-
Notifications
You must be signed in to change notification settings - Fork 0
/
elog.cache.json
4186 lines (4186 loc) · 906 KB
/
elog.cache.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
{
"docs": [
{
"id": "d04a5572-3f9a-486d-ac95-c02ffd093e23",
"doc_id": "d04a5572-3f9a-486d-ac95-c02ffd093e23",
"updated": 1713875760000,
"body_original": "\n# 前言\n\n\n---\n\n\n需求的提出:\n\n- flomo:#想法 在解决问题当中,工具和人是非常重要的两个因素 2024-02-23\n- flomo:#学习 关联zotero和专业课的笔记,可以上传服务器进行查看 2024-02-29\n- flomo:#学习 使用webdav建立文献管理方式 2024-04-19\n- [流动核心](https://matrixcore.top/article/inexhaustible#a14a6f8b2275406ea446d94b9c191dd6):#言论 如果你没有时间集中精力学习新知识,那么就花时间复习已经学过的内容。\n\n# 正文\n\n\n---\n\n\n解决的策略:\n\n\n 首先,为什么是Zotero,引用红薯下士的:[Zotero 简明介绍](https://zhuanlan.zhihu.com/p/445621222#:~:text=Zotero%20%E6%98%AF%E4%B8%80%E4%B8%AA%20%E5%BC%80%E6%BA%90,%E3%80%81%E6%98%93%E7%94%A8%E7%9A%84%E5%A4%9A%E5%B9%B3%E5%8F%B0%E7%A7%91%E7%A0%94%E5%B7%A5%E5%85%B7%EF%BC%8C%E5%8F%AF%E7%94%A8%E6%9D%A5%E5%B8%AE%E5%8A%A9%E6%94%B6%E9%9B%86%E3%80%81%E7%BB%84%E7%BB%87%E3%80%81%E5%BC%95%E7%94%A8%E3%80%81%E5%88%86%E4%BA%AB%E5%90%84%E7%B1%BB%E8%B5%84%E6%96%99%EF%BC%8C%E6%B3%A8%E5%86%8C%E8%B4%A6%E5%8F%B7%E4%B9%8B%E5%90%8E%E5%8F%AF%E4%BB%A5%E4%BD%BF%E7%94%A8%E5%AE%98%E6%96%B9%E6%9C%8D%E5%8A%A1%E5%99%A8%E5%9C%A8%E5%A4%9A%E7%AB%AF%20%E8%87%AA%E5%8A%A8%E5%90%8C%E6%AD%A5%20%E4%BB%A5%E5%8F%8A%E4%BD%BF%E7%94%A8%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8F%92%E4%BB%B6%EF%BC%8C%E8%BF%98%E5%8F%AF%E4%BB%A5%E7%9B%B4%E6%8E%A5%E5%9C%A8%E7%BD%91%E9%A1%B5%E4%B8%AD%E6%93%8D%E4%BD%9C%E3%80%82),在windows端的文献管理方面,Zotero有他的独到之处。尽管我更喜欢苹果生态的Marginnote,但Zotero的多平台特性,使得它能满足绝大多数的使用场景。值得注意的是,Zotero如果是资深用户,就需要考虑有关存储空间的限制,当然如果仅在本地用,就无需考虑这些问题了,但涉及到云的问题,就变得复杂得多。目前很多主流的方式是搭配坚果云作为webdav,但我更倾向于自己折腾。因为就个人体验而言,我更喜欢Nextcloud。\n\n\n## 青菜萝卜各有所爱\n\n\n---\n\n\n 首先我需要声明一点,需求可能具有普遍性,但是做法可能因人而异,选择适合自己的就行。我采用的方案是使用[软云](https://ruan.cloud/aff/HNAAAYYQ)的服务器,目前购置的是2H4G40G4M这款机型。三年的费用在500左右,目前体验下来速度很不错,跑了一个[hugo](http://hugo.matrixcore.top/)练练手,小破站弱不禁风,大佬手下留情😢,效果如下图所示,测试时间为北京时间上午11点左右,响应时长在1-2s之间。首先比较基础的就是,购买服务器之后进行ssh登陆,在终端输入ssh root@ipv4,输入密码进行验证即可。\n\n\n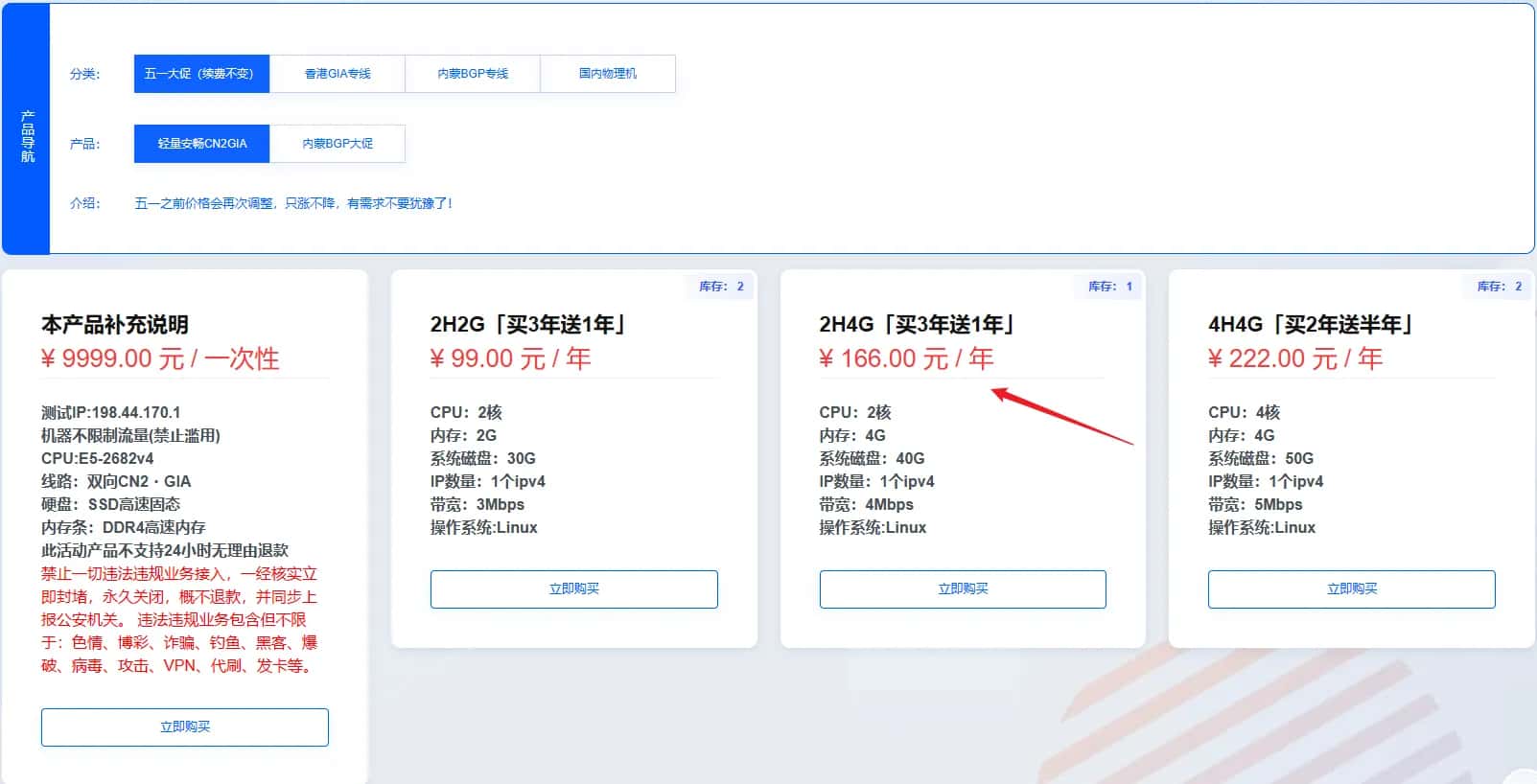\n\n\n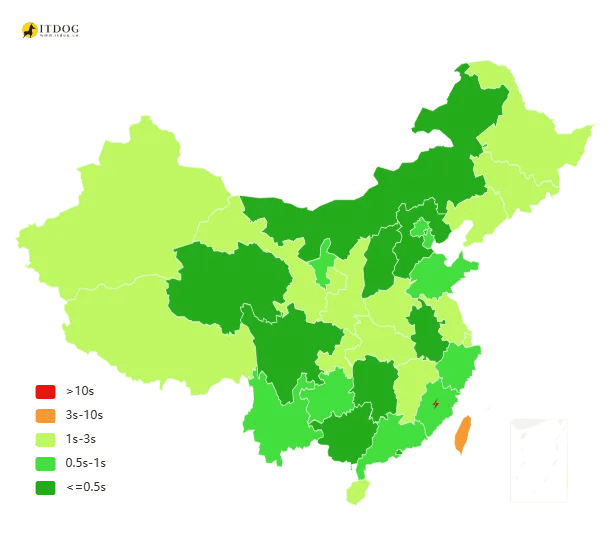\n\n\n## 安装1panel\n\n\n---\n\n\n [1panel](https://1panel.cn/)可以将您 的linux性能可视化,同时在操作上更加亲切,我选的是ubuntu22.04系统,安装1panel非常简单,ubuntu在线安装命令如下,其他系统参照[手册](https://1panel.cn/docs/installation/online_installation/)。\n\n\n```shell\ncurl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sudo bash quick_start.sh\n```\n\n\n 下面来解释为什么安装1panel,不仅是因为在管理服务器上更加方便,而且在装很多应用程序的时候,不需要您手动在命令化中进行复杂的操作,只需要通过内置的商店docker部署就行。额外插一句,1panel包含很多不错的博客框架,包括wordpress,halo都可以一键安装,感兴趣可以试试,目前wordpress对于博客入门来讲都是很好的选择,当然wordpress体量稍微有些大了,在访问速度上可能需要您进行优化。\n\n\n 回归主题,这次我们要通过1panel安装nextcloud和mysql,这一步相对比较简单,装完mysql之后,新建一个账户。作为nextcloud的数据库,同时放开端口,一般是3306,然后安装完nextcloud一般首次需要进行初始化设置,一般是40069端口,同时需要记得放开这两个端口。\n\n\n```shell\nsudo ufw allow 3306 #示例\n```\n\n\n 通过浏览器访问40069一般会出现初始化界面,填入账号密码,然后关联数据库,最下面的对应ipv4:3306。然后初始化完成之后即可进行nextcloud。要注意的是,next可能只能通过https访问,通过http可能访问不了。所以可能得加上https://ipv4:40069的方式进行访问。\n\n\n## 安装nginx\n\n\n---\n\n\n nginx可以隐藏您的ip地址,通过域名进行访问。安装过程也比较简单。\n\n\n```shell\nsudo apt-get update #更新系统\nsudo apt install nginx -y #进行安装\n```\n\n\n 安装完成后您可以按照网上的教程设置。回去补充更新。\n\n\n## nextcloud通过域名访问\n\n\n---\n\n\n一般来讲,刚开始nextcloud还无法通过域名进行访问,需要在设置文件中进行配置,找到1panel安装nextcloud的文件夹,找到config.php,添加受信任的域名。前提是您需要拥有一个域名,并成功通过cloudflare进行dns解析。\n\n\n```php\n'trusted_domains' =>\narray (\n0 => 'localhost',\n1 => 'server1.example.com',\n2 => '192.168.1.50',\n3 => '[fe80::1:50]',\n),\n```\n\n\n## 关联nextcloud和zotero\n\n\n---\n\n\n> 💡 什么是 WebDAV 呢? \n> 简单来说,webdav就像一个存储服务,各种应用都可以连接到它,允许应用直接访问我们的云盘内容,对其进行读写操作。**我们可以网络服务比作一只章鱼,云盘是它的大脑,WebDAV是它的触角。**每个触角都连接到我们智能设备上的应用程序。我们的应用可以通过触角读取章鱼的大脑,并将数据写入大脑,改变大脑的记忆和内容。 \n> 作者:知乎用户 \n> 链接:[https://www.zhihu.com/question/30719209/answer/1229364665](https://www.zhihu.com/question/30719209/answer/1229364665) \n> 来源:知乎\n\n\n参考官方说明,webdav一般格式为:\n\n\n```html\nhttps://example.com/remote.php/dav/files/USERNAME\n<!--一般的webdav格式是这样,然后登入您的账号密码进行验证-->\n```\n\n\n感谢Zotero中文小组对[Zotero webdav的讲解](https://zotero-chinese.com/user-guide/sync.html), 我就不多费口舌了。\n\n\n## 修改nextcloud webdav php上传的限制\n\n\n---\n\n\n一开始我遇到的同步失败的问题,一些较小的文献可以成功,但另外一些较大的文献就会出现413的错误,查询后发现是因为文件体积过大,于是我就联想到了是不是nextcloud和nginx对这个进行了限制。于是进行了查询,发现确实有此限制。\n\n\n> 💡 通过web客户端上传文件时,受PHP和Apache配置的限制。默认PHP只允许2兆字节的上传。此默认配置(2兆字节限制)并不适用,我们建议您的Nextcloud管理员将Nextcloud变量的大小增加到适合用户的大小。\n\n\n修改方式参考[手册](https://docs.nextcloud.com/server/latest/admin_manual/configuration_files/big_file_upload_configuration.html),回去再补充。\n\n\n# 总结\n\n\n---\n\n\n 这篇文章简单介绍了,如何通过Nextcloud Webdav的方式进行Zotero同步,内容包括,服务器的入手,linux运维面板的安装,Nextcloud和Mysql的安装,Nginx的使用,Zotero的Webdav的设置,及如何解除php上传的限制,从而实现在自有网盘间进行数据同步,为搭建大规模数据提提供了基础。\n\n\n## 附录\n\n\n---\n\n\n❤️体验效果:目前因为香港的带宽比较紧俏,所以在初次同步期间时间可能会略长些,但是同步完成之后,下载后就可以多设备正常使用,而且对于文件内修改标记追踪很灵敏,这也是我比较喜欢的地方。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-04-21",
"type": "Post",
"category": "动手实践",
"slug": "Nextcloud_Webdav-Zotero",
"tags": [
"实用教程"
],
"summary": "这篇文章简单介绍了如何通过Nextcloud Webdav的方式进行Zotero同步,内容包括:服务器入门,linux运维面板的安装,Nextcloud和Mysql的安装,Nginx的使用,Zotero的Webdav的设置,解除php上传的限制,从而实现在自有网盘间进行数据同步,为搭建大规模数据集提供了基础。",
"title": "[文献管理] Nextcloud_Webdav的Zotero同步方案",
"status": "Published",
"urlname": "d04a5572-3f9a-486d-ac95-c02ffd093e23",
"updated": "2024-04-23 12:36:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "d04a5572-3f9a-486d-ac95-c02ffd093e23"
}
],
"body": "",
"realName": "[文献管理] Nextcloud_Webdav的Zotero同步方案",
"relativePath": "/实用教程/[文献管理] Nextcloud_Webdav的Zotero同步方案.md"
},
{
"id": "c78e2dc7-6c83-4252-891e-9d3d45fb5d29",
"doc_id": "c78e2dc7-6c83-4252-891e-9d3d45fb5d29",
"updated": 1714636800000,
"body_original": "\n# 更新\n\n\n---\n\n\n这里记录文章的更新。\n\n\n### 增加学习总结 2024-04-29 \n\n\n---\n\n\n 经过这几天的摸索尝试。首先梳理了一遍yolo的网络模型,以及如何从不同的角度去解决多光谱的问题。我将完成的工作列举如下:\n\n- 完成了对于[多光谱前置知识](https://matrixcore.life/article/Yolov5_multispectral#5f61112a1ec34e73b8656d6400475b03)的一些了解,以及对于多光谱航拍黑匣子数据集如何选择合适地方法来进行对黑匣子进行特征捕获,如何结合yolo的网络架构对多光谱进行训练。 2024-04-17 → 2024-04-20\n- 收集并分析现有的多光谱数据集,之前的六组数据集由于无人机视角过高,在人眼识别时也会出现误判,遂采用下降高度数据集。 2024-04-21 → 2024-04-24\n- 了解了[多光谱数据集的处理思路](https://matrixcore.life/article/Yolov5_multispectral#b188f3dd0b1d4768a3cd13092b01f835),主要为前端融合(early-fusion)或数据水平融合(data-level fusion)、后端融合(late-fusion)或决策水平融合(decision-level fusion)和中间融合(intermediate-fusion)。计划借鉴学习红外光和可见光融合的思路。 2024-04-25 → 2024-04-27\n- 进行数据集处理实操,选择[先尝试进行前端融合](https://matrixcore.life/article/Yolov5_multispectral#d2cfeff78f19427eb9c4d04299fe949a)。同时[完成GUI的识别位置坐标和置信度的导出](https://matrixcore.life/article/Yolov5_multispectral#b3c7f248199543f1bab11c137205339f)。后与老师沟通,尝试通过文献检索查找更专业的思路。 2024-04-25\n- 通过[检索文献](https://matrixcore.life/article/Yolov5_multispectral#25de43b2a17945609e35c4561d8a5497)发现,多光谱数据集融合存在传统方法如主成分分析(PCA)方法,小波变换等,深度学习方法有transformer,自动解码器等算法。 2024-04-26 → 2024-04-27\n- 然后基于文献,[寻找领域相关的算法和尝试可进行复现的代码](https://matrixcore.life/article/Yolov5_multispectral#28380e4c5321473ea0fb58533513f7e7)。尝试基于领域算法,选择通用图像融合框架和全色图像锐化相关的论文和代码进行复现。目前仍存在困惑,困难如下:1.较为难复现高相关度的论文和代码。2.实际黑匣子数据集在处理上存在难度,存在分辨度不一致,格式不一致,有的图像可能需要[正射校正](https://baike.baidu.com/item/%E6%AD%A3%E5%B0%84%E6%A0%A1%E6%AD%A3/1443021),以确保在图像融合时黑匣子特征明显,可能需要专业的处理软件,例如ENVI来完成该任务。 2024-04-28 → 2024-04-29\n\n### 240430会议纪要\n\n\n---\n\n- 语法正确,主谓宾搭配,写完之后进行检查\n- 逻辑通顺,论文和说明文之间,先叙述原因和得出的结论,避免”感叹“,避免偏散文,实事求是,恰如其分,符合科技论文的逻辑。例如空难事故,人工搜索,效率角度,无人机检测提升搜寻速度,需要有因果逻辑。\n- 文字数量和篇幅:正文部分,30-50页之间,需要进行组织和修改,控制复制比在25%一下。可以参考,参考完需要根据自己的逻辑理顺。\n- 论文中图标公式需要规范,图片照片清晰度要足够。200dpi以上,拍摄的时候保持环境干净,表格采用三线表,宽度居中,公式需要用公式编辑器。需要有表题,图题,恰如其分,图题表题在十几个字左右,半行左右,特殊情况除外。图标公式需要进行编号。\n- 论文之间需要成体系,要满足基本的逻辑关系。 ——单独说明\n- 实验说明需要描述详细,描述需要进行图文结合。做两次说明。实验数据需要充分。需要有几十种的测量说明,需要有典型实验结果的说明。其二,需要用统计实验结果,需要有曲线。最后得到的结论要可靠。\n- 列出论文章节的目录,根据自己的工作分章节,大框架:绪论:背景和意义,国内外研究综述,主要研究内容,第二部分,算法的设计,网络架构是啥样子的,针对每个模块的公式,介绍该模块的公式。第三部分,软件的模块,图像预处理,特征提取,算法对应的代码的实现,主要介绍步骤,对应的关键源代码。第四部分,实验验证,系统实现。第五章,结论。注意事项,论文中不要大篇幅出现教科书上的东西的基础知识,即使有,三五行带过。参考文献内容,需要在文中进行引用。核心设计部分,参考...方案,这部分引用,引用数量大于20,国内外50%比例,最好超过30,少于50。\n- 时间节点:**5.2列出论文的目录**(要和自己的真实情况匹配)、**5.8号初稿(堆积所有的原始材料),5.12翻译图表**,**5.16完成格式问题修改。**(图题表不能跨页,参考内容不能有水印),**5.20演示毕设成果完善,能现场真实演示**,最后有运行视频的演示来证明成果,来验证工作量和论文数据相吻合,**5.16-5.20交盲审版论文。5.23上传PPT和终稿。5.25正式答辩**,5-15分钟时间。最好在**5.24进行预讲解。**5.23-5.24把PPT做好。辩证使用大模型。\n\n> 💡 计划先把论文的大框架搭出来,再去优化内部具体的细节。 2024-05-02 \n\n\n# 前言\n\n\n---\n\n\n多光谱需求的提出:\n\n\n> _现有的目标检测算法大多数是基于可见光的 RGB 图像进行的,该类算法依赖光照条件,在光照不足的情况下,漏检率会急速上升;热图像在光照不良条件下可以获得稳定的目标特征。_ \n> [_——基于改进的YOLOv4的多光谱目标检测算法研究 党佳_](https://cloud.matrixcore.life/s/QE5Btekc9dbnRcF)\n\n\n我的理解:通过多光谱可以通过对其他光谱的图像特征进行捕捉,从而提高在不同环境下的识别性能,如果单纯训练可见光,也许在夜晚环境下的模型的表现就会变差,而通过其他光谱就可以获得稳定的目标特征,从而实现模型更好地的环境适应性。\n\n\n# 正文\n\n\n---\n\n\n 目前针对多光谱的研究大多针对行人检测、矿藏探测,课题用到的航拍黑匣子数据集,在尝试该方法时具有一定的新颖性和难度,通过查阅各种资料,大概对如何解决多光谱问题的思路有了一个基本的了解。\n\n\n> _目前,多模态数据融合主要有三种融合方式:__**前端融合(early-fusion)或数据水平融合(data-level fusion)、后端融合(late-fusion)或决策水平融合(decision-level fusion)和中间融合(intermediate-fusion)。**_ \n> _前端融合将__**多个独立的数据集融合成一个单一的特征向量**__,然后输入到机器学习分类器中。由于多模态数据的前端融合往往无法充分利用多个模态数据间的互补性,且前端融合的原始数据通常包含大量的冗余信息。因此,多模态前端融合方法常常__**与特征提取方法相结合**__以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。 \n> 后端融合则是__**将不同模态数据分别训练好的分类器输出打分(决策)进行融合。**__这样做的好处是,融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加。常见的后端融合方式包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes’rule based)以及集成学习(ensemble learning)等。其中集成学习作为后端融合方式的典型代表,被广泛应用于通信、计算机识别、语音识别等研究领域。 \n> 中间融合是指__**将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。**__以神经网络为例,中间融合首先利用神经网络将原始数据转化成高维 特征表达,然后获取不同模态数据在高维空间上的共性。中间融合方法的一大优势是__**可以灵活的选择融合的位置。**_ \n> [_—— yolov5可见光+红外双模态融合_ ](https://cloud.matrixcore.life/s/586tdAYkDw9paa6) [_桦树无泪_](https://blog.csdn.net/HUASHUDEYANJING/article/details/126275611)\n\n\n## 多光谱基础知识\n\n\n---\n\n\n<details>\n <summary>多光谱应用的领域</summary>\n\n\n多光谱的领域:多光谱图像的使用涵盖了广泛的领域,主要因为它们提供了比传统RGB图像更加丰富和细致的信息。这些信息对于理解和分析各种自然和人造物体的特性至关重要。以下是使用多光谱图像的一些主要原因和应用领域:\n\n\n1. **增强的视觉信息**\n\n\n多光谱成像能够捕捉到物体在不同波长下的反射或发射光谱,这些信息对于裸眼或传统相机不可见。这使得多光谱图像能够揭示物体的隐藏特征,如健康状况、材质成分、水分含量等。\n\n\n2. **精确的物体识别和分类**\n\n\n在农业、地质学、环境监测等领域,多光谱图像可以用于更精确地识别和分类不同的植被类型、土壤、矿物或其他材料。这是因为不同物质在特定波长下的反射或吸收特性各不相同。\n\n\n3. **健康和疾病监测**\n\n\n在农业中,多光谱成像技术可以用来监测作物的健康状况,识别植物疾病和害虫侵害。通过分析植被在不同光谱带的反射率,可以早期发现作物受损的迹象。\n\n\n4. **环境监控**\n\n\n多光谱图像在环境监控和管理中扮演着重要角色,如监测水体污染、森林覆盖变化、土地利用变化和自然灾害(如洪水、火灾)的影响。\n\n\n5. **搜救和安全应用**\n\n\n在搜救和安全领域,多光谱成像技术可以用于搜救和辅助定位,帮助识别和区分目标和背景,即使在夜间或其他低可见度条件下。\n\n\n6. **艺术品分析**\n\n\n多光谱成像技术也被用于艺术品的鉴定和分析,能够揭示画作下隐藏的图层、笔触细节和使用的材料,有助于确定艺术品的真伪和历史。\n\n\n7. **医学成像**\n\n\n在医学领域,多光谱成像技术用于提高疾病诊断的准确性,如皮肤病变的检测、组织样本的分析等。\n\n\n8. **地图制作和遥感**\n\n\n多光谱图像是制作高精度地图和进行遥感分析的关键。它们在土地覆盖分类、资源勘探和气候变化研究中发挥着重要作用。\n\n\n总之,多光谱图像之所以被广泛使用,是因为它们能提供比传统图像更多的信息,这些信息对于科研、工业、医疗和环境保护等多个领域都极其宝贵。\n\n\n\n </details>\n\n\n<details>\n <summary>yolov5多光谱在结果端进行融合的思路</summary>\n\n\n在使用YOLOv5进行多光谱图像识别时,结果端融合(也称为决策层融合或高层融合)是一个关键步骤,它涉及将来自不同光谱通道的检测结果合并,以提高整体的识别准确性和可靠性。多光谱图像通常包括除了可见光以外的其他波段(如红外、近红外、热红外等),每个波段都能提供不同的物理信息,对于特定应用场景下的目标检测和识别非常有用。\n\n\n结果端融合主要有以下几种策略:\n\n\n**1. 投票法(Voting)**\n\n\n在投票法中,每个模型对同一个目标的检测结果被视为一个“投票”,最终决定该目标的类别和位置基于所有模型投票的多数决。这种方法简单直观,但可能不够灵活,尤其是当不同光谱图像的可靠性存在较大差异时。\n\n\n**2. 加权融合**\n\n\n加权融合方法考虑了不同光谱通道对最终决策的贡献可能不同。每个通道的检测结果根据其可靠性、清晰度或其他相关指标被赋予不同的权重,然后进行加权平均。这要求事先对各个光谱通道的性能有一个准确的评估。\n\n\n**3. 特征级融合**\n\n\n尽管特征级融合通常发生在模型的早期阶段,但在某些情况下,也可以在结果端通过融合不同光谱通道的特征来进行。这涉及到将来自不同光谱的检测结果的特征(如置信度、边界框属性等)合并,然后基于这些融合的特征进行最终的目标分类和定位。\n\n\n**4. 联合模型方法**\n\n\n在联合模型方法中,不是单独处理每个光谱通道,然后再融合结果,而是设计一个能够同时处理多个光谱输入的模型。这种方法通常需要较为复杂的模型架构设计,但能更好地利用不同光谱之间的相关性。\n\n\n**实现步骤**\n\n\n对于YOLOv5识别多光谱图像的结果端融合,可以按照以下步骤进行:\n\n1. **单独检测**:对每个光谱通道分别使用YOLOv5进行目标检测。\n2. **结果提取**:从每个通道的检测结果中提取目标的类别、置信度和边界框等信息。\n3. **融合策略选择**:根据应用需求和不同光谱通道的特性,选择合适的融合策略。\n4. **结果融合**:按照选定的融合策略,合并不同光谱通道的检测结果。\n5. **后处理**:对融合后的结果进行必要的后处理,如非最大抑制(NMS)等,以确保最终结果的准确性和一致性。\n\n通过这样的融合策略,可以充分利用多光谱图像中的信息,提高YOLOv5模型在特定应用场景中的目标检测和识别性能。\n\n\n\n </details>\n\n\n<details>\n <summary>结果融合需要对每个光谱通道的数据分别进行训练</summary>\n\n\n结果融合通常意味着你需要对每个光谱通道的数据分别进行训练,得到各自的模型,然后在推理(inference)阶段将这些模型的结果按照一定的策略进行融合。这种方法的优点是能够充分利用每个光谱通道的特定信息,但同时也意味着需要更多的计算资源和时间来训练和维护多个模型。\n\n\n具体来说,结果融合的流程包括以下几个步骤:\n\n1. **独立训练**:针对多光谱图像中的每个通道,分别训练一个YOLOv5模型。这意味着如果你有三个光谱通道(比如红外、可见光和近红外),你需要分别训练三个YOLOv5模型。\n2. **单独推理**:在模型部署时,对于每个待检测的多光谱图像,分别使用这些训练好的模型对每个光谱通道进行目标检测。\n3. **结果提取**:从每个光谱通道的检测结果中提取关键信息,如目标的位置(边界框)、类别和置信度等。\n4. **融合决策**:根据预先定义的融合策略(如投票法、加权融合等),将从各个光谱通道得到的检测结果进行合并。这一步是关键,它决定了如何从各个通道的结果中提取和结合信息以得到最终的检测结果。\n5. **后处理**:对融合后的结果进行后处理,如应用非最大抑制(NMS)等技术,以消除重复的检测并优化最终的检测结果。\n\n结果融合方法的选择取决于多种因素,包括不同光谱通道的特性、目标应用的特定需求以及可用的计算资源等。正确实施结果融合可以显著提高多光谱图像目标检测的准确性和鲁棒性。\n\n\n\n </details>\n\n\n<details>\n <summary>多光谱某个通道特征不明显的应对方式</summary>\n\n\n在多光谱图像处理中,某个光谱通道的特征不明显是一个常见问题,这可能是由于该通道的图像质量较差、目标与背景的对比度低、或是该光谱范围内目标的特征本身就不明显等原因造成的。面对这种情况,可以采取以下几种策略来改善目标检测和识别的性能:\n\n\n**1. 加权融合调整**\n\n\n在结果融合时,可以对不同光谱通道的结果赋予不同的权重。对于特征不明显的通道,可以降低其权重,增加特征更加明显通道的权重。这种方法需要依据实验或先验知识来调整权重,以确保融合结果的准确性。\n\n\n**2. 特征增强**\n\n\n在对特征不明显的光谱通道进行处理之前,可以尝试使用图像增强技术来提升其目标特征的可见性。这包括对比度增强、直方图均衡化、噪声抑制等方法。通过增强图像,可能能够提高目标的可识别性,从而在后续的目标检测步骤中获得更好的结果。\n\n\n**3. 联合模型优化**\n\n\n如果在预处理和权重调整后仍然面临特征不明显的问题,可以考虑使用或开发专门针对多光谱数据的联合模型。这种模型可以在更深的层次上整合不同光谱通道的信息,可能通过学习不同光谱之间的互补信息来弥补单一通道的不足。\n\n\n**4. 数据融合而非结果融合**\n\n\n在某些情况下,直接在数据层面进行融合(即在输入模型之前将不同光谱的图像信息进行合并)可能比结果融合更有效。这可以通过设计一个能够处理多光谱输入的模型来实现,模型可以学习如何最好地从所有可用的光谱信息中提取特征。\n\n\n**5. 选择性使用通道**\n\n\n在极端情况下,如果某个光谱通道的信息对于目标检测几乎没有帮助,甚至会引入干扰,可以考虑在分析过程中忽略这个通道。这需要通过实验来验证,确保排除某个通道后,整体的检测性能不会下降。\n\n\n**6. 利用深度学习技术**\n\n\n利用深度学习中的一些高级技术,如注意力机制(Attention Mechanisms),可以让模型更加聚焦于图像中的重要特征,即使这些特征在某些光谱通道中不是非常明显。\n\n\n总之,针对多光谱图像中某个通道特征不明显的情况,可以通过多种策略来提高整体的目标检测和识别性能。选择哪种策略取决于具体的应用场景、可用的数据以及目标任务的需求。\n\n\n\n </details>\n\n\n<details>\n <summary>输入端融合的策略</summary>\n\n\n**1. 图像堆叠(Stacking)**\n\n\n最直接的融合方式是将不同光谱通道的图像直接堆叠在一起,形成一个多通道的输入。例如,如果有三个光谱通道(红、绿、蓝),可以将它们堆叠成一个三通道图像。对于多光谱数据,你可能会得到超过三个通道的图像,这对于深度学习模型来说通常不是问题,因为它们可以处理任意数量的输入通道。\n\n\n**2. 特征级融合**\n\n\n在这种方法中,不同光谱通道的图像首先通过一些预处理步骤,比如使用**图像处理算法**来提取特定的特征(如边缘、纹理等),然后将这些特征图像堆叠起来作为模型的输入。这种方法允许模型从一开始就接触到更加丰富的特征信息,可能有助于提高识别的准确性。(之前了解过[FPGA的sobel边缘算法](https://cloud.matrixcore.life/s/ZYwQs2TWJzQA8Xe),可以在这方面的处理发挥作用)\n\n\n**3. 图像融合技术**\n\n\n在将图像送入模型之前,可以使用高级图像融合技术将不同光谱的图像融合成一个单一的图像。这包括加权平均、多分辨率分析(如小波变换)、PCA(主成分分析)融合等方法。这种融合技术尝试在保留重要信息的同时减少数据量,使得模型可以从一个综合的视角来学习数据。\n\n\n**4. 使用深度学习进行特征融合**\n\n\n可以设计一个深度学习架构,在模型的早期阶段就进行特征融合。例如,可以为每个光谱通道设计一个单独的特征提取子网络,然后通过某种方式(如连接(concatenation)、加权平均等)将这些特征融合起来,供后续的网络层进一步处理。这种方法允许模型自动学习如何最有效地融合来自不同光谱通道的信息。\n\n\n**5. 注意力机制**\n\n\n利用注意力机制可以在模型内部自动识别和强调重要的特征,同时忽略不那么重要的信息。在多光谱融合的上下文中,可以设计注意力模型来自动学习每个光谱通道的重要性,并据此调整融合策略。这样,即使某些通道的特征不是很明显,模型也能通过强调其他通道的特征来做出准确的预测。\n\n\n在进行输入端融合时,关键是要选择或设计一个适合你具体任务需求的融合策略。不同的融合技术可能在不同的应用场景下表现出不同的效果,因此可能需要通过实验来确定最佳的融合方法。\n\n\n\n </details>\n\n\n<details>\n <summary>输入端融合是先标注再融合,还是融合后标注</summary>\n\n\n**先标注再融合**\n\n\n在这种策略中,每个光谱通道的图像都被单独标注,然后将这些图像按照一定的方式融合。这种方法的优点在于:\n\n- **标注精确度**:标注者可以针对每个通道的特性进行精确标注,特别是在某些通道的特征比较明显时,可以确保标注的质量。\n- **灵活性**:在融合前进行标注,可以根据需要选择性地融合特定的通道,或者调整融合策略而不影响已有的标注。\n\n然而,这种方法的挑战在于:\n\n- **标注工作量**:需要对每个通道的图像分别进行标注,可能会增加标注的工作量。\n- **一致性问题**:不同通道间的标注需要保持一致,这在实践中可能较难确保,尤其是当不同通道的图像特征差异较大时。\n\n**融合后标注**\n\n\n在这种策略中,先将不同光谱通道的图像融合成一个单一的图像,然后对融合后的图像进行标注。这种方法的优点包括:\n\n- **减少标注工作量**:只需要对融合后的图像进行一次标注,可以显著减少标注的工作量。\n- **利用互补信息**:融合过程可以结合不同通道的互补信息,可能会使得某些在单个通道中不明显的特征在融合后的图像中变得更加突出,从而提高标注的准确性和易性。\n\n然而,这种方法也有其挑战:\n\n- **融合策略的选择**:如何融合不同通道的图像,以及融合方法对最终标注质量的影响,需要仔细考虑。\n- **可能隐藏某些特征**:融合过程可能会导致某些通道的特定特征被其他通道的特征所掩盖,尤其是当某些通道的特征非常微弱时。\n\n在输入端进行融合通常意味着在数据进入模型之前,将来自不同光谱通道的图像信息合并。这种方法尤其适用于处理多光谱或多模态数据,可以让模型直接从融合后的数据中学习到跨通道的特征。输入端的融合可以通过以下几种方式实现:\n\n\n输入端融合的标注策略取决于数据的特性和融合方法,以及最终的应用目标。理解这两种策略——先标注再融合与融合后标注——的优劣及适用情况,对于设计有效的多光谱图像处理流程至关重要。同时,处理特征不明显的通道的策略也需要考虑。\n\n\n\n </details>\n\n\n<details>\n <summary>对于特征不明显的通道,是否需要标注</summary>\n\n\n**对于特征不明显的通道的处理**\n\n\n即使某些通道的特征不是很明显,也建议进行标注,因为:\n\n- **互补信息**:在多光谱分析中,不同通道之间的信息是互补的。即使某个通道的特征不明显,它也可能包含对整体任务有帮助的信息。\n- **模型学习**:深度学习模型尤其擅长从复杂、微妙的数据中学习模式。即使人类观察者难以识别的特征,模型也可能能够识别并利用这些特征。\n\n总的来说,是否先融合后标注,或是先标注再融合,以及如何处理特征不明显的通道,应该基于具体的应用场景、数据特性以及实际操作的便利性来决定。在实际操作中,可能需要通过试验和错误来找到最适合特定项目需求的方法。\n\n\n\n </details>\n\n\n<details>\n <summary>多光谱情况下黑匣子特征</summary>\n\n\n**1. 反射和吸收特性**\n物体在不同波长下的反射和吸收特性是多光谱成像分析中的关键。这意味着,如果“黑匣子”是由特定材料制成,它可能会在特定的光谱波段(如红外线或紫外线)显示出独特的吸收或反射特性。\n**2. 热特性**\n在红外波段,多光谱图像可以揭示物体的热特性,比如它的热发射率。如果“黑匣子”在操作中发热,这种热特性可能在红外图像中显现出来。\n**3. 材料组成**\n通过分析多光谱图像,可以推断出物体的材料组成。不同的材料在特定光谱波段下会有不同的反射和吸收行为。例如,金属和塑料在红外波段的反射率可能会有显著差异。\n**4. 表面特征**\n表面纹理和特征在多光谱图像中也可能被揭示,尤其是在那些能够突出表面细节的波段。这可以帮助识别“黑匣子”的使用状况,例如是否有磨损、划痕或其他物理损伤。\n**5. 内部结构**\n某些多光谱成像技术,如近红外成像,可能透露一些关于物体内部结构的信息,尽管这通常需要特定的条件和较弱的材料吸收。\n**6. 环境影响**\n“黑匣子”与其周围环境的交互也可能在多光谱图像中显示出来,例如,如果“黑匣子”被水覆盖,或者周围有植被等。\n 需要注意的是,要准确地分析“黑匣子”的多光谱图像特征,通常需要**对该物体的材料属性、预期的使用环境和多光谱成像技术的特定能力有深入的了解。**此外,多光谱成像是一个广泛的领域,包括从可见光到红外、甚至X射线的各种波长,不同的应用和目的可能需要不同的成像技术和分析方法。\n\n\n\n </details>\n\n\n<details>\n <summary>TIF格式的图片</summary>\n\n\nTIFF(Tagged Image File Format)是一种常见的图像文件格式,广泛应用于**存储和传输高质量的图像数据**。以下是关于TIF格式的介绍:\n\n- **存储特性**:TIF格式允许存储单个或多个图像,支持灰度图像、彩色图像以及多通道图像。它还支持无损压缩,可以保留图像的高质量细节。\n- **元数据**:TIF文件允许存储丰富的元数据信息,包括图像的描述、颜色空间、像素值范围以及其他与图像相关的信息。这使得TIF文件非常适合用于科学、医学和印刷行业等对图像元数据要求严格的领域。\n- **色彩深度**:TIF格式支持不同的色彩深度,包括1位二进制图像(黑白),8位灰度图像,24位真彩色图像等。此外,TIF还支持16位和32位的高位深度图像,可用于保留更多色彩信息。\n- **适用范围**:TIF格式通常用于存储需要高质量图像和元数据的应用场景,如印刷品质图像、医学影像、地理信息系统(GIS)、数字艺术等。由于其灵活性和可靠性,TIF格式也常被用于数字档案保护和长期保存。\n- **压缩方式**:TIF文件支持多种压缩方式,包括无压缩、LZW压缩、JPEG压缩和ZIP压缩等。这些压缩方式可以根据实际需求选择,平衡图像质量和文件大小。\n\n总的来说,TIF格式以其灵活性、高质量和丰富的元数据支持而闻名,在许多专业领域中被广泛应用。无论是用于存档、打印还是专业图像处理,TIF都是一个可靠的选择。\n\n\n\n </details>\n\n\n<details>\n <summary>多光谱模态融合思路分析</summary>\n\n\n多光谱数据融合是一种将来自不同光谱波段的图像或数据集成到一起的技术,旨在改善图像的解析度、对比度或者提取更多的信息。在深度学习领域,多光谱数据融合技术已经被广泛应用于遥感、医学成像、自动驾驶汽车等多个领域。\n\n1. **改进的深度神经网络结构**:研究者们设计出更加高效的神经网络结构来处理多光谱数据,例如改进的卷积神经网络(CNN)和生成对抗网络(GAN)。这些网络能够更好地从多光谱数据中提取特征,并进行有效的融合。\n2. **端到端的学习方法**:传统的多光谱融合技术往往依赖于手工特征提取和后处理步骤。而最新的研究成果表明,端到端的深度学习方法可以直接从原始多光谱数据中学习到融合的表示,减少了预处理的需求,并提高了融合效果。\n3. **自监督和半监督学习**:由于高质量的多光谱数据标注代价昂贵,自监督学习和半监督学习在多光谱数据融合中变得越来越重要。这些方法可以利用大量未标记的数据来提高模型的泛化能力。\n4. **跨模态融合技术**:跨模态融合技术涉及将多光谱数据与其他类型的数据(如激光雷达、声纳等)结合起来,以提供更加丰富的环境信息。深度学习模型在这方面的应用已经取得了实质性进展,如多模态神经网络能够同时处理和融合来自不同传感器的数据。\n5. **注意力机制和变换器模型**:注意力机制已经被证明在多光谱数据融合中非常有效,它可以使网络聚焦于最重要的特征。同时,变换器(Transformer)模型也被应用于多光谱数据融合,由于其优越的长距离依赖建模能力,变换器模型在处理大规模多光谱数据时显示出了巨大的潜力。\n6. **解释性和可视化**:随着深度学习模型在多光谱融合中的应用越来越广泛,研究者也越来越关注模型的解释性。最新的研究致力于开发可解释的深度学习模型和可视化工具,帮助用户理解模型的决策过程。\n7. **实时处理和边缘计算**:为了在实际应用中实现实时多光谱数据融合,研究者们正在开发更高效的算法和优化模型,以便它们能够在边缘设备上运行,这对于需要快速响应的应用场景(如自动驾驶)尤为重要。\n\n\n </details>\n\n\n## 多光谱处理方向分析\n\n\n---\n\n\n 前端融合(early-fusion)或数据水平融合(data-level fusion)、后端融合(late-fusion)或决策水平融合(decision-level fusion)和中间融合(intermediate-fusion)。\n\n\n### yolov5网络模型基础\n\n\n---\n\n- [YOLOv5 模型结构及代码详细讲解](https://www.bilibili.com/video/BV1zB4y1L7Ay?p=2&vd_source=237e295a40d7aaea043ead8c0d2c78ab)-[笔记](https://zhuanlan.zhihu.com/p/563598234)\n\n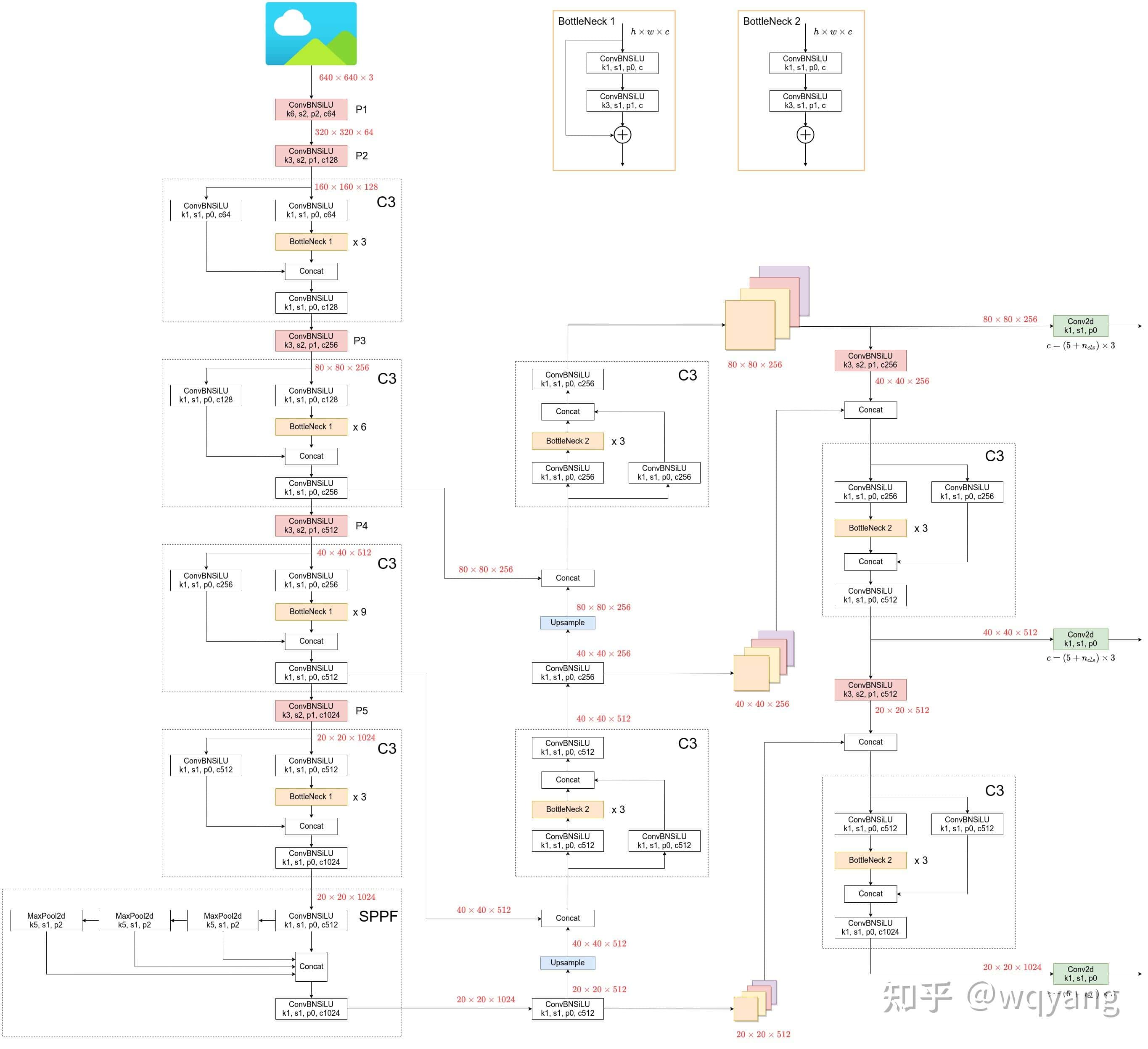\n\n\n### **前端融合-多模态图像融合算法研究**\n\n\n---\n\n\n**理论基础:**\n\n- [基于Transformer的多模态图像融合算法研究_王梓萱](https://cloud.matrixcore.life/s/wwGXZiRog4zmRDp)\n- [Talk | 西安交通大学博士生赵子祥:基于先验知识指导的多模态图像融合算法研究-bilibili](https://www.bilibili.com/video/BV1cg4y1d7MH/?spm_id_from=333.337.search-card.all.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n- [基于深度学习的高光谱与多光谱遥感图像融合方法研究_朱春宇](https://cloud.matrixcore.life/s/pwoDTJTdB6gj2ot)\n- [基于注意力机制的高光谱与多光谱图像融合算法研究_徐炳洁](https://cloud.matrixcore.life/s/2kmDq3Ab3NZqAS4)\n\n**实际应用**\n\n- [跨模态注意力YOLOv5的PET/CT肺部肿瘤检测](https://cloud.matrixcore.life/s/MNRMckWY8AAcLg3)\n- [多光谱图像融合的IC器件表面缺陷检测](https://kns.cnki.net/kcms2/article/abstract?v=29axctaKF3zkJt2wcfPVsG2PeIKEgwN-HqMBkeHlFiVIPEoCaOG27jTNXnaMXMr8N_LSDavvJVi4-O2bi12zFKqhu1LKsPnJnwj-5ejA03aPsOY_TQQuhq4HYfCIL_Ftgi2-VzLcbrA%3D&uniplatform=NZKPT&language=CHS)\n\n### 中间特征融合\n\n\n---\n\n- [**基于孪生网络的无人机目标多模态融合检测**](https://cloud.matrixcore.life/s/EcofGYtjGmz2ke4)\n\n## 多光谱数据处理实操\n\n\n---\n\n\n这里记录多光谱数据集的实操过程。\n\n\n### 完善GUI置信度和位置坐标的导出\n\n\n---\n\n\n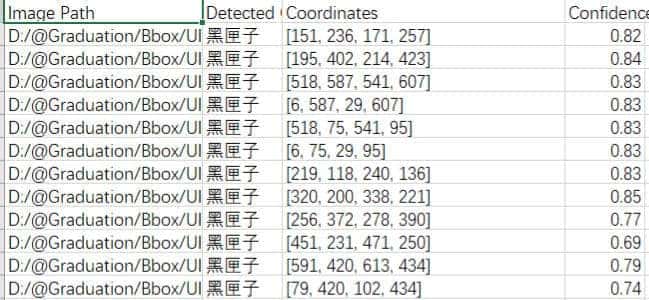\n\n\n### 尝试进行数据融合\n\n\n---\n\n\n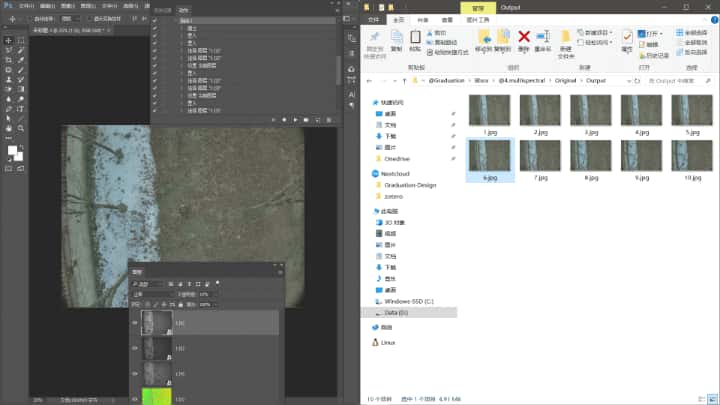\n\n\n### 搜寻领域算法\n\n\n---\n\n\n\n\n- [基于深度学习的全色图像锐化(Pansharpening)论文及代码整理](https://blog.csdn.net/fovever_/article/details/124518130?spm=1001.2014.3001.5502)\n- [通用图像融合框架论文及代码整理](https://blog.csdn.net/fovever_/article/details/124406720)\n\n尝试复现文章中提及的思路和代码,但有的难以复现。\n\n\n\n\n\n# 总结\n\n\n---\n\n\n经过一段时间的摸索,对于多光谱数据集的处理有了一些认识,同时也感受到对于一个问题如何分解为更小的容易解决的目标。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-04-25",
"type": "Post",
"category": "动手实践",
"slug": "Yolov5_multispectral",
"tags": [
"实用教程"
],
"summary": "通过多光谱可以通过对其他光谱的图像特征进行捕捉,从而提高在不同环境下的识别性能,如果单纯训练可见光,也许在夜晚环境下的模型的表现就会变差,而通过其他光谱就可以获得稳定的目标特征,从而实现模型更好地的环境适应性。",
"title": "[毕业设计] Yolov5多光谱解决方案探索",
"status": "Published",
"urlname": "c78e2dc7-6c83-4252-891e-9d3d45fb5d29",
"updated": "2024-05-02 08:00:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "c78e2dc7-6c83-4252-891e-9d3d45fb5d29"
}
],
"body": "",
"realName": "[毕业设计] Yolov5多光谱解决方案探索",
"relativePath": "/实用教程/[毕业设计] Yolov5多光谱解决方案探索.md"
},
{
"id": "22a42fe9-efac-4b4b-8733-f74fc9765abc",
"doc_id": "22a42fe9-efac-4b4b-8733-f74fc9765abc",
"updated": 1713876960000,
"body_original": "\n# 前言\n\n\n---\n\n\n 这是本周的一些记录的归档。主要是用于处理一些未落实的思考和出现的一些问题。\n\n\n# 正文\n\n\n---\n\n\n 从最近往前推进行归档。\n\n\n## 保持二次检查工作的习惯\n\n\n---\n\n\n 就我而言,很多时候,很容易在一些细节上出错,比如早上起床不记得灯有没有关,电有没有断,门有没有锁,有时候出门了之后,脑子里一直在想一些其他的事情,因为之前没有进行确认,导致走到楼下的时候,又不得不上楼再去看一眼。\n\n\n 另外,特别是在长时间工作或者任务堆积起来的时候,很容易会出现一些低级错误,比如命名规则打错了,等等一些奇奇怪怪的低级错误,如果前一天晚上没有休息好,连续工作很多天,精神压力又很大的情况下,发生低级错误的概率会提高很多。\n\n\n 所以**设置一个中断指令**进行检查是很有必要的一件事情,特别是在处理重要的任务的时候,一昧地追求速度是不可取的,因为一旦发生错误,返修的成本会很高,不如先慢下来检查好再进行提交,**忙中有闲**。\n\n\n## 关于中断指令,预终提醒和协同管理的思考\n\n\n---\n\n\n 这些概念是什么意思呢,我记得以前江苏语文作文有一次的命题是节奏,很多优秀的文章的主题都是很偏乡村风的那种慢节奏,对这种生活的追忆,但我今天想说的是**如何将快慢节奏进行结合,也就涉及到中断指令,因为我自身在这方面做得很差,损失很惨重。**\n\n\n 就拿每天的时间来看,每个人每天都是24小时,如果你周一到周五要工作,那么如果你周一晚上为了解决一个很困难的问题熬夜到两点,会发生什么情况。\n\n\n 答案是你没有**任何可替代的时间去修复这段睡眠**,大概率只能要求身体被迫承受第二天的高强度的工作,那这样导致的结果就是**低级错误会频发**,这是**很危险**的一件事情。并且周二周三的晚上不会有任何的精力去做相关的工作,而且这周反馈回来的感受也不会很好,整个人会很玉玉。\n\n\n 所以中断的核心就在于**遵守节点**,优先遵循高优先级的任务,比如睡觉的优先级就高,**白天的很多工作都很依赖晚上的休息**。然后还有周末吃早饭,这个优先级也很高,如果不吃早饭,首先就无法承受上午的工作,这些工作都非常需要能量,**如果没有足够的能量补充,整个人会很虚弱。**当然这些我都是亲身体会过的,而且深陷其中无法自拔,有时候我可能为了解决一个问题,连续几个小时去琢磨,但是要知道**解决问题不是单凭你的时间堆积就能成功的,还需要遵循特有的规律,get不到这个点,再怎么努力也是徒劳无功。**\n\n\n 另外,现在我已经通过,crontab建立了邮箱提醒的办法,在早上,中午,晚上提醒睡觉,但是有时候还是会有个问题,有时候提醒一遍不是很管用,就是你恰好在那个时间点提醒,碰巧你在为一个问题而焦头烂额,心情失落,这个时候还真不一定就能完全按照节点的要求去睡觉,总想着拖延,这个时候,我就在想,能不能**设置一个时间段**来进行提醒,因为之前看到老周的一篇文章,写得很好,就是讲做准备的重要性。[自我励志文(2023年09月) 万事做准备的重要性 (tomatolist.com)](https://www.tomatolist.com/show_blog_page.html?no=6ea857db-8c1a-4402-bb63-1b54c41381c1)**老周说做准备是一件很幸福的事情,我觉得这个观点很有意思。**\n\n\n 所以说建立一个时间段内的提醒,可以根据自己的感受进行调节,比如,22:20睡觉,那么或许可以在22:00就进行预提醒,然后22:20再进行终提醒。因为我看到notion中的日程提醒也都是提前一个时间段进行提醒,还没有到点才提醒的。\n\n\n 另外,什么是协同管理,我感觉很有意思的一个点,就是,每天我妈会很规律地发信息,起床,睡觉等等,我觉得这就像两个主机之间的通信,那我就在想,能不能更好地调动服务器的功能,做定时地提醒,因为服务器在完成定时任务上面总是出色的。这就是协同管理,要知道,**感性有时候会很鲁莽**。\n\n\n## 保证大节点的优先级\n\n\n---\n\n\n 在具体的生活当中,你会清楚地体会到什么叫做**计划赶不上变化**。也就是制定的计划在大部分情况下都是理想的,有时候会遇到很多意想不到的问题,这也就能解释,**为什么有时候理论和实践会产生偏差,这也许就是自动控制核心关注的问题,根据偏差进行修正。**\n\n\n 但我想说的就是,要**明确任务的优先级**,也就是公司一直强调的,要事第一,那么什么是要事呢。我觉得这就**像顺藤摸瓜一样的感觉**。\n\n\n 学习优先级高不高,但没有工作高,工作优先级高不高,但没有生理作息的优先级高,如果低优先级超越高优先级,我们将其称作为不稳定系统,就如同头重脚轻,摇摇晃晃的。所以,保证大节点的优先级是一件非常重要的事情。\n\n\n 在此之上,才有时间和精力去处理很多小事,比如买个水果,买点零食,洗个澡。\n\n\n# 总结\n\n\n---\n\n\n 今天先写这么多吧,写多了太累了,然后今天主要还是对前面几天生活方面的一个简单的总结。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-03-09",
"type": "Post",
"category": "走近生活",
"slug": "240309",
"tags": [
"情绪表达"
],
"summary": " 这是本周的一些记录的归档。主要是用于处理一些未落实的思考和出现的一些问题。",
"title": "[生活感悟] 中断、预终提醒和协同管理",
"status": "Published",
"urlname": "22a42fe9-efac-4b4b-8733-f74fc9765abc",
"updated": "2024-04-23 12:56:00"
},
"catalog": [
{
"title": "情绪表达",
"doc_id": "22a42fe9-efac-4b4b-8733-f74fc9765abc"
}
],
"body": "",
"realName": "[生活感悟] 中断、预终提醒和协同管理",
"relativePath": "/情绪表达/[生活感悟] 中断、预终提醒和协同管理.md"
},
{
"id": "5f3a3c69-a7e5-4cc5-8701-a5a7f441d6f7",
"doc_id": "5f3a3c69-a7e5-4cc5-8701-a5a7f441d6f7",
"updated": 1713876960000,
"body_original": "\n# 更新log\n\n\n---\n\n\n> 💡 这里记录这篇文章的更新历史\n\n\n### 和优质的内容相比,学会整理是首要的事情 2024-03-02 \n\n\n---\n\n\n今天去博友的小窝转悠了一下,发现了不少优秀的文章,其中有两篇文章我是很心动的,预计初步看完一遍之后还会多看几遍,列举如下。\n\n- [NotionNext博客的‘说说’页实现](https://chenge.ink/article/post20240302-1)\n\n在这篇文章里,尘歌介绍了如何部署Memos并融合到NotionNext当中,当时和尘歌在社区中探讨过Memos的定义和价值,在最开始我觉得flomo已经可以处理生活中的很多问题,但是今天我去访问尘歌的[说说](https://chenge.ink/memos),发现做得很精美,很适合存放一些读书笔记和一些思考,经过几天和flomo的磨合,我发现flomo适合处理杂项,同样非常灵活,而Memos我更愿意来积累一些不错的读书笔记,之前在和一位很好的朋友聊天的时候,她在最后都会送给我一段恰到好处的文摘,这些文摘非常耐人寻味和具备启发意义,而时间也许很难留住这些美丽的瞬间,而也许Memos可以,我之前也有过在twikoo评论区写日记的尝试,当时坚持了几个月,也不是天天写,现在回顾来看,Memos也许更适合做这份任务。而且,我发现自己输出深度内容的能力不是很足够了,一方面,确实是阅读量的大量减少,一方面确实是自己静不下心了。如果有时间,我愿意试试这个创意。\n\n- [努力是基本功,借势是破局点](https://blog.tangly1024.com/article/taking-advantage)\n\nTangly写的这篇文章非常有深度,其中有关“点线面体”的比喻非常形象,从个人,到公司,再到整个行业,国家战略,外部因素也许我们很难改变,但是内部因素我们却可以尝试实现,尤其这段我非常欣赏。\n\n\n> [个体独一无二的天赋](https://blog.tangly1024.com/article/taking-advantage#9611d3523b594cbc8e8ec7e5096a3b84)\n\n\n\t> 在一个关键项目遇到困难时,几个同事一起讨论如何应对。此时,同事A提议:“我们先研究一下相关数据,了解情况再做决定。”同事B说:“我们先进行头脑风暴,找出可能存在的问题。” 同事C建议:“我们先了解一下客户的反馈,了解他们的想法。”\n\n\n\t你看,面对同一个问题,每个人的反应都不同。为什么呢?\n\n\n\t这正是各自独特的天赋体现:同事A注重数据和事实;同事B富有创造力;同事C重视客户意见,富有同理心。这展示了每个人天生的、自然而然的思维方式、感知和行为方式的不同。\n\n\n每个人在面对同一个问题的解决策略不尽相同,这也就是为什么需要交流,在柏拉图的《理想国》中,很多内容都是以对话的方式来进行呈现的,所以就非常有意思,但是,我们发现,现在虽然是一个“大交流”的世界,却很难成为一个“大思考”的世界。\n\n\n所以Tangly总结的很好,详见将[“天赋转变为优势”。](https://blog.tangly1024.com/article/taking-advantage#b5b85b6f2f1a40e8bef74211e5ad3c08)\n\n\n### RTFM和STFW,学会提问是解决问题的关键 2024-03-02 \n\n\n---\n\n\n\n\n\n 不管是在工作和生活当中,我们或多或少都会遇到一些问题,我认为,在我们准备好提问之前,最好需要加上思考这一步,先去确认,我是否已经尽力去解决这个问题,第二步,组织好提问的语言,描述清楚自己遇到的问题,第三步才是提出一个好的问题,我发现我也存在这个问题,有时候可能不懂的问题直接就去问同事了,但是我觉得应该需要经过自己大脑的思考,问过的问题需要形成log,以供未来参考。\n\n\n# 前言\n\n\n---\n\n\n这里记录有关笔记的方法。主要是之前一段时间思考的汇总。\n\n\n# 正文\n\n\n---\n\n\n关于笔记的重要性,我之前[[数据中心] 测试crontab同步elog+Onedrive | MatrixCore](https://matrixcore.top/article/crontab-1)这篇文章中提到一些,日志的记录对于未来的工作能提供一些有价值的参考。\n\n\n## 解决末端写作的痛点\n\n\n---\n\n\n这部分主要是年前待在火车上的一些思考\n\n\nflow+memo=flomo\n\n\n末端写作痛点的可能解决方案。\n\n\n需求:出门可以不带电脑,但离不开手机,可以不玩ipad,但很难抗拒不用手机打游戏来度过无聊时光。我觉得低估了移动端在数字化时代的地位和重要性,**我们使用着工具,工具也在塑造着我们。\n\n\n原理:灵感的匮乏,本质上是因为**导向的失误和撷取的难度过高**,而那些更加轻易获得刺激的解决方案更容易占据上风,这使得思考成为一种极为稀缺的资源,而对于思考的整合则更为珍贵,整理出体系和逻辑则更为困难,依附在逻辑之上技能因为得不到训练成长则更为缓慢。\n\n\n方案:每当我在遇到无法解决的问题的时候,我都会先睡一觉,然后回看自己走过的老路。再去审慎地思考和这个问题相关的经验,在阅读1874博主,elog项目开发者的笔记管理法的时候,我受到了新的启发。flomo的开发哲学很符合我的需求,至少在我使用该产品之前,让我得到了产品开发哲学的直接对话,这一点对于了解一个产品是至关重要的。必须清楚产品的定位和特性,才能清楚是否符合自己的需求。然后才是和产品(工具)的磨合。\n\n\n## 末端创作的实现方式\n\n\n---\n\n\n这部分主要是过年时回去的一些思考。\n\n\n上期在博客中只解决了一个问题,但还残留了两个问题亟待解决。\n\n\n1.末端创作如何实现\n\n\n2.源输入的把关\n\n\n针对问题1,末端创作我将其定义为**不依赖特殊学习环境而进行对微思考的影现,通过发挥移动终端的便利性而达到微单元的输出。\n\n\n这个定义不好理解,我举个example,上一篇博客我花费了连续四五个小时的创作,这就是宏思考,包括文档从创作到标准化输出的全过程。午饭没吃,午觉没睡,显然条件是苛刻的。\n\n\n而微思考就是**日常对事务的直观感召和联系**,比方说我想你了,过年应该为你准备礼物,这就可以视为数据码的一环,但是从数据码到被正确执行则需要更多的步骤,我需要回答我为什么想你,如何想你,如何准备礼物三个步骤,拆分为足够小的微单元进行穿插执行,因为我不可能在一天内都想你,都为你准备礼物,而是在特点的周期内达到该目标就行。\n\n\n这就是宏思考与微思考的区别。宏需要更加深度的环境,这个条件是苛刻的。而微思考是离散的,条件更加缓和但对于目标更加模糊。\n\n\n而我们将微思考代号为**精灵**,精灵是具有生命周期的,而且生命周期非常短暂,因为你不能量化想念的指标,一旦指令被中断或者干扰,进程将会被重新进行调度,万一睡觉重启了呢,对吧,搞不好进程的优先级又低了呢。\n\n\n所以**宏在实现上优化于微,微在条件上优化与宏,微可以在何时何地,不管它是不是中秋,是不是新年,微可以无处不在。但微一定是脆弱而离散的。**\n\n\n从微变成宏的最终形态需要**进程更加合理的调度**,涉及到末端数据的处理,我时常纳闷为什么我无法与末端进行好的配合,一打游戏就来劲,一背单词就困。而实际上如果我们失去了**对末端的控制权**,那么宏的基础也就不复存在,上层建筑也就无从谈起。\n\n\n那么问题就聚焦到**末端数据的传输原理,这一层是最接近生物层和硬件层之间的两层传输协议,从生物层的输出的信号能否完整地被硬件层完整正确地接收。波形是怎么变化的,这就涉及到传输信道的安全性原理。**\n\n\n简明来讲,就是我想念你的基础是安全传输协议的加成,因为你具备了我的传输密钥,并能反馈给我正确的配对。经过三次握手确认了传输的安全性,也就是潜在的tcp三次握手。所以在这样的写作环境中,信号的传输是完整的。\n\n\n而末端创作的关键就在于如何获得安全的信道,另外合理地对生物层的源进行进程调度,同时对于输入源的中断指令进行进程再分配。\n\n\n另外另一个值得关注的问题是,对于**输入源的把关上,这一点将直接作用于生物层能否解析到正确的地址当中**,如果被劫持,那么你也不清楚你的非理智行为到底是本能驱使还是潜意识驱使导致错误的输出。\n\n\nend,暂时先到这里。\n\n\n## 笔记的终点会在哪里?\n\n\n---\n\n\n这一部分主要是在回来的火车上完成的。\n\n\n在阅读flomo创始人少楠«笔记的方法»时,阐述了他对于笔记的定位以及管理的理念。\n\n\n但我想提一个问题,笔记的终点会在哪里。\n\n\n我目前对于flomo的定位是一个**优秀的小型数据中心,用于深入收集那些难以摘录的信息黑洞。\n\n\n所谓难以摘录,本质上并不合适摘录的过程多么困难,无非就是复制粘贴,然后找一个合适的容器进行存储,传统的moments和企鹅空间都可以做到这样。但这里的难**指的行为触发上的难,我们宁愿让这些有用的信息忘掉,却很难坚持动动小手来为他们选择合适的地方。\n\n\n所以懒人所要考虑的就是**简化摘录的流程,并进行习惯地训练**。这里可以结合一些自动化工具进行触发,我时常惊艳于ios的快捷指令,经过摸索,安卓上也有一些可以使用的自动化工具,例如MacroDroid、tasker。这里不展开介绍。\n\n\n这次的主题是探讨笔记的终点,为什么我说flomo是一个优秀的小型数据中心,优秀体现在解决了各大笔记软件无法深入底层的痛点。小型体现在于其轻量化。那么笔记应该是什么样子呢?\n\n\n我猜想第一,**笔记是写给自己看的**,如少楠所说,希望能解决未来的问题,来捕捉稍纵即逝的灵感。这是笔记的初始形态。\n\n\n但是灵感一旦多了,即使能有回顾功能,但对于当下的增益也是很有限的。那么从我的观点,flomo在完成这一段工作流的积累之后,可以移交下一步的流水线。\n\n\n更加具体一点,我会在flomo中先花一段时间进行输入,然后再找另外一段时间进行归纳出一个单独的模块。比如我的下一篇文章希望介绍末端创作的方式,那么这篇文章如同一个大饼,持续性创作势必是不现实的,我会耗散大量的能量。并且无法保证质量。这个时候我希望**拆分为一个一个的模组,在flomo中完成。在完成该模组之后,归纳到obsidian的初始写作当中。\n\n\n那么我为什么不愿意让笔记仅仅停留在初阶形态,因为试想,管理2048个碎片和管理64篇文章,维护的成本和精力是不一样的,产出的增益和价值也是不一样的。\n\n\n那么进入笔记的中阶形态将成为一项值得探索的方式,在年前的一篇文章[[数据中心] 测试crontab同步elog+Onedrive | MatrixCore](https://matrixcore.top/article/crontab-1)当中,我已经介绍了基于obsidan+notion+notionnext的笔记管理方式。\n\n\n我认为的笔记中阶形态实际上类似于少楠一直在提醒我们要做的一件事,**以自己的话去记录笔记**。那为什么是obsidian,因为标准的markdown在处理文档笔记时,有着难以抗拒的魅力,这一点请参照上述link的介绍,亦可自行了解为什么是markdown。而obsidian正是markdown的一把好手。当然学习总是要付出代价的。\n\n\n我目前所能认为的笔记的高阶形态是**基于web的知识共享框架**,建立一个独立的博客,在这里对文章进行归档分享探索。无论是写作还是浏览,就如同小王子去往一个个星球的旅行,趣味盎然。朱光潜先生提出,好的作品需要读者和创作者之间的共鸣,没有琵琶女,背不出“同是天涯沦落人,相逢何必曾相识”。\n\n\n那么基本的笔记到这里就可以结束了,这是属于创作过程的结束,就如同蜂箱产出了蜂蜜。后续蜂蜜做出什么产品则隶属于未来的精加工。\n\n\n同样,我们需要始终**保持一颗谦虚的心态,因为在我们往前走一小步的路上,却享用着很多人的智慧结晶和劳动成果,我们不应该忘记我们的起点。\n\n\n致敬flomo,致敬obsidian,致敬marginnote,致敬notion,致敬notionnext,致敬hugo,致敬github,致敬heo主题,致敬linux,致敬vercel,致敬杜老师图床,致敬cloudflare,致敬cdn,致敬twikoo,包括javascript语法,go语言,web框架。细想下来,还有很多前人的智慧结晶,一起致敬。\n\n\n# 总结\n\n\n---\n\n\n这篇文章主要是由三个主要的思考组成的,而且都是通过末端创作的形式完成的,在丰富度上,还是略微优化于宏思考。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-02-29",
"type": "Post",
"category": "走近生活",
"slug": "note",
"tags": [
"对话未来"
],
"summary": "关于笔记的三个思考片段",
"title": "[观点探讨] 末端创作的方式 ",
"status": "Published",
"urlname": "5f3a3c69-a7e5-4cc5-8701-a5a7f441d6f7",
"updated": "2024-04-23 12:56:00"
},
"catalog": [
{
"title": "对话未来",
"doc_id": "5f3a3c69-a7e5-4cc5-8701-a5a7f441d6f7"
}
],
"body": "",
"realName": "[观点探讨] 末端创作的方式 ",
"relativePath": "/对话未来/[观点探讨] 末端创作的方式 .md"
},
{
"id": "4953c12f-b064-475e-aa3b-1a7019651192",
"doc_id": "4953c12f-b064-475e-aa3b-1a7019651192",
"updated": 1713877620000,
"body_original": "\n# 前言\n\n\n---\n\n\n> 💡 首先需要感谢学校为我们提供的一个良好的学习平台,让我们通过毕设来了解项目开发的流程,并通过标准化的书写来规范格式。感谢罗老师的耐心指导和帮助,在实际毕设的写作过程中,关注着我们的每一个节点。 \n> 同时需要感谢公司[Andawell](http://www.andawell.com/)的支持,能为我提供在公司边实习边做毕设的机会。同时能将毕设与项目开发的标准更好地结合。 \n> 最后还需要鼓励自己,因为需要付出很多的努力。\n\n\n# 正文\n\n\n---\n\n\n 一方面主要是技术上的要求,一方面主要是论文上的排版。然后希望我遇到的问题,也能帮到大家。\n\n\n## **word中mathtype公式偏上浮或偏下沉怎么办**\n\n\n---\n\n\n 刚才遇到了公式上浮的问题,我使用的是amath进行公式的编写,搭配图片转latex进行调整。然后找到了这个问题的解决办法。感谢whu数码君提供的[回答](https://jingyan.baidu.com/article/09ea3edef9845480aede39a5.html)。\n\n\n## 如何使用图片转latex\n\n\n---\n\n\n 之前有同学问过我这个问题,我今天也再一次遇到了这个问题,看到论文中复杂的公式,一筹莫展怎么办,可以通过图片转latex的方式,这是我比较常用的方式,但是现在主流的转latex的好的软件不多,在此特别感谢[simpletex](https://simpletex.cn/ai/latex_ocr)提供的支持。\n\n\n## 关于语病的修改\n\n\n---\n\n\n 感谢up主:[用镜头记录成长](https://space.bilibili.com/26021795),参考[论文写作表达语句表达系列课程 一 病句修改 成分残缺_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1PB4y1U7JU/?buvid=XYA9A96A2DBF2E51A918ECE55EFA494C98935&is_story_h5=false&mid=nPIoZdTfuXw2Qtcat9xxZw%3D%3D&p=1&plat_id=114&share_from=ugc&share_medium=android&share_plat=android&share_session_id=e1117509-5d59-4fd0-b122-21d23e500899&share_source=WEIXIN&share_tag=s_i×tamp=1693714483&unique_k=HFqrbnI&up_id=26021795&share_times=1&vd_source=237e295a40d7aaea043ead8c0d2c78ab)该视频进行总结。\n\n\n<details>\n <summary>以下内容是对该视频进行的笔记梳理。</summary>\n\n\n### 一、主语残缺\n\n\n---\n\n- **滥用介词**\n\n> 从这件小事,说明一个道理\n\n\n应改为,这件小事说明一个道理。上述例子中缺少主语。\n\n\n> 当学生了解了美是什么,就会以美的标准米规范自己的行为和思想。\n\n\n应去除“当”字。\n\n- **滥用使令动词**\n\n> 通过这件小事,使我明白了一个道理。\n\n\n去除”通过“二字。\n\n\n> 通过对该课题的研究,得出新时代精神的含义。\n\n\n需添加主语,例如“笔者得出……”**(另外还需要尽量避免在论文中使用“我”字)**\n\n- **偏正短语缺中心语**\n\n> 课堂教学低效,一直未得到解决。\n\n\n需在”低效“后面加上”的问题“\n\n\n> 我对经济与生活这本教材感到困感。\n\n\n需在“教材”后面加上“的内容”\n\n- **滥用省略**\n\n> 在经历了几千年的封建统治后,人们又开始重视被禁锯的古典文化,并成为人文主义者的武器,用米反对神权。\n\n\n应改为”古典文化并成为人文主义者的武器“\n\n- **助词用错**\n\n> 2022年颁布了《家庭教育指导法》,是我国首部家庭教育法。\n\n\n把“了”改成“的”\n\n\n### 二、谓语残缺\n\n\n---\n\n- **句首缺谓另起头**\n\n> 经过几十年的努力,我国己经独立自主地研制、发射、跟踪和测检地球同步通讯卫星的能力。\n\n\n具备……的能力\n\n\n> 某大学工商管理学院在课程设置上除了专业课、外语课、政治理论课,还包括演讲与口才、基础写作等课程,以进一步提高说写方面的技能。\n\n\n除了设置有…… **(第一句话缺少谓语)**\n\n- **动宾缺动**\n\n> 我市最近发动了全面的质量大检查运动,要在这个运动中建立与加强技术管理制度等一系列工作。\n\n\n要在这个运动中**完成**建立与加强技术管理制度等一系列**工作**\n\n\n> 政府必须严厉打击食品安全违法违规行为的高压态势,及时消除各环节领域的隐患,创新食品安全监管惩处体制机制。\n\n\n保持严厉打击…\n\n\n> 教师在法律专业知识和逻辑思维能力提升方面面临困难。\n\n\n教师在法律专业知识拓展… (知识和提升搭配不是非常好,搭配知识拓展可能会更好)\n\n\n### 三、宾语残缺\n\n\n---\n\n- **动宾缺宾**\n\n> 学校宿舍、教学楼等人群密集区,一且发生火灾,后果不堪设想,因此学生掌握火灾中自救互教相当重要。\n\n\n掌握…技能\n\n- **介宾缺宾**\n\n> 这部电影在塑造人物形象所提供的经验是非常宝贵的,\n\n\n在…方面\n\n- **误将定语当宾语**\n\n> 桃花乡走可持续发展之路,按照建成生态环境和谐优美、资源集约节约利用、经济和社会协调发展的生态乡,制定了五年发展建设规划。\n\n\n按照…目标,规划\n\n\n### 四、虚词残缺\n\n\n---\n\n- **介宾缺介**\n\n> 2014年底,我国探月工程三期“再入返回飞行”试验获得成功,确保嫦娥五号任务顺利实施和探月工程持续推进莫定坚实基础,\n\n\n为…奠定坚实基础\n\n- **被动缺被**\n\n> 这本书非常有价值,常常图书馆收藏。\n\n\n常常被图书馆收藏\n\n- **对象缺对**\n\n> 现代女性越来越独立,她们除了自己独立挣钱外,对自身的价值、生活环境也越发重视,那些价值剥削、性骚扰,她们将说不。\n\n\n对那些价值剥削、性骚扰,她们将说不。\n\n\n\n </details>\n\n\n## 搭建yolov5环境\n\n\n---\n\n\n 详细参照up主:[**思绪亦无限**](https://space.bilibili.com/456667721)的介绍:\n\n\n [**Win11中从头安装软件和配置环境运行深度学习项目**](https://www.bilibili.com/video/BV1Hg4y1t78v/?spm_id_from=333.999.0.0&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n\n\n 然后最主要的还需要引入英伟达的CUDA,可以现在本地装,但我还是倾向于选择[autodl](https://www.autodl.com/home),因为这里已经预装了cuda环境。\n\n\n 这里细节很多,但现在又过了好久了,**有点忘了**,在选择基础镜像的时候就应该要注意选择合适的版本,不然后面配置cuda会麻烦死。(看来日志还是要及时记录,当时费了一下午的劲,真是服了)\n\n\n## 数据集的预处理\n\n\n---\n\n\n 课题中yolov5的数据集是采用的航拍视角,在肉眼识别存在困难,还有很多干扰。所以需要预先对数据集进行切片处理。然后挑出切片完后包含黑匣子的图片,再进行标注。\n\n\n以下是切片程序:\n\n\n```python\nfrom PIL import Image\nimport os\nimport random\n#from PIL import Image: 导入Python Imaging Library (PIL) 中的 Image 模块,用于图像处理。\n#import os: 导入 os 模块,用于处理文件和目录。\n#import random: 导入 random 模块,用于生成随机数。\n\ndef slice_and_save_images(input_folder, output_folder, random_size=True, fixed_size=(640, 640), overlap_ratio=0.2):\n #函数的定义,它接收几个参数,包括输入输出文件夹路径、是否随机切片大小、固定切片大小以及重叠比率。\n # 获取输入文件夹中的所有文件\n image_files = [f for f in os.listdir(input_folder) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp'))]\n\n # 创建输出文件夹\n os.makedirs(output_folder, exist_ok=True)\n\n # 循环处理每张图像\n for image_file in image_files:\n input_path = os.path.join(input_folder, image_file)\n\n # 打开图像\n original_image = Image.open(input_path)\n\n # 获取图像大小\n width, height = original_image.size\n\n # 随机生成或手动指定切片大小\n #根据 random_size 参数决定是随机生成切片大小还是使用固定大小。随机大小在固定大小的一半到固定大小之间。\n if random_size:\n slice_width = random.randint(fixed_size[0] // 2, fixed_size[0])\n slice_height = random.randint(fixed_size[1] // 2, fixed_size[1])\n else:\n slice_width, slice_height = fixed_size\n\n # 计算重叠区域大小,由 overlap_ratio 参数决定的。\n overlap_width = int(slice_width * overlap_ratio)\n overlap_height = int(slice_height * overlap_ratio)\n\n # 计算切片数量\n num_slices_horizontal = (width - overlap_width) // (slice_width - overlap_width)\n num_slices_vertical = (height - overlap_height) // (slice_height - overlap_height)\n\n # 创建一个文件夹用于保存切片后的小图片\n output_subfolder = os.path.join(output_folder, os.path.splitext(image_file)[0])\n os.makedirs(output_subfolder, exist_ok=True)\n\n # 切片并保存\n for i in range(num_slices_horizontal):\n for j in range(num_slices_vertical):\n left = i * (slice_width - overlap_width)\n upper = j * (slice_height - overlap_height)\n right = left + slice_width\n lower = upper + slice_height\n\n # 切片\n slice_image = original_image.crop((left, upper, right, lower))\n\n # 生成唯一的切片文件名\n slice_filename = f\"{os.path.splitext(image_file)[0]}_slice_{j}_{i}.jpg\"\n\n # 保存切片\n slice_image.save(os.path.join(output_subfolder, slice_filename))\n\n# 调用函数,传入输入图像文件夹路径和输出文件夹路径,更换为自己的文件夹\nslice_and_save_images(r\"C:\\Users\\Raj\\Desktop\\bbox\", r\"C:\\Users\\Raj\\Desktop\\bbox全部切片\",\n random_size=False, fixed_size=(640, 640))\n```\n\n\n切片完成之后,需要挑出包含切片中包含目标对象的图片,之后作为训练集。\n\n\n\n\n\n## 验证集\n\n\n---\n\n\n 最开始验证集是用的数据集的一部分,但是后面采用新的验证集,难度瞬间就上来了,测试精度从0.996瞬间跌到都到不了0.7。一方面需要扩充数据集,另一方面需要选择合适的模型对网络参数进行调整。\n\n\n\n\n\n## 扩充训练集\n\n\n---\n\n\n 感谢CSDN博主:[**我要变胖哇**](https://blog.csdn.net/qq_44421796)**、**[**路人贾'ω'**](https://blog.csdn.net/weixin_43334693)\n\n\n 参考文章:[**YOLO数据集实现数据增强的方法(裁剪、平移 、旋转、改变亮度、加噪声等)**](https://blog.csdn.net/weixin_43334693/article/details/131744918)\n\n\n### 数据增强的概念和作用\n\n\n---\n\n\n **数据增强**是一种重要的机器学习方法之一,是**基于已有的训练样本数据来生成更多的训练数据**,其目的就是**为了使扩增的训练数据尽可能接近真实分布的数据,从而提高检测精度**。此外,数据增强能够迫使模型**学习到更多鲁棒性的特征,从而有效提高模型的泛化能力**。\n\n\n### 常见的数据增强的办法\n\n\n---\n\n\n(1)比较常用的**几何变换**方法主要有:\n 翻转、旋转、裁剪、缩放、平移、抖动\n(2)比较常用的**像素变换**方法主要有:\n 加椒盐噪声、高斯噪声、进行高斯模糊、调整HSV对比度、调节亮度、饱和度、直方图均衡化、调整白平衡等\n\n\n 具体解释如下:\n\n- 随机裁剪:从原始图像中随机裁剪出一部分,例如裁剪四角、中心或者上下部分等。这种方法能够增加模型的鲁棒性,使其对图像的不同部分都能进行有效的特征提取。\n- 翻转或镜像:可以水平翻转或垂直翻转图像。这种方法能够模拟图像在不同视角下的情况,帮助模型学习到更多的特征。\n- 旋转:将原图像旋转不同的角度来生成新的样本。需要注意的是,旋转后图像的维度可能会发生变化,因此在处理时需要确保图像尺寸的合理性。\n- 亮度或对比度调节:通过改变图像的亮度和对比度,可以模拟不同光照条件下的图像情况,提高模型的适应性。\n- 色度调节:改变图像中R、G、B颜色分量的比例,从而生成具有不同颜色特征的样本。\n饱和度调节:调节图像的饱和度,即改变色彩的纯度。这可以模拟不同颜色鲜艳程度的图像,增加样本的多样性。\n- 高斯模糊、锐化、添加噪声:对图像进行这些处理可以模拟图像在采集和传输过程中可能出现的失真情况,有助于提高模型的鲁棒性。\n灰度化:将彩色图像转换为灰度图像,可以进一步增加样本的多样性\n\n### txt转xml\n\n\n---\n\n\n 在数据增强的时候,代码是对xml进行操作的,所以需要先经历一步,从txt到xml的过程。\n\n\n**核心原理解释**:将 YOLO 格式中的归一化坐标转换为像素坐标。\n\n1. 从 YOLO 格式的文本文件中读取每个目标的类别索引和归一化的边界框坐标 `(class_index, x_center_norm, y_center_norm, width_norm, height_norm)`。\n2. 将归一化的中心点坐标 `(x_center_norm, y_center_norm)` 和宽度、高度 `(width_norm, height_norm)` 转换为像素坐标。\n3. 使用像素坐标来计算 PASCAL VOC 格式的边界框 `(xmin, ymin, xmax, ymax)`\n\n**核心转换逻辑:**\n\n\n```python\n# 计算 PASCAL VOC 的 (xmin, ymin, xmax, ymax)\nxmin = int(round(x_center - (width / 2)))\nymin = int(round(y_center - (height / 2)))\nxmax = int(round(x_center + (width / 2)))\nymax = int(round(y_center + (height / 2)))\n```\n\n\n**转换代码:**\n\n\n```python\n# -*- coding: utf-8 -*-\nimport os\nimport cv2\nfrom lxml.etree import Element, SubElement, tostring\n\n\ndef txt_xml(img_path, img_name, txt_path, img_txt, xml_path, img_xml):\n clas = []\n # 读取txt的信息\n txt_img = os.path.join(txt_path, img_txt)\n\n # 图像的宽度和高度\n imw = 640 # 应当根据实际图片大小进行调整\n imh = 640 # 应当根据实际图片大小进行调整\n\n with open(txt_img, \"r\") as f:\n for line in f.readlines():\n line = line.strip('\\n')\n list = line.split(\" \")\n print(list)\n clas.append(list)\n\n # 创建XML文档的根节点和相关子节点\n # 创建XML文档的根节点\n node_root = Element('annotation')\n node_folder = SubElement(node_root, 'folder')\n node_folder.text = '1'\n node_filename = SubElement(node_root, 'filename')\n\n # 图像名称\n node_filename.text = img_name\n node_size = SubElement(node_root, 'size')\n node_width = SubElement(node_size, 'width')\n node_width.text = str(imw)\n node_height = SubElement(node_size, 'height')\n node_height.text = str(imh)\n node_depth = SubElement(node_size, 'depth')\n node_depth.text = '3'\n\n # 遍历所有的标注信息并添加到XML中\n # 遍历所有的标注信息\n for i in range(len(clas)):\n x_center_norm = float(clas[i][1])\n y_center_norm = float(clas[i][2])\n width_norm = float(clas[i][3])\n height_norm = float(clas[i][4])\n # 转换归一化坐标到像素坐标\n x_center = x_center_norm * imw\n y_center = y_center_norm * imh\n width = width_norm * imw\n height = height_norm * imh\n # 计算并转换为字符串\n xmin = str(int(round(x_center - (width / 2))))\n ymin = str(int(round(y_center - (height / 2))))\n xmax = str(int(round(x_center + (width / 2))))\n ymax = str(int(round(y_center + (height / 2))))\n\n # 创建XML节点并赋值\n node_object = SubElement(node_root, 'object')\n node_name = SubElement(node_object, 'name')\n node_name.text = str(clas[i][0])\n node_pose = SubElement(node_object, 'pose')\n node_pose.text = \"Unspecified\"\n node_truncated = SubElement(node_object, 'truncated')\n node_truncated.text = \"0\"\n node_difficult = SubElement(node_object, 'difficult')\n node_difficult.text = '0'\n node_bndbox = SubElement(node_object, 'bndbox')\n node_xmin = SubElement(node_bndbox, 'xmin')\n node_xmin.text = xmin\n node_ymin = SubElement(node_bndbox, 'ymin')\n node_ymin.text = ymin\n node_xmax = SubElement(node_bndbox, 'xmax')\n node_xmax.text = xmax\n node_ymax = SubElement(node_bndbox, 'ymax')\n node_ymax.text = ymax\n\n # 将XML内容写入文件\n xml = tostring(node_root, pretty_print=True)\n img_newxml = os.path.join(xml_path, img_xml)\n with open(img_newxml, 'wb') as file_object:\n file_object.write(xml)\n\n\nif __name__ == \"__main__\":\n # 图像、标注和XML文件夹所在位置、更换自己的绝对路径\n img_path = r\"D:\\@Graduation\\enhance\\data\\images\\train\"\n txt_path = r\"D:\\@Graduation\\enhance\\data\\labels\\train\"\n xml_path = r\"D:\\@Graduation\\enhance\\data\\labels\\xml\"\n for img_name in os.listdir(img_path):\n img_base_name = os.path.splitext(img_name)[0]\n img_xml = img_base_name + \".xml\"\n img_txt = img_base_name + \".txt\"\n txt_xml(img_path, img_name, txt_path, img_txt, xml_path, img_xml)\n```\n\n\n例如,这就是标注后的归一化坐标\n\n\n```text\n0 0.719594 0.901037 0.108083 0.091896 \n```\n\n\n这就是转换后的xml坐标和其他的一些元素,转换完可以用labelimg验证一下\n\n\n```html\n<annotation>\n <folder>1</folder>\n <filename>000000_slice_2_2.jpg</filename>\n <size>\n <width>640</width>\n <height>640</height>\n <depth>3</depth>\n </size>\n <object>\n <name>0</name>\n <pose>Unspecified</pose>\n <truncated>0</truncated>\n <difficult>0</difficult>\n <bndbox>\n <xmin>426</xmin>\n <ymin>547</ymin>\n <xmax>495</xmax>\n <ymax>606</ymax>\n </bndbox>\n </object>\n</annotation>\n```\n\n\n### 数据集扩充\n\n\n---\n\n\n根据上述分析的方式进行数据集扩充\n\n\n```python\n# -*- coding=utf-8 -*-\n\nimport time\nimport random\nimport copy\nimport cv2\nimport os\nimport math\nimport numpy as np\nfrom skimage.util import random_noise\nfrom lxml import etree, objectify\nimport xml.etree.ElementTree as ET\nimport argparse\n\n\n# 显示图片\ndef show_pic(img, bboxes=None):\n '''\n 输入:\n img:图像array\n bboxes:图像的所有boudning box list, 格式为[[x_min, y_min, x_max, y_max]....]\n names:每个box对应的名称\n '''\n for i in range(len(bboxes)):\n bbox = bboxes[i]\n x_min = bbox[0]\n y_min = bbox[1]\n x_max = bbox[2]\n y_max = bbox[3]\n cv2.rectangle(img, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 255, 0), 3)\n cv2.namedWindow('pic', 0) # 1表示原图\n cv2.moveWindow('pic', 0, 0)\n cv2.resizeWindow('pic', 1200, 800) # 可视化的图片大小\n cv2.imshow('pic', img)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n\n# 图像均为cv2读取\nclass DataAugmentForObjectDetection():\n def __init__(self, rotation_rate=0.5, max_rotation_angle=5,\n crop_rate=0.5, shift_rate=0.5, change_light_rate=0.5,\n add_noise_rate=0.5, flip_rate=0.5,\n cutout_rate=0.5, cut_out_length=50, cut_out_holes=1, cut_out_threshold=0.5,\n is_addNoise=True, is_changeLight=True, is_cutout=True, is_rotate_img_bbox=True,\n is_crop_img_bboxes=True, is_shift_pic_bboxes=True, is_filp_pic_bboxes=True):\n\n # 配置各个操作的属性\n self.rotation_rate = rotation_rate\n self.max_rotation_angle = max_rotation_angle\n self.crop_rate = crop_rate\n self.shift_rate = shift_rate\n self.change_light_rate = change_light_rate\n self.add_noise_rate = add_noise_rate\n self.flip_rate = flip_rate\n self.cutout_rate = cutout_rate\n\n self.cut_out_length = cut_out_length\n self.cut_out_holes = cut_out_holes\n self.cut_out_threshold = cut_out_threshold\n\n # 是否使用某种增强方式\n self.is_addNoise = is_addNoise\n self.is_changeLight = is_changeLight\n self.is_cutout = is_cutout\n self.is_rotate_img_bbox = is_rotate_img_bbox\n self.is_crop_img_bboxes = is_crop_img_bboxes\n self.is_shift_pic_bboxes = is_shift_pic_bboxes\n self.is_filp_pic_bboxes = is_filp_pic_bboxes\n\n # ----1.加噪声---- #\n def _addNoise(self, img):\n '''\n 输入:\n img:图像array\n 输出:\n 加噪声后的图像array,由于输出的像素是在[0,1]之间,所以得乘以255\n '''\n # return cv2.GaussianBlur(img, (11, 11), 0)\n return random_noise(img, mode='gaussian', seed=int(time.time()), clip=True) * 255\n\n # ---2.调整亮度--- #\n def _changeLight(self, img):\n alpha = random.uniform(0.35, 1)\n blank = np.zeros(img.shape, img.dtype)\n return cv2.addWeighted(img, alpha, blank, 1 - alpha, 0)\n\n # ---3.cutout--- #\n def _cutout(self, img, bboxes, length=100, n_holes=1, threshold=0.5):\n '''\n 原版本:https://github.com/uoguelph-mlrg/Cutout/blob/master/util/cutout.py\n Randomly mask out one or more patches from an image.\n Args:\n img : a 3D numpy array,(h,w,c)\n bboxes : 框的坐标\n n_holes (int): Number of patches to cut out of each image.\n length (int): The length (in pixels) of each square patch.\n '''\n\n def cal_iou(boxA, boxB):\n '''\n boxA, boxB为两个框,返回iou\n boxB为bouding box\n '''\n # determine the (x, y)-coordinates of the intersection rectangle\n xA = max(boxA[0], boxB[0])\n yA = max(boxA[1], boxB[1])\n xB = min(boxA[2], boxB[2])\n yB = min(boxA[3], boxB[3])\n\n if xB <= xA or yB <= yA:\n return 0.0\n\n # compute the area of intersection rectangle\n interArea = (xB - xA + 1) * (yB - yA + 1)\n\n # compute the area of both the prediction and ground-truth\n # rectangles\n boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)\n boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)\n iou = interArea / float(boxBArea)\n return iou\n\n # 得到h和w\n if img.ndim == 3:\n h, w, c = img.shape\n else:\n _, h, w, c = img.shape\n mask = np.ones((h, w, c), np.float32)\n for n in range(n_holes):\n chongdie = True # 看切割的区域是否与box重叠太多\n while chongdie:\n y = np.random.randint(h)\n x = np.random.randint(w)\n\n y1 = np.clip(y - length // 2, 0,\n h) # numpy.clip(a, a_min, a_max, out=None), clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min\n y2 = np.clip(y + length // 2, 0, h)\n x1 = np.clip(x - length // 2, 0, w)\n x2 = np.clip(x + length // 2, 0, w)\n\n chongdie = False\n for box in bboxes:\n if cal_iou([x1, y1, x2, y2], box) > threshold:\n chongdie = True\n break\n mask[y1: y2, x1: x2, :] = 0.\n img = img * mask\n return img\n\n # ---4.旋转--- #\n def _rotate_img_bbox(self, img, bboxes, angle=5, scale=1.):\n '''\n 参考:https://blog.csdn.net/u014540717/article/details/53301195crop_rate\n 输入:\n img:图像array,(h,w,c)\n bboxes:该图像包含的所有boundingboxs,一个list,每个元素为[x_min, y_min, x_max, y_max],要确保是数值\n angle:旋转角度\n scale:默认1\n 输出:\n rot_img:旋转后的图像array\n rot_bboxes:旋转后的boundingbox坐标list\n '''\n # 旋转图像\n w = img.shape[1]\n h = img.shape[0]\n # 角度变弧度\n rangle = np.deg2rad(angle) # angle in radians\n # now calculate new image width and height\n nw = (abs(np.sin(rangle) * h) + abs(np.cos(rangle) * w)) * scale\n nh = (abs(np.cos(rangle) * h) + abs(np.sin(rangle) * w)) * scale\n # ask OpenCV for the rotation matrix\n rot_mat = cv2.getRotationMatrix2D((nw * 0.5, nh * 0.5), angle, scale)\n # calculate the move from the old center to the new center combined\n # with the rotation\n rot_move = np.dot(rot_mat, np.array([(nw - w) * 0.5, (nh - h) * 0.5, 0]))\n # the move only affects the translation, so update the translation\n rot_mat[0, 2] += rot_move[0]\n rot_mat[1, 2] += rot_move[1]\n # 仿射变换\n rot_img = cv2.warpAffine(img, rot_mat, (int(math.ceil(nw)), int(math.ceil(nh))), flags=cv2.INTER_LANCZOS4)\n\n # 矫正bbox坐标\n # rot_mat是最终的旋转矩阵\n # 获取原始bbox的四个中点,然后将这四个点转换到旋转后的坐标系下\n rot_bboxes = list()\n for bbox in bboxes:\n xmin = bbox[0]\n ymin = bbox[1]\n xmax = bbox[2]\n ymax = bbox[3]\n point1 = np.dot(rot_mat, np.array([(xmin + xmax) / 2, ymin, 1]))\n point2 = np.dot(rot_mat, np.array([xmax, (ymin + ymax) / 2, 1]))\n point3 = np.dot(rot_mat, np.array([(xmin + xmax) / 2, ymax, 1]))\n point4 = np.dot(rot_mat, np.array([xmin, (ymin + ymax) / 2, 1]))\n # 合并np.array\n concat = np.vstack((point1, point2, point3, point4))\n # 改变array类型\n concat = concat.astype(np.int32)\n # 得到旋转后的坐标\n rx, ry, rw, rh = cv2.boundingRect(concat)\n rx_min = rx\n ry_min = ry\n rx_max = rx + rw\n ry_max = ry + rh\n # 加入list中\n rot_bboxes.append([rx_min, ry_min, rx_max, ry_max])\n\n return rot_img, rot_bboxes\n\n # ---5.裁剪--- #\n def _crop_img_bboxes(self, img, bboxes):\n '''\n 裁剪后的图片要包含所有的框\n 输入:\n img:图像array\n bboxes:该图像包含的所有boundingboxs,一个list,每个元素为[x_min, y_min, x_max, y_max],要确保是数值\n 输出:\n crop_img:裁剪后的图像array\n crop_bboxes:裁剪后的bounding box的坐标list\n '''\n # 裁剪图像\n w = img.shape[1]\n h = img.shape[0]\n x_min = w # 裁剪后的包含所有目标框的最小的框\n x_max = 0\n y_min = h\n y_max = 0\n for bbox in bboxes:\n x_min = min(x_min, bbox[0])\n y_min = min(y_min, bbox[1])\n x_max = max(x_max, bbox[2])\n y_max = max(y_max, bbox[3])\n\n d_to_left = x_min # 包含所有目标框的最小框到左边的距离\n d_to_right = w - x_max # 包含所有目标框的最小框到右边的距离\n d_to_top = y_min # 包含所有目标框的最小框到顶端的距离\n d_to_bottom = h - y_max # 包含所有目标框的最小框到底部的距离\n\n # 随机扩展这个最小框\n crop_x_min = int(x_min - random.uniform(0, d_to_left))\n crop_y_min = int(y_min - random.uniform(0, d_to_top))\n crop_x_max = int(x_max + random.uniform(0, d_to_right))\n crop_y_max = int(y_max + random.uniform(0, d_to_bottom))\n\n # 随机扩展这个最小框 , 防止别裁的太小\n # crop_x_min = int(x_min - random.uniform(d_to_left//2, d_to_left))\n # crop_y_min = int(y_min - random.uniform(d_to_top//2, d_to_top))\n # crop_x_max = int(x_max + random.uniform(d_to_right//2, d_to_right))\n # crop_y_max = int(y_max + random.uniform(d_to_bottom//2, d_to_bottom))\n\n # 确保不要越界\n crop_x_min = max(0, crop_x_min)\n crop_y_min = max(0, crop_y_min)\n crop_x_max = min(w, crop_x_max)\n crop_y_max = min(h, crop_y_max)\n\n crop_img = img[crop_y_min:crop_y_max, crop_x_min:crop_x_max]\n\n # 裁剪boundingbox\n # 裁剪后的boundingbox坐标计算\n crop_bboxes = list()\n for bbox in bboxes:\n crop_bboxes.append([bbox[0] - crop_x_min, bbox[1] - crop_y_min, bbox[2] - crop_x_min, bbox[3] - crop_y_min])\n\n return crop_img, crop_bboxes\n\n # ---6.平移--- #\n def _shift_pic_bboxes(self, img, bboxes):\n '''\n 平移后的图片要包含所有的框\n 输入:\n img:图像array\n bboxes:该图像包含的所有boundingboxs,一个list,每个元素为[x_min, y_min, x_max, y_max],要确保是数值\n 输出:\n shift_img:平移后的图像array\n shift_bboxes:平移后的bounding box的坐标list\n '''\n # 平移图像\n w = img.shape[1]\n h = img.shape[0]\n x_min = w # 裁剪后的包含所有目标框的最小的框\n x_max = 0\n y_min = h\n y_max = 0\n for bbox in bboxes:\n x_min = min(x_min, bbox[0])\n y_min = min(y_min, bbox[1])\n x_max = max(x_max, bbox[2])\n y_max = max(y_max, bbox[3])\n\n d_to_left = x_min # 包含所有目标框的最大左移动距离\n d_to_right = w - x_max # 包含所有目标框的最大右移动距离\n d_to_top = y_min # 包含所有目标框的最大上移动距离\n d_to_bottom = h - y_max # 包含所有目标框的最大下移动距离\n\n x = random.uniform(-(d_to_left - 1) / 3, (d_to_right - 1) / 3)\n y = random.uniform(-(d_to_top - 1) / 3, (d_to_bottom - 1) / 3)\n\n M = np.float32([[1, 0, x], [0, 1, y]]) # x为向左或右移动的像素值,正为向右负为向左; y为向上或者向下移动的像素值,正为向下负为向上\n shift_img = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]))\n\n # 平移boundingbox\n shift_bboxes = list()\n for bbox in bboxes:\n shift_bboxes.append([bbox[0] + x, bbox[1] + y, bbox[2] + x, bbox[3] + y])\n\n return shift_img, shift_bboxes\n\n # ---7.镜像--- #\n def _filp_pic_bboxes(self, img, bboxes):\n '''\n 平移后的图片要包含所有的框\n 输入:\n img:图像array\n bboxes:该图像包含的所有boundingboxs,一个list,每个元素为[x_min, y_min, x_max, y_max],要确保是数值\n 输出:\n flip_img:平移后的图像array\n flip_bboxes:平移后的bounding box的坐标list\n '''\n # 翻转图像\n\n flip_img = copy.deepcopy(img)\n h, w, _ = img.shape\n\n sed = random.random()\n\n if 0 < sed < 0.33: # 0.33的概率水平翻转,0.33的概率垂直翻转,0.33是对角反转\n flip_img = cv2.flip(flip_img, 0) # _flip_x\n inver = 0\n elif 0.33 < sed < 0.66:\n flip_img = cv2.flip(flip_img, 1) # _flip_y\n inver = 1\n else:\n flip_img = cv2.flip(flip_img, -1) # flip_x_y\n inver = -1\n\n # 调整boundingbox\n flip_bboxes = list()\n for box in bboxes:\n x_min = box[0]\n y_min = box[1]\n x_max = box[2]\n y_max = box[3]\n\n if inver == 0:\n # 0:垂直翻转\n flip_bboxes.append([x_min, h - y_max, x_max, h - y_min])\n elif inver == 1:\n # 1:水平翻转\n flip_bboxes.append([w - x_max, y_min, w - x_min, y_max])\n elif inver == -1:\n # -1:水平垂直翻转\n flip_bboxes.append([w - x_max, h - y_max, w - x_min, h - y_min])\n return flip_img, flip_bboxes\n\n # 图像增强方法\n def dataAugment(self, img, bboxes):\n '''\n 图像增强\n 输入:\n img:图像array\n bboxes:该图像的所有框坐标\n 输出:\n img:增强后的图像\n bboxes:增强后图片对应的box\n '''\n change_num = 0 # 改变的次数\n # print('------')\n while change_num < 1: # 默认至少有一种数据增强生效\n\n if self.is_rotate_img_bbox:\n if random.random() > self.rotation_rate: # 旋转\n change_num += 1\n angle = random.uniform(-self.max_rotation_angle, self.max_rotation_angle)\n scale = random.uniform(0.7, 0.8)\n img, bboxes = self._rotate_img_bbox(img, bboxes, angle, scale)\n\n if self.is_shift_pic_bboxes:\n if random.random() < self.shift_rate: # 平移\n change_num += 1\n img, bboxes = self._shift_pic_bboxes(img, bboxes)\n\n if self.is_changeLight:\n if random.random() > self.change_light_rate: # 改变亮度\n change_num += 1\n img = self._changeLight(img)\n\n if self.is_addNoise:\n if random.random() < self.add_noise_rate: # 加噪声\n change_num += 1\n img = self._addNoise(img)\n if self.is_cutout:\n if random.random() < self.cutout_rate: # cutout\n change_num += 1\n img = self._cutout(img, bboxes, length=self.cut_out_length, n_holes=self.cut_out_holes,\n threshold=self.cut_out_threshold)\n if self.is_filp_pic_bboxes:\n if random.random() < self.flip_rate: # 翻转\n change_num += 1\n img, bboxes = self._filp_pic_bboxes(img, bboxes)\n\n return img, bboxes\n\n\n# xml解析工具\nclass ToolHelper():\n # 从xml文件中提取bounding box信息, 格式为[[x_min, y_min, x_max, y_max, name]]\n def parse_xml(self, path):\n '''\n 输入:\n xml_path: xml的文件路径\n 输出:\n 从xml文件中提取bounding box信息, 格式为[[x_min, y_min, x_max, y_max, name]]\n '''\n tree = ET.parse(path)\n root = tree.getroot()\n objs = root.findall('object')\n coords = list()\n for ix, obj in enumerate(objs):\n name = obj.find('name').text\n box = obj.find('bndbox')\n x_min = int(box[0].text)\n y_min = int(box[1].text)\n x_max = int(box[2].text)\n y_max = int(box[3].text)\n coords.append([x_min, y_min, x_max, y_max, name])\n return coords\n\n # 保存图片结果\n def save_img(self, file_name, save_folder, img):\n cv2.imwrite(os.path.join(save_folder, file_name), img)\n\n # 保持xml结果\n def save_xml(self, file_name, save_folder, img_info, height, width, channel, bboxs_info):\n '''\n :param file_name:文件名\n :param save_folder:#保存的xml文件的结果\n :param height:图片的信息\n :param width:图片的宽度\n :param channel:通道\n :return:\n '''\n folder_name, img_name = img_info # 得到图片的信息\n\n E = objectify.ElementMaker(annotate=False)\n\n anno_tree = E.annotation(\n E.folder(folder_name),\n E.filename(img_name),\n E.path(os.path.join(folder_name, img_name)),\n E.source(\n E.database('Unknown'),\n ),\n E.size(\n E.width(width),\n E.height(height),\n E.depth(channel)\n ),\n E.segmented(0),\n )\n\n labels, bboxs = bboxs_info # 得到边框和标签信息\n for label, box in zip(labels, bboxs):\n anno_tree.append(\n E.object(\n E.name(label),\n E.pose('Unspecified'),\n E.truncated('0'),\n E.difficult('0'),\n E.bndbox(\n E.xmin(box[0]),\n E.ymin(box[1]),\n E.xmax(box[2]),\n E.ymax(box[3])\n )\n ))\n\n etree.ElementTree(anno_tree).write(os.path.join(save_folder, file_name), pretty_print=True)\n\n\nif __name__ == '__main__':\n\n need_aug_num = 5 # 每张图片需要增强的次数\n\n is_endwidth_dot = True # 文件是否以.jpg或者png结尾\n\n dataAug = DataAugmentForObjectDetection() # 数据增强工具类\n\n toolhelper = ToolHelper() # 工具\n\n # 获取相关参数\n parser = argparse.ArgumentParser()\n parser.add_argument('--source_img_path', type=str, default='D:\\@Graduation\\enhance\\images')\n parser.add_argument('--source_xml_path', type=str, default='D:\\@Graduation\\enhance\\labels')\n parser.add_argument('--save_img_path', type=str, default='D:\\@Graduation\\enhance\\images2')\n parser.add_argument('--save_xml_path', type=str, default='D:\\@Graduation\\enhance\\Annotations2')\n args = parser.parse_args()\n source_img_path = args.source_img_path # 图片原始位置\n source_xml_path = args.source_xml_path # xml的原始位置\n\n save_img_path = args.save_img_path # 图片增强结果保存文件\n save_xml_path = args.save_xml_path # xml增强结果保存文件\n\n # 如果保存文件夹不存在就创建\n if not os.path.exists(save_img_path):\n os.mkdir(save_img_path)\n\n if not os.path.exists(save_xml_path):\n os.mkdir(save_xml_path)\n\n for parent, _, files in os.walk(source_img_path):\n files.sort()\n for file in files:\n cnt = 0\n pic_path = os.path.join(parent, file)\n xml_path = os.path.join(source_xml_path, file[:-4] + '.xml')\n values = toolhelper.parse_xml(xml_path) # 解析得到box信息,格式为[[x_min,y_min,x_max,y_max,name]]\n coords = [v[:4] for v in values] # 得到框\n labels = [v[-1] for v in values] # 对象的标签\n\n # 如果图片是有后缀的\n if is_endwidth_dot:\n # 找到文件的最后名字\n dot_index = file.rfind('.')\n _file_prefix = file[:dot_index] # 文件名的前缀\n _file_suffix = file[dot_index:] # 文件名的后缀\n img = cv2.imread(pic_path)\n\n # show_pic(img, coords) # 显示原图\n while cnt < need_aug_num: # 继续增强\n auged_img, auged_bboxes = dataAug.dataAugment(img, coords)\n auged_bboxes_int = np.array(auged_bboxes).astype(np.int32)\n height, width, channel = auged_img.shape # 得到图片的属性\n img_name = '{}_{}{}'.format(_file_prefix, cnt + 1, _file_suffix) # 图片保存的信息\n toolhelper.save_img(img_name, save_img_path,\n auged_img) # 保存增强图片\n\n toolhelper.save_xml('{}_{}.xml'.format(_file_prefix, cnt + 1),\n save_xml_path, (save_img_path, img_name), height, width, channel,\n (labels, auged_bboxes_int)) # 保存xml文件\n # show_pic(auged_img, auged_bboxes) # 强化后的图\n print(img_name)\n cnt += 1 # 继续增强下一张\n```\n\n\n**这是扩充数据集后的效果图:**\n\n\n\n\n\n**接下来需要对扩充好的数据集进行xml转txt:**\n\n\n```python\nimport xml.etree.ElementTree as ET\nimport os\nfrom os import getcwd\nimport glob\n\n# 1.\n# 自己创建文件夹,例如:label_mal label_txt 也可以修改别的\nimage_set = 'xml' # 需要转换的文件夹名称(文件夹内放xml标签文件)\nimageset2 = 'labels2' # 保存txt的文件夹\n# 2.\n# 换成你的类别 当前的顺序,就txt 0,1,2,3 四个类别\nclasses = ['0'] # 标注时的标签 注意顺序一定不要错。\n\n# 3.\n# # 转换文件夹的绝对路径\n# data_dir = 'D:/detectAuto_/data'\n# 或者 读取当前路径\ndata_dir = getcwd() # 当前路径\n\n\n'''\nxml中框的左上角坐标和右下角坐标(x1,y1,x2,y2)\n》》txt中的中心点坐标和宽和高(x,y,w,h),并且归一化\n'''\n\n\ndef convert(size, box):\n dw = 1. / size[0]\n dh = 1. / size[1]\n x = (box[0] + box[1]) / 2.0\n y = (box[2] + box[3]) / 2.0\n w = box[1] - box[0]\n h = box[3] - box[2]\n x = x * dw\n w = w * dw\n y = y * dh\n h = h * dh\n return (x, y, w, h)\n\n\ndef convert_annotation(data_dir, imageset1, imageset2, image_id):\n in_file = open(data_dir + '/%s/%s.xml' % (imageset1, image_id),encoding='UTF-8') # 读取xml\n out_file = open(data_dir + '/%s/%s.txt' % (imageset2, image_id), 'w',encoding='UTF-8') # 保存txt\n\n tree = ET.parse(in_file)\n root = tree.getroot()\n size = root.find('size')\n w = int(size.find('width').text)\n h = int(size.find('height').text)\n for obj in root.iter('object'):\n difficult = obj.find('difficult').text\n cls = obj.find('name').text\n if cls not in classes or int(difficult) == 1:\n continue\n cls_id = classes.index(cls) # 获取类别索引\n xmlbox = obj.find('bndbox')\n b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),\n float(xmlbox.find('ymax').text))\n bb = convert((w, h), b)\n out_file.write(str(cls_id) + \" \" + \" \".join([str('%.6f' % a) for a in bb]) + '\\n')\n\n\nimage_ids = []\nfor x in glob.glob(data_dir + '/%s' % image_set + '/*.xml'):\n image_ids.append(os.path.basename(x)[:-4])\nprint('\\n%s数量:' % image_set, len(image_ids)) # 确认数量\ni = 0\nfor image_id in image_ids:\n i = i + 1\n convert_annotation(data_dir, image_set, imageset2, image_id)\n print(\"%s 数据:%s/%s文件完成!\" % (image_set, i, len(image_ids)))\n\nprint(\"Done!!!\")\n```\n\n\n然后打包好数据集上传服务器\n\n\n## Autodl训练效果\n\n\n---\n\n\n 由于引入了数据集进行扩充后,图片的数量增多,训练时间也更长。\n\n\n **50轮训练的效果图:**\n\n\n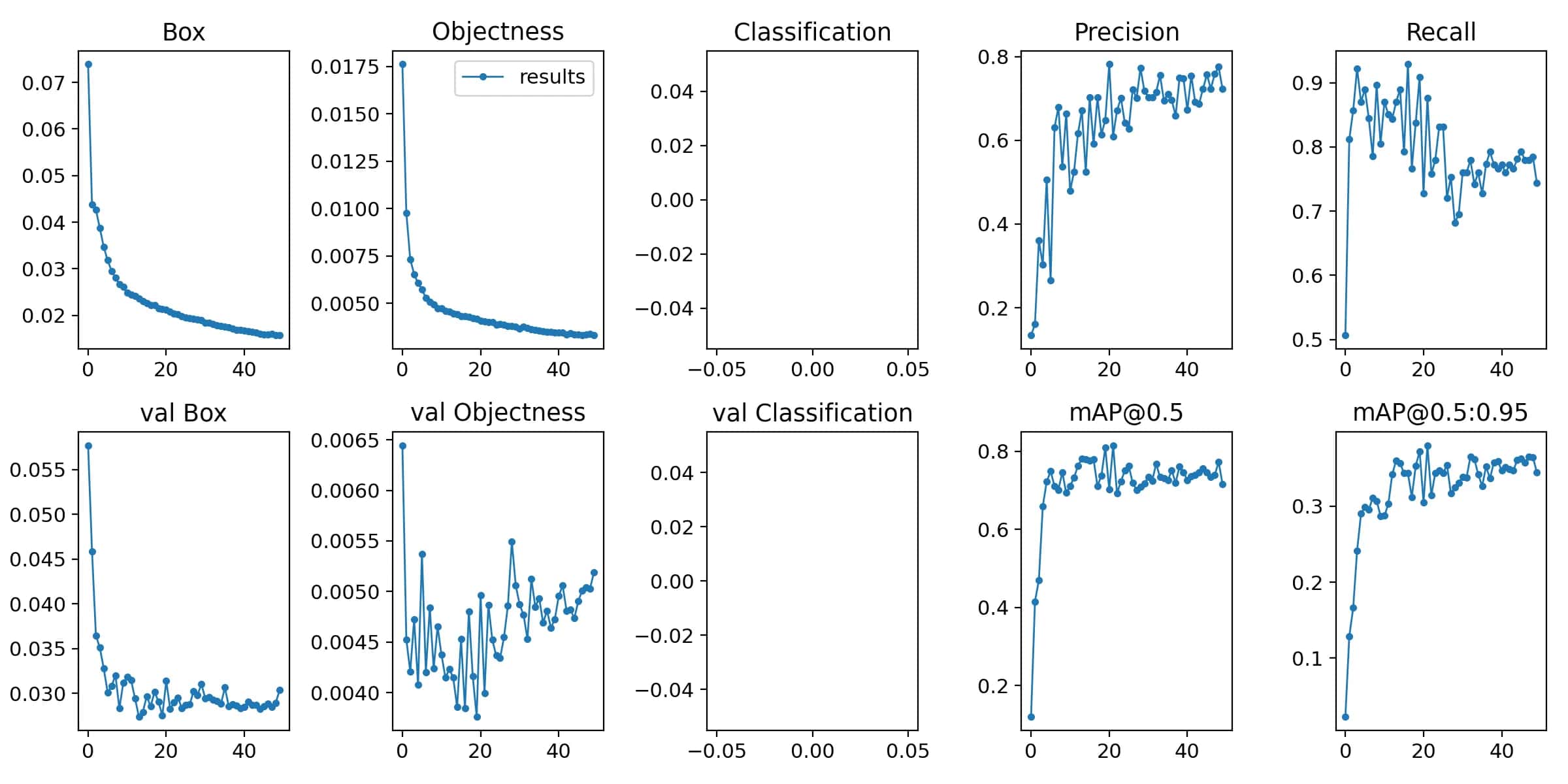\n\n\n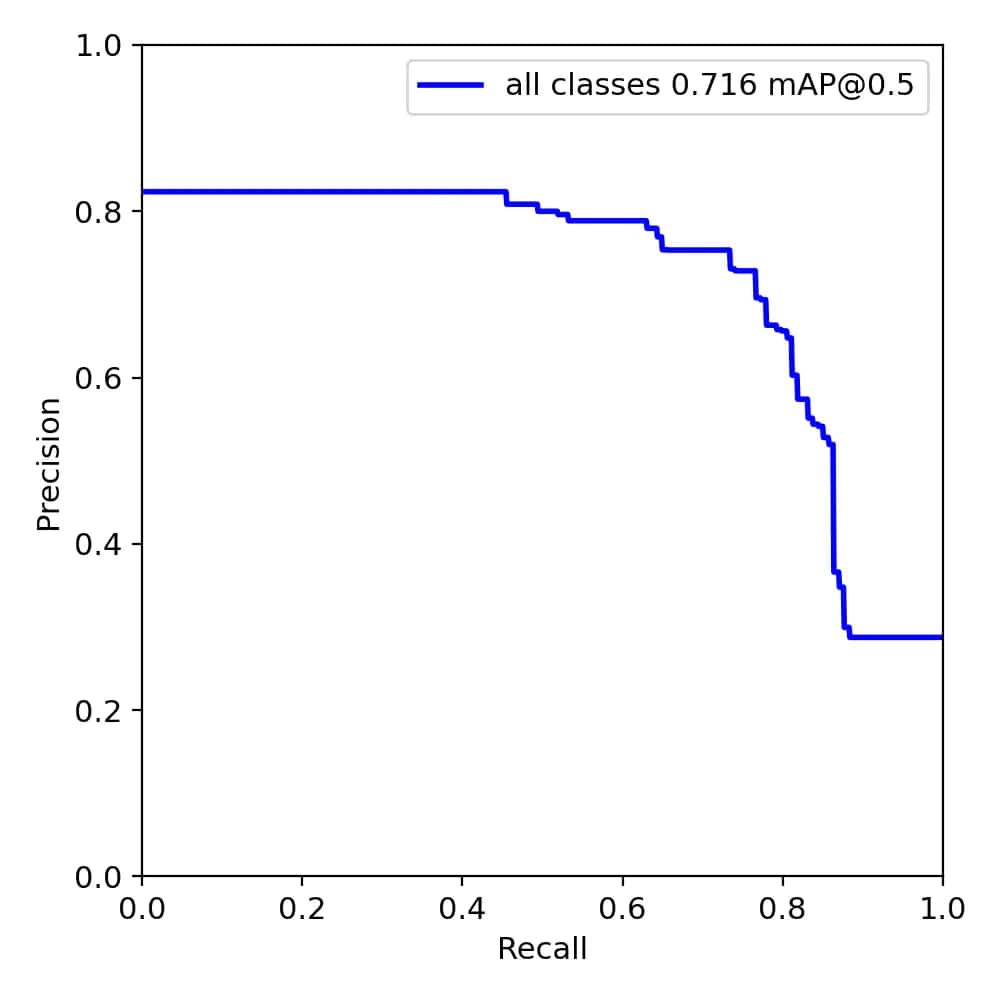\n\n\n **60轮训练的效果图:**\n\n\n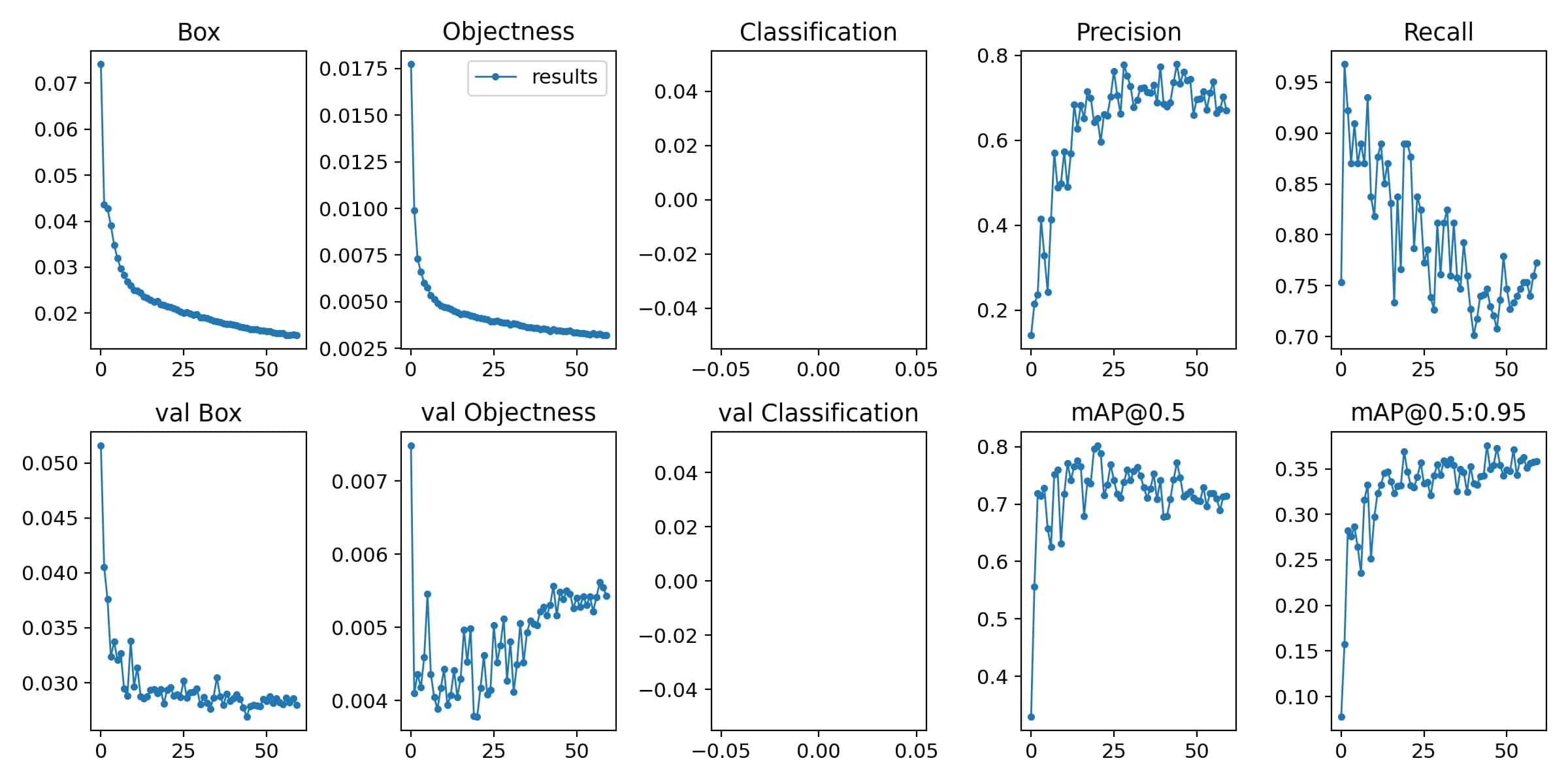\n\n\n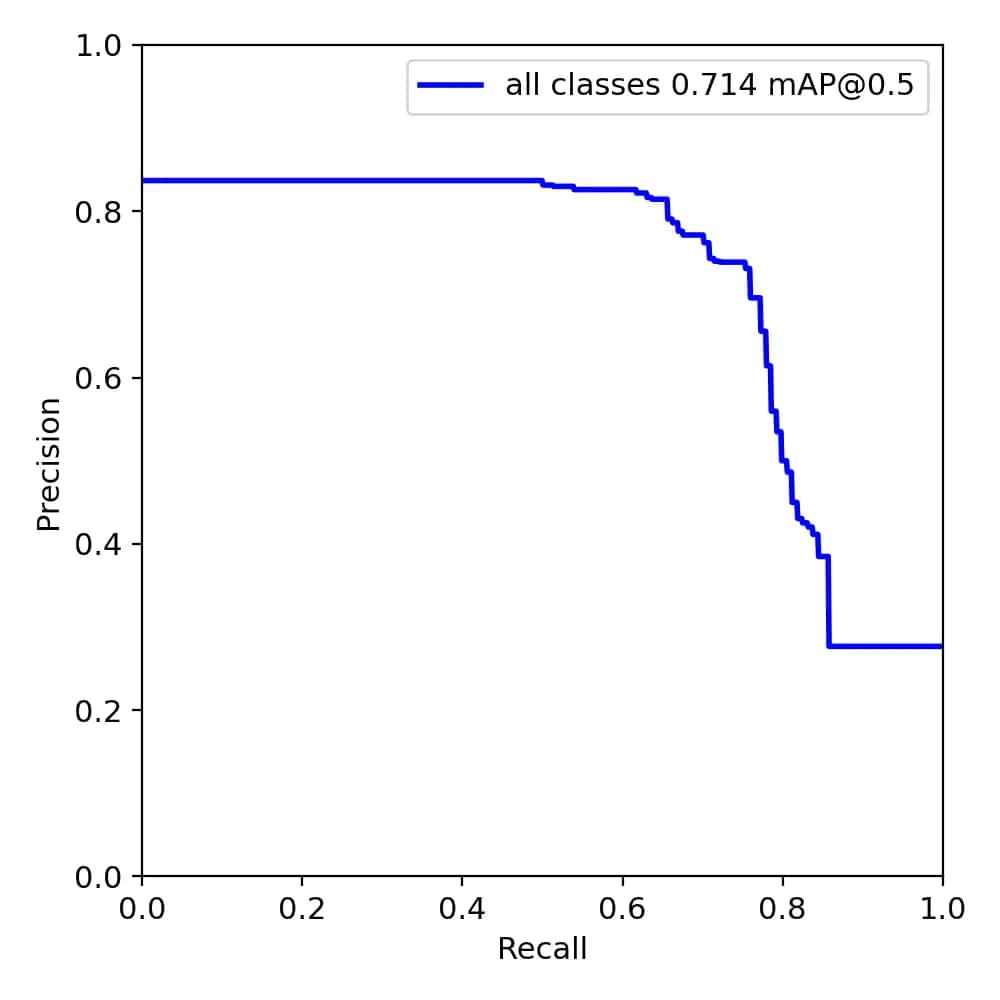\n\n\n **100轮训练的效果图:**\n\n\n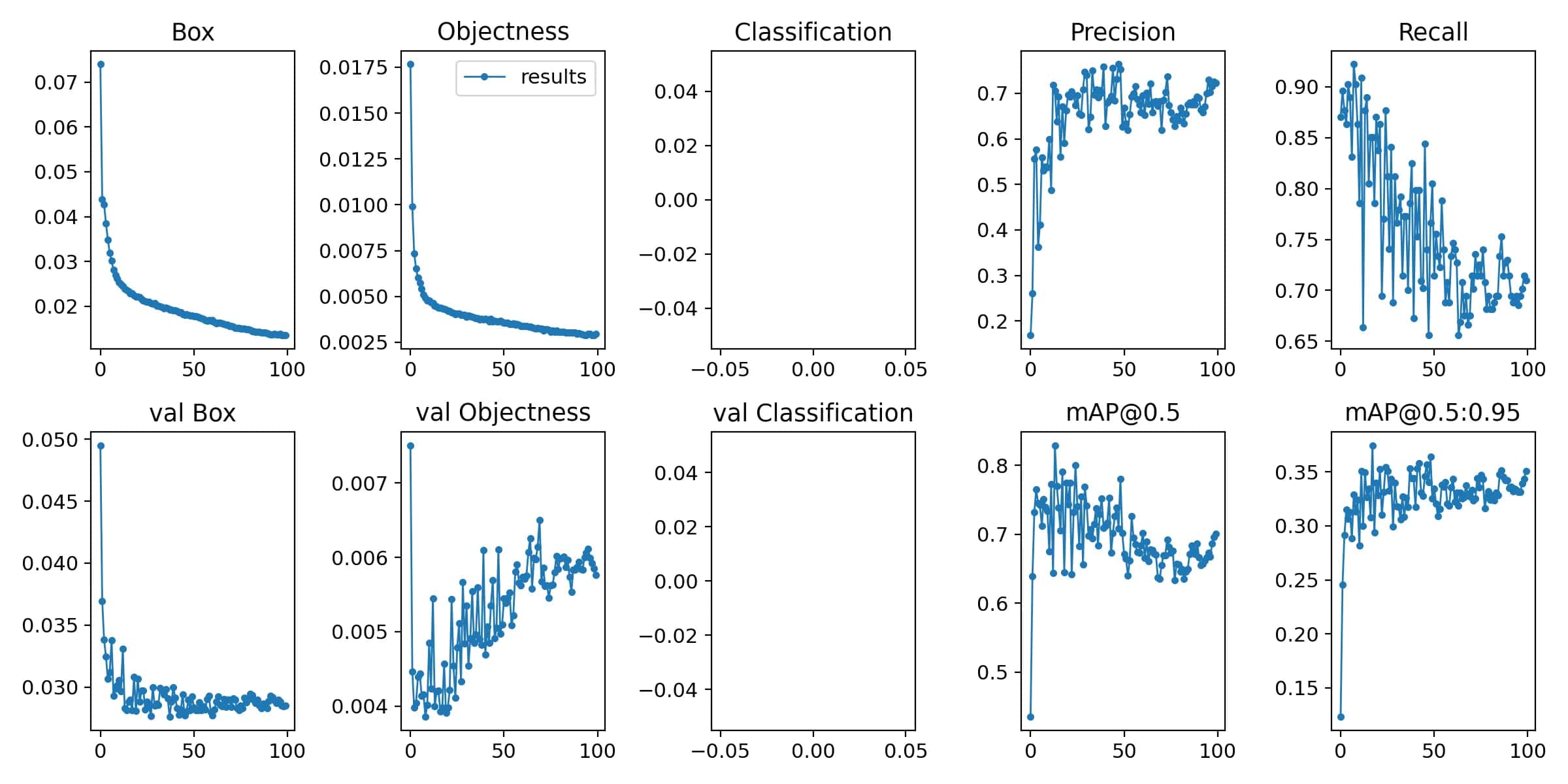\n\n\n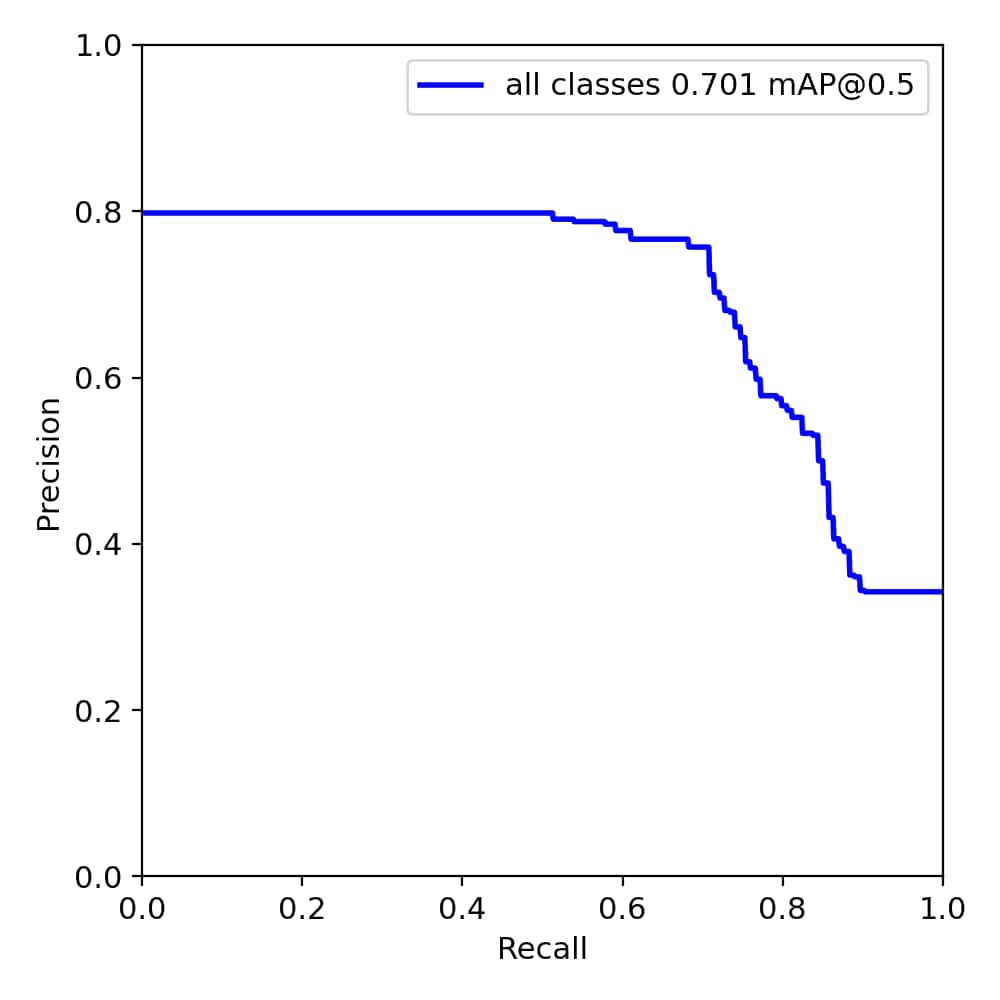\n\n\n 应该还是数据集的问题,出现了过拟合的现象。之后肯定还需要对数据集进行调整,另外由于采用的是最快的训练模型,在训练精度上肯定还有提升的空间。但之前在使用的时候,还出现了一些报错的情况,需要再花时间研究研究。\n\n\n## 测试模块的编写\n\n\n---\n\n\n在设计GUI之前,需要初步完成图片和视频检测的程序编写\n\n\n**1.图片检测测试-核心代码摘录**\n\n\n```python\ndef predict(img):\n img = torch.from_numpy(img).to(device)\n img = img.half() if half else img.float()\n img /= 255.0\n if img.ndimension() == 3:\n img = img.unsqueeze(0)\n\n t1 = time_synchronized()\n pred = model(img, augment=False)[0]\n pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,\n agnostic=opt.agnostic_nms)\n t2 = time_synchronized()\n InferNms = round((t2 - t1), 2)\n\n return pred, InferNms\n\n\ndef cv_imread(filePath):\n # 读取图片\n cv_img = cv2.imdecode(np.fromfile(filePath, dtype=np.uint8), -1)\n\n if len(cv_img.shape) > 2:\n if cv_img.shape[2] > 3:\n cv_img = cv_img[:, :, :3]\n return cv_img\n\n\ndef plot_one_box(img, x, color=None, label=None, line_thickness=None):\n # Plots one bounding box on image img\n tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness\n color = color or [random.randint(0, 255) for _ in range(3)]\n c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))\n cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)\n if label:\n tf = max(tl - 1, 1) # font thickness\n t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]\n c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3\n cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled\n cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)\n\n\nif __name__ == '__main__':\n img_path = \"./UI_rec/testpicture/000743_slice_3_5.jpg\"\n image = cv_imread(img_path)\n image = cv2.resize(image, (640, 640))\n img0 = image.copy()\n img = letterbox(img0, new_shape=imgsz)[0]\n img = np.stack(img, 0)\n img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416\n img = np.ascontiguousarray(img)\n\n pred, useTime = predict(img)\n\n det = pred[0]\n p, s, im0 = None, '', img0\n if det is not None and len(det): # 如果有检测信息则进入\n det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸\n number_i = 0 # 类别预编号\n detInfo = []\n for *xyxy, conf, cls in reversed(det): # 遍历检测信息\n c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))\n # 将检测信息添加到字典中\n detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])\n number_i += 1 # 编号数+1\n\n label = '%s %.2f' % (names[int(cls)], conf)\n\n # 画出检测到的目标物\n plot_one_box(image, xyxy, label=label, color=colors[int(cls)])\n # 实时显示检测画面\n cv2.imshow('Stream', image)\n # if cv2.waitKey(1) & 0xFF == ord('q'):\n # break\n c = cv2.waitKey(0) & 0xff\n\n```\n\n\n\n\n\n2.**视频检测测试-核心代码摘录**\n\n\n```python\ndef predict(img):\n img = torch.from_numpy(img).to(device)\n img = img.half() if half else img.float()\n img /= 255.0\n if img.ndimension() == 3:\n img = img.unsqueeze(0)\n\n t1 = time_synchronized()\n pred = model(img, augment=False)[0]\n pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,\n agnostic=opt.agnostic_nms)\n t2 = time_synchronized()\n InferNms = round((t2 - t1), 2)\n\n return pred, InferNms\n\n\ndef plot_one_box(img, x, color=None, label=None, line_thickness=None):\n # Plots one bounding box on image img\n tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness\n color = color or [random.randint(0, 255) for _ in range(3)]\n c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))\n cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)\n if label:\n tf = max(tl - 1, 1) # font thickness\n t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]\n c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3\n cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled\n cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)\n\n\nif __name__ == '__main__':\n #video_path = 1\n video_path = \"UI_rec/testvideo/test.mp4\"\n # 初始化视频流\n vs = cv2.VideoCapture(video_path)\n (W, H) = (None, None)\n frameIndex = 0 # 视频帧数\n\n try:\n prop = cv2.CAP_PROP_FRAME_COUNT\n total = int(vs.get(prop))\n # print(\"[INFO] 视频总帧数:{}\".format(total))\n # 若读取失败,报错退出\n except:\n print(\"[INFO] could not determine # of frames in video\")\n print(\"[INFO] no approx. completion time can be provided\")\n total = -1\n\n fourcc = cv2.VideoWriter_fourcc(*'XVID')\n ret, frame = vs.read()\n vw = frame.shape[1]\n vh = frame.shape[0]\n print(\"[INFO] 视频尺寸:{} * {}\".format(vw, vh))\n output_video = cv2.VideoWriter(\"./UI_rec/result/results.avi\", fourcc, 20.0, (vw, vh)) # 处理后的视频对象\n\n # 遍历视频帧进行检测\n while True:\n # 从视频文件中逐帧读取画面\n (grabbed, image) = vs.read()\n\n # 若grabbed为空,表示视频到达最后一帧,退出\n if not grabbed:\n print(\"[INFO] 运行结束...\")\n output_video.release()\n vs.release()\n exit()\n # 获取画面长宽\n if W is None or H is None:\n (H, W) = image.shape[:2]\n\n image = cv2.resize(image, (640, 640))\n img0 = image.copy()\n img = letterbox(img0, new_shape=imgsz)[0]\n img = np.stack(img, 0)\n img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416\n img = np.ascontiguousarray(img)\n\n pred, useTime = predict(img)\n\n det = pred[0]\n p, s, im0 = None, '', img0\n if det is not None and len(det): # 如果有检测信息则进入\n det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸\n number_i = 0 # 类别预编号\n detInfo = []\n for *xyxy, conf, cls in reversed(det): # 遍历检测信息\n c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))\n # 将检测信息添加到字典中\n detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])\n number_i += 1 # 编号数+1\n\n label = '%s %.2f' % (names[int(cls)], conf)\n\n # 画出检测到的目标物\n plot_one_box(image, xyxy, label=label, color=colors[int(cls)])\n\n # 实时显示检测画面\n cv2.imshow('Stream', image)\n image = cv2.resize(image, (vw, vh))\n output_video.write(image) # 保存标记后的视频\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\n # print(\"FPS:{}\".format(int(0.6/(end-start))))\n frameIndex += 1\n\n # if frameIndex >= total: # 可设置检测的最大帧数提前退出\n # print(\"[INFO] 运行结束...\")\n # output_video.release()\n # vs.release()\n # exit()\n```\n\n\n[效果呈现](https://www.bilibili.com/video/BV1Lm421E7M2/?spm_id_from=333.999.0.0&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n\n\n## GUI界面\n\n\n---\n\n\n**主控程序:**\n\n\n\n\n\n```python\n# -*- coding: utf-8 -*-\n# runMain.py\nfrom sys import argv, exit\n#这行代码从sys模块中导入了两个函数:argv和exit。argv是一个命令行参数的列表,当从终端运行Python脚本时,可以通过这个列表访问这些参数。exit函数用于退出Python程序。\nfrom PyQt5.QtWidgets import QApplication\n#这行代码从PyQt5的QtWidgets模块中导入了QApplication类。QApplication类管理GUI应用程序的控制流和主要设置,是所有基于Qt的GUI应用程序的起点。\nfrom bboxRecognition import bbox_MainWindow\n#这行代码从bboxRecognition模块(可能是一个自定义模块)中导入了一个名为bbox_MainWindow的类。这个类用于识别黑匣子。\nif __name__ == '__main__':\n#这行代码检查是否是直接运行这个脚本,而不是作为模块导入到其他脚本中。如果是直接运行,那么下面的代码块将被执行\n app = QApplication(argv)\n#这行代码创建了一个QApplication实例,它是任何PyQt5应用程序的入口点。argv参数传递给QApplication,这样它就可以处理来自命令行的参数。\n win = bbox_MainWindow()\n#这行代码创建了box_MainWindow类的一个实例,这个实例很可能是应用程序的主窗口。\n win.showTime()\n#与时间相关的功能。\n exit(app.exec_())\n#最后,这行代码启动了应用程序的主事件循环,通过调用exec_()方法。当事件循环开始后,应用程序将等待用户事件并响应他们。exit函数确保应用程序可以干净地退出,返回码将传递给exit,以便操作系统可以知道程序是正常退出还是发生了错误。\n```\n\n\n**简要摘录核心功能代码:**\n\n\n1.启动GUI界面\n\n\n```python\n#这段代码定义了一个名为bbox_MainWindow的类,它继承自QBeautyUI。这个类是一个GUI窗口,用于某种目标检测或者视频处理应用程序。\nclass bbox_MainWindow(QBeautyUI):\n #这行代码调用父类QBeautyUI的构造函数,确保继承的功能得到正确初始化。\n def __init__(self, *args, obj=None, **kwargs):\n super(bbox_MainWindow, self).__init__(*args, **kwargs)\n\n self.setupUi(self) # 界面生成\n self.retranslateUi(self) # 界面控件\n #这两行代码可能调用了在QBeautyUI中定义的方法,用于初始化和设置用户界面。\n self.setUiStyle(window_flag=True, transBack_flag=True) # 设置界面样式\n #这行代码调用setUiStyle方法来设置窗口的样式,是使窗口透明或者应用其他视觉效果。\n self.path = getcwd()\n self.video_path = getcwd()\n #这里设置了两个路径变量,self.path和self.video_path,它们都被初始化为当前工作目录的路径。\n self.timer_camera = QtCore.QTimer() # 定时器\n self.timer_video = QtCore.QTimer() # 视频定时器\n self.flag_timer = \"\" # 用于标记正在进行的功能项(视频/摄像)\n\n self.LoadModel() # 加载预训练模型\n self.slot_init() # 定义槽函数,这是Qt中用于处理信号和槽机制的函数,用于响应事件。\n self.files = [] #\n self.cap_video = None # 视频流对象\n self.CAM_NUM = 0 # 摄像头标号\n self.cap = cv2.VideoCapture(self.CAM_NUM) # 屏幕画面对象\n #这几行代码初始化了一些变量,包括一个空列表self.files,一个空的视频流对象self.cap_video,一个摄像头编号self.CAM_NUM,以及使用cv2.VideoCapture创建的摄像头视频捕获对象self.cap。\n self.detInfo = []\n self.current_image = []\n self.detected_image = None\n # self.dataset = None\n self.count = 0 # 表格行数,用于记录识别识别条目\n self.res_set = [] # 用于历史结果记录的列表\n self.c_video = 0\n self.count_name = [\"黑匣子\"]\n self.count_table = []\n #这一部分初始化了更多的变量,包括用于存储检测信息、当前图像、检测到的图像、结果集和其他相关数据的列表和变量。\n```\n\n1. 读取预训练模型\n\n```python\ndef LoadModel(self, model_path=None):\n \"\"\"\n 读取预训练模型\n \"\"\"\n parser = argparse.ArgumentParser()\n parser.add_argument('--weights', nargs='+', type=str, default='../weights/best.pt',\n help='model.pt path(s)') # 模型路径仅支持.pt文件\n parser.add_argument('--img-size', type=int, default=480, help='inference size (pixels)') # 检测图像大小,仅支持480\n parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') # 置信度阈值\n parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') # NMS阈值\n # 选中运行机器的GPU或者cpu,有GPU则GPU,没有则cpu,若想仅使用cpu,可以填cpu即可\n parser.add_argument('--device', default='0',\n help='cuda device, i.e. 0 or 0,1,2,3 or cpu')\n parser.add_argument('--save-dir', type=str, default='inference', help='directory to save results') # 文件保存路径\n parser.add_argument('--classes', nargs='+', type=int,\n help='filter by class: --class 0, or --class 0 2 3') # 分开类别\n parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') # 使用NMS\n self.opt = parser.parse_args() # opt局部变量,重要\n out, weight, imgsz = self.opt.save_dir, self.opt.weights, self.opt.img_size # 得到文件保存路径,文件权重路径,图像尺寸\n self.device = select_device(self.opt.device) # 检验计算单元,gpu还是cpu\n self.half = self.device.type != '0' # 如果使用gpu则进行半精度推理\n if model_path:\n weight = model_path\n self.model = attempt_load(weight, map_location=self.device) # 读取模型\n self.imgsz = check_img_size(imgsz, s=self.model.stride.max()) # 检查图像尺寸\n if self.half: # 如果是半精度推理\n self.model.half() # 转换模型的格式\n self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # 得到模型训练的类别名\n \"\"\"\n 这段代码定义了一个名为 `LoadModel` 的方法,它用于加载预训练的机器学习模型,并对模型进行一些初始化设置。这个方法是用于深度学习模型的推理(inference)的准备工作。具体来看,方法的功能包括:\n1. **参数解析**:\n 使用 `argparse` 库来解析命令行参数。这些参数包括模型权重文件的路径、输入图像的大小、置信度阈值、IOU阈值、计算设备(CPU或GPU)、结果保存目录、类别过滤以及是否使用类别无关的非极大值抑制(NMS)。\n2. **设置默认参数**:\n 如果在调用方法时没有指定 `model_path`,它会使用默认的参数设置。\n3. **选择计算设备**:\n 使用 `select_device` 函数(这个函数在代码中没有给出,但可以推断它的功能是选择使用CPU还是GPU进行计算)。\n4. **模型加载**:\n 使用 `attempt_load` 函数加载模型,这个函数可能是一个自定义函数或者来自某个库,用于加载模型并将其映射到指定的计算设备上。\n5. **图像尺寸检查**:\n 使用 `check_img_size` 函数确保输入图像的尺寸与模型的步长兼容。\n6. **半精度推理**:\n 如果计算设备是GPU,则将模型转换为半精度(float16),这样可以加快推理速度并减少内存使用。\n7. **类别名称处理**:\n 获取模型训练时的类别名称,并且如果这些名称在 `Chinese_name` 字典中有对应的中文名称,就替换为中文名称。\n8. **颜色分配**:\n 为每个类别分配一个颜色,这通常用于在图像上绘制检测结果。如果类别的数量没有超过预定义的颜色列表 `color`,它会使用这些颜色;否则,会随机生成颜色。\n9. **预推理**:\n 创建一个零图像张量,并通过模型进行一次前向传递,这通常是为了让模型在实际推理之前“热身”,确保CUDA核心已经加载,从而在后续的推理中能够更快。\n这个方法是深度学习模型部署的常见步骤的集合,用于准备模型进行后续的图像处理和对象检测任务。代码中提到的一些函数和变量(如 `select_device`, `attempt_load`, `check_img_size`, `Chinese_name`)没有在这段代码中定义,所以它们的具体实现细节是未知的,但从上下文中可以推测它们的大致功能。\n```\n\n\n3.融合检测程序-如上面所呈现\n\n\n## 后续多模态的融合\n\n\n---\n\n\n后续完成基础可见光条件的训练之后,还要尝试进行多光谱的融合,提高模型的精确度。\n\n\n# 20240413 会议纪要\n\n\n---\n\n- 明确可检测的图片,进行界限的区分;\n- 在可见光条件下,界定遮挡比例\n- 黑匣子出现极端位置(例如垂直放置情况下),识别灵敏度的控制\n- 漏检率不能低于5%\n- 提高验证集的数量,要有统计结果,配合导出检测结果\n- 更改GUI界面的配色\n- 使用多光谱网络模型\n- 预计五月初开始论文的撰写\n\n# 总结\n\n\n---\n\n\n这篇文章随进度更新,用于记录在毕设过程中遇到的心得和问题。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-03-01",
"type": "Post",
"category": "动手实践",
"slug": "Graduation-Design",
"tags": [
"实用教程"
],
"summary": "这篇文章随进度更新,用于记录在毕设过程中遇到的心得和问题。",
"title": "[毕业设计] 基于Yolo的航拍图像黑匣子检测算法设计",
"status": "Published",
"urlname": "4953c12f-b064-475e-aa3b-1a7019651192",
"updated": "2024-04-23 13:07:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "4953c12f-b064-475e-aa3b-1a7019651192"
}
],
"body": "",
"realName": "[毕业设计] 基于Yolo的航拍图像黑匣子检测算法设计",
"relativePath": "/实用教程/[毕业设计] 基于Yolo的航拍图像黑匣子检测算法设计.md"
},
{
"id": "8a267ce5-f77a-4f5b-986b-3cbdf4aa1f44",
"doc_id": "8a267ce5-f77a-4f5b-986b-3cbdf4aa1f44",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n> 💡 🌺🌺🌺 自您所看到的这个系列的第一篇文章起,都是转载自曲黎敏老师的文章,在此表示对曲老师的诚挚感谢! \n> 这是我第二次阅读曲老师的这本书,所以我希望在空闲时间做一些系统的梳理,同样我愿意为您推荐这三本书,我也曾购买过这三本书赠予同学,我认为阅读过后内容和思想的价值远超纸质书籍的价值,您可以自行尝试阅读。\n\n\n# 正文\n\n\n---\n\n\n 我的初步思路是将书本的内容进行概括性的梳理,但由于时间和精力的因素,进度会非常缓慢,首先致歉。但我希望我整理出的内容,不仅为我,亦可服务大家。\n\n\n## 第二章 中医是如何看病的\n\n\n---\n\n\n 什么样的医生是好医生呢?孙思邈曾经写过一篇非常有名的文章:《大医精诚》。他强调了医家应具备的素质:第一,要学术精;第二,要有慈悲心,有一份对生命的尊重。这两种素质都是至关重要的。\n\n\n### 一 神医传奇——扁鹊使虢太子起死回生\n\n\n---\n\n\n 扁鹊的起死回生术1:三个问诊\n\n\n### 问诊之一——太子得了什么病?\n\n\n---\n\n\n 中庶子回答:“太子病血气不时,交错而不得泄,暴发于外,则为中害。精神不能止邪气,邪气畜积而不得泄,是以阳缓而阴急,故暴厥而死。”即太子是因为血气不按时运行,阴阳交错而不得疏泄,猛烈地暴发在体表,就使得内脏受到伤害。人体的正气不能制止邪气,邪气蓄积而不能疏泄,因此阳脉弛缓、阴脉紧迫,所以突然晕倒而死。中庶子说“精神不能止邪气”,即制止不住邪气,邪气在身体内部蓄积得不到宣泄,因此“阳缓而阴急”而死。即太子的真正病因是“阳缓而阴急”——阳气衰微生发不起来,阴邪又劲急、炽盛,因此就出现了突然昏死的现象。\n\n\n 通过掐人中的方法救治的昏厥,都是因为人体阴阳均很盛大,只是阴阳出现离绝的现象。如果仅仅像虢国太子一样,是“阳缓而阴急”,即人的阴邪特别炽盛,阳气很衰微,阳气克制不了阴气,从而导致身体一派阴霾之象而出现的昏厥,就不能通过掐人中的方法来救治了。\n\n\n 所以,扁鹊问清楚虢太子是“阳缓而阴急”后没有立即掐人中,而是接着问。\n\n\n### 问诊之二——太子是什么时间死的?\n\n\n---\n\n\n 中庶子回答“鸡鸣至今”。“鸡鸣”指的是什么时段?“鸡鸣之时”是丑时(凌晨一点到三点),此时是肝经当令,是阳气渐升、阴气逐渐衰退、阴阳两气相互交通的时间,如果这时人出现了问题,就会出现阳气当升不升、阴气当降不降的现象。\n\n\n 虢太子就是属于阴气该降的时候没有降下来,阴邪克制了阳气,阳气升不起来,被压制住了,就“阳缓而阴急”。这是扁鹊问的第二句话,此时他已经确认虢太子昏死的主要病因,就是因为阴邪阻碍了阳气的生发,并由此判定虢太子只是被憋,是“假死”,而非真死。\n\n\n 这是三个问题当中最关链的一个。发病的时间点是扁鹊问诊的核心。其实,这也是我们日常生活需要注意的一个经验总结,就是当你发现自己身体有任何病症的时候,一定要很认真地看一下病发或感到不适的时间点,看一下在这个时间,你的气血处于一个什么样的状态,是哪条经脉在发挥重要作用,可以把这个作为判断疾病发展的一个重要因素。比如说,如果你是傍晚六点左右发作的心脏病,那你就要小心了,因为那时是酉时,肾经当令,肾水克制心火,有可能是比较严重的心脏病。\n\n\n### 问诊之三——太子已经放进棺材了吗?\n\n\n---\n\n\n 中庶子回答说:还没有放到棺材里。因为“其死未能半日”,指虢太子死亡的时间还很短。这里就牵扯到一个中国古代民俗的问题。人死亡的当天晚上是不会被放到棺材里的,还需要家人“守夜”,从某种意义上来说,家人是害怕这个人没有真的死,也许说不定什么时候他的气就缓过来了。\n\n\n 对于刚刚死去的人,中国的民俗里有“头七”、“二七”的说法,认为一直到“七七”以后,人的灵魂才算是真正走远、走失掉了。为什么风俗里边有“头七”、“二七”这种说法呢?有一本书叫《西藏度亡经》,里面讲了一个非常重要的概念,就是要对灵魂有所等待。在“头七”、“二七”的时候,人的灵魂可能还没有走得很远。\n\n\n 古时中国关于“死亡”的定义和西方社会不一样。西方社会是一个“die”就代表死亡;而在中国,“死亡”这个定义是由两个字组成的,一个是“死”,一个是“亡”。“死”是指肉体的死,而“亡”是指灵魂的走失。古人认为,等到“五七”以后,灵魂基本上已经走得差不多了,“七七”以后就是彻底走远了。\n\n\n 在得知虢国太子还没有被放到棺材里,扁鹊就让中庶子去上报国君,说自己可以让虢太子起死回生。这表现了扁鹊非常自信的一面,他只通过三个问题就已经确认了虢太子没有死。这个问诊问得极其漂亮。\n\n\n### 扁鹊的起死回生术:\n\n\n---\n\n\n**三步治疗法**\n\n\n 虢国太子的父王把扁鹊迎到城里,先说了一些感激之词,然后让扁鹊开始治疗。扁鹊的治疗也非常漂亮。他让弟子子阳“砺针砥石,以取外三阳五会”。古代最早的针是用石头做的,叫砭石。砭石一般出现在东方的海边,这种石头非常圆润,是中国古代最早的治疗工具,可以用它来摁压或者是点刺穴位。\n\n\n 治疗第一步:用石针点刺穴位扁鹊治疗虢太子的第一步,就是先用针刺——用石针来点刺他的穴位。扁鹊选了两个地方,分别是“三阳”、“五会”。三阳会聚之所是百会穴,百会穴是从两个耳尖上去,一直到头部的交汇处。\n\n\n 为什么取百会穴?因为虢太子是阳气升不起来才昏厥的,而百会穴是“诸阳之会”,是所有阳经会聚的地方。人一摁压百会穴,就能够让阳气提升起来。五会穴就是五腧穴,指的是十二经脉肘、膝关节以下的井、荥、输、经、合五个特定穴位。井穴就是指尖处,中医把整个经脉比喻成一条河流,河流的发端就是这些井穴,这些地方是气血最薄的地方,但也是气血最旺盛的地方。如果人指尖麻木,就意味着阴阳的交通出现了问题。\n\n\n 井穴一般有两个问题:一是它为气血刚刚生发之地,生机易受抑制;二是此处气血少,因为少,所以它特别容易堵塞。因此大家要经常活动手指,通过活动手指,可以把五腧穴充分地活动起来,这对我们人体非常有好处。\n\n\n 如果家人突发脑溢血,中医里有一个很有效的急救方法,就是“十宣放血”,用三棱针刺破十指尖,挤出六七滴淤血来,头部的溢血就可以止住。为什么这样做?因为这些地方和头皮都属于末梢,通过点刺手的十井穴,能让气血得到疏解。如果指尖不出血,再挤也挤不出来怎么办?还可以选择指缝这些肉最少、气血特别薄的地方来点刺。\n\n\n 扁鹊的第一个办法是摁压百会穴,第二个办法是通过针刺井穴来疏血,放血以后太子很快就苏醒了。《史记》中写道“有闲,太子苏”,即过了一会儿太子就苏醒了,开始有气息了。\n\n\n**治疗第二步:**\n\n\n 使用热敷法第二步,太子苏醒以后,扁鹊让学生子豹“为五分之熨”,煮“八减之剂”(古方名,今已失传),分别热敷太子的两胁下,使温热药气深入体内五分。两胁下是由胆经所主,在人体是少阳,而少阳是气机的枢纽,是阴阳气血交通的枢纽。热敷的方法实际上是通过皮肤给药,引脏腑之气血外行。\n\n\n 此时,太子的情况得到明显改善,能够坐起来了。这个过程是在治疗肌肤腠理,肌肤腠理就相当于一个很大的呼吸系统,而这个系统我们要充分地利用,比如现在也有用中药进行熏蒸的方法,吃完了中药,用中药渣来泡脚,对身体也是非常有好处的。\n\n\n**治疗第三步:**\n\n\n 给太子服下热汤药第三步,扁鹊才用汤药。对于昏倒的人来讲,一定要先急救,先让他醒过来,如果灌药的话是来不及的,因为煮药也需要时间。所以在现实生活当中,大家要先学一些很便捷的救急方法,比如扁鹊先用针刺,然后用热敷,同时煮中药,等太子坐起来以后,就开始给他服下热汤药,这样可以进一步调整他的阴阳气血。太子吃了二十天左右的中药,就彻底恢复了健康。\n\n\n 扁鹊治虢太子,针法非常妙,取穴非常精到,热敷法好,用药绝,这是扁鹊最终被称为“医家之圣手”的原因。东汉时张仲景在写《伤寒论》序时,第一句话就是“余每览越人入虢之诊,望齐侯之色,未尝不慨然叹其才秀也”。就是说每当张仲景看到秦越人(扁鹊)入虢救治虢太子,使其起死回生,以及望齐侯(齐桓公)之色的故事,都会感慨扁鹊的才华太出众了。\n\n\n# 总结\n\n\n---\n\n\n 之前第一次整理的脑图是希望能整理出完整第二章的,但今天突然觉得,整理不是为了完成任务,没必要急于求成,反而希望能把聚焦于细微之处,耐心去打磨和体会。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-01-16",
"type": "Post",
"category": "走近生活",
"slug": "Wisdom-of-Life-2",
"tags": [
"生命智慧-曲黎敏"
],
"summary": "医家应具备的素质:第一,要学术精;第二,要有慈悲心,有一份对生命的尊重。",
"title": "[生命智慧] 中医是如何看病的-扁鹊使虢太子起死回生-曲黎敏",
"status": "Published",
"urlname": "8a267ce5-f77a-4f5b-986b-3cbdf4aa1f44",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "生命智慧-曲黎敏",
"doc_id": "8a267ce5-f77a-4f5b-986b-3cbdf4aa1f44"
}
],
"body": "",
"realName": "[生命智慧] 中医是如何看病的-扁鹊使虢太子起死回生-曲黎敏",
"relativePath": "/生命智慧-曲黎敏/[生命智慧] 中医是如何看病的-扁鹊使虢太子起死回生-曲黎敏.md"
},
{
"id": "360321b9-eb2a-4fbe-a76a-96c7b2671596",
"doc_id": "360321b9-eb2a-4fbe-a76a-96c7b2671596",
"updated": 1713876660000,
"body_original": "\n# 更新log\n\n\n---\n\n\n 已通过购置usb网卡的方式实现了单设备wifi接受并共享热点,未实现wifi中继,中继和热点还是有区别的。之后有时间更新。\n\n\n# 前言\n\n\n---\n\n\n 这是一篇不成熟的日志,记录了我对于linux中继网络的一些思考。\n\n\n 我突然想到之前玩的一款手游,叫做贪婪洞窟,里面非常让人觉得有意思的事情是,往往在下洞穴探秘的时候,会收到前辈的手稿,这些手稿记录了先驱在探索洞穴的时的一些思考,读这些故事很有趣,此去经年,虽然已经不打这款游戏了,也装过盗版刷通了副本,但是这个片段始终让我觉得和现在的自己很像。\n\n\n# 正文\n\n\n---\n\n\n 首先,这个需求适用于哪些方面,适用于房间wifi信号不好的时候,才会考虑使用设备进行中继。\n\n\n 我先是去京东上看了看无线中继的价格,巴掌大小,也就几十块钱。\n\n\n 但是我突然一想,它能做,我的鲁班猫为什么不能做。\n\n\n 之前闲置了数个月的鲁班猫终于在尘封的袋子里被拿出来。\n\n\n## 未能搞懂的驱动模块\n\n\n---\n\n\n 在Linux上,你可以将你的电脑配置成一个无线信号中继器或扩展器,这样做可以帮助扩展现有无线网络的覆盖范围。这个过程通常包括两个无线网络接口:一个用于连接到现有的无线网络(作为客户端),另一个用于创建一个新的无线热点,其他设备可以连接到这个热点以接入网络。\n\n\n 在最开始,我是沿着这个思路去走的,过程如下;\n\n1. **确保硬件兼容性**:\n\t- 你需要一个支持AP模式的无线网卡。你可以通过运行`iw list`命令来检查你的无线网卡是否支持AP模式。\n2. **安装必要的软件**:\n\t- 确保你的系统上安装了`hostapd`(用于AP模式)和`dnsmasq`(用于DHCP和DNS服务):\n\n\t```shell\n\tsudo apt-get install hostapd dnsmasq\n\t```\n\n3. **配置网络接口**:\n\t- 编辑`/etc/network/interfaces`或使用`nmcli`(NetworkManager的命令行接口)来配置网络接口。你需要为两个无线接口分别配置客户端和AP设置。\n4. **配置****`hostapd`**:\n\t- 创建`/etc/hostapd/hostapd.conf`配置文件,设置SSID和密码等:\n\n\t```shell\n\tinterface=wlan1\n\tdriver=nl80211 #卡在了这一步\n\tssid=YourRepeaterSSID\n\thw_mode=g\n\tchannel=6\n\twmm_enabled=0\n\tmacaddr_acl=0\n\tignore_broadcast_ssid=0\n\tauth_algs=1\n\twpa=2\n\twpa_passphrase=YourPassphrase\n\twpa_key_mgmt=WPA-PSK\n\twpa_pairwise=TKIP\n\trsn_pairwise=CCMP\n\t```\n\n\n\t 最开始我使用hostapd,一种有驱动报错的问题,之后就重启了系统找其他的思路。我也尝试过怎么适配这个驱动,但一时半会搞不成。\n\n\n\t## **使用 create_ap 脚本**\n\n\n\t---\n\n\n\t**使用** **`create_ap`** **脚本**:\n\n\t- `create_ap` 是一个简化创建接入点过程的 shell 脚本。它允许您通过一个命令行界面轻松地创建一个接入点。您可以从 GitHub 获取这个脚本并按照提供的说明进行安装和使用。\n\n\t 我也尝试使用过这个脚本,但是实际情况是这样的,鲁班猫的网卡不具备同时开启wlan0和waln1的能力,在同一时间只能作为设备或者热点存在。\n\n\n\t## 使用 NetworkManager 的热点功能\n\n\n\t---\n\n\n\t我还是比较喜欢这个,原因如下:\n\n\n\t1.系统自带\n\n\n\t2.操作便捷\n\n\n\t### 确认设备网卡是否支持AP模式。\n\n\n\t---\n\n\n\t打开终端,运行以下命令查看无线网卡是否支持 AP 模式:\n\n\n\t```shell\n\tiw list\n\t```\n\n\n\t在输出中寻找 \"Supported interface modes\" 部分,查看是否包含 \"AP\"。\n\n\n\t终端我是使用串口进行连接的。\n\n\n\t### **创建一个共享的网络连接**\n\n\n\t---\n\n\n\t使用命令行:\n\n\n\t```shell\n\tnmcli dev wifi hotspot ifname wlan0 ssid YourHotspotSSID password \"YourPassword\"\n\t```\n\n\n\t请将 `wlan0` 替换为你的无线设备名称,`YourHotspotSSID` 替换为你想要的热点名称,`YourPassword` 替换为你的密码。\n\n\n\t一般在这种情况下,一个wifi热点就被创建完成了,但是需要注意的是,该热点还不具备上网功能,目前只具备信号的中继功能。您还需要输入,就是进入互联网的最根本的设备,可以是您的光猫,当然也可以是手机。\n\n\n\t## 走过的弯路\n\n\n\t---\n\n\n\t 我花了很多时间尝试同时开启wlan0和wlan1,在我一筹莫展的时候,我才突然想起手机可以作为信号的输入,但是由于手机的天线质量比较一般,通过鲁班猫做下一步操作或许更加合适。\n\n\n\t 第一次成功是使用wlan1作为热点,但是缺点是重启后,鲁班猫又重新恢复了作为设备的角色。每一次重启重新用串口进终端显然不是我们需要的效果。\n\n\n\t 而且中途还遇到了很奇怪的事情,让我深深陷进去了。在我执行完这一步之后,或许是一些其他的步骤,导致wlan在软件层面被禁用了,在终端里死活打不开,气得我都快要怀疑是硬件出了问题,都准备好重装系统了。然后还顺带看了点openwrt的知识,很零碎。\n\n\n\t **确保没有冲突的网络服务**:\n\n\n\t\t有时候,其他网络服务(如 `wpa_supplicant` 或 `dhclient`)可能会跟 NetworkManager 冲突,尝试禁用或停止这些服务,然后再次尝试启用接口。\n\n\n\t\t```shell\n\t\tsudo systemctl stop wpa_supplicant\n\t\tsudo systemctl stop dhclient\n\t\t```\n\n\n\t\t然后再次尝试启用 `wlan1`。\n\n\n\t一直在徘徊,找不到问题所在:\n\n\n\t **检查无线设备的 RF-Kill 状态**:\n\n\n\t 有时候无线设备可能被软件或硬件层面的 RF-Kill 锁定,导致设备不可用。\n\n\n\t```shell\n\trfkill list\n\t```\n\n\n\t如果您看到 `wlan1` 被列为 `Soft blocked` 或 `Hard blocked`,您可以解锁它:\n\n\n\t```shell\n\tsudo rfkill unblock wifi\n\t```\n\n\n\t **检查接口状态**:\n\n\n\t 使用以下命令检查两个接口的状态:\n\n\n\t```shell\n\tnmcli device status\n\t```\n\n\n\t 这将显示所有网络设备的列表以及它们的状态。\n\n\n\t 一直是wlan0 state DOWN,搞得我心灰意冷。\n\n\n\t<details>\n\t <summary>反复在终端里排查问题,不知道因为这个问题,绕了多少圈,然后心灰意冷的情况下接mipi显示屏的时候,FPC的线还接反了,我特么还以为mipi屏幕坏了,后来您知道怎么着了么,我在意识到mipi屏幕的问题了之后,重新用图形化界面开启了wlan,解决了在终端死活解决不了的问题,很烦躁。(一般半夜我和白天判若两人,不太能控制情绪,为啥啊,因为这个月流量超了快15块钱,学习通刷课刷得我是真没流量了,平时又好刷个视频,总之很烦)</summary>\n\t\n\t1. **检查无线设备是否被禁用**:\n\t\n\t\t```shell\n\t\trfkill list\n\t\t```\n\t\n\t\n\t\t如果看到 `wlan0` 或 `wlan1` 被列为 `Soft blocked` 或 `Hard blocked`,可以使用以下命令解锁:\n\t\n\t\n\t\t```shell\n\t\tsudo rfkill unblock wifi\n\t\t```\n\t\n\t2. **启动无线接口**:\n\t\n\t\t尝试手动启动 `wlan0`:\n\t\n\t\n\t\t```shell\n\t\tsudo nmcli device set wlan0 managed yes\n\t\tsudo nmcli device connect wlan0\n\t\t```\n\t\n\t3. **检查 NetworkManager 配置**:\n\t\n\t\t确保 NetworkManager 配置没有错误地禁用了 `wlan0`。检查 `/etc/NetworkManager/NetworkManager.conf` 和 `/etc/NetworkManager/conf.d/` 目录下的任何配置文件,看看是否有任何配置可能会导致 `wlan0` 处于关闭状态。\n\t\n\t4. **查看接口状态**:\n\t\n\t\t再次检查接口的状态:\n\t\n\t\n\t\t```shell\n\t\tnmcli device status\n\t\t```\n\t\n\t\n\t\t这将显示所有网络设备的列表以及它们的状态。确保 `wlan0` 和 `wlan1` 都不是 `unavailable` 或 `down`。\n\t\n\t5. **检查驱动和硬件支持**:\n\t\n\t\t确保您的无线网络适配器和驱动程序支持同时用作连接到无线网络和热点。您可以使用 `iw list` 命令来检查无线适配器的功能。\n\t\n\t\n\t\t```shell\n\t\tiw list\n\t\t```\n\t\n\t\n\t\t在输出中查找 `valid interface combinations` 或类似的部分,以确定您的硬件是否支持所需的操作模式。\n\t\n\t6. **查看系统日志**:\n\t\n\t\t如果 `wlan0` 无法启动,查看系统日志可能会提供一些线索:\n\t\n\t\n\t\t```shell\n\t\tjournalctl -u NetworkManager\n\t\t```\n\t\n\t\n\t\t这可能会显示尝试启动接口时遇到的任何错误信息。\n\t\n\t\n\t\n\t </details>\n\n\n\t 更专业的问题的解释:\n\n\n\t 您的无线设备支持接入点(AP)和监控(monitor)模式,但不支持接口组合。这意味着您的无线适配器可能无法同时在两个不同的模式下运行,例如,不能同时作为一个普通的无线网络连接(客户端模式)和一个无线热点(AP模式)。\n\n\n\t 如果您需要 `wlan0` 和 `wlan1` 同时运行,并且一个用于连接到无线网络,另一个用于创建热点,这可能是不可行的,因为硬件不支持这种配置。\n\n\n\t### 热点模式系统守护\n\n\n\t---\n\n\n\t 经过上述一顿操作猛如虎,一看战绩0-5的操作之后,终于迈入了期待的方向,经过和舍友的讨论,确认了问题的解决思路,手机连接wifi同时使用usb共享到鲁班猫,这样就可以解决无法同时开启两个网口的问题,使用usb在传输速率和稳定性上也会好一点,然后鲁班猫进行中继,用两根小天线就可以将wifi广播到整个屋子了。\n\n\n\t 要在系统启动时自动执行`nmcli`命令来创建一个热点,您可以将该命令添加到系统启动脚本中。在Ubuntu系统中,您可以使用`systemd`来管理系统服务和启动脚本。以下是一种在系统启动时自动执行`nmcli`命令创建热点的方法:首先,创建一个`nmcli-hotspot.service`服务文件,您可以使用以下命令创建并编辑该文件:\n\n\n\t```shell\n\tsudo nano /etc/systemd/system/nmcli-hotspot.service\n\t```\n\n\n\t在打开的编辑器中,添加以下内容:\n\n\n\t```text\n\t[Unit]\n\tDescription=Start nmcli wifi hotspot on boot\n\t\n\t[Service]\n\tType=oneshot\n\tExecStart=/usr/bin/nmcli dev wifi hotspot ifname wlan0 ssid cat password cattemppwd\n\tExecStop=/usr/bin/nmcli con up id YourWiFiSSID\n\tRemainAfterExit=yes\n\t\n\t[Install]\n\tWantedBy=multi-user.target\n\t```\n\n\n\t请确保`ExecStart`行中的命令与您想要运行的`nmcli`命令相匹配。启用并启动`systemd`服务:保存并关闭编辑器。然后,运行以下命令启用并启动新创建的`nmcli-hotspot.service`服务:\n\n\n\t```shell\n\tsudo systemctl enable nmcli-hotspot.service\n\tsudo systemctl start nmcli-hotspot.service\n\t```\n\n\n\t这将使您的`nmcli`命令在系统启动时自动执行,创建无线热点。请注意,确保您的系统正确配置了无线网络接口`wlan0`以及`nmcli`命令在系统启动时可以正确执行。如果有任何问题,您可以查看`systemd`日志以获取更多信息:\n\n\n\t```shell\n\tsudo journalctl -u nmcli-hotspot\n\t```\n\n\n\t这样您就可以在系统启动时自动创建无线热点了。\n\n\n\t在我断掉串口和mipi屏幕之后,重新启动之后,发现cat的热点正常启动,遂认为取得了够用的效果。\n\n\n\t## 后话\n\n\n\t---\n\n\n\t 经过测试,ipad可以正常使用,笔记本三个系统,ubuntu好久没用了,没测试,mac在使用cat热点的时候,存在问题,晚上没解决。win是正常可以使用该热点的。\n\n\n\t### 手机为什么既能连接网络又能充当热点\n\n\n\t---\n\n\n\t我不得不感慨,生活中随便用的一个设备,tmd功能这么牛逼。\n\n\n\t手机能够同时连接网络和充当热点是因为它们具备两种无线通信模块:\n\n\t1. **蜂窝数据连接**:手机通过蜂窝网络(如2G, 3G, 4G, 或5G)连接到互联网。这是通过手机内置的蜂窝无线模块实现的,该模块可以连接到移动运营商的网络。\n\t2. **Wi-Fi 热点功能**:同时,手机可以开启Wi-Fi热点功能,这实际上是将手机变成一个无线路由器。其他设备可以通过Wi-Fi连接到这个热点,然后通过手机的蜂窝数据连接访问互联网。\n\n\t 这两种功能可以同时工作,因为它们使用不同的无线技术和频率。蜂窝网络通常在800MHz到2600MHz频段工作,而Wi-Fi则通常在2.4GHz或5GHz频段工作。因此,手机可以通过蜂窝网络接收数据,同时通过Wi-Fi热点功能分享这些数据。\n\n\n\t 不过,值得注意的是,当手机作为热点使用时,它通常会消耗更多的电池电量,并且可能会变热,因为它需要同时处理蜂窝网络和Wi-Fi网络的信号。此外,手机作为热点时,其蜂窝数据使用量可能会增加,这取决于连接到热点的其他设备的数据使用情况。\n\n\n\t 大多数手机和许多现代的无线网卡支持一种叫作“Wi-Fi Direct”或“软件接入点(Soft AP)”的功能,它们可以让设备即作为无线客户端连接到Wi-Fi网络,同时也能作为热点向其他设备提供Wi-Fi连接。\n\n\n\t 但是,大多数手机和设备在使用Wi-Fi连接到网络的同时,通常不能将同一个Wi-Fi适配器用于创建热点来共享这个连接。这是因为大多数Wi-Fi适配器在任何给定时间只能在一个模式下工作,即要么作为客户端连接到一个Wi-Fi网络,要么作为热点允许其他设备连接。\n\n\n\t 不过,一些特定的硬件和驱动程序支持一种名为“虚拟接入点(Virtual Access Point, VAP)”或“多SSID”功能,它可以让单个无线网卡同时扮演多个角色。对于这样的硬件,理论上是可能的,但这需要硬件支持,并且在软件上也需要相应的配置,这通常不是大多数手机或操作系统默认提供的功能。\n\n\n\t 因此,如果您的手机可以做到这一点,那么它可能具有特定的硬件和软件支持,允许其无线网卡同时运行在客户端模式和热点模式。这种功能不是所有设备都支持的,通常取决于设备的硬件能力和操作系统的软件实现。\n\n\n\t# 总结\n\n\n\t---\n\n\n\t 总之,今晚鲁班猫和它的两根小天线给了我巨大的失落和巨大的惊喜,感谢野火的奉献!后续我有机会抽空了解了解。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-03-30",
"type": "Post",
"category": "动手实践",
"slug": "linux-wifi",
"tags": [
"实用教程"
],
"summary": "大多数手机和许多现代的无线网卡支持一种叫作“Wi-Fi Direct”或“软件接入点(Soft AP)”的功能,它们可以让设备即作为无线客户端连接到Wi-Fi网络,同时也能作为热点向其他设备提供Wi-Fi连接。",
"title": "[网络中继] 使用linux来中继wifi信号",
"status": "Published",
"urlname": "360321b9-eb2a-4fbe-a76a-96c7b2671596",
"updated": "2024-04-23 12:51:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "360321b9-eb2a-4fbe-a76a-96c7b2671596"
}
],
"body": "",
"realName": "[网络中继] 使用linux来中继wifi信号",
"relativePath": "/实用教程/[网络中继] 使用linux来中继wifi信号.md"
},
{
"id": "6d3fe114-b343-457d-8adf-79db7bba2f3c",
"doc_id": "6d3fe114-b343-457d-8adf-79db7bba2f3c",
"updated": 1708863120000,
"body_original": "\n> 💡 <u>**230704更新**</u> \n> 最近当然对ubuntu还是有一些学习对兴趣的,但很可惜的是,计划我们得向后移了,目前的主力系统是Mac系统,因为Mac系统对学习的支持属性很棒,而且足够优雅。 \n> 但是Linux有时间我还是会优先考虑学习的,它曾经给我带来很多的乐趣,未来也会如此,只不过我们需要做出暂时性的战略转移。\n\n\n# Module1 我和ubuntu\n\n\n---\n\n\n 这个部分介绍我和ubuntu的故事🥰\n\n\n### 和ubuntu的相遇\n\n\n---\n\n- 从去年看到中科院的“一生一芯”活动中了解了ubuntu系统,当时成功的为电脑装上ubuntu20.04,当时大费周折,光是装双系统的时候都得小心翼翼,后来好不容易,成功地装成之后,才发现,这个系统就像是一座还没装修的毛坯房,什么输入法了,软件了,什么都是陌生的,只有光秃秃的命令行。\n- 后来有一段时间折腾了ubuntu之后,热情也就慢慢冷却了,觉得这个linux系统虽然很帅,但是真的难用啊。而且一堆问题,比如亮度无法调节,非常鸡肋。\n- ubuntu的壁纸一直很吸引我,23.04版本中的主题是[龙虾与月球](https://bu.dusays.com/2023/09/04/64f52c58337d9.jpg)(图片来自于ubuntu社区),但是我在ubuntu上一直用的是第二张[梨花](https://bu.dusays.com/2023/09/04/64f52c70f0a30.jpeg)的图片。 2023-06-03\n\n---\n\n\n### 和ubuntu的相爱相杀\n\n\n---\n\n- 我特别喜欢ubuntu的命令行的使用方式,这样可以更加简洁纯粹的去做一件事情\n- 后来升级到了ubuntu22.04,昨天晚上打开ubuntu一看,图形化界面没了,我吓了一跳,后来又花了一个多小时的时间来捣鼓这个故障。具体参照以下博客。\n\n[bookmark](http://blog.csdn.net/LInthunder/article/details/108394917)\n\n\n\n\n\n帅气的水母,他终于回来了,艺术感拉满。(由于是半夜在床上拍的,太激动了)\n\n\n### ubuntu的发展和使用\n\n\n---\n\n- 以后我主要采用notion作为文件的中转站了,微信毕竟还是麻烦,且耗费精力,我需要一个更加沉静式的环境去做一件自己喜欢的事情。\n- ubuntu我打算还是作为一个专注学习的地方,一些附加功能的软件几乎不装了\n\n### 从linux谈开源与服务(一点拙见)\n\n\n---\n\n\n**1.什么是linux**\n\n\n linux诞生与1991.10.5,是由unix的操作系统衍生的类unix系统,于此同时,苹果的操作系统也是类unix的,还有window,区别在于linux是一个开源的平台,而apple和windows是商业为目的的平台,所以在全世界的用户中,window几乎占据垄断地位(window和apple的竞争故事下次有机会再讲),本期的主角还是linux。\n\n\n\n**2.linux有什么特别之处吗?**\n\n\n 我喜欢linux不仅仅是因为他的开源和强大,还因为它所代表的linux文化,如果把window比作华丽丽的豪宅,那linux就像是自己搭建的小屋,在舒适度上,window桌面化的便捷让电脑的使用成本大大降低,甚至被称为是革命性的标志,但是缺点就在于在这座宫殿里,我们只是扮演一个消费者的角色,我们只是window世界里的访客,我们并不能移动这座宫殿里的任何一件花瓶或者摆设。 \n\n\n 但是linux不一样,linux只会给你一个内核,就像自己亲手遭小木屋一样,之后屋内的陈设都是要自己去设计,从输入法的安装,桌面的安装,linux最有特色的地方就是在于他的命令行的艺术,所以在linux的世界,人机之间处于一个对等的地位,通过命令行可以完成很多高阶的不可思议的操作,他很优雅但是有一定的学习成本。\n\n\n**3.为什么linux的移动端无法成功**\n\n\n 因为一旦移动端的成功,将会重新改写市场的定义,但是在服务器,嵌入式应用领域,linux绝对是好的。\n\n\n\n**4.我对linux的认识**\n\n\n 从使用上,linux给我的感觉是运行更加流畅,但是因为硬件问题,会比使用window系统时稍微发热高一点而且更加耗电。但是linux干净简约,并且具有生命力,就像是江湖中的隐士,武功高强但是不与世人争抢。\n\n\n\n**5.linux的衍生思考**\n\n\nlinux所代表的一种先进的文化体系是一种让人值得敬佩的存在,人们有对向善和美好生活的追求,但是恶所代表的自私恰恰是保护自己免受外界伤害的盾牌。善良是一种理想,自私亦是一种现实。 风云变幻,时过境迁,人生如逆旅,我亦是行人。\n\n\n\n这是[参考文献](https://www.zhihu.com/question/279662825?utm_id=0) 🍒\n\n\n2023-06-07 \n\n\n### ubuntu命令行汇总\n\n\n---\n\n\n打开网页:xdg-open [http://](http://baidu.com/)matrixcore.top\n\n\n打开pdf:xdg-open 1800.pdf\n\n\n启动程序:microsoft edge & (tab可以自动补全)\n\n\n关机重启:sudo shutdown/reboot\n\n\n(win和mac对于关机基本上只需要点击关机按钮,但是当我们用命令行和机器进行沟通时,也许此时你并不会仅仅把它当作一台机器,而是像是在和一位好朋友告别)\n\n\n### 记录ubuntu蓝牙🎧连接失效及解决办法\n\n\n---\n\n\n```shell\nsudo rmmod btusb\nsleep 1\nsudo modprobe btusb\n\nsudo apt install blueman #安装blueman\nsudo /etc/init.d/bluetooth restart #重启blueman\nsudo apt-get upgrade\n```\n\n\n### 记录ubuntu安装mpv播放器\n\n\n---\n\n\n```shell\nsudo apt install mpv\n```\n\n\n# Module2 学习linux命令行\n\n\n---\n\n\n这个部分对命令行进行学习😀\n\n\n## 第1章 shell是什么\n\n\n---\n\n\n shell是一个接收由键盘输入的命令,并将其传递给操作系统来执行的程序。bash是BourneAgain Shell的首字母缩写,Bourne Again Shell基于这样一个事实,即bash是sh的增强版本,而sh是最初的UNIX shell程序,由Steve Bourne编写。\n\n\n### 1.1 终端仿真器\n\n\n---\n\n\n 当使用图形用户界面时,需要另一种叫做终端仿真器(terminalemulator)的程序与shell进行交互。\n\n\n### 1.2.2光标移动\n\n\n---\n\n\n 在终端仿真器中也可以使用鼠标。\n\n\n Ctrl-C和Ctrl-V在一个终端窗口内进行复制和粘贴操作这不起作用。对于shell而言这些组合键在很早之前就已经赋予了不同的含义,而那时微软的Windows操作系统还没有出现。\n\n\n### 1.3几个简单的命令\n\n\n---\n\n\n date命令显示当前系统的时间和日期。\n\n\n cal显示当月的日历。\n\n\n 查看磁盘驱动器当前的可用空间可以使用df命令。\n\n\n 显示可用内存可以使用free命令。\n\n\n### 1.4 结束终端会话\n\n\n---\n\n\n```shell\n[me@linuxbox ~]$ exit \n```\n\n\n**幕后的控制台**\n\n\n---\n\n\n linux虚拟终端或是虚拟控制台。\n\n\n 通过依次按下Ctrl-Alt-F1键到Ctrl-Alt-F6组合键可以访问大部分Linux发行版中的终端会话。访问输入用户名和密码。\n\n\n---\n\n\n## 第2章导航\n\n\n---\n\n\n 我们首先需要学习的是如何在Linux系统中导航文件系统。\n\n\n```shell\npwd #查看当前工作目录。\ncd #改变目录。\nls #列出目录内容。\n```\n\n\n### 2.1 理解文件系统树\n\n\n---\n\n\n 需要注意的是在Windows系统中每个存储设备都有一个独立的文件系统树。而在类UNIX系统中如Linux无论多少驱动器或存储设备与计算机相连通常只有一个文件系统树。根据系统管理员的设置存储设备将会连接更准确的说是“挂载”到文件系统树的不同位置。系统管理员要负责系统的维护。\n\n\n### 2.2 当前工作目录\n\n\n---\n\n\n 需要注意的是树通常是倒立显示的。也就是说顶部是根目录依次向下排列的是子目录。\n\n\n### 2.3 列出目录内容\n\n\n---\n\n\n```shell\n #使用ls命令可以列出当前工作目录的文件和目录。\n[me@linuxbox ~]$ ls\n```\n\n\n### 2.4 更改当前工作目录\n\n\n---\n\n\n 使用cd命令可以改变工作目录,即在文件系统树的位置只需输入cd命令然后再输入目标工作目录的路径名即可。路径名指的是沿着分枝到达目标目录的路由。路径名分为两种绝对路径名和相对路径名。首先来谈谈绝对路径名。\n\n\n**2.4.1 绝对路径名**\n 绝对路径名从根目录开始,其后紧接着一个又一个文件树分支,直到到达目标目录或文件。\n\n\n**2.4.2 相对路径名**\n 绝对路径名是从根目录开始,通向目标目录,而相对路径名则是从工作目录开始的。为了实现这个目的,它通常使用一些特殊符号来表示文件系统树中的相对位置,这些特殊符号是“.”(点)和“..”(点点)。\n 符号“.”代表工作目录,符号“..”代表工作目录的父目录。下面演示它们是如何工作的。\n\n\n 好的,下面来说明一下,我们希望将工作目录改变成/usr/bin的父目录,即/usr。有两种方法可以实现。\n\n\n```shell\n[me@linuxbox bin]$ cd /usr #绝对路径\n[me@linuxbox bin]$ cd .. #相对路径\n```\n\n\n 同样,可以用两种方法将工作目录从/usr变到/usr/bin。\n\n\n```shell\n[me@linuxbox usr]$ cd /usr/bin #绝对路径\n[me@linuxbox usr]$ cd ./bin #相对路径\n\n#必须在这里指出来的是,几乎在所有的情况下都可以省略“./”\n[me@linuxbox usr]$ cd bin\n#一般而言,如果没有指定路径名,则默认为工作目录。\n```\n\n\n**2.4.3 一些有用的快捷方式**\n\n\n```shell\ncd #将工作目录改变成主目录\ncd- #将工作目录改变成先前的工作目录\ncd~username #将工作目录改变为username的主目录。\n```\n\n\n**有关文件名的一些重要说明**\n\n\n 以“.”字符开头的文件名是隐藏的。除非输入ls-a。在创建用户账号时,主目录里会放置一些隐藏文件,用来配置账号信息。\n\n\n 仔细观察这样的文件,可以使我们了解如何自定义工作环境。此外,一些应用程序也会将它们的配置文件和设置文件以隐藏文件的形式放在主目录下面。\n 与UNIX一样,在Linux中,文件名与命令是区分大小写的。文件名File1和file1指向不同的文件。\n 与其他一些操作系统一样,Linux没有文件扩展名的概念。我们可以按照自己的喜好随意给文件命名。文件的内容或用途由其他方式来决定。尽管类UNIX操作系统不使用文件扩展名来决定文件内容或用途,但是一些应用程序却这么做了。\n Linux支持长文件名,文件名可能包含了嵌入的空格和标点符号。但是在创建文件名的过程中,仅句号、连字符和下划线是可以使用的。更为重要的是,文件名中不要嵌入空格。文件名中嵌入空格会使很多命令行任务的实现变得困难,在第7章中我们就会发现这个问题。如果想要表示文件名词语间的空格,可以使用下划线,以后我们就会知道这样的好处了。\n\n\n## 第3章 Linux系统\n\n\n---\n\n\n 既然已经知道了如何在文件系统中跳转,是时候开始Linux操作系统之旅了。但是,在开始之前,我们要先学习一些对研究Linux系统很有帮助的命令。\n\n\n```shell\nls #列出目录内容。\nfile #确定文件类型。\nless #查看文件内容。\n```\n\n\n### 3.1 ls命令的乐趣\n\n\n---\n\n\n通过ls命令可以查看目录内容,确定各种重要文件和目录的属性。\n\n\n```shell\nme@linuxbox ~]$ ls /usr\n#除了当前工作目录之外,我们还可以指定要显示的目录,如下所示。\n\n[me@linuxbox ~]$ ls ~ /usr\n#我们甚至可以指定多个目录。\n#这个例子就列出了用户主目录(由符号“~”表示)和/usr目录的内容。\n\n[me@linuxbox ~]$ ls -l\ntotal 56\ndrwxrwxr-x 2 me me 4096 2012-10-26 17:20 Desktop\n#在命令中加上-l,我们可以将输出以长格式显示。\n```\n\n\n> 💡 之前是把整本书看完了,之后有空闲时间的话,我会继续更新该板块。毕竟,兴趣是最好的老师,但是在兴趣之前,或许还需要维持生计。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-05-01",
"type": "Post",
"category": "动手实践",
"slug": "ubuntu",
"tags": [
"实用教程"
],
"summary": "我特别喜欢ubuntu的命令行的使用方式,这样可以更加简洁纯粹的去做一件事情",
"title": "[技术分享] Ubuntu_linux",
"status": "Published",
"urlname": "6d3fe114-b343-457d-8adf-79db7bba2f3c",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "6d3fe114-b343-457d-8adf-79db7bba2f3c"
}
],
"body": "",
"realName": "[技术分享] Ubuntu_linux",
"relativePath": "/实用教程/[技术分享] Ubuntu_linux.md"
},
{
"id": "b1bc1cc2-1a53-4f83-bc73-f85609a3d00c",
"doc_id": "b1bc1cc2-1a53-4f83-bc73-f85609a3d00c",
"updated": 1713876660000,
"body_original": "\n# 更新log\n\n\n---\n\n\n这里记录对这篇文章的更新,您可以从这里看起,也可以先看完之前写的再看这段。\n\n\n### 细化生活的逻辑 2024-03-31 \n\n\n---\n\n\n 单纯是因为不想新开一篇文章,就打算看看以前的文章,顺便删删改改。\n\n\n 不然文章写了不回顾,还是浪费了,今天去bing搜索自己的时候,发现bing对我的很多文章摘录的关键字很好,大叹一声,果真它都快比我了解自己了。\n\n\n 至于为啥挑中这篇文章,一方面,是番茄钟是在上班时天天用的,不然一天那么长时间坐在电脑前面,干久了头晕眼花,有了番茄钟的陪伴,多少会舒服一点,其二是老周的博客感觉很不错,之后在优化全站友链的时候需要加上。\n\n\n 回归正题,周末感觉自己像个小废物,中午吃完午饭,一觉睡到三点,上午收拾半天屋子,这还自我提升个鸡毛啊。下午稍微花了一个多小时的时间推了一下毕设就到了该吃晚饭的时间了,吃完去仁和公园溜达了一下。\n\n\n 舒展了筋骨,感觉自己来了公司的几个月,大概率是胖了不少,因为引体向上拉不了几个了,跟个秤砣一样。之后周末有空,不忙的时候,去跑个五公里,回来好好睡一觉。\n\n\n 我感觉,在我的意识中,同时运行着很多的进程,而我体会最深的,就是要按照节点去做一些事情,因为当节奏起来了之后,就没有多少留给自己回旋的余地了,要是周日晚上再熬夜,周一起床真的会难受至极,所以在晚上22:20的时候就应该终止绝大多数高负荷的活动了,看看书就行了。\n\n\n 小时候有个爱好,很喜欢数硬币,一毛的,五毛的,一块的,我觉得生活中各种事情就和这些硬币差不多,如果把我们比作服务器,在时间不变的前提下,提高效率的办法就是通过流水线,就是通过预热的方式,但在绝大多数情况下,我们做不到这些,做不到这么精确,因为在很疲惫的情况下,大部分的生命活动就是寻求底层的娱乐了。所以我才强调要细化生活的逻辑,才有可能腾出自己的时间去专心做点事情。\n\n\n 这个时候我觉得提醒很重要,现在很容易高负载,通过外力辅助是一件很不错的方式,今天如果有空的话,再把163的smtp邮箱验证搞一下,这样结合crontab可以细化要做的一些事情。\n\n\n 另外,朋友圈的rss订阅好久没优化了,自己常用的东西最好还是能维护一下。\n\n\n 然后没啥了,再讲点其他有意思的事情吧,看到鸦鸦写的[旅游攻略](https://crowya.com/4002),我不得不回想起自己的旅游经历,坦白来讲,若不是来自于生命中的际遇,单凭我一人,我大概率不会出去玩,因为我感觉外面的世界非常消耗我的资源,我的快乐源泉大部分来自于看书和写作,其他的倒不多。但是呢,巧就巧在有了这些际遇,回想起自己“特种兵”的那些岁月,见证了友情,见证了大海,见证了高山,总而言之,人总不是完美的,但是因为聚在一起,在重合的那些点,就形成了难忘的节点。我是那种大概率会写但是不会做的人,我一直感觉自己的动手能力很差,社交能力也不强,爱好也不广泛的那种人。\n\n\n 另外,虽然我没有什么优点,但或许在其他人眼里,写作也能勉强算上一个优点,对我而言,开诚布公地讲,我在初中的时候也不是很喜欢写作,写不出漂亮的词汇,背不住名人名言,好几次的寒暑假的日记都是最后几天糊弄过去的,但是吧,奇怪的是,现在人老了,突然开始念旧了,也有可能是和自己相处久了,自言自语惯了,仿佛身处另一种时空,在遥遥呼应。\n\n\n 好吧,不讲太多没意思的事情了,下周清明,该做的事情得做,该优化的逻辑得优化,比起被动地接受安排,顺着自己的心去做,或许会好过一点。一招一式,都是学习。我记录的这些,也不都是完美的,好多东西也都遗漏掉了,反正哪天想起来就去修修补补。\n\n\n# 前言\n\n\n---\n\n\n 首先介绍今天的小伙伴,[番茄🍅人生](https://www.tomatolist.com/)\n\n\n <u>**沉没成本会影响人们的决策,使他们倾向于继续投入不划算的项目或关系,以避免承认自己的错误或浪费。**</u>\n\n\n# 正文\n\n\n---\n\n\n 有时候我们喜欢信马由缰自由自在的生活,就像萧峰对阿朱许下的承诺。\n 但是江湖又像诡谲多变的残云,如同萧峰为了找到“带头大哥”而一错再错。\n 这个困境是一直都是会存在的,因为生活并不是时时刻刻地高歌猛进,充满干劲的,更多的时候是静水流深,默默无闻的,而且就算我们一天啥也不干,躺在床上,也都还是要吃饭的,也是需要付出成本的。\n 而且随着时间的流逝,中年危机还会让人愁白了头,真是应了辛弃疾的那一首:\n\n\n> **丑奴儿·书博山道中壁**\n\n\n\t_少年不识愁滋味,爱上层楼。爱上层楼,为赋新词强说愁。_\n\n\n\t_而今识尽愁滋味,欲说还休。欲说还休,却道天凉好个秋。_\n\n\n 与沉没成本相对的,我们在40岁之前我们有很多的试错机会。\n\n\n> _子曰:“吾十有五,而志于学,三十而立,四十而不惑,五十而知天命,六十而耳顺,七十而从心所欲,不逾矩。”_\n\n\n 也就是说,在40岁之前,我们需要找到我们热爱并且能够维生的事业,在我看来,身体第一,事业第二,家庭第三,其余第四。\n 我一直在用番茄人生,大概是从去年的时候,就接触到了番茄钟,当时用的是番茄的客户端,成为第一批我时间管理的工具,再往前推溯,用的是,微软自带的秒表,陪伴我度过一天醒来的十几个小时。后面有一段时间没有使用番茄钟,用的是[workrave](https://workrave.org/),期间我的操作系统从win转到了linux到mac,但是吧,mac又没有这个workrave,虽然有很多类似的其他提醒休息的工具,但是还是有陌生感。\n\n\n 而且呢,最近沉迷于网页版的番茄人生,因为它帮我度过了难熬的期末考试,就是平时学得稀巴烂,期末冲刺猛猛抱佛脚,我当时白天基本上都睡在图书馆的地上了,一天六七个小时,全都在背这枯燥的玩意,从第一门的维修工程管理背到最后一门的无线电导航原理,主打的就是一个猛猛背。\n 然后,后来七月份,我实在受不了番茄这种弹出式的广告,已经有点影响到我的正常使用了,就一气之下,把账号都注销了,在找一种新的替代方案,而且我还暗暗庆幸,我的习惯不是已经养成了嘛。\n 其实后果如您所料,不出意外地出了意外,然后就进入了很摆的生活,生活再度陷入了chaos。\n 后来有一天,我又偷偷回去看了一眼,作者应该是对广告做出了限制,后来有一天,我躺在床上的时候,突然感觉。\n\n\n> _人们常说,心为君主之官,但是我突然觉得我的心成为了客体。_\n\n\n 既然我要吃饭,作者要吃饭的,而且是吧,博客其实也是要费用的,国内的博客方案,猛猛烧钱,服务器,域名,备案,收费和技术成本真的有一些的,所以大家在看到有广告的博主的时候,不要再怒目而视啦,作为一个站长,尤其是一个有着不错文章的独立站长,真的很辛苦。用爱发电不太适合我这种底层人民。记得张宇老师讲那个阿贝尔定理,张宇老师讲了个故事,说他只给了阿贝尔10块钱,但是阿贝尔要12块钱,张宇老师觉得不妥,因为大数学家莱布尼茨才要十块钱,所以只给了阿贝尔十块钱,于是阿贝尔就去了天堂,留下的两个端点值无法判断敛散性,要用定义,因为少了两块钱。\n\n\n\n\n\n\n\n\n 所以智慧虽然不分贫贱,但是是人都是要吃饭的。\n 我又讲偏了,上次讲到我和番茄人生的故事是吧,后面前不久我又重新修建了番茄的自习室,因为我觉得番茄人生的自习室还是很有实践价值的,至少可以作为辅助学习效率的动态监控。\n 这就是[我的自习室](https://www.tomatolist.com/show_group.html?group_id=27f2b200-d549-4ba9-a2cc-1b6025be2c7b),有兴趣的小可爱一起来玩。\n 上午我在学习李老师讲的[小程序开发](https://www.hackwork.org/docs/tcb/intro)的时候,刚开始真的看不懂,或者是进入不了状态,但是专心下来,突然,一种很微妙的感觉就来了,好像是进入了心流的状态,几乎不要主动去推,猛猛往前冲。\n\n\n\n\n\n 下午的时间,我把小程序剩下的几章看了看,关于css,和js的也很很有趣,但是看完的一种是,有那么一点迷茫,因为小程序我觉得在我的学习路径规划体系中,作用不是那么明显,可能是因为刻板映像吧,因为小程序的商业价值掩盖了使用价值,可能是因为从前斗地主打多了。\n 这种迷茫的感觉让我再度重现审视当前的人生进程。也有可能是下午睡多了,导致有点抑郁。\n 所以我提出了沉没成本这个概念,如前面所说。\n 因为我现在还在准备考研,但是遇到一个问题,就是有点摆,专心不了,也正是因为我前面说了,我很放荡不羁,我不希望压抑自己的感受,我想做一些我比较喜欢的事情,所以我的选择在常人眼里看来都很奇葩,比如为什么要睡在教学楼的地板上,当然我铺了席子的,因为教室太冷了,本来脑子就转不动。\n 虽然拥有很多很多的鼓励,来自同学,家人等等,还是我还是感觉少一点东西,我对自己的认知定位还不是很明确。\n 这一段先收一下,写得太长了。\n\n\n# 总结\n\n\n---\n\n\n 总的来说,就是今天的这一天的心态是有些起伏的,从早上的踌躇满志到现在的审慎思考,我并不觉得这些时间或者思考是无用功,因为家人陪伴我们前半生,爱人陪伴我们后半生,中间短短的缝隙,则是承担了我们认知蜕变的黄金年华。正如王德峰教授说,大学是人精神成长的最宝贵的也是大多数人最后的阶段。\n 所以,在剩下的时间里,我还是打算潜心创作,总结一下最近的生活,然后继续发育。\n\n\n 好了,感谢您看我啰里八嗦写了这么长一段。希望能对您有一些启发!\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-08-12",
"type": "Post",
"category": "动手实践",
"slug": "tomato",
"tags": [
"推荐"
],
"summary": "该做的事情得做,该优化的逻辑得优化,比起被动地接受安排,顺着自己的心去做,或许会好过一点。一招一式,都是学习。",
"title": "[沉没成本] 通过番茄人生来聊沉没成本 ",
"status": "Published",
"urlname": "b1bc1cc2-1a53-4f83-bc73-f85609a3d00c",
"updated": "2024-04-23 12:51:00"
},
"catalog": [
{
"title": "推荐",
"doc_id": "b1bc1cc2-1a53-4f83-bc73-f85609a3d00c"
}
],
"body": "",
"realName": "[沉没成本] 通过番茄人生来聊沉没成本 ",
"relativePath": "/推荐/[沉没成本] 通过番茄人生来聊沉没成本 .md"
},
{
"id": "9f509fa3-f0c9-41b0-b86a-3a8a61b86b50",
"doc_id": "9f509fa3-f0c9-41b0-b86a-3a8a61b86b50",
"updated": 1713876480000,
"body_original": "\n# 更新log\n\n\n---\n\n\n 之前我一致在思考如何对于文章进行纵向管理,可以说,也正是这个念头,才产生了这篇文章,当我再去思考纵向管理的时候,它核心的定义是什么的时候,我认为可以这么来理解,即**“站在过去自己的肩膀上”**,为了避免重复造轮子,从而节约时间和精力能去做更多有意义的事情。\n 同时,我们还应该清楚地认识到,每一个开始,都是要付出不下的决心和代价,如果每次想到同一个问题的时候都需要在原地踏步,甚至重新思考,我认为这种模式是低效的,正如同,我们学过了大学的知识,但是在之后运用中却不得不花费时间自己再去学一遍。从结果导向来看,这种结果是不尽如人意的。那么我们就需要反思问题出在哪里。\n 如果再往前追溯,我们甚至还可以想到我们的高中,但是那个时候大部分的知识都忘掉了,我们翻看过去的笔记的概率无限接近于零,因为当下有更多要紧的事情要去完成。所以,电子化时代确实是带来了这个问题解决的思路和可能。\n 当然理论部分,我觉得不应该再花时间做过多的解释和强调了。\n\n\n### 更新视频讲解 2024-03-23 \n\n\n---\n\n\n[[数据中心] 测试crontab同步elog+Onedrive_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1DA4m1P7J9/?spm_id_from=333.999.0.0&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n\n\n### 关于服务器同步原理的更新 2024-03-02 \n\n\n---\n\n- cron在执行elog指令的时候存在困难,**需要配置一些环境变量**,在折腾之后,并没有成功。\n\n```shell\n在 Linux 系统中,cron 任务是在一个相对干净的环境中执行的,通常缺少一些常见的环境变量。这可能导致在 cron 任务中无法访问一些用户环境中可用的变量或路径。下面是一些关于 cron 运行环境的重要信息:\n1. PATH 环境变量:\n cron 任务运行时通常只包含一个非常基本的 PATH 环境变量,这可能导致在 cron 任务中无法直接调用系统中的一些命令或程序。为了解决这个问题,你可以在 crontab 任务中显式设置 PATH 环境变量,或者在命令中使用绝对路径来调用命令。\n2. 当前工作目录:\n cron 任务的默认工作目录通常是用户的家目录。因此,如果你的任务需要在特定目录中执行,最好在 crontab 任务中使用 `cd` 命令切换到正确的工作目录。\n3. 标准输入和标准输出:\n cron 任务通常没有与终端相关联的标准输入和标准输出。如果任务产生输出,最好将输出重定向到文件中,以便后续查看。\n4. 环境变量:\n cron 任务通常缺少用户登录时设置的环境变量,包括一些自定义的 PATH、LD_LIBRARY_PATH 等。为了在 cron 任务中使用这些环境变量,你可以在任务中加载包含这些变量的文件,比如使用 `source` 命令加载一个包含环境变量设置的脚本。\n5. 日志记录:\n 为了方便排查问题,建议在 crontab 任务中将输出和错误信息重定向到日志文件中。这样可以帮助你在任务执行时查看输出信息以及任何错误。\n总的来说,要确保 cron 任务能够正常执行,最好在编写任务时考虑到这些环境限制,并相应地设置环境变量、工作目录和输出记录方式。\n```\n\n- 在[CC康纳百川](/9f509fa3f0c941b0b86a3a8a61b86b50)的提醒下,打算使用git拉取仓库的代码,因为仓库的数据一直都是最新的。经过本地和远程测试,可以成功被执行。操作步骤如下:\n\n```shell\n如果你想拉取整个 GitHub 存储库中的特定文件夹,可以使用 Git 工具来克隆该存储库,并在本地保留所需的文件夹。这种方法可以通过 Git 的子模块或者使用 sparse checkout 功能来实现。\n以下是一个示例,展示如何使用 Git 克隆整个 GitHub 存储库并只保留特定文件夹的内容:\n1. 首先,克隆 GitHub 存储库到本地。假设你已经安装了 Git:\ngit clone <repository_url>\n请将 `<repository_url>` 替换为 GitHub 存储库的 URL。\n2. 进入克隆的存储库目录:\ncd repository_name\n请将 `repository_name` 替换为你克隆的存储库的名称。\n3. 使用 sparse checkout 功能来只保留特定文件夹的内容。首先启用 sparse checkout:\ngit config core.sparsecheckout true\n4. 然后,指定要保留的文件夹路径。编辑 `.git/info/sparse-checkout` 文件,将需要的文件夹路径添加到文件中:\necho \"folder_path/*\" >> .git/info/sparse-checkout\n请将 `folder_path` 替换为你想要保留的文件夹路径。\n5. 最后,更新工作区以应用 sparse checkout:\ngit read-tree -mu HEAD\n现在,你的本地存储库中应该只包含特定文件夹的内容。\n这种方法允许你克隆整个 GitHub 存储库,并只保留特定文件夹的内容,而不是整个存储库。\n\n如果你已经使用 sparse checkout 将特定文件夹的内容克隆到本地,并且想要更新这个文件夹以获取最新的更改,你可以执行以下命令:\n1. 首先,确保你在存储库的根目录中。\n2. 拉取存储库的最新更改:\ngit pull\n这将拉取存储库的最新更改。\n3. 如果你只想更新特定文件夹而不是整个存储库,可以执行以下命令:\ngit checkout HEAD folder_path\n这将更新特定文件夹的内容以反映最新更改。\n通过执行这些命令,你可以更新本地存储库中特定文件夹的内容,而不必拉取整个存储库的内容。\n```\n\n\n# 前言\n\n\n---\n\n\n 建立数据中心的意义:在建立知识体系的环节中,我们正确认识到人类的大脑无法保留过多的缓存,能保留的只能是方式,简而言之,我们无法保留文件的具体内容,更容易记得寻找文件的路径,基于此,数据中心的应运而生。\n\n\n# 正文\n\n\n---\n\n\n 在寻求数据管理中出现了非常多优秀的软件,基于我目前的了解,使用git进行分布式管理是非常有效的方式和手段,作为开源社区的土壤,github为全世界的程序员提供了协作的机会,也是分布式数据中心成功的代表。我们可以从中学到很多有用的经验。\n\n\n 另外,在数据管理中,时间的调度成为不可忽视的重要因素,日志作为过程记录和经验总结的重要经验来源,既承接着举足轻重的地位,又对时间的分配提出了较高的要求,因此,作为一种轻量标记语言的markdown成为log记录的优秀格式。保持高阅读性的同时,最大化地保留了日志的流畅性。\n\n\n 另外,图表在文档介绍中也起到至关重要的作用,mermaid语法成为一种新型的,具备创造力的表现方式,衔接了文字与图片之间的关系,成为一些值得掌握的技能。\n\n\n 与此同时,学会正则表达式,对于文档检索有很大的帮助,这对于精确检索数据提供了快捷有效的方式,obsidian的检索和脑图功能,提供了更简明的搜索技巧,但正则表达式仍然是一项值得学习的技能。\n\n\n### 需求的提出\n\n\n---\n\n\n 我的需求来自于对于多设备之间数据管理的困扰,首先我们需要注意的一点是,我们的技能和工作效率很大程度上来自于学习的积累所得,但同样矛盾的地方在于学习积累的客观困难性,使得效率的提升和体验的优化成为一项极为困难的事情。因此,我们就如同推石头的西西弗斯,没办法用更加优化的方式和思维来进行学习方式和知识管理的优化。\n\n\n## 思路的来源\n\n\n---\n\n\n 我们已经积累了一部分工作流的经验,如下图所示。\n\n\n```mermaid\ngraph LR\nobsidian & marginnote --> notion --> notionnext\n\n```\n\n\n 其中,我主要通过,obsidian和marginnote来进行内容的梳理,我将简单介绍一下两个工具的特点,您也可以自行上网查询了解。\n\n\n obsidian作为md笔记中的佼佼者,凭借其优秀的特性,开源,丰富插件,双链,关系图谱,使之成为md笔记的最佳承载。\n\n\n marginnote作为苹果系统中的学习类软件,将笔记,标注,脑图,搜索一体化,结合社区的强大插件,使得学习得到最优体验。\n\n\n 为什么选择notion,notion本身作为一款极为优秀的笔记管理软件,开启了自由笔记的先河,丰富的块理念和多种数据视图,使得知识管理可以更加富有层次化的呈现,集合管理与协作与一身,在线协作功能也非常出色。\n\n\n notionnext是由tangly开发的博客框架,可以将您在notion上的笔记变为博客进行渲染,使得知识分享更为便捷。让您在任何一台可以连接到互联网上的设备进行随时随地查看并分享给需要的人,同时可以让更多地人参与到对该话题的讨论。细化的功能,可以等到之后有时间的时候进行细讲。\n\n\n## 前后端分离\n\n\n---\n\n\n 在上述的讨论过程中,我们发现,内容的创作是单向流动的,我们无法完成知识的反馈和纵向管理,那么就会导致知识的实时性受到极大的影响。\n\n\n 那么,有没有什么办法可以解决这个问题。首先我们来看知识管理的总架构。\n\n\n```mermaid\ngraph TB\nsubgraph 后端\n\n内容创作 & 本地双链 & 关系图谱 --> id0[\"obsidian\"];\nend\nsubgraph 部署流程\nid2 & id4 & id5 & notion & vercel;\nend;\nsubgraph 前端\nid1[\"notionnext(main)\"] & id3[\"hugo(backup)\"];\nend;\nid0 --> notion --> id4[\"github:repo(1)\"] & id2[\"elog(auto)\"];\nid2[\"elog(auto)\"] --> id5[\"github:repo(2)\"];\nid4[\"github:repo(1)\"] & id5[\"github:repo(2)\"] --> vercel --> id1 & id3;\nstyle id2 color:#f9f\nid1 & notion -- How --> id0;\nstyle id1 color:#ff0000\nstyle id0 color:#ff0000;\n\n```\n\n\n### 后端的组成\n\n\n---\n\n\n 后端主要依赖obsidian,在obsidian中进行如下工作:\n\n- 内容的创作\n- 关系图谱的梳理\n- 通过图谱确认更新需求\n\n### 部署流程\n\n\n---\n\n\n 通过obisidian完成内容的创作后输出到notion中进行标准化处理,所谓标准化处理,就是通过notion的数据数据库给文章分配属性,例如标准化标题、文章分组及标签分配。这些工作便于后续elog按照notion的字段进行对应组别的导出。\n\n\n### 前端的组成\n\n\n---\n\n\n 目前前端的组成分为两个博客,NotionNext为主要架构,Hugo为容灾备份。用于分享交流。\n\n\n## 数据中心的建立\n\n\n---\n\n\n 为了解决提出的需求,也就是上图所示的How的问题。我们打算采用vps中的定时脚本来为我们完成数据库的迁移。简明原理如下。\n\n\n```mermaid\ngraph TB\nid0[\"ondrive(本机)\"];\nid1[\"onedrive(远程)\"]\nsubgraph 本地环境\nobsidian & id0;\nend;\nobsidian -- 创作中remotesave --> id1;\nobsidian -- notion标准化 --> 服务器定时同步;\nsubgraph 服务器定时同步\nvps & crontab & id1[\"onedrive(远程)\"];\nend;\nvps --> crontab -- 先git拉取仓库最新数据,后执行sync确保远程最新 --> id1;\nid1 -- 本机启动之后下载最新版本 --> id0;\nid0 --> obsidian -- 增加双链 --> id1;\n\n```\n\n\n### 服务器同步模块之onedrive安装\n\n\n---\n\n\n 服务器您无需把它想得很高大上,它就像一台24小时开机的远程电脑,可以执行您的需求。基于此,一个好用的定时脚本可以为我们完成很多事情。\n\n\n 第一步,我们通过进入服务器的终端。首先安装必要的远程仓库的组件。如何在ubuntu上安装onedrive,很感谢github为我们提供了onedrive的安装方式,具体的安装步骤需要您参考对应的[项目手册](https://github.com/abraunegg/onedrive/tree/master)。\n\n\n 以下内容是对社区文档的转载。\n\n\n 我的操作系统是ubuntu20.04,对应的安装步骤如下:\n\n- 确认移除旧的客户端\n\n```shell\nsudo apt remove onedrive\nsudo add-apt-repository --remove ppa:yann1ck/onedrive\n```\n\n- 此外,Ubuntu及其克隆在安装“onedrive”软件包时有创建“默认”系统服务文件的坏习惯,这样客户端将自动运行正在验证的客户端帖子。此系统条目是错误的,需要删除。\n\n```shell\nsudo rm /etc/systemd/user/default.target.wants/onedrive.service\n\n```\n\n- 使用类似于以下内容的脚本,以确保您的系统正确更新\n\n```shell\n#!/bin/bash\nrm -rf /var/lib/dpkg/lock-frontend\nrm -rf /var/lib/dpkg/lock\napt-get update\napt-get upgrade -y\napt-get dist-upgrade -y\napt-get autoremove -y\napt-get autoclean -y\n\n```\n\n- 确认您的操作系统,示例如下\n\n```shell\nalex@ubuntu-system:~$ lsb_release -a\nNo LSB modules are available.\nDistributor ID: Ubuntu\nDescription: Ubuntu 22.04 LTS\nRelease: 22.04\nCodename: jammy\n\n```\n\n- 选择对应的发行版(Ubuntu20.04)添加OpenSuSE Build Service存储库发布密钥\n\n```shell\nwget -qO - <https://download.opensuse.org/repositories/home:/npreining:/debian-ubuntu-onedrive/xUbuntu_20.04/Release.key> | sudo apt-key add -\n\n```\n\n- 添加OpenSuSE Build Service存储库\n\n```shell\necho 'deb <https://download.opensuse.org/repositories/home:/npreining:/debian-ubuntu-onedrive/xUbuntu_20.04/> ./' | sudo tee /etc/apt/sources.list.d/onedrive.list\n\n```\n\n- 更新您的apt软件包缓存\n\n```shell\nsudo apt-get update\n\n```\n\n- 安装onedrive\n\n```shell\nsudo apt install --no-install-recommends --no-install-suggests onedrive\n```\n\n- 阅读并了解以下这些软件包的[已知问题](https://github.com/abraunegg/onedrive/blob/master/docs/ubuntu-package-install.md#known-issues-with-installing-from-the-above-packages),采取任何需要的行动。\n\n### 服务器同步模块之onedrive使用\n\n\n---\n\n\n 同样,您应该优先选择阅读项目文档,我的转载未必全面,同时如果转载过于消耗时间,那我将会省略该步骤。\n\n\n 关于[onedrive](https://github.com/abraunegg/onedrive/blob/master/docs/USAGE.md)的使用如下:\n\n- 授权,您将被要求使用网络浏览器打开特定的URL,您必须登录您的微软帐户,并授予应用程序访问文件的权限。授予应用程序权限后,您将被重定向到空白页面。将空白页面的URI复制到应用程序中。\n\n```shell\n[user@hostname ~]$ onedrive\nAuthorize this app visiting:\nhttps://.....\nEnter the response uri:\n```\n\n- 显示您的配置\n\n```shell\nonedrive --display-config\n```\n\n- 执行同步\n\n```shell\nonedrive --synchronize\n```\n\n\n 更多详细的步骤我将不再具体介绍,需要您阅读项目文档。\n\n\n### 服务器同步模块之elog的环境配置\n\n\n---\n\n\n 这部分您需要参考两份文档,由于我之前已经写过关于elog的配置文档,将不再赘述。引用如下:\n\n- [Elog开放式跨平台博客解决方案](https://elog.1874.cool/)\n- [elog+notion实现md优雅备份](https://matrixcore.top/article/elog)\n\n首先您需要阅读官方文档,其次您可以参考我的配置。\n\n\n### 服务器同步模块之crontab定时脚本\n\n\n---\n\n\n 关于crontab定时脚本的功能非常丰富,我认为仍然有很多的玩法可以被开发。这里我主要是结合elog+onedrive来进行使用。\n\n\n 当您在服务器上完成elog和onedrive的环境安装之后,您可以编写同步脚本。\n\n\n```shell\n00 12 * * * cd /root/OneDrive/software/remotely-save/elog && elog sync -e .elog.env\n02 12 * * * onedrive --synchronize\n```\n\n\n 这段代码的意思就是每天中午12点执行一次elog同步,获取notion中的最新数据,过两分钟执行onedrive的主动同步,来保障远程仓库是最新的。(因为我不确定是否onedrive会自动同步,所以我选择了手动的方式。)\n\n\n### 本地环境的使用说明\n\n\n---\n\n\n 在完成上述操作之后,当您打开一台新的设备,如果您的个人机器不在身边,过年了去哥哥姐姐外婆家串门,您就可以在新的设备当中,使用onedrive获取到远程仓库的最新文档。并在obsidian接力未完成的工作,使得假期不再无聊。\n\n\n 那么,obsidian既可以进行文档的初始写作,也可以接力任何一台设备的中断写作。同样,建立双链之后也可以更新到远程仓库,完成文档的写作也可以进行标准化输出。也可以进行旧有文档的更新。\n\n\n```mermaid\ngraph LR\nobsidian --> 初始写作 & 接力写作 & 双链更新 & 翻新旧文档\n\n```\n\n\n# 总结\n\n\n---\n\n\n 由于时间和精力的限制,今天的分享就到这里,因为内容太多了,也会非常疲惫。\n\n\n## 附录\n\n\n---\n\n- 经测试nextcloud和onedrive同理,也可以在服务器上安装nextcloud客户端进行同步指令,remotesave也支持nextcloud的webdav,只不过配置稍微麻烦一点。\n- 关于后端工作流的输入源的优化也是一个值得关注的问题。\n\n## 致谢\n\n\n---\n\n- 🌺感谢1874博主对于本工作流的建议,同时提出了一篇值得参考的[文章](https://www.v2ex.com/t/1005055#reply27)\n- 感谢一位博主提供的工作流图\n\n\t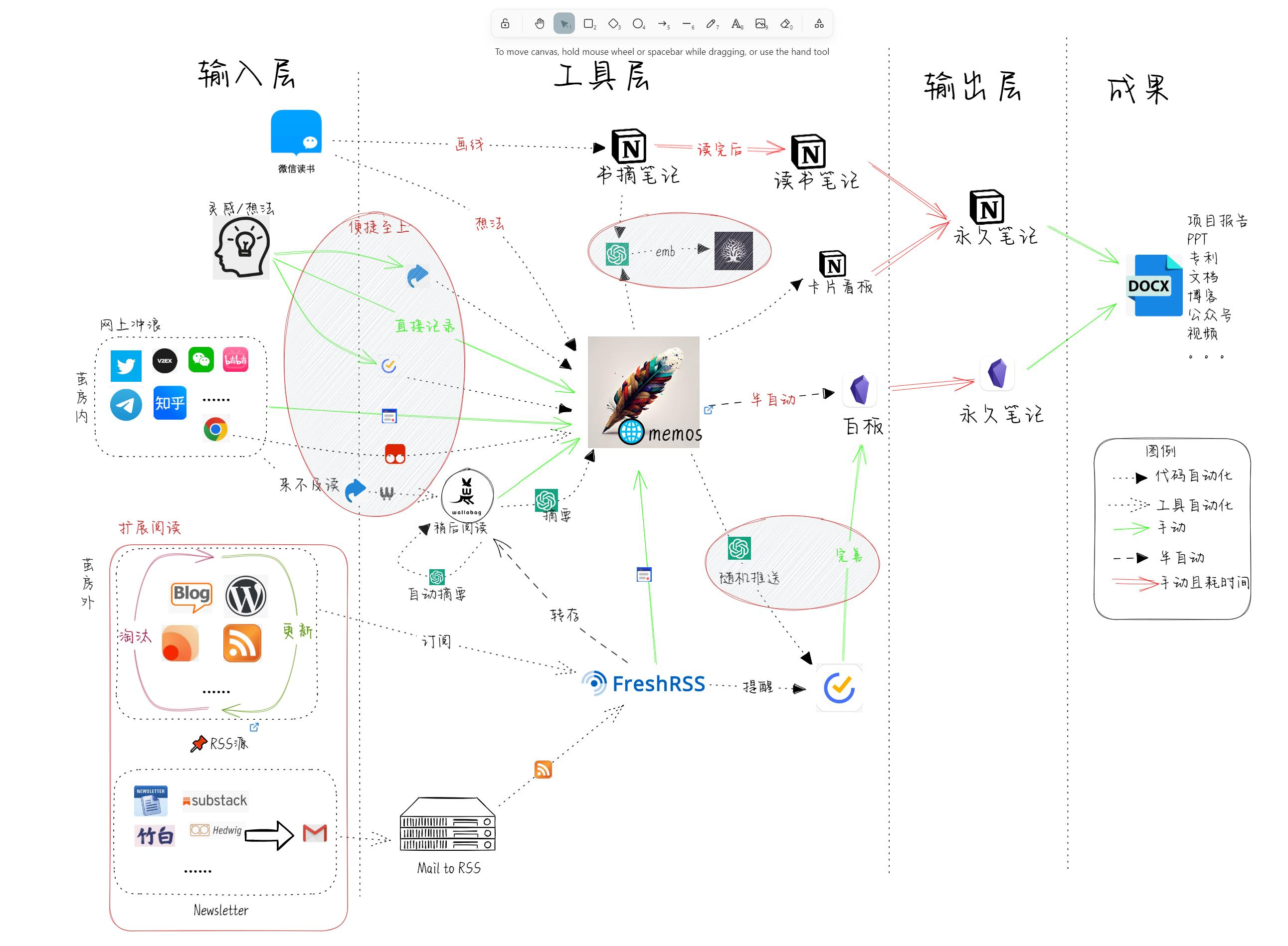\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-01-21",
"type": "Post",
"category": "动手实践",
"slug": "crontab-1",
"tags": [
"推荐"
],
"summary": "为obsidian建立数据中心,使用vps定时同步到onedrive",
"title": "[数据中心] 测试crontab同步elog+Onedrive",
"status": "Published",
"urlname": "9f509fa3-f0c9-41b0-b86a-3a8a61b86b50",
"updated": "2024-04-23 12:48:00"
},
"catalog": [
{
"title": "推荐",
"doc_id": "9f509fa3-f0c9-41b0-b86a-3a8a61b86b50"
}
],
"body": "",
"realName": "[数据中心] 测试crontab同步elog+Onedrive",
"relativePath": "/推荐/[数据中心] 测试crontab同步elog+Onedrive.md"
},
{
"id": "0cbead15-8fc2-44b4-930c-8f3e897b6215",
"doc_id": "0cbead15-8fc2-44b4-930c-8f3e897b6215",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 前几天吃午饭的时候,突然想到一件事情,就是关于博客备份的事情。\n 之前为了对高数18讲进行全部重新CDN加速,一直用的都是notion自带的导出为markdown的功能,但是如果数据一多,速度就很慢,而且一个一个导出很费时间。\n 昨天晚上和今天尝试并使用了elog,实现了notion文章自动批量下载到本地,并根据自定义的数据库属性进行合适的归档。\n 首先非常感谢这个想法的启蒙博主:某中二的黑科技研究中心\n 文章标题及链接:[ ](https://darkreunion.tech/article/backup-notion-to-github?giscus=5b1855710a9073bbb30d3264lzzxL%2FY5boFMZEtzfT2uvrsTkpO815dTCl%2BcFCsI%2FwZTnmkVo1SjQB2CllPRsX9pkEFoeAZ77J%2FviSyilYpOqYYX%2FGm9rbQWTk0T8J0bqUaJf4Q%2BJl9YANenxts%3D)[**备份 Notion 文档到 Github**](https://darkreunion.tech/article/backup-notion-to-github?giscus=5b1855710a9073bbb30d3264lzzxL%2FY5boFMZEtzfT2uvrsTkpO815dTCl%2BcFCsI%2FwZTnmkVo1SjQB2CllPRsX9pkEFoeAZ77J%2FviSyilYpOqYYX%2FGm9rbQWTk0T8J0bqUaJf4Q%2BJl9YANenxts%3D)\n\n\n# 正文\n\n\n---\n\n\n 实践的过程并不顺利,甚至还有些小艰难,作为纯技术小白,以下记录我的一些踩坑经历。\n\n\n 首先从阅读[技术文档](https://elog.1874.cool/)开始。\n\n\n## 一、备份文件夹及环境配置\n\n\n---\n\n\n 导航到技术文档的[快速开始](https://elog.1874.cool/notion/start),使用vscode创建备份文件夹并开始环境配置。\n\n\n ⚠️请注意环境需要正确安装,理论上安装环境的时间在2-3分钟左右。\n\n\n 然后对项目进行初始化配置,生成`elog.config.js`以及`.elog.env`两个文件,接下来就是进入[配置详情](https://elog.1874.cool/notion/fe8ywmt999gon12w),配置相应的参数。\n ⚠️请注意,将您的.elog.env文件列入git的忽略跟踪\n\n\n```markdown\n 使用`.gitignore` 文件:创建一个名为 `.gitignore` 的文件,并在其中列出你想要隐藏的文件或文件夹的名称。在这个文件中,你可以使用通配符或模式来指定要忽略的文件类型或文件夹。当你将 `.gitignore` 文件提交到 GitHub 仓库时,Git 将忽略这些文件,不会将它们包含在版本控制中。\n\n 请注意,`.gitignore` 文件只能隐藏未被跟踪的文件。如果某个文件已经被 Git 跟踪并提交到仓库中,那么即使你在 `.gitignore` 文件中将其列为忽略项,它仍然会在仓库中可见。(解决该问题请导航到结尾彩蛋部分)\n```\n\n\n```shell\n## 下面是一个示例 `.gitignore` 文件的内容:\n\n# 忽略所有 .txt 文件\n*.txt\n\n# 忽略文件夹\nmy_folder/\n\n# 忽略特定文件\nsecret.txt\n```\n\n\n## 二、正确进行参数配置\n\n\n---\n\n\n 我希望对notion的数据库的文章进行批量导出,那么在配置`elog.config.js`就需要注意平台的选择。\n\n\n```javascript\nmodule.exports = {\n write: {\n platform: \"notion\", //注意平台的选择\n },\n};\n```\n\n\n⚠️在最开始的时候,我忽视了平台的选择,导致报错:`未知的写作平台`\n\n\n 然后是notion相关的配置,首先要关注自己的数据库的属性。\n作者大大也提供了数据库的模板,可以参考[配置流程](https://elog.1874.cool/notion/gvnxobqogetukays#notion)。\n\n\n 我采用的数据库是notionnext的数据库格式,并且elog也支持自定义数据库的字段。\n\n\n```javascript\n//这是默认的配置\nnotion: {\n token: process.env.NOTION_TOKEN,\n databaseId: process.env.NOTION_DATABASE_ID,\n filter: false, \n sorts: false, \n catalog: false,\n },\n\n//以下是我修改后针对notionnext数据库的配置\nnotion: {\n token: process.env.NOTION_TOKEN,\n databaseId: process.env.NOTION_DATABASE_ID,\n filter: {\n property: 'type',\n select: {\n equals: 'Post'\n }\n }, \n sorts: true, \n catalog: {\n enable: true,\n property: \"tags\",\n }\n },\n//这里我希望筛选数据库中属性type中的post,也就是发布文章,同时我也希望文章按照tags的标签进行本地归档。所以对此处进行了如下修改。\n```\n\n\n 另外如果想要正确输出到指定目录,还需要注意该问题:\n\n\n```javascript\ndeploy: {\n platform: 'local',\n local: {\n outputDir: './docs',\n filename: 'title',\n format: 'markdown',\n catalog: true,\n//在部署平台配置项中配置deploy.local.catalog=true\n formatExt: '',\n },\n//一定要记得勾选部署时候到目录选项\n```\n\n\n\n\n\n\n\n\n\n\n\n\n\n 如果要做针对自己数据库的属性更改,请参照[**Notion API 文档 - Filter database entries**](https://developers.notion.com/reference/post-database-query-filter)**。**\n\n\n 接下来就是正确获取notion的Integration Token和DatabaseId,按照[配置流程](https://elog.1874.cool/notion/gvnxobqogetukays#notion)走就可以。\n\n\n\n\n\n\n\n\n\n\n\n\n\n## 三、合适的网络条件\n\n\n---\n\n\n 在正确配置notion的集成和id之后,可以开始执行\n\n\n```shell\nelog sync -e .elog.env\n```\n\n\n⚠️注意,由于notion api的延时问题,校园网条件下,notion api会经常超时,所以推荐使用手机流量。\n 如果一切顺利,那么您将可以看到文章被正常输入到本地目录。\n\n\n## 四、进阶操作,自动备份 \n\n\n---\n\n\n 阅读技术文档[持续集成](https://elog.1874.cool/notion/vy55q9xwlqlsfrvk)\n\n\n notion的自动化流程有一定的起手难度。\n\n\n### 原理介绍\n\n\n---\n\n\n 通过slack捕捉notion数据库字段的变化,比如“status”从“Draft”变为“Published”,那么就可以推送到slack的频道中,然后开始触发pipedream,调用github actions的api进行部署。\n\n\n### 关联slack+notion\n\n\n---\n\n\n 首先,需要进行slack注册,授权给notion进行关联。\n\n\n\n\n\n\n\n\n\n\n\n\n\n### pipedream配置\n\n\n---\n\n\n 如果一切顺利,那么接下来进入pipedream的部署,将slack与pipedream进行关联,最困难的是如何配置https请求。\n\n\n\n\n\n 在这里我要特别感谢DC's博主,他的文章给了我启发 :[ 定期备份notion](https://aaqq.cc/article/24c2897b-78f3-4f6a-b8e6-292ea60edf7c)\n\n\n```javascript\nhttps://serverless-api-elog.vercel.app/api/github?user=xxx&repo=xxx&event_type=xxx&token=xxx\n//注意将xxx替换为自己的数据\n```\n\n\n```javascript\nhttps://serverless-api-elog.vercel.app/api/github?user=cyolc932&repo=elog&event_type=deploy&token=xxx\n//例如你的github用户名,仓库名称,部署名称以及github的token\n```\n\n\n```javascript\nuser: Github用户名\nrepo: Github仓库名\ntoken: Github Token\nevent_type: 配置在 Github workflows 中的repository_dispatch.types的值\n```\n\n\n 同时参考1874博主的[文档](https://github.com/LetTTGACO/serverless-api),正确配置该请求。\n\n\n 在这个步骤中,您还要获取[GitHub的token](https://github.com/settings/tokens/)\n\n\n 如果这一步正确,并且serverless api返回`sussess!`,那么恭喜你,已经成功了一半了。\n\n\n### 安装打包环境\n\n\n---\n\n\n 接下来让我们回到vscode的文件夹,进行打包环境的安装\n\n\n```shell\nyarn add @elog/cli\n```\n\n\n在`package.json`加上如下脚本\n\n\n```javascript\n{\n \"dependencies\": {\n \"@elog/cli\": \"^0.8.0\"\n },\n//以下为添加的脚本\n \"scripts\": {\n \"build\": \"yarn\", \n \"elog:init\": \"elog init\",\n \"sync:local\": \"elog sync -e .elog.env\", \n \"sync\": \"elog sync\", \n \"clean\": \"elog clean\"\n }\n}\n```\n\n\n### 调试github自动化脚本\n\n\n---\n\n\n 接下来到了困难的阶段,配置GitHub的actions,首先配置环境变量,主要是notion的token和id,填入在第二步获得的参数。\n\n\n路径如下:`设置-Secrets and variables-Actions-Secrets`\n\n\n\n\n\n接下来创建GitHub的工作流:`.github/workflows/main.yaml`\n\n\n最主要的是这一步,配置完成之后,在vscode拉取仓库内容,进行本地和远程的同步。\n\n\n```yaml\n- name: 配置Git用户名邮箱\n run: |\n git config --global user.name \"xxxx\"\n git config --global user.email \"xxxx\"\n```\n\n\n⚠️请注意,接下来不要随意在本地和远程双向修改,不然会导致冲突。\n\n\n### 放开actions的写入权限\n\n\n---\n\n\n⚠️同时注意放开actions的写入权限,在该仓库的设置,工作流里找到该选项。\n\n\n\n\n\n### 脚本触发\n\n\n---\n\n\n 如果一切顺利,当您在notion中将文章的状态变为“Published”时候,将会自动触发工作流,进行备份,如果遇到错误,请排查工作流的报错信息。\n\n\n\n\n\n 最后当您二次修改文章之后再次触发,文章会进行增量更新。\n\n\n# 总结\n\n\n---\n\n\n elog的项目非常具有实践价值,通过该项目,不仅可以实现博客文档的整洁有序自动化的归档,而且可以兼容多平台,实现数据的自由迁移。 \n\n\n 在我遇到困难的时候,离不开群主和群友的耐心解答和帮助!\n\n\n> 💡 **特别鸣谢: \n> 🌺** [1874博主的elog项目及其技术文档](https://github.com/LetTTGACO/elog) \n> 🌺 [在自行实践遇到困难和解决的宝贵经历](https://bu.dusays.com/2023/10/12/6527510b65304.png) \n> 🌺 [北门清燕](https://www.bmqy.net/2651.html#more)、[DC's](https://aaqq.cc/article/24c2897b-78f3-4f6a-b8e6-292ea60edf7c)、[IMQL.LIFE](https://www.imql.life/2023/08/12/Writing_on_The_Cloud_With_YuQue/)等群友的最佳实践文档\n\n\n### 小彩蛋\n\n\n---\n\n\n<details>\n <summary>介绍一下slack</summary>\n\n\n```markdown\nSlack是一种团队协作工具,旨在改善团队内部沟通和协作的效率。它提供了实时聊天、文件共享、通知和集成等功能,使团队成员能够更轻松地进行交流和合作。\n以下是一些 Slack 的主要特点和功能:\n1. 实时聊天:Slack 提供了实时聊天功能,团队成员可以通过文本消息、表情符号、贴图等方式进行即时交流。你可以创建不同的频道(channels)来组织讨论,例如项目频道、团队频道等。\n2. 文件共享:你可以在 Slack 上轻松共享文件,包括文档、图片、音频和视频等。这样团队成员可以方便地查看、评论和编辑这些文件。\n3. 通知和提醒:Slack 可以发送通知和提醒,包括新消息、提及你的消息、任务截止日期等。你可以通过设置来控制接收哪些通知,以确保你能及时获取重要信息。\n4. 集成和应用程序:Slack 支持与其他工具和应用程序的集成,例如 Google Drive、GitHub、Jira 等。这样你可以在 Slack 中直接访问和操作这些工具,提高工作效率。\n5. 搜索和存档:Slack 有强大的搜索功能,你可以轻松找到之前的消息、文件和链接等。此外,Slack 还会自动存档你的聊天记录,方便你随时回顾和查找。\n6. 多设备支持:你可以在电脑、手机和平板电脑等不同设备上使用 Slack,并且它们之间的聊天同步。\n 总的来说,Slack 是一个强大的团队协作工具,可以帮助团队成员更好地沟通、协作和组织工作。它已经成为许多组织和公司的首选工具之一,无论是小型团队还是大型企业都可以受益于它的功能和便利性。\n```\n\n\n\n </details>\n\n\n<details>\n <summary>actions的权限不够</summary>\n\n\n```markdown\n 使用github action时报错Run ad-m/github-push-action@master\nPush to branch main\nremote: Write access to repository not granted.\nfatal: unable to access '[https://github.com/happyzhangyyds/elog.git/](https://github.com/happyzhangyyds/elog.git/)': The requested URL returned error: 403\nError: Invalid exit code: 128\nat ChildProcess.<anonymous> (/home/runner/work/_actions/ad-m/github-push-action/master/start.js:30:21)\nat ChildProcess.emit (node:events:514:28)\nat maybeClose (node:internal/child_process:1105:16)\nat ChildProcess._handle.onexit (node:internal/child_process:305:5) {\ncode: 128\n```\n\n\n```markdown\n这个错误表明您在尝试使用 GitHub Actions 运行 ad-m/github-push-action@master 时遇到了权限问题。具体来说,错误消息中提到您对存储库的写访问权限不足。\n要解决这个问题,您可以执行以下步骤:\n\n1. 确保您有足够的权限来对该存储库进行写操作。请确保您是该存储库的所有者或具有足够的权限来进行推送操作。\n2. 检查您在 GitHub Actions 的工作流文件中是否正确配置了凭据。您需要在工作流文件中提供正确的凭据,以便能够对存储库进行推送操作。您可以使用 GitHub 提供的 secrets 功能来安全地存储和使用凭据。确保您在工作流文件中使用正确的凭据。\n3. 如果您使用的是个人访问令牌 (Personal Access Token) 进行身份验证,请确保该令牌具有足够的权限来对存储库进行写操作。您可以在 GitHub 的个人设置中生成和管理个人访问令牌。\n4. 如果您使用的是 OAuth 应用程序进行身份验证,请确保您的应用程序已正确设置并被授权对存储库进行写操作。\n\n请检查上述步骤,确认您具有正确的权限和凭据,并且已正确配置 GitHub Actions 的工作流文件。这样应该能够解决您遇到的问题。如果问题仍然存在,请提供更多的上下文和详细信息,以便我能够更好地帮助您解决问题。\n```\n\n\n\n </details>\n\n\n<details>\n <summary>actions的本地远程冲突</summary>\n\n\n```markdown\n产生了如下报错信息:Run ad-m/github-push-action@master\nPush to branch main\nerror: atomic push failed for ref refs/heads/main. status: 5\n\nfatal: protocol error: bad line length character: erro\nTo https://github.com/happyzhangyyds/elog.git\n ! [rejected] HEAD -> main (fetch first)\nerror: failed to push some refs to 'https://github.com/happyzhangyyds/elog.git'\nhint: Updates were rejected because the remote contains work that you do not\nhint: have locally. This is usually caused by another repository pushing to\nhint: the same ref. If you want to integrate the remote changes, use\nhint: 'git pull' before pushing again.\nhint: See the 'Note about fast-forwards' in 'git push --help' for details.\nError: Invalid exit code: 1\n at ChildProcess.<anonymous> (/home/runner/work/_actions/ad-m/github-push-action/master/start.js:30:21)\n at ChildProcess.emit (node:events:514:28)\n at maybeClose (node:internal/child_process:1105:16)\n at ChildProcess._handle.onexit (node:internal/child_process:305:5) {\n code: 1\n}\n```\n\n\n```markdown\n这个错误表明在尝试使用 GitHub Actions 运行 `ad-m/github-push-action@master` 时遇到了推送失败的问题。根据错误消息,推送失败的原因可能是由于远程存储库包含了您本地没有的提交,导致冲突。\n\n要解决这个问题,您可以执行以下步骤:\n\n1. 按照错误消息中的建议,运行 `git pull` 命令来将远程存储库的更改合并到本地仓库。这将更新您的本地分支,使其包含远程存储库中的最新提交。\n\n ```bash\n git pull origin main\n ```\n\n2. 在合并远程更改后,解决可能的冲突。如果存在冲突,您需要手动解决它们以确保代码的一致性。\n\n3. 确保您有足够的权限来对存储库进行推送操作。请确保您是该存储库的所有者或具有足够的权限来进行推送操作。\n\n4. 检查您在 GitHub Actions 的工作流文件中是否正确配置了凭据。您需要在工作流文件中提供正确的凭据,以便能够对存储库进行推送操作。您可以使用 GitHub 提供的 secrets 功能来安全地存储和使用凭据。确保您在工作流文件中使用正确的凭据。\n\n请按照上述步骤逐一检查和解决问题。如果问题仍然存在,请提供更多的上下文和详细信息,以便我能够更好地帮助您解决问题。\n\n尽管您已经尝试了之前提到的解决步骤,但问题仍然存在。根据错误消息,推测可能是由于其他人在您尝试推送时同时对相同的分支进行了推送,导致冲突。\n\n在这种情况下,您可以尝试以下步骤:\n\n1. 确保您的本地仓库是干净的,没有未提交的更改。运行以下命令来查看当前的仓库状态:\n\n ```bash\n git status\n ```\n\n 如果有未提交的更改,请先提交或取消更改,确保仓库是干净的。\n\n2. 删除本地分支 `main`,然后重新拉取远程分支 `main` 的最新状态:\n\n ```bash\n git branch -D main\n git fetch origin main\n git checkout main\n ```\n\n 这将删除您本地的 `main` 分支,并从远程存储库中获取最新的 `main` 分支。\n\n3. 如果您在本地有重要的更改,可以创建一个新的分支来保存这些更改:\n\n ```bash\n git checkout -b my_changes\n ```\n\n 这将创建一个名为 `my_changes` 的新分支,并将您的更改保存在该分支上。\n\n4. 现在,尝试将新分支推送到远程存储库:\n\n ```bash\n git push origin my_changes\n ```\n\n 如果推送成功,您可以在 GitHub 上查看并比较分支,然后创建一个合并请求(Pull Request),将 `my_changes` 分支的更改合并到 `main` 分支中。\n\n请注意,如果其他人在您尝试推送时继续对相同的分支进行推送,可能仍会导致冲突。在这种情况下,您需要与其他人协调,以确保您的更改能够成功地合并到主分支中。\n\n如果问题仍然存在,请提供更多的上下文信息,例如您的工作流文件、代码片段或其他相关细节,以便我能够更好地帮助您解决问题。\n```\n\n\n\n </details>\n\n\n<details>\n <summary>解决环境变量可见性问题</summary>\n\n\n```markdown\n如果某个文件已经被 Git 跟踪并提交到仓库中,即使你在 `.gitignore` 文件中将其列为忽略项,它仍然会在仓库中可见。要解决这个问题,你需要执行以下步骤:\n\n1. 首先,从 Git 仓库中删除已经跟踪的文件。可以使用以下命令将文件从 Git 仓库中删除,但保留在本地文件系统中:\n\n```\ngit rm --cached <file>\n```\n\n将 `<file>` 替换为要从 Git 仓库中删除的文件的路径。\n\n2. 然后,将删除的文件添加到 `.gitignore` 文件中,以确保将来不会再次将其纳入版本控制。在 `.gitignore` 文件中添加文件路径或模式,例如:\n\n```\n<file>\n```\n\n3. 最后,提交对 `.gitignore` 文件和已删除文件的更改:\n\n```\ngit add .gitignore\ngit commit -m \"Remove and ignore the specified file\"\n```\n\n这样,已删除的文件将不再出现在 Git 仓库的历史记录中,并且在将来的提交中也不会被包含。\n\n请注意,这些步骤仅会将文件从 Git 仓库中删除,并阻止将来的提交。如果你希望完全从仓库中删除文件的所有痕迹,你可能需要执行其他操作,如修改 Git 的历史记录。这种情况下,建议谨慎操作,并在进行任何重要操作之前备份你的仓库。\n```\n\n\n\n </details>\n\n\n<details>\n <summary>如何删除git的历史痕迹</summary>\n\n\n```markdown\n要删除 Git 仓库中的文件的所有痕迹,包括历史记录和提交信息,可以按照以下步骤进行操作:\n\n1. 首先,确保你备份了重要的文件和仓库,以防止意外数据丢失。\n\n2. 使用 `git filter-branch` 命令来修改 Git 的历史记录。这个命令可以重写提交历史,并删除指定文件的所有痕迹。以下是一个示例命令:\n\n```\ngit filter-branch --force --index-filter 'git rm --cached --ignore-unmatch <file>' --prune-empty --tag-name-filter cat -- --all\n```\n\n将 `<file>` 替换为要删除痕迹的文件的路径。这个命令将遍历所有提交,并从中删除指定文件的所有痕迹。\n\n3. 执行该命令后,Git 将会重写历史记录。这可能需要一些时间,具体取决于你的仓库大小和提交数量。在完成后,Git 会显示重写的提交数量。\n\n4. 接下来,使用 `git push --force` 命令将修改后的历史记录推送到远程仓库。请注意,这个命令会强制推送修改后的历史记录,因此请确保你在进行此操作之前已经备份了重要的数据。\n\n```\ngit push --force origin <branch-name>\n```\n\n将 `<branch-name>` 替换为你要推送的分支名称。\n\n这样,指定文件的所有痕迹将从 Git 仓库的历史记录中完全删除。\n\n请注意,这个操作是不可逆的,并且会影响到与指定文件相关的所有提交和分支。因此,在执行此操作之前,请务必谨慎,并确保你理解操作的影响。\n```\n\n\n\n </details>\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-10-11",
"type": "Post",
"category": "动手实践",
"slug": "elog",
"tags": [
"推荐"
],
"summary": "通过elog实现notion文章批量下载到本地,以及自动化云端备份和迁移。",
"title": "[跨域协同] elog+notion实现md优雅备份",
"status": "Published",
"urlname": "0cbead15-8fc2-44b4-930c-8f3e897b6215",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "推荐",
"doc_id": "0cbead15-8fc2-44b4-930c-8f3e897b6215"
}
],
"body": "",
"realName": "[跨域协同] elog+notion实现md优雅备份",
"relativePath": "/推荐/[跨域协同] elog+notion实现md优雅备份.md"
},
{
"id": "f501f889-84e0-4b1e-9027-077be106b409",
"doc_id": "f501f889-84e0-4b1e-9027-077be106b409",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n> 💡 这个栏目用于记录《飞行管理与自动飞行控制系统》的学习笔记 \n> 由于这门课采用**双语授课**的形式,所以可能在知识的梳理上存在一定的困难。 \n> 为了提升英语的理解能力,我尽可能对每一部分采用双语翻译。 \n> 我并不打算每一次课做单独的博文post,故所以的上课笔记我都打算整合在这这个模块当中。故这篇博文我会在每一次授课完之后的1-2小时之内进行刷新。 \n> 更新:坚持太难了,我打算采用单章节的方式进行整理,因为内容真的不少 2023-09-24 \n> 非常感谢伍老师的授课🌺🌺🌺 \n> \n> --- \n> \n> This column is used to record learning notes on \"Flight Management and Automatic Flight Control System\" \n> \n> Due to the bilingual teaching format of this course, there may be some difficulties in organizing knowledge. \n> \n> In order to improve my English comprehension ability, I try to use bilingual translation for every part as much as possible. \n> \n> I do not plan to create a separate blog post for each class, so I plan to integrate all the class notes into this module. Therefore, I will refresh this blog post within 1-2 hours after each lecture. \n> \n> Thank you very much for Professor Wu's teaching 🌺🌺🌺\n\n\n# 正文\n\n\n---\n\n\n 自动飞行控制是指通过飞行自动控制系统操纵舵面和油门杆,自动控制飞机的飞行,这时驾驶员只进行监控,不直接参与对飞机的控制。[2](https://baike.baidu.com/item/%E8%87%AA%E5%8A%A8%E9%A3%9E%E8%A1%8C%E6%8E%A7%E5%88%B6)\n\n\nAutomatic flight control refers to the automatic control of the aircraft's flight through the control of the **control surface** and **throttle** lever through the flight automatic control system. At this time, the pilot only monitors and does not directly participate in the control of the aircraft.\n\n\n 自动飞行控制系统(AFCS)是完成飞行器在各种飞行模态下的控制任务,它是通过控制飞行器的姿态和轨迹来实现的。[3](https://www.bilibili.com/read/cv20333773/)\n\n\nThe Automatic Flight Control System (AFCS) is used to complete the control tasks of aircraft in various flight modes. It is achieved by controlling the attitude and **trajectory** of the aircraft.\n\n\n 自动飞行控制系统包括自动驾驶飞行指引系统(AFDS)和自动油门(A/T)等组成部分,它们可以提供自动稳定、导航、着陆、地形跟随等功能。[2](https://baike.baidu.com/item/%E8%87%AA%E5%8A%A8%E9%A3%9E%E8%A1%8C%E6%8E%A7%E5%88%B6)\n\n\nThe automatic flight control system includes components such as the Automatic Flight Guidance System (AFDS) and the Automatic **Throttle** (A/T), which can provide functions such as automatic stability, navigation, landing, and terrain following.\n\n\n 可以通过这个视频入门——[**1.1 自动飞行控制系统引言**](https://www.bilibili.com/video/BV16z4y1s7My/?spm_id_from=333.337.search-card.all.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n\n\n\n\n\nYou can get started with this video - Introduction to 1.1 Automatic Flight Control System\n\n\n 这门课给我最直观的感受就是以《自动控制原理》这门课为基石做综合运用,里面涉及到很多的自控方面的知识。并且具象到民航飞机上的应用。从一个比较抽象的理论知识到具体的实践应用。\n 我则关注于这期间的理论是如何转换到实践当中去的。\n\n\nThe most intuitive feeling this course gave me was to use the course \"Principles of Automatic Control\" as the foundation for comprehensive application, which involves a lot of knowledge in the field of self-control. And concrete application to civil aviation aircraft. From a relatively abstract theoretical knowledge to specific practical applications.\n\n\nI focused on how the theory during this period was transformed into practice.\n\n\n## Aug 29,23 授课及感受\n\n\n---\n\n\n 刚开始双语授课,有点不习惯,因为存在着很多专业名词的理解问题,而且本身对英语的理解能力至少是低于中文理解能力的3-5倍,因为还是刚开始的第一节课,会好一些,但是还是尽可能去加强英语与专业课之间的衔接能力。\n\n\nAt the beginning of bilingual teaching, I feel a bit uncomfortable because there are many problems with understanding professional terms, and my own understanding of English is at least 3-5 times lower than that of Chinese. As it is still the first class, it will be better, but I still try to strengthen the connection between English and professional courses as much as possible.\n\n\n\n\n\n\n\n\n## Sep 1 ,23 授课及感受\n\n\n---\n\n\n 尽可能去靠近一点知识,并做好整理。\n\n\n Try to get as close to the knowledge as possible and organize it well.\n\n\n\n\n\n\n\n\n## Sep 5 ,23 授课及感受\n\n\n---\n\n\n\n\n\n## Sep 8 ,23 授课及感受\n\n\n---\n\n\n\n\n\n\n\n\n\n\n\n## Sep 12 ,23 授课及感受\n\n\n---\n\n\n 今天讲的知识和自控联系很深,教学速度偏快,想要理解更好肯定是要花时间的,在教材和ppt的帮助下,希望能吸收得更好一些。\n 还有个趣事就是课堂最后老师要用英语回答一个问题,很显然我们对英语的运用能力远不及母语。\n\n\nThe knowledge and self-control discussed today are deeply related, and the teaching speed is relatively fast. It will definitely take time to understand better. With the help of textbooks and PowerPoint, I hope to absorb them better.\n\n\nAnother interesting thing is that the teacher has to answer a question in English at the end of the class, and it is obvious that our ability to use English is far inferior to our native language.\n\n\n\n\n\n\n\n\n\n\n\n# 总结\n\n\n通过课程的学习逐步提高专业能力和语言水平\n\n\nGradually improve professional skills and language proficiency through course learning.\n\n\n\n\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-08-29",
"type": "Post",
"category": "璀璨星空",
"slug": "AFCS",
"tags": [
"自动飞控"
],
"summary": "用于记录《飞行管理与自动飞行控制系统》的学习笔记",
"title": "[民航科普] 自动飞行控制概述",
"status": "Published",
"urlname": "f501f889-84e0-4b1e-9027-077be106b409",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "自动飞控",
"doc_id": "f501f889-84e0-4b1e-9027-077be106b409"
}
],
"body": "",
"realName": "[民航科普] 自动飞行控制概述",
"relativePath": "/自动飞控/[民航科普] 自动飞行控制概述.md"
},
{
"id": "1ca299e5-7fc1-4d7c-b3bc-9394883947cd",
"doc_id": "1ca299e5-7fc1-4d7c-b3bc-9394883947cd",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 想乘着周末这个时间,简单分析一下最近的感受,我想把从12月初到12月中旬的心路历程的变化来写一写。\n\n\n 我已经很久没有在主动学习技能上花费很多心力了,自从10月11月的实习和课设之后,每天像生产队的驴一样在疯狂拉磨。然后情绪基本上也处于低谷当中,从我的博客的记录上来看是这样。\n\n\n 但我现在不能把时间和回忆往前回溯太多,不然痛苦太多毫无意义。\n\n\n# 正文\n\n\n---\n\n\n 这一部分,我将分为几个阶段来回忆一下我的经验和教训。\n\n\n### 最后一门理论课的备考\n\n\n---\n\n\n 应该说备考期间是夹杂的课设的,北国的萧瑟更让人提不起丝毫的兴趣,图书馆里的书声琅琅似乎也与我无缘,往我的四楼的小地方一坐就是一天。\n\n\n 2号和3号,配阿浩打了两天饥荒,周一下午开始复习,上午鲁班猫的外壳和串口线到了,折腾了一会鲁班猫。\n\n\n 周二周三周四是复习的三天,周二周三,先是把期末提纲和阿浩搞到的提纲复习了一遍,一开始是对着电子版的提纲开始边抄写边背诵的,周二一天是这样的,后来周三发觉这样效率太低,于是把提纲打出来,之后复习的速度开始提上去了,但是背的东西实在太多了,在周四的晚上把两道计算题弄懂了,周五上午继续背了理论,看了看计算题,熬到下午考完,才如释重负。\n\n\n 除了一道下滑道波束引导的运动方程没写出来之外,其他答得倒还勉勉强强。\n\n\n 和上学期的五门理论课一样,我还是希望就学习和备考方式提出一些我自己的看法,我觉得这样的学习是有些问题的,首先难度很高,其次静不下心了,再者对未来的增益有限,大概大学的意义,对我来说,或者只是一张文凭呢,其他美好的回忆有但不多。\n\n\n 然后考完的下午和晚上把课设的报告继续改一改,其实我不是很喜欢写报告,但是这种能力还是需要具备的,改到晚上0:30,熬夜几乎是大学的常态了,平常就算早点上床,也因为心事睡不着,我只能说,幸福指数很低。\n\n\n 然后9号上午睡到很晚起床,刷了会bilibili,中午不是和同学出去食饭了嘛,在之前的日记里也提到过。然后莫名其妙犯困,又睡了一下午,晚上再配阿浩打了一晚上饥荒。\n\n\n### 奔赴山海的路上\n\n\n---\n\n\n 10号,上午收拾行李,阿浩早上的飞机,吃完早饭就走了,中午12:30我出发去火车站,后面就是一下午的颠簸,晚上大概六点多到宾馆,简单吃了点瑞士卷,晚上坐在床上打完了总结就睡觉了。\n\n\n 天工不作美,只一晚上的时间,大地就银装素裹。对我而言,这可不是欣赏好风景的时候,因为我要拖着20多公斤的行李去公司报道,想来我也有点铸币,为什么10号没想到直接去公司呢。然后早上去肯德基简单食了一个汉堡一杯咖啡,性价比实在有点低,这个咖啡吧,苦伤了心。\n\n\n 到公司报道之后,签了实习协议,安排好事宜之后就先去工作岗位报道,上午装了一台新电脑和一台旧电脑,然后中午在公司食饭,我发现可能大多数时候一个人干饭没什么氛围,但是忙碌之后和同事一起干饭就显得很有劲。公司这边提供餐补,很暖心啦。\n\n\n 下午来到我现在待的小屋,简单收拾一下继续去岗位上班。上班的体验其实没那么痛苦,反正我觉得比待在学校还要舒服一些,为什么啊,因为在搞钱啊。\n\n\n 但上完班之后,对元气消耗还是有点大,晚上学习稍微还是有点打不起精神来,而且一个人待的时候,真是害怕孤独。\n\n\n 但我有一点很喜欢的是,在公司还是比较自由的,最重要的是什么,规律,就是为了上班,你不可能睡懒觉,然后这边小屋虽然没有窗帘,但是我能感受到日出日落,这就已经很了不起了,之前在学校的宿舍还有一点诟病的就是纯火柴盒配置,阳光都照不进来。\n\n\n 然后7:30起床,7:50出门,步行10分钟打卡上班,8:00-8:10食完早饭,再花十分钟上个厕所,8:30开始工作的时候就元气满满。\n\n\n 说实话,比我一个人待的时候,自律太多了,如果精神状态好的话,早上起来背个单词也是完全有可能的。中午准点干饭,休息20分钟以内是刚刚好的,13:00继续上班,不像我今天下午在床上一趟就睡了一个半小时,下午又没了。\n\n\n 但我觉得还有一点要注意的是什么,就是自我提升这一块,我觉得还得安排好,如果生活没有目标,我就永远是一个小废物。奇怪吧,自己驱动不了自己,别人能驱动自己,但是我也发现,环境确实对人很大,公司的环境和氛围都是很好的,这些都是潜在的投入。\n\n\n### 遇到的问题和期望\n\n\n---\n\n\n 其实我也遇到了一些问题,我一向有假期恐惧症,一旦脱离了学习的环境,就像鱼离开了水,心似平原走马,易放难收,所以每每放假回家的时候我的心都要咯噔一下。\n\n\n 所以我才试着走一条不一样的路,人不能总在舒适区呆着。\n\n\n 另外我还想就我之前暑假的一段经历进行比较,大学的文凭其实真的已经给我们带来了一些平台,通过校招比社招已经好很多了,我之前大三的暑假去天津找阿强,阿强暑假没有回去,选择在天津谋生,我考完驾照之后就去找他玩,因为我厌倦了待在家里的无所事事,和各种唠叨。\n\n\n 就我待在阿强的小屋里也没事干嘛,然后就在58同城上找找活干,这就是倒霉的开始,这个逼活吧,看着简单,不算非常累,但是吧,你真正成为流水线上的螺丝钉的时候,大概你也会和许立志一样绝望,这种感觉可不是一般人能挺过来的,但是阿浩挺过来了。但也仅限于体验半个月到一个月。\n\n\n 那个阶段,我就是流水线上的纯牛马,在流水线最后一环,摆放汽车的刹车零件,我大概摆了两千多个,每个零件大概有一到两公斤,就这个能量算下来,我都得寄,累到中午根本吃不下饭,累到干了一天腰疼了三天,更加雪上加霜的是,那家公司很远,离出租的小屋很远,我没带被子,晚上被冻成狗,于是实在受不了,就走了,离开的时候,感觉那时候真的很像点根烟,即使我从来不抽烟。\n\n\n 所以说啊,不接触底层的工作,永远想象不到底层人民的艰辛,这座庞大的大厦,如果没有辛劳的建筑工,哪里来的荣华富贵。\n\n\n 但正如历史规律一样,可怜河边无定骨,犹是春闺梦里人一样,很少有人会在乎的。\n\n\n 有时候我觉得《道德经》说得很有意思,大白若辱,大方无隅,看似矛盾的表述,却隐藏着简单而朴素的道理,就是矛盾本身。\n\n\n 不接触社会本身,我也不知道我生活的意义在哪里。\n\n\n 然后最后我再去,讲一下这个周末的体验,周末其实刚开始体验不好,因为自控能力很差,情绪也没有很稳定,没办法从学习的心流中获得足够多的乐趣,很多的基础设施还没搭建完善。\n\n\n 周五熬夜,周六睡懒觉,中午顶着零下十几度的温度步行去寻找食物,走了一公里多,一碗炸酱面13,再去小店里买了两盒奥利奥,11根香蕉,7*2+8.8=22.8,晚上忙着研究我的计划,连续工作了大概六个多小时。到接近凌晨三点才睡。\n\n\n 周日本能的七点多醒,然后因为太困,睡到九点半才起,早饭又没吃,确实没办法,简单食了香蕉,奥利奥,上了厕所,洗漱,洗衣服,然后稍微工作了一会,中午去公司找找食物。\n\n\n 因为附近实在太荒凉了,爬楼梯到四楼,听见新闻30分,我就知道,可以干饭了,简单挑了三个菜,麻婆豆腐,小青菜,蒜苗炒肉,一碗紫菜蛋汤,好心的师傅给我加了个鸡腿,而且,在公司中午食饭,刷卡只记次数不消费。\n\n\n 我当时觉得,终于能吃顿像样的午餐了,就着电视草草吃完,下午睡了一大觉,然后起床,玩一会,烧壶开水,开始写作,然后就写到现在。\n\n\n \n\n\n# 总结\n\n\n---\n\n\n 差不多快到点了,过会我得继续寻找食物了。\n\n\n 下半年自己租房就可以自己买菜自己煮饭了,当然也可以去公司,如果距离不远的话,我觉得,有句话很好,问道有先后,术业有专攻,社会化大生产所带来的便利是可以感知到的,在寻常小事中的温暖人情也是永远忘不掉的。\n\n\n 人啊,这一生,哪来这么多轰轰烈烈,很多记忆随着时间就忘了,但我至今仍然记得很多温暖的瞬间,这不仅仅是初中时候的一篇记叙文题目,而是实实在在成为了人生中第二阶段的回忆,就像《平凡的世界》少平一样,倔强的青年在风雨的世界里摸索着自己的人生路。\n\n\n 之后,我觉得有些点得重点提一下。\n\n- 工作能力的提升\n- 关注生活中暴露的缺点\n- 自主学习能力的提升\n\n 另外,我觉得每天还是需要和父母发个消息,报平安,因为父母陪伴我们前半生,爱人陪伴我们后半生,中间的短短数十年,是我们陪伴自己的最好年华。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-12-17",
"type": "Post",
"category": "走近生活",
"slug": "231217",
"tags": [
"情绪表达"
],
"summary": "我至今仍然记得很多温暖的瞬间,这不仅仅是初中时候的一篇记叙文题目,而是实实在在成为了人生中第二阶段的回忆。",
"title": "[心路历程] 远赴山海,未来可期",
"status": "Published",
"urlname": "1ca299e5-7fc1-4d7c-b3bc-9394883947cd",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "情绪表达",
"doc_id": "1ca299e5-7fc1-4d7c-b3bc-9394883947cd"
}
],
"body": "",
"realName": "[心路历程] 远赴山海,未来可期",
"relativePath": "/情绪表达/[心路历程] 远赴山海,未来可期.md"
},
{
"id": "6c18dac8-538c-4272-80f0-33bb01eb3c08",
"doc_id": "6c18dac8-538c-4272-80f0-33bb01eb3c08",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 今天做一道极限的题目,用到的等价无穷小,但是图片一直是博客杀手,我等了半天也出不来,却是没办法,notion本身的图片加载速度只能说一般,而且国内的访问速度不是很理想,所以前几天我一直很苦恼。\n 今天我打算用杜老师的图床对图片进行加速,之前使用marginnote+obsidian的时候就研究过这个东东,因为obsidian虽然强大,但是图片都是存储在本地,没办法同步到notion,然后就用到了picgo,一开始我不知道能用杜老师的图床,后来才发现,可以的,腾讯云的图床我用的还不是很舒服,smms的图床虽然免费,但感觉有时候不稳定。\n picgo就是一种快捷的图片上传服务,上传图片的同时还可以给你图片的链接。\n\n\n> 💡 首先感谢杜老师提供的图床服务🌺🌺🌺 \n> 具体可以去杜老师的[博客](https://dusays.com/)看一看 \n> 本文也参考了掘金社区作者**lzg9527的文章:**[**前端性能优化——图片篇**](https://juejin.cn/post/6965761736083243044) \n> 感谢作者热心的分享和介绍😄\n\n\n# 正文\n\n\n---\n\n\n 进行细节介绍,关于网站加载的步骤,图片的格式\n\n\n## 为什么要进行图片优化\n\n\n---\n\n\n 图片众多以及图片体积过大往往会影响页面加载速度,造成不良的用户体验,所以对图片进行优化势在必行。\n\n\n 并发的图片请求次数是有限的,其他的请求会推入到队列中等待或者停滞不前,直到上轮请求完成后新的请求才会发出。所以相当一部分图片资源请求是需要排队等待时间的,过多的图片必然会影响页面的加载和展示。\n\n\n## 图片格式介绍\n\n\n---\n\n\n JPEG 是由 Joint Photographic Experts Group 所开发出的一种图片。它最大的特点是 **有损压缩**。当我们把图片体积压缩至原有体积的 50% 以下时,JPG 仍然可以保持住 60% 的品质。可以呈现多达 1600 万种颜色,足以应对大多数场景下对色彩的要求。\n\n\n PNG(可移植网络图形格式)是由 W3C 开发的图片格式,是一种**无损压缩**的高保真的图片格式。PNG 图片具有比 JPEG 更强的色彩表现力,对线条的处理更加细腻,对透明度有良好的支持。它弥补了上文我们提到的 JPEG 的局限性,唯一的缺点就是 **体积太大**。\n\n\n GIF 是一种最多支持 256 种颜色的 8 位无损图片格式。这个限制让 GIF 格式对于多颜色或者摄影图片的展示无能为力。支持动画,适合去展示一些无限循环的动画,比如图标、表情、广告栏等。\n\n\n WebP 是一种同时提供了有损压缩与无损压缩(可逆压缩)的图片文件格式,派生自影像编码格式 VP8。它像 JPEG 一样对细节丰富的图片信手拈来,像 PNG 一样支持透明,像 GIF 一样可以显示动态图片,集多种图片文件格式的优点于一身。虽然 webP 有诸多优点,但是它不能完全替代 JPEG 和 PNG,因为浏览器对 WebP 支持并不普遍。特别是移动端 IOS 系统基本不支持。\n\n\n## 图片压缩工具\n\n\n---\n\n\n 我使用的是Mac的[ImageOptim](https://imageoptim.com/mac),使用体验还是比较良好的。\n 然后文章的作者也提供了一些其他的方案,比如:\n\n- [tinypng](https://link.juejin.cn/?target=https%3A%2F%2Ftinypng.com%2F) 免费、批量、速度块\n- [智图压缩](https://link.juejin.cn/?target=https%3A%2F%2Fzhitu.isux.us%2F) 百度很难搜到官网了,免费、批量、好用\n- [squoosh](https://link.juejin.cn/?target=https%3A%2F%2Fsquoosh.app%2F) 在线图片压缩工具\n- [compressor](https://link.juejin.cn/?target=https%3A%2F%2Fcompressor.io%2F) 支持 JPG、PNG、SVG、GIF\n\n## 🌟**使用 CDN 图片**\n\n\n---\n\n\n CDN 的全称是 Content Delivery Network,即内容分发网络。<u>CDN 是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。</u>CDN 的关键技术主要有内容存储和分发技术。\n\n\n 举个简单的例子:\n\n\n> _以前买火车票大家都只能去火车站买,后来我们买火车票就可以在楼下的火车票代售点买了。_\n\n\n 这个比喻还是很形象的,通过多地部署,提高速度。\n 这里都是引用的作者的描述\n\n\n**基本原理**\n\n\n CDN 的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。\n\n\n**基本思路**\n\n\n CDN 的基本思路是<u>尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,</u>使内容传输的更快、更稳定。<u>通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN 系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。</u>其目的是使用户可就近取得所需内容,解决 Internet 网络拥挤的状况,提高用户访问网站的响应速度。\n\n\n**CDN 的优势**\n\n- CDN 节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;\n- 大部分请求在 CDN 边缘节点完成,CDN 起到了分流作用,减轻了源站的负载。\n\n## 其他方案\n\n\n---\n\n\n **使用 css 代替图片**。\n\n\n 比如实现修饰效果,如半透明、边框、圆角、阴影、渐变等,在当前主流浏览器中都可以用 CSS 达成,这样能减少图片的请求,达到优化的目的。\n\n\n**缺点**\n\n- 受限于 css 的浏览器的兼容性\n- 对于较复杂的图案就无能为力了,写也麻烦,开发成本大\n\n **图片懒加载**\n\n\n 懒加载是一种网页性能优化的方式,它能极大的提升用户体验。图片一直是影响网页性能的主要元凶,现在一张图片超过几兆已经是很经常的事了。如果每次进入页面就请求所有的图片资源,那么可能等图片加载出来用户也早就走了。所以进入页面的时候,只请求可视区域的图片资源。\n\n\n总结出来就是:\n\n- 减少资源的加载,页面启动只加载首屏的图片,这样能明显减少了服务器的压力和流量,也能够减小浏览器的负担。\n- 防止并发加载的资源过多而阻塞 js 的加载,影响整个网站的启动,影响用户体验\n- 浪费用户的流量,有些用户并不想全部看完,全部加载会耗费大量流量。\n\n> 💡 这个技术博客的开发作者应该也是用上了的,我觉得javascript还是很有意思的,里面蕴含着很多解决问题的思想和办法。\n\n\n **图片预加载**\n\n\n 图片预加载,是指在一些需要展示大量图片的网站,将图片提前加载到本地缓存中,从而提升用户体验。\n\n\n 常用的方式有两种,一种是隐藏在 css 的 background 的 url 属性里面,一种是通过 javascript 的 Image 对象设置实例对象的 src 属性实现图片的预加载。\n\n\n **响应式图片加载**\n\n\n 什么是响应式图片加载?其实就是在不同分辨率的设备上显示不同尺寸的图片,避免资源的浪费。\n\n\n 常用的方法就是 css3 的媒体查询(media query)。\n\n\n **渐进式图片**\n\n\n 渐进式图片的意思是在高画质图像加载完之前会先显示低画质版本。低画质版本由于画质低、压缩率高,尺寸很小,加载很快。在两者之间我们也可以根据需要显示不同画质的版本。\n\n\n\n\n\n 渐进式图片可以让用户产生图片加载变快的印象。用户不再盯着一片空白区域等待图片加载,而能看到图像变得越来越清晰,这样对用户体验也是友好的。\n\n\n 骨架屏技术也是类似的原理。\n\n\n# 总结\n\n\n---\n\n\n 作者的总结还是非常详细的,对于一个问题提供了很多解决问题的思路。再赞一个👍!\n 1. 选择合适的图片格式和压缩大图,可从根源上截图大图加载过慢的问题。\n\n\n 2. 使用雪碧图,iconfont,base64,css 代替图片等可减少图片 http 请求,提高页面加载速度。\n\n\n 3. 使用 CDN 图片可达到分流的效果,减少服务器压力。\n\n\n 4. 图片懒加载,预加载,渐进式图片等可不同程度减少白屏时间,提高产品体验。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-08-13",
"type": "Post",
"category": "动手实践",
"slug": "picturespeed",
"tags": [
"推荐"
],
"summary": "用杜老师的图床对图片进行加速",
"title": "[速度优化] 前端图片性能优化",
"status": "Published",
"urlname": "6c18dac8-538c-4272-80f0-33bb01eb3c08",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "推荐",
"doc_id": "6c18dac8-538c-4272-80f0-33bb01eb3c08"
}
],
"body": "",
"realName": "[速度优化] 前端图片性能优化",
"relativePath": "/推荐/[速度优化] 前端图片性能优化.md"
},
{
"id": "a57cf3cb-9908-4374-8874-d7d05a352042",
"doc_id": "a57cf3cb-9908-4374-8874-d7d05a352042",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n Cadence学习日志。\n\n\n# 正文\n\n\n---\n\n\n 了解Cadence\n\n\n## 在PCB绘制领域,介绍一下Cadence\n\n\n---\n\n\n Cadence是一家知名的电子设计自动化(EDA)公司,提供各种与电子设计相关的软件和工具。在PCB(Printed Circuit Board,印刷电路板)绘制领域,Cadence提供了一系列的软件套件,其中最著名的是OrCAD和Allegro。\n\n\n OrCAD是Cadence旗下的一款PCB设计工具套件,它提供了完整的PCB设计流程,包括原理图绘制、电路仿真、布局和布线等功能。OrCAD具有友好的用户界面和强大的功能,适用于从初学者到专业工程师的各种需求。\n\n\n Allegro则是Cadence的高级PCB设计工具套件,主要面向专业的电子设计工程师和大规模PCB项目。它提供了更高级的功能和性能,包括复杂的布局和布线、信号完整性分析、电磁兼容性分析等。Allegro还支持多层板设计、高速信号设计和封装设计等高级应用。\n\n\n Cadence的PCB设计工具套件具有强大的功能和灵活性,可以帮助工程师进行电路设计和PCB布局布线,提高设计效率和质量。它们支持标准的文件格式如Gerber文件,可以与其他PCB制造商和供应商进行无缝集成。\n\n\n 除了PCB设计工具,Cadence还提供其他与电子设计相关的软件和工具,如模拟电路设计、数字电路设计、射频设计、系统级设计等。这些工具可以帮助工程师在整个电子设计流程中完成各种任务,并提供全面的设计和分析支持。\n\n\n 总而言之,Cadence在PCB绘制领域提供了一系列强大的软件工具,帮助工程师进行电路设计、布局和布线,从而实现高质量的印刷电路板设计。\n\n\n## 如何系统地开始学习Cadence\n\n\n---\n\n\n 要系统地学习Cadence,您可以按照以下步骤进行:\n\n1. **了解基本概念**:开始之前,了解PCB设计的基本概念和术语是很重要的。了解电路板的结构、组成部分以及常用的设计规范和标准。\n2. **学习软件界面和工具**:下载并安装Cadence的软件套件,如OrCAD或Allegro。学习软件界面的基本布局和各个工具的功能。掌握常用的快捷键和操作技巧,以提高工作效率。\n3. **学习原理图设计**:学习如何使用Cadence进行原理图设计。了解如何创建电路图符号、连接元件、添加标签和注释等。掌握元件库的使用和管理。\n4. **学习电路仿真:**掌握Cadence中的电路仿真工具,如PSpice。学习如何设置仿真参数、运行仿真、分析仿真结果等。了解如何进行直流分析、交流分析、时域分析和频域分析等。\n5. **学习布局和布线:**学习如何使用Cadence进行电路板的布局和布线。了解如何放置元件、规划电源和地线、处理信号完整性等。学习使用自动布线工具或手动布线来优化电路板布线。\n6. **学习信号完整性分析:**了解如何使用Cadence进行信号完整性分析,包括时钟分析、信号完整性检查、串扰分析等。学习如何解决信号完整性问题,提高电路板的性能和可靠性。\n7. **学习高级功能:**一旦掌握了基本的设计流程和工具,可以进一步学习Cadence的高级功能。这包括多层板设计、高速信号设计、射频设计、电磁兼容性分析等。根据自己的需求选择学习的方向。\n8. **实践和项目:**通过实践和完成一些小项目来巩固所学的知识。尝试设计简单的电路板,并进行仿真、布局和布线。通过实际项目的经验,深入理解Cadence的使用和应用。\n9. 学习资源和社区:利用Cadence官方提供的文档、教程和培训资源来学习。参与Cadence的用户社区和论坛,与其他用户交流经验和解决问题。\n10. 持续学习和更新:Cadence的软件和工具不断更新和演进,保持学习的态度并持续跟进最新的版本和功能。参加培训课程、研讨会和行业活动,与行业专家和其他工程师进行交流和学习。\n\n通过以上步骤,您可以系统地学习和掌握Cadence的PCB设计工具,提高自己在电子设计领域的能力和技术水平。\n\n\n## PCB设计在硬件开发中的地位\n\n\n---\n\n\n PCB设计在硬件开发中具有重要的地位。作为电子产品的核心组成部分,PCB承载着电路元件的连接和布局,决定了电路的性能、可靠性和成本。\n\n\n 以下是PCB设计在硬件开发中的几个关键方面:\n\n1. 电路连接和布局:PCB设计通过将电路元件连接在一起,并根据设计需求进行布局,实现电路的功能。合理的电路连接和布局可以最大程度地减少信号干扰、提高信号完整性,确保电路的正常运行。\n2. 电路性能和可靠性:PCB设计对电路性能和可靠性有直接影响。通过优化布局、控制信号路径长度、合理规划电源和地线等措施,可以提高电路的性能、降低功耗、减少噪声和串扰等问题,从而提高产品质量和可靠性。\n3. 封装和布线:PCB设计涉及到选择合适的元件封装和布线方式。合适的封装选择可以满足电路的功耗、散热和机械要求,而合理的布线可以最小化电路板上的信号延迟、串扰和电磁干扰,确保电路的稳定性和可靠性。\n4. 制造和组装:PCB设计需要考虑到电路板的制造和组装过程。通过合理的布局和设计规则,可以降低制造成本、提高制造效率,并确保电路板可以被顺利组装和焊接。\n5. 产品迭代和快速开发:PCB设计在硬件开发中具有快速迭代和快速开发的优势。通过使用CAD软件进行PCB设计,可以快速设计、修改和验证电路板,加快产品开发的速度,缩短上市时间。\n\n 总体而言,PCB设计在硬件开发中**扮演着至关重要的角色。**它直接影响着电子产品的性能、可靠性和成本,并且在整个产品开发周期中起到了关键的作用。因此,合理的PCB设计流程和技术能够帮助工程师提高设计效率、降低开发风险,从而实现更优秀的硬件产品。\n\n\n## 硬件工程师的主要职责\n\n\n---\n\n\n 硬件工程师是负责设计、开发和测试电子硬件系统的专业人员。他们在硬件开发的各个阶段发挥重要作用,包括概念设计、详细设计、原型制作、验证测试和产品生产等。\n\n\n 以下是硬件工程师的主要职责:\n\n1. **需求分析**:与产品经理、系统工程师和其他相关团队成员合作,了解产品需求和规格要求。分析和理解硬件设计的功能、性能、接口和可靠性等方面的要求。\n2. **概念设计**:根据产品需求,进行概念设计,包括选择适当的硬件平台、电路拓扑和系统架构。进行初步的电路设计、元器件选择和系统分析。\n3. **详细设计**:根据概念设计,进行详细的硬件设计。包括电路图设计、原理图绘制、PCB布局和布线等。选择和评估元器件,进行电路仿真和分析。\n4. **原型制作**:根据详细设计,制作硬件原型。包括原型电路板的制作、元器件的采购和组装。进行原型测试和验证,确保硬件设计的功能和性能符合要求。\n5. **集成与测试**:与团队成员合作,进行硬件系统的集成和测试。确保硬件与软件的配合良好,进行系统级测试和验证。解决硬件相关的问题和故障。\n6. 产品生产支持:与制造团队合作,提供硬件设计的相关支持。包括制造文件的生成、质量控制和生产过程的监督。解决生产中的问题,确保产品的质量和可靠性。\n7. 文档编写和记录:撰写硬件设计文档,包括设计规格、用户手册和测试报告等。记录设计决策、问题和解决方案,以便于后续的维护和升级。\n8. 技术支持和维护:为客户、销售团队和技术支持团队提供硬件方面的支持。解答客户的技术问题,协助故障排除和维护工作。\n9. 跟踪技术发展:关注新的硬件技术和行业趋势。学习和掌握新的工具、技术和标准,不断提升自己的专业知识和技能。\n\n 总体而言,硬件工程师负责设计、开发和测试电子硬件系统,确保硬件设计满足产品需求和规格要求。他们需要具备电路设计、PCB布局、元器件选择、测试和故障排除等方面的专业知识和技能。同时,他们也需要具备良好的团队合作能力、问题解决能力和沟通能力,与其他团队成员密切合作,共同推动项目的成功。\n\n\n## Cadence软件设计需要具备哪些基本的电路知识\n\n\n---\n\n\n 要进行Cadence软件设计,你需要具备一些基本的电路知识。以下是一些你可能需要了解的关键概念:\n\n1. **电路基础知识**:了解电流、电压、电阻、电感和电容等基本电路元件的概念和特性。了解欧姆定律、基尔霍夫定律和功率计算等基本电路理论。\n2. **电路拓扑和结构**:了解不同类型的电路拓扑,如串联、并联和桥式电路。了解常见的电路结构,如放大器、滤波器、振荡器和计数器等。\n3. **元器件特性**:了解常见的电子元器件,如二极管、晶体管、操作放大器、传感器和逻辑门等。了解元器件的特性参数,如电压放大倍数、频率响应和功耗等。\n4. **信号处理和滤波**:了解信号处理的基本概念,如滤波、放大、混频和调制等。了解不同类型的滤波器,如低通、高通、带通和带阻滤波器。\n5. **时序和时钟**:了解时序和时钟设计的基本原理。了解时钟信号的生成、分配和同步技术。了解时序分析和时钟域交叉等相关概念。\n6. **信号完整性和电磁干扰**:了解信号完整性的重要性,如信号延迟、串扰和反射等问题。了解电磁干扰的原因和减少干扰的方法。\n7. **PCB设计规范**:了解PCB设计的基本规范和标准,如布局规则、信号完整性规范和EMC/EMI要求等。了解PCB层次结构、封装和布线规则等。\n\n 这些是进行Cadence软件设计所需的一些基本电路知识。当然,具体的项目和设计要求可能需要更深入的电路知识。在实际设计过程中,你可能需要进一步学习和应用这些知识,以满足具体项目的要求。\n\n\n## quatusⅡ和Cadence的区别与联系\n\n\n---\n\n\n Quartus II和Cadence是两个不同的电子设计自动化(EDA)软件工具,用于数字电路和模拟电路的设计和验证。它们在功能、应用领域和市场定位等方面存在一些区别。\n\n\n Quartus II是Intel公司(前身为Altera)推出的一款主要用于可编程逻辑器件(FPGA)设计的软件工具。它提供了从设计输入到编译、仿真和布局布线的完整设计流程。Quartus II支持硬件描述语言(HDL)如VHDL和Verilog,以及高级综合(HLS)工具如SystemVerilog和OpenCL。它还提供了丰富的IP(知识产权)库,以及针对FPGA设计的特定功能和优化。\n\n\n 是一家提供广泛的电子设计自动化软件和工具的公司。它的软件套件包括OrCAD和Allegro等,用于原理图设计、电路仿真、布局和布线等。Cadence的工具主要用于模拟电路、射频电路和混合信号设计,以及PCB设计和验证。Cadence的软件在各种应用领域中得到广泛应用,包括消费电子、通信、汽车、航空航天等。\n\n\n 虽然Quartus II和Cadence是不同的软件工具,但它们在一些方面存在联系和集成。例如,在某些项目中,设计团队可能同时使用Quartus II和Cadence工具。在这种情况下,Quartus II用于FPGA设计和验证,而Cadence工具用于模拟电路设计和PCB布局布线。通过集成这些工具,设计团队可以实现更全面的电子系统设计。\n\n\n 需要注意的是,我提供的信息基于2021年的知识。在当前时间(2023年)可能会有新的软件版本和更新,因此建议查阅Intel和Cadence官方网站以获取最新信息和详细比较。\n\n\n## 比较常用的EDA软件\n\n\n---\n\n\n 这部分我想要了解一下,在学校常用的设计软件和工作使用的设计软件的区别与联系。\n\n\n 感谢作者:张飞实战电子提供的文章:[**电路仿真软件哪个好?7款主流电路仿真软件大比拼!**](https://zhuanlan.zhihu.com/p/573448695#:~:text=7%E6%AC%BE%E4%B8%BB%E6%B5%81%E7%94%B5%E8%B7%AF%E4%BB%BF%E7%9C%9F%E8%BD%AF%E4%BB%B6%E5%A4%A7%E6%AF%94%E6%8B%BC%EF%BC%81%201%20%E4%B8%80%E3%80%81Cadence%202%20%E4%BA%8C%E3%80%81Altium%20Designer%203%20%E4%B8%89%E3%80%81Proteus,Multisim%205%20%E4%BA%94%E3%80%81Matlab%E7%94%B5%E8%B7%AF%E4%BB%BF%E7%9C%9F%E8%BD%AF%E4%BB%B6%E5%8C%85Simulink%206%20%E5%85%AD%E3%80%81TINA-TI%207%20%E4%B8%83%E3%80%81Infineon%20Designer)\n\n\n 在学习模电的过程中,感觉最常用的软件还是**Multisim,**通过搭建一些简单的电路进行一些特性的分析。\n\n\n 学习数电的过程中,老师常用的演示软件是**Proteus,**但之后没有什么机会能深入接触和了解这个软件。\n\n\n 同理,**Matlab电路仿真软件包Simulink,**在自动飞控的实验上用过,但也不熟练。\n\n\n 暴露出来的一个问题,就还是对软件这方面不够熟悉,需要重新自己再花时间进行深入学习,同时软件对于理论的反哺也显得很有限,在之后的工作过程中,需要进一步优化学习理念。\n\n\n## PCB焊盘\n\n\n---\n\n\n PCB焊盘(Pad)是印刷电路板(Printed Circuit Board,简称PCB)上用于连接电子元件和焊接引脚的金属区域。焊盘通常是圆形、方形或矩形的金属区域,位于PCB上的电路图案之间。\n\n\n PCB焊盘的主要作用是提供一个可靠的电气连接和机械支撑点,使电子元件能够通过焊接与PCB相连接。焊盘通常由铜或其他导电材料制成,它们被镀上一层锡,以便在焊接过程中形成可靠的焊接连接。\n\n\n 焊盘的设计和尺寸取决于所使用的电子元件和焊接工艺。一般来说,焊盘的尺寸应足够大以容纳焊接引脚,并提供足够的焊接面积以确保良好的焊接连接。焊盘的形状和布局也应适合特定的焊接工艺,如手工焊接、表面贴装技术(SMT)或波峰焊接。\n\n\n 在PCB设计中,焊盘的位置和连接方式需要与电子元件的引脚布局相匹配。通过正确设计和布局焊盘,可以确保电子元件在焊接过程中能够正确地与PCB连接,并提供良好的电气连接和机械支撑。\n\n\n 总之,PCB焊盘是用于连接电子元件和PCB的金属区域,它们提供了可靠的电气连接和机械支撑,是PCB设计中重要的组成部分。\n\n\n## 什么是PCB中的约束管理器\n\n\n---\n\n\n 在PCB设计中,约束管理器(Constraint Manager)是一种工具或功能,用于管理和应用设计中的各种约束。它帮助工程师定义和控制PCB设计中的各种规则和限制,以确保设计满足特定的要求和标准。\n\n\n约束管理器通常包括以下功能和能力:\n\n1. **电气约束**:约束管理器允许工程师定义电气规则,如信号完整性、电源分布、时序要求等。通过定义这些规则,可以确保电路在正常工作条件下具有良好的性能和可靠性。\n2. **物理约束**:约束管理器允许工程师定义物理规则,如元件布局、引脚间距、焊盘尺寸、走线规则等。这些规则帮助确保PCB布局符合设计要求,避免信号干扰、热量积聚和机械冲突等问题。\n3. **信号完整性约束**:约束管理器允许工程师定义信号完整性规则,如最大信号延迟、信号匹配、信号串扰等。这些规则帮助确保信号在传输过程中不会受到损失或干扰,从而保证系统的可靠性和性能。\n4. **DRC(设计规则检查)**:约束管理器通常提供设计规则检查功能,用于自动检查设计是否符合定义的约束和规则。DRC功能可以帮助工程师及早发现和解决潜在的设计问题,提高设计的质量和效率。\n5. **交互式编辑**:约束管理器通常提供交互式编辑界面,使工程师能够直观地定义和修改约束。通过这种界面,工程师可以灵活地调整约束规则,以满足设计要求和优化设计性能。\n\n 通过使用约束管理器,工程师能够在PCB设计过程中有效地管理和应用各种约束,确保设计满足电气、物理和性能要求。它是PCB设计中的重要工具,有助于提高设计的可靠性、性能和生产效率。\n\n\n# 总结\n\n\n---\n\n\n 跟着小马哥的节奏。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-12-18",
"type": "Post",
"category": "璀璨星空",
"slug": "cadence1",
"tags": [
"Cadence"
],
"summary": "需要具备电路设计、PCB布局、元器件选择、测试和故障排除等方面的专业知识和技能。",
"title": "[电路设计] Cadence入门",
"status": "Published",
"urlname": "a57cf3cb-9908-4374-8874-d7d05a352042",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "Cadence",
"doc_id": "a57cf3cb-9908-4374-8874-d7d05a352042"
}
],
"body": "",
"realName": "[电路设计] Cadence入门",
"relativePath": "/Cadence/[电路设计] Cadence入门.md"
},
{
"id": "91bbcdfa-c3bf-4cf8-b2e4-a0fd85d4edef",
"doc_id": "91bbcdfa-c3bf-4cf8-b2e4-a0fd85d4edef",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 在闲暇时,看[老吴的博客](https://www.mr-wu.cn/)的一些比较有感触的地方。\n\n\n 关于麦克斯韦方程组,读[科学家的故事](https://www.mr-wu.cn/james-clerk-maxwell/)一直都是比较有意思的流程,就像小时候看《一千零一夜》一样。老吴讲故事的水平不错的。\n\n\n> 1855年,麦克斯韦发表了他的第一篇电磁学论文**《论法拉第的力线》**。在麦克斯韦手中,深奥的力线、场思想神奇般地用数学语言描述出来了,为法拉第的物理思想做了细致的数学“翻译”,使之定量化、精确化。 \n> \n> 法拉第盛赞麦克斯韦:“我惊讶地看到,这个主题居然处理得如此之好”,“我并不认为自己的学说一定是真理,但你是真正理解它的人”,“你不应该局限于借用数学来解释我的见解,而应该突破它。” \n> ——[老吴的博客](https://www.mr-wu.cn/james-clerk-maxwell/)\n\n\n 对于我这个数学菜狗来说,我只能默默长叹一声,感谢祖师爷赏饭。\n\n\n# 正文\n\n\n---\n\n\n 在电子产品设计的过程中,电磁兼容实验是产品合格的重要指标。\n\n\n## 电磁兼容实验\n\n\n---\n\n\n 电磁兼容实验是用于评估电子设备在电磁环境中的抗干扰和抗辐射能力的实验。它的目的是确保电子设备在正常运行时不会产生或受到不必要的电磁干扰,并且不会对周围的设备或环境产生有害的辐射。\n\n\n 电磁兼容实验通常包括以下几个方面的测试:\n\n1. 辐射发射测试:评估设备在正常操作时是否会产生电磁辐射,以及辐射的强度是否在规定的限制范围内。这个测试通常使用射频干扰场或开放区域测试方法进行。\n2. 抗干扰测试:评估设备在外部电磁场干扰下的正常工作能力。这个测试通常使用射频干扰场或传导干扰场进行,以模拟设备在实际使用环境中可能遇到的干扰情况。\n3. 静电放电测试:评估设备对静电放电的敏感性。这个测试通常使用电静电放电模拟器进行,以模拟设备在操作过程中可能遭受的静电干扰。\n4. 快速瞬变测试:评估设备对电源线上的瞬态电压变化的抗干扰能力。这个测试通常使用快速瞬变发生器进行,以模拟设备在电源线上可能遇到的瞬态干扰。\n5. 浪涌测试:评估设备对电源线上的浪涌电压的抗干扰能力。这个测试通常使用浪涌发生器进行,以模拟设备在电源线上可能遇到的浪涌干扰。\n\n 通过进行这些实验,可以评估电子设备的电磁兼容性能,发现潜在的问题,并采取相应的措施来改善设备的抗干扰和抗辐射能力,确保设备在各种电磁环境中的正常运行和安全性。\n\n\n 感谢作者CTC华商检测的文章:[**电磁兼容测试都包括哪些项目?**](https://zhuanlan.zhihu.com/p/377514932)\n\n\n> 电磁兼容测试:是指设备或系统在其电磁环境中符合要求运作并不对其环境中的任何设备产生无法忍受的电磁干扰能力。\n\n\n\t 电磁兼容测试包括两个方面的要求:一方面是指设备在正常运行过程中对所在的环境产生的电磁干扰不能超过一定的限值;另一方面是指器具对所在环境中存在的电磁干扰具有一定程度的抗扰度,即电磁敏感性。\n\n\n\t EMI:CE(传导干扰),RE(辐射干扰),PT(干扰功率测试)等等。\n\n\n\t EMS:ESD(静电放电),RS(辐射耐受),EFT/B(快速脉冲耐受),surge(雷击),CS(传导耐受)等等。\n\n\n## 如何进行电磁兼容实验\n\n\n---\n\n\n 最主要的是去相关质检中心进行电磁兼容实验的测试。\n\n\n 另外,也许还可以在电脑上用EMC仿真软件进行分析,但对电脑配置要求极高。\n\n\n 在这里引用老吴的一段话:\n\n\n> 采用计算机建模技术,以得到最优的EMC解决方案才是最佳实践,通过计算机EMC仿真建模工具可以直观的告诉我们为什么必须遵循相关的设计规则以及它们在什么情况下适用。\n\n\n\t OK,用上EMC仿真之后,我们是不是就不用愁了,EMC仿真软件会告诉我们正确的设计解决方案?\n\n\n\t emmm,想多了 🙃 你用仪器进行测量,仪器会告诉你有指标超标,但仪器会告诉你怎样才是正确的设计吗?显然不会,仿真亦然,只是让你试错更加方便效率更高,而且不用真的每次修改设计都要去生产一个真正的实物出来,省时省力。\n\n\n## 在前期的设计当中如何考虑电磁兼容\n\n\n---\n\n\n 在前期的设计阶段,考虑电磁兼容性是非常重要的,可以采取以下几个方面的措施:\n\n1. 电磁兼容性设计指南:了解和遵循相关的电磁兼容性设计指南和标准,如国际电工委员会(IEC)的IEC 61000系列标准,以及各个国家和地区的电磁兼容性规定。这些指南和标准提供了关于电磁兼容性设计的基本原则和要求,可以作为设计的参考依据。\n2. 电磁兼容性分析:在设计过程中进行电磁兼容性分析,评估设备可能面临的电磁干扰源和辐射环境。这可以通过使用电磁场仿真软件、频谱分析仪和其他相关工具来完成。分析的结果可以帮助设计人员确定可能的干扰路径和敏感部件,从而指导设计的改进和优化。\n3. **地线和屏蔽设计:**合理设计设备的地线系统和屏蔽结构,以降低电磁干扰的传导和辐射。地线系统的设计应考虑地线的布局、接地电阻的控制和地线回路的优化。屏蔽结构的设计应考虑使用合适的屏蔽材料和屏蔽技术,以减少电磁辐射和接收外部干扰。\n4. **模拟和数字电路分离:**在设计中尽可能将模拟和数字电路分离,以减少彼此之间的相互干扰。这可以通过合理的电路布局、分离的供电和地线系统、合适的滤波器和隔离措施来实现。\n5. **滤波和抑制措施:**在设计中使用适当的滤波器和抑制措施,以降低电磁干扰的传导和辐射。这可以包括使用滤波器来抑制电源线上的高频噪声、使用抑制器来减少电路中的共模干扰、使用衰减器来降低传导干扰等。\n6. **地址布线和电源布线:**合理规划和设计设备的地址布线和电源布线,以减少电磁干扰的传导和辐射。这包括使用合适的布线方式、合理分布信号和电源线路、减少线路的长度和交叉等。\n7. **选择合适的元器件和材料:**在设计中选择符合电磁兼容性要求的元器件和材料。这包括选择具有良好抗干扰性能的元器件、使用低噪声和低辐射的材料,以及避免使用容易受到电磁干扰的元器件和材料。\n\n 综上所述,通过在前期的设计阶段考虑电磁兼容性并采取相应的措施,可以有效降低电子设备的电磁干扰和辐射水平,提高设备的抗干扰和抗辐射能力,确保设备在各种电磁环境中的正常运行和安全性。\n\n\n## 在设计中什么情况下会同时使用数字电路和模拟电路。数字电路和模拟电路的优缺点和应用范围有哪些?\n\n\n---\n\n\n 在设计中,通常会同时使用数字电路和模拟电路的情况包括:\n\n1. 综合性电子系统:许多电子系统需要同时处理数字信号和模拟信号。例如,通信系统中的调制解调器、音频设备中的信号处理电路、传感器接口电路等都需要同时使用数字电路和模拟电路。\n2. 数据转换和接口:当需要将模拟信号转换为数字信号(模数转换)或将数字信号转换为模拟信号(数模转换)时,通常需要同时使用数字电路和模拟电路。例如,音频编解码器、模拟到数字转换器(ADC)和数字到模拟转换器(DAC)等。\n3. 控制系统:控制系统通常需要同时处理数字信号和模拟信号。数字电路用于实现逻辑控制和算法处理,而模拟电路用于接收和生成控制信号。例如,自动化系统、机器人控制系统等。\n\n 数字电路和模拟电路各有优缺点和应用范围:\n\n\n **数字电路的优点包括:**\n\n1. **高稳定性:**数字电路的逻辑门电平稳定,不受温度、电压和噪声的影响,能够在广泛的工作条件下可靠地工作。\n2. **可编程性:**数字电路可以通过编程实现复杂的逻辑功能,具有较高的灵活性和可配置性。\n3. **高精度:**数字电路的精度通常受到器件分辨率的限制,可以实现高精度的计算和处理。\n4. **抗干扰能力强:**数字信号具有较高的抗干扰能力,能够在噪声环境下准确地传输和处理信息。\n\n**模拟电路的优点包括:**\n\n1. **高精确度**:模拟电路能够处理连续变化的信号,具有较高的精确度和分辨率。\n2. 低功耗:模拟电路通常具有较低的功耗,适合于一些对能耗要求较高的应用场景。\n3. **快速响应**:模拟电路能够实时响应输入信号的变化,适用于需要实时处理和控制的应用。\n4. **真实性**:模拟电路能够准确地模拟真实世界中的连续信号,适用于音频、视频和传感器等领域。\n\n 数字电路主要应用于计算、控制、通信和存储等领域,如微处理器、FPGA、数字信号处理器(DSP)等。模拟电路主要应用于音频、视频、传感器、滤波器、功率放大器等领域。\n\n\n 需要注意的是,随着技术的进步,数字电路和模拟电路之间的界限逐渐模糊,出现了数字信号处理技术、混合信号集成电路等融合了数字和模拟特性的设计方法。因此,在实际设计中,数字电路和模拟电路往往是相互结合、相互配合的。\n\n\n## **模拟电路的历史及未来的发展趋势**\n\n\n---\n\n\n 非常感谢[电子发烧友官网](https://www.elecfans.com/analog/20190705983626.html),摩尔定律,半导体工艺,集成电路,晶体管尺寸越来越小,数量越来越多。引用文章里的一段话:\n\n\n> 随着大规[<u>模电</u>](https://www.elecfans.com/v/tag/1180/)路发展,晶体管越来越小,集成数量成几何级增加,其制造工艺却越来越难了。克服这些技术和工艺壁垒不仅需要大量的时间和研究,还需要大量的资金和投资。因此,摩尔定律也中的时间也逐渐放缓,甚至可它可能会很快不成立,摩尔定律危机爆发(当然如果没有巨大变革这是必然的)。 \n> 随着电子元件越来越小(纳米级),量子特性和效应逐渐显现。随着我们不断减小晶体管的尺寸,其Pn结耗尽层的尺寸也越来减小。耗尽层非常重要,用于阻止电子的流动。研究人员通过计算得出,由于电子在其耗尽区中的隧道效应,小于5nm的晶体管将无法阻止电子流动。由于隧穿,电子将不会感知耗尽区域,直接 \"跨穿\"。如果不能阻止电子流动,晶体管就会失效。 \n> 此外,我们现在正在慢慢接近原子本身的大小,理论上我们不能建立一个比原子小的晶体管。硅原子的直径约为1纳米,现在我们制造的晶体管的栅极尺寸约为该尺寸的10倍。就算是不考虑量子效应的,我们也将达到晶体管的物理极限,无法做到更小。 \n> 我们可能已经注意到,尽管晶体管变得更小,但是在过去十年中[<u>CPU</u>](https://m.elecfans.com/v/tag/132/)计算速率并没有上升,这是由于Dennard Scaling崩溃。高时钟速率下的高损耗也是[<u>智能手机</u>](https://m.elecfans.com/v/tag/11230/)[<u>芯片</u>](https://www.elecfans.com/v/tag/137/)使用较低时钟速度(通常为1.5 GHz)的原因。\n\n\n\t 通过改进当前的芯片实现并具有更好的指令流水线,我们可以改善芯片的性能。所以斯坦福的教授乔纳森·库梅提出了库梅(Koomey)定律:每焦耳能量的计算次数将每1.5年翻一番。预计这种情况将持续到2048年,届时Landauer的原理和热力学简单定律将阻止进一步的改进。目前,Landauer Limits的计算机效率约为0.00001%。\n\n\n## 单片机中AD转换的作用\n\n\n---\n\n\n 在单片机中,AD转换(Analog-to-Digital Conversion)的作用是将模拟信号转换为数字信号,使单片机能够对模拟信号进行处理、分析和控制。AD转换器是单片机中的重要模块,它将模拟信号的连续变化转换为离散的数字数值,以便单片机能够对其进行数字化处理。\n\n\n AD转换的主要作用包括:\n\n1. **信号采集:**AD转换器可以将来自外部传感器、信号源或其他模拟设备的模拟信号转换为数字信号,使单片机能够获取和采集外部环境或设备的信息。例如,温度传感器、光敏电阻、压力传感器等模拟传感器输出的模拟信号可以通过AD转换器转换为数字形式,供单片机进行处理和判断。\n2. **数据处理:**通过AD转换,单片机可以对模拟信号进行数字化处理和算法运算。例如,单片机可以对采集到的模拟信号进行滤波、放大、平均、积分等处理,以提取有用的信息或进行特定的控制操作。\n3. **控制决策:**AD转换器可以将模拟信号转换为数字信号后,单片机可以根据这些数字数据进行控制决策。例如,通过对温度传感器输出信号进行AD转换,单片机可以根据温度数值来控制加热或冷却系统,实现温度的自动调节。\n4. **数据传输和通信:**AD转换器可以将模拟信号转换为数字信号后,单片机可以通过数字信号进行数据传输和通信。例如,单片机可以将采集到的模拟信号转换为数字形式后,通过串行通信接口(如UART、SPI、I2C等)将数据发送给其他设备或接收其他设备发送的数据。\n\n 总之,AD转换在单片机中的作用是将模拟信号转换为数字信号,使单片机能够对模拟信号进行处理、分析和控制,实现数据采集、处理、决策和通信等功能。\n\n\n# 总结\n\n\n---\n\n\n 这篇文章是基于兴趣的离散总结,之后仍需进行针对性地深入学习。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-12-21",
"type": "Post",
"category": "璀璨星空",
"slug": "EMC",
"tags": [
"Cadence"
],
"summary": "在前期的设计阶段考虑电磁兼容性并采取相应的措施,可以有效降低电子设备的电磁干扰和辐射水平。",
"title": "[电磁兼容] 学习EMC电磁兼容仿真",
"status": "Published",
"urlname": "91bbcdfa-c3bf-4cf8-b2e4-a0fd85d4edef",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "Cadence",
"doc_id": "91bbcdfa-c3bf-4cf8-b2e4-a0fd85d4edef"
}
],
"body": "",
"realName": "[电磁兼容] 学习EMC电磁兼容仿真",
"relativePath": "/Cadence/[电磁兼容] 学习EMC电磁兼容仿真.md"
},
{
"id": "95fd6070-5679-4c6d-89f2-22184ee14b4b",
"doc_id": "95fd6070-5679-4c6d-89f2-22184ee14b4b",
"updated": 1713876540000,
"body_original": "\n# 更新\n\n\n---\n\n\n前几天回学校,看到满天纷飞的柳絮,突然想到三月初的记起的一首诗,“白雪纷纷何所似,莫若柳絮因风起”,我就在想,其实雪和柳絮有相似之处,但是我觉得柳絮比雪更轻,飞起来不是很规则,不会像雪积在地上很多。\n\n\n### 量的积累是一切的起点 2024-04-15 \n\n\n---\n\n\n没有时间的投入,对于一件事情的认知,永远很难深入,今天烦躁了,趴在地上做俯卧撑,发现因为前几天做猛了,今天再做的时候下不去了,不得不感慨,有天晚上和俩舍友比俯卧撑,结果那晚上我们每人各干了几百个,动辄每轮几十个起步,当然是相对较浅的那种俯卧撑。\n然后转而做仰卧起坐的时候,发现也是越往后做越难做,我想做很多事情大概都是这样,可能有些事情可能是开始难,后面简单,但也有些事情是开始简单,后面难,就比如做引体向上,之前状态好的时候,标准直臂能来个十三四个,但是越到后面肌肉越酸痛。每突破一个就跟要命一样,巴不得立马下杠,或许这就是瓶颈,亦或是临界值。跑步或许也是这种感觉,但跑步熬过的临界值,还能稍微恢复点。\n选择深入做什么样事情或许在塑造我们本身,我想这是一个简单的道理,flomo的创使人说,持续记录,意义自然浮现。而选择深入做什么样的事情,一部分由我们的际遇引导,一部分由我们的性格决定。能够在时间中经受考验的习惯,不论是好习惯还是坏习惯,背后一定有些故事。\n\n\n# 前言\n\n\n---\n\n\n这篇文章是MC-Ⅱ模型产生的过程,具体的解释就是MatrixCore+ModuleCycle,一个是理论层面,个体作为矩阵的核心和矩阵交互,一个是实践层面,通过模块化行为不断深度学习从而加强在某一领域的知识。\n\n\n# 正文\n\n\n---\n\n\n这部分记录这个灵感产生环境和最开始的起点。\n\n\n## 事件梳理和问题暴露\n\n\n---\n\n\n\n\n\n确定了除工作之外的最紧急的任务为毕业设计,我们需要重新拾起四象限规划法在导向模块中使用数据库完成该功能。(目前导向模块还没完成流动,一个是因为博客是具有粒子特征,他不是那种每时每刻都会想起来更新的方式,而是阶段式汇总的地方,所以导向模块就很尴尬,而且还有个问题没解决就是一旦我在导向模块中进行更新,然后内嵌入的界面居然会被收录,这就使得导向模块不能采用数据库的方式,因为会降低质量。但我想这个问题应该会有办法解决的。@Apr 15)\n\n\n提出精力分配的问题,长期保持稳定的工作状态是一件很具有挑战性的事情,周一周二需要保持良好的工作节奏,晚上可以继续处理白天未完成的任务,这是承担学习和工作任务量较大的两天,所以晚上回去之后应当及时洗漱,简单进行总结,保证在 22:30 左右入睡,周三的晚上主要是用来休息的,应当在回去之后进行洗澡,并跟踪任务进度,稍微做一些有创造性的,但是符合规律的事情,比如整理出一篇读书笔记,归档到博客当中,避免博客过于冷清,周四白天及晚上应当加把劲处理完前几天的遗留问题,并进行规划明天的任务,周四是最疲惫的一天,更应该早些休息。周五是这一周工作的收尾,需要总结这一周完成了哪些任务,晚上可以早些回去休息,适当娱乐,但不应该熬夜,不然整个周六的早上就会被毁掉。周六的早上往往与早餐无缘,周末的生活陷入混乱,这个时候就充分暴露出规划能力的漏洞,这个时候应当主动寻求合适的学习和工作的环境,因为周末再不把基本功打打,能力无法提高。而事实上,周末往往是混乱的。需要提出新的解决方案,例如使用邮箱提醒的方式,使用 vps 中的 mailx 对固定的容易出错的时间点进行邮件提醒。\n\n\n## 聚焦“三维一体”的“五眼计划”\n\n\n---\n\n\nExcel 表格是呈现数据的很好方式,而事实上,这种方式仍然值得我们学习。\n\n\n\n\n\n我们将一天划分为熟悉的五个时间段,睡前建立导向,早上进行输入,中午进行存储,下午进行输出,晚上进行反馈,我们是否可以把一天和一周做一个简单的小循环,排除周六周日。在这五个特殊的时间段内进行数据反馈,使用 twikoo 建立数据观测点,事实上 twikoo 只是偶尔在晚上的时候被使用,很显然,还没有充分发挥其作用。(目前已采用memos替代twikoo进行灵感记录 @Apr 15)\n\n\n## 周末和周中的状态对比\n\n\n---\n\n\n\n\n\n周末已经成为了实际上的黑盒,在前一个月的表现中,并不出彩,非常糟糕,周末并没有成为学习的阶梯,反而成为了工作的阻碍,这是为什么呢?\n从健康水平来看,因为没有强制性早起,所以很容易漏掉早餐,这就会影响整个早上的工作学习效率,实际上,周六的早上往往因为贪睡而导致了糟糕的开始。健康水平会比周中下降。\n从压力水平上来看,工作压力减轻,但要求更高的自主性和创新,正如右侧所言,周末应该更多用于创新和休息而不是用于处理残尾。\n\n\n## 问题提出和处理方案\n\n\n---\n\n\n\n\n\n实际上周末工作压力下降,但是生活压力骤增,仍然存在很多过去没有得到修复的问题,对于时间的感知不规范,反馈能力和数据库之间的联系很微弱,生活作息混乱,导向混乱,健康管理混乱。\n\n\n提出的解决方案,为降本增效,在白天的工作时间,70%用于处理常规任务,30%的时间应该被用于**具备规划性的发展**,需要清楚下一步需要做哪些工作,在夜晚处理下行流量时,更多的时候应当减少任务的堆积,提升用于发展和休息的时间,不致使过于疲惫或亢奋。(这部分是最难做到的 评@Apr 15)\n\n\n\n\n\n针对遗留问题,应当遵循三级缓存制度,进行按照重要性原则处理,一级缓存用于专注进行最重要和急迫的任务处理,二级缓存用于过滤后的任务管理,三级缓存用于全部任务的分类。\n\n\n## 管理理念的提升\n\n\n---\n\n\n\n\n\n单凭自身的控制能力进行规划,显然是不够的,我们需要借助 Matrix 的力量,打造自己的 core。\n\n\n\n\n\n使用模块化的思想进行管理和循环。\nMatrix 是我们真实生存的世界, 一招一式,都是学习。\n\n\n# 总结\n\n\n---\n\n\n这篇文章介绍了MC-Ⅱ模型产生的过程,具体的解释就是MatrixCore+ModuleCycle,一个是理论层面,个体作为矩阵的核心和矩阵交互,一个是实践层面,通过模块化行为不断深度学习从而加强在某一领域的知识。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-01-20",
"type": "Post",
"category": "走近生活",
"slug": "240120",
"tags": [
"对话未来"
],
"summary": "这篇文章介绍了MC-Ⅱ模型产生的过程,具体的解释就是MatrixCore+ModuleCycle,一个是理论层面,个体作为矩阵的核心和矩阵交互,一个是实践层面,通过模块化行为不断深度学习从而加强在某一领域的知识。",
"title": "[阶段小结] “M-CⅡ”模型落地生根",
"status": "Published",
"urlname": "95fd6070-5679-4c6d-89f2-22184ee14b4b",
"updated": "2024-04-23 12:49:00"
},
"catalog": [
{
"title": "对话未来",
"doc_id": "95fd6070-5679-4c6d-89f2-22184ee14b4b"
}
],
"body": "",
"realName": "[阶段小结] “M-CⅡ”模型落地生根",
"relativePath": "/对话未来/[阶段小结] “M-CⅡ”模型落地生根.md"
},
{
"id": "04576d88-42cb-493c-ace2-429efecd0439",
"doc_id": "04576d88-42cb-493c-ace2-429efecd0439",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 围绕电路设计和PCB展开工作。\n\n\n# 正文\n\n\n---\n\n\n 步骤分析。感谢记得诚前辈分享的文章:[**硬件工程师如何零基础入门?**](https://www.zhihu.com/question/421337221#:~:text=%E7%A1%AC%E4%BB%B6%E5%B7%A5%E7%A8%8B%E5%B8%88%E5%A6%82%E4%BD%95%E9%9B%B6%E5%9F%BA%E7%A1%80%E5%85%A5%E9%97%A8%3F%201%201%E3%80%81%20%E4%B9%A6%E7%B1%8D%E9%98%85%E8%AF%BB%20%E7%A1%AC%E4%BB%B6%E7%9A%84%E5%85%A5%E9%97%A8%E9%9C%80%E8%A6%81%E5%85%88%E7%9C%8B%E5%9F%BA%E6%9C%AC%E7%9A%84%E4%B9%A6%E7%B1%8D%EF%BC%8C%E5%92%8C%20%E5%B7%A5%E7%A8%8B%E5%AE%9E%E8%B7%B5%20%E7%BB%93%E5%90%88%E7%B4%A7%E5%AF%86%E7%9A%84%E8%AF%BE%E7%A8%8B%E6%9C%89%EF%BC%9A%E7%94%B5%E8%B7%AF%E5%88%86%E6%9E%90%E3%80%81%E6%95%B0%E5%AD%97%E7%94%B5%E8%B7%AF%E3%80%81%20%E6%A8%A1%E6%8B%9F%E7%94%B5%E8%B7%AF,%E4%B8%8B%E9%9D%A2%E7%9A%84%E8%A7%86%E9%A2%91%E9%83%BD%E6%98%AF%E5%A4%A7%E5%8E%82%E5%87%BA%E5%93%81%E7%9A%84%EF%BC%8C%E8%AF%BE%E7%A8%8B%E8%B4%A8%E9%87%8F%E9%9D%9E%E5%B8%B8%E9%AB%98%EF%BC%8C%E6%9B%B4%E9%87%8D%E8%A6%81%E7%9A%84%E6%98%AF%E5%85%8D%E8%B4%B9%EF%BC%81%20...%204%204%E3%80%81%E7%9F%A5%E8%AF%86%E4%BD%93%E7%B3%BB%E7%9A%84%E6%90%AD%E5%BB%BA%20%E7%9F%A5%E9%81%93%E8%A6%81%E7%9C%8B%E4%BB%80%E4%B9%88%E4%B9%A6%EF%BC%8C%E4%B8%8A%E4%BB%80%E4%B9%88%E7%BD%91%E7%AB%99%E5%AD%A6%E4%B9%A0%EF%BC%8C%E5%B9%B6%E9%85%8D%E6%9C%89%E4%B8%8D%E9%94%99%E7%9A%84%E6%95%99%E5%AD%A6%E8%A7%86%E9%A2%91%EF%BC%8C%20%E6%8E%A5%E4%B8%8B%E6%9D%A5%E5%B0%B1%E6%98%AF%E6%90%AD%E5%BB%BA%E8%87%AA%E5%B7%B1%E7%9A%84%E7%9F%A5%E8%AF%86%E4%BD%93%E7%B3%BB%EF%BC%8C%E5%B9%B6%E4%B8%8D%E6%96%AD%E5%AE%8C%E5%96%84%E5%AE%83%E3%80%82%20%E5%9B%A0%E4%B8%BA%E7%A1%AC%E4%BB%B6%E5%B7%A5%E7%A8%8B%E5%B8%88%E8%A6%81%E5%AD%A6%E7%9A%84%E5%86%85%E5%AE%B9%E5%BE%88%E5%A4%9A%EF%BC%8C%E6%88%91%E6%95%B4%E7%90%86%E4%BA%86%E4%B8%80%E4%BB%BD%E6%80%9D%E7%BB%B4%E5%AF%BC%E5%9B%BE%E3%80%82%20)\n\n\n## 基本知识\n\n\n---\n\n\n 电分,数模电,高频,电磁波,最好能系统梳理出这几门课的知识框架,先从适当小的章节为最小单位,不做太过于具体的细节。\n\n\n 在大学期间,是有过这几门课的基础的,但仍需加强。\n\n\n## 寻找相关的电子社区\n\n\n---\n\n\n 感谢记得诚前辈分享的文章:[**学习电子,有什么网站可以推荐?**](https://zhuanlan.zhihu.com/p/365694522)\n\n\n## 搭建知识体系\n\n\n---\n\n\n 这个我觉得是很重要很有意思的一环,知识的输入和转换是很重要的一环。顺着记得诚前辈的思路。\n\n\n### 电子元器件学习\n\n\n---\n\n\n> **电子产品是由一个个电子元器件组成的,了解其特性、原理、学会选型,是基本功。**\n\n\n 感谢[**ICGOO商城**](https://www.zhihu.com/people/zhang-bo-71-56)**的文章:**[**电子元器件种类有哪些?产品一般都如何分类?**](https://zhuanlan.zhihu.com/p/362719557)\n\n\n> **电阻类**:插件薄膜(色环)电阻,金属膜电阻,金属氧化膜电阻,碳膜电阻,绕线电阻,水泥电阻,铝壳电阻,陶瓷片式电阻,热敏电阻,压敏电阻等。\n\n\n\t**电容类**:铝电解电容,钽电容点电容,涤纶电容,聚丙烯薄膜电容,金属化聚丙烯薄膜电容,陶瓷电容,安规电容,抗EMI电容等。\n\n\n\t**电位器类**:线绕电位器,导电塑料电位器,金属陶瓷电位器,碳膜电位器,微调电位器,面板电位器,精密电位器,直滑式电位器等。\n\n\n\t**磁性元件**:绕线片式电感,叠层片式电感,轴向电感,色码电感,径向电感,环形电感,片式磁珠,插件式磁珠,工频变压器,音频变压器,开关电源变压器,脉冲信号变压器,射频变压器等。\n\n\n\t**开关类**:滑动开关,波动开关,轻触开关,微动开关,钮子开关,按键开关,直键开关,旋转开关,拨码开关,薄膜开关等。\n\n\n\t**继电器**:直流电磁继电器,交流电磁继电器,磁保持继电器,舌簧继电器,固态继电器等。\n\n\n\t**接插件**:排针排母,欧式连接器,牛角连接器,简牛连接器,IDC连接器,XH连接器,VH链接器,D-SUB连接器,水晶头水晶座,电源连接器,插头插孔,IC座,射频链接器,光缆连接器,欧式接线端子,栅栏式接线端子,插拔式接线端子,轨道式接线端子,弹簧式接线端子,耳机插座插头,圆形裸端子等。\n\t**保险元件**:保险丝,熔断器,气体放电管等。\n\n\n\t**滤波元件**:压电陶瓷滤波器,声表面波振荡器,石英晶体滤波器。\n\n\n\t**PCB板**:纸基PCB,玻璃布基PCB,合成纤维PCB,陶瓷基底PCB等。\n\n\n\t**电机风扇**:直流电动机,交流电动机,交流发电机,直流发电机,交流风扇,直流风扇等。\n\n\n\t**电声器件**:扬声器,传声器,受话器,送话器,送受话器组合件,耳筒,拾音器,蜂鸣片,蜂鸣器等。\n\n\n\t**线材类**:漆包线,电线电缆,光纤线等。\n\n\n\t**二极管**:整流二极管,快恢复二极管,超快恢复二极管,[肖特基二极管](https://zhuanlan.zhihu.com/p/146572860),开关二极管,稳压二极管,瞬态抑制二极管,TVS二极管,变容二极管,触发二极管,发光二极管等。\n\n\n\t**三极管**:PNP型三极管,NPN型三极管。通用小功率三极管,开关三极管,通用功率三极管,达林顿管,低饱三极管,压降三极管,数字三极管,带阻三极管,射频三极管等。\n\n\n\t**集成电路IC**:模拟IC:电源管理IC:线性稳压IC,电压基准IC,开关稳压控制器,运算放大器,电压比较器。\n\n\n\t数字IC、通用逻辑IC:缓冲器,驱动器,触发器,锁存器,寄存器,门电路,编码器,译码器,计数器,收发器,电平转换器。\n\n\n\t**处理器:**CPU,单片机,DSP,FPGA,CPLD。\n\n\n\t**储存器**:DRAM,SRAM,PROM,EPROM,EEPROM,FLASHMEMORY。\n\n\n\t**其他类**:接口IC,时钟IC,ADC转换器,DAC转器件,专用IC定制IC,微博IC,混合集成电路等。\n\n\n\t**晶振**:普通晶振,温补晶振,恒温晶振,压控晶振等。\n\n\n\t**显示器件**:数码管,LED器件,OLED显示器,LCD液晶显示器等。\n\n\n\t**传感器**:霍尔传感器,温度传感器等。\n\n\n\t**微波元器件**:隔离器,功分器,耦合器,3DB电桥,合路器,衰减器,移相器,谐振器,环形器,混频器等。\n\n\n\t补充:场效应管,晶体管,光耦,光续短期,红外发射管,红外接收管,晶闸管,复合晶体管,可控硅一类。\n\n\n\t1.固定电阻,电位,敏感电阻可以统称为电阻类。\n\n\n\t2.片式电阻的电阻体为氧化膜(厚膜电阻)或金属膜(薄膜电阻),所以可以和色环电阻一起归类为膜式电阻。\n\n\n\t3.热敏电阻又可以归类为传感器类(温度传感器)。\n\n\n\t4.压敏电阻,瞬态抑制二极管,热敏电阻PTC中可恢复保险丝等,可以和保险丝一起归为保护元件器类。保护元件又可以分为电压保护元件和电流保护元件。\n\n\n\t5.陶瓷材料做成的压敏电阻,热敏电阻中用的陶瓷是一种半导体陶瓷,但是这些元件一般并不会归为半导体器件。\n\n\n\t6.片式多层陶瓷电容和插件式陶瓷电容可以合并归类为陶瓷电容。不过由于片式多层陶瓷电容比插件式陶瓷电容,应用广泛得多,所以可以分开归类。单独把片式多才呢过陶瓷电容提出来。\n\n\n\t7.开关,继电器,连接器,电极等又可以归类为机电元件类。\n\n\n\t8.磁珠是一种特殊的电感器,也可以归类为电感器类。\n\t9.驻极体式受话器内含MOS管等半导体器件,固态继电器内含光耦等半导体器件。有缘晶振内涵IC或晶体等半导体器件,但是,一般归类时不会把它们专门放在半导体元件中讲解,而是分别归在电声器件中,继电器,晶振元件中。\n\n\n\t10.有的微电机系统元器件又可以归在传感器类中。\n\n\n### 硬件开发工具的使用\n\n\n---\n\n\n开发工具:学习Cadence的使用,跟着于博士或者小马哥的视频尽快上手。\n\n\n测试工具:熟悉万用表、示波器、电烙铁、热风枪等仪器的使用。\n\n\n### 电路设计和PCB\n\n\n---\n\n\n学习常见的电路,分析电路,模仿电路,设计电路。\n\n\n### 总线接口协议\n\n\n---\n\n\n学习总线接口协议。\n\n\n### 进阶内容学习\n\n\n---\n\n\n 电源完整性,EMC电磁兼容,C语言进阶,射频电路设计,嵌入式Linux,英语,信号完整和PCB设计。\n\n\n# 总结\n\n\n---\n\n\n 兴趣是最好的老师。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-12-22",
"type": "Post",
"category": "动手实践",
"slug": "Hardware-engineer",
"tags": [
"Cadence"
],
"summary": "硬件工程师需要熟悉的一些基本技能。",
"title": "[基本技能] 硬件工程师成长规划",
"status": "Published",
"urlname": "04576d88-42cb-493c-ace2-429efecd0439",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "Cadence",
"doc_id": "04576d88-42cb-493c-ace2-429efecd0439"
}
],
"body": "",
"realName": "[基本技能] 硬件工程师成长规划",
"relativePath": "/Cadence/[基本技能] 硬件工程师成长规划.md"
},
{
"id": "583b9276-91b9-4139-a933-75dbde7b275d",
"doc_id": "583b9276-91b9-4139-a933-75dbde7b275d",
"updated": 1714559520000,
"body_original": "\n# 更新\n\n\n---\n\n\n这部分记录这篇文章的更新\n\n\n### 作为信息的暂存之处 2024-04-14 \n\n\n---\n\n\n承接[笔记同传](https://matrixcore.top/article/video-record)专栏的思考,我们计划在这里建一个游乐场,用于进行归档各类数据流,同时保持较新的任务需求,即意味着信息是会被不断迭代的,持续跟进的。可以善用搜索功能。\n\n\n### 在太隐的笔下感受诗鬼李贺的魅力 2024-05-01 \n\n\n---\n\n\n[王子吹笙鹅管长,呼龙耕烟种瑶草。粉霞红瘦藕丝裙,轻洲步拾兰岧春。](https://wangyurui.com/posts/san-jie-qi-meng-2a4c2e5a) ——李贺\n\n\n# 言论\n\n\n---\n\n- 如果你没有时间集中精力学习新知识,那么就花时间复习已经学过的内容。\n\n> 💡 基于此,我计划将云盘里整理的专业课笔记,上传个人云服务器,如果能结合zotero也很好。\n\n- 一切都是模糊的,直至你试图使其精确时,你才会发现,我们日常表达出来的精确与真正的精确相距甚远。以至于当我们说话时,你无法假设这就是对方真正的意思。\n-- 伯特兰·罗素(Bertrand Russel),英国哲学家\n\n> 💡 这句话至少鼓励我们去探索一些深层次的东西。\n\n\n# 想法\n\n\n---\n\n- ubuntu历代桌面很多都是以动物的形象,羚羊,麋鹿,龙虾,河马,这些图案代表的盎然的趣味和持续不断的创造力,开源作者们希望能以更多的热情去实现自己的想法。\n- linux,fpga,stm32,至少得有一款拿得出手的板子,会一门编程语言,C或者VHDL。目前先学习画PCB,再熟悉32,linux作为爱好,fpga作为学有余力的拓展项。\n- 我很幸运,在很多优秀的博客里看到了鲜活的生命和感受,也因此受益颇多,我很多的知识技能,思维方式大多都源自于其中。\n- 我很欣赏时雨的一点是,能对生活本身拥有巨大的创造力,阅读他写的文章的时候我都能对自身产生一些可供思考的地方。\n- 回想起自己对于学习的心得和态度,仍不由得感叹还有很多可以提升的地方。尤其是对于知识的钻研,刨根究底式的探索,太缺乏了,这种精神。往往泛泛于表面,浮躁于内心。\n——读宇阳开发[博客框架](https://liuyuyang.net/index.php/archives/2444/)有感\n\n# 文摘\n\n\n---\n\n\n> **#礼物** \n> “马换了一次又一次,路愈赶愈远,再要回去也来不及了,于是我只得继续往前赶。朝雾早已在一片肃穆中消散净尽,那花花世界就展现在我的面前。” \n> -- 狄更斯《远大前程》\n\n\n> 因为不愿意相信现实,所以他一辈子都活在虚无当中。我不知道他去哪里了,但他轻得像一片鸿毛,如同朽木一样脆弱,如同覆辙一样僵硬。\n\n\n\tBecause he was unwilling to accept reality, he lived his entire life in a void. I don't know where he has gone, but he was as light as a feather,As fragile as rotten wood, as stiff as a rut.\n\n\t- - Matrix 2024-03-21\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-05-01",
"type": "Post",
"category": "走近生活",
"slug": "inexhaustible",
"tags": [
"流动核心"
],
"summary": "谷神不死 是谓玄牝",
"title": "[流动核心] 闲敲棋子 倩舞灯花",
"status": "Published",
"urlname": "583b9276-91b9-4139-a933-75dbde7b275d",
"updated": "2024-05-01 10:32:00"
},
"catalog": [
{
"title": "流动核心",
"doc_id": "583b9276-91b9-4139-a933-75dbde7b275d"
}
],
"body": "",
"realName": "[流动核心] 闲敲棋子 倩舞灯花",
"relativePath": "/流动核心/[流动核心] 闲敲棋子 倩舞灯花.md"
},
{
"id": "50d7d351-395d-415b-87e7-6d6d3ae562fa",
"doc_id": "50d7d351-395d-415b-87e7-6d6d3ae562fa",
"updated": 1708863120000,
"body_original": "\n```markdown\n第3章 飞行控制系统分析:\n\t- 3.1 概述:\n\t\t- 3.1.1 典型自动飞行控制系统的工作回路:\n\t\t- 3.1.2 典型自动飞行控制系统的分类:\n\t- 3.2 飞机的姿态控制系统:\n\t\t- 3.2.1 姿态控制系统的构成与工作原理:\n\t\t\t- 2. 积分式自动驾驶仪:\n\t\t\t- 3. 比例加积分式自动驾驶仪:\n\t\t- 3.2.2 飞机纵向姿态稳定与控制:\n\t\t- 3.2.3 飞机横侧向姿态稳定与控制:\n\t\t\t- 1. 横侧向姿态的稳定和控制的基本方式:\n\t\t\t\t- 1)通过方向舵实现水平转弯的侧向驾驶仪:\n\t\t\t\t- 2)通过副翼修正航向而用方向舵削弱荷兰滚的方案将上面自动驾驶仪副翼通道的航向控制律修改:\n\t\t\t- 2. 协调转弯控制:\n\t\t\t\t- 1)协调转弯:\n\t\t\t\t- 2)协调转弯飞行时自动驾驶仪的控制规律:\n\t\t\t\t- 3) 协调转弯的纵向控制:\n\t- 3.3 飞机的轨迹控制系统:\n\t\t- 3.3.1 飞行高度的稳定与控制:\n\t\t\t- 1.工作原理:\n\t\t\t- 2.高度稳定系统结构图的建立:\n\t\t- 3.3.2 下滑波束导引系统:\n\t\t\t- 1. 工作原理:\n\t\t\t- 2.建立下滑波束导引系统结构图:\n\t\t\t- 3.3.3 自动拉平着陆系统:\n\t\t- 3.3.4 飞机侧向偏离的自动控制:\n\t\t\t- 1. 飞机侧向偏离运动方程的简化:\n\t\t\t- 2. 侧向偏离的控制规律:\n\t- 3.4 空速和马赫数的保持与控制:\n\t\t- 3.4.1 飞行速度保持与控制的作用:\n\t\t\t- 1. 飞行速度保持与控制系统能保证飞机在低动压平飞时,仍具有速度的稳定性:\n\t\t\t- 2. 飞行速度的保持与控制是航迹控制的必要前提:\n\t\t\t- 3. 当进行跨声速飞行时能够保持速度稳定:\n\t\t- 3.4.2 速度保持与控制系统的构成与工作原理:\n\t\t\t- 1. 控制速度的两种常用方案:\n\t\t\t- 2. 适用于速度控制系统的飞机近似方程:\n\t\t- 3.4.3 控制速度的作用:\n\t\t\t- 1. 速度控制系统可保证飞机在低动压状态平飞时,仍具有速度的稳定性:\n\t\t\t- 2. 速度控制是航迹控制的必要前提:\n\t\t\t- 3. 进行跨声速飞行时,能够保持速度稳定:\n\t- 3.5 自动飞行控制系统基本性能要求:\n\t\t- 1. 姿态角自动控制系统的精度及瞬态响应:\n\t\t- 2. 角速度控制系统及增稳阻尼系统的技术要求:\n\t\t- 3. 轨迹(中心)自动控制系统的精度与瞬态响应要求:\n\t- 3.6 电/光传操纵系统:\n\t\t- 3.6.1 电传操纵系统(余度舵机):\n\t\t- 3.6.2 光传操纵系统:\n\t\t\t- 1. 光传操纵系统的基本组成和原理:\n\t\t\t- 2. 光传操纵系统的分类:\n\t\t\t- 3. 光传操纵系统的优点:\n\t\t\t- 4. 实例验证:\n```\n\n\n# 3.1 概述\n\n\n---\n\n\n一个典型的自动飞行控制系统包括五大功能 : 自动驾驶 ( / A P ) 、 飞行指引 ( / F D ) 、自动油门( ATS )、安定面配平、偏航阻尼( / Y D )。大部分现代飞机都装有飞行管理计算机系统(Flight Management Computer System,FMCS )。自动飞行控制系统能接收并执行 FMCS 的飞行制导指令,按照飞行计划完成整个自动飞行过程动飞行控制系统功能如图 3.1 所示。\n\n\n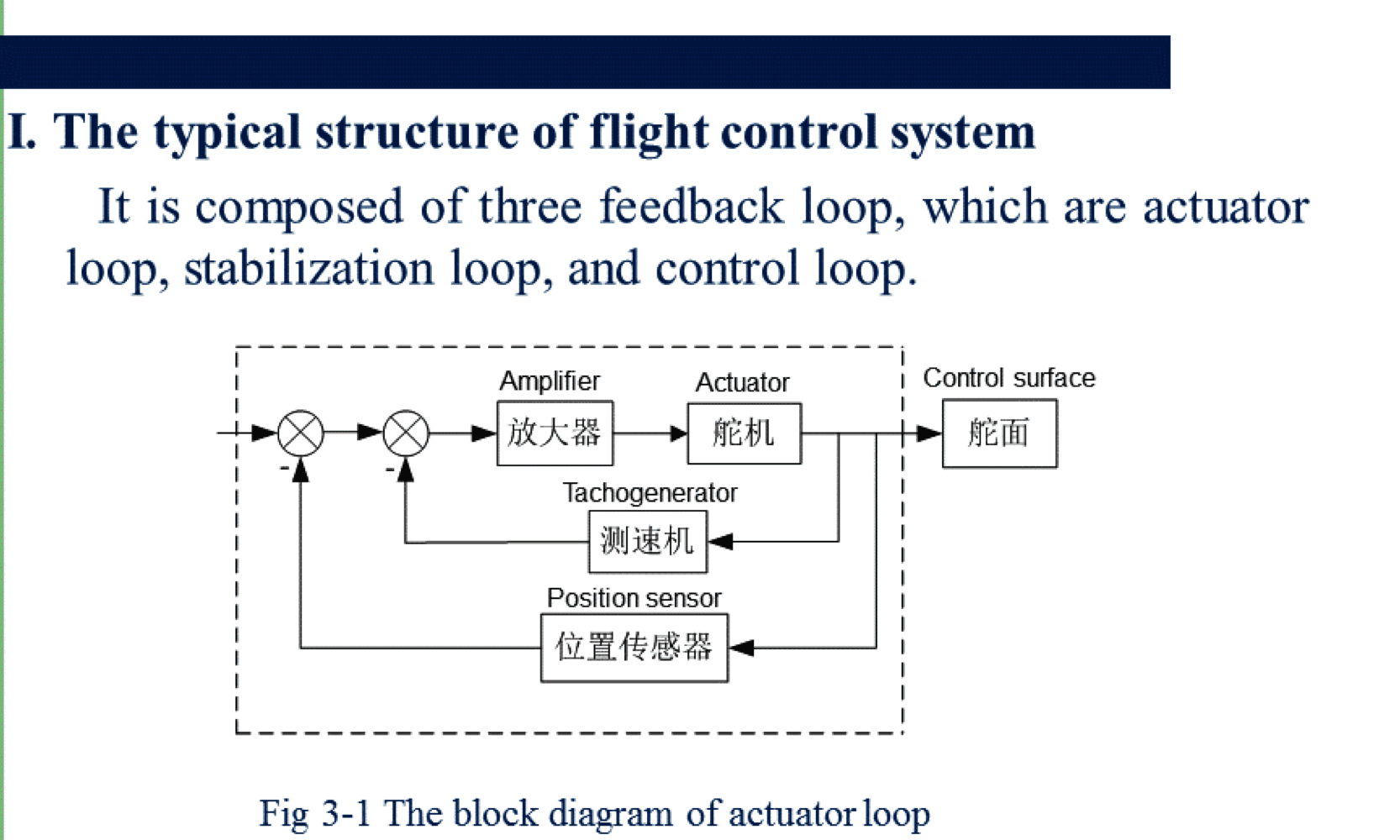\n\n\n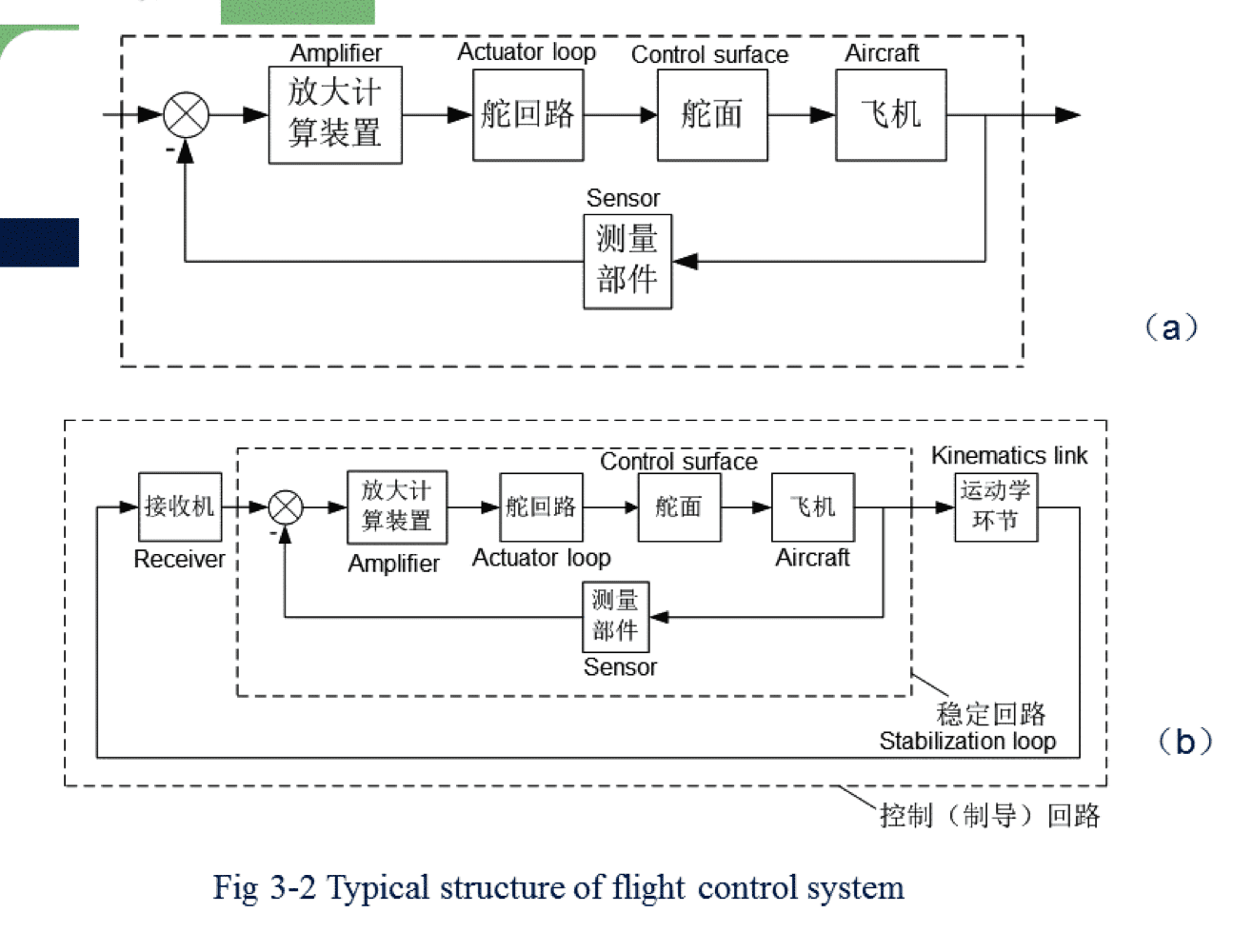\n\n\n\n\n\n## 3.1.1 典型自动飞行控制系统的工作回路\n\n\n---\n\n\n典型自动飞行控制系统一般由四个反馈回路构成,即同步回路、舵回路、稳定回路和控制(制导)回路。自动驾驶仪系统是自动飞行控制系统的典型子系统,下面以自动驾驶仪系统工作回路为例加以说明。\n\n\n## 3.1.2 典型自动飞行控制系统的分类\n\n\n---\n\n\n根据飞行控制系统的功能和作用,基本的自动飞行控制系统包括阻尼器(Damper)、增稳系统(Stability Augmentation Systems, SAS)、控制增稳系统(Control Augmentation Systems, CAS)和自动驾驶仪(Autopilot)等。\n\n\n\n\n\n# 3.2 飞机的姿态控制系统\n\n\n---\n\n\n## 3.2.1 姿态控制系统的构成与工作原理\n\n\n---\n\n\n下面主要分析讨论自动驾驶仪(Autopilot)在姿态控制过程中的工作原理。其中包括比例式自动驾驶仪 、 积分式自动驾驶仪和比例加积分式自动驾驶仪 (均衡反馈式自动驾驶仪) 。\n\n\n\n\n\n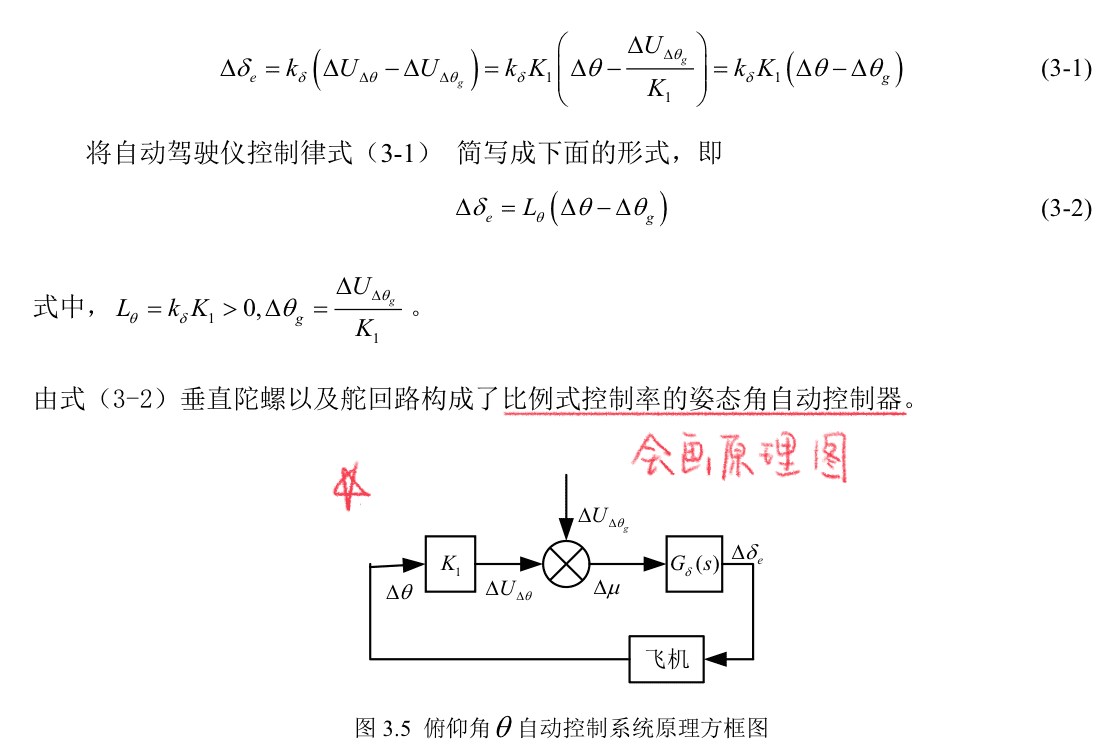\n\n\n**2)工作原理**\n\n\n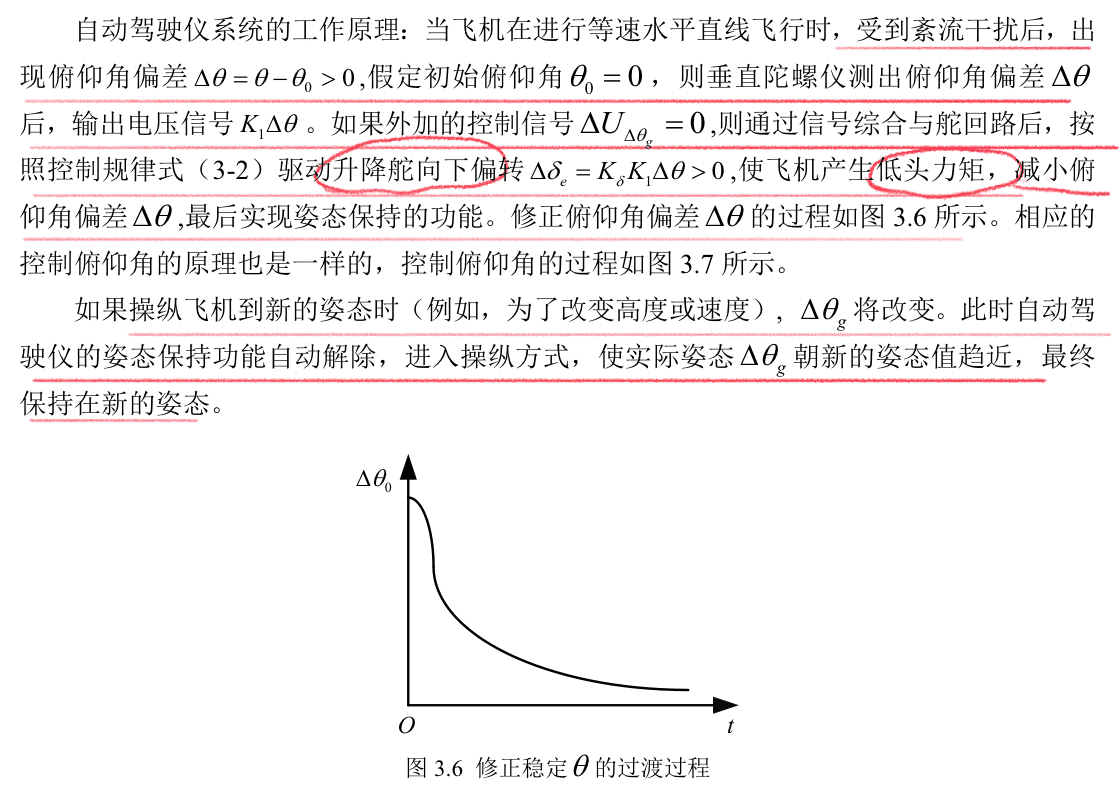\n\n\n\n\n\n\n\n\n\n\n\n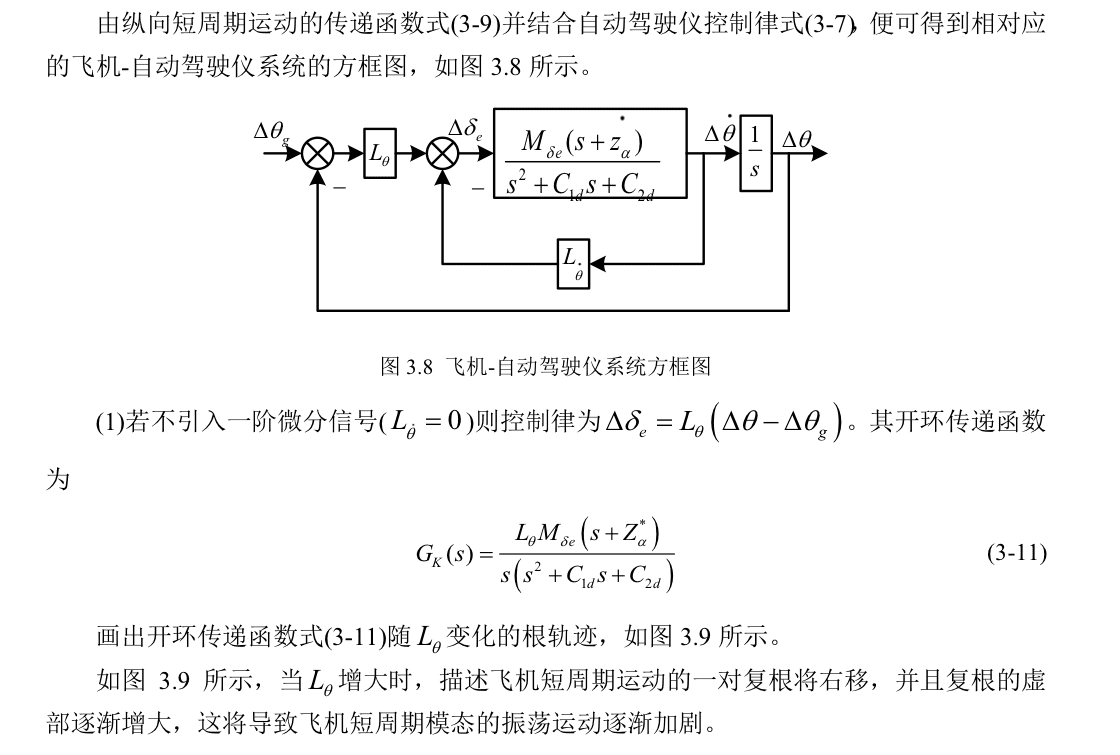\n\n\n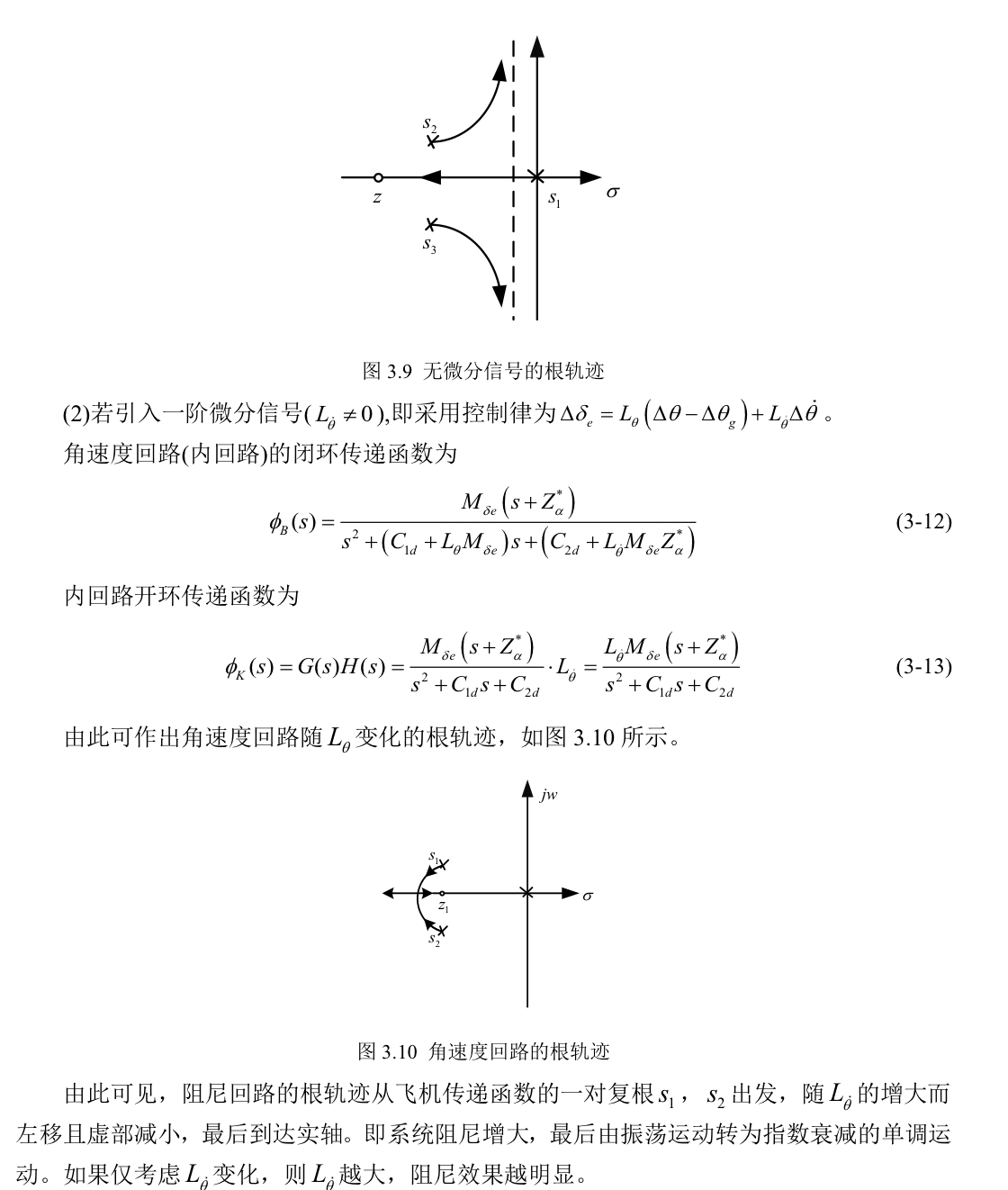\n\n\n\n\n\n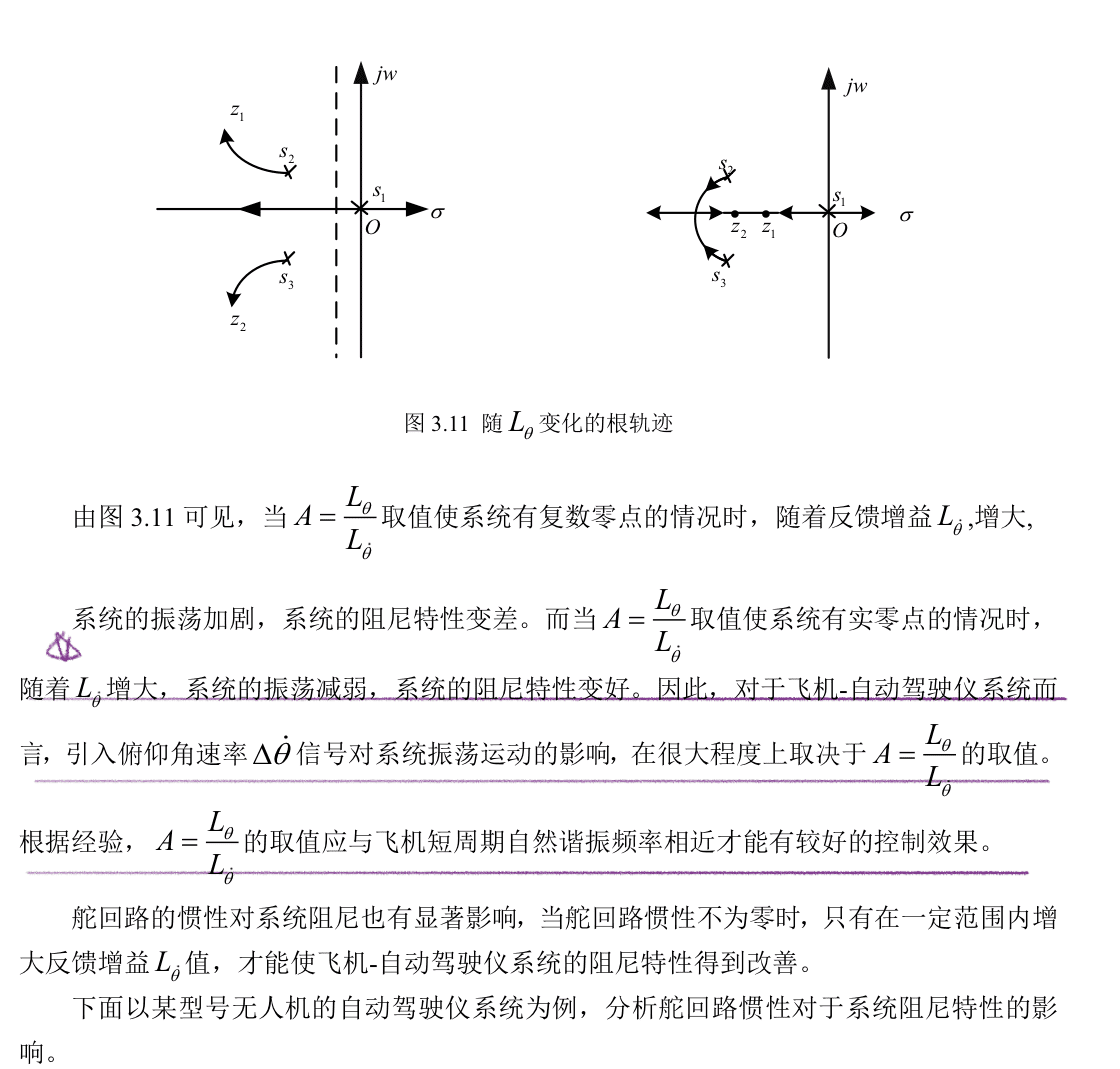\n\n\n\n\n\n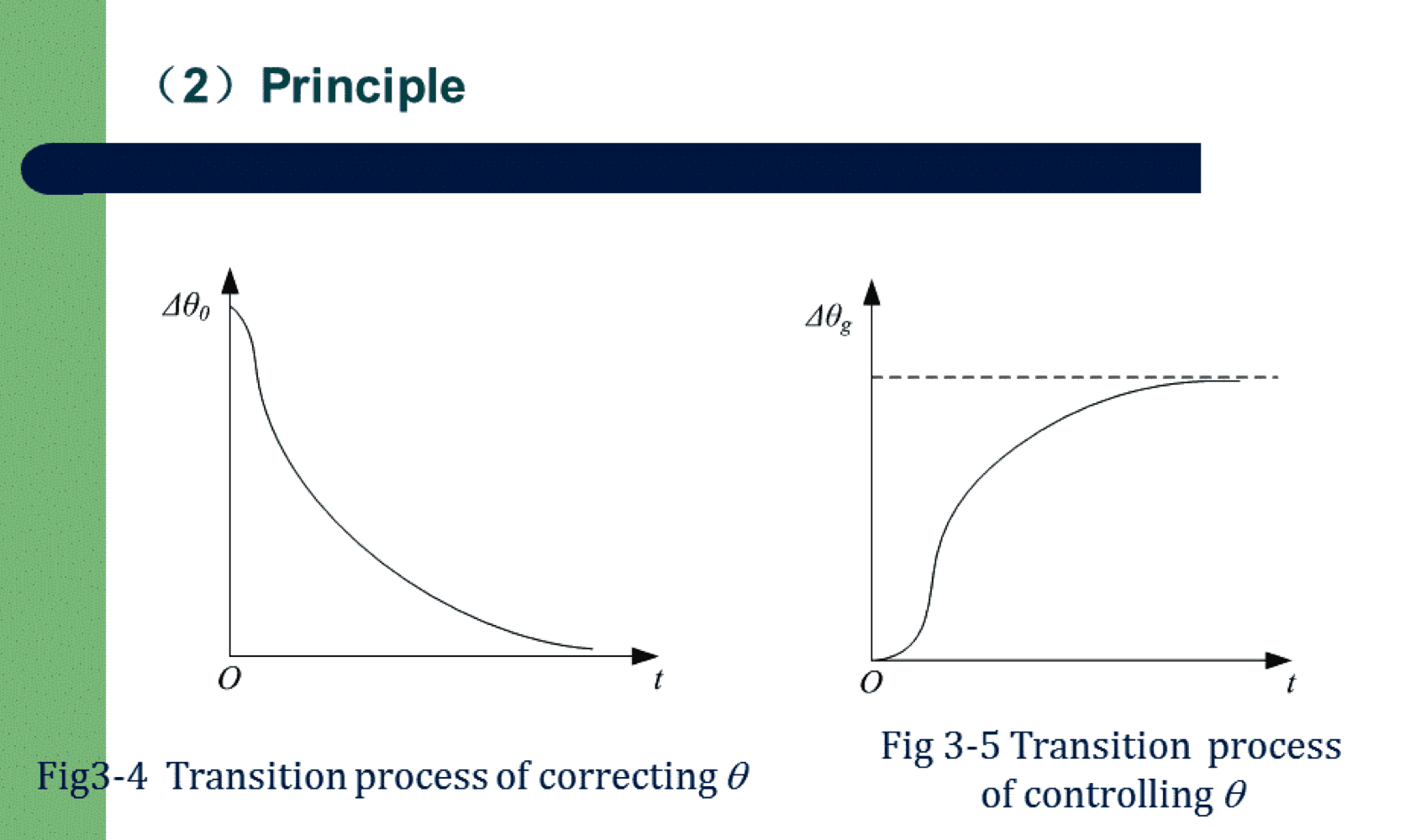\n\n\n\n\n\n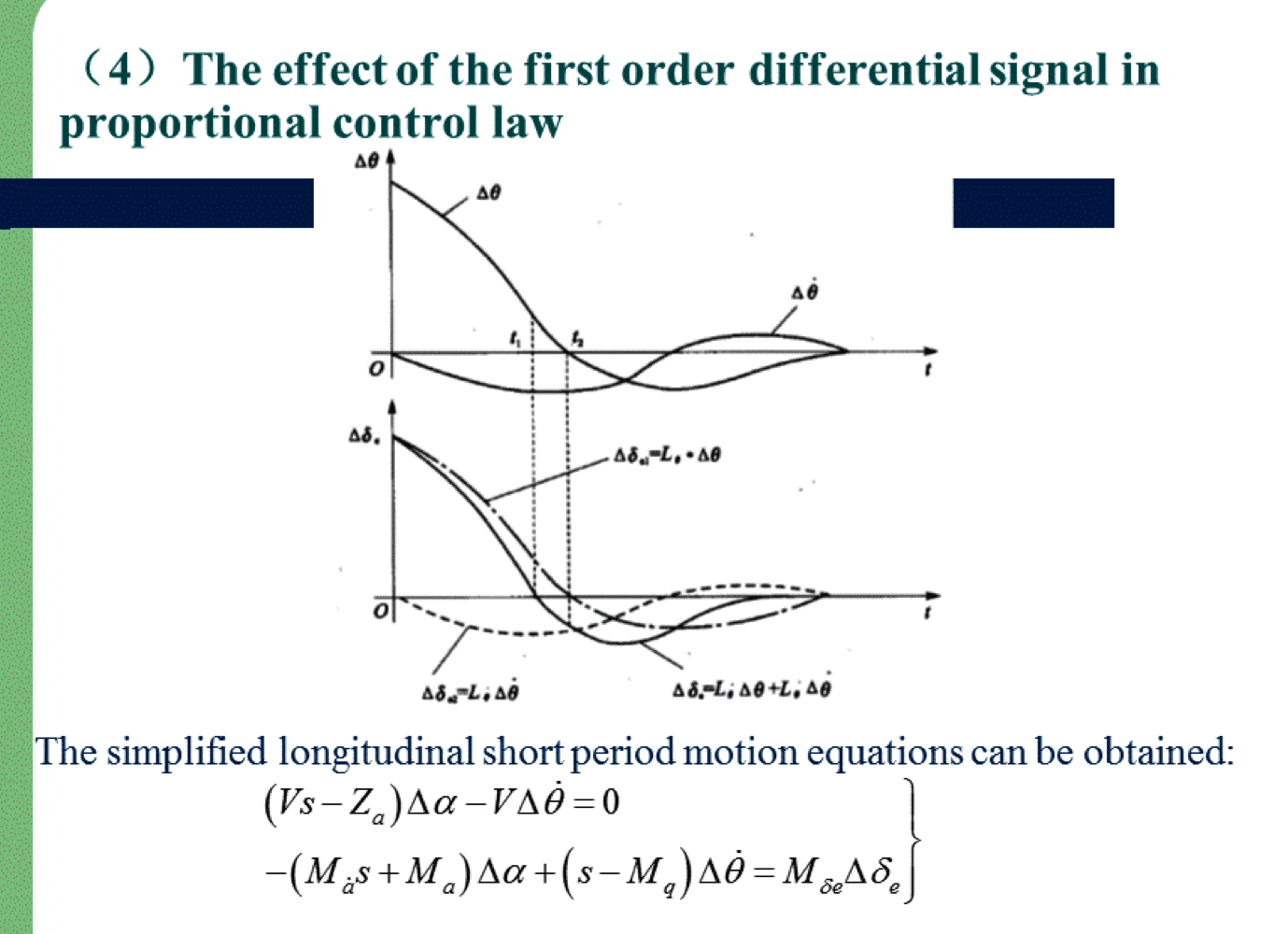\n\n\n\n\n\n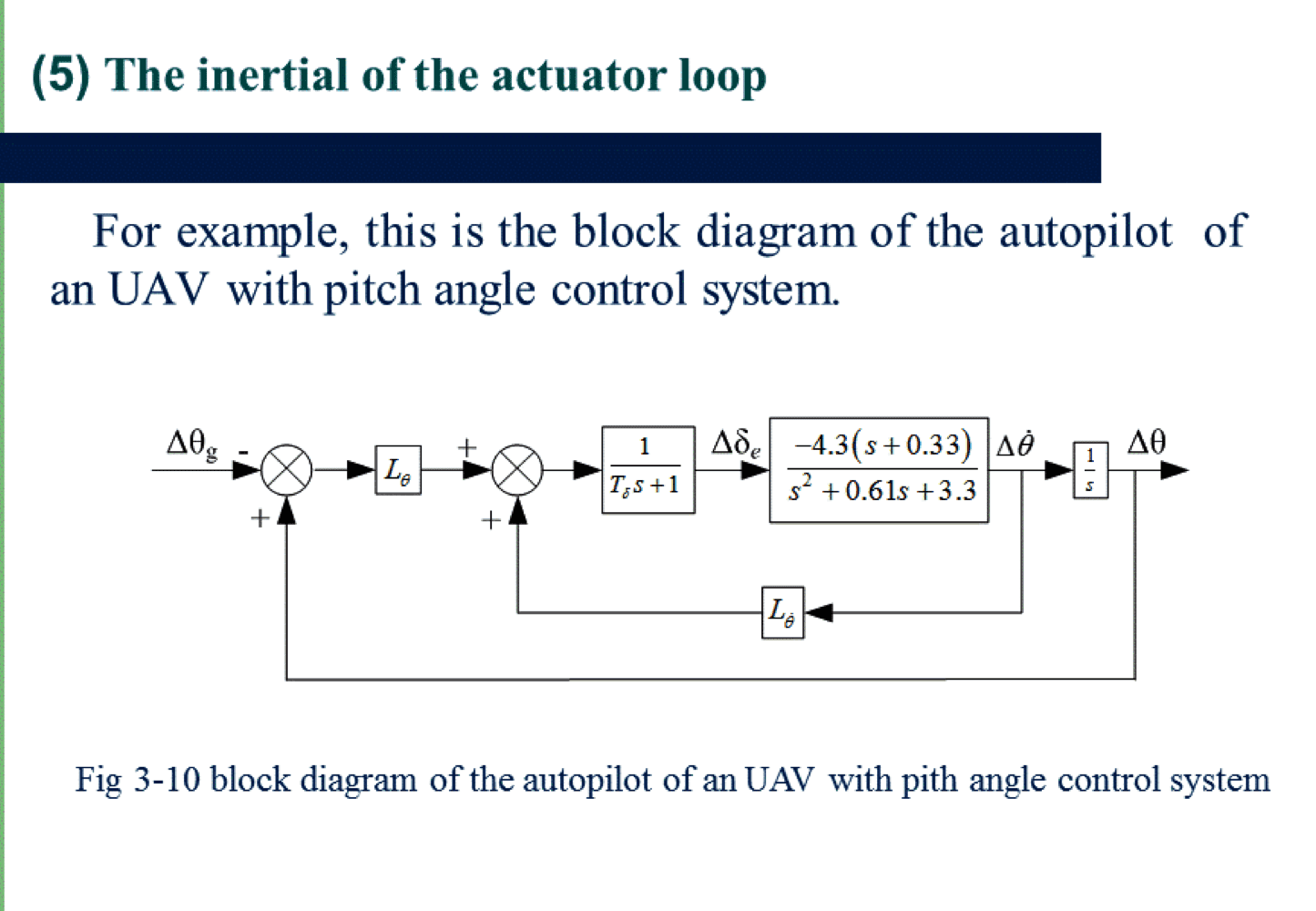\n\n\n### **2. 积分式自动驾驶仪**\n\n\n---\n\n\n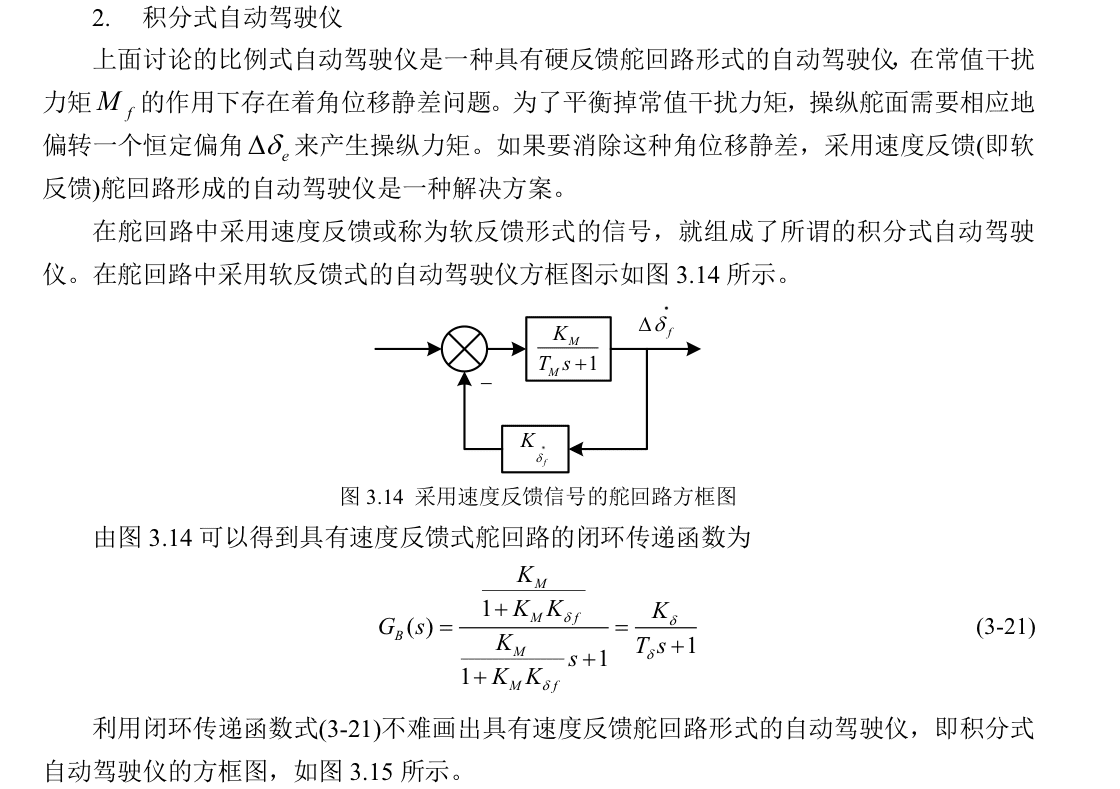\n\n\n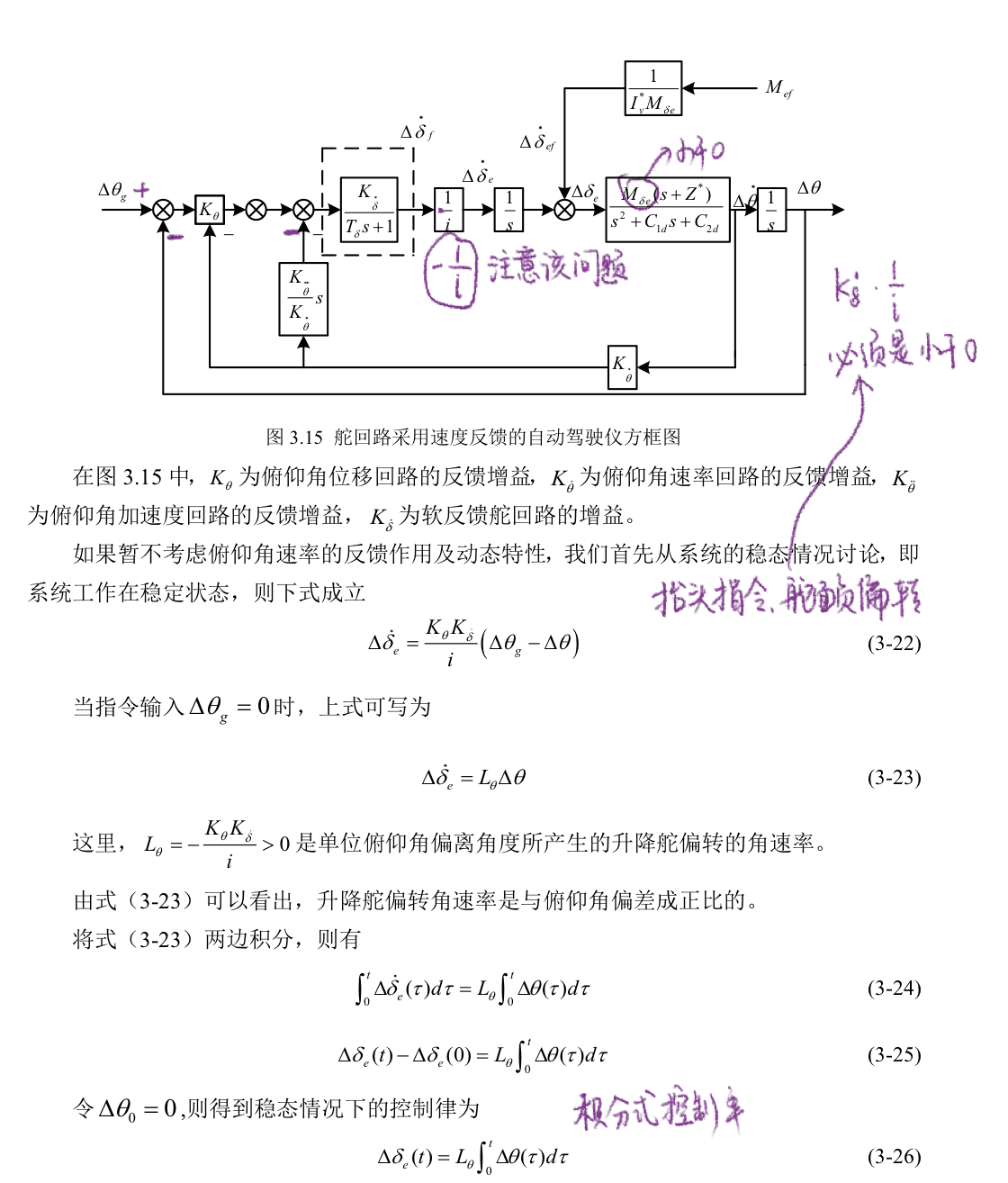\n\n\n\n\n\n\n\n\n\n\n\n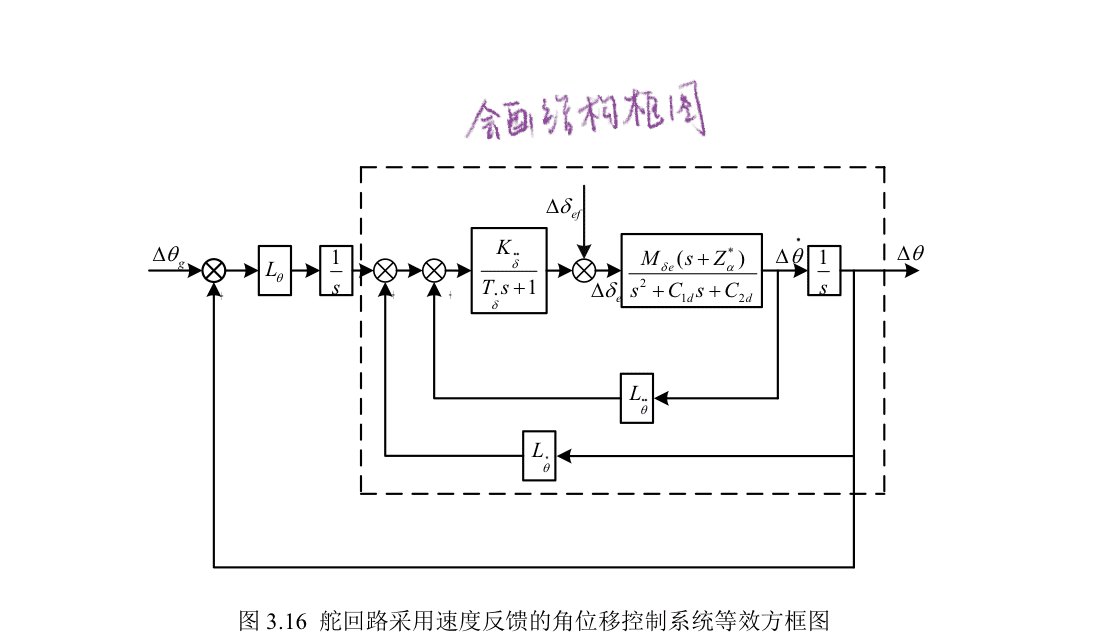\n\n\n### **3. 比例加积分式自动驾驶仪**\n\n\n---\n\n\n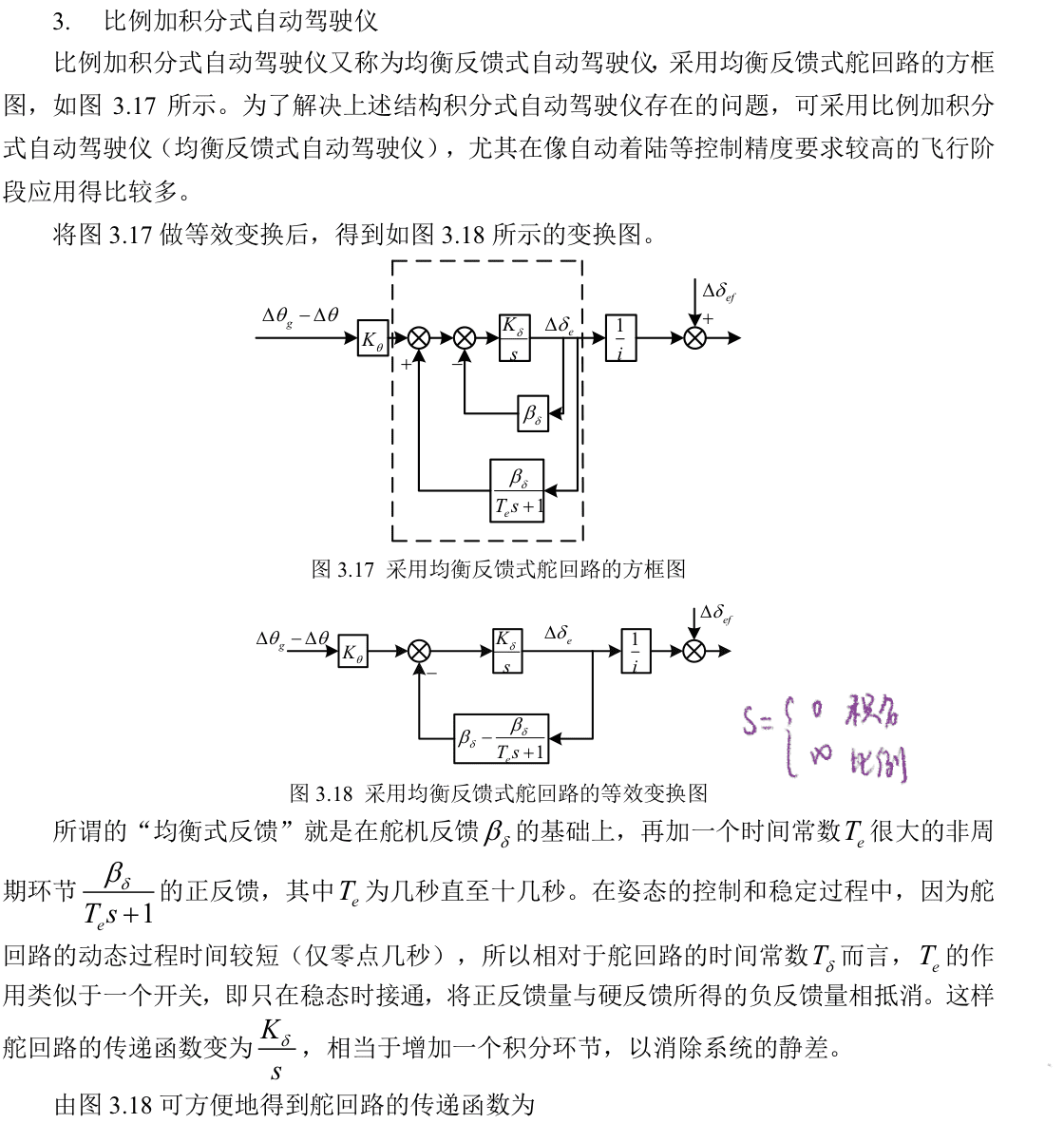\n\n\n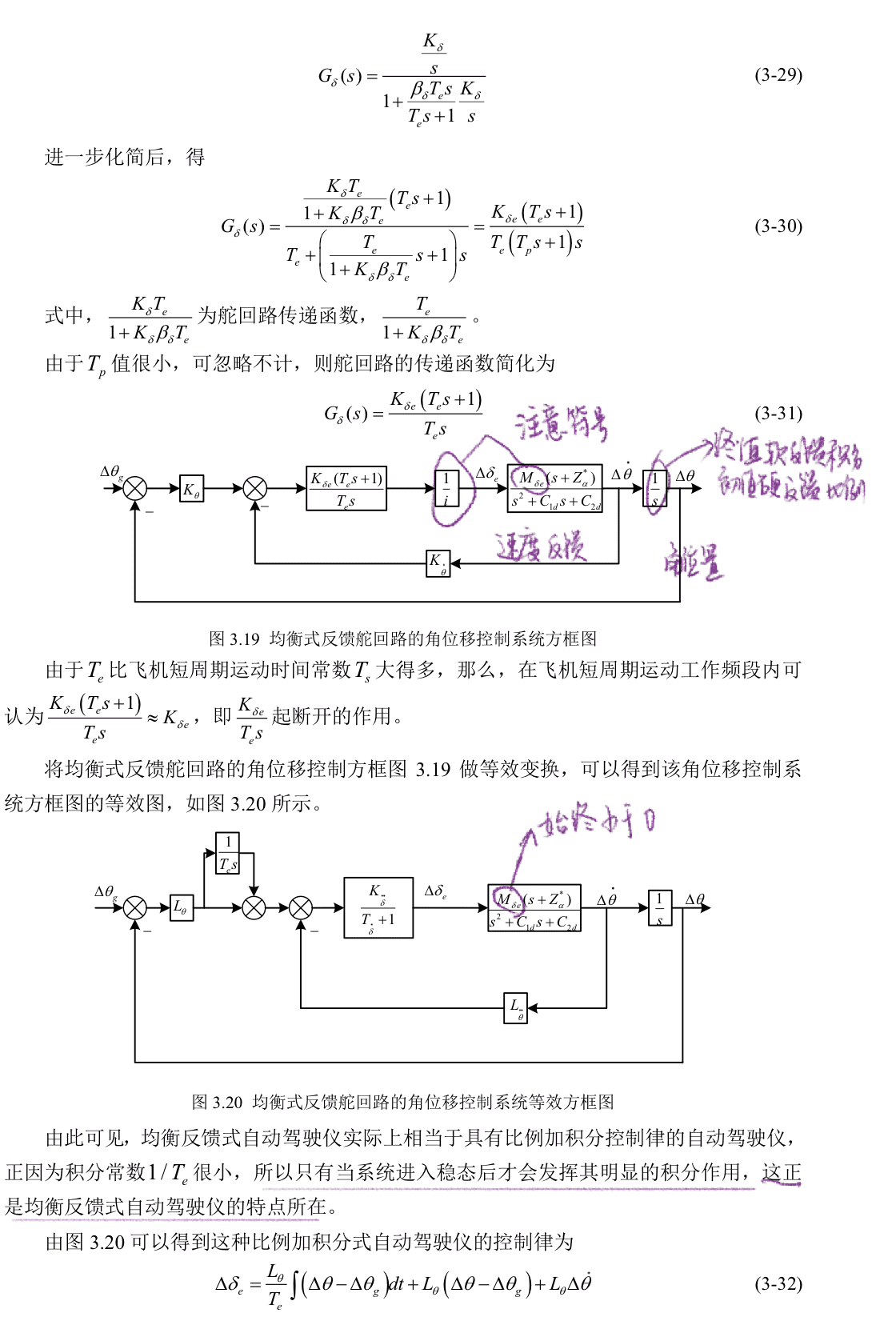\n\n\n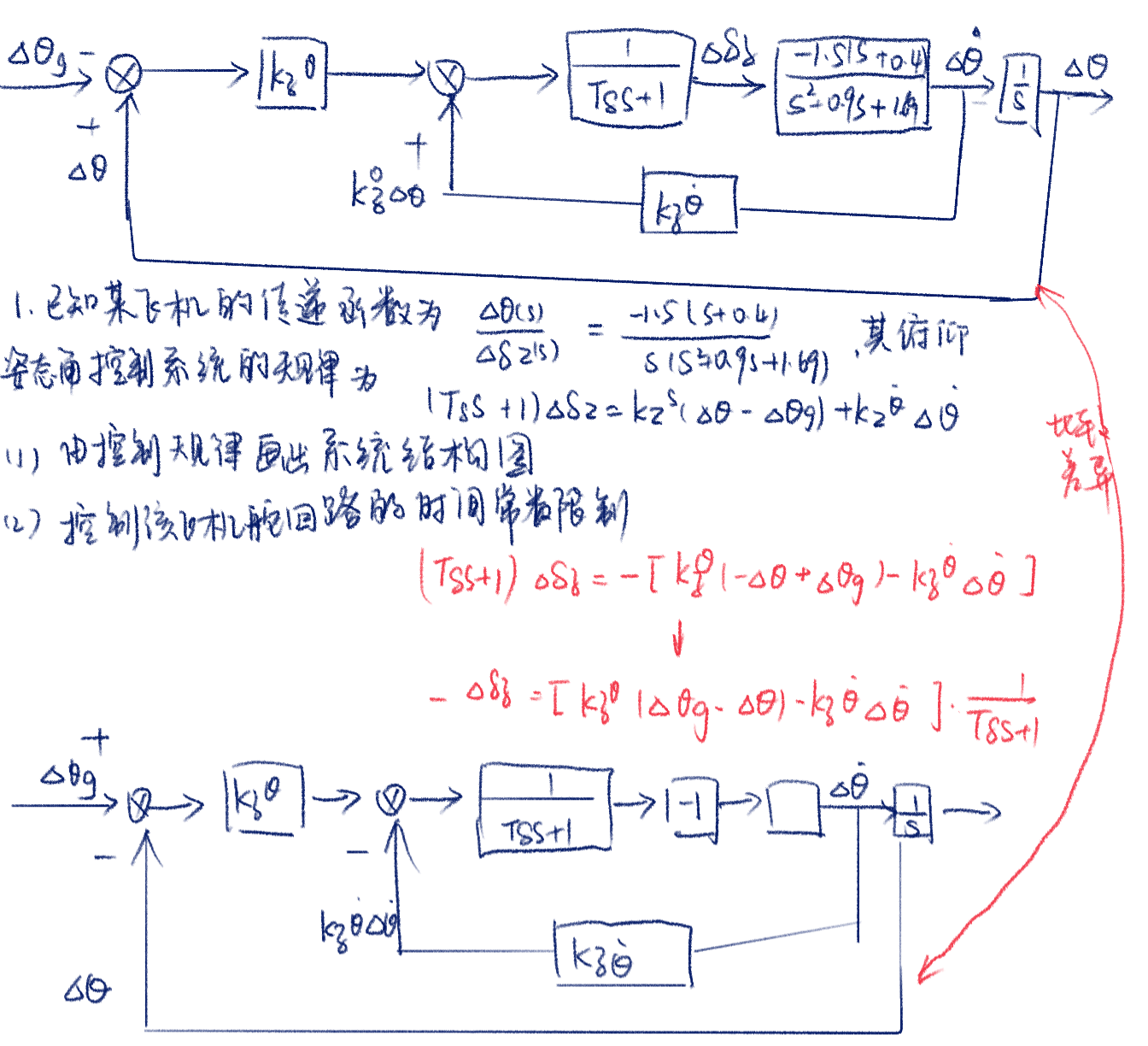\n\n\n## 3.2.2 飞机纵向姿态稳定与控制\n\n\n---\n\n\n\n\n\n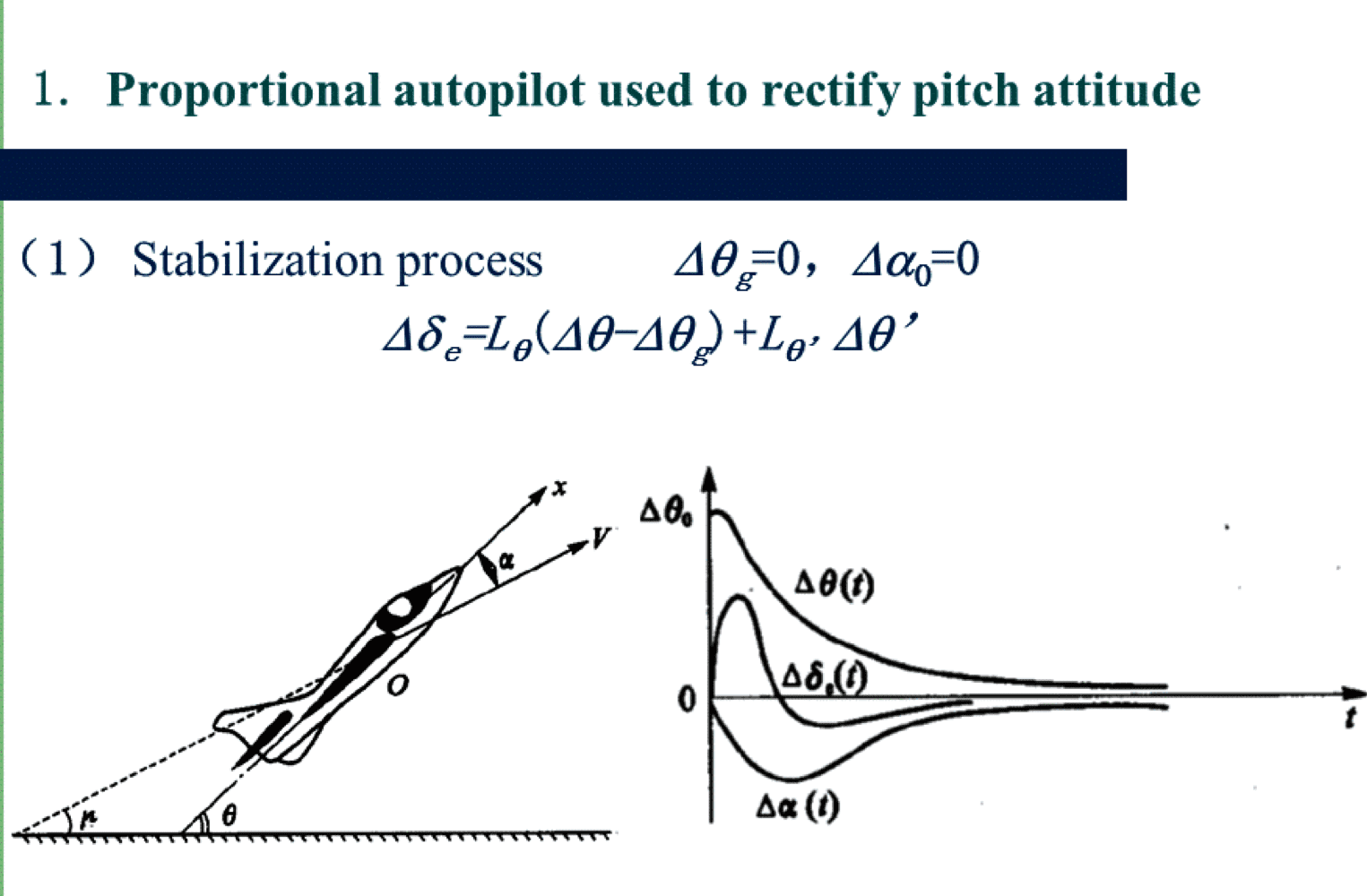\n\n\n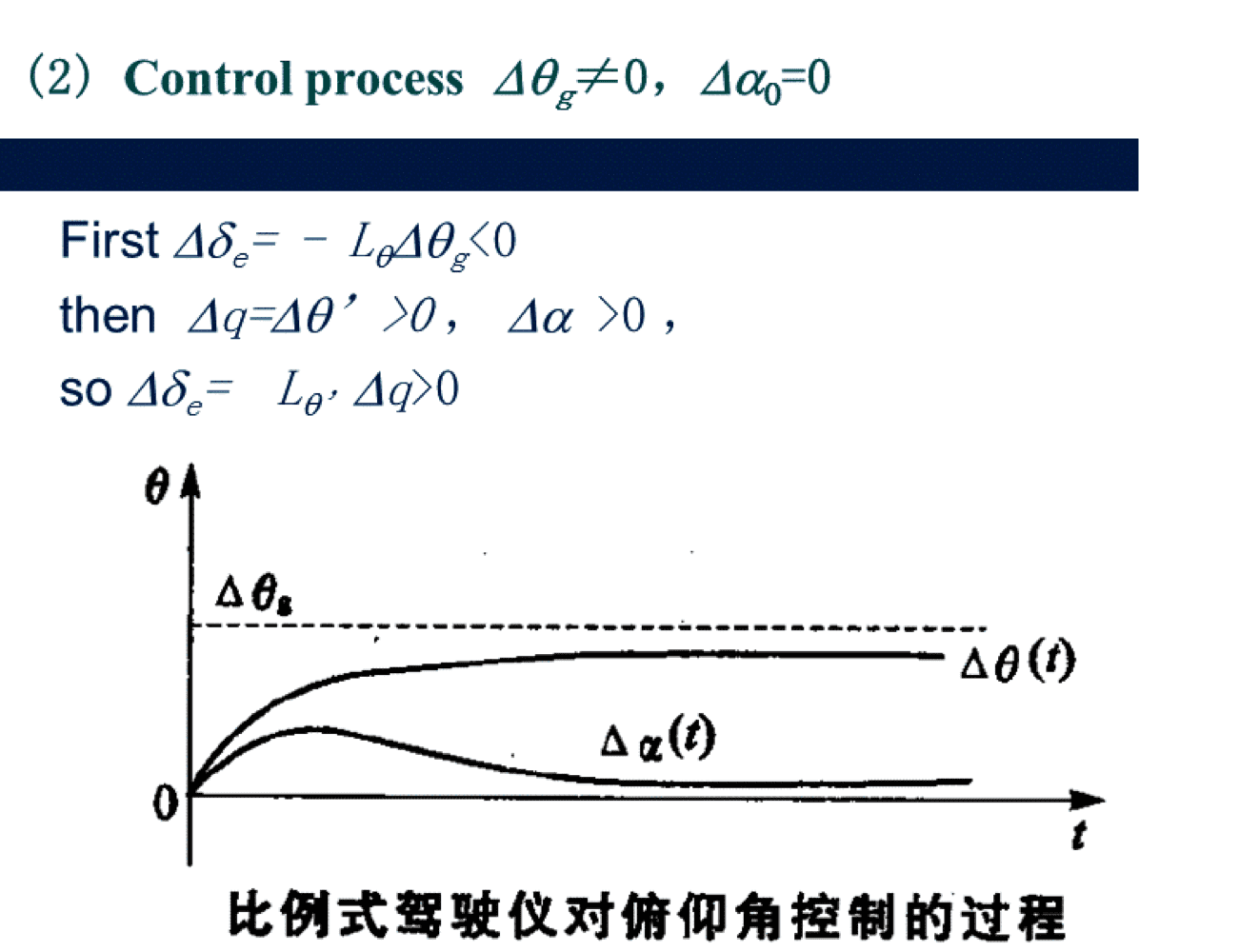\n\n\n## 3.2.3 飞机横侧向姿态稳定与控制\n\n\n---\n\n\n### 1. 横侧向姿态的稳定和控制的基本方式\n\n\n---\n\n\n1)通过方向舵实现水平转弯的侧向驾驶仪\n\n\n2)通过副翼修正航向而用方向舵削弱荷兰滚的方案将上面自动驾驶仪副翼通道的航向控制律修改\n\n\n### 2. 协调转弯控制\n\n\n---\n\n\n为了克服侧滑角的出现,必须研究侧向转弯过程中的协调控制问题。\n\n\n**1)协调转弯**\n\n\n\n\n\n\n\n\n\n\n\n**2)协调转弯飞行时自动驾驶仪的控制规律**\n\n1. 协调转弯的纵向控制\n\n\n\n\n# 3.3 飞机的轨迹控制系统\n\n\n---\n\n\n轨迹控制 (制导) 系统是在姿态 (角运动) 控制系统的基础上构成的。轨迹控制 (制导) 系统的反馈回路可以在飞行器内部闭合,也可以由飞行器通过地面设备进行闭合。\n\n\n## 3.3.1 飞行高度的稳定与控制\n\n\n---\n\n\n根据飞行阶段的不同要求和系统构型不同,通常将飞行高度的稳定与控制划分为巡航、下滑波束引导、拉平三个典型阶段。\n\n\n### 1.工作原理\n\n\n---\n\n\n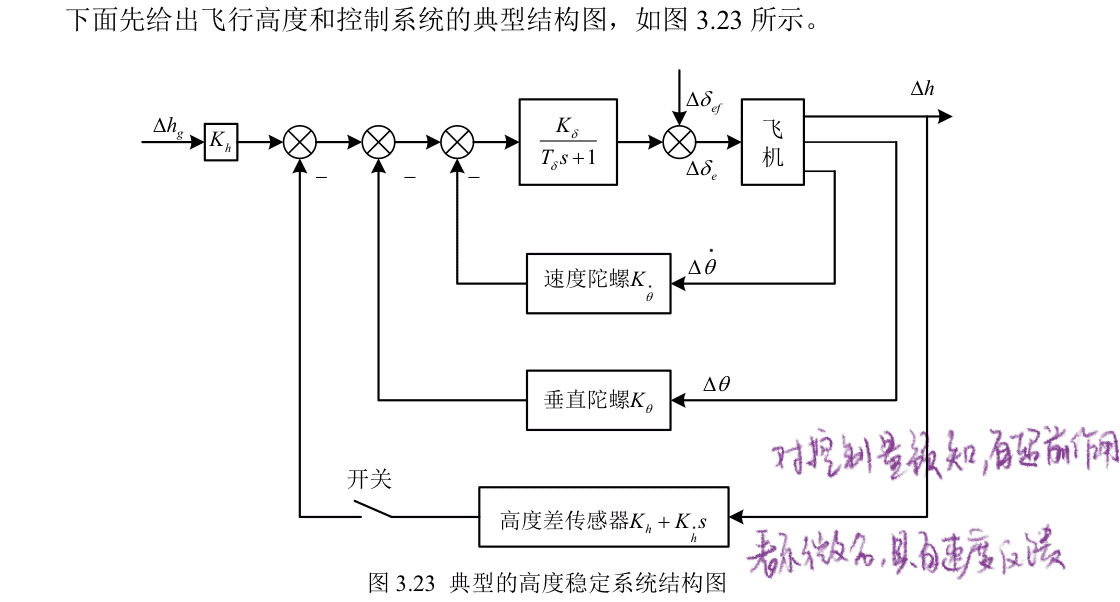\n\n\n由于角稳定系统在常值干扰力矩(例如,垂直风等)的干扰下存在姿态角的静差,因而导致高度飘移,所以不能直接应用于飞行高度的稳定与控制系统中。因此,在飞行高度的稳定与控制系统中需要直接测量飞行高度,使用高度传感器,如气压式高度表或无线电高度表等测高仪器,根据高度差的信息来直接控制飞机的飞行姿态,从而改变航迹倾角,以实现对飞机高度的闭环稳定和控制。\n\n\n### 2.高度稳定系统结构图的建立\n\n\n---\n\n\n\n\n\n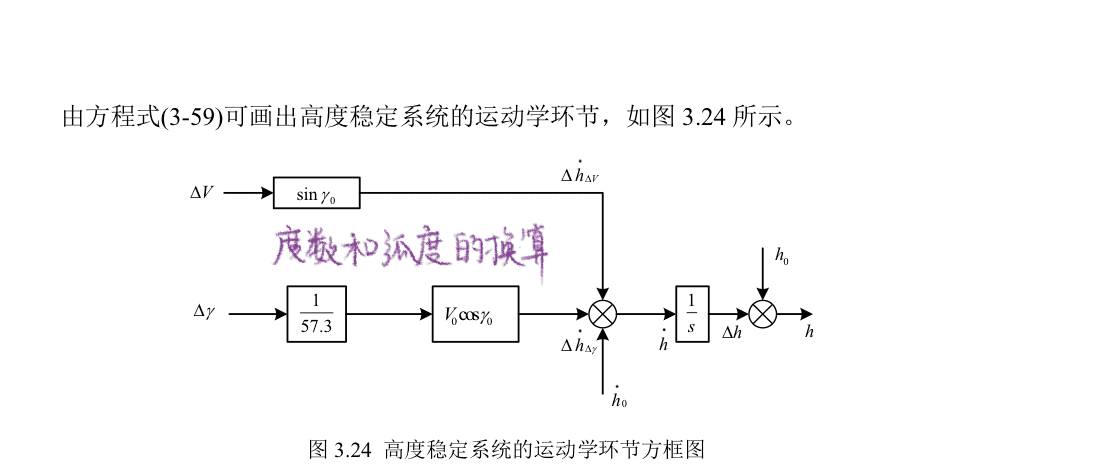\n\n\n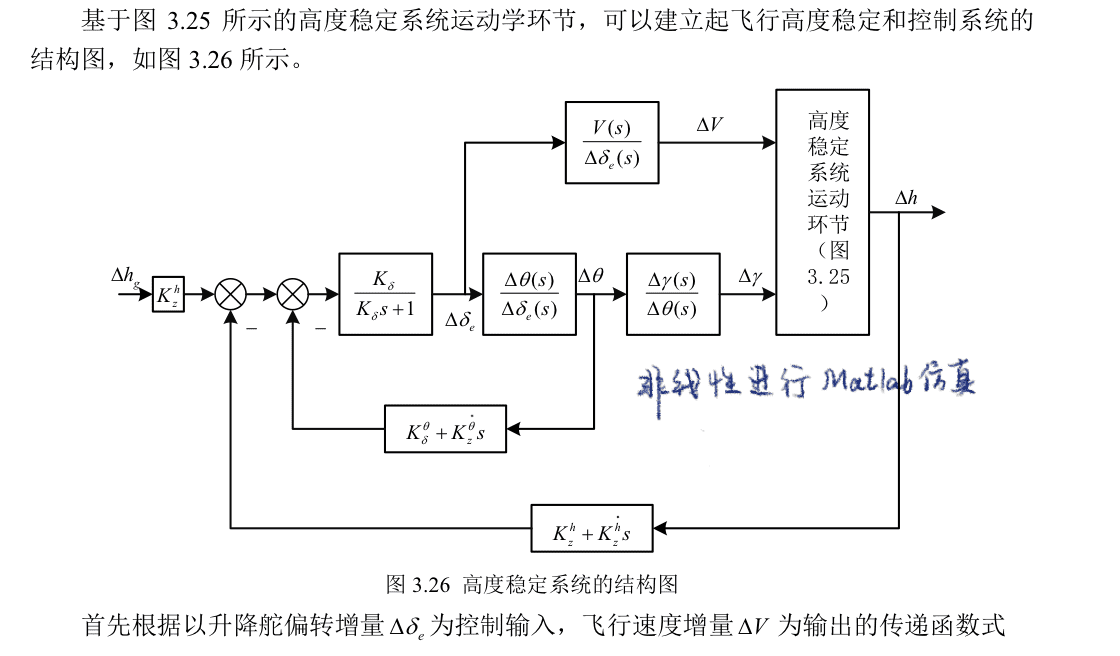\n\n\n\n\n\n## 3.3.2 下滑波束导引系统\n\n\n---\n\n\n### 1. 工作原理\n\n\n---\n\n\n为了实现全天候飞行,保证能在恶劣气象情况、无目视基准的条件下实现自动着陆,下滑波束导引系统是现代高性能飞机必不可少的机载系统。\n\n1. 着陆过程:一般包括定高、下滑、拉平和滑跑等阶段着陆过程如图 3.27 所示\n\n\t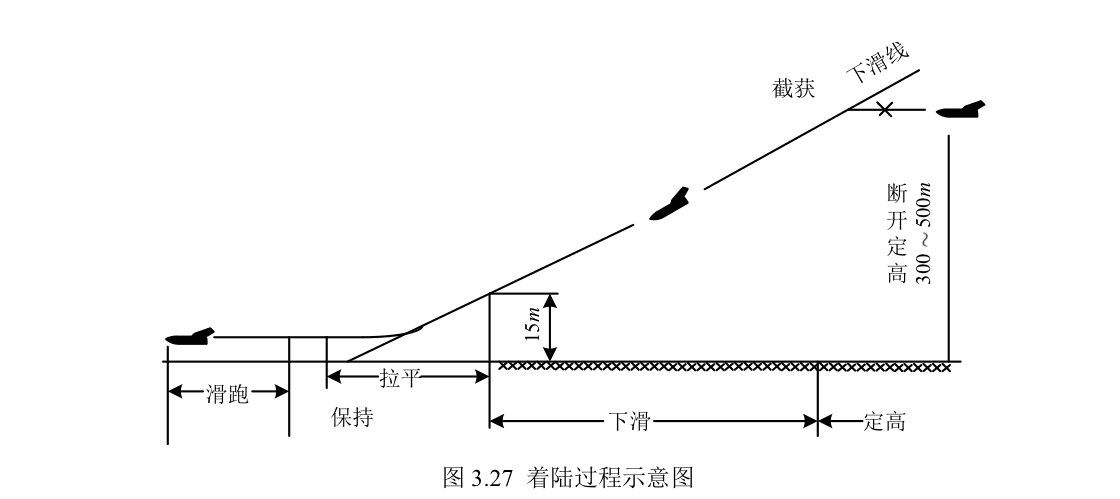\n\n2. 实现下滑波束导引的地面设备和机载设备\n\n\t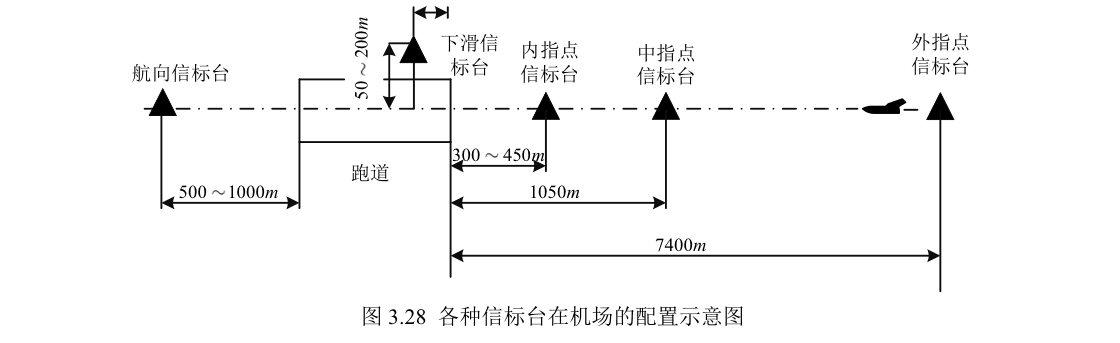\n\n\n### 2.建立下滑波束导引系统结构图\n\n\n---\n\n\n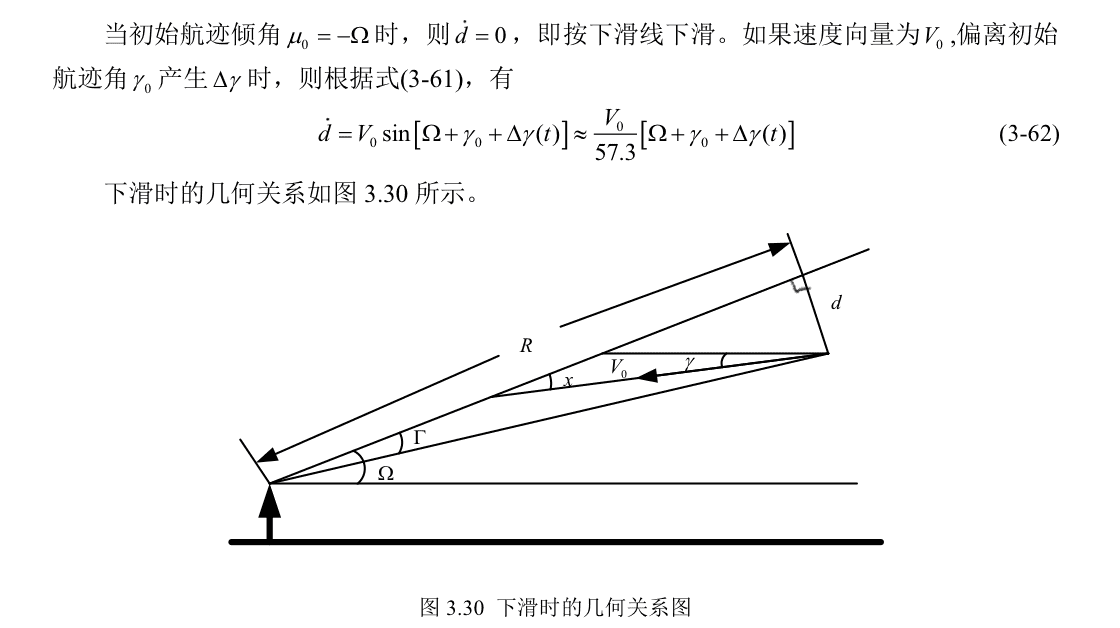\n\n\n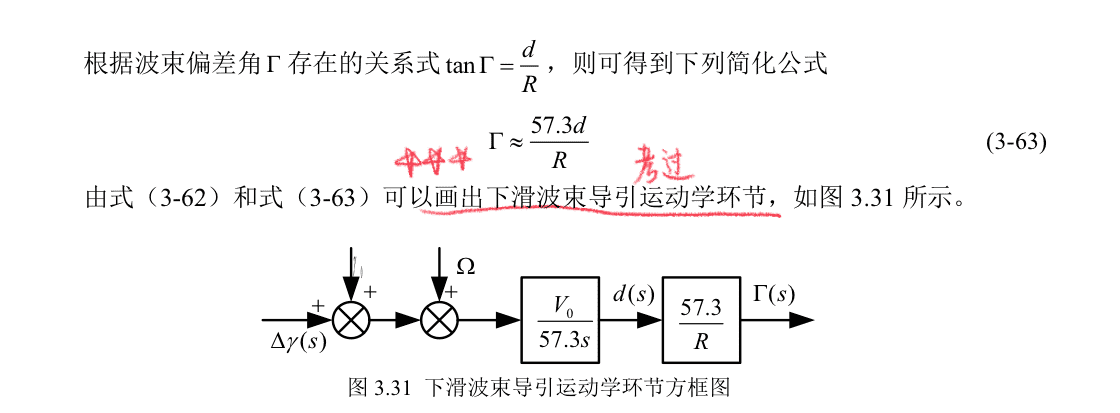\n\n\n## 3.3.3 自动拉平着陆系统\n\n\n---\n\n\n### 1.拉平轨迹\n\n\n---\n\n\n\n\n\n 按照拉平飞行距离公式(3-67),如果给定起始拉平高度0h 、容许接地速度1h 和飞行速度0 V 以及时间常数 ,那么飞机在拉平飞行段的飞行距离 l 就可以计算出来,并可以作为选择降落跑道的参考因素。\n\n\n## 3.3.4 飞机侧向偏离的自动控制\n\n\n---\n\n\n 而侧向偏离控制系统, 则是以偏航角和滚转角控制系统为内回路构成的 , 一般采用飞机倾斜转弯方式来修正和控制侧向偏离。对于侧向轨迹控制系统而言,航向和滚转两个通道的协调控制方法与侧向角运动的控制方法是一致的。\n\n\n 由于在一般情况下侧向偏离控制是由飞机倾斜转弯来实现的,那么,依据转弯的方式可将侧向偏离控制律的方案分为两大类: (1) 利用倾斜转弯(Bank-to-Turn,BTT)的形式,主要是以副翼和方向舵来实现侧向偏离控制的。\n(2) 通过侧滑转弯(Skid-to-Turn,STT)实现侧向偏离控制。侧滑转弯形式通常应用在具有轴对称布局的导弹中,而大多数具有面对称布局的飞机和巡航导弹都采用倾斜转弯(BTT) 形式来进行侧向偏离控制。\n在此,仅讨论第一类方案利用协调转弯(Coordinated-turn)的侧向偏离控制系统。\n\n\n# 3.4 空速和马赫数的保持与控制\n\n\n---\n\n\n## 3.4.1 飞行速度保持与控制的作用\n\n\n---\n\n\n### 1. 飞行速度保持与控制系统能保证飞机在低动压平飞时,仍具有速度的稳定性\n\n\n---\n\n\n\n\n\n\n\n\n### 2. 飞行速度的保持与控制是航迹控制的必要前提\n\n\n---\n\n\n\n\n\n### 3. 当进行跨声速飞行时能够保持速度稳定\n\n\n---\n\n\n\n\n\n## 3.4.2 速度保持与控制系统的构成与工作原理\n\n\n---\n\n\n### 1. 控制速度的两种常用方案\n\n\n---\n\n1. 通过升降舵偏转来改变俯仰角从而实现速度控制\n2. 自动油门系统\n\n### 2. 适用于速度控制系统的飞机近似方程\n\n\n---\n\n1. 单独操纵升降舵或油门\n2. 同时操作升降舵和油门杆\n\n## 3.4.3 控制速度的作用\n\n\n---\n\n\n### 1. 速度控制系统可保证飞机在低动压状态平飞时,仍具有速度的稳定性\n\n\n---\n\n\n\n\n\n\n\n\n### 2. 速度控制是航迹控制的必要前提\n\n\n### 3. 进行跨声速飞行时,能够保持速度稳定\n\n\n# 3.5 自动飞行控制系统基本性能要求\n\n\n---\n\n\n### 1. 姿态角自动控制系统的精度及瞬态响应\n\n\n### 2. 角速度控制系统及增稳阻尼系统的技术要求\n\n\n---\n\n\n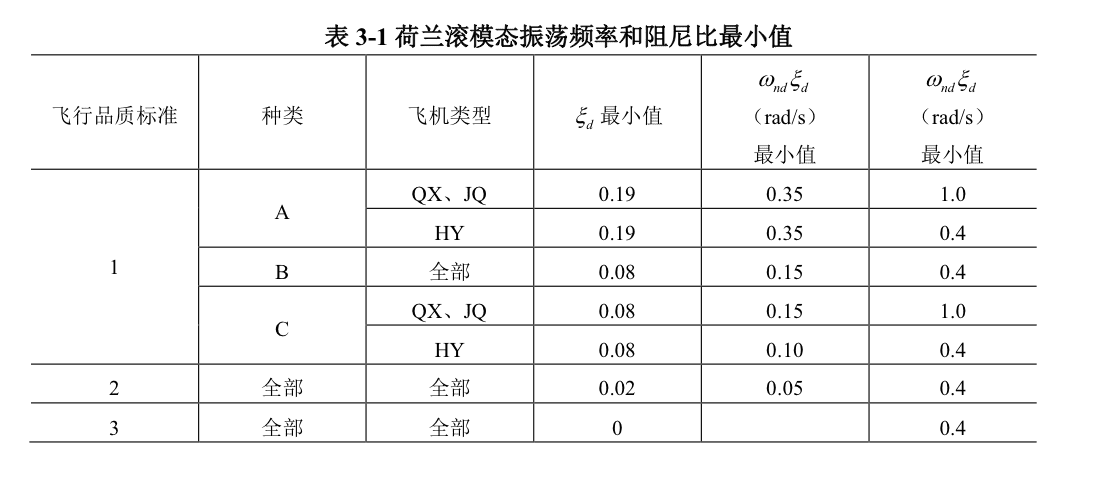\n\n\n### 3. 轨迹(中心)自动控制系统的精度与瞬态响应要求\n\n\n# 3.6 电/光传操纵系统\n\n\n---\n\n\n### 3.6.1 电传操纵系统(余度舵机)\n\n\n### 3.6.2 光传操纵系统\n\n\n### 1. 光传操纵系统的基本组成和原理\n\n\n### 2. 光传操纵系统的分类\n\n\n---\n\n\n光传操纵系统通常可以分为时分复用光传操纵系统和波分复用光传操纵系统两大类 , 这两大类的共同特点是它们均采用了光纤多路复用技术。\n所谓的光纤多路复用是指在一根光纤中同时传输若干路信号 。 光纤多路复用可以极大地提高传输效率,提高传输容量。在飞行器上采用多路复用技术可以进一步减轻重量,减小体积,增加传输灵活性,有利于实现多余度技术,从而提高系统的可靠性。\n\n\n\n\n\n### 3. 光传操纵系统的优点\n\n\n---\n\n\n光传操纵系统不仅能有效地预防电磁感应、电磁干扰及雷击或闪电引起的电磁冲击,而且能有效地消除各个信号之间的串扰,可以极大地减小系统的重量和尺寸。它不存在金属导线所固有的地环流和由此引起的瞬间扰动;光纤的频带很宽、容量大、传输信号速度高,而且利用时分复用或波分复用技术可以实现多路信号的传输;光纤的电隔离性好,消除了电火花的产生及其引起的爆炸的危险;光纤的抗腐蚀性和热防护性优良,故障隔离性好,当一个通道发生故障不会影响到其他通道。光纤传输损耗很低,同轴电缆 1.5 km 需要有中继站, 而光纤可以轻松传输上百千米无须中继;光纤价格低,比同轴电缆低约 30%。\n由于以上这些优点,光纤用作信号传输线获得了广泛的应用。新一代的自适应飞行控制系统也将利用光纤来传输大量数据。光传操纵系统在军、民用飞行器上的应用研究和使用被称为继陀螺和加速度计应用以来飞行控制技术最重大的发展。\n\n\n### 4. 实例验证\n\n\n---\n\n\n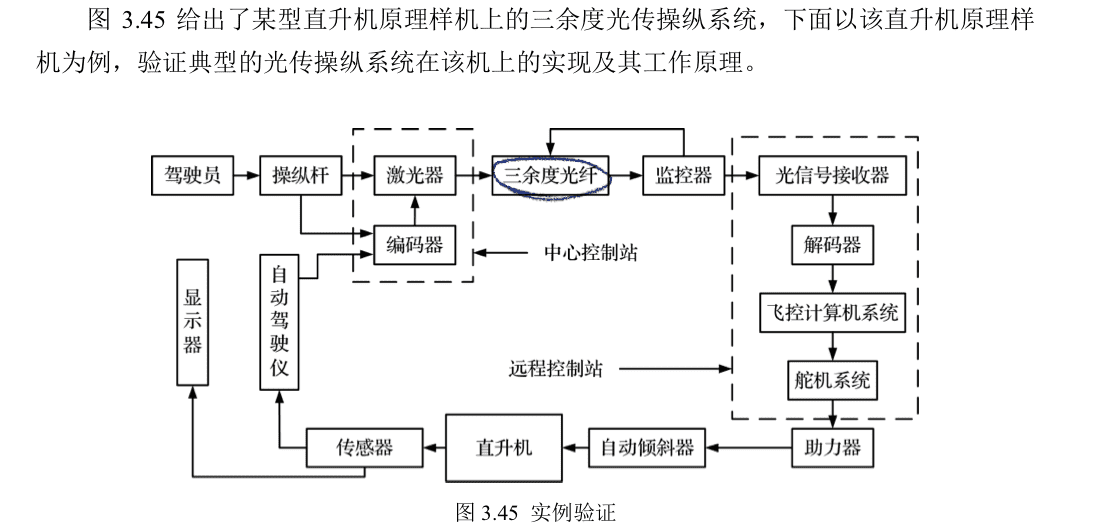\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-09-24",
"type": "Post",
"category": "璀璨星空",
"slug": "AFCS03",
"tags": [
"自动飞控"
],
"summary": "飞机姿态、轨迹控制、空速马赫数、自动飞行性能、电/光传操作系统",
"title": "[自动飞控] 第3章 飞行控制系统分析",
"status": "Published",
"urlname": "50d7d351-395d-415b-87e7-6d6d3ae562fa",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "自动飞控",
"doc_id": "50d7d351-395d-415b-87e7-6d6d3ae562fa"
}
],
"body": "",
"realName": "[自动飞控] 第3章 飞行控制系统分析",
"relativePath": "/自动飞控/[自动飞控] 第3章 飞行控制系统分析.md"
},
{
"id": "c41d1d32-8a6a-498a-adf1-d9b34ddccaac",
"doc_id": "c41d1d32-8a6a-498a-adf1-d9b34ddccaac",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 之前在前面的文章里已经介绍了前期的一些工作流程,但是还有一些没弄明白的地方,比如yolov5训练集、验证集、测试集之间的区别是什么。\n\n\n# 正文\n\n\n---\n\n\n 这部分详细介绍目前存在的疑惑。\n\n\n## 训练集和验证集\n\n\n---\n\n\n 非常感谢给我解答困惑的博主:梅花14的文章,标题为:[训练集、验证集、测试集的区别,这次你一定能看懂](https://blog.csdn.net/qq_41621362/article/details/88979961)。\n\n\n\t**训练集和验证集都是在训练阶段使用的!!!**\n\n\n\t```javascript\n\t相信你看了下面这段立马就明白了\n\t----------------------------\n\tfor each epoch\n\t for each training data instance\n\t propagate error through the network\n\t adjust the weights\n\t calculate the accuracy over training data\n\t for each validation data instance\n\t calculate the accuracy over the validation data\n\t if the threshold validation accuracy is met\n\t exit training\n\t else\n\t continue training\n\t```\n\n\n\t也就是说,训练集和验证集是用于在训练阶段的测试,在我第一次训练的时候,忽视了这个细节的,没有对测试集进行数据标注。\n\n\n\t## 过度拟合\n\n\n\t---\n\n\n\t 过度拟合是指模型在训练数据上表现良好,但在未见过的测试数据上表现较差的情况。为了避免模型的过度拟合,可以采取以下几种方法:\n\n\t1. 数据集扩充(Data Augmentation):通过对训练数据进行随机变换和增强,可以增加数据的多样性,从而减少过度拟合的风险。例如,在图像分类任务中,可以进行随机裁剪、旋转、缩放、翻转等操作来生成更多的训练样本。\n\t2. 正则化(Regularization):正则化是通过在模型的损失函数中引入额外的惩罚项来减少模型复杂度,从而降低过度拟合的风险。常见的正则化方法包括L1正则化和L2正则化。L1正则化通过对模型参数的绝对值进行惩罚,可以促使模型参数稀疏化;L2正则化通过对模型参数的平方进行惩罚,可以防止参数过大。\n\t3. 早停(Early Stopping):早停是指在训练过程中监控模型在验证集上的性能,并在性能不再提升时停止训练,以避免过度拟合。通过早停,可以在模型开始过拟合之前停止训练,从而得到泛化能力更好的模型。\n\t4. Dropout:Dropout是一种在训练过程中随机将部分神经元的输出置为零的操作。通过随机丢弃神经元,可以减少神经网络的复杂性,从而降低过度拟合的风险。\n\t5. 模型复杂度控制:过度复杂的模型更容易过拟合,因此可以通过减少模型的层数、隐藏单元的数量或特征的维度等方式来控制模型的复杂度。\n\t6. 交叉验证(Cross-Validation):交叉验证可以用于评估模型的性能并选择合适的超参数。通过将数据集分为训练集和验证集,并多次进行训练和验证,可以更准确地估计模型的泛化能力。\n\t7. 获取更多数据:增加训练数据量是减少过度拟合的有效方法。更多的数据可以提供更多的样本和场景,有助于模型学习更一般化的特征。\n\n\t综合使用上述方法可以帮助减少模型的过度拟合风险。需要根据具体问题和数据集的特点选择适合的方法,并进行实验和调优以获得最佳结果。\n\n\n\t## 评估yolov5模型性能指标\n\n\n\t---\n\n\n\t在使用YOLOv5或其他目标检测模型时,可以使用以下指标来评估模型的性能:\n\n\t1. 平均精度均值(mAP):mAP是目标检测任务中常用的评估指标之一。它综合考虑了模型在不同类别上的精度和召回率,并计算出一个综合的平均值。通常,mAP值越高,表示模型在目标检测任务上的性能越好。\n\t2. 精度(Precision)和召回率(Recall):精度是指模型预测为正的样本中实际为正的比例,召回率是指实际为正的样本中被模型预测为正的比例。在目标检测任务中,可以根据不同的阈值来计算精度和召回率,并绘制精度-召回率曲线。通常,我们希望模型能够在高精度和高召回率之间取得平衡。\n\t3. 漏检率(False Negative Rate)和虚警率(False Positive Rate):漏检率是指实际为正的样本中被模型错误地预测为负的比例,虚警率是指实际为负的样本中被模型错误地预测为正的比例。在目标检测任务中,我们希望漏检率和虚警率都尽可能地低。\n\t4. 定位误差(Localization Error):定位误差是指模型在预测目标位置时与真实位置之间的差距。通常,可以使用平均定位误差(Mean Localization Error)来评估模型的目标定位准确性。\n\n\t 这些指标可以通过在测试集上进行推理和评估来计算。YOLOv5提供了用于计算mAP和其他指标的评估脚本,可以使用这些脚本来评估模型的性能。此外,还可以可视化模型的预测结果,检查模型在不同类别上的表现,并进行定性评估。\n\n\n\t 需要注意的是,评估模型性能时应该使用独立于训练集和验证集的测试集数据,以确保评估结果的客观性和准确性。\n\n\n\t## 模型拐点\n\n\n\t---\n\n\n\t 在机器学习中,模型的拐点通常指的是学习曲线上的拐点。学习曲线是一种图形,用于显示模型在训练集和验证集上的性能随着训练样本数量或训练迭代次数的变化情况。\n\n\n\t 在学习曲线中,通常会有两条曲线:一条表示模型在训练集上的性能,另一条表示模型在验证集上的性能。随着训练样本数量的增加或训练迭代次数的增加,这两条曲线的性能会发生变化。\n\n\n\t 模型的拐点指的是学习曲线上的一个转折点或拐点,通常是指验证集上的性能开始出现下降或趋于稳定的点。在这个点之前,模型可能还在学习和改进,性能会随着训练的进行而提高;而在这个点之后,模型可能已经过拟合了,继续训练可能不会带来更好的性能。\n\n\n\t 找到模型的拐点可以有助于确定合适的训练迭代次数或训练样本数量。当模型的性能在验证集上达到最佳水平时,可以停止训练,以避免过度拟合。此时,模型的泛化能力可能最好,可以在未见过的数据上表现良好。\n\n\n\t 需要注意的是,模型的拐点并非绝对的,可能因数据集、模型复杂度和任务特点等因素而有所不同。因此,在实际应用中,需要根据具体情况和实验结果来判断模型的拐点,并进行适当的调整和优化。\n\n\n\t## 寻找模型的拐点\n\n\n\t---\n\n\n\t 寻找模型的拐点通常需要观察学习曲线并进行分析。以下是一些方法可以帮助你找到模型的拐点:\n\n\t1. 绘制学习曲线:在训练过程中,记录模型在训练集和验证集上的性能指标,如损失函数、准确率、mAP等。然后,将这些指标随着训练样本数量或训练迭代次数的变化绘制成学习曲线。\n\t2. 观察验证集性能:关注模型在验证集上的性能指标,如验证集上的准确率、mAP等。观察性能是否开始下降或趋于稳定。一般来说,当验证集性能开始下降或趋于平稳时,可能表示模型的拐点。\n\t3. 比较训练集和验证集性能:观察模型在训练集和验证集上的性能差异。如果模型在训练集上的性能远远好于验证集,可能表示模型已经过拟合,继续训练可能不会带来更好的性能。这时可以考虑找到一个合适的拐点停止训练。\n\t4. 使用早停法(Early Stopping):早停法是一种常用的寻找模型拐点的方法。它基于验证集性能的变化,在验证集性能连续一定次数没有提升时,停止训练并选择此时的模型作为最终模型。这可以避免过度拟合,并找到一个在验证集上性能最佳的模型。\n\t5. 交叉验证:使用交叉验证可以更准确地评估模型的性能,并找到模型的拐点。通过将数据集分成多个折(folds),每次使用不同的折作为验证集,其他折作为训练集,进行多次训练和验证,可以得到更稳定的学习曲线和更可靠的拐点估计。\n\n\t 需要注意的是,寻找模型的拐点并不是一个确定性的任务,而是需要结合领域知识和实验结果进行判断。同时,不同的任务和数据集可能会有不同的拐点位置和特点,因此需要根据具体情况进行分析和调整。\n\n\n\t## 图形化理解\n\n\n\t---\n\n\n\t 这部分首先要特别感谢up主:[yolo目标检测](https://space.bilibili.com/3493293505645464)的文章:[目标检测之性能指标](https://www.bilibili.com/video/BV1EQ4y1h7G9?p=4&vd_source=237e295a40d7aaea043ead8c0d2c78ab)\n\n\n\t\t\n\n\n\t\t首先是关于混淆矩阵的理解,用于理解准确率,召回率\n\n\n\t\t\n\n\n\t\t这张图更加形象地解释了什么是准确率和召回率\n\n\n\t\t\n\n\n\t\t这张图介绍了AP和mAP的含义,mAP是取所有类别的平均值。\n\n\n\t\t\n\n\n\t\t这张图我猜测应该是mAP的COCO标准\n\n\n\t\t\n\n\n\t\t这种图是介绍预测框和绘制框重叠率\n\n\n\t\t\n\n\n\t\t这张图用直观的方式介绍了什么是重叠率\n\n\n\t\t\n\n\n\t\t根据不同的重叠率对应的宽松程度\n\n\n\t\t\n\n\n\t\t比较同一数据集不同模型的性能\n\n\n\t\t\n\n\n\t\tAP计算的11点法,在2010前适用\n\n\n\t\t\n\n\n\t\tAP计算之积分法\n\n\n\t\t\n\n\n\t\t总结AP计算方法的变化\n\n\n\t\t\n\n\n\t\t还有一些其他的性能指标来对模型进行评价\n\n\n\t\t## 寻找拐点\n\n\n\t\t---\n\n\n\t\t 现在我感觉对训练多少轮模型是最佳的状态还没能有一个非常好的评估,我也只能通过观察,不同轮数准确率的变化来猜测拐点。当然炼丹太消耗时间和精力了。我跑300轮就得花费两个多小时,100轮差不多也得半个多小时。但是100轮的模型的精准度似乎比300轮的准确度还要高出0.002,应该是出现了拐点。然后我现在在等130轮的训练结果。\n\n\n\t\t\n\n\n\t\t\n\n\n\n\n\n\n\n\n\n\n\n\n\n# 总结\n\n\n---\n\n\n 接下来的主要任务是把中期的课设报告继续完善一下,提升逻辑性,美观度。\n\n- 特别是前期的方案对比,我觉得可以继续搜集一些资料,使得其更加饱满一些\n- 然后对于yolov5原理这部分还需要继续优化\n- 后面对于模型的评估指标,包括自己思考和遇到的一些问题也可以持续优化。\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-11-17",
"type": "Post",
"category": "动手实践",
"slug": "yolov5-2",
"tags": [
"实用教程"
],
"summary": "接下来的主要任务是把中期的课设报告完善一下,提升逻辑性,美观度,加一些问题和思考。",
"title": "[图像处理] yolov5后续的性能调节",
"status": "Published",
"urlname": "c41d1d32-8a6a-498a-adf1-d9b34ddccaac",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "c41d1d32-8a6a-498a-adf1-d9b34ddccaac"
}
],
"body": "",
"realName": "[图像处理] yolov5后续的性能调节",
"relativePath": "/实用教程/[图像处理] yolov5后续的性能调节.md"
},
{
"id": "57b7cb8e-cde8-4740-aa70-db541e0f4c56",
"doc_id": "57b7cb8e-cde8-4740-aa70-db541e0f4c56",
"updated": 1727839380000,
"body_original": "\n# 前言\n\n\n---\n\n\n<details>\n <summary>我的故事</summary>\n\n\n 我大概是从2014年开始,在QQ空间上写作,一直持续到2022年10月,这里承载了我很多的回忆,但是我仍然选择了关闭。\n\n\n 我也在2021年尝试成为一名up主,截至到2023年2月,累计1900的播放,随后放弃。\n\n\n 2022年运行微信公众号,截至到2023年2月,进行了注销。\n\n\n 这里面有我个人主观的原因,有所经历带来的认知改变的原因。倘若一个人已然浑身冰冷,又如何指望他去发光发热呢。\n\n\n 于是我希望重新开启一段新的旅程,2023年是这段旅行的元年,Core_2023_1这是新的名字,2023年,我希望一个人好好爱自己,不去打扰别人,努力学习。\n\n\n 我感觉自己是一个精神能量很大的人,所以有时候,我也在自我克制。\n\n\n 现在我来到了这里,如果有幸能在这里遇见你,那么非常感谢你听过我的故事,往后我也会继续更新和优化博客,只不过因为时间很紧张,要做的事情还有很多,所以更新的进度会很缓慢。\n\n\n 本科期间,电子信息工程,总的来说,我感觉我的自学能力还是有待提高的,疫情三年,我一直在尝试优化学习的方法,我还是感觉到自己的学习力远远不够。\n\n\n 大一大二主要的专业课,像单片机,了解很浅,模电数电当时学得也不是很懂,计算机目前只学过C,专业课,自控,高频电子线路,通信原理,数字信号处理,随机信号分析,EDA,电磁场与电磁波,基本上大三下就开始和民航相关的专业课程。\n\n\n 所以感觉自我的发育还不是很好,自己的人生主线还不是很清晰。\n\n\n 很幸运,在github上遇见了[Tangly](https://tangly1024.com/),在他的帮助下我搭建了这个博客。\n\n\n 在我写下这段文字的时候,博客还很小,尚不满月,但是已经给了我足够的惊喜。\n\n\n 现阶段,我打算用一些时间来更好地了解自己,同时准备考研,当你踏上一段新的旅程的时候,沿途的风景会为你拂去疲惫。\n\n\n2023-05-07 \n\n\n\n </details>\n\n\n 这里记录我对博客优化的过程,您可以看作是博客优化的日志。\n\n\n 为什么要这么做?\n\n\n> _陆陆续续参观了一些优秀的博客,由衷地感觉,博客确实为我打开了一扇新的世界,这里是一座舞台,坚持很难,但很有趣! \n> ——MatrixCore \n> 时间真快啊,转眼之间博客就已经一周年了,时过境迁,从一个尚未满月的宝宝,已经变成一岁的“会爬的小乌龟”了,还记得在一个月时候写下的故事么,当初带着好奇的眼光去展望未来,如今,不妨守护着这颗感恩的心,继续走下去。_ _2024-04-30_ \n> _——MatrixCore_\n\n\n 目前采用的是**heo主题**,支持algolia搜索,可以看看[这篇文章](https://zhuanlan.zhihu.com/p/568538285)的介绍\n\n\n# 正文\n\n\n---\n\n\n 按照时间倒序记录我对博客优化的一些思考,即使有些想法可能已经不适用于现在的博客配置,但也希望能给您带来一些启发!\n\n\n### 基于NotionNext+Memos的多用户功能的实现 2024-09-09 \n\n\n---\n\n\n本功能为非常6+1组合测试Memos多用户在[说说](https://matrixcore.top/memos)页面呈现的功能,本版本为V1.0版本,实现功能和不足如下:\n\n- 基于多用户的Memos呈现,使得Memos不再是个人独奏曲\n- 无法按照时间进行排序,这个需要很多时间以及代码基础,暂时没有攻克该难题\n- 无法自定义头像,此前的头像为css中定义,但是多用户对应不同头像为定义,干脆都删了\n\n本次更新,总历时三小时,期间遇到卡片间隔不均匀问题,原因为css定义的容器最小高度为300px,修正后正常,多用户呈现的难点在于,如何正确获取用户ID,和定义#memos标签,以及使用html呈现,本次修改涉及三个文件,详见[commit](https://github.com/happyzhangyyds/NotionNext/commit/246d4728e29a623b6b16688f1c62714134b59772),本版本还有诸多不足,但已经实现了多用户的基本功能,已经是一个不小的突破了,感兴趣的博友可依据commit进行本地调试。\n\n\n### 进行部分文章的归档 2024-08-11 \n\n\n---\n\n\n```shell\n { \"source\": \"/article/RSS\", \"destination\": \"https://hugo.matrixcore.top/rss/\", \"permanent\": true },\n { \"source\": \"/article/license\", \"destination\": \"https://hugo.matrixcore.top/license/\", \"permanent\": true },\n { \"source\": \"/article/andawell_minji_team_building\", \"destination\": \"https://hugo.matrixcore.top/andawell_minji_team_building/\", \"permanent\": true },\n { \"source\": \"/article/Spring\", \"destination\": \"https://hugo.matrixcore.top/spring/\", \"permanent\": true },\n { \"source\": \"/article/hugo-virgo\", \"destination\": \"https://hugo.matrixcore.top/hugo-virgo/\", \"permanent\": true },\n { \"source\": \"/article/azure\", \"destination\": \"https://hugo.matrixcore.top/azure/\", \"permanent\": true },\n { \"source\": \"/article/Saladict\", \"destination\": \"https://hugo.matrixcore.top/saladict/\", \"permanent\": true },\n { \"source\": \"/article/231210\", \"destination\": \"https://hugo.matrixcore.top/231210/\", \"permanent\": true },\n { \"source\": \"/article/RISC-V\", \"destination\": \"https://hugo.matrixcore.top/risc-v/\", \"permanent\": true },\n { \"source\": \"/article/Shantaram-1\", \"destination\": \"https://hugo.matrixcore.top/shantaram-1/\", \"permanent\": true },\n { \"source\": \"/article/Shantaram-2\", \"destination\": \"https://hugo.matrixcore.top/shantaram-2/\", \"permanent\": true },\n { \"source\": \"/article/231230\", \"destination\": \"https://hugo.matrixcore.top/231230/\", \"permanent\": true },\n { \"source\": \"/article/240216\", \"destination\": \"https://hugo.matrixcore.top/240216/\", \"permanent\": true },\n { \"source\": \"/article/240208\", \"destination\": \"https://hugo.matrixcore.top/240208/\", \"permanent\": true },\n { \"source\": \"/article/240624\", \"destination\": \"https://hugo.matrixcore.top/240624/\", \"permanent\": true },\n { \"source\": \"/article/Pre-employment_Checkup\", \"destination\": \"https://hugo.matrixcore.top/pre-employment_checkup/\", \"permanent\": true },\n { \"source\": \"/article/starry_sky\", \"destination\": \"https://hugo.matrixcore.top/starry_sky/\", \"permanent\": true },\n { \"source\": \"/article/senior_thesis_defense\", \"destination\": \"https://hugo.matrixcore.top/senior_thesis_defense/\", \"permanent\": true },\n { \"source\": \"/article/NotionNext_Hugo\", \"destination\": \"https://hugo.matrixcore.top/notionnext_hugo/\", \"permanent\": true },\n { \"source\": \"/article/boombeach\", \"destination\": \"https://hugo.matrixcore.top/boombeach/\", \"permanent\": true },\n { \"source\": \"/article/lubancat_conky\", \"destination\": \"https://hugo.matrixcore.top/lubancat_conky/\", \"permanent\": true }\n```\n\n\n### 301重定向恢复归档文章访问 2024-06-10 \n\n\n---\n\n\n完成文章[批量重定向](https://matrixcore.life/article/NotionNext_Hugo#17338691489b4554a1e04b326109c9a1), 要注意的是,因为我之前hugo是编译后的,现在用的hugo是自动编译的,更新后的url不一样。\n\n\n### 关于NotionNext架构的合理化运用 2024-05-02 \n\n\n---\n\n\n NotionNext架构目前是我的主力博客架构,我喜欢其如下的优势:1.更高的SEO 2.在Notion中的修改刷新就可以呈现,不必每次重新编译 3.搭配出色的主题和优雅的审美使得其具备现代博客的美感。\n 但是NotionNext架构也还有一个限制,那就是基于Notion_database的Block的限制,可能上限在1000个左右,具体的我没仔细计算,但是此前发生过数据溢出的现象。所以不得不归档一部分数据到HUGO中去,这就导致之前被搜索引擎收录的URL变成了404状态,产生了负面的SEO效果,所以我的设想是如何基于现有的URL为之前失效的URL做301重定向,同时随着日益思考的积累,一定会有部分新的思考替换旧的思考,而HUGO我认为是一个可以值得托付的高性能框架,值得存放之前的静态文章,如果之后有时间,将着手去进行这项工程。 \n\n\n### 使用VPS部署NotionNext对Vercel进行分流 2024-04-30 \n\n\n---\n\n\n使用[软云香港节点](https://ruan.cloud/aff/HNAAAYYQ)部署作为[源服务器](https://matrixcore.life/),同时使用cdn请求服务器资源,实现微信内正常访问,中途出现评论区无法呈现以及图片丢失问题。解决措施,重新拉取仓库,在执行`yarn`之前就修改好内容,同时在正式上线之前进行`yarn start`调试,成功后再改用nohup运行`nohup yarn start >/dev/null` **`2`**`>`**`&1`** `&`最后切记不要直接关闭终端,应执行`exit`退出终端。每次更新代码后,需要重新执行`yarn build`以及`nohup yarn start >/dev/null` **`2`**`>`**`&1`** `&`,过程中我还遇到了yarn的环境问题,每次使用时需手动切换`nvm install v16.14.0`同时`npm install -g yarn` ,可能是环境变量的问题,但不建议直接上手修改系统环境变量配置文件,存在未知风险。图片丢失问题的出现很罕见,起因是是重新更新代码后执行了`yarn dev`,之后一直无法响应图片,怀疑可能是进程占用了,执行`sudo lsof -i :3000`再`sudo kill -9 <PID>`后,最后重新yarn start测试后恢复正常,重新上线部署,整个调试过程非常艰辛,VPS的上手难度要比Vercel高很多。建议参考[手册](https://docs.tangly1024.com/article/deploy-notion-next-on-vps)。但是VPS的优势在于更高的性能,更快的速度,可以搭建更丰富的服务。例如将memos集成到notionnext中去,参考[尘歌的文章](https://chenge.ink/article/post20240302-1)。同时还有个建议,建议将NotionNext安装到`/var/www`目录下,这样nginx能被授予访问权限,nginx对于`/root`下的目录可能存在权限问题。通过搭建博客可以了解http协议以及如何进行数据转发。\n\n\n### 删减不必要的服务分支 2024-04-28 \n\n\n---\n\n\n将Hugo从vercel迁移到软云,减少vercel的开支,集中精力来跑Notionnext,同时删除不必要的服务分支,优化主架构。\n\n\n### 字体优化 2024-03-23 \n\n\n---\n\n\n 之前的字体会拖慢网站加载速度,后采用[LXGW WenKai Screen](https://cdn.staticfile.org/lxgw-wenkai-screen-webfont/1.6.0/style.css)在`blog.config.js`中引入。\n 另外顺带插一句,因为之前写的文章质量不高,然后各种修改和迁移,导致bing产生了大量错误的索引,今天一个一个block的时候极为头疼,所以还是按照对应的规则好好去写一些有意义的文章,让大多数的index具备不错的质量。\n\n\n### 页脚布局-白边溢出 2024-03-23 \n\n\n---\n\n\n 移动端黑夜模式下,此前页脚会出现空白\n 解决方案:**溢出隐藏(Overflow Hidden)**:在包含内容的容器上应用 `overflow: hidden;` 样式,这将隐藏超出容器的内容,而不是让它溢出显示在容器之外。该样式的路径适用于`themes/heo/style.js`\n\n\n```javascript\n#footer-bottom {\n overflow: hidden;\n}\n```\n\n\n### 为博客添加全局友链\n\n\n---\n\n\n 主要是方便我随时去溜达,哈哈。\n\n\n### 借助Memos为博客添加说说界面 2024-03-10 \n\n\n---\n\n\n 之前一直希望能把Memos融入heo主题,但是尝试之后没成功,然后就单独建了一个页面,现在可以通过菜单栏进行预览。\n\n\n### 升级NotionNext至4.3.0版本 2024-03-03 \n\n\n---\n\n\n 感谢tangly和其他群友的付出,持续更新和优化NotionNext,其中我感觉4.3.0版本比上一代4.0.18版本快了很多。\n\n\n 说说我的感受,我觉得notionnext最大的特点就是可以将notion与博客动态结合起来,和静态博客的区别如下:\n\n- 在notion中编辑,可以即时体现在博客中,这一点就使得内容更新非常迅速,静态博客需要重新编译部署,在更新时会稍微麻烦些,但静态博客更加快速和稳定。\n- notion丰富点块理念,有些时候会比markdown更加丰富。\n- notionnext特别需要注意block上限为1000个,这也是我为什么会限制数量的原因,因为溢出之后博客会出现不可预知的故障。所以我把一些旧的内容,重新归档到hugo里去了。\n- notionnext可能需要您耐心研究代码,遇到问题积极提问,因为notionnext的复杂度是比很多静态博客要高的。\n\n### 博客性能优化 2023-09-11 \n\n\n---\n\n\n目前来看博客性能比较一般,有时间需要优化一下\n挑个两个小时的配色,原来的配色感觉看久了很累,我选的是这张荷花\n同时改左边英雄区的标签组为岁月长廊,右边则为如下的荷花\n同时最近将为之前学习过的知识做cdn优化\n\n\n### 关于博客发展的一些思考 2023-09-03 \n\n\n---\n\n\n 随着个人成长,博客的总体的信息量也变得越发地庞杂,哪些信息该被记录到博客当中,又通过什么样的方式进行记录呢,如何看待每一篇博文的含金量和精力的平衡呢?\n 值得庆幸的是,我感觉每一天就像是行走在稻田里的插秧机和收割机。\n 春天播种,秋天收获,或许在冬天只需要想到冬天该做的事情,和春天的播种就好了,如果只是把精力放到来年秋天的收成,或是对老天爷的担忧上,那人生也会不堪重负。\n 到底什么能产生价值,是劳动本身。劳动本身在对于理论的实践中得到了收获。\n 那博客也是这个道理,如果把一天比作是四季,春夏播种,秋季收获,冬季窖藏。\n 早晨应该专心完成早晨的任务,冬季应该好好休息。秋季应该好好收获,夏季应该挥洒汗水。\n 问题就在于我们把所有的一切都想得太超前了,以至于我们的身体和精神不堪重负。\n 除去客观因素的制约,我们的主观的学习方式和学习能力的建立则更加关键,我们通常发现,假期比工作日更加焦虑,十几年的教育使得我们对任务绝对服从,但是在独立规划自己人生的时候却陷入了困境,这也是我当下正在面对的问题。\n 同样也体现在博客当中。\n 我现在总体的打算是,按照板块逻辑进行建设,这是最主要的逻辑,比方说,我会为博客的优化单独开设一个博文,把博客的演化变迁都记录在这个模块当中,这样就可以在一篇文章中看到博客总体的一个变化。\n 分类的方式是非常重要的,另外就是筛选和提取,在数据量特别庞大之后,就需要有更好的筛选方式。这两者之间需要更好的协调,其实本质上两个流程指向的都是同一个结果。\n 另外就是对于价值的一个思考,什么样的东西能带来价值呢,一方面是考虑需求,一方面是要融入自己真实的体会和思考,并且是确确实实对自己的人生路上是有启发的事情,最好还是能够对当下能够造成影响的,这样的优先级就会更加高一些。\n 我们知道信息都是有时间限制的,而在当下的信息时代,我们也是被各种各样的信息包围当中,很难获得一种成就感或者安慰感,更多的是希望追求立竿见影的效果,这种感觉是很折磨人的,我曾经也陷入这种感觉无法自拔,但我现在觉得,我们不仅仅是充当世界的顾客,我们有机会应当成为自己的主人,学着好好去关心自己,爱自己,这样子,或许自己的内心会更加宁静和富有生命力,对待未来和未知也不会很特别焦虑了,好了,今天的分享就先到这里,我们不见不散。\n\n\n### 优化归档 2023-08-18 \n\n\n---\n\n\n> 💡 **main(现阶段可能受影响的配置)** \n> - **【图床相关】**评论区的图床可能支持不了很大的图片,理论上1-2MB左右,<u>如果超过3 MB大概率会上传失败。</u>twikoo作为一个即时的灵感收集容器,可以即时并且有效地进行数据处理 。增加了twikoo评论邮件通知和及时回复功能,最主要的一步是获取邮箱的[授权码(教程)](https://note.youdao.com/ynoteshare/index.html?id=f9fef46114fb922b45460f4f55d96853&type=note&_time=1659422937634)在twikoo的后台管理中配合7bu建立图床,请参阅[twikoo的官方文档](https://twikoo.js.org/faq.html#收不到提醒邮件)。 \n> \n> - **【RSS订阅】** 只能通过手动重新部署项目完成更新 \n> \n> - **【番茄自习室】**借助番茄人生的平台搭建了线上自习室,可以点击[这里](https://www.tomatolist.com/show_group.html?group_id=27f2b200-d549-4ba9-a2cc-1b6025be2c7b) \n> \n> - **【友链功能】**其实之前我想的是,把博客作为一个闭源的平台,用于自己的写作和整理就够了,可是后来慢慢会发现,在上面花费的时间和心思就比较少了。这是一项很有意义的事情,为什么不坚持下去呢,每一个微小的开始都需要有一些勇气。友链也是一个很好的方式,相似和有趣的灵魂同样让人感到喜悦! \n> \n> - **【博客音乐】**后续考虑引入肖邦,莫扎特,舒伯特等音乐大师的作品\n\n\n> 💡 **branch(过期配置,但是曾经发挥过作用)** \n> - 【**medium主题**】由于时间异常,移除了关于创建时间的展示 2023-07-08 **(在heo主题中保留了创建时间和修改时间)** \n> \n> - 【**medium主题**】优化了博客的背景,依依不舍地告别从前绚丽的css背景色,换上了护眼的杏黄色 2023-06-18 \n> \n> - 【**medium主题**】更改了博客的展示逻辑,区别于传统的博客的展示方案,我将五个页面设置成五个端口,这样更加方便内容的管理,如果内容太多,反倒不是一件好事。**(由于二级三级页面会严重拖慢博客的加载速度,所以放弃关于该想法的路径规划,但是保留流动核心的地位)**\n\n\n> 💡 **Tips(一些好玩的小技巧)** \n> - **【全屏浏览】** \n> 方案一,按住F11,即可体验全屏的快乐和奢侈 \n> 方案二,借助edge的展台功能,在命令行(win+r)中输入: \n> \n> - 【快捷键】\n\n\n### Fork大佬[imsyy的项目](https://github.com/imsyy)搭建的[个人导航页](https://nav.matrixcore.top/) 2023-07-17 \n\n\n---\n\n\n完成的工作包括但不限于\n\n- 1.通过meting-api自建稳定的音乐api服务,完成导航页的音乐正常播放\n- 2.引入哲学和诗词类[一言api](https://developer.hitokoto.cn/sentence/),完成一言模块的搭建\n- 3.完成[高德开发者](https://lbs.amap.com/)认证,获取高达30000次日上限的天气api调用,整合到天气模块\n\n 接下来的目标是对导航页的其他资源做更好的整合,包括学习环境的整体搭建,从学习输入,知识输出的整个流程做更好的规划,现在是资源很多,但是还没有投入足量的时间挖掘。一个舒服的小窝就此搭建完成。\n\n\n---\n\n\n### 关于博客和生活之间联系的思考 2023-07-06\n\n\n---\n\n\n 我觉得有一种很奇怪的感觉会经常发生,似乎在某个特定的时刻总会遭遇特定的危机,生活似乎都是有一些不完美的碎片拼接而成的。\n\n\n 这是一个信息相对爆炸的时候,但是似乎又是一个相当空虚的时代,身处于其中 ,似乎任何一个微小的事情都得到了无线的放大,然而人的精力是很有限的。\n\n\n 看上去这总是一个意外,过度的思考在某种程度上不是一件好事。\n 如果把人的感觉视作计算机指令的反馈,我想这其中仍然有很多的规律可循。\n\n\n 每一次陷入精神危机,大抵是由于能量过载所导致的。\n 比如在我们学习累了之后,如何进行放松,面对这么多的事情如何找出重点。\n\n\n 生活最好是能理出一条清洗的主线来,而博客就是在做这样的事情。\n\n\n 我们要尽可能去理解主客体之间的辩证关系,以其能发挥更好的作用\n\n\n### 关于博客设计思路的探讨 2023-06-13 \n\n\n---\n\n\n 传统博客的展示方式,是将博客作为一个大的容器,对容器内部进行更加详细的分类和配置相应的标签,这样,在这个容器当中可以展现出玲琅满目的珍奇异物,加上丰富的图片,相当具有吸引力,这样的博客的展示方式对于知识输出和分享是有非常不错的效果的。但是缺点就在于,数据积累多了之后,总是感觉让人有一种沉重的感觉。\n\n\n 谈谈我的博客的设计思路, 基于notion架构下的博客,我是这么理解的,我将展示的界面仅仅设置为五个,分别以具有特殊意义的名字进行命名,这个五个界面,分别象征着一个完整的工作流所应该具备的几个基本步骤,导向-输入-存储-输出-反馈。\n\n\n 比如我可以这么介绍我的一天:\n\n\n> _今天我希望完成线性代数课程的学习,我听了两节课,我将我的知识存储在mn中,我还没有对我的知识体系做出更好的整理,我希望能够在之后的学习当中优化这个问题。_\n\n\n 在这段话中,分别对应五个步骤,这个五个步骤可以看作是一个通用的模块,无论所做的事情的大或者小都可以找到这件事对应的阶段,我将基于线性的逻辑打造这个博客体系。你可以把这个博客看作是从上到下或者是从左到右。\n\n\n 因此我的博客将会保持一定程度上的简洁,这即是优点也是缺点,但我更喜欢这种优雅的模式,轻量并保持其该有的逻辑,每一部分专注从事其应该做的事情,博客将成为辅助工作流的很棒的方式,在这里可以展示自己创意。\n\n\n 此外在我们收集创意和灵感的时候,有的灵感大或者小,甚至是转瞬即逝,我们不可能在短时间内形成一篇文章来进行输出,文章的形式和内容的丰富度会极大的影响灵感的生命周期,我们试图用一种新的方式来动态品尝灵感的甘露,也许大脑更加喜欢简单的事情,这也就是工作流体系存在的意义。即使记录即标志这一个模块的任务结束,于是我们可以快速进入下一个模块化的工作,并且在模块的间隙中嵌入个性化的休息方式,这样可以保持一个相对良好的心情。\n\n\n 传统的总结方式,往往是遗忘性很强的,大脑不喜欢哪些令人忧伤的事情,但是这些恰恰是我们成长的优秀养分,所以一个更具有生命力的总结方式应当是更好地让各个部分参入进来,更多地去调动内源的数据处理结构,而不仅仅过渡地依赖外源。\n\n\n 格物致知是认识物理世界相当棒的手段,科学与艺术都是自然之子,在相互碰撞中,就会有惊喜。\n\n\n# 写在最后\n\n\n---\n\n\n很感谢您能看到这里,无论是过去现在还是未来,相遇即是缘分。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-04-20",
"type": "Post",
"category": "动手实践",
"slug": "improve",
"tags": [
"推荐"
],
"summary": "记录我对博客优化的过程,您可以看作是博客优化的日志。",
"title": "[技术分享] 博客优化",
"status": "Published",
"urlname": "57b7cb8e-cde8-4740-aa70-db541e0f4c56",
"updated": "2024-10-02 03:23:00"
},
"catalog": [
{
"title": "推荐",
"doc_id": "57b7cb8e-cde8-4740-aa70-db541e0f4c56"
}
],
"body": "",
"realName": "[技术分享] 博客优化",
"relativePath": "/推荐/[技术分享] 博客优化.md"
},
{
"id": "81a26e00-b832-44cd-988c-7e90131186e9",
"doc_id": "81a26e00-b832-44cd-988c-7e90131186e9",
"updated": 1713876780000,
"body_original": "\n```markdown\n- 第一章 什么是中医\n\t- 一 中医使生命长生\n\t- 二 中医是对生命的“心悟”和“心法”\n\t\t- “医者,意也”的体现\n```\n\n\n# 第一篇 中医养生观——老祖宗的神奇智慧\n\n\n---\n\n\n## 第一章 什么是中医\n\n\n---\n\n\n 是使生命能够长生的工具。中国的传统医学强调的就是让生命健康、有序地向前发展。\n\n\n 在汉代,关于中医有两个定义:一个是在《汉书·艺文志》当中提到的“方技者,皆生生之具”;还有一个是在《后汉书·郭玉传》里提到的“医者,意也”。这是关于中医的两个非常著名的定义。\n\n\n\n\n\n## 一 中医使生命长生\n\n\n---\n\n\n 古代,中医被称为“方技”,在《汉书·艺文志》中它涵盖四个方面:医经、经方、房中、神仙。\n\n\n 医经讲医理,是四项的基础;经方讲草本方剂的医理之用;房中就是不用自然而是用人来治病;神仙当然是最高境界了,讲气机导引和修炼。\n\n\n\n\n\n 中国古代的“养”字,写得非常有意思,它的意思是指一个人赶着四只羊,在放牧。其实,“养”也有爱护和放牧的意思。因此,养生意味着要爱护自己的生命,然后我们还要牧养它。所谓的“牧养”就是让生命自由自在地生长,保持一种自由自在的状态。\n\n\n 养生首先是一种主动行为,而不是被动地把生命交付给他人,所以养生的前提是要先明生命之理。其次,养生不是单纯地指不生病,而是使生命品质获得提高。我们要记住,中医永远把质放在量的前面,一个人如果他得了老年痴呆症,即使他活到一百岁,那他病后的人生也是没有意义的。\n\n\n\n\n\n## 二 中医是对生命的“心悟”和“心法”\n\n\n---\n\n\n 在《黄帝内经》当中有一句话,叫做“粗守形,上守神”。西方医学强调的是“形”这个层面,即肉体层面,给人体的定义是——人是机器。所以现在很多人就像对待机器一样对待身体,总是想着怎么样去修理它。但是中医却不同,真正的中医强调的是气和神的层面,这个层面就如同“道”一样有着很多“共时性”的内涵,它真实不虚,却又无法言说……所以《黄帝内经》又说“粗守关,上守机”,真正高明的医生,都是守着神明,是用意念、悟性和用神来看病看人的。\n\n\n “不可言说”其实不是一种玄虚,而是中国传统文化的一种体现。中国文化和西方文明有很大不同,西方文明定义某一件事物,永远是在强调这个事物“是”什么;而中国文化却是说这个事物“像”什么,是在说一个共性的东西。\n\n\n\n\n\n\n\n\n## “医者,意也”的体现\n\n\n---\n\n\n “医者,意也”体现在如下两个方面:把脉、扎针。\n\n\n 《黄帝内经》说春天的浮脉是“春脉浮,如鱼之游在波”,这是一幅灵动阳光的画,即浮脉就像鱼游在波上一样。春天时,人的阳气慢慢地生发起来,而鱼从水底跃在波上的那一瞬间的情景,就像人体的浮脉一样。在教学生把脉的时候,我常会强调:一定要先培养自己对大自然的这种敏感性,然后自己才能够真正地体悟把脉的内涵。甚至有时候心念一动,人的气脉也会动,虽然是“鱼之游在波”,也会有不同的波,也会此波非彼波……\n现在我们会经常说到“针灸”,由于多方面的宣传,大家对中医、养生都很感兴趣,多少都会知道一些关于针灸的知识,对身体的主要穴位也有着一定的认识,可是上医在扎针的时候,除了注意穴位,他似乎更在意人的气血波动。\n 因为我们每个人的气血状况都是不一样的。气血有旺和不旺之分,相同的穴在不同人身上的位置可能就会不一样。\n\n\n\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-01-04",
"type": "Post",
"category": "走近生活",
"slug": "Wisdom-of-Life-1",
"tags": [
"生命智慧-曲黎敏"
],
"summary": "养生意味着要爱护自己的生命,然后我们还要牧养它。所谓的“牧养”就是让生命自由自在地生长,保持一种自由自在的状态。",
"title": "[生命智慧] 什么是中医-曲黎敏",
"status": "Published",
"urlname": "81a26e00-b832-44cd-988c-7e90131186e9",
"updated": "2024-04-23 12:53:00"
},
"catalog": [
{
"title": "生命智慧-曲黎敏",
"doc_id": "81a26e00-b832-44cd-988c-7e90131186e9"
}
],
"body": "",
"realName": "[生命智慧] 什么是中医-曲黎敏",
"relativePath": "/生命智慧-曲黎敏/[生命智慧] 什么是中医-曲黎敏.md"
},
{
"id": "579b2741-41f7-4d04-82a7-b204f98b2558",
"doc_id": "579b2741-41f7-4d04-82a7-b204f98b2558",
"updated": 1713877680000,
"body_original": "\n# 更新\n\n\n---\n\n\n这部分记录这篇文章的更新日志\n\n\n### 删除过于琐碎的描述,增加新理解 2024-04-14 \n\n\n---\n\n\n目前采用memos+flomo的方式进行碎片化记录,memos用于记录读书笔记和一些其他的灵感。计划将一些其他的笔记比如刷bilibili的知识,要么单独开一个[专栏](https://matrixcore.top/article/inexhaustible)放起来,要么就先不刷。\n\n\n# 前言\n\n\n---\n\n\n**概念**:笔记同传用于**解决大脑陷入某种处境下导致的情绪分化**,例如刷视频停不下来,读书读得沉迷停不下来。打游戏打得上瘾停不下来,做工作过于理想。基本原理就是通过记笔记的方式,进行穿插式任务,避免过度沉溺某一种感觉。记笔记其实就是类似于一种中断。\n\n\n# 正文\n\n\n---\n\n\n这部分我将详细介绍我遇到的问题以及我思考出的解决策略。\n\n\n## 笔记同传的定义\n\n\n---\n\n\n和同声传译一样,及时的双向文本转述,有助于双方的配合,而我的假设就是希望大脑和双手能更好的配合,而不是某一方永远占据优势,这样导致的结果,就是大脑会认为我一直在工作,得不到休息,而实际上已经出现信息过载的情况了,要注意我们的大脑并非时时刻刻能保持理性,他需要换一个思维环境才能得到休息。\n\n\n不知道大家玩过没有,倒一本热水,把脸凑近杯口,这种热浪的感觉是一阵一阵的,而且飘出的水气也是很有节奏的,这就是节奏感。\n\n\n所以说,笔记同传的概念就是,在大脑准备休息放松的时候,比如刷视频,旁边最好能放个笔记本,就比如 notion,或者是自己用得顺手的笔记软件,在遇到自己喜欢的部分的时候,做及时的记录,这样存储在大脑当中的信息就不是无序的,混乱的,庞杂的,用一种更加整饬的排列组合更便于自我的提取,这无异是一个重大的前置改进,只是很多时候,我们并没有记录的习惯,所以我们永远会被标题吸引,最终掉进了漩涡。\n\n\n## 双重环境下的魅力\n\n\n---\n\n\n无论你是在阅读一本书,我们最期待的是和作者的观点产生碰撞,这样才能获得最佳的阅读体验,我们可以把这种体验定义为学习体验。\n\n\n而在我们写作的过程当中,打字,就是从无到有,输出自己思想的过程,我们把这个过程称作为思考的过程。\n\n\n这个时候我们来看这样的一句话,学而不思则罔,思而不学则殆。就是你只刷视频不记录,就会很迷惘,然后只是不断反刍自己过去的经历停滞不前就会疲惫。\n\n\n所以我们要做的,就是有节奏地结合学习和思考之间的快乐,使得不过分偏颇某一方。\n\n\n当我们学习完一个预料时,我们更希望通过思考来加深预料的记忆,最终为我所索引,在日后便于二次索引,这样子我们的长期记忆会更加牢固。\n\n\n## 习惯大于形式\n\n\n---\n\n\n在刚开始的时候,永远是最困难的起步阶段,因为你不知道这样做有没有价值,如果换做我而言,这是我的第一篇博客日志,我会觉得非常不自在,我下手会非常慢。\n\n\n但是当我现在积累一定数量的写作量的时候,使用这一门语言进行流畅地书写就完成成了一种肌肉记忆,我只需要把我脑袋里所想的东西,倒出来就行了,而且在写的过程中,就像你在开车一样,当思维流畅了,开车自然而言就走远了。\n\n\n但是这里我觉得比较重要的一点是习惯的养成,我问过很多优秀的小伙伴,但是有持续记录并输出习惯的小伙伴还是比较少。\n\n\n就像我们读书做笔记一样,最开始的是释放天性,不用太在乎形式,做起来之后,在后面再去优化文章的思路和构型。\n\n\n## 多级缓存策略的设想\n\n\n---\n\n\n分享欲是驱动我们做一件事情的很重要的因素,但是有时候小的灵感不足以或者时间条件不允许我们去立刻书写一篇文章,这个时候,我们就会倾向于最合适的存放灵感的容器,当然微信朋友圈可以,flomo 也可以,obsidian 也可以。\n\n\n后面我们可以在有时间的情况下对这些笔记进行归档。\n\n\n保证每个精灵的生命周期。\n\n\n# 总结\n\n\n---\n\n\n笔记同传的思想归根到底还是来自于从前老师的提醒:不动笔墨不读书,本质上就是读电子书,做电子笔记。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-11-18",
"type": "Post",
"category": "走近生活",
"slug": "video-record",
"tags": [
"实用教程"
],
"summary": "笔记同传的思想归根到底还是来自于从前老师的提醒:不动笔墨不读书,本质上就是读电子书,做电子笔记。",
"title": "[笔记同传] 用双手减少大脑过度思考的偏差",
"status": "Published",
"urlname": "579b2741-41f7-4d04-82a7-b204f98b2558",
"updated": "2024-04-23 13:08:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "579b2741-41f7-4d04-82a7-b204f98b2558"
}
],
"body": "",
"realName": "[笔记同传] 用双手减少大脑过度思考的偏差",
"relativePath": "/实用教程/[笔记同传] 用双手减少大脑过度思考的偏差.md"
},
{
"id": "a790414c-1b7c-4d22-a561-dd1e92db27da",
"doc_id": "a790414c-1b7c-4d22-a561-dd1e92db27da",
"updated": 1708863120000,
"body_original": "\n```markdown\n- 第2章 舵机与舵回路:\n\t- 2.1 舵机的工作原理:\n\t\t- 2.1.1 电动舵机:\n\t\t- 2.1.2 液压舵机:\n\t- 2.2 舵面负载及其对舵机工作的影响:\n\t\t- 2.2.1 舵面的负载特性:\n\t\t- 2.2.2 电动舵机的动特性:\n\t\t- 2.2.3 液压舵机的动特性:\n\t\t- 2.2.4 铰链力矩对舵机动特性的影响:\n\t- 2.3 舵回路的基本类型及特点:\n\t\t- 2.3.1 舵回路的构成:\n\t\t- 2.3.2 舵回路的基本类型:\n\t- 2.4 舵机特性对舵回路的影响:\n\t\t- 2.4.1 舵机功率对舵回路的影响:\n\t\t- 2.4.2 舵机传动机构间隙对舵回路的影响:\n```\n\n\n# 第2章 舵机与舵回路\n\n\n---\n\n\n\n\n\n## 2.1 舵机的工作原理\n\n\n---\n\n\n\n\n\n### 2.1.1 电动舵机\n\n\n---\n\n\n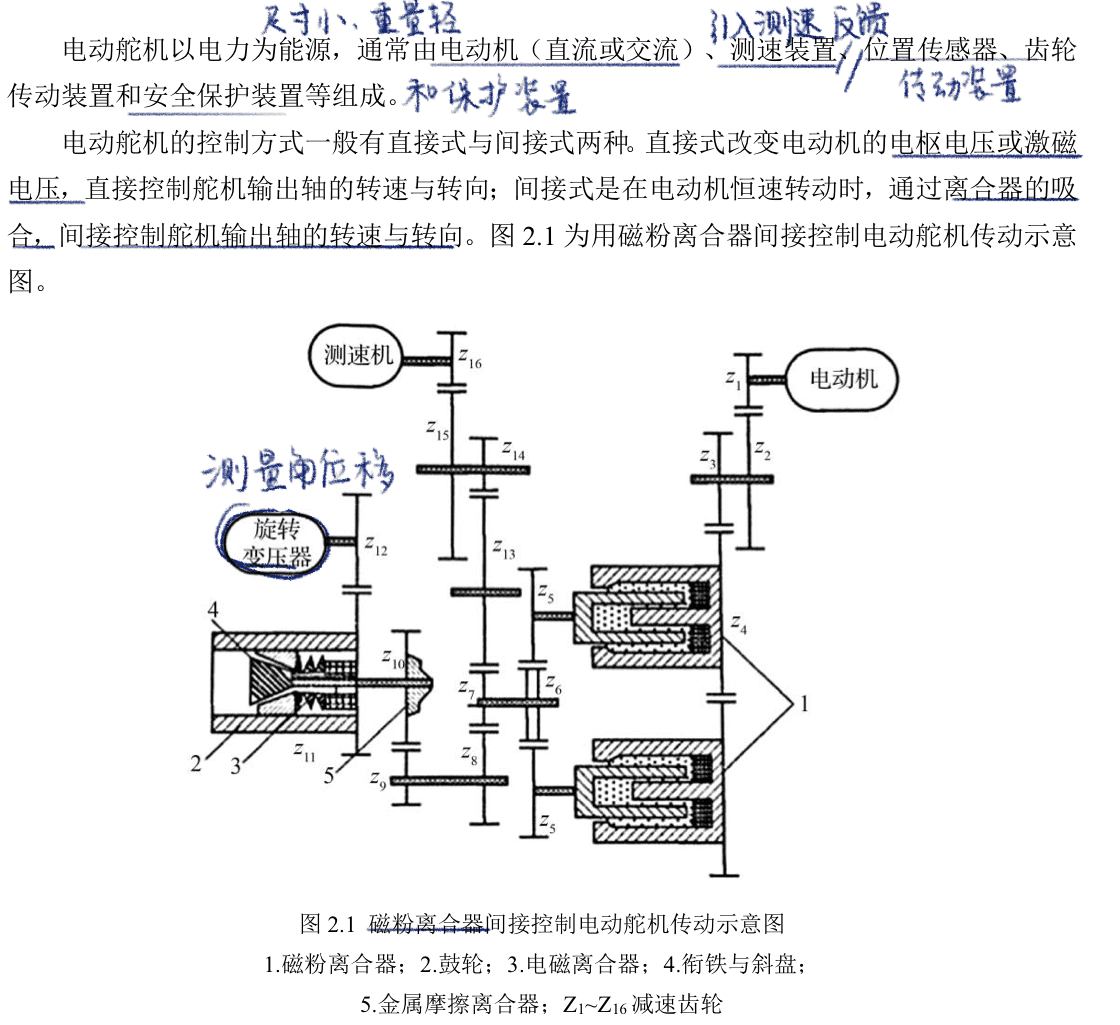\n\n\n### 2.1.2 液压舵机\n\n\n---\n\n\n\n\n\n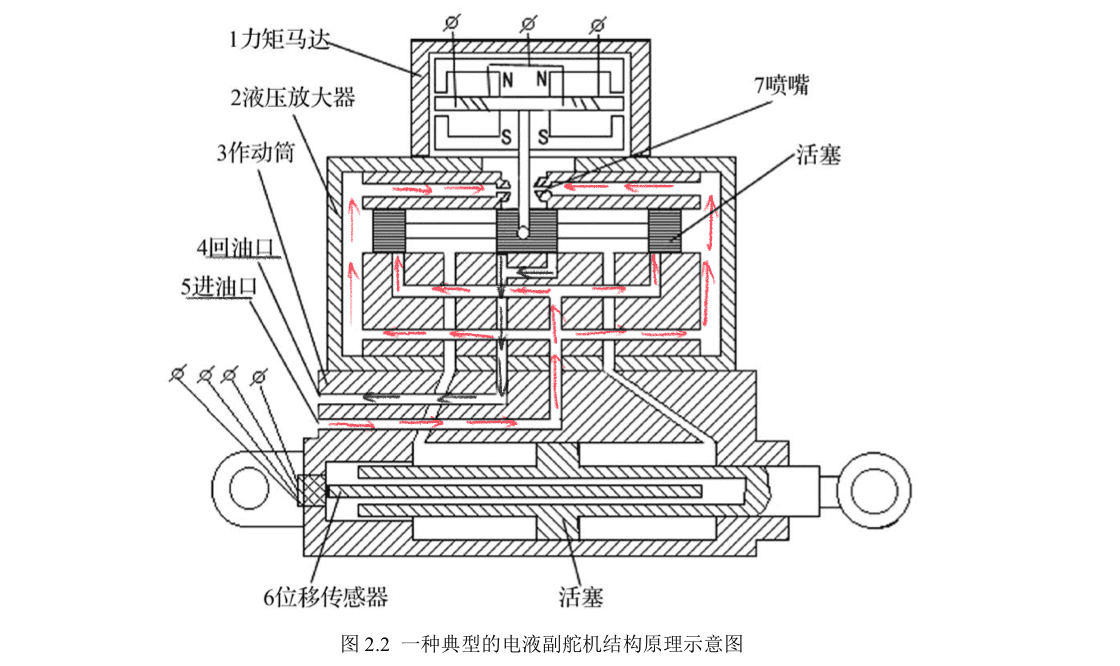\n\n\n## 2.2 舵面负载及其对舵机工作的影响\n\n\n---\n\n\n\n\n\n### 2.2.1 舵面的负载特性\n\n\n---\n\n\n\n\n\n### 2.2.2 电动舵机的动特性\n\n\n---\n\n\n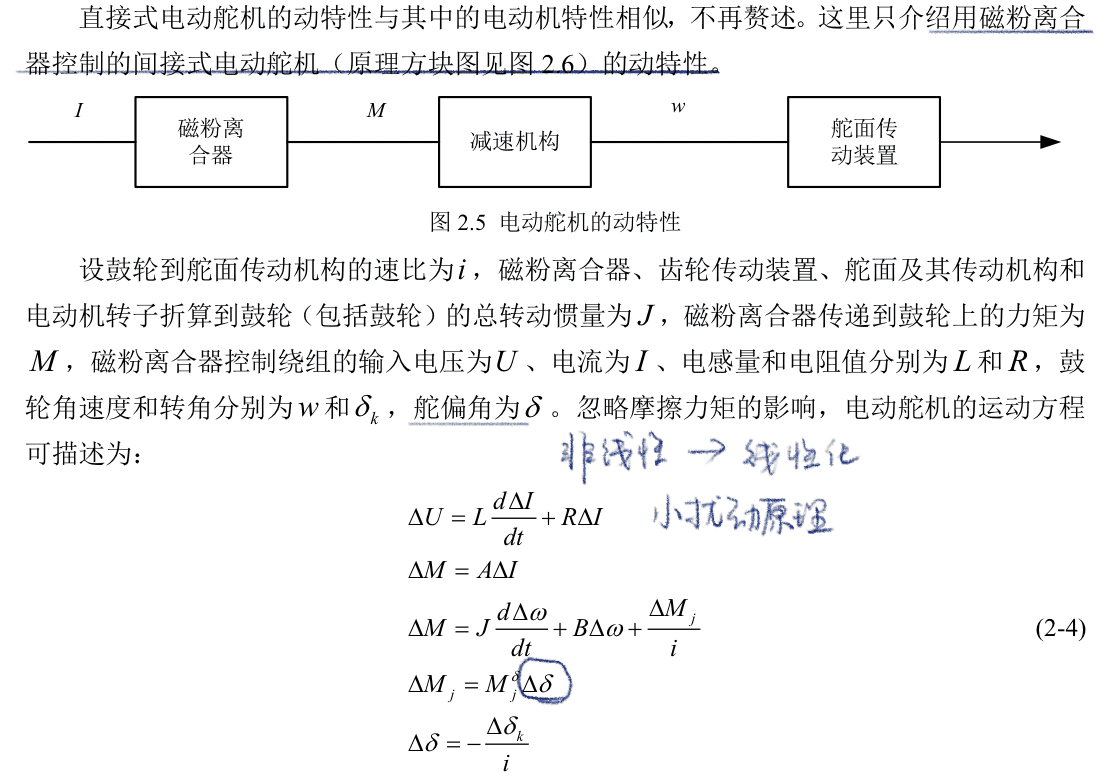\n\n\n\n\n\n\n\n\n\n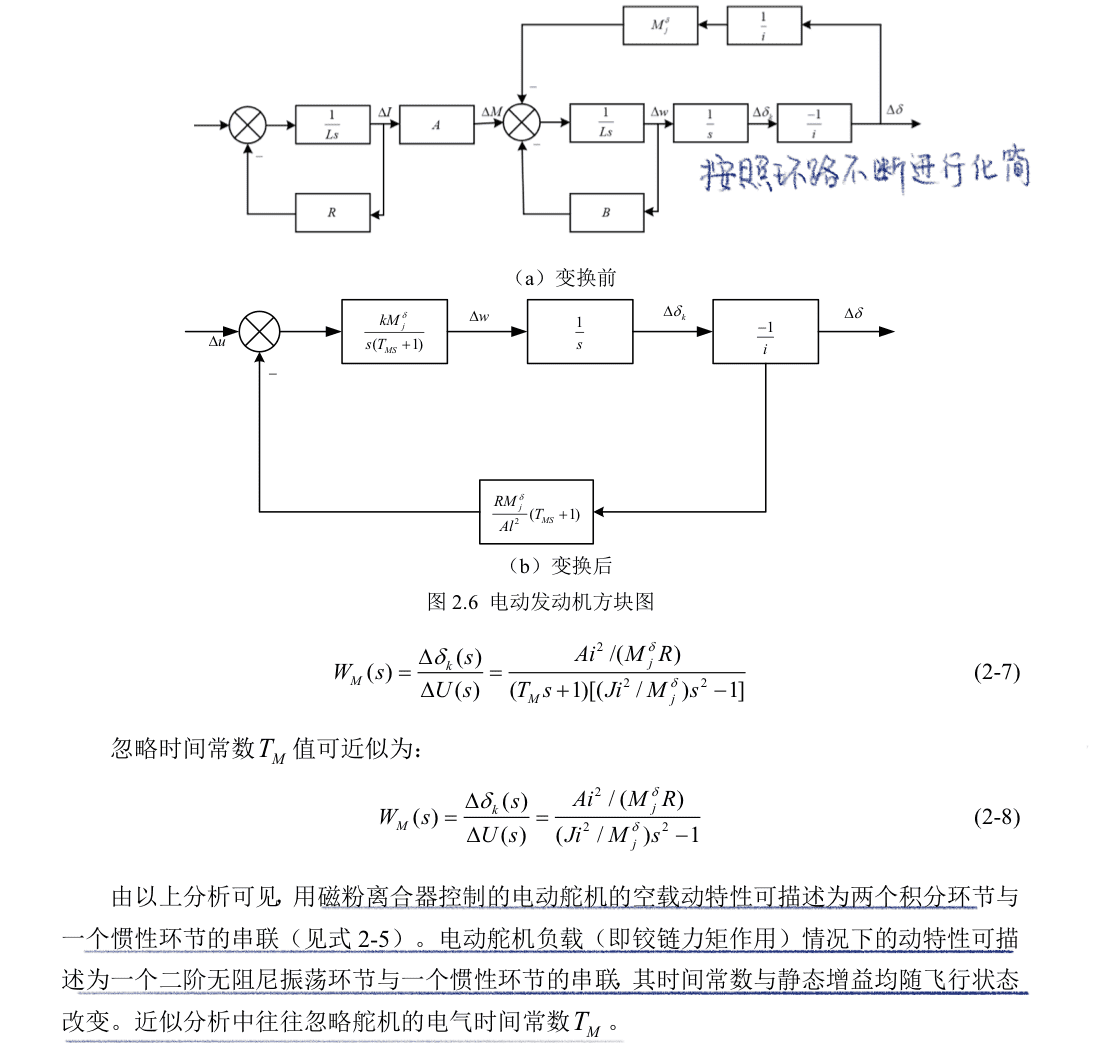\n\n\n### 2.2.3 液压舵机的动特性\n\n\n---\n\n\n\n\n\n\n\n\n\n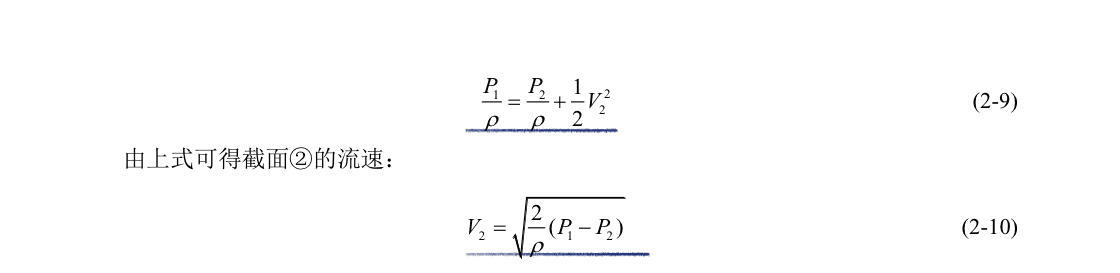\n\n\n\n\n\n### 2.2.4 铰链力矩对舵机动特性的影响\n\n\n---\n\n\n\n\n\n\n\n\n## 2.3 舵回路的基本类型及特点\n\n\n---\n\n\n\n\n\n### 2.3.1 舵回路的构成\n\n\n---\n\n\n\n\n\n### 2.3.2 舵回路的基本类型\n\n\n---\n\n\n\n\n\n## 2.4 舵机特性对舵回路的影响\n\n\n---\n\n\n 实际舵回路中的舵机功率有限,并有间隙饱和等非线性因素,本节讨论舵机特性对舵机回路工作的影响。\n\n\n### 2.4.1 舵机功率对舵回路的影响\n\n\n---\n\n\n即在一定飞行状态下,最大舵偏角正比于舵机的最大输出力矩,与舵回路的输入无关。\n在负载情况下,舵机的功率影响舵回路的静特性,其线性范围随舵机功率减小而变窄。\n\n\n可见,当输入幅值m U 为常值时,鼓轮偏角的幅值仅与舵回路频率特性有关,是角频率 的函数。给定不同输入电压幅值,按式(2-37)可分别画出图 2.12 所示舵回路输出(即鼓轮偏角)随角频率 变化的对数频率特性曲线(见图 2.19)。图 2.19 中的曲线 1、2、3 和 4 是在输入电压1 m U 、2 m U 、3 m U 和4 m U 作用下输出偏角幅频特性曲线,分别对应的稳态输出偏角k =2.5o、5o、10o和 15o。由图可见,在输入幅值一定时,鼓轮转角k 随角频率变化。角频率一定时, k 随输入电压幅值增加而增大。还可看出,舵回路的通频带(即图中b )与输入电压的幅值无关。\n由图可见,舵机功率一定时,输入电压越大,舵回路的动态响应越慢;输入一定时,舵机功率越大,动态响应越快。\n综上所述,舵机功率对舵回路的工作有很大影响。负载情况下,舵回路静态性的线性范围随舵机功率增加而增大;输入一定情况下,舵回路的通频带随舵机功率增大,动态响应加快。因此,在选用舵机时,应考虑其功率对舵回路的影响。\n\n\n### 2.4.2 舵机传动机构间隙对舵回路的影响\n\n\n---\n\n\n 舵机的机械传动机构中的间隙具有非线性特性。在舵机设计中,虽然总是力图使连接件紧密配合 , 间隙仍是不可能完全消除 , 对舵回路影响很大 , 严重时 , 舵回路将不能正常工作。\n\n\n 由以上可知,间隙对舵回路的工作影响很大,间隙所在的位置不同,对舵回路的影响也不同。反馈回路中的传动间隙影响尤为严重,会增大舵回路的延迟时间,增大静差,降低舵回路的稳定性,引起舵回路的输出在零值附近持续振荡(极限环),严重时,舵回路将无法正常工作 。 为了减小反馈回路中的传动间隙 , 避免舵回路振荡 , 在电动舵机内采用了双片齿轮。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-09-24",
"type": "Post",
"category": "璀璨星空",
"slug": "AFSC02",
"tags": [
"自动飞控"
],
"summary": "介绍舵机与舵回路",
"title": "[自动飞控] 第2章 舵机与舵回路",
"status": "Published",
"urlname": "a790414c-1b7c-4d22-a561-dd1e92db27da",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "自动飞控",
"doc_id": "a790414c-1b7c-4d22-a561-dd1e92db27da"
}
],
"body": "",
"realName": "[自动飞控] 第2章 舵机与舵回路",
"relativePath": "/自动飞控/[自动飞控] 第2章 舵机与舵回路.md"
},
{
"id": "ef21172e-15ee-4e5a-bce9-5a026ea68e94",
"doc_id": "ef21172e-15ee-4e5a-bce9-5a026ea68e94",
"updated": 1714562940000,
"body_original": "\n# 更新\n\n\n---\n\n\n这里记录这篇文章的更新。\n\n\n### 没有文学的滋养,我的思想始终单薄得厉害 2024-05-01 \n\n\n---\n\n\n 我仍然记得某一天的下午,和隔壁老爷爷下着象棋,语文老师打电话给我妈,提醒我假期多读点书。当时我并没有放在心上。十年之后,现在的我才略有体会,没有文学滋养的生命,始终单薄的厉害,这里的单薄值得是没有历史的纵深维度,没有在时代中的坐标系。没有思考,没有感触,不知为何而孤独,不知为何而快乐。今天阅读[太隐](https://wangyurui.com/)的文章给我启发很大,晚上花了几十分钟看了看他关于“诗鬼”李贺的介绍,关于朱自清的介绍,行文非常流畅出彩,若非深入研究, 很难写出这么脍炙人口的文章。看完后整个人都感觉非常自在,灵感开始迸发,总是按耐不住心情,打算写些什么。语文是我一直都比较喜欢的学科,单纯是因为喜欢背后的故事,但我很难写好文字,也很难体会试题背后文字的意义。其实大学也有保持阅读的习惯,前两年一直在QQ空间上积淀。但是我记得中途应该有一段时间是没怎么读过书的,23年感觉没有读过很多的书,应该是在2月到10月的这段时间,中途可能在忙各种各样的事情。\n\n\n 谈谈现在对于阅读的体会,我觉得床头最好能有本枕边书,睡前看书是非常不错的一个选择,看书让人沉浸在书里的环境当中,能让人忘记很多烦恼,通过与作者之间的对话,仿佛在另一个世界有了知己。最近晚上在看简媜的《水问》,其实这是第二遍再看,但是仍然有很多新的体会。我在想,对于书籍,如何更好地去梳理去总结,甚至能有自己的话去讲好书中的故事,我觉得这是一种值得培养的能力。另外这个专栏其实很久没有更新了,我得想想这里应该做点什么。\n\n\n### 基本原则\n\n\n---\n\n- 法于阴阳\n 不过分去扰动生物钟的作息,吃早点,不熬夜,适当运动,不胡思乱想。\n- 和于术数\n 耐心完成量的积累,保持平和的心境,多去发现生活中有趣的事情。\n- 恬淡虚无\n 不要过分燃烧自己的欲火,控制自己的精力消耗。多去阅读《道德经》和《心经》\n- 真气从之\n 完成正常的生理循环之后,身体本身是会发出信号的,比如早晨吃早餐和开天门,九十点学习更有动力。\n\n> 💡 使用vps+mailx为每天进行定时提醒 2024-01-25T09:00:00.000+08:00 \n\n\n### 生活画廊\n\n\n---\n\n\n[生活画廊](de6d3e32-4d6f-4a81-98da-7f41dadd39ce)\n\n\n\n\n\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-04-25",
"type": "Post",
"category": "走近生活",
"slug": "sunrise",
"tags": [
"流动核心"
],
"summary": "草木有本心 何求美人折 ",
"title": "[流动核心] 东方璀璨 遗我明珠",
"status": "Published",
"urlname": "ef21172e-15ee-4e5a-bce9-5a026ea68e94",
"updated": "2024-05-01 11:29:00"
},
"catalog": [
{
"title": "流动核心",
"doc_id": "ef21172e-15ee-4e5a-bce9-5a026ea68e94"
}
],
"body": "",
"realName": "[流动核心] 东方璀璨 遗我明珠",
"relativePath": "/流动核心/[流动核心] 东方璀璨 遗我明珠.md"
},
{
"id": "1f88a18f-2bba-4470-a340-9c7b22a8b339",
"doc_id": "1f88a18f-2bba-4470-a340-9c7b22a8b339",
"updated": 1708863120000,
"body_original": "\n# 前言\n\n\n---\n\n\n 这几天一方面在忙着工训的实习,明天就到工训实习的实习的最后一天的,已经五六天没写文章了。简单回顾一下,\n\n\n```text\n 周二早上实习,下午睡到两点,一直工作到晚上九点四十,在AutoDL上跑完了自己的数据集,下午三个小时数据标注,晚上熟悉云服务器的环境配置,从八点多开始跑770张图片200轮的训练;\n 周一早上实习,下午到三点回去,睡到晚上,晚上心情很郁闷,取完快递拆箱,完成了红富士,黄元帅,国光三种小苹果共计770张到数据采集;\n 周日上午实在没有动力,打了一上午饥荒,下午去图书馆打了一下午饥荒,活到了60天,但是差点心态崩了,晚上着手开始写综合课设的中期检查;\n 周六双十一,我翻了翻微信,哔哩哔哩,番茄自习室,sharplingo,但是都没有发现白天在干啥,周六极有可能是心情低落的时期;\n 好的,然后周五的记录就续上了。关于心情的总结不是重点,先把最近yoloV5的工作给梳理出来。\n```\n\n\n# 正文\n\n\n---\n\n\n 这部分主要介绍是怎么认识yolov5的,起因是电子课程设计,选择了基于图像处理的水果识别的这个课题,然后开始查资料,了解相关的技术路线。由于是第一次做这种课题,并且还得负责主要任务,心累之余做肯定是要做的。我先去bilibili查找了相关的课题,大多数是通过matlab进行相对应的识别的,但是我觉得似乎不是很符合我的预期。\n\n\n\n\n\n \n\n\n## 基本思路\n\n\n---\n\n\n 于是我打算更进一步去想如何去做这个问题,当然解决问题,和写报告是很不一样的思路,写报告是不管怎么样,尽可能可读性强,但是解决问题,最主要的是理清楚思路。既然bilibli的综合排序没有找到我要的效果,通过询问gpt我大概得出了以下的思路:\n\n\n```text\n基于图像处理的水果分类系统设计背后的原理如下:\n1.图像获取:系统通过摄像头或其他图像采集设备获取水果的图像。\n2.图像预处理:对获取的图像进行预处理,包括图像去噪、图像增强、图像分割等操作,以提高后续处理的准确性和效果。\n3.特征提取:从预处理后的图像中提取出代表水果特征的信息,例如颜色、纹理、形状等。\n4.特征选择:根据水果分类的需求,选择最具区分度的特征进行分类,可以使用特征选择算法来辅助选择最优特征。\n5.分类器设计:根据选定的特征,设计合适的分类器模型,常用的分类器包括支持向量机(SVM)、人工神经网络(ANN)、决策树等。\n6.训练和测试:使用已标记的水果图像数据集进行分类器的训练,并使用另外的测试数据集评估分类器的性能。\n7.分类结果:将待分类的水果图像输入训练好的分类器,通过分类器进行分类,并输出水果的类别标签或概率。\n8.系统优化:根据分类结果的准确性和效率,对系统进行优化,包括调整参数、改进算法等。\n```\n\n\n 起初我想从比较熟悉的FPGA的相关的技术路线进行尝试,也查阅了相关的材料,但是实现的难度有点高。涉及到特征提取的有Sobel算法,可以对轮廓做很好的处理。\n\n\n 然后还发现一个[up主做的毕设](https://www.bilibili.com/video/BV1rs4y1X7bE/?spm_id_from=333.337.search-card.all.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab)和这个也是相关的,很有意思。\n\n\n 然后查找了一些文献,如下:\n\n\n1.[基于多颜色和局部纹理的水果识别算法研究](http://cloud.matrixcore.top/s/BxpMf7ceWiMbpyY)\n\n\n2.[水果分类的多模板匹配算法及其FPGA实现](http://cloud.matrixcore.top/s/Y8ey2oj99pKee6g)\n\n\n3.[水果自动识别的BP神经网络方法](http://cloud.matrixcore.top/s/nFgerGYRqZZy8b3)\n\n\n4.[基于注意力YOLOv5模型的自动水果识别](http://cloud.matrixcore.top/s/exaX3dNwfn4jgbZ)\n\n\n5.[基于轻量化改进YOLOv5的苹果树产量测定方法](http://cloud.matrixcore.top/s/ecDHTxi8N3SjD4T)\n\n\n 在文献1,当中采取的方式,首先是先对图像进行预处理,对图像进行平滑去噪,图像增强,完成图像从环境中分离出来。然后进行特征提取,其中有颜色特征,纹理特征,然后放入BP神经网络分类器进行训练。\n\n\n 在文献2,主要是针对方案一中的图像预处理进行了相对应的优化,采用了FPGA当中的Soebl边缘化提取特征向量。然后对比SSD、YOLO、CenterNet等方式的性能。\n 在文献3,基本思路是和文献1类似的,多出了一些特征,比如面积特征,周长特征,弧度特征,颜色特征,然后通过神经网络进行分类。\n 在文献4,采用的方式是进行YOLOv5模型进行水果自动识别,但是对模型进行了一些改进。在yolov5对网络后面又增加了一层网络,按照重要程度强化有用的特征,抑制掉无用的特征,替换了边框回归损失函数,提升了预测的精度。\n\n\n 在文献5,同样也是对yolov5算法进行优化和改进,也是通过更换深度可分离卷积和添加注意力机制模块,提升准确度和降低网络负担。 \n\n\n## 选择yolov5\n\n\n---\n\n\n 因为刚接触这个问题,通过查阅的文献,感觉选择yolo的方式更加便于实践学习和操作。\n\n\n 关于yolov5的简介:\n\n\n```text\nYOLOv5是一种基于深度学习的目标检测算法,它是YOLO(You Only Look Once)系列算法的最新版本。YOLOv5的原理可以概括为以下几个步骤:\n\n1. 基础网络:YOLOv5使用了一种轻量级的卷积神经网络作为基础网络。这个网络主要用于提取图像的特征。\n\n2. 特征提取:YOLOv5通过基础网络将输入图像转换为一系列特征图。这些特征图具有不同的尺度和语义信息,用于检测不同大小和类别的目标。\n\n3. Anchor boxes:YOLOv5使用了一种称为Anchor boxes的技术来预测目标的位置和类别。Anchor boxes是一些预定义的边界框,每个框都与一个特定的尺度和长宽比相关联。YOLOv5通过在特征图上滑动这些Anchor boxes来检测目标。\n\n4. 预测:对于每个Anchor box,YOLOv5预测目标的位置和类别。位置预测使用边界框的中心坐标、宽度和高度来表示。类别预测使用一个多类别分类器来确定目标的类别。\n\n5. 损失函数:YOLOv5使用一种称为YOLOv5 Loss的损失函数来训练网络。该损失函数综合考虑了位置和类别的预测误差,并通过最小化损失来优化网络参数。\n\n6. 多尺度检测:YOLOv5通过在不同尺度的特征图上进行检测来提高目标检测的性能。这种多尺度检测可以帮助模型检测不同大小的目标。\n\n总体而言,YOLOv5通过将图像分为不同的网格单元,并在每个网格单元上预测目标的位置和类别来实现目标检测。它具有较快的检测速度和较高的准确率,适用于各种实时应用场景,如自动驾驶、视频监控和物体识别等。\n```\n\n\n 好在,可以站在巨人的肩膀上。我通过博主:思绪无限 的[文章](https://www.cnblogs.com/sixuwuxian/p/17372580.html)进行了学习。\n\n\n \n\n\n## 环境配置\n\n\n---\n\n\n 对于刚开始使用pycharm的我,来说,配置环境还是走了不少弯路的,前期,要下载pycharm和anaconda,用于配置环境,一开始我在Mac系统上配置环境没有成功,一直不知道如何把pycharm关联anaconda的环境,后来就转到win下进行操作。关于如何搭建并配置深度学习环境,我参考了up主:[思绪无限的教程](https://www.bilibili.com/video/BV1Hg4y1t78v/?spm_id_from=333.999.0.0&vd_source=237e295a40d7aaea043ead8c0d2c78ab),初步完成了环境的激活。\n\n\n## 训练自己的数据集\n\n\n---\n\n\n 这部分介绍如何训练自己的数据集。\n\n\n### 采集所需要的识别物体的图像\n\n\n---\n\n\n 我是通过手机进行摄影,然后通过usb上传到电脑,然后手机拍摄的图片肯定太大了,而且在[yolov5的官方文档](https://docs.ultralytics.com/yolov5/)上说,训练的数据集最好能达到1500张以上。然后非常感谢一个宝藏的批量图片裁剪[在线网页](https://uutool.cn/img-clip-batch/),没有广告,而且效率很高,我把770多张图片裁剪为640*640的大小,减小图片的体积。\n 11.18更新:今天用safari测试才发现,可能是我在win上开了插件,所以没广告,所以也在safari上装了插件。\n\n\n### labelimg\n\n\n---\n\n\n 之前通过23张图片,简单熟悉了yolo的训练流程,后面购买了,红富士,黄元帅,和国光,三种类型的苹果进行数据采集,目的是为了通过yolov5来训练模型识别这三种水果的能力。\n\n\n 前期通过不同角度完成了对数据集的拍摄,共计770张图片,然后次日花了很久用labelimg软件对图片进行数据标注,在此不得不提一下。labelimg软件我刚开始觉得非常难用,因为需要配置python环境,而且动不动就闪退。就在我找不到头绪之际,非常感谢up主:[小周不会做](https://www.bilibili.com/video/BV1Xh4y1574N/?spm_id_from=333.880.my_history.page.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab) 提供的灵感,up主提供了labelimg的打包版,这样子就可以启动并进行使用了,让图片得到顺利的标注。\n\n\n### 正确配置路径\n\n\n---\n\n\n 然后可以现在本地环境上进行调试一下,可以参考这位up主:[遗落的教程](https://www.bilibili.com/video/BV1f94y1R7a4/?spm_id_from=333.880.my_history.page.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab),讲解得很详细。还有怎么用快捷键打标签,可以参照这位up主:[圣音去扉](https://space.bilibili.com/471665566)的[教程](https://www.bilibili.com/video/BV1rT411f7Up/?spm_id_from=333.880.my_history.page.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab)。然后需要现在本地环境能够正常的跑成功,在这前提下,可以尝试使用带有GPU的云服务器进行训练。\n\n\n### AutoDL\n\n\n---\n\n\n 关于如何使用AutoDL,非常感谢up主:[你可是处女座啊](https://space.bilibili.com/21060026)的[教程](https://www.bilibili.com/video/BV13s4y1V7b4/?spm_id_from=333.880.my_history.page.click&vd_source=237e295a40d7aaea043ead8c0d2c78ab),介绍得很详细,如何上传文件夹到服务器,可以使用scp命令,也可以使用网页进行上传。\n\n\n 然后,你还需要配置CUDA环境,在服务器上安装必要的环境,然后就可以开始使用gpu进行愉快的训练了。我使用的是英伟达的3080显卡,速度已经感觉很快了,但是770张200轮跑下来,也花了一个半小时。\n\n\n# 总结\n\n\n---\n\n\n 后续还需要进行参数微调,但是自我感觉时间有限,还有点累,所以,这篇文章后面就写得很简单,我又得做又得写报告,虽然很难崩得住,但是也得顶住啊。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-11-15",
"type": "Post",
"category": "动手实践",
"slug": "yolov5-1",
"tags": [
"实用教程"
],
"summary": "选择yolov5自定义数据集对红富士、黄元帅、国光进行识别。",
"title": "[图像处理] 基于yolov5的水果识别",
"status": "Published",
"urlname": "1f88a18f-2bba-4470-a340-9c7b22a8b339",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "实用教程",
"doc_id": "1f88a18f-2bba-4470-a340-9c7b22a8b339"
}
],
"body": "",
"realName": "[图像处理] 基于yolov5的水果识别",
"relativePath": "/实用教程/[图像处理] 基于yolov5的水果识别.md"
},
{
"id": "c32bcf6c-b02c-4440-8ba8-c3df42372cbf",
"doc_id": "c32bcf6c-b02c-4440-8ba8-c3df42372cbf",
"updated": 1723347960000,
"body_original": "\n## 三、建议库的收纳与更新\n\n\n---\n\n\n 建议库相当于CPU的指令集合,作为基本的单元,具有很重要的战略地位,但是过于陈旧的建议库反而无法发挥其应有的作用,为此及时对建议库进行更新是一项非常重要的事情。\n 同时指令集的设计应该遵循简单的原则,在后续的设计当中,将重新对指令集的规模进行测试和考量。\n\n\n### A指令集\n\n\n---\n\n- A0 **‘Burning & Matrix’**\n\n\t 致敬《星际穿越》,在通过引力弹弓去往最后一个星球的时候,男主和小机器人选择了脱离主飞行器,来给女主减轻负载,却意外地进入矩阵空间时,为了致敬这段情节,也就是博客的由来,当面对灾难时,“不要温和地走进那个良夜”,对于我们自己而言,的确是在走一条比较新的人生的路,但是大部分的路,都是前人给我们铺好了的,所以我们面对的挑战,还真没有说到达那种彻底绝望的状态(还记得在去往第一个星球之前,其中的一位宇航员说,就隔着一层铁皮,就是生与死的界限),所以对于我们而言,更多想是在给一只贪玩的小猫咪梳毛一样, 我们只需要把生活做得尽可能有序一些就好,物质生活其实很可以了,精神生活再丰富一点更好,但是我觉得人生或多或少还是有可能会面对一些必须要作出艰难选择的时刻,就像男主和小机器人,选择牺牲自己,坠入卡刚图雅的时候,这也就是博客创造和存在的意义,也是我思考的原因。 May 28, 2023\n\n- A1 **主驱磨损**\n\n\t 学习对抗&生理唤醒 —> 多巴胺异常分配—>物质成瘾&内源失控;\n\t 流动核心对脑区大剂量覆写&深度睡眠强化排异;\n\n- A2 **多巴胺缺失**\n\n\t 刺激,迷失域\n\n- A3 **主驱修复**\n\n\t 人在受到伤害之后,本能地寻找依赖,然而世界是残酷的,每经受一次打击,我们要做的不是去惋惜,而是记录下来,总结好就行,不能总是停留在这里,这一点希望要记住,很重要。\n\n- A4 **睡眠预警**\n\n\t 食谷精微,滋养着我们的身体,睡眠通灵,指引着我们去往何方,不应该在睡前做过度的劳损和被动的干扰,保持心境的和平,诵读《心经》,或者喝点茯苓百合茶,听听音乐,看看小说就睡了,不过23:20。早上需要保持一定的明亮度,保持心境的平和。可以借助闹钟,以七个半小时为宜。\n\n- A5 **无主域风险提示**\n\n\t 孤独是人类非常难以忍受的一种状态,但是只有在孤独的时候,才最接近生命最长久的状态,才能在一次又一次的挫折当中学会与自己调谐,特别是当放假或者以后一个人独自生活或者工作的时候,就会进入完全是由主驱驱动的一个状态,我们习惯了很多年的支配性行为,但是这种命令的方式绝大多数都是由外部产生的,所以在我们内心并没有或者很难建立起一套逻辑,真正由自己的主驱驱动,努力去做的事情,这本身就是一件很困难,很有意义,很具有挑战性的事情,是值得我们花心思的远比打游戏或者其他的娱乐活动更加对生活有增益,适应了孤独,人生才能跨越到一个新的阶段,而此前我们需要经历过很多次无主域的历练。\n\n- A6 **食饮有节,起居有常**\n\n\t上古之人,其知道者,法于阴阳,和于术数,食饮有节,起居有常,不妄作劳,故能形与神俱,而尽终其天年,度百岁乃去。\n\n- A7 **完善提醒机制**\n\n\t 今天还是犯了一个很严重的失误,差点把无线电导航的实验时间给忘记了。\n\t 需要完善提醒机制,通过notion+便签闹钟双提醒\n\n- A8 **光源理论**\n\n\t 在某种程度上,光源可以为人补充能量,换句话说,失去光源,则就会失去很大的一部分能量来源,夜晚会将人变成魔鬼,而白天人则温和地像一个天使,在太阳的辉光之下,良知喜悦也许给人的感受会更深。这也就从侧面说明,宿舍没办法成为一个良好的学习环境之一,或者似乎永远存在这样一个伪命题,在家抑或是放假,人永远是处于被动的休息状态,一种深度的疲惫感正在入侵,坦白来讲,社交活动的确能使人产生一部分令人喜悦的激素,而与之相对应的孤独的思考或者写作则有可能产生一种抑制类的神经激素,舞蹈能让人迅速沉浸在一种氛围之中,而睡完午觉醒来则满是对于惊扰梦境的小可爱的不满。\n\t 总之,光源是重要的辅助条件,在米哈里心流法则中也确实提到过这一点,通过自我的实践和经验感知,在缺乏光源的情况下,人确实比正常情况下更加需要睡眠和能量,而在适当的光源条件下,人则可以拥有更好的表现和拥有动物的警觉,所以通过很多天时间的代价,所总结出的结论就是:珍惜能在学校图书馆的时间,把这段时间的资源转化率进行适当的提高,另外对上述提出的问题进行预警,以便在未来做好应对的准备。\n\n- A9 **主框架完善**\n\n\t 存在一种疲惫感,不是很能安静下来,可能还要对具体的细节再做优化\n\t 睡眠是个好东西,但是不能包治百病,因为睡眠更像是一种旅行,它会短暂清空我们现世的记忆,但是人总是会醒来,正如梭罗在《瓦尔登湖》里写到的那样,他说:“神諭会将人们唤醒”,希望人们投入到“艺术创作当中去”,但是对于我们而言,则有可能乏味而无趣的多,所以来自内源的能源支持并不是那么充足,所以我们亟需搭建一个适合自己的主框架。\n\t 坦白而言,我并不喜欢为时间所支配,时间是我们的老师,但是却不应该时时刻刻居于主导地位,因为时间是无情的,起关键因素的还是人本身。\n\t 但正因为人本身具有诸多不确定的表征,才导致需要时间都约束和辅佐,但是这样总让人觉得有些不适,因为在某些情况下,忘记时间反而更能唤醒于内心中的某种特殊的东西。\n\t 但不管怎么说,一个轻量的主框架总是必须的,这是为了保证最低生存水平所应该具备的基础要求,比如提到过的“法于阴阳,和于术数,食饮有节,起居有常,不妄作劳。”\n\t 其次就是最艰难的一个部分,即对于主驱的支配能力,亦即“动机”,这部分恰恰是人道中最复杂的一个部分,关于这部分的研究应该需要花很长一部分的时间,尤其是对独立主驱的运行,维护和持续的适航能力。要知道,人道中有很大一部分东西是违背天道的,可能会很耗费心神,但从某种程度上,我们还是应该把人道中矛盾的部分转向天道,把不合理的部分进行相应地记录总结和优化。 May 31, 2023\n\n\n### B指令集\n\n\n---\n\n- B1 **注意力流失**\n\n\t 恢复精力,黄金分配,深呼吸放松,导入目标,把握节奏,反思总结\n\n- B2 **时间分配预警**\n\n\t 时间还是比较宝贵的,我不推荐,把大把的时间用来消遣,这是一件很危险的事情,这些时间应该被用来系统修复。\n\n- B3 **半自主域能量散逸**\n\n\t 能量曲线,半自主域,涵道比,即时数据覆写,提高压缩比,尖峰奖偿\n\n- B4 **克制情感表达**\n\n\t 情感虽然是人类的高级情感,但是在和自己相处的时候会占用过多的资源,减缓系统的速度,尽可能抑制过分的情感,把时间投入到行动当中去。\n\n- B5 **重心分配**\n\n\t 做一件事情的时候,需要花时间去寻找一种状态,一种最适合自己的节奏,最能发挥自己的优势和培养的兴趣的那个部分,游戏之所以成功,是因为具备了心流的强必要条件,比如及时反馈和技巧,这些都是被精心设计过的,但是这样的心流是中性乃至有害的,因为这对生活的增益是十分有限的,而且会过分改变我们大脑对于刺激的认知程度,磨损主驱,乃至与沉迷之后因为失败和不断追求强刺激而变得鲁莽和抓狂,所以这是我们要尽力克服的地方,反观主动学习,则是因为缺乏相对应的环境和条件而变得相当而言困难的多,但是学习在某种程度上才能增益生活,提升学历,获得offer,出国留学,过上想要的生活,实现自己的理想和抱负,但是游戏只能给予短暂的快乐和无尽的痛苦,快乐之后,还是要面对一个残酷的世界,和不完美的自己不是吗,然而时间和身体意志等诸多因素,还是被磨损了。\n\n- B6 **减少思考,增加体验**\n\n\t 坦白来讲,过多的思考并不是一件好事,学而不思则惘,思而不学则殆,大概是这么意思,不纠结具体的通假字拼写对不对了,为什么说,过多的思考不好呢,思考就像酸葡萄一样,越想吃,越吃不到,最终陷入追兔子的陷阱当中,李煜曾经有一段很出彩的描述,“剪不断,理还乱,是离愁,别有一番滋味在心头”“最是仓皇辞庙日,教坊犹奏别离歌,垂泪对宫娥”,论才华,咱们比不上南唐后主,论悲惨,咱们也比不上,堂堂一国之君,沦为阶下囚,当一个违命侯,任谁也受不了,所以说,李后主对我们还是有比较不错的启示的,脑袋是会骗人的,虽然古人讲,心为君主,但脑袋似乎又是一个特殊的存在,心也很特殊,因为就算不思考,坐在一个能产生共鸣的姑娘旁边,心跳会不受控制加速,也许心有它自己的想法,但不管说心还是大脑,处于君主的决断地位,对于治国而言,还需要更加关注实实在在的民生,比如其他脏器的运行,遇到困难事,难过事,不要直接伤心,伤肾,一个容易短命,一个容易伤情志,像宝哥哥这样子情不情,对万物都有感情的好孩子,可能遇到同样多情的林姑娘,也是把人间的无味都尝便了,所以这对前世冤家(我想了一下,这个词还可以双关表达我的意思),固然为人间所不容,黛玉把泪还尽了之后,变成天上的绛珠仙子了,宝玉出家之后呢,也就变成赤条条无牵挂的具有石头心的神瑛侍者了,所以《红楼梦》这本书不适合人间的少男少女看,换言之,不适合进入太多的深度思考,之所以这么说,是因为曹公写完已经是“满纸荒唐言,一把心酸泪”了,这本书既是人间事又是非人间事,宝姐姐作为人间的仙子,也只是扮演着映射悲剧的一面镜子的角色,宝姐姐为什么没能拯救这座大厦的倾倒,也是全书的悲剧之一。\n\t 也许思考和体验并不矛盾,礼乐文化确实是一个解决问题的好方法,在某种时刻,思考和体验可以达成一种统一。\n\t 但是归根到底,在人间修炼,人家王阳明还要龙场悟道,躺在棺材板里不吃不喝想几天,所以天道和人道各有各的欢喜,林姑娘是天上的仙子,食不了人间的烟火,本应顺天道而行,天若有情天亦老,天道无情,无常,无仁,但是奉养万物,我们理应对天道保持敬畏之心,在《道德经》《黄帝内经》中均有相关的阐述,同时,宝姐姐作为人间的仙子,的确是承受了太多不应该承受的东西,她也确实没有办法和能力挽救大家族的覆灭,如果宝姐姐最终成了武则天,那么宝姐姐也一定是失去了什么,从而又得到了什么,总之就是不一样了,所以说,人道本就是复杂的,在百家争鸣时期的墨家,法家,儒家,也有各自的闪光点,至于荀子说,人性本恶也的确是有一定的出发点,荀子读不懂庄子,但是庄子也有他的无奈,把自己的真心和善良写在寓言之中,他也却却实实察觉到天道与人道的不同。\n\t 大概唯有阴阳家和医家,不偏离天道,奉养人道,佛家有一种诸法空相,和中道实相的观点也是不太好懂的,但是也还是比较适合的。\n\t 我对近代哲学则没有太大的兴趣,我喜欢去找哲学的源头,所以与其用现代人的眼光看我,倒不如用原始的眼光看我,也许我是做一件在现代效仿古代的事情,看上去像是中了魔法的堂吉诃德,但是这样确实能带给我快乐。 May 28, 2023\n\n- B7 **优化复习模块,增加数据的及时处理能力**\n- B8 **节约资源的配给,提高反应力和敏锐度,排除干扰**\n- B9 **在工作表中对数据误判造成的数据偏移进行优化**\n\n\t 能量曲线和延时效应同样值得关注\n\n- B10 **优化记忆曲线**\n\n\t 坦白而言,记忆真的是一个很神奇的东西,尤其是在期末考试前两天的时候,也许你会为之抓狂,同样记忆不论是对于学习和生活都是有相当大的影响的,不然,人家为什么总说,腹有诗书气自华,对于做题而言,记忆更加重要,把这道题所设计的最核心的东西找出来,简化第一次和第二次之间思考的距离。\n\t 对于roam research这款软件而言,思维导图其实是很大的亮点,notion中也已经有工程师在做这件事情了,这的确是很伟大的一件事情,在某种程度上,图片表达逻辑似乎更有独特的地方。\n\n\n\t> 人类大脑的存储方式不同于文件系统,人类所有的思维方式几乎都是基于神经元这种形式的,因此只有顺应这种开枝散叶的链接逻辑才能真正有效地辅助人脑帮助记忆。起码应该是个 “树” 的存储结构,而且每一条神经都应该是双向链接。\n\n\n\t\t _人类学习新东西的历程就是先检索一遍脑袋里旧的树杈,然后找一个合适的位置把新的果子挂上去。_\n\n\n\t\t _如果找不到合适的树杈,那这个知识点基本是不可能挂上去的。比如对一个还没学过微积分的孩子讲分部积分法,他多半会一脸懵逼像是在听天书。等于浪费时间。_\n\t\t[——鸦鸦的博客](https://crowya.com/1373)\n\n\n\t```markdown\n\t鸦鸦的比喻非常形象,我之前也看过一期视频,讲的就是人类的大脑同化和顺应的过程\n\t```\n\n- B11 聚类和索引特性\n\n\t 重新对题型进行聚类分析,这是形成完整性,试想一下,你拥有一个庞大的数据库,但是发挥不出来的时候,的确是让人恼火的一件事情,索引于是就成为了非常值得研究的一个问题,大脑喜欢简单的事情,也许还比较喜欢联想记忆,喜欢以结果为导向,比如喜欢一个人就一定要在一起嘛,或许不一定,成为最好的朋友或许是一个更为明智的选择,因为距离可以让玫瑰的刺不至于划伤手掌,但是玫瑰的芬芳却可以始终让你想起在小行星上的那些难忘的生活,如果你猜对了,那么也许你猜到我在讲《小王子》的故事。\n\n\n\t 索引特性和记忆强度有一定的关系,记忆强度和主动重复水平以及和体验水平又有很多关系,体验不好但是重复次数多在短时间内有很强的记忆水平,但是随之就会被代谢掉,只能下一次不断重复,但是心流体验就如同老鼠吃到了奶酪,或者火苗舔拭着干柴,任你怎么扑打,都很难熄灭,不然为什么杨过十六年之后还心心念念着心爱的龙儿,见证着一个少年成为一代大侠的故事,当然我讲的只是可能的一个因素,及激素水平的调谐,或许还有更加深层次的因素,比如体验,过龙的爱情之所以让人羡慕,还有很重要的原因就是经历和体验,不管是杨过幼年时期的悲惨经历,还是在龙儿从冰冷逐渐温暖的蜕变,还有肝肠寸断的误会,到互相牺牲的忠贞。所以才让人如此记忆深刻,成为令人难忘的神仙眷侣,所以荧幕前的观众,作为一个具有感性的人,大概率会产生强烈的共鸣,使得经典超越时空,经久不衰。\n\n- B12 能量过载和上下层分离\n\n\t 处于上层地位的大脑,从客观的角度,很重要,但也容易出错误,错误的指令,错误的引导,错误的选择,当然有时候会在正确的时间做错误的事情,错误的时间做正确的事情,而且大脑很累,又要充当存储器,又要当做处理器,除非分时复用,但是如果在短时间内需要调用大量的模块时,就不要指望大脑能给你什么好脸色看了,生产队的驴也没有这么使唤,压力水平影响情绪,影响表现,而且大脑需要娱乐坦白来讲。但是这个时候就容易出现一个问题,大脑会主动回避那些困难的事情,比如对重要的事情进行折叠,过量地摄入新鲜的具有刺激性的事情,从而破坏主域的稳定,进而导致上下层分离,这是一个非常危险的告警情况。一旦失控,就像飞机坠机一样无法控制,尤其是在独立源系统中更危险。\n\t 一方面通过简单的外源辅助,一方面简化系统,一方面强化引导系统,一方面完善反馈系统,花花世界的干扰太多了,我们也许只是其中的一个提线木偶,就连笑容也笑得像小丑。 May 31, 2023\n\n\n### C指令集\n\n\n---\n\n- C01 **连续性验证**\n\n\t理性工具,乐流调谐\n\n- C02 **洗澡时间的优化**\n\n\t下午3:00可以选择去洗个澡\n\n- C03 **午觉时间优化**\n\n\t午觉在图书馆睡\n\n- C04 **留出学习拓展技能的时间**\n\n\tFPGA+Linux\n\n- C05 **Bilibili当作搜索引擎而不是娱乐工具**\n\n\tBilibili是一个很不错的平台,但是要合理使用\n\n- C06 **花点时间做一些赏心悦目的事情**\n\n\t比如多去观察观察大自然,积累图片和素材库,记录自己的灵感\n\n- C07 **按时吃饭**\n\n\t再难受不舒服的时候也要因为打游戏过头或者拖延而忘了吃饭,舍本逐末\n\n- C08 **有仪式感的生活,简化例行程序**\n\n\t 在上面关于《动机》的文章当中,提出有仪式感的生活和例行程序是培养动机的很好方法。大脑承担着module top,即顶层模块的作用,需要给建筑好的上层建筑下达指令,然后由物理可实现的身体与现实世界进行相对应的交互,而仪式相对而言是一种更为高级的习惯,坚持是一件非常困难的事情,非常困难,这也是仪式和习惯面临的最大挑战。仪式感和例行程序的建立本质上还是依赖于顶层模块的认知和决断,并不复杂,从《道德经》《南华经》《黄帝内经》中,是可以找到相对应的答案的。\n\n- C09 **对建立的周工作流进行更加合理的优化**\n\n\t 晚上入睡困难,白天没有动力,生活没有目标,痛苦始终环绕,哦,这听起来真的是相当糟糕的一件事情,就像破旧的毛坯房,风雨一来,就被淋湿了,所以,对于周工作流计划需要做出更加合理的一种优化,困难,确实如你所言,无可避免的,要是能避免,牛顿就该不服气了。 May 28, 2023\n\n- C10 **建立系统的原则需要简单高效**\n\n\t 坦白来讲,越复杂的系统功能越多,但是也越脆弱,就像变速自行车的变速装置,随着时间和使用,更容易比单速自行车损坏,所以生活简单并且有乐趣是一个不错的想法。 May 28, 2023\n\n- C11 **计算资源储备,以及如何进行合理配比**\n- C12 **晚饭的时间最好不要过分地占用,这样会导致整体节奏的滞后,强化对点反应**\n- C13 **锚定人生轨迹**\n\n\t坦白来讲,自我认知是一个相对复杂的过程,尤其是在长阶段的过程当中,每个阶段都有其独特的经历和体会。\n\n- C14 **找到合理稳定的能量修复渠道**\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-10-05",
"type": "Post",
"category": "走近生活",
"slug": "Terminal",
"tags": [
"流动核心"
],
"summary": "及时对建议库进行更新是一项非常重要的事情",
"title": "[二级缓存] Terminal优化",
"status": "Published",
"urlname": "c32bcf6c-b02c-4440-8ba8-c3df42372cbf",
"updated": "2024-08-11 03:46:00"
},
"catalog": [
{
"title": "流动核心",
"doc_id": "c32bcf6c-b02c-4440-8ba8-c3df42372cbf"
}
],
"body": "",
"realName": "[二级缓存] Terminal优化",
"relativePath": "/流动核心/[二级缓存] Terminal优化.md"
},
{
"id": "329c3828-ac3b-493e-a2b5-fa48bbb54941",
"doc_id": "329c3828-ac3b-493e-a2b5-fa48bbb54941",
"updated": 1713876900000,
"body_original": "\n# 前言\n\n\n---\n\n\n就着1月10号的笔记简单谈谈我的感受,希望在半个小时内完成这个工作。\n\n\n> _思考是痛苦的,我们在进行专注思考的同时,应该想好如何用同样专注的方式进行娱乐,如果不这么做,势必会遭到痛苦的反噬。_\n\n\n\t_同样,如果我们决定去爱一个人,应该需要清楚,在天平的另一端,有什么和爱是相当的重物。如果我们想不清楚,我们将困在克莱因瓶里。_\n\n\n\t_——MatrixCore_\n\n\n# 正文\n\n\n---\n\n- 从时间和经历中沉淀理论知识体系,把专业基础课整理出脑图,使得各种知识图谱能够串起来,并能够运用到工程实践当中。\n- 环境影响人的情绪价值,情绪价值影响决定判断和时间精力的投入,我们关注时间精力的输入,希望能获得良好的输出,并希冀在其间获得良好的感性反馈。\n\n在进入今天的主题之前,我还是打算重复一遍我在如厕时的灵感,尽管现在已经有些模糊,但是仍然称得上是好的开端。\n\n- 我们拥有哪些资本:oh,在这里我不得不回忆起一段小故事,在有一次的活动中,主持人问我们最看重的5个元素,然后直到筛选出最后一个,我选择了时间,我的另一个同学选择了知识。 然后我并不打算继续讲这个故事了,我们拥有的为数不多的资本,时间,健康,学历,认知能力,人际关系,当然还有其他的你可以继续列举。我们将这类元素视为输入。\n- 我们希望得到哪些结果:金钱可以让我们获得想要的一些想要的东西,例如一只现烤的全聚德烤鸭需要200元,学历可以让我们得到社会的认可,合适的人际关系可以让我们在处理问题更加便捷,当然还有我们的能力的提升,可以让我们从容地应对更多的挑战。\n- 我们如何取得这些结果:工作占据我们人生50%的时间,工作使得我们生存,其次需要不断学习,提升技能和学习,而且最好还能改正我们的缺点。\n- 西西弗斯推动巨石的循环:客观来讲,推石头很累,但是在推巨石的过程当中,使我们获得经验和智慧。我们将更清楚得获得对自身的认知。\n- 我们如何获得成长:反馈,反馈注定是痛苦的过程,当然如果你处理得很好,就需要另当别论了,但绝大多数人和文学家很擅长反馈却做不好反馈。这不由得让我想起小龙女和杨过在离开古墓后到绝情谷再度重逢的片段,二人并不为世俗所认可,面对充满伤害和恶意的江湖,也曾经历过迷茫和痛苦,算了,我并不打算展开讲故事了。\n\n在梳理完灵感之后,我对上面提出的两点做简单的阐述,第一点呢,是培养适合工作的专业能力,从大学毕业之后,从事的岗位的能力需要培养起来,这是基础也是最重要的事情,但是困难的地方就在于,第二点。\n\n\n环境和启蒙条件,试问,如果令狐冲遇不到风清扬或者任盈盈,金老爷子怎么写?开个玩笑,我的意思是,上面的意思。哦,又想到老石讲的用ai写risc-v的“启蒙一号”了,补充个插曲。\n\n\n环境影响人的情绪价值,什么,情绪还能有价值,好问题,在家和在图书馆,在床上倾向于睡觉,但适合娱乐,在图书馆倾向于学习,但也可以睡觉。站在我的角度,你也可以把自己想象成一株植物,你是不是要从土壤里获取养分,要晒太阳,才能产生淀粉,结出果实。床上的最佳实践在于睡觉而不是学习,图书馆的最佳实践在于学习而不是睡觉。\n\n\n然后上面都是简单的理论分析,人的缺点在于容易遗忘和被同化,绝大部分时间我都是很糟糕的,尤其是周末和放假。\n\n\n# 总结\n\n\n---\n\n\n估计时间已经超过30分钟了,然后接下来,我打算研究如何联系git和onedrive,使得文章能更好地同步。\n\n\n最后介绍一下我写作的一般步骤,写作分为三个平台,移动端和电脑端。都是使用obsidian先进行写作,然后使用remote save插件同步到onedrive,这是后端,也就是内容创作端。然后我会将ob上的文章同步到notion中归档到博客当中,这是前端。然后通过elog进行备份到github中。后续我将尝试使用git将仓库的内容同步到onedrive中,因为后端不需要考虑文章的分类,在导入notion之后会有对应的分类和标题,分类之后形成统一的范式便于管理和建立脑图。\n\n\n\n\n\n这就是脑图的大概样式。还有更多的细节有时间再讲吧,包括在博客中,需要对图片进行压缩和上传图床,以及形成脑图之后该干啥,我还没想好。\n\n\n(最后有个小贴士,markdown语法中,用空白行来进行段落分开,这样在notion中就可以正常识别,当然在notion中进行写作也很方便,但是为什么要用obsidian呢,就在于图片上传,当一篇文章里很多图片的时候,使用notion就不是很方便了,因为notion图床在域外,所以我选择了域内的图床,这就需要先对图片进行压缩,保证性能和质量的平衡,然后进行批量上传和替换外链,这一点,目前只有ob的插件可以做到,然后关于首行缩进,似乎markdown不怎么支持,也许我需要通过插件来增强编辑,之后再研究吧,我也懒得手动调了,而且,原生notion的字体吧,看起来不是很爽,虽然notion enhance可以解决这个问题,但是想来想去,还是先练习练习markdown。)\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2024-01-21",
"type": "Post",
"category": "走近生活",
"slug": "240121",
"tags": [
"情绪表达"
],
"summary": "环境影响人的情绪价值,情绪价值影响决定判断和时间精力的投入,我们关注时间精力的输入,希望能获得良好的输出,并希冀在其间获得良好的感性反馈。",
"title": "[情绪价值] 环境与启蒙的基石",
"status": "Published",
"urlname": "329c3828-ac3b-493e-a2b5-fa48bbb54941",
"updated": "2024-04-23 12:55:00"
},
"catalog": [
{
"title": "情绪表达",
"doc_id": "329c3828-ac3b-493e-a2b5-fa48bbb54941"
}
],
"body": "",
"realName": "[情绪价值] 环境与启蒙的基石",
"relativePath": "/情绪表达/[情绪价值] 环境与启蒙的基石.md"
},
{
"id": "5dca0507-79f1-4ba3-ab6d-272ce8bc6779",
"doc_id": "5dca0507-79f1-4ba3-ab6d-272ce8bc6779",
"updated": 1708863120000,
"body_original": "\n# 写在前面\n\n\n---\n\n\n 这个板块的设计初衷就是为了能更好的完成工作流当中的最后也是最重要的一个功能,即反馈功能。当然您从名称也可以看出,还有其他的寓意。😊\n\n\n 下面这张图可以看作是notion体系最初建立时的工作方式,之后在不断简化的过程中演化出了五个板块,而现在您所看到的,隶属于其中的一个模块。\n\n\n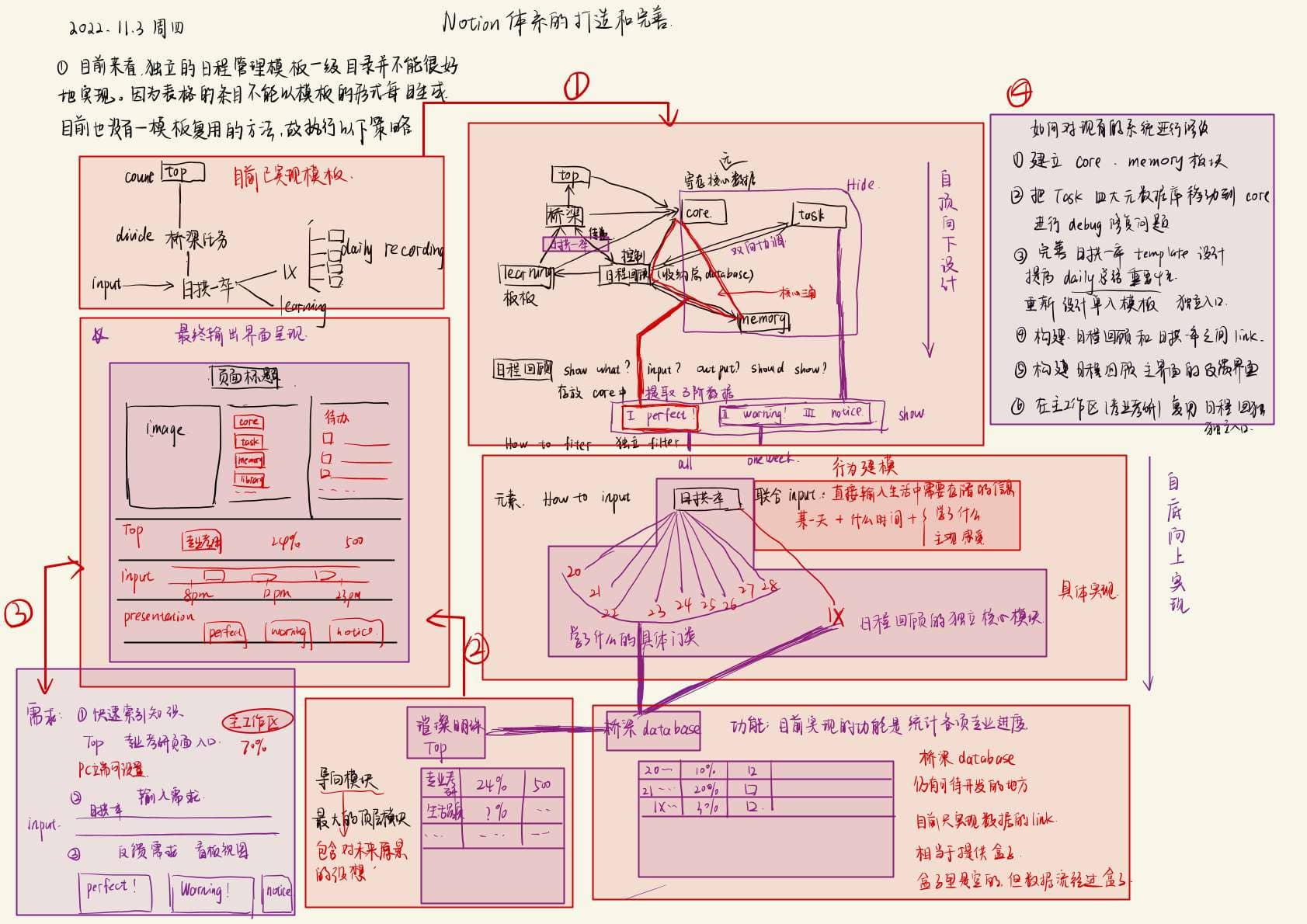\n\n\n### 更新说明:\n\n\n> 💡 **230904更新:**这个板块作为工作流的五大板块之一,曾经是我的掌上明珠,但是随着博客的改版和更新策略的变化对这个板块投入的时间真的是越来越少了,但是不管怎样,对于该板块的建设仍然列入高优先级!\n\n\n# 正文部分\n\n\n---\n\n\n 在这个部分我将介绍有关,健康,事业,家庭以及爱情友情相关的认识。😀\n\n\n## 一、寿比南山的愿景\n\n\n---\n\n\n\n\n\n### **生命运作原理解释——反复思考(****最高优先级****)**\n\n\n 在十二时辰的图中,我们可以从子时开始,由于电的发明和不可抗力的环境因素,现代人的压力水平普遍偏高,生活作息普遍延后,并且形成恶性循环,在夜晚造成报复性熬夜,从某种程度上,这对生命的质量造成了极大的威胁。一般而言,我们将在22:18下班,基本上可以在23:00前上床,但是问题在于,由于环境干扰和白天的cache累计,导致我们的入眠时间要在20-30min左右,并且更为糟糕的是,由于无法主动协调环境因素,加之精神需求(生理需求)的峰值,诸多因素所导致的航道偏离,使得我们唯有做出防御性的措施来应对这种高等级危机。\n 在《黄帝内经》当中,胆对人的影响极为巨大,会影响人的意志,魄力等等,为此,我们不得不提出一个疑问?即,在什么条件下,又有什么重要的事情,可以和养护自身相提并论,答曰,危及生存的事情,这是最高预警,除此以外,任何事情的优先级都应该被降为最低。\n 并且,在保持主域稳定的前提下,我们必须确立最小稳定系统,在协同域中所可以兼容的运行环境,在最小稳定主域中都应该并且被隔离并阻断。\n 由于现实情况的不乐观,在这基础上,仍然有可以希冀的事情,那就是自身的养护得到稳定的进行,我们应该感谢和回馈造物主的馈赠,在我们犯下如此多的罪过的时候,仍然能给予宽恕。\n 我所讲的并不是唯心,而是应该和理性相匹配的感性认知,在夜晚的休息当中,是碳基生物一种非常伟大的自我循环,涉及肝,肺,大肠。\n 在我们在6:30左右起床的时候,这个时候身体对能量的需求依旧处于极高峰。我们需要完成对于食物的摄入,来保证早晨的精力充沛。早晨脾胃的运化,为我们高强度的生产工作提供硬件支持。\n 在阴阳交替的午时,主养心藏神,适当休息。\n 在未时,醒来之后多喝水,学习累了之后,适当外出运动之后再回来学习。\n 经过下午的学习,完成晚餐的摄入和休息。\n 经过测试,夜晚的学习效率较低于白天,这个时候应该做一些收纳和整理的工作,如果对这个存疑,亦可采用及时数据处理的方式学习,减轻夜晚入睡的负担。\n 综上,希望遵守以上的步骤,完成更好的代谢循环。\n\n\n### 天气变化对生活的影响\n\n\n---\n\n\n 根据这两天的观察来看,夏季的气温变化相对来说也更加多端,但是我们的应对措施却极为有限,对于下雨的日子,固然很难忍受,但是燥热的日子也更加煎熬,天气对于人的影响还是比较巨大的,及时做好应对措施。 \n 当时七月底八月初受台风影响,接连下了好几场雨,当时对生活节奏是产生了很巨大的影响。\n ——七八月时候的感受\n\n\n 九月初,这几天的天气还是略微有点燥热,秋季可能是较为不错的一个阶段,接下来就是寒冬的一些特征,所以这几天,最好还是能在天气好的时候,晒晒被子,洗洗衣服,把洗澡的节律调整好,保持两天洗一次澡的频率。 2023-09-04 \n\n\n### 从[心经](https://bu.dusays.com/2023/09/04/64f5d87e37516.jpg)中体会人生智慧\n\n\n---\n\n\n<u>**心经全文**</u>\n\n\n\t 观自在菩萨,行深般若波罗蜜多时,照见五蕴皆空,度一切苦厄。舍利子,色不异空,空不异色,色即是空,空即是色,受想行识,亦复如是。舍利子,是诸法空相,不生不灭,不垢不净,不增不减。是故空中无色,无受想行识,无眼耳鼻舌身意,无色声香味触法,无眼界,乃至无意识界,无无明,亦无无明尽,乃至无老死,亦无老死尽。无苦集灭道,无智亦无得。以无所得故。菩提萨埵,依般若波罗蜜多故,心无挂碍。无挂碍故,无有恐怖,远离颠倒梦想,究竟涅盘。三世诸佛,依般若波罗蜜多故,得阿耨多罗三藐三菩提。故知般若波罗蜜多,是大神咒,是大明咒,是无上咒,是无等等咒,能除一切苦,真实不虚。故说般若波罗蜜多咒,即说咒曰:揭谛揭谛,波罗揭谛,波罗僧揭谛,菩提萨婆诃。\n\n\n<u>**心经译文**</u>\n\n\n\t1、观自在菩萨,行深般若波罗蜜多时,**照见五蕴皆空**,渡一切苦厄。\n\n\n\t【翻译】能够自由自在地观察自身佛性之奥秘的觉者,在运用大智慧深入研究生命是如何到达光辉彼岸的过程时,真实地看到,构成宇宙万事万物的五种因素(色、受、想、行、识)原本具有可变的空态性质,没有不可变的实体,一切痛苦灾难,都能被这一空态度脱而化解掉。\n\n\n\t2、舍利子,色不异空,空不异色,色即是空,空即是色,受想行识,亦复如是。\n\n\n\t【翻译】弟子们,从宏观角度看,色和空没有区别;从微观角度看,空与色也相同。空是色的分解,色是空的化合。尽管你反复透彻地去领受、深思、认知和识别,其结论仍然不变。\n\n\n\tⅠ、色:指可见物体,如人、物品、山水等(非颜色、姿色)\n\n\n\tⅡ、空:不是什么也没有,只是我们肉眼看不见罢了。\n\n\n\t3、舍利子,是**诸法空相**,不生不灭,不垢不净,不增不减。\n\n\n\t【翻译】弟子们,凡有形象和无具体形象的事物,其本质都具有空性和可变的特点,不参在生长灭亡、肮脏洁净、增多减少。\n\n\n\t4、是故空中无色,无受想行识,无眼耳鼻舌身意,无色身香味触法,无眼界,乃至无意识界。无无明,亦无无明尽,乃至无老死,亦无老死尽。无苦集灭道,无智亦无得,以无所得故。\n\n\n\t【翻译】所以,空中没有色的实体,没有对色的思维意思。眼、耳、鼻、舌、身、意这六根要归于空;色、声、香、味、触、法这六尘也要归于空。没有六根六尘的界限和其被认识的界限,心中没有不明白、不自觉和因不明白而烦恼的影子,知直到没有老死和老死的影子,没有累积恶因所造成的苦果,没有修炼道法而成就的品位。不运用智巧去获得什么,那是因为没有什么可以得到的缘故。\n\n\n\t5、菩提萨陀,依般若波罗蜜多故,**心无挂碍,无挂碍故**,无有恐怖,远离颠倒梦想,究竟涅磐。\n\n\n\t【翻译】菩萨因为运用那到达彼岸的大智慧的缘故,清净的心没有一丝挂念,没有挂怀和障碍就免除了恐惧害怕,便脱离了异想天开的梦幻杂念,最终觉悟得道而成正果。\n\n\n\t6、三世诸佛,依般若波罗蜜多故,得阿褥多罗三藐三菩提。\n\n\n\t【翻译】那些过去、现在、未来佛,依靠那到达彼岸的大智慧,荣获了无上正等正觉的大果位。\n\n\n\t7、故知般若波罗蜜多,是大神咒,是大明咒,是无上咒,是无等等咒,能除一切苦,真实不虚,故说般若波罗蜜多咒。\n\n\n\t【翻译】所以确认:到达彼岸的大智慧是修炼中最神圣的准则,是最光明的法器,是至高无上的真理,是无与伦比的规范。能真实而不虚妄地将全部苦难化解清除,所以要牢记“般若波罗蜜多”这句真言。\n\n\n\t8、即说咒曰:揭缔,揭缔!波罗揭缔,波罗僧揭缔,菩提萨婆呵。\n\n\n\t【翻译】既然如此,便号召众生:去吧,去吧!彼岸是归宿,为修我佛,赶快用行动去成就无上正觉吧。\n\n\n## 二、流动核心的设计\n\n\n---\n\n\n 这个部分主要介绍我对于流动核心的理解和设计,你可以把流动核心比作是写作文的提纲,或者是你在回答面试官问题时,脑海里即兴所形成的一种思路。又或者是,你捡到一片树叶,你可以清晰地看到树叶的脉络,有了脉络,才可以有养分。\n 如图所示,下图中呈现出的树叶和鱼骨模型,就是流动核心的思想起源。\n 我再举个很形象的例子,人这一生,肯定有很多心动的瞬间,那为什么会心动,这个问题我不知道大家有没有思考过,我的第一个回答是,命运,命运告诉我,陌生的时候看到她的第一眼时,就觉得冥冥之中她会影响我的生命;第二个回答,是经历,因为有过共同的经历,你将串联和激活起这整个回忆;第三个回答是适合,共鸣,为了共同的目标,相同的遭遇,相似的性格;第四个回答是,执着,在你孤独迷惑的时候,她的出现给你的生活带来阳光。\n 那么从时间轴往前推,从事件(缘分)-作用(经历)-思考(交换情感和认知)-反思(再度回忆),在思维所经历的每一个节点,您都可以看作是脉络,而这,就是流动核心真正的魅力所在。\n 流动+核心,不仅仅是暂态的数据,数据阵列所形成的庞大的规模效应,结合流动的方式,构成生活和生存的知道,这是我对于它的定义。\n\n\n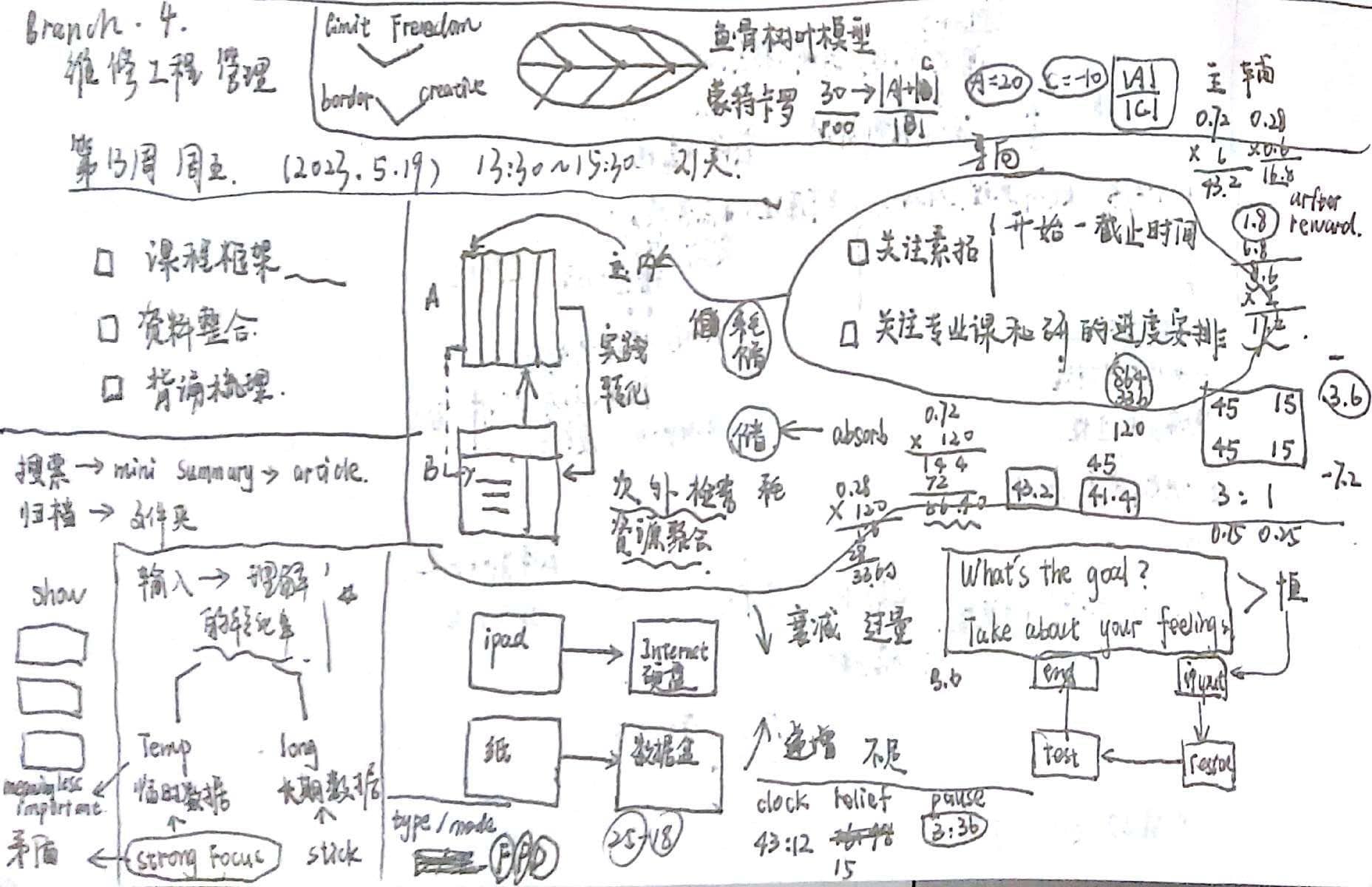\n\n\n### 大数据与流动核心\n\n\n---\n\n\n 在昨晚读到的一文当中,讲到”大数据“的问题,文章最核心的观点是,大数据似乎已经不是最值得考虑的事情,反而是微观的变化更值得考量。\n\n\n 我的观点:如果把人生活的数据聚合起来看,大数据所承载的量,可以看作是结果量,而微观的流动核心所承载的量,可以看过是过程量,过程和结果的比方相对而言则更容易理解。\n\n\n 那么相应的,大数据体现在对数据如何进行更好的收容和筛选,流动核心则体现在如何对数据进行更好的积累,当二者形成相应的纠缠之后,那么自然会有其奥妙与趣味所在。\n\n\n 流动核心的设计的关键在于如何客观认识数据流,从数据的导向-摄入-清洗-存储-输出-反馈,这期间蕴含很多微观过程的奥妙,而这些微观过程恰恰是最难被发现和理解的。\n\n\n---\n\n\n> “这座镜子之城 —— 或蜃景之城 —— 将在奥雷里亚诺・巴比伦全部译出羊皮卷之时被飓风抹去,从世人记忆中根除,羊皮卷上所载一切自永远至永远不会再重复,因为注定经受百年孤独的家族不会有第二次机会在大地上出现。” ——[**鸦鸦的巢穴**](https://crowya.com/shuoshuo/3295)\n\n\n 酣醉过去,则永无遗憾,沙漠下的古城,埋葬着不见天日的宝藏。\n 时间流逝,已经无法复现当时更为生动的场面,那些灿烂的回忆依旧可以在梦境中永生,而在现实当中,过去如同揉旧的情书,又如同高楼上的倦鸟,成为宇宙中眺望着的蓝色星球,直到变成一个又一个小小的点。\n\n\n## 四、宏主域设计\n\n\n---\n\n\n 这个板块我将用于记录生活中的一些思考,为了保持数据的稳定,我将依照写作的情况,保留近1-2个月的记录。这样我可以更好地动态地记录每天的灵感。 😇\n\n\n \n\n\n### 大嵌套与小嵌套\n\n\n---\n\n\n 不管我们对任何感兴趣的东西抱有多么浓厚的热情,我们都必须遵从嵌套的逻辑和法则。我们的大脑的数据庞大量已经为我们自身创设了一个庞大的迷宫,我们已经比庄子聪明很多了,在知识的储备量上而言,但是我们却没有比庄子更加幸福。\n\n\n 如果放到空间上来看,假如我们要建立一座金字塔,我们都知道地基很重要,于是我们把一生中的大部分时间都用来打地基,这些工作我们称为一级缓存,我们在众多庞杂的缓存中迷失了自我,甚至我们都忘记了最初的目的。\n\n\n 这就是我目前面临的最大的问题,大嵌套和小嵌套之间的逻辑问题,坦诚来讲,我一动脑筋感觉就瞌睡,对新鲜事物的接受能力也不是很好,身体也逐渐发出了疲惫的信号,所以是时候该问问自己,要选择什么样的道路了。\n\n\n 暑假留校的一天,我看到有园艺师傅把树下面的刚长出来的小枝条都拔掉了,这也就是过于理想的通病,生活哪可能十全十美呢,我们只是在有限的条件中找最优解。\n\n\n 一个上午也许只能做很少的一点事情,让学习推进很小的一部分进度。但是如果这个时候专注于喜欢玩的游戏,即使收获很大,带来的反馈也不是很好。\n\n\n 所以人生必须要选择取舍,而这一点恰恰是最难做到的,因为就像吸星大法一样,化掉来自自身的执念是最困难的事情。但也正因为此,保全了大嵌套的正常运行,小嵌套内的逻辑才可以执行地更好。 2023-09-10 \n\n\n### 选择还是被选择\n\n\n---\n\n\n 基于A1,A2,我想到一个问题,选择还是被选择?同样的逻辑,但是为什么在有理智的情况下,还是情不自禁地走向了相反的道路,来自内源的自我攻击是非常难解决的,具体的理解可以参照《盗梦空间》,这是一个非常有趣的问题。\n\n\n 今天的第二个小收获,我感觉有时候生活非常仓促,无聊并且夹杂着烦躁,但是有时候也可以静下心来去做一点事情,因为遇见,共鸣,还有坚持,什么才能让紊乱的生活回到正轨,正如同当下每个人的生活都太热闹,但是又很孤独,或许是情绪上的一些微妙的变化,情绪就像是个小孩子一样。\n\n\n 每个人对于生活的定义和追求不一样,当所有的目标都向着生存,就一定会丢掉一些曾经认为很美好的东西,而这些“不需要的东西,不能产生经济价值的东西”,恰恰确实最能安慰我们灵魂的存在,物质的终极奔向虚无本身,而越多的物质意味着越多的能量消耗。\n 安静和停留并不是一件坏事,停车坐爱枫林晚,霜叶红于二月花!\n\n\n 今天意外的第三个收获。\n\n\n 我的性格像是与生俱来一样被施了魔法,又或者是因为漫长的人生经历。 \n\n\n 我之前也许这样说过,我与同龄人显得有些不一样。为此,我很难体会到像其他人一样的简单率直的快乐。 \n\n\n 所以,我一直独行,与寂寞为邻,并且一直习惯了这样的生活,没有波澜,按部就班。 \n\n\n 但是每一次未曾意料的安排,却让我始终觉得一种感觉在撞击着我的灵魂。正如同我从前的某一天晚上写下,我感觉我的心门像是被上了一把锁,而就连我自己也找不到那把钥匙。 \n\n\n 我能感受到我的小伙伴有更加开朗的性格,表现得也比我更加开放,这就像一面镜子一样。 \n\n\n 或许在我看来,所有的遇见都是来自命运的馈赠,每个人擅长的方向不一样,比如我则更擅长用文字记录心情,是典型的理想主义者,而我的小伙伴则是实践家,用行动传达爱与关怀,这也为我上了一堂生动的课!\n\n\n 2023-09-06 \n\n\n### 聚焦——使你的思考更具有针对性 \n\n\n---\n\n\n\n\n\n\n 【雨天摸鱼记】\n\n\n\n\n 写作环境的搭建是一个涉及习惯性的问题,在经历先手机后电脑的背景下,手写,手机,电脑之间,很明显,我对于手机的输入法有着更天然的亲近。\n 纵使头脑里充满想法,没有合适的表达方式,也使得灵感总是昙花一现,然而令人遗憾的是,如果失去了灵感,生活就是琐碎的一地鸡毛,再没有更多的乐趣。 \n 想着去操场上挑战单杠,只是夜晚的风仅仅让我在教学楼附近徘徊了一圈,连下三天的雨并不非常扫兴,只是衣服并没有往常那么快干。 \n 我在教学楼中央的岔路口吹了会凉风,又走到教学楼的镜子前张望了两眼。又穿过狭窄的走廊,回到了我的座位上。 \n 在处理问题层级的优先级上,是容易让人迷路的,通过聚焦才可以使得精力得到更加充分的利用。 \n 在经历一个过程的风暴之后,需要得到合适的休息。如此才可以完成更好地循环。 2023-07-30 \n\n\n\n\n### **关于可能在网站中接入Google adsense的说明** \n\n\n---\n\n\n之前我认真思考和分析过这其间的利弊,当时我认为用爱发电是一件很容易的事情,至少在最初的时候,我只是打算把个人博客作为一个在互联网上远离现实的世外桃源。\n 但是我觉得,事情的发展可能没我想得这么简单,我并没有很好地完成自我的内循环,甚至连创作都成了一件奢侈的事情,在经历一段时间的踌躇满志之后,又回很容易陷入迷失,然而我并没有找到合适的能量,也无法实现人生价值。\n 我将Google Adsense 的数量限制为2,并且在主页进行屏蔽,网站的运行其实还是需要一定的费用和时间精力的,也许可能会受到大家的不满和批评,这些我都会虚心接受。\n 我一直将博客视为精神的圣地,当你来过这里,或者看到这里的时候,无论你对这里的一花一草,一山一水,有任何的感慨,或忧伤,或感动,或愤怒,都不必惊讶,来过的同时就已经是对我最大的肯定。 2023-07-25 \n\n\n### **探索联合点之间的能量转化**\n\n\n 探索联合点之间的能量转化,我们的大脑是情绪控制和指令发出的中心,在通常的情况下,我们可以通过双手来完成信息的输入,并期望我们所获得的反馈,并根据反馈继续作出下一步的决策。\n\n\n 我们在追求效率的道路上永无止境,我们试图提高双手输入的速度,但与此同时我们的大脑也在飞速的运转,在相等的时间内,施佳足够多的能量,并获得丰厚的报酬,被认为是一种高效率的行为模式。\n\n\n 这个理论根据的底层原理,是需要有能量的交互和转化,但我们不能忽略的是,这一行为是具有侵入性的,人类在人际交往中获得收益和能量,在交流中彼此的思想互相被进入,所以人们才会对人际交往所产生的情绪感觉和认知产生依赖,进而将能量势能拔高到一个相对较高的点,最终超出机体的承受范围,引发矛盾和冲突。\n\n\n 但是人类在探索交互的体验中永无止境,因为这种方式始终就有一种神秘的吸引力,似乎是生物与生俱来的属性,他将人体本身的耳朵鼻子眼睛嘴巴双手乃至更细微的瞳孔情绪刺激思维联想发散,等诸多的要素结合在一起。这将生物本身的价值提高到一个新的层面,在追求奖励机制的情况下,这种情况会导致不断的正反馈,从而引发能量危机。\n\n\n 人类一直在探索机体的上限,在追求奖励机制的同时,也付出了沉重的代价。我们将意识和物质做一种新的转化,我们用意识和能量创造新的物质,并将其视为人生最高的意义。我们将我们的一生建筑在这个意义之上。\n\n\n 为此,我们需要不断地投入新的能量,通过更高的奖励机制,来完成任务的继续。\n\n\n 但是,还有一个更值得深层思考的问题,那就是在能量转化和交换之间的侵入性的问题。在交换的过程中,我们失去了能量,但是转化了意志。以当今科技产品为例,人类通过工具改变了现实世界,火源,电能,核能,生物能,太阳能,每一种能量都在不断地超出人类自身的极限。\n\n\n 工具为生活带来的便利,但是现实世界反过来又会影响我们的意识和思维,这使得我们固有的思维得到新的迭代和认知。这就是如同一把双刃剑。\n\n\n 还有一个最重要的角度应当为我们所认知,那就是,在什么情况下,选择独立或选择联合。如何避免能量过侵入所导致的依赖,在当今高速运转的世界,联合远远超过了独立,这时的独立精神和自由意志被无限的压缩,最终反噬我们的肌体和精神。\n\n\n 我们无法对生活做更深层次思考,只是在忙碌中失去了自我,当奖励的评价机制被重新定义,人类陷入了新的樊笼,但又不得不继续向前,因为能量交换的速率远远超过了机体的承受速率。我们没有时间享受独立所带来的宁静,因为紧张压抑和不安的情绪使得我们的未来充满恐惧。\n\n\n 我们必须正视这个问题,以期在未来获得更好的回复。 2023-07-23 \n\n\n### 寻求合适休息方式之研究\n\n\n---\n\n\n 我们需要研究并且创建一个更加适合休息的场所\n 通过更加贴近需求的引导来为进程提供gpu加速是我们下一阶段的目标\n 有时候维持稳定比取得突破更加困难,越复杂的系统反倒是更加的脆弱,同理,人的贪求越多,更容易失去导航。 \n 我们应该始终感谢承载着我们苦难的躯体,生命所赋予的运化能力,疗愈能力,庇佑性灵的平安。\n 记录在解决ohmymn插件使用中遇到的问题,在4.1.1版本中,进行单词的自动摘录和上下文自动摘录和翻译,方式就是对选取进行二次框选。然后今天又遇到一个很奇怪的问题,就是调用百度API进行上下文进行翻译的时候,因为把百度appid和密钥填反来,导致排查了很久才找到问题,最后才发现,为什么采用百度翻译的API,因为每个月有100万次的调用量,对于英语学习是非常好的。彩云翻译作为补充使用。\n\n\n<details>\n <summary>mn自动翻译和摘录上下文演示demo</summary>\n\n\n[image](https://prod-files-secure.s3.us-west-2.amazonaws.com/81a75f5f-eb3b-47db-bd61-d87d1cd413a6/ab3b3f8e-90e4-4295-8b56-daa02f5c3e6e/%E5%B1%8F%E5%B9%95%E5%BD%95%E5%88%B62023-07-09_12.08.25.mov?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45HZZMZUHI%2F20240518%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20240518T113600Z&X-Amz-Expires=3600&X-Amz-Signature=a37a789d0db1633cb2e412ad9f63d69286c5b7cbe84c3b83fdb6e5f0927d9a2d&X-Amz-SignedHeaders=host&x-id=GetObject)\n\n\n\n </details>\n\n\n 与此相对比的技术是沙拉查词的自动摘录上下文,在edge中不仅可以摘录网页的上下文,还可以读取PDF的上下文。\n 作为查词插件,沙拉查词绝对YYDS,但是更加精细化的学习和管理,mn yyds\n\n\n<details>\n <summary>沙拉查词自动翻译和摘录上下文演示demo</summary>\n\n\n[image](https://prod-files-secure.s3.us-west-2.amazonaws.com/81a75f5f-eb3b-47db-bd61-d87d1cd413a6/ecdb5d62-d1a6-4de3-b2ea-f60f16d6930a/%E5%B1%8F%E5%B9%95%E5%BD%95%E5%88%B62023-07-09_12.14.14.mov?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45HZZMZUHI%2F20240518%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20240518T113601Z&X-Amz-Expires=3600&X-Amz-Signature=af685bab03e0725fd565e75bb5217baee5403d2a492740ae336063459a87105c&X-Amz-SignedHeaders=host&x-id=GetObject)\n\n\n\n </details>\n\n\n 我在思考一个问题,mn具有脑图和文档两种方式,到底是以脑图为主还是文档为主,这是一个问题,如果仅仅停留在文档层面,想必mn就不值得花太多的精力去讲解,因为goodnotes甚至可以比他做得更好有着更棒的手写引擎优化,所以mn优势在于脑图,那么文档相对我们而言,可以视作为原始资源,需要对其进行加工,问题在于加工的场所,是在文档里加工还是在脑图里加工,这是一个问题,我想脑图的确是个不错的地方,但问题是,脑图并不是凭空产生,是需要通过手动进行摘录,这个步骤相对而言就如同把原始材料运输到工厂去加工一样,在什么样的情况下需要这么做呢?\n\n\n 为此,我们不得不重新思考,脑图和文档的关系了,脑图不是复制文档,而是作为一种更高级的存储和索引方式,用更少的存储换取更灵活的存储和提取,我们需要区分哪些是需要进入脑图。\n 毫无疑问,脑图是平地建高楼,首先是框架,其次是对知识的总结,<u>**我认为知识的粗加工可以放到原产地进行,而知识的精加工则需要用到脑图,摘录就相当于是线索,但是过分的摘录似乎也不是一件好事,因为线索多了就会造成冗余。**</u>\n 为此,对于文档的粗加工是我们学习知识的第一道门槛,条理性是非常重要的。\n 针对上述的特性我们重新进行了<u>**二次思考,到底知识是以什么为载体的讨论,究竟原材料适不适合作为主阵地**</u>,虽然基于原材料的学习更加符合主观逻辑,但是这一定会产生一种缺点,进行线性二次加工,意味着,重心是放在原材料上,每重复进行一次加工都对应时间的巨量消耗,在实践层面第一种方案是不现实的,并且原材料并不是高度吻合学习逻辑的。\n\n\n 所以,同步到导图才是目前最佳的学习方式。脑图的冗余也是比进行二次摘录要更加方便 的,时代变了,大人,面对海量的学习材料,最高能效,最能调动积极性的方式才是最佳的。\n\n\n 正如前面所说,平地建高楼和毛坯房装修,这中间依然存在很大的跨度。\n\n 文章二,生命悲歌与自由意志\n 在世界大环境如此的条件下,仿佛来自生命之地的土壤中,重金属的正在侵蚀着每一块微小的地方。\n 疾病,战争,饥荒,似乎伴随着人类社会,而我们作为其中的渺小个体,又如同鸟雀般惶恐。\n\n\n 在生命土壤中盛开的苍凉而妖艳的花朵,似乎暗含着神秘的征兆,带血的花朵,拥堵的根茎,盘庚错扰根系,一切似乎都是那么不安。\n 作为其中的个人,在享受着现代化成功的时候,仿佛又成为现代化的奴隶,物质的丰裕无法填满精神的沟壑,何况物质本身就是对于贪婪无尽的追求,生活陷入了一场怪圈。\n 为生存所付出的代价,赢得片刻的欢愉,精神类的刺激又使得人类陷入疯狂,永远填不满的肚子,面对孤独的战栗,在面对现实时如同上瘾般的发作,对于荒诞不经的执着。\n 个人在寻找出路,是钟表上的时间吗,或许是,但也许不是,时间并不属于我们,我们只是按照引力行走在规定轨道的行星。\n 值得庆幸的是,尽管如此,上述种种,我们获得了这张旅行的门票,直到终点。\n\n\n 2023-07-09 → 2023-07-10 \n\n\n### 做一些真正有趣的事情\n\n\n---\n\n\n 正如您所看到和感受到到那样,生活有超出我们掌控能力到烦恼,如果我们把这些时间都用作去解决烦恼上去,那么我们每天所能留给自己的时间将会越来越少,所以,不妨去做一些真正有趣的事情, 来丰富和拓展自己的见闻,让那些烦恼见鬼去吧! 2023-07-06 \n\n\n### 灵感的收集模块\n\n\n---\n\n\n 在最初设计这个模块的时候,我对于这个模块的定义是用于每天的及时反馈,希望用流动的方式,对数据进行更好的总结。\n\n\n 但是我发现,随着时间的积累,这个模块被光顾的频率和作用已经被削弱了,但是问题依然存在,也就是说,在反馈模块,这个抗压模块的作用发挥得实在是太有限了。\n\n\n 为此,我们打算重新转换设计思路,正如您在第二和第三模块所看到的那样,我打算把这个模块定义为对于灵感的收集模块,记录那些“在例行反馈模块无法完成”的补充块。\n\n\n 看上去这样描述相当抽象,具体而言,我采用twikoo作为每天五个时间段的状态记录,提升反馈的及时性,然后把这些状态记录整合到[向阳花笺](/022f7d8a937246cdbb64839cbaed8b9b)当中,这整个流程是反馈的main分支。\n\n\n 但是main分支相对而言更加正式。因为我采用的方式是双语式的总结,对于行文的格式要求会比较高。所以会形成一种新式的总结方式,不再如传统的平铺直叙,而是直接用两句话来描述问题和感受。\n\n\n 但是正如前面所言,如果main分支可以解决80%左右的问题,那么剩下的20%的问题依然存在,并且具有很大的影响,传统的类似于当下的文字叙述的方式也有用武之地。\n\n\n 所以我打算将这个模块设计为branch分支,用于反馈模块的补充设计,同时采用更加生活化的语言来记录生活中的灵感。 2023-07-04 \n\n\n# 写在最后\n\n\n---\n\n\n 很感谢您能看到这里,这里承载了很多很漫长的故事,也见证着我的成长,在每一个不起眼的日子里,不辜负好时光!\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-06-06",
"type": "Post",
"category": "走近生活",
"slug": "feedback",
"tags": [
"流动核心"
],
"summary": "情书写给山鬼 心事寄予西风",
"title": "[流动核心] 蜿蜒曲折 妙遇神女",
"status": "Published",
"urlname": "5dca0507-79f1-4ba3-ab6d-272ce8bc6779",
"updated": "2024-02-25 12:12:00"
},
"catalog": [
{
"title": "流动核心",
"doc_id": "5dca0507-79f1-4ba3-ab6d-272ce8bc6779"
}
],
"body": "",
"realName": "[流动核心] 蜿蜒曲折 妙遇神女",
"relativePath": "/流动核心/[流动核心] 蜿蜒曲折 妙遇神女.md"
},
{
"id": "dbc741cb-93ce-436e-83f3-76744b86b373",
"doc_id": "dbc741cb-93ce-436e-83f3-76744b86b373",
"updated": 1716029820000,
"body_original": "\n 常常惊讶于自己的“新鲜”,像个长不大的孩子。 \n\n\n 那年,一大早起来便到傅园念英文。起先还兴致勃勃,真的念得朗朗有声。后来热劲弱了,卷着书,反翦双手,只是沿着喷水池一来一回地踱步,往往一个早上连一个生词都没背下来。\n 但我仍旧觉得充实,因为太多新鲜的想法都一股脑儿地跳出来。\n 起初,是那棵“橄榄树”,将我安排得紧紧的时间表一下打得湿烂,我从此脑子里把橄榄树列为每天必须拜访的对象之一,而且热情一直不减。其实,让我感兴趣的不是橄榄树,而是橄榄树上的橄榄。\n 后来,我实在无法忍受那些“压枝低”的翠绿小橄榄在我脑子里不时晃荡的诱惑,再加上听说有人一桶一桶地将六号馆附近的橄榄打下来恣意糟蹋,我恨得真是“咬牙切齿”。最后,“相思”得无法自拔,连黄昏也跑去傅园看看,看到树梢上的小橄榄,真是一则以喜,一则以忧。喜的是,还好尚未被那些不知珍惜的人糟蹋;忧的是,任凭自己踮起左脚或右脚,伸长右手或左手,仍旧无法“一亲芳泽”,小橄榄还是那么的“高不可攀”。有几次,甚至想趁着“月黑风高”的夜晚单独行动。只是,不管白天或晚上,傅园一直没有“冷清”过,而我又“胆小”过人,别说打草惊蛇,就连站在橄榄树下的勇气都没有。唉!只怪自己“道德意识”太强,终不能成就此等“美事”。\n 终于,贵人相助。那天我再度痴痴地散步到傅园,一举头,看见三五个小毛头,汗衫短裤,竹竿塑料袋,叽里呱啦地朝着橄榄树打得好不认真。我一看,先是愣住了,然后是怒,最后转怒为喜,真是天赐良机。赶忙过去和小哥儿们互相问好,看看收获情形,终于博得他们的“拔竿相助”,分我一杯羹。\n 我捧着十几颗橄榄,像捧着十几颗祖母绿玉石一般。几乎是跳着回寝室,兴奋地找出玻璃瓶,大致清洗一番。当我把洗过的橄榄放在书桌上吹干时,那晶莹的水珠几乎可以映出我眼里热切的希望,我有着从事探险一般奇妙的兴奋感,久久挥之不去。\n 而更奇妙的,我竟然想到要酿它们,这真是天外闯来的神思。这个遐想让我雀跃了起来,一会儿把橄榄挤进瓶里,一会儿又统统倒出来,简直比拥有十颗祖母绿更紧张。如果只是十颗玉石,倒又简单,保险柜一搁就没事了,偏偏是滑不溜丢的小橄榄,就像一群小精灵似的,才不会安安分分地挤在瓶里,它们会变,会把一个小瓶子变成一个小宇宙,它们不但有奇特的形状、气味,更会变出醉人的馨香,如果它们合作的话。我希望二旬之后,当我打开密封的瓶盖时,醉我的是一股神秘的迷香,而不是腐朽之气,这就是“酿”的功夫了。而我从来没有酿过,却冀望一只只鼓胀着风帆的青涩小船,变成一条条甘甜的轻舟,驶进我双唇的港湾。\n 我时时发痴在想,一点盐一点糖,会把饱绿的橄榄浸成何等模样?真是个神秘的小宇宙。我几次禁不住把玻璃瓶拿出来左右上下瞧一瞧,真是叹绝这浑然不可解的玄机。\n 开瓶那一天,我简直像在拆上天送我的礼物一般。那股紧张、悬疑、急于想知道究竟的心情,真如张满的弓。一声轻快有力的吆喝,瓶盖倏地迸开,一股甜润带酒的柔香,轻轻地散在鼻息之间,令人忍不住闭着眼,深深地吸一口,如酒暖流遍全身,一时半醉起来。\n 原本硬挺的橄榄,浸得软皱皱一身,甘中带有七分柔酸三分酒意,含在嘴里,便会有意无意地从喉间刺滑而过,分不出是甘、是酸、是酒,却觉得又甘、又酸、又酒,妙在一刹那。\n 橄榄吃完了,连暖暖的汁也一滴不剩。自己却又心痴起来,觉得人间万物真是奇妙,可以是最涩苦的东西,也可以是最甘香的东西;极涩处即是极甘处,仿如一体之两面,互为表里。于是我在想,是否人事世情亦是如此,极不幸处,可能是极幸的转机;极痛苦的,也可能是极乐的……那么人间不是“绝对”的种种存有,而是相对的双方必会同时存在的显现。我们常常执于一偏之见,把心灵之眼的焦距,调在某种类型的事物上,于是我们的心版上,久而久之,便只能容下特定类型的事物,逐渐失去涵摄的能力,我们的心灵之眼,亦失去了能远能近、能上能下的弹性视野了。\n 幸与不幸,美与丑,可以是同义复词,看自己有没有“酿”的功夫了,就如硬涩的橄榄变成甘美的蜜饯。\n 一粒沙,是丑的;对蚌而言,肉里嵌进一粒沙,是不幸的。而珍珠是美的,带珠的蚌更是身价百倍。海蚌如此,人又何尝不是如此。\n 生活如浩瀚汪洋,人潮起落之中,我们难免会撞礁搁浅,会掉进诡谲的漩涡,会困在迷洞,会滚了一身刺人的沙粒,苦不堪言……无论如何,告诉自己:也许我就是带珠的蚌。\n 从一颗颗的橄榄,我学会一个“酿”字,从这个“酿”字,我领悟到如何去面对生活,甚至是人生。生活,是门高妙深奥的学问,我只是门外的拾穗者,那么有什么极辛酸苦涩的东西都赐给我吧!卷高双袖,让我来酿!\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-11-27",
"type": "Post",
"category": "璀璨星空",
"slug": "jianzhen-2",
"tags": [
"水问-简媜"
],
"summary": "从一颗颗的橄榄,我学会一个“酿”字,从这个“酿”字,我领悟到如何去面对生活,甚至是人生。",
"title": "[水问] 我来酿——生活细笔之五-简媜",
"status": "Published",
"urlname": "dbc741cb-93ce-436e-83f3-76744b86b373",
"updated": "2024-05-18 10:57:00"
},
"catalog": [
{
"title": "水问-简媜",
"doc_id": "dbc741cb-93ce-436e-83f3-76744b86b373"
}
],
"body": "",
"realName": "[水问] 我来酿——生活细笔之五-简媜",
"relativePath": "/水问-简媜/[水问] 我来酿——生活细笔之五-简媜.md"
},
{
"id": "f7ca2236-a7a8-4847-b553-426c920f2e6e",
"doc_id": "f7ca2236-a7a8-4847-b553-426c920f2e6e",
"updated": 1716030000000,
"body_original": "\n# 更新\n\n\n---\n\n\n这里记录这篇文章的更新。\n\n\n### 重读后的感受 2024-04-23 \n\n\n---\n\n\n买了简媜的《水问》《空灵》,原因如下:\n\n\n> 💡 #想法 \n> 晚上我认为睡前最佳实践一定不是看电子设备,应该是看实体书,我虽然买实体书很少,但我决定入手简媜的《水问》,打算再读一遍。第一次读简媜的书就极为欣赏她的文笔,目前在读和需要整理的书都是大工程,«黄帝内经»«项塔兰»«水问»,我打算穿插着总结,bing说我的高质量文章太少了,还是得催着我多写点读书笔记。但我还得想想怎么把时间利用好,我现在感觉自己还是和热锅上的蚂蚁一样。\n\n\n今天回来,把之前整理的这篇文章,重新看了一下,写了几处读书笔记,我为什么会喜欢简媜的文字呢,其一是因为简媜的文字的包含对于大自然丰富的感受和体会,这种感觉天然地优美而活泼,唤起了我年轻时候的回忆;其二是因为书里的很多内容值得我思考。\n\n\n# 正文\n\n\n---\n\n\n 今天不知不觉就把简媜的《水问》看完了,看完觉得挺有感慨的。《水问》这本书记录了简媜大学生活到毕业的这段心路历程。和我们自身的经历也很像,虽然隔着几十年,但是好的文字读起来不会过时。知识,爱情,友情,自然,等诸多的主题,用轻灵的笔触呈现出瑰丽的画面。\n\n\n### 原文\n\n\n---\n\n\n\n\n\n\n\n\n\n\n\n# 总结\n\n\n---\n\n\n 《浮士德》说,有两个灵魂蕴藏在我心中,当经历过人生的数重悲剧之后,才能得到救赎。走进魔女的丹房,和魔鬼的契约支配着我们追逐无尽的欢愉,财富,声名,理想,当失去的时候才能体会得到,得到的同时又在失去。当我们回到自己的”第一页“时,我们永远年轻,可以赞叹自然的四季轮回,可以赞叹最纯粹的友谊,拥抱最纯粹的欢喜……很喜欢这句,生命是无限的惊喜,我用微笑与泪光送你。\n\n",
"properties": {
"password": "",
"icon": "",
"date": "2023-12-07",
"type": "Post",
"category": "璀璨星空",
"slug": "jianzhen-4",
"tags": [
"水问-简媜"
],
"summary": "《浮士德》说,有两个灵魂蕴藏在我心中,当经历过人生的数重悲剧之后,才能得到救赎。走进魔女的丹房,和魔鬼的契约支配着我们追逐无尽的欢愉,财富,声名,理想,当失去的时候才能体会得到,得到的同时又在失去。当我们回到自己的”第一页“时,我们永远年轻,可以赞叹自然的四季轮回,可以赞叹最纯粹的友谊,拥抱最纯粹的欢喜……很喜欢这句,生命是无限的惊喜,我用微笑与泪光送你。",
"title": "[水问] 水经注——诀朋-简媜",
"status": "Published",
"urlname": "f7ca2236-a7a8-4847-b553-426c920f2e6e",
"updated": "2024-05-18 11:00:00"
},
"catalog": [
{
"title": "水问-简媜",
"doc_id": "f7ca2236-a7a8-4847-b553-426c920f2e6e"
}
],
"body": "",
"realName": "[水问] 水经注——诀朋-简媜",
"relativePath": "/水问-简媜/[水问] 水经注——诀朋-简媜.md"
},
{
"id": "2d81a58a-f00b-4790-bc06-9c09a29bd8ce",
"doc_id": "2d81a58a-f00b-4790-bc06-9c09a29bd8ce",
"updated": 1716029880000,
"body_original": "\n 我不是个画家,但撷取美的片刻是我的心愿。\n\n\n 我不是个作家,但记录每一次的感动是我的习惯。\n\n\n 仔细想想,生活的本身即是书、即是画。也许前一刻,我们是阅书观画的读者,而下一刻,却又变成书中主角、画中人物了。更有可能,我们同时既是读者,又是主角。\n\n\n 每个日子,都是内容不同的一本书,风格迥异的一幅画。只是我们的脚步太匆忙了,常常忘记去读它,欣赏它,随意地浏览过去,便断言生活是一味地今日抄袭昨日,只是公式化的食衣住行罢了。阅读,不仅是认识符号而已,更要懂得符号所传递的内涵;而观画,也不只是五彩缤纷的调配,细细想来,画中原是有画。\n\n\n 我是个小人物,只希望自己别那么匆忙,希望能够静下来,老老实实地把生活一本一幅慢慢地看,用我的心细细品尝,并把愉美的刹那、感动的心情,一字一句、勤劳不倦地做成生活之细笔。\n\n\n 于是,处处美丽。\n\n",
"properties": {