ELMO是一种深层的上下文单词表示模型,它可以同时建模:
(1) 单词使用的复杂特征(例如语法和语义),也就是能够学习到词汇用法的复杂性
(2)这些用法如何在语言上下文之间变化(即建模多义性)
词向量是深度双向语言模型(deep bidirectional language model,BILM)内部状态的可学习函数,这些双向语言模型在大型文本语料库上进行了预训练。可以将这些预训练的词向量添加到现有模型中,能够显著改善NLP问题(问答、文本蕴含、情感分析等)的解决效果。
- 依赖于上下文(Contextual):每个单词的表示形式最终取决于使用该单词的整个上下文。
- 深(deep):单词的向量表示结合了深度预训练神经网络的所有层。
- 基于字符(Character based):ELMO模型的训练完全基于字符,因此网络可以使用形态学线索来为训练中未曾见过的词汇标记成可靠的表示。
前向语言模型就是,已知 ,预测下一个词语$t_k$ 的概率,写成公式就是
后向的语言模型如下,即通过下文预测之前的 词语:
双向语言模型(biLM)将前后向语言模型结合起来,最大化前向、后向模型的联合似然函数即可,如下式所示:
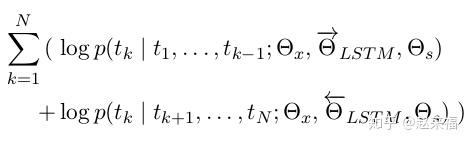
向左和向右的LSTM是不同的, 也就是说有两个LSTM单元.
是输入的意思. 输入的内容是最初始的词向量.
是输出内容, 即LSTM在每个位置的 h. h会再用作softmax的输入, 来进行词汇选择权重赋予.
ELMO 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。

ELMo是双向语言模型biLM的多层表示的组合,对于某一个词语$t_k$ ,一个$L$层的双向语言模型biLM能够由2$L$+1个向量表示:
其中,是对token进行直接编码的结果(这里是字符通过CNN编码),
代表$x_k^{LM}$,
是每个biLSTM层输出的结果。最上面一层的输出
是用softmax来预测下面一个单词$t_{k+1}$。
最后对每一层LSTM的向量进行线性组合,得到最终的向量:
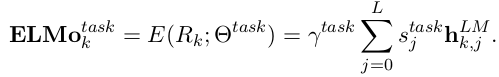
其中$s^{task}$是一个softmax出来的结果, γ是一个任务相关的scale参数。
ELMO 采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
使用上述网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子Snew,句子中每个单词都能得到对应的三个Embedding:最底层是单词的 Word Embedding,往上走是第一层双向LSTM中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。对于这三个EMbedding向量,可以对其进行加权组合成一个向量,然后作为下游任务的输入。因为 ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。

- 在特征抽取器选择上,LSTM弱于Transformer
- ELMO 采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱
参考:
[2]https://zhuanlan.zhihu.com/p/37684922
[3]https://zhuanlan.zhihu.com/p/38254332
[4]https://zhuanlan.zhihu.com/p/63115885
