diff --git a/.github/workflows/build-docker-images.yml b/.github/workflows/build-docker-images.yml
index b267ad7882d89f..be070a95d3a94f 100644
--- a/.github/workflows/build-docker-images.yml
+++ b/.github/workflows/build-docker-images.yml
@@ -271,3 +271,39 @@ jobs:
REF=main
push: true
tags: huggingface/transformers-tensorflow-gpu
+
+ # latest-pytorch-deepspeed-amd:
+ # name: "PyTorch + DeepSpeed (AMD) [dev]"
+
+ # runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
+ # steps:
+ # - name: Set up Docker Buildx
+ # uses: docker/setup-buildx-action@v3
+ # - name: Check out code
+ # uses: actions/checkout@v3
+ # - name: Login to DockerHub
+ # uses: docker/login-action@v3
+ # with:
+ # username: ${{ secrets.DOCKERHUB_USERNAME }}
+ # password: ${{ secrets.DOCKERHUB_PASSWORD }}
+ # - name: Build and push
+ # uses: docker/build-push-action@v5
+ # with:
+ # context: ./docker/transformers-pytorch-deepspeed-amd-gpu
+ # build-args: |
+ # REF=main
+ # push: true
+ # tags: huggingface/transformers-pytorch-deepspeed-amd-gpu${{ inputs.image_postfix }}
+ # # Push CI images still need to be re-built daily
+ # -
+ # name: Build and push (for Push CI) in a daily basis
+ # # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
+ # # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
+ # if: inputs.image_postfix != '-push-ci'
+ # uses: docker/build-push-action@v5
+ # with:
+ # context: ./docker/transformers-pytorch-deepspeed-amd-gpu
+ # build-args: |
+ # REF=main
+ # push: true
+ # tags: huggingface/transformers-pytorch-deepspeed-amd-gpu-push-ci
diff --git a/.github/workflows/check_runner_status.yml b/.github/workflows/check_runner_status.yml
deleted file mode 100644
index 328d284223a857..00000000000000
--- a/.github/workflows/check_runner_status.yml
+++ /dev/null
@@ -1,68 +0,0 @@
-name: Self-hosted runner (check runner status)
-
-# Note that each job's dependencies go into a corresponding docker file.
-#
-# For example for `run_all_tests_torch_cuda_extensions_gpu` the docker image is
-# `huggingface/transformers-pytorch-deepspeed-latest-gpu`, which can be found at
-# `docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile`
-
-on:
- repository_dispatch:
- schedule:
- # run per hour
- - cron: "0 */1 * * *"
-
-env:
- TRANSFORMERS_IS_CI: yes
-
-jobs:
- check_runner_status:
- name: Check Runner Status
- runs-on: ubuntu-22.04
- outputs:
- offline_runners: ${{ steps.set-offline_runners.outputs.offline_runners }}
- steps:
- - name: Checkout transformers
- uses: actions/checkout@v3
- with:
- fetch-depth: 2
-
- - name: Check Runner Status
- run: python utils/check_self_hosted_runner.py --target_runners single-gpu-ci-runner-docker,multi-gpu-ci-runner-docker,single-gpu-scheduled-ci-runner-docker,multi-scheduled-scheduled-ci-runner-docker,single-gpu-doctest-ci-runner-docker --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
-
- - id: set-offline_runners
- name: Set output for offline runners
- if: ${{ always() }}
- run: |
- offline_runners=$(python3 -c 'fp = open("offline_runners.txt"); failed = fp.read(); fp.close(); print(failed)')
- echo "offline_runners=$offline_runners" >> $GITHUB_OUTPUT
-
- send_results:
- name: Send results to webhook
- runs-on: ubuntu-22.04
- needs: check_runner_status
- if: ${{ failure() }}
- steps:
- - name: Preliminary job status
- shell: bash
- run: |
- echo "Runner availability: ${{ needs.check_runner_status.result }}"
-
- - uses: actions/checkout@v3
- - uses: actions/download-artifact@v3
- - name: Send message to Slack
- env:
- CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
- CI_SLACK_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
- CI_SLACK_CHANNEL_ID_DAILY: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
- CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
- CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
- ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
- CI_EVENT: runner status check
- RUNNER_STATUS: ${{ needs.check_runner_status.result }}
- OFFLINE_RUNNERS: ${{ needs.check_runner_status.outputs.offline_runners }}
- # We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
- # `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
- run: |
- pip install slack_sdk
- python utils/notification_service.py
diff --git a/.github/workflows/delete_doc_comment.yml b/.github/workflows/delete_doc_comment.yml
deleted file mode 100644
index 8604019d76eb50..00000000000000
--- a/.github/workflows/delete_doc_comment.yml
+++ /dev/null
@@ -1,14 +0,0 @@
-name: Delete doc comment
-
-on:
- workflow_run:
- workflows: ["Delete doc comment trigger"]
- types:
- - completed
-
-
-jobs:
- delete:
- uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
- secrets:
- comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
\ No newline at end of file
diff --git a/.github/workflows/delete_doc_comment_trigger.yml b/.github/workflows/delete_doc_comment_trigger.yml
deleted file mode 100644
index f87d9bd4dca705..00000000000000
--- a/.github/workflows/delete_doc_comment_trigger.yml
+++ /dev/null
@@ -1,12 +0,0 @@
-name: Delete doc comment trigger
-
-on:
- pull_request:
- types: [ closed ]
-
-
-jobs:
- delete:
- uses: huggingface/doc-builder/.github/workflows/delete_doc_comment_trigger.yml@main
- with:
- pr_number: ${{ github.event.number }}
diff --git a/.github/workflows/self-nightly-scheduled.yml b/.github/workflows/self-nightly-scheduled.yml
index e4b4f7f77cf077..37dc98f340a16d 100644
--- a/.github/workflows/self-nightly-scheduled.yml
+++ b/.github/workflows/self-nightly-scheduled.yml
@@ -212,7 +212,7 @@ jobs:
python3 -m pip uninstall -y deepspeed
rm -rf DeepSpeed
git clone https://github.com/microsoft/DeepSpeed && cd DeepSpeed && rm -rf build
- DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
- name: NVIDIA-SMI
run: |
@@ -286,4 +286,4 @@ jobs:
with:
name: |
single-*
- multi-*
\ No newline at end of file
+ multi-*
diff --git a/.github/workflows/self-past.yml b/.github/workflows/self-past.yml
index 6a154544df8b97..ed60c92f6745a8 100644
--- a/.github/workflows/self-past.yml
+++ b/.github/workflows/self-past.yml
@@ -88,6 +88,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Echo folder ${{ matrix.folders }}
shell: bash
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
@@ -164,6 +168,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Echo folder ${{ matrix.folders }}
shell: bash
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
@@ -240,6 +248,10 @@ jobs:
working-directory: /transformers
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+ - name: Update some packages
+ working-directory: /transformers
+ run: python3 -m pip install -U datasets
+
- name: Install
working-directory: /transformers
run: |
@@ -255,7 +267,7 @@ jobs:
python3 -m pip uninstall -y deepspeed
rm -rf DeepSpeed
git clone https://github.com/microsoft/DeepSpeed && cd DeepSpeed && rm -rf build
- DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
- name: NVIDIA-SMI
run: |
@@ -341,4 +353,4 @@ jobs:
with:
name: |
single-*
- multi-*
\ No newline at end of file
+ multi-*
diff --git a/.github/workflows/self-push-amd-mi210-caller.yml b/.github/workflows/self-push-amd-mi210-caller.yml
index 5dd010ef66d8fb..2e6b9301d8d72a 100644
--- a/.github/workflows/self-push-amd-mi210-caller.yml
+++ b/.github/workflows/self-push-amd-mi210-caller.yml
@@ -18,7 +18,7 @@ on:
jobs:
run_amd_ci:
name: AMD mi210
- if: (cancelled() != true) && ((github.event_name != 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
+ if: (cancelled() != true) && ((github.event_name == 'push') && (github.ref_name == 'main' || startsWith(github.ref_name, 'run_amd_push_ci_caller')))
uses: ./.github/workflows/self-push-amd.yml
with:
gpu_flavor: mi210
diff --git a/.github/workflows/self-push-amd-mi250-caller.yml b/.github/workflows/self-push-amd-mi250-caller.yml
index a55378c4caa54b..412fb8f08870e3 100644
--- a/.github/workflows/self-push-amd-mi250-caller.yml
+++ b/.github/workflows/self-push-amd-mi250-caller.yml
@@ -18,7 +18,7 @@ on:
jobs:
run_amd_ci:
name: AMD mi250
- if: (cancelled() != true) && ((github.event_name != 'schedule') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_push_ci_caller')))
+ if: (cancelled() != true) && ((github.event_name == 'push') && (github.ref_name == 'main' || startsWith(github.ref_name, 'run_amd_push_ci_caller')))
uses: ./.github/workflows/self-push-amd.yml
with:
gpu_flavor: mi250
diff --git a/.github/workflows/self-push-amd.yml b/.github/workflows/self-push-amd.yml
index c72f224a300cc8..19857981b12dbd 100644
--- a/.github/workflows/self-push-amd.yml
+++ b/.github/workflows/self-push-amd.yml
@@ -38,14 +38,16 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
steps:
- name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
run: |
rocminfo | grep "Agent" -A 14
- - name: Show HIP environment
+ - name: Show ROCR environment
run: |
- echo "HIP: $HIP_VISIBLE_DEVICES"
echo "ROCR: $ROCR_VISIBLE_DEVICES"
setup_gpu:
@@ -57,7 +59,7 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
outputs:
matrix: ${{ steps.set-matrix.outputs.matrix }}
test_map: ${{ steps.set-matrix.outputs.test_map }}
@@ -155,7 +157,7 @@ jobs:
runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
container:
image: huggingface/transformers-pytorch-amd-gpu-push-ci # <--- We test only for PyTorch for now
- options: --device /dev/kfd --device /dev/dri --env HIP_VISIBLE_DEVICES --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
steps:
# Necessary to get the correct branch name and commit SHA for `workflow_run` event
# We also take into account the `push` event (we might want to test some changes in a branch)
@@ -206,11 +208,13 @@ jobs:
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
- name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
run: |
rocminfo | grep "Agent" -A 14
- - name: Show HIP environment
+ - name: Show ROCR environment
run: |
- echo "HIP: $HIP_VISIBLE_DEVICES"
echo "ROCR: $ROCR_VISIBLE_DEVICES"
- name: Environment
diff --git a/.github/workflows/self-push.yml b/.github/workflows/self-push.yml
index a6ea5b1e04b942..e6f1f3b3050f7a 100644
--- a/.github/workflows/self-push.yml
+++ b/.github/workflows/self-push.yml
@@ -366,7 +366,7 @@ jobs:
working-directory: /workspace
run: |
python3 -m pip uninstall -y deepspeed
- DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
- name: NVIDIA-SMI
run: |
@@ -456,7 +456,7 @@ jobs:
working-directory: /workspace
run: |
python3 -m pip uninstall -y deepspeed
- DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
- name: NVIDIA-SMI
run: |
diff --git a/.github/workflows/self-scheduled-amd-caller.yml b/.github/workflows/self-scheduled-amd-caller.yml
new file mode 100644
index 00000000000000..dc5c7b7e905bd8
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd-caller.yml
@@ -0,0 +1,14 @@
+name: Self-hosted runner (AMD scheduled CI caller)
+
+on:
+ schedule:
+ - cron: "17 2 * * *"
+
+jobs:
+ run_scheduled_amd_ci:
+ name: Trigger Scheduled AMD CI
+ runs-on: ubuntu-22.04
+ if: ${{ always() }}
+ steps:
+ - name: Trigger scheduled AMD CI via workflow_run
+ run: echo "Trigger scheduled AMD CI via workflow_run"
diff --git a/.github/workflows/self-scheduled-amd-mi210-caller.yml b/.github/workflows/self-scheduled-amd-mi210-caller.yml
new file mode 100644
index 00000000000000..cdb968901058b6
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd-mi210-caller.yml
@@ -0,0 +1,19 @@
+name: Self-hosted runner (AMD mi210 scheduled CI caller)
+
+on:
+ workflow_run:
+ workflows: ["Self-hosted runner (AMD scheduled CI caller)"]
+ branches: ["main"]
+ types: [completed]
+ push:
+ branches:
+ - run_amd_scheduled_ci_caller*
+
+jobs:
+ run_amd_ci:
+ name: AMD mi210
+ if: (cancelled() != true) && ((github.event_name == 'workflow_run') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_scheduled_ci_caller')))
+ uses: ./.github/workflows/self-scheduled-amd.yml
+ with:
+ gpu_flavor: mi210
+ secrets: inherit
diff --git a/.github/workflows/self-scheduled-amd-mi250-caller.yml b/.github/workflows/self-scheduled-amd-mi250-caller.yml
new file mode 100644
index 00000000000000..dc7d12f173935e
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd-mi250-caller.yml
@@ -0,0 +1,19 @@
+name: Self-hosted runner (AMD mi250 scheduled CI caller)
+
+on:
+ workflow_run:
+ workflows: ["Self-hosted runner (AMD scheduled CI caller)"]
+ branches: ["main"]
+ types: [completed]
+ push:
+ branches:
+ - run_amd_scheduled_ci_caller*
+
+jobs:
+ run_amd_ci:
+ name: AMD mi250
+ if: (cancelled() != true) && ((github.event_name == 'workflow_run') || ((github.event_name == 'push') && startsWith(github.ref_name, 'run_amd_scheduled_ci_caller')))
+ uses: ./.github/workflows/self-scheduled-amd.yml
+ with:
+ gpu_flavor: mi250
+ secrets: inherit
diff --git a/.github/workflows/self-scheduled-amd.yml b/.github/workflows/self-scheduled-amd.yml
new file mode 100644
index 00000000000000..3d41a3b95e6c50
--- /dev/null
+++ b/.github/workflows/self-scheduled-amd.yml
@@ -0,0 +1,518 @@
+name: Self-hosted runner (scheduled-amd)
+
+# Note: For the AMD CI, we rely on a caller workflow and on the workflow_call event to trigger the
+# CI in order to run it on both MI210 and MI250, without having to use matrix here which pushes
+# us towards the limit of allowed jobs on GitHub Actions.
+on:
+ workflow_call:
+ inputs:
+ gpu_flavor:
+ required: true
+ type: string
+
+env:
+ HF_HOME: /mnt/cache
+ TRANSFORMERS_IS_CI: yes
+ OMP_NUM_THREADS: 8
+ MKL_NUM_THREADS: 8
+ RUN_SLOW: yes
+ SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
+
+
+# Important note: each job (run_tests_single_gpu, run_tests_multi_gpu, run_examples_gpu, run_pipelines_torch_gpu) requires all the previous jobs before running.
+# This is done so that we avoid parallelizing the scheduled tests, to leave available
+# runners for the push CI that is running on the same machine.
+jobs:
+ check_runner_status:
+ name: Check Runner Status
+ runs-on: ubuntu-22.04
+ steps:
+ - name: Checkout transformers
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 2
+
+ - name: Check Runner Status
+ run: python utils/check_self_hosted_runner.py --target_runners hf-amd-mi210-ci-1gpu-1,hf-amd-mi250-ci-1gpu-1 --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
+
+ check_runners:
+ name: Check Runners
+ needs: check_runner_status
+ strategy:
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ steps:
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ setup:
+ name: Setup
+ needs: check_runners
+ strategy:
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ outputs:
+ matrix: ${{ steps.set-matrix.outputs.matrix }}
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: |
+ git fetch && git checkout ${{ github.sha }}
+
+ - name: Cleanup
+ working-directory: /transformers
+ run: |
+ rm -rf tests/__pycache__
+ rm -rf tests/models/__pycache__
+ rm -rf reports
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - id: set-matrix
+ name: Identify models to test
+ working-directory: /transformers/tests
+ run: |
+ echo "matrix=$(python3 -c 'import os; tests = os.getcwd(); model_tests = os.listdir(os.path.join(tests, "models")); d1 = sorted(list(filter(os.path.isdir, os.listdir(tests)))); d2 = sorted(list(filter(os.path.isdir, [f"models/{x}" for x in model_tests]))); d1.remove("models"); d = d2 + d1; print(d)')" >> $GITHUB_OUTPUT
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ run_tests_single_gpu:
+ name: Single GPU tests
+ strategy:
+ max-parallel: 1 # For now, not to parallelize. Can change later if it works well.
+ fail-fast: false
+ matrix:
+ folders: ${{ fromJson(needs.setup.outputs.matrix) }}
+ machine_type: [single-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Echo folder ${{ matrix.folders }}
+ shell: bash
+ # For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
+ # set the artifact folder names (because the character `/` is not allowed).
+ run: |
+ echo "${{ matrix.folders }}"
+ matrix_folders=${{ matrix.folders }}
+ matrix_folders=${matrix_folders/'models/'/'models_'}
+ echo "$matrix_folders"
+ echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
+
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all tests on GPU
+ working-directory: /transformers
+ run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
+
+ run_tests_multi_gpu:
+ name: Multi GPU tests
+ strategy:
+ max-parallel: 1
+ fail-fast: false
+ matrix:
+ folders: ${{ fromJson(needs.setup.outputs.matrix) }}
+ machine_type: [multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Echo folder ${{ matrix.folders }}
+ shell: bash
+ # For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
+ # set the artifact folder names (because the character `/` is not allowed).
+ run: |
+ echo "${{ matrix.folders }}"
+ matrix_folders=${{ matrix.folders }}
+ matrix_folders=${matrix_folders/'models/'/'models_'}
+ echo "$matrix_folders"
+ echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
+
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all tests on GPU
+ working-directory: /transformers
+ run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
+
+ run_examples_gpu:
+ name: Examples tests
+ strategy:
+ fail-fast: false
+ matrix:
+ machine_type: [single-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run examples tests on GPU
+ working-directory: /transformers
+ run: |
+ pip install -r examples/pytorch/_tests_requirements.txt
+ python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_examples_gpu examples/pytorch
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_examples_gpu/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_examples_gpu
+ path: /transformers/reports/${{ matrix.machine_type }}_examples_gpu
+
+ run_pipelines_torch_gpu:
+ name: PyTorch pipelines tests
+ strategy:
+ fail-fast: false
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ container:
+ image: huggingface/transformers-pytorch-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ needs: setup
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all pipeline tests on GPU
+ working-directory: /transformers
+ run: |
+ python3 -m pytest -n 1 -v --dist=loadfile --make-reports=${{ matrix.machine_type }}_tests_torch_pipeline_gpu tests/pipelines
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_tests_torch_pipeline_gpu
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu
+
+ run_tests_torch_deepspeed_gpu:
+ name: Torch ROCm deepspeed tests
+ strategy:
+ fail-fast: false
+ matrix:
+ machine_type: [single-gpu, multi-gpu]
+
+ runs-on: [self-hosted, docker-gpu, amd-gpu, '${{ matrix.machine_type }}', '${{ inputs.gpu_flavor }}']
+ needs: setup
+ container:
+ image: huggingface/transformers-pytorch-deepspeed-amd-gpu
+ options: --device /dev/kfd --device /dev/dri --env ROCR_VISIBLE_DEVICES --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ steps:
+ - name: Update clone
+ working-directory: /transformers
+ run: git fetch && git checkout ${{ github.sha }}
+
+ - name: Reinstall transformers in edit mode (remove the one installed during docker image build)
+ working-directory: /transformers
+ run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
+
+ - name: ROCM-SMI
+ run: |
+ rocm-smi
+ - name: ROCM-INFO
+ run: |
+ rocminfo | grep "Agent" -A 14
+
+ - name: Show ROCR environment
+ run: |
+ echo "ROCR: $ROCR_VISIBLE_DEVICES"
+
+ - name: Environment
+ working-directory: /transformers
+ run: |
+ python3 utils/print_env.py
+
+ - name: Show installed libraries and their versions
+ working-directory: /transformers
+ run: pip freeze
+
+ - name: Run all tests on GPU
+ working-directory: /transformers
+ run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_torch_deepspeed_gpu tests/deepspeed tests/extended
+
+ - name: Failure short reports
+ if: ${{ failure() }}
+ continue-on-error: true
+ run: cat /transformers/reports/${{ matrix.machine_type }}_tests_torch_deepspeed_gpu/failures_short.txt
+
+ - name: Test suite reports artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: ${{ matrix.machine_type }}_run_tests_torch_deepspeed_gpu_test_reports
+ path: /transformers/reports/${{ matrix.machine_type }}_tests_torch_deepspeed_gpu
+
+ run_extract_warnings:
+ name: Extract warnings in CI artifacts
+ runs-on: ubuntu-22.04
+ if: always()
+ needs: [
+ check_runner_status,
+ check_runners,
+ setup,
+ run_tests_single_gpu,
+ run_tests_multi_gpu,
+ run_examples_gpu,
+ run_pipelines_torch_gpu,
+ run_tests_torch_deepspeed_gpu
+ ]
+ steps:
+ - name: Checkout transformers
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 2
+
+ - name: Install transformers
+ run: pip install transformers
+
+ - name: Show installed libraries and their versions
+ run: pip freeze
+
+ - name: Create output directory
+ run: mkdir warnings_in_ci
+
+ - uses: actions/download-artifact@v3
+ with:
+ path: warnings_in_ci
+
+ - name: Show artifacts
+ run: echo "$(python3 -c 'import os; d = os.listdir(); print(d)')"
+ working-directory: warnings_in_ci
+
+ - name: Extract warnings in CI artifacts
+ run: |
+ python3 utils/extract_warnings.py --workflow_run_id ${{ github.run_id }} --output_dir warnings_in_ci --token ${{ secrets.ACCESS_REPO_INFO_TOKEN }} --from_gh
+ echo "$(python3 -c 'import os; import json; fp = open("warnings_in_ci/selected_warnings.json"); d = json.load(fp); d = "\n".join(d) ;print(d)')"
+
+ - name: Upload artifact
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: warnings_in_ci
+ path: warnings_in_ci/selected_warnings.json
+
+ send_results:
+ name: Send results to webhook
+ runs-on: ubuntu-22.04
+ if: always()
+ needs: [
+ check_runner_status,
+ check_runners,
+ setup,
+ run_tests_single_gpu,
+ run_tests_multi_gpu,
+ run_examples_gpu,
+ run_pipelines_torch_gpu,
+ run_tests_torch_deepspeed_gpu,
+ run_extract_warnings
+ ]
+ steps:
+ - name: Preliminary job status
+ shell: bash
+ # For the meaning of these environment variables, see the job `Setup`
+ run: |
+ echo "Runner availability: ${{ needs.check_runner_status.result }}"
+ echo "Runner status: ${{ needs.check_runners.result }}"
+ echo "Setup status: ${{ needs.setup.result }}"
+
+ - uses: actions/checkout@v3
+ - uses: actions/download-artifact@v3
+ - name: Send message to Slack
+ env:
+ CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
+ CI_SLACK_CHANNEL_ID_DAILY_AMD: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY_AMD }}
+ CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
+ CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY_AMD }}
+ ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
+ CI_EVENT: Scheduled CI (AMD) - ${{ inputs.gpu_flavor }}
+ CI_SHA: ${{ github.sha }}
+ CI_WORKFLOW_REF: ${{ github.workflow_ref }}
+ RUNNER_STATUS: ${{ needs.check_runner_status.result }}
+ RUNNER_ENV_STATUS: ${{ needs.check_runners.result }}
+ SETUP_STATUS: ${{ needs.setup.result }}
+ # We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
+ # `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
+ run: |
+ sudo apt-get install -y curl
+ pip install slack_sdk
+ pip show slack_sdk
+ python utils/notification_service.py "${{ needs.setup.outputs.matrix }}"
+
+ # Upload complete failure tables, as they might be big and only truncated versions could be sent to Slack.
+ - name: Failure table artifacts
+ if: ${{ always() }}
+ uses: actions/upload-artifact@v3
+ with:
+ name: test_failure_tables
+ path: test_failure_tables
diff --git a/.github/workflows/self-scheduled.yml b/.github/workflows/self-scheduled.yml
index 4a04cb14ac7bb3..995df2e07880ac 100644
--- a/.github/workflows/self-scheduled.yml
+++ b/.github/workflows/self-scheduled.yml
@@ -366,7 +366,7 @@ jobs:
working-directory: /workspace
run: |
python3 -m pip uninstall -y deepspeed
- DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
- name: NVIDIA-SMI
run: |
@@ -494,5 +494,5 @@ jobs:
if: ${{ always() }}
uses: actions/upload-artifact@v3
with:
- name: test_failure_tables
- path: test_failure_tables
+ name: prev_ci_results
+ path: prev_ci_results
diff --git a/ISSUES.md b/ISSUES.md
index 95f2334b26c803..a5969a3027f86d 100644
--- a/ISSUES.md
+++ b/ISSUES.md
@@ -152,7 +152,7 @@ You are not required to read the following guidelines before opening an issue. H
```bash
cd examples/seq2seq
- python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py \
+ torchrun --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path sshleifer/distill-mbart-en-ro-12-4 --data_dir wmt_en_ro \
--output_dir output_dir --overwrite_output_dir \
--do_train --n_train 500 --num_train_epochs 1 \
diff --git a/README.md b/README.md
index 12724e60a1881d..4598868474b4c3 100644
--- a/README.md
+++ b/README.md
@@ -397,12 +397,14 @@ Current number of checkpoints: ** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
@@ -415,6 +417,7 @@ Current number of checkpoints: ** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
@@ -439,6 +442,8 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
@@ -464,6 +469,7 @@ Current number of checkpoints: ** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -489,14 +495,17 @@ Current number of checkpoints: ** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
diff --git a/README_es.md b/README_es.md
index 5cdbc27ec7918d..52a35cfb96a948 100644
--- a/README_es.md
+++ b/README_es.md
@@ -372,12 +372,14 @@ Número actual de puntos de control: ** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
@@ -390,6 +392,7 @@ Número actual de puntos de control: ** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
@@ -414,6 +417,8 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
@@ -439,6 +444,7 @@ Número actual de puntos de control: ** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -464,14 +470,17 @@ Número actual de puntos de control: ** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
diff --git a/README_hd.md b/README_hd.md
index 01937532f967c4..c19b944c609189 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -346,12 +346,14 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (दक्षिण चीन प्रौद्योगिकी विश्वविद्यालय से) साथ में कागज [LiLT: एक सरल लेकिन प्रभावी भाषा-स्वतंत्र लेआउट ट्रांसफार्मर संरचित दस्तावेज़ समझ के लिए](https://arxiv.org/abs/2202.13669) जियापेंग वांग, लियानवेन जिन, काई डिंग द्वारा पोस्ट किया गया।
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI से) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. द्वाराअनुसंधान पत्र [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) के साथ जारी किया गया
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI से) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. द्वाराअनुसंधान पत्र [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) के साथ जारी किया गया
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison से) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. द्वाराअनुसंधान पत्र [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) के साथ जारी किया गया
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (मैंडी गुओ, जोशुआ आइंस्ली, डेविड यूथस, सैंटियागो ओंटानन, जियानमो नि, यूं-हुआन सुंग, यिनफेई यांग द्वारा पोस्ट किया गया।
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (स्टूडियो औसिया से) साथ में पेपर [LUKE: डीप कॉन्टेक्स्टुअलाइज्ड एंटिटी रिप्रेजेंटेशन विद एंटिटी-अवेयर सेल्फ-अटेंशन](https ://arxiv.org/abs/2010.01057) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto द्वारा।
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC चैपल हिल से) साथ में पेपर [LXMERT: ओपन-डोमेन क्वेश्चन के लिए ट्रांसफॉर्मर से क्रॉस-मोडलिटी एनकोडर रिप्रेजेंटेशन सीखना Answering](https://arxiv.org/abs/1908.07490) हाओ टैन और मोहित बंसल द्वारा।
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (फेसबुक से) साथ देने वाला पेपर [बियॉन्ड इंग्लिश-सेंट्रिक मल्टीलिंगुअल मशीन ट्रांसलेशन](https://arxiv.org/ एब्स/2010.11125) एंजेला फैन, श्रुति भोसले, होल्गर श्वेन्क, झी मा, अहमद अल-किश्की, सिद्धार्थ गोयल, मनदीप बैनेस, ओनूर सेलेबी, गुइल्लाम वेन्जेक, विश्रव चौधरी, नमन गोयल, टॉम बर्च, विटाली लिपचिंस्की, सर्गेई एडुनोव, एडौर्ड द्वारा ग्रेव, माइकल औली, आर्मंड जौलिन द्वारा पोस्ट किया गया।
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg द्वारा [OPUS](http://opus.nlpl.eu/) डेटा से प्रशिक्षित मशीनी अनुवाद मॉडल पोस्ट किया गया टाइडेमैन द्वारा। [मैरियन फ्रेमवर्क](https://marian-nmt.github.io/) माइक्रोसॉफ्ट ट्रांसलेटर टीम द्वारा विकसित।
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ में पेपर [मार्कअपएलएम: विजुअली-रिच डॉक्यूमेंट अंडरस्टैंडिंग के लिए टेक्स्ट और मार्कअप लैंग्वेज का प्री-ट्रेनिंग] (https://arxiv.org/abs/2110.08518) जुनलॉन्ग ली, यिहेंग जू, लेई कुई, फुरु द्वारा वी द्वारा पोस्ट किया गया।
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC से) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. द्वाराअनुसंधान पत्र [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) के साथ जारी किया गया
@@ -364,6 +366,7 @@ conda install -c huggingface transformers
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA से) साथ वाला पेपर [Megatron-LM: ट्रेनिंग मल्टी-बिलियन पैरामीटर लैंग्वेज मॉडल्स यूजिंग मॉडल पैरेललिज़्म] (https://arxiv.org/abs/1909.08053) मोहम्मद शोएबी, मोस्टोफा पटवारी, राउल पुरी, पैट्रिक लेग्रेस्ले, जेरेड कैस्पर और ब्रायन कैटानज़ारो द्वारा पोस्ट किया गया।
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (Alibaba Research से) Peng Wang, Cheng Da, and Cong Yao. द्वाराअनुसंधान पत्र [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) के साथ जारी किया गया
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (फ्रॉम Studio Ousia) साथ में पेपर [mLUKE: द पावर ऑफ एंटिटी रिप्रेजेंटेशन इन मल्टीलिंगुअल प्रीट्रेन्ड लैंग्वेज मॉडल्स](https://arxiv.org/abs/2110.08151) रयोकन री, इकुया यामाडा, और योशिमासा त्सुरोका द्वारा।
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (Facebook से) Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. द्वाराअनुसंधान पत्र [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) के साथ जारी किया गया
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (सीएमयू/गूगल ब्रेन से) साथ में कागज [मोबाइलबर्ट: संसाधन-सीमित उपकरणों के लिए एक कॉम्पैक्ट टास्क-अज्ञेय बीईआरटी] (https://arxiv.org/abs/2004.02984) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, और Denny Zhou द्वारा पोस्ट किया गया।
@@ -388,6 +391,8 @@ conda install -c huggingface transformers
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI से) साथ में कागज [विज़न ट्रांसफॉर्मर्स के साथ सिंपल ओपन-वोकैबुलरी ऑब्जेक्ट डिटेक्शन](https:/ /arxiv.org/abs/2205.06230) मैथियास मिंडरर, एलेक्सी ग्रिट्सेंको, ऑस्टिन स्टोन, मैक्सिम न्यूमैन, डिर्क वीसेनबोर्न, एलेक्सी डोसोवित्स्की, अरविंद महेंद्रन, अनुराग अर्नब, मुस्तफा देहघानी, ज़ुओरन शेन, जिओ वांग, ज़ियाओहुआ झाई, थॉमस किफ़, और नील हॉल्सबी द्वारा पोस्ट किया गया।
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI से) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. द्वाराअनुसंधान पत्र [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) के साथ जारी किया गया
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** ( IBM Research से) Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. द्वाराअनुसंधान पत्र [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) के साथ जारी किया गया
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (IBM से) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. द्वाराअनुसंधान पत्र [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) के साथ जारी किया गया
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google की ओर से) साथ में दिया गया पेपर [लंबे इनपुट सारांश के लिए ट्रांसफ़ॉर्मरों को बेहतर तरीके से एक्सटेंड करना](https://arxiv .org/abs/2208.04347) जेसन फांग, याओ झाओ, पीटर जे लियू द्वारा।
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (दीपमाइंड से) साथ में पेपर [पर्सीवर आईओ: संरचित इनपुट और आउटपुट के लिए एक सामान्य वास्तुकला] (https://arxiv.org/abs/2107.14795) एंड्रयू जेगल, सेबेस्टियन बोरग्यूड, जीन-बैप्टिस्ट अलायराक, कार्ल डोर्श, कैटलिन इओनेस्कु, डेविड द्वारा डिंग, स्कंद कोप्पुला, डैनियल ज़ोरान, एंड्रयू ब्रॉक, इवान शेलहैमर, ओलिवियर हेनाफ, मैथ्यू एम। बोट्विनिक, एंड्रयू ज़िसरमैन, ओरिओल विनियल्स, जोआओ कैरेरा द्वारा पोस्ट किया गया।
@@ -413,6 +418,7 @@ conda install -c huggingface transformers
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (झुईई टेक्नोलॉजी से), साथ में पेपर [रोफॉर्मर: रोटरी पोजिशन एंबेडिंग के साथ एन्हांस्ड ट्रांसफॉर्मर] (https://arxiv.org/pdf/2104.09864v1.pdf) जियानलिन सु और यू लू और शेंगफेंग पैन और बो वेन और युनफेंग लियू द्वारा प्रकाशित।
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng से) Bo Peng. द्वाराअनुसंधान पत्र [this repo](https://github.com/BlinkDL/RWKV-LM) के साथ जारी किया गया
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI से) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. द्वाराअनुसंधान पत्र [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) के साथ जारी किया गया
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https ://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
@@ -438,14 +444,17 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU की ओर से) कागज के साथ [संस्करण-एक्स: एक ब्लॉग मॉडल चौकस चौक मॉडल मॉडल] (https://arxivorg/abs/1901.02860) क्वोकोक वी. ले, रुस्लैन सलाखुतदी
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research से) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. द्वाराअनुसंधान पत्र [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) के साथ जारी किया गया
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (माइक्रोसॉफ्ट रिसर्च से) साथ में दिया गया पेपर [UniSpeech: यूनिफाइड स्पीच रिप्रेजेंटेशन लर्निंग विद लेबलेड एंड अनलेबल्ड डेटा](https:/ /arxiv.org/abs/2101.07597) चेंगई वांग, यू वू, याओ कियान, केनिची कुमातानी, शुजी लियू, फुरु वेई, माइकल ज़ेंग, ज़ुएदोंग हुआंग द्वारा।
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [UNISPEECH-SAT: यूनिवर्सल स्पीच रिप्रेजेंटेशन लर्निंग विद स्पीकर अवेयर प्री-ट्रेनिंग ](https://arxiv.org/abs/2110.05752) सानयुआन चेन, यू वू, चेंग्यी वांग, झेंगयांग चेन, झूओ चेन, शुजी लियू, जियान वू, याओ कियान, फुरु वेई, जिन्यु ली, जियांगज़ान यू द्वारा पोस्ट किया गया।
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (सिंघुआ यूनिवर्सिटी और ननकाई यूनिवर्सिटी से) साथ में पेपर [विजुअल अटेंशन नेटवर्क](https://arxiv.org/ pdf/2202.09741.pdf) मेंग-हाओ गुओ, चेंग-ज़े लू, झेंग-निंग लियू, मिंग-मिंग चेंग, शि-मिन हू द्वारा।
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (मल्टीमीडिया कम्प्यूटिंग ग्रुप, नानजिंग यूनिवर्सिटी से) साथ में पेपर [वीडियोएमएई: मास्क्ड ऑटोएन्कोडर स्व-पर्यवेक्षित वीडियो प्री-ट्रेनिंग के लिए डेटा-कुशल सीखने वाले हैं] (https://arxiv.org/abs/2203.12602) ज़ान टोंग, यिबिंग सॉन्ग, जुए द्वारा वांग, लिमिन वांग द्वारा पोस्ट किया गया।
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain से) साथ में कागज [ViLT: Vision-and-Language Transformer बिना कनवल्शन या रीजन सुपरविजन](https://arxiv.org/abs/2102.03334) वोनजे किम, बोक्यूंग सोन, इल्डू किम द्वारा पोस्ट किया गया।
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (University of Wisconsin–Madison से) Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee. द्वाराअनुसंधान पत्र [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) के साथ जारी किया गया
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (गूगल एआई से) कागज के साथ [एक इमेज इज़ वर्थ 16x16 वर्ड्स: ट्रांसफॉर्मर्स फॉर इमेज रिकॉग्निशन एट स्केल](https://arxiv.org/abs/2010.11929) एलेक्सी डोसोवित्स्की, लुकास बेयर, अलेक्जेंडर कोलेसनिकोव, डिर्क वीसेनबोर्न, शियाओहुआ झाई, थॉमस अनटरथिनर, मुस्तफा देहघानी, मैथियास मिंडरर, जॉर्ज हेगोल्ड, सिल्वेन गेली, जैकब उस्ज़कोरेइट द्वारा हॉल्सबी द्वारा पोस्ट किया गया।
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP से) साथ वाला पेपर [VisualBERT: A Simple and Performant Baseline for Vision and Language](https:/ /arxiv.org/pdf/1908.03557) लियुनियन हेरोल्ड ली, मार्क यात्स्कर, दा यिन, चो-जुई हसीह, काई-वेई चांग द्वारा।
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
diff --git a/README_ja.md b/README_ja.md
index 5935da396bf165..f54d1c54b5a73d 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -406,12 +406,14 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI から) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. から公開された研究論文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill から) Hao Tan and Mohit Bansal から公開された研究論文: [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490)
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161)
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125)
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg Tiedemann から. [OPUS](http://opus.nlpl.eu/) を使いながら学習された "Machine translation" (マシントランスレーション) モデル. [Marian Framework](https://marian-nmt.github.io/) はMicrosoft Translator Team が現在開発中です.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518)
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
@@ -424,6 +426,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (Alibaba Research から) Peng Wang, Cheng Da, and Cong Yao. から公開された研究論文 [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592)
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia から) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka から公開された研究論文: [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151)
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (Facebook から) Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. から公開された研究論文 [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain から) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou から公開された研究論文: [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984)
@@ -448,6 +451,8 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. から公開された研究論文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** ( IBM Research から) Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf)
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (IBM から) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf)
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
@@ -473,6 +478,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864)
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng から) Bo Peng. から公開された研究論文 [this repo](https://github.com/BlinkDL/RWKV-LM)
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
@@ -498,14 +504,17 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860)
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill から), Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal から公開された研究論文: [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel から), Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding から公開された研究論文: [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995)
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://arxiv.org/abs/2202.09741)
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602)
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain から) Wonjae Kim, Bokyung Son, Ildoo Kim から公開された研究論文: [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (University of Wisconsin–Madison から) Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee. から公開された研究論文 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784)
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557)
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
diff --git a/README_ko.md b/README_ko.md
index e0c38472cc4606..a039331b93d085 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -321,12 +321,14 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology 에서) Jiapeng Wang, Lianwen Jin, Kai Ding 의 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 논문과 함께 발표했습니다.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.의 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)논문과 함께 발표했습니다.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..의 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)논문과 함께 발표했습니다.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison 에서 제공)은 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.의 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)논문과 함께 발표했습니다.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI 에서) Iz Beltagy, Matthew E. Peters, Arman Cohan 의 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 논문과 함께 발표했습니다.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI 에서) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 의 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 논문과 함께 발표했습니다.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia 에서) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 의 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 논문과 함께 발표했습니다.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill 에서) Hao Tan and Mohit Bansal 의 [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) 논문과 함께 발표했습니다.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook 에서) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert 의 [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) 논문과 함께 발표했습니다.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook 에서) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 의 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 논문과 함께 발표했습니다.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia 에서) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 의 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 논문과 함께 발표했습니다.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC 에서 제공)은 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.의 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)논문과 함께 발표했습니다.
@@ -339,6 +341,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA 에서) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro 의 [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) 논문과 함께 발표했습니다.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (Alibaba Research 에서 제공)은 Peng Wang, Cheng Da, and Cong Yao.의 [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592)논문과 함께 발표했습니다.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia 에서) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka 의 [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) 논문과 함께 발표했습니다.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (Facebook 에서 제공)은 Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.의 [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)논문과 함께 발표했습니다.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain 에서) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou 의 [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) 논문과 함께 발표했습니다.
@@ -363,6 +366,8 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI 에서) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 의 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 논문과 함께 발표했습니다.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI 에서) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 의 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 논문과 함께 발표했습니다.
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI 에서 제공)은 Matthias Minderer, Alexey Gritsenko, Neil Houlsby.의 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)논문과 함께 발표했습니다.
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** ( IBM Research 에서 제공)은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.의 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf)논문과 함께 발표했습니다.
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (IBM 에서 제공)은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.의 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf)논문과 함께 발표했습니다.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google 에서) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 의 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 논문과 함께 발표했습니다.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google 에서) Jason Phang, Yao Zhao, Peter J. Liu 의 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 논문과 함께 발표했습니다.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind 에서) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 의 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 논문과 함께 발표했습니다.
@@ -388,6 +393,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology 에서) Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 의 a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 논문과 함께 발표했습니다.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng 에서 제공)은 Bo Peng.의 [this repo](https://github.com/BlinkDL/RWKV-LM)논문과 함께 발표했습니다.
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA 에서) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 의 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 논문과 함께 발표했습니다.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI 에서 제공)은 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.의 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)논문과 함께 발표했습니다.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
@@ -413,14 +419,17 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU 에서) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 의 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 논문과 함께 발표했습니다.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft 에서) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 의 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 논문과 함께 발표했습니다.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill 에서) Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 의 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 논문과 함께 발표했습니다.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel 에서) Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 의 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 논문과 함께 발표했습니다.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research 에서) Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzle 의 [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) 논문과 함께 발표했습니다.
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research 에서 제공)은 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.의 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)논문과 함께 발표했습니다.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research 에서) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 의 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 논문과 함께 발표했습니다.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research 에서) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 의 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 논문과 함께 발표했습니다.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University 에서 제공)은 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.의 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)논문과 함께 발표했습니다.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University 에서) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 의 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 논문과 함께 발표했습니다.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University 에서) Zhan Tong, Yibing Song, Jue Wang, Limin Wang 의 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 논문과 함께 발표했습니다.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain 에서) Wonjae Kim, Bokyung Son, Ildoo Kim 의 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 논문과 함께 발표했습니다.
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (University of Wisconsin–Madison 에서 제공)은 Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.의 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784)논문과 함께 발표했습니다.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI 에서) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 의 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 논문과 함께 발표했습니다.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP 에서) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 의 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 논문과 함께 발표했습니다.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (Google AI 에서) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 의 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 논문과 함께 발표했습니다.
diff --git a/README_pt-br.md b/README_pt-br.md
index 0e5f638bc5f6cc..0c8e8d09e3591a 100644
--- a/README_pt-br.md
+++ b/README_pt-br.md
@@ -409,6 +409,7 @@ Número atual de pontos de verificação: ** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
diff --git a/README_ru.md b/README_ru.md
index cf63f7c67ef9ec..bc32f2f0b44cf1 100644
--- a/README_ru.md
+++ b/README_ru.md
@@ -399,6 +399,7 @@ conda install -c huggingface transformers
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
diff --git a/README_te.md b/README_te.md
index 1b6a1812fa0444..829e27690f9683 100644
--- a/README_te.md
+++ b/README_te.md
@@ -402,6 +402,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 3d84374d5561d5..ef22939374c95a 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -345,12 +345,14 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (来自 South China University of Technology) 伴随论文 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 由 Jiapeng Wang, Lianwen Jin, Kai Ding 发布。
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (来自 The FAIR team of Meta AI) 伴随论文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) 由 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample 发布。
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (来自 The FAIR team of Meta AI) 伴随论文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) 由 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. 发布。
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (来自 Microsoft Research & University of Wisconsin-Madison) 伴随论文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) 由 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee 发布。
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (来自 Google AI) released 伴随论文 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 由 Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 发布。
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (来自 UNC Chapel Hill) 伴随论文 [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) 由 Hao Tan and Mohit Bansal 发布。
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (来自 Facebook) 伴随论文 [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) 由 Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert 发布。
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (来自 Facebook) 伴随论文 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 由 Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 发布。
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** 用 [OPUS](http://opus.nlpl.eu/) 数据训练的机器翻译模型由 Jörg Tiedemann 发布。[Marian Framework](https://marian-nmt.github.io/) 由微软翻译团队开发。
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (来自 Microsoft Research Asia) 伴随论文 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 由 Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 发布。
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (来自 FAIR and UIUC) 伴随论文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) 由 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar 发布。
@@ -363,6 +365,7 @@ conda install -c huggingface transformers
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (来自 NVIDIA) 伴随论文 [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) 由 Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro 发布。
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (来自 Alibaba Research) 伴随论文 [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) 由 Peng Wang, Cheng Da, and Cong Yao 发布。
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (来自 Studio Ousia) 伴随论文 [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) 由 Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka 发布。
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (来自 Facebook) 伴随论文 [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) 由 Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli 发布。
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (来自 CMU/Google Brain) 伴随论文 [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) 由 Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou 发布。
@@ -387,6 +390,8 @@ conda install -c huggingface transformers
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (来自 Meta AI) 伴随论文 [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) 由 Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al 发布。
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (来自 Google AI) 伴随论文 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 由 Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 发布。
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (来自 Google AI) 伴随论文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) 由 Matthias Minderer, Alexey Gritsenko, Neil Houlsby 发布。
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** (来自 IBM Research) 伴随论文 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) 由 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam 发布。
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (来自 IBM) 伴随论文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) 由 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam 发布。
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (来自 Google) 伴随论文 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 由 Jason Phang, Yao Zhao, Peter J. Liu 发布。
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (来自 Deepmind) 伴随论文 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 由 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 发布。
@@ -412,6 +417,7 @@ conda install -c huggingface transformers
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (来自 ZhuiyiTechnology), 伴随论文 [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 由 Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 发布。
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (来自 Bo Peng) 伴随论文 [this repo](https://github.com/BlinkDL/RWKV-LM) 由 Bo Peng 发布。
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (来自 NVIDIA) 伴随论文 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 由 Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 发布。
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (来自 Meta AI) 伴随论文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) 由 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick 发布。
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
@@ -437,14 +443,17 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (来自 Google/CMU) 伴随论文 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 由 Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 发布。
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (来自 UNC Chapel Hill) 伴随论文 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 由 Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 发布。
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (来自 Intel) 伴随论文 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 由 Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 发布.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (来自 Google Research) 伴随论文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) 由 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant 发布。
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (来自 Peking University) 伴随论文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) 由 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun 发布。
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (来自 Multimedia Computing Group, Nanjing University) 伴随论文 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 由 Zhan Tong, Yibing Song, Jue Wang, Limin Wang 发布。
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (来自 NAVER AI Lab/Kakao Enterprise/Kakao Brain) 伴随论文 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 由 Wonjae Kim, Bokyung Son, Ildoo Kim 发布。
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (来自 University of Wisconsin–Madison) 伴随论文 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) 由 Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee 发布。
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (来自 UCLA NLP) 伴随论文 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 由 Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 发布。
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index c095423cce15dd..53fa729020797c 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -357,12 +357,14 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
@@ -375,6 +377,7 @@ conda install -c huggingface transformers
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
+1. **[Mixtral](https://huggingface.co/docs/transformers/main/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
@@ -399,6 +402,8 @@ conda install -c huggingface transformers
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/main/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
+1. **[PatchTST](https://huggingface.co/docs/transformers/main/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
@@ -424,6 +429,7 @@ conda install -c huggingface transformers
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
@@ -449,14 +455,17 @@ conda install -c huggingface transformers
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/main/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[VipLlava](https://huggingface.co/docs/transformers/main/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
diff --git a/docker/transformers-all-latest-gpu/Dockerfile b/docker/transformers-all-latest-gpu/Dockerfile
index d108ba5ace5805..7ab236a55d5902 100644
--- a/docker/transformers-all-latest-gpu/Dockerfile
+++ b/docker/transformers-all-latest-gpu/Dockerfile
@@ -56,7 +56,7 @@ RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://hu
RUN python3 -m pip install --no-cache-dir einops
# Add autoawq for quantization testing
-RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp38-cp38-linux_x86_64.whl
+RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.7/autoawq-0.1.7+cu118-cp38-cp38-linux_x86_64.whl
# For bettertransformer + gptq
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
diff --git a/docker/transformers-pytorch-amd-gpu/Dockerfile b/docker/transformers-pytorch-amd-gpu/Dockerfile
index f19cd4edb0e4f8..46ca1a531b4ab4 100644
--- a/docker/transformers-pytorch-amd-gpu/Dockerfile
+++ b/docker/transformers-pytorch-amd-gpu/Dockerfile
@@ -1,27 +1,32 @@
-FROM rocm/pytorch:rocm5.6_ubuntu20.04_py3.8_pytorch_2.0.1
+FROM rocm/dev-ubuntu-20.04:5.6
+# rocm/pytorch has no version with 2.1.0
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
+ARG PYTORCH='2.1.0'
+ARG TORCH_VISION='0.16.0'
+ARG TORCH_AUDIO='2.1.0'
+ARG ROCM='5.6'
+
RUN apt update && \
- apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg && \
+ apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-dev python3-pip ffmpeg && \
apt clean && \
rm -rf /var/lib/apt/lists/*
-RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
+RUN python3 -m pip install --no-cache-dir --upgrade pip
-# If set to nothing, will install the latest version
-ARG PYTORCH='2.0.1'
-ARG TORCH_VISION='0.15.2'
-ARG TORCH_AUDIO='2.0.2'
-ARG ROCM='5.6'
+RUN python3 -m pip install torch==$PYTORCH torchvision==$TORCH_VISION torchaudio==$TORCH_AUDIO --index-url https://download.pytorch.org/whl/rocm$ROCM
-RUN git clone --depth 1 --branch v$TORCH_AUDIO https://github.com/pytorch/audio.git
-RUN cd audio && USE_ROCM=1 USE_CUDA=0 python setup.py install
+RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
ARG REF=main
WORKDIR /
+
+# Invalidate docker cache from here if new commit is available.
+ADD https://api.github.com/repos/huggingface/transformers/git/refs/heads/main version.json
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
RUN python3 -m pip uninstall -y tensorflow flax
diff --git a/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile b/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
new file mode 100644
index 00000000000000..1fa384dfa2bc03
--- /dev/null
+++ b/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
@@ -0,0 +1,45 @@
+FROM rocm/dev-ubuntu-22.04:5.6
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+ARG PYTORCH='2.1.1'
+ARG TORCH_VISION='0.16.1'
+ARG TORCH_AUDIO='2.1.1'
+ARG ROCM='5.6'
+
+RUN apt update && \
+ apt install -y --no-install-recommends \
+ libaio-dev \
+ git \
+ # These are required to build deepspeed.
+ python3-dev \
+ python-is-python3 \
+ rocrand-dev \
+ rocthrust-dev \
+ hipsparse-dev \
+ hipblas-dev \
+ rocblas-dev && \
+ apt clean && \
+ rm -rf /var/lib/apt/lists/*
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip ninja "pydantic<2"
+RUN python3 -m pip uninstall -y apex torch torchvision torchaudio
+RUN python3 -m pip install torch==$PYTORCH torchvision==$TORCH_VISION torchaudio==$TORCH_AUDIO --index-url https://download.pytorch.org/whl/rocm$ROCM --no-cache-dir
+
+# Pre-build DeepSpeed, so it's be ready for testing (to avoid timeout)
+RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache-dir -v --disable-pip-version-check 2>&1
+
+ARG REF=main
+WORKDIR /
+
+# Invalidate docker cache from here if new commit is available.
+ADD https://api.github.com/repos/huggingface/transformers/git/refs/heads/main version.json
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+RUN python3 -m pip install --no-cache-dir ./transformers[accelerate,testing,sentencepiece,sklearn]
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+RUN python3 -c "from deepspeed.launcher.runner import main"
\ No newline at end of file
diff --git a/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile b/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
index 276f35f3351846..a7b08a8c60d31d 100644
--- a/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
+++ b/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
@@ -1,12 +1,12 @@
-# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12
-FROM nvcr.io/nvidia/pytorch:22.12-py3
+# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-23-11.html#rel-23-11
+FROM nvcr.io/nvidia/pytorch:23.11-py3
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
ARG PYTORCH='2.1.0'
# Example: `cu102`, `cu113`, etc.
-ARG CUDA='cu118'
+ARG CUDA='cu121'
RUN apt -y update
RUN apt install -y libaio-dev
@@ -34,7 +34,7 @@ RUN python3 -m pip uninstall -y torch-tensorrt
# recompile apex
RUN python3 -m pip uninstall -y apex
-RUN git clone https://github.com/NVIDIA/apex
+# RUN git clone https://github.com/NVIDIA/apex
# `MAX_JOBS=1` disables parallel building to avoid cpu memory OOM when building image on GitHub Action (standard) runners
# TODO: check if there is alternative way to install latest apex
# RUN cd apex && MAX_JOBS=1 python3 -m pip install --global-option="--cpp_ext" --global-option="--cuda_ext" --no-cache -v --disable-pip-version-check .
@@ -44,7 +44,7 @@ RUN python3 -m pip uninstall -y deepspeed
# This has to be run (again) inside the GPU VMs running the tests.
# The installation works here, but some tests fail, if we don't pre-build deepspeed again in the VMs running the tests.
# TODO: Find out why test fail.
-RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
+RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
diff --git a/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile b/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
index b3ead0c615471f..06da67049296a5 100644
--- a/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
+++ b/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
@@ -1,11 +1,11 @@
-# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12
-FROM nvcr.io/nvidia/pytorch:22.12-py3
+# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-23-11.html#rel-23-11
+FROM nvcr.io/nvidia/pytorch:23.11-py3
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
# Example: `cu102`, `cu113`, etc.
-ARG CUDA='cu118'
+ARG CUDA='cu121'
RUN apt -y update
RUN apt install -y libaio-dev
diff --git a/docker/transformers-pytorch-gpu/Dockerfile b/docker/transformers-pytorch-gpu/Dockerfile
index 702a837abd0192..44f609589419f2 100644
--- a/docker/transformers-pytorch-gpu/Dockerfile
+++ b/docker/transformers-pytorch-gpu/Dockerfile
@@ -1,4 +1,4 @@
-FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
+FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
@@ -15,7 +15,7 @@ ARG PYTORCH='2.1.0'
ARG TORCH_VISION=''
ARG TORCH_AUDIO=''
# Example: `cu102`, `cu113`, etc.
-ARG CUDA='cu118'
+ARG CUDA='cu121'
RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN [ ${#TORCH_VISION} -gt 0 ] && VERSION='torchvision=='TORCH_VISION'.*' || VERSION='torchvision'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
diff --git a/docs/source/de/preprocessing.md b/docs/source/de/preprocessing.md
index 1e8f6ff4062aea..9c977e10a538a3 100644
--- a/docs/source/de/preprocessing.md
+++ b/docs/source/de/preprocessing.md
@@ -209,7 +209,7 @@ Audioeingaben werden anders vorverarbeitet als Texteingaben, aber das Endziel bl
pip install datasets
```
-Laden Sie den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz (weitere Informationen zum Laden eines Datensatzes finden Sie im 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html)):
+Laden Sie den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz (weitere Informationen zum Laden eines Datensatzes finden Sie im 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub)):
```py
>>> from datasets import load_dataset, Audio
@@ -344,7 +344,7 @@ Laden wir den [food101](https://huggingface.co/datasets/food101) Datensatz für
>>> dataset = load_dataset("food101", split="train[:100]")
```
-Als Nächstes sehen Sie sich das Bild mit dem Merkmal 🤗 Datensätze [Bild] (https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) an:
+Als Nächstes sehen Sie sich das Bild mit dem Merkmal 🤗 Datensätze [Bild] (https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) an:
```py
>>> dataset[0]["image"]
@@ -385,7 +385,7 @@ Bei Bildverarbeitungsaufgaben ist es üblich, den Bildern als Teil der Vorverarb
... return examples
```
-3. Dann verwenden Sie 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform), um die Transformationen im laufenden Betrieb anzuwenden:
+3. Dann verwenden Sie 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform), um die Transformationen im laufenden Betrieb anzuwenden:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/de/quicktour.md b/docs/source/de/quicktour.md
index 139869e5d1eeb3..2b66d2d6a917e9 100644
--- a/docs/source/de/quicktour.md
+++ b/docs/source/de/quicktour.md
@@ -121,7 +121,7 @@ Erstellen wir eine [`pipeline`] mit der Aufgabe die wir lösen und dem Modell we
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
-Als nächstes laden wir den Datensatz (siehe 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) für mehr Details) welches wir nutzen möchten. Zum Beispiel laden wir den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz:
+Als nächstes laden wir den Datensatz (siehe 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) für mehr Details) welches wir nutzen möchten. Zum Beispiel laden wir den [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) Datensatz:
```py
>>> from datasets import load_dataset, Audio
diff --git a/docs/source/de/run_scripts.md b/docs/source/de/run_scripts.md
index 2902d4c084144e..4afe72dae6d662 100644
--- a/docs/source/de/run_scripts.md
+++ b/docs/source/de/run_scripts.md
@@ -130,7 +130,7 @@ Der [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) unt
- Legen Sie die Anzahl der zu verwendenden GPUs mit dem Argument `nproc_per_node` fest.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/de/training.md b/docs/source/de/training.md
index 493de3052bbf19..b1b7c14f261a72 100644
--- a/docs/source/de/training.md
+++ b/docs/source/de/training.md
@@ -43,7 +43,7 @@ Laden Sie zunächst den Datensatz [Yelp Reviews](https://huggingface.co/datasets
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-Wie Sie nun wissen, benötigen Sie einen Tokenizer, um den Text zu verarbeiten und eine Auffüll- und Abschneidungsstrategie einzubauen, um mit variablen Sequenzlängen umzugehen. Um Ihren Datensatz in einem Schritt zu verarbeiten, verwenden Sie die 🤗 Methode Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map), um eine Vorverarbeitungsfunktion auf den gesamten Datensatz anzuwenden:
+Wie Sie nun wissen, benötigen Sie einen Tokenizer, um den Text zu verarbeiten und eine Auffüll- und Abschneidungsstrategie einzubauen, um mit variablen Sequenzlängen umzugehen. Um Ihren Datensatz in einem Schritt zu verarbeiten, verwenden Sie die 🤗 Methode Datasets [`map`](https://huggingface.co/docs/datasets/process#map), um eine Vorverarbeitungsfunktion auf den gesamten Datensatz anzuwenden:
```py
>>> from transformers import AutoTokenizer
diff --git a/docs/source/en/_redirects.yml b/docs/source/en/_redirects.yml
index 0dd4d2bfb34b2f..b6575a6b02f205 100644
--- a/docs/source/en/_redirects.yml
+++ b/docs/source/en/_redirects.yml
@@ -1,3 +1,3 @@
# Optimizing inference
-perf_infer_gpu_many: perf_infer_gpu_one
\ No newline at end of file
+perf_infer_gpu_many: perf_infer_gpu_one
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 4e0ce88c10af31..09210a471e3acd 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -60,7 +60,7 @@
- local: tasks/image_classification
title: Image classification
- local: tasks/semantic_segmentation
- title: Semantic segmentation
+ title: Image segmentation
- local: tasks/video_classification
title: Video classification
- local: tasks/object_detection
@@ -133,6 +133,8 @@
- sections:
- local: performance
title: Overview
+ - local: quantization
+ title: Quantization
- sections:
- local: perf_train_gpu_one
title: Methods and tools for efficient training on a single GPU
@@ -216,6 +218,8 @@
title: Agents and Tools
- local: model_doc/auto
title: Auto Classes
+ - local: main_classes/backbones
+ title: Backbones
- local: main_classes/callback
title: Callbacks
- local: main_classes/configuration
@@ -378,6 +382,8 @@
title: LUKE
- local: model_doc/m2m_100
title: M2M100
+ - local: model_doc/madlad-400
+ title: MADLAD-400
- local: model_doc/marian
title: MarianMT
- local: model_doc/markuplm
@@ -392,6 +398,8 @@
title: MegatronGPT2
- local: model_doc/mistral
title: Mistral
+ - local: model_doc/mixtral
+ title: Mixtral
- local: model_doc/mluke
title: mLUKE
- local: model_doc/mobilebert
@@ -614,6 +622,8 @@
title: Pop2Piano
- local: model_doc/seamless_m4t
title: Seamless-M4T
+ - local: model_doc/seamless_m4t_v2
+ title: SeamlessM4T-v2
- local: model_doc/sew
title: SEW
- local: model_doc/sew-d
@@ -628,6 +638,8 @@
title: UniSpeech
- local: model_doc/unispeech-sat
title: UniSpeech-SAT
+ - local: model_doc/univnet
+ title: UnivNet
- local: model_doc/vits
title: VITS
- local: model_doc/wav2vec2
@@ -695,6 +707,8 @@
title: LayoutXLM
- local: model_doc/lilt
title: LiLT
+ - local: model_doc/llava
+ title: Llava
- local: model_doc/lxmert
title: LXMERT
- local: model_doc/matcha
@@ -723,8 +737,12 @@
title: TrOCR
- local: model_doc/tvlt
title: TVLT
+ - local: model_doc/tvp
+ title: TVP
- local: model_doc/vilt
title: ViLT
+ - local: model_doc/vipllava
+ title: VipLlava
- local: model_doc/vision-encoder-decoder
title: Vision Encoder Decoder Models
- local: model_doc/vision-text-dual-encoder
@@ -747,6 +765,10 @@
title: Autoformer
- local: model_doc/informer
title: Informer
+ - local: model_doc/patchtsmixer
+ title: PatchTSMixer
+ - local: model_doc/patchtst
+ title: PatchTST
- local: model_doc/time_series_transformer
title: Time Series Transformer
title: Time series models
diff --git a/docs/source/en/autoclass_tutorial.md b/docs/source/en/autoclass_tutorial.md
index 833882aa713e3d..876f9d897afd47 100644
--- a/docs/source/en/autoclass_tutorial.md
+++ b/docs/source/en/autoclass_tutorial.md
@@ -31,6 +31,7 @@ In this tutorial, learn to:
* Load a pretrained feature extractor.
* Load a pretrained processor.
* Load a pretrained model.
+* Load a model as a backbone.
## AutoTokenizer
@@ -95,7 +96,7 @@ Load a processor with [`AutoProcessor.from_pretrained`]:
-Finally, the `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
+The `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
@@ -141,3 +142,24 @@ Easily reuse the same checkpoint to load an architecture for a different task:
Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
+
+## AutoBackbone
+
+`AutoBackbone` lets you use pretrained models as backbones and get feature maps as outputs from different stages of the models. Below you can see how to get feature maps from a [Swin](model_doc/swin) checkpoint.
+
+```py
+>>> from transformers import AutoImageProcessor, AutoBackbone
+>>> import torch
+>>> from PIL import Image
+>>> import requests
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
+>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,))
+
+>>> inputs = processor(image, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> feature_maps = outputs.feature_maps
+>>> list(feature_maps[-1].shape)
+[1, 96, 56, 56]
+```
diff --git a/docs/source/en/chat_templating.md b/docs/source/en/chat_templating.md
index 82bdf591ae5f3c..a478c32e6ff393 100644
--- a/docs/source/en/chat_templating.md
+++ b/docs/source/en/chat_templating.md
@@ -376,7 +376,10 @@ input formats. Our default template for models that don't have a class-specific
```
If you like this one, here it is in one-liner form, ready to copy into your code. The one-liner also includes
-handy support for "generation prompts" - see the next section for more!
+handy support for [generation prompts](#what-are-generation-prompts), but note that it doesn't add BOS or EOS tokens!
+If your model expects those, they won't be added automatically by `apply_chat_template` - in other words, the
+text will be tokenized with `add_special_tokens=False`. This is to avoid potential conflicts between the template and
+the `add_special_tokens` logic. If your model expects special tokens, make sure to add them to the template!
```
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
diff --git a/docs/source/en/custom_models.md b/docs/source/en/custom_models.md
index 4abc3ce5773a1f..22ba58b9d9ddc4 100644
--- a/docs/source/en/custom_models.md
+++ b/docs/source/en/custom_models.md
@@ -14,7 +14,7 @@ rendered properly in your Markdown viewer.
-->
-# Sharing custom models
+# Building custom models
The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
@@ -22,7 +22,8 @@ of the repository with no abstraction, so you can easily copy a modeling file an
If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
-Transformers library.
+Transformers library. We'll see how to build upon transformers and extend the framework with your hooks and
+custom code.
We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
[timm library](https://github.com/rwightman/pytorch-image-models) into a [`PreTrainedModel`].
@@ -218,6 +219,27 @@ resnet50d.model.load_state_dict(pretrained_model.state_dict())
Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
code of the model is saved.
+## Registering a model with custom code to the auto classes
+
+If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
+model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
+get the custom models (contrarily to automatically downloading the model code from the Hub).
+
+As long as your config has a `model_type` attribute that is different from existing model types, and that your model
+classes have the right `config_class` attributes, you can just add them to the auto classes like this:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
+of your custom config, and the first argument used when registering your custom models to any auto model class needs
+to match the `config_class` of those models.
+
## Sending the code to the Hub
@@ -350,23 +372,3 @@ model = AutoModelForImageClassification.from_pretrained(
Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
hash of any commit.
-## Registering a model with custom code to the auto classes
-
-If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
-model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
-get the custom models (contrarily to automatically downloading the model code from the Hub).
-
-As long as your config has a `model_type` attribute that is different from existing model types, and that your model
-classes have the right `config_class` attributes, you can just add them to the auto classes like this:
-
-```py
-from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
-
-AutoConfig.register("resnet", ResnetConfig)
-AutoModel.register(ResnetConfig, ResnetModel)
-AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
-```
-
-Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
-of your custom config, and the first argument used when registering your custom models to any auto model class needs
-to match the `config_class` of those models.
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index ae01569e970ce3..f63922d7f854a0 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -1,4 +1,4 @@
-
+
+# Backbones
+
+Backbones are models used for feature extraction for computer vision tasks. One can use a model as backbone in two ways:
+
+* initializing `AutoBackbone` class with a pretrained model,
+* initializing a supported backbone configuration and passing it to the model architecture.
+
+## Using AutoBackbone
+
+You can use `AutoBackbone` class to initialize a model as a backbone and get the feature maps for any stage. You can define `out_indices` to indicate the index of the layers which you would like to get the feature maps from. You can also use `out_features` if you know the name of the layers. You can use them interchangeably. If you are using both `out_indices` and `out_features`, ensure they are consistent. Not passing any of the feature map arguments will make the backbone yield the feature maps of the last layer.
+To visualize how stages look like, let's take the Swin model. Each stage is responsible from feature extraction, outputting feature maps.
+
+
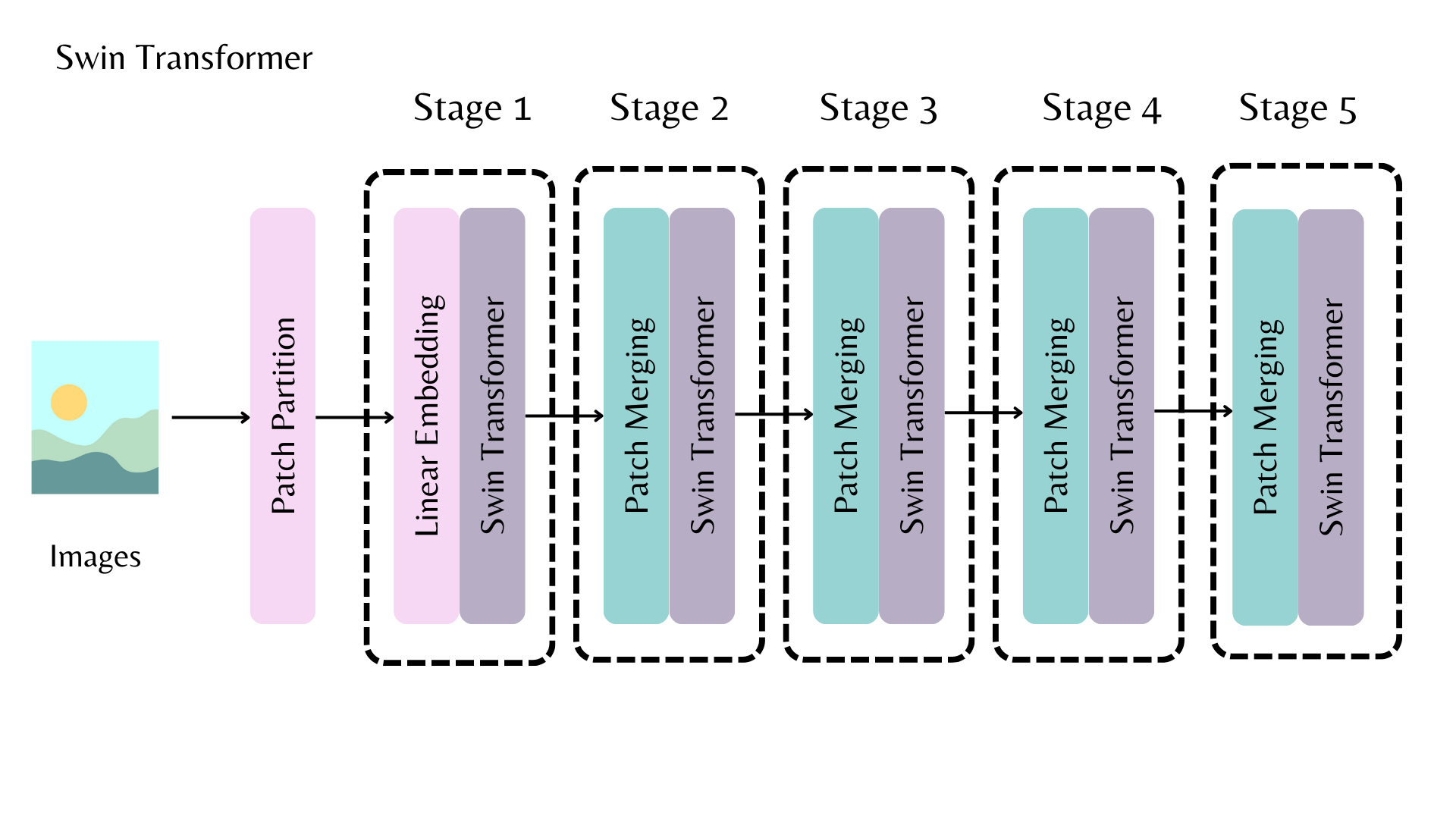
+
+
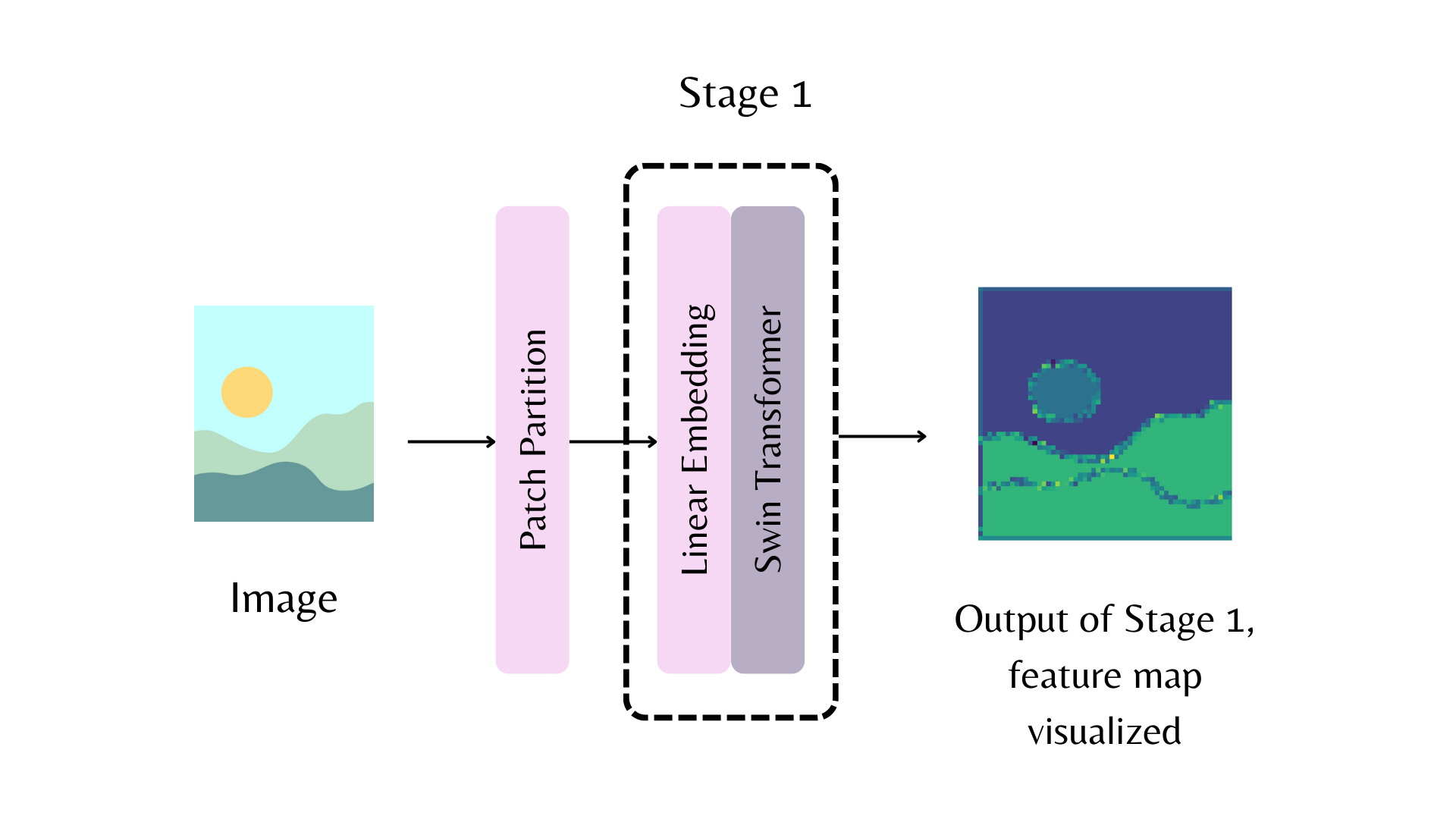
+
-
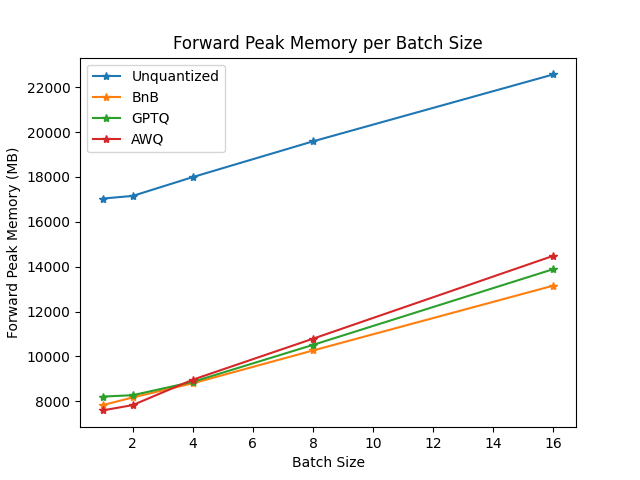
-
-
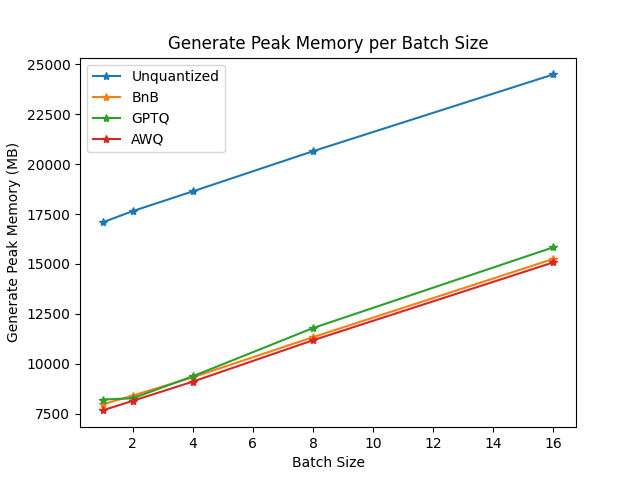
-
-
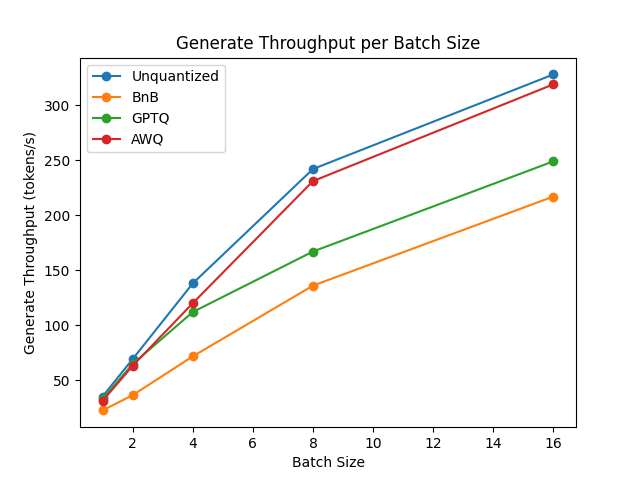
-
-
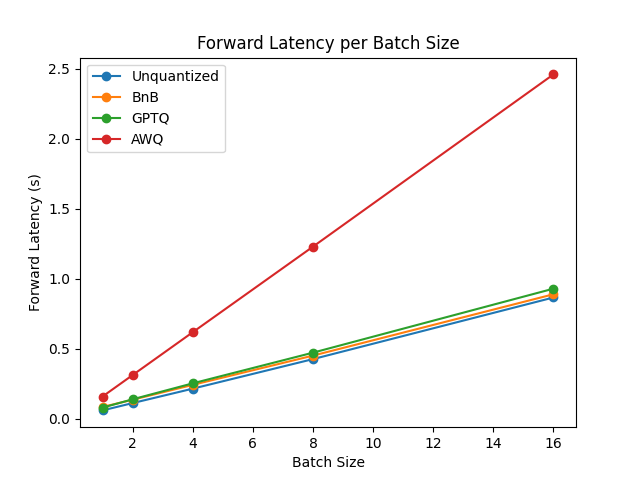
-
+
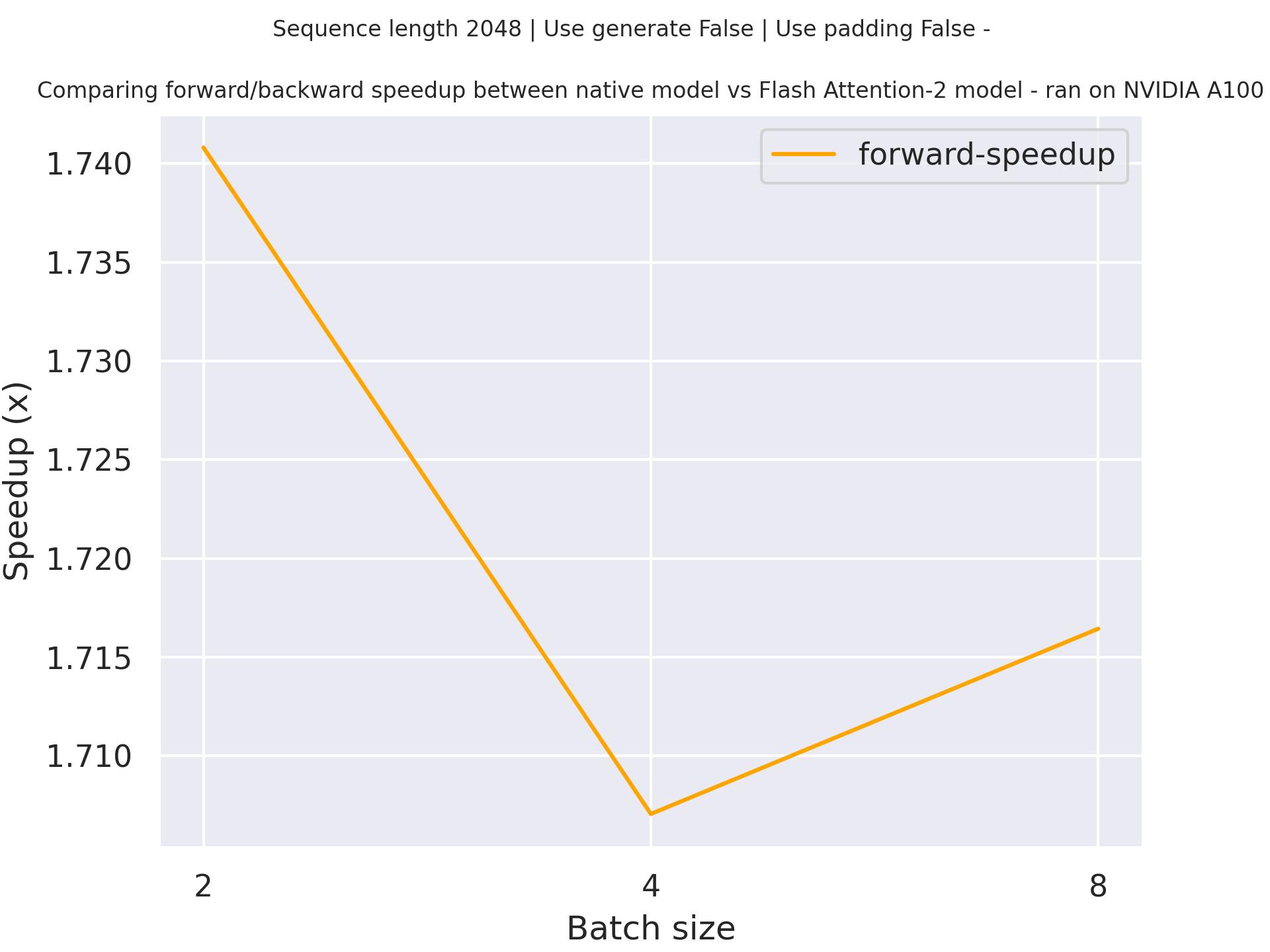
+
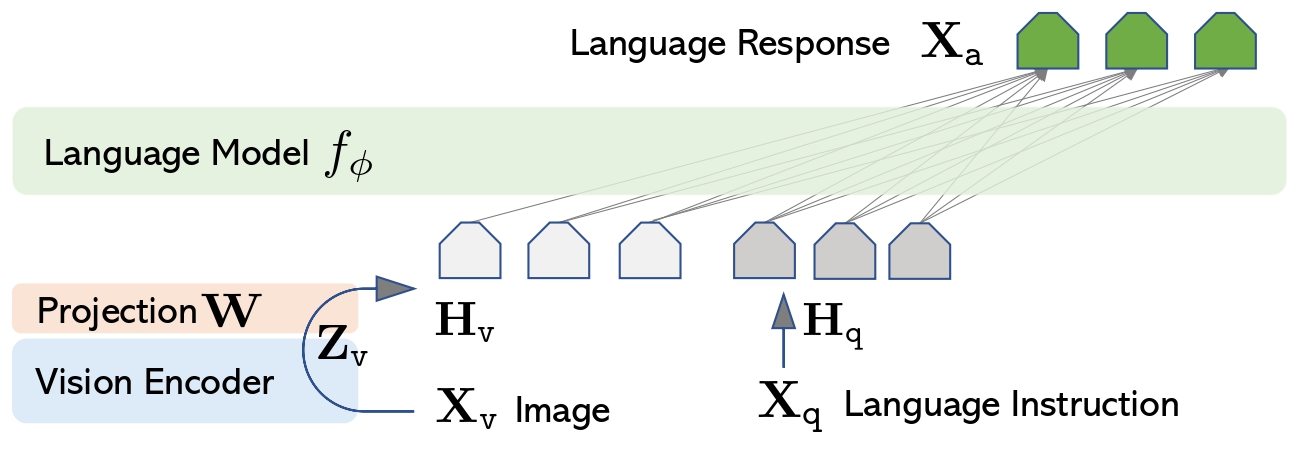 +
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+- For better results, we recommend users to prompt the model with the correct prompt format:
+
+```bash
+"USER: \nASSISTANT:"
+```
+
+For multiple turns conversation:
+
+```bash
+"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
+```
+
+### Using Flash Attention 2
+
+Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
+- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
+
+
+## LlavaConfig
+
+[[autodoc]] LlavaConfig
+
+## LlavaProcessor
+
+[[autodoc]] LlavaProcessor
+
+## LlavaForConditionalGeneration
+
+[[autodoc]] LlavaForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/madlad-400.md b/docs/source/en/model_doc/madlad-400.md
new file mode 100644
index 00000000000000..aeb41938499c29
--- /dev/null
+++ b/docs/source/en/model_doc/madlad-400.md
@@ -0,0 +1,68 @@
+
+
+# MADLAD-400
+
+## Overview
+
+MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
+
+The abstract from the paper is the following:
+
+*We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss
+the limitations revealed by self-auditing MADLAD-400, and the role data auditing
+had in the dataset creation process. We then train and release a 10.7B-parameter
+multilingual machine translation model on 250 billion tokens covering over 450
+languages using publicly available data, and find that it is competitive with models
+that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot
+translation. We make the baseline models 1
+available to the research community.*
+
+This model was added by [Juarez Bochi](https://huggingface.co/jbochi). The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+This is a machine translation model that supports many low-resource languages, and that is competitive with models that are significantly larger.
+
+One can directly use MADLAD-400 weights without finetuning the model:
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/madlad400-3b-mt")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/madlad400-3b-mt")
+
+>>> inputs = tokenizer("<2pt> I love pizza!", return_tensors="pt")
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['Eu amo pizza!']
+```
+
+Google has released the following variants:
+
+- [google/madlad400-3b-mt](https://huggingface.co/google/madlad400-3b-mt)
+
+- [google/madlad400-7b-mt](https://huggingface.co/google/madlad400-7b-mt)
+
+- [google/madlad400-7b-mt-bt](https://huggingface.co/google/madlad400-7b-mt-bt)
+
+- [google/madlad400-10b-mt](https://huggingface.co/google/madlad400-10b-mt)
+
+The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+
+
+Refer to [T5's documentation page](t5) for all API references, code examples, and notebooks. For more details regarding training and evaluation of the MADLAD-400, refer to the model card.
+
+
diff --git a/docs/source/en/model_doc/mistral.md b/docs/source/en/model_doc/mistral.md
index 8e37bc2caf888d..8e4d75ef2382c3 100644
--- a/docs/source/en/model_doc/mistral.md
+++ b/docs/source/en/model_doc/mistral.md
@@ -99,7 +99,7 @@ To load and run a model using Flash Attention 2, refer to the snippet below:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
->>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
diff --git a/docs/source/en/model_doc/mixtral.md b/docs/source/en/model_doc/mixtral.md
new file mode 100644
index 00000000000000..9f1fb49f6c835c
--- /dev/null
+++ b/docs/source/en/model_doc/mixtral.md
@@ -0,0 +1,163 @@
+
+
+# Mixtral
+
+## Overview
+
+Mixtral-8x7B is Mistral AI's second Large Language Model (LLM).
+
+The Mixtral model was proposed in the by the [Mistral AI](https://mistral.ai/) team.
+
+It was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) with the following introduction:
+
+*Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.*
+
+Tips:
+
+
+- The model needs to be converted using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py).
+- If the model is quantized to 4bits, a single A100 is enough to fit the entire 45B model.
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
+The original code can be found [here](https://github.com/mistralai/mistral-src).
+
+
+### Model Details
+
+Mixtral-45B is a decoder-based LM with the following architectural choices:
+
+* Mixtral is a Mixture of Expert (MOE) model with 8 experts per MLP, with a total of 45B paramateres but the compute required is the same as a 14B model. This is because even though each experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dipatched twice (top 2 routing) and thus the compute (the operation required at each foward computation) is just 2 X sequence_length.
+
+The following implementation details are shared with Mistral AI's first model [mistral](~models/doc/mistral):
+* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
+* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
+* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
+
+They also provide an instruction fine-tuned model: `mistralai/Mixtral-8x7B-v0.1` which can be used for chat-based inference.
+
+For more details please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/)
+
+### License
+
+`Mixtral-8x7B` is released under the Apache 2.0 license.
+
+## Usage tips
+
+`Mixtral-8x7B` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
+
+These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-8x7B")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+To use the raw checkpoints with HuggingFace you can use the `convert_mixtral_weights_to_hf.py` script to convert them to the HuggingFace format:
+
+```bash
+python src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py \
+ --input_dir /path/to/downloaded/mistral/weights --output_dir /output/path
+```
+
+You can then load the converted model from the `output/path`:
+
+```python
+from transformers import MixtralForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = MixtralForCausalLM.from_pretrained("/output/path")
+```
+
+## Combining Mixtral and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+### Expected speedups
+
+Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mixtral-8x7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
+
+
+
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+- For better results, we recommend users to prompt the model with the correct prompt format:
+
+```bash
+"USER: \nASSISTANT:"
+```
+
+For multiple turns conversation:
+
+```bash
+"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
+```
+
+### Using Flash Attention 2
+
+Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
+- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
+
+
+## LlavaConfig
+
+[[autodoc]] LlavaConfig
+
+## LlavaProcessor
+
+[[autodoc]] LlavaProcessor
+
+## LlavaForConditionalGeneration
+
+[[autodoc]] LlavaForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/madlad-400.md b/docs/source/en/model_doc/madlad-400.md
new file mode 100644
index 00000000000000..aeb41938499c29
--- /dev/null
+++ b/docs/source/en/model_doc/madlad-400.md
@@ -0,0 +1,68 @@
+
+
+# MADLAD-400
+
+## Overview
+
+MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
+
+The abstract from the paper is the following:
+
+*We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss
+the limitations revealed by self-auditing MADLAD-400, and the role data auditing
+had in the dataset creation process. We then train and release a 10.7B-parameter
+multilingual machine translation model on 250 billion tokens covering over 450
+languages using publicly available data, and find that it is competitive with models
+that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot
+translation. We make the baseline models 1
+available to the research community.*
+
+This model was added by [Juarez Bochi](https://huggingface.co/jbochi). The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+This is a machine translation model that supports many low-resource languages, and that is competitive with models that are significantly larger.
+
+One can directly use MADLAD-400 weights without finetuning the model:
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/madlad400-3b-mt")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/madlad400-3b-mt")
+
+>>> inputs = tokenizer("<2pt> I love pizza!", return_tensors="pt")
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['Eu amo pizza!']
+```
+
+Google has released the following variants:
+
+- [google/madlad400-3b-mt](https://huggingface.co/google/madlad400-3b-mt)
+
+- [google/madlad400-7b-mt](https://huggingface.co/google/madlad400-7b-mt)
+
+- [google/madlad400-7b-mt-bt](https://huggingface.co/google/madlad400-7b-mt-bt)
+
+- [google/madlad400-10b-mt](https://huggingface.co/google/madlad400-10b-mt)
+
+The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+
+
+Refer to [T5's documentation page](t5) for all API references, code examples, and notebooks. For more details regarding training and evaluation of the MADLAD-400, refer to the model card.
+
+
diff --git a/docs/source/en/model_doc/mistral.md b/docs/source/en/model_doc/mistral.md
index 8e37bc2caf888d..8e4d75ef2382c3 100644
--- a/docs/source/en/model_doc/mistral.md
+++ b/docs/source/en/model_doc/mistral.md
@@ -99,7 +99,7 @@ To load and run a model using Flash Attention 2, refer to the snippet below:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
->>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, use_flash_attention_2=True)
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
diff --git a/docs/source/en/model_doc/mixtral.md b/docs/source/en/model_doc/mixtral.md
new file mode 100644
index 00000000000000..9f1fb49f6c835c
--- /dev/null
+++ b/docs/source/en/model_doc/mixtral.md
@@ -0,0 +1,163 @@
+
+
+# Mixtral
+
+## Overview
+
+Mixtral-8x7B is Mistral AI's second Large Language Model (LLM).
+
+The Mixtral model was proposed in the by the [Mistral AI](https://mistral.ai/) team.
+
+It was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) with the following introduction:
+
+*Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.*
+
+Tips:
+
+
+- The model needs to be converted using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py).
+- If the model is quantized to 4bits, a single A100 is enough to fit the entire 45B model.
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
+The original code can be found [here](https://github.com/mistralai/mistral-src).
+
+
+### Model Details
+
+Mixtral-45B is a decoder-based LM with the following architectural choices:
+
+* Mixtral is a Mixture of Expert (MOE) model with 8 experts per MLP, with a total of 45B paramateres but the compute required is the same as a 14B model. This is because even though each experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dipatched twice (top 2 routing) and thus the compute (the operation required at each foward computation) is just 2 X sequence_length.
+
+The following implementation details are shared with Mistral AI's first model [mistral](~models/doc/mistral):
+* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
+* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
+* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
+
+They also provide an instruction fine-tuned model: `mistralai/Mixtral-8x7B-v0.1` which can be used for chat-based inference.
+
+For more details please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/)
+
+### License
+
+`Mixtral-8x7B` is released under the Apache 2.0 license.
+
+## Usage tips
+
+`Mixtral-8x7B` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
+
+These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-8x7B")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+To use the raw checkpoints with HuggingFace you can use the `convert_mixtral_weights_to_hf.py` script to convert them to the HuggingFace format:
+
+```bash
+python src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py \
+ --input_dir /path/to/downloaded/mistral/weights --output_dir /output/path
+```
+
+You can then load the converted model from the `output/path`:
+
+```python
+from transformers import MixtralForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = MixtralForCausalLM.from_pretrained("/output/path")
+```
+
+## Combining Mixtral and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+### Expected speedups
+
+Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mixtral-8x7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
+
+
+
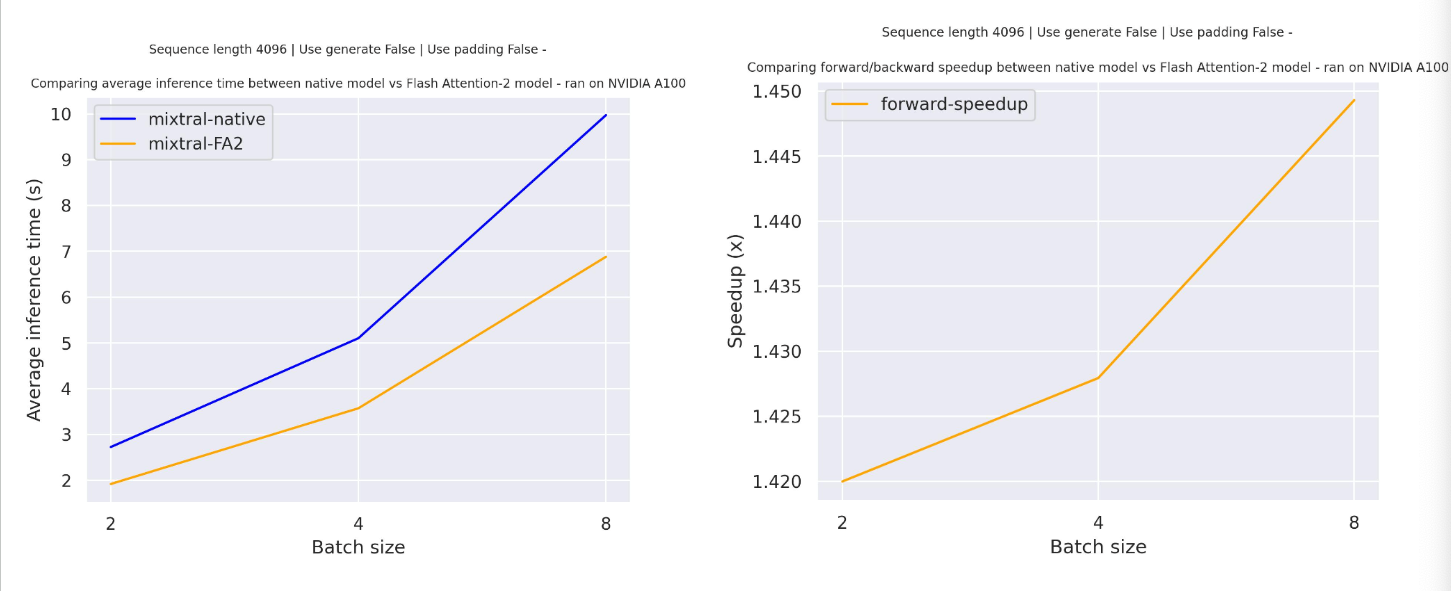
+
+
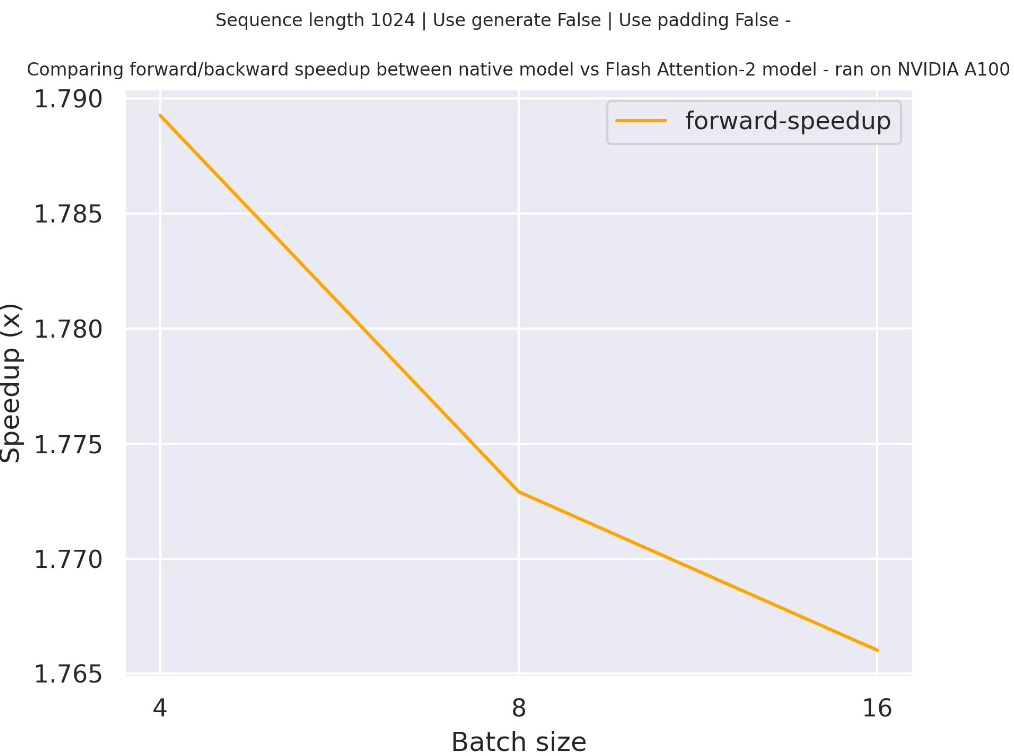
+
+
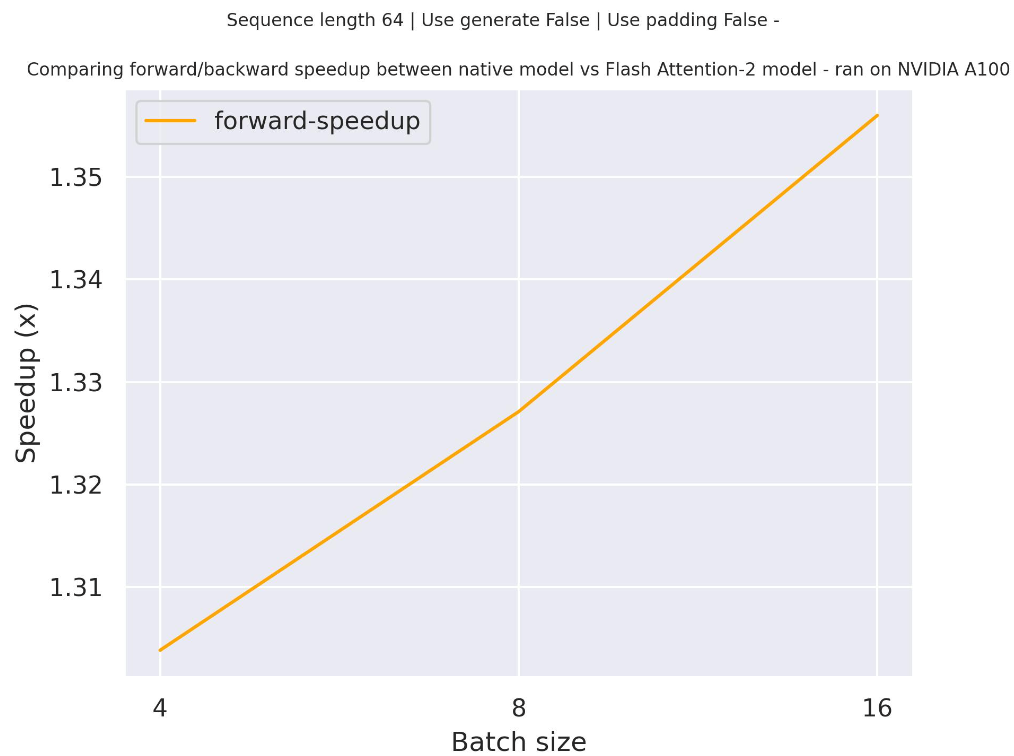
+
+
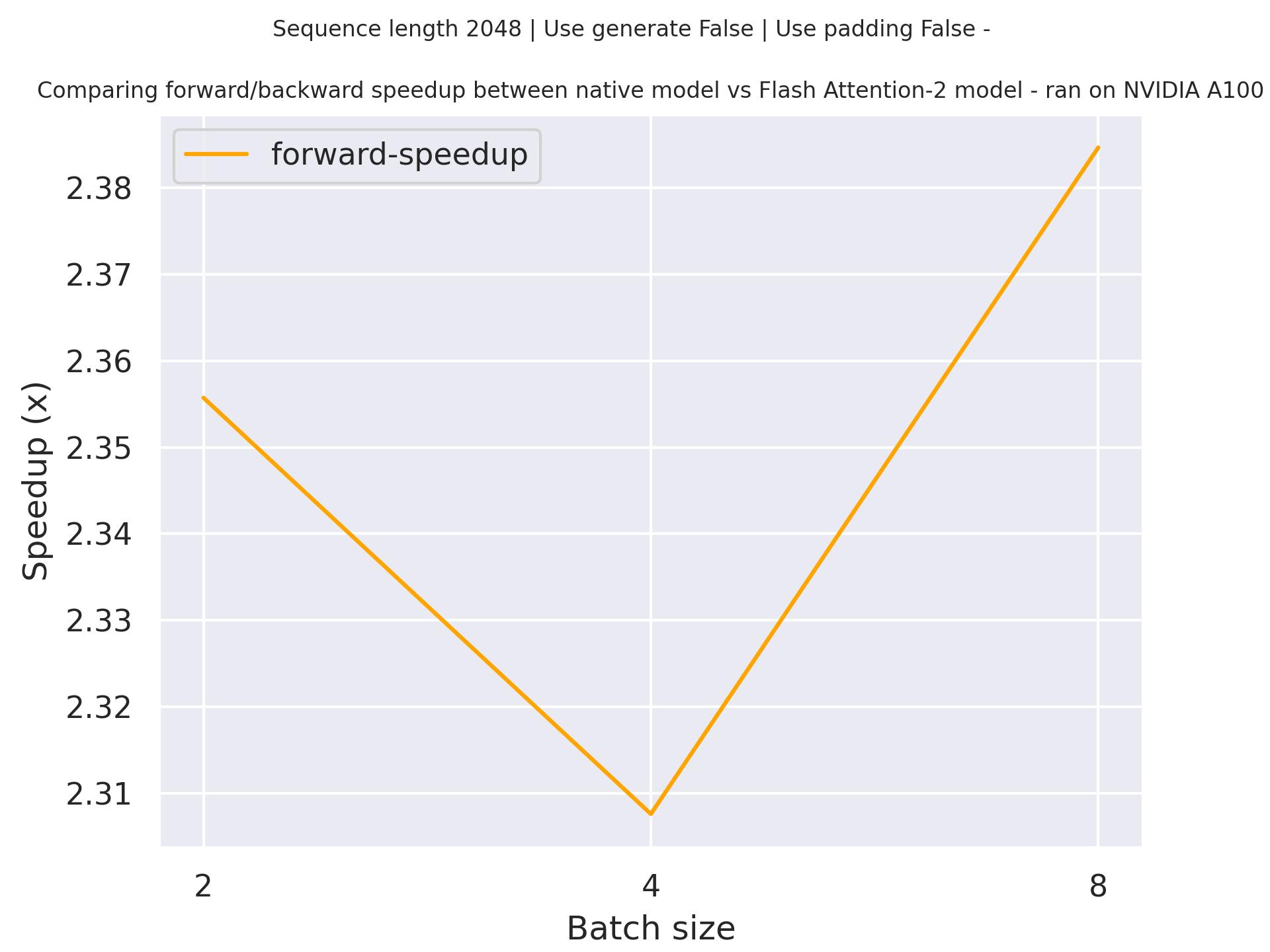
+
 @@ -79,13 +108,13 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
## TransfoXL specific outputs
-[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
-[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
-[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
-[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
new file mode 100644
index 00000000000000..22b400a06c736a
--- /dev/null
+++ b/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,186 @@
+
+
+# TVP
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+
@@ -79,13 +108,13 @@ TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyT
## TransfoXL specific outputs
-[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
-[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
-[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
-[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
diff --git a/docs/source/en/model_doc/tvp.md b/docs/source/en/model_doc/tvp.md
new file mode 100644
index 00000000000000..22b400a06c736a
--- /dev/null
+++ b/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,186 @@
+
+
+# TVP
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+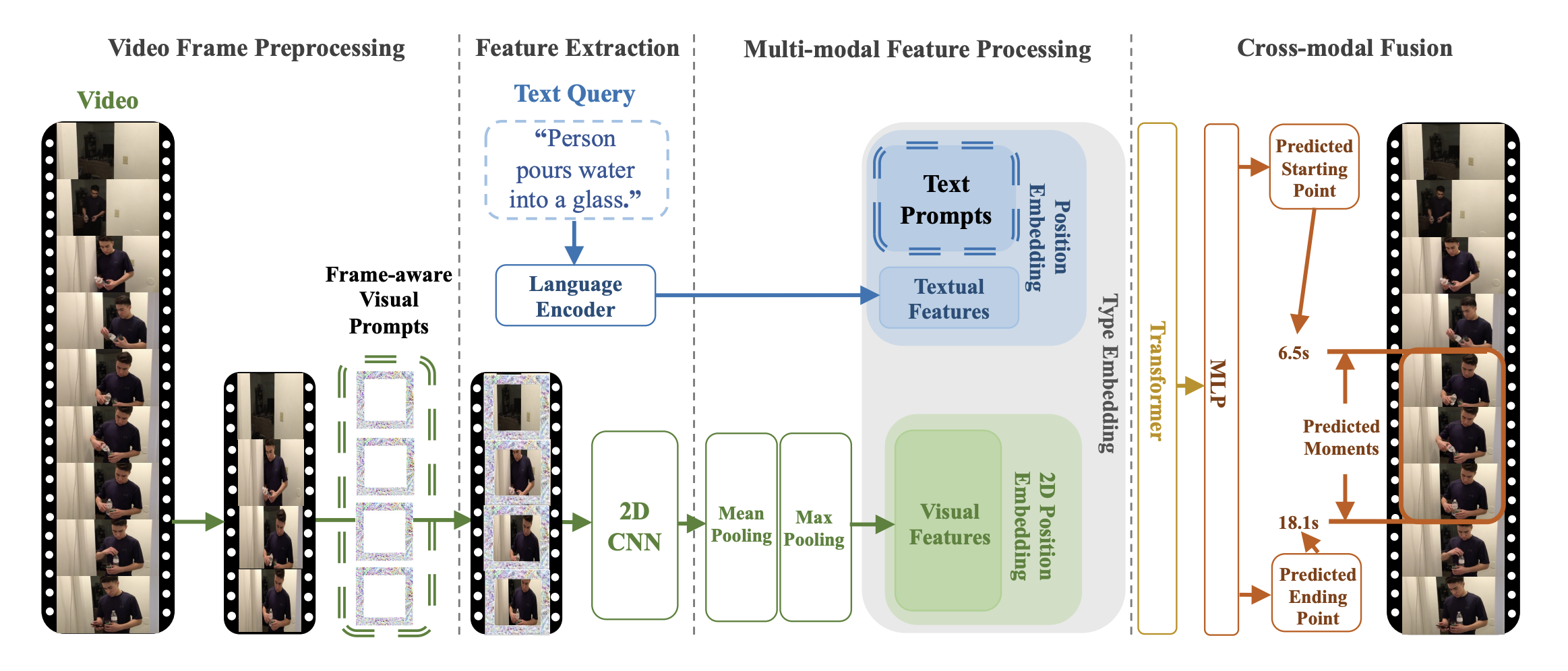 +
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
new file mode 100644
index 00000000000000..45bd94732773ae
--- /dev/null
+++ b/docs/source/en/model_doc/univnet.md
@@ -0,0 +1,80 @@
+
+
+# UnivNet
+
+## Overview
+
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
+
+The abstract from the paper is the following:
+
+*Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.*
+
+Tips:
+
+- The `noise_sequence` argument for [`UnivNetModel.forward`] should be standard Gaussian noise (such as from `torch.randn`) of shape `([batch_size], noise_length, model.config.model_in_channels)`, where `noise_length` should match the length dimension (dimension 1) of the `input_features` argument. If not supplied, it will be randomly generated; a `torch.Generator` can be supplied to the `generator` argument so that the forward pass can be reproduced. (Note that [`UnivNetFeatureExtractor`] will return generated noise by default, so it shouldn't be necessary to generate `noise_sequence` manually.)
+- Padding added by [`UnivNetFeatureExtractor`] can be removed from the [`UnivNetModel`] output through the [`UnivNetFeatureExtractor.batch_decode`] method, as shown in the usage example below.
+- Padding the end of each waveform with silence can reduce artifacts at the end of the generated audio sample. This can be done by supplying `pad_end = True` to [`UnivNetFeatureExtractor.__call__`]. See [this issue](https://github.com/seungwonpark/melgan/issues/8) for more details.
+
+Usage Example:
+
+```python
+import torch
+from scipy.io.wavfile import write
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetFeatureExtractor, UnivNetModel
+
+model_id_or_path = "dg845/univnet-dev"
+model = UnivNetModel.from_pretrained(model_id_or_path)
+feature_extractor = UnivNetFeatureExtractor.from_pretrained(model_id_or_path)
+
+ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+# Resample the audio to the model and feature extractor's sampling rate.
+ds = ds.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+# Pad the end of the converted waveforms to reduce artifacts at the end of the output audio samples.
+inputs = feature_extractor(
+ ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], pad_end=True, return_tensors="pt"
+)
+
+with torch.no_grad():
+ audio = model(**inputs)
+
+# Remove the extra padding at the end of the output.
+audio = feature_extractor.batch_decode(**audio)[0]
+# Convert to wav file
+write("sample_audio.wav", feature_extractor.sampling_rate, audio)
+```
+
+This model was contributed by [dg845](https://huggingface.co/dg845).
+To the best of my knowledge, there is no official code release, but an unofficial implementation can be found at [maum-ai/univnet](https://github.com/maum-ai/univnet) with pretrained checkpoints [here](https://github.com/maum-ai/univnet#pre-trained-model).
+
+
+## UnivNetConfig
+
+[[autodoc]] UnivNetConfig
+
+## UnivNetFeatureExtractor
+
+[[autodoc]] UnivNetFeatureExtractor
+ - __call__
+
+## UnivNetModel
+
+[[autodoc]] UnivNetModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
new file mode 100644
index 00000000000000..c5f3c5f55f2c56
--- /dev/null
+++ b/docs/source/en/model_doc/vipllava.md
@@ -0,0 +1,61 @@
+
+
+# VipLlava
+
+## Overview
+
+The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+
+VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
+
+The abstract from the paper is the following:
+
+*While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.*
+
+Tips:
+
+- The architecture is similar than llava architecture except that the multi-modal projector takes a set of concatenated vision hidden states and has an additional layernorm layer on that module.
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+- For better results, we recommend users to prompt the model with the correct prompt format:
+
+```bash
+"USER: \nASSISTANT:"
+```
+
+For multiple turns conversation:
+
+```bash
+"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
+```
+
+The original code can be found [here](https://github.com/mu-cai/ViP-LLaVA).
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada)
+
+
+## VipLlavaConfig
+
+[[autodoc]] VipLlavaConfig
+
+## VipLlavaForConditionalGeneration
+
+[[autodoc]] VipLlavaForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 8d73a5655fdf3f..37411209bf9157 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -34,13 +34,13 @@ The original code can be found [here](https://github.com/openai/whisper).
- Inference is currently only implemented for short-form i.e. audio is pre-segmented into <=30s segments. Long-form (including timestamps) will be implemented in a future release.
- One can use [`WhisperProcessor`] to prepare audio for the model, and decode the predicted ID's back into text.
-- To convert the tokenizer, we recommend using the following:
+- To convert the model and the processor, we recommend using the following:
```bash
-python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_tokenizer True --whisper_version 3 --multilingual True
+python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_preprocessor True
```
-Here the `whisper_version` will set the number of languages to `100` to account for `cantonese` which was added in `whisper-large-v3`.
-
+The script will automatically determine all necessary parameters from the OpenAI checkpoint. A `tiktoken` library needs to be installed
+to perform the conversion of the OpenAI tokenizer to the `tokenizers` version.
## Inference
@@ -75,6 +75,19 @@ Here is a step-by-step guide to transcribing an audio sample using a pre-trained
' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
```
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Whisper. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A fork with a script to [convert a Whisper model in Hugging Face format to OpenAI format](https://github.com/zuazo-forks/transformers/blob/convert_hf_to_openai/src/transformers/models/whisper/convert_hf_to_openai.py). 🌎
+Usage example:
+```bash
+pip install -U openai-whisper
+python convert_hf_to_openai.py \
+ --checkpoint openai/whisper-tiny \
+ --whisper_dump_path whisper-tiny-openai.pt
+```
+
## WhisperConfig
[[autodoc]] WhisperConfig
diff --git a/docs/source/en/pad_truncation.md b/docs/source/en/pad_truncation.md
index 8094dc1bc2aac2..cc623bca48a402 100644
--- a/docs/source/en/pad_truncation.md
+++ b/docs/source/en/pad_truncation.md
@@ -54,7 +54,7 @@ The following table summarizes the recommended way to setup padding and truncati
| | | `tokenizer(batch_sentences, padding='longest')` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
-| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8) |
+| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8)` |
| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
diff --git a/docs/source/en/perf_hardware.md b/docs/source/en/perf_hardware.md
index a28824346e4b17..18c70e1b30a5c2 100644
--- a/docs/source/en/perf_hardware.md
+++ b/docs/source/en/perf_hardware.md
@@ -134,7 +134,7 @@ Here is the full benchmark code and outputs:
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -143,7 +143,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index ba339c1a3068fa..21fce43427ab5b 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -15,7 +15,7 @@ rendered properly in your Markdown viewer.
# GPU inference
-GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia GPUs.
+GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
@@ -36,15 +36,31 @@ FlashAttention-2 is experimental and may change considerably in future versions.
1. additionally parallelizing the attention computation over sequence length
2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
-FlashAttention-2 supports inference with Llama, Mistral, Falcon and Bark models. You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
+FlashAttention-2 is currently supported for the following architectures:
+* [Bark](https://huggingface.co/docs/transformers/model_doc/bark#transformers.BarkModel)
+* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
+* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
+* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
+* [GPTNeo](https://huggingface.co/docs/transformers/model_doc/gpt_neo#transformers.GPTNeoModel)
+* [GPTNeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox#transformers.GPTNeoXModel)
+* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
+* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
+* [Llava](https://huggingface.co/docs/transformers/model_doc/llava)
+* [VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)
+* [MBart](https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartModel)
+* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
+* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
+* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
+* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
+* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
-Before you begin, make sure you have FlashAttention-2 installed (see the [installation](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) guide for more details about prerequisites):
+You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
-```bash
-pip install flash-attn --no-build-isolation
-```
+Before you begin, make sure you have FlashAttention-2 installed. For NVIDIA GPUs, the library is installable through pip: `pip install flash-attn --no-build-isolation`. We strongly suggest to refer to the [detailed installation instructions](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features).
+
+FlashAttention-2 is also supported on AMD GPUs, with the current support limited to **Instinct MI210 and Instinct MI250**. We strongly suggest to use the following [Dockerfile](https://github.com/huggingface/optimum-amd/tree/main/docker/transformers-pytorch-amd-gpu-flash/Dockerfile) to use FlashAttention-2 on AMD GPUs.
-To enable FlashAttention-2, add the `use_flash_attention_2` parameter to [`~AutoModelForCausalLM.from_pretrained`]:
+To enable FlashAttention-2, pass the argument `attn_implementation="flash_attention_2"` to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import torch
@@ -56,13 +72,15 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
-FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`, and it only runs on Nvidia GPUs. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
+FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
+
+Note that `use_flash_attention_2=True` can also be used to enable Flash Attention 2, but is deprecated in favor of `attn_implementation="flash_attention_2"`.
@@ -79,14 +97,14 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -126,41 +144,21 @@ FlashAttention is more memory efficient, meaning you can train on much larger se
+
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/source/en/model_doc/univnet.md b/docs/source/en/model_doc/univnet.md
new file mode 100644
index 00000000000000..45bd94732773ae
--- /dev/null
+++ b/docs/source/en/model_doc/univnet.md
@@ -0,0 +1,80 @@
+
+
+# UnivNet
+
+## Overview
+
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
+
+The abstract from the paper is the following:
+
+*Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.*
+
+Tips:
+
+- The `noise_sequence` argument for [`UnivNetModel.forward`] should be standard Gaussian noise (such as from `torch.randn`) of shape `([batch_size], noise_length, model.config.model_in_channels)`, where `noise_length` should match the length dimension (dimension 1) of the `input_features` argument. If not supplied, it will be randomly generated; a `torch.Generator` can be supplied to the `generator` argument so that the forward pass can be reproduced. (Note that [`UnivNetFeatureExtractor`] will return generated noise by default, so it shouldn't be necessary to generate `noise_sequence` manually.)
+- Padding added by [`UnivNetFeatureExtractor`] can be removed from the [`UnivNetModel`] output through the [`UnivNetFeatureExtractor.batch_decode`] method, as shown in the usage example below.
+- Padding the end of each waveform with silence can reduce artifacts at the end of the generated audio sample. This can be done by supplying `pad_end = True` to [`UnivNetFeatureExtractor.__call__`]. See [this issue](https://github.com/seungwonpark/melgan/issues/8) for more details.
+
+Usage Example:
+
+```python
+import torch
+from scipy.io.wavfile import write
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetFeatureExtractor, UnivNetModel
+
+model_id_or_path = "dg845/univnet-dev"
+model = UnivNetModel.from_pretrained(model_id_or_path)
+feature_extractor = UnivNetFeatureExtractor.from_pretrained(model_id_or_path)
+
+ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+# Resample the audio to the model and feature extractor's sampling rate.
+ds = ds.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+# Pad the end of the converted waveforms to reduce artifacts at the end of the output audio samples.
+inputs = feature_extractor(
+ ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], pad_end=True, return_tensors="pt"
+)
+
+with torch.no_grad():
+ audio = model(**inputs)
+
+# Remove the extra padding at the end of the output.
+audio = feature_extractor.batch_decode(**audio)[0]
+# Convert to wav file
+write("sample_audio.wav", feature_extractor.sampling_rate, audio)
+```
+
+This model was contributed by [dg845](https://huggingface.co/dg845).
+To the best of my knowledge, there is no official code release, but an unofficial implementation can be found at [maum-ai/univnet](https://github.com/maum-ai/univnet) with pretrained checkpoints [here](https://github.com/maum-ai/univnet#pre-trained-model).
+
+
+## UnivNetConfig
+
+[[autodoc]] UnivNetConfig
+
+## UnivNetFeatureExtractor
+
+[[autodoc]] UnivNetFeatureExtractor
+ - __call__
+
+## UnivNetModel
+
+[[autodoc]] UnivNetModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/vipllava.md b/docs/source/en/model_doc/vipllava.md
new file mode 100644
index 00000000000000..c5f3c5f55f2c56
--- /dev/null
+++ b/docs/source/en/model_doc/vipllava.md
@@ -0,0 +1,61 @@
+
+
+# VipLlava
+
+## Overview
+
+The VipLlava model was proposed in [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+
+VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a "red bounding box" or "pointed arrow" during training.
+
+The abstract from the paper is the following:
+
+*While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.*
+
+Tips:
+
+- The architecture is similar than llava architecture except that the multi-modal projector takes a set of concatenated vision hidden states and has an additional layernorm layer on that module.
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+- For better results, we recommend users to prompt the model with the correct prompt format:
+
+```bash
+"USER: \nASSISTANT:"
+```
+
+For multiple turns conversation:
+
+```bash
+"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
+```
+
+The original code can be found [here](https://github.com/mu-cai/ViP-LLaVA).
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada)
+
+
+## VipLlavaConfig
+
+[[autodoc]] VipLlavaConfig
+
+## VipLlavaForConditionalGeneration
+
+[[autodoc]] VipLlavaForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/whisper.md b/docs/source/en/model_doc/whisper.md
index 8d73a5655fdf3f..37411209bf9157 100644
--- a/docs/source/en/model_doc/whisper.md
+++ b/docs/source/en/model_doc/whisper.md
@@ -34,13 +34,13 @@ The original code can be found [here](https://github.com/openai/whisper).
- Inference is currently only implemented for short-form i.e. audio is pre-segmented into <=30s segments. Long-form (including timestamps) will be implemented in a future release.
- One can use [`WhisperProcessor`] to prepare audio for the model, and decode the predicted ID's back into text.
-- To convert the tokenizer, we recommend using the following:
+- To convert the model and the processor, we recommend using the following:
```bash
-python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_tokenizer True --whisper_version 3 --multilingual True
+python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_preprocessor True
```
-Here the `whisper_version` will set the number of languages to `100` to account for `cantonese` which was added in `whisper-large-v3`.
-
+The script will automatically determine all necessary parameters from the OpenAI checkpoint. A `tiktoken` library needs to be installed
+to perform the conversion of the OpenAI tokenizer to the `tokenizers` version.
## Inference
@@ -75,6 +75,19 @@ Here is a step-by-step guide to transcribing an audio sample using a pre-trained
' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
```
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Whisper. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A fork with a script to [convert a Whisper model in Hugging Face format to OpenAI format](https://github.com/zuazo-forks/transformers/blob/convert_hf_to_openai/src/transformers/models/whisper/convert_hf_to_openai.py). 🌎
+Usage example:
+```bash
+pip install -U openai-whisper
+python convert_hf_to_openai.py \
+ --checkpoint openai/whisper-tiny \
+ --whisper_dump_path whisper-tiny-openai.pt
+```
+
## WhisperConfig
[[autodoc]] WhisperConfig
diff --git a/docs/source/en/pad_truncation.md b/docs/source/en/pad_truncation.md
index 8094dc1bc2aac2..cc623bca48a402 100644
--- a/docs/source/en/pad_truncation.md
+++ b/docs/source/en/pad_truncation.md
@@ -54,7 +54,7 @@ The following table summarizes the recommended way to setup padding and truncati
| | | `tokenizer(batch_sentences, padding='longest')` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
-| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8) |
+| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8)` |
| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
diff --git a/docs/source/en/perf_hardware.md b/docs/source/en/perf_hardware.md
index a28824346e4b17..18c70e1b30a5c2 100644
--- a/docs/source/en/perf_hardware.md
+++ b/docs/source/en/perf_hardware.md
@@ -134,7 +134,7 @@ Here is the full benchmark code and outputs:
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -143,7 +143,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index ba339c1a3068fa..21fce43427ab5b 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -15,7 +15,7 @@ rendered properly in your Markdown viewer.
# GPU inference
-GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia GPUs.
+GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
@@ -36,15 +36,31 @@ FlashAttention-2 is experimental and may change considerably in future versions.
1. additionally parallelizing the attention computation over sequence length
2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
-FlashAttention-2 supports inference with Llama, Mistral, Falcon and Bark models. You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
+FlashAttention-2 is currently supported for the following architectures:
+* [Bark](https://huggingface.co/docs/transformers/model_doc/bark#transformers.BarkModel)
+* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
+* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
+* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
+* [GPTNeo](https://huggingface.co/docs/transformers/model_doc/gpt_neo#transformers.GPTNeoModel)
+* [GPTNeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox#transformers.GPTNeoXModel)
+* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
+* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
+* [Llava](https://huggingface.co/docs/transformers/model_doc/llava)
+* [VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)
+* [MBart](https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartModel)
+* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
+* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
+* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
+* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
+* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
-Before you begin, make sure you have FlashAttention-2 installed (see the [installation](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) guide for more details about prerequisites):
+You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
-```bash
-pip install flash-attn --no-build-isolation
-```
+Before you begin, make sure you have FlashAttention-2 installed. For NVIDIA GPUs, the library is installable through pip: `pip install flash-attn --no-build-isolation`. We strongly suggest to refer to the [detailed installation instructions](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features).
+
+FlashAttention-2 is also supported on AMD GPUs, with the current support limited to **Instinct MI210 and Instinct MI250**. We strongly suggest to use the following [Dockerfile](https://github.com/huggingface/optimum-amd/tree/main/docker/transformers-pytorch-amd-gpu-flash/Dockerfile) to use FlashAttention-2 on AMD GPUs.
-To enable FlashAttention-2, add the `use_flash_attention_2` parameter to [`~AutoModelForCausalLM.from_pretrained`]:
+To enable FlashAttention-2, pass the argument `attn_implementation="flash_attention_2"` to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import torch
@@ -56,13 +72,15 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
-FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`, and it only runs on Nvidia GPUs. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
+FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
+
+Note that `use_flash_attention_2=True` can also be used to enable Flash Attention 2, but is deprecated in favor of `attn_implementation="flash_attention_2"`.
@@ -79,14 +97,14 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -126,41 +144,21 @@ FlashAttention is more memory efficient, meaning you can train on much larger se

-## BetterTransformer
-
-
-
-Check out our benchmarks with BetterTransformer and scaled dot product attention in the [Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0](https://pytorch.org/blog/out-of-the-box-acceleration/) and learn more about the fastpath execution in the [BetterTransformer](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) blog post.
-
-
-
-BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
-
-1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
-2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
-
-BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention (SDPA)](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention), and it calls optimized kernels like [FlashAttention](https://huggingface.co/papers/2205.14135) under the hood.
+## FlashAttention and memory-efficient attention through PyTorch's scaled_dot_product_attention
-Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
+PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers, and is used by default for `torch>=2.1.1` when an implementation is available.
-Then you can enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
+For now, Transformers supports inference and training through SDPA for the following architectures:
+* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
+* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
+* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
+* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
+* [Idefics](https://huggingface.co/docs/transformers/model_doc/idefics#transformers.IdeficsModel)
+* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
-```python
-model = model.to_bettertransformer()
-```
+Note that FlashAttention can only be used for models with the `fp16` or `bf16` torch type, so make sure to cast your model to the appropriate type before using it.
-You can return the original Transformers model with the [`~PreTrainedModel.reverse_bettertransformer`] method. You should use this before saving your model to use the canonical Transformers modeling:
-
-```py
-model = model.reverse_bettertransformer()
-model.save_pretrained("saved_model")
-```
-
-### FlashAttention
-
-SDPA can also call FlashAttention kernels under the hood. FlashAttention can only be used for models using the `fp16` or `bf16` dtype, so make sure to cast your model to the appropriate dtype before using it.
-
-To enable FlashAttention or to check whether it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
+By default, `torch.nn.functional.scaled_dot_product_attention` selects the most performant kernel available, but to check whether a backend is available in a given setting (hardware, problem size), you can use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
```diff
import torch
@@ -189,11 +187,48 @@ RuntimeError: No available kernel. Aborting execution.
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
```
+## BetterTransformer
+
+
+
+Part of BetterTransformer features are being upstreamed in Transformers, with native `torch.nn.scaled_dot_product_attention` default support. BetterTransformer still has a wider coverage than the Transformers SDPA integration, but you can expect more and more architectures to support natively SDPA in Transformers.
+
+
+
+
+
+
+Check out our benchmarks with BetterTransformer and scaled dot product attention in the [Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0](https://pytorch.org/blog/out-of-the-box-acceleration/) and learn more about the fastpath execution in the [BetterTransformer](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) blog post.
+
+
+
+BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
+
+1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
+2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
+
+BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention (SDPA)](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention), and it calls optimized kernels like [FlashAttention](https://huggingface.co/papers/2205.14135) under the hood.
+
+Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
+
+Then you can enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
+
+```python
+model = model.to_bettertransformer()
+```
+
+You can return the original Transformers model with the [`~PreTrainedModel.reverse_bettertransformer`] method. You should use this before saving your model to use the canonical Transformers modeling:
+
+```py
+model = model.reverse_bettertransformer()
+model.save_pretrained("saved_model")
+```
+
## bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
-Make sure you have bitsnbytes and 🤗 Accelerate installed:
+Make sure you have bitsandbytes and 🤗 Accelerate installed:
```bash
# these versions support 8-bit and 4-bit
@@ -276,13 +311,13 @@ Feel free to try running a 11 billion parameter [T5 model](https://colab.researc
-Learn more details about using ORT with 🤗 Optimum in the [Accelerated inference on NVIDIA GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#accelerated-inference-on-nvidia-gpus) guide. This section only provides a brief and simple example.
+Learn more details about using ORT with 🤗 Optimum in the [Accelerated inference on NVIDIA GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#accelerated-inference-on-nvidia-gpus) and [Accelerated inference on AMD GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu#accelerated-inference-on-amd-gpus) guides. This section only provides a brief and simple example.
-ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
+ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use [ROCm](https://www.amd.com/en/products/software/rocm.html) stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
-ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and specify the `provider` parameter which can be set to either [`CUDAExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#cudaexecutionprovider) or [`TensorrtExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#tensorrtexecutionprovider). If you want to load a model that was not yet exported to ONNX, you can set `export=True` to convert your model on-the-fly to the ONNX format :
+ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and specify the `provider` parameter which can be set to either [`CUDAExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#cudaexecutionprovider), [`ROCMExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu) or [`TensorrtExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#tensorrtexecutionprovider). If you want to load a model that was not yet exported to ONNX, you can set `export=True` to convert your model on-the-fly to the ONNX format:
```py
from optimum.onnxruntime import ORTModelForSequenceClassification
diff --git a/docs/source/en/perf_train_cpu_many.md b/docs/source/en/perf_train_cpu_many.md
index 4c131430babdae..4c5ffa35cdb64b 100644
--- a/docs/source/en/perf_train_cpu_many.md
+++ b/docs/source/en/perf_train_cpu_many.md
@@ -15,7 +15,8 @@ rendered properly in your Markdown viewer.
# Efficient Training on Multiple CPUs
-When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling distributed CPU training efficiently.
+When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling
+distributed CPU training efficiently on [bare metal](#usage-in-trainer) and [Kubernetes](#usage-with-kubernetes).
## Intel® oneCCL Bindings for PyTorch
@@ -25,7 +26,7 @@ Module `oneccl_bindings_for_pytorch` (`torch_ccl` before version 1.12) implemen
Check more detailed information for [oneccl_bind_pt](https://github.com/intel/torch-ccl).
-### Intel® oneCCL Bindings for PyTorch installation:
+### Intel® oneCCL Bindings for PyTorch installation
Wheel files are available for the following Python versions:
@@ -68,9 +69,9 @@ torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os
source $torch_ccl_path/env/setvars.sh
```
-#### IPEX installation:
+#### Intel® Extension for PyTorch installation
-IPEX provides performance optimizations for CPU training with both Float32 and BFloat16, you could refer [single CPU section](./perf_train_cpu).
+Intel Extension for PyTorch (IPEX) provides performance optimizations for CPU training with both Float32 and BFloat16 (refer to the [single CPU section](./perf_train_cpu) to learn more).
The following "Usage in Trainer" takes mpirun in Intel® MPI library as an example.
@@ -132,3 +133,185 @@ Now, run the following command in node0 and **4DDP** will be enabled in node0 an
--use_ipex \
--bf16
```
+
+## Usage with Kubernetes
+
+The same distributed training job from the previous section can be deployed to a Kubernetes cluster using the
+[Kubeflow PyTorchJob training operator](https://www.kubeflow.org/docs/components/training/pytorch/).
+
+### Setup
+
+This example assumes that you have:
+* Access to a Kubernetes cluster with [Kubeflow installed](https://www.kubeflow.org/docs/started/installing-kubeflow/)
+* [`kubectl`](https://kubernetes.io/docs/tasks/tools/) installed and configured to access the Kubernetes cluster
+* A [Persistent Volume Claim (PVC)](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) that can be used
+ to store datasets and model files. There are multiple options for setting up the PVC including using an NFS
+ [storage class](https://kubernetes.io/docs/concepts/storage/storage-classes/) or a cloud storage bucket.
+* A Docker container that includes your model training script and all the dependencies needed to run the script. For
+ distributed CPU training jobs, this typically includes PyTorch, Transformers, Intel Extension for PyTorch, Intel
+ oneCCL Bindings for PyTorch, and OpenSSH to communicate between the containers.
+
+The snippet below is an example of a Dockerfile that uses a base image that supports distributed CPU training and then
+extracts a Transformers release to the `/workspace` directory, so that the example scripts are included in the image:
+```
+FROM intel/ai-workflows:torch-2.0.1-huggingface-multinode-py3.9
+
+WORKDIR /workspace
+
+# Download and extract the transformers code
+ARG HF_TRANSFORMERS_VER="4.35.2"
+RUN mkdir transformers && \
+ curl -sSL --retry 5 https://github.com/huggingface/transformers/archive/refs/tags/v${HF_TRANSFORMERS_VER}.tar.gz | tar -C transformers --strip-components=1 -xzf -
+```
+The image needs to be built and copied to the cluster's nodes or pushed to a container registry prior to deploying the
+PyTorchJob to the cluster.
+
+### PyTorchJob Specification File
+
+The [Kubeflow PyTorchJob](https://www.kubeflow.org/docs/components/training/pytorch/) is used to run the distributed
+training job on the cluster. The yaml file for the PyTorchJob defines parameters such as:
+ * The name of the PyTorchJob
+ * The number of replicas (workers)
+ * The python script and it's parameters that will be used to run the training job
+ * The types of resources (node selector, memory, and CPU) needed for each worker
+ * The image/tag for the Docker container to use
+ * Environment variables
+ * A volume mount for the PVC
+
+The volume mount defines a path where the PVC will be mounted in the container for each worker pod. This location can be
+used for the dataset, checkpoint files, and the saved model after training completes.
+
+The snippet below is an example of a yaml file for a PyTorchJob with 4 workers running the
+[question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering).
+```yaml
+apiVersion: "kubeflow.org/v1"
+kind: PyTorchJob
+metadata:
+ name: transformers-pytorchjob
+ namespace: kubeflow
+spec:
+ elasticPolicy:
+ rdzvBackend: c10d
+ minReplicas: 1
+ maxReplicas: 4
+ maxRestarts: 10
+ pytorchReplicaSpecs:
+ Worker:
+ replicas: 4 # The number of worker pods
+ restartPolicy: OnFailure
+ template:
+ spec:
+ containers:
+ - name: pytorch
+ image: : # Specify the docker image to use for the worker pods
+ imagePullPolicy: IfNotPresent
+ command:
+ - torchrun
+ - /workspace/transformers/examples/pytorch/question-answering/run_qa.py
+ - --model_name_or_path
+ - "bert-large-uncased"
+ - --dataset_name
+ - "squad"
+ - --do_train
+ - --do_eval
+ - --per_device_train_batch_size
+ - "12"
+ - --learning_rate
+ - "3e-5"
+ - --num_train_epochs
+ - "2"
+ - --max_seq_length
+ - "384"
+ - --doc_stride
+ - "128"
+ - --output_dir
+ - "/tmp/pvc-mount/output"
+ - --no_cuda
+ - --ddp_backend
+ - "ccl"
+ - --use_ipex
+ - --bf16 # Specify --bf16 if your hardware supports bfloat16
+ env:
+ - name: LD_PRELOAD
+ value: "/usr/lib/x86_64-linux-gnu/libtcmalloc.so.4.5.9:/usr/local/lib/libiomp5.so"
+ - name: TRANSFORMERS_CACHE
+ value: "/tmp/pvc-mount/transformers_cache"
+ - name: HF_DATASETS_CACHE
+ value: "/tmp/pvc-mount/hf_datasets_cache"
+ - name: LOGLEVEL
+ value: "INFO"
+ - name: CCL_WORKER_COUNT
+ value: "1"
+ - name: OMP_NUM_THREADS # Can be tuned for optimal performance
+- value: "56"
+ resources:
+ limits:
+ cpu: 200 # Update the CPU and memory limit values based on your nodes
+ memory: 128Gi
+ requests:
+ cpu: 200 # Update the CPU and memory request values based on your nodes
+ memory: 128Gi
+ volumeMounts:
+ - name: pvc-volume
+ mountPath: /tmp/pvc-mount
+ - mountPath: /dev/shm
+ name: dshm
+ restartPolicy: Never
+ nodeSelector: # Optionally use the node selector to specify what types of nodes to use for the workers
+ node-type: spr
+ volumes:
+ - name: pvc-volume
+ persistentVolumeClaim:
+ claimName: transformers-pvc
+ - name: dshm
+ emptyDir:
+ medium: Memory
+```
+To run this example, update the yaml based on your training script and the nodes in your cluster.
+
+
+
+The CPU resource limits/requests in the yaml are defined in [cpu units](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu)
+where 1 CPU unit is equivalent to 1 physical CPU core or 1 virtual core (depending on whether the node is a physical
+host or a VM). The amount of CPU and memory limits/requests defined in the yaml should be less than the amount of
+available CPU/memory capacity on a single machine. It is usually a good idea to not use the entire machine's capacity in
+order to leave some resources for the kubelet and OS. In order to get ["guaranteed"](https://kubernetes.io/docs/concepts/workloads/pods/pod-qos/#guaranteed)
+[quality of service](https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/) for the worker pods,
+set the same CPU and memory amounts for both the resource limits and requests.
+
+
+
+### Deploy
+
+After the PyTorchJob spec has been updated with values appropriate for your cluster and training job, it can be deployed
+to the cluster using:
+```
+kubectl create -f pytorchjob.yaml
+```
+
+The `kubectl get pods -n kubeflow` command can then be used to list the pods in the `kubeflow` namespace. You should see
+the worker pods for the PyTorchJob that was just deployed. At first, they will probably have a status of "Pending" as
+the containers get pulled and created, then the status should change to "Running".
+```
+NAME READY STATUS RESTARTS AGE
+...
+transformers-pytorchjob-worker-0 1/1 Running 0 7m37s
+transformers-pytorchjob-worker-1 1/1 Running 0 7m37s
+transformers-pytorchjob-worker-2 1/1 Running 0 7m37s
+transformers-pytorchjob-worker-3 1/1 Running 0 7m37s
+...
+```
+
+The logs for worker can be viewed using `kubectl logs -n kubeflow `. Add `-f` to stream the logs, for example:
+```
+kubectl logs -n kubeflow transformers-pytorchjob-worker-0 -f
+```
+
+After the training job completes, the trained model can be copied from the PVC or storage location. When you are done
+with the job, the PyTorchJob resource can be deleted from the cluster using `kubectl delete -f pytorchjob.yaml`.
+
+## Summary
+
+This guide covered running distributed PyTorch training jobs using multiple CPUs on bare metal and on a Kubernetes
+cluster. Both cases utilize Intel Extension for PyTorch and Intel oneCCL Bindings for PyTorch for optimal training
+performance, and can be used as a template to run your own workload on multiple nodes.
diff --git a/docs/source/en/perf_train_gpu_many.md b/docs/source/en/perf_train_gpu_many.md
index 1795782949d1aa..4d89cf341a555d 100644
--- a/docs/source/en/perf_train_gpu_many.md
+++ b/docs/source/en/perf_train_gpu_many.md
@@ -153,7 +153,7 @@ python examples/pytorch/language-modeling/run_clm.py \
```
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -164,7 +164,7 @@ python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-
```
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/en/perf_train_gpu_one.md b/docs/source/en/perf_train_gpu_one.md
index 25117241f78fbc..089c9905cabada 100644
--- a/docs/source/en/perf_train_gpu_one.md
+++ b/docs/source/en/perf_train_gpu_one.md
@@ -237,7 +237,7 @@ You can speedup the training throughput by using Flash Attention 2 integration i
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
-For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed, `adamw_apex_fused` will give you the
+For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
@@ -529,4 +529,4 @@ By default, in training mode, the BetterTransformer integration **drops the mask
-Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
\ No newline at end of file
+Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
diff --git a/docs/source/en/preprocessing.md b/docs/source/en/preprocessing.md
index f08808433c269e..743904cc994c09 100644
--- a/docs/source/en/preprocessing.md
+++ b/docs/source/en/preprocessing.md
@@ -220,7 +220,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
For audio tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from raw audio data, and convert them into tensors.
-Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
```py
>>> from datasets import load_dataset, Audio
@@ -340,7 +340,7 @@ You can use any library you like for image augmentation. For image preprocessing
-Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
+Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
@@ -354,7 +354,7 @@ Use 🤗 Datasets `split` parameter to only load a small sample from the trainin
>>> dataset = load_dataset("food101", split="train[:100]")
```
-Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) feature:
+Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) feature:
```py
>>> dataset[0]["image"]
@@ -467,7 +467,7 @@ from [`DetrImageProcessor`] and define a custom `collate_fn` to batch images tog
For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
-Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
+Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
```py
>>> from datasets import load_dataset
diff --git a/docs/source/en/quantization.md b/docs/source/en/quantization.md
new file mode 100644
index 00000000000000..0a471fd423c6f9
--- /dev/null
+++ b/docs/source/en/quantization.md
@@ -0,0 +1,583 @@
+
+
+# Quantization
+
+Quantization techniques focus on representing data with less information while also trying to not lose too much accuracy. This often means converting a data type to represent the same information with fewer bits. For example, if your model weights are stored as 32-bit floating points and they're quantized to 16-bit floating points, this halves the model size which makes it easier to store and reduces memory-usage. Lower precision can also speedup inference because it takes less time to perform calculations with fewer bits.
+
+Transformers supports several quantization schemes to help you run inference with large language models (LLMs) and finetune adapters on quantized models. This guide will show you how to use Activation-aware Weight Quantization (AWQ), AutoGPTQ, and bitsandbytes.
+
+## AWQ
+
+
+
+Try AWQ quantization with this [notebook](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY)!
+
+
+
+[Activation-aware Weight Quantization (AWQ)](https://hf.co/papers/2306.00978) doesn't quantize all the weights in a model, and instead, it preserves a small percentage of weights that are important for LLM performance. This significantly reduces quantization loss such that you can run models in 4-bit precision without experiencing any performance degradation.
+
+There are several libraries for quantizing models with the AWQ algorithm, such as [llm-awq](https://github.com/mit-han-lab/llm-awq), [autoawq](https://github.com/casper-hansen/AutoAWQ) or [optimum-intel](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc). Transformers supports loading models quantized with the llm-awq and autoawq libraries. This guide will show you how to load models quantized with autoawq, but the processs is similar for llm-awq quantized models.
+
+Make sure you have autoawq installed:
+
+```bash
+pip install autoawq
+```
+
+AWQ-quantized models can be identified by checking the `quantization_config` attribute in the model's [config.json](https://huggingface.co/TheBloke/zephyr-7B-alpha-AWQ/blob/main/config.json) file:
+
+```json
+{
+ "_name_or_path": "/workspace/process/huggingfaceh4_zephyr-7b-alpha/source",
+ "architectures": [
+ "MistralForCausalLM"
+ ],
+ ...
+ ...
+ ...
+ "quantization_config": {
+ "quant_method": "awq",
+ "zero_point": true,
+ "group_size": 128,
+ "bits": 4,
+ "version": "gemm"
+ }
+}
+```
+
+A quantized model is loaded with the [`~PreTrainedModel.from_pretrained`] method. If you loaded your model on the CPU, make sure to move it to a GPU device first. Use the `device_map` parameter to specify where to place the model:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
+```
+
+Loading an AWQ-quantized model automatically sets other weights to fp16 by default for performance reasons. If you want to load these other weights in a different format, use the `torch_dtype` parameter:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float32)
+```
+
+AWQ quantization can also be combined with [FlashAttention-2](perf_infer_gpu_one#flashattention-2) to further accelerate inference:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
+```
+
+### Fused modules
+
+Fused modules offers improved accuracy and performance and it is supported out-of-the-box for AWQ modules for [Llama](https://huggingface.co/meta-llama) and [Mistral](https://huggingface.co/mistralai/Mistral-7B-v0.1) architectures, but you can also fuse AWQ modules for unsupported architectures.
+
+
+
+Fused modules cannot be combined with other optimization techniques such as FlashAttention-2.
+
+
+
+
+
+
+To enable fused modules for supported architectures, create an [`AwqConfig`] and set the parameters `fuse_max_seq_len` and `do_fuse=True`. The `fuse_max_seq_len` parameter is the total sequence length and it should include the context length and the expected generation length. You can set it to a larger value to be safe.
+
+For example, to fuse the AWQ modules of the [TheBloke/Mistral-7B-OpenOrca-AWQ](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ) model.
+
+```python
+import torch
+from transformers import AwqConfig, AutoModelForCausalLM
+
+model_id = "TheBloke/Mistral-7B-OpenOrca-AWQ"
+
+quantization_config = AwqConfig(
+ bits=4,
+ fuse_max_seq_len=512,
+ do_fuse=True,
+)
+
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
+```
+
+
+
+
+For architectures that don't support fused modules yet, you need to create a custom fusing mapping to define which modules need to be fused with the `modules_to_fuse` parameter. For example, to fuse the AWQ modules of the [TheBloke/Yi-34B-AWQ](https://huggingface.co/TheBloke/Yi-34B-AWQ) model.
+
+```python
+import torch
+from transformers import AwqConfig, AutoModelForCausalLM
+
+model_id = "TheBloke/Yi-34B-AWQ"
+
+quantization_config = AwqConfig(
+ bits=4,
+ fuse_max_seq_len=512,
+ modules_to_fuse={
+ "attention": ["q_proj", "k_proj", "v_proj", "o_proj"],
+ "layernorm": ["ln1", "ln2", "norm"],
+ "mlp": ["gate_proj", "up_proj", "down_proj"],
+ "use_alibi": False,
+ "num_attention_heads": 56,
+ "num_key_value_heads": 8,
+ "hidden_size": 7168
+ }
+)
+
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
+```
+
+The parameter `modules_to_fuse` should include:
+
+- `"attention"`: The names of the attention layers to fuse in the following order: query, key, value and output projection layer. If you don't want to fuse these layers, pass an empty list.
+- `"layernorm"`: The names of all the LayerNorm layers you want to replace with a custom fused LayerNorm. If you don't want to fuse these layers, pass an empty list.
+- `"mlp"`: The names of the MLP layers you want to fuse into a single MLP layer in the order: (gate (dense, layer, post-attention) / up / down layers).
+- `"use_alibi"`: If your model uses ALiBi positional embedding.
+- `"num_attention_heads"`: The number of attention heads.
+- `"num_key_value_heads"`: The number of key value heads that should be used to implement Grouped Query Attention (GQA). If `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if `num_key_value_heads=1` the model will use Multi Query Attention (MQA), otherwise GQA is used.
+- `"hidden_size"`: The dimension of the hidden representations.
+
+
+
+
+## AutoGPTQ
+
+
+
+Try GPTQ quantization with PEFT in this [notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) and learn more about it's details in this [blog post](https://huggingface.co/blog/gptq-integration)!
+
+
+
+The [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) library implements the GPTQ algorithm, a post-training quantization technique where each row of the weight matrix is quantized independently to find a version of the weights that minimizes the error. These weights are quantized to int4, but they're restored to fp16 on the fly during inference. This can save your memory-usage by 4x because the int4 weights are dequantized in a fused kernel rather than a GPU's global memory, and you can also expect a speedup in inference because using a lower bitwidth takes less time to communicate.
+
+Before you begin, make sure the following libraries are installed:
+
+```bash
+pip install auto-gptq
+pip install git+https://github.com/huggingface/optimum.git
+pip install git+https://github.com/huggingface/transformers.git
+pip install --upgrade accelerate
+```
+
+To quantize a model (currently only supported for text models), you need to create a [`GPTQConfig`] class and set the number of bits to quantize to, a dataset to calibrate the weights for quantization, and a tokenizer to prepare the dataset.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
+
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+gptq_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
+```
+
+You could also pass your own dataset as a list of strings, but it is highly recommended to use the same dataset from the GPTQ paper.
+
+```py
+dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
+gptq_config = GPTQConfig(bits=4, dataset=dataset, tokenizer=tokenizer)
+```
+
+Load a model to quantize and pass the `gptq_config` to the [`~AutoModelForCausalLM.from_pretrained`] method. Set `device_map="auto"` to automatically offload the model to a CPU to help fit the model in memory, and allow the model modules to be moved between the CPU and GPU for quantization.
+
+```py
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
+```
+
+If you're running out of memory because a dataset is too large, disk offloading is not supported. If this is the case, try passing the `max_memory` parameter to allocate the amount of memory to use on your device (GPU and CPU):
+
+```py
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", max_memory={0: "30GiB", 1: "46GiB", "cpu": "30GiB"}, quantization_config=gptq_config)
+```
+
+
+
+Depending on your hardware, it can take some time to quantize a model from scratch. It can take ~5 minutes to quantize the [faceboook/opt-350m]() model on a free-tier Google Colab GPU, but it'll take ~4 hours to quantize a 175B parameter model on a NVIDIA A100. Before you quantize a model, it is a good idea to check the Hub if a GPTQ-quantized version of the model already exists.
+
+
+
+Once your model is quantized, you can push the model and tokenizer to the Hub where it can be easily shared and accessed. Use the [`~PreTrainedModel.push_to_hub`] method to save the [`GPTQConfig`]:
+
+```py
+quantized_model.push_to_hub("opt-125m-gptq")
+tokenizer.push_to_hub("opt-125m-gptq")
+```
+
+You could also save your quantized model locally with the [`~PreTrainedModel.save_pretrained`] method. If the model was quantized with the `device_map` parameter, make sure to move the entire model to a GPU or CPU before saving it. For example, to save the model on a CPU:
+
+```py
+quantized_model.save_pretrained("opt-125m-gptq")
+tokenizer.save_pretrained("opt-125m-gptq")
+
+# if quantized with device_map set
+quantized_model.to("cpu")
+quantized_model.save_pretrained("opt-125m-gptq")
+```
+
+Reload a quantized model with the [`~PreTrainedModel.from_pretrained`] method, and set `device_map="auto"` to automatically distribute the model on all available GPUs to load the model faster without using more memory than needed.
+
+```py
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
+```
+
+### ExLlama
+
+[ExLlama](https://github.com/turboderp/exllama) is a Python/C++/CUDA implementation of the [Llama](model_doc/llama) model that is designed for faster inference with 4-bit GPTQ weights (check out these [benchmarks](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)). The ExLlama kernel is activated by default when you create a [`GPTQConfig`] object. To boost inference speed even further, use the [ExLlamaV2](https://github.com/turboderp/exllamav2) kernels by configuring the `exllama_config` parameter:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, GPTQConfig
+
+gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
+```
+
+
+
+Only 4-bit models are supported, and we recommend deactivating the ExLlama kernels if you're finetuning a quantized model with PEFT.
+
+
+
+The ExLlama kernels are only supported when the entire model is on the GPU. If you're doing inference on a CPU with AutoGPTQ (version > 0.4.2), then you'll need to disable the ExLlama kernel. This overwrites the attributes related to the ExLlama kernels in the quantization config of the config.json file.
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, GPTQConfig
+gptq_config = GPTQConfig(bits=4, use_exllama=False)
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="cpu", quantization_config=gptq_config)
+```
+
+## bitsandbytes
+
+[bitsandbytes](https://github.com/TimDettmers/bitsandbytes) is the easiest option for quantizing a model to 8 and 4-bit. 8-bit quantization multiplies outliers in fp16 with non-outliers in int8, converts the non-outlier values back to fp16, and then adds them together to return the weights in fp16. This reduces the degradative effect outlier values have on a model's performance. 4-bit quantization compresses a model even further, and it is commonly used with [QLoRA](https://hf.co/papers/2305.14314) to finetune quantized LLMs.
+
+To use bitsandbytes, make sure you have the following libraries installed:
+
+
+
+
+```bash
+pip install transformers accelerate bitsandbytes>0.37.0
+```
+
+
+
+
+```bash
+pip install bitsandbytes>=0.39.0
+pip install --upgrade accelerate
+pip install --upgrade transformers
+```
+
+
+
+
+Now you can quantize a model with the `load_in_8bit` or `load_in_4bit` parameters in the [`~PreTrainedModel.from_pretrained`] method. This works for any model in any modality, as long as it supports loading with Accelerate and contains `torch.nn.Linear` layers.
+
+
+
+
+Quantizing a model in 8-bit halves the memory-usage, and for large models, set `device_map="auto"` to efficiently use the GPUs available:
+
+```py
+from transformers import AutoModelForCausalLM
+
+model_8bit = AutoModelForCausalLM.from_pretrained("bigscience/bloom-1b7", device_map="auto", load_in_8bit=True)
+```
+
+By default, all the other modules such as `torch.nn.LayerNorm` are converted to `torch.float16`. You can change the data type of these modules with the `torch_dtype` parameter if you want:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM
+
+model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
+model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
+```
+
+Once a model is quantized to 8-bit, you can't push the quantized weights to the Hub unless you're using the latest version of Transformers and bitsandbytes. If you have the latest versions, then you can push the 8-bit model to the Hub with the [`~PreTrainedModel.push_to_hub`] method. The quantization config.json file is pushed first, followed by the quantized model weights.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
+tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
+
+model.push_to_hub("bloom-560m-8bit")
+```
+
+
+
+
+Quantizing a model in 4-bit reduces your memory-usage by 4x, and for large models, set `device_map="auto"` to efficiently use the GPUs available:
+
+```py
+from transformers import AutoModelForCausalLM
+
+model_4bit = AutoModelForCausalLM.from_pretrained("bigscience/bloom-1b7", device_map="auto", load_in_4bit=True)
+```
+
+By default, all the other modules such as `torch.nn.LayerNorm` are converted to `torch.float16`. You can change the data type of these modules with the `torch_dtype` parameter if you want:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM
+
+model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, torch_dtype=torch.float32)
+model_4bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
+```
+
+Once a model is quantized to 4-bit, you can't push the quantized weights to the Hub.
+
+
+
+
+
+
+Training with 8-bit and 4-bit weights are only supported for training *extra* parameters.
+
+
+
+You can check your memory footprint with the `get_memory_footprint` method:
+
+```py
+print(model.get_memory_footprint())
+```
+
+Quantized models can be loaded from the [`~PreTrainedModel.from_pretrained`] method without needing to specify the `load_in_8bit` or `load_in_4bit` parameters:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
+```
+
+### 8-bit
+
+
+
+Learn more about the details of 8-bit quantization in this [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration)!
+
+
+
+This section explores some of the specific features of 8-bit models, such as offloading, outlier thresholds, skipping module conversion, and finetuning.
+
+#### Offloading
+
+8-bit models can offload weights between the CPU and GPU to support fitting very large models into memory. The weights dispatched to the CPU are actually stored in **float32**, and aren't converted to 8-bit. For example, to enable offloading for the [bigscience/bloom-1b7](https://huggingface.co/bigscience/bloom-1b7) model, start by creating a [`BitsAndBytesConfig`]:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
+```
+
+Design a custom device map to fit everything on your GPU except for the `lm_head`, which you'll dispatch to the CPU:
+
+```py
+device_map = {
+ "transformer.word_embeddings": 0,
+ "transformer.word_embeddings_layernorm": 0,
+ "lm_head": "cpu",
+ "transformer.h": 0,
+ "transformer.ln_f": 0,
+}
+```
+
+Now load your model with the custom `device_map` and `quantization_config`:
+
+```py
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-1b7",
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+```
+
+#### Outlier threshold
+
+An "outlier" is a hidden state value greater than a certain threshold, and these values are computed in fp16. While the values are usually normally distributed ([-3.5, 3.5]), this distribution can be very different for large models ([-60, 6] or [6, 60]). 8-bit quantization works well for values ~5, but beyond that, there is a significant performance penalty. A good default threshold value is 6, but a lower threshold may be needed for more unstable models (small models or finetuning).
+
+To find the best threshold for your model, we recommend experimenting with the `llm_int8_threshold` parameter in [`BitsAndBytesConfig`]:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_threshold=10,
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+```
+
+#### Skip module conversion
+
+For some models, like [Jukebox](model_doc/jukebox), you don't need to quantize every module to 8-bit which can actually cause instability. With Jukebox, there are several `lm_head` modules that should be skipped using the `llm_int8_skip_modules` parameter in [`BitsAndBytesConfig`]:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_skip_modules=["lm_head"],
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map="auto",
+ quantization_config=quantization_config,
+)
+```
+
+#### Finetuning
+
+With the [PEFT](https://github.com/huggingface/peft) library, you can finetune large models like [flan-t5-large](https://huggingface.co/google/flan-t5-large) and [facebook/opt-6.7b](https://huggingface.co/facebook/opt-6.7b) with 8-bit quantization. You don't need to pass the `device_map` parameter for training because it'll automatically load your model on a GPU. However, you can still customize the device map with the `device_map` parameter if you want to (`device_map="auto"` should only be used for inference).
+
+### 4-bit
+
+
+
+Try 4-bit quantization in this [notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) and learn more about it's details in this [blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
+
+
+
+This section explores some of the specific features of 4-bit models, such as changing the compute data type, using the Normal Float 4 (NF4) data type, and using nested quantization.
+
+#### Compute data type
+
+To speedup computation, you can change the data type from float32 (the default value) to bf16 using the `bnb_4bit_compute_dtype` parameter in [`BitsAndBytesConfig`]:
+
+```py
+import torch
+from transformers import BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
+```
+
+#### Normal Float 4 (NF4)
+
+NF4 is a 4-bit data type from the [QLoRA](https://hf.co/papers/2305.14314) paper, adapted for weights initialized from a normal distribution. You should use NF4 for training 4-bit base models. This can be configured with the `bnb_4bit_quant_type` parameter in the [`BitsAndBytesConfig`]:
+
+```py
+from transformers import BitsAndBytesConfig
+
+nf4_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+)
+
+model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
+```
+
+For inference, the `bnb_4bit_quant_type` does not have a huge impact on performance. However, to remain consistent with the model weights, you should use the `bnb_4bit_compute_dtype` and `torch_dtype` values.
+
+#### Nested quantization
+
+Nested quantization is a technique that can save additional memory at no additional performance cost. This feature performs a second quantization of the already quantized weights to save an addition 0.4 bits/parameter. For example, with nested quantization, you can finetune a [Llama-13b](https://huggingface.co/meta-llama/Llama-2-13b) model on a 16GB NVIDIA T4 GPU with a sequence length of 1024, a batch size of 1, and enabling gradient accumulation with 4 steps.
+
+```py
+from transformers import BitsAndBytesConfig
+
+double_quant_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+)
+
+model_double_quant = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b", quantization_config=double_quant_config)
+```
+
+## Optimum
+
+The [Optimum](https://huggingface.co/docs/optimum/index) library supports quantization for Intel, Furiosa, ONNX Runtime, GPTQ, and lower-level PyTorch quantization functions. Consider using Optimum for quantization if you're using specific and optimized hardware like Intel CPUs, Furiosa NPUs or a model accelerator like ONNX Runtime.
+
+## Benchmarks
+
+To compare the speed, throughput, and latency of each quantization scheme, check the following benchmarks obtained from the [optimum-benchmark](https://github.com/huggingface/optimum-benchmark) library. The benchmark was run on a NVIDIA A1000 for the [TheBloke/Mistral-7B-v0.1-AWQ](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ) and [TheBloke/Mistral-7B-v0.1-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ) models. These were also tested against the bitsandbytes quantization methods as well as a native fp16 model.
+
+
+
+
+
forward peak memory/batch size
+
+
+
+
generate peak memory/batch size
+
+
+
+
+
generate throughput/batch size
+
+
+
+
forward latency/batch size
+
+
+
+
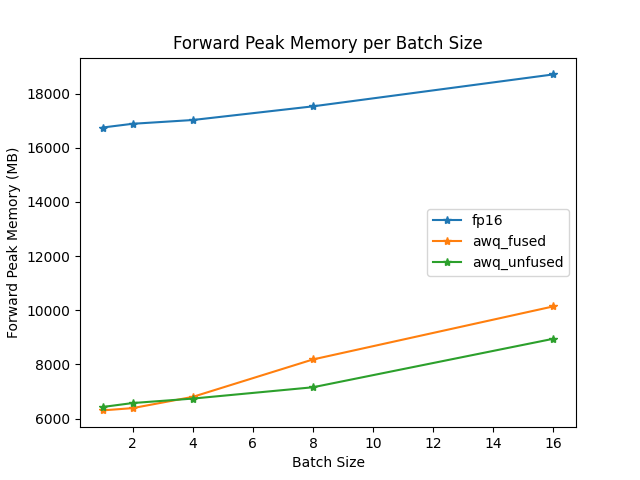
+
foward peak memory/batch size
+
+
+
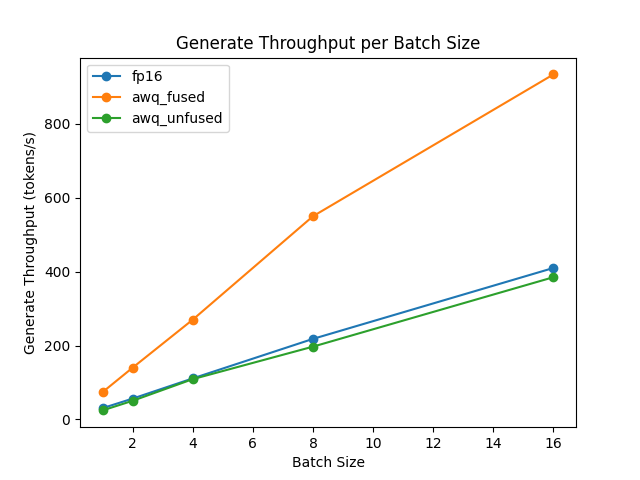
+
generate throughput/batch size
+
+
 -Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index d06b64fbc5a87d..8448e53011494c 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -61,8 +61,8 @@ import torch.nn.functional as F
class ImageDistilTrainer(Trainer):
- def __init__(self, *args, teacher_model=None, **kwargs):
- super().__init__(*args, **kwargs)
+ def __init__(self, teacher_model=None, student_model=None, temperature=None, lambda_param=None, *args, **kwargs):
+ super().__init__(model=student_model, *args, **kwargs)
self.teacher = teacher_model
self.student = student_model
self.loss_function = nn.KLDivLoss(reduction="batchmean")
@@ -164,7 +164,7 @@ trainer = ImageDistilTrainer(
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
- tokenizer=teacher_extractor,
+ tokenizer=teacher_processor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
diff --git a/docs/source/en/tasks/language_modeling.md b/docs/source/en/tasks/language_modeling.md
index 0b9c248702199b..a50555dfcf941a 100644
--- a/docs/source/en/tasks/language_modeling.md
+++ b/docs/source/en/tasks/language_modeling.md
@@ -37,7 +37,7 @@ You can finetune other architectures for causal language modeling following the
Choose one of the following architectures:
-[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
+[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
@@ -110,7 +110,7 @@ The next step is to load a DistilGPT2 tokenizer to process the `text` subfield:
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to
-extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/masked_language_modeling.md b/docs/source/en/tasks/masked_language_modeling.md
index ba1e9e50dbe80c..e716447b83bbe8 100644
--- a/docs/source/en/tasks/masked_language_modeling.md
+++ b/docs/source/en/tasks/masked_language_modeling.md
@@ -105,7 +105,7 @@ For masked language modeling, the next step is to load a DistilRoBERTa tokenizer
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to e
-xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/object_detection.md b/docs/source/en/tasks/object_detection.md
index 7511ee66dd0b99..6f53655e7cbc76 100644
--- a/docs/source/en/tasks/object_detection.md
+++ b/docs/source/en/tasks/object_detection.md
@@ -512,7 +512,7 @@ Finally, load the metrics and run the evaluation.
... outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
... orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
-... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to COCO api
+... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to Pascal VOC format (xmin, ymin, xmax, ymax)
... module.add(prediction=results, reference=labels)
... del batch
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index 2895a1977721d4..f422fef9aeb566 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -14,29 +14,17 @@ rendered properly in your Markdown viewer.
-->
-# Semantic segmentation
+# Image Segmentation
[[open-in-colab]]
-Semantic segmentation assigns a label or class to each individual pixel of an image. There are several types of segmentation, and in the case of semantic segmentation, no distinction is made between unique instances of the same object. Both objects are given the same label (for example, "car" instead of "car-1" and "car-2"). Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
+Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
-This guide will show you how to:
-
-1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
-2. Use your finetuned model for inference.
-
-
-The task illustrated in this tutorial is supported by the following model architectures:
-
-
-
-[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
-
-
-
-
+In this guide, we will:
+1. [Take a look at different types of segmentation](#types-of-segmentation).
+2. [Have an end-to-end fine-tuning example for semantic segmentation](#fine-tuning-a-model-for-segmentation).
Before you begin, make sure you have all the necessary libraries installed:
@@ -52,7 +40,178 @@ We encourage you to log in to your Hugging Face account so you can upload and sh
>>> notebook_login()
```
-## Load SceneParse150 dataset
+## Types of Segmentation
+
+Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
+We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+image
+```
+
+
-Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index d06b64fbc5a87d..8448e53011494c 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -61,8 +61,8 @@ import torch.nn.functional as F
class ImageDistilTrainer(Trainer):
- def __init__(self, *args, teacher_model=None, **kwargs):
- super().__init__(*args, **kwargs)
+ def __init__(self, teacher_model=None, student_model=None, temperature=None, lambda_param=None, *args, **kwargs):
+ super().__init__(model=student_model, *args, **kwargs)
self.teacher = teacher_model
self.student = student_model
self.loss_function = nn.KLDivLoss(reduction="batchmean")
@@ -164,7 +164,7 @@ trainer = ImageDistilTrainer(
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
- tokenizer=teacher_extractor,
+ tokenizer=teacher_processor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
diff --git a/docs/source/en/tasks/language_modeling.md b/docs/source/en/tasks/language_modeling.md
index 0b9c248702199b..a50555dfcf941a 100644
--- a/docs/source/en/tasks/language_modeling.md
+++ b/docs/source/en/tasks/language_modeling.md
@@ -37,7 +37,7 @@ You can finetune other architectures for causal language modeling following the
Choose one of the following architectures:
-[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
+[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
@@ -110,7 +110,7 @@ The next step is to load a DistilGPT2 tokenizer to process the `text` subfield:
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to
-extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/masked_language_modeling.md b/docs/source/en/tasks/masked_language_modeling.md
index ba1e9e50dbe80c..e716447b83bbe8 100644
--- a/docs/source/en/tasks/masked_language_modeling.md
+++ b/docs/source/en/tasks/masked_language_modeling.md
@@ -105,7 +105,7 @@ For masked language modeling, the next step is to load a DistilRoBERTa tokenizer
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to e
-xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
diff --git a/docs/source/en/tasks/object_detection.md b/docs/source/en/tasks/object_detection.md
index 7511ee66dd0b99..6f53655e7cbc76 100644
--- a/docs/source/en/tasks/object_detection.md
+++ b/docs/source/en/tasks/object_detection.md
@@ -512,7 +512,7 @@ Finally, load the metrics and run the evaluation.
... outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
... orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
-... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to COCO api
+... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to Pascal VOC format (xmin, ymin, xmax, ymax)
... module.add(prediction=results, reference=labels)
... del batch
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index 2895a1977721d4..f422fef9aeb566 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -14,29 +14,17 @@ rendered properly in your Markdown viewer.
-->
-# Semantic segmentation
+# Image Segmentation
[[open-in-colab]]
-Semantic segmentation assigns a label or class to each individual pixel of an image. There are several types of segmentation, and in the case of semantic segmentation, no distinction is made between unique instances of the same object. Both objects are given the same label (for example, "car" instead of "car-1" and "car-2"). Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
+Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
-This guide will show you how to:
-
-1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
-2. Use your finetuned model for inference.
-
-
-The task illustrated in this tutorial is supported by the following model architectures:
-
-
-
-[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
-
-
-
-
+In this guide, we will:
+1. [Take a look at different types of segmentation](#types-of-segmentation).
+2. [Have an end-to-end fine-tuning example for semantic segmentation](#fine-tuning-a-model-for-segmentation).
Before you begin, make sure you have all the necessary libraries installed:
@@ -52,7 +40,178 @@ We encourage you to log in to your Hugging Face account so you can upload and sh
>>> notebook_login()
```
-## Load SceneParse150 dataset
+## Types of Segmentation
+
+Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
+We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+image
+```
+
+
+

+
+

+
+

+
+
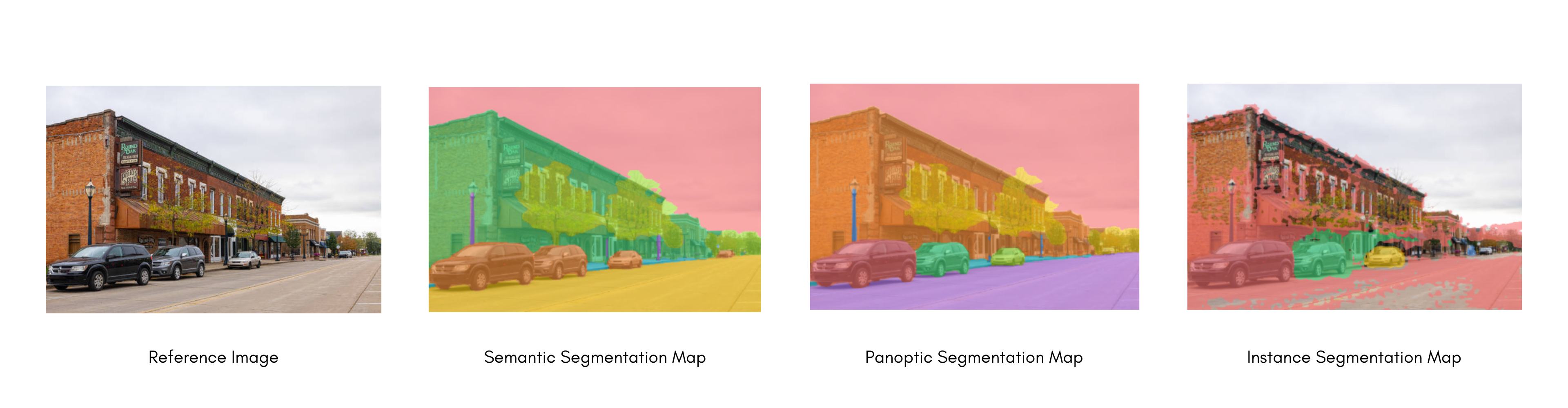
+
 +
+Esta es una aproximación más cercana a la verdadera descomposición de la probabilidad de la secuencia y generalmente dará como resultado una puntuación más favorable. La desventaja es que requiere un pase hacia adelante separado para cada token en el corpus. Un buen compromiso práctico es emplear una ventana deslizante estratificada, moviendo el contexto con pasos más grandes en lugar de deslizarse de 1 token a la vez. Esto permite que la computación avance mucho más rápido, mientras le da al modelo un contexto amplio para hacer
+predicciones en cada paso.
+
+## Ejemplo: Cálculo de la perplejidad con GPT-2 en 🤗 Transformers
+
+Demostremos este proceso con GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+Carguemos el conjunto de datos WikiText-2 y evaluemos la perplejidad utilizando algunas estrategias de ventana deslizante diferentes. Dado que este conjunto de datos es pequeño y solo estamos realizando un pase hacia adelante sobre el conjunto, podemos cargar y codificar todo el conjunto de datos en la memoria.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+Con 🤗 Transformers, simplemente podemos pasar los `input_ids` como las `labels` a nuestro modelo, y la media negativa del log-likelihood para cada token se devuelve como la pérdida. Sin embargo, con nuestro enfoque de ventana deslizante, hay superposición en los tokens que pasamos al modelo en cada iteración. No queremos que el log-likelihood de los tokens que estamos tratando solo como contexto se incluya en nuestra pérdida, por lo que podemos establecer estos objetivos en `-100` para que se ignoren. El siguiente es un ejemplo de cómo podríamos hacer esto con un paso de `512`. Esto significa que el modelo tendrá al menos `512` tokens como contexto al calcular el log-likelihood condicional de cualquier token (siempre que haya `512` tokens precedentes disponibles para condicionar).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # puede ser diferente del paso en el último bucle
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # la pérdida se calcula utilizando CrossEntropyLoss, que promedia las etiquetas válidas
+ # N.B. el modelo solo calcula la pérdida sobre trg_len - 1 etiquetas, porque desplaza las etiqueta internamente
+ # a la izquierda por 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+Ejecuta esto con la longitud de paso igual a la longitud máxima de entrada es equivalente a la estrategia sub óptima,
+sin ventana deslizante, que discutimos anteriormente. Cuanto menor sea el paso, más contexto tendrá el modelo para
+realizar cada predicción y, por lo general, mejor será la perplejidad informada.
+
+Cuando ejecutamos lo anterior con `stride = 1024`, es decir, sin superposición, la PPL resultante es `19.44`, que es
+aproximadamente la misma que la `19.93` informada en el artículo de GPT-2. Al utilizar `stride = 512` y, por lo tanto,
+emplear nuestra estrategia de ventana deslizante, esto disminuye a `16.45`. Esto no solo es una puntuación más favorable, sino que se calcula de una manera más cercana a la verdadera descomposición autorregresiva de la probabilidad de una secuencia.
diff --git a/docs/source/es/preprocessing.md b/docs/source/es/preprocessing.md
index f4eec4862be8be..5ac4c018090bf1 100644
--- a/docs/source/es/preprocessing.md
+++ b/docs/source/es/preprocessing.md
@@ -195,7 +195,7 @@ Las entradas de audio se preprocesan de forma diferente a las entradas textuales
pip install datasets
```
-Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub.html) para que obtengas más detalles sobre cómo cargar un dataset):
+Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub) para que obtengas más detalles sobre cómo cargar un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -234,7 +234,7 @@ Por ejemplo, carga el dataset [LJ Speech](https://huggingface.co/datasets/lj_spe
'sampling_rate': 22050}
```
-1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
+1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
@@ -329,7 +329,7 @@ Vamos a cargar el dataset [food101](https://huggingface.co/datasets/food101) par
>>> dataset = load_dataset("food101", split="train[:100]")
```
-A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image):
+A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image):
```py
>>> dataset[0]["image"]
@@ -370,7 +370,7 @@ Para las tareas de visión por computadora es común añadir algún tipo de aume
... return examples
```
-3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) para aplicar las transformaciones sobre la marcha:
+3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform) para aplicar las transformaciones sobre la marcha:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/es/run_scripts.md b/docs/source/es/run_scripts.md
index a66fd1e47e1386..8b762fdddc28fc 100644
--- a/docs/source/es/run_scripts.md
+++ b/docs/source/es/run_scripts.md
@@ -130,7 +130,7 @@ python examples/tensorflow/summarization/run_summarization.py \
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/es/tasks/image_classification.md b/docs/source/es/tasks/image_classification.md
index 3a959aa934ffa8..f09730caf69fee 100644
--- a/docs/source/es/tasks/image_classification.md
+++ b/docs/source/es/tasks/image_classification.md
@@ -99,7 +99,7 @@ Crea una función de preprocesamiento que aplique las transformaciones y devuelv
... return examples
```
-Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
+Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
```py
>>> food = food.with_transform(transforms)
diff --git a/docs/source/es/tasks/language_modeling.md b/docs/source/es/tasks/language_modeling.md
index 66ac8fb0d4b56a..b3f22f0846335d 100644
--- a/docs/source/es/tasks/language_modeling.md
+++ b/docs/source/es/tasks/language_modeling.md
@@ -94,7 +94,7 @@ Para modelados de lenguaje por enmascaramiento carga el tokenizador DistilRoBERT
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
-Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten):
+Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process#flatten):
```py
>>> eli5 = eli5.flatten()
@@ -249,7 +249,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
@@ -356,7 +356,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
diff --git a/docs/source/es/training.md b/docs/source/es/training.md
index 7b7b0657bd8f16..4f224b0797a3b9 100644
--- a/docs/source/es/training.md
+++ b/docs/source/es/training.md
@@ -102,7 +102,7 @@ Especifica dónde vas a guardar los checkpoints de tu entrenamiento:
### Métricas
-El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para más información):
+El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics) para más información):
```py
>>> import numpy as np
@@ -172,7 +172,7 @@ El [`DefaultDataCollator`] junta los tensores en un batch para que el modelo se
-A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
+A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
@@ -342,7 +342,7 @@ Para hacer un seguimiento al progreso del entrenamiento, utiliza la biblioteca [
### Métricas
-De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
+De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/fr/_toctree.yml b/docs/source/fr/_toctree.yml
index 11632a423b6af1..12c2feb0a02eb5 100755
--- a/docs/source/fr/_toctree.yml
+++ b/docs/source/fr/_toctree.yml
@@ -1,156 +1,30 @@
- sections:
- - local: index
- title: 🤗 Transformers
- - local: quicktour
- title: Visite rapide
- - local: in_translation
- title: Installation
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: Visite rapide
+ - local: installation
+ title: Installation
title: Démarrer
- sections:
- - local: in_translation
- title: Pipelines pour l'inférence
- - local: in_translation
- title: Chargement d'instances pré-entraînées avec une AutoClass
- - local: in_translation
- title: Préparation des données
- - local: in_translation
- title: Fine-tune un modèle pré-entraîné
- - local: in_translation
- title: Entraînement distribué avec 🤗 Accelerate
- - local: in_translation
- title: Partager un modèle
- title: Tutoriels
-- sections:
- - sections:
- - local: in_translation
- title: Créer votre architecture
- - local: in_translation
- title: Partager vos modèles
- - local: in_translation
- title: Entraînement avec un script
- - local: in_translation
- title: Entraînement avec Amazon SageMaker
- - local: in_translation
- title: Convertir depuis des checkpoints Tensorflow
- - local: in_translation
- title: Exporter vers ONNX
- - local: in_translation
- title: Exporter vers TorchScript
- - local: in_translation
- title: Aide au dépannage
- title: Usage général
- - sections:
- - local: in_translation
- title: Utiliser les tokenizers de 🤗 Tokenizers
- - local: in_translation
- title: Inférence avec les modèles multilingues
- - local: in_translation
- title: Stratégies de génération de texte
- - sections:
- - isExpanded: false
- local: in_translation
- title: Classification de texte
- - local: in_translation
- title: Classification de token
- - local: in_translation
- title: Système de question-réponse
- - local: in_translation
- title: Modélisation causale du langage
- - local: in_translation
- title: Modélisation du langage avec masque
- - local: in_translation
- title: Traduction
- - local: in_translation
- title: Génération de résumé
- - local: in_translation
- title: Question à choix multiple
- title: Guides des tâches
- title: Traitement automatique des langues
- - sections:
- - local: in_translation
- title: Classification audio
- - local: in_translation
- title: Reconnaissance automatique de la parole
- title: Audio
- - sections:
- local: in_translation
- title: Classification d'images
+ title: Pipelines pour l'inférence
+ - local: autoclass_tutorial
+ title: Chargement d'instances pré-entraînées avec une AutoClass
- local: in_translation
- title: Segmentation sémantique
+ title: Préparation des données
- local: in_translation
- title: Classification de vidéos
+ title: Fine-tune un modèle pré-entraîné
- local: in_translation
- title: Détection d'objets
- title: Vision par ordinateur
- - sections:
- - local: in_translation
- title: Performance et extensibilité
- - sections:
- - local: in_translation
- title: Comment contribuer à transformers?
- - local: in_translation
- title: Comment ajouter un modèle à 🤗 Transformers?
- - local: in_translation
- title: Comment convertir un modèle 🤗 Transformers vers TensorFlow?
- - local: in_translation
- title: Comment ajouter un pipeline à 🤗 Transformers?
- - local: in_translation
- title: Tester
- - local: in_translation
- title: Vérification pour une Pull Request
- title: Contribuer
- - local: in_translation
- title: 🤗 Transformers Notebooks
- - local: in_translation
- title: Ressources communautaires
- - local: in_translation
- title: Benchmarks
- - local: in_translation
- title: Migration à partir de versions précédentes
- title: Guides d'utilisation
-- sections:
- - local: in_translation
- title: Philosophie
- - local: in_translation
- title: Glossaire
- - local: in_translation
- title: Qu'est ce 🤗 Transformers peut faire ?
- - local: in_translation
- title: Quelles tâches 🤗 Transformers peut résoudre ?
- - local: in_translation
- title: Résumé des modèles
- - local: in_translation
- title: Résumé des tokenizers
- - local: in_translation
- title: Remplissage et troncature
- - local: in_translation
- title: BERTology
- - local: in_translation
- title: Perplexité des modèles à longueur fixe
- - local: in_translation
- title: Pipelines pour inférence avec des serveurs web
- title: Guides conceptuels
-- sections:
- - isExpanded: false
- sections:
- - local: in_translation
- title: Classes principales
- - local: in_translation
- title: Modèles textuels
- - local: in_translation
- title: Modèles visuels
- - local: in_translation
- title: Modèles audio
+ title: Entraînement avec un script
- local: in_translation
- title: Modèles multimodal
+ title: Entraînement distribué avec 🤗 Accelerate
- local: in_translation
- title: Modèles d'apprentissage par renforcement
+ title: Chargement et entraînement des adaptateurs avec 🤗 PEFT
- local: in_translation
- title: Modèles de séries temporelles
+ title: Partager un modèle
- local: in_translation
- title: Graph models
- title: Modèles
- - sections:
+ title: Agents
- local: in_translation
- title: Utilitaires internes
- title: API
+ title: Génération avec LLMs
+ title: Tutoriels
diff --git a/docs/source/fr/autoclass_tutorial.md b/docs/source/fr/autoclass_tutorial.md
new file mode 100644
index 00000000000000..392e2a6807e55d
--- /dev/null
+++ b/docs/source/fr/autoclass_tutorial.md
@@ -0,0 +1,142 @@
+
+
+# Chargement d'instances pré-entraînées avec une AutoClass
+
+Avec autant d'architectures Transformer différentes, il peut être difficile d'en créer une pour votre ensemble de poids (aussi appelés "weights" ou "checkpoint" en anglais). Dans l'idée de créer une librairie facile, simple et flexible à utiliser, 🤗 Transformers fournit une `AutoClass` qui infère et charge automatiquement l'architecture correcte à partir d'un ensemble de poids donné. La fonction `from_pretrained()` vous permet de charger rapidement un modèle pré-entraîné pour n'importe quelle architecture afin que vous n'ayez pas à consacrer du temps et des ressources à l'entraînement d'un modèle à partir de zéro. Produire un tel code indépendant d'un ensemble de poids signifie que si votre code fonctionne pour un ensemble de poids, il fonctionnera avec un autre ensemble - tant qu'il a été entraîné pour une tâche similaire - même si l'architecture est différente.
+
+
+
+Rappel, l'architecture fait référence au squelette du modèle et l'ensemble de poids contient les poids pour une architecture donnée. Par exemple, [BERT](https://huggingface.co/bert-base-uncased) est une architecture, tandis que `bert-base-uncased` est un ensemble de poids. Le terme modèle est général et peut signifier soit architecture soit ensemble de poids.
+
+
+
+Dans ce tutoriel, vous apprendrez à:
+
+ * Charger un tokenizer pré-entraîné.
+ * Charger un processeur d'image pré-entraîné.
+ * Charger un extracteur de caractéristiques pré-entraîné.
+ * Charger un processeur pré-entraîné.
+ * Charger un modèle pré-entraîné.
+
+## AutoTokenizer
+
+Quasiment toutes les tâches de traitement du langage (NLP) commencent avec un tokenizer. Un tokenizer convertit votre texte initial dans un format qui peut être traité par le modèle.
+
+Chargez un tokenizer avec [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+Puis, transformez votre texte initial comme montré ci-dessous:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoImageProcessor
+
+Pour les tâches de vision, un processeur d'image traite l'image pour la formater correctment.
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+## AutoFeatureExtractor
+
+Pour les tâches audio, un extracteur de caractéristiques (aussi appelés "features" en anglais) traite le signal audio pour le formater correctement.
+
+Chargez un extracteur de caractéristiques avec [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor
+
+Les tâches multimodales nécessitent un processeur qui combine deux types d'outils de prétraitement. Par exemple, le modèle [LayoutLMV2](model_doc/layoutlmv2) nécessite un processeur d'image pour traiter les images et un tokenizer pour traiter le texte ; un processeur combine les deux.
+
+Chargez un processeur avec [`AutoProcessor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel
+
+
+
+Enfin, les classes `AutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`AutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+Pour les modèles PyTorch, la fonction `from_pretrained()` utilise `torch.load()` qui utilise `pickle` en interne et est connu pour être non sécurisé. En général, ne chargez jamais un modèle qui pourrait provenir d'une source non fiable, ou qui pourrait avoir été altéré. Ce risque de sécurité est partiellement atténué pour les modèles hébergés publiquement sur le Hugging Face Hub, qui sont [scannés pour les logiciels malveillants](https://huggingface.co/docs/hub/security-malware) à chaque modification. Consultez la [documentation du Hub](https://huggingface.co/docs/hub/security) pour connaître les meilleures pratiques comme la [vérification des modifications signées](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) avec GPG.
+
+Les points de contrôle TensorFlow et Flax ne sont pas concernés, et peuvent être chargés dans des architectures PyTorch en utilisant les arguments `from_tf` et `from_flax` de la fonction `from_pretrained` pour contourner ce problème.
+
+
+
+En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `AutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
+
+
+Enfin, les classes `TFAutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`TFAutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `TFAutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
+
+
diff --git a/docs/source/fr/installation.md b/docs/source/fr/installation.md
new file mode 100644
index 00000000000000..f529c4e201dad3
--- /dev/null
+++ b/docs/source/fr/installation.md
@@ -0,0 +1,258 @@
+
+
+# Installation
+
+Installez 🤗 Transformers pour n'importe quelle librairie d'apprentissage profond avec laquelle vous avez l'habitude de travaillez, configurez votre cache et configurez 🤗 Transformers pour un usage hors ligne (facultatif).
+
+🤗 Transformers est testé avec Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ et Flax.
+Consulter les instructions d'installation ci-dessous pour la librairie d'apprentissage profond que vous utilisez:
+
+ * Instructions d'installation pour [PyTorch](https://pytorch.org/get-started/locally/).
+ * Instructions d'installation pour [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+ * Instructions d'installation pour [Flax](https://flax.readthedocs.io/en/latest/).
+
+## Installation avec pip
+
+Vous devriez installer 🤗 Transformers dans un [environnement virtuel](https://docs.python.org/3/library/venv.html).
+Si vous n'êtes pas à l'aise avec les environnements virtuels, consultez ce [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+Utiliser un environnement virtuel permet de facilement gérer différents projets et d'éviter des erreurs de compatibilité entre les différentes dépendances.
+
+Commencez par créer un environnement virtuel dans l'espace de travail de votre projet :
+
+```bash
+python -m venv .env
+```
+
+Activez l'environnement virtuel. Sur Linux ou MacOs :
+
+```bash
+source .env/bin/activate
+```
+
+Activez l'environnement virtuel sur Windows :
+
+```bash
+.env/Scripts/activate
+```
+
+Maintenant, 🤗 Transformers peut être installé avec la commande suivante :
+
+```bash
+pip install transformers
+```
+
+Pour une utilisation avec CPU seulement, 🤗 Transformers et la librairie d'apprentissage profond de votre choix peuvent être installés en une seule ligne.
+Par exemple, installez 🤗 Transformers et PyTorch avec la commande suivante :
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers et TensorFlow 2.0 :
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+
+
+Pour les architectures mac M1 / ARM
+
+Vous devez installer les outils suivants avant d'installer TensorFLow 2.0
+
+```
+brew install cmake
+brew install pkg-config
+```
+
+
+
+🤗 Transformers et Flax :
+
+```bash
+pip install 'transformers[flax]'
+```
+
+Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante. La commande va télécharger un modèle pré-entraîné :
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Le label et score sont ensuite affichés :
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Installation depuis le code source
+
+Installez 🤗 Transformers depuis le code source avec la commande suivante :
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+Cette commande installe la version depuis la branche `main` au lieu de la dernière version stable. La version de la branche `main` est utile pour avoir les derniers développements. Par exemple, si un bug a été résolu depuis la dernière version stable mais n'a pas encore été publié officiellement. Cependant, cela veut aussi dire que la version de la branche `main` n'est pas toujours stable. Nous nous efforçons de maintenir la version de la branche `main` opérationnelle, et la plupart des problèmes sont généralement résolus en l'espace de quelques heures ou d'un jour. Si vous recontrez un problème, n'hésitez pas à créer une [Issue](https://github.com/huggingface/transformers/issues) pour que l'on puisse trouver une solution au plus vite !
+
+Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante :
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Installation modifiable
+
+Vous aurez besoin d'une installation modifiable si vous le souhaitez :
+
+ * Utiliser la version de la branche `main` du code source.
+ * Contribuer à 🤗 Transformers et vouler tester vos modifications du code source.
+
+Clonez le projet et installez 🤗 Transformers avec les commandes suivantes :
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Ces commandes créent des liens entre le dossier où le projet a été cloné et les chemins de vos librairies Python. Python regardera maintenant dans le dossier que vous avez cloné en plus des dossiers où sont installées vos autres librairies. Par exemple, si vos librairies Python sont installées dans `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cherchera aussi dans le dossier où vous avez cloné : `~/transformers/`.
+
+
+
+Vous devez garder le dossier `transformers` si vous voulez continuer d'utiliser la librairie.
+
+
+
+Maintenant, vous pouvez facilement mettre à jour votre clone avec la dernière version de 🤗 Transformers en utilisant la commande suivante :
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+Votre environnement Python utilisera la version de la branche `main` lors de la prochaine exécution.
+
+## Installation avec conda
+
+Installation via le canal `huggingface` de conda :
+
+```bash
+conda install -c huggingface transformers
+```
+
+## Configuration du cache
+
+Les modèles pré-entraînés sont téléchargés et mis en cache localement dans le dossier suivant : `~/.cache/huggingface/hub`. C'est le dossier par défaut donné par la variable d'environnement `TRANSFORMERS_CACHE`. Sur Windows, le dossier par défaut est `C:\Users\nom_utilisateur\.cache\huggingface\hub`. Vous pouvez modifier les variables d'environnement indiquées ci-dessous - par ordre de priorité - pour spécifier un dossier de cache différent :
+
+1. Variable d'environnement (par défaut) : `HUGGINGFACE_HUB_CACHE` ou `TRANSFORMERS_CACHE`.
+2. Variable d'environnement : `HF_HOME`.
+3. Variable d'environnement : `XDG_CACHE_HOME` + `/huggingface`.
+
+
+
+🤗 Transformers utilisera les variables d'environnement `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE` si vous utilisez une version précédente de cette librairie et avez défini ces variables d'environnement, sauf si vous spécifiez la variable d'environnement `TRANSFORMERS_CACHE`.
+
+
+
+## Mode hors ligne
+
+🤗 Transformers peut fonctionner dans un environnement cloisonné ou hors ligne en n'utilisant que des fichiers locaux. Définissez la variable d'environnement `TRANSFORMERS_OFFLINE=1` pour activer ce mode.
+
+
+
+Ajoutez [🤗 Datasets](https://huggingface.co/docs/datasets/) à votre processus d'entraînement hors ligne en définissant la variable d'environnement `HF_DATASETS_OFFLINE=1`.
+
+
+
+```bash
+HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+Le script devrait maintenant s'exécuter sans rester en attente ou attendre une expiration, car il n'essaiera pas de télécharger des modèle sur le Hub.
+
+Vous pouvez aussi éviter de télécharger un modèle à chaque appel de la fonction [~PreTrainedModel.from_pretrained] en utilisant le paramètre [local_files_only]. Seuls les fichiers locaux sont chargés lorsque ce paramètre est activé (c.-à-d. `local_files_only=True`) :
+
+```py
+from transformers import T5Model
+
+model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
+```
+
+### Récupérer des modèles et des tokenizers pour une utilisation hors ligne
+
+Une autre option pour utiliser 🤗 Transformers hors ligne est de télécharger les fichiers à l'avance, puis d'utiliser les chemins locaux lorsque vous en avez besoin en mode hors ligne. Il existe trois façons de faire cela :
+
+ * Téléchargez un fichier via l'interface utilisateur sur le [Model Hub](https://huggingface.co/models) en cliquant sur l'icône ↓.
+
+ 
+
+ * Utilisez les fonctions [`PreTrainedModel.from_pretrained`] et [`PreTrainedModel.save_pretrained`] :
+
+ 1. Téléchargez vos fichiers à l'avance avec [`PreTrainedModel.from_pretrained`]:
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+ 2. Sauvegardez les fichiers dans un dossier de votre choix avec [`PreTrainedModel.save_pretrained`]:
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. Maintenant, lorsque vous êtes hors ligne, rechargez vos fichiers avec [`PreTrainedModel.from_pretrained`] depuis le dossier où vous les avez sauvegardés :
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+ * Téléchargez des fichiers de manière automatique avec la librairie [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) :
+
+ 1. Installez la librairie `huggingface_hub` dans votre environnement virtuel :
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. Utilisez la fonction [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) pour télécharger un fichier vers un chemin de votre choix. Par exemple, la commande suivante télécharge le fichier `config.json` du modèle [T0](https://huggingface.co/bigscience/T0_3B) vers le chemin de votre choix :
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+Une fois que votre fichier est téléchargé et caché localement, spécifiez son chemin local pour le charger et l'utiliser :
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+Consultez la section [How to download files from the Hub (Comment télécharger des fichiers depuis le Hub)](https://huggingface.co/docs/hub/how-to-downstream) pour plus de détails sur le téléchargement de fichiers stockés sur le Hub.
+
+
diff --git a/docs/source/it/converting_tensorflow_models.md b/docs/source/it/converting_tensorflow_models.md
index 04398636359ce5..f6326daa735fbe 100644
--- a/docs/source/it/converting_tensorflow_models.md
+++ b/docs/source/it/converting_tensorflow_models.md
@@ -104,21 +104,6 @@ transformers-cli convert --model_type gpt2 \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
-## Transformer-XL
-
-
-Ecco un esempio del processo di conversione di un modello Transformer-XL pre-allenato
-(vedi [qui](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models)):
-
-```bash
-export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
-transformers-cli convert --model_type transfo_xl \
- --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
- --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
- [--config TRANSFO_XL_CONFIG] \
- [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
-```
-
## XLNet
Ecco un esempio del processo di conversione di un modello XLNet pre-allenato:
diff --git a/docs/source/it/perf_hardware.md b/docs/source/it/perf_hardware.md
index a579362e2b1b9d..dd1187a01b5938 100644
--- a/docs/source/it/perf_hardware.md
+++ b/docs/source/it/perf_hardware.md
@@ -134,7 +134,7 @@ Ecco il codice benchmark completo e gli output:
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -143,7 +143,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/it/preprocessing.md b/docs/source/it/preprocessing.md
index 94578dfe166b77..76addd2aa0ea3c 100644
--- a/docs/source/it/preprocessing.md
+++ b/docs/source/it/preprocessing.md
@@ -194,7 +194,7 @@ Gli input audio sono processati in modo differente rispetto al testo, ma l'obiet
pip install datasets
```
-Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) per avere maggiori dettagli su come caricare un dataset):
+Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) per avere maggiori dettagli su come caricare un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -233,7 +233,7 @@ Per esempio, il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds1
'sampling_rate': 8000}
```
-1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
+1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
@@ -370,7 +370,7 @@ Per le attività di visione, è usuale aggiungere alcuni tipi di data augmentati
... return examples
```
-3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform)per applicare al volo la trasformazione:
+3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)per applicare al volo la trasformazione:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/it/quicktour.md b/docs/source/it/quicktour.md
index f0e981d18eb77d..07e7a2974a1fbc 100644
--- a/docs/source/it/quicktour.md
+++ b/docs/source/it/quicktour.md
@@ -125,7 +125,7 @@ Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuo
... )
```
-Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
+Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
diff --git a/docs/source/it/run_scripts.md b/docs/source/it/run_scripts.md
index 327eb9374d3873..c376ff32c2a884 100644
--- a/docs/source/it/run_scripts.md
+++ b/docs/source/it/run_scripts.md
@@ -130,7 +130,7 @@ Il [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supp
- Imposta un numero di GPU da usare con l'argomento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/it/training.md b/docs/source/it/training.md
index be0883f07b7715..503a43321799e1 100644
--- a/docs/source/it/training.md
+++ b/docs/source/it/training.md
@@ -43,7 +43,7 @@ Inizia caricando il dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process.html#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
+Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
```py
>>> from transformers import AutoTokenizer
@@ -103,7 +103,7 @@ Specifica dove salvare i checkpoints del tuo addestramento:
### Metriche
-[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics.html) per maggiori informazioni):
+[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics) per maggiori informazioni):
```py
>>> import numpy as np
@@ -346,7 +346,7 @@ Per tenere traccia dei tuoi progressi durante l'addestramento, usa la libreria [
### Metriche
-Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
+Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index df686b475dab35..9766571c6b87eb 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -29,11 +29,76 @@
title: LLM を使用した生成
title: Tutorials
- sections:
+ - isExpanded: false
+ sections:
+ - local: tasks/sequence_classification
+ title: テキストの分類
+ - local: tasks/token_classification
+ title: トークンの分類
+ - local: tasks/question_answering
+ title: 質疑応答
+ - local: tasks/language_modeling
+ title: 因果言語モデリング
+ - local: tasks/masked_language_modeling
+ title: マスクされた言語モデリング
+ - local: tasks/translation
+ title: 翻訳
+ - local: tasks/summarization
+ title: 要約
+ - local: tasks/multiple_choice
+ title: 複数の選択肢
+ title: 自然言語処理
+ - isExpanded: false
+ sections:
+ - local: tasks/audio_classification
+ title: 音声の分類
+ - local: tasks/asr
+ title: 自動音声認識
+ title: オーディオ
+ - isExpanded: false
+ sections:
+ - local: tasks/image_classification
+ title: 画像分類
+ - local: tasks/semantic_segmentation
+ title: セマンティックセグメンテーション
+ - local: tasks/video_classification
+ title: ビデオの分類
+ - local: tasks/object_detection
+ title: 物体検出
+ - local: tasks/zero_shot_object_detection
+ title: ゼロショット物体検出
+ - local: tasks/zero_shot_image_classification
+ title: ゼロショット画像分類
+ - local: tasks/monocular_depth_estimation
+ title: 深さの推定
+ - local: tasks/image_to_image
+ title: 画像から画像へ
+ - local: tasks/knowledge_distillation_for_image_classification
+ title: コンピュータビジョンのための知識の蒸留
+ title: コンピュータビジョン
+ - isExpanded: false
+ sections:
+ - local: tasks/image_captioning
+ title: 画像のキャプション
+ - local: tasks/document_question_answering
+ title: 文書の質問への回答
+ - local: tasks/visual_question_answering
+ title: 視覚的な質問への回答
+ - local: tasks/text-to-speech
+ title: テキスト読み上げ
+ title: マルチモーダル
- isExpanded: false
sections:
- local: generation_strategies
title: 生成戦略をカスタマイズする
- title: Generation
+ title: 世代
+ - isExpanded: false
+ sections:
+ - local: tasks/idefics
+ title: IDEFICS を使用したイメージ タスク
+ - local: tasks/prompting
+ title: LLM プロンプト ガイド
+ title: プロンプト
title: Task Guides
- sections:
- local: fast_tokenizers
@@ -185,11 +250,70 @@
sections:
- local: model_doc/albert
title: ALBERT
+ - local: model_doc/bart
+ title: BART
+ - local: model_doc/barthez
+ title: BARThez
+ - local: model_doc/bartpho
+ title: BARTpho
+ - local: model_doc/bert
+ title: BERT
+ - local: model_doc/bert-generation
+ title: BertGeneration
+ - local: model_doc/bert-japanese
+ title: BertJapanese
+ - local: model_doc/bertweet
+ title: Bertweet
+ - local: model_doc/big_bird
+ title: BigBird
+ - local: model_doc/bigbird_pegasus
+ title: BigBirdPegasus
+ - local: model_doc/biogpt
+ title: BioGpt
+ - local: model_doc/blenderbot
+ title: Blenderbot
+ - local: model_doc/blenderbot-small
+ title: Blenderbot Small
+ - local: model_doc/bloom
+ title: BLOOM
+ - local: model_doc/bort
+ title: BORT
+ - local: model_doc/byt5
+ title: ByT5
+ - local: model_doc/camembert
+ title: CamemBERT
+ - local: model_doc/canine
+ title: CANINE
+ - local: model_doc/codegen
+ title: CodeGen
+ - local: model_doc/code_llama
+ title: CodeLlama
+ - local: model_doc/convbert
+ title: ConvBERT
+ - local: model_doc/cpm
+ title: CPM
title: 文章モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/beit
+ title: BEiT
+ - local: model_doc/bit
+ title: BiT
+ - local: model_doc/conditional_detr
+ title: Conditional DETR
+ - local: model_doc/convnext
+ title: ConvNeXT
+ - local: model_doc/convnextv2
+ title: ConvNeXTV2
+ title: ビジョンモデル
- isExpanded: false
sections:
- local: model_doc/audio-spectrogram-transformer
title: Audio Spectrogram Transformer
+ - local: model_doc/bark
+ title: Bark
+ - local: model_doc/clap
+ title: CLAP
title: 音声モデル
- isExpanded: false
sections:
@@ -197,6 +321,22 @@
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
+ - local: model_doc/blip
+ title: BLIP
+ - local: model_doc/blip-2
+ title: BLIP-2
+ - local: model_doc/bridgetower
+ title: BridgeTower
+ - local: model_doc/bros
+ title: BROS
+ - local: model_doc/chinese_clip
+ title: Chinese-CLIP
+ - local: model_doc/clip
+ title: CLIP
+ - local: model_doc/clipseg
+ title: CLIPSeg
+ - local: model_doc/clvp
+ title: CLVP
title: マルチモーダルモデル
- isExpanded: false
sections:
diff --git a/docs/source/ja/main_classes/trainer.md b/docs/source/ja/main_classes/trainer.md
index 4c1ce95ca38aa6..f18c1b86809f99 100644
--- a/docs/source/ja/main_classes/trainer.md
+++ b/docs/source/ja/main_classes/trainer.md
@@ -196,7 +196,7 @@ _python_、_numpy_、および _pytorch_ の RNG 状態は、そのチェック
[`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.Parallel.DistributedDataParallel.html) を使用して GPU のサブセットのみを使用する場合、使用する GPU の数を指定するだけです。 。たとえば、GPU が 4 つあるが、最初の 2 つを使用したい場合は、次のようにします。
```bash
-python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
+torchrun --nproc_per_node=2 trainer-program.py ...
```
[`accelerate`](https://github.com/huggingface/accelerate) または [`deepspeed`](https://github.com/microsoft/DeepSpeed) がインストールされている場合は、次を使用して同じことを達成することもできます。の一つ:
@@ -209,7 +209,7 @@ accelerate launch --num_processes 2 trainer-program.py ...
deepspeed --num_gpus 2 trainer-program.py ...
```
-これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](Deepspeed) 機能を使用する必要はありません。
+これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](deepspeed) 機能を使用する必要はありません。
これまでは、プログラムに使用する GPU の数を指示できました。次に、特定の GPU を選択し、その順序を制御する方法について説明します。
@@ -223,7 +223,7 @@ deepspeed --num_gpus 2 trainer-program.py ...
たとえば、4 つの GPU (0、1、2、3) があるとします。物理 GPU 0 と 2 のみで実行するには、次のようにします。
```bash
-CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
```
したがって、pytorch は 2 つの GPU のみを認識し、物理 GPU 0 と 2 はそれぞれ `cuda:0` と `cuda:1` にマッピングされます。
@@ -231,7 +231,7 @@ CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py .
順序を変更することもできます。
```bash
-CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
```
ここでは、物理 GPU 0 と 2 がそれぞれ`cuda:1`と`cuda:0`にマッピングされています。
@@ -253,7 +253,7 @@ CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```bash
export CUDA_VISIBLE_DEVICES=0,2
-python -m torch.distributed.launch trainer-program.py ...
+torchrun trainer-program.py ...
```
ただし、この方法では、以前に環境変数を設定したことを忘れて、なぜ間違った GPU が使用されているのか理解できない可能性があるため、混乱を招く可能性があります。したがって、このセクションのほとんどの例で示されているように、同じコマンド ラインで特定の実行に対してのみ環境変数を設定するのが一般的です。
diff --git a/docs/source/ja/model_doc/align.md b/docs/source/ja/model_doc/align.md
index 6e62c3d9f4ca68..84496e605def92 100644
--- a/docs/source/ja/model_doc/align.md
+++ b/docs/source/ja/model_doc/align.md
@@ -51,10 +51,10 @@ inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
-# これは画像-テキスト類似度スコア
+# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
-# Softmaxを取ることで各ラベルの確率を得られる
+# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
diff --git a/docs/source/ja/model_doc/altclip.md b/docs/source/ja/model_doc/altclip.md
index 232b3645544f39..87cf6cc17d6a0b 100644
--- a/docs/source/ja/model_doc/altclip.md
+++ b/docs/source/ja/model_doc/altclip.md
@@ -52,8 +52,8 @@ Transformerエンコーダーに画像を与えるには、各画像を固定サ
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
->>> logits_per_image = outputs.logits_per_image # これは画像-テキスト類似度スコア
->>> probs = logits_per_image.softmax(dim=1) # Softmaxを取ることで各ラベルの確率を得られる
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
diff --git a/docs/source/ja/model_doc/audio-spectrogram-transformer.md b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
index efbadbd4bae67b..a5107b14f83a98 100644
--- a/docs/source/ja/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Audio Spectrogram Transformerモデルは、「[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)」という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
+Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
論文の要旨は以下の通りです:
@@ -35,7 +35,7 @@ alt="drawing" width="600"/>
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
-- ASTは低い学習率が必要であり(著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
diff --git a/docs/source/ja/model_doc/auto.md b/docs/source/ja/model_doc/auto.md
index b104e4c99fe3a8..c6775493baae39 100644
--- a/docs/source/ja/model_doc/auto.md
+++ b/docs/source/ja/model_doc/auto.md
@@ -43,7 +43,7 @@ AutoModel.register(NewModelConfig, NewModel)
-あなたの`NewModelConfig`が[`~transformer.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
+あなたの`NewModelConfig`が[`~transformers.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
同様に、あなたの`NewModel`が[`PreTrainedModel`]のサブクラスである場合、その`config_class`属性がモデルを登録する際に使用するクラス(ここでは`NewModelConfig`)と同じに設定されていることを確認してください。
diff --git a/docs/source/ja/model_doc/bark.md b/docs/source/ja/model_doc/bark.md
new file mode 100644
index 00000000000000..508b8938889bae
--- /dev/null
+++ b/docs/source/ja/model_doc/bark.md
@@ -0,0 +1,198 @@
+
+
+# Bark
+
+## Overview
+
+Bark は、[suno-ai/bark](https://github.com/suno-ai/bark) で Suno AI によって提案されたトランスフォーマーベースのテキスト読み上げモデルです。
+
+
+Bark は 4 つの主要なモデルで構成されています。
+
+- [`BarkSemanticModel`] ('テキスト'モデルとも呼ばれる): トークン化されたテキストを入力として受け取り、テキストの意味を捉えるセマンティック テキスト トークンを予測する因果的自己回帰変換モデル。
+- [`BarkCoarseModel`] ('粗い音響' モデルとも呼ばれる): [`BarkSemanticModel`] モデルの結果を入力として受け取る因果的自己回帰変換器。 EnCodec に必要な最初の 2 つのオーディオ コードブックを予測することを目的としています。
+- [`BarkFineModel`] ('微細音響' モデル)、今回は非因果的オートエンコーダー トランスフォーマーで、以前のコードブック埋め込みの合計に基づいて最後のコードブックを繰り返し予測します。
+- [`EncodecModel`] からすべてのコードブック チャネルを予測したので、Bark はそれを使用して出力オーディオ配列をデコードします。
+
+最初の 3 つのモジュールはそれぞれ、特定の事前定義された音声に従って出力サウンドを調整するための条件付きスピーカー埋め込みをサポートできることに注意してください。
+
+### Optimizing Bark
+
+Bark は、コードを数行追加するだけで最適化でき、**メモリ フットプリントが大幅に削減**され、**推論が高速化**されます。
+
+#### Using half-precision
+
+モデルを半精度でロードするだけで、推論を高速化し、メモリ使用量を 50% 削減できます。
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
+```
+
+#### Using 🤗 Better Transformer
+
+Better Transformer は、内部でカーネル融合を実行する 🤗 最適な機能です。パフォーマンスを低下させることなく、速度を 20% ~ 30% 向上させることができます。モデルを 🤗 Better Transformer にエクスポートするのに必要なコードは 1 行だけです。
+
+```python
+model = model.to_bettertransformer()
+```
+
+この機能を使用する前に 🤗 Optimum をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/optimum/installation)
+
+#### Using CPU offload
+
+前述したように、Bark は 4 つのサブモデルで構成されており、オーディオ生成中に順番に呼び出されます。言い換えれば、1 つのサブモデルが使用されている間、他のサブモデルはアイドル状態になります。
+
+CUDA デバイスを使用している場合、メモリ フットプリントの 80% 削減による恩恵を受ける簡単な解決策は、アイドル状態の GPU のサブモデルをオフロードすることです。この操作は CPU オフロードと呼ばれます。 1行のコードで使用できます。
+
+```python
+model.enable_cpu_offload()
+```
+
+この機能を使用する前に、🤗 Accelerate をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/accelerate/basic_tutorials/install)
+
+#### Combining optimization techniques
+
+最適化手法を組み合わせて、CPU オフロード、半精度、🤗 Better Transformer をすべて一度に使用できます。
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+# load in fp16
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
+
+# convert to bettertransformer
+model = BetterTransformer.transform(model, keep_original_model=False)
+
+# enable CPU offload
+model.enable_cpu_offload()
+```
+
+推論最適化手法の詳細については、[こちら](https://huggingface.co/docs/transformers/perf_infer_gpu_one) をご覧ください。
+
+### Tips
+
+Suno は、多くの言語で音声プリセットのライブラリを提供しています [こちら](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c)。
+これらのプリセットは、ハブ [こちら](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) または [こちら](https://huggingface.co/suno/bark/tree/main/speaker_embeddings)。
+
+```python
+>>> from transformers import AutoProcessor, BarkModel
+
+>>> processor = AutoProcessor.from_pretrained("suno/bark")
+>>> model = BarkModel.from_pretrained("suno/bark")
+
+>>> voice_preset = "v2/en_speaker_6"
+
+>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+Bark は、非常にリアルな **多言語** 音声だけでなく、音楽、背景ノイズ、単純な効果音などの他の音声も生成できます。
+
+```python
+>>> # Multilingual speech - simplified Chinese
+>>> inputs = processor("惊人的!我会说中文")
+
+>>> # Multilingual speech - French - let's use a voice_preset as well
+>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
+
+>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
+>>> inputs = processor("♪ Hello, my dog is cute ♪")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+このモデルは、笑う、ため息、泣くなどの**非言語コミュニケーション**を生成することもできます。
+
+
+```python
+>>> # Adding non-speech cues to the input text
+>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+オーディオを保存するには、モデル設定と scipy ユーティリティからサンプル レートを取得するだけです。
+
+```python
+>>> from scipy.io.wavfile import write as write_wav
+
+>>> # save audio to disk, but first take the sample rate from the model config
+>>> sample_rate = model.generation_config.sample_rate
+>>> write_wav("bark_generation.wav", sample_rate, audio_array)
+```
+
+このモデルは、[Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) および [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi) によって提供されました。
+元のコードは [ここ](https://github.com/suno-ai/bark) にあります。
+
+## BarkConfig
+
+[[autodoc]] BarkConfig
+ - all
+
+## BarkProcessor
+
+[[autodoc]] BarkProcessor
+ - all
+ - __call__
+
+## BarkModel
+
+[[autodoc]] BarkModel
+ - generate
+ - enable_cpu_offload
+
+## BarkSemanticModel
+
+[[autodoc]] BarkSemanticModel
+ - forward
+
+## BarkCoarseModel
+
+[[autodoc]] BarkCoarseModel
+ - forward
+
+## BarkFineModel
+
+[[autodoc]] BarkFineModel
+ - forward
+
+## BarkCausalModel
+
+[[autodoc]] BarkCausalModel
+ - forward
+
+## BarkCoarseConfig
+
+[[autodoc]] BarkCoarseConfig
+ - all
+
+## BarkFineConfig
+
+[[autodoc]] BarkFineConfig
+ - all
+
+## BarkSemanticConfig
+
+[[autodoc]] BarkSemanticConfig
+ - all
diff --git a/docs/source/ja/model_doc/bart.md b/docs/source/ja/model_doc/bart.md
new file mode 100644
index 00000000000000..0f2c3fb006e137
--- /dev/null
+++ b/docs/source/ja/model_doc/bart.md
@@ -0,0 +1,223 @@
+
+
+# BART
+
+
+
+**免責事項:** 何か奇妙なものを見つけた場合は、[Github 問題](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を提出し、割り当ててください。
+@patrickvonplaten
+
+## Overview
+
+Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
+翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
+ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
+
+要約によると、
+
+- Bart は、双方向エンコーダ (BERT など) を備えた標準の seq2seq/機械翻訳アーキテクチャを使用します。
+ 左から右へのデコーダ (GPT など)。
+- 事前トレーニング タスクには、元の文の順序をランダムにシャッフルし、新しい埋め込みスキームが含まれます。
+ ここで、テキストの範囲は単一のマスク トークンに置き換えられます。
+- BART は、テキスト生成用に微調整した場合に特に効果的ですが、理解タスクにも適しています。それ
+ RoBERTa のパフォーマンスを GLUE および SQuAD の同等のトレーニング リソースと同等にし、新たな成果を達成します。
+ さまざまな抽象的な対話、質問応答、要約タスクに関する最先端の結果が得られ、成果が得られます。
+ ルージュは最大6枚まで。
+
+チップ:
+
+- BART は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+- エンコーダーとデコーダーを備えたシーケンスツーシーケンス モデル。エンコーダには破損したバージョンのトークンが供給され、デコーダには元のトークンが供給されます(ただし、通常のトランスフォーマー デコーダと同様に、将来のワードを隠すためのマスクがあります)。次の変換の構成は、エンコーダーの事前トレーニング タスクに適用されます。
+
+ * ランダムなトークンをマスクします (BERT と同様)
+ * ランダムなトークンを削除します
+ * k 個のトークンのスパンを 1 つのマスク トークンでマスクします (0 トークンのスパンはマスク トークンの挿入です)
+ * 文を並べ替えます
+ * ドキュメントを回転して特定のトークンから開始するようにします
+
+このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/pytorch/fairseq/tree/master/examples/bart) にあります。
+
+### Examples
+
+- シーケンス間タスク用の BART およびその他のモデルを微調整するための例とスクリプトは、次の場所にあります。
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
+- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
+ オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+
+## Implementation Notes
+
+- Bart はシーケンスの分類に `token_type_ids` を使用しません。 [`BartTokenizer`] を使用するか、
+ [`~BartTokenizer.encode`] を使用して適切に分割します。
+- [`BartModel`] のフォワードパスは、渡されなかった場合、`decoder_input_ids` を作成します。
+ これは、他のモデリング API とは異なります。この機能の一般的な使用例は、マスクの塗りつぶしです。
+- モデルの予測は、次の場合に元の実装と同一になるように意図されています。
+ `forced_bos_token_id=0`。ただし、これは、渡す文字列が次の場合にのみ機能します。
+ [`fairseq.encode`] はスペースで始まります。
+- [`~generation.GenerationMixin.generate`] は、次のような条件付き生成タスクに使用する必要があります。
+ 要約については、その docstring の例を参照してください。
+- *facebook/bart-large-cnn* 重みをロードするモデルには `mask_token_id` がないか、実行できません。
+ マスクを埋めるタスク。
+
+## Mask Filling
+
+`facebook/bart-base` および `facebook/bart-large` チェックポイントを使用して、マルチトークン マスクを埋めることができます。
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## Resources
+
+BART を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- に関するブログ投稿 [分散トレーニング: 🤗 Transformers と Amazon SageMaker を使用した要約のための BART/T5 のトレーニング](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)。
+- 方法に関するノートブック [blurr を使用して fastai で要約するために BART を微調整する](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb). 🌎 🌎
+- 方法に関するノートブック [トレーナー クラスを使用して 2 つの言語で要約するために BART を微調整する](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)。 🌎
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)。
+- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) でサポートされています。
+- [要約](https://huggingface.co/course/chapter7/5?fw=pt#summarization) 🤗 ハグフェイスコースの章。
+- [要約タスクガイド](../tasks/summarization.md)
+
+
+
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
+- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+
+
+
+- [ヒンディー語から英語への翻訳に Seq2SeqTrainer を使用して mBART を微調整する]方法に関するノート (https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)。 🌎
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)。
+- [翻訳タスクガイド](../tasks/translation)
+
+以下も参照してください。
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+
+## BartConfig
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+## BartModel
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+## TFBartModel
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## TFBartForSequenceClassification
+
+[[autodoc]] TFBartForSequenceClassification
+ - call
+
+## FlaxBartModel
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
diff --git a/docs/source/ja/model_doc/barthez.md b/docs/source/ja/model_doc/barthez.md
new file mode 100644
index 00000000000000..94844c3f675d8a
--- /dev/null
+++ b/docs/source/ja/model_doc/barthez.md
@@ -0,0 +1,60 @@
+
+
+# BARThez
+
+## Overview
+
+BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
+2020年。
+
+論文の要約:
+
+
+*帰納的転移学習は、自己教師あり学習によって可能になり、自然言語処理全体を実行します。
+(NLP) 分野は、BERT や BART などのモデルにより、無数の自然言語に新たな最先端技術を確立し、嵐を巻き起こしています。
+タスクを理解すること。いくつかの注目すべき例外はありますが、利用可能なモデルと研究のほとんどは、
+英語を対象に実施されました。この作品では、フランス語用の最初の BART モデルである BARTez を紹介します。
+(我々の知る限りに)。 BARThez は、過去の研究から得た非常に大規模な単一言語フランス語コーパスで事前トレーニングされました
+BART の摂動スキームに合わせて調整しました。既存の BERT ベースのフランス語モデルとは異なり、
+CamemBERT と FlauBERT、BARThez は、エンコーダだけでなく、
+そのデコーダは事前トレーニングされています。 FLUE ベンチマークからの識別タスクに加えて、BARThez を新しい評価に基づいて評価します。
+この論文とともにリリースする要約データセット、OrangeSum。また、すでに行われている事前トレーニングも継続します。
+BARTHez のコーパス上で多言語 BART を事前訓練し、結果として得られるモデル (mBARTHez と呼ぶ) が次のことを示します。
+バニラの BARThez を大幅に強化し、CamemBERT や FlauBERT と同等かそれを上回ります。*
+
+このモデルは [moussakam](https://huggingface.co/moussakam) によって寄稿されました。著者のコードは[ここ](https://github.com/moussaKam/BARThez)にあります。
+
+
+
+BARThez の実装は、トークン化を除いて BART と同じです。詳細については、[BART ドキュメント](bart) を参照してください。
+構成クラスとそのパラメータ。 BARThez 固有のトークナイザーについては以下に記載されています。
+
+
+
+### Resources
+
+- BARThez は、BART と同様の方法でシーケンス間のタスクを微調整できます。以下を確認してください。
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
+
+
+## BarthezTokenizer
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/source/ja/model_doc/bartpho.md b/docs/source/ja/model_doc/bartpho.md
new file mode 100644
index 00000000000000..a9575d821ef916
--- /dev/null
+++ b/docs/source/ja/model_doc/bartpho.md
@@ -0,0 +1,86 @@
+
+
+# BARTpho
+
+## Overview
+
+BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
+
+論文の要約は次のとおりです。
+
+*BARTpho には、BARTpho_word と BARTpho_syllable の 2 つのバージョンがあり、初の公開された大規模な単一言語です。
+ベトナム語用に事前トレーニングされたシーケンスツーシーケンス モデル。当社の BARTpho は「大規模な」アーキテクチャと事前トレーニングを使用します
+シーケンス間ノイズ除去モデル BART のスキームなので、生成 NLP タスクに特に適しています。実験
+ベトナム語テキスト要約の下流タスクでは、自動評価と人間による評価の両方で、BARTpho が
+強力なベースライン mBART を上回り、最先端の性能を向上させます。将来を容易にするためにBARTphoをリリースします
+生成的なベトナム語 NLP タスクの研究と応用。*
+
+このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [こちら](https://github.com/VinAIResearch/BARTpho) にあります。
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+## Usage tips
+
+- mBARTに続いて、BARTphoはBARTの「大規模な」アーキテクチャを使用し、その上に追加の層正規化層を備えています。
+ エンコーダとデコーダの両方。したがって、[BART のドキュメント](bart) の使用例は、使用に適応する場合に使用されます。
+ BARTpho を使用する場合は、BART に特化したクラスを mBART に特化した対応するクラスに置き換えることによって調整する必要があります。
+ 例えば:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- この実装はトークン化のみを目的としています。`monolingual_vocab_file`はベトナム語に特化した型で構成されています
+ 多言語 XLM-RoBERTa から利用できる事前トレーニング済み SentencePiece モデル`vocab_file`から抽出されます。
+ 他の言語 (サブワードにこの事前トレーニング済み多言語 SentencePiece モデル`vocab_file`を使用する場合)
+ セグメンテーションにより、独自の言語に特化した`monolingual_vocab_file`を使用して BartphoTokenizer を再利用できます。
+
+## BartphoTokenizer
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/source/ja/model_doc/beit.md b/docs/source/ja/model_doc/beit.md
new file mode 100644
index 00000000000000..45eb1efa5dd873
--- /dev/null
+++ b/docs/source/ja/model_doc/beit.md
@@ -0,0 +1,143 @@
+
+
+# BEiT
+
+## Overview
+
+BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
+ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
+ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
+([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
+マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
+パッチ。
+
+論文の要約は次のとおりです。
+
+*自己教師あり視覚表現モデル BEiT (Bidirectional Encoderpresentation) を導入します。
+イメージトランスフォーマーより。自然言語処理分野で開発されたBERTに倣い、マスク画像を提案します。
+ビジョントランスフォーマーを事前にトレーニングするためのモデリングタスク。具体的には、事前トレーニングでは各画像に 2 つのビューがあります。
+パッチ (16x16 ピクセルなど)、およびビジュアル トークン (つまり、個別のトークン)。まず、元の画像を「トークン化」して、
+ビジュアルトークン。次に、いくつかの画像パッチをランダムにマスクし、それらをバックボーンの Transformer に供給します。事前トレーニング
+目的は、破損したイメージ パッチに基づいて元のビジュアル トークンを回復することです。 BEiTの事前トレーニング後、
+事前トレーニングされたエンコーダーにタスク レイヤーを追加することで、ダウンストリーム タスクのモデル パラメーターを直接微調整します。
+画像分類とセマンティックセグメンテーションに関する実験結果は、私たちのモデルが競争力のある結果を達成することを示しています
+以前の事前トレーニング方法を使用して。たとえば、基本サイズの BEiT は、ImageNet-1K で 83.2% のトップ 1 精度を達成します。
+同じ設定でゼロからの DeiT トレーニング (81.8%) を大幅に上回りました。また、大型BEiTは
+86.3% は ImageNet-1K のみを使用しており、ImageNet-22K での教師付き事前トレーニングを使用した ViT-L (85.2%) を上回っています。*
+
+## Usage tips
+
+- BEiT モデルは通常のビジョン トランスフォーマーですが、教師ありではなく自己教師ありの方法で事前トレーニングされています。彼らは
+ ImageNet-1K および CIFAR-100 で微調整すると、[オリジナル モデル (ViT)](vit) と [データ効率の高いイメージ トランスフォーマー (DeiT)](deit) の両方を上回るパフォーマンスを発揮します。推論に関するデモノートブックもチェックできます。
+ カスタム データの微調整は [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (置き換えるだけで済みます)
+ [`BeitImageProcessor`] による [`ViTFeatureExtractor`] と
+ [`ViTForImageClassification`] by [`BeitForImageClassification`])。
+- DALL-E の画像トークナイザーと BEiT を組み合わせる方法を紹介するデモ ノートブックも利用可能です。
+ マスクされた画像モデリングを実行します。 [ここ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT) で見つけることができます。
+- BEiT モデルは各画像が同じサイズ (解像度) であることを期待しているため、次のように使用できます。
+ [`BeitImageProcessor`] を使用して、モデルの画像のサイズを変更 (または再スケール) し、正規化します。
+- 事前トレーニングまたは微調整中に使用されるパッチ解像度と画像解像度の両方が名前に反映されます。
+ 各チェックポイント。たとえば、`microsoft/beit-base-patch16-224`は、パッチ付きの基本サイズのアーキテクチャを指します。
+ 解像度は 16x16、微調整解像度は 224x224 です。すべてのチェックポイントは [ハブ](https://huggingface.co/models?search=microsoft/beit) で見つけることができます。
+- 利用可能なチェックポイントは、(1) [ImageNet-22k](http://www.image-net.org/) で事前トレーニングされています (
+ 1,400 万の画像と 22,000 のクラス) のみ、(2) ImageNet-22k でも微調整、または (3) [ImageNet-1k](http://www.image-net.org/challenges/LSVRC)でも微調整/2012/) (ILSVRC 2012 とも呼ばれ、130 万件のコレクション)
+ 画像と 1,000 クラス)。
+- BEiT は、T5 モデルからインスピレーションを得た相対位置埋め込みを使用します。事前トレーニング中に、著者は次のことを共有しました。
+ いくつかの自己注意層間の相対的な位置の偏り。微調整中、各レイヤーの相対位置
+ バイアスは、事前トレーニング後に取得された共有相対位置バイアスで初期化されます。ご希望の場合は、
+ モデルを最初から事前トレーニングするには、`use_relative_position_bias` または
+ 追加するには、[`BeitConfig`] の `use_relative_position_bias` 属性を `True` に設定します。
+ 位置の埋め込み。
+
+
+
+Esta es una aproximación más cercana a la verdadera descomposición de la probabilidad de la secuencia y generalmente dará como resultado una puntuación más favorable. La desventaja es que requiere un pase hacia adelante separado para cada token en el corpus. Un buen compromiso práctico es emplear una ventana deslizante estratificada, moviendo el contexto con pasos más grandes en lugar de deslizarse de 1 token a la vez. Esto permite que la computación avance mucho más rápido, mientras le da al modelo un contexto amplio para hacer
+predicciones en cada paso.
+
+## Ejemplo: Cálculo de la perplejidad con GPT-2 en 🤗 Transformers
+
+Demostremos este proceso con GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+Carguemos el conjunto de datos WikiText-2 y evaluemos la perplejidad utilizando algunas estrategias de ventana deslizante diferentes. Dado que este conjunto de datos es pequeño y solo estamos realizando un pase hacia adelante sobre el conjunto, podemos cargar y codificar todo el conjunto de datos en la memoria.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+Con 🤗 Transformers, simplemente podemos pasar los `input_ids` como las `labels` a nuestro modelo, y la media negativa del log-likelihood para cada token se devuelve como la pérdida. Sin embargo, con nuestro enfoque de ventana deslizante, hay superposición en los tokens que pasamos al modelo en cada iteración. No queremos que el log-likelihood de los tokens que estamos tratando solo como contexto se incluya en nuestra pérdida, por lo que podemos establecer estos objetivos en `-100` para que se ignoren. El siguiente es un ejemplo de cómo podríamos hacer esto con un paso de `512`. Esto significa que el modelo tendrá al menos `512` tokens como contexto al calcular el log-likelihood condicional de cualquier token (siempre que haya `512` tokens precedentes disponibles para condicionar).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # puede ser diferente del paso en el último bucle
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # la pérdida se calcula utilizando CrossEntropyLoss, que promedia las etiquetas válidas
+ # N.B. el modelo solo calcula la pérdida sobre trg_len - 1 etiquetas, porque desplaza las etiqueta internamente
+ # a la izquierda por 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+Ejecuta esto con la longitud de paso igual a la longitud máxima de entrada es equivalente a la estrategia sub óptima,
+sin ventana deslizante, que discutimos anteriormente. Cuanto menor sea el paso, más contexto tendrá el modelo para
+realizar cada predicción y, por lo general, mejor será la perplejidad informada.
+
+Cuando ejecutamos lo anterior con `stride = 1024`, es decir, sin superposición, la PPL resultante es `19.44`, que es
+aproximadamente la misma que la `19.93` informada en el artículo de GPT-2. Al utilizar `stride = 512` y, por lo tanto,
+emplear nuestra estrategia de ventana deslizante, esto disminuye a `16.45`. Esto no solo es una puntuación más favorable, sino que se calcula de una manera más cercana a la verdadera descomposición autorregresiva de la probabilidad de una secuencia.
diff --git a/docs/source/es/preprocessing.md b/docs/source/es/preprocessing.md
index f4eec4862be8be..5ac4c018090bf1 100644
--- a/docs/source/es/preprocessing.md
+++ b/docs/source/es/preprocessing.md
@@ -195,7 +195,7 @@ Las entradas de audio se preprocesan de forma diferente a las entradas textuales
pip install datasets
```
-Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub.html) para que obtengas más detalles sobre cómo cargar un dataset):
+Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub) para que obtengas más detalles sobre cómo cargar un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -234,7 +234,7 @@ Por ejemplo, carga el dataset [LJ Speech](https://huggingface.co/datasets/lj_spe
'sampling_rate': 22050}
```
-1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
+1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
@@ -329,7 +329,7 @@ Vamos a cargar el dataset [food101](https://huggingface.co/datasets/food101) par
>>> dataset = load_dataset("food101", split="train[:100]")
```
-A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image):
+A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image):
```py
>>> dataset[0]["image"]
@@ -370,7 +370,7 @@ Para las tareas de visión por computadora es común añadir algún tipo de aume
... return examples
```
-3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) para aplicar las transformaciones sobre la marcha:
+3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform) para aplicar las transformaciones sobre la marcha:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/es/run_scripts.md b/docs/source/es/run_scripts.md
index a66fd1e47e1386..8b762fdddc28fc 100644
--- a/docs/source/es/run_scripts.md
+++ b/docs/source/es/run_scripts.md
@@ -130,7 +130,7 @@ python examples/tensorflow/summarization/run_summarization.py \
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/es/tasks/image_classification.md b/docs/source/es/tasks/image_classification.md
index 3a959aa934ffa8..f09730caf69fee 100644
--- a/docs/source/es/tasks/image_classification.md
+++ b/docs/source/es/tasks/image_classification.md
@@ -99,7 +99,7 @@ Crea una función de preprocesamiento que aplique las transformaciones y devuelv
... return examples
```
-Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
+Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
```py
>>> food = food.with_transform(transforms)
diff --git a/docs/source/es/tasks/language_modeling.md b/docs/source/es/tasks/language_modeling.md
index 66ac8fb0d4b56a..b3f22f0846335d 100644
--- a/docs/source/es/tasks/language_modeling.md
+++ b/docs/source/es/tasks/language_modeling.md
@@ -94,7 +94,7 @@ Para modelados de lenguaje por enmascaramiento carga el tokenizador DistilRoBERT
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
-Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten):
+Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process#flatten):
```py
>>> eli5 = eli5.flatten()
@@ -249,7 +249,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
@@ -356,7 +356,7 @@ A este punto, solo faltan tres pasos:
```
-Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
+Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
diff --git a/docs/source/es/training.md b/docs/source/es/training.md
index 7b7b0657bd8f16..4f224b0797a3b9 100644
--- a/docs/source/es/training.md
+++ b/docs/source/es/training.md
@@ -102,7 +102,7 @@ Especifica dónde vas a guardar los checkpoints de tu entrenamiento:
### Métricas
-El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para más información):
+El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics) para más información):
```py
>>> import numpy as np
@@ -172,7 +172,7 @@ El [`DefaultDataCollator`] junta los tensores en un batch para que el modelo se
-A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
+A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
@@ -342,7 +342,7 @@ Para hacer un seguimiento al progreso del entrenamiento, utiliza la biblioteca [
### Métricas
-De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
+De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/fr/_toctree.yml b/docs/source/fr/_toctree.yml
index 11632a423b6af1..12c2feb0a02eb5 100755
--- a/docs/source/fr/_toctree.yml
+++ b/docs/source/fr/_toctree.yml
@@ -1,156 +1,30 @@
- sections:
- - local: index
- title: 🤗 Transformers
- - local: quicktour
- title: Visite rapide
- - local: in_translation
- title: Installation
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: Visite rapide
+ - local: installation
+ title: Installation
title: Démarrer
- sections:
- - local: in_translation
- title: Pipelines pour l'inférence
- - local: in_translation
- title: Chargement d'instances pré-entraînées avec une AutoClass
- - local: in_translation
- title: Préparation des données
- - local: in_translation
- title: Fine-tune un modèle pré-entraîné
- - local: in_translation
- title: Entraînement distribué avec 🤗 Accelerate
- - local: in_translation
- title: Partager un modèle
- title: Tutoriels
-- sections:
- - sections:
- - local: in_translation
- title: Créer votre architecture
- - local: in_translation
- title: Partager vos modèles
- - local: in_translation
- title: Entraînement avec un script
- - local: in_translation
- title: Entraînement avec Amazon SageMaker
- - local: in_translation
- title: Convertir depuis des checkpoints Tensorflow
- - local: in_translation
- title: Exporter vers ONNX
- - local: in_translation
- title: Exporter vers TorchScript
- - local: in_translation
- title: Aide au dépannage
- title: Usage général
- - sections:
- - local: in_translation
- title: Utiliser les tokenizers de 🤗 Tokenizers
- - local: in_translation
- title: Inférence avec les modèles multilingues
- - local: in_translation
- title: Stratégies de génération de texte
- - sections:
- - isExpanded: false
- local: in_translation
- title: Classification de texte
- - local: in_translation
- title: Classification de token
- - local: in_translation
- title: Système de question-réponse
- - local: in_translation
- title: Modélisation causale du langage
- - local: in_translation
- title: Modélisation du langage avec masque
- - local: in_translation
- title: Traduction
- - local: in_translation
- title: Génération de résumé
- - local: in_translation
- title: Question à choix multiple
- title: Guides des tâches
- title: Traitement automatique des langues
- - sections:
- - local: in_translation
- title: Classification audio
- - local: in_translation
- title: Reconnaissance automatique de la parole
- title: Audio
- - sections:
- local: in_translation
- title: Classification d'images
+ title: Pipelines pour l'inférence
+ - local: autoclass_tutorial
+ title: Chargement d'instances pré-entraînées avec une AutoClass
- local: in_translation
- title: Segmentation sémantique
+ title: Préparation des données
- local: in_translation
- title: Classification de vidéos
+ title: Fine-tune un modèle pré-entraîné
- local: in_translation
- title: Détection d'objets
- title: Vision par ordinateur
- - sections:
- - local: in_translation
- title: Performance et extensibilité
- - sections:
- - local: in_translation
- title: Comment contribuer à transformers?
- - local: in_translation
- title: Comment ajouter un modèle à 🤗 Transformers?
- - local: in_translation
- title: Comment convertir un modèle 🤗 Transformers vers TensorFlow?
- - local: in_translation
- title: Comment ajouter un pipeline à 🤗 Transformers?
- - local: in_translation
- title: Tester
- - local: in_translation
- title: Vérification pour une Pull Request
- title: Contribuer
- - local: in_translation
- title: 🤗 Transformers Notebooks
- - local: in_translation
- title: Ressources communautaires
- - local: in_translation
- title: Benchmarks
- - local: in_translation
- title: Migration à partir de versions précédentes
- title: Guides d'utilisation
-- sections:
- - local: in_translation
- title: Philosophie
- - local: in_translation
- title: Glossaire
- - local: in_translation
- title: Qu'est ce 🤗 Transformers peut faire ?
- - local: in_translation
- title: Quelles tâches 🤗 Transformers peut résoudre ?
- - local: in_translation
- title: Résumé des modèles
- - local: in_translation
- title: Résumé des tokenizers
- - local: in_translation
- title: Remplissage et troncature
- - local: in_translation
- title: BERTology
- - local: in_translation
- title: Perplexité des modèles à longueur fixe
- - local: in_translation
- title: Pipelines pour inférence avec des serveurs web
- title: Guides conceptuels
-- sections:
- - isExpanded: false
- sections:
- - local: in_translation
- title: Classes principales
- - local: in_translation
- title: Modèles textuels
- - local: in_translation
- title: Modèles visuels
- - local: in_translation
- title: Modèles audio
+ title: Entraînement avec un script
- local: in_translation
- title: Modèles multimodal
+ title: Entraînement distribué avec 🤗 Accelerate
- local: in_translation
- title: Modèles d'apprentissage par renforcement
+ title: Chargement et entraînement des adaptateurs avec 🤗 PEFT
- local: in_translation
- title: Modèles de séries temporelles
+ title: Partager un modèle
- local: in_translation
- title: Graph models
- title: Modèles
- - sections:
+ title: Agents
- local: in_translation
- title: Utilitaires internes
- title: API
+ title: Génération avec LLMs
+ title: Tutoriels
diff --git a/docs/source/fr/autoclass_tutorial.md b/docs/source/fr/autoclass_tutorial.md
new file mode 100644
index 00000000000000..392e2a6807e55d
--- /dev/null
+++ b/docs/source/fr/autoclass_tutorial.md
@@ -0,0 +1,142 @@
+
+
+# Chargement d'instances pré-entraînées avec une AutoClass
+
+Avec autant d'architectures Transformer différentes, il peut être difficile d'en créer une pour votre ensemble de poids (aussi appelés "weights" ou "checkpoint" en anglais). Dans l'idée de créer une librairie facile, simple et flexible à utiliser, 🤗 Transformers fournit une `AutoClass` qui infère et charge automatiquement l'architecture correcte à partir d'un ensemble de poids donné. La fonction `from_pretrained()` vous permet de charger rapidement un modèle pré-entraîné pour n'importe quelle architecture afin que vous n'ayez pas à consacrer du temps et des ressources à l'entraînement d'un modèle à partir de zéro. Produire un tel code indépendant d'un ensemble de poids signifie que si votre code fonctionne pour un ensemble de poids, il fonctionnera avec un autre ensemble - tant qu'il a été entraîné pour une tâche similaire - même si l'architecture est différente.
+
+
+
+Rappel, l'architecture fait référence au squelette du modèle et l'ensemble de poids contient les poids pour une architecture donnée. Par exemple, [BERT](https://huggingface.co/bert-base-uncased) est une architecture, tandis que `bert-base-uncased` est un ensemble de poids. Le terme modèle est général et peut signifier soit architecture soit ensemble de poids.
+
+
+
+Dans ce tutoriel, vous apprendrez à:
+
+ * Charger un tokenizer pré-entraîné.
+ * Charger un processeur d'image pré-entraîné.
+ * Charger un extracteur de caractéristiques pré-entraîné.
+ * Charger un processeur pré-entraîné.
+ * Charger un modèle pré-entraîné.
+
+## AutoTokenizer
+
+Quasiment toutes les tâches de traitement du langage (NLP) commencent avec un tokenizer. Un tokenizer convertit votre texte initial dans un format qui peut être traité par le modèle.
+
+Chargez un tokenizer avec [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+Puis, transformez votre texte initial comme montré ci-dessous:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoImageProcessor
+
+Pour les tâches de vision, un processeur d'image traite l'image pour la formater correctment.
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+## AutoFeatureExtractor
+
+Pour les tâches audio, un extracteur de caractéristiques (aussi appelés "features" en anglais) traite le signal audio pour le formater correctement.
+
+Chargez un extracteur de caractéristiques avec [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor
+
+Les tâches multimodales nécessitent un processeur qui combine deux types d'outils de prétraitement. Par exemple, le modèle [LayoutLMV2](model_doc/layoutlmv2) nécessite un processeur d'image pour traiter les images et un tokenizer pour traiter le texte ; un processeur combine les deux.
+
+Chargez un processeur avec [`AutoProcessor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel
+
+
+
+Enfin, les classes `AutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`AutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+Pour les modèles PyTorch, la fonction `from_pretrained()` utilise `torch.load()` qui utilise `pickle` en interne et est connu pour être non sécurisé. En général, ne chargez jamais un modèle qui pourrait provenir d'une source non fiable, ou qui pourrait avoir été altéré. Ce risque de sécurité est partiellement atténué pour les modèles hébergés publiquement sur le Hugging Face Hub, qui sont [scannés pour les logiciels malveillants](https://huggingface.co/docs/hub/security-malware) à chaque modification. Consultez la [documentation du Hub](https://huggingface.co/docs/hub/security) pour connaître les meilleures pratiques comme la [vérification des modifications signées](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) avec GPG.
+
+Les points de contrôle TensorFlow et Flax ne sont pas concernés, et peuvent être chargés dans des architectures PyTorch en utilisant les arguments `from_tf` et `from_flax` de la fonction `from_pretrained` pour contourner ce problème.
+
+
+
+En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `AutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
+
+
+Enfin, les classes `TFAutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`TFAutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `TFAutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
+
+
diff --git a/docs/source/fr/installation.md b/docs/source/fr/installation.md
new file mode 100644
index 00000000000000..f529c4e201dad3
--- /dev/null
+++ b/docs/source/fr/installation.md
@@ -0,0 +1,258 @@
+
+
+# Installation
+
+Installez 🤗 Transformers pour n'importe quelle librairie d'apprentissage profond avec laquelle vous avez l'habitude de travaillez, configurez votre cache et configurez 🤗 Transformers pour un usage hors ligne (facultatif).
+
+🤗 Transformers est testé avec Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ et Flax.
+Consulter les instructions d'installation ci-dessous pour la librairie d'apprentissage profond que vous utilisez:
+
+ * Instructions d'installation pour [PyTorch](https://pytorch.org/get-started/locally/).
+ * Instructions d'installation pour [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+ * Instructions d'installation pour [Flax](https://flax.readthedocs.io/en/latest/).
+
+## Installation avec pip
+
+Vous devriez installer 🤗 Transformers dans un [environnement virtuel](https://docs.python.org/3/library/venv.html).
+Si vous n'êtes pas à l'aise avec les environnements virtuels, consultez ce [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+Utiliser un environnement virtuel permet de facilement gérer différents projets et d'éviter des erreurs de compatibilité entre les différentes dépendances.
+
+Commencez par créer un environnement virtuel dans l'espace de travail de votre projet :
+
+```bash
+python -m venv .env
+```
+
+Activez l'environnement virtuel. Sur Linux ou MacOs :
+
+```bash
+source .env/bin/activate
+```
+
+Activez l'environnement virtuel sur Windows :
+
+```bash
+.env/Scripts/activate
+```
+
+Maintenant, 🤗 Transformers peut être installé avec la commande suivante :
+
+```bash
+pip install transformers
+```
+
+Pour une utilisation avec CPU seulement, 🤗 Transformers et la librairie d'apprentissage profond de votre choix peuvent être installés en une seule ligne.
+Par exemple, installez 🤗 Transformers et PyTorch avec la commande suivante :
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers et TensorFlow 2.0 :
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+
+
+Pour les architectures mac M1 / ARM
+
+Vous devez installer les outils suivants avant d'installer TensorFLow 2.0
+
+```
+brew install cmake
+brew install pkg-config
+```
+
+
+
+🤗 Transformers et Flax :
+
+```bash
+pip install 'transformers[flax]'
+```
+
+Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante. La commande va télécharger un modèle pré-entraîné :
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Le label et score sont ensuite affichés :
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Installation depuis le code source
+
+Installez 🤗 Transformers depuis le code source avec la commande suivante :
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+Cette commande installe la version depuis la branche `main` au lieu de la dernière version stable. La version de la branche `main` est utile pour avoir les derniers développements. Par exemple, si un bug a été résolu depuis la dernière version stable mais n'a pas encore été publié officiellement. Cependant, cela veut aussi dire que la version de la branche `main` n'est pas toujours stable. Nous nous efforçons de maintenir la version de la branche `main` opérationnelle, et la plupart des problèmes sont généralement résolus en l'espace de quelques heures ou d'un jour. Si vous recontrez un problème, n'hésitez pas à créer une [Issue](https://github.com/huggingface/transformers/issues) pour que l'on puisse trouver une solution au plus vite !
+
+Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante :
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Installation modifiable
+
+Vous aurez besoin d'une installation modifiable si vous le souhaitez :
+
+ * Utiliser la version de la branche `main` du code source.
+ * Contribuer à 🤗 Transformers et vouler tester vos modifications du code source.
+
+Clonez le projet et installez 🤗 Transformers avec les commandes suivantes :
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Ces commandes créent des liens entre le dossier où le projet a été cloné et les chemins de vos librairies Python. Python regardera maintenant dans le dossier que vous avez cloné en plus des dossiers où sont installées vos autres librairies. Par exemple, si vos librairies Python sont installées dans `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cherchera aussi dans le dossier où vous avez cloné : `~/transformers/`.
+
+
+
+Vous devez garder le dossier `transformers` si vous voulez continuer d'utiliser la librairie.
+
+
+
+Maintenant, vous pouvez facilement mettre à jour votre clone avec la dernière version de 🤗 Transformers en utilisant la commande suivante :
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+Votre environnement Python utilisera la version de la branche `main` lors de la prochaine exécution.
+
+## Installation avec conda
+
+Installation via le canal `huggingface` de conda :
+
+```bash
+conda install -c huggingface transformers
+```
+
+## Configuration du cache
+
+Les modèles pré-entraînés sont téléchargés et mis en cache localement dans le dossier suivant : `~/.cache/huggingface/hub`. C'est le dossier par défaut donné par la variable d'environnement `TRANSFORMERS_CACHE`. Sur Windows, le dossier par défaut est `C:\Users\nom_utilisateur\.cache\huggingface\hub`. Vous pouvez modifier les variables d'environnement indiquées ci-dessous - par ordre de priorité - pour spécifier un dossier de cache différent :
+
+1. Variable d'environnement (par défaut) : `HUGGINGFACE_HUB_CACHE` ou `TRANSFORMERS_CACHE`.
+2. Variable d'environnement : `HF_HOME`.
+3. Variable d'environnement : `XDG_CACHE_HOME` + `/huggingface`.
+
+
+
+🤗 Transformers utilisera les variables d'environnement `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE` si vous utilisez une version précédente de cette librairie et avez défini ces variables d'environnement, sauf si vous spécifiez la variable d'environnement `TRANSFORMERS_CACHE`.
+
+
+
+## Mode hors ligne
+
+🤗 Transformers peut fonctionner dans un environnement cloisonné ou hors ligne en n'utilisant que des fichiers locaux. Définissez la variable d'environnement `TRANSFORMERS_OFFLINE=1` pour activer ce mode.
+
+
+
+Ajoutez [🤗 Datasets](https://huggingface.co/docs/datasets/) à votre processus d'entraînement hors ligne en définissant la variable d'environnement `HF_DATASETS_OFFLINE=1`.
+
+
+
+```bash
+HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+Le script devrait maintenant s'exécuter sans rester en attente ou attendre une expiration, car il n'essaiera pas de télécharger des modèle sur le Hub.
+
+Vous pouvez aussi éviter de télécharger un modèle à chaque appel de la fonction [~PreTrainedModel.from_pretrained] en utilisant le paramètre [local_files_only]. Seuls les fichiers locaux sont chargés lorsque ce paramètre est activé (c.-à-d. `local_files_only=True`) :
+
+```py
+from transformers import T5Model
+
+model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
+```
+
+### Récupérer des modèles et des tokenizers pour une utilisation hors ligne
+
+Une autre option pour utiliser 🤗 Transformers hors ligne est de télécharger les fichiers à l'avance, puis d'utiliser les chemins locaux lorsque vous en avez besoin en mode hors ligne. Il existe trois façons de faire cela :
+
+ * Téléchargez un fichier via l'interface utilisateur sur le [Model Hub](https://huggingface.co/models) en cliquant sur l'icône ↓.
+
+ 
+
+ * Utilisez les fonctions [`PreTrainedModel.from_pretrained`] et [`PreTrainedModel.save_pretrained`] :
+
+ 1. Téléchargez vos fichiers à l'avance avec [`PreTrainedModel.from_pretrained`]:
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+ 2. Sauvegardez les fichiers dans un dossier de votre choix avec [`PreTrainedModel.save_pretrained`]:
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. Maintenant, lorsque vous êtes hors ligne, rechargez vos fichiers avec [`PreTrainedModel.from_pretrained`] depuis le dossier où vous les avez sauvegardés :
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+ * Téléchargez des fichiers de manière automatique avec la librairie [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) :
+
+ 1. Installez la librairie `huggingface_hub` dans votre environnement virtuel :
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. Utilisez la fonction [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) pour télécharger un fichier vers un chemin de votre choix. Par exemple, la commande suivante télécharge le fichier `config.json` du modèle [T0](https://huggingface.co/bigscience/T0_3B) vers le chemin de votre choix :
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+Une fois que votre fichier est téléchargé et caché localement, spécifiez son chemin local pour le charger et l'utiliser :
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+Consultez la section [How to download files from the Hub (Comment télécharger des fichiers depuis le Hub)](https://huggingface.co/docs/hub/how-to-downstream) pour plus de détails sur le téléchargement de fichiers stockés sur le Hub.
+
+
diff --git a/docs/source/it/converting_tensorflow_models.md b/docs/source/it/converting_tensorflow_models.md
index 04398636359ce5..f6326daa735fbe 100644
--- a/docs/source/it/converting_tensorflow_models.md
+++ b/docs/source/it/converting_tensorflow_models.md
@@ -104,21 +104,6 @@ transformers-cli convert --model_type gpt2 \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
-## Transformer-XL
-
-
-Ecco un esempio del processo di conversione di un modello Transformer-XL pre-allenato
-(vedi [qui](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models)):
-
-```bash
-export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
-transformers-cli convert --model_type transfo_xl \
- --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
- --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
- [--config TRANSFO_XL_CONFIG] \
- [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
-```
-
## XLNet
Ecco un esempio del processo di conversione di un modello XLNet pre-allenato:
diff --git a/docs/source/it/perf_hardware.md b/docs/source/it/perf_hardware.md
index a579362e2b1b9d..dd1187a01b5938 100644
--- a/docs/source/it/perf_hardware.md
+++ b/docs/source/it/perf_hardware.md
@@ -134,7 +134,7 @@ Ecco il codice benchmark completo e gli output:
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -143,7 +143,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/it/preprocessing.md b/docs/source/it/preprocessing.md
index 94578dfe166b77..76addd2aa0ea3c 100644
--- a/docs/source/it/preprocessing.md
+++ b/docs/source/it/preprocessing.md
@@ -194,7 +194,7 @@ Gli input audio sono processati in modo differente rispetto al testo, ma l'obiet
pip install datasets
```
-Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) per avere maggiori dettagli su come caricare un dataset):
+Carica il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) (vedi il 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) per avere maggiori dettagli su come caricare un dataset):
```py
>>> from datasets import load_dataset, Audio
@@ -233,7 +233,7 @@ Per esempio, il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds1
'sampling_rate': 8000}
```
-1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
+1. Usa il metodo di 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) per alzare la frequenza di campionamento a 16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
@@ -370,7 +370,7 @@ Per le attività di visione, è usuale aggiungere alcuni tipi di data augmentati
... return examples
```
-3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform)per applicare al volo la trasformazione:
+3. Poi utilizza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)per applicare al volo la trasformazione:
```py
>>> dataset.set_transform(transforms)
diff --git a/docs/source/it/quicktour.md b/docs/source/it/quicktour.md
index f0e981d18eb77d..07e7a2974a1fbc 100644
--- a/docs/source/it/quicktour.md
+++ b/docs/source/it/quicktour.md
@@ -125,7 +125,7 @@ Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuo
... )
```
-Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
+Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
diff --git a/docs/source/it/run_scripts.md b/docs/source/it/run_scripts.md
index 327eb9374d3873..c376ff32c2a884 100644
--- a/docs/source/it/run_scripts.md
+++ b/docs/source/it/run_scripts.md
@@ -130,7 +130,7 @@ Il [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supp
- Imposta un numero di GPU da usare con l'argomento `nproc_per_node`.
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/it/training.md b/docs/source/it/training.md
index be0883f07b7715..503a43321799e1 100644
--- a/docs/source/it/training.md
+++ b/docs/source/it/training.md
@@ -43,7 +43,7 @@ Inizia caricando il dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
-Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process.html#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
+Come già sai, hai bisogno di un tokenizer per processare il testo e includere una strategia di padding e truncation per gestire sequenze di lunghezza variabile. Per processare il dataset in un unico passo, usa il metodo [`map`](https://huggingface.co/docs/datasets/process#map) di 🤗 Datasets che applica la funzione di preprocessing all'intero dataset:
```py
>>> from transformers import AutoTokenizer
@@ -103,7 +103,7 @@ Specifica dove salvare i checkpoints del tuo addestramento:
### Metriche
-[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics.html) per maggiori informazioni):
+[`Trainer`] non valuta automaticamente le performance del modello durante l'addestramento. Dovrai passare a [`Trainer`] una funzione che calcola e restituisce le metriche. La libreria 🤗 Datasets mette a disposizione una semplice funzione [`accuracy`](https://huggingface.co/metrics/accuracy) che puoi caricare con la funzione `load_metric` (guarda questa [esercitazione](https://huggingface.co/docs/datasets/metrics) per maggiori informazioni):
```py
>>> import numpy as np
@@ -346,7 +346,7 @@ Per tenere traccia dei tuoi progressi durante l'addestramento, usa la libreria [
### Metriche
-Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
+Proprio come è necessario aggiungere una funzione di valutazione del [`Trainer`], è necessario fare lo stesso quando si scrive il proprio ciclo di addestramento. Ma invece di calcolare e riportare la metrica alla fine di ogni epoca, questa volta accumulerai tutti i batch con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) e calcolerai la metrica alla fine.
```py
>>> metric = load_metric("accuracy")
diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index df686b475dab35..9766571c6b87eb 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -29,11 +29,76 @@
title: LLM を使用した生成
title: Tutorials
- sections:
+ - isExpanded: false
+ sections:
+ - local: tasks/sequence_classification
+ title: テキストの分類
+ - local: tasks/token_classification
+ title: トークンの分類
+ - local: tasks/question_answering
+ title: 質疑応答
+ - local: tasks/language_modeling
+ title: 因果言語モデリング
+ - local: tasks/masked_language_modeling
+ title: マスクされた言語モデリング
+ - local: tasks/translation
+ title: 翻訳
+ - local: tasks/summarization
+ title: 要約
+ - local: tasks/multiple_choice
+ title: 複数の選択肢
+ title: 自然言語処理
+ - isExpanded: false
+ sections:
+ - local: tasks/audio_classification
+ title: 音声の分類
+ - local: tasks/asr
+ title: 自動音声認識
+ title: オーディオ
+ - isExpanded: false
+ sections:
+ - local: tasks/image_classification
+ title: 画像分類
+ - local: tasks/semantic_segmentation
+ title: セマンティックセグメンテーション
+ - local: tasks/video_classification
+ title: ビデオの分類
+ - local: tasks/object_detection
+ title: 物体検出
+ - local: tasks/zero_shot_object_detection
+ title: ゼロショット物体検出
+ - local: tasks/zero_shot_image_classification
+ title: ゼロショット画像分類
+ - local: tasks/monocular_depth_estimation
+ title: 深さの推定
+ - local: tasks/image_to_image
+ title: 画像から画像へ
+ - local: tasks/knowledge_distillation_for_image_classification
+ title: コンピュータビジョンのための知識の蒸留
+ title: コンピュータビジョン
+ - isExpanded: false
+ sections:
+ - local: tasks/image_captioning
+ title: 画像のキャプション
+ - local: tasks/document_question_answering
+ title: 文書の質問への回答
+ - local: tasks/visual_question_answering
+ title: 視覚的な質問への回答
+ - local: tasks/text-to-speech
+ title: テキスト読み上げ
+ title: マルチモーダル
- isExpanded: false
sections:
- local: generation_strategies
title: 生成戦略をカスタマイズする
- title: Generation
+ title: 世代
+ - isExpanded: false
+ sections:
+ - local: tasks/idefics
+ title: IDEFICS を使用したイメージ タスク
+ - local: tasks/prompting
+ title: LLM プロンプト ガイド
+ title: プロンプト
title: Task Guides
- sections:
- local: fast_tokenizers
@@ -185,11 +250,70 @@
sections:
- local: model_doc/albert
title: ALBERT
+ - local: model_doc/bart
+ title: BART
+ - local: model_doc/barthez
+ title: BARThez
+ - local: model_doc/bartpho
+ title: BARTpho
+ - local: model_doc/bert
+ title: BERT
+ - local: model_doc/bert-generation
+ title: BertGeneration
+ - local: model_doc/bert-japanese
+ title: BertJapanese
+ - local: model_doc/bertweet
+ title: Bertweet
+ - local: model_doc/big_bird
+ title: BigBird
+ - local: model_doc/bigbird_pegasus
+ title: BigBirdPegasus
+ - local: model_doc/biogpt
+ title: BioGpt
+ - local: model_doc/blenderbot
+ title: Blenderbot
+ - local: model_doc/blenderbot-small
+ title: Blenderbot Small
+ - local: model_doc/bloom
+ title: BLOOM
+ - local: model_doc/bort
+ title: BORT
+ - local: model_doc/byt5
+ title: ByT5
+ - local: model_doc/camembert
+ title: CamemBERT
+ - local: model_doc/canine
+ title: CANINE
+ - local: model_doc/codegen
+ title: CodeGen
+ - local: model_doc/code_llama
+ title: CodeLlama
+ - local: model_doc/convbert
+ title: ConvBERT
+ - local: model_doc/cpm
+ title: CPM
title: 文章モデル
+ - isExpanded: false
+ sections:
+ - local: model_doc/beit
+ title: BEiT
+ - local: model_doc/bit
+ title: BiT
+ - local: model_doc/conditional_detr
+ title: Conditional DETR
+ - local: model_doc/convnext
+ title: ConvNeXT
+ - local: model_doc/convnextv2
+ title: ConvNeXTV2
+ title: ビジョンモデル
- isExpanded: false
sections:
- local: model_doc/audio-spectrogram-transformer
title: Audio Spectrogram Transformer
+ - local: model_doc/bark
+ title: Bark
+ - local: model_doc/clap
+ title: CLAP
title: 音声モデル
- isExpanded: false
sections:
@@ -197,6 +321,22 @@
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
+ - local: model_doc/blip
+ title: BLIP
+ - local: model_doc/blip-2
+ title: BLIP-2
+ - local: model_doc/bridgetower
+ title: BridgeTower
+ - local: model_doc/bros
+ title: BROS
+ - local: model_doc/chinese_clip
+ title: Chinese-CLIP
+ - local: model_doc/clip
+ title: CLIP
+ - local: model_doc/clipseg
+ title: CLIPSeg
+ - local: model_doc/clvp
+ title: CLVP
title: マルチモーダルモデル
- isExpanded: false
sections:
diff --git a/docs/source/ja/main_classes/trainer.md b/docs/source/ja/main_classes/trainer.md
index 4c1ce95ca38aa6..f18c1b86809f99 100644
--- a/docs/source/ja/main_classes/trainer.md
+++ b/docs/source/ja/main_classes/trainer.md
@@ -196,7 +196,7 @@ _python_、_numpy_、および _pytorch_ の RNG 状態は、そのチェック
[`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.Parallel.DistributedDataParallel.html) を使用して GPU のサブセットのみを使用する場合、使用する GPU の数を指定するだけです。 。たとえば、GPU が 4 つあるが、最初の 2 つを使用したい場合は、次のようにします。
```bash
-python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
+torchrun --nproc_per_node=2 trainer-program.py ...
```
[`accelerate`](https://github.com/huggingface/accelerate) または [`deepspeed`](https://github.com/microsoft/DeepSpeed) がインストールされている場合は、次を使用して同じことを達成することもできます。の一つ:
@@ -209,7 +209,7 @@ accelerate launch --num_processes 2 trainer-program.py ...
deepspeed --num_gpus 2 trainer-program.py ...
```
-これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](Deepspeed) 機能を使用する必要はありません。
+これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](deepspeed) 機能を使用する必要はありません。
これまでは、プログラムに使用する GPU の数を指示できました。次に、特定の GPU を選択し、その順序を制御する方法について説明します。
@@ -223,7 +223,7 @@ deepspeed --num_gpus 2 trainer-program.py ...
たとえば、4 つの GPU (0、1、2、3) があるとします。物理 GPU 0 と 2 のみで実行するには、次のようにします。
```bash
-CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
```
したがって、pytorch は 2 つの GPU のみを認識し、物理 GPU 0 と 2 はそれぞれ `cuda:0` と `cuda:1` にマッピングされます。
@@ -231,7 +231,7 @@ CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py .
順序を変更することもできます。
```bash
-CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
+CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
```
ここでは、物理 GPU 0 と 2 がそれぞれ`cuda:1`と`cuda:0`にマッピングされています。
@@ -253,7 +253,7 @@ CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```bash
export CUDA_VISIBLE_DEVICES=0,2
-python -m torch.distributed.launch trainer-program.py ...
+torchrun trainer-program.py ...
```
ただし、この方法では、以前に環境変数を設定したことを忘れて、なぜ間違った GPU が使用されているのか理解できない可能性があるため、混乱を招く可能性があります。したがって、このセクションのほとんどの例で示されているように、同じコマンド ラインで特定の実行に対してのみ環境変数を設定するのが一般的です。
diff --git a/docs/source/ja/model_doc/align.md b/docs/source/ja/model_doc/align.md
index 6e62c3d9f4ca68..84496e605def92 100644
--- a/docs/source/ja/model_doc/align.md
+++ b/docs/source/ja/model_doc/align.md
@@ -51,10 +51,10 @@ inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
-# これは画像-テキスト類似度スコア
+# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
-# Softmaxを取ることで各ラベルの確率を得られる
+# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
diff --git a/docs/source/ja/model_doc/altclip.md b/docs/source/ja/model_doc/altclip.md
index 232b3645544f39..87cf6cc17d6a0b 100644
--- a/docs/source/ja/model_doc/altclip.md
+++ b/docs/source/ja/model_doc/altclip.md
@@ -52,8 +52,8 @@ Transformerエンコーダーに画像を与えるには、各画像を固定サ
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
->>> logits_per_image = outputs.logits_per_image # これは画像-テキスト類似度スコア
->>> probs = logits_per_image.softmax(dim=1) # Softmaxを取ることで各ラベルの確率を得られる
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
diff --git a/docs/source/ja/model_doc/audio-spectrogram-transformer.md b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
index efbadbd4bae67b..a5107b14f83a98 100644
--- a/docs/source/ja/model_doc/audio-spectrogram-transformer.md
+++ b/docs/source/ja/model_doc/audio-spectrogram-transformer.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
## 概要
-Audio Spectrogram Transformerモデルは、「[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)」という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
+Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
論文の要旨は以下の通りです:
@@ -35,7 +35,7 @@ alt="drawing" width="600"/>
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
-- ASTは低い学習率が必要であり(著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
+- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
diff --git a/docs/source/ja/model_doc/auto.md b/docs/source/ja/model_doc/auto.md
index b104e4c99fe3a8..c6775493baae39 100644
--- a/docs/source/ja/model_doc/auto.md
+++ b/docs/source/ja/model_doc/auto.md
@@ -43,7 +43,7 @@ AutoModel.register(NewModelConfig, NewModel)
-あなたの`NewModelConfig`が[`~transformer.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
+あなたの`NewModelConfig`が[`~transformers.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
同様に、あなたの`NewModel`が[`PreTrainedModel`]のサブクラスである場合、その`config_class`属性がモデルを登録する際に使用するクラス(ここでは`NewModelConfig`)と同じに設定されていることを確認してください。
diff --git a/docs/source/ja/model_doc/bark.md b/docs/source/ja/model_doc/bark.md
new file mode 100644
index 00000000000000..508b8938889bae
--- /dev/null
+++ b/docs/source/ja/model_doc/bark.md
@@ -0,0 +1,198 @@
+
+
+# Bark
+
+## Overview
+
+Bark は、[suno-ai/bark](https://github.com/suno-ai/bark) で Suno AI によって提案されたトランスフォーマーベースのテキスト読み上げモデルです。
+
+
+Bark は 4 つの主要なモデルで構成されています。
+
+- [`BarkSemanticModel`] ('テキスト'モデルとも呼ばれる): トークン化されたテキストを入力として受け取り、テキストの意味を捉えるセマンティック テキスト トークンを予測する因果的自己回帰変換モデル。
+- [`BarkCoarseModel`] ('粗い音響' モデルとも呼ばれる): [`BarkSemanticModel`] モデルの結果を入力として受け取る因果的自己回帰変換器。 EnCodec に必要な最初の 2 つのオーディオ コードブックを予測することを目的としています。
+- [`BarkFineModel`] ('微細音響' モデル)、今回は非因果的オートエンコーダー トランスフォーマーで、以前のコードブック埋め込みの合計に基づいて最後のコードブックを繰り返し予測します。
+- [`EncodecModel`] からすべてのコードブック チャネルを予測したので、Bark はそれを使用して出力オーディオ配列をデコードします。
+
+最初の 3 つのモジュールはそれぞれ、特定の事前定義された音声に従って出力サウンドを調整するための条件付きスピーカー埋め込みをサポートできることに注意してください。
+
+### Optimizing Bark
+
+Bark は、コードを数行追加するだけで最適化でき、**メモリ フットプリントが大幅に削減**され、**推論が高速化**されます。
+
+#### Using half-precision
+
+モデルを半精度でロードするだけで、推論を高速化し、メモリ使用量を 50% 削減できます。
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
+```
+
+#### Using 🤗 Better Transformer
+
+Better Transformer は、内部でカーネル融合を実行する 🤗 最適な機能です。パフォーマンスを低下させることなく、速度を 20% ~ 30% 向上させることができます。モデルを 🤗 Better Transformer にエクスポートするのに必要なコードは 1 行だけです。
+
+```python
+model = model.to_bettertransformer()
+```
+
+この機能を使用する前に 🤗 Optimum をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/optimum/installation)
+
+#### Using CPU offload
+
+前述したように、Bark は 4 つのサブモデルで構成されており、オーディオ生成中に順番に呼び出されます。言い換えれば、1 つのサブモデルが使用されている間、他のサブモデルはアイドル状態になります。
+
+CUDA デバイスを使用している場合、メモリ フットプリントの 80% 削減による恩恵を受ける簡単な解決策は、アイドル状態の GPU のサブモデルをオフロードすることです。この操作は CPU オフロードと呼ばれます。 1行のコードで使用できます。
+
+```python
+model.enable_cpu_offload()
+```
+
+この機能を使用する前に、🤗 Accelerate をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/accelerate/basic_tutorials/install)
+
+#### Combining optimization techniques
+
+最適化手法を組み合わせて、CPU オフロード、半精度、🤗 Better Transformer をすべて一度に使用できます。
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+# load in fp16
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
+
+# convert to bettertransformer
+model = BetterTransformer.transform(model, keep_original_model=False)
+
+# enable CPU offload
+model.enable_cpu_offload()
+```
+
+推論最適化手法の詳細については、[こちら](https://huggingface.co/docs/transformers/perf_infer_gpu_one) をご覧ください。
+
+### Tips
+
+Suno は、多くの言語で音声プリセットのライブラリを提供しています [こちら](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c)。
+これらのプリセットは、ハブ [こちら](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) または [こちら](https://huggingface.co/suno/bark/tree/main/speaker_embeddings)。
+
+```python
+>>> from transformers import AutoProcessor, BarkModel
+
+>>> processor = AutoProcessor.from_pretrained("suno/bark")
+>>> model = BarkModel.from_pretrained("suno/bark")
+
+>>> voice_preset = "v2/en_speaker_6"
+
+>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+Bark は、非常にリアルな **多言語** 音声だけでなく、音楽、背景ノイズ、単純な効果音などの他の音声も生成できます。
+
+```python
+>>> # Multilingual speech - simplified Chinese
+>>> inputs = processor("惊人的!我会说中文")
+
+>>> # Multilingual speech - French - let's use a voice_preset as well
+>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
+
+>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
+>>> inputs = processor("♪ Hello, my dog is cute ♪")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+このモデルは、笑う、ため息、泣くなどの**非言語コミュニケーション**を生成することもできます。
+
+
+```python
+>>> # Adding non-speech cues to the input text
+>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+オーディオを保存するには、モデル設定と scipy ユーティリティからサンプル レートを取得するだけです。
+
+```python
+>>> from scipy.io.wavfile import write as write_wav
+
+>>> # save audio to disk, but first take the sample rate from the model config
+>>> sample_rate = model.generation_config.sample_rate
+>>> write_wav("bark_generation.wav", sample_rate, audio_array)
+```
+
+このモデルは、[Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) および [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi) によって提供されました。
+元のコードは [ここ](https://github.com/suno-ai/bark) にあります。
+
+## BarkConfig
+
+[[autodoc]] BarkConfig
+ - all
+
+## BarkProcessor
+
+[[autodoc]] BarkProcessor
+ - all
+ - __call__
+
+## BarkModel
+
+[[autodoc]] BarkModel
+ - generate
+ - enable_cpu_offload
+
+## BarkSemanticModel
+
+[[autodoc]] BarkSemanticModel
+ - forward
+
+## BarkCoarseModel
+
+[[autodoc]] BarkCoarseModel
+ - forward
+
+## BarkFineModel
+
+[[autodoc]] BarkFineModel
+ - forward
+
+## BarkCausalModel
+
+[[autodoc]] BarkCausalModel
+ - forward
+
+## BarkCoarseConfig
+
+[[autodoc]] BarkCoarseConfig
+ - all
+
+## BarkFineConfig
+
+[[autodoc]] BarkFineConfig
+ - all
+
+## BarkSemanticConfig
+
+[[autodoc]] BarkSemanticConfig
+ - all
diff --git a/docs/source/ja/model_doc/bart.md b/docs/source/ja/model_doc/bart.md
new file mode 100644
index 00000000000000..0f2c3fb006e137
--- /dev/null
+++ b/docs/source/ja/model_doc/bart.md
@@ -0,0 +1,223 @@
+
+
+# BART
+
+
+
+**免責事項:** 何か奇妙なものを見つけた場合は、[Github 問題](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を提出し、割り当ててください。
+@patrickvonplaten
+
+## Overview
+
+Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
+翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
+ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
+
+要約によると、
+
+- Bart は、双方向エンコーダ (BERT など) を備えた標準の seq2seq/機械翻訳アーキテクチャを使用します。
+ 左から右へのデコーダ (GPT など)。
+- 事前トレーニング タスクには、元の文の順序をランダムにシャッフルし、新しい埋め込みスキームが含まれます。
+ ここで、テキストの範囲は単一のマスク トークンに置き換えられます。
+- BART は、テキスト生成用に微調整した場合に特に効果的ですが、理解タスクにも適しています。それ
+ RoBERTa のパフォーマンスを GLUE および SQuAD の同等のトレーニング リソースと同等にし、新たな成果を達成します。
+ さまざまな抽象的な対話、質問応答、要約タスクに関する最先端の結果が得られ、成果が得られます。
+ ルージュは最大6枚まで。
+
+チップ:
+
+- BART は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+- エンコーダーとデコーダーを備えたシーケンスツーシーケンス モデル。エンコーダには破損したバージョンのトークンが供給され、デコーダには元のトークンが供給されます(ただし、通常のトランスフォーマー デコーダと同様に、将来のワードを隠すためのマスクがあります)。次の変換の構成は、エンコーダーの事前トレーニング タスクに適用されます。
+
+ * ランダムなトークンをマスクします (BERT と同様)
+ * ランダムなトークンを削除します
+ * k 個のトークンのスパンを 1 つのマスク トークンでマスクします (0 トークンのスパンはマスク トークンの挿入です)
+ * 文を並べ替えます
+ * ドキュメントを回転して特定のトークンから開始するようにします
+
+このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/pytorch/fairseq/tree/master/examples/bart) にあります。
+
+### Examples
+
+- シーケンス間タスク用の BART およびその他のモデルを微調整するための例とスクリプトは、次の場所にあります。
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
+- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
+ オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+
+## Implementation Notes
+
+- Bart はシーケンスの分類に `token_type_ids` を使用しません。 [`BartTokenizer`] を使用するか、
+ [`~BartTokenizer.encode`] を使用して適切に分割します。
+- [`BartModel`] のフォワードパスは、渡されなかった場合、`decoder_input_ids` を作成します。
+ これは、他のモデリング API とは異なります。この機能の一般的な使用例は、マスクの塗りつぶしです。
+- モデルの予測は、次の場合に元の実装と同一になるように意図されています。
+ `forced_bos_token_id=0`。ただし、これは、渡す文字列が次の場合にのみ機能します。
+ [`fairseq.encode`] はスペースで始まります。
+- [`~generation.GenerationMixin.generate`] は、次のような条件付き生成タスクに使用する必要があります。
+ 要約については、その docstring の例を参照してください。
+- *facebook/bart-large-cnn* 重みをロードするモデルには `mask_token_id` がないか、実行できません。
+ マスクを埋めるタスク。
+
+## Mask Filling
+
+`facebook/bart-base` および `facebook/bart-large` チェックポイントを使用して、マルチトークン マスクを埋めることができます。
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## Resources
+
+BART を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- に関するブログ投稿 [分散トレーニング: 🤗 Transformers と Amazon SageMaker を使用した要約のための BART/T5 のトレーニング](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)。
+- 方法に関するノートブック [blurr を使用して fastai で要約するために BART を微調整する](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb). 🌎 🌎
+- 方法に関するノートブック [トレーナー クラスを使用して 2 つの言語で要約するために BART を微調整する](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)。 🌎
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)。
+- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) でサポートされています。
+- [要約](https://huggingface.co/course/chapter7/5?fw=pt#summarization) 🤗 ハグフェイスコースの章。
+- [要約タスクガイド](../tasks/summarization.md)
+
+
+
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
+- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+
+
+
+- [ヒンディー語から英語への翻訳に Seq2SeqTrainer を使用して mBART を微調整する]方法に関するノート (https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)。 🌎
+- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)。
+- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)。
+- [翻訳タスクガイド](../tasks/translation)
+
+以下も参照してください。
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
+
+## BartConfig
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+## BartModel
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+## TFBartModel
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## TFBartForSequenceClassification
+
+[[autodoc]] TFBartForSequenceClassification
+ - call
+
+## FlaxBartModel
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
diff --git a/docs/source/ja/model_doc/barthez.md b/docs/source/ja/model_doc/barthez.md
new file mode 100644
index 00000000000000..94844c3f675d8a
--- /dev/null
+++ b/docs/source/ja/model_doc/barthez.md
@@ -0,0 +1,60 @@
+
+
+# BARThez
+
+## Overview
+
+BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
+2020年。
+
+論文の要約:
+
+
+*帰納的転移学習は、自己教師あり学習によって可能になり、自然言語処理全体を実行します。
+(NLP) 分野は、BERT や BART などのモデルにより、無数の自然言語に新たな最先端技術を確立し、嵐を巻き起こしています。
+タスクを理解すること。いくつかの注目すべき例外はありますが、利用可能なモデルと研究のほとんどは、
+英語を対象に実施されました。この作品では、フランス語用の最初の BART モデルである BARTez を紹介します。
+(我々の知る限りに)。 BARThez は、過去の研究から得た非常に大規模な単一言語フランス語コーパスで事前トレーニングされました
+BART の摂動スキームに合わせて調整しました。既存の BERT ベースのフランス語モデルとは異なり、
+CamemBERT と FlauBERT、BARThez は、エンコーダだけでなく、
+そのデコーダは事前トレーニングされています。 FLUE ベンチマークからの識別タスクに加えて、BARThez を新しい評価に基づいて評価します。
+この論文とともにリリースする要約データセット、OrangeSum。また、すでに行われている事前トレーニングも継続します。
+BARTHez のコーパス上で多言語 BART を事前訓練し、結果として得られるモデル (mBARTHez と呼ぶ) が次のことを示します。
+バニラの BARThez を大幅に強化し、CamemBERT や FlauBERT と同等かそれを上回ります。*
+
+このモデルは [moussakam](https://huggingface.co/moussakam) によって寄稿されました。著者のコードは[ここ](https://github.com/moussaKam/BARThez)にあります。
+
+
+
+BARThez の実装は、トークン化を除いて BART と同じです。詳細については、[BART ドキュメント](bart) を参照してください。
+構成クラスとそのパラメータ。 BARThez 固有のトークナイザーについては以下に記載されています。
+
+
+
+### Resources
+
+- BARThez は、BART と同様の方法でシーケンス間のタスクを微調整できます。以下を確認してください。
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
+
+
+## BarthezTokenizer
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/source/ja/model_doc/bartpho.md b/docs/source/ja/model_doc/bartpho.md
new file mode 100644
index 00000000000000..a9575d821ef916
--- /dev/null
+++ b/docs/source/ja/model_doc/bartpho.md
@@ -0,0 +1,86 @@
+
+
+# BARTpho
+
+## Overview
+
+BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
+
+論文の要約は次のとおりです。
+
+*BARTpho には、BARTpho_word と BARTpho_syllable の 2 つのバージョンがあり、初の公開された大規模な単一言語です。
+ベトナム語用に事前トレーニングされたシーケンスツーシーケンス モデル。当社の BARTpho は「大規模な」アーキテクチャと事前トレーニングを使用します
+シーケンス間ノイズ除去モデル BART のスキームなので、生成 NLP タスクに特に適しています。実験
+ベトナム語テキスト要約の下流タスクでは、自動評価と人間による評価の両方で、BARTpho が
+強力なベースライン mBART を上回り、最先端の性能を向上させます。将来を容易にするためにBARTphoをリリースします
+生成的なベトナム語 NLP タスクの研究と応用。*
+
+このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [こちら](https://github.com/VinAIResearch/BARTpho) にあります。
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+## Usage tips
+
+- mBARTに続いて、BARTphoはBARTの「大規模な」アーキテクチャを使用し、その上に追加の層正規化層を備えています。
+ エンコーダとデコーダの両方。したがって、[BART のドキュメント](bart) の使用例は、使用に適応する場合に使用されます。
+ BARTpho を使用する場合は、BART に特化したクラスを mBART に特化した対応するクラスに置き換えることによって調整する必要があります。
+ 例えば:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- この実装はトークン化のみを目的としています。`monolingual_vocab_file`はベトナム語に特化した型で構成されています
+ 多言語 XLM-RoBERTa から利用できる事前トレーニング済み SentencePiece モデル`vocab_file`から抽出されます。
+ 他の言語 (サブワードにこの事前トレーニング済み多言語 SentencePiece モデル`vocab_file`を使用する場合)
+ セグメンテーションにより、独自の言語に特化した`monolingual_vocab_file`を使用して BartphoTokenizer を再利用できます。
+
+## BartphoTokenizer
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/source/ja/model_doc/beit.md b/docs/source/ja/model_doc/beit.md
new file mode 100644
index 00000000000000..45eb1efa5dd873
--- /dev/null
+++ b/docs/source/ja/model_doc/beit.md
@@ -0,0 +1,143 @@
+
+
+# BEiT
+
+## Overview
+
+BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
+ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
+ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
+([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
+マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
+パッチ。
+
+論文の要約は次のとおりです。
+
+*自己教師あり視覚表現モデル BEiT (Bidirectional Encoderpresentation) を導入します。
+イメージトランスフォーマーより。自然言語処理分野で開発されたBERTに倣い、マスク画像を提案します。
+ビジョントランスフォーマーを事前にトレーニングするためのモデリングタスク。具体的には、事前トレーニングでは各画像に 2 つのビューがあります。
+パッチ (16x16 ピクセルなど)、およびビジュアル トークン (つまり、個別のトークン)。まず、元の画像を「トークン化」して、
+ビジュアルトークン。次に、いくつかの画像パッチをランダムにマスクし、それらをバックボーンの Transformer に供給します。事前トレーニング
+目的は、破損したイメージ パッチに基づいて元のビジュアル トークンを回復することです。 BEiTの事前トレーニング後、
+事前トレーニングされたエンコーダーにタスク レイヤーを追加することで、ダウンストリーム タスクのモデル パラメーターを直接微調整します。
+画像分類とセマンティックセグメンテーションに関する実験結果は、私たちのモデルが競争力のある結果を達成することを示しています
+以前の事前トレーニング方法を使用して。たとえば、基本サイズの BEiT は、ImageNet-1K で 83.2% のトップ 1 精度を達成します。
+同じ設定でゼロからの DeiT トレーニング (81.8%) を大幅に上回りました。また、大型BEiTは
+86.3% は ImageNet-1K のみを使用しており、ImageNet-22K での教師付き事前トレーニングを使用した ViT-L (85.2%) を上回っています。*
+
+## Usage tips
+
+- BEiT モデルは通常のビジョン トランスフォーマーですが、教師ありではなく自己教師ありの方法で事前トレーニングされています。彼らは
+ ImageNet-1K および CIFAR-100 で微調整すると、[オリジナル モデル (ViT)](vit) と [データ効率の高いイメージ トランスフォーマー (DeiT)](deit) の両方を上回るパフォーマンスを発揮します。推論に関するデモノートブックもチェックできます。
+ カスタム データの微調整は [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (置き換えるだけで済みます)
+ [`BeitImageProcessor`] による [`ViTFeatureExtractor`] と
+ [`ViTForImageClassification`] by [`BeitForImageClassification`])。
+- DALL-E の画像トークナイザーと BEiT を組み合わせる方法を紹介するデモ ノートブックも利用可能です。
+ マスクされた画像モデリングを実行します。 [ここ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT) で見つけることができます。
+- BEiT モデルは各画像が同じサイズ (解像度) であることを期待しているため、次のように使用できます。
+ [`BeitImageProcessor`] を使用して、モデルの画像のサイズを変更 (または再スケール) し、正規化します。
+- 事前トレーニングまたは微調整中に使用されるパッチ解像度と画像解像度の両方が名前に反映されます。
+ 各チェックポイント。たとえば、`microsoft/beit-base-patch16-224`は、パッチ付きの基本サイズのアーキテクチャを指します。
+ 解像度は 16x16、微調整解像度は 224x224 です。すべてのチェックポイントは [ハブ](https://huggingface.co/models?search=microsoft/beit) で見つけることができます。
+- 利用可能なチェックポイントは、(1) [ImageNet-22k](http://www.image-net.org/) で事前トレーニングされています (
+ 1,400 万の画像と 22,000 のクラス) のみ、(2) ImageNet-22k でも微調整、または (3) [ImageNet-1k](http://www.image-net.org/challenges/LSVRC)でも微調整/2012/) (ILSVRC 2012 とも呼ばれ、130 万件のコレクション)
+ 画像と 1,000 クラス)。
+- BEiT は、T5 モデルからインスピレーションを得た相対位置埋め込みを使用します。事前トレーニング中に、著者は次のことを共有しました。
+ いくつかの自己注意層間の相対的な位置の偏り。微調整中、各レイヤーの相対位置
+ バイアスは、事前トレーニング後に取得された共有相対位置バイアスで初期化されます。ご希望の場合は、
+ モデルを最初から事前トレーニングするには、`use_relative_position_bias` または
+ 追加するには、[`BeitConfig`] の `use_relative_position_bias` 属性を `True` に設定します。
+ 位置の埋め込み。
+
+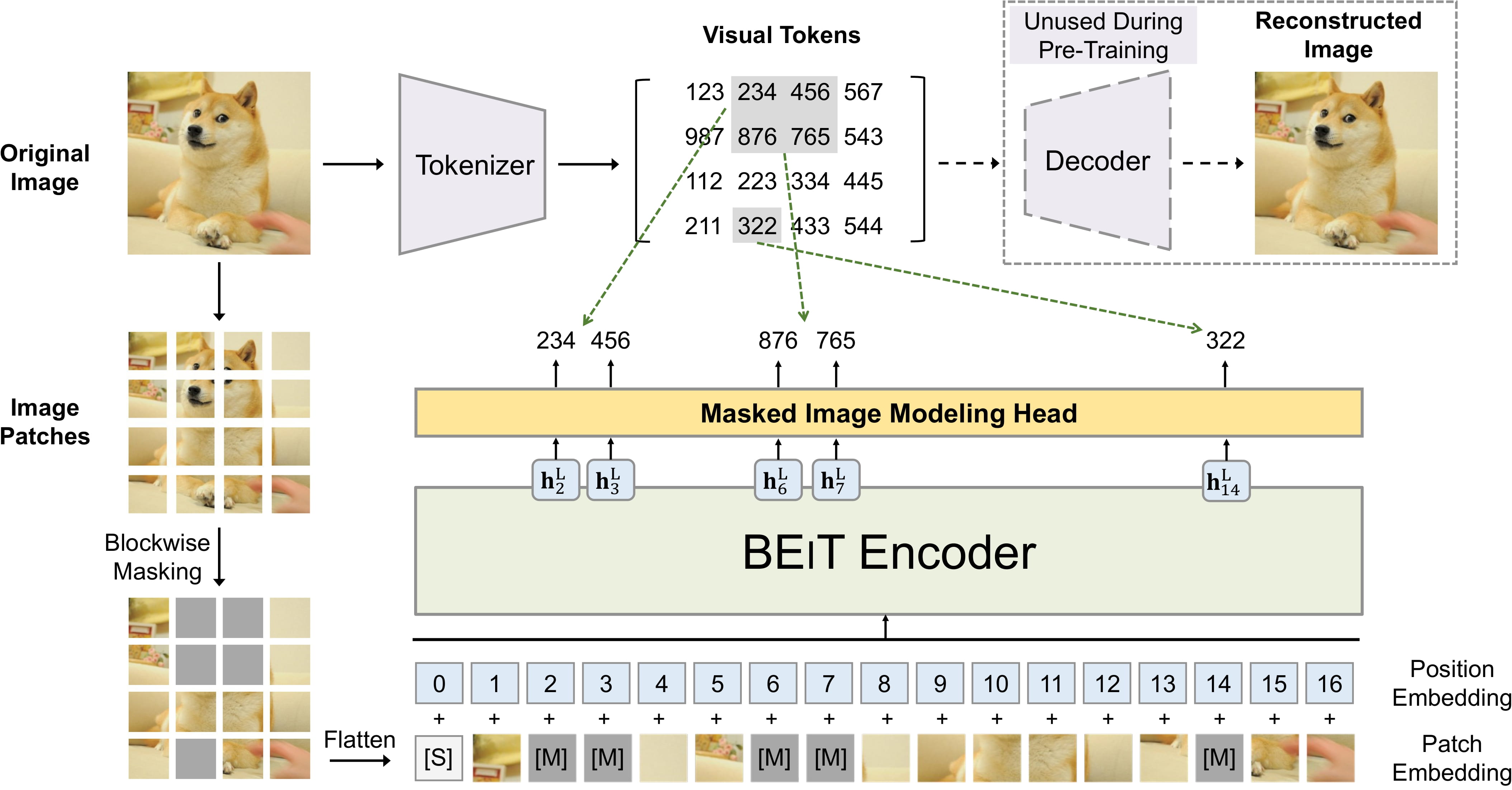 +
+ BEiT の事前トレーニング。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
+[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
+
+## Resources
+
+BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- [`BeitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+**セマンティック セグメンテーション**
+- [セマンティック セグメンテーション タスク ガイド](../tasks/semantic_segmentation)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## BEiT specific outputs
+
+[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
+
+[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
+
+## BeitConfig
+
+[[autodoc]] BeitConfig
+
+## BeitFeatureExtractor
+
+[[autodoc]] BeitFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## BeitImageProcessor
+
+[[autodoc]] BeitImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## BeitModel
+
+[[autodoc]] BeitModel
+ - forward
+
+## BeitForMaskedImageModeling
+
+[[autodoc]] BeitForMaskedImageModeling
+ - forward
+
+## BeitForImageClassification
+
+[[autodoc]] BeitForImageClassification
+ - forward
+
+## BeitForSemanticSegmentation
+
+[[autodoc]] BeitForSemanticSegmentation
+ - forward
+
+## FlaxBeitModel
+
+[[autodoc]] FlaxBeitModel
+ - __call__
+
+## FlaxBeitForMaskedImageModeling
+
+[[autodoc]] FlaxBeitForMaskedImageModeling
+ - __call__
+
+## FlaxBeitForImageClassification
+
+[[autodoc]] FlaxBeitForImageClassification
+ - __call__
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
new file mode 100644
index 00000000000000..4a25ff5d9bc662
--- /dev/null
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -0,0 +1,107 @@
+
+
+# BertGeneration
+
+## Overview
+
+BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
+
+論文の要約は次のとおりです。
+
+*大規模なニューラル モデルの教師なし事前トレーニングは、最近、自然言語処理に革命をもたらしました。による
+NLP 実践者は、公開されたチェックポイントからウォームスタートして、複数の項目で最先端の技術を推進してきました。
+コンピューティング時間を大幅に節約しながらベンチマークを実行します。これまでのところ、主に自然言語に焦点を当ててきました。
+タスクを理解する。この論文では、シーケンス生成のための事前トレーニングされたチェックポイントの有効性を実証します。私たちは
+公開されている事前トレーニング済み BERT と互換性のある Transformer ベースのシーケンス間モデルを開発しました。
+GPT-2 および RoBERTa チェックポイントを使用し、モデルの初期化の有用性について広範な実証研究を実施しました。
+エンコーダとデコーダ、これらのチェックポイント。私たちのモデルは、機械翻訳に関する新しい最先端の結果をもたらします。
+テキストの要約、文の分割、および文の融合。*
+
+## Usage examples and tips
+
+- モデルを [`EncoderDecoderModel`] と組み合わせて使用して、2 つの事前トレーニングされたモデルを活用できます。
+ 後続の微調整のための BERT チェックポイント。
+
+```python
+>>> # leverage checkpoints for Bert2Bert model...
+>>> # use BERT's cls token as BOS token and sep token as EOS token
+>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
+>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
+>>> decoder = BertGenerationDecoder.from_pretrained(
+... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
+... )
+>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
+
+>>> # create tokenizer...
+>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
+
+>>> input_ids = tokenizer(
+... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
+
+>>> # train...
+>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
+>>> loss.backward()
+```
+
+- 事前トレーニングされた [`EncoderDecoderModel`] もモデル ハブで直接利用できます。
+
+```python
+>>> # instantiate sentence fusion model
+>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
+
+>>> input_ids = tokenizer(
+... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+
+>>> outputs = sentence_fuser.generate(input_ids)
+
+>>> print(tokenizer.decode(outputs[0]))
+```
+
+チップ:
+
+- [`BertGenerationEncoder`] と [`BertGenerationDecoder`] は、
+ [`EncoderDecoder`] と組み合わせます。
+- 要約、文の分割、文の融合、および翻訳の場合、入力に特別なトークンは必要ありません。
+ したがって、入力の末尾に EOS トークンを追加しないでください。
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder) があります。
+
+## BertGenerationConfig
+
+[[autodoc]] BertGenerationConfig
+
+## BertGenerationTokenizer
+
+[[autodoc]] BertGenerationTokenizer
+ - save_vocabulary
+
+## BertGenerationEncoder
+
+[[autodoc]] BertGenerationEncoder
+ - forward
+
+## BertGenerationDecoder
+
+[[autodoc]] BertGenerationDecoder
+ - forward
diff --git a/docs/source/ja/model_doc/bert-japanese.md b/docs/source/ja/model_doc/bert-japanese.md
new file mode 100644
index 00000000000000..86cce741aac6cb
--- /dev/null
+++ b/docs/source/ja/model_doc/bert-japanese.md
@@ -0,0 +1,81 @@
+
+
+# BertJapanese
+
+## Overview
+
+BERT モデルは日本語テキストでトレーニングされました。
+
+2 つの異なるトークン化方法を備えたモデルがあります。
+
+- MeCab と WordPiece を使用してトークン化します。これには、[MeCab](https://taku910.github.io/mecab/) のラッパーである [fugashi](https://github.com/polm/fugashi) という追加の依存関係が必要です。
+- 文字にトークン化します。
+
+*MecabTokenizer* を使用するには、`pip installTransformers["ja"]` (または、インストールする場合は `pip install -e .["ja"]`) する必要があります。
+ソースから)依存関係をインストールします。
+
+[cl-tohakuリポジトリの詳細](https://github.com/cl-tohaku/bert-japanese)を参照してください。
+
+MeCab および WordPiece トークン化でモデルを使用する例:
+
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+文字トークン化を使用したモデルの使用例:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+
+
+- この実装はトークン化方法を除いて BERT と同じです。その他の使用例については、[BERT のドキュメント](bert) を参照してください。
+
+
+
+このモデルは[cl-tohaku](https://huggingface.co/cl-tohaku)から提供されました。
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/source/ja/model_doc/bert.md b/docs/source/ja/model_doc/bert.md
new file mode 100644
index 00000000000000..2f65ee49d3376c
--- /dev/null
+++ b/docs/source/ja/model_doc/bert.md
@@ -0,0 +1,312 @@
+
+
+# BERT
+
+
+
+## Overview
+
+BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
+マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
+Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
+
+論文の要約は次のとおりです。
+
+*BERT と呼ばれる新しい言語表現モデルを導入します。これは Bidirectional Encoder Representations の略です
+トランスフォーマーより。最近の言語表現モデルとは異なり、BERT は深い双方向性を事前にトレーニングするように設計されています。
+すべてのレイヤーの左と右の両方のコンテキストを共同で条件付けすることにより、ラベルのないテキストから表現します。結果として、
+事前トレーニングされた BERT モデルは、出力層を 1 つ追加するだけで微調整して、最先端のモデルを作成できます。
+実質的なタスク固有のものを必要とせず、質問応答や言語推論などの幅広いタスクに対応
+アーキテクチャの変更。*
+
+*BERT は概念的にはシンプルですが、経験的に強力です。 11 の自然な要素に関する新しい最先端の結果が得られます。
+言語処理タスク(GLUE スコアを 80.5% に押し上げる(7.7% ポイントの絶対改善)、MultiNLI を含む)
+精度は 86.7% (絶対値 4.6% 向上)、SQuAD v1.1 質問応答テスト F1 は 93.2 (絶対値 1.5 ポイント)
+改善) および SQuAD v2.0 テスト F1 から 83.1 (5.1 ポイントの絶対改善)。*
+
+## Usage tips
+
+- BERT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+- BERT は、マスク言語モデリング (MLM) および次の文予測 (NSP) の目標を使用してトレーニングされました。それは
+ マスクされたトークンの予測や NLU では一般に効率的ですが、テキスト生成には最適ではありません。
+- ランダム マスキングを使用して入力を破壊します。より正確には、事前トレーニング中に、トークンの指定された割合 (通常は 15%) が次によってマスクされます。
+
+ * 確率0.8の特別なマスクトークン
+ * 確率 0.1 でマスクされたトークンとは異なるランダムなトークン
+ * 確率 0.1 の同じトークン
+
+- モデルは元の文を予測する必要がありますが、2 番目の目的があります。入力は 2 つの文 A と B (間に分離トークンあり) です。確率 50% では、文はコーパス内で連続していますが、残りの 50% では関連性がありません。モデルは、文が連続しているかどうかを予測する必要があります。
+
+
+
+このモデルは [thomwolf](https://huggingface.co/thomwolf) によって提供されました。元のコードは [こちら](https://github.com/google-research/bert) にあります。
+
+## Resources
+
+BERT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- に関するブログ投稿 [別の言語での BERT テキスト分類](https://www.philschmid.de/bert-text-classification-in-a-different-language)。
+- [マルチラベル テキスト分類のための BERT (およびその友人) の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb) のノートブック.
+- 方法に関するノートブック [PyTorch を使用したマルチラベル分類のための BERT の微調整](https://colab.research.google.com/github/abhmishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)。
+- 方法に関するノートブック [要約のために BERT を使用して EncoderDecoder モデルをウォームスタートする](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)。
+- [`BertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)。
+- [`TFBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)。
+- [`FlaxBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)。
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+
+
+
+- [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf) の使用方法に関するブログ投稿。
+- 各単語の最初の単語部分のみを使用した [固有表現認識のための BERT の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) のノートブックトークン化中の単語ラベル内。単語のラベルをすべての単語部分に伝播するには、代わりにノートブックのこの [バージョン](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) を参照してください。
+- [`BertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)。
+- [`TFBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
+- [`FlaxBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification) によってサポートされています。
+- [トークン分類](https://huggingface.co/course/chapter7/2?fw=pt) 🤗 ハグフェイスコースの章。
+- [トークン分類タスクガイド](../tasks/token_classification)
+
+
+
+- [`BertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
+- [`TFBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/lang-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+- [`FlaxBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
+- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+
+
+
+
+- [`BertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)。
+- [`TFBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)。
+- [`FlaxBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering) でサポートされています。
+- [質問回答](https://huggingface.co/course/chapter7/7?fw=pt) 🤗 ハグフェイスコースの章。
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+**複数の選択肢**
+- [`BertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)。
+- [`TFBertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)。
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+⚡️ **推論**
+- 方法に関するブログ投稿 [Hugging Face Transformers と AWS Inferentia を使用して BERT 推論を高速化する](https://huggingface.co/blog/bert-inferentia-sagemaker)。
+- 方法に関するブログ投稿 [GPU 上の DeepSpeed-Inference を使用して BERT 推論を高速化する](https://www.philschmid.de/bert-deepspeed-inference)。
+
+⚙️ **事前トレーニング**
+- [Hugging Face Transformers と Habana Gaudi を使用した BERT の事前トレーニング] に関するブログ投稿 (https://www.philschmid.de/pre-training-bert-habana)。
+
+🚀 **デプロイ**
+- 方法に関するブログ投稿 [ハグフェイス最適化でトランスフォーマーを ONNX に変換する](https://www.philschmid.de/convert-transformers-to-onnx)。
+- 方法に関するブログ投稿 [AWS 上の Habana Gaudi を使用したハグ顔トランスフォーマーのための深層学習環境のセットアップ](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)。
+- に関するブログ投稿 [Hugging Face Transformers、Amazon SageMaker、および Terraform モジュールを使用した自動スケーリング BERT](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)。
+- に関するブログ投稿 [HuggingFace、AWS Lambda、Docker を使用したサーバーレス BERT](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)。
+- に関するブログ投稿 [Amazon SageMaker と Training Compiler を使用した Hugging Face Transformers BERT 微調整](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)。
+- に関するブログ投稿 [Transformers と Amazon SageMaker を使用した BERT のタスク固有の知識の蒸留](https://www.philschmid.de/knowledge-distillation-bert-transformers)
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+
+
+
+## TFBertTokenizer
+
+[[autodoc]] TFBertTokenizer
+
+
+
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+
+
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+
+
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+
+
+
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bertweet.md b/docs/source/ja/model_doc/bertweet.md
new file mode 100644
index 00000000000000..3a5dddbf04cc58
--- /dev/null
+++ b/docs/source/ja/model_doc/bertweet.md
@@ -0,0 +1,68 @@
+
+
+# BERTweet
+
+## Overview
+
+BERTweet モデルは、Dat Quoc Nguyen、Thanh Vu によって [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) で提案されました。アン・トゥアン・グエンさん。
+
+論文の要約は次のとおりです。
+
+*私たちは、英語ツイート用に初めて公開された大規模な事前トレーニング済み言語モデルである BERTweet を紹介します。私たちのBERTweetは、
+BERT ベースと同じアーキテクチャ (Devlin et al., 2019) は、RoBERTa 事前トレーニング手順 (Liu et al.) を使用してトレーニングされます。
+al.、2019)。実験では、BERTweet が強力なベースラインである RoBERTa ベースおよび XLM-R ベースを上回るパフォーマンスを示すことが示されています (Conneau et al.,
+2020)、3 つのツイート NLP タスクにおいて、以前の最先端モデルよりも優れたパフォーマンス結果が得られました。
+品詞タグ付け、固有表現認識およびテキスト分類。*
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # For transformers v4.x+:
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # For transformers v3.x:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # INPUT TWEET IS ALREADY NORMALIZED!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+
+この実装は、トークン化方法を除いて BERT と同じです。詳細については、[BERT ドキュメント](bert) を参照してください。
+API リファレンス情報。
+
+
+
+このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [ここ](https://github.com/VinAIResearch/BERTweet) にあります。
+
+## BertweetTokenizer
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/source/ja/model_doc/big_bird.md b/docs/source/ja/model_doc/big_bird.md
new file mode 100644
index 00000000000000..4c0dabbebb46d4
--- /dev/null
+++ b/docs/source/ja/model_doc/big_bird.md
@@ -0,0 +1,176 @@
+
+
+# BigBird
+
+## Overview
+
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
+サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
+BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
+アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
+まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
+長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や
+BERT または RoBERTa と比較した要約。
+
+論文の要約は次のとおりです。
+
+*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
+残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
+完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
+この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
+チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
+理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
+スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
+同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
+ゲノミクスデータへの新しいアプリケーションを提案します。*
+
+チップ:
+
+- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
+- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
+ **block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
+- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
+- シーケンスの長さはブロック サイズで割り切れる必要があります。
+- 現在の実装では **ITC** のみがサポートされています。
+- 現在の実装では **num_random_blocks = 0** はサポートされていません
+- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+ このモデルは、[vasudevgupta](https://huggingface.co/vasudevgupta) によって提供されました。元のコードが見つかる
+[こちら](https://github.com/google-research/bigbird)。
+
+## ドキュメント リソース
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## BigBirdConfig
+
+[[autodoc]] BigBirdConfig
+
+## BigBirdTokenizer
+
+[[autodoc]] BigBirdTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BigBirdTokenizerFast
+
+[[autodoc]] BigBirdTokenizerFast
+
+## BigBird specific outputs
+
+[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+
+
+
+## BigBirdModel
+
+[[autodoc]] BigBirdModel
+ - forward
+
+## BigBirdForPreTraining
+
+[[autodoc]] BigBirdForPreTraining
+ - forward
+
+## BigBirdForCausalLM
+
+[[autodoc]] BigBirdForCausalLM
+ - forward
+
+## BigBirdForMaskedLM
+
+[[autodoc]] BigBirdForMaskedLM
+ - forward
+
+## BigBirdForSequenceClassification
+
+[[autodoc]] BigBirdForSequenceClassification
+ - forward
+
+## BigBirdForMultipleChoice
+
+[[autodoc]] BigBirdForMultipleChoice
+ - forward
+
+## BigBirdForTokenClassification
+
+[[autodoc]] BigBirdForTokenClassification
+ - forward
+
+## BigBirdForQuestionAnswering
+
+[[autodoc]] BigBirdForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBigBirdModel
+
+[[autodoc]] FlaxBigBirdModel
+ - __call__
+
+## FlaxBigBirdForPreTraining
+
+[[autodoc]] FlaxBigBirdForPreTraining
+ - __call__
+
+## FlaxBigBirdForCausalLM
+
+[[autodoc]] FlaxBigBirdForCausalLM
+ - __call__
+
+## FlaxBigBirdForMaskedLM
+
+[[autodoc]] FlaxBigBirdForMaskedLM
+ - __call__
+
+## FlaxBigBirdForSequenceClassification
+
+[[autodoc]] FlaxBigBirdForSequenceClassification
+ - __call__
+
+## FlaxBigBirdForMultipleChoice
+
+[[autodoc]] FlaxBigBirdForMultipleChoice
+ - __call__
+
+## FlaxBigBirdForTokenClassification
+
+[[autodoc]] FlaxBigBirdForTokenClassification
+ - __call__
+
+## FlaxBigBirdForQuestionAnswering
+
+[[autodoc]] FlaxBigBirdForQuestionAnswering
+ - __call__
+
+
+
+
diff --git a/docs/source/ja/model_doc/bigbird_pegasus.md b/docs/source/ja/model_doc/bigbird_pegasus.md
new file mode 100644
index 00000000000000..e0132b4b5f86b5
--- /dev/null
+++ b/docs/source/ja/model_doc/bigbird_pegasus.md
@@ -0,0 +1,95 @@
+
+
+# BigBirdPegasus
+
+## Overview
+
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
+サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
+BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
+アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
+まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
+長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や
+BERT または RoBERTa と比較した要約。
+
+論文の要約は次のとおりです。
+
+*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
+残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
+完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
+この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
+チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
+理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
+スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
+同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
+ゲノミクスデータへの新しいアプリケーションを提案します。*
+
+## Usage tips
+
+- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
+- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
+ **block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
+- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
+- シーケンスの長さはブロック サイズで割り切れる必要があります。
+- 現在の実装では **ITC** のみがサポートされています。
+- 現在の実装では **num_random_blocks = 0** はサポートされていません。
+- BigBirdPegasus は [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py) を使用します。
+- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+元のコードは [こちら](https://github.com/google-research/bigbird) にあります。
+
+## ドキュメント リソース
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [翻訳タスクガイド](../tasks/translation)
+- [要約タスクガイド](../tasks/summarization)
+
+## BigBirdPegasusConfig
+
+[[autodoc]] BigBirdPegasusConfig
+ - all
+
+## BigBirdPegasusModel
+
+[[autodoc]] BigBirdPegasusModel
+ - forward
+
+## BigBirdPegasusForConditionalGeneration
+
+[[autodoc]] BigBirdPegasusForConditionalGeneration
+ - forward
+
+## BigBirdPegasusForSequenceClassification
+
+[[autodoc]] BigBirdPegasusForSequenceClassification
+ - forward
+
+## BigBirdPegasusForQuestionAnswering
+
+[[autodoc]] BigBirdPegasusForQuestionAnswering
+ - forward
+
+## BigBirdPegasusForCausalLM
+
+[[autodoc]] BigBirdPegasusForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/biogpt.md b/docs/source/ja/model_doc/biogpt.md
new file mode 100644
index 00000000000000..0634062a6b7214
--- /dev/null
+++ b/docs/source/ja/model_doc/biogpt.md
@@ -0,0 +1,73 @@
+
+
+# BioGPT
+
+## Overview
+
+BioGPT モデルは、[BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo、Liai Sun、Yingce Xia、 Tao Qin、Sheng Zhang、Hoifung Poon、Tie-Yan Liu。 BioGPT は、生物医学テキストの生成とマイニングのための、ドメイン固有の生成事前トレーニング済み Transformer 言語モデルです。 BioGPT は、Transformer 言語モデルのバックボーンに従い、1,500 万の PubMed 抄録で最初から事前トレーニングされています。
+
+論文の要約は次のとおりです。
+
+*事前トレーニング済み言語モデルは、一般的な自然言語領域での大きな成功に触発されて、生物医学領域でますます注目を集めています。一般言語ドメインの事前トレーニング済み言語モデルの 2 つの主なブランチ、つまり BERT (およびそのバリアント) と GPT (およびそのバリアント) のうち、1 つ目は BioBERT や PubMedBERT などの生物医学ドメインで広く研究されています。これらはさまざまな下流の生物医学的タスクで大きな成功を収めていますが、生成能力の欠如により応用範囲が制限されています。この論文では、大規模な生物医学文献で事前トレーニングされたドメイン固有の生成 Transformer 言語モデルである BioGPT を提案します。私たちは 6 つの生物医学的自然言語処理タスクで BioGPT を評価し、ほとんどのタスクで私たちのモデルが以前のモデルよりも優れていることを実証しました。特に、BC5CDR、KD-DTI、DDI のエンドツーエンド関係抽出タスクではそれぞれ 44.98%、38.42%、40.76% の F1 スコアを獲得し、PubMedQA では 78.2% の精度を獲得し、新記録を樹立しました。テキスト生成に関する私たちのケーススタディは、生物医学文献における BioGPT の利点をさらに実証し、生物医学用語の流暢な説明を生成します。*
+
+## Usage tips
+
+- BioGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を左側ではなく右側にパディングすることをお勧めします。
+- BioGPT は因果言語モデリング (CLM) 目的でトレーニングされているため、シーケンス内の次のトークンを予測するのに強力です。 run_generation.py サンプル スクリプトで確認できるように、この機能を利用すると、BioGPT は構文的に一貫したテキストを生成できます。
+- モデルは、以前に計算されたキーと値のアテンション ペアである`past_key_values`(PyTorch の場合) を入力として受け取ることができます。この (past_key_values または past) 値を使用すると、モデルがテキスト生成のコンテキストで事前に計算された値を再計算できなくなります。 PyTorch の使用法の詳細については、BioGptForCausalLM.forward() メソッドの past_key_values 引数を参照してください。
+
+このモデルは、[kamalkraj](https://huggingface.co/kamalkraj) によって提供されました。元のコードは [ここ](https://github.com/microsoft/BioGPT) にあります。
+
+## Documentation resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## BioGptConfig
+
+[[autodoc]] BioGptConfig
+
+
+## BioGptTokenizer
+
+[[autodoc]] BioGptTokenizer
+ - save_vocabulary
+
+
+## BioGptModel
+
+[[autodoc]] BioGptModel
+ - forward
+
+
+## BioGptForCausalLM
+
+[[autodoc]] BioGptForCausalLM
+ - forward
+
+
+## BioGptForTokenClassification
+
+[[autodoc]] BioGptForTokenClassification
+ - forward
+
+
+## BioGptForSequenceClassification
+
+[[autodoc]] BioGptForSequenceClassification
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bit.md b/docs/source/ja/model_doc/bit.md
new file mode 100644
index 00000000000000..76b24fa64470a2
--- /dev/null
+++ b/docs/source/ja/model_doc/bit.md
@@ -0,0 +1,65 @@
+
+
+# Big Transfer (BiT)
+
+## Overview
+
+BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
+BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた表現の転送により、サンプル効率が向上し、視覚用のディープ ニューラル ネットワークをトレーニングする際のハイパーパラメーター調整が簡素化されます。大規模な教師ありデータセットでの事前トレーニングと、ターゲット タスクでのモデルの微調整のパラダイムを再検討します。私たちは事前トレーニングをスケールアップし、Big Transfer (BiT) と呼ぶシンプルなレシピを提案します。いくつかの慎重に選択されたコンポーネントを組み合わせ、シンプルなヒューリスティックを使用して転送することにより、20 を超えるデータセットで優れたパフォーマンスを実現します。 BiT は、クラスごとに 1 つのサンプルから合計 100 万のサンプルまで、驚くほど広範囲のデータ領域にわたって良好にパフォーマンスを発揮します。 BiT は、ILSVRC-2012 で 87.5%、CIFAR-10 で 99.4%、19 タスクの Visual Task Adaptation Benchmark (VTAB) で 76.3% のトップ 1 精度を達成しました。小規模なデータセットでは、BiT は ILSVRC-2012 (クラスあたり 10 例) で 76.8%、CIFAR-10 (クラスあたり 10 例) で 97.0% を達成しました。高い転写性能を実現する主要成分を詳細に分析※。
+
+## Usage tips
+
+- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
+2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
+転移学習への影響。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [こちら](https://github.com/google-research/big_transfer) にあります。
+
+## Resources
+
+BiT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- [`BitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## BitConfig
+
+[[autodoc]] BitConfig
+
+## BitImageProcessor
+
+[[autodoc]] BitImageProcessor
+ - preprocess
+
+## BitModel
+
+[[autodoc]] BitModel
+ - forward
+
+## BitForImageClassification
+
+[[autodoc]] BitForImageClassification
+ - forward
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
new file mode 100644
index 00000000000000..ecb9c1174b285b
--- /dev/null
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -0,0 +1,110 @@
+
+
+# Blenderbot Small
+
+[`BlenderbotSmallModel`] と
+[`BlenderbotSmallForConditionalGeneration`] はチェックポイントと組み合わせてのみ使用されます
+[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M)。より大規模な Blenderbot チェックポイントは、
+代わりに [`BlenderbotModel`] とともに使用してください。
+[`BlenderbotForConditionalGeneration`]
+
+## Overview
+
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
+
+論文の要旨は次のとおりです。
+
+*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
+ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
+高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
+会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
+一貫した態度を維持しながら、知識、共感、個性を適切に表現する
+ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
+世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
+コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
+魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
+弊社機種の故障事例*
+
+チップ:
+
+- Blenderbot Small は絶対位置埋め込みを備えたモデルなので、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。著者のコードは次のとおりです
+[ここ](https://github.com/facebookresearch/ParlAI) をご覧ください。
+
+## Documentation resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [翻訳タスクガイド](../tasks/translation)
+- [要約タスクガイド](../tasks/summarization)
+
+## BlenderbotSmallConfig
+
+[[autodoc]] BlenderbotSmallConfig
+
+## BlenderbotSmallTokenizer
+
+[[autodoc]] BlenderbotSmallTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BlenderbotSmallTokenizerFast
+
+[[autodoc]] BlenderbotSmallTokenizerFast
+
+## BlenderbotSmallModel
+
+[[autodoc]] BlenderbotSmallModel
+ - forward
+
+## BlenderbotSmallForConditionalGeneration
+
+[[autodoc]] BlenderbotSmallForConditionalGeneration
+ - forward
+
+## BlenderbotSmallForCausalLM
+
+[[autodoc]] BlenderbotSmallForCausalLM
+ - forward
+
+## TFBlenderbotSmallModel
+
+[[autodoc]] TFBlenderbotSmallModel
+ - call
+
+## TFBlenderbotSmallForConditionalGeneration
+
+[[autodoc]] TFBlenderbotSmallForConditionalGeneration
+ - call
+
+## FlaxBlenderbotSmallModel
+
+[[autodoc]] FlaxBlenderbotSmallModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
new file mode 100644
index 00000000000000..f7ee23e7557d7b
--- /dev/null
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -0,0 +1,132 @@
+
+
+# Blenderbot
+
+**免責事項:** 何か奇妙なものを見つけた場合は、 [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を報告してください。
+
+## Overview
+
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
+
+論文の要旨は次のとおりです。
+
+*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
+ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
+高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
+会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
+一貫した態度を維持しながら、知識、共感、個性を適切に表現する
+ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
+世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
+コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
+魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
+弊社機種の故障事例*
+
+チップ:
+
+- Blenderbot は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/facebookresearch/ParlAI) にあります。
+
+## Implementation Notes
+
+- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
+- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
+- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
+ `facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
+ [BlenderbotSmall](ブレンダーボット小)。
+
+## Usage
+
+モデルの使用例を次に示します。
+
+```python
+>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
+
+>>> mname = "facebook/blenderbot-400M-distill"
+>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
+>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
+>>> UTTERANCE = "My friends are cool but they eat too many carbs."
+>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
+>>> reply_ids = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(reply_ids))
+["
+
+ BEiT の事前トレーニング。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
+[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
+
+## Resources
+
+BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- [`BeitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+**セマンティック セグメンテーション**
+- [セマンティック セグメンテーション タスク ガイド](../tasks/semantic_segmentation)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## BEiT specific outputs
+
+[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
+
+[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
+
+## BeitConfig
+
+[[autodoc]] BeitConfig
+
+## BeitFeatureExtractor
+
+[[autodoc]] BeitFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## BeitImageProcessor
+
+[[autodoc]] BeitImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## BeitModel
+
+[[autodoc]] BeitModel
+ - forward
+
+## BeitForMaskedImageModeling
+
+[[autodoc]] BeitForMaskedImageModeling
+ - forward
+
+## BeitForImageClassification
+
+[[autodoc]] BeitForImageClassification
+ - forward
+
+## BeitForSemanticSegmentation
+
+[[autodoc]] BeitForSemanticSegmentation
+ - forward
+
+## FlaxBeitModel
+
+[[autodoc]] FlaxBeitModel
+ - __call__
+
+## FlaxBeitForMaskedImageModeling
+
+[[autodoc]] FlaxBeitForMaskedImageModeling
+ - __call__
+
+## FlaxBeitForImageClassification
+
+[[autodoc]] FlaxBeitForImageClassification
+ - __call__
diff --git a/docs/source/ja/model_doc/bert-generation.md b/docs/source/ja/model_doc/bert-generation.md
new file mode 100644
index 00000000000000..4a25ff5d9bc662
--- /dev/null
+++ b/docs/source/ja/model_doc/bert-generation.md
@@ -0,0 +1,107 @@
+
+
+# BertGeneration
+
+## Overview
+
+BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
+[Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
+タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
+
+論文の要約は次のとおりです。
+
+*大規模なニューラル モデルの教師なし事前トレーニングは、最近、自然言語処理に革命をもたらしました。による
+NLP 実践者は、公開されたチェックポイントからウォームスタートして、複数の項目で最先端の技術を推進してきました。
+コンピューティング時間を大幅に節約しながらベンチマークを実行します。これまでのところ、主に自然言語に焦点を当ててきました。
+タスクを理解する。この論文では、シーケンス生成のための事前トレーニングされたチェックポイントの有効性を実証します。私たちは
+公開されている事前トレーニング済み BERT と互換性のある Transformer ベースのシーケンス間モデルを開発しました。
+GPT-2 および RoBERTa チェックポイントを使用し、モデルの初期化の有用性について広範な実証研究を実施しました。
+エンコーダとデコーダ、これらのチェックポイント。私たちのモデルは、機械翻訳に関する新しい最先端の結果をもたらします。
+テキストの要約、文の分割、および文の融合。*
+
+## Usage examples and tips
+
+- モデルを [`EncoderDecoderModel`] と組み合わせて使用して、2 つの事前トレーニングされたモデルを活用できます。
+ 後続の微調整のための BERT チェックポイント。
+
+```python
+>>> # leverage checkpoints for Bert2Bert model...
+>>> # use BERT's cls token as BOS token and sep token as EOS token
+>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
+>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
+>>> decoder = BertGenerationDecoder.from_pretrained(
+... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
+... )
+>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
+
+>>> # create tokenizer...
+>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
+
+>>> input_ids = tokenizer(
+... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
+
+>>> # train...
+>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
+>>> loss.backward()
+```
+
+- 事前トレーニングされた [`EncoderDecoderModel`] もモデル ハブで直接利用できます。
+
+```python
+>>> # instantiate sentence fusion model
+>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
+
+>>> input_ids = tokenizer(
+... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+
+>>> outputs = sentence_fuser.generate(input_ids)
+
+>>> print(tokenizer.decode(outputs[0]))
+```
+
+チップ:
+
+- [`BertGenerationEncoder`] と [`BertGenerationDecoder`] は、
+ [`EncoderDecoder`] と組み合わせます。
+- 要約、文の分割、文の融合、および翻訳の場合、入力に特別なトークンは必要ありません。
+ したがって、入力の末尾に EOS トークンを追加しないでください。
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder) があります。
+
+## BertGenerationConfig
+
+[[autodoc]] BertGenerationConfig
+
+## BertGenerationTokenizer
+
+[[autodoc]] BertGenerationTokenizer
+ - save_vocabulary
+
+## BertGenerationEncoder
+
+[[autodoc]] BertGenerationEncoder
+ - forward
+
+## BertGenerationDecoder
+
+[[autodoc]] BertGenerationDecoder
+ - forward
diff --git a/docs/source/ja/model_doc/bert-japanese.md b/docs/source/ja/model_doc/bert-japanese.md
new file mode 100644
index 00000000000000..86cce741aac6cb
--- /dev/null
+++ b/docs/source/ja/model_doc/bert-japanese.md
@@ -0,0 +1,81 @@
+
+
+# BertJapanese
+
+## Overview
+
+BERT モデルは日本語テキストでトレーニングされました。
+
+2 つの異なるトークン化方法を備えたモデルがあります。
+
+- MeCab と WordPiece を使用してトークン化します。これには、[MeCab](https://taku910.github.io/mecab/) のラッパーである [fugashi](https://github.com/polm/fugashi) という追加の依存関係が必要です。
+- 文字にトークン化します。
+
+*MecabTokenizer* を使用するには、`pip installTransformers["ja"]` (または、インストールする場合は `pip install -e .["ja"]`) する必要があります。
+ソースから)依存関係をインストールします。
+
+[cl-tohakuリポジトリの詳細](https://github.com/cl-tohaku/bert-japanese)を参照してください。
+
+MeCab および WordPiece トークン化でモデルを使用する例:
+
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+文字トークン化を使用したモデルの使用例:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+
+
+- この実装はトークン化方法を除いて BERT と同じです。その他の使用例については、[BERT のドキュメント](bert) を参照してください。
+
+
+
+このモデルは[cl-tohaku](https://huggingface.co/cl-tohaku)から提供されました。
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/source/ja/model_doc/bert.md b/docs/source/ja/model_doc/bert.md
new file mode 100644
index 00000000000000..2f65ee49d3376c
--- /dev/null
+++ b/docs/source/ja/model_doc/bert.md
@@ -0,0 +1,312 @@
+
+
+# BERT
+
+
+
+## Overview
+
+BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
+マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
+Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
+
+論文の要約は次のとおりです。
+
+*BERT と呼ばれる新しい言語表現モデルを導入します。これは Bidirectional Encoder Representations の略です
+トランスフォーマーより。最近の言語表現モデルとは異なり、BERT は深い双方向性を事前にトレーニングするように設計されています。
+すべてのレイヤーの左と右の両方のコンテキストを共同で条件付けすることにより、ラベルのないテキストから表現します。結果として、
+事前トレーニングされた BERT モデルは、出力層を 1 つ追加するだけで微調整して、最先端のモデルを作成できます。
+実質的なタスク固有のものを必要とせず、質問応答や言語推論などの幅広いタスクに対応
+アーキテクチャの変更。*
+
+*BERT は概念的にはシンプルですが、経験的に強力です。 11 の自然な要素に関する新しい最先端の結果が得られます。
+言語処理タスク(GLUE スコアを 80.5% に押し上げる(7.7% ポイントの絶対改善)、MultiNLI を含む)
+精度は 86.7% (絶対値 4.6% 向上)、SQuAD v1.1 質問応答テスト F1 は 93.2 (絶対値 1.5 ポイント)
+改善) および SQuAD v2.0 テスト F1 から 83.1 (5.1 ポイントの絶対改善)。*
+
+## Usage tips
+
+- BERT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+- BERT は、マスク言語モデリング (MLM) および次の文予測 (NSP) の目標を使用してトレーニングされました。それは
+ マスクされたトークンの予測や NLU では一般に効率的ですが、テキスト生成には最適ではありません。
+- ランダム マスキングを使用して入力を破壊します。より正確には、事前トレーニング中に、トークンの指定された割合 (通常は 15%) が次によってマスクされます。
+
+ * 確率0.8の特別なマスクトークン
+ * 確率 0.1 でマスクされたトークンとは異なるランダムなトークン
+ * 確率 0.1 の同じトークン
+
+- モデルは元の文を予測する必要がありますが、2 番目の目的があります。入力は 2 つの文 A と B (間に分離トークンあり) です。確率 50% では、文はコーパス内で連続していますが、残りの 50% では関連性がありません。モデルは、文が連続しているかどうかを予測する必要があります。
+
+
+
+このモデルは [thomwolf](https://huggingface.co/thomwolf) によって提供されました。元のコードは [こちら](https://github.com/google-research/bert) にあります。
+
+## Resources
+
+BERT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- に関するブログ投稿 [別の言語での BERT テキスト分類](https://www.philschmid.de/bert-text-classification-in-a-different-language)。
+- [マルチラベル テキスト分類のための BERT (およびその友人) の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb) のノートブック.
+- 方法に関するノートブック [PyTorch を使用したマルチラベル分類のための BERT の微調整](https://colab.research.google.com/github/abhmishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)。
+- 方法に関するノートブック [要約のために BERT を使用して EncoderDecoder モデルをウォームスタートする](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)。
+- [`BertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)。
+- [`TFBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)。
+- [`FlaxBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)。
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+
+
+
+- [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf) の使用方法に関するブログ投稿。
+- 各単語の最初の単語部分のみを使用した [固有表現認識のための BERT の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) のノートブックトークン化中の単語ラベル内。単語のラベルをすべての単語部分に伝播するには、代わりにノートブックのこの [バージョン](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) を参照してください。
+- [`BertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)。
+- [`TFBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
+- [`FlaxBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification) によってサポートされています。
+- [トークン分類](https://huggingface.co/course/chapter7/2?fw=pt) 🤗 ハグフェイスコースの章。
+- [トークン分類タスクガイド](../tasks/token_classification)
+
+
+
+- [`BertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
+- [`TFBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/lang-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+- [`FlaxBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
+- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+
+
+
+
+- [`BertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)。
+- [`TFBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)。
+- [`FlaxBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering) でサポートされています。
+- [質問回答](https://huggingface.co/course/chapter7/7?fw=pt) 🤗 ハグフェイスコースの章。
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+**複数の選択肢**
+- [`BertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)。
+- [`TFBertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)。
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+⚡️ **推論**
+- 方法に関するブログ投稿 [Hugging Face Transformers と AWS Inferentia を使用して BERT 推論を高速化する](https://huggingface.co/blog/bert-inferentia-sagemaker)。
+- 方法に関するブログ投稿 [GPU 上の DeepSpeed-Inference を使用して BERT 推論を高速化する](https://www.philschmid.de/bert-deepspeed-inference)。
+
+⚙️ **事前トレーニング**
+- [Hugging Face Transformers と Habana Gaudi を使用した BERT の事前トレーニング] に関するブログ投稿 (https://www.philschmid.de/pre-training-bert-habana)。
+
+🚀 **デプロイ**
+- 方法に関するブログ投稿 [ハグフェイス最適化でトランスフォーマーを ONNX に変換する](https://www.philschmid.de/convert-transformers-to-onnx)。
+- 方法に関するブログ投稿 [AWS 上の Habana Gaudi を使用したハグ顔トランスフォーマーのための深層学習環境のセットアップ](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)。
+- に関するブログ投稿 [Hugging Face Transformers、Amazon SageMaker、および Terraform モジュールを使用した自動スケーリング BERT](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)。
+- に関するブログ投稿 [HuggingFace、AWS Lambda、Docker を使用したサーバーレス BERT](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)。
+- に関するブログ投稿 [Amazon SageMaker と Training Compiler を使用した Hugging Face Transformers BERT 微調整](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)。
+- に関するブログ投稿 [Transformers と Amazon SageMaker を使用した BERT のタスク固有の知識の蒸留](https://www.philschmid.de/knowledge-distillation-bert-transformers)
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+
+
+
+## TFBertTokenizer
+
+[[autodoc]] TFBertTokenizer
+
+
+
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+
+
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+
+
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+
+
+
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bertweet.md b/docs/source/ja/model_doc/bertweet.md
new file mode 100644
index 00000000000000..3a5dddbf04cc58
--- /dev/null
+++ b/docs/source/ja/model_doc/bertweet.md
@@ -0,0 +1,68 @@
+
+
+# BERTweet
+
+## Overview
+
+BERTweet モデルは、Dat Quoc Nguyen、Thanh Vu によって [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) で提案されました。アン・トゥアン・グエンさん。
+
+論文の要約は次のとおりです。
+
+*私たちは、英語ツイート用に初めて公開された大規模な事前トレーニング済み言語モデルである BERTweet を紹介します。私たちのBERTweetは、
+BERT ベースと同じアーキテクチャ (Devlin et al., 2019) は、RoBERTa 事前トレーニング手順 (Liu et al.) を使用してトレーニングされます。
+al.、2019)。実験では、BERTweet が強力なベースラインである RoBERTa ベースおよび XLM-R ベースを上回るパフォーマンスを示すことが示されています (Conneau et al.,
+2020)、3 つのツイート NLP タスクにおいて、以前の最先端モデルよりも優れたパフォーマンス結果が得られました。
+品詞タグ付け、固有表現認識およびテキスト分類。*
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # For transformers v4.x+:
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # For transformers v3.x:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # INPUT TWEET IS ALREADY NORMALIZED!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+
+この実装は、トークン化方法を除いて BERT と同じです。詳細については、[BERT ドキュメント](bert) を参照してください。
+API リファレンス情報。
+
+
+
+このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [ここ](https://github.com/VinAIResearch/BERTweet) にあります。
+
+## BertweetTokenizer
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/source/ja/model_doc/big_bird.md b/docs/source/ja/model_doc/big_bird.md
new file mode 100644
index 00000000000000..4c0dabbebb46d4
--- /dev/null
+++ b/docs/source/ja/model_doc/big_bird.md
@@ -0,0 +1,176 @@
+
+
+# BigBird
+
+## Overview
+
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
+サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
+BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
+アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
+まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
+長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や
+BERT または RoBERTa と比較した要約。
+
+論文の要約は次のとおりです。
+
+*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
+残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
+完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
+この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
+チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
+理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
+スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
+同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
+ゲノミクスデータへの新しいアプリケーションを提案します。*
+
+チップ:
+
+- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
+- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
+ **block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
+- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
+- シーケンスの長さはブロック サイズで割り切れる必要があります。
+- 現在の実装では **ITC** のみがサポートされています。
+- 現在の実装では **num_random_blocks = 0** はサポートされていません
+- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+ このモデルは、[vasudevgupta](https://huggingface.co/vasudevgupta) によって提供されました。元のコードが見つかる
+[こちら](https://github.com/google-research/bigbird)。
+
+## ドキュメント リソース
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## BigBirdConfig
+
+[[autodoc]] BigBirdConfig
+
+## BigBirdTokenizer
+
+[[autodoc]] BigBirdTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BigBirdTokenizerFast
+
+[[autodoc]] BigBirdTokenizerFast
+
+## BigBird specific outputs
+
+[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+
+
+
+## BigBirdModel
+
+[[autodoc]] BigBirdModel
+ - forward
+
+## BigBirdForPreTraining
+
+[[autodoc]] BigBirdForPreTraining
+ - forward
+
+## BigBirdForCausalLM
+
+[[autodoc]] BigBirdForCausalLM
+ - forward
+
+## BigBirdForMaskedLM
+
+[[autodoc]] BigBirdForMaskedLM
+ - forward
+
+## BigBirdForSequenceClassification
+
+[[autodoc]] BigBirdForSequenceClassification
+ - forward
+
+## BigBirdForMultipleChoice
+
+[[autodoc]] BigBirdForMultipleChoice
+ - forward
+
+## BigBirdForTokenClassification
+
+[[autodoc]] BigBirdForTokenClassification
+ - forward
+
+## BigBirdForQuestionAnswering
+
+[[autodoc]] BigBirdForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBigBirdModel
+
+[[autodoc]] FlaxBigBirdModel
+ - __call__
+
+## FlaxBigBirdForPreTraining
+
+[[autodoc]] FlaxBigBirdForPreTraining
+ - __call__
+
+## FlaxBigBirdForCausalLM
+
+[[autodoc]] FlaxBigBirdForCausalLM
+ - __call__
+
+## FlaxBigBirdForMaskedLM
+
+[[autodoc]] FlaxBigBirdForMaskedLM
+ - __call__
+
+## FlaxBigBirdForSequenceClassification
+
+[[autodoc]] FlaxBigBirdForSequenceClassification
+ - __call__
+
+## FlaxBigBirdForMultipleChoice
+
+[[autodoc]] FlaxBigBirdForMultipleChoice
+ - __call__
+
+## FlaxBigBirdForTokenClassification
+
+[[autodoc]] FlaxBigBirdForTokenClassification
+ - __call__
+
+## FlaxBigBirdForQuestionAnswering
+
+[[autodoc]] FlaxBigBirdForQuestionAnswering
+ - __call__
+
+
+
+
diff --git a/docs/source/ja/model_doc/bigbird_pegasus.md b/docs/source/ja/model_doc/bigbird_pegasus.md
new file mode 100644
index 00000000000000..e0132b4b5f86b5
--- /dev/null
+++ b/docs/source/ja/model_doc/bigbird_pegasus.md
@@ -0,0 +1,95 @@
+
+
+# BigBirdPegasus
+
+## Overview
+
+BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
+ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
+サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
+BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
+アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
+まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
+長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や
+BERT または RoBERTa と比較した要約。
+
+論文の要約は次のとおりです。
+
+*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
+残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
+完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
+この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
+チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
+理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
+スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
+同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
+BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
+ゲノミクスデータへの新しいアプリケーションを提案します。*
+
+## Usage tips
+
+- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
+- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
+ **block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
+- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
+- シーケンスの長さはブロック サイズで割り切れる必要があります。
+- 現在の実装では **ITC** のみがサポートされています。
+- 現在の実装では **num_random_blocks = 0** はサポートされていません。
+- BigBirdPegasus は [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py) を使用します。
+- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+元のコードは [こちら](https://github.com/google-research/bigbird) にあります。
+
+## ドキュメント リソース
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [翻訳タスクガイド](../tasks/translation)
+- [要約タスクガイド](../tasks/summarization)
+
+## BigBirdPegasusConfig
+
+[[autodoc]] BigBirdPegasusConfig
+ - all
+
+## BigBirdPegasusModel
+
+[[autodoc]] BigBirdPegasusModel
+ - forward
+
+## BigBirdPegasusForConditionalGeneration
+
+[[autodoc]] BigBirdPegasusForConditionalGeneration
+ - forward
+
+## BigBirdPegasusForSequenceClassification
+
+[[autodoc]] BigBirdPegasusForSequenceClassification
+ - forward
+
+## BigBirdPegasusForQuestionAnswering
+
+[[autodoc]] BigBirdPegasusForQuestionAnswering
+ - forward
+
+## BigBirdPegasusForCausalLM
+
+[[autodoc]] BigBirdPegasusForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/biogpt.md b/docs/source/ja/model_doc/biogpt.md
new file mode 100644
index 00000000000000..0634062a6b7214
--- /dev/null
+++ b/docs/source/ja/model_doc/biogpt.md
@@ -0,0 +1,73 @@
+
+
+# BioGPT
+
+## Overview
+
+BioGPT モデルは、[BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo、Liai Sun、Yingce Xia、 Tao Qin、Sheng Zhang、Hoifung Poon、Tie-Yan Liu。 BioGPT は、生物医学テキストの生成とマイニングのための、ドメイン固有の生成事前トレーニング済み Transformer 言語モデルです。 BioGPT は、Transformer 言語モデルのバックボーンに従い、1,500 万の PubMed 抄録で最初から事前トレーニングされています。
+
+論文の要約は次のとおりです。
+
+*事前トレーニング済み言語モデルは、一般的な自然言語領域での大きな成功に触発されて、生物医学領域でますます注目を集めています。一般言語ドメインの事前トレーニング済み言語モデルの 2 つの主なブランチ、つまり BERT (およびそのバリアント) と GPT (およびそのバリアント) のうち、1 つ目は BioBERT や PubMedBERT などの生物医学ドメインで広く研究されています。これらはさまざまな下流の生物医学的タスクで大きな成功を収めていますが、生成能力の欠如により応用範囲が制限されています。この論文では、大規模な生物医学文献で事前トレーニングされたドメイン固有の生成 Transformer 言語モデルである BioGPT を提案します。私たちは 6 つの生物医学的自然言語処理タスクで BioGPT を評価し、ほとんどのタスクで私たちのモデルが以前のモデルよりも優れていることを実証しました。特に、BC5CDR、KD-DTI、DDI のエンドツーエンド関係抽出タスクではそれぞれ 44.98%、38.42%、40.76% の F1 スコアを獲得し、PubMedQA では 78.2% の精度を獲得し、新記録を樹立しました。テキスト生成に関する私たちのケーススタディは、生物医学文献における BioGPT の利点をさらに実証し、生物医学用語の流暢な説明を生成します。*
+
+## Usage tips
+
+- BioGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を左側ではなく右側にパディングすることをお勧めします。
+- BioGPT は因果言語モデリング (CLM) 目的でトレーニングされているため、シーケンス内の次のトークンを予測するのに強力です。 run_generation.py サンプル スクリプトで確認できるように、この機能を利用すると、BioGPT は構文的に一貫したテキストを生成できます。
+- モデルは、以前に計算されたキーと値のアテンション ペアである`past_key_values`(PyTorch の場合) を入力として受け取ることができます。この (past_key_values または past) 値を使用すると、モデルがテキスト生成のコンテキストで事前に計算された値を再計算できなくなります。 PyTorch の使用法の詳細については、BioGptForCausalLM.forward() メソッドの past_key_values 引数を参照してください。
+
+このモデルは、[kamalkraj](https://huggingface.co/kamalkraj) によって提供されました。元のコードは [ここ](https://github.com/microsoft/BioGPT) にあります。
+
+## Documentation resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## BioGptConfig
+
+[[autodoc]] BioGptConfig
+
+
+## BioGptTokenizer
+
+[[autodoc]] BioGptTokenizer
+ - save_vocabulary
+
+
+## BioGptModel
+
+[[autodoc]] BioGptModel
+ - forward
+
+
+## BioGptForCausalLM
+
+[[autodoc]] BioGptForCausalLM
+ - forward
+
+
+## BioGptForTokenClassification
+
+[[autodoc]] BioGptForTokenClassification
+ - forward
+
+
+## BioGptForSequenceClassification
+
+[[autodoc]] BioGptForSequenceClassification
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bit.md b/docs/source/ja/model_doc/bit.md
new file mode 100644
index 00000000000000..76b24fa64470a2
--- /dev/null
+++ b/docs/source/ja/model_doc/bit.md
@@ -0,0 +1,65 @@
+
+
+# Big Transfer (BiT)
+
+## Overview
+
+BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
+BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた表現の転送により、サンプル効率が向上し、視覚用のディープ ニューラル ネットワークをトレーニングする際のハイパーパラメーター調整が簡素化されます。大規模な教師ありデータセットでの事前トレーニングと、ターゲット タスクでのモデルの微調整のパラダイムを再検討します。私たちは事前トレーニングをスケールアップし、Big Transfer (BiT) と呼ぶシンプルなレシピを提案します。いくつかの慎重に選択されたコンポーネントを組み合わせ、シンプルなヒューリスティックを使用して転送することにより、20 を超えるデータセットで優れたパフォーマンスを実現します。 BiT は、クラスごとに 1 つのサンプルから合計 100 万のサンプルまで、驚くほど広範囲のデータ領域にわたって良好にパフォーマンスを発揮します。 BiT は、ILSVRC-2012 で 87.5%、CIFAR-10 で 99.4%、19 タスクの Visual Task Adaptation Benchmark (VTAB) で 76.3% のトップ 1 精度を達成しました。小規模なデータセットでは、BiT は ILSVRC-2012 (クラスあたり 10 例) で 76.8%、CIFAR-10 (クラスあたり 10 例) で 97.0% を達成しました。高い転写性能を実現する主要成分を詳細に分析※。
+
+## Usage tips
+
+- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
+2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
+転移学習への影響。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [こちら](https://github.com/google-research/big_transfer) にあります。
+
+## Resources
+
+BiT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- [`BitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## BitConfig
+
+[[autodoc]] BitConfig
+
+## BitImageProcessor
+
+[[autodoc]] BitImageProcessor
+ - preprocess
+
+## BitModel
+
+[[autodoc]] BitModel
+ - forward
+
+## BitForImageClassification
+
+[[autodoc]] BitForImageClassification
+ - forward
diff --git a/docs/source/ja/model_doc/blenderbot-small.md b/docs/source/ja/model_doc/blenderbot-small.md
new file mode 100644
index 00000000000000..ecb9c1174b285b
--- /dev/null
+++ b/docs/source/ja/model_doc/blenderbot-small.md
@@ -0,0 +1,110 @@
+
+
+# Blenderbot Small
+
+[`BlenderbotSmallModel`] と
+[`BlenderbotSmallForConditionalGeneration`] はチェックポイントと組み合わせてのみ使用されます
+[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M)。より大規模な Blenderbot チェックポイントは、
+代わりに [`BlenderbotModel`] とともに使用してください。
+[`BlenderbotForConditionalGeneration`]
+
+## Overview
+
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
+
+論文の要旨は次のとおりです。
+
+*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
+ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
+高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
+会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
+一貫した態度を維持しながら、知識、共感、個性を適切に表現する
+ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
+世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
+コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
+魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
+弊社機種の故障事例*
+
+チップ:
+
+- Blenderbot Small は絶対位置埋め込みを備えたモデルなので、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。著者のコードは次のとおりです
+[ここ](https://github.com/facebookresearch/ParlAI) をご覧ください。
+
+## Documentation resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [翻訳タスクガイド](../tasks/translation)
+- [要約タスクガイド](../tasks/summarization)
+
+## BlenderbotSmallConfig
+
+[[autodoc]] BlenderbotSmallConfig
+
+## BlenderbotSmallTokenizer
+
+[[autodoc]] BlenderbotSmallTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BlenderbotSmallTokenizerFast
+
+[[autodoc]] BlenderbotSmallTokenizerFast
+
+## BlenderbotSmallModel
+
+[[autodoc]] BlenderbotSmallModel
+ - forward
+
+## BlenderbotSmallForConditionalGeneration
+
+[[autodoc]] BlenderbotSmallForConditionalGeneration
+ - forward
+
+## BlenderbotSmallForCausalLM
+
+[[autodoc]] BlenderbotSmallForCausalLM
+ - forward
+
+## TFBlenderbotSmallModel
+
+[[autodoc]] TFBlenderbotSmallModel
+ - call
+
+## TFBlenderbotSmallForConditionalGeneration
+
+[[autodoc]] TFBlenderbotSmallForConditionalGeneration
+ - call
+
+## FlaxBlenderbotSmallModel
+
+[[autodoc]] FlaxBlenderbotSmallModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/ja/model_doc/blenderbot.md b/docs/source/ja/model_doc/blenderbot.md
new file mode 100644
index 00000000000000..f7ee23e7557d7b
--- /dev/null
+++ b/docs/source/ja/model_doc/blenderbot.md
@@ -0,0 +1,132 @@
+
+
+# Blenderbot
+
+**免責事項:** 何か奇妙なものを見つけた場合は、 [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を報告してください。
+
+## Overview
+
+Blender チャットボット モデルは、[Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
+ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
+
+論文の要旨は次のとおりです。
+
+*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
+ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
+高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
+会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
+一貫した態度を維持しながら、知識、共感、個性を適切に表現する
+ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
+世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
+コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
+魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
+弊社機種の故障事例*
+
+チップ:
+
+- Blenderbot は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左。
+
+このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/facebookresearch/ParlAI) にあります。
+
+## Implementation Notes
+
+- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
+- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
+- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
+ `facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
+ [BlenderbotSmall](ブレンダーボット小)。
+
+## Usage
+
+モデルの使用例を次に示します。
+
+```python
+>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
+
+>>> mname = "facebook/blenderbot-400M-distill"
+>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
+>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
+>>> UTTERANCE = "My friends are cool but they eat too many carbs."
+>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
+>>> reply_ids = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(reply_ids))
+[" That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?"]
+```
+
+## Documentation resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [翻訳タスクガイド](../tasks/translation)
+- [要約タスクガイド](../tasks/summarization)
+
+## BlenderbotConfig
+
+[[autodoc]] BlenderbotConfig
+
+## BlenderbotTokenizer
+
+[[autodoc]] BlenderbotTokenizer
+ - build_inputs_with_special_tokens
+
+## BlenderbotTokenizerFast
+
+[[autodoc]] BlenderbotTokenizerFast
+ - build_inputs_with_special_tokens
+
+## BlenderbotModel
+
+*forward* および *generate* の引数については、`transformers.BartModel`を参照してください。
+
+[[autodoc]] BlenderbotModel
+ - forward
+
+## BlenderbotForConditionalGeneration
+
+*forward* と *generate* の引数については、[`~transformers.BartForConditionalGeneration`] を参照してください。
+
+[[autodoc]] BlenderbotForConditionalGeneration
+ - forward
+
+## BlenderbotForCausalLM
+
+[[autodoc]] BlenderbotForCausalLM
+ - forward
+
+## TFBlenderbotModel
+
+[[autodoc]] TFBlenderbotModel
+ - call
+
+## TFBlenderbotForConditionalGeneration
+
+[[autodoc]] TFBlenderbotForConditionalGeneration
+ - call
+
+## FlaxBlenderbotModel
+
+[[autodoc]] FlaxBlenderbotModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/ja/model_doc/blip-2.md b/docs/source/ja/model_doc/blip-2.md
new file mode 100644
index 00000000000000..bd110522e27d60
--- /dev/null
+++ b/docs/source/ja/model_doc/blip-2.md
@@ -0,0 +1,90 @@
+
+
+# BLIP-2
+
+## Overview
+
+BLIP-2 モデルは、[BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) で提案されました。
+Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.・サバレーゼ、スティーブン・ホイ。 BLIP-2 は、軽量の 12 層 Transformer をトレーニングすることで、フリーズされた事前トレーニング済み画像エンコーダーと大規模言語モデル (LLM) を活用します。
+それらの間にエンコーダーを配置し、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。最も注目すべき点は、BLIP-2 が 800 億パラメータ モデルである [Flamingo](https://arxiv.org/abs/2204.14198) を 8.7% 改善していることです。
+ゼロショット VQAv2 ではトレーニング可能なパラメーターが 54 分の 1 に減少します。
+
+論文の要約は次のとおりです。
+
+*大規模モデルのエンドツーエンドのトレーニングにより、視覚と言語の事前トレーニングのコストはますます法外なものになってきています。この論文では、市販の凍結済み事前トレーニング画像エンコーダと凍結された大規模言語モデルから視覚言語の事前トレーニングをブートストラップする、汎用的で効率的な事前トレーニング戦略である BLIP-2 を提案します。 BLIP-2 は、2 段階で事前トレーニングされた軽量の Querying Transformer でモダリティのギャップを橋渡しします。最初のステージでは、フリーズされた画像エンコーダーから学習する視覚言語表現をブートストラップします。第 2 段階では、凍結された言語モデルから視覚から言語への生成学習をブートストラップします。 BLIP-2 は、既存の方法よりもトレーニング可能なパラメーターが大幅に少ないにもかかわらず、さまざまな視覚言語タスクで最先端のパフォーマンスを実現します。たとえば、私たちのモデルは、トレーニング可能なパラメーターが 54 分の 1 少ないゼロショット VQAv2 で、Flamingo80B を 8.7% 上回っています。また、自然言語の命令に従うことができる、ゼロショット画像からテキストへの生成というモデルの新しい機能も実証します*
+
+ +
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
new file mode 100644
index 00000000000000..c145af701f23bb
--- /dev/null
+++ b/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,134 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+
+
+
+## BlipModel
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipVisionModel
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipVisionModel
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bloom.md b/docs/source/ja/model_doc/bloom.md
new file mode 100644
index 00000000000000..1ac9396fa8ab76
--- /dev/null
+++ b/docs/source/ja/model_doc/bloom.md
@@ -0,0 +1,107 @@
+
+
+# BLOOM
+
+## Overview
+
+BLOOM モデルは、[BigScience Workshop](https://bigscience.huggingface.co/) を通じてさまざまなバージョンで提案されています。 BigScience は、研究者が時間とリソースをプールして共同でより高い効果を達成する他のオープン サイエンス イニシアチブからインスピレーションを得ています。
+BLOOM のアーキテクチャは基本的に GPT3 (次のトークン予測のための自己回帰モデル) に似ていますが、46 の異なる言語と 13 のプログラミング言語でトレーニングされています。
+モデルのいくつかの小さいバージョンが同じデータセットでトレーニングされています。 BLOOM は次のバージョンで利用できます。
+
+- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
+- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
+- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
+- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
+- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
+
+## Resources
+
+BLOOM を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [`BloomForCausalLM`] これによってサポートされています [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+
+以下も参照してください。
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+
+⚡️ 推論
+- に関するブログ [最適化の話: ブルーム推論](https://huggingface.co/blog/bloom-inference-optimization)。
+- に関するブログ [DeepSpeed と Accelerate を使用した信じられないほど高速な BLOOM 推論](https://huggingface.co/blog/bloom-inference-pytorch-scripts)。
+
+⚙️トレーニング
+- に関するブログ [BLOOM トレーニングの背後にあるテクノロジー](https://huggingface.co/blog/bloom-megatron-deepspeed)。
+
+## BloomConfig
+
+[[autodoc]] BloomConfig
+ - all
+
+## BloomTokenizerFast
+
+[[autodoc]] BloomTokenizerFast
+ - all
+
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
+## BloomForCausalLM
+
+[[autodoc]] BloomForCausalLM
+ - forward
+
+## BloomForSequenceClassification
+
+[[autodoc]] BloomForSequenceClassification
+ - forward
+
+## BloomForTokenClassification
+
+[[autodoc]] BloomForTokenClassification
+ - forward
+
+## BloomForQuestionAnswering
+
+[[autodoc]] BloomForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBloomModel
+
+[[autodoc]] FlaxBloomModel
+ - __call__
+
+## FlaxBloomForCausalLM
+
+[[autodoc]] FlaxBloomForCausalLM
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
new file mode 100644
index 00000000000000..2b892a35bb9cc3
--- /dev/null
+++ b/docs/source/ja/model_doc/bort.md
@@ -0,0 +1,55 @@
+
+
+# BORT
+
+
+
+このモデルはメンテナンス モードのみであり、コードを変更する新しい PR は受け付けられません。
+
+このモデルの実行中に問題が発生した場合は、このモデルをサポートしていた最後のバージョン (v4.30.0) を再インストールしてください。
+これを行うには、コマンド `pip install -U Transformers==4.30.0` を実行します。
+
+
+
+## Overview
+
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
+著者は「ボルト」と呼んでいます。
+
+論文の要約は次のとおりです。
+
+*Devlin らから BERT アーキテクチャのアーキテクチャ パラメータの最適なサブセットを抽出します。 (2018)
+ニューラル アーキテクチャ検索のアルゴリズムにおける最近の画期的な技術を適用します。この最適なサブセットを次のように呼びます。
+"Bort" は明らかに小さく、有効 (つまり、埋め込み層を考慮しない) サイズは 5.5% です。
+オリジナルの BERT 大規模アーキテクチャ、およびネット サイズの 16%。 Bort は 288 GPU 時間で事前トレーニングすることもできます。
+最高パフォーマンスの BERT パラメトリック アーキテクチャ バリアントである RoBERTa-large の事前トレーニングに必要な時間の 1.2%
+(Liu et al., 2019)、同じマシンで BERT-large をトレーニングするのに必要な GPU 時間の世界記録の約 33%
+ハードウェア。また、CPU 上で 7.9 倍高速であるだけでなく、他の圧縮バージョンよりもパフォーマンスが優れています。
+アーキテクチャ、および一部の非圧縮バリアント: 0.3% ~ 31% のパフォーマンス向上が得られます。
+BERT-large に関して、複数の公開自然言語理解 (NLU) ベンチマークにおける絶対的な評価。*
+
+このモデルは [stefan-it](https://huggingface.co/stefan-it) によって提供されました。元のコードは[ここ](https://github.com/alexa/bort/)にあります。
+
+## Usage tips
+
+- BORT のモデル アーキテクチャは BERT に基づいています。詳細については、[BERT のドキュメント ページ](bert) を参照してください。
+ モデルの API リファレンスと使用例。
+- BORT は BERT トークナイザーの代わりに RoBERTa トークナイザーを使用します。トークナイザーの API リファレンスと使用例については、[RoBERTa のドキュメント ページ](roberta) を参照してください。
+- BORT には、 [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) と呼ばれる特定の微調整アルゴリズムが必要です。
+ 残念ながらまだオープンソース化されていません。誰かが実装しようとすると、コミュニティにとって非常に役立ちます。
+ BORT の微調整を機能させるためのアルゴリズム。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
new file mode 100644
index 00000000000000..12be1fcc26c6ca
--- /dev/null
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -0,0 +1,171 @@
+
+
+# BridgeTower
+
+## Overview
+
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
+
+この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
+
+論文の要約は次のとおりです。
+
+*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
+現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
+どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
+これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
+特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
+特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
+
+
+
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/blip.md b/docs/source/ja/model_doc/blip.md
new file mode 100644
index 00000000000000..c145af701f23bb
--- /dev/null
+++ b/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,134 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+
+
+
+## BlipModel
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipVisionModel
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipVisionModel
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bloom.md b/docs/source/ja/model_doc/bloom.md
new file mode 100644
index 00000000000000..1ac9396fa8ab76
--- /dev/null
+++ b/docs/source/ja/model_doc/bloom.md
@@ -0,0 +1,107 @@
+
+
+# BLOOM
+
+## Overview
+
+BLOOM モデルは、[BigScience Workshop](https://bigscience.huggingface.co/) を通じてさまざまなバージョンで提案されています。 BigScience は、研究者が時間とリソースをプールして共同でより高い効果を達成する他のオープン サイエンス イニシアチブからインスピレーションを得ています。
+BLOOM のアーキテクチャは基本的に GPT3 (次のトークン予測のための自己回帰モデル) に似ていますが、46 の異なる言語と 13 のプログラミング言語でトレーニングされています。
+モデルのいくつかの小さいバージョンが同じデータセットでトレーニングされています。 BLOOM は次のバージョンで利用できます。
+
+- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
+- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
+- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
+- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
+- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
+
+## Resources
+
+BLOOM を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [`BloomForCausalLM`] これによってサポートされています [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+
+以下も参照してください。
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+
+
+⚡️ 推論
+- に関するブログ [最適化の話: ブルーム推論](https://huggingface.co/blog/bloom-inference-optimization)。
+- に関するブログ [DeepSpeed と Accelerate を使用した信じられないほど高速な BLOOM 推論](https://huggingface.co/blog/bloom-inference-pytorch-scripts)。
+
+⚙️トレーニング
+- に関するブログ [BLOOM トレーニングの背後にあるテクノロジー](https://huggingface.co/blog/bloom-megatron-deepspeed)。
+
+## BloomConfig
+
+[[autodoc]] BloomConfig
+ - all
+
+## BloomTokenizerFast
+
+[[autodoc]] BloomTokenizerFast
+ - all
+
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
+## BloomForCausalLM
+
+[[autodoc]] BloomForCausalLM
+ - forward
+
+## BloomForSequenceClassification
+
+[[autodoc]] BloomForSequenceClassification
+ - forward
+
+## BloomForTokenClassification
+
+[[autodoc]] BloomForTokenClassification
+ - forward
+
+## BloomForQuestionAnswering
+
+[[autodoc]] BloomForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBloomModel
+
+[[autodoc]] FlaxBloomModel
+ - __call__
+
+## FlaxBloomForCausalLM
+
+[[autodoc]] FlaxBloomForCausalLM
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/bort.md b/docs/source/ja/model_doc/bort.md
new file mode 100644
index 00000000000000..2b892a35bb9cc3
--- /dev/null
+++ b/docs/source/ja/model_doc/bort.md
@@ -0,0 +1,55 @@
+
+
+# BORT
+
+
+
+このモデルはメンテナンス モードのみであり、コードを変更する新しい PR は受け付けられません。
+
+このモデルの実行中に問題が発生した場合は、このモデルをサポートしていた最後のバージョン (v4.30.0) を再インストールしてください。
+これを行うには、コマンド `pip install -U Transformers==4.30.0` を実行します。
+
+
+
+## Overview
+
+BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
+Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
+著者は「ボルト」と呼んでいます。
+
+論文の要約は次のとおりです。
+
+*Devlin らから BERT アーキテクチャのアーキテクチャ パラメータの最適なサブセットを抽出します。 (2018)
+ニューラル アーキテクチャ検索のアルゴリズムにおける最近の画期的な技術を適用します。この最適なサブセットを次のように呼びます。
+"Bort" は明らかに小さく、有効 (つまり、埋め込み層を考慮しない) サイズは 5.5% です。
+オリジナルの BERT 大規模アーキテクチャ、およびネット サイズの 16%。 Bort は 288 GPU 時間で事前トレーニングすることもできます。
+最高パフォーマンスの BERT パラメトリック アーキテクチャ バリアントである RoBERTa-large の事前トレーニングに必要な時間の 1.2%
+(Liu et al., 2019)、同じマシンで BERT-large をトレーニングするのに必要な GPU 時間の世界記録の約 33%
+ハードウェア。また、CPU 上で 7.9 倍高速であるだけでなく、他の圧縮バージョンよりもパフォーマンスが優れています。
+アーキテクチャ、および一部の非圧縮バリアント: 0.3% ~ 31% のパフォーマンス向上が得られます。
+BERT-large に関して、複数の公開自然言語理解 (NLU) ベンチマークにおける絶対的な評価。*
+
+このモデルは [stefan-it](https://huggingface.co/stefan-it) によって提供されました。元のコードは[ここ](https://github.com/alexa/bort/)にあります。
+
+## Usage tips
+
+- BORT のモデル アーキテクチャは BERT に基づいています。詳細については、[BERT のドキュメント ページ](bert) を参照してください。
+ モデルの API リファレンスと使用例。
+- BORT は BERT トークナイザーの代わりに RoBERTa トークナイザーを使用します。トークナイザーの API リファレンスと使用例については、[RoBERTa のドキュメント ページ](roberta) を参照してください。
+- BORT には、 [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) と呼ばれる特定の微調整アルゴリズムが必要です。
+ 残念ながらまだオープンソース化されていません。誰かが実装しようとすると、コミュニティにとって非常に役立ちます。
+ BORT の微調整を機能させるためのアルゴリズム。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/bridgetower.md b/docs/source/ja/model_doc/bridgetower.md
new file mode 100644
index 00000000000000..12be1fcc26c6ca
--- /dev/null
+++ b/docs/source/ja/model_doc/bridgetower.md
@@ -0,0 +1,171 @@
+
+
+# BridgeTower
+
+## Overview
+
+BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
+各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
+
+この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
+
+論文の要約は次のとおりです。
+
+*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
+現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
+どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
+これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
+特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
+特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
+
+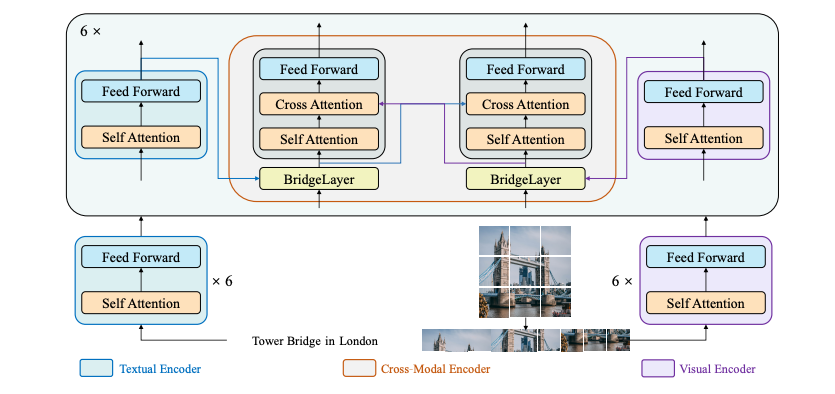 +
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a looking out of the window"
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # prepare inputs
+>>> encoding = processor(image, text, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
+
+>>> print(results)
+.a cat looking out of the window.
+```
+
+チップ:
+
+- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
+- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
+
+## BridgeTowerConfig
+
+[[autodoc]] BridgeTowerConfig
+
+## BridgeTowerTextConfig
+
+[[autodoc]] BridgeTowerTextConfig
+
+## BridgeTowerVisionConfig
+
+[[autodoc]] BridgeTowerVisionConfig
+
+## BridgeTowerImageProcessor
+
+[[autodoc]] BridgeTowerImageProcessor
+ - preprocess
+
+## BridgeTowerProcessor
+
+[[autodoc]] BridgeTowerProcessor
+ - __call__
+
+## BridgeTowerModel
+
+[[autodoc]] BridgeTowerModel
+ - forward
+
+## BridgeTowerForContrastiveLearning
+
+[[autodoc]] BridgeTowerForContrastiveLearning
+ - forward
+
+## BridgeTowerForMaskedLM
+
+[[autodoc]] BridgeTowerForMaskedLM
+ - forward
+
+## BridgeTowerForImageAndTextRetrieval
+
+[[autodoc]] BridgeTowerForImageAndTextRetrieval
+ - forward
+
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
new file mode 100644
index 00000000000000..3749a172a8286b
--- /dev/null
+++ b/docs/source/ja/model_doc/bros.md
@@ -0,0 +1,113 @@
+
+
+# BROS
+
+## Overview
+
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+
+BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
+
+BERT で使用されるトークンマスク言語モデリング目標 (TMLM) と新しいエリアマスク言語モデリング目標 (AMLM) の 2 つの目標で事前トレーニングされています。
+TMLM では、トークンはランダムにマスクされ、モデルは空間情報と他のマスクされていないトークンを使用してマスクされたトークンを予測します。
+AMLM は TMLM の 2D バージョンです。テキスト トークンをランダムにマスクし、TMLM と同じ情報で予測しますが、テキスト ブロック (領域) をマスクします。
+
+`BrosForTokenClassification`には、BrosModel の上に単純な線形層があります。各トークンのラベルを予測します。
+`BrosSpadeEEForTokenClassification`には、BrosModel の上に`initial_token_classifier`と`subsequent_token_classifier`があります。 `initial_token_classifier` は各エンティティの最初のトークンを予測するために使用され、`subsequent_token_classifier` はエンティティ内の次のトークンを予測するために使用されます。 `BrosSpadeELForTokenClassification`には BrosModel の上に`entity_linker`があります。 `entity_linker` は 2 つのエンティティ間の関係を予測するために使用されます。
+
+`BrosForTokenClassification`と`BrosSpadeEEForTokenClassification`は基本的に同じジョブを実行します。ただし、`BrosForTokenClassification`は入力トークンが完全にシリアル化されていることを前提としています (トークンは 2D 空間に存在するため、これは非常に困難な作業です)。一方、`BrosSpadeEEForTokenClassification`は 1 つのトークンから次の接続トークンを予測するため、シリアル化エラーの処理をより柔軟に行うことができます。
+
+`BrosSpadeELForTokenClassification` はエンティティ内のリンク タスクを実行します。これら 2 つのエンティティが何らかの関係を共有する場合、(あるエンティティの) 1 つのトークンから (別のエンティティの) 別のトークンへの関係を予測します。
+
+BROS は、明示的な視覚機能に依存せずに、FUNSD、SROIE、CORD、SciTSR などの Key Information Extraction (KIE) ベンチマークで同等以上の結果を達成します。
+
+論文の要約は次のとおりです。
+
+*文書画像からの重要情報抽出 (KIE) には、2 次元 (2D) 空間におけるテキストの文脈的および空間的意味論を理解する必要があります。最近の研究の多くは、文書画像の視覚的特徴とテキストおよびそのレイアウトを組み合わせることに重点を置いた事前トレーニング済み言語モデルを開発することで、この課題を解決しようとしています。一方、このペーパーでは、テキストとレイアウトの効果的な組み合わせという基本に立ち返ってこの問題に取り組みます。具体的には、BROS (BERT Relying On Spatality) という名前の事前トレーニング済み言語モデルを提案します。この言語モデルは、2D 空間内のテキストの相対位置をエンコードし、エリア マスキング戦略を使用してラベルのないドキュメントから学習します。 2D 空間内のテキストを理解するためのこの最適化されたトレーニング スキームにより、BROS は、視覚的な特徴に依存することなく、4 つの KIE ベンチマーク (FUNSD、SROIE*、CORD、および SciTSR) で以前の方法と比較して同等以上のパフォーマンスを示しました。また、この論文では、KIE タスクにおける 2 つの現実世界の課題 ((1) 間違ったテキスト順序によるエラーの最小化、および (2) 少数の下流例からの効率的な学習) を明らかにし、以前の方法に対する BROS の優位性を実証します。*
+
+このモデルは [jinho8345](https://huggingface.co/jinho8345) によって寄稿されました。元のコードは [ここ](https://github.com/clovaai/bros) にあります。
+
+## Usage tips and examples
+
+- [`~transformers.BrosModel.forward`] には、`input_ids` と `bbox` (バウンディング ボックス) が必要です。各境界ボックスは、(x0、y0、x1、y1) 形式 (左上隅、右下隅) である必要があります。境界ボックスの取得は外部 OCR システムに依存します。 「x」座標はドキュメント画像の幅で正規化する必要があり、「y」座標はドキュメント画像の高さで正規化する必要があります。
+
+```python
+def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
+ # here, bboxes are numpy array
+
+ # Normalize bbox -> 0 ~ 1
+ bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
+ bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
+```
+
+- [`~transformers.BrosForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`] では、損失計算に `input_ids` と `bbox` だけでなく `box_first_token_mask` も必要です。これは、各ボックスの先頭以外のトークンを除外するためのマスクです。このマスクは、単語から `input_ids` を作成するときに境界ボックスの開始トークン インデックスを保存することで取得できます。次のコードで`box_first_token_mask`を作成できます。
+
+```python
+def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
+
+ box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
+
+ # encode(tokenize) each word from words (List[str])
+ input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
+
+ # get the length of each box
+ tokens_length_list: List[int] = [len(l) for l in input_ids_list]
+
+ box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
+ box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
+
+ # filter out the indices that are out of max_seq_length
+ box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
+ if len(box_start_token_indices) > len(box_end_token_indices):
+ box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
+
+ # set box_start_token_indices to True
+ box_first_token_mask[box_start_token_indices] = True
+
+ return box_first_token_mask
+
+```
+
+## Resources
+
+- デモ スクリプトは [こちら](https://github.com/clovaai/bros) にあります。
+
+## BrosConfig
+
+[[autodoc]] BrosConfig
+
+## BrosProcessor
+
+[[autodoc]] BrosProcessor
+ - __call__
+
+## BrosModel
+
+[[autodoc]] BrosModel
+ - forward
+
+
+## BrosForTokenClassification
+
+[[autodoc]] BrosForTokenClassification
+ - forward
+
+## BrosSpadeEEForTokenClassification
+
+[[autodoc]] BrosSpadeEEForTokenClassification
+ - forward
+
+## BrosSpadeELForTokenClassification
+
+[[autodoc]] BrosSpadeELForTokenClassification
+ - forward
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
new file mode 100644
index 00000000000000..c6796f981817dc
--- /dev/null
+++ b/docs/source/ja/model_doc/byt5.md
@@ -0,0 +1,154 @@
+
+
+# ByT5
+
+## Overview
+
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+論文の要約は次のとおりです。
+
+*最も広く使用されている事前トレーニング済み言語モデルは、単語またはサブワード単位に対応するトークンのシーケンスで動作します。
+テキストをトークンのシーケンスとしてエンコードするには、トークナイザーが必要です。トークナイザーは通常、
+モデル。代わりに生のテキスト (バイトまたは文字) を直接操作するトークンフリー モデルには多くの利点があります。
+すぐに使用できるあらゆる言語のテキストを処理でき、ノイズに対してより堅牢であり、技術的負債を最小限に抑えます。
+複雑でエラーが発生しやすいテキスト前処理パイプラインを削除します。バイトまたは文字列がトークンより長いため
+トークンフリー モデルに関する過去の研究では、シーケンスのコストを償却するように設計された新しいモデル アーキテクチャが導入されることがよくありました。
+生のテキストを直接操作します。この論文では、標準的な Transformer アーキテクチャが次のようなもので使用できることを示します。
+バイトシーケンスを処理するための最小限の変更。パラメータ数の観点からトレードオフを注意深く特徴付けます。
+FLOP のトレーニングと推論速度を調べ、バイトレベルのモデルがトークンレベルと競合できることを示します。
+対応者。また、バイトレベルのモデルはノイズに対して大幅に堅牢であり、より優れたパフォーマンスを発揮することも示しています。
+スペルと発音に敏感なタスク。私たちの貢献の一環として、新しいセットをリリースします。
+T5 アーキテクチャに基づいた事前トレーニング済みのバイトレベルの Transformer モデルと、そこで使用されるすべてのコードとデータ
+実験。*
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://github.com/google-research/byt5) にあります。
+
+
+
+ByT5 のアーキテクチャは T5v1.1 モデルに基づいています。API リファレンスについては、[T5v1.1 のドキュメント ページ](t5v1.1) を参照してください。彼らは
+モデルの入力を準備する方法が異なるだけです。以下のコード例を参照してください。
+
+
+
+ByT5 は教師なしで事前トレーニングされているため、単一タスク中にタスク プレフィックスを使用する利点はありません。
+微調整。マルチタスクの微調整を行う場合は、プレフィックスを使用する必要があります。
+
+## Usage Examples
+
+ByT5 は生の UTF-8 バイトで動作するため、トークナイザーなしで使用できます。
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします。
+
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+[T5](t5) と同様に、ByT5 はスパンマスクノイズ除去タスクでトレーニングされました。しかし、
+モデルはキャラクターに直接作用するため、事前トレーニングタスクは少し複雑です
+違う。のいくつかの文字を破損してみましょう
+`"The dog chases a ball in the park."`という文を入力し、ByT5 に予測してもらいます。
+わたしたちのため。
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+詳細については、[`ByT5Tokenizer`] を参照してください。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
new file mode 100644
index 00000000000000..db8e0aa936936d
--- /dev/null
+++ b/docs/source/ja/model_doc/camembert.md
@@ -0,0 +1,135 @@
+
+
+# CamemBERT
+
+## Overview
+
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
+138GBのフランス語テキストでトレーニングされました。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデルは現在、自然言語処理で広く普及しています。成功にもかかわらず、利用可能なほとんどの
+モデルは英語のデータ、または複数言語のデータの連結でトレーニングされています。これにより、
+このようなモデルの実際の使用は、英語を除くすべての言語で非常に限られています。フランス人にとってこの問題に対処することを目指して、
+Bi-direction Encoders for Transformers (BERT) のフランス語版である CamemBERT をリリースします。測定します
+複数の下流タスク、つまり品詞タグ付けにおける多言語モデルと比較した CamemBERT のパフォーマンス
+依存関係解析、固有表現認識、自然言語推論。 CamemBERT は最先端技術を向上させます
+検討されているほとんどのタスクに対応します。私たちは、研究と
+フランス語 NLP の下流アプリケーション。*
+
+このモデルは [camembert](https://huggingface.co/camembert) によって提供されました。元のコードは [ここ](https://camembert-model.fr/) にあります。
+
+
+
+
+この実装はRoBERTaと同じです。使用例については[RoBERTaのドキュメント](roberta)も参照してください。
+入力と出力に関する情報として。
+
+
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+
+
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+
+
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCasualLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
new file mode 100644
index 00000000000000..18af699967d1ad
--- /dev/null
+++ b/docs/source/ja/model_doc/canine.md
@@ -0,0 +1,144 @@
+
+
+# CANINE
+
+## Overview
+
+CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
+エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
+キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
+ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
+
+論文の要約は次のとおりです。
+
+*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
+依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
+レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
+言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
+明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
+文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
+よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
+コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
+TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
+
+## Usage tips
+
+- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
+ レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
+ ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
+ アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
+ ダウンサンプリングについては論文に記載されています。
+- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
+ モデル用のテキストを準備します。
+- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
+ (事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
+ トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
+ 詳細については、論文を参照してください。
+
+モデルのチェックポイント:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
+ 12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+ - [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
+ 768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+
+## Usage example
+
+CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
+シーケンスを同じ長さにします):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
new file mode 100644
index 00000000000000..8d7dc401d2ae7e
--- /dev/null
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -0,0 +1,112 @@
+
+
+# Chinese-CLIP
+
+## Overview
+
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
+
+論文の要約は次のとおりです。
+
+*CLIP の大成功 (Radford et al., 2021) により、視覚言語の事前訓練のための対照学習の研究と応用が促進されました。この研究では、ほとんどのデータが公開されているデータセットから取得された中国語の画像とテキストのペアの大規模なデータセットを構築し、新しいデータセットで中国語の CLIP モデルを事前トレーニングします。当社では、7,700 万から 9 億 5,800 万のパラメータにわたる、複数のサイズの 5 つの中国 CLIP モデルを開発しています。さらに、モデルのパフォーマンスを向上させるために、最初に画像エンコーダーをフリーズさせてモデルをトレーニングし、次にすべてのパラメーターを最適化してトレーニングする 2 段階の事前トレーニング方法を提案します。私たちの包括的な実験では、中国の CLIP がゼロショット学習と微調整のセットアップで MUGE、Flickr30K-CN、および COCO-CN 上で最先端のパフォーマンスを達成でき、ゼロで競争力のあるパフォーマンスを達成できることを実証しています。 - ELEVATER ベンチマークでの評価に基づくショット画像の分類 (Li et al., 2022)。コード、事前トレーニング済みモデル、デモがリリースされました。*
+
+Chinese-CLIP モデルは、[OFA-Sys](https://huggingface.co/OFA-Sys) によって提供されました。
+
+## Usage example
+
+以下のコード スニペットは、画像とテキストの特徴と類似性を計算する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
+
+>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+
+>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
+>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
+
+>>> # compute image feature
+>>> inputs = processor(images=image, return_tensors="pt")
+>>> image_features = model.get_image_features(**inputs)
+>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute text features
+>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+>>> text_features = model.get_text_features(**inputs)
+>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute image-text similarity scores
+>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
+```
+
+現在、次のスケールの事前トレーニング済み Chinese-CLIP モデルが 🤗 Hub で利用可能です。
+
+- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
+- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
+- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
+- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
+
+## ChineseCLIPConfig
+
+[[autodoc]] ChineseCLIPConfig
+ - from_text_vision_configs
+
+## ChineseCLIPTextConfig
+
+[[autodoc]] ChineseCLIPTextConfig
+
+## ChineseCLIPVisionConfig
+
+[[autodoc]] ChineseCLIPVisionConfig
+
+## ChineseCLIPImageProcessor
+
+[[autodoc]] ChineseCLIPImageProcessor
+ - preprocess
+
+## ChineseCLIPFeatureExtractor
+
+[[autodoc]] ChineseCLIPFeatureExtractor
+
+## ChineseCLIPProcessor
+
+[[autodoc]] ChineseCLIPProcessor
+
+## ChineseCLIPModel
+
+[[autodoc]] ChineseCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## ChineseCLIPTextModel
+
+[[autodoc]] ChineseCLIPTextModel
+ - forward
+
+## ChineseCLIPVisionModel
+
+[[autodoc]] ChineseCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
new file mode 100644
index 00000000000000..f1e08d76018fac
--- /dev/null
+++ b/docs/source/ja/model_doc/clap.md
@@ -0,0 +1,80 @@
+
+
+# CLAP
+
+## Overview
+
+CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
+feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+
+CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
+
+論文の要約は次のとおりです。
+
+*対照学習は、マルチモーダル表現学習の分野で目覚ましい成功を収めています。この論文では、音声データと自然言語記述を組み合わせて音声表現を開発する、対照的な言語音声事前トレーニングのパイプラインを提案します。この目標を達成するために、私たちはまず、さまざまなデータ ソースからの 633,526 個の音声とテキストのペアの大規模なコレクションである LAION-Audio-630K をリリースします。次に、さまざまなオーディオ エンコーダとテキスト エンコーダを考慮して、対照的な言語とオーディオの事前トレーニング モデルを構築します。機能融合メカニズムとキーワードからキャプションへの拡張をモデル設計に組み込んで、モデルが可変長の音声入力を処理できるようにし、パフォーマンスを向上させます。 3 番目に、包括的な実験を実行して、テキストから音声への取得、ゼロショット音声分類、教師付き音声分類の 3 つのタスクにわたってモデルを評価します。結果は、私たちのモデルがテキストから音声への検索タスクにおいて優れたパフォーマンスを達成していることを示しています。オーディオ分類タスクでは、モデルはゼロショット設定で最先端のパフォーマンスを達成し、非ゼロショット設定でもモデルの結果に匹敵するパフォーマンスを得ることができます。 LAION-オーディオ-6*
+
+このモデルは、[Younes Belkada](https://huggingface.co/ybelkada) および [Arthur Zucker](https://huggingface.co/ArthurZ) によって提供されました。
+元のコードは [こちら](https://github.com/LAION-AI/Clap) にあります。
+
+## ClapConfig
+
+[[autodoc]] ClapConfig
+ - from_text_audio_configs
+
+## ClapTextConfig
+
+[[autodoc]] ClapTextConfig
+
+## ClapAudioConfig
+
+[[autodoc]] ClapAudioConfig
+
+## ClapFeatureExtractor
+
+[[autodoc]] ClapFeatureExtractor
+
+## ClapProcessor
+
+[[autodoc]] ClapProcessor
+
+## ClapModel
+
+[[autodoc]] ClapModel
+ - forward
+ - get_text_features
+ - get_audio_features
+
+## ClapTextModel
+
+[[autodoc]] ClapTextModel
+ - forward
+
+## ClapTextModelWithProjection
+
+[[autodoc]] ClapTextModelWithProjection
+ - forward
+
+## ClapAudioModel
+
+[[autodoc]] ClapAudioModel
+ - forward
+
+## ClapAudioModelWithProjection
+
+[[autodoc]] ClapAudioModelWithProjection
+ - forward
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
new file mode 100644
index 00000000000000..741d240b0ce9c8
--- /dev/null
+++ b/docs/source/ja/model_doc/clip.md
@@ -0,0 +1,220 @@
+
+
+# CLIP
+
+## Overview
+
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
+(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
+直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
+GPT-2 および 3 のゼロショット機能と同様に、タスクに対して。
+
+論文の要約は次のとおりです。
+
+*最先端のコンピューター ビジョン システムは、あらかじめ定められたオブジェクト カテゴリの固定セットを予測するようにトレーニングされています。これ
+制限された形式の監視では、指定するために追加のラベル付きデータが必要となるため、一般性と使いやすさが制限されます。
+その他の視覚的なコンセプト。画像に関する生のテキストから直接学習することは、
+より広範な監督源。どのキャプションが表示されるかを予測するという単純な事前トレーニング タスクが有効であることを示します。
+400 のデータセットで SOTA 画像表現を最初から学習するための効率的かつスケーラブルな方法はどの画像ですか
+インターネットから収集された数百万の(画像、テキスト)ペア。事前トレーニング後、自然言語を使用して参照します。
+視覚的な概念を学習し(または新しい概念を説明し)、下流のタスクへのモデルのゼロショット転送を可能にします。私たちは勉強します
+30 を超えるさまざまな既存のコンピューター ビジョン データセットでタスクをまたがってベンチマークを行うことにより、このアプローチのパフォーマンスを評価します。
+OCR、ビデオ内のアクション認識、地理的位置特定、およびさまざまな種類のきめ細かいオブジェクト分類など。の
+モデルはほとんどのタスクに簡単に移行でき、多くの場合、必要がなくても完全に監視されたベースラインと競合します。
+データセット固有のトレーニングに適しています。たとえば、ImageNet ゼロショットではオリジナルの ResNet-50 の精度と一致します。
+トレーニングに使用された 128 万のトレーニング サンプルを使用する必要はありません。コードをリリースし、事前トレーニング済み
+モデルの重みはこの https URL で確認できます。*
+
+このモデルは [valhalla](https://huggingface.co/valhalla) によって提供されました。元のコードは [ここ](https://github.com/openai/CLIP) にあります。
+
+## Usage tips and example
+
+CLIP は、マルチモーダルなビジョンおよび言語モデルです。画像とテキストの類似性やゼロショット画像に使用できます。
+分類。 CLIP は、ViT のようなトランスフォーマーを使用して視覚的特徴を取得し、因果言語モデルを使用してテキストを取得します
+特徴。次に、テキストと視覚の両方の特徴が、同じ次元の潜在空間に投影されます。ドット
+投影された画像とテキストの特徴間の積が同様のスコアとして使用されます。
+
+画像を Transformer エンコーダに供給するために、各画像は固定サイズの重複しないパッチのシーケンスに分割されます。
+これらは線形に埋め込まれます。 [CLS] トークンは、イメージ全体の表現として機能するために追加されます。作家たち
+また、絶対位置埋め込みを追加し、結果として得られるベクトルのシーケンスを標準の Transformer エンコーダに供給します。
+[`CLIPImageProcessor`] を使用して、モデルの画像のサイズ変更 (または再スケール) および正規化を行うことができます。
+
+[`CLIPTokenizer`] はテキストのエンコードに使用されます。 [`CLIPProcessor`] はラップします
+[`CLIPImageProcessor`] と [`CLIPTokenizer`] を両方の単一インスタンスに統合
+テキストをエンコードして画像を準備します。次の例は、次のメソッドを使用して画像とテキストの類似性スコアを取得する方法を示しています。
+[`CLIPProcessor`] と [`CLIPModel`]。
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+```
+
+## Resources
+
+CLIP を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- [リモート センシング (衛星) 画像とキャプションを使用した CLIP の微調整](https://huggingface.co/blog/fine-tune-clip-rsicd)、[RSICD データセット] を使用して CLIP を微調整する方法に関するブログ投稿(https://github.com/201528014227051/RSICD_optimal) と、データ拡張によるパフォーマンスの変化の比較。
+- この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) は、プレ- [COCO データセット](https://cocodataset.org/#home) を使用してトレーニングされたビジョンおよびテキスト エンコーダー。
+
+
+
+- 画像キャプションのビーム検索による推論に事前トレーニング済み CLIP を使用する方法に関する [ノートブック](https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing)。 🌎
+
+**画像検索**
+
+- 事前トレーニングされた CLIP を使用した画像検索と MRR (平均相互ランク) スコアの計算に関する [ノートブック](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)。 🌎
+- 画像の取得と類似性スコアの表示に関する [ノートブック](https://colab.research.google.com/github/deep-diver/image_search_with_natural_language/blob/main/notebooks/Image_Search_CLIP.ipynb)。 🌎
+- 多言語 CLIP を使用して画像とテキストを同じベクトル空間にマッピングする方法に関する [ノートブック](https://colab.research.google.com/drive/1xO-wC_m_GNzgjIBQ4a4znvQkvDoZJvH4?usp=sharing)。 🌎
+- を使用してセマンティック イメージ検索で CLIP を実行する方法に関する [ノートブック](https://colab.research.google.com/github/vivien000/clip-demo/blob/master/clip.ipynb#scrollTo=uzdFhRGqiWkR) [Unsplash](https://unsplash.com) および [TMBD](https://www.themoviedb.org/) データセット。 🌎
+
+**説明可能性**
+
+- 入力トークンと画像セグメントの類似性を視覚化する方法に関する [ノートブック](https://colab.research.google.com/github/hila-chefer/Transformer-MM-Explainability/blob/main/CLIP_explainability.ipynb)。 🌎
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。
+リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## CLIPConfig
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
+## CLIPFeatureExtractor
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor
+
+[[autodoc]] CLIPProcessor
+
+
+
+
+## CLIPModel
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPTextModelWithProjection
+
+[[autodoc]] CLIPTextModelWithProjection
+ - forward
+
+## CLIPVisionModelWithProjection
+
+[[autodoc]] CLIPVisionModelWithProjection
+ - forward
+
+## CLIPVisionModel
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+
+
+
+## TFCLIPModel
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+
+
+
+## FlaxCLIPModel
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPTextModelWithProjection
+
+[[autodoc]] FlaxCLIPTextModelWithProjection
+ - __call__
+
+## FlaxCLIPVisionModel
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
new file mode 100644
index 00000000000000..c8bdb0a0e4789b
--- /dev/null
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -0,0 +1,104 @@
+
+
+# CLIPSeg
+
+## Overview
+
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
+
+論文の要約は次のとおりです。
+
+*画像のセグメンテーションは通常、トレーニングによって解決されます。
+オブジェクト クラスの固定セットのモデル。後で追加のクラスやより複雑なクエリを組み込むとコストがかかります
+これらの式を含むデータセットでモデルを再トレーニングする必要があるためです。ここでシステムを提案します
+任意の情報に基づいて画像セグメンテーションを生成できます。
+テスト時にプロンプトが表示されます。プロンプトはテキストまたは
+画像。このアプローチにより、統一されたモデルを作成できます。
+3 つの一般的なセグメンテーション タスクについて (1 回トレーニング済み)
+参照式のセグメンテーション、ゼロショット セグメンテーション、ワンショット セグメンテーションという明確な課題が伴います。
+CLIP モデルをバックボーンとして構築し、これをトランスベースのデコーダで拡張して、高密度なデータ通信を可能にします。
+予測。の拡張バージョンでトレーニングした後、
+PhraseCut データセット、私たちのシステムは、フリーテキスト プロンプトまたは
+クエリを表す追加の画像。後者の画像ベースのプロンプトのさまざまなバリエーションを詳細に分析します。
+この新しいハイブリッド入力により、動的適応が可能になります。
+前述の 3 つのセグメンテーション タスクのみですが、
+テキストまたは画像をクエリするバイナリ セグメンテーション タスクに
+定式化することができる。最後に、システムがうまく適応していることがわかりました
+アフォーダンスまたはプロパティを含む一般化されたクエリ*
+
+
+
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent)。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a looking out of the window"
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # prepare inputs
+>>> encoding = processor(image, text, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
+
+>>> print(results)
+.a cat looking out of the window.
+```
+
+チップ:
+
+- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
+- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
+- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
+- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
+
+## BridgeTowerConfig
+
+[[autodoc]] BridgeTowerConfig
+
+## BridgeTowerTextConfig
+
+[[autodoc]] BridgeTowerTextConfig
+
+## BridgeTowerVisionConfig
+
+[[autodoc]] BridgeTowerVisionConfig
+
+## BridgeTowerImageProcessor
+
+[[autodoc]] BridgeTowerImageProcessor
+ - preprocess
+
+## BridgeTowerProcessor
+
+[[autodoc]] BridgeTowerProcessor
+ - __call__
+
+## BridgeTowerModel
+
+[[autodoc]] BridgeTowerModel
+ - forward
+
+## BridgeTowerForContrastiveLearning
+
+[[autodoc]] BridgeTowerForContrastiveLearning
+ - forward
+
+## BridgeTowerForMaskedLM
+
+[[autodoc]] BridgeTowerForMaskedLM
+ - forward
+
+## BridgeTowerForImageAndTextRetrieval
+
+[[autodoc]] BridgeTowerForImageAndTextRetrieval
+ - forward
+
diff --git a/docs/source/ja/model_doc/bros.md b/docs/source/ja/model_doc/bros.md
new file mode 100644
index 00000000000000..3749a172a8286b
--- /dev/null
+++ b/docs/source/ja/model_doc/bros.md
@@ -0,0 +1,113 @@
+
+
+# BROS
+
+## Overview
+
+BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
+
+BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
+
+BERT で使用されるトークンマスク言語モデリング目標 (TMLM) と新しいエリアマスク言語モデリング目標 (AMLM) の 2 つの目標で事前トレーニングされています。
+TMLM では、トークンはランダムにマスクされ、モデルは空間情報と他のマスクされていないトークンを使用してマスクされたトークンを予測します。
+AMLM は TMLM の 2D バージョンです。テキスト トークンをランダムにマスクし、TMLM と同じ情報で予測しますが、テキスト ブロック (領域) をマスクします。
+
+`BrosForTokenClassification`には、BrosModel の上に単純な線形層があります。各トークンのラベルを予測します。
+`BrosSpadeEEForTokenClassification`には、BrosModel の上に`initial_token_classifier`と`subsequent_token_classifier`があります。 `initial_token_classifier` は各エンティティの最初のトークンを予測するために使用され、`subsequent_token_classifier` はエンティティ内の次のトークンを予測するために使用されます。 `BrosSpadeELForTokenClassification`には BrosModel の上に`entity_linker`があります。 `entity_linker` は 2 つのエンティティ間の関係を予測するために使用されます。
+
+`BrosForTokenClassification`と`BrosSpadeEEForTokenClassification`は基本的に同じジョブを実行します。ただし、`BrosForTokenClassification`は入力トークンが完全にシリアル化されていることを前提としています (トークンは 2D 空間に存在するため、これは非常に困難な作業です)。一方、`BrosSpadeEEForTokenClassification`は 1 つのトークンから次の接続トークンを予測するため、シリアル化エラーの処理をより柔軟に行うことができます。
+
+`BrosSpadeELForTokenClassification` はエンティティ内のリンク タスクを実行します。これら 2 つのエンティティが何らかの関係を共有する場合、(あるエンティティの) 1 つのトークンから (別のエンティティの) 別のトークンへの関係を予測します。
+
+BROS は、明示的な視覚機能に依存せずに、FUNSD、SROIE、CORD、SciTSR などの Key Information Extraction (KIE) ベンチマークで同等以上の結果を達成します。
+
+論文の要約は次のとおりです。
+
+*文書画像からの重要情報抽出 (KIE) には、2 次元 (2D) 空間におけるテキストの文脈的および空間的意味論を理解する必要があります。最近の研究の多くは、文書画像の視覚的特徴とテキストおよびそのレイアウトを組み合わせることに重点を置いた事前トレーニング済み言語モデルを開発することで、この課題を解決しようとしています。一方、このペーパーでは、テキストとレイアウトの効果的な組み合わせという基本に立ち返ってこの問題に取り組みます。具体的には、BROS (BERT Relying On Spatality) という名前の事前トレーニング済み言語モデルを提案します。この言語モデルは、2D 空間内のテキストの相対位置をエンコードし、エリア マスキング戦略を使用してラベルのないドキュメントから学習します。 2D 空間内のテキストを理解するためのこの最適化されたトレーニング スキームにより、BROS は、視覚的な特徴に依存することなく、4 つの KIE ベンチマーク (FUNSD、SROIE*、CORD、および SciTSR) で以前の方法と比較して同等以上のパフォーマンスを示しました。また、この論文では、KIE タスクにおける 2 つの現実世界の課題 ((1) 間違ったテキスト順序によるエラーの最小化、および (2) 少数の下流例からの効率的な学習) を明らかにし、以前の方法に対する BROS の優位性を実証します。*
+
+このモデルは [jinho8345](https://huggingface.co/jinho8345) によって寄稿されました。元のコードは [ここ](https://github.com/clovaai/bros) にあります。
+
+## Usage tips and examples
+
+- [`~transformers.BrosModel.forward`] には、`input_ids` と `bbox` (バウンディング ボックス) が必要です。各境界ボックスは、(x0、y0、x1、y1) 形式 (左上隅、右下隅) である必要があります。境界ボックスの取得は外部 OCR システムに依存します。 「x」座標はドキュメント画像の幅で正規化する必要があり、「y」座標はドキュメント画像の高さで正規化する必要があります。
+
+```python
+def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
+ # here, bboxes are numpy array
+
+ # Normalize bbox -> 0 ~ 1
+ bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
+ bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
+```
+
+- [`~transformers.BrosForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`] では、損失計算に `input_ids` と `bbox` だけでなく `box_first_token_mask` も必要です。これは、各ボックスの先頭以外のトークンを除外するためのマスクです。このマスクは、単語から `input_ids` を作成するときに境界ボックスの開始トークン インデックスを保存することで取得できます。次のコードで`box_first_token_mask`を作成できます。
+
+```python
+def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
+
+ box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
+
+ # encode(tokenize) each word from words (List[str])
+ input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
+
+ # get the length of each box
+ tokens_length_list: List[int] = [len(l) for l in input_ids_list]
+
+ box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
+ box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
+
+ # filter out the indices that are out of max_seq_length
+ box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
+ if len(box_start_token_indices) > len(box_end_token_indices):
+ box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
+
+ # set box_start_token_indices to True
+ box_first_token_mask[box_start_token_indices] = True
+
+ return box_first_token_mask
+
+```
+
+## Resources
+
+- デモ スクリプトは [こちら](https://github.com/clovaai/bros) にあります。
+
+## BrosConfig
+
+[[autodoc]] BrosConfig
+
+## BrosProcessor
+
+[[autodoc]] BrosProcessor
+ - __call__
+
+## BrosModel
+
+[[autodoc]] BrosModel
+ - forward
+
+
+## BrosForTokenClassification
+
+[[autodoc]] BrosForTokenClassification
+ - forward
+
+## BrosSpadeEEForTokenClassification
+
+[[autodoc]] BrosSpadeEEForTokenClassification
+ - forward
+
+## BrosSpadeELForTokenClassification
+
+[[autodoc]] BrosSpadeELForTokenClassification
+ - forward
diff --git a/docs/source/ja/model_doc/byt5.md b/docs/source/ja/model_doc/byt5.md
new file mode 100644
index 00000000000000..c6796f981817dc
--- /dev/null
+++ b/docs/source/ja/model_doc/byt5.md
@@ -0,0 +1,154 @@
+
+
+# ByT5
+
+## Overview
+
+ByT5 モデルは、[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+論文の要約は次のとおりです。
+
+*最も広く使用されている事前トレーニング済み言語モデルは、単語またはサブワード単位に対応するトークンのシーケンスで動作します。
+テキストをトークンのシーケンスとしてエンコードするには、トークナイザーが必要です。トークナイザーは通常、
+モデル。代わりに生のテキスト (バイトまたは文字) を直接操作するトークンフリー モデルには多くの利点があります。
+すぐに使用できるあらゆる言語のテキストを処理でき、ノイズに対してより堅牢であり、技術的負債を最小限に抑えます。
+複雑でエラーが発生しやすいテキスト前処理パイプラインを削除します。バイトまたは文字列がトークンより長いため
+トークンフリー モデルに関する過去の研究では、シーケンスのコストを償却するように設計された新しいモデル アーキテクチャが導入されることがよくありました。
+生のテキストを直接操作します。この論文では、標準的な Transformer アーキテクチャが次のようなもので使用できることを示します。
+バイトシーケンスを処理するための最小限の変更。パラメータ数の観点からトレードオフを注意深く特徴付けます。
+FLOP のトレーニングと推論速度を調べ、バイトレベルのモデルがトークンレベルと競合できることを示します。
+対応者。また、バイトレベルのモデルはノイズに対して大幅に堅牢であり、より優れたパフォーマンスを発揮することも示しています。
+スペルと発音に敏感なタスク。私たちの貢献の一環として、新しいセットをリリースします。
+T5 アーキテクチャに基づいた事前トレーニング済みのバイトレベルの Transformer モデルと、そこで使用されるすべてのコードとデータ
+実験。*
+
+このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
+[ここ](https://github.com/google-research/byt5) にあります。
+
+
+
+ByT5 のアーキテクチャは T5v1.1 モデルに基づいています。API リファレンスについては、[T5v1.1 のドキュメント ページ](t5v1.1) を参照してください。彼らは
+モデルの入力を準備する方法が異なるだけです。以下のコード例を参照してください。
+
+
+
+ByT5 は教師なしで事前トレーニングされているため、単一タスク中にタスク プレフィックスを使用する利点はありません。
+微調整。マルチタスクの微調整を行う場合は、プレフィックスを使用する必要があります。
+
+## Usage Examples
+
+ByT5 は生の UTF-8 バイトで動作するため、トークナイザーなしで使用できます。
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします。
+
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+[T5](t5) と同様に、ByT5 はスパンマスクノイズ除去タスクでトレーニングされました。しかし、
+モデルはキャラクターに直接作用するため、事前トレーニングタスクは少し複雑です
+違う。のいくつかの文字を破損してみましょう
+`"The dog chases a ball in the park."`という文を入力し、ByT5 に予測してもらいます。
+わたしたちのため。
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+詳細については、[`ByT5Tokenizer`] を参照してください。
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/camembert.md b/docs/source/ja/model_doc/camembert.md
new file mode 100644
index 00000000000000..db8e0aa936936d
--- /dev/null
+++ b/docs/source/ja/model_doc/camembert.md
@@ -0,0 +1,135 @@
+
+
+# CamemBERT
+
+## Overview
+
+CamemBERT モデルは、[CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) で提案されました。
+Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, Djamé Seddah, and Benoît Sagot. 2019年にリリースされたFacebookのRoBERTaモデルをベースにしたモデルです。
+138GBのフランス語テキストでトレーニングされました。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデルは現在、自然言語処理で広く普及しています。成功にもかかわらず、利用可能なほとんどの
+モデルは英語のデータ、または複数言語のデータの連結でトレーニングされています。これにより、
+このようなモデルの実際の使用は、英語を除くすべての言語で非常に限られています。フランス人にとってこの問題に対処することを目指して、
+Bi-direction Encoders for Transformers (BERT) のフランス語版である CamemBERT をリリースします。測定します
+複数の下流タスク、つまり品詞タグ付けにおける多言語モデルと比較した CamemBERT のパフォーマンス
+依存関係解析、固有表現認識、自然言語推論。 CamemBERT は最先端技術を向上させます
+検討されているほとんどのタスクに対応します。私たちは、研究と
+フランス語 NLP の下流アプリケーション。*
+
+このモデルは [camembert](https://huggingface.co/camembert) によって提供されました。元のコードは [ここ](https://camembert-model.fr/) にあります。
+
+
+
+
+この実装はRoBERTaと同じです。使用例については[RoBERTaのドキュメント](roberta)も参照してください。
+入力と出力に関する情報として。
+
+
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+
+
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+
+
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCasualLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
diff --git a/docs/source/ja/model_doc/canine.md b/docs/source/ja/model_doc/canine.md
new file mode 100644
index 00000000000000..18af699967d1ad
--- /dev/null
+++ b/docs/source/ja/model_doc/canine.md
@@ -0,0 +1,144 @@
+
+
+# CANINE
+
+## Overview
+
+CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
+明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
+エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
+キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
+ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
+
+論文の要約は次のとおりです。
+
+*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
+依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
+レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
+言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
+明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
+文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
+よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
+コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
+TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
+
+## Usage tips
+
+- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
+ レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
+ ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
+ アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
+ ダウンサンプリングについては論文に記載されています。
+- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
+ モデル用のテキストを準備します。
+- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
+ (事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
+ トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
+ 詳細については、論文を参照してください。
+
+モデルのチェックポイント:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
+ 12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+ - [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
+ 768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
+
+## Usage example
+
+CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
+シーケンスを同じ長さにします):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/source/ja/model_doc/chinese_clip.md b/docs/source/ja/model_doc/chinese_clip.md
new file mode 100644
index 00000000000000..8d7dc401d2ae7e
--- /dev/null
+++ b/docs/source/ja/model_doc/chinese_clip.md
@@ -0,0 +1,112 @@
+
+
+# Chinese-CLIP
+
+## Overview
+
+Chinese-CLIP An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) で提案されました。周、張周。
+Chinese-CLIP は、中国語の画像とテキストのペアの大規模なデータセットに対する CLIP (Radford et al., 2021) の実装です。クロスモーダル検索を実行できるほか、ゼロショット画像分類、オープンドメインオブジェクト検出などのビジョンタスクのビジョンバックボーンとしても機能します。オリジナルの中国語-CLIPコードは[このリンクで](https://github.com/OFA-Sys/Chinese-CLIP)。
+
+論文の要約は次のとおりです。
+
+*CLIP の大成功 (Radford et al., 2021) により、視覚言語の事前訓練のための対照学習の研究と応用が促進されました。この研究では、ほとんどのデータが公開されているデータセットから取得された中国語の画像とテキストのペアの大規模なデータセットを構築し、新しいデータセットで中国語の CLIP モデルを事前トレーニングします。当社では、7,700 万から 9 億 5,800 万のパラメータにわたる、複数のサイズの 5 つの中国 CLIP モデルを開発しています。さらに、モデルのパフォーマンスを向上させるために、最初に画像エンコーダーをフリーズさせてモデルをトレーニングし、次にすべてのパラメーターを最適化してトレーニングする 2 段階の事前トレーニング方法を提案します。私たちの包括的な実験では、中国の CLIP がゼロショット学習と微調整のセットアップで MUGE、Flickr30K-CN、および COCO-CN 上で最先端のパフォーマンスを達成でき、ゼロで競争力のあるパフォーマンスを達成できることを実証しています。 - ELEVATER ベンチマークでの評価に基づくショット画像の分類 (Li et al., 2022)。コード、事前トレーニング済みモデル、デモがリリースされました。*
+
+Chinese-CLIP モデルは、[OFA-Sys](https://huggingface.co/OFA-Sys) によって提供されました。
+
+## Usage example
+
+以下のコード スニペットは、画像とテキストの特徴と類似性を計算する方法を示しています。
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
+
+>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+
+>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
+>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
+
+>>> # compute image feature
+>>> inputs = processor(images=image, return_tensors="pt")
+>>> image_features = model.get_image_features(**inputs)
+>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute text features
+>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+>>> text_features = model.get_text_features(**inputs)
+>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute image-text similarity scores
+>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
+```
+
+現在、次のスケールの事前トレーニング済み Chinese-CLIP モデルが 🤗 Hub で利用可能です。
+
+- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
+- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
+- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
+- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
+
+## ChineseCLIPConfig
+
+[[autodoc]] ChineseCLIPConfig
+ - from_text_vision_configs
+
+## ChineseCLIPTextConfig
+
+[[autodoc]] ChineseCLIPTextConfig
+
+## ChineseCLIPVisionConfig
+
+[[autodoc]] ChineseCLIPVisionConfig
+
+## ChineseCLIPImageProcessor
+
+[[autodoc]] ChineseCLIPImageProcessor
+ - preprocess
+
+## ChineseCLIPFeatureExtractor
+
+[[autodoc]] ChineseCLIPFeatureExtractor
+
+## ChineseCLIPProcessor
+
+[[autodoc]] ChineseCLIPProcessor
+
+## ChineseCLIPModel
+
+[[autodoc]] ChineseCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## ChineseCLIPTextModel
+
+[[autodoc]] ChineseCLIPTextModel
+ - forward
+
+## ChineseCLIPVisionModel
+
+[[autodoc]] ChineseCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clap.md b/docs/source/ja/model_doc/clap.md
new file mode 100644
index 00000000000000..f1e08d76018fac
--- /dev/null
+++ b/docs/source/ja/model_doc/clap.md
@@ -0,0 +1,80 @@
+
+
+# CLAP
+
+## Overview
+
+CLAP モデルは、[Large Scale Contrastive Language-Audio pretraining with
+feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf)、Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Taylor Berg-Kirkpatrick、Shlomo Dubnov 著。
+
+CLAP (Contrastive Language-Audio Pretraining) は、さまざまな (音声、テキスト) ペアでトレーニングされたニューラル ネットワークです。タスクに合わせて直接最適化することなく、音声が与えられた場合に最も関連性の高いテキスト スニペットを予測するように指示できます。 CLAP モデルは、SWINTransformer を使用して log-Mel スペクトログラム入力からオーディオ特徴を取得し、RoBERTa モデルを使用してテキスト特徴を取得します。次に、テキストとオーディオの両方の特徴が、同じ次元の潜在空間に投影されます。投影されたオーディオとテキストの特徴の間のドット積が、同様のスコアとして使用されます。
+
+論文の要約は次のとおりです。
+
+*対照学習は、マルチモーダル表現学習の分野で目覚ましい成功を収めています。この論文では、音声データと自然言語記述を組み合わせて音声表現を開発する、対照的な言語音声事前トレーニングのパイプラインを提案します。この目標を達成するために、私たちはまず、さまざまなデータ ソースからの 633,526 個の音声とテキストのペアの大規模なコレクションである LAION-Audio-630K をリリースします。次に、さまざまなオーディオ エンコーダとテキスト エンコーダを考慮して、対照的な言語とオーディオの事前トレーニング モデルを構築します。機能融合メカニズムとキーワードからキャプションへの拡張をモデル設計に組み込んで、モデルが可変長の音声入力を処理できるようにし、パフォーマンスを向上させます。 3 番目に、包括的な実験を実行して、テキストから音声への取得、ゼロショット音声分類、教師付き音声分類の 3 つのタスクにわたってモデルを評価します。結果は、私たちのモデルがテキストから音声への検索タスクにおいて優れたパフォーマンスを達成していることを示しています。オーディオ分類タスクでは、モデルはゼロショット設定で最先端のパフォーマンスを達成し、非ゼロショット設定でもモデルの結果に匹敵するパフォーマンスを得ることができます。 LAION-オーディオ-6*
+
+このモデルは、[Younes Belkada](https://huggingface.co/ybelkada) および [Arthur Zucker](https://huggingface.co/ArthurZ) によって提供されました。
+元のコードは [こちら](https://github.com/LAION-AI/Clap) にあります。
+
+## ClapConfig
+
+[[autodoc]] ClapConfig
+ - from_text_audio_configs
+
+## ClapTextConfig
+
+[[autodoc]] ClapTextConfig
+
+## ClapAudioConfig
+
+[[autodoc]] ClapAudioConfig
+
+## ClapFeatureExtractor
+
+[[autodoc]] ClapFeatureExtractor
+
+## ClapProcessor
+
+[[autodoc]] ClapProcessor
+
+## ClapModel
+
+[[autodoc]] ClapModel
+ - forward
+ - get_text_features
+ - get_audio_features
+
+## ClapTextModel
+
+[[autodoc]] ClapTextModel
+ - forward
+
+## ClapTextModelWithProjection
+
+[[autodoc]] ClapTextModelWithProjection
+ - forward
+
+## ClapAudioModel
+
+[[autodoc]] ClapAudioModel
+ - forward
+
+## ClapAudioModelWithProjection
+
+[[autodoc]] ClapAudioModelWithProjection
+ - forward
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
new file mode 100644
index 00000000000000..741d240b0ce9c8
--- /dev/null
+++ b/docs/source/ja/model_doc/clip.md
@@ -0,0 +1,220 @@
+
+
+# CLIP
+
+## Overview
+
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
+(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
+直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
+GPT-2 および 3 のゼロショット機能と同様に、タスクに対して。
+
+論文の要約は次のとおりです。
+
+*最先端のコンピューター ビジョン システムは、あらかじめ定められたオブジェクト カテゴリの固定セットを予測するようにトレーニングされています。これ
+制限された形式の監視では、指定するために追加のラベル付きデータが必要となるため、一般性と使いやすさが制限されます。
+その他の視覚的なコンセプト。画像に関する生のテキストから直接学習することは、
+より広範な監督源。どのキャプションが表示されるかを予測するという単純な事前トレーニング タスクが有効であることを示します。
+400 のデータセットで SOTA 画像表現を最初から学習するための効率的かつスケーラブルな方法はどの画像ですか
+インターネットから収集された数百万の(画像、テキスト)ペア。事前トレーニング後、自然言語を使用して参照します。
+視覚的な概念を学習し(または新しい概念を説明し)、下流のタスクへのモデルのゼロショット転送を可能にします。私たちは勉強します
+30 を超えるさまざまな既存のコンピューター ビジョン データセットでタスクをまたがってベンチマークを行うことにより、このアプローチのパフォーマンスを評価します。
+OCR、ビデオ内のアクション認識、地理的位置特定、およびさまざまな種類のきめ細かいオブジェクト分類など。の
+モデルはほとんどのタスクに簡単に移行でき、多くの場合、必要がなくても完全に監視されたベースラインと競合します。
+データセット固有のトレーニングに適しています。たとえば、ImageNet ゼロショットではオリジナルの ResNet-50 の精度と一致します。
+トレーニングに使用された 128 万のトレーニング サンプルを使用する必要はありません。コードをリリースし、事前トレーニング済み
+モデルの重みはこの https URL で確認できます。*
+
+このモデルは [valhalla](https://huggingface.co/valhalla) によって提供されました。元のコードは [ここ](https://github.com/openai/CLIP) にあります。
+
+## Usage tips and example
+
+CLIP は、マルチモーダルなビジョンおよび言語モデルです。画像とテキストの類似性やゼロショット画像に使用できます。
+分類。 CLIP は、ViT のようなトランスフォーマーを使用して視覚的特徴を取得し、因果言語モデルを使用してテキストを取得します
+特徴。次に、テキストと視覚の両方の特徴が、同じ次元の潜在空間に投影されます。ドット
+投影された画像とテキストの特徴間の積が同様のスコアとして使用されます。
+
+画像を Transformer エンコーダに供給するために、各画像は固定サイズの重複しないパッチのシーケンスに分割されます。
+これらは線形に埋め込まれます。 [CLS] トークンは、イメージ全体の表現として機能するために追加されます。作家たち
+また、絶対位置埋め込みを追加し、結果として得られるベクトルのシーケンスを標準の Transformer エンコーダに供給します。
+[`CLIPImageProcessor`] を使用して、モデルの画像のサイズ変更 (または再スケール) および正規化を行うことができます。
+
+[`CLIPTokenizer`] はテキストのエンコードに使用されます。 [`CLIPProcessor`] はラップします
+[`CLIPImageProcessor`] と [`CLIPTokenizer`] を両方の単一インスタンスに統合
+テキストをエンコードして画像を準備します。次の例は、次のメソッドを使用して画像とテキストの類似性スコアを取得する方法を示しています。
+[`CLIPProcessor`] と [`CLIPModel`]。
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+```
+
+## Resources
+
+CLIP を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- [リモート センシング (衛星) 画像とキャプションを使用した CLIP の微調整](https://huggingface.co/blog/fine-tune-clip-rsicd)、[RSICD データセット] を使用して CLIP を微調整する方法に関するブログ投稿(https://github.com/201528014227051/RSICD_optimal) と、データ拡張によるパフォーマンスの変化の比較。
+- この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) は、プレ- [COCO データセット](https://cocodataset.org/#home) を使用してトレーニングされたビジョンおよびテキスト エンコーダー。
+
+
+
+- 画像キャプションのビーム検索による推論に事前トレーニング済み CLIP を使用する方法に関する [ノートブック](https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing)。 🌎
+
+**画像検索**
+
+- 事前トレーニングされた CLIP を使用した画像検索と MRR (平均相互ランク) スコアの計算に関する [ノートブック](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)。 🌎
+- 画像の取得と類似性スコアの表示に関する [ノートブック](https://colab.research.google.com/github/deep-diver/image_search_with_natural_language/blob/main/notebooks/Image_Search_CLIP.ipynb)。 🌎
+- 多言語 CLIP を使用して画像とテキストを同じベクトル空間にマッピングする方法に関する [ノートブック](https://colab.research.google.com/drive/1xO-wC_m_GNzgjIBQ4a4znvQkvDoZJvH4?usp=sharing)。 🌎
+- を使用してセマンティック イメージ検索で CLIP を実行する方法に関する [ノートブック](https://colab.research.google.com/github/vivien000/clip-demo/blob/master/clip.ipynb#scrollTo=uzdFhRGqiWkR) [Unsplash](https://unsplash.com) および [TMBD](https://www.themoviedb.org/) データセット。 🌎
+
+**説明可能性**
+
+- 入力トークンと画像セグメントの類似性を視覚化する方法に関する [ノートブック](https://colab.research.google.com/github/hila-chefer/Transformer-MM-Explainability/blob/main/CLIP_explainability.ipynb)。 🌎
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。
+リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## CLIPConfig
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
+## CLIPFeatureExtractor
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor
+
+[[autodoc]] CLIPProcessor
+
+
+
+
+## CLIPModel
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPTextModelWithProjection
+
+[[autodoc]] CLIPTextModelWithProjection
+ - forward
+
+## CLIPVisionModelWithProjection
+
+[[autodoc]] CLIPVisionModelWithProjection
+ - forward
+
+## CLIPVisionModel
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+
+
+
+## TFCLIPModel
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+
+
+
+## FlaxCLIPModel
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPTextModelWithProjection
+
+[[autodoc]] FlaxCLIPTextModelWithProjection
+ - __call__
+
+## FlaxCLIPVisionModel
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
new file mode 100644
index 00000000000000..c8bdb0a0e4789b
--- /dev/null
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -0,0 +1,104 @@
+
+
+# CLIPSeg
+
+## Overview
+
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
+
+論文の要約は次のとおりです。
+
+*画像のセグメンテーションは通常、トレーニングによって解決されます。
+オブジェクト クラスの固定セットのモデル。後で追加のクラスやより複雑なクエリを組み込むとコストがかかります
+これらの式を含むデータセットでモデルを再トレーニングする必要があるためです。ここでシステムを提案します
+任意の情報に基づいて画像セグメンテーションを生成できます。
+テスト時にプロンプトが表示されます。プロンプトはテキストまたは
+画像。このアプローチにより、統一されたモデルを作成できます。
+3 つの一般的なセグメンテーション タスクについて (1 回トレーニング済み)
+参照式のセグメンテーション、ゼロショット セグメンテーション、ワンショット セグメンテーションという明確な課題が伴います。
+CLIP モデルをバックボーンとして構築し、これをトランスベースのデコーダで拡張して、高密度なデータ通信を可能にします。
+予測。の拡張バージョンでトレーニングした後、
+PhraseCut データセット、私たちのシステムは、フリーテキスト プロンプトまたは
+クエリを表す追加の画像。後者の画像ベースのプロンプトのさまざまなバリエーションを詳細に分析します。
+この新しいハイブリッド入力により、動的適応が可能になります。
+前述の 3 つのセグメンテーション タスクのみですが、
+テキストまたは画像をクエリするバイナリ セグメンテーション タスクに
+定式化することができる。最後に、システムがうまく適応していることがわかりました
+アフォーダンスまたはプロパティを含む一般化されたクエリ*
+
+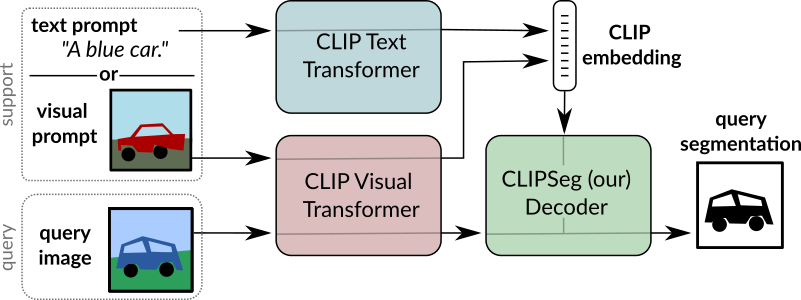 +
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [CLIPSeg を使用したゼロショット画像セグメンテーション](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb) を説明するノートブック。
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
new file mode 100644
index 00000000000000..0803f5e027ce81
--- /dev/null
+++ b/docs/source/ja/model_doc/clvp.md
@@ -0,0 +1,123 @@
+
+
+# CLVP
+
+## Overview
+
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+
+論文の要約は次のとおりです。
+
+*近年、画像生成の分野は自己回帰変換器と DDPM の応用によって革命を起こしています。これらのアプローチは、画像生成のプロセスを段階的な確率的プロセスとしてモデル化し、大量のコンピューティングとデータを活用して画像の分布を学習します。パフォーマンスを向上させるこの方法論は、画像に限定される必要はありません。この論文では、画像生成ドメインの進歩を音声合成に適用する方法について説明します。その結果、表現力豊かなマルチ音声テキスト読み上げシステムである TorToise が誕生しました。
+
+
+このモデルは [Susnato Dhar](https://huggingface.co/susnato) によって提供されました。
+元のコードは [ここ](https://github.com/neonbjb/tortoise-tts) にあります。
+
+## Usage tips
+
+1. CLVP は Tortoise TTS モデルの不可欠な部分です。
+2. CLVP を使用して、生成されたさまざまな音声候補を提供されたテキストと比較することができ、最良の音声トークンが拡散モデルに転送されます。
+3. Tortoise の使用には、[`ClvpModelForConditionalGeneration.generate()`] メソッドの使用を強くお勧めします。
+4. 16 kHz を期待する他のオーディオ モデルとは対照的に、CLVP モデルはオーディオが 22.05 kHz でサンプリングされることを期待していることに注意してください。
+
+## Brief Explanation:
+
+- [`ClvpTokenizer`] はテキスト入力をトークン化し、[`ClvpFeatureExtractor`] は目的のオーディオからログ メル スペクトログラムを抽出します。
+- [`ClvpConditioningEncoder`] は、これらのテキスト トークンとオーディオ表現を取得し、テキストとオーディオに基づいて条件付けされた埋め込みに変換します。
+- [`ClvpForCausalLM`] は、これらの埋め込みを使用して複数の音声候補を生成します。
+- 各音声候補は音声エンコーダ ([`ClvpEncoder`]) を通過してベクトル表現に変換され、テキスト エンコーダ ([`ClvpEncoder`]) はテキスト トークンを同じ潜在空間に変換します。
+- 最後に、各音声ベクトルをテキスト ベクトルと比較して、どの音声ベクトルがテキスト ベクトルに最も類似しているかを確認します。
+- [`ClvpModelForConditionalGeneration.generate()`] は、上記のすべてのロジックを 1 つのメソッドに圧縮します。
+
+例 :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/ja/model_doc/code_llama.md b/docs/source/ja/model_doc/code_llama.md
new file mode 100644
index 00000000000000..4ba345b8d7b9c5
--- /dev/null
+++ b/docs/source/ja/model_doc/code_llama.md
@@ -0,0 +1,125 @@
+
+
+# CodeLlama
+
+## Overview
+
+Code Llama モデルはによって [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) で提案されました。 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
+論文の要約は次のとおりです。
+
+*私たちは Code Llama をリリースします。これは Llama 2 に基づくコードの大規模言語モデル ファミリであり、オープン モデルの中で最先端のパフォーマンス、埋め込み機能、大規模な入力コンテキストのサポート、プログラミング タスクのゼロショット命令追従機能を提供します。 。幅広いアプリケーションをカバーするための複数のフレーバーを提供しています。基盤モデル (Code Llama)、Python 特化 (Code Llama - Python)、およびそれぞれ 7B、13B、および 34B パラメーターを備えた命令追従モデル (Code Llama - Instruct) です。すべてのモデルは 16,000 トークンのシーケンスでトレーニングされ、最大 100,000 トークンの入力で改善が見られます。 7B および 13B コード ラマとコード ラマ - 命令バリアントは、周囲のコンテンツに基づいた埋め込みをサポートします。 Code Llama は、いくつかのコード ベンチマークでオープン モデルの中で最先端のパフォーマンスに達し、HumanEval と MBPP でそれぞれ最大 53% と 55% のスコアを獲得しました。特に、Code Llama - Python 7B は HumanEval および MBPP 上で Llama 2 70B よりも優れたパフォーマンスを示し、すべてのモデルは MultiPL-E 上で公開されている他のすべてのモデルよりも優れています。私たちは、研究と商業利用の両方を許可する寛容なライセンスに基づいて Code Llama をリリースしています。*
+
+すべての Code Llama モデル チェックポイントを [こちら](https://huggingface.co/models?search=code_llama) で確認し、[codellama org](https://huggingface.co/codellama) で正式にリリースされたチェックポイントを確認してください。
+
+このモデルは [ArthurZucker](https://huggingface.co/ArthurZ) によって提供されました。著者のオリジナルのコードは [こちら](https://github.com/facebookresearch/llama) にあります。
+
+## Usage tips and examples
+
+
+
+Code Llama のベースとなる`Llama2`ファミリー モデルは、`bfloat16`を使用してトレーニングされましたが、元の推論では`float16`を使用します。さまざまな精度を見てみましょう。
+
+* `float32`: モデルの初期化に関する PyTorch の規約では、モデルの重みがどの `dtype` で格納されたかに関係なく、モデルを `float32` にロードします。 「transformers」も、PyTorch との一貫性を保つためにこの規則に従っています。これはデフォルトで選択されます。 `AutoModel` API でストレージの重み付けタイプを使用してチェックポイントのロードをキャストする場合は、`torch_dtype="auto"` を指定する必要があります。 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`。
+* `bfloat16`: コード Llama はこの精度でトレーニングされているため、さらなるトレーニングや微調整に使用することをお勧めします。
+* `float16`: この精度を使用して推論を実行することをお勧めします。通常は `bfloat16` より高速であり、評価メトリクスには `bfloat16` と比べて明らかな低下が見られないためです。 bfloat16 を使用して推論を実行することもできます。微調整後、float16 と bfloat16 の両方で推論結果を確認することをお勧めします。
+
+上で述べたように、モデルを初期化するときに `torch_dtype="auto"` を使用しない限り、ストレージの重みの `dtype` はほとんど無関係です。その理由は、モデルが最初にダウンロードされ (オンラインのチェックポイントの `dtype` を使用)、次に `torch` のデフォルトの `dtype` にキャストされるためです (`torch.float32` になります)。指定された `torch_dtype` がある場合は、代わりにそれが使用されます。
+
+
+
+チップ:
+- 充填タスクはすぐにサポートされます。入力を埋めたい場所には `tokenizer.fill_token` を使用する必要があります。
+- モデル変換スクリプトは、`Llama2` ファミリの場合と同じです。
+
+使用例は次のとおりです。
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+スクリプトを実行するには、(最大のバージョンであっても) float16 精度でモデル全体をホストするのに十分な CPU RAM が必要であることに注意してください。
+いくつかのチェックポイントがあり、それぞれにモデルの各重みの一部が含まれているため、すべてを RAM にロードする必要があります)。
+
+変換後、モデルとトークナイザーは次の方法でロードできます。
+
+```python
+>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
+
+>>> tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> model = LlamaForCausalLM.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> PROMPT = '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+'''
+>>> input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
+>>> generated_ids = model.generate(input_ids, max_new_tokens=128)
+
+>>> filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
+>>> print(PROMPT.replace("", filling))
+def remove_non_ascii(s: str) -> str:
+ """ Remove non-ASCII characters from a string.
+
+ Args:
+ s: The string to remove non-ASCII characters from.
+
+ Returns:
+ The string with non-ASCII characters removed.
+ """
+ result = ""
+ for c in s:
+ if ord(c) < 128:
+ result += c
+ return result
+```
+
+塗りつぶされた部分だけが必要な場合:
+
+```python
+>>> from transformers import pipeline
+>>> import torch
+
+>>> generator = pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16, device_map="auto")
+>>> generator('def remove_non_ascii(s: str) -> str:\n """ \n return result', max_new_tokens = 128, return_type = 1)
+```
+
+内部では、トークナイザーが [`` によって自動的に分割](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) して、[ に続く書式設定された入力文字列を作成します。オリジナルのトレーニング パターン](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402)。これは、パターンを自分で準備するよりも堅牢です。トークンの接着など、デバッグが非常に難しい落とし穴を回避できます。このモデルまたは他のモデルに必要な CPU および GPU メモリの量を確認するには、その値を決定するのに役立つ [この計算ツール](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) を試してください。
+
+LLaMA トークナイザーは、[sentencepiece](https://github.com/google/sentencepiece) に基づく BPE モデルです。センテンスピースの癖の 1 つは、シーケンスをデコードするときに、最初のトークンが単語の先頭 (例: 「Banana」) である場合、トークナイザーは文字列の先頭にプレフィックス スペースを追加しないことです。
+
+
+
+コード Llama は、`Llama2` モデルと同じアーキテクチャを持っています。API リファレンスについては、[Llama2 のドキュメント ページ](llama2) を参照してください。
+以下の Code Llama トークナイザーのリファレンスを見つけてください。
+
+
+## CodeLlamaTokenizer
+
+[[autodoc]] CodeLlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeLlamaTokenizerFast
+
+[[autodoc]] CodeLlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
new file mode 100644
index 00000000000000..78caefe043319b
--- /dev/null
+++ b/docs/source/ja/model_doc/codegen.md
@@ -0,0 +1,90 @@
+
+
+# CodeGen
+
+## Overview
+
+
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+
+CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
+
+論文の要約は次のとおりです。
+
+*プログラム合成は、与えられた問題仕様の解決策としてコンピューター プログラムを生成することを目的としています。我々は、大規模な言語モデルを介した会話型プログラム合成アプローチを提案します。これは、従来のアプローチで直面した広大なプログラム空間とユーザーの意図の仕様を検索するという課題に対処します。私たちの新しいアプローチでは、仕様とプログラムを作成するプロセスを、ユーザーとシステムの間の複数回の対話として捉えます。これはプログラム合成をシーケンス予測問題として扱い、仕様が自然言語で表現され、目的のプログラムが条件付きでサンプリングされます。私たちは、自然言語とプログラミング言語のデータに基づいて、CodeGen と呼ばれる大規模な言語モデルのファミリーをトレーニングします。データの監視が弱く、データ サイズとモデル サイズが拡大すると、単純な自己回帰言語モデリングから会話能力が生まれます。会話型プログラム合成におけるモデルの動作を研究するために、マルチターン プログラミング ベンチマーク (MTPB) を開発します。このベンチマークでは、各問題を解決するには、ユーザーとモデル間のマルチターン会話を介したマルチステップ合成が必要です。私たちの調査結果は、会話機能の出現と、提案されている会話プログラム合成パラダイムの有効性を示しています。さらに、私たちのモデル CodeGen (TPU-v4 でトレーニングされた最大 16B パラメーターを含む) は、HumanEval ベンチマークで OpenAI の Codex を上回ります。私たちはチェックポイントを含むトレーニング ライブラリ JaxFormer をオープン ソースのコントリビューションとして利用できるようにしています: [この https URL](https://github.com/salesforce/codegen)*。
+
+このモデルは [林 宏明](https://huggingface.co/rooa) によって寄稿されました。
+元のコードは [ここ](https://github.com/salesforce/codegen) にあります。
+
+## Checkpoint Naming
+
+* CodeGen モデル [チェックポイント](https://huggingface.co/models?other=codegen) は、可変サイズのさまざまな事前トレーニング データで利用できます。
+* 形式は「Salesforce/codegen-{size}-{data}」です。ここで、
+ * `size`: `350M`、`2B`、`6B`、`16B`
+ * `data`:
+ * `nl`: パイルで事前トレーニング済み
+ * `multi`: `nl` で初期化され、複数のプログラミング言語データでさらに事前トレーニングされます。
+ * `mono`: `multi` で初期化され、Python データでさらに事前トレーニングされます。
+* たとえば、`Salesforce/codegen-350M-mono` は、Pile、複数のプログラミング言語、および Python で順次事前トレーニングされた 3 億 5,000 万のパラメーターのチェックポイントを提供します。
+
+## Usage example
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## Resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
new file mode 100644
index 00000000000000..4ef09f0b6d898e
--- /dev/null
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -0,0 +1,75 @@
+
+
+# Conditional DETR
+
+## Overview
+
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+
+論文の要約は次のとおりです。
+
+*最近開発された DETR アプローチは、トランスフォーマー エンコーダーおよびデコーダー アーキテクチャを物体検出に適用し、有望なパフォーマンスを実現します。この論文では、トレーニングの収束が遅いという重要な問題を扱い、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを紹介します。私たちのアプローチは、DETR におけるクロスアテンションが 4 つの四肢の位置特定とボックスの予測にコンテンツの埋め込みに大きく依存しているため、高品質のコンテンツの埋め込みの必要性が高まり、トレーニングの難易度が高くなるという点に動機づけられています。条件付き DETR と呼ばれる私たちのアプローチは、デコーダーのマルチヘッド クロスアテンションのためにデコーダーの埋め込みから条件付きの空間クエリを学習します。利点は、条件付き空間クエリを通じて、各クロスアテンション ヘッドが、個別の領域 (たとえば、1 つのオブジェクトの端またはオブジェクト ボックス内の領域) を含むバンドに注目できることです。これにより、オブジェクト分類とボックス回帰のための個別の領域をローカライズするための空間範囲が狭まり、コンテンツの埋め込みへの依存が緩和され、トレーニングが容易になります。実験結果は、条件付き DETR がバックボーン R50 および R101 で 6.7 倍速く収束し、より強力なバックボーン DC5-R50 および DC5-R101 で 10 倍速く収束することを示しています。コードは https://github.com/Atten4Vis/ConditionalDETR で入手できます。*
+
+
+
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [CLIPSeg を使用したゼロショット画像セグメンテーション](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb) を説明するノートブック。
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
new file mode 100644
index 00000000000000..0803f5e027ce81
--- /dev/null
+++ b/docs/source/ja/model_doc/clvp.md
@@ -0,0 +1,123 @@
+
+
+# CLVP
+
+## Overview
+
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+
+論文の要約は次のとおりです。
+
+*近年、画像生成の分野は自己回帰変換器と DDPM の応用によって革命を起こしています。これらのアプローチは、画像生成のプロセスを段階的な確率的プロセスとしてモデル化し、大量のコンピューティングとデータを活用して画像の分布を学習します。パフォーマンスを向上させるこの方法論は、画像に限定される必要はありません。この論文では、画像生成ドメインの進歩を音声合成に適用する方法について説明します。その結果、表現力豊かなマルチ音声テキスト読み上げシステムである TorToise が誕生しました。
+
+
+このモデルは [Susnato Dhar](https://huggingface.co/susnato) によって提供されました。
+元のコードは [ここ](https://github.com/neonbjb/tortoise-tts) にあります。
+
+## Usage tips
+
+1. CLVP は Tortoise TTS モデルの不可欠な部分です。
+2. CLVP を使用して、生成されたさまざまな音声候補を提供されたテキストと比較することができ、最良の音声トークンが拡散モデルに転送されます。
+3. Tortoise の使用には、[`ClvpModelForConditionalGeneration.generate()`] メソッドの使用を強くお勧めします。
+4. 16 kHz を期待する他のオーディオ モデルとは対照的に、CLVP モデルはオーディオが 22.05 kHz でサンプリングされることを期待していることに注意してください。
+
+## Brief Explanation:
+
+- [`ClvpTokenizer`] はテキスト入力をトークン化し、[`ClvpFeatureExtractor`] は目的のオーディオからログ メル スペクトログラムを抽出します。
+- [`ClvpConditioningEncoder`] は、これらのテキスト トークンとオーディオ表現を取得し、テキストとオーディオに基づいて条件付けされた埋め込みに変換します。
+- [`ClvpForCausalLM`] は、これらの埋め込みを使用して複数の音声候補を生成します。
+- 各音声候補は音声エンコーダ ([`ClvpEncoder`]) を通過してベクトル表現に変換され、テキスト エンコーダ ([`ClvpEncoder`]) はテキスト トークンを同じ潜在空間に変換します。
+- 最後に、各音声ベクトルをテキスト ベクトルと比較して、どの音声ベクトルがテキスト ベクトルに最も類似しているかを確認します。
+- [`ClvpModelForConditionalGeneration.generate()`] は、上記のすべてのロジックを 1 つのメソッドに圧縮します。
+
+例 :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/ja/model_doc/code_llama.md b/docs/source/ja/model_doc/code_llama.md
new file mode 100644
index 00000000000000..4ba345b8d7b9c5
--- /dev/null
+++ b/docs/source/ja/model_doc/code_llama.md
@@ -0,0 +1,125 @@
+
+
+# CodeLlama
+
+## Overview
+
+Code Llama モデルはによって [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) で提案されました。 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
+論文の要約は次のとおりです。
+
+*私たちは Code Llama をリリースします。これは Llama 2 に基づくコードの大規模言語モデル ファミリであり、オープン モデルの中で最先端のパフォーマンス、埋め込み機能、大規模な入力コンテキストのサポート、プログラミング タスクのゼロショット命令追従機能を提供します。 。幅広いアプリケーションをカバーするための複数のフレーバーを提供しています。基盤モデル (Code Llama)、Python 特化 (Code Llama - Python)、およびそれぞれ 7B、13B、および 34B パラメーターを備えた命令追従モデル (Code Llama - Instruct) です。すべてのモデルは 16,000 トークンのシーケンスでトレーニングされ、最大 100,000 トークンの入力で改善が見られます。 7B および 13B コード ラマとコード ラマ - 命令バリアントは、周囲のコンテンツに基づいた埋め込みをサポートします。 Code Llama は、いくつかのコード ベンチマークでオープン モデルの中で最先端のパフォーマンスに達し、HumanEval と MBPP でそれぞれ最大 53% と 55% のスコアを獲得しました。特に、Code Llama - Python 7B は HumanEval および MBPP 上で Llama 2 70B よりも優れたパフォーマンスを示し、すべてのモデルは MultiPL-E 上で公開されている他のすべてのモデルよりも優れています。私たちは、研究と商業利用の両方を許可する寛容なライセンスに基づいて Code Llama をリリースしています。*
+
+すべての Code Llama モデル チェックポイントを [こちら](https://huggingface.co/models?search=code_llama) で確認し、[codellama org](https://huggingface.co/codellama) で正式にリリースされたチェックポイントを確認してください。
+
+このモデルは [ArthurZucker](https://huggingface.co/ArthurZ) によって提供されました。著者のオリジナルのコードは [こちら](https://github.com/facebookresearch/llama) にあります。
+
+## Usage tips and examples
+
+
+
+Code Llama のベースとなる`Llama2`ファミリー モデルは、`bfloat16`を使用してトレーニングされましたが、元の推論では`float16`を使用します。さまざまな精度を見てみましょう。
+
+* `float32`: モデルの初期化に関する PyTorch の規約では、モデルの重みがどの `dtype` で格納されたかに関係なく、モデルを `float32` にロードします。 「transformers」も、PyTorch との一貫性を保つためにこの規則に従っています。これはデフォルトで選択されます。 `AutoModel` API でストレージの重み付けタイプを使用してチェックポイントのロードをキャストする場合は、`torch_dtype="auto"` を指定する必要があります。 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`。
+* `bfloat16`: コード Llama はこの精度でトレーニングされているため、さらなるトレーニングや微調整に使用することをお勧めします。
+* `float16`: この精度を使用して推論を実行することをお勧めします。通常は `bfloat16` より高速であり、評価メトリクスには `bfloat16` と比べて明らかな低下が見られないためです。 bfloat16 を使用して推論を実行することもできます。微調整後、float16 と bfloat16 の両方で推論結果を確認することをお勧めします。
+
+上で述べたように、モデルを初期化するときに `torch_dtype="auto"` を使用しない限り、ストレージの重みの `dtype` はほとんど無関係です。その理由は、モデルが最初にダウンロードされ (オンラインのチェックポイントの `dtype` を使用)、次に `torch` のデフォルトの `dtype` にキャストされるためです (`torch.float32` になります)。指定された `torch_dtype` がある場合は、代わりにそれが使用されます。
+
+
+
+チップ:
+- 充填タスクはすぐにサポートされます。入力を埋めたい場所には `tokenizer.fill_token` を使用する必要があります。
+- モデル変換スクリプトは、`Llama2` ファミリの場合と同じです。
+
+使用例は次のとおりです。
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+スクリプトを実行するには、(最大のバージョンであっても) float16 精度でモデル全体をホストするのに十分な CPU RAM が必要であることに注意してください。
+いくつかのチェックポイントがあり、それぞれにモデルの各重みの一部が含まれているため、すべてを RAM にロードする必要があります)。
+
+変換後、モデルとトークナイザーは次の方法でロードできます。
+
+```python
+>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
+
+>>> tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> model = LlamaForCausalLM.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> PROMPT = '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+'''
+>>> input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
+>>> generated_ids = model.generate(input_ids, max_new_tokens=128)
+
+>>> filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
+>>> print(PROMPT.replace("", filling))
+def remove_non_ascii(s: str) -> str:
+ """ Remove non-ASCII characters from a string.
+
+ Args:
+ s: The string to remove non-ASCII characters from.
+
+ Returns:
+ The string with non-ASCII characters removed.
+ """
+ result = ""
+ for c in s:
+ if ord(c) < 128:
+ result += c
+ return result
+```
+
+塗りつぶされた部分だけが必要な場合:
+
+```python
+>>> from transformers import pipeline
+>>> import torch
+
+>>> generator = pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16, device_map="auto")
+>>> generator('def remove_non_ascii(s: str) -> str:\n """ \n return result', max_new_tokens = 128, return_type = 1)
+```
+
+内部では、トークナイザーが [`` によって自動的に分割](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) して、[ に続く書式設定された入力文字列を作成します。オリジナルのトレーニング パターン](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402)。これは、パターンを自分で準備するよりも堅牢です。トークンの接着など、デバッグが非常に難しい落とし穴を回避できます。このモデルまたは他のモデルに必要な CPU および GPU メモリの量を確認するには、その値を決定するのに役立つ [この計算ツール](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) を試してください。
+
+LLaMA トークナイザーは、[sentencepiece](https://github.com/google/sentencepiece) に基づく BPE モデルです。センテンスピースの癖の 1 つは、シーケンスをデコードするときに、最初のトークンが単語の先頭 (例: 「Banana」) である場合、トークナイザーは文字列の先頭にプレフィックス スペースを追加しないことです。
+
+
+
+コード Llama は、`Llama2` モデルと同じアーキテクチャを持っています。API リファレンスについては、[Llama2 のドキュメント ページ](llama2) を参照してください。
+以下の Code Llama トークナイザーのリファレンスを見つけてください。
+
+
+## CodeLlamaTokenizer
+
+[[autodoc]] CodeLlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeLlamaTokenizerFast
+
+[[autodoc]] CodeLlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
new file mode 100644
index 00000000000000..78caefe043319b
--- /dev/null
+++ b/docs/source/ja/model_doc/codegen.md
@@ -0,0 +1,90 @@
+
+
+# CodeGen
+
+## Overview
+
+
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+
+CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
+
+論文の要約は次のとおりです。
+
+*プログラム合成は、与えられた問題仕様の解決策としてコンピューター プログラムを生成することを目的としています。我々は、大規模な言語モデルを介した会話型プログラム合成アプローチを提案します。これは、従来のアプローチで直面した広大なプログラム空間とユーザーの意図の仕様を検索するという課題に対処します。私たちの新しいアプローチでは、仕様とプログラムを作成するプロセスを、ユーザーとシステムの間の複数回の対話として捉えます。これはプログラム合成をシーケンス予測問題として扱い、仕様が自然言語で表現され、目的のプログラムが条件付きでサンプリングされます。私たちは、自然言語とプログラミング言語のデータに基づいて、CodeGen と呼ばれる大規模な言語モデルのファミリーをトレーニングします。データの監視が弱く、データ サイズとモデル サイズが拡大すると、単純な自己回帰言語モデリングから会話能力が生まれます。会話型プログラム合成におけるモデルの動作を研究するために、マルチターン プログラミング ベンチマーク (MTPB) を開発します。このベンチマークでは、各問題を解決するには、ユーザーとモデル間のマルチターン会話を介したマルチステップ合成が必要です。私たちの調査結果は、会話機能の出現と、提案されている会話プログラム合成パラダイムの有効性を示しています。さらに、私たちのモデル CodeGen (TPU-v4 でトレーニングされた最大 16B パラメーターを含む) は、HumanEval ベンチマークで OpenAI の Codex を上回ります。私たちはチェックポイントを含むトレーニング ライブラリ JaxFormer をオープン ソースのコントリビューションとして利用できるようにしています: [この https URL](https://github.com/salesforce/codegen)*。
+
+このモデルは [林 宏明](https://huggingface.co/rooa) によって寄稿されました。
+元のコードは [ここ](https://github.com/salesforce/codegen) にあります。
+
+## Checkpoint Naming
+
+* CodeGen モデル [チェックポイント](https://huggingface.co/models?other=codegen) は、可変サイズのさまざまな事前トレーニング データで利用できます。
+* 形式は「Salesforce/codegen-{size}-{data}」です。ここで、
+ * `size`: `350M`、`2B`、`6B`、`16B`
+ * `data`:
+ * `nl`: パイルで事前トレーニング済み
+ * `multi`: `nl` で初期化され、複数のプログラミング言語データでさらに事前トレーニングされます。
+ * `mono`: `multi` で初期化され、Python データでさらに事前トレーニングされます。
+* たとえば、`Salesforce/codegen-350M-mono` は、Pile、複数のプログラミング言語、および Python で順次事前トレーニングされた 3 億 5,000 万のパラメーターのチェックポイントを提供します。
+
+## Usage example
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## Resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
new file mode 100644
index 00000000000000..4ef09f0b6d898e
--- /dev/null
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -0,0 +1,75 @@
+
+
+# Conditional DETR
+
+## Overview
+
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+
+論文の要約は次のとおりです。
+
+*最近開発された DETR アプローチは、トランスフォーマー エンコーダーおよびデコーダー アーキテクチャを物体検出に適用し、有望なパフォーマンスを実現します。この論文では、トレーニングの収束が遅いという重要な問題を扱い、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを紹介します。私たちのアプローチは、DETR におけるクロスアテンションが 4 つの四肢の位置特定とボックスの予測にコンテンツの埋め込みに大きく依存しているため、高品質のコンテンツの埋め込みの必要性が高まり、トレーニングの難易度が高くなるという点に動機づけられています。条件付き DETR と呼ばれる私たちのアプローチは、デコーダーのマルチヘッド クロスアテンションのためにデコーダーの埋め込みから条件付きの空間クエリを学習します。利点は、条件付き空間クエリを通じて、各クロスアテンション ヘッドが、個別の領域 (たとえば、1 つのオブジェクトの端またはオブジェクト ボックス内の領域) を含むバンドに注目できることです。これにより、オブジェクト分類とボックス回帰のための個別の領域をローカライズするための空間範囲が狭まり、コンテンツの埋め込みへの依存が緩和され、トレーニングが容易になります。実験結果は、条件付き DETR がバックボーン R50 および R101 で 6.7 倍速く収束し、より強力なバックボーン DC5-R50 および DC5-R101 で 10 倍速く収束することを示しています。コードは https://github.com/Atten4Vis/ConditionalDETR で入手できます。*
+
+ +
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 00000000000000..5d15f86c5136b7
--- /dev/null
+++ b/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
new file mode 100644
index 00000000000000..4386a7df8ceadb
--- /dev/null
+++ b/docs/source/ja/model_doc/convnext.md
@@ -0,0 +1,94 @@
+
+
+# ConvNeXT
+
+## Overview
+
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
+
+論文の要約は次のとおりです。
+
+*視覚認識の「狂騒の 20 年代」は、最先端の画像分類モデルとして ConvNet にすぐに取って代わられた Vision Transformers (ViT) の導入から始まりました。
+一方、バニラ ViT は、オブジェクト検出やセマンティック セグメンテーションなどの一般的なコンピューター ビジョン タスクに適用すると困難に直面します。階層型トランスフォーマーです
+(Swin Transformers など) は、いくつかの ConvNet の以前の機能を再導入し、Transformers を汎用ビジョン バックボーンとして実用的に可能にし、幅広い環境で顕著なパフォーマンスを実証しました。
+さまざまな視覚タスク。ただし、このようなハイブリッド アプローチの有効性は、依然として、固有の誘導性ではなく、トランスフォーマーの本質的な優位性によるところが大きいと考えられています。
+畳み込みのバイアス。この作業では、設計空間を再検討し、純粋な ConvNet が達成できる限界をテストします。標準 ResNet を設計に向けて徐々に「最新化」します。
+ビジョン Transformer の概要を確認し、途中でパフォーマンスの違いに寄与するいくつかの重要なコンポーネントを発見します。この調査の結果は、純粋な ConvNet モデルのファミリーです。
+ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュールから構築されており、精度と拡張性の点で Transformers と有利に競合し、87.8% の ImageNet トップ 1 精度を達成しています。
+標準 ConvNet のシンプルさと効率を維持しながら、COCO 検出と ADE20K セグメンテーションでは Swin Transformers よりも優れたパフォーマンスを発揮します。*
+
+
+
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 00000000000000..5d15f86c5136b7
--- /dev/null
+++ b/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
new file mode 100644
index 00000000000000..4386a7df8ceadb
--- /dev/null
+++ b/docs/source/ja/model_doc/convnext.md
@@ -0,0 +1,94 @@
+
+
+# ConvNeXT
+
+## Overview
+
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
+
+論文の要約は次のとおりです。
+
+*視覚認識の「狂騒の 20 年代」は、最先端の画像分類モデルとして ConvNet にすぐに取って代わられた Vision Transformers (ViT) の導入から始まりました。
+一方、バニラ ViT は、オブジェクト検出やセマンティック セグメンテーションなどの一般的なコンピューター ビジョン タスクに適用すると困難に直面します。階層型トランスフォーマーです
+(Swin Transformers など) は、いくつかの ConvNet の以前の機能を再導入し、Transformers を汎用ビジョン バックボーンとして実用的に可能にし、幅広い環境で顕著なパフォーマンスを実証しました。
+さまざまな視覚タスク。ただし、このようなハイブリッド アプローチの有効性は、依然として、固有の誘導性ではなく、トランスフォーマーの本質的な優位性によるところが大きいと考えられています。
+畳み込みのバイアス。この作業では、設計空間を再検討し、純粋な ConvNet が達成できる限界をテストします。標準 ResNet を設計に向けて徐々に「最新化」します。
+ビジョン Transformer の概要を確認し、途中でパフォーマンスの違いに寄与するいくつかの重要なコンポーネントを発見します。この調査の結果は、純粋な ConvNet モデルのファミリーです。
+ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュールから構築されており、精度と拡張性の点で Transformers と有利に競合し、87.8% の ImageNet トップ 1 精度を達成しています。
+標準 ConvNet のシンプルさと効率を維持しながら、COCO 検出と ADE20K セグメンテーションでは Swin Transformers よりも優れたパフォーマンスを発揮します。*
+
+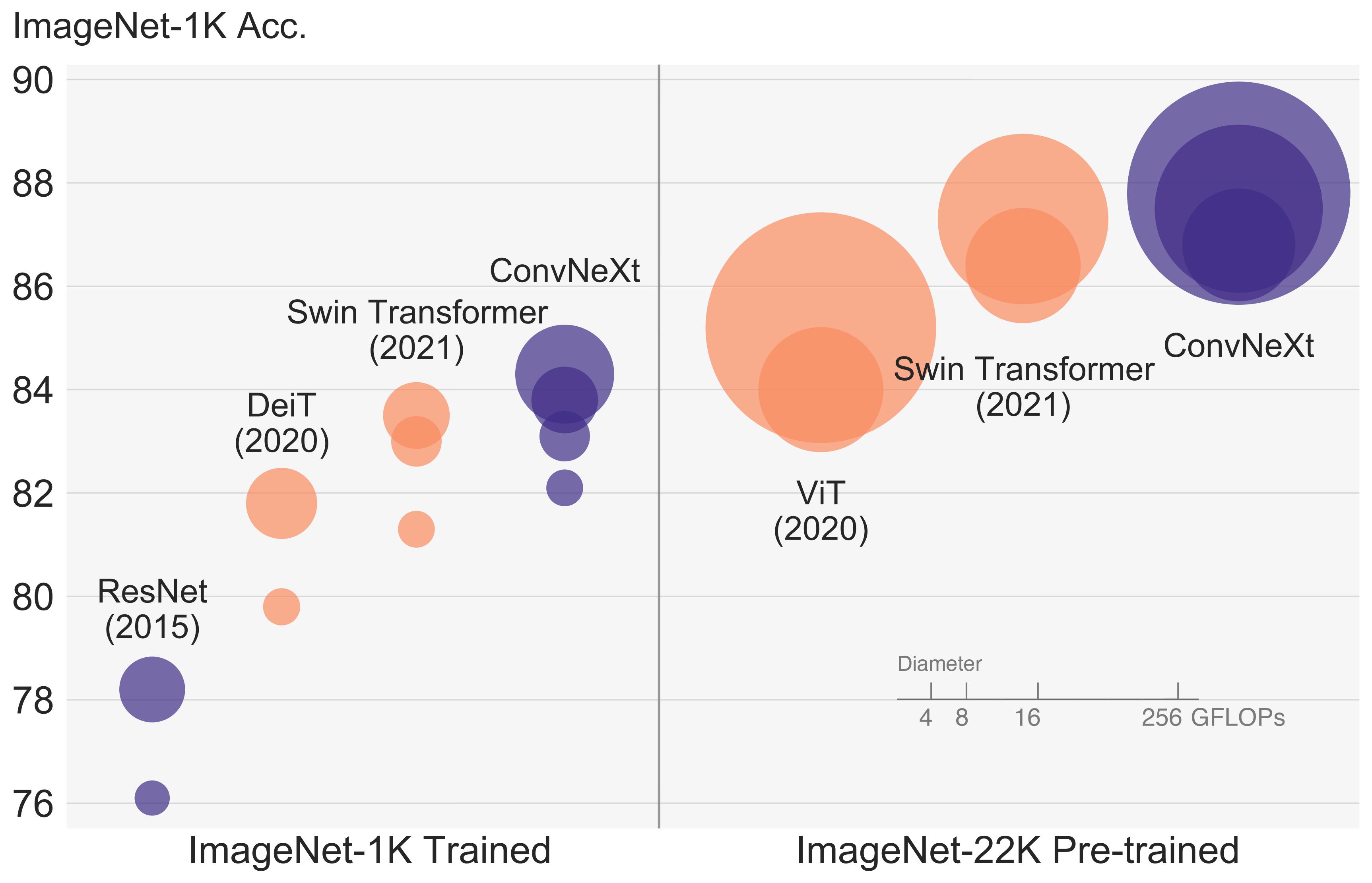 +
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
+
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
new file mode 100644
index 00000000000000..9e4d54df24b1c1
--- /dev/null
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -0,0 +1,68 @@
+
+
+# ConvNeXt V2
+
+## Overview
+
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
+
+論文の要約は次のとおりです。
+
+*アーキテクチャの改善と表現学習フレームワークの改善により、視覚認識の分野は 2020 年代初頭に急速な近代化とパフォーマンスの向上を実現しました。たとえば、ConvNeXt に代表される最新の ConvNet は、さまざまなシナリオで強力なパフォーマンスを実証しています。これらのモデルはもともと ImageNet ラベルを使用した教師あり学習用に設計されましたが、マスク オートエンコーダー (MAE) などの自己教師あり学習手法からも潜在的に恩恵を受けることができます。ただし、これら 2 つのアプローチを単純に組み合わせると、パフォーマンスが標準以下になることがわかりました。この論文では、完全畳み込みマスク オートエンコーダ フレームワークと、チャネル間の機能競合を強化するために ConvNeXt アーキテクチャに追加できる新しい Global Response Normalization (GRN) 層を提案します。この自己教師あり学習手法とアーキテクチャの改善の共同設計により、ConvNeXt V2 と呼ばれる新しいモデル ファミリが誕生しました。これにより、ImageNet 分類、COCO 検出、ADE20K セグメンテーションなどのさまざまな認識ベンチマークにおける純粋な ConvNet のパフォーマンスが大幅に向上します。また、ImageNet でトップ 1 の精度 76.7% を誇る効率的な 370 万パラメータの Atto モデルから、最先端の 88.9% を達成する 650M Huge モデルまで、さまざまなサイズの事前トレーニング済み ConvNeXt V2 モデルも提供しています。公開トレーニング データのみを使用した精度*。
+
+
+
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
+
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
new file mode 100644
index 00000000000000..9e4d54df24b1c1
--- /dev/null
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -0,0 +1,68 @@
+
+
+# ConvNeXt V2
+
+## Overview
+
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
+
+論文の要約は次のとおりです。
+
+*アーキテクチャの改善と表現学習フレームワークの改善により、視覚認識の分野は 2020 年代初頭に急速な近代化とパフォーマンスの向上を実現しました。たとえば、ConvNeXt に代表される最新の ConvNet は、さまざまなシナリオで強力なパフォーマンスを実証しています。これらのモデルはもともと ImageNet ラベルを使用した教師あり学習用に設計されましたが、マスク オートエンコーダー (MAE) などの自己教師あり学習手法からも潜在的に恩恵を受けることができます。ただし、これら 2 つのアプローチを単純に組み合わせると、パフォーマンスが標準以下になることがわかりました。この論文では、完全畳み込みマスク オートエンコーダ フレームワークと、チャネル間の機能競合を強化するために ConvNeXt アーキテクチャに追加できる新しい Global Response Normalization (GRN) 層を提案します。この自己教師あり学習手法とアーキテクチャの改善の共同設計により、ConvNeXt V2 と呼ばれる新しいモデル ファミリが誕生しました。これにより、ImageNet 分類、COCO 検出、ADE20K セグメンテーションなどのさまざまな認識ベンチマークにおける純粋な ConvNet のパフォーマンスが大幅に向上します。また、ImageNet でトップ 1 の精度 76.7% を誇る効率的な 370 万パラメータの Atto モデルから、最先端の 88.9% を達成する 650M Huge モデルまで、さまざまなサイズの事前トレーニング済み ConvNeXt V2 モデルも提供しています。公開トレーニング データのみを使用した精度*。
+
+ +
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextV2ForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextV2Config
+
+[[autodoc]] ConvNextV2Config
+
+## ConvNextV2Model
+
+[[autodoc]] ConvNextV2Model
+ - forward
+
+## ConvNextV2ForImageClassification
+
+[[autodoc]] ConvNextV2ForImageClassification
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
new file mode 100644
index 00000000000000..9776f676844e7d
--- /dev/null
+++ b/docs/source/ja/model_doc/cpm.md
@@ -0,0 +1,54 @@
+
+
+# CPM
+
+## Overview
+
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
+Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデル (PLM) は、さまざまな下流の NLP タスクに有益であることが証明されています。最近ではGPT-3、
+1,750億個のパラメータと570GBの学習データを備え、数回の撮影(1枚でも)の容量で大きな注目を集めました
+ゼロショット)学習。ただし、GPT-3 を適用して中国語の NLP タスクに対処することは依然として困難です。
+GPT-3 の言語は主に英語であり、パラメーターは公開されていません。この技術レポートでは、
+大規模な中国語トレーニング データに対する生成的事前トレーニングを備えた中国語事前トレーニング済み言語モデル (CPM)。最高に
+私たちの知識の限りでは、26 億のパラメータと 100GB の中国語トレーニング データを備えた CPM は、事前トレーニングされた中国語としては最大のものです。
+言語モデルは、会話、エッセイの作成、
+クローゼテストと言語理解。広範な実験により、CPM が多くの環境で優れたパフォーマンスを達成できることが実証されています。
+少数ショット (ゼロショットでも) 学習の設定での NLP タスク。*
+
+このモデルは [canwenxu](https://huggingface.co/canwenxu) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/TsinghuaAI/CPM-Generate
+
+
+
+
+CPM のアーキテクチャは、トークン化方法を除いて GPT-2 と同じです。詳細については、[GPT-2 ドキュメント](gpt2) を参照してください。
+API リファレンス情報。
+
+
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
diff --git a/docs/source/ja/perf_hardware.md b/docs/source/ja/perf_hardware.md
index b58db6e76d0995..a0db527a94b662 100644
--- a/docs/source/ja/perf_hardware.md
+++ b/docs/source/ja/perf_hardware.md
@@ -139,7 +139,7 @@ NVLinkを使用すると、トレーニングが約23%速く完了すること
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -148,7 +148,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/ja/perf_infer_gpu_one.md b/docs/source/ja/perf_infer_gpu_one.md
index d6a18a6f3e2047..6d7466e022220a 100644
--- a/docs/source/ja/perf_infer_gpu_one.md
+++ b/docs/source/ja/perf_infer_gpu_one.md
@@ -44,7 +44,7 @@ Flash Attention 2は、モデルのdtypeが`fp16`または`bf16`の場合にの
### Quick usage
-モデルでFlash Attention 2を有効にするには、`from_pretrained`の引数に`use_flash_attention_2`を追加します。
+モデルでFlash Attention 2を有効にするには、`from_pretrained`の引数に`attn_implementation="flash_attention_2"`を追加します。
```python
@@ -57,7 +57,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -114,7 +114,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -132,7 +132,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -151,7 +151,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
lora_config = LoraConfig(
diff --git a/docs/source/ja/perf_train_gpu_many.md b/docs/source/ja/perf_train_gpu_many.md
index fd7713c49369f6..71d6c2805865aa 100644
--- a/docs/source/ja/perf_train_gpu_many.md
+++ b/docs/source/ja/perf_train_gpu_many.md
@@ -143,7 +143,7 @@ python examples/pytorch/language-modeling/run_clm.py \
# DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -151,7 +151,7 @@ python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-
# DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/ja/preprocessing.md b/docs/source/ja/preprocessing.md
index c4e3566fd3aee4..b8fad2a0d21b36 100644
--- a/docs/source/ja/preprocessing.md
+++ b/docs/source/ja/preprocessing.md
@@ -227,7 +227,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
オーディオタスクの場合、データセットをモデル用に準備するために[特徴抽出器](main_classes/feature_extractor)が必要です。
特徴抽出器は生のオーディオデータから特徴を抽出し、それらをテンソルに変換するために設計されています。
-[PolyAI/minds14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードして(データセットのロード方法の詳細については🤗 [Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照)、
+[PolyAI/minds14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードして(データセットのロード方法の詳細については🤗 [Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照)、
オーディオデータセットで特徴抽出器をどのように使用できるかを確認してみましょう:
```python
@@ -349,7 +349,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
-コンピュータビジョンのデータセットで画像プロセッサを使用する方法を示すために、[food101](https://huggingface.co/datasets/food101)データセットをロードします(データセットのロード方法の詳細については🤗[Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照):
+コンピュータビジョンのデータセットで画像プロセッサを使用する方法を示すために、[food101](https://huggingface.co/datasets/food101)データセットをロードします(データセットのロード方法の詳細については🤗[Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
@@ -363,7 +363,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>>> dataset = load_dataset("food101", split="train[:100]")
```
-次に、🤗 Datasetsの [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) 機能で画像を見てみましょう:
+次に、🤗 Datasetsの [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) 機能で画像を見てみましょう:
```python
>>> dataset[0]["image"]
@@ -419,7 +419,7 @@ AutoImageProcessorを[`AutoImageProcessor.from_pretrained`]を使用してロー
画像を増強変換の一部として正規化したい場合は、`image_processor.image_mean` と `image_processor.image_std` の値を使用してください。
-3. 次に、🤗 Datasetsの[`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform)を使用して、変換をリアルタイムで適用します:
+3. 次に、🤗 Datasetsの[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)を使用して、変換をリアルタイムで適用します:
```python
>>> dataset.set_transform(transforms)
@@ -474,7 +474,7 @@ AutoImageProcessorを[`AutoImageProcessor.from_pretrained`]を使用してロー
マルチモーダル入力を使用するタスクの場合、モデル用にデータセットを準備するための[プロセッサ](main_classes/processors)が必要です。プロセッサは、トークナイザや特徴量抽出器などの2つの処理オブジェクトを結合します。
-自動音声認識(ASR)のためのプロセッサの使用方法を示すために、[LJ Speech](https://huggingface.co/datasets/lj_speech)データセットをロードします(データセットのロード方法の詳細については🤗 [Datasets チュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照):
+自動音声認識(ASR)のためのプロセッサの使用方法を示すために、[LJ Speech](https://huggingface.co/datasets/lj_speech)データセットをロードします(データセットのロード方法の詳細については🤗 [Datasets チュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
```python
>>> from datasets import load_dataset
diff --git a/docs/source/ja/run_scripts.md b/docs/source/ja/run_scripts.md
index 1fde9afc0c6e5d..a7cc89d1348491 100644
--- a/docs/source/ja/run_scripts.md
+++ b/docs/source/ja/run_scripts.md
@@ -140,7 +140,7 @@ python examples/tensorflow/summarization/run_summarization.py \
以下は提供されたBashコードです。このコードの日本語訳をMarkdown形式で記載します。
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/ja/tasks/asr.md b/docs/source/ja/tasks/asr.md
new file mode 100644
index 00000000000000..fd564abdc5c908
--- /dev/null
+++ b/docs/source/ja/tasks/asr.md
@@ -0,0 +1,380 @@
+
+
+# Automatic speech recognition
+
+[[open-in-colab]]
+
+
+
+自動音声認識 (ASR) は音声信号をテキストに変換し、一連の音声入力をテキスト出力にマッピングします。 Siri や Alexa などの仮想アシスタントは ASR モデルを使用してユーザーを日常的に支援しており、ライブキャプションや会議中のメモ取りなど、他にも便利なユーザー向けアプリケーションが数多くあります。
+
+このガイドでは、次の方法を説明します。
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) を微調整して、音声をテキストに書き起こします。
+2. 微調整したモデルを推論に使用します。
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
+
+
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate jiwer
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load MInDS-14 dataset
+
+まず、🤗 データセット ライブラリから [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの小さいサブセットをロードします。これにより、完全なデータセットのトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
+```
+
+[`~Dataset.train_test_split`] メソッドを使用して、データセットの `train` 分割をトレイン セットとテスト セットに分割します。
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+次に、データセットを見てみましょう。
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 16
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 4
+ })
+})
+```
+
+データセットには`lang_id`や`english_transcription`などの多くの有用な情報が含まれていますが、このガイドでは「`audio`」と「`transciption`」に焦点を当てます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して他の列を削除します。
+
+```py
+>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
+```
+
+もう一度例を見てみましょう。
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
+ 0.00024414, 0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 8000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+次の 2 つのフィールドがあります。
+
+- `audio`: 音声ファイルをロードしてリサンプリングするために呼び出す必要がある音声信号の 1 次元の `array`。
+- `transcription`: ターゲットテキスト。
+
+## Preprocess
+
+次のステップでは、Wav2Vec2 プロセッサをロードしてオーディオ信号を処理します。
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MInDS-14 データセットのサンプリング レートは 8000kHz です (この情報は [データセット カード](https://huggingface.co/datasets/PolyAI/minds14) で確認できます)。つまり、データセットを再サンプリングする必要があります。事前トレーニングされた Wav2Vec2 モデルを使用するには、16000kHz に設定します。
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
+ 2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 16000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+上の `transcription` でわかるように、テキストには大文字と小文字が混在しています。 Wav2Vec2 トークナイザーは大文字のみでトレーニングされるため、テキストがトークナイザーの語彙と一致することを確認する必要があります。
+
+```py
+>>> def uppercase(example):
+... return {"transcription": example["transcription"].upper()}
+
+
+>>> minds = minds.map(uppercase)
+```
+
+次に、次の前処理関数を作成します。
+
+1. `audio`列を呼び出して、オーディオ ファイルをロードしてリサンプリングします。
+2. オーディオ ファイルから `input_values` を抽出し、プロセッサを使用して `transcription` 列をトークン化します。
+
+```py
+>>> def prepare_dataset(batch):
+... audio = batch["audio"]
+... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
+... batch["input_length"] = len(batch["input_values"][0])
+... return batch
+```
+
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
+
+```py
+>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
+```
+
+🤗 Transformers には ASR 用のデータ照合器がないため、[`DataCollatorWithPadding`] を調整してサンプルのバッチを作成する必要があります。また、テキストとラベルが (データセット全体ではなく) バッチ内の最も長い要素の長さに合わせて動的に埋め込まれ、均一な長さになります。 `padding=True` を設定すると、`tokenizer` 関数でテキストを埋め込むことができますが、動的な埋め込みの方が効率的です。
+
+他のデータ照合器とは異なり、この特定のデータ照合器は、`input_values`と `labels`」に異なるパディング方法を適用する必要があります。
+
+```py
+>>> import torch
+
+>>> from dataclasses import dataclass, field
+>>> from typing import Any, Dict, List, Optional, Union
+
+
+>>> @dataclass
+... class DataCollatorCTCWithPadding:
+... processor: AutoProcessor
+... padding: Union[bool, str] = "longest"
+
+... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+... # split inputs and labels since they have to be of different lengths and need
+... # different padding methods
+... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
+... label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
+
+... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
+
+... # replace padding with -100 to ignore loss correctly
+... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+... batch["labels"] = labels
+
+... return batch
+```
+
+次に、`DataCollatorForCTCWithPadding` をインスタンス化します。
+
+```py
+>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
+```
+
+## Evaluate
+
+トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[単語エラー率](https://huggingface.co/spaces/evaluate-metric/wer) (WER) メトリクスを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照して、メトリクスをロードして計算する方法の詳細を確認してください)。
+
+```py
+>>> import evaluate
+
+>>> wer = evaluate.load("wer")
+```
+
+次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して WER を計算する関数を作成します。
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(pred):
+... pred_logits = pred.predictions
+... pred_ids = np.argmax(pred_logits, axis=-1)
+
+... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
+
+... pred_str = processor.batch_decode(pred_ids)
+... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
+
+... wer = wer.compute(predictions=pred_str, references=label_str)
+
+... return {"wer": wer}
+```
+
+これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForCTC`] で Wav2Vec2 をロードします。 `ctc_loss_reduction` パラメータで適用する削減を指定します。多くの場合、デフォルトの合計ではなく平均を使用する方が適切です。
+
+```py
+>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
+
+>>> model = AutoModelForCTC.from_pretrained(
+... "facebook/wav2vec2-base",
+... ctc_loss_reduction="mean",
+... pad_token_id=processor.tokenizer.pad_token_id,
+... )
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`トレーナー`] は WER を評価し、トレーニング チェックポイントを保存します。
+2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_asr_mind_model",
+... per_device_train_batch_size=8,
+... gradient_accumulation_steps=2,
+... learning_rate=1e-5,
+... warmup_steps=500,
+... max_steps=2000,
+... gradient_checkpointing=True,
+... fp16=True,
+... group_by_length=True,
+... evaluation_strategy="steps",
+... per_device_eval_batch_size=8,
+... save_steps=1000,
+... eval_steps=1000,
+... logging_steps=25,
+... load_best_model_at_end=True,
+... metric_for_best_model="wer",
+... greater_is_better=False,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=processor,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+
+自動音声認識用にモデルを微調整する方法のより詳細な例については、英語 ASR および英語のこのブログ [投稿](https://huggingface.co/blog/fine-tune-wav2vec2-english) を参照してください。多言語 ASR については、この [投稿](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) を参照してください。
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+推論を実行したい音声ファイルをロードします。必要に応じて、オーディオ ファイルのサンプリング レートをモデルのサンプリング レートと一致するようにリサンプリングすることを忘れないでください。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して自動音声認識用の`pipeline`をインスタンス化し、オーディオ ファイルをそれに渡します。
+
+```py
+>>> from transformers import pipeline
+
+>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
+>>> transcriber(audio_file)
+{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
+```
+
+
+
+転写はまあまあですが、もっと良くなる可能性があります。さらに良い結果を得るには、より多くの例でモデルを微調整してみてください。
+
+
+
+必要に応じて、「パイプライン」の結果を手動で複製することもできます。
+
+
+
+
+プロセッサをロードしてオーディオ ファイルと文字起こしを前処理し、`input`を PyTorch テンソルとして返します。
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+Pass your inputs to the model and return the logits:
+
+```py
+>>> from transformers import AutoModelForCTC
+
+>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+最も高い確率で予測された `input_ids` を取得し、プロセッサを使用して予測された `input_ids` をデコードしてテキストに戻します。
+
+
+```py
+>>> import torch
+
+>>> predicted_ids = torch.argmax(logits, dim=-1)
+>>> transcription = processor.batch_decode(predicted_ids)
+>>> transcription
+['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
+```
+
+
+
diff --git a/docs/source/ja/tasks/audio_classification.md b/docs/source/ja/tasks/audio_classification.md
new file mode 100644
index 00000000000000..58d42f3f4d4ff1
--- /dev/null
+++ b/docs/source/ja/tasks/audio_classification.md
@@ -0,0 +1,330 @@
+
+
+# Audio classification
+
+[[open-in-colab]]
+
+
+
+
+音声分類では、テキストと同様に、入力データから出力されたクラス ラベルを割り当てます。唯一の違いは、テキスト入力の代わりに生のオーディオ波形があることです。音声分類の実際的な応用例には、話者の意図、言語分類、さらには音による動物の種類の識別などがあります。
+
+このガイドでは、次の方法を説明します。
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットで [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) を微調整して話者の意図を分類します。
+2. 微調整したモデルを推論に使用します。
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
+
+
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load MInDS-14 dataset
+
+まず、🤗 データセット ライブラリから MInDS-14 データセットをロードします。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットの `train` をより小さなトレインとテスト セットに分割します。これにより、完全なデータセットにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+次に、データセットを見てみましょう。
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 450
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 113
+ })
+})
+```
+
+
+データセットには`lang_id`や`english_transcription`などの多くの有用な情報が含まれていますが、このガイドでは`audio`と`intent_class`に焦点を当てます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して他の列を削除します。
+
+```py
+>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
+```
+
+ここで例を見てみましょう。
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
+ -0.00024414, -0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 8000},
+ 'intent_class': 2}
+```
+
+次の 2 つのフィールドがあります。
+
+- `audio`: 音声ファイルをロードしてリサンプリングするために呼び出す必要がある音声信号の 1 次元の `array`。
+- `intent_class`: スピーカーのインテントのクラス ID を表します。
+
+モデルがラベル ID からラベル名を取得しやすくするために、ラベル名を整数に、またはその逆にマップする辞書を作成します。
+
+```py
+>>> labels = minds["train"].features["intent_class"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+これで、ラベル ID をラベル名に変換できるようになりました。
+
+```py
+>>> id2label[str(2)]
+'app_error'
+```
+
+## Preprocess
+
+次のステップでは、Wav2Vec2 特徴抽出プログラムをロードしてオーディオ信号を処理します。
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MInDS-14 データセットのサンプリング レートは 8000khz です (この情報は [データセット カード](https://huggingface.co/datasets/PolyAI/minds14) で確認できます)。つまり、データセットを再サンプリングする必要があります。事前トレーニングされた Wav2Vec2 モデルを使用するには、16000kHz に設定します。
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
+ -2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 16000},
+ 'intent_class': 2}
+```
+
+次に、次の前処理関数を作成します。
+
+1. `audio`列を呼び出してロードし、必要に応じてオーディオ ファイルをリサンプリングします。
+2. オーディオ ファイルのサンプリング レートが、モデルが事前トレーニングされたオーディオ データのサンプリング レートと一致するかどうかを確認します。この情報は、Wav2Vec2 [モデル カード](https://huggingface.co/facebook/wav2vec2-base) で見つけることができます。
+3. 入力の最大長を設定して、長い入力を切り捨てずにバッチ処理します。
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
+... )
+... return inputs
+```
+
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `batched=True` を設定してデータセットの複数の要素を一度に処理することで、`map` を高速化できます。不要な列を削除し、`intent_class` の名前を `label` に変更します。これはモデルが期待する名前であるためです。
+
+```py
+>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
+>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
+```
+## Evaluate
+
+トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) メトリクスを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照してください) メトリクスの読み込みと計算方法の詳細については、次を参照してください。
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して精度を計算する関数を作成します。
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions = np.argmax(eval_pred.predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
+```
+
+これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForAudioClassification`] を使用して、予期されるラベルの数とラベル マッピングを使用して Wav2Vec2 を読み込みます。
+
+```py
+>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
+
+>>> num_labels = len(id2label)
+>>> model = AutoModelForAudioClassification.from_pretrained(
+... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
+... )
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`トレーナー`] は精度を評価し、トレーニング チェックポイントを保存します。
+2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_mind_model",
+... evaluation_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=3e-5,
+... per_device_train_batch_size=32,
+... gradient_accumulation_steps=4,
+... per_device_eval_batch_size=32,
+... num_train_epochs=10,
+... warmup_ratio=0.1,
+... logging_steps=10,
+... load_best_model_at_end=True,
+... metric_for_best_model="accuracy",
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=feature_extractor,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+音声分類用のモデルを微調整する方法の詳細な例については、対応する [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+推論を実行したい音声ファイルをロードします。必要に応じて、オーディオ ファイルのサンプリング レートをモデルのサンプリング レートと一致するようにリサンプリングすることを忘れないでください。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して音声分類用の`pipeline`をインスタンス化し、それに音声ファイルを渡します。
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
+>>> classifier(audio_file)
+[
+ {'score': 0.09766869246959686, 'label': 'cash_deposit'},
+ {'score': 0.07998877018690109, 'label': 'app_error'},
+ {'score': 0.0781070664525032, 'label': 'joint_account'},
+ {'score': 0.07667109370231628, 'label': 'pay_bill'},
+ {'score': 0.0755252093076706, 'label': 'balance'}
+]
+```
+
+必要に応じて、`pipeline` の結果を手動で複製することもできます。
+
+
+
+
+特徴抽出器をロードしてオーディオ ファイルを前処理し、`input`を PyTorch テンソルとして返します。
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+入力をモデルに渡し、ロジットを返します。
+
+```py
+>>> from transformers import AutoModelForAudioClassification
+
+>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+最も高い確率でクラスを取得し、モデルの `id2label` マッピングを使用してそれをラベルに変換します。
+
+```py
+>>> import torch
+
+>>> predicted_class_ids = torch.argmax(logits).item()
+>>> predicted_label = model.config.id2label[predicted_class_ids]
+>>> predicted_label
+'cash_deposit'
+```
+
+
\ No newline at end of file
diff --git a/docs/source/ja/tasks/document_question_answering.md b/docs/source/ja/tasks/document_question_answering.md
new file mode 100644
index 00000000000000..478c6af2235490
--- /dev/null
+++ b/docs/source/ja/tasks/document_question_answering.md
@@ -0,0 +1,502 @@
+
+
+# Document Question Answering
+
+[[open-in-colab]]
+
+文書による質問応答は、文書による視覚的な質問応答とも呼ばれ、以下を提供するタスクです。
+ドキュメント画像に関する質問への回答。このタスクをサポートするモデルへの入力は通常、画像と画像の組み合わせです。
+質問があり、出力は自然言語で表現された回答です。これらのモデルは、以下を含む複数のモダリティを利用します。
+テキスト、単語の位置 (境界ボックス)、および画像自体。
+
+このガイドでは、次の方法を説明します。
+
+- [DocVQA データセット](https://huggingface.co/datasets/nielsr/docvqa_1200_examples_donut) の [LayoutLMv2](../model_doc/layoutlmv2) を微調整します。
+- 微調整されたモデルを推論に使用します。
+
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+
+[LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3)
+
+
+
+
+
+LayoutLMv2 は、最後の非表示のヘッダーの上に質問応答ヘッドを追加することで、ドキュメントの質問応答タスクを解決します。
+トークンの状態を調べて、トークンの開始トークンと終了トークンの位置を予測します。
+答え。言い換えれば、問題は抽出的質問応答として扱われます。つまり、コンテキストを考慮して、どの部分を抽出するかということです。
+の情報が質問に答えます。コンテキストは OCR エンジンの出力から取得されます。ここでは Google の Tesseract です。
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。 LayoutLMv2 は detectron2、torchvision、tesseract に依存します。
+
+```bash
+pip install -q transformers datasets
+```
+
+```bash
+pip install 'git+https://github.com/facebookresearch/detectron2.git'
+pip install torchvision
+```
+
+```bash
+sudo apt install tesseract-ocr
+pip install -q pytesseract
+```
+
+すべての依存関係をインストールしたら、ランタイムを再起動します。
+
+モデルをコミュニティと共有することをお勧めします。 Hugging Face アカウントにログインして、🤗 ハブにアップロードします。
+プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+いくつかのグローバル変数を定義しましょう。
+
+```py
+>>> model_checkpoint = "microsoft/layoutlmv2-base-uncased"
+>>> batch_size = 4
+```
+
+## Load the data
+
+このガイドでは、🤗 Hub にある前処理された DocVQA の小さなサンプルを使用します。フルに使いたい場合は、
+DocVQA データセットは、[DocVQA ホームページ](https://rrc.cvc.uab.es/?ch=17) で登録してダウンロードできます。そうすれば、
+このガイドを進めて、[🤗 データセットにファイルをロードする方法](https://huggingface.co/docs/datasets/loading#local-and-remote-files) を確認してください。
+
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("nielsr/docvqa_1200_examples")
+>>> dataset
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 1000
+ })
+ test: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 200
+ })
+})
+```
+
+ご覧のとおり、データセットはすでにトレーニング セットとテスト セットに分割されています。理解するためにランダムな例を見てみましょう
+機能を備えた自分自身。
+
+```py
+>>> dataset["train"].features
+```
+
+個々のフィールドが表す内容は次のとおりです。
+* `id`: サンプルのID
+* `image`: ドキュメント画像を含む PIL.Image.Image オブジェクト
+* `query`: 質問文字列 - いくつかの言語での自然言語による質問
+* `answers`: ヒューマン アノテーターによって提供された正解のリスト
+* `words` と `bounding_boxes`: OCR の結果。ここでは使用しません。
+* `answer`: 別のモデルと一致する答え。ここでは使用しません。
+
+英語の質問だけを残し、別のモデルによる予測が含まれていると思われる`answer`機能を削除しましょう。
+また、アノテーターによって提供されたセットから最初の回答を取得します。あるいは、ランダムにサンプリングすることもできます。
+
+```py
+>>> updated_dataset = dataset.map(lambda example: {"question": example["query"]["en"]}, remove_columns=["query"])
+>>> updated_dataset = updated_dataset.map(
+... lambda example: {"answer": example["answers"][0]}, remove_columns=["answer", "answers"]
+... )
+```
+
+このガイドで使用する LayoutLMv2 チェックポイントは、`max_position_embeddings = 512` でトレーニングされていることに注意してください (
+この情報は、[チェックポイントの `config.json` ファイル](https://huggingface.co/microsoft/layoutlmv2-base-uncased/blob/main/config.json#L18)) で見つけてください。
+例を省略することもできますが、答えが大きな文書の最後にあり、結局省略されてしまうという状況を避けるために、
+ここでは、埋め込みが 512 を超える可能性があるいくつかの例を削除します。
+データセット内のほとんどのドキュメントが長い場合は、スライディング ウィンドウ戦略を実装できます。詳細については、[このノートブック](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb) を確認してください。 。
+
+```py
+>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
+```
+
+この時点で、このデータセットから OCR 機能も削除しましょう。これらは、異なるデータを微調整するための OCR の結果です。
+モデル。これらは入力要件と一致しないため、使用したい場合はさらに処理が必要になります。
+このガイドで使用するモデルの。代わりに、OCR と OCR の両方の元のデータに対して [`LayoutLMv2Processor`] を使用できます。
+トークン化。このようにして、モデルの予想される入力と一致する入力を取得します。画像を手動で加工したい場合は、
+モデルがどのような入力形式を想定しているかを知るには、[`LayoutLMv2` モデルのドキュメント](../model_doc/layoutlmv2) を確認してください。
+
+```py
+>>> updated_dataset = updated_dataset.remove_columns("words")
+>>> updated_dataset = updated_dataset.remove_columns("bounding_boxes")
+```
+
+最後に、画像サンプルを確認しないとデータ探索は完了しません。
+
+
+```py
+>>> updated_dataset["train"][11]["image"]
+```
+
+
+
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextV2ForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextV2Config
+
+[[autodoc]] ConvNextV2Config
+
+## ConvNextV2Model
+
+[[autodoc]] ConvNextV2Model
+ - forward
+
+## ConvNextV2ForImageClassification
+
+[[autodoc]] ConvNextV2ForImageClassification
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
new file mode 100644
index 00000000000000..9776f676844e7d
--- /dev/null
+++ b/docs/source/ja/model_doc/cpm.md
@@ -0,0 +1,54 @@
+
+
+# CPM
+
+## Overview
+
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
+Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデル (PLM) は、さまざまな下流の NLP タスクに有益であることが証明されています。最近ではGPT-3、
+1,750億個のパラメータと570GBの学習データを備え、数回の撮影(1枚でも)の容量で大きな注目を集めました
+ゼロショット)学習。ただし、GPT-3 を適用して中国語の NLP タスクに対処することは依然として困難です。
+GPT-3 の言語は主に英語であり、パラメーターは公開されていません。この技術レポートでは、
+大規模な中国語トレーニング データに対する生成的事前トレーニングを備えた中国語事前トレーニング済み言語モデル (CPM)。最高に
+私たちの知識の限りでは、26 億のパラメータと 100GB の中国語トレーニング データを備えた CPM は、事前トレーニングされた中国語としては最大のものです。
+言語モデルは、会話、エッセイの作成、
+クローゼテストと言語理解。広範な実験により、CPM が多くの環境で優れたパフォーマンスを達成できることが実証されています。
+少数ショット (ゼロショットでも) 学習の設定での NLP タスク。*
+
+このモデルは [canwenxu](https://huggingface.co/canwenxu) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/TsinghuaAI/CPM-Generate
+
+
+
+
+CPM のアーキテクチャは、トークン化方法を除いて GPT-2 と同じです。詳細については、[GPT-2 ドキュメント](gpt2) を参照してください。
+API リファレンス情報。
+
+
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
diff --git a/docs/source/ja/perf_hardware.md b/docs/source/ja/perf_hardware.md
index b58db6e76d0995..a0db527a94b662 100644
--- a/docs/source/ja/perf_hardware.md
+++ b/docs/source/ja/perf_hardware.md
@@ -139,7 +139,7 @@ NVLinkを使用すると、トレーニングが約23%速く完了すること
```bash
# DDP w/ NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -148,7 +148,7 @@ rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch
# DDP w/o NVLink
-rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/ja/perf_infer_gpu_one.md b/docs/source/ja/perf_infer_gpu_one.md
index d6a18a6f3e2047..6d7466e022220a 100644
--- a/docs/source/ja/perf_infer_gpu_one.md
+++ b/docs/source/ja/perf_infer_gpu_one.md
@@ -44,7 +44,7 @@ Flash Attention 2は、モデルのdtypeが`fp16`または`bf16`の場合にの
### Quick usage
-モデルでFlash Attention 2を有効にするには、`from_pretrained`の引数に`use_flash_attention_2`を追加します。
+モデルでFlash Attention 2を有効にするには、`from_pretrained`の引数に`attn_implementation="flash_attention_2"`を追加します。
```python
@@ -57,7 +57,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -114,7 +114,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -132,7 +132,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
```
@@ -151,7 +151,7 @@ tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
)
lora_config = LoraConfig(
diff --git a/docs/source/ja/perf_train_gpu_many.md b/docs/source/ja/perf_train_gpu_many.md
index fd7713c49369f6..71d6c2805865aa 100644
--- a/docs/source/ja/perf_train_gpu_many.md
+++ b/docs/source/ja/perf_train_gpu_many.md
@@ -143,7 +143,7 @@ python examples/pytorch/language-modeling/run_clm.py \
# DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
@@ -151,7 +151,7 @@ python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-
# DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
-python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
diff --git a/docs/source/ja/preprocessing.md b/docs/source/ja/preprocessing.md
index c4e3566fd3aee4..b8fad2a0d21b36 100644
--- a/docs/source/ja/preprocessing.md
+++ b/docs/source/ja/preprocessing.md
@@ -227,7 +227,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
オーディオタスクの場合、データセットをモデル用に準備するために[特徴抽出器](main_classes/feature_extractor)が必要です。
特徴抽出器は生のオーディオデータから特徴を抽出し、それらをテンソルに変換するために設計されています。
-[PolyAI/minds14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードして(データセットのロード方法の詳細については🤗 [Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照)、
+[PolyAI/minds14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードして(データセットのロード方法の詳細については🤗 [Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照)、
オーディオデータセットで特徴抽出器をどのように使用できるかを確認してみましょう:
```python
@@ -349,7 +349,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
-コンピュータビジョンのデータセットで画像プロセッサを使用する方法を示すために、[food101](https://huggingface.co/datasets/food101)データセットをロードします(データセットのロード方法の詳細については🤗[Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照):
+コンピュータビジョンのデータセットで画像プロセッサを使用する方法を示すために、[food101](https://huggingface.co/datasets/food101)データセットをロードします(データセットのロード方法の詳細については🤗[Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
@@ -363,7 +363,7 @@ array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
>>> dataset = load_dataset("food101", split="train[:100]")
```
-次に、🤗 Datasetsの [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) 機能で画像を見てみましょう:
+次に、🤗 Datasetsの [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) 機能で画像を見てみましょう:
```python
>>> dataset[0]["image"]
@@ -419,7 +419,7 @@ AutoImageProcessorを[`AutoImageProcessor.from_pretrained`]を使用してロー
画像を増強変換の一部として正規化したい場合は、`image_processor.image_mean` と `image_processor.image_std` の値を使用してください。
-3. 次に、🤗 Datasetsの[`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform)を使用して、変換をリアルタイムで適用します:
+3. 次に、🤗 Datasetsの[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)を使用して、変換をリアルタイムで適用します:
```python
>>> dataset.set_transform(transforms)
@@ -474,7 +474,7 @@ AutoImageProcessorを[`AutoImageProcessor.from_pretrained`]を使用してロー
マルチモーダル入力を使用するタスクの場合、モデル用にデータセットを準備するための[プロセッサ](main_classes/processors)が必要です。プロセッサは、トークナイザや特徴量抽出器などの2つの処理オブジェクトを結合します。
-自動音声認識(ASR)のためのプロセッサの使用方法を示すために、[LJ Speech](https://huggingface.co/datasets/lj_speech)データセットをロードします(データセットのロード方法の詳細については🤗 [Datasets チュートリアル](https://huggingface.co/docs/datasets/load_hub.html)を参照):
+自動音声認識(ASR)のためのプロセッサの使用方法を示すために、[LJ Speech](https://huggingface.co/datasets/lj_speech)データセットをロードします(データセットのロード方法の詳細については🤗 [Datasets チュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
```python
>>> from datasets import load_dataset
diff --git a/docs/source/ja/run_scripts.md b/docs/source/ja/run_scripts.md
index 1fde9afc0c6e5d..a7cc89d1348491 100644
--- a/docs/source/ja/run_scripts.md
+++ b/docs/source/ja/run_scripts.md
@@ -140,7 +140,7 @@ python examples/tensorflow/summarization/run_summarization.py \
以下は提供されたBashコードです。このコードの日本語訳をMarkdown形式で記載します。
```bash
-python -m torch.distributed.launch \
+torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
diff --git a/docs/source/ja/tasks/asr.md b/docs/source/ja/tasks/asr.md
new file mode 100644
index 00000000000000..fd564abdc5c908
--- /dev/null
+++ b/docs/source/ja/tasks/asr.md
@@ -0,0 +1,380 @@
+
+
+# Automatic speech recognition
+
+[[open-in-colab]]
+
+
+
+自動音声認識 (ASR) は音声信号をテキストに変換し、一連の音声入力をテキスト出力にマッピングします。 Siri や Alexa などの仮想アシスタントは ASR モデルを使用してユーザーを日常的に支援しており、ライブキャプションや会議中のメモ取りなど、他にも便利なユーザー向けアプリケーションが数多くあります。
+
+このガイドでは、次の方法を説明します。
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) を微調整して、音声をテキストに書き起こします。
+2. 微調整したモデルを推論に使用します。
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
+
+
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate jiwer
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load MInDS-14 dataset
+
+まず、🤗 データセット ライブラリから [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの小さいサブセットをロードします。これにより、完全なデータセットのトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
+```
+
+[`~Dataset.train_test_split`] メソッドを使用して、データセットの `train` 分割をトレイン セットとテスト セットに分割します。
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+次に、データセットを見てみましょう。
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 16
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 4
+ })
+})
+```
+
+データセットには`lang_id`や`english_transcription`などの多くの有用な情報が含まれていますが、このガイドでは「`audio`」と「`transciption`」に焦点を当てます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して他の列を削除します。
+
+```py
+>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
+```
+
+もう一度例を見てみましょう。
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
+ 0.00024414, 0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 8000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+次の 2 つのフィールドがあります。
+
+- `audio`: 音声ファイルをロードしてリサンプリングするために呼び出す必要がある音声信号の 1 次元の `array`。
+- `transcription`: ターゲットテキスト。
+
+## Preprocess
+
+次のステップでは、Wav2Vec2 プロセッサをロードしてオーディオ信号を処理します。
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MInDS-14 データセットのサンプリング レートは 8000kHz です (この情報は [データセット カード](https://huggingface.co/datasets/PolyAI/minds14) で確認できます)。つまり、データセットを再サンプリングする必要があります。事前トレーニングされた Wav2Vec2 モデルを使用するには、16000kHz に設定します。
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
+ 2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 16000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+上の `transcription` でわかるように、テキストには大文字と小文字が混在しています。 Wav2Vec2 トークナイザーは大文字のみでトレーニングされるため、テキストがトークナイザーの語彙と一致することを確認する必要があります。
+
+```py
+>>> def uppercase(example):
+... return {"transcription": example["transcription"].upper()}
+
+
+>>> minds = minds.map(uppercase)
+```
+
+次に、次の前処理関数を作成します。
+
+1. `audio`列を呼び出して、オーディオ ファイルをロードしてリサンプリングします。
+2. オーディオ ファイルから `input_values` を抽出し、プロセッサを使用して `transcription` 列をトークン化します。
+
+```py
+>>> def prepare_dataset(batch):
+... audio = batch["audio"]
+... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
+... batch["input_length"] = len(batch["input_values"][0])
+... return batch
+```
+
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
+
+```py
+>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
+```
+
+🤗 Transformers には ASR 用のデータ照合器がないため、[`DataCollatorWithPadding`] を調整してサンプルのバッチを作成する必要があります。また、テキストとラベルが (データセット全体ではなく) バッチ内の最も長い要素の長さに合わせて動的に埋め込まれ、均一な長さになります。 `padding=True` を設定すると、`tokenizer` 関数でテキストを埋め込むことができますが、動的な埋め込みの方が効率的です。
+
+他のデータ照合器とは異なり、この特定のデータ照合器は、`input_values`と `labels`」に異なるパディング方法を適用する必要があります。
+
+```py
+>>> import torch
+
+>>> from dataclasses import dataclass, field
+>>> from typing import Any, Dict, List, Optional, Union
+
+
+>>> @dataclass
+... class DataCollatorCTCWithPadding:
+... processor: AutoProcessor
+... padding: Union[bool, str] = "longest"
+
+... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+... # split inputs and labels since they have to be of different lengths and need
+... # different padding methods
+... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
+... label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
+
+... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
+
+... # replace padding with -100 to ignore loss correctly
+... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+... batch["labels"] = labels
+
+... return batch
+```
+
+次に、`DataCollatorForCTCWithPadding` をインスタンス化します。
+
+```py
+>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
+```
+
+## Evaluate
+
+トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[単語エラー率](https://huggingface.co/spaces/evaluate-metric/wer) (WER) メトリクスを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照して、メトリクスをロードして計算する方法の詳細を確認してください)。
+
+```py
+>>> import evaluate
+
+>>> wer = evaluate.load("wer")
+```
+
+次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して WER を計算する関数を作成します。
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(pred):
+... pred_logits = pred.predictions
+... pred_ids = np.argmax(pred_logits, axis=-1)
+
+... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
+
+... pred_str = processor.batch_decode(pred_ids)
+... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
+
+... wer = wer.compute(predictions=pred_str, references=label_str)
+
+... return {"wer": wer}
+```
+
+これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForCTC`] で Wav2Vec2 をロードします。 `ctc_loss_reduction` パラメータで適用する削減を指定します。多くの場合、デフォルトの合計ではなく平均を使用する方が適切です。
+
+```py
+>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
+
+>>> model = AutoModelForCTC.from_pretrained(
+... "facebook/wav2vec2-base",
+... ctc_loss_reduction="mean",
+... pad_token_id=processor.tokenizer.pad_token_id,
+... )
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`トレーナー`] は WER を評価し、トレーニング チェックポイントを保存します。
+2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_asr_mind_model",
+... per_device_train_batch_size=8,
+... gradient_accumulation_steps=2,
+... learning_rate=1e-5,
+... warmup_steps=500,
+... max_steps=2000,
+... gradient_checkpointing=True,
+... fp16=True,
+... group_by_length=True,
+... evaluation_strategy="steps",
+... per_device_eval_batch_size=8,
+... save_steps=1000,
+... eval_steps=1000,
+... logging_steps=25,
+... load_best_model_at_end=True,
+... metric_for_best_model="wer",
+... greater_is_better=False,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=processor,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+
+自動音声認識用にモデルを微調整する方法のより詳細な例については、英語 ASR および英語のこのブログ [投稿](https://huggingface.co/blog/fine-tune-wav2vec2-english) を参照してください。多言語 ASR については、この [投稿](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) を参照してください。
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+推論を実行したい音声ファイルをロードします。必要に応じて、オーディオ ファイルのサンプリング レートをモデルのサンプリング レートと一致するようにリサンプリングすることを忘れないでください。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して自動音声認識用の`pipeline`をインスタンス化し、オーディオ ファイルをそれに渡します。
+
+```py
+>>> from transformers import pipeline
+
+>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
+>>> transcriber(audio_file)
+{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
+```
+
+
+
+転写はまあまあですが、もっと良くなる可能性があります。さらに良い結果を得るには、より多くの例でモデルを微調整してみてください。
+
+
+
+必要に応じて、「パイプライン」の結果を手動で複製することもできます。
+
+
+
+
+プロセッサをロードしてオーディオ ファイルと文字起こしを前処理し、`input`を PyTorch テンソルとして返します。
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+Pass your inputs to the model and return the logits:
+
+```py
+>>> from transformers import AutoModelForCTC
+
+>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+最も高い確率で予測された `input_ids` を取得し、プロセッサを使用して予測された `input_ids` をデコードしてテキストに戻します。
+
+
+```py
+>>> import torch
+
+>>> predicted_ids = torch.argmax(logits, dim=-1)
+>>> transcription = processor.batch_decode(predicted_ids)
+>>> transcription
+['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
+```
+
+
+
diff --git a/docs/source/ja/tasks/audio_classification.md b/docs/source/ja/tasks/audio_classification.md
new file mode 100644
index 00000000000000..58d42f3f4d4ff1
--- /dev/null
+++ b/docs/source/ja/tasks/audio_classification.md
@@ -0,0 +1,330 @@
+
+
+# Audio classification
+
+[[open-in-colab]]
+
+
+
+
+音声分類では、テキストと同様に、入力データから出力されたクラス ラベルを割り当てます。唯一の違いは、テキスト入力の代わりに生のオーディオ波形があることです。音声分類の実際的な応用例には、話者の意図、言語分類、さらには音による動物の種類の識別などがあります。
+
+このガイドでは、次の方法を説明します。
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットで [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) を微調整して話者の意図を分類します。
+2. 微調整したモデルを推論に使用します。
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
+
+
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load MInDS-14 dataset
+
+まず、🤗 データセット ライブラリから MInDS-14 データセットをロードします。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットの `train` をより小さなトレインとテスト セットに分割します。これにより、完全なデータセットにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+次に、データセットを見てみましょう。
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 450
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 113
+ })
+})
+```
+
+
+データセットには`lang_id`や`english_transcription`などの多くの有用な情報が含まれていますが、このガイドでは`audio`と`intent_class`に焦点を当てます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して他の列を削除します。
+
+```py
+>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
+```
+
+ここで例を見てみましょう。
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
+ -0.00024414, -0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 8000},
+ 'intent_class': 2}
+```
+
+次の 2 つのフィールドがあります。
+
+- `audio`: 音声ファイルをロードしてリサンプリングするために呼び出す必要がある音声信号の 1 次元の `array`。
+- `intent_class`: スピーカーのインテントのクラス ID を表します。
+
+モデルがラベル ID からラベル名を取得しやすくするために、ラベル名を整数に、またはその逆にマップする辞書を作成します。
+
+```py
+>>> labels = minds["train"].features["intent_class"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+これで、ラベル ID をラベル名に変換できるようになりました。
+
+```py
+>>> id2label[str(2)]
+'app_error'
+```
+
+## Preprocess
+
+次のステップでは、Wav2Vec2 特徴抽出プログラムをロードしてオーディオ信号を処理します。
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MInDS-14 データセットのサンプリング レートは 8000khz です (この情報は [データセット カード](https://huggingface.co/datasets/PolyAI/minds14) で確認できます)。つまり、データセットを再サンプリングする必要があります。事前トレーニングされた Wav2Vec2 モデルを使用するには、16000kHz に設定します。
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
+ -2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 16000},
+ 'intent_class': 2}
+```
+
+次に、次の前処理関数を作成します。
+
+1. `audio`列を呼び出してロードし、必要に応じてオーディオ ファイルをリサンプリングします。
+2. オーディオ ファイルのサンプリング レートが、モデルが事前トレーニングされたオーディオ データのサンプリング レートと一致するかどうかを確認します。この情報は、Wav2Vec2 [モデル カード](https://huggingface.co/facebook/wav2vec2-base) で見つけることができます。
+3. 入力の最大長を設定して、長い入力を切り捨てずにバッチ処理します。
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
+... )
+... return inputs
+```
+
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `batched=True` を設定してデータセットの複数の要素を一度に処理することで、`map` を高速化できます。不要な列を削除し、`intent_class` の名前を `label` に変更します。これはモデルが期待する名前であるためです。
+
+```py
+>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
+>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
+```
+## Evaluate
+
+トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) メトリクスを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照してください) メトリクスの読み込みと計算方法の詳細については、次を参照してください。
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して精度を計算する関数を作成します。
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions = np.argmax(eval_pred.predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
+```
+
+これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForAudioClassification`] を使用して、予期されるラベルの数とラベル マッピングを使用して Wav2Vec2 を読み込みます。
+
+```py
+>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
+
+>>> num_labels = len(id2label)
+>>> model = AutoModelForAudioClassification.from_pretrained(
+... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
+... )
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`トレーナー`] は精度を評価し、トレーニング チェックポイントを保存します。
+2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_mind_model",
+... evaluation_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=3e-5,
+... per_device_train_batch_size=32,
+... gradient_accumulation_steps=4,
+... per_device_eval_batch_size=32,
+... num_train_epochs=10,
+... warmup_ratio=0.1,
+... logging_steps=10,
+... load_best_model_at_end=True,
+... metric_for_best_model="accuracy",
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=feature_extractor,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+音声分類用のモデルを微調整する方法の詳細な例については、対応する [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+推論を実行したい音声ファイルをロードします。必要に応じて、オーディオ ファイルのサンプリング レートをモデルのサンプリング レートと一致するようにリサンプリングすることを忘れないでください。
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して音声分類用の`pipeline`をインスタンス化し、それに音声ファイルを渡します。
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
+>>> classifier(audio_file)
+[
+ {'score': 0.09766869246959686, 'label': 'cash_deposit'},
+ {'score': 0.07998877018690109, 'label': 'app_error'},
+ {'score': 0.0781070664525032, 'label': 'joint_account'},
+ {'score': 0.07667109370231628, 'label': 'pay_bill'},
+ {'score': 0.0755252093076706, 'label': 'balance'}
+]
+```
+
+必要に応じて、`pipeline` の結果を手動で複製することもできます。
+
+
+
+
+特徴抽出器をロードしてオーディオ ファイルを前処理し、`input`を PyTorch テンソルとして返します。
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+入力をモデルに渡し、ロジットを返します。
+
+```py
+>>> from transformers import AutoModelForAudioClassification
+
+>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+最も高い確率でクラスを取得し、モデルの `id2label` マッピングを使用してそれをラベルに変換します。
+
+```py
+>>> import torch
+
+>>> predicted_class_ids = torch.argmax(logits).item()
+>>> predicted_label = model.config.id2label[predicted_class_ids]
+>>> predicted_label
+'cash_deposit'
+```
+
+
\ No newline at end of file
diff --git a/docs/source/ja/tasks/document_question_answering.md b/docs/source/ja/tasks/document_question_answering.md
new file mode 100644
index 00000000000000..478c6af2235490
--- /dev/null
+++ b/docs/source/ja/tasks/document_question_answering.md
@@ -0,0 +1,502 @@
+
+
+# Document Question Answering
+
+[[open-in-colab]]
+
+文書による質問応答は、文書による視覚的な質問応答とも呼ばれ、以下を提供するタスクです。
+ドキュメント画像に関する質問への回答。このタスクをサポートするモデルへの入力は通常、画像と画像の組み合わせです。
+質問があり、出力は自然言語で表現された回答です。これらのモデルは、以下を含む複数のモダリティを利用します。
+テキスト、単語の位置 (境界ボックス)、および画像自体。
+
+このガイドでは、次の方法を説明します。
+
+- [DocVQA データセット](https://huggingface.co/datasets/nielsr/docvqa_1200_examples_donut) の [LayoutLMv2](../model_doc/layoutlmv2) を微調整します。
+- 微調整されたモデルを推論に使用します。
+
+
+
+このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
+
+
+
+
+[LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3)
+
+
+
+
+
+LayoutLMv2 は、最後の非表示のヘッダーの上に質問応答ヘッドを追加することで、ドキュメントの質問応答タスクを解決します。
+トークンの状態を調べて、トークンの開始トークンと終了トークンの位置を予測します。
+答え。言い換えれば、問題は抽出的質問応答として扱われます。つまり、コンテキストを考慮して、どの部分を抽出するかということです。
+の情報が質問に答えます。コンテキストは OCR エンジンの出力から取得されます。ここでは Google の Tesseract です。
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。 LayoutLMv2 は detectron2、torchvision、tesseract に依存します。
+
+```bash
+pip install -q transformers datasets
+```
+
+```bash
+pip install 'git+https://github.com/facebookresearch/detectron2.git'
+pip install torchvision
+```
+
+```bash
+sudo apt install tesseract-ocr
+pip install -q pytesseract
+```
+
+すべての依存関係をインストールしたら、ランタイムを再起動します。
+
+モデルをコミュニティと共有することをお勧めします。 Hugging Face アカウントにログインして、🤗 ハブにアップロードします。
+プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+いくつかのグローバル変数を定義しましょう。
+
+```py
+>>> model_checkpoint = "microsoft/layoutlmv2-base-uncased"
+>>> batch_size = 4
+```
+
+## Load the data
+
+このガイドでは、🤗 Hub にある前処理された DocVQA の小さなサンプルを使用します。フルに使いたい場合は、
+DocVQA データセットは、[DocVQA ホームページ](https://rrc.cvc.uab.es/?ch=17) で登録してダウンロードできます。そうすれば、
+このガイドを進めて、[🤗 データセットにファイルをロードする方法](https://huggingface.co/docs/datasets/loading#local-and-remote-files) を確認してください。
+
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("nielsr/docvqa_1200_examples")
+>>> dataset
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 1000
+ })
+ test: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 200
+ })
+})
+```
+
+ご覧のとおり、データセットはすでにトレーニング セットとテスト セットに分割されています。理解するためにランダムな例を見てみましょう
+機能を備えた自分自身。
+
+```py
+>>> dataset["train"].features
+```
+
+個々のフィールドが表す内容は次のとおりです。
+* `id`: サンプルのID
+* `image`: ドキュメント画像を含む PIL.Image.Image オブジェクト
+* `query`: 質問文字列 - いくつかの言語での自然言語による質問
+* `answers`: ヒューマン アノテーターによって提供された正解のリスト
+* `words` と `bounding_boxes`: OCR の結果。ここでは使用しません。
+* `answer`: 別のモデルと一致する答え。ここでは使用しません。
+
+英語の質問だけを残し、別のモデルによる予測が含まれていると思われる`answer`機能を削除しましょう。
+また、アノテーターによって提供されたセットから最初の回答を取得します。あるいは、ランダムにサンプリングすることもできます。
+
+```py
+>>> updated_dataset = dataset.map(lambda example: {"question": example["query"]["en"]}, remove_columns=["query"])
+>>> updated_dataset = updated_dataset.map(
+... lambda example: {"answer": example["answers"][0]}, remove_columns=["answer", "answers"]
+... )
+```
+
+このガイドで使用する LayoutLMv2 チェックポイントは、`max_position_embeddings = 512` でトレーニングされていることに注意してください (
+この情報は、[チェックポイントの `config.json` ファイル](https://huggingface.co/microsoft/layoutlmv2-base-uncased/blob/main/config.json#L18)) で見つけてください。
+例を省略することもできますが、答えが大きな文書の最後にあり、結局省略されてしまうという状況を避けるために、
+ここでは、埋め込みが 512 を超える可能性があるいくつかの例を削除します。
+データセット内のほとんどのドキュメントが長い場合は、スライディング ウィンドウ戦略を実装できます。詳細については、[このノートブック](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb) を確認してください。 。
+
+```py
+>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
+```
+
+この時点で、このデータセットから OCR 機能も削除しましょう。これらは、異なるデータを微調整するための OCR の結果です。
+モデル。これらは入力要件と一致しないため、使用したい場合はさらに処理が必要になります。
+このガイドで使用するモデルの。代わりに、OCR と OCR の両方の元のデータに対して [`LayoutLMv2Processor`] を使用できます。
+トークン化。このようにして、モデルの予想される入力と一致する入力を取得します。画像を手動で加工したい場合は、
+モデルがどのような入力形式を想定しているかを知るには、[`LayoutLMv2` モデルのドキュメント](../model_doc/layoutlmv2) を確認してください。
+
+```py
+>>> updated_dataset = updated_dataset.remove_columns("words")
+>>> updated_dataset = updated_dataset.remove_columns("bounding_boxes")
+```
+
+最後に、画像サンプルを確認しないとデータ探索は完了しません。
+
+
+```py
+>>> updated_dataset["train"][11]["image"]
+```
+
+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
 +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/zh/main_classes/output.md b/docs/source/zh/main_classes/output.md
new file mode 100644
index 00000000000000..1619e27219d834
--- /dev/null
+++ b/docs/source/zh/main_classes/output.md
@@ -0,0 +1,309 @@
+
+
+# 模型输出
+
+所有模型的输出都是 [`~utils.ModelOutput`] 的子类的实例。这些是包含模型返回的所有信息的数据结构,但也可以用作元组或字典。
+
+让我们看一个例子:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs` 对象是 [`~modeling_outputs.SequenceClassifierOutput`],如下面该类的文档中所示,它表示它有一个可选的 `loss`,一个 `logits`,一个可选的 `hidden_states` 和一个可选的 `attentions` 属性。在这里,我们有 `loss`,因为我们传递了 `labels`,但我们没有 `hidden_states` 和 `attentions`,因为我们没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
+
+
+
+当传递 `output_hidden_states=True` 时,您可能希望 `outputs.hidden_states[-1]` 与 `outputs.last_hidden_states` 完全匹配。然而,这并不总是成立。一些模型在返回最后的 hidden state时对其应用归一化或其他后续处理。
+
+
+
+
+您可以像往常一样访问每个属性,如果模型未返回该属性,您将得到 `None`。在这里,例如,`outputs.loss` 是模型计算的损失,而 `outputs.attentions` 是 `None`。
+
+当将我们的 `outputs` 对象视为元组时,它仅考虑那些没有 `None` 值的属性。例如这里它有两个元素,`loss` 和 `logits`,所以
+
+```python
+outputs[:2]
+```
+
+将返回元组 `(outputs.loss, outputs.logits)`。
+
+将我们的 `outputs` 对象视为字典时,它仅考虑那些没有 `None` 值的属性。例如在这里它有两个键,分别是 `loss` 和 `logits`。
+
+我们在这里记录了被多个类型模型使用的通用模型输出。特定输出类型在其相应的模型页面上有文档。
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## Seq2SeqSpectrogramOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
+
+## SemanticSegmenterOutput
+
+[[autodoc]] modeling_outputs.SemanticSegmenterOutput
+
+## ImageClassifierOutput
+
+[[autodoc]] modeling_outputs.ImageClassifierOutput
+
+## ImageClassifierOutputWithNoAttention
+
+[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
+
+## DepthEstimatorOutput
+
+[[autodoc]] modeling_outputs.DepthEstimatorOutput
+
+## Wav2Vec2BaseModelOutput
+
+[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
+
+## XVectorOutput
+
+[[autodoc]] modeling_outputs.XVectorOutput
+
+## Seq2SeqTSModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
+
+## Seq2SeqTSPredictionOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
+
+## SampleTSPredictionOutput
+
+[[autodoc]] modeling_outputs.SampleTSPredictionOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/source/zh/main_classes/pipelines.md b/docs/source/zh/main_classes/pipelines.md
new file mode 100644
index 00000000000000..4d2f1f0f9386a3
--- /dev/null
+++ b/docs/source/zh/main_classes/pipelines.md
@@ -0,0 +1,474 @@
+
+
+# Pipelines
+
+pipelines是使用模型进行推理的一种简单方法。这些pipelines是抽象了库中大部分复杂代码的对象,提供了一个专用于多个任务的简单API,包括专名识别、掩码语言建模、情感分析、特征提取和问答等。请参阅[任务摘要](../task_summary)以获取使用示例。
+
+有两种pipelines抽象类需要注意:
+
+- [`pipeline`],它是封装所有其他pipelines的最强大的对象。
+- 针对特定任务pipelines,适用于[音频](#audio)、[计算机视觉](#computer-vision)、[自然语言处理](#natural-language-processing)和[多模态](#multimodal)任务。
+
+## pipeline抽象类
+
+*pipeline*抽象类是对所有其他可用pipeline的封装。它可以像任何其他pipeline一样实例化,但进一步提供额外的便利性。
+
+简单调用一个项目:
+
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+如果您想使用 [hub](https://huggingface.co) 上的特定模型,可以忽略任务,如果hub上的模型已经定义了该任务:
+
+```python
+>>> pipe = pipeline(model="roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
+```
+
+要在多个项目上调用pipeline,可以使用*列表*调用它。
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+为了遍历整个数据集,建议直接使用 `dataset`。这意味着您不需要一次性分配整个数据集,也不需要自己进行批处理。这应该与GPU上的自定义循环一样快。如果不是,请随时提出issue。
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+为了方便使用,也可以使用生成器:
+
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+## Pipeline batching
+
+所有pipeline都可以使用批处理。这将在pipeline使用其流处理功能时起作用(即传递列表或 `Dataset` 或 `generator` 时)。
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+然而,这并不自动意味着性能提升。它可能是一个10倍的加速或5倍的减速,具体取决于硬件、数据和实际使用的模型。
+
+主要是加速的示例:
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+主要是减速的示例:
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+与其他句子相比,这是一个非常长的句子。在这种情况下,**整个**批次将需要400个tokens的长度,因此整个批次将是 [64, 400] 而不是 [64, 4],从而导致较大的减速。更糟糕的是,在更大的批次上,程序会崩溃。
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+对于这个问题,没有好的(通用)解决方案,效果可能因您的用例而异。经验法则如下:
+
+对于用户,一个经验法则是:
+
+- **使用硬件测量负载性能。测量、测量、再测量。真实的数字是唯一的方法。**
+- 如果受到延迟的限制(进行推理的实时产品),不要进行批处理。
+- 如果使用CPU,不要进行批处理。
+- 如果您在GPU上处理的是吞吐量(您希望在大量静态数据上运行模型),则:
+ - 如果对序列长度的大小没有概念("自然"数据),默认情况下不要进行批处理,进行测试并尝试逐渐添加,添加OOM检查以在失败时恢复(如果您不能控制序列长度,它将在某些时候失败)。
+ - 如果您的序列长度非常规律,那么批处理更有可能非常有趣,进行测试并推动它,直到出现OOM。
+ - GPU越大,批处理越有可能变得更有趣
+- 一旦启用批处理,确保能够很好地处理OOM。
+
+## Pipeline chunk batching
+
+`zero-shot-classification` 和 `question-answering` 在某种意义上稍微特殊,因为单个输入可能会导致模型的多次前向传递。在正常情况下,这将导致 `batch_size` 参数的问题。
+
+为了规避这个问题,这两个pipeline都有点特殊,它们是 `ChunkPipeline` 而不是常规的 `Pipeline`。简而言之:
+
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+现在变成:
+
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+这对您的代码应该是非常直观的,因为pipeline的使用方式是相同的。
+
+这是一个简化的视图,因为Pipeline可以自动处理批次!这意味着您不必担心您的输入实际上会触发多少次前向传递,您可以独立于输入优化 `batch_size`。前面部分的注意事项仍然适用。
+
+## Pipeline自定义
+
+如果您想要重载特定的pipeline。
+
+请随时为您手头的任务创建一个issue,Pipeline的目标是易于使用并支持大多数情况,因此 `transformers` 可能支持您的用例。
+
+如果您想简单地尝试一下,可以:
+
+- 继承您选择的pipeline
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+这样就可以让您编写所有想要的自定义代码。
+
+
+## 实现一个pipeline
+
+[实现一个新的pipeline](../add_new_pipeline)
+
+## 音频
+
+可用于音频任务的pipeline包括以下几种。
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### TextToAudioPipeline
+
+[[autodoc]] TextToAudioPipeline
+ - __call__
+ - all
+
+
+### ZeroShotAudioClassificationPipeline
+
+[[autodoc]] ZeroShotAudioClassificationPipeline
+ - __call__
+ - all
+
+## 计算机视觉
+
+可用于计算机视觉任务的pipeline包括以下几种。
+
+### DepthEstimationPipeline
+[[autodoc]] DepthEstimationPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### ImageToImagePipeline
+
+[[autodoc]] ImageToImagePipeline
+ - __call__
+ - all
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### VideoClassificationPipeline
+
+[[autodoc]] VideoClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotObjectDetectionPipeline
+
+[[autodoc]] ZeroShotObjectDetectionPipeline
+ - __call__
+ - all
+
+## 自然语言处理
+
+可用于自然语言处理任务的pipeline包括以下几种。
+
+### ConversationalPipeline
+
+[[autodoc]] Conversation
+
+[[autodoc]] ConversationalPipeline
+ - __call__
+ - all
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### NerPipeline
+
+[[autodoc]] NerPipeline
+
+See [`TokenClassificationPipeline`] for all details.
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+## 多模态
+
+可用于多模态任务的pipeline包括以下几种。
+
+### DocumentQuestionAnsweringPipeline
+
+[[autodoc]] DocumentQuestionAnsweringPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### ImageToTextPipeline
+
+[[autodoc]] ImageToTextPipeline
+ - __call__
+ - all
+
+### MaskGenerationPipeline
+
+[[autodoc]] MaskGenerationPipeline
+ - __call__
+ - all
+
+### VisualQuestionAnsweringPipeline
+
+[[autodoc]] VisualQuestionAnsweringPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/source/zh/main_classes/processors.md b/docs/source/zh/main_classes/processors.md
new file mode 100644
index 00000000000000..60167e317adf90
--- /dev/null
+++ b/docs/source/zh/main_classes/processors.md
@@ -0,0 +1,146 @@
+
+
+# Processors
+
+在 Transformers 库中,processors可以有两种不同的含义:
+- 为多模态模型,例如[Wav2Vec2](../model_doc/wav2vec2)(语音和文本)或[CLIP](../model_doc/clip)(文本和视觉)预处理输入的对象
+- 在库的旧版本中用于预处理GLUE或SQUAD数据的已弃用对象。
+
+## 多模态processors
+
+任何多模态模型都需要一个对象来编码或解码将多个模态(包括文本、视觉和音频)组合在一起的数据。这由称为processors的对象处理,这些processors将两个或多个处理对象组合在一起,例如tokenizers(用于文本模态),image processors(用于视觉)和feature extractors(用于音频)。
+
+这些processors继承自以下实现保存和加载功能的基类:
+
+
+[[autodoc]] ProcessorMixin
+
+## 已弃用的processors
+
+所有processor都遵循与 [`~data.processors.utils.DataProcessor`] 相同的架构。processor返回一个 [`~data.processors.utils.InputExample`] 列表。这些 [`~data.processors.utils.InputExample`] 可以转换为 [`~data.processors.utils.InputFeatures`] 以供输送到模型。
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) 是一个基准测试,评估模型在各种现有的自然语言理解任务上的性能。它与论文 [GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) 一同发布。
+
+该库为以下任务提供了总共10个processor:MRPC、MNLI、MNLI(mismatched)、CoLA、SST2、STSB、QQP、QNLI、RTE 和 WNLI。
+
+这些processor是:
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+此外,还可以使用以下方法从数据文件加载值并将其转换为 [`~data.processors.utils.InputExample`] 列表。
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+
+## XNLI
+
+[跨语言NLI语料库(XNLI)](https://www.nyu.edu/projects/bowman/xnli/) 是一个评估跨语言文本表示质量的基准测试。XNLI是一个基于[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/)的众包数据集:”文本对“被标记为包含15种不同语言(包括英语等高资源语言和斯瓦希里语等低资源语言)的文本蕴涵注释。
+
+它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) 一同发布。
+
+该库提供了加载XNLI数据的processor:
+
+- [`~data.processors.utils.XnliProcessor`]
+
+请注意,由于测试集上有“gold”标签,因此评估是在测试集上进行的。
+
+使用这些processor的示例在 [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) 脚本中提供。
+
+
+## SQuAD
+
+[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822) 一同发布。
+
+该库为两个版本各自提供了一个processor:
+
+### Processors
+
+这两个processor是:
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+它们都继承自抽象类 [`~data.processors.utils.SquadProcessor`]。
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+此外,可以使用以下方法将 SQuAD 示例转换为可用作模型输入的 [`~data.processors.utils.SquadFeatures`]。
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+
+这些processor以及前面提到的方法可以与包含数据的文件以及tensorflow_datasets包一起使用。下面给出了示例。
+
+
+### Example使用
+
+以下是使用processor以及使用数据文件的转换方法的示例:
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+使用 *tensorflow_datasets* 就像使用数据文件一样简单:
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+另一个使用这些processor的示例在 [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) 脚本中提供。
\ No newline at end of file
diff --git a/docs/source/zh/main_classes/quantization.md b/docs/source/zh/main_classes/quantization.md
new file mode 100644
index 00000000000000..3c7e4d9212a1d0
--- /dev/null
+++ b/docs/source/zh/main_classes/quantization.md
@@ -0,0 +1,572 @@
+
+
+# 量化 🤗 Transformers 模型
+
+## AWQ集成
+
+AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://arxiv.org/abs/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
+
+我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
+
+
+### 量化一个模型
+
+我们建议用户查看生态系统中不同的现有工具,以使用AWQ算法对其模型进行量化,例如:
+
+- [`llm-awq`](https://github.com/mit-han-lab/llm-awq),来自MIT Han Lab
+- [`autoawq`](https://github.com/casper-hansen/AutoAWQ),来自[`casper-hansen`](https://github.com/casper-hansen)
+- Intel neural compressor,来自Intel - 通过[`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)使用
+
+生态系统中可能存在许多其他工具,请随时提出PR将它们添加到列表中。
+目前与🤗 Transformers的集成仅适用于使用`autoawq`和`llm-awq`量化后的模型。大多数使用`auto-awq`量化的模型可以在🤗 Hub的[`TheBloke`](https://huggingface.co/TheBloke)命名空间下找到,要使用`llm-awq`对模型进行量化,请参阅[`llm-awq`](https://github.com/mit-han-lab/llm-awq/)的示例文件夹中的[`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py)脚本。
+
+
+### 加载一个量化的模型
+
+您可以使用`from_pretrained`方法从Hub加载一个量化模型。通过检查模型配置文件(`configuration.json`)中是否存在`quantization_config`属性,来进行确认推送的权重是量化的。您可以通过检查字段`quantization_config.quant_method`来确认模型是否以AWQ格式进行量化,该字段应该设置为`"awq"`。请注意,为了性能原因,默认情况下加载模型将设置其他权重为`float16`。如果您想更改这种设置,可以通过将`torch_dtype`参数设置为`torch.float32`或`torch.bfloat16`。在下面的部分中,您可以找到一些示例片段和notebook。
+
+
+## 示例使用
+
+首先,您需要安装[`autoawq`](https://github.com/casper-hansen/AutoAWQ)库
+
+```bash
+pip install autoawq
+```
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
+```
+
+如果您首先将模型加载到CPU上,请确保在使用之前将其移动到GPU设备上。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
+```
+
+### 结合 AWQ 和 Flash Attention
+
+您可以将AWQ量化与Flash Attention结合起来,得到一个既被量化又更快速的模型。只需使用`from_pretrained`加载模型,并传递`attn_implementation="flash_attention_2"`参数。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
+```
+
+### 基准测试
+
+我们使用[`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark)库进行了一些速度、吞吐量和延迟基准测试。
+
+请注意,在编写本文档部分时,可用的量化方法包括:`awq`、`gptq`和`bitsandbytes`。
+
+基准测试在一台NVIDIA-A100实例上运行,使用[`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)作为AWQ模型,[`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)作为GPTQ模型。我们还将其与`bitsandbytes`量化模型和`float16`模型进行了对比。以下是一些结果示例:
+
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/zh/main_classes/output.md b/docs/source/zh/main_classes/output.md
new file mode 100644
index 00000000000000..1619e27219d834
--- /dev/null
+++ b/docs/source/zh/main_classes/output.md
@@ -0,0 +1,309 @@
+
+
+# 模型输出
+
+所有模型的输出都是 [`~utils.ModelOutput`] 的子类的实例。这些是包含模型返回的所有信息的数据结构,但也可以用作元组或字典。
+
+让我们看一个例子:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs` 对象是 [`~modeling_outputs.SequenceClassifierOutput`],如下面该类的文档中所示,它表示它有一个可选的 `loss`,一个 `logits`,一个可选的 `hidden_states` 和一个可选的 `attentions` 属性。在这里,我们有 `loss`,因为我们传递了 `labels`,但我们没有 `hidden_states` 和 `attentions`,因为我们没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
+
+
+
+当传递 `output_hidden_states=True` 时,您可能希望 `outputs.hidden_states[-1]` 与 `outputs.last_hidden_states` 完全匹配。然而,这并不总是成立。一些模型在返回最后的 hidden state时对其应用归一化或其他后续处理。
+
+
+
+
+您可以像往常一样访问每个属性,如果模型未返回该属性,您将得到 `None`。在这里,例如,`outputs.loss` 是模型计算的损失,而 `outputs.attentions` 是 `None`。
+
+当将我们的 `outputs` 对象视为元组时,它仅考虑那些没有 `None` 值的属性。例如这里它有两个元素,`loss` 和 `logits`,所以
+
+```python
+outputs[:2]
+```
+
+将返回元组 `(outputs.loss, outputs.logits)`。
+
+将我们的 `outputs` 对象视为字典时,它仅考虑那些没有 `None` 值的属性。例如在这里它有两个键,分别是 `loss` 和 `logits`。
+
+我们在这里记录了被多个类型模型使用的通用模型输出。特定输出类型在其相应的模型页面上有文档。
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## Seq2SeqSpectrogramOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
+
+## SemanticSegmenterOutput
+
+[[autodoc]] modeling_outputs.SemanticSegmenterOutput
+
+## ImageClassifierOutput
+
+[[autodoc]] modeling_outputs.ImageClassifierOutput
+
+## ImageClassifierOutputWithNoAttention
+
+[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
+
+## DepthEstimatorOutput
+
+[[autodoc]] modeling_outputs.DepthEstimatorOutput
+
+## Wav2Vec2BaseModelOutput
+
+[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
+
+## XVectorOutput
+
+[[autodoc]] modeling_outputs.XVectorOutput
+
+## Seq2SeqTSModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
+
+## Seq2SeqTSPredictionOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
+
+## SampleTSPredictionOutput
+
+[[autodoc]] modeling_outputs.SampleTSPredictionOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/source/zh/main_classes/pipelines.md b/docs/source/zh/main_classes/pipelines.md
new file mode 100644
index 00000000000000..4d2f1f0f9386a3
--- /dev/null
+++ b/docs/source/zh/main_classes/pipelines.md
@@ -0,0 +1,474 @@
+
+
+# Pipelines
+
+pipelines是使用模型进行推理的一种简单方法。这些pipelines是抽象了库中大部分复杂代码的对象,提供了一个专用于多个任务的简单API,包括专名识别、掩码语言建模、情感分析、特征提取和问答等。请参阅[任务摘要](../task_summary)以获取使用示例。
+
+有两种pipelines抽象类需要注意:
+
+- [`pipeline`],它是封装所有其他pipelines的最强大的对象。
+- 针对特定任务pipelines,适用于[音频](#audio)、[计算机视觉](#computer-vision)、[自然语言处理](#natural-language-processing)和[多模态](#multimodal)任务。
+
+## pipeline抽象类
+
+*pipeline*抽象类是对所有其他可用pipeline的封装。它可以像任何其他pipeline一样实例化,但进一步提供额外的便利性。
+
+简单调用一个项目:
+
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+如果您想使用 [hub](https://huggingface.co) 上的特定模型,可以忽略任务,如果hub上的模型已经定义了该任务:
+
+```python
+>>> pipe = pipeline(model="roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
+```
+
+要在多个项目上调用pipeline,可以使用*列表*调用它。
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+为了遍历整个数据集,建议直接使用 `dataset`。这意味着您不需要一次性分配整个数据集,也不需要自己进行批处理。这应该与GPU上的自定义循环一样快。如果不是,请随时提出issue。
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+为了方便使用,也可以使用生成器:
+
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+## Pipeline batching
+
+所有pipeline都可以使用批处理。这将在pipeline使用其流处理功能时起作用(即传递列表或 `Dataset` 或 `generator` 时)。
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+然而,这并不自动意味着性能提升。它可能是一个10倍的加速或5倍的减速,具体取决于硬件、数据和实际使用的模型。
+
+主要是加速的示例:
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+主要是减速的示例:
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+与其他句子相比,这是一个非常长的句子。在这种情况下,**整个**批次将需要400个tokens的长度,因此整个批次将是 [64, 400] 而不是 [64, 4],从而导致较大的减速。更糟糕的是,在更大的批次上,程序会崩溃。
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+对于这个问题,没有好的(通用)解决方案,效果可能因您的用例而异。经验法则如下:
+
+对于用户,一个经验法则是:
+
+- **使用硬件测量负载性能。测量、测量、再测量。真实的数字是唯一的方法。**
+- 如果受到延迟的限制(进行推理的实时产品),不要进行批处理。
+- 如果使用CPU,不要进行批处理。
+- 如果您在GPU上处理的是吞吐量(您希望在大量静态数据上运行模型),则:
+ - 如果对序列长度的大小没有概念("自然"数据),默认情况下不要进行批处理,进行测试并尝试逐渐添加,添加OOM检查以在失败时恢复(如果您不能控制序列长度,它将在某些时候失败)。
+ - 如果您的序列长度非常规律,那么批处理更有可能非常有趣,进行测试并推动它,直到出现OOM。
+ - GPU越大,批处理越有可能变得更有趣
+- 一旦启用批处理,确保能够很好地处理OOM。
+
+## Pipeline chunk batching
+
+`zero-shot-classification` 和 `question-answering` 在某种意义上稍微特殊,因为单个输入可能会导致模型的多次前向传递。在正常情况下,这将导致 `batch_size` 参数的问题。
+
+为了规避这个问题,这两个pipeline都有点特殊,它们是 `ChunkPipeline` 而不是常规的 `Pipeline`。简而言之:
+
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+现在变成:
+
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+这对您的代码应该是非常直观的,因为pipeline的使用方式是相同的。
+
+这是一个简化的视图,因为Pipeline可以自动处理批次!这意味着您不必担心您的输入实际上会触发多少次前向传递,您可以独立于输入优化 `batch_size`。前面部分的注意事项仍然适用。
+
+## Pipeline自定义
+
+如果您想要重载特定的pipeline。
+
+请随时为您手头的任务创建一个issue,Pipeline的目标是易于使用并支持大多数情况,因此 `transformers` 可能支持您的用例。
+
+如果您想简单地尝试一下,可以:
+
+- 继承您选择的pipeline
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+这样就可以让您编写所有想要的自定义代码。
+
+
+## 实现一个pipeline
+
+[实现一个新的pipeline](../add_new_pipeline)
+
+## 音频
+
+可用于音频任务的pipeline包括以下几种。
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### TextToAudioPipeline
+
+[[autodoc]] TextToAudioPipeline
+ - __call__
+ - all
+
+
+### ZeroShotAudioClassificationPipeline
+
+[[autodoc]] ZeroShotAudioClassificationPipeline
+ - __call__
+ - all
+
+## 计算机视觉
+
+可用于计算机视觉任务的pipeline包括以下几种。
+
+### DepthEstimationPipeline
+[[autodoc]] DepthEstimationPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### ImageToImagePipeline
+
+[[autodoc]] ImageToImagePipeline
+ - __call__
+ - all
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### VideoClassificationPipeline
+
+[[autodoc]] VideoClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotObjectDetectionPipeline
+
+[[autodoc]] ZeroShotObjectDetectionPipeline
+ - __call__
+ - all
+
+## 自然语言处理
+
+可用于自然语言处理任务的pipeline包括以下几种。
+
+### ConversationalPipeline
+
+[[autodoc]] Conversation
+
+[[autodoc]] ConversationalPipeline
+ - __call__
+ - all
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### NerPipeline
+
+[[autodoc]] NerPipeline
+
+See [`TokenClassificationPipeline`] for all details.
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+## 多模态
+
+可用于多模态任务的pipeline包括以下几种。
+
+### DocumentQuestionAnsweringPipeline
+
+[[autodoc]] DocumentQuestionAnsweringPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### ImageToTextPipeline
+
+[[autodoc]] ImageToTextPipeline
+ - __call__
+ - all
+
+### MaskGenerationPipeline
+
+[[autodoc]] MaskGenerationPipeline
+ - __call__
+ - all
+
+### VisualQuestionAnsweringPipeline
+
+[[autodoc]] VisualQuestionAnsweringPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/source/zh/main_classes/processors.md b/docs/source/zh/main_classes/processors.md
new file mode 100644
index 00000000000000..60167e317adf90
--- /dev/null
+++ b/docs/source/zh/main_classes/processors.md
@@ -0,0 +1,146 @@
+
+
+# Processors
+
+在 Transformers 库中,processors可以有两种不同的含义:
+- 为多模态模型,例如[Wav2Vec2](../model_doc/wav2vec2)(语音和文本)或[CLIP](../model_doc/clip)(文本和视觉)预处理输入的对象
+- 在库的旧版本中用于预处理GLUE或SQUAD数据的已弃用对象。
+
+## 多模态processors
+
+任何多模态模型都需要一个对象来编码或解码将多个模态(包括文本、视觉和音频)组合在一起的数据。这由称为processors的对象处理,这些processors将两个或多个处理对象组合在一起,例如tokenizers(用于文本模态),image processors(用于视觉)和feature extractors(用于音频)。
+
+这些processors继承自以下实现保存和加载功能的基类:
+
+
+[[autodoc]] ProcessorMixin
+
+## 已弃用的processors
+
+所有processor都遵循与 [`~data.processors.utils.DataProcessor`] 相同的架构。processor返回一个 [`~data.processors.utils.InputExample`] 列表。这些 [`~data.processors.utils.InputExample`] 可以转换为 [`~data.processors.utils.InputFeatures`] 以供输送到模型。
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) 是一个基准测试,评估模型在各种现有的自然语言理解任务上的性能。它与论文 [GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) 一同发布。
+
+该库为以下任务提供了总共10个processor:MRPC、MNLI、MNLI(mismatched)、CoLA、SST2、STSB、QQP、QNLI、RTE 和 WNLI。
+
+这些processor是:
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+此外,还可以使用以下方法从数据文件加载值并将其转换为 [`~data.processors.utils.InputExample`] 列表。
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+
+## XNLI
+
+[跨语言NLI语料库(XNLI)](https://www.nyu.edu/projects/bowman/xnli/) 是一个评估跨语言文本表示质量的基准测试。XNLI是一个基于[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/)的众包数据集:”文本对“被标记为包含15种不同语言(包括英语等高资源语言和斯瓦希里语等低资源语言)的文本蕴涵注释。
+
+它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) 一同发布。
+
+该库提供了加载XNLI数据的processor:
+
+- [`~data.processors.utils.XnliProcessor`]
+
+请注意,由于测试集上有“gold”标签,因此评估是在测试集上进行的。
+
+使用这些processor的示例在 [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) 脚本中提供。
+
+
+## SQuAD
+
+[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822) 一同发布。
+
+该库为两个版本各自提供了一个processor:
+
+### Processors
+
+这两个processor是:
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+它们都继承自抽象类 [`~data.processors.utils.SquadProcessor`]。
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+此外,可以使用以下方法将 SQuAD 示例转换为可用作模型输入的 [`~data.processors.utils.SquadFeatures`]。
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+
+这些processor以及前面提到的方法可以与包含数据的文件以及tensorflow_datasets包一起使用。下面给出了示例。
+
+
+### Example使用
+
+以下是使用processor以及使用数据文件的转换方法的示例:
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+使用 *tensorflow_datasets* 就像使用数据文件一样简单:
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+另一个使用这些processor的示例在 [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) 脚本中提供。
\ No newline at end of file
diff --git a/docs/source/zh/main_classes/quantization.md b/docs/source/zh/main_classes/quantization.md
new file mode 100644
index 00000000000000..3c7e4d9212a1d0
--- /dev/null
+++ b/docs/source/zh/main_classes/quantization.md
@@ -0,0 +1,572 @@
+
+
+# 量化 🤗 Transformers 模型
+
+## AWQ集成
+
+AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://arxiv.org/abs/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
+
+我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
+
+
+### 量化一个模型
+
+我们建议用户查看生态系统中不同的现有工具,以使用AWQ算法对其模型进行量化,例如:
+
+- [`llm-awq`](https://github.com/mit-han-lab/llm-awq),来自MIT Han Lab
+- [`autoawq`](https://github.com/casper-hansen/AutoAWQ),来自[`casper-hansen`](https://github.com/casper-hansen)
+- Intel neural compressor,来自Intel - 通过[`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)使用
+
+生态系统中可能存在许多其他工具,请随时提出PR将它们添加到列表中。
+目前与🤗 Transformers的集成仅适用于使用`autoawq`和`llm-awq`量化后的模型。大多数使用`auto-awq`量化的模型可以在🤗 Hub的[`TheBloke`](https://huggingface.co/TheBloke)命名空间下找到,要使用`llm-awq`对模型进行量化,请参阅[`llm-awq`](https://github.com/mit-han-lab/llm-awq/)的示例文件夹中的[`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py)脚本。
+
+
+### 加载一个量化的模型
+
+您可以使用`from_pretrained`方法从Hub加载一个量化模型。通过检查模型配置文件(`configuration.json`)中是否存在`quantization_config`属性,来进行确认推送的权重是量化的。您可以通过检查字段`quantization_config.quant_method`来确认模型是否以AWQ格式进行量化,该字段应该设置为`"awq"`。请注意,为了性能原因,默认情况下加载模型将设置其他权重为`float16`。如果您想更改这种设置,可以通过将`torch_dtype`参数设置为`torch.float32`或`torch.bfloat16`。在下面的部分中,您可以找到一些示例片段和notebook。
+
+
+## 示例使用
+
+首先,您需要安装[`autoawq`](https://github.com/casper-hansen/AutoAWQ)库
+
+```bash
+pip install autoawq
+```
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
+```
+
+如果您首先将模型加载到CPU上,请确保在使用之前将其移动到GPU设备上。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
+```
+
+### 结合 AWQ 和 Flash Attention
+
+您可以将AWQ量化与Flash Attention结合起来,得到一个既被量化又更快速的模型。只需使用`from_pretrained`加载模型,并传递`attn_implementation="flash_attention_2"`参数。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
+```
+
+### 基准测试
+
+我们使用[`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark)库进行了一些速度、吞吐量和延迟基准测试。
+
+请注意,在编写本文档部分时,可用的量化方法包括:`awq`、`gptq`和`bitsandbytes`。
+
+基准测试在一台NVIDIA-A100实例上运行,使用[`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)作为AWQ模型,[`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)作为GPTQ模型。我们还将其与`bitsandbytes`量化模型和`float16`模型进行了对比。以下是一些结果示例:
+
+
+
+
+
+
+
+
+
+
+
+
+
", "A", ",", "", "ĠAllen", "N", "LP", "Ġsentence", ".", ""]
)
- # Copied from tests.models.roberta.test_tokenization_roberta.RobertaTokenizationTest.test_change_add_prefix_space_and_trim_offsets_args
def test_change_add_prefix_space_and_trim_offsets_args(self):
for trim_offsets, add_prefix_space in itertools.product([True, False], repeat=2):
tokenizer_r = self.rust_tokenizer_class.from_pretrained(
@@ -223,7 +215,6 @@ def test_change_add_prefix_space_and_trim_offsets_args(self):
self.assertEqual(post_processor_state["add_prefix_space"], add_prefix_space)
self.assertEqual(post_processor_state["trim_offsets"], trim_offsets)
- # Copied from tests.models.roberta.test_tokenization_roberta.RobertaTokenizationTest.test_offsets_mapping_with_different_add_prefix_space_and_trim_space_arguments
def test_offsets_mapping_with_different_add_prefix_space_and_trim_space_arguments(self):
# Test which aims to verify that the offsets are well adapted to the argument `add_prefix_space` and
# `trim_offsets`
diff --git a/tests/models/mask2former/test_modeling_mask2former.py b/tests/models/mask2former/test_modeling_mask2former.py
index b2fc84e7d324f5..8dc70d7c750d1b 100644
--- a/tests/models/mask2former/test_modeling_mask2former.py
+++ b/tests/models/mask2former/test_modeling_mask2former.py
@@ -14,7 +14,6 @@
# limitations under the License.
""" Testing suite for the PyTorch Mask2Former model. """
-import inspect
import unittest
import numpy as np
@@ -242,18 +241,6 @@ def test_resize_tokens_embeddings(self):
def test_multi_gpu_data_parallel_forward(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@slow
def test_model_from_pretrained(self):
for model_name in ["facebook/mask2former-swin-small-coco-instance"]:
diff --git a/tests/models/maskformer/test_modeling_maskformer.py b/tests/models/maskformer/test_modeling_maskformer.py
index fe1cc3423e0fbc..ffa77a051259e0 100644
--- a/tests/models/maskformer/test_modeling_maskformer.py
+++ b/tests/models/maskformer/test_modeling_maskformer.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MaskFormer model. """
import copy
-import inspect
import unittest
import numpy as np
@@ -266,18 +265,6 @@ def test_resize_tokens_embeddings(self):
def test_multi_gpu_data_parallel_forward(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@slow
def test_model_from_pretrained(self):
for model_name in ["facebook/maskformer-swin-small-coco"]:
diff --git a/tests/models/maskformer/test_modeling_maskformer_swin.py b/tests/models/maskformer/test_modeling_maskformer_swin.py
index 4125f36db798e1..8d29e8ebee096d 100644
--- a/tests/models/maskformer/test_modeling_maskformer_swin.py
+++ b/tests/models/maskformer/test_modeling_maskformer_swin.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MaskFormer Swin model. """
import collections
-import inspect
import unittest
from typing import Dict, List, Tuple
@@ -234,18 +233,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@unittest.skip(reason="MaskFormerSwin is only used as backbone and doesn't support output_attentions")
def test_attention_outputs(self):
pass
diff --git a/tests/models/mgp_str/test_modeling_mgp_str.py b/tests/models/mgp_str/test_modeling_mgp_str.py
index d8ba50a3500288..a7fd95a1311c5c 100644
--- a/tests/models/mgp_str/test_modeling_mgp_str.py
+++ b/tests/models/mgp_str/test_modeling_mgp_str.py
@@ -14,7 +14,6 @@
# limitations under the License.
""" Testing suite for the PyTorch MGP-STR model. """
-import inspect
import unittest
import requests
@@ -151,18 +150,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@unittest.skip(reason="MgpstrModel does not support feedforward chunking")
def test_feed_forward_chunking(self):
pass
diff --git a/tests/models/mistral/test_modeling_mistral.py b/tests/models/mistral/test_modeling_mistral.py
index b30e70ba71f92e..35a2341b4e69d6 100644
--- a/tests/models/mistral/test_modeling_mistral.py
+++ b/tests/models/mistral/test_modeling_mistral.py
@@ -24,6 +24,7 @@
from transformers import AutoTokenizer, MistralConfig, is_torch_available
from transformers.testing_utils import (
backend_empty_cache,
+ require_bitsandbytes,
require_flash_attn,
require_torch,
require_torch_gpu,
@@ -33,7 +34,7 @@
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
-from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
@@ -106,7 +107,7 @@ def prepare_config_and_inputs(self):
input_mask = None
if self.use_input_mask:
- input_mask = random_attention_mask([self.batch_size, self.seq_length])
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
token_type_ids = None
if self.use_token_type_ids:
@@ -301,6 +302,12 @@ class MistralModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMi
test_headmasking = False
test_pruning = False
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
def setUp(self):
self.model_tester = MistralModelTester(self)
self.config_tester = ConfigTester(self, config_class=MistralConfig, hidden_size=37)
@@ -375,17 +382,14 @@ def test_flash_attn_2_generate_padding_right(self):
import torch
for model_class in self.all_generative_model_classes:
- if not model_class._supports_flash_attn_2:
- return
-
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
- model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=False, low_cpu_mem_usage=True
- ).to(torch_device)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device)
@@ -393,7 +397,10 @@ def test_flash_attn_2_generate_padding_right(self):
model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=True, low_cpu_mem_usage=True
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
).to(torch_device)
with self.assertRaises(ValueError):
@@ -405,36 +412,53 @@ def test_flash_attn_2_generate_padding_right(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_generate_use_cache(self):
import torch
- for model_class in self.all_model_classes:
- if not model_class._supports_flash_attn_2:
- return
+ max_new_tokens = 30
+
+ for model_class in self.all_generative_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
- model_fa = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=True
- )
- model_fa.to(torch_device)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # NOTE: Mistral apparently does not support right padding + use_cache with FA2.
+ dummy_attention_mask[:, -1] = 1
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=False
- )
- model.to(torch_device)
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
- dummy_input = torch.LongTensor([[1, 2, 3, 4, 5]]).to(torch_device)
- dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1, 0]]).to(torch_device)
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
- _ = model(dummy_input, output_hidden_states=True).hidden_states[-1]
- with self.assertRaises(ValueError):
- _ = model_fa(
- dummy_input, attention_mask=dummy_attention_mask, output_hidden_states=True
- ).hidden_states[-1]
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_padding_right(self):
+ self.skipTest("Mistral flash attention does not support right padding")
@require_torch
@@ -474,3 +498,32 @@ def test_model_7b_generation(self):
del model
backend_empty_cache(torch_device)
gc.collect()
+
+ @require_bitsandbytes
+ @slow
+ @require_flash_attn
+ def test_model_7b_long_prompt(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = MistralForCausalLM.from_pretrained(
+ "mistralai/Mistral-7B-v0.1",
+ device_map="auto",
+ load_in_4bit=True,
+ attn_implementation="flash_attention_2",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/tests/models/mixtral/__init__.py b/tests/models/mixtral/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/mixtral/test_modeling_mixtral.py b/tests/models/mixtral/test_modeling_mixtral.py
new file mode 100644
index 00000000000000..a2d5af00237b74
--- /dev/null
+++ b/tests/models/mixtral/test_modeling_mixtral.py
@@ -0,0 +1,537 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Mixtral model. """
+
+
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import MixtralConfig, is_torch_available
+from transformers.testing_utils import (
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MixtralForCausalLM,
+ MixtralForSequenceClassification,
+ MixtralModel,
+ )
+
+
+class MixtralModelTester:
+ # Copied from tests.models.mistral.test_modeling_mistral.MistralModelTester.__init__
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ # Copied from tests.models.mistral.test_modeling_mistral.MistralModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return MixtralConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ num_experts_per_tok=2,
+ num_local_experts=2,
+ )
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Mixtral
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = MixtralModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Mixtral
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = MixtralModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Mixtral
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = MixtralForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Mixtral
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = MixtralForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common with Llama->Mixtral
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTest with Mistral->Mixtral
+class MixtralModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (MixtralModel, MixtralForCausalLM, MixtralForSequenceClassification) if is_torch_available() else ()
+ )
+ all_generative_model_classes = (MixtralForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": MixtralModel,
+ "text-classification": MixtralForSequenceClassification,
+ "text-generation": MixtralForCausalLM,
+ "zero-shot": MixtralForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
+ def setUp(self):
+ self.model_tester = MixtralModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=MixtralConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_Mixtral_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ print(config)
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = MixtralForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Mixtral_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = MixtralForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Mixtral_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = MixtralForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ @unittest.skip("Mixtral buffers include complex numbers, which breaks this test")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip("Mixtral uses GQA on all models so the KV cache is a non standard format")
+ def test_past_key_values_format(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_padding_right(self):
+ import torch
+
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
+ dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device)
+
+ model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False)
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ with self.assertRaises(ValueError):
+ _ = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_use_cache(self):
+ import torch
+
+ max_new_tokens = 30
+
+ for model_class in self.all_generative_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # NOTE: Mixtral apparently does not support right padding + use_cache with FA2.
+ dummy_attention_mask[:, -1] = 1
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_padding_right(self):
+ self.skipTest("Mixtral flash attention does not support right padding")
+
+ # Ignore copy
+ def test_load_balancing_loss(self):
+ r"""
+ Let's make sure we can actually compute the loss and do a backward on it.
+ """
+
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.output_router_logits = True
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = MixtralForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask)
+ self.assertEqual(result.router_logits[0].shape, (91, config.num_experts_per_tok))
+ torch.testing.assert_close(result.aux_loss.cpu(), torch.tensor(1, dtype=torch.float32))
+
+
+@require_torch
+class MixtralIntegrationTest(unittest.TestCase):
+ @slow
+ @require_torch_gpu
+ def test_small_model_logits(self):
+ model_id = "hf-internal-testing/Mixtral-tiny"
+ dummy_input = torch.LongTensor([[0, 1, 0], [0, 1, 0]]).to(torch_device)
+
+ model = MixtralForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+ # TODO: might need to tweak it in case the logits do not match on our daily runners
+ # these logits have been obtained with the original megablocks impelmentation.
+ EXPECTED_LOGITS = torch.Tensor(
+ [[0.1670, 0.1620, 0.6094], [-0.8906, -0.1588, -0.6060], [0.1572, 0.1290, 0.7246]]
+ ).to(torch_device)
+
+ with torch.no_grad():
+ logits = model(dummy_input).logits
+
+ torch.testing.assert_close(logits[0, :3, :3].half(), EXPECTED_LOGITS, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(logits[1, :3, :3].half(), EXPECTED_LOGITS, atol=1e-3, rtol=1e-3)
+
+ @slow
+ # @require_torch_gpu
+ def test_small_model_logits_batched(self):
+ model_id = "hf-internal-testing/Mixtral-tiny"
+ dummy_input = torch.LongTensor([[0, 0, 0, 0, 0, 0, 1, 2, 3], [1, 1, 2, 3, 4, 5, 6, 7, 8]]).to(torch_device)
+ attention_mask = dummy_input.ne(0).to(torch.long)
+
+ model = MixtralForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ # TODO: might need to tweak it in case the logits do not match on our daily runners
+ EXPECTED_LOGITS_LEFT = torch.Tensor(
+ [[0.1750, 0.0537, 0.7007], [0.1750, 0.0537, 0.7007], [0.1750, 0.0537, 0.7007]],
+ )
+
+ # logits[0, -3:, -3:].half()
+ EXPECTED_LOGITS_LEFT_UNPADDED = torch.Tensor(
+ [[0.2212, 0.5200, -0.3816], [0.8213, -0.2313, 0.6069], [0.2664, -0.7090, 0.2468]],
+ )
+
+ # logits[1, -3:, -3:].half()
+ EXPECTED_LOGITS_RIGHT_UNPADDED = torch.Tensor(
+ [[0.2205, 0.1232, -0.1611], [-0.3484, 0.3030, -1.0312], [0.0742, 0.7930, 0.7969]]
+ )
+
+ with torch.no_grad():
+ logits = model(dummy_input, attention_mask=attention_mask).logits
+
+ torch.testing.assert_close(logits[0, :3, :3].half(), EXPECTED_LOGITS_LEFT, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(logits[0, -3:, -3:].half(), EXPECTED_LOGITS_LEFT_UNPADDED, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(logits[1, -3:, -3:].half(), EXPECTED_LOGITS_RIGHT_UNPADDED, atol=1e-3, rtol=1e-3)
diff --git a/tests/models/mobilebert/test_modeling_mobilebert.py b/tests/models/mobilebert/test_modeling_mobilebert.py
index a914ce578dc88c..e4ebca4b6e5b64 100644
--- a/tests/models/mobilebert/test_modeling_mobilebert.py
+++ b/tests/models/mobilebert/test_modeling_mobilebert.py
@@ -302,10 +302,6 @@ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
def test_resize_tokens_embeddings(self):
super().test_resize_tokens_embeddings()
- @unittest.skip("This test is currently broken because of safetensors.")
- def test_tf_from_pt_safetensors(self):
- pass
-
def setUp(self):
self.model_tester = MobileBertModelTester(self)
self.config_tester = ConfigTester(self, config_class=MobileBertConfig, hidden_size=37)
diff --git a/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py b/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
index 8c24935800b900..35848da3161d51 100644
--- a/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
+++ b/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MobileNetV1 model. """
-import inspect
import unittest
from transformers import MobileNetV1Config
@@ -177,18 +176,6 @@ def test_model_common_attributes(self):
def test_attention_outputs(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py b/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
index 06b2bd9d3fc466..bbd83408853ceb 100644
--- a/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
+++ b/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MobileNetV2 model. """
-import inspect
import unittest
from transformers import MobileNetV2Config
@@ -228,18 +227,6 @@ def test_model_common_attributes(self):
def test_attention_outputs(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/mobilevit/test_modeling_mobilevit.py b/tests/models/mobilevit/test_modeling_mobilevit.py
index 2c01ea0c99bb4e..563bee802322d0 100644
--- a/tests/models/mobilevit/test_modeling_mobilevit.py
+++ b/tests/models/mobilevit/test_modeling_mobilevit.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MobileViT model. """
-import inspect
import unittest
from transformers import MobileViTConfig
@@ -221,18 +220,6 @@ def test_model_common_attributes(self):
def test_attention_outputs(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/mobilevitv2/test_modeling_mobilevitv2.py b/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
index b1961b2e6d4a3c..192cf3a9e1e896 100644
--- a/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
+++ b/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch MobileViTV2 model. """
-import inspect
import unittest
from transformers import MobileViTV2Config
@@ -228,18 +227,6 @@ def test_attention_outputs(self):
def test_multi_gpu_data_parallel_forward(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/mpnet/test_modeling_mpnet.py b/tests/models/mpnet/test_modeling_mpnet.py
index 52d8d1f8b4c68c..10c0c164d16f30 100644
--- a/tests/models/mpnet/test_modeling_mpnet.py
+++ b/tests/models/mpnet/test_modeling_mpnet.py
@@ -246,7 +246,7 @@ def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_mpnet_for_question_answering(*config_and_inputs)
- @unittest.skip("This isn't passing but should, seems like a misconfiguration of tied weights.")
+ @unittest.skip("TFMPNet adds poolers to all models, unlike the PT model class.")
def test_tf_from_pt_safetensors(self):
return
diff --git a/tests/models/nat/test_modeling_nat.py b/tests/models/nat/test_modeling_nat.py
index a27b087ce51904..3ab49d2d9557fa 100644
--- a/tests/models/nat/test_modeling_nat.py
+++ b/tests/models/nat/test_modeling_nat.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch Nat model. """
import collections
-import inspect
import unittest
from transformers import NatConfig
@@ -261,18 +260,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_attention_outputs(self):
self.skipTest("Nat's attention operation is handled entirely by NATTEN.")
diff --git a/tests/models/nllb_moe/test_modeling_nllb_moe.py b/tests/models/nllb_moe/test_modeling_nllb_moe.py
index 1109948e0e7092..2e8ba30ce675a6 100644
--- a/tests/models/nllb_moe/test_modeling_nllb_moe.py
+++ b/tests/models/nllb_moe/test_modeling_nllb_moe.py
@@ -348,10 +348,6 @@ def test_get_loss(self):
self.assertIsNotNone(model(**input_dict)["encoder_router_logits"][1])
self.assertIsNotNone(model(**input_dict)["decoder_router_logits"][0])
- @unittest.skip("Test does not fail individually but fails on the CI @ArthurZucker looking into it")
- def test_assisted_decoding_sample(self):
- pass
-
@require_torch
@require_sentencepiece
diff --git a/tests/models/owlv2/test_modeling_owlv2.py b/tests/models/owlv2/test_modeling_owlv2.py
index 51d9e537840944..8dbf3fcde89bbc 100644
--- a/tests/models/owlv2/test_modeling_owlv2.py
+++ b/tests/models/owlv2/test_modeling_owlv2.py
@@ -840,10 +840,12 @@ def test_inference_object_detection(self):
num_queries = int((model.config.vision_config.image_size / model.config.vision_config.patch_size) ** 2)
self.assertEqual(outputs.pred_boxes.shape, torch.Size((1, num_queries, 4)))
- expected_slice_logits = torch.tensor([[-21.4139, -21.6130], [-19.0084, -19.5491], [-20.9592, -21.3830]])
+ expected_slice_logits = torch.tensor(
+ [[-21.413497, -21.612638], [-19.008193, -19.548841], [-20.958896, -21.382694]]
+ ).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice_logits, atol=1e-4))
expected_slice_boxes = torch.tensor(
- [[0.2413, 0.0519, 0.4533], [0.1395, 0.0457, 0.2507], [0.2330, 0.0505, 0.4277]],
+ [[0.241309, 0.051896, 0.453267], [0.139474, 0.045701, 0.250660], [0.233022, 0.050479, 0.427671]],
).to(torch_device)
self.assertTrue(torch.allclose(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, atol=1e-4))
diff --git a/tests/models/patchtsmixer/__init__.py b/tests/models/patchtsmixer/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/patchtsmixer/test_modeling_patchtsmixer.py b/tests/models/patchtsmixer/test_modeling_patchtsmixer.py
new file mode 100644
index 00000000000000..4f91dc0301c2af
--- /dev/null
+++ b/tests/models/patchtsmixer/test_modeling_patchtsmixer.py
@@ -0,0 +1,1094 @@
+# coding=utf-8
+# Copyright 2023 IBM and HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch PatchTSMixer model. """
+
+import inspect
+import itertools
+import random
+import tempfile
+import unittest
+from typing import Dict, List, Optional, Tuple, Union
+
+from huggingface_hub import hf_hub_download
+from parameterized import parameterized
+
+from transformers import is_torch_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import is_flaky, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+TOLERANCE = 1e-4
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING,
+ MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING,
+ PatchTSMixerConfig,
+ PatchTSMixerForPrediction,
+ PatchTSMixerForPretraining,
+ PatchTSMixerForRegression,
+ PatchTSMixerForTimeSeriesClassification,
+ PatchTSMixerModel,
+ )
+ from transformers.models.patchtsmixer.modeling_patchtsmixer import (
+ PatchTSMixerEncoder,
+ PatchTSMixerForPredictionHead,
+ PatchTSMixerForPredictionOutput,
+ PatchTSMixerForRegressionOutput,
+ PatchTSMixerForTimeSeriesClassificationOutput,
+ PatchTSMixerLinearHead,
+ PatchTSMixerPretrainHead,
+ )
+
+
+@require_torch
+class PatchTSMixerModelTester:
+ def __init__(
+ self,
+ context_length: int = 32,
+ patch_length: int = 8,
+ num_input_channels: int = 3,
+ patch_stride: int = 8,
+ # d_model: int = 128,
+ hidden_size: int = 8,
+ # num_layers: int = 8,
+ num_hidden_layers: int = 2,
+ expansion_factor: int = 2,
+ dropout: float = 0.5,
+ mode: str = "common_channel",
+ gated_attn: bool = True,
+ norm_mlp="LayerNorm",
+ swin_hier: int = 0,
+ # masking related
+ mask_type: str = "forecast",
+ random_mask_ratio=0.5,
+ mask_patches: list = [2, 3],
+ forecast_mask_ratios: list = [1, 1],
+ mask_value=0,
+ masked_loss: bool = False,
+ mask_mode: str = "mask_before_encoder",
+ channel_consistent_masking: bool = True,
+ scaling: Optional[Union[str, bool]] = "std",
+ # Head related
+ head_dropout: float = 0.2,
+ # forecast related
+ prediction_length: int = 16,
+ out_channels: int = None,
+ # Classification/regression related
+ # num_labels: int = 3,
+ num_targets: int = 3,
+ output_range: list = None,
+ head_aggregation: str = None,
+ # Trainer related
+ batch_size=13,
+ is_training=True,
+ seed_number=42,
+ post_init=True,
+ num_parallel_samples=4,
+ ):
+ self.num_input_channels = num_input_channels
+ self.context_length = context_length
+ self.patch_length = patch_length
+ self.patch_stride = patch_stride
+ # self.d_model = d_model
+ self.hidden_size = hidden_size
+ self.expansion_factor = expansion_factor
+ # self.num_layers = num_layers
+ self.num_hidden_layers = num_hidden_layers
+ self.dropout = dropout
+ self.mode = mode
+ self.gated_attn = gated_attn
+ self.norm_mlp = norm_mlp
+ self.swin_hier = swin_hier
+ self.scaling = scaling
+ self.head_dropout = head_dropout
+ # masking related
+ self.mask_type = mask_type
+ self.random_mask_ratio = random_mask_ratio
+ self.mask_patches = mask_patches
+ self.forecast_mask_ratios = forecast_mask_ratios
+ self.mask_value = mask_value
+ self.channel_consistent_masking = channel_consistent_masking
+ self.mask_mode = mask_mode
+ self.masked_loss = masked_loss
+ # patching related
+ self.patch_last = True
+ # forecast related
+ self.prediction_length = prediction_length
+ self.out_channels = out_channels
+ # classification/regression related
+ # self.num_labels = num_labels
+ self.num_targets = num_targets
+ self.output_range = output_range
+ self.head_aggregation = head_aggregation
+ # Trainer related
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.seed_number = seed_number
+ self.post_init = post_init
+ self.num_parallel_samples = num_parallel_samples
+
+ def get_config(self):
+ config_ = PatchTSMixerConfig(
+ num_input_channels=self.num_input_channels,
+ context_length=self.context_length,
+ patch_length=self.patch_length,
+ patch_stride=self.patch_stride,
+ # d_model = self.d_model,
+ d_model=self.hidden_size,
+ expansion_factor=self.expansion_factor,
+ # num_layers = self.num_layers,
+ num_layers=self.num_hidden_layers,
+ dropout=self.dropout,
+ mode=self.mode,
+ gated_attn=self.gated_attn,
+ norm_mlp=self.norm_mlp,
+ swin_hier=self.swin_hier,
+ scaling=self.scaling,
+ head_dropout=self.head_dropout,
+ mask_type=self.mask_type,
+ random_mask_ratio=self.random_mask_ratio,
+ mask_patches=self.mask_patches,
+ forecast_mask_ratios=self.forecast_mask_ratios,
+ mask_value=self.mask_value,
+ channel_consistent_masking=self.channel_consistent_masking,
+ mask_mode=self.mask_mode,
+ masked_loss=self.masked_loss,
+ prediction_length=self.prediction_length,
+ out_channels=self.out_channels,
+ # num_labels=self.num_labels,
+ num_targets=self.num_targets,
+ output_range=self.output_range,
+ head_aggregation=self.head_aggregation,
+ post_init=self.post_init,
+ )
+ self.num_patches = config_.num_patches
+ return config_
+
+ def prepare_patchtsmixer_inputs_dict(self, config):
+ _past_length = config.context_length
+ # bs, n_vars, num_patch, patch_length
+
+ # [bs x context_length x n_vars]
+ past_values = floats_tensor([self.batch_size, _past_length, self.num_input_channels])
+
+ future_values = floats_tensor([self.batch_size, config.prediction_length, self.num_input_channels])
+
+ inputs_dict = {
+ "past_values": past_values,
+ "future_values": future_values,
+ }
+ return inputs_dict
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ inputs_dict = self.prepare_patchtsmixer_inputs_dict(config)
+ return config, inputs_dict
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+
+@require_torch
+class PatchTSMixerModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ PatchTSMixerModel,
+ PatchTSMixerForPrediction,
+ PatchTSMixerForPretraining,
+ PatchTSMixerForTimeSeriesClassification,
+ PatchTSMixerForRegression,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (
+ (PatchTSMixerForPrediction, PatchTSMixerForPretraining) if is_torch_available() else ()
+ )
+ pipeline_model_mapping = {"feature-extraction": PatchTSMixerModel} if is_torch_available() else {}
+ is_encoder_decoder = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ test_torchscript = False
+ test_inputs_embeds = False
+ test_model_common_attributes = False
+
+ test_resize_embeddings = True
+ test_resize_position_embeddings = False
+ test_mismatched_shapes = True
+ test_model_parallel = False
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = PatchTSMixerModelTester()
+ self.config_tester = ConfigTester(
+ self,
+ config_class=PatchTSMixerConfig,
+ has_text_modality=False,
+ prediction_length=self.model_tester.prediction_length,
+ common_properties=["hidden_size", "expansion_factor", "num_hidden_layers"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ # if classification model:
+ if model_class in get_values(MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING):
+ rng = random.Random(self.model_tester.seed_number)
+ labels = ids_tensor([self.model_tester.batch_size], self.model_tester.num_targets, rng=rng)
+ # inputs_dict["labels"] = labels
+ inputs_dict["future_values"] = labels
+ # inputs_dict.pop("future_values")
+ elif model_class in get_values(MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING):
+ rng = random.Random(self.model_tester.seed_number)
+ labels = floats_tensor([self.model_tester.batch_size, self.model_tester.num_targets], rng=rng)
+ # inputs_dict["labels"] = labels
+ inputs_dict["future_values"] = labels
+ # inputs_dict.pop("future_values")
+ elif model_class in [PatchTSMixerModel, PatchTSMixerForPretraining]:
+ inputs_dict.pop("future_values")
+
+ inputs_dict["output_hidden_states"] = True
+ return inputs_dict
+
+ def test_save_load_strict(self):
+ config, _ = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester,
+ "expected_num_hidden_layers",
+ self.model_tester.num_hidden_layers,
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ expected_hidden_size = self.model_tester.hidden_size
+ self.assertEqual(hidden_states[0].shape[-1], expected_hidden_size)
+
+ num_patch = self.model_tester.num_patches
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [num_patch, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip("No tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ output_ = model(**dict_inputs, return_dict=True, **additional_kwargs)
+ attributes_ = vars(output_)
+ dict_output = tuple(attributes_.values())
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object),
+ set_nan_tensor_to_zero(dict_object),
+ atol=1e-5,
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ print(model_class)
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ tuple_inputs.update({"output_hidden_states": False})
+ dict_inputs.update({"output_hidden_states": False})
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ tuple_inputs.update({"output_hidden_states": False})
+ dict_inputs.update({"output_hidden_states": False})
+ check_equivalence(
+ model,
+ tuple_inputs,
+ dict_inputs,
+ )
+
+ def test_model_main_input_name(self):
+ model_signature = inspect.signature(getattr(PatchTSMixerModel, "forward"))
+ # The main input is the name of the argument after `self`
+ observed_main_input_name = list(model_signature.parameters.keys())[1]
+ self.assertEqual(PatchTSMixerModel.main_input_name, observed_main_input_name)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names_with_target = [
+ "past_values",
+ "observed_mask",
+ "future_values",
+ "output_hidden_states",
+ "return_loss",
+ ]
+ expected_arg_names_without_target = [
+ "past_values",
+ "observed_mask",
+ "output_hidden_states",
+ ]
+
+ expected_arg_names = expected_arg_names_with_target
+ if model_class == PatchTSMixerForPretraining:
+ expected_arg_names = expected_arg_names_without_target + ["return_loss"]
+ if model_class == PatchTSMixerModel:
+ expected_arg_names = expected_arg_names_without_target
+ if model_class in get_values(MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING) or model_class in get_values(
+ MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING
+ ):
+ expected_arg_names.remove("observed_mask")
+
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ @is_flaky()
+ def test_retain_grad_hidden_states_attentions(self):
+ super().test_retain_grad_hidden_states_attentions()
+
+
+def prepare_batch(repo_id="ibm/patchtsmixer-etth1-test-data", file="pretrain_batch.pt"):
+ # TODO: Make repo public
+ file = hf_hub_download(repo_id=repo_id, filename=file, repo_type="dataset")
+ batch = torch.load(file, map_location=torch_device)
+ return batch
+
+
+@require_torch
+@slow
+class PatchTSMixerModelIntegrationTests(unittest.TestCase):
+ def test_pretrain_head(self):
+ model = PatchTSMixerForPretraining.from_pretrained("ibm/patchtsmixer-etth1-pretrain").to(torch_device)
+ batch = prepare_batch()
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(past_values=batch["past_values"].to(torch_device)).prediction_outputs
+ num_patch = (
+ max(model.config.context_length, model.config.patch_length) - model.config.patch_length
+ ) // model.config.patch_stride + 1
+ expected_shape = torch.Size(
+ [
+ 32,
+ model.config.num_input_channels,
+ num_patch,
+ model.config.patch_length,
+ ]
+ )
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor([[[[0.1870]],[[-1.5819]],[[-0.0991]],[[-1.2609]],[[0.5633]],[[-0.5723]],[[0.3387]],]],device=torch_device) # fmt: skip
+ self.assertTrue(torch.allclose(output[0, :7, :1, :1], expected_slice, atol=TOLERANCE))
+
+ def test_forecasting_head(self):
+ model = PatchTSMixerForPrediction.from_pretrained("ibm/patchtsmixer-etth1-forecasting").to(torch_device)
+ batch = prepare_batch(file="forecast_batch.pt")
+
+ model.eval()
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"].to(torch_device),
+ future_values=batch["future_values"].to(torch_device),
+ ).prediction_outputs
+
+ expected_shape = torch.Size([32, model.config.prediction_length, model.config.num_input_channels])
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.4271, -0.0651, 0.4656, 0.7104, -0.3085, -1.9658, 0.4560]],
+ device=torch_device,
+ )
+ self.assertTrue(torch.allclose(output[0, :1, :7], expected_slice, atol=TOLERANCE))
+
+ def test_prediction_generation(self):
+ torch_device = "cpu"
+ model = PatchTSMixerForPrediction.from_pretrained("ibm/patchtsmixer-etth1-generate").to(torch_device)
+ batch = prepare_batch(file="forecast_batch.pt")
+ print(batch["past_values"])
+
+ model.eval()
+ torch.manual_seed(0)
+ with torch.no_grad():
+ outputs = model.generate(past_values=batch["past_values"].to(torch_device))
+ expected_shape = torch.Size((32, 1, model.config.prediction_length, model.config.num_input_channels))
+
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.0091, -0.3625, -0.0887, 0.6544, -0.4100, -2.3124, 0.3376]],
+ device=torch_device,
+ )
+ mean_prediction = outputs.sequences.mean(dim=1)
+
+ self.assertTrue(torch.allclose(mean_prediction[0, -1:], expected_slice, atol=TOLERANCE))
+
+
+@require_torch
+class PatchTSMixerFunctionalTests(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ """Setup method: Called once before test-cases execution"""
+ cls.params = {}
+ cls.params.update(
+ context_length=32,
+ patch_length=8,
+ num_input_channels=3,
+ patch_stride=8,
+ d_model=4,
+ expansion_factor=2,
+ num_layers=3,
+ dropout=0.2,
+ mode="common_channel", # common_channel, mix_channel
+ gated_attn=True,
+ norm_mlp="LayerNorm",
+ mask_type="random",
+ random_mask_ratio=0.5,
+ mask_patches=[2, 3],
+ forecast_mask_ratios=[1, 1],
+ mask_value=0,
+ masked_loss=True,
+ channel_consistent_masking=True,
+ head_dropout=0.2,
+ prediction_length=64,
+ out_channels=None,
+ # num_labels=3,
+ num_targets=3,
+ output_range=None,
+ head_aggregation=None,
+ scaling="std",
+ use_positional_encoding=False,
+ positional_encoding="sincos",
+ self_attn=False,
+ self_attn_heads=1,
+ num_parallel_samples=4,
+ )
+
+ cls.num_patches = (
+ max(cls.params["context_length"], cls.params["patch_length"]) - cls.params["patch_length"]
+ ) // cls.params["patch_stride"] + 1
+
+ # batch_size = 32
+ batch_size = 2
+
+ int(cls.params["prediction_length"] / cls.params["patch_length"])
+
+ cls.data = torch.rand(
+ batch_size,
+ cls.params["context_length"],
+ cls.params["num_input_channels"],
+ )
+
+ cls.enc_data = torch.rand(
+ batch_size,
+ cls.params["num_input_channels"],
+ cls.num_patches,
+ cls.params["patch_length"],
+ )
+
+ cls.enc_output = torch.rand(
+ batch_size,
+ cls.params["num_input_channels"],
+ cls.num_patches,
+ cls.params["d_model"],
+ )
+
+ cls.flat_enc_output = torch.rand(
+ batch_size,
+ cls.num_patches,
+ cls.params["d_model"],
+ )
+
+ cls.correct_pred_output = torch.rand(
+ batch_size,
+ cls.params["prediction_length"],
+ cls.params["num_input_channels"],
+ )
+ cls.correct_regression_output = torch.rand(batch_size, cls.params["num_targets"])
+
+ cls.correct_pretrain_output = torch.rand(
+ batch_size,
+ cls.params["num_input_channels"],
+ cls.num_patches,
+ cls.params["patch_length"],
+ )
+
+ cls.correct_forecast_output = torch.rand(
+ batch_size,
+ cls.params["prediction_length"],
+ cls.params["num_input_channels"],
+ )
+
+ cls.correct_sel_forecast_output = torch.rand(batch_size, cls.params["prediction_length"], 2)
+
+ cls.correct_classification_output = torch.rand(
+ batch_size,
+ cls.params["num_targets"],
+ )
+
+ cls.correct_classification_classes = torch.randint(0, cls.params["num_targets"], (batch_size,))
+
+ def test_patchtsmixer_encoder(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ enc = PatchTSMixerEncoder(config)
+ output = enc(self.__class__.enc_data)
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+
+ def test_patchmodel(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerModel(config)
+ output = mdl(self.__class__.data)
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.patch_input.shape, self.__class__.enc_data.shape)
+
+ def test_pretrainhead(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ head = PatchTSMixerPretrainHead(
+ config=config,
+ )
+ output = head(self.__class__.enc_output)
+
+ self.assertEqual(output.shape, self.__class__.correct_pretrain_output.shape)
+
+ def test_pretrain_full(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForPretraining(config)
+ output = mdl(self.__class__.data)
+ self.assertEqual(
+ output.prediction_outputs.shape,
+ self.__class__.correct_pretrain_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ def test_pretrain_full_with_return_dict(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForPretraining(config)
+ output = mdl(self.__class__.data, return_dict=False)
+ self.assertEqual(output[1].shape, self.__class__.correct_pretrain_output.shape)
+ self.assertEqual(output[2].shape, self.__class__.enc_output.shape)
+ self.assertEqual(output[0].item() < 100, True)
+
+ def test_forecast_head(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ head = PatchTSMixerForPredictionHead(
+ config=config,
+ )
+ # output = head(self.__class__.enc_output, raw_data = self.__class__.correct_pretrain_output)
+ output = head(self.__class__.enc_output)
+
+ self.assertEqual(output.shape, self.__class__.correct_forecast_output.shape)
+
+ def check_module(
+ self,
+ task,
+ params=None,
+ output_hidden_states=True,
+ ):
+ config = PatchTSMixerConfig(**params)
+ if task == "forecast":
+ mdl = PatchTSMixerForPrediction(config)
+ target_input = self.__class__.correct_forecast_output
+ if config.prediction_channel_indices is not None:
+ target_output = self.__class__.correct_sel_forecast_output
+ else:
+ target_output = target_input
+ ref_samples = target_output.unsqueeze(1).expand(-1, config.num_parallel_samples, -1, -1)
+
+ elif task == "classification":
+ mdl = PatchTSMixerForTimeSeriesClassification(config)
+ target_input = self.__class__.correct_classification_classes
+ target_output = self.__class__.correct_classification_output
+ elif task == "regression":
+ mdl = PatchTSMixerForRegression(config)
+ target_input = self.__class__.correct_regression_output
+ target_output = self.__class__.correct_regression_output
+ ref_samples = target_output.unsqueeze(1).expand(-1, config.num_parallel_samples, -1)
+ elif task == "pretrain":
+ mdl = PatchTSMixerForPretraining(config)
+ target_input = None
+ target_output = self.__class__.correct_pretrain_output
+ else:
+ print("invalid task")
+
+ enc_output = self.__class__.enc_output
+
+ if target_input is None:
+ output = mdl(self.__class__.data, output_hidden_states=output_hidden_states)
+ else:
+ output = mdl(
+ self.__class__.data,
+ future_values=target_input,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if isinstance(output.prediction_outputs, tuple):
+ for t in output.prediction_outputs:
+ self.assertEqual(t.shape, target_output.shape)
+ else:
+ self.assertEqual(output.prediction_outputs.shape, target_output.shape)
+
+ self.assertEqual(output.last_hidden_state.shape, enc_output.shape)
+
+ if output_hidden_states is True:
+ self.assertEqual(len(output.hidden_states), params["num_layers"])
+
+ else:
+ self.assertEqual(output.hidden_states, None)
+
+ self.assertEqual(output.loss.item() < 100, True)
+
+ if config.loss == "nll" and task in ["forecast", "regression"]:
+ samples = mdl.generate(self.__class__.data)
+ self.assertEqual(samples.sequences.shape, ref_samples.shape)
+
+ @parameterized.expand(
+ list(
+ itertools.product(
+ ["common_channel", "mix_channel"],
+ [True, False],
+ [True, False, "mean", "std"],
+ [True, False],
+ [None, [0, 2]],
+ ["mse", "nll"],
+ )
+ )
+ )
+ def test_forecast(self, mode, self_attn, scaling, gated_attn, prediction_channel_indices, loss):
+ params = self.__class__.params.copy()
+ params.update(
+ mode=mode,
+ self_attn=self_attn,
+ scaling=scaling,
+ prediction_channel_indices=prediction_channel_indices,
+ gated_attn=gated_attn,
+ loss=loss,
+ )
+
+ self.check_module(task="forecast", params=params)
+
+ @parameterized.expand(
+ list(
+ itertools.product(
+ ["common_channel", "mix_channel"],
+ [True, False],
+ [True, False, "mean", "std"],
+ [True, False],
+ ["max_pool", "avg_pool"],
+ )
+ )
+ )
+ def test_classification(self, mode, self_attn, scaling, gated_attn, head_aggregation):
+ params = self.__class__.params.copy()
+ params.update(
+ mode=mode,
+ self_attn=self_attn,
+ scaling=scaling,
+ head_aggregation=head_aggregation,
+ gated_attn=gated_attn,
+ )
+
+ self.check_module(task="classification", params=params)
+
+ @parameterized.expand(
+ list(
+ itertools.product(
+ ["common_channel", "mix_channel"],
+ [True, False],
+ [True, False, "mean", "std"],
+ [True, False],
+ ["max_pool", "avg_pool"],
+ ["mse", "nll"],
+ )
+ )
+ )
+ def test_regression(self, mode, self_attn, scaling, gated_attn, head_aggregation, loss):
+ params = self.__class__.params.copy()
+ params.update(
+ mode=mode,
+ self_attn=self_attn,
+ scaling=scaling,
+ head_aggregation=head_aggregation,
+ gated_attn=gated_attn,
+ loss=loss,
+ )
+
+ self.check_module(task="regression", params=params)
+
+ @parameterized.expand(
+ list(
+ itertools.product(
+ ["common_channel", "mix_channel"],
+ [True, False],
+ [True, False, "mean", "std"],
+ [True, False],
+ ["random", "forecast"],
+ [True, False],
+ [True, False],
+ )
+ )
+ )
+ def test_pretrain(
+ self,
+ mode,
+ self_attn,
+ scaling,
+ gated_attn,
+ mask_type,
+ masked_loss,
+ channel_consistent_masking,
+ ):
+ params = self.__class__.params.copy()
+ params.update(
+ mode=mode,
+ self_attn=self_attn,
+ scaling=scaling,
+ gated_attn=gated_attn,
+ mask_type=mask_type,
+ masked_loss=masked_loss,
+ channel_consistent_masking=channel_consistent_masking,
+ )
+
+ self.check_module(task="pretrain", params=params)
+
+ def forecast_full_module(self, params=None, output_hidden_states=False, return_dict=None):
+ config = PatchTSMixerConfig(**params)
+ mdl = PatchTSMixerForPrediction(config)
+
+ target_val = self.__class__.correct_forecast_output
+
+ if config.prediction_channel_indices is not None:
+ target_val = self.__class__.correct_sel_forecast_output
+
+ enc_output = self.__class__.enc_output
+
+ output = mdl(
+ self.__class__.data,
+ future_values=self.__class__.correct_forecast_output,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if isinstance(output, tuple):
+ output = PatchTSMixerForPredictionOutput(*output)
+
+ if config.loss == "mse":
+ self.assertEqual(output.prediction_outputs.shape, target_val.shape)
+
+ self.assertEqual(output.last_hidden_state.shape, enc_output.shape)
+
+ if output_hidden_states is True:
+ self.assertEqual(len(output.hidden_states), params["num_layers"])
+
+ else:
+ self.assertEqual(output.hidden_states, None)
+
+ self.assertEqual(output.loss.item() < 100, True)
+
+ if config.loss == "nll":
+ samples = mdl.generate(self.__class__.data)
+ ref_samples = target_val.unsqueeze(1).expand(-1, params["num_parallel_samples"], -1, -1)
+ self.assertEqual(samples.sequences.shape, ref_samples.shape)
+
+ def test_forecast_full(self):
+ self.check_module(task="forecast", params=self.__class__.params, output_hidden_states=True)
+ # self.forecast_full_module(self.__class__.params, output_hidden_states = True)
+
+ def test_forecast_full_2(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ )
+ self.forecast_full_module(params, output_hidden_states=True)
+
+ def test_forecast_full_2_with_return_dict(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ )
+ self.forecast_full_module(params, output_hidden_states=True, return_dict=False)
+
+ def test_forecast_full_3(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ )
+ self.forecast_full_module(params, output_hidden_states=True)
+
+ def test_forecast_full_5(self):
+ params = self.__class__.params.copy()
+ params.update(
+ self_attn=True,
+ use_positional_encoding=True,
+ positional_encoding="sincos",
+ )
+ self.forecast_full_module(params, output_hidden_states=True)
+
+ def test_forecast_full_4(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ prediction_channel_indices=[0, 2],
+ )
+ self.forecast_full_module(params)
+
+ def test_forecast_full_distributional(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ prediction_channel_indices=[0, 2],
+ loss="nll",
+ distribution_output="normal",
+ )
+
+ self.forecast_full_module(params)
+
+ def test_forecast_full_distributional_2(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ prediction_channel_indices=[0, 2],
+ loss="nll",
+ # distribution_output = "normal",
+ )
+ self.forecast_full_module(params)
+
+ def test_forecast_full_distributional_3(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ # prediction_channel_indices=[0, 2],
+ loss="nll",
+ distribution_output="normal",
+ )
+ self.forecast_full_module(params)
+
+ def test_forecast_full_distributional_4(self):
+ params = self.__class__.params.copy()
+ params.update(
+ mode="mix_channel",
+ # prediction_channel_indices=[0, 2],
+ loss="nll",
+ distribution_output="normal",
+ )
+ self.forecast_full_module(params)
+
+ def test_classification_head(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ head = PatchTSMixerLinearHead(
+ config=config,
+ )
+ # output = head(self.__class__.enc_output, raw_data = self.__class__.correct_pretrain_output)
+ output = head(self.__class__.enc_output)
+
+ self.assertEqual(output.shape, self.__class__.correct_classification_output.shape)
+
+ def test_classification_full(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForTimeSeriesClassification(config)
+ output = mdl(
+ self.__class__.data,
+ future_values=self.__class__.correct_classification_classes,
+ )
+ self.assertEqual(
+ output.prediction_outputs.shape,
+ self.__class__.correct_classification_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ def test_classification_full_with_return_dict(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForTimeSeriesClassification(config)
+ output = mdl(
+ self.__class__.data,
+ future_values=self.__class__.correct_classification_classes,
+ return_dict=False,
+ )
+ if isinstance(output, tuple):
+ output = PatchTSMixerForTimeSeriesClassificationOutput(*output)
+ self.assertEqual(
+ output.prediction_outputs.shape,
+ self.__class__.correct_classification_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ def test_regression_head(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ head = PatchTSMixerLinearHead(
+ config=config,
+ )
+ output = head(self.__class__.enc_output)
+ self.assertEqual(output.shape, self.__class__.correct_regression_output.shape)
+
+ def test_regression_full(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForRegression(config)
+ output = mdl(self.__class__.data, future_values=self.__class__.correct_regression_output)
+ self.assertEqual(
+ output.prediction_outputs.shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ def test_regression_full_with_return_dict(self):
+ config = PatchTSMixerConfig(**self.__class__.params)
+ mdl = PatchTSMixerForRegression(config)
+ output = mdl(
+ self.__class__.data,
+ future_values=self.__class__.correct_regression_output,
+ return_dict=False,
+ )
+ if isinstance(output, tuple):
+ output = PatchTSMixerForRegressionOutput(*output)
+ self.assertEqual(
+ output.prediction_outputs.shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ def test_regression_full_distribute(self):
+ params = self.__class__.params.copy()
+ params.update(loss="nll", distribution_output="normal")
+
+ config = PatchTSMixerConfig(**params)
+
+ mdl = PatchTSMixerForRegression(config)
+ output = mdl(self.__class__.data, future_values=self.__class__.correct_regression_output)
+ self.assertEqual(
+ output.prediction_outputs[0].shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(
+ output.prediction_outputs[1].shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ if config.loss == "nll":
+ samples = mdl.generate(self.__class__.data)
+ ref_samples = self.__class__.correct_regression_output.unsqueeze(1).expand(
+ -1, params["num_parallel_samples"], -1
+ )
+ self.assertEqual(samples.sequences.shape, ref_samples.shape)
+
+ def test_regression_full_distribute_2(self):
+ params = self.__class__.params.copy()
+ params.update(loss="nll", distribution_output="student_t")
+
+ config = PatchTSMixerConfig(**params)
+
+ mdl = PatchTSMixerForRegression(config)
+ output = mdl(self.__class__.data, future_values=self.__class__.correct_regression_output)
+ self.assertEqual(
+ output.prediction_outputs[0].shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(
+ output.prediction_outputs[1].shape,
+ self.__class__.correct_regression_output.shape,
+ )
+ self.assertEqual(output.last_hidden_state.shape, self.__class__.enc_output.shape)
+ self.assertEqual(output.loss.item() < 100, True)
+
+ if config.loss == "nll":
+ samples = mdl.generate(self.__class__.data)
+ ref_samples = self.__class__.correct_regression_output.unsqueeze(1).expand(
+ -1, params["num_parallel_samples"], -1
+ )
+ self.assertEqual(samples.sequences.shape, ref_samples.shape)
diff --git a/tests/models/patchtst/__init__.py b/tests/models/patchtst/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/patchtst/test_modeling_patchtst.py b/tests/models/patchtst/test_modeling_patchtst.py
new file mode 100644
index 00000000000000..beb122849eb083
--- /dev/null
+++ b/tests/models/patchtst/test_modeling_patchtst.py
@@ -0,0 +1,385 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch PatchTST model. """
+
+import inspect
+import random
+import tempfile
+import unittest
+
+from huggingface_hub import hf_hub_download
+
+from transformers import is_torch_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import is_flaky, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+TOLERANCE = 1e-4
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING,
+ MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING,
+ PatchTSTConfig,
+ PatchTSTForClassification,
+ PatchTSTForPrediction,
+ PatchTSTForPretraining,
+ PatchTSTForRegression,
+ PatchTSTModel,
+ )
+
+
+@require_torch
+class PatchTSTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ prediction_length=7,
+ context_length=14,
+ patch_length=5,
+ patch_stride=5,
+ num_input_channels=1,
+ num_time_features=1,
+ is_training=True,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ distil=False,
+ seed=42,
+ num_targets=2,
+ mask_type="random",
+ random_mask_ratio=0,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.prediction_length = prediction_length
+ self.context_length = context_length
+ self.patch_length = patch_length
+ self.patch_stride = patch_stride
+ self.num_input_channels = num_input_channels
+ self.num_time_features = num_time_features
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.mask_type = mask_type
+ self.random_mask_ratio = random_mask_ratio
+
+ self.seed = seed
+ self.num_targets = num_targets
+ self.distil = distil
+ self.num_patches = (max(self.context_length, self.patch_length) - self.patch_length) // self.patch_stride + 1
+ # define seq_length so that it can pass the test_attention_outputs
+ self.seq_length = self.num_patches
+
+ def get_config(self):
+ return PatchTSTConfig(
+ prediction_length=self.prediction_length,
+ patch_length=self.patch_length,
+ patch_stride=self.patch_stride,
+ num_input_channels=self.num_input_channels,
+ d_model=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ context_length=self.context_length,
+ activation_function=self.hidden_act,
+ seed=self.seed,
+ num_targets=self.num_targets,
+ mask_type=self.mask_type,
+ random_mask_ratio=self.random_mask_ratio,
+ )
+
+ def prepare_patchtst_inputs_dict(self, config):
+ _past_length = config.context_length
+ # bs, num_input_channels, num_patch, patch_len
+
+ # [bs x seq_len x num_input_channels]
+ past_values = floats_tensor([self.batch_size, _past_length, self.num_input_channels])
+
+ future_values = floats_tensor([self.batch_size, config.prediction_length, self.num_input_channels])
+
+ inputs_dict = {
+ "past_values": past_values,
+ "future_values": future_values,
+ }
+ return inputs_dict
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ inputs_dict = self.prepare_patchtst_inputs_dict(config)
+ return config, inputs_dict
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+
+@require_torch
+class PatchTSTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ PatchTSTModel,
+ PatchTSTForPrediction,
+ PatchTSTForPretraining,
+ PatchTSTForClassification,
+ PatchTSTForRegression,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ pipeline_model_mapping = {"feature-extraction": PatchTSTModel} if is_torch_available() else {}
+ is_encoder_decoder = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = True
+ test_torchscript = False
+ test_inputs_embeds = False
+ test_model_common_attributes = False
+
+ test_resize_embeddings = True
+ test_resize_position_embeddings = False
+ test_mismatched_shapes = True
+ test_model_parallel = False
+ has_attentions = True
+
+ def setUp(self):
+ self.model_tester = PatchTSTModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=PatchTSTConfig,
+ has_text_modality=False,
+ prediction_length=self.model_tester.prediction_length,
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ # if PatchTSTForPretraining
+ if model_class == PatchTSTForPretraining:
+ inputs_dict.pop("future_values")
+ # else if classification model:
+ elif model_class in get_values(MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING):
+ rng = random.Random(self.model_tester.seed)
+ labels = ids_tensor([self.model_tester.batch_size], self.model_tester.num_targets, rng=rng)
+ inputs_dict["target_values"] = labels
+ inputs_dict.pop("future_values")
+ elif model_class in get_values(MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING):
+ rng = random.Random(self.model_tester.seed)
+ target_values = floats_tensor([self.model_tester.batch_size, self.model_tester.num_targets], rng=rng)
+ inputs_dict["target_values"] = target_values
+ inputs_dict.pop("future_values")
+ return inputs_dict
+
+ def test_save_load_strict(self):
+ config, _ = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ num_patch = self.model_tester.num_patches
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [num_patch, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip(reason="we have no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ def test_model_main_input_name(self):
+ model_signature = inspect.signature(getattr(PatchTSTModel, "forward"))
+ # The main input is the name of the argument after `self`
+ observed_main_input_name = list(model_signature.parameters.keys())[1]
+ self.assertEqual(PatchTSTModel.main_input_name, observed_main_input_name)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ if model_class == PatchTSTForPretraining:
+ expected_arg_names = [
+ "past_values",
+ "past_observed_mask",
+ ]
+ elif model_class in get_values(MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING) or model_class in get_values(
+ MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING
+ ):
+ expected_arg_names = ["past_values", "target_values", "past_observed_mask"]
+ else:
+ expected_arg_names = [
+ "past_values",
+ "past_observed_mask",
+ "future_values",
+ ]
+
+ expected_arg_names.extend(
+ [
+ "output_hidden_states",
+ "output_attentions",
+ "return_dict",
+ ]
+ )
+
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ @is_flaky()
+ def test_retain_grad_hidden_states_attentions(self):
+ super().test_retain_grad_hidden_states_attentions()
+
+
+def prepare_batch(repo_id="hf-internal-testing/etth1-hourly-batch", file="train-batch.pt"):
+ file = hf_hub_download(repo_id=repo_id, filename=file, repo_type="dataset")
+ batch = torch.load(file, map_location=torch_device)
+ return batch
+
+
+# Note: Pretrained model is not yet downloadable.
+@require_torch
+@slow
+class PatchTSTModelIntegrationTests(unittest.TestCase):
+ # Publishing of pretrained weights are under internal review. Pretrained model is not yet downloadable.
+ def test_pretrain_head(self):
+ model = PatchTSTForPretraining.from_pretrained("namctin/patchtst_etth1_pretrain").to(torch_device)
+ batch = prepare_batch()
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(past_values=batch["past_values"].to(torch_device)).prediction_output
+ num_patch = (
+ max(model.config.context_length, model.config.patch_length) - model.config.patch_length
+ ) // model.config.patch_stride + 1
+ expected_shape = torch.Size([64, model.config.num_input_channels, num_patch, model.config.patch_length])
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[[-0.0173]], [[-1.0379]], [[-0.1030]], [[0.3642]], [[0.1601]], [[-1.3136]], [[0.8780]]],
+ device=torch_device,
+ )
+ self.assertTrue(torch.allclose(output[0, :7, :1, :1], expected_slice, atol=TOLERANCE))
+
+ # Publishing of pretrained weights are under internal review. Pretrained model is not yet downloadable.
+ def test_prediction_head(self):
+ model = PatchTSTForPrediction.from_pretrained("namctin/patchtst_etth1_forecast").to(torch_device)
+ batch = prepare_batch(file="test-batch.pt")
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"].to(torch_device),
+ future_values=batch["future_values"].to(torch_device),
+ ).prediction_outputs
+ expected_shape = torch.Size([64, model.config.prediction_length, model.config.num_input_channels])
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.5142, 0.6928, 0.6118, 0.5724, -0.3735, -0.1336, -0.7124]],
+ device=torch_device,
+ )
+ self.assertTrue(torch.allclose(output[0, :1, :7], expected_slice, atol=TOLERANCE))
+
+ def test_prediction_generation(self):
+ model = PatchTSTForPrediction.from_pretrained("namctin/patchtst_etth1_forecast").to(torch_device)
+ batch = prepare_batch(file="test-batch.pt")
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ outputs = model.generate(past_values=batch["past_values"].to(torch_device))
+ expected_shape = torch.Size((64, 1, model.config.prediction_length, model.config.num_input_channels))
+
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.4075, 0.3716, 0.4786, 0.2842, -0.3107, -0.0569, -0.7489]],
+ device=torch_device,
+ )
+ mean_prediction = outputs.sequences.mean(dim=1)
+ self.assertTrue(torch.allclose(mean_prediction[0, -1:], expected_slice, atol=TOLERANCE))
+
+ def test_regression_generation(self):
+ model = PatchTSTForRegression.from_pretrained("namctin/patchtst_etth1_regression").to(torch_device)
+ batch = prepare_batch(file="test-batch.pt")
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ outputs = model.generate(past_values=batch["past_values"].to(torch_device))
+ expected_shape = torch.Size((64, model.config.num_parallel_samples, model.config.num_targets))
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.3228, 0.4320, 0.4591, 0.4066, -0.3461, 0.3094, -0.8426]],
+ device=torch_device,
+ )
+ mean_prediction = outputs.sequences.mean(dim=1)
+
+ self.assertTrue(torch.allclose(mean_prediction[0, -1:], expected_slice, rtol=TOLERANCE))
diff --git a/tests/models/persimmon/test_modeling_persimmon.py b/tests/models/persimmon/test_modeling_persimmon.py
index 0ffb999145be22..864db992772772 100644
--- a/tests/models/persimmon/test_modeling_persimmon.py
+++ b/tests/models/persimmon/test_modeling_persimmon.py
@@ -32,7 +32,7 @@
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
-from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
@@ -104,7 +104,7 @@ def prepare_config_and_inputs(self):
input_mask = None
if self.use_input_mask:
- input_mask = random_attention_mask([self.batch_size, self.seq_length])
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
token_type_ids = None
if self.use_token_type_ids:
diff --git a/tests/models/phi/test_modeling_phi.py b/tests/models/phi/test_modeling_phi.py
index 93c5ca85e9a4a3..516dd1ee626e7f 100644
--- a/tests/models/phi/test_modeling_phi.py
+++ b/tests/models/phi/test_modeling_phi.py
@@ -18,8 +18,17 @@
import unittest
+import pytest
+
from transformers import PhiConfig, is_torch_available
-from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.testing_utils import (
+ require_bitsandbytes,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
@@ -31,6 +40,7 @@
import torch
from transformers import (
+ AutoTokenizer,
PhiForCausalLM,
PhiForSequenceClassification,
PhiForTokenClassification,
@@ -38,7 +48,6 @@
)
-# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester with Llama->Phi
class PhiModelTester:
def __init__(
self,
@@ -288,6 +297,12 @@ class PhiModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin,
test_headmasking = False
test_pruning = False
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79292/workflows/fa2ba644-8953-44a6-8f67-ccd69ca6a476/jobs/1012905
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.setUp with Llama->Phi
def setUp(self):
self.model_tester = PhiModelTester(self)
@@ -345,6 +360,43 @@ def test_phi_sequence_classification_model_for_multi_label(self):
result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+ @require_flash_attn
+ @require_torch_gpu
+ @require_bitsandbytes
+ @pytest.mark.flash_attn_test
+ @slow
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_flash_attn_2_generate_padding_right with LlamaForCausalLM->PhiForCausalLM,LlamaTokenizer->AutoTokenizer,meta-llama/Llama-2-7b-hf->susnato/phi-1_5_dev
+ def test_flash_attn_2_generate_padding_right(self):
+ """
+ Overwritting the common test as the test is flaky on tiny models
+ """
+ model = PhiForCausalLM.from_pretrained(
+ "susnato/phi-1_5_dev",
+ load_in_4bit=True,
+ device_map={"": 0},
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
+
+ texts = ["hi", "Hello this is a very long sentence"]
+
+ tokenizer.padding_side = "right"
+ tokenizer.pad_token = tokenizer.eos_token
+
+ inputs = tokenizer(texts, return_tensors="pt", padding=True).to(0)
+
+ output_native = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_native = tokenizer.batch_decode(output_native)
+
+ model = PhiForCausalLM.from_pretrained(
+ "susnato/phi-1_5_dev", load_in_4bit=True, device_map={"": 0}, attn_implementation="flash_attention_2"
+ )
+
+ output_fa_2 = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_fa_2 = tokenizer.batch_decode(output_fa_2)
+
+ self.assertListEqual(output_native, output_fa_2)
+
@slow
@require_torch
diff --git a/tests/models/poolformer/test_modeling_poolformer.py b/tests/models/poolformer/test_modeling_poolformer.py
index 99667d6f1b4523..070564e718bf1e 100644
--- a/tests/models/poolformer/test_modeling_poolformer.py
+++ b/tests/models/poolformer/test_modeling_poolformer.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch PoolFormer model. """
-import inspect
import unittest
from transformers import is_torch_available, is_vision_available
@@ -208,18 +207,6 @@ def test_training(self):
loss = model(**inputs).loss
loss.backward()
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@slow
def test_model_from_pretrained(self):
for model_name in POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
diff --git a/tests/models/pvt/test_modeling_pvt.py b/tests/models/pvt/test_modeling_pvt.py
index 04ce2153053188..e174b67a07887c 100644
--- a/tests/models/pvt/test_modeling_pvt.py
+++ b/tests/models/pvt/test_modeling_pvt.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch Pvt model. """
-import inspect
import unittest
from transformers import is_torch_available, is_vision_available
@@ -253,18 +252,6 @@ def test_training(self):
loss = model(**inputs).loss
loss.backward()
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@slow
def test_model_from_pretrained(self):
for model_name in PVT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
diff --git a/tests/models/rag/test_retrieval_rag.py b/tests/models/rag/test_retrieval_rag.py
index d4c119815c96f4..1cf155b39a9e2d 100644
--- a/tests/models/rag/test_retrieval_rag.py
+++ b/tests/models/rag/test_retrieval_rag.py
@@ -14,7 +14,6 @@
import json
import os
-import pickle
import shutil
import tempfile
from unittest import TestCase
@@ -174,37 +173,6 @@ def get_dummy_custom_hf_index_retriever(self, from_disk: bool):
)
return retriever
- def get_dummy_legacy_index_retriever(self):
- dataset = Dataset.from_dict(
- {
- "id": ["0", "1"],
- "text": ["foo", "bar"],
- "title": ["Foo", "Bar"],
- "embeddings": [np.ones(self.retrieval_vector_size + 1), 2 * np.ones(self.retrieval_vector_size + 1)],
- }
- )
- dataset.add_faiss_index("embeddings", string_factory="Flat", metric_type=faiss.METRIC_INNER_PRODUCT)
-
- index_file_name = os.path.join(self.tmpdirname, "hf_bert_base.hnswSQ8_correct_phi_128.c_index")
- dataset.save_faiss_index("embeddings", index_file_name + ".index.dpr")
- pickle.dump(dataset["id"], open(index_file_name + ".index_meta.dpr", "wb"))
-
- passages_file_name = os.path.join(self.tmpdirname, "psgs_w100.tsv.pkl")
- passages = {sample["id"]: [sample["text"], sample["title"]] for sample in dataset}
- pickle.dump(passages, open(passages_file_name, "wb"))
-
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- index_name="legacy",
- index_path=self.tmpdirname,
- )
- retriever = RagRetriever(
- config, question_encoder_tokenizer=self.get_dpr_tokenizer(), generator_tokenizer=self.get_bart_tokenizer()
- )
- return retriever
-
def test_canonical_hf_index_retriever_retrieve(self):
n_docs = 1
retriever = self.get_dummy_canonical_hf_index_retriever()
@@ -288,33 +256,6 @@ def test_custom_hf_index_retriever_save_and_from_pretrained_from_disk(self):
out = retriever.retrieve(hidden_states, n_docs=1)
self.assertTrue(out is not None)
- def test_legacy_index_retriever_retrieve(self):
- n_docs = 1
- retriever = self.get_dummy_legacy_index_retriever()
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
- retrieved_doc_embeds, doc_ids, doc_dicts = retriever.retrieve(hidden_states, n_docs=n_docs)
- self.assertEqual(retrieved_doc_embeds.shape, (2, n_docs, self.retrieval_vector_size))
- self.assertEqual(len(doc_dicts), 2)
- self.assertEqual(sorted(doc_dicts[0]), ["text", "title"])
- self.assertEqual(len(doc_dicts[0]["text"]), n_docs)
- self.assertEqual(doc_dicts[0]["text"][0], "bar") # max inner product is reached with second doc
- self.assertEqual(doc_dicts[1]["text"][0], "foo") # max inner product is reached with first doc
- self.assertListEqual(doc_ids.tolist(), [[1], [0]])
-
- def test_legacy_hf_index_retriever_save_and_from_pretrained(self):
- retriever = self.get_dummy_legacy_index_retriever()
- with tempfile.TemporaryDirectory() as tmp_dirname:
- retriever.save_pretrained(tmp_dirname)
- retriever = RagRetriever.from_pretrained(tmp_dirname)
- self.assertIsInstance(retriever, RagRetriever)
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
- out = retriever.retrieve(hidden_states, n_docs=1)
- self.assertTrue(out is not None)
-
@require_torch
@require_tokenizers
@require_sentencepiece
diff --git a/tests/models/regnet/test_modeling_regnet.py b/tests/models/regnet/test_modeling_regnet.py
index debd8271b5c640..9840575f317ecd 100644
--- a/tests/models/regnet/test_modeling_regnet.py
+++ b/tests/models/regnet/test_modeling_regnet.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch RegNet model. """
-import inspect
import unittest
from transformers import RegNetConfig
@@ -161,18 +160,6 @@ def test_inputs_embeds(self):
def test_model_common_attributes(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/rembert/test_tokenization_rembert.py b/tests/models/rembert/test_tokenization_rembert.py
new file mode 100644
index 00000000000000..12c43643be7a48
--- /dev/null
+++ b/tests/models/rembert/test_tokenization_rembert.py
@@ -0,0 +1,243 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the RemBert tokenizer. """
+
+
+import tempfile
+import unittest
+
+from tests.test_tokenization_common import AddedToken, TokenizerTesterMixin
+from transformers import RemBertTokenizer, RemBertTokenizerFast
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers
+
+
+SENTENCEPIECE_UNDERLINE = "▁"
+SPIECE_UNDERLINE = SENTENCEPIECE_UNDERLINE # Kept for backward compatibility
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_sentencepiece
+@require_tokenizers
+class RemBertTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = RemBertTokenizer
+ rust_tokenizer_class = RemBertTokenizerFast
+ space_between_special_tokens = True
+ test_rust_tokenizer = True
+ test_sentencepiece_ignore_case = True
+ pre_trained_model_path = "google/rembert"
+
+ def setUp(self):
+ super().setUp()
+
+ tokenizer = RemBertTokenizer(SAMPLE_VOCAB)
+ tokenizer.save_pretrained(self.tmpdirname)
+
+ # Copied from ReformerTokenizationTest.get_input_output_texts
+ def get_input_output_texts(self, tokenizer):
+ input_text = "this is a test"
+ output_text = "this is a test"
+ return input_text, output_text
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+
+ self.assertEqual(vocab_keys[5], "▁the")
+ self.assertEqual(vocab_keys[2], "")
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 1_000)
+
+ def test_full_tokenizer(self):
+ tokenizer = RemBertTokenizer(SAMPLE_VOCAB, keep_accents=True)
+
+ tokens = tokenizer.tokenize("This is a test")
+ self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
+
+ self.assertListEqual(
+ tokenizer.convert_tokens_to_ids(tokens),
+ [285, 46, 10, 170, 382],
+ )
+
+ tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
+ self.assertListEqual( tokens, [SPIECE_UNDERLINE + "I",SPIECE_UNDERLINE + "was",SPIECE_UNDERLINE + "b","or","n",SPIECE_UNDERLINE + "in",SPIECE_UNDERLINE + "","9","2","0","0","0",",",SPIECE_UNDERLINE + "and",SPIECE_UNDERLINE + "this",SPIECE_UNDERLINE + "is",SPIECE_UNDERLINE + "f","al","s","é",".",],) # fmt: skip
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(ids, [8, 21, 84, 55, 24, 19, 7, 0, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 0, 4])
+
+ def test_encode_decode_round_trip(self):
+ tokenizer = RemBertTokenizer(SAMPLE_VOCAB, keep_accents=True)
+
+ text = "清水寺は京都にある。"
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, ["▁", "清水寺は京都にある。"])
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(encoded_string, [1000, 7, 0, 1001])
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEquals(decode_text, text)
+
+ text = "That's awesome! 🤩 #HuggingFace, 🌟 Have a great day! 🌈"
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual( tokens, ['▁That', "'", 's', '▁a', 'w', 'es', 'ome', '!', '▁', '🤩', '▁', '#', 'H', 'u', 'g', 'g', 'ing', 'F', 'a', 'ce', ',', '▁', '🌟', '▁H', 'a', 've', '▁a', '▁great', '▁day', '!', '▁', '🌈']) # fmt: skip
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEquals(decode_text, "That's awesome! 🤩 #HuggingFace, 🌟 Have a great day! 🌈")
+
+ text = "In the sky up above"
+ tokens = tokenizer._tokenize(text)
+ self.assertListEqual(tokens, ["▁In", "▁the", "▁s", "k", "y", "▁up", "▁a", "b", "o", "ve"]) # fmt: skip
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(encoded_string, [1000, 388, 5, 47, 45, 30, 118, 10, 65, 20, 123, 1001])
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual(text, decode_text)
+
+ text = "The cat. . Sat .In a room"
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(
+ tokens, ["▁The", "▁c", "at", ".", "▁", ".", "▁S", "at", "▁", "<", "s", ">", ".", "I", "n", "▁a", "▁room"]
+ )
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(
+ encoded_string, [1000, 68, 69, 76, 4, 7, 4, 166, 76, 7, 0, 6, 0, 4, 100, 24, 10, 136, 1001]
+ )
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual(text, decode_text)
+
+ text = "Invoice #12345, dated 2023-12-01, is due on 2024-01-15."
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, ['▁In', 'v', 'o', 'ic', 'e', '▁', '#', '1', '2', '34', '5', ',', '▁da', 'ted', '▁', '2', '0', '2', '3', '-', '1', '2', '-', '0', '1', ',', '▁is', '▁d', 'u', 'e', '▁on', '▁', '2', '0', '2', '4', '-', '0', '1', '-', '1', '5', '.']) # fmt: skip
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(encoded_string, [1000, 388, 83, 20, 113, 15, 7, 0, 356, 602, 0, 555, 3, 417, 273, 7, 602, 347, 602, 0, 33, 356, 602, 33, 347, 356, 3, 46, 229, 51, 15, 59, 7, 602, 347, 602, 0, 33, 347, 356, 33, 356, 555, 4, 1001]) # fmt: skip
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual(text, decode_text)
+
+ text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit..."
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, ['▁', 'L', 'or', 'em', '▁', 'i', 'p', 's', 'um', '▁do', 'l', 'or', '▁sit', '▁am', 'e', 't', ',', '▁con', 'se', 'c', 'te', 't', 'ur', '▁a', 'd', 'i', 'p', 'is', 'c', 'ing', '▁', 'el', 'it', '.', '.', '.']) # fmt: skip
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual( encoded_string, [1000, 7, 279, 55, 300, 7, 23, 29, 6, 155, 92, 27, 55, 615, 219, 15, 14, 3, 247, 114, 28, 181, 14, 108, 10, 16, 23, 29, 125, 28, 17, 7, 168, 137, 4, 4, 4, 1001] ) # fmt: skip
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual(text, decode_text)
+
+ # for multiple language in one sentence
+ text = "Bonjour! Hello! こんにちは!"
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, ["▁B", "on", "j", "o", "ur", "!", "▁He", "ll", "o", "!", "▁", "こんにちは", "!"])
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(encoded_string, [1000, 295, 109, 999, 20, 108, 146, 156, 86, 20, 146, 7, 0, 146, 1001])
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual(text, decode_text)
+
+ text = "Extra spaces\tand\nline breaks\r\nshould be handled."
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, ['▁E', 'x', 't', 'r', 'a', '▁sp', 'a', 'ce', 's', '▁and', '▁line', '▁b', 're', 'a', 'k', 's', '▁should', '▁be', '▁hand', 'led', '.']) # fmt: skip
+ encoded_string = tokenizer.encode(text)
+ self.assertListEqual(
+ encoded_string,
+ [1000, 454, 297, 14, 35, 18, 277, 18, 133, 6, 12, 485, 84, 56, 18, 45, 6, 173, 36, 363, 338, 4, 1001],
+ )
+ decode_text = tokenizer.convert_tokens_to_string(tokens)
+ self.assertEqual("Extra spaces and line breaks should be handled.", decode_text)
+
+ def test_sequence_builders(self):
+ tokenizer = RemBertTokenizer(SAMPLE_VOCAB)
+
+ text = tokenizer.encode("sequence builders")
+ text_2 = tokenizer.encode("multi-sequence build")
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ assert encoded_sentence == [tokenizer.cls_token_id] + text + [tokenizer.sep_token_id]
+ assert encoded_pair == [tokenizer.cls_token_id] + text + [tokenizer.sep_token_id] + text_2 + [
+ tokenizer.sep_token_id
+ ]
+
+ def test_added_tokens_serialization(self):
+ # Utility to test the added vocab
+ def _test_added_vocab_and_eos(expected, tokenizer_class, expected_eos, temp_dir):
+ tokenizer = tokenizer_class.from_pretrained(temp_dir)
+ self.assertTrue(str(expected_eos) not in tokenizer.additional_special_tokens)
+ self.assertIn(new_eos, tokenizer.added_tokens_decoder.values())
+ self.assertEqual(tokenizer.added_tokens_decoder[tokenizer.eos_token_id], new_eos)
+ self.assertDictEqual(expected, tokenizer.added_tokens_decoder)
+ return tokenizer
+
+ new_eos = AddedToken("[NEW_EOS]", rstrip=False, lstrip=True, normalized=False, special=True)
+ new_masked_token = AddedToken("[MASK]", lstrip=True, rstrip=False, normalized=False)
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ # Load a slow tokenizer from the hub, init with the new token for fast to also include it
+ tokenizer = self.tokenizer_class.from_pretrained(
+ pretrained_name, eos_token=new_eos, mask_token=new_masked_token
+ )
+ EXPECTED_ADDED_TOKENS_DECODER = tokenizer.added_tokens_decoder
+ with self.subTest("Hub -> Slow: Test loading a slow tokenizer from the hub)"):
+ self.assertEqual(tokenizer._eos_token, new_eos)
+ self.assertIn(new_eos, list(tokenizer.added_tokens_decoder.values()))
+
+ with tempfile.TemporaryDirectory() as tmp_dir_2:
+ tokenizer.save_pretrained(tmp_dir_2)
+ with self.subTest(
+ "Hub -> Slow -> Slow: Test saving this slow tokenizer and reloading it in the fast class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_2
+ )
+
+ if self.rust_tokenizer_class is not None:
+ with self.subTest(
+ "Hub -> Slow -> Fast: Test saving this slow tokenizer and reloading it in the fast class"
+ ):
+ tokenizer_fast = _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_2
+ )
+ with tempfile.TemporaryDirectory() as tmp_dir_3:
+ tokenizer_fast.save_pretrained(tmp_dir_3)
+ with self.subTest(
+ "Hub -> Slow -> Fast -> Fast: Test saving this fast tokenizer and reloading it in the fast class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
+ )
+
+ with self.subTest(
+ "Hub -> Slow -> Fast -> Slow: Test saving this slow tokenizer and reloading it in the slow class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
+ )
+
+ with self.subTest("Hub -> Fast: Test loading a fast tokenizer from the hub)"):
+ if self.rust_tokenizer_class is not None:
+ tokenizer_fast = self.rust_tokenizer_class.from_pretrained(pretrained_name, eos_token=new_eos)
+ self.assertEqual(tokenizer_fast._eos_token, new_eos)
+ self.assertIn(new_eos, list(tokenizer_fast.added_tokens_decoder.values()))
+ # We can't test the following because for BC we kept the default rstrip lstrip in slow not fast. Will comment once normalization is alright
+ with self.subTest("Hub -> Fast == Hub -> Slow: make sure slow and fast tokenizer match"):
+ self.assertDictEqual(EXPECTED_ADDED_TOKENS_DECODER, tokenizer_fast.added_tokens_decoder)
+
+ EXPECTED_ADDED_TOKENS_DECODER = tokenizer_fast.added_tokens_decoder
+ with tempfile.TemporaryDirectory() as tmp_dir_4:
+ tokenizer_fast.save_pretrained(tmp_dir_4)
+ with self.subTest("Hub -> Fast -> Fast: saving Fast1 locally and loading"):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_4
+ )
+
+ with self.subTest("Hub -> Fast -> Slow: saving Fast1 locally and loading"):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_4
+ )
diff --git a/tests/models/resnet/test_modeling_resnet.py b/tests/models/resnet/test_modeling_resnet.py
index 4cfa18d6bcf456..bae9eb6d24c8cb 100644
--- a/tests/models/resnet/test_modeling_resnet.py
+++ b/tests/models/resnet/test_modeling_resnet.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch ResNet model. """
-import inspect
import unittest
from transformers import ResNetConfig
@@ -206,18 +205,6 @@ def test_inputs_embeds(self):
def test_model_common_attributes(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/sam/test_modeling_sam.py b/tests/models/sam/test_modeling_sam.py
index a84e3695c13fa1..3e63edb23a0c6d 100644
--- a/tests/models/sam/test_modeling_sam.py
+++ b/tests/models/sam/test_modeling_sam.py
@@ -16,7 +16,6 @@
import gc
-import inspect
import unittest
import requests
@@ -338,18 +337,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/seamless_m4t/test_modeling_seamless_m4t.py b/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
index ab7a48694d2fd7..cddaddda183cd7 100644
--- a/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
+++ b/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
@@ -16,7 +16,6 @@
import copy
-import inspect
import tempfile
import unittest
@@ -34,6 +33,7 @@
ids_tensor,
random_attention_mask,
)
+from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
@@ -478,10 +478,6 @@ def test_model_weights_reload_no_missing_tied_weights(self):
def test_save_load_fast_init_to_base(self):
pass
- @unittest.skip(reason="The speech encoder doesn't support head masking")
- def test_generate_with_head_masking(self):
- pass
-
@unittest.skip(reason="SeamlessM4TModel can takes input_ids or input_features")
def test_forward_signature(self):
pass
@@ -616,7 +612,9 @@ def test_attention_outputs(self):
@require_torch
-class SeamlessM4TModelWithTextInputTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+class SeamlessM4TModelWithTextInputTest(
+ ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase
+):
is_encoder_decoder = True
fx_compatible = False
test_missing_keys = False
@@ -636,6 +634,19 @@ class SeamlessM4TModelWithTextInputTest(ModelTesterMixin, GenerationTesterMixin,
else ()
)
all_generative_model_classes = (SeamlessM4TForTextToText,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "automatic-speech-recognition": SeamlessM4TForSpeechToText,
+ "conversational": SeamlessM4TForTextToText,
+ "feature-extraction": SeamlessM4TModel,
+ "summarization": SeamlessM4TForTextToText,
+ "text-to-audio": SeamlessM4TForTextToSpeech,
+ "text2text-generation": SeamlessM4TForTextToText,
+ "translation": SeamlessM4TForTextToText,
+ }
+ if is_torch_available()
+ else {}
+ )
def setUp(self):
self.model_tester = SeamlessM4TModelTester(self, input_modality="text")
@@ -698,43 +709,6 @@ def test_initialization(self):
def test_model_weights_reload_no_missing_tied_weights(self):
pass
- def test_generate_with_head_masking(self):
- """Test designed for encoder-decoder models to ensure the attention head masking is used."""
- attention_names = ["encoder_attentions", "decoder_attentions", "cross_attentions"]
- for model_class in self.all_generative_model_classes:
- config, input_ids, attention_mask, max_length = self._get_input_ids_and_config()
-
- model = model_class(config).to(torch_device).eval()
-
- head_masking = {
- "head_mask": torch.zeros(config.encoder_layers, config.encoder_attention_heads, device=torch_device),
- "decoder_head_mask": torch.zeros(
- config.decoder_layers, config.decoder_attention_heads, device=torch_device
- ),
- "cross_attn_head_mask": torch.zeros(
- config.decoder_layers, config.decoder_attention_heads, device=torch_device
- ),
- }
-
- signature = inspect.signature(model.forward)
- # We want to test only models where encoder/decoder head masking is implemented
- if not set(head_masking.keys()) < {*signature.parameters.keys()}:
- continue
-
- for attn_name, (name, mask) in zip(attention_names, head_masking.items()):
- out = model.generate(
- input_ids,
- attention_mask=attention_mask,
- num_beams=1,
- output_attentions=True,
- return_dict_in_generate=True,
- remove_invalid_values=True,
- **{name: mask},
- )
- # We check the state of decoder_attentions and cross_attentions just from the last step
- attn_weights = out[attn_name] if attn_name == attention_names[0] else out[attn_name][-1]
- self.assertEqual(sum([w.sum().item() for w in attn_weights]), 0.0)
-
@unittest.skip(reason="SeamlessM4TModel can take input_ids or input_features")
def test_forward_signature(self):
pass
diff --git a/tests/models/seamless_m4t_v2/__init__.py b/tests/models/seamless_m4t_v2/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py b/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py
new file mode 100644
index 00000000000000..8627220c71aa51
--- /dev/null
+++ b/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py
@@ -0,0 +1,1165 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch SeamlessM4Tv2 model. """
+
+
+import copy
+import tempfile
+import unittest
+
+from transformers import SeamlessM4Tv2Config, is_speech_available, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.trainer_utils import set_seed
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ SeamlessM4Tv2ForSpeechToSpeech,
+ SeamlessM4Tv2ForSpeechToText,
+ SeamlessM4Tv2ForTextToSpeech,
+ SeamlessM4Tv2ForTextToText,
+ SeamlessM4Tv2Model,
+ )
+ from transformers.models.seamless_m4t_v2.modeling_seamless_m4t_v2 import (
+ SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST,
+ )
+
+if is_speech_available():
+ from transformers import SeamlessM4TProcessor
+
+
+class SeamlessM4Tv2ModelTester:
+ def __init__(
+ self,
+ parent,
+ input_modality="speech",
+ batch_size=2,
+ seq_length=4,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ max_new_tokens=None,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ vocab_size=20,
+ t2u_vocab_size=20,
+ hidden_size=6,
+ num_hidden_layers=2,
+ intermediate_size=6,
+ max_position_embeddings=256,
+ encoder_layers=2,
+ decoder_layers=2,
+ encoder_ffn_dim=6,
+ decoder_ffn_dim=6,
+ t2u_encoder_layers=2,
+ t2u_decoder_layers=2,
+ t2u_encoder_ffn_dim=6,
+ t2u_decoder_ffn_dim=6,
+ num_heads=2,
+ vocoder_num_spkrs=5,
+ vocoder_num_langs=5,
+ upsample_initial_channel=32,
+ unit_embed_dim=25,
+ spkr_embed_dim=6,
+ lang_embed_dim=6,
+ num_conv_pos_embeddings=8,
+ unit_hifi_gan_vocab_size=20,
+ t2u_num_langs=0,
+ t2u_offset_tgt_lang=0,
+ vocoder_offset=0,
+ t2u_variance_predictor_hidden_dim=4,
+ char_vocab_size=4,
+ left_max_position_embeddings=2,
+ right_max_position_embeddings=1,
+ speech_encoder_chunk_size=2,
+ speech_encoder_left_chunk_num=1,
+ ):
+ self.parent = parent
+ self.input_modality = input_modality
+
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ self.vocab_size = vocab_size
+ self.t2u_vocab_size = t2u_vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.intermediate_size = intermediate_size
+ self.max_position_embeddings = max_position_embeddings
+ self.encoder_layers = encoder_layers
+ self.decoder_layers = decoder_layers
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.t2u_encoder_layers = t2u_encoder_layers
+ self.t2u_decoder_layers = t2u_decoder_layers
+ self.t2u_encoder_ffn_dim = t2u_encoder_ffn_dim
+ self.t2u_decoder_ffn_dim = t2u_decoder_ffn_dim
+ self.num_heads = num_heads
+ self.num_attention_heads = num_heads
+
+ self.vocoder_num_spkrs = vocoder_num_spkrs
+ self.vocoder_num_langs = vocoder_num_langs
+ self.upsample_initial_channel = upsample_initial_channel
+ self.unit_embed_dim = unit_embed_dim
+ self.spkr_embed_dim = spkr_embed_dim
+ self.num_conv_pos_embeddings = num_conv_pos_embeddings
+ self.lang_embed_dim = lang_embed_dim
+
+ self.max_new_tokens = max_new_tokens
+
+ self.unit_hifi_gan_vocab_size = unit_hifi_gan_vocab_size
+ self.t2u_num_langs = t2u_num_langs
+ self.t2u_offset_tgt_lang = t2u_offset_tgt_lang
+ self.vocoder_offset = vocoder_offset
+
+ self.t2u_variance_predictor_hidden_dim = t2u_variance_predictor_hidden_dim
+ self.char_vocab_size = char_vocab_size
+ self.left_max_position_embeddings = left_max_position_embeddings
+ self.right_max_position_embeddings = right_max_position_embeddings
+ self.speech_encoder_chunk_size = speech_encoder_chunk_size
+ self.speech_encoder_left_chunk_num = speech_encoder_left_chunk_num
+
+ def prepare_config_and_inputs(self):
+ if self.input_modality == "text":
+ inputs = ids_tensor([self.batch_size, self.seq_length], self.vocab_size - 1)
+ else:
+ inputs = ids_tensor([self.batch_size, self.seq_length, 160], self.vocab_size - 1).float()
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size - 1)
+
+ lm_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return config, inputs, decoder_input_ids, input_mask, lm_labels
+
+ def get_config(self):
+ return SeamlessM4Tv2Config(
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ initializer_range=self.initializer_range,
+ vocab_size=self.vocab_size,
+ t2u_vocab_size=self.t2u_vocab_size,
+ hidden_size=self.hidden_size,
+ speech_encoder_layers=self.num_heads,
+ speech_encoder_intermediate_size=self.intermediate_size,
+ max_position_embeddings=self.max_position_embeddings,
+ encoder_layers=self.encoder_layers,
+ decoder_layers=self.decoder_layers,
+ encoder_ffn_dim=self.encoder_ffn_dim,
+ decoder_ffn_dim=self.decoder_ffn_dim,
+ t2u_encoder_layers=self.t2u_encoder_layers,
+ t2u_decoder_layers=self.t2u_decoder_layers,
+ t2u_encoder_ffn_dim=self.t2u_encoder_ffn_dim,
+ t2u_decoder_ffn_dim=self.t2u_decoder_ffn_dim,
+ num_attention_heads=self.num_heads,
+ encoder_attention_heads=self.num_heads,
+ decoder_attention_heads=self.num_heads,
+ t2u_encoder_attention_heads=self.num_heads,
+ t2u_decoder_attention_heads=self.num_heads,
+ speech_encoder_attention_heads=self.num_heads,
+ unit_hifigan_vocab_vise=self.t2u_vocab_size,
+ vocoder_num_spkrs=self.vocoder_num_spkrs,
+ vocoder_num_langs=self.vocoder_num_langs,
+ upsample_initial_channel=self.upsample_initial_channel,
+ unit_embed_dim=self.unit_embed_dim,
+ spkr_embed_dim=self.spkr_embed_dim,
+ num_conv_pos_embeddings=self.num_conv_pos_embeddings,
+ lang_embed_dim=self.lang_embed_dim,
+ max_new_tokens=self.max_new_tokens,
+ unit_hifi_gan_vocab_size=self.unit_hifi_gan_vocab_size,
+ t2u_num_langs=self.t2u_num_langs,
+ t2u_offset_tgt_lang=self.t2u_offset_tgt_lang,
+ vocoder_offset=self.vocoder_offset,
+ t2u_variance_predictor_embed_dim=self.hidden_size,
+ t2u_variance_predictor_hidden_dim=self.t2u_variance_predictor_hidden_dim,
+ char_vocab_size=self.char_vocab_size,
+ left_max_position_embeddings=self.left_max_position_embeddings,
+ right_max_position_embeddings=self.right_max_position_embeddings,
+ speech_encoder_chunk_size=self.speech_encoder_chunk_size,
+ speech_encoder_left_chunk_num=self.speech_encoder_left_chunk_num,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ decoder_input_ids,
+ input_mask,
+ lm_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ decoder_input_ids,
+ input_mask,
+ lm_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(self, config, input_ids, decoder_input_ids, input_mask, labels):
+ model = SeamlessM4Tv2Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ if self.input_modality == "text":
+ result = model(input_ids=input_ids, attention_mask=input_mask, decoder_input_ids=decoder_input_ids)
+ result = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ else:
+ result = model(input_features=input_ids, attention_mask=input_mask, decoder_input_ids=decoder_input_ids)
+ result = model(input_features=input_ids, decoder_input_ids=decoder_input_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ decoder_output = result.logits
+ decoder_past = result.past_key_values
+ encoder_output = result.encoder_last_hidden_state
+
+ if self.input_modality == "text":
+ seq_length = self.seq_length
+ else:
+ # if speech, expected length has been subsampled.
+ seq_length = model._compute_sub_sample_lengths_from_attention_mask(input_mask).max().item()
+
+ self.parent.assertEqual(encoder_output.size(), (self.batch_size, seq_length, self.hidden_size))
+ self.parent.assertEqual(decoder_output.size(), (self.batch_size, decoder_input_ids.shape[1], self.vocab_size))
+ # There should be `num_layers` key value embeddings stored in decoder_past
+ self.parent.assertEqual(len(decoder_past), config.decoder_layers)
+ # There should be a self attn key, a self attn value, a cross attn key and a cross attn value stored in each decoder_past tuple
+ self.parent.assertEqual(len(decoder_past[0]), 4)
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ decoder_input_ids,
+ input_mask,
+ lm_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ model = SeamlessM4Tv2Model(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # make sure no pad token in decoder_input_ids
+ decoder_input_ids = torch.clamp(decoder_input_ids, config.pad_token_id + 1)
+
+ # first forward pass
+ outputs = model(
+ input_ids, decoder_input_ids=decoder_input_ids, decoder_attention_mask=input_mask, use_cache=True
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([decoder_input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ input_ids,
+ decoder_input_ids=next_input_ids,
+ decoder_attention_mask=next_attention_mask,
+ output_hidden_states=True,
+ )
+ output_from_no_past = output_from_no_past["decoder_hidden_states"][0]
+ output_from_past = model(
+ input_ids,
+ decoder_input_ids=next_tokens,
+ decoder_attention_mask=next_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["decoder_hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ decoder_input_ids,
+ input_mask,
+ lm_labels,
+ ) = config_and_inputs
+
+ input_name = "input_ids" if self.input_modality == "text" else "input_features"
+
+ inputs_dict = {
+ input_name: input_ids,
+ "attention_mask": input_mask,
+ "decoder_input_ids": decoder_input_ids,
+ "labels": lm_labels,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class SeamlessM4Tv2ModelWithSpeechInputTest(ModelTesterMixin, unittest.TestCase):
+ is_encoder_decoder = True
+ fx_compatible = False
+ test_missing_keys = False
+ test_pruning = False
+ test_model_parallel = False
+ test_resize_embeddings = False
+ test_headmasking = False
+ test_torchscript = False
+
+ all_model_classes = (
+ (
+ SeamlessM4Tv2Model,
+ SeamlessM4Tv2ForSpeechToSpeech,
+ SeamlessM4Tv2ForSpeechToText,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (SeamlessM4Tv2ForSpeechToText,) if is_torch_available() else ()
+
+ input_name = "input_features"
+
+ def setUp(self):
+ self.model_tester = SeamlessM4Tv2ModelTester(self, input_modality="speech")
+ self.config_tester = ConfigTester(self, config_class=SeamlessM4Tv2Config)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST:
+ model = SeamlessM4Tv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def _get_input_ids_and_config(self, batch_size=2):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ input_ids = inputs_dict[self.input_name]
+
+ # cut to half length & take max batch_size 3
+ sequence_length = input_ids.shape[-1] // 2
+ input_ids = input_ids[:batch_size, :sequence_length]
+
+ # generate max 3 tokens
+ max_length = input_ids.shape[-1] + 3
+ if config.eos_token_id is not None and config.pad_token_id is None:
+ # hack to allow generate for models such as GPT2 as is done in `generate()`
+ if isinstance(config.eos_token_id, int):
+ config.eos_token_id = [config.eos_token_id]
+ config.pad_token_id = config.eos_token_id[0]
+
+ attention_mask = torch.ones(input_ids.shape[:2], dtype=torch.long)[:batch_size, :sequence_length]
+
+ return config, input_ids.float(), attention_mask, max_length
+
+ @staticmethod
+ def _get_encoder_outputs(
+ model, input_ids, attention_mask, output_attentions=None, output_hidden_states=None, num_interleave=1
+ ):
+ encoder = model.get_encoder()
+ encoder_outputs = encoder(
+ input_ids,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ encoder_outputs["last_hidden_state"] = encoder_outputs.last_hidden_state.repeat_interleave(
+ num_interleave, dim=0
+ )
+ input_ids = (
+ torch.zeros(input_ids.shape[:2], dtype=torch.int64, layout=input_ids.layout, device=input_ids.device)
+ + model._get_decoder_start_token_id()
+ )
+ attention_mask = None
+ return encoder_outputs, input_ids, attention_mask
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv",
+ "masked_spec_embed",
+ "codevectors",
+ "quantizer.weight_proj.weight",
+ "project_hid.weight",
+ "project_hid.bias",
+ "project_q.weight",
+ "project_q.bias",
+ "pos_bias_v",
+ "pos_bias_u",
+ "pointwise_conv1",
+ "pointwise_conv2",
+ "feature_projection.projection.weight",
+ "feature_projection.projection.bias",
+ "objective.weight",
+ "adapter",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @unittest.skip(reason="SeamlessM4Tv2SpeechEncoder doesn't have an embedding layer")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(
+ reason="Expected missing keys serve when using SeamlessM4Tv2ForXXX.from_pretrained from a checkpoint saved by SeamlessM4Tv2Model.save_pretrained."
+ )
+ def test_model_weights_reload_no_missing_tied_weights(self):
+ pass
+
+ @unittest.skip(
+ reason="SeamlessM4Tv2Model is base class but has actually a bigger architecture than seamlessM4T task-specific models."
+ )
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="SeamlessM4Tv2Model can takes input_ids or input_features")
+ def test_forward_signature(self):
+ pass
+
+ @unittest.skip(reason="SeamlessM4Tv2 has no base model")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_attention_outputs(self):
+ # expected length is subsampled so need to change a bit this test
+ if not self.has_attentions:
+ self.skipTest(reason="Model does not output attentions")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+ encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
+ decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
+ encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
+ # no more chunk_length test
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+
+ if self.is_encoder_decoder:
+ correct_outlen = 5
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+
+ sub_sampled_length = (
+ model._compute_sub_sample_lengths_from_attention_mask(inputs_dict["attention_mask"]).max().item()
+ )
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ sub_sampled_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ added_hidden_states = 2
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+
+
+@require_torch
+class SeamlessM4Tv2ModelWithTextInputTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ is_encoder_decoder = True
+ fx_compatible = False
+ test_missing_keys = False
+ test_pruning = False
+ test_model_parallel = False
+ test_resize_embeddings = True
+ test_headmasking = False
+ test_torchscript = False
+
+ all_model_classes = (
+ (
+ SeamlessM4Tv2Model,
+ SeamlessM4Tv2ForTextToSpeech,
+ SeamlessM4Tv2ForTextToText,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (SeamlessM4Tv2ForTextToText,) if is_torch_available() else ()
+
+ def setUp(self):
+ self.model_tester = SeamlessM4Tv2ModelTester(self, input_modality="text")
+ self.config_tester = ConfigTester(self, config_class=SeamlessM4Tv2Config)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST:
+ model = SeamlessM4Tv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv",
+ "masked_spec_embed",
+ "codevectors",
+ "quantizer.weight_proj.weight",
+ "project_hid.weight",
+ "project_hid.bias",
+ "project_q.weight",
+ "project_q.bias",
+ "pos_bias_v",
+ "pos_bias_u",
+ "pointwise_conv1",
+ "pointwise_conv2",
+ "feature_projection.projection.weight",
+ "feature_projection.projection.bias",
+ "objective.weight",
+ "adapter",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @unittest.skip(
+ reason="Expected missing keys serve when using SeamlessM4Tv2ForXXX.from_pretrained from a checkpoint saved by SeamlessM4Tv2Model.save_pretrained."
+ )
+ def test_model_weights_reload_no_missing_tied_weights(self):
+ pass
+
+ @unittest.skip(reason="SeamlessM4Tv2Model can take input_ids or input_features")
+ def test_forward_signature(self):
+ pass
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ @unittest.skip(
+ reason="SeamlessM4Tv2Model is base class but has actually a bigger architecture than seamlessM4T task-specific models."
+ )
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="SeamlessM4Tv2 has no base model")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+
+@require_torch
+class SeamlessM4Tv2GenerationTest(unittest.TestCase):
+ # test that non-standard generation works
+ # test generation of: SeamlessM4Tv2Model, SeamlessM4Tv2ForSpeechToSpeech, SeamlessM4Tv2ForSpeechToText, SeamlessM4Tv2ForTextToSpeech
+
+ def setUp(self):
+ self.speech_model_tester = SeamlessM4Tv2ModelTester(self, input_modality="speech")
+ self.text_model_tester = SeamlessM4Tv2ModelTester(self, input_modality="text")
+ self.tmpdirname = tempfile.mkdtemp()
+
+ def update_generation(self, model):
+ lang_code_to_id = {
+ "fra": 4,
+ "eng": 4,
+ }
+
+ id_to_text = {str(i): "a" for i in range(model.config.vocab_size)}
+ id_to_text["0"] = "ab"
+ id_to_text["1"] = "_b"
+ id_to_text["3"] = ","
+ id_to_text["4"] = "_cd"
+
+ char_to_id = {char: i for (i, char) in enumerate("abcd")}
+
+ generation_config = copy.deepcopy(model.generation_config)
+
+ generation_config.__setattr__("text_decoder_lang_to_code_id", lang_code_to_id)
+ generation_config.__setattr__("t2u_lang_code_to_id", lang_code_to_id)
+ generation_config.__setattr__("vocoder_lang_code_to_id", lang_code_to_id)
+ generation_config.__setattr__("id_to_text", id_to_text)
+ generation_config.__setattr__("char_to_id", char_to_id)
+ generation_config.__setattr__("eos_token_id", 0)
+
+ generation_config._from_model_config = False
+
+ model.generation_config = generation_config
+
+ def prepare_text_input(self):
+ config, inputs, decoder_input_ids, input_mask, lm_labels = self.text_model_tester.prepare_config_and_inputs()
+
+ input_dict = {
+ "input_ids": inputs,
+ "attention_mask": input_mask,
+ "tgt_lang": "eng",
+ "num_beams": 2,
+ "do_sample": True,
+ }
+
+ return config, input_dict
+
+ def prepare_speech_input(self):
+ config, inputs, decoder_input_ids, input_mask, lm_labels = self.speech_model_tester.prepare_config_and_inputs()
+
+ input_dict = {
+ "input_features": inputs,
+ "attention_mask": input_mask,
+ "tgt_lang": "fra",
+ "num_beams": 2,
+ "do_sample": True,
+ }
+
+ return config, input_dict
+
+ def prepare_speech_and_text_input(self):
+ config, inputs, decoder_input_ids, input_mask, lm_labels = self.speech_model_tester.prepare_config_and_inputs()
+
+ input_speech = {
+ "input_features": inputs,
+ "attention_mask": input_mask,
+ "tgt_lang": "fra",
+ "num_beams": 2,
+ "do_sample": True,
+ }
+
+ config, inputs, decoder_input_ids, input_mask, lm_labels = self.text_model_tester.prepare_config_and_inputs()
+
+ input_text = {
+ "input_ids": inputs,
+ "attention_mask": input_mask,
+ "tgt_lang": "eng",
+ "num_beams": 2,
+ "do_sample": True,
+ }
+ return config, input_speech, input_text
+
+ def factory_generation_speech_test(self, model, inputs):
+ set_seed(0)
+ output = model.generate(**inputs)
+ return output
+
+ def test_speech_generation(self):
+ config, input_speech, input_text = self.prepare_speech_and_text_input()
+
+ model = SeamlessM4Tv2Model(config=config)
+ self.update_generation(model)
+ model.save_pretrained(self.tmpdirname)
+ model.to(torch_device)
+ model.eval()
+
+ output_original_text = self.factory_generation_speech_test(model, input_text)
+ output_original_speech = self.factory_generation_speech_test(model, input_speech)
+
+ state_dict = model.state_dict()
+
+ text_model = SeamlessM4Tv2ForTextToSpeech.from_pretrained(self.tmpdirname)
+ self.update_generation(text_model)
+ text_model.to(torch_device)
+ text_model.eval()
+
+ output_text = self.factory_generation_speech_test(model, input_text)
+
+ speech_model = SeamlessM4Tv2ForSpeechToSpeech.from_pretrained(self.tmpdirname)
+ self.update_generation(speech_model)
+ speech_model.to(torch_device)
+ speech_model.eval()
+
+ for name, tensor in speech_model.state_dict().items():
+ right_tensor = state_dict.get(name)
+ self.assertEqual(tensor.tolist(), right_tensor.tolist(), f"Tensor {name}")
+
+ output_speech = self.factory_generation_speech_test(model, input_speech)
+
+ # test same text output from input text
+ self.assertListEqual(output_original_text[0].ravel().tolist(), output_text[0].ravel().tolist())
+ self.assertListEqual(output_original_text[1].ravel().tolist(), output_text[1].ravel().tolist())
+
+ # test same speech output from input text
+ # assertTrue because super long list makes this hang in case of failure
+ self.assertTrue(
+ output_original_speech[0].ravel().tolist() == output_speech[0].ravel().tolist(),
+ "Speech generated was different",
+ )
+ self.assertTrue(
+ output_original_speech[1].ravel().tolist() == output_speech[1].ravel().tolist(),
+ "Speech generated was different",
+ )
+
+ def test_text_generation(self):
+ config, input_speech, input_text = self.prepare_speech_and_text_input()
+
+ # to return speech
+ input_speech["generate_speech"] = False
+ input_text["generate_speech"] = False
+
+ model = SeamlessM4Tv2Model(config=config)
+ self.update_generation(model)
+ model.save_pretrained(self.tmpdirname)
+ model.to(torch_device)
+ model.eval()
+
+ output_original_text = self.factory_generation_speech_test(model, input_text)
+ output_original_speech = self.factory_generation_speech_test(model, input_speech)
+
+ # other models don't need it
+ input_speech.pop("generate_speech")
+ input_text.pop("generate_speech")
+
+ state_dict = model.state_dict()
+
+ text_model = SeamlessM4Tv2ForTextToText.from_pretrained(self.tmpdirname)
+ self.update_generation(text_model)
+ text_model.to(torch_device)
+ text_model.eval()
+
+ for name, tensor in text_model.state_dict().items():
+ right_tensor = state_dict.get(name)
+ self.assertEqual(tensor.tolist(), right_tensor.tolist())
+
+ output_text = self.factory_generation_speech_test(text_model, input_text)
+
+ speech_model = SeamlessM4Tv2ForSpeechToText.from_pretrained(self.tmpdirname)
+
+ for name, tensor in speech_model.state_dict().items():
+ right_tensor = state_dict.get(name)
+ self.assertEqual(tensor.tolist(), right_tensor.tolist(), f"Tensor {name}")
+
+ self.update_generation(speech_model)
+ speech_model.to(torch_device)
+ speech_model.eval()
+
+ output_speech = self.factory_generation_speech_test(speech_model, input_speech)
+
+ # test same text output from input text
+ self.assertListEqual(output_original_text[0].ravel().tolist(), output_text.ravel().tolist())
+
+ # test same speech output from input text
+ self.assertListEqual(output_original_speech[0].ravel().tolist(), output_speech.ravel().tolist())
+
+ def test_generation(self):
+ config, input_speech, input_text = self.prepare_speech_and_text_input()
+
+ input_speech["num_beams"] = 3
+ input_speech["do_sample"] = True
+ input_speech["temperature"] = 0.5
+ input_speech["num_return_sequences"] = 3
+
+ input_text["num_beams"] = 3
+ input_text["do_sample"] = True
+ input_text["temperature"] = 0.5
+ input_text["num_return_sequences"] = 3
+
+ for model_class in [SeamlessM4Tv2ForSpeechToSpeech, SeamlessM4Tv2ForSpeechToText, SeamlessM4Tv2Model]:
+ model = model_class(config=config)
+ self.update_generation(model)
+ model.to(torch_device)
+ model.eval()
+
+ output = model.generate(**input_speech)
+ output = output[0] if isinstance(output, tuple) else output
+
+ self.assertEqual(output.shape[0], 3 * input_speech["input_features"].shape[0])
+
+ for model_class in [SeamlessM4Tv2ForTextToSpeech, SeamlessM4Tv2ForTextToText, SeamlessM4Tv2Model]:
+ model = model_class(config=config)
+ self.update_generation(model)
+ model.to(torch_device)
+ model.eval()
+
+ output = model.generate(**input_text)
+
+ output = output[0] if isinstance(output, tuple) else output
+
+ self.assertEqual(output.shape[0], 3 * input_text["input_ids"].shape[0])
+
+
+@require_torch
+class SeamlessM4Tv2ModelIntegrationTest(unittest.TestCase):
+ repo_id = "facebook/seamless-m4t-v2-large"
+
+ def assertListAlmostEqual(self, list1, list2, tol=1e-4):
+ self.assertEqual(len(list1), len(list2))
+ for a, b in zip(list1, list2):
+ self.assertAlmostEqual(a, b, delta=tol)
+
+ @cached_property
+ def processor(self):
+ return SeamlessM4TProcessor.from_pretrained(self.repo_id)
+
+ @cached_property
+ def input_text(self):
+ # corresponds to "C'est un test." with seamlessM4T_medium checkpoint
+
+ input_ids = torch.tensor([[256026, 109, 247729, 171, 128, 6816, 247676, 3]]) # fmt: skip
+
+ input_ids = input_ids.to(torch_device)
+
+ attention_mask = torch.ones_like(input_ids).to(torch_device)
+
+ inputs = {
+ "attention_mask": attention_mask,
+ "input_ids": input_ids,
+ }
+
+ return inputs
+
+ @cached_property
+ def input_audio(self):
+ set_seed(0)
+ seq_len = 20000
+ sampling_rate = 16000
+ input_features = torch.rand((2, seq_len))
+
+ return self.processor(audios=[input_features.tolist()], sampling_rate=sampling_rate, return_tensors="pt").to(
+ torch_device
+ )
+
+ def factory_test_task(self, class1, class2, inputs, class1_kwargs, class2_kwargs):
+ # half-precision loading to limit GPU usage
+ model1 = class1.from_pretrained(self.repo_id, torch_dtype=torch.float16).to(torch_device)
+ model2 = class2.from_pretrained(self.repo_id, torch_dtype=torch.float16).to(torch_device)
+
+ set_seed(0)
+ output_1 = model1.generate(**inputs, **class1_kwargs)
+ set_seed(0)
+ output_2 = model2.generate(**inputs, **class2_kwargs)
+
+ for key in output_1:
+ if isinstance(output_1[key], torch.Tensor):
+ if len(output_1[key].shape) == 0:
+ self.assertEqual(output_1[key].item(), output_2[key].item())
+ else:
+ self.assertListAlmostEqual(output_1[key].squeeze().tolist(), output_2[key].squeeze().tolist())
+
+ @slow
+ def test_to_eng_text(self):
+ model = SeamlessM4Tv2Model.from_pretrained(self.repo_id).to(torch_device)
+
+ # test text - tgt lang: eng
+
+ expected_text_tokens = [3, 256022, 3080, 1, 247669, 10, 6816, 247676, 3] # fmt: skip
+
+ # fmt: off
+ expected_unit_tokens = [
+ 4746,7163,8208,8208,1315,1266,4307,1119,989,9594,3007,3007,4341,5205,7631,7631,3202,4061,9092,3191,7509,1715,
+ 5280,5280,3554,8812,8197,6366,5382,5382,7330,2758,9433,9433,6863,7510,5800,5800,5286,1948,1825,1825,3956,8724,
+ 8724,5331,8914,9315,9315,5288,2588,8167,8787,8787,8063,6008,2621,2621,2621,5696
+ ]
+ # fmt: on
+
+ expected_wav_slice = [9.485097e-04, 8.320558e-04, 7.178137e-04, 9.349979e-04, 1.121628e-03, 1.091766e-03, 1.279693e-03, 1.387754e-03, 1.296396e-03, 1.143557e-03] # fmt: skip
+
+ set_seed(0)
+ output = model.generate(**self.input_text, num_beams=1, tgt_lang="eng", return_intermediate_token_ids=True)
+
+ self.assertListEqual(expected_text_tokens, output.sequences.squeeze().tolist())
+ self.assertListEqual(
+ expected_unit_tokens, (output.unit_sequences - model.config.vocoder_offset).squeeze().tolist()
+ )
+
+ self.assertListAlmostEqual(expected_wav_slice, output.waveform.squeeze().tolist()[50:60])
+
+ # assert mean and std equality
+ self.assertListAlmostEqual(
+ [-2.349690e-04, 9.920777e-02], [output.waveform.mean().item(), output.waveform.std().item()]
+ )
+
+ @slow
+ @unittest.skip(reason="Equivalence is broken since a new update")
+ def test_to_swh_text(self):
+ model = SeamlessM4Tv2Model.from_pretrained(self.repo_id).to(torch_device)
+
+ # test text - tgt lang: swh
+
+ expected_text_tokens = [3, 256084, 109, 247729, 171, 10, 6816, 247676, 3] # fmt: skip
+
+ # fmt: off
+ expected_unit_tokens = [
+ 5725,7163,7472,7472,6915,3099,3099,9921,2765,6515,6515,1374,1374,1347,8252,9854,9854,5662,2420,6600,2216,4503,
+ 7208,6107,6107,7298,9123,6472,9663,9663,6366,6366,6445,575,3575,2052,2052,5788,5800,5800,5286,5286,1825,1825,3956,
+ 3956,8724,8724,5331,8914,8914,9315,9315,2821,8167,8167,8787,8787,8787,8700,8700,8700,2175,2175,3196,3196,2621,1725,
+ 1725,7507,5696
+ ]
+ # fmt: on
+
+ expected_wav_slice = [3.124037e-04, 2.450471e-04, 2.286572e-04, 2.317214e-04, 2.732605e-04, 2.478790e-04, 2.704144e-04, 2.665847e-04, 2.828784e-04, 2.684390e-04] # fmt: skip
+
+ set_seed(0)
+ output = model.generate(**self.input_text, num_beams=1, tgt_lang="swh", return_intermediate_token_ids=True)
+
+ self.assertListEqual(expected_text_tokens, output.sequences.squeeze().tolist())
+ self.assertListEqual(
+ expected_unit_tokens, (output.unit_sequences - model.config.vocoder_offset).squeeze().tolist()
+ )
+
+ self.assertListAlmostEqual(expected_wav_slice, output.waveform.squeeze().tolist()[50:60])
+
+ # assert mean and std equality
+ self.assertListAlmostEqual(
+ [-2.001826e-04, 8.580012e-02], [output.waveform.mean().item(), output.waveform.std().item()]
+ )
+
+ @slow
+ def test_to_rus_speech(self):
+ model = SeamlessM4Tv2Model.from_pretrained(self.repo_id).to(torch_device)
+
+ # test audio - tgt lang: rus
+
+ expected_text_tokens = [3, 256074, 107, 248213, 404, 247792, 247789, 3] # fmt: skip
+
+ # fmt: off
+ expected_unit_tokens = [
+ 8976,7163,6915,2728,2728,5198,3318,3318,3686,1049,9643,1200,2052,2052,8196,8196,7624,7624,7555,7555,7555,7555,
+ 9717,9717,4869,8167,8167,8167,8053,972,9362,8167,297,297,297,3993,3993,3993,3993,4660,4660,4660,4660,4660,4660,
+ 7962,7962,225,225,8737,4199
+ ]
+ # fmt: on
+
+ expected_wav_slice = [1.415287e-03, 1.360976e-03, 1.297727e-03, 1.305321e-03, 1.352087e-03, 1.283812e-03, 1.352623e-03, 1.387384e-03, 1.449627e-03, 1.411701e-03] # fmt: skip
+
+ set_seed(0)
+ output = model.generate(**self.input_audio, num_beams=1, tgt_lang="rus", return_intermediate_token_ids=True)
+
+ self.assertListEqual(expected_text_tokens, output.sequences.squeeze().tolist())
+ self.assertListEqual(
+ expected_unit_tokens, (output.unit_sequences - model.config.vocoder_offset).squeeze().tolist()
+ )
+
+ self.assertListAlmostEqual(expected_wav_slice, output.waveform.squeeze().tolist()[50:60])
+
+ # assert mean and std equality - higher tolerance for speech
+ self.assertListAlmostEqual(
+ [-2.818016e-04, 7.169888e-02], [output.waveform.mean().item(), output.waveform.std().item()], tol=5e-4
+ )
+
+ @slow
+ def test_text_to_text_model(self):
+ kwargs1 = {"tgt_lang": "eng", "return_intermediate_token_ids": True, "generate_speech": False}
+ kwargs2 = {
+ "tgt_lang": "eng",
+ "output_hidden_states": True,
+ "return_dict_in_generate": True,
+ "output_scores": True,
+ }
+ self.factory_test_task(SeamlessM4Tv2Model, SeamlessM4Tv2ForTextToText, self.input_text, kwargs1, kwargs2)
+
+ @slow
+ def test_speech_to_text_model(self):
+ kwargs1 = {"tgt_lang": "eng", "return_intermediate_token_ids": True, "generate_speech": False}
+ kwargs2 = {
+ "tgt_lang": "eng",
+ "output_hidden_states": True,
+ "return_dict_in_generate": True,
+ "output_scores": True,
+ }
+ self.factory_test_task(SeamlessM4Tv2Model, SeamlessM4Tv2ForSpeechToText, self.input_audio, kwargs1, kwargs2)
+
+ @slow
+ def test_speech_to_speech_model(self):
+ kwargs1 = {"tgt_lang": "eng", "return_intermediate_token_ids": True}
+ self.factory_test_task(SeamlessM4Tv2Model, SeamlessM4Tv2ForSpeechToSpeech, self.input_audio, kwargs1, kwargs1)
+
+ @slow
+ def test_text_to_speech_model(self):
+ kwargs1 = {"tgt_lang": "eng", "return_intermediate_token_ids": True}
+
+ self.factory_test_task(SeamlessM4Tv2Model, SeamlessM4Tv2ForTextToSpeech, self.input_text, kwargs1, kwargs1)
diff --git a/tests/models/segformer/test_modeling_segformer.py b/tests/models/segformer/test_modeling_segformer.py
index 0506be9b1f1115..d9a4dce9ffeb3c 100644
--- a/tests/models/segformer/test_modeling_segformer.py
+++ b/tests/models/segformer/test_modeling_segformer.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch SegFormer model. """
-import inspect
import unittest
from transformers import SegformerConfig, is_torch_available, is_vision_available
@@ -212,18 +211,6 @@ def test_inputs_embeds(self):
def test_model_common_attributes(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
diff --git a/tests/models/speech_to_text_2/test_modeling_speech_to_text_2.py b/tests/models/speech_to_text_2/test_modeling_speech_to_text_2.py
index b2220a9e74d8a3..cbb449c6e7ae73 100644
--- a/tests/models/speech_to_text_2/test_modeling_speech_to_text_2.py
+++ b/tests/models/speech_to_text_2/test_modeling_speech_to_text_2.py
@@ -196,10 +196,6 @@ def setUp(
def test_inputs_embeds(self):
pass
- @unittest.skip("This test is currently broken because of safetensors.")
- def test_tf_from_pt_safetensors(self):
- pass
-
# speech2text2 has no base model
def test_save_load_fast_init_from_base(self):
pass
diff --git a/tests/models/swiftformer/test_modeling_swiftformer.py b/tests/models/swiftformer/test_modeling_swiftformer.py
index 3e286cc32048b3..83b6aa3510d925 100644
--- a/tests/models/swiftformer/test_modeling_swiftformer.py
+++ b/tests/models/swiftformer/test_modeling_swiftformer.py
@@ -16,7 +16,6 @@
import copy
-import inspect
import unittest
from transformers import PretrainedConfig, SwiftFormerConfig
@@ -177,18 +176,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/swin/test_modeling_swin.py b/tests/models/swin/test_modeling_swin.py
index 383f0fe867d4fb..e82c13f8db2744 100644
--- a/tests/models/swin/test_modeling_swin.py
+++ b/tests/models/swin/test_modeling_swin.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch Swin model. """
import collections
-import inspect
import unittest
from transformers import SwinConfig
@@ -300,18 +299,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
diff --git a/tests/models/swin2sr/test_modeling_swin2sr.py b/tests/models/swin2sr/test_modeling_swin2sr.py
index f94e11ad646095..581e8debc7e7d7 100644
--- a/tests/models/swin2sr/test_modeling_swin2sr.py
+++ b/tests/models/swin2sr/test_modeling_swin2sr.py
@@ -13,7 +13,6 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch Swin2SR model. """
-import inspect
import unittest
from transformers import Swin2SRConfig
@@ -162,7 +161,11 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
class Swin2SRModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (Swin2SRModel, Swin2SRForImageSuperResolution) if is_torch_available() else ()
- pipeline_model_mapping = {"feature-extraction": Swin2SRModel} if is_torch_available() else {}
+ pipeline_model_mapping = (
+ {"feature-extraction": Swin2SRModel, "image-to-image": Swin2SRForImageSuperResolution}
+ if is_torch_available()
+ else {}
+ )
fx_compatible = False
test_pruning = False
@@ -228,18 +231,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
@slow
def test_model_from_pretrained(self):
for model_name in SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
diff --git a/tests/models/swinv2/test_modeling_swinv2.py b/tests/models/swinv2/test_modeling_swinv2.py
index 5a771b2c4b6353..9b9d08b39fd1b9 100644
--- a/tests/models/swinv2/test_modeling_swinv2.py
+++ b/tests/models/swinv2/test_modeling_swinv2.py
@@ -14,7 +14,6 @@
# limitations under the License.
""" Testing suite for the PyTorch Swinv2 model. """
import collections
-import inspect
import unittest
from transformers import Swinv2Config
@@ -220,18 +219,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
diff --git a/tests/models/switch_transformers/test_modeling_switch_transformers.py b/tests/models/switch_transformers/test_modeling_switch_transformers.py
index 5458b566667903..aa226f82ae3606 100644
--- a/tests/models/switch_transformers/test_modeling_switch_transformers.py
+++ b/tests/models/switch_transformers/test_modeling_switch_transformers.py
@@ -726,10 +726,6 @@ def test_generate_with_head_masking(self):
def test_disk_offload(self):
pass
- @unittest.skip("Test does not fail individually but fails on the CI @ArthurZucker looking into it")
- def test_assisted_decoding_sample(self):
- pass
-
class SwitchTransformersEncoderOnlyModelTester:
def __init__(
diff --git a/tests/models/t5/test_modeling_t5.py b/tests/models/t5/test_modeling_t5.py
index fe098304735931..68b9f45e155b53 100644
--- a/tests/models/t5/test_modeling_t5.py
+++ b/tests/models/t5/test_modeling_t5.py
@@ -1036,10 +1036,6 @@ def test_model_fp16_forward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_fp16_forward(*config_and_inputs)
- @unittest.skip("Test does not fail individually but fails on the CI @ArthurZucker looking into it")
- def test_assisted_decoding_sample(self):
- pass
-
def use_task_specific_params(model, task):
model.config.update(model.config.task_specific_params[task])
diff --git a/tests/models/timesformer/test_modeling_timesformer.py b/tests/models/timesformer/test_modeling_timesformer.py
index 2b7a5e279fe7ad..d4e71c8c599967 100644
--- a/tests/models/timesformer/test_modeling_timesformer.py
+++ b/tests/models/timesformer/test_modeling_timesformer.py
@@ -16,7 +16,6 @@
import copy
-import inspect
import unittest
import numpy as np
@@ -204,18 +203,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/transfo_xl/test_modeling_tf_transfo_xl.py b/tests/models/transfo_xl/test_modeling_tf_transfo_xl.py
deleted file mode 100644
index fdbff90b24b0ca..00000000000000
--- a/tests/models/transfo_xl/test_modeling_tf_transfo_xl.py
+++ /dev/null
@@ -1,282 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-
-from __future__ import annotations
-
-import random
-import unittest
-
-from transformers import TransfoXLConfig, is_tf_available
-from transformers.testing_utils import require_tf, slow
-
-from ...test_configuration_common import ConfigTester
-from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
-from ...test_pipeline_mixin import PipelineTesterMixin
-
-
-if is_tf_available():
- import tensorflow as tf
-
- from transformers import (
- TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST,
- TFTransfoXLForSequenceClassification,
- TFTransfoXLLMHeadModel,
- TFTransfoXLModel,
- )
-
-
-class TFTransfoXLModelTester:
- def __init__(
- self,
- parent,
- ):
- self.parent = parent
- self.batch_size = 13
- self.seq_length = 7
- self.mem_len = 30
- self.key_length = self.seq_length + self.mem_len
- self.clamp_len = 15
- self.is_training = True
- self.use_labels = True
- self.vocab_size = 99
- self.cutoffs = [10, 50, 80]
- self.hidden_size = 32
- self.d_embed = 32
- self.num_attention_heads = 4
- self.d_head = 8
- self.d_inner = 128
- self.div_val = 2
- self.num_hidden_layers = 2
- self.scope = None
- self.seed = 1
- self.eos_token_id = 0
- self.num_labels = 3
- self.pad_token_id = self.vocab_size - 1
- self.init_range = 0.01
-
- def prepare_config_and_inputs(self):
- input_ids_1 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
- input_ids_2 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
-
- lm_labels = None
- if self.use_labels:
- lm_labels = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
-
- config = TransfoXLConfig(
- vocab_size=self.vocab_size,
- mem_len=self.mem_len,
- clamp_len=self.clamp_len,
- cutoffs=self.cutoffs,
- d_model=self.hidden_size,
- d_embed=self.d_embed,
- n_head=self.num_attention_heads,
- d_head=self.d_head,
- d_inner=self.d_inner,
- div_val=self.div_val,
- n_layer=self.num_hidden_layers,
- eos_token_id=self.eos_token_id,
- pad_token_id=self.vocab_size - 1,
- init_range=self.init_range,
- num_labels=self.num_labels,
- )
-
- return (config, input_ids_1, input_ids_2, lm_labels)
-
- def set_seed(self):
- random.seed(self.seed)
- tf.random.set_seed(self.seed)
-
- def create_and_check_transfo_xl_model(self, config, input_ids_1, input_ids_2, lm_labels):
- model = TFTransfoXLModel(config)
-
- hidden_states_1, mems_1 = model(input_ids_1).to_tuple()
-
- inputs = {"input_ids": input_ids_2, "mems": mems_1}
-
- hidden_states_2, mems_2 = model(inputs).to_tuple()
-
- self.parent.assertEqual(hidden_states_1.shape, (self.batch_size, self.seq_length, self.hidden_size))
- self.parent.assertEqual(hidden_states_2.shape, (self.batch_size, self.seq_length, self.hidden_size))
- self.parent.assertListEqual(
- [mem.shape for mem in mems_1],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
- self.parent.assertListEqual(
- [mem.shape for mem in mems_2],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- def create_and_check_transfo_xl_lm_head(self, config, input_ids_1, input_ids_2, lm_labels):
- model = TFTransfoXLLMHeadModel(config)
-
- lm_logits_1, mems_1 = model(input_ids_1).to_tuple()
-
- inputs = {"input_ids": input_ids_1, "labels": lm_labels}
- _, mems_1 = model(inputs).to_tuple()
-
- lm_logits_2, mems_2 = model([input_ids_2, mems_1]).to_tuple()
-
- inputs = {"input_ids": input_ids_1, "mems": mems_1, "labels": lm_labels}
-
- _, mems_2 = model(inputs).to_tuple()
-
- self.parent.assertEqual(lm_logits_1.shape, (self.batch_size, self.seq_length, self.vocab_size))
- self.parent.assertListEqual(
- [mem.shape for mem in mems_1],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- self.parent.assertEqual(lm_logits_2.shape, (self.batch_size, self.seq_length, self.vocab_size))
- self.parent.assertListEqual(
- [mem.shape for mem in mems_2],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- def create_and_check_transfo_xl_for_sequence_classification(self, config, input_ids_1, input_ids_2, lm_labels):
- model = TFTransfoXLForSequenceClassification(config)
- result = model(input_ids_1)
- self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
-
- def prepare_config_and_inputs_for_common(self):
- config_and_inputs = self.prepare_config_and_inputs()
- (config, input_ids_1, input_ids_2, lm_labels) = config_and_inputs
- inputs_dict = {"input_ids": input_ids_1}
- return config, inputs_dict
-
-
-@require_tf
-class TFTransfoXLModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
- all_model_classes = (
- (TFTransfoXLModel, TFTransfoXLLMHeadModel, TFTransfoXLForSequenceClassification) if is_tf_available() else ()
- )
- all_generative_model_classes = () if is_tf_available() else ()
- pipeline_model_mapping = (
- {
- "feature-extraction": TFTransfoXLModel,
- "text-classification": TFTransfoXLForSequenceClassification,
- "text-generation": TFTransfoXLLMHeadModel,
- "zero-shot": TFTransfoXLForSequenceClassification,
- }
- if is_tf_available()
- else {}
- )
- # TODO: add this test when TFTransfoXLLMHead has a linear output layer implemented
- test_resize_embeddings = False
- test_head_masking = False
- test_onnx = False
- test_mismatched_shapes = False
-
- # TODO: Fix the failed tests
- def is_pipeline_test_to_skip(
- self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
- ):
- if pipeline_test_casse_name == "TextGenerationPipelineTests":
- # Get `ValueError: AttributeError: 'NoneType' object has no attribute 'new_ones'` or `AssertionError`.
- # `TransfoXLConfig` was never used in pipeline tests: cannot create a simple
- # tokenizer.
- return True
-
- return False
-
- def setUp(self):
- self.model_tester = TFTransfoXLModelTester(self)
- self.config_tester = ConfigTester(self, config_class=TransfoXLConfig, d_embed=37)
-
- def test_config(self):
- self.config_tester.run_common_tests()
-
- def test_transfo_xl_model(self):
- self.model_tester.set_seed()
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
- self.model_tester.create_and_check_transfo_xl_model(*config_and_inputs)
-
- def test_transfo_xl_lm_head(self):
- self.model_tester.set_seed()
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
- self.model_tester.create_and_check_transfo_xl_lm_head(*config_and_inputs)
-
- def test_transfo_xl_sequence_classification_model(self):
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
- self.model_tester.create_and_check_transfo_xl_for_sequence_classification(*config_and_inputs)
-
- def test_model_common_attributes(self):
- config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
- list_other_models_with_output_ebd = [TFTransfoXLForSequenceClassification]
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- assert isinstance(model.get_input_embeddings(), tf.keras.layers.Layer)
- if model_class in list_other_models_with_output_ebd:
- x = model.get_output_embeddings()
- assert isinstance(x, tf.keras.layers.Layer)
- name = model.get_bias()
- assert name is None
- else:
- x = model.get_output_embeddings()
- assert x is None
- name = model.get_bias()
- assert name is None
-
- def test_xla_mode(self):
- # TODO JP: Make TransfoXL XLA compliant
- pass
-
- @slow
- def test_model_from_pretrained(self):
- for model_name in TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFTransfoXLModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
-
- @unittest.skip(reason="This model doesn't play well with fit() due to not returning a single loss.")
- def test_dataset_conversion(self):
- pass
-
-
-@require_tf
-class TFTransfoXLModelLanguageGenerationTest(unittest.TestCase):
- @unittest.skip("Skip test until #12651 is resolved.")
- @slow
- def test_lm_generate_transfo_xl_wt103(self):
- model = TFTransfoXLLMHeadModel.from_pretrained("transfo-xl-wt103")
- input_ids = tf.convert_to_tensor([[33, 1297, 2, 1, 1009, 4, 1109, 11739, 4762, 358, 5, 25, 245, 22, 1706, 17, 20098, 5, 3215, 21, 37, 1110, 3, 13, 1041, 4, 24, 603, 490, 2, 71477, 20098, 104447, 2, 20961, 1, 2604, 4, 1, 329, 3, 6224, 831, 16002, 2, 8, 603, 78967, 29546, 23, 803, 20, 25, 416, 5, 8, 232, 4, 277, 6, 1855, 4601, 3, 29546, 54, 8, 3609, 5, 57211, 49, 4, 1, 277, 18, 8, 1755, 15691, 3, 341, 25, 416, 693, 42573, 71, 17, 401, 94, 31, 17919, 2, 29546, 7873, 18, 1, 435, 23, 11011, 755, 5, 5167, 3, 7983, 98, 84, 2, 29546, 3267, 8, 3609, 4, 1, 4865, 1075, 2, 6087, 71, 6, 346, 8, 5854, 3, 29546, 824, 1400, 1868, 2, 19, 160, 2, 311, 8, 5496, 2, 20920, 17, 25, 15097, 3, 24, 24, 0]]) # fmt: skip
- # In 1991 , the remains of Russian Tsar Nicholas II and his family
- # ( except for Alexei and Maria ) are discovered .
- # The voice of Nicholas's young son , Tsarevich Alexei Nikolaevich , narrates the
- # remainder of the story . 1883 Western Siberia ,
- # a young Grigori Rasputin is asked by his father and a group of men to perform magic .
- # Rasputin has a vision and denounces one of the men as a horse thief . Although his
- # father initially slaps him for making such an accusation , Rasputin watches as the
- # man is chased outside and beaten . Twenty years later , Rasputin sees a vision of
- # the Virgin Mary , prompting him to become a priest . Rasputin quickly becomes famous ,
- # with people , even a bishop , begging for his blessing .
-
- expected_output_ids = [33,1297,2,1,1009,4,1109,11739,4762,358,5,25,245,22,1706,17,20098,5,3215,21,37,1110,3,13,1041,4,24,603,490,2,71477,20098,104447,2,20961,1,2604,4,1,329,3,6224,831,16002,2,8,603,78967,29546,23,803,20,25,416,5,8,232,4,277,6,1855,4601,3,29546,54,8,3609,5,57211,49,4,1,277,18,8,1755,15691,3,341,25,416,693,42573,71,17,401,94,31,17919,2,29546,7873,18,1,435,23,11011,755,5,5167,3,7983,98,84,2,29546,3267,8,3609,4,1,4865,1075,2,6087,71,6,346,8,5854,3,29546,824,1400,1868,2,19,160,2,311,8,5496,2,20920,17,25,15097,3,24,24,0,33,1,142,1298,188,2,29546,113,8,3654,4,1,1109,7136,833,3,13,1645,4,29546,11,104,7,1,1109,532,7129,2,10,83507,2,1162,1123,2,6,7245,10,2,5,11,104,7,1,1109,532,7129,2,10,24,24,10,22,10,13,770,5863,4,7245,10] # fmt: skip
- # In 1991, the remains of Russian Tsar Nicholas II and his family ( except for
- # Alexei and Maria ) are discovered. The voice of young son, Tsarevich Alexei
- # Nikolaevich, narrates the remainder of the story. 1883 Western Siberia, a young
- # Grigori Rasputin is asked by his father and a group of men to perform magic.
- # Rasputin has a vision and denounces one of the men as a horse thief. Although
- # his father initially slaps him for making such an accusation, Rasputin watches
- # as the man is chased outside and beaten. Twenty years later, Rasputin sees a
- # vision of the Virgin Mary, prompting him to become a priest. Rasputin quickly
- # becomes famous, with people, even a bishop, begging for his blessing. In the
- # early 20th century, Rasputin became a symbol of the Russian Orthodox Church.
- # The image of Rasputin was used in the Russian national anthem, " Nearer, My God,
- # to Heaven ", and was used in the Russian national anthem, " " ( " The Great Spirit
- # of Heaven "
-
- output_ids = model.generate(input_ids, max_length=200, do_sample=False)
- self.assertListEqual(output_ids[0].numpy().tolist(), expected_output_ids)
diff --git a/tests/models/transfo_xl/test_modeling_transfo_xl.py b/tests/models/transfo_xl/test_modeling_transfo_xl.py
deleted file mode 100644
index 9534b13c852629..00000000000000
--- a/tests/models/transfo_xl/test_modeling_transfo_xl.py
+++ /dev/null
@@ -1,533 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import copy
-import random
-import unittest
-
-from transformers import TransfoXLConfig, is_torch_available
-from transformers.testing_utils import require_torch, require_torch_multi_gpu, slow, torch_device
-
-from ...generation.test_utils import GenerationTesterMixin
-from ...test_configuration_common import ConfigTester
-from ...test_modeling_common import ModelTesterMixin, ids_tensor
-from ...test_pipeline_mixin import PipelineTesterMixin
-
-
-if is_torch_available():
- import torch
- from torch import nn
-
- from transformers import TransfoXLForSequenceClassification, TransfoXLLMHeadModel, TransfoXLModel
- from transformers.models.transfo_xl.modeling_transfo_xl import TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST
-
-
-class TransfoXLModelTester:
- def __init__(
- self,
- parent,
- batch_size=14,
- seq_length=7,
- mem_len=30,
- clamp_len=15,
- is_training=False,
- use_labels=True,
- vocab_size=99,
- cutoffs=[10, 50, 80],
- hidden_size=32,
- d_embed=32,
- num_attention_heads=4,
- d_head=8,
- d_inner=128,
- div_val=2,
- num_hidden_layers=2,
- scope=None,
- seed=1,
- eos_token_id=0,
- num_labels=3,
- ):
- self.parent = parent
- self.batch_size = batch_size
- self.seq_length = seq_length
- self.mem_len = mem_len
- self.key_length = self.seq_length + self.mem_len
- self.clamp_len = clamp_len
- self.is_training = is_training
- self.use_labels = use_labels
- self.vocab_size = vocab_size
- self.cutoffs = cutoffs
- self.hidden_size = hidden_size
- self.d_embed = d_embed
- self.num_attention_heads = num_attention_heads
- self.d_head = d_head
- self.d_inner = d_inner
- self.div_val = div_val
- self.num_hidden_layers = num_hidden_layers
- self.scope = scope
- self.seed = seed
- self.eos_token_id = eos_token_id
- self.num_labels = num_labels
- self.pad_token_id = self.vocab_size - 1
-
- def prepare_config_and_inputs(self):
- input_ids_1 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
- input_ids_2 = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
-
- lm_labels = None
- if self.use_labels:
- lm_labels = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
-
- config = self.get_config()
-
- return (config, input_ids_1, input_ids_2, lm_labels)
-
- def get_config(self):
- return TransfoXLConfig(
- vocab_size=self.vocab_size,
- mem_len=self.mem_len,
- clamp_len=self.clamp_len,
- cutoffs=self.cutoffs,
- d_model=self.hidden_size,
- d_embed=self.d_embed,
- n_head=self.num_attention_heads,
- d_head=self.d_head,
- d_inner=self.d_inner,
- div_val=self.div_val,
- n_layer=self.num_hidden_layers,
- eos_token_id=self.eos_token_id,
- pad_token_id=self.pad_token_id,
- )
-
- def set_seed(self):
- random.seed(self.seed)
- torch.manual_seed(self.seed)
-
- def create_transfo_xl_model(self, config, input_ids_1, input_ids_2, lm_labels):
- model = TransfoXLModel(config)
- model.to(torch_device)
- model.eval()
-
- outputs1 = model(input_ids_1)
- outputs2 = model(input_ids_2, outputs1["mems"])
- outputs = {
- "hidden_states_1": outputs1["last_hidden_state"],
- "mems_1": outputs1["mems"],
- "hidden_states_2": outputs2["last_hidden_state"],
- "mems_2": outputs2["mems"],
- }
- return outputs
-
- def check_transfo_xl_model_output(self, result):
- self.parent.assertEqual(result["hidden_states_1"].shape, (self.batch_size, self.seq_length, self.hidden_size))
- self.parent.assertEqual(result["hidden_states_2"].shape, (self.batch_size, self.seq_length, self.hidden_size))
- self.parent.assertListEqual(
- [mem.shape for mem in result["mems_1"]],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
- self.parent.assertListEqual(
- [mem.shape for mem in result["mems_2"]],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- def create_transfo_xl_lm_head(self, config, input_ids_1, input_ids_2, lm_labels):
- model = TransfoXLLMHeadModel(config)
- model.to(torch_device)
- model.eval()
-
- lm_logits_1 = model(input_ids_1)["prediction_scores"]
- outputs1 = model(input_ids_1, labels=lm_labels)
- lm_logits_2 = model(input_ids_2, mems=outputs1["mems"])["prediction_scores"]
- outputs2 = model(input_ids_2, labels=lm_labels, mems=outputs1["mems"])
-
- outputs = {
- "loss_1": outputs1["loss"],
- "losses_1": outputs1["losses"],
- "mems_1": outputs1["mems"],
- "lm_logits_1": lm_logits_1,
- "loss_2": outputs2["loss"],
- "losses_2": outputs2["losses"],
- "mems_2": outputs2["mems"],
- "lm_logits_2": lm_logits_2,
- }
- return outputs
-
- def check_transfo_xl_lm_head_output(self, result):
- self.parent.assertEqual(result["loss_1"].shape, ())
- self.parent.assertEqual(result["losses_1"].shape, (self.batch_size, self.seq_length - 1))
- self.parent.assertEqual(result["lm_logits_1"].shape, (self.batch_size, self.seq_length, self.vocab_size))
- self.parent.assertListEqual(
- [mem.shape for mem in result["mems_1"]],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- self.parent.assertEqual(result["loss_2"].shape, ())
- self.parent.assertEqual(result["losses_2"].shape, (self.batch_size, self.seq_length - 1))
- self.parent.assertEqual(result["lm_logits_2"].shape, (self.batch_size, self.seq_length, self.vocab_size))
- self.parent.assertListEqual(
- [mem.shape for mem in result["mems_2"]],
- [(self.mem_len, self.batch_size, self.hidden_size)] * self.num_hidden_layers,
- )
-
- def create_transfo_xl_lm_head_trainer_compatible_tuple(self, config, input_ids_1, input_ids_2, lm_labels):
- config.trainer_compatible = True
- model = TransfoXLLMHeadModel(config)
- model.to(torch_device)
- model.eval()
-
- lm_logits_1 = model(input_ids_1, return_dict=False)[0]
- outputs1 = model(input_ids_1, labels=lm_labels, return_dict=False)
- loss_1, _, losses_1, mems_1 = outputs1[:4]
- lm_logits_2 = model(input_ids_2, mems=mems_1, return_dict=False)[0]
- outputs2 = model(input_ids_2, labels=lm_labels, mems=mems_1, return_dict=False)
- loss_2, _, losses_2, mems_2 = outputs2[:4]
-
- outputs = {
- "losses_1": losses_1,
- "mems_1": mems_1,
- "lm_logits_1": lm_logits_1,
- "loss_1": loss_1,
- "losses_2": losses_2,
- "mems_2": mems_2,
- "lm_logits_2": lm_logits_2,
- "loss_2": loss_2,
- }
-
- config.trainer_compatible = None
- return outputs
-
- def create_transfo_xl_lm_head_trainer_incompatible_tuple(self, config, input_ids_1, input_ids_2, lm_labels):
- config.trainer_compatible = False
- model = TransfoXLLMHeadModel(config)
- model.to(torch_device)
- model.eval()
-
- lm_logits_1 = model(input_ids_1, return_dict=False)[0]
- outputs1 = model(input_ids_1, labels=lm_labels, return_dict=False)
- losses_1, _, mems_1 = outputs1[:3]
- loss_1 = outputs1[-1]
- lm_logits_2 = model(input_ids_2, mems=mems_1, return_dict=False)[0]
- outputs2 = model(input_ids_2, labels=lm_labels, mems=mems_1)
- losses_2, _, mems_2 = outputs2[:3]
- loss_2 = outputs2[-1]
-
- outputs = {
- "losses_1": losses_1,
- "mems_1": mems_1,
- "lm_logits_1": lm_logits_1,
- "loss_1": loss_1,
- "losses_2": losses_2,
- "mems_2": mems_2,
- "lm_logits_2": lm_logits_2,
- "loss_2": loss_2,
- }
-
- config.trainer_compatible = None
- return outputs
-
- def create_and_check_transfo_xl_for_sequence_classification(self, config, input_ids_1, input_ids_2, lm_labels):
- config.num_labels = self.num_labels
- model = TransfoXLForSequenceClassification(config)
- model.to(torch_device)
- model.eval()
- result = model(input_ids_1)
- self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
-
- def prepare_config_and_inputs_for_common(self):
- config_and_inputs = self.prepare_config_and_inputs()
- (config, input_ids_1, input_ids_2, lm_labels) = config_and_inputs
- inputs_dict = {"input_ids": input_ids_1}
- return config, inputs_dict
-
-
-@require_torch
-class TransfoXLModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
- all_model_classes = (
- (TransfoXLModel, TransfoXLLMHeadModel, TransfoXLForSequenceClassification) if is_torch_available() else ()
- )
- all_generative_model_classes = (TransfoXLLMHeadModel,) if is_torch_available() else ()
- pipeline_model_mapping = (
- {
- "feature-extraction": TransfoXLModel,
- "text-classification": TransfoXLForSequenceClassification,
- "text-generation": TransfoXLLMHeadModel,
- "zero-shot": TransfoXLForSequenceClassification,
- }
- if is_torch_available()
- else {}
- )
- test_pruning = False
- test_resize_embeddings = True
- test_mismatched_shapes = False
-
- # TODO: Fix the failed tests
- def is_pipeline_test_to_skip(
- self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
- ):
- if pipeline_test_casse_name == "TextGenerationPipelineTests":
- # Get `ValueError: AttributeError: 'NoneType' object has no attribute 'new_ones'` or `AssertionError`.
- # `TransfoXLConfig` was never used in pipeline tests: cannot create a simple
- # tokenizer.
- return True
-
- return False
-
- def check_cutoffs_and_n_token(
- self, copied_cutoffs, layer, model_embed, model, model_class, resized_value, vocab_size
- ):
- # Check that the cutoffs were modified accordingly
- for i in range(len(copied_cutoffs)):
- if i < layer:
- self.assertEqual(model_embed.cutoffs[i], copied_cutoffs[i])
- if model_class == TransfoXLLMHeadModel:
- self.assertEqual(model.crit.cutoffs[i], copied_cutoffs[i])
- if i < len(model.config.cutoffs):
- self.assertEqual(model.config.cutoffs[i], copied_cutoffs[i])
- else:
- self.assertEqual(model_embed.cutoffs[i], copied_cutoffs[i] + resized_value)
- if model_class == TransfoXLLMHeadModel:
- self.assertEqual(model.crit.cutoffs[i], copied_cutoffs[i] + resized_value)
- if i < len(model.config.cutoffs):
- self.assertEqual(model.config.cutoffs[i], copied_cutoffs[i] + resized_value)
-
- self.assertEqual(model_embed.n_token, vocab_size + resized_value)
- if model_class == TransfoXLLMHeadModel:
- self.assertEqual(model.crit.n_token, vocab_size + resized_value)
-
- def setUp(self):
- self.model_tester = TransfoXLModelTester(self)
- self.config_tester = ConfigTester(self, config_class=TransfoXLConfig, d_embed=37)
-
- def test_config(self):
- self.config_tester.run_common_tests()
-
- def test_transfo_xl_model(self):
- self.model_tester.set_seed()
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
- output_result = self.model_tester.create_transfo_xl_model(*config_and_inputs)
- self.model_tester.check_transfo_xl_model_output(output_result)
-
- def test_transfo_xl_lm_head(self):
- self.model_tester.set_seed()
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
-
- output_result = self.model_tester.create_transfo_xl_lm_head(*config_and_inputs)
- self.model_tester.check_transfo_xl_lm_head_output(output_result)
-
- output_result = self.model_tester.create_transfo_xl_lm_head_trainer_compatible_tuple(*config_and_inputs)
- self.model_tester.check_transfo_xl_lm_head_output(output_result)
-
- output_result = self.model_tester.create_transfo_xl_lm_head_trainer_incompatible_tuple(*config_and_inputs)
- self.model_tester.check_transfo_xl_lm_head_output(output_result)
-
- def test_transfo_xl_sequence_classification_model(self):
- config_and_inputs = self.model_tester.prepare_config_and_inputs()
- self.model_tester.create_and_check_transfo_xl_for_sequence_classification(*config_and_inputs)
-
- def test_retain_grad_hidden_states_attentions(self):
- # xlnet cannot keep gradients in attentions or hidden states
- return
-
- @require_torch_multi_gpu
- def test_multi_gpu_data_parallel_forward(self):
- # Opt-out of this test.
- pass
-
- @slow
- def test_model_from_pretrained(self):
- for model_name in TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TransfoXLModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
-
- def test_resize_tokens_embeddings(self):
- (original_config, inputs_dict) = self.model_tester.prepare_config_and_inputs_for_common()
- if not self.test_resize_embeddings:
- return
-
- for model_class in self.all_model_classes:
- config = copy.deepcopy(original_config)
- model = model_class(config)
- model.to(torch_device)
-
- if self.model_tester.is_training is False:
- model.eval()
-
- model_vocab_size = config.vocab_size
- # Retrieve the embeddings and clone theme
- model_embed = model.resize_token_embeddings(model_vocab_size)
- cloned_embeddings = [emb.weight.clone() for emb in model_embed.emb_layers]
- # Retrieve the cutoffs and copy them
- copied_cutoffs = copy.copy(model_embed.cutoffs)
-
- test_layers = list(range(config.div_val))
- for layer in test_layers:
- # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
- model_embed = model.resize_token_embeddings(model_vocab_size + 10, layer)
- self.assertEqual(model.config.vocab_size, model_vocab_size + 10)
- # Check that it actually resizes the embeddings matrix
- self.assertEqual(model_embed.emb_layers[layer].weight.shape[0], cloned_embeddings[layer].shape[0] + 10)
- # Check that the cutoffs were modified accordingly
- self.check_cutoffs_and_n_token(
- copied_cutoffs, layer, model_embed, model, model_class, 10, model_vocab_size
- )
-
- # Check that the model can still do a forward pass successfully (every parameter should be resized)
- model(**inputs_dict)
-
- # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
- model_embed = model.resize_token_embeddings(model_vocab_size - 5, layer)
- self.assertEqual(model.config.vocab_size, model_vocab_size - 5)
- # Check that it actually resizes the embeddings matrix
- self.assertEqual(model_embed.emb_layers[layer].weight.shape[0], cloned_embeddings[layer].shape[0] - 5)
- # Check that the cutoffs were modified accordingly
- self.check_cutoffs_and_n_token(
- copied_cutoffs, layer, model_embed, model, model_class, -5, model_vocab_size
- )
-
- # Check that the model can still do a forward pass successfully (every parameter should be resized)
- # Input ids should be clamped to the maximum size of the vocabulary
- inputs_dict["input_ids"].clamp_(max=model_vocab_size - 5 - 1)
- model(**inputs_dict)
-
- # Check that adding and removing tokens has not modified the first part of the embedding matrix.
- models_equal = True
- for p1, p2 in zip(cloned_embeddings[layer], model_embed.emb_layers[layer].weight):
- if p1.data.ne(p2.data).sum() > 0:
- models_equal = False
-
- self.assertTrue(models_equal)
-
- # Reset model embeddings to original size
- model.resize_token_embeddings(model_vocab_size, layer)
- self.assertEqual(model_vocab_size, model.config.vocab_size)
- self.assertEqual(model_embed.emb_layers[layer].weight.shape[0], cloned_embeddings[layer].shape[0])
-
- def test_resize_embeddings_untied(self):
- # transfo-xl requires special resize for lm-head
- return
-
- def _check_attentions_for_generate(
- self, batch_size, attentions, min_length, max_length, config, use_cache=False, num_beam_groups=1
- ):
- self.assertIsInstance(attentions, tuple)
- self.assertListEqual(
- [isinstance(iter_attentions, tuple) for iter_attentions in attentions], [True] * len(attentions)
- )
- self.assertEqual(len(attentions), (max_length - min_length) * num_beam_groups)
-
- for idx, iter_attentions in enumerate(attentions):
- tgt_len = min_length if idx == 0 else (min_length - 2)
- src_len = (min_length + config.mem_len) if idx == 0 else (min_length + config.mem_len - 2)
-
- expected_shape = (
- batch_size * num_beam_groups,
- config.num_attention_heads,
- tgt_len,
- src_len,
- )
-
- # check attn size
- self.assertListEqual(
- [layer_attention.shape for layer_attention in iter_attentions], [expected_shape] * len(iter_attentions)
- )
-
- def _check_hidden_states_for_generate(
- self, batch_size, hidden_states, min_length, max_length, config, use_cache=False, num_beam_groups=1
- ):
- self.assertIsInstance(hidden_states, tuple)
- self.assertListEqual(
- [isinstance(iter_hidden_states, tuple) for iter_hidden_states in hidden_states],
- [True] * len(hidden_states),
- )
- self.assertEqual(len(hidden_states), (max_length - min_length) * num_beam_groups)
-
- for idx, iter_hidden_states in enumerate(hidden_states):
- seq_len = min_length if idx == 0 else min_length - 2
- expected_shape = (batch_size * num_beam_groups, seq_len, config.hidden_size)
- # check hidden size
- self.assertListEqual(
- [layer_hidden_states.shape for layer_hidden_states in iter_hidden_states],
- [expected_shape] * len(iter_hidden_states),
- )
-
- # overwrite from test_modeling_common
- def _mock_init_weights(self, module):
- if hasattr(module, "weight") and module.weight is not None:
- module.weight.data.fill_(3)
- if hasattr(module, "cluster_weight") and module.cluster_weight is not None:
- module.cluster_weight.data.fill_(3)
- if hasattr(module, "bias") and module.bias is not None:
- module.bias.data.fill_(3)
- if hasattr(module, "cluster_bias") and module.cluster_bias is not None:
- module.cluster_bias.data.fill_(3)
-
- if hasattr(module, "emb_projs"):
- for i in range(len(module.emb_projs)):
- if module.emb_projs[i] is not None:
- nn.init.constant_(module.emb_projs[i], 0.0003)
- if hasattr(module, "out_projs"):
- for i in range(len(module.out_projs)):
- if module.out_projs[i] is not None:
- nn.init.constant_(module.out_projs[i], 0.0003)
-
- for param in ["r_emb", "r_w_bias", "r_r_bias", "r_bias"]:
- if hasattr(module, param) and getattr(module, param) is not None:
- weight = getattr(module, param)
- weight.data.fill_(3)
-
- @unittest.skip("The model doesn't support left padding") # and it's not used enough to be worth fixing :)
- def test_left_padding_compatibility(self):
- pass
-
- @unittest.skip("This test is currently broken because of safetensors.")
- def test_tf_from_pt_safetensors(self):
- pass
-
-
-@require_torch
-class TransfoXLModelLanguageGenerationTest(unittest.TestCase):
- @slow
- def test_lm_generate_transfo_xl_wt103(self):
- model = TransfoXLLMHeadModel.from_pretrained("transfo-xl-wt103")
- model.to(torch_device)
-
- input_ids = torch.tensor([[33, 1297, 2, 1, 1009, 4, 1109, 11739, 4762, 358, 5, 25, 245, 22, 1706, 17, 20098, 5, 3215, 21, 37, 1110, 3, 13, 1041, 4, 24, 603, 490, 2, 71477, 20098, 104447, 2, 20961, 1, 2604, 4, 1, 329, 3, 6224, 831, 16002, 2, 8, 603, 78967, 29546, 23, 803, 20, 25, 416, 5, 8, 232, 4, 277, 6, 1855, 4601, 3, 29546, 54, 8, 3609, 5, 57211, 49, 4, 1, 277, 18, 8, 1755, 15691, 3, 341, 25, 416, 693, 42573, 71, 17, 401, 94, 31, 17919, 2, 29546, 7873, 18, 1, 435, 23, 11011, 755, 5, 5167, 3, 7983, 98, 84, 2, 29546, 3267, 8, 3609, 4, 1, 4865, 1075, 2, 6087, 71, 6, 346, 8, 5854, 3, 29546, 824, 1400, 1868, 2, 19, 160, 2, 311, 8, 5496, 2, 20920, 17, 25, 15097, 3, 24, 24, 0]], dtype=torch.long,device=torch_device) # fmt: skip
- # In 1991 , the remains of Russian Tsar Nicholas II and his family
- # ( except for Alexei and Maria ) are discovered .
- # The voice of Nicholas's young son , Tsarevich Alexei Nikolaevich , narrates the
- # remainder of the story . 1883 Western Siberia ,
- # a young Grigori Rasputin is asked by his father and a group of men to perform magic .
- # Rasputin has a vision and denounces one of the men as a horse thief . Although his
- # father initially slaps him for making such an accusation , Rasputin watches as the
- # man is chased outside and beaten . Twenty years later , Rasputin sees a vision of
- # the Virgin Mary , prompting him to become a priest . Rasputin quickly becomes famous ,
- # with people , even a bishop , begging for his blessing .
-
- expected_output_ids = [33,1297,2,1,1009,4,1109,11739,4762,358,5,25,245,22,1706,17,20098,5,3215,21,37,1110,3,13,1041,4,24,603,490,2,71477,20098,104447,2,20961,1,2604,4,1,329,3,6224,831,16002,2,8,603,78967,29546,23,803,20,25,416,5,8,232,4,277,6,1855,4601,3,29546,54,8,3609,5,57211,49,4,1,277,18,8,1755,15691,3,341,25,416,693,42573,71,17,401,94,31,17919,2,29546,7873,18,1,435,23,11011,755,5,5167,3,7983,98,84,2,29546,3267,8,3609,4,1,4865,1075,2,6087,71,6,346,8,5854,3,29546,824,1400,1868,2,19,160,2,311,8,5496,2,20920,17,25,15097,3,24,24,0,33,1,142,1298,188,2,29546,113,8,3654,4,1,1109,7136,833,3,13,1645,4,29546,11,104,7,1,1109,532,7129,2,10,83507,2,1162,1123,2,6,7245,10,2,5,11,104,7,1,1109,532,7129,2,10,24,24,10,22,10,13,770,5863,4,7245,10] # fmt: skip
- # In 1991, the remains of Russian Tsar Nicholas II and his family ( except for
- # Alexei and Maria ) are discovered. The voice of young son, Tsarevich Alexei
- # Nikolaevich, narrates the remainder of the story. 1883 Western Siberia, a young
- # Grigori Rasputin is asked by his father and a group of men to perform magic.
- # Rasputin has a vision and denounces one of the men as a horse thief. Although
- # his father initially slaps him for making such an accusation, Rasputin watches
- # as the man is chased outside and beaten. Twenty years later, Rasputin sees a
- # vision of the Virgin Mary, prompting him to become a priest. Rasputin quickly
- # becomes famous, with people, even a bishop, begging for his blessing. In the
- # early 20th century, Rasputin became a symbol of the Russian Orthodox Church.
- # The image of Rasputin was used in the Russian national anthem, " Nearer, My God,
- # to Heaven ", and was used in the Russian national anthem, " " ( " The Great Spirit
- # of Heaven "
-
- output_ids = model.generate(input_ids, max_length=200, do_sample=False)
- self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
diff --git a/tests/models/transfo_xl/test_tokenization_transfo_xl.py b/tests/models/transfo_xl/test_tokenization_transfo_xl.py
deleted file mode 100644
index 15b712ff3784e3..00000000000000
--- a/tests/models/transfo_xl/test_tokenization_transfo_xl.py
+++ /dev/null
@@ -1,130 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-
-import os
-import unittest
-
-from transformers.models.transfo_xl.tokenization_transfo_xl import VOCAB_FILES_NAMES, TransfoXLTokenizer
-
-from ...test_tokenization_common import TokenizerTesterMixin
-
-
-class TransfoXLTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
- tokenizer_class = TransfoXLTokenizer
- test_rust_tokenizer = False
- test_seq2seq = False
-
- def setUp(self):
- super().setUp()
-
- vocab_tokens = [
- "",
- "[CLS]",
- "[SEP]",
- "want",
- "unwanted",
- "wa",
- "un",
- "running",
- ",",
- "low",
- "l",
- ]
- self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
- with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
- vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
-
- def get_tokenizer(self, **kwargs):
- kwargs["lower_case"] = True
- return TransfoXLTokenizer.from_pretrained(self.tmpdirname, **kwargs)
-
- def get_input_output_texts(self, tokenizer):
- input_text = " UNwanted , running"
- output_text = " unwanted, running"
- return input_text, output_text
-
- def test_full_tokenizer(self):
- tokenizer = TransfoXLTokenizer(vocab_file=self.vocab_file, lower_case=True)
-
- tokens = tokenizer.tokenize(" UNwanted , running")
- self.assertListEqual(tokens, ["", "unwanted", ",", "running"])
-
- self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), [0, 4, 8, 7])
-
- def test_full_tokenizer_lower(self):
- tokenizer = TransfoXLTokenizer(lower_case=True)
-
- self.assertListEqual(
- tokenizer.tokenize(" \tHeLLo ! how \n Are yoU ? "), ["hello", "!", "how", "are", "you", "?"]
- )
-
- def test_full_tokenizer_no_lower(self):
- tokenizer = TransfoXLTokenizer(lower_case=False)
-
- self.assertListEqual(
- tokenizer.tokenize(" \tHeLLo ! how \n Are yoU ? "), ["HeLLo", "!", "how", "Are", "yoU", "?"]
- )
-
- def test_full_tokenizer_moses_numbers(self):
- tokenizer = TransfoXLTokenizer(lower_case=False)
- text_in = "Hello (bracket) and side-scrolled [and] Henry's $5,000 with 3.34 m. What's up!?"
- tokens_out = [
- "Hello",
- "(",
- "bracket",
- ")",
- "and",
- "side",
- "@-@",
- "scrolled",
- "[",
- "and",
- "]",
- "Henry",
- "'s",
- "$",
- "5",
- "@,@",
- "000",
- "with",
- "3",
- "@.@",
- "34",
- "m",
- ".",
- "What",
- "'s",
- "up",
- "!",
- "?",
- ]
-
- self.assertListEqual(tokenizer.tokenize(text_in), tokens_out)
-
- self.assertEqual(tokenizer.convert_tokens_to_string(tokens_out), text_in)
-
- def test_move_added_token(self):
- tokenizer = self.get_tokenizer()
- original_len = len(tokenizer)
-
- tokenizer.add_tokens(["new1", "new2"])
- tokenizer.move_added_token("new1", 1)
-
- # Check that moved token is not copied (duplicate)
- self.assertEqual(len(tokenizer), original_len + 2)
- # Check that token is moved to specified id
- self.assertEqual(tokenizer.encode("new1"), [1])
- self.assertEqual(tokenizer.decode([1]), "new1")
diff --git a/tests/models/tvp/__init__.py b/tests/models/tvp/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/tvp/test_image_processing_tvp.py b/tests/models/tvp/test_image_processing_tvp.py
new file mode 100644
index 00000000000000..1c9a84beb8427b
--- /dev/null
+++ b/tests/models/tvp/test_image_processing_tvp.py
@@ -0,0 +1,306 @@
+# coding=utf-8
+# Copyright 2023 The Intel Team Authors, The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+
+from transformers.image_transforms import PaddingMode
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_video_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import TvpImageProcessor
+
+
+class TvpImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ do_resize: bool = True,
+ size: Dict[str, int] = {"longest_edge": 40},
+ do_center_crop: bool = False,
+ crop_size: Dict[str, int] = None,
+ do_rescale: bool = False,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_pad: bool = True,
+ pad_size: Dict[str, int] = {"height": 80, "width": 80},
+ fill: int = None,
+ pad_mode: PaddingMode = None,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = [0.48145466, 0.4578275, 0.40821073],
+ image_std: Optional[Union[float, List[float]]] = [0.26862954, 0.26130258, 0.27577711],
+ batch_size=2,
+ min_resolution=40,
+ max_resolution=80,
+ num_channels=3,
+ num_frames=2,
+ ):
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.pad_size = pad_size
+ self.fill = fill
+ self.pad_mode = pad_mode
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.num_frames = num_frames
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_rescale": self.do_rescale,
+ "do_center_crop": self.do_center_crop,
+ "do_pad": self.do_pad,
+ "pad_size": self.pad_size,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to TvpImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ return (int(self.pad_size["height"]), int(self.pad_size["width"]))
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ def prepare_video_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_video_inputs(
+ batch_size=self.batch_size,
+ num_frames=self.num_frames,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class TvpImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = TvpImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.image_processor_tester = TvpImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "pad_size"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"longest_edge": 40})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size={"longest_edge": 12})
+ self.assertEqual(image_processor.size, {"longest_edge": 12})
+
+ def test_call_pil(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PIL videos
+ video_inputs = self.image_processor_tester.prepare_video_inputs(equal_resolution=False)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], Image.Image)
+
+ # Test not batched input
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs)
+ encoded_videos = image_processing(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs, batched=True)
+ encoded_videos = image_processing(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ video_inputs = self.image_processor_tester.prepare_video_inputs(equal_resolution=False, numpify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], np.ndarray)
+
+ # Test not batched input
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs)
+ encoded_videos = image_processing(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs, batched=True)
+ encoded_videos = image_processing(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ def test_call_numpy_4_channels(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ video_inputs = self.image_processor_tester.prepare_video_inputs(equal_resolution=False, numpify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], np.ndarray)
+
+ # Test not batched input
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs)
+ encoded_videos = image_processing(
+ video_inputs[0], return_tensors="pt", image_mean=0, image_std=1, input_data_format="channels_first"
+ ).pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs, batched=True)
+ encoded_videos = image_processing(
+ video_inputs, return_tensors="pt", image_mean=0, image_std=1, input_data_format="channels_first"
+ ).pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+ self.image_processor_tester.num_channels = 3
+
+ def test_call_pytorch(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ video_inputs = self.image_processor_tester.prepare_video_inputs(equal_resolution=False, torchify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], torch.Tensor)
+
+ # Test not batched input
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs)
+ encoded_videos = image_processing(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
+
+ # Test batched
+ expected_height, expected_width = self.image_processor_tester.get_expected_values(video_inputs, batched=True)
+ encoded_videos = image_processing(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_frames,
+ self.image_processor_tester.num_channels,
+ expected_height,
+ expected_width,
+ ),
+ )
diff --git a/tests/models/tvp/test_modeling_tvp.py b/tests/models/tvp/test_modeling_tvp.py
new file mode 100644
index 00000000000000..14ec02ed6fd9a9
--- /dev/null
+++ b/tests/models/tvp/test_modeling_tvp.py
@@ -0,0 +1,266 @@
+# coding=utf-8
+# Copyright 2023 The Intel Team Authors, The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch TVP model. """
+
+
+import unittest
+
+from transformers import ResNetConfig, TvpConfig
+from transformers.testing_utils import require_torch, require_vision, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import TvpForVideoGrounding, TvpModel
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import TvpImageProcessor
+
+
+# Copied from test.models.videomae.test_modeling_videomae.VideoMAEModelTester with VideoMAE->TVP
+class TVPModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=1,
+ seq_length=2,
+ alpha=1.0,
+ beta=0.1,
+ visual_prompter_type="framepad",
+ visual_prompter_apply="replace",
+ num_frames=2,
+ max_img_size=448,
+ visual_prompt_size=96,
+ vocab_size=100,
+ hidden_size=32,
+ intermediate_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ max_position_embeddings=30,
+ max_grid_col_position_embeddings=30,
+ max_grid_row_position_embeddings=30,
+ hidden_dropout_prob=0.1,
+ hidden_act="gelu",
+ layer_norm_eps=1e-12,
+ initializer_range=0.02,
+ pad_token_id=0,
+ type_vocab_size=2,
+ attention_probs_dropout_prob=0.1,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.input_id_length = seq_length
+ self.seq_length = seq_length + 10 + 784 # include text prompt length and visual input length
+ self.alpha = alpha
+ self.beta = beta
+ self.visual_prompter_type = visual_prompter_type
+ self.visual_prompter_apply = visual_prompter_apply
+ self.num_frames = num_frames
+ self.max_img_size = max_img_size
+ self.visual_prompt_size = visual_prompt_size
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.max_grid_col_position_embeddings = max_grid_col_position_embeddings
+ self.max_grid_row_position_embeddings = max_grid_row_position_embeddings
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.pad_token_id = pad_token_id
+ self.type_vocab_size = type_vocab_size
+ self.is_training = False
+ self.num_channels = 3
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.input_id_length], self.vocab_size)
+ attention_mask = random_attention_mask([self.batch_size, self.input_id_length])
+ pixel_values = floats_tensor(
+ [self.batch_size, self.num_frames, self.num_channels, self.max_img_size, self.max_img_size]
+ )
+
+ config = self.get_config()
+
+ return (config, input_ids, pixel_values, attention_mask)
+
+ def get_config(self):
+ resnet_config = ResNetConfig(
+ num_channels=3,
+ embeddings_size=64,
+ hidden_sizes=[64, 128],
+ depths=[2, 2],
+ hidden_act="relu",
+ out_features=["stage2"],
+ out_indices=[2],
+ )
+ return TvpConfig(
+ backbone_config=resnet_config,
+ alpha=self.alpha,
+ beta=self.beta,
+ visual_prompter_type=self.visual_prompter_type,
+ visual_prompter_apply=self.visual_prompter_apply,
+ num_frames=self.num_frames,
+ max_img_size=self.max_img_size,
+ visual_prompt_size=self.visual_prompt_size,
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ max_grid_col_position_embeddings=self.max_grid_col_position_embeddings,
+ max_grid_row_position_embeddings=self.max_grid_row_position_embeddings,
+ layer_norm_eps=self.layer_norm_eps,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ type_vocab_size=self.type_vocab_size,
+ )
+
+ def create_and_check_model(self, config, input_ids, pixel_values, attention_mask):
+ model = TvpModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, pixel_values, attention_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "pixel_values": pixel_values, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class TVPModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as TVP does not use, inputs_embeds.
+ The seq_length in TVP contain textual and visual inputs, and prompt.
+ """
+
+ all_model_classes = (TvpModel, TvpForVideoGrounding) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"feature-extraction": TvpModel, "temporal-video-grounding": TvpForVideoGrounding}
+ if is_torch_available()
+ else {}
+ )
+
+ # TODO: Enable this once this model gets more usage
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = TVPModelTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="TVP does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="TVPModel does not have input/output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ # override as the `logit_scale` parameter initilization is different for TVP
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # params are randomly initialized.
+ self.assertAlmostEqual(
+ param.data.mean().item(),
+ 0.0,
+ delta=1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_vision
+@require_torch
+class TvpModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return TvpImageProcessor.from_pretrained("Jiqing/tiny-random-tvp") if is_vision_available() else None
+
+ def test_inference_no_head(self):
+ model = TvpModel.from_pretrained("Jiqing/tiny-random-tvp").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt")
+ input_ids = torch.tensor([[1, 2]])
+ attention_mask = torch.tensor([[1, 1]])
+ encoding.update({"input_ids": input_ids, "attention_mask": attention_mask})
+ encoding.to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape = torch.Size((1, 796, 128))
+ assert outputs.last_hidden_state.shape == expected_shape
+ expected_slice = torch.tensor(
+ [[-0.4902, -0.4121, -1.7872], [-0.2184, 2.1211, -0.9371], [0.1180, 0.5003, -0.1727]]
+ ).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.last_hidden_state[0, :3, :3], expected_slice, atol=1e-4))
+
+ def test_inference_with_head(self):
+ model = TvpForVideoGrounding.from_pretrained("Jiqing/tiny-random-tvp").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt")
+ input_ids = torch.tensor([[1, 2]])
+ attention_mask = torch.tensor([[1, 1]])
+ encoding.update({"input_ids": input_ids, "attention_mask": attention_mask})
+ encoding.to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape = torch.Size((1, 2))
+ assert outputs.logits.shape == expected_shape
+ expected_slice = torch.tensor([[0.5061, 0.4988]]).to(torch_device)
+ self.assertTrue(torch.allclose(outputs.logits, expected_slice, atol=1e-4))
diff --git a/tests/models/univnet/__init__.py b/tests/models/univnet/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/univnet/test_feature_extraction_univnet.py b/tests/models/univnet/test_feature_extraction_univnet.py
new file mode 100644
index 00000000000000..dfa335d15383ee
--- /dev/null
+++ b/tests/models/univnet/test_feature_extraction_univnet.py
@@ -0,0 +1,365 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import itertools
+import os
+import random
+import tempfile
+import unittest
+
+import numpy as np
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetFeatureExtractor
+from transformers.testing_utils import check_json_file_has_correct_format, require_torch, slow
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+if is_torch_available():
+ import torch
+
+
+global_rng = random.Random()
+
+
+# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+class UnivNetFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=1,
+ sampling_rate=24000,
+ padding_value=0.0,
+ do_normalize=True,
+ num_mel_bins=100,
+ hop_length=256,
+ win_length=1024,
+ win_function="hann_window",
+ filter_length=1024,
+ max_length_s=10,
+ fmin=0.0,
+ fmax=12000,
+ mel_floor=1e-9,
+ center=False,
+ compression_factor=1.0,
+ compression_clip_val=1e-5,
+ normalize_min=-11.512925148010254,
+ normalize_max=2.3143386840820312,
+ model_in_channels=64,
+ pad_end_length=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+
+ self.feature_size = feature_size
+ self.sampling_rate = sampling_rate
+ self.padding_value = padding_value
+ self.do_normalize = do_normalize
+ self.num_mel_bins = num_mel_bins
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.win_function = win_function
+ self.filter_length = filter_length
+ self.max_length_s = max_length_s
+ self.fmin = fmin
+ self.fmax = fmax
+ self.mel_floor = mel_floor
+ self.center = center
+ self.compression_factor = compression_factor
+ self.compression_clip_val = compression_clip_val
+ self.normalize_min = normalize_min
+ self.normalize_max = normalize_max
+ self.model_in_channels = model_in_channels
+ self.pad_end_length = pad_end_length
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "sampling_rate": self.sampling_rate,
+ "padding_value": self.padding_value,
+ "do_normalize": self.do_normalize,
+ "num_mel_bins": self.num_mel_bins,
+ "hop_length": self.hop_length,
+ "win_length": self.win_length,
+ "win_function": self.win_function,
+ "filter_length": self.filter_length,
+ "max_length_s": self.max_length_s,
+ "fmin": self.fmin,
+ "fmax": self.fmax,
+ "mel_floor": self.mel_floor,
+ "center": self.center,
+ "compression_factor": self.compression_factor,
+ "compression_clip_val": self.compression_clip_val,
+ "normalize_min": self.normalize_min,
+ "normalize_max": self.normalize_max,
+ "model_in_channels": self.model_in_channels,
+ "pad_end_length": self.pad_end_length,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = floats_list((self.batch_size, self.max_seq_length))
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ _flatten(floats_list((x, self.feature_size)))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+
+ return speech_inputs
+
+
+class UnivNetFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+ feature_extraction_class = UnivNetFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = UnivNetFeatureExtractionTester(self)
+
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.test_feat_extract_from_and_save_pretrained
+ def test_feat_extract_from_and_save_pretrained(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_file = feat_extract_first.save_pretrained(tmpdirname)[0]
+ check_json_file_has_correct_format(saved_file)
+ feat_extract_second = self.feature_extraction_class.from_pretrained(tmpdirname)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ mel_1 = feat_extract_first.mel_filters
+ mel_2 = feat_extract_second.mel_filters
+ self.assertTrue(np.allclose(mel_1, mel_2))
+ self.assertEqual(dict_first, dict_second)
+
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.test_feat_extract_to_json_file
+ def test_feat_extract_to_json_file(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ json_file_path = os.path.join(tmpdirname, "feat_extract.json")
+ feat_extract_first.to_json_file(json_file_path)
+ feat_extract_second = self.feature_extraction_class.from_json_file(json_file_path)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ mel_1 = feat_extract_first.mel_filters
+ mel_2 = feat_extract_second.mel_filters
+ self.assertTrue(np.allclose(mel_1, mel_2))
+ self.assertEqual(dict_first, dict_second)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # Test feature size
+ input_features = feature_extractor(
+ np_speech_inputs, padding="max_length", max_length=1600, return_tensors="np"
+ ).input_features
+ self.assertTrue(input_features.ndim == 3)
+ # Note: for some reason I get a weird padding error when feature_size > 1
+ # self.assertTrue(input_features.shape[-2] == feature_extractor.feature_size)
+ # Note: we use the shape convention (batch_size, seq_len, num_mel_bins)
+ self.assertTrue(input_features.shape[-1] == feature_extractor.num_mel_bins)
+
+ # Test not batched input
+ encoded_sequences_1 = feature_extractor(speech_inputs[0], return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs[0], return_tensors="np").input_features
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test 2-D numpy arrays are batched.
+ speech_inputs = [floats_list((1, x))[0] for x in (800, 800, 800)]
+ np_speech_inputs = np.asarray(speech_inputs)
+ encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test truncation required
+ speech_inputs = [
+ floats_list((1, x))[0]
+ for x in range((feature_extractor.num_max_samples - 100), (feature_extractor.num_max_samples + 500), 200)
+ ]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ speech_inputs_truncated = [x[: feature_extractor.num_max_samples] for x in speech_inputs]
+ np_speech_inputs_truncated = [np.asarray(speech_input) for speech_input in speech_inputs_truncated]
+
+ encoded_sequences_1 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs_truncated, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ def test_batched_unbatched_consistency(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ speech_inputs = floats_list((1, 800))[0]
+ np_speech_inputs = np.asarray(speech_inputs)
+
+ # Test unbatched vs batched list
+ encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor([speech_inputs], return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test np.ndarray vs List[np.ndarray]
+ encoded_sequences_1 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor([np_speech_inputs], return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test unbatched np.ndarray vs batched np.ndarray
+ encoded_sequences_1 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(
+ np.expand_dims(np_speech_inputs, axis=0), return_tensors="np"
+ ).input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ def test_generate_noise(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+
+ features = feature_extractor(speech_inputs, return_noise=True)
+ input_features = features.input_features
+ noise_features = features.noise_sequence
+
+ for spectrogram, noise in zip(input_features, noise_features):
+ self.assertEqual(spectrogram.shape[0], noise.shape[0])
+
+ def test_pad_end(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+
+ input_features1 = feature_extractor(speech_inputs, padding=False, pad_end=False).input_features
+ input_features2 = feature_extractor(speech_inputs, padding=False, pad_end=True).input_features
+
+ for spectrogram1, spectrogram2 in zip(input_features1, input_features2):
+ self.assertEqual(spectrogram1.shape[0] + self.feat_extract_tester.pad_end_length, spectrogram2.shape[0])
+
+ def test_generate_noise_and_pad_end(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+
+ features = feature_extractor(speech_inputs, padding=False, return_noise=True, pad_end=True)
+ input_features = features.input_features
+ noise_features = features.noise_sequence
+
+ for spectrogram, noise in zip(input_features, noise_features):
+ self.assertEqual(spectrogram.shape[0], noise.shape[0])
+
+ @require_torch
+ def test_batch_decode(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ input_lengths = list(range(800, 1400, 200))
+ pad_samples = feature_extractor.pad_end_length * feature_extractor.hop_length
+ output_features = {
+ "waveforms": torch.tensor(floats_list((3, max(input_lengths) + pad_samples))),
+ "waveform_lengths": torch.tensor(input_lengths),
+ }
+ waveforms = feature_extractor.batch_decode(**output_features)
+
+ for input_length, waveform in zip(input_lengths, waveforms):
+ self.assertTrue(len(waveform.shape) == 1, msg="Individual output waveforms should be 1D")
+ self.assertEqual(waveform.shape[0], input_length)
+
+ @require_torch
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.test_double_precision_pad
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100, 32).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_features.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_features.dtype == torch.float32)
+
+ def _load_datasamples(self, num_samples):
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ ds = ds.cast_column("audio", Audio(sampling_rate=self.feat_extract_tester.sampling_rate))
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples], [x["sampling_rate"] for x in speech_samples]
+
+ @slow
+ @require_torch
+ def test_integration(self):
+ # fmt: off
+ EXPECTED_INPUT_FEATURES = torch.tensor(
+ [
+ -5.0229, -6.1358, -5.8346, -5.4447, -5.6707, -5.8577, -5.0464, -5.0058,
+ -5.6015, -5.6410, -5.4325, -5.6116, -5.3700, -5.7956, -5.3196, -5.3274,
+ -5.9655, -5.6057, -5.8382, -5.9602, -5.9005, -5.9123, -5.7669, -6.1441,
+ -5.5168, -5.1405, -5.3927, -6.0032, -5.5784, -5.3728
+ ],
+ )
+ # fmt: on
+
+ input_speech, sr = self._load_datasamples(1)
+
+ feature_extractor = UnivNetFeatureExtractor()
+ input_features = feature_extractor(input_speech, sampling_rate=sr[0], return_tensors="pt").input_features
+ self.assertEqual(input_features.shape, (1, 548, 100))
+
+ input_features_mean = torch.mean(input_features)
+ input_features_stddev = torch.std(input_features)
+
+ EXPECTED_MEAN = torch.tensor(-6.18862009)
+ EXPECTED_STDDEV = torch.tensor(2.80845642)
+
+ torch.testing.assert_close(input_features_mean, EXPECTED_MEAN, atol=5e-5, rtol=5e-6)
+ torch.testing.assert_close(input_features_stddev, EXPECTED_STDDEV)
+ torch.testing.assert_close(input_features[0, :30, 0], EXPECTED_INPUT_FEATURES, atol=1e-4, rtol=1e-5)
diff --git a/tests/models/univnet/test_modeling_univnet.py b/tests/models/univnet/test_modeling_univnet.py
new file mode 100644
index 00000000000000..b1512af284ef01
--- /dev/null
+++ b/tests/models/univnet/test_modeling_univnet.py
@@ -0,0 +1,369 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import inspect
+import random
+import unittest
+
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetConfig, UnivNetFeatureExtractor
+from transformers.testing_utils import (
+ is_torch_available,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ floats_tensor,
+)
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import UnivNetModel
+
+
+class UnivNetModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ seq_length=7,
+ in_channels=8,
+ hidden_channels=8,
+ num_mel_bins=20,
+ kernel_predictor_hidden_channels=8,
+ seed=0,
+ is_training=False,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.in_channels = in_channels
+ self.hidden_channels = hidden_channels
+ self.num_mel_bins = num_mel_bins
+ self.kernel_predictor_hidden_channels = kernel_predictor_hidden_channels
+ self.seed = seed
+ self.is_training = is_training
+
+ def prepare_noise_sequence(self):
+ generator = torch.manual_seed(self.seed)
+ noise_shape = (self.seq_length, self.in_channels)
+ # Create noise on CPU for reproducibility
+ noise_sequence = torch.randn(noise_shape, generator=generator, dtype=torch.float)
+ return noise_sequence
+
+ def prepare_config_and_inputs(self):
+ spectrogram = floats_tensor([self.seq_length, self.num_mel_bins], scale=1.0)
+ noise_sequence = self.prepare_noise_sequence()
+ noise_sequence = noise_sequence.to(spectrogram.device)
+ config = self.get_config()
+ return config, spectrogram, noise_sequence
+
+ def get_config(self):
+ return UnivNetConfig(
+ model_in_channels=self.in_channels,
+ model_hidden_channels=self.hidden_channels,
+ num_mel_bins=self.num_mel_bins,
+ kernel_predictor_hidden_channels=self.kernel_predictor_hidden_channels,
+ )
+
+ def create_and_check_model(self, config, spectrogram, noise_sequence):
+ model = UnivNetModel(config=config).to(torch_device).eval()
+ result = model(spectrogram, noise_sequence)[0]
+ self.parent.assertEqual(result.shape, (1, self.seq_length * 256))
+
+ def prepare_config_and_inputs_for_common(self):
+ config, spectrogram, noise_sequence = self.prepare_config_and_inputs()
+ inputs_dict = {"input_features": spectrogram, "noise_sequence": noise_sequence}
+ return config, inputs_dict
+
+
+@require_torch
+class UnivNetModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (UnivNetModel,) if is_torch_available() else ()
+ # UnivNetModel currently cannot be traced with torch.jit.trace.
+ test_torchscript = False
+ # The UnivNetModel is not a transformer and does not use any attention mechanisms, so skip transformer/attention
+ # related tests.
+ test_pruning = False
+ test_resize_embeddings = False
+ test_resize_position_embeddings = False
+ test_head_masking = False
+ # UnivNetModel is not a sequence classification model.
+ test_mismatched_shapes = False
+ # UnivNetModel does not have a base_model_prefix attribute.
+ test_missing_keys = False
+ # UnivNetModel does not implement a parallelize method.
+ test_model_parallel = False
+ is_encoder_decoder = False
+ has_attentions = False
+
+ input_name = "input_features"
+
+ def setUp(self):
+ self.model_tester = UnivNetModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=UnivNetConfig)
+
+ @unittest.skip(reason="fix this once it gets more usage")
+ def test_multi_gpu_data_parallel_forward(self):
+ super().test_multi_gpu_data_parallel_forward()
+
+ def test_config(self):
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_from_and_save_pretrained_subfolder()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = [
+ "input_features",
+ ]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ @unittest.skip(reason="UnivNetModel does not output hidden_states.")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="UnivNetModel.forward does not accept an inputs_embeds argument.")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="UnivNetModel does not use input embeddings and thus has no get_input_embeddings method.")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="UnivNetModel does not support all arguments tested, such as output_hidden_states.")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ @unittest.skip(reason="UnivNetModel does not output hidden_states.")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ def test_batched_inputs_outputs(self):
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ batched_spectrogram = inputs["input_features"].unsqueeze(0).repeat(2, 1, 1)
+ batched_noise_sequence = inputs["noise_sequence"].unsqueeze(0).repeat(2, 1, 1)
+ with torch.no_grad():
+ batched_outputs = model(
+ batched_spectrogram.to(torch_device),
+ batched_noise_sequence.to(torch_device),
+ )[0]
+
+ self.assertEqual(
+ batched_spectrogram.shape[0],
+ batched_outputs.shape[0],
+ msg="Got different batch dims for input and output",
+ )
+
+ def test_unbatched_inputs_outputs(self):
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(inputs["input_features"].to(torch_device), inputs["noise_sequence"].to(torch_device))[
+ 0
+ ]
+ self.assertTrue(outputs.shape[0] == 1, msg="Unbatched input should create batched output with bsz = 1")
+
+ def test_unbatched_batched_outputs_consistency(self):
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ unbatched_spectrogram = inputs["input_features"].detach().clone()
+ unbatched_noise_sequence = inputs["noise_sequence"].detach().clone()
+ batched_spectrogram = inputs["input_features"].unsqueeze(0)
+ batched_noise_sequence = inputs["noise_sequence"].unsqueeze(0)
+
+ with torch.no_grad():
+ unbatched_outputs = model(
+ unbatched_spectrogram.to(torch_device),
+ unbatched_noise_sequence.to(torch_device),
+ )[0]
+
+ batched_outputs = model(
+ batched_spectrogram.to(torch_device),
+ batched_noise_sequence.to(torch_device),
+ )[0]
+
+ torch.testing.assert_close(unbatched_outputs, batched_outputs)
+
+
+@require_torch_gpu
+@slow
+class UnivNetModelIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def _load_datasamples(self, num_samples, sampling_rate=24000):
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ ds = ds.cast_column("audio", Audio(sampling_rate=sampling_rate))
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples], [x["sampling_rate"] for x in speech_samples]
+
+ def get_inputs(self, device, num_samples: int = 3, noise_length: int = 10, seed: int = 0):
+ generator = torch.manual_seed(seed)
+ # Note: hardcode model_in_channels -> 64
+ if num_samples == 1:
+ noise_sequence_shape = (64, noise_length)
+ else:
+ noise_sequence_shape = (num_samples, 64, noise_length)
+ # Explicity generate noise_sequence on CPU for consistency.
+ noise_sequence = torch.randn(noise_sequence_shape, generator=generator, dtype=torch.float32, device="cpu")
+ # Put noise_sequence on the desired device.
+ noise_sequence = noise_sequence.to(device)
+
+ # Note: hardcode num_mel_channels -> 100
+ if num_samples == 1:
+ spectrogram_shape = [100, noise_length]
+ else:
+ spectrogram_shape = [num_samples, 100, noise_length]
+ spectrogram = floats_tensor(spectrogram_shape, scale=1.0, rng=random.Random(seed))
+ # Note: spectrogram should already be on torch_device
+
+ # Permute to match diffusers implementation
+ if num_samples == 1:
+ noise_sequence = noise_sequence.transpose(1, 0)
+ spectrogram = spectrogram.transpose(1, 0)
+ else:
+ noise_sequence = noise_sequence.transpose(2, 1)
+ spectrogram = spectrogram.transpose(2, 1)
+
+ inputs = {
+ "input_features": spectrogram,
+ "noise_sequence": noise_sequence,
+ "generator": generator,
+ }
+
+ return inputs
+
+ def test_model_inference_batched(self):
+ # Load sample checkpoint from Tortoise TTS
+ model = UnivNetModel.from_pretrained("dg845/univnet-dev")
+ model.eval().to(torch_device)
+
+ # Get batched noise and spectrogram inputs.
+ input_speech = self.get_inputs(torch_device, num_samples=3)
+
+ with torch.no_grad():
+ waveform = model(**input_speech)[0]
+ waveform = waveform.cpu()
+
+ waveform_mean = torch.mean(waveform)
+ waveform_stddev = torch.std(waveform)
+ waveform_slice = waveform[-1, -9:].flatten()
+
+ EXPECTED_MEAN = torch.tensor(-0.19989729)
+ EXPECTED_STDDEV = torch.tensor(0.35230172)
+ EXPECTED_SLICE = torch.tensor([-0.3408, -0.6045, -0.5052, 0.1160, -0.1556, -0.0405, -0.3024, -0.5290, -0.5019])
+
+ torch.testing.assert_close(waveform_mean, EXPECTED_MEAN, atol=1e-4, rtol=1e-5)
+ torch.testing.assert_close(waveform_stddev, EXPECTED_STDDEV, atol=1e-4, rtol=1e-5)
+ torch.testing.assert_close(waveform_slice, EXPECTED_SLICE, atol=5e-4, rtol=1e-5)
+
+ def test_model_inference_unbatched(self):
+ # Load sample checkpoint from Tortoise TTS
+ model = UnivNetModel.from_pretrained("dg845/univnet-dev")
+ model.eval().to(torch_device)
+
+ # Get unbatched noise and spectrogram inputs.
+ input_speech = self.get_inputs(torch_device, num_samples=1)
+
+ with torch.no_grad():
+ waveform = model(**input_speech)[0]
+ waveform = waveform.cpu()
+
+ waveform_mean = torch.mean(waveform)
+ waveform_stddev = torch.std(waveform)
+ waveform_slice = waveform[-1, -9:].flatten()
+
+ EXPECTED_MEAN = torch.tensor(-0.22895093)
+ EXPECTED_STDDEV = torch.tensor(0.33986747)
+ EXPECTED_SLICE = torch.tensor([-0.3276, -0.5504, -0.3484, 0.3574, -0.0373, -0.1826, -0.4880, -0.6431, -0.5162])
+
+ torch.testing.assert_close(waveform_mean, EXPECTED_MEAN, atol=1e-4, rtol=1e-5)
+ torch.testing.assert_close(waveform_stddev, EXPECTED_STDDEV, atol=1e-4, rtol=1e-5)
+ torch.testing.assert_close(waveform_slice, EXPECTED_SLICE, atol=1e-3, rtol=1e-5)
+
+ def test_integration(self):
+ feature_extractor = UnivNetFeatureExtractor.from_pretrained("dg845/univnet-dev")
+ model = UnivNetModel.from_pretrained("dg845/univnet-dev")
+ model.eval().to(torch_device)
+
+ audio, sr = self._load_datasamples(1, sampling_rate=feature_extractor.sampling_rate)
+
+ input_features = feature_extractor(audio, sampling_rate=sr[0], return_tensors="pt").input_features
+ input_features = input_features.to(device=torch_device)
+
+ input_speech = self.get_inputs(torch_device, num_samples=1, noise_length=input_features.shape[1])
+ input_speech["input_features"] = input_features
+
+ with torch.no_grad():
+ waveform = model(**input_speech)[0]
+ waveform = waveform.cpu()
+
+ waveform_mean = torch.mean(waveform)
+ waveform_stddev = torch.std(waveform)
+ waveform_slice = waveform[-1, -9:].flatten()
+
+ EXPECTED_MEAN = torch.tensor(0.00051374)
+ EXPECTED_STDDEV = torch.tensor(0.058105603)
+ # fmt: off
+ EXPECTED_SLICE = torch.tensor([-4.3934e-04, -1.8203e-04, -3.3033e-04, -3.8716e-04, -1.6125e-04, 3.5389e-06, -3.3149e-04, -3.7613e-04, -2.3331e-04])
+ # fmt: on
+
+ torch.testing.assert_close(waveform_mean, EXPECTED_MEAN, atol=5e-6, rtol=1e-5)
+ torch.testing.assert_close(waveform_stddev, EXPECTED_STDDEV, atol=1e-4, rtol=1e-5)
+ torch.testing.assert_close(waveform_slice, EXPECTED_SLICE, atol=5e-6, rtol=1e-5)
diff --git a/tests/models/upernet/test_modeling_upernet.py b/tests/models/upernet/test_modeling_upernet.py
index 84c32f7233e73a..aeeba191b67af2 100644
--- a/tests/models/upernet/test_modeling_upernet.py
+++ b/tests/models/upernet/test_modeling_upernet.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch UperNet framework. """
-import inspect
import unittest
from huggingface_hub import hf_hub_download
@@ -170,18 +169,6 @@ def test_config(self):
def create_and_test_config_common_properties(self):
return
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_for_semantic_segmentation(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_semantic_segmentation(*config_and_inputs)
diff --git a/tests/models/videomae/test_modeling_videomae.py b/tests/models/videomae/test_modeling_videomae.py
index 9fb9c9e7f376b2..2fd9f90c308558 100644
--- a/tests/models/videomae/test_modeling_videomae.py
+++ b/tests/models/videomae/test_modeling_videomae.py
@@ -16,7 +16,6 @@
import copy
-import inspect
import unittest
import numpy as np
@@ -228,18 +227,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vipllava/__init__.py b/tests/models/vipllava/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/vipllava/test_modeling_vipllava.py b/tests/models/vipllava/test_modeling_vipllava.py
new file mode 100644
index 00000000000000..e09527343e24fa
--- /dev/null
+++ b/tests/models/vipllava/test_modeling_vipllava.py
@@ -0,0 +1,216 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch VipLlava model. """
+
+import gc
+import unittest
+
+import requests
+
+from transformers import (
+ AutoProcessor,
+ VipLlavaConfig,
+ VipLlavaForConditionalGeneration,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.testing_utils import require_bitsandbytes, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+else:
+ is_torch_greater_or_equal_than_2_0 = False
+
+if is_vision_available():
+ from PIL import Image
+
+
+# Copied from transformers.tests.models.llava.test_modeling_llava.LlavaVisionText2TextModelTester with Llava->VipLlava
+class VipLlavaVisionText2TextModelTester:
+ # Ignore copy
+ def __init__(
+ self,
+ parent,
+ ignore_index=-100,
+ image_token_index=0,
+ projector_hidden_act="gelu",
+ seq_length=7,
+ vision_feature_layers=[0, 0, 1, 1, 0],
+ text_config={
+ "model_type": "llama",
+ "seq_length": 7,
+ "is_training": True,
+ "use_input_mask": True,
+ "use_token_type_ids": False,
+ "use_labels": True,
+ "vocab_size": 99,
+ "hidden_size": 32,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 37,
+ "hidden_act": "gelu",
+ "hidden_dropout_prob": 0.1,
+ "attention_probs_dropout_prob": 0.1,
+ "max_position_embeddings": 512,
+ "type_vocab_size": 16,
+ "type_sequence_label_size": 2,
+ "initializer_range": 0.02,
+ "num_labels": 3,
+ "num_choices": 4,
+ "pad_token_id": 0,
+ },
+ is_training=True,
+ vision_config={
+ "batch_size": 12,
+ "image_size": 30,
+ "patch_size": 2,
+ "num_channels": 3,
+ "is_training": True,
+ "hidden_size": 32,
+ "projection_dim": 32,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 37,
+ "dropout": 0.1,
+ "attention_dropout": 0.1,
+ "initializer_range": 0.02,
+ },
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.image_token_index = image_token_index
+ self.projector_hidden_act = projector_hidden_act
+ self.vision_feature_layers = vision_feature_layers
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.seq_length = seq_length
+
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.vocab_size = text_config["vocab_size"]
+ self.hidden_size = text_config["hidden_size"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+ self.is_training = is_training
+
+ self.batch_size = 3
+ self.num_channels = 3
+ self.image_size = 336
+ self.encoder_seq_length = 231
+
+ def get_config(self):
+ return VipLlavaConfig(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ ignore_index=self.ignore_index,
+ image_token_index=self.image_token_index,
+ projector_hidden_act=self.projector_hidden_act,
+ vision_feature_layers=self.vision_feature_layers,
+ )
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ self.vision_config["num_channels"],
+ self.vision_config["image_size"],
+ self.vision_config["image_size"],
+ ]
+ )
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 1) + 1
+ attention_mask = input_ids.ne(1).to(torch_device)
+ # we are giving 3 images let's make sure we pass in 3 image tokens
+ input_ids[:, 1] = config.image_token_index
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from transformers.tests.models.llava.test_modeling_llava.LlavaForConditionalGenerationModelTest with Llava->VipLlava
+class VipLlavaForConditionalGenerationModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Model tester for `VipLlavaForConditionalGeneration`.
+ """
+
+ all_model_classes = (VipLlavaForConditionalGeneration,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = VipLlavaVisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=VipLlavaConfig, has_text_modality=False)
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+
+@require_torch
+class VipLlavaForConditionalGenerationIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("llava-hf/vip-llava-7b-hf")
+
+ def tearDown(self):
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @slow
+ @require_bitsandbytes
+ def test_small_model_integration_test(self):
+ model_id = "llava-hf/vip-llava-7b-hf"
+
+ model = VipLlavaForConditionalGeneration.from_pretrained(model_id, load_in_4bit=True)
+ processor = AutoProcessor.from_pretrained(model_id)
+
+ url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/compel-neg.png"
+
+ image = Image.open(requests.get(url, stream=True).raw)
+ prompt = "USER: \nCan you please describe this image?\nASSISTANT:"
+
+ inputs = processor(prompt, image, return_tensors="pt").to(torch_device, torch.float16)
+
+ outputs = model.generate(**inputs, max_new_tokens=10)
+
+ EXPECTED_OUTPUT = "USER: \nCan you please describe this image?\nASSISTANT: The image features a brown and white cat sitting on"
+ self.assertEqual(processor.decode(outputs[0], skip_special_tokens=True), EXPECTED_OUTPUT)
diff --git a/tests/models/vision_encoder_decoder/test_modeling_vision_encoder_decoder.py b/tests/models/vision_encoder_decoder/test_modeling_vision_encoder_decoder.py
index 8ac4449cf3c9c6..71b1ff71067944 100644
--- a/tests/models/vision_encoder_decoder/test_modeling_vision_encoder_decoder.py
+++ b/tests/models/vision_encoder_decoder/test_modeling_vision_encoder_decoder.py
@@ -800,7 +800,7 @@ def generate_step(pixel_values):
preds, scores = generate_step(pixel_values)
- EXPECTED_SCORES = np.array([-0.59562886])
+ EXPECTED_SCORES = np.array([-0.5956343])
max_diff = np.amax(np.abs(scores - EXPECTED_SCORES))
self.assertLessEqual(max_diff, 1e-4)
diff --git a/tests/models/vit/test_modeling_vit.py b/tests/models/vit/test_modeling_vit.py
index d1e887183329c9..2e9a632a3719d4 100644
--- a/tests/models/vit/test_modeling_vit.py
+++ b/tests/models/vit/test_modeling_vit.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch ViT model. """
-import inspect
import unittest
from transformers import ViTConfig
@@ -224,18 +223,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vit_hybrid/test_modeling_vit_hybrid.py b/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
index 3ea407eafd4e27..870a4c83358315 100644
--- a/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
+++ b/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch ViT Hybrid model. """
-import inspect
import unittest
from transformers import ViTHybridConfig
@@ -185,18 +184,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vit_mae/test_modeling_vit_mae.py b/tests/models/vit_mae/test_modeling_vit_mae.py
index 89a3a0d803e469..21a66b8a6d92a2 100644
--- a/tests/models/vit_mae/test_modeling_vit_mae.py
+++ b/tests/models/vit_mae/test_modeling_vit_mae.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch ViTMAE model. """
-import inspect
import math
import tempfile
import unittest
@@ -192,18 +191,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vit_msn/test_modeling_vit_msn.py b/tests/models/vit_msn/test_modeling_vit_msn.py
index a5316377515036..2125e897b9ca49 100644
--- a/tests/models/vit_msn/test_modeling_vit_msn.py
+++ b/tests/models/vit_msn/test_modeling_vit_msn.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch ViTMSN model. """
-import inspect
import unittest
from transformers import ViTMSNConfig
@@ -183,18 +182,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vitdet/test_modeling_vitdet.py b/tests/models/vitdet/test_modeling_vitdet.py
index 361e563d58d448..2df1b7925789aa 100644
--- a/tests/models/vitdet/test_modeling_vitdet.py
+++ b/tests/models/vitdet/test_modeling_vitdet.py
@@ -15,11 +15,10 @@
""" Testing suite for the PyTorch ViTDet model. """
-import inspect
import unittest
from transformers import VitDetConfig
-from transformers.testing_utils import require_torch, torch_device
+from transformers.testing_utils import is_flaky, require_torch, torch_device
from transformers.utils import is_torch_available
from ...test_backbone_common import BackboneTesterMixin
@@ -91,6 +90,7 @@ def prepare_config_and_inputs(self):
def get_config(self):
return VitDetConfig(
image_size=self.image_size,
+ pretrain_image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
hidden_size=self.hidden_size,
@@ -175,6 +175,10 @@ def setUp(self):
self.model_tester = VitDetModelTester(self)
self.config_tester = ConfigTester(self, config_class=VitDetConfig, has_text_modality=False, hidden_size=37)
+ @is_flaky(max_attempts=3, description="`torch.nn.init.trunc_normal_` is flaky.")
+ def test_initialization(self):
+ super().test_initialization()
+
# TODO: Fix me (once this model gets more usage)
@unittest.skip("Does not work on the tiny model as we keep hitting edge cases.")
def test_cpu_offload(self):
@@ -210,18 +214,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/vitmatte/test_modeling_vitmatte.py b/tests/models/vitmatte/test_modeling_vitmatte.py
index fcc99de0ba93d2..c9446b116f1e45 100644
--- a/tests/models/vitmatte/test_modeling_vitmatte.py
+++ b/tests/models/vitmatte/test_modeling_vitmatte.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch VitMatte model. """
-import inspect
import unittest
from huggingface_hub import hf_hub_download
@@ -189,18 +188,6 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
def test_model_common_attributes(self):
pass
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/models/whisper/test_modeling_whisper.py b/tests/models/whisper/test_modeling_whisper.py
index e26527267fcb2f..9de3b8ff2c21b6 100644
--- a/tests/models/whisper/test_modeling_whisper.py
+++ b/tests/models/whisper/test_modeling_whisper.py
@@ -17,6 +17,7 @@
import copy
import inspect
import os
+import random
import tempfile
import time
import unittest
@@ -47,7 +48,7 @@
if is_datasets_available():
import datasets
- from datasets import load_dataset
+ from datasets import Audio, load_dataset
if is_torch_available():
import torch
@@ -61,8 +62,81 @@
WhisperProcessor,
set_seed,
)
+ from transformers.generation.logits_process import LogitsProcessor
from transformers.models.whisper.modeling_whisper import WhisperDecoder, WhisperEncoder, sinusoids
+ class DummyTimestampLogitProcessor(LogitsProcessor):
+ """This processor fakes the correct timestamps tokens pattern [TOK_1] [TOK_2] ... [TOK_N] [TIME_STAMP_TOK_1] [TIME_STAMP_TOK_2] [TOK_N+1] ..."""
+
+ def __init__(
+ self, timestamp_begin, vocab_size, batch_size, max_length, min_space=3, seed=0, is_length_ascending=True
+ ):
+ self.timestamp_begin = timestamp_begin
+ self.vocab_size = vocab_size
+
+ self.min_space_between_timestamps = min_space
+ self.timestamp_tokens = torch.arange(self.timestamp_begin, self.vocab_size)
+ self.timestamp_tokens.to(torch_device)
+ self.is_length_ascending = is_length_ascending
+
+ self.no_time_stamp_counter = batch_size * [0]
+ self.prev_highest_timestamp = batch_size * [0]
+ self.batch_size = batch_size
+ self.max_length = max_length
+ self.count = 0
+
+ self.let_pass = [[] for _ in range(batch_size)]
+ for k in range(batch_size):
+ random.seed(seed + k)
+ for _ in range(10000):
+ self.let_pass[k].append(random.randint(1, 10) <= 3)
+
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
+ # we don't want to randomely sample timestamp tokens
+ if input_ids.shape[-1] > 1:
+ scores[:, self.timestamp_begin :] = -float("inf")
+
+ self.no_time_stamp_counter = [x + 1 for x in self.no_time_stamp_counter]
+ for k in range(input_ids.shape[0]):
+ # make sure to use correct index if a batch was removed
+ if self.is_length_ascending and input_ids.shape[0] < self.batch_size:
+ prev_k = k + self.batch_size - input_ids.shape[0]
+ else:
+ prev_k = k
+
+ if input_ids[k, -1] == self.timestamp_begin:
+ self.no_time_stamp_counter[prev_k] = 0
+
+ can_produce = self.no_time_stamp_counter[prev_k] > self.min_space_between_timestamps
+ must_produce = (
+ input_ids[k][2:].le(self.timestamp_begin).all() and input_ids.shape[-1] == self.max_length - 1
+ )
+ # produce timestamp with 30%
+ if (can_produce and self.let_pass[prev_k][self.count]) or must_produce:
+ self.no_time_stamp_counter[prev_k] = 0
+ self.prev_highest_timestamp[prev_k] = max(input_ids[k].max() + 1, self.timestamp_tokens[0].item())
+
+ # force a timestamp
+ scores[k, :] = -float("inf")
+ scores[k, self.prev_highest_timestamp[prev_k]] = 10.0
+
+ if (
+ input_ids.shape[-1] > 3
+ and input_ids[k, -1].item() in self.timestamp_tokens
+ and input_ids[k, -2].item() not in self.timestamp_tokens
+ ):
+ # force the same as before
+ scores[k, :] = -float("inf")
+ scores[k, input_ids[k, -1].item()] = 10.0
+
+ self.count += 1
+
+ if torch.isinf(scores).all():
+ raise ValueError("Dummy logit processor is incorrectly set up. Scores should not be all inf.")
+
+ return scores
+
+
if is_flax_available():
import jax.numpy as jnp
@@ -293,6 +367,7 @@ class WhisperModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMi
"audio-classification": WhisperForAudioClassification,
"automatic-speech-recognition": WhisperForConditionalGeneration,
"feature-extraction": WhisperModel,
+ "text-generation": WhisperForCausalLM,
}
if is_torch_available()
else {}
@@ -816,12 +891,13 @@ def test_flash_attn_2_inference(self):
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model_fa = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=True
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model_fa.to(torch_device)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=False
+ tmpdirname,
+ torch_dtype=torch.bfloat16,
)
model.to(torch_device)
@@ -861,11 +937,11 @@ def test_flash_attn_2_inference_padding_right(self):
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model_fa = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=True
+ tmpdirname, torch_dtype=torch.float16, attn_implementation="flash_attention_2"
)
model_fa.to(torch_device)
- model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=False)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16)
model.to(torch_device)
dummy_input = inputs_dict[model.main_input_name][:1]
@@ -906,6 +982,7 @@ def _create_and_check_torchscript(self, config, inputs_dict):
configs_no_init = _config_zero_init(config) # To be sure we have no Nan
configs_no_init.torchscript = True
+ configs_no_init._attn_implementation = "eager"
for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
model.to(torch_device)
@@ -1237,6 +1314,133 @@ def test_generate_with_prompt_ids_max_length(self):
model.generate(input_features, max_new_tokens=1, prompt_ids=prompt_ids)
+ def test_longform_generate_single_batch(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ model = WhisperForConditionalGeneration(config).eval().to(torch_device)
+ input_features = input_dict["input_features"]
+
+ # len = 250 with num_input_frames = 60
+ long_input_features = torch.cat([input_features.repeat(1, 1, 4), input_features[:, :, :10]], dim=-1)
+
+ # force bsz=1
+ long_input_features = long_input_features[:1]
+ vocab_size = model.config.vocab_size
+
+ batch_size = 1
+ num_timestamp_tokens = 20
+ max_length = 16
+ logits_processor = [
+ DummyTimestampLogitProcessor(
+ vocab_size - num_timestamp_tokens,
+ vocab_size,
+ batch_size=batch_size,
+ max_length=max_length,
+ min_space=4,
+ )
+ ]
+
+ # each chunk should not be longer than 10
+ model.generation_config.max_length = max_length
+
+ # if input features are long can't set return_timestamps to False
+ with self.assertRaises(ValueError):
+ _ = model.generate(long_input_features, logits_processor=logits_processor, return_timestamps=False)
+
+ # if input features are long need to set generation config
+ with self.assertRaises(ValueError):
+ _ = model.generate(long_input_features, logits_processor=logits_processor)
+
+ timestamp_begin = vocab_size - num_timestamp_tokens
+ model.generation_config.no_timestamps_token_id = timestamp_begin - 1
+ model.generation_config.eos_token_id = None
+ model.generation_config._detect_timestamp_from_logprob = False
+ # make sure that we only have the same begin token
+ model.generation_config.max_initial_timestamp_index = 0
+
+ outputs = model.generate(long_input_features, logits_processor=logits_processor, return_segments=True)
+
+ segments = outputs["segments"][0]
+
+ for i, segment in enumerate(segments):
+ assert segment["start"] <= segment["end"], "start has to be smaller equal end"
+ assert (
+ segment["tokens"][0] == model.generation_config.decoder_start_token_id
+ or segment["tokens"][0] >= timestamp_begin
+ ), "First segment token should be a timestamp token"
+ assert any(
+ s > timestamp_begin for s in segment["tokens"][1:]
+ ), f"At least one segment token should be a timestamp token, but not first., {segment['tokens']}"
+ assert (
+ segment["tokens"].shape[-1] <= max_length
+ ), "make sure that no segment is larger than max generation length"
+
+ def test_longform_generate_multi_batch(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ model = WhisperForConditionalGeneration(config).eval().to(torch_device)
+ input_features = input_dict["input_features"].to(torch_device)
+
+ # len = 250 with num_input_frames = 60
+ long_input_features = torch.cat([input_features.repeat(1, 1, 4), input_features[:, :, :10]], dim=-1)
+ long_input_features[:1, :, :200]
+ input_features_2 = long_input_features[1:]
+ attention_mask = torch.ones(
+ (2, long_input_features.shape[-1]), dtype=input_features.dtype, device=input_features.device
+ )
+ attention_mask[0, 200:] = 0
+
+ # force bsz=1
+ vocab_size = model.config.vocab_size
+
+ batch_size = 1
+ num_timestamp_tokens = 20
+ max_length = 16
+ timestamp_begin = vocab_size - num_timestamp_tokens
+ model.generation_config.no_timestamps_token_id = timestamp_begin - 1
+ model.generation_config.eos_token_id = None
+ model.generation_config._detect_timestamp_from_logprob = False
+ # make sure that we only have the same begin token
+ model.generation_config.max_initial_timestamp_index = 0
+
+ logits_processor = [
+ DummyTimestampLogitProcessor(
+ vocab_size - num_timestamp_tokens,
+ vocab_size,
+ batch_size=batch_size,
+ max_length=max_length,
+ min_space=4,
+ seed=1,
+ )
+ ]
+ outputs_2 = model.generate(input_features_2, logits_processor=logits_processor, return_segments=True)
+ tokens_2 = outputs_2["sequences"][0]
+ segments_2 = outputs_2["segments"][0]
+
+ batch_size = 2
+ logits_processor = [
+ DummyTimestampLogitProcessor(
+ vocab_size - num_timestamp_tokens,
+ vocab_size,
+ batch_size=batch_size,
+ max_length=max_length,
+ min_space=4,
+ seed=0,
+ )
+ ]
+ outputs = model.generate(
+ long_input_features, attention_mask=attention_mask, logits_processor=logits_processor, return_segments=True
+ )
+ tokens = outputs["sequences"][1]
+ segments = outputs["segments"][1]
+
+ assert tokens_2.tolist() == tokens.tolist()
+
+ for seg1, seg2 in zip(segments_2, segments):
+ assert seg1["start"] == seg2["start"]
+ assert seg1["end"] == seg2["end"]
+ assert seg1["tokens"].tolist() == seg2["tokens"].tolist()
+
@require_torch
@require_torchaudio
@@ -1831,6 +2035,125 @@ def test_speculative_decoding_non_distil(self):
]
assert total_time_non_assist > total_time_assist, "Make sure that assistant decoding is faster"
+ @slow
+ def test_whisper_longform_single_batch(self):
+ # fmt: off
+ EXPECTED_TEXT = [' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter\'s manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton\'s work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell\'s pictures are a sort of up-gards and atom paintings, and Mason\'s exquisite idles are as national as a jingo poem. Mr. Birk at Foster\'s landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampoo or a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Makes the customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire, any ornaments Fred brought home from India on the mantelboard. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man. And remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the Tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon\'s body trickling into the tight-lowing cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered his muscles into complete relaxation. Oli\'s heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the twenties needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, The thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I\'m here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenties, he must have drawn his gun because the intruder said quickly, but that away you\'re being a fool. out, through his silence then, and still wondering, Breon was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. A red-haired mountain of a man, with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing. Just thrust and parry, and victory to the stronger. man who entered the twenties had his own training tricks. They were appeared to be an immediate association with the death trauma, as if the two were inextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. had died before during the 20s and death during the last round was in some ways easier than defeat. Breathing deeply, Breon\'s softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent\'s face when the man finally recognized his error. A wave of despair rolled out from our rogue. Breon sensed it and knew the fifth point was his. Then the powerful twist that\'s rested aside, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, accooing dove. He has gone, and gone for good," answered Polychrom, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with says he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn\'t work too hard, said Shaggy. He doesn\'t work at all. In fact, there\'s nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we\'ve turned Calico. Where is my brother now, inquired Shaggy. In the metal forest. Where is that? The middle forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I\'m quite sure he didn\'t. That\'s funny, remarked Betsy thoughtfully. I don\'t believe Anne knew any magic, or she\'d have worked it before. I do not know, confess Shaggy. True, agreed Calico. Calico went to the big gong and pounded on it just as Virgato used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the throne, wearing Virgato\'s discarded ruby crown and holding in his hand to scepter which reggative head so often thrown at his head.']
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ model = model.to("cuda")
+
+ ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean")
+ one_audio = np.concatenate([x["array"] for x in ds["validation"]["audio"]], dtype=np.float32)
+
+ input_features = processor(one_audio, return_tensors="pt", truncation=False, padding="longest")[
+ "input_features"
+ ]
+ input_features = input_features.to(device="cuda")
+
+ result = model.generate(input_features, return_timestamps=True)
+ decoded = processor.batch_decode(result, skip_special_tokens=True)
+
+ assert decoded == EXPECTED_TEXT
+
+ @slow
+ def test_whisper_longform_multi_batch(self):
+ # fmt: off
+ EXPECTED_TEXT_1 = [" Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-gards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Birkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampooer and a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. Painting he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Mix a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing a poster or near the fire, and the ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man. And remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only unfortunately his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the Tupper of painting. a Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the tight-wing cloth that was the only germany war. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were, triggered his muscles into complete relaxation. Oily his heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, knights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenty's he must have drawn his gun, because the intruder said quickly, but that away you're being a fool. Out there was silence then, and still wondering, Breon was once more asleep. Ten seconds he asked the handler who was needing his aching muscles. a red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the twenties had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were andextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the twenties and death during the last round was, in some ways, easier than defeat. Breeding deeply, Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. I rolled the mazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue, pre-inscented and new to fifth point was his. Then the powerful twist that's rest of the side, in and under the guard, because you were sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, a cooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions, as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, return Calico. Where is my brother now? choir-dshaggy, in the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh, no, I'm quite sure he didn't. That's funny, remarked Betsy thoughtfully. I don't believe and knew any magic, or she'd have worked it before. I do not know, confess shaggy. True, a great calico. Calico went to the big gong and pounded on it, just as Virgado used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the throne, wearing Virgados discarded Ruby Crown, and holding in his hand to scepter, which Virgado had so often thrown at his head. head."]
+ EXPECTED_TEXT_2 = [" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-gards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Burkett Foster's landscapes smile at one much in the same way that Mr. Carker."]
+ EXPECTED_TEXT_3 = [" possible. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grieved doubts whether Sir Frederick Layton's work is really greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-guards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Birk at Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampooer and a Turkish bath, next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. Under general principles of art, Mr. Quilter writes with equal lucidity. Painting, he tells us, is of a different quality to mathematics and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Mix a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire. any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man, and remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the titling cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes. Even to soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered as muscles into complete relaxation. Oily his heart and lungs worked on at a strong measured rate. He was in In reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenty's he must have drawn his gun, because the intruder said quickly, but that away you're being a fool. Out there was silence then, and still wondering, Breon was once more asleep. Ten seconds he asked the handler who was needing his aching muscles. a red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the twenties had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were andextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the twenties and death during the last round was, in some ways, easier than defeat. Breeding deeply, Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue, re-insunced it and knew the fifth point was his. Then the powerful twist that's rest of the side, in and under the guard, because you were sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, a cooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled and disgraced, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Where is my brother now? quared shaggy. In the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. And that's funny, remarked Betsy thoughtfully. I don't believe Anne knew any magic, or she'd have worked it before. I do not know, confess Shaggy. True, a great calico. Calico went to the big gong and pounded on it, just as we're good to have used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the thrown wearing ruggedos discarded ruby crown and holding in his hand to septor which Ruggato had so often thrown at his head."]
+ EXPECTED_TEXT_4 = [' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter\'s manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton\'s work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell\'s pictures are a sort of up-gards and atom paintings, and Mason\'s exquisite idles are as national as a jingo poem. Mr. Birk at Foster\'s landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampoo or a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Makes the customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire, any ornaments Fred brought home from India on the mantelboard. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man. And remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the Tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon\'s body trickling into the tight-lowing cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered his muscles into complete relaxation. Oli\'s heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the twenties needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, The thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I\'m here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenties, he must have drawn his gun because the intruder said quickly, but that away you\'re being a fool. out, through his silence then, and still wondering, Breon was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. A red-haired mountain of a man, with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing. Just thrust and parry, and victory to the stronger. man who entered the twenties had his own training tricks. They were appeared to be an immediate association with the death trauma, as if the two were inextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. had died before during the 20s and death during the last round was in some ways easier than defeat. Breathing deeply, Breon\'s softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent\'s face when the man finally recognized his error. A wave of despair rolled out from our rogue. Breon sensed it and knew the fifth point was his. Then the powerful twist that\'s rested aside, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, accooing dove. He has gone, and gone for good," answered Polychrom, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with says he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn\'t work too hard, said Shaggy. He doesn\'t work at all. In fact, there\'s nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we\'ve turned Calico. Where is my brother now, inquired Shaggy. In the metal forest. Where is that? The middle forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I\'m quite sure he didn\'t. That\'s funny, remarked Betsy thoughtfully. I don\'t believe Anne knew any magic, or she\'d have worked it before. I do not know, confess Shaggy. True, agreed Calico. Calico went to the big gong and pounded on it just as Virgato used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the throne, wearing Virgato\'s discarded ruby crown and holding in his hand to scepter which reggative head so often thrown at his head.']
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ model = model.to("cuda")
+
+ ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean")
+ one_audio = np.concatenate([x["array"] for x in ds["validation"]["audio"]], dtype=np.float32)
+ audios = []
+ audios.append(one_audio[110000:])
+ audios.append(one_audio[:800000])
+ audios.append(one_audio[80000:])
+ audios.append(one_audio[:])
+
+ decoded_single = []
+ for audio in audios:
+ inputs = processor(audio, return_tensors="pt", truncation=False)
+ inputs = inputs.to(device="cuda")
+
+ result = model.generate(**inputs, return_timestamps=True)
+ decoded_single.append(processor.batch_decode(result, skip_special_tokens=True))
+
+ inputs = processor(
+ audios, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True
+ )
+ inputs = inputs.to(device="cuda")
+
+ result = model.generate(**inputs, return_timestamps=True)
+ decoded_all = processor.batch_decode(result, skip_special_tokens=True)
+
+ # make sure single & batch is exactly the same
+ assert decoded_all[0:1] == decoded_single[0]
+ assert decoded_all[1:2] == decoded_single[1]
+ assert decoded_all[2:3] == decoded_single[2]
+ assert decoded_all[3:4] == decoded_single[3]
+
+ # exact match
+ assert decoded_all[0:1] == EXPECTED_TEXT_1
+ assert decoded_all[1:2] == EXPECTED_TEXT_2
+ assert decoded_all[2:3] == EXPECTED_TEXT_3
+ assert decoded_all[3:4] == EXPECTED_TEXT_4
+
+ @slow
+ def test_whisper_longform_multi_batch_hard(self):
+ # fmt: off
+ EXPECTED_TEXT = [
+ " Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!",
+ " Folks, I spend a lot of time right over there, night after night after night, actually. Carefully selecting for you the day's noosiest, most aerodynamic headlines, stress testing, and those topical anti-lock breaks and power steering, painstakingly stitching, leather seating so soft, it would make JD power and her associates blush to create the luxury sedan that is my nightly monologue. But sometimes, you sometimes, folks. I lurched a consciousness in the back of an abandoned school and slap myself awake with a crusty floor mat. Before using a mouse-bitten timing belt to strap some old plywood to a couple of discarded oil drums, then by the light of a heathen moon, render a gas tank out of an empty big gulp, fill with white claw and denatured alcohol, then light a match and let her rip and the demented one man soapbox derby of news that is my segment. Me, Guadalupe! No!",
+ " Ladies and gentlemen, you know, I spent a lot of time right over there Raising the finest Holstein news cattle firmly yet tenderly milking the latest headlines from their jokes swollen teats Churning the daily stories into the decadent proven-style style triple cream breed that is my nightly monologue But sometimes sometimes folks I stagger home hungry after being released by the police and Root around in the neighbor's trash can for an old milk carton scrape out the blooming dairy residue into the remains of a wet cheese rod I won from a rat in a pre-donned street fight. Put it in a discarded paint can to leave it to ferment next to a trash fire then hunker down and hallucinate while eating the listeria laden demon custard of news that is my segment. You mean one of them.",
+ " Folks, if you watch this show, you know I spend most of my time right over there carefully sorting through the day's biggest stories and selecting only the most subtle and unblemished ostrich and crocodile news leather, which I then entrust to artisan graduates of the Ichol Gregoire Ferrandi, who carefully dye them in a palette of bright zesty shades and adorn them in the finest and most topical inlay work using hand tools and double magnifying glasses, then assemble them according to now classic and elegant geometry using our signature saddles stitching. In line it with bees, wax, coated linen, finely attached a mallet, hammered strap, pearled hardware, and close-shit to create for you the one-of-a-kind hoke couture, Erme's Birkin bag that is my monologue. But sometimes, sometimes folks, sometimes. Sometimes I wake up in the last car of an abandoned roller coaster at Coney Island where I'm I'm hiding from the triads. I have some engine lubricants out of a safe way bag and stagger down the shore to tear the sail off a beach schooner. Then I rip the coaxial cable out of an RV and elderly couple from Utah, Hank, and Mabel lovely folks. And use it to stitch the sail into a loose pouch like a rock sack. And I stow away in the back of a garbage truck to the junkyard where I pick through to the debris for only the broken toys that make me the saddest until I have loaded for you. The Hobo Fugitives bug out, bindle of news that is my segment. Me one!",
+ " You know, folks, I spent a lot of time crafting for you a bespoke playlist of the day's biggest stories right over there. Meticulously selecting the most topical chakra affirming scented candles, and using Feng Shui to perfectly align the joke energy in the exclusive boutique yoga retreat that is my monologue. But sometimes just sometimes I go to the dumpster behind the waffle house at three in the morning, take off my shirt, cover myself, and used fry oil, wrap my hands with some double-duct tape by stole from the broken car window. Pound a six-pack of blueberry hard-seltzer and a sack of pills I stole from a parked ambulance. Then arm wrestle a raccoon in the back alley vision quest of news that is my segment. Meanwhile!",
+ " You know, folks, I spend most of my time right over there. Mining the day's biggest, most important stories, collecting the finest, most topical iron or hand hammering it into joke panels. Then I craft sheets of bronze and blazing with patterns that tell an epic tale of conquest and glory. Then, using the Germanic tradition press-black process, I place thin sheets of foil against the scenes and by hammering or otherwise applying pressure from the back, I project these scenes into a pair of cheat cards in a faceplate and, finally, using fluted strips of white alloyed molding, I divide the designs into framed panels and hold it all together using bronze rivets to create the beautiful and intimidating, Anglo-Saxon battle helm that is my nightly monologue. Sometimes, sometimes folks. Sometimes, just sometimes, I come into my sense as fully naked on the deck of a pirate besieged melee container ship that picked me up floating on the detached door of a portapotty in the Indian Ocean. Then after a sunstroke-induced realization of the crew of this ship plans to sell me an exchange for a bag of oranges to fight off scurvy, I lead a mutiny using only a PVC pipe at a pool chain that accepting my new role as Captain and declaring myself king of the windarc seas. I grab a dirty mop bucket covered in barnacles and adorn it with the teeth of the vanquished to create the sopping wet pirate crown of news that is my segment. Meanwhile!",
+ " Folks, if you watch this show, you know I spend most of my time right over there carefully blending for you the day's Newsiest most topical flower eggs milk and butter and Stranding into a fine batter to make delicate and informative comedy pancakes Then I glaze them in the juice and zest of the most relevant midnight Valencia oranges and douse it all and a fine Dela main de voyage cognac Before prom baying and basting them tables. I deserve for you the James Beard award worthy crepe suzzette That is my nightly monologue, but sometimes just sometimes folks. I wake up in the baggage hold of Greyhound bus. It's being hoisted by the scrap yard claw toward the burn pit. Escape to a nearby abandoned price chopper where I scrounge for old bread scraps and busted open bags of starfruit candies and expired eggs. Chuck it all on a dirty hubcap and slap it over a tire fire before using the legs of a strain, pair of sweatpants and as oven mitts to extract and serve the demented transience poundcake of news that is my segment. Me, Guadalupe!",
+ " Folks, if you watched the show and I hope you do, I spent a lot of time right over there. Tiredlessly studying the lineage of the days most important thoroughbred stories and whole-stiner headlines, working with the best trainers, money can buy to rear their comedy offspring with a hand that is stern yet gentle into the triple crown winning equine specimen. That is my nightly monologue, but sometimes, sometimes, folks, I break into an unincorporated veterinary genetics lab and grab whatever test tubes I can find and then under a grow light I got from a discarded chia pet. I mixed the pilfered DNA of a horse and whatever was in a tube labeled Keith Colan extra. Slurrying the concoction with caffeine pills and a microwave red bull, I screamed, sang a prayer to Janice, initiator of human life and God of transformation as a half horse, half man, freak. Seizes to life before me and the hideous collection of loose animal parts and corrupted man tissue that is my segment. Meanwhile!",
+ ]
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ model = model.to("cuda")
+
+ ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
+ ds = ds.cast_column("audio", Audio(sampling_rate=16000))
+
+ num_samples = 8
+
+ audio = ds[:num_samples]["audio"]
+ audios = [x["array"] for x in audio]
+
+ decoded_single = []
+ for audio in audios:
+ inputs = processor(audio, return_tensors="pt", truncation=False, sampling_rate=16_000)
+ inputs = inputs.to(device="cuda")
+
+ result = model.generate(**inputs, return_timestamps=True)
+ decoded_single += processor.batch_decode(result, skip_special_tokens=True)
+
+ inputs = processor(
+ audios, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True
+ )
+ inputs = inputs.to(device="cuda")
+
+ result = model.generate(**inputs, return_timestamps=True)
+ decoded_all = processor.batch_decode(result, skip_special_tokens=True)
+
+ for i in range(num_samples):
+ assert decoded_all[i] == decoded_single[i]
+ assert decoded_all[i] == EXPECTED_TEXT[i]
+
def prepare_whisper_encoder_inputs_dict(config, input_features, head_mask=None):
if head_mask is None:
@@ -2016,13 +2339,20 @@ def test_encoder_outputs(self):
with torch.no_grad():
outputs = model(**inputs)[0]
- input_ids = inputs["input_features"]
+ encoder = model.encoder
+
+ encoder_inputs = {"input_features": inputs["input_features"]}
del inputs["input_features"]
- encoder = model.encoder
+ if "head_mask" in inputs:
+ encoder_inputs["head_mask"] = inputs["head_mask"]
+ if "attention_mask" in inputs:
+ encoder_inputs["attention_mask"] = inputs["attention_mask"]
+ if "output_attentions" in inputs:
+ encoder_inputs["output_attentions"] = inputs["output_attentions"]
with torch.no_grad():
- inputs["encoder_outputs"] = encoder(input_ids)
+ inputs["encoder_outputs"] = encoder(**encoder_inputs)
outputs_embeds = model(**inputs)[0]
self.assertTrue((outputs_embeds == outputs).all())
diff --git a/tests/models/xglm/test_modeling_xglm.py b/tests/models/xglm/test_modeling_xglm.py
index 457317f0783681..e482b1b384f3ee 100644
--- a/tests/models/xglm/test_modeling_xglm.py
+++ b/tests/models/xglm/test_modeling_xglm.py
@@ -357,10 +357,6 @@ def test_model_from_pretrained(self):
def test_model_parallelism(self):
super().test_model_parallelism()
- @unittest.skip("This test is currently broken because of safetensors.")
- def test_tf_from_pt_safetensors(self):
- pass
-
@require_torch
class XGLMModelLanguageGenerationTest(unittest.TestCase):
diff --git a/tests/models/yolos/test_image_processing_yolos.py b/tests/models/yolos/test_image_processing_yolos.py
index 003a00611059cf..1039e4c91bc6e1 100644
--- a/tests/models/yolos/test_image_processing_yolos.py
+++ b/tests/models/yolos/test_image_processing_yolos.py
@@ -21,7 +21,7 @@
from transformers.testing_utils import require_torch, require_vision, slow
from transformers.utils import is_torch_available, is_vision_available
-from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
if is_torch_available():
@@ -127,7 +127,7 @@ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=F
@require_torch
@require_vision
-class YolosImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+class YolosImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
image_processing_class = YolosImageProcessor if is_vision_available() else None
def setUp(self):
diff --git a/tests/models/yolos/test_modeling_yolos.py b/tests/models/yolos/test_modeling_yolos.py
index c1fb50e30b766b..73281df02560d0 100644
--- a/tests/models/yolos/test_modeling_yolos.py
+++ b/tests/models/yolos/test_modeling_yolos.py
@@ -15,7 +15,6 @@
""" Testing suite for the PyTorch YOLOS model. """
-import inspect
import unittest
from transformers import YolosConfig
@@ -217,18 +216,6 @@ def test_model_common_attributes(self):
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
- def test_forward_signature(self):
- config, _ = self.model_tester.prepare_config_and_inputs_for_common()
-
- for model_class in self.all_model_classes:
- model = model_class(config)
- signature = inspect.signature(model.forward)
- # signature.parameters is an OrderedDict => so arg_names order is deterministic
- arg_names = [*signature.parameters.keys()]
-
- expected_arg_names = ["pixel_values"]
- self.assertListEqual(arg_names[:1], expected_arg_names)
-
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
diff --git a/tests/pipelines/test_pipelines_automatic_speech_recognition.py b/tests/pipelines/test_pipelines_automatic_speech_recognition.py
index b5dee1e00fc9e1..2ccaf71255670e 100644
--- a/tests/pipelines/test_pipelines_automatic_speech_recognition.py
+++ b/tests/pipelines/test_pipelines_automatic_speech_recognition.py
@@ -16,7 +16,7 @@
import numpy as np
import pytest
-from datasets import load_dataset
+from datasets import Audio, load_dataset
from huggingface_hub import hf_hub_download, snapshot_download
from transformers import (
@@ -329,16 +329,16 @@ def test_return_timestamps_in_preprocess(self):
self.assertEqual(
res,
{
- "text": " Conquered returned to its place amidst the tents.",
- "chunks": [
- {"text": " Conquered", "timestamp": (0.5, 1.2)},
- {"text": " returned", "timestamp": (1.2, 1.64)},
- {"text": " to", "timestamp": (1.64, 1.84)},
- {"text": " its", "timestamp": (1.84, 2.02)},
- {"text": " place", "timestamp": (2.02, 2.28)},
- {"text": " amidst", "timestamp": (2.28, 2.78)},
- {"text": " the", "timestamp": (2.78, 2.96)},
- {"text": " tents.", "timestamp": (2.96, 3.48)},
+ 'text': ' Conquered returned to its place amidst the tents.',
+ 'chunks': [
+ {'text': ' Conquered', 'timestamp': (0.5, 1.2)},
+ {'text': ' returned', 'timestamp': (1.2, 1.64)},
+ {'text': ' to', 'timestamp': (1.64, 1.84)},
+ {'text': ' its', 'timestamp': (1.84, 2.02)},
+ {'text': ' place', 'timestamp': (2.02, 2.28)},
+ {'text': ' amidst', 'timestamp': (2.28, 2.8)},
+ {'text': ' the', 'timestamp': (2.8, 2.98)},
+ {'text': ' tents.', 'timestamp': (2.98, 3.48)},
],
},
)
@@ -776,27 +776,27 @@ def test_simple_whisper_asr(self):
self.assertEqual(
output,
{
- "text": " Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.",
- "chunks": [
- {'text': ' Mr.', 'timestamp': (0.0, 1.02)},
- {'text': ' Quilter', 'timestamp': (1.02, 1.18)},
+ 'text': ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.',
+ 'chunks': [
+ {'text': ' Mr.', 'timestamp': (0.38, 1.04)},
+ {'text': ' Quilter', 'timestamp': (1.04, 1.18)},
{'text': ' is', 'timestamp': (1.18, 1.44)},
{'text': ' the', 'timestamp': (1.44, 1.58)},
{'text': ' apostle', 'timestamp': (1.58, 1.98)},
- {'text': ' of', 'timestamp': (1.98, 2.3)},
- {'text': ' the', 'timestamp': (2.3, 2.46)},
+ {'text': ' of', 'timestamp': (1.98, 2.32)},
+ {'text': ' the', 'timestamp': (2.32, 2.46)},
{'text': ' middle', 'timestamp': (2.46, 2.56)},
- {'text': ' classes,', 'timestamp': (2.56, 3.38)},
- {'text': ' and', 'timestamp': (3.38, 3.52)},
- {'text': ' we', 'timestamp': (3.52, 3.6)},
- {'text': ' are', 'timestamp': (3.6, 3.72)},
+ {'text': ' classes,', 'timestamp': (2.56, 3.4)},
+ {'text': ' and', 'timestamp': (3.4, 3.54)},
+ {'text': ' we', 'timestamp': (3.54, 3.62)},
+ {'text': ' are', 'timestamp': (3.62, 3.72)},
{'text': ' glad', 'timestamp': (3.72, 4.0)},
{'text': ' to', 'timestamp': (4.0, 4.26)},
- {'text': ' welcome', 'timestamp': (4.26, 4.54)},
- {'text': ' his', 'timestamp': (4.54, 4.92)},
- {'text': ' gospel.', 'timestamp': (4.92, 6.66)},
- ],
- },
+ {'text': ' welcome', 'timestamp': (4.26, 4.56)},
+ {'text': ' his', 'timestamp': (4.56, 4.92)},
+ {'text': ' gospel.', 'timestamp': (4.92, 5.84)}
+ ]
+ }
)
# fmt: on
@@ -1087,6 +1087,51 @@ def test_with_local_lm_fast(self):
self.assertEqual(output, [{"text": ANY(str)}])
self.assertEqual(output[0]["text"][:6], " " + "Lorem ipsum dolor sit amet, consectetur adipiscing elit," * 100,
+ "My name is " + dummy_str,
tokenizer_kwargs={"truncation": True},
)
+ simplified = nested_simplify(outputs, decimals=4)
self.assertEqual(
- nested_simplify(outputs, decimals=6),
+ [{"sequence": x["sequence"][:100]} for x in simplified],
[
- {"sequence": "My name is grouped", "score": 2.2e-05, "token": 38015, "token_str": " grouped"},
- {"sequence": "My name is accuser", "score": 2.1e-05, "token": 25506, "token_str": " accuser"},
+ {"sequence": f"My name is,{dummy_str}"[:100]},
+ {"sequence": f"My name is:,{dummy_str}"[:100]},
+ ],
+ )
+ self.assertEqual(
+ [{k: x[k] for k in x if k != "sequence"} for x in simplified],
+ [
+ {"score": 0.2819, "token": 6, "token_str": ","},
+ {"score": 0.0954, "token": 46686, "token_str": ":,"},
],
)
diff --git a/tests/pipelines/test_pipelines_image_to_text.py b/tests/pipelines/test_pipelines_image_to_text.py
index 7514f17919b1f0..4f5b5780277bfc 100644
--- a/tests/pipelines/test_pipelines_image_to_text.py
+++ b/tests/pipelines/test_pipelines_image_to_text.py
@@ -252,3 +252,24 @@ def test_large_model_tf(self):
[{"generated_text": "a cat laying on a blanket next to a cat laying on a bed "}],
],
)
+
+ @slow
+ @require_torch
+ def test_conditional_generation_llava(self):
+ pipe = pipeline("image-to-text", model="llava-hf/bakLlava-v1-hf")
+ url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+
+ prompt = (
+ "\nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud?\nASSISTANT:"
+ )
+
+ outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
+ self.assertEqual(
+ outputs,
+ [
+ {
+ "generated_text": " \nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud?\nASSISTANT: Lava"
+ }
+ ],
+ )
diff --git a/tests/pipelines/test_pipelines_text_generation.py b/tests/pipelines/test_pipelines_text_generation.py
index b9a5febb560919..dc77204f3e13d1 100644
--- a/tests/pipelines/test_pipelines_text_generation.py
+++ b/tests/pipelines/test_pipelines_text_generation.py
@@ -242,7 +242,12 @@ def run_pipeline_test(self, text_generator, _):
# We don't care about infinite range models.
# They already work.
# Skip this test for XGLM, since it uses sinusoidal positional embeddings which are resized on-the-fly.
- EXTRA_MODELS_CAN_HANDLE_LONG_INPUTS = ["RwkvForCausalLM", "XGLMForCausalLM", "GPTNeoXForCausalLM"]
+ EXTRA_MODELS_CAN_HANDLE_LONG_INPUTS = [
+ "RwkvForCausalLM",
+ "XGLMForCausalLM",
+ "GPTNeoXForCausalLM",
+ "FuyuForCausalLM",
+ ]
if (
tokenizer.model_max_length < 10000
and text_generator.model.__class__.__name__ not in EXTRA_MODELS_CAN_HANDLE_LONG_INPUTS
diff --git a/tests/quantization/autoawq/test_awq.py b/tests/quantization/autoawq/test_awq.py
index f0854e42553e16..8f9cbd91aad773 100644
--- a/tests/quantization/autoawq/test_awq.py
+++ b/tests/quantization/autoawq/test_awq.py
@@ -13,6 +13,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import gc
import tempfile
import unittest
@@ -107,6 +108,11 @@ def setUpClass(cls):
device_map=cls.device_map,
)
+ def tearDown(self):
+ gc.collect()
+ torch.cuda.empty_cache()
+ gc.collect()
+
def test_quantized_model_conversion(self):
"""
Simple test that checks if the quantized model has been converted properly
@@ -158,6 +164,13 @@ def test_quantized_model(self):
output = self.quantized_model.generate(**input_ids, max_new_tokens=40)
self.assertEqual(self.tokenizer.decode(output[0], skip_special_tokens=True), self.EXPECTED_OUTPUT)
+ def test_raise_if_non_quantized(self):
+ model_id = "facebook/opt-125m"
+ quantization_config = AwqConfig(bits=4)
+
+ with self.assertRaises(ValueError):
+ _ = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
+
def test_quantized_model_bf16(self):
"""
Simple test that checks if the quantized model is working properly with bf16
@@ -195,22 +208,6 @@ def test_save_pretrained(self):
output = model.generate(**input_ids, max_new_tokens=40)
self.assertEqual(self.tokenizer.decode(output[0], skip_special_tokens=True), self.EXPECTED_OUTPUT)
- def test_raise_quantization(self):
- """
- Simple test that checks if one passes a quantization config to quantize a model, it raises an error
- """
- quantization_config = AwqConfig(bits=4)
-
- with self.assertRaises(ValueError) as context:
- _ = AutoModelForCausalLM.from_pretrained(
- self.dummy_transformers_model_name, quantization_config=quantization_config
- )
-
- self.assertEqual(
- str(context.exception),
- "You cannot pass an `AwqConfig` when loading a model as you can only use AWQ models for inference. To quantize transformers models with AWQ algorithm, please refer to our quantization docs: https://huggingface.co/docs/transformers/main_classes/quantization ",
- )
-
@require_torch_multi_gpu
def test_quantized_model_multi_gpu(self):
"""
@@ -225,3 +222,144 @@ def test_quantized_model_multi_gpu(self):
output = quantized_model.generate(**input_ids, max_new_tokens=40)
self.assertEqual(self.tokenizer.decode(output[0], skip_special_tokens=True), self.EXPECTED_OUTPUT)
+
+
+@slow
+@require_torch_gpu
+@require_auto_awq
+@require_accelerate
+class AwqFusedTest(unittest.TestCase):
+ model_name = "TheBloke/Mistral-7B-OpenOrca-AWQ"
+ model_revision = "7048b2af77d0dd1c81b000b19d73f9cc8950b510"
+
+ custom_mapping_model_id = "TheBloke/Yi-34B-AWQ"
+ custom_model_revision = "f1b2cd1b7459ceecfdc1fac5bb8725f13707c589"
+
+ prompt = (
+ "You're standing on the surface of the Earth. "
+ "You walk one mile south, one mile west and one mile north. "
+ "You end up exactly where you started. Where are you?"
+ )
+
+ EXPECTED_GENERATION = prompt + "\n\nThis is a classic puzzle that has been around for"
+ EXPECTED_GENERATION_CUSTOM_MODEL = "HelloWorld.java:11)\r\n\tat org"
+
+ def tearDown(self):
+ gc.collect()
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ def _check_fused_modules(self, model):
+ has_fused_modules = False
+ fused_modules_name = ["QuantAttentionFused", "QuantFusedMLP", "FasterTransformerRMSNorm"]
+
+ for _, module in model.named_modules():
+ if module.__class__.__name__ in fused_modules_name:
+ has_fused_modules = True
+ break
+
+ self.assertTrue(has_fused_modules, "Modules fusing not performed correctly!")
+
+ def test_raise_save_pretrained(self):
+ """
+ Test that `save_pretrained` is effectively blocked for fused models
+ """
+ quantization_config = AwqConfig(bits=4, fuse_max_seq_len=128, do_fuse=True)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_name,
+ quantization_config=quantization_config,
+ low_cpu_mem_usage=True,
+ revision=self.model_revision,
+ ).to(torch_device)
+
+ self._check_fused_modules(model)
+
+ with self.assertRaises(ValueError), tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ def test_generation_fused(self):
+ """
+ Test generation quality for fused models - single batch case
+ """
+ quantization_config = AwqConfig(bits=4, fuse_max_seq_len=128, do_fuse=True)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_name,
+ quantization_config=quantization_config,
+ low_cpu_mem_usage=True,
+ revision=self.model_revision,
+ ).to(torch_device)
+
+ self._check_fused_modules(model)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_name, revision=self.model_revision)
+
+ inputs = tokenizer(self.prompt, return_tensors="pt").to(torch_device)
+
+ outputs = model.generate(**inputs, max_new_tokens=12)
+
+ self.assertEqual(tokenizer.decode(outputs[0], skip_special_tokens=True), self.EXPECTED_GENERATION)
+
+ def test_generation_fused_batched(self):
+ """
+ Test generation quality for fused models - multi batch case
+ """
+ quantization_config = AwqConfig(bits=4, fuse_max_seq_len=128, do_fuse=True)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_name,
+ quantization_config=quantization_config,
+ low_cpu_mem_usage=True,
+ revision=self.model_revision,
+ ).to(torch_device)
+
+ self._check_fused_modules(model)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_name, revision=self.model_revision)
+
+ tokenizer.pad_token_id = tokenizer.eos_token_id
+ inputs = tokenizer([self.prompt, self.prompt], return_tensors="pt", padding=True).to(torch_device)
+
+ outputs = model.generate(**inputs, max_new_tokens=12)
+
+ self.assertEqual(tokenizer.decode(outputs[0], skip_special_tokens=True), self.EXPECTED_GENERATION)
+
+ @require_torch_multi_gpu
+ def test_generation_custom_model(self):
+ """
+ Test generation quality for fused models using custom fused map.
+ """
+ quantization_config = AwqConfig(
+ bits=4,
+ fuse_max_seq_len=512,
+ modules_to_fuse={
+ "attention": ["q_proj", "k_proj", "v_proj", "o_proj"],
+ "layernorm": ["ln1", "ln2", "norm"],
+ "mlp": ["gate_proj", "up_proj", "down_proj"],
+ "use_alibi": False,
+ "num_attention_heads": 56,
+ "num_key_value_heads": 8,
+ "hidden_size": 7168,
+ },
+ )
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.custom_mapping_model_id,
+ quantization_config=quantization_config,
+ trust_remote_code=True,
+ device_map="balanced",
+ revision=self.custom_model_revision,
+ )
+
+ self._check_fused_modules(model)
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ self.custom_mapping_model_id, revision=self.custom_model_revision, trust_remote_code=True
+ )
+
+ prompt = "Hello"
+ inputs = tokenizer(prompt, return_tensors="pt").to(torch_device)
+
+ outputs = model.generate(**inputs, max_new_tokens=12)
+ self.assertEqual(tokenizer.decode(outputs[0], skip_special_tokens=True), self.EXPECTED_GENERATION_CUSTOM_MODEL)
diff --git a/tests/repo_utils/test_check_copies.py b/tests/repo_utils/test_check_copies.py
index e3e8e47a873f72..6afed02895a9b3 100644
--- a/tests/repo_utils/test_check_copies.py
+++ b/tests/repo_utils/test_check_copies.py
@@ -95,13 +95,156 @@ def forward(self, x):
"""
+MOCK_DUMMY_BERT_CODE_MATCH = """
+class BertDummyModel:
+ attr_1 = 1
+ attr_2 = 2
+
+ def __init__(self, a=1, b=2):
+ self.a = a
+ self.b = b
+
+ # Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
+ def forward(self, c):
+ return 1
+
+ def existing_common(self, c):
+ return 4
+
+ def existing_diff_to_be_ignored(self, c):
+ return 9
+"""
+
+
+MOCK_DUMMY_ROBERTA_CODE_MATCH = """
+# Copied from transformers.models.dummy_bert_match.modeling_dummy_bert_match.BertDummyModel with BertDummy->RobertaBertDummy
+class RobertaBertDummyModel:
+
+ attr_1 = 1
+ attr_2 = 2
+
+ def __init__(self, a=1, b=2):
+ self.a = a
+ self.b = b
+
+ # Ignore copy
+ def only_in_roberta_to_be_ignored(self, c):
+ return 3
+
+ # Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
+ def forward(self, c):
+ return 1
+
+ def existing_common(self, c):
+ return 4
+
+ # Ignore copy
+ def existing_diff_to_be_ignored(self, c):
+ return 6
+"""
+
+
+MOCK_DUMMY_BERT_CODE_NO_MATCH = """
+class BertDummyModel:
+ attr_1 = 1
+ attr_2 = 2
+
+ def __init__(self, a=1, b=2):
+ self.a = a
+ self.b = b
+
+ # Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
+ def forward(self, c):
+ return 1
+
+ def only_in_bert(self, c):
+ return 7
+
+ def existing_common(self, c):
+ return 4
+
+ def existing_diff_not_ignored(self, c):
+ return 8
+
+ def existing_diff_to_be_ignored(self, c):
+ return 9
+"""
+
+
+MOCK_DUMMY_ROBERTA_CODE_NO_MATCH = """
+# Copied from transformers.models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel with BertDummy->RobertaBertDummy
+class RobertaBertDummyModel:
+
+ attr_1 = 1
+ attr_2 = 3
+
+ def __init__(self, a=1, b=2):
+ self.a = a
+ self.b = b
+
+ # Ignore copy
+ def only_in_roberta_to_be_ignored(self, c):
+ return 3
+
+ # Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
+ def forward(self, c):
+ return 1
+
+ def only_in_roberta_not_ignored(self, c):
+ return 2
+
+ def existing_common(self, c):
+ return 4
+
+ def existing_diff_not_ignored(self, c):
+ return 5
+
+ # Ignore copy
+ def existing_diff_to_be_ignored(self, c):
+ return 6
+"""
+
+
+EXPECTED_REPLACED_CODE = """
+# Copied from transformers.models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel with BertDummy->RobertaBertDummy
+class RobertaBertDummyModel:
+ attr_1 = 1
+ attr_2 = 2
+
+ def __init__(self, a=1, b=2):
+ self.a = a
+ self.b = b
+
+ # Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
+ def forward(self, c):
+ return 1
+
+ def only_in_bert(self, c):
+ return 7
+
+ def existing_common(self, c):
+ return 4
+
+ def existing_diff_not_ignored(self, c):
+ return 8
+
+ # Ignore copy
+ def existing_diff_to_be_ignored(self, c):
+ return 6
+
+ # Ignore copy
+ def only_in_roberta_to_be_ignored(self, c):
+ return 3
+"""
+
+
def replace_in_file(filename, old, new):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
content = content.replace(old, new)
- with open(filename, "w", encoding="utf-8") as f:
+ with open(filename, "w", encoding="utf-8", newline="\n") as f:
f.write(content)
@@ -117,11 +260,18 @@ def create_tmp_repo(tmp_dir):
model_dir = tmp_dir / "src" / "transformers" / "models"
model_dir.mkdir(parents=True, exist_ok=True)
- models = {"bert": MOCK_BERT_CODE, "bertcopy": MOCK_BERT_COPY_CODE}
+ models = {
+ "bert": MOCK_BERT_CODE,
+ "bertcopy": MOCK_BERT_COPY_CODE,
+ "dummy_bert_match": MOCK_DUMMY_BERT_CODE_MATCH,
+ "dummy_roberta_match": MOCK_DUMMY_ROBERTA_CODE_MATCH,
+ "dummy_bert_no_match": MOCK_DUMMY_BERT_CODE_NO_MATCH,
+ "dummy_roberta_no_match": MOCK_DUMMY_ROBERTA_CODE_NO_MATCH,
+ }
for model, code in models.items():
model_subdir = model_dir / model
model_subdir.mkdir(exist_ok=True)
- with open(model_subdir / f"modeling_{model}.py", "w", encoding="utf-8") as f:
+ with open(model_subdir / f"modeling_{model}.py", "w", encoding="utf-8", newline="\n") as f:
f.write(code)
@@ -176,11 +326,47 @@ def test_is_copy_consistent(self):
diffs = is_copy_consistent(file_to_check)
self.assertEqual(diffs, [["models.bert.modeling_bert.BertModel", 22]])
- diffs = is_copy_consistent(file_to_check, overwrite=True)
+ _ = is_copy_consistent(file_to_check, overwrite=True)
with open(file_to_check, "r", encoding="utf-8") as f:
self.assertEqual(f.read(), MOCK_BERT_COPY_CODE)
+ def test_is_copy_consistent_with_ignored_match(self):
+ path_to_check = ["src", "transformers", "models", "dummy_roberta_match", "modeling_dummy_roberta_match.py"]
+ with tempfile.TemporaryDirectory() as tmp_folder:
+ # Base check
+ create_tmp_repo(tmp_folder)
+ with patch_transformer_repo_path(tmp_folder):
+ file_to_check = os.path.join(tmp_folder, *path_to_check)
+ diffs = is_copy_consistent(file_to_check)
+ self.assertEqual(diffs, [])
+
+ def test_is_copy_consistent_with_ignored_no_match(self):
+ path_to_check = [
+ "src",
+ "transformers",
+ "models",
+ "dummy_roberta_no_match",
+ "modeling_dummy_roberta_no_match.py",
+ ]
+ with tempfile.TemporaryDirectory() as tmp_folder:
+ # Base check with an inconsistency
+ create_tmp_repo(tmp_folder)
+ with patch_transformer_repo_path(tmp_folder):
+ file_to_check = os.path.join(tmp_folder, *path_to_check)
+
+ diffs = is_copy_consistent(file_to_check)
+ # line 6: `attr_2 = 3` in `MOCK_DUMMY_ROBERTA_CODE_NO_MATCH`.
+ # (which has a leading `\n`.)
+ self.assertEqual(
+ diffs, [["models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel", 6]]
+ )
+
+ _ = is_copy_consistent(file_to_check, overwrite=True)
+
+ with open(file_to_check, "r", encoding="utf-8") as f:
+ self.assertEqual(f.read(), EXPECTED_REPLACED_CODE)
+
def test_convert_to_localized_md(self):
localized_readme = check_copies.LOCALIZED_READMES["README_zh-hans.md"]
diff --git a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
index c38ee542e6ce8a..fd8b36fc9ab208 100644
--- a/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
+++ b/tests/sagemaker/scripts/pytorch/run_glue_model_parallelism.py
@@ -282,7 +282,7 @@ def main():
# Loading a dataset from local json files
datasets = load_dataset("json", data_files=data_files)
# See more about loading any type of standard or custom dataset at
- # https://huggingface.co/docs/datasets/loading_datasets.html.
+ # https://huggingface.co/docs/datasets/loading_datasets.
# Labels
if data_args.task_name is not None:
@@ -299,7 +299,7 @@ def main():
num_labels = 1
else:
# A useful fast method:
- # https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.unique
+ # https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.unique
label_list = datasets["train"].unique("label")
label_list.sort() # Let's sort it for determinism
num_labels = len(label_list)
diff --git a/tests/test_cache_utils.py b/tests/test_cache_utils.py
new file mode 100644
index 00000000000000..72d055c8806afd
--- /dev/null
+++ b/tests/test_cache_utils.py
@@ -0,0 +1,231 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import set_seed
+from transformers.testing_utils import is_torch_available, require_auto_gptq, require_torch, require_torch_gpu, slow
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoModelForCausalLM, AutoTokenizer, DynamicCache, LlamaForCausalLM, SinkCache
+
+
+@require_torch
+class CacheTest(unittest.TestCase):
+ def test_cache_equivalence(self):
+ """Tests that we can convert back and forth between the legacy cache format and DynamicCache"""
+ legacy_cache = ()
+ new_cache = DynamicCache()
+
+ # Creates a new cache with 10 layers in both formats
+ for layer_idx in range(10):
+ new_key = torch.rand((2, 4, 8, 16))
+ new_value = torch.rand((2, 4, 8, 16))
+ new_cache.update(new_key, new_value, layer_idx)
+ legacy_cache += ((new_key, new_value),)
+
+ # Sanity check 1: they must have the same shapes
+ self.assertTrue(len(legacy_cache), len(new_cache))
+ for layer_idx in range(10):
+ self.assertTrue(len(legacy_cache[layer_idx]), len(legacy_cache[layer_idx]))
+ for key_value_idx in range(2):
+ self.assertTrue(
+ legacy_cache[layer_idx][key_value_idx].shape == new_cache[layer_idx][key_value_idx].shape
+ )
+
+ # Sanity check 2: we can get the sequence length in multiple ways with DynamicCache, and they return the
+ # expected value
+ self.assertTrue(legacy_cache[0][0].shape[-2] == new_cache[0][0].shape[-2] == new_cache.get_seq_length() == 8)
+
+ # Sanity check 3: they must be equal, and both support indexing
+ for layer_idx in range(10):
+ for key_value_idx in range(2):
+ self.assertTrue(
+ torch.allclose(new_cache[layer_idx][key_value_idx], legacy_cache[layer_idx][key_value_idx])
+ )
+
+ # Test 1: We can convert from legacy to new with no changes
+ from_legacy = DynamicCache.from_legacy_cache(legacy_cache)
+ for layer_idx in range(10):
+ for key_value_idx in range(2):
+ self.assertTrue(
+ torch.allclose(from_legacy[layer_idx][key_value_idx], legacy_cache[layer_idx][key_value_idx])
+ )
+
+ # Test 2: We can convert from new to legacy with no changes
+ to_legacy = new_cache.to_legacy_cache()
+ for layer_idx in range(10):
+ for key_value_idx in range(2):
+ self.assertTrue(
+ torch.allclose(to_legacy[layer_idx][key_value_idx], new_cache[layer_idx][key_value_idx])
+ )
+
+ def test_reorder_cache_retrocompatibility(self):
+ """Tests that Cache.reorder_cache is retrocompatible with the legacy code path"""
+ legacy_reorder_fn = LlamaForCausalLM._reorder_cache # An example of a legacy `_reorder_cache` function
+
+ legacy_cache = ()
+ new_cache = DynamicCache()
+
+ # Creates a new cache with 10 layers in both formats
+ for layer_idx in range(10):
+ new_key = torch.rand((4, 4, 8, 16))
+ new_value = torch.rand((4, 4, 8, 16))
+ new_cache.update(new_key, new_value, layer_idx)
+ legacy_cache += ((new_key, new_value),)
+
+ # Let's create some dummy beam indices. From the shape above, it is equivalent to the case where num_beams=4
+ # and batch_size=1
+ beam_idx = torch.randint(low=0, high=4, size=(4,))
+
+ legacy_cache_reordered = legacy_reorder_fn(legacy_cache, beam_idx)
+ new_cache.reorder_cache(beam_idx)
+
+ # Let's check that the results are the same
+ for layer_idx in range(10):
+ for key_value_idx in range(2):
+ self.assertTrue(
+ torch.allclose(
+ new_cache[layer_idx][key_value_idx], legacy_cache_reordered[layer_idx][key_value_idx]
+ )
+ )
+
+
+@require_torch_gpu
+@slow
+class CacheIntegrationTest(unittest.TestCase):
+ def test_dynamic_cache_hard(self):
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", padding_side="left")
+ model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-2-7b-hf", device_map="auto", torch_dtype=torch.float16
+ )
+ inputs = tokenizer(["Here's everything I know about cats. Cats"], return_tensors="pt").to(model.device)
+
+ # DynamicCache and the legacy cache format should be equivalent
+ set_seed(0)
+ gen_out_legacy = model.generate(**inputs, do_sample=True, max_new_tokens=256)
+ set_seed(0)
+ gen_out = model.generate(**inputs, do_sample=True, max_new_tokens=256, past_key_values=DynamicCache())
+ self.assertListEqual(gen_out_legacy.tolist(), gen_out.tolist())
+
+ decoded = tokenizer.batch_decode(gen_out, skip_special_tokens=True)
+ expected_text = (
+ "Here's everything I know about cats. Cats are mysterious creatures. They can't talk, and they don't like "
+ "to be held. They don't play fetch, and they don't like to be hugged. But they do like to be petted.\n"
+ "Cats are also very independent. They don't like to be told what to do, and they don't like to be told "
+ "what to eat. They are also very territorial. They don't like to share their food or their toys.\nCats "
+ "are also very curious. They like to explore, and they like to play. They are also very fast. They can "
+ "run very fast, and they can jump very high.\nCats are also very smart. They can learn tricks, and they "
+ "can solve problems. They are also very playful. They like to play with toys, and they like to play with "
+ "other cats.\nCats are also very affectionate. They like to be petted, and they like to be held. They "
+ "also like to be scratched.\nCats are also very clean. They like to groom themselves, and they like to "
+ "clean their litter box.\nCats are also very independent. They don't"
+ )
+ self.assertEqual(decoded[0], expected_text)
+
+ def test_dynamic_cache_batched(self):
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", padding_side="left")
+ tokenizer.pad_token = tokenizer.eos_token
+ model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-2-7b-hf", device_map="auto", torch_dtype=torch.float16
+ )
+ inputs = tokenizer(["A sequence: 1, 2, 3, 4, 5", "A sequence: A, B, C"], padding=True, return_tensors="pt").to(
+ model.device
+ )
+
+ gen_out = model.generate(**inputs, do_sample=False, max_new_tokens=10, past_key_values=DynamicCache())
+ decoded = tokenizer.batch_decode(gen_out, skip_special_tokens=True)
+ expected_text = ["A sequence: 1, 2, 3, 4, 5, 6, 7, 8,", "A sequence: A, B, C, D, E, F, G, H"]
+ self.assertListEqual(decoded, expected_text)
+
+ def test_dynamic_cache_beam_search(self):
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", padding_side="left")
+ model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-2-7b-hf", device_map="auto", torch_dtype=torch.float16
+ )
+
+ inputs = tokenizer(["The best color is"], return_tensors="pt").to(model.device)
+ gen_out = model.generate(
+ **inputs,
+ do_sample=False,
+ max_new_tokens=20,
+ num_beams=2,
+ num_return_sequences=2,
+ )
+ decoded = tokenizer.batch_decode(gen_out, skip_special_tokens=True)
+ expected_text = [
+ "The best color is the one that makes you feel good.\nThe best color is the one that makes you feel good",
+ "The best color is the one that suits you.\nThe best color is the one that suits you. The",
+ ]
+ self.assertListEqual(decoded, expected_text)
+
+ @require_auto_gptq
+ def test_sink_cache_hard(self):
+ tokenizer = AutoTokenizer.from_pretrained("TheBloke/LLaMa-7B-GPTQ")
+ model = AutoModelForCausalLM.from_pretrained("TheBloke/LLaMa-7B-GPTQ", device_map="auto")
+
+ inputs = tokenizer(["Vaswani et al. (2017) introduced the Transformers"], return_tensors="pt").to(model.device)
+
+ # Set up the SinkCache. Using a small window length to contain computational complexity. If this example is run
+ # without a SinkCache, the last few tokens are gibberish (ends in "of the of the of a of a of")
+ cache = SinkCache(window_length=508, num_sink_tokens=4)
+ gen_out = model.generate(**inputs, do_sample=False, max_new_tokens=3000, past_key_values=cache)
+ decoded = tokenizer.batch_decode(gen_out, skip_special_tokens=True)
+ self.assertTrue(decoded[0].endswith("to perform a variety of tasks. The Transformer is a neural network"))
+
+ def test_sink_cache_iterative_prompts(self):
+ """Tests that SinkCache supports more than one new token at once, when shifting the cache"""
+ tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
+ model = AutoModelForCausalLM.from_pretrained(
+ "HuggingFaceH4/zephyr-7b-beta", device_map="auto", torch_dtype=torch.float16
+ )
+ prompt = (
+ "Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences "
+ "and must-see attractions."
+ )
+
+ # Prepare generation settings
+ cache = SinkCache(window_length=256, num_sink_tokens=4)
+ input_ids = torch.tensor([], device=model.device, dtype=torch.int)
+ for _ in range(3):
+ # Tokenize the prompt with the correct chat template
+ chat = [{"role": "user", "content": prompt}]
+ tokenized_chat = tokenizer.apply_chat_template(chat, return_tensors="pt", add_generation_prompt=True).to(
+ model.device
+ )
+ input_ids = torch.cat((input_ids, tokenized_chat), dim=1)
+
+ # Perform the generation
+ gen_out = model.generate(
+ input_ids, do_sample=False, max_new_tokens=100, past_key_values=cache, use_cache=True
+ )
+ input_ids = gen_out
+
+ # We went well beyond the cache length
+ self.assertTrue(input_ids.shape[1] > cache.get_max_length() * 1.5)
+
+ # And it still produces a coherent english
+ decoded = tokenizer.batch_decode(input_ids, skip_special_tokens=True)
+ last_output = (
+ "<|assistant|>\nAs the sun began to set over the Pacific Ocean, I found myself standing on the shores of "
+ "Waikiki Beach, my heart filled with awe and wonder. I had just returned from a two-week journey to the "
+ "beautiful island of Hawaii, and it had been an unforgettable experience filled with cultural experiences "
+ "and must-see attractions that left me breathless.\n\nOne of the most memorable experiences of my trip "
+ "was visiting the historic district of Honolulu. Here,"
+ )
+ self.assertTrue(decoded[0].endswith(last_output))
diff --git a/tests/test_configuration_utils.py b/tests/test_configuration_utils.py
index a6e9e6b0390abe..2ceb1695fa96cc 100644
--- a/tests/test_configuration_utils.py
+++ b/tests/test_configuration_utils.py
@@ -198,7 +198,14 @@ def test_config_common_kwargs_is_complete(self):
missing_keys = [key for key in base_config.__dict__ if key not in config_common_kwargs]
# If this part of the test fails, you have arguments to addin config_common_kwargs above.
self.assertListEqual(
- missing_keys, ["is_encoder_decoder", "_name_or_path", "_commit_hash", "transformers_version"]
+ missing_keys,
+ [
+ "is_encoder_decoder",
+ "_name_or_path",
+ "_commit_hash",
+ "_attn_implementation_internal",
+ "transformers_version",
+ ],
)
keys_with_defaults = [key for key, value in config_common_kwargs.items() if value == getattr(base_config, key)]
if len(keys_with_defaults) > 0:
diff --git a/tests/test_image_processing_common.py b/tests/test_image_processing_common.py
index cb78b33375568e..dcbee270f90b6e 100644
--- a/tests/test_image_processing_common.py
+++ b/tests/test_image_processing_common.py
@@ -15,8 +15,11 @@
import json
import os
+import pathlib
import tempfile
+from transformers import BatchFeature
+from transformers.image_utils import AnnotationFormat, AnnotionFormat
from transformers.testing_utils import check_json_file_has_correct_format, require_torch, require_vision
from transformers.utils import is_torch_available, is_vision_available
@@ -285,3 +288,81 @@ def test_call_numpy_4_channels(self):
self.assertEqual(
tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
)
+
+
+class AnnotationFormatTestMixin:
+ # this mixin adds a test to assert that usages of the
+ # to-be-deprecated `AnnotionFormat` continue to be
+ # supported for the time being
+
+ def test_processor_can_use_legacy_annotation_format(self):
+ image_processor_dict = self.image_processor_tester.prepare_image_processor_dict()
+ fixtures_path = pathlib.Path(__file__).parent / "fixtures" / "tests_samples" / "COCO"
+
+ with open(fixtures_path / "coco_annotations.txt", "r") as f:
+ detection_target = json.loads(f.read())
+
+ detection_annotations = {"image_id": 39769, "annotations": detection_target}
+
+ detection_params = {
+ "images": Image.open(fixtures_path / "000000039769.png"),
+ "annotations": detection_annotations,
+ "return_tensors": "pt",
+ }
+
+ with open(fixtures_path / "coco_panoptic_annotations.txt", "r") as f:
+ panoptic_target = json.loads(f.read())
+
+ panoptic_annotations = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": panoptic_target}
+
+ masks_path = pathlib.Path(fixtures_path / "coco_panoptic")
+
+ panoptic_params = {
+ "images": Image.open(fixtures_path / "000000039769.png"),
+ "annotations": panoptic_annotations,
+ "return_tensors": "pt",
+ "masks_path": masks_path,
+ }
+
+ test_cases = [
+ ("coco_detection", detection_params),
+ ("coco_panoptic", panoptic_params),
+ (AnnotionFormat.COCO_DETECTION, detection_params),
+ (AnnotionFormat.COCO_PANOPTIC, panoptic_params),
+ (AnnotationFormat.COCO_DETECTION, detection_params),
+ (AnnotationFormat.COCO_PANOPTIC, panoptic_params),
+ ]
+
+ def _compare(a, b) -> None:
+ if isinstance(a, (dict, BatchFeature)):
+ self.assertEqual(a.keys(), b.keys())
+ for k, v in a.items():
+ _compare(v, b[k])
+ elif isinstance(a, list):
+ self.assertEqual(len(a), len(b))
+ for idx in range(len(a)):
+ _compare(a[idx], b[idx])
+ elif isinstance(a, torch.Tensor):
+ self.assertTrue(torch.allclose(a, b, atol=1e-3))
+ elif isinstance(a, str):
+ self.assertEqual(a, b)
+
+ for annotation_format, params in test_cases:
+ with self.subTest(annotation_format):
+ image_processor_params = {**image_processor_dict, **{"format": annotation_format}}
+ image_processor_first = self.image_processing_class(**image_processor_params)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ image_processor_first.save_pretrained(tmpdirname)
+ image_processor_second = self.image_processing_class.from_pretrained(tmpdirname)
+
+ # check the 'format' key exists and that the dicts of the
+ # first and second processors are equal
+ self.assertIn("format", image_processor_first.to_dict().keys())
+ self.assertEqual(image_processor_second.to_dict(), image_processor_first.to_dict())
+
+ # perform encoding using both processors and compare
+ # the resulting BatchFeatures
+ first_encoding = image_processor_first(**params)
+ second_encoding = image_processor_second(**params)
+ _compare(first_encoding, second_encoding)
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index 0edc23c7af2048..85e69300516164 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -12,7 +12,6 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-
import collections
import copy
import gc
@@ -28,15 +27,19 @@
from typing import Dict, List, Tuple
import numpy as np
+from parameterized import parameterized
from pytest import mark
import transformers
from transformers import (
AutoModel,
+ AutoModelForCausalLM,
AutoModelForSequenceClassification,
PretrainedConfig,
+ PreTrainedModel,
is_torch_available,
logging,
+ set_seed,
)
from transformers.models.auto import get_values
from transformers.models.auto.modeling_auto import (
@@ -70,6 +73,7 @@
require_torch,
require_torch_gpu,
require_torch_multi_gpu,
+ require_torch_sdpa,
slow,
torch_device,
)
@@ -81,8 +85,9 @@
is_flax_available,
is_tf_available,
is_torch_fx_available,
+ is_torch_sdpa_available,
)
-from transformers.utils.generic import ModelOutput
+from transformers.utils.generic import ContextManagers, ModelOutput
if is_accelerate_available():
@@ -96,6 +101,7 @@
from torch import nn
from transformers import MODEL_MAPPING, AdaptiveEmbedding
+ from transformers.modeling_utils import no_init_weights
from transformers.pytorch_utils import id_tensor_storage
@@ -425,6 +431,56 @@ class CopyClass(model_class):
max_diff = (model_slow_init.state_dict()[key] - model_fast_init.state_dict()[key]).sum().item()
self.assertLessEqual(max_diff, 1e-3, msg=f"{key} not identical")
+ def test_fast_init_context_manager(self):
+ # 1. Create a dummy class. Should have buffers as well? To make sure we test __init__
+ class MyClass(PreTrainedModel):
+ config_class = PretrainedConfig
+
+ def __init__(self, config=None):
+ super().__init__(config if config is not None else PretrainedConfig())
+ self.linear = nn.Linear(10, 10, bias=True)
+ self.embedding = nn.Embedding(10, 10)
+ self.std = 1
+
+ def _init_weights(self, module):
+ if isinstance(module, nn.Linear):
+ module.weight.data = nn.init.kaiming_uniform_(module.weight.data, np.sqrt(5))
+ if module.bias is not None:
+ module.bias.data.normal_(mean=0.0, std=self.std)
+
+ # 2. Make sure a linear layer's reset params is properly skipped:
+ with ContextManagers([no_init_weights(True)]):
+ no_init_instance = MyClass()
+
+ set_seed(0)
+ expected_bias = torch.tensor(
+ ([0.2975, 0.2131, -0.1379, -0.0796, -0.3012, -0.0057, -0.2381, -0.2439, -0.0174, 0.0475])
+ )
+ init_instance = MyClass()
+ torch.testing.assert_allclose(init_instance.linear.bias, expected_bias, rtol=1e-3, atol=1e-4)
+
+ set_seed(0)
+ torch.testing.assert_allclose(
+ init_instance.linear.weight, nn.init.kaiming_uniform_(no_init_instance.linear.weight, np.sqrt(5))
+ )
+
+ # 3. Make sure weights that are not present use init_weight_ and get expected values
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ state_dict = init_instance.state_dict()
+ del state_dict["linear.weight"]
+
+ init_instance.config.save_pretrained(tmpdirname)
+ torch.save(state_dict, os.path.join(tmpdirname, "pytorch_model.bin"))
+ set_seed(0)
+ model_fast_init = MyClass.from_pretrained(tmpdirname)
+
+ set_seed(0)
+ model_slow_init = MyClass.from_pretrained(tmpdirname, _fast_init=False)
+
+ for key in model_fast_init.state_dict().keys():
+ max_diff = torch.max(torch.abs(model_slow_init.state_dict()[key] - model_fast_init.state_dict()[key]))
+ self.assertLessEqual(max_diff.item(), 1e-3, msg=f"{key} not identical")
+
def test_save_load_fast_init_to_base(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
if config.__class__ not in MODEL_MAPPING:
@@ -541,8 +597,14 @@ def test_forward_signature(self):
else ["encoder_outputs"]
)
self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ elif model_class.__name__ in [*get_values(MODEL_FOR_BACKBONE_MAPPING_NAMES)] and self.has_attentions:
+ expected_arg_names = ["pixel_values", "output_hidden_states", "output_attentions", "return_dict"]
+ self.assertListEqual(arg_names, expected_arg_names)
+ elif model_class.__name__ in [*get_values(MODEL_FOR_BACKBONE_MAPPING_NAMES)] and not self.has_attentions:
+ expected_arg_names = ["pixel_values", "output_hidden_states", "return_dict"]
+ self.assertListEqual(arg_names, expected_arg_names)
else:
- expected_arg_names = ["input_ids"]
+ expected_arg_names = [model.main_input_name]
self.assertListEqual(arg_names[:1], expected_arg_names)
def check_training_gradient_checkpointing(self, gradient_checkpointing_kwargs=None):
@@ -550,10 +612,6 @@ def check_training_gradient_checkpointing(self, gradient_checkpointing_kwargs=No
return
for model_class in self.all_model_classes:
- config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
- config.use_cache = False
- config.return_dict = True
-
if (
model_class.__name__
in [*get_values(MODEL_MAPPING_NAMES), *get_values(MODEL_FOR_BACKBONE_MAPPING_NAMES)]
@@ -562,6 +620,8 @@ def check_training_gradient_checkpointing(self, gradient_checkpointing_kwargs=No
continue
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
model = model_class(config)
model.to(torch_device)
@@ -771,102 +831,120 @@ def _create_and_check_torchscript(self, config, inputs_dict):
configs_no_init = _config_zero_init(config) # To be sure we have no Nan
configs_no_init.torchscript = True
for model_class in self.all_model_classes:
- model = model_class(config=configs_no_init)
- model.to(torch_device)
- model.eval()
- inputs = self._prepare_for_class(inputs_dict, model_class)
-
- main_input_name = model_class.main_input_name
-
- try:
- if model.config.is_encoder_decoder:
- model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
- main_input = inputs[main_input_name]
- attention_mask = inputs["attention_mask"]
- decoder_input_ids = inputs["decoder_input_ids"]
- decoder_attention_mask = inputs["decoder_attention_mask"]
- model(main_input, attention_mask, decoder_input_ids, decoder_attention_mask)
- traced_model = torch.jit.trace(
- model, (main_input, attention_mask, decoder_input_ids, decoder_attention_mask)
- )
- elif "bbox" in inputs and "image" in inputs: # LayoutLMv2 requires additional inputs
- input_ids = inputs["input_ids"]
- bbox = inputs["bbox"]
- image = inputs["image"].tensor
- model(input_ids, bbox, image)
- traced_model = torch.jit.trace(
- model, (input_ids, bbox, image), check_trace=False
- ) # when traced model is checked, an error is produced due to name mangling
- elif "bbox" in inputs: # Bros requires additional inputs (bbox)
- input_ids = inputs["input_ids"]
- bbox = inputs["bbox"]
- model(input_ids, bbox)
- traced_model = torch.jit.trace(
- model, (input_ids, bbox), check_trace=False
- ) # when traced model is checked, an error is produced due to name mangling
- else:
- main_input = inputs[main_input_name]
- model(main_input)
- traced_model = torch.jit.trace(model, main_input)
- except RuntimeError:
- self.fail("Couldn't trace module.")
+ for attn_implementation in ["eager", "sdpa"]:
+ if attn_implementation == "sdpa" and (not model_class._supports_sdpa or not is_torch_sdpa_available()):
+ continue
- with tempfile.TemporaryDirectory() as tmp_dir_name:
- pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+ configs_no_init._attn_implementation = attn_implementation
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+ inputs = self._prepare_for_class(inputs_dict, model_class)
- try:
- torch.jit.save(traced_model, pt_file_name)
- except Exception:
- self.fail("Couldn't save module.")
+ main_input_name = model_class.main_input_name
try:
- loaded_model = torch.jit.load(pt_file_name)
- except Exception:
- self.fail("Couldn't load module.")
+ if model.config.is_encoder_decoder:
+ model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
+ main_input = inputs[main_input_name]
+ attention_mask = inputs["attention_mask"]
+ decoder_input_ids = inputs["decoder_input_ids"]
+ decoder_attention_mask = inputs["decoder_attention_mask"]
+ model(main_input, attention_mask, decoder_input_ids, decoder_attention_mask)
+ traced_model = torch.jit.trace(
+ model, (main_input, attention_mask, decoder_input_ids, decoder_attention_mask)
+ )
+ elif "bbox" in inputs and "image" in inputs: # LayoutLMv2 requires additional inputs
+ input_ids = inputs["input_ids"]
+ bbox = inputs["bbox"]
+ image = inputs["image"].tensor
+ model(input_ids, bbox, image)
+ traced_model = torch.jit.trace(
+ model, (input_ids, bbox, image), check_trace=False
+ ) # when traced model is checked, an error is produced due to name mangling
+ elif "bbox" in inputs: # Bros requires additional inputs (bbox)
+ input_ids = inputs["input_ids"]
+ bbox = inputs["bbox"]
+ model(input_ids, bbox)
+ traced_model = torch.jit.trace(
+ model, (input_ids, bbox), check_trace=False
+ ) # when traced model is checked, an error is produced due to name mangling
+ else:
+ main_input = inputs[main_input_name]
+
+ if model.config._attn_implementation == "sdpa":
+ trace_input = {main_input_name: main_input}
+
+ if "attention_mask" in inputs:
+ trace_input["attention_mask"] = inputs["attention_mask"]
+ else:
+ self.skipTest("testing SDPA without attention_mask is not supported")
+
+ model(main_input, attention_mask=inputs["attention_mask"])
+ # example_kwarg_inputs was introduced in torch==2.0, but it is fine here since SDPA has a requirement on torch>=2.1.
+ traced_model = torch.jit.trace(model, example_kwarg_inputs=trace_input)
+ else:
+ model(main_input)
+ traced_model = torch.jit.trace(model, (main_input,))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
- model.to(torch_device)
- model.eval()
+ model.to(torch_device)
+ model.eval()
- loaded_model.to(torch_device)
- loaded_model.eval()
+ loaded_model.to(torch_device)
+ loaded_model.eval()
- model_state_dict = model.state_dict()
- loaded_model_state_dict = loaded_model.state_dict()
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
- non_persistent_buffers = {}
- for key in loaded_model_state_dict.keys():
- if key not in model_state_dict.keys():
- non_persistent_buffers[key] = loaded_model_state_dict[key]
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
- loaded_model_state_dict = {
- key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
- }
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
- self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
- model_buffers = list(model.buffers())
- for non_persistent_buffer in non_persistent_buffers.values():
- found_buffer = False
- for i, model_buffer in enumerate(model_buffers):
- if torch.equal(non_persistent_buffer, model_buffer):
- found_buffer = True
- break
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
- self.assertTrue(found_buffer)
- model_buffers.pop(i)
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
- models_equal = True
- for layer_name, p1 in model_state_dict.items():
- if layer_name in loaded_model_state_dict:
- p2 = loaded_model_state_dict[layer_name]
- if p1.data.ne(p2.data).sum() > 0:
- models_equal = False
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ if layer_name in loaded_model_state_dict:
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
- self.assertTrue(models_equal)
+ self.assertTrue(models_equal)
- # Avoid memory leak. Without this, each call increase RAM usage by ~20MB.
- # (Even with this call, there are still memory leak by ~0.04MB)
- self.clear_torch_jit_class_registry()
+ # Avoid memory leak. Without this, each call increase RAM usage by ~20MB.
+ # (Even with this call, there are still memory leak by ~0.04MB)
+ self.clear_torch_jit_class_registry()
def test_torch_fx(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -1926,7 +2004,6 @@ def _postprocessing_to_ignore_test_cases(self, tf_outputs, pt_outputs, model_cla
"FunnelForPreTraining",
"ElectraForPreTraining",
"XLMWithLMHeadModel",
- "TransfoXLLMHeadModel",
]:
for k in key_differences:
if k in ["loss", "losses"]:
@@ -2828,20 +2905,18 @@ def test_model_is_small(self):
@mark.flash_attn_test
@slow
def test_flash_attn_2_conversion(self):
- import torch
-
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=True
+ tmpdirname, torch_dtype=torch.float16, attn_implementation="flash_attention_2"
).to(torch_device)
for _, module in model.named_modules():
@@ -2855,11 +2930,9 @@ def test_flash_attn_2_conversion(self):
@mark.flash_attn_test
@slow
def test_flash_attn_2_inference(self):
- import torch
-
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
@@ -2867,12 +2940,12 @@ def test_flash_attn_2_inference(self):
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model_fa = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=True
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model_fa.to(torch_device)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=False
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model.to(torch_device)
@@ -2952,11 +3025,9 @@ def test_flash_attn_2_inference(self):
@mark.flash_attn_test
@slow
def test_flash_attn_2_inference_padding_right(self):
- import torch
-
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
@@ -2964,12 +3035,12 @@ def test_flash_attn_2_inference_padding_right(self):
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model_fa = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=True
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model_fa.to(torch_device)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, use_flash_attention_2=False
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model.to(torch_device)
@@ -3045,20 +3116,18 @@ def test_flash_attn_2_inference_padding_right(self):
@mark.flash_attn_test
@slow
def test_flash_attn_2_generate_left_padding(self):
- import torch
-
for model_class in self.all_generative_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
- model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=False, low_cpu_mem_usage=True
- ).to(torch_device)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
dummy_input = inputs_dict[model.main_input_name]
if dummy_input.dtype in [torch.float32, torch.bfloat16]:
@@ -3074,41 +3143,42 @@ def test_flash_attn_2_generate_left_padding(self):
)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=True, low_cpu_mem_usage=True
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
).to(torch_device)
out_fa = model.generate(
dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
)
- self.assertTrue(torch.equal(out, out_fa))
+ self.assertTrue(torch.allclose(out, out_fa))
@require_flash_attn
@require_torch_gpu
@mark.flash_attn_test
@slow
def test_flash_attn_2_generate_padding_right(self):
- import torch
-
for model_class in self.all_generative_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
- model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=False, low_cpu_mem_usage=True
- ).to(torch_device)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
dummy_input = inputs_dict[model.main_input_name]
if dummy_input.dtype in [torch.float32, torch.bfloat16]:
dummy_input = dummy_input.to(torch.float16)
dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
- # make sure we do left padding
+ # make sure we do right padding
dummy_attention_mask[:, :-1] = 1
dummy_attention_mask[:, -1:] = 0
@@ -3117,27 +3187,347 @@ def test_flash_attn_2_generate_padding_right(self):
)
model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.float16, use_flash_attention_2=True, low_cpu_mem_usage=True
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
).to(torch_device)
out_fa = model.generate(
dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
)
- self.assertTrue(torch.equal(out, out_fa))
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
+ if not self.all_model_classes[0]._supports_sdpa:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ if torch_device == "cpu" and torch_dtype == "float16":
+ self.skipTest("float16 not supported on cpu")
+
+ # Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
+ if torch_dtype == "float16":
+ torch_dtype = torch.float16
+ elif torch_dtype == "bfloat16":
+ torch_dtype = torch.bfloat16
+ elif torch_dtype == "float32":
+ torch_dtype = torch.float32
+
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 1e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ rtols = {
+ ("cpu", False, torch.float32): 1e-4,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-4,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-4,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 1e-3,
+ ("cuda", True, torch.float32): 1e-4,
+ ("cuda", True, torch.bfloat16): 3e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+
+ def get_mean_reldiff(failcase, x, ref, atol, rtol):
+ return f"{failcase}: mean relative difference: {((x - ref).abs() / (ref.abs() + 1e-12)).mean():.3e}, torch atol = {atol}, torch rtol = {rtol}"
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ is_encoder_decoder = model.config.is_encoder_decoder
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname, torch_dtype=torch_dtype)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch_dtype,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa and model_sdpa.config.model_type != "falcon":
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # We use these for loops instead of parameterized.expand just for the interest of avoiding loading/saving 8 times the model,
+ # but it would be nicer to have an efficient way to use parameterized.expand
+ fail_cases = []
+ for padding_side in ["left", "right"]:
+ for use_mask in [False, True]:
+ for batch_size in [1, 5]:
+ dummy_input = inputs_dict[model.main_input_name]
+
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ dummy_input = dummy_input.to(torch_dtype)
+
+ dummy_input = dummy_input[:batch_size]
+ if dummy_input.shape[0] != batch_size:
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ extension = torch.rand(
+ batch_size - dummy_input.shape[0],
+ *dummy_input.shape[1:],
+ dtype=torch_dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+ else:
+ extension = torch.randint(
+ high=5,
+ size=(batch_size - dummy_input.shape[0], *dummy_input.shape[1:]),
+ dtype=dummy_input.dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+
+ if not use_mask:
+ dummy_attention_mask = None
+ else:
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+ if dummy_attention_mask is None:
+ if is_encoder_decoder:
+ seqlen = inputs_dict.get("decoder_input_ids", dummy_input).shape[-1]
+ else:
+ seqlen = dummy_input.shape[-1]
+ dummy_attention_mask = (
+ torch.ones(batch_size, seqlen).to(torch.int64).to(torch_device)
+ )
+
+ dummy_attention_mask = dummy_attention_mask[:batch_size]
+ if dummy_attention_mask.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - dummy_attention_mask.shape[0],
+ *dummy_attention_mask.shape[1:],
+ dtype=dummy_attention_mask.dtype,
+ device=torch_device,
+ )
+ dummy_attention_mask = torch.cat((dummy_attention_mask, extension), dim=0)
+ dummy_attention_mask = dummy_attention_mask.to(torch_device)
+
+ dummy_attention_mask[:] = 1
+ if padding_side == "left":
+ dummy_attention_mask[-1, :-1] = 1
+ dummy_attention_mask[-1, -4:] = 0
+ elif padding_side == "right":
+ dummy_attention_mask[-1, 1:] = 1
+ dummy_attention_mask[-1, :3] = 0
+
+ for enable_kernels in [False, True]:
+ failcase = f"padding_side={padding_side}, use_mask={use_mask}, batch_size={batch_size}, enable_kernels={enable_kernels}"
+ if is_encoder_decoder:
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)[:batch_size]
+ if decoder_input_ids.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - decoder_input_ids.shape[0],
+ *decoder_input_ids.shape[1:],
+ dtype=decoder_input_ids.dtype,
+ device=torch_device,
+ )
+ decoder_input_ids = torch.cat((decoder_input_ids, extension), dim=0)
+ decoder_input_ids = decoder_input_ids.to(torch_device)
+
+ # TODO: never an `attention_mask` arg here?
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+ else:
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+
+ # Otherwise fails for e.g. WhisperEncoderModel
+ if "attention_mask" in inspect.signature(model_eager.forward).parameters:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ # TODO: test gradients as well (& for FA2 as well!)
+ with torch.no_grad():
+ with torch.backends.cuda.sdp_kernel(
+ enable_flash=enable_kernels,
+ enable_math=True,
+ enable_mem_efficient=enable_kernels,
+ ):
+ outputs_eager = model_eager(dummy_input, **other_inputs)
+ outputs_sdpa = model_sdpa(dummy_input, **other_inputs)
+
+ logits_eager = (
+ outputs_eager.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_eager.decoder_hidden_states[-1]
+ )
+ logits_sdpa = (
+ outputs_sdpa.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_sdpa.decoder_hidden_states[-1]
+ )
+
+ if torch_device in ["cpu", "cuda"]:
+ atol = atols[torch_device, enable_kernels, torch_dtype]
+ rtol = rtols[torch_device, enable_kernels, torch_dtype]
+ else:
+ atol = 1e-7
+ rtol = 1e-4
+
+ # Masked tokens output slightly deviates - we don't mind that.
+ if use_mask:
+ if padding_side == "left":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, :-4]
+ sub_eager = logits_eager[-1, :-4]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, -4:]
+ # sub_eager = logits_eager[-1, -4:]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+ elif padding_side == "right":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, 3:]
+ sub_eager = logits_eager[-1, 3:]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, :3]
+ # sub_eager = logits_eager[-1, :3]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+
+ else:
+ if not torch.allclose(logits_sdpa, logits_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, logits_sdpa, logits_eager, atol, rtol)
+ )
+
+ self.assertTrue(len(fail_cases) == 0, "\n".join(fail_cases))
+
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ max_new_tokens = 30
+
+ if len(self.all_generative_model_classes) == 0:
+ self.skipTest(f"{self.__class__.__name__} tests a model that does support generate: skipping this test")
+
+ for model_class in self.all_generative_model_classes:
+ if not model_class._supports_sdpa:
+ self.skipTest(f"{model_class.__name__} does not support SDPA")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model_sdpa = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # Just test that a large cache works as expected
+ res_eager = model_eager.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ res_sdpa = model_sdpa.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(res_eager, res_sdpa))
@require_flash_attn
@require_torch_gpu
@mark.flash_attn_test
@slow
def test_flash_attn_2_generate_use_cache(self):
- import torch
-
max_new_tokens = 30
for model_class in self.all_generative_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -3159,13 +3549,17 @@ def test_flash_attn_2_generate_use_cache(self):
model = model_class.from_pretrained(
tmpdirname,
torch_dtype=torch.float16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
low_cpu_mem_usage=True,
).to(torch_device)
# Just test that a large cache works as expected
_ = model.generate(
- dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
)
@require_flash_attn
@@ -3174,11 +3568,9 @@ def test_flash_attn_2_generate_use_cache(self):
@mark.flash_attn_test
@slow
def test_flash_attn_2_fp32_ln(self):
- import torch
-
for model_class in self.all_generative_model_classes:
if not model_class._supports_flash_attn_2:
- return
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = model_class(config)
@@ -3196,7 +3588,7 @@ def test_flash_attn_2_fp32_ln(self):
model = model_class.from_pretrained(
tmpdirname,
torch_dtype=torch.float16,
- use_flash_attention_2=True,
+ attn_implementation="flash_attention_2",
low_cpu_mem_usage=True,
load_in_4bit=True,
)
@@ -3269,6 +3661,51 @@ def test_flax_from_pt_safetensors(self):
# Check models are equal
self.assertTrue(check_models_equal(flax_model_1, flax_model_2))
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_from_config(self):
+ for model_class in self.all_generative_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ # TODO: to change it in the future with other relevant auto classes
+ fa2_model = AutoModelForCausalLM.from_config(
+ config, attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
+ dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [0, 1, 1, 1]]).to(torch_device)
+
+ fa2_correctly_converted = False
+
+ for _, module in fa2_model.named_modules():
+ if "FlashAttention" in module.__class__.__name__:
+ fa2_correctly_converted = True
+ break
+
+ self.assertTrue(fa2_correctly_converted)
+
+ _ = fa2_model(input_ids=dummy_input, attention_mask=dummy_attention_mask)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ fa2_model.save_pretrained(tmpdirname)
+
+ model_from_pretrained = AutoModelForCausalLM.from_pretrained(tmpdirname)
+
+ self.assertTrue(model_from_pretrained.config._attn_implementation != "flash_attention_2")
+
+ fa2_correctly_converted = False
+
+ for _, module in model_from_pretrained.named_modules():
+ if "FlashAttention" in module.__class__.__name__:
+ fa2_correctly_converted = True
+ break
+
+ self.assertFalse(fa2_correctly_converted)
+
global_rng = random.Random()
diff --git a/tests/test_modeling_tf_common.py b/tests/test_modeling_tf_common.py
index d7cd62b41a025e..7ac744263cc023 100644
--- a/tests/test_modeling_tf_common.py
+++ b/tests/test_modeling_tf_common.py
@@ -465,7 +465,6 @@ def _postprocessing_to_ignore_test_cases(self, tf_outputs, pt_outputs, model_cla
"TFFunnelForPreTraining",
"TFElectraForPreTraining",
"TFXLMWithLMHeadModel",
- "TFTransfoXLLMHeadModel",
]:
for k in key_differences:
if k in ["loss", "losses"]:
diff --git a/tests/test_modeling_utils.py b/tests/test_modeling_utils.py
index 62a639a95f5695..ddfaad5214dc50 100755
--- a/tests/test_modeling_utils.py
+++ b/tests/test_modeling_utils.py
@@ -21,9 +21,11 @@
import tempfile
import unittest
import unittest.mock as mock
+import uuid
from pathlib import Path
-from huggingface_hub import HfFolder, delete_repo
+import requests
+from huggingface_hub import HfApi, HfFolder, delete_repo
from huggingface_hub.file_download import http_get
from pytest import mark
from requests.exceptions import HTTPError
@@ -58,7 +60,13 @@
WEIGHTS_INDEX_NAME,
WEIGHTS_NAME,
)
-from transformers.utils.import_utils import is_flax_available, is_tf_available, is_torchdynamo_available
+from transformers.utils.import_utils import (
+ is_flash_attn_2_available,
+ is_flax_available,
+ is_tf_available,
+ is_torch_sdpa_available,
+ is_torchdynamo_available,
+)
sys.path.append(str(Path(__file__).parent.parent / "utils"))
@@ -83,7 +91,12 @@
T5Config,
T5ForConditionalGeneration,
)
- from transformers.modeling_attn_mask_utils import AttentionMaskConverter
+ from transformers.modeling_attn_mask_utils import (
+ AttentionMaskConverter,
+ _create_4d_causal_attention_mask,
+ _prepare_4d_attention_mask,
+ _prepare_4d_causal_attention_mask,
+ )
from transformers.modeling_utils import shard_checkpoint
# Fake pretrained models for tests
@@ -148,6 +161,32 @@ def forward(self, x):
def tie_weights(self):
self.decoder.weight = self.base.linear.weight
+ class Prepare4dCausalAttentionMaskModel(nn.Module):
+ def forward(self, inputs_embeds):
+ batch_size, seq_length, _ = inputs_embeds.shape
+ past_key_values_length = 4
+ attention_mask = _prepare_4d_causal_attention_mask(
+ None, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+ return attention_mask
+
+ class Create4dCausalAttentionMaskModel(nn.Module):
+ def forward(self, inputs_embeds):
+ batch_size, seq_length, _ = inputs_embeds.shape
+ past_key_values_length = 4
+ attention_mask = _create_4d_causal_attention_mask(
+ (batch_size, seq_length),
+ dtype=inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+ return attention_mask
+
+ class Prepare4dAttentionMaskModel(nn.Module):
+ def forward(self, mask, inputs_embeds):
+ attention_mask = _prepare_4d_attention_mask(mask, dtype=inputs_embeds.dtype)
+ return attention_mask
+
if is_flax_available():
from transformers import FlaxBertModel
@@ -829,14 +868,8 @@ def test_legacy_load_from_url(self):
@require_safetensors
def test_use_safetensors(self):
- # test nice error message if no safetensor files available
- with self.assertRaises(OSError) as env_error:
- AutoModel.from_pretrained("hf-internal-testing/tiny-random-RobertaModel", use_safetensors=True)
-
- self.assertTrue(
- "model.safetensors or model.safetensors.index.json and thus cannot be loaded with `safetensors`"
- in str(env_error.exception)
- )
+ # Should not raise anymore
+ AutoModel.from_pretrained("hf-internal-testing/tiny-random-RobertaModel", use_safetensors=True)
# test that error if only safetensors is available
with self.assertRaises(OSError) as env_error:
@@ -1171,6 +1204,203 @@ def test_safetensors_torch_from_torch_sharded(self):
self.assertTrue(torch.equal(p1, p2))
+@slow
+@require_torch
+class ModelOnTheFlyConversionTester(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ cls.user = "huggingface-hub-ci"
+ cls.token = os.getenv("HUGGINGFACE_PRODUCTION_USER_TOKEN", None)
+
+ if cls.token is None:
+ raise ValueError("Cannot run tests as secret isn't setup.")
+
+ cls.api = HfApi(token=cls.token)
+
+ def setUp(self) -> None:
+ self.repo_name = f"{self.user}/test-model-on-the-fly-{uuid.uuid4()}"
+
+ def tearDown(self) -> None:
+ self.api.delete_repo(self.repo_name)
+
+ def test_safetensors_on_the_fly_conversion(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False)
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, "SFconvertbot")
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_conversion_private(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False, private=True)
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name, token=self.token)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, self.user)
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_conversion_gated(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False)
+ headers = {"Authorization": f"Bearer {self.token}"}
+ requests.put(
+ f"https://huggingface.co/api/models/{self.repo_name}/settings", json={"gated": "auto"}, headers=headers
+ )
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, "SFconvertbot")
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_sharded_conversion(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False, max_shard_size="200kb")
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, "SFconvertbot")
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_sharded_conversion_private(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(
+ self.repo_name, token=self.token, safe_serialization=False, max_shard_size="200kb", private=True
+ )
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, self.user)
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_sharded_conversion_gated(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, max_shard_size="200kb", safe_serialization=False)
+ headers = {"Authorization": f"Bearer {self.token}"}
+ requests.put(
+ f"https://huggingface.co/api/models/{self.repo_name}/settings", json={"gated": "auto"}, headers=headers
+ )
+ converted_model = BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ with self.subTest("Initial and converted models are equal"):
+ for p1, p2 in zip(initial_model.parameters(), converted_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, "SFconvertbot")
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ @unittest.skip("Edge case, should work once the Space is updated`")
+ def test_safetensors_on_the_fly_wrong_user_opened_pr(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False, private=True)
+ BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ # This should have opened a PR with the user's account
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+ discussion = next(discussions)
+ self.assertEqual(discussion.author, self.user)
+ self.assertEqual(discussion.title, "Adding `safetensors` variant of this model")
+
+ # We now switch the repo visibility to public
+ self.api.update_repo_visibility(self.repo_name, private=False)
+
+ # We once again call from_pretrained, which should call the bot to open a PR
+ BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token)
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+
+ bot_opened_pr = None
+ bot_opened_pr_title = None
+
+ for discussion in discussions:
+ if discussion.author == "SFconvertBot":
+ bot_opened_pr = True
+ bot_opened_pr_title = discussion.title
+
+ self.assertTrue(bot_opened_pr)
+ self.assertEqual(bot_opened_pr_title, "Adding `safetensors` variant of this model")
+
+ def test_safetensors_on_the_fly_specific_revision(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ # Push a model on `main`
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False)
+
+ # Push a model on a given revision
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False, revision="new-branch")
+
+ # Try to convert the model on that revision should raise
+ with self.assertRaises(EnvironmentError):
+ BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token, revision="new-branch")
+
+
@require_torch
@is_staging_test
class ModelPushToHubTester(unittest.TestCase):
@@ -1300,7 +1530,7 @@ def check_to_4d(self, mask_converter, q_len, kv_len, additional_mask=None, bsz=3
for bsz_idx, seq_idx in additional_mask:
mask_2d[bsz_idx, seq_idx] = 0
- mask_4d = mask_converter.to_4d(mask_2d, query_length=q_len, key_value_length=kv_len)
+ mask_4d = mask_converter.to_4d(mask_2d, query_length=q_len, key_value_length=kv_len, dtype=torch.float32)
assert mask_4d.shape == (bsz, 1, q_len, kv_len)
@@ -1336,7 +1566,9 @@ def check_to_4d(self, mask_converter, q_len, kv_len, additional_mask=None, bsz=3
self.check_non_causal(bsz, q_len, kv_len, mask_2d, mask_4d)
def check_to_causal(self, mask_converter, q_len, kv_len, bsz=3):
- mask_4d = mask_converter.to_causal_4d(bsz, query_length=q_len, key_value_length=kv_len, device=torch_device)
+ mask_4d = mask_converter.to_causal_4d(
+ bsz, query_length=q_len, key_value_length=kv_len, device=torch_device, dtype=torch.float32
+ )
if q_len == 1 and mask_converter.sliding_window is None:
# no causal mask if q_len is 1
@@ -1428,3 +1660,193 @@ def test_causal_mask_sliding(self):
self.check_to_causal(mask_converter, q_len=3, kv_len=7)
# non auto-regressive case
self.check_to_causal(mask_converter, q_len=7, kv_len=7)
+
+ def test_torch_compile_fullgraph(self):
+ model = Prepare4dCausalAttentionMaskModel()
+
+ inputs_embeds = torch.rand([1, 3, 32])
+ res_non_compiled = model(inputs_embeds)
+
+ compiled_model = torch.compile(model, fullgraph=True)
+
+ res_compiled = compiled_model(inputs_embeds)
+
+ self.assertTrue(torch.equal(res_non_compiled, res_compiled))
+
+ model = Create4dCausalAttentionMaskModel()
+
+ inputs_embeds = torch.rand(2, 4, 16)
+ res_non_compiled = model(inputs_embeds)
+
+ compiled_model = torch.compile(model, fullgraph=True)
+ res_compiled = compiled_model(inputs_embeds)
+
+ self.assertTrue(torch.equal(res_non_compiled, res_compiled))
+
+ model = Prepare4dAttentionMaskModel()
+
+ mask = torch.ones(2, 4)
+ mask[0, :2] = 0
+ inputs_embeds = torch.rand(2, 4, 16)
+
+ res_non_compiled = model(mask, inputs_embeds)
+
+ compiled_model = torch.compile(model, fullgraph=True)
+ res_compiled = compiled_model(mask, inputs_embeds)
+
+ self.assertTrue(torch.equal(res_non_compiled, res_compiled))
+
+ @require_torch
+ @slow
+ def test_unmask_unattended_left_padding(self):
+ attention_mask = torch.Tensor([[0, 0, 1], [1, 1, 1], [0, 1, 1]]).to(torch.int64)
+
+ expanded_mask = torch.Tensor(
+ [
+ [[[0, 0, 0], [0, 0, 0], [0, 0, 1]]],
+ [[[1, 0, 0], [1, 1, 0], [1, 1, 1]]],
+ [[[0, 0, 0], [0, 1, 0], [0, 1, 1]]],
+ ]
+ ).to(torch.int64)
+
+ reference_output = torch.Tensor(
+ [
+ [[[1, 1, 1], [1, 1, 1], [0, 0, 1]]],
+ [[[1, 0, 0], [1, 1, 0], [1, 1, 1]]],
+ [[[1, 1, 1], [0, 1, 0], [0, 1, 1]]],
+ ]
+ ).to(torch.int64)
+
+ result = AttentionMaskConverter._unmask_unattended(expanded_mask, attention_mask, unmasked_value=1)
+
+ self.assertTrue(torch.equal(result, reference_output))
+
+ attention_mask = torch.Tensor([[0, 0, 1, 1, 1], [1, 1, 1, 1, 1], [0, 1, 1, 1, 1]]).to(torch.int64)
+
+ attn_mask_converter = AttentionMaskConverter(is_causal=True)
+ past_key_values_length = 0
+ key_value_length = attention_mask.shape[-1] + past_key_values_length
+
+ expanded_mask = attn_mask_converter.to_4d(
+ attention_mask, attention_mask.shape[-1], key_value_length=key_value_length, dtype=torch.float32
+ )
+
+ result = AttentionMaskConverter._unmask_unattended(expanded_mask, attention_mask, unmasked_value=0)
+ min_inf = torch.finfo(torch.float32).min
+ reference_output = torch.Tensor(
+ [
+ [
+ [
+ [0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0],
+ [min_inf, min_inf, 0, min_inf, min_inf],
+ [min_inf, min_inf, 0, 0, min_inf],
+ [min_inf, min_inf, 0, 0, 0],
+ ]
+ ],
+ [
+ [
+ [0, min_inf, min_inf, min_inf, min_inf],
+ [0, 0, min_inf, min_inf, min_inf],
+ [0, 0, 0, min_inf, min_inf],
+ [0, 0, 0, 0, min_inf],
+ [0, 0, 0, 0, 0],
+ ]
+ ],
+ [
+ [
+ [0, 0, 0, 0, 0],
+ [min_inf, 0, min_inf, min_inf, min_inf],
+ [min_inf, 0, 0, min_inf, min_inf],
+ [min_inf, 0, 0, 0, min_inf],
+ [min_inf, 0, 0, 0, 0],
+ ]
+ ],
+ ]
+ )
+
+ self.assertTrue(torch.equal(reference_output, result))
+
+ @require_torch
+ @slow
+ def test_unmask_unattended_right_padding(self):
+ attention_mask = torch.Tensor([[1, 1, 1, 0], [1, 1, 1, 1], [1, 1, 0, 0]]).to(torch.int64)
+
+ attn_mask_converter = AttentionMaskConverter(is_causal=True)
+ past_key_values_length = 0
+ key_value_length = attention_mask.shape[-1] + past_key_values_length
+
+ expanded_mask = attn_mask_converter.to_4d(
+ attention_mask, attention_mask.shape[-1], key_value_length=key_value_length, dtype=torch.float32
+ )
+
+ result = AttentionMaskConverter._unmask_unattended(expanded_mask, attention_mask, unmasked_value=0)
+
+ self.assertTrue(torch.equal(expanded_mask, result))
+
+ @require_torch
+ @slow
+ def test_unmask_unattended_random_mask(self):
+ attention_mask = torch.Tensor([[1, 0, 1, 0], [1, 0, 1, 1], [1, 1, 0, 1]]).to(torch.int64)
+
+ attn_mask_converter = AttentionMaskConverter(is_causal=True)
+ past_key_values_length = 0
+ key_value_length = attention_mask.shape[-1] + past_key_values_length
+
+ expanded_mask = attn_mask_converter.to_4d(
+ attention_mask, attention_mask.shape[-1], key_value_length=key_value_length, dtype=torch.float32
+ )
+
+ result = AttentionMaskConverter._unmask_unattended(expanded_mask, attention_mask, unmasked_value=0)
+
+ self.assertTrue(torch.equal(expanded_mask, result))
+
+
+@require_torch
+class TestAttentionImplementation(unittest.TestCase):
+ def test_error_no_sdpa_available(self):
+ with self.assertRaises(ValueError) as cm:
+ _ = AutoModel.from_pretrained("hf-tiny-model-private/tiny-random-MCTCTModel", attn_implementation="sdpa")
+
+ self.assertTrue(
+ "does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention"
+ in str(cm.exception)
+ )
+
+ _ = AutoModel.from_pretrained("hf-tiny-model-private/tiny-random-MCTCTModel")
+
+ def test_error_no_flash_available(self):
+ with self.assertRaises(ValueError) as cm:
+ _ = AutoModel.from_pretrained(
+ "hf-tiny-model-private/tiny-random-MCTCTModel", attn_implementation="flash_attention_2"
+ )
+
+ self.assertTrue("does not support Flash Attention 2.0" in str(cm.exception))
+
+ def test_error_wrong_attn_implementation(self):
+ with self.assertRaises(ValueError) as cm:
+ _ = AutoModel.from_pretrained("hf-tiny-model-private/tiny-random-MCTCTModel", attn_implementation="foo")
+
+ self.assertTrue('The only possible arguments are `attn_implementation="eager"' in str(cm.exception))
+
+ def test_not_available_flash(self):
+ if is_flash_attn_2_available():
+ self.skipTest("Please uninstall flash-attn package to run test_not_available_flash")
+
+ with self.assertRaises(ImportError) as cm:
+ _ = AutoModel.from_pretrained(
+ "hf-internal-testing/tiny-random-GPTBigCodeModel", attn_implementation="flash_attention_2"
+ )
+
+ self.assertTrue("the package flash_attn seems to be not installed" in str(cm.exception))
+
+ def test_not_available_sdpa(self):
+ if is_torch_sdpa_available():
+ self.skipTest("This test requires torch<=2.0")
+
+ with self.assertRaises(ImportError) as cm:
+ _ = AutoModel.from_pretrained(
+ "hf-internal-testing/tiny-random-GPTBigCodeModel", attn_implementation="sdpa"
+ )
+
+ self.assertTrue("PyTorch SDPA requirements in Transformers are not met" in str(cm.exception))
diff --git a/tests/trainer/test_trainer.py b/tests/trainer/test_trainer.py
index b9f801fabd7f1e..05f84bc00fa2af 100644
--- a/tests/trainer/test_trainer.py
+++ b/tests/trainer/test_trainer.py
@@ -38,7 +38,9 @@
AutoTokenizer,
IntervalStrategy,
PretrainedConfig,
+ TrainerCallback,
TrainingArguments,
+ get_polynomial_decay_schedule_with_warmup,
is_torch_available,
logging,
)
@@ -78,7 +80,8 @@
slow,
torch_device,
)
-from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR, HPSearchBackend
+from transformers.tokenization_utils_base import PreTrainedTokenizerBase
+from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR, HPSearchBackend, get_last_checkpoint
from transformers.training_args import OptimizerNames
from transformers.utils import (
SAFE_WEIGHTS_INDEX_NAME,
@@ -643,6 +646,33 @@ def test_custom_optimizer(self):
self.assertFalse(torch.allclose(trainer.model.b, b))
self.assertEqual(trainer.optimizer.state_dict()["param_groups"][0]["lr"], 1.0)
+ def test_lr_scheduler_kwargs(self):
+ # test scheduler kwargs passed via TrainingArguments
+ train_dataset = RegressionDataset()
+ model = RegressionModel()
+ num_steps, num_warmup_steps = 10, 2
+ extra_kwargs = {"power": 5.0, "lr_end": 1e-5} # Non-default arguments
+ args = TrainingArguments(
+ "./regression",
+ lr_scheduler_type="polynomial",
+ lr_scheduler_kwargs=extra_kwargs,
+ learning_rate=0.2,
+ warmup_steps=num_warmup_steps,
+ )
+ trainer = Trainer(model, args, train_dataset=train_dataset)
+ trainer.create_optimizer_and_scheduler(num_training_steps=num_steps)
+
+ # Checking that the scheduler was created
+ self.assertIsNotNone(trainer.lr_scheduler)
+
+ # Checking that the correct args were passed
+ sched1 = trainer.lr_scheduler
+ sched2 = get_polynomial_decay_schedule_with_warmup(
+ trainer.optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_steps, **extra_kwargs
+ )
+ self.assertEqual(sched1.lr_lambdas[0].args, sched2.lr_lambdas[0].args)
+ self.assertEqual(sched1.lr_lambdas[0].keywords, sched2.lr_lambdas[0].keywords)
+
def test_reduce_lr_on_plateau_args(self):
# test passed arguments for a custom ReduceLROnPlateau scheduler
train_dataset = RegressionDataset(length=64)
@@ -672,7 +702,7 @@ class TrainerWithLRLogs(Trainer):
def log(self, logs):
# the LR is computed after metrics and does not exist for the first epoch
if hasattr(self.lr_scheduler, "_last_lr"):
- logs["learning_rate"] = self.lr_scheduler._last_lr
+ logs["learning_rate"] = self.lr_scheduler._last_lr[0]
super().log(logs)
train_dataset = RegressionDataset(length=64)
@@ -702,14 +732,14 @@ def log(self, logs):
if loss > best_loss:
bad_epochs += 1
if bad_epochs > patience:
- self.assertLess(logs[i + 1]["learning_rate"][0], log["learning_rate"][0])
+ self.assertLess(logs[i + 1]["learning_rate"], log["learning_rate"])
just_decreased = True
bad_epochs = 0
else:
best_loss = loss
bad_epochs = 0
if not just_decreased:
- self.assertEqual(logs[i + 1]["learning_rate"][0], log["learning_rate"][0])
+ self.assertEqual(logs[i + 1]["learning_rate"], log["learning_rate"])
def test_adafactor_lr_none(self):
# test the special case where lr=None, since Trainer can't not have lr_scheduler
@@ -1282,6 +1312,19 @@ def test_save_checkpoints(self):
trainer.train()
self.check_saved_checkpoints(tmpdir, 5, int(self.n_epochs * 64 / self.batch_size), False)
+ def test_save_checkpoints_is_atomic(self):
+ class UnsaveableTokenizer(PreTrainedTokenizerBase):
+ def save_pretrained(self, *args, **kwargs):
+ raise OSError("simulated file write error")
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ trainer = get_regression_trainer(output_dir=tmpdir, save_steps=5)
+ # Attach unsaveable tokenizer to partially fail checkpointing
+ trainer.tokenizer = UnsaveableTokenizer()
+ with self.assertRaises(OSError) as _context:
+ trainer.train()
+ assert get_last_checkpoint(tmpdir) is None
+
@require_safetensors
def test_safe_checkpoints(self):
for save_safetensors in [True, False]:
@@ -1504,6 +1547,41 @@ def test_auto_batch_size_finder(self):
with patch.object(sys, "argv", testargs):
run_glue.main()
+ def test_auto_batch_size_with_resume_from_checkpoint(self):
+ train_dataset = RegressionDataset(length=128)
+
+ config = RegressionModelConfig(a=0, b=2)
+ model = RegressionRandomPreTrainedModel(config)
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+
+ class MockCudaOOMCallback(TrainerCallback):
+ def on_step_end(self, args, state, control, **kwargs):
+ # simulate OOM on the first step
+ if state.train_batch_size >= 16:
+ raise RuntimeError("CUDA out of memory.")
+
+ args = RegressionTrainingArguments(
+ tmp_dir,
+ do_train=True,
+ max_steps=2,
+ save_steps=1,
+ per_device_train_batch_size=16,
+ auto_find_batch_size=True,
+ )
+ trainer = Trainer(model, args, train_dataset=train_dataset, callbacks=[MockCudaOOMCallback()])
+ trainer.train()
+ # After `auto_find_batch_size` is ran we should now be at 8
+ self.assertEqual(trainer._train_batch_size, 8)
+
+ # We can then make a new Trainer
+ trainer = Trainer(model, args, train_dataset=train_dataset)
+ # Check we are at 16 to start
+ self.assertEqual(trainer._train_batch_size, 16 * max(trainer.args.n_gpu, 1))
+ trainer.train(resume_from_checkpoint=True)
+ # We should be back to 8 again, picking up based upon the last ran Trainer
+ self.assertEqual(trainer._train_batch_size, 8)
+
# regression for this issue: https://github.com/huggingface/transformers/issues/12970
def test_training_with_resume_from_checkpoint_false(self):
train_dataset = RegressionDataset(length=128)
diff --git a/tests/utils/test_doc_samples.py b/tests/utils/test_doc_samples.py
index 84c5a4d2bf5008..953654537843ee 100644
--- a/tests/utils/test_doc_samples.py
+++ b/tests/utils/test_doc_samples.py
@@ -12,11 +12,11 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-
import doctest
import logging
import os
import unittest
+from glob import glob
from pathlib import Path
from typing import List, Union
@@ -27,6 +27,63 @@
logger = logging.getLogger()
+@require_torch
+class TestDocLists(unittest.TestCase):
+ def test_flash_support_list(self):
+ with open("./docs/source/en/perf_infer_gpu_one.md", "r") as f:
+ doctext = f.read()
+
+ doctext = doctext.split("FlashAttention-2 is currently supported for the following architectures:")[1]
+ doctext = doctext.split("You can request to add FlashAttention-2 support")[0]
+
+ patterns = glob("./src/transformers/models/**/modeling_*.py")
+ patterns_tf = glob("./src/transformers/models/**/modeling_tf_*.py")
+ patterns_flax = glob("./src/transformers/models/**/modeling_flax_*.py")
+ patterns = list(set(patterns) - set(patterns_tf) - set(patterns_flax))
+ archs_supporting_fa2 = []
+ for filename in patterns:
+ with open(filename, "r") as f:
+ text = f.read()
+
+ if "_supports_flash_attn_2 = True" in text:
+ model_name = os.path.basename(filename).replace(".py", "").replace("modeling_", "")
+ archs_supporting_fa2.append(model_name)
+
+ for arch in archs_supporting_fa2:
+ if arch not in doctext:
+ raise ValueError(
+ f"{arch} should be in listed in the flash attention documentation but is not. Please update the documentation."
+ )
+
+ def test_sdpa_support_list(self):
+ with open("./docs/source/en/perf_infer_gpu_one.md", "r") as f:
+ doctext = f.read()
+
+ doctext = doctext.split(
+ "For now, Transformers supports inference and training through SDPA for the following architectures:"
+ )[1]
+ doctext = doctext.split("Note that FlashAttention can only be used for models using the")[0]
+
+ patterns = glob("./src/transformers/models/**/modeling_*.py")
+ patterns_tf = glob("./src/transformers/models/**/modeling_tf_*.py")
+ patterns_flax = glob("./src/transformers/models/**/modeling_flax_*.py")
+ patterns = list(set(patterns) - set(patterns_tf) - set(patterns_flax))
+ archs_supporting_sdpa = []
+ for filename in patterns:
+ with open(filename, "r") as f:
+ text = f.read()
+
+ if "_supports_sdpa = True" in text:
+ model_name = os.path.basename(filename).replace(".py", "").replace("modeling_", "")
+ archs_supporting_sdpa.append(model_name)
+
+ for arch in archs_supporting_sdpa:
+ if arch not in doctext:
+ raise ValueError(
+ f"{arch} should be in listed in the SDPA documentation but is not. Please update the documentation."
+ )
+
+
@unittest.skip("Temporarily disable the doc tests.")
@require_torch
@require_tf
diff --git a/tests/utils/tiny_model_summary.json b/tests/utils/tiny_model_summary.json
index 2a1efa7d88d283..5f2c6c0b4e7438 100644
--- a/tests/utils/tiny_model_summary.json
+++ b/tests/utils/tiny_model_summary.json
@@ -877,6 +877,16 @@
],
"sha": "a7874595b900f9b2ddc79130dafc3ff48f4fbfb9"
},
+ "ClvpModelForConditionalGeneration": {
+ "tokenizer_classes": [
+ "ClvpTokenizer"
+ ],
+ "processor_classes": [
+ "ClvpFeatureExtractor"
+ ],
+ "model_classes": [],
+ "sha": "45df7581535be337ff781707b6c20994ca221f05"
+ },
"CodeGenForCausalLM": {
"tokenizer_classes": [
"CodeGenTokenizer",
@@ -1039,7 +1049,8 @@
"ConvNextImageProcessor"
],
"model_classes": [
- "ConvNextV2ForImageClassification"
+ "ConvNextV2ForImageClassification",
+ "TFConvNextV2ForImageClassification"
],
"sha": "ee22bae1cbb87d66fc7f62f7e15a43d6ff80d3cc"
},
@@ -1049,7 +1060,8 @@
"ConvNextImageProcessor"
],
"model_classes": [
- "ConvNextV2Model"
+ "ConvNextV2Model",
+ "TFConvNextV2Model"
],
"sha": "c4dd68ee1102cba05bcc483da2a88e39427b7249"
},
@@ -2136,6 +2148,56 @@
],
"sha": "683f6f73a2ab87801f1695a72d1af63cf173ab7c"
},
+ "FalconForCausalLM": {
+ "tokenizer_classes": [
+ "PreTrainedTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "FalconForCausalLM"
+ ],
+ "sha": "60076d5dafc5e33ba9c90dcd05e7c0834e44049a"
+ },
+ "FalconForQuestionAnswering": {
+ "tokenizer_classes": [
+ "PreTrainedTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "FalconForQuestionAnswering"
+ ],
+ "sha": "b1ee9cd5fad2d177ea5a46df4611cd02f66ae788"
+ },
+ "FalconForSequenceClassification": {
+ "tokenizer_classes": [
+ "PreTrainedTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "FalconForSequenceClassification"
+ ],
+ "sha": "007838c0991c2b6a87dc49a8a5c20f29149a00fa"
+ },
+ "FalconForTokenClassification": {
+ "tokenizer_classes": [
+ "PreTrainedTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "FalconForTokenClassification"
+ ],
+ "sha": "0ea6ae548773daa6e3317fddc058957e956eebf4"
+ },
+ "FalconModel": {
+ "tokenizer_classes": [
+ "PreTrainedTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "FalconModel"
+ ],
+ "sha": "ca15a579c946eb00c5b39cc8e0ea63d0c1460f84"
+ },
"FlaubertForMultipleChoice": {
"tokenizer_classes": [
"FlaubertTokenizer"
@@ -2364,6 +2426,18 @@
],
"sha": "bfbaa8fa21c3abf80b94e7168b5ecff8ec5b5f76"
},
+ "FuyuForCausalLM": {
+ "tokenizer_classes": [
+ "LlamaTokenizerFast"
+ ],
+ "processor_classes": [
+ "FuyuImageProcessor"
+ ],
+ "model_classes": [
+ "FuyuForCausalLM"
+ ],
+ "sha": "685d78258ea95c5c82e0e4555d0d4a2270ab8bff"
+ },
"GLPNForDepthEstimation": {
"tokenizer_classes": [],
"processor_classes": [
@@ -2866,6 +2940,30 @@
],
"sha": "5a7983e48d5841704733dd0756177680ed50c074"
},
+ "Kosmos2ForConditionalGeneration": {
+ "tokenizer_classes": [
+ "XLMRobertaTokenizerFast"
+ ],
+ "processor_classes": [
+ "CLIPImageProcessor"
+ ],
+ "model_classes": [
+ "Kosmos2ForConditionalGeneration"
+ ],
+ "sha": "d1d4607782b911411676f1ee79997dee645def58"
+ },
+ "Kosmos2Model": {
+ "tokenizer_classes": [
+ "XLMRobertaTokenizerFast"
+ ],
+ "processor_classes": [
+ "CLIPImageProcessor"
+ ],
+ "model_classes": [
+ "Kosmos2Model"
+ ],
+ "sha": "379d8944a65312094d9ab1c4b8a82058a2d3274e"
+ },
"LEDForConditionalGeneration": {
"tokenizer_classes": [
"LEDTokenizer",
@@ -3820,6 +3918,39 @@
],
"sha": "f197d5bfa1fe27b5f28a6e6d4e3ad229b753450a"
},
+ "MistralForCausalLM": {
+ "tokenizer_classes": [
+ "LlamaTokenizer",
+ "LlamaTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "MistralForCausalLM"
+ ],
+ "sha": "f7e06aeedbba8f4f665b438b868ed932d451f64b"
+ },
+ "MistralForSequenceClassification": {
+ "tokenizer_classes": [
+ "LlamaTokenizer",
+ "LlamaTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "MistralForSequenceClassification"
+ ],
+ "sha": "65045444ea1933309270d8b08b21d3fa94a84290"
+ },
+ "MistralModel": {
+ "tokenizer_classes": [
+ "LlamaTokenizer",
+ "LlamaTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "MistralModel"
+ ],
+ "sha": "becd727ad72b1e8a7c0fa0ea39b61904fa68aeac"
+ },
"MobileBertForMaskedLM": {
"tokenizer_classes": [
"MobileBertTokenizer",
@@ -4558,6 +4689,32 @@
],
"sha": "f0e27b2b4e53ba70e05d13dcfea8e85272b292a5"
},
+ "Owlv2ForObjectDetection": {
+ "tokenizer_classes": [
+ "CLIPTokenizer",
+ "CLIPTokenizerFast"
+ ],
+ "processor_classes": [
+ "Owlv2ImageProcessor"
+ ],
+ "model_classes": [
+ "Owlv2ForObjectDetection"
+ ],
+ "sha": "30439c0b2749726468dc13a755261e8101170052"
+ },
+ "Owlv2Model": {
+ "tokenizer_classes": [
+ "CLIPTokenizer",
+ "CLIPTokenizerFast"
+ ],
+ "processor_classes": [
+ "Owlv2ImageProcessor"
+ ],
+ "model_classes": [
+ "Owlv2Model"
+ ],
+ "sha": "7aeebdad5f72b36cb07c74355afad8e6052e2377"
+ },
"PLBartForCausalLM": {
"tokenizer_classes": [
"PLBartTokenizer"
@@ -4760,6 +4917,50 @@
],
"sha": "b8c8d479e29e9ee048e2d0b05b001ac835ad8859"
},
+ "PhiForCausalLM": {
+ "tokenizer_classes": [
+ "CodeGenTokenizer",
+ "CodeGenTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "PhiForCausalLM"
+ ],
+ "sha": "3fecc0109a4a3a230e3a5509eaf47a26eba85d79"
+ },
+ "PhiForSequenceClassification": {
+ "tokenizer_classes": [
+ "CodeGenTokenizer",
+ "CodeGenTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "PhiForSequenceClassification"
+ ],
+ "sha": "e1c9f8ebf1317516acc1cd6338de71a53e770245"
+ },
+ "PhiForTokenClassification": {
+ "tokenizer_classes": [
+ "CodeGenTokenizer",
+ "CodeGenTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "PhiForTokenClassification"
+ ],
+ "sha": "d3a8054903753b5c96c05eaf9877905a116a1d5e"
+ },
+ "PhiModel": {
+ "tokenizer_classes": [
+ "CodeGenTokenizer",
+ "CodeGenTokenizerFast"
+ ],
+ "processor_classes": [],
+ "model_classes": [
+ "PhiModel"
+ ],
+ "sha": "99c38d5ce7ace35127d00ed3eeb3561308ea6b21"
+ },
"Pix2StructForConditionalGeneration": {
"tokenizer_classes": [
"T5TokenizerFast"
@@ -4768,7 +4969,9 @@
"Pix2StructImageProcessor",
"Pix2StructProcessor"
],
- "model_classes": [],
+ "model_classes": [
+ "Pix2StructForConditionalGeneration"
+ ],
"sha": "42b3de00ad535076c4893e4ac5ae2d2748cc4ccb"
},
"PoolFormerForImageClassification": {
@@ -5691,6 +5894,16 @@
],
"sha": "25ba2d88c770533f8c69811d2a454a00c1d09f5d"
},
+ "Swin2SRForImageSuperResolution": {
+ "tokenizer_classes": [],
+ "processor_classes": [
+ "Swin2SRImageProcessor"
+ ],
+ "model_classes": [
+ "Swin2SRForImageSuperResolution"
+ ],
+ "sha": "3a2780de0b455084c018ac8a62b56040969e26ec"
+ },
"Swin2SRModel": {
"tokenizer_classes": [],
"processor_classes": [
@@ -6625,6 +6838,18 @@
],
"sha": "d71b13674b1a67443cd19d0594a3b5b1e5968f0d"
},
+ "WhisperForCausalLM": {
+ "tokenizer_classes": [
+ "WhisperTokenizer"
+ ],
+ "processor_classes": [
+ "WhisperFeatureExtractor"
+ ],
+ "model_classes": [
+ "WhisperForCausalLM"
+ ],
+ "sha": "e7febfd7f4512e029293c677e6d2633e23fc459a"
+ },
"WhisperForConditionalGeneration": {
"tokenizer_classes": [
"WhisperTokenizer",
diff --git a/utils/check_config_attributes.py b/utils/check_config_attributes.py
index 7a116d5af3178b..e1682fb07589ba 100644
--- a/utils/check_config_attributes.py
+++ b/utils/check_config_attributes.py
@@ -96,6 +96,21 @@
"t2u_encoder_layers",
"t2u_max_position_embeddings",
],
+ # Actually used in the config or generation config, in that case necessary for the sub-components generation
+ "SeamlessM4Tv2Config": [
+ "max_new_tokens",
+ "t2u_decoder_attention_heads",
+ "t2u_decoder_ffn_dim",
+ "t2u_decoder_layers",
+ "t2u_encoder_attention_heads",
+ "t2u_encoder_ffn_dim",
+ "t2u_encoder_layers",
+ "t2u_max_position_embeddings",
+ "t2u_variance_pred_dropout",
+ "t2u_variance_predictor_embed_dim",
+ "t2u_variance_predictor_hidden_dim",
+ "t2u_variance_predictor_kernel_size",
+ ],
}
@@ -127,7 +142,6 @@
"SwitchTransformersConfig": True,
"TableTransformerConfig": True,
"TapasConfig": True,
- "TransfoXLConfig": True,
"UniSpeechConfig": True,
"UniSpeechSatConfig": True,
"WavLMConfig": True,
diff --git a/utils/check_copies.py b/utils/check_copies.py
index c536eb800ff084..3d352cc8310e4f 100644
--- a/utils/check_copies.py
+++ b/utils/check_copies.py
@@ -41,7 +41,8 @@
import os
import re
import subprocess
-from typing import List, Optional, Tuple
+from collections import OrderedDict
+from typing import List, Optional, Tuple, Union
from transformers.utils import direct_transformers_import
@@ -125,13 +126,213 @@
transformers_module = direct_transformers_import(TRANSFORMERS_PATH)
+def _is_definition_header_ending_line(line: str) -> bool:
+ # Helper function. Returns `True` if `line` is the end parenthesis of a class/function definition
+ return re.search(r"^\s*\)(\s*->.*:|:)\s*$", line) is not None
+
+
def _should_continue(line: str, indent: str) -> bool:
# Helper function. Returns `True` if `line` is empty, starts with the `indent` or is the end parenthesis of a
- # function definition
- return line.startswith(indent) or len(line.strip()) == 0 or re.search(r"^\s*\)(\s*->.*:|:)\s*$", line) is not None
+ # class/function definition
+ return line.startswith(indent) or len(line.strip()) == 0 or _is_definition_header_ending_line(line)
+
+
+def _sanity_check_splits(splits_1, splits_2, is_class):
+ """Check the two (inner) block structures of the corresponding code block given by `split_code_into_blocks` match.
+
+ For the case of `class`, they must be of one of the following 3 cases:
+
+ - a single block without name:
+
+ class foo:
+ a = 1
+
+ - a consecutive sequence of (1 or more) blocks with name
+
+ class foo:
+
+ def f(x):
+ return x
+
+ - a block without name, followed by a consecutive sequence of (1 or more) blocks with name
+
+ class foo:
+ a = 1
+
+ def f(x):
+ return x
+
+ def g(x):
+ return None
+
+ The 2 code snippets that give `splits_1` and `splits_2` have to be in the same case to pass this check, but the
+ number of blocks with name in the consecutive sequence is not taken into account.
+
+ For the case of `function or method`, we don't require it to be in one of the above 3 cases. However, the structure
+ of`splits_1` and `splits_2` have to match exactly. In particular, the number of blocks with name in a consecutive
+ sequence is taken into account.
+ """
+ block_names_1 = []
+ block_names_2 = []
+
+ for block in splits_1[1:]:
+ if block[0].startswith("_block_without_name_"):
+ block_names_1.append("block_without_name")
+ elif not block[0].startswith("_empty_block_") and (
+ not is_class or len(block_names_1) == 0 or block_names_1[-1].startswith("block_without_name")
+ ):
+ block_names_1.append("block_with_name")
+
+ for block in splits_2[1:]:
+ if block[0].startswith("_block_without_name_"):
+ block_names_2.append("block_without_name")
+ elif not block[0].startswith("_empty_block_") and (
+ not is_class or len(block_names_2) == 0 or block_names_2[-1].startswith("block_without_name")
+ ):
+ block_names_2.append("block_with_name")
+
+ if is_class:
+ if block_names_1 not in [
+ ["block_without_name"],
+ ["block_with_name"],
+ ["block_without_name", "block_with_name"],
+ ]:
+ raise ValueError(
+ "For a class, it must have a specific structure. See the docstring of `_sanity_check_splits` in the file `utils/check_copies.py`"
+ )
+
+ if block_names_1 != block_names_2:
+ raise ValueError("The structures in the 2 code blocks differ.")
+
+
+def find_block_end(lines: List[str], start_index: int, indent: int) -> int:
+ """
+ Find the end of the class/func block starting at `start_index` in a source code (defined by `lines`).
+
+ Args:
+ lines (`List[str]`):
+ The source code, represented by a list of lines.
+ start_index (`int`):
+ The starting index of the target class/func block.
+ indent (`int`):
+ The indent of the class/func body.
+
+ Returns:
+ `int`: The index of the block's ending line plus by 1 (i.e. exclusive).
+ """
+ indent = " " * indent
+ # enter the block body
+ line_index = start_index + 1
+
+ while line_index < len(lines) and _should_continue(lines[line_index], indent):
+ line_index += 1
+ # Clean up empty lines at the end (if any).
+ while len(lines[line_index - 1]) <= 1:
+ line_index -= 1
+
+ return line_index
+
+
+def split_code_into_blocks(
+ lines: List[str], start_index: int, end_index: int, indent: int, backtrace: bool = False
+) -> List[Tuple[str, int, int]]:
+ """
+ Split the class/func block starting at `start_index` in a source code (defined by `lines`) into *inner blocks*.
+
+ The block's header is included as the first element. The contiguous regions (without empty lines) that are not
+ inside any inner block are included as blocks. The contiguous regions of empty lines that are not inside any inner
+ block are also included as (dummy) blocks.
+ Args:
+ lines (`List[str]`):
+ The source code, represented by a list of lines.
+ start_index (`int`):
+ The starting index of the target class/func block.
+ end_index (`int`):
+ The ending index of the target class/func block.
+ indent (`int`):
+ The indent of the class/func body.
+ backtrace (`bool`, *optional*, defaults to `False`):
+ Whether or not to include the lines before the inner class/func block's header (e.g. comments, decorators,
+ etc.) until an empty line is encountered.
-def find_code_in_transformers(object_name: str, base_path: str = None) -> str:
+ Returns:
+ `List[Tuple[str, int, int]]`: A list of elements with the form `(block_name, start_index, end_index)`.
+ """
+ splits = []
+ # `indent - 4` is the indent level of the target class/func header
+ target_block_name = re.search(rf"^{' ' * (indent - 4)}((class|def)\s+\S+)(\(|\:)", lines[start_index]).groups()[0]
+
+ # from now on, the `block` means inner blocks unless explicitly specified
+ indent_str = " " * indent
+ block_without_name_idx = 0
+ empty_block_idx = 0
+
+ # Find the lines for the definition header
+ index = start_index
+ if "(" in lines[start_index] and "):" not in lines[start_index] in lines[start_index]:
+ while index < end_index:
+ if _is_definition_header_ending_line(lines[index]):
+ break
+ index += 1
+
+ # the first line outside the definition header
+ index += 1
+ splits.append((target_block_name, start_index, index))
+
+ block_start_index, prev_block_end_index = index, index
+ while index < end_index:
+ # if found, it will be an inner block
+ block_found = re.search(rf"^{indent_str}((class|def)\s+\S+)(\(|\:)", lines[index])
+ if block_found:
+ name = block_found.groups()[0]
+
+ block_end_index = find_block_end(lines, index, indent + 4)
+
+ # backtrace to include the lines before the found block's definition header (e.g. comments, decorators,
+ # etc.) until an empty line is encountered.
+ block_start_index = index
+ if index > prev_block_end_index and backtrace:
+ idx = index - 1
+ for idx in range(index - 1, prev_block_end_index - 2, -1):
+ if not (len(lines[idx].strip()) > 0 and lines[idx].startswith(indent_str)):
+ break
+ idx += 1
+ if idx < index:
+ block_start_index = idx
+
+ # between the current found block and the previous found block
+ if block_start_index > prev_block_end_index:
+ # give it a dummy name
+ if len("".join(lines[prev_block_end_index:block_start_index]).strip()) == 0:
+ prev_block_name = f"_empty_block_{empty_block_idx}"
+ empty_block_idx += 1
+ else:
+ prev_block_name = f"_block_without_name_{block_without_name_idx}"
+ block_without_name_idx += 1
+ # Add it as a block
+ splits.append((prev_block_name, prev_block_end_index, block_start_index))
+
+ # Add the current found block
+ splits.append((name, block_start_index, block_end_index))
+ prev_block_end_index = block_end_index
+ index = block_end_index - 1
+
+ index += 1
+
+ if index > prev_block_end_index:
+ if len("".join(lines[prev_block_end_index:index]).strip()) == 0:
+ prev_block_name = f"_empty_block_{empty_block_idx}"
+ else:
+ prev_block_name = f"_block_without_name_{block_without_name_idx}"
+ splits.append((prev_block_name, prev_block_end_index, index))
+
+ return splits
+
+
+def find_code_in_transformers(
+ object_name: str, base_path: str = None, return_indices: bool = False
+) -> Union[str, Tuple[List[str], int, int]]:
"""
Find and return the source code of an object.
@@ -140,9 +341,15 @@ def find_code_in_transformers(object_name: str, base_path: str = None) -> str:
The name of the object we want the source code of.
base_path (`str`, *optional*):
The path to the base folder where files are checked. If not set, it will be set to `TRANSFORMERS_PATH`.
+ return_indices(`bool`, *optional*, defaults to `False`):
+ If `False`, will only return the code (as a string), otherwise it will also return the whole lines of the
+ file where the object specified by `object_name` is defined, together the start/end indices of the block in
+ the file that defines the object.
Returns:
- `str`: The source code of the object.
+ `Union[str, Tuple[List[str], int, int]]`: If `return_indices=False`, only the source code of the object will be
+ returned. Otherwise, it also returns the whole lines of the file where the object specified by `object_name` is
+ defined, together the start/end indices of the block in the file that defines the object.
"""
parts = object_name.split(".")
i = 0
@@ -181,22 +388,91 @@ def find_code_in_transformers(object_name: str, base_path: str = None) -> str:
line_index < len(lines) and re.search(rf"^{indent}(class|def)\s+{name}(\(|\:)", lines[line_index]) is None
):
line_index += 1
+ # find the target specified in the current level in `parts` -> increase `indent` so we can search the next
indent += " "
+ # the index of the first line in the (currently found) block *body*
line_index += 1
if line_index >= len(lines):
raise ValueError(f" {object_name} does not match any function or class in {module}.")
+ # `indent` is already one level deeper than the (found) class/func block's definition header
+
# We found the beginning of the class / func, now let's find the end (when the indent diminishes).
+ # `start_index` is the index of the class/func block's definition header
start_index = line_index - 1
- while line_index < len(lines) and _should_continue(lines[line_index], indent):
- line_index += 1
- # Clean up empty lines at the end (if any).
- while len(lines[line_index - 1]) <= 1:
- line_index -= 1
+ end_index = find_block_end(lines, start_index, len(indent))
+
+ code = "".join(lines[start_index:end_index])
+ return (code, (lines, start_index, end_index)) if return_indices else code
+
+
+def replace_code(code: str, replace_pattern: str) -> str:
+ """Replace `code` by a pattern of the form `with X1->X2,Y1->Y2,Z1->Z2`.
+
+ Args:
+ code (`str`): The code to be modified.
+ replace_pattern (`str`): The pattern used to modify `code`.
+
+ Returns:
+ `str`: The modified code.
+ """
+ if len(replace_pattern) > 0:
+ patterns = replace_pattern.replace("with", "").split(",")
+ patterns = [_re_replace_pattern.search(p) for p in patterns]
+ for pattern in patterns:
+ if pattern is None:
+ continue
+ obj1, obj2, option = pattern.groups()
+ code = re.sub(obj1, obj2, code)
+ if option.strip() == "all-casing":
+ code = re.sub(obj1.lower(), obj2.lower(), code)
+ code = re.sub(obj1.upper(), obj2.upper(), code)
+
+ return code
+
- code_lines = lines[start_index:line_index]
- return "".join(code_lines)
+def find_code_and_splits(object_name: str, base_path: str, buffer: dict = None):
+ """Find the code of an object (specified by `object_name`) and split it into blocks.
+
+ Args:
+ object_name (`str`):
+ The name of the object, e.g. `transformers.models.bert.modeling_bert.BertAttention` or
+ `tests.models.llama.test_modeling_llama.LlamaModelTest.test_config`.
+ base_path (`str`):
+ The path to the base directory within which the search will be performed. It could be either
+ `TRANSFORMERS_PATH` or `MODEL_TEST_PATH`.
+ buffer (`dict`, *optional*):
+ The buffer used to store the previous results in order to speed up the process.
+
+ Returns:
+ lines (`List[str]`):
+ The lines of the whole file where the object is defined.
+ code (`str`):
+ The object's code.
+ code_splits (`List[Tuple[str, int, int]]`):
+ `code` splitted into blocks. See `split_code_into_blocks`.
+ """
+ if buffer is None:
+ buffer = {}
+
+ if (object_name, base_path) in buffer:
+ lines, code, code_splits = buffer[(object_name, base_path)]
+ else:
+ code, (lines, target_start_index, target_end_index) = find_code_in_transformers(
+ object_name, base_path=base_path, return_indices=True
+ )
+ indent = get_indent(code)
+
+ # Split the code into blocks
+ # `indent` is the indent of the class/func definition header, but `code_splits` expects the indent level of the
+ # block body.
+ code_splits = split_code_into_blocks(
+ lines, target_start_index, target_end_index, len(indent) + 4, backtrace=True
+ )
+ buffer[(object_name, base_path)] = lines, code, code_splits
+
+ return lines, code, code_splits
_re_copy_warning = re.compile(r"^(\s*)#\s*Copied from\s+transformers\.(\S+\.\S+)\s*($|\S.*$)")
@@ -285,7 +561,7 @@ def check_codes_match(observed_code: str, theoretical_code: str) -> Optional[int
diff_index += 1
-def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[Tuple[str, int]]]:
+def is_copy_consistent(filename: str, overwrite: bool = False, buffer: dict = None) -> Optional[List[Tuple[str, int]]]:
"""
Check if the code commented as a copy in a file matches the original.
@@ -294,11 +570,15 @@ def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[
The name of the file to check.
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
+ buffer (`dict`, *optional*):
+ The buffer used to store the previous results in order to speed up the process.
Returns:
`Optional[List[Tuple[str, int]]]`: If `overwrite=False`, returns the list of differences as tuples `(str, int)`
with the name of the object having a diff and the line number where theere is the first diff.
"""
+ base_path = TRANSFORMERS_PATH if not filename.startswith("tests") else MODEL_TEST_PATH
+
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
diffs = []
@@ -317,16 +597,31 @@ def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[
# There is some copied code here, let's retrieve the original.
indent, object_name, replace_pattern = search.groups()
- base_path = TRANSFORMERS_PATH if not filename.startswith("tests") else MODEL_TEST_PATH
- theoretical_code = find_code_in_transformers(object_name, base_path=base_path)
+ # Find the file lines, the object's code, and its blocks
+ target_lines, theoretical_code, theoretical_code_splits = find_code_and_splits(
+ object_name, base_path, buffer=buffer
+ )
+
+ # code replaced by the patterns
+ theoretical_code_blocks = OrderedDict()
+ for name, start, end in theoretical_code_splits:
+ name = replace_code(name, replace_pattern)
+ code = "".join(target_lines[start:end])
+ code = replace_code(code, replace_pattern)
+ theoretical_code_blocks[name] = code
+
theoretical_indent = get_indent(theoretical_code)
+ # `start_index` is the index of the first line (the definition header) after `# Copied from`.
+ # (`indent != theoretical_indent` doesn't seem to occur so far, not sure what this case is for.)
start_index = line_index + 1 if indent == theoretical_indent else line_index
+ # enter the block body
line_index = start_index + 1
subcode = "\n".join(theoretical_code.split("\n")[1:])
indent = get_indent(subcode)
# Loop to check the observed code, stop when indentation diminishes or if we see a End copy comment.
+ # We can't call `find_block_end` directly as there is sth. special `# End copy"` here.
should_continue = True
while line_index < len(lines) and should_continue:
line_index += 1
@@ -336,33 +631,118 @@ def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[
# There is a special pattern `# End copy` to stop early. It's not documented cause it shouldn't really be
# used.
should_continue = _should_continue(line, indent) and re.search(f"^{indent}# End copy", line) is None
+ # `line_index` is outside the block
# Clean up empty lines at the end (if any).
while len(lines[line_index - 1]) <= 1:
line_index -= 1
- observed_code_lines = lines[start_index:line_index]
- observed_code = "".join(observed_code_lines)
-
- # Before comparing, use the `replace_pattern` on the original code.
- if len(replace_pattern) > 0:
- patterns = replace_pattern.replace("with", "").split(",")
- patterns = [_re_replace_pattern.search(p) for p in patterns]
- for pattern in patterns:
- if pattern is None:
- continue
- obj1, obj2, option = pattern.groups()
- theoretical_code = re.sub(obj1, obj2, theoretical_code)
- if option.strip() == "all-casing":
- theoretical_code = re.sub(obj1.lower(), obj2.lower(), theoretical_code)
- theoretical_code = re.sub(obj1.upper(), obj2.upper(), theoretical_code)
+ # Split the observed code into blocks
+ observed_code_splits = split_code_into_blocks(lines, start_index, line_index, len(indent), backtrace=True)
+
+ is_class = lines[start_index].startswith(f"{' ' * (len(indent) - 4)}class ")
+ # sanity check
+ _sanity_check_splits(theoretical_code_splits, observed_code_splits, is_class=is_class)
+
+ # observed code in a structured way (a dict mapping block names to blocks' code)
+ observed_code_blocks = OrderedDict()
+ for name, start, end in observed_code_splits:
+ code = "".join(lines[start:end])
+ observed_code_blocks[name] = code
+
+ # Below, we change some names in `theoretical_code_blocks` and `observed_code_blocks`. These mappings map the
+ # original names to the modified names: this is used to restore the original order of the code blocks.
+ name_mappings_1 = {k: k for k in theoretical_code_blocks.keys()}
+ name_mappings_2 = {k: k for k in observed_code_blocks.keys()}
+
+ # Update code blocks' name and content:
+ # If `"# Ignore copy"` is found in a block of the observed code:
+ # 1. if it's a block only in the observed code --> add it to the theoretical code.
+ # 2. if it's also in the theoretical code () --> put its content (body) to the corresponding block under the
+ # same name in the theoretical code.
+ # In both cases, we change the name to have a prefix `_ignored_` so we know if we can discard them during the
+ # comparison.
+ ignored_existing_block_index = 0
+ ignored_new_block_index = 0
+ for name in list(observed_code_blocks.keys()):
+ code = observed_code_blocks[name]
+ if "# Ignore copy" in code:
+ if name in theoretical_code_blocks:
+ # in the target --> just copy the content
+ del theoretical_code_blocks[name]
+ theoretical_code_blocks[f"_ignored_existing_block_{ignored_existing_block_index}"] = code
+ name_mappings_1[name] = f"_ignored_existing_block_{ignored_existing_block_index}"
+
+ del observed_code_blocks[name]
+ observed_code_blocks[f"_ignored_existing_block_{ignored_existing_block_index}"] = code
+ name_mappings_2[name] = f"_ignored_existing_block_{ignored_existing_block_index}"
+ ignored_existing_block_index += 1
+ else:
+ # not in the target --> add it
+ theoretical_code_blocks[f"_ignored_new_block_{ignored_new_block_index}"] = code
+ name_mappings_1[
+ f"_ignored_new_block_{ignored_new_block_index}"
+ ] = f"_ignored_new_block_{ignored_new_block_index}"
+
+ del observed_code_blocks[name]
+ observed_code_blocks[f"_ignored_new_block_{ignored_new_block_index}"] = code
+ name_mappings_2[name] = f"_ignored_new_block_{ignored_new_block_index}"
+ ignored_new_block_index += 1
+
+ # Respect the original block order:
+ # 1. in `theoretical_code_blocks`: the new blocks will follow the existing ones
+ # 2. in `observed_code_blocks`: the original order are kept with names modified potentially. This is necessary
+ # to compute the correct `diff_index` if `overwrite=True` and there is a diff.
+ theoretical_code_blocks = {
+ name_mappings_1[orig_name]: theoretical_code_blocks[name_mappings_1[orig_name]]
+ for orig_name in name_mappings_1
+ }
+ observed_code_blocks = {
+ name_mappings_2[orig_name]: observed_code_blocks[name_mappings_2[orig_name]]
+ for orig_name in name_mappings_2
+ }
+
+ # Ignore the blocks specified to be ignored. This is the version used to check if there is a mismatch
+ theoretical_code_blocks_clean = {
+ k: v
+ for k, v in theoretical_code_blocks.items()
+ if not (k.startswith(("_ignored_existing_block_", "_ignored_new_block_")))
+ }
+ theoretical_code = "".join(list(theoretical_code_blocks_clean.values()))
+
+ # stylify `theoretical_code` before compare (this is needed only when `replace_pattern` is not empty)
+ if replace_pattern:
theoretical_code = stylify(theoretical_code)
+ # Remove `\n\n` in `theoretical_code` before compare (so no empty line)
+ while "\n\n" in theoretical_code:
+ theoretical_code = theoretical_code.replace("\n\n", "\n")
+
+ # Compute `observed_code` where we don't include any empty line + keep track the line index between the
+ # original/processed `observed_code` so we can have the correct `diff_index`.
+ idx_to_orig_idx_mapping_for_observed_code_lines = {}
+ idx = -1
+ orig_idx = -1
+ observed_code = ""
+ for name, code in observed_code_blocks.items():
+ if code.endswith("\n"):
+ code = code[:-1]
+ for code_line in code.split("\n"):
+ orig_idx += 1
+ if code_line.strip() and not name.startswith(("_ignored_existing_block_", "_ignored_new_block_")):
+ idx += 1
+ observed_code += code_line + "\n"
+ idx_to_orig_idx_mapping_for_observed_code_lines[idx] = orig_idx
# Test for a diff and act accordingly.
diff_index = check_codes_match(observed_code, theoretical_code)
if diff_index is not None:
+ # switch to the index in the original `observed_code` (i.e. before removing empty lines)
+ diff_index = idx_to_orig_idx_mapping_for_observed_code_lines[diff_index]
diffs.append([object_name, diff_index + start_index + 1])
if overwrite:
- lines = lines[:start_index] + [theoretical_code] + lines[line_index:]
+ # `theoretical_code_to_write` is a single string but may have several lines.
+ theoretical_code_to_write = stylify("".join(list(theoretical_code_blocks.values())))
+ lines = lines[:start_index] + [theoretical_code_to_write] + lines[line_index:]
+ # Here we treat it as a single entry in `lines`.
line_index = start_index + 1
if overwrite and len(diffs) > 0:
@@ -373,7 +753,7 @@ def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[
return diffs
-def check_copies(overwrite: bool = False):
+def check_copies(overwrite: bool = False, file: str = None):
"""
Check every file is copy-consistent with the original. Also check the model list in the main README and other
READMEs are consistent.
@@ -381,14 +761,21 @@ def check_copies(overwrite: bool = False):
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
+ file (`bool`, *optional*):
+ The path to a specific file to check and/or fix.
"""
- all_files = glob.glob(os.path.join(TRANSFORMERS_PATH, "**/*.py"), recursive=True)
- all_test_files = glob.glob(os.path.join(MODEL_TEST_PATH, "**/*.py"), recursive=True)
- all_files = list(all_files) + list(all_test_files)
+ buffer = {}
+
+ if file is None:
+ all_files = glob.glob(os.path.join(TRANSFORMERS_PATH, "**/*.py"), recursive=True)
+ all_test_files = glob.glob(os.path.join(MODEL_TEST_PATH, "**/*.py"), recursive=True)
+ all_files = list(all_files) + list(all_test_files)
+ else:
+ all_files = [file]
diffs = []
for filename in all_files:
- new_diffs = is_copy_consistent(filename, overwrite)
+ new_diffs = is_copy_consistent(filename, overwrite, buffer)
diffs += [f"- {filename}: copy does not match {d[0]} at line {d[1]}" for d in new_diffs]
if not overwrite and len(diffs) > 0:
diff = "\n".join(diffs)
@@ -673,6 +1060,7 @@ def check_model_list_copy(overwrite: bool = False):
"TimmBackbone",
"Vision Encoder decoder",
"VisionTextDualEncoder",
+ "CLIPVisionModel",
]
# Template for new entries to add in the main README when we have missing models.
@@ -732,9 +1120,10 @@ def check_readme(overwrite: bool = False):
if __name__ == "__main__":
parser = argparse.ArgumentParser()
+ parser.add_argument("--file", type=str, default=None, help="A specific file to check and/or fix")
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_readme(args.fix_and_overwrite)
- check_copies(args.fix_and_overwrite)
+ check_copies(args.fix_and_overwrite, args.file)
check_full_copies(args.fix_and_overwrite)
diff --git a/utils/check_docstrings.py b/utils/check_docstrings.py
index cddd04ac6516d1..b9a1f0fde1c0cf 100644
--- a/utils/check_docstrings.py
+++ b/utils/check_docstrings.py
@@ -233,6 +233,8 @@
"FlaxGPTJModel",
"FlaxGPTNeoForCausalLM",
"FlaxGPTNeoModel",
+ "FlaxLlamaForCausalLM",
+ "FlaxLlamaModel",
"FlaxMBartForConditionalGeneration",
"FlaxMBartForQuestionAnswering",
"FlaxMBartForSequenceClassification",
@@ -463,6 +465,7 @@
"SamConfig",
"SamPromptEncoderConfig",
"SeamlessM4TConfig", # use of unconventional markdown
+ "SeamlessM4Tv2Config", # use of unconventional markdown
"Seq2SeqTrainingArguments",
"SpecialTokensMixin",
"Speech2Text2Config",
@@ -738,7 +741,6 @@
"TrainerState",
"TrainingArguments",
"TrajectoryTransformerConfig",
- "TransfoXLConfig",
"TranslationPipeline",
"TvltImageProcessor",
"UMT5Config",
diff --git a/utils/check_inits.py b/utils/check_inits.py
index 383aa9c5db1f39..b9a637e6354bba 100644
--- a/utils/check_inits.py
+++ b/utils/check_inits.py
@@ -330,6 +330,7 @@ def get_transformers_submodules() -> List[str]:
"modeling_flax_pytorch_utils",
"models.esm.openfold_utils",
"modeling_attn_mask_utils",
+ "safetensors_conversion",
]
diff --git a/utils/check_repo.py b/utils/check_repo.py
index d740eefed01936..aac06276234632 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -76,6 +76,9 @@
"Kosmos2TextModel",
"Kosmos2TextForCausalLM",
"Kosmos2VisionModel",
+ "SeamlessM4Tv2TextToUnitModel",
+ "SeamlessM4Tv2CodeHifiGan",
+ "SeamlessM4Tv2TextToUnitForConditionalGeneration",
]
# Update this list for models that are not tested with a comment explaining the reason it should not be.
@@ -114,7 +117,7 @@
"BridgeTowerTextModel", # No need to test it as it is tested by BridgeTowerModel model.
"BridgeTowerVisionModel", # No need to test it as it is tested by BridgeTowerModel model.
"BarkCausalModel", # Building part of bigger (tested) model.
- "BarkModel", # Does not have a forward signature - generation tested with integration tests
+ "BarkModel", # Does not have a forward signature - generation tested with integration tests.
"SeamlessM4TTextToUnitModel", # Building part of bigger (tested) model.
"SeamlessM4TCodeHifiGan", # Building part of bigger (tested) model.
"SeamlessM4TTextToUnitForConditionalGeneration", # Building part of bigger (tested) model.
@@ -185,6 +188,8 @@
"TimeSeriesTransformerForPrediction",
"InformerForPrediction",
"AutoformerForPrediction",
+ "PatchTSTForPretraining",
+ "PatchTSTForPrediction",
"JukeboxVQVAE",
"JukeboxPrior",
"SamModel",
@@ -246,6 +251,8 @@
"Owlv2TextModel",
"Owlv2VisionModel",
"OwlViTForObjectDetection",
+ "PatchTSMixerForPrediction",
+ "PatchTSMixerForPretraining",
"RagModel",
"RagSequenceForGeneration",
"RagTokenForGeneration",
@@ -293,6 +300,11 @@
"SeamlessM4TTextToUnitForConditionalGeneration",
"SeamlessM4TCodeHifiGan",
"SeamlessM4TForSpeechToSpeech", # no auto class for speech-to-speech
+ "TvpForVideoGrounding",
+ "SeamlessM4Tv2NARTextToUnitModel",
+ "SeamlessM4Tv2NARTextToUnitForConditionalGeneration",
+ "SeamlessM4Tv2CodeHifiGan",
+ "SeamlessM4Tv2ForSpeechToSpeech", # no auto class for speech-to-speech
]
# DO NOT edit this list!
@@ -396,13 +408,11 @@ def get_model_modules() -> List[str]:
"modeling_flax_speech_encoder_decoder",
"modeling_flax_vision_encoder_decoder",
"modeling_timm_backbone",
- "modeling_transfo_xl_utilities",
"modeling_tf_auto",
"modeling_tf_encoder_decoder",
"modeling_tf_outputs",
"modeling_tf_pytorch_utils",
"modeling_tf_utils",
- "modeling_tf_transfo_xl_utilities",
"modeling_tf_vision_encoder_decoder",
"modeling_vision_encoder_decoder",
]
@@ -964,6 +974,7 @@ def find_all_documented_objects() -> List[str]:
"TensorFlowBenchmark",
"TensorFlowBenchmarkArguments",
"AutoBackbone",
+ "BeitBackbone",
"BitBackbone",
"ConvNextBackbone",
"ConvNextV2Backbone",
diff --git a/utils/check_table.py b/utils/check_table.py
index 6417858db0964f..6eec4754032e8e 100644
--- a/utils/check_table.py
+++ b/utils/check_table.py
@@ -155,6 +155,7 @@ def _center_text(text: str, width: int) -> str:
"HerBERT": "BERT",
"LayoutXLM": "LayoutLMv2",
"Llama2": "LLaMA",
+ "MADLAD-400": "T5",
"MatCha": "Pix2Struct",
"mBART-50": "mBART",
"Megatron-GPT2": "OpenAI GPT-2",
@@ -170,6 +171,7 @@ def _center_text(text: str, width: int) -> str:
"XLS-R": "Wav2Vec2",
"XLSR-Wav2Vec2": "Wav2Vec2",
}
+MODEL_NAMES_TO_IGNORE = ["CLIPVisionModel"]
def get_model_table_from_auto_modules() -> str:
@@ -242,6 +244,8 @@ def get_model_table_from_auto_modules() -> str:
check = {True: "✅", False: "❌"}
for name in model_names:
+ if name in MODEL_NAMES_TO_IGNORE:
+ continue
if name in MODEL_NAMES_WITH_SAME_CONFIG.keys():
prefix = model_name_to_prefix[MODEL_NAMES_WITH_SAME_CONFIG[name]]
else:
diff --git a/utils/create_dummy_models.py b/utils/create_dummy_models.py
index 5ee53ef7dab623..3a2c39de4c8f93 100644
--- a/utils/create_dummy_models.py
+++ b/utils/create_dummy_models.py
@@ -420,17 +420,25 @@ def get_tiny_config(config_class, model_class=None, **model_tester_kwargs):
error = f"Tiny config not created for {model_type} - no model tester is found in the testing module."
raise ValueError(error)
+ # CLIP-like models have `text_model_tester` and `vision_model_tester`, and we need to pass `vocab_size` to
+ # `text_model_tester` via `text_kwargs`. The same trick is also necessary for `Flava`.
+
+ if "vocab_size" in model_tester_kwargs:
+ if "text_kwargs" in inspect.signature(model_tester_class.__init__).parameters.keys():
+ vocab_size = model_tester_kwargs.pop("vocab_size")
+ model_tester_kwargs["text_kwargs"] = {"vocab_size": vocab_size}
+
# `parent` is an instance of `unittest.TestCase`, but we don't need it here.
model_tester = model_tester_class(parent=None, **model_tester_kwargs)
if hasattr(model_tester, "get_pipeline_config"):
- return model_tester.get_pipeline_config()
+ config = model_tester.get_pipeline_config()
elif hasattr(model_tester, "prepare_config_and_inputs"):
# `PoolFormer` has no `get_config` defined. Furthermore, it's better to use `prepare_config_and_inputs` even if
# `get_config` is defined, since there might be some extra changes in `prepare_config_and_inputs`.
- return model_tester.prepare_config_and_inputs()[0]
+ config = model_tester.prepare_config_and_inputs()[0]
elif hasattr(model_tester, "get_config"):
- return model_tester.get_config()
+ config = model_tester.get_config()
else:
error = (
f"Tiny config not created for {model_type} - the model tester {model_tester_class.__name__} lacks"
@@ -438,6 +446,26 @@ def get_tiny_config(config_class, model_class=None, **model_tester_kwargs):
)
raise ValueError(error)
+ # make sure this is long enough (some model tester has `20` for this attr.) to pass `text-generation`
+ # pipeline tests.
+ max_positions = []
+ for key in ["max_position_embeddings", "max_source_positions", "max_target_positions"]:
+ if getattr(config, key, 0) > 0:
+ max_positions.append(getattr(config, key))
+ if getattr(config, "text_config", None) is not None:
+ if getattr(config.text_config, key, None) is not None:
+ max_positions.append(getattr(config.text_config, key))
+ if len(max_positions) > 0:
+ max_position = max(200, min(max_positions))
+ for key in ["max_position_embeddings", "max_source_positions", "max_target_positions"]:
+ if getattr(config, key, 0) > 0:
+ setattr(config, key, max_position)
+ if getattr(config, "text_config", None) is not None:
+ if getattr(config.text_config, key, None) is not None:
+ setattr(config.text_config, key, max_position)
+
+ return config
+
def convert_tokenizer(tokenizer_fast: PreTrainedTokenizerFast):
new_tokenizer = tokenizer_fast.train_new_from_iterator(
@@ -1006,26 +1034,8 @@ def get_config_overrides(config_class, processors):
# Used to create a new model tester with `tokenizer.vocab_size` in order to get the (updated) special token ids.
model_tester_kwargs = {"vocab_size": vocab_size}
- # CLIP-like models have `text_model_tester` and `vision_model_tester`, and we need to pass `vocab_size` to
- # `text_model_tester` via `text_kwargs`. The same trick is also necessary for `Flava`.
- if config_class.__name__ in [
- "AlignConfig",
- "AltCLIPConfig",
- "ChineseCLIPConfig",
- "CLIPSegConfig",
- "ClapConfig",
- "CLIPConfig",
- "GroupViTConfig",
- "OwlViTConfig",
- "XCLIPConfig",
- "FlavaConfig",
- "BlipConfig",
- "Blip2Config",
- ]:
- del model_tester_kwargs["vocab_size"]
- model_tester_kwargs["text_kwargs"] = {"vocab_size": vocab_size}
# `FSMTModelTester` accepts `src_vocab_size` and `tgt_vocab_size` but not `vocab_size`.
- elif config_class.__name__ == "FSMTConfig":
+ if config_class.__name__ == "FSMTConfig":
del model_tester_kwargs["vocab_size"]
model_tester_kwargs["src_vocab_size"] = tokenizer.src_vocab_size
model_tester_kwargs["tgt_vocab_size"] = tokenizer.tgt_vocab_size
@@ -1158,7 +1168,9 @@ def build(config_class, models_to_create, output_dir):
if hasattr(tiny_config, k):
setattr(tiny_config, k, v)
# So far, we only have to deal with `text_config`, as `config_overrides` contains text-related attributes only.
- elif (
+ # `FuyuConfig` saves data under both FuyuConfig and its `text_config`. This is not good, but let's just update
+ # every involved fields to avoid potential failure.
+ if (
hasattr(tiny_config, "text_config")
and tiny_config.text_config is not None
and hasattr(tiny_config.text_config, k)
diff --git a/utils/not_doctested.txt b/utils/not_doctested.txt
index 07775fe823a4dd..2cd16a0283e0ce 100644
--- a/utils/not_doctested.txt
+++ b/utils/not_doctested.txt
@@ -146,11 +146,13 @@ docs/source/en/model_doc/levit.md
docs/source/en/model_doc/lilt.md
docs/source/en/model_doc/llama.md
docs/source/en/model_doc/llama2.md
+docs/source/en/model_doc/llava.md
docs/source/en/model_doc/longformer.md
docs/source/en/model_doc/longt5.md
docs/source/en/model_doc/luke.md
docs/source/en/model_doc/lxmert.md
docs/source/en/model_doc/m2m_100.md
+docs/source/en/model_doc/madlad-400.md
docs/source/en/model_doc/marian.md
docs/source/en/model_doc/mask2former.md
docs/source/en/model_doc/maskformer.md
@@ -237,6 +239,7 @@ docs/source/en/model_doc/upernet.md
docs/source/en/model_doc/van.md
docs/source/en/model_doc/videomae.md
docs/source/en/model_doc/vilt.md
+docs/source/en/model_doc/vipllava.md
docs/source/en/model_doc/vision-encoder-decoder.md
docs/source/en/model_doc/vision-text-dual-encoder.md
docs/source/en/model_doc/visual_bert.md
@@ -293,7 +296,7 @@ docs/source/en/serialization.md
docs/source/en/tasks/asr.md
docs/source/en/tasks/audio_classification.md
docs/source/en/tasks/document_question_answering.md
-docs/source/en/tasks/idefics.md # causes other tests to fail
+docs/source/en/tasks/idefics.md
docs/source/en/tasks/image_captioning.md
docs/source/en/tasks/image_classification.md
docs/source/en/tasks/language_modeling.md
@@ -431,7 +434,7 @@ src/transformers/models/blip/modeling_blip_text.py
src/transformers/models/blip/modeling_tf_blip_text.py
src/transformers/models/blip_2/configuration_blip_2.py
src/transformers/models/blip_2/convert_blip_2_original_to_pytorch.py
-src/transformers/models/blip_2/modeling_blip_2.py # causes other tests to fail
+src/transformers/models/blip_2/modeling_blip_2.py
src/transformers/models/bloom/convert_bloom_original_checkpoint_to_pytorch.py
src/transformers/models/bloom/modeling_bloom.py
src/transformers/models/bloom/modeling_flax_bloom.py
@@ -496,6 +499,11 @@ src/transformers/models/deprecated/tapex/tokenization_tapex.py
src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
src/transformers/models/deprecated/trajectory_transformer/convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
+src/transformers/models/deprecated/transfo_xl/convert_transfo_xl_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
+src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl_utilities.py
+src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
+src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl_utilities.py
src/transformers/models/deprecated/van/configuration_van.py
src/transformers/models/deprecated/van/convert_van_to_pytorch.py
src/transformers/models/deprecated/van/modeling_van.py
@@ -628,6 +636,8 @@ src/transformers/models/lilt/configuration_lilt.py
src/transformers/models/llama/configuration_llama.py
src/transformers/models/llama/convert_llama_weights_to_hf.py
src/transformers/models/llama/modeling_llama.py
+src/transformers/models/llava/configuration_llava.py
+src/transformers/models/llava/modeling_llava.py
src/transformers/models/longformer/configuration_longformer.py
src/transformers/models/longformer/convert_longformer_original_pytorch_lightning_to_pytorch.py
src/transformers/models/longt5/configuration_longt5.py
@@ -668,6 +678,8 @@ src/transformers/models/mgp_str/configuration_mgp_str.py
src/transformers/models/mgp_str/modeling_mgp_str.py
src/transformers/models/mistral/configuration_mistral.py
src/transformers/models/mistral/modeling_mistral.py
+src/transformers/models/mixtral/configuration_mixtral.py
+src/transformers/models/mixtral/modeling_mixtral.py
src/transformers/models/mluke/convert_mluke_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/mobilebert/convert_mobilebert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
@@ -770,6 +782,7 @@ src/transformers/models/sam/modeling_sam.py
src/transformers/models/sam/modeling_tf_sam.py
src/transformers/models/sam/processing_sam.py
src/transformers/models/seamless_m4t/convert_fairseq2_to_hf.py
+src/transformers/models/seamless_m4t_v2/convert_fairseq2_to_hf.py
src/transformers/models/segformer/configuration_segformer.py
src/transformers/models/segformer/convert_segformer_original_to_pytorch.py
src/transformers/models/sew/convert_sew_original_pytorch_checkpoint_to_pytorch.py
@@ -818,11 +831,6 @@ src/transformers/models/tapas/modeling_tf_tapas.py
src/transformers/models/timesformer/convert_timesformer_to_pytorch.py
src/transformers/models/timm_backbone/configuration_timm_backbone.py
src/transformers/models/timm_backbone/modeling_timm_backbone.py
-src/transformers/models/transfo_xl/convert_transfo_xl_original_tf_checkpoint_to_pytorch.py
-src/transformers/models/transfo_xl/modeling_tf_transfo_xl.py
-src/transformers/models/transfo_xl/modeling_tf_transfo_xl_utilities.py
-src/transformers/models/transfo_xl/modeling_transfo_xl.py
-src/transformers/models/transfo_xl/modeling_transfo_xl_utilities.py
src/transformers/models/trocr/convert_trocr_unilm_to_pytorch.py
src/transformers/models/tvlt/configuration_tvlt.py
src/transformers/models/tvlt/modeling_tvlt.py
@@ -840,6 +848,8 @@ src/transformers/models/videomae/configuration_videomae.py
src/transformers/models/videomae/convert_videomae_to_pytorch.py
src/transformers/models/vilt/configuration_vilt.py
src/transformers/models/vilt/convert_vilt_original_to_pytorch.py
+src/transformers/models/vipllava/configuration_vipllava.py
+src/transformers/models/vipllava/modeling_vipllava.py
src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
@@ -990,4 +1000,4 @@ src/transformers/utils/peft_utils.py
src/transformers/utils/quantization_config.py
src/transformers/utils/sentencepiece_model_pb2.py
src/transformers/utils/sentencepiece_model_pb2_new.py
-src/transformers/utils/versions.py
\ No newline at end of file
+src/transformers/utils/versions.py
diff --git a/utils/notification_service.py b/utils/notification_service.py
index 4df3b299448475..969107b3f88481 100644
--- a/utils/notification_service.py
+++ b/utils/notification_service.py
@@ -100,7 +100,13 @@ def dicts_to_sum(objects: Union[Dict[str, Dict], List[dict]]):
class Message:
def __init__(
- self, title: str, ci_title: str, model_results: Dict, additional_results: Dict, selected_warnings: List = None
+ self,
+ title: str,
+ ci_title: str,
+ model_results: Dict,
+ additional_results: Dict,
+ selected_warnings: List = None,
+ prev_ci_artifacts=None,
):
self.title = title
self.ci_title = ci_title
@@ -119,10 +125,17 @@ def __init__(
# Failures and success of the additional tests
self.n_additional_success = sum(r["success"] for r in additional_results.values())
- all_additional_failures = dicts_to_sum([r["failed"] for r in additional_results.values()])
- self.n_additional_single_gpu_failures = all_additional_failures["single"]
- self.n_additional_multi_gpu_failures = all_additional_failures["multi"]
- self.n_additional_unknown_gpu_failures = all_additional_failures["unclassified"]
+ if len(additional_results) > 0:
+ # `dicts_to_sum` uses `dicts_to_sum` which requires a non empty dictionary. Let's just add an empty entry.
+ all_additional_failures = dicts_to_sum([r["failed"] for r in additional_results.values()])
+ self.n_additional_single_gpu_failures = all_additional_failures["single"]
+ self.n_additional_multi_gpu_failures = all_additional_failures["multi"]
+ self.n_additional_unknown_gpu_failures = all_additional_failures["unclassified"]
+ else:
+ self.n_additional_single_gpu_failures = 0
+ self.n_additional_multi_gpu_failures = 0
+ self.n_additional_unknown_gpu_failures = 0
+
self.n_additional_failures = (
self.n_additional_single_gpu_failures
+ self.n_additional_multi_gpu_failures
@@ -143,6 +156,8 @@ def __init__(
selected_warnings = []
self.selected_warnings = selected_warnings
+ self.prev_ci_artifacts = prev_ci_artifacts
+
@property
def time(self) -> str:
all_results = [*self.model_results.values(), *self.additional_results.values()]
@@ -391,8 +406,6 @@ def per_model_sum(model_category_dict):
# Save the complete (i.e. no truncation) failure tables (of the current workflow run)
# (to be uploaded as artifacts)
- if not os.path.isdir(os.path.join(os.getcwd(), "test_failure_tables")):
- os.makedirs(os.path.join(os.getcwd(), "test_failure_tables"))
model_failures_report = prepare_reports(
title="These following model modules had failures",
@@ -400,7 +413,7 @@ def per_model_sum(model_category_dict):
reports=sorted_model_reports,
to_truncate=False,
)
- file_path = os.path.join(os.getcwd(), "test_failure_tables/model_failures_report.txt")
+ file_path = os.path.join(os.getcwd(), "prev_ci_results/model_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(model_failures_report)
@@ -410,27 +423,18 @@ def per_model_sum(model_category_dict):
reports=sorted_module_reports,
to_truncate=False,
)
- file_path = os.path.join(os.getcwd(), "test_failure_tables/module_failures_report.txt")
+ file_path = os.path.join(os.getcwd(), "prev_ci_results/module_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(module_failures_report)
- target_workflow = "huggingface/transformers/.github/workflows/self-scheduled.yml@refs/heads/main"
- if os.environ.get("CI_WORKFLOW_REF") == target_workflow:
- # Get the last previously completed CI's failure tables
- artifact_names = ["test_failure_tables"]
- output_dir = os.path.join(os.getcwd(), "previous_reports")
- os.makedirs(output_dir, exist_ok=True)
- prev_tables = get_last_daily_ci_reports(
- artifact_names=artifact_names, output_dir=output_dir, token=os.environ["ACCESS_REPO_INFO_TOKEN"]
- )
-
- # if the last run produces artifact named `test_failure_tables`
+ if self.prev_ci_artifacts is not None:
+ # if the last run produces artifact named `prev_ci_results`
if (
- "test_failure_tables" in prev_tables
- and "model_failures_report.txt" in prev_tables["test_failure_tables"]
+ "prev_ci_results" in self.prev_ci_artifacts
+ and "model_failures_report.txt" in self.prev_ci_artifacts["prev_ci_results"]
):
# Compute the difference of the previous/current (model failure) table
- prev_model_failures = prev_tables["test_failure_tables"]["model_failures_report.txt"]
+ prev_model_failures = self.prev_ci_artifacts["prev_ci_results"]["model_failures_report.txt"]
entries_changed = self.compute_diff_for_failure_reports(model_failures_report, prev_model_failures)
if len(entries_changed) > 0:
# Save the complete difference
@@ -440,7 +444,7 @@ def per_model_sum(model_category_dict):
reports=entries_changed,
to_truncate=False,
)
- file_path = os.path.join(os.getcwd(), "test_failure_tables/changed_model_failures_report.txt")
+ file_path = os.path.join(os.getcwd(), "prev_ci_results/changed_model_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(diff_report)
@@ -506,6 +510,10 @@ def payload(self) -> str:
if len(self.selected_warnings) > 0:
blocks.append(self.warnings)
+ new_failure_blocks = self.get_new_model_failure_blocks(with_header=False)
+ if len(new_failure_blocks) > 0:
+ blocks.extend(new_failure_blocks)
+
return json.dumps(blocks)
@staticmethod
@@ -625,6 +633,67 @@ def get_reply_blocks(self, job_name, job_result, failures, device, text):
{"type": "section", "text": {"type": "mrkdwn", "text": failure_text}},
]
+ def get_new_model_failure_blocks(self, with_header=True):
+ if self.prev_ci_artifacts is None:
+ return {}
+
+ sorted_dict = sorted(self.model_results.items(), key=lambda t: t[0])
+
+ prev_model_results = {}
+ if (
+ "prev_ci_results" in self.prev_ci_artifacts
+ and "model_results.json" in self.prev_ci_artifacts["prev_ci_results"]
+ ):
+ prev_model_results = json.loads(self.prev_ci_artifacts["prev_ci_results"]["model_results.json"])
+
+ all_failure_lines = {}
+ for job, job_result in sorted_dict:
+ if len(job_result["failures"]):
+ devices = sorted(job_result["failures"].keys(), reverse=True)
+ for device in devices:
+ failures = job_result["failures"][device]
+ prev_error_lines = {}
+ if job in prev_model_results and device in prev_model_results[job]["failures"]:
+ prev_error_lines = {error["line"] for error in prev_model_results[job]["failures"][device]}
+
+ url = None
+ if job_result["job_link"] is not None and job_result["job_link"][device] is not None:
+ url = job_result["job_link"][device]
+
+ for idx, error in enumerate(failures):
+ if error["line"] in prev_error_lines:
+ continue
+
+ new_text = f'{error["line"]}\n\n'
+
+ if new_text not in all_failure_lines:
+ all_failure_lines[new_text] = []
+
+ all_failure_lines[new_text].append(f"<{url}|{device}>" if url is not None else device)
+
+ MAX_ERROR_TEXT = 3000 - len("[Truncated]") - len("```New model failures```\n\n")
+ failure_text = ""
+ for line, devices in all_failure_lines.items():
+ new_text = failure_text + f"{'|'.join(devices)} gpu\n{line}"
+ if len(new_text) > MAX_ERROR_TEXT:
+ # `failure_text` here has length <= 3000
+ failure_text = failure_text + "[Truncated]"
+ break
+ # `failure_text` here has length <= MAX_ERROR_TEXT
+ failure_text = new_text
+
+ blocks = []
+ if failure_text:
+ if with_header:
+ blocks.append(
+ {"type": "header", "text": {"type": "plain_text", "text": "New model failures", "emoji": True}}
+ )
+ else:
+ failure_text = f"*New model failures*\n\n{failure_text}"
+ blocks.append({"type": "section", "text": {"type": "mrkdwn", "text": failure_text}})
+
+ return blocks
+
def post_reply(self):
if self.thread_ts is None:
raise ValueError("Can only post reply if a post has been made.")
@@ -674,6 +743,20 @@ def post_reply(self):
time.sleep(1)
+ blocks = self.get_new_model_failure_blocks()
+ if blocks:
+ print("Sending the following reply")
+ print(json.dumps({"blocks": blocks}))
+
+ client.chat_postMessage(
+ channel=os.environ["CI_SLACK_REPORT_CHANNEL_ID"],
+ text="Results for new failures",
+ blocks=blocks,
+ thread_ts=self.thread_ts["ts"],
+ )
+
+ time.sleep(1)
+
def retrieve_artifact(artifact_path: str, gpu: Optional[str]):
if gpu not in [None, "single", "multi"]:
@@ -903,6 +986,9 @@ def prepare_reports(title, header, reports, to_truncate=True):
elif ci_event.startswith("Push CI (AMD) - "):
flavor = ci_event.replace("Push CI (AMD) - ", "")
job_name_prefix = f"AMD {flavor}"
+ elif ci_event.startswith("Scheduled CI (AMD) - "):
+ flavor = ci_event.replace("Scheduled CI (AMD) - ", "")
+ job_name_prefix = f"AMD {flavor}"
for model in model_results.keys():
for artifact_path in available_artifacts[f"run_all_tests_gpu_{model}_test_reports"].paths:
@@ -968,10 +1054,15 @@ def prepare_reports(title, header, reports, to_truncate=True):
"Torch CUDA extension tests": "run_tests_torch_cuda_extensions_gpu_test_reports",
}
- if ci_event in ["push", "Nightly CI"] or ci_event.startswith("Past CI") or ci_event.startswith("Push CI (AMD)"):
+ if ci_event in ["push", "Nightly CI"] or ci_event.startswith("Past CI"):
del additional_files["Examples directory"]
del additional_files["PyTorch pipelines"]
del additional_files["TensorFlow pipelines"]
+ elif ci_event.startswith("Scheduled CI (AMD)"):
+ del additional_files["TensorFlow pipelines"]
+ del additional_files["Torch CUDA extension tests"]
+ elif ci_event.startswith("Push CI (AMD)"):
+ additional_files = {}
additional_results = {
key: {
@@ -1030,7 +1121,31 @@ def prepare_reports(title, header, reports, to_truncate=True):
with open(os.path.join(directory, "selected_warnings.json")) as fp:
selected_warnings = json.load(fp)
- message = Message(title, ci_title, model_results, additional_results, selected_warnings=selected_warnings)
+ if not os.path.isdir(os.path.join(os.getcwd(), "prev_ci_results")):
+ os.makedirs(os.path.join(os.getcwd(), "prev_ci_results"))
+
+ with open("prev_ci_results/model_results.json", "w", encoding="UTF-8") as fp:
+ json.dump(model_results, fp, indent=4, ensure_ascii=False)
+
+ prev_ci_artifacts = None
+ target_workflow = "huggingface/transformers/.github/workflows/self-scheduled.yml@refs/heads/main"
+ if os.environ.get("CI_WORKFLOW_REF") == target_workflow:
+ # Get the last previously completed CI's failure tables
+ artifact_names = ["prev_ci_results"]
+ output_dir = os.path.join(os.getcwd(), "previous_reports")
+ os.makedirs(output_dir, exist_ok=True)
+ prev_ci_artifacts = get_last_daily_ci_reports(
+ artifact_names=artifact_names, output_dir=output_dir, token=os.environ["ACCESS_REPO_INFO_TOKEN"]
+ )
+
+ message = Message(
+ title,
+ ci_title,
+ model_results,
+ additional_results,
+ selected_warnings=selected_warnings,
+ prev_ci_artifacts=prev_ci_artifacts,
+ )
# send report only if there is any failure (for push CI)
if message.n_failures or (ci_event != "push" and not ci_event.startswith("Push CI (AMD)")):
diff --git a/utils/slow_documentation_tests.txt b/utils/slow_documentation_tests.txt
index 64841a19cb6cf5..302778c7320039 100644
--- a/utils/slow_documentation_tests.txt
+++ b/utils/slow_documentation_tests.txt
@@ -2,6 +2,7 @@ docs/source/en/generation_strategies.md
docs/source/en/model_doc/ctrl.md
docs/source/en/model_doc/kosmos-2.md
docs/source/en/model_doc/seamless_m4t.md
+docs/source/en/model_doc/seamless_m4t_v2.md
docs/source/en/task_summary.md
docs/source/en/tasks/prompting.md
src/transformers/models/blip_2/modeling_blip_2.py
diff --git a/utils/tests_fetcher.py b/utils/tests_fetcher.py
index c7638a129a0c25..1aae59e4b33602 100644
--- a/utils/tests_fetcher.py
+++ b/utils/tests_fetcher.py
@@ -51,9 +51,11 @@
import argparse
import collections
+import importlib.util
import json
import os
import re
+import tempfile
from contextlib import contextmanager
from pathlib import Path
from typing import Dict, List, Optional, Tuple, Union
@@ -254,6 +256,122 @@ def diff_contains_doc_examples(repo: Repo, branching_point: str, filename: str)
return old_content_clean != new_content_clean
+def get_impacted_files_from_tiny_model_summary(diff_with_last_commit: bool = False) -> List[str]:
+ """
+ Return a list of python modeling files that are impacted by the changes of `tiny_model_summary.json` in between:
+
+ - the current head and the main branch if `diff_with_last_commit=False` (default)
+ - the current head and its parent commit otherwise.
+
+ Returns:
+ `List[str]`: The list of Python modeling files that are impacted by the changes of `tiny_model_summary.json`.
+ """
+ repo = Repo(PATH_TO_REPO)
+
+ folder = Path(repo.working_dir)
+
+ if not diff_with_last_commit:
+ print(f"main is at {repo.refs.main.commit}")
+ print(f"Current head is at {repo.head.commit}")
+
+ commits = repo.merge_base(repo.refs.main, repo.head)
+ for commit in commits:
+ print(f"Branching commit: {commit}")
+ else:
+ print(f"main is at {repo.head.commit}")
+ commits = repo.head.commit.parents
+ for commit in commits:
+ print(f"Parent commit: {commit}")
+
+ if not os.path.isfile(folder / "tests/utils/tiny_model_summary.json"):
+ return []
+
+ files = set()
+ for commit in commits:
+ with checkout_commit(repo, commit):
+ with open(folder / "tests/utils/tiny_model_summary.json", "r", encoding="utf-8") as f:
+ old_content = f.read()
+
+ with open(folder / "tests/utils/tiny_model_summary.json", "r", encoding="utf-8") as f:
+ new_content = f.read()
+
+ # get the content as json object
+ old_content = json.loads(old_content)
+ new_content = json.loads(new_content)
+
+ old_keys = set(old_content.keys())
+ new_keys = set(new_content.keys())
+
+ # get the difference
+ keys_with_diff = old_keys.symmetric_difference(new_keys)
+ common_keys = old_keys.intersection(new_keys)
+ # if both have the same key, check its content
+ for key in common_keys:
+ if old_content[key] != new_content[key]:
+ keys_with_diff.add(key)
+
+ # get the model classes
+ impacted_model_classes = []
+ for key in keys_with_diff:
+ if key in new_keys:
+ impacted_model_classes.extend(new_content[key]["model_classes"])
+
+ # get the module where the model classes are defined. We want to use the main `__init__` file, but it requires
+ # all the framework being installed, which is not ideal for a simple script like test fetcher.
+ # So we create a temporary and modified main `__init__` and access its `_import_structure`.
+ with open(folder / "src/transformers/__init__.py") as fp:
+ lines = fp.readlines()
+ new_lines = []
+ # Get all the code related to `_import_structure`
+ for line in lines:
+ if line == "_import_structure = {\n":
+ new_lines.append(line)
+ elif line == "# Direct imports for type-checking\n":
+ break
+ elif len(new_lines) > 0:
+ # bypass the framework check so we can get all the information even if frameworks are not available
+ line = re.sub(r"is_.+_available\(\)", "True", line)
+ line = line.replace("OptionalDependencyNotAvailable", "Exception")
+ line = line.replace("Exception()", "Exception")
+ new_lines.append(line)
+
+ # create and load the temporary module
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ with open(os.path.join(tmpdirname, "temp_init.py"), "w") as fp:
+ fp.write("".join(new_lines))
+
+ spec = importlib.util.spec_from_file_location("temp_init", os.path.join(tmpdirname, "temp_init.py"))
+ module = importlib.util.module_from_spec(spec)
+ spec.loader.exec_module(module)
+ # Finally, get `_import_structure` that we need
+ import_structure = module._import_structure
+
+ # map model classes to their defined module
+ reversed_structure = {}
+ for key, values in import_structure.items():
+ for value in values:
+ reversed_structure[value] = key
+
+ # Get the corresponding modeling file path
+ for model_class in impacted_model_classes:
+ module = reversed_structure[model_class]
+ framework = ""
+ if model_class.startswith("TF"):
+ framework = "tf"
+ elif model_class.startswith("Flax"):
+ framework = "flax"
+ fn = (
+ f"modeling_{module.split('.')[-1]}.py"
+ if framework == ""
+ else f"modeling_{framework}_{module.split('.')[-1]}.py"
+ )
+ files.add(
+ f"src.transformers.{module}.{fn}".replace(".", os.path.sep).replace(f"{os.path.sep}py", ".py")
+ )
+
+ return sorted(files)
+
+
def get_diff(repo: Repo, base_commit: str, commits: List[str]) -> List[str]:
"""
Get the diff between a base commit and one or several commits.
@@ -949,18 +1067,16 @@ def infer_tests_to_run(
if any(x in modified_files for x in ["setup.py", ".circleci/create_circleci_config.py"]):
test_files_to_run = ["tests", "examples"]
repo_utils_launch = True
- # in order to trigger pipeline tests even if no code change at all
- elif "tests/utils/tiny_model_summary.json" in modified_files:
- test_files_to_run = ["tests"]
- repo_utils_launch = any(f.split(os.path.sep)[0] == "utils" for f in modified_files)
else:
# All modified tests need to be run.
test_files_to_run = [
f for f in modified_files if f.startswith("tests") and f.split(os.path.sep)[-1].startswith("test")
]
+ impacted_files = get_impacted_files_from_tiny_model_summary(diff_with_last_commit=diff_with_last_commit)
+
# Then we grab the corresponding test files.
test_map = create_module_to_test_map(reverse_map=reverse_map, filter_models=filter_models)
- for f in modified_files:
+ for f in modified_files + impacted_files:
if f in test_map:
test_files_to_run.extend(test_map[f])
test_files_to_run = sorted(set(test_files_to_run))