git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'Inference for yi-vl-6b-chat:
# Experimental environment: A10, 3090, V100...
# 18GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type yi-vl-6b-chatOutput: (supports passing in local path or URL)
"""
<<< Describe this type of image
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
The image shows a kitten sitting on the floor, eyes open, staring at the camera. The kitten looks very cute, with gray and white fur, and blue eyes. It seems to be looking at the camera, possibly curious about the surroundings.
--------------------------------------------------
<<< How many sheep are in the picture
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the image.
--------------------------------------------------
<<< clear
<<< What is the calculation result
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
1452 + 45304 = 46756
--------------------------------------------------
<<< clear
<<< Write a poem based on the content in the image
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
Night falls, starlight twinkles,
A small boat drifts on the river,
A bright lantern hangs on the bow,
Illuminating the surrounding darkness.
Two people are on the boat,
One at the bow, the other at the stern,
They seem to be talking,
Enjoying a tranquil moment under the starlight.
On the riverbank, trees stand in the dark,
Casting long shadows in the starlight.
The scene is so peaceful,
Reminiscent of an ancient legend.
The boat, the people, and the starlight,
Form a beautiful picture,
Evoking a feeling of serenity,
Beyond the hustle and bustle of city life.
"""Sample images are as follows:
cat:

animal:

math:
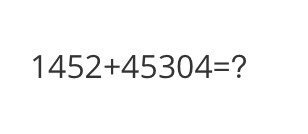
poem:

Single Sample Inference
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.yi_vl_6b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(2) # ...
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, history = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the furthest away?'
images = images * 2
gen = inference_stream(model, template, query, history, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: How far is it from each city?
response: It's 14 kilometers from Jiata, 62 kilometers from Yangjiang, 293 kilometers from Guangzhou, 293 kilometers from Guangzhou.
query: Which city is the furthest away?
response: The furthest distance is 293 kilometers.
history: [['How far is it from each city?', "It's 14 kilometers from Jiata, 62 kilometers from Yangjiang, 293 kilometers from Guangzhou, 293 kilometers from Guangzhou."], ['Which city is the furthest away?', 'The furthest distance is 293 kilometers.']]
"""Sample image as follows:
road:

Fine-tuning multimodal large models usually uses custom datasets. Here shows a demo that can run directly:
(By default, only the qkv of the LLM part is lora fine-tuned. If you want to fine-tune all linears including the vision model part, you can specify --lora_target_modules ALL. Full parameter fine-tuning is also supported.)
# Experimental environment: A10, 3090, V100...
# 19GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type yi-vl-6b-chat \
--dataset coco-mini-en-2 \Custom datasets support json, jsonl format, here is an example of a custom dataset:
(Multi-turn dialogue is supported, each turn must include an image, which can be passed as a local path or URL)
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path", "image_path2", "image_path3"]}Direct inference:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/yi-vl-6b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora and inference:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/yi-vl-6b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/yi-vl-6b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true