Code for CVPR 2024 paper, Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning, by Desai Xie, Jiahao Li, Hao Tan, Xin Sun, Zhixin Shu, Yi Zhou, Sai Bi, Sören Pirk, Arie E. Kaufman, a collaboration between Adobe Research, Stony Brook University, TTIC, and Kiel University.

This repository does not contain the implementation of the SDXL-based multiview diffusion model and the sparse-view large reconstruction model proposed in Instant3D. To implement the full Carve3D pipeline, an open-sourced sparse-view reconstruction model is needed, such as OpenLRM, GRM, LGM, etc. Pull requests are welcome!
- training and testing text prompt dataset
- SDXL LoRA training code adapted from diffusers and DDPO
- a multi-view diffusion model (e.g. MVDream), replacing Instant3D's finetuned SDXL. Pull requests are welcomed!
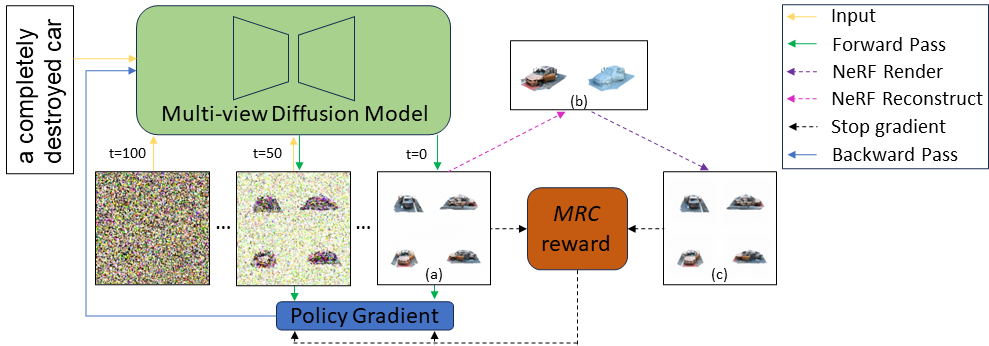
- Multi-view Reconstruction Consistency (MRC) metric
- an open-sourced multi-view/sparse-view reconstruction model. Pull requests are welcomed!
cd ddpo
pip install -e .
bash carve3d_train.sh
carve3d_train.py uses configuration files.
The base configuration file is config/base.py.
The final training config reported in the paper is in carve3d_train() in config/dgx.py.
The training code carve3d_train.py, configurations in config/, and DDPO's change to diffusers library codes diffusers_patch/ are based on ddpo-pytorch.
carve3d_train.py is also based on diffusers sdxl lora train example.
Our improvement to DDPO include pure on-policy training, and KL-divergence regularization.
In the original DDPO, total sample batch size, sample.batch_size * sample.num_batches_per_epoch * num_nodes * 8, is 2x the total training batch size, train.batch_size * train.gradient_accumulation_steps * num_nodes * 8, so that in each epoch of sampling, there will be 2 updates, each on half of the samples.
Our modification is to simply set them to be equal, so that in each epoch of sampling, there will be only 1 update, using all of the samples. We didn't remove the importance sampling ratio, but I think removing it shouldn't make a difference.
Our KL-divergence Regularization is enabled by default with config.kl_penalty = True, config.kl_in_reward = True, config.kl_per_prompt_stat_tracking = True, and config.kl_normalized_coeff = 0.2.
The coefficient could be tuned, as a trade-off between focusing on optimizing more for higher reward or more for lower KL-divergence.
The main hyperparameters to tune are
- KL-divergence regularization coefficient
config.kl_normalized_coeff, - training data size
config.train_size, - total sample batch size,
sample.batch_size * sample.num_batches_per_epoch * num_nodes * 8, - and total train batch size,
train.batch_size * train.gradient_accumulation_steps * num_nodes * 8.
Keep total sample batch size and total train batch size equal to use our pure on-policy training. Otherwise, set total sample batch size to be 2x (or 3x, etc.) of total train batch size to use the PPO multi-round update. Tune the total batch size and the training data size according to Section 4.3 of the paper.
If you find this code useful, please consider citing:
@inproceedings{xie2024carve3d,
title={Carve3d: Improving multi-view reconstruction consistency for diffusion models with rl finetuning},
author={Xie, Desai and Li, Jiahao and Tan, Hao and Sun, Xin and Shu, Zhixin and Zhou, Yi and Bi, Sai and Pirk, S{\"o}ren and Kaufman, Arie E},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6369--6379},
year={2024}
}
@inproceedings{black2024training,
title={Training Diffusion Models with Reinforcement Learning},
author={Kevin Black and Michael Janner and Yilun Du and Ilya Kostrikov and Sergey Levine},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YCWjhGrJFD}
}