diff --git a/content/post/2023-08-04-A-Conversation-with-Jerry-Friedman-CN.md b/content/post/2023-08-04-A-Conversation-with-Jerry-Friedman-CN.md
new file mode 100644
index 000000000..d4dfd0793
--- /dev/null
+++ b/content/post/2023-08-04-A-Conversation-with-Jerry-Friedman-CN.md
@@ -0,0 +1,872 @@
+---
+title: '对话杰里-弗里德曼'
+author: 'N.I.Fisher'
+date: '2023-08-04'
+categories:
+ - 推荐文章
+tags:
+ - 机器学习
+ - 统计计算
+ - 统计学习
+ - CART
+ - 投影追寻
+slug: A-Conversation-with-Jerry-Friedman-CN
+forum_id:
+---
+
+# 摘要
+
+杰罗姆-H-弗里德曼于 1939 年 12 月 29 日出生于美国加利福尼亚州的伊雷卡。他在尤里卡高中接受了高中教育,然后在奇科州立学院学习了两年,1959 年转入加州大学伯克利分校。他于 1962 年获得物理学研究生学位,1968 年获得高能粒子物理学博士学位,1968-1972 年在劳伦斯伯克利实验室担任博士后研究物理学家。1972 年,他被调往斯坦福直线加速器中心(SLAC),担任计算研究小组组长,直至 2006 年。1981 年,他被任命为斯坦福大学统计系的半职教授,并继续在斯坦福直线加速器中心担任兼职教授。他曾在悉尼的澳大利亚联邦科学与工业研究组织、欧洲核子研究中心和伯克利大学统计系担任客座教授,并一直担任非常活跃的商业顾问。2007 年,杰里成为统计系的名誉教授。除了在职业生涯早期发表过 30 多篇高能物理方面的文章外,杰里还发表过 70 多篇统计和计算机科学方面的文章和书籍,其中包括与他人合著的开创性书籍《分类与回归树》和《统计学习要素》。他的许多出版物都有成百上千次的引用(例如,《CART》一书的引用次数就超过了 21,000 次)。他的许多软件已被纳入商业产品,其中至少包括一个流行的搜索引擎。他的许多方法和算法是现代统计和数据挖掘软件包的重要组成部分他获得的荣誉包括里茨讲座(1999 年)和沃尔德讲座(2009 年);入选美国艺术与科学院(2005 年)和美国国家科学院(2010 年);美国统计协会会员;年度论文(JASA 1980 年、1985 年;Technometrics 1998 年、1992 年);年度统计学家(美国统计学会芝加哥分会,1999 年);美国计算机协会数据挖掘终身成就奖(2002 年)、伊曼纽尔和卡罗尔-帕岑统计创新奖(2004 年);诺特高级讲师(美国统计学会,2010 年);以及电气和电子工程师学会计算机协会数据挖掘研究贡献奖(2012 年)。
+
+访谈于 2012 年 8 月 3-4 日在他位于加利福尼亚州帕洛阿尔托的家中录制。
+
+**关键词和短语**:ACE, boosting, CART, 机器学习, MARS, MART, 投影追寻, RuleFit, 统计计算, sta-统计图形、统计学习
+
+
+
+
+
+
+
+图1:Yreka小时候。
+
+
+
+
+
+# 1 早期(1939-1959 年)
+
+**NF**:欢迎杰瑞(Jerry Friedman)。让我们从头开始吧,加州的这块地方并不在这里。
+
+**JF**:没错。我是在俄勒冈州边境附近一个叫 Yreka 的小镇长大的:"bakery "是倒过来拼的,没有 "b","Yreka Bakery "是个谐音。......在 Yreka 有一家 Yreka 面包店。
+
+**NF**:你的父母在做什么?
+
+**JF**:我的母亲是一名家庭主妇,我的父亲和他的兄弟在那里拥有一家洗衣和干洗店,他们和我的祖父母在 20 世纪 30 年代创办了这家店。
+
+**NF**:你的祖父母是在美国出生的吗?
+
+**JF**:不,我想有人是在乌克兰出生的;我不确定其他人是在哪里出生的。他们肯定不是在美国出生的,因为他们都有很重的口音。
+
+**NF**:你有兄弟姐妹吗?
+
+**JF**:有一个弟弟比我小一点。他现在退休了,住在洛杉矶。他做了大半辈子的会计。
+
+**NF**:学校怎么样?
+
+**JF**:学校还不错。我成绩很差。我对学校不是很感兴趣;我主要对电子产品感兴趣,所以我从小就喜欢无线电,制造无线电电子产品--发射机、接收机之类的东西。这对尤里卡的人来说很不寻常。我真的是个异类,但我觉得电子产品很迷人,能够在没有电线的情况下与世界另一端的人交谈。而现在,这已经是理所当然的事了。在那个年代,短波无线电是唯一的方式。当我还在上文法学校的时候--10 岁到 13 岁--我一直在做晶体机。后来我开始接触真空管、发射机和接收机。这与今天的电子技术非常不同。真空管的工作电压非常高。因此,当你在探究一个电路为什么不工作时,你会突然在房间的另一侧站起来,因为你触及了一个大约 400 或 500 伏特的地方。现在的电子器件电压为 5 伏。我记得在中学时,我曾央求数学老师教我平方根,因为我需要平方根来理解我正在读的这本电子书中的一些内容。
+
+**NF**:有什么人可以跟你聊这些事吗?
+
+**JF**:是的,我有一个朋友,他的父亲是做无线电广播的,对电子技术很了解,所以我可以和他讨论这个问题。我高中毕业前,父亲去找校长谈话,问他该拿我怎么办。校长说:"他上不了大学。"你可以试试奇科州立大学" "等他长大了,你可以把他送去当兵"就这样,我进入了奇科州立大学。奇科州立大学现在的名声是内华达山脉淡色啤酒(Sierra Nevada Pale Ale)酿造的产地。
+
+**NF**:你是如何看待这一观点的?
+
+**JF**:我不想去奇科州立大学,我想去伯克利。所以我们达成协议,我先去奇科读两年,如果成绩不差,我可以考虑转学到伯克利。我父亲是对的。他不是经常说对,但他说对了。当时,奇科州立大学是美国最大、最著名的派对学校之一,虽然规模不大,但其派对学校的美誉却是实至名归。每晚都有盛大的派对。我一直盼着暑假能从这些派对中解脱出来。每天晚上,我们都喝得酩酊大醉。那时没有毒品,但有很多酒。两年后,当我去伯克利时,我已经准备好做更多的事情了。如果我直接去了伯克利,可能就不会发生这种情况。
+
+**NF**:你去奇科州立大学实际上是想学一些特别的东西吗?
+
+**JF**:我不确定自己想成为什么,是化学家还是工程师。我想我想成为一名化学家,于是我选修了初级化学课程。我记得当时我们正在学习如何用石蕊试纸测试酸度,这真是一种折磨,我注意到工程专业的学生和我们上同样的课,他们也在同一个实验室,但他们的实验不像我们的那么紧张,他们使用的是某种仪表。你把仪器放在溶液中,它就会显示 pH 值。我说:"我喜欢这个。"于是我转到了工程系,并在奇科攻读工程学。但那里有一位非常非常优秀的物理学教授,他让我对物理学产生了浓厚的兴趣,所以当我转学到伯克利的时候,我决定学习物理。
+
+
+
+# 2 伯克利大学 (1959- 1972 年)
+
+**NF**:之后的两年,你在伯克利攻读本科。成绩如何?
+
+**JF**:实际上,我花了两年半的时间。我当时在学校里打工。我没有钱。我的成绩还不错。那是成绩并轨之前的年代,所以我的平均成绩大约是 B+/A,在那个年代算是不错了。现在,如果你的成绩不是全 A,他们就会很不耐烦,但在那个年代,A 可没那么容易拿到。(参见 Fisher (2015)一文中关于六十年代初伯克利大学本科生的轶事)。
+
+**NF**:让我们来谈谈你从本科生到研究生的转变。你的本科课程已经结束,现在你正在决定做什么。你当时的激情是什么?
+
+**JF**:我想学习物理。我觉得它非常有趣,而且我也找不到比它更有趣的东西了。我从未选修过统计学课程。
+
+**NF**:毫无疑问,你想在伯克利做这件事?
+
+**JF**:是的,我喜欢伯克利,现在也是。我喜欢湾区。不过,有一个问题。
+
+那时候有征兵制度。因为我多上了一个学期的研究生,所以没有资格自动延期毕业。为了避免被征召入伍,你必须上学。我觉得读研究生绝对比参军好。所以有一段时间我很担心我会被征召入伍,因为我是1A级,身体健康,随时可以入伍。我甚至去奥克兰征兵中心做了入伍前体检,于是我想,就这样吧,我要去参军了。 那时越战还不严重,所以我并不担心这个问题。学习物理似乎比参军更有趣。有一天,我重新拿到了新的征兵卡--他们每年都会重新发放征兵卡之类的东西--上面写的不是1A,而是2E,意思是学生延期入伍。于是我陷入了两难的境地,因为我觉得可能是印刷错误。下一次我去伊雷卡的时候,我很纠结,要么闭上嘴巴,希望他们不会发现这个错误,要么去征兵委员会问他们这是不是真的。最后我决定还是去问清楚。征兵委员会的秘书说:"你是2E,"当我不解地看着她时,她说:"好吧,征兵委员会决定,既然你是靠自己的努力完成学业的,那么你多花一个学期来完成学业也是可以的。
+
+**NF**:美德不仅仅是它本身的回报。
+
+**JF**:我想是的。另外,他们也有生病的配额。尤里卡有很多孩子没有上大学。事实上,在那些日子里,上大学的人很少,所以有很多没上大学的年轻人,他们可以让他们入会。他们并不一定需要我去填补他们的名额。
+
+**NF**:读研究生难吗?
+
+**JF**:我不知道,我想是的,但我不是很负责任。伯克利物理系是我唯一申请的研究生系。你应该到处申请,但我只申请了这一个。如果没被录取,我就去参军了。
+
+**NF**:你父母对你攻读研究生而不是回去帮助企业是怎么看的?
+
+**JF**:哦,我真的知道我不会再回尤里卡了。乡村歌手兼作曲家麦克-戴维斯(Mack Davis)在得克萨斯州的卢博克长大。有人曾问他在卢博克长大是什么感觉。他说:"嗯,幸福就是你后视镜里的卢伯克。"这就是我通常对尤里卡的看法。那是个好地方,但不适合我。
+
+**NF**:你的博士研究进展如何?
+
+**JF**:进展顺利。随着事情越来越多,我的平均成绩似乎不降反升,我真的很享受;我喜欢这样做。我更加努力地工作,当然还有在那里,如果你被征召入伍,只要你还在上学,就可以缓征。幸运的是,我没有被退学,而且我非常喜欢学习物理。
+
+夏天我在广播电台工作,冬天我在学校工作。我不太喜欢在图书馆堆书。我的室友提到,劳伦斯伯克利辐射实验室(Lawrence Berkeley Ra- diation Laboratory)有一些很棒的工作。他们对基本粒子反应的气泡室图像进行人工模式识别。他们需要有人扫描图像,找出他们正在寻找的特定模式。这是一份很棒的工作,虽然有点无聊,但报酬比图书馆高得多,于是我就去了那里。从那时起,我开始对高能物理感兴趣。那个小组的组长是路易斯-阿尔瓦雷斯(Louis Alvarez)。当时阿尔瓦雷斯还没有获得诺贝尔奖。他后来在 1968 年获得了诺贝尔奖,当时我在他的研究小组里读研究生。我拿到学位后,他和他的儿子提出了流星/恐龙灭绝的理论。他是我见过的最聪明的人之一。
+
+**NF**:你最终和他合作了吗?
+
+**JF**:不,我曾与罗恩-罗斯(Ron Ross)共事,他是他小组的教授之一。我在那里做了一段时间的气泡室扫描仪。后来,当我必须选择一个论文题目时,有两个原因让我选择了高能物理。一个是阿尔瓦雷斯小组。另一个原因是,在前两年的课程中,我最薄弱的科目是量子力学。我想,如果我进入高能粒子物理学领域,我就真的要好好学习量子力学了。
+
+**NF**:在这个阶段,你做过任何计算工作吗?
+
+**JF**:我没有做任何计算。......实际上我做过,大约是在 1962 年。我开始计算的方式是一个有趣的故事。我当时在那里做扫描工作,有一位物理学专业的研究生有时会让我帮他做一些扫描以外的工作。有一次,他让我画一张散点图。他给了我一张图纸、一支笔和一张数字对列表。他说:"你要做的是,对于每对数字,找到在图上对应的点,然后用笔在那里画一个点。"我做了一段时间,当然会反复搞砸,不得不重新开始。另一个学生说:"你知道吗,在一楼,他们有一种叫计算机的东西,它连接着阴极射线管,可以自动绘制散点图。你可以编写一个程序,把这些点放在阴极射线管上。然后用照相机拍下显像管,这样你就可以把这个散点图制成幻灯片并打印出来。"我想,这真是个好主意!我找来一本关于计算机编程的书,轻松地画出了我的散点图。
+
+**NF**:你用什么编程?
+
+**JF**:机器语言和 Fortran。Fortran 在当时是全新的语言,也是唯一的高级编程语言。这引起了很大争议,因为真正的程序员不是用 Fortran 编程,而是用机器(汇编)语言编程。在 ce 编程小组的入口处有一块牌子,上面写着:"任何可以用 Fortran 编写的程序都值得用 Fortran 编写。"我想,这句话今天仍然适用。
+
+**NF**:硬件的性质是什么?
+
+**JF**:我实际使用的第一台计算机是一台真空管计算机(当时还不是分立晶体管计算机),名为 IBM 704。它有磁芯存储器。还有一台 IBM 650,采用旋转鼓式内存。我喜欢 650,尽管它的速度要慢得多,因为你可以直接走上前去使用它。而使用 704 时,你必须预约时间,等待作业运行。伯克利的所有设备都使用打卡机。直到去了 SLAC,我才见到文本编辑器。
+
+我见过的最伟大的发明是带有退格键的终端机。使用打孔卡时,如果你犯了错误,就得扔掉卡片,从头再来。在阿尔瓦雷斯集团,我是负责大部分编程工作的人之一。在那个年代,编程在某种程度上被认为是娘娘腔的工作。真正的物理学家制造硬件--探测器、粒子束等。编程是娘娘腔的工作。现在,高能物理学家不再这么想了,因为他们中的大多数人都会编程。但比起制造硬件,我更喜欢编程。
+
+**NF**:你在攻读博士学位期间在做什么?
+
+**JF**:这是在 72 英寸氢气泡室进行的大型物理实验的一部分,也就是产生我之前扫描图片的那个探测器。我的论文研究了一个特殊的反应:涉及 k 介子的反应。
+
+**NF**:这需要什么样的硬技能,数学技能还是计算技能?
+
+**JF**:当然是计算技能和对当时理论物理学的理解,这确实涉及到一些数学知识。你必须建立一个程序,这就意味着要找出编写程序的算法。我在那里读研究生的时候,写了一套探索性数据分析程序,几乎所有高能物理领域的人都在使用这套程序。
+
+**NF**:所以你实际上是在编写一个统计软件包。
+
+**JF**:是的。物理学家并没有做太多假设检验之类的事情;他们主要是进行前瞻性研究,自动绘制散点图、他形图以及其他各种显示,这些显示大多是在当时的硬件上进行的,而当时的硬件大多是行式打印机输出。 Kiowa(这是一个印第安部落的名字)是我编写的一个软件包。多年来,它一直是全世界高能物理领域的标准统计软件包。我还写了一个快速通用蒙特卡洛程序,叫做 Sage。物理学家在模拟粒子反应时使用了大量蒙特卡罗程序。二十年后,我仍然收到关于 Sage 的询问,我相信有些人仍在使用它。
+
+**NF**:在你的计算活动中,你曾接触过最大似然法。
+
+**JF**:大概就是从那时开始,我才真正开始对统计学感兴趣。阿尔瓦雷斯小组里有一位物理学家弗兰克-索尔米茨(Frank Solmitz),他对统计学非常了解。他为物理学家写了一本关于基础统计学的技术小册子,我觉得非常有趣。后来,另一位同样是物理学家的杰伊-奥瑞尔(Jay Orear)写了一篇关于最大似然模型的小论文(Orear (1982))。我们当时正在研究很多模型,他知道最小二乘法。我认为最大似然是我见过的最优雅的想法,它激起了我对统计学的兴趣。当然,它是费雪发明的,但我并不知道;我以为是杰伊-奥里尔发明的。
+
+**NF**:你什么时候毕业的?
+
+**JF**:我在 1968 年拿到了学位,然后他们认为我是一个优秀的研究生,所以想聘用我在伯克利做物理博士后。那时候的博士后可以一直做下去,很多人都是这样。因此,我一直在同一个阿尔瓦雷斯小组工作到 1972 年,做的事情大同小异,实验不同,但研究内容基本相同。当时,斯坦福直线加速器中心(SLAC)已经投入使用,所以我在伯克利的时候就参与了在SLAC进行的一项实验。
+
+**NF**:你开始与 SLAC 互动了吗?
+
+**JF**:嗯,不是真的,我是说数据被带到了SLAC,但我从未真正去过SLAC除了观察光束之外。观察光束意味着你在采集数据;这是一束电子束(在伯克利,这是一束质子束),它撞击物质,然后反应产物出来,由粒子探测器探测到。所有这些都需要大量的电子设备来控制。因此,必须有人在控制室里对电子设备进行监控,以确保一切正常,并以可重复的速度获取数据。
+
+**NF**:SLAC 是什么时候成立的?
+
+**JF**:拉加宇航中心建于 60 年代,可能在 50 年代就开始了,在 60 年代中期(1966 年)投入使用。这是 SLAC 的首批实验之一。这是一台电子机器,因此我们与伯克利的一些 SLAC 人员进行了合作。我们的气泡室被搬到了SLAC。数据在那里采集,然后带到伯克利进行扫描、测量和分析。在此期间,我并没有花太多时间在 SLAC。
+
+**NF**:为什么要把数据送到伯克利?
+
+**JF**:因为这就是今天高能物理的工作方式。有大量的数据需要分析,非常耗费人力,所以你把工作分散开来,就能更快地完成。
+
+**NF**:换句话说,就是分布式计算?
+
+**JF**:从某种意义上说,是的。而且,这些实验的运行成本非常高,所以人们喜欢聚在一起合作完成。当时有几十位物理学家合作,现在有数十个实验室的合作。
+
+
+
+# 3 迁往拉丁美洲及加勒比地区(1972 年)
+
+**NF**:你为什么搬到 SLAC?
+
+**JF**:嗯,我们伯克利分校研究部新来了一位主任,他认为博士后不应该永远待下去,三年是博士后的最长期限。所以他解雇了所有在那里工作超过三年的博士后。包括我在内,所以我不得不出去找工作。
+
+那时,高能物理的工作机会是周期性的。一会儿有很多,一会儿又没几个。那时候的工作机会并不多。我确实有几个好机会,但都涉及到搬离海湾地区,我不想那么做。于是,物理统计学家弗兰克-索尔米茨(Frank Solmitz)有一天在走廊里走过来对我说:"SLAC有一个领导计算机科学研究小组的职位,他们在问我谁是合适的计算物理学家,我提到了你的名字。你有兴趣研究吗?”我觉得这不适合我,但我可以试试。于是我去面试。首先,我被SLAC的所有主任和小组负责人面试,然后我又被校内计算机科学系的所有教授面试。他们原本想找一位著名的计算机科学家来管理这个小组,但他们找不到一个合适的人选。
+
+所以他们决定找一位计算物理学家,这就是他们找到我的原因。
+
+面试回来后,我觉得就这样了。这是一次有趣的经历,但我觉得我不想要这份工作,他们也不想要我。一周左右后,我接到一个电话,说 "他们对你很感兴趣。你想做什么?"我说:“我想在做任何事情之前,我最好先和组里的人谈谈。"我去和组里的人谈了谈。他们都是非常好的人,所以我想,为什么不呢?于是我去了SLAC,领导这个计算研究小组。该小组是由比尔-米勒(Bill Miller)建立的,他最初在SLAC建立了计算设施。他们希望他建立计算中心,但是他只在特定条件下加入。条件之一是让他成为计算机科学系的教授。另一个条件是,他必须能够在 SLAC 拥有自己的计算机科学研究小组。SLAC 有很多物理研究小组,但他将拥有自己的计算机科学研究小组。他最终成为了大学(斯坦福大学)的教务长,所以那个职位空缺,我就去了那里。
+
+**NF**:事情是怎么安排的?
+
+**JF**:他手下有很多聪明人。有不少人从事计算机制图工作,当时计算机制图还处于起步阶段。他建立了一个非常先进的计算机制图设施,包括价值数百万美元的电影制作设备,这在当时是一大笔钱。这在当时是一笔巨款。当时还有人在从事计算机科学其他领域的研究工作,也有一些纯粹的服务型人员在为SLAC的物理学家进行工作坊编程;总的来说,这个小组大约有10个人。
+
+**NF**:因此,你们拥有贝尔实验室统计小组后来在工作站方面拥有的那种技术优势。
+
+**JF**:是的,这是一个很棒的设施。另外,SLAC 是一个物理实验室,而高能物理实验室的计算能力比任何人都强,除了武器实验室。我可以使用 SLAC 的计算设施,包括他们的大型计算机系统。在当时,甚至在十几年后,也很少有统计学家能使用这样的计算设施。
+
+**NF**:工作内容是什么?
+
+**JF**:我的工作主要是作为管理员管理小组,然后自己做研究。我想他们希望我的工作能各占一半:我做了大约四分之一的行政工作和四分之三的研究工作。我于 1972 年初到达那里,头六个月从伯克利上下班。此外,我还应邀在计算机科学系教授一门初级计算机文学课程。这是一门关于算法、数据结构和计算机体系结构的课程。我对其中的一些内容略知一二,但为了讲授这门课程,我必须详细学习所有内容。就我学到的东西而言,这是我教过的最有价值的课程之一。如今,我在工作中仍会用到其中的大部分内容。
+
+我想做的研究是模式识别。即使是在伯克利做学生和博士后时,我也对数据很感兴趣。我写过一些分析软件包,做过蒙特卡洛,还写过一个最大似然法的程序。我对数据的兴趣很好,因为当时大多数其他物理学家对制造新设备更感兴趣,而我对分析数据感兴趣,这就是我进入计算机领域的原因。我热爱计算机。
+
+**NF**:你在模式识别方面做了哪些尝试?
+
+**JF**:当时叫模式识别,现在叫机器学习,算是基本的模式识别,比如近邻技术。我读过 Cover 和 Hart(1967 年)的论文,对聚类和一般的统计学习很感兴趣,但当时还不叫这个名字。当时最接近的名称是 "模式识别"。
+
+**NF**:从数据中寻找群体?
+
+
+
+
+
+
+
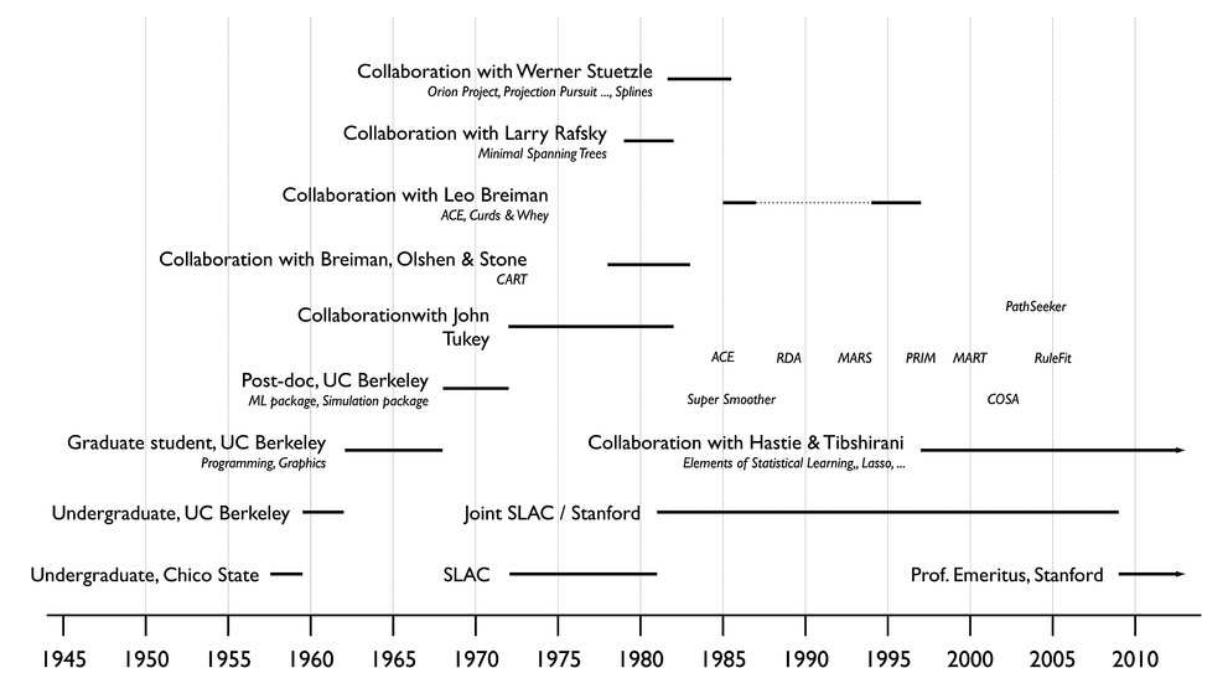
+图2: 杰瑞的一些主要研究领域和研究合作的大致时间表。
+
+
+
+
+
+
+**JF**:是的,从数据中找出群体,利用数据进行预测,诸如此类。当时我并没有明确的研究计划。我刚刚离开伯克利,在那里我主要从事物理研究,还有其他统计方面的工作,所以我还没有真正制定研究计划。我不确定自己是否有过这样的计划。
+
+**NF**:据我所知,你参与的那个小组有一些非同寻常的人。
+
+**JF**:是的,确实如此。我来的时候,在(斯坦福大学)计算机科学系里,当时很普遍,现在可能也是如此。科学系教授的一半工资由系里支付,另一半工资则要到外面去筹集。其中一个办法就是到其他地方工作。在我们小组,经常有计算机科学教授兼职工作。我刚来的时候,吉恩-戈鲁布(Gene Golub)在小组里兼职。我们还有两个有远见的人,哈里-萨赫尔和福雷斯特-巴斯克特。我来的时候,哈里就在那里。福雷斯特是后来加入的。这促成了一些非凡的发展。(参见 Fisher (2015) 中的轶事:Build-ing the hrst Graphics Workstation)。
+
+
+
+**与约翰-图基合作 1972--1980**
+
+**NF**:就在你搬到 SLAC 之后,你开始与约翰-图基(John Tukey)合作。
+
+**JF**:是的,我的前任比尔-米勒(Bill Miller)和约翰-图基(John Tukey)是好朋友,所以他邀请图基在休假期间过来,因为我们都知道,约翰对图形学非常感兴趣,尤其是对动态图形学。我们的实验室是为数不多的可以制作动态图形的地方之一。当我来到SLAC时,每个人都为这个家伙的到来而兴奋不已,这并不是因为他是一个伟大的统计学家,而是因为他因发明了快速傅立叶变换而在计算机科学领域享有盛誉。他们都很兴奋,而我却从没听说过他。
+
+**NF**:所以当约翰出现的时候,你实际上并没有想好要做什么研究项目?
+
+**JF**:不。我和他聊了聊,他告诉我他在做什么,对什么感兴趣,我觉得非常有趣。我们一拍即合。他在在图形方面,我做了一点工作,但不是很多。我会观察他们如何处理图形--旋转点云、分离子集,然后说:"好吧,让我们看看这些",等等--试图直观地发现数据中的模式。 约翰主要是和我们小组的一位程序员一起工作。
+
+**NF**:约翰自己从不编程?
+
+**JF**:据我所知没有,至少没有在计算机上运行过的代码。他用一种伪Fortran语言写出了他的想法,但据我所知,他从未真正坐在终端前执行过代码。(参见 Fisher (2015)中的图基研究笔记样本)。
+
+**NF**:当时他有什么样的想法,点云旋转等等?
+
+**JF**:嗯,如果你看过 PRIM-9 电影,那就是他的产品和想法。它从理论上整合了任意方向旋转点云的想法。他对人机界面非常感兴趣,开发出了一些非常流畅的控制方式,特别是考虑到他不得不使用的设备的简陋程度。我一直在观察他在做什么,他会反复提到一张有趣的图片,于是我开始思考:是什么让这幅画变得有趣? 我和他讨论这个问题。他说:"我们最喜欢的图片似乎是那些有内容的图片;它们有很多小的点间距离,但它们又能覆盖整个图片。"我在伯克利大学时,一直在研究优化算法,我想,如果我们先确定一些结块指数,然后尝试用优化算法将其最大化,会怎么样呢?这基本上就是投影追寻的开端,我们就此展开了互动。因此,我做的是分析算法,约翰做的是图形。
+
+**NF**:约翰的兴趣是什么?他不是真的想解决物理学方面的科学问题?
+
+**JF**:他认为这在物理学中会有很大的应用,因为物理学中的数据本身就具有很高的维度和结构。它不像社会科学中的数据那样分散:物理学中的数据具有非常清晰的结构。事实上,我认为电影中展示的数据集就是高能物理数据集。所以他的设想是,这可以用于高能物理,但我认为他肯定是在考虑更大的问题。
+
+我想他在那里待了四个月。后来他回来待了一段时间,我说:"约翰,我觉得我们应该把这个拍成电影,"因为我们有很多电影制作设备。我的前任比尔-米勒(Bill Miller)是个筹款天才。他有一个对图形学感兴趣的研究生。这个学生非常聪明,想要最好的一切,所以他得到了最好的一切。他知道如何使用电影设备,所以他制作了一部电影,只需将摄像机对准屏幕,然后约翰在那里说话。于是我们有了一部电影.......然后就没人想剪辑它了。我问他:"你愿意做剪辑吗?"他说:"当然愿意。"结果这成了一项艰巨的任务。总之,这就是约翰-图基第一次和我们一起去SLAC的结果。整个20世纪70年代,我们都保持着联系,七年后他再次回来休假。
+
+**NF**:在最初的《投影追求》论文中,你是如何与他互动的?
+
+**JF**:他的想法非常多,也很有启发性。我们似乎说着同样的语言,以同样的方式思考问题。他的方法是操作:任务在这里,问题在这里,我们如何处理,我们如何完成。他似乎对基本原则不感兴趣;他可能感兴趣,但从未说过。
+
+**NF**:非常工程化的方法。
+
+**JF**:非常工程化,这一直是他的方法。他总是喜欢藏着掖着,不告诉你他做任何事情的根本原因,背后隐藏着什么,他的理由是什么。他会对你说:"好吧,这是一个程序:你做这个,然后做这个,然后做这个,然后做那个。"当时我年轻气盛,所以我会说:"约翰,好吧,我明白了,但你为什么要做这个和这个?为什么这是个好主意?"他又会说:"好吧,你这样做,然后你这样做,然后你这样做,然后你这样做,"我说:"约翰,但是为什么呢?"就这样来来回回,他表现得好像没有什么指导原则一样。我想,我的锲而不舍足以让他最终气急败坏地说:"哦,好吧,"然后清晰地阐明指导原则;他一直都有指导原则,只是不想说出来,至少不想马上说出来。他的主要想法是,他将根据程序的性能而不是动机来评估程序。他的主要想法是,他将根据程序的性能而不是动机来评价程序。他对这些问题不感兴趣:这是一个具有特定先验的贝叶斯程序吗?这是一个在某种意义上最优的程序吗?在某种意义上是最优的?他不是从这个角度出发的。他会说:"好吧,你有一个程序,告诉我对数据的运算,明确的运算。我不管它来自哪里,也不管你的动机是什么;你告诉我适用于数据的操作,我会告诉你我是否认为它是个好主意。这就是他思考问题的方式。
+
+**NF**:你觉得他是在心理上根据一套隐藏的原则来检验这件事,还是在看它是否符合他的直觉?
+
+**JF**:我不知道他是一直有一个指导原则,还是为了让我不再问他而编造了一个。
+
+我写了 "投影追寻 "论文的初稿,他进行了编辑,然后我们进行了讨论。我在期刊上发表的第一篇统计学论文就是与约翰合作的《投影追寻》(Projection Pursuit)(弗里德曼和图基,1974 年)。这是我提交过的唯一一篇论文,而且没有修改就立即被接受了,我当时想,这真是太好了,我喜欢这篇论文。但从那以后就再也没有发生过。
+
+**NF**:你在SLAC跟他做了一些后续工作。
+
+
+
+
+
+
+(a)
+
+
+
+(b)
+
+图3: PRIM-9视频的画面。(a)杰瑞-弗里德曼。(b)约翰-图基坐在PRIM-9硬件前,用黑板对粒子物理数据中的变量进行解释。
+
+
+
+
+**JF**:是的,他下一次休假回来是在 20 世纪 80 年代初。我想那时他正在去夏威夷的路上,因为他的一个表亲或其他人要结婚了,伊丽莎白最终说服他去海边度假。于是他顺道去了斯坦福大学,我们一起工作。
+
+给他留下深刻印象的是,他住在校园里的房子里有一个游泳池;那是一位正在休假的教授的房子。因此,他早上不会来,而是坐在游泳池边,也许还会游泳,写出关于如何分析高维数据的想法,通常是用隐晦的文字或伪Fortran语言写出来的。然后,他会在下午晚些时候把这些想法拿过来,请我们的秘书把它们打出来。这样的事情每天都在发生。之后,维尔纳(斯图亚特兹勒)和我会看一看,有时还会和他讨论。
+
+最后,他去夏威夷度假了,纸条也就停止了。几天后,邮包开始寄来,每天都有来自夏威夷的包裹。他在海滩上思考,而不是在游泳池。我至今还保留着许多这些笔记。约翰去世后,有一期《年鉴》刊登了大卫-布里林格(David Brillinger)撰写的一篇关于他的长文(Brillinger (2002)),维尔纳-斯图兹勒(Werner Stuetzle)和我写了一篇较短的文章(弗里德曼和斯图兹勒 (2002)),谈到了他的制图工作以及我们在他的制图工作中与他共事的经历。当时我们想,也许我们应该把这些笔记收集起来,看一看。在数据分析方面,其中可能有大量的想法在今天的标准下仍然是革命性的,但这是你在有时间才能做的事情。
+
+**NF**:回到你自己的个人研究,似乎它正变得越来越统计化。
+
+**JF**:确实如此。我对一般意义上的模式识别很感兴趣,当时比较流行的方法有近邻法和核方法。Cover和Hart已经证明,从渐进的角度来看,近邻分类法仅用近邻就能达到贝叶斯风险的一半。当然,当时我们并没有意识到在高维环境下实现渐近的难度 。当时人们对此非常兴奋,我想,如果我们要在高能物理等更大数据集的应用中使用这种方法,我们需要一种快速算法来找到数据集中的近邻。当时,SLAC 实验产生了数以万计的观测数据,不是像现在这样数以百万计,而是数以万计。计算近邻的直接方法通常是 n2 平方运算:对于每个点,你都必须对所有其他点进行遍历。因此,我开始研究快速计算近邻的算法,但没有取得太大成功。
+
+后来,我遇到了唐-诺思的学生乔恩-本特利(Jon Bentley)。他有一些非常聪明的想法,基于他所谓的 k-d 树,于是我和他开始和另一个学生拉斐尔-芬克尔(Raphael Finkel)合作,尝试开发快速的近邻搜索算法。因此,我在统计学之外最著名的论文之一可能就是那篇论文:快速近邻识别算法(fast algo-rithms for finding near neighbors)(Friedman, Bent- ley and Finkel (1977))。之后,乔恩进入北卡罗来纳大学攻读研究生。之后,他继续做着伟大的事业,并成为了在计算机科学领域非常有名。整个k- d 树的想法被认为是计算几何中的一个非常重要的发展,而约翰就是这个想法的发明者,一个令人难以置信的聪明人。
+
+另一个有趣的方面是,这也是我开始接触决策树的原因,因为用于查找近邻的 k- d 树算法涉及将数据空间递归划分为多个方框。如果你想找出一个点的近邻,你就会沿着树向下遍历到包含该点的方框,找出它在该方框中的近邻,然后向上回溯,利用树结构找出它在其他相邻方框中的近邻。这就是算法。我当时在想:好吧,如果你想找出近邻,那就没问题,但假设找出近邻的目的是为了进行分类,也许在这种情况下,对树的构建进行修改会更适合近邻。于是我想到,在近邻算法中,你可以递归地ind出散布最大的变量,然后在中位数处将其分割开来,形成方框。我们为什么不找出最具判别力的变量,并在最佳判别点进行分割呢?于是,我想出了这个范式来找出近邻。后来我突然想到,你根本不需要最近邻;你可以使用方框(终端节点)本身来进行分类。
+
+**NF**:这是什么时候的事?
+
+**JF**:大概是 1974 年左右,在我去欧洲核子研究中心之前。
+
+这就是我对最终成为 CART 的最初想法:它来自于获得树形结构的递归分区近邻算法。稍后,我与里奥-布雷曼(Leo Breiman)、理查德-奥尔森(Richard Olshen)和查克-斯通(Chuck Stone)一起,他们一直在独立追求非常相似的想法。
+
+哦,忘了说了,上世纪七十年代初我刚加入计算研究组时,有一天吉恩-戈鲁布(Gene Golub)来找我说:"我明年要去休假,这意味着我不会在这里了,我担心如果你们空出一年的职位,等我回来时可能就不在了。所以我觉得你们应该找个人来解决这个问题,而我正好认识一个理想人选。他叫理查德-奥尔森(Richard Olshen),在统计部工作。"于是,我雇用了理查德半工半读。那是在我研究树木的早期。我和理查德聊天,他问:"你在做什么?""嗯,我在研究这个递归分割的想法。"理查德对此非常感兴趣,他说在随后的几年里,他为基于树的方法学做出了巨大贡献。
+
+
+
+**访问欧洲核子研究中心 (1975- 1976)**
+
+**NF**:在 SLAC 工作几年后,您决定到欧洲核子研究中心休假。在这个阶段,你成家了吗?
+
+**JF**:是的,当时我有一个妻子和一个三岁的女儿,我们都去了日内瓦的欧洲核子研究中心。物理学家休假一年去欧洲核子研究中心是很自然的事。这不是官方的假日,我只是决定想离开一年,所以申请了休假。我是工作人员,但不是教员。理智上看,这对我的刺激并不大。我所在的计算机小组被称为数据处理小组,是欧洲核子研究中心拥有计算机的一个大小组。我做的专业工作是研究自适应蒙特卡洛算法。我的主要工作是吃他们做的菜,喝红酒,在很多米其林三星级餐厅用餐,这就是我的主要工作。欧洲核子研究中心非常有趣。SLAC是一个相当紧张的地方,而欧洲核子研究中心当时要悠闲得多。
+
+**NF**:你在欧洲核子研究中心工作期间,还访问过其他小组吗?
+
+**JF**:是的,我做到了,这对我来说非常重要。我在欧洲核子研究中心的时候,收到了约翰-图基的一封信。约翰-图基(John Tukey)来信说:"我认识苏黎世联邦理工学院的彼得-胡贝尔(Peter Huber)。他对这些投影追求方面的研究很感兴趣。你应该去拜访他。"于是我去了苏黎世,从火车站找到了去 ETH 的路。我从未见过彼得或ETH的其他人,所以我站在走廊里,一个人走过来问我:"我能帮你吗?"我猜他知道我会说英语,也许我身上写满了英语。我说:"是的,我想找彼得-胡贝尔。"他原来是安德烈亚斯-布哈,当时是彼得的学生。在那次旅行中,我还遇到了彼得的另一位学生维尔纳-斯图茨勒(Werner Stuetzle)。上世纪80年代初,当他来到SLAC和斯坦福大学时,我们一直保持着密切的合作关系。我认为安德烈亚斯也曾多次访问 SLAC。两人都是聪明绝顶的家伙。
+
+
+
+**界面会议**
+
+**NF**:回到你在SLAC工作的时候,你已经开始参加界面会议并结识朋友。.
+
+**JF**:是的。我和里欧-布雷曼(Leo Breiman)和查克-斯通(Chuck Stone)是在1975 年的一次界面会议。Leo做了一个关于近邻分类法之类的演讲,当时我正在研究这些快速算法,所以 我在会场后面举手说:"我们一直在研究一些新的快速算法。” 演讲结束后,Leo看了我一眼。他很感兴趣,我们开始交谈,但也仅此而已。但我在欧洲核子研究中心时,他给我寄了一封信,说他将于1977年在达拉斯组织一次会议,他称之为 "大型复杂数据集分析会议"。Leo是另一位有远见的人,他看到了数据挖掘的未来。他邀请我去那里演讲。我从未去过达拉斯,所以回来后不久我就去参加了那次会议,那次会议在很大程度上改变了我的职业生涯。我在那里认识了拉里-拉夫斯基(Larry Rafsky),后来与他合作。后来我和他合作过 我还认识了比尔-克利夫兰(Bill Cleveland)。
+
+**NF**:这次会议如何改变了你的生活?
+
+**JF**:因为我又遇到了 Leo。
+
+**NF**:我们很快就会谈到 Leo。你在这段时间与拉里-拉夫斯基(Larry Rafsky)合作过一些作品。
+
+**JF**:是的,我们开始讨论我们在计算几何方面的一些共同兴趣(近邻)。这促使我们在 20 世纪 70 年代末、80 年代初开始使用最小跨度树进行多变量良好性和双样本测试,并由此产生了多变量关联的一般测量方法。由此产生了两篇《年鉴》论文((Friedman and Rafsky,1979 年,1983 年)。我还重新引入了递归分区思想,并以各种方式对其进行了扩展。也是如此。他是一个非常聪明的人,有很多想法。我从他身上学到了很多东西。
+
+
+
+**CART 和 Leo Breiman (1974- 1997)**
+
+**NF**:让我们把递归分区的背景杂音带到前台,谈谈 CART。这次著名的合作是如何产生的?
+
+**JF**:在拉里和我撰写了两篇使用最小生成树的论文后,我们开始研究 CART 的想法。理查德-奥尔森(Richard Olshen)当时(20 世纪 70 年代中期)在加州大学圣迭戈分校工作,他每隔一段时间就会回斯坦福大学一趟,并到 SLAC 来看望我。有时,我会告诉他最近关于树的工作。他和路-戈登(Louis I. Gordon)一起做了一些很好的理论工作,路-戈登是斯坦福大学的前教授,他当时在工业界工作。我告诉他我们是如何扩展决策的,他说:"这听起来很像 Leo Breiman 和 Chuck Stone 的做法。
+
+他试图向我解释他们在做什么,但我不太明白;同样,他也试图向他们解释我们在做什么,但他们也不太明白。最后,Chuck打电话给我,我们讨论了很久。我们完全是独立工作,但我们所做的事情有很多共同点。因此,我猜是Leo建议我们在南加州开个会。他们都是一家名为 "技术服务公司 "的公司的顾问,该公司主要负责政府合同,我想主要是环境方面的合同。Leo基本上是那里的全职顾问,Chuck也是顾问。事实上,他们当时写的一些技术报告都是关于树木的经典文章。于是,Larry、我、Chuck和Leo一起去了那里(Richard不在),并在 TSC 开了一次会。我们谈到了这是多么令人兴奋的事情,而且我们各自的方法有很多共通之处。也有一些不同之处,我们讨论了哪些似乎是最好的。然后Leo说:"嘿,我觉得我们应该写一本专著。"我们永远不会把这样的东西发表在(当时的)统计期刊上。于是我们开始写,专著就这样诞生了(Breiman et al).
+
+**NF**:我记得,差不多在这个时候,还有其他关于递归分区的研究。
+
+**JF**:嗯,这是一个不断被重新发明的想法。每个重新发明它的人都认为这是他们获得 "诺贝尔奖 "的时刻。20世纪60年代初,密歇根大学社会科学中心的摩根和松奎斯特(1963)开始研究树算法。然后是罗斯-昆兰(Ross Quinlan,1986 年),差不多在同一时期,他在做一种叫做 "迭代二分法 3"(ID3)的算法,这是一种粗略的树型算法。后来,他开发了 C4.5,结果发现它与 CART 非常相似,尽管有一些不同之处。我们引以为豪的是,CART 比 C4.5 早了十年,但正是昆兰和机器学习者普及了树。我们做了 CART 之后,它就停在那里:统计学家们说:"这是干什么用的?你用它做什么?"
+
+**NF**:你还实施了软件,并将其投入使用。
+
+**JF**:是的,我们提供了它。然后我们就有了想把它卖出去的想法,我们的小公司就这样开始了。
+
+**NF**:首先,让我们谈谈你与 Leo 的长期合作。这是开始。
+
+**JF**:没错,这是从 CART 开始的,因为我们当时正在尝试编写软件。最初的软件是我写的,但 Leo 对软件的内容、结构、用户界面等有很多好的想法,因此我们在这方面进行了合作。与此同时,LEO离开了加州大学洛杉矶分校,成为了一名全职顾问。
+
+**NF**:他曾经是一个概率学家。
+
+**JF**:他是个概率学家,他常说 probobobilist。1980 年,他回到学术界,加入了伯克利的统计系,与此同时,Chuck也来到了伯克利。
+
+**NF**:在当时的伯克利,你觉得 Leo 的任命不寻常吗?
+
+**JF**:是的。他有扎实的数学功底。在这个意义上,他就像图基(Tukey):他能做这种超级经验主义的研究,但他的数学也很强,所以他们不能说他在做方法论,因为他不会做数学。我不知道他们为什么要雇他,但我猜他们想开始进入计算机时代,于是就把他请来了。他买下了他们的第一台电脑,一台 VAX 电脑,安装好后,又对它进行了长时间的维护和保养,从这个角度以及其他很多角度来看,他的任命都是非常明智的。
+
+**NF**:合作进展如何?
+
+**JF**:我们开始了CART 的合作,我们决定写这本书,我们把它分成了不同的部分。然后Leo说:"如果我们写了这个叫 CART 的程序,并决定把它卖出去,以每份 100 美元的价格卖出 1000 份,你知道这能赚多少钱吗?"于是我们决定,好吧,我们成立一家公司--加州统计软件公司,并尝试销售 CART。所以我们必须有一个产品。Leo当时在伯克利,所以我们开始了一种模式,这种模式大概持续了十年。每周四我都会去伯克利。我会在上午 10 点左右离开这里,11 点左右到达那里,然后把车停在赫斯特大道上。Leo会把一整天的时间都安排好,那天不会有其他人来看他。我们会去他的办公室开始工作。到了中午,他会说:"杰瑞,我们去吃午饭吧。"所以我们每次都会去同一个地方,赫斯特大道上的一家餐馆。我们通常会吃同样的菠菜配酸奶油,还有一杯浓咖啡。然后我们回到他的办公室工作,期间我会跑出去给赫斯特大道上的停车计时器加油。我们不是坐在那里写作,也不是在电脑上打字,而是一直在聊天。一般来说,在 5 点半左右,或者进度似乎放缓的时候,Leo会说:"杰瑞,我们去喝啤酒吧。"于是我们就去沙塔克大道上的一家酒吧 Spats。喝了几杯啤酒后,Leo会说:"杰瑞,我们去吃晚饭吧。"于是我们就去伯克利一家比较好的餐馆,美美地吃上一顿。然后Leo回家,我开车回帕洛阿尔托。在很长一段时间里,这都是每周四的惯例。
+
+**NF**:他是如何处理问题的?
+
+**JF**:他就像图基(Tukey)一样:"不要告诉我动机,告诉我你对数据做了什么。”他没有明显的基本原理,比如:这是一种具有特定先验的贝叶斯方法。他从来没有那种从任何指导原则出发的思维方式;他只是对数据进行有意义的处理。
+
+**NF**:你是否认为这是处理数据的计算机科学方法,而不是统计方法。. .?
+
+**JF**:那我会的。
+
+**NF**:......从这个意义上说,你正在做的是研究一个特定的数据集,你不知道你所做的是否会在其他数据集上起作用?
+
+**JF**:嗯,我们通常不是在研究特殊的数据集,而是在尝试开发针对各类问题的方法。这就像开发 CART:CART 可用于各种数据集,ACE(Alternating Conditional Expectation)(布莱曼和弗里德曼,1985 年)也可以,Curds and Whey(布莱曼和弗里德曼,1997 年)也可以。我们从方法论的角度进行了思考。换句话说:问题。我有数据,有结果,有预测变量,数据是特定类型的。现在我们该如何制定一个程序来解决这个问题呢? 我认为,除了在论文中用来说明方法的例子,我们从未真正一起分析过一个特定的数据集。分析数据集的关键不在于方法的好坏,而在于你从数据集中得到的答案,我们俩也做过很多这样的分析。
+
+**NF**:是什么激励了ACE?
+
+**JF**:我们的想法是同时进行最优变换。在线性回归问题中,有很多关于数据变换的启发式方法和规则:是取对数,还是取其他类型的对数的变换?事实上,我认为Box-Cox是一种试图从参数函数族中找出变换的自动方法。我们参与了平滑器的研究,因此我们思考如何自动找出好的变换,而不必限制它们必须来自参数函数类,只需看看能否估算出一组最佳变换。
+
+**NF**:什么意义上的 "最佳"?
+
+**JF**:平方误差意义上的最优。......当然是在平滑性约束下,否则会有无数种变换能完美地处理数据。所以你必须加入平滑性约束,我们在算法的核心部分明确使用了平滑器。我记得我去伯克利的时候,有一个星期四,Leo问我:"如果我有两个变量,我该如何找出其中一个变量与另一个变量最大相关的函数?"我说:"如果你做平滑,你就取其中一个变量给定另一个变量的条件期望值,好吗?"这并不一定能最大化相关性,所以我们开始思考:于是我们开始思考:好吧,如果我们用一种方法,然后给定这条曲线,将其与另一条曲线进行平滑,会怎么样呢?后来我们又去了 Leo 的家,他在那里有一个Apple 2。他用 Basic 编程,只使用了简单的双变量算法。他模拟了一个模型的数据,在这个模型中,两种情况下的最优变换都是平方根。Apple 2 的运行速度并不快,因此我们可以实时观看它的运行情况,并显示每一步的当前变换。从线性直线开始,我们看到变换随着每次迭代开始变得越来越弯曲,直到收敛。这对我们来说是一个激动人心的时刻。
+
+于是我们提出了这个想法,然后Leo对理论产生了浓厚的兴趣。他从来没有认真地研究过理论,但他喜欢研究,所以他研究了渐近一致性之类的东西,我们玩得很开心。
+
+20 世纪 90 年代初,我休假了一年,那时我们没有合作,但到了 90 年代中期,我们又开始合作了。有一天,Leo打电话给我,说:"杰瑞,我想和你再次合作。"当时我们甚至没有具体的合作项目。我去了伯克利,我们讨论了可以合作的项目。我说:"嗯,有一个问题我一直在想,但一直没有解决,那就是多元回归,你有多种反应。"于是我们开始讨论这个问题,并由此产生了《Curds and Whey》这篇论文。这是皇家统计学会的一份讨论文件。
+
+这种合作模式与以前不太一样。我不会经常去伯克利,因为基础设施已经发展到可以分开工作的程度,所以我们基本上是通过电子邮件来工作的。我对 PLS(偏最小二乘法)的熟悉促使我产生了这个想法。PLS 有一种模式,它有多个结果变量和多个预测变量。单结果变量只是一种特殊情况。在我和 Ildiko [Frank] 为理解 PLS 所做的工作中(见下文),我们只处理了单一结果的情况。我想尝试理解多结果程序,看看是否能找到一种在统计上更合理的方法。所以 Leo 和我一起研究了这个问题,非常有趣。
+
+在本文中,我们颠倒了角色。一般来说,在我们的合作中,我主要负责方法和计算部分。利奥通常负责理论部分。在这篇论文中,我们的角色颠倒了:Leo 编写程序,Leo 掌握数据,而我负责理论。
+
+**NF**:为什么是Curds and Whey??
+
+**JF**:我将重述我在纪念文章中讲述的关于 Leo 的故事。我想出了 ACE 这个名字。我很喜欢这个名字,但Leo不喜欢,非常不喜欢。那是我们结束工作后的一个下午,我们去 Splats 喝啤酒,还在讨论这个名字。里欧不喜欢它,而我喜欢,所以我们来来回回地讨论。然后里欧突然说:"好吧,杰瑞,你说对了,是 ACE。"里欧如此轻易地屈服是很不寻常的。我不解地看着他,心想,这也太容易了吧,他说,"你看街对面,"于是我看了看街对面,有一家五金店。这家店有一个红色的大招牌,叫做 "Ace"。1987 年,当我们应邀发表 JASA 论文时,Leo从王牌五金店带了一大堆印有王牌字样的袋子,分发给听众。后来,当我们做多重响应多变量回归工作时,我们又为如何给程序命名争论不休。Leo 提议叫 " Curds andWhey, ",我很不喜欢这个名字,但我觉得既然他在 ACE 问题上让步了,我也就让步了。这一点。这是 Leo 在思考一个事实,即我们要把信号从噪音中分离出来,把好的东西从坏的东西中分离出来,把凝乳从乳清中分离出来。
+
+我想,在奶酪生产过程中,乳清和乳清之间的比例应该是相反的。那次合作持续了几年,也许是三年。我认为在某种程度上,我们的兴趣在那时就已经分开了。他们倾向于关注非常相似的问题。他做了非负伽罗特,然后开始研究袋式算法,而我当时正与罗布(Tib- shirani)和特雷弗(Trevor Hastie)一起研究提升算法。这两种方法都基于树的集合,但从不同的角度出发。我知道他在做什么,但我们没有持续的互动和参与。当我们聚在一起时,我们总是玩得很开心。
+
+**NF**:谈起Leo,我们的思绪飞跃了几十年。让我们回到您仍在 SLAC 全职工作的时期。在这个阶段,你有没有遇到过统计部的人?
+
+**JF**:不,现阶段没有。我没有开始互动,直到 20 世纪 70 年代末,他一直在统计局工作。
+
+
+
+# 4 迁入斯坦福大学
+
+**JF**:我在系里参加研讨会,但我没有正职。于是布拉德-埃夫隆(Brad [Efron] )请我去教一门课。
+
+**NF**:你觉得你在做统计吗?
+
+**JF**:是的,我知道Rafsky的课程是统计学,是假设检验。这就是我在课程中讲授的内容。这可能是我最接近经典统计学的地方了。最小生成树不是经典统计学,但其他部分都是。
+
+这拉近了我与系里的距离。当我在 SLAC 工作时,我还不是那里的教员。我只是一名工作人员,这意味着我无法撰写提案并提交给国家科学基金会或其他机构、能源部或其他可能赞助我这种工作的机构。SLAC提供了赞助,这很好,但有时我真的需要更多的钱来做事。所以我想写提案,为此我需要成为某种教授。保罗-斯威策(Paul Switzer)当时是系主任,于是我去找他,对他说:"你有没有办法让我成为系里的顾问教授?这样我就可以代表斯坦福大学撰写基金和报告了"。他说:"好吧,我们试试看。"于是,所有的文件工作都准备好了,并提交给了行政部门,包括信件和其他一切。回来后,保罗说:"对不起,我们不能这样做。我们不会有一些与你的情况无关的政治问题,但他们不做顾问教授了。不过,他们确实说过,你的文件夹看起来很有说服力,为什么不试试找一个普通教授呢?"保罗就这样做了,而且成功了。保罗可能做了大部分的工作,因为他是主席。就这样,我成了一名教授。
+
+**NF**:除了在 SLAC 工作之外?
+
+**JF**:我成了一名半职教授,在 SLAC 半职工作,而不是全职。
+
+**NF**:所以这实际上是你正式进入统计界。你觉得自己受欢迎吗?在主流统计学低迷的情况下,这个人从一个没有任何统计学背景的合流中乘风破浪而来,但他拥有很多技能和关于如何处理数据的不同想法。这对你来说是个大问题吗?
+
+**JF**:一般来说是的,但肯定不是在斯坦福,因为他们雇用了我。我在系里一直感到很受欢迎。但我不认为统计界的一般人理解我的动机。我记得有一次科林-马洛斯(Colin Mallows)听了我的一次演讲,他事后说:"孩子,这真的很吸引人,但这不是统计学。"我想这就是大家的普遍感觉,我所做的也许很有趣,但不是统计学。数学在哪里?统计学研究的通常特征在哪里?除了最小生成树的工作之外,我做的真的不是那种工作。因此,从这个意义上说,我不认为存在任何敌意,只是人们感到困惑:我所做的与统计学有什么关系?
+
+**NF**:然而你真正在做的是你之前描述过的事情:你和约翰-图基(John Tukey)的思维方式是一样的,你会有一个关于如何解决某些问题的想法,然后你会看到它在数据上是如何工作的。你们的工作并没有遵循基本原则,还是遵循了?
+
+**JF**:我认为这对多年后的我影响更大,约翰认为我出卖了自己。他真的认为我是在试图思考基本原理,而我是在开发东西,并把算法的优雅性作为标准。约翰对此非常反感。
+
+**NF**:你是否觉得你已经形成了某种处理你所接触的问题的经典方式?
+
+**JF**:可能吧,但我现在想不出来。我是以解决问题者的模式来工作的:这里有一个问题,我有一套特定的工具和技能,我用它们来指导一切。可能因为我的技能有限,所以有很多共同点,但我不认为我有意识地这么想。
+
+**NF**:假设一个年轻人来和你一起工作,而你对待他的方式就像约翰-图基对待你的方式一样:你这样做,你这样做。如果你被逼急了,你会编出一个原则,还是你真的能找到一个原则?你刚才说,也许约翰是为了让你闭嘴才编造了这个原则。
+
+**JF**:也许是启发式原理,我不认为我能想出一个深奥的理论原理,或者我仔细想想也许能想出来。
+
+**NF**:加入这个部门让你接触到了主流统计和统计学家,你开始参加更多的统计会议?在该系是如何改变正在发生的事情的?
+
+**JF**:嗯,我开始越来越意识到统计原理。我不认为这对我处理问题的方式有很大改变。我记得约翰-赖斯曾说过一句话,当有人问他是贝叶斯主义者还是频数主义者时,他说:"我是个机会主义者。"我也是这么看的:这是个问题。我们该如何解决它?我会尝试从我力所能及的任何方向去解决问题。
+
+**NF**:你在系里还接触到了一批值得注意的统计学家,他们都在做非凡的事情。
+
+**JF**:我想在潜意识里,这确实影响了我的很多想法。这也许就是Tukey晚年认为我在卖弄的原因。我确实考虑过原则问题,但我认为这些原则都在我的脑海里,是我没有正式应用的非正式原则。
+
+**NF**:你搬到那个部门后,约翰有没有来看过你?
+
+**JF**:是的,哦,是的,至少有几次。我记得有一次,我们沿着校园大道开车,我说:"约翰,你知道吗,现在我在统计系,尤其是在统计方面,也许我真的应该去学习基础统计、理论统计,以及所有常见的东西:(咂嘴声)。每当你对约翰说了什么,提出了一个想法或什么的时候,约翰都不会大加赞赏,那不是他的风格。所以,如果他静静地坐着听你说,你就知道他真的很喜欢。如果他有疑虑,他什么也不会说,但你会看到他的头慢慢地前后摆动;如果他真的不喜欢,他会竖起大拇指打断你的话并吹起了咂舌。所以,当我问他我是否应该学习统计学时,他就是这样回答我的。我不确定他是否完全正确,几年来,在朋友、同事和学生的帮助下,我确实学习了一些传统的统计学知识,我认为这对我帮助很大。
+
+
+
+**猎户座项目(The Orion Project)**
+
+**NF**:你在斯坦福大学开展了更多强有力的合作。第一个合作项目是什么?
+
+**JF**:1981 年左右,系里招聘助理教授,我想当时 Werner [Stuet- zle] 刚刚拿到学位。我说:"我在 ETH 认识了一个非常聪明的家伙。我想我可以把他拉过来,这样我们就可以付他一半的薪水,让他和我的小组一起工作,你们想聘用他吗?"他们考虑了一下,长话短说,他们说:"当然可以。"我说服了我在 SLAC 的老板,我们可以做到这一点,所以我们在斯坦福聘用了沃纳一半的工作时间,而我在 SLAC 的小组也有沃纳一半的工作时间。我开始了与沃纳的合作,多年来,我们的合作非常成熟,也非常有趣。
+
+**NF**:你当时在做什么样的事情?
+
+**JF**:嗯,我们启动了一个图形项目。沃纳曾与彼得-休伯(Peter Huber)合作研究图形技术,彼得对此非常感兴趣。因此,我们从 Office of Naval Research 拿到了一些钱,开始组装一个图形工作站。我们觉得:PRIM 9 已经过去十年了,技术已经有了长足的进步,让我们看看现在能做些什么。
+
+因此,我们共同开展了这项工作;我们称之为 "猎户座项目",非常有趣。(参见 "猎户座项目--在费舍尔建立第二个图形工作站"(2015 年))。
+
+
+**寻找模式**
+
+**NF**:您在 SLAC 的全职工作是您人生中非常激动人心的一段时期。现在您转到了统计系,与 SLAC 的交流还持续了多久?
+
+**JF**:我在那里只做了一半的工作,而管理这个小组大约需要四分之一的时间,所以我做 SLAC 类型工作的时间就少了一些。但在该小组工作仍然非常有价值。我仍然有机会接触到很多资源,而这些资源是我在其他情况下无法获得的。
+
+**NF**:这如何改变了你的灵感来源?
+
+**JF**:我一直对 Leo 所说的大型复杂数据集(现在称为 "数据挖掘")很感兴趣:收集这些数据不一定是为了研究,也不一定是为了开发。它有各种变量的混合物;实验没有签名;它通常是观测数据。我想这是我第一次在物理学中遇到的一种数据,它具有中等高维、数据量相当大的特点,观测数据的数量通常大大超过测量变量的数量。我一直对开发通用算法很感兴趣,在这种算法中,人们可以把数据倒进去,希望能得到一些合理的结果,而不需要数据分析师做大量的劳动密集型工作。
+
+**NF**:杰瑞在寻找模式吗?
+
+**JF**:是的,我猜是对数据进行通用模式搜索,通常侧重于预测问题。
+
+**NF**:从你来到 SLAC 开始,首先是 "投影追寻"(Projection Pursuit),你在高维数据中寻找群组?
+
+**JF**:我想我与四篇 "投影追求"(Projection Pursuit)论文有关。其中一篇是最初的 Tukey 论文(Friedman and Tukey (1974)),然后是与 Werner Stuetzle 合著的回归论文(Friedman and Stuetzle (1981)),之后我又以最初 Tukey 的风格写了另一篇后续论文(Friedman (1987)),还有一篇是与 Werner 合著的密度估计论文(Fried-man, Stuetzle and Schroeder (1984))。
+
+20 世纪 70 年代中期,我开始研究树,并一直延续到 CART。后来,在 20 世纪 90 年代,我又回到了树研究领域,当时我正在研究各种合奏方法。的出现。树的集合似乎特别适合这类学习机器,因为树在数据挖掘方面有很多非常理想的特性。树有一个问题:它们并不总是非常准确。因此,树状结构既解决了准确性问题,又保持了之前的所有优点;它们非常稳健,可以处理各种数据和缺失数据,而这正是我感兴趣的:现成的学习算法。你永远不可能像一个细心的统计学家或科学家那样对数据进行细致入微的分析,但它可以给你很好的第一答案,这就是我的想法。这基本上就是我的动力所在。
+
+研究兴趣是随机的。你有了一个想法,就会去追寻一段时间。它可能与你之前的研究类似,也可能是一个全新的方向。你会研究它一段时间,直到你陷入困境或发现更感兴趣的东西。我往往会遇到这些我想解决却无法立即解决的问题。我把它们放在脑后,然后在阅读或听讲座时,或者偶尔有人说我的脑海中可能会浮现出一些与我的想法无关的东西,但它会触发我的灵感:啊哈!我有个想法可以试着解决这个问题。于是,我回去努力工作了一段时间;要么我把它推得更远一些,要么我没有,但它仍然存在。我希望有一天能解决这些残留的问题;有时我确实能解决它们。
+
+**NF**:你曾与几个人合作开发过 CART,与 John Tukey 和 Werner Stuetzle 合作过 Projection Pursuit,与 Leo 合作过 ACE。然后呢?
+
+**JF**:与 Werner 一起完成的其他研究,包括 SuperSmoother(Friedman,1984 年)和一篇关于样条曲线的论文(Friedman, Grosse and Stuetzle (1983))。ACE之后是MARS(多变量自适应回归样条)。它始于20世纪80年代末。我希望有一种技术能具备 CART 的特性,但它必须是连续的近似值。树的致命弱点之一是,它能得出一个不连续的、片断恒定的近似值。
+
+这限制了它们的精度。此外,我还阅读了 de Boor 关于样条曲线(splines)的入门读物(de Boor (2001),Werner给我看的。我从Werner那里学到了关于平滑的大部分知识。平滑是一种重要的工具,我相信他的论文中有很多关于平滑的内容。在那之后,我知道了一些关于样条曲线的知识,所以我拼凑出了这个想法。你可以将 CART 视为递归的样条线逼近,但使用的是零阶样条线,它是片断恒定的,因此我尝试将其扩展,以便使用一阶样条线,它是连续的逼近,导数不连续,但却是连续的逼近,然后你可以将这种方法推广到更高阶(尽管在实现过程中我没有这样做)。
+
+**NF**:我记得,这最终成为了一篇非常大的论文。
+
+**JF**:是的,MARS 论文有 60 页的描述,然后又有 80 页的讨论,所以最后成了 140 页的论文(Friedman (1991))。
+
+除 MARS 外,我还开发了一种称为正则判别分析(RDA;Friedman (1989a))的技术。我的一些工作受到了化学计量学工作的启发。他们有一种叫做 SIMCA 的技术,从统计学的角度来看,基本上是一种奇怪的二次判别分析。它是 Soft Independent Modelling of Class Analogies 的缩写(Wold 和 Sjostrom,1977 年)。这在化学计量学的分类问题中被大量使用。
+
+**NF**:我记得在一次有一些化学家参加的会议上,你和 Ildiko 提交了一篇论文,阐述了你们对 PLS 的看法,你们在论文中指出 PLS 有一些明显的缺陷。你们在这个问题上的观点是否被化学家们接受过?
+
+**JF**:我不这么认为。两三年前我去参加一个化学计量学会议,20 年过去了,一切都还是 PLS。在机器学习文献中,一切都是机器,每种算法都被称为机器。在此之前,每种算法在神经网络中都被称为网络。在化学计量学中,所有东西都被称为某种 PLS。你提醒了我:Ildiko 和我写过一篇论文,试图从统计学的角度解释 PLS(Frank 和 Friedman (1993))。而且,当助推技术出现得更晚的时候,Rob、Trevor和我试图从统计的角度来展示它是怎么做的。我们做了 PLS,结果发现它非常接近脊回归。我觉得 PLS 的人一点都不欣赏它。
+
+PLS 有其局限性。其中之一就是,如果变量都是不相关的,那么它根本不会正则化。至少与之非常相似的脊回归在这种情况下仍能正则化。因此,它依赖于预测变量的高度相关性来实现正则化,而岭回归虽然对高度相关的变量给出了基本相同的结果,但也会在没有高度相关性的情况下实现正则化。
+
+**NF**:那 RDA 呢?
+
+**JF**:RDA 与 SIMCA 有关。这是一个关于线性判别分析和二次判别分析的非常简单的想法。你要考虑的算法是两者的混合。然后在第二部分,当你进行二次判别分析时,你会对协方差矩阵进行脊式正则化,这样两个协方差矩阵就有了两个正则化参数,每个参数都是单独估计的。每个单独的协方差估计值都与共同的协方差(它们的平均值)混合,混合程度是程序的另一个参数。我喜欢这个想法。
+
+1992 年我休假期间,我们撰写了关于 PLS 的论文。我的休假被分成了几小块,其中一部分在澳大利亚。你和我就是在那时开始研究多变量地球化学数据的。
+
+**NF**:是的,这让我们想到了 PRIM。你想谈谈 PRIM(Patient Rule Induction Method)吗?
+
+**JF**:当时的想法是热点分析。数据挖掘技术的出现,让人们想要做的事情之一,就是在数据中大海捞针,寻找热点,比如欺诈检测。你期望一个相当微弱的信号,但你希望的是它至少在几个变量中被一个非常清晰的结构所识别。PRIM(弗里德曼和费舍尔(1999 年))是一种递归分区方案,但不同于 CART,后者非常贪婪和激进。这就是 "耐心 "的由来:它的目的是找到一个好的分割点,但只分割一点点,耐心等待,然后再寻找另一个分割点,这就是它的理念。
+
+**NF**:上世纪 90 年代有一篇关于偏差-方差的论文。
+
+**JF**:是的。在 20 世纪 90 年代中期,有一种非正式工商企业的尝试;每个人都知道平方误差损失回归预测误差的偏差-方差分解,这吸引了人们去尝试开发类似的分类方法。这里的损失要么是零,要么是一,目标是对错误分类风险进行相应的分解。这方面的论文不胜枚举。Leo 写了一篇(Breiman (1996)),机器学习文献中也有很多。我得到的印象是,你确实无法得出这样的分解,但你可以做的是,看看传统的偏差和方差,它们都是很好的定义,看看这两种估计误差,如估计概率时的偏差和方差,是如何在错误分类风险中反映出来的。于是,我写了这篇论文(弗里德曼(1997)),在这篇文章中,我从理论上证明了维度诅咒对分类的影响比对回归的影响要小得多。在回归中,随着维度的增加,情况会呈指数级恶化,但对于许多类型的分类来说,情况未必如此。这就是为什么近邻法和核方法等在高维回归中效果不佳的方法,在分类法中却能有相当好的表现:维度诅咒对它们的伤害并没有那么大。这一点在过度平滑密度估计时尤为明显:过度平滑可能非常严重,会在密度估计中引入巨大误差,但在分类中却不需要引入太多误差。
+
+我不知道该在哪里发表这篇论文,也不知道该不该发表。后来,我的一位朋友乌萨马-法耶兹(Usama Fayyad)联系了我。他是数据挖掘领域的早期人物之一,甚至可能是 "数据挖掘 "一词的创造者,他着手创了办数据挖掘的杂志。他说,"我希望你能在第一期发表一篇论文,"我说好吧。我就把这篇论文寄给了他。结果--我后来才知道--那篇论文被以色列的一位数据挖掘研究员萨哈龙-罗塞特(Saharon Rosset)读到了。他认为这表明统计学可以为数据挖掘做出贡献。于是,他决定来斯坦福学习。他是我们最好的学生之一。我从萨哈龙身上学到了很多,现在依然如此。所以我想说,那篇论文最大的成功之处在于,我们让萨哈隆来到了我们系。
+
+**NF**:你是什么时候对高维数据有了洞察力,认为每个点都是自己方向上的离群点?
+
+**JF**:这来自于 Projection Pursuit。20 世纪 80 年代末、90 年代初,离群点检测对人们来说是个大问题。我在各种论文和演讲中都看到过。我认为这可能是投影追寻的一种自然应用。投影追寻法在空间中寻找方向,这样当你投影数据时,它就会有一个特定的 "有趣 "结构,而这个结构是由一个标准决定的,然后你就会试图优化这个标准。于是我就想,好吧,我们来制定一个寻找异常值的标准。我想出了一个标准,编了程序,试了一下,效果非常好。它能发现各种离群值,最棒的是你能看到投影。在投影中,这里是数据,这里是点,不需要做其他推论;这是一个离群值,就在这里。我非常兴奋,在对模拟数据和真实数据进行尝试后,我想,好吧,我们必须校准它。当没有离群值时,它能发现多少离群值? 我从多元正态分布中生成数据,试用算法,结果发现了一个不可思议的离群值。我想,好吧,这可能会发生,这只是个意外,于是我删除了那个点,重新搜索。它又发现了另一个,另一个有一个离群点的投影。它就一直这样做。我可以直接剥开数据。我觉得这很奇怪,就跟别人提了一下,我相信是伊恩-约翰斯通(Iain Johnstone)提出了这样的解释:每个点都是自己投影中的离群点。这就是我根据经验发现的现象。
+
+**NF**:你提到过 "数据挖掘 "这个词,它来自一个非统计社区。你与这些其他社区的互动情况如何?
+
+**JF**:20 世纪 90 年代初,我开始关注机器学习领域。我应邀在一次 (NIPSSaharon Rosset)会议上做了一次演讲。那次会议为我打开了一个不同的世界,因为当时有很多人都怀着类似的动机在做一些事情,但他们并不使用统计方法,也不采用统计模式。他们几乎完全由算法驱动。我觉得这真是太棒了,所以我在那里做了一次演讲,后来我又参加了那些会议
+
+**NF**:他们知道你的作品吗?
+
+**JF**:嗯,他们肯定知道一些,因为他们邀请我去做演讲。我不知道他们的论文引用了多少我的研究成果,可能有一些吧。整个 20 世纪 90 年代,我参加这些会议的进展情况很有意思。在我参加的第一个会议上,有很多关于硬件的讨论,这些人主要是电子工程师。事实上,当时有两类人:一类是工程师,他们利用神经网络和神经网络类型的想法来解决预测问题;另一类是心理学家,他们利用神经网络和神经网络类型的想法来理解大脑,以及自适应网络如何学习事物,即 "大脑学习理论"。在工程学方面,有趣的是,它是如何从专注于程序和硬件发展到越来越像统计学的。现在,它基本上就是统计学了。他们发现了贝叶斯方法。我记得在早期与机器学习人员的讨论中,我曾试图解释为什么尽可能接近训练数据并不一定能得到最好的未来预判,也就是所谓的泛化误差。现在他们完全理解了,但在当时,他们中的一些人还很难理解这个概念。平心而论,他们感兴趣的是噪音极低的问题,比如模式识别。显然,有一种算法每次都能分辨出椅子和桌子,大脑也能做到这一点,所以贝叶斯误差率是零。只是你无法想出一种算法来达到贝叶斯错误率。这就是他们感兴趣的问题。因此,在这种情况下,尽可能完善训练数据才是正确的策略。如果贝叶斯误差率为零,就不存在噪音。
+
+**NF**:有许多不同的社区。. .
+
+**JF**:是的。据我所知,有三个不同的领域,也许更多。有统计,有官方情报,还有数据库管理。
+
+**NF**:计算机科学家在哪里?
+
+**JF**:计算机科学家从事的是数据库管理和人工智能。至少据我所知,机器学习是从人工智能发展而来的。数据挖掘最初产生于数据库管理领域。现在这一切都融合在一起,每个人都在学习更多其他人正在做的事情。机器学习者和数据挖掘者正在学习更多的统计学知识,他们的研究越来越像统计学。一些统计学家正在学习更多的方法论和算法,他们的工作看起来更像机器学习或数据挖掘。
+
+
+
+**学生**
+
+**NF**:我们已经谈到过一两个学生,你在加入该系之前就已经参与其中,但是一旦你加入,你就有一些正式的责任来监督这些学生。
+
+**JF**:是的,我有很多学生,我都以不同的方式喜欢他们。在学术部门工作的一个真正好处是,你可以和那些有新鲜想法的年轻学生在一起,他们的热情还没有被时间磨灭。
+
+**NF**:你和你的学生进行了哪些合作?
+
+**JF**:我当然与他们合作过论文工作。与我合作最多、时间最长的学生可能是罗马尼亚的博格丹-波佩斯库(Bogdan Popescu)。
+
+**NF**:你的做事风格显然影响了当时在你身边的很多学生。
+
+**JF**:我想是的。特别是我在新闻部工作的早期,我思考问题的方式确实很不一样,现在已经不一样了。我们有罗布、特雷弗和阿特[欧文],他们都是我刚来时的学生。阿特实际上是我的学生。罗布和特雷弗不是我的正式学生,但他们经常来SLAC。
+
+**NF**:他们被看到的东西影响了。
+
+**JF**:特雷弗是维尔纳的学生,所以他受到了强烈的影响,罗布也是,我认为:更多的是现象学的思维方式,而不是定理证明-定理证明-定理证明的方法。我并不是贬低这种方法。我不想给人留下这种印象,这只是不同而已。我不擅长这个。我没有这方面的技能。
+
+
+
+# 5 斯坦福大学--新千年
+
+**NF**:到目前为止,在斯坦福,我们已经走过了90年代,进入了新千年的第一个十年,在此期间,您与斯坦福的一些同事开始了另一项非常重要的合作。
+
+**JF**:没错。20 世纪 90 年代末,机器学习领域和统计学领域都出现了一些非常重要和有趣的发展。其中之一就是 Leo 的 bagging 创意,这是一个非常简单但聪明的创意。然后是 Freund 和 Shapire(1996 年)在机器学习文献中提出的提升思想。我开始对此着迷,因为它在某种意义上与PLS有类似的味道,它似乎工作得相当好,但不清楚为什么。同样,一个非正式工商企业也发展起来了。机器学习者有自己的方法,他们称之为 PAC 学习理论(PAC 是 "可能几乎正确 "的缩写)。这是一种很好的方法,但我认为我们还不太理解。如果这是在分析数据,那么它就是在做统计算法的工作,因此,它应该有某种合理的统计基础。于是,罗布、特雷弗和我开始合作,试图从统计学的角度来弄明白,为什么这东西能运行得这么好。
+
+有趣的是,我们在开始合作时并没有答案。这与我们与 Leo 的合作类似,我们只是提出了问题。很多时候,当你开始合作时,你已经有了一个解决方案的想法,然后你把它组合在一起,但我们不知道为什么这件事能做得这么好。因此,我们一路走来,获得了各种启发,我相信我们已经弄明白了(弗里德曼、哈斯蒂和蒂布希拉尼(2000 年)),至少让我们感到满意。......但不是每个人都满意:Leo从不认为我们的解释是根本原因。他认为我们的理论发展是正确的,但他并不认为这是导致助推器取得惊人表现的原因。但我坚信,我们已经解释清楚了。我认为机器学习者、PAC 学习者从来没有这么想过,我认为他们没有完全理解我们看待问题的方式。
+
+**NF**:从那时起,你就与Rob和Trevor进行了非常积极的合作。
+
+**JF**:是的。我们在 20 世纪 90 年代末就这样做了,后来在 2000 年代中期,我被邀请担任荷兰博士口试的外部裁判员。Jacq Meulman的一名学生Anita vander Kooij 正在撰写毕业论文,她有了一个想法。此时,罗布-蒂布希兰尼(Rob Tibshirani)在 20 世纪 90 年代中期提出的 LASSO 已经开始崭露头角;现在依然如此。L1正则化方法,尤其是LASSO,真的开始流行起来。当时有一个开发快速算法的非正式工商企业。工程师们在这方面做了很多工作,机器学习者们也在这方面做了很多工作,布拉德-埃夫隆(Brad Efron)和一些同事还发表了一篇非常精彩的论文(Efron et al. (2004))。因此,这在当时非常活跃。
+
+然后,安妮塔和杰奎琳有了一个非常简单的想法,一个专业的优化专家肯定会立刻放弃,那就是一次只做一个。他们当时正在研究一个需要对变量进行最优化转换的计算机程序,为此他们使用了后坐法算法(back-itting algorithm)。包括正则化在内的工作原来很简单。很多人都提出了一次优化一个变量的想法。在优化理论中,这通常被认为效果不佳。这是对的,除非可以非常方便快捷地获得一次求解:然后它就会变得有竞争力。沃纳和我曾在项目追求回归和加法模型中,用我们所谓的 "back-itting "算法探讨过这个问题。总之,他们的想法是,保持所有系数不变,只有一个变,然后求出那个系数的最优解。这可以很快完成。然后,你只需在它们之间循环。他们是独立开发的,但这并不是什么新想法:以前也有人开发过,但似乎并没有得到很认真的对待。
+
+所以当我从荷兰回来的时候,我告诉了Rob和Trevor讨论了这个问题,他们很兴奋,我们开始将这个想法应用到各种各样的约束和正则化问题中,并一直持续到今天。罗布和特雷弗以及他们的学生提出了各种新的正则化方法,我们可以一次做一件事,而且速度非常快。我们将其应用于 LASSO 和 Elastic Net,这是特雷弗和学生邹辉(Hui Zou)在 2000 年代中期完成的(邹辉和哈斯蒂(2005))。它是脊回归和LASSO之间正则化方法的连续体。你可以根据自己的需要选择变量。在山脊中没有变量选择,LASSO 可以进行适度的变量选择,因此我们将其扩展到了弹性网。杰奎琳和安妮塔还将其扩展到了 "弹性网"。然后我们将其扩展到其他 GLM、逻辑回归、二项式、泊松、考克斯比例危险模型,并将其整合成一个名为 glmnet 的软件包,该软件包现在似乎已被广泛使用。它允许你用各种不同的 GLM 概率进行所有这些不同的正则化回归,这项工作仍在继续。
+
+我喜欢编写程序,因为它们似乎比别人的程序运行得更快。这可能是我年轻时穷困潦倒的缘故,那时我使用的电脑和现在的电脑完全不一样,你真的必须编写电子 cient 程序。这项技能似乎一直伴随着我。
+
+**NF**:这次与罗布和特雷弗的合作结果是出版了一本特别重要的出版物。
+
+**JF**:是的,我们的书(Hastie, Tibshirani and Fried- man (2001))。这本书取得了令人难以置信的成功,我参与了其中的一些部分,但大部分是罗布和特雷弗撰写的。它在正确的时间击中了正确的利基市场,我想它现在仍然是现在您可以从网上免费下载 pdf 版本。
+
+**NF**:再来回顾一下您关于编程的观点,我记得您多年前告诉过我,直到您编写了代码来演示该技术,您才解决了问题。
+
+**JF**:我没有必要的技能去做所有的理论研究。我想知道这是否是个好主意的唯一办法,就是把它编成程序并试用,在各种情况下进行测试,看看效果如何。
+
+**NF**:让我们从 MART 开始,回顾一下你所参与的一些平行活动。
+
+**JF**:1998/1999 年,我第二次到澳大利亚进行长时间访问时,我对boosting的想法非常着迷。MART 是我与罗布和特雷弗合作,试图了解助boosting如何工作的一个衍生产物。我对如何扩展boosting技术有了一些想法。Boosting(提升法)最初是作为二元分类问题开发的,当我在悉尼访问 CSIRO 时,我想把它扩展到回归和其他类型的损失函数上,于是我开发了梯度提升的概念,后来演变成了我所说的 MART,即多元回归树。我编写了那个程序(也叫 MART),并发展了这些想法。我相信这就是我的里茨讲座,它发表在《年鉴》上(弗里德曼(2001a)),对他们来说,这是一篇不寻常的论文。
+
+我仍然想更多地了解提升法的工作原理。我对梯度提升法的一个想法是--这也是一种耐心的想法--你可以把提升法看作是普通的逐步回归或阶段回归。你建立一个模型,比如说,一个树(大多数人都使用树),你得到残差,然后再根据残差建立一个模型。你从这两棵树的总和中提取残差,然后根据这些残差建立另一个模型。这样做非常贪婪;每次你都试图用下一个模型尽可能多地解释当前的残差。我想出了一个办法(又回到了耐心规则归纳法!),即当我们找到最能解释残差的树时,只增加该树的一点点,换句话说,缩小它的贡献。因此,在将该树添加到模型之前,先将其乘以一个小数,如 0.1 或 0.01。结果证明,这确实提高了性能。因此,我想弄明白为什么它能提高性能,并试图进一步了解梯度提升技术。
+
+当时博格丹-波佩斯库(Bogdan Popescu)还是我的学生。他证明了收缩只影响方差而不影响偏差。我认为这是一个非常重要的线索。后来,我们和其他人一起发现,这其实是一种 LASSO 方法。如果不进行收缩,就会产生类似逐步回归或阶段回归的结果。它产生的解与 LASSO 非常相似,如果在线性回归中遵循这一策略,它产生的解路径与 LASSO 非常接近。一开始,我们认为它们可能是完全相同的,因为我们运行了几个示例,它们产生的路径完全相同。结果发现,只有在两个维度中,或者 LASSO 路径是正则化参数的单调函数时,才会产生相同的路径。
+
+Saharon Rosset 和其他一些人在这方面做了很好的工作。《统计年鉴》(Annals)中有一期专门讨论提升问题[Annals of Statistics 32(1), 2004]。有几篇非常重量级的理论论文,非常好的论文,显示了这种联系,显示了提升是一致的,只要你以这种方式正则化。
+
+**NF**:杰瑞,你长期热衷于缩略语。ISLE 和 RuleFit 代表什么?
+
+**JF**:ISLE代表重要性样本学习集合(Importance Sample Learning Ensembles)。同样,在这段时间里,我一直在研究为什么集合学习方法如此有效,而 ISLE 是一种看待集合方法的不同方式。我们的想法是你定义了一类函数,并从中挑选函数。我想到的第一件事是,使用提升法、袋法和其他集合方法,你只需不断添加树。有些人想,好吧,如果你有一个集合,你怎么才能找出对每棵树加权的最佳方法呢? 我认为这是一个非常简单的问题:如果我想要一个函数在一组东西中是线性的,我知道如何找到系数,这叫做回归。此时,Leo正在做随机森林,很多人都在做boost-ing。我建议,一旦你得到了集合,你就可以进行正则化回归,得到每棵树的权重或其他权重。在机器学习文献中,合集的每个元素都被称为基础学习器或弱学习器,因为一般来说,没有一个元素本身是非常好的,但它们的合集是非常好的。这就是我们所理解的boosting有效的原因之一。boosting之所以如此令人惊讶,其中一个原因是,在机器学习领域,他们有一个弱学习者和强学习者的概念:弱学习者的学习能力低,而强学习者的学习能力高。罗布-沙皮尔(Rob Schapire)是最初成功的提升算法的共同发明人之一,他的理论研究给人留下了深刻印象。他表明,利用这种提升技术,只要弱学习者的错误率超过 50%,就能将弱学习者变成强学习者。这是一项非常了不起的工作。
+
+但当你从线性回归的角度来处理它时,似乎就不那么令人惊讶了。我们遇到过很多问题,在这些问题中,单靠一个变量并不能解决很多问题,但将多个变量组合在一起进行回归却能取得很好的效果。从我的统计学角度来看,这就是正在发生的事情。我认为你可以用很多不同的东西来做这件事。如果你有一类函数,你可以从这一类函数中挑选函数,然后进行线性拟合。那么问题来了:如何从这一类函数中挑选函数?如果你只是随机挑选,那么几乎所有的函数都没有执行力,它们的合集也是如此。如果你挑选的函数都很强,那么它们的输出都高度相关,你从集合中得不到任何好处。集合函数的预测结果与其中任何一个函数的预测结果都是一样的。
+
+
+
+
+
+图4: Steve Marron向杰瑞颁发奖项,表彰他在2009年联合统计会议上发表Wald讲座。
+
+摄影:塔蒂·豪厄尔。
+
+
+
+因此,你需要权衡利弊,这一点Leo已经讨论过很多次了。你不希望集合中的学习者在预测时高度相关,但是你确实希望它们有一定的预测能力。这是需要权衡的。这一点在提出post-fitting之前就已众所周知。LASSO和其他正则化方法对于后拟合来说是很自然的,因为它们即使在集合的大小比观测的数量大得多的情况下也可以应用。所以你需要快速的LASSO算法和当时正在开发的其他正则化回归算法。这是一个集合。
+
+RuleFit是一种完全受此概念启发的集成方法。主要的区别在于,你不是先用提升树拟合集成,然后进行后回归,而是取树,将其分解为规则,忘记规则来自的树,并将它们作为线性拟合中的一批“变量”。
+
+Leo曾经说过一句话,也许是在他去世前不久的2000年代中期,他说机器学习的真正挑战并不是更好的算法,也不是提高一点点预测准确率。我们最好的机器学习往往是黑盒子模型--神经网络、支持向量机、决策树集合--它们即使有解释价值,也微乎其微。它们可以预测的很好,但是,你没有办法告诉你的客户,它为什么或如何做出预测,为什么会做出这样的预测而不是另一种预测。他认为,真正的挑战在于可解释性,他在随机森林中加入了一些解释工具,即预测变量和其他一些东西的相对重要性。我想看看是否有办法实现可解释性,我的想法是,如果你有一个集合方法,它基本上是一个线性模型,只要你能解释模型中的成分和实际项,线性模型就非常容易解释。树状模型可以解释,但我认为解释规则更容易。树从根节点到终端节点的路径中推导出一条规则:这就是为什么树具有很强的可解释性。它能准确地告诉你预测时使用了哪些变量,以及如何使用这些变量,这也是树如此受欢迎的原因。在机器学习的历史上,基于规则的学习也一直是机器学习的主力军。
+
+于是,我想到把树分解成规则,把规则放在一个容器里,然后对规则进行 LASSO 线性回归。我希望,由于规则并不复杂,而且您可以通过简单易懂的解释,使模型可解释。
+
+这本身只取得了部分成功。不过,我还是开发出了评估变量对单个集合预测重要性的方法。在这项工作中,我做的另一件事是开发了一些检测相互作用效应的技术,看看哪些变量在相互作用,探索变量的相互作用模式。
+
+这就是 RuleFit。除此以外,我在开发 MARS 和 MART 等通用学习机器方面没有太多建树。RuleFit 是我迄今为止开发的最后一款机器。
+
+**NF**:我敢说以后还会有更多。你在斯坦福大学统计系已经工作了三十多年。作为一名统计科学家,您觉得斯坦福的环境如何?
+
+**JF**:难以置信的棒,我想不出还有什么地方比这更棒了。我最大的快乐就是能在 ce 大厅里与这么多杰出的名人共处。我的近邻是布拉德-埃夫隆(Brad Efron)、珀西-迪亚科尼斯(Percy Diaconis)和王荣(Wing Wong),以及大厅里其他所有出色的人。这是一个令人振奋的环境。每个人都是那么敏锐、聪明、富有创造力和独创性。一段时间后,你会觉得这是理所当然的,但当你去其他地方参观时,你会发现并不是所有地方都是这样的。我认为我能够加入该部门是莫大的幸运,我感谢他们接受了我,因为当时我是一个有点奇怪的任命。
+
+**NF**:我相信你现在看起来像一个主流任命。你是否觉得新闻部在某种程度上已经向你靠拢了?
+
+**JF**:好吧,也许有一点,是的。
+
+
+
+# 6 当前兴趣
+
+**NF**:你目前的兴趣是什么?
+
+**JF**:还有整个正则化的想法,我仍然认为这很吸引人。目前的研究还没有解决一些遗留问题。我想更多地思考这方面的问题。另一个领域是改进决策树。在我看来,树之所以变得非常重要,主要是因为集合方法的出现。决策树具有很好的鲁棒性。它们可以快速构建,不受预测因子单调变换的影响,不受预测因子中异常值的影响,有优雅的方法来处理缺失值,并同时纳入数字变量和分类变量。它们是一种非常好的学习机器:你只需要输入数据,而不需要在此之前对数据进行过多的处理。
+
+它们有几个致命弱点,其中之一当然是准确性,但我认为集合方法已经解决了这个问题,集合方法继承了所有这些优点,同时大幅提高了准确性:不仅提高了10%或20%,有时甚至提高了3或4倍。我认为提升是机器学习的关键理念之一。它确实推动了理论和实践的发展。
+
+树的另一个致命弱点是具有大量层次的分类变量。在我们做 CART 的时候,一个典型的分类变量可能有 6 个级别。现在,通常会有数百或数千个级别。这就破坏了树,因为不存在顺序关系。可能的拆分数量会随着层次数的增加而呈指数增长。对所有这些可能性进行优化可能会导致严重的过度拆分。在存在大量噪声的情况下,这可能会导致虚假拆分,从而掩盖真正重要的拆分。
+
+所以,这就是我提到的那些我一直记在脑海里的东西之一,每隔一段时间我都会试着再想一想,这就是我现在做的这件事。
+
+我最近一直在思考的另一个问题是,现在出现的许多数据问题,尤其是商业数据,往往都是二元分类问题。在我的行业咨询中,我看到的分类问题要比回归问题多得多。这很令人吃惊,因为历史上大多数统计研究都是围绕回归展开的。分类是统计学中的一个次要问题。在机器学习领域,分类一直是重点。事实上,他们将回归称为带有连续类标签的分类。
+
+很多数据非常不平衡,你可能有数百万个观测值,但一个类别的观测值却很少。在工程学和机器学习中,他们倾向于将该类标注为+1 和-1。通常情况下,阳性数据的比例非常小,比如在欺诈检测中,你有一个包含大量数据的数据库,但欺诈的情况只占数据的一小部分--至少你希望是这样!在电子商务中也是如此,点击页面上广告的比率约为 1%,而转化率(这是指你点击广告,然后去买一些东西)比这低两个数量级。因此,问题在于如何处理这样的数据,以及有经验法则指出,如果你在一百万个阴性样本中有一百个阳性样本,你就不能使用所有的一百万个样本,而要随机抽样。那么问题来了:策略是什么,你需要多少个? 还有一条经验法则说,如果你的阴性数量是阳性数量的 5 倍,那你就真的需要这么多了。我怀疑这在一般情况下是否属实,但我希望能更精确一些,因为这有很大的实际意义:如果你有数百万个观测值,而你可以随机抽样到一千或几千个,这就完全改变了你的分析动态。因此,这也是我正在思考的另一件事。特雷弗-哈斯蒂(Trevor Hastie)和他的学生威尔-菲瑟安(Will Fithian)最近在逻辑回归方面做了一些很好的工作(Fithian and Hastie (2013))。
+
+当前另一个令人感兴趣的领域是损失函数。机器学习程序由结果损失函数和模型参数正则化函数组成。为不同的问题定义合适的正则化函数及其对应的预估器是当前机器学习和统计学领域的研究热点。关于这一主题的论文层出不穷。但人们似乎对为不同问题找出合适的损失函数兴趣不大。损失函数 L(y, F) 规定了当真实值为 y 而模型预测值为 F 时的损失或成本。我在咨询工作中发现,针对手头的问题调整损失函数往往能大大提高性能。大多数应用程序只是在回归时使用默认的平方误差损失,在分类时使用伯努利对数似然法。我想研究更广泛的损失函数类别,这些函数适合于特定的应用。这些问题超出了通常在 glms 中使用。
+
+我花了很多时间在我的程序上。我把大部分程序放在网上,人们可以下载并使用它们,他们会反馈错误,我觉得我有义务尝试修正它们。随着职业生涯的发展,你所做的事情越来越多,你就必须把越来越多的时间花在后方--为这些事情提供支持--以及向前迈进。我的职业生涯已经很长了,花在维护过去工作上的时间不可忽视。
+
+**NF**:这就像熵,不是吗,一直在增加?勘误表永远不会减少。
+
+**JF**:是的。然后人们就会有问题,他们不理解,或者人们会以你做梦也想不到的方式使用算法。我还想到了其他一些事情。20 世纪 90 年代中期,我花了大量时间尝试将正则化与非凸惩罚结合起来。我花了相当多的时间研究一种技术,这种技术在某种程度上类似于提升技术,但却是在线性回归的背景下。LASSO 强加了适度的稀疏性,而不是 L0 惩罚(所有子集回归),后者会诱导出最稀疏的解决方案。因此,我在所有子集与 LASSO 之间做了大量工作,前者是非常激进的变量选择,但往往不起作用,尤其是在低信号环境下;后者则是适度激进的变量选择。这涉及到非凸惩罚。LASSO 是最稀疏的诱导凸惩罚。当然,有了凸惩罚,只要你有一个凸损失函数,你就有了一个凸优化,当你有多个局部最小值和其他问题时,这比非凸优化要好得多。因此,我花了很多时间研究将提升技术应用于非凸惩罚的线性回归。
+
+**NF**:全世界的统计学家使用你的技术已经有很长一段时间了,有一家公司的存在就是为了销售你的软件,是你创造了这个行业。Yahoo也使用了你的想法和方法!
+
+**JF**:是的。他们使用 MART 的商用模拟版本作为搜索引擎的主要部分。我不知道他们现在用的到底是什么,也许是 Mi- crosoft 搜索引擎。但在很长一段时间里,MART 是雅虎搜索引擎不可分割的一部分。
+
+
+
+# 7 统计之外的生活
+
+**NF**:事实上,我们暂且不谈统计学,因为你确实有统计学之外的生活。
+
+**JF**:嗯,有点。(参见 Fisher(2015)中的轶事 Life out-side Statistics)。
+
+**NF**:还有你长期以来对赌博和计算机的兴趣。
+
+**JF**:是的,这是从我读研究生时开始的。 (见 Fisher (2015) 中的轶事《统计、计算机和赌博》)。
+
+
+
+
+
+图5:1997年,家里的一顿美餐。
+
+
+
+# 8 回到未来
+
+**NF**:最后,让我们回过头来,或者说让我们从更高的角度来看待某些时期的统计学。至少有两次(弗里德曼,1989b,2001b),您将自己的想法付梓成书,主题是 "我们现在的统计学和计算机在哪里?"让我们回到 1987 年,当时有一个关于 "科学、工业和公共政策中的统计学(Statistics in Science, Industry and Public Policy.) "的研讨会,您应邀提交了一篇关于 "现代统计学和计算机革命(Modern Statistics and the Computer Revolution) "的论文。
+
+**JF**:这是一项我无法拒绝的任务,因为它来自美国国家科学基金会负责统计经费的负责人。当时我有一项国家自然科学基金资助,所以我必须回去做一个演讲,谈谈我对统计学未来的看法,以及未来计算会如何影响统计学。
+
+**NF**:在这篇论文中,您谈到了自动数据采集、它的一些好处以及它所引发的一些问题。你在论文的开头说:"统计学在很大程度上与信息科学的区别在于,我们试图理解推断有效性的限度。"你认为在机器学习等领域,这种区别还存在吗?
+
+**JF**:虽然没有以前那么多,但我还是要说。统计学对数据分析的巨大贡献是推断,你从数据中得到什么,或者从数据中学习到什么。其中有多少是真正有效的。这一直是统计学的主旨。只是因为数据集变得越来越大,所以抽样变异的问题也变得不那么严重了,但它仍然存在。最初,我认为神经网络和机器学习领域的一些人根本不关心这个问题,无论他们发现了什么,他们都认为这就是现实。公平地说,至少在机器学习领域,那是因为他们处理的是模式识别问题,其中的固有噪声并不大,分类问题中的贝叶斯误差率即使不是零,也非常接近零。能达到这个误差率的特定分类器非常复杂,而且难以捉摸。因此,我不认为推理是这类问题中的大问题。统计学家最初来自数据集很小、信噪比很低的其他领域。在这种情况下,推理是学习过程中非常重要的一部分。
+
+**NF**:但计算机科学家和数学学习者并没有停留在他们的小框框里,他们开始研究其他问题。
+
+**JF**:哦,是的,贝叶斯式的思想现在已经遍布机器学习、计算机科学和工程学等领域。推理就在那里,而且尽管它可能不像我们统计学家那样受到高度重视。
+
+**NF**:你评论说,1986年《统计学》中使用的大多数方法实际上是在1950年之前开发的,但是计算机将我们从封闭形式的解决方案和无法验证的假设等数学束缚中解放出来。
+
+我特别喜欢你的结束语:“计算成本不断下降,但我们为错误假设付出的代价仍然保持不变。”你现在愿意修改一下那份声明吗?
+
+**JF**:不,我认为是一样的,如今我们必须做出的无法验证的假设越来越少了。交叉验证和自举法等样本重用技术确实解放了我们;它们对我所做的工作帮助很大。很多时候,当你想出一个新的复杂程序时,有人会说:"你怎么做推断?你怎么把误差线放进去?"或者诸如此类的话,你只需回答:"你可以引导它。"这是对统计学的巨大贡献。但在我工作的领域,这一点尤为重要。
+
+**NF**:12 年后,在赫尔辛基举行的国际统计学会会议上,你又有了一次从空中俯瞰的机会,会议的主题是 "未来二十年统计学的关键问题"。你发表了一篇题为“数据革命中统计学的作用?”,我注意到这句话末尾的问号!你在总结中说:“数据的性质正在迅速变化。数据集变得越来越大和复杂。用于分析这些新类型数据的现代方法正在数据库管理、人工智能、机器学习、模式识别和数据可视化等领域涌现。到目前为止,统计作为一个领域发挥了次要作用。本文探讨了其中的一些原因,以及为什么统计学家应该对此感兴趣。”等等。我感兴趣的是:从那以后事情发生了什么变化,需要做什么,以及什么阻碍了这种变化?
+
+**JF**:哦,我认为变化很大。也许我在斯坦福德的观点不具代表性,但我认为统计学在这些领域正在稳步向前发展。数据分析方面的统计研究与机器学习和模式识别有了更多的重叠。正如我在 1987 年的论文中所指出的,也正如我在每次被问及统计学的未来时所说的,你无法回答这个问题,你必须问:数据的未来是什么?统计学和所有数据科学将对任何数据做出反应。20 世纪 80 年代末,没有人能预料到基因表达阵列的出现。现在,统计学家们已经适应了基因表达阵列以及整个生物信息学革命,并为这些领域做出了巨大贡献。
+
+**NF**:特别是在 1999 年的论文中,您在回顾统计学与数据挖掘之间的关系时说:"然而,从统计学数据分析的角度来看,我们可以问,数据挖掘方法论是否是一门知识学科。到目前为止,答案是,还不是。. ."是研究对象变了,还是问题变得无关紧要了?
+
+**JF**:这个问题问得好。我想说的是,它既重要又在变化;我不确定它是否已经完全改变。我认为,你需要的是能提出多种数据分析方法的人,但他们可能不具备基本的技能来理解发生了什么。你还需要一些人,他们需要非常熟练地掌握一种方法和一种情况,然后在这种情况下推导出该方法的特性。我认为数据挖掘界的态度是:"如果它有效,那就太好了!我们会尝试各种方法,然后找出有效的方法"。我认为这是一个完全合理的方法。有些人喜欢从基本原则出发:让我们先了解基本原则,然后再制定正确的做法或好的做法。另一种方法则是临时抱佛脚--只要认真思考问题,试着把它弄明白--图基当年就是这么做的--然后试着想出一些行之有效的办法。当然,这种方法充满危险:并不是每个人都像图基一样聪明。人们在开发技术的过程中,会做一些广告,让人们相信他们真的很厉害,其实不然,所以必须小心谨慎。但一般来说,如果有一种方法,如 PLS、支持向量机、提升法或更多一般的集合方法,似乎屡试不爽,那么很可能有一个很好的统计原因,即使一开始并不知道。后来,人们才理解了这些方法为什么能很好地发挥作用的基本原理。
+
+**NF**:在那篇论文的后面,你说:"也许统计学比过去任何时候都更处于十字路口;我们可以决定适应或抵制变革。"我们是否已经适应,是否仍在抵制变革,你如何看待统计学现在在信息科学中的地位?
+
+**JF**:我认为统计学是在适应变化,虽然没有我想的那么快,比其他人想的快,但肯定是在适应变化。最终是数据推动了统计学和其他信息科学的发展。但我认为今天的统计数据更能反映问题。当新的数据形式出现时,统计学家、工程师和其他人立即看到了机会。
+
+**NF**:那么从某种意义上说,我认为你已经回答了你在本文中的结语,那就是"多年来,推动这一讨论的主要是我们这一领域的两位领军人物。约翰-图基(John Tukey)在 1962 年《数学统计年鉴》上发表的论文(Tukey (1962))和利奥-布雷曼(Leo Breiman)在 1977 年达拉斯会议上发表的论文。那次会议已经过去二十多年了。我们再次有机会重新审视我们在信息科学中的地位。”你觉得我们现在坐得比以前舒服多了吗?
+
+**JF**:还是那句话,在斯坦福这样的好地方,我也这么认为,是的。我认为我们做得对。我们没有放弃形式推理的传统,这是非常好的,因为其他信息科学在这方面做得远不如我们。其他领域也有个别做得很好的人,但这不是统计学的重点。这也是我们的优先事项之一,对我们帮助很大,因为你必须在某些时候了解推论的局限性。我认为,在早期阶段,我们一直在尝试,看看哪些方法可行,利用我们的直觉,我认为我们已经开始有了自己的见解。如今,如果你看看生物统计学、计算机科学和统计学领域的工作,就会发现它们之间存在着巨大的重叠。无论是在态度上,还是在实际工作中,或是在我们试图解决的问题上,都是如此。
+
+**NF**:嗯,我们仍然坚持理解和管理变异性的指导标准。
+
+**JF**:是的,我认为我们比其他领域更关注这一点,我认为这很好。在过去,也许我们对它关注得太多了。好吧,不要太关注,因为统计学是针对特定类型的数据研究方法的——小数据集,高噪声,推理就是一切,你是否看到了信号?这就是假设检验的本质。不是信号有多大,它的性质是什么?我们能否判断是否存在一个?在小数据集和高噪声的情况下,这通常是你唯一能问的问题。假设检验是一项巨大的智力胜利。但现在有了更大的数据集和更好的信噪比,我们就可以开始提出更详细的问题:信号的性质是什么? 哪些变量参与了预测问题?它们是如何参与的?它们是如何共同产生结果的?
+
+**NF**:你确实改变了很多人对统计学的看法,你认为你在做统计学,而且一直在做。如果科林-马洛斯现在在我们面前,你认为他会把你所做的事情称为统计学吗?
+
+**JF**:我想你得问问他。也许吧。我一直这么认为--也许是错误的!--但我一直认为我是在做统计。你知道人们常说:玫瑰换个名字也一样香甜。我认为,我们没有必要把事情分门别类。只要有趣、有用,谁会在乎你所做的事情叫什么名字呢?现在的分类似乎都模糊了,这都是好事。
+
+**NF**:好吧,现代科学的奇迹让我们看到了杰瑞-弗里德曼的转世,只不过他只有 20 岁,他在想大学该干什么。你有什么建议?
+
+**JF**:每当有人问我:"我应该学什么,做什么?"我总是建议说:“学习和做你最感兴趣的事情。不要担心十年后哪些技能会有市场需求,因为这一切都会改变。”如果你去学校学习一门你不喜欢的技能,因为你认为它在你 5 年、6 年或 8 年后毕业时会特别有市场,那么这可能会改变。你花了那么多钱,最终却学不到适合市场的技能。至少,如果你学习的是你真正喜欢或热衷的东西,你就会享受到其中的乐趣。如果你像我一样幸运,发现自己的技能可以在市场上销售,那就更好了。追随你的激情。
+
+**NF**:你认为统计很容易成为其中之一吗?
+
+**JF**:哦,我同意哈尔-瓦里安(Hal Varian,谷歌首席经济学家)的说法,统计学将在未来一段时间内成为最有魅力的领域("我一直在说,未来十年最性感的工作将是统计学家。"瓦里安(2009 年))。人们认为我在开玩笑,但谁又能想到计算机工程师会成为 20 世纪 90 年代的热门职业呢?数据革命--利用数据回答问题和解决问题的能力已经真正崭露头角。不久前,当你在工厂或生产线上发现产量下降时,你会怎么做?好吧,你会召集主管和专家,你们走进一个房间,试图找出产量下降的原因。人们通常不会想到要收集数据。现在,每个人都在收集数据。几乎每条生产线和工厂的每个环节都安装了大量的仪器,数据也被收集起来。事实上,我认为也许到了人们对数据要求过高的地步;数据无法回答每一个问题。
+
+
+
+
+
+图6:一支上等雪茄。
+
+摄影:Ildiko Frank。
+
+
+
+# 尾声
+
+**NF**:我一直在思考如何给这次对话起标题,我确实想过 "杰瑞对模式的探索 "这样的标题,但后来我想到,模式只是模式。
+
+**JF**:......但一支好雪茄就是一支烟。我同意。
+
+**NF**:曾经有人说过类似的话。
+
+**JF**:是的,当然是吉卜林(如《吉卜林》(1886 年))。我年轻时就开始抽雪茄了,那时我还在上高中,刚从高中毕业。我在林业局工作,负责扑灭森林火灾。以及勘测木材通道。在我居住的地方,大部分农村都是国家森林,所以这是一项传统的工作。在其中一个营地,唯一的设施就是外屋,而且气味非常非常难闻。使用这些设施真是一种折磨,特别是如果你必须呆上十几二十秒钟的话。我唯一能忍受的办法就是点燃一支非常难闻的雪茄,在里面抽。这就是我开始抽雪茄的原因。我现在抽更好的雪茄了。
+
+**NF**:那你觉得我们现在应该停止讨论模式,休会吗?
+
+**JF**:这不是个坏主意。
+
+**NF**:那么,非常感谢你,杰瑞,让我领略了一场引人入胜的科学奥德赛。我觉得自己好像在和斯利姆-皮肯斯(Slim Pickens)一起,乘着火箭在统计和通信密不可分的岁月里一路前行,只不过你一直坐在火箭的鼻锥上,为火箭指路,而斯利姆-皮肯斯却没有这样的能力。愿你在未来的很长一段时间里驰骋疆场。
+
+**JF**:非常感谢你,尼克,我真的很喜欢。
+
+
+
+# 致谢
+
+作者感谢 Rudy Beran 和 Bill van Zwet 对本文草稿提出的宝贵意见,感谢编辑和一位副主编提供的有益反馈,并感谢 Jerry 在 采访期间的热情款待和在文章准备过程中的耐心指导。这项工作得到了澳大利亚 Val- ueMetrics 公司的部分支持。
+
+# 补充材料
+
+《与杰里-弗里德曼的对话》(DOI: 10.1214/14-STS509SUPP; .pdf)的补充。 与这篇文章相关的补充材料包括一些趣闻轶事,以及约翰-图基在与杰里-弗里德曼(Jerry Fried-man)的交谈过程中向杰里-弗里德曼(Jerry Fried-man)传达其研究观点的一种方式的考 ple。这些资料可查阅 Fisher (2015)。
+
+
+
+# 参考文献
+
+BREIMAN, L. (1996). Arcing classifiers. Technical Report 460, Univ. California, Berkeley.
+
+BREIMAN, L. and FRIEDMAN, J. H. (1985). Estimating optimal transformations for multiple regression and correlation. J. Amer. Statist. Assoc. 80 580–619. MR0803258
+
+BREIMAN, L. and FRIEDMAN, J. H. (1997). Predicting multi-variate responses in multiple linear regression. J. R. Stat. Soc. Ser. B Stat. Methodol. 59 3–54. MR1436554
+
+BREIMAN, L., FRIEDMAN, J. H., OLSHEN, R. A. and STONE, C. J. (1984). Classification and Regression Trees. Wadsworth, Belmont, CA. MR0726392
+
+BRILLINGER, D. R. (2002). John W. Tukey: His life and professional contributions. Ann. Statist. 30 1535–1575. In memory of John W. Tukey. MR1969439 COVER, T. M. and HART, P. E. (1967). Nearest neighbor pattern classification. IEEE Trans. Inform. Theory IT-13 2–27.
+
+DE BOOR, C. (2001). A Practical Guide to Splines, Revised ed. Applied Mathematical Sciences 27. Springer, New York. MR1900298
+
+EFRON, B., HASTIE, T., JOHNSTONE, I. and TIBSHIRANI, R. (2004). Least angle regression. Ann. Statist. 32 407–499. MR2060166
+
+FISHER, N. I. (2015). Supplement to “A conversation with Jerry Friedman.” DOI:10.1214/14-STS509SUPP.
+
+FITHIAN, W. and HASTIE, T. (2013). Finite-sample equiv- alence in statistical models for presence-only data. Ann. Appl. Stat. 7 1917–1939. MR3161707
+
+FRANK, I. E. and FRIEDMAN, J. H. (1993). A statistical view of some chemometrics regression tools. Technometrics 35 109–148.
+
+FREUND, Y. and SHAPIRE, R. E. (1996). Experiments with a new boosting algorithm. In Machine Learning: Proceed- ings of the Thirteenth International Conference 148–156. Morgan Kaufmann, San Francisco, CA.
+
+FRIEDMAN, J. H. (1984). A variable span smoother. Technical Report 5, Laboratory for Computational Statistics, Stanford Univ., Stanford, CA.
+
+FRIEDMAN, J. H. (1987). Exploratory projection pursuit. J. Amer. Statist. Assoc. 82 249–266. MR0883353
+
+FRIEDMAN, J. H. (1989a). Regularized discriminant analysis. J. Amer. Statist. Assoc. 84 165–175. MR0999675
+
+FRIEDMAN, J. H. (1989b). Modern statistics and the computer revolution. In Symposium on Statistics in Science, Industry, and Public Policy, Part 3 14–29. National Academies Press, Washington, DC.
+
+FRIEDMAN, J. H. (1991). Multivariate adaptive regression splines. Ann. Statist. 19 1–141. MR1091842
+
+FRIEDMAN, J. H. (1997). On bias, variance, 0/1-loss, and the curse-of-dimensionality. Data Min. Knowl. Discov. 1 55–77.
+
+FRIEDMAN, J. H. (2001a). Greedy function approximation: A gradient boosting machine. Ann. Statist. 29 1189–1232. MR1873328
+
+FRIEDMAN, J. H. (2001b). The role of statistics in the data revolution? Int. Stat. Rev. 69 5–10.
+
+FRIEDMAN, J. H., BENTLEY, J. L. and FINKEL, R. A. (1977). An algorithm for finding best matches in logarithmic time. ACM Trans. Math. Software 3 209–226.
+
+FRIEDMAN, J. H. and FISHER, N. I. (1999). Bump hunting in high-dimensional data. Stat. Comput. 9 123–162.
+
+FRIEDMAN, J. H., GROSSE, E. and STUETZLE, W. (1983). Multidimensional additive spline approximation. SIAM J. Sci. Statist. Comput. 4 291–301. MR0697182
+
+
+FRIEDMAN, J., HASTIE, T. and TIBSHIRANI, R. (2000). Additive logistic regression: A statistical view of boosting. Ann. Statist. 28 337–407. MR1790002
+
+FRIEDMAN, J. H. and RAFSKY, L. C. (1979). Multivariate generalizations of the Wald–Wolfowitz and Smirnov two-sample tests. Ann. Statist. 7 697–717. MR0532236
+
+FRIEDMAN, J. H. and RAFSKY, L. C. (1983). Graph-theoretic measures of multivariate association and prediction. Ann. Statist. 11 377–391. MR0696054
+
+FRIEDMAN, J. H. and STUETZLE, W. (1981). Projection pursuit regression. J. Amer. Statist. Assoc. 76 817–823. MR0650892
+
+FRIEDMAN, J. H. and STUETZLE, W. (2002). John W.
+
+Tukey’s work on interactive graphics. Ann. Statist. 30 1629–1639. In memory of John W. Tukey. MR1969443
+
+FRIEDMAN, J. H., STUETZLE, W. and SCHROEDER, A. (1984). Projection pursuit density estimation. J. Amer. Statist. Assoc. 79 599–608. MR0763579
+
+FRIEDMAN, J. H. and TUKEY, J. W. (1974). A projection pursuit algorithm for exploratory data analysis. IEEE Trans. Comput. C-23 881–889.
+
+HASTIE, T., TIBSHIRANI, R. and FRIEDMAN, J. (2001). The Elements of Statistical Learning. Data Mining, Inference, and Prediction. Springer, New York. MR1851606
+
+KIPLING, R. (1886). Part of the second last couplet of “The Betrothed.” First published in Departmental Ditties. Avail- able at http://en.wikipedia.org/wiki/The_Betrothed_%28Kipling_poem%29.
+
+MORGAN, J. N. and SONQUIST, J. A. (1963). Problems in the analysis of survey data, and a proposal. J. Amer. Statist. Assoc. 58 415–435.
+
+OREAR, J. (1982). Notes on statistics for physicists, revised. Available at http://ned.ipac.caltech.edu/level5/Sept01/Orear/frames.html.
+
+QUINLAN, J. R. (1986). Induction of decision trees. Machine Learning 1 81–106. Reprinted in Readings in Ma- chine Learning (J. W. SHAvLIK and T. G. DIETTERICH, eds.).
+
+Morgan Kaufmann, San Francisco, 1990, and also, in Readings in Knowledge Acquisition and Learning (B. G. Buchanan and D. Wilkins, eds.). Morgan Kaufmann, San Francisco, 1993.
+
+TUKEY, J. W. (1962). The future of data analysis. Ann. Math. Statist. 33 1–67. MR0133937
+
+VARIAN, H. (2009). Hal Varian on how the Web challenges managers. Available at http://www.mckinsey.com/insights/innovation/hal_varian_on_how_the_web_challenges_managers.
+
+WOLD, S. and SJOSTROM, M. (1977). SIMCA: A method for analyzing chemical data in terms of similarity and analogy. In Chemometrics Theory and Application (B. R. KOWAL-SKI, ed.). American Chemical Society Symposium Series 52 243–282. American Chemical Society, Washington, D.C.
+
+ZOU, H. and HASTIE, T. (2005). Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 67 301–320. MR2137327
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+