介绍隐马尔可夫模型之前,首先了解马尔科夫过程。马尔科夫过程是满足无后效性的随机过程。**当前状态仅与前一状态相关。**时间和状态都是离散的马尔科夫过程也叫马尔科夫链 隐马尔可夫模型是对含有未知参数(隐状态)的马尔科夫链进行建模的过程



隐马尔可夫模型通常用来做序列标注问题,因此可以将分词问题转化为序列标注问题





首先需要弄清楚生成式模型与判别式模型的区别。 假设可观测的变量集合为X,需要预测的变量集合为Y,其他的变量集合为Z。生成式模式是对联合概率分布P ( X , Y , Z )进行建模,在给定观测集合X的条件下,通过计算边缘分布来求得对变量集合Y的推断。

判别式模型是直接对条件概率分布P ( Y , Z ∣ X ) 进行建模,然后消掉无关变量Z就可以得到对变量集合Y的预测,即

常见的概率图模型由朴素贝叶斯、最大熵模型、贝叶斯网络、隐马尔可夫模型、条件随机场、pLSA、LDA等。其中朴素贝叶斯、贝叶斯网络、pLSA、LDA属于生成式。最大熵模型属于判别式。隐马尔可夫模型、条件随机场是对序列数据进行建模的方法,其中隐马尔可夫属于生成式,条件随机场属于判别式。
1)HMM是有向图模型,是生成模型;HMM有两个假设:一阶马尔科夫假设和观测独立性假设;但对于序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
2)MEMM(最大熵马尔科夫模型)是有向图模型,是判别模型;MEMM打破了HMM的观测独立性假设,MEMM考虑到相邻状态之间依赖关系,且考虑整个观察序列,因此MEMM的表达能力更强;但MEMM会带来标注偏置问题:由于局部归一化问题,MEMM倾向于选择拥有更少转移的状态。这就是标记偏置问题。
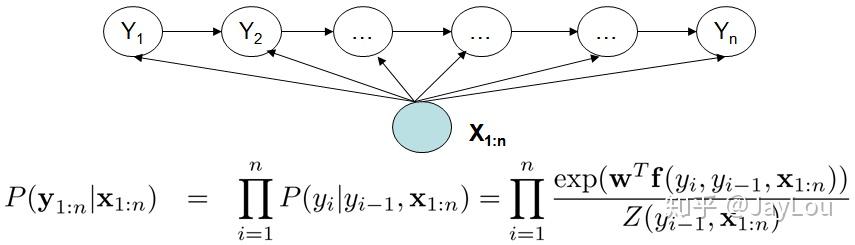
最大熵模型(MEMM)
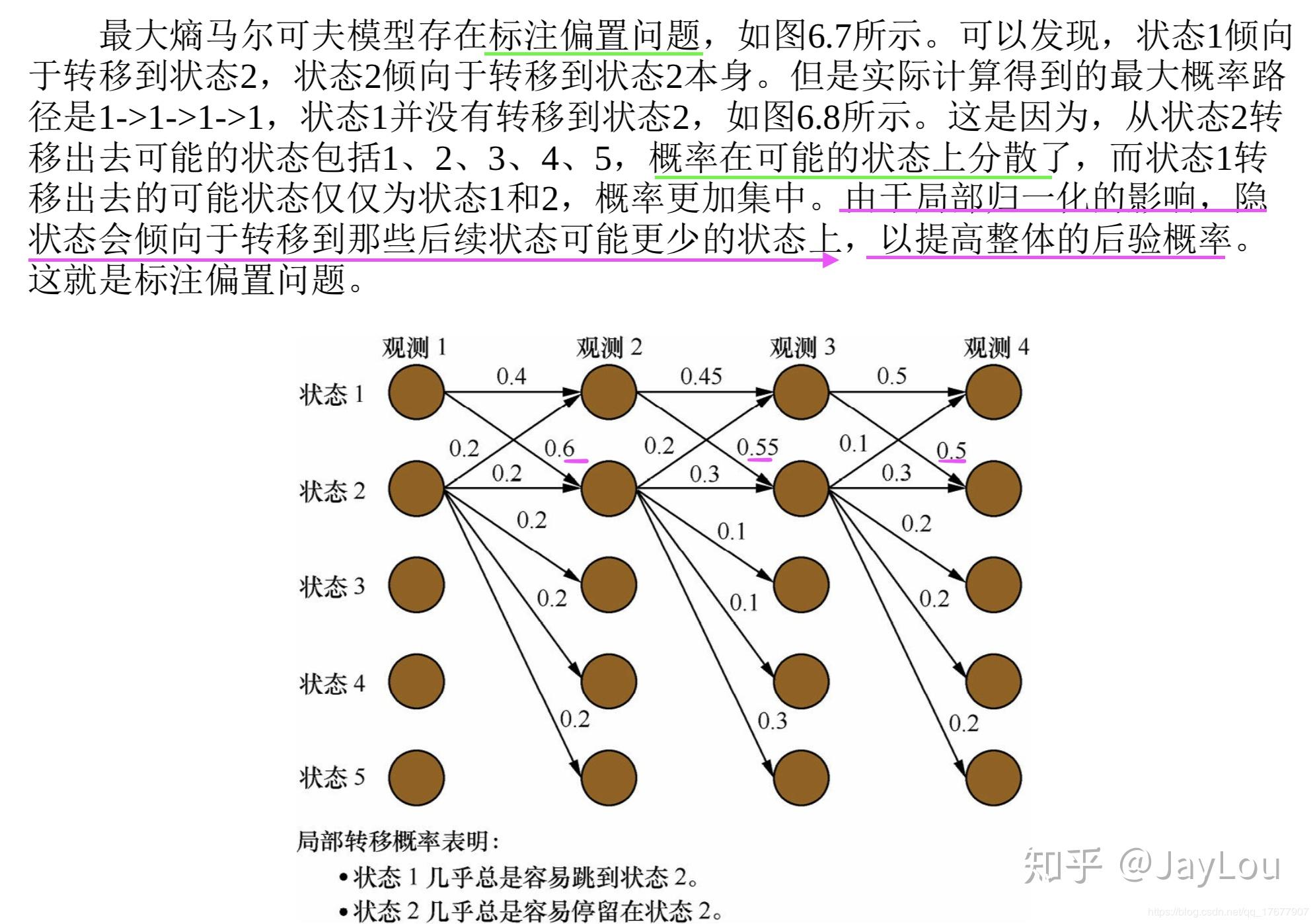
3)CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设,当然,模型相应得也变复杂了。
HMM、MEMM和CRF的优缺点比较:
a)与HMM比较。CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
b)与MEMM比较。由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
c)与ME比较。CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布.
首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像分词、词性标注,以及命名实体标注 隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择 最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉。 条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
HMM是个五元组 λ =( S, O , π ,A,B)
S:状态值集合,O:观察值集合,π:初始化概率,A:状态转移概率矩阵,B:给定状态下,观察值概率矩阵
HMM 的定义建立在两个基本假设的前提上,这两个假设是 HMM 的重点,一定要了解模型的 2 个假设。
1)齐次马尔科夫假设
齐次马尔科夫假设,通俗地说就是 HMM 的任一时刻 t 的某一状态只依赖于其前一时刻的状态,与其它时刻的状态及观测无关,也与时刻 t 无关。
2)观测独立假设
观测独立性假设,是任一时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测及状态无关。
以上这两个假设是 HMM 的核心,之后的公式推导都是依赖这两个假设成立的基础上进行的。
1:评估问题,已知模型参数 λ= (A, B, π),计算某个观测序列发生的概率,即求P(O|λ)
2:解码问题,给出观测序列O和模型λ= (A, B, π),选择一个状态序列S(s1,s2,...st+1),能最好的解释观测序列O
3:学习问题,观测序列O,如何估计模型参数 λ=(π, A, B), 使得P(O|λ)最大? 利用极大似然估计。
https://sm1les.com/2019/07/26/maximum-entropy-markov-model/
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
-
句子s(就是我们要标注词性的句子)
-
i,用来表示句子s中第i个单词
-
l_i,表示要评分的标注序列给第i个单词标注的词性
-
l_i-1,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
**Note:**这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
定义好一组特征函数后,我们要给每个特征函数f_j赋予一个权重λ_j。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。

上式中有两个求和,外面的求和用来求每一个特征函数f_j评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:

前面我们已经举过特征函数的例子,下面我们再看几个具体的例子,帮助增强大家的感性认识。

当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 = 1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列

如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。

当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。

如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
好了,一个条件随机场就这样建立起来了,让我们总结一下: 为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
观察公式:

是不是有点逻辑回归的味道? 事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
对于词性标注问题,HMM模型也可以解决。HMM的思路是用生成办法,就是说,在已知要标注的句子s的情况下,去判断生成标注序列l的概率,如下所示:

那么,HMM和CRF怎么比较呢? 答案是:CRF比HMM要强大的多,它可以解决所有HMM能够解决的问题,并且还可以解决许多HMM解决不了的问题。事实上,我们可以对上面的HMM模型取对数,就变成下面这样:

我们把这个式子与CRF的式子进行比较:
不难发现,如果我们把第一个HMM式子中的log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。
换句话说,我们可以构造一个CRF,使它与HMM的对数形式相同。怎么构造呢?
对于HMM中的每一个转移概率p(l_i=y|l_i-1=x),我们可以定义这样的一个特征函数:


同样的,对于HMM中的每一个发射概率,我们也都可以定义相应的特征函数,并让该特征函数的权重等于HMM中的log形式的发射概率。
用这些形式的特征函数和相应的权重计算出来的p(l|s)和对数形式的HMM模型几乎是一样的!
用一句话来说明HMM和CRF的关系就是这样: 每一个HMM模型都等价于某个CRF 每一个HMM模型都等价于某个CRF 每一个HMM模型都等价于某个CRF
但是,CRF要比HMM更加强大,原因主要有两点:
- CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。
-
CRF可以使用任意的权重 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,如
但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。

https://blog.csdn.net/asdfsadfasdfsa/article/details/80833781
Maximum Entropy Markov Model (MEMM) 最大熵马尔科夫模型 最大熵的体现
隐马尔可夫模型,最大熵模型,最大熵马尔可夫模型与条件随机场的比较
CRF算法学习——自己动手实现一个简单的CRF分词(java)
https://github.com/1000-7/xinlp
NLP-Maximum-entropy Markov model
Hidden Markov model vs. Maximum-entropy Markov model
https://github.com/hankcs/MaxEnt
[最大熵原理](https://www.cnblogs.com/xueqiuqiu/articles/7527339.html)