| title | thumbnail | authors | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Introducing Idefics2: A Powerful 8B Vision-Language Model for the community |
/blog/assets/idefics/thumbnail.png |
|

We are excited to release Idefics2, a general multimodal model that takes as input arbitrary sequences of texts and images, and generates text responses. It can answer questions about images, describe visual content, create stories grounded in multiple images, extract information from documents, and perform basic arithmetic operations.
Idefics2 improves upon Idefics1: with 8B parameters, an open license (Apache 2.0), and enhanced OCR (Optical Character Recognition) capabilities, Idefics2 is a strong foundation for the community working on multimodality. Its performance on Visual Question Answering benchmarks is top of its class size, and competes with much larger models such as LLava-Next-34B and MM1-30B-chat.
Idefics2 is also integrated in 🤗 Transformers from the get-go and therefore is straightforward to finetune for many multimodal applications. You can try out the models on the Hub right now!
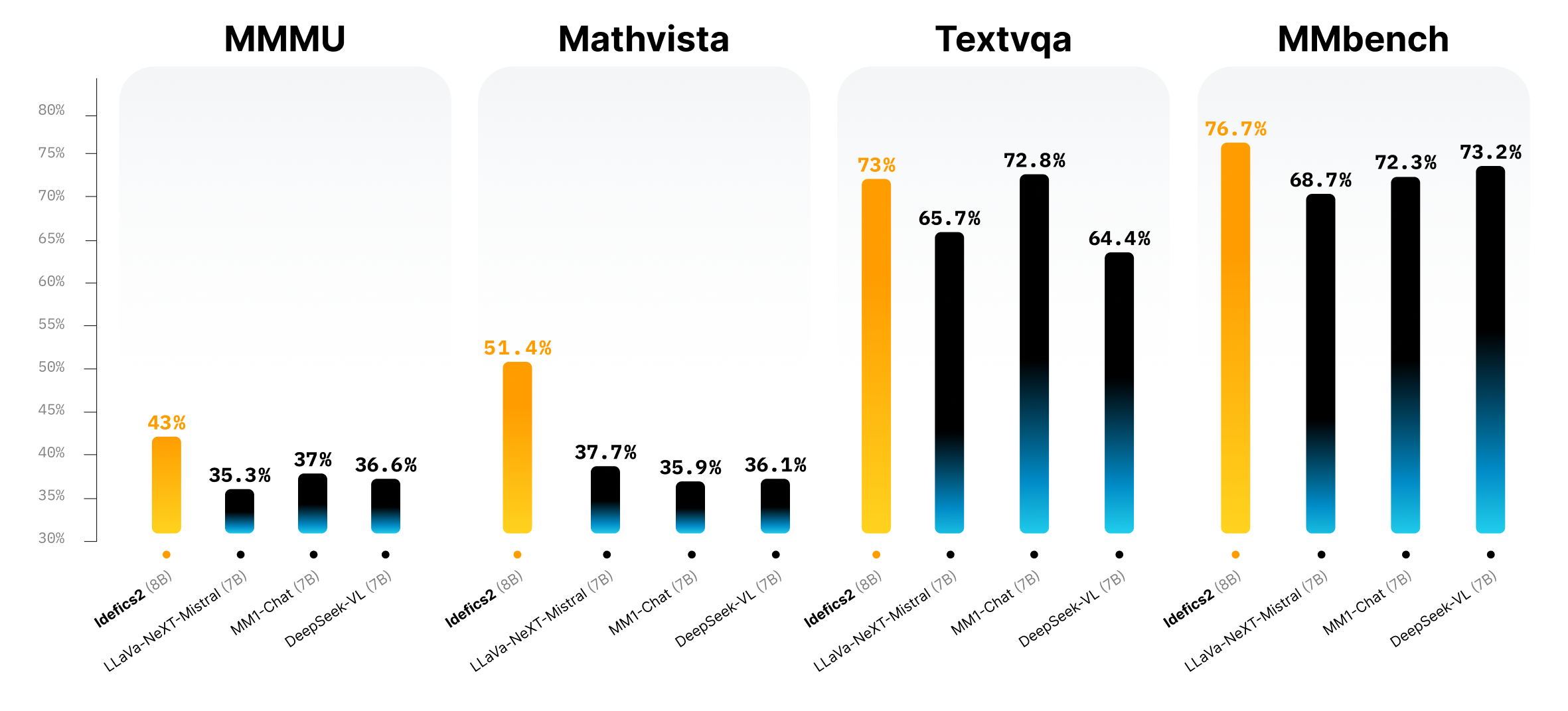
| Model | Open weights |
Size | # tokens per image |
MMMU (val/test) |
MathVista (testmini) |
TextVQA (val) |
MMBench (test) |
VQAv2 (test-dev) |
DocVQA (test) |
|---|---|---|---|---|---|---|---|---|---|
| DeepSeek-VL | ✅ | 7B | 576 | 36.6/- | 36.1 | 64.4 | 73.2 | - | 49.6 |
| LLaVa-NeXT-Mistral-7B | ✅ | 7B | 2880 | 35.3/- | 37.7 | 65.7 | 68.7 | 82.2 | - |
| LLaVa-NeXT-13B | ✅ | 13B | 2880 | 36.2/- | 35.3 | 67.1 | 70.0 | 82.8 | - |
| LLaVa-NeXT-34B | ✅ | 34B | 2880 | 51.1/44.7 | 46.5 | 69.5 | 79.3 | 83.7 | - |
| MM1-Chat-7B | ❌ | 7B | 720 | 37.0/35.6 | 35.9 | 72.8 | 72.3 | 82.8 | - |
| MM1-Chat-30B | ❌ | 30B | 720 | 44.7/40.3 | 39.4 | 73.5 | 75.1 | 83.7 | |
| Gemini 1.0 Pro | ❌ | 🤷♂️ | 🤷♂️ | 47.9/- | 45.2 | 74.6 | - | 71.2 | 88.1 |
| Gemini 1.5 Pro | ❌ | 🤷♂️ | 🤷♂️ | 58.5/- | 52.1 | 73.5 | - | 73.2 | 86.5 |
| Claude 3 Haiku | ❌ | 🤷♂️ | 🤷♂️ | 50.2/- | 46.4 | - | - | - | 88.8 |
| Idefics1 instruct (32-shots) | ✅ | 80B | - | - | - | 39.3 | - | 68.8 | - |
| Idefics2 (w/o im. split)* | ✅ | 8B | 64 | 43.5/37.9 | 51.6 | 70.4 | 76.8 | 80.8 | 67.3 |
| Idefics2 (w/ im. split)* | ✅ | 8B | 320 | 43.0/37.7 | 51.4 | 73.0 | 76.7 | 81.2 | 74.0 |
* w/ im. split: Following the strategy from SPHINX and LLaVa-NeXT, we allow for an optional sub-image splitting in 4.
Idefics2 was trained on a mixture of openly available datasets for the pretraining: Interleaved webdocuments (Wikipedia,OBELICS), image-caption pairs (Public Multimodal Dataset, LAION-COCO), OCR data (PDFA (en), IDL and Rendered-text, and image-to-code data (WebSight)).
The interactive visualization allows exploring the OBELICS dataset.
Following common practices in the foundation model community, we further train the base model on task-oriented data. However, these data are often in disparate formats, and scattered in various places. Gathering them is a barrier for the community. To address that problem, we are releasing the multimodal instruction fine-tuning dataset we've been cooking: The Cauldron, an open compilation of 50 manually-curated datasets formatted for multi-turn conversations. We instruction fine-tuned Idefics2 on the concatenation of The Cauldron and various text-only instruction fine-tuning datasets.

- We manipulate images in their native resolutions (up to 980 x 980) and native aspect ratios by following the NaViT strategy. That circumvents the need to resize images to fixed-size squares as it has been historically done in the computer vision community. Additionally, we follow the strategy from SPHINX and (optionally) allow sub-image splitting and passing images of very large resolution.
- We significantly enhanced OCR abilities by integrating data that requires the model to transcribe text in an image or a document. We also improved abilities in answering questions on charts, figures, and documents with appropriate training data.
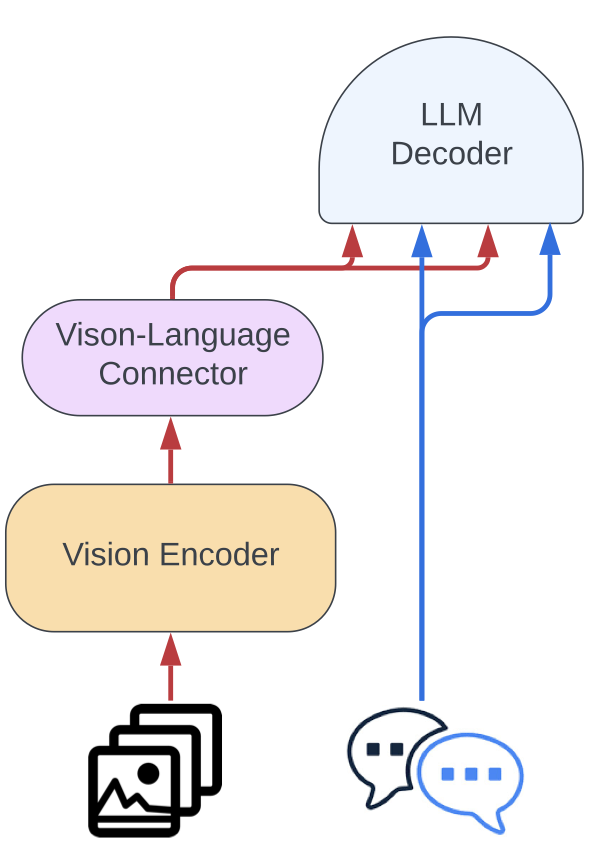
- We departed from the Idefics1's architecture (gated cross-attentions) and simplified the integration of visual features into the language backbone. The images are fed to the vision encoder followed by a learned Perceiver pooling and an MLP modality projection. That pooled sequence is then concatenated with the text embeddings to obtain an (interleaved) sequence of image(s) and text(s).
All of these improvements along with better pre-trained backbones yield a significant jump in performance over Idefics1 for a model that is 10x smaller.
Idefics2 is available on the Hugging Face Hub and supported in the last transformers version. Here is a code sample to try it out:
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda:0"
# Note that passing the image urls (instead of the actual pil images) to the processor is also possible
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg")
image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg")
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceM4/idefics2-8b",
).to(DEVICE)
# Create inputs
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What do we see in this image?"},
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."},
]
},
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "And how about this image?"},
]
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)We also provide a fine-tuning colab which should come in handy for anyone looking to improve Idefics2 on specific use cases.
If you wish to deep dive further, here is the compilation of all resources for Idefics2:
- Idefics2 collection
- Idefics2 model with model card
- Idefics2-base model with model card
- Idefics2-chat model with model card (coming soon)
- The Cauldron with its dataset card
- OBELICS with its dataset card
- WebSight with its dataset card
- Idefics2 fine-tuning colab
- Idefics2-8B model demo (not the chatty model)
- Idefics2 demo: (coming soon)
- Idefics2 paper: (coming soon)
The model is built on top of two pre-trained models: Mistral-7B-v0.1 and siglip-so400m-patch14-384. Both of them have been released under Apache-2.0 license. We release Idefics2 weights under an Apache-2.0 license as well.
Thank you to the Google Team and Mistral AI for releasing and making their models available to the open-source AI community!
Special thanks to Chun Te Lee for the barplot, and Merve Noyan for the review and suggestions on the blogpost 🤗