LSTM FCN模型,摘自LSTM时间序列分类的完全卷积网络,通过长短记忆递归神经网络的精确分类,增强了时间卷积层的快速分类性能。
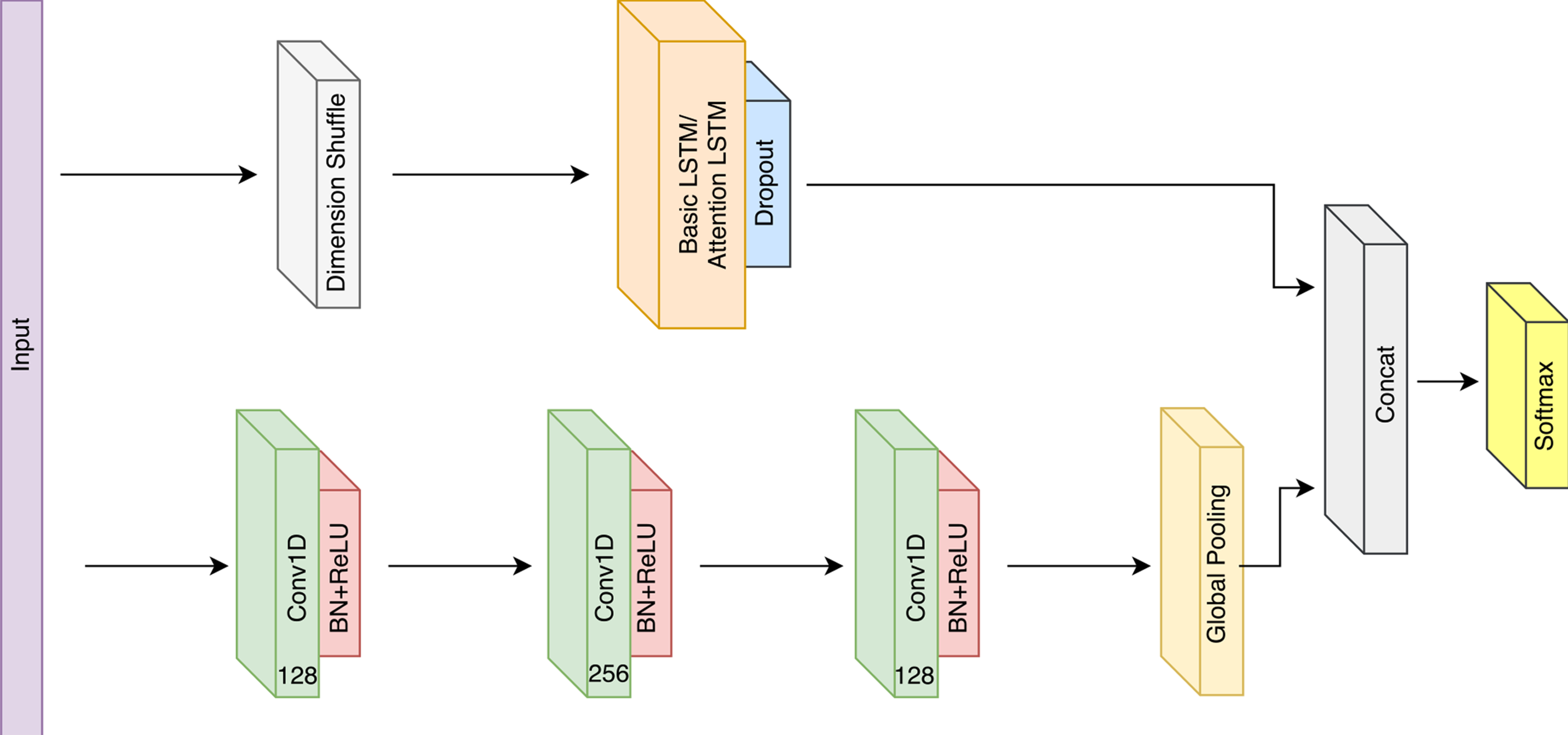
通用LSTM FCN是单变量数据集的高性能模型。然而,在多变量数据集上,我们发现如果直接应用,它们的性能并不是最优的。因此,我们为此类数据集引入多元LSTM-FCN(MLSTM-FCN)。
论文: Multivariate LSTM-FCNs for Time Series Classification
存储库: MLSTM-FCN
在过去的一年里,社区对该模型的细节提出了几个问题,例如:
-
为什么我们选择用LSTM扩充一个完全卷积的网络?
-
dimension shuffle 到底在做什么?
-
维度洗牌后,LSTM是否会失去所有重复的行为?
-
为什么不用另一个RNN(如GRU)替换LSTM?
-
是否有任何实际的改善可以从这一扩大?
因此,我们进行了详细的消融研究,包括近3627个实验,试图分析和回答这些问题,并更好地理解 LSTM-FCN/ALSTM-FCN 时间序列分类模型及其每个子模块。 这篇题为关于时间序列分类的LSTM完全卷积网络的见解的论文可以阅读,以便对维度无序LSTM对完全卷积网络的益处进行深入讨论和统计分析。
Paper: Insights into LSTM Fully Convolutional Networks for Time Series Classification Repository: LSTM-FCN-Ablation
下载存储库并应用 pip install -r requirements.txt 安装所需的库。
带有 Tensorflow 后端的 Keras 已用于开发模型,目前不支持 Theano 或 CNTK 后端。权重还没有用这些后端进行测试。
这些数据可以从这里以zip文件的形式获得—— http://www.cs.ucr.edu/~eamonn/time_series_data/
将其解压缩到某个文件夹中,它将给出127个不同的文件夹。复制粘贴util脚本 extract_all_datasets.py 到文件夹并运行它以获得单个文件夹_data,其中提取了所有127个数据集。剪切并将这些文件粘贴到 Data 目录中。
注意:所有模型的 Input 层的输入都会被预先打乱为形状(Batchsize, 1, Number of timesteps),输入在应用于 CNN 之前会再次打乱(以 获得正确的形状(批量大小,时间步数,1))。 这与输入为形状(Batchsize, Number of timesteps, 1)的论文形成对比,并且在 LSTM 之前应用 shuffle 操作以获得输入形状(Batchsize, 1, Number of timesteps)。 这些操作是等效的。
所有 127 个 UCR 数据集都可以使用提供的代码和权重文件进行评估。 有关说明,请参阅权重目录。
现在只有 1 个脚本可以在循环中的所有 127 个数据集上运行 LSTM-FCN 的所有组合及其注意变体,在三个不同的单元组合(8、64、128)上。
- 使用 LSTM FCN 模型:
model = generate_lstmfcn() - 使用 ALSTM FCN 模型:
model = generate_alstmfcn()
训练现在发生在 all_datasets_training.py 的最内层循环中。
必须提前设置几个参数:
-
数据集:数据集必须成对列出(数据集名称、ID)。所有 127 个数据集的 (name, id) 对已预设。它们对应于
utils目录中的constants.py中的 id。 -
模型:列表中的模型必须定义为 (
model_name,model_function) 对。请注意:model_function必须是返回 Keras 模型的模型,而不是实际模型本身。model_function可以接受 3 个参数 - 最大序列长度、类数和可选的单元格数。 -
细胞:需要训练的细胞的配置。默认为 [8, 64, 128],对应论文。
在此之后,一旦训练开始,每个模型将根据规范进行训练,并且将写入日志文件,其中描述所有参数以方便起见,以及训练结束时的训练和测试集准确性。
权重文件将自动保存在正确的目录中,可用于以后的分析。
要训练模型,请取消注释下面的行并执行脚本。 **注意 '???????' 已经提供,因此无需更换。 指保存的权重文件的前缀。 此外,如果已经提供了权重,则此操作将覆盖这些权重。
train_model(模型,做,dataset_name_,epochs=2000,batch_size=128,normalize_timeseries=normalize_dataset)
要评估模型的性能,只需执行未注释以下行的脚本。
evaluate_model(model, did, dataset_name_, batch_size=128,normalize_timeseries=normalize_dataset)
没有用于评估的单独脚本。 为了重新评估经过训练的模型,请注释掉最内层循环中的 train_model 函数。
由于文件夹和权重路径的自动名称生成,以下所有可视化都需要仔细选择 3 个常用参数:
-
DATASET_ID:
constants.py中的唯一整数 id,指的是数据集。 -
num_cells:LSTM / Attention LSTM Cells 的数量。
-
model:用于构建相应Keras Model的模型函数。
接下来是 dataset_name 和 model_name 的选择。 dataset_name 必须与 all_dataset_traning.py 脚本中的数据集名称匹配。 同样,model_name 必须与 all_dataset_training.py 中的 MODELS 中的模型名称匹配。
要可视化 LSTMFCN 或 Attention LSTMFCN 的卷积过滤器的输出,请使用“visualize_filters.py”脚本。
有两个参数,CONV_ID 表示卷积块编号(因此范围为 [0, 2])和 FILTER_ID,其值指示选择卷积层的哪些过滤器。它的范围取决于选择的 CONV_ID,范围从 [0, 127] 到 CONV_ID = {0, 2} 和 [0, 255] 到 CONV_ID = 1。
要可视化 Attention LSTM 模块的上下文向量,请使用“visualize_context.py”脚本。
要为数据集中的所有样本生成上下文,请修改“LIMIT=None”。还建议设置 VISUALIZE_CLASSWISE=False 以加快计算速度。请注意,对于较大的数据集,图像的生成可能会花费大量时间,并且输出可能并不令人愉快。我们建议使用每个类 1 个样本来可视化分类,如上所示。
要可视化最终卷积层的类激活图,请执行“visualize_cam.py”。可以通过将“CLASS_ID”从(0 更改为 NumberOfClasses - 1)来更改被可视化的输入信号的类别。
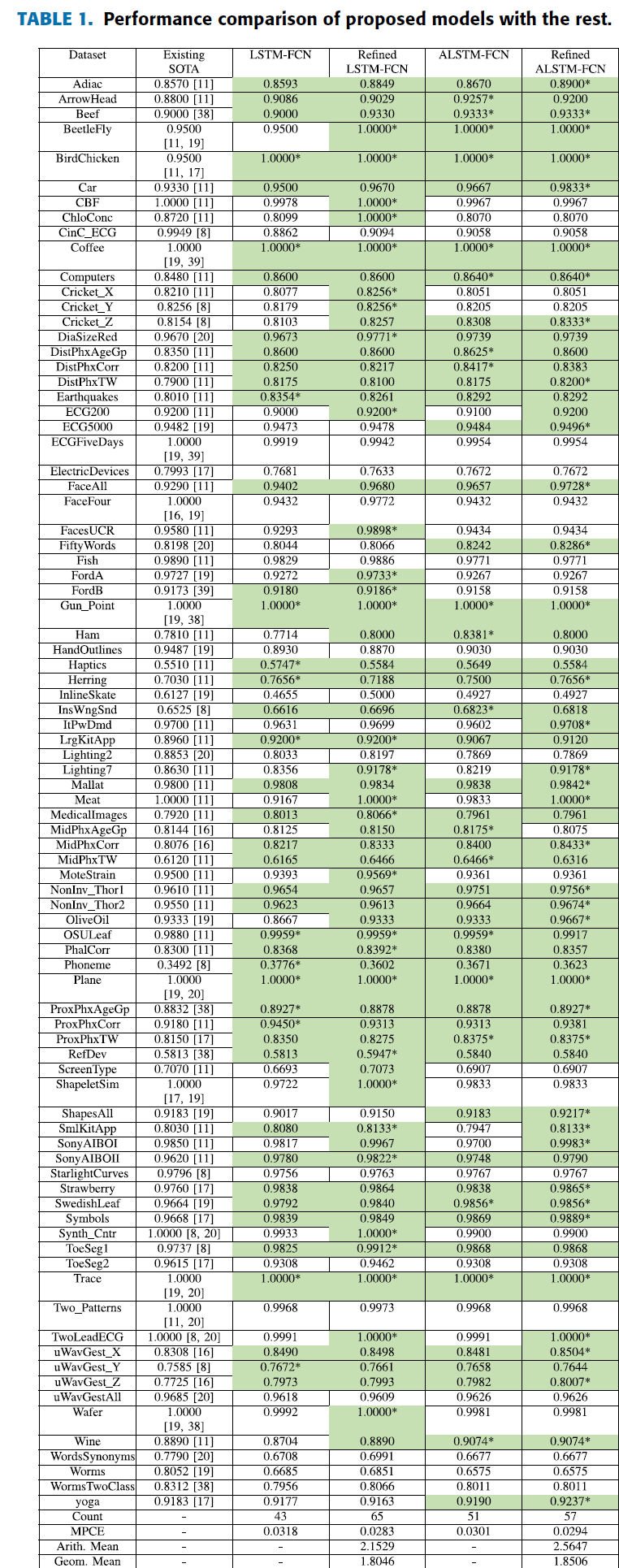
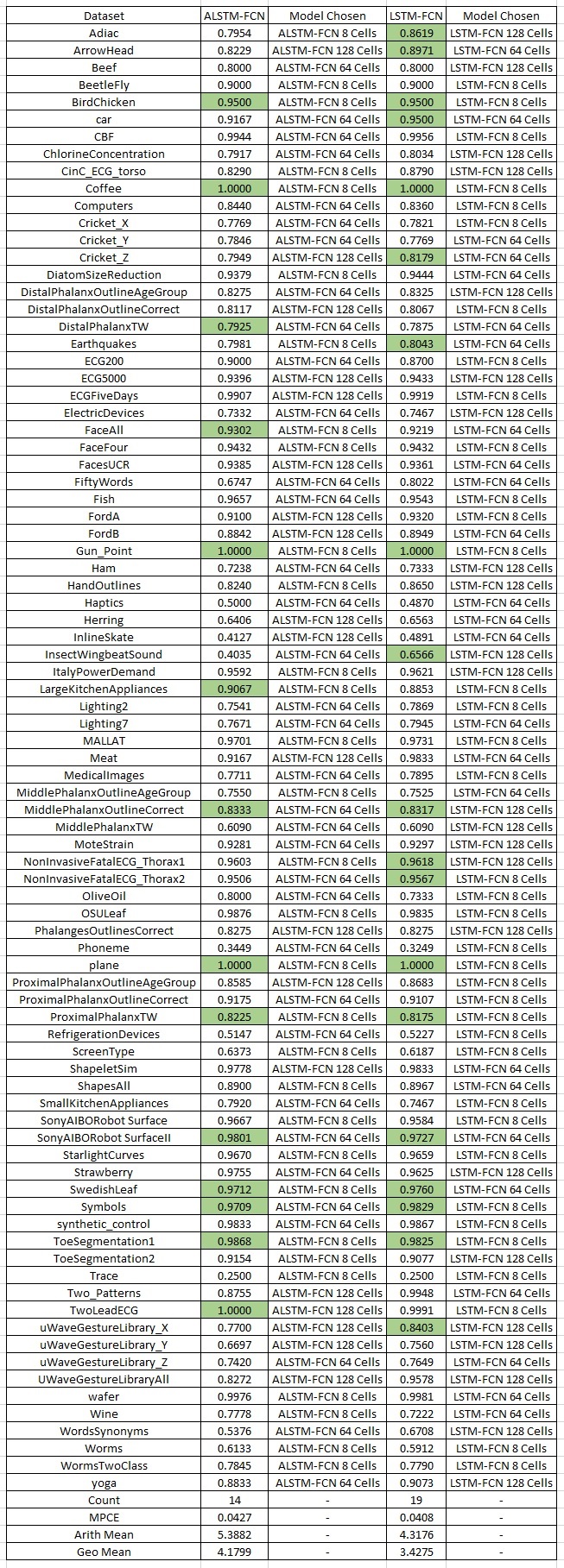
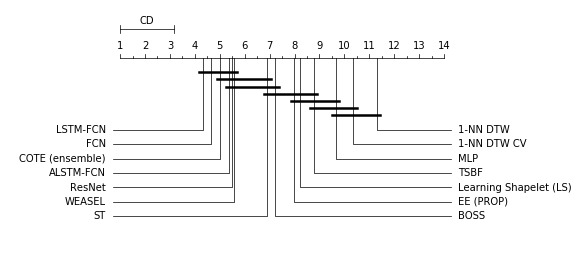
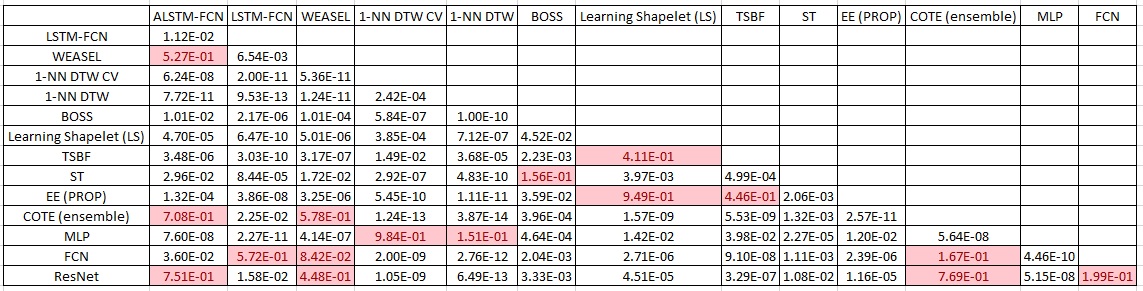
应用 Dunn-Sidak 校正后,我们将 p 值表与 0.00465 的 alpha 水平进行比较。 结果显示 ALSTM、LSTM 和集成方法(COTE 和 EE)在统计上是相同的。
@article{karim2018lstm,
title={LSTM fully convolutional networks for time series classification},
author={Karim, Fazle and Majumdar, Somshubra and Darabi, Houshang and Chen, Shun},
journal={IEEE Access},
volume={6},
pages={1662--1669},
year={2018},
publisher={IEEE}
}