Architektur
Dieses Dokument gibt zuerst einen Überblick über die aktuelle Architektur des MDM. Anschließend wird auf die wichtigsten Evolutionsschritte eingegangen, um einen Eindruck zu vermitteln, wie wir zu der aktuellen Architektur gekommen sind.
Das MDM ist eine SPA (Single Page Application) mit einem zustandslosen Server. Der Server nutzt mehrere externe Dienste u.a. für Datenspeicherung, Suche und Kommunikation mit dem Benutzer.
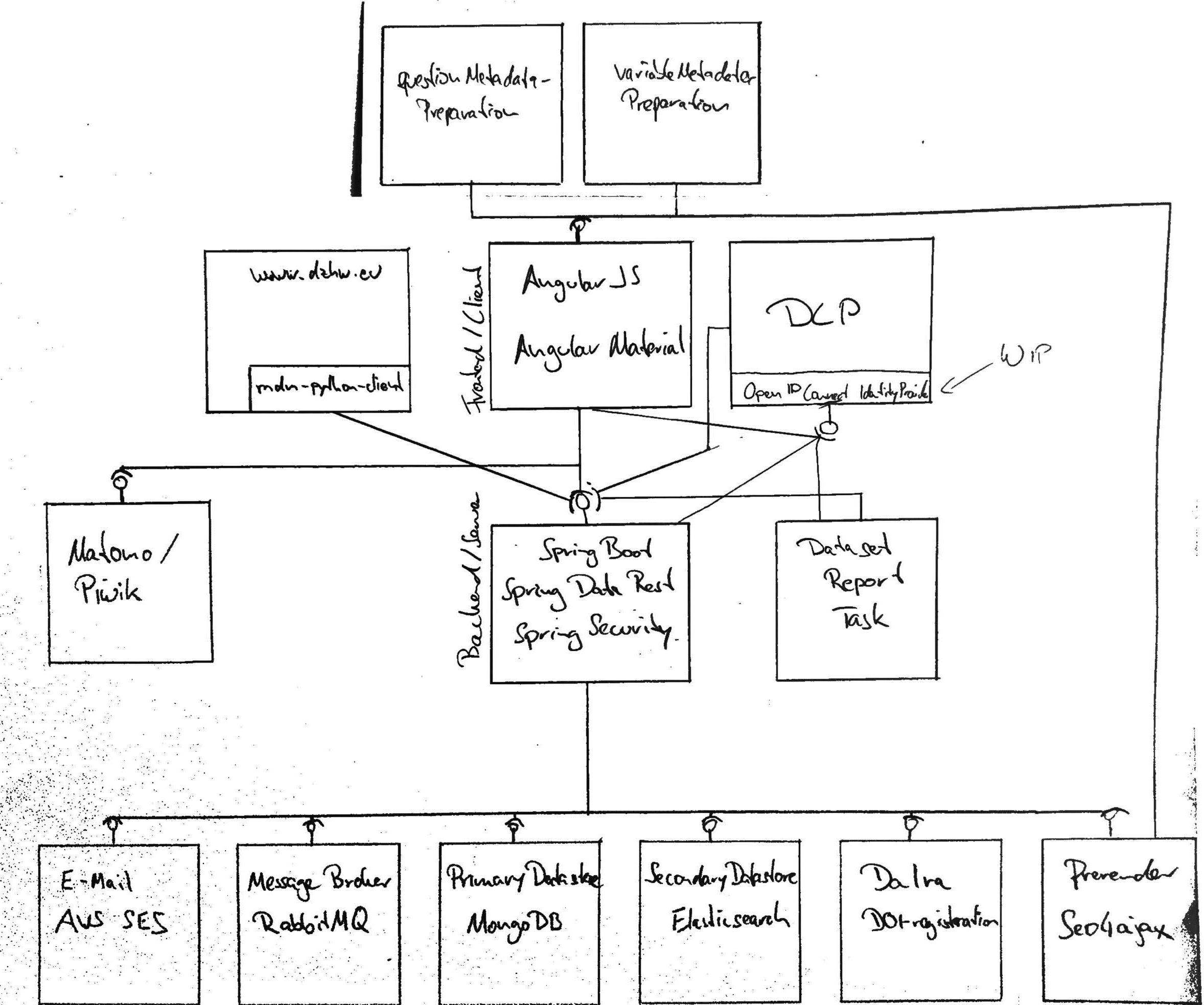
Der Client ist eine SPA (Single Page Application), die mit AngularJS realisiert wurde. Die GUI-Komponenten von Angular Material sind die Grundlage für das visuelle Design der Anwendung.
Angular Ressourcen bilden eine Fassade für die Kommunikation mit dem HTTP-server.
Der Server ist eine 12-factor-app welche Spring Boot (ein Java-Framework) und Cloudfoundry (eine Plattform für skalierbare Webanwendungen) nutzt, um die 12 Faktoren in einer Java Anwendung zu implementieren.
Der Server Prozess ist ein Java-Prozess, der eine JSON-over-HTTP API (manchmal auch REST-API genannt) für die Kommunikation mit dem Client anbietet. Die REST-API wird aktuell mit Spring MVC realisiert, was zur Folge hat, dass der Server jeden Request in einem separaten Thread abarbeitet. Zur Benutzerauthentifizierung wird OAuth2 verwendet, welches mit Spring Security implementiert wurde.
Der Server Prozess ist zustandslos und kann dadurch sehr einfach horizontal hoch bzw. runter skaliert werden, indem einfach mehrere Instanzen gestartet bzw. gestoppt werden. Um die Containerisierung der Java-Anwendung, müssen wir uns dank Cloudfoundries Buildpacks nicht selber kümmern. Die Containerinstanzen werden von Cloudfoundry automatisch neugestartet falls sie nicht mehr "gesund" sind, d.h. wenn sie auf spezielle HTTP Request nicht in einer vorgegebenen Zeit mit einem vorgegebenen Wert antworten.
Der Loadbalancer von Cloudfoundry übernimmt außerdem automatisch die Verteilung der HTTP-Requests auf die unterschiedlichen Containerinstanzen. Zusätzlich übernimmt er das SSL-Offloading.
Für die Fehleranalyse sammelt Cloudfoundries Loggregator automatisch die Logausgaben aller Server Instanzen ein. Metriken über CPU-Last, Memoryverbrauch, etc. sowie eigene Metriken werden von Pivotals Cloudfoundry Instanz (Pivotal Web Services) ebenfalls von den Containerinstanzen für die Fehleranalyse eingesammelt.
Intern ist die Java Anwendung wie eine klassische Spring Anwendung strukturiert, d.h. es gibt fachliche Slices abgeleitet von den Aggregates (Studie, Erhebung, Instrument, Frage, Datensatz, Variable, Publikation) der Anwendung und technische Schichten (Web bzw. REST, Service, Repository).
Die Containerinstanzen nutzen die folgenden externen Dienste für Datenspeicherung, Suche und Kommunikation mit dem Benutzer.
MongoDB ist unsere primärer Datenstore, welcher eine normalisierte Form unserer Aggregates (Studie, Erhebung, Instrument, Frage, Datensatz, Variable, Publikation) persistiert.
Elasticsearch ist unser sekundärer Datenstore, welcher eine stark denormalisierte Form unserer Aggregates (Studie, Erhebung, Instrument, Frage, Datensatz, Variable, Publikation) indiziert, um dem Benutzer eine performante Suche auch über die Aggregatsgrenzen hinweg zu erlauben.
Der Server nutzt SendGrid um den Benutzern HTML-E-Mails zu senden. Diese Mails werden mit Thymeleaf (eine Template Engine für HTML Dokumente) erstellt.
Der Server nutzt RabbitMQ als Message Broker um (administrative) Nachrichten via WebSockets an alle Benutzer zu senden.
Wir nutzen da|ra's XML-API um DOIs für unsere Studien bei jedem Release zu registrieren. Um ein da|ra-konformes XML aus unseren Metadaten zu erzeugen, nutzen wir Freemarker.
Im Folgenden wird beschrieben, wie die aktuelle Architektur des MDM schrittweise entstanden ist.
Zu Projektbeginn waren bereits die folgenden Entscheidungen getroffen:
- Teamstruktur: 3 Java-Entwickler (2x Junior, 1x Senior) und ein quantitativen (technikaffiner) Sozialwissenschaftler
- Scrum als Vorgehensmodell
- DevOps (You Build it, you run it!)
- Keine (personenbezogenen) Befragungsdaten im System, um Datenschutzproblemen aus dem Weg zu gehen
- Im Projektantrag wurden die folgenden Technologien erwähnt: JSF, PostgreSQL, Elasticsearch/Solr
- Die Anzahl an Benutzern des Systems und die Menge der Daten waren nicht abschätzbar, beides soll langfristig gesehen steigen
Auf Grund der Teamgröße und der DevOps Forderung, wurde gleich auf Spring Boot und Pivotal Web Services (eine Cloudfoundry Instanz) gesetzt, weil dies im Java-Umfeld die kompletteste Lösung für die Implementierung und den professionellen Betrieb eines HTTP- Servers war.
Da die Suche von Metadaten eine zentrale Anforderung an das System war wurde Elasticsearch als Datenbank ausgewählt. Der Einarbeitungsaufwand in den professionellen Betrieb von Elasticsearch erschien uns jedoch zu groß, daher buchten wir bei Pivotal Web Services eine kostenlose Entwicklerinstanz dazu.
Als Frontendtechnologie entschieden wir uns gleich gegen JSF, weil wir damit bereits in früheren Projekten schlechte Erfahrungen gemacht haben. Spring propagierte damals Thymeleaf für das serverseitige Rendern von HTML-Seiten, also starteten wir damit. Twitters Bootstrap wurde als CSS Framework verwendet, da wir kein Know-How und dementsprechend keine Zeit für GUI-Design hatten. Da wir auch kein großes Know-How in Javascript hatten entschieden wir uns möglichst wenig Javascript einzusetzen.
Als Entwicklungsplattform wurde von Anfang an Github als Versionsverwaltungssystem und Travis CI für Continous Integration verwendet.
Dank SCRUM stellten wir die verwendeten Technologien früh in Frage und bemerkten folgendes:
- Da wir nicht nur eine Metadatensuche, sondern auch eine Metadatenerfassung brauchten, reichte serverseitiges Rendern nicht mehr aus. Wir mussten den aktuellen Zustand des Clients immer wieder zwischen Client und Server Hin- und Herübertragen, damit Thymeleaf die Seite in dem richtigen Zustand erzeugte (z.B. vom Benutzer hinzugefügte Formularfelder, offene Menüs,...). Wir brauchten also mehr Javascript, als wir dachten.
- Elasticsearch stellte sich als komplexe Technologie heraus. Ein Berater schulte uns und riet uns Elasticsearch nicht als primären Datenstore für die Metadatenerfassung zu nutzen.
Wir entschieden uns PostgreSQL als primären relationalen Datenstore zu verwenden. Mit dem Spring Boot Server, und der Unterstützung von PostgreSQL durch Spring Data JPA, waren wir dabei sehr zufrieden. Pivotal Web Services hatte auch für PostgreSQL ein kostenloses Angebot für Entwickler.
Als Alternativen für das serverseitige Rendern von HTML booten sich damals AngularJS, React und EmberJS an. Da unsere Javascript-Fähigkeiten damals sehr begrenzt waren, waren wir froh, als wir JHipster fanden, welches uns einen Großteil der Anwendung generieren konnte, inklusive automatischer Tests (sowohl statischer als auch dynamischer) und Paketierung für den Produktivbetrieb.
JHipster generierte uns also einen zustandslosen Server mit PostgreSQL-Anbindung und AngularJS Client. Die Elasticsearch-Integration mussten wir selbst implementieren.
Wieder dank SCRUM stellten wir auch diese Technologien in Frage, nachdem wir den generierten Technologiestack verstanden hatten:
- Da wir uns bei der Metadatenerfassung zu erst auf die Variablen konzentrierten, wurde uns das Mapping dieser Objekte auf die relationale PostgreSQL Datenbank schnell zu aufwändig und erschien uns auch unnötig. Variablen sind nämlich ein relativ komplexes Aggregate mit vielen Teilobjekten sind.
- Das automatisierte Testen des Clients wurde immer wichtiger und nur das Testen des Javascript-Codes ohne die View genügte uns nicht, zumal diese Art der Unittest für Java-Entwickler eine schwierige Hürde waren, was hauptsächlich an der ereignisgesteuerten Verarbeitung von Javascript lag.
Wir ersetzten also PostgreSQL durch MongoDB, was sich dank Spring Data und Pivotal Web Services als unkompliziert herausstellte.
Um auch Änderungen am Client kontinuierlich testen zu können implementierten wir E2E-Tests in verschiedenen Browsern welche von Saucelabs zur Verfügung gestellt wurden.
Die Benutzeroberfläche war allerdings immer noch eine Baustelle:
- Die Metadatenerfassung erforderte mehr GUI-Komponenten als Bootstrap bieten konnte (Autocomplete, Toasts, Datepicker, ...)
- Auch die Metadatensuche brauchte bessere Lösungen, beispielsweise für Forschrittsanzeige.
Da wir weder das Know-How noch die Zeit hatten, GUI-Komponenten selbst zu entwickeln, entschieden wir uns für Angular Material, was viele Komponenten mitlieferte.
Damit sind wir bei der aktuellen Architektur angekommen. Aber auch diese stellen wir schon in Frage:
- Die User Experiences wird von vielen kritisiert, da das MDM sich nicht in das Design der DZHW-Umsysteme integriert und auch nicht die Komplexität der Domäne vor dem Benutzer versteckt.
- Multithreading zur Verarbeitung von HTTP-Requests ist ressourcenintensiv. Webflux erscheint eine bessere Alternative.
- Microservice Architekturen versprechen eine bessere Modularisierung des Backends. Momentan favorisieren wir allerdings Modulithen.
- Elasticsearch liefert nicht die gleichen Features wie die Google Search Engine, welche man auf der Google Cloud Platform dazubuchen könnte.