Предлагаю ознакомиться с рашифровкой доклада Александра Сигачева из Inventos "Процесс разработки и тестирования с Docker + Gitlab CI"
Те, кто только начинает внедрять процесс разработки и тестирования на базе Docker + Gitlab CI часто спрашивают базовые вопросы. С чего начать? Как организовать? Как тестировать?
Этот доклад хорош тем, что структурировано рассказывает о процессе разрабоки и тестировании с использованием Docker и Gitlab CI. Сам доклад 2017 года. Но основы, методология, идея, опыт использования актуально до сих пор.
Ссылка на видеодоклад https://www.youtube.com/watch?v=lJsqRwULRVA

Меня зовут Александр Сигачев. Работаю в компании Inventos. Расскажу о своем опыте использования Docker и о том как его понемногу внедряем на проектах в компании.
Тема доклада: Процесс разработки с использованием Docker и Gitlab CI.
Это мой второй доклад про Docker. На момент первого доклада мы использовали Docker только в Development на машинах разработчиков. Количество сотрудников, которые использовали Docker было около 2-3 человек. Постепенно был накоплен опыт и мы немного продвинулись дальше. Ссылка на наш первый доклад.
Что будет в этом докладе? Мы поделимся опытом о том какие грабли собрали, какие проблемы как решили. Не везде это было красиво, но позволило двинуться дальше.
Наш девиз: докеризируй все, до чего доходят наши руки.
Какие проблемы решаем?
Когда в компании несколько команд, то программист является шареным ресурсом. Бывают этапы когда программиста выдергивают из одного проекта и дают на какое-то время в другой проект.
Чтобы программист быстро вник ему необходимо скачать исходный код проекта и как можно быстрее запустить среду, которая позволит ему дальше продвигаться решая задачи данного проекта.
Обычно, если начинать с нуля, то документации в проекте ведется мало. Информация о том, как настроить, есть только у старожилов. Самостоятельно сотрудники настраивают свое рабочее место за один-два дня. Чтобы это ускорить, мы применили Docker.
Следующая причина - это стандартизации настроек в Development. По моему опыту, разработчики всегда проявляют инициативу. В каждом пятом случае вводится кастомным домен, например vasya.dev. Рядом сидит сосед Петя, у которого домен petya.dev. Они разрабатывают сайт или какой-то компонент системы, используя это доменное имя.
Когда система разрастается и эти доменные имена начинают попадать в конфигурации, то возникает конфликт Development окружений и переписывается путь сайта.
То же самое происходит с настройками базы данных. Кто-то не заморачивается безопасностью и работает с пустым паролем root. У кого-то на этапе установки MySQL потребовал пароль и пароль оказался один 123. Часто случается, что конфиг базы данных постоянно менялся в зависимости от commit разработчика. Кто-то поправил, кто-то не поправил конфиг. Были ухищрения, когда мы выносили какой-то тестовый конфиг в .gitignore и каждый разработчик должен был устанавливать базу данных. Это усложняло процесс старта. Нужно кроме всего прочего помнить про базу данных. Базу данных надо инициилизировать, надо прописать пароль, надо прописать пользователя, создать табличку и так далее.
Еще одна из проблем - это разные версии библиотек. Часто бывает что разработчик работает с разными проектами. Есть Legacy проект, который начинали пять лет назад (от 2017 года - примеч. ред.). В момент старта стартовали с MySQL 5.5. Есть и современные проекты, где мы стараемся внедрять уже более современные версии MySQL, например 5.7 или старше (в 2017 году - примеч. ред.)
Тот кто работает с MySQL знает, что эти библиотеки тянут за собой зависимости. Достаточно проблематично запустить 2 базы вместе. По крайне мере, старые клиенты проблематично подключить к новой базе данных. Это порождает в свою очередь несколько проблем.
Следующая проблема - это когда разработчик работает на локальной машине, он использует локальные ресурсы, локальные файлы, локальное ОЗУ. Все взаимодействие на момент разработки решения задач выполняется в рамках того, что это работает на одной машине. Примером может служить, когда у нас в Production 3 backend-сервера, а разработчик сохраняет файлы в корневой каталог и оттуда nginx берет файлы для ответа на запрос. Когда такой код попадает в Production, то получается, что файл присутствует на одном из 3 серверов.
Cейчас развивается направление микросервисов. Когда мы делим наши большие приложения на какие-то небольшие компоненты, взаимодействующие между собой. Это позволяет под конкретный стек задач выбрать технологии. Так же это позволяет разделить работу и зону ответственности между разработчиками.
Frondend-разработчик, разрабатывая на JS, практически не влияет на Backend. Backend-разработчик в свою очередь разрабатывает, в нашем случае, Ruby on Rails и не мешает Frondend. Взаимодействие выполняется при помощи API.
Как бонус, при помощи Docker нам удалось утилизировать ресурсы на Staging. Каждый проект в силу своей специфики требовал определенные настройки. Физически нужно было выделять либо по виртуальному серверу и отдельно их настраивать, либо же делить какое-то переменное окружение и проекты могли в зависимости от версии библиотек влиять друг на друга.

Инструменты. Что мы используем?
- Непосредственно сам Docker. В Dockerfile описываются зависимости одного приложения.
- Docker-compose - это связка, которая объединяет самые несколько наших Docker приложений.
- GitLab мы используем для хранения исходного кода.
- GitLab-CI мы используем для системной интеграции.

Доклад состоит из двух частей.
Первая часть расскажет о том, как запускали Docker на машинах разработчиков.
Вторая часть расскажет о том, как взаимодействовать с GitLab, как мы запускаем тесты и как мы выкатываем на Staging.
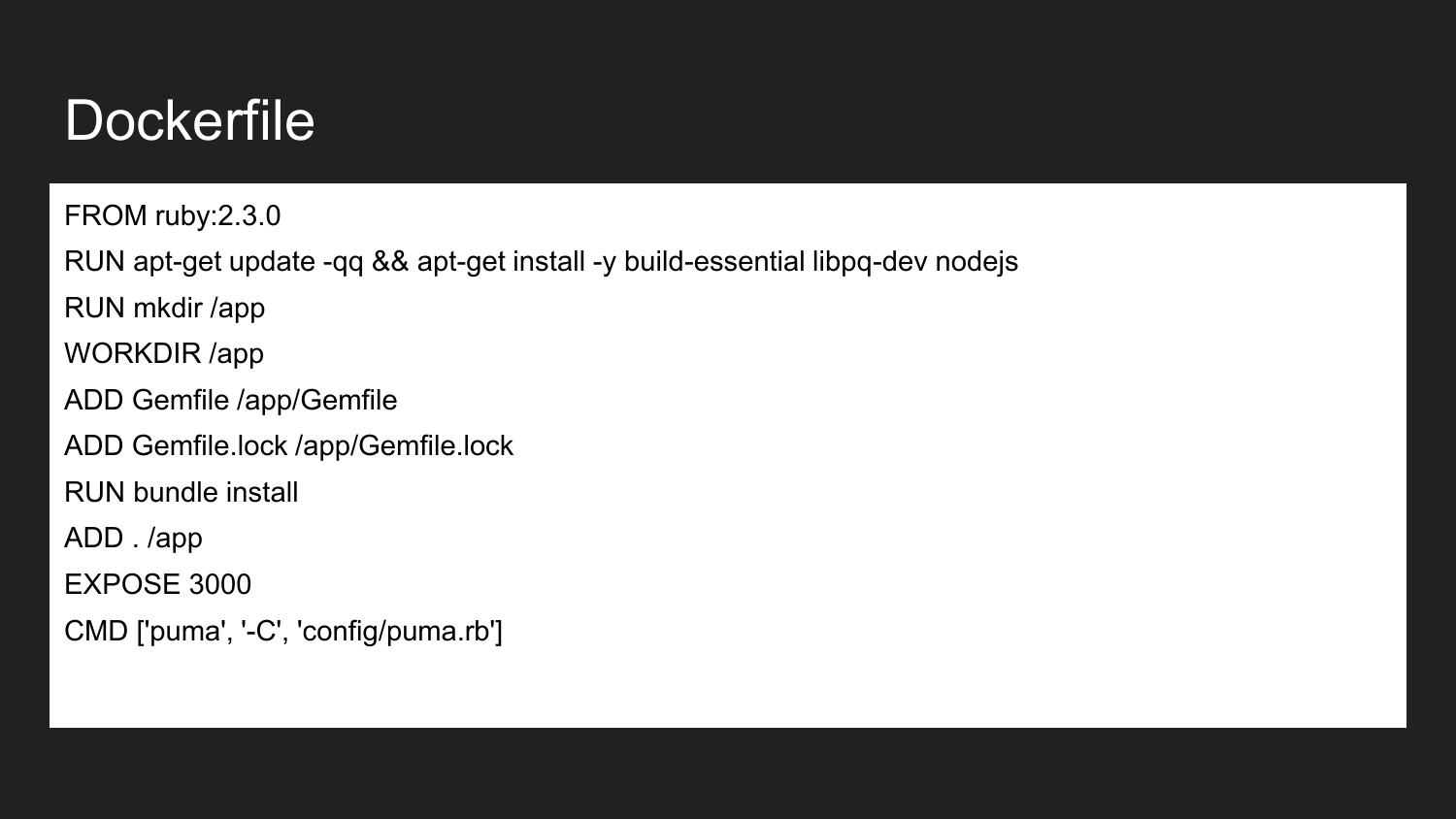
Docker - эта технология, которая позволяет (используя декларативный подход) описать необходимые компоненты. Это пример Dockerfile. Здесь мы объявляем что мы наследуемся от официального Docker-образа Ruby:2.3.0. Он содержит в себе установленный Ruby версии 2.3. Мы устанавливаем необходимые библиотеки сборки и NodeJS. Описываем, что создаем каталог /app. Назначаем каталог app рабочей директорией. В этот каталог помещаем необходимый минимальный Gemfile и Gemfile.lock. Затем выполняем сборку проектов, которые устанавливают этот образ зависимости. Указываем, что контейнер будет готов слушать на внешнем порту 3000. Последная команда - это команда, которая непосредственно запускает наше приложение. Если мы выполним команду запуска проекта, то приложение попробует выполниться и запустит указанную команду.

Это минимальный пример docker-compose файла. В данном случае мы показываем, что происходит связь двух контейнеров. Это непосредственно в сервис базы данных и сервис web. Наши web-приложения в большинстве случаях требуют в качестве backend для хранения данных какую-то базу данных. Так как мы используем MySQL, то пример с MySQL - но ничто не мешает использовать какую-то другу базу данных (PostgreSQL, Redis).
Мы берем из официального источника с Docker hub образ MySQL 5.7.14 без изменений. Образ, который отвечает за наше web-приложение мы собираем с текущей директории. Он во время первого запуска собирает нам образ. После чего запускает команду которую мы здесь выполняем. Если мы вернёмся назад, то увидим что была определена команда запуска через Puma. Puma - сервис, написанный на Ruby. Во втором случаем мы переопределяем. Эта команда может быть произвольной в зависимости от наших потребностей или задач.
Также мы описываем что нужно пробросить порт на нашей хост-машине разработчика с 3000 на 3000 порт контейнера. Это выполняется автоматически при помощи iptables и своего механизма, который непосредственно заложен в Docker.
Разработчик может также как и ранее обратиться на любой доступный IP-адрес, например, 127.0.0.1 локальный или внешний IP-адрес машины.
Последняя строчка говорит, что контейнер web зависит от контейнера db. Когда мы вызываем запуск контейнера web предварительно docker-compose запустит нам базу данных. Уже по старту базы данных(на самом деле - после запуска контейнера! Готовности БД это не гарантирует) запустит нам приложение, наш backend.
Это позволяет избежать ошибок, когда база данных не поднята и позволяет экономить ресурсы, когда мы останавливаем контейнер баз данных, освобождая этим сам ресурсы под другие проекты.

Что нам даёт использование докеризации базы данных на проекте. Мы у всех разработчиков фиксируем версию MySQL. Это позволяет избежать некоторых ошибок, которые могут возникнуть при расхождении версий, когда меняется синтаксис, конфигурация, дефолтные настройки. Это позволяет указать общие hostname для базы данных, login, password. Отходим от того зоопарка имен и конфликтов в config-файлов, которые были ранее.
Мы имеем возможность использовать более оптимальный config для Development среды, который будет отличаться от дефолтного. MySQL по умолчанию настроен на слабые машины и его производительность из коробки очень низкая.

Docker позволяет использовать интерпретатор Python, Ruby, NodeJS, PHP нужной версии. Мы избавляемся от необходимости использовать какой-то менеджер версий. Раньше для Ruby использовали rpm-пакет, который позволял менять версию в зависимости от проекта. Также это позволяет благодаря Docker-контейнеру плавно мигрировать код и версионировать его вместе зависимостями. У нас не возникает проблемы понять версию как интерпретатора, так и кода. Для обновления версии необходимо опустить старый контейнер и поднять новый контейнер. Если что пошло не так, мы можем опустить новый контейнер, поднять старый контейнер.
После сборки образа контейнеры как в Development так и в Production будет одинаковыми. Это особо актуально для больших инсталляций.

Сейчас последний проект у нас на ReacJS. Разработчик запускал все контейнере и разрабатывал используя hot-reload.
Далее запускается задача по сборке JavaScipt и код, собранный в статику, отдается через nginx экономя ресурсы.
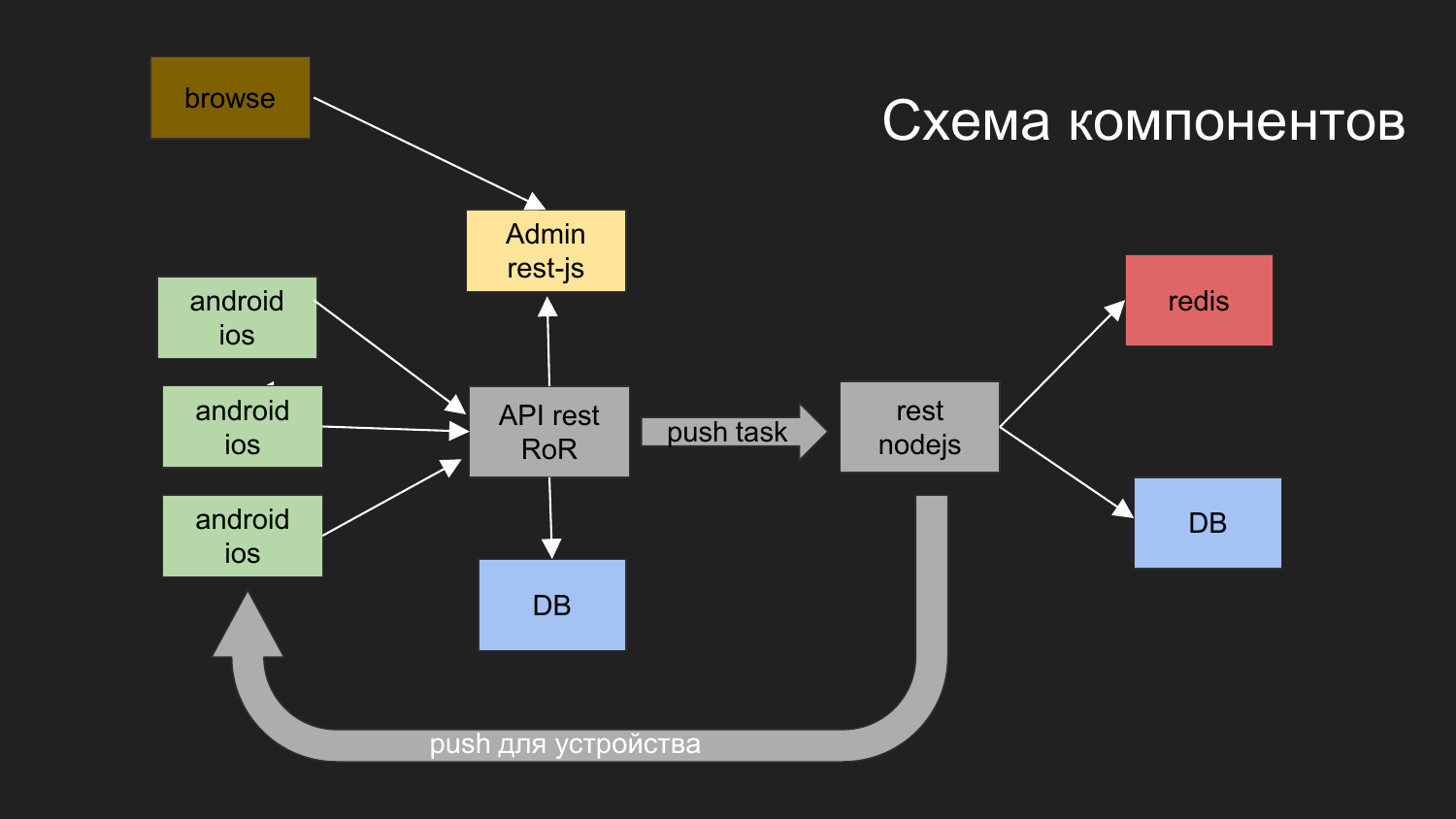
Здесь я привел схему нашего последнего проекта.
Какие задачи решали? У нас возникла необходимость построить систему, с которой взаимодействует мобильные устройства. Они получают данные. Одна из возможностей послать push-уведомления в данное устройство.
Чтоы мы для этого сделали?
Мы разделили на приложение такие компоненты как: админская часть на JS, backend, который работает через REST-интерфейс под Ruby on Rails. Backend взаимодействует с базой данных. Результат, который генерируется отдаются клиенту. Админка с backend и базой данных взаимодействует по REST-интерфейсу.
Также у нас была необходимость отправлять Push уведомления. До этого у нас был проект, в котором было реализован механизм, который отвечает за доставку уведомлений на мобильные платформы.
Мы разработали такую схему: оператор из браузера взаимодействует с админкой, админка взаимодействует с backend, ставится задача что надо послать Push уведомления.
Push уведомления взаимодействуют с другим компонентом, который реализован на NodeJS.
Строятся очереди и дальше идет по своему механизму отправка уведомлений.
Здесь нарисованы две базы данных. На текущий момент у нас при помощи Docker используются 2 независимые базы данных, которые никак не связаны с собой. Кроме того, что у них это общая виртуальная сеть, а физические данные хранятся в разных каталогах на машине разработчика.
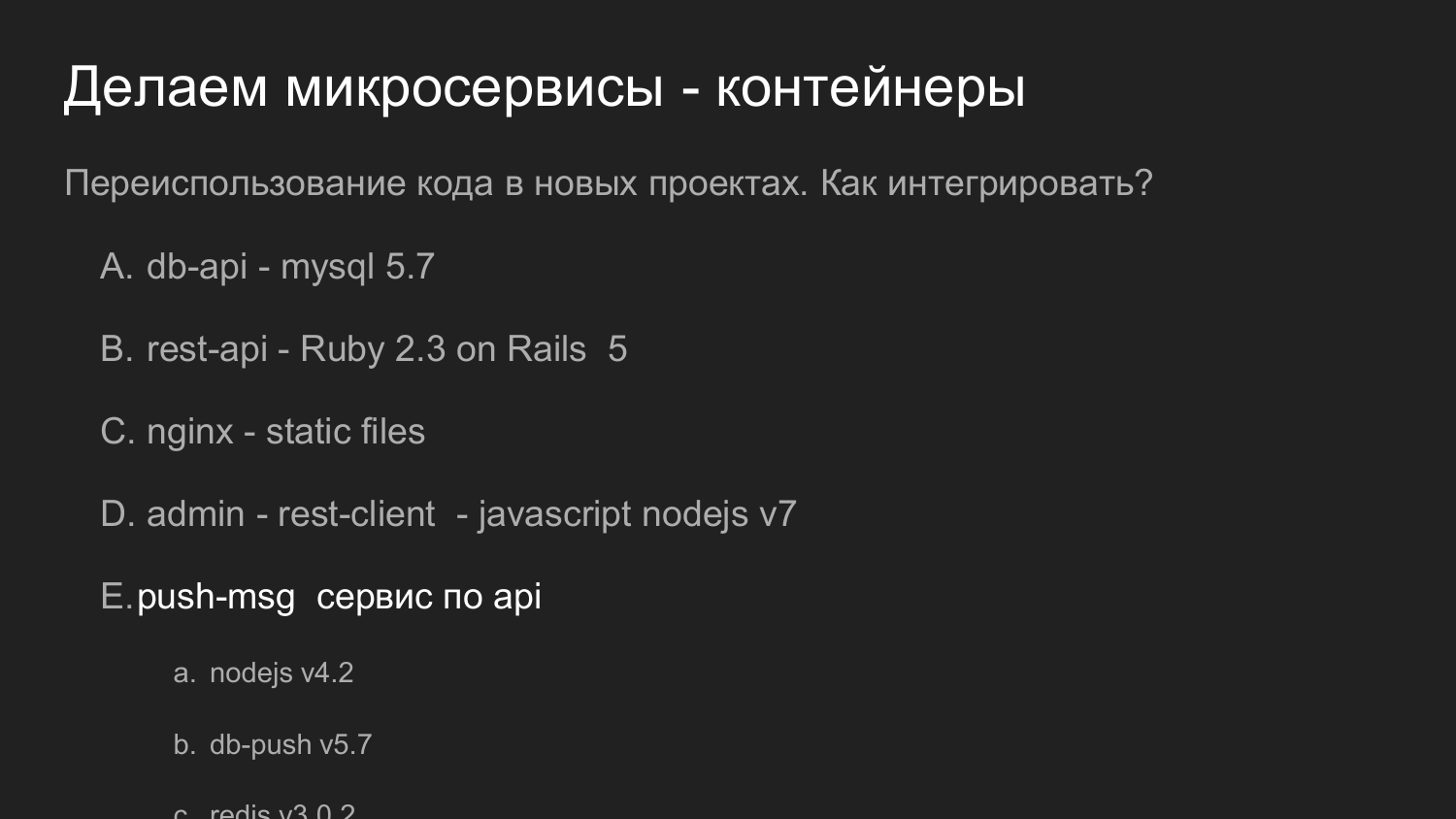
Тоже самое но в цифрах. Здесь важно переиспользование кода.
Если ранее мы говорили про переиспользование кода в виде библиотек, то в данном примере наш сервис, который отвечает Push уведомления, переиспользуется как полностью сервер. Он предоставляет API. А с ним взаимодействует уже наша новая разработка.
На тот момент мы использовали 4 версию NodeJS. Сейчас (в 2017 году - примеч. ред.) в свежих разработках мы используем 7 версию NodeJS. Нет проблем в новых компонентах привлекать новые версии библиотек.
При необходимости можно провести рефакторинг и поднять версию NodeJS у сервиса Push уведомлений.
А если мы сможем сохранить совместимость по API, то можно будет его заменить на других проектах, которые использовались ранее.

Что надо чтобы добавить Docker? Добавляем в наш репозиторий Dockerfile, который описывает необходимые зависимости. В данном примере компоненты разбиты по логике. Это минимальный набор backend-разработчика.
При создании нового проекта создаем Dockerfile, описываем нужную экосистему (Python, Ruby, NodeJS). В docker-compose описывает необходимую зависимость - базу данных. Описываем что нужна база такой-то версии, хранить данные там там-то.
Мы используем для отдачи статики отдельный третий контейнер с nginx. Предусмотрена возможность загрузки картинок. Backend кладет их в заранее подготовленный том, который так же смонтирован в контейнер с nginx, который отдаёт статику.
Чтобы хранить конфигурацию nginx, mysql мы добавили папку Docker, в которой храним необходимые конфиги. Когда разработчик делает git clone репозитория себе на машину, у него получается уже проект готовый для локальной разработки. Не возникает вопрос какой порт или какие настройки применить.

Далее у нас есть несколько компонентов: админ, информ-API, push-уведомления.
Для того чтобы это все запустить мы создали еще один репозиторий, которые назвали dockerized-app. На текущий момент мы используем несколько репозиториев до каждого компонента. Они просто логически отличаются - в GitLab это выгдятит как папка, а на машине разработчика папка под конкретный проект. На уровень ниже лежат компоненты, которые будут объединяться.
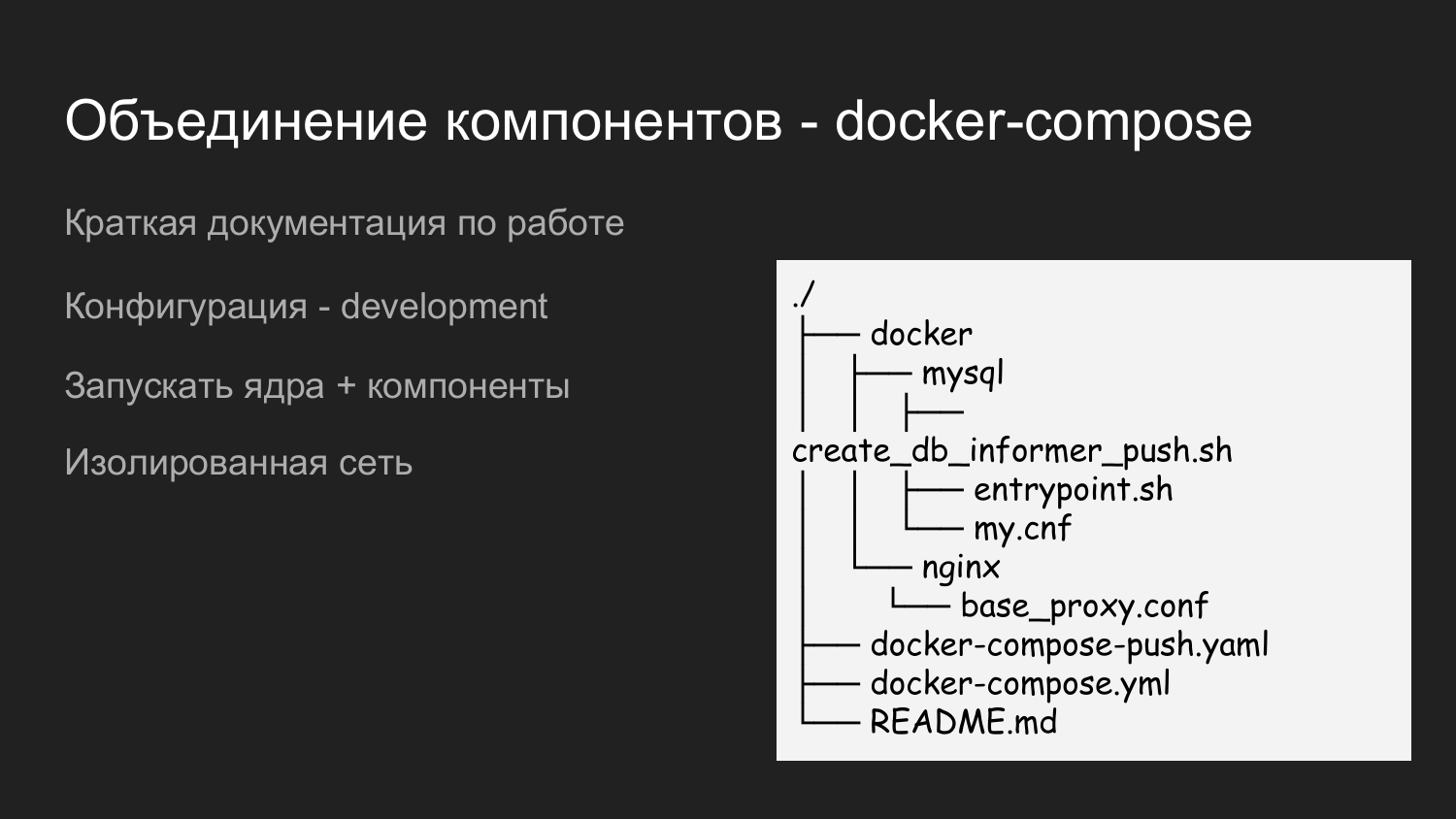
Это пример как раз содержимого dockerized-app. Мы также выносим сюда Docker каталог, в котором наполняем конфигурации, требуемые для взаимодействий всех компонентов. Есть README.md, в котором кратко описано как запускать проект.
Здесь мы применили два docker-compose файла. Это сделано для того чтобы иметь возможность запускать ступенчато. Когда разработчик работать с ядром, ему не нужны Push-уведомления, то он запускает просто docker-compose файл и соответственно ресурс экономится.
Если есть необходимость интеграции с Push-уведомлениями, то запускается docker-compose.yaml и docker-compose-push.yaml.
Так как docker-compose.yaml и docker-compose-push.yaml лежат в папке, то автоматически создается единая виртуальную сеть.
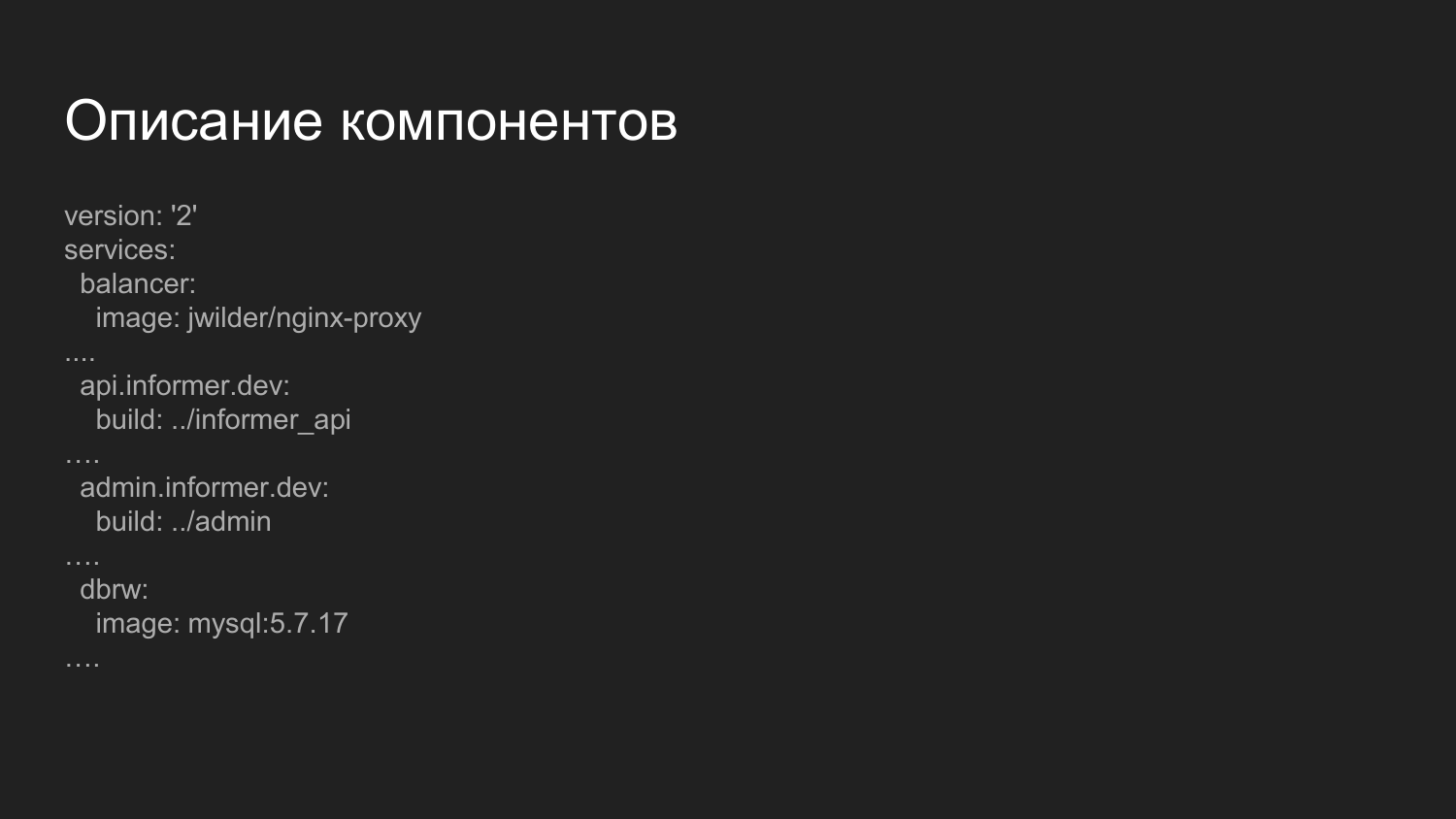
Описание компонентов. Это более расширенный файлик, который отвечает за сбор компонентов. Что здесь примечательно? Здесь мы вводим компонент балансер.
Это готовый Docker-образ, в котором запускается nginx и приложение, которое слушает Docker socket. Динамические, по мере включения и выключения контейнеров, перегенирирует конфиг nginx. Обращение с компонентами мы разносим по доменным именам третьего уровня.
Для Development среды мы используем домен .dev - api.informer.dev. Приложения с доменом .dev допустен на локальной машине разработчика.
Дальше передаться конфиги до каждого проекта и запускается все проекты вместе одновременно.
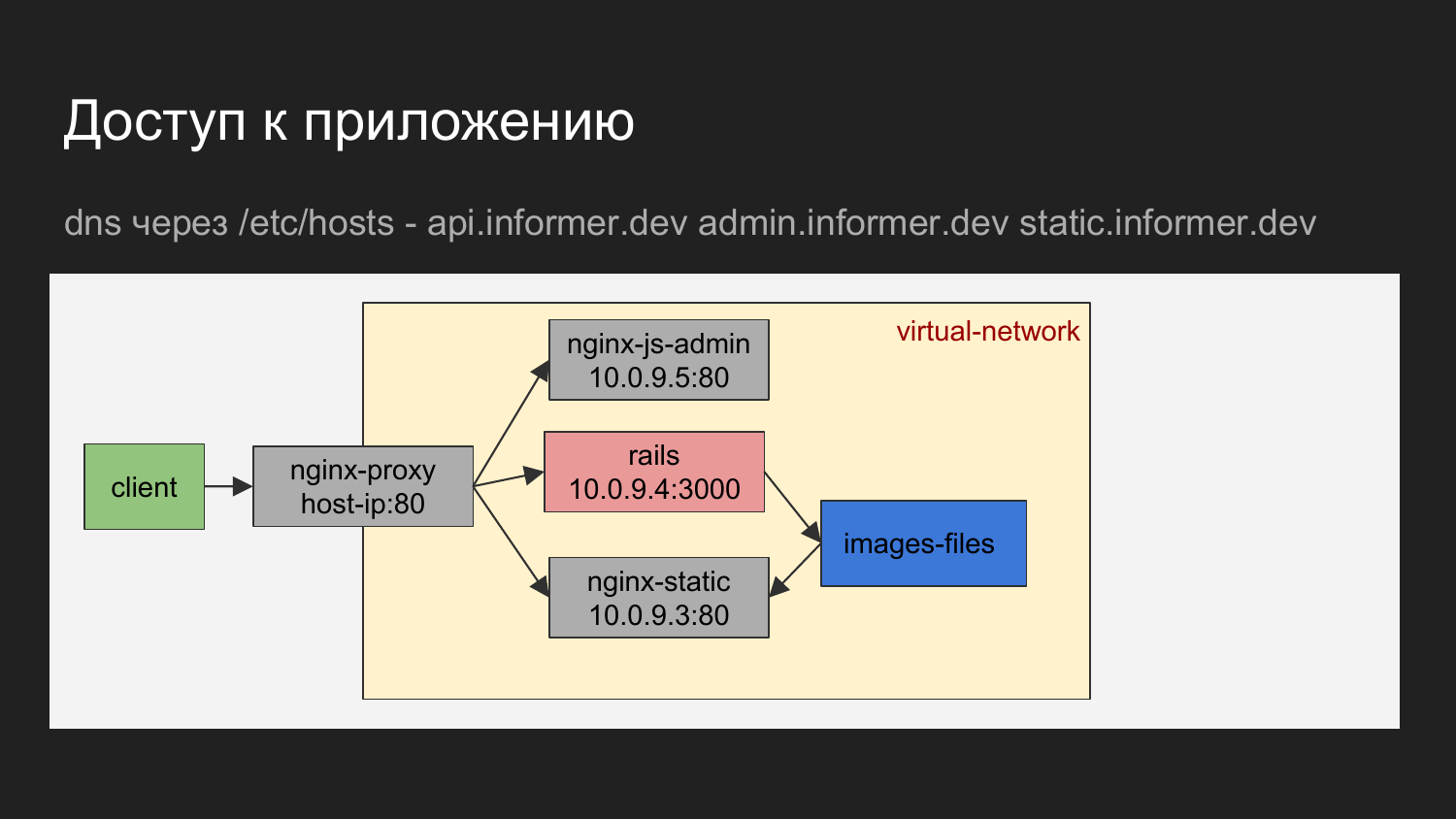
Если графически изобразить, то получается клиент это наш браузер или какой-то инструмент, которым мы осуществляем запросы на баланер.
Балансен по доменному имени определяет к какому контейнеру нужно обратиться.
Это может быть nginx, который отдает JS админки. Это может nginx, который отдает API или же статические файлы, которые отдаются nginx в виде загрузки картинок.
На схеме видно что контейнеры объединены виртуальную сеть и скрыты за прокси.
На машине разработчика можно обратиться к контейнеру зная IP, но мы в принципе это не применяем. Необходимости прямого обращения практически не возникает.

Какой пример посмотреть чтобы докеризировать свое приложение? На мой взгляд хорошим примером является официальной docker образ для MySQL.
Он достаточно сложной. Там много версий. Но его функционал позволяет покрыть множество потребностей, которые могут возникнуть в процессе дальнейшей разработки. Если вы потратите время и разберетесь как все это взаимодействует, то я думаю в самостоятельном внедрении у вас проблем не возникнет.
В hub.docker.com обычно присутстуют ссылки на github.com, где приведены непосредственно сырые данные, из которых можно самостоятельно собрать образ.
Дальше в этом репозитории присутствует скрипт docker-endpoint.sh, который отвечает за первичную инициализацию и за дальнейшую обработку запуска приложения.
Также в этом примере присутствует возможность конфигурирования при помощи переменных окружения. Определяя переменное окружение при запуске одиночного контейнера или через docker-compose можно сказать что нам нужно задать пустой пароль для docker на для root на MySQL или либо же какой-то, который мы хотим.
Есть вариант создать рандомный пароль. Мы говорим что нам требуется пользователь, требуется установить пользователю пароль и требуется создать базу данных.
В своих проектах мы немного унифицировали Dockerfile, который отвечает за инициализацию. Там мы поправили под свои нужды сделать просто расширение прав пользователя, которую использует приложение. Это пользволило в дальнейшем просто создать базу данных из консоли приложения. В Ruby приложениях есть команда создания, изменения и удаления баз данных.

Этот пример того как выглядит конкретная версия MySQL на github.com. Dockerfile можно открыть и посмотреть как там происходит устанавка.
docker-endpoint.sh скрипт отвечающий за точку входа. При первичной инициализации требуются некоторые действия по подготовке и все эти действия вынесены как раз в скрипт инициализации.

Переходим ко второй части.
Для хранения исходных кодов мы перешли на gitlab. Это достаточно мощная система, которая имеет визуальный интерфейс.
Один из компонентов Gitlab это Gitlab CI. Он позволяет описывать последовать команд, которые впоследствии будут использоваться того чтобы организовать систему доставки кода или запуска автоматического тестирования.
Доклад по Gitlab CI 2 https://goo.gl/uohKjI - доклад с Ruby Russia club - достаточно подробный и возможно он вас заинтересует.

Cейчас мы с вами рассмотрим что требуется для того чтобы активировать Gitlab CI. Для того чтобы запустить Gitlab CI нам достаточно в корень проекта положить файлик .gitlab-ci.yml.
Здесь мы описываем что мы хотим выполнять последовательность состояний типа теста, деплоя.
Выполняем скрипты, которые вызывают непосредственно docker-compose сборку нашего приложения. Это пример как раз backend.
Далее мы говорим что необходимо прогнать миграции по изменению базы данных и выполнить тесты.
Если скрипты выполняются корректно и не возвращает код ошибки, то соответственно система переходит ко второй стадии деполоя.
Стадия деплоя на текущий момент реализована для staging. Мы не организовывали безпростойный перезапуск.
Мы принудительно гасим все контейнеры, а потом все контейнеры поднимаем заново, собранные на первом этапе при тестировании.
Прогоняем уже для текущего переменного окружения миграции баз данных, которые были написаны разработчиками.
Есть пометка, что применять это только для ветки мастер.
При изменении других веток не выполяется.
Есть возможность организовать выкатки по веткам.
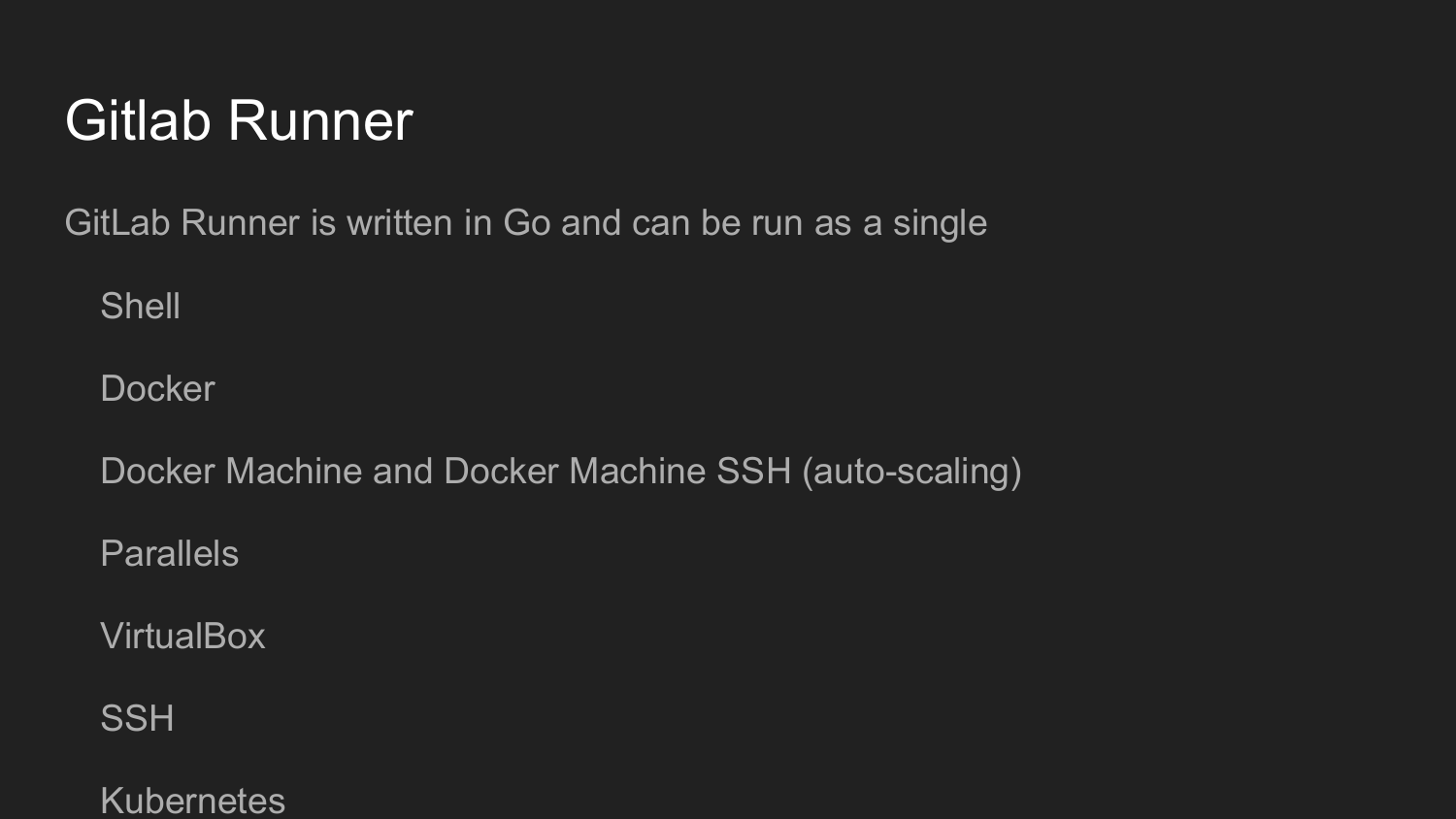
Чтобы дальше это организовать, нам нужно установить Gitlab Runner.
Это утилита написана на Golang. Она является единичным файлом как это принято в мире Golang, которые не требуется никаких независимостей.
При запуске мы регистрируем Gitlab Runner.
Получаем в web-интерфейсе Gitlab ключ.
Потом вызываем команду инициилизации в командной строке.
Настраиваем Gitlab Runner в диалоговом режиме (Shell, Docker, VirtualBox, SSH)
Код на Gitlab Runner будет выполнять при каждом коммите в зависимости от настройки .gitlab-ci.yml.
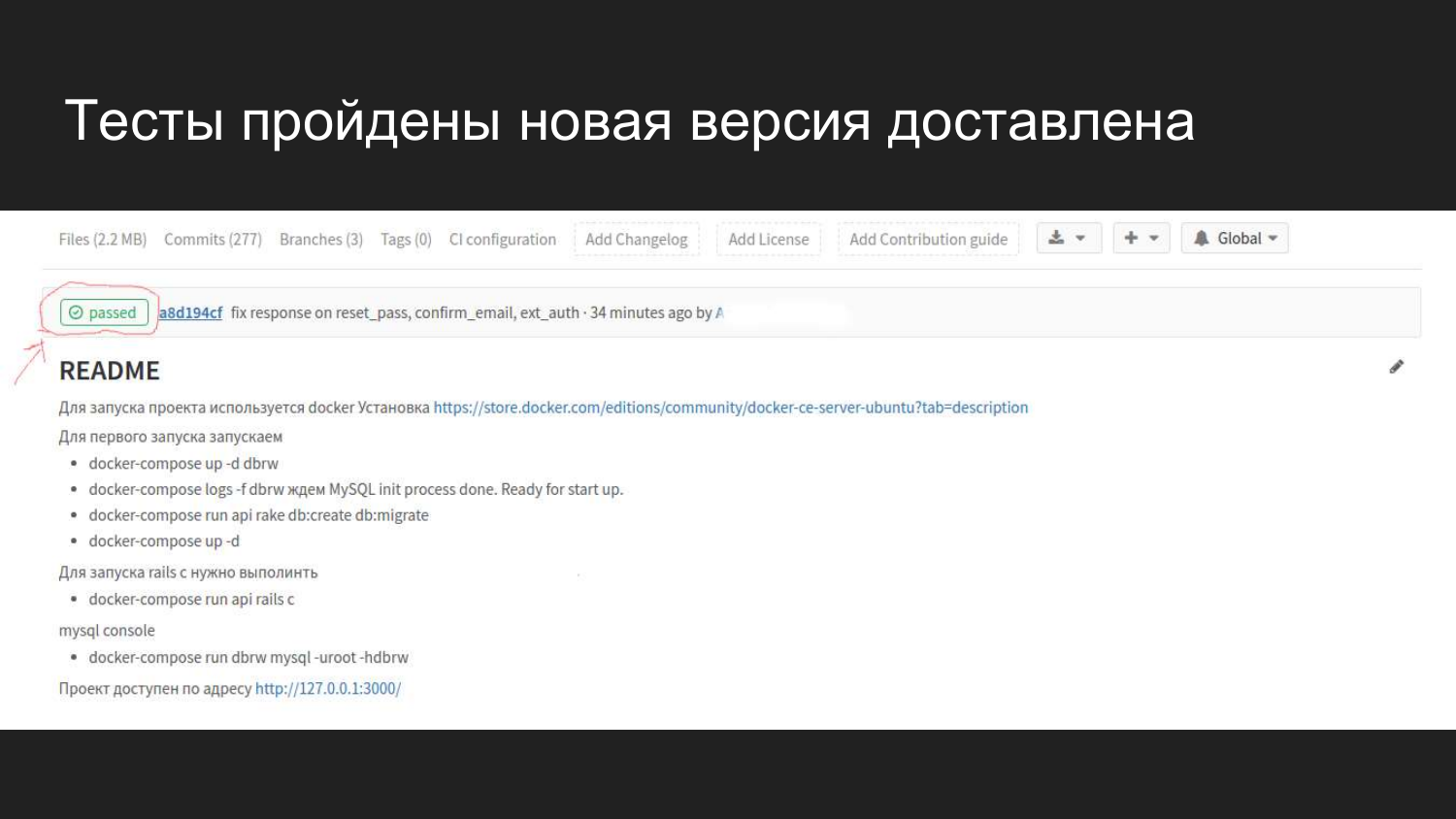
Как это визуально выглядит в Gitlab в web-интерфейсе. После того как подключили GItlab CI у нас появляется флаг, который показывает в каком состоянии находится билд на текущий момент.
Мы видим что вот 4 минут назад был сделан коммит, который прошел все тесты и проблем не вызвал.
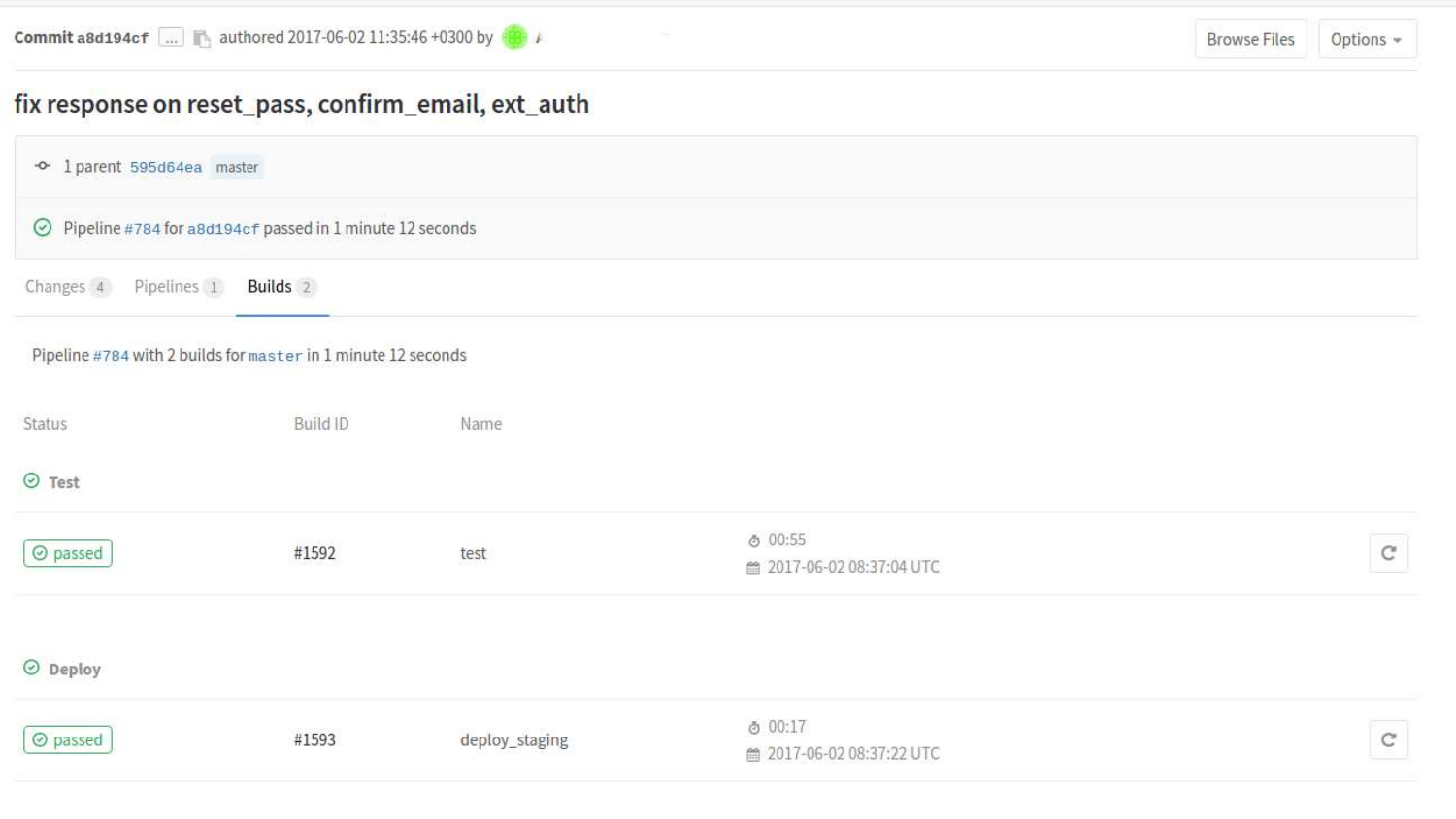
Мы можем более подробно посмотреть по билдам. Здесь мы видим что уже прошли два состояния. Состояние тестирования и состояние деплоя на staging.
Если мы кликнем на конкретный билд, то там будет консольный вывод команд, которые были запущены в процессе согласно .gitlab-ci.yml.
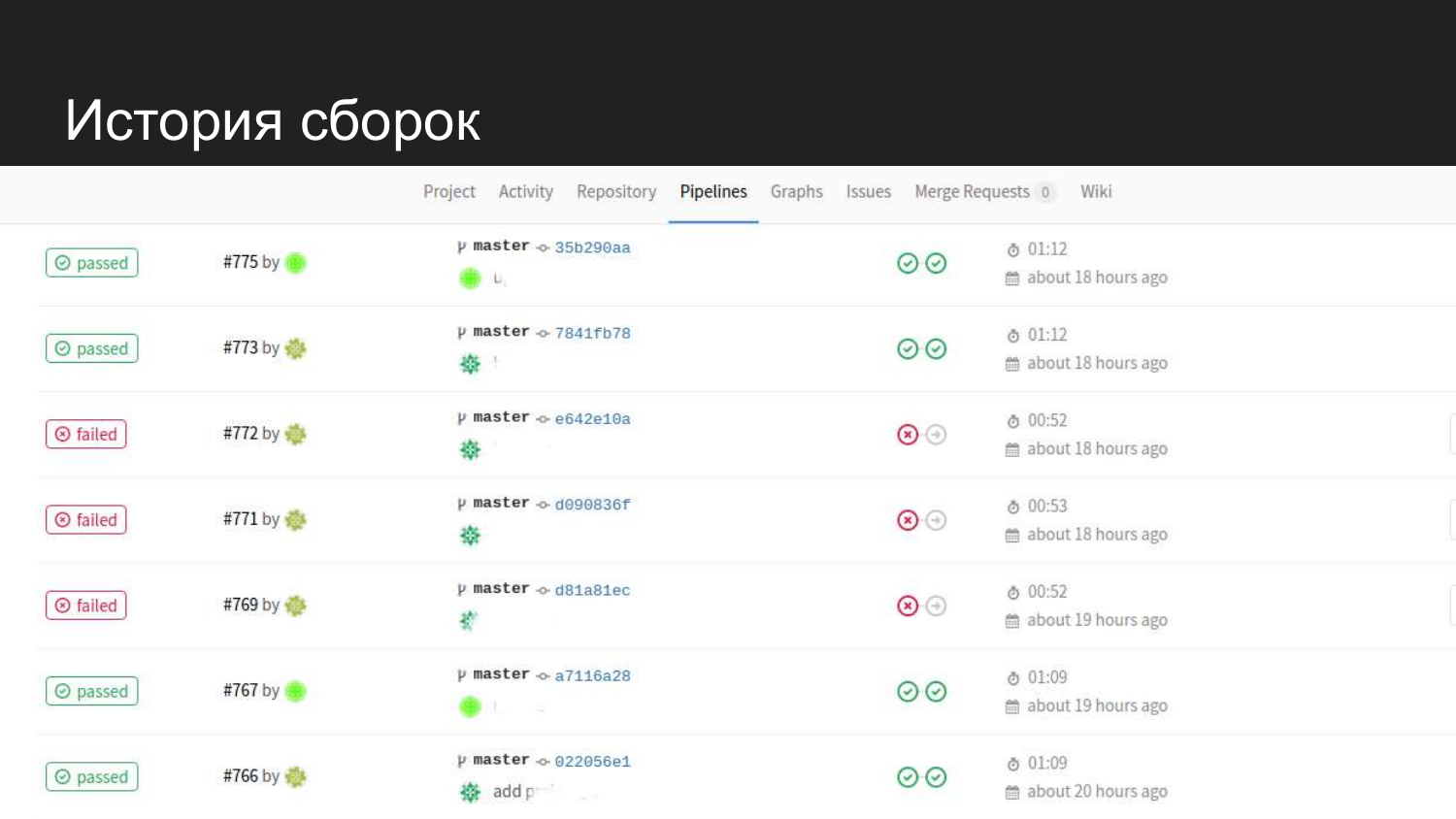
Вот так выглядит история нашего продукта. Мы видим чтобы были удачные попытки. Когда тесты подают, то на следующий шаг не переходит и код на staging не обновляется.

Какие задачи мы решали на staging когда внедрили docker? Наша система состоит из компонентов и у нас возникла необходимость перезапускать, только часть компонентов, которые были обновлены в репозитории, а не всю систему целиком.
Для этого нам пришлось разнести все по отдельным папочкам.
После того как мы это сделали у нас возникла проблема с тем что Docker-compose создает для каждой папочки свое пространство сети не видит компоненты соседа.
Для того чтобы обойти, мы создали сеть в Docker вручную. В Docker-compose прописали что используй для этого проекта такую сеть.
Таким образом каждый компонент, который стартует с этой сеткой видит компоненты в других частях системы.
Следующая проблема - это разделение staging между несколькими проектами.
Так как чтобы все это выглядело красиво и максимально прибрежено к production хорошо использовать 80 либо 443 порт, который использует повсеместно в WEB.

Как мы решили это? Мы назначили один Gitlab Runner всем крупным проектам.
Gitlab позволяет запустить несколько распределенных Gitlab Runner, которые будут просто по-очереди в хаотичном порядке брать все задания, прогонять их.
Чтобы у нас не возникло хауса мы ограничили группу наших проектов одним Gitlab Runner, который при наших объемах справляется без проблем.
Мы вынесли nginx-proxy в отдельный скрипт запуска и в нем прописали сетки всех проектов.
У нас проект имеет одну сетку, а балансер имеет несколько сеток по именам проектов. Он может по доменным именам проксировать дальше.
У нас запросы приходят по домену на 80 порт и разруливаются в группу контейнеров, которая обслуживает этот домен.

Какие еще были проблемы? Это то что по умолчанию все контейнеры выполняют от пользователя root. Это root неравный root хост системы.
Однако если войти в контейнер, то это будет root и файл, который мы создаем в этом контейнере получает права root.
Если разработчик вошел в контейнер и сделал там какие-то команды, которые порождают файлы, затем вышел из контейнера, то в свой рабочей директории он имеет файл, к которому доступа не имеет.
Как можно это решить? Можно добавить пользователей, которые будет в контейнере.
Какие проблемы возникли, когда мы добавили пользователя?
Создавая пользователя у нас часто не совпадают ID группы (UID) и ID пользователя (GID).
Чтобы решить эту проблему в контейнре мы использоуем пользователей с ID 1000.
В нашем случае это совпало с тем что практически у всех разработчиков используется ОС Ubuntu. А у ОС Ubuntu первый пользователь имеет ID 1000.
Какие у нас планы?
Перечитать документацию по Docker. Проект активно развивается, документация меняется. Данные, которые были получены два-три месяца назад, уже потихоньку устаревают.
Часть проблем, которые мы решали ввполне возможно уже решены стандартными средствами.
Так хочется пройти дальше уже перейти непосредственно к оркестрации.
Один из примеров это встроенный в Docker механизм под названием Docker Swarm, который представляется из коробки. Хочется запустить что-то продакшене на базе технология Docker Swarm.
Порождение контейнеров делает неудоство работу с логами. Сейчас логи изолированные. Они разбросаны по контейнерам. Одна из задач сделать удобный доступ к логам через web-интерфейс.
