

Kagome is an open source Japanese morphological analyzer written in pure golang. The MeCab-IPADIC dictionary/statiscal model is used and packaged in Kagome binary.
% kagome tokenize
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
% go get -u github.com/ikawaha/kagome/...
$ kagome -h
usage: main <command>
The commands are:
tokenize - command line tokenize
server - run tokenize server
lattice - lattice viewer
$ go run cmd/kagome/main.go tokenize -h
Usage of tokenize:
-dic="": dic
-file="": input file
-mode="normal": tokenize mode (normal|search|extended)
-udic="": user dic
$ go run cmd/kagome/main.go server -h
Usage of server:
-http=":6060": HTTP service address (e.g., ':6060')
-mode="normal": tokenize mode (normal|search|extended)
-udic="": user dictionary
Kagome has segmentation mode for search such as Kuromoji.
- Normal: Regular segmentation
- Search: Use a heuristic to do additional segmentation useful for search
- Extended: Similar to search mode, but also unigram unknown words
| Untokenized | Normal | Search | Extended |
|---|---|---|---|
| 関西国際空港 | 関西国際空港 | 関西 国際 空港 | 関西 国際 空港 |
| 日本経済新聞 | 日本経済新聞 | 日本 経済 新聞 | 日本 経済 新聞 |
| シニアソフトウェアエンジニア | シニアソフトウェアエンジニア | シニア ソフトウェア エンジニア | シニア ソフトウェア エンジニア |
| デジカメを買った | デジカメ を 買っ た | デジカメ を 買っ た | デ ジ カ メ を 買っ た |
$ kagome server -http=":8080" &
$ curl -XPUT localhost:8080/a -d'{"sentence":"すもももももももものうち"}'
{"status":true,"tokens":[{"id":36163,"start":0,"end":3,"surface":"すもも","class":"KNOWN","features":["名詞","一般","*","*","*","*","すもも","スモモ","スモモ"]},{"id":73244,"start":3,"end":4,"surface":"も","class":"KNOWN","features":["助詞","係助詞","*","*","*","*","も","モ","モ"]},{"id":74989,"start":4,"end":6,"surface":"もも","class":"KNOWN","features":["名詞","一般","*","*","*","*","もも","モモ","モモ"]},{"id":73244,"start":6,"end":7,"surface":"も","class":"KNOWN","features":["助詞","係助詞","*","*","*","*","も","モ","モ"]},{"id":74989,"start":7,"end":9,"surface":"もも","class":"KNOWN","features":["名詞","一般","*","*","*","*","もも","モモ","モモ"]},{"id":55829,"start":9,"end":10,"surface":"の","class":"KNOWN","features":["助詞","連体化","*","*","*","*","の","ノ","ノ"]},{"id":8024,"start":10,"end":12,"surface":"うち","class":"KNOWN","features":["名詞","非自立","副詞可能","*","*","*","うち","ウチ","ウチ"]}]}
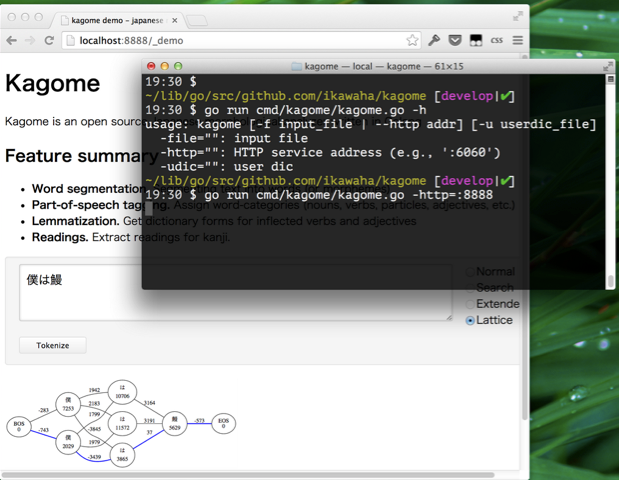
Launch a server and access http://localhost:8888.
(To draw a lattice, demo application uses graphviz . You need graphviz installed.)
$ kagome -http=":8888" &
User dictionary format is same as Kuromoji. There is a sample in _sample dir.
% kagome tokenize -udic _sample/userdic.txt
第68代横綱朝青龍
第 接頭詞,数接続,*,*,*,*,第,ダイ,ダイ
68 名詞,数,*,*,*,*,*
代 名詞,接尾,助数詞,*,*,*,代,ダイ,ダイ
横綱 名詞,一般,*,*,*,*,横綱,ヨコヅナ,ヨコズナ
朝青龍 カスタム人名,朝青龍,アサショウリュウ
EOS
A debug tool of tokenize process outputs a lattice in graphviz dot format.
$ kagome lattice -v すもももももももものうち |dot -Tpng -o lattice.png
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
Below is a simple go example that demonstrates how a simple text can be segmented.
sample code:
package main
import (
"fmt"
"strings"
"github.com/ikawaha/kagome/tokenizer"
)
func main() {
t := tokenizer.New()
tokens := t.Tokenize("寿司が食べたい。") // t.Analyze("寿司が食べたい。", tokenizer.Normal)
for _, token := range tokens {
if token.Class == tokenizer.DUMMY {
// BOS: Begin Of Sentence, EOS: End Of Sentence.
fmt.Printf("%s\n", token.Surface)
continue
}
features := strings.Join(token.Features(), ",")
fmt.Printf("%s\t%v\n", token.Surface, features)
}
}
output:
BOS
寿司 名詞,一般,*,*,*,*,寿司,スシ,スシ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ
たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ
。 記号,句点,*,*,*,*,。,。,。
EOS
Kagome is licensed under the Apache License v2.0 and uses the MeCab-IPADIC dictionary/statistical model. See NOTICE.txt for license details.