You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
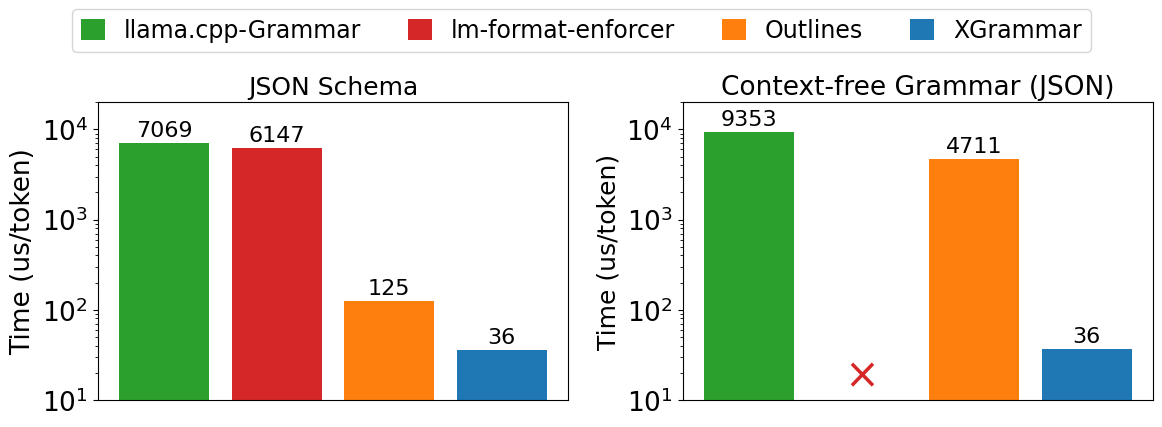
"As shown in Figure 1, XGrammar outperforms existing structured generation solutions by up to 3.5x on the JSON schema workload and more than 10x on the CFG workload. Notably, the gap in CFG-guided generation is larger. This is because many JSON schema specifications can be expressed as regular expressions, bringing more optimizations that are not directly applicable to CFGs."
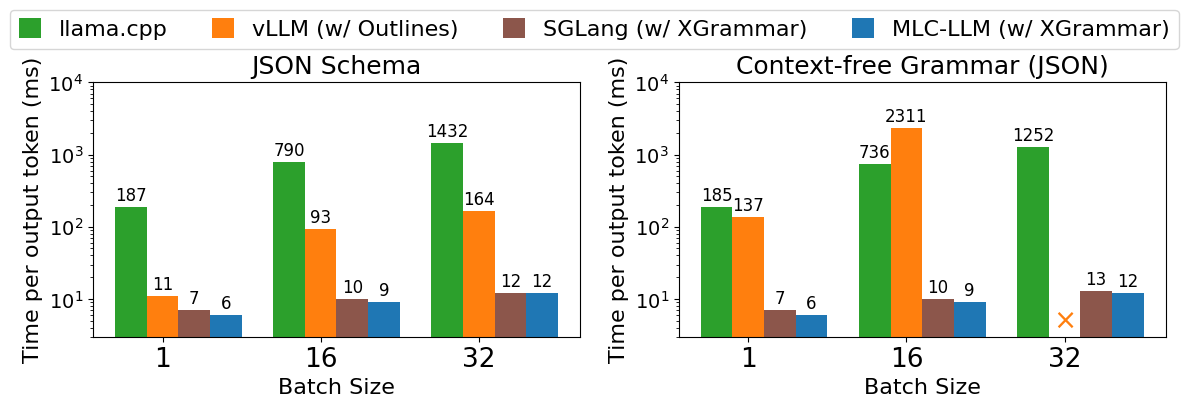
"Figure 2 shows end-to-end inference performance on LLM serving tasks. We can find the trend again that the gap on CFG-guided settings is larger, and the gap grows on larger batch sizes. This is because the GPU throughput is higher on larger batch sizes, putting greater pressure on the grammar engine running on CPUs. Note that the main slowdown of vLLM comes from its structured generation engine, which can be potentially eliminated by integrating with XGrammar. In all cases, XGrammar enables high-performance generation in both settings without compromising flexibility and efficiency."
Feature request
Support the use of XGrammar instead of Outlines for the backend Structured-Output generation.
Motivation
XGrammar has been shown to be much faster than Outlines for generation structured output
BlogPost:
https://blog.mlc.ai/2024/11/22/achieving-efficient-flexible-portable-structured-generation-with-xgrammar
"As shown in Figure 1, XGrammar outperforms existing structured generation solutions by up to 3.5x on the JSON schema workload and more than 10x on the CFG workload. Notably, the gap in CFG-guided generation is larger. This is because many JSON schema specifications can be expressed as regular expressions, bringing more optimizations that are not directly applicable to CFGs."
"Figure 2 shows end-to-end inference performance on LLM serving tasks. We can find the trend again that the gap on CFG-guided settings is larger, and the gap grows on larger batch sizes. This is because the GPU throughput is higher on larger batch sizes, putting greater pressure on the grammar engine running on CPUs. Note that the main slowdown of vLLM comes from its structured generation engine, which can be potentially eliminated by integrating with XGrammar. In all cases, XGrammar enables high-performance generation in both settings without compromising flexibility and efficiency."
Paper / Technical Report from XGrammar:
https://arxiv.org/abs/2411.15100
Your contribution
XGrammar Repo:
https://github.com/mlc-ai/xgrammar
SGLang Repo:
https://github.com/sgl-project/sglang/
SGLang Docs on Structured Output generation including using XGrammar:
https://sgl-project.github.io/backend/openai_api_completions.html#Structured-Outputs-(JSON,-Regex,-EBNF)
Note: Those docs do note that XGrammar does not support regular expressions
The text was updated successfully, but these errors were encountered: