You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
PAttern MIning (PAMI) is a Python library containing several algorithms to discover user interest-based patterns in a wide-spectrum of datasets across multiple computing platforms. Useful links to utilize the services of this library were provided below:
🔋 Highly optimized to our best effort, light-weight, and energy-efficient
👀 Proper code documentation
🍼 Ample examples of using various algorithms at ./notebooks folder
🤖 Works with AI libraries such as TensorFlow, PyTorch, and sklearn.
⚡️ Supports Cuda and PySpark
🖥️ Operating System Independence
🔬 Knowledge discovery in static data and streams
🐎 Snappy
🐻 Ease of use
Maintenance
Installation
Installing basic pami package (recommended)
pip install pami
Installing pami package in a GPU machine that supports CUDA
pip install 'pami[gpu]'
Installing pami package in a distributed network environment supporting Spark
pip install 'pami[spark]'
Installing pami package for developing purpose
pip install 'pami[dev]'
Installing complete Library of pami
pip install 'pami[all]'
Upgradation
pip install --upgrade pami
Uninstallation
pip uninstall pami
Information
pip show pami
Try your first PAMI program
$ python
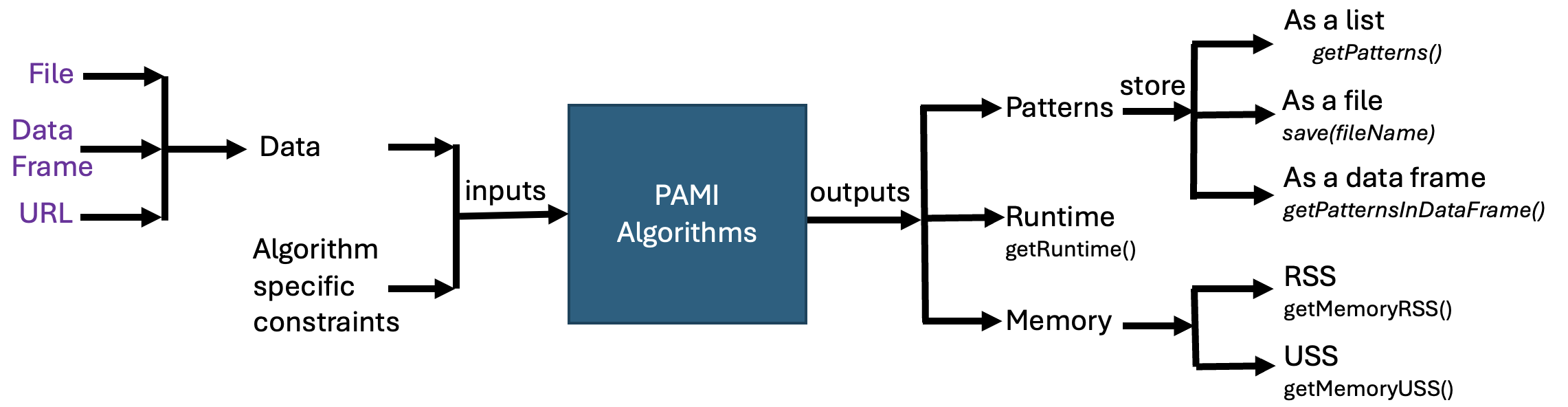
# first import pami fromPAMI.frequentPattern.basicimportFPGrowthasalgfileURL="https://u-aizu.ac.jp/~udayrage/datasets/transactionalDatabases/Transactional_T10I4D100K.csv"minSup=300obj=alg.FPGrowth(iFile=fileURL, minSup=minSup, sep='\t')
#obj.mine() #deprecatedobj.mine()
obj.save('frequentPatternsAtMinSupCount300.txt')
frequentPatternsDF=obj.getPatternsAsDataFrame()
print('Total No of patterns: '+str(len(frequentPatternsDF))) #print the total number of patternsprint('Runtime: '+str(obj.getRuntime())) #measure the runtimeprint('Memory (RSS): '+str(obj.getMemoryRSS()))
print('Memory (USS): '+str(obj.getMemoryUSS()))
Output:
Frequent patterns were generated successfully using frequentPatternGrowth algorithm
Total No of patterns: 4540
Runtime: 8.749667644500732
Memory (RSS): 522911744
Memory (USS): 475353088
Evaluation:
we compared three different Python libraries such as PAMI, mlxtend and efficient-apriori for Apriori.
(Transactional_T10I4D100K.csv)is a transactional database downloaded from PAMI and
used as an input file for all libraries.
Minimum support values and seperator are also same.
The performance of the Apriori algorithm is shown in the graphical results below:
Comparing the Patterns Generated by different Python libraries for the Apriori algorithm:
Evaluating the Runtime of the Apriori algorithm across different Python libraries:
Comparing the Memory Consumption of the Apriori algorithm across different Python libraries:
For more information, we have uploaded the evaluation file in two formats:
The idea and motivation to develop PAMI was from Kitsuregawa Lab at the University of Tokyo. Work on PAMI started at University of Aizu in 2020 and
has been under active development since then.
Getting Help
For any queries, the best place to go to is Github Issues GithubIssues.
Discussion and Development
In our GitHub repository, the primary platform for discussing development-related matters is the university lab. We encourage our team members and contributors to utilize this platform for a wide range of discussions, including bug reports, feature requests, design decisions, and implementation details.
Contribution to PAMI
We invite and encourage all community members to contribute, report bugs, fix bugs, enhance documentation, propose improvements, and share their creative ideas.
Tutorials
0. Association Rule Mining
Basic
Confidence
Lift
Leverage
1. Pattern mining in binary transactional databases