A debian:jessie based Spark container. Use it in a standalone cluster with the accompanying docker-compose.yml, or as a base for more complex recipes.
This repository is a fork of gettyimages/docker-spark.
To run SparkPi, run the image with Docker:
docker run --rm -it -p 4040:4040 gettyimages/spark bin/run-example SparkPi 10
To start spark-shell with your AWS credentials:
docker run --rm -it -e "AWS_ACCESS_KEY_ID=YOURKEY" -e "AWS_SECRET_ACCESS_KEY=YOURSECRET" -p 4040:4040 gettyimages/spark bin/spark-shell
To do a thing with Pyspark
echo "import pyspark\nprint(pyspark.SparkContext().parallelize(range(0, 10)).count())" > count.py
docker run --rm -it -p 4040:4040 -v $(pwd)/count.py:/count.py gettyimages/spark bin/spark-submit /count.py
To create a simplistic standalone cluster with docker-compose:
docker-compose up
The SparkUI will be running at http://${YOUR_DOCKER_HOST}:8080 with one worker listed. To run pyspark, exec into a container:
docker exec -it dockerspark_master_1 /bin/bash
bin/pyspark
Then you can paste this code:
RDDread = sc.textFile("file:///usr/spark-2.3.0/README.md")
RDDread.first()
RDDread.take(5)
RDDread.takeSample(False, 10, 2)
RDDread.count()
To run SparkPi, exec into a container:
docker exec -it dockerspark_master_1 /bin/bash
bin/run-example SparkPi 10
To run Jupyter notebooks, exec into a container and run the jupyter server:
jupyter notebook --port 8889 --notebook-dir='/media/notebooks' --ip='*' --no-browser --allow-root
After that, you can run your favourite web browser and go to localhost:8889. There, you can create a new notebook and paste the following code inside one or more cells:
import findspark
findspark.init()
import pyspark
sc = pyspark.SparkContext(appName="test")
RDDread = sc.textFile("file:///usr/spark-2.3.0/README.md")
RDDread.first()
RDDread.take(5)
RDDread.takeSample(False, 10, 2)
RDDread.count()
This is shown in the following figure:
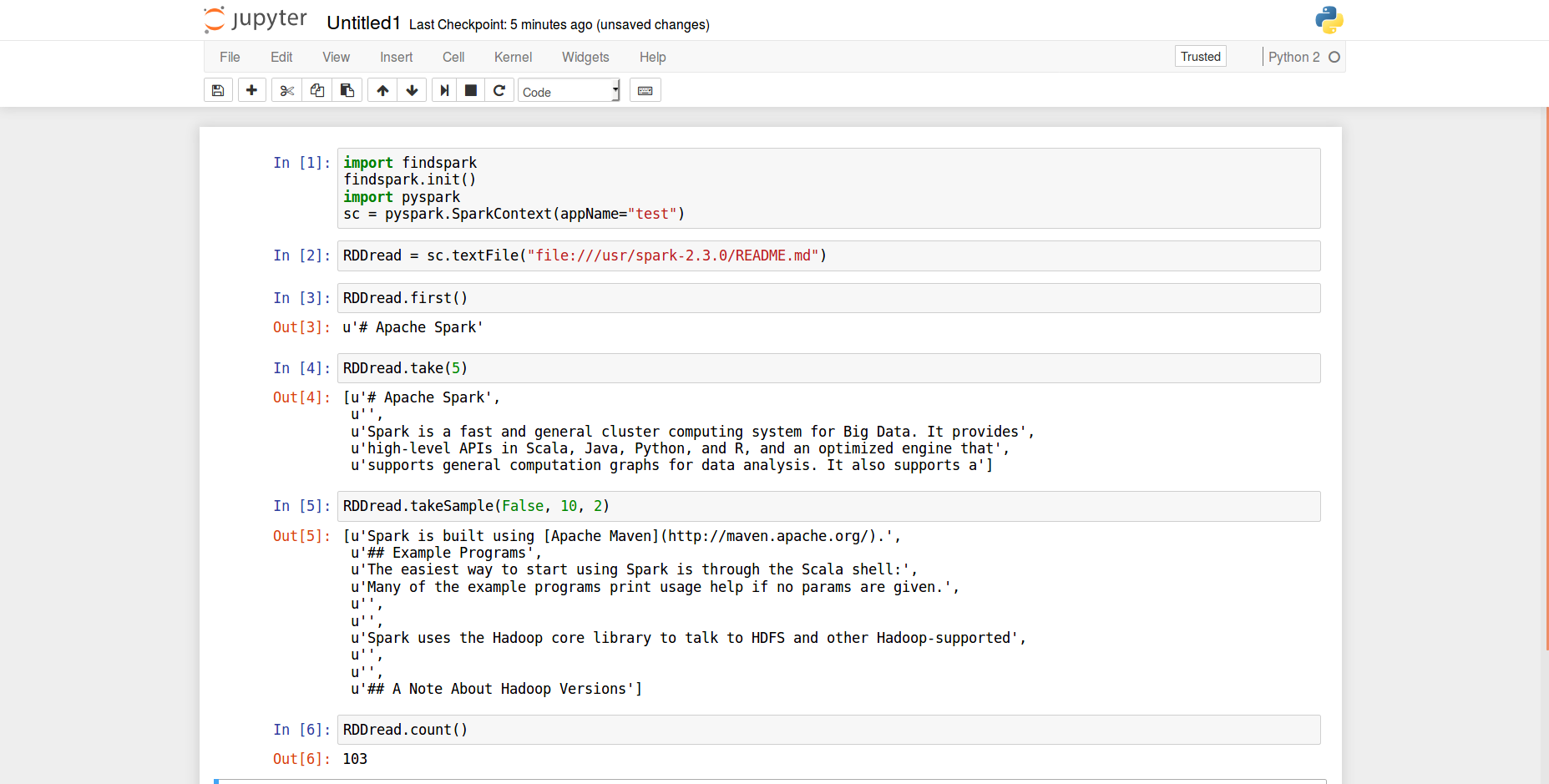
TO DO
First of all we exec into a container, as shown before. Then, we can paste the following code in a file:
# cat test.py
import sys
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from pyspark.sql.context import SQLContext
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: kafka_wordcount.py <zk> <topic>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 10)
zkQuorum, topic = sys.argv[1:]
kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1})
lines = kvs.map(lambda x: x[1])
lines.pprint()
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
To run this application, we run the next command:
bin/spark-submit --jars spark-streaming-kafka-0-8-assembly_2.11-2.3.0.jar test.py 172.18.0.1:2181 topic
MIT