ encoder_hidden_states=vision_encoder_hidden_states,
+ encoder_attention_mask=vision_encoder_attention_mask,
+ position_embeddings=position_embeddings,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = third_residual + hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, text_cross_attn_weights, cross_attn_weights)
+
+ return outputs
+
+
+class GroundingDinoContrastiveEmbedding(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.max_text_len = config.max_text_len
+
+ def forward(
+ self,
+ vision_hidden_state: torch.FloatTensor,
+ text_hidden_state: torch.FloatTensor,
+ text_token_mask: torch.BoolTensor,
+ ) -> torch.FloatTensor:
+ output = vision_hidden_state @ text_hidden_state.transpose(-1, -2)
+ output = output.masked_fill(~text_token_mask[:, None, :], float("-inf"))
+
+ # padding to max_text_len
+ new_output = torch.full((*output.shape[:-1], self.max_text_len), float("-inf"), device=output.device)
+ new_output[..., : output.shape[-1]] = output
+
+ return new_output
+
+
+class GroundingDinoPreTrainedModel(PreTrainedModel):
+ config_class = GroundingDinoConfig
+ base_model_prefix = "model"
+ main_input_name = "pixel_values"
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+
+ if isinstance(module, GroundingDinoLearnedPositionEmbedding):
+ nn.init.uniform_(module.row_embeddings.weight)
+ nn.init.uniform_(module.column_embeddings.weight)
+ elif isinstance(module, GroundingDinoMultiscaleDeformableAttention):
+ module._reset_parameters()
+ elif isinstance(module, GroundingDinoBiMultiHeadAttention):
+ nn.init.xavier_uniform_(module.vision_proj.weight)
+ module.vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.text_proj.weight)
+ module.text_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.values_vision_proj.weight)
+ module.values_vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.values_text_proj.weight)
+ module.values_text_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.out_vision_proj.weight)
+ module.out_vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.out_text_proj.weight)
+ module.out_text_proj.bias.data.fill_(0)
+ elif isinstance(module, (GroundingDinoEncoderLayer, GroundingDinoDecoderLayer)):
+ for p in module.parameters():
+ if p.dim() > 1:
+ nn.init.normal_(p, mean=0.0, std=std)
+ elif isinstance(module, (nn.Linear, nn.Conv2d, nn.BatchNorm2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, GroundingDinoMLPPredictionHead):
+ nn.init.constant_(module.layers[-1].weight.data, 0)
+ nn.init.constant_(module.layers[-1].bias.data, 0)
+
+ if hasattr(module, "reference_points") and not self.config.two_stage:
+ nn.init.xavier_uniform_(module.reference_points.weight.data, gain=1.0)
+ nn.init.constant_(module.reference_points.bias.data, 0.0)
+ if hasattr(module, "level_embed"):
+ nn.init.normal_(module.level_embed)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, GroundingDinoDecoder):
+ module.gradient_checkpointing = value
+
+
+GROUNDING_DINO_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`GroundingDinoConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+GROUNDING_DINO_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it.
+
+ Pixel values can be obtained using [`AutoImageProcessor`]. See [`GroundingDinoImageProcessor.__call__`] for
+ details.
+
+ input_ids (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`GroundingDinoTokenizer.__call__`] for details.
+
+ token_type_ids (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`: 0 corresponds to a `sentence A` token, 1 corresponds to a `sentence B` token
+
+ [What are token type IDs?](../glossary#token-type-ids)
+
+ attention_mask (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are real (i.e. **not masked**),
+ - 0 for tokens that are padding (i.e. **masked**).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
+
+ - 1 for pixels that are real (i.e. **not masked**),
+ - 0 for pixels that are padding (i.e. **masked**).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
+ Tuple consists of (`last_hidden_state_vision`, *optional*: `last_hidden_state_text`, *optional*:
+ `vision_hidden_states`, *optional*: `text_hidden_states`, *optional*: `attentions`)
+ `last_hidden_state_vision` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence
+ of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the
+ decoder.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+class GroundingDinoEncoder(GroundingDinoPreTrainedModel):
+ """
+ Transformer encoder consisting of *config.encoder_layers* deformable attention layers. Each layer is a
+ [`GroundingDinoEncoderLayer`].
+
+ The encoder updates the flattened multi-scale feature maps through multiple deformable attention layers.
+
+ Args:
+ config: GroundingDinoConfig
+ """
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+ self.layers = nn.ModuleList([GroundingDinoEncoderLayer(config) for _ in range(config.encoder_layers)])
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @staticmethod
+ def get_reference_points(spatial_shapes, valid_ratios, device):
+ """
+ Get reference points for each feature map.
+
+ Args:
+ spatial_shapes (`torch.LongTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of each feature map.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`):
+ Valid ratios of each feature map.
+ device (`torch.device`):
+ Device on which to create the tensors.
+ Returns:
+ `torch.FloatTensor` of shape `(batch_size, num_queries, num_feature_levels, 2)`
+ """
+ reference_points_list = []
+ for level, (height, width) in enumerate(spatial_shapes):
+ ref_y, ref_x = meshgrid(
+ torch.linspace(0.5, height - 0.5, height, dtype=torch.float32, device=device),
+ torch.linspace(0.5, width - 0.5, width, dtype=torch.float32, device=device),
+ indexing="ij",
+ )
+ # TODO: valid_ratios could be useless here. check https://github.com/fundamentalvision/Deformable-DETR/issues/36
+ ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, level, 1] * height)
+ ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, level, 0] * width)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+ def forward(
+ self,
+ vision_features: Tensor,
+ vision_attention_mask: Tensor,
+ vision_position_embedding: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios=None,
+ text_features: Optional[Tensor] = None,
+ text_attention_mask: Optional[Tensor] = None,
+ text_position_embedding: Optional[Tensor] = None,
+ text_self_attention_masks: Optional[Tensor] = None,
+ text_position_ids: Optional[Tensor] = None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Flattened feature map (output of the backbone + projection layer) that is passed to the encoder.
+ vision_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding pixel features. Mask values selected in `[0, 1]`:
+ - 0 for pixel features that are real (i.e. **not masked**),
+ - 1 for pixel features that are padding (i.e. **masked**).
+ [What are attention masks?](../glossary#attention-mask)
+ vision_position_embedding (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Position embeddings that are added to the queries and keys in each self-attention layer.
+ spatial_shapes (`torch.LongTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of each feature map.
+ level_start_index (`torch.LongTensor` of shape `(num_feature_levels)`):
+ Starting index of each feature map.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`):
+ Ratio of valid area in each feature level.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_seq_len, hidden_size)`):
+ Flattened text features that are passed to the encoder.
+ text_attention_mask (`torch.Tensor` of shape `(batch_size, text_seq_len)`, *optional*):
+ Mask to avoid performing attention on padding text features. Mask values selected in `[0, 1]`:
+ - 0 for text features that are real (i.e. **not masked**),
+ - 1 for text features that are padding (i.e. **masked**).
+ [What are attention masks?](../glossary#attention-mask)
+ text_position_embedding (`torch.FloatTensor` of shape `(batch_size, text_seq_len)`):
+ Position embeddings that are added to the queries and keys in each self-attention layer.
+ text_self_attention_masks (`torch.BoolTensor` of shape `(batch_size, text_seq_len, text_seq_len)`):
+ Masks to avoid performing attention between padding text features. Mask values selected in `[0, 1]`:
+ - 1 for text features that are real (i.e. **not masked**),
+ - 0 for text features that are padding (i.e. **masked**).
+ text_position_ids (`torch.LongTensor` of shape `(batch_size, num_queries)`):
+ Position ids for text features.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=vision_features.device)
+
+ encoder_vision_states = () if output_hidden_states else None
+ encoder_text_states = () if output_hidden_states else None
+ all_attns = () if output_attentions else None
+ all_attn_fused_text = () if output_attentions else None
+ all_attn_fused_vision = () if output_attentions else None
+ all_attn_enhanced_text = () if output_attentions else None
+ all_attn_deformable = () if output_attentions else None
+ for i, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_vision_states += (vision_features,)
+ encoder_text_states += (text_features,)
+
+ (vision_features, text_features), attentions = encoder_layer(
+ vision_features=vision_features,
+ vision_position_embedding=vision_position_embedding,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ key_padding_mask=vision_attention_mask,
+ reference_points=reference_points,
+ text_features=text_features,
+ text_attention_mask=text_attention_mask,
+ text_position_embedding=text_position_embedding,
+ text_self_attention_masks=text_self_attention_masks,
+ text_position_ids=text_position_ids,
+ )
+
+ if output_attentions:
+ all_attn_fused_vision += (attentions[0],)
+ all_attn_fused_text += (attentions[1],)
+ all_attn_enhanced_text += (attentions[2],)
+ all_attn_deformable += (attentions[3],)
+
+ if output_hidden_states:
+ encoder_vision_states += (vision_features,)
+ encoder_text_states += (text_features,)
+
+ if output_attentions:
+ all_attns = (all_attn_fused_vision, all_attn_fused_text, all_attn_enhanced_text, all_attn_deformable)
+
+ if not return_dict:
+ enc_outputs = [vision_features, text_features, encoder_vision_states, encoder_text_states, all_attns]
+ return tuple(v for v in enc_outputs if v is not None)
+ return GroundingDinoEncoderOutput(
+ last_hidden_state_vision=vision_features,
+ last_hidden_state_text=text_features,
+ vision_hidden_states=encoder_vision_states,
+ text_hidden_states=encoder_text_states,
+ attentions=all_attns,
+ )
+
+
+class GroundingDinoDecoder(GroundingDinoPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`GroundingDinoDecoderLayer`].
+
+ The decoder updates the query embeddings through multiple self-attention and cross-attention layers.
+
+ Some tweaks for Grounding DINO:
+
+ - `position_embeddings`, `reference_points`, `spatial_shapes` and `valid_ratios` are added to the forward pass.
+ - it also returns a stack of intermediate outputs and reference points from all decoding layers.
+
+ Args:
+ config: GroundingDinoConfig
+ """
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+ self.layer_norm = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layers = nn.ModuleList([GroundingDinoDecoderLayer(config) for _ in range(config.decoder_layers)])
+ self.reference_points_head = GroundingDinoMLPPredictionHead(
+ config.query_dim // 2 * config.d_model, config.d_model, config.d_model, 2
+ )
+ self.gradient_checkpointing = False
+
+ # hack implementation for iterative bounding box refinement as in two-stage Deformable DETR
+ self.bbox_embed = None
+ self.class_embed = None
+ self.query_scale = None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def forward(
+ self,
+ inputs_embeds,
+ vision_encoder_hidden_states,
+ vision_encoder_attention_mask=None,
+ text_encoder_hidden_states=None,
+ text_encoder_attention_mask=None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ valid_ratios=None,
+ self_attn_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`):
+ The query embeddings that are passed into the decoder.
+ vision_encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Last hidden state from encoder related to vision feature map.
+ vision_encoder_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding pixel features. Mask values selected in `[0, 1]`:
+ - 1 for pixel features that are real (i.e. **not masked**),
+ - 0 for pixel features that are padding (i.e. **masked**).
+ text_encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, text_seq_len, hidden_size)`):
+ Last hidden state from encoder related to text features.
+ text_encoder_attention_mask (`torch.Tensor` of shape `(batch_size, text_seq_len)`, *optional*):
+ Mask to avoid performing attention on padding text features. Mask values selected in `[0, 1]`:
+ - 0 for text features that are real (i.e. **not masked**),
+ - 1 for text features that are padding (i.e. **masked**).
+ reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)` is `as_two_stage` else `(batch_size, num_queries, 2)` or , *optional*):
+ Reference point in range `[0, 1]`, top-left (0,0), bottom-right (1, 1), including padding area.
+ spatial_shapes (`torch.FloatTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of the feature maps.
+ level_start_index (`torch.LongTensor` of shape `(num_feature_levels)`, *optional*):
+ Indexes for the start of each feature level. In range `[0, sequence_length]`.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`, *optional*):
+ Ratio of valid area in each feature level.
+ self_attn_mask (`torch.BoolTensor` of shape `(batch_size, text_seq_len)`):
+ Masks to avoid performing self-attention between vision hidden state. Mask values selected in `[0, 1]`:
+ - 1 for queries that are real (i.e. **not masked**),
+ - 0 for queries that are padding (i.e. **masked**).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if inputs_embeds is not None:
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_attns = () if output_attentions else None
+ all_cross_attns_vision = () if (output_attentions and vision_encoder_hidden_states is not None) else None
+ all_cross_attns_text = () if (output_attentions and text_encoder_hidden_states is not None) else None
+ intermediate = ()
+ intermediate_reference_points = ()
+
+ for idx, decoder_layer in enumerate(self.layers):
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
+ reference_points_input = (
+ reference_points[:, :, None] * torch.cat([valid_ratios, valid_ratios], -1)[:, None]
+ )
+ elif num_coordinates == 2:
+ reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
+ else:
+ raise ValueError("Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}")
+ query_pos = get_sine_pos_embed(reference_points_input[:, :, 0, :], num_pos_feats=self.config.d_model // 2)
+ query_pos = self.reference_points_head(query_pos)
+
+ # In original implementation they apply layer norm before outputting intermediate hidden states
+ # Though that's not through between layers so the layers use as input the output of the previous layer
+ # withtout layer norm
+ if output_hidden_states:
+ all_hidden_states += (self.layer_norm(hidden_states),)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ query_pos,
+ reference_points_input,
+ spatial_shapes,
+ level_start_index,
+ vision_encoder_hidden_states,
+ vision_encoder_attention_mask,
+ text_encoder_hidden_states,
+ text_encoder_attention_mask,
+ self_attn_mask,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states=hidden_states,
+ position_embeddings=query_pos,
+ reference_points=reference_points_input,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ vision_encoder_hidden_states=vision_encoder_hidden_states,
+ vision_encoder_attention_mask=vision_encoder_attention_mask,
+ text_encoder_hidden_states=text_encoder_hidden_states,
+ text_encoder_attention_mask=text_encoder_attention_mask,
+ self_attn_mask=self_attn_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ # hack implementation for iterative bounding box refinement
+ if self.bbox_embed is not None:
+ tmp = self.bbox_embed[idx](hidden_states)
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
+ new_reference_points = tmp + torch.special.logit(reference_points, eps=1e-5)
+ new_reference_points = new_reference_points.sigmoid()
+ elif num_coordinates == 2:
+ new_reference_points = tmp
+ new_reference_points[..., :2] = tmp[..., :2] + torch.special.logit(reference_points, eps=1e-5)
+ new_reference_points = new_reference_points.sigmoid()
+ else:
+ raise ValueError(
+ f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}"
+ )
+ reference_points = new_reference_points.detach()
+
+ intermediate += (self.layer_norm(hidden_states),)
+ intermediate_reference_points += (reference_points,)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if text_encoder_hidden_states is not None:
+ all_cross_attns_text += (layer_outputs[2],)
+
+ if vision_encoder_hidden_states is not None:
+ all_cross_attns_vision += (layer_outputs[3],)
+
+ # Keep batch_size as first dimension
+ intermediate = torch.stack(intermediate, dim=1)
+ intermediate_reference_points = torch.stack(intermediate_reference_points, dim=1)
+ hidden_states = self.layer_norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if output_attentions:
+ all_attns += (all_self_attns, all_cross_attns_text, all_cross_attns_vision)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ intermediate,
+ intermediate_reference_points,
+ all_hidden_states,
+ all_attns,
+ ]
+ if v is not None
+ )
+ return GroundingDinoDecoderOutput(
+ last_hidden_state=hidden_states,
+ intermediate_hidden_states=intermediate,
+ intermediate_reference_points=intermediate_reference_points,
+ hidden_states=all_hidden_states,
+ attentions=all_attns,
+ )
+
+
+# these correspond to [CLS], [SEP], . and ?
+SPECIAL_TOKENS = [101, 102, 1012, 1029]
+
+
+def generate_masks_with_special_tokens_and_transfer_map(input_ids: torch.LongTensor) -> Tuple[Tensor, Tensor]:
+ """Generate attention mask between each pair of special tokens and positional ids.
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+ Returns:
+ `tuple(torch.Tensor)` comprising attention mask between each special tokens and position_ids:
+ - **attention_mask** (`torch.BoolTensor` of shape `(batch_size, sequence_length, sequence_length)`)
+ - **position_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`)
+ """
+ batch_size, num_token = input_ids.shape
+ # special_tokens_mask: batch_size, num_token. 1 for special tokens. 0 for normal tokens
+ special_tokens_mask = torch.zeros((batch_size, num_token), device=input_ids.device).bool()
+ for special_token in SPECIAL_TOKENS:
+ special_tokens_mask |= input_ids == special_token
+
+ # idxs: each row is a list of indices of special tokens
+ idxs = torch.nonzero(special_tokens_mask)
+
+ # generate attention mask and positional ids
+ attention_mask = torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(batch_size, 1, 1)
+ position_ids = torch.zeros((batch_size, num_token), device=input_ids.device)
+ previous_col = 0
+ for i in range(idxs.shape[0]):
+ row, col = idxs[i]
+ if (col == 0) or (col == num_token - 1):
+ attention_mask[row, col, col] = True
+ position_ids[row, col] = 0
+ else:
+ attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True
+ position_ids[row, previous_col + 1 : col + 1] = torch.arange(
+ 0, col - previous_col, device=input_ids.device
+ )
+
+ previous_col = col
+
+ return attention_mask, position_ids.to(torch.long)
+
+
+@add_start_docstrings(
+ """
+ The bare Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) outputting raw
+ hidden-states without any specific head on top.
+ """,
+ GROUNDING_DINO_START_DOCSTRING,
+)
+class GroundingDinoModel(GroundingDinoPreTrainedModel):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ # Create backbone + positional encoding
+ backbone = GroundingDinoConvEncoder(config)
+ position_embeddings = build_position_encoding(config)
+ self.backbone = GroundingDinoConvModel(backbone, position_embeddings)
+
+ # Create input projection layers
+ if config.num_feature_levels > 1:
+ num_backbone_outs = len(backbone.intermediate_channel_sizes)
+ input_proj_list = []
+ for i in range(num_backbone_outs):
+ in_channels = backbone.intermediate_channel_sizes[i]
+ input_proj_list.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels, config.d_model, kernel_size=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ )
+ for _ in range(config.num_feature_levels - num_backbone_outs):
+ input_proj_list.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels, config.d_model, kernel_size=3, stride=2, padding=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ )
+ in_channels = config.d_model
+ self.input_proj_vision = nn.ModuleList(input_proj_list)
+ else:
+ self.input_proj_vision = nn.ModuleList(
+ [
+ nn.Sequential(
+ nn.Conv2d(backbone.intermediate_channel_sizes[-1], config.d_model, kernel_size=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ ]
+ )
+
+ # Create text backbone
+ self.text_backbone = AutoModel.from_config(config.text_config, add_pooling_layer=False)
+ self.text_projection = nn.Linear(config.text_config.hidden_size, config.d_model)
+
+ if config.embedding_init_target or not config.two_stage:
+ self.query_position_embeddings = nn.Embedding(config.num_queries, config.d_model)
+
+ self.encoder = GroundingDinoEncoder(config)
+ self.decoder = GroundingDinoDecoder(config)
+
+ self.level_embed = nn.Parameter(torch.Tensor(config.num_feature_levels, config.d_model))
+
+ if config.two_stage:
+ self.enc_output = nn.Linear(config.d_model, config.d_model)
+ self.enc_output_norm = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ if (
+ config.two_stage_bbox_embed_share
+ and config.decoder_bbox_embed_share
+ and self.decoder.bbox_embed is not None
+ ):
+ self.encoder_output_bbox_embed = self.decoder.bbox_embed
+ else:
+ self.encoder_output_bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+
+ self.encoder_output_class_embed = GroundingDinoContrastiveEmbedding(config)
+ else:
+ self.reference_points = nn.Embedding(config.num_queries, 4)
+
+ self.post_init()
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ def freeze_backbone(self):
+ for name, param in self.backbone.conv_encoder.model.named_parameters():
+ param.requires_grad_(False)
+
+ def unfreeze_backbone(self):
+ for name, param in self.backbone.conv_encoder.model.named_parameters():
+ param.requires_grad_(True)
+
+ def get_valid_ratio(self, mask):
+ """Get the valid ratio of all feature maps."""
+
+ _, height, width = mask.shape
+ valid_height = torch.sum(mask[:, :, 0], 1)
+ valid_width = torch.sum(mask[:, 0, :], 1)
+ valid_ratio_heigth = valid_height.float() / height
+ valid_ratio_width = valid_width.float() / width
+ valid_ratio = torch.stack([valid_ratio_width, valid_ratio_heigth], -1)
+ return valid_ratio
+
+ def generate_encoder_output_proposals(self, enc_output, padding_mask, spatial_shapes):
+ """Generate the encoder output proposals from encoded enc_output.
+
+ Args:
+ enc_output (`torch.Tensor[batch_size, sequence_length, hidden_size]`): Output of the encoder.
+ padding_mask (`torch.Tensor[batch_size, sequence_length]`): Padding mask for `enc_output`.
+ spatial_shapes (`torch.Tensor[num_feature_levels, 2]`): Spatial shapes of the feature maps.
+
+ Returns:
+ `tuple(torch.FloatTensor)`: A tuple of feature map and bbox prediction.
+ - object_query (Tensor[batch_size, sequence_length, hidden_size]): Object query features. Later used to
+ directly predict a bounding box. (without the need of a decoder)
+ - output_proposals (Tensor[batch_size, sequence_length, 4]): Normalized proposals, after an inverse
+ sigmoid.
+ """
+ batch_size = enc_output.shape[0]
+ proposals = []
+ current_position = 0
+ for level, (height, width) in enumerate(spatial_shapes):
+ mask_flatten_ = padding_mask[:, current_position : (current_position + height * width)]
+ mask_flatten_ = mask_flatten_.view(batch_size, height, width, 1)
+ valid_height = torch.sum(~mask_flatten_[:, :, 0, 0], 1)
+ valid_width = torch.sum(~mask_flatten_[:, 0, :, 0], 1)
+
+ grid_y, grid_x = meshgrid(
+ torch.linspace(0, height - 1, height, dtype=torch.float32, device=enc_output.device),
+ torch.linspace(0, width - 1, width, dtype=torch.float32, device=enc_output.device),
+ indexing="ij",
+ )
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+
+ scale = torch.cat([valid_width.unsqueeze(-1), valid_height.unsqueeze(-1)], 1).view(batch_size, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(batch_size, -1, -1, -1) + 0.5) / scale
+ width_heigth = torch.ones_like(grid) * 0.05 * (2.0**level)
+ proposal = torch.cat((grid, width_heigth), -1).view(batch_size, -1, 4)
+ proposals.append(proposal)
+ current_position += height * width
+
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True)
+ output_proposals = torch.log(output_proposals / (1 - output_proposals)) # inverse sigmoid
+ output_proposals = output_proposals.masked_fill(padding_mask.unsqueeze(-1), float("inf"))
+ output_proposals = output_proposals.masked_fill(~output_proposals_valid, float("inf"))
+
+ # assign each pixel as an object query
+ object_query = enc_output
+ object_query = object_query.masked_fill(padding_mask.unsqueeze(-1), float(0))
+ object_query = object_query.masked_fill(~output_proposals_valid, float(0))
+ object_query = self.enc_output_norm(self.enc_output(object_query))
+ return object_query, output_proposals
+
+ @add_start_docstrings_to_model_forward(GROUNDING_DINO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=GroundingDinoModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Tensor,
+ input_ids: Tensor,
+ token_type_ids: Optional[Tensor] = None,
+ attention_mask: Optional[Tensor] = None,
+ pixel_mask: Optional[Tensor] = None,
+ encoder_outputs=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> text = "a cat."
+
+ >>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
+ >>> model = AutoModel.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ >>> inputs = processor(images=image, text=text, return_tensors="pt")
+ >>> outputs = model(**inputs)
+
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 900, 256]
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_self_attention_masks, position_ids = generate_masks_with_special_tokens_and_transfer_map(input_ids)
+
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros_like(input_ids)
+
+ text_token_mask = attention_mask.bool() # just to avoid renaming everywhere
+
+ max_text_len = self.config.max_text_len
+ if text_self_attention_masks.shape[1] > max_text_len:
+ text_self_attention_masks = text_self_attention_masks[:, :max_text_len, :max_text_len]
+ position_ids = position_ids[:, :max_text_len]
+ input_ids = input_ids[:, :max_text_len]
+ token_type_ids = token_type_ids[:, :max_text_len]
+ text_token_mask = text_token_mask[:, :max_text_len]
+
+ # Extract text features from text backbone
+ text_outputs = self.text_backbone(
+ input_ids, text_self_attention_masks, token_type_ids, position_ids, return_dict=return_dict
+ )
+ text_features = text_outputs.last_hidden_state if return_dict else text_outputs[0]
+ text_features = self.text_projection(text_features)
+
+ batch_size, num_channels, height, width = pixel_values.shape
+ device = pixel_values.device
+
+ if pixel_mask is None:
+ pixel_mask = torch.ones(((batch_size, height, width)), dtype=torch.long, device=device)
+
+ # Extract multi-scale feature maps of same resolution `config.d_model` (cf Figure 4 in paper)
+ # First, sent pixel_values + pixel_mask through Backbone to obtain the features
+ # which is a list of tuples
+ vision_features, position_embeddings_list = self.backbone(pixel_values, pixel_mask)
+
+ # Then, apply 1x1 convolution to reduce the channel dimension to d_model (256 by default)
+ feature_maps = []
+ masks = []
+ for level, (source, mask) in enumerate(vision_features):
+ feature_maps.append(self.input_proj_vision[level](source))
+ masks.append(mask)
+
+ # Lowest resolution feature maps are obtained via 3x3 stride 2 convolutions on the final stage
+ if self.config.num_feature_levels > len(feature_maps):
+ _len_sources = len(feature_maps)
+ for level in range(_len_sources, self.config.num_feature_levels):
+ if level == _len_sources:
+ source = self.input_proj_vision[level](vision_features[-1][0])
+ else:
+ source = self.input_proj_vision[level](feature_maps[-1])
+ mask = nn.functional.interpolate(pixel_mask[None].float(), size=source.shape[-2:]).to(torch.bool)[0]
+ pos_l = self.backbone.position_embedding(source, mask).to(source.dtype)
+ feature_maps.append(source)
+ masks.append(mask)
+ position_embeddings_list.append(pos_l)
+
+ # Create queries
+ query_embeds = None
+ if self.config.embedding_init_target or self.config.two_stage:
+ query_embeds = self.query_position_embeddings.weight
+
+ # Prepare encoder inputs (by flattening)
+ source_flatten = []
+ mask_flatten = []
+ lvl_pos_embed_flatten = []
+ spatial_shapes = []
+ for level, (source, mask, pos_embed) in enumerate(zip(feature_maps, masks, position_embeddings_list)):
+ batch_size, num_channels, height, width = source.shape
+ spatial_shape = (height, width)
+ spatial_shapes.append(spatial_shape)
+ source = source.flatten(2).transpose(1, 2)
+ mask = mask.flatten(1)
+ pos_embed = pos_embed.flatten(2).transpose(1, 2)
+ lvl_pos_embed = pos_embed + self.level_embed[level].view(1, 1, -1)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ source_flatten.append(source)
+ mask_flatten.append(mask)
+ source_flatten = torch.cat(source_flatten, 1)
+ mask_flatten = torch.cat(mask_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=source_flatten.device)
+ level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
+ valid_ratios = valid_ratios.float()
+
+ # Fourth, sent source_flatten + mask_flatten + lvl_pos_embed_flatten (backbone + proj layer output) through encoder
+ # Also provide spatial_shapes, level_start_index and valid_ratios
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ vision_features=source_flatten,
+ vision_attention_mask=~mask_flatten,
+ vision_position_embedding=lvl_pos_embed_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ text_features=text_features,
+ text_attention_mask=~text_token_mask,
+ text_position_embedding=None,
+ text_self_attention_masks=~text_self_attention_masks,
+ text_position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ # If the user passed a tuple for encoder_outputs, we wrap it in a GroundingDinoEncoderOutput when return_dict=True
+ elif return_dict and not isinstance(encoder_outputs, GroundingDinoEncoderOutput):
+ encoder_outputs = GroundingDinoEncoderOutput(
+ last_hidden_state_vision=encoder_outputs[0],
+ last_hidden_state_text=encoder_outputs[1],
+ vision_hidden_states=encoder_outputs[2] if output_hidden_states else None,
+ text_hidden_states=encoder_outputs[3] if output_hidden_states else None,
+ attentions=encoder_outputs[-1] if output_attentions else None,
+ )
+
+ # Fifth, prepare decoder inputs
+ enc_outputs_class = None
+ enc_outputs_coord_logits = None
+ if self.config.two_stage:
+ object_query_embedding, output_proposals = self.generate_encoder_output_proposals(
+ encoder_outputs[0], ~mask_flatten, spatial_shapes
+ )
+
+ # hack implementation as in two-stage Deformable DETR
+ # apply a detection head to each pixel (A.4 in paper)
+ # linear projection for bounding box binary classification (i.e. foreground and background)
+ enc_outputs_class = self.encoder_output_class_embed(
+ object_query_embedding, encoder_outputs[1], text_token_mask
+ )
+ # 3-layer FFN to predict bounding boxes coordinates (bbox regression branch)
+ delta_bbox = self.encoder_output_bbox_embed(object_query_embedding)
+ enc_outputs_coord_logits = delta_bbox + output_proposals
+
+ # only keep top scoring `config.num_queries` proposals
+ topk = self.config.num_queries
+ topk_logits = enc_outputs_class.max(-1)[0]
+ topk_proposals = torch.topk(topk_logits, topk, dim=1)[1]
+ topk_coords_logits = torch.gather(
+ enc_outputs_coord_logits, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)
+ )
+
+ topk_coords_logits = topk_coords_logits.detach()
+ reference_points = topk_coords_logits.sigmoid()
+ init_reference_points = reference_points
+ if query_embeds is not None:
+ target = query_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
+ else:
+ target = torch.gather(
+ object_query_embedding, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model)
+ ).detach()
+ else:
+ target = query_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
+ reference_points = self.reference_points.weight.unsqueeze(0).repeat(batch_size, 1, 1).sigmoid()
+ init_reference_points = reference_points
+
+ decoder_outputs = self.decoder(
+ inputs_embeds=target,
+ vision_encoder_hidden_states=encoder_outputs[0],
+ vision_encoder_attention_mask=mask_flatten,
+ text_encoder_hidden_states=encoder_outputs[1],
+ text_encoder_attention_mask=~text_token_mask,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ self_attn_mask=None,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ enc_outputs = tuple(value for value in [enc_outputs_class, enc_outputs_coord_logits] if value is not None)
+ tuple_outputs = (
+ (decoder_outputs[0], init_reference_points) + decoder_outputs[1:] + encoder_outputs + enc_outputs
+ )
+
+ return tuple_outputs
+
+ return GroundingDinoModelOutput(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ init_reference_points=init_reference_points,
+ intermediate_hidden_states=decoder_outputs.intermediate_hidden_states,
+ intermediate_reference_points=decoder_outputs.intermediate_reference_points,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ encoder_last_hidden_state_vision=encoder_outputs.last_hidden_state_vision,
+ encoder_last_hidden_state_text=encoder_outputs.last_hidden_state_text,
+ encoder_vision_hidden_states=encoder_outputs.vision_hidden_states,
+ encoder_text_hidden_states=encoder_outputs.text_hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ enc_outputs_class=enc_outputs_class,
+ enc_outputs_coord_logits=enc_outputs_coord_logits,
+ )
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrMLPPredictionHead
+class GroundingDinoMLPPredictionHead(nn.Module):
+ """
+ Very simple multi-layer perceptron (MLP, also called FFN), used to predict the normalized center coordinates,
+ height and width of a bounding box w.r.t. an image.
+
+ Copied from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+
+ """
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = nn.functional.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t: Tensor) -> Tensor:
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+# Copied from transformers.models.detr.modeling_detr.box_area
+def box_area(boxes: Tensor) -> Tensor:
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+# Copied from transformers.models.detr.modeling_detr.box_iou
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+# Copied from transformers.models.detr.modeling_detr.generalized_box_iou
+def generalized_box_iou(boxes1, boxes2):
+ """
+ Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
+
+ Returns:
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ if not (boxes1[:, 2:] >= boxes1[:, :2]).all():
+ raise ValueError(f"boxes1 must be in [x0, y0, x1, y1] (corner) format, but got {boxes1}")
+ if not (boxes2[:, 2:] >= boxes2[:, :2]).all():
+ raise ValueError(f"boxes2 must be in [x0, y0, x1, y1] (corner) format, but got {boxes2}")
+ iou, union = box_iou(boxes1, boxes2)
+
+ top_left = torch.min(boxes1[:, None, :2], boxes2[:, :2])
+ bottom_right = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])
+
+ width_height = (bottom_right - top_left).clamp(min=0) # [N,M,2]
+ area = width_height[:, :, 0] * width_height[:, :, 1]
+
+ return iou - (area - union) / area
+
+
+# Copied from transformers.models.detr.modeling_detr._max_by_axis
+def _max_by_axis(the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+
+# Copied from transformers.models.detr.modeling_detr.dice_loss
+def dice_loss(inputs, targets, num_boxes):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.sigmoid_focal_loss
+def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
+ """
+ Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+
+ Args:
+ inputs (`torch.FloatTensor` of arbitrary shape):
+ The predictions for each example.
+ targets (`torch.FloatTensor` with the same shape as `inputs`)
+ A tensor storing the binary classification label for each element in the `inputs` (0 for the negative class
+ and 1 for the positive class).
+ alpha (`float`, *optional*, defaults to `0.25`):
+ Optional weighting factor in the range (0,1) to balance positive vs. negative examples.
+ gamma (`int`, *optional*, defaults to `2`):
+ Exponent of the modulating factor (1 - p_t) to balance easy vs hard examples.
+
+ Returns:
+ Loss tensor
+ """
+ prob = inputs.sigmoid()
+ ce_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+ # add modulating factor
+ p_t = prob * targets + (1 - prob) * (1 - targets)
+ loss = ce_loss * ((1 - p_t) ** gamma)
+
+ if alpha >= 0:
+ alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
+ loss = alpha_t * loss
+
+ return loss.mean(1).sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.NestedTensor
+class NestedTensor(object):
+ def __init__(self, tensors, mask: Optional[Tensor]):
+ self.tensors = tensors
+ self.mask = mask
+
+ def to(self, device):
+ cast_tensor = self.tensors.to(device)
+ mask = self.mask
+ if mask is not None:
+ cast_mask = mask.to(device)
+ else:
+ cast_mask = None
+ return NestedTensor(cast_tensor, cast_mask)
+
+ def decompose(self):
+ return self.tensors, self.mask
+
+ def __repr__(self):
+ return str(self.tensors)
+
+
+# Copied from transformers.models.detr.modeling_detr.nested_tensor_from_tensor_list
+def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
+ if tensor_list[0].ndim == 3:
+ max_size = _max_by_axis([list(img.shape) for img in tensor_list])
+ batch_shape = [len(tensor_list)] + max_size
+ batch_size, num_channels, height, width = batch_shape
+ dtype = tensor_list[0].dtype
+ device = tensor_list[0].device
+ tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
+ mask = torch.ones((batch_size, height, width), dtype=torch.bool, device=device)
+ for img, pad_img, m in zip(tensor_list, tensor, mask):
+ pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
+ m[: img.shape[1], : img.shape[2]] = False
+ else:
+ raise ValueError("Only 3-dimensional tensors are supported")
+ return NestedTensor(tensor, mask)
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrHungarianMatcher with DeformableDetr->GroundingDino
+class GroundingDinoHungarianMatcher(nn.Module):
+ """
+ This class computes an assignment between the targets and the predictions of the network.
+
+ For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
+ predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
+ un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
+ """
+
+ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
+ super().__init__()
+ requires_backends(self, ["scipy"])
+
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ if class_cost == 0 and bbox_cost == 0 and giou_cost == 0:
+ raise ValueError("All costs of the Matcher can't be 0")
+
+ @torch.no_grad()
+ def forward(self, outputs, targets):
+ """
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
+
+ Returns:
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
+ For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
+ """
+ batch_size, num_queries = outputs["logits"].shape[:2]
+
+ # We flatten to compute the cost matrices in a batch
+ out_prob = outputs["logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
+ out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
+
+ # Also concat the target labels and boxes
+ target_ids = torch.cat([v["class_labels"] for v in targets])
+ target_bbox = torch.cat([v["boxes"] for v in targets])
+
+ # Compute the classification cost.
+ alpha = 0.25
+ gamma = 2.0
+ neg_cost_class = (1 - alpha) * (out_prob**gamma) * (-(1 - out_prob + 1e-8).log())
+ pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ class_cost = pos_cost_class[:, target_ids] - neg_cost_class[:, target_ids]
+
+ # Compute the L1 cost between boxes
+ bbox_cost = torch.cdist(out_bbox, target_bbox, p=1)
+
+ # Compute the giou cost between boxes
+ giou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(target_bbox))
+
+ # Final cost matrix
+ cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
+
+ sizes = [len(v["boxes"]) for v in targets]
+ indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
+ return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrLoss with DeformableDetr->GroundingDino
+class GroundingDinoLoss(nn.Module):
+ """
+ This class computes the losses for `GroundingDinoForObjectDetection`. The process happens in two steps: 1) we
+ compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each pair of
+ matched ground-truth / prediction (supervise class and box).
+
+ Args:
+ matcher (`GroundingDinoHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ focal_alpha (`float`):
+ Alpha parameter in focal loss.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
+ """
+
+ def __init__(self, matcher, num_classes, focal_alpha, losses):
+ super().__init__()
+ self.matcher = matcher
+ self.num_classes = num_classes
+ self.focal_alpha = focal_alpha
+ self.losses = losses
+
+ # removed logging parameter, which was part of the original implementation
+ def loss_labels(self, outputs, targets, indices, num_boxes):
+ """
+ Classification loss (Binary focal loss) targets dicts must contain the key "class_labels" containing a tensor
+ of dim [nb_target_boxes]
+ """
+ if "logits" not in outputs:
+ raise KeyError("No logits were found in the outputs")
+ source_logits = outputs["logits"]
+
+ idx = self._get_source_permutation_idx(indices)
+ target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])
+ target_classes = torch.full(
+ source_logits.shape[:2], self.num_classes, dtype=torch.int64, device=source_logits.device
+ )
+ target_classes[idx] = target_classes_o
+
+ target_classes_onehot = torch.zeros(
+ [source_logits.shape[0], source_logits.shape[1], source_logits.shape[2] + 1],
+ dtype=source_logits.dtype,
+ layout=source_logits.layout,
+ device=source_logits.device,
+ )
+ target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
+
+ target_classes_onehot = target_classes_onehot[:, :, :-1]
+ loss_ce = (
+ sigmoid_focal_loss(source_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2)
+ * source_logits.shape[1]
+ )
+ losses = {"loss_ce": loss_ce}
+
+ return losses
+
+ @torch.no_grad()
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss.loss_cardinality
+ def loss_cardinality(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the cardinality error, i.e. the absolute error in the number of predicted non-empty boxes.
+
+ This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients.
+ """
+ logits = outputs["logits"]
+ device = logits.device
+ target_lengths = torch.as_tensor([len(v["class_labels"]) for v in targets], device=device)
+ # Count the number of predictions that are NOT "no-object" (which is the last class)
+ card_pred = (logits.argmax(-1) != logits.shape[-1] - 1).sum(1)
+ card_err = nn.functional.l1_loss(card_pred.float(), target_lengths.float())
+ losses = {"cardinality_error": card_err}
+ return losses
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss.loss_boxes
+ def loss_boxes(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss.
+
+ Targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]. The target boxes
+ are expected in format (center_x, center_y, w, h), normalized by the image size.
+ """
+ if "pred_boxes" not in outputs:
+ raise KeyError("No predicted boxes found in outputs")
+ idx = self._get_source_permutation_idx(indices)
+ source_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ loss_bbox = nn.functional.l1_loss(source_boxes, target_boxes, reduction="none")
+
+ losses = {}
+ losses["loss_bbox"] = loss_bbox.sum() / num_boxes
+
+ loss_giou = 1 - torch.diag(
+ generalized_box_iou(center_to_corners_format(source_boxes), center_to_corners_format(target_boxes))
+ )
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss._get_source_permutation_idx
+ def _get_source_permutation_idx(self, indices):
+ # permute predictions following indices
+ batch_idx = torch.cat([torch.full_like(source, i) for i, (source, _) in enumerate(indices)])
+ source_idx = torch.cat([source for (source, _) in indices])
+ return batch_idx, source_idx
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss._get_target_permutation_idx
+ def _get_target_permutation_idx(self, indices):
+ # permute targets following indices
+ batch_idx = torch.cat([torch.full_like(target, i) for i, (_, target) in enumerate(indices)])
+ target_idx = torch.cat([target for (_, target) in indices])
+ return batch_idx, target_idx
+
+ def get_loss(self, loss, outputs, targets, indices, num_boxes):
+ loss_map = {
+ "labels": self.loss_labels,
+ "cardinality": self.loss_cardinality,
+ "boxes": self.loss_boxes,
+ }
+ if loss not in loss_map:
+ raise ValueError(f"Loss {loss} not supported")
+ return loss_map[loss](outputs, targets, indices, num_boxes)
+
+ def forward(self, outputs, targets):
+ """
+ This performs the loss computation.
+
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that `len(targets) == batch_size`. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
+ """
+ outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs" and k != "enc_outputs"}
+
+ # Retrieve the matching between the outputs of the last layer and the targets
+ indices = self.matcher(outputs_without_aux, targets)
+
+ # Compute the average number of target boxes accross all nodes, for normalization purposes
+ num_boxes = sum(len(t["class_labels"]) for t in targets)
+ num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
+ world_size = 1
+ if is_accelerate_available():
+ if PartialState._shared_state != {}:
+ num_boxes = reduce(num_boxes)
+ world_size = PartialState().num_processes
+ num_boxes = torch.clamp(num_boxes / world_size, min=1).item()
+
+ # Compute all the requested losses
+ losses = {}
+ for loss in self.losses:
+ losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
+
+ # In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
+ if "auxiliary_outputs" in outputs:
+ for i, auxiliary_outputs in enumerate(outputs["auxiliary_outputs"]):
+ indices = self.matcher(auxiliary_outputs, targets)
+ for loss in self.losses:
+ l_dict = self.get_loss(loss, auxiliary_outputs, targets, indices, num_boxes)
+ l_dict = {k + f"_{i}": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ if "enc_outputs" in outputs:
+ enc_outputs = outputs["enc_outputs"]
+ bin_targets = copy.deepcopy(targets)
+ for bt in bin_targets:
+ bt["class_labels"] = torch.zeros_like(bt["class_labels"])
+ indices = self.matcher(enc_outputs, bin_targets)
+ for loss in self.losses:
+ l_dict = self.get_loss(loss, enc_outputs, bin_targets, indices, num_boxes)
+ l_dict = {k + "_enc": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ return losses
+
+
+@add_start_docstrings(
+ """
+ Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) with object detection heads on top,
+ for tasks such as COCO detection.
+ """,
+ GROUNDING_DINO_START_DOCSTRING,
+)
+class GroundingDinoForObjectDetection(GroundingDinoPreTrainedModel):
+ # When using clones, all layers > 0 will be clones, but layer 0 *is* required
+ # the bbox_embed in the decoder are all clones though
+ _tied_weights_keys = [r"bbox_embed\.[1-9]\d*", r"model\.decoder\.bbox_embed\.[0-9]\d*"]
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.model = GroundingDinoModel(config)
+ _class_embed = GroundingDinoContrastiveEmbedding(config)
+
+ if config.decoder_bbox_embed_share:
+ _bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+ self.bbox_embed = nn.ModuleList([_bbox_embed for _ in range(config.decoder_layers)])
+ else:
+ for _ in range(config.decoder_layers):
+ _bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+ self.bbox_embed = nn.ModuleList([_bbox_embed for _ in range(config.decoder_layers)])
+ self.class_embed = nn.ModuleList([_class_embed for _ in range(config.decoder_layers)])
+ # hack for box-refinement
+ self.model.decoder.bbox_embed = self.bbox_embed
+ # hack implementation for two-stage
+ self.model.decoder.class_embed = self.class_embed
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # taken from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+ @torch.jit.unused
+ def _set_aux_loss(self, outputs_class, outputs_coord):
+ # this is a workaround to make torchscript happy, as torchscript
+ # doesn't support dictionary with non-homogeneous values, such
+ # as a dict having both a Tensor and a list.
+ return [{"logits": a, "pred_boxes": b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+
+ @add_start_docstrings_to_model_forward(GROUNDING_DINO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=GroundingDinoObjectDetectionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ input_ids: torch.LongTensor,
+ token_type_ids: torch.LongTensor = None,
+ attention_mask: torch.LongTensor = None,
+ pixel_mask: Optional[torch.BoolTensor] = None,
+ encoder_outputs: Optional[Union[GroundingDinoEncoderOutput, Tuple]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: List[Dict[str, Union[torch.LongTensor, torch.FloatTensor]]] = None,
+ ):
+ r"""
+ labels (`List[Dict]` of len `(batch_size,)`, *optional*):
+ Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the
+ following 2 keys: 'class_labels' and 'boxes' (the class labels and bounding boxes of an image in the batch
+ respectively). The class labels themselves should be a `torch.LongTensor` of len `(number of bounding boxes
+ in the image,)` and the boxes a `torch.FloatTensor` of shape `(number of bounding boxes in the image, 4)`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, GroundingDinoForObjectDetection
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> text = "a cat."
+
+ >>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
+ >>> model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ >>> inputs = processor(images=image, text=text, return_tensors="pt")
+ >>> outputs = model(**inputs)
+
+ >>> # convert outputs (bounding boxes and class logits) to COCO API
+ >>> target_sizes = torch.tensor([image.size[::-1]])
+ >>> results = processor.image_processor.post_process_object_detection(
+ ... outputs, threshold=0.35, target_sizes=target_sizes
+ ... )[0]
+ >>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+ ... box = [round(i, 2) for i in box.tolist()]
+ ... print(f"Detected {label.item()} with confidence " f"{round(score.item(), 3)} at location {box}")
+ Detected 1 with confidence 0.453 at location [344.82, 23.18, 637.4, 373.83]
+ Detected 1 with confidence 0.408 at location [11.92, 51.58, 316.57, 472.89]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ # First, sent images through Grounding DINO base model to obtain encoder + decoder outputs
+ outputs = self.model(
+ pixel_values=pixel_values,
+ input_ids=input_ids,
+ token_type_ids=token_type_ids,
+ attention_mask=attention_mask,
+ pixel_mask=pixel_mask,
+ encoder_outputs=encoder_outputs,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ idx = 5 + (1 if output_attentions else 0) + (1 if output_hidden_states else 0)
+ enc_text_hidden_state = outputs.encoder_last_hidden_state_text if return_dict else outputs[idx]
+ hidden_states = outputs.intermediate_hidden_states if return_dict else outputs[2]
+ init_reference_points = outputs.init_reference_points if return_dict else outputs[1]
+ inter_references_points = outputs.intermediate_reference_points if return_dict else outputs[3]
+
+ # class logits + predicted bounding boxes
+ outputs_classes = []
+ outputs_coords = []
+
+ # hidden_states are of shape (batch_size, num_stages, height, width)
+ # predict class and bounding box deltas for each stage
+ num_levels = hidden_states.shape[1]
+ for level in range(num_levels):
+ if level == 0:
+ reference = init_reference_points
+ else:
+ reference = inter_references_points[:, level - 1]
+ reference = torch.special.logit(reference, eps=1e-5)
+ outputs_class = self.class_embed[level](
+ vision_hidden_state=hidden_states[:, level],
+ text_hidden_state=enc_text_hidden_state,
+ text_token_mask=attention_mask.bool(),
+ )
+ delta_bbox = self.bbox_embed[level](hidden_states[:, level])
+
+ reference_coordinates = reference.shape[-1]
+ if reference_coordinates == 4:
+ outputs_coord_logits = delta_bbox + reference
+ elif reference_coordinates == 2:
+ delta_bbox[..., :2] += reference
+ outputs_coord_logits = delta_bbox
+ else:
+ raise ValueError(f"reference.shape[-1] should be 4 or 2, but got {reference.shape[-1]}")
+ outputs_coord = outputs_coord_logits.sigmoid()
+ outputs_classes.append(outputs_class)
+ outputs_coords.append(outputs_coord)
+ outputs_class = torch.stack(outputs_classes)
+ outputs_coord = torch.stack(outputs_coords)
+
+ logits = outputs_class[-1]
+ pred_boxes = outputs_coord[-1]
+
+ loss, loss_dict, auxiliary_outputs = None, None, None
+ if labels is not None:
+ # First: create the matcher
+ matcher = GroundingDinoHungarianMatcher(
+ class_cost=self.config.class_cost, bbox_cost=self.config.bbox_cost, giou_cost=self.config.giou_cost
+ )
+ # Second: create the criterion
+ losses = ["labels", "boxes", "cardinality"]
+ criterion = GroundingDinoLoss(
+ matcher=matcher,
+ num_classes=self.config.num_labels,
+ focal_alpha=self.config.focal_alpha,
+ losses=losses,
+ )
+ criterion.to(self.device)
+ # Third: compute the losses, based on outputs and labels
+ outputs_loss = {}
+ outputs_loss["logits"] = logits
+ outputs_loss["pred_boxes"] = pred_boxes
+ if self.config.auxiliary_loss:
+ auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_loss["auxiliary_outputs"] = auxiliary_outputs
+ if self.config.two_stage:
+ enc_outputs_coord = outputs[-1].sigmoid()
+ outputs_loss["enc_outputs"] = {"logits": outputs[-2], "pred_boxes": enc_outputs_coord}
+
+ loss_dict = criterion(outputs_loss, labels)
+ # Fourth: compute total loss, as a weighted sum of the various losses
+ weight_dict = {"loss_ce": 1, "loss_bbox": self.config.bbox_loss_coefficient}
+ weight_dict["loss_giou"] = self.config.giou_loss_coefficient
+ if self.config.auxiliary_loss:
+ aux_weight_dict = {}
+ for i in range(self.config.decoder_layers - 1):
+ aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
+ weight_dict.update(aux_weight_dict)
+ loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
+
+ if not return_dict:
+ if auxiliary_outputs is not None:
+ output = (logits, pred_boxes) + auxiliary_outputs + outputs
+ else:
+ output = (logits, pred_boxes) + outputs
+ tuple_outputs = ((loss, loss_dict) + output) if loss is not None else output
+
+ return tuple_outputs
+
+ dict_outputs = GroundingDinoObjectDetectionOutput(
+ loss=loss,
+ loss_dict=loss_dict,
+ logits=logits,
+ pred_boxes=pred_boxes,
+ last_hidden_state=outputs.last_hidden_state,
+ auxiliary_outputs=auxiliary_outputs,
+ decoder_hidden_states=outputs.decoder_hidden_states,
+ decoder_attentions=outputs.decoder_attentions,
+ encoder_last_hidden_state_vision=outputs.encoder_last_hidden_state_vision,
+ encoder_last_hidden_state_text=outputs.encoder_last_hidden_state_text,
+ encoder_vision_hidden_states=outputs.encoder_vision_hidden_states,
+ encoder_text_hidden_states=outputs.encoder_text_hidden_states,
+ encoder_attentions=outputs.encoder_attentions,
+ intermediate_hidden_states=outputs.intermediate_hidden_states,
+ intermediate_reference_points=outputs.intermediate_reference_points,
+ init_reference_points=outputs.init_reference_points,
+ enc_outputs_class=outputs.enc_outputs_class,
+ enc_outputs_coord_logits=outputs.enc_outputs_coord_logits,
+ )
+
+ return dict_outputs
diff --git a/src/transformers/models/grounding_dino/processing_grounding_dino.py b/src/transformers/models/grounding_dino/processing_grounding_dino.py
new file mode 100644
index 00000000000000..44b99811d931ce
--- /dev/null
+++ b/src/transformers/models/grounding_dino/processing_grounding_dino.py
@@ -0,0 +1,228 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for Grounding DINO.
+"""
+
+from typing import List, Optional, Tuple, Union
+
+from ...image_processing_utils import BatchFeature
+from ...image_transforms import center_to_corners_format
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType, is_torch_available
+
+
+if is_torch_available():
+ import torch
+
+
+def get_phrases_from_posmap(posmaps, input_ids):
+ """Get token ids of phrases from posmaps and input_ids.
+
+ Args:
+ posmaps (`torch.BoolTensor` of shape `(num_boxes, hidden_size)`):
+ A boolean tensor of text-thresholded logits related to the detected bounding boxes.
+ input_ids (`torch.LongTensor`) of shape `(sequence_length, )`):
+ A tensor of token ids.
+ """
+ left_idx = 0
+ right_idx = posmaps.shape[-1] - 1
+
+ # Avoiding altering the input tensor
+ posmaps = posmaps.clone()
+
+ posmaps[:, 0 : left_idx + 1] = False
+ posmaps[:, right_idx:] = False
+
+ token_ids = []
+ for posmap in posmaps:
+ non_zero_idx = posmap.nonzero(as_tuple=True)[0].tolist()
+ token_ids.append([input_ids[i] for i in non_zero_idx])
+
+ return token_ids
+
+
+class GroundingDinoProcessor(ProcessorMixin):
+ r"""
+ Constructs a Grounding DINO processor which wraps a Deformable DETR image processor and a BERT tokenizer into a
+ single processor.
+
+ [`GroundingDinoProcessor`] offers all the functionalities of [`GroundingDinoImageProcessor`] and
+ [`AutoTokenizer`]. See the docstring of [`~GroundingDinoProcessor.__call__`] and [`~GroundingDinoProcessor.decode`]
+ for more information.
+
+ Args:
+ image_processor (`GroundingDinoImageProcessor`):
+ An instance of [`GroundingDinoImageProcessor`]. The image processor is a required input.
+ tokenizer (`AutoTokenizer`):
+ An instance of ['PreTrainedTokenizer`]. The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "GroundingDinoImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: ImageInput = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = None,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_token_type_ids: bool = True,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> BatchEncoding:
+ """
+ This method uses [`GroundingDinoImageProcessor.__call__`] method to prepare image(s) for the model, and
+ [`BertTokenizerFast.__call__`] to prepare text for the model.
+
+ Please refer to the docstring of the above two methods for more information.
+ """
+ if images is None and text is None:
+ raise ValueError("You have to specify either images or text.")
+
+ # Get only text
+ if images is not None:
+ encoding_image_processor = self.image_processor(images, return_tensors=return_tensors)
+ else:
+ encoding_image_processor = BatchFeature()
+
+ if text is not None:
+ text_encoding = self.tokenizer(
+ text=text,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_token_type_ids=return_token_type_ids,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ **kwargs,
+ )
+ else:
+ text_encoding = BatchEncoding()
+
+ text_encoding.update(encoding_image_processor)
+
+ return text_encoding
+
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.batch_decode with BertTokenizerFast->PreTrainedTokenizer
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.decode with BertTokenizerFast->PreTrainedTokenizer
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.model_input_names
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+ def post_process_grounded_object_detection(
+ self,
+ outputs,
+ input_ids,
+ box_threshold: float = 0.25,
+ text_threshold: float = 0.25,
+ target_sizes: Union[TensorType, List[Tuple]] = None,
+ ):
+ """
+ Converts the raw output of [`GroundingDinoForObjectDetection`] into final bounding boxes in (top_left_x, top_left_y,
+ bottom_right_x, bottom_right_y) format and get the associated text label.
+
+ Args:
+ outputs ([`GroundingDinoObjectDetectionOutput`]):
+ Raw outputs of the model.
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The token ids of the input text.
+ box_threshold (`float`, *optional*, defaults to 0.25):
+ Score threshold to keep object detection predictions.
+ text_threshold (`float`, *optional*, defaults to 0.25):
+ Score threshold to keep text detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ probs = torch.sigmoid(logits) # (batch_size, num_queries, 256)
+ scores = torch.max(probs, dim=-1)[0] # (batch_size, num_queries)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for idx, (s, b, p) in enumerate(zip(scores, boxes, probs)):
+ score = s[s > box_threshold]
+ box = b[s > box_threshold]
+ prob = p[s > box_threshold]
+ label_ids = get_phrases_from_posmap(prob > text_threshold, input_ids[idx])
+ label = self.batch_decode(label_ids)
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 1bdab80a13f667..c3bf96fef96692 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -4236,6 +4236,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class GroundingDinoForObjectDetection(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class GroundingDinoModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class GroundingDinoPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index d7a629a1b24026..80b418adc16f37 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -247,6 +247,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class GroundingDinoImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class IdeficsImageProcessor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/grounding_dino/__init__.py b/tests/models/grounding_dino/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/grounding_dino/test_image_processing_grounding_dino.py b/tests/models/grounding_dino/test_image_processing_grounding_dino.py
new file mode 100644
index 00000000000000..df69784bbb4523
--- /dev/null
+++ b/tests/models/grounding_dino/test_image_processing_grounding_dino.py
@@ -0,0 +1,530 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GroundingDinoImageProcessor
+
+
+class GroundingDinoImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.num_queries = 5
+ self.embed_dim = 5
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_processor_dict with DeformableDetr->GroundingDino
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ }
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.get_expected_values with DeformableDetr->GroundingDino
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to GroundingDinoImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.expected_output_image_shape with DeformableDetr->GroundingDino
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ )
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_inputs with DeformableDetr->GroundingDino
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class GroundingDinoImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = GroundingDinoImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.image_processor_tester = GroundingDinoImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_properties with DeformableDetr->GroundingDino
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_from_dict_with_kwargs with DeformableDetr->GroundingDino
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = self.image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ def test_post_process_object_detection(self):
+ image_processor = self.image_processing_class(**self.image_processor_dict)
+ outputs = self.image_processor_tester.get_fake_grounding_dino_output()
+ results = image_processor.post_process_object_detection(outputs, threshold=0.0)
+
+ self.assertEqual(len(results), self.image_processor_tester.batch_size)
+ self.assertEqual(list(results[0].keys()), ["scores", "labels", "boxes"])
+ self.assertEqual(results[0]["boxes"].shape, (self.image_processor_tester.num_queries, 4))
+ self.assertEqual(results[0]["scores"].shape, (self.image_processor_tester.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ self.assertTrue(torch.allclose(results[0]["scores"], expected_scores, atol=1e-4))
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ self.assertTrue(torch.allclose(results[0]["boxes"][0], expected_box_slice, atol=1e-4))
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_detection_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor()
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ self.assertTrue(torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4))
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["area"], expected_area))
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3))
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["image_id"], expected_image_id))
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd))
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size))
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["size"], expected_size))
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_detection_annotations with Detr->GroundingDino
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ image_processing = GroundingDinoImageProcessor()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1e-3))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1e-3))
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1))
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_panoptic_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor(format="coco_panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ self.assertTrue(torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4))
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["area"], expected_area))
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3))
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["image_id"], expected_image_id))
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd))
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
+ # verify masks
+ expected_masks_sum = 822873
+ self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size))
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["size"], expected_size))
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_panoptic_annotations with Detr->GroundingDino
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1e-3))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1e-3))
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1))
diff --git a/tests/models/grounding_dino/test_modeling_grounding_dino.py b/tests/models/grounding_dino/test_modeling_grounding_dino.py
new file mode 100644
index 00000000000000..42486f92da9746
--- /dev/null
+++ b/tests/models/grounding_dino/test_modeling_grounding_dino.py
@@ -0,0 +1,689 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Grounding DINO model. """
+
+import collections
+import inspect
+import math
+import re
+import unittest
+
+from transformers import (
+ GroundingDinoConfig,
+ SwinConfig,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.file_utils import cached_property
+from transformers.testing_utils import (
+ require_timm,
+ require_torch,
+ require_torch_gpu,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import GroundingDinoForObjectDetection, GroundingDinoModel
+ from transformers.pytorch_utils import id_tensor_storage
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoProcessor
+
+
+class GroundingDinoModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=4,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=2,
+ num_channels=3,
+ image_size=98,
+ n_targets=8,
+ num_labels=3,
+ num_feature_levels=4,
+ encoder_n_points=2,
+ decoder_n_points=6,
+ max_text_len=7,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+ self.max_text_len = max_text_len
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length_vision = (
+ math.ceil(self.image_size / 8) ** 2
+ + math.ceil(self.image_size / 16) ** 2
+ + math.ceil(self.image_size / 32) ** 2
+ + math.ceil(self.image_size / 64) ** 2
+ )
+
+ self.encoder_seq_length_text = self.max_text_len
+
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ pixel_mask = torch.ones([self.batch_size, self.image_size, self.image_size], device=torch_device)
+
+ input_ids = ids_tensor([self.batch_size, self.max_text_len], self.num_labels)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.image_size, self.image_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, input_ids, labels
+
+ def get_config(self):
+ swin_config = SwinConfig(
+ window_size=7,
+ embed_dim=8,
+ depths=[1, 1, 1, 1],
+ num_heads=[1, 1, 1, 1],
+ image_size=self.image_size,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ text_backbone = {
+ "hidden_size": 8,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 2,
+ "intermediate_size": 8,
+ "max_position_embeddings": 8,
+ "model_type": "bert",
+ }
+ return GroundingDinoConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ num_feature_levels=self.num_feature_levels,
+ encoder_n_points=self.encoder_n_points,
+ decoder_n_points=self.decoder_n_points,
+ use_timm_backbone=False,
+ backbone_config=swin_config,
+ max_text_len=self.max_text_len,
+ text_config=text_backbone,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, input_ids, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask, "input_ids": input_ids}
+ return config, inputs_dict
+
+ def create_and_check_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.num_queries, self.hidden_size))
+
+ def create_and_check_object_detection_head_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class GroundingDinoModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GroundingDinoModel, GroundingDinoForObjectDetection) if is_torch_available() else ()
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ pipeline_model_mapping = (
+ {"image-feature-extraction": GroundingDinoModel, "zero-shot-object-detection": GroundingDinoForObjectDetection}
+ if is_torch_available()
+ else {}
+ )
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.image_size,
+ self.model_tester.image_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GroundingDinoModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GroundingDinoConfig, has_text_modality=False)
+
+ def test_config(self):
+ # we don't test common_properties and arguments_init as these don't apply for Grounding DINO
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_object_detection_head_model(*config_and_inputs)
+
+ @unittest.skip(reason="Grounding DINO does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not have a get_input_embeddings method")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 10
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ correct_outlen += 2
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions[0]
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, self.model_tester.num_queries, self.model_tester.num_queries],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.decoder_attentions[-1]
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.decoder_n_points,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 3, len(outputs))
+
+ self_attentions = outputs.encoder_attentions[-1]
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+
+ # overwrite since hidden_states are called encoder_text_hidden_states
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_vision_hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_vision
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.encoder_text_hidden_states
+
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_text
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.decoder_hidden_states
+
+ self.assertIsInstance(hidden_states, (list, tuple))
+ self.assertEqual(len(hidden_states), expected_num_layers)
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [decoder_seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_vision_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0][0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ cross_attentions = outputs.decoder_attentions[-1][0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values", "input_ids"]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.use_timm_backbone = True
+ config.backbone_config = None
+ config.backbone_kwargs = {"in_chans": 3, "out_indices": (2, 3, 4)}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ config.max_text_len,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if (
+ "level_embed" in name
+ or "sampling_offsets.bias" in name
+ or "text_param" in name
+ or "vision_param" in name
+ or "value_proj" in name
+ or "output_proj" in name
+ or "reference_points" in name
+ ):
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # Copied from tests.models.deformable_detr.test_modeling_deformable_detr.DeformableDetrModelTest.test_two_stage_training with DeformableDetr->GroundingDino
+ def test_two_stage_training(self):
+ model_class = GroundingDinoForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+ config.two_stage = True
+ config.auxiliary_loss = True
+ config.with_box_refine = True
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_tied_weights_keys(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.tie_word_embeddings = True
+ for model_class in self.all_model_classes:
+ model_tied = model_class(config)
+
+ ptrs = collections.defaultdict(list)
+ for name, tensor in model_tied.state_dict().items():
+ ptrs[id_tensor_storage(tensor)].append(name)
+
+ # These are all the pointers of shared tensors.
+ tied_params = [names for _, names in ptrs.items() if len(names) > 1]
+
+ tied_weight_keys = model_tied._tied_weights_keys if model_tied._tied_weights_keys is not None else []
+ # Detect we get a hit for each key
+ for key in tied_weight_keys:
+ if not any(re.search(key, p) for group in tied_params for p in group):
+ raise ValueError(f"{key} is not a tied weight key for {model_class}.")
+
+ # Removed tied weights found from tied params -> there should only be one left after
+ for key in tied_weight_keys:
+ for i in range(len(tied_params)):
+ tied_params[i] = [p for p in tied_params[i] if re.search(key, p) is None]
+
+ # GroundingDino when sharing weights also uses the shared ones in GroundingDinoDecoder
+ # Therefore, differently from DeformableDetr, we expect the group lens to be 2
+ # one for self.bbox_embed in GroundingDinoForObejectDetection and another one
+ # in the decoder
+ tied_params = [group for group in tied_params if len(group) > 2]
+ self.assertListEqual(
+ tied_params,
+ [],
+ f"Missing `_tied_weights_keys` for {model_class}: add all of {tied_params} except one.",
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+def prepare_text():
+ text = "a cat."
+ return text
+
+
+@require_timm
+@require_vision
+@slow
+class GroundingDinoModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_processor(self):
+ return AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny") if is_vision_available() else None
+
+ def test_inference_object_detection_head(self):
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(torch_device)
+
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.d_model))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+
+ expected_boxes = torch.tensor(
+ [[0.7674, 0.4136, 0.4572], [0.2566, 0.5463, 0.4760], [0.2585, 0.5442, 0.4641]]
+ ).to(torch_device)
+ expected_logits = torch.tensor(
+ [[-4.8913, -0.1900, -0.2161], [-4.9653, -0.3719, -0.3950], [-5.9599, -3.3765, -3.3104]]
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_logits, atol=1e-3))
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ self.assertTrue(torch.allclose(outputs.pred_boxes[0, :3, :3], expected_boxes, atol=1e-4))
+
+ # verify postprocessing
+ results = processor.image_processor.post_process_object_detection(
+ outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.4526, 0.4082]).to(torch_device)
+ expected_slice_boxes = torch.tensor([344.8143, 23.1796, 637.4004, 373.8295]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 2)
+ self.assertTrue(torch.allclose(results["scores"], expected_scores, atol=1e-3))
+ self.assertTrue(torch.allclose(results["boxes"][0, :], expected_slice_boxes, atol=1e-2))
+
+ # verify grounded postprocessing
+ expected_labels = ["a cat", "a cat"]
+ results = processor.post_process_grounded_object_detection(
+ outputs=outputs,
+ input_ids=encoding.input_ids,
+ box_threshold=0.35,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]],
+ )[0]
+
+ self.assertTrue(torch.allclose(results["scores"], expected_scores, atol=1e-3))
+ self.assertTrue(torch.allclose(results["boxes"][0, :], expected_slice_boxes, atol=1e-2))
+ self.assertListEqual(results["labels"], expected_labels)
+
+ @require_torch_gpu
+ def test_inference_object_detection_head_equivalence_cpu_gpu(self):
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt")
+
+ # 1. run model on CPU
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ with torch.no_grad():
+ cpu_outputs = model(**encoding)
+
+ # 2. run model on GPU
+ model.to("cuda")
+ encoding = encoding.to("cuda")
+ with torch.no_grad():
+ gpu_outputs = model(**encoding)
+
+ # 3. assert equivalence
+ for key in cpu_outputs.keys():
+ self.assertTrue(torch.allclose(cpu_outputs[key], gpu_outputs[key].cpu(), atol=1e-3))
+
+ expected_logits = torch.tensor(
+ [[-4.8915, -0.1900, -0.2161], [-4.9658, -0.3716, -0.3948], [-5.9596, -3.3763, -3.3103]]
+ )
+ self.assertTrue(torch.allclose(cpu_outputs.logits[0, :3, :3], expected_logits, atol=1e-3))
+
+ # assert postprocessing
+ results_cpu = processor.image_processor.post_process_object_detection(
+ cpu_outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+
+ result_gpu = processor.image_processor.post_process_object_detection(
+ gpu_outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+
+ self.assertTrue(torch.allclose(results_cpu["scores"], result_gpu["scores"].cpu(), atol=1e-3))
+ self.assertTrue(torch.allclose(results_cpu["boxes"], result_gpu["boxes"].cpu(), atol=1e-3))
diff --git a/tests/models/grounding_dino/test_processor_grounding_dino.py b/tests/models/grounding_dino/test_processor_grounding_dino.py
new file mode 100644
index 00000000000000..a788d09ca7eed1
--- /dev/null
+++ b/tests/models/grounding_dino/test_processor_grounding_dino.py
@@ -0,0 +1,253 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+
+from transformers import BertTokenizer, BertTokenizerFast, GroundingDinoProcessor
+from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import IMAGE_PROCESSOR_NAME, is_torch_available, is_vision_available
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GroundingDinoImageProcessor
+
+
+@require_torch
+@require_vision
+class GroundingDinoProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.tmpdirname = tempfile.mkdtemp()
+
+ vocab_tokens = ["[UNK]","[CLS]","[SEP]","[PAD]","[MASK]","want","##want","##ed","wa","un","runn","##ing",",","low","lowest"] # fmt: skip
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": None,
+ "do_normalize": True,
+ "image_mean": [0.5, 0.5, 0.5],
+ "image_std": [0.5, 0.5, 0.5],
+ "do_rescale": True,
+ "rescale_factor": 1 / 255,
+ "do_pad": True,
+ }
+ self.image_processor_file = os.path.join(self.tmpdirname, IMAGE_PROCESSOR_NAME)
+ with open(self.image_processor_file, "w", encoding="utf-8") as fp:
+ json.dump(image_processor_map, fp)
+
+ self.batch_size = 7
+ self.num_queries = 5
+ self.embed_dim = 5
+ self.seq_length = 5
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_tokenizer with CLIP->Bert
+ def get_tokenizer(self, **kwargs):
+ return BertTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_rust_tokenizer with CLIP->Bert
+ def get_rust_tokenizer(self, **kwargs):
+ return BertTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_image_processor with CLIP->GroundingDino
+ def get_image_processor(self, **kwargs):
+ return GroundingDinoImageProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.tearDown
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.prepare_image_inputs
+ def prepare_image_inputs(self):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+ """
+
+ image_inputs = [np.random.randint(255, size=(3, 30, 400), dtype=np.uint8)]
+
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ return image_inputs
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ )
+
+ def get_fake_grounding_dino_input_ids(self):
+ input_ids = torch.tensor([101, 1037, 4937, 1012, 102])
+ return torch.stack([input_ids] * self.batch_size, dim=0)
+
+ def test_post_process_grounded_object_detection(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ grounding_dino_output = self.get_fake_grounding_dino_output()
+ grounding_dino_input_ids = self.get_fake_grounding_dino_input_ids()
+
+ post_processed = processor.post_process_grounded_object_detection(
+ grounding_dino_output, grounding_dino_input_ids
+ )
+
+ self.assertEqual(len(post_processed), self.batch_size)
+ self.assertEqual(list(post_processed[0].keys()), ["scores", "labels", "boxes"])
+ self.assertEqual(post_processed[0]["boxes"].shape, (self.num_queries, 4))
+ self.assertEqual(post_processed[0]["scores"].shape, (self.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ self.assertTrue(torch.allclose(post_processed[0]["scores"], expected_scores, atol=1e-4))
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ self.assertTrue(torch.allclose(post_processed[0]["boxes"][0], expected_box_slice, atol=1e-4))
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_default with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ image_processor = self.get_image_processor()
+
+ processor_slow = GroundingDinoProcessor(tokenizer=tokenizer_slow, image_processor=image_processor)
+ processor_slow.save_pretrained(self.tmpdirname)
+ processor_slow = GroundingDinoProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = GroundingDinoProcessor(tokenizer=tokenizer_fast, image_processor=image_processor)
+ processor_fast.save_pretrained(self.tmpdirname)
+ processor_fast = GroundingDinoProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, BertTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor_slow.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertEqual(processor_fast.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor_slow.image_processor, GroundingDinoImageProcessor)
+ self.assertIsInstance(processor_fast.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_additional_features with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_additional_features(self):
+ processor = GroundingDinoProcessor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = GroundingDinoProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_image_processor with CLIP->GroundingDino
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_image_proc = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_image_proc.keys():
+ self.assertAlmostEqual(input_image_proc[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer with CLIP->GroundingDino
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(
+ list(inputs.keys()), ["input_ids", "token_type_ids", "attention_mask", "pixel_values", "pixel_mask"]
+ )
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer_decode with CLIP->GroundingDino
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_model_input_names with CLIP->GroundingDino
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)
+
+ Grounding DINO overview. Taken from the original paper.
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
+
+## Usage tips
+
+- One can use [`GroundingDinoProcessor`] to prepare image-text pairs for the model.
+- To separate classes in the text use a period e.g. "a cat. a dog."
+- When using multiple classes (e.g. `"a cat. a dog."`), use `post_process_grounded_object_detection` from [`GroundingDinoProcessor`] to post process outputs. Since, the labels returned from `post_process_object_detection` represent the indices from the model dimension where prob > threshold.
+
+Here's how to use the model for zero-shot object detection:
+
+```python
+import requests
+
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection,
+
+model_id = "IDEA-Research/grounding-dino-tiny"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(image_url, stream=True).raw)
+# Check for cats and remote controls
+text = "a cat. a remote control."
+
+inputs = processor(images=image, text=text, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = processor.post_process_grounded_object_detection(
+ outputs,
+ inputs.input_ids,
+ box_threshold=0.4,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]]
+)
+```
+
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+ - post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+ - forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index da29d77972f425..ff6c04155f5a5f 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -488,9 +488,11 @@
"GPTSanJapaneseConfig",
"GPTSanJapaneseTokenizer",
],
- "models.graphormer": [
- "GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
- "GraphormerConfig",
+ "models.graphormer": ["GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "GraphormerConfig"],
+ "models.grounding_dino": [
+ "GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "GroundingDinoConfig",
+ "GroundingDinoProcessor",
],
"models.groupvit": [
"GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1330,6 +1332,7 @@
_import_structure["models.flava"].extend(["FlavaFeatureExtractor", "FlavaImageProcessor", "FlavaProcessor"])
_import_structure["models.fuyu"].extend(["FuyuImageProcessor", "FuyuProcessor"])
_import_structure["models.glpn"].extend(["GLPNFeatureExtractor", "GLPNImageProcessor"])
+ _import_structure["models.grounding_dino"].extend(["GroundingDinoImageProcessor"])
_import_structure["models.idefics"].extend(["IdeficsImageProcessor"])
_import_structure["models.imagegpt"].extend(["ImageGPTFeatureExtractor", "ImageGPTImageProcessor"])
_import_structure["models.layoutlmv2"].extend(["LayoutLMv2FeatureExtractor", "LayoutLMv2ImageProcessor"])
@@ -2390,6 +2393,14 @@
"GraphormerPreTrainedModel",
]
)
+ _import_structure["models.grounding_dino"].extend(
+ [
+ "GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "GroundingDinoForObjectDetection",
+ "GroundingDinoModel",
+ "GroundingDinoPreTrainedModel",
+ ]
+ )
_import_structure["models.groupvit"].extend(
[
"GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -5372,9 +5383,11 @@
GPTSanJapaneseConfig,
GPTSanJapaneseTokenizer,
)
- from .models.graphormer import (
- GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
- GraphormerConfig,
+ from .models.graphormer import GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, GraphormerConfig
+ from .models.grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ GroundingDinoConfig,
+ GroundingDinoProcessor,
)
from .models.groupvit import (
GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -6186,6 +6199,7 @@
)
from .models.fuyu import FuyuImageProcessor, FuyuProcessor
from .models.glpn import GLPNFeatureExtractor, GLPNImageProcessor
+ from .models.grounding_dino import GroundingDinoImageProcessor
from .models.idefics import IdeficsImageProcessor
from .models.imagegpt import ImageGPTFeatureExtractor, ImageGPTImageProcessor
from .models.layoutlmv2 import (
@@ -7103,6 +7117,12 @@
GraphormerModel,
GraphormerPreTrainedModel,
)
+ from .models.grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST,
+ GroundingDinoForObjectDetection,
+ GroundingDinoModel,
+ GroundingDinoPreTrainedModel,
+ )
from .models.groupvit import (
GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST,
GroupViTModel,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 0599d3b876e6af..89baf93f6886f8 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -105,6 +105,7 @@
gptj,
gptsan_japanese,
graphormer,
+ grounding_dino,
groupvit,
herbert,
hubert,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index bf46066002feb9..ce8298d8c5cfc8 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -120,6 +120,7 @@
("gptj", "GPTJConfig"),
("gptsan-japanese", "GPTSanJapaneseConfig"),
("graphormer", "GraphormerConfig"),
+ ("grounding-dino", "GroundingDinoConfig"),
("groupvit", "GroupViTConfig"),
("hubert", "HubertConfig"),
("ibert", "IBertConfig"),
@@ -382,6 +383,7 @@
("gptj", "GPT-J"),
("gptsan-japanese", "GPTSAN-japanese"),
("graphormer", "Graphormer"),
+ ("grounding-dino", "Grounding DINO"),
("groupvit", "GroupViT"),
("herbert", "HerBERT"),
("hubert", "Hubert"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index 3debf97fea2081..6ae28bfa32cb63 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -68,6 +68,7 @@
("fuyu", "FuyuImageProcessor"),
("git", "CLIPImageProcessor"),
("glpn", "GLPNImageProcessor"),
+ ("grounding-dino", "GroundingDinoImageProcessor"),
("groupvit", "CLIPImageProcessor"),
("idefics", "IdeficsImageProcessor"),
("imagegpt", "ImageGPTImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 150dea04f3745a..d422fe8c19b799 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -115,6 +115,7 @@
("gptj", "GPTJModel"),
("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
("graphormer", "GraphormerModel"),
+ ("grounding-dino", "GroundingDinoModel"),
("groupvit", "GroupViTModel"),
("hubert", "HubertModel"),
("ibert", "IBertModel"),
@@ -751,6 +752,7 @@
MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
[
# Model for Zero Shot Object Detection mapping
+ ("grounding-dino", "GroundingDinoForObjectDetection"),
("owlv2", "Owlv2ForObjectDetection"),
("owlvit", "OwlViTForObjectDetection"),
]
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 4bc5d8105316bf..c9143fd8be5200 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -195,6 +195,7 @@
("gpt_neox_japanese", ("GPTNeoXJapaneseTokenizer", None)),
("gptj", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
("gptsan-japanese", ("GPTSanJapaneseTokenizer", None)),
+ ("grounding-dino", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
("groupvit", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
("herbert", ("HerbertTokenizer", "HerbertTokenizerFast" if is_tokenizers_available() else None)),
("hubert", ("Wav2Vec2CTCTokenizer", None)),
diff --git a/src/transformers/models/deformable_detr/modeling_deformable_detr.py b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
index 1e2296d177c4de..c0ac7cffc7ab44 100755
--- a/src/transformers/models/deformable_detr/modeling_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
@@ -710,13 +710,14 @@ def forward(
batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
)
# batch_size, num_queries, n_heads, n_levels, n_points, 2
- if reference_points.shape[-1] == 2:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = (
reference_points[:, :, None, :, None, :]
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
)
- elif reference_points.shape[-1] == 4:
+ elif num_coordinates == 4:
sampling_locations = (
reference_points[:, :, None, :, None, :2]
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
@@ -1401,14 +1402,15 @@ def forward(
intermediate_reference_points = ()
for idx, decoder_layer in enumerate(self.layers):
- if reference_points.shape[-1] == 4:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
reference_points_input = (
reference_points[:, :, None] * torch.cat([valid_ratios, valid_ratios], -1)[:, None]
)
- else:
- if reference_points.shape[-1] != 2:
- raise ValueError("Reference points' last dimension must be of size 2")
+ elif reference_points.shape[-1] == 2:
reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
+ else:
+ raise ValueError("Reference points' last dimension must be of size 2")
if output_hidden_states:
all_hidden_states += (hidden_states,)
@@ -1442,17 +1444,18 @@ def forward(
# hack implementation for iterative bounding box refinement
if self.bbox_embed is not None:
tmp = self.bbox_embed[idx](hidden_states)
- if reference_points.shape[-1] == 4:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
new_reference_points = tmp + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
- else:
- if reference_points.shape[-1] != 2:
- raise ValueError(
- f"Reference points' last dimension must be of size 2, but is {reference_points.shape[-1]}"
- )
+ elif num_coordinates == 2:
new_reference_points = tmp
new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points)
new_reference_points = new_reference_points.sigmoid()
+ else:
+ raise ValueError(
+ f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}"
+ )
reference_points = new_reference_points.detach()
intermediate += (hidden_states,)
diff --git a/src/transformers/models/deta/modeling_deta.py b/src/transformers/models/deta/modeling_deta.py
index 35d9b67d2f9923..e8491355591ab8 100644
--- a/src/transformers/models/deta/modeling_deta.py
+++ b/src/transformers/models/deta/modeling_deta.py
@@ -682,13 +682,14 @@ def forward(
batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
)
# batch_size, num_queries, n_heads, n_levels, n_points, 2
- if reference_points.shape[-1] == 2:
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = (
reference_points[:, :, None, :, None, :]
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :]
)
- elif reference_points.shape[-1] == 4:
+ elif num_coordinates == 4:
sampling_locations = (
reference_points[:, :, None, :, None, :2]
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
diff --git a/src/transformers/models/grounding_dino/__init__.py b/src/transformers/models/grounding_dino/__init__.py
new file mode 100644
index 00000000000000..3b0f792068c5f0
--- /dev/null
+++ b/src/transformers/models/grounding_dino/__init__.py
@@ -0,0 +1,81 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_grounding_dino": [
+ "GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "GroundingDinoConfig",
+ ],
+ "processing_grounding_dino": ["GroundingDinoProcessor"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_grounding_dino"] = [
+ "GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "GroundingDinoForObjectDetection",
+ "GroundingDinoModel",
+ "GroundingDinoPreTrainedModel",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_grounding_dino"] = ["GroundingDinoImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ GroundingDinoConfig,
+ )
+ from .processing_grounding_dino import GroundingDinoProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_grounding_dino import (
+ GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST,
+ GroundingDinoForObjectDetection,
+ GroundingDinoModel,
+ GroundingDinoPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_grounding_dino import GroundingDinoImageProcessor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/grounding_dino/configuration_grounding_dino.py b/src/transformers/models/grounding_dino/configuration_grounding_dino.py
new file mode 100644
index 00000000000000..fe683035039600
--- /dev/null
+++ b/src/transformers/models/grounding_dino/configuration_grounding_dino.py
@@ -0,0 +1,301 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Grounding DINO model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+from ..auto import CONFIG_MAPPING
+
+
+logger = logging.get_logger(__name__)
+
+GROUNDING_DINO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "IDEA-Research/grounding-dino-tiny": "https://huggingface.co/IDEA-Research/grounding-dino-tiny/resolve/main/config.json",
+}
+
+
+class GroundingDinoConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`GroundingDinoModel`]. It is used to instantiate a
+ Grounding DINO model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the Grounding DINO
+ [IDEA-Research/grounding-dino-tiny](https://huggingface.co/IDEA-Research/grounding-dino-tiny) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ backbone_config (`PretrainedConfig` or `dict`, *optional*, defaults to `ResNetConfig()`):
+ The configuration of the backbone model.
+ backbone (`str`, *optional*):
+ Name of backbone to use when `backbone_config` is `None`. If `use_pretrained_backbone` is `True`, this
+ will load the corresponding pretrained weights from the timm or transformers library. If `use_pretrained_backbone`
+ is `False`, this loads the backbone's config and uses that to initialize the backbone with random weights.
+ use_pretrained_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to use pretrained weights for the backbone.
+ use_timm_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to load `backbone` from the timm library. If `False`, the backbone is loaded from the transformers
+ library.
+ backbone_kwargs (`dict`, *optional*):
+ Keyword arguments to be passed to AutoBackbone when loading from a checkpoint
+ e.g. `{'out_indices': (0, 1, 2, 3)}`. Cannot be specified if `backbone_config` is set.
+ text_config (`Union[AutoConfig, dict]`, *optional*, defaults to `BertConfig`):
+ The config object or dictionary of the text backbone.
+ num_queries (`int`, *optional*, defaults to 900):
+ Number of object queries, i.e. detection slots. This is the maximal number of objects
+ [`GroundingDinoModel`] can detect in a single image.
+ encoder_layers (`int`, *optional*, defaults to 6):
+ Number of encoder layers.
+ encoder_ffn_dim (`int`, *optional*, defaults to 2048):
+ Dimension of the "intermediate" (often named feed-forward) layer in decoder.
+ encoder_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ decoder_layers (`int`, *optional*, defaults to 6):
+ Number of decoder layers.
+ decoder_ffn_dim (`int`, *optional*, defaults to 2048):
+ Dimension of the "intermediate" (often named feed-forward) layer in decoder.
+ decoder_attention_heads (`int`, *optional*, defaults to 8):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ is_encoder_decoder (`bool`, *optional*, defaults to `True`):
+ Whether the model is used as an encoder/decoder or not.
+ activation_function (`str` or `function`, *optional*, defaults to `"relu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ d_model (`int`, *optional*, defaults to 256):
+ Dimension of the layers.
+ dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ activation_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for activations inside the fully connected layer.
+ auxiliary_loss (`bool`, *optional*, defaults to `False`):
+ Whether auxiliary decoding losses (loss at each decoder layer) are to be used.
+ position_embedding_type (`str`, *optional*, defaults to `"sine"`):
+ Type of position embeddings to be used on top of the image features. One of `"sine"` or `"learned"`.
+ num_feature_levels (`int`, *optional*, defaults to 4):
+ The number of input feature levels.
+ encoder_n_points (`int`, *optional*, defaults to 4):
+ The number of sampled keys in each feature level for each attention head in the encoder.
+ decoder_n_points (`int`, *optional*, defaults to 4):
+ The number of sampled keys in each feature level for each attention head in the decoder.
+ two_stage (`bool`, *optional*, defaults to `True`):
+ Whether to apply a two-stage deformable DETR, where the region proposals are also generated by a variant of
+ Grounding DINO, which are further fed into the decoder for iterative bounding box refinement.
+ class_cost (`float`, *optional*, defaults to 1.0):
+ Relative weight of the classification error in the Hungarian matching cost.
+ bbox_cost (`float`, *optional*, defaults to 5.0):
+ Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost.
+ giou_cost (`float`, *optional*, defaults to 2.0):
+ Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost.
+ bbox_loss_coefficient (`float`, *optional*, defaults to 5.0):
+ Relative weight of the L1 bounding box loss in the object detection loss.
+ giou_loss_coefficient (`float`, *optional*, defaults to 2.0):
+ Relative weight of the generalized IoU loss in the object detection loss.
+ focal_alpha (`float`, *optional*, defaults to 0.25):
+ Alpha parameter in the focal loss.
+ disable_custom_kernels (`bool`, *optional*, defaults to `False`):
+ Disable the use of custom CUDA and CPU kernels. This option is necessary for the ONNX export, as custom
+ kernels are not supported by PyTorch ONNX export.
+ max_text_len (`int`, *optional*, defaults to 256):
+ The maximum length of the text input.
+ text_enhancer_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the text enhancer.
+ fusion_droppath (`float`, *optional*, defaults to 0.1):
+ The droppath ratio for the fusion module.
+ fusion_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the fusion module.
+ embedding_init_target (`bool`, *optional*, defaults to `True`):
+ Whether to initialize the target with Embedding weights.
+ query_dim (`int`, *optional*, defaults to 4):
+ The dimension of the query vector.
+ decoder_bbox_embed_share (`bool`, *optional*, defaults to `True`):
+ Whether to share the bbox regression head for all decoder layers.
+ two_stage_bbox_embed_share (`bool`, *optional*, defaults to `False`):
+ Whether to share the bbox embedding between the two-stage bbox generator and the region proposal
+ generation.
+ positional_embedding_temperature (`float`, *optional*, defaults to 20):
+ The temperature for Sine Positional Embedding that is used together with vision backbone.
+ init_std (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+
+ Examples:
+
+ ```python
+ >>> from transformers import GroundingDinoConfig, GroundingDinoModel
+
+ >>> # Initializing a Grounding DINO IDEA-Research/grounding-dino-tiny style configuration
+ >>> configuration = GroundingDinoConfig()
+
+ >>> # Initializing a model (with random weights) from the IDEA-Research/grounding-dino-tiny style configuration
+ >>> model = GroundingDinoModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "grounding-dino"
+ attribute_map = {
+ "hidden_size": "d_model",
+ "num_attention_heads": "encoder_attention_heads",
+ }
+
+ def __init__(
+ self,
+ backbone_config=None,
+ backbone=None,
+ use_pretrained_backbone=False,
+ use_timm_backbone=False,
+ backbone_kwargs=None,
+ text_config=None,
+ num_queries=900,
+ encoder_layers=6,
+ encoder_ffn_dim=2048,
+ encoder_attention_heads=8,
+ decoder_layers=6,
+ decoder_ffn_dim=2048,
+ decoder_attention_heads=8,
+ is_encoder_decoder=True,
+ activation_function="relu",
+ d_model=256,
+ dropout=0.1,
+ attention_dropout=0.0,
+ activation_dropout=0.0,
+ auxiliary_loss=False,
+ position_embedding_type="sine",
+ num_feature_levels=4,
+ encoder_n_points=4,
+ decoder_n_points=4,
+ two_stage=True,
+ class_cost=1.0,
+ bbox_cost=5.0,
+ giou_cost=2.0,
+ bbox_loss_coefficient=5.0,
+ giou_loss_coefficient=2.0,
+ focal_alpha=0.25,
+ disable_custom_kernels=False,
+ # other parameters
+ max_text_len=256,
+ text_enhancer_dropout=0.0,
+ fusion_droppath=0.1,
+ fusion_dropout=0.0,
+ embedding_init_target=True,
+ query_dim=4,
+ decoder_bbox_embed_share=True,
+ two_stage_bbox_embed_share=False,
+ positional_embedding_temperature=20,
+ init_std=0.02,
+ layer_norm_eps=1e-5,
+ **kwargs,
+ ):
+ if not use_timm_backbone and use_pretrained_backbone:
+ raise ValueError(
+ "Loading pretrained backbone weights from the transformers library is not supported yet. `use_timm_backbone` must be set to `True` when `use_pretrained_backbone=True`"
+ )
+
+ if backbone_config is not None and backbone is not None:
+ raise ValueError("You can't specify both `backbone` and `backbone_config`.")
+
+ if backbone_config is None and backbone is None:
+ logger.info("`backbone_config` is `None`. Initializing the config with the default `Swin` backbone.")
+ backbone_config = CONFIG_MAPPING["swin"](
+ window_size=7,
+ image_size=224,
+ embed_dim=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ out_indices=[2, 3, 4],
+ )
+ elif isinstance(backbone_config, dict):
+ backbone_model_type = backbone_config.pop("model_type")
+ config_class = CONFIG_MAPPING[backbone_model_type]
+ backbone_config = config_class.from_dict(backbone_config)
+
+ if backbone_kwargs is not None and backbone_kwargs and backbone_config is not None:
+ raise ValueError("You can't specify both `backbone_kwargs` and `backbone_config`.")
+
+ if text_config is None:
+ text_config = {}
+ logger.info("text_config is None. Initializing the text config with default values (`BertConfig`).")
+
+ self.backbone_config = backbone_config
+ self.backbone = backbone
+ self.use_pretrained_backbone = use_pretrained_backbone
+ self.use_timm_backbone = use_timm_backbone
+ self.backbone_kwargs = backbone_kwargs
+ self.num_queries = num_queries
+ self.d_model = d_model
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.encoder_layers = encoder_layers
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.decoder_layers = decoder_layers
+ self.decoder_attention_heads = decoder_attention_heads
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.activation_function = activation_function
+ self.auxiliary_loss = auxiliary_loss
+ self.position_embedding_type = position_embedding_type
+ # deformable attributes
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+ self.two_stage = two_stage
+ # Hungarian matcher
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ # Loss coefficients
+ self.bbox_loss_coefficient = bbox_loss_coefficient
+ self.giou_loss_coefficient = giou_loss_coefficient
+ self.focal_alpha = focal_alpha
+ self.disable_custom_kernels = disable_custom_kernels
+ # Text backbone
+ if isinstance(text_config, dict):
+ text_config["model_type"] = text_config["model_type"] if "model_type" in text_config else "bert"
+ text_config = CONFIG_MAPPING[text_config["model_type"]](**text_config)
+ elif text_config is None:
+ text_config = CONFIG_MAPPING["bert"]()
+
+ self.text_config = text_config
+ self.max_text_len = max_text_len
+
+ # Text Enhancer
+ self.text_enhancer_dropout = text_enhancer_dropout
+ # Fusion
+ self.fusion_droppath = fusion_droppath
+ self.fusion_dropout = fusion_dropout
+ # Others
+ self.embedding_init_target = embedding_init_target
+ self.query_dim = query_dim
+ self.decoder_bbox_embed_share = decoder_bbox_embed_share
+ self.two_stage_bbox_embed_share = two_stage_bbox_embed_share
+ if two_stage_bbox_embed_share and not decoder_bbox_embed_share:
+ raise ValueError("If two_stage_bbox_embed_share is True, decoder_bbox_embed_share must be True.")
+ self.positional_embedding_temperature = positional_embedding_temperature
+ self.init_std = init_std
+ self.layer_norm_eps = layer_norm_eps
+ super().__init__(is_encoder_decoder=is_encoder_decoder, **kwargs)
+
+ @property
+ def num_attention_heads(self) -> int:
+ return self.encoder_attention_heads
+
+ @property
+ def hidden_size(self) -> int:
+ return self.d_model
diff --git a/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py b/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py
new file mode 100644
index 00000000000000..ac8e82bfd825d6
--- /dev/null
+++ b/src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py
@@ -0,0 +1,491 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Grounding DINO checkpoints from the original repository.
+
+URL: https://github.com/IDEA-Research/GroundingDINO"""
+
+import argparse
+
+import requests
+import torch
+from PIL import Image
+from torchvision import transforms as T
+
+from transformers import (
+ AutoTokenizer,
+ GroundingDinoConfig,
+ GroundingDinoForObjectDetection,
+ GroundingDinoImageProcessor,
+ GroundingDinoProcessor,
+ SwinConfig,
+)
+
+
+IMAGENET_MEAN = [0.485, 0.456, 0.406]
+IMAGENET_STD = [0.229, 0.224, 0.225]
+
+
+def get_grounding_dino_config(model_name):
+ if "tiny" in model_name:
+ window_size = 7
+ embed_dim = 96
+ depths = (2, 2, 6, 2)
+ num_heads = (3, 6, 12, 24)
+ image_size = 224
+ elif "base" in model_name:
+ window_size = 12
+ embed_dim = 128
+ depths = (2, 2, 18, 2)
+ num_heads = (4, 8, 16, 32)
+ image_size = 384
+ else:
+ raise ValueError("Model not supported, only supports base and large variants")
+
+ backbone_config = SwinConfig(
+ window_size=window_size,
+ image_size=image_size,
+ embed_dim=embed_dim,
+ depths=depths,
+ num_heads=num_heads,
+ out_indices=[2, 3, 4],
+ )
+
+ config = GroundingDinoConfig(backbone_config=backbone_config)
+
+ return config
+
+
+def create_rename_keys(state_dict, config):
+ rename_keys = []
+ # fmt: off
+ ########################################## VISION BACKBONE - START
+ # patch embedding layer
+ rename_keys.append(("backbone.0.patch_embed.proj.weight",
+ "model.backbone.conv_encoder.model.embeddings.patch_embeddings.projection.weight"))
+ rename_keys.append(("backbone.0.patch_embed.proj.bias",
+ "model.backbone.conv_encoder.model.embeddings.patch_embeddings.projection.bias"))
+ rename_keys.append(("backbone.0.patch_embed.norm.weight",
+ "model.backbone.conv_encoder.model.embeddings.norm.weight"))
+ rename_keys.append(("backbone.0.patch_embed.norm.bias",
+ "model.backbone.conv_encoder.model.embeddings.norm.bias"))
+
+ for layer, depth in enumerate(config.backbone_config.depths):
+ for block in range(depth):
+ # layernorms
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm1.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_before.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm1.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_before.bias"))
+
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm2.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_after.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.norm2.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.layernorm_after.bias"))
+ # attention
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.relative_position_bias_table",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.relative_position_bias_table"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.proj.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.output.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.attn.proj.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.output.dense.bias"))
+ # intermediate
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc1.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.intermediate.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc1.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.intermediate.dense.bias"))
+
+ # output
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc2.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.output.dense.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.blocks.{block}.mlp.fc2.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.output.dense.bias"))
+
+ # downsample
+ if layer!=len(config.backbone_config.depths)-1:
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.reduction.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.reduction.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.norm.weight",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.norm.weight"))
+ rename_keys.append((f"backbone.0.layers.{layer}.downsample.norm.bias",
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.downsample.norm.bias"))
+
+ for out_indice in config.backbone_config.out_indices:
+ # Grounding DINO implementation of out_indices isn't aligned with transformers
+ rename_keys.append((f"backbone.0.norm{out_indice-1}.weight",
+ f"model.backbone.conv_encoder.model.hidden_states_norms.stage{out_indice}.weight"))
+ rename_keys.append((f"backbone.0.norm{out_indice-1}.bias",
+ f"model.backbone.conv_encoder.model.hidden_states_norms.stage{out_indice}.bias"))
+
+ ########################################## VISION BACKBONE - END
+
+ ########################################## ENCODER - START
+ deformable_key_mappings = {
+ 'self_attn.sampling_offsets.weight': 'deformable_layer.self_attn.sampling_offsets.weight',
+ 'self_attn.sampling_offsets.bias': 'deformable_layer.self_attn.sampling_offsets.bias',
+ 'self_attn.attention_weights.weight': 'deformable_layer.self_attn.attention_weights.weight',
+ 'self_attn.attention_weights.bias': 'deformable_layer.self_attn.attention_weights.bias',
+ 'self_attn.value_proj.weight': 'deformable_layer.self_attn.value_proj.weight',
+ 'self_attn.value_proj.bias': 'deformable_layer.self_attn.value_proj.bias',
+ 'self_attn.output_proj.weight': 'deformable_layer.self_attn.output_proj.weight',
+ 'self_attn.output_proj.bias': 'deformable_layer.self_attn.output_proj.bias',
+ 'norm1.weight': 'deformable_layer.self_attn_layer_norm.weight',
+ 'norm1.bias': 'deformable_layer.self_attn_layer_norm.bias',
+ 'linear1.weight': 'deformable_layer.fc1.weight',
+ 'linear1.bias': 'deformable_layer.fc1.bias',
+ 'linear2.weight': 'deformable_layer.fc2.weight',
+ 'linear2.bias': 'deformable_layer.fc2.bias',
+ 'norm2.weight': 'deformable_layer.final_layer_norm.weight',
+ 'norm2.bias': 'deformable_layer.final_layer_norm.bias',
+ }
+ text_enhancer_key_mappings = {
+ 'self_attn.in_proj_weight': 'text_enhancer_layer.self_attn.in_proj_weight',
+ 'self_attn.in_proj_bias': 'text_enhancer_layer.self_attn.in_proj_bias',
+ 'self_attn.out_proj.weight': 'text_enhancer_layer.self_attn.out_proj.weight',
+ 'self_attn.out_proj.bias': 'text_enhancer_layer.self_attn.out_proj.bias',
+ 'linear1.weight': 'text_enhancer_layer.fc1.weight',
+ 'linear1.bias': 'text_enhancer_layer.fc1.bias',
+ 'linear2.weight': 'text_enhancer_layer.fc2.weight',
+ 'linear2.bias': 'text_enhancer_layer.fc2.bias',
+ 'norm1.weight': 'text_enhancer_layer.layer_norm_before.weight',
+ 'norm1.bias': 'text_enhancer_layer.layer_norm_before.bias',
+ 'norm2.weight': 'text_enhancer_layer.layer_norm_after.weight',
+ 'norm2.bias': 'text_enhancer_layer.layer_norm_after.bias',
+ }
+ fusion_key_mappings = {
+ 'gamma_v': 'fusion_layer.vision_param',
+ 'gamma_l': 'fusion_layer.text_param',
+ 'layer_norm_v.weight': 'fusion_layer.layer_norm_vision.weight',
+ 'layer_norm_v.bias': 'fusion_layer.layer_norm_vision.bias',
+ 'layer_norm_l.weight': 'fusion_layer.layer_norm_text.weight',
+ 'layer_norm_l.bias': 'fusion_layer.layer_norm_text.bias',
+ 'attn.v_proj.weight': 'fusion_layer.attn.vision_proj.weight',
+ 'attn.v_proj.bias': 'fusion_layer.attn.vision_proj.bias',
+ 'attn.l_proj.weight': 'fusion_layer.attn.text_proj.weight',
+ 'attn.l_proj.bias': 'fusion_layer.attn.text_proj.bias',
+ 'attn.values_v_proj.weight': 'fusion_layer.attn.values_vision_proj.weight',
+ 'attn.values_v_proj.bias': 'fusion_layer.attn.values_vision_proj.bias',
+ 'attn.values_l_proj.weight': 'fusion_layer.attn.values_text_proj.weight',
+ 'attn.values_l_proj.bias': 'fusion_layer.attn.values_text_proj.bias',
+ 'attn.out_v_proj.weight': 'fusion_layer.attn.out_vision_proj.weight',
+ 'attn.out_v_proj.bias': 'fusion_layer.attn.out_vision_proj.bias',
+ 'attn.out_l_proj.weight': 'fusion_layer.attn.out_text_proj.weight',
+ 'attn.out_l_proj.bias': 'fusion_layer.attn.out_text_proj.bias',
+ }
+ for layer in range(config.encoder_layers):
+ # deformable
+ for src, dest in deformable_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ # text enhance
+ for src, dest in text_enhancer_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.text_layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ # fusion layers
+ for src, dest in fusion_key_mappings.items():
+ rename_keys.append((f"transformer.encoder.fusion_layers.{layer}.{src}",
+ f"model.encoder.layers.{layer}.{dest}"))
+ ########################################## ENCODER - END
+
+ ########################################## DECODER - START
+ key_mappings_decoder = {
+ 'cross_attn.sampling_offsets.weight': 'encoder_attn.sampling_offsets.weight',
+ 'cross_attn.sampling_offsets.bias': 'encoder_attn.sampling_offsets.bias',
+ 'cross_attn.attention_weights.weight': 'encoder_attn.attention_weights.weight',
+ 'cross_attn.attention_weights.bias': 'encoder_attn.attention_weights.bias',
+ 'cross_attn.value_proj.weight': 'encoder_attn.value_proj.weight',
+ 'cross_attn.value_proj.bias': 'encoder_attn.value_proj.bias',
+ 'cross_attn.output_proj.weight': 'encoder_attn.output_proj.weight',
+ 'cross_attn.output_proj.bias': 'encoder_attn.output_proj.bias',
+ 'norm1.weight': 'encoder_attn_layer_norm.weight',
+ 'norm1.bias': 'encoder_attn_layer_norm.bias',
+ 'ca_text.in_proj_weight': 'encoder_attn_text.in_proj_weight',
+ 'ca_text.in_proj_bias': 'encoder_attn_text.in_proj_bias',
+ 'ca_text.out_proj.weight': 'encoder_attn_text.out_proj.weight',
+ 'ca_text.out_proj.bias': 'encoder_attn_text.out_proj.bias',
+ 'catext_norm.weight': 'encoder_attn_text_layer_norm.weight',
+ 'catext_norm.bias': 'encoder_attn_text_layer_norm.bias',
+ 'self_attn.in_proj_weight': 'self_attn.in_proj_weight',
+ 'self_attn.in_proj_bias': 'self_attn.in_proj_bias',
+ 'self_attn.out_proj.weight': 'self_attn.out_proj.weight',
+ 'self_attn.out_proj.bias': 'self_attn.out_proj.bias',
+ 'norm2.weight': 'self_attn_layer_norm.weight',
+ 'norm2.bias': 'self_attn_layer_norm.bias',
+ 'linear1.weight': 'fc1.weight',
+ 'linear1.bias': 'fc1.bias',
+ 'linear2.weight': 'fc2.weight',
+ 'linear2.bias': 'fc2.bias',
+ 'norm3.weight': 'final_layer_norm.weight',
+ 'norm3.bias': 'final_layer_norm.bias',
+ }
+ for layer_num in range(config.decoder_layers):
+ source_prefix_decoder = f'transformer.decoder.layers.{layer_num}.'
+ target_prefix_decoder = f'model.decoder.layers.{layer_num}.'
+
+ for source_name, target_name in key_mappings_decoder.items():
+ rename_keys.append((source_prefix_decoder + source_name,
+ target_prefix_decoder + target_name))
+ ########################################## DECODER - END
+
+ ########################################## Additional - START
+ for layer_name, params in state_dict.items():
+ #### TEXT BACKBONE
+ if "bert" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("bert", "model.text_backbone")))
+ #### INPUT PROJ - PROJECT OUTPUT FEATURES FROM VISION BACKBONE
+ if "input_proj" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("input_proj", "model.input_proj_vision")))
+ #### INPUT PROJ - PROJECT OUTPUT FEATURES FROM TEXT BACKBONE
+ if "feat_map" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("feat_map", "model.text_projection")))
+ #### DECODER REFERENCE POINT HEAD
+ if "transformer.decoder.ref_point_head" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.decoder.ref_point_head",
+ "model.decoder.reference_points_head")))
+ #### DECODER BBOX EMBED
+ if "transformer.decoder.bbox_embed" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.decoder.bbox_embed",
+ "model.decoder.bbox_embed")))
+ if "transformer.enc_output" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer", "model")))
+
+ if "transformer.enc_out_bbox_embed" in layer_name:
+ rename_keys.append((layer_name, layer_name.replace("transformer.enc_out_bbox_embed",
+ "model.encoder_output_bbox_embed")))
+
+ rename_keys.append(("transformer.level_embed", "model.level_embed"))
+ rename_keys.append(("transformer.decoder.norm.weight", "model.decoder.layer_norm.weight"))
+ rename_keys.append(("transformer.decoder.norm.bias", "model.decoder.layer_norm.bias"))
+ rename_keys.append(("transformer.tgt_embed.weight", "model.query_position_embeddings.weight"))
+ ########################################## Additional - END
+
+ # fmt: on
+ return rename_keys
+
+
+def rename_key(dct, old, new):
+ val = dct.pop(old)
+ dct[new] = val
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v_encoder(state_dict, config):
+ ########################################## VISION BACKBONE - START
+ embed_dim = config.backbone_config.embed_dim
+ for layer, depth in enumerate(config.backbone_config.depths):
+ hidden_size = embed_dim * 2**layer
+ for block in range(depth):
+ # read in weights + bias of input projection layer (in timm, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"backbone.0.layers.{layer}.blocks.{block}.attn.qkv.weight")
+ in_proj_bias = state_dict.pop(f"backbone.0.layers.{layer}.blocks.{block}.attn.qkv.bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.query.weight"
+ ] = in_proj_weight[:hidden_size, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.query.bias"
+ ] = in_proj_bias[:hidden_size]
+
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.key.weight"
+ ] = in_proj_weight[hidden_size : hidden_size * 2, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.key.bias"
+ ] = in_proj_bias[hidden_size : hidden_size * 2]
+
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.value.weight"
+ ] = in_proj_weight[-hidden_size:, :]
+ state_dict[
+ f"model.backbone.conv_encoder.model.encoder.layers.{layer}.blocks.{block}.attention.self.value.bias"
+ ] = in_proj_bias[-hidden_size:]
+ ########################################## VISION BACKBONE - END
+
+
+def read_in_q_k_v_text_enhancer(state_dict, config):
+ hidden_size = config.hidden_size
+ for idx in range(config.encoder_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.query.weight"] = in_proj_weight[
+ :hidden_size, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.value.weight"] = in_proj_weight[
+ -hidden_size:, :
+ ]
+ state_dict[f"model.encoder.layers.{idx}.text_enhancer_layer.self_attn.value.bias"] = in_proj_bias[
+ -hidden_size:
+ ]
+
+
+def read_in_q_k_v_decoder(state_dict, config):
+ hidden_size = config.hidden_size
+ for idx in range(config.decoder_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"model.decoder.layers.{idx}.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.decoder.layers.{idx}.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.decoder.layers.{idx}.self_attn.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.decoder.layers.{idx}.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.key.bias"] = in_proj_bias[hidden_size : hidden_size * 2]
+
+ state_dict[f"model.decoder.layers.{idx}.self_attn.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"model.decoder.layers.{idx}.self_attn.value.bias"] = in_proj_bias[-hidden_size:]
+
+ # read in weights + bias of cross-attention
+ in_proj_weight = state_dict.pop(f"model.decoder.layers.{idx}.encoder_attn_text.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"model.decoder.layers.{idx}.encoder_attn_text.in_proj_bias")
+
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"model.decoder.layers.{idx}.encoder_attn_text.value.bias"] = in_proj_bias[-hidden_size:]
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ return image
+
+
+def preprocess_caption(caption: str) -> str:
+ result = caption.lower().strip()
+ if result.endswith("."):
+ return result
+ return result + "."
+
+
+@torch.no_grad()
+def convert_grounding_dino_checkpoint(args):
+ model_name = args.model_name
+ pytorch_dump_folder_path = args.pytorch_dump_folder_path
+ push_to_hub = args.push_to_hub
+ verify_logits = args.verify_logits
+
+ checkpoint_mapping = {
+ "grounding-dino-tiny": "https://huggingface.co/ShilongLiu/GroundingDino/resolve/main/groundingdino_swint_ogc.pth",
+ "grounding-dino-base": "https://huggingface.co/ShilongLiu/GroundingDino/resolve/main/groundingdino_swinb_cogcoor.pth",
+ }
+ # Define default GroundingDino configuation
+ config = get_grounding_dino_config(model_name)
+
+ # Load original checkpoint
+ checkpoint_url = checkpoint_mapping[model_name]
+ original_state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")["model"]
+ original_state_dict = {k.replace("module.", ""): v for k, v in original_state_dict.items()}
+
+ for name, param in original_state_dict.items():
+ print(name, param.shape)
+
+ # Rename keys
+ new_state_dict = original_state_dict.copy()
+ rename_keys = create_rename_keys(original_state_dict, config)
+
+ for src, dest in rename_keys:
+ rename_key(new_state_dict, src, dest)
+ read_in_q_k_v_encoder(new_state_dict, config)
+ read_in_q_k_v_text_enhancer(new_state_dict, config)
+ read_in_q_k_v_decoder(new_state_dict, config)
+
+ # Load HF model
+ model = GroundingDinoForObjectDetection(config)
+ model.eval()
+ missing_keys, unexpected_keys = model.load_state_dict(new_state_dict, strict=False)
+ print("Missing keys:", missing_keys)
+ print("Unexpected keys:", unexpected_keys)
+
+ # Load and process test image
+ image = prepare_img()
+ transforms = T.Compose([T.Resize(size=800, max_size=1333), T.ToTensor(), T.Normalize(IMAGENET_MEAN, IMAGENET_STD)])
+ original_pixel_values = transforms(image).unsqueeze(0)
+
+ image_processor = GroundingDinoImageProcessor()
+ tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+ processor = GroundingDinoProcessor(image_processor=image_processor, tokenizer=tokenizer)
+
+ text = "a cat"
+ inputs = processor(images=image, text=preprocess_caption(text), return_tensors="pt")
+
+ assert torch.allclose(original_pixel_values, inputs.pixel_values, atol=1e-4)
+
+ if verify_logits:
+ # Running forward
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ print(outputs.logits[0, :3, :3])
+
+ expected_slice = torch.tensor(
+ [[-4.8913, -0.1900, -0.2161], [-4.9653, -0.3719, -0.3950], [-5.9599, -3.3765, -3.3104]]
+ )
+
+ assert torch.allclose(outputs.logits[0, :3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ model.save_pretrained(pytorch_dump_folder_path)
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"EduardoPacheco/{model_name}")
+ processor.push_to_hub(f"EduardoPacheco/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="grounding-dino-tiny",
+ type=str,
+ choices=["grounding-dino-tiny", "grounding-dino-base"],
+ help="Name of the GroundingDino model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+ parser.add_argument(
+ "--verify_logits", action="store_false", help="Whether or not to verify logits after conversion."
+ )
+
+ args = parser.parse_args()
+ convert_grounding_dino_checkpoint(args)
diff --git a/src/transformers/models/grounding_dino/image_processing_grounding_dino.py b/src/transformers/models/grounding_dino/image_processing_grounding_dino.py
new file mode 100644
index 00000000000000..8b39d6801ca000
--- /dev/null
+++ b/src/transformers/models/grounding_dino/image_processing_grounding_dino.py
@@ -0,0 +1,1511 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for Deformable DETR."""
+
+import io
+import pathlib
+from collections import defaultdict
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Union
+
+import numpy as np
+
+from ...feature_extraction_utils import BatchFeature
+from ...image_processing_utils import BaseImageProcessor, get_size_dict
+from ...image_transforms import (
+ PaddingMode,
+ center_to_corners_format,
+ corners_to_center_format,
+ id_to_rgb,
+ pad,
+ rescale,
+ resize,
+ rgb_to_id,
+ to_channel_dimension_format,
+)
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_annotations,
+ validate_kwargs,
+ validate_preprocess_arguments,
+)
+from ...utils import (
+ ExplicitEnum,
+ TensorType,
+ is_flax_available,
+ is_jax_tensor,
+ is_scipy_available,
+ is_tf_available,
+ is_tf_tensor,
+ is_torch_available,
+ is_torch_tensor,
+ is_vision_available,
+ logging,
+)
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_vision_available():
+ import PIL
+
+if is_scipy_available():
+ import scipy.special
+ import scipy.stats
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+AnnotationType = Dict[str, Union[int, str, List[Dict]]]
+
+
+class AnnotationFormat(ExplicitEnum):
+ COCO_DETECTION = "coco_detection"
+ COCO_PANOPTIC = "coco_panoptic"
+
+
+SUPPORTED_ANNOTATION_FORMATS = (AnnotationFormat.COCO_DETECTION, AnnotationFormat.COCO_PANOPTIC)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_size_with_aspect_ratio
+def get_size_with_aspect_ratio(image_size, size, max_size=None) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size.
+
+ Args:
+ image_size (`Tuple[int, int]`):
+ The input image size.
+ size (`int`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ """
+ height, width = image_size
+ if max_size is not None:
+ min_original_size = float(min((height, width)))
+ max_original_size = float(max((height, width)))
+ if max_original_size / min_original_size * size > max_size:
+ size = int(round(max_size * min_original_size / max_original_size))
+
+ if (height <= width and height == size) or (width <= height and width == size):
+ return height, width
+
+ if width < height:
+ ow = size
+ oh = int(size * height / width)
+ else:
+ oh = size
+ ow = int(size * width / height)
+ return (oh, ow)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_resize_output_image_size
+def get_resize_output_image_size(
+ input_image: np.ndarray,
+ size: Union[int, Tuple[int, int], List[int]],
+ max_size: Optional[int] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+) -> Tuple[int, int]:
+ """
+ Computes the output image size given the input image size and the desired output size. If the desired output size
+ is a tuple or list, the output image size is returned as is. If the desired output size is an integer, the output
+ image size is computed by keeping the aspect ratio of the input image size.
+
+ Args:
+ input_image (`np.ndarray`):
+ The image to resize.
+ size (`int` or `Tuple[int, int]` or `List[int]`):
+ The desired output size.
+ max_size (`int`, *optional*):
+ The maximum allowed output size.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred from the input image.
+ """
+ image_size = get_image_size(input_image, input_data_format)
+ if isinstance(size, (list, tuple)):
+ return size
+
+ return get_size_with_aspect_ratio(image_size, size, max_size)
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_numpy_to_framework_fn
+def get_numpy_to_framework_fn(arr) -> Callable:
+ """
+ Returns a function that converts a numpy array to the framework of the input array.
+
+ Args:
+ arr (`np.ndarray`): The array to convert.
+ """
+ if isinstance(arr, np.ndarray):
+ return np.array
+ if is_tf_available() and is_tf_tensor(arr):
+ import tensorflow as tf
+
+ return tf.convert_to_tensor
+ if is_torch_available() and is_torch_tensor(arr):
+ import torch
+
+ return torch.tensor
+ if is_flax_available() and is_jax_tensor(arr):
+ import jax.numpy as jnp
+
+ return jnp.array
+ raise ValueError(f"Cannot convert arrays of type {type(arr)}")
+
+
+# Copied from transformers.models.detr.image_processing_detr.safe_squeeze
+def safe_squeeze(arr: np.ndarray, axis: Optional[int] = None) -> np.ndarray:
+ """
+ Squeezes an array, but only if the axis specified has dim 1.
+ """
+ if axis is None:
+ return arr.squeeze()
+
+ try:
+ return arr.squeeze(axis=axis)
+ except ValueError:
+ return arr
+
+
+# Copied from transformers.models.detr.image_processing_detr.normalize_annotation
+def normalize_annotation(annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ image_height, image_width = image_size
+ norm_annotation = {}
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ boxes = corners_to_center_format(boxes)
+ boxes /= np.asarray([image_width, image_height, image_width, image_height], dtype=np.float32)
+ norm_annotation[key] = boxes
+ else:
+ norm_annotation[key] = value
+ return norm_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.max_across_indices
+def max_across_indices(values: Iterable[Any]) -> List[Any]:
+ """
+ Return the maximum value across all indices of an iterable of values.
+ """
+ return [max(values_i) for values_i in zip(*values)]
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_max_height_width
+def get_max_height_width(
+ images: List[np.ndarray], input_data_format: Optional[Union[str, ChannelDimension]] = None
+) -> List[int]:
+ """
+ Get the maximum height and width across all images in a batch.
+ """
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if input_data_format == ChannelDimension.FIRST:
+ _, max_height, max_width = max_across_indices([img.shape for img in images])
+ elif input_data_format == ChannelDimension.LAST:
+ max_height, max_width, _ = max_across_indices([img.shape for img in images])
+ else:
+ raise ValueError(f"Invalid channel dimension format: {input_data_format}")
+ return (max_height, max_width)
+
+
+# Copied from transformers.models.detr.image_processing_detr.make_pixel_mask
+def make_pixel_mask(
+ image: np.ndarray, output_size: Tuple[int, int], input_data_format: Optional[Union[str, ChannelDimension]] = None
+) -> np.ndarray:
+ """
+ Make a pixel mask for the image, where 1 indicates a valid pixel and 0 indicates padding.
+
+ Args:
+ image (`np.ndarray`):
+ Image to make the pixel mask for.
+ output_size (`Tuple[int, int]`):
+ Output size of the mask.
+ """
+ input_height, input_width = get_image_size(image, channel_dim=input_data_format)
+ mask = np.zeros(output_size, dtype=np.int64)
+ mask[:input_height, :input_width] = 1
+ return mask
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_coco_poly_to_mask
+def convert_coco_poly_to_mask(segmentations, height: int, width: int) -> np.ndarray:
+ """
+ Convert a COCO polygon annotation to a mask.
+
+ Args:
+ segmentations (`List[List[float]]`):
+ List of polygons, each polygon represented by a list of x-y coordinates.
+ height (`int`):
+ Height of the mask.
+ width (`int`):
+ Width of the mask.
+ """
+ try:
+ from pycocotools import mask as coco_mask
+ except ImportError:
+ raise ImportError("Pycocotools is not installed in your environment.")
+
+ masks = []
+ for polygons in segmentations:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ mask = coco_mask.decode(rles)
+ if len(mask.shape) < 3:
+ mask = mask[..., None]
+ mask = np.asarray(mask, dtype=np.uint8)
+ mask = np.any(mask, axis=2)
+ masks.append(mask)
+ if masks:
+ masks = np.stack(masks, axis=0)
+ else:
+ masks = np.zeros((0, height, width), dtype=np.uint8)
+
+ return masks
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_detection_annotation with DETR->GroundingDino
+def prepare_coco_detection_annotation(
+ image,
+ target,
+ return_segmentation_masks: bool = False,
+ input_data_format: Optional[Union[ChannelDimension, str]] = None,
+):
+ """
+ Convert the target in COCO format into the format expected by GroundingDino.
+ """
+ image_height, image_width = get_image_size(image, channel_dim=input_data_format)
+
+ image_id = target["image_id"]
+ image_id = np.asarray([image_id], dtype=np.int64)
+
+ # Get all COCO annotations for the given image.
+ annotations = target["annotations"]
+ annotations = [obj for obj in annotations if "iscrowd" not in obj or obj["iscrowd"] == 0]
+
+ classes = [obj["category_id"] for obj in annotations]
+ classes = np.asarray(classes, dtype=np.int64)
+
+ # for conversion to coco api
+ area = np.asarray([obj["area"] for obj in annotations], dtype=np.float32)
+ iscrowd = np.asarray([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in annotations], dtype=np.int64)
+
+ boxes = [obj["bbox"] for obj in annotations]
+ # guard against no boxes via resizing
+ boxes = np.asarray(boxes, dtype=np.float32).reshape(-1, 4)
+ boxes[:, 2:] += boxes[:, :2]
+ boxes[:, 0::2] = boxes[:, 0::2].clip(min=0, max=image_width)
+ boxes[:, 1::2] = boxes[:, 1::2].clip(min=0, max=image_height)
+
+ keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])
+
+ new_target = {}
+ new_target["image_id"] = image_id
+ new_target["class_labels"] = classes[keep]
+ new_target["boxes"] = boxes[keep]
+ new_target["area"] = area[keep]
+ new_target["iscrowd"] = iscrowd[keep]
+ new_target["orig_size"] = np.asarray([int(image_height), int(image_width)], dtype=np.int64)
+
+ if annotations and "keypoints" in annotations[0]:
+ keypoints = [obj["keypoints"] for obj in annotations]
+ # Converting the filtered keypoints list to a numpy array
+ keypoints = np.asarray(keypoints, dtype=np.float32)
+ # Apply the keep mask here to filter the relevant annotations
+ keypoints = keypoints[keep]
+ num_keypoints = keypoints.shape[0]
+ keypoints = keypoints.reshape((-1, 3)) if num_keypoints else keypoints
+ new_target["keypoints"] = keypoints
+
+ if return_segmentation_masks:
+ segmentation_masks = [obj["segmentation"] for obj in annotations]
+ masks = convert_coco_poly_to_mask(segmentation_masks, image_height, image_width)
+ new_target["masks"] = masks[keep]
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.masks_to_boxes
+def masks_to_boxes(masks: np.ndarray) -> np.ndarray:
+ """
+ Compute the bounding boxes around the provided panoptic segmentation masks.
+
+ Args:
+ masks: masks in format `[number_masks, height, width]` where N is the number of masks
+
+ Returns:
+ boxes: bounding boxes in format `[number_masks, 4]` in xyxy format
+ """
+ if masks.size == 0:
+ return np.zeros((0, 4))
+
+ h, w = masks.shape[-2:]
+ y = np.arange(0, h, dtype=np.float32)
+ x = np.arange(0, w, dtype=np.float32)
+ # see https://github.com/pytorch/pytorch/issues/50276
+ y, x = np.meshgrid(y, x, indexing="ij")
+
+ x_mask = masks * np.expand_dims(x, axis=0)
+ x_max = x_mask.reshape(x_mask.shape[0], -1).max(-1)
+ x = np.ma.array(x_mask, mask=~(np.array(masks, dtype=bool)))
+ x_min = x.filled(fill_value=1e8)
+ x_min = x_min.reshape(x_min.shape[0], -1).min(-1)
+
+ y_mask = masks * np.expand_dims(y, axis=0)
+ y_max = y_mask.reshape(x_mask.shape[0], -1).max(-1)
+ y = np.ma.array(y_mask, mask=~(np.array(masks, dtype=bool)))
+ y_min = y.filled(fill_value=1e8)
+ y_min = y_min.reshape(y_min.shape[0], -1).min(-1)
+
+ return np.stack([x_min, y_min, x_max, y_max], 1)
+
+
+# Copied from transformers.models.detr.image_processing_detr.prepare_coco_panoptic_annotation with DETR->GroundingDino
+def prepare_coco_panoptic_annotation(
+ image: np.ndarray,
+ target: Dict,
+ masks_path: Union[str, pathlib.Path],
+ return_masks: bool = True,
+ input_data_format: Union[ChannelDimension, str] = None,
+) -> Dict:
+ """
+ Prepare a coco panoptic annotation for GroundingDino.
+ """
+ image_height, image_width = get_image_size(image, channel_dim=input_data_format)
+ annotation_path = pathlib.Path(masks_path) / target["file_name"]
+
+ new_target = {}
+ new_target["image_id"] = np.asarray([target["image_id"] if "image_id" in target else target["id"]], dtype=np.int64)
+ new_target["size"] = np.asarray([image_height, image_width], dtype=np.int64)
+ new_target["orig_size"] = np.asarray([image_height, image_width], dtype=np.int64)
+
+ if "segments_info" in target:
+ masks = np.asarray(PIL.Image.open(annotation_path), dtype=np.uint32)
+ masks = rgb_to_id(masks)
+
+ ids = np.array([segment_info["id"] for segment_info in target["segments_info"]])
+ masks = masks == ids[:, None, None]
+ masks = masks.astype(np.uint8)
+ if return_masks:
+ new_target["masks"] = masks
+ new_target["boxes"] = masks_to_boxes(masks)
+ new_target["class_labels"] = np.array(
+ [segment_info["category_id"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["iscrowd"] = np.asarray(
+ [segment_info["iscrowd"] for segment_info in target["segments_info"]], dtype=np.int64
+ )
+ new_target["area"] = np.asarray(
+ [segment_info["area"] for segment_info in target["segments_info"]], dtype=np.float32
+ )
+
+ return new_target
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_segmentation_image
+def get_segmentation_image(
+ masks: np.ndarray, input_size: Tuple, target_size: Tuple, stuff_equiv_classes, deduplicate=False
+):
+ h, w = input_size
+ final_h, final_w = target_size
+
+ m_id = scipy.special.softmax(masks.transpose(0, 1), -1)
+
+ if m_id.shape[-1] == 0:
+ # We didn't detect any mask :(
+ m_id = np.zeros((h, w), dtype=np.int64)
+ else:
+ m_id = m_id.argmax(-1).reshape(h, w)
+
+ if deduplicate:
+ # Merge the masks corresponding to the same stuff class
+ for equiv in stuff_equiv_classes.values():
+ for eq_id in equiv:
+ m_id[m_id == eq_id] = equiv[0]
+
+ seg_img = id_to_rgb(m_id)
+ seg_img = resize(seg_img, (final_w, final_h), resample=PILImageResampling.NEAREST)
+ return seg_img
+
+
+# Copied from transformers.models.detr.image_processing_detr.get_mask_area
+def get_mask_area(seg_img: np.ndarray, target_size: Tuple[int, int], n_classes: int) -> np.ndarray:
+ final_h, final_w = target_size
+ np_seg_img = seg_img.astype(np.uint8)
+ np_seg_img = np_seg_img.reshape(final_h, final_w, 3)
+ m_id = rgb_to_id(np_seg_img)
+ area = [(m_id == i).sum() for i in range(n_classes)]
+ return area
+
+
+# Copied from transformers.models.detr.image_processing_detr.score_labels_from_class_probabilities
+def score_labels_from_class_probabilities(logits: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ probs = scipy.special.softmax(logits, axis=-1)
+ labels = probs.argmax(-1, keepdims=True)
+ scores = np.take_along_axis(probs, labels, axis=-1)
+ scores, labels = scores.squeeze(-1), labels.squeeze(-1)
+ return scores, labels
+
+
+# Copied from transformers.models.detr.image_processing_detr.post_process_panoptic_sample
+def post_process_panoptic_sample(
+ out_logits: np.ndarray,
+ masks: np.ndarray,
+ boxes: np.ndarray,
+ processed_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ is_thing_map: Dict,
+ threshold=0.85,
+) -> Dict:
+ """
+ Converts the output of [`DetrForSegmentation`] into panoptic segmentation predictions for a single sample.
+
+ Args:
+ out_logits (`torch.Tensor`):
+ The logits for this sample.
+ masks (`torch.Tensor`):
+ The predicted segmentation masks for this sample.
+ boxes (`torch.Tensor`):
+ The prediced bounding boxes for this sample. The boxes are in the normalized format `(center_x, center_y,
+ width, height)` and values between `[0, 1]`, relative to the size the image (disregarding padding).
+ processed_size (`Tuple[int, int]`):
+ The processed size of the image `(height, width)`, as returned by the preprocessing step i.e. the size
+ after data augmentation but before batching.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, `(height, width)` corresponding to the requested final size of the
+ prediction.
+ is_thing_map (`Dict`):
+ A dictionary mapping class indices to a boolean value indicating whether the class is a thing or not.
+ threshold (`float`, *optional*, defaults to 0.85):
+ The threshold used to binarize the segmentation masks.
+ """
+ # we filter empty queries and detection below threshold
+ scores, labels = score_labels_from_class_probabilities(out_logits)
+ keep = (labels != out_logits.shape[-1] - 1) & (scores > threshold)
+
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_boxes = center_to_corners_format(boxes[keep])
+
+ if len(cur_boxes) != len(cur_classes):
+ raise ValueError("Not as many boxes as there are classes")
+
+ cur_masks = masks[keep]
+ cur_masks = resize(cur_masks[:, None], processed_size, resample=PILImageResampling.BILINEAR)
+ cur_masks = safe_squeeze(cur_masks, 1)
+ b, h, w = cur_masks.shape
+
+ # It may be that we have several predicted masks for the same stuff class.
+ # In the following, we track the list of masks ids for each stuff class (they are merged later on)
+ cur_masks = cur_masks.reshape(b, -1)
+ stuff_equiv_classes = defaultdict(list)
+ for k, label in enumerate(cur_classes):
+ if not is_thing_map[label]:
+ stuff_equiv_classes[label].append(k)
+
+ seg_img = get_segmentation_image(cur_masks, processed_size, target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(cur_masks, processed_size, n_classes=len(cur_scores))
+
+ # We filter out any mask that is too small
+ if cur_classes.size() > 0:
+ # We know filter empty masks as long as we find some
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ while filtered_small.any():
+ cur_masks = cur_masks[~filtered_small]
+ cur_scores = cur_scores[~filtered_small]
+ cur_classes = cur_classes[~filtered_small]
+ seg_img = get_segmentation_image(cur_masks, (h, w), target_size, stuff_equiv_classes, deduplicate=True)
+ area = get_mask_area(seg_img, target_size, n_classes=len(cur_scores))
+ filtered_small = np.array([a <= 4 for a in area], dtype=bool)
+ else:
+ cur_classes = np.ones((1, 1), dtype=np.int64)
+
+ segments_info = [
+ {"id": i, "isthing": is_thing_map[cat], "category_id": int(cat), "area": a}
+ for i, (cat, a) in enumerate(zip(cur_classes, area))
+ ]
+ del cur_classes
+
+ with io.BytesIO() as out:
+ PIL.Image.fromarray(seg_img).save(out, format="PNG")
+ predictions = {"png_string": out.getvalue(), "segments_info": segments_info}
+
+ return predictions
+
+
+# Copied from transformers.models.detr.image_processing_detr.resize_annotation
+def resize_annotation(
+ annotation: Dict[str, Any],
+ orig_size: Tuple[int, int],
+ target_size: Tuple[int, int],
+ threshold: float = 0.5,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+):
+ """
+ Resizes an annotation to a target size.
+
+ Args:
+ annotation (`Dict[str, Any]`):
+ The annotation dictionary.
+ orig_size (`Tuple[int, int]`):
+ The original size of the input image.
+ target_size (`Tuple[int, int]`):
+ The target size of the image, as returned by the preprocessing `resize` step.
+ threshold (`float`, *optional*, defaults to 0.5):
+ The threshold used to binarize the segmentation masks.
+ resample (`PILImageResampling`, defaults to `PILImageResampling.NEAREST`):
+ The resampling filter to use when resizing the masks.
+ """
+ ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(target_size, orig_size))
+ ratio_height, ratio_width = ratios
+
+ new_annotation = {}
+ new_annotation["size"] = target_size
+
+ for key, value in annotation.items():
+ if key == "boxes":
+ boxes = value
+ scaled_boxes = boxes * np.asarray([ratio_width, ratio_height, ratio_width, ratio_height], dtype=np.float32)
+ new_annotation["boxes"] = scaled_boxes
+ elif key == "area":
+ area = value
+ scaled_area = area * (ratio_width * ratio_height)
+ new_annotation["area"] = scaled_area
+ elif key == "masks":
+ masks = value[:, None]
+ masks = np.array([resize(mask, target_size, resample=resample) for mask in masks])
+ masks = masks.astype(np.float32)
+ masks = masks[:, 0] > threshold
+ new_annotation["masks"] = masks
+ elif key == "size":
+ new_annotation["size"] = target_size
+ else:
+ new_annotation[key] = value
+
+ return new_annotation
+
+
+# Copied from transformers.models.detr.image_processing_detr.binary_mask_to_rle
+def binary_mask_to_rle(mask):
+ """
+ Converts given binary mask of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ mask (`torch.Tensor` or `numpy.array`):
+ A binary mask tensor of shape `(height, width)` where 0 denotes background and 1 denotes the target
+ segment_id or class_id.
+ Returns:
+ `List`: Run-length encoded list of the binary mask. Refer to COCO API for more information about the RLE
+ format.
+ """
+ if is_torch_tensor(mask):
+ mask = mask.numpy()
+
+ pixels = mask.flatten()
+ pixels = np.concatenate([[0], pixels, [0]])
+ runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
+ runs[1::2] -= runs[::2]
+ return list(runs)
+
+
+# Copied from transformers.models.detr.image_processing_detr.convert_segmentation_to_rle
+def convert_segmentation_to_rle(segmentation):
+ """
+ Converts given segmentation map of shape `(height, width)` to the run-length encoding (RLE) format.
+
+ Args:
+ segmentation (`torch.Tensor` or `numpy.array`):
+ A segmentation map of shape `(height, width)` where each value denotes a segment or class id.
+ Returns:
+ `List[List]`: A list of lists, where each list is the run-length encoding of a segment / class id.
+ """
+ segment_ids = torch.unique(segmentation)
+
+ run_length_encodings = []
+ for idx in segment_ids:
+ mask = torch.where(segmentation == idx, 1, 0)
+ rle = binary_mask_to_rle(mask)
+ run_length_encodings.append(rle)
+
+ return run_length_encodings
+
+
+# Copied from transformers.models.detr.image_processing_detr.remove_low_and_no_objects
+def remove_low_and_no_objects(masks, scores, labels, object_mask_threshold, num_labels):
+ """
+ Binarize the given masks using `object_mask_threshold`, it returns the associated values of `masks`, `scores` and
+ `labels`.
+
+ Args:
+ masks (`torch.Tensor`):
+ A tensor of shape `(num_queries, height, width)`.
+ scores (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ labels (`torch.Tensor`):
+ A tensor of shape `(num_queries)`.
+ object_mask_threshold (`float`):
+ A number between 0 and 1 used to binarize the masks.
+ Raises:
+ `ValueError`: Raised when the first dimension doesn't match in all input tensors.
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`, `torch.Tensor`]`: The `masks`, `scores` and `labels` without the region
+ < `object_mask_threshold`.
+ """
+ if not (masks.shape[0] == scores.shape[0] == labels.shape[0]):
+ raise ValueError("mask, scores and labels must have the same shape!")
+
+ to_keep = labels.ne(num_labels) & (scores > object_mask_threshold)
+
+ return masks[to_keep], scores[to_keep], labels[to_keep]
+
+
+# Copied from transformers.models.detr.image_processing_detr.check_segment_validity
+def check_segment_validity(mask_labels, mask_probs, k, mask_threshold=0.5, overlap_mask_area_threshold=0.8):
+ # Get the mask associated with the k class
+ mask_k = mask_labels == k
+ mask_k_area = mask_k.sum()
+
+ # Compute the area of all the stuff in query k
+ original_area = (mask_probs[k] >= mask_threshold).sum()
+ mask_exists = mask_k_area > 0 and original_area > 0
+
+ # Eliminate disconnected tiny segments
+ if mask_exists:
+ area_ratio = mask_k_area / original_area
+ if not area_ratio.item() > overlap_mask_area_threshold:
+ mask_exists = False
+
+ return mask_exists, mask_k
+
+
+# Copied from transformers.models.detr.image_processing_detr.compute_segments
+def compute_segments(
+ mask_probs,
+ pred_scores,
+ pred_labels,
+ mask_threshold: float = 0.5,
+ overlap_mask_area_threshold: float = 0.8,
+ label_ids_to_fuse: Optional[Set[int]] = None,
+ target_size: Tuple[int, int] = None,
+):
+ height = mask_probs.shape[1] if target_size is None else target_size[0]
+ width = mask_probs.shape[2] if target_size is None else target_size[1]
+
+ segmentation = torch.zeros((height, width), dtype=torch.int32, device=mask_probs.device)
+ segments: List[Dict] = []
+
+ if target_size is not None:
+ mask_probs = nn.functional.interpolate(
+ mask_probs.unsqueeze(0), size=target_size, mode="bilinear", align_corners=False
+ )[0]
+
+ current_segment_id = 0
+
+ # Weigh each mask by its prediction score
+ mask_probs *= pred_scores.view(-1, 1, 1)
+ mask_labels = mask_probs.argmax(0) # [height, width]
+
+ # Keep track of instances of each class
+ stuff_memory_list: Dict[str, int] = {}
+ for k in range(pred_labels.shape[0]):
+ pred_class = pred_labels[k].item()
+ should_fuse = pred_class in label_ids_to_fuse
+
+ # Check if mask exists and large enough to be a segment
+ mask_exists, mask_k = check_segment_validity(
+ mask_labels, mask_probs, k, mask_threshold, overlap_mask_area_threshold
+ )
+
+ if mask_exists:
+ if pred_class in stuff_memory_list:
+ current_segment_id = stuff_memory_list[pred_class]
+ else:
+ current_segment_id += 1
+
+ # Add current object segment to final segmentation map
+ segmentation[mask_k] = current_segment_id
+ segment_score = round(pred_scores[k].item(), 6)
+ segments.append(
+ {
+ "id": current_segment_id,
+ "label_id": pred_class,
+ "was_fused": should_fuse,
+ "score": segment_score,
+ }
+ )
+ if should_fuse:
+ stuff_memory_list[pred_class] = current_segment_id
+
+ return segmentation, segments
+
+
+class GroundingDinoImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a Grounding DINO image processor.
+
+ Args:
+ format (`str`, *optional*, defaults to `AnnotationFormat.COCO_DETECTION`):
+ Data format of the annotations. One of "coco_detection" or "coco_panoptic".
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Controls whether to resize the image's (height, width) dimensions to the specified `size`. Can be
+ overridden by the `do_resize` parameter in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"shortest_edge": 800, "longest_edge": 1333}`):
+ Size of the image's (height, width) dimensions after resizing. Can be overridden by the `size` parameter in
+ the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Controls whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
+ `preprocess` method. Controls whether to normalize the image. Can be overridden by the `do_normalize`
+ parameter in the `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
+ Mean values to use when normalizing the image. Can be a single value or a list of values, one for each
+ channel. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
+ Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one
+ for each channel. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_convert_annotations (`bool`, *optional*, defaults to `True`):
+ Controls whether to convert the annotations to the format expected by the DETR model. Converts the
+ bounding boxes to the format `(center_x, center_y, width, height)` and in the range `[0, 1]`.
+ Can be overridden by the `do_convert_annotations` parameter in the `preprocess` method.
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Controls whether to pad the image to the largest image in a batch and create a pixel mask. Can be
+ overridden by the `do_pad` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask"]
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.__init__
+ def __init__(
+ self,
+ format: Union[str, AnnotationFormat] = AnnotationFormat.COCO_DETECTION,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Union[float, List[float]] = None,
+ image_std: Union[float, List[float]] = None,
+ do_convert_annotations: Optional[bool] = None,
+ do_pad: bool = True,
+ **kwargs,
+ ) -> None:
+ if "pad_and_return_pixel_mask" in kwargs:
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None if size is None else 1333
+
+ size = size if size is not None else {"shortest_edge": 800, "longest_edge": 1333}
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+
+ # Backwards compatibility
+ if do_convert_annotations is None:
+ do_convert_annotations = do_normalize
+
+ super().__init__(**kwargs)
+ self.format = format
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.do_convert_annotations = do_convert_annotations
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+ self.do_pad = do_pad
+ self._valid_processor_keys = [
+ "images",
+ "annotations",
+ "return_segmentation_masks",
+ "masks_path",
+ "do_resize",
+ "size",
+ "resample",
+ "do_rescale",
+ "rescale_factor",
+ "do_normalize",
+ "do_convert_annotations",
+ "image_mean",
+ "image_std",
+ "do_pad",
+ "format",
+ "return_tensors",
+ "data_format",
+ "input_data_format",
+ ]
+
+ @classmethod
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.from_dict with Detr->GroundingDino
+ def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
+ """
+ Overrides the `from_dict` method from the base class to make sure parameters are updated if image processor is
+ created using from_dict and kwargs e.g. `GroundingDinoImageProcessor.from_pretrained(checkpoint, size=600,
+ max_size=800)`
+ """
+ image_processor_dict = image_processor_dict.copy()
+ if "max_size" in kwargs:
+ image_processor_dict["max_size"] = kwargs.pop("max_size")
+ if "pad_and_return_pixel_mask" in kwargs:
+ image_processor_dict["pad_and_return_pixel_mask"] = kwargs.pop("pad_and_return_pixel_mask")
+ return super().from_dict(image_processor_dict, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_annotation with DETR->GroundingDino
+ def prepare_annotation(
+ self,
+ image: np.ndarray,
+ target: Dict,
+ format: Optional[AnnotationFormat] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> Dict:
+ """
+ Prepare an annotation for feeding into GroundingDino model.
+ """
+ format = format if format is not None else self.format
+
+ if format == AnnotationFormat.COCO_DETECTION:
+ return_segmentation_masks = False if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_detection_annotation(
+ image, target, return_segmentation_masks, input_data_format=input_data_format
+ )
+ elif format == AnnotationFormat.COCO_PANOPTIC:
+ return_segmentation_masks = True if return_segmentation_masks is None else return_segmentation_masks
+ target = prepare_coco_panoptic_annotation(
+ image,
+ target,
+ masks_path=masks_path,
+ return_masks=return_segmentation_masks,
+ input_data_format=input_data_format,
+ )
+ else:
+ raise ValueError(f"Format {format} is not supported.")
+ return target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare
+ def prepare(self, image, target, return_segmentation_masks=None, masks_path=None):
+ logger.warning_once(
+ "The `prepare` method is deprecated and will be removed in a v4.33. "
+ "Please use `prepare_annotation` instead. Note: the `prepare_annotation` method "
+ "does not return the image anymore.",
+ )
+ target = self.prepare_annotation(image, target, return_segmentation_masks, masks_path, self.format)
+ return image, target
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.convert_coco_poly_to_mask
+ def convert_coco_poly_to_mask(self, *args, **kwargs):
+ logger.warning_once("The `convert_coco_poly_to_mask` method is deprecated and will be removed in v4.33. ")
+ return convert_coco_poly_to_mask(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_detection
+ def prepare_coco_detection(self, *args, **kwargs):
+ logger.warning_once("The `prepare_coco_detection` method is deprecated and will be removed in v4.33. ")
+ return prepare_coco_detection_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.prepare_coco_panoptic
+ def prepare_coco_panoptic(self, *args, **kwargs):
+ logger.warning_once("The `prepare_coco_panoptic` method is deprecated and will be removed in v4.33. ")
+ return prepare_coco_panoptic_annotation(*args, **kwargs)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> np.ndarray:
+ """
+ Resize the image to the given size. Size can be `min_size` (scalar) or `(height, width)` tuple. If size is an
+ int, smaller edge of the image will be matched to this number.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Dictionary containing the size to resize to. Can contain the keys `shortest_edge` and `longest_edge` or
+ `height` and `width`.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Resampling filter to use if resizing the image.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ """
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` parameter is deprecated and will be removed in v4.26. "
+ "Please specify in `size['longest_edge'] instead`.",
+ )
+ max_size = kwargs.pop("max_size")
+ else:
+ max_size = None
+ size = get_size_dict(size, max_size=max_size, default_to_square=False)
+ if "shortest_edge" in size and "longest_edge" in size:
+ size = get_resize_output_image_size(
+ image, size["shortest_edge"], size["longest_edge"], input_data_format=input_data_format
+ )
+ elif "height" in size and "width" in size:
+ size = (size["height"], size["width"])
+ else:
+ raise ValueError(
+ "Size must contain 'height' and 'width' keys or 'shortest_edge' and 'longest_edge' keys. Got"
+ f" {size.keys()}."
+ )
+ image = resize(
+ image, size=size, resample=resample, data_format=data_format, input_data_format=input_data_format, **kwargs
+ )
+ return image
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.resize_annotation
+ def resize_annotation(
+ self,
+ annotation,
+ orig_size,
+ size,
+ resample: PILImageResampling = PILImageResampling.NEAREST,
+ ) -> Dict:
+ """
+ Resize the annotation to match the resized image. If size is an int, smaller edge of the mask will be matched
+ to this number.
+ """
+ return resize_annotation(annotation, orig_size=orig_size, target_size=size, resample=resample)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.rescale
+ def rescale(
+ self,
+ image: np.ndarray,
+ rescale_factor: float,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Rescale the image by the given factor. image = image * rescale_factor.
+
+ Args:
+ image (`np.ndarray`):
+ Image to rescale.
+ rescale_factor (`float`):
+ The value to use for rescaling.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. If unset, is inferred from the input image. Can be
+ one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ """
+ return rescale(image, rescale_factor, data_format=data_format, input_data_format=input_data_format)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.normalize_annotation
+ def normalize_annotation(self, annotation: Dict, image_size: Tuple[int, int]) -> Dict:
+ """
+ Normalize the boxes in the annotation from `[top_left_x, top_left_y, bottom_right_x, bottom_right_y]` to
+ `[center_x, center_y, width, height]` format and from absolute to relative pixel values.
+ """
+ return normalize_annotation(annotation, image_size=image_size)
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._update_annotation_for_padded_image
+ def _update_annotation_for_padded_image(
+ self,
+ annotation: Dict,
+ input_image_size: Tuple[int, int],
+ output_image_size: Tuple[int, int],
+ padding,
+ update_bboxes,
+ ) -> Dict:
+ """
+ Update the annotation for a padded image.
+ """
+ new_annotation = {}
+ new_annotation["size"] = output_image_size
+
+ for key, value in annotation.items():
+ if key == "masks":
+ masks = value
+ masks = pad(
+ masks,
+ padding,
+ mode=PaddingMode.CONSTANT,
+ constant_values=0,
+ input_data_format=ChannelDimension.FIRST,
+ )
+ masks = safe_squeeze(masks, 1)
+ new_annotation["masks"] = masks
+ elif key == "boxes" and update_bboxes:
+ boxes = value
+ boxes *= np.asarray(
+ [
+ input_image_size[1] / output_image_size[1],
+ input_image_size[0] / output_image_size[0],
+ input_image_size[1] / output_image_size[1],
+ input_image_size[0] / output_image_size[0],
+ ]
+ )
+ new_annotation["boxes"] = boxes
+ elif key == "size":
+ new_annotation["size"] = output_image_size
+ else:
+ new_annotation[key] = value
+ return new_annotation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor._pad_image
+ def _pad_image(
+ self,
+ image: np.ndarray,
+ output_size: Tuple[int, int],
+ annotation: Optional[Dict[str, Any]] = None,
+ constant_values: Union[float, Iterable[float]] = 0,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ update_bboxes: bool = True,
+ ) -> np.ndarray:
+ """
+ Pad an image with zeros to the given size.
+ """
+ input_height, input_width = get_image_size(image, channel_dim=input_data_format)
+ output_height, output_width = output_size
+
+ pad_bottom = output_height - input_height
+ pad_right = output_width - input_width
+ padding = ((0, pad_bottom), (0, pad_right))
+ padded_image = pad(
+ image,
+ padding,
+ mode=PaddingMode.CONSTANT,
+ constant_values=constant_values,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ )
+ if annotation is not None:
+ annotation = self._update_annotation_for_padded_image(
+ annotation, (input_height, input_width), (output_height, output_width), padding, update_bboxes
+ )
+ return padded_image, annotation
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.pad
+ def pad(
+ self,
+ images: List[np.ndarray],
+ annotations: Optional[Union[AnnotationType, List[AnnotationType]]] = None,
+ constant_values: Union[float, Iterable[float]] = 0,
+ return_pixel_mask: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ update_bboxes: bool = True,
+ ) -> BatchFeature:
+ """
+ Pads a batch of images to the bottom and right of the image with zeros to the size of largest height and width
+ in the batch and optionally returns their corresponding pixel mask.
+
+ Args:
+ images (List[`np.ndarray`]):
+ Images to pad.
+ annotations (`AnnotationType` or `List[AnnotationType]`, *optional*):
+ Annotations to transform according to the padding that is applied to the images.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ return_pixel_mask (`bool`, *optional*, defaults to `True`):
+ Whether to return a pixel mask.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ update_bboxes (`bool`, *optional*, defaults to `True`):
+ Whether to update the bounding boxes in the annotations to match the padded images. If the
+ bounding boxes have not been converted to relative coordinates and `(centre_x, centre_y, width, height)`
+ format, the bounding boxes will not be updated.
+ """
+ pad_size = get_max_height_width(images, input_data_format=input_data_format)
+
+ annotation_list = annotations if annotations is not None else [None] * len(images)
+ padded_images = []
+ padded_annotations = []
+ for image, annotation in zip(images, annotation_list):
+ padded_image, padded_annotation = self._pad_image(
+ image,
+ pad_size,
+ annotation,
+ constant_values=constant_values,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ update_bboxes=update_bboxes,
+ )
+ padded_images.append(padded_image)
+ padded_annotations.append(padded_annotation)
+
+ data = {"pixel_values": padded_images}
+
+ if return_pixel_mask:
+ masks = [
+ make_pixel_mask(image=image, output_size=pad_size, input_data_format=input_data_format)
+ for image in images
+ ]
+ data["pixel_mask"] = masks
+
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in padded_annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.detr.image_processing_detr.DetrImageProcessor.preprocess
+ def preprocess(
+ self,
+ images: ImageInput,
+ annotations: Optional[Union[AnnotationType, List[AnnotationType]]] = None,
+ return_segmentation_masks: bool = None,
+ masks_path: Optional[Union[str, pathlib.Path]] = None,
+ do_resize: Optional[bool] = None,
+ size: Optional[Dict[str, int]] = None,
+ resample=None, # PILImageResampling
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[Union[int, float]] = None,
+ do_normalize: Optional[bool] = None,
+ do_convert_annotations: Optional[bool] = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_pad: Optional[bool] = None,
+ format: Optional[Union[str, AnnotationFormat]] = None,
+ return_tensors: Optional[Union[TensorType, str]] = None,
+ data_format: Union[str, ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> BatchFeature:
+ """
+ Preprocess an image or a batch of images so that it can be used by the model.
+
+ Args:
+ images (`ImageInput`):
+ Image or batch of images to preprocess. Expects a single or batch of images with pixel values ranging
+ from 0 to 255. If passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ annotations (`AnnotationType` or `List[AnnotationType]`, *optional*):
+ List of annotations associated with the image or batch of images. If annotation is for object
+ detection, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "annotations" (`List[Dict]`): List of annotations for an image. Each annotation should be a
+ dictionary. An image can have no annotations, in which case the list should be empty.
+ If annotation is for segmentation, the annotations should be a dictionary with the following keys:
+ - "image_id" (`int`): The image id.
+ - "segments_info" (`List[Dict]`): List of segments for an image. Each segment should be a dictionary.
+ An image can have no segments, in which case the list should be empty.
+ - "file_name" (`str`): The file name of the image.
+ return_segmentation_masks (`bool`, *optional*, defaults to self.return_segmentation_masks):
+ Whether to return segmentation masks.
+ masks_path (`str` or `pathlib.Path`, *optional*):
+ Path to the directory containing the segmentation masks.
+ do_resize (`bool`, *optional*, defaults to self.do_resize):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to self.size):
+ Size of the image after resizing.
+ resample (`PILImageResampling`, *optional*, defaults to self.resample):
+ Resampling filter to use when resizing the image.
+ do_rescale (`bool`, *optional*, defaults to self.do_rescale):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to self.rescale_factor):
+ Rescale factor to use when rescaling the image.
+ do_normalize (`bool`, *optional*, defaults to self.do_normalize):
+ Whether to normalize the image.
+ do_convert_annotations (`bool`, *optional*, defaults to self.do_convert_annotations):
+ Whether to convert the annotations to the format expected by the model. Converts the bounding
+ boxes from the format `(top_left_x, top_left_y, width, height)` to `(center_x, center_y, width, height)`
+ and in relative coordinates.
+ image_mean (`float` or `List[float]`, *optional*, defaults to self.image_mean):
+ Mean to use when normalizing the image.
+ image_std (`float` or `List[float]`, *optional*, defaults to self.image_std):
+ Standard deviation to use when normalizing the image.
+ do_pad (`bool`, *optional*, defaults to self.do_pad):
+ Whether to pad the image. If `True` will pad the images in the batch to the largest image in the batch
+ and create a pixel mask. Padding will be applied to the bottom and right of the image with zeros.
+ format (`str` or `AnnotationFormat`, *optional*, defaults to self.format):
+ Format of the annotations.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to self.return_tensors):
+ Type of tensors to return. If `None`, will return the list of images.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ if "pad_and_return_pixel_mask" in kwargs:
+ logger.warning_once(
+ "The `pad_and_return_pixel_mask` argument is deprecated and will be removed in a future version, "
+ "use `do_pad` instead."
+ )
+ do_pad = kwargs.pop("pad_and_return_pixel_mask")
+
+ max_size = None
+ if "max_size" in kwargs:
+ logger.warning_once(
+ "The `max_size` argument is deprecated and will be removed in a future version, use"
+ " `size['longest_edge']` instead."
+ )
+ size = kwargs.pop("max_size")
+
+ do_resize = self.do_resize if do_resize is None else do_resize
+ size = self.size if size is None else size
+ size = get_size_dict(size=size, max_size=max_size, default_to_square=False)
+ resample = self.resample if resample is None else resample
+ do_rescale = self.do_rescale if do_rescale is None else do_rescale
+ rescale_factor = self.rescale_factor if rescale_factor is None else rescale_factor
+ do_normalize = self.do_normalize if do_normalize is None else do_normalize
+ image_mean = self.image_mean if image_mean is None else image_mean
+ image_std = self.image_std if image_std is None else image_std
+ do_convert_annotations = (
+ self.do_convert_annotations if do_convert_annotations is None else do_convert_annotations
+ )
+ do_pad = self.do_pad if do_pad is None else do_pad
+ format = self.format if format is None else format
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ validate_kwargs(captured_kwargs=kwargs.keys(), valid_processor_keys=self._valid_processor_keys)
+
+ # Here, the pad() method pads to the maximum of (width, height). It does not need to be validated.
+ validate_preprocess_arguments(
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ )
+
+ if annotations is not None and isinstance(annotations, dict):
+ annotations = [annotations]
+
+ if annotations is not None and len(images) != len(annotations):
+ raise ValueError(
+ f"The number of images ({len(images)}) and annotations ({len(annotations)}) do not match."
+ )
+
+ format = AnnotationFormat(format)
+ if annotations is not None:
+ validate_annotations(format, SUPPORTED_ANNOTATION_FORMATS, annotations)
+
+ if (
+ masks_path is not None
+ and format == AnnotationFormat.COCO_PANOPTIC
+ and not isinstance(masks_path, (pathlib.Path, str))
+ ):
+ raise ValueError(
+ "The path to the directory containing the mask PNG files should be provided as a"
+ f" `pathlib.Path` or string object, but is {type(masks_path)} instead."
+ )
+
+ # All transformations expect numpy arrays
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ # prepare (COCO annotations as a list of Dict -> DETR target as a single Dict per image)
+ if annotations is not None:
+ prepared_images = []
+ prepared_annotations = []
+ for image, target in zip(images, annotations):
+ target = self.prepare_annotation(
+ image,
+ target,
+ format,
+ return_segmentation_masks=return_segmentation_masks,
+ masks_path=masks_path,
+ input_data_format=input_data_format,
+ )
+ prepared_images.append(image)
+ prepared_annotations.append(target)
+ images = prepared_images
+ annotations = prepared_annotations
+ del prepared_images, prepared_annotations
+
+ # transformations
+ if do_resize:
+ if annotations is not None:
+ resized_images, resized_annotations = [], []
+ for image, target in zip(images, annotations):
+ orig_size = get_image_size(image, input_data_format)
+ resized_image = self.resize(
+ image, size=size, max_size=max_size, resample=resample, input_data_format=input_data_format
+ )
+ resized_annotation = self.resize_annotation(
+ target, orig_size, get_image_size(resized_image, input_data_format)
+ )
+ resized_images.append(resized_image)
+ resized_annotations.append(resized_annotation)
+ images = resized_images
+ annotations = resized_annotations
+ del resized_images, resized_annotations
+ else:
+ images = [
+ self.resize(image, size=size, resample=resample, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_rescale:
+ images = [self.rescale(image, rescale_factor, input_data_format=input_data_format) for image in images]
+
+ if do_normalize:
+ images = [
+ self.normalize(image, image_mean, image_std, input_data_format=input_data_format) for image in images
+ ]
+
+ if do_convert_annotations and annotations is not None:
+ annotations = [
+ self.normalize_annotation(annotation, get_image_size(image, input_data_format))
+ for annotation, image in zip(annotations, images)
+ ]
+
+ if do_pad:
+ # Pads images and returns their mask: {'pixel_values': ..., 'pixel_mask': ...}
+ encoded_inputs = self.pad(
+ images,
+ annotations=annotations,
+ return_pixel_mask=True,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ update_bboxes=do_convert_annotations,
+ return_tensors=return_tensors,
+ )
+ else:
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
+ for image in images
+ ]
+ encoded_inputs = BatchFeature(data={"pixel_values": images}, tensor_type=return_tensors)
+ if annotations is not None:
+ encoded_inputs["labels"] = [
+ BatchFeature(annotation, tensor_type=return_tensors) for annotation in annotations
+ ]
+
+ return encoded_inputs
+
+ # Copied from transformers.models.owlvit.image_processing_owlvit.OwlViTImageProcessor.post_process_object_detection with OwlViT->GroundingDino
+ def post_process_object_detection(
+ self, outputs, threshold: float = 0.1, target_sizes: Union[TensorType, List[Tuple]] = None
+ ):
+ """
+ Converts the raw output of [`GroundingDinoForObjectDetection`] into final bounding boxes in (top_left_x, top_left_y,
+ bottom_right_x, bottom_right_y) format.
+
+ Args:
+ outputs ([`GroundingDinoObjectDetectionOutput`]):
+ Raw outputs of the model.
+ threshold (`float`, *optional*):
+ Score threshold to keep object detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ # TODO: (amy) add support for other frameworks
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ probs = torch.max(logits, dim=-1)
+ scores = torch.sigmoid(probs.values)
+ labels = probs.indices
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for s, l, b in zip(scores, labels, boxes):
+ score = s[s > threshold]
+ label = l[s > threshold]
+ box = b[s > threshold]
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/models/grounding_dino/modeling_grounding_dino.py b/src/transformers/models/grounding_dino/modeling_grounding_dino.py
new file mode 100644
index 00000000000000..7f9149de9155e4
--- /dev/null
+++ b/src/transformers/models/grounding_dino/modeling_grounding_dino.py
@@ -0,0 +1,3132 @@
+# coding=utf-8
+# Copyright 2024 IDEA Research and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Grounding DINO model."""
+
+import copy
+import math
+import os
+import warnings
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor, nn
+from torch.autograd import Function
+from torch.autograd.function import once_differentiable
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_scipy_available,
+ is_timm_available,
+ is_torch_cuda_available,
+ is_vision_available,
+ replace_return_docstrings,
+ requires_backends,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import meshgrid
+from ...utils import is_accelerate_available, is_ninja_available, logging
+from ...utils.backbone_utils import load_backbone
+from ..auto import AutoModel
+from .configuration_grounding_dino import GroundingDinoConfig
+
+
+if is_vision_available():
+ from transformers.image_transforms import center_to_corners_format
+
+if is_accelerate_available():
+ from accelerate import PartialState
+ from accelerate.utils import reduce
+
+if is_scipy_available():
+ from scipy.optimize import linear_sum_assignment
+
+if is_timm_available():
+ from timm import create_model
+
+
+logger = logging.get_logger(__name__)
+
+MultiScaleDeformableAttention = None
+
+
+# Copied from models.deformable_detr.load_cuda_kernels
+def load_cuda_kernels():
+ from torch.utils.cpp_extension import load
+
+ global MultiScaleDeformableAttention
+
+ root = Path(__file__).resolve().parent.parent.parent / "kernels" / "grounding_dino"
+ src_files = [
+ root / filename
+ for filename in [
+ "vision.cpp",
+ os.path.join("cpu", "ms_deform_attn_cpu.cpp"),
+ os.path.join("cuda", "ms_deform_attn_cuda.cu"),
+ ]
+ ]
+
+ MultiScaleDeformableAttention = load(
+ "MultiScaleDeformableAttention",
+ src_files,
+ with_cuda=True,
+ extra_include_paths=[str(root)],
+ extra_cflags=["-DWITH_CUDA=1"],
+ extra_cuda_cflags=[
+ "-DCUDA_HAS_FP16=1",
+ "-D__CUDA_NO_HALF_OPERATORS__",
+ "-D__CUDA_NO_HALF_CONVERSIONS__",
+ "-D__CUDA_NO_HALF2_OPERATORS__",
+ ],
+ )
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.MultiScaleDeformableAttentionFunction
+class MultiScaleDeformableAttentionFunction(Function):
+ @staticmethod
+ def forward(
+ context,
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ im2col_step,
+ ):
+ context.im2col_step = im2col_step
+ output = MultiScaleDeformableAttention.ms_deform_attn_forward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ context.im2col_step,
+ )
+ context.save_for_backward(
+ value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights
+ )
+ return output
+
+ @staticmethod
+ @once_differentiable
+ def backward(context, grad_output):
+ (
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ ) = context.saved_tensors
+ grad_value, grad_sampling_loc, grad_attn_weight = MultiScaleDeformableAttention.ms_deform_attn_backward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ grad_output,
+ context.im2col_step,
+ )
+
+ return grad_value, None, None, grad_sampling_loc, grad_attn_weight, None
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "GroundingDinoConfig"
+_CHECKPOINT_FOR_DOC = "IDEA-Research/grounding-dino-tiny"
+
+GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "IDEA-Research/grounding-dino-tiny",
+ # See all Grounding DINO models at https://huggingface.co/models?filter=grounding-dino
+]
+
+
+@dataclass
+class GroundingDinoDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of the GroundingDinoDecoder. This class adds two attributes to
+ BaseModelOutputWithCrossAttentions, namely:
+ - a stacked tensor of intermediate decoder hidden states (i.e. the output of each decoder layer)
+ - a stacked tensor of intermediate reference points.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, sequence_length, hidden_size)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ intermediate_hidden_states: torch.FloatTensor = None
+ intermediate_reference_points: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class GroundingDinoEncoderOutput(ModelOutput):
+ """
+ Base class for outputs of the GroundingDinoEncoder. This class extends BaseModelOutput, due to:
+ - vision and text last hidden states
+ - vision and text intermediate hidden states
+
+ Args:
+ last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the vision encoder.
+ last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the text encoder.
+ vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads.
+ """
+
+ last_hidden_state_vision: torch.FloatTensor = None
+ last_hidden_state_text: torch.FloatTensor = None
+ vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class GroundingDinoModelOutput(ModelOutput):
+ """
+ Base class for outputs of the Grounding DINO encoder-decoder model.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ init_reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Initial reference points sent through the Transformer decoder.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, 4)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_queries, hidden_size)`. Hidden-states of the decoder at the output of each layer
+ plus the initial embedding outputs.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ encoder_last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ encoder_text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads. attention softmax, used to compute the weighted average in the
+ bi-attention heads.
+ enc_outputs_class (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`, *optional*, returned when `config.two_stage=True`):
+ Predicted bounding boxes scores where the top `config.num_queries` scoring bounding boxes are picked as
+ region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and
+ background).
+ enc_outputs_coord_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, 4)`, *optional*, returned when `config.two_stage=True`):
+ Logits of predicted bounding boxes coordinates in the first stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ init_reference_points: torch.FloatTensor = None
+ intermediate_hidden_states: torch.FloatTensor = None
+ intermediate_reference_points: torch.FloatTensor = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ encoder_last_hidden_state_vision: Optional[torch.FloatTensor] = None
+ encoder_last_hidden_state_text: Optional[torch.FloatTensor] = None
+ encoder_vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ enc_outputs_class: Optional[torch.FloatTensor] = None
+ enc_outputs_coord_logits: Optional[torch.FloatTensor] = None
+
+
+@dataclass
+class GroundingDinoObjectDetectionOutput(ModelOutput):
+ """
+ Output type of [`GroundingDinoForObjectDetection`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` are provided)):
+ Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a
+ bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized
+ scale-invariant IoU loss.
+ loss_dict (`Dict`, *optional*):
+ A dictionary containing the individual losses. Useful for logging.
+ logits (`torch.FloatTensor` of shape `(batch_size, num_queries, num_classes + 1)`):
+ Classification logits (including no-object) for all queries.
+ pred_boxes (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These
+ values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding
+ possible padding). You can use [`~GroundingDinoProcessor.post_process_object_detection`] to retrieve the
+ unnormalized bounding boxes.
+ auxiliary_outputs (`List[Dict]`, *optional*):
+ Optional, only returned when auxilary losses are activated (i.e. `config.auxiliary_loss` is set to `True`)
+ and labels are provided. It is a list of dictionaries containing the two above keys (`logits` and
+ `pred_boxes`) for each decoder layer.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, num_queries, hidden_size)`. Hidden-states of the decoder at the output of each layer
+ plus the initial embedding outputs.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the self-attention, cross-attention and multi-scale deformable attention heads.
+ encoder_last_hidden_state_vision (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_last_hidden_state_text (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_vision_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the vision embeddings + one for the output of each
+ layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the vision encoder at the
+ output of each layer plus the initial embedding outputs.
+ encoder_text_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the text embeddings + one for the output of each layer)
+ of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the text encoder at the output of
+ each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of tuples of `torch.FloatTensor` (one for attention for each layer) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`. Attentions weights after the attention softmax, used to compute the
+ weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and
+ multi-scale deformable attention heads.
+ intermediate_hidden_states (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, hidden_size)`):
+ Stacked intermediate hidden states (output of each layer of the decoder).
+ intermediate_reference_points (`torch.FloatTensor` of shape `(batch_size, config.decoder_layers, num_queries, 4)`):
+ Stacked intermediate reference points (reference points of each layer of the decoder).
+ init_reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)`):
+ Initial reference points sent through the Transformer decoder.
+ enc_outputs_class (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`, *optional*, returned when `config.two_stage=True`):
+ Predicted bounding boxes scores where the top `config.num_queries` scoring bounding boxes are picked as
+ region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and
+ background).
+ enc_outputs_coord_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, 4)`, *optional*, returned when `config.two_stage=True`):
+ Logits of predicted bounding boxes coordinates in the first stage.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ loss_dict: Optional[Dict] = None
+ logits: torch.FloatTensor = None
+ pred_boxes: torch.FloatTensor = None
+ auxiliary_outputs: Optional[List[Dict]] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ init_reference_points: Optional[torch.FloatTensor] = None
+ intermediate_hidden_states: Optional[torch.FloatTensor] = None
+ intermediate_reference_points: Optional[torch.FloatTensor] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ encoder_last_hidden_state_vision: Optional[torch.FloatTensor] = None
+ encoder_last_hidden_state_text: Optional[torch.FloatTensor] = None
+ encoder_vision_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_text_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ enc_outputs_class: Optional[torch.FloatTensor] = None
+ enc_outputs_coord_logits: Optional[torch.FloatTensor] = None
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrFrozenBatchNorm2d with Detr->GroundingDino
+class GroundingDinoFrozenBatchNorm2d(nn.Module):
+ """
+ BatchNorm2d where the batch statistics and the affine parameters are fixed.
+
+ Copy-paste from torchvision.misc.ops with added eps before rqsrt, without which any other models than
+ torchvision.models.resnet[18,34,50,101] produce nans.
+ """
+
+ def __init__(self, n):
+ super().__init__()
+ self.register_buffer("weight", torch.ones(n))
+ self.register_buffer("bias", torch.zeros(n))
+ self.register_buffer("running_mean", torch.zeros(n))
+ self.register_buffer("running_var", torch.ones(n))
+
+ def _load_from_state_dict(
+ self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ ):
+ num_batches_tracked_key = prefix + "num_batches_tracked"
+ if num_batches_tracked_key in state_dict:
+ del state_dict[num_batches_tracked_key]
+
+ super()._load_from_state_dict(
+ state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
+ )
+
+ def forward(self, x):
+ # move reshapes to the beginning
+ # to make it user-friendly
+ weight = self.weight.reshape(1, -1, 1, 1)
+ bias = self.bias.reshape(1, -1, 1, 1)
+ running_var = self.running_var.reshape(1, -1, 1, 1)
+ running_mean = self.running_mean.reshape(1, -1, 1, 1)
+ epsilon = 1e-5
+ scale = weight * (running_var + epsilon).rsqrt()
+ bias = bias - running_mean * scale
+ return x * scale + bias
+
+
+# Copied from transformers.models.detr.modeling_detr.replace_batch_norm with Detr->GroundingDino
+def replace_batch_norm(model):
+ r"""
+ Recursively replace all `torch.nn.BatchNorm2d` with `GroundingDinoFrozenBatchNorm2d`.
+
+ Args:
+ model (torch.nn.Module):
+ input model
+ """
+ for name, module in model.named_children():
+ if isinstance(module, nn.BatchNorm2d):
+ new_module = GroundingDinoFrozenBatchNorm2d(module.num_features)
+
+ if not module.weight.device == torch.device("meta"):
+ new_module.weight.data.copy_(module.weight)
+ new_module.bias.data.copy_(module.bias)
+ new_module.running_mean.data.copy_(module.running_mean)
+ new_module.running_var.data.copy_(module.running_var)
+
+ model._modules[name] = new_module
+
+ if len(list(module.children())) > 0:
+ replace_batch_norm(module)
+
+
+class GroundingDinoConvEncoder(nn.Module):
+ """
+ Convolutional backbone, using either the AutoBackbone API or one from the timm library.
+
+ nn.BatchNorm2d layers are replaced by GroundingDinoFrozenBatchNorm2d as defined above.
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.config = config
+
+ if config.use_timm_backbone:
+ requires_backends(self, ["timm"])
+ backbone = create_model(
+ config.backbone,
+ pretrained=config.use_pretrained_backbone,
+ features_only=True,
+ **config.backbone_kwargs,
+ )
+ else:
+ backbone = load_backbone(config)
+
+ # replace batch norm by frozen batch norm
+ with torch.no_grad():
+ replace_batch_norm(backbone)
+ self.model = backbone
+ self.intermediate_channel_sizes = (
+ self.model.feature_info.channels() if config.use_timm_backbone else self.model.channels
+ )
+
+ backbone_model_type = config.backbone if config.use_timm_backbone else config.backbone_config.model_type
+ if "resnet" in backbone_model_type:
+ for name, parameter in self.model.named_parameters():
+ if config.use_timm_backbone:
+ if "layer2" not in name and "layer3" not in name and "layer4" not in name:
+ parameter.requires_grad_(False)
+ else:
+ if "stage.1" not in name and "stage.2" not in name and "stage.3" not in name:
+ parameter.requires_grad_(False)
+
+ # Copied from transformers.models.detr.modeling_detr.DetrConvEncoder.forward with Detr->GroundingDino
+ def forward(self, pixel_values: torch.Tensor, pixel_mask: torch.Tensor):
+ # send pixel_values through the model to get list of feature maps
+ features = self.model(pixel_values) if self.config.use_timm_backbone else self.model(pixel_values).feature_maps
+
+ out = []
+ for feature_map in features:
+ # downsample pixel_mask to match shape of corresponding feature_map
+ mask = nn.functional.interpolate(pixel_mask[None].float(), size=feature_map.shape[-2:]).to(torch.bool)[0]
+ out.append((feature_map, mask))
+ return out
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrConvModel with Detr->GroundingDino
+class GroundingDinoConvModel(nn.Module):
+ """
+ This module adds 2D position embeddings to all intermediate feature maps of the convolutional encoder.
+ """
+
+ def __init__(self, conv_encoder, position_embedding):
+ super().__init__()
+ self.conv_encoder = conv_encoder
+ self.position_embedding = position_embedding
+
+ def forward(self, pixel_values, pixel_mask):
+ # send pixel_values and pixel_mask through backbone to get list of (feature_map, pixel_mask) tuples
+ out = self.conv_encoder(pixel_values, pixel_mask)
+ pos = []
+ for feature_map, mask in out:
+ # position encoding
+ pos.append(self.position_embedding(feature_map, mask).to(feature_map.dtype))
+
+ return out, pos
+
+
+class GroundingDinoSinePositionEmbedding(nn.Module):
+ """
+ This is a more standard version of the position embedding, very similar to the one used by the Attention is all you
+ need paper, generalized to work on images.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.embedding_dim = config.d_model // 2
+ self.temperature = config.positional_embedding_temperature
+ self.scale = 2 * math.pi
+
+ def forward(self, pixel_values, pixel_mask):
+ y_embed = pixel_mask.cumsum(1, dtype=torch.float32)
+ x_embed = pixel_mask.cumsum(2, dtype=torch.float32)
+ eps = 1e-6
+ y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
+ x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
+
+ dim_t = torch.arange(self.embedding_dim, dtype=torch.float32, device=pixel_values.device)
+ dim_t = self.temperature ** (2 * torch.div(dim_t, 2, rounding_mode="floor") / self.embedding_dim)
+
+ pos_x = x_embed[:, :, :, None] / dim_t
+ pos_y = y_embed[:, :, :, None] / dim_t
+ pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+ return pos
+
+
+class GroundingDinoLearnedPositionEmbedding(nn.Module):
+ """
+ This module learns positional embeddings up to a fixed maximum size.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ embedding_dim = config.d_model // 2
+ self.row_embeddings = nn.Embedding(50, embedding_dim)
+ self.column_embeddings = nn.Embedding(50, embedding_dim)
+
+ def forward(self, pixel_values, pixel_mask=None):
+ height, width = pixel_values.shape[-2:]
+ width_values = torch.arange(width, device=pixel_values.device)
+ height_values = torch.arange(height, device=pixel_values.device)
+ x_emb = self.column_embeddings(width_values)
+ y_emb = self.row_embeddings(height_values)
+ pos = torch.cat([x_emb.unsqueeze(0).repeat(height, 1, 1), y_emb.unsqueeze(1).repeat(1, width, 1)], dim=-1)
+ pos = pos.permute(2, 0, 1)
+ pos = pos.unsqueeze(0)
+ pos = pos.repeat(pixel_values.shape[0], 1, 1, 1)
+ return pos
+
+
+def build_position_encoding(config):
+ if config.position_embedding_type == "sine":
+ position_embedding = GroundingDinoSinePositionEmbedding(config)
+ elif config.position_embedding_type == "learned":
+ position_embedding = GroundingDinoLearnedPositionEmbedding(config)
+ else:
+ raise ValueError(f"Not supported {config.position_embedding_type}")
+
+ return position_embedding
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.multi_scale_deformable_attention
+def multi_scale_deformable_attention(
+ value: Tensor, value_spatial_shapes: Tensor, sampling_locations: Tensor, attention_weights: Tensor
+) -> Tensor:
+ batch_size, _, num_heads, hidden_dim = value.shape
+ _, num_queries, num_heads, num_levels, num_points, _ = sampling_locations.shape
+ value_list = value.split([height.item() * width.item() for height, width in value_spatial_shapes], dim=1)
+ sampling_grids = 2 * sampling_locations - 1
+ sampling_value_list = []
+ for level_id, (height, width) in enumerate(value_spatial_shapes):
+ # batch_size, height*width, num_heads, hidden_dim
+ # -> batch_size, height*width, num_heads*hidden_dim
+ # -> batch_size, num_heads*hidden_dim, height*width
+ # -> batch_size*num_heads, hidden_dim, height, width
+ value_l_ = (
+ value_list[level_id].flatten(2).transpose(1, 2).reshape(batch_size * num_heads, hidden_dim, height, width)
+ )
+ # batch_size, num_queries, num_heads, num_points, 2
+ # -> batch_size, num_heads, num_queries, num_points, 2
+ # -> batch_size*num_heads, num_queries, num_points, 2
+ sampling_grid_l_ = sampling_grids[:, :, :, level_id].transpose(1, 2).flatten(0, 1)
+ # batch_size*num_heads, hidden_dim, num_queries, num_points
+ sampling_value_l_ = nn.functional.grid_sample(
+ value_l_, sampling_grid_l_, mode="bilinear", padding_mode="zeros", align_corners=False
+ )
+ sampling_value_list.append(sampling_value_l_)
+ # (batch_size, num_queries, num_heads, num_levels, num_points)
+ # -> (batch_size, num_heads, num_queries, num_levels, num_points)
+ # -> (batch_size, num_heads, 1, num_queries, num_levels*num_points)
+ attention_weights = attention_weights.transpose(1, 2).reshape(
+ batch_size * num_heads, 1, num_queries, num_levels * num_points
+ )
+ output = (
+ (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights)
+ .sum(-1)
+ .view(batch_size, num_heads * hidden_dim, num_queries)
+ )
+ return output.transpose(1, 2).contiguous()
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrMultiscaleDeformableAttention with DeformableDetr->GroundingDino, Deformable DETR->Grounding DINO
+class GroundingDinoMultiscaleDeformableAttention(nn.Module):
+ """
+ Multiscale deformable attention as proposed in Deformable DETR.
+ """
+
+ def __init__(self, config: GroundingDinoConfig, num_heads: int, n_points: int):
+ super().__init__()
+
+ kernel_loaded = MultiScaleDeformableAttention is not None
+ if is_torch_cuda_available() and is_ninja_available() and not kernel_loaded:
+ try:
+ load_cuda_kernels()
+ except Exception as e:
+ logger.warning(f"Could not load the custom kernel for multi-scale deformable attention: {e}")
+
+ if config.d_model % num_heads != 0:
+ raise ValueError(
+ f"embed_dim (d_model) must be divisible by num_heads, but got {config.d_model} and {num_heads}"
+ )
+ dim_per_head = config.d_model // num_heads
+ # check if dim_per_head is power of 2
+ if not ((dim_per_head & (dim_per_head - 1) == 0) and dim_per_head != 0):
+ warnings.warn(
+ "You'd better set embed_dim (d_model) in GroundingDinoMultiscaleDeformableAttention to make the"
+ " dimension of each attention head a power of 2 which is more efficient in the authors' CUDA"
+ " implementation."
+ )
+
+ self.im2col_step = 64
+
+ self.d_model = config.d_model
+ self.n_levels = config.num_feature_levels
+ self.n_heads = num_heads
+ self.n_points = n_points
+
+ self.sampling_offsets = nn.Linear(config.d_model, num_heads * self.n_levels * n_points * 2)
+ self.attention_weights = nn.Linear(config.d_model, num_heads * self.n_levels * n_points)
+ self.value_proj = nn.Linear(config.d_model, config.d_model)
+ self.output_proj = nn.Linear(config.d_model, config.d_model)
+
+ self.disable_custom_kernels = config.disable_custom_kernels
+
+ self._reset_parameters()
+
+ def _reset_parameters(self):
+ nn.init.constant_(self.sampling_offsets.weight.data, 0.0)
+ default_dtype = torch.get_default_dtype()
+ thetas = torch.arange(self.n_heads, dtype=torch.int64).to(default_dtype) * (2.0 * math.pi / self.n_heads)
+ grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
+ grid_init = (
+ (grid_init / grid_init.abs().max(-1, keepdim=True)[0])
+ .view(self.n_heads, 1, 1, 2)
+ .repeat(1, self.n_levels, self.n_points, 1)
+ )
+ for i in range(self.n_points):
+ grid_init[:, :, i, :] *= i + 1
+ with torch.no_grad():
+ self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
+ nn.init.constant_(self.attention_weights.weight.data, 0.0)
+ nn.init.constant_(self.attention_weights.bias.data, 0.0)
+ nn.init.xavier_uniform_(self.value_proj.weight.data)
+ nn.init.constant_(self.value_proj.bias.data, 0.0)
+ nn.init.xavier_uniform_(self.output_proj.weight.data)
+ nn.init.constant_(self.output_proj.bias.data, 0.0)
+
+ def with_pos_embed(self, tensor: torch.Tensor, position_embeddings: Optional[Tensor]):
+ return tensor if position_embeddings is None else tensor + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ position_embeddings: Optional[torch.Tensor] = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ output_attentions: bool = False,
+ ):
+ # add position embeddings to the hidden states before projecting to queries and keys
+ if position_embeddings is not None:
+ hidden_states = self.with_pos_embed(hidden_states, position_embeddings)
+
+ batch_size, num_queries, _ = hidden_states.shape
+ batch_size, sequence_length, _ = encoder_hidden_states.shape
+ if (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() != sequence_length:
+ raise ValueError(
+ "Make sure to align the spatial shapes with the sequence length of the encoder hidden states"
+ )
+
+ value = self.value_proj(encoder_hidden_states)
+ if attention_mask is not None:
+ # we invert the attention_mask
+ value = value.masked_fill(~attention_mask[..., None], float(0))
+ value = value.view(batch_size, sequence_length, self.n_heads, self.d_model // self.n_heads)
+ sampling_offsets = self.sampling_offsets(hidden_states).view(
+ batch_size, num_queries, self.n_heads, self.n_levels, self.n_points, 2
+ )
+ attention_weights = self.attention_weights(hidden_states).view(
+ batch_size, num_queries, self.n_heads, self.n_levels * self.n_points
+ )
+ attention_weights = F.softmax(attention_weights, -1).view(
+ batch_size, num_queries, self.n_heads, self.n_levels, self.n_points
+ )
+ # batch_size, num_queries, n_heads, n_levels, n_points, 2
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 2:
+ offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
+ sampling_locations = (
+ reference_points[:, :, None, :, None, :]
+ + sampling_offsets / offset_normalizer[None, None, None, :, None, :]
+ )
+ elif num_coordinates == 4:
+ sampling_locations = (
+ reference_points[:, :, None, :, None, :2]
+ + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
+ )
+ else:
+ raise ValueError(f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}")
+
+ if self.disable_custom_kernels:
+ # PyTorch implementation
+ output = multi_scale_deformable_attention(value, spatial_shapes, sampling_locations, attention_weights)
+ else:
+ try:
+ # custom kernel
+ output = MultiScaleDeformableAttentionFunction.apply(
+ value,
+ spatial_shapes,
+ level_start_index,
+ sampling_locations,
+ attention_weights,
+ self.im2col_step,
+ )
+ except Exception:
+ # PyTorch implementation
+ output = multi_scale_deformable_attention(value, spatial_shapes, sampling_locations, attention_weights)
+ output = self.output_proj(output)
+
+ return output, attention_weights
+
+
+class GroundingDinoTextEnhancerLayer(nn.Module):
+ """Vanilla Transformer with text embeddings as input"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.self_attn = GroundingDinoMultiheadAttention(
+ config, num_attention_heads=config.encoder_attention_heads // 2
+ )
+
+ # Implementation of Feedforward model
+ self.fc1 = nn.Linear(config.d_model, config.encoder_ffn_dim // 2)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim // 2, config.d_model)
+
+ self.layer_norm_before = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layer_norm_after = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+
+ self.activation = ACT2FN[config.activation_function]
+ self.num_heads = config.encoder_attention_heads // 2
+ self.dropout = config.text_enhancer_dropout
+
+ def with_pos_embed(self, hidden_state: Tensor, position_embeddings: Optional[Tensor]):
+ return hidden_state if position_embeddings is None else hidden_state + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_masks: Optional[torch.BoolTensor] = None,
+ position_embeddings: Optional[torch.FloatTensor] = None,
+ ) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
+ """Text self-attention to enhance projection of text features generated by
+ the text encoder (AutoModel based on text_config) within GroundingDinoEncoderLayer
+
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_dim)`):
+ Text features generated by the text encoder.
+ attention_masks (`torch.BoolTensor`, *optional*):
+ Attention mask for text self-attention. False for real tokens and True for padding tokens.
+ position_embeddings (`torch.FloatTensor`, *optional*):
+ Position embeddings to be added to the hidden states.
+
+ Returns:
+ `tuple(torch.FloatTensor)` comprising two elements:
+ - **hidden_states** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`) --
+ Output of the text self-attention layer.
+ - **attention_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`) --
+ Attention weights of the text self-attention layer.
+ """
+
+ # repeat attn mask
+ if attention_masks.dim() == 3 and attention_masks.shape[0] == hidden_states.shape[0]:
+ # batch_size, num_queries, num_keys
+ attention_masks = attention_masks[:, None, :, :]
+ attention_masks = attention_masks.repeat(1, self.num_heads, 1, 1)
+
+ dtype = torch.float16
+ attention_masks = attention_masks.to(dtype=dtype) # fp16 compatibility
+ attention_masks = (1.0 - attention_masks) * torch.finfo(dtype).min
+
+ queries = keys = self.with_pos_embed(hidden_states, position_embeddings)
+ attention_output, attention_weights = self.self_attn(
+ queries=queries,
+ keys=keys,
+ values=hidden_states,
+ attention_mask=attention_masks,
+ output_attentions=True,
+ )
+ attention_output = nn.functional.dropout(attention_output, p=self.dropout, training=self.training)
+ hidden_states = hidden_states + attention_output
+ hidden_states = self.layer_norm_before(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = hidden_states + residual
+ hidden_states = self.layer_norm_after(hidden_states)
+
+ return hidden_states, attention_weights
+
+
+class GroundingDinoBiMultiHeadAttention(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+
+ vision_dim = text_dim = config.d_model
+ embed_dim = config.encoder_ffn_dim // 2
+ num_heads = config.encoder_attention_heads // 2
+ dropout = config.fusion_dropout
+
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.head_dim = embed_dim // num_heads
+ self.vision_dim = vision_dim
+ self.text_dim = text_dim
+
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"`embed_dim` must be divisible by `num_heads` (got `embed_dim`: {self.embed_dim} and `num_heads`: {self.num_heads})."
+ )
+ self.scale = self.head_dim ** (-0.5)
+ self.dropout = dropout
+
+ self.vision_proj = nn.Linear(self.vision_dim, self.embed_dim)
+ self.text_proj = nn.Linear(self.text_dim, self.embed_dim)
+ self.values_vision_proj = nn.Linear(self.vision_dim, self.embed_dim)
+ self.values_text_proj = nn.Linear(self.text_dim, self.embed_dim)
+
+ self.out_vision_proj = nn.Linear(self.embed_dim, self.vision_dim)
+ self.out_text_proj = nn.Linear(self.embed_dim, self.text_dim)
+
+ def _reshape(self, tensor: torch.Tensor, seq_len: int, batch_size: int):
+ return tensor.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ vision_features: torch.FloatTensor,
+ text_features: torch.FloatTensor,
+ vision_attention_mask: Optional[torch.BoolTensor] = None,
+ text_attention_mask: Optional[torch.BoolTensor] = None,
+ ) -> Tuple[Tuple[torch.FloatTensor, torch.FloatTensor], Tuple[torch.FloatTensor, torch.FloatTensor]]:
+ """Image-to-text and text-to-image cross-attention
+
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_dim)`):
+ Projected flattened image features generated by the vision backbone.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`):
+ Projected text features generated by the text encoder.
+ vision_attention_mask (`torch.BoolTensor`, **optional**):
+ Attention mask for image-to-text cross-attention. False for real tokens and True for padding tokens.
+ text_attention_mask (`torch.BoolTensor`, **optional**):
+ Attention mask for text-to-image cross-attention. False for real tokens and True for padding tokens.
+
+ Returns:
+ `tuple(tuple(torch.FloatTensor), tuple(torch.FloatTensor))` where each inner tuple comprises an attention
+ output and weights:
+ - **vision_attn_output** (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_din)`)
+ --
+ Output of the image-to-text cross-attention layer.
+ - **vision_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, vision_sequence_length,
+ vision_sequence_length)`) --
+ Attention weights of the image-to-text cross-attention layer.
+ - **text_attn_output** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`) --
+ Output of the text-to-image cross-attention layer.
+ - **text_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, text_sequence_length,
+ text_sequence_length)`) --
+ Attention weights of the text-to-image cross-attention layer.
+ """
+ batch_size, tgt_len, _ = vision_features.size()
+
+ vision_query_states = self.vision_proj(vision_features) * self.scale
+ vision_query_states = self._reshape(vision_query_states, tgt_len, batch_size)
+
+ text_key_states = self.text_proj(text_features)
+ text_key_states = self._reshape(text_key_states, -1, batch_size)
+
+ vision_value_states = self.values_vision_proj(vision_features)
+ vision_value_states = self._reshape(vision_value_states, -1, batch_size)
+
+ text_value_states = self.values_text_proj(text_features)
+ text_value_states = self._reshape(text_value_states, -1, batch_size)
+
+ proj_shape = (batch_size * self.num_heads, -1, self.head_dim)
+
+ vision_query_states = vision_query_states.view(*proj_shape)
+ text_key_states = text_key_states.view(*proj_shape)
+ vision_value_states = vision_value_states.view(*proj_shape)
+ text_value_states = text_value_states.view(*proj_shape)
+
+ src_len = text_key_states.size(1)
+ attn_weights = torch.bmm(vision_query_states, text_key_states.transpose(1, 2)) # bs*nhead, nimg, ntxt
+
+ if attn_weights.size() != (batch_size * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(batch_size * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
+ )
+
+ attn_weights = attn_weights - attn_weights.max()
+ # Do not increase -50000/50000, data type half has quite limited range
+ attn_weights = torch.clamp(attn_weights, min=-50000, max=50000)
+
+ attn_weights_transposed = attn_weights.transpose(1, 2)
+ text_attn_weights = attn_weights_transposed - torch.max(attn_weights_transposed, dim=-1, keepdim=True)[0]
+
+ # Do not increase -50000/50000, data type half has quite limited range
+ text_attn_weights = torch.clamp(text_attn_weights, min=-50000, max=50000)
+
+ # mask vision for language
+ if vision_attention_mask is not None:
+ vision_attention_mask = (
+ vision_attention_mask[:, None, None, :].repeat(1, self.num_heads, 1, 1).flatten(0, 1)
+ )
+ text_attn_weights.masked_fill_(vision_attention_mask, float("-inf"))
+
+ text_attn_weights = text_attn_weights.softmax(dim=-1)
+
+ # mask language for vision
+ if text_attention_mask is not None:
+ text_attention_mask = text_attention_mask[:, None, None, :].repeat(1, self.num_heads, 1, 1).flatten(0, 1)
+ attn_weights.masked_fill_(text_attention_mask, float("-inf"))
+ vision_attn_weights = attn_weights.softmax(dim=-1)
+
+ vision_attn_probs = F.dropout(vision_attn_weights, p=self.dropout, training=self.training)
+ text_attn_probs = F.dropout(text_attn_weights, p=self.dropout, training=self.training)
+
+ vision_attn_output = torch.bmm(vision_attn_probs, text_value_states)
+ text_attn_output = torch.bmm(text_attn_probs, vision_value_states)
+
+ if vision_attn_output.size() != (batch_size * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`vision_attn_output` should be of size {(batch_size, self.num_heads, tgt_len, self.head_dim)}, but is {vision_attn_output.size()}"
+ )
+
+ if text_attn_output.size() != (batch_size * self.num_heads, src_len, self.head_dim):
+ raise ValueError(
+ f"`text_attn_output` should be of size {(batch_size, self.num_heads, src_len, self.head_dim)}, but is {text_attn_output.size()}"
+ )
+
+ vision_attn_output = vision_attn_output.view(batch_size, self.num_heads, tgt_len, self.head_dim)
+ vision_attn_output = vision_attn_output.transpose(1, 2)
+ vision_attn_output = vision_attn_output.reshape(batch_size, tgt_len, self.embed_dim)
+
+ text_attn_output = text_attn_output.view(batch_size, self.num_heads, src_len, self.head_dim)
+ text_attn_output = text_attn_output.transpose(1, 2)
+ text_attn_output = text_attn_output.reshape(batch_size, src_len, self.embed_dim)
+
+ vision_attn_output = self.out_vision_proj(vision_attn_output)
+ text_attn_output = self.out_text_proj(text_attn_output)
+
+ return (vision_attn_output, vision_attn_weights), (text_attn_output, text_attn_weights)
+
+
+# Copied from transformers.models.beit.modeling_beit.drop_path
+def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ Comment by Ross Wightman: This is the same as the DropConnect impl I created for EfficientNet, etc networks,
+ however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the
+ layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the
+ argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return input
+ keep_prob = 1 - drop_prob
+ shape = (input.shape[0],) + (1,) * (input.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=input.dtype, device=input.device)
+ random_tensor.floor_() # binarize
+ output = input.div(keep_prob) * random_tensor
+ return output
+
+
+# Copied from transformers.models.beit.modeling_beit.BeitDropPath with Beit->GroundingDino
+class GroundingDinoDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob: Optional[float] = None) -> None:
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ return drop_path(hidden_states, self.drop_prob, self.training)
+
+ def extra_repr(self) -> str:
+ return "p={}".format(self.drop_prob)
+
+
+class GroundingDinoFusionLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ drop_path = config.fusion_droppath
+
+ # pre layer norm
+ self.layer_norm_vision = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layer_norm_text = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.attn = GroundingDinoBiMultiHeadAttention(config)
+
+ # add layer scale for training stability
+ self.drop_path = GroundingDinoDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+ init_values = 1e-4
+ self.vision_param = nn.Parameter(init_values * torch.ones((config.d_model)), requires_grad=True)
+ self.text_param = nn.Parameter(init_values * torch.ones((config.d_model)), requires_grad=True)
+
+ def forward(
+ self,
+ vision_features: torch.FloatTensor,
+ text_features: torch.FloatTensor,
+ attention_mask_vision: Optional[torch.BoolTensor] = None,
+ attention_mask_text: Optional[torch.BoolTensor] = None,
+ ) -> Tuple[Tuple[torch.FloatTensor, torch.FloatTensor], Tuple[torch.FloatTensor, torch.FloatTensor]]:
+ """Image and text features fusion
+
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, hidden_dim)`):
+ Projected flattened image features generated by the vision backbone.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_dim)`):
+ Projected text features generated by the text encoder.
+ attention_mask_vision (`torch.BoolTensor`, **optional**):
+ Attention mask for image-to-text cross-attention. False for real tokens and True for padding tokens.
+ attention_mask_text (`torch.BoolTensor`, **optional**):
+ Attention mask for text-to-image cross-attention. False for real tokens and True for padding tokens.
+
+ Returns:
+ `tuple(tuple(torch.FloatTensor), tuple(torch.FloatTensor))` where each inner tuple comprises an enhanced
+ feature and attention output and weights:
+ - **vision_features** (`torch.FloatTensor` of shape `(batch_size, vision_sequence_length, vision_dim)`) --
+ Updated vision features with attention output from image-to-text cross-attention layer.
+ - **vision_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, vision_sequence_length,
+ vision_sequence_length)`) --
+ Attention weights of the image-to-text cross-attention layer.
+ - **text_features** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, text_dim)`) --
+ Updated text features with attention output from text-to-image cross-attention layer.
+ - **text_attn_weights** (`torch.FloatTensor` of shape `(batch_size, num_heads, text_sequence_length,
+ text_sequence_length)`) --
+ Attention weights of the text-to-image cross-attention layer.
+ """
+ vision_features = self.layer_norm_vision(vision_features)
+ text_features = self.layer_norm_text(text_features)
+ (delta_v, vision_attn), (delta_t, text_attn) = self.attn(
+ vision_features,
+ text_features,
+ vision_attention_mask=attention_mask_vision,
+ text_attention_mask=attention_mask_text,
+ )
+ vision_features = vision_features + self.drop_path(self.vision_param * delta_v)
+ text_features = text_features + self.drop_path(self.text_param * delta_t)
+
+ return (vision_features, vision_attn), (text_features, text_attn)
+
+
+class GroundingDinoDeformableLayer(nn.Module):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+ self.self_attn = GroundingDinoMultiscaleDeformableAttention(
+ config, num_heads=config.encoder_attention_heads, n_points=config.encoder_n_points
+ )
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+ self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ position_embeddings: torch.Tensor = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ output_attentions: bool = False,
+ ):
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Input to the layer.
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Attention mask.
+ position_embeddings (`torch.FloatTensor`, *optional*):
+ Position embeddings, to be added to `hidden_states`.
+ reference_points (`torch.FloatTensor`, *optional*):
+ Reference points.
+ spatial_shapes (`torch.LongTensor`, *optional*):
+ Spatial shapes of the backbone feature maps.
+ level_start_index (`torch.LongTensor`, *optional*):
+ Level start index.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ # Apply Multi-scale Deformable Attention Module on the multi-scale feature maps.
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=attention_mask,
+ position_embeddings=position_embeddings,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if self.training:
+ if torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any():
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ return hidden_states, attn_weights
+
+
+# Based on https://github.com/IDEA-Research/GroundingDINO/blob/2b62f419c292ca9c518daae55512fabc3fead4a4/groundingdino/models/GroundingDINO/utils.py#L24
+def get_sine_pos_embed(
+ pos_tensor: torch.Tensor, num_pos_feats: int = 128, temperature: int = 10000, exchange_xy: bool = True
+) -> Tensor:
+ """
+ Generate sine position embeddings from a position tensor.
+
+ Args:
+ pos_tensor (torch.Tensor):
+ Tensor containing positions. Shape: [..., n].
+ num_pos_feats (`int`, *optional*, defaults to 128):
+ Projected shape for each float in the tensor.
+ temperature (`int`, *optional*, defaults to 10000):
+ Temperature in the sine/cosine function.
+ exchange_xy (`bool`, *optional*, defaults to `True`):
+ Exchange pos x and pos y. For example, input tensor is [x,y], the results will be [pos(y), pos(x)].
+
+ Returns:
+ position_embeddings (torch.Tensor): shape: [..., n * hidden_size].
+ """
+ scale = 2 * math.pi
+ dim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos_tensor.device)
+ dim_t = temperature ** (2 * torch.div(dim_t, 2, rounding_mode="floor") / num_pos_feats)
+
+ def sine_func(x: torch.Tensor):
+ sin_x = x * scale / dim_t
+ sin_x = torch.stack((sin_x[..., 0::2].sin(), sin_x[..., 1::2].cos()), dim=3).flatten(2)
+ return sin_x
+
+ pos_tensor = pos_tensor.split([1] * pos_tensor.shape[-1], dim=-1)
+ position_embeddings = [sine_func(x) for x in pos_tensor]
+ if exchange_xy:
+ position_embeddings[0], position_embeddings[1] = position_embeddings[1], position_embeddings[0]
+ position_embeddings = torch.cat(position_embeddings, dim=-1)
+ return position_embeddings
+
+
+class GroundingDinoEncoderLayer(nn.Module):
+ def __init__(self, config) -> None:
+ super().__init__()
+
+ self.d_model = config.d_model
+
+ self.text_enhancer_layer = GroundingDinoTextEnhancerLayer(config)
+ self.fusion_layer = GroundingDinoFusionLayer(config)
+ self.deformable_layer = GroundingDinoDeformableLayer(config)
+
+ def get_text_position_embeddings(
+ self,
+ text_features: Tensor,
+ text_position_embedding: Optional[torch.Tensor],
+ text_position_ids: Optional[torch.Tensor],
+ ) -> Tensor:
+ batch_size, seq_length, _ = text_features.shape
+ if text_position_embedding is None and text_position_ids is None:
+ text_position_embedding = torch.arange(seq_length, device=text_features.device)
+ text_position_embedding = text_position_embedding.float()
+ text_position_embedding = text_position_embedding.unsqueeze(0).unsqueeze(-1)
+ text_position_embedding = text_position_embedding.repeat(batch_size, 1, 1)
+ text_position_embedding = get_sine_pos_embed(
+ text_position_embedding, num_pos_feats=self.d_model, exchange_xy=False
+ )
+ if text_position_ids is not None:
+ text_position_embedding = get_sine_pos_embed(
+ text_position_ids[..., None], num_pos_feats=self.d_model, exchange_xy=False
+ )
+
+ return text_position_embedding
+
+ def forward(
+ self,
+ vision_features: Tensor,
+ vision_position_embedding: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ key_padding_mask: Tensor,
+ reference_points: Tensor,
+ text_features: Optional[Tensor] = None,
+ text_attention_mask: Optional[Tensor] = None,
+ text_position_embedding: Optional[Tensor] = None,
+ text_self_attention_masks: Optional[Tensor] = None,
+ text_position_ids: Optional[Tensor] = None,
+ ):
+ text_position_embedding = self.get_text_position_embeddings(
+ text_features, text_position_embedding, text_position_ids
+ )
+
+ (vision_features, vision_fused_attn), (text_features, text_fused_attn) = self.fusion_layer(
+ vision_features=vision_features,
+ text_features=text_features,
+ attention_mask_vision=key_padding_mask,
+ attention_mask_text=text_attention_mask,
+ )
+
+ (text_features, text_enhanced_attn) = self.text_enhancer_layer(
+ hidden_states=text_features,
+ attention_masks=~text_self_attention_masks, # note we use ~ for mask here
+ position_embeddings=(text_position_embedding if text_position_embedding is not None else None),
+ )
+
+ (vision_features, vision_deformable_attn) = self.deformable_layer(
+ hidden_states=vision_features,
+ attention_mask=~key_padding_mask,
+ position_embeddings=vision_position_embedding,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ )
+
+ return (
+ (vision_features, text_features),
+ (vision_fused_attn, text_fused_attn, text_enhanced_attn, vision_deformable_attn),
+ )
+
+
+class GroundingDinoMultiheadAttention(nn.Module):
+ """Equivalent implementation of nn.MultiheadAttention with `batch_first=True`."""
+
+ def __init__(self, config, num_attention_heads=None):
+ super().__init__()
+ if config.hidden_size % num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({num_attention_heads})"
+ )
+
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_size = int(config.hidden_size / num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.out_proj = nn.Linear(config.hidden_size, config.hidden_size)
+
+ self.dropout = nn.Dropout(config.attention_dropout)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ queries: torch.Tensor,
+ keys: torch.Tensor,
+ values: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ query_layer = self.transpose_for_scores(self.query(queries))
+ key_layer = self.transpose_for_scores(self.key(keys))
+ value_layer = self.transpose_for_scores(self.value(values))
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in GroundingDinoModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ context_layer = self.out_proj(context_layer)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+class GroundingDinoDecoderLayer(nn.Module):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+
+ # self-attention
+ self.self_attn = GroundingDinoMultiheadAttention(config, num_attention_heads=config.decoder_attention_heads)
+
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # cross-attention text
+ self.encoder_attn_text = GroundingDinoMultiheadAttention(
+ config, num_attention_heads=config.decoder_attention_heads
+ )
+ self.encoder_attn_text_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # cross-attention
+ self.encoder_attn = GroundingDinoMultiscaleDeformableAttention(
+ config,
+ num_heads=config.decoder_attention_heads,
+ n_points=config.decoder_n_points,
+ )
+ self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+ # feedforward neural networks
+ self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
+ self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim, config.layer_norm_eps)
+
+ def with_pos_embed(self, tensor: torch.Tensor, position_embeddings: Optional[Tensor]):
+ return tensor if position_embeddings is None else tensor + position_embeddings
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: Optional[torch.Tensor] = None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ vision_encoder_hidden_states: Optional[torch.Tensor] = None,
+ vision_encoder_attention_mask: Optional[torch.Tensor] = None,
+ text_encoder_hidden_states: Optional[torch.Tensor] = None,
+ text_encoder_attention_mask: Optional[torch.Tensor] = None,
+ self_attn_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ):
+ residual = hidden_states
+
+ # Self Attention
+ queries = keys = self.with_pos_embed(hidden_states, position_embeddings)
+ hidden_states, self_attn_weights = self.self_attn(
+ queries=queries,
+ keys=keys,
+ values=hidden_states,
+ attention_mask=self_attn_mask,
+ output_attentions=True,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ second_residual = hidden_states
+
+ # Cross-Attention Text
+ queries = self.with_pos_embed(hidden_states, position_embeddings)
+
+ hidden_states, text_cross_attn_weights = self.encoder_attn_text(
+ queries=queries,
+ keys=text_encoder_hidden_states,
+ values=text_encoder_hidden_states,
+ # attention_mask=text_encoder_attention_mask, # TODO fix cross-attention mask here
+ output_attentions=True,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = second_residual + hidden_states
+ hidden_states = self.encoder_attn_text_layer_norm(hidden_states)
+
+ third_residual = hidden_states
+
+ # Cross-Attention
+ cross_attn_weights = None
+ hidden_states, cross_attn_weights = self.encoder_attn(
+ hidden_states=hidden_states,
+ attention_mask=vision_encoder_attention_mask,
+ encoder_hidden_states=vision_encoder_hidden_states,
+ encoder_attention_mask=vision_encoder_attention_mask,
+ position_embeddings=position_embeddings,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = third_residual + hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, text_cross_attn_weights, cross_attn_weights)
+
+ return outputs
+
+
+class GroundingDinoContrastiveEmbedding(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.max_text_len = config.max_text_len
+
+ def forward(
+ self,
+ vision_hidden_state: torch.FloatTensor,
+ text_hidden_state: torch.FloatTensor,
+ text_token_mask: torch.BoolTensor,
+ ) -> torch.FloatTensor:
+ output = vision_hidden_state @ text_hidden_state.transpose(-1, -2)
+ output = output.masked_fill(~text_token_mask[:, None, :], float("-inf"))
+
+ # padding to max_text_len
+ new_output = torch.full((*output.shape[:-1], self.max_text_len), float("-inf"), device=output.device)
+ new_output[..., : output.shape[-1]] = output
+
+ return new_output
+
+
+class GroundingDinoPreTrainedModel(PreTrainedModel):
+ config_class = GroundingDinoConfig
+ base_model_prefix = "model"
+ main_input_name = "pixel_values"
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+
+ if isinstance(module, GroundingDinoLearnedPositionEmbedding):
+ nn.init.uniform_(module.row_embeddings.weight)
+ nn.init.uniform_(module.column_embeddings.weight)
+ elif isinstance(module, GroundingDinoMultiscaleDeformableAttention):
+ module._reset_parameters()
+ elif isinstance(module, GroundingDinoBiMultiHeadAttention):
+ nn.init.xavier_uniform_(module.vision_proj.weight)
+ module.vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.text_proj.weight)
+ module.text_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.values_vision_proj.weight)
+ module.values_vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.values_text_proj.weight)
+ module.values_text_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.out_vision_proj.weight)
+ module.out_vision_proj.bias.data.fill_(0)
+ nn.init.xavier_uniform_(module.out_text_proj.weight)
+ module.out_text_proj.bias.data.fill_(0)
+ elif isinstance(module, (GroundingDinoEncoderLayer, GroundingDinoDecoderLayer)):
+ for p in module.parameters():
+ if p.dim() > 1:
+ nn.init.normal_(p, mean=0.0, std=std)
+ elif isinstance(module, (nn.Linear, nn.Conv2d, nn.BatchNorm2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, GroundingDinoMLPPredictionHead):
+ nn.init.constant_(module.layers[-1].weight.data, 0)
+ nn.init.constant_(module.layers[-1].bias.data, 0)
+
+ if hasattr(module, "reference_points") and not self.config.two_stage:
+ nn.init.xavier_uniform_(module.reference_points.weight.data, gain=1.0)
+ nn.init.constant_(module.reference_points.bias.data, 0.0)
+ if hasattr(module, "level_embed"):
+ nn.init.normal_(module.level_embed)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, GroundingDinoDecoder):
+ module.gradient_checkpointing = value
+
+
+GROUNDING_DINO_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`GroundingDinoConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+GROUNDING_DINO_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it.
+
+ Pixel values can be obtained using [`AutoImageProcessor`]. See [`GroundingDinoImageProcessor.__call__`] for
+ details.
+
+ input_ids (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`GroundingDinoTokenizer.__call__`] for details.
+
+ token_type_ids (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`: 0 corresponds to a `sentence A` token, 1 corresponds to a `sentence B` token
+
+ [What are token type IDs?](../glossary#token-type-ids)
+
+ attention_mask (`torch.LongTensor` of shape `(batch_size, text_sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are real (i.e. **not masked**),
+ - 0 for tokens that are padding (i.e. **masked**).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
+
+ - 1 for pixels that are real (i.e. **not masked**),
+ - 0 for pixels that are padding (i.e. **masked**).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
+ Tuple consists of (`last_hidden_state_vision`, *optional*: `last_hidden_state_text`, *optional*:
+ `vision_hidden_states`, *optional*: `text_hidden_states`, *optional*: `attentions`)
+ `last_hidden_state_vision` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence
+ of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the
+ decoder.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+class GroundingDinoEncoder(GroundingDinoPreTrainedModel):
+ """
+ Transformer encoder consisting of *config.encoder_layers* deformable attention layers. Each layer is a
+ [`GroundingDinoEncoderLayer`].
+
+ The encoder updates the flattened multi-scale feature maps through multiple deformable attention layers.
+
+ Args:
+ config: GroundingDinoConfig
+ """
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+ self.layers = nn.ModuleList([GroundingDinoEncoderLayer(config) for _ in range(config.encoder_layers)])
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @staticmethod
+ def get_reference_points(spatial_shapes, valid_ratios, device):
+ """
+ Get reference points for each feature map.
+
+ Args:
+ spatial_shapes (`torch.LongTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of each feature map.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`):
+ Valid ratios of each feature map.
+ device (`torch.device`):
+ Device on which to create the tensors.
+ Returns:
+ `torch.FloatTensor` of shape `(batch_size, num_queries, num_feature_levels, 2)`
+ """
+ reference_points_list = []
+ for level, (height, width) in enumerate(spatial_shapes):
+ ref_y, ref_x = meshgrid(
+ torch.linspace(0.5, height - 0.5, height, dtype=torch.float32, device=device),
+ torch.linspace(0.5, width - 0.5, width, dtype=torch.float32, device=device),
+ indexing="ij",
+ )
+ # TODO: valid_ratios could be useless here. check https://github.com/fundamentalvision/Deformable-DETR/issues/36
+ ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, level, 1] * height)
+ ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, level, 0] * width)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+ def forward(
+ self,
+ vision_features: Tensor,
+ vision_attention_mask: Tensor,
+ vision_position_embedding: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios=None,
+ text_features: Optional[Tensor] = None,
+ text_attention_mask: Optional[Tensor] = None,
+ text_position_embedding: Optional[Tensor] = None,
+ text_self_attention_masks: Optional[Tensor] = None,
+ text_position_ids: Optional[Tensor] = None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Args:
+ vision_features (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Flattened feature map (output of the backbone + projection layer) that is passed to the encoder.
+ vision_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding pixel features. Mask values selected in `[0, 1]`:
+ - 0 for pixel features that are real (i.e. **not masked**),
+ - 1 for pixel features that are padding (i.e. **masked**).
+ [What are attention masks?](../glossary#attention-mask)
+ vision_position_embedding (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Position embeddings that are added to the queries and keys in each self-attention layer.
+ spatial_shapes (`torch.LongTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of each feature map.
+ level_start_index (`torch.LongTensor` of shape `(num_feature_levels)`):
+ Starting index of each feature map.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`):
+ Ratio of valid area in each feature level.
+ text_features (`torch.FloatTensor` of shape `(batch_size, text_seq_len, hidden_size)`):
+ Flattened text features that are passed to the encoder.
+ text_attention_mask (`torch.Tensor` of shape `(batch_size, text_seq_len)`, *optional*):
+ Mask to avoid performing attention on padding text features. Mask values selected in `[0, 1]`:
+ - 0 for text features that are real (i.e. **not masked**),
+ - 1 for text features that are padding (i.e. **masked**).
+ [What are attention masks?](../glossary#attention-mask)
+ text_position_embedding (`torch.FloatTensor` of shape `(batch_size, text_seq_len)`):
+ Position embeddings that are added to the queries and keys in each self-attention layer.
+ text_self_attention_masks (`torch.BoolTensor` of shape `(batch_size, text_seq_len, text_seq_len)`):
+ Masks to avoid performing attention between padding text features. Mask values selected in `[0, 1]`:
+ - 1 for text features that are real (i.e. **not masked**),
+ - 0 for text features that are padding (i.e. **masked**).
+ text_position_ids (`torch.LongTensor` of shape `(batch_size, num_queries)`):
+ Position ids for text features.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=vision_features.device)
+
+ encoder_vision_states = () if output_hidden_states else None
+ encoder_text_states = () if output_hidden_states else None
+ all_attns = () if output_attentions else None
+ all_attn_fused_text = () if output_attentions else None
+ all_attn_fused_vision = () if output_attentions else None
+ all_attn_enhanced_text = () if output_attentions else None
+ all_attn_deformable = () if output_attentions else None
+ for i, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_vision_states += (vision_features,)
+ encoder_text_states += (text_features,)
+
+ (vision_features, text_features), attentions = encoder_layer(
+ vision_features=vision_features,
+ vision_position_embedding=vision_position_embedding,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ key_padding_mask=vision_attention_mask,
+ reference_points=reference_points,
+ text_features=text_features,
+ text_attention_mask=text_attention_mask,
+ text_position_embedding=text_position_embedding,
+ text_self_attention_masks=text_self_attention_masks,
+ text_position_ids=text_position_ids,
+ )
+
+ if output_attentions:
+ all_attn_fused_vision += (attentions[0],)
+ all_attn_fused_text += (attentions[1],)
+ all_attn_enhanced_text += (attentions[2],)
+ all_attn_deformable += (attentions[3],)
+
+ if output_hidden_states:
+ encoder_vision_states += (vision_features,)
+ encoder_text_states += (text_features,)
+
+ if output_attentions:
+ all_attns = (all_attn_fused_vision, all_attn_fused_text, all_attn_enhanced_text, all_attn_deformable)
+
+ if not return_dict:
+ enc_outputs = [vision_features, text_features, encoder_vision_states, encoder_text_states, all_attns]
+ return tuple(v for v in enc_outputs if v is not None)
+ return GroundingDinoEncoderOutput(
+ last_hidden_state_vision=vision_features,
+ last_hidden_state_text=text_features,
+ vision_hidden_states=encoder_vision_states,
+ text_hidden_states=encoder_text_states,
+ attentions=all_attns,
+ )
+
+
+class GroundingDinoDecoder(GroundingDinoPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`GroundingDinoDecoderLayer`].
+
+ The decoder updates the query embeddings through multiple self-attention and cross-attention layers.
+
+ Some tweaks for Grounding DINO:
+
+ - `position_embeddings`, `reference_points`, `spatial_shapes` and `valid_ratios` are added to the forward pass.
+ - it also returns a stack of intermediate outputs and reference points from all decoding layers.
+
+ Args:
+ config: GroundingDinoConfig
+ """
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+ self.layer_norm = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ self.layers = nn.ModuleList([GroundingDinoDecoderLayer(config) for _ in range(config.decoder_layers)])
+ self.reference_points_head = GroundingDinoMLPPredictionHead(
+ config.query_dim // 2 * config.d_model, config.d_model, config.d_model, 2
+ )
+ self.gradient_checkpointing = False
+
+ # hack implementation for iterative bounding box refinement as in two-stage Deformable DETR
+ self.bbox_embed = None
+ self.class_embed = None
+ self.query_scale = None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def forward(
+ self,
+ inputs_embeds,
+ vision_encoder_hidden_states,
+ vision_encoder_attention_mask=None,
+ text_encoder_hidden_states=None,
+ text_encoder_attention_mask=None,
+ reference_points=None,
+ spatial_shapes=None,
+ level_start_index=None,
+ valid_ratios=None,
+ self_attn_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`):
+ The query embeddings that are passed into the decoder.
+ vision_encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Last hidden state from encoder related to vision feature map.
+ vision_encoder_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding pixel features. Mask values selected in `[0, 1]`:
+ - 1 for pixel features that are real (i.e. **not masked**),
+ - 0 for pixel features that are padding (i.e. **masked**).
+ text_encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, text_seq_len, hidden_size)`):
+ Last hidden state from encoder related to text features.
+ text_encoder_attention_mask (`torch.Tensor` of shape `(batch_size, text_seq_len)`, *optional*):
+ Mask to avoid performing attention on padding text features. Mask values selected in `[0, 1]`:
+ - 0 for text features that are real (i.e. **not masked**),
+ - 1 for text features that are padding (i.e. **masked**).
+ reference_points (`torch.FloatTensor` of shape `(batch_size, num_queries, 4)` is `as_two_stage` else `(batch_size, num_queries, 2)` or , *optional*):
+ Reference point in range `[0, 1]`, top-left (0,0), bottom-right (1, 1), including padding area.
+ spatial_shapes (`torch.FloatTensor` of shape `(num_feature_levels, 2)`):
+ Spatial shapes of the feature maps.
+ level_start_index (`torch.LongTensor` of shape `(num_feature_levels)`, *optional*):
+ Indexes for the start of each feature level. In range `[0, sequence_length]`.
+ valid_ratios (`torch.FloatTensor` of shape `(batch_size, num_feature_levels, 2)`, *optional*):
+ Ratio of valid area in each feature level.
+ self_attn_mask (`torch.BoolTensor` of shape `(batch_size, text_seq_len)`):
+ Masks to avoid performing self-attention between vision hidden state. Mask values selected in `[0, 1]`:
+ - 1 for queries that are real (i.e. **not masked**),
+ - 0 for queries that are padding (i.e. **masked**).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if inputs_embeds is not None:
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_attns = () if output_attentions else None
+ all_cross_attns_vision = () if (output_attentions and vision_encoder_hidden_states is not None) else None
+ all_cross_attns_text = () if (output_attentions and text_encoder_hidden_states is not None) else None
+ intermediate = ()
+ intermediate_reference_points = ()
+
+ for idx, decoder_layer in enumerate(self.layers):
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
+ reference_points_input = (
+ reference_points[:, :, None] * torch.cat([valid_ratios, valid_ratios], -1)[:, None]
+ )
+ elif num_coordinates == 2:
+ reference_points_input = reference_points[:, :, None] * valid_ratios[:, None]
+ else:
+ raise ValueError("Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}")
+ query_pos = get_sine_pos_embed(reference_points_input[:, :, 0, :], num_pos_feats=self.config.d_model // 2)
+ query_pos = self.reference_points_head(query_pos)
+
+ # In original implementation they apply layer norm before outputting intermediate hidden states
+ # Though that's not through between layers so the layers use as input the output of the previous layer
+ # withtout layer norm
+ if output_hidden_states:
+ all_hidden_states += (self.layer_norm(hidden_states),)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ query_pos,
+ reference_points_input,
+ spatial_shapes,
+ level_start_index,
+ vision_encoder_hidden_states,
+ vision_encoder_attention_mask,
+ text_encoder_hidden_states,
+ text_encoder_attention_mask,
+ self_attn_mask,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states=hidden_states,
+ position_embeddings=query_pos,
+ reference_points=reference_points_input,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ vision_encoder_hidden_states=vision_encoder_hidden_states,
+ vision_encoder_attention_mask=vision_encoder_attention_mask,
+ text_encoder_hidden_states=text_encoder_hidden_states,
+ text_encoder_attention_mask=text_encoder_attention_mask,
+ self_attn_mask=self_attn_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ # hack implementation for iterative bounding box refinement
+ if self.bbox_embed is not None:
+ tmp = self.bbox_embed[idx](hidden_states)
+ num_coordinates = reference_points.shape[-1]
+ if num_coordinates == 4:
+ new_reference_points = tmp + torch.special.logit(reference_points, eps=1e-5)
+ new_reference_points = new_reference_points.sigmoid()
+ elif num_coordinates == 2:
+ new_reference_points = tmp
+ new_reference_points[..., :2] = tmp[..., :2] + torch.special.logit(reference_points, eps=1e-5)
+ new_reference_points = new_reference_points.sigmoid()
+ else:
+ raise ValueError(
+ f"Last dim of reference_points must be 2 or 4, but got {reference_points.shape[-1]}"
+ )
+ reference_points = new_reference_points.detach()
+
+ intermediate += (self.layer_norm(hidden_states),)
+ intermediate_reference_points += (reference_points,)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if text_encoder_hidden_states is not None:
+ all_cross_attns_text += (layer_outputs[2],)
+
+ if vision_encoder_hidden_states is not None:
+ all_cross_attns_vision += (layer_outputs[3],)
+
+ # Keep batch_size as first dimension
+ intermediate = torch.stack(intermediate, dim=1)
+ intermediate_reference_points = torch.stack(intermediate_reference_points, dim=1)
+ hidden_states = self.layer_norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if output_attentions:
+ all_attns += (all_self_attns, all_cross_attns_text, all_cross_attns_vision)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ intermediate,
+ intermediate_reference_points,
+ all_hidden_states,
+ all_attns,
+ ]
+ if v is not None
+ )
+ return GroundingDinoDecoderOutput(
+ last_hidden_state=hidden_states,
+ intermediate_hidden_states=intermediate,
+ intermediate_reference_points=intermediate_reference_points,
+ hidden_states=all_hidden_states,
+ attentions=all_attns,
+ )
+
+
+# these correspond to [CLS], [SEP], . and ?
+SPECIAL_TOKENS = [101, 102, 1012, 1029]
+
+
+def generate_masks_with_special_tokens_and_transfer_map(input_ids: torch.LongTensor) -> Tuple[Tensor, Tensor]:
+ """Generate attention mask between each pair of special tokens and positional ids.
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+ Returns:
+ `tuple(torch.Tensor)` comprising attention mask between each special tokens and position_ids:
+ - **attention_mask** (`torch.BoolTensor` of shape `(batch_size, sequence_length, sequence_length)`)
+ - **position_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`)
+ """
+ batch_size, num_token = input_ids.shape
+ # special_tokens_mask: batch_size, num_token. 1 for special tokens. 0 for normal tokens
+ special_tokens_mask = torch.zeros((batch_size, num_token), device=input_ids.device).bool()
+ for special_token in SPECIAL_TOKENS:
+ special_tokens_mask |= input_ids == special_token
+
+ # idxs: each row is a list of indices of special tokens
+ idxs = torch.nonzero(special_tokens_mask)
+
+ # generate attention mask and positional ids
+ attention_mask = torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(batch_size, 1, 1)
+ position_ids = torch.zeros((batch_size, num_token), device=input_ids.device)
+ previous_col = 0
+ for i in range(idxs.shape[0]):
+ row, col = idxs[i]
+ if (col == 0) or (col == num_token - 1):
+ attention_mask[row, col, col] = True
+ position_ids[row, col] = 0
+ else:
+ attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True
+ position_ids[row, previous_col + 1 : col + 1] = torch.arange(
+ 0, col - previous_col, device=input_ids.device
+ )
+
+ previous_col = col
+
+ return attention_mask, position_ids.to(torch.long)
+
+
+@add_start_docstrings(
+ """
+ The bare Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) outputting raw
+ hidden-states without any specific head on top.
+ """,
+ GROUNDING_DINO_START_DOCSTRING,
+)
+class GroundingDinoModel(GroundingDinoPreTrainedModel):
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ # Create backbone + positional encoding
+ backbone = GroundingDinoConvEncoder(config)
+ position_embeddings = build_position_encoding(config)
+ self.backbone = GroundingDinoConvModel(backbone, position_embeddings)
+
+ # Create input projection layers
+ if config.num_feature_levels > 1:
+ num_backbone_outs = len(backbone.intermediate_channel_sizes)
+ input_proj_list = []
+ for i in range(num_backbone_outs):
+ in_channels = backbone.intermediate_channel_sizes[i]
+ input_proj_list.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels, config.d_model, kernel_size=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ )
+ for _ in range(config.num_feature_levels - num_backbone_outs):
+ input_proj_list.append(
+ nn.Sequential(
+ nn.Conv2d(in_channels, config.d_model, kernel_size=3, stride=2, padding=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ )
+ in_channels = config.d_model
+ self.input_proj_vision = nn.ModuleList(input_proj_list)
+ else:
+ self.input_proj_vision = nn.ModuleList(
+ [
+ nn.Sequential(
+ nn.Conv2d(backbone.intermediate_channel_sizes[-1], config.d_model, kernel_size=1),
+ nn.GroupNorm(32, config.d_model),
+ )
+ ]
+ )
+
+ # Create text backbone
+ self.text_backbone = AutoModel.from_config(config.text_config, add_pooling_layer=False)
+ self.text_projection = nn.Linear(config.text_config.hidden_size, config.d_model)
+
+ if config.embedding_init_target or not config.two_stage:
+ self.query_position_embeddings = nn.Embedding(config.num_queries, config.d_model)
+
+ self.encoder = GroundingDinoEncoder(config)
+ self.decoder = GroundingDinoDecoder(config)
+
+ self.level_embed = nn.Parameter(torch.Tensor(config.num_feature_levels, config.d_model))
+
+ if config.two_stage:
+ self.enc_output = nn.Linear(config.d_model, config.d_model)
+ self.enc_output_norm = nn.LayerNorm(config.d_model, config.layer_norm_eps)
+ if (
+ config.two_stage_bbox_embed_share
+ and config.decoder_bbox_embed_share
+ and self.decoder.bbox_embed is not None
+ ):
+ self.encoder_output_bbox_embed = self.decoder.bbox_embed
+ else:
+ self.encoder_output_bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+
+ self.encoder_output_class_embed = GroundingDinoContrastiveEmbedding(config)
+ else:
+ self.reference_points = nn.Embedding(config.num_queries, 4)
+
+ self.post_init()
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ def freeze_backbone(self):
+ for name, param in self.backbone.conv_encoder.model.named_parameters():
+ param.requires_grad_(False)
+
+ def unfreeze_backbone(self):
+ for name, param in self.backbone.conv_encoder.model.named_parameters():
+ param.requires_grad_(True)
+
+ def get_valid_ratio(self, mask):
+ """Get the valid ratio of all feature maps."""
+
+ _, height, width = mask.shape
+ valid_height = torch.sum(mask[:, :, 0], 1)
+ valid_width = torch.sum(mask[:, 0, :], 1)
+ valid_ratio_heigth = valid_height.float() / height
+ valid_ratio_width = valid_width.float() / width
+ valid_ratio = torch.stack([valid_ratio_width, valid_ratio_heigth], -1)
+ return valid_ratio
+
+ def generate_encoder_output_proposals(self, enc_output, padding_mask, spatial_shapes):
+ """Generate the encoder output proposals from encoded enc_output.
+
+ Args:
+ enc_output (`torch.Tensor[batch_size, sequence_length, hidden_size]`): Output of the encoder.
+ padding_mask (`torch.Tensor[batch_size, sequence_length]`): Padding mask for `enc_output`.
+ spatial_shapes (`torch.Tensor[num_feature_levels, 2]`): Spatial shapes of the feature maps.
+
+ Returns:
+ `tuple(torch.FloatTensor)`: A tuple of feature map and bbox prediction.
+ - object_query (Tensor[batch_size, sequence_length, hidden_size]): Object query features. Later used to
+ directly predict a bounding box. (without the need of a decoder)
+ - output_proposals (Tensor[batch_size, sequence_length, 4]): Normalized proposals, after an inverse
+ sigmoid.
+ """
+ batch_size = enc_output.shape[0]
+ proposals = []
+ current_position = 0
+ for level, (height, width) in enumerate(spatial_shapes):
+ mask_flatten_ = padding_mask[:, current_position : (current_position + height * width)]
+ mask_flatten_ = mask_flatten_.view(batch_size, height, width, 1)
+ valid_height = torch.sum(~mask_flatten_[:, :, 0, 0], 1)
+ valid_width = torch.sum(~mask_flatten_[:, 0, :, 0], 1)
+
+ grid_y, grid_x = meshgrid(
+ torch.linspace(0, height - 1, height, dtype=torch.float32, device=enc_output.device),
+ torch.linspace(0, width - 1, width, dtype=torch.float32, device=enc_output.device),
+ indexing="ij",
+ )
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+
+ scale = torch.cat([valid_width.unsqueeze(-1), valid_height.unsqueeze(-1)], 1).view(batch_size, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(batch_size, -1, -1, -1) + 0.5) / scale
+ width_heigth = torch.ones_like(grid) * 0.05 * (2.0**level)
+ proposal = torch.cat((grid, width_heigth), -1).view(batch_size, -1, 4)
+ proposals.append(proposal)
+ current_position += height * width
+
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True)
+ output_proposals = torch.log(output_proposals / (1 - output_proposals)) # inverse sigmoid
+ output_proposals = output_proposals.masked_fill(padding_mask.unsqueeze(-1), float("inf"))
+ output_proposals = output_proposals.masked_fill(~output_proposals_valid, float("inf"))
+
+ # assign each pixel as an object query
+ object_query = enc_output
+ object_query = object_query.masked_fill(padding_mask.unsqueeze(-1), float(0))
+ object_query = object_query.masked_fill(~output_proposals_valid, float(0))
+ object_query = self.enc_output_norm(self.enc_output(object_query))
+ return object_query, output_proposals
+
+ @add_start_docstrings_to_model_forward(GROUNDING_DINO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=GroundingDinoModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Tensor,
+ input_ids: Tensor,
+ token_type_ids: Optional[Tensor] = None,
+ attention_mask: Optional[Tensor] = None,
+ pixel_mask: Optional[Tensor] = None,
+ encoder_outputs=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> text = "a cat."
+
+ >>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
+ >>> model = AutoModel.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ >>> inputs = processor(images=image, text=text, return_tensors="pt")
+ >>> outputs = model(**inputs)
+
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 900, 256]
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_self_attention_masks, position_ids = generate_masks_with_special_tokens_and_transfer_map(input_ids)
+
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ if token_type_ids is None:
+ token_type_ids = torch.zeros_like(input_ids)
+
+ text_token_mask = attention_mask.bool() # just to avoid renaming everywhere
+
+ max_text_len = self.config.max_text_len
+ if text_self_attention_masks.shape[1] > max_text_len:
+ text_self_attention_masks = text_self_attention_masks[:, :max_text_len, :max_text_len]
+ position_ids = position_ids[:, :max_text_len]
+ input_ids = input_ids[:, :max_text_len]
+ token_type_ids = token_type_ids[:, :max_text_len]
+ text_token_mask = text_token_mask[:, :max_text_len]
+
+ # Extract text features from text backbone
+ text_outputs = self.text_backbone(
+ input_ids, text_self_attention_masks, token_type_ids, position_ids, return_dict=return_dict
+ )
+ text_features = text_outputs.last_hidden_state if return_dict else text_outputs[0]
+ text_features = self.text_projection(text_features)
+
+ batch_size, num_channels, height, width = pixel_values.shape
+ device = pixel_values.device
+
+ if pixel_mask is None:
+ pixel_mask = torch.ones(((batch_size, height, width)), dtype=torch.long, device=device)
+
+ # Extract multi-scale feature maps of same resolution `config.d_model` (cf Figure 4 in paper)
+ # First, sent pixel_values + pixel_mask through Backbone to obtain the features
+ # which is a list of tuples
+ vision_features, position_embeddings_list = self.backbone(pixel_values, pixel_mask)
+
+ # Then, apply 1x1 convolution to reduce the channel dimension to d_model (256 by default)
+ feature_maps = []
+ masks = []
+ for level, (source, mask) in enumerate(vision_features):
+ feature_maps.append(self.input_proj_vision[level](source))
+ masks.append(mask)
+
+ # Lowest resolution feature maps are obtained via 3x3 stride 2 convolutions on the final stage
+ if self.config.num_feature_levels > len(feature_maps):
+ _len_sources = len(feature_maps)
+ for level in range(_len_sources, self.config.num_feature_levels):
+ if level == _len_sources:
+ source = self.input_proj_vision[level](vision_features[-1][0])
+ else:
+ source = self.input_proj_vision[level](feature_maps[-1])
+ mask = nn.functional.interpolate(pixel_mask[None].float(), size=source.shape[-2:]).to(torch.bool)[0]
+ pos_l = self.backbone.position_embedding(source, mask).to(source.dtype)
+ feature_maps.append(source)
+ masks.append(mask)
+ position_embeddings_list.append(pos_l)
+
+ # Create queries
+ query_embeds = None
+ if self.config.embedding_init_target or self.config.two_stage:
+ query_embeds = self.query_position_embeddings.weight
+
+ # Prepare encoder inputs (by flattening)
+ source_flatten = []
+ mask_flatten = []
+ lvl_pos_embed_flatten = []
+ spatial_shapes = []
+ for level, (source, mask, pos_embed) in enumerate(zip(feature_maps, masks, position_embeddings_list)):
+ batch_size, num_channels, height, width = source.shape
+ spatial_shape = (height, width)
+ spatial_shapes.append(spatial_shape)
+ source = source.flatten(2).transpose(1, 2)
+ mask = mask.flatten(1)
+ pos_embed = pos_embed.flatten(2).transpose(1, 2)
+ lvl_pos_embed = pos_embed + self.level_embed[level].view(1, 1, -1)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ source_flatten.append(source)
+ mask_flatten.append(mask)
+ source_flatten = torch.cat(source_flatten, 1)
+ mask_flatten = torch.cat(mask_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=source_flatten.device)
+ level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)
+ valid_ratios = valid_ratios.float()
+
+ # Fourth, sent source_flatten + mask_flatten + lvl_pos_embed_flatten (backbone + proj layer output) through encoder
+ # Also provide spatial_shapes, level_start_index and valid_ratios
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ vision_features=source_flatten,
+ vision_attention_mask=~mask_flatten,
+ vision_position_embedding=lvl_pos_embed_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ text_features=text_features,
+ text_attention_mask=~text_token_mask,
+ text_position_embedding=None,
+ text_self_attention_masks=~text_self_attention_masks,
+ text_position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ # If the user passed a tuple for encoder_outputs, we wrap it in a GroundingDinoEncoderOutput when return_dict=True
+ elif return_dict and not isinstance(encoder_outputs, GroundingDinoEncoderOutput):
+ encoder_outputs = GroundingDinoEncoderOutput(
+ last_hidden_state_vision=encoder_outputs[0],
+ last_hidden_state_text=encoder_outputs[1],
+ vision_hidden_states=encoder_outputs[2] if output_hidden_states else None,
+ text_hidden_states=encoder_outputs[3] if output_hidden_states else None,
+ attentions=encoder_outputs[-1] if output_attentions else None,
+ )
+
+ # Fifth, prepare decoder inputs
+ enc_outputs_class = None
+ enc_outputs_coord_logits = None
+ if self.config.two_stage:
+ object_query_embedding, output_proposals = self.generate_encoder_output_proposals(
+ encoder_outputs[0], ~mask_flatten, spatial_shapes
+ )
+
+ # hack implementation as in two-stage Deformable DETR
+ # apply a detection head to each pixel (A.4 in paper)
+ # linear projection for bounding box binary classification (i.e. foreground and background)
+ enc_outputs_class = self.encoder_output_class_embed(
+ object_query_embedding, encoder_outputs[1], text_token_mask
+ )
+ # 3-layer FFN to predict bounding boxes coordinates (bbox regression branch)
+ delta_bbox = self.encoder_output_bbox_embed(object_query_embedding)
+ enc_outputs_coord_logits = delta_bbox + output_proposals
+
+ # only keep top scoring `config.num_queries` proposals
+ topk = self.config.num_queries
+ topk_logits = enc_outputs_class.max(-1)[0]
+ topk_proposals = torch.topk(topk_logits, topk, dim=1)[1]
+ topk_coords_logits = torch.gather(
+ enc_outputs_coord_logits, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)
+ )
+
+ topk_coords_logits = topk_coords_logits.detach()
+ reference_points = topk_coords_logits.sigmoid()
+ init_reference_points = reference_points
+ if query_embeds is not None:
+ target = query_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
+ else:
+ target = torch.gather(
+ object_query_embedding, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model)
+ ).detach()
+ else:
+ target = query_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
+ reference_points = self.reference_points.weight.unsqueeze(0).repeat(batch_size, 1, 1).sigmoid()
+ init_reference_points = reference_points
+
+ decoder_outputs = self.decoder(
+ inputs_embeds=target,
+ vision_encoder_hidden_states=encoder_outputs[0],
+ vision_encoder_attention_mask=mask_flatten,
+ text_encoder_hidden_states=encoder_outputs[1],
+ text_encoder_attention_mask=~text_token_mask,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ self_attn_mask=None,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ enc_outputs = tuple(value for value in [enc_outputs_class, enc_outputs_coord_logits] if value is not None)
+ tuple_outputs = (
+ (decoder_outputs[0], init_reference_points) + decoder_outputs[1:] + encoder_outputs + enc_outputs
+ )
+
+ return tuple_outputs
+
+ return GroundingDinoModelOutput(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ init_reference_points=init_reference_points,
+ intermediate_hidden_states=decoder_outputs.intermediate_hidden_states,
+ intermediate_reference_points=decoder_outputs.intermediate_reference_points,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ encoder_last_hidden_state_vision=encoder_outputs.last_hidden_state_vision,
+ encoder_last_hidden_state_text=encoder_outputs.last_hidden_state_text,
+ encoder_vision_hidden_states=encoder_outputs.vision_hidden_states,
+ encoder_text_hidden_states=encoder_outputs.text_hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ enc_outputs_class=enc_outputs_class,
+ enc_outputs_coord_logits=enc_outputs_coord_logits,
+ )
+
+
+# Copied from transformers.models.detr.modeling_detr.DetrMLPPredictionHead
+class GroundingDinoMLPPredictionHead(nn.Module):
+ """
+ Very simple multi-layer perceptron (MLP, also called FFN), used to predict the normalized center coordinates,
+ height and width of a bounding box w.r.t. an image.
+
+ Copied from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+
+ """
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = nn.functional.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+# Copied from transformers.models.detr.modeling_detr._upcast
+def _upcast(t: Tensor) -> Tensor:
+ # Protects from numerical overflows in multiplications by upcasting to the equivalent higher type
+ if t.is_floating_point():
+ return t if t.dtype in (torch.float32, torch.float64) else t.float()
+ else:
+ return t if t.dtype in (torch.int32, torch.int64) else t.int()
+
+
+# Copied from transformers.models.detr.modeling_detr.box_area
+def box_area(boxes: Tensor) -> Tensor:
+ """
+ Computes the area of a set of bounding boxes, which are specified by its (x1, y1, x2, y2) coordinates.
+
+ Args:
+ boxes (`torch.FloatTensor` of shape `(number_of_boxes, 4)`):
+ Boxes for which the area will be computed. They are expected to be in (x1, y1, x2, y2) format with `0 <= x1
+ < x2` and `0 <= y1 < y2`.
+
+ Returns:
+ `torch.FloatTensor`: a tensor containing the area for each box.
+ """
+ boxes = _upcast(boxes)
+ return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+
+# Copied from transformers.models.detr.modeling_detr.box_iou
+def box_iou(boxes1, boxes2):
+ area1 = box_area(boxes1)
+ area2 = box_area(boxes2)
+
+ left_top = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
+ right_bottom = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
+
+ width_height = (right_bottom - left_top).clamp(min=0) # [N,M,2]
+ inter = width_height[:, :, 0] * width_height[:, :, 1] # [N,M]
+
+ union = area1[:, None] + area2 - inter
+
+ iou = inter / union
+ return iou, union
+
+
+# Copied from transformers.models.detr.modeling_detr.generalized_box_iou
+def generalized_box_iou(boxes1, boxes2):
+ """
+ Generalized IoU from https://giou.stanford.edu/. The boxes should be in [x0, y0, x1, y1] (corner) format.
+
+ Returns:
+ `torch.FloatTensor`: a [N, M] pairwise matrix, where N = len(boxes1) and M = len(boxes2)
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ if not (boxes1[:, 2:] >= boxes1[:, :2]).all():
+ raise ValueError(f"boxes1 must be in [x0, y0, x1, y1] (corner) format, but got {boxes1}")
+ if not (boxes2[:, 2:] >= boxes2[:, :2]).all():
+ raise ValueError(f"boxes2 must be in [x0, y0, x1, y1] (corner) format, but got {boxes2}")
+ iou, union = box_iou(boxes1, boxes2)
+
+ top_left = torch.min(boxes1[:, None, :2], boxes2[:, :2])
+ bottom_right = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])
+
+ width_height = (bottom_right - top_left).clamp(min=0) # [N,M,2]
+ area = width_height[:, :, 0] * width_height[:, :, 1]
+
+ return iou - (area - union) / area
+
+
+# Copied from transformers.models.detr.modeling_detr._max_by_axis
+def _max_by_axis(the_list):
+ # type: (List[List[int]]) -> List[int]
+ maxes = the_list[0]
+ for sublist in the_list[1:]:
+ for index, item in enumerate(sublist):
+ maxes[index] = max(maxes[index], item)
+ return maxes
+
+
+# Copied from transformers.models.detr.modeling_detr.dice_loss
+def dice_loss(inputs, targets, num_boxes):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs (0 for the negative class and 1 for the positive
+ class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.sigmoid_focal_loss
+def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
+ """
+ Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
+
+ Args:
+ inputs (`torch.FloatTensor` of arbitrary shape):
+ The predictions for each example.
+ targets (`torch.FloatTensor` with the same shape as `inputs`)
+ A tensor storing the binary classification label for each element in the `inputs` (0 for the negative class
+ and 1 for the positive class).
+ alpha (`float`, *optional*, defaults to `0.25`):
+ Optional weighting factor in the range (0,1) to balance positive vs. negative examples.
+ gamma (`int`, *optional*, defaults to `2`):
+ Exponent of the modulating factor (1 - p_t) to balance easy vs hard examples.
+
+ Returns:
+ Loss tensor
+ """
+ prob = inputs.sigmoid()
+ ce_loss = nn.functional.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+ # add modulating factor
+ p_t = prob * targets + (1 - prob) * (1 - targets)
+ loss = ce_loss * ((1 - p_t) ** gamma)
+
+ if alpha >= 0:
+ alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
+ loss = alpha_t * loss
+
+ return loss.mean(1).sum() / num_boxes
+
+
+# Copied from transformers.models.detr.modeling_detr.NestedTensor
+class NestedTensor(object):
+ def __init__(self, tensors, mask: Optional[Tensor]):
+ self.tensors = tensors
+ self.mask = mask
+
+ def to(self, device):
+ cast_tensor = self.tensors.to(device)
+ mask = self.mask
+ if mask is not None:
+ cast_mask = mask.to(device)
+ else:
+ cast_mask = None
+ return NestedTensor(cast_tensor, cast_mask)
+
+ def decompose(self):
+ return self.tensors, self.mask
+
+ def __repr__(self):
+ return str(self.tensors)
+
+
+# Copied from transformers.models.detr.modeling_detr.nested_tensor_from_tensor_list
+def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
+ if tensor_list[0].ndim == 3:
+ max_size = _max_by_axis([list(img.shape) for img in tensor_list])
+ batch_shape = [len(tensor_list)] + max_size
+ batch_size, num_channels, height, width = batch_shape
+ dtype = tensor_list[0].dtype
+ device = tensor_list[0].device
+ tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
+ mask = torch.ones((batch_size, height, width), dtype=torch.bool, device=device)
+ for img, pad_img, m in zip(tensor_list, tensor, mask):
+ pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
+ m[: img.shape[1], : img.shape[2]] = False
+ else:
+ raise ValueError("Only 3-dimensional tensors are supported")
+ return NestedTensor(tensor, mask)
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrHungarianMatcher with DeformableDetr->GroundingDino
+class GroundingDinoHungarianMatcher(nn.Module):
+ """
+ This class computes an assignment between the targets and the predictions of the network.
+
+ For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are more
+ predictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others are
+ un-matched (and thus treated as non-objects).
+
+ Args:
+ class_cost:
+ The relative weight of the classification error in the matching cost.
+ bbox_cost:
+ The relative weight of the L1 error of the bounding box coordinates in the matching cost.
+ giou_cost:
+ The relative weight of the giou loss of the bounding box in the matching cost.
+ """
+
+ def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):
+ super().__init__()
+ requires_backends(self, ["scipy"])
+
+ self.class_cost = class_cost
+ self.bbox_cost = bbox_cost
+ self.giou_cost = giou_cost
+ if class_cost == 0 and bbox_cost == 0 and giou_cost == 0:
+ raise ValueError("All costs of the Matcher can't be 0")
+
+ @torch.no_grad()
+ def forward(self, outputs, targets):
+ """
+ Args:
+ outputs (`dict`):
+ A dictionary that contains at least these entries:
+ * "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
+ * "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.
+ targets (`List[dict]`):
+ A list of targets (len(targets) = batch_size), where each target is a dict containing:
+ * "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of
+ ground-truth
+ objects in the target) containing the class labels
+ * "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.
+
+ Returns:
+ `List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:
+ - index_i is the indices of the selected predictions (in order)
+ - index_j is the indices of the corresponding selected targets (in order)
+ For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
+ """
+ batch_size, num_queries = outputs["logits"].shape[:2]
+
+ # We flatten to compute the cost matrices in a batch
+ out_prob = outputs["logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
+ out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
+
+ # Also concat the target labels and boxes
+ target_ids = torch.cat([v["class_labels"] for v in targets])
+ target_bbox = torch.cat([v["boxes"] for v in targets])
+
+ # Compute the classification cost.
+ alpha = 0.25
+ gamma = 2.0
+ neg_cost_class = (1 - alpha) * (out_prob**gamma) * (-(1 - out_prob + 1e-8).log())
+ pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ class_cost = pos_cost_class[:, target_ids] - neg_cost_class[:, target_ids]
+
+ # Compute the L1 cost between boxes
+ bbox_cost = torch.cdist(out_bbox, target_bbox, p=1)
+
+ # Compute the giou cost between boxes
+ giou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(target_bbox))
+
+ # Final cost matrix
+ cost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_cost
+ cost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()
+
+ sizes = [len(v["boxes"]) for v in targets]
+ indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]
+ return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
+
+
+# Copied from transformers.models.deformable_detr.modeling_deformable_detr.DeformableDetrLoss with DeformableDetr->GroundingDino
+class GroundingDinoLoss(nn.Module):
+ """
+ This class computes the losses for `GroundingDinoForObjectDetection`. The process happens in two steps: 1) we
+ compute hungarian assignment between ground truth boxes and the outputs of the model 2) we supervise each pair of
+ matched ground-truth / prediction (supervise class and box).
+
+ Args:
+ matcher (`GroundingDinoHungarianMatcher`):
+ Module able to compute a matching between targets and proposals.
+ num_classes (`int`):
+ Number of object categories, omitting the special no-object category.
+ focal_alpha (`float`):
+ Alpha parameter in focal loss.
+ losses (`List[str]`):
+ List of all the losses to be applied. See `get_loss` for a list of all available losses.
+ """
+
+ def __init__(self, matcher, num_classes, focal_alpha, losses):
+ super().__init__()
+ self.matcher = matcher
+ self.num_classes = num_classes
+ self.focal_alpha = focal_alpha
+ self.losses = losses
+
+ # removed logging parameter, which was part of the original implementation
+ def loss_labels(self, outputs, targets, indices, num_boxes):
+ """
+ Classification loss (Binary focal loss) targets dicts must contain the key "class_labels" containing a tensor
+ of dim [nb_target_boxes]
+ """
+ if "logits" not in outputs:
+ raise KeyError("No logits were found in the outputs")
+ source_logits = outputs["logits"]
+
+ idx = self._get_source_permutation_idx(indices)
+ target_classes_o = torch.cat([t["class_labels"][J] for t, (_, J) in zip(targets, indices)])
+ target_classes = torch.full(
+ source_logits.shape[:2], self.num_classes, dtype=torch.int64, device=source_logits.device
+ )
+ target_classes[idx] = target_classes_o
+
+ target_classes_onehot = torch.zeros(
+ [source_logits.shape[0], source_logits.shape[1], source_logits.shape[2] + 1],
+ dtype=source_logits.dtype,
+ layout=source_logits.layout,
+ device=source_logits.device,
+ )
+ target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
+
+ target_classes_onehot = target_classes_onehot[:, :, :-1]
+ loss_ce = (
+ sigmoid_focal_loss(source_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2)
+ * source_logits.shape[1]
+ )
+ losses = {"loss_ce": loss_ce}
+
+ return losses
+
+ @torch.no_grad()
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss.loss_cardinality
+ def loss_cardinality(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the cardinality error, i.e. the absolute error in the number of predicted non-empty boxes.
+
+ This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients.
+ """
+ logits = outputs["logits"]
+ device = logits.device
+ target_lengths = torch.as_tensor([len(v["class_labels"]) for v in targets], device=device)
+ # Count the number of predictions that are NOT "no-object" (which is the last class)
+ card_pred = (logits.argmax(-1) != logits.shape[-1] - 1).sum(1)
+ card_err = nn.functional.l1_loss(card_pred.float(), target_lengths.float())
+ losses = {"cardinality_error": card_err}
+ return losses
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss.loss_boxes
+ def loss_boxes(self, outputs, targets, indices, num_boxes):
+ """
+ Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss.
+
+ Targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]. The target boxes
+ are expected in format (center_x, center_y, w, h), normalized by the image size.
+ """
+ if "pred_boxes" not in outputs:
+ raise KeyError("No predicted boxes found in outputs")
+ idx = self._get_source_permutation_idx(indices)
+ source_boxes = outputs["pred_boxes"][idx]
+ target_boxes = torch.cat([t["boxes"][i] for t, (_, i) in zip(targets, indices)], dim=0)
+
+ loss_bbox = nn.functional.l1_loss(source_boxes, target_boxes, reduction="none")
+
+ losses = {}
+ losses["loss_bbox"] = loss_bbox.sum() / num_boxes
+
+ loss_giou = 1 - torch.diag(
+ generalized_box_iou(center_to_corners_format(source_boxes), center_to_corners_format(target_boxes))
+ )
+ losses["loss_giou"] = loss_giou.sum() / num_boxes
+ return losses
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss._get_source_permutation_idx
+ def _get_source_permutation_idx(self, indices):
+ # permute predictions following indices
+ batch_idx = torch.cat([torch.full_like(source, i) for i, (source, _) in enumerate(indices)])
+ source_idx = torch.cat([source for (source, _) in indices])
+ return batch_idx, source_idx
+
+ # Copied from transformers.models.detr.modeling_detr.DetrLoss._get_target_permutation_idx
+ def _get_target_permutation_idx(self, indices):
+ # permute targets following indices
+ batch_idx = torch.cat([torch.full_like(target, i) for i, (_, target) in enumerate(indices)])
+ target_idx = torch.cat([target for (_, target) in indices])
+ return batch_idx, target_idx
+
+ def get_loss(self, loss, outputs, targets, indices, num_boxes):
+ loss_map = {
+ "labels": self.loss_labels,
+ "cardinality": self.loss_cardinality,
+ "boxes": self.loss_boxes,
+ }
+ if loss not in loss_map:
+ raise ValueError(f"Loss {loss} not supported")
+ return loss_map[loss](outputs, targets, indices, num_boxes)
+
+ def forward(self, outputs, targets):
+ """
+ This performs the loss computation.
+
+ Args:
+ outputs (`dict`, *optional*):
+ Dictionary of tensors, see the output specification of the model for the format.
+ targets (`List[dict]`, *optional*):
+ List of dicts, such that `len(targets) == batch_size`. The expected keys in each dict depends on the
+ losses applied, see each loss' doc.
+ """
+ outputs_without_aux = {k: v for k, v in outputs.items() if k != "auxiliary_outputs" and k != "enc_outputs"}
+
+ # Retrieve the matching between the outputs of the last layer and the targets
+ indices = self.matcher(outputs_without_aux, targets)
+
+ # Compute the average number of target boxes accross all nodes, for normalization purposes
+ num_boxes = sum(len(t["class_labels"]) for t in targets)
+ num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
+ world_size = 1
+ if is_accelerate_available():
+ if PartialState._shared_state != {}:
+ num_boxes = reduce(num_boxes)
+ world_size = PartialState().num_processes
+ num_boxes = torch.clamp(num_boxes / world_size, min=1).item()
+
+ # Compute all the requested losses
+ losses = {}
+ for loss in self.losses:
+ losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
+
+ # In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
+ if "auxiliary_outputs" in outputs:
+ for i, auxiliary_outputs in enumerate(outputs["auxiliary_outputs"]):
+ indices = self.matcher(auxiliary_outputs, targets)
+ for loss in self.losses:
+ l_dict = self.get_loss(loss, auxiliary_outputs, targets, indices, num_boxes)
+ l_dict = {k + f"_{i}": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ if "enc_outputs" in outputs:
+ enc_outputs = outputs["enc_outputs"]
+ bin_targets = copy.deepcopy(targets)
+ for bt in bin_targets:
+ bt["class_labels"] = torch.zeros_like(bt["class_labels"])
+ indices = self.matcher(enc_outputs, bin_targets)
+ for loss in self.losses:
+ l_dict = self.get_loss(loss, enc_outputs, bin_targets, indices, num_boxes)
+ l_dict = {k + "_enc": v for k, v in l_dict.items()}
+ losses.update(l_dict)
+
+ return losses
+
+
+@add_start_docstrings(
+ """
+ Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) with object detection heads on top,
+ for tasks such as COCO detection.
+ """,
+ GROUNDING_DINO_START_DOCSTRING,
+)
+class GroundingDinoForObjectDetection(GroundingDinoPreTrainedModel):
+ # When using clones, all layers > 0 will be clones, but layer 0 *is* required
+ # the bbox_embed in the decoder are all clones though
+ _tied_weights_keys = [r"bbox_embed\.[1-9]\d*", r"model\.decoder\.bbox_embed\.[0-9]\d*"]
+
+ def __init__(self, config: GroundingDinoConfig):
+ super().__init__(config)
+
+ self.model = GroundingDinoModel(config)
+ _class_embed = GroundingDinoContrastiveEmbedding(config)
+
+ if config.decoder_bbox_embed_share:
+ _bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+ self.bbox_embed = nn.ModuleList([_bbox_embed for _ in range(config.decoder_layers)])
+ else:
+ for _ in range(config.decoder_layers):
+ _bbox_embed = GroundingDinoMLPPredictionHead(
+ input_dim=config.d_model, hidden_dim=config.d_model, output_dim=4, num_layers=3
+ )
+ self.bbox_embed = nn.ModuleList([_bbox_embed for _ in range(config.decoder_layers)])
+ self.class_embed = nn.ModuleList([_class_embed for _ in range(config.decoder_layers)])
+ # hack for box-refinement
+ self.model.decoder.bbox_embed = self.bbox_embed
+ # hack implementation for two-stage
+ self.model.decoder.class_embed = self.class_embed
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # taken from https://github.com/facebookresearch/detr/blob/master/models/detr.py
+ @torch.jit.unused
+ def _set_aux_loss(self, outputs_class, outputs_coord):
+ # this is a workaround to make torchscript happy, as torchscript
+ # doesn't support dictionary with non-homogeneous values, such
+ # as a dict having both a Tensor and a list.
+ return [{"logits": a, "pred_boxes": b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+
+ @add_start_docstrings_to_model_forward(GROUNDING_DINO_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=GroundingDinoObjectDetectionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ input_ids: torch.LongTensor,
+ token_type_ids: torch.LongTensor = None,
+ attention_mask: torch.LongTensor = None,
+ pixel_mask: Optional[torch.BoolTensor] = None,
+ encoder_outputs: Optional[Union[GroundingDinoEncoderOutput, Tuple]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: List[Dict[str, Union[torch.LongTensor, torch.FloatTensor]]] = None,
+ ):
+ r"""
+ labels (`List[Dict]` of len `(batch_size,)`, *optional*):
+ Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the
+ following 2 keys: 'class_labels' and 'boxes' (the class labels and bounding boxes of an image in the batch
+ respectively). The class labels themselves should be a `torch.LongTensor` of len `(number of bounding boxes
+ in the image,)` and the boxes a `torch.FloatTensor` of shape `(number of bounding boxes in the image, 4)`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, GroundingDinoForObjectDetection
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> text = "a cat."
+
+ >>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
+ >>> model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ >>> inputs = processor(images=image, text=text, return_tensors="pt")
+ >>> outputs = model(**inputs)
+
+ >>> # convert outputs (bounding boxes and class logits) to COCO API
+ >>> target_sizes = torch.tensor([image.size[::-1]])
+ >>> results = processor.image_processor.post_process_object_detection(
+ ... outputs, threshold=0.35, target_sizes=target_sizes
+ ... )[0]
+ >>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+ ... box = [round(i, 2) for i in box.tolist()]
+ ... print(f"Detected {label.item()} with confidence " f"{round(score.item(), 3)} at location {box}")
+ Detected 1 with confidence 0.453 at location [344.82, 23.18, 637.4, 373.83]
+ Detected 1 with confidence 0.408 at location [11.92, 51.58, 316.57, 472.89]
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ # First, sent images through Grounding DINO base model to obtain encoder + decoder outputs
+ outputs = self.model(
+ pixel_values=pixel_values,
+ input_ids=input_ids,
+ token_type_ids=token_type_ids,
+ attention_mask=attention_mask,
+ pixel_mask=pixel_mask,
+ encoder_outputs=encoder_outputs,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ idx = 5 + (1 if output_attentions else 0) + (1 if output_hidden_states else 0)
+ enc_text_hidden_state = outputs.encoder_last_hidden_state_text if return_dict else outputs[idx]
+ hidden_states = outputs.intermediate_hidden_states if return_dict else outputs[2]
+ init_reference_points = outputs.init_reference_points if return_dict else outputs[1]
+ inter_references_points = outputs.intermediate_reference_points if return_dict else outputs[3]
+
+ # class logits + predicted bounding boxes
+ outputs_classes = []
+ outputs_coords = []
+
+ # hidden_states are of shape (batch_size, num_stages, height, width)
+ # predict class and bounding box deltas for each stage
+ num_levels = hidden_states.shape[1]
+ for level in range(num_levels):
+ if level == 0:
+ reference = init_reference_points
+ else:
+ reference = inter_references_points[:, level - 1]
+ reference = torch.special.logit(reference, eps=1e-5)
+ outputs_class = self.class_embed[level](
+ vision_hidden_state=hidden_states[:, level],
+ text_hidden_state=enc_text_hidden_state,
+ text_token_mask=attention_mask.bool(),
+ )
+ delta_bbox = self.bbox_embed[level](hidden_states[:, level])
+
+ reference_coordinates = reference.shape[-1]
+ if reference_coordinates == 4:
+ outputs_coord_logits = delta_bbox + reference
+ elif reference_coordinates == 2:
+ delta_bbox[..., :2] += reference
+ outputs_coord_logits = delta_bbox
+ else:
+ raise ValueError(f"reference.shape[-1] should be 4 or 2, but got {reference.shape[-1]}")
+ outputs_coord = outputs_coord_logits.sigmoid()
+ outputs_classes.append(outputs_class)
+ outputs_coords.append(outputs_coord)
+ outputs_class = torch.stack(outputs_classes)
+ outputs_coord = torch.stack(outputs_coords)
+
+ logits = outputs_class[-1]
+ pred_boxes = outputs_coord[-1]
+
+ loss, loss_dict, auxiliary_outputs = None, None, None
+ if labels is not None:
+ # First: create the matcher
+ matcher = GroundingDinoHungarianMatcher(
+ class_cost=self.config.class_cost, bbox_cost=self.config.bbox_cost, giou_cost=self.config.giou_cost
+ )
+ # Second: create the criterion
+ losses = ["labels", "boxes", "cardinality"]
+ criterion = GroundingDinoLoss(
+ matcher=matcher,
+ num_classes=self.config.num_labels,
+ focal_alpha=self.config.focal_alpha,
+ losses=losses,
+ )
+ criterion.to(self.device)
+ # Third: compute the losses, based on outputs and labels
+ outputs_loss = {}
+ outputs_loss["logits"] = logits
+ outputs_loss["pred_boxes"] = pred_boxes
+ if self.config.auxiliary_loss:
+ auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_loss["auxiliary_outputs"] = auxiliary_outputs
+ if self.config.two_stage:
+ enc_outputs_coord = outputs[-1].sigmoid()
+ outputs_loss["enc_outputs"] = {"logits": outputs[-2], "pred_boxes": enc_outputs_coord}
+
+ loss_dict = criterion(outputs_loss, labels)
+ # Fourth: compute total loss, as a weighted sum of the various losses
+ weight_dict = {"loss_ce": 1, "loss_bbox": self.config.bbox_loss_coefficient}
+ weight_dict["loss_giou"] = self.config.giou_loss_coefficient
+ if self.config.auxiliary_loss:
+ aux_weight_dict = {}
+ for i in range(self.config.decoder_layers - 1):
+ aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
+ weight_dict.update(aux_weight_dict)
+ loss = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
+
+ if not return_dict:
+ if auxiliary_outputs is not None:
+ output = (logits, pred_boxes) + auxiliary_outputs + outputs
+ else:
+ output = (logits, pred_boxes) + outputs
+ tuple_outputs = ((loss, loss_dict) + output) if loss is not None else output
+
+ return tuple_outputs
+
+ dict_outputs = GroundingDinoObjectDetectionOutput(
+ loss=loss,
+ loss_dict=loss_dict,
+ logits=logits,
+ pred_boxes=pred_boxes,
+ last_hidden_state=outputs.last_hidden_state,
+ auxiliary_outputs=auxiliary_outputs,
+ decoder_hidden_states=outputs.decoder_hidden_states,
+ decoder_attentions=outputs.decoder_attentions,
+ encoder_last_hidden_state_vision=outputs.encoder_last_hidden_state_vision,
+ encoder_last_hidden_state_text=outputs.encoder_last_hidden_state_text,
+ encoder_vision_hidden_states=outputs.encoder_vision_hidden_states,
+ encoder_text_hidden_states=outputs.encoder_text_hidden_states,
+ encoder_attentions=outputs.encoder_attentions,
+ intermediate_hidden_states=outputs.intermediate_hidden_states,
+ intermediate_reference_points=outputs.intermediate_reference_points,
+ init_reference_points=outputs.init_reference_points,
+ enc_outputs_class=outputs.enc_outputs_class,
+ enc_outputs_coord_logits=outputs.enc_outputs_coord_logits,
+ )
+
+ return dict_outputs
diff --git a/src/transformers/models/grounding_dino/processing_grounding_dino.py b/src/transformers/models/grounding_dino/processing_grounding_dino.py
new file mode 100644
index 00000000000000..44b99811d931ce
--- /dev/null
+++ b/src/transformers/models/grounding_dino/processing_grounding_dino.py
@@ -0,0 +1,228 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for Grounding DINO.
+"""
+
+from typing import List, Optional, Tuple, Union
+
+from ...image_processing_utils import BatchFeature
+from ...image_transforms import center_to_corners_format
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType, is_torch_available
+
+
+if is_torch_available():
+ import torch
+
+
+def get_phrases_from_posmap(posmaps, input_ids):
+ """Get token ids of phrases from posmaps and input_ids.
+
+ Args:
+ posmaps (`torch.BoolTensor` of shape `(num_boxes, hidden_size)`):
+ A boolean tensor of text-thresholded logits related to the detected bounding boxes.
+ input_ids (`torch.LongTensor`) of shape `(sequence_length, )`):
+ A tensor of token ids.
+ """
+ left_idx = 0
+ right_idx = posmaps.shape[-1] - 1
+
+ # Avoiding altering the input tensor
+ posmaps = posmaps.clone()
+
+ posmaps[:, 0 : left_idx + 1] = False
+ posmaps[:, right_idx:] = False
+
+ token_ids = []
+ for posmap in posmaps:
+ non_zero_idx = posmap.nonzero(as_tuple=True)[0].tolist()
+ token_ids.append([input_ids[i] for i in non_zero_idx])
+
+ return token_ids
+
+
+class GroundingDinoProcessor(ProcessorMixin):
+ r"""
+ Constructs a Grounding DINO processor which wraps a Deformable DETR image processor and a BERT tokenizer into a
+ single processor.
+
+ [`GroundingDinoProcessor`] offers all the functionalities of [`GroundingDinoImageProcessor`] and
+ [`AutoTokenizer`]. See the docstring of [`~GroundingDinoProcessor.__call__`] and [`~GroundingDinoProcessor.decode`]
+ for more information.
+
+ Args:
+ image_processor (`GroundingDinoImageProcessor`):
+ An instance of [`GroundingDinoImageProcessor`]. The image processor is a required input.
+ tokenizer (`AutoTokenizer`):
+ An instance of ['PreTrainedTokenizer`]. The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "GroundingDinoImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: ImageInput = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = None,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_token_type_ids: bool = True,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> BatchEncoding:
+ """
+ This method uses [`GroundingDinoImageProcessor.__call__`] method to prepare image(s) for the model, and
+ [`BertTokenizerFast.__call__`] to prepare text for the model.
+
+ Please refer to the docstring of the above two methods for more information.
+ """
+ if images is None and text is None:
+ raise ValueError("You have to specify either images or text.")
+
+ # Get only text
+ if images is not None:
+ encoding_image_processor = self.image_processor(images, return_tensors=return_tensors)
+ else:
+ encoding_image_processor = BatchFeature()
+
+ if text is not None:
+ text_encoding = self.tokenizer(
+ text=text,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_token_type_ids=return_token_type_ids,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ **kwargs,
+ )
+ else:
+ text_encoding = BatchEncoding()
+
+ text_encoding.update(encoding_image_processor)
+
+ return text_encoding
+
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.batch_decode with BertTokenizerFast->PreTrainedTokenizer
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.decode with BertTokenizerFast->PreTrainedTokenizer
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.blip.processing_blip.BlipProcessor.model_input_names
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+ def post_process_grounded_object_detection(
+ self,
+ outputs,
+ input_ids,
+ box_threshold: float = 0.25,
+ text_threshold: float = 0.25,
+ target_sizes: Union[TensorType, List[Tuple]] = None,
+ ):
+ """
+ Converts the raw output of [`GroundingDinoForObjectDetection`] into final bounding boxes in (top_left_x, top_left_y,
+ bottom_right_x, bottom_right_y) format and get the associated text label.
+
+ Args:
+ outputs ([`GroundingDinoObjectDetectionOutput`]):
+ Raw outputs of the model.
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The token ids of the input text.
+ box_threshold (`float`, *optional*, defaults to 0.25):
+ Score threshold to keep object detection predictions.
+ text_threshold (`float`, *optional*, defaults to 0.25):
+ Score threshold to keep text detection predictions.
+ target_sizes (`torch.Tensor` or `List[Tuple[int, int]]`, *optional*):
+ Tensor of shape `(batch_size, 2)` or list of tuples (`Tuple[int, int]`) containing the target size
+ `(height, width)` of each image in the batch. If unset, predictions will not be resized.
+ Returns:
+ `List[Dict]`: A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
+ in the batch as predicted by the model.
+ """
+ logits, boxes = outputs.logits, outputs.pred_boxes
+
+ if target_sizes is not None:
+ if len(logits) != len(target_sizes):
+ raise ValueError(
+ "Make sure that you pass in as many target sizes as the batch dimension of the logits"
+ )
+
+ probs = torch.sigmoid(logits) # (batch_size, num_queries, 256)
+ scores = torch.max(probs, dim=-1)[0] # (batch_size, num_queries)
+
+ # Convert to [x0, y0, x1, y1] format
+ boxes = center_to_corners_format(boxes)
+
+ # Convert from relative [0, 1] to absolute [0, height] coordinates
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
+
+ results = []
+ for idx, (s, b, p) in enumerate(zip(scores, boxes, probs)):
+ score = s[s > box_threshold]
+ box = b[s > box_threshold]
+ prob = p[s > box_threshold]
+ label_ids = get_phrases_from_posmap(prob > text_threshold, input_ids[idx])
+ label = self.batch_decode(label_ids)
+ results.append({"scores": score, "labels": label, "boxes": box})
+
+ return results
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 1bdab80a13f667..c3bf96fef96692 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -4236,6 +4236,30 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+GROUNDING_DINO_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class GroundingDinoForObjectDetection(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class GroundingDinoModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class GroundingDinoPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index d7a629a1b24026..80b418adc16f37 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -247,6 +247,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class GroundingDinoImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class IdeficsImageProcessor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/grounding_dino/__init__.py b/tests/models/grounding_dino/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/grounding_dino/test_image_processing_grounding_dino.py b/tests/models/grounding_dino/test_image_processing_grounding_dino.py
new file mode 100644
index 00000000000000..df69784bbb4523
--- /dev/null
+++ b/tests/models/grounding_dino/test_image_processing_grounding_dino.py
@@ -0,0 +1,530 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GroundingDinoImageProcessor
+
+
+class GroundingDinoImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.num_queries = 5
+ self.embed_dim = 5
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_processor_dict with DeformableDetr->GroundingDino
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ }
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.get_expected_values with DeformableDetr->GroundingDino
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to GroundingDinoImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.expected_output_image_shape with DeformableDetr->GroundingDino
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ )
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_inputs with DeformableDetr->GroundingDino
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class GroundingDinoImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = GroundingDinoImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.image_processor_tester = GroundingDinoImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_properties with DeformableDetr->GroundingDino
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_from_dict_with_kwargs with DeformableDetr->GroundingDino
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = self.image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ def test_post_process_object_detection(self):
+ image_processor = self.image_processing_class(**self.image_processor_dict)
+ outputs = self.image_processor_tester.get_fake_grounding_dino_output()
+ results = image_processor.post_process_object_detection(outputs, threshold=0.0)
+
+ self.assertEqual(len(results), self.image_processor_tester.batch_size)
+ self.assertEqual(list(results[0].keys()), ["scores", "labels", "boxes"])
+ self.assertEqual(results[0]["boxes"].shape, (self.image_processor_tester.num_queries, 4))
+ self.assertEqual(results[0]["scores"].shape, (self.image_processor_tester.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ self.assertTrue(torch.allclose(results[0]["scores"], expected_scores, atol=1e-4))
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ self.assertTrue(torch.allclose(results[0]["boxes"][0], expected_box_slice, atol=1e-4))
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_detection_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor()
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ self.assertTrue(torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4))
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["area"], expected_area))
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3))
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["image_id"], expected_image_id))
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd))
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size))
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["size"], expected_size))
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_detection_annotations with Detr->GroundingDino
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ image_processing = GroundingDinoImageProcessor()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1e-3))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1e-3))
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1))
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_panoptic_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor(format="coco_panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ self.assertTrue(torch.allclose(encoding["pixel_values"][0, 0, 0, :3], expected_slice, atol=1e-4))
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["area"], expected_area))
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"][0], expected_boxes_slice, atol=1e-3))
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["image_id"], expected_image_id))
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["iscrowd"], expected_is_crowd))
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["class_labels"], expected_class_labels))
+ # verify masks
+ expected_masks_sum = 822873
+ self.assertEqual(encoding["labels"][0]["masks"].sum().item(), expected_masks_sum)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["orig_size"], expected_orig_size))
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ self.assertTrue(torch.allclose(encoding["labels"][0]["size"], expected_size))
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_panoptic_annotations with Detr->GroundingDino
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt", "r") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ # encode them
+ image_processing = GroundingDinoImageProcessor(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1e-3))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1e-3))
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ self.assertTrue(torch.allclose(encoding["labels"][0]["boxes"], expected_boxes_0, rtol=1))
+ self.assertTrue(torch.allclose(encoding["labels"][1]["boxes"], expected_boxes_1, rtol=1))
diff --git a/tests/models/grounding_dino/test_modeling_grounding_dino.py b/tests/models/grounding_dino/test_modeling_grounding_dino.py
new file mode 100644
index 00000000000000..42486f92da9746
--- /dev/null
+++ b/tests/models/grounding_dino/test_modeling_grounding_dino.py
@@ -0,0 +1,689 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Grounding DINO model. """
+
+import collections
+import inspect
+import math
+import re
+import unittest
+
+from transformers import (
+ GroundingDinoConfig,
+ SwinConfig,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.file_utils import cached_property
+from transformers.testing_utils import (
+ require_timm,
+ require_torch,
+ require_torch_gpu,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import GroundingDinoForObjectDetection, GroundingDinoModel
+ from transformers.pytorch_utils import id_tensor_storage
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoProcessor
+
+
+class GroundingDinoModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=4,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=2,
+ num_channels=3,
+ image_size=98,
+ n_targets=8,
+ num_labels=3,
+ num_feature_levels=4,
+ encoder_n_points=2,
+ decoder_n_points=6,
+ max_text_len=7,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+ self.max_text_len = max_text_len
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length_vision = (
+ math.ceil(self.image_size / 8) ** 2
+ + math.ceil(self.image_size / 16) ** 2
+ + math.ceil(self.image_size / 32) ** 2
+ + math.ceil(self.image_size / 64) ** 2
+ )
+
+ self.encoder_seq_length_text = self.max_text_len
+
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ pixel_mask = torch.ones([self.batch_size, self.image_size, self.image_size], device=torch_device)
+
+ input_ids = ids_tensor([self.batch_size, self.max_text_len], self.num_labels)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.image_size, self.image_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, input_ids, labels
+
+ def get_config(self):
+ swin_config = SwinConfig(
+ window_size=7,
+ embed_dim=8,
+ depths=[1, 1, 1, 1],
+ num_heads=[1, 1, 1, 1],
+ image_size=self.image_size,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ text_backbone = {
+ "hidden_size": 8,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 2,
+ "intermediate_size": 8,
+ "max_position_embeddings": 8,
+ "model_type": "bert",
+ }
+ return GroundingDinoConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ num_feature_levels=self.num_feature_levels,
+ encoder_n_points=self.encoder_n_points,
+ decoder_n_points=self.decoder_n_points,
+ use_timm_backbone=False,
+ backbone_config=swin_config,
+ max_text_len=self.max_text_len,
+ text_config=text_backbone,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, input_ids, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask, "input_ids": input_ids}
+ return config, inputs_dict
+
+ def create_and_check_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.num_queries, self.hidden_size))
+
+ def create_and_check_object_detection_head_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class GroundingDinoModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GroundingDinoModel, GroundingDinoForObjectDetection) if is_torch_available() else ()
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ pipeline_model_mapping = (
+ {"image-feature-extraction": GroundingDinoModel, "zero-shot-object-detection": GroundingDinoForObjectDetection}
+ if is_torch_available()
+ else {}
+ )
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.image_size,
+ self.model_tester.image_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GroundingDinoModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GroundingDinoConfig, has_text_modality=False)
+
+ def test_config(self):
+ # we don't test common_properties and arguments_init as these don't apply for Grounding DINO
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_object_detection_head_model(*config_and_inputs)
+
+ @unittest.skip(reason="Grounding DINO does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not have a get_input_embeddings method")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 10
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ correct_outlen += 2
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions[0]
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, self.model_tester.num_queries, self.model_tester.num_queries],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.decoder_attentions[-1]
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.decoder_n_points,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 3, len(outputs))
+
+ self_attentions = outputs.encoder_attentions[-1]
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+
+ # overwrite since hidden_states are called encoder_text_hidden_states
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_vision_hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_vision
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.encoder_text_hidden_states
+
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_text
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.decoder_hidden_states
+
+ self.assertIsInstance(hidden_states, (list, tuple))
+ self.assertEqual(len(hidden_states), expected_num_layers)
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [decoder_seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_vision_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0][0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ cross_attentions = outputs.decoder_attentions[-1][0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values", "input_ids"]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.use_timm_backbone = True
+ config.backbone_config = None
+ config.backbone_kwargs = {"in_chans": 3, "out_indices": (2, 3, 4)}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ config.max_text_len,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if (
+ "level_embed" in name
+ or "sampling_offsets.bias" in name
+ or "text_param" in name
+ or "vision_param" in name
+ or "value_proj" in name
+ or "output_proj" in name
+ or "reference_points" in name
+ ):
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # Copied from tests.models.deformable_detr.test_modeling_deformable_detr.DeformableDetrModelTest.test_two_stage_training with DeformableDetr->GroundingDino
+ def test_two_stage_training(self):
+ model_class = GroundingDinoForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+ config.two_stage = True
+ config.auxiliary_loss = True
+ config.with_box_refine = True
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_tied_weights_keys(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.tie_word_embeddings = True
+ for model_class in self.all_model_classes:
+ model_tied = model_class(config)
+
+ ptrs = collections.defaultdict(list)
+ for name, tensor in model_tied.state_dict().items():
+ ptrs[id_tensor_storage(tensor)].append(name)
+
+ # These are all the pointers of shared tensors.
+ tied_params = [names for _, names in ptrs.items() if len(names) > 1]
+
+ tied_weight_keys = model_tied._tied_weights_keys if model_tied._tied_weights_keys is not None else []
+ # Detect we get a hit for each key
+ for key in tied_weight_keys:
+ if not any(re.search(key, p) for group in tied_params for p in group):
+ raise ValueError(f"{key} is not a tied weight key for {model_class}.")
+
+ # Removed tied weights found from tied params -> there should only be one left after
+ for key in tied_weight_keys:
+ for i in range(len(tied_params)):
+ tied_params[i] = [p for p in tied_params[i] if re.search(key, p) is None]
+
+ # GroundingDino when sharing weights also uses the shared ones in GroundingDinoDecoder
+ # Therefore, differently from DeformableDetr, we expect the group lens to be 2
+ # one for self.bbox_embed in GroundingDinoForObejectDetection and another one
+ # in the decoder
+ tied_params = [group for group in tied_params if len(group) > 2]
+ self.assertListEqual(
+ tied_params,
+ [],
+ f"Missing `_tied_weights_keys` for {model_class}: add all of {tied_params} except one.",
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+def prepare_text():
+ text = "a cat."
+ return text
+
+
+@require_timm
+@require_vision
+@slow
+class GroundingDinoModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_processor(self):
+ return AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny") if is_vision_available() else None
+
+ def test_inference_object_detection_head(self):
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(torch_device)
+
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.d_model))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+
+ expected_boxes = torch.tensor(
+ [[0.7674, 0.4136, 0.4572], [0.2566, 0.5463, 0.4760], [0.2585, 0.5442, 0.4641]]
+ ).to(torch_device)
+ expected_logits = torch.tensor(
+ [[-4.8913, -0.1900, -0.2161], [-4.9653, -0.3719, -0.3950], [-5.9599, -3.3765, -3.3104]]
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_logits, atol=1e-3))
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ self.assertTrue(torch.allclose(outputs.pred_boxes[0, :3, :3], expected_boxes, atol=1e-4))
+
+ # verify postprocessing
+ results = processor.image_processor.post_process_object_detection(
+ outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.4526, 0.4082]).to(torch_device)
+ expected_slice_boxes = torch.tensor([344.8143, 23.1796, 637.4004, 373.8295]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 2)
+ self.assertTrue(torch.allclose(results["scores"], expected_scores, atol=1e-3))
+ self.assertTrue(torch.allclose(results["boxes"][0, :], expected_slice_boxes, atol=1e-2))
+
+ # verify grounded postprocessing
+ expected_labels = ["a cat", "a cat"]
+ results = processor.post_process_grounded_object_detection(
+ outputs=outputs,
+ input_ids=encoding.input_ids,
+ box_threshold=0.35,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]],
+ )[0]
+
+ self.assertTrue(torch.allclose(results["scores"], expected_scores, atol=1e-3))
+ self.assertTrue(torch.allclose(results["boxes"][0, :], expected_slice_boxes, atol=1e-2))
+ self.assertListEqual(results["labels"], expected_labels)
+
+ @require_torch_gpu
+ def test_inference_object_detection_head_equivalence_cpu_gpu(self):
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt")
+
+ # 1. run model on CPU
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ with torch.no_grad():
+ cpu_outputs = model(**encoding)
+
+ # 2. run model on GPU
+ model.to("cuda")
+ encoding = encoding.to("cuda")
+ with torch.no_grad():
+ gpu_outputs = model(**encoding)
+
+ # 3. assert equivalence
+ for key in cpu_outputs.keys():
+ self.assertTrue(torch.allclose(cpu_outputs[key], gpu_outputs[key].cpu(), atol=1e-3))
+
+ expected_logits = torch.tensor(
+ [[-4.8915, -0.1900, -0.2161], [-4.9658, -0.3716, -0.3948], [-5.9596, -3.3763, -3.3103]]
+ )
+ self.assertTrue(torch.allclose(cpu_outputs.logits[0, :3, :3], expected_logits, atol=1e-3))
+
+ # assert postprocessing
+ results_cpu = processor.image_processor.post_process_object_detection(
+ cpu_outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+
+ result_gpu = processor.image_processor.post_process_object_detection(
+ gpu_outputs, threshold=0.35, target_sizes=[image.size[::-1]]
+ )[0]
+
+ self.assertTrue(torch.allclose(results_cpu["scores"], result_gpu["scores"].cpu(), atol=1e-3))
+ self.assertTrue(torch.allclose(results_cpu["boxes"], result_gpu["boxes"].cpu(), atol=1e-3))
diff --git a/tests/models/grounding_dino/test_processor_grounding_dino.py b/tests/models/grounding_dino/test_processor_grounding_dino.py
new file mode 100644
index 00000000000000..a788d09ca7eed1
--- /dev/null
+++ b/tests/models/grounding_dino/test_processor_grounding_dino.py
@@ -0,0 +1,253 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+
+from transformers import BertTokenizer, BertTokenizerFast, GroundingDinoProcessor
+from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import IMAGE_PROCESSOR_NAME, is_torch_available, is_vision_available
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GroundingDinoImageProcessor
+
+
+@require_torch
+@require_vision
+class GroundingDinoProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.tmpdirname = tempfile.mkdtemp()
+
+ vocab_tokens = ["[UNK]","[CLS]","[SEP]","[PAD]","[MASK]","want","##want","##ed","wa","un","runn","##ing",",","low","lowest"] # fmt: skip
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": None,
+ "do_normalize": True,
+ "image_mean": [0.5, 0.5, 0.5],
+ "image_std": [0.5, 0.5, 0.5],
+ "do_rescale": True,
+ "rescale_factor": 1 / 255,
+ "do_pad": True,
+ }
+ self.image_processor_file = os.path.join(self.tmpdirname, IMAGE_PROCESSOR_NAME)
+ with open(self.image_processor_file, "w", encoding="utf-8") as fp:
+ json.dump(image_processor_map, fp)
+
+ self.batch_size = 7
+ self.num_queries = 5
+ self.embed_dim = 5
+ self.seq_length = 5
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_tokenizer with CLIP->Bert
+ def get_tokenizer(self, **kwargs):
+ return BertTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_rust_tokenizer with CLIP->Bert
+ def get_rust_tokenizer(self, **kwargs):
+ return BertTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_image_processor with CLIP->GroundingDino
+ def get_image_processor(self, **kwargs):
+ return GroundingDinoImageProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.tearDown
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.prepare_image_inputs
+ def prepare_image_inputs(self):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+ """
+
+ image_inputs = [np.random.randint(255, size=(3, 30, 400), dtype=np.uint8)]
+
+ image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+
+ return image_inputs
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ )
+
+ def get_fake_grounding_dino_input_ids(self):
+ input_ids = torch.tensor([101, 1037, 4937, 1012, 102])
+ return torch.stack([input_ids] * self.batch_size, dim=0)
+
+ def test_post_process_grounded_object_detection(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ grounding_dino_output = self.get_fake_grounding_dino_output()
+ grounding_dino_input_ids = self.get_fake_grounding_dino_input_ids()
+
+ post_processed = processor.post_process_grounded_object_detection(
+ grounding_dino_output, grounding_dino_input_ids
+ )
+
+ self.assertEqual(len(post_processed), self.batch_size)
+ self.assertEqual(list(post_processed[0].keys()), ["scores", "labels", "boxes"])
+ self.assertEqual(post_processed[0]["boxes"].shape, (self.num_queries, 4))
+ self.assertEqual(post_processed[0]["scores"].shape, (self.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ self.assertTrue(torch.allclose(post_processed[0]["scores"], expected_scores, atol=1e-4))
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ self.assertTrue(torch.allclose(post_processed[0]["boxes"][0], expected_box_slice, atol=1e-4))
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_default with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ image_processor = self.get_image_processor()
+
+ processor_slow = GroundingDinoProcessor(tokenizer=tokenizer_slow, image_processor=image_processor)
+ processor_slow.save_pretrained(self.tmpdirname)
+ processor_slow = GroundingDinoProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = GroundingDinoProcessor(tokenizer=tokenizer_fast, image_processor=image_processor)
+ processor_fast.save_pretrained(self.tmpdirname)
+ processor_fast = GroundingDinoProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, BertTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor_slow.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertEqual(processor_fast.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor_slow.image_processor, GroundingDinoImageProcessor)
+ self.assertIsInstance(processor_fast.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_additional_features with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_additional_features(self):
+ processor = GroundingDinoProcessor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = GroundingDinoProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_image_processor with CLIP->GroundingDino
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_image_proc = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_image_proc.keys():
+ self.assertAlmostEqual(input_image_proc[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer with CLIP->GroundingDino
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(
+ list(inputs.keys()), ["input_ids", "token_type_ids", "attention_mask", "pixel_values", "pixel_mask"]
+ )
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer_decode with CLIP->GroundingDino
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_model_input_names with CLIP->GroundingDino
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)