+  +
+
+
+Este modelo tiene cuatro componentes principales:
+
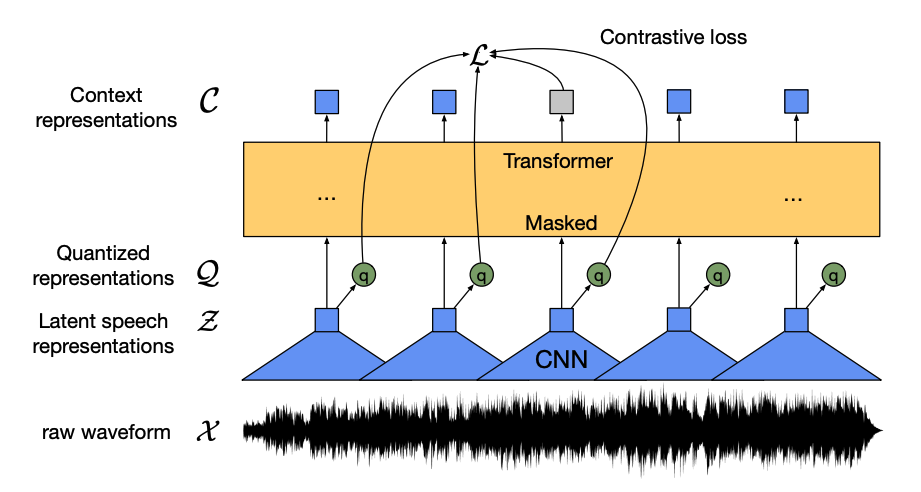
+1. Un *codificador de características* toma la forma de onda de audio cruda, la normaliza a media cero y varianza unitaria, y la convierte en una secuencia de vectores de características, cada uno de 20 ms de duración.
+
+2. Las formas de onda son continuas por naturaleza, por lo que no se pueden dividir en unidades separadas como una secuencia de texto se puede dividir en palabras. Por eso, los vectores de características se pasan a un *módulo de cuantificación*, que tiene como objetivo aprender unidades de habla discretas. La unidad de habla se elige de una colección de palabras de código, conocidas como *codebook* (puedes pensar en esto como el vocabulario). Del codebook, se elige el vector o unidad de habla que mejor representa la entrada de audio continua y se envía a través del modelo.
+
+3. Alrededor de la mitad de los vectores de características se enmascaran aleatoriamente, y el vector de características enmascarado se alimenta a una *red de contexto*, que es un codificador Transformer que también agrega incrustaciones posicionales relativas.
+
+4. El objetivo del preentrenamiento de la red de contexto es una *tarea contrastiva*. El modelo tiene que predecir la verdadera representación de habla cuantizada de la predicción enmascarada a partir de un conjunto de falsas, lo que anima al modelo a encontrar el vector de contexto y la unidad de habla cuantizada más similares (la etiqueta objetivo).
+
+¡Ahora que wav2vec2 está preentrenado, puedes ajustarlo con tus datos para clasificación de audio o reconocimiento automático de voz!
+
+### Clasificación de audio
+
+Para usar el modelo preentrenado para la clasificación de audio, añade una capa de clasificación de secuencia encima del modelo base de Wav2Vec2. La capa de clasificación es una capa lineal que acepta los estados ocultos del codificador. Los estados ocultos representan las características aprendidas de cada fotograma de audio, que pueden tener longitudes variables. Para crear un vector de longitud fija, primero se agrupan los estados ocultos y luego se transforman en logits sobre las etiquetas de clase. La pérdida de entropía cruzada se calcula entre los logits y el objetivo para encontrar la clase más probable.
+
+¿Listo para probar la clasificación de audio? ¡Consulta nuestra guía completa de [clasificación de audio](https://huggingface.co/docs/transformers/tasks/audio_classification) para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
+
+### Reconocimiento automático de voz
+
+Para usar el modelo preentrenado para el reconocimiento automático de voz, añade una capa de modelado del lenguaje encima del modelo base de Wav2Vec2 para [CTC (clasificación temporal conexista)](glossary#connectionist-temporal-classification-ctc). La capa de modelado del lenguaje es una capa lineal que acepta los estados ocultos del codificador y los transforma en logits. Cada logit representa una clase de token (el número de tokens proviene del vocabulario de la tarea). La pérdida de CTC se calcula entre los logits y los objetivos para encontrar la secuencia de tokens más probable, que luego se decodifican en una transcripción.
+
+¿Listo para probar el reconocimiento automático de voz? ¡Consulta nuestra guía completa de [reconocimiento automático de voz](tasks/asr) para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
+
+## Visión por computadora
+
+Hay dos formas de abordar las tareas de visión por computadora:
+
+1. Dividir una imagen en una secuencia de parches y procesarlos en paralelo con un Transformer.
+2. Utilizar una CNN moderna, como [ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext), que se basa en capas convolucionales pero adopta diseños de redes modernas.
+
+
+
+  +
+
+
+El cambio principal que introdujo ViT fue en cómo se alimentan las imágenes a un Transformer:
+
+1. Una imagen se divide en parches cuadrados no superpuestos, cada uno de los cuales se convierte en un vector o *incrustación de parche*(patch embedding). Las incrustaciones de parche se generan a partir de una capa convolucional 2D que crea las dimensiones de entrada adecuadas (que para un Transformer base son 768 valores para cada incrustación de parche). Si tuvieras una imagen de 224x224 píxeles, podrías dividirla en 196 parches de imagen de 16x16. Al igual que el texto se tokeniza en palabras, una imagen se "tokeniza" en una secuencia de parches.
+
+2. Se agrega una *incrustación aprendida* - un token especial `[CLS]` - al principio de las incrustaciones del parche, al igual que en BERT. El estado oculto final del token `[CLS]` se utiliza como la entrada para la cabecera de clasificación adjunta; otras salidas se ignoran. Este token ayuda al modelo a aprender cómo codificar una representación de la imagen.
+
+3. Lo último que se agrega a las incrustaciones de parche e incrustaciones aprendidas son las *incrustaciones de posición* porque el modelo no sabe cómo están ordenados los parches de imagen. Las incrustaciones de posición también son aprendibles y tienen el mismo tamaño que las incrustaciones de parche. Finalmente, todas las incrustaciones se pasan al codificador Transformer.
+
+4. La salida, específicamente solo la salida con el token `[CLS]`, se pasa a una cabecera de perceptrón multicapa (MLP). El objetivo del preentrenamiento de ViT es simplemente la clasificación. Al igual que otras cabeceras de clasificación, la cabecera de MLP convierte la salida en logits sobre las etiquetas de clase y calcula la pérdida de entropía cruzada para encontrar la clase más probable.
+
+¿Listo para probar la clasificación de imágenes? ¡Consulta nuestra guía completa de [clasificación de imágenes](tasks/image_classification) para aprender cómo ajustar ViT y usarlo para inferencia!
+
+#### CNN
+
+
+
+  +
+
+
+Una convolución básica sin relleno ni paso, tomada de Una guía para la aritmética de convoluciones para el aprendizaje profundo.
+
+Puedes alimentar esta salida a otra capa convolucional, y con cada capa sucesiva, la red aprende cosas más complejas y abstractas como perros calientes o cohetes. Entre capas convolucionales, es común añadir una capa de agrupación para reducir la dimensionalidad y hacer que el modelo sea más robusto a las variaciones de la posición de una característica.
+
+
+
+  +
+
+
+ConvNeXT moderniza una CNN de cinco maneras:
+
+1. Cambia el número de bloques en cada etapa y "fragmenta" una imagen con un paso y tamaño de kernel más grandes. La ventana deslizante no superpuesta hace que esta estrategia de fragmentación sea similar a cómo ViT divide una imagen en parches.
+
+2. Una capa de *cuello de botella* reduce el número de canales y luego lo restaura porque es más rápido hacer una convolución de 1x1, y se puede aumentar la profundidad. Un cuello de botella invertido hace lo contrario al expandir el número de canales y luego reducirlos, lo cual es más eficiente en memoria.
+
+3. Reemplaza la típica capa convolucional de 3x3 en la capa de cuello de botella con una convolución *depthwise*, que aplica una convolución a cada canal de entrada por separado y luego los apila de nuevo al final. Esto ensancha el ancho de la red para mejorar el rendimiento.
+
+4. ViT tiene un campo receptivo global, lo que significa que puede ver más de una imagen a la vez gracias a su mecanismo de atención. ConvNeXT intenta replicar este efecto aumentando el tamaño del kernel a 7x7.
+
+5. ConvNeXT también hace varios cambios en el diseño de capas que imitan a los modelos Transformer. Hay menos capas de activación y normalización, la función de activación se cambia a GELU en lugar de ReLU, y utiliza LayerNorm en lugar de BatchNorm.
+
+La salida de los bloques convolucionales se pasa a una cabecera de clasificación que convierte las salidas en logits y calcula la pérdida de entropía cruzada para encontrar la etiqueta más probable.
+
+### Object detection
+
+[DETR](https://huggingface.co/docs/transformers/model_doc/detr), *DEtection TRansformer*, es un modelo de detección de objetos de un extremo a otro que combina una CNN con un codificador-decodificador Transformer.
+
+
+
+  +
+
+
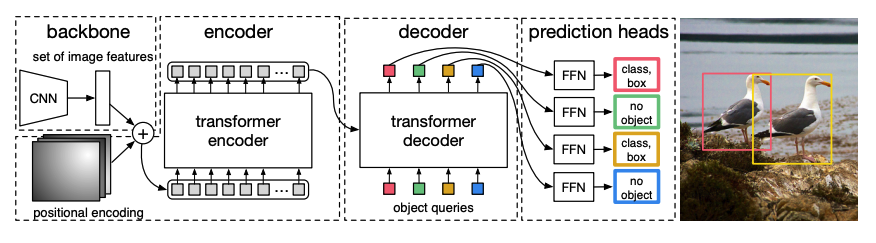
+1. Una CNN preentrenada *backbone* toma una imagen, representada por sus valores de píxeles, y crea un mapa de características de baja resolución de la misma. A continuación, se aplica una convolución 1x1 al mapa de características para reducir la dimensionalidad y se crea un nuevo mapa de características con una representación de imagen de alto nivel. Dado que el Transformer es un modelo secuencial, el mapa de características se aplana en una secuencia de vectores de características que se combinan con incrustaciones posicionales.
+
+2. Los vectores de características se pasan al codificador, que aprende las representaciones de imagen usando sus capas de atención. A continuación, los estados ocultos del codificador se combinan con *consultas de objeto* en el decodificador. Las consultas de objeto son incrustaciones aprendidas que se enfocan en las diferentes regiones de una imagen, y se actualizan a medida que avanzan a través de cada capa de atención. Los estados ocultos del decodificador se pasan a una red feedforward que predice las coordenadas del cuadro delimitador y la etiqueta de clase para cada consulta de objeto, o `no objeto` si no hay ninguno.
+
+ DETR descodifica cada consulta de objeto en paralelo para producir *N* predicciones finales, donde *N* es el número de consultas. A diferencia de un modelo autoregresivo típico que predice un elemento a la vez, la detección de objetos es una tarea de predicción de conjuntos (`cuadro delimitador`, `etiqueta de clase`) que hace *N* predicciones en un solo paso.
+
+3. DETR utiliza una **pérdida de coincidencia bipartita** durante el entrenamiento para comparar un número fijo de predicciones con un conjunto fijo de etiquetas de verdad básica. Si hay menos etiquetas de verdad básica en el conjunto de *N* etiquetas, entonces se rellenan con una clase `no objeto`. Esta función de pérdida fomenta que DETR encuentre una asignación uno a uno entre las predicciones y las etiquetas de verdad básica. Si los cuadros delimitadores o las etiquetas de clase no son correctos, se incurre en una pérdida. Del mismo modo, si DETR predice un objeto que no existe, se penaliza. Esto fomenta que DETR encuentre otros objetos en una imagen en lugar de centrarse en un objeto realmente prominente.
+
+Se añade una cabecera de detección de objetos encima de DETR para encontrar la etiqueta de clase y las coordenadas del cuadro delimitador. Hay dos componentes en la cabecera de detección de objetos: una capa lineal para transformar los estados ocultos del decodificador en logits sobre las etiquetas de clase, y una MLP para predecir el cuadro delimitador.
+
+¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de [detección de objetos](https://huggingface.co/docs/transformers/tasks/object_detection) para aprender cómo ajustar DETR y usarlo para inferencia!
+
+### Segmentación de imágenes
+
+[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) es una arquitectura universal para resolver todos los tipos de tareas de segmentación de imágenes. Los modelos de segmentación tradicionales suelen estar adaptados a una tarea particular de segmentación de imágenes, como la segmentación de instancias, semántica o panóptica. Mask2Former enmarca cada una de esas tareas como un problema de *clasificación de máscaras*. La clasificación de máscaras agrupa píxeles en *N* segmentos, y predice *N* máscaras y su etiqueta de clase correspondiente para una imagen dada. Explicaremos cómo funciona Mask2Former en esta sección, y luego podrás probar el ajuste fino de SegFormer al final.
+
+
+
+  +
+
+
+Hay tres componentes principales en Mask2Former:
+
+1. Un [backbone Swin](https://huggingface.co/docs/transformers/model_doc/swin) acepta una imagen y crea un mapa de características de imagen de baja resolución a partir de 3 convoluciones consecutivas de 3x3.
+
+2. El mapa de características se pasa a un *decodificador de píxeles* que aumenta gradualmente las características de baja resolución en incrustaciones de alta resolución por píxel. De hecho, el decodificador de píxeles genera características multiescala (contiene características de baja y alta resolución) con resoluciones de 1/32, 1/16 y 1/8 de la imagen original.
+
+3. Cada uno de estos mapas de características de diferentes escalas se alimenta sucesivamente a una capa decodificadora Transformer a la vez para capturar objetos pequeños de las características de alta resolución. La clave de Mask2Former es el mecanismo de *atención enmascarada* en el decodificador. A diferencia de la atención cruzada que puede atender a toda la imagen, la atención enmascarada solo se centra en cierta área de la imagen. Esto es más rápido y conduce a un mejor rendimiento porque las características locales de una imagen son suficientes para que el modelo aprenda.
+
+4. Al igual que [DETR](tasks_explained#object-detection), Mask2Former también utiliza consultas de objetos aprendidas y las combina con las características de la imagen del decodificador de píxeles para hacer una predicción de conjunto (`etiqueta de clase`, `predicción de máscara`). Los estados ocultos del decodificador se pasan a una capa lineal y se transforman en logits sobre las etiquetas de clase. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta de clase para encontrar la más probable.
+
+ Las predicciones de máscara se generan combinando las incrustaciones de píxeles con los estados ocultos finales del decodificador. La pérdida de entropía cruzada sigmoidea y de la pérdida DICE se calcula entre los logits y la máscara de verdad básica para encontrar la máscara más probable.
+
+¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de [segmentación de imágenes](https://huggingface.co/docs/transformers/tasks/semantic_segmentation) para aprender cómo ajustar SegFormer y usarlo para inferencia!
+
+### Estimación de profundidad
+
+[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn), *Global-Local Path Network*, es un Transformer para la estimación de profundidad que combina un codificador [SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer) con un decodificador ligero.
+
+
+
+  +
+
+
+1. Al igual que ViT, una imagen se divide en una secuencia de parches, excepto que estos parches de imagen son más pequeños. Esto es mejor para tareas de predicción densa como la segmentación o la estimación de profundidad. Los parches de imagen se transforman en incrustaciones de parches (ver la sección de [clasificación de imágenes](#clasificación-de-imágenes) para más detalles sobre cómo se crean las incrustaciones de parches), que se alimentan al codificador.
+
+2. El codificador acepta las incrustaciones de parches y las pasa a través de varios bloques codificadores. Cada bloque consiste en capas de atención y Mix-FFN. El propósito de este último es proporcionar información posicional. Al final de cada bloque codificador hay una capa de *fusión de parches* para crear representaciones jerárquicas. Las características de cada grupo de parches vecinos se concatenan, y se aplica una capa lineal a las características concatenadas para reducir el número de parches a una resolución de 1/4. Esto se convierte en la entrada al siguiente bloque codificador, donde se repite todo este proceso hasta que tengas características de imagen con resoluciones de 1/8, 1/16 y 1/32.
+
+3. Un decodificador ligero toma el último mapa de características (escala 1/32) del codificador y lo aumenta a una escala de 1/16. A partir de aquí, la característica se pasa a un módulo de *Fusión Selectiva de Características (SFF)*, que selecciona y combina características locales y globales de un mapa de atención para cada característica y luego la aumenta a 1/8. Este proceso se repite hasta que las características decodificadas sean del mismo tamaño que la imagen original. La salida se pasa a través de dos capas de convolución y luego se aplica una activación sigmoide para predecir la profundidad de cada píxel.
+
+## Procesamiento del lenguaje natural
+
+El Transformer fue diseñado inicialmente para la traducción automática, y desde entonces, prácticamente se ha convertido en la arquitectura predeterminada para resolver todas las tareas de procesamiento del lenguaje natural (NLP, por sus siglas en inglés). Algunas tareas se prestan a la estructura del codificador del Transformer, mientras que otras son más adecuadas para el decodificador. Todavía hay otras tareas que hacen uso de la estructura codificador-decodificador del Transformer.
+
+### Clasificación de texto
+
+[BERT](https://huggingface.co/docs/transformers/model_doc/bert) es un modelo que solo tiene codificador y es el primer modelo en implementar efectivamente la bidireccionalidad profunda para aprender representaciones más ricas del texto al atender a las palabras en ambos lados.
+
+1. BERT utiliza la tokenización [WordPiece](https://huggingface.co/docs/transformers/tokenizer_summary#wordpiece) para generar una incrustación de tokens del texto. Para diferenciar entre una sola oración y un par de oraciones, se agrega un token especial `[SEP]` para diferenciarlos. También se agrega un token especial `[CLS]` al principio de cada secuencia de texto. La salida final con el token `[CLS]` se utiliza como la entrada a la cabeza de clasificación para tareas de clasificación. BERT también agrega una incrustación de segmento para indicar si un token pertenece a la primera o segunda oración en un par de oraciones.
+
+2. BERT se preentrena con dos objetivos: modelar el lenguaje enmascarado y predecir de próxima oración. En el modelado de lenguaje enmascarado, un cierto porcentaje de los tokens de entrada se enmascaran aleatoriamente, y el modelo necesita predecir estos. Esto resuelve el problema de la bidireccionalidad, donde el modelo podría hacer trampa y ver todas las palabras y "predecir" la siguiente palabra. Los estados ocultos finales de los tokens de máscara predichos se pasan a una red feedforward con una softmax sobre el vocabulario para predecir la palabra enmascarada.
+
+ El segundo objetivo de preentrenamiento es la predicción de próxima oración. El modelo debe predecir si la oración B sigue a la oración A. La mitad del tiempo, la oración B es la siguiente oración, y la otra mitad del tiempo, la oración B es una oración aleatoria. La predicción, ya sea que sea la próxima oración o no, se pasa a una red feedforward con una softmax sobre las dos clases (`EsSiguiente` y `NoSiguiente`).
+
+3. Las incrustaciones de entrada se pasan a través de múltiples capas codificadoras para producir algunos estados ocultos finales.
+
+Para usar el modelo preentrenado para clasificación de texto, se añade una cabecera de clasificación de secuencia encima del modelo base de BERT. La cabecera de clasificación de secuencia es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y el objetivo para encontrar la etiqueta más probable.
+
+¿Listo para probar la clasificación de texto? ¡Consulta nuestra guía completa de [clasificación de texto](https://huggingface.co/docs/transformers/tasks/sequence_classification) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
+
+### Clasificación de tokens
+
+Para usar BERT en tareas de clasificación de tokens como el reconocimiento de entidades nombradas (NER), añade una cabecera de clasificación de tokens encima del modelo base de BERT. La cabecera de clasificación de tokens es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y cada token para encontrar la etiqueta más probable.
+
+¿Listo para probar la clasificación de tokens? ¡Consulta nuestra guía completa de [clasificación de tokens](https://huggingface.co/docs/transformers/tasks/token_classification) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
+
+### Respuesta a preguntas
+
+Para usar BERT en la respuesta a preguntas, añade una cabecera de clasificación de span encima del modelo base de BERT. Esta capa lineal acepta los estados ocultos finales y realiza una transformación lineal para calcular los logits de inicio y fin del `span` correspondiente a la respuesta. Se calcula la pérdida de entropía cruzada entre los logits y la posición de la etiqueta para encontrar el span más probable de texto correspondiente a la respuesta.
+
+¿Listo para probar la respuesta a preguntas? ¡Consulta nuestra guía completa de [respuesta a preguntas](tasks/question_answering) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
+
+
+
+  +
+
+
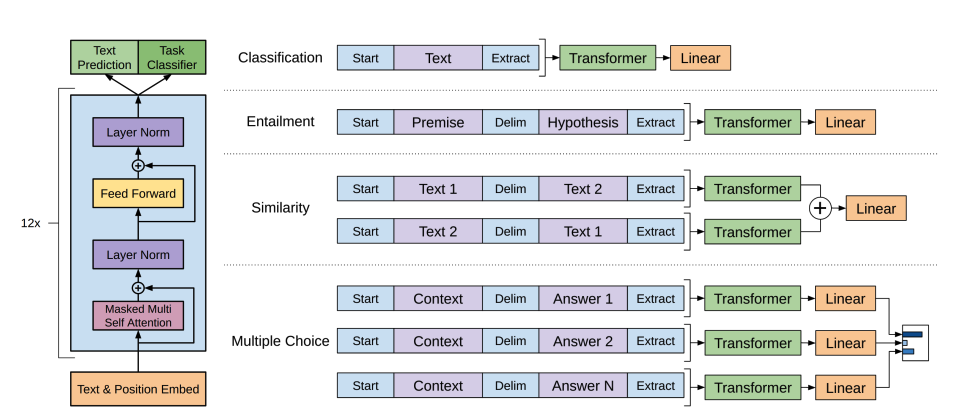
+1. GPT-2 utiliza [codificación de pares de bytes (BPE)](https://huggingface.co/docs/transformers/tokenizer_summary#bytepair-encoding-bpe) para tokenizar palabras y generar una incrustación de token. Se añaden incrustaciones posicionales a las incrustaciones de token para indicar la posición de cada token en la secuencia. Las incrustaciones de entrada se pasan a través de varios bloques decodificadores para producir algún estado oculto final. Dentro de cada bloque decodificador, GPT-2 utiliza una capa de *autoatención enmascarada*, lo que significa que GPT-2 no puede atender a los tokens futuros. Solo puede atender a los tokens a la izquierda. Esto es diferente al token [`mask`] de BERT porque, en la autoatención enmascarada, se utiliza una máscara de atención para establecer la puntuación en `0` para los tokens futuros.
+
+2. La salida del decodificador se pasa a una cabecera de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. La etiqueta es el siguiente token en la secuencia, que se crea desplazando los logits a la derecha en uno. Se calcula la pérdida de entropía cruzada entre los logits desplazados y las etiquetas para obtener el siguiente token más probable.
+
+El objetivo del preentrenamiento de GPT-2 se basa completamente en el [modelado de lenguaje causal](glossary#causal-language-modeling), prediciendo la siguiente palabra en una secuencia. Esto hace que GPT-2 sea especialmente bueno en tareas que implican la generación de texto.
+
+¿Listo para probar la generación de texto? ¡Consulta nuestra guía completa de [modelado de lenguaje causal](tasks/language_modeling#modelado-de-lenguaje-causal) para aprender cómo ajustar DistilGPT-2 y usarlo para inferencia!
+
+
+
+  +
+
+
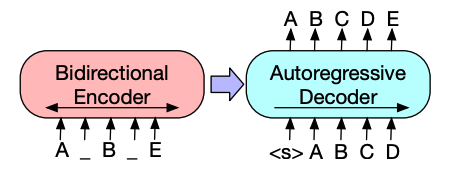
+1. La arquitectura del codificador de BART es muy similar a la de BERT y acepta una incrustación de token y posicional del texto. BART se preentrena corrompiendo la entrada y luego reconstruyéndola con el decodificador. A diferencia de otros codificadores con estrategias específicas de corrupción, BART puede aplicar cualquier tipo de corrupción. Sin embargo, la estrategia de corrupción de *relleno de texto* funciona mejor. En el relleno de texto, varios fragmentos de texto se reemplazan con un **único** token [`mask`]. Esto es importante porque el modelo tiene que predecir los tokens enmascarados, y le enseña al modelo a predecir la cantidad de tokens faltantes. Las incrustaciones de entrada y los fragmentos enmascarados se pasan a través del codificador para producir algunos estados ocultos finales, pero a diferencia de BERT, BART no añade una red feedforward final al final para predecir una palabra.
+
+2. La salida del codificador se pasa al decodificador, que debe predecir los tokens enmascarados y cualquier token no corrompido de la salida del codificador. Esto proporciona un contexto adicional para ayudar al decodificador a restaurar el texto original. La salida del decodificador se pasa a una cabeza de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta, que es simplemente el token desplazado hacia la derecha.
+
+¿Listo para probar la sumarización? ¡Consulta nuestra guía completa de [Generación de resúmenes](tasks/summarization) para aprender cómo ajustar T5 y usarlo para inferencia!
+
+
+diff --git a/README_te.md b/README_te.md index 2c0b97dada67ed..8da790e1820460 100644 --- a/README_te.md +++ b/README_te.md @@ -59,6 +59,7 @@ limitations under the License. తెలుగు | Français | Deutsch | + Tiếng Việt |
diff --git a/README_vi.md b/README_vi.md new file mode 100644 index 00000000000000..9ccd5118b6e4f4 --- /dev/null +++ b/README_vi.md @@ -0,0 +1,579 @@ + + +
+ ![]() +
+
+
+
+
+ 
 +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+ ![]() +
+
+
+ ![]() +
+
+
+ English | + 简体中文 | + 繁體中文 | + 한국어 | + Español | + 日本語 | + हिन्दी | + Русский | + Рortuguês | + తెలుగు | + Français | + Deutsch | + Tiếng việt | +
+ + ++
Công nghệ Học máy tiên tiến cho JAX, PyTorch và TensorFlow
+ + +
+  +
+
+
+🤗 Transformers cung cấp hàng ngàn mô hình được huấn luyện trước để thực hiện các nhiệm vụ trên các modalities khác nhau như văn bản, hình ảnh và âm thanh.
+
+Các mô hình này có thể được áp dụng vào:
+
+* 📝 Văn bản, cho các nhiệm vụ như phân loại văn bản, trích xuất thông tin, trả lời câu hỏi, tóm tắt, dịch thuật và sinh văn bản, trong hơn 100 ngôn ngữ.
+* 🖼️ Hình ảnh, cho các nhiệm vụ như phân loại hình ảnh, nhận diện đối tượng và phân đoạn.
+* 🗣️ Âm thanh, cho các nhiệm vụ như nhận dạng giọng nói và phân loại âm thanh.
+
+Các mô hình Transformer cũng có thể thực hiện các nhiệm vụ trên **nhiều modalities kết hợp**, như trả lời câu hỏi về bảng, nhận dạng ký tự quang học, trích xuất thông tin từ tài liệu quét, phân loại video và trả lời câu hỏi hình ảnh.
+
+🤗 Transformers cung cấp các API để tải xuống và sử dụng nhanh chóng các mô hình được huấn luyện trước đó trên văn bản cụ thể, điều chỉnh chúng trên tập dữ liệu của riêng bạn và sau đó chia sẻ chúng với cộng đồng trên [model hub](https://huggingface.co/models) của chúng tôi. Đồng thời, mỗi module python xác định một kiến trúc là hoàn toàn độc lập và có thể được sửa đổi để cho phép thực hiện nhanh các thí nghiệm nghiên cứu.
+
+🤗 Transformers được hỗ trợ bởi ba thư viện học sâu phổ biến nhất — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) và [TensorFlow](https://www.tensorflow.org/) — với tích hợp mượt mà giữa chúng. Việc huấn luyện mô hình của bạn với một thư viện trước khi tải chúng để sử dụng trong suy luận với thư viện khác là rất dễ dàng.
+
+## Các demo trực tuyến
+
+Bạn có thể kiểm tra hầu hết các mô hình của chúng tôi trực tiếp trên trang của chúng từ [model hub](https://huggingface.co/models). Chúng tôi cũng cung cấp [dịch vụ lưu trữ mô hình riêng tư, phiên bản và API suy luận](https://huggingface.co/pricing) cho các mô hình công khai và riêng tư.
+
+Dưới đây là một số ví dụ:
+
+Trong Xử lý Ngôn ngữ Tự nhiên:
+- [Hoàn thành từ vụng về từ với BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Nhận dạng thực thể đặt tên với Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Tạo văn bản tự nhiên với Mistral](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
+- [Suy luận Ngôn ngữ Tự nhiên với RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Tóm tắt văn bản với BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Trả lời câu hỏi với DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Dịch văn bản với T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+Trong Thị giác Máy tính:
+- [Phân loại hình ảnh với ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Phát hiện đối tượng với DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Phân đoạn ngữ nghĩa với SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Phân đoạn toàn diện với Mask2Former](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
+- [Ước lượng độ sâu với Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
+- [Phân loại video với VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Phân đoạn toàn cầu với OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+Trong âm thanh:
+- [Nhận dạng giọng nói tự động với Whisper](https://huggingface.co/openai/whisper-large-v3)
+- [Phát hiện từ khóa với Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Phân loại âm thanh với Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+Trong các nhiệm vụ đa phương thức:
+- [Trả lời câu hỏi về bảng với TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Trả lời câu hỏi hình ảnh với ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Mô tả hình ảnh với LLaVa](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- [Phân loại hình ảnh không cần nhãn với SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384)
+- [Trả lời câu hỏi văn bản tài liệu với LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Phân loại video không cần nhãn với X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+- [Phát hiện đối tượng không cần nhãn với OWLv2](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
+- [Phân đoạn hình ảnh không cần nhãn với CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)
+- [Tạo mặt nạ tự động với SAM](https://huggingface.co/docs/transformers/model_doc/sam)
+
+
+## 100 dự án sử dụng Transformers
+
+Transformers không chỉ là một bộ công cụ để sử dụng các mô hình được huấn luyện trước: đó là một cộng đồng các dự án xây dựng xung quanh nó và Hugging Face Hub. Chúng tôi muốn Transformers giúp các nhà phát triển, nhà nghiên cứu, sinh viên, giáo sư, kỹ sư và bất kỳ ai khác xây dựng những dự án mơ ước của họ.
+
+Để kỷ niệm 100.000 sao của transformers, chúng tôi đã quyết định tập trung vào cộng đồng và tạo ra trang [awesome-transformers](./awesome-transformers.md) liệt kê 100 dự án tuyệt vời được xây dựng xung quanh transformers.
+
+Nếu bạn sở hữu hoặc sử dụng một dự án mà bạn tin rằng nên được thêm vào danh sách, vui lòng mở một PR để thêm nó!
+
+## Nếu bạn đang tìm kiếm hỗ trợ tùy chỉnh từ đội ngũ Hugging Face
+
+
+  +
++ +## Hành trình nhanh + +Để ngay lập tức sử dụng một mô hình trên một đầu vào cụ thể (văn bản, hình ảnh, âm thanh, ...), chúng tôi cung cấp API `pipeline`. Pipelines nhóm một mô hình được huấn luyện trước với quá trình tiền xử lý đã được sử dụng trong quá trình huấn luyện của mô hình đó. Dưới đây là cách sử dụng nhanh một pipeline để phân loại văn bản tích cực so với tiêu cực: + +```python +>>> from transformers import pipeline + +# Cấp phát một pipeline cho phân tích cảm xúc +>>> classifier = pipeline('sentiment-analysis') +>>> classifier('We are very happy to introduce pipeline to the transformers repository.') +[{'label': 'POSITIVE', 'score': 0.9996980428695679}] +``` + +Dòng code thứ hai tải xuống và lưu trữ bộ mô hình được huấn luyện được sử dụng bởi pipeline, trong khi dòng thứ ba đánh giá nó trên văn bản đã cho. Ở đây, câu trả lời là "tích cực" với độ tin cậy là 99,97%. + +Nhiều nhiệm vụ có sẵn một `pipeline` được huấn luyện trước, trong NLP nhưng cũng trong thị giác máy tính và giọng nói. Ví dụ, chúng ta có thể dễ dàng trích xuất các đối tượng được phát hiện trong một hình ảnh: + +``` python +>>> import requests +>>> from PIL import Image +>>> from transformers import pipeline + +# Tải xuống một hình ảnh với những con mèo dễ thương +>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" +>>> image_data = requests.get(url, stream=True).raw +>>> image = Image.open(image_data) + +# Cấp phát một pipeline cho phát hiện đối tượng +>>> object_detector = pipeline('object-detection') +>>> object_detector(image) +[{'score': 0.9982201457023621, + 'label': 'remote', + 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}}, + {'score': 0.9960021376609802, + 'label': 'remote', + 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}}, + {'score': 0.9954745173454285, + 'label': 'couch', + 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}}, + {'score': 0.9988006353378296, + 'label': 'cat', + 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}}, + {'score': 0.9986783862113953, + 'label': 'cat', + 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}] +``` + +Ở đây, chúng ta nhận được một danh sách các đối tượng được phát hiện trong hình ảnh, với một hộp bao quanh đối tượng và một điểm đánh giá độ tin cậy. Đây là hình ảnh gốc ở bên trái, với các dự đoán hiển thị ở bên phải: + +
+  +
+  +
+
+
+Bạn có thể tìm hiểu thêm về các nhiệm vụ được hỗ trợ bởi API `pipeline` trong [hướng dẫn này](https://huggingface.co/docs/transformers/task_summary).
+
+Ngoài `pipeline`, để tải xuống và sử dụng bất kỳ mô hình được huấn luyện trước nào cho nhiệm vụ cụ thể của bạn, chỉ cần ba dòng code. Đây là phiên bản PyTorch:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+Và đây là mã tương đương cho TensorFlow:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Tokenizer là thành phần chịu trách nhiệm cho việc tiền xử lý mà mô hình được huấn luyện trước mong đợi và có thể được gọi trực tiếp trên một chuỗi đơn (như trong các ví dụ trên) hoặc một danh sách. Nó sẽ xuất ra một từ điển mà bạn có thể sử dụng trong mã phụ thuộc hoặc đơn giản là truyền trực tiếp cho mô hình của bạn bằng cách sử dụng toán tử ** để giải nén đối số.
+
+Chính mô hình là một [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) thông thường hoặc một [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (tùy thuộc vào backend của bạn) mà bạn có thể sử dụng như bình thường. [Hướng dẫn này](https://huggingface.co/docs/transformers/training) giải thích cách tích hợp một mô hình như vậy vào một vòng lặp huấn luyện cổ điển PyTorch hoặc TensorFlow, hoặc cách sử dụng API `Trainer` của chúng tôi để tinh chỉnh nhanh chóng trên một bộ dữ liệu mới.
+
+## Tại sao tôi nên sử dụng transformers?
+
+1. Các mô hình tiên tiến dễ sử dụng:
+ - Hiệu suất cao trong việc hiểu và tạo ra ngôn ngữ tự nhiên, thị giác máy tính và âm thanh.
+ - Ngưỡng vào thấp cho giảng viên và người thực hành.
+ - Ít trừu tượng dành cho người dùng với chỉ ba lớp học.
+ - Một API thống nhất để sử dụng tất cả các mô hình được huấn luyện trước của chúng tôi.
+
+2. Giảm chi phí tính toán, làm giảm lượng khí thải carbon:
+ - Các nhà nghiên cứu có thể chia sẻ các mô hình đã được huấn luyện thay vì luôn luôn huấn luyện lại.
+ - Người thực hành có thể giảm thời gian tính toán và chi phí sản xuất.
+ - Hàng chục kiến trúc với hơn 400.000 mô hình được huấn luyện trước trên tất cả các phương pháp.
+
+3. Lựa chọn framework phù hợp cho mọi giai đoạn của mô hình:
+ - Huấn luyện các mô hình tiên tiến chỉ trong 3 dòng code.
+ - Di chuyển một mô hình duy nhất giữa các framework TF2.0/PyTorch/JAX theo ý muốn.
+ - Dễ dàng chọn framework phù hợp cho huấn luyện, đánh giá và sản xuất.
+
+4. Dễ dàng tùy chỉnh một mô hình hoặc một ví dụ theo nhu cầu của bạn:
+ - Chúng tôi cung cấp các ví dụ cho mỗi kiến trúc để tái tạo kết quả được công bố bởi các tác giả gốc.
+ - Các thành phần nội tại của mô hình được tiết lộ một cách nhất quán nhất có thể.
+ - Các tệp mô hình có thể được sử dụng độc lập với thư viện để thực hiện các thử nghiệm nhanh chóng.
+
+## Tại sao tôi không nên sử dụng transformers?
+
+- Thư viện này không phải là một bộ công cụ modul cho các khối xây dựng mạng neural. Mã trong các tệp mô hình không được tái cấu trúc với các trừu tượng bổ sung một cách cố ý, để các nhà nghiên cứu có thể lặp nhanh trên từng mô hình mà không cần đào sâu vào các trừu tượng/tệp bổ sung.
+- API huấn luyện không được thiết kế để hoạt động trên bất kỳ mô hình nào, mà được tối ưu hóa để hoạt động với các mô hình được cung cấp bởi thư viện. Đối với vòng lặp học máy chung, bạn nên sử dụng một thư viện khác (có thể là [Accelerate](https://huggingface.co/docs/accelerate)).
+- Mặc dù chúng tôi cố gắng trình bày càng nhiều trường hợp sử dụng càng tốt, nhưng các tập lệnh trong thư mục [examples](https://github.com/huggingface/transformers/tree/main/examples) chỉ là ví dụ. Dự kiến rằng chúng sẽ không hoạt động ngay tức khắc trên vấn đề cụ thể của bạn và bạn sẽ phải thay đổi một số dòng mã để thích nghi với nhu cầu của bạn.
+
+## Cài đặt
+
+### Sử dụng pip
+
+Thư viện này được kiểm tra trên Python 3.8+, Flax 0.4.1+, PyTorch 1.11+ và TensorFlow 2.6+.
+
+Bạn nên cài đặt 🤗 Transformers trong một [môi trường ảo Python](https://docs.python.org/3/library/venv.html). Nếu bạn chưa quen với môi trường ảo Python, hãy xem [hướng dẫn sử dụng](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+Trước tiên, tạo một môi trường ảo với phiên bản Python bạn sẽ sử dụng và kích hoạt nó.
+
+Sau đó, bạn sẽ cần cài đặt ít nhất một trong số các framework Flax, PyTorch hoặc TensorFlow.
+Vui lòng tham khảo [trang cài đặt TensorFlow](https://www.tensorflow.org/install/), [trang cài đặt PyTorch](https://pytorch.org/get-started/locally/#start-locally) và/hoặc [Flax](https://github.com/google/flax#quick-install) và [Jax](https://github.com/google/jax#installation) để biết lệnh cài đặt cụ thể cho nền tảng của bạn.
+
+Khi đã cài đặt một trong các backend đó, 🤗 Transformers có thể được cài đặt bằng pip như sau:
+
+```bash
+pip install transformers
+```
+
+Nếu bạn muốn thực hiện các ví dụ hoặc cần phiên bản mới nhất của mã và không thể chờ đợi cho một phiên bản mới, bạn phải [cài đặt thư viện từ nguồn](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Với conda
+
+🤗 Transformers có thể được cài đặt bằng conda như sau:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_GHI CHÚ:_** Cài đặt `transformers` từ kênh `huggingface` đã bị lỗi thời.
+
+Hãy làm theo trang cài đặt của Flax, PyTorch hoặc TensorFlow để xem cách cài đặt chúng bằng conda.
+
+> **_GHI CHÚ:_** Trên Windows, bạn có thể được yêu cầu kích hoạt Chế độ phát triển để tận dụng việc lưu cache. Nếu điều này không phải là một lựa chọn cho bạn, hãy cho chúng tôi biết trong [vấn đề này](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Kiến trúc mô hình
+
+**[Tất cả các điểm kiểm tra mô hình](https://huggingface.co/models)** được cung cấp bởi 🤗 Transformers được tích hợp một cách mượt mà từ trung tâm mô hình huggingface.co [model hub](https://huggingface.co/models), nơi chúng được tải lên trực tiếp bởi [người dùng](https://huggingface.co/users) và [tổ chức](https://huggingface.co/organizations).
+
+Số lượng điểm kiểm tra hiện tại: 
+
+🤗 Transformers hiện đang cung cấp các kiến trúc sau đây (xem [ở đây](https://huggingface.co/docs/transformers/model_summary) để có một tóm tắt tổng quan về mỗi kiến trúc):
+
+1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (từ Google Research và Toyota Technological Institute tại Chicago) được phát hành với bài báo [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), của Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (từ Google Research) được phát hành với bài báo [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) của Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (từ BAAI) được phát hành với bài báo [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) của Chen, Zhongzhi và Liu, Guang và Zhang, Bo-Wen và Ye, Fulong và Yang, Qinghong và Wu, Ledell.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (từ MIT) được phát hành với bài báo [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) của Yuan Gong, Yu-An Chung, James Glass.
+1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (từ Đại học Tsinghua) được phát hành với bài báo [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) của Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
+1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (từ Suno) được phát hành trong kho lưu trữ [suno-ai/bark](https://github.com/suno-ai/bark) bởi đội ngũ Suno AI.
+1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (từ Facebook) được phát hành với bài báo [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) của Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov và Luke Zettlemoyer.
+1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (từ École polytechnique) được phát hành với bài báo [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) của Moussa Kamal Eddine, Antoine J.-P. Tixier và Michalis Vazirgiannis.
+1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (từ VinAI Research) được phát hành với bài báo [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) của Nguyen Luong Tran, Duong Minh Le và Dat Quoc Nguyen.
+1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (từ Microsoft) được phát hành với bài báo [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) của Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (từ Google) được phát hành với bài báo [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) của Jacob Devlin, Ming-Wei Chang, Kenton Lee và Kristina Toutanova.
+1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (từ Google) được phát hành với bài báo [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) của Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (từ VinAI Research) được phát hành với bài báo [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) của Dat Quoc Nguyen, Thanh Vu và Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (từ Google Research) được phát hành với bài báo [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) của Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang và Amr Ahmed.
+1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (từ Google Research) được phát hành với bài báo [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) của Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang và Amr Ahmed.
+1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (từ Microsoft Research AI4Science) được phát hành với bài báo [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
+1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (từ Google AI) được phát hành với bài báo [Big Transfer (BiT): Học biểu diễn hình ảnh tổng quát](https://arxiv.org/abs/1912.11370) của Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (từ Facebook) được phát hành với bài báo [Công thức xây dựng một chatbot miền mở](https://arxiv.org/abs/2004.13637) của Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (từ Facebook) được phát hành với bài báo [Công thức xây dựng một chatbot miền mở](https://arxiv.org/abs/2004.13637) của Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (từ Salesforce) được phát hành với bài báo [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) của Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (từ Salesforce) được phát hành với bài báo [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
+1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (từ BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
+1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (từ Alexa) được phát hành với bài báo [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (từ Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) được phát hành với bài báo [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
+1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (từ NAVER CLOVA) được phát hành với bài báo [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
+1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (từ Google Research) được phát hành với bài báo [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (từ Inria/Facebook/Sorbonne) được phát hành với bài báo [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (từ Google Research) được phát hành với bài báo [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (từ OFA-Sys) được phát hành với bài báo [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (từ LAION-AI) được phát hành với bài báo [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
+1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (từ OpenAI) được phát hành với bài báo [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (từ University of Göttingen) được phát hành với bài báo [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** được phát hành với bài báo [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (từ Salesforce) được phát hành với bài báo [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (từ MetaAI) được phát hành với bài báo [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
+1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (từ Microsoft Research Asia) được phát hành với bài báo [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (từ YituTech) được phát hành với bài báo [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (từ Facebook AI) được phát hành với bài báo [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (từ Facebook AI) được phát hành với bài báo [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (từ Tsinghua University) được phát hành với bài báo [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (từ OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
+1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (từ Salesforce) được phát hành với bài báo [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (từ Microsoft) được phát hành với bài báo [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (từ Facebook) được phát hành với bài báo [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (từ Microsoft) được phát hành với bài báo [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (từ Microsoft) được phát hành với bài báo [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (từ Berkeley/Facebook/Google) được phát hành với bài báo [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (từ SenseTime Research) được phát hành với bài báo [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (từ Facebook) được phát hành với bài báo [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (từ Google AI) được phát hành với bài báo [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (từ University of Hong Kong and TikTok) được phát hành với bài báo [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
+1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (từ The University of Texas at Austin) được phát hành với bài báo [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (từ Facebook) được phát hành với bài báo [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (từ Microsoft Research) được phát hành với bài báo [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (từ SHI Labs) được phát hành với bài báo [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
+1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (từ Meta AI) được phát hành với bài báo [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
+1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (từ HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
+1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (từ Microsoft Research) được phát hành với bài báo [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (từ NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (từ Facebook) được phát hành với bài báo [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (từ Intel Labs) được phát hành với bài báo [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (từ Snap Research) được phát hành với bài báo [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
+1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (từ Google Brain) được phát hành với bài báo [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
+1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (từ Google Research/Stanford University) được phát hành với bài báo [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (từ Meta AI) được phát hành với bài báo [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
+1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (từ Google Research) được phát hành với bài báo [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (từ Baidu) được phát hành với bài báo [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (từ Baidu) được phát hành với bài báo [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
+1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (từ Meta AI) are transformer protein language models. **ESM-1b** was được phát hành với bài báo [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was được phát hành với bài báo [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were được phát hành với bài báo [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
+1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (từ Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
+1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (từ ESPnet) được phát hành với bài báo [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (từ Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (từ Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (từ CNRS) được phát hành với bài báo [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (từ Facebook AI) được phát hành với bài báo [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (từ Google Research) được phát hành với bài báo [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (từ Microsoft Research) được phát hành với bài báo [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (từ CMU/Google Brain) được phát hành với bài báo [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (từ ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. được phát hành với bài báo [blog post](https://www.adept.ai/blog/fuyu-8b)
+1. **[Gemma](https://huggingface.co/docs/transformers/main/model_doc/gemma)** (từ Google) được phát hành với bài báo [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
+1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (từ Microsoft Research) được phát hành với bài báo [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
+1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (từ KAIST) được phát hành với bài báo [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (từ OpenAI) được phát hành với bài báo [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (từ EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (từ EleutherAI) được phát hành với bài báo [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (từ ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
+1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (từ OpenAI) được phát hành với bài báo [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (từ EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (từ AI-Sweden) được phát hành với bài báo [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
+1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (từ BigCode) được phát hành với bài báo [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (từ Microsoft) được phát hành với bài báo [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (từ UCSD, NVIDIA) được phát hành với bài báo [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (từ Allegro.pl, AGH University of Science and Technology) được phát hành với bài báo [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
+1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (từ Facebook) được phát hành với bài báo [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (từ Berkeley) được phát hành với bài báo [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (từ HuggingFace) được phát hành với bài báo [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
+1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (từ OpenAI) được phát hành với bài báo [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (từ Beihang University, UC Berkeley, Rutgers University, SEDD Company) được phát hành với bài báo [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (từ Salesforce) được phát hành với bài báo [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (từ OpenAI) được phát hành với bài báo [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (từ Microsoft Research Asia) được phát hành với bài báo [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (từ AllenAI) được phát hành với bài báo [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (từ Meta AI) được phát hành với bài báo [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (từ South China University of Technology) được phát hành với bài báo [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (từ The FAIR team of Meta AI) được phát hành với bài báo [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
+1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (từ The FAIR team of Meta AI) được phát hành với bài báo [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
+1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (từ Microsoft Research & University of Wisconsin-Madison) được phát hành với bài báo [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (từ AllenAI) được phát hành với bài báo [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (từ Google AI) được phát hành với bài báo [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (từ Studio Ousia) được phát hành với bài báo [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (từ UNC Chapel Hill) được phát hành với bài báo [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (từ Facebook) được phát hành với bài báo [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (từ Facebook) được phát hành với bài báo [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (từ Google) được phát hành với bài báo [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
+1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (từ Microsoft Research Asia) được phát hành với bài báo [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (từ FAIR and UIUC) được phát hành với bài báo [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (từ Meta and UIUC) được phát hành với bài báo [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (từ Google AI) được phát hành với bài báo [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (từ Facebook) được phát hành với bài báo [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (từ Facebook) được phát hành với bài báo [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (từ Meta/USC/CMU/SJTU) được phát hành với bài báo [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (từ NVIDIA) được phát hành với bài báo [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (từ NVIDIA) được phát hành với bài báo [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (từ Alibaba Research) được phát hành với bài báo [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
+1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (từ Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
+1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (từ Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
+1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (từ Studio Ousia) được phát hành với bài báo [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (từ Facebook) được phát hành với bài báo [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
+1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (từ CMU/Google Brain) được phát hành với bài báo [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (từ Google Inc.) được phát hành với bài báo [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
+1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (từ Google Inc.) được phát hành với bài báo [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
+1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (từ Apple) được phát hành với bài báo [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (từ Apple) được phát hành với bài báo [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (từ Microsoft Research) được phát hành với bài báo [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (từ MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
+1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
+1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (từ Google AI) được phát hành với bài báo [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (từ Meta) được phát hành với bài báo [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (từ RUC AI Box) được phát hành với bài báo [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (từ SHI Labs) được phát hành với bài báo [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
+1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (từ Huawei Noah’s Ark Lab) được phát hành với bài báo [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (từ Meta) được phát hành với bài báo [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (từ Meta) được phát hành với bài báo [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (từ Meta AI) được phát hành với bài báo [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
+1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (từ SHI Labs) được phát hành với bài báo [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (từ [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
+1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (từ Meta AI) được phát hành với bài báo [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (từ Google AI) được phát hành với bài báo [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (từ Google AI) được phát hành với bài báo [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
+1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (từ IBM Research) được phát hành với bài báo [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
+1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (từ IBM) được phát hành với bài báo [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
+1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (từ Google) được phát hành với bài báo [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (từ Google) được phát hành với bài báo [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (từ Deepmind) được phát hành với bài báo [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (từ ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (từ Microsoft) được phát hành với bài báos - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
+1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (từ VinAI Research) được phát hành với bài báo [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (từ Google) được phát hành với bài báo [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (từ UCLA NLP) được phát hành với bài báo [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (từ Sea AI Labs) được phát hành với bài báo [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** được phát hành với bài báo [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
+1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (từ Microsoft Research) được phát hành với bài báo [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (từ Nanjing University, The University of Hong Kong etc.) được phát hành với bài báo [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
+1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (từ NVIDIA) được phát hành với bài báo [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (từ the Qwen team, Alibaba Group) được phát hành với bài báo [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (từ Facebook) được phát hành với bài báo [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (từ Google Research) được phát hành với bài báo [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (từ Google Research) được phát hành với bài báo [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (từ META Platforms) được phát hành với bài báo [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (từ Google Research) được phát hành với bài báo [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (từ Microsoft Research) được phát hành với bài báo [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (từ Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (từ Facebook) được phát hành với bài báo [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (từ WeChatAI) được phát hành với bài báo [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (từ ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (từ Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
+1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (từ Meta AI) được phát hành với bài báo [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
+1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (từ Meta AI) được phát hành với bài báo [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
+1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (từ NVIDIA) được phát hành với bài báo [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (từ Meta AI) được phát hành với bài báo [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (từ ASAPP) được phát hành với bài báo [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (từ ASAPP) được phát hành với bài báo [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (từ Google AI) được phát hành với bài báo [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
+1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (từ Microsoft Research) được phát hành với bài báo [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (từ Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (từ Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (từ Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (từ Berkeley) được phát hành với bài báo [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (từ Stability AI) được phát hành với bài báo [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
+1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (từ MBZUAI) được phát hành với bài báo [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (từ Microsoft) được phát hành với bài báo [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (từ Microsoft) được phát hành với bài báo [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (từ University of Würzburg) được phát hành với bài báo [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (từ Google) được phát hành với bài báo [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (từ Google AI) được phát hành với bài báo [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (từ Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (từ Microsoft Research) được phát hành với bài báo [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (từ Google AI) được phát hành với bài báo [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (từ Microsoft Research) được phát hành với bài báo [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (từ HuggingFace).
+1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (từ Facebook) được phát hành với bài báo [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
+1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (từ the University of California at Berkeley) được phát hành với bài báo [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (từ Google/CMU) được phát hành với bài báo [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (từ Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (từ UNC Chapel Hill) được phát hành với bài báo [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (từ Intel) được phát hành với bài báo [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (từ Google Research) được phát hành với bài báo [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (từ Google Research) được phát hành với bài báo [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
+1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (từ Microsoft Research) được phát hành với bài báo [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (từ Microsoft Research) được phát hành với bài báo [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (từ Kakao Corporation) được phát hành với bài báo [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
+1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (từ Peking University) được phát hành với bài báo [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
+1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (từ Tsinghua University and Nankai University) được phát hành với bài báo [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (từ Multimedia Computing Group, Nanjing University) được phát hành với bài báo [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (từ NAVER AI Lab/Kakao Enterprise/Kakao Brain) được phát hành với bài báo [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (từ University of Wisconsin–Madison) được phát hành với bài báo [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
+1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (từ Google AI) được phát hành với bài báo [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (từ UCLA NLP) được phát hành với bài báo [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (từ Google AI) được phát hành với bài báo [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (từ Meta AI) được phát hành với bài báo [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
+1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (từ Meta AI) được phát hành với bài báo [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (từ HUST-VL) được phát hành với bài báo [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
+1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (từ Meta AI) được phát hành với bài báo [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (từ Kakao Enterprise) được phát hành với bài báo [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
+1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (từ Google Research) được phát hành với bài báo [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
+1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (từ Facebook AI) được phát hành với bài báo [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (từ Meta AI) được phát hành với bài báo [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
+1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (từ Facebook AI) được phát hành với bài báo [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (từ Facebook AI) được phát hành với bài báo [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (từ Microsoft Research) được phát hành với bài báo [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (từ OpenAI) được phát hành với bài báo [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
+1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (từ Microsoft Research) được phát hành với bài báo [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (từ Meta AI) được phát hành với bài báo [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
+1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (từ Facebook AI) được phát hành với bài báo [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (từ Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (từ Microsoft Research) được phát hành với bài báo [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (từ Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (từ Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (từ Meta AI) được phát hành với bài báo [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
+1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (từ Google/CMU) được phát hành với bài báo [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (từ Facebook AI) được phát hành với bài báo [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (từ Facebook AI) được phát hành với bài báo [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (từ Huazhong University of Science & Technology) được phát hành với bài báo [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. Muốn đóng góp một mô hình mới? Chúng tôi đã thêm một **hướng dẫn chi tiết và mẫu** để hướng dẫn bạn trong quá trình thêm một mô hình mới. Bạn có thể tìm thấy chúng trong thư mục [`templates`](./templates) của kho lưu trữ. Hãy chắc chắn kiểm tra [hướng dẫn đóng góp](./CONTRIBUTING.md) và liên hệ với người duy trì hoặc mở một vấn đề để thu thập phản hồi trước khi bắt đầu PR của bạn.
+
+Để kiểm tra xem mỗi mô hình có một phiên bản thực hiện trong Flax, PyTorch hoặc TensorFlow, hoặc có một tokenizer liên quan được hỗ trợ bởi thư viện 🤗 Tokenizers, vui lòng tham khảo [bảng này](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Những phiên bản này đã được kiểm tra trên một số tập dữ liệu (xem các tập lệnh ví dụ) và nên tương đương với hiệu suất của các phiên bản gốc. Bạn có thể tìm thấy thêm thông tin về hiệu suất trong phần Ví dụ của [tài liệu](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## Tìm hiểu thêm
+
+| Phần | Mô tả |
+|-|-|
+| [Tài liệu](https://huggingface.co/docs/transformers/) | Toàn bộ tài liệu API và hướng dẫn |
+| [Tóm tắt nhiệm vụ](https://huggingface.co/docs/transformers/task_summary) | Các nhiệm vụ được hỗ trợ bởi 🤗 Transformers |
+| [Hướng dẫn tiền xử lý](https://huggingface.co/docs/transformers/preprocessing) | Sử dụng lớp `Tokenizer` để chuẩn bị dữ liệu cho các mô hình |
+| [Huấn luyện và điều chỉnh](https://huggingface.co/docs/transformers/training) | Sử dụng các mô hình được cung cấp bởi 🤗 Transformers trong vòng lặp huấn luyện PyTorch/TensorFlow và API `Trainer` |
+| [Hướng dẫn nhanh: Điều chỉnh/sử dụng các kịch bản](https://github.com/huggingface/transformers/tree/main/examples) | Các kịch bản ví dụ để điều chỉnh mô hình trên nhiều nhiệm vụ khác nhau |
+| [Chia sẻ và tải lên mô hình](https://huggingface.co/docs/transformers/model_sharing) | Tải lên và chia sẻ các mô hình đã điều chỉnh của bạn với cộng đồng |
+
+## Trích dẫn
+
+Bây giờ chúng ta có một [bài báo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) mà bạn có thể trích dẫn cho thư viện 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 08007a4e110d62..a3394b00a658ea 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -77,6 +77,7 @@ checkpoint: 检查点
తెలుగు |
Français |
Deutsch |
+ Tiếng Việt |
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 07c3f8a40b92a6..024fecdcc6d6fc 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -89,6 +89,7 @@ user: 使用者
తెలుగు |
Français |
Deutsch |
+ Tiếng Việt |
From a44d2dc3a94cbbb44eccb1a60e1bf4a998b4d2b6 Mon Sep 17 00:00:00 2001
From: Michael  +
+ UDOP architecture. Taken from the original paper.
+
+## Usage tips
+
+- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
+- One can use [`UdopProcessor`] to prepare images and text for the model. By default, this class uses the Tesseract engine to extract a list of words
+and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either
+`apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/UDOP).
+
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+ - __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+ - forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+ - forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 027cf495466c50..6cdd561b41e1ba 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -856,6 +856,11 @@
"TvpConfig",
"TvpProcessor",
],
+ "models.udop": [
+ "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "UdopConfig",
+ "UdopProcessor",
+ ],
"models.umt5": ["UMT5Config"],
"models.unispeech": [
"UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1135,6 +1140,7 @@
_import_structure["models.speech_to_text"].append("Speech2TextTokenizer")
_import_structure["models.speecht5"].append("SpeechT5Tokenizer")
_import_structure["models.t5"].append("T5Tokenizer")
+ _import_structure["models.udop"].append("UdopTokenizer")
_import_structure["models.xglm"].append("XGLMTokenizer")
_import_structure["models.xlm_prophetnet"].append("XLMProphetNetTokenizer")
_import_structure["models.xlm_roberta"].append("XLMRobertaTokenizer")
@@ -1214,6 +1220,7 @@
_import_structure["models.splinter"].append("SplinterTokenizerFast")
_import_structure["models.squeezebert"].append("SqueezeBertTokenizerFast")
_import_structure["models.t5"].append("T5TokenizerFast")
+ _import_structure["models.udop"].append("UdopTokenizerFast")
_import_structure["models.whisper"].append("WhisperTokenizerFast")
_import_structure["models.xglm"].append("XGLMTokenizerFast")
_import_structure["models.xlm_roberta"].append("XLMRobertaTokenizerFast")
@@ -3411,6 +3418,15 @@
"TvpPreTrainedModel",
]
)
+ _import_structure["models.udop"].extend(
+ [
+ "UDOP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "UdopEncoderModel",
+ "UdopForConditionalGeneration",
+ "UdopModel",
+ "UdopPreTrainedModel",
+ ],
+ )
_import_structure["models.umt5"].extend(
[
"UMT5EncoderModel",
@@ -5640,6 +5656,7 @@
TvpConfig,
TvpProcessor,
)
+ from .models.udop import UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP, UdopConfig, UdopProcessor
from .models.umt5 import UMT5Config
from .models.unispeech import (
UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5915,6 +5932,7 @@
from .models.speech_to_text import Speech2TextTokenizer
from .models.speecht5 import SpeechT5Tokenizer
from .models.t5 import T5Tokenizer
+ from .models.udop import UdopTokenizer
from .models.xglm import XGLMTokenizer
from .models.xlm_prophetnet import XLMProphetNetTokenizer
from .models.xlm_roberta import XLMRobertaTokenizer
@@ -5987,6 +6005,7 @@
from .models.splinter import SplinterTokenizerFast
from .models.squeezebert import SqueezeBertTokenizerFast
from .models.t5 import T5TokenizerFast
+ from .models.udop import UdopTokenizerFast
from .models.whisper import WhisperTokenizerFast
from .models.xglm import XGLMTokenizerFast
from .models.xlm_roberta import XLMRobertaTokenizerFast
@@ -7827,6 +7846,13 @@
TvpModel,
TvpPreTrainedModel,
)
+ from .models.udop import (
+ UDOP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ UdopEncoderModel,
+ UdopForConditionalGeneration,
+ UdopModel,
+ UdopPreTrainedModel,
+ )
from .models.umt5 import (
UMT5EncoderModel,
UMT5ForConditionalGeneration,
diff --git a/src/transformers/convert_slow_tokenizer.py b/src/transformers/convert_slow_tokenizer.py
index c44592f8a0f9fb..707bfae89db56f 100644
--- a/src/transformers/convert_slow_tokenizer.py
+++ b/src/transformers/convert_slow_tokenizer.py
@@ -1039,6 +1039,17 @@ def post_processor(self):
)
+class UdopConverter(SpmConverter):
+ def post_processor(self):
+ return processors.TemplateProcessing(
+ single=["$A", ""],
+ pair=["$A", "", "$B", ""],
+ special_tokens=[
+ ("", self.original_tokenizer.convert_tokens_to_ids("")),
+ ],
+ )
+
+
class WhisperConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
@@ -1471,6 +1482,7 @@ def converted(self) -> Tokenizer:
"SeamlessM4TTokenizer": SeamlessM4TConverter,
"SqueezeBertTokenizer": BertConverter,
"T5Tokenizer": T5Converter,
+ "UdopTokenizer": UdopConverter,
"WhisperTokenizer": WhisperConverter,
"XLMRobertaTokenizer": XLMRobertaConverter,
"XLNetTokenizer": XLNetConverter,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index ebb3db25fb96be..89ca6ab2b8660c 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -220,6 +220,7 @@
trocr,
tvlt,
tvp,
+ udop,
umt5,
unispeech,
unispeech_sat,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 7bc637f3e1060a..87ff925e55eaa1 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -231,6 +231,7 @@
("trocr", "TrOCRConfig"),
("tvlt", "TvltConfig"),
("tvp", "TvpConfig"),
+ ("udop", "UdopConfig"),
("umt5", "UMT5Config"),
("unispeech", "UniSpeechConfig"),
("unispeech-sat", "UniSpeechSatConfig"),
@@ -454,6 +455,7 @@
("transfo-xl", "TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("tvlt", "TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("tvp", "TVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("udop", "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("univnet", "UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -715,6 +717,7 @@
("trocr", "TrOCR"),
("tvlt", "TVLT"),
("tvp", "TVP"),
+ ("udop", "UDOP"),
("ul2", "UL2"),
("umt5", "UMT5"),
("unispeech", "UniSpeech"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index aef894a425bae1..50e9266cdee161 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -108,6 +108,7 @@
("timesformer", "VideoMAEImageProcessor"),
("tvlt", "TvltImageProcessor"),
("tvp", "TvpImageProcessor"),
+ ("udop", "LayoutLMv3ImageProcessor"),
("upernet", "SegformerImageProcessor"),
("van", "ConvNextImageProcessor"),
("videomae", "VideoMAEImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 05b519d2bcd16b..0d28d224f19106 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -219,6 +219,7 @@
("transfo-xl", "TransfoXLModel"),
("tvlt", "TvltModel"),
("tvp", "TvpModel"),
+ ("udop", "UdopModel"),
("umt5", "UMT5Model"),
("unispeech", "UniSpeechModel"),
("unispeech-sat", "UniSpeechSatModel"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 2c21f1cd529c74..d586068fb9c095 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -418,6 +418,13 @@
("tapex", ("TapexTokenizer", None)),
("transfo-xl", ("TransfoXLTokenizer", None)),
("tvp", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "udop",
+ (
+ "UdopTokenizer" if is_sentencepiece_available() else None,
+ "UdopTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
(
"umt5",
(
diff --git a/src/transformers/models/udop/__init__.py b/src/transformers/models/udop/__init__.py
new file mode 100644
index 00000000000000..5066fde6af1d15
--- /dev/null
+++ b/src/transformers/models/udop/__init__.py
@@ -0,0 +1,98 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_sentencepiece_available,
+ is_tokenizers_available,
+ is_torch_available,
+)
+
+
+_import_structure = {
+ "configuration_udop": ["UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP", "UdopConfig"],
+ "processing_udop": ["UdopProcessor"],
+}
+
+try:
+ if not is_sentencepiece_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_udop"] = ["UdopTokenizer"]
+
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_udop_fast"] = ["UdopTokenizerFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_udop"] = [
+ "UDOP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "UdopForConditionalGeneration",
+ "UdopPreTrainedModel",
+ "UdopModel",
+ "UdopEncoderModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_udop import UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP, UdopConfig
+ from .processing_udop import UdopProcessor
+
+ try:
+ if not is_sentencepiece_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_udop import UdopTokenizer
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_udop_fast import UdopTokenizerFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_udop import (
+ UDOP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ UdopEncoderModel,
+ UdopForConditionalGeneration,
+ UdopModel,
+ UdopPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/udop/configuration_udop.py b/src/transformers/models/udop/configuration_udop.py
new file mode 100644
index 00000000000000..8647a7bae29acf
--- /dev/null
+++ b/src/transformers/models/udop/configuration_udop.py
@@ -0,0 +1,162 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" UDOP model configuration"""
+
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/config.json",
+}
+
+
+class UdopConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`UdopForConditionalGeneration`]. It is used to
+ instantiate a UDOP model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the UDOP
+ [microsoft/udop-large](https://huggingface.co/microsoft/udop-large) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Arguments:
+ vocab_size (`int`, *optional*, defaults to 33201):
+ Vocabulary size of the UDOP model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`UdopForConditionalGeneration`].
+ d_model (`int`, *optional*, defaults to 1024):
+ Size of the encoder layers and the pooler layer.
+ d_kv (`int`, *optional*, defaults to 64):
+ Size of the key, query, value projections per attention head. The `inner_dim` of the projection layer will
+ be defined as `num_heads * d_kv`.
+ d_ff (`int`, *optional*, defaults to 4096):
+ Size of the intermediate feed forward layer in each `UdopBlock`.
+ num_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder and decoder.
+ num_decoder_layers (`int`, *optional*):
+ Number of hidden layers in the Transformer decoder. Will use the same value as `num_layers` if not set.
+ num_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder and decoder.
+ relative_attention_num_buckets (`int`, *optional*, defaults to 32):
+ The number of buckets to use for each attention layer.
+ relative_attention_max_distance (`int`, *optional*, defaults to 128):
+ The maximum distance of the longer sequences for the bucket separation.
+ relative_bias_args (`List[dict]`, *optional*, defaults to `[{'type': '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}]`):
+ A list of dictionaries containing the arguments for the relative bias layers.
+ dropout_rate (`float`, *optional*, defaults to 0.1):
+ The ratio for all dropout layers.
+ layer_norm_epsilon (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ initializer_factor (`float`, *optional*, defaults to 1.0):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+ feed_forward_proj (`string`, *optional*, defaults to `"relu"`):
+ Type of feed forward layer to be used. Should be one of `"relu"` or `"gated-gelu"`. Udopv1.1 uses the
+ `"gated-gelu"` feed forward projection. Original Udop uses `"relu"`.
+ is_encoder_decoder (`bool`, *optional*, defaults to `True`):
+ Whether the model should behave as an encoder/decoder or not.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models).
+ pad_token_id (`int`, *optional*, defaults to 0):
+ The id of the padding token in the vocabulary.
+ eos_token_id (`int`, *optional*, defaults to 1):
+ The id of the end-of-sequence token in the vocabulary.
+ max_2d_position_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum absolute position embeddings for relative position encoding.
+ image_size (`int`, *optional*, defaults to 224):
+ The size of the input images.
+ patch_size (`int`, *optional*, defaults to 16):
+ The patch size used by the vision encoder.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of channels in the input images.
+ """
+
+ model_type = "udop"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ attribute_map = {"hidden_size": "d_model", "num_attention_heads": "num_heads", "num_hidden_layers": "num_layers"}
+
+ def __init__(
+ self,
+ vocab_size=33201,
+ d_model=1024,
+ d_kv=64,
+ d_ff=4096,
+ num_layers=24,
+ num_decoder_layers=None,
+ num_heads=16,
+ relative_attention_num_buckets=32,
+ relative_attention_max_distance=128,
+ relative_bias_args=[{"type": "1d"}, {"type": "horizontal"}, {"type": "vertical"}],
+ dropout_rate=0.1,
+ layer_norm_epsilon=1e-6,
+ initializer_factor=1.0,
+ feed_forward_proj="relu",
+ is_encoder_decoder=True,
+ use_cache=True,
+ pad_token_id=0,
+ eos_token_id=1,
+ max_2d_position_embeddings=1024,
+ image_size=224,
+ patch_size=16,
+ num_channels=3,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.d_kv = d_kv
+ self.d_ff = d_ff
+ self.num_layers = num_layers
+ self.num_decoder_layers = (
+ num_decoder_layers if num_decoder_layers is not None else self.num_layers
+ ) # default = symmetry
+ self.num_heads = num_heads
+ self.relative_attention_num_buckets = relative_attention_num_buckets
+ self.relative_attention_max_distance = relative_attention_max_distance
+ self.dropout_rate = dropout_rate
+ self.layer_norm_epsilon = layer_norm_epsilon
+ self.initializer_factor = initializer_factor
+ self.feed_forward_proj = feed_forward_proj
+ self.use_cache = use_cache
+
+ # UDOP attributes
+ self.max_2d_position_embeddings = max_2d_position_embeddings
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ if not isinstance(relative_bias_args, list):
+ raise ValueError("`relative_bias_args` should be a list of dictionaries.")
+ self.relative_bias_args = relative_bias_args
+
+ act_info = self.feed_forward_proj.split("-")
+ self.dense_act_fn = act_info[-1]
+ self.is_gated_act = act_info[0] == "gated"
+
+ if len(act_info) > 1 and act_info[0] != "gated" or len(act_info) > 2:
+ raise ValueError(
+ f"`feed_forward_proj`: {feed_forward_proj} is not a valid activation function of the dense layer."
+ "Please make sure `feed_forward_proj` is of the format `gated-{ACT_FN}` or `{ACT_FN}`, e.g. "
+ "'gated-gelu' or 'relu'"
+ )
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ is_encoder_decoder=is_encoder_decoder,
+ **kwargs,
+ )
diff --git a/src/transformers/models/udop/convert_udop_to_hf.py b/src/transformers/models/udop/convert_udop_to_hf.py
new file mode 100644
index 00000000000000..f9cf07f1286bf1
--- /dev/null
+++ b/src/transformers/models/udop/convert_udop_to_hf.py
@@ -0,0 +1,213 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert UDOP checkpoints from the original repository. URL: https://github.com/microsoft/i-Code/tree/main/i-Code-Doc"""
+
+
+import argparse
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from torchvision import transforms as T
+
+from transformers import (
+ LayoutLMv3ImageProcessor,
+ UdopConfig,
+ UdopForConditionalGeneration,
+ UdopProcessor,
+ UdopTokenizer,
+)
+from transformers.image_utils import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
+
+
+def original_transform(image, image_size=224):
+ transform = T.Compose(
+ [
+ T.Resize([image_size, image_size]),
+ T.ToTensor(),
+ T.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD),
+ ]
+ )
+
+ image = transform(image)
+ return image
+
+
+def get_image():
+ filepath = hf_hub_download(
+ repo_id="hf-internal-testing/fixtures_docvqa", filename="document_2.png", repo_type="dataset"
+ )
+ image = Image.open(filepath).convert("RGB")
+
+ return image
+
+
+def prepare_dummy_inputs(tokenizer, image_processor):
+ prompt = "Question answering. What is the name of the company?"
+ prompt = "Question answering. In which year is the report made?"
+ prompt_ids = tokenizer.encode(prompt, add_special_tokens=False)
+
+ image = get_image()
+ # words, boxes = apply_tesseract(image, lang=None)
+ # fmt: off
+ words = ['7', 'ITC', 'Limited', 'REPORT', 'AND', 'ACCOUNTS', '2013', 'ITC’s', 'Brands:', 'An', 'Asset', 'for', 'the', 'Nation', 'The', 'consumer', 'needs', 'and', 'aspirations', 'they', 'fulfil,', 'the', 'benefit', 'they', 'generate', 'for', 'millions', 'across', 'ITC’s', 'value', 'chains,', 'the', 'future-ready', 'capabilities', 'that', 'support', 'them,', 'and', 'the', 'value', 'that', 'they', 'create', 'for', 'the', 'country,', 'have', 'made', 'ITC’s', 'brands', 'national', 'assets,', 'adding', 'to', 'India’s', 'competitiveness.', 'It', 'is', 'ITC’s', 'aspiration', 'to', 'be', 'the', 'No', '1', 'FMCG', 'player', 'in', 'the', 'country,', 'driven', 'by', 'its', 'new', 'FMCG', 'businesses.', 'A', 'recent', 'Nielsen', 'report', 'has', 'highlighted', 'that', "ITC's", 'new', 'FMCG', 'businesses', 'are', 'the', 'fastest', 'growing', 'among', 'the', 'top', 'consumer', 'goods', 'companies', 'operating', 'in', 'India.', 'ITC', 'takes', 'justifiable', 'pride', 'that,', 'along', 'with', 'generating', 'economic', 'value,', 'these', 'celebrated', 'Indian', 'brands', 'also', 'drive', 'the', 'creation', 'of', 'larger', 'societal', 'capital', 'through', 'the', 'virtuous', 'cycle', 'of', 'sustainable', 'and', 'inclusive', 'growth.', 'DI', 'WILLS', '*', ';', 'LOVE', 'DELIGHTFULLY', 'SOFT', 'SKIN?', 'aia', 'Ans', 'Source:', 'https://www.industrydocuments.ucsf.edu/docs/snbx0223']
+ boxes = [[0, 45, 67, 80], [72, 56, 109, 67], [116, 56, 189, 67], [198, 59, 253, 66], [257, 59, 285, 66], [289, 59, 365, 66], [372, 59, 407, 66], [74, 136, 161, 158], [175, 137, 306, 158], [318, 137, 363, 158], [374, 137, 472, 158], [483, 136, 529, 158], [540, 137, 593, 158], [608, 137, 717, 158], [73, 194, 100, 203], [106, 196, 177, 203], [183, 194, 227, 203], [233, 194, 259, 203], [265, 194, 344, 205], [74, 211, 104, 222], [109, 210, 141, 221], [147, 211, 169, 220], [175, 210, 223, 220], [229, 211, 259, 222], [265, 211, 329, 222], [334, 210, 352, 220], [74, 227, 127, 236], [133, 229, 180, 236], [187, 227, 221, 236], [226, 227, 264, 236], [270, 227, 320, 237], [327, 227, 349, 236], [74, 243, 161, 254], [166, 243, 249, 254], [254, 243, 281, 252], [286, 244, 342, 254], [74, 260, 112, 270], [119, 260, 145, 269], [151, 260, 174, 269], [179, 260, 217, 269], [222, 260, 249, 269], [254, 260, 285, 271], [290, 260, 335, 269], [340, 259, 359, 269], [74, 276, 95, 284], [101, 276, 156, 287], [164, 276, 198, 284], [203, 276, 244, 284], [251, 275, 285, 284], [291, 276, 340, 284], [74, 292, 129, 301], [135, 292, 185, 302], [192, 292, 242, 303], [248, 292, 261, 301], [267, 292, 312, 301], [74, 308, 195, 319], [75, 335, 82, 344], [88, 335, 98, 344], [105, 335, 138, 344], [144, 335, 214, 346], [220, 336, 233, 344], [239, 335, 256, 344], [262, 335, 283, 344], [290, 335, 309, 344], [316, 335, 320, 344], [74, 351, 119, 360], [126, 352, 170, 362], [176, 352, 186, 360], [192, 352, 214, 360], [220, 352, 276, 362], [282, 352, 326, 360], [333, 352, 349, 362], [74, 368, 89, 377], [95, 370, 124, 377], [129, 367, 175, 377], [181, 368, 266, 377], [272, 368, 283, 376], [289, 368, 333, 377], [74, 384, 126, 393], [134, 385, 175, 395], [181, 384, 206, 393], [212, 384, 292, 395], [298, 384, 325, 393], [330, 384, 366, 393], [74, 403, 103, 409], [109, 400, 154, 409], [161, 401, 241, 409], [247, 403, 269, 409], [275, 401, 296, 409], [302, 400, 349, 409], [74, 417, 131, 428], [137, 419, 186, 428], [192, 417, 214, 426], [219, 417, 242, 428], [248, 419, 319, 426], [74, 433, 119, 444], [125, 433, 204, 444], [210, 433, 278, 444], [285, 433, 295, 441], [302, 433, 340, 442], [75, 449, 98, 458], [104, 449, 142, 458], [146, 449, 215, 460], [221, 449, 258, 460], [263, 449, 293, 459], [300, 449, 339, 460], [74, 466, 101, 474], [108, 466, 185, 476], [191, 466, 261, 474], [267, 466, 309, 476], [315, 466, 354, 474], [74, 482, 151, 491], [158, 482, 201, 491], [208, 482, 258, 491], [263, 482, 292, 491], [298, 482, 333, 491], [338, 482, 360, 491], [74, 498, 131, 507], [137, 498, 150, 507], [156, 498, 197, 509], [202, 498, 257, 507], [263, 498, 310, 509], [74, 515, 128, 525], [134, 515, 156, 523], [161, 515, 218, 523], [223, 515, 261, 525], [267, 514, 280, 523], [74, 531, 156, 540], [162, 531, 188, 540], [195, 531, 257, 540], [263, 531, 315, 542], [871, 199, 878, 202], [883, 199, 908, 202], [894, 251, 904, 257], [841, 268, 841, 270], [784, 373, 811, 378], [816, 373, 896, 378], [784, 381, 811, 387], [815, 381, 847, 387], [645, 908, 670, 915], [692, 908, 712, 915], [220, 984, 285, 993], [293, 983, 779, 996]]
+ # fmt: on
+ text_list = []
+ bbox_list = []
+ for text, box in zip(words, boxes):
+ if text == "":
+ continue
+ sub_tokens = tokenizer.tokenize(text)
+ for sub_token in sub_tokens:
+ text_list.append(sub_token)
+ bbox_list.append(box)
+
+ input_ids = tokenizer.convert_tokens_to_ids(text_list)
+
+ input_ids = prompt_ids + input_ids
+ bbox = [[0, 0, 0, 0]] * len(prompt_ids) + bbox_list
+
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+ original_pixel_values = original_transform(image, image_size=image_processor.size["height"]).unsqueeze(0)
+ # verify pixel values
+ assert torch.allclose(original_pixel_values, pixel_values)
+ print("Pixel values are ok!")
+
+ return torch.tensor(input_ids).unsqueeze(0), torch.tensor(bbox).unsqueeze(0).float(), pixel_values
+
+
+def convert_udop_checkpoint(model_name, pytorch_dump_folder_path=None, push_to_hub=False):
+ # model_name to checkpoint_path
+ name_to_checkpoint_path = {
+ "udop-large": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-224/pytorch_model.bin",
+ "udop-large-512": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-512/pytorch_model.bin",
+ "udop-large-512-300k": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-512-300k-steps/pytorch_model.bin",
+ }
+
+ # load original state dict
+ checkpoint_path = name_to_checkpoint_path[model_name]
+ state_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ print("Checkpoint path:", checkpoint_path)
+
+ # create HF model
+ image_size = 512 if "512" in model_name else 224
+ config = UdopConfig(decoder_start_token_id=0, image_size=image_size)
+ model = UdopForConditionalGeneration(config)
+ model.eval()
+
+ # rename keys
+ state_dict = {k.replace("cell2dembedding", "cell_2d_embedding"): v for k, v in state_dict.items()}
+
+ # load weights
+ missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
+ print("Missing keys:", missing_keys)
+ print("Unexpected keys:", unexpected_keys)
+ assert missing_keys == ["encoder.embed_patches.proj.weight", "encoder.embed_patches.proj.bias"]
+ assert unexpected_keys == ["pos_embed"]
+
+ # prepare dummy inputs
+ tokenizer = UdopTokenizer.from_pretrained("t5-base", legacy=True)
+ size = {"height": image_size, "width": image_size}
+ image_processor = LayoutLMv3ImageProcessor(
+ image_mean=IMAGENET_DEFAULT_MEAN, image_std=IMAGENET_DEFAULT_STD, size=size
+ )
+ processor = UdopProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ input_ids, bbox, image = prepare_dummy_inputs(tokenizer, image_processor)
+ prompt = "Question answering. In which year is the report made?"
+ encoding = processor(images=get_image(), text=prompt, return_tensors="pt")
+
+ input_ids = encoding.input_ids
+ try:
+ EXPECTED_INPUT_IDS = torch.tensor([[11860, 18243, 5, 86, 84, 215, 19, 8, 934, 263, 58, 1, 489, 27, 3838, 7363, 4083, 14536, 3430, 5686, 5911, 17161, 134, 2038, 27, 3838, 22, 7, 4688, 7, 10, 389, 18202, 21, 8, 11046, 37, 3733, 523, 11, 38, 2388, 1628, 3, 13133, 23334, 6, 8, 1656, 79, 3806, 21, 4040, 640, 27, 3838, 22, 7, 701, 16534, 6, 8, 3, 76, 2693, 18, 23015, 5644, 24, 380, 3, 6015, 6, 11, 8, 701, 24, 79, 482, 21, 3, 88, 684, 6, 43, 263, 27, 3838, 22, 7, 3635, 1157, 4089, 6, 2651, 12, 1547, 22, 7, 3265, 655, 5, 19, 27, 3838, 22, 7, 38, 2388, 257, 12, 36, 8, 465, 209, 13409, 12150, 1959, 16, 8, 684, 6, 6737, 57, 165, 126, 13409, 12150, 1623, 5, 71, 1100, 30298, 934, 65, 12566, 24, 27, 3838, 31, 7, 126, 13409, 12150, 1623, 33, 8, 10391, 1710, 859, 8, 420, 3733, 4968, 688, 2699, 16, 1547, 5, 27, 3838, 1217, 131, 99, 23, 179, 6064, 24, 6, 590, 28, 3, 11600, 1456, 701, 6, 175, 9443, 2557, 3635, 92, 1262, 8, 3409, 13, 2186, 3, 27908, 1784, 190, 8, 3, 5771, 17, 13281, 4005, 13, 5086, 11, 13066, 1170, 5, 10826, 16309, 134, 3, 2, 276, 26, 3, 55, 391, 13570, 5, 10315, 309, 3577, 19114, 371, 4254, 5121, 5055, 6245, 3, 10047, 3162, 58, 3, 9, 61, 1713, 2703, 476, 667, 25158, 301, 6058, 6038, 476, 3765, 9149, 10, 4893, 1303, 1986, 5, 13580, 7, 8224, 28244, 7, 5, 76, 75, 7, 89, 5, 15, 1259, 87, 7171, 7, 87, 7, 29, 115, 226, 4305, 2773, 1]]) # fmt: skip
+ torch.testing.assert_close(EXPECTED_INPUT_IDS, input_ids)
+ bbox = encoding.bbox.float()
+ pixel_values = encoding.pixel_values
+ except Exception:
+ print("Input_ids don't match, preparing dummy inputs")
+ input_ids, bbox, pixel_values = prepare_dummy_inputs(tokenizer, image_processor)
+
+ # Verify single forward pass
+ print("Testing single forward pass..")
+ with torch.no_grad():
+ decoder_input_ids = torch.tensor([[101]])
+ outputs = model(input_ids=input_ids, bbox=bbox, pixel_values=pixel_values, decoder_input_ids=decoder_input_ids)
+ print("Shape of logits:", outputs.logits.shape)
+ print("First values of logits:", outputs.logits[0, :3, :3])
+
+ # tensor([[-18.5262, 1.5087, -15.7051]]) on linux
+ # tensor([[-19.4976, 0.8515, -17.1873]]) on mac
+ try:
+ assert torch.allclose(outputs.logits[0, :3, :3], torch.tensor([[-18.5262, 1.5087, -15.7051]]), atol=1e-4)
+ print("Looks ok!")
+ except Exception:
+ print("logits don't match let's try to generate")
+
+ # Verify autoregressive decoding
+ print("Testing generation...")
+ model_kwargs = {"bbox": bbox, "pixel_values": pixel_values}
+ outputs = model.generate(input_ids=input_ids, **model_kwargs, max_new_tokens=20)
+
+ print("Generated:", tokenizer.batch_decode(outputs, skip_special_tokens=True))
+
+ # autoregressive decoding with original input data
+ print("Testing generation with original inputs...")
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="input_ids_udop.pt", repo_type="dataset")
+ input_ids = torch.load(filepath)
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="bbox_udop.pt", repo_type="dataset")
+ bbox = torch.load(filepath)
+ pixel_values_filename = "pixel_values_udop_512.pt" if "512" in model_name else "pixel_values_udop_224.pt"
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename=pixel_values_filename, repo_type="dataset")
+ pixel_values = torch.load(filepath)
+
+ print("Decoded input ids:", tokenizer.decode(input_ids[0], skip_special_tokens=True))
+ print("Bbox shape:", bbox.shape)
+
+ model_kwargs = {"bbox": bbox, "pixel_values": pixel_values}
+ outputs = model.generate(input_ids=input_ids, **model_kwargs, max_new_tokens=20)
+ generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
+ print("Generated:", generated_text)
+
+ if pytorch_dump_folder_path is not None:
+ model.save_pretrained(pytorch_dump_folder_path)
+ tokenizer.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"microsoft/{model_name}")
+ processor.push_to_hub(f"microsoft/{model_name}")
+ # BIG note here: to save the fast tokenizer files in the repo on the hub, you need to do the following:
+ # see https://discuss.huggingface.co/t/convert-slow-xlmrobertatokenizer-to-fast-one/20876
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="udop-large",
+ type=str,
+ choices=["udop-large", "udop-large-512", "udop-large-512-300k"],
+ help=("Name of the UDOP model you'd like to convert."),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_udop_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/udop/modeling_udop.py b/src/transformers/models/udop/modeling_udop.py
new file mode 100644
index 00000000000000..62192eea7f5a5e
--- /dev/null
+++ b/src/transformers/models/udop/modeling_udop.py
@@ -0,0 +1,2030 @@
+# coding=utf-8
+# Copyright 2024 Microsoft Research and HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch UDOP model."""
+
+import collections
+import logging
+import math
+import random
+from abc import ABC, abstractmethod
+from copy import deepcopy
+from dataclasses import dataclass
+from typing import Any, Dict, Optional, Sequence, Tuple, Union
+
+import torch
+from torch import Tensor, nn
+from torch.nn import CrossEntropyLoss
+
+from transformers import UdopConfig
+from transformers.modeling_outputs import (
+ Seq2SeqLMOutput,
+ Seq2SeqModelOutput,
+)
+
+from ...activations import ACT2FN
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+
+
+logger = logging.getLogger(__name__)
+
+UDOP_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "microsoft/udop-large",
+ # See all UDOP models at https://huggingface.co/models?filter=udop
+]
+
+
+_CONFIG_FOR_DOC = "UdopConfig"
+
+
+UDOP_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Args:
+ config ([`UdopConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+UDOP_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. UDOP is a model with relative position embeddings so
+ you should be able to pad the inputs on both the right and the left. Indices can be obtained using
+ [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for detail.
+ [What are input IDs?](../glossary#input-ids)
+
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ [What are attention masks?](../glossary#attention-mask)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner.
+
+ Note that `sequence_length = token_sequence_length + patch_sequence_length + 1` where `1` is for [CLS]
+ token. See `pixel_values` for `patch_sequence_length`.
+
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Batch of document images. Each image is divided into patches of shape `(num_channels, config.patch_size,
+ config.patch_size)` and the total number of patches (=`patch_sequence_length`) equals to `((height /
+ config.patch_size) * (width / config.patch_size))`.
+
+ visual_bbox (`torch.LongTensor` of shape `(batch_size, patch_sequence_length, 4)`, *optional*):
+ Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model.
+
+ decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
+ Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using
+ [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details.
+ [What are decoder input IDs?](../glossary#decoder-input-ids) T5 uses the `pad_token_id` as the starting
+ token for `decoder_input_ids` generation. If `past_key_values` is used, optionally only the last
+ `decoder_input_ids` have to be input (see `past_key_values`). To know more on how to prepare
+ `decoder_input_ids` for pretraining take a look at [T5 Training](./t5#training).
+ decoder_attention_mask (`torch.BoolTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
+ Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
+ be used by default.
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules in the encoder. Mask values selected in `[0,
+ 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ decoder_head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules in the decoder. Mask values selected in `[0,
+ 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ cross_attn_head_mask (`torch.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in
+ `[0, 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
+ Tuple consists of (`last_hidden_state`, `optional`: *hidden_states*, `optional`: *attentions*)
+ `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)` is a sequence of hidden states at
+ the output of the last layer of the encoder. Used in the cross-attention of the decoder.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
+ representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds` have to be
+ input (see `past_key_values`). This is useful if you want more control over how to convert
+ `decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix. If
+ `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds` takes the value of
+ `inputs_embeds`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+UDOP_ENCODER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. T5 is a model with relative position embeddings so you
+ should be able to pad the inputs on both the right and the left.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for detail.
+
+ To know more on how to prepare `input_ids` for pretraining take a look a [T5 Training](./t5#training).
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner.
+
+ Note that `sequence_length = token_sequence_length + patch_sequence_length + 1` where `1` is for [CLS]
+ token. See `pixel_values` for `patch_sequence_length`.
+
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Batch of document images. Each image is divided into patches of shape `(num_channels, config.patch_size,
+ config.patch_size)` and the total number of patches (=`patch_sequence_length`) equals to `((height /
+ config.patch_size) * (width / config.patch_size))`.
+
+ visual_bbox (`torch.LongTensor` of shape `(batch_size, patch_sequence_length, 4)`, *optional*):
+ Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@dataclass
+class BaseModelOutputWithAttentionMask(ModelOutput):
+ """
+ Class for the model's outputs that may also contain a past key/values (to speed up sequential decoding). Includes
+ an additional attention mask.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model. If `past_key_values` is used only
+ the last hidden-state of the sequences of shape `(batch_size, 1, hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
+ when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`. Contains pre-computed hidden-states (key and values in the
+ self-attention blocks and optionally if `config.is_encoder_decoder=True` in the cross-attention blocks)
+ that can be used (see `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or
+ when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
+ the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when
+ `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and
+ `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights of the decoder's cross-attention layer, after the attention softmax,
+ used to compute the weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ attention_mask: torch.FloatTensor = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+def get_visual_bbox(image_size=224, patch_size=16):
+ image_feature_pool_shape = [image_size // patch_size, image_size // patch_size]
+ visual_bbox_x = torch.arange(0, 1.0 * (image_feature_pool_shape[1] + 1), 1.0)
+ visual_bbox_x /= image_feature_pool_shape[1]
+
+ visual_bbox_y = torch.arange(0, 1.0 * (image_feature_pool_shape[0] + 1), 1.0)
+ visual_bbox_y /= image_feature_pool_shape[0]
+
+ visual_bbox_input = torch.stack(
+ [
+ visual_bbox_x[:-1].repeat(image_feature_pool_shape[0], 1),
+ visual_bbox_y[:-1].repeat(image_feature_pool_shape[1], 1).transpose(0, 1),
+ visual_bbox_x[1:].repeat(image_feature_pool_shape[0], 1),
+ visual_bbox_y[1:].repeat(image_feature_pool_shape[1], 1).transpose(0, 1),
+ ],
+ dim=-1,
+ )
+
+ visual_bbox_input = visual_bbox_input.view(-1, 4)
+
+ return visual_bbox_input
+
+
+def pad_sequence(seq, target_len, pad_value=0):
+ if isinstance(seq, torch.Tensor):
+ n = seq.shape[0]
+ else:
+ n = len(seq)
+ seq = torch.tensor(seq)
+ m = target_len - n
+ if m > 0:
+ ret = torch.stack([pad_value] * m).to(seq)
+ seq = torch.cat([seq, ret], dim=0)
+ return seq[:target_len]
+
+
+def combine_image_text_embeddings(
+ image_embeddings,
+ inputs_embeds,
+ bbox,
+ visual_bbox,
+ attention_mask=None,
+ num_patches=14,
+ max_len=0,
+ image_size=224,
+ patch_size=16,
+):
+ """
+ Combine the image and text embeddings for the input to the encoder/decoder of UDOP.
+
+ First, the image embeddings are created by checking for each visual patch if it is inside the bounding box of a
+ token. If it is, the visual patch is combined with the token embedding. Then, the visual bounding boxes are combined
+ with the text bounding boxes. Finally, the visual bounding boxes are combined with the text attention mask.
+ """
+
+ sequence_length = num_patches
+ ocr_points_x = torch.clip(
+ torch.floor((bbox[:, :, 0] + bbox[:, :, 2]) / 2.0 * sequence_length).long(), 0, sequence_length - 1
+ )
+ ocr_points_y = (
+ torch.clip(torch.floor((bbox[:, :, 1] + bbox[:, :, 3]) / 2.0 * sequence_length).long(), 0, sequence_length - 1)
+ * sequence_length
+ )
+ ocr_points = ocr_points_x + ocr_points_y
+ # make sure bounding boxes are of type float to calculate means
+ bbox = bbox.to(torch.float64)
+ target_seg = (bbox.mean(-1) == 0.0) | (bbox.mean(-1) == 1.0)
+ repeated_vision_embeds = torch.gather(
+ image_embeddings, 1, ocr_points.unsqueeze(-1).repeat(1, 1, image_embeddings.size(-1))
+ )
+ repeated_vision_embeds[target_seg] = 0.0
+ inputs_embeds += repeated_vision_embeds
+
+ patch_inds = torch.full_like(image_embeddings[:, :, 0], True).bool()
+ ind = torch.cat(
+ [
+ torch.arange(len(ocr_points))[:, None].repeat(1, ocr_points.size(-1))[:, :, None].to(ocr_points),
+ ocr_points[:, :, None],
+ ],
+ dim=-1,
+ )
+ ind = ind.flatten(0, 1)
+ rows, cols = zip(*ind)
+ patch_inds[rows, cols] = False
+
+ input_vision_patches = [image_embeddings[i][patch_inds[i]] for i in range(len(patch_inds))]
+
+ if visual_bbox is None:
+ visual_bbox = get_visual_bbox(image_size=image_size, patch_size=patch_size)
+ visual_bbox = visual_bbox.unsqueeze(0).repeat(image_embeddings.size(0), 1, 1)
+ visual_bbox = visual_bbox.to(image_embeddings.device)
+
+ visual_bbox = [visual_bbox[i][patch_inds[i]] for i in range(len(patch_inds))]
+ if attention_mask is not None:
+ visual_attention_mask = [torch.tensor([1] * len(item)).to(attention_mask) for item in visual_bbox]
+
+ if max_len == 0:
+ max_len = image_embeddings.size(1)
+ else:
+ max_len = max_len - inputs_embeds.size(1)
+ inputs_vision_patches = torch.stack(
+ [pad_sequence(item, max_len, torch.zeros_like(image_embeddings[0, 0])) for item in input_vision_patches]
+ )
+ visual_bbox = torch.stack([pad_sequence(item, max_len, torch.zeros_like(bbox[0, 0])) for item in visual_bbox])
+ if attention_mask is not None:
+ visual_attention_mask = torch.stack(
+ [pad_sequence(item, max_len, torch.zeros_like(attention_mask[0, 0])) for item in visual_attention_mask]
+ )
+
+ inputs_embeds = torch.cat([inputs_embeds, inputs_vision_patches], 1)
+ bbox = torch.cat([bbox, visual_bbox], 1)
+ if attention_mask is not None:
+ attention_mask = torch.cat([attention_mask, visual_attention_mask], 1)
+ return inputs_embeds, bbox, attention_mask
+
+
+class UdopPatchEmbeddings(nn.Module):
+ """2D Image to Patch Embeddings"""
+
+ def __init__(self, config):
+ super().__init__()
+ image_size, patch_size = config.image_size, config.patch_size
+ num_channels, hidden_size = config.num_channels, config.hidden_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.num_patches = num_patches
+
+ self.proj = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
+
+ def forward(self, pixel_values):
+ batch_size, num_channels, height, width = pixel_values.shape
+ if height != self.image_size[0] or width != self.image_size[1]:
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model"
+ f" ({self.image_size[0]}*{self.image_size[1]})."
+ )
+ embeddings = self.proj(pixel_values)
+ embeddings = embeddings.flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class UdopPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models. Based on `T5PreTrainedModel`.
+ """
+
+ config_class = UdopConfig
+ base_model_prefix = "transformer"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["UdopBlock"]
+ _keep_in_fp32_modules = ["wo"]
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ factor = self.config.initializer_factor # Used for testing weights initialization
+ if isinstance(module, UdopLayerNorm):
+ module.weight.data.fill_(factor * 1.0)
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=factor)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.Conv2d):
+ # Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
+ # `trunc_normal_cpu` not implemented in `half` issues
+ module.weight.data = nn.init.trunc_normal_(module.weight.data.to(torch.float32), mean=0.0, std=factor).to(
+ module.weight.dtype
+ )
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, RelativePositionBiasBase):
+ factor = self.config.initializer_factor
+ d_model = self.config.d_model
+ module.relative_attention_bias.weight.data.normal_(mean=0.0, std=factor * ((d_model) ** -0.5))
+ elif isinstance(module, UdopModel):
+ # Mesh TensorFlow embeddings initialization
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L1624
+ module.shared.weight.data.normal_(mean=0.0, std=factor * 1.0)
+ elif isinstance(module, UdopForConditionalGeneration):
+ if hasattr(module, "lm_head") and not self.config.tie_word_embeddings:
+ module.lm_head.weight.data.normal_(mean=0.0, std=factor * 1.0)
+ elif isinstance(module, UdopDenseActDense):
+ # Mesh TensorFlow FF initialization
+ # See https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/transformer_layers.py#L56
+ # and https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L89
+ module.wi.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi, "bias") and module.wi.bias is not None:
+ module.wi.bias.data.zero_()
+ module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff) ** -0.5))
+ if hasattr(module.wo, "bias") and module.wo.bias is not None:
+ module.wo.bias.data.zero_()
+ elif isinstance(module, UdopDenseGatedActDense):
+ module.wi_0.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi_0, "bias") and module.wi_0.bias is not None:
+ module.wi_0.bias.data.zero_()
+ module.wi_1.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi_1, "bias") and module.wi_1.bias is not None:
+ module.wi_1.bias.data.zero_()
+ module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff) ** -0.5))
+ if hasattr(module.wo, "bias") and module.wo.bias is not None:
+ module.wo.bias.data.zero_()
+ elif isinstance(module, UdopAttention):
+ # Mesh TensorFlow attention initialization to avoid scaling before softmax
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/attention.py#L136
+ d_model = self.config.d_model
+ key_value_proj_dim = self.config.d_kv
+ n_heads = self.config.num_heads
+ module.q.weight.data.normal_(mean=0.0, std=factor * ((d_model * key_value_proj_dim) ** -0.5))
+ module.k.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
+ module.v.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
+ module.o.weight.data.normal_(mean=0.0, std=factor * ((n_heads * key_value_proj_dim) ** -0.5))
+ if module.has_relative_attention_bias:
+ module.relative_attention_bias.weight.data.normal_(mean=0.0, std=factor * ((d_model) ** -0.5))
+
+ # Copied from transformers.models.prophetnet.modeling_prophetnet.ProphetNetPreTrainedModel._shift_right with ProphetNet->Udop
+ def _shift_right(self, input_ids):
+ decoder_start_token_id = self.config.decoder_start_token_id
+ pad_token_id = self.config.pad_token_id
+
+ assert decoder_start_token_id is not None, (
+ "self.model.config.decoder_start_token_id has to be defined. In Udop it is usually set to the"
+ " pad_token_id. See Udop docs for more information"
+ )
+
+ # shift inputs to the right
+ shifted_input_ids = input_ids.new_zeros(input_ids.shape)
+ shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
+ shifted_input_ids[..., 0] = decoder_start_token_id
+
+ assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
+ # replace possible -100 values in labels by `pad_token_id`
+ shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
+
+ assert torch.all(shifted_input_ids >= 0).item(), "Verify that `shifted_input_ids` has only positive values"
+
+ return shifted_input_ids
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerNorm with T5->Udop
+class UdopLayerNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Construct a layernorm module in the Udop style. No bias and no subtraction of mean.
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ # Udop uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
+ # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus varience is calculated
+ # w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
+ # half-precision inputs is done in fp32
+
+ variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+
+ # convert into half-precision if necessary
+ if self.weight.dtype in [torch.float16, torch.bfloat16]:
+ hidden_states = hidden_states.to(self.weight.dtype)
+
+ return self.weight * hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5DenseActDense with T5->Udop
+class UdopDenseActDense(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ self.wi = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.act = ACT2FN[config.dense_act_fn]
+
+ def forward(self, hidden_states):
+ hidden_states = self.wi(hidden_states)
+ hidden_states = self.act(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ if (
+ isinstance(self.wo.weight, torch.Tensor)
+ and hidden_states.dtype != self.wo.weight.dtype
+ and self.wo.weight.dtype != torch.int8
+ ):
+ hidden_states = hidden_states.to(self.wo.weight.dtype)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5DenseGatedActDense with T5->Udop
+class UdopDenseGatedActDense(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.act = ACT2FN[config.dense_act_fn]
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+
+ # To make 8bit quantization work for google/flan-t5-xxl, self.wo is kept in float32.
+ # See https://github.com/huggingface/transformers/issues/20287
+ # we also make sure the weights are not in `int8` in case users will force `_keep_in_fp32_modules` to be `None``
+ if (
+ isinstance(self.wo.weight, torch.Tensor)
+ and hidden_states.dtype != self.wo.weight.dtype
+ and self.wo.weight.dtype != torch.int8
+ ):
+ hidden_states = hidden_states.to(self.wo.weight.dtype)
+
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerFF with T5->Udop
+class UdopLayerFF(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ if config.is_gated_act:
+ self.DenseReluDense = UdopDenseGatedActDense(config)
+ else:
+ self.DenseReluDense = UdopDenseActDense(config)
+
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(self, hidden_states):
+ forwarded_states = self.layer_norm(hidden_states)
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = hidden_states + self.dropout(forwarded_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5Attention with T5->Udop
+class UdopAttention(nn.Module):
+ def __init__(self, config: UdopConfig, has_relative_attention_bias=False):
+ super().__init__()
+ self.is_decoder = config.is_decoder
+ self.has_relative_attention_bias = has_relative_attention_bias
+ self.relative_attention_num_buckets = config.relative_attention_num_buckets
+ self.relative_attention_max_distance = config.relative_attention_max_distance
+ self.d_model = config.d_model
+ self.key_value_proj_dim = config.d_kv
+ self.n_heads = config.num_heads
+ self.dropout = config.dropout_rate
+ self.inner_dim = self.n_heads * self.key_value_proj_dim
+
+ # Mesh TensorFlow initialization to avoid scaling before softmax
+ self.q = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.k = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.v = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.o = nn.Linear(self.inner_dim, self.d_model, bias=False)
+
+ if self.has_relative_attention_bias:
+ self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets, self.n_heads)
+ self.pruned_heads = set()
+ self.gradient_checkpointing = False
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.n_heads, self.key_value_proj_dim, self.pruned_heads
+ )
+ # Prune linear layers
+ self.q = prune_linear_layer(self.q, index)
+ self.k = prune_linear_layer(self.k, index)
+ self.v = prune_linear_layer(self.v, index)
+ self.o = prune_linear_layer(self.o, index, dim=1)
+ # Update hyper params
+ self.n_heads = self.n_heads - len(heads)
+ self.inner_dim = self.key_value_proj_dim * self.n_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ @staticmethod
+ def _relative_position_bucket(relative_position, bidirectional=True, num_buckets=32, max_distance=128):
+ """
+ Adapted from Mesh Tensorflow:
+ https://github.com/tensorflow/mesh/blob/0cb87fe07da627bf0b7e60475d59f95ed6b5be3d/mesh_tensorflow/transformer/transformer_layers.py#L593
+
+ Translate relative position to a bucket number for relative attention. The relative position is defined as
+ memory_position - query_position, i.e. the distance in tokens from the attending position to the attended-to
+ position. If bidirectional=False, then positive relative positions are invalid. We use smaller buckets for
+ small absolute relative_position and larger buckets for larger absolute relative_positions. All relative
+ positions >=max_distance map to the same bucket. All relative positions <=-max_distance map to the same bucket.
+ This should allow for more graceful generalization to longer sequences than the model has been trained on
+
+ Args:
+ relative_position: an int32 Tensor
+ bidirectional: a boolean - whether the attention is bidirectional
+ num_buckets: an integer
+ max_distance: an integer
+
+ Returns:
+ a Tensor with the same shape as relative_position, containing int32 values in the range [0, num_buckets)
+ """
+ relative_buckets = 0
+ if bidirectional:
+ num_buckets //= 2
+ relative_buckets += (relative_position > 0).to(torch.long) * num_buckets
+ relative_position = torch.abs(relative_position)
+ else:
+ relative_position = -torch.min(relative_position, torch.zeros_like(relative_position))
+ # now relative_position is in the range [0, inf)
+
+ # half of the buckets are for exact increments in positions
+ max_exact = num_buckets // 2
+ is_small = relative_position < max_exact
+
+ # The other half of the buckets are for logarithmically bigger bins in positions up to max_distance
+ relative_position_if_large = max_exact + (
+ torch.log(relative_position.float() / max_exact)
+ / math.log(max_distance / max_exact)
+ * (num_buckets - max_exact)
+ ).to(torch.long)
+ relative_position_if_large = torch.min(
+ relative_position_if_large, torch.full_like(relative_position_if_large, num_buckets - 1)
+ )
+
+ relative_buckets += torch.where(is_small, relative_position, relative_position_if_large)
+ return relative_buckets
+
+ def compute_bias(self, query_length, key_length, device=None):
+ """Compute binned relative position bias"""
+ if device is None:
+ device = self.relative_attention_bias.weight.device
+ context_position = torch.arange(query_length, dtype=torch.long, device=device)[:, None]
+ memory_position = torch.arange(key_length, dtype=torch.long, device=device)[None, :]
+ relative_position = memory_position - context_position # shape (query_length, key_length)
+ relative_position_bucket = self._relative_position_bucket(
+ relative_position, # shape (query_length, key_length)
+ bidirectional=(not self.is_decoder),
+ num_buckets=self.relative_attention_num_buckets,
+ max_distance=self.relative_attention_max_distance,
+ )
+ values = self.relative_attention_bias(relative_position_bucket) # shape (query_length, key_length, num_heads)
+ values = values.permute([2, 0, 1]).unsqueeze(0) # shape (1, num_heads, query_length, key_length)
+ return values
+
+ def forward(
+ self,
+ hidden_states,
+ mask=None,
+ key_value_states=None,
+ position_bias=None,
+ past_key_value=None,
+ layer_head_mask=None,
+ query_length=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ """
+ Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states).
+ """
+ # Input is (batch_size, seq_length, dim)
+ # Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)
+ # past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)
+ batch_size, seq_length = hidden_states.shape[:2]
+
+ real_seq_length = seq_length
+
+ if past_key_value is not None:
+ if len(past_key_value) != 2:
+ raise ValueError(
+ f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states"
+ )
+ real_seq_length += past_key_value[0].shape[2] if query_length is None else query_length
+
+ key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
+
+ def shape(states):
+ """projection"""
+ return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim).transpose(1, 2)
+
+ def unshape(states):
+ """reshape"""
+ return states.transpose(1, 2).contiguous().view(batch_size, -1, self.inner_dim)
+
+ def project(hidden_states, proj_layer, key_value_states, past_key_value):
+ """projects hidden states correctly to key/query states"""
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(hidden_states))
+ elif past_key_value is None:
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+
+ if past_key_value is not None:
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, key_length, dim_per_head)
+ hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
+ elif past_key_value.shape[2] != key_value_states.shape[1]:
+ # checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+ else:
+ # cross-attn
+ hidden_states = past_key_value
+ return hidden_states
+
+ # get query states
+ query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
+
+ # get key/value states
+ key_states = project(
+ hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
+ )
+ value_states = project(
+ hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
+ )
+
+ # compute scores
+ scores = torch.matmul(
+ query_states, key_states.transpose(3, 2)
+ ) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
+
+ if position_bias is None:
+ if not self.has_relative_attention_bias:
+ position_bias = torch.zeros(
+ (1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
+ )
+ if self.gradient_checkpointing and self.training:
+ position_bias.requires_grad = True
+ else:
+ position_bias = self.compute_bias(real_seq_length, key_length, device=scores.device)
+
+ # if key and values are already calculated
+ # we want only the last query position bias
+ if past_key_value is not None:
+ position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
+
+ if mask is not None:
+ position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
+
+ if self.pruned_heads:
+ mask = torch.ones(position_bias.shape[1])
+ mask[list(self.pruned_heads)] = 0
+ position_bias_masked = position_bias[:, mask.bool()]
+ else:
+ position_bias_masked = position_bias
+
+ scores += position_bias_masked
+ attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
+ scores
+ ) # (batch_size, n_heads, seq_length, key_length)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.dropout, training=self.training
+ ) # (batch_size, n_heads, seq_length, key_length)
+
+ # Mask heads if we want to
+ if layer_head_mask is not None:
+ attn_weights = attn_weights * layer_head_mask
+
+ attn_output = unshape(torch.matmul(attn_weights, value_states)) # (batch_size, seq_length, dim)
+ attn_output = self.o(attn_output)
+
+ present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
+ outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
+
+ if output_attentions:
+ outputs = outputs + (attn_weights,)
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerSelfAttention with T5->Udop
+class UdopLayerSelfAttention(nn.Module):
+ def __init__(self, config, has_relative_attention_bias=False):
+ super().__init__()
+ self.SelfAttention = UdopAttention(config, has_relative_attention_bias=has_relative_attention_bias)
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ position_bias=None,
+ layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.SelfAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = hidden_states + self.dropout(attention_output[0])
+ outputs = (hidden_states,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerCrossAttention with T5->Udop
+class UdopLayerCrossAttention(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.EncDecAttention = UdopAttention(config, has_relative_attention_bias=False)
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ key_value_states,
+ attention_mask=None,
+ position_bias=None,
+ layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ query_length=None,
+ output_attentions=False,
+ ):
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.EncDecAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ key_value_states=key_value_states,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ query_length=query_length,
+ output_attentions=output_attentions,
+ )
+ layer_output = hidden_states + self.dropout(attention_output[0])
+ outputs = (layer_output,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5Block with T5->Udop
+class UdopBlock(nn.Module):
+ def __init__(self, config, has_relative_attention_bias=False):
+ super().__init__()
+ self.is_decoder = config.is_decoder
+ self.layer = nn.ModuleList()
+ self.layer.append(UdopLayerSelfAttention(config, has_relative_attention_bias=has_relative_attention_bias))
+ if self.is_decoder:
+ self.layer.append(UdopLayerCrossAttention(config))
+
+ self.layer.append(UdopLayerFF(config))
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ position_bias=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ encoder_decoder_position_bias=None,
+ layer_head_mask=None,
+ cross_attn_layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ output_attentions=False,
+ return_dict=True,
+ ):
+ if past_key_value is not None:
+ if not self.is_decoder:
+ logger.warning("`past_key_values` is passed to the encoder. Please make sure this is intended.")
+ expected_num_past_key_values = 2 if encoder_hidden_states is None else 4
+
+ if len(past_key_value) != expected_num_past_key_values:
+ raise ValueError(
+ f"There should be {expected_num_past_key_values} past states. "
+ f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"Got {len(past_key_value)} past key / value states"
+ )
+
+ self_attn_past_key_value = past_key_value[:2]
+ cross_attn_past_key_value = past_key_value[2:]
+ else:
+ self_attn_past_key_value, cross_attn_past_key_value = None, None
+
+ self_attention_outputs = self.layer[0](
+ hidden_states,
+ attention_mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=self_attn_past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states, present_key_value_state = self_attention_outputs[:2]
+ attention_outputs = self_attention_outputs[2:] # Keep self-attention outputs and relative position weights
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ do_cross_attention = self.is_decoder and encoder_hidden_states is not None
+ if do_cross_attention:
+ # the actual query length is unknown for cross attention
+ # if using past key value states. Need to inject it here
+ if present_key_value_state is not None:
+ query_length = present_key_value_state[0].shape[2]
+ else:
+ query_length = None
+
+ cross_attention_outputs = self.layer[1](
+ hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ position_bias=encoder_decoder_position_bias,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ query_length=query_length,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = cross_attention_outputs[0]
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ # Combine self attn and cross attn key value states
+ if present_key_value_state is not None:
+ present_key_value_state = present_key_value_state + cross_attention_outputs[1]
+
+ # Keep cross-attention outputs and relative position weights
+ attention_outputs = attention_outputs + cross_attention_outputs[2:]
+
+ # Apply Feed Forward layer
+ hidden_states = self.layer[-1](hidden_states)
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if use_cache:
+ outputs = outputs + (present_key_value_state,) + attention_outputs
+ else:
+ outputs = outputs + attention_outputs
+
+ return outputs # hidden-states, present_key_value_states, (self-attention position bias), (self-attention weights), (cross-attention position bias), (cross-attention weights)
+
+
+class UdopCellEmbeddings(nn.Module):
+ def __init__(self, max_2d_position_embeddings=501, hidden_size=1024):
+ super(UdopCellEmbeddings, self).__init__()
+ self.max_2d_position_embeddings = max_2d_position_embeddings
+
+ self.x_position_embeddings = nn.Embedding(max_2d_position_embeddings, hidden_size)
+ self.y_position_embeddings = nn.Embedding(max_2d_position_embeddings, hidden_size)
+
+ def forward(self, bbox):
+ bbox = torch.clip(bbox, 0.0, 1.0)
+ bbox = (bbox * (self.max_2d_position_embeddings - 1)).long()
+ left_position_embeddings = self.x_position_embeddings(bbox[:, :, 0])
+ upper_position_embeddings = self.y_position_embeddings(bbox[:, :, 1])
+ right_position_embeddings = self.x_position_embeddings(bbox[:, :, 2])
+ lower_position_embeddings = self.y_position_embeddings(bbox[:, :, 3])
+
+ embeddings = (
+ left_position_embeddings
+ + upper_position_embeddings
+ + right_position_embeddings
+ + lower_position_embeddings
+ )
+
+ return embeddings
+
+
+# get function for bucket computation
+# protected member access seems to be lesser evil than copy paste whole function
+get_relative_position_bucket = UdopAttention._relative_position_bucket
+AUGMENTATION_RANGE = (0.80, 1.25)
+
+
+class RelativePositionBiasBase(nn.Module, ABC):
+ """
+ Base class of relative biases.
+
+ Args:
+ num_heads (`int`):
+ Number of attention heads in the model, it will create embeddings of size `num_heads`, which will be added to the scores of each token pair.
+ relative_attention_num_buckets (`int`, *optional*, defaults to 32):
+ Pair token metric (distance in the sequence, distance in pixels etc.) will be bucketed, parameter is defining number of such
+ buckets.
+ bidirectional (`bool`, *optional*, defaults to `True`):
+ Whether the distance should be bidirectional for a pair of tokens. If `False`, then distance(tok1, tok2) == distance(tok2, tok1).
+ scaling_factor (`int`, *optional*, defaults to 1):
+ Defining factor which will be used to scale relative distance.
+ max_distance (`int`, *optional*, defaults to 128):
+ All distances above this value will end up in the one/same bucket.
+ augmentation (`bool`, *optional*, defaults to `False`):
+ Whether to multiply relative distances by a random scalar.
+ expand (`bool`, *optional*, defaults to `False`):
+ Whether to expand an existing pretrained model with subsequent additions of prefix_bucket.
+ """
+
+ def __init__(
+ self,
+ num_heads=None,
+ relative_attention_num_buckets=32,
+ bidirectional=True,
+ scaling_factor=1,
+ max_distance=128,
+ level="tokens",
+ augmentation=False,
+ prefix_bucket=False,
+ expand=False,
+ ):
+ super(RelativePositionBiasBase, self).__init__()
+ self.prefix_bucket = prefix_bucket
+ self.augmentation = augmentation
+ self.level = level
+ self.max_distance = max_distance
+ self.scaling_factor = scaling_factor
+ self.bidirectional = bidirectional
+ self.num_heads = num_heads
+ self.expand = expand
+ self.relative_attention_num_buckets = relative_attention_num_buckets
+ extra_head = 2 if prefix_bucket and not self.expand else 0
+ self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets + extra_head, self.num_heads)
+
+ @abstractmethod
+ def prepare_input(
+ self,
+ attention_mask: Optional[Tensor] = None,
+ bbox: Optional[Dict[str, Any]] = None,
+ ) -> Tensor:
+ pass
+
+ def get_bucket(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ relative_position = self.prepare_input(attention_mask, bbox)
+ rp_bucket: Tensor = get_relative_position_bucket(
+ relative_position,
+ bidirectional=self.bidirectional,
+ num_buckets=self.relative_attention_num_buckets,
+ max_distance=self.max_distance,
+ )
+ return rp_bucket
+
+ def get_relative_position(self, positions):
+ context_position = positions[:, :, None]
+ memory_position = positions[:, None, :]
+ relative_position = memory_position - context_position
+ if self.augmentation and self.training:
+ relative_position *= random.uniform(*AUGMENTATION_RANGE)
+ relative_position *= self.scaling_factor
+
+ return relative_position.to(torch.long)
+
+ def forward(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ # re-using pretrained model with subsequent addition of prefix_bucket
+ if self.expand and self.prefix_bucket:
+ new_bias = nn.Embedding(self.relative_attention_num_buckets + 2, self.num_heads)
+ new_bias.weight.data[: self.relative_attention_num_buckets] = self.relative_attention_bias.weight.data
+ new_bias.weight.data[self.relative_attention_num_buckets :] = 0.1
+ self.relative_attention_bias = new_bias
+ self.expand = False
+
+ rp_bucket = self.get_bucket(attention_mask, bbox)
+
+ if self.prefix_bucket:
+ if rp_bucket.size(0) == 1 and attention_mask.size(0) > 1:
+ rp_bucket = rp_bucket.repeat(attention_mask.size(0), 1, 1)
+ # based on assumption that prefix bboxes are negative
+ is_prefix = bbox[:, :, 1] < 0
+ num_prefix = is_prefix.sum(-1)
+ for idx, num_prefix_row in enumerate(num_prefix.cpu().numpy()):
+ rp_bucket[idx, :num_prefix_row, num_prefix_row:] = self.relative_attention_num_buckets
+ rp_bucket[idx, num_prefix_row:, :num_prefix_row] = self.relative_attention_num_buckets + 1
+
+ values: Tensor = self.relative_attention_bias(rp_bucket)
+ if values.dim() != 4:
+ raise ValueError("Wrong dimension of values tensor")
+ values = values.permute([0, 3, 1, 2])
+
+ return values
+
+
+class RelativePositionBias1D(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=1, max_distance=128, **kwargs):
+ """
+ Reimplementation of T5 relative position bias. Distance between given tokens is their distance in the sequence.
+ Parameters are the same as in base class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if self.scaling_factor != 1:
+ raise ValueError("No need to scale 1d features")
+ relative_position = self.get_relative_position(
+ torch.arange(attention_mask.size(1), dtype=torch.long, device=attention_mask.device)[None, :]
+ )
+
+ return relative_position
+
+
+class RelativePositionBiasHorizontal(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=100, max_distance=100, **kwargs):
+ """
+ Represents in the bucket embeddings horizontal distance between two tokens. Parameters are the same as in base
+ class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if not self.scaling_factor > 1.0:
+ raise ValueError("Need to scale the values of bboxes, as there are in small (0,1) range")
+ if bbox is None:
+ raise ValueError("Bbox is required for horizontal relative position bias")
+ # get x positions of left point of bbox
+ horizontal_position: Tensor = bbox[:, :, [0, 2]].mean(dim=-1)
+
+ return self.get_relative_position(horizontal_position)
+
+
+class RelativePositionBiasVertical(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=100, max_distance=100, **kwargs):
+ """
+ Represents in the bucket embeddings vertical distance between two tokens. Parameters are the same as in base
+ class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if not self.scaling_factor > 1.0:
+ raise ValueError("Need to scale the values of bboxes, as there are in small (0,1) range")
+ if bbox is None:
+ raise ValueError("Bbox is required for vertical relative position bias")
+ # get y positions of middle of bbox
+ vertical_position: Tensor = bbox[:, :, [1, 3]].mean(dim=-1)
+
+ return self.get_relative_position(vertical_position)
+
+
+class RelativePositionBiasAggregated(nn.Module):
+ def __init__(self, modules: Sequence[RelativePositionBiasBase]):
+ """
+ Class which sums up various computed biases.
+
+ Args:
+ modules (Sequence[RelativePositionBiasBase]):
+ List of relative bias modules.
+ """
+ super().__init__()
+ self.biases = nn.ModuleList(modules)
+
+ def forward(
+ self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None
+ ) -> Union[float, Tensor]:
+ output = 0.0
+ for bias in self.biases: # type: ignore
+ output = bias(attention_mask, bbox) + output
+
+ return output
+
+
+BIAS_CLASSES = {
+ "1d": RelativePositionBias1D,
+ "horizontal": RelativePositionBiasHorizontal,
+ "vertical": RelativePositionBiasVertical,
+}
+
+
+def create_relative_bias(config: UdopConfig) -> Sequence[RelativePositionBiasBase]:
+ """
+ Creates empty list or one/multiple relative biases.
+
+ :param config: Model's configuration :return: Sequence with created bias modules.
+ """
+ bias_list = []
+ if hasattr(config, "relative_bias_args"):
+ for bias_kwargs_org in config.relative_bias_args:
+ bias_kwargs = deepcopy(bias_kwargs_org)
+ bias_type = bias_kwargs.pop("type")
+ model_num_heads = config.num_heads if hasattr(config, "num_heads") else config.num_attention_heads
+ if "num_heads" in bias_kwargs:
+ if bias_kwargs["num_heads"] != model_num_heads:
+ raise ValueError("Number of heads must match num of heads in the model")
+ else:
+ bias_kwargs["num_heads"] = model_num_heads
+ bias_list.append(BIAS_CLASSES[bias_type](**bias_kwargs)) # type: ignore
+
+ return bias_list
+
+
+class UdopStack(UdopPreTrainedModel):
+ """
+ This class is based on `T5Stack`, but modified to take into account the image modality as well as 2D position
+ embeddings.
+ """
+
+ def __init__(self, config, embed_tokens=None, embed_patches=None):
+ super().__init__(config)
+
+ self.embed_tokens = embed_tokens
+ self.embed_patches = embed_patches
+ self.is_decoder = config.is_decoder
+ self._max_length = config.max_length
+ self.num_layers = config.num_layers
+
+ self.block = nn.ModuleList(
+ [UdopBlock(config, has_relative_attention_bias=bool(i == 0)) for i in range(self.num_layers)]
+ )
+ self.final_layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ if not self.is_decoder:
+ self.cell_2d_embedding = UdopCellEmbeddings(config.max_2d_position_embeddings, config.hidden_size)
+
+ # get weights from encoder position bias
+ self.relative_bias = self._get_relative_bias(config)
+
+ # tie weights of original position bias of encoder
+ for bias in self.relative_bias.biases:
+ if isinstance(bias, RelativePositionBias1D):
+ self._tie_or_clone_weights(
+ bias.relative_attention_bias, self.block[0].layer[0].SelfAttention.relative_attention_bias
+ )
+
+ @staticmethod
+ def _get_relative_bias(config: UdopConfig) -> RelativePositionBiasAggregated:
+ relative_bias_list = create_relative_bias(config)
+ return RelativePositionBiasAggregated(relative_bias_list)
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def get_output_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, new_embeddings):
+ self.embed_tokens = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ bbox=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ visual_bbox=None,
+ image_embeddings=None,
+ position_bias=None,
+ head_mask=None,
+ cross_attn_head_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # input embeddings processing
+
+ if input_ids is not None and inputs_embeds is not None:
+ err_msg_prefix = "decoder_" if self.is_decoder else ""
+ raise ValueError(
+ f"You cannot specify both {err_msg_prefix}inputs and {err_msg_prefix}inputs_embeds at the same time"
+ )
+ elif input_ids is not None and torch.numel(input_ids) > 0:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ elif inputs_embeds is None and input_ids is not None and torch.numel(input_ids) == 0:
+ input_ids = torch.full((4, 1024), self.config.pad_token_id, device=input_ids.device, dtype=input_ids.dtype)
+ attention_mask = torch.zeros((4, 1024), device=input_ids.device, dtype=input_ids.dtype)
+ bbox = torch.zeros((4, 1024, 4), device=input_ids.device, dtype=input_ids.dtype)
+ input_shape = input_ids.size()
+ position_bias = torch.zeros_like(self.get_extended_attention_mask(attention_mask, input_shape))
+ # encoder_attention_mask = attention_mask
+ logger.warning("Empty batch")
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ err_msg_prefix = "decoder_" if self.is_decoder else ""
+ raise ValueError(f"You have to specify either {err_msg_prefix}inputs or {err_msg_prefix}inputs_embeds")
+
+ if inputs_embeds is None:
+ if self.embed_tokens is None:
+ raise ValueError("You have to intialize the model with valid token embeddings")
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if pixel_values is not None:
+ image_embeddings = self.embed_patches(pixel_values)
+
+ if image_embeddings is not None:
+ # combine visual and OCR text embeddings
+ num_patches = self.config.image_size // self.config.patch_size
+ inputs_embeds, bbox, attention_mask = combine_image_text_embeddings(
+ image_embeddings,
+ inputs_embeds,
+ bbox,
+ visual_bbox,
+ attention_mask,
+ num_patches,
+ 0,
+ self.config.image_size,
+ self.config.patch_size,
+ )
+ input_shape = inputs_embeds.size()[:-1]
+
+ if not self.is_decoder and bbox is not None:
+ inputs_embeds += self.cell_2d_embedding(bbox)
+
+ batch_size, seq_length = input_shape
+
+ # required mask seq length can be calculated via length of past
+ mask_seq_length = past_key_values[0][0].shape[2] + seq_length if past_key_values is not None else seq_length
+
+ if use_cache is True:
+ assert self.is_decoder, "`use_cache` can only be set to `True` if {} is used as a decoder".format(self)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(batch_size, mask_seq_length).to(inputs_embeds.device)
+ if self.is_decoder and encoder_attention_mask is None and encoder_hidden_states is not None:
+ encoder_seq_length = encoder_hidden_states.shape[1]
+ encoder_attention_mask = torch.ones(
+ batch_size, encoder_seq_length, device=inputs_embeds.device, dtype=torch.long
+ )
+
+ # initialize past_key_values with `None` if past does not exist
+ if past_key_values is None:
+ past_key_values = [None] * len(self.block)
+
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ if self.is_decoder and encoder_attention_mask is not None:
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ head_mask = self.get_head_mask(head_mask, self.num_layers)
+ present_key_value_states = () if use_cache else None
+ all_hidden_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+ all_cross_attentions = () if (output_attentions and self.is_decoder) else None
+
+ if self.is_decoder: # modified lines
+ position_bias = None
+ else:
+ position_bias = self.relative_bias(attention_mask=attention_mask, bbox=bbox)
+ position_bias = position_bias + extended_attention_mask
+ encoder_decoder_position_bias = None
+
+ hidden_states = inputs_embeds
+
+ hidden_states = self.dropout(hidden_states)
+
+ for i, (layer_module, past_key_value) in enumerate(zip(self.block, past_key_values)):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask=extended_attention_mask,
+ position_bias=position_bias,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ layer_head_mask=head_mask[i],
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ # layer_outputs is a tuple with:
+ # hidden-states, key-value-states, (self-attention weights), (self-attention position bias), (cross-attention weights), (cross-attention position bias)
+ if use_cache is False: # MP fixes
+ layer_outputs = layer_outputs[:1] + (None,) + layer_outputs[1:]
+ hidden_states, present_key_value_state = layer_outputs[:2]
+
+ # We share the position biases between the layers - the first layer store them
+ # layer_outputs = hidden-states, key-value-states (self-attention weights),
+ # (self-attention position bias), (cross-attention weights), (cross-attention position bias)
+
+ position_bias = layer_outputs[2]
+ if self.is_decoder and encoder_hidden_states is not None:
+ encoder_decoder_position_bias = layer_outputs[4 if output_attentions else 3]
+ # append next layer key value states
+ if use_cache:
+ present_key_value_states = present_key_value_states + (present_key_value_state,)
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[2],) # We keep only self-attention weights for now
+ if self.is_decoder:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
+
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ # Add last layer
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ attention_mask,
+ present_key_value_states,
+ all_hidden_states,
+ all_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+
+ return BaseModelOutputWithAttentionMask(
+ last_hidden_state=hidden_states,
+ attention_mask=attention_mask,
+ past_key_values=present_key_value_states,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+@add_start_docstrings(
+ "The bare UDOP encoder-decoder Transformer outputting raw hidden-states without any specific head on top.",
+ UDOP_START_DOCSTRING,
+)
+class UdopModel(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "decoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "decoder.relative_bias.biases.0.relative_attention_bias.weight",
+ ]
+
+ def __init__(self, config):
+ super(UdopModel, self).__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ decoder_config = deepcopy(config)
+ decoder_config.is_decoder = True
+ decoder_config.is_encoder_decoder = False
+ decoder_config.num_layers = config.num_decoder_layers
+ self.decoder = UdopStack(decoder_config, self.shared)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+ self.decoder.set_input_embeddings(new_embeddings)
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(UDOP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=Seq2SeqModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ attention_mask: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ decoder_input_ids: Optional[Tensor] = None,
+ decoder_attention_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ encoder_outputs: Optional[Tensor] = None,
+ past_key_values: Optional[Tensor] = None,
+ head_mask: Optional[Tensor] = None,
+ decoder_inputs_embeds: Optional[Tensor] = None,
+ decoder_head_mask: Optional[Tensor] = None,
+ cross_attn_head_mask: Optional[Tensor] = None,
+ use_cache=True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Tuple[Tensor, ...]:
+ r"""
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = AutoModel.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> inputs = processor(image, words, boxes=boxes, return_tensors="pt")
+
+ >>> decoder_input_ids = torch.tensor([[model.config.decoder_start_token_id]])
+
+ >>> # forward pass
+ >>> outputs = model(**inputs, decoder_input_ids=decoder_input_ids)
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 1, 1024]
+ ```"""
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Encode if needed (training, first prediction pass)
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ bbox=bbox,
+ pixel_values=pixel_values,
+ visual_bbox=visual_bbox,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+ encoder_attention_mask = encoder_outputs.attention_mask if return_dict else encoder_outputs[1]
+
+ # Decode
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ # we filter out the attention mask
+ decoder_outputs = tuple(value for idx, value in enumerate(decoder_outputs) if idx != 1)
+ encoder_outputs = tuple(value for idx, value in enumerate(encoder_outputs) if idx != 1)
+ return decoder_outputs + encoder_outputs
+
+ return Seq2SeqModelOutput(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """The UDOP encoder-decoder Transformer with a language modeling head on top, enabling to generate text given document
+ images and an optional prompt.
+
+ This class is based on [`T5ForConditionalGeneration`], extended to deal with images and layout (2D) data.""",
+ UDOP_START_DOCSTRING,
+)
+class UdopForConditionalGeneration(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "decoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "decoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "lm_head.weight",
+ ]
+
+ def __init__(self, config):
+ super(UdopForConditionalGeneration, self).__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ decoder_config = deepcopy(config)
+ decoder_config.is_decoder = True
+ decoder_config.is_encoder_decoder = False
+ decoder_config.num_layers = config.num_decoder_layers
+ self.decoder = UdopStack(decoder_config, self.shared)
+
+ # The weights of the language modeling head are shared with those of the encoder and decoder
+ self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+ self.decoder.set_input_embeddings(new_embeddings)
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(UDOP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ attention_mask: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ decoder_input_ids: Optional[Tensor] = None,
+ decoder_attention_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ encoder_outputs: Optional[Tensor] = None,
+ past_key_values: Optional[Tensor] = None,
+ head_mask: Optional[Tensor] = None,
+ decoder_inputs_embeds: Optional[Tensor] = None,
+ decoder_head_mask: Optional[Tensor] = None,
+ cross_attn_head_mask: Optional[Tensor] = None,
+ use_cache=True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[Tensor] = None,
+ ) -> Tuple[Tensor, ...]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the language modeling loss. Indices should be in `[-100, 0, ..., config.vocab_size -
+ 1]`. All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ...,
+ config.vocab_size]`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, UdopForConditionalGeneration
+ >>> from datasets import load_dataset
+
+ >>> # load model and processor
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> question = "Question answering. What is the date on the form?"
+ >>> encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
+
+ >>> # autoregressive generation
+ >>> predicted_ids = model.generate(**encoding)
+ >>> print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
+ 9/30/92
+ ```"""
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if decoder_input_ids is None and labels is not None:
+ decoder_input_ids = self._shift_right(labels)
+
+ # Encode if needed (training, first prediction pass)
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ bbox=bbox,
+ visual_bbox=visual_bbox,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+ encoder_attention_mask = encoder_outputs.attention_mask if return_dict else encoder_outputs[1]
+
+ # Decode
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = decoder_outputs[0]
+
+ if self.config.tie_word_embeddings:
+ # Rescale output before projecting on vocab
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
+ sequence_output = sequence_output * (self.config.d_model**-0.5)
+
+ lm_logits = self.lm_head(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
+
+ if not return_dict:
+ output = (lm_logits,) + decoder_outputs[2:] + (encoder_outputs[0],) + encoder_outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return Seq2SeqLMOutput(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ head_mask=None,
+ decoder_head_mask=None,
+ cross_attn_head_mask=None,
+ use_cache=None,
+ encoder_outputs=None,
+ **kwargs,
+ ):
+ # cut decoder_input_ids if past is used
+ if past_key_values is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ "decoder_input_ids": input_ids,
+ "past_key_values": past_key_values,
+ "encoder_outputs": encoder_outputs,
+ "attention_mask": attention_mask,
+ "head_mask": head_mask,
+ "decoder_head_mask": decoder_head_mask,
+ "cross_attn_head_mask": cross_attn_head_mask,
+ "use_cache": use_cache,
+ "bbox": kwargs.get("bbox", None),
+ "pixel_values": kwargs.get("pixel_values", None),
+ "visual_bbox": kwargs.get("visual_bbox", None),
+ }
+
+ # Copied from transformers.models.t5.modeling_t5.T5ForConditionalGeneration._reorder_cache
+ def _reorder_cache(self, past_key_values, beam_idx):
+ # if decoder past is not included in output
+ # speedy decoding is disabled and no need to reorder
+ if past_key_values is None:
+ logger.warning("You might want to consider setting `use_cache=True` to speed up decoding")
+ return past_key_values
+
+ reordered_decoder_past = ()
+ for layer_past_states in past_key_values:
+ # get the correct batch idx from layer past batch dim
+ # batch dim of `past` is at 2nd position
+ reordered_layer_past_states = ()
+ for layer_past_state in layer_past_states:
+ # need to set correct `past` for each of the four key / value states
+ reordered_layer_past_states = reordered_layer_past_states + (
+ layer_past_state.index_select(0, beam_idx.to(layer_past_state.device)),
+ )
+
+ if reordered_layer_past_states[0].shape != layer_past_states[0].shape:
+ raise ValueError(
+ f"reordered_layer_past_states[0] shape {reordered_layer_past_states[0].shape} and layer_past_states[0] shape {layer_past_states[0].shape} mismatched"
+ )
+ if len(reordered_layer_past_states) != len(layer_past_states):
+ raise ValueError(
+ f"length of reordered_layer_past_states {len(reordered_layer_past_states)} and length of layer_past_states {len(layer_past_states)} mismatched"
+ )
+
+ reordered_decoder_past = reordered_decoder_past + (reordered_layer_past_states,)
+ return reordered_decoder_past
+
+
+@add_start_docstrings(
+ "The bare UDOP Model transformer outputting encoder's raw hidden-states without any specific head on top.",
+ UDOP_START_DOCSTRING,
+)
+class UdopEncoderModel(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ ]
+
+ def __init__(self, config: UdopConfig):
+ super().__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+
+ def get_encoder(self):
+ return self.encoder
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.block[layer].layer[0].SelfAttention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(UDOP_ENCODER_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithAttentionMask, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ attention_mask: Tensor = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ head_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.FloatTensor], BaseModelOutputWithAttentionMask]:
+ r"""
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, UdopEncoderModel
+ >>> from huggingface_hub import hf_hub_download
+ >>> from datasets import load_dataset
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = UdopEncoderModel.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> encoding = processor(image, words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ bbox=bbox,
+ visual_bbox=visual_bbox,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ return encoder_outputs
diff --git a/src/transformers/models/udop/processing_udop.py b/src/transformers/models/udop/processing_udop.py
new file mode 100644
index 00000000000000..2902541d6f5b46
--- /dev/null
+++ b/src/transformers/models/udop/processing_udop.py
@@ -0,0 +1,204 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for UDOP.
+"""
+
+from typing import List, Optional, Union
+
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType
+
+
+class UdopProcessor(ProcessorMixin):
+ r"""
+ Constructs a UDOP processor which combines a LayoutLMv3 image processor and a UDOP tokenizer into a single processor.
+
+ [`UdopProcessor`] offers all the functionalities you need to prepare data for the model.
+
+ It first uses [`LayoutLMv3ImageProcessor`] to resize, rescale and normalize document images, and optionally applies OCR
+ to get words and normalized bounding boxes. These are then provided to [`UdopTokenizer`] or [`UdopTokenizerFast`],
+ which turns the words and bounding boxes into token-level `input_ids`, `attention_mask`, `token_type_ids`, `bbox`.
+ Optionally, one can provide integer `word_labels`, which are turned into token-level `labels` for token
+ classification tasks (such as FUNSD, CORD).
+
+ Additionally, it also supports passing `text_target` and `text_pair_target` to the tokenizer, which can be used to
+ prepare labels for language modeling tasks.
+
+ Args:
+ image_processor (`LayoutLMv3ImageProcessor`):
+ An instance of [`LayoutLMv3ImageProcessor`]. The image processor is a required input.
+ tokenizer (`UdopTokenizer` or `UdopTokenizerFast`):
+ An instance of [`UdopTokenizer`] or [`UdopTokenizerFast`]. The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "LayoutLMv3ImageProcessor"
+ tokenizer_class = ("UdopTokenizer", "UdopTokenizerFast")
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: Optional[ImageInput] = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ text_pair: Optional[Union[PreTokenizedInput, List[PreTokenizedInput]]] = None,
+ boxes: Union[List[List[int]], List[List[List[int]]]] = None,
+ word_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ text_target: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ text_pair_target: Optional[
+ Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]
+ ] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ ) -> BatchEncoding:
+ """
+ This method first forwards the `images` argument to [`~UdopImageProcessor.__call__`]. In case
+ [`UdopImageProcessor`] was initialized with `apply_ocr` set to `True`, it passes the obtained words and
+ bounding boxes along with the additional arguments to [`~UdopTokenizer.__call__`] and returns the output,
+ together with the prepared `pixel_values`. In case [`UdopImageProcessor`] was initialized with `apply_ocr` set
+ to `False`, it passes the words (`text`/``text_pair`) and `boxes` specified by the user along with the
+ additional arguments to [`~UdopTokenizer.__call__`] and returns the output, together with the prepared
+ `pixel_values`.
+
+ Alternatively, one can pass `text_target` and `text_pair_target` to prepare the targets of UDOP.
+
+ Please refer to the docstring of the above two methods for more information.
+ """
+ # verify input
+ if self.image_processor.apply_ocr and (boxes is not None):
+ raise ValueError(
+ "You cannot provide bounding boxes if you initialized the image processor with apply_ocr set to True."
+ )
+
+ if self.image_processor.apply_ocr and (word_labels is not None):
+ raise ValueError(
+ "You cannot provide word labels if you initialized the image processor with apply_ocr set to True."
+ )
+
+ if return_overflowing_tokens is True and return_offsets_mapping is False:
+ raise ValueError("You cannot return overflowing tokens without returning the offsets mapping.")
+
+ if text_target is not None:
+ # use the processor to prepare the targets of UDOP
+ return self.tokenizer(
+ text_target=text_target,
+ text_pair_target=text_pair_target,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ )
+
+ else:
+ # use the processor to prepare the inputs of UDOP
+ # first, apply the image processor
+ features = self.image_processor(images=images, return_tensors=return_tensors)
+
+ # second, apply the tokenizer
+ if text is not None and self.image_processor.apply_ocr and text_pair is None:
+ if isinstance(text, str):
+ text = [text] # add batch dimension (as the image processor always adds a batch dimension)
+ text_pair = features["words"]
+
+ encoded_inputs = self.tokenizer(
+ text=text if text is not None else features["words"],
+ text_pair=text_pair if text_pair is not None else None,
+ boxes=boxes if boxes is not None else features["boxes"],
+ word_labels=word_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ )
+
+ # add pixel values
+ pixel_values = features.pop("pixel_values")
+ if return_overflowing_tokens is True:
+ pixel_values = self.get_overflowing_images(pixel_values, encoded_inputs["overflow_to_sample_mapping"])
+ encoded_inputs["pixel_values"] = pixel_values
+
+ return encoded_inputs
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.get_overflowing_images
+ def get_overflowing_images(self, images, overflow_to_sample_mapping):
+ # in case there's an overflow, ensure each `input_ids` sample is mapped to its corresponding image
+ images_with_overflow = []
+ for sample_idx in overflow_to_sample_mapping:
+ images_with_overflow.append(images[sample_idx])
+
+ if len(images_with_overflow) != len(overflow_to_sample_mapping):
+ raise ValueError(
+ "Expected length of images to be the same as the length of `overflow_to_sample_mapping`, but got"
+ f" {len(images_with_overflow)} and {len(overflow_to_sample_mapping)}"
+ )
+
+ return images_with_overflow
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.batch_decode
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.decode
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer
+ to the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.model_input_names
+ def model_input_names(self):
+ return ["input_ids", "bbox", "attention_mask", "pixel_values"]
diff --git a/src/transformers/models/udop/tokenization_udop.py b/src/transformers/models/udop/tokenization_udop.py
new file mode 100644
index 00000000000000..10e92db48cebba
--- /dev/null
+++ b/src/transformers/models/udop/tokenization_udop.py
@@ -0,0 +1,1483 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License
+""" Tokenization classes for UDOP model."""
+
+
+import os
+import re
+import warnings
+from shutil import copyfile
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import sentencepiece as spm
+
+from ...tokenization_utils import PreTrainedTokenizer
+from ...tokenization_utils_base import (
+ AddedToken,
+ BatchEncoding,
+ EncodedInput,
+ PreTokenizedInput,
+ TextInput,
+ TextInputPair,
+ TruncationStrategy,
+)
+from ...utils import PaddingStrategy, TensorType, add_end_docstrings, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+SPIECE_UNDERLINE = "▁"
+
+
+UDOP_ENCODE_KWARGS_DOCSTRING = r"""
+ add_special_tokens (`bool`, *optional*, defaults to `True`):
+ Whether or not to encode the sequences with the special tokens relative to their model.
+ padding (`bool`, `str` or [`~file_utils.PaddingStrategy`], *optional*, defaults to `False`):
+ Activates and controls padding. Accepts the following values:
+
+ - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
+ acceptable input length for the model if that argument is not provided.
+ - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
+ lengths).
+ truncation (`bool`, `str` or [`~tokenization_utils_base.TruncationStrategy`], *optional*, defaults to `False`):
+ Activates and controls truncation. Accepts the following values:
+
+ - `True` or `'longest_first'`: Truncate to a maximum length specified with the argument `max_length` or
+ to the maximum acceptable input length for the model if that argument is not provided. This will
+ truncate token by token, removing a token from the longest sequence in the pair if a pair of
+ sequences (or a batch of pairs) is provided.
+ - `'only_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `'only_second'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `False` or `'do_not_truncate'` (default): No truncation (i.e., can output batch with sequence lengths
+ greater than the model maximum admissible input size).
+ max_length (`int`, *optional*):
+ Controls the maximum length to use by one of the truncation/padding parameters.
+
+ If left unset or set to `None`, this will use the predefined model maximum length if a maximum length
+ is required by one of the truncation/padding parameters. If the model has no specific maximum input
+ length (like XLNet) truncation/padding to a maximum length will be deactivated.
+ stride (`int`, *optional*, defaults to 0):
+ If set to a number along with `max_length`, the overflowing tokens returned when
+ `return_overflowing_tokens=True` will contain some tokens from the end of the truncated sequence
+ returned to provide some overlap between truncated and overflowing sequences. The value of this
+ argument defines the number of overlapping tokens.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
+ the use of Tensor Cores on NVIDIA hardware with compute capability `>= 7.5` (Volta).
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+ return_token_type_ids (`bool`, *optional*):
+ Whether to return token type IDs. If left to the default, will return the token type IDs according to
+ the specific tokenizer's default, defined by the `return_outputs` attribute.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ return_attention_mask (`bool`, *optional*):
+ Whether to return the attention mask. If left to the default, will return the attention mask according
+ to the specific tokenizer's default, defined by the `return_outputs` attribute.
+
+ [What are attention masks?](../glossary#attention-mask)
+ return_overflowing_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch
+ of pairs) is provided with `truncation_strategy = longest_first` or `True`, an error is raised instead
+ of returning overflowing tokens.
+ return_special_tokens_mask (`bool`, *optional*, defaults to `False`):
+ Whether or not to return special tokens mask information.
+ return_offsets_mapping (`bool`, *optional*, defaults to `False`):
+ Whether or not to return `(char_start, char_end)` for each token.
+
+ This is only available on fast tokenizers inheriting from [`PreTrainedTokenizerFast`], if using
+ Python's tokenizer, this method will raise `NotImplementedError`.
+ return_length (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the lengths of the encoded inputs.
+ verbose (`bool`, *optional*, defaults to `True`):
+ Whether or not to print more information and warnings.
+ **kwargs: passed to the `self.tokenize()` method
+
+ Return:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model.
+
+ [What are input IDs?](../glossary#input-ids)
+
+ - **bbox** -- List of bounding boxes to be fed to a model.
+
+ - **token_type_ids** -- List of token type ids to be fed to a model (when `return_token_type_ids=True` or
+ if *"token_type_ids"* is in `self.model_input_names`).
+
+ [What are token type IDs?](../glossary#token-type-ids)
+
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names`).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ - **labels** -- List of labels to be fed to a model. (when `word_labels` is specified).
+ - **overflowing_tokens** -- List of overflowing tokens sequences (when a `max_length` is specified and
+ `return_overflowing_tokens=True`).
+ - **num_truncated_tokens** -- Number of tokens truncated (when a `max_length` is specified and
+ `return_overflowing_tokens=True`).
+ - **special_tokens_mask** -- List of 0s and 1s, with 1 specifying added special tokens and 0 specifying
+ regular sequence tokens (when `add_special_tokens=True` and `return_special_tokens_mask=True`).
+ - **length** -- The length of the inputs (when `return_length=True`).
+"""
+
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/spiece.model",
+ },
+ "tokenizer_file": {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/tokenizer.json",
+ },
+}
+
+
+# TODO(PVP) - this should be removed in Transformers v5
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "microsoft/udop-large": 512,
+}
+
+
+class UdopTokenizer(PreTrainedTokenizer):
+ """
+ Adapted from [`LayoutXLMTokenizer`] and [`T5Tokenizer`]. Based on
+ [SentencePiece](https://github.com/google/sentencepiece).
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+
+
+
+ UDOP architecture. Taken from the original paper.
+
+## Usage tips
+
+- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
+- One can use [`UdopProcessor`] to prepare images and text for the model. By default, this class uses the Tesseract engine to extract a list of words
+and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either
+`apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/UDOP).
+
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+ - __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+ - forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+ - forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 027cf495466c50..6cdd561b41e1ba 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -856,6 +856,11 @@
"TvpConfig",
"TvpProcessor",
],
+ "models.udop": [
+ "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "UdopConfig",
+ "UdopProcessor",
+ ],
"models.umt5": ["UMT5Config"],
"models.unispeech": [
"UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1135,6 +1140,7 @@
_import_structure["models.speech_to_text"].append("Speech2TextTokenizer")
_import_structure["models.speecht5"].append("SpeechT5Tokenizer")
_import_structure["models.t5"].append("T5Tokenizer")
+ _import_structure["models.udop"].append("UdopTokenizer")
_import_structure["models.xglm"].append("XGLMTokenizer")
_import_structure["models.xlm_prophetnet"].append("XLMProphetNetTokenizer")
_import_structure["models.xlm_roberta"].append("XLMRobertaTokenizer")
@@ -1214,6 +1220,7 @@
_import_structure["models.splinter"].append("SplinterTokenizerFast")
_import_structure["models.squeezebert"].append("SqueezeBertTokenizerFast")
_import_structure["models.t5"].append("T5TokenizerFast")
+ _import_structure["models.udop"].append("UdopTokenizerFast")
_import_structure["models.whisper"].append("WhisperTokenizerFast")
_import_structure["models.xglm"].append("XGLMTokenizerFast")
_import_structure["models.xlm_roberta"].append("XLMRobertaTokenizerFast")
@@ -3411,6 +3418,15 @@
"TvpPreTrainedModel",
]
)
+ _import_structure["models.udop"].extend(
+ [
+ "UDOP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "UdopEncoderModel",
+ "UdopForConditionalGeneration",
+ "UdopModel",
+ "UdopPreTrainedModel",
+ ],
+ )
_import_structure["models.umt5"].extend(
[
"UMT5EncoderModel",
@@ -5640,6 +5656,7 @@
TvpConfig,
TvpProcessor,
)
+ from .models.udop import UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP, UdopConfig, UdopProcessor
from .models.umt5 import UMT5Config
from .models.unispeech import (
UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5915,6 +5932,7 @@
from .models.speech_to_text import Speech2TextTokenizer
from .models.speecht5 import SpeechT5Tokenizer
from .models.t5 import T5Tokenizer
+ from .models.udop import UdopTokenizer
from .models.xglm import XGLMTokenizer
from .models.xlm_prophetnet import XLMProphetNetTokenizer
from .models.xlm_roberta import XLMRobertaTokenizer
@@ -5987,6 +6005,7 @@
from .models.splinter import SplinterTokenizerFast
from .models.squeezebert import SqueezeBertTokenizerFast
from .models.t5 import T5TokenizerFast
+ from .models.udop import UdopTokenizerFast
from .models.whisper import WhisperTokenizerFast
from .models.xglm import XGLMTokenizerFast
from .models.xlm_roberta import XLMRobertaTokenizerFast
@@ -7827,6 +7846,13 @@
TvpModel,
TvpPreTrainedModel,
)
+ from .models.udop import (
+ UDOP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ UdopEncoderModel,
+ UdopForConditionalGeneration,
+ UdopModel,
+ UdopPreTrainedModel,
+ )
from .models.umt5 import (
UMT5EncoderModel,
UMT5ForConditionalGeneration,
diff --git a/src/transformers/convert_slow_tokenizer.py b/src/transformers/convert_slow_tokenizer.py
index c44592f8a0f9fb..707bfae89db56f 100644
--- a/src/transformers/convert_slow_tokenizer.py
+++ b/src/transformers/convert_slow_tokenizer.py
@@ -1039,6 +1039,17 @@ def post_processor(self):
)
+class UdopConverter(SpmConverter):
+ def post_processor(self):
+ return processors.TemplateProcessing(
+ single=["$A", ""],
+ pair=["$A", "", "$B", ""],
+ special_tokens=[
+ ("", self.original_tokenizer.convert_tokens_to_ids("")),
+ ],
+ )
+
+
class WhisperConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
@@ -1471,6 +1482,7 @@ def converted(self) -> Tokenizer:
"SeamlessM4TTokenizer": SeamlessM4TConverter,
"SqueezeBertTokenizer": BertConverter,
"T5Tokenizer": T5Converter,
+ "UdopTokenizer": UdopConverter,
"WhisperTokenizer": WhisperConverter,
"XLMRobertaTokenizer": XLMRobertaConverter,
"XLNetTokenizer": XLNetConverter,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index ebb3db25fb96be..89ca6ab2b8660c 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -220,6 +220,7 @@
trocr,
tvlt,
tvp,
+ udop,
umt5,
unispeech,
unispeech_sat,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 7bc637f3e1060a..87ff925e55eaa1 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -231,6 +231,7 @@
("trocr", "TrOCRConfig"),
("tvlt", "TvltConfig"),
("tvp", "TvpConfig"),
+ ("udop", "UdopConfig"),
("umt5", "UMT5Config"),
("unispeech", "UniSpeechConfig"),
("unispeech-sat", "UniSpeechSatConfig"),
@@ -454,6 +455,7 @@
("transfo-xl", "TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("tvlt", "TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("tvp", "TVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("udop", "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("univnet", "UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -715,6 +717,7 @@
("trocr", "TrOCR"),
("tvlt", "TVLT"),
("tvp", "TVP"),
+ ("udop", "UDOP"),
("ul2", "UL2"),
("umt5", "UMT5"),
("unispeech", "UniSpeech"),
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index aef894a425bae1..50e9266cdee161 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -108,6 +108,7 @@
("timesformer", "VideoMAEImageProcessor"),
("tvlt", "TvltImageProcessor"),
("tvp", "TvpImageProcessor"),
+ ("udop", "LayoutLMv3ImageProcessor"),
("upernet", "SegformerImageProcessor"),
("van", "ConvNextImageProcessor"),
("videomae", "VideoMAEImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 05b519d2bcd16b..0d28d224f19106 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -219,6 +219,7 @@
("transfo-xl", "TransfoXLModel"),
("tvlt", "TvltModel"),
("tvp", "TvpModel"),
+ ("udop", "UdopModel"),
("umt5", "UMT5Model"),
("unispeech", "UniSpeechModel"),
("unispeech-sat", "UniSpeechSatModel"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 2c21f1cd529c74..d586068fb9c095 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -418,6 +418,13 @@
("tapex", ("TapexTokenizer", None)),
("transfo-xl", ("TransfoXLTokenizer", None)),
("tvp", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "udop",
+ (
+ "UdopTokenizer" if is_sentencepiece_available() else None,
+ "UdopTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
(
"umt5",
(
diff --git a/src/transformers/models/udop/__init__.py b/src/transformers/models/udop/__init__.py
new file mode 100644
index 00000000000000..5066fde6af1d15
--- /dev/null
+++ b/src/transformers/models/udop/__init__.py
@@ -0,0 +1,98 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_sentencepiece_available,
+ is_tokenizers_available,
+ is_torch_available,
+)
+
+
+_import_structure = {
+ "configuration_udop": ["UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP", "UdopConfig"],
+ "processing_udop": ["UdopProcessor"],
+}
+
+try:
+ if not is_sentencepiece_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_udop"] = ["UdopTokenizer"]
+
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_udop_fast"] = ["UdopTokenizerFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_udop"] = [
+ "UDOP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "UdopForConditionalGeneration",
+ "UdopPreTrainedModel",
+ "UdopModel",
+ "UdopEncoderModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_udop import UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP, UdopConfig
+ from .processing_udop import UdopProcessor
+
+ try:
+ if not is_sentencepiece_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_udop import UdopTokenizer
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_udop_fast import UdopTokenizerFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_udop import (
+ UDOP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ UdopEncoderModel,
+ UdopForConditionalGeneration,
+ UdopModel,
+ UdopPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/udop/configuration_udop.py b/src/transformers/models/udop/configuration_udop.py
new file mode 100644
index 00000000000000..8647a7bae29acf
--- /dev/null
+++ b/src/transformers/models/udop/configuration_udop.py
@@ -0,0 +1,162 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" UDOP model configuration"""
+
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/config.json",
+}
+
+
+class UdopConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`UdopForConditionalGeneration`]. It is used to
+ instantiate a UDOP model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the UDOP
+ [microsoft/udop-large](https://huggingface.co/microsoft/udop-large) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Arguments:
+ vocab_size (`int`, *optional*, defaults to 33201):
+ Vocabulary size of the UDOP model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`UdopForConditionalGeneration`].
+ d_model (`int`, *optional*, defaults to 1024):
+ Size of the encoder layers and the pooler layer.
+ d_kv (`int`, *optional*, defaults to 64):
+ Size of the key, query, value projections per attention head. The `inner_dim` of the projection layer will
+ be defined as `num_heads * d_kv`.
+ d_ff (`int`, *optional*, defaults to 4096):
+ Size of the intermediate feed forward layer in each `UdopBlock`.
+ num_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder and decoder.
+ num_decoder_layers (`int`, *optional*):
+ Number of hidden layers in the Transformer decoder. Will use the same value as `num_layers` if not set.
+ num_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder and decoder.
+ relative_attention_num_buckets (`int`, *optional*, defaults to 32):
+ The number of buckets to use for each attention layer.
+ relative_attention_max_distance (`int`, *optional*, defaults to 128):
+ The maximum distance of the longer sequences for the bucket separation.
+ relative_bias_args (`List[dict]`, *optional*, defaults to `[{'type': '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}]`):
+ A list of dictionaries containing the arguments for the relative bias layers.
+ dropout_rate (`float`, *optional*, defaults to 0.1):
+ The ratio for all dropout layers.
+ layer_norm_epsilon (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ initializer_factor (`float`, *optional*, defaults to 1.0):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+ feed_forward_proj (`string`, *optional*, defaults to `"relu"`):
+ Type of feed forward layer to be used. Should be one of `"relu"` or `"gated-gelu"`. Udopv1.1 uses the
+ `"gated-gelu"` feed forward projection. Original Udop uses `"relu"`.
+ is_encoder_decoder (`bool`, *optional*, defaults to `True`):
+ Whether the model should behave as an encoder/decoder or not.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models).
+ pad_token_id (`int`, *optional*, defaults to 0):
+ The id of the padding token in the vocabulary.
+ eos_token_id (`int`, *optional*, defaults to 1):
+ The id of the end-of-sequence token in the vocabulary.
+ max_2d_position_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum absolute position embeddings for relative position encoding.
+ image_size (`int`, *optional*, defaults to 224):
+ The size of the input images.
+ patch_size (`int`, *optional*, defaults to 16):
+ The patch size used by the vision encoder.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of channels in the input images.
+ """
+
+ model_type = "udop"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ attribute_map = {"hidden_size": "d_model", "num_attention_heads": "num_heads", "num_hidden_layers": "num_layers"}
+
+ def __init__(
+ self,
+ vocab_size=33201,
+ d_model=1024,
+ d_kv=64,
+ d_ff=4096,
+ num_layers=24,
+ num_decoder_layers=None,
+ num_heads=16,
+ relative_attention_num_buckets=32,
+ relative_attention_max_distance=128,
+ relative_bias_args=[{"type": "1d"}, {"type": "horizontal"}, {"type": "vertical"}],
+ dropout_rate=0.1,
+ layer_norm_epsilon=1e-6,
+ initializer_factor=1.0,
+ feed_forward_proj="relu",
+ is_encoder_decoder=True,
+ use_cache=True,
+ pad_token_id=0,
+ eos_token_id=1,
+ max_2d_position_embeddings=1024,
+ image_size=224,
+ patch_size=16,
+ num_channels=3,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.d_kv = d_kv
+ self.d_ff = d_ff
+ self.num_layers = num_layers
+ self.num_decoder_layers = (
+ num_decoder_layers if num_decoder_layers is not None else self.num_layers
+ ) # default = symmetry
+ self.num_heads = num_heads
+ self.relative_attention_num_buckets = relative_attention_num_buckets
+ self.relative_attention_max_distance = relative_attention_max_distance
+ self.dropout_rate = dropout_rate
+ self.layer_norm_epsilon = layer_norm_epsilon
+ self.initializer_factor = initializer_factor
+ self.feed_forward_proj = feed_forward_proj
+ self.use_cache = use_cache
+
+ # UDOP attributes
+ self.max_2d_position_embeddings = max_2d_position_embeddings
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ if not isinstance(relative_bias_args, list):
+ raise ValueError("`relative_bias_args` should be a list of dictionaries.")
+ self.relative_bias_args = relative_bias_args
+
+ act_info = self.feed_forward_proj.split("-")
+ self.dense_act_fn = act_info[-1]
+ self.is_gated_act = act_info[0] == "gated"
+
+ if len(act_info) > 1 and act_info[0] != "gated" or len(act_info) > 2:
+ raise ValueError(
+ f"`feed_forward_proj`: {feed_forward_proj} is not a valid activation function of the dense layer."
+ "Please make sure `feed_forward_proj` is of the format `gated-{ACT_FN}` or `{ACT_FN}`, e.g. "
+ "'gated-gelu' or 'relu'"
+ )
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ is_encoder_decoder=is_encoder_decoder,
+ **kwargs,
+ )
diff --git a/src/transformers/models/udop/convert_udop_to_hf.py b/src/transformers/models/udop/convert_udop_to_hf.py
new file mode 100644
index 00000000000000..f9cf07f1286bf1
--- /dev/null
+++ b/src/transformers/models/udop/convert_udop_to_hf.py
@@ -0,0 +1,213 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert UDOP checkpoints from the original repository. URL: https://github.com/microsoft/i-Code/tree/main/i-Code-Doc"""
+
+
+import argparse
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from torchvision import transforms as T
+
+from transformers import (
+ LayoutLMv3ImageProcessor,
+ UdopConfig,
+ UdopForConditionalGeneration,
+ UdopProcessor,
+ UdopTokenizer,
+)
+from transformers.image_utils import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
+
+
+def original_transform(image, image_size=224):
+ transform = T.Compose(
+ [
+ T.Resize([image_size, image_size]),
+ T.ToTensor(),
+ T.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD),
+ ]
+ )
+
+ image = transform(image)
+ return image
+
+
+def get_image():
+ filepath = hf_hub_download(
+ repo_id="hf-internal-testing/fixtures_docvqa", filename="document_2.png", repo_type="dataset"
+ )
+ image = Image.open(filepath).convert("RGB")
+
+ return image
+
+
+def prepare_dummy_inputs(tokenizer, image_processor):
+ prompt = "Question answering. What is the name of the company?"
+ prompt = "Question answering. In which year is the report made?"
+ prompt_ids = tokenizer.encode(prompt, add_special_tokens=False)
+
+ image = get_image()
+ # words, boxes = apply_tesseract(image, lang=None)
+ # fmt: off
+ words = ['7', 'ITC', 'Limited', 'REPORT', 'AND', 'ACCOUNTS', '2013', 'ITC’s', 'Brands:', 'An', 'Asset', 'for', 'the', 'Nation', 'The', 'consumer', 'needs', 'and', 'aspirations', 'they', 'fulfil,', 'the', 'benefit', 'they', 'generate', 'for', 'millions', 'across', 'ITC’s', 'value', 'chains,', 'the', 'future-ready', 'capabilities', 'that', 'support', 'them,', 'and', 'the', 'value', 'that', 'they', 'create', 'for', 'the', 'country,', 'have', 'made', 'ITC’s', 'brands', 'national', 'assets,', 'adding', 'to', 'India’s', 'competitiveness.', 'It', 'is', 'ITC’s', 'aspiration', 'to', 'be', 'the', 'No', '1', 'FMCG', 'player', 'in', 'the', 'country,', 'driven', 'by', 'its', 'new', 'FMCG', 'businesses.', 'A', 'recent', 'Nielsen', 'report', 'has', 'highlighted', 'that', "ITC's", 'new', 'FMCG', 'businesses', 'are', 'the', 'fastest', 'growing', 'among', 'the', 'top', 'consumer', 'goods', 'companies', 'operating', 'in', 'India.', 'ITC', 'takes', 'justifiable', 'pride', 'that,', 'along', 'with', 'generating', 'economic', 'value,', 'these', 'celebrated', 'Indian', 'brands', 'also', 'drive', 'the', 'creation', 'of', 'larger', 'societal', 'capital', 'through', 'the', 'virtuous', 'cycle', 'of', 'sustainable', 'and', 'inclusive', 'growth.', 'DI', 'WILLS', '*', ';', 'LOVE', 'DELIGHTFULLY', 'SOFT', 'SKIN?', 'aia', 'Ans', 'Source:', 'https://www.industrydocuments.ucsf.edu/docs/snbx0223']
+ boxes = [[0, 45, 67, 80], [72, 56, 109, 67], [116, 56, 189, 67], [198, 59, 253, 66], [257, 59, 285, 66], [289, 59, 365, 66], [372, 59, 407, 66], [74, 136, 161, 158], [175, 137, 306, 158], [318, 137, 363, 158], [374, 137, 472, 158], [483, 136, 529, 158], [540, 137, 593, 158], [608, 137, 717, 158], [73, 194, 100, 203], [106, 196, 177, 203], [183, 194, 227, 203], [233, 194, 259, 203], [265, 194, 344, 205], [74, 211, 104, 222], [109, 210, 141, 221], [147, 211, 169, 220], [175, 210, 223, 220], [229, 211, 259, 222], [265, 211, 329, 222], [334, 210, 352, 220], [74, 227, 127, 236], [133, 229, 180, 236], [187, 227, 221, 236], [226, 227, 264, 236], [270, 227, 320, 237], [327, 227, 349, 236], [74, 243, 161, 254], [166, 243, 249, 254], [254, 243, 281, 252], [286, 244, 342, 254], [74, 260, 112, 270], [119, 260, 145, 269], [151, 260, 174, 269], [179, 260, 217, 269], [222, 260, 249, 269], [254, 260, 285, 271], [290, 260, 335, 269], [340, 259, 359, 269], [74, 276, 95, 284], [101, 276, 156, 287], [164, 276, 198, 284], [203, 276, 244, 284], [251, 275, 285, 284], [291, 276, 340, 284], [74, 292, 129, 301], [135, 292, 185, 302], [192, 292, 242, 303], [248, 292, 261, 301], [267, 292, 312, 301], [74, 308, 195, 319], [75, 335, 82, 344], [88, 335, 98, 344], [105, 335, 138, 344], [144, 335, 214, 346], [220, 336, 233, 344], [239, 335, 256, 344], [262, 335, 283, 344], [290, 335, 309, 344], [316, 335, 320, 344], [74, 351, 119, 360], [126, 352, 170, 362], [176, 352, 186, 360], [192, 352, 214, 360], [220, 352, 276, 362], [282, 352, 326, 360], [333, 352, 349, 362], [74, 368, 89, 377], [95, 370, 124, 377], [129, 367, 175, 377], [181, 368, 266, 377], [272, 368, 283, 376], [289, 368, 333, 377], [74, 384, 126, 393], [134, 385, 175, 395], [181, 384, 206, 393], [212, 384, 292, 395], [298, 384, 325, 393], [330, 384, 366, 393], [74, 403, 103, 409], [109, 400, 154, 409], [161, 401, 241, 409], [247, 403, 269, 409], [275, 401, 296, 409], [302, 400, 349, 409], [74, 417, 131, 428], [137, 419, 186, 428], [192, 417, 214, 426], [219, 417, 242, 428], [248, 419, 319, 426], [74, 433, 119, 444], [125, 433, 204, 444], [210, 433, 278, 444], [285, 433, 295, 441], [302, 433, 340, 442], [75, 449, 98, 458], [104, 449, 142, 458], [146, 449, 215, 460], [221, 449, 258, 460], [263, 449, 293, 459], [300, 449, 339, 460], [74, 466, 101, 474], [108, 466, 185, 476], [191, 466, 261, 474], [267, 466, 309, 476], [315, 466, 354, 474], [74, 482, 151, 491], [158, 482, 201, 491], [208, 482, 258, 491], [263, 482, 292, 491], [298, 482, 333, 491], [338, 482, 360, 491], [74, 498, 131, 507], [137, 498, 150, 507], [156, 498, 197, 509], [202, 498, 257, 507], [263, 498, 310, 509], [74, 515, 128, 525], [134, 515, 156, 523], [161, 515, 218, 523], [223, 515, 261, 525], [267, 514, 280, 523], [74, 531, 156, 540], [162, 531, 188, 540], [195, 531, 257, 540], [263, 531, 315, 542], [871, 199, 878, 202], [883, 199, 908, 202], [894, 251, 904, 257], [841, 268, 841, 270], [784, 373, 811, 378], [816, 373, 896, 378], [784, 381, 811, 387], [815, 381, 847, 387], [645, 908, 670, 915], [692, 908, 712, 915], [220, 984, 285, 993], [293, 983, 779, 996]]
+ # fmt: on
+ text_list = []
+ bbox_list = []
+ for text, box in zip(words, boxes):
+ if text == "":
+ continue
+ sub_tokens = tokenizer.tokenize(text)
+ for sub_token in sub_tokens:
+ text_list.append(sub_token)
+ bbox_list.append(box)
+
+ input_ids = tokenizer.convert_tokens_to_ids(text_list)
+
+ input_ids = prompt_ids + input_ids
+ bbox = [[0, 0, 0, 0]] * len(prompt_ids) + bbox_list
+
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+ original_pixel_values = original_transform(image, image_size=image_processor.size["height"]).unsqueeze(0)
+ # verify pixel values
+ assert torch.allclose(original_pixel_values, pixel_values)
+ print("Pixel values are ok!")
+
+ return torch.tensor(input_ids).unsqueeze(0), torch.tensor(bbox).unsqueeze(0).float(), pixel_values
+
+
+def convert_udop_checkpoint(model_name, pytorch_dump_folder_path=None, push_to_hub=False):
+ # model_name to checkpoint_path
+ name_to_checkpoint_path = {
+ "udop-large": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-224/pytorch_model.bin",
+ "udop-large-512": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-512/pytorch_model.bin",
+ "udop-large-512-300k": "/Users/nielsrogge/Documents/UDOP/udop-unimodel-large-512-300k-steps/pytorch_model.bin",
+ }
+
+ # load original state dict
+ checkpoint_path = name_to_checkpoint_path[model_name]
+ state_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ print("Checkpoint path:", checkpoint_path)
+
+ # create HF model
+ image_size = 512 if "512" in model_name else 224
+ config = UdopConfig(decoder_start_token_id=0, image_size=image_size)
+ model = UdopForConditionalGeneration(config)
+ model.eval()
+
+ # rename keys
+ state_dict = {k.replace("cell2dembedding", "cell_2d_embedding"): v for k, v in state_dict.items()}
+
+ # load weights
+ missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
+ print("Missing keys:", missing_keys)
+ print("Unexpected keys:", unexpected_keys)
+ assert missing_keys == ["encoder.embed_patches.proj.weight", "encoder.embed_patches.proj.bias"]
+ assert unexpected_keys == ["pos_embed"]
+
+ # prepare dummy inputs
+ tokenizer = UdopTokenizer.from_pretrained("t5-base", legacy=True)
+ size = {"height": image_size, "width": image_size}
+ image_processor = LayoutLMv3ImageProcessor(
+ image_mean=IMAGENET_DEFAULT_MEAN, image_std=IMAGENET_DEFAULT_STD, size=size
+ )
+ processor = UdopProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ input_ids, bbox, image = prepare_dummy_inputs(tokenizer, image_processor)
+ prompt = "Question answering. In which year is the report made?"
+ encoding = processor(images=get_image(), text=prompt, return_tensors="pt")
+
+ input_ids = encoding.input_ids
+ try:
+ EXPECTED_INPUT_IDS = torch.tensor([[11860, 18243, 5, 86, 84, 215, 19, 8, 934, 263, 58, 1, 489, 27, 3838, 7363, 4083, 14536, 3430, 5686, 5911, 17161, 134, 2038, 27, 3838, 22, 7, 4688, 7, 10, 389, 18202, 21, 8, 11046, 37, 3733, 523, 11, 38, 2388, 1628, 3, 13133, 23334, 6, 8, 1656, 79, 3806, 21, 4040, 640, 27, 3838, 22, 7, 701, 16534, 6, 8, 3, 76, 2693, 18, 23015, 5644, 24, 380, 3, 6015, 6, 11, 8, 701, 24, 79, 482, 21, 3, 88, 684, 6, 43, 263, 27, 3838, 22, 7, 3635, 1157, 4089, 6, 2651, 12, 1547, 22, 7, 3265, 655, 5, 19, 27, 3838, 22, 7, 38, 2388, 257, 12, 36, 8, 465, 209, 13409, 12150, 1959, 16, 8, 684, 6, 6737, 57, 165, 126, 13409, 12150, 1623, 5, 71, 1100, 30298, 934, 65, 12566, 24, 27, 3838, 31, 7, 126, 13409, 12150, 1623, 33, 8, 10391, 1710, 859, 8, 420, 3733, 4968, 688, 2699, 16, 1547, 5, 27, 3838, 1217, 131, 99, 23, 179, 6064, 24, 6, 590, 28, 3, 11600, 1456, 701, 6, 175, 9443, 2557, 3635, 92, 1262, 8, 3409, 13, 2186, 3, 27908, 1784, 190, 8, 3, 5771, 17, 13281, 4005, 13, 5086, 11, 13066, 1170, 5, 10826, 16309, 134, 3, 2, 276, 26, 3, 55, 391, 13570, 5, 10315, 309, 3577, 19114, 371, 4254, 5121, 5055, 6245, 3, 10047, 3162, 58, 3, 9, 61, 1713, 2703, 476, 667, 25158, 301, 6058, 6038, 476, 3765, 9149, 10, 4893, 1303, 1986, 5, 13580, 7, 8224, 28244, 7, 5, 76, 75, 7, 89, 5, 15, 1259, 87, 7171, 7, 87, 7, 29, 115, 226, 4305, 2773, 1]]) # fmt: skip
+ torch.testing.assert_close(EXPECTED_INPUT_IDS, input_ids)
+ bbox = encoding.bbox.float()
+ pixel_values = encoding.pixel_values
+ except Exception:
+ print("Input_ids don't match, preparing dummy inputs")
+ input_ids, bbox, pixel_values = prepare_dummy_inputs(tokenizer, image_processor)
+
+ # Verify single forward pass
+ print("Testing single forward pass..")
+ with torch.no_grad():
+ decoder_input_ids = torch.tensor([[101]])
+ outputs = model(input_ids=input_ids, bbox=bbox, pixel_values=pixel_values, decoder_input_ids=decoder_input_ids)
+ print("Shape of logits:", outputs.logits.shape)
+ print("First values of logits:", outputs.logits[0, :3, :3])
+
+ # tensor([[-18.5262, 1.5087, -15.7051]]) on linux
+ # tensor([[-19.4976, 0.8515, -17.1873]]) on mac
+ try:
+ assert torch.allclose(outputs.logits[0, :3, :3], torch.tensor([[-18.5262, 1.5087, -15.7051]]), atol=1e-4)
+ print("Looks ok!")
+ except Exception:
+ print("logits don't match let's try to generate")
+
+ # Verify autoregressive decoding
+ print("Testing generation...")
+ model_kwargs = {"bbox": bbox, "pixel_values": pixel_values}
+ outputs = model.generate(input_ids=input_ids, **model_kwargs, max_new_tokens=20)
+
+ print("Generated:", tokenizer.batch_decode(outputs, skip_special_tokens=True))
+
+ # autoregressive decoding with original input data
+ print("Testing generation with original inputs...")
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="input_ids_udop.pt", repo_type="dataset")
+ input_ids = torch.load(filepath)
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="bbox_udop.pt", repo_type="dataset")
+ bbox = torch.load(filepath)
+ pixel_values_filename = "pixel_values_udop_512.pt" if "512" in model_name else "pixel_values_udop_224.pt"
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename=pixel_values_filename, repo_type="dataset")
+ pixel_values = torch.load(filepath)
+
+ print("Decoded input ids:", tokenizer.decode(input_ids[0], skip_special_tokens=True))
+ print("Bbox shape:", bbox.shape)
+
+ model_kwargs = {"bbox": bbox, "pixel_values": pixel_values}
+ outputs = model.generate(input_ids=input_ids, **model_kwargs, max_new_tokens=20)
+ generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
+ print("Generated:", generated_text)
+
+ if pytorch_dump_folder_path is not None:
+ model.save_pretrained(pytorch_dump_folder_path)
+ tokenizer.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"microsoft/{model_name}")
+ processor.push_to_hub(f"microsoft/{model_name}")
+ # BIG note here: to save the fast tokenizer files in the repo on the hub, you need to do the following:
+ # see https://discuss.huggingface.co/t/convert-slow-xlmrobertatokenizer-to-fast-one/20876
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="udop-large",
+ type=str,
+ choices=["udop-large", "udop-large-512", "udop-large-512-300k"],
+ help=("Name of the UDOP model you'd like to convert."),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_udop_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/udop/modeling_udop.py b/src/transformers/models/udop/modeling_udop.py
new file mode 100644
index 00000000000000..62192eea7f5a5e
--- /dev/null
+++ b/src/transformers/models/udop/modeling_udop.py
@@ -0,0 +1,2030 @@
+# coding=utf-8
+# Copyright 2024 Microsoft Research and HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch UDOP model."""
+
+import collections
+import logging
+import math
+import random
+from abc import ABC, abstractmethod
+from copy import deepcopy
+from dataclasses import dataclass
+from typing import Any, Dict, Optional, Sequence, Tuple, Union
+
+import torch
+from torch import Tensor, nn
+from torch.nn import CrossEntropyLoss
+
+from transformers import UdopConfig
+from transformers.modeling_outputs import (
+ Seq2SeqLMOutput,
+ Seq2SeqModelOutput,
+)
+
+from ...activations import ACT2FN
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+
+
+logger = logging.getLogger(__name__)
+
+UDOP_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "microsoft/udop-large",
+ # See all UDOP models at https://huggingface.co/models?filter=udop
+]
+
+
+_CONFIG_FOR_DOC = "UdopConfig"
+
+
+UDOP_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Args:
+ config ([`UdopConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+UDOP_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. UDOP is a model with relative position embeddings so
+ you should be able to pad the inputs on both the right and the left. Indices can be obtained using
+ [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for detail.
+ [What are input IDs?](../glossary#input-ids)
+
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ [What are attention masks?](../glossary#attention-mask)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner.
+
+ Note that `sequence_length = token_sequence_length + patch_sequence_length + 1` where `1` is for [CLS]
+ token. See `pixel_values` for `patch_sequence_length`.
+
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Batch of document images. Each image is divided into patches of shape `(num_channels, config.patch_size,
+ config.patch_size)` and the total number of patches (=`patch_sequence_length`) equals to `((height /
+ config.patch_size) * (width / config.patch_size))`.
+
+ visual_bbox (`torch.LongTensor` of shape `(batch_size, patch_sequence_length, 4)`, *optional*):
+ Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model.
+
+ decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
+ Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using
+ [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details.
+ [What are decoder input IDs?](../glossary#decoder-input-ids) T5 uses the `pad_token_id` as the starting
+ token for `decoder_input_ids` generation. If `past_key_values` is used, optionally only the last
+ `decoder_input_ids` have to be input (see `past_key_values`). To know more on how to prepare
+ `decoder_input_ids` for pretraining take a look at [T5 Training](./t5#training).
+ decoder_attention_mask (`torch.BoolTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
+ Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
+ be used by default.
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules in the encoder. Mask values selected in `[0,
+ 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ decoder_head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules in the decoder. Mask values selected in `[0,
+ 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ cross_attn_head_mask (`torch.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in
+ `[0, 1]`:
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
+ Tuple consists of (`last_hidden_state`, `optional`: *hidden_states*, `optional`: *attentions*)
+ `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)` is a sequence of hidden states at
+ the output of the last layer of the encoder. Used in the cross-attention of the decoder.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
+ representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds` have to be
+ input (see `past_key_values`). This is useful if you want more control over how to convert
+ `decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix. If
+ `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds` takes the value of
+ `inputs_embeds`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+UDOP_ENCODER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. T5 is a model with relative position embeddings so you
+ should be able to pad the inputs on both the right and the left.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for detail.
+
+ To know more on how to prepare `input_ids` for pretraining take a look a [T5 Training](./t5#training).
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ bbox (`torch.LongTensor` of shape `({0}, 4)`, *optional*):
+ Bounding boxes of each input sequence tokens. Selected in the range `[0,
+ config.max_2d_position_embeddings-1]`. Each bounding box should be a normalized version in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1,
+ y1) represents the position of the lower right corner.
+
+ Note that `sequence_length = token_sequence_length + patch_sequence_length + 1` where `1` is for [CLS]
+ token. See `pixel_values` for `patch_sequence_length`.
+
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Batch of document images. Each image is divided into patches of shape `(num_channels, config.patch_size,
+ config.patch_size)` and the total number of patches (=`patch_sequence_length`) equals to `((height /
+ config.patch_size) * (width / config.patch_size))`.
+
+ visual_bbox (`torch.LongTensor` of shape `(batch_size, patch_sequence_length, 4)`, *optional*):
+ Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@dataclass
+class BaseModelOutputWithAttentionMask(ModelOutput):
+ """
+ Class for the model's outputs that may also contain a past key/values (to speed up sequential decoding). Includes
+ an additional attention mask.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model. If `past_key_values` is used only
+ the last hidden-state of the sequences of shape `(batch_size, 1, hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
+ when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`. Contains pre-computed hidden-states (key and values in the
+ self-attention blocks and optionally if `config.is_encoder_decoder=True` in the cross-attention blocks)
+ that can be used (see `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or
+ when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
+ the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when
+ `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and
+ `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights of the decoder's cross-attention layer, after the attention softmax,
+ used to compute the weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ attention_mask: torch.FloatTensor = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+def get_visual_bbox(image_size=224, patch_size=16):
+ image_feature_pool_shape = [image_size // patch_size, image_size // patch_size]
+ visual_bbox_x = torch.arange(0, 1.0 * (image_feature_pool_shape[1] + 1), 1.0)
+ visual_bbox_x /= image_feature_pool_shape[1]
+
+ visual_bbox_y = torch.arange(0, 1.0 * (image_feature_pool_shape[0] + 1), 1.0)
+ visual_bbox_y /= image_feature_pool_shape[0]
+
+ visual_bbox_input = torch.stack(
+ [
+ visual_bbox_x[:-1].repeat(image_feature_pool_shape[0], 1),
+ visual_bbox_y[:-1].repeat(image_feature_pool_shape[1], 1).transpose(0, 1),
+ visual_bbox_x[1:].repeat(image_feature_pool_shape[0], 1),
+ visual_bbox_y[1:].repeat(image_feature_pool_shape[1], 1).transpose(0, 1),
+ ],
+ dim=-1,
+ )
+
+ visual_bbox_input = visual_bbox_input.view(-1, 4)
+
+ return visual_bbox_input
+
+
+def pad_sequence(seq, target_len, pad_value=0):
+ if isinstance(seq, torch.Tensor):
+ n = seq.shape[0]
+ else:
+ n = len(seq)
+ seq = torch.tensor(seq)
+ m = target_len - n
+ if m > 0:
+ ret = torch.stack([pad_value] * m).to(seq)
+ seq = torch.cat([seq, ret], dim=0)
+ return seq[:target_len]
+
+
+def combine_image_text_embeddings(
+ image_embeddings,
+ inputs_embeds,
+ bbox,
+ visual_bbox,
+ attention_mask=None,
+ num_patches=14,
+ max_len=0,
+ image_size=224,
+ patch_size=16,
+):
+ """
+ Combine the image and text embeddings for the input to the encoder/decoder of UDOP.
+
+ First, the image embeddings are created by checking for each visual patch if it is inside the bounding box of a
+ token. If it is, the visual patch is combined with the token embedding. Then, the visual bounding boxes are combined
+ with the text bounding boxes. Finally, the visual bounding boxes are combined with the text attention mask.
+ """
+
+ sequence_length = num_patches
+ ocr_points_x = torch.clip(
+ torch.floor((bbox[:, :, 0] + bbox[:, :, 2]) / 2.0 * sequence_length).long(), 0, sequence_length - 1
+ )
+ ocr_points_y = (
+ torch.clip(torch.floor((bbox[:, :, 1] + bbox[:, :, 3]) / 2.0 * sequence_length).long(), 0, sequence_length - 1)
+ * sequence_length
+ )
+ ocr_points = ocr_points_x + ocr_points_y
+ # make sure bounding boxes are of type float to calculate means
+ bbox = bbox.to(torch.float64)
+ target_seg = (bbox.mean(-1) == 0.0) | (bbox.mean(-1) == 1.0)
+ repeated_vision_embeds = torch.gather(
+ image_embeddings, 1, ocr_points.unsqueeze(-1).repeat(1, 1, image_embeddings.size(-1))
+ )
+ repeated_vision_embeds[target_seg] = 0.0
+ inputs_embeds += repeated_vision_embeds
+
+ patch_inds = torch.full_like(image_embeddings[:, :, 0], True).bool()
+ ind = torch.cat(
+ [
+ torch.arange(len(ocr_points))[:, None].repeat(1, ocr_points.size(-1))[:, :, None].to(ocr_points),
+ ocr_points[:, :, None],
+ ],
+ dim=-1,
+ )
+ ind = ind.flatten(0, 1)
+ rows, cols = zip(*ind)
+ patch_inds[rows, cols] = False
+
+ input_vision_patches = [image_embeddings[i][patch_inds[i]] for i in range(len(patch_inds))]
+
+ if visual_bbox is None:
+ visual_bbox = get_visual_bbox(image_size=image_size, patch_size=patch_size)
+ visual_bbox = visual_bbox.unsqueeze(0).repeat(image_embeddings.size(0), 1, 1)
+ visual_bbox = visual_bbox.to(image_embeddings.device)
+
+ visual_bbox = [visual_bbox[i][patch_inds[i]] for i in range(len(patch_inds))]
+ if attention_mask is not None:
+ visual_attention_mask = [torch.tensor([1] * len(item)).to(attention_mask) for item in visual_bbox]
+
+ if max_len == 0:
+ max_len = image_embeddings.size(1)
+ else:
+ max_len = max_len - inputs_embeds.size(1)
+ inputs_vision_patches = torch.stack(
+ [pad_sequence(item, max_len, torch.zeros_like(image_embeddings[0, 0])) for item in input_vision_patches]
+ )
+ visual_bbox = torch.stack([pad_sequence(item, max_len, torch.zeros_like(bbox[0, 0])) for item in visual_bbox])
+ if attention_mask is not None:
+ visual_attention_mask = torch.stack(
+ [pad_sequence(item, max_len, torch.zeros_like(attention_mask[0, 0])) for item in visual_attention_mask]
+ )
+
+ inputs_embeds = torch.cat([inputs_embeds, inputs_vision_patches], 1)
+ bbox = torch.cat([bbox, visual_bbox], 1)
+ if attention_mask is not None:
+ attention_mask = torch.cat([attention_mask, visual_attention_mask], 1)
+ return inputs_embeds, bbox, attention_mask
+
+
+class UdopPatchEmbeddings(nn.Module):
+ """2D Image to Patch Embeddings"""
+
+ def __init__(self, config):
+ super().__init__()
+ image_size, patch_size = config.image_size, config.patch_size
+ num_channels, hidden_size = config.num_channels, config.hidden_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.num_patches = num_patches
+
+ self.proj = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
+
+ def forward(self, pixel_values):
+ batch_size, num_channels, height, width = pixel_values.shape
+ if height != self.image_size[0] or width != self.image_size[1]:
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model"
+ f" ({self.image_size[0]}*{self.image_size[1]})."
+ )
+ embeddings = self.proj(pixel_values)
+ embeddings = embeddings.flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class UdopPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models. Based on `T5PreTrainedModel`.
+ """
+
+ config_class = UdopConfig
+ base_model_prefix = "transformer"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["UdopBlock"]
+ _keep_in_fp32_modules = ["wo"]
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ factor = self.config.initializer_factor # Used for testing weights initialization
+ if isinstance(module, UdopLayerNorm):
+ module.weight.data.fill_(factor * 1.0)
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=factor)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.Conv2d):
+ # Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
+ # `trunc_normal_cpu` not implemented in `half` issues
+ module.weight.data = nn.init.trunc_normal_(module.weight.data.to(torch.float32), mean=0.0, std=factor).to(
+ module.weight.dtype
+ )
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, RelativePositionBiasBase):
+ factor = self.config.initializer_factor
+ d_model = self.config.d_model
+ module.relative_attention_bias.weight.data.normal_(mean=0.0, std=factor * ((d_model) ** -0.5))
+ elif isinstance(module, UdopModel):
+ # Mesh TensorFlow embeddings initialization
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L1624
+ module.shared.weight.data.normal_(mean=0.0, std=factor * 1.0)
+ elif isinstance(module, UdopForConditionalGeneration):
+ if hasattr(module, "lm_head") and not self.config.tie_word_embeddings:
+ module.lm_head.weight.data.normal_(mean=0.0, std=factor * 1.0)
+ elif isinstance(module, UdopDenseActDense):
+ # Mesh TensorFlow FF initialization
+ # See https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/transformer_layers.py#L56
+ # and https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L89
+ module.wi.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi, "bias") and module.wi.bias is not None:
+ module.wi.bias.data.zero_()
+ module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff) ** -0.5))
+ if hasattr(module.wo, "bias") and module.wo.bias is not None:
+ module.wo.bias.data.zero_()
+ elif isinstance(module, UdopDenseGatedActDense):
+ module.wi_0.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi_0, "bias") and module.wi_0.bias is not None:
+ module.wi_0.bias.data.zero_()
+ module.wi_1.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model) ** -0.5))
+ if hasattr(module.wi_1, "bias") and module.wi_1.bias is not None:
+ module.wi_1.bias.data.zero_()
+ module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff) ** -0.5))
+ if hasattr(module.wo, "bias") and module.wo.bias is not None:
+ module.wo.bias.data.zero_()
+ elif isinstance(module, UdopAttention):
+ # Mesh TensorFlow attention initialization to avoid scaling before softmax
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/attention.py#L136
+ d_model = self.config.d_model
+ key_value_proj_dim = self.config.d_kv
+ n_heads = self.config.num_heads
+ module.q.weight.data.normal_(mean=0.0, std=factor * ((d_model * key_value_proj_dim) ** -0.5))
+ module.k.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
+ module.v.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
+ module.o.weight.data.normal_(mean=0.0, std=factor * ((n_heads * key_value_proj_dim) ** -0.5))
+ if module.has_relative_attention_bias:
+ module.relative_attention_bias.weight.data.normal_(mean=0.0, std=factor * ((d_model) ** -0.5))
+
+ # Copied from transformers.models.prophetnet.modeling_prophetnet.ProphetNetPreTrainedModel._shift_right with ProphetNet->Udop
+ def _shift_right(self, input_ids):
+ decoder_start_token_id = self.config.decoder_start_token_id
+ pad_token_id = self.config.pad_token_id
+
+ assert decoder_start_token_id is not None, (
+ "self.model.config.decoder_start_token_id has to be defined. In Udop it is usually set to the"
+ " pad_token_id. See Udop docs for more information"
+ )
+
+ # shift inputs to the right
+ shifted_input_ids = input_ids.new_zeros(input_ids.shape)
+ shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
+ shifted_input_ids[..., 0] = decoder_start_token_id
+
+ assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
+ # replace possible -100 values in labels by `pad_token_id`
+ shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
+
+ assert torch.all(shifted_input_ids >= 0).item(), "Verify that `shifted_input_ids` has only positive values"
+
+ return shifted_input_ids
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerNorm with T5->Udop
+class UdopLayerNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Construct a layernorm module in the Udop style. No bias and no subtraction of mean.
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ # Udop uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
+ # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus varience is calculated
+ # w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
+ # half-precision inputs is done in fp32
+
+ variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+
+ # convert into half-precision if necessary
+ if self.weight.dtype in [torch.float16, torch.bfloat16]:
+ hidden_states = hidden_states.to(self.weight.dtype)
+
+ return self.weight * hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5DenseActDense with T5->Udop
+class UdopDenseActDense(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ self.wi = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.act = ACT2FN[config.dense_act_fn]
+
+ def forward(self, hidden_states):
+ hidden_states = self.wi(hidden_states)
+ hidden_states = self.act(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ if (
+ isinstance(self.wo.weight, torch.Tensor)
+ and hidden_states.dtype != self.wo.weight.dtype
+ and self.wo.weight.dtype != torch.int8
+ ):
+ hidden_states = hidden_states.to(self.wo.weight.dtype)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5DenseGatedActDense with T5->Udop
+class UdopDenseGatedActDense(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.act = ACT2FN[config.dense_act_fn]
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+
+ # To make 8bit quantization work for google/flan-t5-xxl, self.wo is kept in float32.
+ # See https://github.com/huggingface/transformers/issues/20287
+ # we also make sure the weights are not in `int8` in case users will force `_keep_in_fp32_modules` to be `None``
+ if (
+ isinstance(self.wo.weight, torch.Tensor)
+ and hidden_states.dtype != self.wo.weight.dtype
+ and self.wo.weight.dtype != torch.int8
+ ):
+ hidden_states = hidden_states.to(self.wo.weight.dtype)
+
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerFF with T5->Udop
+class UdopLayerFF(nn.Module):
+ def __init__(self, config: UdopConfig):
+ super().__init__()
+ if config.is_gated_act:
+ self.DenseReluDense = UdopDenseGatedActDense(config)
+ else:
+ self.DenseReluDense = UdopDenseActDense(config)
+
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(self, hidden_states):
+ forwarded_states = self.layer_norm(hidden_states)
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = hidden_states + self.dropout(forwarded_states)
+ return hidden_states
+
+
+# Copied from transformers.models.t5.modeling_t5.T5Attention with T5->Udop
+class UdopAttention(nn.Module):
+ def __init__(self, config: UdopConfig, has_relative_attention_bias=False):
+ super().__init__()
+ self.is_decoder = config.is_decoder
+ self.has_relative_attention_bias = has_relative_attention_bias
+ self.relative_attention_num_buckets = config.relative_attention_num_buckets
+ self.relative_attention_max_distance = config.relative_attention_max_distance
+ self.d_model = config.d_model
+ self.key_value_proj_dim = config.d_kv
+ self.n_heads = config.num_heads
+ self.dropout = config.dropout_rate
+ self.inner_dim = self.n_heads * self.key_value_proj_dim
+
+ # Mesh TensorFlow initialization to avoid scaling before softmax
+ self.q = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.k = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.v = nn.Linear(self.d_model, self.inner_dim, bias=False)
+ self.o = nn.Linear(self.inner_dim, self.d_model, bias=False)
+
+ if self.has_relative_attention_bias:
+ self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets, self.n_heads)
+ self.pruned_heads = set()
+ self.gradient_checkpointing = False
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.n_heads, self.key_value_proj_dim, self.pruned_heads
+ )
+ # Prune linear layers
+ self.q = prune_linear_layer(self.q, index)
+ self.k = prune_linear_layer(self.k, index)
+ self.v = prune_linear_layer(self.v, index)
+ self.o = prune_linear_layer(self.o, index, dim=1)
+ # Update hyper params
+ self.n_heads = self.n_heads - len(heads)
+ self.inner_dim = self.key_value_proj_dim * self.n_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ @staticmethod
+ def _relative_position_bucket(relative_position, bidirectional=True, num_buckets=32, max_distance=128):
+ """
+ Adapted from Mesh Tensorflow:
+ https://github.com/tensorflow/mesh/blob/0cb87fe07da627bf0b7e60475d59f95ed6b5be3d/mesh_tensorflow/transformer/transformer_layers.py#L593
+
+ Translate relative position to a bucket number for relative attention. The relative position is defined as
+ memory_position - query_position, i.e. the distance in tokens from the attending position to the attended-to
+ position. If bidirectional=False, then positive relative positions are invalid. We use smaller buckets for
+ small absolute relative_position and larger buckets for larger absolute relative_positions. All relative
+ positions >=max_distance map to the same bucket. All relative positions <=-max_distance map to the same bucket.
+ This should allow for more graceful generalization to longer sequences than the model has been trained on
+
+ Args:
+ relative_position: an int32 Tensor
+ bidirectional: a boolean - whether the attention is bidirectional
+ num_buckets: an integer
+ max_distance: an integer
+
+ Returns:
+ a Tensor with the same shape as relative_position, containing int32 values in the range [0, num_buckets)
+ """
+ relative_buckets = 0
+ if bidirectional:
+ num_buckets //= 2
+ relative_buckets += (relative_position > 0).to(torch.long) * num_buckets
+ relative_position = torch.abs(relative_position)
+ else:
+ relative_position = -torch.min(relative_position, torch.zeros_like(relative_position))
+ # now relative_position is in the range [0, inf)
+
+ # half of the buckets are for exact increments in positions
+ max_exact = num_buckets // 2
+ is_small = relative_position < max_exact
+
+ # The other half of the buckets are for logarithmically bigger bins in positions up to max_distance
+ relative_position_if_large = max_exact + (
+ torch.log(relative_position.float() / max_exact)
+ / math.log(max_distance / max_exact)
+ * (num_buckets - max_exact)
+ ).to(torch.long)
+ relative_position_if_large = torch.min(
+ relative_position_if_large, torch.full_like(relative_position_if_large, num_buckets - 1)
+ )
+
+ relative_buckets += torch.where(is_small, relative_position, relative_position_if_large)
+ return relative_buckets
+
+ def compute_bias(self, query_length, key_length, device=None):
+ """Compute binned relative position bias"""
+ if device is None:
+ device = self.relative_attention_bias.weight.device
+ context_position = torch.arange(query_length, dtype=torch.long, device=device)[:, None]
+ memory_position = torch.arange(key_length, dtype=torch.long, device=device)[None, :]
+ relative_position = memory_position - context_position # shape (query_length, key_length)
+ relative_position_bucket = self._relative_position_bucket(
+ relative_position, # shape (query_length, key_length)
+ bidirectional=(not self.is_decoder),
+ num_buckets=self.relative_attention_num_buckets,
+ max_distance=self.relative_attention_max_distance,
+ )
+ values = self.relative_attention_bias(relative_position_bucket) # shape (query_length, key_length, num_heads)
+ values = values.permute([2, 0, 1]).unsqueeze(0) # shape (1, num_heads, query_length, key_length)
+ return values
+
+ def forward(
+ self,
+ hidden_states,
+ mask=None,
+ key_value_states=None,
+ position_bias=None,
+ past_key_value=None,
+ layer_head_mask=None,
+ query_length=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ """
+ Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states).
+ """
+ # Input is (batch_size, seq_length, dim)
+ # Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)
+ # past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)
+ batch_size, seq_length = hidden_states.shape[:2]
+
+ real_seq_length = seq_length
+
+ if past_key_value is not None:
+ if len(past_key_value) != 2:
+ raise ValueError(
+ f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states"
+ )
+ real_seq_length += past_key_value[0].shape[2] if query_length is None else query_length
+
+ key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
+
+ def shape(states):
+ """projection"""
+ return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim).transpose(1, 2)
+
+ def unshape(states):
+ """reshape"""
+ return states.transpose(1, 2).contiguous().view(batch_size, -1, self.inner_dim)
+
+ def project(hidden_states, proj_layer, key_value_states, past_key_value):
+ """projects hidden states correctly to key/query states"""
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(hidden_states))
+ elif past_key_value is None:
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+
+ if past_key_value is not None:
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, key_length, dim_per_head)
+ hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
+ elif past_key_value.shape[2] != key_value_states.shape[1]:
+ # checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+ else:
+ # cross-attn
+ hidden_states = past_key_value
+ return hidden_states
+
+ # get query states
+ query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
+
+ # get key/value states
+ key_states = project(
+ hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
+ )
+ value_states = project(
+ hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
+ )
+
+ # compute scores
+ scores = torch.matmul(
+ query_states, key_states.transpose(3, 2)
+ ) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
+
+ if position_bias is None:
+ if not self.has_relative_attention_bias:
+ position_bias = torch.zeros(
+ (1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
+ )
+ if self.gradient_checkpointing and self.training:
+ position_bias.requires_grad = True
+ else:
+ position_bias = self.compute_bias(real_seq_length, key_length, device=scores.device)
+
+ # if key and values are already calculated
+ # we want only the last query position bias
+ if past_key_value is not None:
+ position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
+
+ if mask is not None:
+ position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
+
+ if self.pruned_heads:
+ mask = torch.ones(position_bias.shape[1])
+ mask[list(self.pruned_heads)] = 0
+ position_bias_masked = position_bias[:, mask.bool()]
+ else:
+ position_bias_masked = position_bias
+
+ scores += position_bias_masked
+ attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
+ scores
+ ) # (batch_size, n_heads, seq_length, key_length)
+ attn_weights = nn.functional.dropout(
+ attn_weights, p=self.dropout, training=self.training
+ ) # (batch_size, n_heads, seq_length, key_length)
+
+ # Mask heads if we want to
+ if layer_head_mask is not None:
+ attn_weights = attn_weights * layer_head_mask
+
+ attn_output = unshape(torch.matmul(attn_weights, value_states)) # (batch_size, seq_length, dim)
+ attn_output = self.o(attn_output)
+
+ present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
+ outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
+
+ if output_attentions:
+ outputs = outputs + (attn_weights,)
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerSelfAttention with T5->Udop
+class UdopLayerSelfAttention(nn.Module):
+ def __init__(self, config, has_relative_attention_bias=False):
+ super().__init__()
+ self.SelfAttention = UdopAttention(config, has_relative_attention_bias=has_relative_attention_bias)
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ position_bias=None,
+ layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.SelfAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = hidden_states + self.dropout(attention_output[0])
+ outputs = (hidden_states,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5LayerCrossAttention with T5->Udop
+class UdopLayerCrossAttention(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.EncDecAttention = UdopAttention(config, has_relative_attention_bias=False)
+ self.layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ key_value_states,
+ attention_mask=None,
+ position_bias=None,
+ layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ query_length=None,
+ output_attentions=False,
+ ):
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.EncDecAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ key_value_states=key_value_states,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ query_length=query_length,
+ output_attentions=output_attentions,
+ )
+ layer_output = hidden_states + self.dropout(attention_output[0])
+ outputs = (layer_output,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.t5.modeling_t5.T5Block with T5->Udop
+class UdopBlock(nn.Module):
+ def __init__(self, config, has_relative_attention_bias=False):
+ super().__init__()
+ self.is_decoder = config.is_decoder
+ self.layer = nn.ModuleList()
+ self.layer.append(UdopLayerSelfAttention(config, has_relative_attention_bias=has_relative_attention_bias))
+ if self.is_decoder:
+ self.layer.append(UdopLayerCrossAttention(config))
+
+ self.layer.append(UdopLayerFF(config))
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ position_bias=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ encoder_decoder_position_bias=None,
+ layer_head_mask=None,
+ cross_attn_layer_head_mask=None,
+ past_key_value=None,
+ use_cache=False,
+ output_attentions=False,
+ return_dict=True,
+ ):
+ if past_key_value is not None:
+ if not self.is_decoder:
+ logger.warning("`past_key_values` is passed to the encoder. Please make sure this is intended.")
+ expected_num_past_key_values = 2 if encoder_hidden_states is None else 4
+
+ if len(past_key_value) != expected_num_past_key_values:
+ raise ValueError(
+ f"There should be {expected_num_past_key_values} past states. "
+ f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"Got {len(past_key_value)} past key / value states"
+ )
+
+ self_attn_past_key_value = past_key_value[:2]
+ cross_attn_past_key_value = past_key_value[2:]
+ else:
+ self_attn_past_key_value, cross_attn_past_key_value = None, None
+
+ self_attention_outputs = self.layer[0](
+ hidden_states,
+ attention_mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=self_attn_past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states, present_key_value_state = self_attention_outputs[:2]
+ attention_outputs = self_attention_outputs[2:] # Keep self-attention outputs and relative position weights
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ do_cross_attention = self.is_decoder and encoder_hidden_states is not None
+ if do_cross_attention:
+ # the actual query length is unknown for cross attention
+ # if using past key value states. Need to inject it here
+ if present_key_value_state is not None:
+ query_length = present_key_value_state[0].shape[2]
+ else:
+ query_length = None
+
+ cross_attention_outputs = self.layer[1](
+ hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ position_bias=encoder_decoder_position_bias,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ query_length=query_length,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = cross_attention_outputs[0]
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ # Combine self attn and cross attn key value states
+ if present_key_value_state is not None:
+ present_key_value_state = present_key_value_state + cross_attention_outputs[1]
+
+ # Keep cross-attention outputs and relative position weights
+ attention_outputs = attention_outputs + cross_attention_outputs[2:]
+
+ # Apply Feed Forward layer
+ hidden_states = self.layer[-1](hidden_states)
+
+ # clamp inf values to enable fp16 training
+ if hidden_states.dtype == torch.float16:
+ clamp_value = torch.where(
+ torch.isinf(hidden_states).any(),
+ torch.finfo(hidden_states.dtype).max - 1000,
+ torch.finfo(hidden_states.dtype).max,
+ )
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if use_cache:
+ outputs = outputs + (present_key_value_state,) + attention_outputs
+ else:
+ outputs = outputs + attention_outputs
+
+ return outputs # hidden-states, present_key_value_states, (self-attention position bias), (self-attention weights), (cross-attention position bias), (cross-attention weights)
+
+
+class UdopCellEmbeddings(nn.Module):
+ def __init__(self, max_2d_position_embeddings=501, hidden_size=1024):
+ super(UdopCellEmbeddings, self).__init__()
+ self.max_2d_position_embeddings = max_2d_position_embeddings
+
+ self.x_position_embeddings = nn.Embedding(max_2d_position_embeddings, hidden_size)
+ self.y_position_embeddings = nn.Embedding(max_2d_position_embeddings, hidden_size)
+
+ def forward(self, bbox):
+ bbox = torch.clip(bbox, 0.0, 1.0)
+ bbox = (bbox * (self.max_2d_position_embeddings - 1)).long()
+ left_position_embeddings = self.x_position_embeddings(bbox[:, :, 0])
+ upper_position_embeddings = self.y_position_embeddings(bbox[:, :, 1])
+ right_position_embeddings = self.x_position_embeddings(bbox[:, :, 2])
+ lower_position_embeddings = self.y_position_embeddings(bbox[:, :, 3])
+
+ embeddings = (
+ left_position_embeddings
+ + upper_position_embeddings
+ + right_position_embeddings
+ + lower_position_embeddings
+ )
+
+ return embeddings
+
+
+# get function for bucket computation
+# protected member access seems to be lesser evil than copy paste whole function
+get_relative_position_bucket = UdopAttention._relative_position_bucket
+AUGMENTATION_RANGE = (0.80, 1.25)
+
+
+class RelativePositionBiasBase(nn.Module, ABC):
+ """
+ Base class of relative biases.
+
+ Args:
+ num_heads (`int`):
+ Number of attention heads in the model, it will create embeddings of size `num_heads`, which will be added to the scores of each token pair.
+ relative_attention_num_buckets (`int`, *optional*, defaults to 32):
+ Pair token metric (distance in the sequence, distance in pixels etc.) will be bucketed, parameter is defining number of such
+ buckets.
+ bidirectional (`bool`, *optional*, defaults to `True`):
+ Whether the distance should be bidirectional for a pair of tokens. If `False`, then distance(tok1, tok2) == distance(tok2, tok1).
+ scaling_factor (`int`, *optional*, defaults to 1):
+ Defining factor which will be used to scale relative distance.
+ max_distance (`int`, *optional*, defaults to 128):
+ All distances above this value will end up in the one/same bucket.
+ augmentation (`bool`, *optional*, defaults to `False`):
+ Whether to multiply relative distances by a random scalar.
+ expand (`bool`, *optional*, defaults to `False`):
+ Whether to expand an existing pretrained model with subsequent additions of prefix_bucket.
+ """
+
+ def __init__(
+ self,
+ num_heads=None,
+ relative_attention_num_buckets=32,
+ bidirectional=True,
+ scaling_factor=1,
+ max_distance=128,
+ level="tokens",
+ augmentation=False,
+ prefix_bucket=False,
+ expand=False,
+ ):
+ super(RelativePositionBiasBase, self).__init__()
+ self.prefix_bucket = prefix_bucket
+ self.augmentation = augmentation
+ self.level = level
+ self.max_distance = max_distance
+ self.scaling_factor = scaling_factor
+ self.bidirectional = bidirectional
+ self.num_heads = num_heads
+ self.expand = expand
+ self.relative_attention_num_buckets = relative_attention_num_buckets
+ extra_head = 2 if prefix_bucket and not self.expand else 0
+ self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets + extra_head, self.num_heads)
+
+ @abstractmethod
+ def prepare_input(
+ self,
+ attention_mask: Optional[Tensor] = None,
+ bbox: Optional[Dict[str, Any]] = None,
+ ) -> Tensor:
+ pass
+
+ def get_bucket(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ relative_position = self.prepare_input(attention_mask, bbox)
+ rp_bucket: Tensor = get_relative_position_bucket(
+ relative_position,
+ bidirectional=self.bidirectional,
+ num_buckets=self.relative_attention_num_buckets,
+ max_distance=self.max_distance,
+ )
+ return rp_bucket
+
+ def get_relative_position(self, positions):
+ context_position = positions[:, :, None]
+ memory_position = positions[:, None, :]
+ relative_position = memory_position - context_position
+ if self.augmentation and self.training:
+ relative_position *= random.uniform(*AUGMENTATION_RANGE)
+ relative_position *= self.scaling_factor
+
+ return relative_position.to(torch.long)
+
+ def forward(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ # re-using pretrained model with subsequent addition of prefix_bucket
+ if self.expand and self.prefix_bucket:
+ new_bias = nn.Embedding(self.relative_attention_num_buckets + 2, self.num_heads)
+ new_bias.weight.data[: self.relative_attention_num_buckets] = self.relative_attention_bias.weight.data
+ new_bias.weight.data[self.relative_attention_num_buckets :] = 0.1
+ self.relative_attention_bias = new_bias
+ self.expand = False
+
+ rp_bucket = self.get_bucket(attention_mask, bbox)
+
+ if self.prefix_bucket:
+ if rp_bucket.size(0) == 1 and attention_mask.size(0) > 1:
+ rp_bucket = rp_bucket.repeat(attention_mask.size(0), 1, 1)
+ # based on assumption that prefix bboxes are negative
+ is_prefix = bbox[:, :, 1] < 0
+ num_prefix = is_prefix.sum(-1)
+ for idx, num_prefix_row in enumerate(num_prefix.cpu().numpy()):
+ rp_bucket[idx, :num_prefix_row, num_prefix_row:] = self.relative_attention_num_buckets
+ rp_bucket[idx, num_prefix_row:, :num_prefix_row] = self.relative_attention_num_buckets + 1
+
+ values: Tensor = self.relative_attention_bias(rp_bucket)
+ if values.dim() != 4:
+ raise ValueError("Wrong dimension of values tensor")
+ values = values.permute([0, 3, 1, 2])
+
+ return values
+
+
+class RelativePositionBias1D(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=1, max_distance=128, **kwargs):
+ """
+ Reimplementation of T5 relative position bias. Distance between given tokens is their distance in the sequence.
+ Parameters are the same as in base class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if self.scaling_factor != 1:
+ raise ValueError("No need to scale 1d features")
+ relative_position = self.get_relative_position(
+ torch.arange(attention_mask.size(1), dtype=torch.long, device=attention_mask.device)[None, :]
+ )
+
+ return relative_position
+
+
+class RelativePositionBiasHorizontal(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=100, max_distance=100, **kwargs):
+ """
+ Represents in the bucket embeddings horizontal distance between two tokens. Parameters are the same as in base
+ class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if not self.scaling_factor > 1.0:
+ raise ValueError("Need to scale the values of bboxes, as there are in small (0,1) range")
+ if bbox is None:
+ raise ValueError("Bbox is required for horizontal relative position bias")
+ # get x positions of left point of bbox
+ horizontal_position: Tensor = bbox[:, :, [0, 2]].mean(dim=-1)
+
+ return self.get_relative_position(horizontal_position)
+
+
+class RelativePositionBiasVertical(RelativePositionBiasBase):
+ def __init__(self, scaling_factor=100, max_distance=100, **kwargs):
+ """
+ Represents in the bucket embeddings vertical distance between two tokens. Parameters are the same as in base
+ class
+ """
+ super().__init__(scaling_factor=scaling_factor, max_distance=max_distance, **kwargs)
+
+ def prepare_input(self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None) -> Tensor:
+ if not self.scaling_factor > 1.0:
+ raise ValueError("Need to scale the values of bboxes, as there are in small (0,1) range")
+ if bbox is None:
+ raise ValueError("Bbox is required for vertical relative position bias")
+ # get y positions of middle of bbox
+ vertical_position: Tensor = bbox[:, :, [1, 3]].mean(dim=-1)
+
+ return self.get_relative_position(vertical_position)
+
+
+class RelativePositionBiasAggregated(nn.Module):
+ def __init__(self, modules: Sequence[RelativePositionBiasBase]):
+ """
+ Class which sums up various computed biases.
+
+ Args:
+ modules (Sequence[RelativePositionBiasBase]):
+ List of relative bias modules.
+ """
+ super().__init__()
+ self.biases = nn.ModuleList(modules)
+
+ def forward(
+ self, attention_mask: Optional[Tensor] = None, bbox: Optional[Dict[str, Any]] = None
+ ) -> Union[float, Tensor]:
+ output = 0.0
+ for bias in self.biases: # type: ignore
+ output = bias(attention_mask, bbox) + output
+
+ return output
+
+
+BIAS_CLASSES = {
+ "1d": RelativePositionBias1D,
+ "horizontal": RelativePositionBiasHorizontal,
+ "vertical": RelativePositionBiasVertical,
+}
+
+
+def create_relative_bias(config: UdopConfig) -> Sequence[RelativePositionBiasBase]:
+ """
+ Creates empty list or one/multiple relative biases.
+
+ :param config: Model's configuration :return: Sequence with created bias modules.
+ """
+ bias_list = []
+ if hasattr(config, "relative_bias_args"):
+ for bias_kwargs_org in config.relative_bias_args:
+ bias_kwargs = deepcopy(bias_kwargs_org)
+ bias_type = bias_kwargs.pop("type")
+ model_num_heads = config.num_heads if hasattr(config, "num_heads") else config.num_attention_heads
+ if "num_heads" in bias_kwargs:
+ if bias_kwargs["num_heads"] != model_num_heads:
+ raise ValueError("Number of heads must match num of heads in the model")
+ else:
+ bias_kwargs["num_heads"] = model_num_heads
+ bias_list.append(BIAS_CLASSES[bias_type](**bias_kwargs)) # type: ignore
+
+ return bias_list
+
+
+class UdopStack(UdopPreTrainedModel):
+ """
+ This class is based on `T5Stack`, but modified to take into account the image modality as well as 2D position
+ embeddings.
+ """
+
+ def __init__(self, config, embed_tokens=None, embed_patches=None):
+ super().__init__(config)
+
+ self.embed_tokens = embed_tokens
+ self.embed_patches = embed_patches
+ self.is_decoder = config.is_decoder
+ self._max_length = config.max_length
+ self.num_layers = config.num_layers
+
+ self.block = nn.ModuleList(
+ [UdopBlock(config, has_relative_attention_bias=bool(i == 0)) for i in range(self.num_layers)]
+ )
+ self.final_layer_norm = UdopLayerNorm(config.d_model, eps=config.layer_norm_epsilon)
+
+ self.dropout = nn.Dropout(config.dropout_rate)
+
+ if not self.is_decoder:
+ self.cell_2d_embedding = UdopCellEmbeddings(config.max_2d_position_embeddings, config.hidden_size)
+
+ # get weights from encoder position bias
+ self.relative_bias = self._get_relative_bias(config)
+
+ # tie weights of original position bias of encoder
+ for bias in self.relative_bias.biases:
+ if isinstance(bias, RelativePositionBias1D):
+ self._tie_or_clone_weights(
+ bias.relative_attention_bias, self.block[0].layer[0].SelfAttention.relative_attention_bias
+ )
+
+ @staticmethod
+ def _get_relative_bias(config: UdopConfig) -> RelativePositionBiasAggregated:
+ relative_bias_list = create_relative_bias(config)
+ return RelativePositionBiasAggregated(relative_bias_list)
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def get_output_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, new_embeddings):
+ self.embed_tokens = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ bbox=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ visual_bbox=None,
+ image_embeddings=None,
+ position_bias=None,
+ head_mask=None,
+ cross_attn_head_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # input embeddings processing
+
+ if input_ids is not None and inputs_embeds is not None:
+ err_msg_prefix = "decoder_" if self.is_decoder else ""
+ raise ValueError(
+ f"You cannot specify both {err_msg_prefix}inputs and {err_msg_prefix}inputs_embeds at the same time"
+ )
+ elif input_ids is not None and torch.numel(input_ids) > 0:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ elif inputs_embeds is None and input_ids is not None and torch.numel(input_ids) == 0:
+ input_ids = torch.full((4, 1024), self.config.pad_token_id, device=input_ids.device, dtype=input_ids.dtype)
+ attention_mask = torch.zeros((4, 1024), device=input_ids.device, dtype=input_ids.dtype)
+ bbox = torch.zeros((4, 1024, 4), device=input_ids.device, dtype=input_ids.dtype)
+ input_shape = input_ids.size()
+ position_bias = torch.zeros_like(self.get_extended_attention_mask(attention_mask, input_shape))
+ # encoder_attention_mask = attention_mask
+ logger.warning("Empty batch")
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ err_msg_prefix = "decoder_" if self.is_decoder else ""
+ raise ValueError(f"You have to specify either {err_msg_prefix}inputs or {err_msg_prefix}inputs_embeds")
+
+ if inputs_embeds is None:
+ if self.embed_tokens is None:
+ raise ValueError("You have to intialize the model with valid token embeddings")
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if pixel_values is not None:
+ image_embeddings = self.embed_patches(pixel_values)
+
+ if image_embeddings is not None:
+ # combine visual and OCR text embeddings
+ num_patches = self.config.image_size // self.config.patch_size
+ inputs_embeds, bbox, attention_mask = combine_image_text_embeddings(
+ image_embeddings,
+ inputs_embeds,
+ bbox,
+ visual_bbox,
+ attention_mask,
+ num_patches,
+ 0,
+ self.config.image_size,
+ self.config.patch_size,
+ )
+ input_shape = inputs_embeds.size()[:-1]
+
+ if not self.is_decoder and bbox is not None:
+ inputs_embeds += self.cell_2d_embedding(bbox)
+
+ batch_size, seq_length = input_shape
+
+ # required mask seq length can be calculated via length of past
+ mask_seq_length = past_key_values[0][0].shape[2] + seq_length if past_key_values is not None else seq_length
+
+ if use_cache is True:
+ assert self.is_decoder, "`use_cache` can only be set to `True` if {} is used as a decoder".format(self)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(batch_size, mask_seq_length).to(inputs_embeds.device)
+ if self.is_decoder and encoder_attention_mask is None and encoder_hidden_states is not None:
+ encoder_seq_length = encoder_hidden_states.shape[1]
+ encoder_attention_mask = torch.ones(
+ batch_size, encoder_seq_length, device=inputs_embeds.device, dtype=torch.long
+ )
+
+ # initialize past_key_values with `None` if past does not exist
+ if past_key_values is None:
+ past_key_values = [None] * len(self.block)
+
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ if self.is_decoder and encoder_attention_mask is not None:
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ head_mask = self.get_head_mask(head_mask, self.num_layers)
+ present_key_value_states = () if use_cache else None
+ all_hidden_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+ all_cross_attentions = () if (output_attentions and self.is_decoder) else None
+
+ if self.is_decoder: # modified lines
+ position_bias = None
+ else:
+ position_bias = self.relative_bias(attention_mask=attention_mask, bbox=bbox)
+ position_bias = position_bias + extended_attention_mask
+ encoder_decoder_position_bias = None
+
+ hidden_states = inputs_embeds
+
+ hidden_states = self.dropout(hidden_states)
+
+ for i, (layer_module, past_key_value) in enumerate(zip(self.block, past_key_values)):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask=extended_attention_mask,
+ position_bias=position_bias,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ encoder_decoder_position_bias=encoder_decoder_position_bias,
+ layer_head_mask=head_mask[i],
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ # layer_outputs is a tuple with:
+ # hidden-states, key-value-states, (self-attention weights), (self-attention position bias), (cross-attention weights), (cross-attention position bias)
+ if use_cache is False: # MP fixes
+ layer_outputs = layer_outputs[:1] + (None,) + layer_outputs[1:]
+ hidden_states, present_key_value_state = layer_outputs[:2]
+
+ # We share the position biases between the layers - the first layer store them
+ # layer_outputs = hidden-states, key-value-states (self-attention weights),
+ # (self-attention position bias), (cross-attention weights), (cross-attention position bias)
+
+ position_bias = layer_outputs[2]
+ if self.is_decoder and encoder_hidden_states is not None:
+ encoder_decoder_position_bias = layer_outputs[4 if output_attentions else 3]
+ # append next layer key value states
+ if use_cache:
+ present_key_value_states = present_key_value_states + (present_key_value_state,)
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[2],) # We keep only self-attention weights for now
+ if self.is_decoder:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
+
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ # Add last layer
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ attention_mask,
+ present_key_value_states,
+ all_hidden_states,
+ all_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+
+ return BaseModelOutputWithAttentionMask(
+ last_hidden_state=hidden_states,
+ attention_mask=attention_mask,
+ past_key_values=present_key_value_states,
+ hidden_states=all_hidden_states,
+ attentions=all_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+@add_start_docstrings(
+ "The bare UDOP encoder-decoder Transformer outputting raw hidden-states without any specific head on top.",
+ UDOP_START_DOCSTRING,
+)
+class UdopModel(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "decoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "decoder.relative_bias.biases.0.relative_attention_bias.weight",
+ ]
+
+ def __init__(self, config):
+ super(UdopModel, self).__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ decoder_config = deepcopy(config)
+ decoder_config.is_decoder = True
+ decoder_config.is_encoder_decoder = False
+ decoder_config.num_layers = config.num_decoder_layers
+ self.decoder = UdopStack(decoder_config, self.shared)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+ self.decoder.set_input_embeddings(new_embeddings)
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(UDOP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=Seq2SeqModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ attention_mask: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ decoder_input_ids: Optional[Tensor] = None,
+ decoder_attention_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ encoder_outputs: Optional[Tensor] = None,
+ past_key_values: Optional[Tensor] = None,
+ head_mask: Optional[Tensor] = None,
+ decoder_inputs_embeds: Optional[Tensor] = None,
+ decoder_head_mask: Optional[Tensor] = None,
+ cross_attn_head_mask: Optional[Tensor] = None,
+ use_cache=True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Tuple[Tensor, ...]:
+ r"""
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = AutoModel.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> inputs = processor(image, words, boxes=boxes, return_tensors="pt")
+
+ >>> decoder_input_ids = torch.tensor([[model.config.decoder_start_token_id]])
+
+ >>> # forward pass
+ >>> outputs = model(**inputs, decoder_input_ids=decoder_input_ids)
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 1, 1024]
+ ```"""
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Encode if needed (training, first prediction pass)
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ bbox=bbox,
+ pixel_values=pixel_values,
+ visual_bbox=visual_bbox,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+ encoder_attention_mask = encoder_outputs.attention_mask if return_dict else encoder_outputs[1]
+
+ # Decode
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ # we filter out the attention mask
+ decoder_outputs = tuple(value for idx, value in enumerate(decoder_outputs) if idx != 1)
+ encoder_outputs = tuple(value for idx, value in enumerate(encoder_outputs) if idx != 1)
+ return decoder_outputs + encoder_outputs
+
+ return Seq2SeqModelOutput(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """The UDOP encoder-decoder Transformer with a language modeling head on top, enabling to generate text given document
+ images and an optional prompt.
+
+ This class is based on [`T5ForConditionalGeneration`], extended to deal with images and layout (2D) data.""",
+ UDOP_START_DOCSTRING,
+)
+class UdopForConditionalGeneration(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "decoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "decoder.relative_bias.biases.0.relative_attention_bias.weight",
+ "lm_head.weight",
+ ]
+
+ def __init__(self, config):
+ super(UdopForConditionalGeneration, self).__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ decoder_config = deepcopy(config)
+ decoder_config.is_decoder = True
+ decoder_config.is_encoder_decoder = False
+ decoder_config.num_layers = config.num_decoder_layers
+ self.decoder = UdopStack(decoder_config, self.shared)
+
+ # The weights of the language modeling head are shared with those of the encoder and decoder
+ self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+ self.decoder.set_input_embeddings(new_embeddings)
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(UDOP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ attention_mask: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ decoder_input_ids: Optional[Tensor] = None,
+ decoder_attention_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ encoder_outputs: Optional[Tensor] = None,
+ past_key_values: Optional[Tensor] = None,
+ head_mask: Optional[Tensor] = None,
+ decoder_inputs_embeds: Optional[Tensor] = None,
+ decoder_head_mask: Optional[Tensor] = None,
+ cross_attn_head_mask: Optional[Tensor] = None,
+ use_cache=True,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[Tensor] = None,
+ ) -> Tuple[Tensor, ...]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the language modeling loss. Indices should be in `[-100, 0, ..., config.vocab_size -
+ 1]`. All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ...,
+ config.vocab_size]`.
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, UdopForConditionalGeneration
+ >>> from datasets import load_dataset
+
+ >>> # load model and processor
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> question = "Question answering. What is the date on the form?"
+ >>> encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
+
+ >>> # autoregressive generation
+ >>> predicted_ids = model.generate(**encoding)
+ >>> print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
+ 9/30/92
+ ```"""
+
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if decoder_input_ids is None and labels is not None:
+ decoder_input_ids = self._shift_right(labels)
+
+ # Encode if needed (training, first prediction pass)
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ bbox=bbox,
+ visual_bbox=visual_bbox,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+ encoder_attention_mask = encoder_outputs.attention_mask if return_dict else encoder_outputs[1]
+
+ # Decode
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=decoder_attention_mask,
+ inputs_embeds=decoder_inputs_embeds,
+ past_key_values=past_key_values,
+ encoder_hidden_states=hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = decoder_outputs[0]
+
+ if self.config.tie_word_embeddings:
+ # Rescale output before projecting on vocab
+ # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
+ sequence_output = sequence_output * (self.config.d_model**-0.5)
+
+ lm_logits = self.lm_head(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss(ignore_index=-100)
+ loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
+
+ if not return_dict:
+ output = (lm_logits,) + decoder_outputs[2:] + (encoder_outputs[0],) + encoder_outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return Seq2SeqLMOutput(
+ loss=loss,
+ logits=lm_logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ head_mask=None,
+ decoder_head_mask=None,
+ cross_attn_head_mask=None,
+ use_cache=None,
+ encoder_outputs=None,
+ **kwargs,
+ ):
+ # cut decoder_input_ids if past is used
+ if past_key_values is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ "decoder_input_ids": input_ids,
+ "past_key_values": past_key_values,
+ "encoder_outputs": encoder_outputs,
+ "attention_mask": attention_mask,
+ "head_mask": head_mask,
+ "decoder_head_mask": decoder_head_mask,
+ "cross_attn_head_mask": cross_attn_head_mask,
+ "use_cache": use_cache,
+ "bbox": kwargs.get("bbox", None),
+ "pixel_values": kwargs.get("pixel_values", None),
+ "visual_bbox": kwargs.get("visual_bbox", None),
+ }
+
+ # Copied from transformers.models.t5.modeling_t5.T5ForConditionalGeneration._reorder_cache
+ def _reorder_cache(self, past_key_values, beam_idx):
+ # if decoder past is not included in output
+ # speedy decoding is disabled and no need to reorder
+ if past_key_values is None:
+ logger.warning("You might want to consider setting `use_cache=True` to speed up decoding")
+ return past_key_values
+
+ reordered_decoder_past = ()
+ for layer_past_states in past_key_values:
+ # get the correct batch idx from layer past batch dim
+ # batch dim of `past` is at 2nd position
+ reordered_layer_past_states = ()
+ for layer_past_state in layer_past_states:
+ # need to set correct `past` for each of the four key / value states
+ reordered_layer_past_states = reordered_layer_past_states + (
+ layer_past_state.index_select(0, beam_idx.to(layer_past_state.device)),
+ )
+
+ if reordered_layer_past_states[0].shape != layer_past_states[0].shape:
+ raise ValueError(
+ f"reordered_layer_past_states[0] shape {reordered_layer_past_states[0].shape} and layer_past_states[0] shape {layer_past_states[0].shape} mismatched"
+ )
+ if len(reordered_layer_past_states) != len(layer_past_states):
+ raise ValueError(
+ f"length of reordered_layer_past_states {len(reordered_layer_past_states)} and length of layer_past_states {len(layer_past_states)} mismatched"
+ )
+
+ reordered_decoder_past = reordered_decoder_past + (reordered_layer_past_states,)
+ return reordered_decoder_past
+
+
+@add_start_docstrings(
+ "The bare UDOP Model transformer outputting encoder's raw hidden-states without any specific head on top.",
+ UDOP_START_DOCSTRING,
+)
+class UdopEncoderModel(UdopPreTrainedModel):
+ _tied_weights_keys = [
+ "encoder.embed_tokens.weight",
+ "encoder.embed_patches.proj.weight",
+ "encoder.embed_patches.proj.bias",
+ "encoder.relative_bias.biases.0.relative_attention_bias.weight",
+ ]
+
+ def __init__(self, config: UdopConfig):
+ super().__init__(config)
+
+ # text and image embeddings
+ self.shared = nn.Embedding(config.vocab_size, config.d_model)
+ self.patch_embed = UdopPatchEmbeddings(config)
+
+ encoder_config = deepcopy(config)
+ encoder_config.is_decoder = False
+ encoder_config.use_cache = False
+ encoder_config.is_encoder_decoder = False
+ self.encoder = UdopStack(encoder_config, self.shared, self.patch_embed)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.shared
+
+ def set_input_embeddings(self, new_embeddings):
+ self.shared = new_embeddings
+ self.encoder.set_input_embeddings(new_embeddings)
+
+ def get_encoder(self):
+ return self.encoder
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.block[layer].layer[0].SelfAttention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(UDOP_ENCODER_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithAttentionMask, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Tensor = None,
+ bbox: Dict[str, Any] = None,
+ attention_mask: Tensor = None,
+ pixel_values: Optional[Tensor] = None,
+ visual_bbox: Dict[str, Any] = None,
+ head_mask: Optional[Tensor] = None,
+ inputs_embeds: Optional[Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.FloatTensor], BaseModelOutputWithAttentionMask]:
+ r"""
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, UdopEncoderModel
+ >>> from huggingface_hub import hf_hub_download
+ >>> from datasets import load_dataset
+
+ >>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
+ >>> model = UdopEncoderModel.from_pretrained("microsoft/udop-large")
+
+ >>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
+ >>> example = dataset[0]
+ >>> image = example["image"]
+ >>> words = example["tokens"]
+ >>> boxes = example["bboxes"]
+ >>> encoding = processor(image, words, boxes=boxes, return_tensors="pt")
+
+ >>> outputs = model(**encoding)
+ >>> last_hidden_states = outputs.last_hidden_state
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ bbox=bbox,
+ visual_bbox=visual_bbox,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ return encoder_outputs
diff --git a/src/transformers/models/udop/processing_udop.py b/src/transformers/models/udop/processing_udop.py
new file mode 100644
index 00000000000000..2902541d6f5b46
--- /dev/null
+++ b/src/transformers/models/udop/processing_udop.py
@@ -0,0 +1,204 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for UDOP.
+"""
+
+from typing import List, Optional, Union
+
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType
+
+
+class UdopProcessor(ProcessorMixin):
+ r"""
+ Constructs a UDOP processor which combines a LayoutLMv3 image processor and a UDOP tokenizer into a single processor.
+
+ [`UdopProcessor`] offers all the functionalities you need to prepare data for the model.
+
+ It first uses [`LayoutLMv3ImageProcessor`] to resize, rescale and normalize document images, and optionally applies OCR
+ to get words and normalized bounding boxes. These are then provided to [`UdopTokenizer`] or [`UdopTokenizerFast`],
+ which turns the words and bounding boxes into token-level `input_ids`, `attention_mask`, `token_type_ids`, `bbox`.
+ Optionally, one can provide integer `word_labels`, which are turned into token-level `labels` for token
+ classification tasks (such as FUNSD, CORD).
+
+ Additionally, it also supports passing `text_target` and `text_pair_target` to the tokenizer, which can be used to
+ prepare labels for language modeling tasks.
+
+ Args:
+ image_processor (`LayoutLMv3ImageProcessor`):
+ An instance of [`LayoutLMv3ImageProcessor`]. The image processor is a required input.
+ tokenizer (`UdopTokenizer` or `UdopTokenizerFast`):
+ An instance of [`UdopTokenizer`] or [`UdopTokenizerFast`]. The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "LayoutLMv3ImageProcessor"
+ tokenizer_class = ("UdopTokenizer", "UdopTokenizerFast")
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: Optional[ImageInput] = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ text_pair: Optional[Union[PreTokenizedInput, List[PreTokenizedInput]]] = None,
+ boxes: Union[List[List[int]], List[List[List[int]]]] = None,
+ word_labels: Optional[Union[List[int], List[List[int]]]] = None,
+ text_target: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ text_pair_target: Optional[
+ Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]
+ ] = None,
+ add_special_tokens: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = False,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_token_type_ids: Optional[bool] = None,
+ return_attention_mask: Optional[bool] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ ) -> BatchEncoding:
+ """
+ This method first forwards the `images` argument to [`~UdopImageProcessor.__call__`]. In case
+ [`UdopImageProcessor`] was initialized with `apply_ocr` set to `True`, it passes the obtained words and
+ bounding boxes along with the additional arguments to [`~UdopTokenizer.__call__`] and returns the output,
+ together with the prepared `pixel_values`. In case [`UdopImageProcessor`] was initialized with `apply_ocr` set
+ to `False`, it passes the words (`text`/``text_pair`) and `boxes` specified by the user along with the
+ additional arguments to [`~UdopTokenizer.__call__`] and returns the output, together with the prepared
+ `pixel_values`.
+
+ Alternatively, one can pass `text_target` and `text_pair_target` to prepare the targets of UDOP.
+
+ Please refer to the docstring of the above two methods for more information.
+ """
+ # verify input
+ if self.image_processor.apply_ocr and (boxes is not None):
+ raise ValueError(
+ "You cannot provide bounding boxes if you initialized the image processor with apply_ocr set to True."
+ )
+
+ if self.image_processor.apply_ocr and (word_labels is not None):
+ raise ValueError(
+ "You cannot provide word labels if you initialized the image processor with apply_ocr set to True."
+ )
+
+ if return_overflowing_tokens is True and return_offsets_mapping is False:
+ raise ValueError("You cannot return overflowing tokens without returning the offsets mapping.")
+
+ if text_target is not None:
+ # use the processor to prepare the targets of UDOP
+ return self.tokenizer(
+ text_target=text_target,
+ text_pair_target=text_pair_target,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ )
+
+ else:
+ # use the processor to prepare the inputs of UDOP
+ # first, apply the image processor
+ features = self.image_processor(images=images, return_tensors=return_tensors)
+
+ # second, apply the tokenizer
+ if text is not None and self.image_processor.apply_ocr and text_pair is None:
+ if isinstance(text, str):
+ text = [text] # add batch dimension (as the image processor always adds a batch dimension)
+ text_pair = features["words"]
+
+ encoded_inputs = self.tokenizer(
+ text=text if text is not None else features["words"],
+ text_pair=text_pair if text_pair is not None else None,
+ boxes=boxes if boxes is not None else features["boxes"],
+ word_labels=word_labels,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_token_type_ids=return_token_type_ids,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ )
+
+ # add pixel values
+ pixel_values = features.pop("pixel_values")
+ if return_overflowing_tokens is True:
+ pixel_values = self.get_overflowing_images(pixel_values, encoded_inputs["overflow_to_sample_mapping"])
+ encoded_inputs["pixel_values"] = pixel_values
+
+ return encoded_inputs
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.get_overflowing_images
+ def get_overflowing_images(self, images, overflow_to_sample_mapping):
+ # in case there's an overflow, ensure each `input_ids` sample is mapped to its corresponding image
+ images_with_overflow = []
+ for sample_idx in overflow_to_sample_mapping:
+ images_with_overflow.append(images[sample_idx])
+
+ if len(images_with_overflow) != len(overflow_to_sample_mapping):
+ raise ValueError(
+ "Expected length of images to be the same as the length of `overflow_to_sample_mapping`, but got"
+ f" {len(images_with_overflow)} and {len(overflow_to_sample_mapping)}"
+ )
+
+ return images_with_overflow
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.batch_decode
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.decode
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer
+ to the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.layoutlmv3.processing_layoutlmv3.LayoutLMv3Processor.model_input_names
+ def model_input_names(self):
+ return ["input_ids", "bbox", "attention_mask", "pixel_values"]
diff --git a/src/transformers/models/udop/tokenization_udop.py b/src/transformers/models/udop/tokenization_udop.py
new file mode 100644
index 00000000000000..10e92db48cebba
--- /dev/null
+++ b/src/transformers/models/udop/tokenization_udop.py
@@ -0,0 +1,1483 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License
+""" Tokenization classes for UDOP model."""
+
+
+import os
+import re
+import warnings
+from shutil import copyfile
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import sentencepiece as spm
+
+from ...tokenization_utils import PreTrainedTokenizer
+from ...tokenization_utils_base import (
+ AddedToken,
+ BatchEncoding,
+ EncodedInput,
+ PreTokenizedInput,
+ TextInput,
+ TextInputPair,
+ TruncationStrategy,
+)
+from ...utils import PaddingStrategy, TensorType, add_end_docstrings, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+SPIECE_UNDERLINE = "▁"
+
+
+UDOP_ENCODE_KWARGS_DOCSTRING = r"""
+ add_special_tokens (`bool`, *optional*, defaults to `True`):
+ Whether or not to encode the sequences with the special tokens relative to their model.
+ padding (`bool`, `str` or [`~file_utils.PaddingStrategy`], *optional*, defaults to `False`):
+ Activates and controls padding. Accepts the following values:
+
+ - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
+ acceptable input length for the model if that argument is not provided.
+ - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
+ lengths).
+ truncation (`bool`, `str` or [`~tokenization_utils_base.TruncationStrategy`], *optional*, defaults to `False`):
+ Activates and controls truncation. Accepts the following values:
+
+ - `True` or `'longest_first'`: Truncate to a maximum length specified with the argument `max_length` or
+ to the maximum acceptable input length for the model if that argument is not provided. This will
+ truncate token by token, removing a token from the longest sequence in the pair if a pair of
+ sequences (or a batch of pairs) is provided.
+ - `'only_first'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `'only_second'`: Truncate to a maximum length specified with the argument `max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided. This will only
+ truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
+ - `False` or `'do_not_truncate'` (default): No truncation (i.e., can output batch with sequence lengths
+ greater than the model maximum admissible input size).
+ max_length (`int`, *optional*):
+ Controls the maximum length to use by one of the truncation/padding parameters.
+
+ If left unset or set to `None`, this will use the predefined model maximum length if a maximum length
+ is required by one of the truncation/padding parameters. If the model has no specific maximum input
+ length (like XLNet) truncation/padding to a maximum length will be deactivated.
+ stride (`int`, *optional*, defaults to 0):
+ If set to a number along with `max_length`, the overflowing tokens returned when
+ `return_overflowing_tokens=True` will contain some tokens from the end of the truncated sequence
+ returned to provide some overlap between truncated and overflowing sequences. The value of this
+ argument defines the number of overlapping tokens.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
+ the use of Tensor Cores on NVIDIA hardware with compute capability `>= 7.5` (Volta).
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+ return_token_type_ids (`bool`, *optional*):
+ Whether to return token type IDs. If left to the default, will return the token type IDs according to
+ the specific tokenizer's default, defined by the `return_outputs` attribute.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ return_attention_mask (`bool`, *optional*):
+ Whether to return the attention mask. If left to the default, will return the attention mask according
+ to the specific tokenizer's default, defined by the `return_outputs` attribute.
+
+ [What are attention masks?](../glossary#attention-mask)
+ return_overflowing_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch
+ of pairs) is provided with `truncation_strategy = longest_first` or `True`, an error is raised instead
+ of returning overflowing tokens.
+ return_special_tokens_mask (`bool`, *optional*, defaults to `False`):
+ Whether or not to return special tokens mask information.
+ return_offsets_mapping (`bool`, *optional*, defaults to `False`):
+ Whether or not to return `(char_start, char_end)` for each token.
+
+ This is only available on fast tokenizers inheriting from [`PreTrainedTokenizerFast`], if using
+ Python's tokenizer, this method will raise `NotImplementedError`.
+ return_length (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the lengths of the encoded inputs.
+ verbose (`bool`, *optional*, defaults to `True`):
+ Whether or not to print more information and warnings.
+ **kwargs: passed to the `self.tokenize()` method
+
+ Return:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model.
+
+ [What are input IDs?](../glossary#input-ids)
+
+ - **bbox** -- List of bounding boxes to be fed to a model.
+
+ - **token_type_ids** -- List of token type ids to be fed to a model (when `return_token_type_ids=True` or
+ if *"token_type_ids"* is in `self.model_input_names`).
+
+ [What are token type IDs?](../glossary#token-type-ids)
+
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names`).
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ - **labels** -- List of labels to be fed to a model. (when `word_labels` is specified).
+ - **overflowing_tokens** -- List of overflowing tokens sequences (when a `max_length` is specified and
+ `return_overflowing_tokens=True`).
+ - **num_truncated_tokens** -- Number of tokens truncated (when a `max_length` is specified and
+ `return_overflowing_tokens=True`).
+ - **special_tokens_mask** -- List of 0s and 1s, with 1 specifying added special tokens and 0 specifying
+ regular sequence tokens (when `add_special_tokens=True` and `return_special_tokens_mask=True`).
+ - **length** -- The length of the inputs (when `return_length=True`).
+"""
+
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/spiece.model",
+ },
+ "tokenizer_file": {
+ "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/tokenizer.json",
+ },
+}
+
+
+# TODO(PVP) - this should be removed in Transformers v5
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "microsoft/udop-large": 512,
+}
+
+
+class UdopTokenizer(PreTrainedTokenizer):
+ """
+ Adapted from [`LayoutXLMTokenizer`] and [`T5Tokenizer`]. Based on
+ [SentencePiece](https://github.com/google/sentencepiece).
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+
+ + +Siéntete libre de consultar [la referencia de API](./main_classes/trainer) para estas otras clases tipo [`Trainer`] para aprender más sobre cuándo usar cada una. En general, [`Trainer`] es la opción más versátil y es apropiada para una amplia gama de tareas. [`Seq2SeqTrainer`] está diseñado para tareas de secuencia a secuencia y [`~trl.SFTTrainer`] está diseñado para entrenar modelos de lenguaje. + +