Cada vez que abres tu navegador, escribes alguna direccion URL y pulsas ENTER, verás hermosas páginas web que aparecen en pantalla. Pero, ¿sabes lo que está sucediendo detrás de esta simple acción?
Normalmente, el navegador es un cliente, después de teclear la URL, envía peticiones a un servidor DNS, para obtener la dirección IP de la URL. Luego de encontrar el servidor en esta dirección IP, configura una conexión TCP. El navegador envía las peticiones HTTP a través de la conexión. El servidor las maneja y responde con respuestas HTTP que contiene el contenido que puedes ver en tu página web. Finalmente, el navegador renderiza el cuerpo de la página web y se desconecta del servidor.

Figura 3.1 Procesos de usuarios que visitan una página web
Un servidor web también conocido como un servidor HTTP, utiliza el protocolo HTTP para comunicarse con los clientes. Todos los navegadores web pueden ser vistos como clientes.
Podemos dividir los principios de trabajo de Internet en los pasos siguientes:
- El cliente utiliza el protocolo TCP / IP para conectarse al servidor.
- El cliente envía paquetes de solicitud HTTP al servidor.
- El servidor devuelve los paquetes de respuesta HTTP para el cliente, si los recursos de petición incluyen scripts dinámicos , el servidor llama al motor de scripts primero.
- El cliente se desconecta del servidor, comienza renderizado HTML.
Este es un sencillo flujo de trabajo de asuntos HTTP, observe que el servidor despues de un tiempo cierra las conexiones de datos que se envían a los clientes, y espera a que la próxima petición.
Siempre estamos utilizando URL para acceder a páginas web , pero ¿sabes cómo funciona el URL ?
El nombre completo de la dirección URL es Uniform Resource Locator (Localizador de Recursos Uniforme), esto es para la descripción de recursos en Internet. Su forma básica como sigue.
esquema://host[:port #]/ruta/.../[? cadena de consulta ][# ancla ]
esquema: asignación de protocolo subyacente (como HTTP , HTTPS, FTP )
host: IP o nombre de dominio del servidor HTTP
puerto#: puerto por defecto es 80 , y se puede omitir en este caso.
Si desea utilizar otros puertos , debe especificar qué puerto . Por ejemplo ,
http://www.cnblogs.com:8080/
ruta: ruta de los recursos
datos: datos de consulta se envían al servidor
ancla AnclaDNS es la abreviatura de Domain Name Server (Servidor de Nombres de Dominio), que es el sistema de nombres de servicios informáticos en red, convierte nombres de dominio a direcciones IP reales, al igual que un traductor.
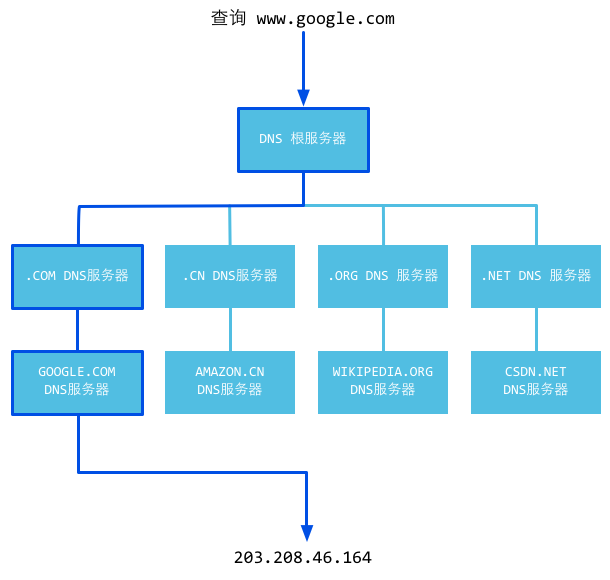
Figura 3.2 Principios de funcionamiento de DNS
Para entender más acerca de su principio de funcionamiento, veamos en detalle el proceso de resolución de DNS de la siguiente manera.
- Después de escrito el nombre de dominio www.qq.com en el navegador , el sistema operativo comprueba si hay alguna relación de correspondencia en el archivo hosts para el nombre de dominio, si es así, termina la resolución de nombres de dominio.
- Si no hay relación de proyección en el archivo hosts, el sistema operativo comprueba si hay alguna caché en el DNS, si es así, termina la resolución de nombres de dominio.
- Si no hay relación entre el computador y el servirdor de caché DNS, el sistema operativo busca el primer servidor de resolución de DNS en la configuración de TCP / IP, que es el servidor DNS local en este momento. Cuando el servidor DNS local recibió consulta, si el nombre de dominio que desea consultar está contenida en la configuración local de los recursos regionales, a continuación, devuelve los resultados al cliente. Esta resolución DNS es autoritaria.
- Si el servidor DNS local no contiene el nombre de dominio, y hay una relación de correspondencia en con el servidor caché DNS, el servidor DNS local devuelve este resultado a cliente. Esta resolución DNS no es autoritaria.
- Si el servidor DNS local no puede resolver el nombre de dominio, ya sea por la configuración de los recursos regionales o caché, se procede al próximo paso, que depende de la configuración del servidor DNS local. Si el servidor local de DNS no permite seguir avanzando, el enruta la petición a la raiz del servidor DNS, entonces retorna la dirección IP de un servidor DNS de alto nivel, que debería conocer el nombre de dominio,
.comen este caso. Si el primer servidor de mas alto nivel no reconoce el nombre de dominio, de nuevo re enruta la petición al siguiente servidor DNS de mayor nivel, así sucesivamente hasta que encuentre un servidor DNS que pueda reconocer el nombre de dominio. Entonces, se le solicita al servidor DNS la IP correspondiente al dominio, en este casowww.qq.com
- Si el servidor DNS local habilita seguir adelante, envía la solicitud al servidor DNS de nivel superior, si el servidor DNS de nivel superior también no sabe el nombre de dominio , a continuación, seguira enviando solicitudes a nivel superior.
- Si el servidor DNS local permite a modo de avance , la dirección IP del servidor de nombre de dominio devuelve al servidor DNS local, y el servidor local envía a los clientes.
Sea que el cliente DNS local habilite o no el redireccionamiento, la dirección IP del dominio siempre se retornará al serviror local de DNS, y el servidor local DNS se lo enviará de vuelta al cliente

Figura 3.3 DNS flujo de trabajo de resolución.
Proceso de consulta recursiva significa que las solicitudes de información están cambiando en el proceso, encambio las solicitudes de información no cambian en el proceso de consulta iterativa .
Ahora sabemos que los clientes obtendran direcciones IP , al final, por lo que los navegadores estan comunicandose con los servidores a través de las direcciones IP.
Protocolo HTTP es la parte fundamental de los servicios web. Es importante saber lo que es el protocolo HTTP antes de entender cómo funciona la web.
HTTP es el protocolo que se utiliza para la comunicación entre navegadores y servidores web, se basa en el protocolo TCP, y por lo general utilizan el puerto 80 en el servidor web. Es un protocolo que utiliza el modelo de petición-respuesta, los clientes envían peticiones y el servidor responde. De acuerdo con el protocolo HTTP, los clientes siempre configuran una nueva conexión y envian una petición HTTP al servidor en cada asunto. Los servidor no son capaces de conectar con el cliente de forma proactiva, o establecer conexiones que inicien desde ellos. La conexión entre el cliente y el servidor puede ser cerrada por cualquier lado. Por ejemplo, puedes cancelar su tarea de descarga y conexión HTTP tu navegador se desconecta del servidor antes de que termine la descarga.
El protocolo HTTP no tiene estado, lo que significa que el servidor no tiene idea acerca de la relación entre dos conexiones, a pesar de que puedan ser ambas de un mismo cliente. Para solucionar este problema, las aplicaciones web usan Cookies para mantener el estado sostenible de conexiones.
Por esta causa, debido a que el protocolo HTTP se basa en el protocolo TCP , todos los ataques TCP afectarán a la comunicación HTTP en el servidor, como por ejemplo SYN Flood, DoS y DDoS .
Solicitar paquetes tienen tres partes: la línea de petición , solicitud de encabezado y cuerpo . Hay una línea en blanco entre la cabecera y el cuerpo.
GET/domains/ejemplo/ HTTP/1.1 // línea de solicitud : método de la petición , la dirección URL , el protocolo y su versión.
Host: www.iana.org / / nombre de dominio
User-Agent : Mozilla/5.0 (Windows NT 6.1 ) AppleWebKit/537.4 ( KHTML , like Gecko ) Chrome/22.0.1229.94 Safari/537.4 // información del navegador
Accept: text/html,application/xhtml+xml,application/xml;q=0,9,*/*;q=0.8 // MIME que los clientes pueden aceptar
Accept- Encoding : gzip, deflate, sdch // métodos de compresión
Accept- Charset : UTF- 8 , * ; q = 0.5 / / conjunto de caracteres en el lado del cliente
// Línea en blanco
// Cuerpo , los argumentos de recursos solicitud (por ejemplo , los argumentos de la POST )Utilizamos fiddler que obtener la siguiente información de la solicitud.
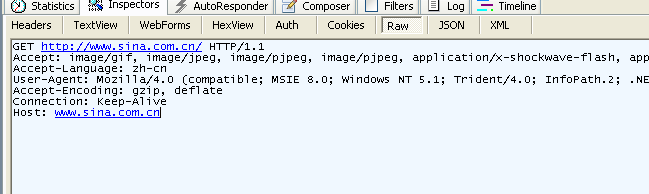
Figura 3.4 Información de método GET capturado por fiddler

Figura 3.5 Información de método POST capturado por fiddler
Podemos ver que el método GET no tiene cuerpo de la solicitud, el método POST sí.
Hay muchos métodos que puede utilizar para comunicarse con los servidores de HTTP ; GET, POST, PUT, DELETE son los 4 métodos básicos que utilizamos. Una URL representa un recurso en la red, por lo que estos 4 métodos significan consultar, cambiar, agregar y eliminar operaciones. GET y POST son los más utilizados en HTTP. GET puede añadir los parámetros de búsqueda usando el separador ? para separa la URL de los parámetros y & entre parámetros como por ejemplo: EditPosts.aspx?name=test1&id=123456. POST puede colocar muchísima mas información en el cuerpo de la petición, porque la URL solo puede tener un tamaño máximo, dependiendo del navegador. También, cuando pasamos nuestro nombre de usuario y contraseña, no queremos que este tipo de información aparesca en la URL, por lo que utilizamos la POST para mantenerlos invisibles.
Vamos a ver qué tipo de información se incluye en los paquetes de respuesta.
HTTP/1.1 200 OK // estado
Server : nginx/1.0.8 // web server y su versión en el equipo servidor
Date:Date: Tue, 30 Oct 2012 04:14:25 GMT // hora en que se respondió
Content-Type : text / html // tipo de datos que responde
Transfer-Encoding: chunked // significa que los datos se envían en fragmentos
Conexión : keep-alive // mantener la conexión
Content-Length: 90 // longitud del cuerpo
// Línea en blanco
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... // cuerpo del mensajeLa primera línea se llama línea de estado , que tiene la versión de HTTP, el código de estado y el mensaje de estado.
El código de estado informa al cliente del estado de la respuesta del servidor HTTP, en HTTP/1.1 existen 5 tipos de códigos de estado
- 1xx Información
- 2xx Éxito
- 3xx Redirección
- 4xx Errores del CLiente
- 5xx Errores del ServidorVamos a ver más ejemplos sobre los paquetes de respuesta, 200 significa servidor respondió correctamente, 302 significa la redirección .

Figura 3.6 La información completa al visitar un sitio web
Sin Estado no significa que el servidor no tiene la capacidad para mantener una conexión. Simplemente significa que el servidor no distingue la relación entre dos peticiones.
En HTTP/1.1 , Keep-alive se utiliza como valor predeterminado , si los clientes tienen más solicitudes, van a utilizar la misma conexión para muchas peticiones diferentes.
Observe que Keep Alive no puede mantener una conexión siempre, el software que se ejecuta en el servidor tiene cierto tiempo para mantener la conexión, y puedes cambiarlo.
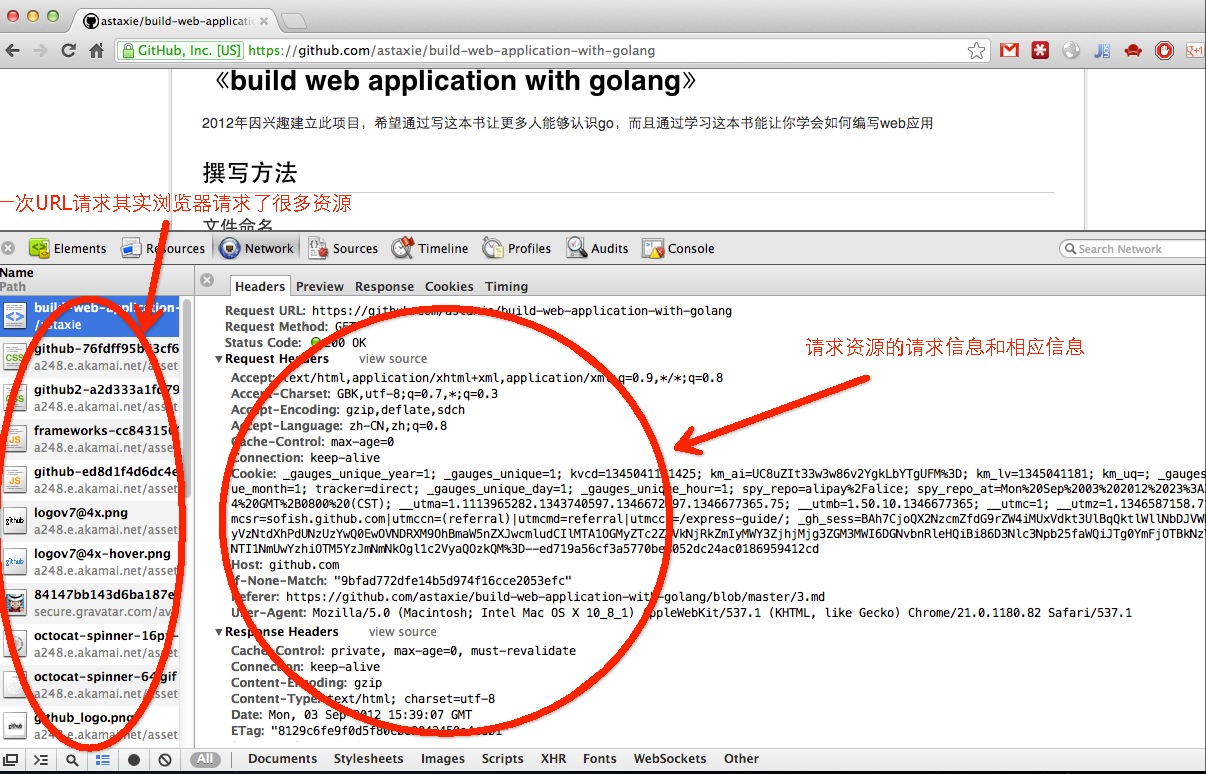
Figura 3.7 Todos los paquetes para abrir una página Web
Podemos ver todo el proceso de comunicación entre el cliente y el servidor en la imagen superior. Puedes notar que hay muchos archivos de recursos en la lista, se les llama archivos estáticos, y Go ha especializado métodos de procesamiento de estos archivos.
Esta es la función más importante de los navegadores, solicitud de una URL y obtener datos de los servidores web, y luego renderizar HTML para tener una buena interfaz de usuario. Si encuentra algún archivo en el DOM, como archivos CSS o JS, los navegadores solicitarán estos recursos al servidor nuevamente, hasta que todos los recursos terminen de renderizarse en la pantalla.
Reducir las veces que se hacen peticiones HTTP es una manera de mejorar la velocidad de carga de las páginas. Al reducir el número de peticiones CSS y JS que tienen que ser cargadas, la latencia de petición y la presión en tu servidor web puede ser reducida al mismo tiempo.
- Indice
- Sección anterior: Conocimientos básicos sobre la Web
- Siguiente sección: Armando un servidor web sencillo