

![]()
Yet another serialization library on top of dataclasses.
Put additional @serialize and @deserialize decorator in your ordinary dataclass.
@deserialize
@serialize
@dataclass
class Foo:
i: int
s: str
f: float
b: boolNow you can convert an object to JSON,
>>> to_json(Foo(i=10, s='foo', f=100.0, b=True))
{"i": 10, "s": "foo", "f": 100.0, "b": true}Converted back from JSON to the object quite easily!
>>> from_json(Foo, '{"i": 10, "s": "foo", "f": 100.0, "b": true}')
Foo(i=10, s='foo', f=100.0, b=True)pyserde supports other data formats (YAML, Toml, MsgPack) and offers many more features!
- macOS 10.14 Mojave
- Intel 2.3GHz 8-core Intel Core i9
- DDR4 32GB RAM
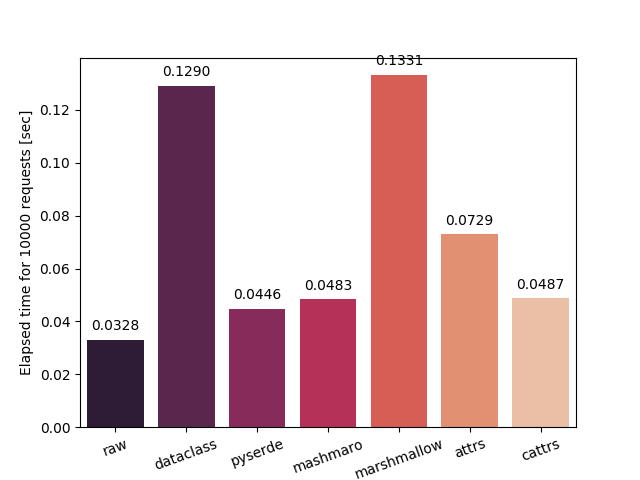
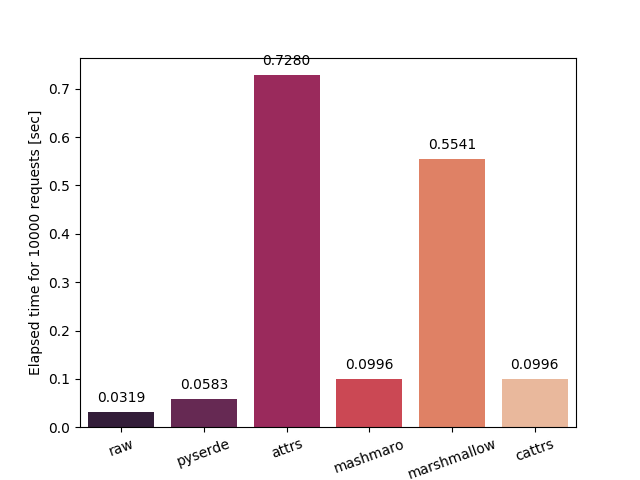
Serialize and deserialize a struct into and from json 10,000 times.
| Serialize | Deserialize |
|---|---|
 |
 |
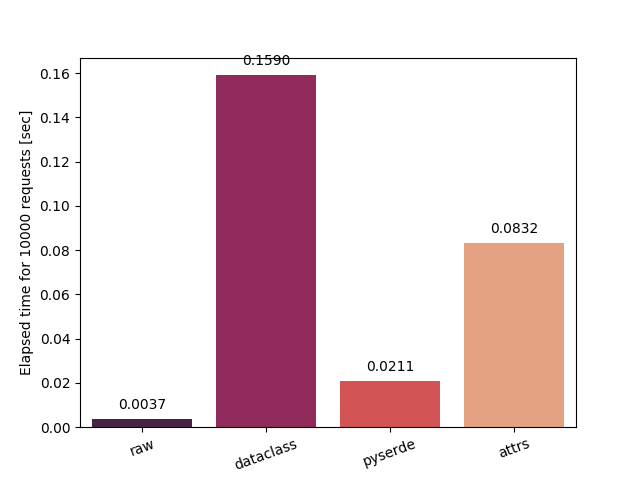
Serialize the struct into tuple and dictionary.
| to_tuple | to_dict |
|---|---|
 |
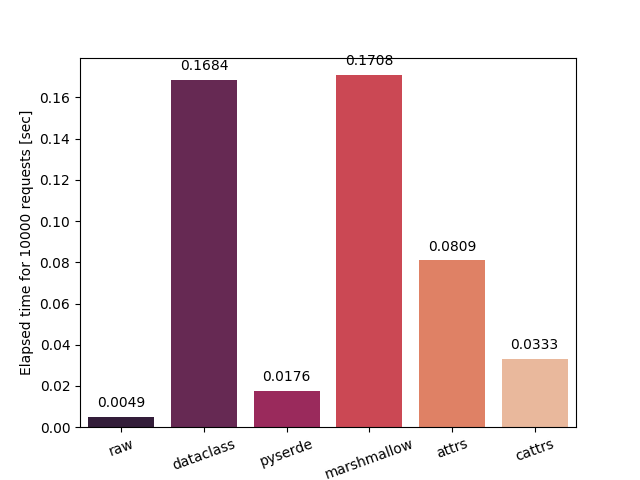 |
raw: Serialize and deserialize manually. Fastest in theory.dataclass: Serialize using dataclass's asdict.pyserde: This library.dacite: Simple creation of data classes from dictionaries.mashumaro: Fast and well tested serialization framework on top of dataclasses.marshallow: A lightweight library for converting complex objects to and from simple datatypes.attrs: Python Classes Without Boilerplate.cattrs: Complex custom class converters for attrs.
To run benchmark in your environment:
git clone [email protected]:yukinarit/pyserde.git
cd pyserde/bench
poetry install
poetry run python bench.py --fullYou can check the benchmarking code for more information.
Install pyserde from PyPI. pyserde requires Python>=3.6.
pip install pyserdeAdditional data formats besides JSON need additional dependencies installed. Install msgpack, toml, or yaml extras to work with the appropriate data formats; you can skip formats that you don't plan to use. For example, if you want to use Toml and YAML:
pip install "pyserde[toml,yaml]"Or all at once:
pip install "pyserde[all]"Put additional @serialize and @deserialize decorator in your ordinary dataclass. Be careful that module name is serde, not pyserde. If you are new to dataclass, I would recommend to read dataclasses documentation first.
from serde import serialize, deserialize
from dataclasses import dataclass
@deserialize
@serialize
@dataclass
class Foo:
i: int
s: str
f: float
b: boolpyserde generates methods necessary for serialization by @serialize and methods necessary for deserialization by @deserialize when a class is loaded into python interpreter. Generation occurs exactly only once (This is more like how decorator work, not pyserde) and there is no overhead when you actually use the generated methods. Now your class is serializable and deserializable in the data formats supported by pyserde.
Next, import pyserde helper methods. For JSON:
from serde.json import from_json, to_jsonSimilarly, you can use other data formats.
from serde.yaml import from_yaml, to_yaml
from serde.toml import from_toml, to_toml
from serde.msgpack import from_msgpack to_msgpackUse to_json to serialize the object into JSON.
f = Foo(i=10, s='foo', f=100.0, b=True)
print(to_json(f))
Pass Foo class and JSON string in from_json to deserialize into Object.
s = '{"i": 10, "s": "foo", "f": 100.0, "b": true}'
print(from_json(Foo, s))That's it! pyserde offers many more features. If you're interested, please read the rest of the documentation.
- Primitives (int, float, str, bool)
- Containers (List, Set, Tuple, Dict)
typing.Optionaltyping.Union- User defined class with
@dataclass typing.NewTypefor primitive typestyping.AnyEnumandIntEnum- More types
You can write pretty complex class like this:
@deserialize
@serialize
@dataclass
class bar:
i: int
@deserialize
@serialize
class Foo:
i: int
l: List[str]
t: Tuple[int, float, str, bool]
d: Dict[str, List[Tuple[str, int]]]
o: Optional[str]
nested: Barfrom serde.json import from_json, to_json
print(to_json(f))
print(from_json(Foo, s))from serde.yaml import from_yaml, to_yaml
print(to_yaml(f))
print(from_yaml(Foo, s))from serde.toml import from_toml, to_toml
print(to_toml(f))
print(from_toml(Foo, s))from serde.msgpack import from_msgpack, to_msgpack
print(to_msgpack(f))
print(from_msgpack(Foo, s))For python >= 3.9, you can use PEP585 style type annotations for standard collections.
@deserialize
@serialize
class Foo:
i: int
l: list[str]
t: tuple[int, float, str, bool]
d: dict[str, list[tuple[str, int]]]
o: Optional[str]
nested: BarFor complete example, please see ./examples/collection.py
PEP563 Postponed evaluation of type annotation is supported.
from __future__ import annotations
from dataclasses import dataclass
from serde import deserialize, serialize
@deserialize
@serialize
@dataclass
class Foo:
i: int
s: str
f: float
b: bool
def foo(self, cls: Foo): # You can use "Foo" type before it's defined.
print('foo')For complete example, please see ./examples/lazy_type_evaluation.py
You can use a forward reference in annotations.
@dataclass
class Foo:
i: int
s: str
bar: 'Bar' # Specify type annotation in string.
@deserialize
@serialize
@dataclass
class Bar:
f: float
b: bool
# Evaluate pyserde decorators after `Bar` is defined.
deserialize(Foo)
serialize(Foo)For complete example, please see ./examples/forward_reference.py
You can flatten the fields of the nested structure.
@deserialize
@serialize
@dataclass
class Bar:
c: float
d: bool
@deserialize
@serialize
@dataclass
class Foo:
a: int
b: str
bar: Bar = field(metadata={'serde_flatten': True})
Bar's c, d fields will be deserialized as if they are defined in Foo.
Converting snake_case fields into supported case styles e.g. camelCase and kebab-case.
@serialize(rename_all = 'camelcase')
@dataclass
class Foo:
int_field: int
str_field: str
f = Foo(int_field=10, str_field='foo')
print(to_json(f))Here, the output is all camelCase.
'{"intField": 10, "strField": "foo"}'In case you want to use a keyword as field such as class, you can use serde_rename field attribute.
@serialize
@dataclass
class Foo:
class_name: str = field(metadata={'serde_rename': 'class'})
print(to_json(Foo(class_name='Foo')))Output json is having class instead of class_name.
{"class": "Foo"}For complete example, please see ./examples/rename.py
You can skip serialization for a certain field, you can use serde_skip.
@serialize
@dataclass
class Resource:
name: str
hash: str
metadata: Dict[str, str] = field(default_factory=dict, metadata={'serde_skip': True})
resources = [
Resource("Stack Overflow", "hash1"),
Resource("GitHub", "hash2", metadata={"headquarters": "San Francisco"}) ]
print(to_json(resources))Here, metadata is not present in output json.
[{"name": "Stack Overflow", "hash": "hash1"}, {"name": "GitHub", "hash": "hash2"}]For complete example, please see ./examples/skip.py
If you conditionally skip some fields, you can pass function or lambda in serde_skip_if.
@serialize
@dataclass
class World:
player: str
buddy: str = field(default='', metadata={'serde_skip_if': lambda v: v == 'Pikachu'})
world = World('satoshi', 'Pikachu')
print(to_json(world))
world = World('green', 'Charmander')
print(to_json(world))As you can see below, field is skipped in serialization if buddy is "Pikachu".
{"player": "satoshi"}
{"player": "green", "buddy": "Charmander"}For complete example, please see ./examples/skip.py
If you want to provide a custom function to override the default (de)serialization behaviour of a field, you can pass your functions to serde_serializer and serde_deserializer dataclass metadata.
@deserialize
@serialize
@dataclass
class Foo:
dt1: datetime
dt2: datetime = field(
metadata={
'serde_serializer': lambda x: x.strftime('%d/%m/%y'),
'serde_deserializer': lambda x: datetime.strptime(x, '%d/%m/%y'),
}
)dt1 in the example will serialized into 2021-01-01T00:00:00 because the pyserde's default (de)serializier for datetime is ISO 8601. dt2 field in the example will be serialized into 01/01/21 by the custom field serializer.
For complete example, please see ./examples/custom_field_serializer.py
If you want to provide (de)serializer at class level, you can pass your functions to serializer and deserializer class attributes.
def serializer(cls, o):
if cls is datetime:
return o.strftime('%d/%m/%y')
else:
raise SerdeSkip()
def deserializer(cls, o):
if cls is datetime:
return datetime.strptime(o, '%d/%m/%y')
else:
raise SerdeSkip()
@deserialize(deserializer=deserializer)
@serialize(serializer=serializer)
@dataclass
class Foo:
i: int
dt1: datetime
dt2: datetimeFor complete example, please see ./examples/custom_class_serializer.py
pyserde provides inspect submodule that works as commandline:
python -m serde.inspect <PATH_TO_FILE> <CLASS>
e.g. in pyserde project
cd pyserde
poetry shell
python -m serde.inspect examples/simple.py Foo
Output
Loading simple.Foo from examples.
==================================================
Foo
==================================================
--------------------------------------------------
Functions generated by pyserde
--------------------------------------------------
def to_iter(obj, reuse_instances=True, convert_sets=False):
if reuse_instances is Ellipsis:
reuse_instances = True
if convert_sets is Ellipsis:
convert_sets = False
if not is_dataclass(obj):
return copy.deepcopy(obj)
Foo = serde_scope.types["Foo"]
res = []
res.append(obj.i)
res.append(obj.s)
res.append(obj.f)
res.append(obj.b)
return tuple(res)
...MIT