使用GitHub Action运行爬虫,并将结果保存到七牛云对象存储。
必须要先装python再pip
- name: Setup Python environment
uses: actions/[email protected]
- name: Install Dependence
run: pip install requests-html - name: Run pa.py
run: python pa.py需要 fs 和 marked,这一次没有直接安装,而是使用了 package-lock.json。
- name: Setup Node.js for use with actions
uses: actions/[email protected]
- name: Install Dependence
run: npm install可以利用marked库将titles.md转成index.html,开启Github Pages就能在浏览器查看结果。
fs.readFile('./titles.md', 'utf-8', (err, data)=>{
if(err){
throw err
}else{
// 3.使用marked方法,将md格式的文件转化为html格式
let htmlStr = marked(data.toString());
// 4.将转化的html格式的字符串,写入到新的文件中
fs.writeFile('./index.html', htmlStr, err=>{
if(err){
throw err
}else{
console.log("success")
console.log(htmlStr)
}
})
}
})由于我使用的七牛云对象存储,我觉得好用一点的工具qrsctl。
需要先下载,并赋予可执行权限。具体语法见官方文档。
- name: Install qrsctl
run: |
wget http://devtools.qiniu.com/linux/amd64/qrsctl
chmod +x qrsctl
sudo cp qrsctl /usr/local/bin/ && echo ok - name: Upload to Qiniu
run: |
qrsctl login [email protected] lfr139931
qrsctl info
qrsctl put 111imgbed titles.txt titles.txt妈耶,发现能直接上传到本仓库,之前的好多努力都是瞎搞。直接上传到github它不香吗?
- name: Upload to this repo
run: |
git config --global user.name "growvv"
git config --global user.email "[email protected]"
git add index.html && echo A
git commit -m 'upload pachong result' && echo B
git push -u origin master && echo C带上echo信息便于调试。
完整的工作流真好看,忍不住截幅图:
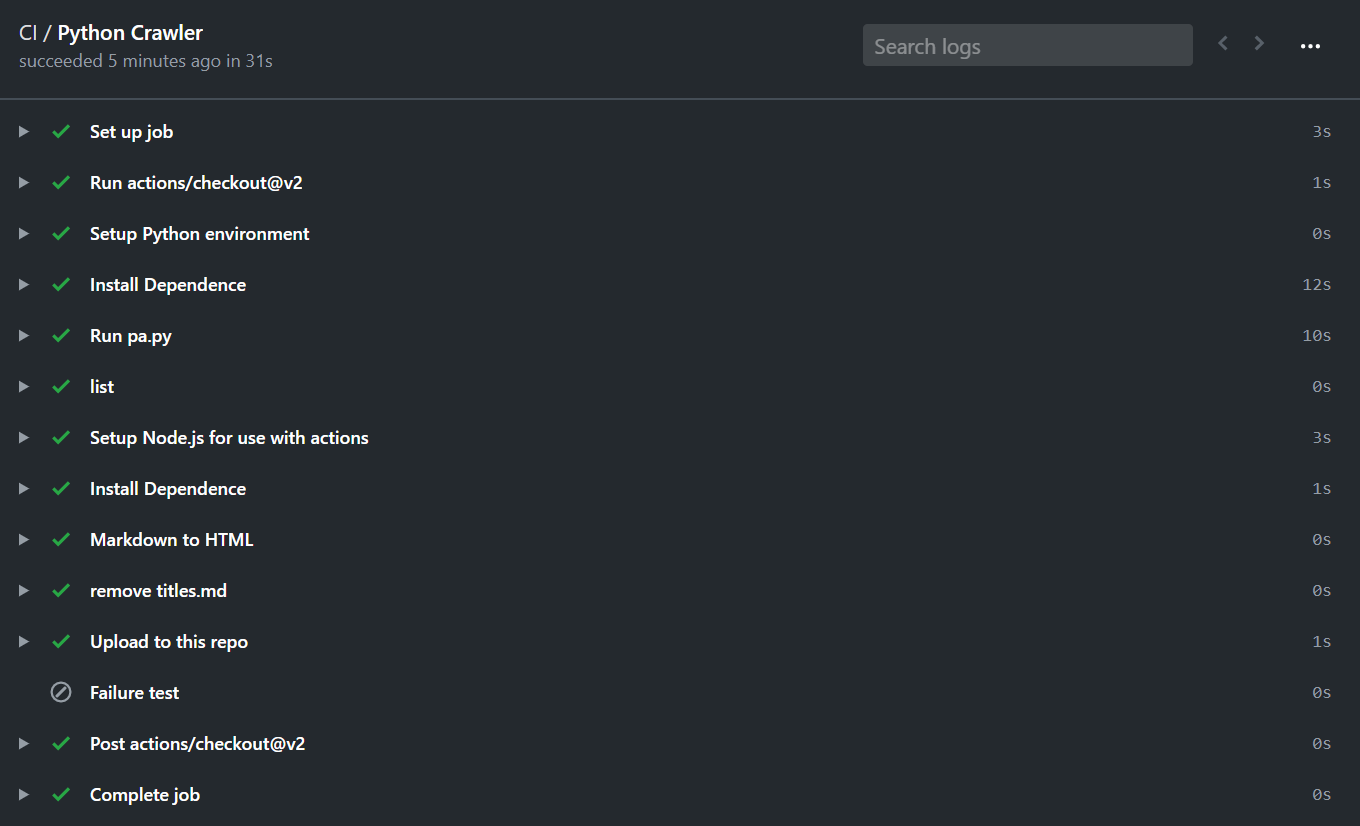
-
如果能直接上传到本仓库该多好啊【已解决】
-
pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 8000 ms exceeded.
爬虫有时会因为超时失败,可以换个爬虫框架试试
pa.py中把下拉3次去掉即可,因为其在程序中没有起到实际作用。
然而pa2.py必须要用render(),,不然find不到,这样随机Timeout问题又回来了。
妈耶,pa2.py的Timeout概率有、大,提高运行频率能缓解吗?😔😔
- 如果index.html没有改变会push失败,git语法需要进一步学习
好像不变有时也passing,不知道什么规则,不过
passing图标真好看,就像https的小锁一样。😂😂
ls显示checkout出的文件和生成的文件都无法跨job,用needs也莫用,咋回事
虽然可以把step放到一个job里,但是这个job好累啊