Collective communication routines in MPI include also routines for global communication between all the processes. Global collective communication is extremely costly in terms of performance, so if possible one should avoid using them. Nevertheless, in some situations they are exactly the correct approach to implement an parallel algorithm.
Let us look next how to use collective communication to exchange data between all the processes in a communicator, i.e. how to move data from many to many.
Allreduce is in principle just a Reduce operation followed by Broadcast, so that in the end of the operation all processes have the results of reduction. The MPI library can, however, implement the operation more efficiently than when using two successive calls.
Only difference in the function call compared to Reduce is that there is no root argument, as seen in the following example:
from mpi4py import MPI
from numpy import arange, empty
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
data = arange(10 * size, dtype=float) * (rank + 1)
buffer = empty(size * 10, float)
n = comm.allreduce(rank, op=MPI.SUM) # returns the value
comm.Allreduce(data, buffer, op=MPI.SUM) # in-place modificationIn Alltoall operation each process sends and receives to/from each other, and can be considered as combination of Scatter and Gather. The operation can be also viewed as "transpose".
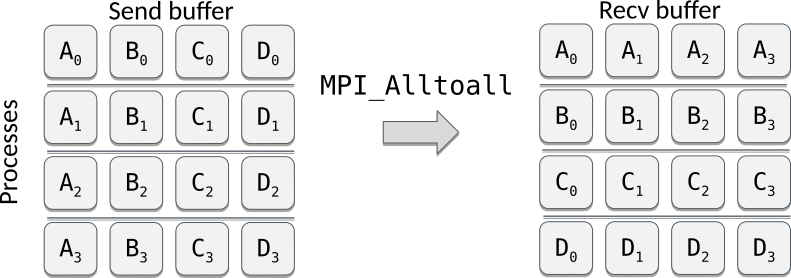
An example of Alltoall both with a Python list and a NumPy array:
from mpi4py import MPI
from numpy import arange, empty, zeros_like
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
py_data = range(size)
data = arange(size**2, dtype=float)
new_data = comm.alltoall(py_data) # returns the value
buffer = zeros_like(data) # prepare a receive buffer
comm.Alltoall(data, buffer) # in-place modificationSome common mistakes to avoid when using collectives include:
-
Using a collective operation within one branch of an if-else test based on the rank of the process
if rank == 0: comm.bcast(...)
All processes in a communicator must call a collective routine!
-
Assuming that all processes making a collective call would complete at the same time.
Even a collective operation such a barrier only ensures that a process holds until everyone reaches the call. With data movement call (scatter, bcast etc.) even this may not be true, since MPI only guarantees that the process will proceed only when it is safe to do so. MPI implementations can (and do!) use communication caches that may allow some of the processes to continue from a collective call even before communication happens.
-
Using the input buffer also as an output buffer.
comm.Scatter(a, a, MPI.SUM)
Always use different memory locations (arrays) for input and output!