diff --git a/profile/README.md b/profile/README.md
index 8038c78..61dbc97 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -9,60 +9,74 @@ See what SEA indigenous and non-indigenous languages we accept [here](https://gi
It is essential to greatly increase the accessibility of SEA datasets, promote research in SEA languages and cultures, as well as build more AI models that represent SEA.
-## Contributing to SEACrowd
+## On-going Projects
-Everyone can join and contribute to this initiative from 1 November 2023 to 31 March 2024, win some SWAG, and become a co-author of our upcoming paper. We aim to publish the results of our findings in AACL/EMNLP 2024.
+We will start discussing our next directions by the end of June 2024. Stay tuned via [SEACrowd's Discord channel](https://discord.gg/XXRHFuvkTA)!
-Specifically, we have identified four tasks for contributions:
+Check out our [past projects](#past-projects).
-### 🗃️ Task 1: Submitting Metadata for Existing Public Datasets
+## Contributing to SEACrowd
-You can submit detailed metadata for existing datasets through [this form](https://form.jotform.com/team/232952680898069/seacrowd-sea-datasets). You will provide important information such as data license, size, language and dialect, annotation method, and so on. The approved datasheets as well as under review datasheets will show up and indexed in [this sheet](https://docs.google.com/spreadsheets/d/1ibbywsC1tQ_sLPX8bUAjC-vrTrUqZgZA46W_sxWw4Ss/edit?usp=sharing). [SEACrowd Catalogue](https://seacrowd.github.io/seacrowd-catalogue/) is still under construction for now.
+Everyone can join and contribute to this initiative. Specifically, we have identified four tasks for contributions:
-> Update (2024/03/30): The call for contribution for public datasheet has ended. Form submissions are still recorded, but contribution points are no longer given. Reviewing effort will be allocated to dataloader implementations and private datasheets for now. We will continue reviewing the public datasheet submissions for SEA after SEACrowd ends.
+### 🗃️ Task 1: Submitting Metadata for Existing Public Datasets
+
+You can submit detailed metadata for existing datasets through [this form](https://form.jotform.com/team/232952680898069/seacrowd-sea-datasets). You will provide important information such as data license, size, language and dialect, annotation method, and so on. The approved datasheets as well as under review datasheets will show up and indexed in SEACrowd Catalogue ([web](https://seacrowd.github.io/seacrowd-catalogue/)/[csv](https://docs.google.com/spreadsheets/d/1ibbywsC1tQ_sLPX8bUAjC-vrTrUqZgZA46W_sxWw4Ss/edit?usp=sharing)).
### 🖥️ Task 2: Building DataLoader
From the approved datasheets from the previous task, you can help us build HuggingFace’s dataset dataloader to ensure that all datasets in SEACrowd are standardized in terms of formatting. You can take a look at the [dataloader guide](https://github.com/SEACrowd/seacrowd-datahub/blob/master/DATALOADER.md) and [examples](https://github.com/SEACrowd/seacrowd-datahub/tree/master/seacrowd/sea_datasets) in [SEACrowd Data Hub](https://github.com/SEACrowd/seacrowd-datahub). We will also ping the taken dataloader issues after 2 weeks of inactivity in case there's any trouble.
-> Update (2024/03/30): The call for contribution for dataloader implementation will end on 15 May 2024.
-
### 🔍 Task 3: Identifying Private AI Datasets of SEA Languages, Cultures, and/or Regions
Unfortunately, some prior AI research on SEA languages is still hidden behind closed data. Surprisingly, the reason is as simple as the authors not considering releasing the data as an option before!
In this task, you will search for prior research publications that did not make their data open and fill out [this form](https://form.jotform.com/team/232952680898069/seacrowd-paper-with-private-dataset). Our team will contact the reported work to negotiate the opening of their data with us.
-> Update (2024/03/30): The call for contribution for private datasheet will end on 15 May 2024.
-
### 🔓 Task 4: Opening Your Private AI Dataset of SEA
If you have previous work with closed data (or have been contacted by us thanks to Task 3 :wink:), you can release your data and log it with us [here](https://form.jotform.com/team/232952680898069/seacrowd-sea-datasets). The data will still be owned by you and tied to your previous work, as we simply create a catalog of it.
-> Update (2024/03/30): The call for contribution for opening private dataset will end on 15 May 2024.
-
## Is there any other way to help?
For sure. You can message one of the initiators to learn about the details.
-## How much should I contribute?
+## Communication Channels
-Generally, you can contribute as much as you want and as little as you want! However, in order to reward contributors fairly, we came up with a contribution point system.
+Join us in [Discord](https://discord.gg/XXRHFuvkTA) or [SEACrowd mailing list via Google Groups](https://groups.google.com/u/0/g/seacrowd) to keep in touch and be the first to know the updates!
-**Contribution Point**
+## I'm still confused. Could you please help me?
-Each confirmed contribution will be rewarded with points. The details of the contribution point system are provided in [our Data Hub](https://github.com/SEACrowd/seacrowd-datahub/blob/master/POINTS.md). A general rule of thumb is that the more complex the task is, the higher the number of points it will earn you.
+Definitely. Please feel free to ask in `#general` on Discord or message one of the initiators so we can help you. :wink:
-For example, since our goal is to open access to as many NLP datasets as possible, releasing your own private data should earn you a substantial number of points, especially if the languages are rare and the data quality is superb.
+## Past Projects
-Once your points reach 20, you will be rewarded with **merchandise and co-authorship**. For co-authorship, the number of your contribution points will determine your position in the authorship list in our upcoming publication.
+### SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
-Contribution point tracking is now live at [this sheet](https://docs.google.com/spreadsheets/d/e/2PACX-1vQDZtJjA6i7JsxS5IlMtVuwOYjr2Pbl_b47yMSH4aAdHDBIpf-CiJQjNQAzcJPEu_aE7kwH4ZvKvPm0/pubhtml?gid=225616890&single=true)!
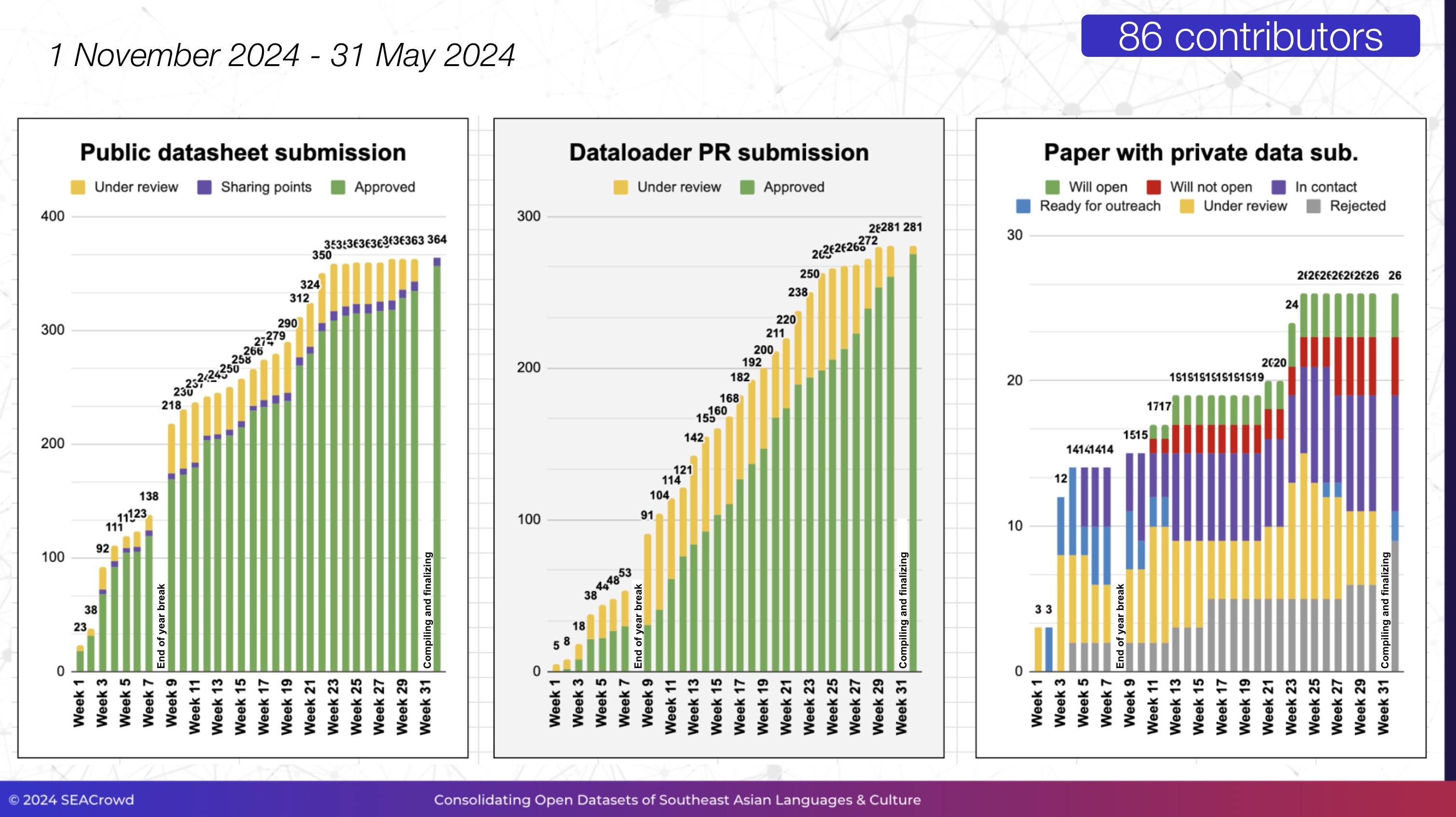
+Our first collaboration ran from 1 November 2023 to 15 June 2024 with a total of [86 contributors](https://docs.google.com/spreadsheets/d/e/2PACX-1vQDZtJjA6i7JsxS5IlMtVuwOYjr2Pbl_b47yMSH4aAdHDBIpf-CiJQjNQAzcJPEu_aE7kwH4ZvKvPm0/pubhtml?gid=225616890&single=true). We managed to consolidate 498 datasheets in SEACrowd Catalogue ([web](https://seacrowd.github.io/seacrowd-catalogue/)/[csv](https://docs.google.com/spreadsheets/d/1ibbywsC1tQ_sLPX8bUAjC-vrTrUqZgZA46W_sxWw4Ss/edit?usp=sharing)) and standardize 399 dataloaders in [SEACrowd Data Hub](https://github.com/SEACrowd/seacrowd-datahub/), covering 980 out of 1308 SEA languages.
-## Communication Channels
+Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
-Join us in [Discord](https://discord.gg/XXRHFuvkTA) or [SEACrowd mailing list via Google Groups](https://groups.google.com/u/0/g/seacrowd) to keep in touch and be the first to know the updates!
+Find our experiment repository at [`SEACrowd/seacrowd-experiments`](https://github.com/SEACrowd/seacrowd-experiments).
-## I'm still confused. Could you please help me?
+> Note: The URL to our paper is coming soon!
-Definitely. Please feel free to ask in `#general` on Discord or message one of the initiators so we can help you. :wink:
+#### Timeline
+
+ +
+#### How did they become contributors?
+
+Generally, anyone could contribute as much as they wanted and as little as they wanted! However, in order to reward contributors fairly, we came up with a contribution point system.
+
+**Contribution Point**
+
+Each confirmed contribution was rewarded with points. The details of the contribution point system were provided in [SEACrowd Data Hub](https://github.com/SEACrowd/seacrowd-datahub/blob/master/POINTS.md). A general rule of thumb is that the more complex the task was, the higher the number of points it would earn you.
+
+For example, since our goal was to open access to as many NLP datasets as possible, releasing their own private data should earn them a substantial number of points, especially if the languages were rare and the data quality was superb.
+
+Once their points reached 20, they would be rewarded with **merchandise and co-authorship**. For co-authorship, the number of their contribution points would determine their position in the authorship list in our publication.
+
+The contribution point tracking for this past project is available at [this sheet](https://docs.google.com/spreadsheets/d/e/2PACX-1vQDZtJjA6i7JsxS5IlMtVuwOYjr2Pbl_b47yMSH4aAdHDBIpf-CiJQjNQAzcJPEu_aE7kwH4ZvKvPm0/pubhtml?gid=225616890&single=true)!
+
+
+
+#### How did they become contributors?
+
+Generally, anyone could contribute as much as they wanted and as little as they wanted! However, in order to reward contributors fairly, we came up with a contribution point system.
+
+**Contribution Point**
+
+Each confirmed contribution was rewarded with points. The details of the contribution point system were provided in [SEACrowd Data Hub](https://github.com/SEACrowd/seacrowd-datahub/blob/master/POINTS.md). A general rule of thumb is that the more complex the task was, the higher the number of points it would earn you.
+
+For example, since our goal was to open access to as many NLP datasets as possible, releasing their own private data should earn them a substantial number of points, especially if the languages were rare and the data quality was superb.
+
+Once their points reached 20, they would be rewarded with **merchandise and co-authorship**. For co-authorship, the number of their contribution points would determine their position in the authorship list in our publication.
+
+The contribution point tracking for this past project is available at [this sheet](https://docs.google.com/spreadsheets/d/e/2PACX-1vQDZtJjA6i7JsxS5IlMtVuwOYjr2Pbl_b47yMSH4aAdHDBIpf-CiJQjNQAzcJPEu_aE7kwH4ZvKvPm0/pubhtml?gid=225616890&single=true)!
+
+ \ No newline at end of file
diff --git a/profile/assets/seacrowd-contribution-progress.png b/profile/assets/seacrowd-contribution-progress.png
new file mode 100644
index 0000000..f45be56
Binary files /dev/null and b/profile/assets/seacrowd-contribution-progress.png differ
diff --git a/profile/assets/seacrowd-timeline.png b/profile/assets/seacrowd-timeline.png
new file mode 100644
index 0000000..4f0cdee
Binary files /dev/null and b/profile/assets/seacrowd-timeline.png differ
\ No newline at end of file
diff --git a/profile/assets/seacrowd-contribution-progress.png b/profile/assets/seacrowd-contribution-progress.png
new file mode 100644
index 0000000..f45be56
Binary files /dev/null and b/profile/assets/seacrowd-contribution-progress.png differ
diff --git a/profile/assets/seacrowd-timeline.png b/profile/assets/seacrowd-timeline.png
new file mode 100644
index 0000000..4f0cdee
Binary files /dev/null and b/profile/assets/seacrowd-timeline.png differ