The STAC is a specification to describe geospatial information, so it can easily searched and downloaded. STAC includes metadata of datasets and links to actual files, the data files are usually stored in the cloud. See Paituli STAC page for general introduction about STAC and what Collections (=datasets) are included in Paituli STAC.
In this repository we provide examples to work with:
- STAC API:
- Static STAC:
- See, also similar R STAC examples
The examples mainly cover data search and download, using pystac-client and stackstac. For analyzing data, xarray and xarray-spatial can be used. If unfamiliar with xarray, Pangeo 101 is one option to get started. When working with bigger datasets, xarray supports also parallelization with dask.
The examples can be run on any computer with Python installation, the required Python packages can be seen from beginning of the notebooks. The examples download all data from cloud storage, so relatively good internet connection is needed.
In CSC Puhti supercomputer, the notebooks can be run with geoconda module, which includes all necessary Python packages. The easiest is to use Jupyter with Puhti web interface:
- Open Puhti web interface
- Click "Jupyter" on dashboard
- Select following settings:
- Project: project_2002044 during course, own project otherwise
- Partition: interactive
- CPU cores: 1
- Memory (Gb): 8
- Local disk: 0
- Time: 1:00:00 (or adjust to reasonable)
- Python: geoconda
- Jupyter type: Lab
- Working directory: /scratch/project_2002044 during course, own project scratch otherwise
- Click launch and wait until granted resources
- Click "Connect to Jupyter"
- If you want to use Dask extension in JupyterLab, see Dask instructions in docs.csc.fi
You can also run the STAC example notebook on your own computer.
Download the example code to your computer (either by copying the whole repository to your computer with git (git clone https://github.com/csc-training/geocomputing.git) or by downloading only the needed files via github webinterface (find python/STAC/environment.yml and python/STAC/STAC_CSC_example.ipynb and in the upper right corner of the file "Download raw file button").
If you have Conda installed, you can for example create a new environment and use the provided environment.yml file to create a new Python environment with all needed packages:
conda env create -f path/to/your/downloaded/environment.yml
The example notebook covers only small area and therefore runs fast and requires little resources. The same code can be easily extended to cover whole Finland or some other bigger area. Basically only a few changes are needed:
- Extend analysis area in the Python code
- Change location criteria in the STAC search, use a bigger bbox or remove the location criteria.
- Change
boundssetting instackstac.stack, use a bigger bbox or removeboundssetting.
- If running in HPC, give your Jupyter more computing resources. Start a new Jupyter session and give it more cores and memory than recommended in the example. If running the notebook locally, then no changes are needed.
- Dask will pick up all available computing resources automatically.
From Dask point of view, it is easy to use up to the full node of HPC, that would be 40 cores in Puhti supercomputer. With Dask-Jobqueue it is possible to run also multi-node jobs. But in STAC use case, the computation time is heavily dependent on data download speed, which does not scale so well. So in practice a smaller number of cores is more reasonable. With computationally easier analysis, the recommended number of cores is 5-10. If the computational part takes significant amount of time compared to data download, also bigger numbers of cores could be used.
The memory requirements depend more on the specific analysis, but a starting point could be 6-10Gb/core.
One more optimization option is to manually assign Dask chunksize. Chunksize defines how big part of data is analysed at once. Using bigger chunksize decreases the amount of data requests to the data storage, which might make the process faster. On the other hand, bigger chunksize also increases the required memory. The default chunksize in most cases is likely good enough, but if you have data cube with 1 or only few dates, increasing the chunkzise to 2048x2048 for coordinates might be better.
For longer analysis, it is recommended to switch from Jupyter notebook to usual Python code and run it via HPC batch job system. See csc_stac_example.py and csc_stac_example_batch_job.sh
Some HPC specific comments:
- Use
--mem-per-cpuin the batch job file, when defining the memory reservation. - The dask clusters are unlikely to give direct "Out of memory" errors to SLURM scheduler, that would directly kill the job. Rather different warnings and errors appear in the job output file, so keep an eye on that.
- Normally
seffoutput can be used for planning batch jobs memory requirements, but with Dask clusters bigger than usual extra buffer is needed.
We did some tests with different settings (data storage location, chunksize, number of cores) for the same STAC analysis, below are the results.
In this case exactly the same files were used, but the data was fetched from FMI object storage or from Puhti local disk. Analysis was done for whole Finland. The optimal number of cores was 5-10. Using local data was slightly faster, but especially with parallel analysis, the difference was small.
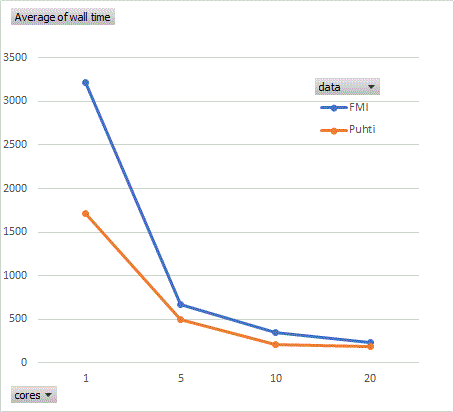
Also different chunksizes were tested, the bigger chunk sizes were signifantly faster, if only 1 or 5 cores were used.

In this case the data values were the same, but storage details varied. All options had data as GeoTiffs.
- FMI - in FMI object storage in Sodankylä.
- Geocubes - in GeoCubes service (technically in CSC cPouta in Kajaani), divided into mapsheets, one mapsheet relatively big.
- Paituli - in Paituli service (technically at CSC in Espoo), divided into mapsheets, one mapsheet relatively small.
- Puhti - Paituli files in Puhti local disk
The compute area was 1600 km2, the original 2m pixel size was used. The STAC search found 1 item from FMI, 16 from GeoCubes and 33 from Paituli/Puhti. Slope was computed with spatial-xarray's slope function.
The optimal number of cores was 5-10. The compute time was very similar for all data sources.

Also the chunksize had little importance for the compute time. In general still bigger chunksize decreased the compute time slightly.

Notes:
- The STAC search and data cube creation part is faster with smaller number of STAC items, items fetching takes some time, if hundreds or thousands of items are found.
- Using Cloud-Optimized GeoTiffs becomes much more important if you want to use the data in lower than native resolution.
- GeoCubes provides the same data in different resolutions via different assets and also as Cloud-Optimized GeoTiff, choose the correct one.
- In case of GeoCubes, Paituli, and Puhti the created datacube had several dates present, but because the exact dates were not important here, the datacube was flattened in time dimension with:
cube2 = cube.max(dim='time').