For information about the current release, please refer to the V0.1 release notes
For researchers and small research groups:
There is currently a significant push for published research to be backed up by publicly accessible, sharable, re-usable datasets. But publishing re-usable data on the web is not easy, especially for small research groups. But it is in the nature of research that no two projects have exactly the same requirements, so a tool developed specifically for one projhect is probably not going to be very helpful for another.
Currently, the tool of choice (or necessity) for many researchers is a spreadsheet. Spreadsheets have many good properties, in that they do not have a steep learning code to be useful, and are flexible enough to be readily adapted to the requirements of a particular research project. But they are less effective when it comes to sharing and re-mixing data sets between projects, as much of the information about the specific structure and relationships in the tabular data is opaque to automated processing.
-
Large projects may have resources to develop custom software to manage publication of their research data, but small groups generally don't have the skills or the capacity. What is required is an "out of box" solution that allows individual researchers and small groups to publish and share their data.
-
It is not always clear at the outset of a research activity what form the final data will take. A project I worked on around 2005-06 had as its goal the publication of in situ gene expression images from fruit fly testes, along with their interpretation, annotations and supporting evidence, for publication as a web-accessible and queryable database. Notable in this project was that the form of the final image annotations in the late stages of the project, after much of the data had been gathered, was revised several times to support the nature of the observations made, and the desired query patterns.
-
It is increasingly the case that research builds on not only the outcomes, but also the specific datasets, from other research projects. Often (e.g. in the field of bioinformatics), results need to be referred to global public genomic databases. It is highly desirable that datasets be remixable and cross-linkable.
For indivuduals, clubs, small businesses, etc:
Many of the above problems may be faced in smaller ways by anyone who uses a computer to store data.
Personal information, TODO lists, accounting records, object catalogues, and photo galleries are just a few examples of applications that combine structured annotations with other information. Current tools (of which I am aware) that can be used for creatinmg these kinds of datasets (a) require some non-trivial level of technical expertise to use, (b) tend to require a data model to be defined in advance, when often one wants to allow details to be added into the structure as they are encountered, and (c) don't really lend themselves to collaborative work or sharing and cross-linking with public datasets.
Drawing from the above observations, Annalist aims to be a linked data notebook, supporting collection, organization and sharing of structured and semi-structured data. (The name "annalist" derives from "a person who writes annals".)
Four key goals for Annalist that have been identified are:
- Easy data: out-of-box data acquisition, modification and organization of small data records.
- Flexible data: new record types and fields can be added as-required.
- Sharable data: use textual, easy to read file formats that can be shared by web, email, file transfer, version management system, memory stick, etc.
- Remixable data: records that can be first class participants in a wider ecosystem of linked data, with links in and links out.
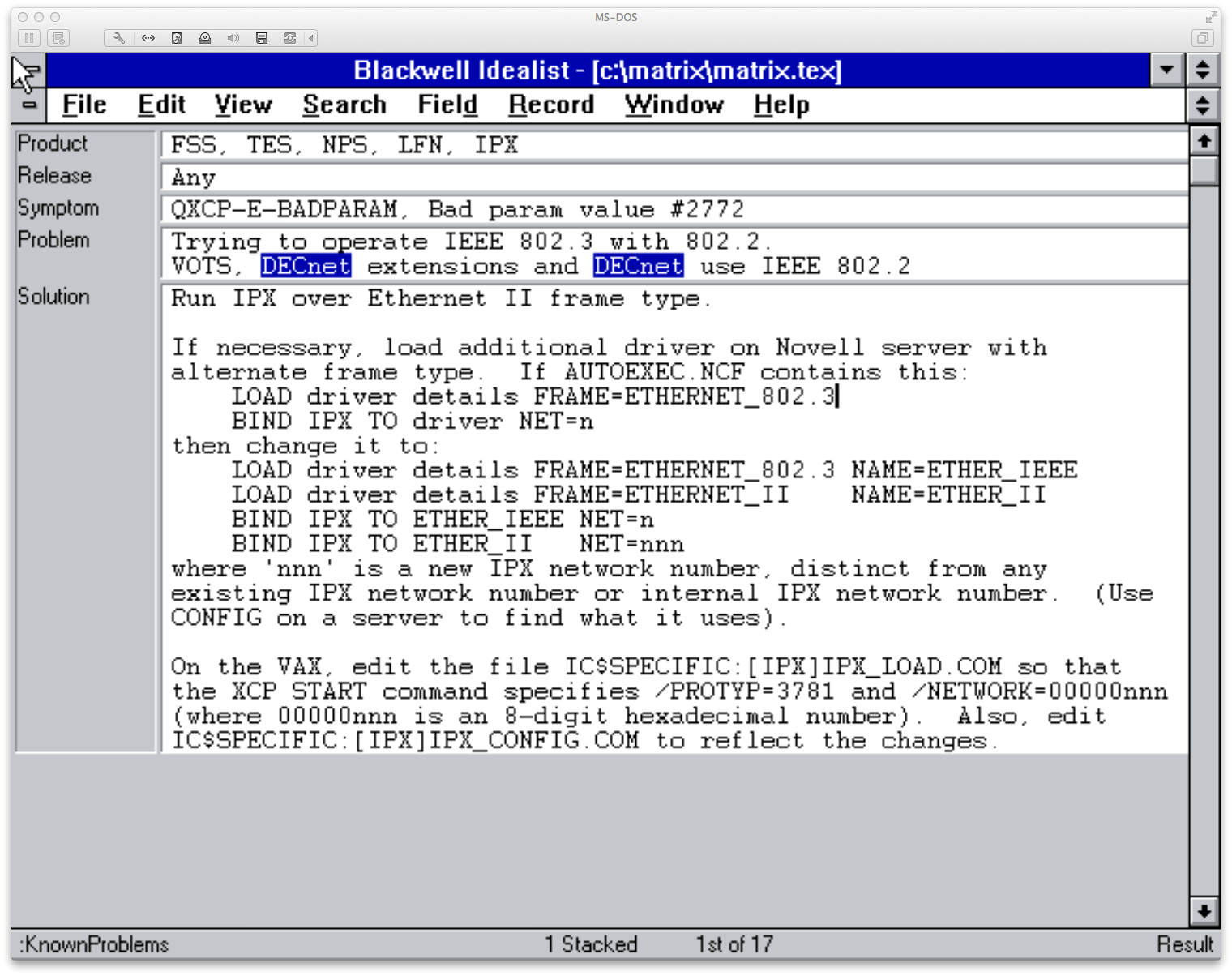
In Annalist, I hope to create a generic linked data notebook which can be used for diverse purposes, in which I have been motivated by the needs of small academic research groups, and my own past experiences running a small business. I want to deliver a self-hostable, web-based tool that will, "out-of-box", allow collection of web accessible, linked data without prior design of its structure. I aim to allow structure in data to be developed as needs arise. Some of my ideas for this are drawn from pre-web PC tools (e.g. WordPerfect Notebook and Blackwell Idealist) which used simple text based file formats to drive flexible, small-scale databases.
{kind=link}
{kind=link}
There are also a number of secondary goals which have informed some of the design choices made in developing Annalist:
- end user configuration via incremental definition of structures
- semi-structured data - free text and "semantics"
- no lock-in: possible to usefully publish raw Annalist data from a regular web server, or from a file server
- VCS-friendly (e.g. local data is also git repository)
- Dropbox-friendly; etc.
- mobile-friendly
- desktop or web hosting
- usable with separately hosted data
- support data hosting for external applications (REST API)
- "source as resource": data is viewable by end user using just a text viewer
- incremental backup friendly
- search across all or selected fields
Aimed at technically- and data-literate users who are not necessarily software developers, or who don't have resources to undertake software developent
Small research groups, or individuals building subsidiary datasets that may contribute to the work of a larger research group or project.
Broadly the notion of the Research Object is that a researcher can bundle together all the bits and pieces that make up the record of a piece of research into one sharable and citable object.
David De Roure, University of Oxford. Executable Music Documents.
Reasearch Objects thus contain a diverse mixture of information bundled together as a logically singular entity. In past work on Research Objects, a question that has often been asked by researchers, without an entirely satisfactory answer, is "how can I create an research object". Annalist allows the diverse elements of a research object to be drawn together and exposed as a single bundle, which is straightforward to convert to one's favoured form of Research Object package for sharing and distribution.
Annalist is also a tool that can be used to organize and collate various kinds of personal and/or hobby related data. In many cases, suitable tools for these data do not exist, or where they do they often create a silo from which it is difficult to extract data, or they may be insufficiently flexible to adequately meet local needs.
@@TODO: flesh out with more design/architecture information
flat file storage
small data (storage and referencability of small item descriptions)
linked data format(s) (JSON-LD)
indexing and search as a separate linked service
transferrability of data
data-driven presentation
self-maintaining: configuration data is stored and managed as Annalist data records
versionable data
mobile-capable
There is a rough survey of some related technolgies and systems performed about mid-2013, which can be seen in slides 20-28 of this presentation. The survey uses colour coding of a selection of features, where green indicates the product supports the feature, red that it is believed to not support the feature, and yellow indicating that the status a feature was unknown in that system.
The surveyed systems included:
- Callimachus
- Semantic wiki / wikidata
- Spreadsheets
- Rightfield
- Figshare
- Access (database)
- Idealist (software no longer available, but an inspiration for Annalist)
- ResearchSpace
With the exception of Callimachus, which scored about 60-80%, none of these scored more than about 50% of availability of the features to be targetted by Annalist. (This is not to critisize these systems, just observing that the requirements addressed don't entirely align with those for Annalist.)
A tool that I use for a lot of rough data recording is SimpleNote (and Notational Velocity). This is a pure text tool that addresses many of the desiderata targetted by Annalist, but deals with simple raw text files rather than data. It would, in theory, be possible to encode the data as test in such a system, but I don't think that would be a truly viable option for any serous data.
Related to some aspects of Annalist's design is the work on linked data fragments by Ruben Verborgh et al at iMinds, University of Ghent. Annalist's use of flat files for storing small frames of data has similarities with some of these ideas. One way in which Annalist differs from the Linked Data Fragments work is that the fragments are used as the native form of stored data, and amalgamation into larger datasets only comes later, if at all. Also, it is not a goal of Annalist to support high performance querying over large datasets. It is conceivable that Annalist data records would play well with the developing Linked Data Fragments infrastructure.
A development not in the original survey is DBWiki, whose goals appear to be much closer to those of Annalist. See Using Links to prototype a Database Wiki for more details.